ОБЛАСТЬ ТЕХНИКИ
[0001] Варианты осуществления изобретения в целом относятся к компьютерным системам, а в частности - к системам и способам обработки изображений. В частности, варианты осуществления настоящего изобретения относятся к разделению изображения на отдельные цветовые слои для последующей обработки изображения и извлечения информации из этих слоев.
УРОВЕНЬ ТЕХНИКИ
[0002] При обработке документов и изображений часто встречаются изображения документов, содержащие более одного слоя записанной информации. Например, в настоящее время документы и изображения, содержащие дополнительные объекты, такие как штампы, печати, оттиски, сепараторы/разделители и другую информацию в дополнение к тексту, становятся все более распространенными. В таких типах документов и изображений может возникнуть проблема с оптическим распознаванием символов (OCR), когда печати (или другие объекты) расположены поверх текста и перекрывают его. Таким образом, наличие таких объектов, содержащих информацию, наложенную поверх других объектов или текста, который уже находился на поверхности документа или изображения, может помешать процессу оптического распознавания символов и снизить его качество и точность (например, печать на более высоком слое изображения поверх текста на нижнем слое изображения).
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[0003] Варианты осуществления настоящего изобретения описывают механизмы разделения изображения документа на отдельные цветовые слои.
[0004] Способ, применяемый в настоящем изобретении, включает в себя получение устройством обработки данных изображения документа, разделение изображения документа на множество патчей и определение для каждого патча, является ли данный патч монохромным или не монохромным (полихромным, многоцветным). Он также включает в себя кластеризацию множества монохромных патчей на множество кластеров в цветовом пространстве, где каждый кластер соответствует цветовому слою из множества цветовых слоев изображения документа, а также сегментирование/сегментацию каждого не монохромного патча на соответствующее множество монохромных сегментов. Способ также включает в себя связывание/ассоциирование, для каждого не монохромного патча, каждого монохромного сегмента соответствующего множества монохромных сегментов с одним кластером из множества кластеров и использование множества кластеров для выполнения задачи извлечения информации из изображения документа.
[0005] Система, используемая в изобретении, включает в себя память и процессор, связанный с памятью, при этом процессор сконфигурирован для получения изображения документа, разделения изображения документа на множество патчей и определения для каждого патча, является ли данный патч монохромным или не монохромным. Кроме того, конфигурация процессора обеспечивает кластеризацию множества монохромных патчей на множество кластеров в цветовом пространстве, где каждый кластер соответствует цветовому слою из множества цветовых слоев изображения документа, а также сегментирование каждого не монохромного патча на соответствующее множество монохромных сегментов. Конфигурация процессора также обеспечивает связывание, для каждого не монохромного патча, каждого монохромного сегмента соответствующего множества монохромных сегментов с одним кластером из множества кластеров и использование множества кластеров для выполнения задачи извлечения информации из изображения документа.
[0006] Энергонезависимый машиночитаемый носитель данных в настоящем изобретении включает в себя команды/инструкции, которые при доступе к ним устройством обработки данных вынуждают устройство обработки данных принимать изображение документа, разделять изображение документа на множество патчей и определять для каждого патча, является ли данный патч монохромным или не монохромным. К тому же команды вынуждают устройство обработки данных выполнять кластеризацию множества монохромных патчей на множество кластеров в цветовом пространстве, где каждый кластер соответствует цветовому слою из множества цветовых слоев изображения документа, а также сегментирование каждого не монохромного патча на соответствующее множество монохромных сегментов. Дополнительно команды вынуждают устройство обработки данных обеспечивать связывание, для каждого не монохромного патча, каждого монохромного сегмента соответствующего множества монохромных сегментов с одним кластером из множества кластеров и использование множества кластеров для выполнения задачи извлечения информации из изображения документа.
[0007] Эти и другие элементы и признаки станут более ясными в последующем подробном описании иллюстративных реализаций и вариантов осуществления настоящего изобретения, которое следует рассматривать вместе с прилагаемыми чертежами.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0008] Изобретение станет более понятным из подробного описания, приведенного ниже, и из прилагаемых чертежей различных вариантов осуществления изобретения. Однако чертежи не должны использоваться с целью ограничения изобретения конкретными вариантами осуществления. Чертежи предназначены только для пояснения и понимания.
[0009] На Фиг. 1 представлена блок-схема способа разделения изображения документа на отдельные цветовые слои для извлечения информации в соответствии с вариантом осуществления настоящего изобретения.
[0010] На Фиг. 2A показан пример серии корректировок свойств документа в соответствии с некоторыми вариантами осуществления настоящего изобретения.
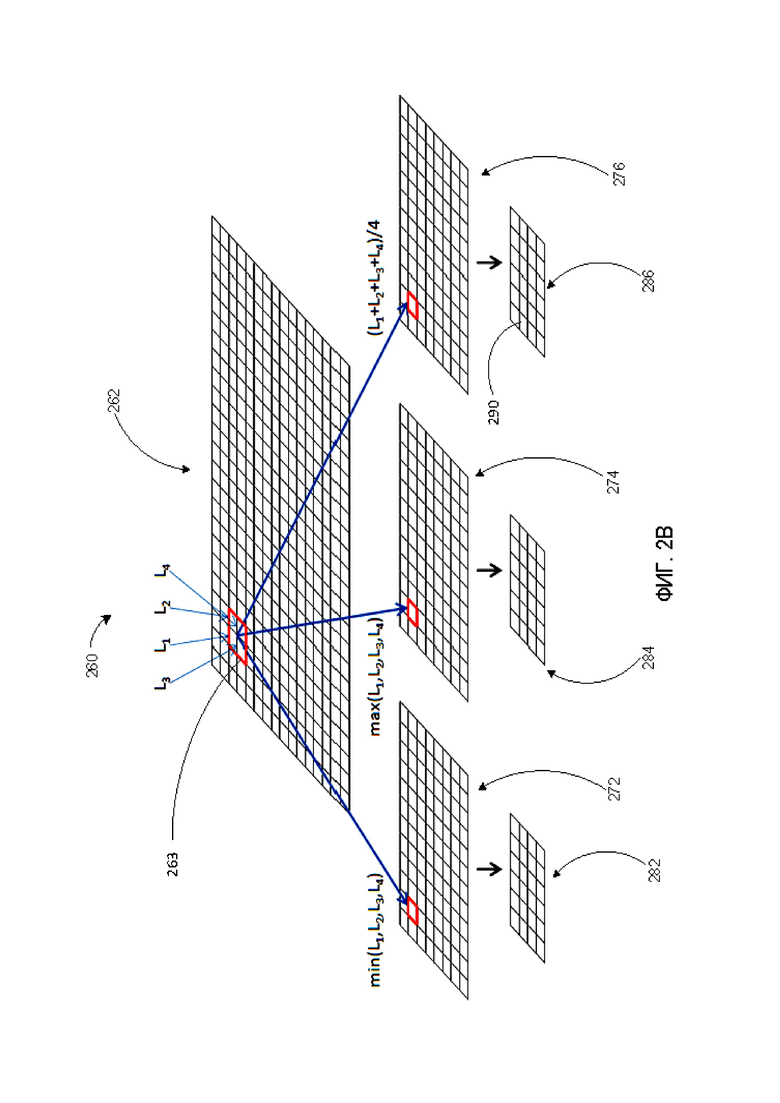
[0011] На Фиг. 2B показан пример диаграммы генерирования карты порогов в соответствии с некоторыми вариантами осуществления настоящего изобретения.
[0012] На Фиг. 3 представлена схема примера изображения документа, разделенного на патчи, в соответствии с некоторыми вариантами осуществления настоящего изобретения.
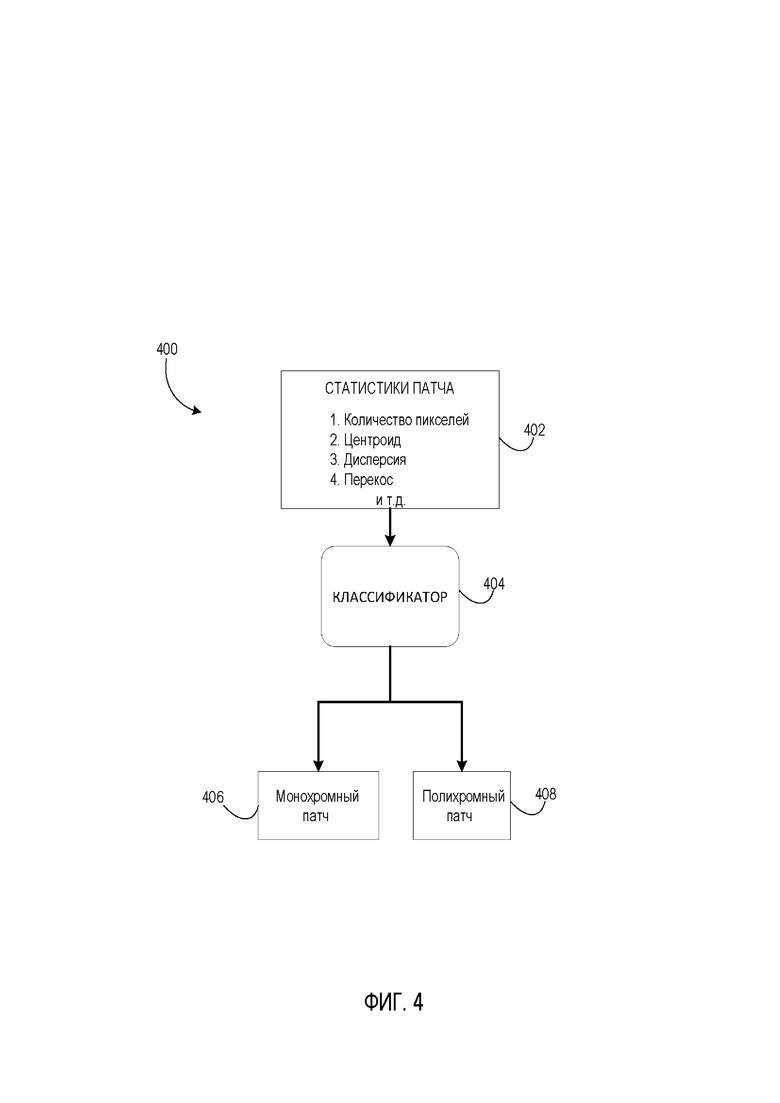
[0013] На Фиг. 4 представлена блок-схема способа классификации патчей в соответствии с некоторыми вариантами осуществления настоящего изобретения.
[0014] На Фиг. 5 представлена блок-схема кластеризации патчей в соответствии с некоторыми вариантами осуществления настоящего изобретения.
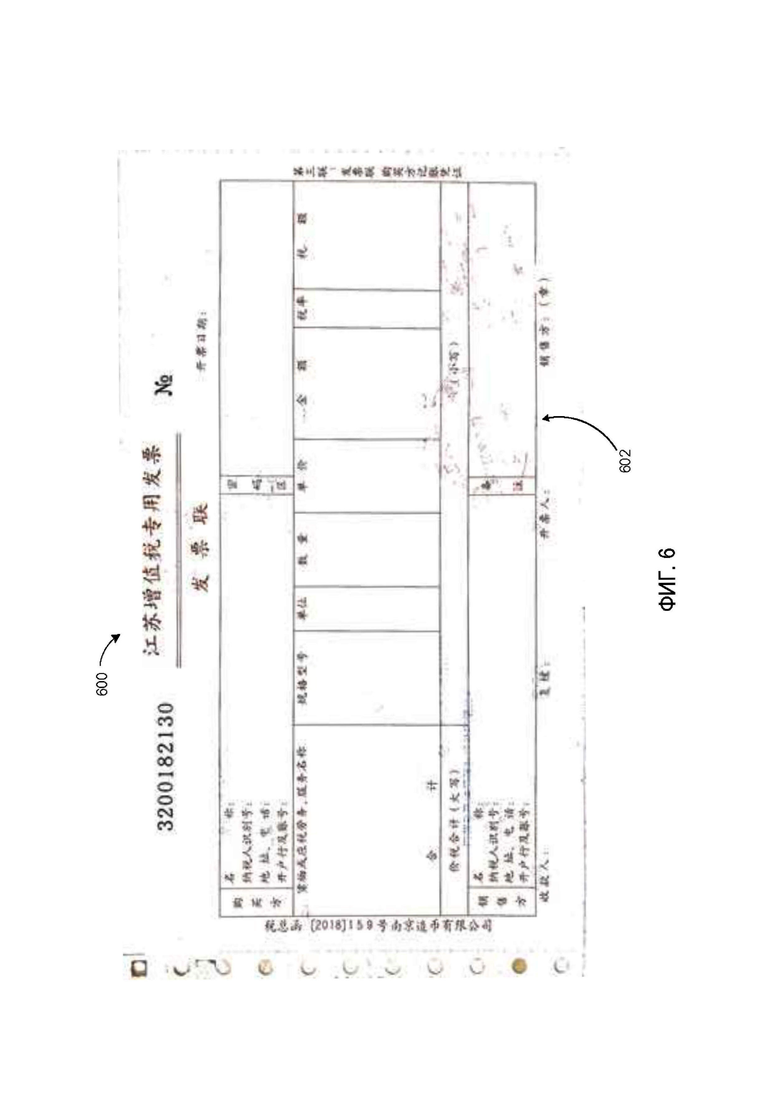
[0015] На Фиг. 6 показана схема цветового слоя примерного изображения документа в соответствии с некоторыми вариантами осуществления настоящего изобретения.
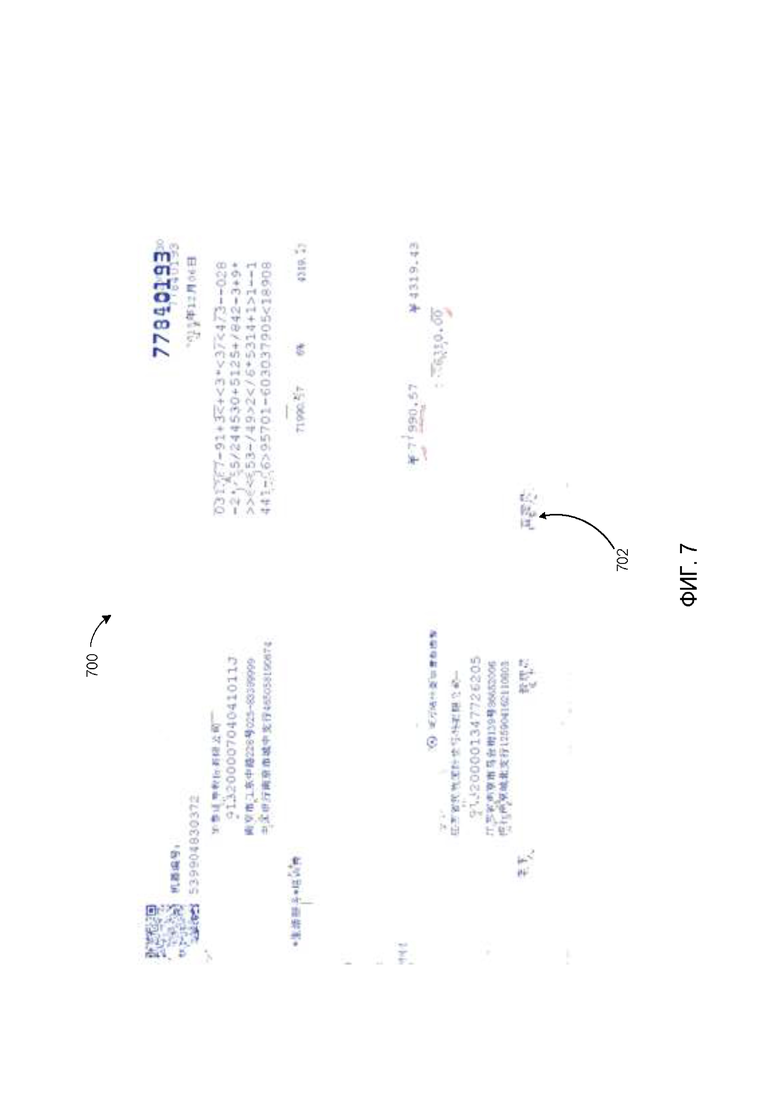
[0016] На Фиг. 7 показана схема цветового слоя примерного изображения документа в соответствии с некоторыми вариантами осуществления настоящего изобретения.
[0017] На Фиг. 8 показана схема цветового слоя примерного изображения документа в соответствии с некоторыми вариантами осуществления настоящего изобретения.
[0018] На Фиг. 9 представлена блок-схема компьютерной системы в соответствии с некоторыми вариантами осуществления настоящего изобретения.
ПОДРОБНОЕ ОПИСАНИЕ
[0019] Настоящее изобретение описывает способы и системы для разделения изображения документа на отдельные цветовые слои, которые можно использовать для извлечения информации из изображения документа. Учитывая распространение документов с несколькими слоями информации, записанными один на другом (например, текст, введенный в форму, а затем заверенный печатью, наложенной поверх текста и поля формы), возникают трудности с выполнением задачи оптического распознавания символов (OCR). В документах, где несколько слоев информации, таких как текст и объекты, перекрывают друг друга или накладываются друг на друга, уровень качества и точности операций оптического распознавания символов значительно снижается.
[0020] В ситуациях, когда документы содержат несколько слоев наложенной информации, разные типы информации могут быть выражены с помощью знаков разных цветов в изображении документа. Например, документы-формы могут представлять собой заполняемые формы с различными полями и метками полей с инструкциями по заполнению форм, а также разделителями и другими разделяющими элементами, определяющими заполняемые поля. Некоторые цветные документы-формы (например, формы с исключением цветов (color dropout)), где поля, инструкции, разделители полей и другие элементы могут быть представлены одним цветом, а текст или другая информация, введенная в форму и ее соответствующие поля, представлены другим цветом (т.е. записи полей имеют другой цвет, чем остальная часть документа-формы). Однако в некоторых ситуациях введенный текст или информация могут пересекаться с разделяющими элементами (например, с разделителями полей формы) документа-формы, а также полями и текстом с инструкциями документа-формы. Точно также штампы или подписи, которые наносятся на документ после его заполнения, могут перекрываться как с информацией, введенной в документ-форму, так и с полями и элементами самого документа-формы. В этих ситуациях распознавание символов существенно усложняется, поскольку перекрывающиеся элементы мешают процессу оптического распознавания символов.
[0021] Аспекты и варианты осуществления настоящего изобретения направлены на устранение вышеупомянутых недостатков и проблем существующей технологии и представляют новые подходы и механизмы для разделения изображения документа на множество цветовых слоев для последующего выполнения более точных и более эффективных операций оптического распознавания символов с целью извлечения информации.
[0022] Примечательно, что для целей оптического распознавания символов или извлечения информации данные из разных слоев документа могут иметь различную важность. Например, может потребоваться получить информацию, содержащуюся только в одном из слоев изображения документа. Довольно часто желаемая информация присутствует на изображении документа в одном или нескольких цветах, визуально похожих друг на друга. В таких случаях достаточно разделить изображение документа на отдельные цветовые слои, чтобы иметь возможность выполнять оптическое распознавание символов на цветовом слое, содержащем необходимую информацию.
[0023] С другой стороны, в других ситуациях может быть желательно извлечь информацию, содержащуюся в нескольких слоях изображения документа. В этих случаях значительно проще и эффективнее выполнять оптическое распознавание символов или другие операции извлечения информации отдельно для каждого слоя. Элементы изображения документа вместе с их координатами на изображении документа могут использоваться для связывания записей полей с метками полей (например, для идентификации, к какому полю или категории относится информация, содержащаяся в данном элементе). Такие связи особенно полезны для извлечения структурированной информации из документов.
[0024] Используемый здесь термин «документ» может относиться к любому типу документа, включая, например, счета-фактуры, документы, удостоверяющие личность, чеки, кредитные заявки, банковские документы, соглашения, одно- или многостраничные документы, коносаменты, акты, бухгалтерские документы, финансовые отчеты, патенты, отчеты о патентном поиске, а также любые другие документы, которые часто хранятся на предприятиях в бумажной или отсканированной форме.
[0025] На Фиг. 1 представлена блок-схема способа 100 разделения изображения документа на отдельные цветовые слои для извлечения информации в соответствии с вариантом осуществления настоящего изобретения. В целом, операции, описанные в настоящем изобретении, могут включать в себя несколько процессов, в том числе получение или извлечение изображения документа в блоке 102 и выполнение корректировки его визуальных свойств, таких как выравнивание яркости/освещения, изменение контрастности в блоке 104 и бинаризацию (преобразование в двоичную форму) в блоке 106. Кроме того, варианты осуществления настоящего изобретения могут включать в себя поиск связных компонент в блоке 108, разделение изображения документа на патчи в блоке 110 и вычисление статистик в блоке 112 для каждого патча с последующей возможностью классификации патчей на монохромные или не монохромные (т.е. полихромные, многоцветные) в блоке 114 и кластеризацией в блоке 116. В некоторых вариантах осуществления изобретения кластеризация может быть основана на вычислении центроидов кластеров в цветовом пространстве, которое может соответствовать цветовому слою изображения документа. Кластеризация патчей может быть выполнена первоначально для монохромных патчей (участков), а не монохромные патчи могут быть сегментированы в блоке 118 на монохромные сегменты, каждый из которых затем может быть связан в блоке 120 с соответствующим кластером. Таким образом, отдельные цветовые слои изображения документа, каждый из которых соответствует разному кластеру монохромных патчей, а также монохромные сегменты не монохромных патчей могут быть идентифицированы в блоке 122 на данном исходном/входном изображении документа. Затем информация может быть извлечена в блоке 124 из одного или нескольких слоев изображения документа с использованием оптического распознавания символов или других методов извлечения информации.
[0026] В следующем описании подробно объясняются признаки и элементы некоторых вариантов осуществления настоящего изобретения. Особое внимание уделяется основным аспектам разделения изображения документа на отдельные/обособленные цветовые слои для последующей обработки и анализа. В некоторых вариантах осуществления изобретения способ извлечения информации из изображения документа может включать в себя получение одного или нескольких изображений документа. Изображения документа могут быть получены с устройства (например, камеры или сканера), способного записывать цифровую копию документа с физической копии. В некоторых вариантах осуществления изобретения изображения документа могут быть извлечены из цифрового хранилища.
[0027] На Фиг. 2 показан пример серии корректировок свойств документа в соответствии с некоторыми вариантами осуществления настоящего изобретения. Изображение 202 документа показывает состояние изображения при его получении, в то время как изображение 204 документа и изображение 206 документа показывают состояние изображения, соответственно, после корректировки свойств и бинаризации. В некоторых вариантах осуществления изобретения документы могут представлять собой цветные документы-формы 202, содержащие записи в полях 211 формы, на которые наложены печати 213. Этот тип структуры часто можно увидеть в квитанциях и счетах. В частности, хотя нижеследующее описание будет сосредоточено на варианте осуществления изобретения, в котором задействован один одностраничный документ, различные аспекты описанных здесь вариантов осуществления изобретения могут быть в равной степени применимы к наборам из нескольких документов и к многостраничным документам.
[0028] Таким образом, в некоторых вариантах осуществления визуальные свойства полученного изображения 202 документа могут корректироваться. Это, в частности, подразумевает выполнение выравнивания яркости изображения 202 документа. Более конкретно, яркость изображения 202 документа изменяют так, чтобы области изображения документа, которые должны выглядеть белыми, но не выглядят таковыми, например, поле 211 формы, из-за неравномерного освещения, выглядели как истинно белые. Этого можно добиться разными способами, включая использование цифровых и электронных фильтров.
[0029] Неравномерность (т.е. постепенные переходы от более темных областей к более светлым, плавные градиенты изменения яркости) представлена низкой частотой сигнала (т.е. низкой частотой изменения сигнала яркости). Напротив, основное содержимое изображения 202 документа (например, текст, печати/штампы, элементы формы, разделители и т.д.) представлено высокой частотой сигнала (т.е. сигнал яркости часто изменяется по величине, поскольку имеется много близко расположенных областей с чередованием темных и светлых участков). Соответственно, целью процесса выравнивания яркости является удаление или компенсация низкочастотной составляющей изображения и, таким образом, выравнивание яркости по всему изображению. Таким образом, яркость элементов, расположенных в более плохо освещенных областях изображения документа, также будет скорректирована.
[0030] В различных вариантах осуществления можно использовать разнообразные фильтры для отфильтровывания высокочастотных компонентов от низкочастотных компонентов изображения 202 (например, медианный фильтр (median filter), фильтр верхних частот (high-pass filter), фильтр размытия по Гауссу (Gaussian blur filter), билатеральный фильтр (bilateral filter) и т.д.). После применения фильтра (например, медианного фильтра) будут удалены высокочастотные объекты / элементы, такие как текст, разделители и другие мелкие детали на изображении документа. На выходе фильтра может быть получено промежуточное изображение, содержащее только плавные изменения освещенности/интенсивности (т.е. информацию об изменениях яркости). Таким образом, в некоторых вариантах осуществления может применяться фильтр для удаления мелких детальных элементов из изображения 202 документа, оставляющий только фон с относительно плавными/постепенными изменениями яркости. Высокочастотные компоненты, удаленные фильтром, впоследствии могут быть восстановлены, поскольку именно эти компоненты могут использоваться для оптического распознавания символов и извлечения информации.
[0031] В некоторых вариантах осуществления, в зависимости от типа используемого фильтра, может быть предпочтительно использован фильтр большего, а не меньшего радиуса везде, где такая опция имеется. Однако в другом варианте осуществления для увеличения скорости и точности фильтрации могут применяться другие способы оптимизации фильтрации. Например, размер изображения 202 документа перед применением фильтра может быть уменьшен. Затем может быть применен фильтр меньшего радиуса (поскольку изображение меньше), после чего промежуточное изображение, полученное после применения фильтра, может быть возвращено к его исходному размеру.
[0032] Ниже описывается модификация свойства яркости изображения после применения вышеупомянутого фильтра к изображению 202 документа. Если I - начальная яркость канала (например, красный/зеленый/синий канал (RGB)) исходного изображения 202 документа, то после фильтрации оставшуюся компоненту яркости (т.е. яркости того же канала в промежуточном изображении, полученном после применения фильтра) можно обозначить как I'. Соответственно, изображение можно корректировать путем нормализации/нормирования низкочастотного сигнала. Например, в некоторых вариантах осуществления для каждого канала яркость рассчитывается по формуле Iнов. = I/ I'. Таким образом, яркость исходного изображения 202 делится на компонент яркости, полученный после применения фильтра, чтобы получить новую яркость Iнов, которая выравнивается по всему изображению 204 и не содержит градаций яркости освещения, сохраняя при этом детализацию таких элементов, как текст, печати, разделители и т.д. (которые могут быть важными элементами для последующего оптического распознавания символов и извлечения информации). Выравнивание яркости делает ранее более темные области исходного изображения 202 более яркими, а ранее более светлые области изображения более темными, чтобы выровнять интенсивность освещения по всему изображению 204.
[0033] Описанный выше способ выравнивания яркости относится к обычно встречающимся документам со светлым или белым фоном. Соответственно, цвет фона корректируется по всему изображению так, чтобы цвет фона соответствовал истинному белому цвету, а остальные цвета изображения нормализовались соответствующим образом. Однако аналогичный процесс может быть выполнен с документами с темным фоном (т.е. с документами, в которых светлый текст и другая информация представлены на черном или темном фоне). В этих случаях исходное изображение сначала инвертируется по цвету, чтобы привести его в стандартное представление с темным текстом и другой информацией на светлом фоне. После этого вышеупомянутый процесс корректировки и выравнивания яркости может выполняться в соответствии с описанием.
[0034] В некоторых вариантах осуществления также можно корректировать контрастность изображения. Существуют различные алгоритмы изменения контрастности изображения, которые можно применять для улучшения четкости границ различных существенных элементов изображения документа. Однако алгоритмы, учитывающие неравномерность освещения, могут быть предпочтительнее других. В одном из вариантов осуществления может применяться адаптивное увеличение контрастности относительно локального среднего значения. Это применимо к документам с относительно простой версткой. В одном варианте осуществления для адаптивного увеличения контрастности на различных участках/областях изображения к такому изображению может быть применено гауссово окно с прокруткой (например, окно с размытыми / нечеткими краями и с плотностью, постепенно уменьшающейся в направлении от центра).
[0035] Для документов с более сложной версткой такой алгоритм адаптивной бинаризации может генерировать карту порогов посредством итеративного пирамидального процесса, приведенного на Фиг. 2B, относительно которого увеличение контрастности приводит к улучшению визуального качества. Соответственно, в этих вариантах осуществления для генерирования карты порогов к изображению применяется итеративный процесс разложения. Например, в одном варианте осуществления разложение может начинаться в масштабе исходного изображения 262. Изображение может быть разделено на непересекающиеся блоки 263 одинакового заданного размера (например, квадраты 2×2 пикселя, квадраты 3×3 пикселя и т.д.). Для каждого из блоков 263 (например, квадратов пикселей) могут быть определены значения минимальной, максимальной и средней яркости пикселей, составляющих блок (например, для квадрата 2×2 можно определить яркость 4-х составляющих пикселей). Из этих значений могут быть сформированы три изображения: (i) изображение 272, содержащее минимальные значения, (ii) изображение 274, содержащее максимальные значения, и (iii) изображение 276, содержащее средние значения, каждое из которых будет в два раза меньше по горизонтали и вертикали относительно исходного (или предыдущего) изображения. Эту процедуру можно повторять для размещения получаемых в результате изображений в пирамидальной структуре 260 до тех пор, пока не будет достигнут уровень, на котором размер получаемого в результате изображения 282, 284, 286 станет не меньше необходимого минимального размера (например, 2×2 пикселя).
[0036] Таким образом, в некоторых вариантах осуществления с использованием вышеописанного пирамидального разложения 260 получают минимальные, максимальные и средние значения для исходных областей изображения в различных масштабах его представления. Способ построения карты порогов на основе пирамидального разложения может представлять собой многоступенчатый процесс. На нижнем уровне 282, 284, 286 пирамидального разложения, где изображение состоит только из нескольких пикселей, карта порогов может быть сгенерирована с использованием одного из двух следующих значений: (a) локальное среднее значение яркости пикселей этого участка изображения (т.е. яркость пикселя из изображения, сгенерированного из изображения 276, содержащего средние значения в пирамиде) или (b) среднее значение между локальным минимумом и максимумом (т.е. среднее значение яркости эквивалентного числа (например, 2) пикселей, взятых из изображения 272, сформированного из минимальных значений в пирамиде, и пикселей, взятых из изображения 274, сформированного из максимальных значений в пирамиде). Затем на следующем уровне разложения карта порогов может быть расширена в 2 раза как по горизонтали, так и по вертикали с использованием интерполяции со свертками [1 3], [3 1].
[0037] Для каждого пикселя на каждом последующем уровне пирамидального разложения 260 может быть вычислена разность между значением пикселя из изображения 272, сформированного из минимальных значений в пирамиде, и изображения, сформированного из максимальных 274 значений в пирамиде. Если эта разница не превышает заранее определенного порогового значения (например, заранее определенного порогового значения шума, ниже которого информация считается незначительным шумом), можно предположить, что на этом участке изображения полезного сигнала нет, причем как на этом, так и на последующих уровнях пирамидального разложения 260. Следовательно, пороговое значение, полученное на предыдущем уровне разложения, можно оставить без изменений. В противном случае, если превышено предварительно определенное пороговое значение, может быть вычислено новое уточненное пороговое значение на основе комбинации (a) и (b) выше.
[0038] Вышеописанную процедуру можно повторять до тех пор, пока не будет достигнут такой уровень разложения, при котором участки 290 изображения, соответствующие пикселям в пирамиде, все еще больше самых маленьких элементов (например, букв, символов, чисел и т.д.), различаемых на изображении. В результате получается карта порогов, относительно которой увеличение контрастности не приводит к потере или удалению объектов различного размера, и при этом однородные участки на изображении не содержат шум. Соответственно, карта порогов используется для увеличения контрастности, чтобы яркость участков в каждом окне, где яркость выше порогового значения, усиливалась, а яркость участков в каждом окне, где яркость ниже порогового значения, уменьшалась для более четкого определения различных элементов изображения документа. В других вариантах осуществления для цветных изображений контраст может быть усилен для компоненты яркости (т.е. для компоненты серого в изображении) при одновременном уменьшении коэффициента усиления контрастности для насыщенных цветом участков изображения.
[0039] В некоторых вариантах осуществления изображение документа может быть бинаризовано для создания черно-белого изображения 206. Процесс бинаризации - это преобразование цветного изображения или изображения в градациях серого в бинарное черно-белое изображение 206. Как более подробно описано далее, процесс бинаризации может выполняться различными способами, такими как, например, метод Отцу (т.е. глобальная бинаризация) и методы локальной адаптивной бинаризации (например, метод порогового значения Ниблэка и Совола (Niblack and Sauvola)). Одним из основных параметров этого преобразования является пороговое значение t, с которым сравнивается яркость / насыщенность каждого пикселя. После сравнения путем определения, является ли яркость данного пикселя ниже или выше порогового значения t, пикселю соответственно присваивается значение 0 или 1.
[0040] Бинаризованное изображение 206 может быть представлено в виде региона, представленного структурой данных, где соответствующий регион имеет максимальные значения (т.е. значения, равные 1) в структуре данных. Соответственно, регионом можно считать все черные части бинаризованного изображения, содержащие весь текст, объекты, разделители и т.д. (т.е. значимые объекты изображения). Другими словами, регион - это маска значимых элементов, присутствующих на изображении документа. Эта маска содержит элементы, которые можно использовать для последующего оптического распознавания символов и извлечения информации. В частности, вышеупомянутый процесс бинаризации также может быть далее использован для получения масок для каждого цветового слоя изображения. Например, белые пиксели в бинаризованном изображении документа могут быть автоматически связаны с фоновым слоем по всем каналам. Соответственно, после бинаризации изображение 206 может быть разделено на два класса пикселей: пиксели фона и пиксели, принадлежащие объектам / элементам изображения документа.
[0041] В некоторых вариантах осуществления связные компоненты могут быть выявлены в изображении документа и проанализированы. В этих вариантах осуществления связные компоненты выявляются в бинаризованном изображении документа, после чего они могут быть проанализированы для определения их соответствующих размеров. Выявление и анализ связных компонент может облегчить разделение изображения на патчи, как показано на Фиг. 3. Связная компонента - это объект, пиксели которого примыкают к соседним пикселям. Связность может быть определена смежностью с другими пикселями в любом из четырех направлений (например, влево, вправо, вверх, вниз) или в любом из восьми направлений, если дополнительные четыре диагональных направления рассматриваются как возможные связи между начальными четырьмя направлениями. В случае, если пара пикселей не имеет каких-либо соседних связанных пикселей между ними, можно определить, что эти пиксели принадлежат разным связным компонентам. Например, число «12» включает две отдельных связных компоненты «1» и «2», в то время как буква «B» сформирована одной связной компонентой. Соответственно, если элементы на бинаризованном изображении документа перекрываются, пересекаются, сливаются, соприкасаются или иным образом связаны друг с другом каким-либо образом, их можно рассматривать как часть единой связной компоненты.
[0042] Затем, в некоторых вариантах осуществления, может быть определен размер идентифицированных связных компонент, на основе которого будет определяться конкретный размер соответствующего патча для разделения изображения документа. Патч можно понимать, как непересекающуюся прямоугольную область, содержащую связную компоненту. Размер патча может быть таким же или немного больше, чем размер соответствующей связной компоненты, чтобы каждый патч полностью включал в себя соответствующую связную компоненту. Соответственно, в одном из вариантов осуществления каждая связная компонента может быть заключена в отчетливый отдельный патч. В таком варианте осуществления меньший патч, заключающий в себе маленькую связную компоненту, может содержаться в более крупном патче, заключающем в себе более крупную связную компоненту. Например, как показано, изображение 300 документа разделено на различные патчи разного размера. Область 310 содержит связные элементы, полностью содержащиеся в патчах 312.
[0043] В другом варианте осуществления размеры различных связных компонент изображения документа могут быть кластеризованы в заранее определенное количество кластеров, а средний размер связной компоненты в наиболее репрезентативном/характерном кластере (т.е. в кластере с наибольшим количеством элементов) может быть выбран в качестве репрезентативного/типового размера патча. В этом варианте осуществления связные компоненты могут быть покрыты патчами типичного размера; при этом все связанные компоненты покрываются / охвачены по крайней мере одним патчем, и, если отдельный патч не охватывает данную связную компоненту, он покрывается несколькими непересекающимися патчами.
[0044] Таким образом, изображение документа разбивается на патчи, содержащие связные компоненты. В частности, патчи содержат некоторые важные элементы изображения документа, а не исключительно пустые / белые области. В результате патч 312 может содержать элементы или пиксели одного цвета, или же патч 322 может содержать элементы и пиксели нескольких цветов. Чтобы разделить изображение документа на разные цветовые слои, патчи 312, содержащие один и тот же цвет (монохромные патчи), могут быть идентифицированы и соотнесены с соответствующим цветовым слоем. Оставшиеся патчи, такие как патчи 322 в области 320, где связные области штампа перекрывают связные области нижележащего текста и элементов документа-формы, будут не монохромными / полихромными и впоследствии могут быть сегментированы, а их сегменты связаны с соответствующим цветом.
[0045] Как показано на Фиг. 4, для достижения этой цели, первоначально в рамках способа 400, в блоке 402 может выполняться вычисление различных статистических характеристик (статистик) для набора патчей. После этого, как более подробно описано ниже, патчи могут быть классифицированы в блоке 404 согласно рассчитанной статистике. Например, в одном из вариантов осуществления скорректированное/выровненное изображение документа (т.е. изображение, которое подверглось изменению уровня яркости и контрастности) может быть преобразовано из пространства «красный-зеленый-синий» (RGB) в пространство «тон-насыщенность-значение» (HSV). Кроме того, цилиндрическую модель пространства «тон-насыщенность-значение» (HSV) можно модифицировать, сжав ее по оси «Значение» и преобразовав координаты в декартовы координаты; тогда расстояние между точками в пространстве можно рассчитать как расстояние в евклидовом пространстве (т.е. евклидово расстояние ≈ √(H2+S2+cV2) , где H - значение цвета, S - значение насыщенности, V - значение яркости, а c - коэффициент для уменьшения важности / веса значения яркости V и, таким образом, сжимая цилиндр по оси V). Этот расчет расстояния, как более подробно описано ниже, можно использовать для вычисления центроидов, расстояния в цветовом пространстве, а также других статистических показателей для патчей.
[0046] Кроме того, в некоторых вариантах осуществления для пикселей каждого патча оценивается набор статистических значений: (i) количество пикселей в патче, (ii) центроид (т.е. среднее значение пикселей по трем параметрам: «тон-насыщенность-значение» (HSV)), (iii) дисперсия (т.е. значения пикселей относительно центроида в цветовом пространстве «тон-насыщенность-значение» (HSV)) и (iv) перекос/асимметрия (т.е. вдоль одномерного расстояния относительно центроида). Существующие стандартные статистические / математические формулы могут использоваться для расчета этой статистики и могут быть реализованы с помощью исполняемого кода.
[0047] Как отмечалось ранее, патчи, на которые делится изображение документа, могут быть монохромными (т.е. содержащими пиксели только одного цвета) и не монохромными / полихромными (т.е. содержащими пиксели двух или более цветов). Используемые здесь термины «не монохромный» и «полихромный» являются взаимозаменяемыми. В одном из вариантов осуществления патчи, содержащие более двух цветов, могут рассматриваться как патчи, содержащие два цвета, путем игнорирования наименее представленного цвета пикселей.
[0048] Таким образом, при использовании классификатора 404 монохромности каждый патч может быть классифицирован либо как монохромный 406, либо как полихромный 408. В классификатор 404 могут вводиться статистические данные 402 патчей (например, количество/число пикселей, центроид, дисперсия, перекос и т.д.). Классификатор монохромности можно предварительно обучить на основе размеченных обучающих изображений и настроить с использованием соответствующих параметров классификации во время обучения. На выходе классификатор выдает решение относительно каждого патча, чтобы определить, является ли он монохромным 406 или полихромным 408. Для целей некоторых описанных здесь вариантов осуществления может быть использован любой классификатор на основе алгоритмов машинного обучения (например, модель градиентного бустинга (gradient boosting model), машина опорных векторов (support-vector machine), линейный классификатор (linear classifier) и т.д.). В других вариантах осуществления может использоваться и нейросетевой классификатор.
[0049] В некоторых вариантах осуществления, после классификации патчей как монохромные и не монохромные может применяться двухэтапный способ 500 кластеризации, показанный на Фиг. 5, для получения центроидов кластеров, каждый из которых соответствует отдельному цветовому слою изображения документа. Как более подробно описано ниже, для этого процесса могут быть выбраны монохромные патчи вместе с их соответствующими статистиками в блоке 502, а также могут быть вычислены центроиды (т.е. центроиды в цветовом пространстве) каждого кластера.
[0050] Первоначально статистические характеристики монохромных патчей могут быть сгруппированы в подкластеры с использованием классических механизмов кластеризации на этапе 504, таких как кластеризация k-средних, ЕМ-алгоритм кластеризации (Expectation-Maximization algorithm), иерархическая кластеризация и другие подобные методы. Однако на данном этапе в блоке 504 может быть создано множество кластеров, которые могут подлежать дальнейшему уточнению. Соответственно, после первого этапа кластеризации в блоке 504 может быть сгенерировано очень большое / избыточное количество кластеров (каждый из которых соответствует разному цветовому слою), которые могут быть впоследствии объединены в блоке 506 в меньшее количество кластеров.
[0051] Соответственно, для каждого из подкластеров вычисляется набор объединенных статистик. Объединенные статистики вычисляются среди всех возможных пар подкластеров, чтобы определить лучших кандидатов для объединения (например, объединение статистических областей (SRM)). Таким образом производится попарный перебор всех возможных вариантов слияния. Пары подкластеров могут быть выбраны на основе условий максимизации сумм взвешенных межкластерных дисперсий и расстояния между центроидами соответствующих кластеров. Как только обнаруживается пара подкластеров, которая дает лучшую дисперсионную характеристику, эта пара объединяется в единый кластер. В некоторых вариантах осуществления предпочтительно максимизировать расстояние между центроидами окончательного набора кластеров. Соответственно, кластеры, которые являются кандидатами на объединение, могут быть кластерами, соответствующие центроиды которых имеют наименьшее расстояние друг от друга в цветовом пространстве.
[0052] Таким образом, попарное слияние кластеров выполняется до тех пор, пока не будет удовлетворен заранее определенный пороговый критерий (например, будет достигнуто заранее определенное количество кластеров или будет достигнута заранее определенная сумма взвешенных межкластерных дисперсий и расстояния между центроидами). Предварительно определенный критерий может быть константой, которая предварительно задается в механизме кластеризации на основе обучающих данных. Следовательно, на выходе слияния и на втором этапе процесса кластеризации получается несколько кластеров с соответствующими статистиками. Таким образом, конкретное количество кластеров, получаемое в блоке 508, может соответствовать набору/числу отдельных цветовых слоев (т.е. каналов) исходного изображения документа. Соответственно, изображение может быть разделено на количество слоев, равное количеству полученных кластеров.
[0053] Однако, хотя вышеупомянутая процедура относится к монохромным патчам, в процесс предстоит включить еще и не монохромные патчи. Каждый из оставшихся не монохромных патчей (каждый из которых может быть уменьшен, чтобы его можно было рассматривать как содержащий два цвета) может быть связан/объединен с кластерами, образованными из монохромных патчей.
[0054] Чтобы осуществить это объединение, на полихромных патчах выполняются операции сегментации. Полихромные патчи, идентифицированные классификатором монохромности, могут быть сегментированы на монохромные сегменты. В некоторых вариантах осуществления каждый не монохромный патч может быть разделен на два сегмента (т.е. цветовых канала), и каждый сегмент затем может быть объединен с соответствующим цветовым слоем (на основе ранее полученных кластеров). Подобно описанному выше процессу кластеризации, для пикселей каждого сегмента каждого не монохромного патча может быть вычислен центроид (в цветовом пространстве).
[0055] В некоторых вариантах осуществления сегментация может выполняться с использованием нейронной сети (например, сверточной нейронной сети, автоэнкодера и т.д.). Нейронная сеть может быть обучена на синтетических обучающих данных или реальных обучающих данных, предварительно размеченных в соответствии с тремя цветовыми каналами, один из которых представляет собой цвет фона, а два других - каналы разных цветов для значимых объектов. В других вариантах осуществления для сегментации могут применяться и другие способы, в которых не используются нейронные сети. Например, сегментация может выполняться эвристически или с использованием стандартных подходов к цветовой сегментации, таких как: сегментация по возрастанию области на основе цвета с использованием слияния статистических областей (затравок) и без него (SRM), нормализация сокращений/разрезов (Normalized Cuts) и эффективной сегментации изображений на основе графов (Efficient Graph-Based Image Segmentation).
[0056] В некоторых вариантах осуществления при использовании эвристического метода сегментации изображение каждого не монохромного патча представляется в отдельных каналах, которые могут содержать информацию о цвете, такую как красный, зеленый, синий цвет, насыщенность, оттенок и т.д. В другом варианте осуществления могут использоваться другие переменные / каналы других цветовых пространств. Таким образом, в одном варианте осуществления каждый из четырех каналов (красный, зеленый, синий и насыщенность) преобразуется в двоичную форму с использованием метода Отцу (т.е. с использованием единого порога интенсивности, который разделяет пиксели на два класса, передний план и фон), чтобы получить бинаризованные маски каждого канала / переменной. Из бинаризованных масок для каждого канала выбираются сегменты цветов, которые имеют самую низкую метрику пересечения по объединению (IoU). Другими словами, для всех возможных пар бинаризованных масок рассчитывается метрика IoU и выбирается пара, для которой метрика IoU является наименьшей. Как более подробно описано ниже, затем каждая из масок может быть связана с соответствующим кластером и цветовым слоем изображения. Таким образом, изображение, разделенное на патчи, представлено в четырех версиях, каждая из которых соответствует четко определенной маске другого цвета / канала.
[0057] В некоторых случаях сегменты не монохромных патчей могут перекрываться в определенных областях. Однако при вычислении центроидов каждого из монохромных сегментов пиксели в области перекрытия можно игнорировать. Таким образом, центроиды в цветовом пространстве сегментов, полученных на этом этапе, можно использовать для составления полных отдельных цветовых слоев изображения документа.
[0058] Соответственно, в некоторых вариантах осуществления настоящего изобретения различные цветовые слои изображения документа могут быть составлены из вышеупомянутых полученных ранее кластеров и сегментов. На данный момент известна следующая информация: (i) информация, касающаяся всех монохромных сегментов не монохромных патчей и их соответствующих центроидов в цветовом пространстве, и (ii) информация, касающаяся центроидов кластеров монохромных патчей, соответствующих отдельным цветовым слоям изображения документа (полученным после кластеризации, например, 3-4 и более кластеров).
[0059] В некоторых вариантах осуществления центроиды каждого монохромного сегмента не монохромных патчей объединяются/связываются с ближайшим кластером (т.е. цветовым слоем изображения документа) на основе евклидова расстояния в цветовом пространстве. Другими словами, на основе центроида каждого сегмента каждого совпадения сегмент связывается с одним из ранее идентифицированных кластеров до тех пор, пока все монохромные сегменты полихромных патчей не будут связаны с кластером монохромных патчей (и с их соответствующим отдельным цветовым слоем изображения документа).
[0060] Таким образом, результат некоторых вариантов осуществления содержит отдельные цветовые слои изображения документа, где каждый слой состоит из кластеров монохромных патчей и связанных монохромных сегментов из не монохромных патчей. Следует отметить, что в некоторых случаях разные цветовые слои могут иметь области пересечения (т.е. общие области), которые могут соответствовать местам наложения друг на друга нескольких объектов или информационных элементов.
[0061] Таким образом, в одном из вариантов осуществления документ, ранее изображенный на Фиг. 2, можно разделить на три отдельных цветовых слоя. На Фиг.6 изображен первый цветовой слой 600, содержащий информацию 602 заполняемого документа-формы. На Фиг. 7 изображен второй цветовой слой 700, содержащий входную информацию / данные 702, которыми заполнены поля формы. На Фиг. 8 изображен третий цветовой слой 800, содержащий печати 802, которые были поставлены поверх документа-формы и входных данных.
[0062] В некоторых вариантах осуществления различные задачи оптического распознавания символов и извлечения информации могут выполняться на каждом из полученных слоев изображения документа. Например, каждый слой, состоящий из одного из кластеров, может быть подвергнут операции оптического распознавания символов для выявления и извлечения содержащейся в нем текстовой информации. В других примерах кластеры могут использоваться нейронной сетью для идентификации и извлечения информации, состоящей из элементов или полей в слое, содержащем незаполненные поля и инструкции заполняемого документа-формы.
[0063] При выполнении таких задач оптического распознавания символов часто бывает, что слой, содержащий данные, вводимые в поля формы, может быть, по существу, наиболее важным. Однако для получения структурированной информации, извлеченной из документа, может быть полезно дополнительно выполнить оптическое распознавание символов слоя, содержащего элементы, относящиеся к незаполненному документу-форме, чтобы иметь возможность связать входную информацию с соответствующими полями формы. Кроме того, хотя в некоторых случаях слой, содержащий печати/штампы, может иметь ограниченное значение, в других случаях штампы могут содержать важную информацию, относящуюся к вводу данных в поля формы (например, свидетельствующие об их подтверждении, правдивости или принятии), и поэтому может быть полезно выполнить оптическое распознавание символов цветового слоя, содержащего информацию из штампов. На основе координат информации, распознанной способом оптического распознавания символов, информация из каждого слоя может быть связана и объединена с информацией, полученной из других слоев, и в конечном итоге, можно сформировать составное изображение документа с распознанной информацией, готовое к последующей обработке и извлечению.
[0064] В некоторых других вариантах осуществления изображение документа можно разделить на цветовые слои с использованием другого подхода. Этот подход можно грубо разделить на четыре этапа: (i) загрузка / получение изображения документа, (ii) корректировка яркости и контрастности изображения документа, (iii) кластеризация и разделение изображения на промежуточные слои и (iv) объединение слоев изображения с использованием классификатора объединения слоев.
[0065] Хотя первые два этапа могут выполняться аналогично описанным ранее, третий этап может включать в себя три основных действия: (а) преобразование изображения в цветовое пространство «тон-насыщенность-значение» (HSV); (b) выбор серых пикселей, которые должны быть связаны с цветом фона, идентификация цветовых кластеров путем генерации гистограмм пикселей конкретных цветовых тонов и определение цветовых секторов в цветовом пространстве «тон-насыщенность-значение» (HSV) внутри пикселей, сгруппированных в два кластера, для которых вычислены их центроиды; и (c) связывание пикселей со слоями, соответствующими серому слою и кластерам (т.е. после вычисления центроидов кластеров пиксели связываются либо с серым фоновым слоем, либо с кластером с ближайшим центроидом в цветовом пространстве). В результате этого процесса может быть получено несколько изображений, каждое из которых может содержать часть исходного изображения документа другого цвета. Однако элементы некоторых слоев могут выглядеть размытыми. На четвертом этапе изображения промежуточных слоев выборочно объединяются для получения заранее определенного количества цветовых слоев исходного изображения документа.
[0066] На Фиг. 9 представлен пример вычислительной системы 900, которая может выполнять любой один или несколько описанных в настоящем документе способов. Вычислительная система может быть подключена (например, по сети) к другим вычислительным системам в локальной сети, интрасети, экстрасети или интернету. Вычислительная система может работать в качестве сервера в сетевой среде «клиент-сервер». Вычислительная система может представлять собой персональный компьютер (ПК), планшет, телевизионную приставку (STB), карманный персональный компьютер (КПК), мобильный телефон, фотоаппарат, видеокамеру или любое устройство, способное выполнять набор команд (последовательных или иных), определяющих действия, которые должны быть выполнены таким устройством. Кроме того, несмотря на наглядное изображение только одной вычислительной системы, термин «компьютер» должен также включать любую совокупность компьютеров, которые индивидуально или совместно выполняют набор (или несколько наборов) команд для реализации любого одного или нескольких способов, раскрытых в настоящем документе.
[0067] Иллюстративная вычислительная система 900 включает устройство 902 обработки данных, основную память 904 (например, постоянное запоминающее устройство (ПЗУ), флэш-память, динамическое оперативное запоминающее устройство (ДОЗУ), такое как синхронное ДОЗУ (СДОЗУ)), статическую память (например, флэш-память, статическое оперативное запоминающее устройство (СОЗУ)) и устройство 918 хранения данных, которые взаимодействуют друг с другом по шине 930.
[0068] Устройство 902 обработки данных представляет собой одно или несколько устройств обработки общего назначения, таких как микропроцессор, центральный процессор и т.п. Точнее говоря, устройство 902 обработки данных может быть микропроцессором для вычисления сложных наборов команд (CISC), микропроцессором для вычисления сокращенных наборов команд (RISC), микропроцессором с очень длинным командным словом (VLIW), процессором, реализующим другие наборы команд, или процессором, реализующим сочетание наборов команд. Устройство 902 обработки данных также может представлять собой одно или несколько устройств обработки специального назначения, таких как специализированная интегральная схема (ASIC), программируемая логическая интегральная схема (FPGA), цифровой сигнальный процессор (DSP), сетевой процессор и т.п. Устройство 902 обработки данных сконфигурировано для выполнения инструкций 926 с целью реализации описанных здесь способов, таких как способ 100 на Фиг. 1, способ 400 на Фиг. 4 и / или способ 500 на Фиг. 5, а также для выполнения описанных здесь операций (например, операции по способам 100, 400, 500).
[0069] Вычислительная система 900 может дополнительно включать устройство 922 сетевого интерфейса. Вычислительная система 900 также может включать видеодисплей 910 (например, жидкокристаллический дисплей (ЖКД) или электронно-лучевую трубку (ЭЛТ)), устройство 912 буквенно-цифрового ввода (например, клавиатуру), устройство 914 управления курсором (например, мышь) и устройство формирования сигнала (например, динамик). В одном иллюстративном примере устройство визуального отображения / видеодисплей 910, устройство буквенно-цифрового ввода 912 и устройство управления курсором 914 объединены в один компонент или устройство (например, сенсорный жидкокристаллический дисплей).
[0070] Устройство 918 хранения данных может включать машиночитаемый носитель 924 данных, на котором хранятся инструкции 926, воплощающие любую одну или несколько методик или функций, описанных в настоящем документе. Команды 926 во время их исполнения вычислительной системой 900 также могут находиться, полностью или как минимум частично, в основном запоминающем устройстве 904 и (или) в устройстве 902 обработки данных, причем основная память 904 и устройство 902 обработки данных также представляют собой машиночитаемые носители. В некоторых вариантах осуществления инструкции 926 могут дополнительно передаваться или приниматься по сети 916 через сетевое интерфейсное устройство 922.
[0071] Несмотря на то, что в иллюстративных примерах машиночитаемый носитель 924 данных представлен в единственном числе, термин «машиночитаемый носитель данных» следует понимать как включающий в себя один или несколько носителей (например, централизованную или распределенную базу данных и (или) связанные с ней кэши и серверы), в которых хранится один или несколько наборов инструкций. Термин «машиночитаемый носитель данных» также следует понимать как включающий в себя какой-либо носитель, способный хранить, кодировать или переносить набор команд для выполнения машиной и заставляющий машину выполнять любую одну или несколько методик настоящего изобретения. Термин «машиночитаемый носитель данных», соответственно, включает, помимо прочего, твердотельные запоминающие устройства, оптические носители и магнитные носители.
[0072] Несмотря на то, что приведенные в настоящем документе операции способов изображены и описаны в определенном порядке, порядок выполнения операций каждого способа может быть изменен таким образом, что определенные операции могут выполняться в обратном порядке или определенные операции могут выполняться по крайней мере частично, одновременно с иными операциями. В некоторых вариантах осуществления команды или подоперации отдельных операций могут выполняться с перерывами и (или) чередоваться.
[0073] Следует понимать, что приведенное выше описание служит для наглядности и не носит ограничительный характер. Многие иные варианты осуществления будут очевидны специалистам в данной области после прочтения и понимания приведенного выше описания. Поэтому область применения изобретения должна определяться со ссылкой на прилагаемую формулу изобретения наряду с полным объемом эквивалентов, на которые распространяется такая формула.
[0074] В приведенном выше описании изложены многочисленные подробности. Однако специалисту в данной области будет очевидно, что аспекты настоящего изобретения могут быть реализованы без таких конкретных деталей. В некоторых случаях известные структуры и устройства показаны в виде блок-схемы, без подробностей, чтобы не затруднять понимание предмета настоящего изобретения.
[0075] Некоторые части подробного описания, приведенного выше, представлены в виде алгоритмов и символьных представлений операций с битами данных в памяти компьютера. Такие алгоритмические описания и представления являются средствами, используемыми специалистами в области обработки данных с целью наиболее эффективной передачи содержания своей работы иным специалистам в данной области. Как в рамках настоящего документа, так и в целом алгоритм понимается как самосогласованная последовательность действий, приводящая к желаемому результату. Эти действия представляют собой этапы, требующие физических манипуляций с физическими величинами. Обычно, хотя и не обязательно, такие величины принимают форму электрических или магнитных сигналов, которые можно хранить, передавать, комбинировать, сравнивать или использовать иным образом. Иногда, в основном по соображениям общепринятой практики, удобно называть такие сигналы битами, значениями, элементами, символами, знаками, терминами, числами и т.п.
[0076] Однако следует помнить, что все такие и подобные термины должны быть связаны с соответствующими физическими величинами и являются лишь удобными обозначениями, применяемыми к таким величинам. Если специально не указано иное, как очевидно из последующего обсуждения, следует понимать, что во всем описании изобретения обсуждения, использующие такие термины, как «получение», «определение», «выбор», «хранение», «анализ» и т.п., относятся к действиям и процессам вычислительной системы или аналогичного электронного вычислительного устройства, которое использует и преобразует данные, представленные в виде физических (электронных) величин в регистрах и памяти вычислительной системы, в иные данные, аналогично представленные в виде физических величин в памяти или регистрах вычислительной системы или иных подобных устройствах хранения, передачи или отображения информации.
[0077] Настоящее изобретение также относится к устройству для выполнения операций, описанных в настоящем документе. Данное устройство может быть специально сконструировано для требуемых целей, или оно может состоять из компьютера общего назначения, избирательно активируемого или реконфигурируемого компьютерной программой, хранящейся в компьютере. Такая компьютерная программа может храниться на машиночитаемом носителе данных, таком как любой тип диска, включая дискеты, оптические диски, компакт-диски и магнитно-оптические диски, постоянные запоминающие устройства (ПЗУ), оперативные запоминающие устройства (ОЗУ), ППЗУ, ЭСППЗУ, магнитные или оптические платы или любой тип носителя, подходящий для хранения электронных команд, каждый из которых соединен с шиной вычислительной системы.
[0078] Алгоритмы и представления, показанные в настоящем документе, необязательно связаны с каким-либо конкретным компьютером или иным устройством. Различные системы общего назначения могут использоваться с программами в соответствии с идеей, изложенной в настоящем документе, или, возможно, окажется более удобным создать более специализированные устройства с целью выполнения требуемых этапов способа. Необходимая структура для множества этих систем будет выглядеть так, как указано в данном описании. Кроме того, аспекты настоящего изобретения не описаны со ссылкой на какой-либо конкретный язык программирования. Следует понимать, что для реализации описанной в данном документе идеи настоящего изобретения можно использовать различные языки программирования.
[0079] Аспекты настоящего изобретения могут быть представлены в виде компьютерного программного продукта или программного обеспечения, которое может включать в себя машиночитаемый носитель данных с хранящимися на нем командами, которые могут использоваться для программирования вычислительной системы (или иных электронных устройств) с целью выполнения процесса в соответствии с настоящим изобретением. Машиночитаемый носитель данных включает любой механизм для хранения или передачи информации в форме, читаемой машиной (например, компьютером). Так, машиночитаемый (например, читаемый компьютером) носитель включает машиночитаемый (например, читаемый компьютером) носитель данных (например, постоянное запоминающее устройство, далее - «ПЗУ», оперативное запоминающее устройство, далее - «ОЗУ», магнитные дисковые носители, оптические носители, устройства флэш-памяти и т.д.).
[0080] Слова «пример» или «примерный» используются в настоящем документе для обозначения того, что служит примером, образцом или наглядным изображением. Любой аспект или решение, описанные в настоящем документе как «пример» или «примерный», необязательно должны толковаться как предпочтительные или преимущественные по сравнению с иными аспектами или техническими решениями. Напротив, использование слов «пример» или «примерный» предназначено для конкретного представления понятий. Используемый в данной заявке термин «или» предназначен для обозначения, включающего «или», а не исключающего «или». То есть, если не указано иное или не ясно из контекста, фраза «X включает A или B» означает любую из естественных включающих перестановок. То есть если X включает A, X включает B или X включает и A, и B, то условие «X включает A или B» удовлетворяется в любом из вышеперечисленных случаев. Кроме того, слова в единственном числе, используемые в данной заявке и прилагаемой формуле изобретения, следует толковать как «один или несколько», если не указано иное или если из контекста не ясно, что они относятся к форме единственного числа. Более того, использование терминов «вариант осуществления», «один из вариантов осуществления», «вариант реализации» или «один вариант реализации» во всем тексте не означает один и тот же вариант осуществления или тот же вариант реализации, если они не описаны как таковые. Кроме того, термины «первый», «второй», «третий», «четвертый» и т.д., используемые в настоящем документе, предназначены для обозначения различий между различными элементами и не обязательно имеют порядковое значение в соответствии с их цифровым обозначением.
[0081] Несмотря на то, что многие изменения и модификации изобретения, несомненно, будут очевидны для специалиста в данной области после прочтения вышеизложенного описания, следует понимать, что конкретный вариант осуществления, показанный и описанный с помощью иллюстрации, ни при каких условиях не должен считаться ограничивающим. Таким образом, ссылки на детали различных вариантов осуществления не предназначены для ограничения области применения формулы изобретения, которая сама по себе описывает только те признаки, которые считаются изобретением.






Изобретение относится к способу, носителю данных и системе обработки изображения. Технический результат заключается в повышении точности распознавания объектов на изображении за счет разделения изображения на цветовые слои и извлечения информации из изображения с использованием выделенных цветовых слоев. В способе получение изображения документа устройством обработки данных; разделение изображения документа на множество патчей, каждый из которых представляет собой область изображения, содержащую объект изображения; определение для каждого патча, является ли данный патч монохромным или не монохромных; кластеризацию множества монохромных патчей на множество кластеров в цветовом пространстве, при этом каждый кластер соответствует одному цветовому слою из множества цветовых слоев изображения документа; сегментацию каждого не монохромного патча на соответствующее множество монохромных сегментов; связывание, для каждого не монохромного патча, каждого монохромного сегмента соответствующего множества монохромных сегментов с кластером из множества кластеров; и использование множества кластеров для выполнения задачи извлечения информации из изображения документа. 3 н. и 17 з.п. ф-лы, 10 ил.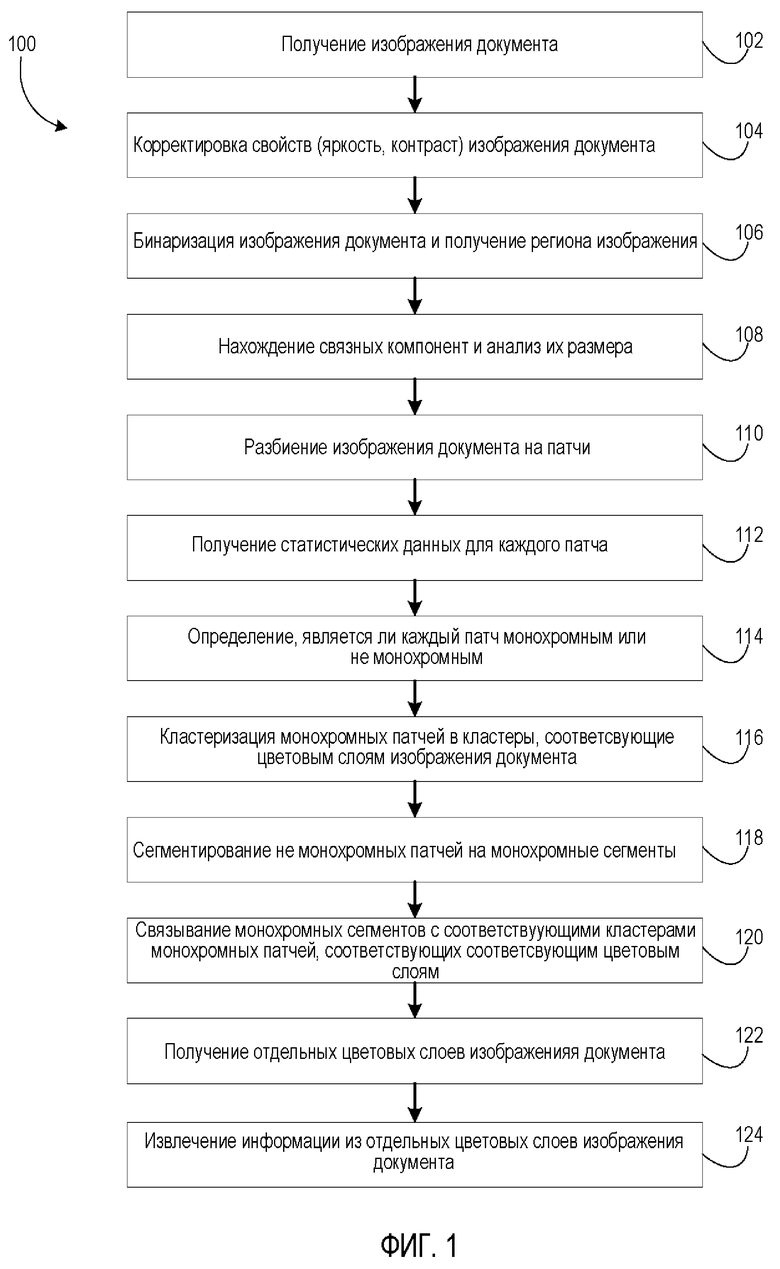
1. Способ обработки изображения, включающий:
получение изображения документа устройством обработки данных;
разделение изображения документа на множество патчей, каждый из которых представляет собой область изображения, содержащую объект изображения;
определение для каждого патча, является ли данный патч монохромным или не монохромных;
кластеризацию множества монохромных патчей на множество кластеров в цветовом пространстве, при этом каждый кластер соответствует одному цветовому слою из множества цветовых слоев изображения документа;
сегментацию каждого не монохромного патча на соответствующее множество монохромных сегментов;
связывание, для каждого не монохромного патча, каждого монохромного сегмента соответствующего множества монохромных сегментов с кластером из множества кластеров; и
использование множества кластеров для выполнения задачи извлечения информации из изображения документа.
2. Способ по п. 1, дополнительно включающий корректировку одного или нескольких свойств изображения документа и бинаризацию изображения документа.
3. Способ по п. 1, дополнительно включающий выявление одной или нескольких связных компонент в изображении документа, причем каждый патч полностью охватывает одну связную компоненту.
4. Способ по п. 1, дополнительно включающий сбор статистических данных для каждого патча из множества патчей, при этом статистические данные по каждому патчу содержат по меньшей мере одно из: количества пикселей, центроида в цветовом пространстве, меры дисперсии и меры перекоса.
5. Способ по п. 1, в котором кластеризация множества монохромных патчей на множество кластеров включает выполнение итеративного процесса кластеризации для создания заранее определенного количества кластеров.
6. Способ по п. 1, в котором каждый монохромный сегмент из множества монохромных сегментов соответствует одному цветовому слою из множества цветовых слоев.
7. Способ по п. 1, в котором выполнение задачи извлечения информации включает извлечение информации из каждого цветового слоя изображения документа и объединение информации из каждого цветового слоя в изображении документа.
8. Система обработки изображения, содержащая:
память, и
процессор, соединенный с памятью, причем процессор выполнен с возможностью:
получения изображения документа;
разделения изображения документа на множество патчей, каждый из которых представляет собой область изображения, содержащую объект изображения;
определения для каждого патча, является ли данный патч монохромным или не монохромным;
кластеризации множества монохромных патчей на множество кластеров в цветовом пространстве, при этом каждый кластер соответствует одному цветовому слою из множества цветовых слоев изображения документа;
сегментации каждого не монохромного патча на соответствующее множество монохромных сегментов;
связывания, для каждого не монохромного патча, каждого монохромного сегмента соответствующего множества монохромных сегментов с кластером из множества кластеров; и
использования множества кластеров для выполнения задачи извлечения информации из изображения документа.
9. Система по п. 8, в которой процессор дополнительно выполнен с возможностью корректировки одного или нескольких свойств изображения документа и бинаризации изображения документа.
10. Система по п. 8, в которой процессор дополнительно выполнен с возможностью выявления одной или нескольких связных компонент в изображении документа, причем каждый патч полностью охватывает одну связную компоненту.
11. Система по п. 8, в которой процессор дополнительно выполнен с возможностью сбора статистических данных для каждого патча из множества патчей, при этом статистические данные по каждому патчу содержат по меньшей мере одно из: количества пикселей, центроида в цветовом пространстве, меры дисперсии и меры перекоса.
12. Система по п. 8, в которой кластеризация множества монохромных патчей на множество кластеров включает выполнение итеративного процесса кластеризации для создания заранее определенного количества кластеров.
13. Система по п. 8, в которой каждый монохромный сегмент из множества монохромных сегментов соответствует одному цветовому слою из множества цветовых слоев.
14. Система по п. 8, в которой выполнение задачи извлечения информации включает извлечение информации из каждого цветового слоя изображения документа и объединение информации из каждого цветового слоя в изображении документа.
15. Энергонезависимый машиночитаемый носитель данных, содержащий команды, которые при обращении к ним устройством обработки данных вынуждают устройство обработки данных реализовывать:
получение изображения документа;
разделение изображения документа на множество патчей, каждый из которых представляет собой область изображения, содержащую объект изображения;
определение для каждого патча, является ли данный патч монохромным или не монохромным;
кластеризацию множества монохромных патчей на множество кластеров в цветовом пространстве, при этом каждый кластер соответствует одному цветовому слою из множества цветовых слоев изображения документа;
сегментацию каждого не монохромного патча на соответствующее множество монохромных сегментов;
связывание, для каждого не монохромного патча, каждого монохромного сегмента соответствующего множества монохромных сегментов с кластером из множества кластеров; и
использование множества кластеров для выполнения задачи извлечения информации из изображения документа.
16. Носитель данных по п. 15, содержащий команды устройству обработки данных на выявление одной или нескольких связных компонент в изображении документа, причем каждый патч полностью охватывает одну связную компоненту.
17. Носитель данных по п. 15, содержащий команды устройству обработки данных на сбор статистических данных для каждого патча из множества патчей, при этом статистические данные по каждому патчу содержат по меньшей мере одно из: количества пикселей, центроида в цветовом пространстве, меры дисперсии и меры перекоса.
18. Носитель данных по п. 15, в котором кластеризация множества монохромных патчей на множество кластеров включает выполнение итеративного процесса кластеризации для создания заранее определенного количества кластеров.
19. Носитель данных по п. 15, в котором каждый монохромный сегмент из множества монохромных сегментов соответствует одному цветовому слою из множества цветовых слоев.
20. Носитель данных носитель по п. 15, в котором выполнение задачи извлечения информации включает извлечение информации из каждого цветового слоя изображения документа и объединение информации из каждого цветового слоя в изображении документа.
| US 20120092359 A1, 19.04.2012 | |||
| Устройство для бурения скважин под анкерную крепь | 1976 |
|
SU618545A1 |
| US 8571317 B2, 29.10.2013 | |||
| US 20210224969 A1, 22.07.2021 | |||
| US 11087123 B2, 10.08.2021 | |||
| US 20160371543 A1, 22.12.2016 | |||
| US 6865290 B2, 08.03.2005. | |||

