Изобретение относится к способам геолого-гидродинамического моделирования залежей нефти и газа на основе керновых, геофизических, сейсмических данных с применением интеллектуальных методов анализа данных.
Источниками информации о строении недр Земли являются данные геофизических, геохимических, геологических и других методов исследования. Информативность большинства этих методов постоянно растет, что напрямую связано с непрерывным развитием технологий разведки месторождений. При постоянном увеличении данных также возрастают требования к скорости их обработки. Нефтяными компаниями ставится вопрос о максимальной оптимизации процесса разведки-добычи без расширения штата компании, занимающейся геологоразведочными работами (ГРР). Этот вопрос решается путем автоматизации различных процессов при помощи алгоритмов машинного обучения и использования искусственных нейронных сетей.
В последнее время в нефтяной геологии происходит переход к освоению месторождений нефти и газа со сложной геологией структур и распределение фильтрационно-емкостных свойств.
Все это ведет к усложнению схем разработки месторождений. Одним из первых этапов для осуществления максимально эффективной схемы разработки месторождения нефти и газа является построение реалистичной и достоверной геологической модели залежи.
Геологическая модель используется на всех этапах изучения залежи, начиная с поиска и разведки нефтяных и газовых залежей и заканчивая выработкой остаточных запасов. Геологические модели используются для подсчета геологических запасов, проектирования скважин и моделирования движения флюидов на месторождении. Гидродинамические модели в свою очередь являются основой проектирования и управления разработкой залежей и месторождения и обоснования коэффициентов извлечения УВ. Геологическая модель включает в себя информацию о геологическом строении объекта, тектоническом строении, геометрии, стратиграфии, литолого-фациальной характеристике пластов-коллекторов, кубе распределения фильтрационно-емкостных свойств (ФЕС) (пористость, проницаемость, нефтегазонасыщенность) и других характеристиках.
Цифровая геологическая модель строится на основе двух типов данных. Первый тип основан на отборе и исследовании керна или образцов горных пород (обычно – цилиндры, отбираемые с определённым интервалом), полученных из скважины. Преимуществом этого типа данных является то, что он содержит в себе прямые источники информации о изучаемых породах, исследования можно повторять несколько раз с разным масштабом и на разных приборах. Недостатком является малый охват исследуемой области в масштабах месторождения, “старение” материала (потеря физических свойств, флюида, образование трещин) со временем и высокая цена отбора образцов. Второй тип данных основан на использовании дистанционных методов исследования (сейсмические волны, гравитационные и электромагнитные поля, радиоактивность и прочее). Преимуществом этого типа данных является возможность покрытия больших площадей даже в пределах скважины (разные методы имеют разную глубинность исследования), низкая стоимость исследований. Основным недостатком является сильное влияние внешней (флюид, буровой раствор, физические параметры пластов при проведении сейсмических исследований) среды на исследуемые объекты, точность приборов, ограниченный спектр исследуемых характеристик, масштаб исследований, невозможность повторного проведения некоторых исследований в случае обсадки скважины.
В результате разной стоимости и сложности исследований в большинстве случаев количество данных второго типа сильно преобладает над количеством данных первого типа. Это приводит к тому, что большинство геологических и гидродинамических моделей имеют низкую разрешающую способность.
В патенте РФ 2206911 описан способ создания геологической модели, подсчета запасов и мониторинга нефтяных месторождений с использованием данных по скважинам, результатов геофизических, геохимических, технологических исследований в скважинах, обеспечивающий формирование каркаса из разрезов, кубов скважин-эталонов на основе обработки и интерпретации информации о скважинах с помощью детерминистских и статистических зависимостей и методик. В данной способе используется только субъективная экспертная интерпретация данных.
В патенте РФ 2541348 описан ряд методов, направленных на уточнение геологической модели путём совмещения информации из разных источников. При этом анализ производится людьми и на каждый этап создания модели уходит большое количество времени, связанное с описанием керна, фотографическим документированием, интерпретацией данных геофизического исследования скважин (ГИС), анализом предыдущей информации. Основной недостаток данного изобретения – ручная обработка и анализ данных, в результате на получение конечной геологической модели уходит значительное количество времени (месяцы и годы), а также участие человеческого фактора, обусловленного опытом и мировоззрением множества экспертов, участвующих в процессе подготовки модели.
Технический результат, достигаемый при реализации изобретения, заключается в снижении временных затрат на геологическое моделирование, снижении неопределенности за счет минимизации или полного устранения человеческого фактора и повышении достоверности построения геологической модели месторождения, а также облегчении поиска перспективных месторождений путем создания и динамического обновления трехмерной геологической модели на основе применения методов машинного обучения.
Указанный технический результат достигается тем, что в соответствии с предлагаемым способом автоматизированного построения геологической модели залежи собирают исходные данные исследований залежи, содержащие по меньшей мере один тип данных, выбранных из группы, содержащей данные исследований керна, сейсмические данные, данные геофизических и гидродинамических исследований, геодезические данные, предварительное геологическое описание. Осуществляют обработку всех собранных исходных данных и формируют из обработанных данных структурированные массивы данных каждого типа. Затем осуществляют интерпретацию данных из сформированных структурированных массивов данных каждого типа, и, используя исходные и интерпретированные данные, осуществляют построение актуальной геологической модели залежи.
В соответствии с одним из вариантов осуществления изобретения исходные данные исследований залежи дополнительно содержат исходную геологическую модель.
Для каждого типа данных обработка собранных данных для формирования структурированных массивов данных содержит по меньшей мере одно действие, выбранное из группы, содержащей приведение данных к единому формату, заполнение пропусков с помощью методов машинного обучения, оценка погрешности интеллектуального заполнения, генерация синтетических данных методами машинного обучения.
Интерпретация данных из структурированных массивов данных, сформированных из обработанных сейсмических данных, представляет собой выделение геологических структур, разломов, горизонтов, соляных тел, сейсмических фаций.
Интерпретация данных из структурированных массивов данных, сформированных из обработанных данных исследований керна, представляет собой анализ изображений и результатов лабораторных исследований керна с получением информации о литотипе (типе породы), палеонтологических остатках, текстуре и структуре, стратиграфической единице, карте минералов, пористости, размере зёрен, сортировке и распространению свойств по породе, проницаемости.
Интерпретация данных из структурированных массивов данных, сформированных из обработанных данных геофизических и гидродинамических исследований и геодезических данных, представляет собой литологическое расчленение разреза, выявление пластов-коллекторов в залежи и их физических свойств, определение фильтрационно-емкостных свойств и характер насыщения интервалов коллекторов, определение характера и объемного содержания флюидов, заполняющих поровое пространство коллекторов.
Система автоматизированного построения геологической модели залежи в соответствии с настоящим изобретением включает блок агрегации данных исследований залежи, предназначенный для сбора и анализа исходных данных; блок обработки собранных исходных данных, предназначенный для обработки собранных исходных данных и формирования структурированных массивов данных; блок интерпретации данных из сформированных структурированных массивов данных, предназначенный для получения информации о изучаемом объекте и блок построения актуальной геологической модели залежи.
Блок агрегации данных содержит по меньшей мере один тип данных, выбранных из группы, содержащей данные исследований керна, сейсмические данные, данные геофизических и гидродинамических исследований, геодезические данные, предварительное геологическое описание.
Блок обработки собранных данных, предназначенный для обработки собранных исходных данных и формирования структурированных массивов данных, использует методы машинного обучения для выполнения по меньшей мере одного действия, выбранного из группы, содержащей приведение данных как единому формату, заполнение пропусков с помощью методов машинного обучения, оценка погрешности интеллектуального заполнения, генерация синтетических данных методами машинного обучения.
Блок интерпретации данных из структурированных массивов данных содержит первый блок-реконструктор, предназначенный для интерпретации структурированных массивов данных, сформированных из обработанных сейсмических данных, обеспечивающей выделение геологических структур, разломов, горизонтов, соляных тел, сейсмических фаций. блок интерпретации данных из структурированных массивов данных содержит блок-типизатор, предназначенный для интерпретации структурированных массивов данных, сформированных из обработанных данных геофизических и гидродинамических исследований и геодезических данных, и обеспечивающий литологическое расчленение разреза, выявление коллекторов в залежи и их физических свойств, определение фильтрационно-емкостных свойств и характера насыщения интервалов коллекторов, определение характера и объемного содержания флюидов, заполняющих поровое пространство коллекторов.
Блок интерпретации данных из структурированных массивов данных содержит второй блок-реконструктор, предназначенный для интерпретации данных из структурированных массивов данных, сформированных из обработанных данных исследований керна, и обеспечивающий получение информации о литотипе, палеонтологических остатках, текстуре и структуре, стратиграфической единице, карте минералов, пористости, размере зёрен, сортировке и распространению свойств по породе, проницаемости..
Блок построения актуальной геологической модели залежи содержит фидер данных, генератор геологической модели и блок вывода результатов, при этом фидер обеспечивает выбор и подачу интерпретированных и исходных данных в генератор геологической модели.
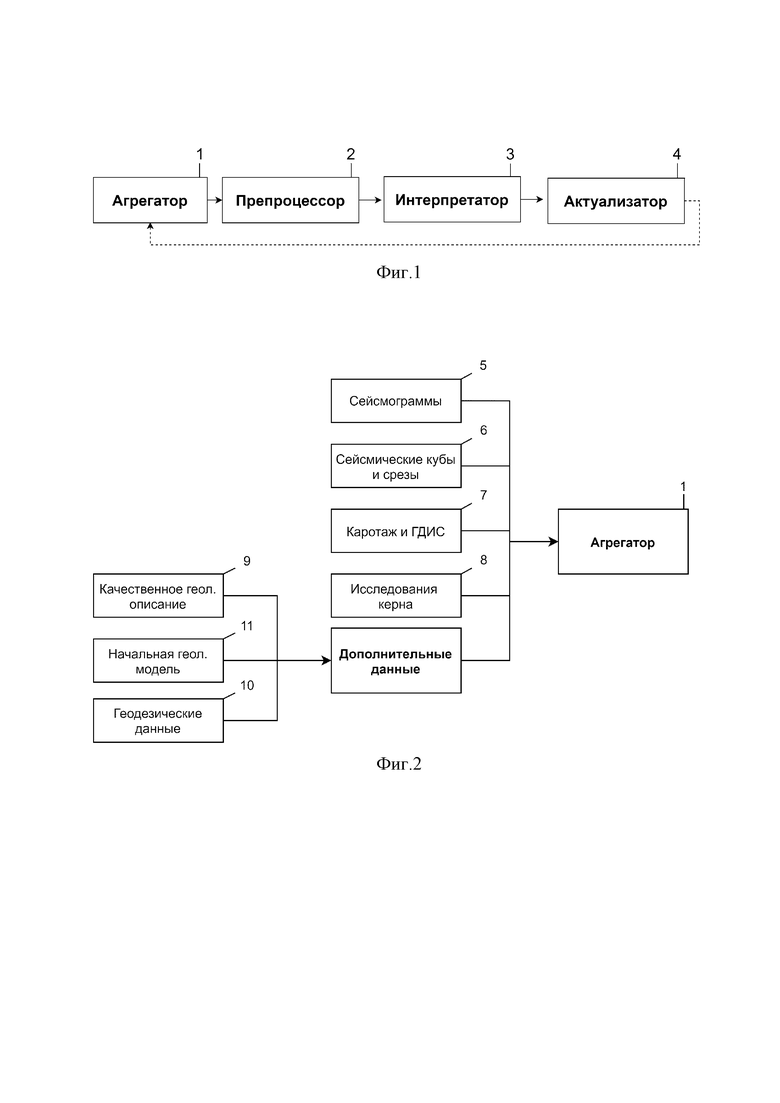
Изобретение поясняется чертежами, где на Фиг.1 представлена общая схема системы построения геологической модели залежи; на Фиг.2 – блок-схема подаваемых в агрегатор данных; на Фиг. 3 – блок-схема работы агрегатора; на Фиг.4 – блок-схема работы блока обработки данных – препроцессора; на Фиг.5 показана блок-схема работы блока интерпретации данных; на Фиг. 6 – блок-схема подаваемых в актуализатор данных, на Фиг. 7 – блок-схема работы блока построения актуальной геологической модели залежи (актуализатора).
На фиг.1 представлена общая схема системы построения геологической модели залежи, содержащая блок агрегации - агрегатор 1 для сбора и анализа исходных данных (определения типа и количества изначальных данных), блок обработки собранных исходных данных - препроцессор 2, предназначенный для обработки собранных данных и формирования структурированных массивов данных, а также оценки качества интерпретации, в случае наличия интерпретированных данных, блок интерпретации данных из сформированных структурированных массивов данных – интерпретатор 3 для автоматической интерпретации не интерпретированных данных и переинтерпретации выделенных в предыдущем блоке 2 некондиционных интервалов, интерпретированная часть данных, которая оценена как качественная, при этом не затрагивается, блок построения актуальной геологической модели залежи – актуализатор 4. Интерпретация представляет собой различные автоматизированные рутинные операции, которые ранее выполнялись специалистами в области геологии и геофизики (анализ и классификация данных).
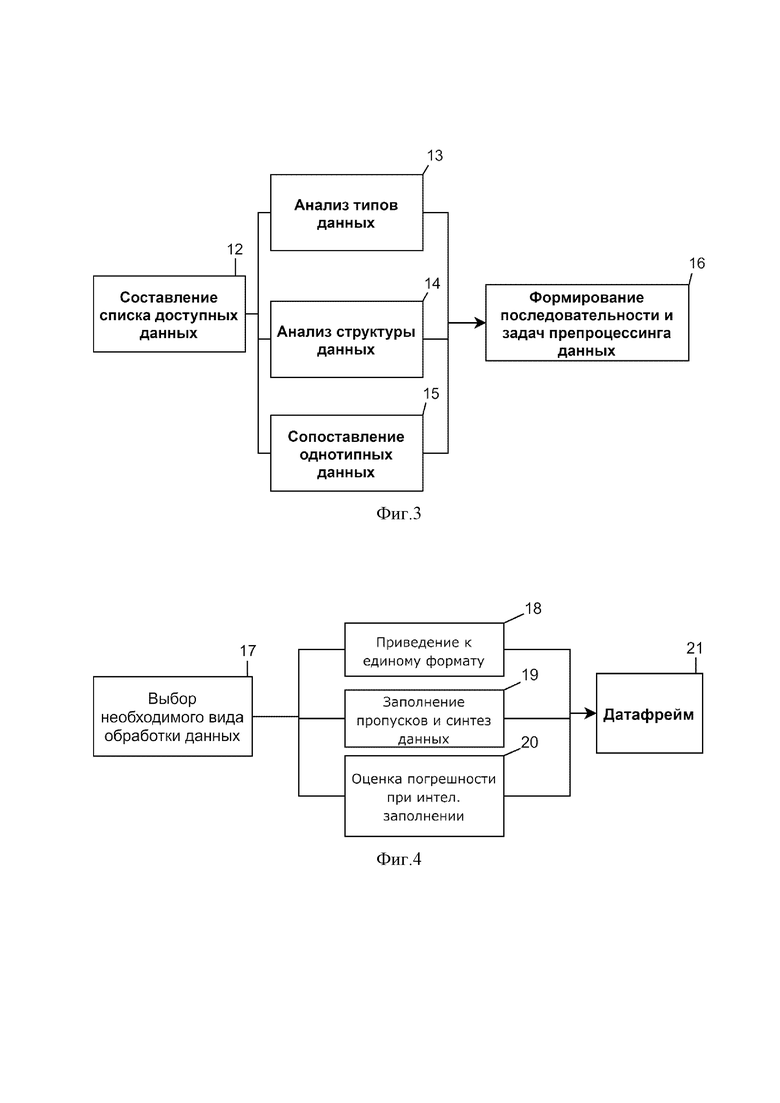
Как показано на фиг. 2, посредством агрегатора 1 собирают исходные данные исследования залежи, содержащие по меньшей мере один тип данных, выбранных из группы, содержащей сейсмические данные, такие, как сейсмограммы 5, сейсмические кубы и срезы 6, данные 7 геофизических (каротаж) и гидродинамических исследований (ГДИС) скважин, данные 8 исследований керна, а также ряд дополнительных данных, включающих предварительное геологическое описание 9, геодезические данные 10. Дополнительно исходные данные могут содержать начальную геологическую модель 11.
Сейсмические данные двух- и трёхмерной сейсморазведки, представленные в виде сейсмограмм 5, сейсмических кубов и срезов 6, позволяют получить информацию о внутреннем строении залежи на площади в несколько сотен километров. Формат сейсмических данных обычно представлен в виде seg-y (Hagelund, Rune; Stewart A. Levin, eds. SEG-Y_r2.0: SEG-Y revision 2.0 Data Exchange format. 2017. Tulsa, Oklahoma, USA: Society of Exploration Geophysicists).
Данные 7 геофизических (каротаж) и гидродинамических исследований скважин (ГДИС) позволяют определить положение ствола скважины в пространстве, провести стратиграфическую корреляцию, провести литологическое расчленение, определить ФЕС (фильтрационно-емкостные свойства) и характер насыщения интервалов пластов-коллекторов в залежи, провести привязку основных отражающих сейсмических горизонтов, восстановить условия осадконакопления. Формат данных 7 - las (LAS Specification 1.4 - R15. 2019. The American Society for Photogrammetry & Remote Sensing, Bethesda, Maryland, USA).
Данные 8 исследований керна позволяют определить литологический состав пород, условия осадконакопления и постседиментационные преобразования. Изучения полноразмерного керна дают прямую информацию об обстановках осадконакопления и возможность создания концептуальной седиментационной модели залежи, а также каверзность, трещиноватость пород внутри пластов. Керновые данные представлены в текстовом, табличном или графическом формате. В них входят данные лабораторных исследований и фотографии шлифов, полноразмерного керна, томографические изображения.
Предварительное геологическое описание 9, которое может быть составлено как экспертом-геологом, так и взято из геологических фондов, представляет собой общее описание развития региона, стратиграфическую шкалу или список известных обстановок осадконакопления для региона, а также может содержать геологические отчеты. Предварительное геологическое описание 9, представленное в виде формата doc, pdf, позволяет получать дополнительную информацию из текстовых отчетов в текстовом и графическом формате.
Начальная геологическая модель 10, которая может быть взята как из различных геологических фондов, так и из представлений пользователя о строении региона — это представленный в цифровом виде объект, где данные находятся в виде массива интерпретированных и сырых геолого-физических данных.
Геодезические данные 11 позволяют получить данные о пространственном местоположении объекта и общем рельефе местности.
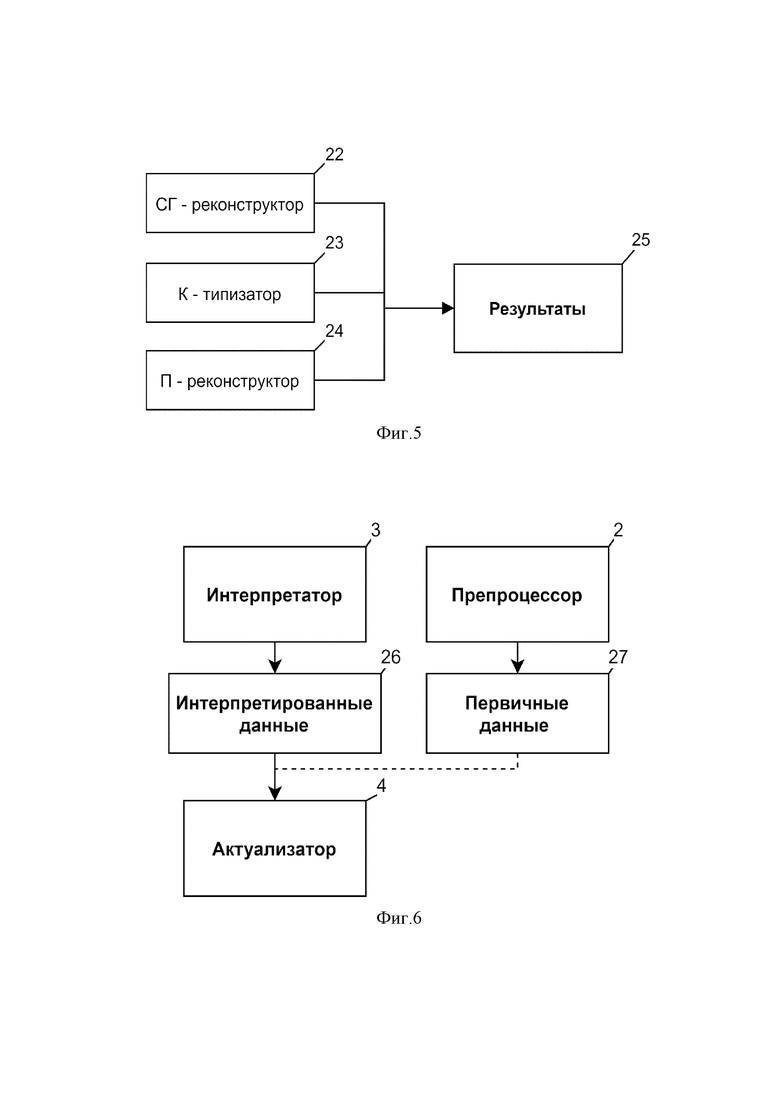
Один, несколько или все типы собранных исходных данных исследования залежи поступают в блок агрегации данных исследований, предназначенный для сбора и анализа исходных данных - агрегатор 1. Как показано на Фиг.3, агрегатор 1 обеспечивает составление 12 списка доступных данных, проводит анализ 13 типов поступивших данных, осуществляет анализ 14 структуры данных и сопоставление 15 однотипных данных. В результате проведённого анализа формируется последовательность и задачи препроцессинга 16 данных для выполнения блоком обработки собранных исходных данных - препроцессором 2.
Препроцессор 2 обрабатывает собранные исходные данные, оценивает их качество и количество и для каждого типа данных выбирает алгоритм обработки в зависимости от типа и качества данных.
Как показано на Фиг. 4, препроцессор 2 производит анализ и выбор 17 поступивших из агрегатора 1 однотипных данных (ГИС, геологическое описание и прочее), которые могут быть поданы в разных видах (таблицы, специальные форматы данных (LAS), графические данные), и приводит каждый тип исходных данных в рамках своего типа к единому формату, удобному для дальнейшей обработки алгоритмами (блок 18 на фиг. 4).
Так, в отношении сейсмических данных – сейсмограмм 5, сейсмических кубов и срезов 6 - в автоматическом режиме анализируются и убираются нежелательные волны-помехи и мешающие колебания (см., например, W. Whiteside, B. Wang, H. Bondeson, Z. Li, 3D imaging from 2D seismic data, an enhanced methodology, in: Soc. Explor. Geophys. Int. Expo. 83rd Annu. Meet. SEG 2013 Expand. Geophys. Front., Society of Exploration Geophysicists, 2013, стр. 3618–3622). Это позволяет получить очищенную информацию для дальнейшей интерпретации. Так, например, при поступлении сейсмического куба с большим количеством шума, шум убирается, увеличивая количество полезной информации.
В случае, если выявлена неполнота данных или невозможность синтеза данных на основе имеющихся данных, препроцессор 2 синтезирует аналогичные или новые типы данных, заполняющие пропуски или дополняющие информацию об объекте (блок 19 на фиг. 4), используя алгоритмы машинного обучения, обученные на интервалах с полным комплексом измерений или алгоритмы по интерполяции данных (см., например, D. Volkhonskiy, E. Muravleva, O. Sudakov, D. Orlov, B. Belozerov, E. Burnaev, D. Koroteev, Reconstruction of 3D Porous Media From 2D Slices, 2019, стр. 1–16, или A. Siahkoohi, R. Kumar, F. Herrmann, Seismic data reconstruction with generative adversarial networks, in: 80th EAGE Conf. Exhib. 2018, Oppor. Present. by Energy Transit., European Association of Geoscientists and Engineers, EAGE, 2018). Таким образом, в случае отсутствия записей каротажей они могут быть восстановлены при использовании других данных, что увеличивает ценность подаваемых на анализ данных (см. CN 106991509).
Для каждого типа собранных данных (сейсмических, геофизических, керновых) производится оценка погрешности проведенного интеллектуального заполнения пропусков (блок 20 на фиг. 4). Оценка может проводится как с помощью конформных предикторов (G. Shafer, V. Vovk, A Tutorial on Conformal Prediction, 2008, Journal of Machine Learning Research, v.9 371-421), так и с помощью встроенных в алгоритмы машинного обучения измерений погрешности аналогичных softmax (I. Goodfellow, Y. Bengio, A. Courville, Deep Learning, MIT Press, 2016, 78-80, ISBN: 9780262035613 ).
Как показано на фиг. 4, результатом работы препроцессора 2 являются датафреймы 21 - структурированные массивы данных 21, пригодные для дальнейшего анализа.
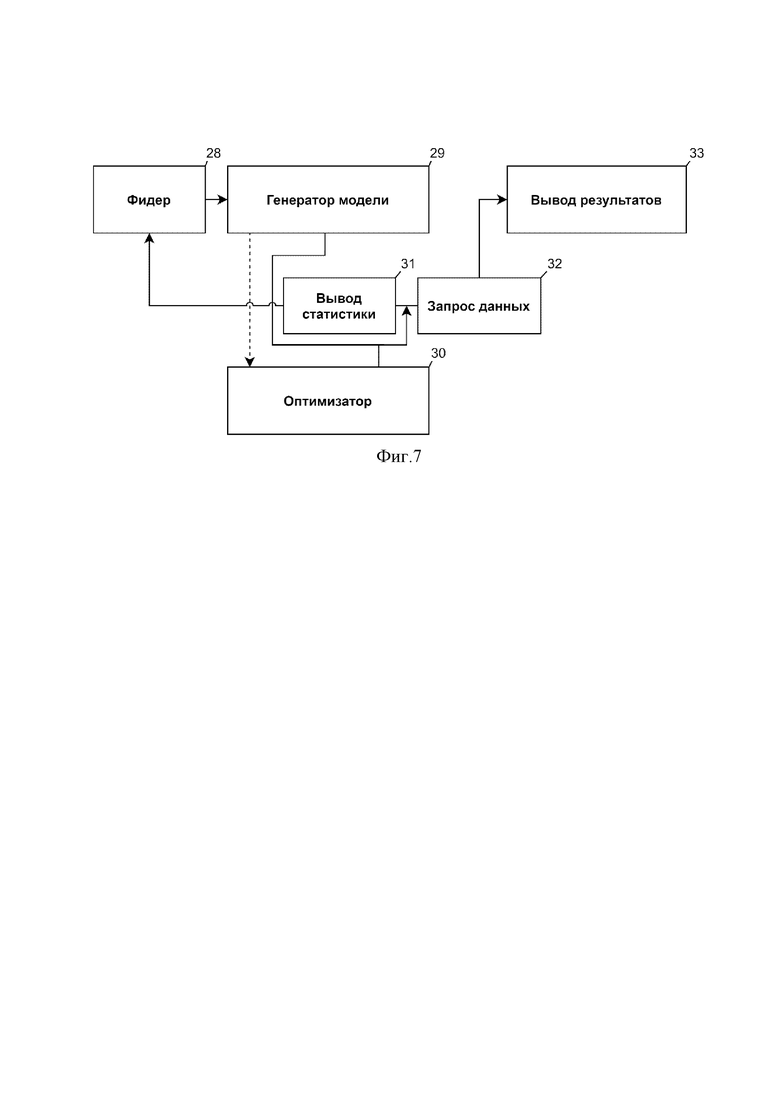
На фиг. 5 приведена схема интерпретатора 3 - блока интерпретации данных из сформированных структурированных массивов данных - датафреймов 21, который содержит первый блок-реконструктор - СГ – реконструктор 22, блок-типизатор -К-типизатор 23, второй блок-реконструктор - П-реконструктор 24. Результаты интерпретации данных в этих блоках поступают в блок 25 результатов, а затем в блок построения актуальной геологической модели залежи – актуализатор 4.
Первый блок-реконструктор - блок СГ-реконструктор 22 - предназначен для работы с сейсмическими данными. На основе методов машинного обучения и других известных алгоритмов корреляции и интерполяции результатов происходит выделение геологических структур, разломов, горизонтов, соляных тел, сейсмических фаций и прочих характерных структур, нужных для формирования геологической модели. При поступлении данных блок начинает их анализ, при проведении анализа выделяются разломы (R. Zhou, Y. Cai, F. Yu, G. Hu, Seismic fault detection with iterative deep learning, 2019, Society of Exploration Geophysicists, SEG International Exposition and Annual Meeting, Conf. paper, p.15-20), сейсмические фации (A.U. Waldeland, A.H.S.S. Solberg, Salt Classification Using Deep Learning, 79th EAGE Conf. Exhib. 2017, 2017, стр.12–15 или J.F.L. Souza, M.D. Santos, R.M. Magalhães, E.M. Neto, G.P. Oliveira, W.L. Roque, Automatic classification of hydrocarbon “leads” in seismic images through artificial and convolutional neural networks, Comput. Geosci., 132 (2019), стр. 23–32), прослеживаются горизонты (см. M.M. Dyrendahl, A better Horizon Auto Tracker - Powered by Machine Learning. 2018. NTNU. Norway. Master thesis. 117 p.).
В блоке-типизаторе - К-типизаторе 23 - производится интерпретация геофизических данных (каротаж), гидродинамических и геотехнических исследований скважин. На основе методов машинного обучения и методов оптимизации происходит увязка скважин (в случае анализа нескольких скважин одновременно) между собой, расчленение разреза, увязка каротажа в скважине и на керне, описывается литологическая характеристика пород, слагающих разрез скважины, в залеже выявляются пласты-коллекторы и их физические свойства (пористость, проницаемость, глинистость и др.), определяется характер, тип и уровень содержания флюидов, заполняющих поровое пространство коллекторов (нефть, газ, вода). Для увязки каротажей как между скважин, так и с каротажем на керне используют традиционные алгоритмы, основанные на статистике и сравнении форм каротажных кривых (см. D.K. Gupta, D. Bhowmick, R. Chatterjee, A new tool for automated correlation of wells, in: 75th Eur. Assoc. Geosci. Eng. Conf. Exhib. 2013 Inc. SPE Eur. 2013 Chang. Front., European Association of Geoscientists and Engineers, EAGE, 2013, стр.. 6286–6288, или Р.А. Шайбаков, Обоснование комплексной методики идентификации трёхмерных объектов, Уфа, 2014, диссер. на соиск. уч. степени к. г.-м. н., ООО НПФ “Геофизика”), так и продвинутые алгоритмы основанные на использовании методов машинного обучения (см. L. Zhu, H. Li, Z. Yang, C. Li, Y. Ao, Intelligent Logging Lithological Interpretation With Convolution Neural Networks, Petrophysics, 59 (2018), стр. 799–810, или B. Hall, Facies classification using machine learning, Lead. Edge. 35 (2016), стр. 906–909). Аналогичным образом происходит определение остальных характеристик.
Во второй блок-реконструктор - П-реконструктор 24 - для интерпретации поступают данные всех доступных лабораторных исследований керна, двух или трёхмерные массивы данных (цветные или в градациях серого изображения), представляющие собой томограмму, фотографию шлифа или керна с привязкой по глубине. С использованием алгоритмов машинного обучения и машинного зрения происходит анализ изображения, при наличии лабораторных исследований керна они также подаются на анализ. В результате анализа может быть получена информация о литотипе, палеонтологических остатках, текстуре и структуре, стратиграфической единице, карте минералов, пористости, размере зёрен, сортировке и распространению свойств по породе, проницаемости. Так, при анализе изображения происходит выделение типов пород и описание структурно-текстурных характеристик и другие параметры (см. Evgeny E. Baraboshkin, Leyla S. Ismailova, Denis M. Orlov, Elena A. Zhukovskaya, Georgy A. Kalmykov, Oleg V. Khotylev, Evgeny Yu. Baraboshkin, Dmitry A. Koroteev, Deep convolutions for in-depth automated rock typing, Computers & Geosciences, V. 135, 2020, p.1-14). При анализе шлифов также происходит анализ размера зёрен, определение их состава (см., например, B. Lu, M. Cui, Y. Wang, Computers & Geosciences Automated grain boundary detection using the level set method, Comput. Geosci. 35 (2009), стр. 267–275) и других характеристик. Вся эта информация также необходима для создания геологической модели залежи и выявления продуктивных пластов-коллекторов
Результаты работы блоков 22, 23 и 24 (по отдельности, парами или все вместе в зависимости от изначальных данных) передаются в блок 25 результатов, где происходит сопоставление и увязка (приведение к единой системе координат) интерпретированных данных между собой, а также данных, не требующих интерпретации. Формируется единый массив данных для формирования геологической модели. На данном этапе результаты работы каждого блока интерпретации могут быть выгружены в виде текстовых, графических и табличных данных и в виде структурированных массивов.
Затем результаты работы передаются в блок построения актуальной геологической модели залежи – актуализатор 4, как представлено на фиг.6. Передаются как интерпретированные или переинтерпретированные данные 26 из интерпретатора 3, так и первичные интерпретированные или необработанные данные 27 из препроцессора 2 в случае наличия таковых.
Как показано на фиг. 7, актуализатор 4 с помощью фидера 28 данных выбирает один или несколько типов интерпретированных данных для генератора 29 геологической модели. Подача может происходить как одновременно, так и последовательно в зависимости от объема данных и информативности данных. В случае последовательной передачи нескольких типов данных в генератор 29 происходит генерация геологической модели и определяется доверительный интервал построенной модели. Далее поступает следующая часть данных, которая передается в оптимизатор 30, где происходит оптимизация модели за счёт уменьшения стохастичности системы (увеличения коэффициента корреляции между новыми данными и смоделированными данными). Если данные подаются в генератор 29 одновременно (или если подается только один тип)– модель генерируется на их основе и результаты передаются в блок 33 вывода результатов. В случае наличия первичной геологической модели она также подаётся в генератор 29 модели непосредственно из препроцессора 2 и используется для дальнейшей работы с данными и оптимизации модели. Генерация происходит за счёт использования методов машинного обучения и оптимизации.
На каждом этапе генерации осуществляется вывод 31 статистики по характеристикам модели (количество литотипов, протяженность фаций, средние и медианные значения параметров пористости и проницаемости, погрешность определения, количество разломов и другие), а также происходит запрос данных 32 и формируется список данных, которые могли бы улучшить модель в порядке информативности. Этот список состоит из отсутствующих данных, при добавлении которых точность модели увеличится. Так, например, в случае подачи только сейсмических данных будет выведена информация о потребности в данных каротажей, скважинных данных, лабораторных исследований и прочих с процентным увеличением точности геологической модели в зависимости от данных. В случае последовательной подачи данных этот список соотносится со списком фидера 28 и происходит следующий этап генерации. В конце работы алгоритма формируется итоговый отчет, в который также входит список данных, сформированный в процессе работы блока запроса данных 32 и статистика из блока 31 вывода статистики. Если изначальных данных недостаточно для построения первичной геологической модели, то дополнительные данные для построения могут быть взяты из глобальных палеогеографической реконструкции заданной области или введены пользователем на основе его представления о регионе. При этом уровень неопределенности высчитывается учитывая эти данные.
Результаты в блоке 33 могут включать в себя как готовую геологическую модель, так и интерпретированные данные из интерпретатора 3, структурированный массив данных из препроцессора 2, отчеты по каждому этапу преобразования данных, первичные данные не обработанные данные и список данных, которые могут улучшить модель. Полученные результаты можно использовать совместно с новыми данными для улучшения результатов актуализатора 4.
Результаты из блока 30 могут быть записаны в один или несколько файлов-отчётов в виде:
а) графической информации (седиментологические колонки, 3-х и 2-х-мерные изображения и т.п.);
б) текстовой информации;
в) таблиц данных для импорта в другие программы;
г) структурированные массивы данных.
Результаты могут быть переданы в гидродинамическую модель.
Предлагаемая система автоматизированного построения динамической геологической модели залежи может быть реализована с помощью аппаратных и программных средств. Для аппаратной части реализации устройство должно содержать по крайней мере процессор и постоянное запоминающее устройство (ПЗУ). Для программной части реализации предлагаемый способ оценки характеристик пород может представлять собой набор функциональных модулей (функции или классы), написанных на языках программирования (например, С++, Python). Программный код может храниться в блоках памяти ПЗУ и извлекаться процессором для выполнения.
Далее приведен пример пример реализации способа и системы автоматизированного построения геологической модели залежи.
На вход системы поступают сырые и обработанные данные, состоящие из сейсмического куба, 2d сейсмических профилей, каротажа и геодезической информации, а также результаты лабораторных исследований одной скважины. Агрегатор 1 составляет описание полученной информации. Просматривается информация из заголовков файлов, составляется описание имеющихся каротажей и их единиц измерения, проверяется наличие двойников скважин, оценка разрешающей способности куба, происходит сопоставление местоположения скважин в пределах куба. Оценивается достаточность данных для анализа, наличие пропусков в данных. Составляется список задач для препроцессора 2.
Препроцессор 2 в соответствии со списком задач выполняет предобработку данных. Каротажи скважин одинаковых типов приводятся к одинаковым единицам измерения. Происходит сопоставление заголовков файлов скважин и приведение их к единому виду. Сейсмический куб и 2d срезы также приводятся к одинаковым или сопоставимым единицам измерения и единому формату файлов. Результаты исследований скважины приводятся к единому формату В случае наличия в списке задач на обработку, полученного из агрегатора дополнительных действий, они выполняются. Происходит удаление шума из сейсмических кубов, заполнение пропусков в каротажных данных, интерполирование информации из сейсмического куба и 2d сейсмограмм, собирается априорная информация о регионе исследования. Геодезическая информация о всех объектах также приводится к единой системе измерения. Происходит сопоставление объектов в объединённой системе координат, взятой из геодезической информации. Производится оценка погрешности для каждого метода. Результатом работы этого блока являются каротажные данные, места пропусков заполнены, для каждого из таких мест есть аналогичная кривая погрешности заполнения. Для каротажа скважины с лабораторными исследованиями произведено сопоставление керновых и каротажных данных. Увязаны изображения керна и остальные исследования. В проинтерпретированных интервалах произведена оценка интерпретации и выделены регионы для переинтерпретации в следующем блоке. Сейсмические данные очищены от шумов, в местах отсутствия данных синтезированы новые, для таких мест присутствует маска погрешностей восстановления. Все данные увязаны между собой в пространстве и по пластам. Для пластов сгенерирована априорная информация, т.к. она не была подана в основном массиве данных.
Происходит интерпретация подготовленных данных в Интерпретаторе 3. Так как сейсмические данные интерпретированы не были, происходит полная их интерпретация с выделением сейсмофаций, разломов, перспективных регионов для дальнейшего бурения с наиболее вероятными нефтяными ловушками в блоке СГ-реконструктор 22. Основная часть каротажных данных была проинтерпретирована, происходит частичная повторная интерпретация выделенных на предыдущих этапах сомнительных и синтезированных интервалов в К-типизаторе 23. Не интерпретированные скважины также автоматически интерпретируются. Лабораторные анализы прикрепляются к результатам интерпретации в П-реконструкторе 24, изображения керна и данные ГИС используются для получения информации о составе пород, текстурно-структурных хакрактеристиках, пористости, проницаемости и фациальной характеристике отложений и распространении свойств по породе.
Результаты интерпретации блоков передаются в блок результатов для увязки всех интерпретированных данных между собой. Скважинные данные увязываются с сейсмическим кубом, к одной из скважин привязываются интерпретированные данные лабораторных исследований. Формируется единый массив данных. Для изучения результатов работы оператор выгружает массивы данных в графическом виде, а также в виде массивов для передачи в программу геологического моделирования.
Объединенные результаты передаются в блок Актуализатор 4. Происходит генерация геологической модели с распространением по ней фильтрационно-емкостных свойств и фаций. Формируется отчет о достоверности модели и статистике распространения различных её свойств. В дополнение к этому формируется список данных, которые могут увеличить достоверность модели (кол-во скважин для ГИС и их расположение, кол-во дополнительных скважин с извлечение керна, дополнительные сейсмические данные).
В случае наличия данных для увеличения точности модели пользователь может их добавить. Актуализатор 4 учтёт эти данные, проитерирует через блок препроцессинга и интерпретации и запустит процесс оптимизации модели.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И КОМПЬЮТЕРНАЯ СИСТЕМА ОБРАБОТКИ СКВАЖИННЫХ ДАННЫХ | 2020 |
|
RU2782505C2 |
| Способ построения геолого-гидродинамических моделей неоднородных пластов с тонким линзовидным переслаиванием песчано-алевритовых и глинистых пород | 2017 |
|
RU2656303C1 |
| Способ построения геологических и гидродинамических моделей месторождений нефти и газа | 2020 |
|
RU2731004C1 |
| СПОСОБ РАЗРАБОТКИ НЕФТЯНЫХ ИЛИ НЕФТЕГАЗОКОНДЕНСАТНЫХ МЕСТОРОЖДЕНИЙ НА ПОЗДНЕЙ СТАДИИ | 2008 |
|
RU2346148C1 |
| СПОСОБ ПОСТРОЕНИЯ ГЕОЛОГО-ГИДРОДИНАМИЧЕСКИХ МОДЕЛЕЙ ДВОЙНОЙ СРЕДЫ ЗАЛЕЖЕЙ БАЖЕНОВСКОЙ СВИТЫ | 2014 |
|
RU2601733C2 |
| СПОСОБ И КОМПЬЮТЕРНАЯ СИСТЕМА УПРАВЛЕНИЯ БУРЕНИЕМ СКВАЖИН | 2019 |
|
RU2723805C1 |
| СПОСОБ РАЗМЕЩЕНИЯ НАКЛОННЫХ И ГОРИЗОНТАЛЬНЫХ НЕФТЕГАЗОВЫХ СКВАЖИН НА ОСНОВЕ СПЕКТРАЛЬНОЙ ДЕКОМПОЗИЦИИ ГЕОФИЗИЧЕСКИХ ДАННЫХ | 2006 |
|
RU2314554C1 |
| СПОСОБ КОНТРОЛЯ ЗА РАЗРАБОТКОЙ НЕФТЯНОЙ ЗАЛЕЖИ, ОСЛОЖНЕННОЙ ПАЛЕОКАРСТОМ | 2024 |
|
RU2837022C1 |
| Способ локализации запасов трещинных кремнистых коллекторов | 2023 |
|
RU2814152C1 |
| Способ комплексирования исходных данных для уточнения фильтрационного строения неоднородных карбонатных коллекторов | 2017 |
|
RU2661489C1 |
Изобретение относится к способам геолого-гидродинамического моделирования залежей нефти и газа на основе керновых, геофизических, сейсмических данных с применением интеллектуальных методов анализа данных. В соответствии со способом автоматизированного построения геологической модели залежи собирают исходные данные исследований залежи, содержащие по меньшей мере один тип данных, выбранных из группы, содержащей данные исследований керна, сейсмические данные, данные геофизических и гидродинамических исследований, геодезические данные, предварительное геологическое описание. Осуществляют обработку собранных исходных данных и формируют из обработанных данных структурированные массивы данных каждого типа. Затем осуществляют интерпретацию данных из сформированных структурированных массивов данных каждого типа, и осуществляют построение актуальной геологической модели залежи, используя исходные и интерпретированные данные. Технический результат - повышение достоверности построения геологической модели месторождения, а также облегчение поиска перспективных месторождений. 4 з.п. ф-лы, 7 ил.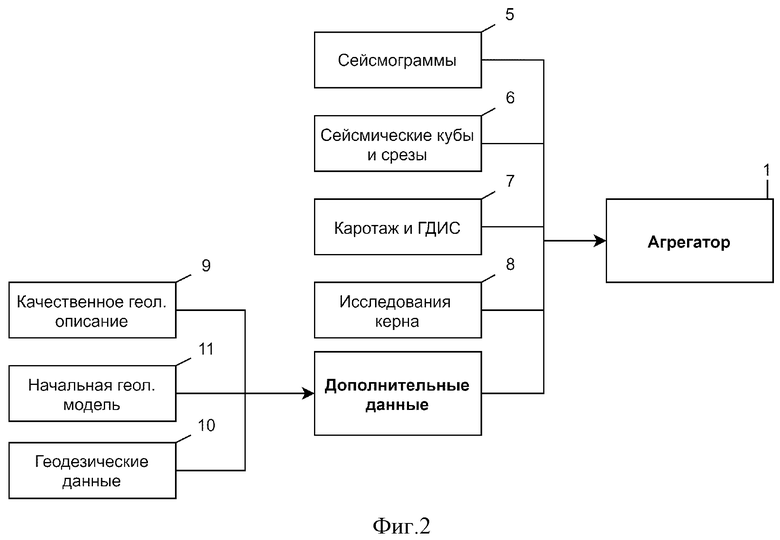
1. Способ автоматизированного построения геологической модели залежи, в соответствии с которым:
- собирают исходные данные исследований залежи, содержащие по меньшей мере один тип данных, выбранных из группы, содержащей данные исследований керна, сейсмические данные, данные геофизических и гидродинамических исследований, геодезические данные, предварительное геологическое описание,
- осуществляют обработку всех собранных исходных данных и формируют из обработанных данных структурированные массивы данных каждого типа, при этом для каждого типа данных обработка содержит по меньшей мере одно действие, выбранное из группы, содержащей приведение данных к единому формату, заполнение пропусков, оценка погрешности интеллектуального заполнения, генерация синтетических данных методами машинного обучения, причем заполнение пропусков и генерацию синтетических данных осуществляют используя алгоритмы машинного обучения, обученные на интервалах с полным комплексом измерений или алгоритмы по интерполяции данных,
- осуществляют интерпретацию данных из сформированных структурированных массивов данных каждого типа, и
- осуществляют построение актуальной геологической модели залежи, используя исходные и интерпретированные данные.
2. Способ автоматизированного построения геологической модели залежи по п. 1, в соответствии с которым исходные данные исследований залежи дополнительно содержат исходную геологическую модель.
3. Способ автоматизированного построения геологической модели залежи по п. 1, в соответствии с которым интерпретация данных из структурированных массивов данных, сформированных из обработанных сейсмических данных, представляет собой выделение геологических структур, разломов, горизонтов, соляных тел, сейсмических фаций.
4. Способ автоматизированного построения геологической модели залежи по п. 1, в соответствии с которым интерпретация данных из структурированных массивов данных, сформированных из обработанных данных исследований керна, представляет собой анализ изображений и результатов лабораторных исследований керна с получением информации о литотипе (типе породы), палеонтологических остатках, текстуре и структуре, стратиграфической единице, карте минералов, пористости, размере зерен, сортировке и распространению свойств по породе, проницаемости.
5. Способ автоматизированного построения геологической модели залежи по п. 1, в соответствии с которым интерпретация данных из структурированных массивов данных, сформированных из обработанных данных геофизических и гидродинамических исследований и геодезических данных, представляет собой литологическое расчленение разреза, выявление пластов-коллекторов в залежи и их физических свойств, определение фильтрационно-емкостных свойств и характер насыщения интервалов коллекторов, определение характера и объемного содержания флюидов, заполняющих поровое пространство коллекторов.
| АНТИПОВА К.А., ГУРИНА Е.В., КЛЮЧНИКОВ Н.А | |||
| и др., " ИНФОРМАЦИОННАЯ СИСТЕМА ДЕТЕКТИРОВАНИЯ ПРЕДВЕСТНИКОВ АВАРИЙНЫХ СИТУАЦИЙ", ж-л "НЕФТЬ | |||
| ГАЗ | |||
| НОВАЦИИ", номер 6, 2020 с.27-30 | |||
| ЧЕРНИКОВ А.Д., ЕРЕМИН Н.А., СТОЛЯРОВ В.Е | |||
| и др., "ПРИМЕНЕНИЕ МЕТОДОВ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА ДЛЯ ВЫЯВЛЕНИЯ И ПРОГНОЗИРОВАНИЯ ОСЛОЖНЕНИЙ ПРИ СТРОИТЕЛЬСТВЕ НЕФТЯНЫХ И |

