Изобретение относится к системам и способам распознавания объектов трехмерной сцены, в частности, определения истинных размеров объектов трехмерной сцены по ее двухмерным изображениям, и может быть использовано для систем технического зрения в робототехнике и других областях техники, в том числе для систем манипулирования объектами, предназначенными для помощи пользователям с ограниченной подвижностью.
Известно множество разных способов построения трехмерных сцен, в частности, получения трехмерной информации по множеству двухмерных изображений сцены. Эта задача является одной из наиболее сложных в компьютерном анализе изображений и в настоящий момент решена только для ряда частных случаев. Для ее решения требуется предварительное построение карты диспаратности.
Карта диспаратности - это визуальное отображение сдвигов между одинаково расположенными фрагментами снимков левой и правой камер (чем ближе находится точка сцены, тем эти сдвиги больше). Как известно, это «расхождение» можно представить как числовой массив, элементы которого показывают разность в пикселах точек правого и левого изображений, привязанную к одному из них. Ректификация разноракурсных изображений (выравнивание правого и левого снимков по горизонтали) позволяют уменьшить размерность массива - свести его к двумерному. Для удобства восприятия эта матрица представляется в графическом виде: чем больше расхождение между снимками, тем светлее соответствующие пикселы изображения.
Для построения карт диспаратности используется ряд алгоритмов, в целом подразделяющихся на три класса: локальные, глобальные и полуглобальные (частично глобальные).
Локальные алгоритмы рассчитывают диспаратность в отдельности для каждого пиксела, при этом учитывая информацию лишь из узкой его окрестности. Алгоритмы используют, в основном, квадратные или прямоугольные окна фиксированного размера и по какой-либо метрике сравнивают суммы абсолютных значений яркости внутри этих окон. Такие алгоритмы характеризуются высокой скоростью и вычислительной эффективностью. Однако приемлемое качество работы обеспечивается только при условии гладкости функции интенсивности пикселей. На границах объектов, где функция интенсивности терпит разрыв, алгоритмы допускают значительное количество ошибок. Дальнейшее развитие методов привело к появлению многооконных алгоритмов и окон с адаптивной структурой, что улучшило качество расчета диспаратности. Но «платой» за это стало значительное увеличение времени работы, что зачастую приводит к невозможности анализа изображений в реальном времени.
Глобальные алгоритмы основаны на вычислении диспаратности одновременно для всего изображения, при этом каждый пиксел изображения оказывает влияние на решение во всех остальных пикселах. Глобальные алгоритмы различаются как видом унарного и парного потенциалов, так и алгоритмами минимизации и структурой графа. Несмотря на то, что, как правило, по результативности глобальные алгоритмы превосходят локальные, полученные карты диспаратности не свободны от ошибок, обусловленных теми упрощениями, которые изначально заложены в формулу для функционала энергии. При этом глобальные алгоритмы являются более медленными.
Полуглобальные, или частично глобальные, способы являются разумным компромиссом между быстрыми, но неточными локальными методами и более точными, но медленными глобальными, позволяющим рационально использовать их «сильные стороны». Идея методов состоит в независимости решения для каждого пиксела с учетом влияния всех (или части, не ограниченной локальной окрестностью) остальных пикселов изображения.
Одной из наиболее известных реализаций способа частично глобального установления стереосоответствий является метод Semi-Global Matching (далее также SGM), описанный, например, в Heiko Hirschmuller. Accurate and Efficient Stereo Processing by Semi-Global Matching and Mutual Information. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA. June 20-26, 2005. Граф в алгоритме не содержит циклов и представляет собой дерево фиксированной формы: совокупность лучей, выходящих из одной точки. Такой граф строится для каждого пиксела, а затем осуществляются несколько проходов по всем лучам, исходящим из этого пиксела. Глобальный минимум вычисляется методами динамического программирования.
Метод SGM считается наиболее практичным или функциональным методом для использования в системах реального времени. Это обеспечивает как высокое качество карты глубины, так и, по сравнению с большинством других алгоритмов, низкую потребность в вычислительной мощности и памяти.
Построение карты диспаратности осуществляют следующим образом:
1) получают два изображения с левой и правой монокамер стереокамеры;
2) к полученной паре изображений, или стереопаре, применяют метод SGM, при котором для каждой точки с координатами в пикселах (х, у) на левом снимке со стереопары находят соответствующую ей точку на правом снимке стереопары, и находят распределение d(x, y) - диспаратность, определяющую, на сколько пикселов на правом снимке эта точка левее, чем на левом снимке, то есть на правом снимке координаты этой точки будут (x-d, y). Если каждой точке левого снимка (х, у) сопоставить ее диспаратность d, получается карта диспаратности.
Далее, зная координаты точки (х, у) и диспаратность d, получают истинные координаты (X, Y, Z) данной точки в пространстве по следующим формулам:
X=(x⋅Q00+Q03)/W,
Y=(y⋅Q11+Q13)/W,
Z=Q23/W,
где W=d⋅Q32+Q33, a Q00, Q03, Q11, Q13, Q23 - постоянные, вычисляемые по фокусным расстояниям монокамер стереокамеры и по расстоянию между монокамерами. Указанные постоянные вычисляются один раз и больше не меняются.
Примером использования метода SGM является способ определения карты глубины из пар стереоизображений, раскрытый в патенте США US 10223802, в котором соответствующее несоответствие, по меньшей мере, для одного соответствующего пикселя одной из пар стереоизображений определяется из дискретного количества предопределенных значений несоответствия, которые распределены по всему предопределенному диапазону значений несоответствия с распределением, которое имеет по меньшей мере два разных интервала между разными соседними значениями диспаратности. Еще в одном варианте реализации способ определения карты глубины содержит этапы получения одной пары стереоизображений; предоставления в блоке оценки предварительно определенного набора дискретных значений диспаратности, которые охватывают диапазон значений диспаратности, причем интервалы между последовательными значениями диспаратности включают в себя первые интервалы и вторые интервалы, причем первые интервалы имеют величину, меньшую, чем величина вторые интервалы; определения соответствующего неравенства для соответствующего пикселя опорного изображения, по меньшей мере, одной пары изображений стерео, содержащего выбор соответствующего неравенства из числа дискретных значений несоразмерности в заранее определенном наборе; и определения соответствующего значение глубины для соответствующего пикселя путем вычисления из соответствующего несоответствия, которое было определено для соответствующего пикселя.
С целью дальнейшей экономии вычислительных мощностей проводились разработки, направленные на оптимизацию метода SGM. Так, в патенте США US 9704253 предлагается определять диспаратность для объектов, находящихся вдали от плоскости камеры, с удвоенным разрешением; а для объектов, находящихся вблизи от плоскости камеры, определение диспаратности проводят с обычным разрешением. Таким образом, удается получить более точную карту глубин, в том числе для объектов, находящихся на удалении от плоскости камеры.
Для решения задачи идентификации объекта на сформированной модулем технического зрения двумерной карте глубин применяются методы машинного обучения.
Известен способ распознавания объектов, разработанный П. Виолой и М. Дж. Джонсом (P. Viola, M.J. Jones. Robust Real-Time Face Detection International Journal of Computer Vision 57 (2), 137-154, 2004) (далее также метод Виолы-Джонса), также известный как каскады Хаара, обеспечивающий относительно высокую скорость и сравнительно низкую потребную вычислительную мощность. Недостатком этого способа является повышенная чувствительность к обучающим данным, что в дальнейшем может привести к невозможности идентификации объекта, если такой объект окажется расположенным в условиях, сильно отличающихся от условий обучающей выборки (например, при слабом освещении сцены, наличии апериодических помех в виде теней и т.п.).
Еще одним известным способом распознавания объектов является применение нейронных сетей. Так, в заявке на патент Китая CN 109398688 раскрыто применение нейронной сети с архитектурой SSD-mobilenet для распознавания в режиме реального времени объекта с передачей полученных данных манипулятору транспортного средства. А в публикации Kaiming Не, Georgia Gkioxari, Piotr Dollar Ross Girshick. Mask R-CNN (опубликовано 24.01.2018, доступно по ссылке в сети Интернет https://arxiv.org/pdf/1703.06870.pdf) предложена нейронная сеть архитектуры Mask Region-Based Convolutional Neural Network (сокращенно Mask R-CNN), которая обеспечивает высокую точность распознавания объектов даже в неблагоприятной среде сцены. Однако в сравнении с методом Виолы-Джонса и нейронной сетью архитектуры SSD-mobilenet, сеть архитектуры Mask R-CNN требует, со слов разработчиков, ориентировочно в 20 раз больше вычислительного времени при равных вычислительных мощностях.
Указанные выше способы находят широкое применение в совершенно разных областях техники. Одной из таких областей являются роботизированные системы, предназначенные для помощи пользователям, в том числе с низкой или ограниченной подвижностью.
Так, изобретение согласно заявке на патент США US 2007016425 направлено на повышение качества жизни пользователя, страдающего параличом, и заключается в распознавании в режиме реального времени трехмерной сцены, регистрируемой стереоскопическим модулем системы содействия пользователю, для последующей передачи полученных данных модулю манипуляции указанной системы содействия. Распознавание включает в себя идентификацию объекта, находящегося в пределах указанной сцены. Система содействия содержит модуль манипуляции, модуль технического зрения и модуль обработки и хранения данных. Посредством модуля технического зрения, который включает модуль отслеживания положения глаз пользователя, регистрируется сцена, в которой расположен предполагаемый объект интереса пользователя. Данные, полученные при регистрации сцены, обрабатываются и передаются модулю манипуляции. Модуль манипуляции может включать по меньшей мере один манипулятор для манипулирования объектом.
Применение системы технического зрения для содействия пользователю с нарушениями зрения раскрыто в заявке на патент США US 2007016425. Предлагается распознавать положение объектов в пространстве и затем преобразовывать эти данные в сигналы, которые обеспечат тактильные ощущения пользователю, что позволит ощущать пространство и расположение предметов в пространстве. В качестве средства определения расстояния используется стереокамера, изображения с которой позволяют получить карту глубин. Для этого строят карту диспаратности, которую затем преобразуют в карту глубин. Данные с карты глубин далее направляются в тактильный интерфейс для формирования тактильных ощущений пациента. Недостатком этого известного решения является отсутствие средств и методов распознавания объектов, находящихся в пространстве. Другим недостатком является рекомендуемый алгоритм вычисления диспаратности и карты глубин, который требует большой вычислительной мощности.
У описанных выше, а также других известных способов распознавания объектов есть недостатки. Во-первых, для повышения точности и эффективности требуются мощные вычислительные системы. Во-вторых, известные способы с большими ошибками или вообще не работают со сложными объектами сцен, такими как объекты сложной и случайной расцветки, прозрачные объекты, сложно окрашенные объекты на сложно окрашенном фоне и т.п.
Таким образом, существует задача разработки такого способа распознавания объектов трехмерной сцены, который позволяет надежно работать со сложными объектами, как перечислены выше, не требуя при этом исключительных вычислительных ресурсов.
Техническим результатом заявленного изобретения является повышение точности распознавания объектов сложной и случайной расцветки, прозрачных объектов, сложно окрашенных объектов на сложно окрашенном фоне, в том числе таких узоров и окрасок, которых не было и не могло быть в обучающей выборке.
Поставленная задача решается, а заявленный технический результат достигается в заявленном способе получения набора объектов трехмерной сцены, в котором одновременно получают изображения кадров с левой камеры и правой камеры (в составе стереокамеры), для каждой точки изображения с пиксельными координатами формируют карту диспаратности методом полуглобального установления стереосоответствий, по ней определяют истинные координаты указанной точки, формируют карту глубин точек в истинных координатах, формируют двухмерное изображение в шкале серого, в котором яркость точки зависит от истинного расстояния до точки, и на полученном двухмерном изображении в шкале серого выполняют детекцию и идентификацию объектов одним из методов, выбранных из метода Виолы-Джонса, метода нейронной сети SSD-mobilenet и метода нейронной сети Mask R-CNN, с получением набора объектов трехмерной сцены. При этом карту диспаратности формируют методом полуглобального установления стереосоответствий. Истинные координаты точки определяют с учетом фокусных расстояний камер стереокамеры и расстояния между ними. Яркость точки принимается равной нулю, если истинное расстояние до нее выходит за заданный диапазон.
В частности, заявленный способ получения набора объектов трехмерной сцены включает следующие шаги.
Обеспечивают по существу одновременное получение левого кадра с левой камеры и правого кадра с правой камеры при съемке сцены.
Формируют карту диспаратности способом полуглобального установления стереосоответствий с получением диспаратности d(x, y) для каждой точки изображения с пиксельными координатами (х, у).
Определяют истинные координаты (X, Y, Z) точки с пиксельными координатами (х, у) по формулам:
X=(x⋅Q00+Q03)/W,
Y=(y⋅Q11+Q13)/W,
Z=Q23/W,
где W=d⋅Q32+Q33, a Q00, Q03, Q11, Q13, Q23 - постоянные, определяемые фокусными расстояниями левой камеры и правой камеры и расстоянием между левой камерой и правой камерой.
Формируют карту глубин D(x, y), где D - истинное расстояние от левой камеры или правой камеры до точки с пиксельными координатами (х, у),
Формируют двухмерное изображение в шкале серого, в котором яркость Ф(х, у) точки с пиксельными координатами (х, у) определяют по формулам:
Ф(х,у)=0, если D(x,y)<Dmin,
Ф(х,у)=255, если D(x,y)>Dmax,
Ф(х,у)=255⋅(D(x,y) - Dmin)/(Dmax - Dmin) - в остальных случаях,
где Dmin и Dmax - заданные соответственно минимальное и максимальное значения глубины, определяемые из контекста применения заявленного способа. Например, если стереокамера обслуживает манипулятор для захвата и перемещения объектов с диаметром рабочей зоны манипулятора 3 м, при этом находясь на расстоянии 1,5 м от центра рабочей зоны, можно взять Dmin=0,2 м, полагая, что в более ближней к стереокамере зоне манипуляции не планируются, a Dmax=5 м, чтобы гарантированно отображать рабочую зону манипулятора и ее окрестность, т.е. задав запас примерно 0,3 м и 0,5 м соответственно от ближней границы рабочей зоны манипулятора и от дальней границы рабочей зоны манипулятора.
На полученном двухмерном изображении в шкале серого выполняют детекцию и идентификацию объектов одним из методов, выбранных из метода Виолы-Джонса, метода нейронной сети SSD-mobilenet и метода нейронной сети Mask R-CNN, с получением набора объектов трехмерной сцены.
Главной особенностью заявленного способа, отличающего его от известных аналогов, является то, что детекцию и идентификацию объектов выполняют не на изображении точек в пиксельных координатах, а на двухмерном изображении в шкале серого (предпочтительно, 8-битного), в котором яркость точки зависит от истинного расстояния до точки, т.е. от истинных координат точки. При этом детектированию и идентификации подвергают не узоры, рисунки, надписи на объектах и т.п., а темные силуэты объектов на светлом фоне. Поскольку фон является более удаленным, чем объекты, и между фоном и объектами есть некоторое расстояние, то фон на двухмерном изображении в шкале серого светлее объектов, причем есть контрастная граница между фоном и объектами. Объекты выглядят компактными, контрастными темными силуэтами именно потому, что они расположены ближе, чем фон, и чем ближе объект, тем темнее силуэт объекта. Как следствие, периодические, квазипериодические и стохастические узоры, вообще свойства прозрачности фона и объектов не влияют на процесс детекции и идентификации, потому что обрабатывается только геометрический силуэт, полученный из карты глубин, а на этом этапе данные о цветовых и оптических характеристиках объекта уже отсутствуют, т.к. они были отсеяны на этапе стереореконструкции, когда вместо видимого двумерного изображения работают с картой глубин, на которой отсутствуют данные о раскраске объекта.
Устойчивость предложенного способа обусловлена тем, что при непосредственном анализе изображений, как это принято в аналогах, помехообразующие факторы раскраски и прозрачности влияют непосредственно на менее устойчивый к ошибкам алгоритм 20-распознавания. В заявленном способе изображения сначала проводят стереореконструкцию, результат которой несравнимо более устойчив к помехообразующим факторам, и получаемая карта глубин не подвержена данным факторам. Иными словами, стереореконструкция используется как фильтр, удаляющий помехообразующие факторы раскраски и прозрачности объектов и фона, так что даже простое поднесение к камерам плоского изображения объекта, например фотографии, будет распознано именно как плоский объект-фотография. При этом эффективность способа обусловлена тем, что результат стереореконструкции несравнимо более устойчив к помехообразующим факторам, чем этап детекции и идентификации объектов, и за счет этого производится более устойчивая и точная детекция и идентификация объектов со сложной раскраской, с полной или частичной прозрачностью и т.п.
Детекцию и идентификацию объектов для получения набора объектов трехмерной сцены выполняют одним из методов, выбранных из метода Виолы-Джонса, метода нейронной сети SSD-mobilenet и метода нейронной сети Mask R-CNN.
При выборе метода Виолы-Джонса является предпочтительным, если область изображения просматривают с применением процедуры скользящего, поскольку объекты могут присутствовать в любом месте изображения. Скользящее окно - это окно, размер которого вначале совпадает с изображением сцены, затем пропорционально уменьшается с заданным шагом, например, шагом 0,1 от размеров окна на предыдущем шаге. При каждом размере окна данным окном последовательно накрывают различные участки изображения сцены и выполняют проверку наличия объекта интереса в окне. Скользящее окно применяется в задачах детектирования объекта на изображении для накрытия им всех участков, которые могут быть заняты объектом, с последующей проверкой соответствующим классификатором нахождения объектов в окне. Также предпочтительно, если формируют обучающую выборку и проводят обучение классификатора до этапа детекции и идентификации объектов. При этом обучение классификатора включает в себя представление тестового изображения вектором признаков, установление принадлежности изображения определенному классу изображений, оценку правильности классификации, причем в случае ошибки вывода корректируют по меньшей мере одно из описания класса изображений и модели объекта, и формирование усредненного объекта, относящегося к данному классу изображений, и правила, по которому классификация осуществляется наиболее точно. Например, цветное изображение рассматривается как набор чисел (признаков), по которым производится детектирование объекта. Обученный детектор объектов - это описание, каким должно быть входное изображение (размер и цветность); описание, каким способом входное изображение преобразуют в набор признаков-чисел для подачи на вход детектора (построчное чтение и нормировка); и собственно сам обученный детектор объектов, дающий либо бинарное суждение (метод Виолы-Джонса) либо «оценку правильности», то есть вес принадлежности объекта к заданной категории, например: объект на 97% кошка, на 2% собака, на 1% кирпич. Выбирают категорию, вес которой максимален.
Для реализации метода Виолы-Джонса можно использовать функцию cvHaarDetectObjects() открытой библиотеки OpenCV.
При выборе метода нейронной сети SSD-mobilenet или метода нейронной сети Mask R-CNN также предпочтительно, если формируют обучающую выборку и проводят обучение классификатора до этапа детекции и идентификации объектов. При этом формирование обучающей выборки включает выделение объектов на плоском цветном изображении, формирование для каждого объекта первого образца объекта из плоского цветного изображения и второго образца объекта из соответствующего участка карты диспаратности. Обучающую выборку применяют до тех пор, пока точность распознавания не достигнет заданного значения, при котором, в частности, вероятность ошибки первого рода (не обнаружить наличествующий объект) и вероятность ошибки второго рода (детекция объекта, который на самом деле отсутствует) менее заданного значения (обычно варьируется от 0,001 до 0,01), а относительная ошибка позиционирования (отношение площади разности рамок объектов к площади объединения рамок), например, менее 0,1.
Выбор конкретных методов нейронный сетей SSD-mobilenet и Mask R-CNN обусловлен тем, что в данном классе задач SSD-mobilenet оптимально сочетает качество и скорость распознавания при выделении объекта прямоугольной рамкой, а Mask R-CNN оптимально сочетает качество и скорость распознавания при построении бинарной маски, максимально аккуратно накрывающей объект, когда относительная разность области, ограниченной границей объекта и области, накрытой маской, минимальна. Здесь относительная разность областей - это отношение площади разности областей к площади их объединения. Данные нейронные сети могут быть реализованы, например, в среде tensorflow как приложение на языке Python.
Так как для каждого используемого метода детекции и идентификации объектов обучение происходит не в реальном времени (т.е. затраты времени на него слабо лимитированы), а также обученный классификатор можно тиражировать столько раз, сколько нужно, целесообразно обучить все три классификатора, соответствующие указанным выше методам детекции и идентификации объектов.
Тогда появляется возможность использования классификатора, который обеспечит максимальное качество распознавания по следующим критериям:
- устойчивость, минимальная зависимость от вида освещения и фоновых объектов сцены;
- минимизация ошибки первого рода, когда присутствующий на сцене объект не определяется, т.е. не распознается;
- минимизация ошибки второго рода, когда определяется объект, который на самом деле отсутствует;
- минимизация ошибок оценки форм-фактора, когда сформированная рамка объекта отличается от «истинной» рамки, ограничивающей объект. При этом используется универсальный относительный критерий близости двух рамок - отношение площади симметрической разности рамок (то есть участков, которые находятся внутри одной рамки, но вне другой), к площади объединения двух рамок.
В каждом случае применяется тот метод детекции и идентификации объектов, который обеспечит максимальное качество детектирования объектов. Выбор метода детекции и идентификации объектов осуществляют на основании анализа сцены, анализа фона и анализа окружения, в частности, на основании эмпирических данных о наилучшем методе детекции при данной структуре сцены. Например, если происходит классификация объекта как объекта фиксированной известной формы (например, круглое яблоко, цилиндрический стакан), то достаточно данных классификатора метода Виолы-Джонса или данных классификатора метода нейронной сети SSD-mobilenet, так как они определят класс объекта и с достаточной точностью отрисуют рамку, ограничивающую объект. В случае, если форма объекта может сильно меняться (могут появляться выступы, изгибы, впадины в достаточно произвольных местах), предпочтительней будет использовать метод нейронной сети Mask R-CNN, которая, помимо прочего, позволит определить формы объекта, указывая бинарной маской истинную текущую форму объекта.
Заявленный способ многократно испытывали на разных объектах сложной формы и текстуры, в том числе при распознавании прозрачных объектов и объектов неизвестной (случайной) окраски, а также сложном фоне.
При испытаниях заявленного способа получения набора объектов трехмерной сцены использовался видеорежим 640x480 для левой камеры и правой камеры стереокамеры. Расстояние до объектов варьировалось от 1 до 5 м, характерные размеры объектов составляли 0,03 до 0,5 метров. В качестве объектов использовались сделанные из папье-маше яблоки диаметром примерно 0,1 м, картонные и пластиковые стаканы емкостью 0,25-0,5 л, стеклянные и пластиковые бутылки той же емкости, другое. Яблоки из папье-маше имели монохромную раскраску зеленого, желтого, красного цвета; стаканы и бутылки использовались прозрачные, монохромные, а также с различными цветными узорами и рисунками на боковых поверхностях.
Пример реализации заявленного способа приведен на фигуре. На левом кадре представлено изображение от стереокамеры, на правом кадре - соответствующая ему карта глубин (цветные изображения были переведены в изображения в градациях серого). Прямоугольными рамками выделен результат работы классификатора, совместно обрабатывающего данные цветности и глубины (рамки на левом и на правом кадре идентичны). Виден захват классификатором прозрачных объектов (пластиковых бутылок) именно за счет их четкого отображения на карте глубин.
При использовании способов-аналогов, основанных на распознавании двумерного изображения, прозрачные пластиковые бутылки не детектировались.
Кроме того, рисунок, нанесенный на объект, может выполнять маскировочную роль, то есть мешать распознаванию объекта либо вызвать распознавание нанесенного двумерного изображения вместо фактического объекта. Заявленный способ лишен и этого недостатка.
Таким образом, заявленный способ получения набора объектов трехмерной сцены выполняет распознавание объектов сложной и случайной расцветки, прозрачных объектов, сложно окрашенных объектов на сложно окрашенном фоне, причем таких узоров и окрасок, которых не было и не могло быть в обучающей выборке. Способ позволяет искать объекты не только заданного назначения, но и объекты форм-фактора, удобного для упаковки, удобного для манипуляций данной моделью манипулятора и т.д. При этом реализация способа не имеет особых требований к аппаратным ресурсам, поскольку сводится к стереореконструкции и методам детекции и идентификации объектов типа методов Виолы-Джонса, нейронных сетей SSD-mobilenet nMask R-CNN, а значит, быстр и прост в использовании.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ выполнения манипуляции с объектом | 2019 |
|
RU2800443C1 |
| СПОСОБ И СИСТЕМА ОПРЕДЕЛЕНИЯ ПОДЛИННОСТИ ЛИЦА НА ИЗОБРАЖЕНИИ | 2024 |
|
RU2840316C1 |
| МЕТОД ДЛЯ ВЫДЕЛЕНИЯ И КЛАССИФИКАЦИИ ТИПОВ КЛЕТОК КРОВИ С ПОМОЩЬЮ ГЛУБОКИХ СВЕРТОЧНЫХ НЕЙРОННЫХ СЕТЕЙ | 2019 |
|
RU2732895C1 |
| СПОСОБ И СИСТЕМА ТОЧНОЙ ЛОКАЛИЗАЦИИ СЛАБОВИДЯЩЕГО ИЛИ СЛЕПОГО ЧЕЛОВЕКА | 2017 |
|
RU2681346C2 |
| СПОСОБ ОБУЧЕНИЯ СВЕРТОЧНОЙ НЕЙРОННОЙ СЕТИ ДЛЯ ВОССТАНОВЛЕНИЯ ИЗОБРАЖЕНИЯ И СИСТЕМА ДЛЯ ФОРМИРОВАНИЯ КАРТЫ ГЛУБИНЫ ИЗОБРАЖЕНИЯ (ВАРИАНТЫ) | 2018 |
|
RU2698402C1 |
| Способ оценки действительности документа при помощи оптического распознавания текста на изображении круглого оттиска печати/штампа на цифровом изображении документа | 2020 |
|
RU2750395C1 |
| РАСПОЗНАВАНИЕ СОБЫТИЙ НА ФОТОГРАФИЯХ С АВТОМАТИЧЕСКИМ ВЫДЕЛЕНИЕМ АЛЬБОМОВ | 2020 |
|
RU2742602C1 |
| Способ обработки данных и система технического зрения для роботизированного устройства | 2021 |
|
RU2782662C1 |
| СИСТЕМА СИНТЕЗА ПРОМЕЖУТОЧНЫХ ВИДОВ СВЕТОВОГО ПОЛЯ И СПОСОБ ЕЕ ФУНКЦИОНИРОВАНИЯ | 2018 |
|
RU2690757C1 |
| СПОСОБ И СИСТЕМА АВТОМАТИЧЕСКОЙ ПРОВЕРКИ ПРИСУТСТВИЯ ЛИЦА ЖИВОГО ЧЕЛОВЕКА В БИОМЕТРИЧЕСКИХ СИСТЕМАХ БЕЗОПАСНОСТИ | 2005 |
|
RU2316051C2 |

Изобретение относится к системам и способам распознавания объектов трехмерной сцены, в частности, определения истинных размеров объектов трехмерной сцены по ее двухмерным изображениям. Способ получения набора объектов трехмерной сцены включает одновременное получение изображения кадров с камер стереокамеры, формирование карты диспаратности методом полуглобального установления стереосоответствий для каждой точки изображения с пиксельными координатами, определение истинных координат указанной точки, формирование карты глубин точек в истинных координатах, формирование двухмерного изображения в шкале серого, в котором яркость точки зависит от истинного расстояния до точки, и выполнение детекции и идентификации объектов одним из методов, выбранных из метода Виолы-Джонса, метода нейронной сети SSD-mobilenet и метода нейронной сети Mask R-CNN, с получением набора объектов трехмерной сцены. При этом карту диспаратности формируют методом полуглобального установления стереосоответствий. Истинные координаты точки определяют с учетом фокусных расстояний камер стереокамеры и расстоянием между ними. Яркость точки принимается равной нулю, если истинное расстояние до нее выходит за заданный диапазон. Технический результат - повышение точности распознавания объектов сложной и случайной расцветки, прозрачных объектов, сложно окрашенных объектов на сложно окрашенном фоне, в том числе таких узоров и окрасок. 9 з.п. ф-лы, 1 ил.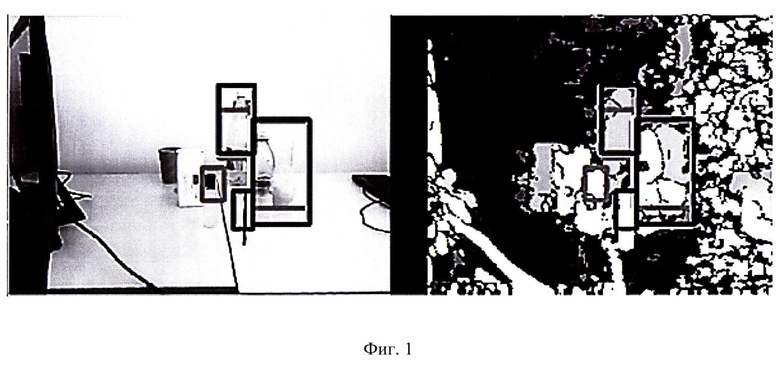
1. Способ получения набора объектов трехмерной сцены, в котором выполняют следующие шаги:
a) обеспечивают по существу одновременное получение левого кадра с левой камеры и правого кадра с правой камеры при съемке сцены,
b) формируют карту диспаратности способом полуглобального установления стереосоответствий с получением диспаратности d(x, y) для каждой точки изображения с пиксельными координатами (х, у),
c) определяют истинные координаты (X, Y, Z) точки с пиксельными координатами (х, у) по формулам
X=(x⋅Q00+Q03)/W,
Y=(y⋅Q11+Q13)/W,
Z=Q23/W,
где W=d⋅Q32+Q33, a Q00, Q03, Q11, Q13, Q23 - постоянные, определяемые фокусными расстояниями левой камеры и правой камеры и расстоянием между левой камерой и правой камерой,
d) формируют карту глубин D(x, y), где D - истинное расстояние от левой камеры или правой камеры до точки с пиксельными координатами (х, у),
e) формируют двухмерное изображение в шкале серого, в котором яркость Ф(х, у) точки с пиксельными координатами (х, у) определяют по формулам:
Ф(х, у)=0, если D(x, y)<Dmin,
Ф(х, у)=255, если D(x, y)>Dmax,
Ф(x, y)=255⋅(D(x, y)-Dmin)/(Dmax-Dmin) - в остальных случаях,
где Dmin и Dmax - заданные соответственно минимальное и максимальное значения глубины,
f) на полученном двухмерном изображении в шкале серого выполняют детекцию и идентификацию объектов одним из методов, выбранных из метода Виолы-Джонса, метода нейронной сети SSD-mobilenet и метода нейронной сети Mask R-CNN, с получением набора объектов трехмерной сцены.
2. Способ по п. 1, в котором этап f) выполняют методом Виолы-Джонса, причем область изображения просматривают с применением процедуры скользящего окна.
3. Способ по п. 2, в котором до начала этапа f) формируют обучающую выборку и проводят обучение классификатора.
4. Способ по п. 3, в котором обучение классификатора включает:
- представление тестового изображения вектором признаков,
- установление принадлежности изображения определенному классу изображений,
- оценку правильности классификации, причем в случае ошибки вывода корректируют по меньшей мере одно из описания класса изображений и модели объекта, и
- формирование усредненного объекта, относящегося к данному классу изображений, и правила, по которому классификация осуществляется наиболее точно.
5. Способ по п. 1, в котором этап f) выполняют методом нейронной сети SSD-mobilenet.
6. Способ по п. 1, в котором этап f) выполняют методом нейронной сети Mask R-CNN.
7. Способ по п. 5 или 6, в котором до начала этапа f) формируют обучающую выборку и проводят обучение классификатора.
8. Способ по п. 7, в котором формирование обучающей выборки включает:
- выделение объектов на плоском цветном изображении,
- формирование для каждого объекта первого образца объекта из плоского цветного изображения и второго образца объекта из соответствующего участка карты диспаратности.
9. Способ по п. 8, в котором обучение классификатора включает применение обучающей выборки до тех пор, пока точность распознавания не достигнет заданного значения.
10. Способ по п. 1, в котором на этапе f) выбор метода детекции и идентификации объектов осуществляют на основании анализа сцены, анализа фона и анализа окружения.
| Невидимов Александр Валентинович "Анализ и комбинирование алгоритмов стереосопоставления", Выпускная квалификационная работа бакалавра, Томск, 2011 г., получено из интернет http://www.inf.tsu.ru/library/DiplomaWorks/CompScience/2011/Nevedimov/diplom.pdf | |||
| US 20090226079 A1, 10.09.2009 | |||
| US 2017270680 A1, 21.09.2017 | |||
| Paul Viola, Michael Jones "Rapid |
