Область техники, к которой относится изобретение
Настоящее раскрытие относится к области техники обработки данных, в частности, к способу, устройству и компьютерному устройству генного анализа, основанных на совместно используемой памяти, и к считываемому компьютером носителю запоминающего устройства.
Уровень техники
При постепенной реализации Проекта человеческого генома и быстром развитии технологии секвенирования стоимость секвенирования значительно снизилась, а скорость секвенирования была значительно повышена. Стоимость секвенирования всего человеческого генома понизилась до менее 1000 долларов США, а объем данных последовательности ДНК вырос по экспоненте. Как быстро использовать и представлять данные, затем анализировать и объяснять потенциальные проблемы в последовательностях генов и раскрывать информацию, нужную людям, из огромного объема данных, стало насущной проблемой, которая должна быть решена. Все больше и больше применений данных последовательностей, формируемых секвенированием полного человеческого генома (whole genome sequencing, WGS), и постоянное требование быстрого анализа и обработки больших объемов данных последовательностей сформировали новое узкое место в технике анализа данных, которое ограничивает клиническое применение технологии секвенирования второго поколения.
В настоящее время на международном уровне в области биоинформатики существует много разного вида способов и инструментов для анализа данных секвенирования второго поколения. Наиболее часто используемый процесс содержит, главным образом, ввод данных, операцию предварительной обработки, сравнение последовательностей, аннотацию, определение вариантов и анализ путей прохождения. Однако, для применения всего процесса в WGS требуются большие затраты времени. Кроме того, специализированные процессы, нуждающиеся во вводе выборок, такие как слияние выборок, разбиение выборок и так далее, должны выполняться отдельно и поэтому эффективность операций является низкой и потребность во вводе-выводе увеличивается. Кроме того, в процессе анализа данных индексные файлы должны загружаться отдельно для каждого этапа анализа и обработки. Если во многочисленных задачах загружают один и тот же индексный файл, то решение задач расходует больше памяти и занимает больше времени.
Расктытие сущности изобретения
С этой точки зрения раскрытие представляет способ, устройство, компьютерное устройство генного анализа, основанные на совместно используемой памяти, и считываемый компьютером носитель для решения технической проблемы низкой операционной эффективности, вызванной требованием таких процессов, как слияние входных выборок в некоторых конвейерах, высоким потреблением памяти, вызванным повторяющейся загрузкой индексных файлов в процессе анализа данных на предшествующем уровне развития техники.
Некоторые варианты осуществления этого раскрытия обеспечивают способ генного анализа, основанный на совместно используемой памяти, содержащий этапы, на которых: считывают данные образцов и предварительно обрабатывают данные образцов; выполняют генный анализ предварительно обработанных данных образцов и определяют, находится ли требуемый при генном анализе библиотечный файл в совместно используемой генной памяти; если да, то получают требуемый библиотечный файл из совместно используемой генной памяти, преобразуют требуемый библиотечный файл в процессе генного анализа предварительно обработанных данных образцов и завершают генный анализ.
В некоторых вариантах осуществления способ дополнительно содержит этапы, на которых: определяют, удовлетворяет ли требуемый библиотечный файл условию загрузки в случае, когда требуемый при генном анализе библиотечный файл не находится в совместно используемой генной памяти; и загружают требуемый библиотечный файл в совместно используемую генную память, в случае, когда удовлетворяется условие загрузки.
В некоторых вариантах осуществления определение, удовлетворяет ли требуемый библиотечный файл условию загрузки в случае, когда требуемый при генном анализе библиотечный файл не присутствует в совместно используемой генной памяти и загружать ли требуемый библиотечный файл в совместно используемую генную память в случае, когда удовлетворяется условие загрузки, содержит: получение информации требуемого библиотечного файла и информации совместно используемой генной памяти, где информация требуемого библиотечного файла содержит пространство, запрашиваемое требуемым библиотечным файлом и количеством архивных запросов загрузки требуемого библиотечного файла, и информация совместно используемой генной памяти содержит остающееся пространство совместно используемой генной памяти; и если количество архивных запросов загрузки требуемого библиотечного файла больше первого заданного количества, и пространство, запрашиваемое требуемым библиотечным файлом, меньше остающегося пространства совместно используемой генной памяти, загружают требуемый библиотечный файл в совместно используемую генную память.
В некоторых вариантах осуществления информация требуемого библиотечного файла содержит частоту запросов загрузки требуемого библиотечного файла, информация о совместно используемой генной памяти содержит частоты запроса загрузки всех библиотечных файлов в совместно используемой генной памяти; определение, удовлетворяет ли требуемый библиотечный файл условию загрузки, и загружать ли требуемый библиотечный файл в совместно используемую генную память в случае, когда удовлетворяется условие загрузки, дополнительно содержит: если количество архивных запросов загрузки требуемого библиотечног файла больше первого заданного количества и пространство, запрашиваемое требуемым библиотечным файлом, больше остающегося пространства совместно используемой генной памяти, ранжируют требуемый библиотечный файл и все библиотечные файлы в порядке приоритета в соответствии с частотой запроса загрузки требуемых библиотечных файлов и частотами запроса загрузки всех библиотечных файлов, чтобы получить приоритет частот запроса загрузки каждого библиотечного файла; если приоритет частот запроса загрузки требуемого библиотечного файла выше, чем приоритет библиотечного файла в совместно используемой генной памяти, и если остающееся пространство совместно используемой генной памяти после удаления библиотечного файла с более низким приоритетом частоты запроса загрузки в совместно используемой генной памяти больше или равно пространству, запрашиваемому требуемым библиотечным файлом, удаляют библиотечный файл с более низким приоритетом частоты запроса загрузки в совместно используемой генной памяти; и загружают требуемый библиотечный файл в совместно используемую генную память.
В некоторых вариантах осуществления способ дополнительно содержит этапы, на которых: устанавливают совместно используемую генную память для библиотечных файлов, используемых при генном анализе, устанавливают размер совместно используемой генной памяти, количество библиотечных файлов, которые могут быть размещены, имя каждого библиотечного файла и смещение размера каждого библиотечного файла; и загружают библиотечные файлы, обычно используемые при генном анализе, в совместно используемую генную память, соответствующую размеру совместно используемой генной памяти, количеству библиотечных файлов, которые могут быть размещены, имени каждого библиотечного файла и смещению размера каждого библиотечного файла.
В некоторых вариантах осуществления генный анализ содержит анализ выравнивания, вариационный анализ и аннотационный анализ, способ дополнительно содержит: выполнение анализа выравнивания, вариационного анализа и аннотационного анализа данных образцов, предварительно обработанных в последовательности, в котором, в случае, когда предварительно обработанные данные образцов содержат многочисленные группы данных образцов, многочисленные группы данных образцов одновременно находятся на одном и том же этапе или на разных этапах генного анализа.
В некоторых вариантах осуществления генный анализ дополнительно содержит сортировочный анализ и анализ с маркировкой-дублированием, где после выполнения анализа выравнивания, вариационного анализа и аннотационного анализа данных образцов, предварительно обработанных в последовательности, способ дополнительно содержит этапы, на которых: маркируют данные образцов после анализа выравнивания с помощью позиционного тега; и выполняют посредством модуля сортировочный анализ и анализ с маркировкой-дублированием на маркированных данных образцов.
В некоторых вариантах осуществления способ дополнительно содержит соединение нескольких или всех этапов генного анализа посредством использования памяти.
В некоторых вариантах осуществления предварительная обработка данных образцов содержит выполнение на данных образцов контроля качества, операции фильтрации и статистической обработки.
Некоторые варианты осуществления раскрытия также обеспечивают устройство генного анализа, основанное на совместно используемой генной памяти, содержащее: модуль считывания данных, выполненный с возможностью считывания данных образцов; модуль предварительной обработки данных, выполненный с возможностью предварительной обработки данных образцов; и модуль генного анализа, выполненный с возможностью осуществления генного анализа предварительно обработанных данных образцов и определения, находится ли требуемый при генном анализе библиотечный файл в совместно используемой генной памяти; и если да, то получают требуемый библиотечный файл из совместно используемой генной памяти, преобразуют требуемый библиотечный файл в процессе генного анализа предварительно обработанных данных образцов и завершают генный анализ.
Некоторые варианты осуществления раскрытия дополнительно обеспечивают компьютерное устройство, содержащее память, процессор и компьютерную программу, хранящуюся в памяти и исполняемую процессором. Процессор исполняет следующие этапы, на которых: считывают данные образцов и предварительно обрабатывают данные образцов; выполняют генный анализ предварительно обработанных данных образцов и определяют, находится ли требуемый при генном анализе библиотечный файл в совместно используемой генной памяти; если да, то получают требуемый библиотечный файл из совместно используемой генной памяти, преобразуют требуемый библиотечный файл в процессе генного анализа предварительно обработанных данных образцов и завершают генный анализ.
Некоторые варианты осуществления раскрытия дополнительно обеспечивают считываемый компьютером носитель запоминающего устройства, на котором хранится компьютерная программа, где компьютерная программа, когда исполняется процессором, реализует следующие этапы, на которых: считывают данные образцов данных образцов и предварительно обрабатывают данные образцов; выполняют генный анализ предварительно обработанных данных образцов и определяют, находится ли требуемый при генном анализе библиотечный файл в совместно используемой генной памяти; и если да, получают требуемый библиотечный файл из совместно используемой генной памяти, преобразуют требуемый библиотечный файл в процессе генного анализа предварительно обработанных данных образцов и завершают генный анализ.
Способ, устройство, компьютерное устройство для генного анализа, основанные на совместно используемой генной памяти, и считываемый компьютером носитель запоминающего устройства представляются в вариантах осуществления раскрытия. Сначала считывают данные образцов, затем данные образцов предварительно обрабатывают и далее выполняют генный анализ предварительно обработанных данных образцов. При генном анализе необходимо определить, находится ли требуемый при генном анализе библиотечный файл в совместно используемой генной памяти библиотеки файлов; если да, получают требуемый библиотечный файл из совместно используемой генной памяти и преобразуют его при генном анализе, соответствующем данным образцов, чтобы завершить соответствующий анализ. В способе генного анализа, основанном на совместно используемой генной памяти, механизм совместно используемой генной памяти используется для установления индексов генного анализа (например, содержащего анализ выравнивания, вариационный анализ, аннотационный анализ и так далее) и затем сохранения в базе данных файлов (то есть, библиотечных файлов), требующихся при генном анализе, в совместно используемой генной памяти. Библиотечный файл с легкостью может преобразцовываться из совместно используемой генной памяти в процессе генного анализа, выполняемого на данных образцов. С одной стороны, значительно снижаются время и занятость ввода-вывода для загрузки библиотечного файла с жесткого диска. С другой стороны, связь множества процессов в ходе генного анализа облегчается иизбегают повторяющейся загрузки библиотечного файла.
Краткое описание чертежей
Чтобы более ясно объяснить варианты осуществления настоящего раскрытия или технические решения на предшествующем уровне техники, ниже будет представлено краткое введение для чертежей, требующихся для использования при описании вариантов осуществления или предшествующего уровня техники. Очевидно, что, чертежи, поясняемые ниже, являются просто вариантами осуществления настоящего раскрытия. Специалисты в данной области техники могут получить также и другие чертежи, соответствующие таким чертежам, при условии, что никакие изобретательские усилия не прикладываются.
Фиг. 1 - вариант осуществления применения способа генного анализа, основанного на совместно используемой памяти, соответствующего некоторым вариантам осуществления настоящего раскрытия;
Фиг. 2 - блок-схема последовательности выполнения операций способа генного анализа, основанного на совместно используемой памяти, соответствующего некоторым вариантам осуществления настоящего раскрытия;
Фиг. 3 - принцип действия совместно используемой памяти, соответствующей некоторым вариантам осуществления настоящего раскрытия;
Фиг. 4 - блок-схема последовательности выполнения операций построения совместно используемой памяти в некоторых вариантах осуществления настоящего раскрытия;
Фиг. 5 - структурная схема совместно используемой памяти в некоторых вариантах осуществления настоящего раскрытия;
Фиг. 6 - блок-схема последовательности выполнения операций способа генного анализа, основанного на совместно используемой памяти, соответствующего некоторым вариантам осуществления настоящего раскрытия;
Фиг. 7 - использование центрального процессора (CPU) и использование ввода-вывода, когда генный анализ выполняется, используя способ А, соответствующий некоторым вариантам осуществления настоящего раскрытия;
Фиг. 8 - использование CPU и использование ввода-вывода, когда генный анализ выполняется, используя способ В, соответствующий некоторым вариантам осуществления настоящего раскрытия;
Фиг. 9 - использование CPU и использование ввода-вывода, когда генный анализ выполняется, используя способ С, соответствующий некоторым вариантам осуществления настоящего раскрытия;
Фиг. 10 - структурная схема устройства генного анализа, основанного на совместно используемой памяти, соответствующего некоторым вариантам осуществления настоящего
Фиг. 11 - структурная схема компьютерного устройства, соответствующего некоторым вариантам осуществления настоящего раскрытия.
Осуществление изобретения
Ниже технические решения вариантов осуществления настоящего раскрытия будут описаны ясно и полностью. Очевидно, описанные варианты осуществления являются только частью вариантов осуществления настоящего раскрытия, а не всеми вариантами осуществления. Все другие варианты осуществления, получаемые без творческих усилий специалистами в данной области техники, основываясь на вариантах осуществления настоящего раскрытия, должны попадать в рамки объема защиты настоящего раскрытия.
Глоссарий:
Ген (менделевский фактор) относится к последовательности ДНК или РНК, которая переносит генетическую информацию (то есть, ген является фрагментом ДНК или РНК с генетическими эффектами), также известнен как генетический фактор, который является основным генетическим блоком, управляющим биологическими признаками. Ген выражает генетическую информацию, которую он переносит, направляя синтез протеинов и управляя, таким образом, признаками индивидуальных организмов. Генное секвенирование является новым типом генной технологии обнаружения, которая анализирует и определяет всю последовательность генов из крови или слюны, чтобы предсказывать возможность множества болезней, характеристик индивидуального поведения и разумного поведения.
Считывание: короткий фрагмент секвенирования, который является данными секвенирования, сформированными высокопроизводительным секвенатором. Секвенированием всего генома будут формироваться десятки миллионов считываний. Затем, сращивая эти считывания вместе, может быть получена полная последовательность генома.
Анализ выравнивания: Считывания, упорядоченные посредством NGS, сохраняются в файлах FASTQ. Хотя первоначально они поступают из упорядоченного генома, последовательное соотношение между различными считываниями в файлах оказывается потерянным после создания библиотеки ДНК и секвенирования. Поэтому между двумя считываниями, находящимися рядом друг с другом в файлах FASTQ, нет никакого позиционного соотношения. Все они являются короткими последовательностями, выводимыми в случайном порядке из определенных позиций в исходном геноме. Поэтому сначала мы должны привести в порядок множество коротких последовательностей, один за другим сравнить их с опорным геномом разновидности, обнаружить позицию каждого считывания на опорном геноме, и затем расположить их по порядку. Этот процесс вызывают сравнением данных секвенирования.
Сортировочный анализ: Почему файлы BAM после сравнения BWA выводятся беспорядочно? Причина состоит в том, что эти упорядоченные считывания в файлах FASTQ распределяются на геноме в произвольном порядке. Первый этап сравнения должен одно за другим определить местоположение считываний на опорном геноме в соответствии с их порядком в файлах FASTQ и затем выводить их напрямую. Невозможно на этом этапе автоматически распознать последовательность их позиций сравнения и перестроить результаты сравнения. Поэтому в полученном в результате файле после сравнения позиционный порядок записей является хаотическим. Нам необходимо сортировать записи для последующего этапа, такого как маркировка-дублирование, что и является причиной необходимости сортировки.
Маркировка-дублирование: После того, как сортировка закончена, выполняется дедупликация (то есть, удаление дублированных последовательностей PCR). Что такое дублированная последовательность? Как она создается и почему ее нужно удалить? Это связано с построением библиотеки и секвенированием в экспериментальном процессе. Перед секвенированием NGS должна быть создана библиотека секвенирования: сокращают исходную последовательность ДНК путем физического (ультразвукового) прерывания или используют химический реагент (ферментное усвоение) и затем выбирают последовательности в определенном диапазоне длин для амплификации PCR и компьютерного секвенирования. Поэтому, дублированная последовательность здесь фактически вводится во время процесса PCR.
Коррекция подсчета базового качества: в процессе секвенирования необходимо (в максимально возможной степени) корректировать систематические ошибки, потому что определение вариантов является этапом, который в большой степени опирается на результаты подсчета баллов базового качества секвенирования. Этот подсчет качества является важным (даже единственным) индикатором, чтобы измерять, насколько корректировать базу, которую мы секвенировали. Это не может быть измерено напрямую, но очень близкий результат распределения может быть получен статистическими способами. Известная вариация, найденная в совокупности, вероятно, в чем-то будет одной и той же. Поэтому мы можем сравнивать и анализировать результат сравнения напрямую, исключить все известные места вариаций и затем вычислить, сколько баз отличаются от баз на опорном геноме после сравнения для каждого (сообщенного) результата подсчета качества. Эти другие базы рассматриваются как ложные базы и их количественное отношение отражает реальные показатели ошибок базы, которые преобразуются в баллы системы Phred. Эта информация выводится в файл калибровочной таблицы и используется для повторного регулирования результата подсчета баллов качества базы в исходном файле BAM. Новый файл BAM выводится, используя эти новые результаты подсчета баллов качества.
Определение вариантов и анализ: целью определения вариантов и анализа должно быть точное обнаружение набора выриантов в геноме каждого образца (такого как человек), то есть, те последовательностей ДНК, которые отличаются у различных людей.
Чтобы более четко и ясно определить задачу, техническое решение и преимущества настоящей заявки, настоящая заявка будет дополнительно подробно описана в сочетании с чертежами и вариантами осуществления. Следует понимать, что подробные варианты осуществления, которые будут здесь описаны, используются только для объяснения настоящей заявки, но не используются для ограничения настоящей заявки.
Этот способ может быть применен к терминалу 102, показанному на фиг. 1. Терминал может быть персональным компьютером, ноутбуком и т. д. Терминал 102 соединяется с устройством 104 генного секвенирования, которое может быть генным секвенатором и т.д.
Когда терминал 102 через локальный интерфейссоединяется с устройством 104 генного секвенирования, устройство 104 генного секвенирования может посылать данные образцов после секвенирования терминалу 102. Кроме того, терминал 102 может получать данные образцов после секвенирования в устройстве 104 генного секвенирования посредством команд.
В некоторых вариантах осуществления, как показано на фиг. 2, обеспечивается способ генного анализа, основанный на совместно используемой памяти. В качестве иллюстрации, этот способ применяется к терминалу, показанному на фиг. 1 в качестве примера, и содержит нижеследующие этапы: S202 - S206.
На этапе S202 считывают данные образцов и данные образцов предварительно обрабатывают.
Данные образцов являются данными, генерируемыми или формируемыми после генного секвенирования образцов. Количество образцов может быть одной или более группами.
В необязательном варианте осуществления предварительная обработка данных образцов содержит выполнение контроля качества, операции фильтрации и статистическую обработку данных образцов.
Данные, полученные из генного секвенирования, называются необработанными данными (то есть, необработанными считываниями или необработанными данными). Необработанные данные могут содержать последовательности низкого качества и сращенные последовательности, которые будут влиять на результат анализа. Поэтому для необработанных данных должна выполняться пеоследовательность обработки данных, такая как контроль качества, операция фильтрации и статистическая обработка, чтобы удалять посторонние добавления в необработанные данные и определять, являются ли данные секвенирования пригодными для последующего анализа.
На этапе S204 выполняют генный анализ предварительно обработанных данных образцов и определяют, находится ли требуемый при генном анализе библиотечный файл в совместно используемой генной памяти.
Обычно после предварительной обработки данных образцов необходимо выполнить соответствующий генный анализ данных образцов. Общий анализ содержит, главным образом, выравнивание последовательности (то есть, анализ выравнивания), определение вариантов (то есть, вариационный анализ), аннотационную статистику (то есть аннотационный анализ) и анализ последовательного пути прохождения (такой как GO, анализ KEGG и анализ пути прохождения протеинов). Однако, независимо от того, какой анализ выполняется, он должен использовать аналитическую базу данных. Например, база данных опорного генома требуется для анализа выравнивания, база данных генома разновидностей (такая как база данных генома человека) требуется для определения вариантов, база данных аннотации требуется для аннотационного анализа, база данных пути прохождения требуется для анализа пути прохождения и т. д. У каждой базы данных есть большой объем данных. Эти базы данных должны загружаться, когда выполняется анализ данных образцов.
Совместно используемая память является современным способом связи между процессами в System V. Совместно используемая память, как подразумевает ее название, позволяет двум несвязанным процессам получать доступ к одной и той же логической памяти и является очень эффективным способом совместного использования и передачи данных между двумя работающими процессами. Память, совместно используемая различными процессами, обычно является одним и тем же фрагментом физической памяти. Процессы могут присоединять один и тот же фрагмент физической памяти к их собственному адресному пространству и все процессы могут получать доступ к адресам в совместно используемой памяти. Если процесс записывает данные в совместно используемую память, то это изменение будет сразу влиять на любой другой процесс, который может получать доступ к тому же самому фрагменту совместно используемой памяти.
На фиг. 3 схематично показан принцип связи совместно используемой памяти. В Linux каждый процесс имеет свой собственный блок управления процессом (process control block, PCB) и адресное пространство (Addr Space), и имеет соответствующую таблицу страниц, которая используется для преобразцования виртуальных адресов процесса в физические адреса и управляется через блок управления памятью (memory management unit, MMU). Два различных виртуальных адреса могут быть преобразцованы в одну и ту же область в физическом пространстве, используя таблицу страниц, и та область, на которую они указывают, является совместно используемой памятью. На фиг. 3 показаны два процесса, ProcA и ProcB. Когда виртуальные адреса через таблицы страниц этих двух процессов преобразуются в физический адрес, существует общая область памяти физического адреса, то есть, совместно используемая память, которая может видна двум процессам одновременно. Таким образом, когда один процесс записывает, а другой процесс считывает, между двумя процессами может быть реализована межпроцессовая связь. Для совместно используемой памяти ее реализация использует принцип подсчета ссылок. Когда процесс отсоединяет область совместно используемой памяти, счетчик уменьшается на единицу. Когда процесс успешно присоединяется к области совместно используемой памяти, счетчик увеличивается на единицу. Область совместно используемой памяти может быть удалена, только если счетчик становится равным нулю. Когда процесс завершается, область совместно используемой памяти, присоединенная к нему, автоматически отсоединятся от него.
В вариантах осуществления совместно используемая генная память создается при генном анализе для библиотечных файлов и в ней могут храниться базы данных, обычно используемые при обработке путем генного анализа. Когда при анализе данных образцов необходима база данных, она может быть получена напрямую из совместно используемой генной памяти, что значительно снижает время загрузки базы данных из библиотеки загрузки с диска. Кроме того, когда многочисленные группы данных образцов анализируются одновременно, база данных может быть использоваться совместно для множества групп данных образцов, что снижает количество повторяющихся загрузок и занятость ввода-вывода.
В необязательном варианте осуществления, как показано в фиг. 4, обеспечивается также способ построения совместно используемой памяти, содержащий этапы S402-S404.
На этапе S402 устанавливают совместно используемую генную память для библиотечных файлов, используемых при генном анализе, а также устанавливают размер совместно используемой генной памяти, количество библиотечных файлов, которое может быть размещено, имя каждого библиотечного файла и смещение размера каждого библиотечного файла.
На этапе S404 библиотечные файлы, обычно используемые при генном анализе, загружаются в совместно используемую генную память в соответствии с размером совместно используемой генной памяти, количеством библиотечных файлов, которое может быть размещено, именем каждого библиотечного файла и смещением размера каждого библиотечного файла.
Как показано на фиг. 5, в оконечной системе (то есть, аппаратном устройстве, используемом для генного анализа данных образцов ) выбирается определенная область в качестве совместно используемых при генном анализе библиотечных файлов. Соответствующий размер совместно используемой генной памяти определяется согласно пространству для хранения, возможности обработки данных и другим характеристикам оконечной системы. Содержание, записанное или хранящееся в области совместно используемой генной памяти, главным образом, содержит: построение заголовка таблицы совместно используемой генной памяти в физической памяти узла: 1) сначала, сохраняют количество (n) определенных совместно используемых библиотек и полную длину (Len) совместно используемой области; 2) сохраняют имя (например, Lib1, Lib2) и смещение длины (offset1, offset2) каждого указанного библиотечного файла в совместно используемой генной памяти; 3) поочередно сохраняют данные каждого указанного библиотечного файла в выбранной области.
Ее рабочий принцип заключается в следующем: данные образцов могут содержать многочисленные группы данных; каждая группа данных имеет соответствующий процесс обработки образца. Среди процессов P1-PN обработки образца каждый процесс имеет свой собственный блок управления процессом (process control block, PCB) и адресное пространство (Addr Space) и имеет соответствующую таблицу страниц, которая используется для преобразцования виртуальных адресов процесса в физические адреса и управляется через блок управления памятью (memory management unit, MMU). Два различных виртуальных адреса могут преобразцовываться в одну и ту же область в физическом пространстве, используя таблицу страниц, и эта область, на которую они указывают, является совместно используемой памятью. С помощью вышеупомянутого способа каждый процесс обработки образца может вводить область совместно используемой памяти, чтобы получить требуемый библиотечный файл в области совместно используемой памяти.
На этапе S206, если да, то получают требуемый библиотечный файл из совместно используемой генной памяти, требуемый библиотечный файл преобразуется в процесс генного анализа предварительно обработанных данных образцов и генный анализ завершается.
В способе генного анализа, основанном на совместно используемой генной памяти, обеспечиваемой в вариантах осуществления раскрытия, сначала считывают данные образцов и затем данные образцов предварительно обрабатывают и далее на предварительно обработанных данных образцов выполняют генный анализ. При генном анализе необходимо определить, находится ли требуемый при генном анализе библиотечный файл в совместно используемой генной памяти библиотечных файлов; если да, получают требуемый библиотечный файл из совместно используемой генной памяти и преобразуют в процессе генного анализа, соответствующего данным образцов, чтобы завершить соответствующий анализ. В способе генного анализа, основанном на совместно используемой генной памяти, используется механизм совместно используемой генной памяти, чтобы установить индексы для генного анализа (например, содержащего анализ выравнивания, вариационный анализ, аннотационный анализ и так далее) и затем сохранить требуемые при генном анализе файлы в базе данных (то есть, библиотечные файлы) совместно используемой генной памяти. Библиотечный файл может быть легко преобразцован из совместно используемой генной памяти в процесс генного анализа, выполняемого на данных образцов. С одной стороны, время и занятость ввода-вывода для загрузки библиотечного файла с жесткого диска значительно снижаются. С другой стороны, связи среди многочисленными процессами в процессе генного анализа упрощаются, и повторной загрузки библиотечного файла можно избежать.
В некоторых вариантах осуществления способ дополнительно содержит этапы, на которых: определяют, удовлетворяет ли требуемый библиотечный файл условию загрузки в случае, когда требуемый при генном анализе библиотечный файл не находится в совместно используемой генной памяти; и загружают требуемый библиотечный файл в совместно используемую генную память в случае, когда условие загрузки удовлетворяется.
Конкретно, если требуемый при генном анализе библиотечный файл не находится в совместно используемой генной памяти, определяют, удовлетворяет ли требуемый библиотечный файл условию загрузки. Если условие загрузки удовлетворяется, требуемый библиотечный файл может быть загружен в совместно используемую генную память. С одной стороны, можно более быстро и более эффективно загружать требуемый библиотечный файл в совместно используемую генную память и затем получать требуемый библиотечный файл из совместно используемой генной памяти; с другой стороны, это может также облегчить другие процессы работы с данными образцов, чтобы использовать требуемый библиотечный файл, избегая повторной загрузки.
В некоторых вариантах осуществления, определение, удовлетворяет ли требуемый библиотечный файл условию загрузки в случае, когда требуемый при генном анализе библиотечный файл не находится в совместно используемой генной памяти и загружать ли требуемый библиотечный файл в совместно используемую генную память в случае, когда условие загрузки удовлетворяется, содержит:
получение информации о требуемом библиотечном файле и информации о совместно используемой генной памяти, в которой информация о требуемом библиотечном файле содержит пространство, запрашиваемое требуемым библиотечным файлом, и количество архивных запросов загрузки требуемого библиотиечного файла, и информация о совместно используемой генной памяти содержит остающееся пространство совместно используемой генной памяти; и если количество архивных запросов загрузки требуемого библиотечного файла больше, чем первое заданное количество, и пространство, запрашиваемое требуемым библиотечным файлом меньше, чем остающееся пространство совместно используемой генной памяти, загружают требуемый библиотечный файл в совместно используемую генную память.
Информация о требуемомо библиотечномо файле относится к информации, связанной с требуемым библиотечным файлом, которая может содержать тип требуемого библиотечного файла, размер требуемого библиотечного файла, пространство, запрашиваемое требуемым библиотечным файлом, количество архивных запросов загрузки и частоту запроса загрузки требуемого библиотечного файла и т.д. Информация о совместно используемой генной памяти относится к информации, связанной с совместно используемой генной памятью, главным образом, содержащей размер совместно используемой генной памяти, остающееся пространство совместно используемой генной памяти и т.д.
Первое заданное количество является заданным значением, которое может использоваться, чтобы в некоторой степени отразить важность библиотечного файла. Таким образом, если количество архивных запросов загрузки больше, чем первое заранее установленное количество, это указывает, что требуемый библиотечный файл необходим или часто используется, то есть, требуемый библиотечный файл важен при генном анализе и может загружаться в совместно используемую генную память, чтобы облегчить его использование для других данных образцов. После определения важности требуемого библиотечного файла дополнительно необходимо определить, достаточно ли остающееся пространство совместно используемой генной памяти, чтобы сохранить требуемый библиотечный файл, то есть, определить, является ли пространство, запрашиваемое требуемым библиотечным файлом, меньшим, чем остающееся пространство совместно используемой генной памяти. Если это так, то требуемый библиотечный файл может быть напрямую загружен в совместно используемую генную память.
В некоторых вариантах осуществления когда информация о требуемом библиотечном файле дополнительно содержит частоту запросов загрузки требуемого библиотечного файла, информация о совместно используемой генной памяти содержит частоты запроса загрузки всех библиотечных файлов в совместно используемой генной памяти; определение, удовлетворяет ли требуемый библиотечный файл условию загрузки, и загружать ли требуемый библиотечный файл в совместно используемую генную память в случае, когда условие загрузки удовлетворяется, дополнительно содержит: если количество архивных запросов загрузки требуемого библиотечного файла больше, чем первое заданное количество, и пространство, запрашиваемое требуемым библиотечным файлом, больше, чем остающееся пространство совместно используемой генной памяти, ранжируют требуемый библиотечный файл и все библиотечные файлы в порядке приоритета в соответствии с частотой запроса загрузки требуемого библиотечного файла и частотами запроса загрузки всех библиотечных файлов, чтобы получить приоритет частоты запроса загрузки каждого библиотечного файла; если приоритет частоты запроса загрузки требуемого библиотечного файла выше, чем приоритет библиотечного файла в совместно используемой генной памяти, и если остающееся пространство совместно используемой генной памяти после удаления библиотечного файла с более низким приоритетом частоты запроса загрузки в совместно используемой генной памяти больше или равно пространству, запрашиваемому требуемым библиотечным файлом, удаляют библиотечный файл с более низким приоритетом частоты запроса загрузки в совместно используемой генной памяти; и загружают требуемый библиотечный файл в совместно используемую генную память.
Конкретно, если определено, что пространство, запрошиваемое для требуемого библиотечного файла, больше, чем остающееся пространство совместно используемой генной памяти, это указывает, что остающегося пространства совместно используемой генной памяти недостаточно, чтобы хранить требуемый библиотечный файл; в этом случае, необходимо сравнить требуемый библиотечный файл с библиотечным файлом, уже хранящимся в совместно используемой генной памяти, удалить библиотечный файл с низкой частотой запроса загрузки, соответствующий приоритетам частот запроса загрузки библиотечных файлов, и затем загрузить требуемый библиотечный файл в совместно используемую генную память.
В вариантах осуществления требуемый библиотечный файл и библиотечные файлы, хранящиеся в совместно используемой генной памяти, ранжируются в порядке приоритета, главным образом, в соответствии с частотой запроса загрузки каждого библиотечного файла. Если приоритет частоты запроса загрузки требуемого библиотечного файла выше, чем приоритет библиотечного файла в совместно используемой генной памяти, библиотечный файл в совместно используемой генной памяти удаляется, чтобы загрузить требуемый библиотечный файл в совместно используемую генную память. В вышеупомянутом процессе всесторонне рассматриваются размеры всех библиотечных файлов. Необходимо только гарантировать, что память, занятая удаленным библиотечным файлом, достаточна, чтобы хранить требуемый библиотечный файл.
Таким образом, когда требуемый библиотечный файл в процессе генного анализа не находится в совместно используемой генной памяти, библиотечный файл может быть сначала загружен в совместно используемую генную память, чтобы повысить эффективность последующего вычисления.
В некоторых вариантах осуществления генный анализ содержит анализ выравнивания, вариационный анализ и аннотационный анализ; способ дополнительно содержит этапы, на которых: выполняют анализ выравнивания, вариационный анализ и аннотационный анализ данных образцов, предварительно обработанных в последовательности, в котором в случае, когда предварительно обработанные данные образцов содержат многочисленные группы данных образцов, многочисленные группы данных образцов одновременно находятся на одном и том же этапе или на разных этапах генного анализа.
В вариантах осуществления способ генного анализа содержит анализ выравнивания, вариационный анализ и аннотационный анализ. Однако, в процессе генного анализа обычно существует требование последовательности, то есть, сначала обычно выполняется анализ выравнивания, сопровождаемый вариационным анализом и затем аннотационным анализом. Однако, когда существует множество групп данных образцов, каждая группа данных образцов может находиться на одном и том же этапе или на различных этапах генного анализа. Например, данные образцов 1 могут находиться на этапе анализа выравнивания, данные образцов 2 могут находиться на этапе вариационного анализа и данные образцов 3 могут находиться на этапе аннотационного анализа. Для данных образцов 1, данных образцов 2 и данных образцов 3 также возможно одновременно находиться на этапе анализа выравнивания, вариационного анализа или аннотационного анализа. Многочисленные группы данных образцов могут обрабатываться одновременно, используя способ, который может дополнительно повышать скорость обработки данных.
В некоторых вариантах осуществления генный анализ дополнительно содержит сортировочный анализ и анализ маркировки-дублирования, в котором после выполнения анализа выравнивания, вариационного анализа и аннотационного анализа данных образцов, предварительно обработанных в последовательности, способ дополнительно содержит этапы, на которых: маркируют данные образцов после анализа выравнивания с помощью позиционных тегов; и выполняют посредством модуля сортировочный анализ и анализ маркировки-дублирования на маркированных данных образцов.
Конкретно, генный анализ дополнительно содержит анализ секвенирования и анализ маркировки-дублирования; маркировка данных образцов после анализа выравнивания с помощью позиционных тегов состоит в том, чтобы добавить тег, связанный с позицией, к файлу после сравнения, так чтобы анализ секвенирования и анализ маркировки-дублирования могли быть выполнены посредством модуля, и в анализе секвенирования и в анализе маркировки-дублирования может быть получена более эффективная многопоточная сортировка.
В некоторых вариантах осуществления способ дополнительно содержит соединение некоторых или всех этапов генного анализа путем использования памяти.
Конкретно, несколько этапов или все этапы в процессах сравнения, сортировки, маркировки-дублирования и определения вариантов в процессе генного анализа могут быть соединены с помощью памяти. Файлы sam/bam, выводимые промежуточно, могут быть уменьшены, присоединяя каждый этап при помощи памяти, что снижает занятость ввода-вывода.
Для простоты понимания ниже приводится подробный вариант осуществления. На фиг. 6 показан весь процесс генного анализа и процесс в совместно используемой генной области памяти. Процесс генного анализа проходит следующим образом: после введения образцов, данные каждого из образцов предварительно обрабатываются и затем определяется, загружается ли в совместно используемую область памяти библиотечный файл, требующийся для анализа выравнивания; если да, запускается анализ выравнивания или, в противном случае, библиотечный файл загружается с жесткого диска, чтобы выполнить анализ выравнивания; процесс анализа выравнивания синтезируется как гибкий этап путем соединения памяти и оптимизацией алгоритма; затем выполняется определение вариантов и определяется, был ли загружен в совместно используемую генную память библиотечный файл аннотационной информации; если да, то запускается статистика аннотации, или, в противном случае, библиотечный файл загружается с жесткого диска для статистики аннотации; аналитический процесс заканчивается.
Процесс в совместно используемой области генной памяти является следующим: если существует запрос на информацию библиотеки lib-x (то есть, требуемый библиотечный файл), определяют, находится ли требуемый библиотечный файл в совместно используемой области генной памяти; если да, то библиотечные данные являются обратной связью и процесс заканчивается; если требуемый библиотечный файл не находится в совместно используемой области генной памяти, определяют, загружать ли требуемый библиотечный файл способом Q загрузки; если да, требуемый библиотечный файл загружается в совместно используемую область генной памяти, библиотечные данные выводятся и процесс заканчивается; если требуемый библиотечный файл не должен загружаться способом Q загрузки, никакая информация не выводится и процесс заканчивается.
Конкретные этапы способа Q загрузки являются следующими: 1) определяют тип и размер требуемого библиотечного файла; 2) получают файл записи; 3) из файла записи считывают общий размер памяти узла, размер совместно используемой области памяти, количество архивных запросов загрузки каждого типа библиотеки (f_type) и общее количество архивных запросов загрузки всех типов библиотек (f_total); 4) размер памяти узла обновляется с жесткого диска, чтобы препятствовать изменению размера памяти узла; 5) для типа требуемого библиотечного файла количество архивных запросов загрузки этого типа библиотеки увеличивается на 1 (f_type+1); 6) общее количество архивных запросов загрузки всех типов библиотек увеличивается на 1 (f_total+1); 7) определяют, достаточно ли остающегося пространства, чтобы загрузить библиотеку; 8) частоты запроса (f_type/f_total) всех типов библиотек в файле записи ранжируются в порядке убывания и выводят ранжированный связанный список; 9) определяют, был ли загружен требуемый библиотечный файл; если требуемый библиотечный файл был загружен, выводят индекс библиотеки; если требуемый библиотечный файл не был загружен и количество архивных запросов загрузки этого типа библиотеки больше 10, определяют приоритет и позицию по порядку этого типа библиотеки во всех выгруженных библиотеках; 10) если приоритет этого типа библиотеки превышает приоритет загруженной библиотеки, система предсказывает, удовлетворяет ли сумма размеров загруженных библиотек, упорядоченных после этого типа библиотеки в type_list, условию W размера памяти для загрузки этого типа библиотеки; если да, эти загруженные библиотеки выгружаются в обратном порядке до тех пор, пока не будет удовлетворено условие W; в противном случае никакой процесс не выполняется; 11) если условие загрузки удовлетворяется, запись размера области совместно используемой памяти обновляется; 12) в противном случае, когда библиотека не была загружена, потому что нет достаточной памяти для загрузки, библиотека маркируется и ее обновляют в файле записи.
Формат файла записи приводится ниже:
М: 63492649171200
Len: 13492649171200
f_total: 100
type_flag указывает причину отсутствия загрузки, где 1 указывает, что приоритет загрузки этого типа библиотеки был признан первым, и она не была загружена по причине недостаточной памяти, а type_flag загруженной библиотеки равен 0.
Кроме того, псевдокод способа Q загрузки следующий.
RequestShareMem (тип, размер) //type: тип библиотеки для совместного использования, size: размер библиотеки для совместного использования
File = RecordFile //файл записи
ReadFromFile (М., Len, f_type, f_total) //считывание из файла записи (М: общий размер памяти узла; Len : текущий размер совместно используемой области памяти; f_type: количество архивных запросов загрузки этого типа библиотеки; f_total: общее количество архивных запросов загрузки всех типов библиотек;
Update (M) //обновление размера памяти узла с жесткого диска, чтобы предотвратить изменение размера памяти узла;
f_type = f_type + 1 //обновление f_type
f_total = f_total + 1 //обновление f_total
W = M*0,5 - Len - size> 0 //условие W: определить, существует ли остаточное пространство для загрузки, 0,5 - регулируемый коэффициент, в настоящий момент используется 50 % общей памяти
type_list = SortAllTypeInFile () //ранжируют частоты запросов (f_type/f_total) всех типов библиотек в файле записи в порядке убывания, и выводят ранжированный связанный список;
if AlreadyLoaded(type) then
id = GetShareMemId(type) // если требуемый библиотечный файл был загружен, выводят индекс библиотеки
else if f_type > 10 //количество архивных запросов загрузки этого типа библиотеки больше 10
if IsPrior (type_list, type) //определяют, является ли это первым приоритетом: первый по порядку перед всеми другими выгруженными библиотеками, type_flag которых равен 0
if type_flag = 1
UnloadShareMem (type_list, type),//, если сумма размеров загруженных библиотек, упорядоченных после этого типа библиотеки в type_list, удовлетворяет условию W, выгружают эти загруженные библиотеки в обратном порядке, пока не будет удовлетворено условие W; в противном случае, никакой процесс не выполняется
if W
id = LoadShareMem ( type, size)
Len = Len + size //обновляют размер совместно используемой области памяти
type_flag = 0
else
type_flag = 1 //отметка, что нет достаточного объема памяти, обновить запись
id = 0
else
id = 0 //не выводят информацию
UpdateFile (М., Len, f_type, f_total, type_flag) //обновляют файл записи
return id //выводят индекс области совместно используемой памяти, “0” не представляет информации
end
Некоторые варианты осуществления, чтобы показать результаты:
Чтобы проверить эффективность способа генного анализа, основанного на совместно используемой памяти, в вариантах осуществления раскрытия, три способа генного анализа, а именно, способ А (программное обеспечение без оптимизации (то есть, все этапы генного анализа не соединяются, используя память, и этапы независимы друг от друга) + без использования совместно используемой генной памяти), способ B (программное обеспечение с оптимизацией (то есть, все этапы генного анализа соединяются, используя память) + без использования совместно используемой генной памяти) и способ C (программное обеспечение с оптимизацией (то есть, все этапы генного анализа соединяются, используя память), + с использованием совместно используемой генной памяти), приводятся, чтобы сравнить использование CPU и время занятости ввода-вывода для разных способов. Результаты показаны на фиг. 7-9, где на фиг. 7 показан результат анализа способа A, на фиг. 8 показан результат анализа способа B и на фиг. 9 показан результат анализа способа C.
На фиг. 7 можно видеть, что время работы части анализа по способу А перед ускорением (то есть, каждый этап считывания данных образцов и этап предварительной обработки перед анализом выравнивания работает независимо и сравнение обрабатывается напрямую без использования совместно используемой генной памяти) равно 2,83 часа и использование CPU значительно варьируется. Время выполнения участка сравнения и участка аннотации перед ускорением (то есть, сравнение и аннотация обрабатываются напрямую без использования совместно используемой генной памяти) составляет 2,61 часа, использование CPU высокое, и использование ввода-вывода в расчете на секунду (то есть, количество передач, выводимых на физический диск в секунду) высокое, что указывает на высокое использование ввода-вывода, и вероятность блокирования высокая.
Как можно видеть на фиг. 8, рабочее время участка анализа по способу B после ускорения (то есть, этап считывания данных образцов и этап предварительной обработки перед анализом выравнивания соединяются, используя память, и сравнение выполняется, используя совместно используемую генную память) составляет 1,75 часа и использование CPU варьируется меньше, чем при способе А. Рабочее время участка сравнения библиотек перед использованием совместно используемой генной памяти (то есть, сравнение выполняется напрямую без использования совместно используемой генной памяти) составляет 2,38 часа, использование CPU высокое и использование ввода-вывода в расчете на секунду (то есть, количество передач, выводимых на физический диск в секунду) высокое, что указывает, что использование ввода-вывода высокое и вероятность блокирования высокая.
Как можно видеть на фиг. 9, рабочее время участка анализа по способу C после ускорения (то есть, этап считывания данных образцов и этап предварительной обработки перед анализом выравнивания соединяются при помощи памяти и сравнение выполняется, используя совместно используемую генную память) составляет 1,75 часа и использование CPU варьируется меньше, чем при способе А (этот участок является таким же, как при способе B). Время выполнения участка сравнения библиотек после использования совместно используемой генной памяти (то есть, сравнение выполняется с использованием совместно используемой генной памяти) составляет 0,82 часа, использование CPU высокое и использование ввода-вывода в расчете на секунду (то есть, количество передач, выводимых на физический диск в секунду) низкое, что указывает, что использование ввода-вывода низкое и вероятность блокирования низкая.
Поэтому для генного анализа используется способ C, то есть, этапы генного анализа соединяются с помощью памяти. Способ адаптации совместно используемой генной памяти при сравнении, аннотации и других процессах может значительно снизить время, используемое для генного анализа, и уменьшить показатель использования ввода-вывода, то есть, сократить блокирование ввода-вывода.
Следует понимать, хотя этапы на блок-схемах последовательности выполнения этапов на фиг. 2, 4 и 6 показаны в порядке, обозначенном стрелками, эти этапы не обязательно выполняются в порядке, обозначенном стрелками. Если здесь явно не заявлено, исполнение этих этапов не ограничивается строгим порядком и эти этапы могут исполняться в других порядках. Кроме того, по меньшей мере некоторые этапы на фиг. 2, 4 и 6 могут содержать многочисленные подэтапы или многочисленные этапы. Эти подэтапы или этапы не обязательно исполняются одновременно, но альтернативно могут выполняться совместн с другими этапами или, по меньшей мере, с некоторыми подэтапами или стадиями других этапов.
В некоторых вариантах осуществления, как показано на фиг. 10, обеспечивается устройство генного анализа, основанное на совместно используемой памяти, содержащее: модуль 102 считывания данных, модуль 104 предварительной обработки данных и модуль 106 генного анализа.
Модуль 102 считывания данных, выполненный с возможностью считывания данных образцов.
Модуль 104 предварительной обработки данных, выполненный с возможностью предварительной обработки данных образцов.
Модуль 106 генного анализа, выполненный с возможностью осуществления генного анализа предварительно обработанных данных образцов и определения, находится ли требуемый при генном анализе библиотечный файл в совместно используемой генной памяти; если да, то получают требуемый библиотечный файл из совместно используемой генной памяти, преобразуют требуемый библиотечный файл в процессе генного анализа предварительно обработанных данных выработок и завершают генный анализ.
В некоторых вариантах осуществления устройство генного анализа на основе совместно используемой памяти содержит: модуль загрузки библиотечного файла, выполненный с возможностью определения, удовлетворяет ли требуемый библиотечный файл условию загрузки в случае, когда требуемый при генном анализе библиотечный файл не находится в совместно используемой генной памяти; и загружают требуемый библиотечный файл в совместно используемую генную память, в случае, когда условие загрузки удовлетворяется.
В некоторых вариантах осуществления модуль загрузки библиотечного файла содержит модуль получения информации о библиотеке и информации о памяти.
Модуль получения информации о библиотеке и информации о памяти, выполненный с возможностью получения информации о требуемом библиотечном файле и информации о совместно используемой генной памяти, где информация о требуемом библиотечном файле содержит пространство, запрашиваемое заданным файлом библиотеки, и количество архивных запросов загрузки требуемого библиотечного файла и информация о совместно используемой генной памяти содержит остающееся пространство совместно используемой генной памяти.
Модуль загрузки библиотечного файла, выполненный с возможностью загрузки требуемого библиотечного файла в совместно используемую генную память, если количество архивных запросов загрузки требуемого библиотечного файла больше первого требуемого количества и пространство, запрашиваемое требуемым библиотечным файлом, меньше, чем остающееся пространство совместно используемой генной памяти.
В некоторых вариантах осуществления информация требуемого библиотечного файла дополнительно содержит частоту запроса загрузки требуемого библиотечного файла, информация о совместно используемой генной памяти дополнительно содержит частоты запроса загрузки всех библиотечных файлов в совместно используемой генной памяти; и модуль загрузки библиотечного файла дополнительно содержит модуль ранжирования приоритетов и модуль удаления библиотечного файла.
Модуль сортировки по приоритетам, выполненный с возможностью ранжирования требуемого библиотечного файла и всех библиотечных файлов в порядке приоритета в соответствии с частотой запроса загрузки требуемого библиотечного файла и частотами запроса загрузки всех библиотечных файлов, чтобы получить приоритет частоты запроса загрузки каждого библиотечного файла, если количество архивных запросов загрузки требуемого библиотечного файла больше первого заданного количества и пространство, запрашиваемое заданным библиотечным файлом, больше остающегося пространства совместно используемой генной памяти.
Модуль удаления библиотечного файла, выполненный с возможностью удаления библиотечного файла с более низким приоритетом частоты запроса загрузки в совместно используемой генной памяти, если приоритет частоты запроса загрузки требуемого библиотечного файла выше, чем приоритет библиотечного файла в совместно используемой генной памяти, и если остающееся пространство совместно используемой генной памяти после удаления библиотечного файла с более низким приоритетом частоты запроса загрузки в совместно используемой генной памяти больше или равно пространству, запрашиваемому заданным библиотечным файлом.
Модуль загрузки библиотечного файла, дополнительно выполненный с возможностью загрузкой требуемого библиотечного файла в совместно используемую генную память.
В некоторых вариантах осуществления устройство дополнительно содержит: модуль установки совместно используемой генной памяти, выполненный с возможностью установки совместно используемой генной памяти для библиотечных файлов, используемых при генном анализе, установки размера совместно используемой генной памяти, количества библиотечных файлов, которые могут быть размещены, имя каждого библиотечного файла и смещение размера каждого библиотечного файла.
Модуль загрузки библиотечного файла дополнительно выполненный с возможностью загрузки библиотечных файлов, обычно используемых при генном анализе, в совместно используемую генную память, соответствующую размеру совместно используемой генной памяти, количества библиотечных файлов, которые могут быть размещены, имени каждого библиотечного файла и смещения размера каждого библиотечного файла.
В некоторых вариантах осуществления генный анализ содержит анализ выравнивания, вариационный анализ и аннотационный анализ.
Модуль 106 генного анализа выполнен с возможностью осуществления анализа выравнивания, вариационного анализа и аннотационного анализа данных образцов, предварительно обработанных в последовательности, где в случае, когда предварительно обработанные данные образцов содержат многочисленные группы данных образцов, многочисленные группы данных образцов одновременно находятся на одном и том же этапе или на разных этапах генного анализа.
В некоторых вариантах осуществления генный анализ дополнительно содержит сортировочный анализ и анализ маркировки-дублирования и устройство дополнительно содержит: модуль сортировки и маркировки-дублирования, выполненный с возможностью маркировки данных образцов после анализа выравнивания с помощью позиционного тега; и выполнения сортировочного анализа и анализа маркировки-дублирования модулем на маркированных данных образцов.
В некоторых вариантах осуществления устройство дополнительно содержит модуль соединения с памятью, выполненный с возможностью соединения нескольких или всех этапов генного анализа, используя память.
В некоторых вариантах осуществления модуль 104 предварительной обработки данных дополнительно является модулем контроля качества, операции фильтрации и статистической обработки данных образцов и выполняет контроль качества, операцию фильтрации и статистическую обработку данных образцов.
Для конкретного определения устройства генного анализа на основе совместно используемой памяти, обращайтесь к определению способа генного анализа, основанного на совместно используемой памяти, описанном выше, которое не будет здесь повторяться. Все или некоторые из модулей устройства генного анализа на основе совместно используемой памяти могут быть реализованы программным обеспечением, аппаратными средствами или их сочетанием. Вышеупомянутые модули могут быть встроены или быть независимыми от процессора компьютерного устройства в форме аппаратных средств или сохраняются в памяти в компьютерном устройстве в форме программного обеспечения, чтобы облегчить процессору вызов и выполнение соответствующих операций вышеупомянутых модулей.
В некоторых вариантах осуществления обеспечивается компьютерное устройство, который может быть сервером, и его внутренняя структура может быть такой, как показано на фиг. 11. Компьютерное устройство содержит процессор, память, сетевой интерфейс и базу данных, соединенные через системную шину. Процессор компьютерного устройства используется дл обеспечения возможностей вычислений и управления. Память компьютерного устройства содержит энергонезависимый носитель запоминающего устройства и устройство памяти. Энергонезависимый носитель запоминающего устройства хранит операционную систему, компьютерную программу, и базу данных. Устройство памяти обеспечивает среду для работы операционной системы и компьютерной программы в энергонезависимом носителе запоминающего устройства. База данных компьютерного устройства используется для хранения данных резистентной эквивалентной модели и эквивалентных субмоделей, так же как эквивалентной резистентности, рабочей резистентности и контактной резистентности, полученных во время вычисления. Сетевой интерфейс компьютерного устройства используется для связи с внешними терминалами через сетевое соединение. Компьютерная программа исполняется процессором, чтобы реализовать способ генного анализа, основанный на совместно используемой памяти.
Специалисты в данной области техники могут понимать, что структура, показанная на фиг. 11, является блок-схемой только некоторых структур, связанных со схемой этой заявки, и не составляет ограничение для компьютерного устройства, к которому применяется схема этой заявки. Конкретное компьютерное устройство может содержать больше или меньше компонентов, чем показано на чертеже, или объединять несколько компонентов или иметь другие компоновки элементов.
В некоторых вариантах осуществления обеспечивается компьютерное устройство, содержащее процессор, память и компьютерную программу, хранящуюся в памяти и исполняемую процессором, который, когда исполняет компьютерную программу, реализует следующие этапы, на которых: считывают данные образцов и предварительно обрабатывают данные образцов; выполняют генный анализ предварительно обработанных данных образцов, и определяют, находится ли требуемый при генном анализе библиотечный файл в совместно используемой генной памяти; если да, получают требуемый библиотечный файл из совместно используемой генной памяти, преобразуют требуемый библиотечный файл в процессе генного анализа предварительно обработанных данных образцов и завершают генный анализ.
В некоторых вариантах осуществления процессор, когда исполняет компьютерную программу, дополнительно реализует следующие этапы, на которых: определяют, удовлетворяет ли требуемый библиотечный файл условию загрузки, в случае, когда требуемый при генном анализе библиотечный файл не находится в совместно используемой генной памяти; и загружают требуемый библиотечный файл в совместно используемую генную память в случае, когда условие загрузки удовлетворяется.
В некоторых вариантах осуществления определение, удовлетворяет ли требуемый библиотечный файл условию загрузки в случае, когда требуемый при генном анализе библиотечный файл не находится в совместно используемой генной памяти, и загружать ли требуемый библиотечный файл в совместно используемую генную память, в случае, когда удовлетворяется условие загрузки, содержит этап, на котором: получают информацию о требуемом библиотечном файле и информацию о совместно используемой генной памяти, где информация о требуемом библиотечном файле содержит пространство, запрашиваемое требуемым библиотечным файлом, и количество архивных запросов загрузки требуемого библиотечного файла, и информация о совместно используемой генной памяти содержит остающееся пространство совместно используемой генной памяти; и если количество архивных запросов загрузки требуемого библиотечного файла больше первого заданного количества и пространство, запрашиваемое требуемым библиотечным файлом, меньше остающегося пространства совместно используемой генной памяти, загружают требуемый библиотечный файл в совместно используемую генную память.
В некоторых вариантах осуществления информация о требуемом библиотечном файле дополнительно содержит частоту запроса загрузки требуемого библиотечного файла, информация о совместно используемой памяти содержит частоты запроса загрузки всех библиотечных файлов в совместно используемой генной памяти; определение, удовлетворяет ли требуемый библиотечный файл условию загрузки и загружать ли требуемый библиотечный файл в совместно используемую генную память, в случае, когда удовлетворяется условие загрузки, дополнительно содержит этапы, на которых: если количество архивных запросов загрузки требуемого библиотечного файла больше первого заданного количества и пространство, запрашиваемое требуемым библиотечным файлом, больше остающегося пространства совместно используемой генной памяти, ранжируют требуемый библиотечный файл и все библиотечные файлы в порядке приоритета в соответствии с частотой запроса загрузки требуемого библиотечного файла и частотами запросов загрузки всех библиотечных файлов, чтобы получить приоритет частоты загрузки каждого библиотечного файла; если приоритет частоты запроса загрузки требуемого библиотечного файла выше, чем приоритет библиотечного файла в совместно используемой генной памяти, и если остающееся пространство совместно используемой генной памяти после удаления библиотечного файла с более низким приоритетом частоты запроса загрузки в совместно используемой генной памяти больше или равно пространству, запрашиваемому заданным библиотечным файлом, удаляют библиотечный файл с более низким приоритетом частоты запроса загрузки в совместно используемой генной памяти; и если количество архивных запросов загрузки требуемого библиотечного файла больше первого заданного количества, и пространство, запрашиваемое требуемым библиотечным файлом меньше, чем остающееся пространство совместно используемой генной памяти, загружают требуемый библиотечный файл в совместно используемую генную память.
В некоторых вариантах осуществления информация о требуемом библиотечном файле дополнительно содержит частоту запроса загрузки требуемого библиотечного файла, информация о совместно используемой генной памяти дополнительно содержит частоты запроса загрузки всех библиотечных файлов; определение, удовлетворяет ли требуемый библиотечный файл условию загрузки и загружать ли требуемый библиотечный файл в совместно используемую генную память, в случае, когда удовлетворяется условие загрузки, дополнительно содержит: если количество архивных запросов загрузки требуемого библиотечного файла больше первого заданного количества и пространство, запрашиваемое требуемым библиотечным файлом, больше остающегося пространства совместно используемой генной памяти, ранжируют требуемый библиотечный файл и все библиотечные файлы в порядке приоритета в соответствии с частотой запроса загрузки требуемого библиотечного файла и частотами запроса загрузки всех библиотечных файлов, чтобы получить приоритет частоты запроса загрузки каждого библиотечного файла; если приоритет частоты запроса загрузки требуемого библиотечного файла выше, чем приоритет библиотечного файла в совместно используемой генной памяти и если остающееся пространство совместно используемой генной памяти после удаления библиотечного файла с более низким приоритетом частоты запроса загрузки в совместно используемой генной памяти больше или равно пространству, запрашиваемому требуемым библиотечным файлом, удаляют библиотечный файл с более низким приоритетом частоты запроса загрузки в совместно используемой генной памяти; и загружают требуемый библиотечный файл в совместно используемую генную память.
В некоторых вариантах осуществления процессор, когда исполняет компьютерную программу, дополнительно реализует следующие этапы, на которых: устанавливают совместно используемую генную память для используемых при генном анализе библиотечных файлов, устанавливают размер совместно используемой генной памяти, количество библиотечных файлов, которые могут быть размещены, имя каждого библиотечного файла и смещение размера каждого библиотечного файла; и загружают библиотечные файлы, обычно используемые при генном анализе, в совместно используемую генную память в соответствии с размером совместно используемой генной памяти, количеством библиотечных файлов, которые могут быть размещены, именем каждого библиотечного файла и смещением размера каждого библиотечного файла.
В некоторых вариантах осуществления генный анализ содержит анализ выравнивания, вариационный анализ и аннотационный анализ, и процессор, когда исполняет компьютерную программу, дополнительно реализует следующий этап, на котором выполняют анализ выравнивания, вариационный анализ и аннотационный анализ предварительно обработанных данных образцов в последовательности, где в случае, когда предварительно обработанные данные образцов содержат многочисленные группы данных образцов, многочисленные группы данных образцов одновременно находятся на одном и том же этапе или на различных этапах генного анализа.
В некоторых вариантах осуществления генный анализ дополнительно содержит сортировочный анализ и анализ маркировки-дублирования, где после выполнения анализа выравнивания, вариационного анализа и аннотационного анализа данных образцов, предварительно обработанных в последовательности, процессор, когда исполняет компьютерную программу, дополнительно реализует следующие этапы, на которых: маркируют данные образцов после анализа выравнивания с помощью позиционного тега; и выполняют посредством модуля на данных образцов сортировочный анализа и анализ маркировки-дублирования.
В некоторых вариантах осуществления процессор, когда исполняет компьютерную программу, дополнительно реализует следующий этап, на котором соединяют некоторые или все этапы генного анализа путем использования памяти.
В некоторых вариантах осуществления предварительная обработка данных образцов содержит выполнение контроля качества, операцию фильтрации и статистическую обработку данных образцов.
Некоторые варианты осуществления обеспечивают считываемый компьютером носитель запоминающего устройства, на котором хранится компьютерная программа, которая, когда исполняется процессором, реализует следующие этапы, на которых: считывают данные образцов и предварительно обрабатывают данные образцов; выполняют генный анализ предварительно обработанных данных образцов, и определяют, находится ли требуемый при генном анализе библиотечный файл в совместно используемой генной памяти; если да, то получают требуемый библиотечный файл из совместно используемой генной памяти, преобразуют требуемый библиотечный файл в процессе генного анализа предварительно обработанных данных образцов, и завершают генный анализ.
В некоторых вариантах осуществления процессор, когда исполняет компьютерную программу, дополнительно реализует следующие этапы, на которых: определяют, удовлетворяет ли требуемый библиотечный файл условию загрузки в случае, когда требуемый при генном анализе библиотечный файл не находится в совместно используемой генной памяти; и загружают требуемый библиотечный файл в совместно используемую генную память в случае, когда удовлетворяется условие загрузки.
В некоторых вариантах осуществления определение, удовлетворяет ли требуемый библиотечный файл условию загрузки в случае, когда требуемый при генном анализе библиотечный файл не находится в совместно используемой генной памяти, и загружать ли требуемый библиотечный файл в совместно используемую генную память в случае, когда удовлетворяется условие загрузки, содержит: получение информации о требуемом библиотечном файле и информации о совместно используемой генной памяти, где информация о требуемом библиотечном файле содержит пространство, запрашиваемое заданным библиотечным файлом, и количество архивных запросов загрузки требуемого библиотечного файла, и информация о совместно используемой генной памяти содержит остающееся пространство совместно используемой генной памяти; и если количество архивных запросов загрузки требуемого библиотечного файла больше первого заданного количества и пространство, запрашиваемое заданным библиотечным файлом, меньше остающегося пространства совместно используемой генной памяти, загружают требуемый библиотечный файл в совместно используемую генную память.
В некоторых вариантах осуществления информация о требуемом библиотечном файле дополнительно содержит частоту запроса загрузки требуемого библиотечного файла, информация о совместно используемой генной памяти дополнительно содержит частоты запроса загрузки всех библиотечных файлов в совместно используемой генной памяти; определение, удовлетворяет ли требуемый библиотечный файл условию загрузки и загружать ли требуемый библиотечный файл в совместно используемую генную память, в случае, когда условие загрузки удовлетворяется, дополнительно содержит: если количество архивных запросов загрузки требуемого библиотечного файла больше первого заданного количества и пространство, запрашиваемое заданным файлом библиотеки, больше остающегося пространства совместно используемой генной памяти, ранжируют требуемый библиотечный файл и все библиотечные файлы в порядке приоритета в соответствии с частотой запроса загрузки требуемого библиотечного файла и частотами запроса загрузки всех библиотечных файлов, чтобы получить приоритет частоты запроса загрузки каждого библиотечного файла; если приоритет частоты запроса загрузки требуемого библиотечного файла больше приоритета библиотечного файла в совместно используемой генной памяти и если остающееся пространство совместно используемой генной памяти после удаления библиотечного файла с более низким приоритетом частоты запроса загрузки в совместно используемой генной памяти больше или равно пространству, запрашиваемому требуемым библиотечным файлом, удаляют библиотечный файл с более низким приоритетом частоты запроса загрузки в совместно используемой генной памяти; и если количество архивных запросов загрузки требуемого библиотечного файла больше первого заданного количества и пространство, запрашиваемое требуемым библиотечным файлом, меньше, чем остающееся пространство совместно используемой генной памяти, загружают требуемый библиотечный файл в совместно используемую генную память.
В некоторых вариантах осуществления информация о требуемом библиотечном файле дополнительно содержит частоту запроса загрузки требуемого библиотечного файла, информация о совместно используемой генной памяти дополнительно содержит частоты запроса загрузки всех библиотечных файлов в совместно используемой генной памяти; определение, удовлетворяет ли требуемый библиотечный файл условию загрузки и загружать ли требуемый библиотечный файл в совместно используемую генную память, в случае, когда условие загрузки соблюдается, дополнительно содержит: если количество архивных запросов загрузки требуемого библиотечного файла больше первого заданного количества и пространство, запрашиваемое требуемым библиотечным файлом, больше остающегося пространства совместно используемой генной памяти, ранжируют требуемый библиотечный файл и все библиотечные файлы в порядке приоритета в соответствии с частотой запроса загрузки требуемого библиотечного файла и частотами запроса загрузки всех библиотечных файлов, чтобы получить приоритет частоты запроса загрузки каждого библиотечного файла; если приоритет частоты запроса загрузки требуемого библиотечного файла выше, чем приоритет библиотечного файла в совместно используемой генной памяти, и если остающееся пространство совместно используемой генной памяти после удаления библиотечного файла с более низким приоритетом частоты запроса загрузки в совместно используемой генной памяти больше или равно пространству, запрашиваемому требуемым заданным библиотечным файлом, удаляют библиотечный файл с более низким приоритетом частоты запроса загрузки в совместно используемой генной памяти; и загружают требуемый библиотечный файл в совместно используемую генную память.
В некоторых вариантах осуществления компьютерная программа, когда исполняется процессором, дополнительно реализует следующие этапы, на которых: устанавливают совместно используемую генную память для используемых при генном анализе библиотечных файлов, устанавливают размер совместно используемой генной памяти, количество библиотечных файлов, которые могут быть размещены, имя каждого библиотечного файла и смещение размера каждого библиотечного файла; и загружают библиотечные файлы, обычно используемые при генном анализе, в совместно используемую генную память в соответствии с размером совместно используемой генной памяти, количеством библиотечных файлов, которые могут быть размещены, именем каждого библиотечного файла и смещением размера каждого библиотечного файла.
В некоторых вариантах осуществления генный анализ содержит анализ выравнивания, вариационный анализ и аннотационный анализ и компьютерная программа, когда исполняется процессором, дополнительно реализует следующий этап, на котором: выполняют анализ выравнивания, вариационный анализ и аннотационный анализ данных образцов, предварительно обработанных в последовательности, где в случае, когда предварительно обработанные данные образцов содержат многочисленные группы данных образцов, многочисленные группы данных образцов одновременно находятся на одном и том же этапе или различных этапах генного анализа.
В некоторых вариантах осуществления генный анализ дополнительно содержит сортировочный анализ и анализ маркировки-дублирования, где после выполнения анализа выравнивания, вариационного анализа и аннотационного анализа данных образцов, предварительно обработанных в последовательности, компьютерная программа, когда исполняется процессором, дополнительно реализует следующие этапы, на которых: маркируют данные образцов после анализа выравнивания с помощью позиционного тега; и выполняют посредством модуля сортировочный анализ и анализ маркировки-дублирования на маркированных данных образцов.
В некоторых вариантах осуществления компьютерная программа, когда исполняется процессором, дополнительно реализует следующий этап, на котором, используя память, соединяют некоторые или все этапы генного анализа.
В некоторых вариантах осуществления предварительная обработка данных образцов содержит выполнение контроля качества, операцию фильтрации и статистическую обработку данных образцов.
Как должно быть понятно специалистам в данной области техники, все или часть этапов выполнения способа в вышеупомянутых вариантах осуществления могут выполняться аппаратными средствами или программой, подающей команды, сязанные с аппаратными средствами, причем программа может храниться на считываемом компьютером энергонезависимом носителе запоминающего устройства; программа, которая, когда исполняется, может выполнять этапы вариантов осуществления вышеупомянутых способов. Любая ссылка на память, запоминающее устройство, базу данных или другие носители, используемые в вариантах осуществления, представляемых в настоящей заявке, может содержать энергонезависимую и/или энергозависимую память. Энергонезависимая память может содержать постоянную память (ROM), программируемую ROM (PROM), электрически программируемую ROM (EPROM), электрически стираемую программируемую ROM (EEPROM) или флэш-память. Энергозависимая память может содержать оперативную память (RAM) или внешнюю кэш-память. Как иллюстрация, но не ограничение, RAM доступна в различных формах, таких как статическая RAM (SRAM), динамическая RAM (DRAM), синхронная DRAM (SDRAM), SDRAM с удвоенной скоростью передачи данных (DDRSDRAM), улучшенная SDRAM (ESDRAM), синхронно связанная DRAM (SLDRAM), прямая Rambus RAM (RDRAM), динамическая RAM с прямым доступом шине к памяти (DRDRAM) и динамическая Rambus RAM (RDRAM) и т.д.
Технические признаки вышеупомянутых вариантов осуществления могут сочетаться произвольно. Чтобы сделать описание кратким, все возможные сочетания различных технических признаков в вариантах осуществления не описываются, но должны рассматриваться как присутствующие в рамках объема защиты настоящего описания, пока в этих сочетаниях технических признаков нет никакого противоречия.
Вышеупомянутые варианты осуществления просто представляют несколько вариантов осуществления настоящей заявки. Однако их относительно конкретные и подробные описания не могут поэтому истолковываться как ограничение объема защиты настоящей заявки. Следует указать, специалист в данной области техники способен создавать различные модификации и улучшения, не отступая от концепции настоящей заявки. Такие модификации и улучшения должны считаться попадающими в рамки объема защиты настоящей заявки. Поэтому объем защиты настоящей заявки должен определяться условиями формулы изобретения.
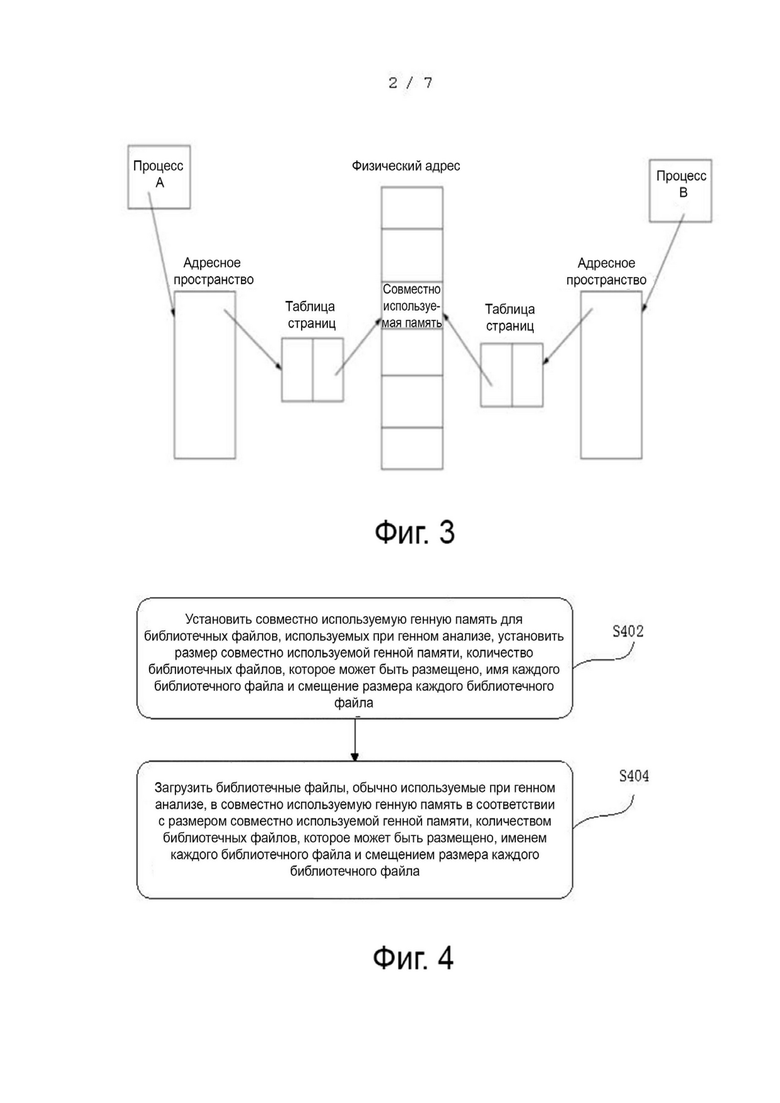
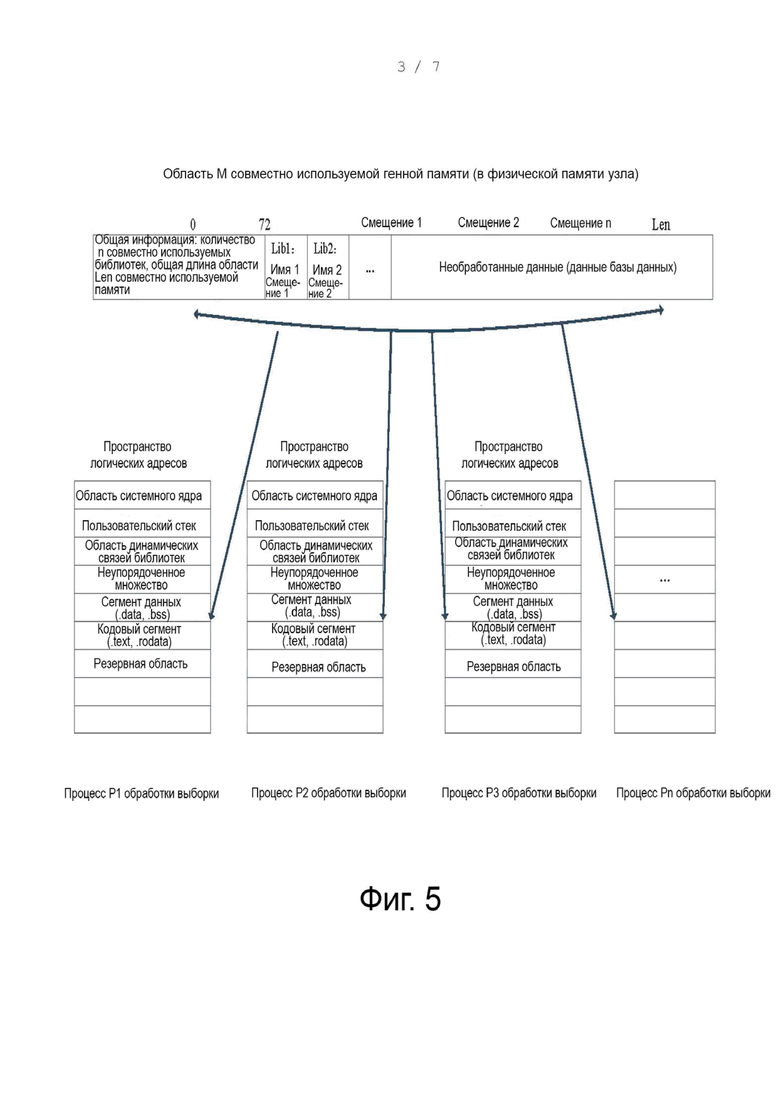
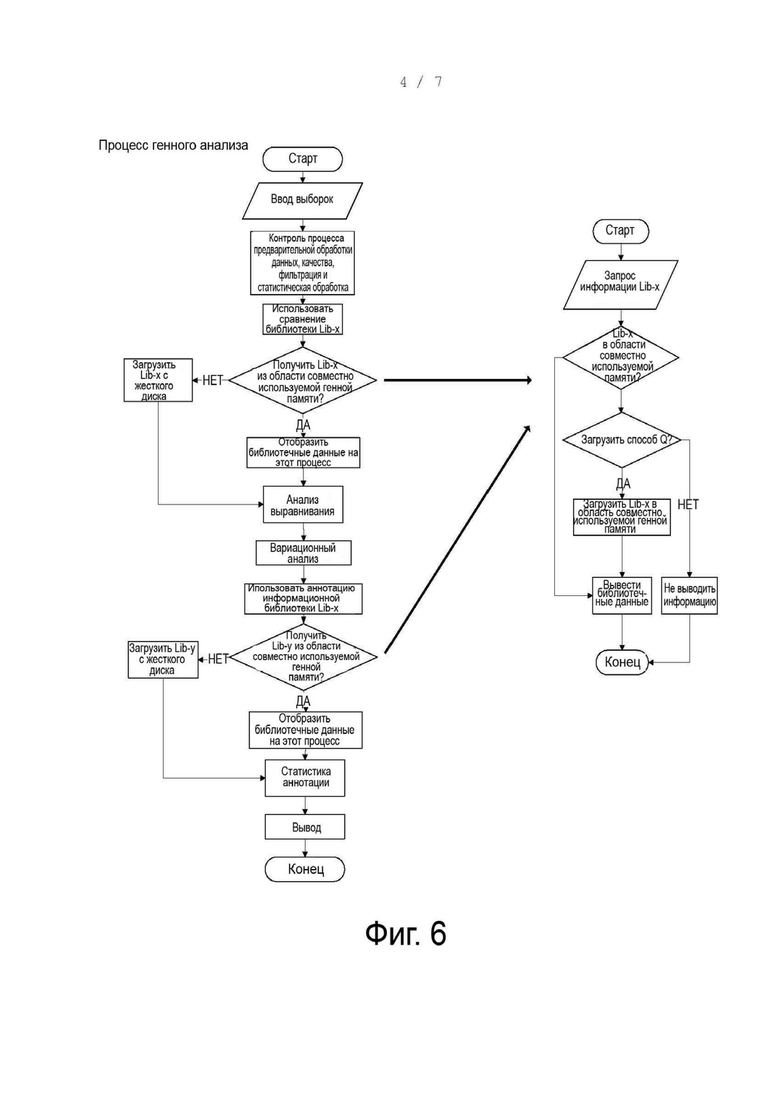
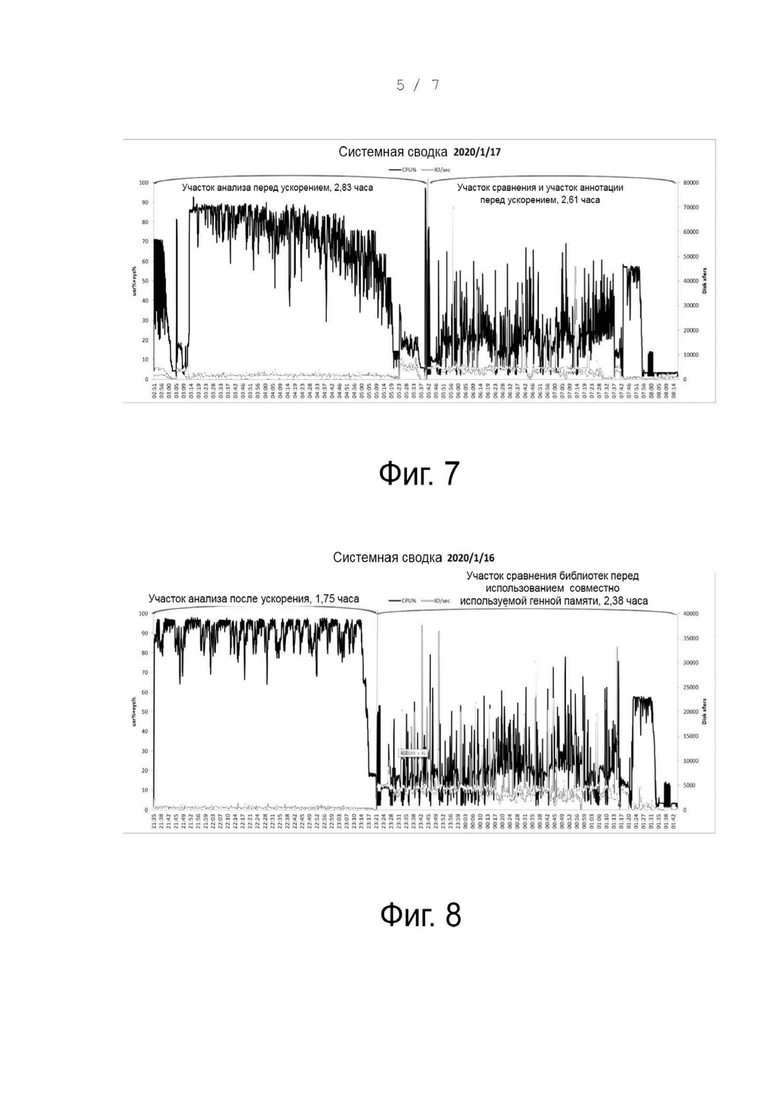
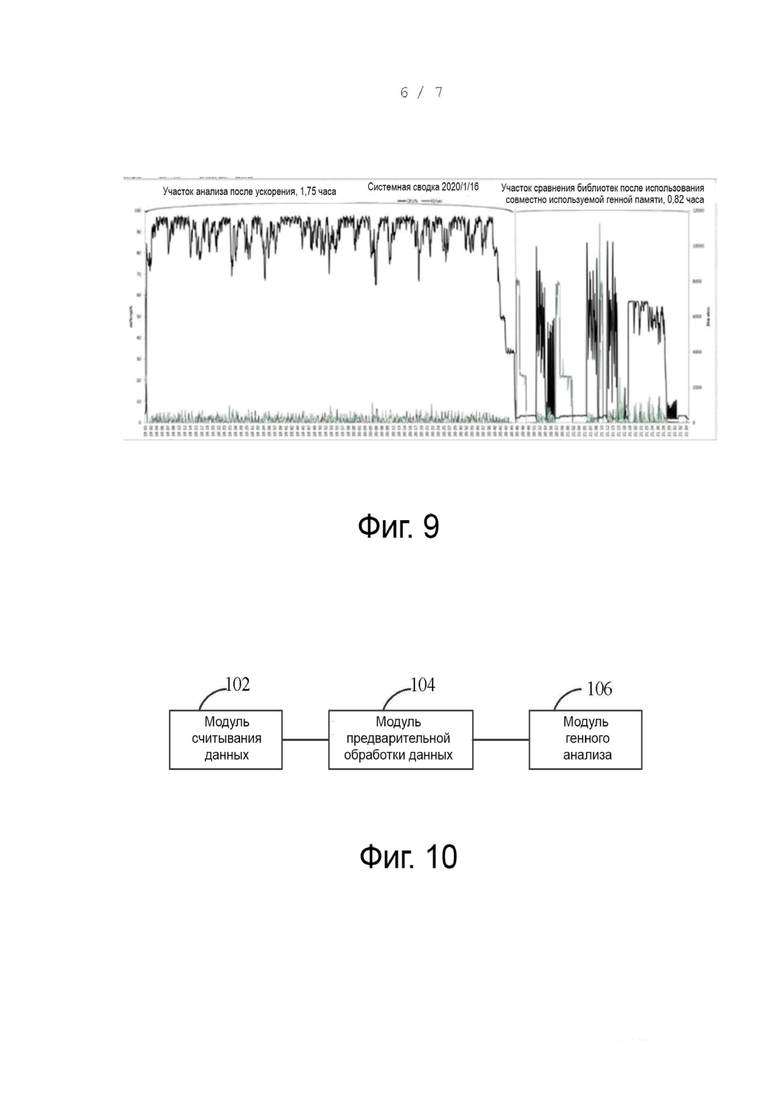
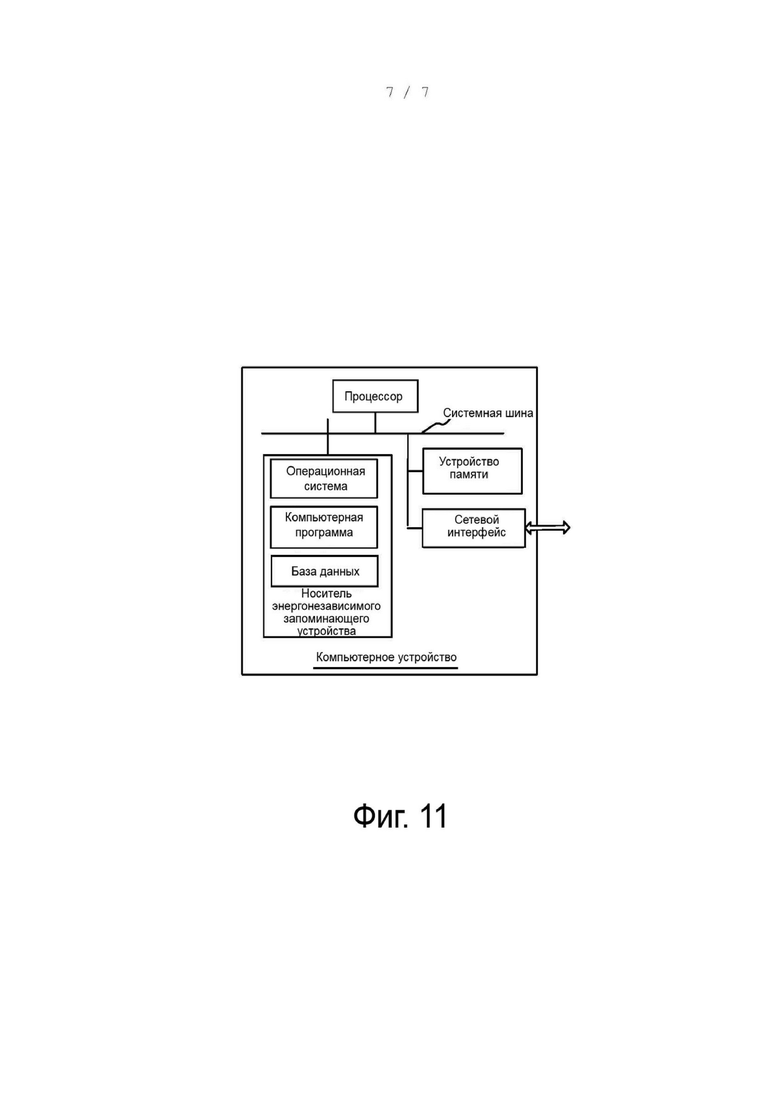
Изобретение относится к биотехнологии. Описаны способ генного анализа, основанный на совместно используемой памяти, выполняемый компьютером и содержащий этапы, на которых: считывают данные образцов и предварительно обрабатывают данные образцов, причем данные образцов являются данными, генерируемыми или формируемыми после генного секвенирования образцов; выполняют генный анализ предварительно обработанных данных образцов и определяют, находится ли требуемый при генном анализе библиотечный файл в совместно используемой генной памяти; если находится, получают требуемый библиотечный файл из совместно используемой генной памяти, преобразуют требуемый библиотечный файл в процесс генного анализа предварительно обработанных данных образцов и выполняют генный анализ, при этом данные образцов содержат множество групп данных, причем каждая группа данных имеет соответствующий процесс обработки образца, причем каждый процесс обработки образца входит в область совместно используемой генной памяти для получения требуемого библиотечного файла. Также описано соответствующее устройство, компьютерное устройство, считываемый компьютером носитель. Способ может значительно сократить время и занятость ввода-вывода для загрузки библиотечного файла с жесткого диска. Поэтому эффективность анализа может быть повышена. 4 н. и 8 з.п. ф-лы, 11 ил.
1. Способ генного анализа, основанный на совместно используемой памяти, выполняемый компьютером и содержащий этапы, на которых:
считывают данные образцов и предварительно обрабатывают данные образцов, причем данные образцов являются данными, генерируемыми или формируемыми после генного секвенирования образцов;
выполняют генный анализ предварительно обработанных данных образцов и определяют, находится ли требуемый при генном анализе библиотечный файл в совместно используемой генной памяти;
если находится, получают требуемый библиотечный файл из совместно используемой генной памяти, преобразуют требуемый библиотечный файл в процесс генного анализа предварительно обработанных данных образцов и выполняют генный анализ, при этом данные образцов содержат множество групп данных, причем каждая группа данных имеет соответствующий процесс обработки образца, причем каждый процесс обработки образца входит в область совместно используемой генной памяти для получения требуемого библиотечного файла.
2. Способ генного анализа, основанный на совместно используемой памяти, по п. 1, дополнительно содержащий этапы, на которых:
определяют, удовлетворяет ли требуемый библиотечный файл условию загрузки, в случае, когда требуемый при генном анализе библиотечный файл не находится в совместно используемой генной памяти; и
загружают требуемый библиотечный файл в совместно используемую генную память в случае, когда условие загрузки удовлетворяется.
3. Способ генного анализа, основанный на совместно используемой памяти, по п. 2, в котором на этапах определения, удовлетворяет ли требуемый библиотечный файл условию загрузки, в случае, когда требуемый при генном анализе библиотечный файл не находится в совместно используемой генной памяти, и загрузки требуемого библиотечного файла в совместно используемую генную память в случае, когда удовлетворяется условие загрузки:
получают информацию о требуемом библиотечном файле и информацию о совместно используемой генной памяти, причем информация о требуемом библиотечном файле содержит объем памяти, требующийся требуемому библиотечному файлу, и количество архивных запросов загрузки требуемого библиотечного файла, а информация о совместно используемой генной памяти содержит оставшийся объем памяти в совместно используемой генной памяти; и
если количество архивных запросов загрузки больше первого заданного количества и объем памяти, требующийся требуемому библиотечному файлу, меньше оставшегося объема памяти в совместно используемой генной памяти, загружают требуемый библиотечный файл в совместно используемую генную память.
4. Способ генного анализа, основанный на совместно используемой памяти, по п. 4, в котором информация о требуемом библиотечном файле дополнительно содержит частоту запросов загрузки требуемого библиотечного файла, информация о совместно используемой генной памяти содержит частоты запроса загрузки всех библиотечных файлов; при этом на этапах определения, удовлетворяет ли требуемый библиотечный файл условию загрузки, и загрузки требуемого библиотечного файла в совместно используемую генную память в случае, когда условие загрузки удовлетворяется, дополнительно:
если количество архивных запросов загрузки больше первого заданного количества и объем памяти, требующийся требуемому библиотечному файлу, больше, чем остающийся объем памяти совместно используемой генной памяти, ранжируют требуемый библиотечный файл и все библиотечные файлы в порядке приоритета в соответствии с частотой запроса загрузки требуемого библиотечного файла и частотами запроса загрузки всех библиотечных файлов, чтобы получить приоритет частоты запроса загрузки каждого библиотечного файла;
если приоритет частоты запроса загрузки требуемого библиотечного файла выше, чем приоритет библиотечного файла в совместно используемой генной памяти, и если оставшийся объем памяти в совместно используемой генной памяти после удаления библиотечного файла с более низким приоритетом частоты запроса загрузки в совместно используемой генной памяти больше или равен объему памяти, требующемуся требуемому библиотечному файлу, удаляют библиотечный файл с более низким приоритетом частоты запроса загрузки из совместно используемой генной памяти; и
загружают требуемый библиотечный файл в совместно используемую генную память.
5. Способ генного анализа, основанный на совместно используемой генной памяти, по любому из пп. 1-4, дополнительно содержащий этапы, на которых:
устанавливают совместно используемую генную память для используемых при генном анализе библиотечных файлов, устанавливают размер совместно используемой генной памяти, количество библиотечных файлов, которые могут быть размещены, имя каждого библиотечного файла и смещение размера каждого библиотечного файла; и
загружают библиотечные файлы, обычно используемые при генном анализе, в совместно используемую генную память в соответствии с размером совместно используемой генной памяти, количеством библиотечных файлов, которые могут быть размещены, именем каждого библиотечного файла и смещением размера каждого библиотечного файла.
6. Способ генного анализа, основанный на совместно используемой памяти, по п. 1, в котором генный анализ содержит анализ выравнивания, вариационный анализ и аннотационный анализ, при этом способ дополнительно содержит этап, на котором:
выполняют анализ выравнивания, вариационный анализ и аннотационный анализ данных образцов, предварительно обработанных в последовательности, при этом в случае, когда предварительно обработанные данные образцов содержат множество групп данных образцов, указанное множество групп данных образцов одновременно находятся на одном и том же этапе или на различных этапах генного анализа.
7. Способ генного анализа, основанный на совместно используемой памяти, по п. 6, в котором генный анализ дополнительно содержит сортировочный анализ и анализ маркировки-дублирования, при этом после выполнения анализа выравнивания, вариационного анализа и аннотационного анализа данных образцов, предварительно обработанных в последовательности, способ дополнительно содержит этапы, на которых:
маркируют данные образцов после анализа выравнивания с помощью позиционного тега; и выполняют сортировочный анализ и анализ маркировки-дублирования маркированных данных образцов.
8. Способ генного анализа, основанный на совместно используемой памяти, по п. 7, дополнительно содержащий этап, на котором:
соединяют некоторые или все этапы генного анализа с использованием памяти.
9. Способ генного анализа, основанный на совместно используемой памяти, по любому из пп. 6-8, в котором на этапе предварительной подготовки данных образцов:
выполняют контроль качества, операцию фильтрации и статистическую обработку данных образцов.
10. Устройство генного анализа, основанное на совместно используемой памяти, содержащее:
модуль считывания данных, выполненный с возможностью считывания данных образцов, причем данные образцов являются данными, генерируемыми или формируемыми после генного секвенирования образцов;
модуль предварительной обработки данных, выполненный с возможностью предварительной обработки данных образцов; и
модуль генного анализа, выполненный с возможностью генного анализа предварительно обработанных данных образцов и определения, находится ли требуемый при генном анализе библиотечный файл в совместно используемой генной памяти; если находится, получения требуемого библиотечного файла из совместно используемой генной памяти, преобразования требуемого библиотечного файла в процесс генного анализа предварительно обработанных данных образцов и выполнения генного анализа, при этом данные образцов содержат множество групп данных, причем каждая группа данных имеет соответствующий процесс обработки образца, причем каждый процесс обработки образца входит в область совместно используемой генной памяти для получения требуемого библиотечного файла.
11. Компьютерное устройство, содержащее: память, процессор и компьютерную программу, хранящуюся в памяти и исполняемую на процессоре, при этом процессор при исполнении компьютерной программы реализует этапы способа по любому из пп. 1-9.
12. Считываемый компьютером носитель, на котором хранится компьютерная программа, причем компьютерная программа при исполнении процессором реализует этапы способа по любому из пп. 1-9.
| CN 108197433 A, 22.06.2018 | |||
| CN 108776617 A, 09.11.2018 | |||
| АВТОМАТИЗИРОВАННАЯ БИБЛИОТЕКА ДАННЫХ С УНИВЕРСАЛЬНЫМИ ГНЕЗДАМИ (ВАРИАНТЫ), СПОСОБ УПРАВЛЕНИЯ ЕЮ (ВАРИАНТЫ), А ТАКЖЕ НОСИТЕЛЬ СИГНАЛОВ И ЛОГИЧЕСКАЯ СХЕМА ДЛЯ ОСУЩЕСТВЛЕНИЯ СПОСОБА | 2001 |
|
RU2280277C2 |

