Для данной заявки испрашивается приоритет в соответствии с китайской патентной заявкой №202011139823.4, поданной 22 октября 2020 г. в Национальное управление по интеллектуальной собственности Китая, под названием «Способ обработки данных секвенирования генов и устройство для обработки данных секвенирования генов», полное содержание которой включено в настоящий документ посредством ссылки.
ОБЛАСТЬ ТЕХНИКИ
Изобретение относится к области технологий обработки данных и, в частности, к способу обработки данных секвенирования генов и устройству для обработки данных секвенирования генов.
УРОВЕНЬ ТЕХНИКИ
Благодаря постоянному развитию технологии секвенирования генов, эта технология широко применяется для исследования, разработки и анализа новых биологических видов, вирусов и болезней. В то же время появился большой объем данных секвенирования генов, что делает актуальным эффективное завершение анализа и обработки большого количества данных секвенирования генов.
В существующем процессе генетического анализа (генетического выравнивания) большинство шагов можно выполнить только на платформе х86. Например, традиционный алгоритм выравнивания bwa, использующий алгоритм bwt, и алгоритм Смита-Уотермана (Smith-Waterman) для алгоритма неточного выравнивания, также реализован на основе инструкций SSE2 архитектуры х86.
Хотя алгоритм выравнивания BWT, основанный на архитектуре х86, быстро работает на центральном процессоре (CPU, ЦП) архитектуры х86, алгоритм не может одновременно вычислять большой объем данных, а алгоритм BWT не может адаптироваться к режиму работы SIMT графического процессора (GPU, ГП), что в значительной степени снижает эффективность BWT на графическом процессоре, тем самым влияя на эффективность всего процесса выравнивания. Точно так же, существующий алгоритм Смита-Уотермана работает только на архитектуре х86 и не поддерживает ускорение SSE2 на платформе ARM, и из-за низкой скорости работы алгоритм не подходит для вычислений на архитектуре ГП.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
В связи с этим в описании представлены способ обработки данных секвенирования генов и устройство для обработки данных секвенирования генов для решения проблемы, заключающейся в том, что существующий способ анализа и обработки данных секвенирования генов может работать только на архитектуре х86 и работает медленно на ГП, что приводит к низкой эффективности обработки данных секвенирования генов.
Варианты осуществления изобретения предлагают способ обработки данных секвенирования генов. Способ применяется в устройстве для обработки данных секвенирования генов. Устройство имеет гетерогенную многоядерную архитектуру, включающую архитектуру усовершенствованной машины RISC (advanced RISC machine, ARM), архитектуру графического процессора (ГП) и шину соединения периферийных компонентов (peripheral component interconnect, PCI). Архитектура ARM связана с архитектурой ГП через шину PCI. Архитектура ARM содержит по меньшей мере один модуль центрального процессора (ЦП). Архитектура ГП содержит по меньшей мере один модуль графического процессора. Способ содержит:
S1, получение, модулем ЦП в состоянии ожидания, порций данных секвенирования генов путем считывания данных секвенирования генов порциями;
S2, получение, модулем ЦП в состоянии ожидания, первого алгоритма и второго алгоритма путем разделения способа анализа генов;
S3: получение, модулем ЦП в состоянии ожидания, множества прочтений путем разделения каждой порции данных секвенирования генов на основе первого алгоритма и отправку множества прочтений и второго алгоритма модулю ГП в состоянии ожидания;
S4, выполнение, модулем ГП в состоянии ожидания, вычисления для каждого прочтения на основе второго алгоритма и отправку соответствующих результатов вычислений модулю ЦП в состоянии ожидания;
S5, получение, модулем ЦП в состоянии ожидания, результата обработки порции данных на основе результатов вычислений и первого алгоритма; и
повторение шагов S1-S5 до тех пор, пока обработка данных секвенирования генов не будет завершена, и получение, модулем ЦП в состоянии ожидания, окончательного результата обработки путем интегрирования результатов обработки порций данных.
Опционально, модуль ЦП в состоянии ожидания определяет количество модулей ГП в состоянии ожидания и объем обработки данных, соответствующий каждому модулю ГП в состоянии ожидания, путем сканирования по меньшей мере одного модуля и считывает данные секвенирования генов порциями на основании количества модулей ГП в состоянии ожидания и соответствующего объема обработки данных.
Опционально, способ анализа генов содержит алгоритм выравнивания генов, алгоритм Dotplot, алгоритм blast, алгоритм разделения вокруг медоидов (РАМ), алгоритм скрытой марковской модели (НММ) и алгоритм логического вывода на основе искусственного интеллекта (AI).
Опционально, алгоритм выравнивания генов содержит алгоритм преобразования Барроуза-Уиллера (BWT), а первый алгоритм содержит алгоритм разрезания по опорным точкам (anchor point cutting algorithm); и способ дополнительно содержит:
выполнение, модулем ЦП в состоянии ожидания, операции позиционирования опорных точек для каждой порции данных секвенирования генов с помощью алгоритма разрезания по опорным точкам и получение множества прочтений путем расширения на расстояние N×bp вперед и назад, соответственно, с опорной точкой в качестве центра, и деление каждой порции данных секвенирования генов на отрезки длиной (2N+1)×bp на основе инструкции NEON, где N - положительное целое число.
Опционально, получение множества прочтений содержит:
получение множества прочтений с использованием следующей формулы:
(2*N+1)*x<L
где х - количество опорных точек, N - количество bp расширения, a L -длина каждой порции данных секвенирования генов.
Опционально, второй алгоритм - это алгоритм хэширования; и способ содержит: выполнение, модулем ГП в состоянии ожидания, операции хэширования для каждого из множества прочтений на основе алгоритма хэширования для получения результата вычисления хэша и отправку результата вычисления хэша модулю ЦП в состояние ожидания, при этом результатом вычисления хэша является значение матрицы алгоритма BWT, используемое для вычисления матрицы алгоритма BWT.
Опционально, первый алгоритм дополнительно содержит алгоритм преобразования матрицы BWT; и способ дополнительно содержит: выполнение, модулем ЦП в состоянии ожидания, операции преобразования алгоритма матрицы BWT на основе алгоритма преобразования матрицы BWT, чтобы получить результат преобразования BWT для множества прочтений.
Опционально, алгоритм выравнивания содержит алгоритм Смита-Уотермана, а второй алгоритм содержит алгоритм матрицы оценок (scoring matrix algorithm). Способ дополнительно содержит: получение, модулем ГП в состоянии ожидания, матрицы оценок Смита-Уотермана на основе алгоритма матрицы оценок, множества прочтений и эталонной последовательности вида (reference species sequence) и отправку матрицы оценок Смита-Уотермана в модуль ЦП в состоянии ожидания. Опционально, получение матрицы оценок Смита-Уотермана содержит:
получение матрицы оценок Смита-Уотермана по следующим формулам:
M=R*C:
R=a*L2+b
где М - матрица оценок Смита-Уотермана, R - длина участка-кандидата эталонной последовательности вида, С - длина прочтения, генерированного с помощью скрининга и сплайсинга прочтений, полученных от модуля ЦП в состоянии ожидания, L - длина каждой порции данных секвенирования генов, и а и b являются константами.
Варианты осуществления изобретения предлагают устройство для обработки данных секвенирования генов, которое представляет собой гетерогенную многоядерную структуру. Устройство выполнено с возможностью выполнять способ обработки данных секвенирования генов.
С устройством для обработки данных секвенирования генов и способом обработки данных секвенирования генов в соответствии с вариантами осуществления настоящего изобретения, способ применяется в устройстве для обработки данных секвенирования генов, которое имеет гетерогенную многоядерную архитектуру, содержащую архитектуру усовершенствованной машины RISC (ARM), архитектуру графического процессора (ГП) и шину соединения периферийных компонентов (PCI). Архитектура ARM содержит по меньшей мере один модуль ЦП, и архитектура ГП содержит по меньшей мере один модуль ГП, и модуль ЦП подключен к модулю ГП через шину PCI для передачи информации между ними. Модуль ЦП в состоянии ожидания в основном выполнен с возможностью считывать данные секвенирования генов порциями и разделять способ анализа генов для получения порций данных секвенирования генов, на первый алгоритм (этот алгоритм является наиболее подходящим алгоритмом для модуля ЦП) и второй алгоритм (этот алгоритм является наиболее подходящим алгоритмом для модуля ГП). Каждая порция данных секвенирования генов разделяется на основе первого алгоритма для получения множества прочтений, и множество прочтений и второй алгоритм отправляются в модуль ГП в состоянии ожидания через шину PCI. Модуль ГП выполняет вычисление для каждого прочтения на основе второго алгоритма и отправляет соответствующие результаты вычислений модулю ЦП в состоянии ожидания. Модуль ЦП в состоянии ожидания получает результат обработки порции данных на основе результатов вычислений и первого алгоритма. Модуль ЦП в состоянии ожидания и модуль ГП в состоянии ожидания повторяют вышеуказанные шаги до тех пор, пока не будет завершена обработка данных секвенирования генов. Модуль ЦП в состоянии ожидания получает окончательный результат обработки, интегрируя результаты обработки порций данных. Устройство для обработки данных секвенирования генов и способ обработки данных секвенирования генов разделяют способ анализа (т.е. процесс анализа) данных секвенирования генов для запуска на модуле ЦП и модуле ГП по отдельности в соответствии с характеристиками этих модулей, что значительно повышает эффективность анализа данных секвенирования генов. Кроме того, в устройстве могут быть предусмотрены множество модулей ЦП и модулей ГП для обработки данных секвенирования генов, и множество модулей ГП могут одновременно вычислять прочтения разной длины, что может решить проблему низкой эффективности параллельной обработки в ГП.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Чтобы ясно проиллюстрировать технические решения вариантов осуществления изобретения, ниже приводится краткое описание чертежей, используемых в вариантах осуществления. Очевидно, что чертежи в нижеследующем описании являются лишь частичными вариантами осуществления изобретения, и для специалистов в данной области техники могут быть получены другие чертежи согласно этим чертежам без творческого труда.
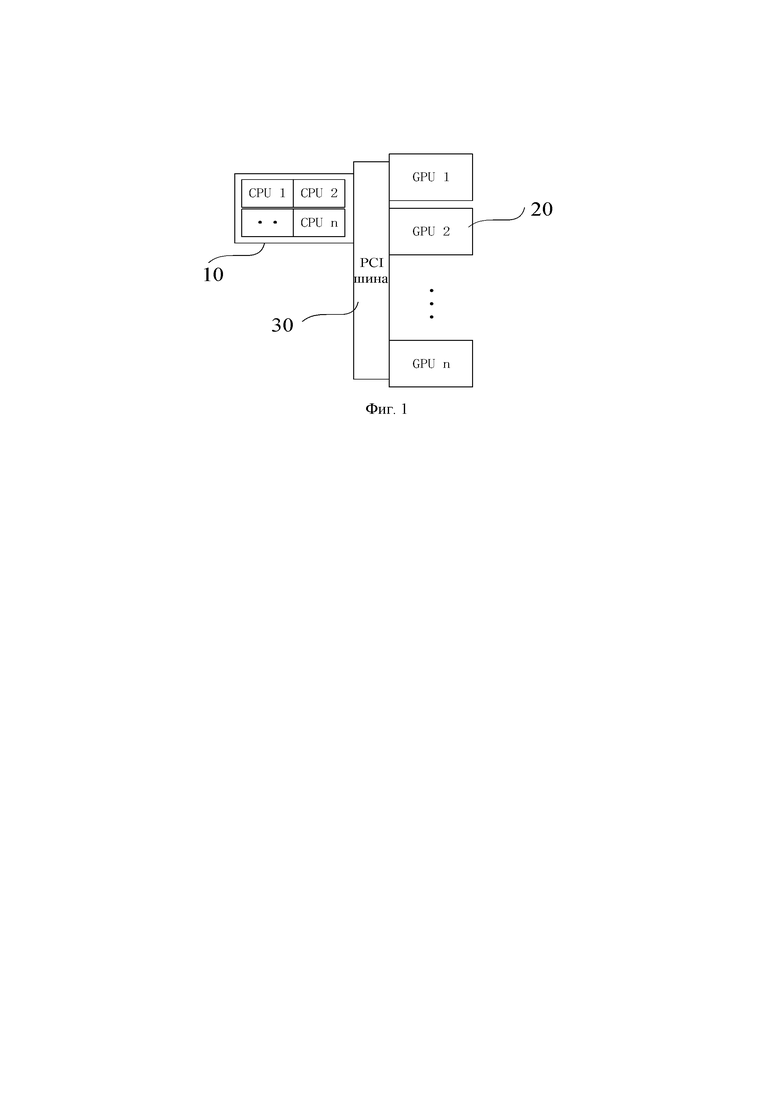
Фиг. 1 - схематическое изображение, иллюстрирующее устройство для обработки данных секвенирования генов согласно вариантам осуществления изобретения.
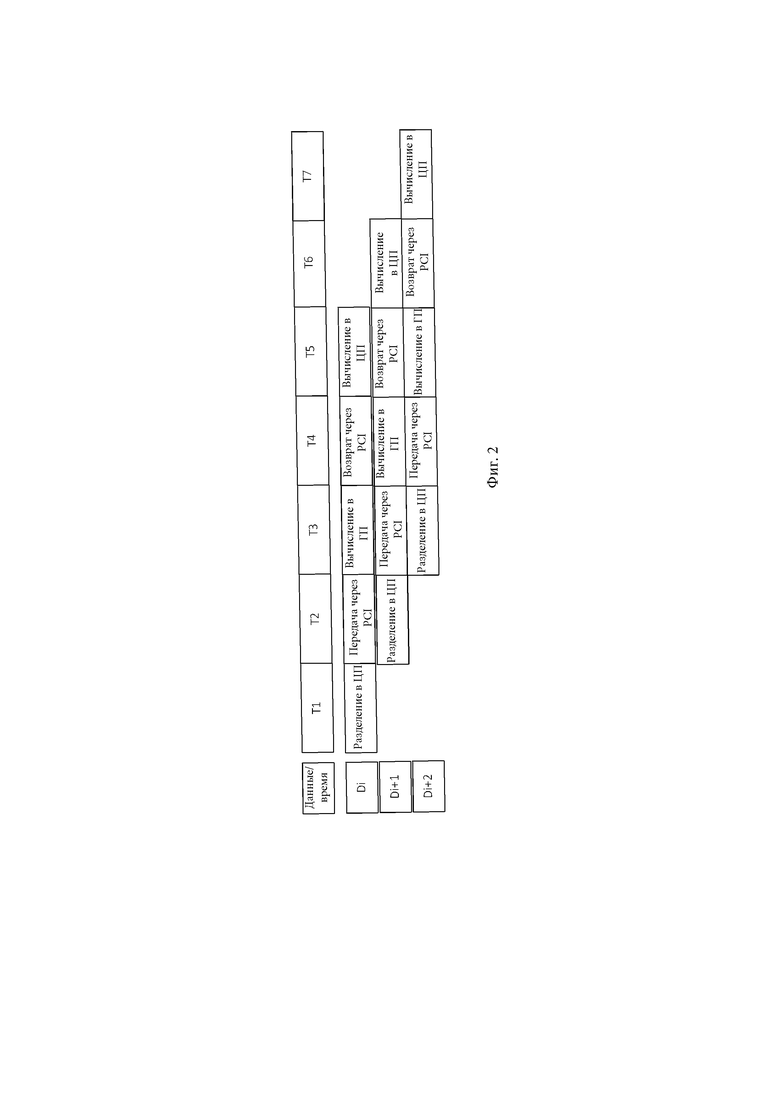
Фиг. 2 - схематическое изображение, иллюстрирующее процедуру обработки данных устройством для обработки данных секвенирования генов согласно вариантам осуществления настоящего изобретения.
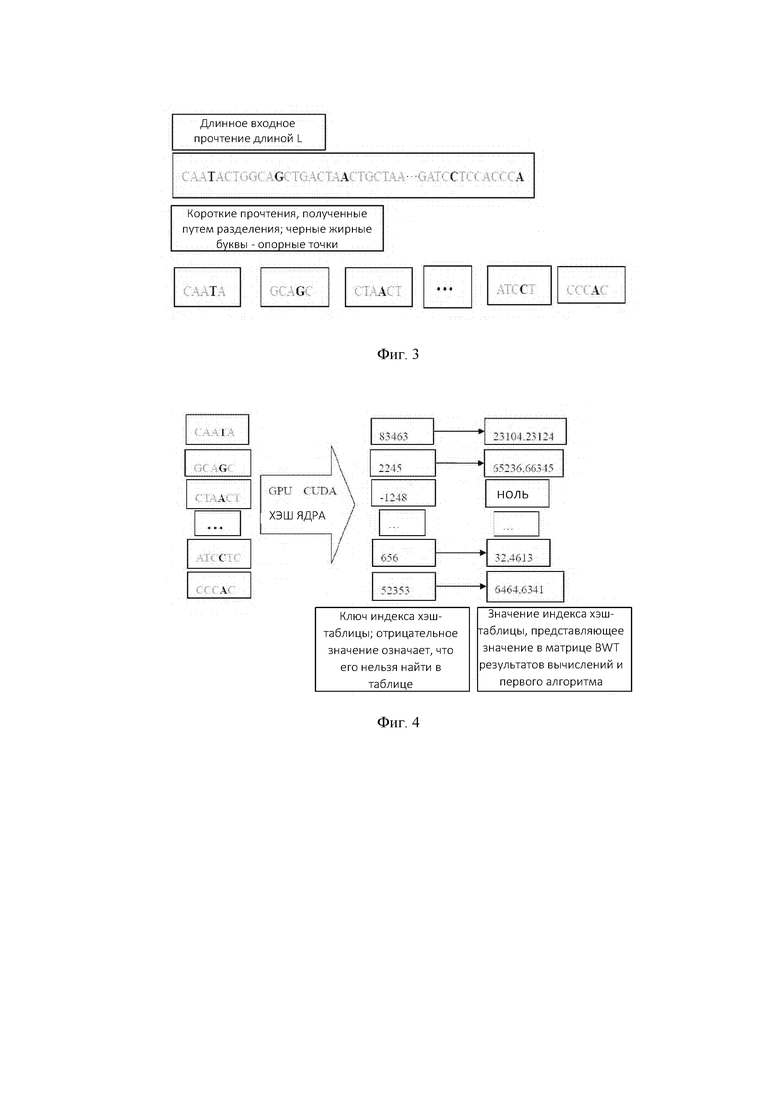
Фиг. 3 - схематическое изображение выполнения операции разрезания по опорным точкам для порции данных секвенирования генов модулем ЦП согласно вариантам осуществления настоящего изобретения.
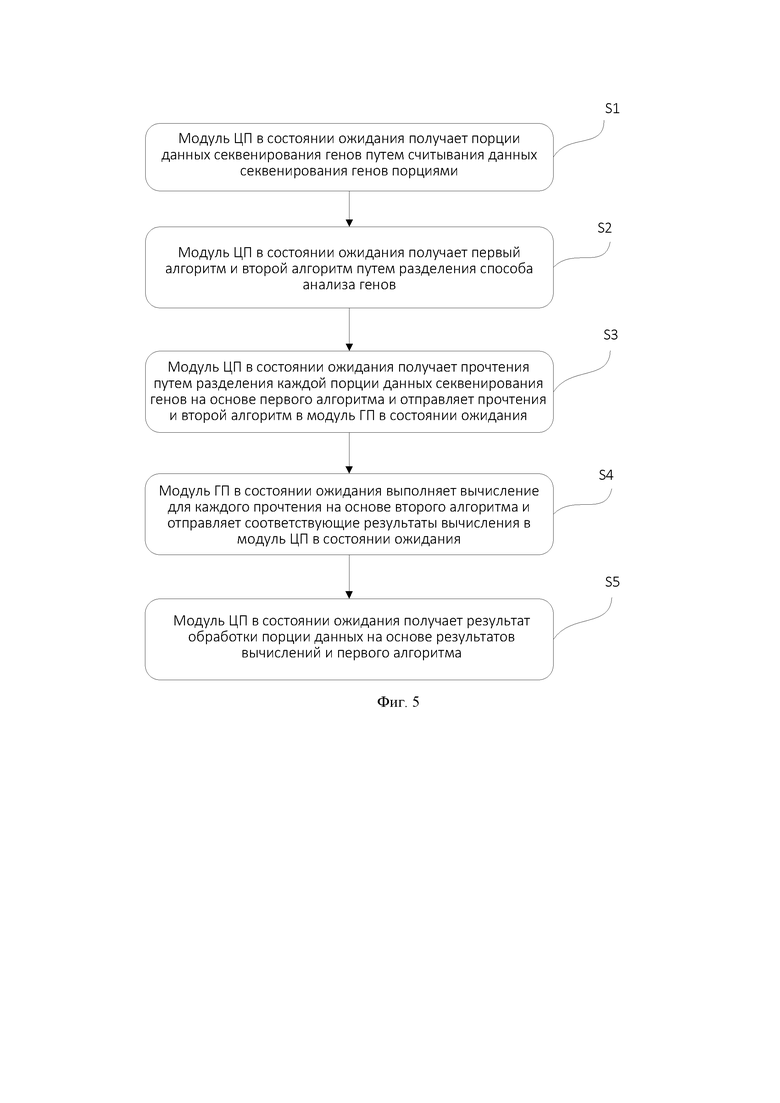
Фиг. 4 - схематическое изображение выполнения операции хэширования на основе алгоритма хэширования модулем ГП согласно вариантам осуществления настоящего изобретения.
Фиг. 5 - блок-схема способа обработки данных секвенирования генов согласно вариантам осуществления настоящего изобретения.
ПОДРОБНОЕ ОПИСАНИЕ
Чтобы дать возможность специалистам в данной области техники понять технические решения изобретения, будет приведено подробное описание предложенных технических решений с сопроводительными чертежами. Очевидно, что варианты осуществления, описанные здесь, являются только частью возможных вариантов осуществления изобретения, а не всеми вариантами осуществления изобретения. Другие варианты осуществления, полученные специалистами в данной области на основе этих вариантов осуществления изобретения без творческого труда, находятся в пределах объема изобретения.
Объяснение терминов
Ген (менделевский фактор) относится к последовательности ДНК или РНК, которая несет генетическую информацию (то есть ген представляет собой фрагмент ДНК или РНК с генетическими эффектами), также известен как генетический фактор, является базовой генетической единицей, управляющей биологическими признаками. Ген выражает генетическую информацию, управляя синтезом белка, чтобы управлять фенотипическим выражением биологических идентичностей.
Секвенирование генов - это новый тип технологии обнаружения генов, который анализирует и определяет полную последовательность генов из крови или слюны, чтобы предсказать возможность различных заболеваний, индивидуальных особенностей поведения и разумного поведения.
Прочтение (read, рид), это короткий фрагмент секвенирования, который представляет собой данные секвенирования, созданные высокопроизводительным секвенатором. Десятки миллионов прочтений будут произведены путем секвенирования всего генома, и полная генная последовательность генома может быть получена путем сплайсинга (соединения) этих прочтений.
Анализ выравнивания (alignment analysis): прочтения, полученные после секвенирования следующего поколения (next generation sequencing, NGS), сохраняют в файле FASTQ. Хотя они изначально происходят из упорядоченного генома, после создания библиотеки ДНК и выполнения секвенирования генов относительные последовательности между различными прочтениями в файле теряются. Следовательно, нет позиционной связи между двумя близко расположенными друг к другу прочтениями в файле FASTQ, и эти два близко расположенных прочтения получены случайным образом из двух позиций в исходном геноме. В результате эти прочтения необходимо сначала расположить последовательно, по очереди сравнить с эталонным геномом того же биологического вида, чтобы найти соответствующее положение в эталонном геноме для каждого прочтения, и, наконец, расположить по порядку. Весь этот процесс называется выравниванием данных секвенирования.
Алгоритм выравнивания: в общем, существует два способа расчета для выравнивания последовательностей: один - глобальное выравнивание, а другой - локальное выравнивание. Вычисляется глобальный маршрут, который является формой глобальной оптимизации и заставляет все последовательности запросов быть выровненными по всей длине. Напротив, локальное выравнивание определяет только локальное сходство, что сильно отличается от всей длинной последовательности. Локальное выравнивание часто желательно, но его трудно рассчитать из-за сложности идентификации других подобных областей. Для решения задач выравнивания последовательностей применялись различные вычислительные алгоритмы, включая медленные, но формальные методы оптимизации, такие как динамическое программирование, эффективные, но неполные эвристические алгоритмы или вероятностные методы для поиска в больших базах данных.
ARM, или архитектура ARM (Advanced RISC Machine, ранее известная как Acorn RISC Machine) - это семейство архитектуры процессоров RISC, широко используемое во многих конструкциях встроенных систем. Благодаря своим энергосберегающим характеристикам ARM также внесла большой вклад в другие области. Процессор ARM хорошо подходит для области мобильной связи в соответствии с основными целями проектирования: низкая стоимость, высокая производительность и низкое энергопотребление. С другой стороны, суперкомпьютеры потребляют много энергии, и ARM считается более эффективным выбором по сравнению с суперкомпьютерами. ARM Holdings разработала эту архитектуру и разрешила другим компаниям использовать эту архитектуру для реализации определенной архитектуры ARM и разработки собственного системного микроконтроллера (MCU) и системы на модуле (SoC).
GUP, графический процессор (также известный как ядро дисплея, визуальный процессор, устройство отображения или устройство для прорисовки) - это вид микропроцессора, который специально выполняет графические операции на персональных компьютерах, рабочих станциях, игровых консолях и мобильных устройствах (таких как планшеты и смартфоны). ГП снижает зависимость видеокарты от ЦП и разделяет часть работы, первоначально выполняемой ЦП, и эффект более очевиден, особенно при выполнении операций трехмерного рисования.
CUDA (compute unified device architecture), вычислительная архитектура унифицированных устройств - это интегрированная технология, запущенная NVIDIA, которая является официальным названием GPGPU (графический процессор общего назначения). Благодаря этой технологии пользователи могут использовать графический процессор, после NVIDIA GeForce 8 и новых графических процессоров Quadro? для вычислений, что является первым случаем, когда графический процессор может использоваться в качестве среды разработки для компилятора языка Си (C-compiler). В маркетинге NVIDIA часто продвигает компиляторы, смешанные с архитектурами, что приводит к путанице. Фактически, CUDA совместим с OpenCL или собственным компилятором языка Си. Независимо от того, является ли это языком Си CUDA или OpenCL, инструкции в конечном итоге будут преобразованы в коды РТХ программой управления и переданы ядру дисплея для вычисления.
BWT, преобразование Барроуза-Уилера (Burrows-Wheeler Transform) - это алгоритм, используемый в технологии сжатия данных, такой как bzip2. Алгоритм был предложен в 1994 году Майклом Берроузом и Дэвидом Уилером в центре системных исследований DEC в Пало-Альто, Калифорния. В основе этого алгоритма лежит нераскрытый способ преобразования, разработанный Уилером в 1983 году. Когда символьная строка преобразуется с помощью этого алгоритма, алгоритм изменяет только порядок символов в символьной строке, не изменяя символы. Если исходная символьная строка имеет несколько подстрок, которые появляются несколько раз, в преобразованной символьной строке будет несколько последовательных повторяющихся символов, что очень полезно для сжатия. Этот способ может упростить сжатие кодировки на основе технологии (такой как преобразование MTF и кодирование длин серий), которая имеет дело с непрерывно повторяющимися символами в строке символов.
Смит-Уотерман, алгоритм Смита-Уотермана, это алгоритм локального выравнивания последовательностей (по сравнению с глобальным выравниванием) для поиска аналогичных областей между двумя нуклеотидными последовательностями или последовательностями белков. Целью этого алгоритма является не выравнивание полной последовательности, а поиск фрагментов с высоким сходством между двумя последовательностями.
HASH, также известный как алгоритм хэширования или функция хэширования, представляет собой метод создания небольших цифровых «отпечатков» из любых данных. Функция хэширования сжимает сообщение или данные в дайджест, так что объем данных уменьшается, а формат данных фиксируется. Эта функция скремблирует и смешивает данные и создает "отпечаток", называемый хэш-значением (хэш-код, хэш-сумма или хэш). Хэш-значение обычно представлено короткой символьной строкой, состоящей из случайных букв и цифр. Хорошая хэш-функция редко имеет хэш-коллизии в области входных данных. В хэш-таблицах и при обработке данных, различение данных без подавления конфликтов затруднит поиск записей в базе данных.
SSE2, Streaming SIMD Extensions 2 (потоковые SIMD-расширения), это набор команд с одной командой и множеством данных (SIMD) с архитектурой IA-32. SSE2 - это набор команд, представленный в 2001 году вместе с первым поколением процессоров Pentium 4, выпущенных Intel. SSE2 является расширением более раннего набора команд SSE и может полностью заменить набор команд ММХ.
Чтобы подробно объяснить изобретение, ниже будут подробно описаны способ обработки данных секвенирования генов и устройство для обработки данных секвенирования генов в соответствии с изобретением со ссылкой на сопроводительные чертежи.
Фиг. 1 - схематическое изображение, иллюстрирующее устройство для обработки данных секвенирования генов согласно вариантам осуществления изобретения. Как показано на фиг. 1, устройство представляет собой гетерогенную многоядерную архитектуру, включающую архитектуру 10 ARM, архитектуру 20 ГП и шину 30 PCI. Архитектура 10 ARM подключается к архитектуре 20 ГП через шину 30 PCI. Архитектура 10 ARM содержит по меньшей мере один модуль ЦП. Архитектура 20 ГП содержит по меньшей мере один модуль ГП. Модуль ЦП выполнен с возможностью в состоянии ожидания получать порции данных секвенирования генов путем считывания данных секвенирования генов порциями и получать первый алгоритм и второй алгоритм путем разделения способа анализа гена. Модуль ЦП выполнен с возможностью в состоянии ожидания получать прочтения (риды) путем разделения каждой порции данных секвенирования генов на основе первого алгоритма и отправлять прочтения и второй алгоритм в модуль графического процессора в состоянии ожидания. Модуль ГП выполнен с возможностью в состоянии ожидания выполнять вычисления для каждого прочтения на основе второго алгоритма и отправлять результат вычислений модулю ЦП в состоянии ожидания. Модуль ЦП также выполнен с возможностью в состоянии ожидания получать результат обработки порции данных на основе результатов вычислений и первого алгоритма. Модуль ЦП в состоянии ожидания и модуль ГП в состоянии ожидания повторяют вышеуказанные процессы до тех пор, пока обработка данных секвенирования генов не будет завершена, и модуль ЦП в состоянии ожидания не получит окончательный результат обработки путем интеграции результатов обработки порций данных.
В частности, устройство для обработки данных секвенирования генов представляет собой неоднородную многоядерную архитектуру, то есть архитектуру ARM+GPU (ARM+ГП). Архитектура 10 ARM содержит модули ЦП, а архитектура 20 ГП включает модули ГП. Количество модулей ЦП и количество модулей ГП не фиксировано и может быть установлено в зависимости от реальных условий, например, на основе количества данных секвенирования генов, производительности модуля ЦП, производительности модуля ГП (например, памяти ГП, количества ядер CUDA, частоты ядер CUDA) и сложности алгоритма анализа генов.
Возможности обработки или вычисления ядра каждого модуля ЦП могут быть одинаковыми или разными. Точно так же, возможности обработки или вычислений каждого модуля ГП могут быть одинаковыми или разными. Опционально, модуль ГП может быть вычислительной платой графического процессора, которая обычно использует архитектуру SIMT.
В дополнительной реализации модуль ЦП использует технологию ускорения NENO. Скорость работы модуля ЦП может быть дополнительно улучшена за счет использования этой технологии ускорения.
В опциональной реализации устройство для обработки данных секвенирования генов может использовать Jetson nano ТХ1, выпущенный NVIDIA. В устройстве используется графический процессор архитектуры Maxwell со 128 ядрами Cuda и вычислительной мощностью 472 ГБ. Кроме того, Jetson-nano также имеет 4-ядерный процессор А57 в качестве оператора ядра процессора ARM.
Способ анализа генов относится к способу, используемому для анализа и обработки данных секвенирования генов, включая выравнивание последовательностей, анализ обогащения набора генов (включая анализ GO и анализ KEGG) и анализ регуляторной сети генов.
Способ анализа генов делят на первый алгоритм и второй алгоритм, в основном на основе характеристик способа анализа генов. То есть алгоритм, подходящий для модуля ЦП, выделяют из способа анализа гена в качестве первого алгоритма, а алгоритм, подходящий для модуля ГП, выделяют из способа анализа генов в качестве второго алгоритма. Можно видеть, что первый алгоритм и второй алгоритм могут быть частями способа анализа генов и могут состоять из одного или более небольших этапов. Не существует строгих правил в процессе разделения алгоритма, но соблюдается принцип разделения. Принцип разделения в основном заключается в том, что первый алгоритм обычно требует множества логических заключений, и существует зависимость между результатами вычислений, например, вычисление на втором этапе зависит от результата вычисления на первом этапе или основано на нем, или используется решение "да" или "нет"; а второй алгоритм обычно состоит в том, что множество данных могут быть вычислены параллельно, и каждое из них не требует логического заключения или нет зависимости между этими данными.
Следует понимать, что «первый» и «второй» в вариантах осуществления не являются ограничениями алгоритма, а используются только для их различения.
Кроме того, поскольку в архитектуре 10 ARM имеется множество модулей ЦП, соответствующие операции или рабочие состояния модулей ЦП могут быть разными, то есть некоторые модули ЦП находятся в состоянии работы, а некоторые - в состоянии ожидания. Точно так же, модули ГП в архитектуре 20 ГП находятся в аналогичной ситуации. Следовательно, в вариантах осуществления модули ЦП, находящиеся в состоянии ожидания, и модули ГП, находящиеся в состоянии ожидания, принимаются для выполнения соответствующих операций, где выбранные модули ЦП и модули ГП могут быть всеми модулями, находящимися в состоянии ожидания, или могут быть некоторыми из модулей, находящихся в состоянии ожидания.
Кроме того, данные секвенирования генов могут быть данными, полученными путем выполнения секвенирования генов любого вида, включая фрагменты секвенирования ДНК, фрагменты секвенирования РНК и т.п. Поскольку при однократном выполнении секвенирования генов будет генерирован большой объем данных, объем данных секвенирования генов будет относительно большим. Данные можно анализировать и обрабатывать порциями, что позволяет избежать перегрузок при передаче данных. Следовательно, в вариантах осуществления модуль ЦП в состоянии ожидания считывает данные секвенирования генов порциями. Количество фрагментов данных секвенирования генов, считываемых каждый раз, может быть неодинаковым. В частности, наиболее подходящее количество фрагментов данных секвенирования генов может быть определено путем всестороннего учета количества модулей ГП, способности обработки данных каждого модуля ГП, возможности считывания данных модулем ЦП и возможности передачи данных по шине PCI для обеспечения максимальной эффективности обработки данных.
После считывания данных секвенирования генов порциями, в общем, необходимо разделить каждую порцию данных секвенирования генов, соответственно, для генерации множества прочтений. В вариантах осуществления первый алгоритм используется для разделения каждой порции данных секвенирования генов. Порция данных секвенирования генов может быть разделена на прочтения, имеющие разную длину, и количество прочтений, полученных при разделении каждой порции, не является фиксированным, что может быть определено путем всестороннего рассмотрения количества порций данных секвенирования генов, количества модулей ГП в состоянии ожидания и возможности обработки ГП.
После того, как модуль ЦП в состоянии ожидания передает каждое прочтение и второй алгоритм в ГП в состоянии ожидания, модуль ГП в состоянии ожидания выполняет вычисление для каждого прочтения на основе второго алгоритма. В это время модуль ЦП в состоянии ожидания может считывать и разделять следующую порцию данных секвенирования генов. Когда модуль ГП в состоянии ожидания завершает обработку прочтений, результаты вычислений передаются модулю ЦП в состоянии ожидания. Модуль ЦП может получить результат обработки порции данных на основе результатов вычислений и первого алгоритма. Вышеупомянутый процесс непрерывно повторяется для формирования конвейера между модулем ЦП и модулем ГП, пока не будет завершена обработка данных секвенирования генов.
Что касается устройства для обработки данных секвенирования генов, согласно вариантам осуществления настоящего изобретения, устройство представляет собой гетерогенную многоядерную архитектуру, включающую архитектуру 10 ARM, архитектуру 20 ГП и шину 30 PCI. Архитектура ARM содержит по меньшей мере один модуль ЦП, а архитектура ГП содержит по меньшей мере один модуль ГП. Модуль ЦП подключается к модулю ГП через шину PCI для передачи информации между ними. Модуль ЦП в состоянии ожидания выполнен с возможностью считывать данные секвенирования генов порциями и разделять способ анализа генов, чтобы получать порции данных секвенирования генов, на первый алгоритм (этот алгоритм является наиболее подходящим алгоритмом для модуля ЦП) и второй алгоритм (этот алгоритм является наиболее подходящим алгоритмом для модуля ГП). Модуль ЦП в состоянии ожидания выполнен с возможностью разделять каждую порцию данных секвенирования генов на основе первого алгоритма для получения прочтений и отправлять прочтения и второй алгоритм модулю ГП в состоянии ожидания через шину PCI. Модуль ГП выполняет расчет для каждого прочтения на основе второго алгоритма и отправляет результат расчета модулю ЦП в состоянии ожидания. Модуль ЦП в состоянии ожидания получает результат обработки порции данных на основе каждого результата вычисления и первого алгоритма. Модуль ЦП в состоянии ожидания и модуль ГП в состоянии ожидания повторяют вышеуказанные шаги до тех пор, пока обработка данных секвенирования генов не будет завершена, и модуль ЦП в состоянии ожидания не получит окончательный результат обработки путем интегрирования каждого результата обработки порции данных. Устройство для обработки данных секвенирования генов и способ обработки данных секвенирования генов разделяют способ анализа (т.е. процесс анализа) данных секвенирования генов для запуска на модуле ЦП и модуле ГП по отдельности в соответствии с характеристиками этих модулей, что значительно повышает эффективность анализа данных секвенирования генов. Кроме того, в устройстве могут быть предусмотрены множество модулей ЦП и модулей ГП для обработки данных секвенирования генов, и множество модулей ГП могут одновременно выполнять вычисления с прочтениями разной длины, что может решить проблему низкой эффективности параллельной обработки в ГП.
В варианте осуществления модуль ЦП в состоянии ожидания также выполнен с возможностью сканировать каждый модуль ГП, чтобы определить количество модулей ГП в состоянии ожидания и производительность обработки данных каждого модуля ГП в состоянии ожидания, а также считывать данные секвенирования генов порциями в соответствии с количеством модулей ГП в состоянии ожидания и мощностью обработки данных каждого модуля ГП.
Более подробно, когда начинается анализ генов, модуль ЦП в состоянии ожидания сканирует модули ГП, чтобы определить количество доступных в настоящее время ГП и производительность обработки данных каждого доступного модуля ГП, для того чтобы определить объем данных секвенирования генов для считывания в этой порции данных и считывать данные секвенирования генов в зависимости от определенного количества.
Чтобы облегчить понимание этого решения, в сочетании с фиг. 1 и фиг. 2 далее представлен подробный вариант реализации конвейера способа обработки данных секвенирования генов. В этом варианте осуществления способ анализа генов представляет собой способ выравнивания генов.
В момент времени Т1 модуль ЦП в состоянии ожидания принимает данные D секвенирования генов, запускает программу задачи выравнивания и сканирует количество доступных в настоящее время модулей ГП. Количество обозначим как G. Длину последовательности данных D обозначим как L1. Модуль ЦП считывает данные D порциями. Количество считываемых данных Di в каждой порции обозначим как K, где значение K может быть скорректировано в зависимости от количества модулей ГП с помощью формулы расчета K=А * G, где А представляет количество данных, которые модуль ГП может обрабатывать за один раз (в этом варианте осуществления возможности обработки каждого модуля ГП выбраны одинаковыми). Данные Di разделяют на основе первого алгоритма для генерации множества прочтений.
В момент времени Т2 прочтения передаются в модуль ГП в состоянии ожидания через шину PCI, и в то же время модуль ЦП может обрабатывать следующую порцию данных Di+1, чтобы формировать 2-х ступенчатый конвейер.
В момент времени Т3, когда данные Di передаются и поступают в видеопамять ГП, ГП запускает второй алгоритм. В это время Di+1 переходит на ступень передачи через PCI, а модуль ЦП обрабатывает следующую порцию данных Di+2 для создания 3-ступенчатого конвейера.
В момент времени Т4, после завершения вычисления данных Di, результат вычисления возвращается обратно в модуль ЦП через PCI. В это время данные Di+1 поступают на ступень вычисления модуля ГП, данные Di+2 поступают на ступень ввода в PCI, а данные Di+3 обрабатываются модулем ЦП для создания 4-ступенчатого конвейера.
В момент времени Т5, после завершения возврата результата вычисления данных Di, результат передается модулю ЦП для использования первого алгоритма для продолжения последующих этапов алгоритма выравнивания для создания 5-ступенчатого конвейера.
В варианте осуществления способ анализа генов содержит алгоритм выравнивания генов, алгоритм Dotplot, алгоритм blast, алгоритм разделения вокруг медоидов (РАМ), алгоритм скрытой марковской модели (НММ) и алгоритм логического вывода на основе искусственного интеллекта (AI).
Более подробно, алгоритм Dotplot и алгоритм blast представляют собой разновидности алгоритма выравнивания последовательностей.
Алгоритм РАМ - это алгоритм кластеризации для интеллектуального анализа данных, который можно использовать при секвенировании одной клетки для анализа подвидов клеток.
Алгоритм НММ, скрытая марковская модель, представляет собой статистическую модель, которая используется для описания марковского процесса, включающего скрытые неизвестные параметры, и может использоваться для прогнозирования целевых генов.
Алгоритм логического вывода AI (DeepVariant) - это алгоритм глубокого обучения, который можно использовать для выявления генных мутаций. Опционально, алгоритм логического вывода AI может быть алгоритмом вывода, относящимся к сверточной нейронной сети (CNN) или рекуррентной нейронной сети (RNN).
Опционально, когда алгоритм анализа генов представляет собой алгоритм Dotplot, алгоритм blast или алгоритм РАМ, обычно необходимо сначала выполнить CUDA для этого алгоритма. Выполнение CUDA в отношении алгоритма делает способ более подходящим для работы в устройстве для обработки данных секвенирования генов согласно вариантам осуществления настоящего изобретения.
В варианте осуществления алгоритм выравнивания генов содержит алгоритм BWT, и первый алгоритм содержит алгоритм разрезания по опорным точкам. Модуль ЦП в состоянии ожидания выполнен с возможностью выполнять операцию позиционирования опорных точек в порциях данных секвенирования генов с помощью алгоритма разрезания по опорным точкам и получать множество прочтений путем расширения на расстояние N × bp вперед и назад, соответственно, с опорной точкой в качестве центра и делением каждой порции данных секвенирования генов на отрезки длиной (2N+1) × bp на основе инструкции NEON, где N - положительное целое число.
В варианте осуществления получение множества прочтений содержит: получение множества прочтений с использованием следующей формулы:
(2*N+1) *x<L
где х - количество опорных точек, N - количество bp расширения, a L -длина каждой порции данных секвенирования генов.
Опционально, алгоритм выравнивания генов может быть алгоритмом BWT, первый алгоритм может быть алгоритмом разрезания по опорным точкам и алгоритмом преобразования матрицы BWT, а второй алгоритм является алгоритмом хэширования. Как показано на фиг. 3, модуль ЦП в состоянии ожидания обрабатывает данные Di на основе первого алгоритма (то есть алгоритма разрезания по опорным точкам). Модуль ЦП в состоянии ожидания выполняет операцию позиционирования опорных точек для каждой порции данных секвенирования генов (прочтений) длиной L и получает множество коротких прочтений, имеющих длину 2N+1, путем расширения на расстояние N × bp вперед и назад, соответственно, делит каждую порцию данных секвенирования генов на отрезки длиной 2N+1 на основе инструкции NEON и передает их. Когда количество опорных точек равно х, это число, то есть N, связано со следующей формулой:
(2*N+1)*x<L
где х - количество опорных точек, N - количество bp расширения, a L -длина каждой порции данных секвенирования генов. Множество прочтений могут быть получены вышеупомянутым способом, который подходит для работы в модуле ГП.
В варианте осуществления второй алгоритм представляет собой алгоритм хэширования. Модуль ГП в состоянии ожидания выполняет операцию хэширования для каждого из множества прочтений на основе алгоритма хэширования для получения результата вычисления хэша и отправляет результат вычисления хэша модулю ЦП в состоянии ожидания. Результат вычисления хэша - это значение матрицы алгоритма BWT, используемое для вычисления матрицы алгоритма BWT.
Более подробно, алгоритм выравнивания генов может быть алгоритмом BWT, первый алгоритм может быть алгоритмом разрезания по опорным точкам и алгоритмом преобразования матрицы BWT, а второй алгоритм может быть алгоритмом хэширования. Как показано на фиг. 4, х * K прочтений, вычисленных на основе первого алгоритма, передаются в видеопамять модуля ГП в состоянии ожидания, где K - количество частей данных Di. Количество прочтений положительно коррелирует с общим объемом видеопамяти множества модулей ГП. Поскольку алгоритм хэширования способствует работе SIMT-архитектуры модуля ГП, функция ядра ГП используется для выполнения операции хэширования в отношении множества прочтений для получения результатов вычисления хэша, а результаты вычисления хэша отправляются в модуль ЦП в состоянии ожидания. Результатом вычисления хэша являются значения матрицы алгоритма BWT, используемые для вычисления матрицы алгоритма BWT. По сравнению с другими традиционными вычислениями (такими как алгоритм вычисления положения k-меров), использование алгоритма хэширования может значительно сэкономить место в памяти.
В варианте осуществления первый алгоритм может быть алгоритмом преобразования матрицы BWT. Модуль ЦП в состоянии ожидания также выполнен с возможностью получать результаты преобразования BWT для прочтений путем переноса матрицы алгоритма BWT на основе алгоритма преобразования матрицы BWT.
Более подробно, алгоритм выравнивания генов может быть алгоритмом BWT, а первый алгоритм может быть алгоритмом разрезания по опорным точкам и алгоритмом преобразования матрицы BWT. После того, как модуль ГП отправляет результаты вычисления хэша модулю ЦП в состоянии ожидания, модуль ЦП выполняет операцию вычисления для матрицы алгоритма BWT, определяя результаты вычисления хэша как значения матрицы алгоритма BWT, и выполняет операцию преобразования на матрице алгоритма BWT на основе алгоритма преобразования матрицы BWT, чтобы получить результат преобразования BWT для прочтений. Опционально, взаимосвязь между результатами вычисления хэша и матрицей алгоритма BWT следующая: h=Hash (х, r), Y=BWT (h, r), где h - результат вычисления хэша, Y - матрица алгоритма BWT, а г - прочтение. Этот способ позволяет быстро и точно получить результат преобразования BWT для прочтений, тем самым быстро завершая сжатие данных секвенирования генов, что более удобно для последующей обработки.
В варианте осуществления алгоритм выравнивания содержит алгоритм Смита-Уотермана, а второй алгоритм содержит алгоритм матрицы оценок (scoring matrix algorithm). Модуль ГП в состоянии ожидания вычисляет матрицу оценок Смита-Ватермана на основе алгоритма матрицы оценок, множества прочтений и эталонной последовательности биологического вида и отправляет матрицу оценок Смита-Уотермана в модуль ЦП в состоянии ожидания.
В варианте осуществления получение матрицы оценок Смита-Уотермана содержит получение матрицы оценок Смита-Уотермана с использованием следующих формул:
M=R*C,
R=a*L2+b
где М представляет собой матрицу оценок Смита-Уотермана, R представляет собой длину участка-кандидата эталонной последовательности вида, С представляет длину прочтения, генерированного с помощью скрининга и сплайсинга множества прочтений, полученных от модуля ЦП в состоянии ожидания, L представляет длину каждой порции данных секвенирования генов, а и b - константы.
Более подробно, традиционный алгоритм Смита-Уотермана работает в ГП с низкой эффективностью и не может быть напрямую использован в устройстве для обработки данных секвенирования генов согласно вариантам осуществления настоящего изобретения. Таким образом, алгоритм Смита-Уотермана улучшается. В частности, в алгоритме Смита-Уотермана есть матрица оценок, размер которой равен R * С. Процесс вычисления матрицы оценок выполняется модулем ГП, и в это время второй алгоритм является алгоритмом матрицы оценок. Матрица оценок Смита-Уотермана получается с использованием следующих формул:
M=R*C:
R=a*L2+b
где М представляет собой матрицу оценок Смита-Уотермана, R представляет собой длину участка-кандидата эталонной последовательности вида, С представляет длину прочтения, генерированного с помощью скрининга и сплайсинга множества прочтений, полученных от модуля ЦП в состоянии ожидания, L представляет длину данных порции секвенирования генов, а и b - константы. Кроме того, длина С связана с результатом вычисления хэша, вычисленным модулем ГП в алгоритме BWT. Используя этот метод, можно улучшить традиционный алгоритм Смита-Уотермана, сделав его пригодным для работы в ГП с высокой производительностью.
В соответствии с вышеупомянутым устройством для обработки данных секвенирования генов, варианты осуществления изобретения также предоставляют способ обработки данных секвенирования генов.
Как показано на фиг. 5, способ обработки данных секвенирования генов применяется в устройстве для обработки данных секвенирования генов. Способ содержит следующее.
В блоке S1 модуль ЦП в состоянии ожидания получает порции данных секвенирования генов, считывая данные секвенирования генов порциями.
В блоке S2 модуль ЦП в состоянии ожидания получает первый алгоритм и второй алгоритм путем разделения способа анализа генов.
В блоке S3 модуль ЦП в состоянии ожидания получает множество прочтений путем разделения каждой порции данных секвенирования генов на основе первого алгоритма, и отправляет множество прочтений и второй алгоритм в модуль ГП в состоянии ожидания.
В блоке S4 модуль ГП в состоянии ожидания выполняет вычисление для каждого прочтения на основе второго алгоритма и отправляет соответствующие результаты вычислений модулю ЦП в состоянии ожидания.
В блоке S5 модуль ЦП в состоянии ожидания получает результат обработки порции данных на основе результатов вычислений и первого алгоритма.
Блоки с S1 по S5 повторяются до тех пор, пока обработка данных секвенирования генов не будет завершена, и модуль ЦП в состоянии ожидания не получит окончательный результат обработки путем интегрирования результатов обработки порций данных.
Более подробно, поскольку при одном секвенировании генерируется большой объем данных, и объем данных секвенирования генов относительно велик, данные можно анализировать и обрабатывать порциями, тем самым избегая перегрузки при передаче данных. Обозначим i-ю порцию данных секвенирования генов, считанную модулем ЦП в состоянии ожидания, как Di. Модуль ЦП в состоянии ожидания считывает данные Di секвенирования генов и разделяет способ анализа генов для получения первого алгоритма и второго алгоритма. Согласно первому алгоритму, данные Di секвенирования генов разделяют на множество прочтений, и множество прочтений и второй алгоритм отправляют в модуль ГП в состоянии ожидания. Модуль ГП в состоянии ожидания выполняет вычисление для каждого прочтения на основе второго алгоритма и отправляет результат вычисления модулю ЦП в состоянии ожидания. Модуль ЦП в состоянии ожидания получает результат обработки порции данных на основе результатов вычислений и первого алгоритма. Кроме того, модуль ЦП в состоянии ожидания считывает данные секвенирования генов Di+1, делит данные секвенирования генов Di+1 и отправляет прочтения, полученные путем разделения данных секвенирования генов Di+1, в модуль ГП в состоянии ожидания. Di+1 представляет прочитанную (i+1)-ю порцию данных секвенирования генов. Прочтения данных Di+1 секвенирования генов после разделения модулем ГП в состоянии ожидания обрабатывают, а результаты обработки отправляют в модуль ЦП в состоянии ожидания. Модуль ЦП в состоянии ожидания и модуль ГП в состоянии ожидания продолжают считывать данные секвенирования генов, делить, передавать, вычислять и возвращать (то есть повторять шаги S1-S5) до тех пор, пока обработка данных секвенирования генов не будет завершена. В этом процессе создается конвейер между модулем ЦП в состоянии ожидания и модулем ГП в состоянии ожидания.
В варианте осуществления модуль ЦП в состоянии ожидания сканирует каждый модуль ГП, чтобы определить количество модулей ГП в состоянии ожидания и производительность обработки данных каждого модуля ГП в состоянии ожидания, чтобы считывать данные секвенирования генов порциями на основе количества модулей ГП в состоянии ожидания и производительности обработки данных каждого из модулей ГП в состоянии ожидания.
В варианте осуществления способ анализа генов содержит алгоритм выравнивания генов, алгоритм Dotplot, алгоритм blast, алгоритм РАМ, алгоритм НММ и алгоритм логического вывода на основе AI.
В варианте осуществления алгоритм выравнивания генов содержит алгоритм BWT, а первый алгоритм содержит алгоритм разрезания по опорным точкам. Модуль ЦП в состоянии ожидания выполняет операцию позиционирования опорных точек на порциях данных секвенирования генов с помощью алгоритма разрезания по опорным точкам и получает множество прочтений путем расширения на расстояние N × bp вперед и назад, соответственно, с опорной точкой в качестве центра и деления каждой порции данных секвенирования генов на отрезки длиной (2N+1) × bp на основе инструкции NEON, где N - положительное целое число.
В варианте осуществления получение множества прочтений содержит: получение множества прочтений с использованием следующей формулы:
(2*N+1)*x<L
где х - количество опорных точек, N - количество bp расширения, a L -длина каждой порции данных секвенирования генов.
В варианте осуществления второй алгоритм представляет собой алгоритм хэширования. Модуль ГП в состоянии ожидания выполняет операцию хэширования для каждого из множества прочтений на основе алгоритма хэширования для получения результата вычисления хэша и отправляет результат вычисления хэша модулю ЦП в состоянии ожидания. Результат вычисления хэша - это значение матрицы алгоритма BWT, используемое для вычисления матрицы алгоритма BWT.
В варианте осуществления первый алгоритм дополнительно содержит алгоритм преобразования матрицы BWT. Модуль ЦП в состоянии ожидания выполнен с возможностью выполнять операцию преобразования в отношении матрицы алгоритма BWT на основе алгоритма преобразования матрицы BWT, чтобы получить результат преобразования BWT для множества прочтений.
В варианте осуществления алгоритм выравнивания содержит алгоритм Смита-Уотермана, а второй алгоритм содержит алгоритм матрицы оценок. Модуль ГП в состоянии ожидания дополнительно выполнен с возможностью получать матрицу оценок Смита-Уотермана на основе алгоритма матрицы оценок, множества прочтений и эталонной последовательности вида и отправлять матрицу оценок Смита-Уотермана в модуль ЦП в режиме ожидания.
В одном варианте осуществления получение матрицы оценок Смита-Уотермана содержит: получение матрицы оценок Смита-Уотермана с использованием следующих формул:
M=R*C,
R=a*L2+b
где М представляет собой матрицу оценок Смита-Уотермана, R представляет собой длину участка-кандидата эталонной последовательности вида, С представляет длину прочтения, сгенерированного с помощью скрининга и сплайсинга множества прочтений, полученных от модуля ЦП в состоянии ожидания, L представляет длину каждой порции данных секвенирования генов, а и b - константы.
Конкретные ограничения способа обработки данных секвенирования генов аналогичны рассмотренным выше вариантам осуществления устройства для обработки данных секвенирования генов, и здесь повторяться не будут.
Хотя были показаны и описаны примеры осуществления, специалистам в данной области техники будет понятно, что эти варианты осуществления не могут быть истолкованы как ограничивающие изобретение, и изменения, альтернативы и модификации могут быть сделаны в вариантах осуществления в объеме изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ АНАЛИЗА И УСТРОЙСТВО ДЛЯ СЕКВЕНИРОВАНИЯ ГЕНОВ, НАКОПИТЕЛЬ ДЛЯ ХРАНЕНИЯ ДАННЫХ И ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО | 2022 |
|
RU2821785C2 |
| ГЕНОМНАЯ ИНФРАСТРУКТУРА ДЛЯ ЛОКАЛЬНОЙ И ОБЛАЧНОЙ ОБРАБОТКИ И АНАЛИЗА ДНК И РНК | 2017 |
|
RU2804029C2 |
| ГЕНОМНАЯ ИНФРАСТРУКТУРА ДЛЯ ЛОКАЛЬНОЙ И ОБЛАЧНОЙ ОБРАБОТКИ И АНАЛИЗА ДНК И РНК | 2017 |
|
RU2761066C2 |
| СИСТЕМА И СПОСОБ ВТОРИЧНОГО АНАЛИЗА ДАННЫХ СЕКВЕНИРОВАНИЯ НУКЛЕОТИДОВ | 2017 |
|
RU2741807C2 |
| СПОСОБ, УСТРОЙСТВО И КОМПЬЮТЕРНОЕ УСТРОЙСТВО ГЕННОГО АНАЛИЗА, ОСНОВАННЫЕ НА СОВМЕСТНО ИСПОЛЬЗУЕМОЙ ПАМЯТИ | 2020 |
|
RU2792228C1 |
| Способ обработки данных полногеномного секвенирования | 2023 |
|
RU2806429C1 |
| СПОСОБ И УСТРОЙСТВО ОПРЕДЕЛЕНИЯ СТЕПЕНИ ГЕННОЙ АССОЦИАЦИИ | 2021 |
|
RU2790285C1 |
| БИОИНФОРМАЦИОННЫЕ СИСТЕМЫ, УСТРОЙСТВА И СПОСОБЫ ДЛЯ ВЫПОЛНЕНИЯ ВТОРИЧНОЙ И/ИЛИ ТРЕТИЧНОЙ ОБРАБОТКИ | 2017 |
|
RU2799750C2 |
| БИОИНФОРМАЦИОННЫЕ СИСТЕМЫ,УСТРОЙСТВА И СПОСОБЫ ВЫПОЛНЕНИЯ ВТОРИЧНОЙ И/ИЛИ ТРЕТИЧНОЙ ОБРАБОТКИ | 2017 |
|
RU2750706C2 |
| Система обработки данных полногеномного секвенирования | 2023 |
|
RU2804535C1 |
Изобретение относится к биоинформатике. Представлен способ обработки данных секвенирования генов. Способ применяется в устройстве для обработки данных секвенирования генов. Устройство содержит архитектуру усовершенствованной машины RISC (ARM), архитектуру графического процессора (ГП) и шину соединения периферийных компонентов (PCI); архитектура ARM содержит по меньшей мере один модуль центрального процессора (ЦП); архитектура ГП содержит по меньшей мере один модуль ГП. Способ включает: получение модулем ЦП в состоянии ожидания порций данных секвенирования генов путем считывания данных секвенирования генов порциями; получение, модулем ЦП в состоянии ожидания, первого алгоритма и второго алгоритма путем разделения способа анализа генов; получение, модулем ЦП в состоянии ожидания, множества прочтений посредством разделения каждой порции данных секвенирования генов на основе первого алгоритма и отправку множества прочтений и второго алгоритма в модуль ГП в состоянии ожидания; выполнение модулем ГП в состоянии ожидания вычисления для каждого прочтения на основе второго алгоритма и отправку соответствующих результатов вычислений модулю ЦП в состоянии ожидания; и получение, модулем ЦП в состоянии ожидания, результата обработки порции данных на основе результатов вычислений и первого алгоритма. Этот способ разделяет способ анализа для выполнения частей способа в модуле ЦП и модуле ГП, что значительно повышает эффективность анализа данных. 2 н. и 16 з.п. ф-лы, 5 ил.
1. Способ обработки данных секвенирования генов, применяемый в устройстве для обработки данных секвенирования генов, которое имеет гетерогенную многоядерную архитектуру, содержащую архитектуру усовершенствованной машины RISC (ARM), архитектуру графического процессора (ГП) и шину соединения периферийных компонентов (PCI); при этом архитектура ARM связана с архитектурой ГП через шину PCI; и архитектура ARM содержит по меньшей мере один модуль центрального процессора (ЦП); а архитектура ГП содержит по меньшей мере один модуль ГП; и способ содержит:
S1, получение, модулем ЦП в состоянии ожидания, порций данных секвенирования генов путем считывания данных секвенирования генов порциями;
S2, получение, модулем ЦП в состоянии ожидания, первого алгоритма и второго алгоритма путем разделения способа анализа генов на основе того, требуются ли логические заключения или существует ли зависимость между результатами вычислений;
S3, получение, модулем ЦП в состоянии ожидания, множества прочтений путем разделения каждой порции данных секвенирования генов на основе первого алгоритма и отправку множества прочтений и второго алгоритма модулю ГП в состоянии ожидания;
S4, выполнение, модулем ГП в состоянии ожидания, вычисления для каждого прочтения на основе второго алгоритма и отправку соответствующих результатов вычислений модулю ЦП в состоянии ожидания;
S5, получение, модулем ЦП в состоянии ожидания, результата обработки порции данных на основе результатов вычислений и первого алгоритма; и
повторение шагов S1-S5 до тех пор, пока обработка данных секвенирования генов не будет завершена, и получение, модулем ЦП в состоянии ожидания, окончательного результата обработки путем интегрирования результатов обработки порций данных.
2. Способ по п.1, в котором модуль ЦП в состоянии ожидания определяет количество модулей ГП, находящихся в состоянии ожидания, и объем обработки данных, соответствующий каждому модулю ГП в состоянии ожидания, путем сканирования по меньшей мере одного модуля, и считывает данные секвенирования генов порциями на основании количества модулей ГП, находящихся в состоянии ожидания, и соответствующего объема обработки данных.
3. Способ по п.1, в котором способ анализа генов содержит алгоритм выравнивания генов, алгоритм Dotplot, алгоритм blast, алгоритм разделения вокруг медоидов (PAM), алгоритм скрытой марковской модели (HMM) и алгоритм логического вывода на основе искусственного интеллекта (AI).
4. Способ по п.3, в котором алгоритм выравнивания генов содержит алгоритм преобразования Барроуза-Уиллера (BWT), а первый алгоритм содержит алгоритм разрезания по опорным точкам; и способ дополнительно содержит
выполнение, модулем ЦП в состоянии ожидания, операции позиционирования опорных точек для каждой порции данных секвенирования генов с помощью алгоритма разрезания по опорным точкам и получение множества прочтений путем расширения на расстояние N × bp вперед и назад, соответственно, с опорной точкой в качестве центра и деления каждой порции данных секвенирования генов на отрезки длиной (2N + 1) × bp на основе инструкции NEON, где N - положительное целое число.
5. Способ по п.4, в котором получение множества прочтений содержит получение множества прочтений с использованием следующей формулы:
(2*N+1)*x<L,
где x - количество опорных точек, N - количество bp расширения, а L - длина каждой порции данных секвенирования генов.
6. Способ по п.3 или 4, в котором второй алгоритм представляет собой алгоритм хэширования; и способ содержит
выполнение, модулем ГП в состоянии ожидания, операции хэширования для каждого из множества прочтений на основе алгоритма хэширования для получения результата вычисления хэша и отправку результата вычисления хэша модулю ЦП в состоянии ожидания, при этом результат вычисления хэша - это значение матрицы алгоритма BWT, используемое для вычисления матрицы алгоритма BWT.
7. Способ по п.6, в котором первый алгоритм также содержит алгоритм преобразования матрицы BWT; и способ дополнительно содержит
выполнение, модулем ЦП в состоянии ожидания, операции преобразования матрицы алгоритма BWT на основе алгоритма преобразования матрицы BWT для получения результата преобразования BWT для множества прочтений.
8. Способ по п.3, в котором алгоритм выравнивания содержит алгоритм Смита-Уотермана, а второй алгоритм содержит алгоритм матрицы оценок; и способ дополнительно содержит
получение, модулем ГП в состоянии ожидания, матрицы оценок Смита-Уотермана на основе алгоритма матрицы оценок, множества прочтений и эталонной последовательности вида и отправку матрицы оценок Смита-Уотермана в модуль ЦП в состоянии ожидания.
9. Способ по п.8, в котором получение матрицы оценок Смита-Уотермана содержит
получение матрицы оценок Смита-Уотермана по следующим формулам:
M=R*C;
R=a*L2+b,
где M - матрица оценок Смита-Уотермана, R - длина участка-кандидата эталонной последовательности вида, C - длина прочтения, генерированного путем скрининга и сплайсинга прочтений, полученных от модуля ЦП в состоянии ожидания, L - длина каждой порции данных секвенирования генов, a и b - константы.
10. Устройство для обработки данных секвенирования генов, которое имеет гетерогенную многоядерную архитектуру, содержащую архитектуру усовершенствованной машины RISC (ARM), архитектуру графического процессора (ГП) и шину соединения периферийных компонентов (PCI); при этом архитектура ARM связана с архитектурой ГП через шину PCI; и архитектура ARM содержит по меньшей мере один модуль центрального процессора (ЦП); а архитектура ГП содержит по меньшей мере один модуль ГП,
при этом модуль ЦП в состоянии ожидания выполнен с возможностью получения порций данных секвенирования генов путем считывания данных секвенирования генов порциями, получения первого алгоритма и второго алгоритма путем разделения способа анализа генов на основе того, требуются ли логические заключения или существует ли зависимость между результатами вычислений, получения множества прочтений путем разделения каждой порции данных секвенирования генов на основе первого алгоритма и отправки множества прочтений и второго алгоритма модулю ГП в состоянии ожидания,
а модуль ГП в состоянии ожидания выполнен с возможностью выполнения вычисления для каждого прочтения на основе второго алгоритма и отправки соответствующих результатов вычислений модулю ЦП в состоянии ожидания,
причем модуль ЦП в состоянии ожидания выполнен с возможностью получения результата обработки порции данных на основе результатов вычислений и первого алгоритма после того, как обработка данных секвенирования генов завершена, и получения окончательного результата обработки путем интегрирования результатов обработки порций данных.
11. Устройство по п.10, в котором модуль ЦП в состоянии ожидания выполнен с возможностью определения количества модулей ГП, находящихся в состоянии ожидания, и объема обработки данных, соответствующего каждому модулю ГП в состоянии ожидания, путем сканирования по меньшей мере одного модуля, и считывания данных секвенирования генов порциями на основании количества модулей ГП, находящихся в состоянии ожидания, и соответствующего объема обработки данных.
12. Устройство по п.10, в котором упомянутый способ анализа генов содержит алгоритм выравнивания генов, алгоритм Dotplot, алгоритм blast, алгоритм разделения вокруг медоидов (PAM), алгоритм скрытой марковской модели (HMM) и алгоритм логического вывода на основе искусственного интеллекта (AI).
13. Устройство по п.12, в котором алгоритм выравнивания генов содержит алгоритм преобразования Барроуза-Уиллера (BWT), а первый алгоритм содержит алгоритм разрезания по опорным точкам, и
модуль ЦП в состоянии ожидания выполнен с возможностью выполнения операции позиционирования опорных точек для каждой порции данных секвенирования генов с помощью алгоритма разрезания по опорным точкам и получения множества прочтений путем расширения на расстояние N × bp вперед и назад, соответственно, с опорной точкой в качестве центра и деления каждой порции данных секвенирования генов на отрезки длиной (2N + 1) × bp на основе инструкции NEON, где N - положительное целое число.
14. Устройство по п.13, в котором модуль ЦП в состоянии ожидания выполнен с возможностью получения множества прочтений с использованием следующей формулы:
(2*N+1)*x<L,
где x - количество опорных точек, N - количество bp расширения, а L - длина каждой порции данных секвенирования генов.
15. Устройство по п.12 или 13, в котором второй алгоритм представляет собой алгоритм хэширования, и
модуль ГП в состоянии ожидания выполнен с возможностью выполнения операции хэширования для каждого из множества прочтений на основе алгоритма хэширования для получения результата вычисления хэша и отправки результата вычисления хэша модулю ЦП в состоянии ожидания, при этом результат вычисления хэша - это значение матрицы алгоритма BWT, используемое для вычисления матрицы алгоритма BWT.
16. Устройство по п.15, в котором первый алгоритм также содержит алгоритм преобразования матрицы BWT, и
модуль ЦП в состоянии ожидания выполнен с возможностью выполнения операции преобразования матрицы алгоритма BWT на основе алгоритма преобразования матрицы BWT для получения результата преобразования BWT для множества прочтений.
17. Устройство по п.12, в котором алгоритм выравнивания содержит алгоритм Смита-Уотермана, а второй алгоритм содержит алгоритм матрицы оценок, и
модуль ГП в состоянии ожидания выполнен с возможностью получения матрицы оценок Смита-Уотермана на основе алгоритма матрицы оценок, множества прочтений и эталонной последовательности вида и отправки матрицы оценок Смита-Уотермана в модуль ЦП в режиме ожидания.
18. Устройство по п.17, в котором модуль ГП в состоянии ожидания выполнен с возможностью получения матрицы оценок Смита-Уотермана по следующим формулам:
M=R*C;
R=a*L2+b,
где M - матрица оценок Смита-Уотермана, R - длина участка-кандидата эталонной последовательности вида, C - длина прочтения, генерированного путем скрининга и сплайсинга прочтений, полученных от модуля ЦП в состоянии ожидания, L - длина каждой порции данных секвенирования генов, a и b - константы.
| CN 104239732 А, 24.12.2014 | |||
| CN 0110473593 А, 19.11.2019 | |||
| CN 0104504303 В, 28.09.2018 | |||
| CN 0110135584 А, 16.08.2019 | |||
| EP 3428798 В1, 02.09.2020 | |||
| СПОСОБ СЕКВЕНИРОВАНИЯ ДНК И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ (ВАРИАНТЫ) | 2013 |
|
RU2539038C1 |
