ПЕРЕКРЕСТНАЯ ССЫЛКА НА РОДСТВЕННЫЕ ЗАЯВКИ
[1] По данной заявке испрашивается приоритет по предварительной заявке на патент США №62/954,096, поданной 27 декабря 2019 года, и заявке на патент США №17/038,541, поданной 30 сентября 2020 года, раскрытие которых включено в состав настоящего описания посредством ссылки.
ОБЛАСТЬ ТЕХНИКИ
[2] Раскрытие настоящего изобретения относится к кодированию и декодированию видеосигналов, а более конкретно - к способу ссылки на набор параметров адаптации в кодированном видеопотоке и к ограничениям, связанным с этим набором.
ПРЕДПОСЫЛКИ СОЗДАНИЯ ИЗОБРЕТЕНИЯ
[3] В этой области техники известны функции кодирования и декодирования видеосигналов с использованием внешнего предсказания с компенсацией движения. Несжатые цифровые видеоданные могут содержать ряд изображений, каждое из которых характеризуется пространственным размером, например, 1920 × 1080 отсчетов сигнала яркости и связанных отсчетов сигнала цветности. Ряд изображений может характеризоваться фиксированной или переменной частотой смены изображений (также неформально называемой частотой кадров), например, 60 изображений в секунду или 60 Гц. Несжатые видеоданные предъявляют значительные требования в отношении битовой скорости передачи. Например, для видеосигнала 1080р60 4:2:0 при 8 битах на отсчет (разрешение отсчетов 1920×1080 при частоте кадров 60 Гц) требуется полоса пропускания, близкая к 1,5 Гбит/с. Час такого видео занимает более 600 Гбайт пространства на запоминающем устройстве.
[4] Одной из целей кодирования и декодирования видеосигнала может быть снижение избыточности во входном видеосигнале посредством сжатия. Сжатие может помочь уменьшить вышеупомянутую полосу пропускания или снизить требования к пространству памяти в некоторых случаях на два порядка величины или более. Для этого может применяться сжатие как без потерь, так и с потерями, а также комбинация этих способов. Сжатие без потерь относится к технологиям, при использовании которых на основе сжатого исходного сигнала может быть восстановлена точная копия исходного сигнала. При использовании сжатия с потерями восстановленный сигнал может отличаться от исходного сигнала, но искажение между исходным и восстановленным сигналом настолько мало, что восстановленный сигнал пригоден для предусмотренного применения. В случае видеосигнала широко применяется сжатие с потерями. Допустимый уровень искажений зависит от применения; например, пользователи определенных потребительских потоковых приложений могут допускать более высокий уровень искажений по сравнению с пользователями приложений распределения телевизионного сигнала. Достижимый коэффициент сжатия может отражать тот факт, что более высокий допустимый/приемлемый уровень искажения может позволять использовать более высокие коэффициенты сжатия.
[5] Видеокодер и видеодекодер могут применять технологии из нескольких широких категорий, включающих, например, компенсацию движения, преобразование, квантование и энтропийное кодирование, некоторые из которых представлены ниже.
[6] Исторически сложилась тенденция, когда видеокодеры и видеодекодеры функционируют с заданным размером изображения, который в большинстве случаев определен и остается постоянным для кодированной видеопоследовательности (CVS, Coded Video Sequence), группы изображений (GOP, Group of Pictures) или подобного временного интервала формирования множества изображений. Например, в MPEG-2 известно, что в структурах систем горизонтальное разрешение (и, таким образом, размер изображения) изменяется в зависимости от таких факторов, как активность сцены, но только в I-изображениях, что типично для GOP. Передискретизация опорных изображений для использования различных разрешений в пределах CVS определяется, например, в ITU-T, в приложении Р к рекомендации Н.263. Однако в данном случае размер изображения не меняется, передискретизация применяется только к опорным изображениям, в результате только в частях изображения используется "холст" (в случае понижающей дискретизации) или захватываются только части сцены (в случае повышающей дискретизации). Кроме того, в приложении Q Н.263 допускается передискретизация отдельного макроблока с коэффициентом два (в каждом измерении) в верхнем и в нижнем направлениях. В этом случае размер изображения также не изменяется. Размер макроблока зафиксирован в Н.263 и не должен сообщаться посредством сигнализации.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[7] Согласно варианту осуществления настоящего изобретения предлагается способ декодирования кодированного битового видеопотока с использованием по меньшей мере одного процессора, включающий: получение из кодированного битового видеопотока кодированной видеопоследовательности, содержащей блок изображения, соответствующий кодированному изображению; получение блока уровня сетевой абстракции (NAL, Network Abstraction Layer) заголовка изображения (РН, Picture Header), включенного в блок изображения; получение по меньшей мере одного блока уровня сетевой абстракции (NAL) уровня кодирования видео (VCL, Video Coding Layer), включенного в блок изображения; декодирование кодированного изображения на основе блока NAL РН, по меньшей мере одного блока NAL VCL и набора параметров адаптации (APS, Adaptation Parameter Set), включенного в блок NAL APS, полученный из кодированной видеопоследовательности; и вывод декодированного изображения, при этом блок NAL APS доступен по меньшей мере одному процессору перед по меньшей мере одним блоком NAL VCL.
[8] Согласно варианту осуществления настоящего изобретения предлагается устройство для декодирования кодированного битового видеопотока, содержащее по меньшей мере одну память, сконфигурированную для хранения программного кода, и по меньшей мере один процессор, сконфигурированный для считывания программного кода и функционирования в соответствии с инструкциями, определяемыми программным кодом, при этом программный код содержит: первый код получения данных, сконфигурированный так, чтобы заставлять по меньшей мере один процессор получать из кодированного битового видеопотока кодированную видеопоследовательность, содержащую блок изображения, соответствующий кодированному изображению; второй код получения данных, сконфигурированный так, чтобы заставлять по меньшей мере один процессор получать блок уровня сетевой абстракции (NAL) заголовка изображения (РН), включенный в блок изображения; третий код получения данных, сконфигурированный так, чтобы заставлять по меньшей мере один процессор получать по меньшей мере один блок уровня сетевой абстракции (NAL) уровня кодирования видео (VCL), включенный в блок изображения; код декодирования, сконфигурированный так, чтобы заставлять по меньшей мере один процессор декодировать кодированное изображение на основе блока NAL РН, по меньшей мере одного блока NAL VCL и набора параметров адаптации (APS), включенного в блок NAL APS, полученный из кодированной видеопоследовательности; и код вывода, сконфигурированный так, чтобы заставлять по меньшей мере один процессор выводить декодированное изображение, при этом блок NAL APS доступен по меньшей мере одному процессору перед по меньшей мере одним блоком NAL VCL.
[9] Согласно варианту осуществления настоящего изобретения
предлагается машиночитаемый носитель информации, на котором хранятся инструкции, включающие одну или более инструкций, при выполнении которых одним или более процессорами устройства декодирования кодированного битового видеопотока один или более процессоров получают из кодированного битового видеопотока кодированную видеопоследовательность, содержащую блок изображения, соответствующий кодированному изображению; получают блок уровня сетевой абстракции (NAL) заголовка изображения (РН), включенный в блок изображения; получают по меньшей мере один блок уровня сетевой абстракции (NAL) уровня кодирования видео (VCL), включенный в блок изображения; декодируют кодированное изображение на основе блока NAL РН, по меньшей мере одного блока NAL VCL и набора параметров адаптации (APS), включенного в блок NAL APS, полученный из кодированной видеопоследовательности; и выводят декодированное изображение, при этом блок NAL APS доступен по меньшей мере одному процессору перед по меньшей мере одним блоком NAL VCL.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[10] Дополнительные признаки, особенности и различные преимущества раскрываемого предмета изобретения станут более понятными из последующего подробного описания и прилагаемых чертежей, на которых:
[11] на фиг. 1 показано схематическое представление упрощенной блок-схемы системы связи в соответствии с вариантом осуществления настоящего изобретения.
[12] На фиг. 2 показано схематическое представление упрощенной блок-схемы системы связи в соответствии с вариантом осуществления настоящего изобретения.
[13] На фиг. 3 показано схематическое представление упрощенной блок-схемы декодера в соответствии с вариантом осуществления настоящего изобретения.
[14] На фиг. 4 показано схематическое представление упрощенной блок-схемы кодера в соответствии с вариантом осуществления настоящего изобретения.
[15] На фиг. 5А-5Е схематично показаны варианты сигнализации параметров ARC в соответствии с вариантом осуществления настоящего изобретения.
[16] На фиг. 6А-6В схематично показаны примеры синтаксических таблиц в соответствии с вариантом осуществления настоящего изобретения.
[17] На фиг. 7 показан пример структуры предсказания для масштабирования с адаптивным изменением разрешения в соответствии с вариантом осуществления настоящего изобретения.
[18] На фиг. 8 показан пример синтаксической таблицы в соответствии с вариантом осуществления настоящего изобретения.
[19] На фиг. 9 показано схематическое представление упрощенной блок-схемы анализа и декодирования цикла РОС для блока доступа и значения счетчика блока доступа в соответствии с вариантом осуществления настоящего изобретения.
[20] На фиг. 10 показано схематическое представление структуры битового видеопотока, содержащего многоуровневые субизображения, в соответствии с вариантом осуществления настоящего изобретения.
[21] На фиг. 11 показано схематическое представление отображения выбранного субизображения с расширенным разрешением в соответствии с вариантом осуществления настоящего изобретения.
[22] На фиг. 12 показана блок-схема процесса декодирования и отображения для битового видеопотока, содержащего многоуровневые субизображения, в соответствии с вариантом осуществления настоящего изобретения.
[23] На фиг. 13 показано схематическое представление отображения видео в формате 360 градусов с уровнем улучшения субизображения в соответствии с вариантом осуществления настоящего изобретения.
[24] На фиг. 14 показан пример информационной структуры субизображений и соответствующий им уровень и структура предсказания изображения в соответствии с вариантом осуществления настоящего изобретения.
[25] На фиг. 15 показан пример информационной структуры субизображений и соответствующий им уровень и структура предсказания изображения с модальностью пространственного масштабирования локальной области в соответствии с вариантом осуществления настоящего изобретения.
[26] На фиг. 16А-16В показаны примеры синтаксических таблиц для информации о структуре субизображений в соответствии с вариантом осуществления настоящего изобретения.
[27] На фиг. 17 показан пример синтаксической таблицы сообщения SEI для структуры субизображений в соответствии с вариантом осуществления настоящего изобретения.
[28] На фиг. 18 показан пример синтаксической таблицы для указания выходных уровней и информации профилей/ярусов/уровней для каждого набора выходных уровней в соответствии с вариантом осуществления настоящего изобретения.
[29] На фиг. 19 показан пример синтаксической таблицы для указания режима выходного уровня в соответствии с вариантом осуществления настоящего изобретения.
[30] На фиг. 20 показан пример синтаксической таблицы для указания текущего субизображения для каждого уровня в каждом наборе выходных уровней в соответствии с вариантом осуществления настоящего изобретения.
[31] На фиг. 21 показано схема, иллюстрирующая требования к согласованию битового потока в соответствии с вариантом осуществления настоящего изобретения.
[32] На фиг. 22 показан алгоритм примера процесса декодирования кодированного битового видеопотока в соответствии с вариантом осуществления настоящего изобретения.
[33] На фиг. 23 показано схематическое представление компьютерной системы в соответствии с вариантом осуществления настоящего изобретения.
ПОДРОБНОЕ ОПИСАНИЕ
[34] На фиг. 1 показана упрощенная блок-схема системы (100) связи в соответствии с вариантом раскрытия настоящего изобретения. Система (100) может содержать по меньшей мере два терминала (110-120), взаимосвязанных через сеть (150). Для однонаправленной передачи данных первый терминал (ПО) может кодировать видеоданные в локальном местоположении для передачи их в другой терминал (120) через сеть (150). Второй терминал (120) может принимать кодированные видеоданные другого терминала из сети (150), декодировать кодированные данные и отображать восстановленные видеоданные. Однонаправленная передача данных может представлять собой общую функцию в медийных обслуживающих приложениях и т.п.
[35] На фиг. 1 показана вторая пара терминалов (130, 140), предназначенных для поддержки двусторонней передачи кодированных видеоданных, которая может осуществляться, например, в процессе видеоконференц-связи. Для двунаправленной передачи данных каждый терминал (130, 140) может кодировать видеоданные, захваченные в локальном местоположении, для передачи их в другой терминал через сеть (150). Каждый терминал (130, 140) может принимать кодированные видеоданные, переданные другим терминалом, декодировать кодированные данные и отображать восстановленные видеоданные в локальном устройстве отображения.
[36] В примере, показанном на фиг. 1, терминалы (110-140) могут быть показаны как серверы, персональные компьютеры и смартфоны, однако принципы раскрытия настоящего изобретения, могут не ограничиваться этими устройствами. В вариантах раскрытия настоящего изобретения находится применение для ноутбуков, планшетов, медиаплееров и/или специализированного оборудования для видеоконференций. Сеть (150) представляет любое количество сетей, которые передают кодированные видеоданные между терминалами (110-140), включая, например, проводные и/или беспроводные сети связи. Сеть (150) связи может осуществлять обмен данными по линиям связи с коммутацией каналов или с коммутацией пакетов. Типичные сети включают телекоммуникационные сети, локальные и глобальные сети и/или Интернет. С целью настоящего обсуждения можно полагать, что архитектура и топология сети (150) не существенны для принципов раскрытия изобретения, если ниже не указано иное.
[37] На фиг. 2 в качестве примера применения раскрываемого предмета изобретения показано расположение кодера и декодера видеосигнала в потоковой среде. Раскрываемый предмет настоящего изобретения может равным образом использоваться с другими допустимыми применениями видео, включая, например, видеоконференц-связь, цифровое телевидение, хранение сжатых видеоданных на цифровых носителях, включая CD, DVD, карту памяти и т.п.
[38] Система потоковой передачи может содержать подсистему (213) захвата, которая может содержать источник (201) видеосигнала, например, цифровую камеру, создающую, например, несжатый поток (202) отсчетов видеоизображений. Этот поток (202) отсчетов, показанный полужирной линией, чтобы обратить внимание на большой объем данных по сравнению с кодированными битовыми видеопотоками может обрабатываться кодером (203), соединенным с камерой (201). Кодер (203) может содержать аппаратуру, программное обеспечение или комбинацию этих компонентов, позволяющую активировать или реализовать аспекты предмета раскрытия настоящего изобретения в соответствии с более подробным описанием, приведенным ниже. Битовый кодированный видеопоток (204), изображенный в виде тонкой линии, чтобы обратить внимание на небольшой объем данных по сравнению с потоком отсчетов, может для дальнейшего использования храниться на потоковом сервере (205). Один или более клиентов (206, 208) системы потоковой передачи данных могут осуществлять доступ к потоковому серверу (205) для извлечения копий (207, 209) кодированных битовых видеопотоков (204). Клиент (206) может содержать видеодекодер (210), который декодирует входящую копию кодированного битового видеопотока (207) и создает исходящий видеопоток (211) отсчетов, который может визуализироваться на дисплее (212) или на другом устройстве визуализации (не обозначенном на чертеже). В некоторых системах потоковой передачи данных битовые видеопотоки (204, 207, 209) могут кодироваться в соответствии с определенными стандартами кодирования/сжатия видеоданных. Примером таких стандартов может являться рекомендация Н.265 ITU-T. В стадии разработки находится стандарт кодирования видеоданных, неформально известный как универсальное кодирование видео или VVC (Versatile Video Coding). Раскрываемый предмет настоящего изобретения может использоваться в контексте VVC.
[39] На фиг. 3 показана функциональная блок-схема видеодекодера (210) в соответствии с вариантом раскрытия настоящего изобретения.
[40] В этом и других вариантах осуществления приемник (310) может принимать одну или более кодированных видеопоследовательностей, подлежащих декодированию декодером (210), по одной последовательности в конкретный момент времени, при этом декодирование каждой кодированной видеопоследовательности не зависит от других кодированных видеопоследовательностей. Кодированная видеопоследовательность может приниматься по каналу (312), который может представлять собой аппаратную/программную линию связи с запоминающим устройством, хранящим кодированные видеоданные. Приемник (310) может принимать кодированные видеоданные совместно с другими данными, например, с кодированными звуковыми данными и/или с потоками служебных данных, которые могут пересылаться в соответствующие им объекты применения (не показанные на чертеже). Приемник (310) может отделять кодированную видеопоследовательность от других данных. Для устранения флуктуации в сети между приемником (310) и энтропийным декодером/анализатором (320) (далее называемым "анализатор") может устанавливаться буферная память (315). Если приемник (310) принимает данные из запоминающего устройства/устройства пересылки с достаточной полосой пропускания и управляемостью или из изосинхронной сети, буфер (315) может не понадобиться или может иметь небольшой размер. Для использования в пакетных сетях наилучшего качества обслуживания, таких как Интернет, может потребоваться буфер (315), который предпочтительно может быть достаточно большим и адаптируемым по размеру.
[41] Видеодекодер (210) может содержать анализатор (320) для восстановления символов (321) из энтропийно кодированной видеопоследовательности. Категории таких символов включают, например, информацию, используемую для управления функционированием декодера (210), а также потенциальную информацию для управления устройством визуализации, таким как дисплей (212), который не интегрирован с декодером, но может быть связан с ним, как показано на фиг 3. Управляющая информация для устройства (устройств) визуализации может передаваться в формате сообщений дополнительной информации улучшения (SEI, Supplementary Enhancement Information) или фрагментов набора параметров применимости видео (VUI, Video Usability Information) (не показанных на чертеже). Анализатор (320) может анализировать и/или энтропийно декодировать принятую кодированную видеопоследовательность. Кодирование кодированной видеопоследовательности может выполняться в соответствии с технологией или стандартом видеокодирования и может следовать принципам, хорошо известным специалисту в этой области техники, включая кодирование с переменной длиной, кодирование по методу Хаффмана, арифметическое кодирование с учетом или без учета контекстной зависимости и т.д. Анализатор (320) может извлекать из кодированной видеопоследовательности набор параметров подгрупп для по меньшей мере одной из подгрупп пикселей в видеодекодере на основе по меньшей мере одного из параметров, соответствующих группе. Подгруппы могут включать группы изображений (GOP, Groups of Pictures), изображения, субизображения, тайлы, слайсы, макроблоки, блоки дерева кодирования (CTU, Coding Tree Unit), блоки кодирования (CU, Coding Unit), блоки (blocks), блоки преобразования (TU, Transform Unit), блоки предсказания (PU, Prediction Unit) и т.д. Тайл может указывать на прямоугольную область CU/CTU в пределах конкретного столбца и конкретной строки тайлов в изображении. "Кирпич" (brick) может указывать на прямоугольную область строк CU/CTU в конкретном тайле. Слайс может указывать один или более "кирпичей" изображения, находящихся в блоке NAL. Субизображение может указывать на прямоугольную область одного или более слайсов в изображении. Энтропийный декодер/анализатор также может извлекать из кодированной видеопоследовательности такую информацию, как коэффициенты преобразования, значения параметров квантователя, векторы движения и т.д.
[42] Анализатор (320) может выполнять операцию энтропийного декодирования и/или анализа видеопоследовательности, принятой из буфера (315), для создания символов (321).
[43] При восстановлении символов (321) может быть использовано множество различных блоков, в зависимости от типа кодированного видеоизображения или его части (например, изображения с внешним и внутренним кодированием или блока с внешним и внутренним кодированием) и других факторов. Используемыми блоками и способами их использования можно управлять с использованием управляющей информации подгруппы, которая анализируется на основе кодированной видеопоследовательности анализатором (320). Поток такой управляющей информации подгруппы между анализатором (320) и множеством блоков далее не описывается для простоты изложения.
[44] Помимо уже упомянутых функциональных блоков, декодер 210, как описано ниже, концептуально может подразделяться на ряд других функциональных блоков. В практических реализациях при работе в условиях коммерческих ограничений множество этих блоков тесно взаимодействуют друг с другом и могут, по меньшей мере частично, интегрироваться друг в друга. Однако с целью описания раскрываемого предмета изобретения применяется приведенное ниже концептуальное разделение на функциональные блоки.
[45] Первым блоком является блок (351) масштабирования и/или обратного преобразования. Блок (351) масштабирования и/или обратного преобразования принимает квантованный коэффициент преобразования, а также управляющую информацию, включая информацию об используемом преобразовании, размере блока, коэффициенте квантования, матрицах масштабирования при квантовании и т.д., в виде символа(-ов) (321), поступающих из анализатора (320). Этот блок может выводить блоки, содержащие значения отсчетов, которые могут подаваться в агрегатор (355).
[46] В некоторых случаях выходные отсчеты блока (351) масштабирования и/или обратного преобразования могут принадлежать внутренне кодированному блоку; то есть блоку, который не использует информацию предсказания из ранее восстановленных изображений, но может использовать информацию предсказания из ранее восстановленных частей текущего изображения. Такая информация предсказания может предоставляться блоком (352) внутреннего предсказания. В некоторых случаях блок (352) внутреннего предсказания генерирует блок того же размера и формы, что и восстанавливаемый блок, с использованием окружающей, уже восстановленной информации, извлеченной из текущего (частично восстановленного) изображения (358). Агрегатор (355) в некоторых случаях добавляет, на основе отсчетов, информацию предсказания, которую сгенерировал блок (352) внутреннего предсказания, в выходную информацию отсчетов, предоставленную блоком (351) масштабирования и/или обратного преобразования.
[47] В других случаях выходные отсчеты блока 351 масштабирования и/или обратного преобразования могут принадлежать внешне кодированному блоку, возможно с компенсацией движения. В таком случае блок (353) предсказания компенсации движения может осуществлять доступ к памяти (357) опорных изображений для извлечения отсчетов, используемых для предсказания. После компенсации движения извлеченные отсчеты в соответствии с символами (321), принадлежащими блоку, могут добавляться агрегатором (355) к выходным данным блока 351 масштабирования и/или обратного преобразования (в этом случае эти данные называются разностными отсчетами или разностным сигналом), для того чтобы генерировать выходную информацию отсчетов. Адреса в памяти опорных изображений, по которым блок компенсации движения извлекает отсчеты предсказания, могут управляться векторами движения, доступными блоку компенсации движения в виде символов (321), которые могут характеризоваться, например, компонентами X, Y и опорным изображением. Компенсация движения также может включать интерполяцию значений отсчетов при извлечении из памяти опорных изображений, если используются точные векторы движения подотсчетов, механизмы предсказания векторов движения и т.д.
[48] Выходные отсчеты агрегатора (355) могут обрабатываться с использованием различных технологий контурной фильтрации в блоке (356) контурного фильтра. Технологии сжатия видеоданных могут включать технологии внутриконтурной фильтрации, управляемые параметрами, которые включаются в кодированную битовую видеопоследовательность и становятся доступными блоку (356) контурной фильтрации в виде символов (321) из анализатора (320), но также могут реагировать на метаинформацию, получаемую в процессе декодирования предшествующих (в порядке декодирования) частей кодированного изображения или кодированной видеопоследовательности, а также реагировать на ранее восстановленные и подвергшиеся контурной фильтрации значения отсчетов.
[49] Выход блока (356) контурного фильтра может представлять собой поток отсчетов, который может подаваться на устройство (212) визуализации, а также сохраняться в памяти опорных изображений для последующего использования во внешнем предсказании.
[50] Определенные кодированные изображения после полного восстановления могут использоваться в качестве опорных изображений для последующего предсказания. После того как кодированное изображение полностью восстановлено и идентифицировано как опорное изображение (например, анализатором (320)), текущее опорное изображение (358) может стать частью буферной памяти (357) изображений, и обновленная память текущих изображений может перераспределяться перед началом восстановления следующего кодированного изображения.
[51] Видеодекодер 210 может выполнять операции декодирования в соответствии с предварительно определенной технологией сжатия видеоданных, которая может документироваться в стандарте, таком как рекомендация ITU-T Н.265. Кодированная видеопоследовательность может соответствовать синтаксису, указанному используемыми технологией или стандартом сжатия видеоданных, в том смысле, что она придерживается синтаксиса технологии или стандарта сжатия видеоданных, заданным в документе или стандарте по технологии сжатия видеоданных и, в особенности, в профильных документах этих стандартов. Кроме того, для соответствия сложность кодированных видеопоследовательностей может находиться в пределах, определенных уровнем технологии или стандарта сжатия видеоданных. В некоторых случаях уровни сложности ограничивают максимальный размер изображения, максимальную частоту кадров, максимальную частоту отсчетов для восстановления (измеряемую, например, в миллионах отсчетов в секунду), максимальный размер опорного изображения и т.д. Уровни сложности могут также в некоторых случаях ограничиваться спецификациями гипотетического эталонного декодера (HRD, Hypothetical Reference Decoder) и метаданными для управления буфером HRD, сообщаемыми в кодированной видеопоследовательности.
[52] Согласно варианту осуществления приемник (310) может принимать дополнительные (избыточные) данные вместе с кодированной видеоинформацией. Дополнительные данные могут вставляться в кодированную видеопоследовательность(-и). Дополнительные данные могут использоваться видеодекодером (210) для корректного декодирования данных и/или для более точного восстановления исходных видеоданных. Дополнительные данные могут предоставляться в виде, например, временных, пространственных или расширенных уровней SNR, избыточных слайсов, избыточных изображений, кодов с прямым исправлением ошибок и т.д.
[53] На фиг. 4 показана функциональная блок-схема видеокодера (203) в соответствии с вариантом раскрытия настоящего изобретения.
[54] Кодер (203) может принимать отсчеты видеосигнала из источника (201) видеосигнала (не являющегося частью кодера), который может захватывать видеоизображение(-я), подлежащее кодированию кодером (203).
[55] Источник (201) видеосигнала может предоставлять исходную видеопоследовательность, подлежащую кодированию кодером (203), в виде цифрового видеопотока отсчетов, который может иметь любую подходящую битовую глубину (например, 8 бит, 10 бит, 12 бит, …), любое цветовое пространство (например, ВТ.601 Y CrCB, RGB, …) и любую подходящую структуру отсчетов (например, Y CrCb 4:2:0, Y CrCb 4:4:4). В обслуживающей медийной системе источник (201) видеосигнала может представлять собой запоминающее устройство, на котором хранятся ранее подготовленные видеоданные. В системе видеоконференц-связи источник (203) видеосигнала может представлять собой камеру, которая захватывает локальную графическую информацию в форме видеопоследовательности. Видеоданные могут предоставляться в виде множества отдельных изображений, которые передают движение при последовательном просмотре. Непосредственно изображения могут быть организованы как пространственный массив пикселей, каждый из которых может содержать один или более отсчетов, в зависимости от используемых структуры дискретизации, цветового пространства и т.д. Специалисту в этой области техники нетрудно понять взаимосвязь между пикселями и отсчетами. В последующем описании делается акцент на отсчеты.
[56] Согласно варианту осуществления кодер (203) может кодировать и сжимать изображения исходной видеопоследовательности для преобразования ее в кодированную видеопоследовательность (443) в реальном времени или в соответствии с любыми другими ограничениями по времени, зависящими от применения. Обеспечение подходящей скорости кодирования является одной из функций, выполняемых контроллером (450). Контроллер управляет другими функциональными блоками, как описывается ниже, и функционально соединяется с этими блоками. Для простоты эта связь не обозначена на чертеже. Параметры, устанавливаемые контроллером, могут включать в свой состав параметры, относящиеся к управлению скоростью (пропуск изображения, квантователь, значение лямбда для технологий оптимизации искажения от скорости передачи, …), размер изображения, уровень группы изображений (GOP), максимальный диапазон поиска вектора движения и т.д. Специалист в этой области техники может легко идентифицировать другие функции контроллера (450), в той мере, в какой они могут относиться к видеокодеру (203), оптимизированному для структуры определенной системы.
[57] Некоторые видеокодеры работают в режиме, который специалисту в этой области техники известен как "петля кодирования". В упрощенном описании петля кодирования может состоять из частей кодирования кодера (430) (далее "кодер источника"), ответственного за создание символов на основе входного изображения, подлежащего кодированию, и опорного изображения(-ий)) и (локального) декодера (433), встроенного в кодер (203) и восстанавливающего символы для создания данных отсчетов, которые (удаленный) декодер также должен создавать (поскольку любое сжатие между символами и кодированным битовым видеопотоком выполняется без потерь согласно технологиям сжатия видеоданных, рассматриваемым в рамках раскрытия предмета настоящего изобретения). Восстановленный поток отсчетов записывается в память (434) опорных изображений. Поскольку декодирование символьного потока приводит к точным битовым результатам независимо от местоположения декодера (локальное или удаленное), буфер опорных изображений также содержит точные биты между локальным кодером и удаленным кодером. Другими словами, подсистема предсказания кодера "видит" в качестве отсчетов опорных изображений в точности те же значения отсчетов, которые должен "увидеть" декодер при использовании предсказания в процессе декодирования. Этот фундаментальный принцип синхронности ссылочных изображений (и результирующий сдвиг, если синхронность не может поддерживаться, например, из-за ошибок в канале) хорошо известен специалисту в этой области техники.
[58] Работа "локального" декодера (433), по существу, может быть аналогична функционированию "удаленного" декодера (210), который уже подробно описывался выше со ссылкой на фиг.3. Однако, как показано на фиг.4, поскольку символы доступны и кодирование и/или декодирование символов в кодированную видеопоследовательность энтропийным кодером (445) и анализатором (320) может выполняться без потерь, подсистемы энтропийного декодирования декодера (210), включая канал (312), приемник (310), буфер (315) и анализатор (320), могут быть не полностью реализованы в локальном декодере (433).
[59] Здесь следует заметить, что любая технология декодирования, за исключением анализа и/или энтропийного декодирования, используемая в декодере, также обязательно требуется по существу в идентичном функциональном виде в соответствующем кодере. По этой причине при раскрытии предмета настоящего изобретения акцент делается на работе декодера. Описание технологий кодера может быть сокращено, поскольку они являются обратными по отношению к всесторонне описанным технологиям декодера. Более подробного описания, приводимого ниже, требуют только определенные области.
[60] Одной из функций кодера (430) источника может являться выполнение кодирования с предсказанием и компенсацией движения, при котором с предсказанием кодируются входные кадры со ссылкой на один или более ранее кодированных кадров видеопоследовательности, обозначаемых как "опорные кадры". Таким образом, ядро (432) кодирования кодирует разности между блоками пикселей входного кадра и блоками пикселей опорного кадра(-ов), которые могут выбираться в качестве ссылки(-ок) предсказания на входной кадр.
[61] Локальный видеодекодер (433) может декодировать кодированные видеоданные кадров, которые могут обозначаться как опорные кадры, на основе символов, созданных кодером (430) источника. Операции ядра (432) кодирования могут преимущественно являться процессами с потерями. Если кодированные видеоданные могут декодироваться в видеодекодере (не показанном на фиг.4), то восстановленная видеопоследовательность обычно может представлять собой копию исходной видеопоследовательности с некоторыми ошибками. Локальный видеодекодер (433) дублирует процессы декодирования, которые могут выполняться видеодекодером с опорными кадрами, и может сохранять опорные кадры в кэш-памяти (434) опорных изображений. Таким образом, кодер (203) может локально сохранять копии восстановленных опорных кадров, имеющие то же содержимое, что и восстановленные опорные кадры, которые должны быть получены видеодекодером на дальнем конце (отсутствие ошибок при передаче).
[62] Предсказатель (435) может выполнять поиск с предсказанием для ядра (432) кодирования. То есть, для нового кадра, подлежащего кодированию, предсказатель (435) может осуществлять поиск данных отсчетов в памяти (434) опорных изображений (в качестве подходящих опорных блоков пикселей) или определенных метаданных, таких как векторы движения опорных изображений, формы блоков и т.д., которые могут служить в качестве подходящей ссылки предсказания для новых изображений. Предсказатель (435) может работать в режиме "блока отсчетов за блоком пикселей" для нахождения подходящих ссылок предсказания. В некоторых случаях, определяемых результатами поиска, получаемыми предсказателем (435), входное изображение может характеризоваться ссылками предсказания, полученными на основе множества опорных изображений, хранимых в памяти (434) опорных изображений.
[63] Контроллер (450) может управлять операциями кодирования видеокодера (430), включая, например, установку параметров и параметров подгрупп, используемых для кодирования видеоданных.
[64] К выходным данным всех упомянутых выше функциональных блоков может применяться энтропийное кодирование в энтропийном кодере (445). Энтропийнный кодер транслирует символы, генерированные различными функциональными блоками, в кодированную видеопоследовательность путем сжатия символов без потерь в соответствии с технологиями, известными специалисту в этой области техники, такими как кодирование Хаффмана, кодирование с переменной длиной, арифметическое кодирование и т.д.
[65] Передатчик (440) может буферизировать кодированную видеопоследовательность(-и), созданную энтропийным кодером (445), с целью подготовки ее для передачи по каналу (460) связи, который может представлять собой аппаратную/программную линию связи с запоминающим устройством, в котором должны храниться кодированные видеоданные. Передатчик (440) может объединять кодированные видеоданные из видеокодера (430) с другими данными, подлежащими передаче, например, с кодированными потоками звуковых и/или служебных данных (эти источники не показаны на чертеже).
[66] Контроллер (450) может управлять работой кодера (203). В процессе кодирования контроллер (450) может назначать каждому кодированному изображению определенный тип кодированного изображения, который может влиять на технологию кодирования, которая может применяться к соответствующему изображению. Например, изображениям часто может назначаться один из следующих типов.
[67] Внутренне кодированное (интра) изображение (I-изображение) может представлять собой изображение, которое может кодироваться и декодироваться без использования любого другого кадра в последовательности в качестве источника предсказания. Некоторые видеокодеки предусматривают различные типы интра-изображений, включая, например, изображения независимого обновления декодера (Independent Decoder Refresh). Специалист в этой области техники осведомлен об этих вариантах I-изображений, их применениях и признаках.
[68] Изображение с предсказанием (Р-изображение) может кодироваться и декодироваться с использованием внутреннего или внешнего предсказания с помощью не более чем одного вектора движения и опорного индекса для предсказания значений отсчетов каждого блока.
[69] Двунаправленное изображение с предсказанием (В-изображение) может кодироваться и декодироваться с использованием внутреннего или внешнего предсказания с помощью не более чем двух векторов движения и опорных индексов для предсказания значений отсчетов каждого блока. Подобным образом изображения с множественным предсказанием могут использовать более двух опорных изображений и связанных метаданных для восстановления одного блока.
[70] Исходные изображения в общем случае могут пространственно разделяться на множество блоков отсчетов (например, блоков отсчетов 4x4, 8x8, 4x8 или 16x16) и кодироваться в режиме "блок за блоком". Блоки могут кодироваться с предсказанием со ссылкой на другие (уже кодированные) блоки, как определяется назначением кодирования, применимого к соответствующим изображениям блоков. Например, блоки I-изображений могут кодироваться без предсказания или с предсказанием со ссылкой на уже кодированные блоки того же изображения (пространственное предсказание или внутреннее предсказание). Блоки пикселей Р-изображений могут кодироваться без предсказания, с использованием пространственного предсказания или временного предсказания со ссылкой на одно предварительно кодированное опорное изображение. Блоки В-изображений могут кодироваться без предсказания, с использованием пространственного предсказания или временного предсказания со ссылкой на одно или два предварительно кодированных опорных изображений.
[71] Видеокодер (203) может выполнять операции кодирования в соответствии с предварительно определенной технологией или стандартом кодирования видеоданных, таким как рекомендация ITU-T Н.265. В процессе функционирования видеокодер (203) может выполнять различные операции сжатия, включая операции кодирования с предсказанием, в которых используется временная или пространственная избыточность входной видеопоследовательности. Кодированные видеоданные, таким образом, могут соответствовать синтаксису, указанному используемыми технологией или стандартом видеокодирования.
[72] Согласно варианту осуществления передатчик (440) может передавать дополнительные данные вместе с кодированной видеоинформацией. Видеокодер (430) может включать такие данные в кодированную видеопоследовательность. Дополнительные данные могут включать в свой состав временные/пространственные/SNR расширенные уровни, другие виды избыточных данных, такие как избыточные изображения и слайсы, сообщения дополнительной расширенной информации (SEI), фрагменты набора параметров применимости визуальной информации (VUI, Visual Usability Information) и т.д.
[73] В последнее время определенное внимание привлекает агрегирование или извлечение множества семантически независимых частей изображения из одного видеоизображения. В частности, в контексте, например, кодирования видео в формате 360 градусов или определенных приложений контроля для множества семантически независимых исходных изображений (например, шести кубических пространств заключенной в куб сцены в формате 360 градусов, или отдельных входных данных камеры в случае многокамерной установки видеонаблюдения) могут потребоваться отдельные адаптивные настройки разрешения для функционирования в условиях различной активности в зависимости от сцены в различные моменты времени. Другими словами, кодеры в заданный момент времени могут выбирать для использования различные коэффициенты пере дискретизации для различных семантически независимых изображений, охватывающих все пространство в 360 градусов или сцену наблюдения. При объединении в одно изображение, в свою очередь, требуется выполнение передискретизации опорного изображения и требуется доступность сигнализации кодирования с адаптивным разрешением для частей кодированного изображения.
[74] Ниже вводится несколько терминов, применяемых в оставшейся части описания.
[75] Субизображение (Sub-Picture) может указывать в некоторых случаях на прямоугольную структуру отсчетов, блоков, макроблоков, блоков кодирования или подобных семантически группируемых объектов, которые могут независимо кодироваться в условиях изменяющегося разрешения. Одно или более субизображений могут формировать изображение в целом. Одно или более кодированных субизображений могут формировать кодированное изображение. Одно или более субизображений могут объединяться в изображение, и одно или более субизображений могут извлекаться из изображения. В некоторых вариантах осуществления одно или более кодированных субизображений могут собираться в сжатой области без транскодирования на уровне отсчетов в кодированное изображение, и в подобных или иных случаях одно или более кодированных субизображений могут извлекаться из кодированного изображения в сжатой области.
[76] Термин адаптивное изменение разрешения (ARC, Adaptive Resolution Change) может относиться к механизмам, позволяющим изменять разрешение изображения или субизображения в пределах кодированной видеопоследовательности посредством, например, передискретизации опорного изображения. Параметры ARC означают управляющую информацию, требуемую для выполнения адаптивного изменения разрешения, которая может содержать, например, параметры фильтрации, коэффициенты масштабирования, информацию о разрешении выходных и/или опорных изображений, различные флаги управления и т.д.
[77] Согласно вариантам осуществления кодироваться и декодироваться может одно семантически независимое кодированное видеоизображение. Перед описанием результатов кодирования/декодирования множества субизображений с использованием независимых параметров ARC и связанной с этим дополнительной сложности следует описать варианты сигнализации параметров ARC.
[78] На фиг. 5А-5Е показано несколько вариантов осуществления сигнализации параметров ARC. Как отмечалось, каждый вариант осуществления может обладать определенными преимуществами и определенными недостатками с точки зрения эффективности кодирования, сложности и архитектуры. В стандарте или технологии видеокодирования могут выбираться один или более этих вариантов осуществления или вариантов, известных на соответствующем уровне техники, для сигнализации параметров ARC. Варианты осуществления могут не быть взаимоисключающими и, возможно, могут взаимно заменяться в зависимости от требований применения, использованных технологических стандартов или выбора кодера.
[79] Классы параметров ARC могут включать:
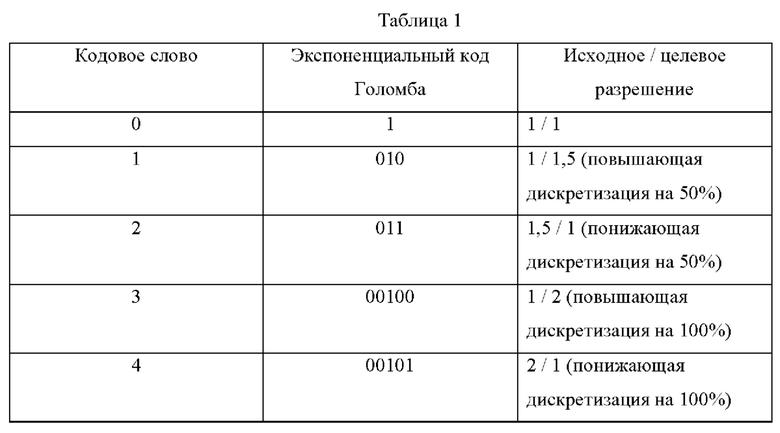
[80] - коэффициенты повышающей и/или понижающей дискретизации, отдельные или объединенные в измерениях X и Y.
[81] - Коэффициенты повышающей и/или понижающей дискретизации с добавлением временного измерения, указывающего увеличение/уменьшение масштаба с постоянной скоростью для заданного количества изображений.
[82] - В любом из указанных выше двух классах может быть использовано кодирование одного или более предположительно коротких синтаксических элементов, которые могут указывать на таблицу, содержащую коэффициент(ы).
[83] - Объединенное или отдельное разрешение в направлении X или Y, измеряемое в отсчетах, блоках, макроблоках, блоках кодирования (CU) или с использованием любой другой гранулярности, входного изображения, выходного изображения, опорного изображения, кодированного изображения. Если имеется несколько разрешений (например, одно для входного изображения, одно для опорного изображения), то в определенных случаях один набор значений может выводиться из другого набора значений. Переключения можно достичь, например, путем использования флагов. Более подробный пример приведен ниже.
[84] - Координаты "деформации" ("warping" coordinates), то есть координаты, используемые в приложении Р рекомендации Н.263, также задаваемые с подходящей гранулярностью, как описывалось выше. В приложении Р рекомендации Н.263 описывается один эффективный способ кодирования таких координат "деформации", но также потенциально возможно разработать другой, более эффективный способ. Например, обратимое кодирование с переменной длиной "в стиле Хаффмана" координат деформации согласно приложению Р может быть заменено двоичным кодированием с подходящей длиной, в котором длина двоичного кода может, например, выводиться на основе максимального размера изображения, возможно умноженного на определенный коэффициент и смещенного на определенное значение, чтобы позволить "деформацию" вне границ максимального размера изображения.
[85] - Параметры фильтрации с повышающей и/или понижающей дискретизацией. Согласно вариантам осуществления, может существовать только один фильтр для повышающей и/или понижающей дискретизации. Однако в некоторых вариантах осуществления желательно допускать большую гибкость в конструкции фильтра, при этом может потребоваться осуществлять сигнализацию параметров фильтрации. Такие параметры могут выбираться с использованием индекса в списке возможных конструкций фильтра, фильтр может быть полностью определен (например, посредством списка коэффициентов фильтрации с использованием подходящей технологии энтропийного кодирования), фильтр может выбираться неявно посредством коэффициентов повышающей и/или понижающей дискретизации, которые, в свою очередь, сообщаются в соответствии с любыми механизмами, упомянутыми выше, и т.д.
[86] Таким образом, в описании предполагается, что кодирование конечного набора коэффициентов повышающей и/или понижающей дискретизации (в направлениях X и Y должен использоваться одинаковый коэффициент) указывается с помощью кодового слова. Такое кодовое слово может кодироваться с переменной длиной, например, с использованием экспоненциального кода Голомба (Ext-Golomb code), общего для определенных синтаксических элементов в таких спецификациях кодирования видеосигналов как Н.264 и Н.265. Один из подходящих вариантов преобразования значений в коэффициенты повышающей и/или понижающей дискретизации может, например, выбираться согласно таблице 1:
[87] В соответствии с требованиями применения и возможностями механизмов повышающей и/или понижающей дискретизации, доступных в стандарте или технологии сжатия видеосигналов, могут разрабатываться множество схожих способов преобразования. В таблицу могут добавляться дополнительные значения. Значения могут также представляться механизмами энтропийного кодирования, отличными от экспоненциального кода Голомба, например, с помощью двоичного кодирования. Это может обеспечивать определенные преимущества, если коэффициенты передискретизации представляют интерес вне самих ядер обработки видеосигнала (прежде всего кодера и декодера), например в MANE. Следует отметить, что в ситуациях, в которых не требуется изменение разрешения может быть выбран короткий экспоненциального код Голомба, занимающий в приведенной выше таблице только один бит.Это дает преимущество с точки зрения эффективности кодирования по сравнению с использованием двоичных кодов в большинстве общих случаев.
[88] Количество элементов в таблице, а также их семантика может полностью или частично конфигурироваться. Например, базовая структура таблицы может передаваться в наборе параметров "верхнего уровня", таком как последовательность или набор параметров декодера. Согласно вариантам осуществления, одна или более таких таблиц могут определяться в технологии или стандарте видеокодирования и могут выбираться, например, через набор параметров декодера или последовательности.
[89] Ниже описывается, каким образом коэффициент повышающей и/или понижающей дискретизации (информация ARC), кодированный как описано выше, может включаться в синтаксис технологии или стандарта видеокодирования. Схожие соображения могут применяться к одному или нескольким кодовым словам, управляющим фильтрами повышающей и/или понижающей дискретизации. Ниже обсуждается, в каких случаях для фильтра или других структур данных требуется относительно большой объем данных.
[90] Как показано на фиг. 5А, согласно приложению Р Н.263, в заголовок (501) изображения, более точно в расширение заголовка (503) Н.263 PLUSPTYPE, включается информация (502) ARC в виде четырех координат деформации. Такая конструкция может быть практичной, если а) существует доступный заголовок изображения, и Ь) ожидаются частые изменения информации ARC. Однако при использовании сигнализации формата Н.263 объем служебных данных может быть достаточно большим, и коэффициенты масштабирования могут не относиться к границам изображения, поскольку заголовок по своей природе является изменяющимся объектом.
[91] Как показано на фиг. 5В, технология JVCET-M135-v1 включает опорную информацию (505) ARC (индекс), расположенную в наборе (504) параметров изображения, индексирующих таблицу (506), содержащую целевые разрешения, которые, в свою очередь, расположены внутри набора (507) параметров последовательности. Размещение возможного разрешения в таблице (506) в наборе (507) параметров последовательности может, согласно устным заявлениям, сделанным авторами, согласовываться путем использования SPS в качестве точки согласования взаимодействия в процессе обмена информацией о возможностях. Разрешение в пределах границ, установленных значениями из таблицы (506), может изменяться от изображения к изображению путем ссылки на подходящий набор (504) параметров изображения.
[92] На фиг. 5С-5Е показано, что могут существовать последующие варианты осуществления для передачи информации ARC в битовом видеопотоке. Каждый из этих вариантов имеет определенные преимущества по сравнению с описанными выше вариантами осуществления. Варианты осуществления могут одновременно существовать в одной и той же технологии или стандарте кодирования видеосигнала.
[93] Согласно вариантам осуществления, например, варианту, показанному на фиг. 5С, информация (509) ARC, такая как коэффициент передискретизации (масштабирования), может содержаться в заголовке слайса, заголовке GOP, заголовке тайла или в заголовке группы тайлов. На фиг. 5С показан вариант осуществления, в котором используется заголовок (508) группы тайлов. Такой вариант может быть адекватным, если объем информации ARC небольшой, например, один ue(v) переменной длины или кодовое слово фиксированной длины, содержащее несколько битов, как, например, показано выше. Расположение информации ARC в группе тайлов обладает дополнительным преимуществом, заключающимся в том, что информация ARC может применяться к субизображению, представленному, например, этой группой тайлов, а не всему изображению. Дополнительная информация приводится ниже. Кроме того, если даже технология или стандарт сжатия видеосигнала предусматривает только адаптивные изменения разрешения всего изображения (в отличие, например, от адаптивных изменений разрешения на основе группы тайлов), помещение информации ARC в заголовок группы тайлов в сравнении с размещением ее в заголовке изображения формата Н.263 обладает определенными преимуществами с точки зрения устойчивости к ошибкам.
[94] Согласно вариантам осуществления, например, варианту, показанному на фиг. 5D, информация (512) ARC непосредственно может быть представлена в подходящем наборе параметров, таком, например, как набор параметров изображения, набор параметров заголовка, набор параметров тайла, набор параметров адаптации и т.д. На фиг. 5D показан вариант осуществления, в котором используется набор (511) параметров адаптации. Диапазон охвата этого набора параметров преимущественно не может превышать изображение, например, группу тайлов. Информация ARC используется неявно через активизацию соответствующего набора параметров. Например, если технология или стандарт кодирования рассматривает только ARC на основе изображения, то может подходящим образом использоваться набор параметров изображения или эквивалентная ему информация.
[95] Согласно вариантам осуществления, например варианту, показанному на фиг. 5Е, опорная информация (513) ARC может находиться в заголовке (514) группы тайлов или в подобной структуре данных. Эта опорная информация (513) может указывать на подмножество информации (515) ARC, доступное в наборе (516) параметров, в диапазоне, превышающем одно изображение, например набор параметров последовательности или набор параметров декодера.
[96] Как показано на фиг. 6А, заголовок (601) группы тайлов, как пример синтаксической структуры заголовка, применимой к (возможно прямоугольной) части изображения, может условно содержать синтаксический элемент dec_pic_size_idx (602) переменной длины, кодированный с помощью экспоненциального кода Голомба (обозначен полужирным шрифтом). Наличие этого синтаксического элемента в заголовке группы тайлов позволяет использовать адаптивное разрешение (603) - в данном случае значение флага не выделено полужирным шрифтом, и это означает, что флаг находится в битовом потоке, в точке, в которой он появляется в синтаксической схеме. О том, используется ли адаптивное разрешение для этого изображения или его части, может сообщаться в любой синтаксической структуре высокого уровня внутри или вне битового потока. В показанном примере флаг сообщается в наборе параметров последовательности, как отмечается ниже.
[97] На фиг. 6В также показана выборка из набора (610) параметров последовательности. Первым показанным синтаксическим элементом является adaptive_pic_resolution_change_flag (611). Если этот флаг принимает значение "истина", это указывает на использование адаптивного разрешения, что, в свою очередь, может потребовать определенной управляющей информации. В примере такая управляющая информация условно присутствует согласно значению флага, основанного на операторе if() в наборе (612) параметров и в заголовке (601) группы тайлов.
[98] Если адаптивное разрешение используется, то в этом примере выходное разрешение кодированных данных измеряется в отсчетах (613). Число 613 относится как к output_pic_width_in_luma_samples, так и к output_pic_height_in_luma_samples, которые совместно могут определять разрешение выходного изображения. В другом разделе технологии или стандарта видеокодирования могут определяться определенные ограничения для любого из двух значений. Например, определение уровня может ограничивать общее количество выходных отсчетов, которое может представлять собой произведение значений этих двух синтаксических элементов. Кроме того, определенные технологии или стандарты видеокодирования, либо внешние технологии или стандарты, такие, например, как системные стандарты, могут ограничивать диапазон нумерации (например, одно или оба измерения должны делится на степень числа 2) или формат изображения (например, отношение между шириной и высотой должны быть, например, 4:3 или 16:9). Такие ограничения могут вводиться для упрощения аппаратных реализаций или по другим причинам и хорошо известны в этой области техники.
[99] В определенных применениях рекомендуется, чтобы кодер инструктировал декодер для использования определенного размера опорного изображения, а не предполагал неявно значение размера изображения, подлежащего выводу. В этом примере синтаксический элемент reference_pic_size_present_flag (614) определяет условное наличие измерений (615) опорного изображения (снова, число указывает как на ширину, так и на длину).
[100] Наконец, показана таблица возможной ширины и высоты декодируемого изображения. Такая таблица может выражаться, например, своим идентификатором (num_dec_pi_ siz_in_lumasamples_minus1) (616). Обозначение "minus 1" может указывать на интерпретацию значения этого синтаксического элемента. Например, если кодированное значение равно нулю, то существует один элемент таблицы. Если значение равно пяти, то существуют шесть элементов таблицы. Для каждой "строки" таблицы затем в синтаксис (617) включается ширина и высота декодированного изображения.
[101] Представленные элементы таблицы (617) могут индексироваться с использованием синтаксического элемента dec_pic_size_idx (602) в заголовке группы тайлов, что позволяет использовать различные декодированные размеры - фактически, коэффициенты масштабирования - для группы тайлов.
[102] Определенные технологии или стандарты видеокодирования, например VP9, поддерживают пространственное масштабирование путем реализации определенных форм передискретизации опорного изображения (которая сигнализируется способом, отличным от того, что предлагается в раскрытии предмета настоящего изобретения) совместно с временным масштабированием, таким образом, чтобы разрешить пространственное масштабирование. В частности, для определенных опорных изображений может применяться повышающая дискретизация с использованием технологий в стиле ARC для получения более высокого разрешения с целью формирования основы пространственного расширенного уровня. Эти изображения с повышенной дискретизацией для добавления деталей могут улучшаться с использованием обычных механизмов предсказания при высоком разрешении.
[103] Обсуждаемые в этом описании варианты осуществления настоящего изобретения могут использоваться в такой среде. В определенных случаях, в том же или другом варианте осуществления, значение в заголовке блока NAL, например поле temporal_id (временной идентификатор), может использоваться для индикации не только временного, но и пространственного уровня. Такая операция может обладать определенными преимуществами для определенных структур системы; например, существующие блоки выбранной пересылки (SFU, Selected Forwarding Unit), созданные и оптимизированные для выбранной пересылки временного уровня, основанной на значении временного идентификатора заголовка блока NAL, могут использоваться без модификации для масштабируемых сред. Для инициирования этого режима может потребоваться, чтобы преобразование между размером кодированного изображения и временным уровнем указывалось в поле временного идентификатора в заголовке блока NAL.
[104] В соответствии с некоторыми технологиями видеокодирования, блок доступа (AU, Access Unit) может ссылаться на кодированное изображение(-я), слайс(ы), тайл(ы), блок(-и) NAL и т.д., которые захвачены и скомпонованы в соответствующий битовый поток изображений, слайсов, тайлов и/или блоков NAL в заданный момент времени. Этот момент времени может представлять собой, например, время композиции.
[105] Согласно HEVC и некоторым другим технологиям видеокодирования, значение счетчика очередности изображений (РОС, Picture Order Count) может использоваться для индикации выбранного опорного изображения, входящего в состав множества опорных изображений, хранимых в буфере декодированных изображений (DPB, Decoded Picture Buffer). Если блок доступа (AU) содержит одно или более изображений, слайсов или тайлов, каждое изображение, слайс или тайл, принадлежащие одинаковому AU, могут нести одинаковое значение РОС, из чего можно заключить, что они созданы из содержимого, соответствующего одному и тому же времени композиции. Другими словами, в сценарии, в котором два изображения/слайса/тайла переносят одинаковое заданное значение РОС, можно определить, что два изображения/слайса/тайла принадлежат одному AU и характеризуются одинаковым временем композиции. С другой стороны, два изображения/слайса/тайла с различными значениями РОС могут указывать на то, что эти изображения/слайсы/тайлы принадлежат различным AU и характеризуются разным временем композиции.
[106] Согласно вариантам осуществления эта жесткая взаимосвязь может быть ослаблена, так, что блок доступа может содержать изображения, слайсы или тайлы с различными значениями РОС. Путем разрешения различных значений РОС в AU становится возможным использовать значение РОС для идентификации потенциально независимо декодируемых изображений/слайсов/тайлов с идентичным временем представления. Это, в свою очередь, может позволить осуществлять поддержку множества масштабируемых уровней без изменения сигнализации выбора опорного изображения, например, сигнализации набора опорных изображений или сигнализации списка опорных изображений, как более подробно описывается ниже.
[107] Однако все еще желательно иметь возможность идентифицировать AU, которому принадлежит изображение/слайс/тайл, относительно других изображений/слайсов/тайлов, имеющих отличающиеся значения РОС, исходя только из значения РОС. Этого можно достичь таким образом, как описывается ниже.
[108] Согласно вариантам осуществления, значение счетчика блока доступа (AUC, Access Unit Count) может сообщаться в высокоуровневой синтаксической структуре, такой как заголовок блока NAL, заголовок слайса, заголовок группы тайлов, сообщение SEI, набор параметров или разделитель AU. Значение AUC может использоваться для идентификации блоков NAL, изображений, слайсов или тайлов, принадлежащих заданной AU. Значение AUC может соответствовать различным моментам времени композиции. Значение AUC может быть кратно значению РОС. Значение AUC можно вычислить путем деления значения РОС на целое число. В некоторых случаях операции деления могут привести к дополнительной нагрузке на декодер в определенных реализациях. В таких случаях небольшие ограничения в числовом пространстве значений AUC могут позволить заменить операцию деления на операции сдвига. Например, значение AUC может быть равно значению самого старшего бита (MSB, Most Significant Bit) диапазона значений РОС.
[109] Согласно вариантам осуществления, значение цикла РОС для одного AU (poc_cycle_au) может сообщаться в высокоуровневой синтаксической структуре, такой как заголовок блока NAL, заголовок слайса, заголовок группы тайлов, сообщение SEI, набор параметров или разделитель AU. Значение рос_cycle_au может указывать на то, как много различных и последовательных значений РОС может быть связано с одним значением AU. Например, если значение рос_cycle_au равно 4, то изображения, слайсы или тайлы со значением РОС, равным 0-3, включительно, могут быть связаны с AU со значением AUC, равным 0, и изображения, слайсы или тайлы со значением РОС, равным 4-7, включительно, могут быть связаны с AU со значением AUC, равным 1. Следовательно, значение AUC может быть получено путем деления значения РОС на значение poc_cycle_au.
[110] Согласно вариантам осуществления, значение poc_cyle_au может выводиться из информации, расположенной, например, в наборе параметров видео (VPS, Video Parameter Set), который идентифицирует количество пространственных уровней или уровней SNR в кодированной видеопоследовательности. Ниже кратко описывается пример такого возможного отношения. В то время как описанное выше выведение может позволить сократить несколько битов в VPS и, следовательно, повысить эффективность кодирования, в некоторых вариантах осуществления рос_cycle_au может явно кодироваться в подходящей высокоуровневой синтаксической структуре, иерархически расположенной ниже набора параметров видео, для того чтобы иметь возможность минимизировать poc_cycle_au для заданной небольшой части битового потока, такой как изображение. Такая оптимизация может сэкономить больше битов, чем это возможно в процессе выведения значений РОС, описанного выше, поскольку значения РОС и/или значения синтаксических элементов, косвенно ссылающихся на РОС, могут кодироваться в низкоуровневых синтаксических структурах.
[111] Согласно вариантам осуществления, на фиг.8 показан пример синтаксических таблиц для сигнализации синтаксического элемента vps_рос_cycle_au в VPS (или SPS), который указывает значение рос_cycle_au, используемое для всех изображений/слайсов в кодированной видеопоследовательности, и синтаксического элемента slice_poc_cycle_au, который указывает значение poc_cycle_au текущего слайса в заголовке слайса. Если значение РОС увеличивается единообразно на каждый AU, значение vps_contant_poc_cycle_per_au в VPS может устанавливаться равным 1, и vpsjtoc cycle au может сообщаться в VPS. В этом случае slice_poc_cycle_au может явно не сообщаться, и значение AUC для каждого AU может рассчитываться путем деления РОС на vps_poc_cycle_au. Если значение РОС не увеличивается единообразно на каждый AU, то значение vps_contant_poc_cycle_per_au в VPS может устанавливаться равным 0. В этом случае vps_access_unit_cnt может не сообщаться, в то время как slice_access_uni_cnt может сообщаться в заголовке слайса для каждого слайса или изображения. Каждому слайсу или изображению может присваиваться различное значение slice_access_unit_cnt. Значение AUC для каждой AU может вычисляться путем деления значения РОС на slice_рос_cycle_au.
[112] На фиг.9 показана блок-схема, иллюстрирующая пример процесса, описанного выше. Например, в ходе выполнения операции S910 может анализироваться VPS (или SPS), и в ходе выполнения операции S920 может определяться, является ли цикл РОС для AU постоянным в кодированной видеопоследовательности. Если цикл РОС для AU является постоянным (переход по ветви "ДА" после выполнения операции S920), то значение счетчика блока доступа для конкретного блока доступа может в ходе выполнения операции S930 вычисляться на основе значения рос_cycle_au, сообщаемого для кодированного видеопотока, и значения РОС конкретного блока доступа. Если цикл РОС для AU не является постоянным (переход по ветви "НЕТ" после выполнения операции S920), то значение счетчика блока доступа для конкретного блока доступа может в ходе выполнения операции S940 вычисляться на основе значения poc_cycle_au, сообщаемого на уровне изображения, и значения РОС конкретного блока доступа. В ходе выполнения операции S950 может анализироваться новый VPS (или SPS).
[113] Согласно вариантам осуществления, даже если значение РОС изображения, слайса или тайла могут различаться, изображение, слайс или тайл, соответствующие AU с одинаковым значением AUC, могут быть связаны с тем же моментом времени декодирования или вывода. Следовательно, без наличия любой зависимости внешнего анализа/декодирования в пределах изображений, слайсов или тайлов в одинаковом AU все или подмножество изображений, слайсов или тайлов, связанных с одинаковым AU, могут декодироваться параллельно и выводиться в один и тот же момент времени.
[114] Согласно вариантам осуществления, даже если значение РОС для изображения, слайса или тайла может различаться, изображение, слайс или тайл, соответствующие AU с одинаковым значением AUC, могут быть связаны с тем же моментом времени композиции/отображения. Если время композиции содержится в формате контейнера, даже если изображения соответствуют различным AU, то если для изображений время композиции одинаково, изображения могут отображаться в один и тот же момент времени.
[115] Согласно вариантам осуществления каждое изображение, слайс или тайл могут иметь одинаковый временной идентификатор (temporal_id) в одинаковом AU. Все или подмножество изображений, слайсов или тайлов, соответствующих моменту времени, могут быть связаны с одинаковым временным подуровнем. Согласно вариантам осуществления, каждое изображение, слайс или тайл могут иметь различные идентификаторы пространственного уровня (layer_id) в одинаковом AU. Все или подмножество изображений, слайсов или тайлов, соответствующих моменту времени, могут быть связаны с одинаковым пространственным уровнем или с различными пространственными уровнями.
[116] На фиг. 7 показан пример структуры видеопоследовательности с комбинацией значений temporal_id, layer_id, РОС и AUC и с адаптивным изменением разрешения. В этом примере изображение, слайс или тайл в первом AU с AUC=0 может иметь temporal_id=0 и layer_id=0 или 1, в то время как изображение, слайс или тайл во втором AU с AUC=1 может иметь temporal_id=1 и layer_id=0 или 1, соответственно. Значение РОС увеличивается на 1 для каждого изображения, независимо от значений temporal_id and layer_id. В этом примере значение poc_cycle_au может равняться 2. Согласно вариантам осуществления, значение poc_cycle_au может устанавливаться равным количеству (пространственно масштабируемых) уровней. Следовательно, в этом примере значение РОС увеличивается на 2, а значение AUC увеличивается на 1.
[117] В описанных выше вариантах осуществления индикация всей или части структуры внешнего предсказания изображения или уровня и опорного изображения может поддерживаться с использованием сигнализации существующего набора опорных изображений (RPS, Reference Picture Set) в HEVC или сигнализации списка опорных изображений (RPL, Reference Picture List). В RPS или RPL выбираемое опорное изображение может указываться путем сигнализации значения РОС или разностного значения РОС между текущим изображением и выбранным опорным изображением. Согласно вариантам осуществления, RPS и RPL могут использоваться для указания структуры внешнего предсказания изображения или уровня без изменения сигнализации, но со следующими ограничениями. Если значение temporal_id опорного изображения больше значения temporal_id текущего изображения, то текущее изображение не может использовать опорное изображение для компенсации движения или других видов предсказания. Если значение layer_id опорного изображения больше значения layer_id текущего изображения, то текущее изображение не может использовать опорное изображение для компенсации движения или других видов предсказания.
[118] Согласно вариантам осуществления, масштабирование вектора движения на основе разности РОС для предсказания временного вектора движения может запрещаться в пределах множества изображений в блоке доступа. Следовательно, хотя каждое изображение может иметь различное значение РОС в блоке доступа, вектор движения не масштабируется и используется для предсказания временного вектора движения в блоке доступа. Это связано с тем, что опорное изображение с другим РОС в том же AU рассматривается как опорное изображение с тем же моментом времени. Таким образом, согласно варианту осуществления, функция масштабирования вектора движения может возвращать значение 1, если опорное изображение принадлежит к AU, связанной с текущим изображением.
[119] Согласно вариантам осуществления, масштабирование вектора движения на основе разности РОС для предсказания временного вектора движения может дополнительно запрещаться в пределах множества изображений, если пространственное разрешение опорного изображения отличается от пространственного разрешения текущего изображения. Если масштабирование вектора движения разрешено, то вектор движения масштабируется на основе как разности РОС, так и коэффициента пространственного разрешения между текущим изображением и опорным изображением.
[120] Согласно вариантам осуществления вектор движения может масштабироваться на основе разности AUC, а не разности РОС, для предсказания временного вектора движения, в особенности, если значение рос_cycle_au не является единообразным (например, если vps_contant_poc_cycle_perau=0). В противном случае (например, если vps_contant_poc_cycle_per_au=1), масштабирование вектора движения на основе разности AUC может выполняться идентично масштабированию вектора движения на основе разности РОС.
[121] Согласно вариантам осуществления, если вектор движения масштабируется на основе разности AUC, то опорный вектор движения в том же AU (с тем же значением AUC) с текущим изображением не масштабируется на основе разности и используется для предсказания вектора движения без масштабирования или с масштабированием на основе коэффициента пространственного разрешения между текущим изображением и опорным изображением.
[122] Согласно вариантам осуществления, значение AUC может использоваться для идентификации границы AU, а также использоваться для функционирования гипотетического эталонного декодера (HRD, Hypothetical Reference Decoder), которому требуются временные интервалы ввода и вывода с гранулярностью AU. Согласно вариантам осуществления, для отображения может выводиться декодированное изображение с наивысшим уровнем в AU. Значения AUC и layer_id могут использоваться для идентификации выходного изображения.
[123] Согласно вариантам осуществления, изображение может содержать одно или более субизображений. Каждое субизображение может охватывать локальную область или всю область изображения. Области, поддерживаемые различными субизображениями, могут перекрываться или могут не пересекаться друг с другом. Область, охватываемая одним или более субизображениями, может охватывать всю область изображения или его часть. Если изображение состоит из субизображения, область, поддерживаемая субизображением, может быть идентична области, поддерживаемой изображением.
[124] Согласно вариантам осуществления, субизображение может кодироваться с помощью способа, аналогичного способу, используемому для кодирования изображения. Субизображение может кодироваться независимо или в зависимости от другого субизображения либо от кодированного изображения. Субизображение может иметь любую зависимость анализа от другого субизображения либо от кодированного изображения.
[125] Согласно вариантам осуществления, кодированное субизображение может содержаться в одном или более уровней. Кодированное субизображение в уровне может иметь различное пространственное разрешение. Исходное субизображение может пространственно передискретизироваться (например, с использованием повышающей или понижающей дискретизации), кодироваться с различными параметрами пространственного разрешения и содержаться в битовом потоке, соответствующем уровню.
[126] Согласно вариантам осуществления, субизображение с параметрами (W, Н), где W указывает ширину субизображения, а Н - его длину, соответственно, может кодироваться и содержаться в кодированном битовом потоке, соответствующем уровню 0, в то время как субизображения с повышенной (пониженной) дискретизацией, основанные на субизображении с исходным пространственным разрешением, с параметрами (W*Sw,k, Н* Sh,k) могут кодироваться и содержаться в кодированном битовом потоке, соответствующем уровню к, где Sw,k, Sh,k - коэффициенты передискретизации по горизонтали и вертикали. Если значения Sw,k, Sh,k больше 1, то может осуществляться повышающая передискретизация. Если же значения Бщк, Sh,k меньше 1, то может осуществляться понижающая передискретизация.
[127] Согласно вариантам осуществления, кодированное субизображение в уровне может характеризоваться качеством визуализации, отличным от качества кодированного субизображения в другом уровне, в том же или другом субизображении. Например, субизображение i в уровне n может быть кодировано с использованием параметра Qi,n, квантования, в то время как субизображение j в уровне m может быть кодировано с использованием параметра Qj,m квантования.
[128] Согласно вариантам осуществления, кодированное субизображение в уровне может независимо декодироваться, без какой-либо зависимости при анализе или декодировании от кодированного субизображения в другом уровне той же локальной области. Уровень субизображения, который может независимо декодироваться без ссылки на другой уровень субизображения той же локальной области, может представлять собой независимый уровень субизображения. Кодированное субизображение в независимом уровне субизображения может при декодировании или анализе зависеть от предшествующего кодированного субизображения в том же уровне субизображения, но может и не иметь такой зависимости, однако кодированное субизображение может не зависеть каким-либо образом от кодированного субизображения в другом уровне субизображения.
[129] Согласно вариантам осуществления, кодированное субизображение в уровне может зависимо декодироваться с любой зависимостью при анализе или декодировании от кодированного субизображения в другом уровне той же локальной области. Уровень субизображения, который может зависимо декодироваться со ссылкой на другой уровень субизображения той же локальной области, может представлять собой зависимый уровень субизображения. Кодированное субизображение в зависимом субизображении может ссылаться на кодированное субизображение, принадлежащее тому же субизображению, ранее кодированное субизображение в том же уровне субизображения или на оба этих опорных субизображения.
[130] Согласно вариантам осуществления кодированное субизображение может включать один или более независимых уровней субизображения и один или более зависимых уровней субизображения. Однако по меньшей мере один независимый уровень субизображения может быть представлен для кодированного субизображения. Значение идентификатора уровня (layer_id), которое может быть представлено в заголовке блока NAL или в другой высокоуровневой синтаксической структуре, для независимого уровня субизображения может быть равно 0. Уровень субизображения с layer_id, равным 0, может представлять собой базовый уровень субизображения.
[131] Согласно вариантам осуществления, изображение может содержать одно или более субизображений переднего плана и одно или более фоновых субизображений. Область, поддерживаемая фоновым субизображением, может совпадать с областью изображения. Область, поддерживаемая субизображением переднего плана, может перекрываться с областью, поддерживаемой фоновым субизображением. Фоновое субизображение может представлять базовый уровень субизображения, в то время как субизображение переднего плана может представлять собой уровень субизображения, отличный от базового (расширенный уровень). Один или более уровней субизображения, отличных от базового, могут ссылаться на тот же базовый уровень для декодирования. Каждый уровень субизображения, отличный от базового, с layer_id, равным а, может ссылаться на уровень субизображения, отличный от базового, с layer_id, равным b, где а больше b.
[132] Согласно вариантам осуществления, изображение может содержать одно или более субизображений переднего плана, с наличием или отсутствием фонового субизображения. Каждое субизображение может иметь свой собственный базовый уровень субизображения и один или более уровней субизображения, отличных от базового (расширенных уровней). На каждый базовый уровень субизображения может ссылаться один или более уровней субизображения, отличных от базового. Каждый уровень субизображения, отличный от базового, с layer_id, равным а, может ссылаться на уровень субизображения, отличный от базового, с layer_id, равным b, где а больше b.
[133] Согласно вариантам осуществления, изображение может содержать одно или более субизображений переднего плана с наличием или отсутствием фонового субизображения. На каждое кодированное субизображение в (базовом или отличном от базового) уровне субизображения может ссылаться одно или более субизображений уровня субизображения, отличного от базового, принадлежащих одинаковому субизображению, и одно или более субизображений уровней субизображения, отличного от базового, которые не принадлежат одинаковому субизображению.
[134] Согласно вариантам осуществления, изображение может содержать одно или более субизображений переднего плана с наличием или отсутствием фонового субизображения. Субизображение в уровне а может далее разбиваться на множество субизображений в том же уровне. Одно или более кодированных субизображений в уровне Ь могут ссылаться на разделенное субизображение в уровне а.
[135] Согласно вариантам осуществления, кодированная
видеопоследовательность (CVS, Coded Video Sequence) может представлять собой группу кодированных изображений. CVS может содержать одну или более кодированных последовательностей субизображений (CSPS, Coded Sub-Picture Sequences), где CSPS может представлять собой группу кодированных субизображений, охватывающих одинаковую локальную область изображения. CSPS могут иметь одинаковое или различное временное разрешение по сравнению с кодированной видеопоследовательностью.
[136] Согласно вариантам осуществления, CSPS могут кодироваться и содержаться в одном или более уровней. CSPS могут включать один или более уровней CSPS. Декодирование одного или более уровней CSPS, соответствующих CSPS, может восстановить последовательность субизображений, соответствующих одной и той же локальной области.
[137] Согласно вариантам осуществления, количество уровней CSPS, соответствующих CSPS, может совпадать с количеством уровней CSPS, соответствующих другим CSPS, или отличаться от этого количества.
[138] Согласно вариантам осуществления, уровень CSPS может иметь временное разрешение (например, частоту кадров), отличное от другого уровня CSPS. Исходная (несжатая) последовательность субизображений может передискретизироваться во времени (например, с использованием повышающей или понижающей дискретизации), кодироваться с различными параметрами временного разрешения и содержаться в битовом потоке, соответствующем уровню.
[139] Согласно вариантам осуществления, последовательность субизображений с частотой кадров F может кодироваться и содержаться в кодированном битовом потоке, соответствующем уровню 0, в то время как последовательность субизображений с повышающей (или понижающей) временной дискретизацией, основанная на исходной последовательности субизображений, с параметром F*St,k может кодироваться и содержаться в кодированном битовом потоке, соответствующем уровню k, где St,k указывает коэффициент временной дискретизации для уровня к. Если значение St,k больше 1, то процесс временной пере дискретизации может представлять собой преобразование с повышением частоты кадров. Если же значение St,k меньше 1, то процесс временной пере дискретизации может представлять собой преобразование с понижением частоты кадров.
[140] Согласно вариантам осуществления, если на субизображение с уровнем a CSPS ссылается субизображение с уровнем b CSPS для компенсации движения или любого межуровневого предсказания, то если пространственное разрешение уровня a CSPS отличается от пространственного разрешения уровня b CSPS, декодированные пиксели в уровне a CSPS передискретизируются и используются для ссылки. В процессе передискретизации может использоваться фильтрация с повышающей или понижающей дискретизацией.
[141] На фиг. 10 показан пример видеопотока, содержащего фоновые видеопотоки CSPS с layer_id, равным 0, и множеством уровней CSPS переднего плана. Поскольку кодированные субизображения могут содержать один или более уровней CSPS, фоновая область, которая не принадлежит какому-либо уровню CSPS переднего плана, может содержать базовый уровень. Базовый уровень может содержать фоновую область и области переднего плана, в то время как расширенный уровень CSPS может содержать область переднего плана. Качество визуализации расширенного уровня CSPS может быть лучше, чем у базового уровня в той же области. Расширенный уровень CSPS может ссылаться на восстановленные пиксели и векторы движения базового уровня, соответствующего той же области.
[142] Согласно вариантам осуществления, битовый видеопоток, соответствующий базовому уровню, содержится в дорожке, в то время как уровни CSPS, соответствующие каждому субизображению, содержатся в отдельной дорожке в видеофайле.
[143] Согласно вариантам осуществления, битовый видеопоток, соответствующий базовому уровню, содержится в дорожке, в то время как уровни CSPS с одинаковым layer_id содержатся в отдельной дорожке. В этом примере дорожка, соответствующая уровню k, содержит только уровни CSPS, соответствующие уровню k.
[144] Согласно вариантам осуществления, каждый уровень CSPS каждого субизображения хранится в отдельной дорожке. Каждая дорожка может при анализе или декодировании зависеть от одной или более других дорожек, или такая зависимость может отсутствовать.
[145] Согласно вариантам осуществления, каждая дорожка может содержать битовые потоки, соответствующие уровням от i до j уровней CSPS всех или подмножества субизображений, где 0<i=<j=<k, k - наивысший уровень CSPS.
[146] Согласно вариантам осуществления, изображение содержит один или более элементов связанных медийных данных, включая карту глубины, альфа-карту, данные 3D-геометрии, карту занятости и т.д. Такие связанные синхронизированные медийные данные могут разделяться на один или множество подпотоков данных, каждый из которых соответствует одному субизображению.
[147] На фиг. 11 показан пример видеоконференции, основанной на способе многоуровневых субизображений. В видеопотоке содержатся один битовый видеопоток базового уровня, соответствующий фоновому изображению, и один или более битовых видеопотоков расширенного уровня, соответствующих субизображениям переднего плана. Каждый битовый видеопоток расширенного уровня может соответствовать уровню CSPS. По умолчанию отображается изображение, соответствующее базовому уровню. Оно содержит одно или более пользовательских изображений в изображении (PIP, Picture In Picture). Если средствами управления клиента выбирается конкретный пользователь, то расширенный уровень CSPS, соответствующий выбранному пользователю, может декодироваться и отображаться с улучшенным качеством или пространственным разрешением.
[148] На фиг. 12 показана блок-схема, иллюстрирующая пример процесса, описанного выше. Например, в ходе выполнения операции S1210 может декодироваться битовый видеопоток с множеством уровней. В ходе выполнения операции S1220 может идентифицироваться фоновая область и одно или более субизображений переднего плана. В ходе выполнения операции S1230 может определяться, выбрана ли конкретная область субизображения, например, одно из субизображений переднего плана. Если конкретная область субизображения выбрана (переход по ветви "ДА" к операции S1240), то может декодироваться и отображаться улучшенное субизображение. Если конкретная область субизображения не выбрана (переход по ветви "НЕТ" к операции S1250), то может декодироваться и отображаться фоновая область.
[149] Согласно вариантам осуществления, сетевой промежуточный блок (например, маршрутизатор) может выбирать подмножество уровней для передачи пользователю в зависимости от своей пропускной способности. Для адаптации пропускной способности может использоваться структура изображения/субизображения. Например, если пользователь не обеспечивает достаточную пропускную способность, маршрутизатор отбрасывает уровни или выбирает некоторые субизображения вследствие их важности или на основе используемых установок, и эта операция может выполняться динамически для адаптации пропускной способности.
[150] На фиг. 13 показан вариант осуществления, относящийся к случаю применения видео 360 градусов. Если сферическое изображение в формате 360 градусов, например изображение 1310, проецируется на плоское изображение, то изображение проекции формата 360 градусов может разбиваться на множество субизображений в качестве базового уровня. Например, множество субизображений может включать в свой состав заднее субизображение, верхнее субизображение, правое субизображение, левое субизображение, переднее субизображение и нижнее субизображение. Расширенный уровень конкретного субизображения, например, переднего субизображения, может кодироваться и передаваться клиенту. Декодер может иметь возможность декодировать как базовый уровень, включая все субизображения, так и расширенный уровень выбранного субизображения. Если текущее поле просмотра идентично выбранному субизображению, отображаемое изображение может иметь более высокое качество с использованием декодированного субизображения с расширенным уровнем. В противном случае может отображаться декодированное изображение с базовым уровнем и более низким качеством.
[151] Согласно вариантам осуществления любая информация о структуре для отображения может находиться в файле в качестве дополнительной информации (такой как сообщение SEI или метаданные). Одно или более декодированных субизображений могут перемещаться и отображаться в зависимости от сообщаемой информации о структуре. Информация о структуре может сообщаться потоковым сервером или вещательной станцией, или может регенерироваться объектом сети либо облачным сервером, или может определяться настройками, устанавливаемыми пользователем.
[152] Согласно вариантам осуществления, если входное изображение разделено на одну или более (прямоугольных) подобластей, каждая подобласть может кодироваться как независимый уровень. Каждому независимому уровню, соответствующему локальной области, может назначаться уникальное значение layer_id. Для каждого независимого уровня может сообщаться информация о размере субизображения и его местоположении. Например, размер изображения (ширина, длина), информация о смещении левого верхнего угла (х_offset, у_offset). На фиг. 14 показан пример структуры разделенных субизображений, размеров субизображений и информации о позиции, а также соответствующей им структуре предсказания изображения. Информация о структуре, включающая размер(ы) субизображения и позицию(-и) субизображения, может сообщаться в высокоуровневой синтаксической структуре, такой как набор(ы) параметров, заголовок слайса или группы тайлов, или сообщение SEI.
[153] Согласно вариантам осуществления, каждому субизображению, соответствующему независимому уровню, может присваиваться его уникальное значение РОС в пределах AU. Если с использованием синтаксического элемента(-ов) в структуре RPS или RPL указывается опорное изображение, входящее в состав изображений, хранимых в DPB, то могут использоваться значение(-я) РОС каждого субизображения, соответствующего уровню.
[154] Согласно вариантам осуществления, для указания структуры (межуровневого) предсказания значение layer_id может не использоваться, а может использоваться значение РОС (разностное).
[155] Согласно вариантам осуществления, субизображение со значением РОС, равным N и соответствующим уровню (или локальной области), может (но не обязательно) использоваться в качестве опорного изображения субизображения со значением РОС, равным N+K, соответствующим тому же уровню (или той же локальной области), для предсказания с компенсацией движения. В большинстве случаев значение числа К может равняться максимальному количеству (независимых) уровней, которое может быть идентично количеству подобластей.
[156] Согласно вариантам осуществления, на фиг. 15 показан более полный вариант случая, изображенного на фиг. 14. Если входное изображение разделено на несколько подобластей (например, четыре), каждая локальная область может кодироваться с использованием одного или более уровней. В этом случае количество независимых уровней может совпадать с количеством подобластей, и один или более уровней может соответствовать подобласти. Таким образом, каждая подобласть может кодироваться с использованием одного или более независимых уровней или нескольких зависимых уровней, либо без использования зависимых уровней.
[157] Согласно вариантам осуществления, на фиг. 15 показано, что входное изображение может быть разделено на четыре подобласти. Например, расположенная в правом верхнем углу подобласть может кодироваться как два уровня, уровень 1 и уровень 4, в то время как правая нижняя подобласть может кодироваться как уровни 3 и 5. В этом случае уровень 4 может ссылаться на уровень 1 для предсказания с компенсацией движения, в то время как уровень 5 может ссылаться на уровень 3 для предсказания с компенсацией движения.
[158] Согласно вариантам осуществления, внутриконтурная фильтрация (такая как деблокирующая фильтрация, адаптивная контурная фильтрация, решейпер, двусторонняя фильтрация или любая фильтрация, основанная на глубоком обучении) в пределах границ уровня может быть (необязательно) запрещена.
[159] Согласно вариантам осуществления, предсказание с компенсацией движения или внутриблочное копирование в пределах границы уровня может быть запрещено (необязательно).
[160] Согласно вариантам осуществления, дополнительно может обрабатываться заполнение (padding) границы для предсказания с компенсацией движения или внутриконтурной фильтрации на границе субизображения. Флаг, указывающий, обрабатывается ли заполнение границы, может сообщаться с помощью высокоуровневой синтаксической структуры, такой как набор(ы) параметров (VPS, SPS, PPS или APS), заголовок группы слайсов или тайлов, или сообщение SEI.
[161] Согласно вариантам осуществления, информация о структуре подобласти(-ей) (или субизображения(-й)) может сигнализироваться в VPS или SPS. На фиг. 16А показан пример синтаксических элементов в VPS, и на фиг. 16В показан пример синтаксических элементов в SPS. В этом примере флаг vps_sub_picture_dividing_flag сообщается в VPS. Этот флаг может указывать, разделено ли входное изображение(-я) на множество подобластей. Если значение флага vps_sub_picture_dividing_flag равно 0, входное изображение(я) в кодированной видеопоследовательности(-ях), соответствующей текущему VPS, может не разделяться на множество подобластей. В этом случае размер входного изображения может быть равен размеру кодированного изображения (pic_width_in_luma_samples, pic_height_in_luma_samples), сообщаемому в SPS. Если значение флага vps_sub_picture_dividing_flag равно 1, входное изображение(я) может разделяться на множество подобластей. В этом случае синтаксические элементы vps_full_pic_width_in_luma_samples и vps_full_pic_height_in_luma_samples сообщаются в VPS. Значения vps_full_pic_width_in_luma_samples и vps_full_pic_height_in_luma_samples могут совпадать с шириной и высотой входного изображения (-ий), соответственно.
[162] Согласно вариантам осуществления, значения vps_full_pic_width_in_luma_samples и vps_full_pic_height_in_luma_samples могут не использоваться для декодирования, но могут использоваться для композиции и отображения.
[163] Согласно вариантам осуществления, если значение vps_sub_picture_dividing_flag равно 1, синтаксические элементы pic_offset_х и pic_offset_у могут сообщаться в SPS, соответствующем конкретному уровню(-ям). В этом случае размер кодированного изображения (pic_width_in_luma_samples, pic_height_in_luma_samples), сообщаемый в SPS, может совпадать с шириной и высотой подобласти, соответствующей конкретному уровню. Кроме того, позиция (pic_offset_x, pic_offset_y) левого верхнего угла подобласти может сообщаться в SPS.
[164] Кроме того, информация о позиции (pic_offset_х, pic_offset_у) левого верхнего угла подобласти может не использоваться для декодирования, но может использоваться для композиции и отображения.
[165] Согласно вариантам осуществления, информация о структуре (размер и позиция) всех или подмножества подобластей входного изображения(-ий), информация о зависимости между уровнями может сообщаться в наборе параметров или в сообщении SEI. На фиг. 17 показан пример синтаксических элементов для указания информации о структуре подобластей, зависимости между уровнями и взаимосвязи между подобластью и одним или более уровнями. В этом примере синтаксический элемент num sub region указывает количество (прямоугольных) подобластей в текущей кодированной видеопоследовательности. Синтаксический элемент num_layers указывает количество уровней в текущей кодированной видеопоследовательности. Значение num_layers может быть больше или равно значению num_sub_region. Если любая подобласть кодирована в виде одного уровня, значение num_layers может быть равно значению num_sub_region. Если одна или более подобластей кодирована в виде множества уровней, значение num_layers может превышать значение num_subregion. Синтаксический элемент direct_dependency_flag_[i][j] указывает на зависимость от j-ro до i-ro уровня, num_layers_for_region_[i] указывает количество уровней, связанных с i-й подобластью, sub_region_layer_id[i][j] указывает layer_id j-го уровня, связанного с i-й подобластью, sub_region_offset_х[i] и sub_region_offset_y[i] указывают горизонтальное и вертикальное местоположение левого верхнего угла i-й подобласти, соответственно, sub_region_width_[i] и sub_region_height[i] указывают ширину и высоту i-й подобласти, соответственно.
[166] Согласно вариантам осуществления один или более синтаксических элементов, определяющих набор выходных уровней, для указания одного или более уровней, подлежащих выводу совместно с информацией об уровне яруса профиля или без таковой, могут сообщаться в высокоуровневой синтаксической структуре, например в VPS, DPS, SPS, PPS, APS или в сообщении SEI. На фиг. 18 показано, что синтаксический элемент num_output_layer_sets, указывающий количество наборов выходных уровней (OLS, Output Layer Set) в кодированной видеопоследовательности, ссылающейся на VPS, может сообщаться в VPS. Для каждого набора выходных уровней значение output layer flag может сообщаться столько раз, сколько существует выходных уровней.
[167] Согласно вариантам осуществления значение output layer flag[i], равное 1, указывает на то, что выводится i-й уровень. Значение vps_output_layer_flag[i], равное 0, указывает на то, что i-й уровень не выводится.
[168] Согласно вариантам осуществления один или более синтаксических элементов, определяющих информацию уровня яруса профиля для каждого набора выходных уровней, могут сообщаться в высокоуровневой синтаксической структуре, например в VPS, DPS, SPS, PPS, APS или в сообщении SEI. На фиг.18 показано, что синтаксический элемент num_profile_tile_level, указывающий информацию о количестве уровней ярусов профиля для OLS в кодированной видеопоследовательности, ссылающейся на VPS, может сообщаться в VPS. Для каждого набора выходного уровня может сообщаться набор синтаксических элементов для информации уровня яруса профиля или индекс, указывающий конкретную информацию уровня яруса профиля среди записей информации уровня яруса профиля, столько раз, сколько существует выходных уровней.
[169] Согласно вариантам осуществления, profile_tier_level_idx[i][j] указывает индекс, в списке синтаксических структур profile_tier_level() в VPS, синтаксической структуры profile_tier_level(), которая применяется к j-му уровню i-го OLS.
[170] Согласно вариантам осуществления, на фиг. 19 показано, что синтаксические элементы num_profile_tile_level и/или num_output_layer_sets могут сообщаться, если количество максимальных уровней больше 1 (vps_max_layers_minus1>0).
[171] Согласно вариантам осуществления, на фиг. 19 показано, что синтаксический элемент vps_output_layers_mode[i], указывающий режим сигнализации выходного уровня для i-ro набора выходных уровней, может быть представлен в VPS.
[172] Согласно вариантам осуществления, значение vps_output_layers_mode[i], равное 0, указывает на то, что выводится только наивысший уровень с i-м набором выходных уровней. Значение vps_output_layer_mode[i], равное 1, указывает на то, что выводятся все уровни с i-м набором выходных уровней. Значение vps_output_layer_mode[i], равное 2, указывает на то, что выводимые уровни являются уровнями со значением vps_output_layer_flag_[i][j], равным 1, с i-м набором выходных уровней. Может резервироваться большее количество значений.
[173] Согласно вариантам осуществления, значение output_layer_flag[i][j] может сообщаться (не обязательно) в зависимости от значения vps_output_layers_mode_[i] для i-го набора выходных уровней.
[174] Согласно вариантам осуществления, на фиг. 19 показано, что флаг vps_ptl_signal_flag[i] может быть задан для i-ro набора выходных уровней. В зависимости от значения vps_ptl_signal_flag[i] принимается решение о том, следует ли сообщать информацию уровня яруса профиля для i-ro набора выходных уровней.
[175] Согласно вариантам осуществления, на фиг. 20 показано, что количество субизображений, max_subpics_minus1, в текущей CVS может сообщаться в высокоуровневой синтаксической структуре, например в VPS, DPS, SPS, PPS, APS или в сообщении SEI.
[176] Согласно вариантам осуществления, на фиг. 20 показано, что идентификатор субизображения, sub_pic_id[i], для i-го субизображения может сигнализироваться, если количество субизображений больше 1 (max_subpics_minus1>0).
[177] Согласно вариантам осуществления один или более синтаксических элементов, указывающих идентификатор субизображения, принадлежащего каждому уровню каждого набора выходных уровней, может сигнализироваться в VPS. На фиг. 20 показано, что значение sub_pic_id_layer[i][j][k], которое указывает k-e субизображение, присутствует в j-м уровне i-го набора выходных уровней. С помощью этой информации декодер может распознавать, какое субизображение может декодироваться и выводиться для каждого уровня конкретного набора выходных уровней.
[178] Согласно вариантам осуществления заголовок изображения (РН, Picture Header) может представлять собой синтаксическую структуру, содержащую синтаксические элементы, применимые ко всем слайсам кодированного изображения. Блок изображения (PU, Picture Unit) может представлять собой набор блоков NAL, связанных друг с другом в соответствии с указанным правилом классификации, следующих друг за другом в порядке декодирования и содержащих в точности одно кодированное изображение. PU может содержать заголовок изображения (РН) и один или более блок NAL уровня кодирования видео (VCL), формирующих кодированное изображение.
[179] Согласно вариантам осуществления, набор параметров адаптации (APS) может представлять собой синтаксическую структуру, содержащую синтаксические элементы, которые могут применяться к нулю или более слайсам, как определяется нулем или более синтаксическими элементами, находящимися в заголовках слайсов.
[180] Согласно вариантам осуществления значение adaptation_parameter_set_id, сообщаемое (например, как и(5)) в APS, может предоставлять идентификатор APS для ссылки, осуществляемой другими синтаксическими элементами. Если значение ps_params_type равно ALF_APS или SCALING_APS, то значение adaptation_parameter_set_id может находиться в диапазоне от 0 до 7, включительно. Если значение aps_params type равно LMCS_APS, то значение adaptation_parameter_set_id может находиться в диапазоне от 0 до 3, включительно.
[181] Согласно вариантам осуществления значение adaptation_parameter_set_id, сообщаемое как ue(v) в APS, может предоставлять идентификатор APS для ссылки, осуществляемой другими синтаксическими элементами. Если значение ps_params_type равно ALF_APS или SCALING_APS, то значение adaptation_parameter_set_id может находиться в диапазоне от 0 до 7*(максимальное количество уровней в текущей CVS), включительно. Если значение aps_params_type равно LMCS_APS, то значение adaptation_parameter_set_id может находиться в диапазоне от 0 до 3*(максимальное количество уровней в текущей CVS), включительно.
[182] Согласно вариантам осуществления, каждый APS (RBSP) может быть доступен процессу декодирования перед ссылкой на него и включаться по меньшей мере в один AU с временным идентификатором (например, temporalId), меньшим или равным временному идентификатору (e.g., temporalId) блока NAL кодированного слайса, которая ссылается на него, либо предоставляться через внешние средства. Если блок NAL APS включается в AU, значение временного идентификатора (например, temporalId) блока NAL APS может совпадать со значением временного идентификатора (например, temporalId) AU, включающего блок NAL APS.
[183] Согласно вариантам осуществления каждый APS (RBSP) может быть доступен процессу декодирования перед ссылкой на него и может включаться по меньшей мере в один AU с временным идентификатором (например, temporal_id), равным 0, либо предоставляться через внешние средства. Если блок NAL APS включается в AU, значение временного идентификатора (например, temporalId) блока NAL APS может равняться 0.
[184] Согласно вариантам осуществления APS (RBSP) может быть доступен процессу декодирования перед ссылкой на него и может включаться по меньшей мере в один AU с временным идентификатором (например, temporalId), равным временному идентификатору (e.g., temporalId) блока NAL APS в CVS, который содержит один или более блок NAL кодированного слайса, ссылающийся на APS, либо может предоставляться через внешние средства.
[185] Согласно вариантам осуществления APS (RBSP) может быть доступен процессу декодирования перед ссылкой на него и может включаться по меньшей мере в один AU с временным идентификатором (например, temporal_id), равным 0 в CVS, который содержит один или более блок NAL кодированного слайса, ссылающийся на APS, либо может предоставляться через внешние средства.
[186] Согласно вариантам осуществления, если сигнализируется флаг no_temporal_sublayer_switching_flag в DPS, VPS, SPS или PPS, значение временного идентификатора (например, temporalId) APS, ссылающегося на набор параметров, содержащий флаг, равный 1, может быть равно 0, в то время как значение временного идентификатора (например, temporalId) APS, ссылающегося на набор параметров, содержащий флаг, равный 1, может быть больше или равно значению временного идентификатора (например, temporalId) набора параметров.
[187] Согласно вариантам осуществления каждый APS (RBSP) может быть доступен процессу декодирования перед ссылкой на него и может включаться по меньшей мере в один AU с временным идентификатором (например, temporalId), меньшим или равным временному идентификатору (e.g., temporalId) блока NAL кодированного слайса (или блока NAL РН), которая ссылается на него, либо может предоставляться через внешние средства. Если блок NAL APS включен в AU перед AU, содержащим блок NAL кодированного слайса, ссылающийся на APS, блок NAL VCL, разрешающий временное переключение на более высокий уровень, или блок NAL VCL с nal_unit_type, равным STSA_NUT, что указывает на то, что изображение в блоке NAL VCL может быть изображением пошагового доступа к временному подуровню (STSA, Step-wise Temporal Sublayer Access), не могут присутствовать после блока NAL APS и перед блоком NAL кодированного слайса, ссылающимся на APS. На фиг. 21 показан пример такого ограничения.
[188] Согласно вариантам осуществления, блок NAL APS и блок NAL кодированного слайса (и ее блок NAL РН), ссылающийся на APS, могут включаться в один и тот же AU.
[189] Согласно вариантам осуществления, блок NAL APS и блок NAL STSA слайса могут включаться в один и тот же AU, который может предшествовать блоку NAL кодированного слайса (и его блоку NAL РН), ссылающемуся на APS.
[190] Согласно вариантам осуществления, блок NAL STSA, блок NAL APS и блок NAL кодированного слайса (и ее блок NAL РН), ссылающийся на APS, могут быть представлены в одном и том же AU.
[191] Согласно вариантам осуществления, значение временного идентификатора (например, temporalId) блока NAL VCL, содержащего APS, может совпадать со значением временного идентификатора (например, temporalId) предшествующего блока NAL STSA.
[192] Согласно вариантам осуществления, значение счетчика очередности изображений (РОС) блока NAL APS может быть больше или равно значению РОС блока NAL STSA. На фиг.21 показано, что значение М РОС для APS может быть больше значения L РОС блока NAL STSA.
[193] Согласно вариантам осуществления значение счетчика очередности изображений (РОС) кодированного слайса или блока NAL РН, ссылающегося на блок NAL APS, может быть больше или равно значению РОС блока NAL STSA, на который осуществляется ссылка. На фиг.21 показано, что значение М РОС блока NAL VCL, ссылающегося на APS, может быть больше или равно значению L РОС блока NAL APS.
[194] Согласно варианту осуществления, APS (RBSP) может быть доступен процессу декодирования перед ссылкой на него одним или более РН или одним или более блоком NAL кодированного слайса и может включаться по меньшей мере в один PU со значением nuh_layer_id, равным наименьшему значению nuh_layer_id блоков NAL кодированного слайса, ссылающихся на блок NAL APS в CVS, который содержит один или более РН или один или более блок NAL кодированного слайса, ссылающийся на APS, либо может предоставляться через внешние средства.
[195] Согласно варианту осуществления, APS (RBSP) может быть доступен процессу декодирования перед ссылкой на него одним или более РН или одним или более блоком NAL кодированного слайса и может включаться по меньшей мере в один PU со значением temporalId, равным temporalId блока NAL APS, и значением nuh_layer_id, равным наименьшему значению nuh_layer_id блоков NAL кодированного слайса, ссылающихся на блок NAL APS в CVS, который содержит один или более РН или один или более блок NAL кодированного слайса, ссылающийся на PPS, либо может предоставляться через внешние средства.
[196] Согласно варианту осуществления настоящего изобретения, APS (RBSP) может быть доступен процессу декодирования перед ссылкой на него одним или более РН или одним или более блоком NAL кодированного слайса и включаться по меньшей мере в одну PU со значением temporalId, равным 0, и nuh_layer_id, равным наименьшему значению nuh_layer_id блоков NAL кодированного слайса, ссылающихся на блок NAL APS в CVS, который содержит один или более РН или один или более блок NAL кодированного слайса, ссылающийся на PPS, либо может предоставляться через внешние средства.
[197] Согласно варианту осуществления настоящего изобретения, APS (RBSP) может быть доступен процессу декодирования перед ссылкой на него одним или более РН или одним или более блоком NAL кодированного слайса и может включаться по меньшей мере в один PU со значением temporalId, равным 0, и nuh_layer_id, равным наименьшему значению nuh_layer_id блоков NAL кодированного слайса, ссылающихся на блок NAL APS в CVS, который содержит один или более РН или один или более блок NAL кодированного слайса, ссылающийся на PPS, либо может предоставляться через внешние средства.
[198] Согласно вариантам осуществления, все блока NAL APS с конкретным значением adaptation_parameter_set_id и конкретным значением aps_params_type в PU, независимо от того, являются ли они префиксом или суффиксом блоков NAL APS, могут иметь одинаковое содержимое.
[199] Согласно вариантам осуществления, независимо от значений nuh_layer_id, блоки NAL APS могут совместно использовать одинаковое пространство значений adaptation_parameterset id и aps_params_type.
[200] Согласно вариантам осуществления значение nuh_layer_id блока NAL APS может равняться наименьшему значению nuh_layer_id блоков NAL кодированного слайса, которые ссылаются на блок NAL, ссылающийся на блок NAL APS.
[201] Согласно варианту осуществления, если на APS с nuh_layer_id, равным т, ссылается один или более блок NAL кодированного слайса с nuh_layer_id, равным m, уровень с nuh_layer_id, равным n, может совпадать с уровнем с nuh_layer_id, равным n, или (явно или косвенно) может являться опорным уровнем уровня с nuh_layer_id, равным n.
[202] На фиг. 22 показан алгоритм примера процесса 2200 декодирования кодированного битового видеопотока. В некоторых вариантах реализации один или более блоков процесса, показанных на фиг. 22, могут выполняться декодером 210. В некоторых вариантах реализации один или более блоков процесса, показанных на фиг. 22, могут выполняться другим устройством или группой устройств, отдельных от декодера или содержащих декодер 210, такими как кодер 203.
[203] Как показано на фиг. 22, процесс 2200 может включать получение из кодированного битового видеопотока кодированной видеопоследовательности, содержащей блок изображения, соответствующий кодированному изображению (блок 2210).
[204] Далее, как показано на фиг. 22, процесс 2200 может включать получение блока NAL РН, включенного в блок изображения (блок 2220).
[205] Затем, как показано на фиг. 22, процесс 2200 может включать получение по меньшей мере одного блока NAL VCL, включенного в блок изображения (блок 2230).
[206] Далее, как показано на фиг. 22, процесс 2200 может включать декодирование кодированного изображения на основе блока NAL РН, по меньшей мере одного блока NAL VCL и набора параметров адаптации (APS), включенного в блок NAL APS, полученный из кодированной видеопоследовательности, при этом блок NAL APS доступен по меньшей мере одному процессору перед по меньшей мере одним блоком NAL VCL (блок 2240).
[207] Далее, как показано на фиг. 22, процесс 2200 может включать вывод декодированного изображения (блок 2250).
[208] Согласно варианту осуществления, блок NAL APS доступен процессу декодирования перед ссылкой на него одним или более заголовками изображения (РН) или одним или более блоком уровня сетевой абстракции (NAL) кодированного слайса, включенным по меньшей мере в один блок предсказания (PU) со значением nuh_layer_id, равным наименьшему значению nuh_layer_id одного или более блока NAL кодированного слайса, ссылающегося на блок NAL APS в CVS, который содержит один или более РН или один или более блок NAL кодированного слайса, ссылающийся на APS.
[209] Согласно вариантам осуществления, временной идентификатор по меньшей мере одного блока NAL VCL больше или равен временному идентификатору блока NAL APS.
[210] Согласно вариантам осуществления, временной идентификатор блока NAL APS может быть равен нулю.
[211] Согласно вариантам осуществления, РОС по меньшей мере одного блока NAL VCL может быть больше или равен РОС блока NAL APS.
[212] Согласно вариантам осуществления, идентификатор уровня блока NAL РН и идентификатор уровня по меньшей мере одного блока NAL VCL больше или равны идентификатору уровня блока NAL APS.
[213] Согласно вариантам осуществления, блок NAL РН, по меньшей мере один блок NAL VCL и блок NAL APS включены в один блок доступа.
[214] Согласно вариантам осуществления, кодированная
видеопоследовательность также содержит блок NAL STSA, соответствующий изображению STSA, и блок NAL STSA не расположен между блоком NAL APS и по меньшей мере одним блоком NAL VCL.
[215] Согласно вариантам осуществления по меньшей мере один блок NAL VCL, блок NAL APS и блок NAL STSA могут включаться в один блок доступа.
[216] Согласно вариантам осуществления, временной идентификатор блока NAL APS может быть больше или равен временному идентификатору блока NAL STSA.
[217] Согласно вариантам осуществления, значение счетчика очередности изображений (РОС) блока NAL APS может быть больше или равно значению РОС блока NAL STSA.
[218] Хотя на фиг.22 показаны типовые блоки процесса 2200 в некоторых его реализациях, процесс 2200 может включать дополнительные блоки, меньшее количество блоков, другие блоки или блоки, организованные иначе по сравнению с блоками, показанными на фиг. 22. Кроме того или в альтернативном варианте, два или более блоков процесса 2200 могут выполняться параллельно.
[219] Кроме того, предлагаемые способы могут быть реализованы схемой обработки (например, одним или более процессорами или одной или более интегральными схемами). В одном из примеров для выполнения одного или более предложенных способов один или более процессоров исполняют программу, записанную на машиночитаемом носителе.
[220] Технологии, описанные выше, могут быть реализованы в виде компьютерного программного обеспечения с использованием машиночитаемых инструкций, которые физически хранятся на одном или более машиночитаемых носителях. Например, на фиг.23 показана компьютерная система 2300, подходящая для реализации определенных вариантов раскрытия предмета настоящего изобретения.
[221] Компьютерное программное обеспечение может быть кодировано с использованием любого подходящего машинного кода или языка программирования, который может ассемблироваться, компилироваться, компоноваться или с помощью подобных механизмов формировать код, содержащий команды, которые могут выполняться непосредственно или интерпретироваться, выполняться в виде микрокоманд и т.п. центральными процессорами компьютера (CPU, Central Processing Unit), графическими процессорами (GPU, Graphics Processing Unit) и т.п.
[222] Инструкции могут выполняться на компьютерах различных типов или на их компонентах, включая, например, персональные компьютеры, планшеты, серверы, смартфоны, игровые устройства, устройства "Интернета вещей" и т.п.
[223] Компоненты, показанные на фиг.23 для компьютерной системы 2300, являются по сути примерами, и не предполагается, что они каким-либо образом ограничивают объем использования или функциональность компьютерного программного обеспечения, реализующего раскрытие настоящего изобретения. Кроме того, конфигурация компонентов не должна рассматриваться в плане какой-либо зависимости или каких-либо требований, связанных с любым компонентом или с комбинацией компонентов, показанных в рамках типового варианта осуществления компьютерной системы 2300.
[224] Компьютерная система 2300 может включать в свой состав устройства ввода пользовательского интерфейса. Такое устройство ввода пользовательского интерфейса может отвечать за ввод информации одним или более пользователями с помощью, например, тактильных средств ввода (таких как нажатие клавиш, сдвиг экрана, движения информационной перчаткой), звукового ввода (например, голосом, хлопками), визуального ввода (например, жестикуляцией), обонятельного ввода (не изображено на чертеже). Устройства пользовательского интерфейса также могут применяться для захвата определенной медийной информации, не обязательно непосредственно связанной с сознательным вводом пользователя, такой как звуковой сигнал (например, речь, музыка, звуковое сопровождение), изображения (например, отсканированные изображения, фотографии, полученные с помощью камеры получения неподвижных изображений), видеоинформация (такая как двумерное видео, трехмерное видео, включая стереоскопическое видео).
[225] Устройства пользовательского интерфейса могут включать в свой состав (на чертеже показано только одно устройство каждого типа) клавиатуру 2301, мышь 2302, сенсорную панель 2303, сенсорный экран 2310 и связанный с ним графический адаптер 2350, информационную перчатку, джойстик 2305, микрофон 2306, сканер 2307, камеру 2308.
[226] Компьютерная система 2300 может также включать в свой состав устройства вывода пользовательского интерфейса. Такие устройства вывода пользовательского интерфейса могут стимулировать восприятие одного или более пользователей с помощью, например, тактильного вывода, звука, света и запаха/вкуса. Такие устройства вывода пользовательского интерфейса могут включать в свой состав устройства тактильного вывода (например, тактильную обратную связь через сенсорный экран 2310, информационную перчатку или джойстик 2305, но также могут существовать устройства тактильной обратной связи, которые не являются устройствами ввода), устройства вывода звукового сигнала (такие как громкоговорители 2309, наушники (не показаны на чертеже), устройства визуального вывода (такие как экраны 2310, включая экраны на электронно-лучевой трубке (CRT, Cathode Ray Tube), жидкокристаллические экраны (LCD, Liquid-Crystal Display), плазменные экраны, экраны на органических светодиодах (OLED, Organic Light-Emitting Diode), каждый из которых может быть оснащен средствами сенсорного ввода, средствами тактильной обратной связи, некоторые из которых могут выводить двумерные изображения или изображения с размерностью, большей чем три измерения, через такие средства, как стереографический вывод; очки виртуальной реальности (не показаны на чертеже), голографические дисплеи и дымовые баки (не показаны на чертеже)), и принтеры (не показаны на чертеже).
[227] Компьютерная система 2300 также может содержать доступные пользователю запоминающие устройства и связанные с ними носители, такие как оптические носители, включая CD/DVD ROM/RW 2320 с CD/DVD или похожие носители 2321, флеш-накопитель 2322, съемный или несъемный жесткий диск 2323, традиционные магнитные носители, такие как дискета (не показана на чертеже), специализированные устройства, основанные на ROM/ASIC/PLD, такие как аппаратные ключи (не показаны на чертеже) и т.п.
[228] Специалистам в этой области техники должно быть понятно, что термин "машиночитаемый носитель", используемый в связи с предметом раскрытия настоящего изобретения, не охватывает среду передачи, сигналы несущей или другие кратковременные сигналы.
[229] Компьютерная система 2300 также может содержать интерфейс(ы) с одной или более сетями (2355) связи. Сети, например, могут быть беспроводными, проводными, оптическими. Сети также могут быть локальными, глобальными, городскими, транспортными и промышленными, реального времени, устойчивыми к задержке и т.д. Примеры сетей включают локальные сети, такие как Ethernet, беспроводные LAN, сотовые сети, включая глобальные системы мобильной связи (GSM, Global Systems For Mobile Communications), сети третьего поколения (3G), четвертого поколения (4G), пятого поколения (5G), LTE и т.п., телевизионные проводные или беспроводные глобальные цифровые сети, включая кабельное ТВ, спутниковое ТВ и наземное телевизионное вещание, транспортные и промышленные сети, включая CANBus и т.д. В определенных сетях обычно требуются внешние адаптеры (954) сетевого интерфейса, которые подключаются к определенным портам данных общего назначения или к периферийным шинам (949) (такие, например, как порты универсальной последовательной шины (USB, Universal Serial Bus) компьютерной системы 2300); другие обычно интегрируются в ядро компьютерной системы 2300 путем подключения к системной шине, как описано ниже (например, Ethernet-интерфейс в персональном компьютере или сотовый сетевой интерфейс в компьютерной системе смартфона). Например, сеть 2355 может соединяться с периферийной шиной 2349 с использованием интерфейса 2354. С помощью этих сетей система 2300 может взаимодействовать с другими объектами. Такая связь может быть однонаправленной, только в приемном направлении (например, телевизионное вещание), однонаправленной, только в передающем направлении (например, CANbus с определенными устройствами CANbus), или двунаправленной, например, с другими компьютерными системами с использованием локальных или глобальных цифровых сетей. Определенные протоколы и стеки протоколов могут использоваться в каждой из этих сетей и в сетевых интерфейсах (954), как описано выше.
[230] Вышеупомянутые пользовательские интерфейсные устройства, доступные пользователю запоминающие устройства и сетевые интерфейсы могут подключаться к ядру 2340 компьютерной системы 2300.
[231] Ядро 2340 может содержать один или более центральных процессоров (CPU, Central Processing Unit) 2341, графических процессоров (GPU, Graphics Processing Unit) 2342, специализированных программируемых процессорных блоков в виде программируемых пользователем вентильных матриц (FPGA, Field Programmable Gate Area) 2343, аппаратных ускорителей 2344 для определенных задач и т.д. Эти устройства совместно с постоянной памятью (ROM, Read-Only Memory) 2345, оперативной памятью (RAM, Random Access Memory) 2346, внутренними массовыми запоминающими устройствами 2347, такими как внутренние, не доступные пользователю жесткие диски, твердотельные диски (SSD, Solid State Drive) и т.п., могут соединяться через системную шину 2348. В некоторых компьютерных системах доступ к системной шине 2348 может осуществляться в виде одного или более физических разъемов, позволяющих добавлять CPU, GPU и т.п. Периферийные устройства могут подключаться либо непосредственно к системной шине 2348 ядра, либо через периферийную шину 2349. Архитектуры периферийной шины включают соединение периферийных устройств (PCI, Peripheral Component Interconnect), USB и т.п.
[232] CPU 2341, GPU 2342, FPGA 2343 и ускорители 2344 могут исполнять определенные инструкции, которые в совокупности могут улучшать упомянутый выше компьютерный код. Компьютерный код может храниться в ROM 2345 или RAM 2346. Промежуточные данные могут также храниться в RAM 2346, в то время как постоянные данные могут храниться, например, во внутреннем массовом запоминающем устройстве 2347. Быстрая запись и извлечение данных из любых запоминающих устройств может выполняться с использованием кэш-памяти, которая может быть тесно связана с одним или более CPU 2341, GPU 2342, внутренними массовыми запоминающими устройствами 2347, ROM 2345, RAM 2346 и т.п.
[233] Машиночитаемый носитель может содержать компьютерный код для выполнения различных операций, реализуемых на компьютере. Носитель и компьютерный код может быть специально разработан и составлен в целях раскрытия настоящего изобретения, или эти коды могут быть хорошо известны и доступны специалистам в области компьютерного программного обеспечения.
[234] Например, без ограничения приведенным примером, компьютерная система 2300 определенной архитектуры и, в частности, ядро 2340 может обеспечивать функциональность в результате выполнения процессором(-ами) (включая CPU, GPU, FPGA, ускорители и т.п.) программного обеспечения, реализованного на одном или более машиночитаемых носителях. Такой машиночитаемый носитель, как указывалось выше, может представлять собой носитель, связанный с соответствующим массовым запоминающим устройством, доступным пользователю, а также определенный носитель ядра 2340, являющийся по своей природе долговременным носителем информации, таким как массовое запоминающее устройство 2347, расположенное внутри ядра, или ROM 2345. Программное обеспечение, реализующее различные варианты раскрытия настоящего изобретения, может храниться на таких устройствах и выполняться ядром 2340. Машиночитаемый носитель может содержать одно или более запоминающих устройств или микросхем в соответствии с конкретными требованиями. Программное обеспечение может заставлять ядро 2340 и, в частности, процессоры, расположенные в нем (включая CPU, GPU, FPGA и т.п.), выполнять конкретные процессы или части конкретных процессов, рассмотренных в этом описании, включая определение структур данных в RAM 2346 и модификацию таких структур данных в соответствии с процессами, определенными программным обеспечением. Кроме этого или в качестве альтернативы, компьютерная система может обеспечивать функциональность в результате логических аппаратно-кодированных или, в противном случае, встроенных в схему (например, ускорителя 2344) решений, которые могут работать вместо или совместно с программным обеспечением для выполнения конкретных процессов или конкретных частей конкретных процессов, приведенных в этом описании. Ссылка на программное обеспечение может охватывать логические схемы и наоборот, там где это приемлемо. Ссылка на машиночитаемый носитель может охватывать схему (например, интегральную микросхему (1С, Integrated Circuit)), в которой хранится исполняемое программное обеспечение, схему, в которой реализованы исполняемые логические команды, или оба этих компонента, там где это приемлемо. Раскрытие настоящего изобретения охватывает любую подходящую комбинацию аппаратуры и программного обеспечения.
[235] Хотя изобретение было описано посредством нескольких не ограничивающих его вариантов осуществления, существуют изменения, перестановки и различные заменяющие эквиваленты, которые находятся в объеме раскрытия настоящего изобретения. Следует отметить, что специалисты в этой области техники способны разработать ряд систем и способов, которые, хотя явно не показаны и не описаны, но реализуют принципы настоящего изобретения и, следовательно, соответствуют его сущности и объему.
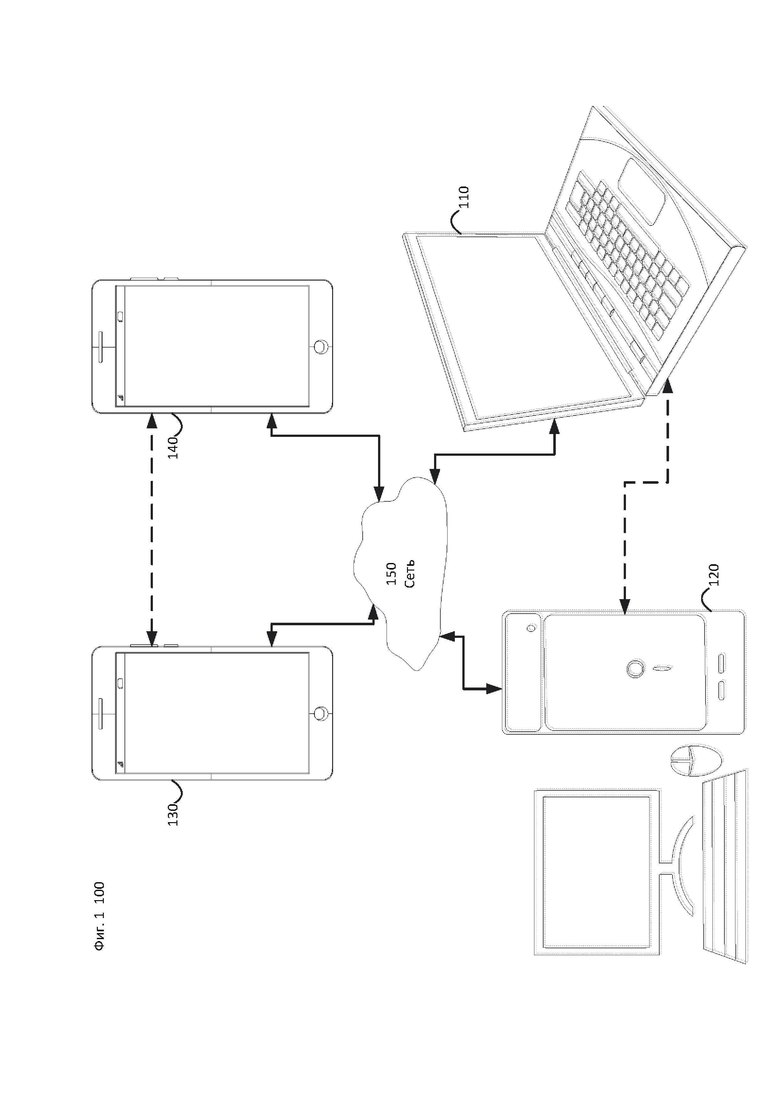
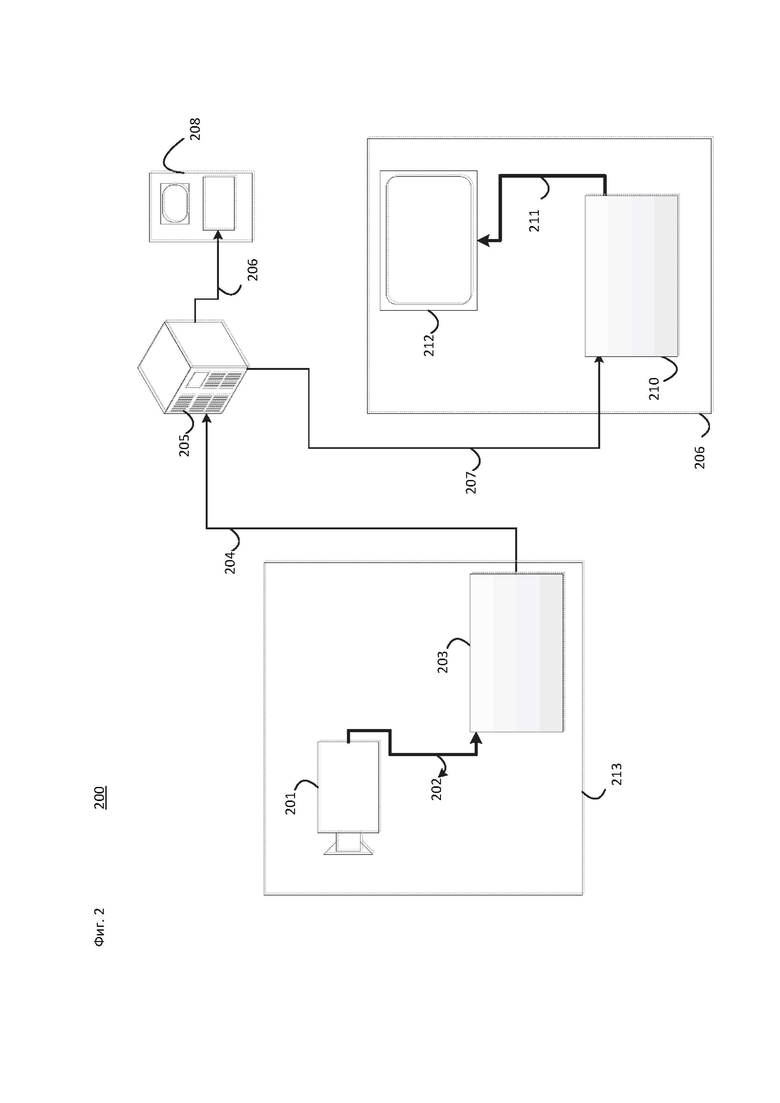
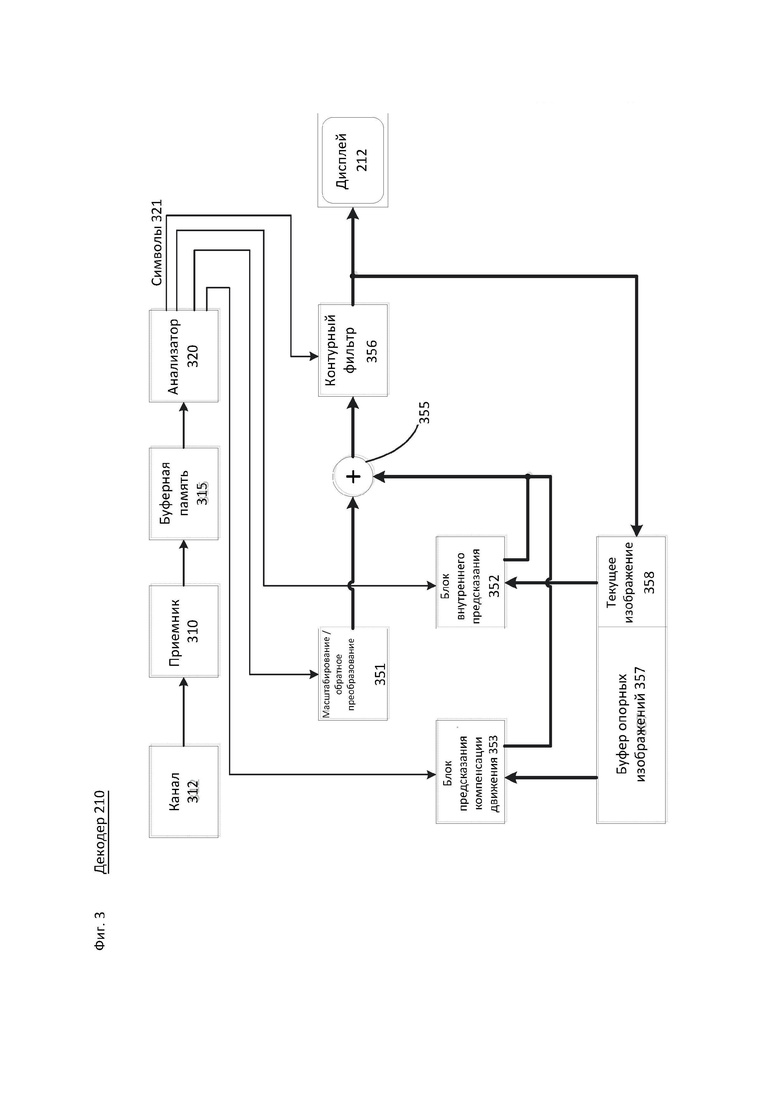

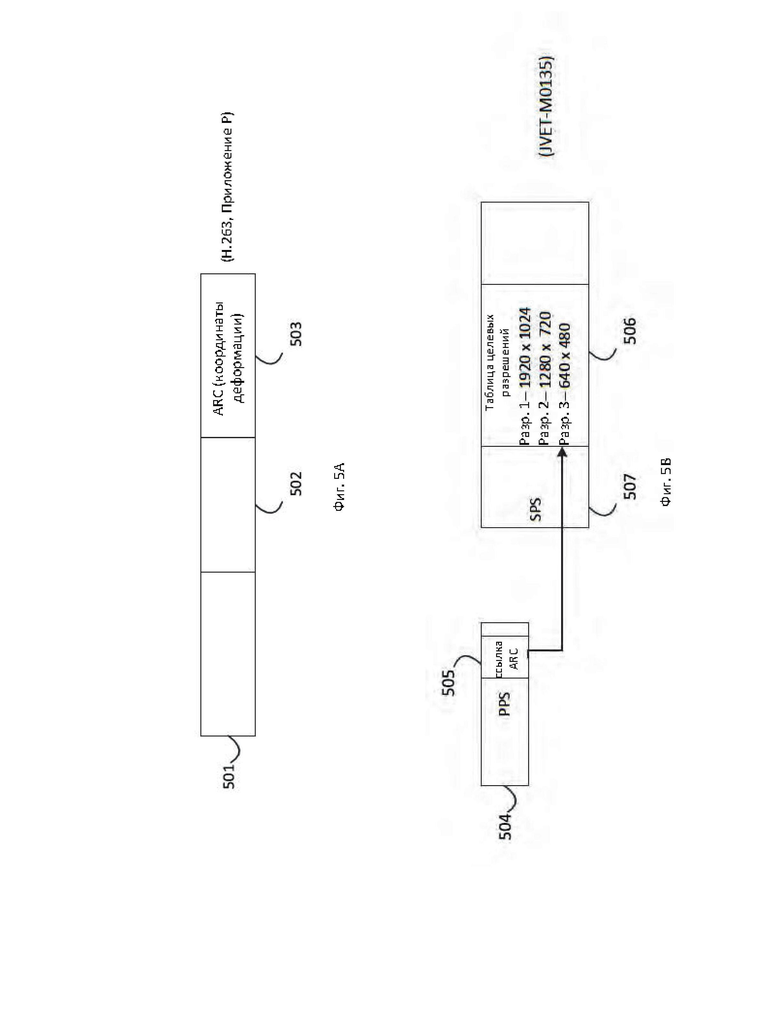
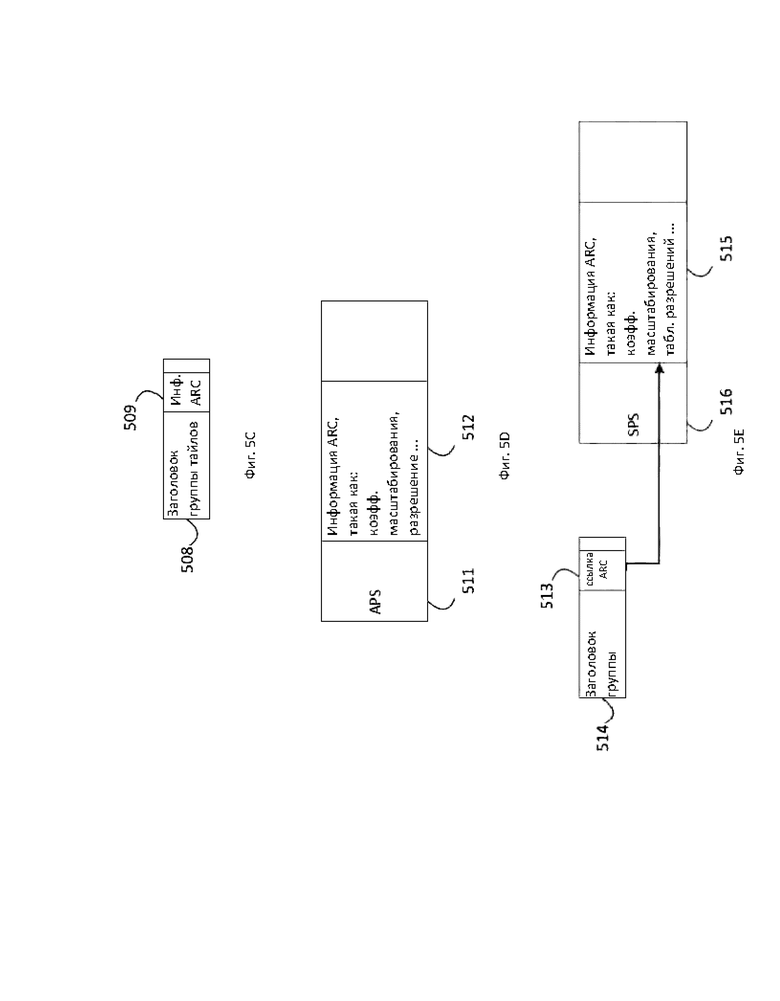
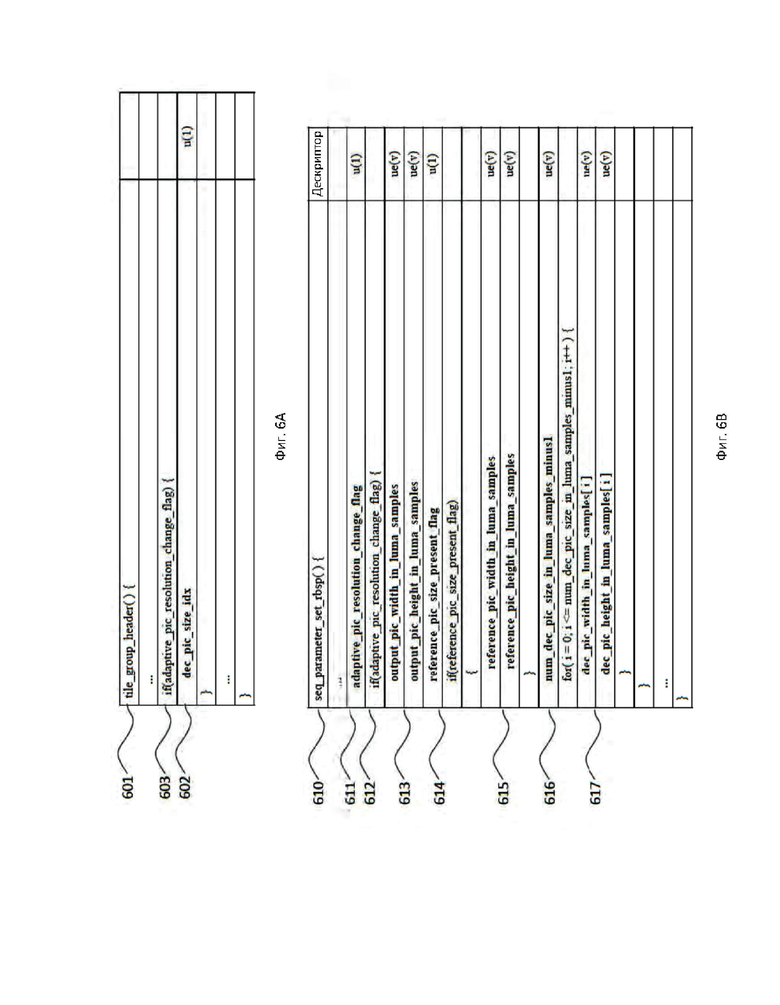
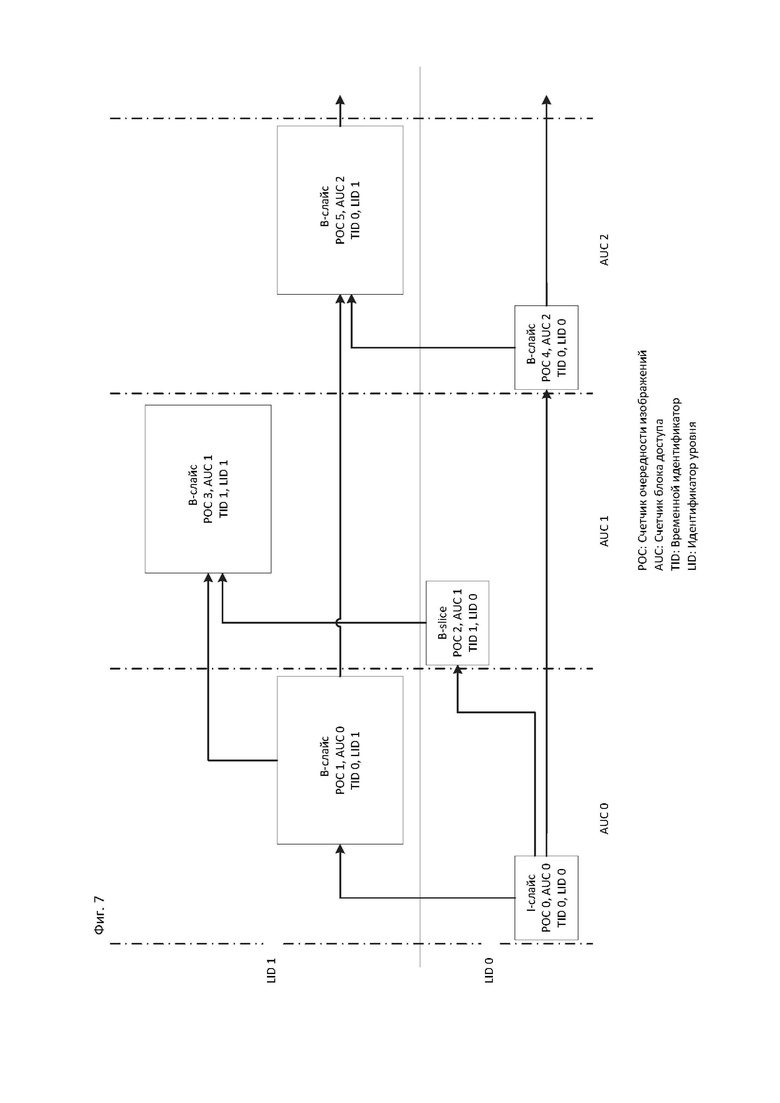

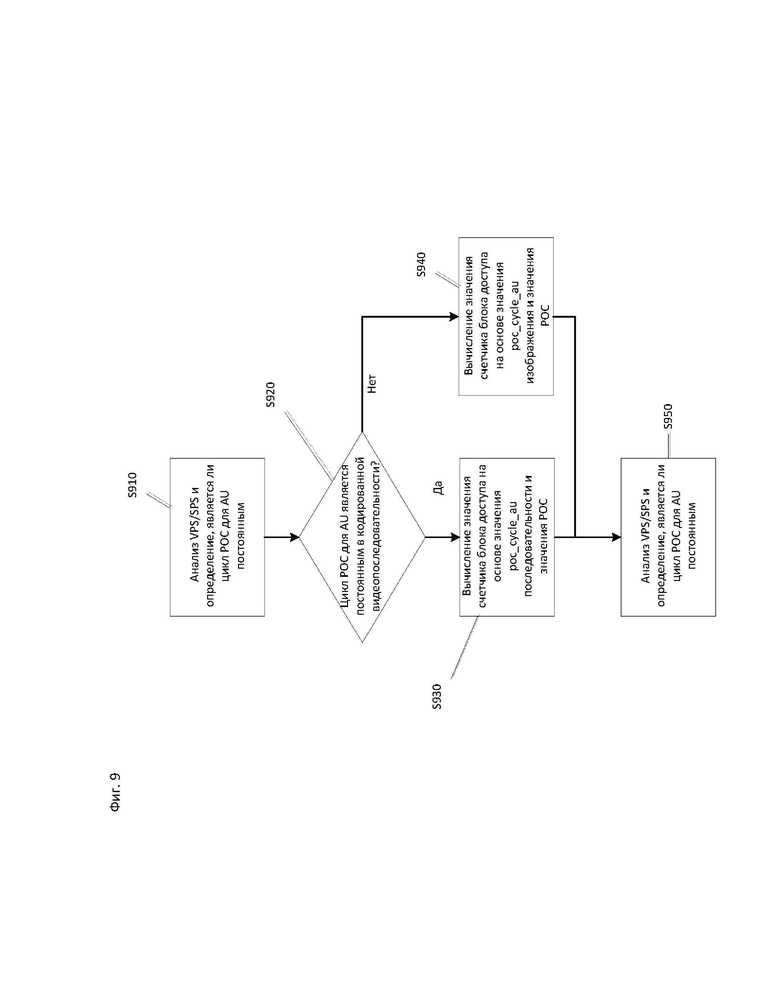
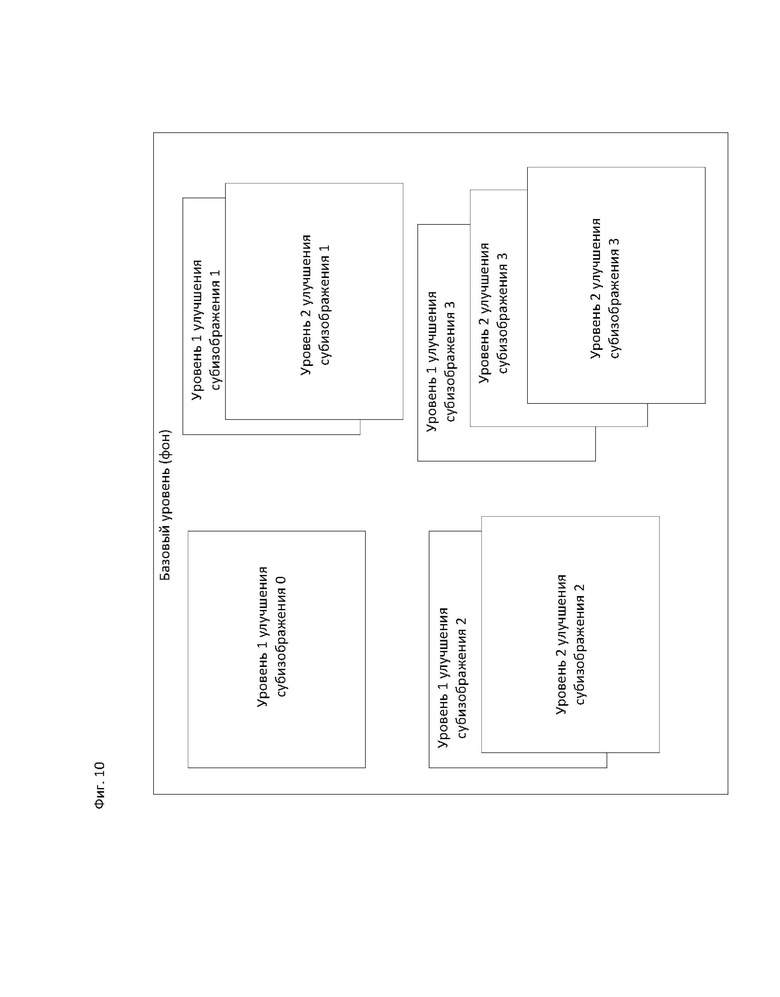
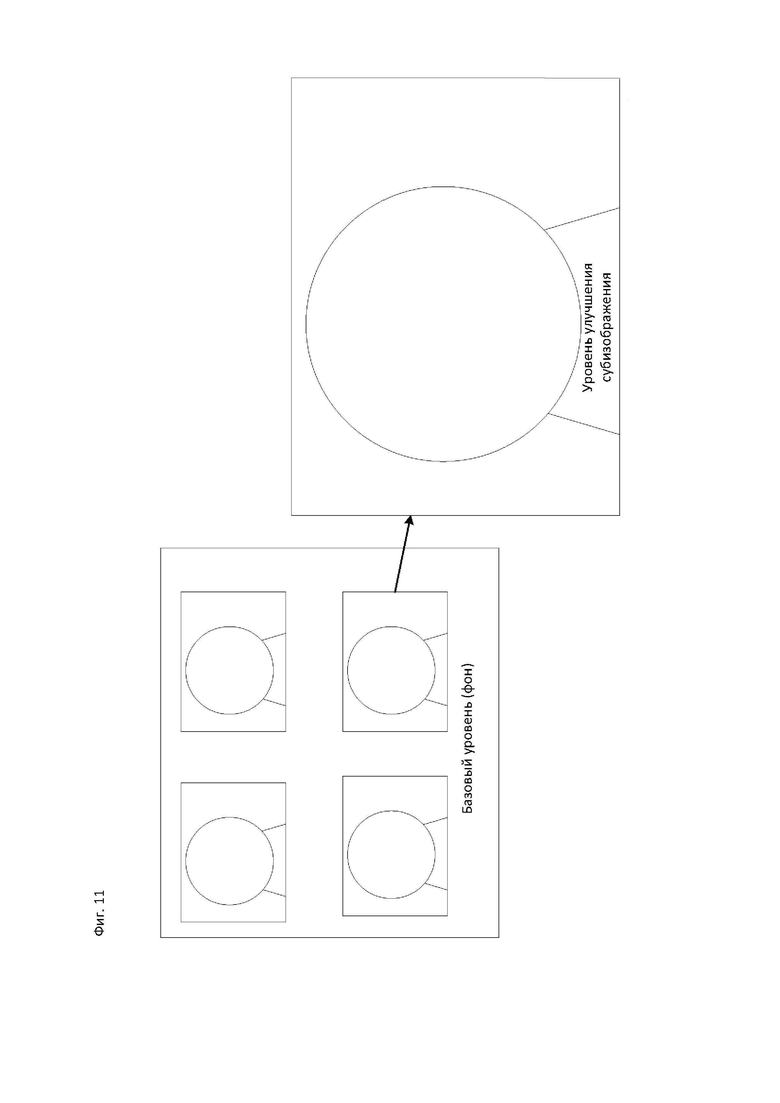
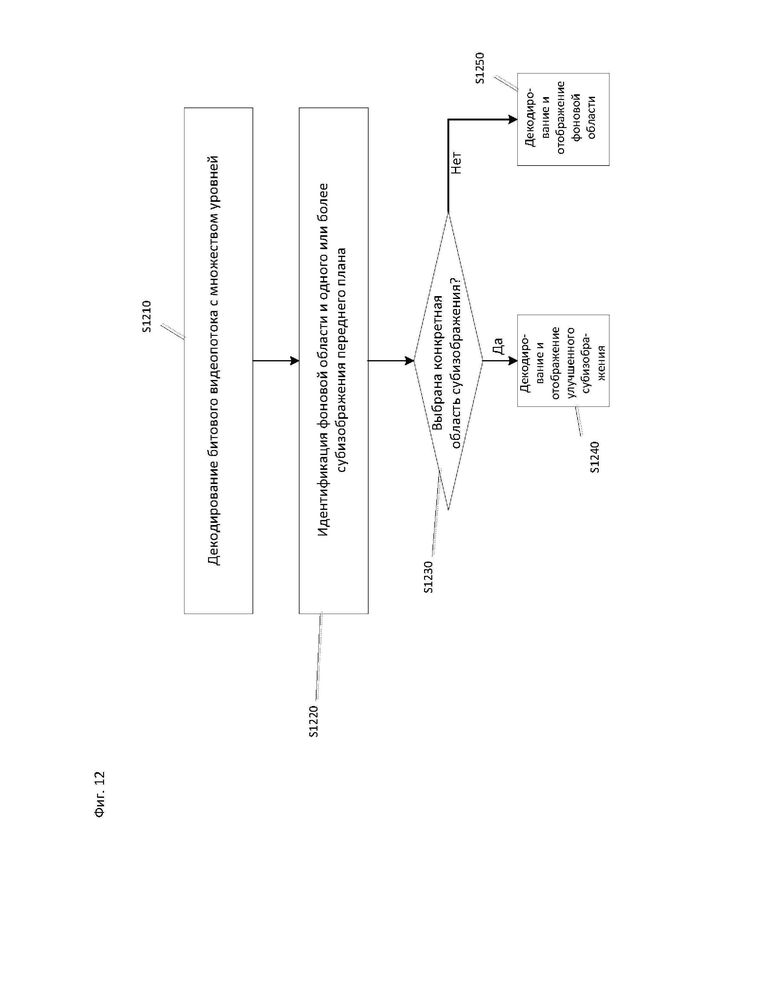

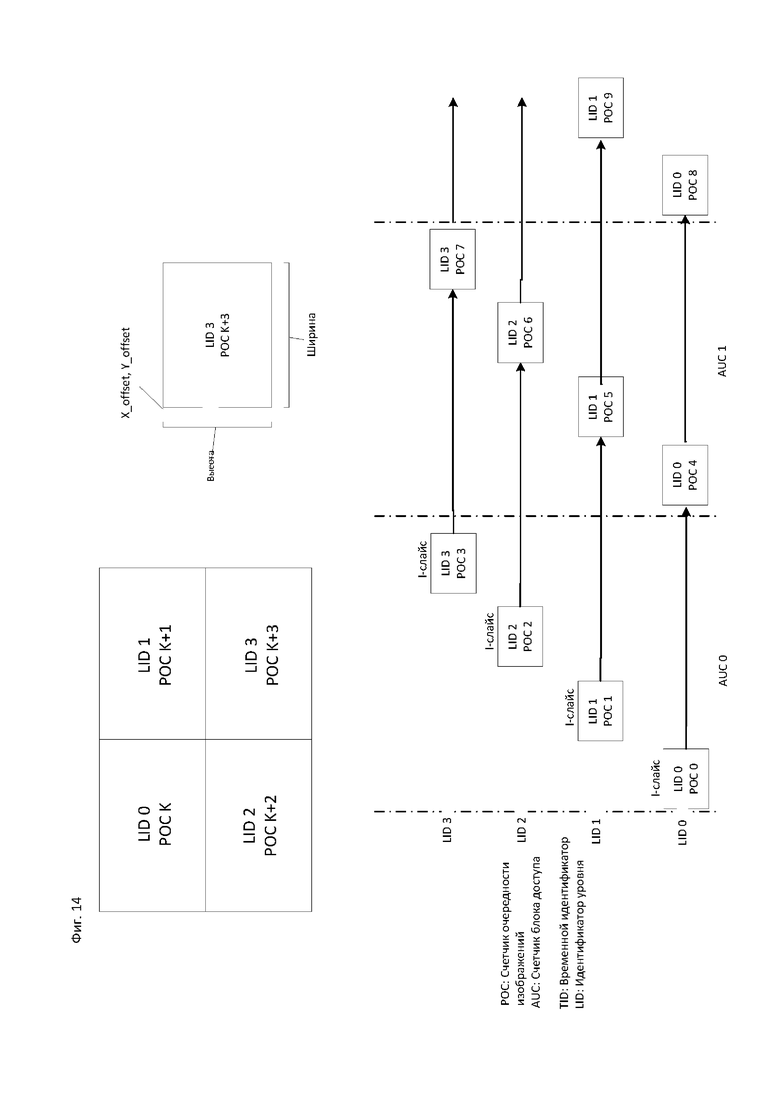
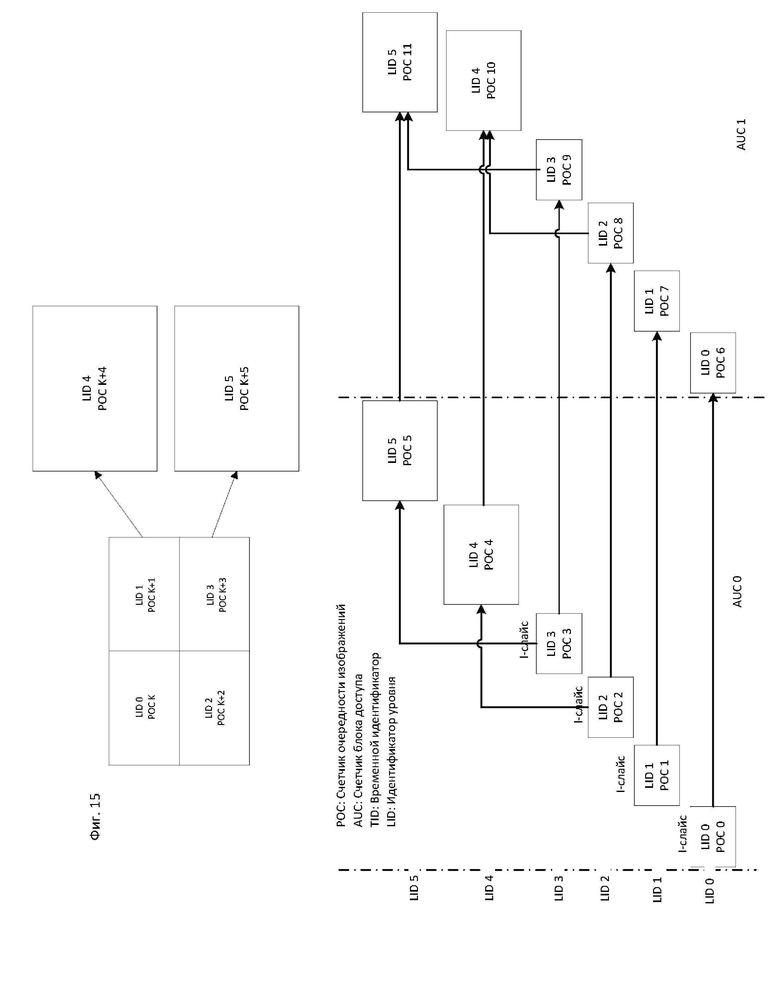
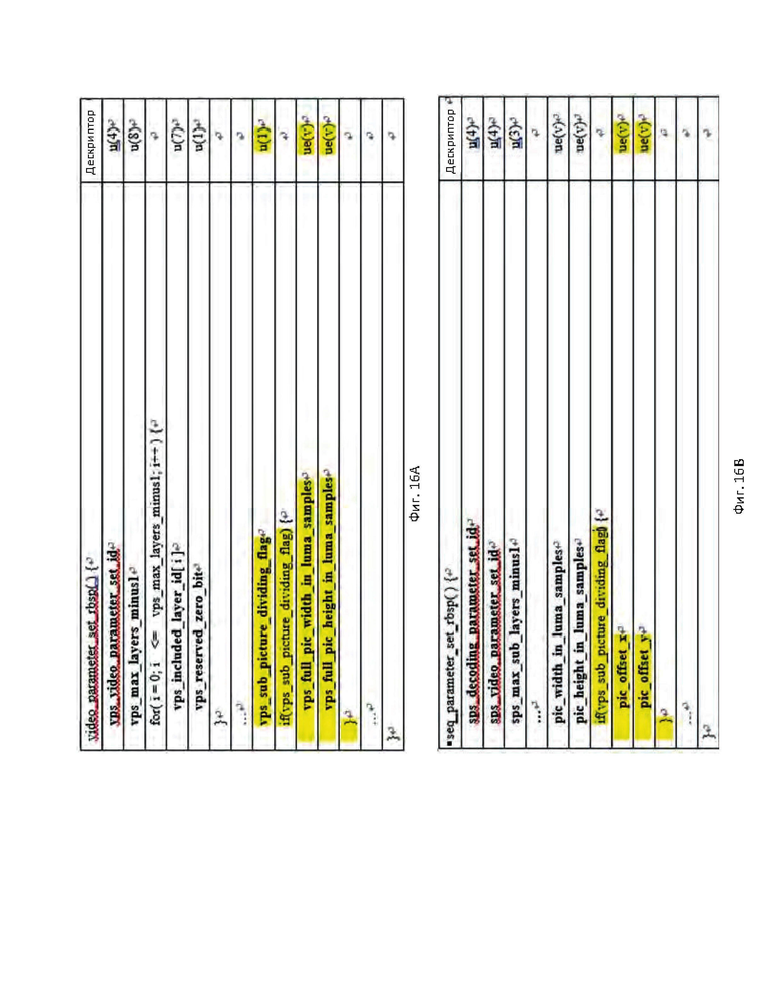
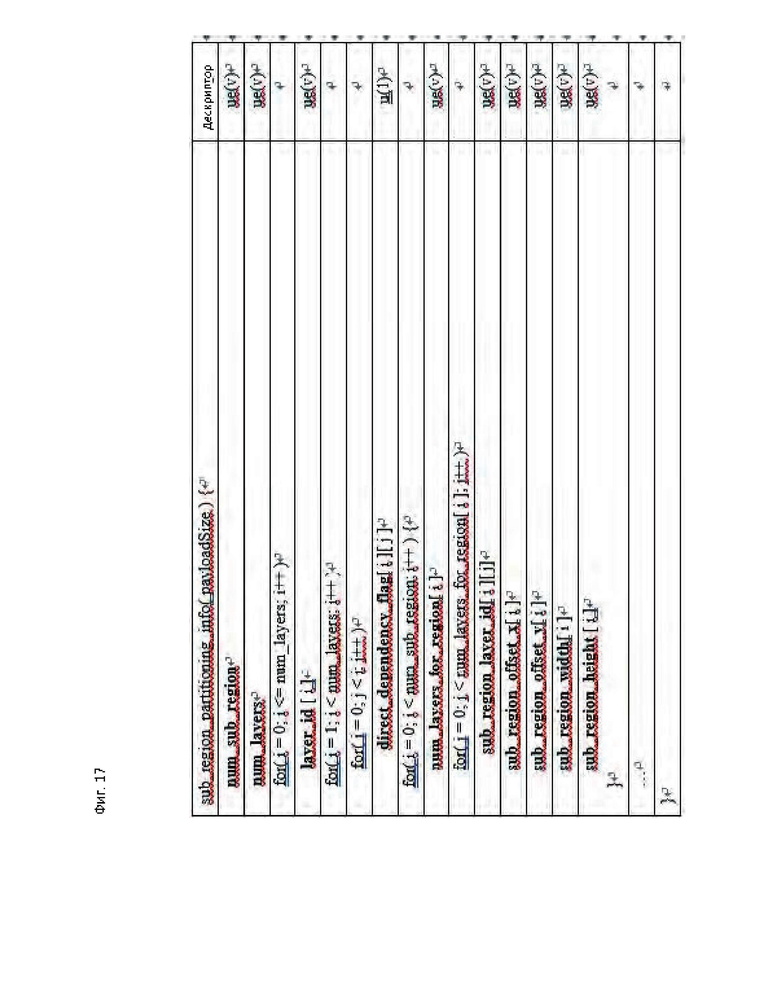



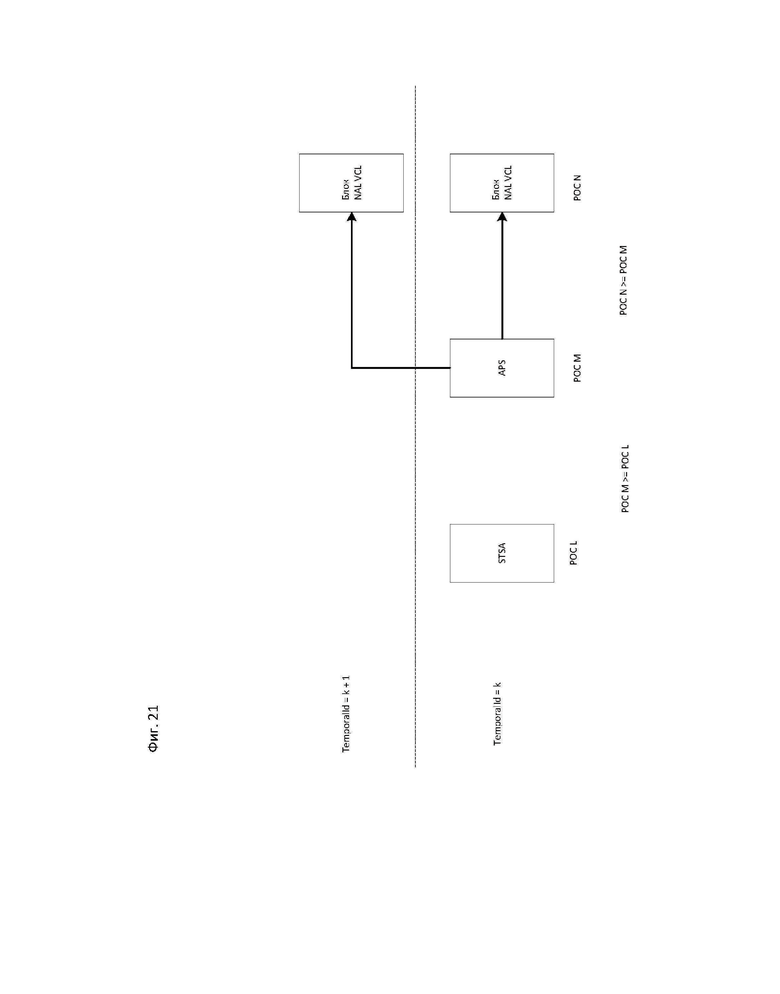

Изобретение относится к кодированию и декодированию видеосигналов. Технический результат заключается в уменьшении объема служебных данных в процессе декодирования и повышении точности предсказания, тем самым повышается эффективность кодирования. Способ декодирования кодированного битового видеопотока с использованием по меньшей мере одного процессора включает: получение из кодированного битового видеопотока кодированной видеопоследовательности, содержащей блок изображения, соответствующий кодированному изображению; получение блока уровня сетевой абстракции (NAL) заголовка изображения (РН), включенного в блок изображения; получение по меньшей мере одного блока уровня сетевой абстракции (NAL) уровня кодирования видео (VCL), включенного в блок изображения; декодирование кодированного изображения на основе блока NAL РН по меньшей мере одного блока NAL VCL и набора параметров адаптации (APS), включенного в блок NAL APS, полученный из кодированной видеопоследовательности; и вывод декодированного изображения, при этом блок NAL APS доступен по меньшей мере одному процессору перед по меньшей мере одним блоком NAL VCL. 3 н. и 16 з.п. ф-лы, 1 табл., 23 ил.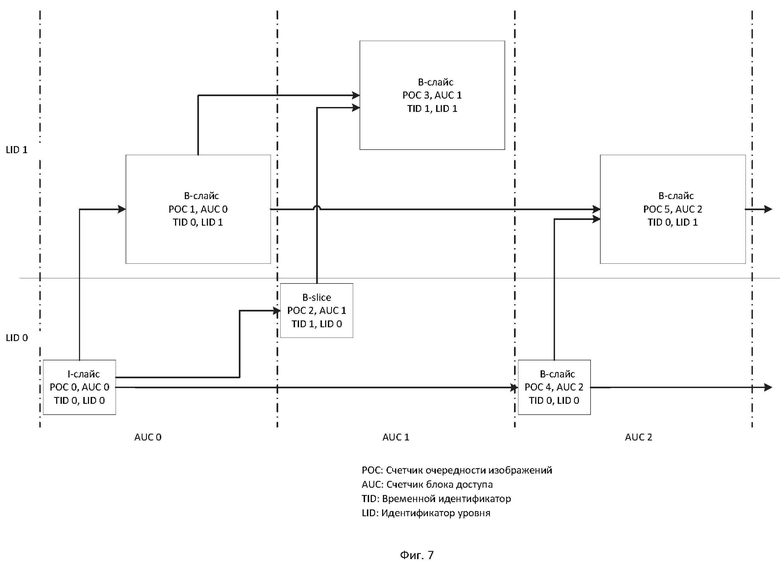
1. Способ декодирования кодированного битового видеопотока с использованием по меньшей мере одного процессора, включающий:
получение из кодированного битового видеопотока кодированной видеопоследовательности (CVS), содержащей блок изображения, соответствующий кодированному изображению;
получение блока уровня сетевой абстракции (NAL) заголовка изображения (PH), включенного в блок изображения;
получение по меньшей мере одного блока NAL уровня кодирования видео (VCL), включенного в блок изображения;
декодирование кодированного изображения на основе блока NAL PH, по меньшей мере одного блока NAL VCL и набора параметров адаптации (APS), включенного в блок NAL APS, полученный из кодированной видеопоследовательности;
и
вывод декодированного изображения,
при этом блок NAL APS доступен по меньшей мере одному процессору перед по меньшей мере одним блоком NAL VCL,
блок NAL APS доступен по меньшей мере одному процессору перед ссылкой на него одного или более заголовка изображения (PH) или одного или более блока NAL кодированного слайса, включенного в CVS, и
блок NAL APS включен по меньшей мере в один блок предсказания (PU), имеющий значение nuh_layer_id, равное наименьшему значению nuh_layer_id одного или более блоков NAL кодированного слайса, ссылающихся на блок NAL APS в CVS, который содержит один или более PH или один или более блоков NAL кодированного слайса, ссылающихся на блок NAL APS.
2. Способ по п. 1, в котором временной идентификатор по меньшей мере одного блока NAL VCL больше или равен временному идентификатору блока NAL APS.
3. Способ по п. 1, в котором значение счетчика очередности изображений (POC) по меньшей мере одного блока NAL VCL больше или равно значению POC блока NAL APS.
4. Способ по п. 1, в котором идентификатор уровня блока NAL PH и идентификатор уровня по меньшей мере одного блока NAL VCL больше или равны идентификатору уровня блока NAL APS.
5. Способ по п. 1, в котором блок NAL PH, по меньшей мере один блок NAL VCL и блок NAL APS включены в единый блок доступа.
6. Способ по п. 1, в котором кодированная видеопоследовательность также включает блок NAL поэтапного доступа к временному подуровню (STSA), соответствующий изображению STSA,
при этом блок NAL STSA не расположен между блоком NAL APS и по меньшей мере одним блоком NAL VCL.
7. Способ по п. 6, в котором блок NAL PH, по меньшей мере один блок NAL VCL и блок NAL STSA включены в единый блок доступа.
8. Способ по п. 6, в котором временной идентификатор блока NAL APS больше или равен временному идентификатору блока NAL STSA.
9. Способ по п. 6, в котором значение счетчика очередности изображений (POC) блока NAL APS больше или равно значению POC блока NAL STSA.
10. Устройство для декодирования кодированного битового видеопотока, содержащее:
по меньшей мере одну память, в которой хранится программный код; и
по меньшей мере один процессор, сконфигурированный для считывания программного кода и работы под управлением программного кода, при этом программный код содержит:
первый код получения, сконфигурированный так, чтобы заставлять по меньшей мере один процессор получать из кодированного битового видеопотока кодированную видеопоследовательность, содержащую блок изображения, соответствующий кодированному изображению;
второй код получения, сконфигурированный так, чтобы заставлять по меньшей мере один процессор получать блок уровня сетевой абстракции (NAL) заголовка изображения (PH), включенный в блок изображения;
третий код получения, сконфигурированный так, чтобы заставлять по меньшей мере один процессор получать по меньшей мере один блок NAL уровня кодирования видео (VCL), включенный в блок изображения;
код декодирования, сконфигурированный так, чтобы заставлять по меньшей мере один процессор декодировать кодированное изображение на основе блока NAL PH, по меньшей мере одного блока NAL VCL и набора параметров адаптации (APS), включенного в блок NAL APS, полученный из кодированной видеопоследовательности;
и
код вывода, сконфигурированный так, чтобы заставлять по меньшей мере один процессор выводить декодированное изображение,
при этом блок NAL APS доступен по меньшей мере одному процессору перед по меньшей мере одним блоком NAL VCL,
блок NAL APS доступен по меньшей мере одному процессору перед ссылкой на него одного или более заголовка изображения (PH) или одного или более блока NAL кодированного слайса, включенного в CVS, и
блок NAL APS включен по меньшей мере в один блок предсказания (PU), имеющий значение nuh_layer_id, равное наименьшему значению nuh_layer_id одного или более блоков NAL кодированного слайса, ссылающихся на блок NAL APS в CVS, который содержит один или более PH или один или более блоков NAL кодированного слайса, ссылающихся на блок NAL APS.
11. Устройство по п. 10, в котором временной идентификатор по меньшей мере одного блока NAL VCL больше или равен временному идентификатору блока NAL APS.
12. Устройство по п. 10, в котором значение счетчика очередности изображений (POC) по меньшей мере одного блока NAL VCL больше или равно значению POC блока NAL APS.
13. Устройство по п. 10, в котором идентификатор уровня блока NAL PH и идентификатор уровня по меньшей мере одного блока NAL VCL больше или равны идентификатору уровня блока NAL APS.
14. Устройство по п. 10, в котором блок NAL PH, по меньшей мере один блок NAL VCL и блок NAL APS включены в единый блок доступа.
15. Устройство по п. 10, в котором кодированная видеопоследовательность также включает блок NAL поэтапного доступа к временному подуровню (STSA), соответствующий изображению STSA,
при этом блок NAL STSA не расположен между блоком NAL APS и по меньшей мере одним блоком NAL VCL.
16. Устройство по п. 15, в котором блок NAL PH, по меньшей мере один блок NAL VCL и блок NAL STSA включены в единый блок доступа.
17. Устройство по п. 15, в котором временной идентификатор блока NAL APS больше или равен временному идентификатору блока NAL STSA.
18. Устройство по п. 15, в котором значение счетчика очередности изображений (POC) блока NAL APS больше или равно значению POC блока NAL STSA.
19. Машиночитаемый носитель, на котором хранятся инструкции, содержащие одну или более инструкций, при исполнении которых одним или более процессорами устройства декодирования кодированного битового видеопотока один или более процессоров выполняют следующие операции:
получение из кодированного битового видеопотока кодированной видеопоследовательности, содержащей блок изображения, соответствующий кодированному изображению;
получение блока уровня сетевой абстракции (NAL) заголовка изображения (PH), включенного в блок изображения;
получение по меньшей мере одного блока NAL уровня кодирования видео (VCL), включенного в блок изображения;
декодирование кодированного изображения на основе блока NAL PH, по меньшей мере одного блока NAL VCL и набора параметров адаптации (APS), включенного в блок NAL APS, полученный из кодированной видеопоследовательности;
и
вывод декодированного изображения,
при этом блок NAL APS доступен по меньшей мере одному процессору перед по меньшей мере одним блоком NAL VCL,
блок NAL APS доступен по меньшей мере одному процессору перед ссылкой на него одного или более заголовка изображения (PH) или одного или более блока NAL кодированного слайса, включенного в CVS, и
блок NAL APS включен по меньшей мере в один блок предсказания (PU), имеющий значение nuh_layer_id, равное наименьшему значению nuh_layer_id одного или более блоков NAL кодированного слайса, ссылающихся на блок NAL APS в CVS, который содержит один или более PH или один или более блоков NAL кодированного слайса, ссылающихся на блок NAL APS.
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| US 9451252 B2, 20.09.2016 | |||
| СПОСОБ КОДИРОВАНИЯ, СПОСОБ ДЕКОДИРОВАНИЯ, УСТРОЙСТВО КОДИРОВАНИЯ, УСТРОЙСТВО ДЕКОДИРОВАНИЯ И УСТРОЙСТВО КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ | 2013 |
|
RU2627109C2 |

