[0001] Данная заявка испрашивает приоритет непредварительной заявки на патент США №: 16/443113, поданной 17 июня 2019 года, которая испрашивает приоритет предварительной заявки на патент США № 62/687052, поданной 19 июня 2018 года, содержимое которой полностью содержится по ссылке в данном документе.
Область техники, к которой относится изобретение
[0002] Данное раскрытие сущности относится к кодированию видео и декодированию видео.
Уровень техники
[0003] Возможности цифрового видео могут быть включены в широкий диапазон устройств, включающих в себя цифровые телевизионные приемники, системы цифровой прямой широковещательной передачи, беспроводные широковещательные системы, персональные цифровые помощники (PDA), переносные или настольные компьютеры, планшетные компьютеры, устройства для чтения электронных книг, цифровые камеры, цифровые записывающие устройства, цифровые мультимедийные проигрыватели, устройства видеоигр, консоли для видеоигр, сотовые или спутниковые радиотелефоны, так называемые смартфоны, устройства видеоконференц-связи, устройства потоковой передачи видео и т.п. Цифровые видеоустройства реализуют такие технологии кодирования видео, как технологии кодирования видео, описанные в стандартах, заданных посредством MPEG-2, MPEG-4, ITU-T H.263, ITU-T H.264/MPEG-4, часть 10, усовершенствованное кодирование видео (AVC), стандарта высокоэффективного кодирования видео (HEVC), и стандарта ITU-T H.265/высокоэффективного кодирования видео (HEVC) и расширений таких стандартов. Видеоустройства могут передавать, принимать, кодировать, декодировать и/или сохранять цифровую видеоинформацию более эффективно посредством реализации таких технологий кодирования видео.
[0004] Технологии кодирования видео включают в себя пространственное (внутри картинки) предсказание и/или временное (между картинок) предсказание для того, чтобы уменьшать или удалять избыточность, внутренне присущую в видеопоследовательностях. Для кодирования видео на основе блоков, видеослайс (например, видеокартинка или часть видеокартинки) может разбиваться на видеоблоки, которые также могут называться единицами дерева кодирования (CTU), единицами кодирования (CU) и/или узлами кодирования. Видеоблоки во внутренне кодированном (I) слайсе картинки кодируются с использованием пространственного предсказания относительно опорных выборок в соседних блоках в той же картинке. Видеоблоки во внешне кодированном (P или B) слайсе картинки могут использовать пространственное предсказание относительно опорных выборок в соседних блоках в той же картинке или временное предсказание относительно опорных выборок в других опорных картинках. Картинки могут называться кадрами, и опорные картинки могут называться опорными кадрами.
Сущность изобретения
[0005] В общем, данное раскрытие сущности относится к предсказанию векторов движения в видеокодеках. Например, предиктор вектора движения выбирается адаптивно из двух списков кандидатов предсказания векторов движения, которые извлекаются.  Первый список включает в себя кандидатов предсказания векторов движения на уровне PU, второй список включает в себя кандидатов предсказания векторов движения на уровне суб-PU.
Первый список включает в себя кандидатов предсказания векторов движения на уровне PU, второй список включает в себя кандидатов предсказания векторов движения на уровне суб-PU.
[0006] В одном примерном варианте осуществления, обсуждается способ декодирования видеоданных. Способ включает в себя прием кодированных видеоданных, синтаксический анализ флага движения на основе субъединиц предсказания из кодированных видеоданных, в ответ на определение, что флаг движения на основе субъединиц предсказания является активным, извлечение списка кандидатов предсказания движения на уровне субъединиц предсказания, в ответ на определение, что флаг движения на основе субъединиц предсказания не является активным, извлечение списка кандидатов предсказания движения на уровне единиц предсказания, выбор предиктора вектора движения либо из списка кандидатов предсказания движения на уровне субъединиц предсказания, либо из списка кандидатов предсказания движения на уровне единиц предсказания и декодирование кодированных видеоданных с использованием выбранного предиктора вектора движения. Кодированные видеоданные включают в себя текущий блок, и при этом список кандидатов предсказания движения на уровне субъединиц предсказания и список кандидатов предсказания движения на уровне единиц предсказания извлекаются из соседних блоков текущего блока. Соседние блоки представляют собой пространственных соседей упомянутого текущего блока в текущей картинке или временных соседей текущего блока в ранее кодированной картинке. Список кандидатов предсказания движения на уровне субъединиц предсказания или список кандидатов предсказания движения на уровне единиц предсказания, по меньшей мере, частично упорядочивается на основе возникновений предсказания движения в соседних блоках. Пикселы в единице предсказания совместно используют первую информацию вектора движения, и пикселы в субъединице предсказания совместно используют вторую информацию вектора движения, при этом первая информация вектора движения или вторая векторная информация определяется из выбранного предиктора вектора движения. Список кандидатов векторов движения на уровне единиц предсказания включает в себя по меньшей мере одно из следующего: пространственные соседние кандидаты и временные соседние кандидаты. Список кандидатов предсказания движения на уровне субъединиц предсказания включает в себя по меньшей мере одно из следующего: аффинное предсказание векторов движения, альтернативное временное предсказание векторов движения (ATMVP), пространственно-временное предсказание векторов движения (STMVP), планарное предсказание векторов движения и извлечение векторов движения на основе сопоставления шаблонов (PMVD). Способ включает в себя извлечение индекса кандидата слияния в ответ на определение, что флаг движения на основе субъединиц предсказания является активным, при этом индекс кандидата слияния указывает предиктор вектора движения, который должен выбираться.
[0007] В другом примерном варианте осуществления, поясняется оборудование для декодирования видеоданных. Оборудование включает в себя запоминающее устройство для сохранения принимаемых кодированных видеоданных и процессор. Процессор выполнен с возможностью синтаксически анализировать флаг движения на основе субъединиц предсказания из кодированных видеоданных, в ответ на определение, что флаг движения на основе субъединиц предсказания является активным, извлекать список кандидатов предсказания движения на уровне субъединиц предсказания, в ответ на определение, что флаг движения на основе субъединиц предсказания не является активным, извлекать список кандидатов предсказания движения на уровне единиц предсказания, выбирать предиктор вектора движения либо из списка кандидатов предсказания движения на уровне субъединиц предсказания, либо из списка кандидатов предсказания движения на уровне единиц предсказания и декодировать кодированные видеоданные с использованием выбранного предиктора вектора движения. Кодированные видеоданные включают в себя текущий блок, при этом список кандидатов предсказания движения на уровне субъединиц предсказания и список кандидатов предсказания движения на уровне единиц предсказания извлекаются из соседних блоков текущего блока. Соседние блоки представляют собой пространственных соседей текущего блока в текущей картинке или временных соседей текущего блока в ранее кодированной картинке. Список кандидатов предсказания движения на уровне субъединиц предсказания или список кандидатов предсказания движения на уровне единиц предсказания, по меньшей мере, частично упорядочивается на основе возникновений предсказания движения в соседних блоках. Пикселы в единице предсказания совместно используют первую информацию вектора движения, и пикселы в субъединице предсказания совместно используют вторую информацию вектора движения, при этом первая информация вектора движения или вторая векторная информация определяется из выбранного предиктора вектора движения. Список кандидатов векторов движения на уровне единиц предсказания включает в себя по меньшей мере одно из следующего: пространственные соседние кандидаты и временные соседние кандидаты. Список кандидатов предсказания движения на уровне субъединиц предсказания включает в себя по меньшей мере одно из следующего: аффинное предсказание векторов движения, альтернативное временное предсказание векторов движения (ATMVP), пространственно-временное предсказание векторов движения (STMVP), планарное предсказание векторов движения и извлечение векторов движения на основе сопоставления шаблонов (PMVD). Процессор дополнительно выполнен с возможностью извлекать индекс кандидата слияния в ответ на определение, что флаг движения на основе субъединиц предсказания является активным, при этом индекс кандидата слияния указывает предиктор вектора движения, который должен выбираться.
[0008] В другом примерном варианте осуществления, поясняется оборудование для декодирования видеоданных. Оборудование включает в себя средство запоминающего устройства для сохранения принимаемых кодированных видеоданных и средство процессора. Средство процессора выполнено с возможностью синтаксически анализировать флаг движения на основе субъединиц предсказания из кодированных видеоданных, в ответ на определение, что флаг движения на основе субъединиц предсказания является активным, извлекать список кандидатов предсказания движения на уровне субъединиц предсказания, в ответ на определение, что флаг движения на основе субъединиц предсказания не является активным, извлекать список кандидатов предсказания движения на уровне единиц предсказания, выбирать предиктор вектора движения либо из списка кандидатов предсказания движения на уровне субъединиц предсказания, либо из списка кандидатов предсказания движения на уровне единиц предсказания и декодировать кодированные видеоданные с использованием выбранного предиктора вектора движения. Кодированные видеоданные включают в себя текущий блок, при этом список кандидатов предсказания движения на уровне субъединиц предсказания и список кандидатов предсказания движения на уровне единиц предсказания извлекаются из соседних блоков текущего блока. Соседние блоки представляют собой пространственных соседей текущего блока в текущей картинке или временных соседей текущего блока в ранее кодированной картинке. Список кандидатов предсказания движения на уровне субъединиц предсказания или список кандидатов предсказания движения на уровне единиц предсказания, по меньшей мере, частично упорядочивается на основе возникновений предсказания движения в соседних блоках. Пикселы в единице предсказания совместно используют первую информацию вектора движения, и пикселы в субъединице предсказания совместно используют вторую информацию вектора движения, при этом первая информация вектора движения или вторая векторная информация определяется из выбранного предиктора вектора движения. Список кандидатов векторов движения на уровне единиц предсказания включает в себя по меньшей мере одно из следующего: пространственные соседние кандидаты и временные соседние кандидаты. Список кандидатов предсказания движения на уровне субъединиц предсказания включает в себя по меньшей мере одно из следующего: аффинное предсказание векторов движения, альтернативное временное предсказание векторов движения (ATMVP), пространственно-временное предсказание векторов движения (STMVP), планарное предсказание векторов движения и извлечение векторов движения на основе сопоставления шаблонов (PMVD). Средство процессора дополнительно выполнено с возможностью извлекать индекс кандидата слияния в ответ на определение, что флаг движения на основе субъединиц предсказания является активным, при этом индекс кандидата слияния указывает предиктор вектора движения, который должен выбираться.
[0009] В другом примерном варианте осуществления, энергонезависимый машиночитаемый носитель хранения данных, имеющий сохраненные инструкции, которые при выполнении инструктируют одному или более процессоров осуществлять способ. Способ включает в себя прием кодированных видеоданных, синтаксический анализ флага движения на основе субъединиц предсказания из кодированных видеоданных, в ответ на определение, что флаг движения на основе субъединиц предсказания является активным, извлечение списка кандидатов предсказания движения на уровне субъединиц предсказания, в ответ на определение, что флаг движения на основе субъединиц предсказания не является активным, извлечение списка кандидатов предсказания движения на уровне единиц предсказания, выбор предиктора вектора движения либо из списка кандидатов предсказания движения на уровне субъединиц предсказания, либо из списка кандидатов предсказания движения на уровне единиц предсказания и декодирование кодированных видеоданных с использованием выбранного предиктора вектора движения. Кодированные видеоданные включают в себя текущий блок, при этом список кандидатов предсказания движения на уровне субъединиц предсказания и список кандидатов предсказания движения на уровне единиц предсказания извлекаются из соседних блоков текущего блока. Соседние блоки представляют собой пространственных соседей текущего блока в текущей картинке или временных соседей текущего блока в ранее кодированной картинке. Список кандидатов предсказания движения на уровне субъединиц предсказания или список кандидатов предсказания движения на уровне единиц предсказания, по меньшей мере, частично упорядочивается на основе возникновений предсказания движения в соседних блоках. Пикселы в единице предсказания совместно используют первую информацию вектора движения, и пикселы в субъединице предсказания совместно используют вторую информацию вектора движения, при этом первая информация вектора движения или вторая векторная информация определяется из выбранного предиктора вектора движения. Список кандидатов векторов движения на уровне единиц предсказания включает в себя по меньшей мере одно из следующего: пространственные соседние кандидаты и временные соседние кандидаты. Список кандидатов предсказания движения на уровне субъединиц предсказания включает в себя по меньшей мере одно из следующего: аффинное предсказание векторов движения, альтернативное временное предсказание векторов движения (ATMVP), пространственно-временное предсказание векторов движения (STMVP), планарное предсказание векторов движения и извлечение векторов движения на основе сопоставления шаблонов (PMVD). Способ включает в себя извлечение индекса кандидата слияния в ответ на определение, что флаг движения на основе субъединиц предсказания является активным, при этом индекс кандидата слияния указывает предиктор вектора движения, который должен выбираться.
[0010] Подробности одного или более примеров изложены на прилагаемых чертежах и в нижеприведенном описании. Другие признаки, цели и преимущества должны становиться очевидными из описания, чертежей и формулы изобретения.
Краткое описание чертежей
[0011] Фиг. 1 является блок-схемой, иллюстрирующей примерную систему кодирования и декодирования видео, которая может выполнять технологии этого раскрытия сущности.
[0012] Фиг. 2A и 2B являются концептуальными схемами, иллюстрирующими примерную структуру двоичного дерева квадродерева (QTBT) и соответствующую единицу дерева кодирования (CTU).
[0013] Фиг. 3 является блок-схемой последовательности операций способа, иллюстрирующей извлечение предикторов векторов движения.
[0014] Фиг. 4 является концептуальной схемой, иллюстрирующей пространственные соседние кандидаты векторов движения для режима слияния.
[0015] Фиг. 5 является концептуальной схемой, иллюстрирующей временные кандидаты векторов движения.
[0016] Фиг. 6 иллюстрирует технологии выбора блоков кандидатов векторов движения.
[0017] Фиг. 7 является концептуальной схемой, иллюстрирующей пространственно-временное предсказание векторов движения (STMVP).
[0018] Фиг. 8 является концептуальной схемой, иллюстрирующей технологии билатерального сопоставления.
[0019] Фиг. 9 является концептуальной схемой, иллюстрирующей технологии сопоставления с эталоном.
[0020] Фиг. 10 является концептуальной схемой, иллюстрирующей планарное предсказание векторов движения.
[0021] Фиг. 11 является блок-схемой, иллюстрирующей примерный видеокодер, который может выполнять технологии этого раскрытия сущности.
[0022] Фиг. 12 является блок-схемой, иллюстрирующей примерный видеодекодер, который может выполнять технологии этого раскрытия сущности.
Подробное описание изобретения
[0023] Это раскрытие сущности относится к извлечению векторов движения на стороне декодера (DMVD). Технологии извлечения векторов движения на стороне декодера, описанные в этом раскрытии сущности, могут использоваться в сочетании с любым из существующих видеокодеков, таких как HEVC (стандарт высокоэффективного кодирования видео), либо могут использоваться в качестве технологий кодирования для любых будущих стандартов кодирования видео, таких как универсальное кодирование видео (VVC) H.266 и фундаментальное кодирование видео (EVC).
[0024] Фиг. 1 является блок-схемой, иллюстрирующей примерную систему 100 кодирования и декодирования видео, которая может выполнять технологии этого раскрытия сущности. Технологии этого раскрытия сущности, в общем, направлены на кодирование (кодирование и/или декодирование) видеоданных и, в частности, относятся к технологиям, поясненным в данном документе. В общем, видеоданные включают любые данные для обработки видео. Таким образом, видеоданные могут включать в себя необработанное некодированное видео, кодированное видео, декодированное (например, восстановленное) видео и видеометаданные, такие как служебные данные.
[0025] Как показано на фиг. 1, система 100 включает в себя исходное устройство 102, которое предоставляет кодированные видеоданные, которые должны декодироваться и отображаться посредством целевого устройства 116, в этом примере. В частности, исходное устройство 102 предоставляет видеоданные в целевое устройство 116 через машиночитаемый носитель 110. Исходное устройство 102 и целевое устройство 116 могут содержать любые из широкого диапазона устройств, включающих в себя настольные компьютеры, ноутбуки (т.е. переносные компьютеры), планшетные компьютеры, абонентские приставки, телефонные трубки, к примеру, смартфоны, телевизионные приемники, камеры, устройства отображения, цифровые мультимедийные проигрыватели, консоли для видеоигр, устройство потоковой передачи видео и т.п. В некоторых случаях, исходное устройство 102 и целевое устройство 116 могут оснащаться возможностями беспроводной связи и в силу этого могут называться "устройствами беспроводной связи".
[0026] В примере по фиг. 1, исходное устройство 102 включает в себя видеоисточник 104, запоминающее устройство 106, видеокодер 200 и интерфейс 108 вывода. Целевое устройство 116 включает в себя интерфейс 122 ввода, видеодекодер 300, запоминающее устройство 120 и устройство 118 отображения. В соответствии с этим раскрытием сущности, видеокодер 200 исходного устройства 102 и видеодекодер 300 целевого устройства 116 могут быть выполнены с возможностью применять технологии для извлечения векторов движения на стороне декодера. Таким образом, исходное устройство 102 представляет пример устройства кодирования видео, в то время как целевое устройство 116 представляет пример устройства декодирования видео. В других примерах, исходное устройство и целевое устройство могут включать в себя другие компоненты или компоновки. Например, исходное устройство 102 может принимать видеоданные из внешнего видеоисточника, такого как внешняя камера. Аналогично, целевое устройство 116 может взаимодействовать с внешним устройством отображения вместо включения в себя интегрированного устройства отображения.
[0027] Система 100, как показано на фиг. 1, представляет собой просто один пример. В общем, любое устройство кодирования и/или декодирования цифрового видео может выполнять технологии для извлечения векторов движения на стороне декодера. Исходное устройство 102 и целевое устройство 116 представляют собой просто примеры таких устройств кодирования, в которых исходное устройство 102 формирует кодированные видеоданные для передачи в целевое устройство 116. Это раскрытие сущности упоминает устройство "кодирования" в качестве устройства, которое выполняет кодирование (кодирование и/или декодирование) данных. Таким образом, видеокодер 200 и видеодекодер 300 представляют примеры устройств кодирования, в частности, видеокодера и видеодекодера, соответственно. В некоторых примерах, устройства 102, 116 могут работать практически симметрично, так что каждое из устройств 102, 116 включает в себя компоненты кодирования и декодирования видео. Следовательно, система 100 может поддерживать одностороннюю и двухстороннюю передачу видео между видеоустройствами 102, 116, к примеру, для потоковой передачи видео, воспроизведения видео, широковещательной передачи видео или видеотелефонии.
[0028] В общем, видеоисточник 104 представляет источник видеоданных (т.е. необработанных некодированных видеоданных) и предоставляет последовательную серию картинок (также называемых кадрами) видеоданных в видеокодер 200, который кодирует данные для картинок. Видеоисточник 104 исходного устройства 102 может включать в себя устройство видеозахвата, такое как видеокамера, видеоархив, содержащий ранее захваченное необработанное видео, и/или интерфейс прямой видеотрансляции, чтобы принимать видео от поставщика видеосодержимого. В качестве дополнительной альтернативы, видеоисточник 104 может формировать данные компьютерной графики в качестве исходного видео либо комбинацию передаваемого вживую видео, архивного видео и машиногенерируемого видео. В каждом случае, видеокодер 200 кодирует захваченные, предварительно захваченные или машиногенерируемые видеоданные. Видеокодер 200 может перекомпоновывать картинки из принимаемого порядка (иногда называемого "порядком отображения") в порядок кодирования для кодирования. Видеокодер 200 может формировать поток битов, включающий в себя кодированные видеоданные. Исходное устройство 102 затем может выводить кодированные видеоданные через интерфейс 108 вывода на машиночитаемый носитель 110 для приема и/или извлечения, например, посредством интерфейса 122 ввода целевого устройства 116.
[0029] Запоминающее устройство 106 исходного устройства 102 и запоминающее устройство 120 целевого устройства 116 представляют запоминающие устройства общего назначения. В некотором примере, запоминающие устройства 106, 120 могут сохранять необработанные видеоданные, например, необработанное видео из видеоисточника 104 и необработанные декодированные видеоданные из видеодекодера 300. Дополнительно или альтернативно, запоминающие устройства 106, 120 могут сохранять программные инструкции, выполняемые, например, посредством видеокодера 200 и видеодекодера 300, соответственно. Хотя показаны отдельно от видеокодера 200 и видеодекодера 300 в этом примере, следует понимать, что видеокодер 200 и видеодекодер 300 также могут включать в себя внутренние запоминающие устройства для функционально аналогичных или эквивалентных целей. Кроме того, запоминающие устройства 106, 120 могут сохранять кодированные видеоданные, например, выводимые из видеокодера 200 и вводимые в видеодекодер 300. В некоторых примерах, части запоминающих устройств 106, 120 могут выделяться в качестве одного или более видеобуферов, например, чтобы сохранять необработанные, декодированные и/или кодированные видеоданные.
[0030] Машиночитаемый носитель 110 может представлять любой тип носителя или устройства, допускающего транспортировку кодированных видеоданных из исходного устройства 102 в целевое устройство 116. В одном примере, машиночитаемый носитель 110 представляет среду связи, чтобы обеспечивать возможность исходному устройству 102 передавать кодированные видеоданные непосредственно в целевое устройство 116 в реальном времени, например, через радиочастотную сеть или компьютерную сеть. Интерфейс 108 вывода может модулировать передаваемый сигнал, включающий в себя кодированные видеоданные, и интерфейс 122 ввода может модулировать принимаемый сигнал передачи, согласно стандарту связи, такому как протокол беспроводной связи. Среда связи может содержать любую беспроводную или проводную среду связи, такую как радиочастотный (RF) спектр либо одна или более физических линий передачи. Среда связи может формировать часть сети с коммутацией пакетов, такой как локальная вычислительная сеть, глобальная вычислительная сеть либо глобальная сеть, такая как Интернет. Среда связи может включать в себя маршрутизаторы, коммутаторы, базовые станции или любое другое оборудование, которое может быть полезным для того, чтобы упрощать передачу из исходного устройства 102 в целевое устройство 116.
[0031] В некоторых примерах, исходное устройство 102 может выводить кодированные данные из интерфейса 108 вывода в устройство 112 хранения данных. Аналогично, целевое устройство 116 может осуществлять доступ к кодированным данным из устройства 112 хранения данных через интерфейс 122 ввода. Устройство 112 хранения данных может включать в себя любое множество распределенных или локально доступных носителей хранения данных, таких как жесткий диск, Blu-Ray-диски, DVD, CD-ROM, флэш-память, энергозависимое или энергонезависимое запоминающее устройство либо любые другие подходящие цифровые носители хранения данных для сохранения кодированных видеоданных.
[0032] В некоторых примерах, исходное устройство 102 может выводить кодированные видеоданные на файловый сервер 114 или другое промежуточное устройство хранения данных, которое может сохранять кодированное видео, сформированное посредством исходного устройства 102. Целевое устройство 116 может осуществлять доступ к сохраненным видеоданным из файлового сервера 114 через потоковую передачу или загрузку. Файловый сервер 114 может представлять собой любой тип серверного устройства, допускающего сохранение кодированных видеоданных и передачу этих кодированных видеоданных в целевое устройство 116. Файловый сервер 114 может представлять веб-сервер (например, для веб-узла), сервер по протоколу передачи файлов (FTP), сетевое устройство доставки контента или устройство по протоколу системы хранения данных с подключением по сети (NAS). Целевое устройство 116 может осуществлять доступ к кодированным видеоданным из файлового сервера 114 через любое стандартное соединение для передачи данных, включающее в себя Интернет-соединение. Оно может включать в себя беспроводной канал (например, Wi-Fi-соединение), проводное соединение (например, DSL, кабельный модем и т.д.) либо комбинацию означенного, которая является подходящей для осуществления доступа к кодированным видеоданным, сохраненным на файловом сервере 114. Файловый сервер 114 и интерфейс 122 ввода могут быть выполнены с возможностью работать согласно протоколу потоковой передачи, протоколу передачи на основе загрузки либо комбинации вышеозначенного.
[0033] Интерфейс 108 вывода и интерфейс 122 ввода могут представлять беспроводные передающие устройства/приемные устройства, модемы, проводные сетевые компоненты (например, Ethernet-карты), компоненты беспроводной связи, которые работают согласно любым из множества IEEE 802.11-стандартов, либо другие физические компоненты. В примерах, в которых интерфейс 108 вывода и интерфейс 122 ввода содержат беспроводные компоненты, интерфейс 108 вывода и интерфейс 122 ввода могут быть выполнены с возможностью передавать данные, к примеру, кодированные видеоданные, согласно стандарту сотовой связи, такому как 4G, 4G LTE (стандарт долгосрочного развития), усовершенствованный стандарт LTE, 5G и т.п. В некоторых примерах, в которых интерфейс 108 вывода содержит беспроводное передающее устройство, интерфейс 108 вывода и интерфейс 122 ввода могут быть выполнены с возможностью передавать данные, к примеру, кодированные видеоданные, согласно другим стандартам беспроводной связи, таким как IEEE 802.11-спецификация, IEEE 802.15-спецификация (например, ZigBee™), стандарт Bluetooth™ и т.п. В некоторых примерах, исходное устройство 102 и/или целевое устройство 116 могут включать в себя соответствующие внутримикросхемные (SoC) устройства. Например, исходное устройство 102 может включать в себя SoC-устройство, чтобы выполнять функциональность, приписываемую видеокодеру 200 и/или интерфейсу 108 вывода, и целевое устройство 116 может включать в себя SoC-устройство, чтобы выполнять функциональность, приписываемую видеодекодеру 300 и/или интерфейсу 122 ввода.
[0034] Технологии этого раскрытия сущности могут применяться к кодированию видео в поддержку любых из множества мультимедийных приложений, таких как телевизионные широковещательные передачи по радиоинтерфейсу, кабельные телевизионные передачи, спутниковые телевизионные передачи, потоковые передачи видео по Интернету, такие как динамическая адаптивная потоковая передача по HTTP (DASH), цифровое видео, которое кодируется на носитель хранения данных, декодирование цифрового видео, сохраненного на носителе хранения данных, или другие приложения.
[0035] Интерфейс 122 ввода целевого устройства 116 принимает кодированный битовый поток видео из машиночитаемого носителя 110 (например, энергонезависимого устройства 112 хранения данных, файлового сервера 114 и т.п.). Машиночитаемый носитель 110 кодированных битовых потоков видео может включать в себя служебную информацию, заданную посредством видеокодера 200, которая также используется посредством видеодекодера 300, такую как синтаксические элементы, имеющие значения, которые описывают характеристики и/или обработку видеоблоков либо других кодированных единиц (например, серий последовательных макроблоков, картинок, групп картинок, последовательностей и т.п.). Устройство 118 отображения отображает декодированные картинки декодированных видеоданных пользователю. Устройство 118 отображения может представлять любое из множества устройств отображения, таких как дисплей на электронно-лучевой трубке (CRT), жидкокристаллический дисплей (LCD), плазменный дисплей, дисплей на органических светодиодах (OLED) или другой тип устройства отображения.
[0036] Хотя не показано на фиг. 1, в некоторых примерах, видеокодер 200 и видеодекодер 300 могут быть интегрированы с аудиокодером и/или аудиодекодером и могут включать в себя соответствующие модули мультиплексора-демультиплексора либо другие аппаратные средства и программное обеспечение для того, чтобы обрабатывать мультимедийные потоки, включающие в себя как аудио, так и видео в общем потоке данных. Если применимо, модули мультиплексора-демультиплексора могут соответствовать протоколу мультиплексора ITU H.223 или другим протоколам, таким как протокол пользовательских дейтаграмм (UDP).
[0037] Видеокодер 200 и видеодекодер 300 могут реализовываться как любая из множества надлежащих схем кодера и/или декодера, к примеру, как один или более микропроцессоров, процессоров цифровых сигналов (DSP), специализированных интегральных схем (ASIC), программируемых пользователем вентильных матриц (FPGA), как дискретная логика, программное обеспечение, аппаратные средства, микропрограммное обеспечение либо как любые комбинации вышеозначенного. Когда технологии реализуются частично в программном обеспечении, устройство может сохранять инструкции для программного обеспечения на подходящем энергонезависимом машиночитаемом носителе и выполнять инструкции в аппаратных средствах с использованием одного или более процессоров, чтобы осуществлять технологии этого раскрытия сущности. Каждый из видеокодера 200 и видеодекодера 300 может быть включен в один или более кодеров или декодеров, любой из которых может быть интегрирован как часть комбинированного кодера/декодера (кодека) в соответствующем устройстве. Устройство, включающее в себя видеокодер 200 и/или видеодекодер 300, может содержать интегральную схему, микропроцессор и/или устройство беспроводной связи, такое как сотовый телефон.
[0038] Стандарты кодирования видео включают в себя ITU-T H.261, ISO/IEC MPEG-1 Visual, ITU-T H.262 или ISO/IEC MPEG-2 Visual, ITU-T H.263, ISO/IEC MPEG-4 Visual и ITU-T H.264 (также известный как ISO/IEC MPEG-4 AVC), включающий в себя расширения масштабируемого кодирования видео (SVC) и кодирования многовидового видео (MVC).
[0039] Новый стандарт кодирования видео, а именно стандарт высокоэффективного кодирования видео (HEVC) или ITU-T H.265, в том числе его расширение диапазона, многовидовое расширение (MV-HEVC) и масштабируемое расширение (SHVC), разработан посредством Объединенной группы для совместной работы над видеостандартами (JCT-VC), а также Объединенной группы для совместной работы над расширениями кодирования трехмерного видео (JCT-3V) Экспертной группы в области кодирования видео (VCEG) ITU-T и Экспертной группы по киноизображению (MPEG) ISO/IEC.
[0040] ITU-T VCEG (Q6/16) и ISO/IEC MPEG (JTC 1/SC 29/WG 11) теперь изучают потенциальную потребность в стандартизации будущей технологии кодирования видео с возможностями сжатия, которые превышают возможности сжатия текущего HEVC-стандарта (в том числе его текущих расширений и ближнесрочных расширений для кодирования экранного контента и кодирования с расширенным динамическим диапазоном). Группы совместно проводят эти изыскания объединенными коллективными усилиями, известными как Объединенная группа для исследования видео (JVET), чтобы оценивать проектные решения по технологиям сжатия, предлагаемые их экспертами в этой области. JVET в первый раз провела встречу 19-21 октября 2015 года. Кроме того, последняя версия эталонного программного обеспечения, т.е. стандарт объединенной исследовательской группы тестовой модели 7 (JEM7) может загружаться по адресу:
https://jvet.hhi.fraunhofer.de/svn/svn_HMJEMSoftware/tags/HM-16.6-JEM-57.0/
Описание алгоритма стандарта объединенной исследовательской группы тестовой модели 7 (JEM7) может упоминаться как "JVET-G1001".
[0041] Видеокодер 200 и видеодекодер 300 могут работать согласно стандарту кодирования видео, такому как ITU-T H.265, также называемому "стандартом высокоэффективного кодирования видео (HEVC)", либо его расширениям, таким как расширения кодирования многовидового видео и/или масштабируемого кодирования видео. Альтернативно, видеокодер 200 и видеодекодер 300 могут работать согласно другим собственным или отраслевым стандартам, таким как стандарт объединенной исследовательской группы тестовой модели (JEM) или ITU-T H.266, также называемый "универсальным кодированием видео (VVC)". Недавний проект стандарта VVC описывается в работе авторов Bross и др. "Versatile Video Coding (Draft 3)", Joint Video Experts Team (JVET) of ITU-T SG 16 WP 3 and ISO/IEC JTC 1/SC 29/WG 11, 13 конференция: Марракеш, MA, 9-18 января 2019 года, JVET-M1001-v3 (далее "VVC-проект 4"). Тем не менее, технологии этого раскрытия сущности не ограничены каким-либо конкретным стандартом кодирования.
Как пояснено видеодекодер 300 может быть выполнен с возможностью выполнять одну или более технологий этого раскрытия сущности. Например, видеодекодер 300 может синтаксически анализировать флаг движения на основе субъединиц предсказания из принимаемых кодированных видеоданных, извлекать список кандидатов предсказания движения на уровне субъединиц предсказания, если флаг движения на основе субъединиц предсказания является активным, извлекать список кандидатов предсказания движения на уровне единиц предсказания, если флаг движения на основе субъединиц предсказания не является активным, и декодировать кодированные видеоданные с использованием выбранного предиктора вектора движения.
[0042] В общем, видеокодер 200 и видеодекодер 300 могут выполнять кодирование картинок на основе блоков. Термин "блок", в общем, означает структуру, включающую в себя данные, которые должны обрабатываться (например, кодироваться, декодироваться или иным образом использоваться в процессе кодирования и/или декодирования). Например, блок может включать в себя двумерную матрицу выборок данных яркости и/или цветности. В общем, видеокодер 200 и видеодекодер 300 могут кодировать видеоданные, представленные в YUV- (например, Y, Cb, Cr) формате. Таким образом, вместо кодирования данных красного цвета, зеленого цвета и синего цвета (RGB) для выборок картинки, видеокодер 200 и видеодекодер 300 могут кодировать компоненты яркости и цветности, при этом компоненты цветности могут включать в себя компоненты цветности оттенков красного цвета и оттенков синего цвета. В некоторых примерах, видеокодер 200 преобразует принимаемые RGB-отформатированные данные в YUV-представление до кодирования, и видеодекодер 300 преобразует YUV-представление в RGB-формат. Альтернативно, модули предварительной и постобработки (не показаны) могут выполнять эти преобразования.
[0043] Это раскрытие сущности, в общем, может означать кодирование (например, кодирование и декодирование) картинок, которое включает в себя процесс кодирования или декодирования данных картинки. Аналогично, это раскрытие сущности может означать кодирование блоков картинки, которое включает в себя процесс кодирования или декодирования данных для блоков, например, предсказание и/или остаточное кодирование. Кодированный битовый поток видео, в общем, включает в себя последовательность значений для синтаксических элементов, представляющих решения по кодированию (например, режимы кодирования) и сегментацию картинок на блоки. Таким образом, ссылки на кодирование картинки или блока, в общем, должны пониматься как кодирование значений для синтаксических элементов, формирующих картинку или блок.
[0044] HEVC задает различные блоки, включающие в себя единицы кодирования (CU), единицы предсказания (PU) и единицы преобразования (TU). Согласно HEVC, видеокодер (к примеру, видеокодер 200) сегментирует единицу дерева кодирования (CTU) на CU согласно структуре в виде дерева квадрантов. Таким образом, видеокодер сегментируют CTU и CU на четыре равных неперекрывающихся квадрата, и каждый узел дерева квадрантов имеет либо нуль, либо четыре дочерних узла. Узлы без дочерних узлов могут называться "узлами-листьями", и CU таких узлов-листьев могут включать в себя одну или более PU и/или одну или более TU. Видеокодер дополнительно может сегментировать PU и TU. Например, в HEVC, остаточное дерево квадрантов (RQT) представляет сегментацию TU. В HEVC, PU представляют данные взаимного предсказания, в то время как TU представляют остаточные данные. CU, которые внутренне предсказываются, включают в себя информацию внутреннего предсказания, такую как индикатор внутреннего режима.
[0045] В качестве другого примера, видеокодер 200 и видеодекодер 300 могут быть выполнены с возможностью работать согласно JEM или VVC. Согласно JEM или VVC, видеокодер (к примеру, видеокодер 200) сегментирует картинку на множество единиц дерева кодирования (CTU). Видеокодер 200 может сегментировать CTU согласно древовидной структуре, такой как структура в виде дерева квадрантов и двоичного дерева (QTBT). QTBT-структура удаляет понятия нескольких типов сегментации, к примеру, разделение между CU, PU и TU HEVC. QTBT-структура JEM включает в себя два уровня: первый уровень, сегментированный согласно сегментации на дерево квадрантов, и второй уровень, сегментированный согласно сегментации на двоичное дерево. Корневой узел QTBT-структуры соответствует CTU. Узлы-листья двоичных деревьев соответствуют единицам кодирования (CU).
[0046] В MTT-структуре сегментации, блоки могут сегментироваться с использованием сегмента дерева квадрантов (QT), сегмента двоичного дерева (BT) и одного или более типов сегментов троичного дерева (TT). Сегмент троичного дерева представляет собой сегмент, в котором блок разбивается на три субблока. В некоторых примерах, сегмент троичного дерева разделяет блок на три субблока без разделения исходного блока через центр. Типы сегментации в MTT (например, QT, BT и TT) могут быть симметричными или асимметричными.
[0047] В некоторых примерах, видеокодер 200 и видеодекодер 300 могут использовать одну QTBT- или MTT-структуру для того, чтобы представлять каждый из компонентов яркости и цветности, в то время как в других примерах, видеокодер 200 и видеодекодер 300 могут использовать две или более QTBT- или MTT-структуры, к примеру, одну QTBT/MTT-структуру для компонента яркости и другую QTBT- или MTT-структуру для обоих компонентов цветности (либо две QTBT/MTT-структуры для соответствующих компонентов цветности).
[0048] Видеокодер 200 и видеодекодер 300 могут быть выполнены с возможностью использовать сегментацию на дерево квадрантов согласно HEVC, QTBT-сегментации или MTT-сегментации либо другим структурам сегментации. Для целей пояснения, описание технологий этого раскрытия сущности представляется относительно QTBT-сегментации. Тем не менее, следует понимать, что технологии этого раскрытия сущности также могут применяться к видеокодерам, выполненным с возможностью использовать также сегментацию на дерево квадрантов или другие типы сегментации.
[0049] Это раскрытие сущности может использовать "NxN" и "N на N" взаимозаменяемо, чтобы ссылаться на размеры в выборках блока (к примеру, CU или другого видеоблока) с точки зрения размеров по вертикали и горизонтали, например, на выборки 16×16 или выборки 16 на 16. В общем, CU 16×16 должна иметь 16 пикселов в вертикальном направлении (y=16) и 16 пикселов в горизонтальном направлении (x=16). Аналогично, CU NxN, в общем, имеет N выборок в вертикальном направлении и N выборок в горизонтальном направлении, при этом N представляет неотрицательное целочисленное значение. Выборки в CU могут размещаться в строках и столбцах. Кроме того, CU не обязательно должны иметь идентичное число выборок в горизонтальном направлении и в вертикальном направлении. Например, CU могут содержать NxM выборок, причем M не обязательно равно N.
[0050] Видеокодер 200 кодирует видеоданные для CU, представляющих информацию предсказания и/или остаточную информацию и другую информацию. Информация предсказания указывает то, как CU должна предсказываться, чтобы формировать блок предсказания для CU. Остаточная информация, в общем, представляет последовательные выборочные разности между выборками CU до кодирования и блоком предсказания.
[0051] Чтобы предсказывать CU, видеокодер 200, в общем, может формировать блок предсказания для CU через взаимное предсказание или внутреннее предсказание. Взаимное предсказание, в общем, означает предсказание CU из данных ранее кодированного картинки , тогда как внутреннее предсказание, в общем, означает предсказание CU из ранее кодированных данных идентичного картинки . Чтобы выполнять взаимное предсказание, видеокодер 200 может формировать блок предсказания с использованием одного или более векторов движения. Видеокодер 200, в общем, может выполнять поиск движения, чтобы идентифицировать опорный блок, который тесно совпадает с CU, например, с точки зрения разностей между CU и опорным блоком. Видеокодер 200 может вычислять разностный показатель с использованием суммы абсолютных разностей (SAD), суммы квадратов разности (SSD), средней абсолютной разности (MAD), среднеквадратических разностей (MSD) или других таких вычислений разности, чтобы определять то, совпадает или нет опорный блок тесно с текущей CU. В некоторых примерах, видеокодер 200 может предсказывать текущую CU с использованием однонаправленного предсказания или двунаправленного предсказания.
[0052] Некоторые примеры JEM и VVC также предоставляют аффинный режим компенсации движения, который может считаться режимом взаимного предсказания. В аффинном режиме компенсации движения, видеокодер 200 может определять два или более векторов движения, которые представляют непоступательное движение в пространстве, такие как увеличение или уменьшение масштаба, вращение, перспективное движение или другие типы нерегулярного движения.
[0053] Чтобы выполнять внутреннее предсказание, видеокодер 200 может выбирать режим внутреннего предсказания для того, чтобы формировать блок предсказания. Некоторые примеры JEM и VVC предоставляют шестьдесят семь режимов внутреннего предсказания, включающих в себя различные направленные режимы, а также планарный режим и DC-режим. В общем, видеокодер 200 выбирает режим внутреннего предсказания, который описывает соседние выборки для текущего блока (например, блока CU), из которых можно предсказывать выборки текущего блока. Такие выборки, в общем, могут находиться выше, выше и слева или слева от текущего блока в идентичной картинке с текущим блоком, при условии, что видеокодер 200 кодирует CTU и CU в порядке растрового сканирования (слева направо, сверху вниз).
[0054] Видеокодер 200 кодирует данные, представляющие режим предсказания для текущего блока. Например, для режимов взаимного предсказания, видеокодер 200 может кодировать данные, представляющие то, какой из различных доступных режимов взаимного предсказания используется, а также информацию движения для соответствующего режима. Для однонаправленного или двунаправленного взаимного предсказания, например, видеокодер 200 может кодировать векторы движения с использованием усовершенствованного предсказания векторов движения (AMVP) или режима слияния. Видеокодер 200 может использовать аналогичные режимы, чтобы кодировать векторы движения для аффинного режима компенсации движения.
[0055] После предсказания, такого как внутреннее предсказание или взаимное предсказание блока, видеокодер 200 может вычислять остаточные данные для блока. Остаточные данные, такие как остаточный блок, представляют выборку посредством примерных разностей между блоком и блоком предсказания для блока, сформированного с использованием соответствующего режима предсказания. Видеокодер 200 может применять одно или более преобразований к остаточному блоку, чтобы формировать преобразованные данные в области преобразования вместо выборочной области. Например, видеокодер 200 может применять дискретное косинусное преобразование (DCT), целочисленное преобразование, вейвлет-преобразование или концептуально аналогичное преобразование к остаточным видеоданным. Дополнительно, видеокодер 200 может применять вторичное преобразование после первого преобразования, такое как зависимое от режима неразделимое вторичное преобразование (MDNSST), зависимое от сигнала преобразование, преобразование Карунена-Лоэва (KLT) и т.п. Видеокодер 200 формирует коэффициенты преобразования после применения одного или более преобразований.
[0056] Как отмечено выше, после преобразований для того, чтобы формировать коэффициенты преобразования, видеокодер 200 может выполнять квантование коэффициентов преобразования. Квантование, в общем, означает процесс, в котором коэффициенты преобразования квантуются, чтобы, возможно, уменьшать объем данных, используемых для того, чтобы представлять коэффициенты, обеспечивая дополнительное сжатие. Посредством выполнения процесса квантования, видеокодер 200 может уменьшать битовую глубину, ассоциированную с некоторыми или всеми коэффициентами. Например, видеокодер 200 может округлять n-битовое значение в меньшую сторону до m-битового значения во время квантования, где n превышает m. В некоторых примерах, чтобы выполнять квантование, видеокодер 200 может выполнять побитовый сдвиг вправо значения, которое должно квантоваться.
[0057] После квантования, видеокодер 200 может сканировать коэффициенты преобразования, формирующие одномерный вектор, из двумерной матрицы, включающей в себя квантованные коэффициенты преобразования. Сканирование может проектироваться с возможностью размещать коэффициенты с более высокой энергией (и в силу этого с более низкой частотой) в начале вектора и размещать коэффициенты с более низкой энергией (и в силу этого с более высокой частотой) в конце векторов. В некоторых примерах, видеокодер 200 может использовать предварительно заданный порядок сканирования для того, чтобы сканировать квантованные коэффициенты преобразования, чтобы формировать преобразованный в последовательную форму вектор, и затем энтропийно кодировать квантованные коэффициенты преобразования вектора. В других примерах, видеокодер 200 может выполнять адаптивное сканирование. После сканирования квантованных коэффициентов преобразования, чтобы формировать одномерный вектор, видеокодер 200 может энтропийно кодировать одномерный вектор, например, согласно контекстно-адаптивному двоичному арифметическому кодированию (CABAC). Видеокодер 200 также может энтропийно кодировать другие синтаксические элементы, описывающие метаданные, ассоциированные с кодированными видеоданными, для использования посредством видеодекодера 300 при декодировании видеоданных.
[0058] Чтобы выполнять CABAC, видеокодер 200 может назначать контекст в контекстной модели символу, который должен быть передаваться. Контекст может быть связан, например, с тем, имеют соседние значения символа нулевое значение или нет. Определение вероятности может быть основано на контексте, назначаемом символу.
[0059] Видеокодер 200 дополнительно может формировать синтаксические данные, к примеру, синтаксические данные на основе блоков, синтаксические данные на основе картинок и синтаксические данные на основе последовательностей, в видеодекодер 300, например, в заголовке картинки , заголовке блока, заголовке серии последовательных макроблоков, либо другие синтаксические данные, к примеру, набор параметров последовательности (SPS), набор параметров картинки (PPS) или набор параметров видео (VPS). Видеодекодер 300 аналогично может декодировать такие синтаксические данные, чтобы определять то, как декодировать соответствующие видеоданные.
[0060] Таким образом, видеокодер 200 может формировать поток битов, включающий в себя кодированные видеоданные, например, синтаксические элементы, описывающие сегментацию картинки на блоки (например, CU), и информацию предсказания и/или остаточную информацию для блоков. В конечном счете, видеодекодер 300 может принимать поток битов и декодировать кодированные видеоданные.
[0061] В общем, видеодекодер 300 выполняет взаимообратный процесс относительно процесса, выполняемого посредством видеокодера 200, чтобы декодировать кодированные видеоданные потока битов. Например, видеодекодер 300 может декодировать значения для синтаксических элементов потока битов с использованием CABAC способом, практически аналогичным, хотя и взаимообратным, относительно процесса CABAC-кодирования видеокодера 200. Синтаксические элементы могут задавать сегментацию информации картинки на CTU и сегментацию каждой CTU согласно соответствующей структуре сегментации, такой как QTBT-структура, чтобы задавать CU CTU. Синтаксические элементы дополнительно могут задавать информацию предсказания и остаточную информацию для блоков (например, CU) видеоданных.
[0062] Остаточная информация может представляться, например, посредством квантованных коэффициентов преобразования. Видеодекодер 300 может обратно квантовать и обратно преобразовывать квантованные коэффициенты преобразования блока, чтобы воспроизводить остаточный блок для блока. Видеодекодер 300 использует передаваемый в служебных сигналах режим предсказания (внутреннее или взаимное предсказание) и связанную информацию предсказания (например, информацию движения для взаимного предсказания), чтобы формировать блок предсказания для блока. Видеодекодер 300 затем может комбинировать блок предсказания и остаточный блок (на основе каждой выборки), чтобы воспроизводить исходный блок. Видеодекодер 300 может выполнять дополнительную обработку, такую как выполнение процесса удаления блочности, чтобы уменьшать визуальные артефакты вдоль границ блока.
[0063] Это раскрытие сущности, в общем, может относиться к "передаче в служебных сигналах" определенной информации, такой как синтаксические элементы. Термин "передача служебных сигналов", в общем, может означать передачу значений синтаксических элементов и/или других данных, используемых для того, чтобы декодировать кодированных видеоданные. Таким образом, видеокодер 200 может передавать в служебных сигналах значения для синтаксических элементов в потоке битов. В общем, передача служебных сигналов означает формирование значения в потоке битов. Как отмечено выше, исходное устройство 102 может транспортировать поток битов в целевое устройство 116 практически в реальном времени или не в реальном времени, к примеру, что может происходить при сохранении синтаксических элементов в устройство 112 хранения данных для последующего извлечения посредством целевого устройства 116.
[0064] Фиг. 2A и 2B является концептуальной схемой, иллюстрирующей примерную структуру 130 двоичного дерева квадродерева (QTBT) и соответствующую единицу 132 дерева кодирования (CTU). Сплошные линии представляют разбиение на дерево квадрантов, и пунктирные линии указывают разбиение на двоичное дерево. В каждом разбитом (т.е. нелисте) узле двоичного дерева, один флаг передается в служебных сигналах, чтобы указывать то, какой тип разбиения (т.е. горизонтальное или вертикальное) используется, где 0 указывает то горизонтальное разбиение, и 1 указывает вертикальное разбиение в этом примере. Для разбиения на дерево квадрантов, нет необходимости указывать тип разбиения, поскольку узлы дерева квадрантов разбивают блок горизонтально и вертикально на 4 субблока с равным размером. Соответственно, видеокодер 200 может кодировать, и видеодекодер 300 может декодировать синтаксические элементы (к примеру, информацию разбиения) для древовидного уровня области QTBT-структуры 130 (т.е. сплошные линии) и синтаксические элементы (к примеру, информацию разбиения) для древовидного уровня предсказания QTBT-структуры 130 (т.е. пунктирные линии). Видеокодер 200 может кодировать, и видеодекодер 300 может декодировать видеоданные, такие как данные предсказания и преобразования, для CU, представленных посредством терминальных узлов-листьев QTBT-структуры 130.
[0065] В общем, CTU 132 по фиг. 2B может быть ассоциирован с параметрами, задающими размеры блоков, соответствующих узлам QTBT-структуры 130 на первом и втором уровнях. Эти параметры могут включать в себя CTU-размер (представляющий размер CTU 132 в выборках), минимальный размер дерева квадрантов (MinQTSize, представляющий минимальный разрешенный размер узлов-листьев дерева квадрантов), максимальный размер двоичного дерева (MaxBTSize, представляющий максимальный разрешенный размер корневых узлов двоичного дерева), максимальную глубину двоичного дерева (MaxBTDepth, представляющий максимальную разрешенную глубину двоичного дерева) и минимальный размер двоичного дерева (MinBTSize, представляющий минимальный разрешенный размер узлов-листьев двоичного дерева).
[0066] Корневой узел QTBT-структуры, соответствующей CTU, может иметь четыре дочерних узла на первом уровне QTBT-структуры, каждый из которых может сегментироваться согласно сегментации на дерево квадрантов. Таким образом, узлы первого уровня либо представляют собой узлы-листья (имеющие дочерние узлы), либо имеют четыре дочерних узла. Пример QTBT-структуры 130 представляет такие узлы как включающие в себя родительский узел и дочерний узлы, имеющие сплошные линии для ветвей. Если узлы первого уровня не превышают максимальный разрешенный размер корневых узлов двоичного дерева (MaxBTSize), они дополнительно могут сегментироваться посредством соответствующих двоичных деревьев. Разбиение на двоичное дерево одного узла может обрабатываться с помощью итераций до тех пор, пока узлы, получающиеся в результате разбиения, не достигают минимального разрешенного размера узлов-листьев двоичного дерева (MinBTSize) или максимальной разрешенной глубины двоичного дерева (MaxBTDepth). Пример QTBT-структуры 130 представляет такие узлы как имеющие пунктирные линии для ветвей. Узел-лист двоичного дерева называется "единицей кодирования (CU)", которая используется для предсказания (например, внутрикартинокого или межкартинокого предсказания) и преобразования, без дальнейшей сегментации. Как пояснено выше, CU также могут называться "видеоблоками" или "блоками".
[0067] В одном примере QTBT-структуры сегментации, CTU-размер задается как 128×128 (выборки сигнала яркости и две соответствующих выборки сигнала цветности 64×64), MinQTSize задается как 16×16, MaxBTSize задается как 64×64, MinBTSize (для ширины и высоты) задается как 4, и MaxBTDepth задается как 4. Сегментация на дерево квадрантов применяется к CTU сначала, чтобы формировать узлы-листья дерева квадрантов. Узлы-листья дерева квадрантов могут иметь размер до 16×16 (т.е. MinQTSize) до 128×128 (т.е. CTU-размера). Если узел-лист дерева квадрантов представляет собой 128×128, то он не должен дополнительно разбиваться посредством двоичного дерева, поскольку размер превышает MaxBTSize (т.е. 64×64, в этом примере). В противном случае, узел-лист дерева квадрантов дополнительно сегментируется посредством двоичного дерева. Следовательно, узел-лист дерева квадрантов также представляет собой корневой узел для двоичного дерева и имеет глубину двоичного дерева как 0. Когда глубина двоичного дерева достигает MaxBTDepth (4, в этом примере), дополнительное разбиение не разрешается. Когда узел двоичного дерева имеет ширину, равную MinBTSize (4, в этом примере), это подразумевает то, что дополнительное горизонтальное разбиение не разрешается. Аналогично, узел двоичного дерева, имеющий высоту, равную MinBTSize, подразумевает то, что дополнительное вертикальное разбиение не разрешается для этого узла двоичного дерева. Как отмечено выше, узлы-листья двоичного дерева называются "CU" и дополнительно обрабатываются согласно предсказанию и преобразованию без дополнительной сегментации.
[0068] В этом разделе, поясняются стандарты кодирования видео, в частности, связанные с предсказанием векторов движения технологии предыдущих стандартов.
[0069] Стандарты кодирования видео включают в себя ITU-T H.261, ISO/IEC MPEG-1 Visual, ITU-T H.262 или ISO/IEC MPEG-2 Visual, ITU-T H.263, ISO/IEC MPEG-4 Visual и ITU-T H.264 (также известный как ISO/IEC MPEG-4 AVC), включающий в себя расширения масштабируемого кодирования видео (SVC) и кодирования многовидового видео (MVC). Последний совместный проект MVC описывается в документе "Advanced video coding for generic audiovisual services", ITU-T Recommendation H.264, март 2010 года.
[0070] Помимо этого, предусмотрен новый разработанный стандарт кодирования видео, а именно стандарт высокоэффективного кодирования видео (HEVC), разрабатываемый посредством Объединенной группы для совместной работы над видеостандартами (JCT-VC) Экспертной группы в области кодирования видео (VCEG) ITU-T и Экспертной группы по киноизображению (MPEG) ISO/IEC. Самый свежий проект HEVC доступен по адресу http://phenix.int-evry.fr/jct/doc_end_user/documents/12_Geneva/wg11/JCTVC-L1003-v34.zip.
[0071] Информация движения
[0072] Для каждого блока, набор информации движения может быть доступным. Набор информации движения содержит информацию движения для прямого и обратного направлений предсказания. Здесь, прямое и обратное направления предсказания представляют собой два направления предсказания, соответствующих списку 0 (RefPicList0) опорных картинок и списку 1 (RefPicList1) опорных картинок для текущего картинки или серии последовательных макроблоков. Термин "прямой" и "обратный" не обязательно имеет смысл геометрии. Вместо этого, они используются для того, чтобы отличать то, на каком списке опорных картинок основан вектор движения. Прямое предсказание означает предсказание, сформированное на основе опорного списка 0, в то время как обратное предсказание означает предсказание, сформированное на основе опорного списка 1. В случае если как опорный список 0, так и опорный список 1 используются для того, чтобы формировать предсказание для данного блока, оно называется "двунаправленным предсказанием".
[0073] Для данного картинки или серии последовательных макроблоков, если используется только один список опорных картинок, каждый блок внутри картинки или серии последовательных макроблоков подвергается прямому предсказанию. Если оба списка опорных картинок используются для данного картинки или серии последовательных макроблоков, блок внутри картинки или серии последовательных макроблоков может подвергаться прямому предсказанию или обратному предсказанию, или двунаправленному предсказанию.
[0074] Для каждого направления предсказания, информация движения содержит опорный индекс и вектор движения. Опорный индекс используется для того, чтобы идентифицировать опорную картинку в соответствующем списке опорных картинок (например, RefPicList0 или RefPicList1). Вектор движения имеет как горизонтальный, так и вертикальный компонент, каждый из которых указывает значение смещения вдоль горизонтального и вертикального направления, соответственно. В некоторых описаниях, для простоты, формулировка "вектор движения" может использоваться наравне с информацией движения, чтобы указывать как вектор движения, так и его ассоциированный опорный индекс.
[0075] POC
[0076] Номер в последовательности картинок (POC) используется в стандартах кодирования видео для того, чтобы идентифицировать порядок отображения картинки . Хотя возникают случаи, когда два картинки в одной кодированной видеопоследовательности могут иметь идентичное POC-значение, это типично не происходит в кодированной видеопоследовательности. Когда несколько кодированных видеопоследовательностей присутствуют в потоке битов, картинки с идентичным значением POC могут находиться ближе друг к другу с точки зрения порядка декодирования.
[0077] POC-значения картинок типично используются для составления списков опорных картинок, извлечения набора опорных картинок, аналогично HEVC, и масштабирования векторов движения.
[0078] Единица предсказания
[0079] Единица предсказания (PU) означает базовую единицу выборок, которые совместно используют идентичную информацию предсказания. В PU для взаимного предсказания информация, предсказания может представлять собой идентичный набор информации движения или идентичный способ для того, чтобы извлекать информацию движения для PU. В одном примере, PU может быть идентичной в блочной HEVC-структуре и также может представлять собой базисный блок в других структурах сегментации на блоки, сегментации на дерево квадрантов плюс двоичное дерево, сегментации на многотипное дерево и др.
[0080] Суб-PU представляет собой субблок в PU, в которой выборки совместно используют идентичный набор информации движения. В движении на уровне суб-PU, выборки в PU совместно используют идентичный способ/модель для извлечения информации движения, но суб-PU может иметь собственный набор информации движения и может отличаться от другой суб-PU в идентичной PU.
[0081] Фиг. 3 иллюстрирует примерную блок-схему последовательности операций способа извлечения предикторов векторов движения, как пояснено в данном документе. Два списка кандидатов предикторов векторов движения извлекаются из информации соседних блоков в трехмерной области. Декодер адаптивно выбирает список согласно декодированному синтаксическому элементу is_sub_pu_motion_flag из потока битов.
[0082] В одном примере, список sub_pu может существовать только в том случае, если текущий блок превышает предварительно заданное значение. В другом примере, блок может содержать только суб-PU, например, блок 4×4, флаг в таком случае служит для того, чтобы указывать то, что формирование информации движения основано на способе суб-PU или нет. Два списка могут включать в себя различное число кандидатов предсказания движения, которые могут быть предварительно заданы или передаваться в служебных сигналах в SPS, PPS или заголовке серии последовательных макроблоков. Соседние блоки могут представлять собой пространственных соседей в текущей картинке или временных соседей в предыдущих кодированных картинки х.
[0083] Как проиллюстрировано на фиг. 3, в дальнейшем поясняется процесс извлечения двух списков. На 300, декодер определяет то, является флаг активным или нет. Если декодер определяет то, что флаг не является активным, декодер переходит к 302. Если флаг является активным, декодер переходит к 306.
[0084] На 302, извлекается первый список кандидатов предсказания движения на уровне PU. На 306, извлекается второй список кандидатов предсказания движения на уровне суб-PU. Возможный вариант предсказания движения на уровне PU означает то, что все пикселы в идентичной PU совместно используют идентичный набор информации движения. Возможный вариант предсказания движения на уровне суб-PU означает то, что все пикселы в идентичной суб-PU совместно используют идентичный набор информации движения, но другая суб-PU в PU может иметь различные наборы информации движения. Набор информации движения может включать в себя направление взаимного предсказания, индекс или индексы опорных картинок при использованием нескольких ссылок, вектор движения или векторы движения при использовании нескольких ссылок.
[0085] Пример кандидатов вектора движения на уровне PU, список представляет собой список кандидатов HEVC-слияния. Примеры предсказания движения на уровне суб-PU включают в себя, но не только, аффинное предсказание векторов движения (афинный), альтернативное временное предсказание векторов движения (ATMVP), пространственно-временное предсказание векторов движения (STMVP), планарное предсказание векторов движения и извлечение векторов движения на основе сопоставления шаблонов (PMVD) и т.п. Примерная синтаксическая таблица показывается в нижеприведенной таблице 1. Синтаксический элемент sub_pu_motion_idx может использоваться для того, чтобы указывать выбранный возможный вариант в списке кандидатов предсказания движения на уровне суб-PU, и синтаксический элемент pu_motion_idx используется для того, чтобы указывать выбранный возможный вариант в списке кандидатов предсказания движения на уровне PU.
Табл. 1

[0086] В другом способе, кандидаты вектора движения на уровне PU могут разделяться на две группы; is_sub_pu_motion_flag передается в служебных сигналах, когда декодер принимает синтаксис, указывающий то, что выбранный возможный вариант не находится в первой группе кандидатов информации движения на уровне PU. Is_sub_pu_motion_flag может неявно передаваться в служебных сигналах в индексе слияния уровня PU в качестве одного из индексов. Затем индекс слияния уровня суб-PU должен дополнительно передаваться в служебных сигналах, если is_sub_pu_motion_flag является истинным. В одном примере, порядок вставки в списки кандидатов предсказания движения на уровне PU представляет собой "A BSCDE". A, B, C, D, E обозначают кандидаты предсказания движения на уровне PU, и S представляет собой индикатор sub_pu_motion_flag. Если S выбирается, то sub_pu_motion_flag логически выводится как истинный. Один пример A может представлять собой левый нижний возможный вариант пространственного слияния, и один пример B может представлять собой правый верхний возможный вариант пространственного слияния. Следует отметить, что также может применяться другой порядок вставки.
BSCDE". A, B, C, D, E обозначают кандидаты предсказания движения на уровне PU, и S представляет собой индикатор sub_pu_motion_flag. Если S выбирается, то sub_pu_motion_flag логически выводится как истинный. Один пример A может представлять собой левый нижний возможный вариант пространственного слияния, и один пример B может представлять собой правый верхний возможный вариант пространственного слияния. Следует отметить, что также может применяться другой порядок вставки.
[0087] Следует отметить, что кандидаты предсказания движения на уровне суб-PU группируются во всех способах, описанных выше.
[0088] Передача служебных сигналов для выбора кандидата предсказания векторов движения
[0089] Синтаксический элемент is_sub_pu_motion_flag сначала используется для того, чтобы указывать то, представляет собой возможный вариант предсказания движения или нет уровень суб-PU. Is_sub_pu_motion_flag может преобразовываться в двоичную форму с использованием одного элемента разрешения (0/1) и кодироваться посредством контекстного двоичного арифметического кодера. Контекст может зависеть от PU-размера/зоны или PU-глубины в дереве сегментации на блоки. Большая PU может иметь тенденцию более частого использования при выборе предсказания вектора движения на уровне суб-PU, чем меньшая PU. Контекст также может зависеть от sub_pu_motion_flag из пространственных/временных соседних блоков. Вероятность того, что текущая PU использует движение на основе суб-PU, является более высокой, если соседние блоки имеют движение на основе суб-PU.
[0090] Если is_sub_pu_motion_flag является истинным ("1"), синтаксический элемент sub_pu_motion_idx используется для того, чтобы указывать способ, чтобы извлекать возможный вариант предсказания движения на основе суб-PU. Общее число способов, т.е. общее число кандидатов предсказания движения на уровне суб-PU, num_sub_pu_motion может передаваться в служебных сигналах в высокоуровневом синтаксисе. Sub_pu_motion_idx может преобразовываться в двоичную форму с использованием усеченного унарного кода в зависимости от num_sub_pu_motion. Тем не менее, также может применяться другой способ преобразования в двоичную форму.
[0091] Если is_sub_pu_motion_flag является ложным ("0"), синтаксический элемент nor_pu_motion_idx используется для того, чтобы указывать способ, чтобы извлекать возможный вариант предсказания движения на уровне PU. Общее число кандидатов предсказания векторов движения на уровне PU, num_nor_pu_motion может передаваться в служебных сигналах в высокоуровневом синтаксисе. Nor_pu_motion_idx может преобразовываться в двоичную форму с использованием усеченного унарного кода в зависимости от num_nor_pu_motion. Тем не менее, также может применяться другой способ преобразования в двоичную форму.
[0092] Извлечение кандидатов предсказания движения на уровне PU
[0093] Возможный вариант предсказания движения на уровне PU может извлекаться из пространственных или временных соседних кодированных блоков, аналогично HEVC. В HEVC-режиме слияния,
[0094] В HEVC, список возможных MV-вариантов содержит вплоть до 5 кандидатов для режима слияния и только два возможных варианта для AMVP-режима. Возможный вариант слияния может содержать набор информации движения, например, векторов движения, соответствующих как спискам опорных картинок (списку 0 и списку 1), так и опорным индексам. Если возможный вариант слияния идентифицируется посредством индекса слияния, опорные картинки используются для предсказания текущих блоков, а также определяются ассоциированные векторы движения.
[0095] На основе вышеописанного, одни или более предикторов векторов движения выбираются на основе декодированного индекса кандидата.
[0096] В HEVC-режиме слияния, вплоть до четырех пространственных возможных MV-вариантов 402, 404, 406 и 408 блока 400 могут извлекаться с порядками, показанными на фиг. 4. Порядок является следующим: левый (0, A1), верхний (1, B1), правый верхний (2, B0), левый нижний (3, A0) и левый верхний (4, B2).
[0097] Ниже поясняются временные соседние кандидаты в HEVC. Возможный вариант временного предиктора вектора движения (TMVP), если активируется и является доступным, добавляется в список возможных MV-вариантов после кандидатов пространственных векторов движения. Первичное блочное местоположение для извлечения возможных TMVP-вариантов представляет собой правый нижний блок за пределами совместно размещенной PU, как показано на фиг. 5 в качестве блока "T" 500, чтобы компенсировать смещение в верхнем и левом блоках, используемых для того, чтобы формировать пространственные соседние кандидаты. Тем не менее, если этот блок 502 расположен за пределами текущей CTB-строки, или информация движения не доступна, блок заменяется на центральный блок 504 PU. Вектор движения для возможного TMVP-варианта извлекается из совместно размещенной PU совместно размещенного картинки , указываемого на уровне серии последовательных макроблоков. Вектор движения для совместно размещенной PU называется "совместно размещаемым MV".
[0098] Извлечение кандидатов предсказания движения на уровне суб-PU
[0099] Кандидаты предсказания движения на уровне суб-PU могут включать в себя, но не только, аффинное предсказание движения, альтернативное временное предсказание векторов движения (ATMVP), пространственно-временное предсказание векторов движения (STMVP), планарное предсказание векторов движения, извлечение векторов движения на основе сопоставления шаблонов (PMVD) и т.п. Далее, иллюстрируются примеры этого предсказания движения на уровне суб-PU. Тем не менее, также могут добавляться некоторые варьирования или другое предсказание движения на уровне суб-PU.
[0100] Аффинное предсказание движения
[0101] В способе аффинного предсказания движения с 4 параметрами, поле векторов движения блока описывается посредством уравнения (1):
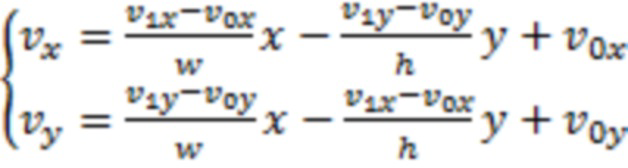 , (1)
, (1)
[0102] где (w, h) является размером блока, и (x, y) является координатой; 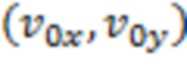 является вектором движения левой верхней угловой управляющей точки, и
является вектором движения левой верхней угловой управляющей точки, и 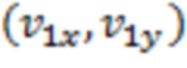 является вектором движения правой верхней угловой управляющей точки.
является вектором движения правой верхней угловой управляющей точки.
[0103] В способе аффинного предсказания движения с 6 параметрами, поле движения блока описывается посредством уравнения (2):
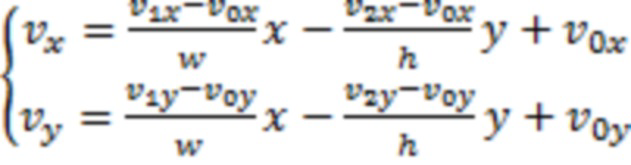 , (2)
, (2)
[0104] где, помимо этого, 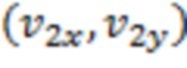 является вектором движения левой нижней угловой управляющей точки.
является вектором движения левой нижней угловой управляющей точки.
[0105] В аффинном предсказании движения на основе суб-PU, MV суб-PU может извлекаться посредством вычисления MV в центре суб-PU. Альтернативно, можно понижающе масштабировать (w, h) и (x, y) согласно размеру суб-PU.
[0106] В одном способе, 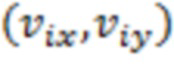 может извлекаться из соседнего блока, который ранее кодируется посредством аффинного движения, с учетом того, что текущий блок совместно использует идентичную модель аффинного движения с предыдущим кодированным соседним блоком.
может извлекаться из соседнего блока, который ранее кодируется посредством аффинного движения, с учетом того, что текущий блок совместно использует идентичную модель аффинного движения с предыдущим кодированным соседним блоком.
[0107] В другом способе, может извлекаться посредством вектора движения в соседнем кодированном блоке. Например, как показано на фиг. 6, может извлекаться из вектора движения в блоке A 600, B 602 или C 604, может извлекаться из вектора движения в блоке C 606 или D 608, может извлекаться из блока E 610 или F 612.
[0108] Альтернативное временное предсказание векторов движения
[0109] В альтернативном способе (ATMVP) временного предсказания векторов движения (или иногда называемом "усовершенствованным временным предсказанием векторов движения"), временное предсказание векторов движения (TMVP) модифицируется посредством выборки нескольких наборов информации движения (включающих в себя векторы движения и опорные индексы) из суб-PU текущей PU.
[0110] Пространственно-временное предсказание векторов движения
[0111] В способе пространственно-временного предсказания векторов движения, векторы движения суб-PU извлекаются рекурсивно, согласно порядку растрового сканирования. Фиг. 7 иллюстрирует понятие STMVP. Рассмотрим PU 8×8, которая содержит четыре суб-PU A, B, C и D 4×4. Соседние блоки 4×4 в текущем кадре помечаются в качестве a, b, c и d. Извлечение движения для суб-CU начинается посредством идентификации ее двух пространственных соседних узлов. Первый соседний узел представляет собой блок NxN выше суб-CU (блок c). Если этот блок c не доступен или внутренне кодируется, другие блоки NxN выше суб-CU A проверяются (слева направо, начиная с блока c). Второй соседний узел представляет собой блок слева от суб-CU (блок b). Если блок b не доступен или внутренне кодируется, другие блоки слева от суб-CU A проверяются (сверху вниз, начиная с блока b). Информация движения, полученная из соседних блоков для каждого списка, масштабируется до первого опорного кадра для данного списка. Далее, временной предиктор вектора движения (TMVP) субблока A извлекается посредством выполнения идентичной процедуры TMVP-извлечения, как указано в HEVC. Информация движения совместно размещенного блока в местоположении D отбирается и масштабируется, соответственно. В завершение, после извлечения и масштабирования информации движения, все доступные векторы движения (до 3) усредняются отдельно для каждого опорного списка. Усредненный вектор движения назначается в качестве вектора движения текущей суб-CU.
[0112] Извлечение векторов движения на основе сопоставления шаблонов
[0113] Способ извлечения векторов движения на основе сопоставления с шаблоном (PMMVD) основан на технологиях преобразования с повышением частоты картинок. Процесс извлечения движения имеет два этапа. Поиск движения на уровне PU сначала выполняется, с последующей детализацией движения на уровне суб-PU. На уровне PU, начальный вектор движения извлекается для всей PU на основе билатерального сопоставления или сопоставления с эталоном. Во-первых, список возможных MV-вариантов формируется, и возможный вариант, который приводит к минимальным затратам на сопоставление, выбирается в качестве начальной точки для дополнительной детализации на уровне PU. Затем выполняется локальный поиск на основе билатерального сопоставления или сопоставления с эталоном вокруг начальной точки, и MV, приводящий к минимальным затратам на сопоставление, рассматривается в качестве MV для всей CU. После этого, информация движения дополнительно детализируется на уровне суб-PU с извлеченными CU-векторами движения в качестве начальных точек.
[0114] Понятие билатерального сопоставления проиллюстрировано на фиг. 8. Билатеральное сопоставление используется для того, чтобы извлекать информацию движения посредством нахождения ближайшего соответствия между двумя блоками вдоль траектории движения текущего блока в двух различных опорных картинки х. При допущении траектории непрерывного движения, векторы MV0 и MV1 движения, указывающие на два опорных блока, должны быть пропорциональными временным расстояниям, т.е. TD0 и TD1, между текущей картинкой и двумя опорными картинками. В качестве частного случая, когда текущая картинка временно находится между двумя опорными картинками, и временное расстояние от текущего картинки до двух опорных картинок является идентичным, билатеральное сопоставление становится двунаправленным MV на основе зеркалирования.
[0115] Сопоставление с эталоном, как проиллюстрировано на фиг. 9, используется для того, чтобы извлекать информацию движения посредством нахождения ближайшего соответствия между эталоном (верхним и/или левым соседними блоками текущего блока) в текущей картинке и блоком (идентичного размера с эталоном) в опорной картинке.
[0116] Планарное предсказание векторов движения
[0117] Планарное предсказание векторов движения достигается посредством усреднения горизонтальной и вертикальной линейной интерполяции на основе блоков 4×4 следующим образом.
[0118] W и H обозначают ширину и высоту блока; (x, y) являются координатами текущего субблока относительно вышеуказанного субблока левого угла. Все расстояния обозначаются посредством пиксельных расстояний, деленных на 4. P(x, y) является вектором движения текущего субблока.
[0119] Горизонтальное предсказание Ph(x, y) и вертикальное предсказание Pv(x, y) для местоположения (x, y) вычисляются следующим образом:
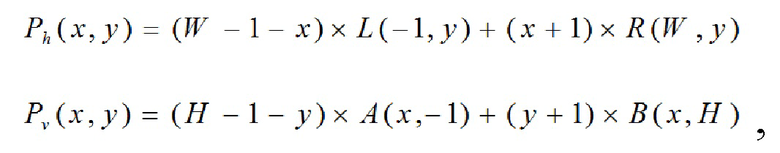
[0120] где L(-1, y) и R(W, y) являются векторами движения блоков 4×4 слева и справа от текущего блока; A(x, -1) и B(x, H) являются векторами движения блоков 4×4 сверху и снизу от текущего блока, как показано на фиг. 9.
[0121] Опорная информация движения соседних блоков из левого столбца и верхней строки извлекается из пространственных соседних блоков текущего блока.
[0122] Опорная информация движения соседних блоков из правого столбца и нижней строки извлекается следующим образом.
1) Извлечение информации движения правого нижнего временного соседнего блока 4×4.
2) Вычисление векторов движения соседних блоков 4×4 в правом столбце, с использованием извлеченной информации движения правого нижнего соседнего блока 4×4 наряду с информацией движения вышеуказанного правого соседнего блока 4×4, в качестве R(W, y)=((H-y-1)xAR+(y+1)xBR)/H.
3) Вычисление векторов движения соседних блоков 4×4 в нижней строке, с использованием извлеченной информации движения правого нижнего соседнего блока 4×4 наряду с информацией движения левого нижнего соседнего блока 4×4, в качестве B(x, H)=((W-x-1)xBL+(x+1)xBR)/W.
[0123] - где AR является вектором движения правого верхнего пространственного соседнего блока 4×4, BR является вектором движения правого нижнего временного соседнего блока 4×4, и BL является вектором движения левого нижнего пространственного соседнего блока 4×4, как показано на фиг. 10.
[0124] Информация движения, полученная из соседних блоков для каждого списка, масштабируется до первого опорного картинки для данного списка.
[0125] Вставка в списки кандидатов
[0126] При наличии, кандидаты предсказания движения на уровне суб-PU вставляются в список в следующем порядке по умолчанию: "аффинныйATMVPSTMVPPMMVDпланарный". Порядок по умолчанию может быть предварительно задан или передаваться в служебных сигналах на основе типа серии последовательных макроблоков, временного слоя, модели аффинного движения и/или доступности временного предиктора движения. Порядок по умолчанию также может отличаться на основе типа блока, формы блока или размера блока. Максимальное число кандидатов предсказания движения на уровне суб-PU определяется посредством предварительно заданного числа и/или общего числа доступных кандидатов предсказания движения на уровне суб-PU, как указано посредством высокоуровневого синтаксиса. В одном примере, если предварительно заданное число равно 3, и все из аффинного, ATMVP-, STMVP-, PMMVD- и планарного кандидатов доступны, то максимальное число равно 3. Но если только аффинный и ATMVP доступны, то максимальное число равно 2. Если максимальное число равно 0, то is_sub_pu_motion_flag логически выводится как ложный (0) и не передается в служебных сигналах в потоке битов.
[0127] Также может использоваться другой порядок кандидатов по умолчанию.
В одном примере, "аффинныйPMMVDATMVPSTMVPпланарный".
В другом примере, "PMMVDаффинныйATMVPSTMVPпланарный".
В другом примере, могут использоваться два или более аффинных возможных варианта:
"аффинный 1аффинный 2PMMVDATMVPSTMVPпланарный";
либо, "аффинный 1Affine1ATMVPаффинный 2планарный"
[0128] Приоритезированное переупорядочивание кандидатов
[0129] Список кандидатов предсказания движения на уровне суб-PU по умолчанию может переупорядочиваться на основе их возникновений в соседние кодированные блоки. В одном примере, возможный вариант, который имеет большее число возникновений в соседние кодированные блоки, размещается в более низкой индексной позиции в списке.
[0130] Частичное приоритезированное переупорядочивание кандидатов
[0131] Чтобы уменьшать сложность переупорядочения кандидатов, приоритезированное переупорядочивание кандидатов применяется только к одному или более подсписков. Например, возможный вариант 1-2, 3-4 в порядке по умолчанию переупорядочивается отдельно на основе своего появления в соседних кодированных блоках.
[0132] Отсечение
[0133] Чтобы уменьшать сложность, отсечение или частичное отсечение не может применяться в списке кандидатов суб-PU. В одном примере, отсечение между ATMVP, STMVP и планарным может применяться, но отсечение не применяется между аффинным и остальными возможными вариантами суб-PU.
[0134] В другом примере, отсечение применяется только к числу суб-PU, меньшему или равному предварительно заданному значению.
[0135] Альтернативные способы передачи в служебных сигналах кандидата предсказания движения на основе суб-PU
[0136] Выбор кандидата предсказания движения на основе суб-PU может передаваться в служебных сигналах посредством активации флагов согласно порядку вставки кандидатов вместо индекса. В одном примере, если порядок вставки представляет собой "аффинныйPMMVDATMVPSTMVPпланарный", то передача служебных сигналов является такой, как показано в таблице 2.
[0137] В другом альтернативном способе, кандидаты предсказания движения на основе суб-PU могут группироваться в несколько подгрупп. Например, аффинный, планарный группируются в подгруппу 1, ATMVP и STMVP группируются в подгруппу 2, и PMMVD представляет собой еще одну другую подгруппу 3. Примерная передача служебных сигналов показывается в таблице 3. Синтаксис pmmvd_flag сначала передается в служебных сигналах, чтобы указывать то, представляет он собой возможный PMMVD-вариант или нет. Затем, если он не представляет собой возможный PMMVD-вариант, другой синтаксический элемент sub_group1_flag передается в служебных сигналах, чтобы указывать то, представляет он собой кандидаты подгруппы 1 или нет. Если sub_group1_flag является истинным, что указывает то, что он представляет собой кандидаты подгруппы 1, affine_flag передается в служебных сигналах, чтобы указывать то, представляет он или нет собой аффинный возможный вариант. Если он не представляет собой аффинный возможный вариант, то planar_mv_flag задается как истинный, чтобы указывать то, он представляет собой планарный возможный вариант. Если sub_group1_flag является ложным, то atmvp_flag передается в служебных сигналах, чтобы указывать то, представляет он собой возможный ATMVP-вариант или нет. Если он не представляет собой возможный ATMVP-вариант, stmvp_flag задается как истинный, чтобы указывать то, что он представляет собой возможный STMVP-вариант.
Табл. 2

Табл. 3

[0138] Следует отметить, что в таблице 2 и таблице 3, проверка доступности игнорируется для просторы примера. Флаг логически выводится как ложный (0), если соответствующий возможный вариант не доступен. Также следует отметить, также могут применяться что другие варьирования группировки.
[0139] Фиг. 11 является блок-схемой, иллюстрирующей примерный видеокодер 200, который может выполнять технологии этого раскрытия сущности. Фиг. 11 предоставляется для целей пояснения и не должен считаться ограничением технологий, как проиллюстрировано и описано в общих чертах в этом раскрытии сущности. Для целей пояснения, это раскрытие сущности описывает видеокодер 200 в контексте стандартов кодирования видео, таких как стандарт HEVC-кодирования видео и разрабатываемый стандарт кодирования видео H.266. Тем не менее, технологии этого раскрытия сущности не ограничены этими стандартами кодирования видео и, в общем, являются применимыми к кодированию и декодированию видео.
[0140] В примере по фиг. 11, видеокодер 200 включает в себя запоминающее устройство 230 видеоданных, модуль 202 выбора режима, модуль 204 формирования остатков, модуль 206 обработки преобразования, модуль 208 квантования, модуль 202 обратного квантования, модуль 212 обработки обратного преобразования, модуль 214 восстановления, модуль 216 фильтрации, буфер 218 декодированных картинок (DPB) и модуль 220 энтропийного кодирования.
[0141] Запоминающее устройство 230 видеоданных может сохранять видеоданные, которые должны кодироваться посредством компонентов видеокодера 200. Видеокодер 200 может принимать видеоданные, сохраненные в запоминающем устройстве 230 видеоданных, например, из видеоисточника 104 (фиг. 1). DPB 218 может выступать в качестве запоминающего устройства опорных картинок, которое сохраняет опорные видеоданные для использования при предсказании последующих видеоданных посредством видеокодера 200. Запоминающее устройство 230 видеоданных и DPB 218 могут формироваться посредством любых из множества запоминающих устройств, к примеру, как динамическое оперативное запоминающее устройство (DRAM), включающее в себя синхронное DRAM (SDRAM), магниторезистивное RAM (MRAM), резистивное RAM (RRAM) или другие типы запоминающих устройств. Запоминающее устройство 230 видеоданных и DPB 218 могут предоставляться посредством идентичного запоминающего устройства или отдельных запоминающих устройств. В различных примерах, запоминающее устройство 230 видеоданных может быть внутримикросхемным с другими компонентами видеокодера 200, как проиллюстрировано, или внемикросхемным относительно этих компонентов.
[0142] В этом раскрытии сущности, ссылка на запоминающее устройство 230 видеоданных не должна интерпретироваться как ограниченная запоминающим устройством, внутренним для видеокодера 200, если не описывается конкретно в таком качестве, или запоминающим устройством, внешним для видеокодера 200, если не описывается конкретно в таком качестве. Наоборот, ссылка на запоминающее устройство 230 видеоданных должна пониматься как опорное запоминающее устройство, которое сохраняет видеоданные, которые видеокодер 200 принимает для кодирования (например, видеоданные для текущего блока, который должен кодироваться). Запоминающее устройство 106 по фиг. 1 также может предоставлять временное хранение выводов из различных модулей видеокодера 200.
[0143] Различные модули по фиг. 11 проиллюстрированы для того, чтобы помогать в понимании операций, выполняемых посредством видеокодера 200. Модули могут реализовываться как схемы с фиксированной функцией, программируемые схемы либо комбинация вышеозначенного. Схемы с фиксированной функцией означают схемы, которые предоставляют конкретную функциональность и предварительно установлены в отношении операций, которые могут выполняться. Программируемые схемы означают схемы, которые могут программироваться с возможностью выполнять различные задачи и предоставлять гибкую функциональность в операциях, которые могут выполняться. Например, программируемые схемы могут выполнять программное обеспечение или микропрограммное обеспечение, которое инструктирует программируемым схемам работать способом, заданным посредством инструкций программного обеспечения или микропрограммного обеспечения. Схемы с фиксированной функцией могут выполнять программные инструкции (например, чтобы принимать параметры или выводить параметры), но типы операций, которые выполняют схемы с фиксированной функцией, в общем, являются неизменными. В некоторых примерах, один или более модулей могут представлять собой различные схемные блоки (с фиксированной функцией или программируемые), и в некоторых примерах, один или более модулей могут представлять собой интегральные схемы.
[0144] Видеокодер 200 может включать в себя арифметико-логические устройства (ALU), элементарные функциональные модули (EFU), цифровые схемы, аналоговые схемы и/или программируемые ядра, сформированные из программируемых схем. В примерах, в которых операции видеокодера 200 выполняются с использованием программного обеспечения, выполняемого посредством программируемых схем, запоминающее устройство 106 (фиг. 1) может сохранять объектный код программного обеспечения, которое видеокодер 200 принимает и выполняет, или другое запоминающее устройство в видеокодере 200 (не показано) может сохранять такие инструкции.
[0145] Запоминающее устройство 230 видеоданных выполнено с возможностью сохранять принимаемые видеоданные. Видеокодер 200 может извлекать картинку видеоданных из запоминающего устройства 230 видеоданных и предоставлять видеоданные в модуль 204 формирования остатков и модуль 202 выбора режима. Видеоданные в запоминающем устройстве 230 видеоданных могут представлять собой необработанные видеоданные, которые должны кодироваться.
[0146] Модуль 202 выбора режима включает в себя модуль 222 оценки движения, модуль 224 компенсации движения и модуль 226 внутреннего предсказания. Модуль 202 выбора режима может включать в себя дополнительные функциональные модули, чтобы выполнять предсказание видео в соответствии с другими режимами предсказания. В качестве примера, модуль 202 выбора режима может включать в себя модуль палитровой обработки, модуль внутриблочного копирования (который может представлять собой часть модуля 222 оценки движения и/или модуля 224 компенсации движения), модуль аффинной обработки, модуль обработки на основе линейной модели (LM) и т.п.
[0147] Модуль 202 выбора режима, в общем, координирует несколько проходов кодирования, чтобы тестировать комбинации параметров кодирования и результирующих значений искажения в зависимости от скорости передачи для таких комбинаций. Параметры кодирования могут включать в себя сегментацию CTU на CU, режимы предсказания для CU, типы преобразования для остаточных данных CU, параметры квантования для остаточных данных CU и т.д. Модуль 202 выбора режима в конечном счете может выбирать комбинацию параметров кодирования, имеющих значения искажения в зависимости от скорости передачи, которые лучше других тестированных комбинаций.
[0148] Видеокодер 200 может сегментировать картинку, извлеченный из запоминающего устройства 230 видеоданных, на последовательность CTU и инкапсулировать одну или более CTU в серии последовательных макроблоков. Модуль 210 выбора режима может сегментировать CTU картинки в соответствии с древовидной структурой, такой как QTBT-структура или структура в виде дерева квадрантов HEVC, описанного выше. Как описано выше, видеокодер 200 может формировать одну или более CU из сегментации CTU согласно древовидной структуре. Такая CU также, в общем, может называться "видеоблоком" или "блоком".
[0149] В общем, модуль 202 выбора режима также управляет своими компонентами (например, модулем 222 оценки движения, модулем 224 компенсации движения и модулем 226 внутреннего предсказания), чтобы формировать блок предсказания для текущего блока (например, текущей CU либо, в HEVC, перекрывающейся части PU и TU). Для взаимного предсказания текущего блока, модуль 222 оценки движения может выполнять поиск движения, чтобы идентифицировать один или более тесно совпадающих опорных блоков в одном или более опорных картинок (например, в одном или более ранее кодированных картинок, сохраненных в DPB 218). В частности, модуль 222 оценки движения может вычислять значение, представляющее то, насколько аналогичным является потенциальный опорный блок для текущего блока, например, согласно сумме абсолютных разностей (SAD), сумме квадратов разности (SSD), средней абсолютной разности (MAD), среднеквадратическим разностями (MSD) и т.п. Модуль 222 оценки движения, в общем, может выполнять эти вычисления с использованием повыборочных разностей между текущим блоком и рассматриваемым опорным блоком. Модуль 222 оценки движения может идентифицировать опорный блок, имеющий наименьшее значение, получающееся в результате этих вычислений, указывающее опорный блок, который наиболее тесно совпадает с текущим блоком.
[0150] Модуль 222 оценки движения может формировать один или более векторов движения (MV), которые задают позиции опорных блоков в опорных картинки х относительно позиции текущего блока в текущей картинке. Модуль 222 оценки движения затем может предоставлять векторы движения в модуль 224 компенсации движения. Например, для однонаправленного взаимного предсказания, модуль 222 оценки движения может предоставлять один вектор движения, тогда как для двунаправленного взаимного предсказания, модуль 222 оценки движения может предоставлять два вектора движения. Модуль 224 компенсации движения затем может формировать блок предсказания с использованием векторов движения. Например, модуль 224 компенсации движения может извлекать данные опорного блока с использованием вектора движения. В качестве другого примера, если вектор движения имеет точность в дробную часть выборки, модуль 224 компенсации движения может интерполировать значения для блока предсказания согласно одному или более интерполяционных фильтров. Кроме того, для двунаправленного взаимного предсказания, модуль 224 компенсации движения может извлекать данные для двух опорных блоков, идентифицированных посредством соответствующих векторов движения, и комбинировать извлеченные данные, например, посредством последовательного выборочного усреднения или усреднения со взвешиванием.
[0151] В качестве другого примера, для внутреннего предсказания или внутреннего предсказывающего кодирования, модуль 226 внутреннего предсказания может формировать блок предсказания из выборок, соседних с текущим блоком. Например, для направленных режимов, модуль 226 внутреннего предсказания, в общем, может математически комбинировать значения соседних выборок и заполнять эти вычисленные значения в заданном направлении для текущего блока, чтобы формировать блок предсказания. В качестве другого примера, для DC-режима, модуль 226 внутреннего предсказания может вычислять среднее соседних выборок по отношению к текущему блоку и формировать блок предсказания, который включает в себя это результирующее среднее для каждой выборки блока предсказания.
[0152] Модуль 202 выбора режима предоставляет блок предсказания в модуль 204 формирования остатков. Модуль 204 формирования остатков принимает необработанную некодированную версию текущего блока из запоминающего устройства 230 видеоданных и блок предсказания из модуля 202 выбора режима. Модуль 204 формирования остатков вычисляет последовательные выборочные разности между текущим блоком и блоком предсказания. Результирующие последовательные выборочные разности задают остаточный блок для текущего блока. В некоторых примерах, модуль 204 формирования остатков также может определять разности между выборочными значениями в остаточном блоке, чтобы формировать остаточный блок с использованием остаточной дифференциальной импульсно-кодовой модуляции (RDPCM). В некоторых примерах, модуль 204 формирования остатков может формироваться с использованием одной или более схем вычитателя, которые выполняют двоичное вычитание.
[0153] В примерах, в которых модуль 202 выбора режима сегментирует CU на PU, каждая PU может быть ассоциирована с единицей предсказания сигналов яркости и соответствующими единицами предсказания сигналов цветности. Видеокодер 200 и видеодекодер 300 могут поддерживать PU, имеющие различные размеры. Как указано выше, размер CU может означать размер блока кодирования сигналов яркости CU, и размер PU может означать размер единицы предсказания сигналов яркости PU. При условии, что размер конкретной CU составляет 2Nx2N, видеокодер 200 может поддерживать PU-размеры в 2Nx2N или NxN для внутреннего предсказания и симметричные PU-размеры в 2Nx2N, 2NxN, Nx2N, NxN или аналогичные для взаимного предсказания. Видеокодер 200 и видеодекодер 300 также могут поддерживать асимметричное сегментирование для PU-размеров в 2NxnU, 2NxnD, nLx2N и nRx2N для взаимного предсказания.
[0154] В примерах, в которых модуль 202 выбора режима дополнительно не сегментирует CU на PU, каждая CU может быть ассоциирована с блоком кодирования сигналов яркости и соответствующими блоками кодирования сигналов цветности. Как описано выше, размер CU может означать размер блока кодирования сигналов яркости CU. Видеокодер 200 и видеодекодер 300 могут поддерживать CU-размеры в 2Nx2N, 2NxN или Nx2N.
[0155] Для других технологий кодирования видео, таких как кодирование в режиме внутриблочного копирования, кодирование в аффинном режиме и кодирование в режиме на основе линейной модели (LM), в качестве нескольких примеров, модуль 202 выбора режима, через соответствующие модули, ассоциированные с технологиями кодирования, формирует блок предсказания для кодируемого текущего блока. В некоторых примерах, таких как кодирование в палитровом режиме, модуль 202 выбора режима может не формировать блок предсказания и вместо этого формировать синтаксические элементы, которые указывают способ, которым следует восстанавливать блок на основе выбранной палитры. В таких режимах, модуль 202 выбора режима может предоставлять эти синтаксические элементы в модуль 220 энтропийного кодирования для кодирования.
[0156] Как описано выше, модуль 204 формирования остатков принимает видеоданные для текущего блока и соответствующего блока предсказания. Модуль 204 формирования остатков затем формирует остаточный блок для текущего блока. Чтобы формировать остаточный блок, модуль 204 формирования остатков вычисляет последовательные выборочные разности между блоком предсказания и текущим блоком. Таким образом:
[0157] Модуль 206 обработки преобразования применяет одно или более преобразований к остаточному блоку, чтобы формировать блок коэффициентов преобразования (называется в данном документе "блоком коэффициентов преобразования"). Модуль 206 обработки преобразования может применять различные преобразования к остаточному блоку, чтобы формировать блок коэффициентов преобразования. Например, модуль 206 обработки преобразования может применять дискретное косинусное преобразование (DCT), направленное преобразование, преобразование Карунена-Лоэва (KLT) или концептуально аналогичное преобразование к остаточному блоку. В некоторых примерах, модуль 206 обработки преобразования может выполнять несколько преобразований для остаточного блока, например, первичное преобразование и вторичное преобразование, такое как вращательное преобразование. В некоторых примерах, модуль 206 обработки преобразования не применяет преобразования к остаточному блоку.
[0158] Модуль 208 квантования может квантовать коэффициенты преобразования в блоке коэффициентов преобразования, чтобы формировать блок квантованных коэффициентов преобразования. Модуль 208 квантования может квантовать коэффициенты преобразования блока коэффициентов преобразования согласно значению параметра квантования (QP), ассоциированному с текущим блоком. Видеокодер 200 (например, через модуль 202 выбора режима) может регулировать степень квантования, применяемую к блокам коэффициентов, ассоциированным с текущим блоком, посредством регулирования QP-значения, ассоциированного с CU. Квантование может вводить потери информации, и в силу этого квантованные коэффициенты преобразования могут иметь меньшую точность, чем исходные коэффициенты преобразования, сформированные посредством модуля 206 обработки преобразования.
[0159] Модуль 210 обратного квантования и модуль 212 обработки обратного преобразования могут применять обратное квантование и обратные преобразования к блоку квантованных коэффициентов преобразования, соответственно, для того чтобы восстанавливать остаточный блок из блока коэффициентов преобразования. Модуль 214 восстановления может формировать восстановленный блок, соответствующий текущему блоку (хотя потенциально с определенной степенью искажения) на основе восстановленного остаточного блока и блока предсказания, сформированного посредством модуля 202 выбора режима. Например, модуль 214 восстановления может суммировать выборки восстановленного остаточного блока с соответствующими выборками из блока предсказания, сформированного посредством модуля 202 выбора режима, чтобы формировать восстановленный блок.
[0160] Модуль 216 фильтрации может выполнять одну или более операций фильтрации для восстановленных блоков. Например, модуль 216 фильтрации может выполнять операции удаления блочности, чтобы уменьшать артефакты блочности вдоль краев CU. Операции модуля 216 фильтрации могут пропускаться в некоторых примерах.
[0161] Видеокодер 200 сохраняет восстановленные блоки в DPB 218. Например, в примерах, в которых операции модуля 216 фильтрации не требуются, модуль 216 восстановления может сохранять восстановленные блоки в DPB 218. В примерах, в которых операции модуля 224 фильтрации необходимы, модуль 216 фильтрации может сохранять фильтрованные восстановленные блоки в DPB 218. Модуль 222 оценки движения и модуль 224 компенсации движения могут извлекать опорную картинку из DPB 218, сформированного из восстановленных (и потенциально фильтрованных) блоков, чтобы взаимно предсказывать блоки последующих кодированных картинок. Помимо этого, модуль 226 внутреннего предсказания может использовать восстановленные блоки в DPB 218 текущей картинки, чтобы внутренне предсказывать другие блоки в текущей картинке.
[0162] В общем, модуль 220 энтропийного кодирования может энтропийно кодировать синтаксические элементы, принимаемые из других функциональных компонентов видеокодера 200. Например, модуль 220 энтропийного кодирования может энтропийно кодировать блоки квантованных коэффициентов преобразования из модуля 208 квантования. В качестве другого примера, модуль 220 энтропийного кодирования может энтропийно кодировать синтаксические элементы предсказания (например, информацию движения для взаимного предсказания или информацию внутреннего режима для внутреннего предсказания) из модуля 202 выбора режима. Модуль 220 энтропийного кодирования может выполнять одну или более операций энтропийного кодирования для синтаксических элементов, которые представляют собой другой пример видеоданных, чтобы формировать энтропийно кодированные данные. Например, модуль 220 энтропийного кодирования может выполнять операцию контекстно-адаптивного кодирования переменной длины (CAVLC), CABAC-операцию, операцию кодирования переменно-переменной (V2V) длины, операцию синтаксического контекстно-адаптивного двоичного арифметического кодирования (SBAC), операцию энтропийного кодирования на основе сегментирования на интервалы вероятности (PIPE), операцию экспоненциального кодирования кодом Голомба или другой тип операции энтропийного кодирования для данных. В некоторых примерах, модуль 220 энтропийного кодирования может работать в обходном режиме, в котором синтаксические элементы не подвергаются энтропийному кодированию.
[0163] Видеокодер 200 может выводить поток битов, который включает в себя энтропийно кодированные синтаксические элементы, требуемые для того, чтобы восстанавливать блоки серии последовательных макроблоков или картинки . В частности, модуль 220 энтропийного кодирования может выводить поток битов.
[0164] Операции, описанные выше, описываются относительно блока. Такое описание должно пониматься как операции для блока кодирования сигналов яркости и/или блоков кодирования сигналов цветности. Как описано выше, в некоторых примерах, блок кодирования сигналов яркости и блоки кодирования сигналов цветности представляют собой компоненты сигнала яркости и сигнала цветности CU. В некоторых примерах, блок кодирования сигналов яркости и блоки кодирования сигналов цветности представляют собой компоненты сигнала яркости и сигнала цветности PU.
[0165] В некоторых примерах, операции, выполняемые относительно блока кодирования сигналов яркости, не должны повторяться для блоков кодирования сигналов цветности. В качестве одного примера, операции, чтобы идентифицировать вектор движения (MV) и опорную картинку для блока кодирования сигналов яркости, не должны повторяться для идентификации MV и опорной картинки для блоков сигналов цветности. Наоборот, MV для блока кодирования сигналов яркости может масштабироваться, чтобы определять MV для блоков сигналов цветности, и опорная картинка может быть такой же. В качестве другого примера, процесс внутреннего предсказания может быть одинаковым для блоков кодирования сигналов яркости и блоков кодирования сигналов цветности.
[0166] Видеокодер 200 представляет пример устройства, выполненного с возможностью кодировать видеоданные, включающего в себя запоминающее устройство, выполненное с возможностью сохранять видеоданные, и один или более модулей обработки, реализованных в схеме и выполненных с возможностью извлекать эталон преобразования с повышением частоты картинок (FRUC) с использованием значения пикселы предсказания и выполнять технологию извлечения векторов движения на стороне декодера с использованием извлеченного эталона. В другом примере, видеодекодер 300 может быть выполнен с возможностью определять соответствующие векторы движения из одного или более соседних блоков видеоданных и извлекать вектор движения для текущего блока видеоданных с использованием соответствующих векторов движения из одного или более соседних блоков видеоданных. В другом примере, видеодекодер 300 может быть выполнен с возможностью определять соответствующие векторы движения из одного или более совместно размещенных блоков видеоданных и извлекать вектор движения для текущего блока видеоданных с использованием соответствующих векторов движения из одного или более совместно размещенных блоков видеоданных.
[0167] Фиг. 12 является блок-схемой, иллюстрирующей примерный видеодекодер 300, который может выполнять технологии этого раскрытия сущности. Фиг. 12 предоставляется для целей пояснения и не является ограничением технологий, как проиллюстрировано и описано в общих чертах в этом раскрытии сущности. Для целей пояснения, это раскрытие сущности описывает видеодекодер 300, описываемый согласно технологиям JEM, H.266/VVC и HEVC. Тем не менее, технологии этого раскрытия сущности могут выполняться посредством устройств кодирования видео, которые сконфигурированы для других стандартов кодирования видео.
[0168] В примере по фиг. 12, видеодекодер 300 включает в себя буферное запоминающее устройство 320 кодированных картинок (CPB), модуль 302 энтропийного декодирования, модуль 304 обработки предсказания, модуль 306 обратного квантования, модуль 308 обработки обратного преобразования, модуль 310 восстановления, модуль 312 фильтрации и буфер 314 декодированных картинок (DPB). Модуль 304 обработки предсказания включает в себя модуль 316 компенсации движения и модуль 318 внутреннего предсказания. Модуль 304 обработки предсказания может включать в себя модули суммирования, чтобы выполнять предсказание в соответствии с другими режимами предсказания. В качестве примера, модуль 304 обработки предсказания может включать в себя модуль палитровой обработки, модуль внутриблочного копирования (который может составлять часть модуля 316 компенсации движения), модуль аффинной обработки, модуль обработки на основе линейной модели (LM) и т.п. В других примерах, видеодекодер 300 может включать в себя большее, меньшее число или другие функциональные компоненты.
[0169] Запоминающее CPB-устройство 320 может сохранять видеоданные, такие как кодированный битовый поток видео, который должен декодироваться посредством компонентов видеодекодера 300. Видеоданные, сохраненные в запоминающем CPB-устройстве 320, могут получаться, например, из машиночитаемого носителя 110 (фиг. 1). Запоминающее CPB-устройство 320 может включать в себя CPB, который сохраняет кодированные видеоданные (например, синтаксические элементы) из кодированного битового потока видео. Кроме того, запоминающее CPB-устройство 320 может сохранять видеоданные, отличные от синтаксических элементов кодированного картинки , такие как временные данные, представляющие выводы из различных модулей видеодекодера 300. DPB 314, в общем, сохраняет декодированные картинки, которые видеодекодер 300 может выводить и/или использовать в качестве опорных видеоданных при декодировании последующих данных или картинок кодированного битового потока видео. Запоминающее CPB-устройство 320 и DPB 314 могут формироваться посредством любого из множества запоминающих устройств, к примеру, как динамическое оперативное запоминающее устройство (DRAM), включающее в себя синхронное DRAM (SDRAM), магниторезистивное RAM (MRAM), резистивное RAM (RRAM) или другие типы запоминающих устройств. Запоминающее CPB-устройство 320 и DPB 314 могут предоставляться посредством идентичного запоминающего устройства или отдельных запоминающих устройств. В различных примерах, запоминающее CPB-устройство 320 может быть внутримикросхемным с другими компонентами видеодекодера 300 или внемикросхемным относительно этих компонентов.
[0170] Дополнительно или альтернативно, в некоторых примерах, видеодекодер 300 может извлекать кодированные видеоданные из запоминающего устройства 120 (фиг. 1). Таким образом, запоминающее устройство 120 может сохранять данные, как пояснено выше для запоминающего CPB-устройства 320. Аналогично, запоминающее устройство 120 может сохранять инструкции, которые должны выполняться посредством видеодекодера 300, когда часть или вся функциональность видеодекодера 300 реализуется в программном обеспечении для выполнения посредством схемы обработки видеодекодера 300.
[0171] Различные модули, показанные на фиг. 12, проиллюстрированы для того, чтобы помогать в понимании операций, выполняемых посредством видеодекодера 300. Модули могут реализовываться как схемы с фиксированной функцией, программируемые схемы либо комбинация вышеозначенного. Аналогично фиг. 11, схемы с фиксированной функцией означают схемы, которые предоставляют конкретную функциональность и предварительно установлены в отношении операций, которые могут выполняться. Программируемые схемы означают схемы, которые могут программироваться с возможностью выполнять различные задачи и предоставлять гибкую функциональность в операциях, которые могут выполняться. Например, программируемые схемы могут выполнять программное обеспечение или микропрограммное обеспечение, которое инструктирует программируемым схемам работать способом, заданным посредством инструкций программного обеспечения или микропрограммного обеспечения. Схемы с фиксированной функцией могут выполнять программные инструкции (например, чтобы принимать параметры или выводить параметры), но типы операций, которые выполняют схемы с фиксированной функцией, в общем, являются неизменными. В некоторых примерах, один или более модулей могут представлять собой различные схемные блоки (с фиксированной функцией или программируемые), и в некоторых примерах, один или более модулей могут представлять собой интегральные схемы.
[0172] Видеодекодер 300 может включать в себя ALU, EFU, цифровые схемы, аналоговые схемы и/или программируемые ядра, сформированные из программируемых схем. В примерах, в которых операции видеодекодера 300 выполняются посредством программного обеспечения, выполняющегося в программируемых схемах, внутримикросхемное или внемикросхемное запоминающее устройство может сохранять инструкции (например, объектный код) программного обеспечения, которые принимает и выполняет видеодекодер 300.
[0173] Модуль 302 энтропийного декодирования может принимать кодированные видеоданные из CPB и энтропийно декодировать видеоданные, чтобы воспроизводить синтаксические элементы. Модуль 304 обработки предсказания, модуль 306 обратного квантования, модуль 308 обработки обратного преобразования, модуль 310 восстановления и модуль 312 фильтрации могут формировать декодированные видеоданные на основе синтаксических элементов, извлеченных из потока битов.
[0174] В общем, видеодекодер 300 восстанавливает картинку на поблочной основе. Видеодекодер 300 может выполнять операцию восстановления для каждого блока отдельно (причем блок, в данный момент восстанавливаемый, т.е. декодируемый, может называться "текущим блоком").
[0175] Модуль 302 энтропийного декодирования может энтропийно декодировать синтаксические элементы, задающие квантованные коэффициенты преобразования блока квантованных коэффициентов преобразования, а также информацию преобразования, такую как параметр квантования (QP), и/или преобразовывать индикатор(ы) режима. Модуль 306 обратного квантования может использовать QP, ассоциированный с блоком квантованных коэффициентов преобразования, чтобы определять степень квантования и, аналогично, степень обратного квантования для модуля 306 обратного квантования, которая должна применяться. Модуль 306 обратного квантования, например, может выполнять операцию побитового сдвига влево, чтобы обратно квантовать квантованные коэффициенты преобразования. Модуль 306 обратного квантования в силу этого может формировать блок коэффициентов преобразования, включающий в себя коэффициенты преобразования.
[0176] После того, как модуль 306 обратного квантования формирует блок коэффициентов преобразования, модуль 308 обработки обратного преобразования может применять одно или более обратных преобразований к блоку коэффициентов преобразования, чтобы формировать остаточный блок, ассоциированный с текущим блоком. Например, модуль 308 обработки обратного преобразования может применять обратное DCT, обратное целочисленное преобразование, обратное преобразование Карунена-Лоэва (KLT), обратное вращательное преобразование, обратное направленное преобразование или другое обратное преобразование к блоку коэффициентов.
[0177] Кроме того, модуль 304 обработки предсказания формирует блок предсказания согласно синтаксическим элементам с информацией предсказания, которые энтропийно декодированы посредством модуля 302 энтропийного декодирования. Например, если синтаксические элементы с информацией предсказания указывают то, что текущий блок взаимно предсказывается, модуль 316 компенсации движения может формировать блок предсказания. В этом случае, синтаксические элементы с информацией предсказания могут указывать опорную картинку в DPB 314, из которого можно извлекать опорный блок, а также вектор движения, идентифицирующий местоположение опорного блока в опорной картинке относительно местоположения текущего блока в текущей картинке. Модуль 316 компенсации движения, в общем, может выполнять процесс взаимного предсказания таким способом, который является практически аналогичным способу, описанному относительно модуля 224 компенсации движения (фиг. 11).
[0178] В качестве другого примера, если синтаксические элементы с информацией предсказания указывают то, что текущий блок внутренне предсказывается, модуль 318 внутреннего предсказания может формировать блок предсказания согласно режиму внутреннего предсказания, указываемому посредством синтаксических элементов с информацией предсказания. С другой стороны, модуль 318 внутреннего предсказания, в общем, может выполнять процесс внутреннего предсказания таким способом, который является практически аналогичным способу, описанному относительно модуля 226 внутреннего предсказания (фиг. 11). Модуль 318 внутреннего предсказания может извлекать данные соседних выборок по отношению к текущему блоку из DPB 314.
[0179] Модуль 310 восстановления может восстанавливать текущий блок с использованием блока предсказания и остаточного блока. Например, модуль 310 восстановления может суммировать выборки остаточного блока с соответствующими выборками блока предсказания, чтобы восстанавливать текущий блок.
[0180] Модуль 312 фильтрации может выполнять одну или более операций фильтрации для восстановленных блоков. Например, модуль 312 фильтрации может выполнять операции удаления блочности, чтобы уменьшать артефакты блочности вдоль краев восстановленных блоков. Операции модуля 312 фильтрации не обязательно выполняются во всех примерах.
[0181] Видеодекодер 300 может сохранять восстановленные блоки в DPB 314. Как пояснено выше, DPB 314 может предоставлять ссылочную информацию, такую как выборки текущего картинки для внутреннего предсказания и ранее декодированных картинок для последующей компенсации движения, в модуль 304 обработки предсказания. Кроме того, видеодекодер 300 может выводить декодированные картинки из DPB для последующего представления на устройстве отображения, таком как устройство 118 отображения по фиг. 1.
[0182] Таким образом, видеодекодер 300 представляет пример устройства декодирования видео, включающего в себя запоминающее устройство, выполненное с возможностью сохранять видеоданные, и один или более модулей обработки, реализованных в схеме и выполненных с возможностью реализовывать способы и процессы, поясненные в данном документе.
[0183] Например, кодированные видеоданные могут включать в себя следующий синтаксис:
Таблица 4. Синтаксис данных слияния
[0184] Merge_subblock_flag[x0][y0] указывает то, логически выводятся или нет параметры взаимного предсказания на основе субблоков для текущей единицы кодирования из соседних блоков. Индексы x0, y0 массива указывают местоположение (x0, y0) левой верхней выборки сигнала яркости рассматриваемого блока кодирования относительно левой верхней выборки сигнала яркости картинки . Когда merge_subblock_flag[x0][y0] не присутствует, он логически выводится как равный 0.
[0185] Merge_subblock_idx[x0][y0] указывает индекс кандидата слияния из списка кандидатов слияния на основе субблоков, где x0, y0 указывают местоположение (x0, y0) левой верхней выборки сигнала яркости рассматриваемого блока кодирования относительно левой верхней выборки сигнала яркости картинки .
[0186] Когда merge_subblock_idx[x0][y0] не присутствует, он логически выводится как равный 0.
[0187] Если merge_subblock_flag[xCb][yCb] равен 1, процесс извлечения для векторов движения и опорных индексов в режиме слияния на основе субблоков, как указано в 8.4.4.2, активируется с местоположением (xCb, yCb) блока кодирования сигналов яркости, шириной cbWidth блока кодирования сигналов яркости и высотой cbHeight блока кодирования сигналов яркости в качестве вводов, числом субблоков кодирования сигналов яркости в горизонтальном направлении numSbX и в вертикальном направлении numSbY, опорными индексами refIdxL0, refIdxL1, массивами predFlagL0[xSbIdx][ySbIdx] и predFlagL1[xSbIdx][ySbIdx] флагов использования списков предсказания, массивами mvL0[xSbIdx][ySbIdx] и mvL0[xSbIdx][ySbIdx] векторов движения субблоков сигнала яркости и массивами mvCL0[xSbIdx][ySbIdx], и mvCL1[xSbIdx][ySbIdx] векторов движения субблоков сигналов цветности, с xSbIdx=0...numSbX-1, ySbIdx=0...numSbY-1 и индексом gbiIdx весового коэффициента бипредсказания в качестве выводов.
[0188] Следует признавать, что в зависимости от примера, определенные этапы или события любой из технологий, описанных в данном документе, могут выполняться в другой последовательности, могут добавляться, объединяться или вообще исключаться (например, не все описанные этапы или события требуются для практической реализации технологий). Кроме того, в определенных примерах, этапы или события могут выполняться одновременно, например, посредством многопоточной обработки, обработки прерывания или посредством нескольких процессоров, а не последовательно.
[0189] В одном или более примеров, описанные функции могут реализовываться в аппаратных средствах, программном обеспечении, микропрограммном обеспечении или в любой комбинации вышеозначенного. При реализации в программном обеспечении, функции могут сохраняться или передаваться, в качестве одной или более инструкций или кода, по машиночитаемому носителю и выполняться посредством аппаратного модуля обработки. Машиночитаемые носители могут включать в себя машиночитаемые носители хранения данных, которые соответствуют материальному носителю, такие как носители хранения данных, или среды связи, включающие в себя любой носитель, который упрощает перенос компьютерной программы из одного места в другое, например, согласно протоколу связи. Таким образом, машиночитаемые носители, в общем, могут соответствовать (1) материальному машиночитаемому носителю хранения данных, который является энергонезависимым, или (2) среде связи, такой как сигнал или несущая. Носители хранения данных могут представлять собой любые доступные носители, к которым может осуществляться доступ посредством одного или более компьютеров или одного или более процессоров, с тем чтобы извлекать инструкции, код и/или структуры данных для реализации технологий, описанных в этом раскрытии сущности. Компьютерный программный продукт может включать в себя машиночитаемый носитель.
[0190] В качестве примера, а не ограничения, эти машиночитаемые носители хранения данных могут содержать RAM, ROM, EEPROM, CD-ROM или другое устройство хранения данных на оптических дисках, устройство хранения данных на магнитных дисках или другие магнитные устройства хранения, флэш-память либо любой другой носитель, который может использоваться для того, чтобы сохранять требуемый программный код в форме инструкций или структур данных, и к которому можно осуществлять доступ посредством компьютера. Кроме того, любое соединение корректно называть машиночитаемым носителем. Например, если инструкции передаются из веб-узла, сервера или другого удаленного источника с помощью коаксиального кабеля, оптоволоконного кабеля, "витой пары", цифровой абонентской линии (DSL), или беспроводных технологий, таких как инфракрасные, радиопередающие и микроволновые среды, то коаксиальный кабель, оптоволоконный кабель, "витая пара", DSL или беспроводные технологии, такие как инфракрасные, радиопередающие и микроволновые среды, включаются в определение носителя. Тем не менее, следует понимать, что машиночитаемые носители хранения данных и носители хранения данных не включают в себя соединения, несущие, сигналы или другие энергозависимые носители, а вместо этого направлены на энергонезависимые материальные носители хранения данных. Диск (disk) и диск (disc) при использовании в данном документе включают в себя компакт-диск (CD), лазерный диск, оптический диск, универсальный цифровой диск (DVD), гибкий диск и диск Blu-Ray, при этом диски (disk) обычно воспроизводят данные магнитно, тогда как диски (disc) обычно воспроизводят данные оптически с помощью лазеров. Комбинации вышеперечисленного также следует включать в число машиночитаемых носителей.
[0191] Инструкции могут выполняться посредством одного или более процессоров, например, одного или более процессоров цифровых сигналов (DSP), микропроцессоров общего назначения, специализированных интегральных схем (ASIC), программируемых пользователем вентильных матриц (FPGA) либо других эквивалентных интегральных или дискретных логических схем. Соответственно, термин "процессор" при использовании в данном документе может означать любую вышеуказанную структуру или другую структуру, подходящую для реализации технологий, описанных в данном документе. Помимо этого, в некоторых аспектах функциональность, описанная в данном документе, может предоставляться в рамках специализированных аппаратных и/или программных модулей, выполненных с возможностью кодирования или декодирования либо встроенных в комбинированный кодек. Кроме того, технологии могут полностью реализовываться в одной или более схем или логических элементов.
[0192] Технологии этого раскрытия сущности могут реализовываться в широком спектре устройств или оборудования, в том числе в беспроводном переносном телефоне, в интегральной схеме (IC), или в наборе IC (к примеру, в наборе микросхем). Различные компоненты, модули или блоки описываются в этом раскрытии сущности для того, чтобы подчеркивать функциональные аспекты устройств, выполненных с возможностью осуществлять раскрытые технологии, но необязательно требуют реализации посредством различных аппаратных модулей. Наоборот, как описано выше, различные модули могут комбинироваться в аппаратный модуль кодека или предоставляться посредством набора взаимодействующих аппаратных модулей, включающих в себя один или более процессоров, как описано выше, в сочетании с надлежащим программным обеспечением и/или микропрограммным обеспечением.
[0193] Выше описаны различные примеры. Эти и другие примеры находятся в пределах объема прилагаемой формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| БУФЕРИЗАЦИЯ ДАННЫХ ПРЕДСКАЗАНИЯ ПРИ КОДИРОВАНИИ ВИДЕО | 2012 |
|
RU2573744C2 |
| ПРЕДСКАЗАНИЕ ВЕКТОРОВ ДВИЖЕНИЯ ПРИ КОДИРОВАНИИ ВИДЕО | 2012 |
|
RU2575690C2 |
| СПОСОБЫ И УСТРОЙСТВА ДЛЯ КОДИРОВАНИЯ ВИДЕО С ИСПОЛЬЗОВАНИЕМ ВЕКТОРА ДВИЖЕНИЯ ВРЕМЕННОГО ПРЕДСКАЗАНИЯ НА ОСНОВЕ СУББЛОКОВ | 2019 |
|
RU2757209C1 |
| ОГРАНИЧЕНИЕ ОДНОНАПРАВЛЕННЫМ ИНТЕР-ПРЕДСКАЗАНИЕМ ДЛЯ БЛОКОВ ПРЕДСКАЗАНИЯ В В-СЛАЙСАХ | 2013 |
|
RU2620723C2 |
| УСТРОЙСТВО И СПОСОБ ВНЕШНЕГО ПРЕДСКАЗАНИЯ | 2019 |
|
RU2785725C2 |
| ВЫВЕДЕНИЕ ВЕКТОРА ДВИЖЕНИЯ ПРИ ВИДЕОКОДИРОВАНИИ | 2016 |
|
RU2742298C2 |
| ВЫВОД ИНФОРМАЦИИ ДВИЖЕНИЯ ДЛЯ ПОДБЛОКОВ ПРИ ВИДЕОКОДИРОВАНИИ | 2016 |
|
RU2705428C2 |
| ГЕНЕРИРОВАНИЕ ДОПОЛНИТЕЛЬНЫХ КАНДИДАТОВ ДЛЯ СЛИЯНИЯ | 2012 |
|
RU2577779C2 |
| ОПРЕДЕЛЕНИЕ РЕЖИМА ВЫВОДА ИНФОРМАЦИИ ДВИЖЕНИЯ ПРИ ВИДЕОКОДИРОВАНИИ | 2016 |
|
RU2719296C2 |
| ВЫПОЛНЕНИЕ ПРЕДСКАЗАНИЯ ВЕКТОРА ДВИЖЕНИЯ ДЛЯ ВИДЕОКОДИРОВАНИЯ | 2012 |
|
RU2550554C2 |
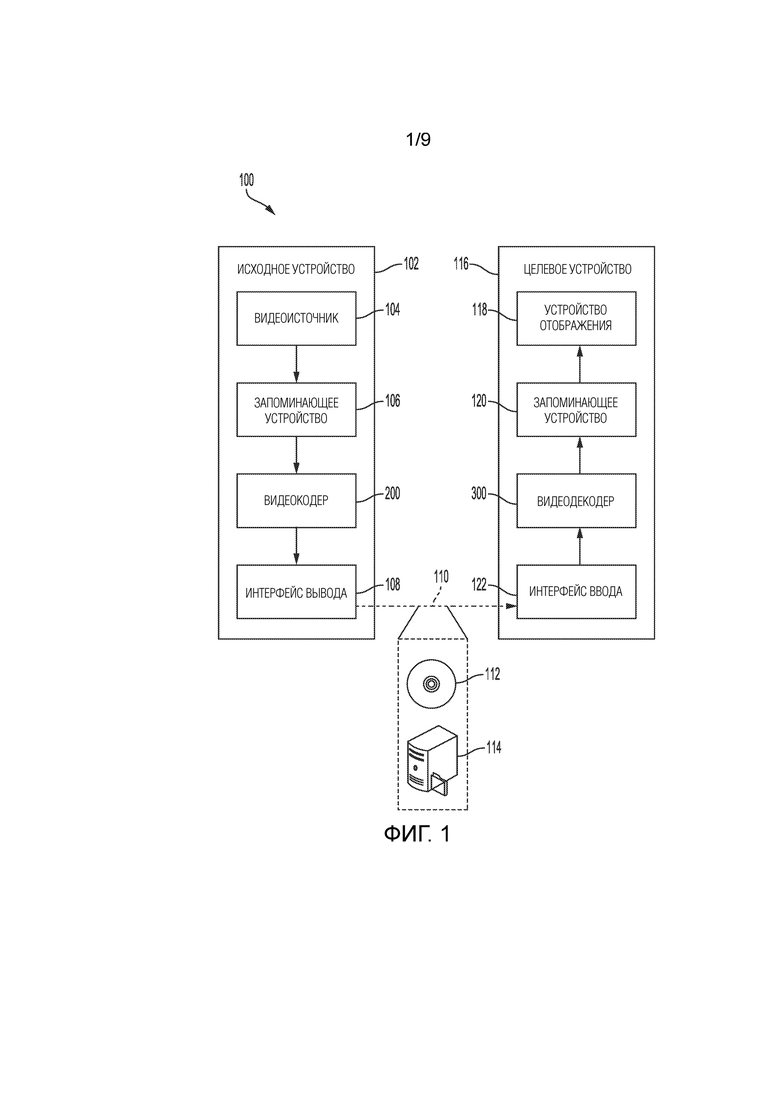
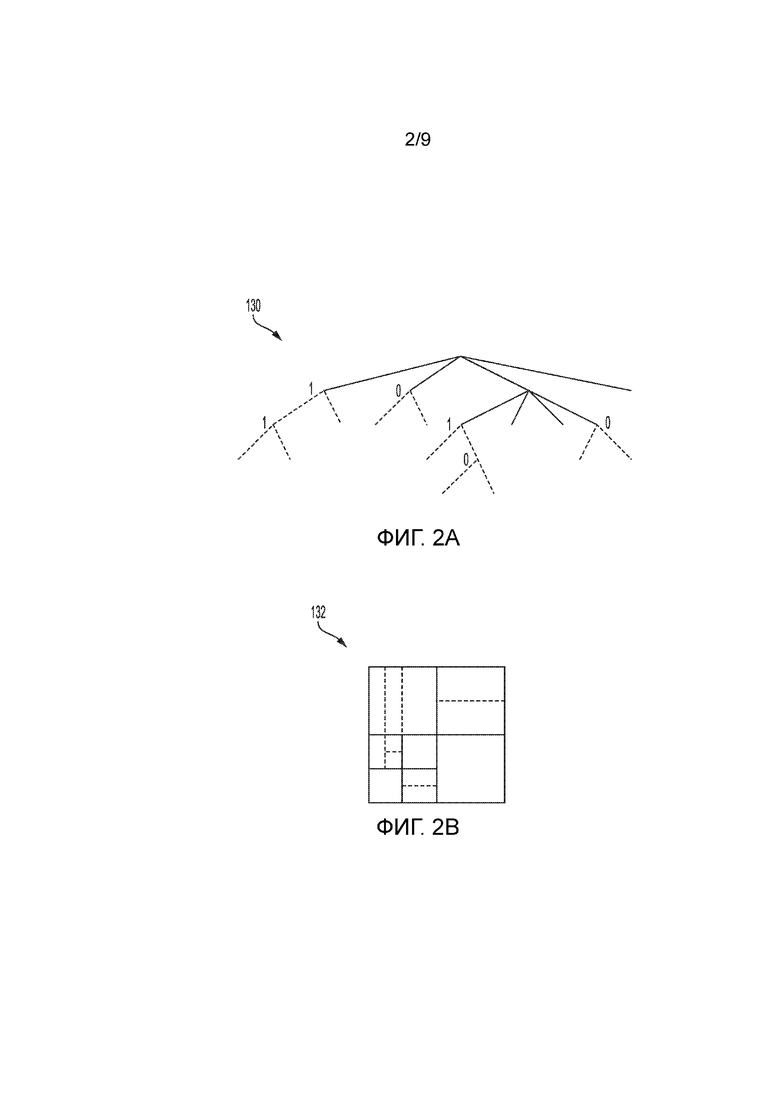
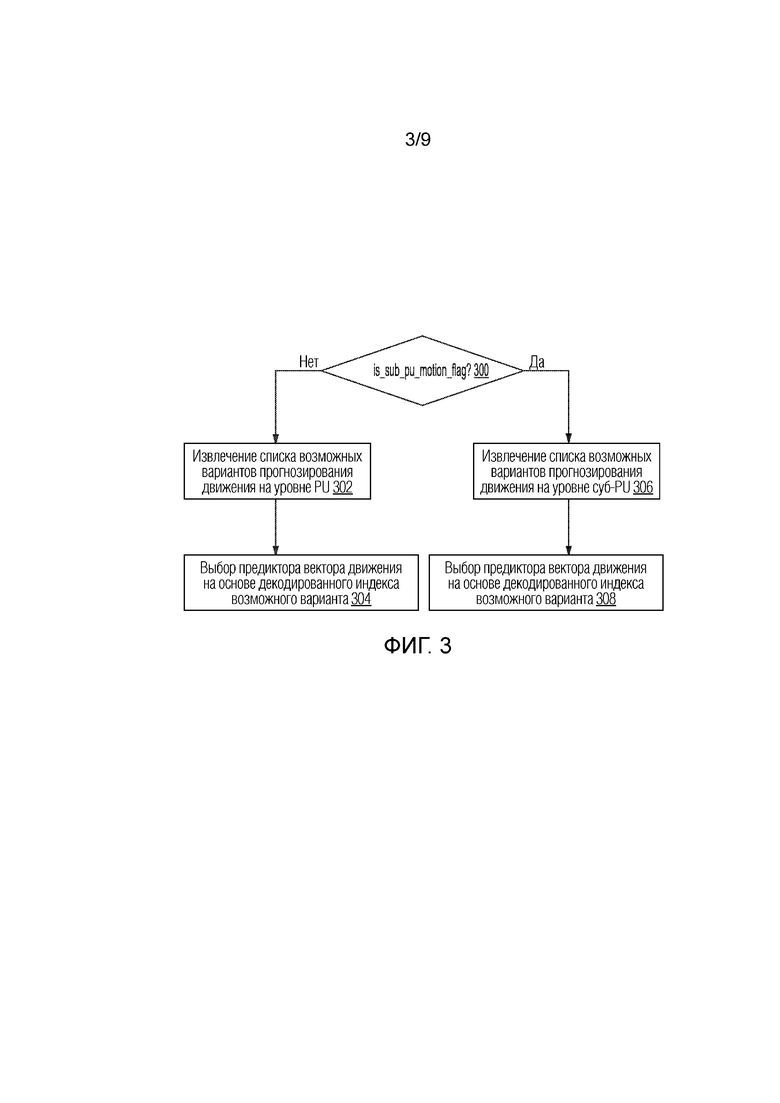
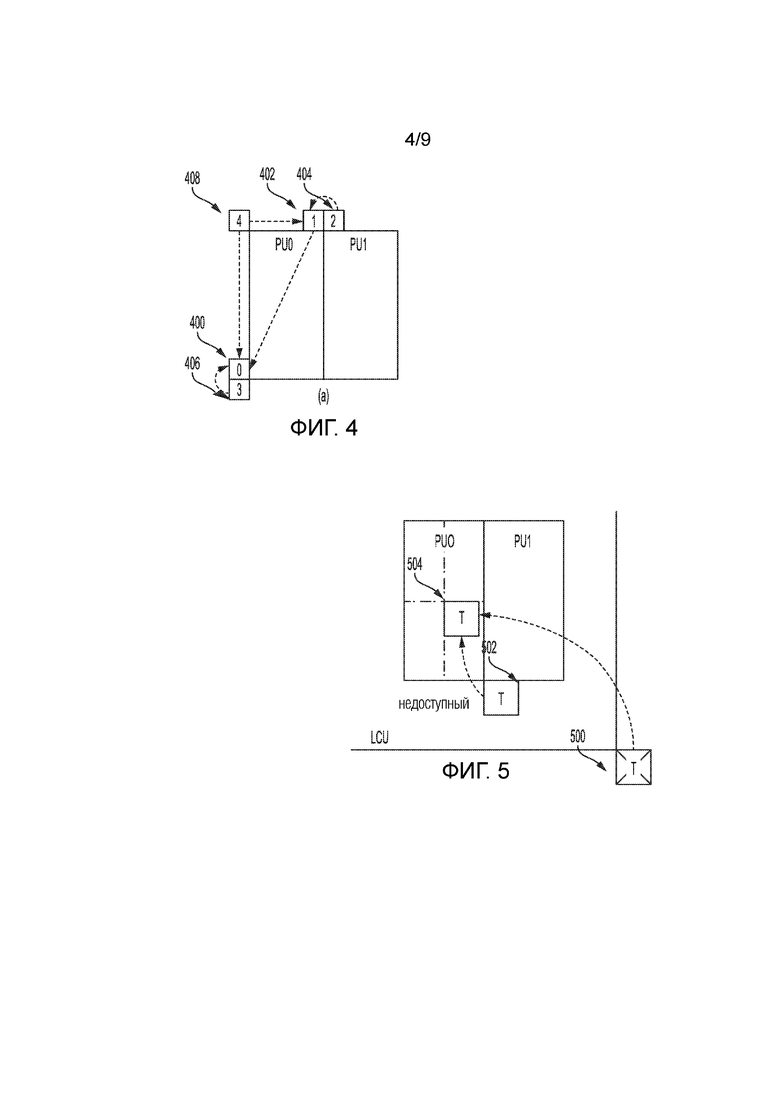
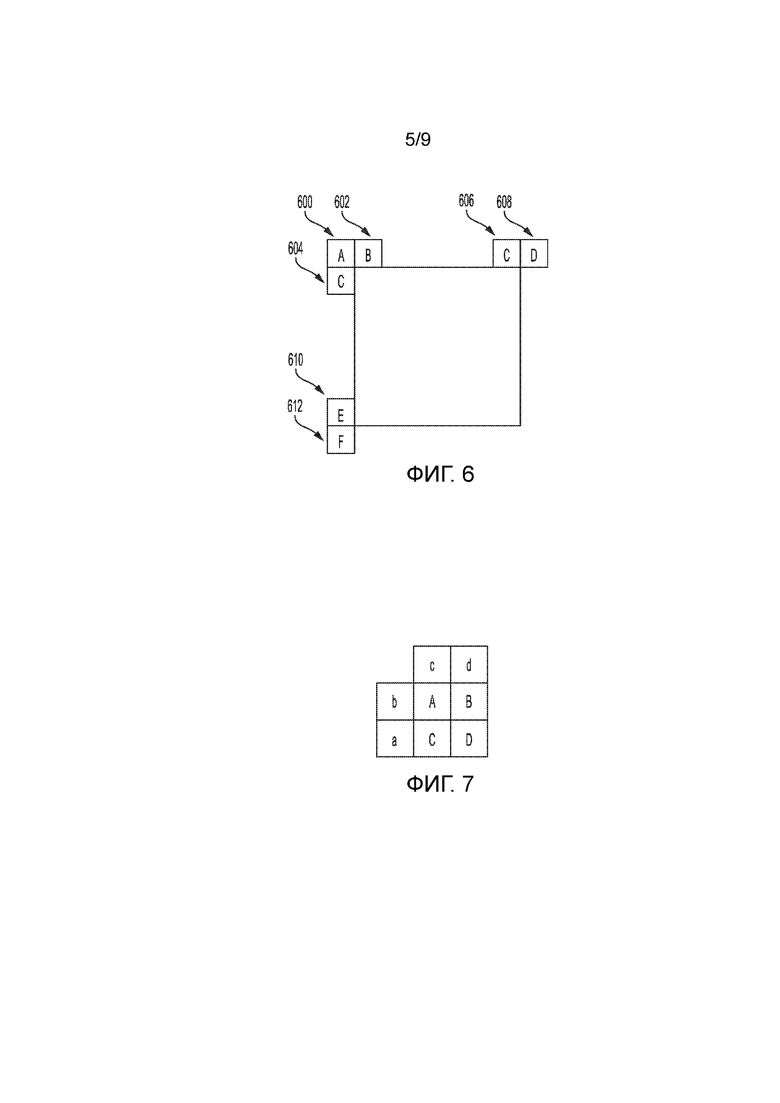
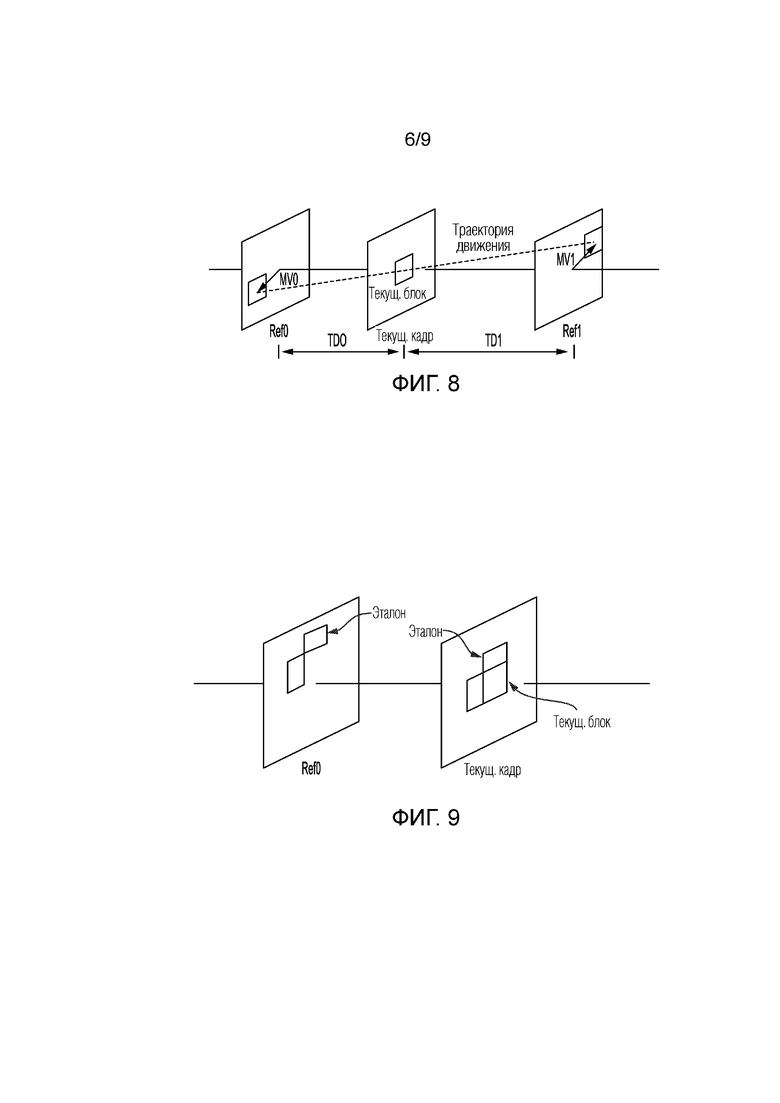
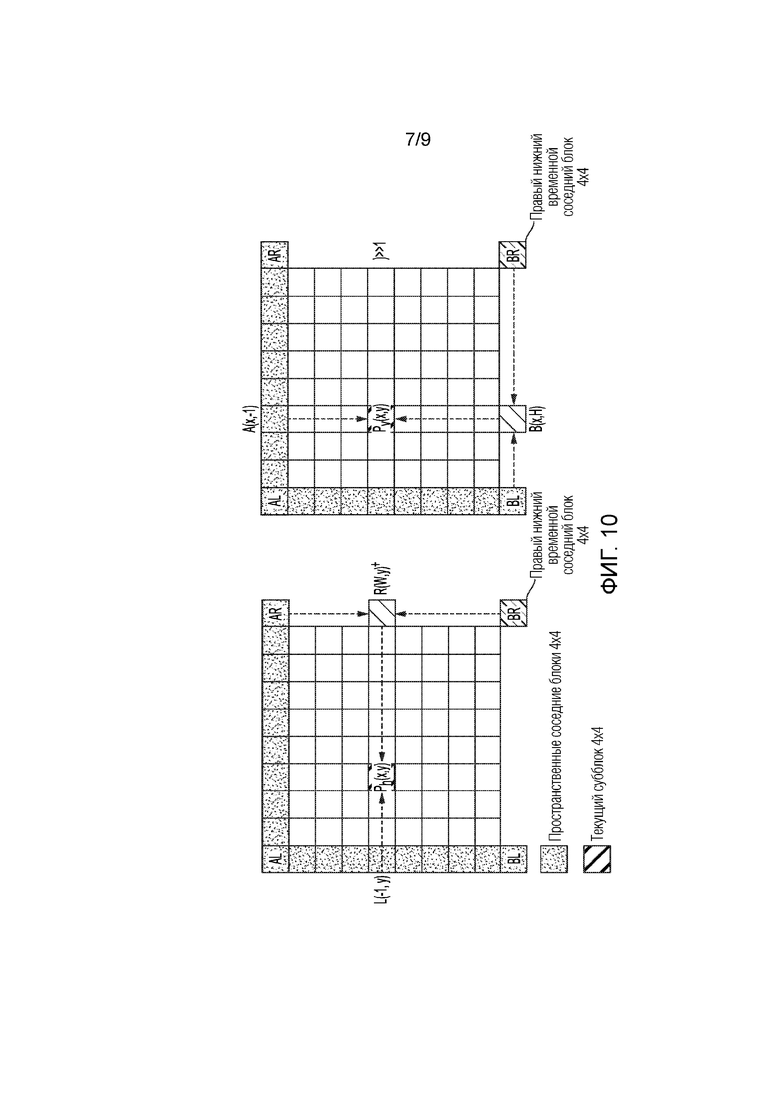
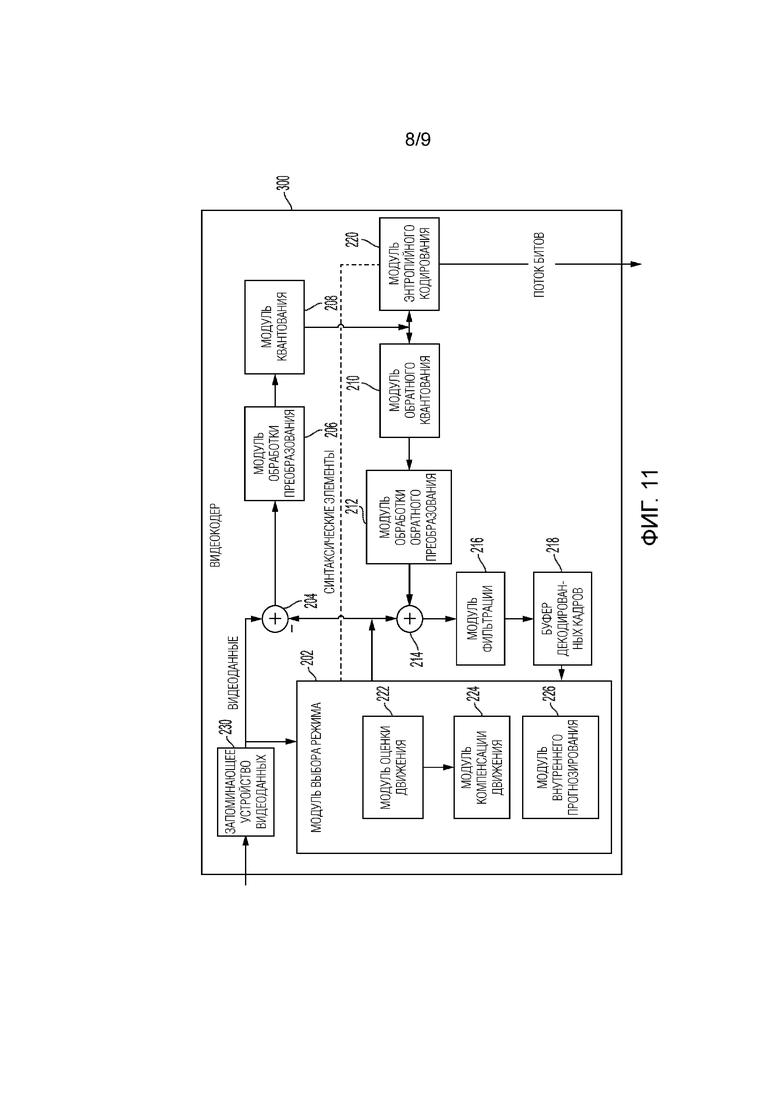
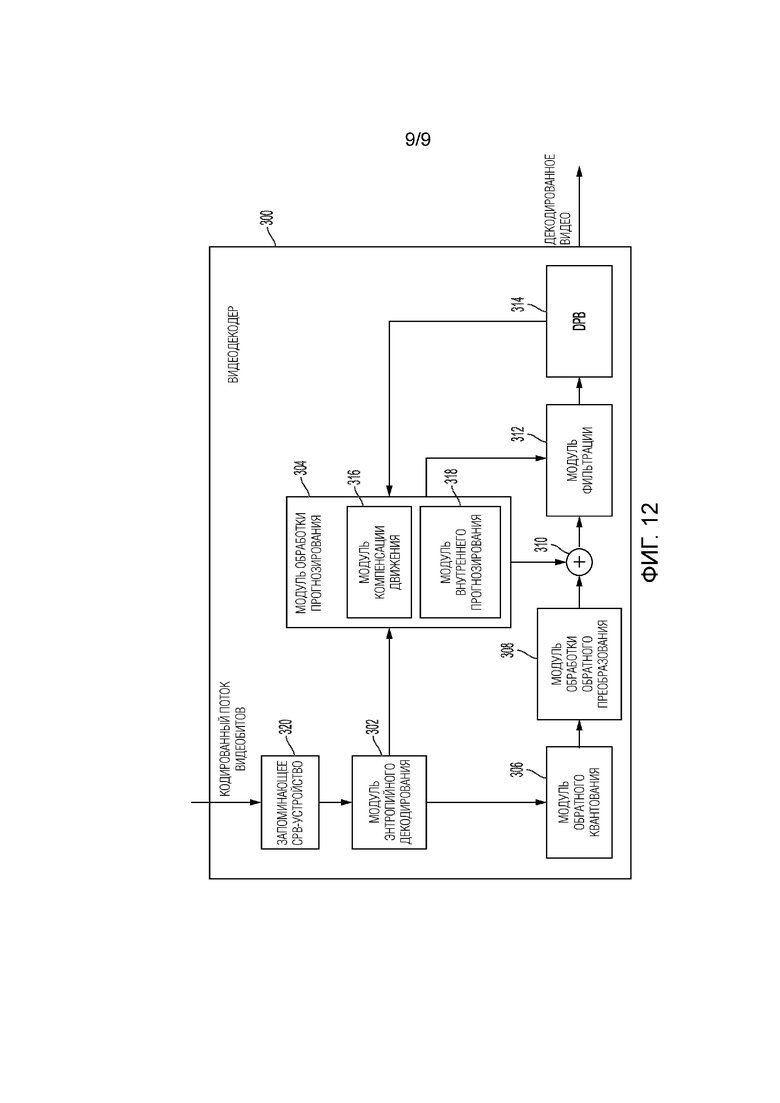
Группа изобретений относится к технологиям кодирования/декодирования видеоданных. Техническим результатом является повышение эффективности декодирования видеоданных. Предложен способ декодирования видеоданных. Способ содержит этап, на котором принимают кодированные видеоданные. Далее, синтаксически анализируют флаг движения на основе субъединиц предсказания из кодированных видеоданных. В ответ на определение, что флаг движения на основе субъединиц предсказания является активным, извлекают список кандидатов предсказания движения на уровне субъединиц предсказания. В ответ на определение, что флаг движения на основе субъединиц предсказания не является активным, извлекают список кандидатов предсказания движения на уровне единиц предсказания. При этом список кандидатов предсказания движения на уровне субъединиц предсказания или список кандидатов предсказания движения на уровне единиц предсказания, по меньшей мере, частично упорядочивается на основе возникновений предсказания движения в соседних блоках. А также декодируют кодированные видеоданные с использованием выбранного предиктора вектора движения. 4 н. и 22 з.п. ф-лы, 13 ил., 4 табл.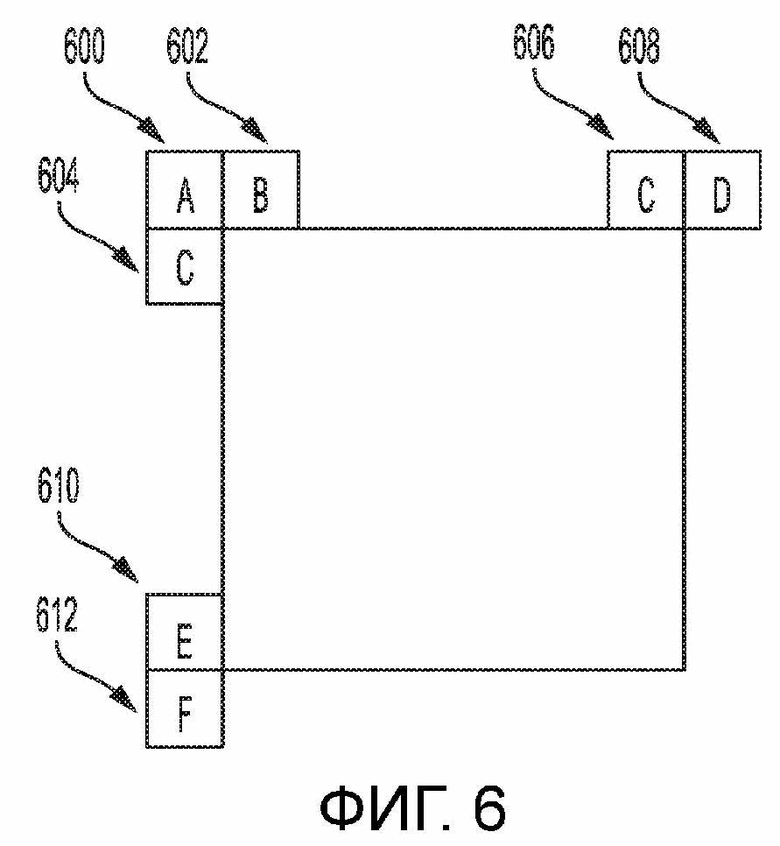
1. Способ декодирования видеоданных, при этом способ содержит этапы, на которых:
- принимают кодированные видеоданные;
- синтаксически анализируют флаг движения на основе субъединиц предсказания из кодированных видеоданных;
- в ответ на определение, что флаг движения на основе субъединиц предсказания является активным, извлекают список кандидатов предсказания движения на уровне субъединиц предсказания;
- в ответ на определение, что флаг движения на основе субъединиц предсказания не является активным, извлекают список кандидатов предсказания движения на уровне единиц предсказания;
- выбирают предиктор вектора движения либо из списка кандидатов предсказания движения на уровне субъединиц предсказания, либо из списка кандидатов предсказания движения на уровне единиц предсказания, при этом
список кандидатов предсказания движения на уровне субъединиц предсказания или список кандидатов предсказания движения на уровне единиц предсказания, по меньшей мере, частично упорядочивается на основе возникновений предсказания движения в соседних блоках; и
- декодируют кодированные видеоданные с использованием выбранного предиктора вектора движения.
2. Способ по п. 1, в котором кодированные видеоданные включают в себя текущий блок, и при этом список кандидатов предсказания движения на уровне субъединиц предсказания и список кандидатов предсказания движения на уровне единиц предсказания извлекаются из соседних блоков текущего блока.
3. Способ по п. 2, в котором соседние блоки представляют собой пространственных соседей текущего блока в текущей картинке или временных соседей текущего блока в ранее кодированной картинке.
4. Способ по п. 1, в котором пикселы в единице предсказания совместно используют первую информацию вектора движения, и пикселы в субъединице предсказания совместно используют вторую информацию вектора движения, при этом первая информация вектора движения или вторая векторная информация определяется из выбранного предиктора вектора движения.
5. Способ по п. 1, в котором список кандидатов векторов движения на уровне единиц предсказания включает в себя по меньшей мере одно из следующего: пространственные соседние кандидаты и временные соседние кандидаты.
6. Способ по п. 1, в котором список кандидатов предсказания движения на уровне субъединиц предсказания включает в себя по меньшей мере одно из следующего: аффинное предсказание векторов движения, альтернативное временное предсказание векторов движения (ATMVP), пространственно-временное предсказание векторов движения (STMVP), планарное предсказание векторов движения и извлечение векторов движения на основе сопоставления шаблонов (PMVD).
7. Способ по п. 1, дополнительно содержащий этап, на котором:
- извлекают индекс кандидата слияния в ответ на определение, что флаг движения на основе субъединиц предсказания является активным, при этом индекс кандидата слияния указывает предиктор вектора движения, который должен выбираться.
8. Оборудование для декодирования видеоданных, причем оборудование содержит:
- запоминающее устройство для сохранения принимаемых кодированных видеоданных; и
- процессор, причем процессор выполнен с возможностью:
- синтаксически анализировать флаг движения на основе субъединиц предсказания из кодированных видеоданных,
- в ответ на определение, что флаг движения на основе субъединиц предсказания является активным, извлекать список кандидатов предсказания движения на уровне субъединиц предсказания,
- в ответ на определение, что флаг движения на основе субъединиц предсказания не является активным, извлекать список кандидатов предсказания движения на уровне единиц предсказания,
- выбирать предиктор вектора движения либо из списка кандидатов предсказания движения на уровне субъединиц предсказания, либо из списка кандидатов предсказания движения на уровне единиц предсказания, при этом
список кандидатов предсказания движения на уровне субъединиц предсказания или список кандидатов предсказания движения на уровне единиц предсказания, по меньшей мере, частично упорядочивается на основе возникновений предсказания движения в соседних блоках, и
- декодировать кодированные видеоданные с использованием выбранного предиктора вектора движения.
9. Оборудование по п. 8, в котором кодированные видеоданные включают в себя текущий блок, и при этом список кандидатов предсказания движения на уровне субъединиц предсказания и список кандидатов предсказания движения на уровне единиц предсказания извлекаются из соседних блоков текущего блока.
10. Оборудование по п. 9, в котором соседние блоки представляют собой пространственных соседей текущего блока в текущей картинке или временных соседей текущего блока в ранее кодированной картинке.
11. Оборудование по п. 8, в котором пикселы в единице предсказания совместно используют первую информацию вектора движения, и пикселы в субъединице предсказания совместно используют вторую информацию вектора движения, при этом первая информация вектора движения или вторая векторная информация определяется из выбранного предиктора вектора движения.
12. Оборудование по п. 8, в котором список кандидатов векторов движения на уровне единиц предсказания включает в себя по меньшей мере одно из следующего: пространственные соседние кандидаты и временные соседние кандидаты.
13. Оборудование по п. 8, в котором список кандидатов предсказания движения на уровне субъединиц предсказания включает в себя по меньшей мере одно из следующего: аффинное предсказание векторов движения, альтернативное временное предсказание векторов движения (ATMVP), пространственно-временное предсказание векторов движения (STMVP), планарное предсказание векторов движения и извлечение векторов движения на основе сопоставления шаблонов (PMVD).
14. Оборудование по п. 8, в котором процессор дополнительно выполнен с возможностью:
- извлекать индекс кандидата слияния в ответ на определение, что флаг движения на основе субъединиц предсказания является активным, при этом индекс кандидата слияния указывает предиктор вектора движения, который должен выбираться.
15. Оборудование для декодирования видеоданных, причем оборудование содержит:
- средство запоминающего устройства для сохранения принимаемых кодированных видеоданных; и
- средство процессора, причем средство процессора выполнено с возможностью:
- синтаксически анализировать флаг движения на основе субъединиц предсказания из кодированных видеоданных,
- в ответ на определение, что флаг движения на основе субъединиц предсказания является активным, извлекать список кандидатов предсказания движения на уровне субъединиц предсказания,
- в ответ на определение, что флаг движения на основе субъединиц предсказания не является активным, извлекать список кандидатов предсказания движения на уровне единиц предсказания,
- выбирать предиктор вектора движения либо из списка кандидатов предсказания движения на уровне субъединиц предсказания, либо из списка кандидатов предсказания движения на уровне единиц предсказания, при этом
список кандидатов предсказания движения на уровне субъединиц предсказания или список кандидатов предсказания движения на уровне единиц предсказания, по меньшей мере, частично упорядочивается на основе возникновений предсказания движения в соседних блоках, и
- декодировать кодированные видеоданные с использованием выбранного предиктора вектора движения.
16. Оборудование по п. 15, в котором кодированные видеоданные включают в себя текущий блок, и при этом список кандидатов предсказания движения на уровне субъединиц предсказания и список кандидатов предсказания движения на уровне единиц предсказания извлекаются из соседних блоков текущего блока.
17. Оборудование по п. 16, в котором соседние блоки представляют собой пространственных соседей текущего блока в текущей картинке или временных соседей текущего блока в ранее кодированной картинке.
18. Оборудование по п. 15, в котором пикселы в единице предсказания совместно используют первую информацию вектора движения, и пикселы в субъединице предсказания совместно используют вторую информацию вектора движения, при этом первая информация вектора движения или вторая векторная информация определяется из выбранного предиктора вектора движения.
19. Оборудование по п. 15, в котором список кандидатов векторов движения на уровне единиц предсказания включает в себя по меньшей мере одно из следующего: пространственные соседние кандидаты и временные соседние кандидаты.
20. Оборудование по п. 15, в котором список кандидатов предсказания движения на уровне субъединиц предсказания включает в себя по меньшей мере одно из следующего: аффинное предсказание векторов движения, альтернативное временное предсказание векторов движения (ATMVP), пространственно-временное предсказание векторов движения (STMVP), планарное предсказание векторов движения и извлечение векторов движения на основе сопоставления шаблонов (PMVD).
21. Оборудование по п. 15, в котором средство процессора дополнительно выполнено с возможностью:
- извлекать индекс кандидата слияния в ответ на определение, что флаг движения на основе субъединиц предсказания является активным, при этом индекс кандидата слияния указывает предиктор вектора движения, который должен выбираться.
22. Энергонезависимый машиночитаемый носитель хранения данных, имеющий сохраненные инструкции, которые при выполнении инструктируют одному или более процессоров осуществлять способ, содержащий:
- прием кодированных видеоданных;
- синтаксический анализ флага движения на основе субъединиц предсказания из кодированных видеоданных;
- в ответ на определение, что флаг движения на основе субъединиц предсказания является активным, извлечение списка кандидатов предсказания движения на уровне субъединиц предсказания;
- в ответ на определение, что флаг движения на основе субъединиц предсказания не является активным, извлечение списка кандидатов предсказания движения на уровне единиц предсказания;
- выбор предиктора вектора движения либо из списка кандидатов предсказания движения на уровне субъединиц предсказания, либо из списка кандидатов предсказания движения на уровне единиц предсказания, при этом
список кандидатов предсказания движения на уровне субъединиц предсказания или список кандидатов предсказания движения на уровне единиц предсказания, по меньшей мере, частично упорядочивается на основе возникновений предсказания движения в соседних блоках; и
- декодирование кодированных видеоданных с использованием выбранного предиктора вектора движения.
23. Носитель по п. 22, в котором кодированные видеоданные включают в себя текущий блок, при этом список кандидатов предсказания движения на уровне субъединиц предсказания и список кандидатов предсказания движения на уровне единиц предсказания извлекаются из соседних блоков текущего блока.
24. Носитель по п. 23, в котором соседние блоки представляют собой пространственных соседей текущего блока в текущей картинке или временных соседей текущего блока в ранее кодированной картинке.
25. Носитель по п. 22, в котором:
- пикселы в единице предсказания совместно используют первую информацию вектора движения, и пикселы в субъединице предсказания совместно используют вторую информацию вектора движения, при этом первая информация вектора движения или вторая векторная информация определяется из выбранного предиктора вектора движения,
- при этом список кандидатов векторов движения на уровне единиц предсказания включает в себя по меньшей мере одно из следующего: пространственные соседние кандидаты и временные соседние кандидаты, и
- при этом список кандидатов предсказания движения на уровне субъединиц предсказания включает в себя по меньшей мере одно из следующего: аффинное предсказание векторов движения, альтернативное временное предсказание векторов движения (ATMVP), пространственно-временное предсказание векторов движения (STMVP), планарное предсказание векторов движения и извлечение векторов движения на основе сопоставления шаблонов (PMVD).
26. Носитель по п. 22, в котором способ дополнительно содержит:
- извлечение индекса кандидата слияния в ответ на определение, что флаг движения на основе субъединиц предсказания является активным, при этом индекс кандидата слияния указывает предиктор вектора движения, который должен выбираться.
| WO 2018061522 A1, 05.04.2018 | |||
| US 5337086 A1, 09.08.1994 | |||
| US 20170332099 A1, 16.11.2017 | |||
| US 20170111654 A1, 20.04.2017 | |||
| СПОСОБ И УСТРОЙСТВО ДЛЯ ПРОГНОЗИРОВАНИЯ ВЕКТОРА ДВИЖЕНИЯ ДЛЯ КОДИРОВАНИЯ ВИДЕО ИЛИ ДЕКОДИРОВАНИЯ ВИДЕО | 2013 |
|
RU2624578C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ ВЕКТОРА ДВИЖЕНИЯ | 2011 |
|
RU2514929C2 |

