[0001] В данной заявке испрашивается приоритет по патентной заявке Китая № 202110698855.6, поданной в Государственную администрацию Китая по интеллектуальной собственности 23 июня 2021 года, которая включена в настоящий документ в полном объеме посредством ссылки.
ОБЛАСТЬ ТЕХНИКИ
[0002] Настоящее изобретение относится к области биологической информации и, в частности, к способу анализа и устройству для секвенирования генов, накопителю для хранения данных и вычислительному устройству.
УРОВЕНЬ ТЕХНИКИ
[0003] С момента своего появления технология секвенирования ДНК играет важную роль в развитии молекулярной биологии. Эта область техники претерпела огромные изменения — от ручного секвенирования, разработанного Фредериком Сэнгером, и автоматизированных секвенаторов первого поколения, основанных на секвенировании Сэнгера, до современных платформ секвенирования нового поколения.
[0004] Процесс секвенирования у платформ секвенирования нового поколения в основном включает в себя следующие этапы: во время каждого цикла секвенирования происходит одновременное добавление в проточные каналы четырех нуклеотидов, меченных разными флуорофорами и ДНК-полимеразами, для удлинения цепи ДНК в соответствии с принципом комплементарного сопряжения; получение флуоресцентных изображений со специфичным для оснований флуоресцентным мечением, которое показывает, какие нуклеотиды вновь добавлены к цепи в этом цикле, чтобы получить последовательности ДНК в этом положении в матрице; и далее осуществляется следующий цикл реакции. Такой процесс повторяют несколько раз для получения множества последовательностей ДНК. Например, последовательность ДНК, включающая в себя 50 оснований, может быть получена путем выполнения 50 циклов секвенирования. Одиночная последовательность, полученная с помощью этого способа, является очень короткой, поэтому ее также называют короткой последовательностью.
[0005] В связи с этим в платформах секвенирования нового поколения биохимические операции и визуализацию необходимо завершить до распознавания оснований, а результаты распознавания должны быть преобразованы в другие формы для хранения. После этого сохраненные файлы передают на основной накопитель для выполнения контроля качества данных, проверки информации об образце и информации о секвенировании, при этом данные архивируют с применением вспомогательного накопителя. Такое секвенирование характеризуется значительными затратами времени и имеет низкую эффективность передачи, что приводит к относительно медленному процессу анализа.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0006] Настоящее изобретение имеет своей целью устранение по меньшей мере одного из вышеупомянутых технических недостатков, в частности, технических недостатков предшествующего уровня техники, таких как значительные затраты времени на секвенирование и низкая эффективность передачи, которые в дальнейшем приводят к относительно медленному процессу анализа.
[0007] В первом аспекте настоящее изобретение предлагает способ анализа для секвенирования генов. Указанный способ анализа для секвенирования генов включает в себя следующие этапы: получение данных фрагмента, передаваемых в реальном времени от платформы секвенирования, причем указанные данные фрагмента представляют собой набор коротких последовательностей, считываемых в библиотеке секвенирования после выполнения по меньшей мере одного цикла секвенирования; ввод данных фрагмента в запоминающее устройство; и выполнение, с помощью вызова программы инкапсуляции, предварительно установленной в запоминающем устройстве, обработки данных и анализа распознаванием данных фрагмента для получения соответствующего результата анализа, при этом программа инкапсуляции является пользовательской программой.
[0008] Согласно варианту осуществления настоящего изобретения, вышеупомянутый способ анализа для секвенирования генов может дополнительно включать в себя по меньшей мере один из следующих дополнительных технических признаков.
[0009] Согласно варианту осуществления настоящего изобретения, этап получения данных фрагмента включает в себя: определение размера фрагмента; и выполнение фрагментации, на основе размера фрагмента, всех нефрагментированных коротких последовательностей, передаваемых в данный момент от платформы секвенирования и считанных после одного цикла секвенирования, причем набор фрагментированных коротких последовательностей используют в качестве данных фрагмента.
[0010] Согласно варианту осуществления настоящего изобретения, этап определения размера фрагмента включает в себя: получение информации о текущем состоянии бездействия центрального процессора (ЦП); и корректировку размера фрагмента, исходя из текущего состояния бездействия ЦП.
[0011] Согласно варианту осуществления настоящего изобретения, программа инкапсуляции включает в себя программу контроля качества данных, программу обработки данных и программу анализа распознаванием. Этап выполнения с помощью вызова программы инкапсуляции, предварительно установленной в запоминающем устройстве, обработки данных и анализа распознаванием данных фрагмента для получения соответствующего результата анализа включает в себя: выполнение, путем вызова программы контроля качества данных, предварительно установленной в запоминающем устройстве, контроль качества обработки данных фрагмента для получения результата контроля качества; выполнение обработки данных, с помощью вызова предварительно установленной в запоминающем устройстве программы обработки данных, по результату контроля качества для получения результата обработки; и выполнение с помощью вызова программы анализа распознаванием, предварительно установленной в запоминающем устройстве, анализа распознаванием результата обработки для получения окончательного результата анализа.
[0012] Согласно варианту осуществления настоящего изобретения, выполнение этапа контроля качества обработки данных фрагмента с помощью вызова программы контроля качества данных, предварительно установленной в запоминающем устройстве, включает в себя: вызов программы контроля качества данных, предварительно установленной в запоминающем устройстве, вычисление коэффициента погрешности положения коротких последовательностей в данных фрагмента, статистический анализ распределения оснований в данных фрагмента и/или удаление низкокачественных оснований из данных фрагмента, при этом низкокачественные основания представляют собой основания с качеством ниже порогового уровня качества.
[0013] Согласно варианту осуществления настоящего изобретения, этап выполнения обработки данных по результату контроля качества с помощью вызова программы обработки данных, предварительно установленной в запоминающем устройстве, включает в себя: выполнение путем вызова программы обработки данных, предварительно установленной в запоминающем устройстве, по меньшей мере одного из сопоставления, упорядочивания, дедупликации и повторного сопоставления по короткой последовательности в результате контроля качества.
[0014] Согласно варианту осуществления настоящего изобретения, этап выполнения по меньшей мере одного из сопоставления, упорядочивания, дедупликации и повторного сопоставления по короткой последовательности в результате контроля качества путем вызова предварительно установленной в запоминающем устройстве программы обработки данных, включает в себя: выполнение, путем вызова предварительно установленной в запоминающем устройстве программы обработки данных, сопоставления между короткой последовательностью в результате контроля качества и референсным геном для определения положения короткой последовательности в референсном гене; определение метки положения короткой последовательности, исходя из положения короткой последовательности в референсном гене; определение среди предварительно установленных в запоминающем устройстве потоков выполнения целевого потока выполнения, который в данный момент находится в незанятом состоянии; и выполнение, путем вызова целевого потока выполнения и с учетом метки положения короткой последовательности, по меньшей мере одного из упорядочивания, дедупликации и повторного сопоставления по короткой последовательности.
[0015] Согласно варианту осуществления настоящего изобретения, этап выполнения анализа распознаванием результата обработки с помощью вызова программы анализа распознаванием, предварительно установленной в запоминающем устройстве, включает в себя: выполнение, путем вызова программы анализа распознаванием, предварительно установленной в запоминающем устройстве, распознавания мутации и интерпретации результата обработки.
[0016] Во втором аспекте настоящее изобретение дополнительно предлагает устройство анализа для секвенирования генов. Указанное устройство анализа для секвенирования генов включает в себя: модуль получения данных фрагмента, выполненный с возможностью получения данных фрагмента, передаваемых в реальном времени от платформы секвенирования, причем указанные данные фрагмента представляют собой набор коротких последовательностей, считываемых в библиотеке секвенирования после выполнения по меньшей мере одного цикла секвенирования; модуль передачи данных фрагмента, выполненный с возможностью ввода данных фрагмента в запоминающее устройство; и обрабатывающий аналитический модуль, выполненный с возможностью выполнения, с помощью вызова программы инкапсуляции, предварительно установленной в запоминающем устройстве, обработки данных и анализа распознаванием данных фрагмента для получения соответствующего результата анализа, при этом программа инкапсуляции является пользовательской программой.
[0017] В третьем аспекте настоящее изобретение также предлагает накопитель данных, на котором хранятся машиночитаемые команды. Машиночитаемые команды при выполнении одним или несколькими процессорами предписывают указанным одному или нескольким процессорам выполнение этапов способа анализа для секвенирования генов, как описано в любом из вышеприведенных вариантов осуществления.
[0018] В четвертом аспекте настоящее изобретение также предлагает компьютерное устройство, имеющее хранящиеся в нем машиночитаемые команды. Машиночитаемые команды при выполнении одним или несколькими процессорами предписывают указанным одному или нескольким процессорам выполнение этапов способа анализа для секвенирования генов, как описано в любом из вышеприведенных вариантов осуществления.
[0019] Из приведенных выше технических решений видно, что варианты осуществления настоящего изобретения имеют следующие преимущества.
[0020] В способе анализа и устройстве для секвенирования генов, накопителе для хранения данных и вычислительном устройстве по настоящему изобретению короткие последовательности, передаваемые в реальном времени от платформы секвенирования, сначала фрагментируют для выполнения соответствующей обработки фрагментов, а затем данные фрагмента вводят в запоминающее устройство. Таким образом, предварительно загруженная в запоминающее устройство программа инкапсуляции может быть вызвана для выполнения биоинформационного анализа данных фрагмента с целью получения соответствующего результата анализа. Такой процесс позволяет получать данные секвенирования фрагмента от платформы секвенирования в режиме реального времени и выполнять секвенирование и анализ данных фрагмента вместо того, чтобы выполнять анализ обработки только после того, как платформа секвенирования завершает секвенирование и полные результаты секвенирования переданы на соответствующую платформу. Таким образом, настоящее изобретение позволяет в целом ускорить секвенирование и анализ. Кроме того, данные для анализа представляют собой данные фрагмента, которые могут быть переданы быстрее при меньших затратах времени по сравнению с полным результатом секвенирования.
[0021] Кроме того, процесс анализа по настоящему изобретению выполняют с помощью программы инкапсуляции, предварительно установленной в запоминающем устройстве. Таким образом, нет необходимости передавать данные секвенирования для обработки на другую платформу, что эффективно снижает нагрузку ввода-вывода и расход памяти, за счет чего дополнительно повышается эффективность работы оборудования и срок его службы.
ОПИСАНИЕ ГРАФИЧЕСКИХ МАТЕРИАЛОВ
[0022] Для полного разъяснения технических решений вариантов осуществления настоящего изобретения или предшествующего уровня техники ниже приведены прилагаемые графические материалы, требуемые для описания указанных вариантов осуществления или предшествующего уровня техники. Сопутствующие графические материалы в последующем описании предназначены исключительно для иллюстрирования некоторых вариантов осуществления настоящего изобретения. На основе этих сопутствующих графических материалов специалисты в данной области техники могут разработать другие графические материалы, не прилагая творческих усилий.
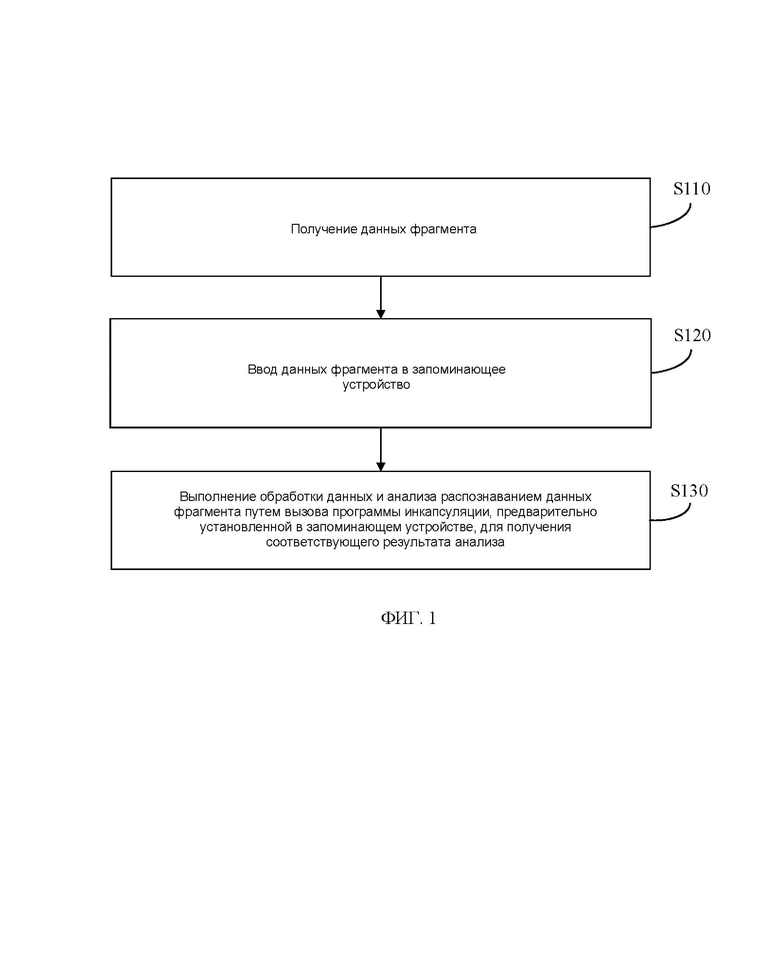
[0023] На ФИГ. 1 показана блок-схема способа анализа для секвенирования генов в соответствии с вариантом осуществления настоящего изобретения;
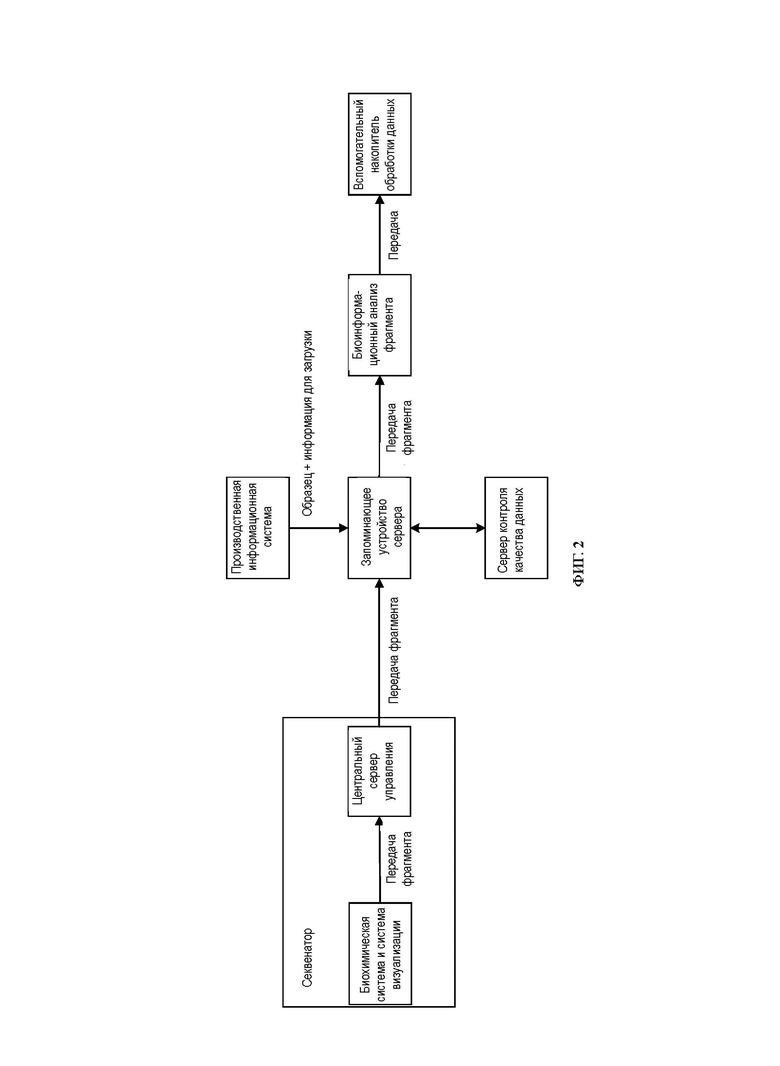
[0024] На ФИГ. 2 показана схема порядка осуществления процесса анализа в соответствии с вариантом осуществления настоящего изобретения;
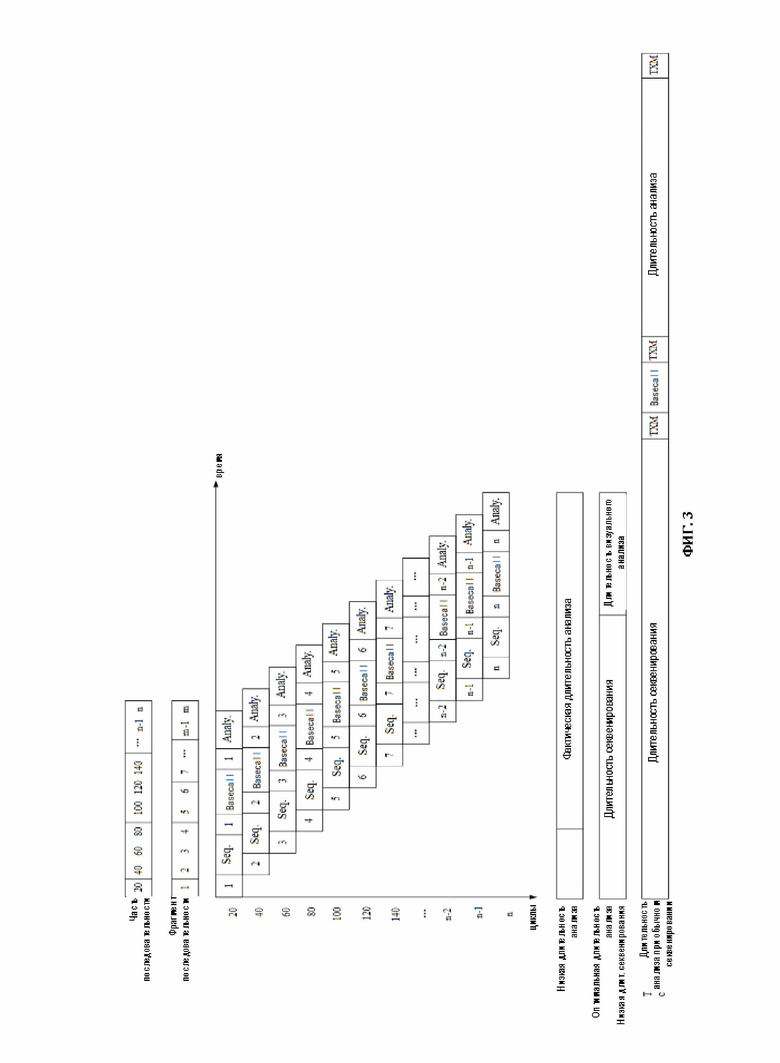
[0025] На ФИГ. 3 показана схема процесса анализа для секвенирования генов в соответствии с вариантом осуществления настоящего изобретения;
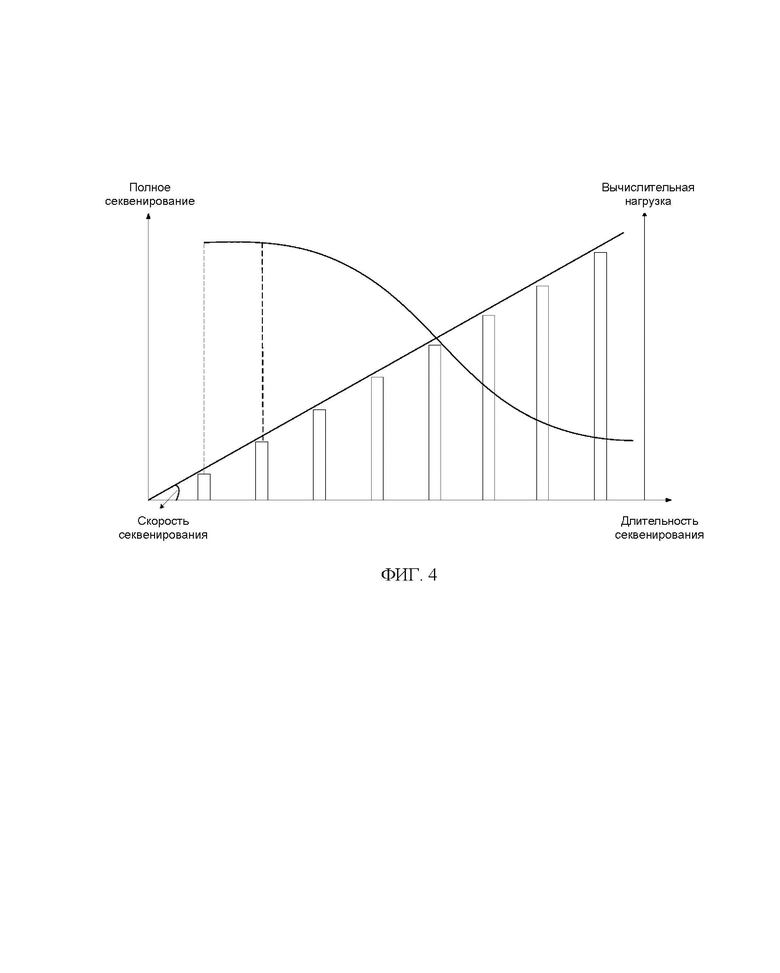
[0026] На ФИГ. 4 показана схема, иллюстрирующая процесс секвенирования в связи со временем процесса анализа для секвенирования генов в соответствии с вариантом осуществления настоящего изобретения;
[0027] На ФИГ. 5 показана структурная схема устройства анализа для секвенирования генов в соответствии с вариантом осуществления настоящего изобретения;
[0028] На ФИГ. 6 показана схема внутренней структуры вычислительного устройства в соответствии с вариантом осуществления настоящего изобретения.
ПОДРОБНОЕ ОПИСАНИЕ
[0029] Технические решения в вариантах осуществления настоящего изобретения подробно описаны ниже со ссылкой на прилагаемые графические материалы вариантов осуществления настоящего изобретения. Варианты осуществления, описанные ниже, являются лишь частью, а не всеми вариантами осуществления настоящего изобретения. Другие варианты осуществления, созданные специалистами в данной области техники на основе вариантов осуществления настоящего изобретения без приложения творческих усилий, должны подпадать под объем защиты настоящего изобретения.
[0030] Если говорить коротко, секвенирование — это преобразование химических сигналов ДНК в цифровые сигналы, пригодные для компьютерной обработки. Со времени ручного секвенирования, разработанного Фредериком Сэнгером, и автоматизированных секвенаторов первого поколения, основанных на секвенировании Сэнгера, до современных платформ секвенирования нового поколения область секвенирования претерпела огромные изменения. Изменения и прорыв в технологии секвенирования играют важную роль в исследованиях в области геномики, медицинских исследованиях болезней, исследованиях лекарств, селекции и других областях.
[0031] В настоящее время процесс секвенирования у платформ секвенирования нового поколения в основном включает в себя следующие этапы: во время каждого цикла секвенирования происходит одновременное добавление в проточные каналы четырех нуклеотидов, меченных разными флуорофорами и ДНК-полимеразами, для удлинения цепи ДНК в соответствии с принципом комплементарного сопряжения; получение флуоресцентных изображений со специфичным для оснований флуоресцентным мечением, которое показывает, какие нуклеотиды вновь добавлены к цепи в этом цикле, чтобы получить последовательности ДНК в этом положении в матрице; и далее осуществляется следующий цикл реакции. Такой процесс повторяют несколько раз для получения множества последовательностей ДНК. Например, последовательность ДНК, включающая в себя 50 оснований, может быть получена путем выполнения 50 циклов секвенирования. Одиночная последовательность, полученная с помощью этого способа, является очень короткой, поэтому ее также называют короткой последовательностью.
[0032] В связи с вышеуказанным, в платформах секвенирования нового поколения биохимические операции и визуализацию необходимо завершить до распознавания оснований, а результаты распознавания должны быть преобразованы в другие формы для хранения. После этого сохраненные файлы передают на основной накопитель для выполнения контроля качества данных, проверки информации об образце и информации о секвенировании, при этом данные архивируют с применением вспомогательного накопителя. Такое секвенирование характеризуется значительными затратами времени и имеет низкую эффективность передачи, что приводит к относительно медленному процессу анализа.
[0033] Следовательно, настоящее изобретение направлено на решение технических проблем, связанных с медленным процессом анализа, что обусловлено значительным расходом времени и низкой эффективностью передачи при секвенировании в предшествующем уровне техники. В настоящем изобретении предусмотрены следующие технические решения.
[0034] На ФИГ. 1 показана блок-схема способа анализа для секвенирования генов в соответствии с вариантом осуществления настоящего изобретения. Как показано на ФИГ. 1, настоящее изобретение предлагает способ анализа для секвенирования генов, который, в частности, включает в себя следующие этапы.
[0035] S110: получены данные о фрагменте.
[0036] На этом этапе для выполнения соответствующего биоинформационного анализа на основе данных фрагмента перед выполнением биоинформационного анализа необходимо получить данные фрагмента, переданные от платформы секвенирования.
[0037] Следует понимать, что в настоящем изобретении, поскольку принимается во внимание эффективность анализа последующих платформ и ситуация с заполнением памяти и т. д., требуются входные данные о фрагментировании, поступающие от платформы секвенирования в режиме реального времени, при этом размер фрагмента может быть адаптивно отрегулирован, исходя из степени незанятости сервера. Следовательно, в настоящем изобретении полученные данные фрагмента представляют собой набор коротких последовательностей, считанных в библиотеке секвенирования после выполнения по меньшей мере одного цикла секвенирования и переданных от платформы секвенирования в режиме реального времени.
[0038] Следует отметить, что адаптивная настройка размера фрагмента на основе степени незанятости сервера может, в основном, включать в себя следующие ситуации. Если сервер не простаивает, размер фрагмента можно отрегулировать так, чтобы иметь возможность фрагментировать короткие последовательности, которые можно считать после одного цикла секвенирования. Если сервер простаивает, размер фрагмента можно отрегулировать так, чтобы иметь возможность фрагментировать короткие последовательности, которые могут быть считаны после множественных циклов секвенирования. Кроме того, первое фрагментирование может происходить после выполнения нескольких циклов секвенирования. Например, после 10 циклов секвенирования один фрагмент выполняют путем фрагментирования.
[0039] Например, в настоящем изобретении для получения данных фрагмента может быть применена платформа секвенирования нового поколения. Секвенирование нового поколения (NGS – англ.: Next-Generation Sequencing) и секвенирование по Сэнгеру сходны в том, что для выявления флуоресцентных сигналов, генерируемых во время связывания меченных флуорофором дНТФ с ДНК-матрицей с катализатором ДНК-полимеразы, в каждом цикле секвенирования применяют компьютер. Однако, в отличие от секвенирования по Сэнгеру, при котором в единицу времени распознают одиночный фрагмент, NGS позволяет одновременно распознавать сигналы от тысяч каналов, за счет чего значительно повышается эффективность.
[0040] Следует понимать, что рассматриваемые в настоящем документе платформы секвенирования нового поколения включают в себя, помимо прочего, секвенатор Illumina (Solexa), секвенатор Roche 454, секвенатор Ion torrent: Proton/PGM и секвенатор SOLiD.
[0041] В качестве примера далее пояснено, как платформа секвенирования нового поколения получает данные фрагмента. Для разъяснения, по настоящему изобретению перед секвенированием с помощью платформы секвенирования нового поколения требуется создание библиотеки секвенирования. Библиотека секвенирования — это смесь фрагментов ДНК, имеющих специфические адаптерные последовательности ДНК, присоединенные на обоих концах. Например, смесь фрагментов ДНК получают путем разрушения геномной ДНК ультразвуком, заполнения концов фрагментов разрушенной ДНК ферментами и лигирования адаптерных последовательностей с помощью лигаз, при этом такая смесь фрагментов ДНК называют «библиотекой».
[0042] Перед осуществлением секвенирования библиотеки секвенирования с применением платформы секвенирования нового поколения, в библиотеке секвенирования может быть выполнена ПЦР-амплификация, чтобы амплифицировать небольшое количество фрагментов ДНК в растворе, подлежащем секвенированию, в несколько или даже в десятки раз. Таким образом, в растворе можно увеличить плотность распределения фрагментов ДНК, подлежащих секвенированию, что позволяет получить небольшое количество фрагментов ДНК во время отбора проб.
[0043] Во время секвенирования может быть добавлен нейтральный раствор, а к нейтральному раствору могут быть добавлены праймеры дНТФ для секвенирования. Поскольку 3’-конец дНТФ заблокирован азидной группой, за один цикл секвенирования цепочку матрицы можно удлинить только на одно основание. После завершения одного цикла секвенирования азидную группу и флуорофор отщепляют путем добавления определенного химического реагента, чтобы обнажить гидроксильную группу на 3'-конце дНТФ, что позволяет считывать последовательность оснований.
[0044] В настоящем изобретении биохимическую часть и часть визуализации каждого цикла секвенирования в процессе секвенирования передают в запоминающее устройство в режиме реального времени для осуществления вызова основания (Basecall) с целью получения соответствующей короткой последовательности, а при удовлетворительном размере фрагмента данные фрагмента выводят и сохраняют в запоминающем устройстве.
[0045] Например, после секвенирования с помощью существующей платформы секвенирования нового поколения, осуществляют вывод в файл формата fastq. Файл формата fastq с расширением fastq или fq, где q обозначает качество, представляет собой файл последовательности для хранения исходных данных секвенирования, содержащий качественную оценку. Ниже приведен общий формат последовательности в файлах формата fastq:
@DJB775P1:248:D0MDGACXX:7:1202:12362:49613
TGCTTACTCTGCGTTGATACCACTGCTTAGATCGGAAGAGCACACGTCTGAA
+
JJJJJIIJJJJJJHIHHHGHFFFFFFCEEEEEDBD?DDDDDDBDDDABDDCA
@DJB775P1:248:D0MDGACXX:7:1202:12782:49716
CTCTGCGTTGATACCACTGCTTACTCTGCGTTGATACCACTGCTTAGATCGG
+
IIIIIIIIIIIIIIIHHHHHHFFFFFFEECCCCBCECCCCCCCCCCCCCCCC
[0046] Ввиду указанного выше формата последовательности каждые четыре строки в файле fastq рассматриваются как самостоятельная единица, т. е. как короткая последовательность. Первая строка начинается с символа «@», за которой следует обозначение DJB775P1, указывающее имя короткой последовательности, а ряд символов в первой строке без пробела между ними преобразуется во время секвенирования в соответствии с информацией о состоянии, и представляет собой уникальный идентификатор короткой последовательности. Вторая строка указывает последовательность считывания при секвенировании, то есть последовательность ДНК, представляющую реальный интерес. Последовательность состоит из пяти букв A, C, G, T и N, где N представляет собой основание, которое невозможно идентифицировать во время секвенирования. Третья строка начинается с символа «+» и в предыдущей версии файла FASTQ может повторять информацию первой строки. В настоящее время в третью строку информацию не добавляют в целях экономии пространства для хранения. В четвертой строке указан показатель качества считывания при секвенировании, который так же важен, как и информация второй строки об основании, а показатель качества считывания при секвенировании показывает надежность каждого секвенированного основания, выраженного с помощью кода ASCII.
[0047] В настоящем изобретении для повышения эффективности анализа процессы секвенирования и анализа подвергаются фрагментированию, а при последовательной обработке для одновременного выполнения секвенирования, кодирования, передачи и анализа применяют структуру потока. Результат, полученный в биохимической части и части визуализации каждого цикла секвенирования в процессе секвенирования, сначала передают в запоминающее устройство для обработки распознаванием изображения в процессе распознавания основания (base calling), с целью получить множество коротких последовательностей. После этого определяют размер фрагмента, исходя из степени незанятости сервера. То есть основания в упомянутой выше второй строке фрагментируют, исходя из степени незанятости сервера. Если сервер простаивает, основания фрагментируют как единую часть данных фрагмента. Если сервер не простаивает, одиночное основание фрагментируют как единую часть данных фрагмента. Данные фрагмента, полученные после фрагментирования, сохраняют в запоминающем устройстве.
[0048] При считывании данных фрагмента в запоминающем устройстве с целью анализа сначала может быть удален адаптер. Адаптер расположен в начале первого фрагмента, как правило, от 6 до 8 оснований, и данные адаптера могут быть использованы для различения разных образцов, что удобно для последующего вывода. Затем оставшиеся данные фрагмента сопоставляют с геномом человека. Каждое основание каждой новой части данных фрагмента позволяет постоянно сужать диапазон считывания в геноме человека, и, таким образом, сопоставление положения становится более точным.
[0049] Кроме того, в настоящем изобретении во время секвенирования и анализа используемая платформа может представлять собой машину, объединяющую секвенирование и анализ, или может представлять собой машину, соединяющую существующий секвенатор и анализатор через сетевое соединение для передачи данных и анализа работы, которые в настоящем документе не ограничиваются.
[0050] S120: данные фрагмента вводят в запоминающее устройство.
[0051] На этом этапе, после получения на этапе S110 данных фрагмента, указанные данные фрагмента могут быть введены в запоминающее устройство интегрированной машины или в память анализатора, связанного с секвенатором. Таким образом, обработка данных и анализ распознаванием могут быть выполнены на данных фрагмента с помощью программы инкапсуляции, имеющейся в запоминающем устройстве.
[0052] Следует понимать, что после выполнения секвенирования библиотеки с помощью существующего секвенатора полученный результат секвенирования обычно выводят в виде файла формата fastq и сохраняют на жестком диске. При выполнении анализа сопоставлением файл fastq считывают с жесткого диска и сопоставляют с геномом человека (файл reference. fa). Напротив, в настоящем изобретении полученные данные фрагмента непосредственно передают в запоминающее устройство для выполнения обработки сопоставлением, без вывода и передачи на жесткий диск, тем самым устраняя процессы записи на жесткий диск и чтения с него и уменьшая объем ввода-вывода информации.
[0053] Кроме того, следует отметить, что память может представлять собой память с удвоенной скоростью передачи данных (DDR). Из-за большого количества данных генов и ограниченной памяти сервера ее часто расширяют до памяти DDR. Соответственно, данные передают по переднему фронту и заднему фронту тактового сигнала в памяти DDR, что обеспечивает скорость передачи данных у памяти DDR в два раза выше, чем у обычной памяти SDRAM. Более того, при этом не увеличивается потребление энергии, так как дополнительно используется только задний фронт сигнала. Сигналы адресации и управления идентичны сигналам обычной памяти SDRAM и передаются только по переднему фронту тактового сигнала.
[0054] S130: для получения результата анализа для данных фрагмента выполняют обработку данных и анализ распознаванием путем вызова в запоминающее устройство программы инкапсуляции.
[0055] На этом этапе, чтобы выполнить обработку данных и анализ распознаванием данных фрагмента и получить соответствующий результат анализа, при обработке данных фрагмента необходимо вызвать предварительно установленную в запоминающем устройстве программу инкапсуляции.
[0056] Следует отметить, что программой инкапсуляции в данном документе называют программное обеспечение, инкапсулирующее множество программ в одну программу, при этом программа инкапсуляции является пользовательской программой, которая может инкапсулировать множество различных программ в одну программу в соответствии с требованиями пользователя для выполнения обработка данных и анализа распознаванием данных фрагмента.
[0057] Кроме того, по настоящему документу программа инкапсуляции оптимизирована на основе существующей программы, имеющей международное признание, за счет чего увеличена связность памяти, повышена многопоточность и добавлены функции обработки данных фрагмента. Во время обработки данных с помощью программы инкапсуляции в рамках рабочей задачи может быть включена и загружена в память соответствующая программа инкапсуляции, имеющаяся на диске, за счет чего эффективно снижается объем ввода-вывода, сокращается время чтения и записи и повышается эффективность анализа.
[0058] Например, необходимо выполнить обработку данных фрагмента до того, как указанные данные фрагмента будут подвергнуты анализу распознаванием, и процесс обработки данных может быть реализован одной или несколькими программами, такими как программа контроля качества данных, программа обработки данных и т. д. После этого подключается программа анализа распознаванием для выполнения анализа распознаванием результата, полученного после обработки данных. Таким образом, окончательный результат анализа может являться более точным.
[0059] На ФИГ. 2 показана схема порядка осуществления процесса анализа в соответствии с вариантом осуществления настоящего изобретения. Как показано на ФИГ. 2,
[0060] для выполнения биохимической визуализации по библиотеке секвенирования и передачи изображений, полученных после биохимической визуализации, на центральный управляющий сервер способом передачи фрагментов, в секвенаторе могут быть применены биохимическая система и система визуализации. Центральный управляющий сервер может передавать изображения в аналитическое устройство для обработки данных и анализа распознаванием. Процесс контроля качества данных включает в себя получение запоминающим устройством сервера контроля качества данных информации об образце и секвенировании от производственной информационной системы и данных фрагмента, передаваемых центральным управляющим сервером; контроль качества данных выполняется для данных фрагмента с последующим архивированием и доставкой данных; и, наконец, результат анализа сохраняют, тем самым реализуя процесс поточного анализа.
[0061] Как видно из ФИГ. 2, набор коротких последовательностей, передаваемых от платформы секвенирования, фрагментируют, часть времени на выполнение анализа скрыта внутри времени исходного секвенирования, а процесс обработки данных и процесс анализа распознаванием связаны друг с другом через запоминающее устройство. Таким образом, процесс поточного анализа, применяемый в настоящем изобретении, способен эффективно снизить объем ввода-вывода, сократить время чтения и записи и повысить эффективность анализа.
[0062] По способу анализа для секвенирования генов в вышеупомянутых вариантах осуществления короткие последовательности, передаваемые в реальном времени от платформы секвенирования, сначала фрагментируют для выполнения соответствующей обработки фрагментов, а затем данные фрагментов вводят в запоминающее устройство. Таким образом, предварительно загруженная в запоминающее устройство программа инкапсуляции может быть вызвана для выполнения биоинформационного анализа данных фрагмента с целью получения соответствующего результата анализа. Такой процесс позволяет получать данные секвенирования фрагмента от платформы секвенирования в режиме реального времени и выполнять секвенирование и анализ данных фрагмента вместо того, чтобы выполнять анализ обработки только после того, как платформа секвенирования завершает секвенирование и полные результаты секвенирования переданы на соответствующую платформу. Таким образом, настоящее изобретение позволяет в целом ускорить секвенирование и анализ. Кроме того, данные для анализа представляют собой данные фрагмента, которые могут быть переданы быстрее при меньших затратах времени по сравнению с полным результатом секвенирования.
[0063] Кроме того, процесс анализа по настоящему изобретению выполняют с помощью программы инкапсуляции, предварительно установленной в запоминающем устройстве. Таким образом, нет необходимости передавать данные секвенирования для обработки на другую платформу, что эффективно снижает нагрузку ввода-вывода и расход памяти, за счет чего дополнительно повышается эффективность работы оборудования и срок его службы.
[0064] Способ анализа для секвенирования генов по настоящему изобретению будет дополнительно разъяснен с помощью следующих вариантов осуществления. Как описано ниже, процесс получения данных фрагмента подробно описан в следующих вариантах осуществления.
[0065] В одном варианте осуществления этап получения данных фрагмента на этапе S110 может включать в себя следующее:
[0066] S111: определяют размер фрагмента.
[0067] S112: исходя из размера фрагмента, всех нефрагментированные короткие последовательности, которые в данный момент передают от платформы секвенирования и считывают после одного цикла секвенирования, фрагментируют, причем набор фрагментированных коротких последовательностей используют в качестве данных фрагмента.
[0068] В этом варианте осуществления биохимическая часть и часть визуализации в процессе секвенирования каждого цикла в режиме реального времени передают в память для распознавания оснований. После получения соответствующих коротких последовательностей требуется сначала определить размер фрагмента, а короткие последовательности, удовлетворяющие указанному размеру фрагмента, выводят в виде комбинации в качестве данных фрагмента, при этом данные фрагмента сохраняют в запоминающем устройстве.
[0069] Например, каждые m + n циклов (циклов секвенирования) принимают за одну часть данных фрагмента, где m — первый фрагмент, m > = 10, а n относится ко всем последующим фрагментам, n> = 1 и n <= 20, при этом сумма m + n позволяет адаптивно регулировать размер фрагмента в соответствии со скоростью выполнения анализа.
[0070] На ФИГ. 3 показана схема процесса анализа для секвенирования генов в соответствии с вариантом осуществления настоящего изобретения, а на ФИГ. 4 показана схема процесса секвенирования в связи со временем процесса анализа для секвенирования генов в соответствии с вариантом осуществления настоящего изобретения. Как показано на ФИГ. 3 и ФИГ. 4, настоящее изобретение позволяет ускорить процесс секвенирования и анализа за счет получения данных фрагмента в режиме реального времени от платформы секвенирования и поточного выполнения секвенирования и анализа данных фрагмента. Далее выполняют распознавание мутации или сопоставление с библиотекой РНК патогенов с последующей аннотацией, тем самым завершая процесс анализа и выдачу результата.
[0071] Процесс получения данных фрагмента подробно описан в приведенном выше варианте осуществления. Этап определения размера фрагмента в вышеупомянутом варианте осуществления будет дополнительно описан ниже.
[0072] В одном варианте осуществления этап определения размера фрагмента на этапе S111 может включать в себя следующее.
[0073] S1111: получены данные о текущем состоянии бездействия центрального процессора (ЦП).
[0074] S1112: размер фрагмента скорректирован, исходя из текущего состояния бездействия ЦП.
[0075] В настоящем варианте осуществления, когда получены данные фрагмента для анализа распознаванием, указанные данные фрагмента представляют собой набор коротких последовательностей, передаваемых от платформы секвенирования в режиме реального времени и считываемых после выполнения по меньшей мере одного цикла секвенирования фрагментов гена в библиотеке секвенирования.
[0076] Размер фрагмента может быть адаптивно отрегулирован в соответствии со скоростью анализа, а скорость анализа может быть получена за счет получения и анализа текущего состояния незанятости ЦП. Текущее состояние незанятости ЦП связано с текущим заполнением запоминающего устройства. Большее текущее заполнение запоминающего устройства указывает на то, что память не является незанятой, и, следовательно, скорость анализа в запоминающем устройстве является относительно низкой. Следовательно, размер фрагмента можно отрегулировать так, чтобы иметь возможность фрагментировать набор коротких последовательностей, которые считывают после нескольких циклов секвенирования. Меньшее текущее заполнение запоминающего устройства указывает на то, что память не является занятой, и, следовательно, скорость анализа в запоминающем устройстве является относительно высокой. Следовательно, размер фрагмента можно отрегулировать так, чтобы иметь возможность фрагментировать набор коротких последовательностей, которые считывают после одного цикла секвенирования.
[0077] Например, каждые m + n циклов (циклов секвенирования) принимаются как одна часть данных фрагмента, а для фрагмента после m фрагментов контроль осуществляется автоматически. То есть размер фрагмента n определяют, исходя из состояния незанятости машины от начала второго фрагмента до конца последнего фрагмента. При относительной незанятости машины передачу осуществляют один раз после каждого цикла, т. е. n = 1; а если машина относительно занята, то передачу осуществляют через 20 циклов, т. е. n = 20.
[0078] Следует понимать, что в соответствии с принципом сопоставления в настоящем изобретении данные фрагмента передают в процесс сопоставления и сопоставляют с геномом человека, при этом определяют диапазон сопоставления данных фрагмента. Если данные фрагмента больше, диапазон сопоставления сужается более точно.
[0079] Этапы определения размера фрагмента дополнительно разъяснены в приведенных выше вариантах осуществления, а программа инкапсуляции и процесс вызова программы инкапсуляции для обработки данных и анализа распознаванием будут подробно описаны в последующих вариантах осуществления.
[0080] В одном варианте осуществления программа инкапсуляции может включать в себя программу контроля качества данных, программу обработки данных и программу анализа распознаванием.
[0081] На этапе S130 этап выполнения, путем вызова программы инкапсуляции, предварительно установленной в запоминающем устройстве, обработки данных и анализа обнаружения данных фрагмента включает в себя следующие этапы.
[0082] S131: контроль качества обработки для данных фрагмента выполняют путем вызова программы контроля качества данных, предварительно установленной в запоминающем устройстве, для получения результата контроля качества.
[0083] S132: обработку данных по результату контроля качества выполняют путем вызова предварительно установленной в запоминающем устройстве программы обработки данных для получения результата обработки.
[0084] S133: анализ распознаванием выполняют для результата обработки путем вызова программы анализа распознаванием, предварительно установленной в запоминающем устройстве, для получения окончательного результата анализа.
[0085] В этом варианте осуществления при обработке данных фрагмента может быть вызвана программа инкапсуляции, предварительно установленная в запоминающем устройстве, обеспечивающая выполнение обработки данных и анализа распознаванием данных фрагмента с целью получения соответствующего результата анализа.
[0086] Программа инкапсуляции, предварительно установленная в запоминающем устройстве, может представлять собой пользовательскую программу. Пользовательская программа может представлять собой одну программу с несколькими инкапсулированными программами. Например, программа инкапсуляции может включать в себя программу контроля качества данных, программу обработки данных и программу анализа распознаванием.
[0087] Программу контроля качества данных в основном используют для осуществления контроля качества обработки данных фрагмента для получения результата контроля качества. Программу обработки данных в основном используют для выполнения обработки данных по результату контроля качества, с целью получения результата обработки. Программу анализа распознаванием используют для выполнения анализа распознаванием результата обработки для получения окончательного результата анализа.
[0088] В вышеупомянутых вариантах осуществления подробно описаны программа инкапсуляции и выполнение обработки данных и анализа распознаванием путем вызова программы инкапсуляции. Процесс выполнения контроля качества обработки посредством вызова программы контроля качества данных подробно описан ниже.
[0089] В одном варианте осуществления этап S131 выполнения контроля качества обработки данных фрагмента с помощью вызова программы контроля качества данных, предварительно установленной в запоминающем устройстве, может включать в себя следующие этапы: вычисление, путем вызова программы контроля качества данных, предварительно установленной в запоминающем устройстве, коэффициента погрешности положения коротких последовательностей в данных фрагмента, статистический анализ распределения оснований в данных фрагмента и/или удаление низкокачественных оснований из данных фрагмента. Низкокачественные основания представляют собой основания, качество которых ниже порогового уровня качества.
[0090] В этом варианте осуществления при выполнении контроля качества обработки данных фрагмента вызывают программу контроля качества данных в программе инкапсуляции для выполнения контроля качества обработки.
[0091] В частности, программу контроля качества данных в основном используют для выполнения контроля качества обработки данных фрагмента, при этом контроль качества обработки может включать в себя: вычисление коэффициента погрешности положения коротких последовательностей в данных фрагмента, статистический анализ распределения оснований в данных фрагмента, удаление низкокачественных оснований из данных фрагмента и другой контроль качества обработки, применимый к коротким последовательностям. Один или более контроль качества обработки и инструментальные средства, которые будут применены при контроле качества обработки, могут быть специально выбраны в соответствии с имеющимися условиями.
[0092] Например, когда необходимо удалить низкокачественные основания из данных фрагмента, среднее качество оснований в окне определенной длины может быть вычислено путем сдвига указанного окна. Если среднее качество является слишком низким, все основания удаляются непосредственно.
[0093] В вышеупомянутом варианте осуществления подробно описан процесс выполнения контроля качества обработки посредством вызова программы контроля качества данных. Процесс выполнения обработки данных путем вызова программы обработки данных подробно описан с помощью вариантов осуществления.
[0094] В одном варианте осуществления этап S132 выполнения обработки данных по результату контроля качества с помощью вызова программы обработки данных, предварительно установленной в запоминающем устройстве, может включать в себя: выполнение, путем вызова программы обработки данных, предварительно установленной в запоминающем устройстве, по меньшей мере одного из сопоставления, упорядочивания, дедупликации и повторного сопоставления по короткой последовательности в результате контроля качества.
[0095] В этом варианте осуществления, после выполнения контроля качества обработки данных фрагмента, может быть вызвана программа обработки данных, предварительно установленная в запоминающем устройстве, для осуществления сопоставления, упорядочивания, дедупликации и/или повторного сопоставления по короткой последовательности в результате контроля качества, полученном после контроля качества обработки.
[0096] Хотя все данные фрагментов, взятые из генома, имеют последовательность, различные короткие последовательности в данных фрагментов полностью утратили свою последовательную связь после создания библиотеки ДНК и секвенирования. Следовательно, две смежные короткие последовательности в данных фрагмента представляют собой случайные короткие последовательности в определенных положениях в исходном геноме, и соотношение положений между двумя соседними короткими последовательностями в данных фрагмента является неизвестным.
[0097] Таким образом, в настоящем изобретении после выполнения контроля качества обработки данных фрагмента может быть вызвана программа обработки данных, предварительно установленная в запоминающем устройстве, для поочередного сопоставления коротких последовательностей в данных фрагмента, соответствующих результату контроля качества, с референсным геном соответствующих видов, таким образом находя положение каждой короткой последовательности в референсном гене. После этого короткие последовательности располагают по порядку. Такой процесс называется процессом сопоставления данных фрагмента.
[0098] Следует отметить, что референсный ген, описанный в настоящем документе, относится к геномной последовательности вида, т. е. скомпонованной полной геномной последовательности, которую часто используют в качестве эталона для вида.
[0099] После завершения сопоставления коротких последовательностей, указанные короткие последовательности подвергают процедуре сортировки. Процедура сортировки, в основном, заключается в сортировке ранее сопоставленных коротких последовательностей в соответствии с порядком их положения, чтобы сформировать непрерывное соотношение положений коротких последовательностей.
[00100] После процедуры упорядочения в данных фрагмента может быть выполнена операция дедупликации коротких последовательностей, чтобы удалить повторяющиеся короткие последовательности в данных фрагмента, тем самым облегчив последующий анализ распознаванием.
[00101] Наконец, процесс повторного сопоставления коротких последовательностей предназначен, в основном, для повторной коррекции областей последовательности с потенциальными инсерциями или делециями, которые были обнаружены в ходе вышеупомянутого процесса сопоставления, что позволяет сделать результат последующего анализа распознаванием более точным.
[00102] Следует понимать, что вышеупомянутые процессы обработки данных сопоставлением, упорядочиванием, дедупликацией и повторным сопоставлением могут быть установлены выборочно в соответствии с фактическими ситуациями, а последовательный порядок также может быть задан вручную, что конкретно в настоящем документе не ограничивается.
[00103] Например, обычными процедурами анализа являются сопоставление, упорядочение, дедупликация, повторное сопоставление, распознавание мутаций и аннотация. Во время сопоставления входным файлом является файл формата fastq, а выходным файлом — файл формата bam. Вывод представляет собой непрерывный файл формата bam до повторного сопоставления. Выходной файл распознавания мутаций представляет собой файл формата vcf, а аннотация основана на результате распознавания мутации. Когда для секвенирования применяют метод анализа для секвенирования генов по настоящему изобретению и платформу секвенирования нового поколения, сопоставление требуется для процессов анализа всех необработанных данных fastq нового поколения, следуют за ними процессы, или нет. Если анализ не начат по необработанным данным, на любом этапе также может быть введен файл формата bam для последующей аналитической обработки.
[00104] Процесс сопоставления по настоящему изобретению будет дополнительно описан ниже. Например, при сопоставлении данных фрагмента по настоящему изобретению, основания коротких последовательностей в данных фрагмента можно сопоставить со всем геномом, чтобы найти положение каждой короткой последовательности в референсном гене. После того, как все данные фрагмента позиционированы в определенных положениях во всем геноме, информация о совпадении при сопоставлении интегрируется для выполнения скрининга и расширения на смежные позиции сопоставления. Кроме того, допускаются пробелы (т. е. положения, в которых сопоставление не удалось), и, таким образом, можно получить более длинную цепь последовательности, сопоставленную по всему геному.
[00105] Кроме того, в вышеупомянутом процессе сопоставления для выбора информации об оптимальном результате сопоставления может быть применен алгоритм динамического программирования, объединяющий ситуации глобального и локального сопоставления, после чего результат сопоставления различных образцов соответствующим образом выводят в память в соответствии с информацией адаптера.
[00106] Например, в распространенном алгоритме BWA-MEM применяется, в основном, стратегия источника и расширения. На начальном этапе BWA берет базовый фрагмент считывания для выполнения точного сопоставления с эталоном, и в качестве начального значения выбирает считанный фрагмент, который удовлетворяет определенным требованиям по сопоставлению времени и длины. Алгоритм этого этапа ориентирован на точное сопоставление FM-индекса. На этапе расширения в BWA используют алгоритм Смита-Уотермана для расширения источника на считываниях и эталоне в обе стороны для сопоставления (допускающего пробелы), тем самым находя подходящее глобальное совпадение для всего считывания по эталону.
[00107] Приведенные выше варианты осуществления описывают, в основном, как вызывают программу обработки данных для выполнения процедуры обработки данных, а конкретные варианты осуществления обработки данных будут дополнительно описаны ниже.
[00108] В одном варианте осуществления этап выполнения, путем вызова программы обработки данных, предварительно установленной в запоминающем устройстве, по меньшей мере одного из сопоставления, упорядочивания, дедупликации и повторного сопоставления по короткой последовательности в результате контроля качества может включать в себя следующие этапы.
[00109] A11: сопоставление между короткой последовательностью в результате контроля качества и референсным геном выполняют путем вызова программы обработки данных, предварительно установленной в запоминающем устройстве, чтобы определить положение короткой последовательности в референсном гене.
[00110] A12: метку положения короткой последовательности определяют, исходя из положения короткой последовательности в референсном гене;
[00111] A13: среди предварительно установленных в запоминающем устройстве потоков выполнения определяют целевой поток выполнения, который в данный момент находится в незанятом состоянии.
[00112] A14: выполняют, путем вызова целевого потока выполнения и с учетом метки положения короткой последовательности, по меньшей мере одно из упорядочивания, дедупликации и повторного сопоставления по короткой последовательности.
[00113] В этом варианте осуществления при выполнении обработки данных короткой последовательности в результате контроля качества, к сопоставленной короткой последовательности может быть добавлена метка положения; и затем определяют, имеется ли в настоящий момент среди соответствующих потоков выполнения, предварительно заданных в запоминающем устройстве, поток выполнения в состоянии незанятости. Если поток выполнения в состоянии незанятости имеется, этот поток служит в качестве целевого потока выполнения, и, с учетом метки положения короткой последовательности, вызывают целевой поток для выполнения упорядочения, дедупликации и/или повторного сопоставления по короткой последовательности. Таким образом, упорядочивание и дедупликация являются более эффективными.
[00114] Например, после того, как короткая последовательность в результате контроля качества сопоставлена с референсным геном путем вызова программы обработки данных и, исходя из положения короткой последовательности в референсном гене, определена метка положения, соответствующая короткой последовательности, может быть вызван целевой поток для выполнения таких операций, как упорядочивание и дедупликация по короткой последовательности. Например, в процессе упорядочивания, когда для обработки используется многопоточность, с целью повышения эффективности многопоточной обработки упорядочивание может быть выполнено с учетом метки положения короткой последовательности. Таким образом, результат упорядочения, полученный после многопоточного упорядочения, является точным, а эффективность упорядочения повышается.
[00115] Процесс обработки данных дополнительно разъяснен в приведенных выше вариантах осуществления, а процесс выполнения анализа распознаванием для результата обработки путем вызова программы анализа распознаванием подробно описан ниже.
[00116] В одном варианте осуществления настоящего изобретения, этап S133 этап выполнения, с помощью вызова программы анализа распознаванием, предварительно установленной в запоминающем устройстве, анализа распознаванием результата обработки может включать в себя: выполнение, путем вызова программы анализа распознаванием, предварительно установленной в запоминающем устройстве, распознавания мутации и интерпретации результата обработки.
[00117] В этом варианте осуществления одной из целей выполнения анализа секвенирования генов является получение точного набора мутаций в образце, который необходимо определить путем распознавания мутаций, интерпретации и т. д. В настоящее время результаты распознавания мутаций включают в себя однонуклеотидный полиморфизм (SNP), инсерционно-делеционную мутацию (Indel), вариацию числа копий (CNV) и структурные вариации (SV). В процессе распознавания мутаций могут быть использованы алгоритмы, в которых применены байесовский вывод или алгоритм HaplotypeCaller.
[00118] Например, когда для распознавания мутаций применяют алгоритм HaplotypeCaller, будет выведена гаплоидная комбинация популяции, рассчитана вероятность каждой комбинации, а затем, в соответствии с этой информацией, будет выведена комбинация генотипов каждого образца.
[00119] Кроме того, при выполнении анализа распознаванием, такого как распознавание мутации в результате обработки, распознавание мутации может быть выполнено без ожидания завершения сопоставления. Различные хромосомы во всем геноме могут быть разделены на несколько областей. Когда для каждой области накоплена часть результатов сопоставления, можно выявить область с высоким уровнем мутацией для распознавания. В последующий результат сопоставления добавляют непрерывно проверяемую ситуацию с мутацией в существующей области с высоким уровнем мутаций, включая несоответствие/инсерцию/делецию и т. п. После компоновки данных области с высоким уровнем мутаций можно получить упрощенные данные о гаплотипе. Оценку максимального правдоподобия гаплотипа выполняют с применением скрытой марковской модели (HMM) для получения результата типирования каждого сайта этой области, после чего выводится информация о мутации.
[00120] Следует понимать, что для повышения эффективности всего биоинформационного анализа в случае выполнения распознавания мутаций в результате обработки по настоящему изобретению, распознавание мутаций выполняют в области с высоким уровнем мутаций, а не во всех сайтах всего генома. Область с высоким уровнем мутаций может быть выбрана, исходя из вероятности появления мутации в каждом сайте. Например, после вычисления вероятности появления мутации в каждом сайте, область с высоким уровнем мутаций может быть определена, исходя из заданного порога вероятности.
[00121] Кроме того, во время компоновки данных области с высоким уровнем мутаций, если в наборе фрагментов, соответствующих референсному геному, имеется дупликация, длина короткого фрагмента будет постепенно увеличиваться до тех пор, пока дупликация не исчезнет или не будет достигнут максимальный предел длины, а границе, полученной путем компоновки, может быть присвоен вес в соответствии с количеством коротких последовательностей, полученных путем сопоставления.
[00122] Кроме того, после получения результата распознавания мутации, указанный результат распознавания мутации может быть подвергнут контролю качества и фильтрации, чтобы дополнительно оценить качество результата распознавания мутации.
[00123] Устройство анализа для секвенирования генов, предложенное в вариантах осуществления настоящего изобретения, описано ниже. Устройство анализа для секвенирования генов, описанное ниже, может быть соответственно связано со способом анализа для секвенирования генов, который описан выше.
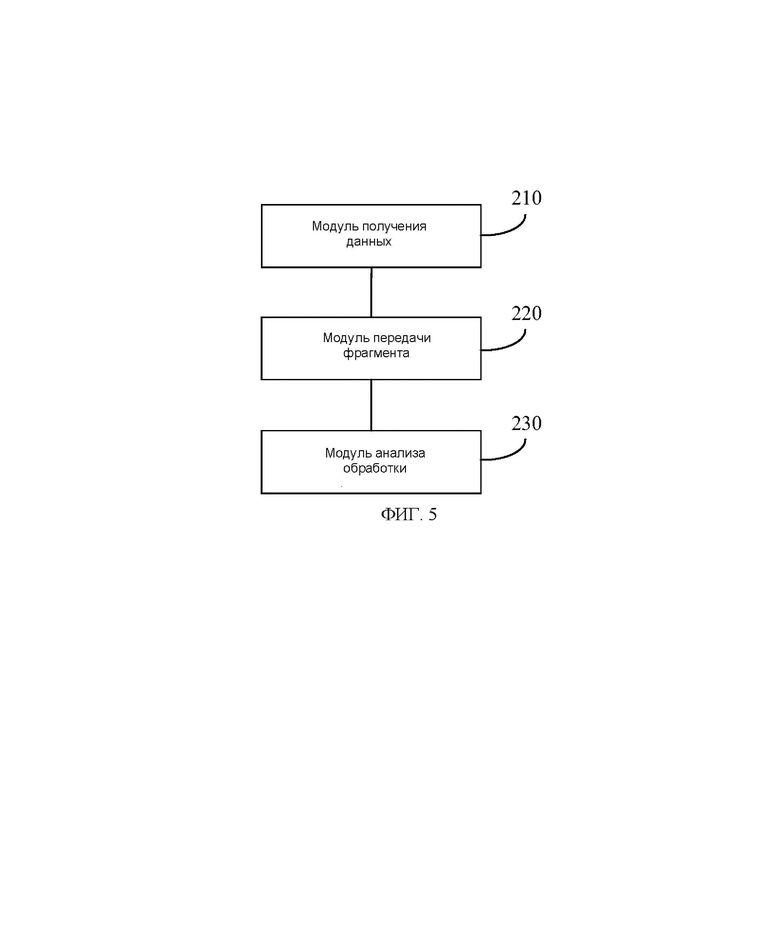
[00124] На ФИГ. 5 показана структурная схема устройства анализа для секвенирования генов в соответствии с вариантом осуществления настоящего изобретения. В варианте осуществления, как показано на Фиг. 5, настоящее изобретение также предлагает устройство анализа для секвенирования генов, которое включает в себя модуль 210 сбора данных, модуль 220 передачи фрагмента и модуль 230 анализа обработки.
[00125] Модуль 210 сбора данных выполнен с возможностью получения данных фрагмента, переданных в режиме реального времени от платформы секвенирования, причем данные фрагмента представляют собой набор коротких последовательностей, считанных в библиотеке секвенирования после выполнения по меньшей мере одного цикла секвенирования.
[00126] Модуль 220 передачи фрагмента выполнен с возможностью ввода данных фрагмента в запоминающее устройство.
[00127] Модуль 230 анализа обработки выполнен с возможностью выполнения, с помощью вызова программы инкапсуляции, предварительно установленной в запоминающем устройстве, обработки данных и анализа распознаванием данных фрагмента для получения соответствующего результата анализа, при этом программа инкапсуляции является пользовательской программой.
[00128] С помощью устройства анализа для секвенирования генов, предусмотренного в вышеупомянутом варианте осуществления, короткие последовательности, передаваемые от платформы секвенирования в реальном времени, сначала фрагментируют для выполнения соответствующей обработки фрагментов, а затем данные фрагментов вводят в запоминающее устройство. Таким образом, предварительно загруженная в запоминающее устройство программа инкапсуляции может быть вызвана для выполнения биоинформационного анализа данных фрагмента с целью получения соответствующего результата анализа. Такой процесс позволяет получать данные секвенирования фрагмента от платформы секвенирования в режиме реального времени и выполнять секвенирование и анализ данных фрагмента вместо того, чтобы выполнять анализ обработки только после того, как платформа секвенирования завершает секвенирование и полные результаты секвенирования переданы на соответствующую платформу. Таким образом, настоящее изобретение позволяет в целом ускорить секвенирование и анализ. Кроме того, данные для анализа представляют собой данные фрагмента, которые могут быть переданы быстрее при меньших затратах времени по сравнению с полным результатом секвенирования.
[00129] Кроме того, процесс анализа по настоящему изобретению выполняют с помощью программы инкапсуляции, предварительно установленной в запоминающем устройстве. Таким образом, нет необходимости передавать данные секвенирования для обработки на другую платформу, что эффективно снижает нагрузку ввода-вывода и расход памяти, за счет чего дополнительно повышается эффективность работы оборудования и срок его службы.
[00130] В одном варианте осуществления модуль 210 сбора данных может включать в себя модуль 211 определения, выполненный с возможностью определения размера фрагмента, и модуль 212 фрагментирования, выполненный с возможностью фрагментирования, исходя из размера фрагмента, всех нефрагментированных коротких последовательностей, передаваемых в настоящее время от платформы секвенирования и считываемых после одиночного цикла секвенирования, в набор фрагментированных коротких последовательностей, используемых в качестве данных фрагмента.
[00131] В одном варианте осуществления модуль 211 определения может включать в себя модуль 2111 получения данных о состояния запоминающего устройства, выполненный с возможностью получения информации о текущем состояния незанятости запоминающего устройства, и модуль 2112 регулировки фрагмента, выполненный с возможностью регулирования размера фрагмента, исходя из текущего состояния незанятости запоминающего устройства.
[00132] В одном варианте осуществления программа инкапсуляции в модуле 230 анализа обработки может включать в себя программу контроля качества данных, программу обработки данных и программу анализа распознаванием.
[00133] Модуль 230 анализа обработки, который выполнен с возможностью выполнения, путем вызова программы инкапсуляции, предварительно установленной в запоминающем устройстве, обработки данных и анализа распознаванием данных фрагмента для получения соответствующего результата анализа, может включать в себя: модуль 231 контроля качества данных, выполненный с возможностью выполнения, путем вызова предварительно установленной в запоминающем устройстве программы контроля качества данных, контроля качества обработки данных фрагмента для получения результата контроля качества; модуль 232 обработки данных, выполненный с возможностью выполнения, путем вызова предварительно установленной в запоминающем устройстве программы обработки данных, указанной обработки данных по результату контроля качества для получения результата обработки; и модуль 233 анализа распознаванием, выполненный с возможностью выполнения, путем вызова программы анализа распознаванием, предварительно установленной в запоминающем устройстве, анализа распознаванием результата обработки для получения окончательного результата анализа.
[00134] В одном варианте осуществления модуль 231 контроля качества данных может включать в себя первый обрабатывающий модуль 2311. Первый обрабатывающий модуль 2311 выполнен с возможностью вычисления, путем вызова программы контроля качества данных, предварительно установленной в запоминающем устройстве, коэффициента погрешности положения коротких последовательностей в данных фрагмента, статистического анализа распределения основания в данных фрагмента и/или удаления низкокачественных оснований из данных фрагмента. Низкокачественные основания представляют собой основания, качество которых ниже порогового уровня качества.
[00135] В одном варианте осуществления модуль 232 контроля качества данных может включать в себя второй обрабатывающий модуль 2321. Второй обрабатывающий модуль 2321 выполнен с возможностью выполнения, путем вызова программы обработки данных, предварительно установленной в запоминающем устройстве, по меньшей мере одного из сопоставления, упорядочивания, дедупликации и повторного сопоставления по короткой последовательности в результате контроля качества.
[00136] В одном варианте осуществления второй обрабатывающий модуль 2321 может включать в себя модуль 310 сопоставления, модуль 311 определения метки, модуль 312 определения потока выполнения и модуль 313 многопоточной работы.
[00137] Модуль 310 сопоставления выполнен с возможностью выполнения, путем вызова предварительно установленной в запоминающем устройстве программы обработки данных, сопоставления между короткой последовательностью в результате контроля качества и референсным геном для определения положения короткой последовательности в референсном гене.
[00138] Модуль 311 определения метки выполнен с возможностью определения метки положения короткой последовательности, исходя из положения короткой последовательности в референсном гене.
[00139] Модуль 312 определения потока выполнения выполнен с возможностью определения среди предварительно заданных в запоминающем устройстве потоков выполнения целевого потока выполнения, который на текущий момент находится в состоянии незанятости.
[00140] Модуль 313 многопоточной работы выполнен с возможностью выполнения, путем вызова целевого потока выполнения и с учетом метки положения короткой последовательности, по меньшей мере одного из упорядочивания, дедупликации и повторного сопоставления по короткой последовательности.
[00141] В одном варианте осуществления модуль 233 анализа распознаванием может включать в себя третий обрабатывающий модуль 2331. Третий обрабатывающий модуль 2331 выполнен с возможностью выполнения, путем вызова программы анализа распознаванием, предварительно установленной в запоминающем устройстве, распознавания мутации и интерпретации результата обработки.
[00142] В одном варианте осуществления настоящее изобретение также предлагает накопитель данных, на котором хранятся машиночитаемые команды. Машиночитаемые команды при выполнении одним или несколькими процессорами предписывают указанным одному или нескольким процессорам выполнение этапов способа анализа для секвенирования генов, как описано в любом из вышеприведенных вариантов осуществления.
[00143] В одном варианте осуществления настоящее изобретение также предлагает компьютерное устройство, имеющее хранящиеся в нем машиночитаемые команды. Машиночитаемые команды при выполнении одним или несколькими процессорами предписывают указанным одному или нескольким процессорам выполнение этапов способа анализа для секвенирования генов, как описано в любом из вышеприведенных вариантов осуществления.
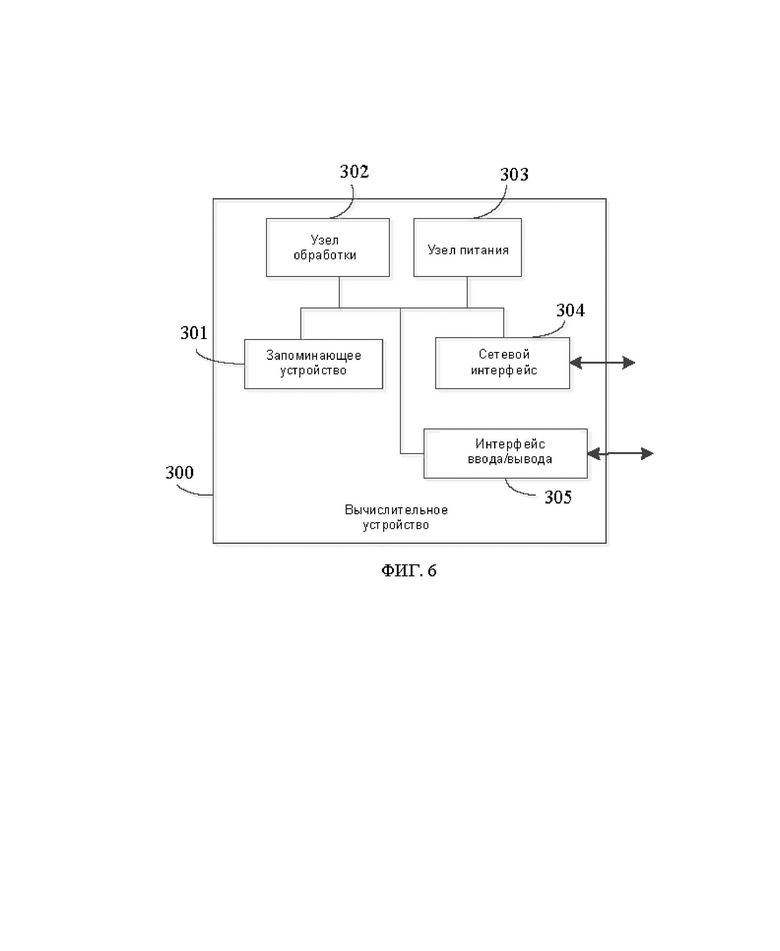
[00144] На ФИГ. 6 показана схема внутренней структуры вычислительного устройства в соответствии с вариантом осуществления настоящего изобретения. Вычислительное устройство 300 может быть предусмотрено в виде сервера. Со ссылкой на ФИГ. 6, вычислительное устройство 300 включает в себя: обрабатывающий компонент 302, который дополнительно включает в себя один или несколько процессоров; и ресурс запоминающего устройства, представленный запоминающим устройством 301 и выполненный с возможностью хранения команд, таких как прикладная программа, которая может быть выполнена обрабатывающим компонентом 302. Прикладная программа, хранящаяся в запоминающем устройстве 301, может включать в себя один или несколько модулей, каждый из которых соответствует набору команд. Кроме того, обрабатывающий компонент 302 выполнен с возможностью выполнения команд для осуществления способа анализа для секвенирования генов, как описано в любом из вариантов осуществления, приведенных выше.
[00145] Вычислительное устройство 300 может дополнительно включать в себя компонент 303 источника питания, выполненный с возможностью управления питанием вычислительного устройства 300, проводной или беспроводной сетевой интерфейс 304, выполненный с возможностью подключения вычислительного устройства 300 к сети, и интерфейс 305 ввода/вывода (I/O). Вычислительное устройство 300 может работать под управлением операционной системы, хранящейся в запоминающем устройстве 301, такой как Windows Server TM, Mac OS XTM, Unix TM, Linux TM, Free BSDTM и т. п.
[00146] Специалистам в данной области техники должно быть понятно, что структура, показанная на ФИГ. 6, представляет собой просто блок-схему части структуры, относящейся к техническому решению по настоящему изобретению, и не налагает никаких ограничений на вычислительное устройство, которое применено в техническом решении по настоящему изобретению. Конкретное вычислительное устройство может включать в себя компоненты, отличающиеся от показанных в графических материалах, или объединять некоторые из компонентов, или иметь другое расположение компонентов.
[00147] Наконец, следует отметить, что в данном описании относительные термины, такие как «первый» и «второй», применяют исключительно для того, чтобы отличить объект или операцию от другого объекта или операции, и эти термины не обязательно требуют или подразумевают, что между этими объектами или операциями существует какое-либо фактическое соотношение или последовательность. Кроме того, термины «включать в себя», «содержать» или любое другое их видоизменение предназначены для указания неисключительного включения, то есть процесс, способ, изделие или оборудование, которые включают в себя перечень элементов, могут дополнительно включать в себя другие элементы, которые не перечислены непосредственно или присущи такому процессу, способу, изделию или оборудованию. Без дополнительных ограничений элементы, определяемые выражением «включая...», не исключают существования в процессе, способе, изделии или оборудовании, включающих в себя указанные элементы, других идентичных элементов.
[00148] Различные варианты осуществления описаны в данном документе поочередно, причем каждый вариант осуществления сфокусирован на отличиях от других вариантов осуществления, и эти варианты осуществления по мере необходимости могут быть объединены друг с другом в своих сходных и аналогичных частях.
[00149] Вышеупомянутые варианты осуществления настоящего изобретения предназначены для того, чтобы специалисты в данной области техники могли реализовать или применить настоящее изобретение на практике. Специалистам в данной области техники будут очевидны различные модификации этих вариантов осуществления, при этом ограниченные в данном документе общие принципы могут быть реализованы в других вариантах осуществления без отклонения от сущности или объема настоящего изобретения. Таким образом, настоящее изобретение не ограничено вариантами осуществления, приведенными в настоящем документе, но должно подпадать под защиту в самом широком объеме, соответствующем принципам и признакам новизны, описанным в настоящем документе.
| название | год | авторы | номер документа |
|---|---|---|---|
| ИНСТРУМЕНТ НА ОСНОВЕ ГРАФОВ ПОСЛЕДОВАТЕЛЬНОСТЕЙ ДЛЯ ОПРЕДЕЛЕНИЯ ВАРИАЦИЙ В ОБЛАСТЯХ КОРОТКИХ ТАНДЕМНЫХ ПОВТОРОВ | 2020 |
|
RU2825664C2 |
| ИНСТРУМЕНТ НА ОСНОВЕ ГРАФОВ ПОСЛЕДОВАТЕЛЬНОСТЕЙ ДЛЯ ОПРЕДЕЛЕНИЯ ВАРИАЦИЙ В ОБЛАСТЯХ КОРОТКИХ ТАНДЕМНЫХ ПОВТОРОВ | 2020 |
|
RU2799654C2 |
| Компьютерно-реализуемый интегральный способ для оценки качества результатов таргетного секвенирования | 2018 |
|
RU2717809C1 |
| СПОСОБЫ И СИСТЕМЫ ДЛЯ ПОЛУЧЕНИЯ НАБОРОВ УНИКАЛЬНЫХ МОЛЕКУЛЯРНЫХ ИНДЕКСОВ С ГЕТЕРОГЕННОЙ ДЛИНОЙ МОЛЕКУЛ И КОРРЕКЦИИ В НИХ ОШИБОК | 2018 |
|
RU2766198C2 |
| СПОСОБ, УСТРОЙСТВО И КОМПЬЮТЕРНОЕ УСТРОЙСТВО ГЕННОГО АНАЛИЗА, ОСНОВАННЫЕ НА СОВМЕСТНО ИСПОЛЬЗУЕМОЙ ПАМЯТИ | 2020 |
|
RU2792228C1 |
| ПОДАВЛЕНИЕ ОШИБОК В СЕКВЕНИРОВАННЫХ ФРАГМЕНТАХ ДНК ПОСРЕДСТВОМ ПРИМЕНЕНИЯ ИЗБЫТОЧНЫХ ПРОЧТЕНИЙ С УНИКАЛЬНЫМИ МОЛЕКУЛЯРНЫМИ ИНДЕКСАМИ (UMI) | 2016 |
|
RU2704286C2 |
| КОРРЕКЦИЯ ФАЗИРОВАНИЯ | 2018 |
|
RU2805952C2 |
| КОРРЕКЦИЯ ФАЗИРОВАНИЯ | 2018 |
|
RU2765996C2 |
| КЛАССИФИКАЦИЯ САЙТОВ СПЛАЙСИНГА НА ОСНОВЕ ГЛУБОКОГО ОБУЧЕНИЯ | 2018 |
|
RU2780442C2 |
| СПОСОБЫ ВЫЯВЛЕНИЯ РАКА ЛЕГКОГО | 2017 |
|
RU2760913C2 |
Изобретение относится к области молекулярной биологии. Описан способ анализа для секвенирования генов, включающий получение данных фрагмента, переданных в режиме реального времени от платформы секвенирования, ввод данных фрагмента в запоминающее устройство. Далее следует выполнение с помощью вызова программы инкапсуляции обработки данных и анализа распознаванием данных фрагмента для получения соответствующего результата анализа, выполнение контроля качества обработки данных фрагмента для получения результата контроля качества, выполнение обработки данных по результату контроля качества для получения результата обработки. Затем идет выполнение анализа распознаванием результата обработки, с помощью вызова предварительно установленной в запоминающем устройстве программы анализа распознаванием, для получения окончательного результата анализа. Также описано устройство анализа для секвенирования генов для осуществления способа. Технический результат заключается в устранении технических недостатков предшествующего уровня техники, таких как значительные затраты времени на секвенирование и низкая эффективность передачи, которые в дальнейшем приводят к относительно медленному процессу анализа. 4 н. и 6 з.п. ф-лы, 6 ил.
1. Способ анализа для секвенирования генов, включающий в себя:
получение данных фрагмента, переданных в режиме реального времени от платформы секвенирования, причем данные фрагмента представляют собой набор коротких последовательностей, считанных в библиотеке секвенирования после выполнения по меньшей мере одного цикла секвенирования;
ввод данных фрагмента в запоминающее устройство; и
выполнение, с помощью вызова программы инкапсуляции, предварительно установленной в запоминающем устройстве, обработки данных и анализа распознаванием данных фрагмента для получения соответствующего результата анализа, при этом программа инкапсуляции является пользовательской программой,
в котором программа инкапсуляции включает в себя программу контроля качества данных, программу обработки данных и программу анализа распознаванием, и
в котором упомянутое выполнение обработки данных и анализа распознаванием данных фрагмента для получения соответствующего результата анализа, с помощью вызова программы инкапсуляции, предварительно установленной в запоминающем устройстве, включает в себя:
выполнение, путем вызова программы контроля качества данных, предварительно установленной в запоминающем устройстве, контроля качества обработки данных фрагмента для получения результата контроля качества;
выполнение, с помощью вызова предварительно установленной в запоминающем устройстве программы обработки данных, обработки данных по результату контроля качества для получения результата обработки; и
выполнение анализа распознаванием результата обработки, с помощью вызова предварительно установленной в запоминающем устройстве программы анализа распознаванием, для получения окончательного результата анализа.
2. Способ анализа для секвенирования генов по п. 1, в котором упомянутое получение данных фрагмента включает в себя:
определение размера фрагмента;
выполнение фрагментации, на основе размера фрагмента, всех нефрагментированных коротких последовательностей, передаваемых в данный момент от платформы секвенирования и считанных после одного цикла секвенирования, причем набор фрагментированных коротких последовательностей используют в качестве данных фрагмента.
3. Способ анализа для секвенирования генов по п. 2, в котором упомянутое определение размера фрагмента включает в себя:
получение данных о текущем состоянии бездействия центрального процессора (ЦП); и
корректировку размера фрагмента, исходя из текущего состояния бездействия ЦП.
4. Способ анализа для секвенирования генов по п. 1, в котором упомянутое выполнение контроля качества обработки данных фрагмента с помощью вызова предварительно установленной в запоминающем устройстве программы контроля качества данных включает в себя:
вычисление, путем вызова программы контроля качества данных, предварительно установленной в запоминающем устройстве, коэффициента погрешности положения коротких последовательностей в данных фрагмента, статистический анализ распределения оснований в данных фрагмента и/или удаление низкокачественных оснований из данных фрагмента, при этом низкокачественные основания представляют собой основания с качеством ниже порогового уровня качества.
5. Способ анализа для секвенирования генов по п. 1, в котором упомянутое выполнение обработки данных по результату контроля качества с помощью вызова предварительно установленной в запоминающем устройстве программы обработки данных включает в себя:
выполнение путем вызова программы обработки данных, предварительно установленной в запоминающем устройстве, по меньшей мере одного из сопоставления, упорядочивания, дедупликации, повторного сопоставления и коррекции показателя качества основания по короткой последовательности в результате контроля качества.
6. Способ анализа для секвенирования генов по п. 5, в котором упомянутое по меньшей мере одно из сопоставления, упорядочивания, дедупликации и повторного сопоставления по короткой последовательности в результате контроля качества включает в себя:
выполнение, путем вызова предварительно установленной в запоминающем устройстве программы обработки данных, сопоставления между короткой последовательностью в результате контроля качества и референсным геном для определения положения короткой последовательности в референсном гене;
определение метки положения короткой последовательности, исходя из положения короткой последовательности в референсном гене;
определение среди предварительно установленных в запоминающем устройстве нитей целевой нити, которая в данный момент находится в незанятом состоянии; и
выполнение, путем вызова целевой нити и с учетом метки положения короткой последовательности, по меньшей мере одного из упорядочивания, дедупликации и повторного сопоставления по короткой последовательности.
7. Способ анализа для секвенирования генов по п. 1, в котором упомянутое выполнение анализа распознаванием по результату обработки с помощью вызова предварительно установленной в запоминающем устройстве программы анализа распознаванием включает в себя:
выполнение, путем вызова программы анализа распознаванием, предварительно установленной в запоминающем устройстве, распознавания мутации и интерпретации результата обработки.
8. Устройство анализа для секвенирования генов, включающее в себя:
модуль сбора данных, выполненный с возможностью получения данных фрагмента, переданных в режиме реального времени от платформы секвенирования, причем данные фрагмента представляют собой набор коротких последовательностей, считанных в библиотеке секвенирования после выполнения по меньшей мере одного цикла секвенирования;
модуль передачи фрагмента, выполненный с возможностью ввода данных фрагмента в память; и
модуль анализа обработки, выполненный с возможностью выполнения, путем вызова программы инкапсуляции, предварительно установленной в запоминающем устройстве, обработки данных и анализа распознаванием данных фрагмента для получения соответствующего результата анализа, при этом программа инкапсуляции является пользовательской программой,
в котором программа инкапсуляции включает в себя программу контроля качества данных, программу обработки данных и программу анализа распознаванием, и
в котором упомянутое выполнение обработки данных и анализа распознаванием данных фрагмента для получения соответствующего результата анализа, с помощью вызова программы инкапсуляции, предварительно установленной в запоминающем устройстве, включает в себя:
выполнение, путем вызова программы контроля качества данных, предварительно установленной в запоминающем устройстве, контроля качества обработки данных фрагмента для получения результата контроля качества;
выполнение, с помощью вызова предварительно установленной в запоминающем устройстве программы обработки данных, обработки данных по результату контроля качества для получения результата обработки; и
выполнение анализа распознаванием результата обработки, с помощью вызова предварительно установленной в запоминающем устройстве программы анализа распознаванием, для получения окончательного результата анализа.
9. Накопитель для хранения данных, имеющий хранящиеся на нем машиночитаемые команды, причем указанные машиночитаемые команды при выполнении процессором предписывают указанному процессору выполнение этапов способа анализа для секвенирования генов согласно любому из пп. 1–7.
10. Вычислительное устройство для анализа секвенирования генов, имеющее хранящиеся на нем машиночитаемые команды, причем указанные машиночитаемые команды при выполнении процессором предписывают указанному процессору выполнение этапов способа анализа для секвенирования генов согласно любому из пп. 1–7.
| CN 109801677 A, 24.05.2019 | |||
| CN 112259168 A, 22.01.2021 | |||
| СИСТЕМА И СПОСОБ ВТОРИЧНОГО АНАЛИЗА ДАННЫХ СЕКВЕНИРОВАНИЯ НУКЛЕОТИДОВ | 2017 |
|
RU2741807C2 |
| WO 2014113736 A1, 24.07.2014. | |||
