Область техники, к которой относится изобретение
Изобретение относится к области компьютерных технологий, в частности, к способам обработки и анализа изображений, и может быть использовано для организации фотогалереи в мобильных системах.
Описание известного уровня техники
В последнее время благодаря быстрому росту социальных сетей, облачных сервисов и мобильных технологий люди стали делать гораздо больше фотографий, чем когда-либо прежде [13]. Чтобы организовать личную коллекцию, фотографии обычно относят к альбомам в соответствии с какими-то событиями. Системы организации фотографий (Apple iPhoto, Google Photos и т.д.) позволяют пользователю быстро находить нужные фотографии, а также повышают эффективность работы с галереей [27]. На сегодняшний день в этих системах обычно задействован контент-анализ фотографий и автоматическое ассоциирование каждой фотографии с различными тегами (описание сцены, люди, объекты, места и т.п.). Такой анализ можно использовать не только для выборочного извлечения фотографий по определенному тегу, чтобы сохранить приятные воспоминания о некоторых эпизодах жизни пользователя [32], но и для предоставления персональных рекомендаций, которые помогают пользователям находить соответствующие объекты в больших коллекциях. Разработка таких систем требует тщательного анализа пользовательского подхода к моделированию [26]. Большую галерею фотографий на мобильном устройстве можно использовать для понимания таких интересов пользователя, как спорт, технические приспособления, фитнес, одежда, автомобили, еда, путешествия, домашние животные и т.д. [12, 20].
Настоящее изобретение сконцентрировано на одной из самых сложных частей механизма организации фотографий, а именно на задаче распознавания событий на фотографиях [1] для извлечения таких событий, как праздники, спортивные мероприятия, свадьбы, различные виды деятельности и т.д. Термин "событие" можно определить как категорию, которая фиксирует "сложное поведение группы людей, взаимодействующих с множеством объектов, происходящее в определенной обстановке" [32]. Существуют две различные задачи в области распознавания событий. Первая задача сфокусирована на обработке отдельных фотографий, т.е. событие рассматривается как сложная сцена с большими вариациями внешнего вида и структуры [32]. Вторая задача направлена на предсказание категорий событий группы фотографий (альбома) [4]. В последнем случае предполагается, что все фотографии в альбоме имеют слабую разметку [2], при этом каждая фотография может иметь разную важность [33]. Однако на практике имеется в наличии только галерея фотографий, поэтому для второго подхода требуется, чтобы пользователь выбрал альбомы вручную. В другом варианте применяется создание альбомов на основе местоположения, если включены теги GPS. В обоих случаях использование распознавания событий на основе альбома ограничено или даже невозможно.
Сущность изобретения
В настоящем изобретении изучается новая постановка задачи распознавания событий: требуется предсказать категории событий в галерее фотографий, для которых неизвестны альбомы (группы фотографий, соответствующие одному событию). Предложен новый двухэтапный подход. Сначала из каждой фотографии извлекаются векторные представления (признаки) с помощью предобученной сверточной нейронной сети. Эти векторные представления классифицируются индивидуально. Оценки классификатора используются, чтобы группировать последовательные фотографии в несколько кластеров. В заключение, векторные представления фотографий в каждой группе агрегируются в единый дескриптор с помощью нейронного механизма внимания. Этот механизм представляет собой весовую схему для линейного объединения всех векторных представлений во входном наборе. Веса вычисляются адаптивно с помощью нейронной сети прямого распространения. Благодаря механизму внимания агрегация инвариантна по отношению к порядку изображений и не зависит от количества изображений во входном наборе. Этот алгоритм можно при необходимости расширить, чтобы повысить точность классификации каждой фотографии в группе. В отличие от обычной тонкой настройки (дообучения) сверточных нейронных сетей (CNN) предлагается использовать составление подписи к изображению, то есть генеративную модель, которая преобразует фотографии в текстовые описания. Они подвергаются унитарному кодированию и преобразуются в разреженное векторное представление, подходящее для обучения произвольного классификатора. Экспериментальные работы с коллекцией Photo Event Collection и набором данных Multi-Label Curation Flickr Events показали, что точность предлагаемого подхода на 9-20% выше, чем распознавание событий на отдельных фотографиях. Кроме того, предлагаемый метод имеет на 13-16% меньшую вероятность ошибки, чем классификация групп фотографий, полученных с помощью иерархической кластеризации. Было экспериментально показано, что подписи фотографий, обученные на наборе данных Conceptual Captions, можно классифицировать более точно, чем векторные представления из детектора объектов, хотя по всей видимости они оба не так содержательны, как векторные представления на основе CNN. Тем не менее, можно объединить предложенный подход с обычными CNN в ансамбль, чтобы получить самую высокую точность для нескольких наборов данных событий.
Таким образом, в основу настоящего изобретения положена новая задача распознавания событий, в которой дана галерея фотографий и известно, что эта галерея содержит упорядоченные альбомы с неизвестными границами. Предлагается автоматически присваивать эти границы на основе анализа визуального содержания последовательных фотографий в галерее. Затем последовательные фотографии группируют и вычисляют дескриптор каждой группы с помощью механизма внимания из нейронного агрегационного модуля [37]. В завершение, этот подход расширяется следующим образом. Несмотря на традиционное использование CNN в качестве дискриминационных моделей в программной структуре классификатора, предлагается заимствовать генеративные модели для представления входной фотографии в другой области. В частности, используются известные методы автоматического составления подписи к изображению [14], которые генерируют текстовые описания фотографий. Основной вклад изобретения состоит в демонстрации того, что сгенерированные описания можно подать на вход классификатора в ансамбле, чтобы повысить точность распознавания событий по сравнению с традиционными методами. Хотя предлагаемое визуальное представление не так содержательно, как векторные представления, извлеченные с помощью дообученных CNN, оно лучше, чем выходы детекторов объектов [20].
Задача распознавания событий в личных коллекциях фотографий заключается в распознавании события не на отдельной фотографии, а во всем альбоме [29]. События и подсобытия на фотографиях подпоследовательности идентифицируются в работе [8] путем интеграции оптимизированного линейного программирования с дескриптором цвета изображения подписи. В работе [5] применялись скрытые модели Маркова (Stopwatch Hidden Markov) путем обработки фотографий в альбоме как последовательных данных. Детекторы объектов, релевантных для событий, обучались на наборе данных праздников [29]. Затем праздники классифицировались на основе выходов детектора объектов. В статье [2] рассматривается наличие нерелевантных изображений в альбоме с помощью методов обучения на множестве экземпляров. В [33] представлена процедура итеративного обновления для предсказания типа события и оценки важности изображения в сиамской сети. Авторы этой статьи использовали CNN, которая распознает тип события, и классификатор событий в последовательности на основе долгой краткосрочной памяти (LSTM) во всем альбоме. Кроме того, они успешно применили этот метод для обучения репрезентативных глубоких признаков для анализа набора изображений [34]. Последний подход фокусируется на оценке совместных появлений и частот признаков, вследствие чего не требуется временная когерентность фотографий в альбоме. В [13] предложена модель распознавания событий от крупного до мелкого уровня иерархии с использованием мультигранулярных признаков [24] на основе сети внимания, которая изучает представления фотоальбомов. Эффективность повторного обнаружения ожидаемых фотографий в мобильных телефонах была улучшена с помощью метода классификации личных фотографий на основании взаимосвязи времени и места съемки с конкретными событиями [10].
Информация о границах альбома не всегда имеется в наличии, так как галерея содержит неструктурированный список фотографий, упорядоченный по времени их создания. В этом случае можно использовать существующие методы распознавания событий на отдельных фотографиях [1]. Как и в других областях компьютерного зрения, в наиболее распространенном подходе преимущественно применяются архитектуры на основе CNN. Например, четыре различных слоя дообученной CNN использовались для извлечения признаков и выполнения линейного дискриминантного анализа, чтобы выиграть в конкурсе распознавания культурных событий ChaLearn LAP 20 [9]. Для повышения точности распознавания событий на многомасштабные пространственные карты проецируются ограничительные рамки обнаруженных объектов [35]. В [32] введен новый метод итеративного выбора для идентификации подмножества классов, наиболее релевантных для передачи глубоких представлений, обученных на наборах данных объектов (ImageNet) и сцен (Places2).
Предложен способ распознавания событий на фотографиях с автоматическим выделением альбомов, заключающийся в том, что: автоматически присваивают границы альбомов на основе визуального содержания последовательных фотографий в галерее; группируют последовательные фотографии из галереи в альбомы; вычисляют дескриптор каждого альбома с помощью механизма внимания из нейронного агрегационного модуля; распознают тег типа события каждого альбома путем подачи его дескриптора на вход классификатора; распознают событие на фотографиях в галерее путем присвоения соответствующего тега типа события всем фотографиям в каждом альбоме. При этом при автоматическом присвоении границ альбомов: оценивают сходство между степенями уверенностями для каждой пары последовательных фотографий в галерее; если сходство не превышает заданный порог, то обе фотографии включают в один и тот же альбом. При этом сходство между фотографиями вычисляют как расстояние между степенями уверенностями для каждого типа события, оцененного с помощью классификации каждой фотографии. При этом сходство между фотографиями вычисляют как сумму сходств между степенями уверенностями для каждого типа события, оцененного на основе классификации каждой фотографии, и сходства между их местоположениями, если данные EXIF (Exchangeable Photo File Format) этих фотографий содержат информацию о местоположении. При этом заданный порог вычисляют автоматически во время процедуры предварительного обучения, используя предоставленный обучающий набор альбомов.
Также предложен способ распознавания события на фотографии с ее представлением в текстовой области, заключающийся в том, что: вычисляют векторные представления фотографии путем подачи ее RGB (красный-зеленый-синий) представления на вход сверточной нейронной сети; используют метод автоматического составления подписи к изображению для генерации текстовых описаний фотографии на основе ее векторных представлений; кодируют сгенерированную подпись; подают сгенерированные текстовые описания на вход классификатора событий; распознают событие путем присвоения выхода классификатора тегу событий соответствующей фотографии. При этом сгенерированную подпись кодируют как разреженный вектор с помощью унитарного кодирования текстового описания фотографии: v-й компонент вектора равен 1, только в том случае, если сгенерированная подпись содержит по меньшей мере одно v-е слово из словаря. Согласно предложенному способу дополнительно объединяют выходы классификатора сгенерированных текстовых описаний и традиционного классификатора векторных представлений в ансамбль для повышения точности распознавания событий. При этом выходы классификаторов получают следующим образом: вычисляют оценки степени уверенности для всех типов событий для фотографии путем подачи ее векторных представлений в произвольный классификатор; вычисляют оценки степени уверенности для всех типов событий для фотографии путем подачи разреженного вектора унитарно кодированного текстового описания в произвольный классификатор; объединяют выходы классификаторов векторных представлений и текстов в ансамбле на основе простого голосования с мягким агрегированием. При этом текстовое описание фотографии генерируют следующим образом: подают извлеченные векторные представления и последовательность ранее сгенерированных слов в рекуррентную нейронную сеть (RNN) для прогнозирования следующего слова в текстовом описании фотографии; отображают номера, сгенерированные RNN, в реальные слова из словаря; выбирают подмножество словаря путем выбора наиболее часто встречающихся слов в обучающих данных с необязательным исключением стоп-слов. В предложенном способе дополнительно добавляют спрогнозированное слово в эту последовательность ранее сгенерированных слов и подают извлеченные визуальные векторные представления и эту последовательность в одну и ту же RNN. При этом обучающая выборка представляет собой набор фотографий с известным типом события. При этом следует предварительно обучить традиционный классификатор распознаванию событий в обучающей выборке, в которой каждая фотография представлена вместе с ее извлеченными собственными визуальными векторными представлениями. При этом, в частности, агрегированные степени уверенности вычисляют как взвешенную сумму оценок степеней уверенности, и решение принимают в пользу класса с максимальной агрегированной степенью уверенности.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Описанные выше и/или другие аспекты станут более очевидными из описания примерных вариантов осуществления изобретения со ссылками на прилагаемые чертежи.
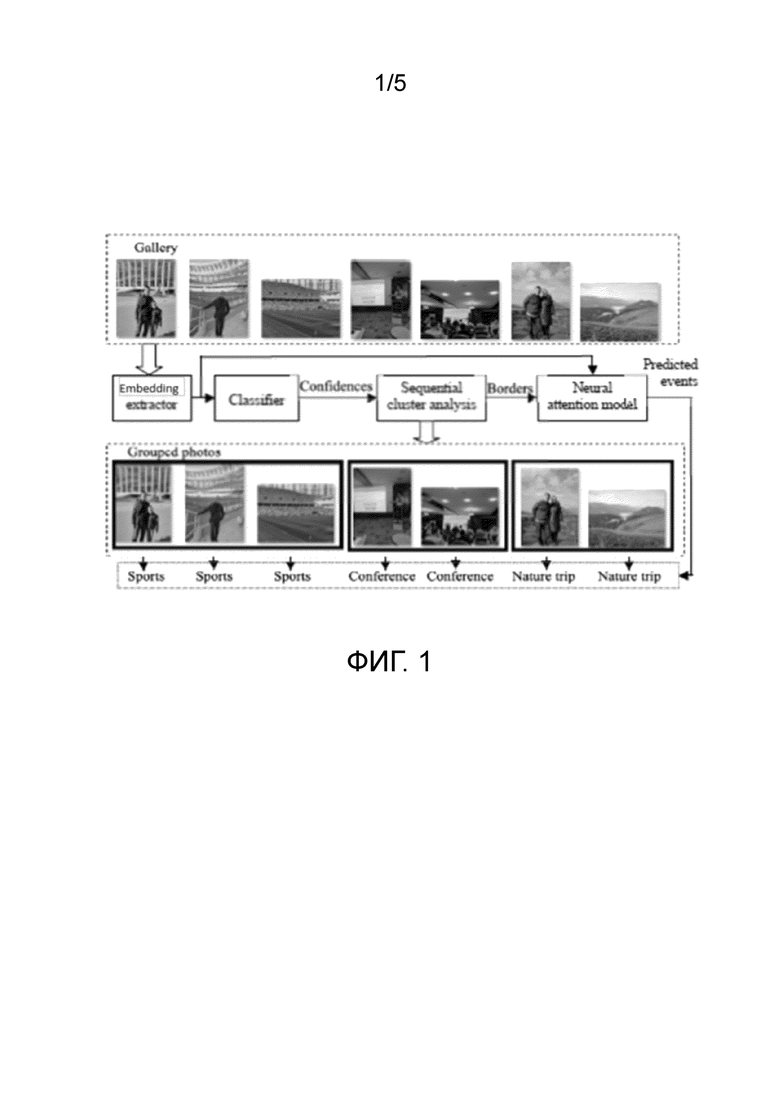
Фиг. 1 изображает предлагаемый подход для распознавания событий на основе галереи.
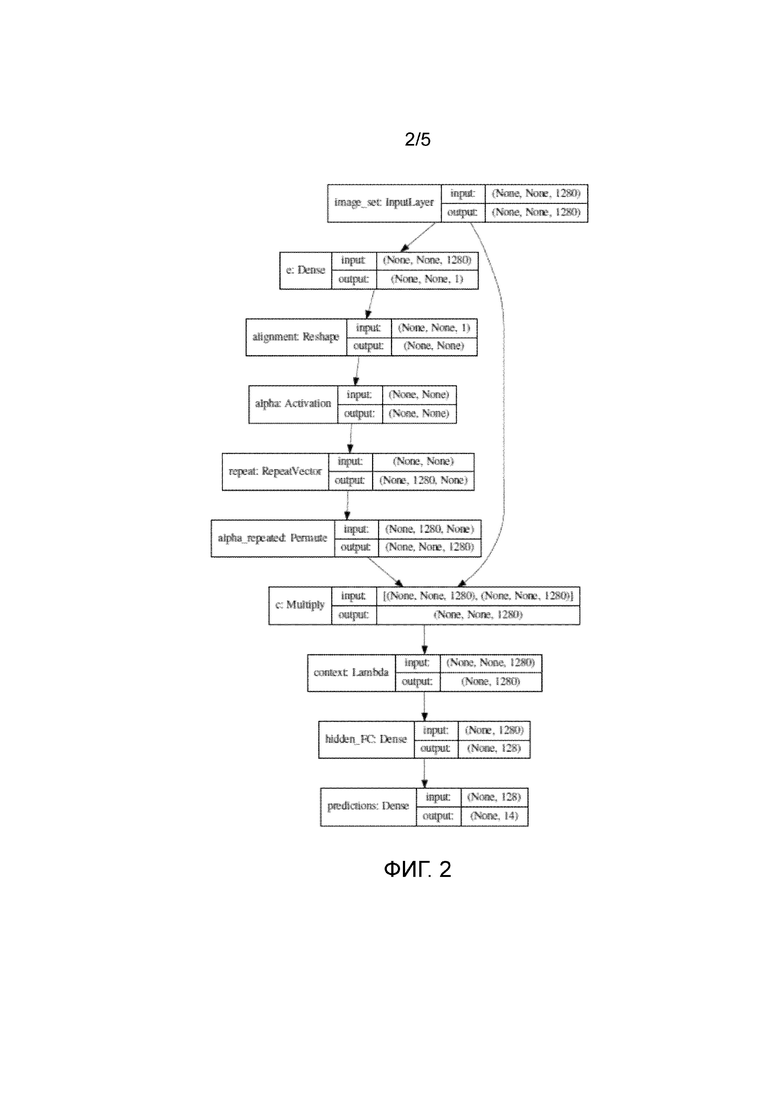
Фиг. 2 изображает основанную на механизме внимания нейронную сеть для векторных представлений из MobileNet v2.
Фиг. 3 изображает демонстрационный графический интерфейс для мобильных устройств.
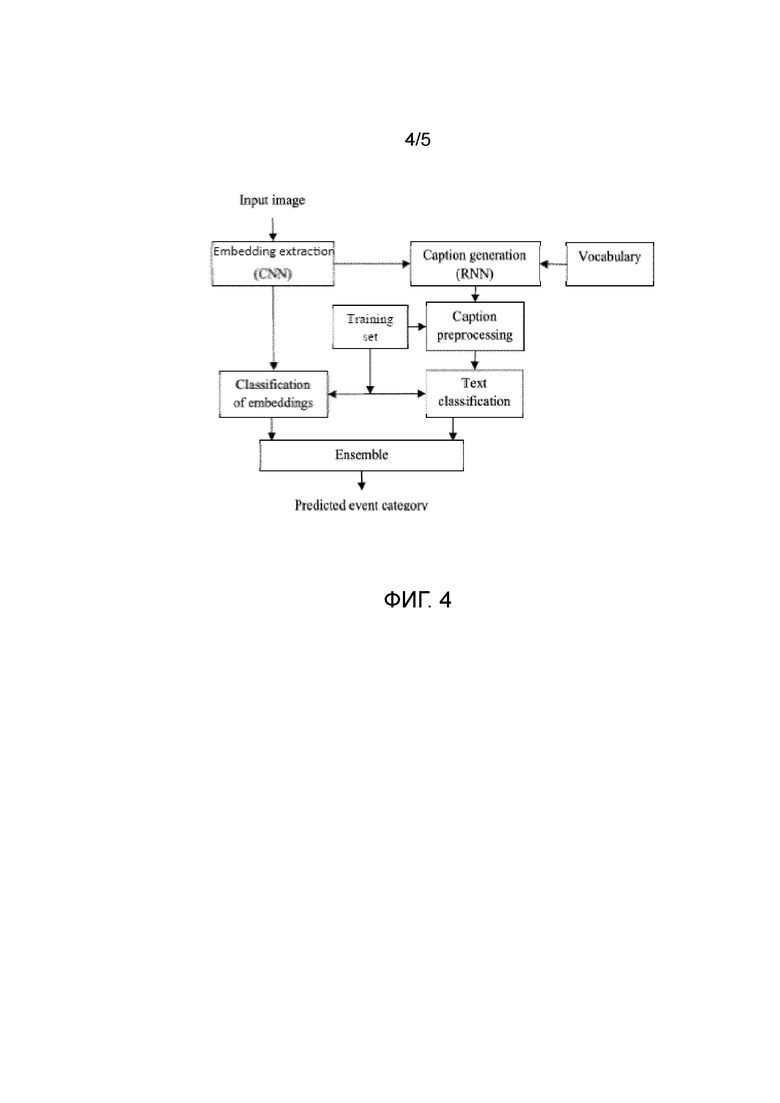
Фиг. 4 изображает предлагаемый конвейер для распознавания событий на основе составления подписи к изображению.
Фиг. 5 изображает примерные результаты распознавания событий.
ПОДРОБНОЕ ОПИСАНИЕ
Изобретение можно использовать в программном обеспечении для организации фотографий, которое можно при желании реализовать, например, на машиночитаемом носителе, для автоматического выбора альбомов из неразмеченного набора фотографий и ассоциирования каждого альбома с конкретными тегами (типами событий или сцен). Настоящее изобретение можно реализовать программными и/или аппаратными средствами в любом устройстве, например, смартфоне, мобильном телефоне, планшетном ПК, ноутбуке, компьютере и т.п.
Технический эффект заключается в значительном улучшении точности распознавания событий посредством объединения последовательно снятых фотографий в альбомы (то есть группы последовательных фотографий со сходным содержанием) с последующей классификацией каждого альбома на основе нейронного механизма внимания. Для нахождения похожих фотографий вместо обычного сопоставления визуальных векторных представлений используется оценка степеней уверенности классификаторов событий. Кроме традиционных визуальных векторных представлений используются их автоматически генерируемые текстовые описания (подписи) для повышения точности ансамбля классификаторов за счет повышения диверсификации визуальных векторных представлений.
Предлагаемое решение заключается в следующем:
Для каждой фотографии в галерее выполняется следующая обработка. Вычисляются векторные представления фотографии путем подачи ее RGB (красный-зеленый-синий) представления на вход сверточной нейронной сети. Предлагается использовать дополнительное представление фотографии с использованием методов автоматического составления подписи к изображению, чтобы повысить диверсификацию визуальных векторных представлений. В частности, создается подпись (текстовое описание) фотографии посредством подачи ее векторных представлений в специально обученную рекуррентную нейронную сеть. Далее осуществляется унитарное кодирование сгенерированных подписей. Оцениваются степени уверенности для каждого типа события путем классификации фотографии с помощью ансамбля, состоящего из традиционного классификатора векторных представлений и классификатора унитарно кодированных подписей к фотографиям. Ансамбль традиционного классификатора векторных представлений и классификатора унитарно кодированных подписей к фотографиям представляет собой следующее: при традиционном подходе классифицируют векторные представления фотографий, извлеченные с помощью сверточных нейронных сетей; в предлагаемом подходе сначала генерируют текстовое описание фотографии, затем этот текст преобразуют в числовую форму, используя метод унитарного кодирования, и полученный вектор классифицируют посредством известных методов.
Оценивается сходство между каждой парой последовательных фотографий в галерее. Вместо традиционного вычисления сходства между векторными представлениями, извлеченными сверточной нейронной сетью, предлагается вычислять сходство между описанными выше нормированными оценками степеней уверенности. Для нормирования оценок степеней уверенности вычисляется их L2-норма как квадратный корень из суммы квадратов всех оценок степеней уверенности, и каждая оценка делится на эту L2-норму. Если данные EXIF (Exchangeable Photo File Format) этих фотографий содержат информацию о местоположении, то к сходству между нормированными оценками степенями уверенности можно добавить сходство между их местоположениями. Последовательные фотографии в галерее автоматически группируются в альбомы по следующему правилу: если сходство не превышает заданный порог, то предполагается, что обе фотографии включаются в один и тот же альбом. Этот порог вычисляется автоматически во время процедуры предварительного обучения с использованием предоставленного обучающего набора альбомов. Обучающие альбомы берутся из доступной обучающей выборки, например, из Photo Event Collection (PEC) или из набора данных Multi-Label Curation of Flickr Events (ML-CUFED), они необходимы для обучения классификатора.
В отличие от существующих методов обнаружения событий в коллекциях фотографий, присваивается тег типа события всем фотографиям в каждом альбоме с использованием специальной нейронной сети с механизмом внимания, обученной классифицировать события в наборе фотографий из одного альбома. Изобретение позволяет повысить точность по сравнению с обычной техникой присвоения тегов фотографиям, потому что события распознаются одновременно для всех фотографий в выбранных альбомах и ошибки для отдельных фотографий могут исправляться автоматически.
Новым трендом в сервисах организации фотографий является аннотирование личных фотоальбомов [8]. В [17] предложен метод иерархической организации фотографий на смартфоне по темам и тематическим категориям, основанный на интеграции сверточной нейронной сети (CNN) и тематического моделирования для классификации фотографий. В [16] предложены автоматическая иерархическая кластеризация и решение для выбора лучшей фотографии для моделирования пользовательских решений при организации или кластеризации похожих фотографий в альбомах. В [24] рассматривается организация фотоальбомов для предсказания пользовательских предпочтений на мобильном устройстве.
К сожалению, точность классификации событий на статических фотоснимках [32] обычно намного ниже, чем точность распознавания по альбомам [33]. Поэтому в настоящем изобретении предлагается сконцентрироваться на других подходящих визуальных векторных представлениях, извлеченных с помощью генеративных моделей, в частности, на методах автоматического составления подписи к изображению. Существует широкий спектр приложений для составления подписи: от автоматической генерации описаний для фотографий, размещаемых в социальных сетях, до извлечения фотографий из баз данных с использованием сгенерированных текстовых описаний [30]. В основе методов составления подписи к изображению обычно лежит нейросеть с архитектурой кодер-декодер, которая сначала кодирует фотографию в векторное представление фиксированной длины, используя предварительно обученную CNN, а затем декодирует это представление в подпись (описание на естественном языке). Во время обучения декодера (генератора) входная фотография и ее истинное текстовое описание подаются в нейронную сеть в качестве ввода, а желаемый вывод сети представляет собой одно унитарно кодированное описание. Описание кодируется с использованием текстовых векторных представлений в слое "Векторное представление (таблица поиска)" [11]. Сгенерированные векторные представления фотографии и текста объединяются посредством конкатенации или суммирования, и они образуют ввод для декодирующей части сети. Обычно предусматривается слой рекуррентной нейронной сети (RNN), за которым следует полносвязный слой с выходным слоем Soft-max.
Одна из первых успешных моделей, Show and Tell [31], выиграла первое соревнование MS COCO Image Captioning Challenge в 2015 году. В части декодера в ней используется RNN с блоками долгой краткосрочной памяти (LSTM). Ее усовершенствованная модель Show, Attend and Tell [36] включает в себя мягкий механизм внимания для улучшения качества генерации подписи. Модель составления подписи к изображению "Neural Baby Talk" [18] основана на создании шаблона с местоположениями слотов, явно привязанными к определенным областям изображения. Эти слоты затем заполняются визуальными концептами, идентифицированными в детекторах объектов. Области переднего плана получают с помощью сети Faster-RCNN [21], а декодером служит LSTM с механизмом внимания. Мультимодальная рекуррентная нейронная сеть (mRNN) [19] основана на сети Inception для извлечения векторных представлений фотографий и глубокой RNN для генерации предложений. Одной из лучших моделей в настоящее время является сеть Auto-Reconstructor Network (ARNet) [6], в кодере которой используется сеть Inception-V4 [28], а декодер основан на LSTM. Существуют две предварительно обученные модели с жадным поиском (ARNet-g) и лучевым поиском (ARNet-b) с размером 3, предназначенные для генерации окончательной подписи для каждой входной фотографии.
МАТЕРИАЛЫ И МЕТОДЫ
Постановка задачи
Как отмечалось выше, решается задача распознавания событий на каждой фотографии в галерее. При этом на первом этапе автоматически выделяются альбомы (группы снятых пользователем последовательных фотографий одного и того же события) на основе анализа содержания фотографии. Затем распознаются события, соответствующие каждому выделенному альбому. После этого событие, распознанное для данного альбома, отображается в каждой фотографии данного альбома. Это позволяет в результате распознавать события более точно, чем просто классифицировать события на каждой отдельной фотографии.
В данном подразделе описывается технологический механизм, позволяющий решить эту задачу посредством последовательной обработки фотографий аналогично кластерному анализу с использованием базовой последовательной алгоритмической схемы (Basic Sequential Algorithmic Scheme, BSAS) [3]. Основную задачу можно сформулировать следующим образом. требуется приписать каждую фотографию 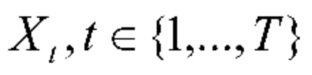 из галереи входного пользователя к одной из С>1 категорий событий (классов). В данном случае T≥1 - общее количество фотографий в галерее. Имеется обучающий набор N≥1 альбомов для обучения классификатора событий. n-й обучающий (эталонный) альбом образован коллекцией Ln фотографий
из галереи входного пользователя к одной из С>1 категорий событий (классов). В данном случае T≥1 - общее количество фотографий в галерее. Имеется обучающий набор N≥1 альбомов для обучения классификатора событий. n-й обучающий (эталонный) альбом образован коллекцией Ln фотографий 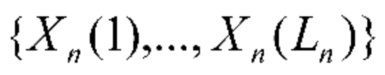 . Предполагается, что предоставлена метка класса
. Предполагается, что предоставлена метка класса 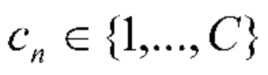 каждого n-го альбома, т.е. что альбом связан с одним конкретным типом события.
каждого n-го альбома, т.е. что альбом связан с одним конкретным типом события.
Обычное распознавание событий на отдельных фотографиях [32] представляет собой специальный случай сформулированной выше задачи, если T=l. Следовательно, эту задачу можно решить путем классифицирования событий отдельно на каждой t-й фотографии (t=1,2,…,T). Однако можно принять во внимание, что галерея {Xt} в данной задаче не является случайной коллекцией фотографий, а может быть представлена как последовательность несвязных альбомов. Каждая фотография в альбоме связана с одним и тем же событием. В отличие от распознавания событий в альбоме, нам не известны границы каждого альбома, т.е. номер первой t1 и последней t2 фотографии из галереи, для которых гарантируется, что все фотографии Xt, t=t1+1,…,t2 соответствуют данному альбому. Эта задача обладает рядом характеристик, придающих ей чрезвычайную сложность по сравнению с ранее изученными проблемами. Одной из таких характеристик является наличие нерелевантных или несущественных фотографий, которые в принципе могут быть ассоциированы с любым событием [1]. Эти фотографии легко обнаруживаются в основанных на внимании моделях [13, 37], но могут существенно повлиять на точность автоматического определения границ альбома.
В данном случае базовый подход заключается в независимой друг от друга классификации всех фотографий T, чтобы решение для каждой фотографии не влияло на решение для любой другой фотографии. В таком случае обычно разворачивают обучающие альбомы в набор X = {X1(1),…,X1(L1),X2(1),…,X2(L2),…,XN(1),…,XN(LN)} из L=L1+…+LN фотографий таким образом, чтобы метка cn уровня коллекции n-го альбома присваивалась меткам каждой 1-й фотографии 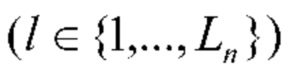 . Метки cn - это номера события, соответствующие всему альбому (коллекции фотографий). Затем можно обучить произвольный известный классификатор, который способен возвращать вектор оценок степени уверенности для каждого класса, вместо того, чтобы предсказывать только метку класса. Если L достаточно мало для обучения глубокой CNN (сверточной нейронной сети) с нуля, то можно применить перенос обучения или адаптацию домена [11]. В этих методах используется большой внешний набор данных, например, ImageNet-1000 или Places2 [38], для предварительного обучения глубокой CNN. Поскольку особое внимание уделяется автономному распознаванию на мобильных устройствах, целесообразно использовать такие CNN, как MobileNet vl/v2 [15, 22]. Заключительным этапом в переносе обучении является дообучение этой нейронной сети на наборе данных X. Данный этап включает в себя замену последнего слоя предварительно обученной CNN новым слоем с активациями Softmax и выводами С. Во время процесса классификации каждая входная фотография Xt подается в дообученную CNN для вычисления оценок (прогнозов на последнем слое:
. Метки cn - это номера события, соответствующие всему альбому (коллекции фотографий). Затем можно обучить произвольный известный классификатор, который способен возвращать вектор оценок степени уверенности для каждого класса, вместо того, чтобы предсказывать только метку класса. Если L достаточно мало для обучения глубокой CNN (сверточной нейронной сети) с нуля, то можно применить перенос обучения или адаптацию домена [11]. В этих методах используется большой внешний набор данных, например, ImageNet-1000 или Places2 [38], для предварительного обучения глубокой CNN. Поскольку особое внимание уделяется автономному распознаванию на мобильных устройствах, целесообразно использовать такие CNN, как MobileNet vl/v2 [15, 22]. Заключительным этапом в переносе обучении является дообучение этой нейронной сети на наборе данных X. Данный этап включает в себя замену последнего слоя предварительно обученной CNN новым слоем с активациями Softmax и выводами С. Во время процесса классификации каждая входная фотография Xt подается в дообученную CNN для вычисления оценок (прогнозов на последнем слое:
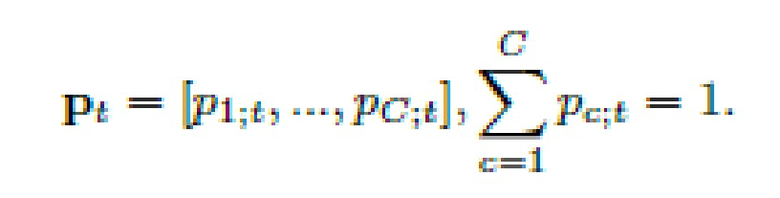
Эту процедуру можно модифицировать, заменив С логистических регрессий в последнем слое более сложным классификатором, например, случайным лесом (RF), машиной опорных векторов (SVM) или градиентным бустингом. В этом случае векторные представления [25] извлекаются с использованием выходов одного из последних слоев предварительно обученной CNN. В частности, фотографии Xt и Xn(l) подаются в CNN, а выходы предпоследнего слоя используются в качестве D-мерных векторов векторных представлений xt=[x1;t,…,xD;;t] и xn(l)=[xn;1(l),…,xn;D(l)], соответственно. Такие блоки извлечения векторных представлений на основе глубокого обучения позволяют обучать произвольный классификатор. В этот классификатор подается t-тое фото для получения C-мерных оценок степени уверенности  .
.
В заключение, степени уверенности , вычисленные любым из вышеперечисленных способов, используются для принятия решения в пользу наиболее вероятного класса:
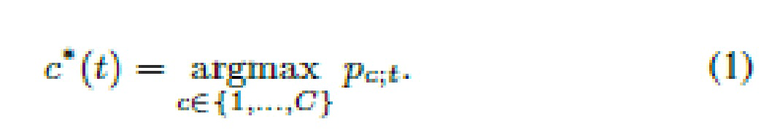
Распознавание событий в галерее фотографий.
На фиг. 1 показан предлагаемый подход для распознавания событий на основе галереи. Следует отметить, что все описанные блоки можно реализовать программными и/или аппаратными средствами.
В блоке "Извлечение векторных представлений (CNN)" выполняется следующее: извлекаются визуальные векторные представления (векторные представления) путем подачи RGB-представления каждой фотографии из галереи на вход сверточной нейронной сети для вычисления выходов одного из ее последних слоев (обычно предпоследнего).
В блоке "Классификатор" выполняется следующее: вычисляются оценки степени уверенности для всех типов событий для каждой фотографии путем подачи их векторных представлений в произвольный классификатор. Этот классификатор должен быть предварительно обучен распознавать события в обучающей выборке. Вектор оценок степеней уверенности нормализуется с использованием L2-нормы.
В блоке "Последовательный кластерный анализ" выполняется следующее: для каждой фотографии из галереи вычисляется сходство между ее нормированными оценками степеней уверенности и нормированными оценками уверенности следующей фотографии. Если данные EXIF (Exchangeable Photo File Format) этих фотографий содержат информацию о местоположении, то к сходству между нормированными оценками степеней уверенности можно добавить их местоположения. Если это сходство превышает заданный порог, то фотографии будут включены в различные альбомы, и будет установлена граница между альбомами этих двух последовательных фотографий.
В блоке "Нейронная модель внимания" выполняется следующее: для каждой последовательной пары границ альбома, извлеченных на предыдущем этапе, получают визуальные векторные представления всех фотографий между этими границами. Это набор векторных представлений подают в нейронную модель внимания, которая предсказывает один класс событий для набора фотографий. Предсказанный класс событий присваивается всем фотографиям между этими границами.
В данном случае сначала "Блок извлечения векторных представлений" вычисляет векторные представления xt каждой отдельной t-й фотографии, как было описано выше. В блоке "Классификатор" оцениваются степени уверенности классификатора. Затем используется последовательный анализ по аналогии с кластеризацией BSAS [3] в блоке "Последовательный кластерный анализ" для определения последовательности степеней уверенностей {} для получения границ альбомов. В частности, вычисляются сходства между степенями уверенностями всех последующих фотографий p(, 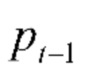 ). При этом можно использовать любое подходящее сходство, например, эвклидово, Минковского, хи-квадрат, расхождения Кульбака-Лейблера и Дженсена-Шеннона и т.п. Если сходство не превышает заданный порог
). При этом можно использовать любое подходящее сходство, например, эвклидово, Минковского, хи-квадрат, расхождения Кульбака-Лейблера и Дженсена-Шеннона и т.п. Если сходство не превышает заданный порог 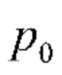 , то предполагается, что обе фотографии включены в один и тот же альбом. Если в данных EXIF (Exchangeable Photo File Format) этих фотографий содержится информация о местоположении, то к p(,
, то предполагается, что обе фотографии включены в один и тот же альбом. Если в данных EXIF (Exchangeable Photo File Format) этих фотографий содержится информация о местоположении, то к p(,  ) можно добавить сходство между их местоположениями, чтобы получить окончательное сходство, сопоставимое с порогом. В противном случае граница между двумя альбомами устанавливается в t-й позиции. В результате получаются границы
) можно добавить сходство между их местоположениями, чтобы получить окончательное сходство, сопоставимое с порогом. В противном случае граница между двумя альбомами устанавливается в t-й позиции. В результате получаются границы 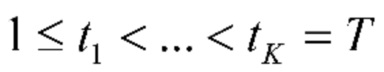 ,
, 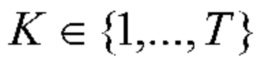 , так что k-й альбом содержит фотографии
, так что k-й альбом содержит фотографии 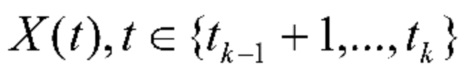 , где t0=0. См. фиг. 2.
, где t0=0. См. фиг. 2.
На втором этапе создается итоговый дескриптор x(k) k-го альбома как взвешенная сумма отдельных векторных представлений xt:
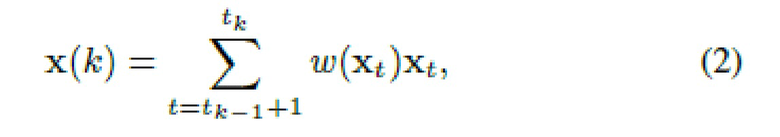
где веса w могут зависеть от векторных представлений xt. При этом обычно используется усредненный пулинг (группировка) (AvgPool) с равными весами, так что реализуется обычное вычисление среднего векторного представления.
Алгоритм 1 Предложенное распознавание событий на основе галереи
Ввод: входная галерея 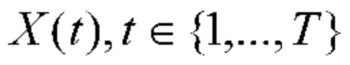 }, классификатор C, порог o.
}, классификатор C, порог o.
Вывод: метки событий c*(t) всех входных изображений.
1: Присвоить К: = 0, инициализировать список границ В: = □
2: для каждого входного изображения  повторить:
повторить:
3: Подать t-е изображение в CNN и вычислить векторные представления xt
4: Вычислить степени уверенности pt с использованием классификатора С
5: если t=1 или 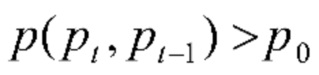 , то
, то
6: Присвоить К:=К+1, добавить t-1 в список В
7: закончить, если
8: закончить для
9: Добавить T к списку В
10: для каждого извлеченного альбома 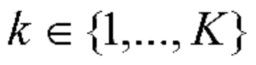 повторить:
повторить:
11: Подать входные изображения 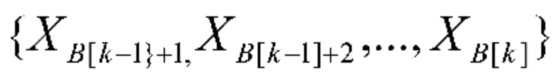 в
в
сеть внимания (2)-(3) и получить класс событий c*
12: Присвоить c*{t):=c* для всех 
13: закончить для
14: возвратить метки c*(t), {1,…,T}
Однако в настоящем изобретении предлагается обучать веса w(xt), в частности, с помощью механизма внимания из нейронного агрегационного модуля, использовавшегося ранее только для распознавания видео [37]:
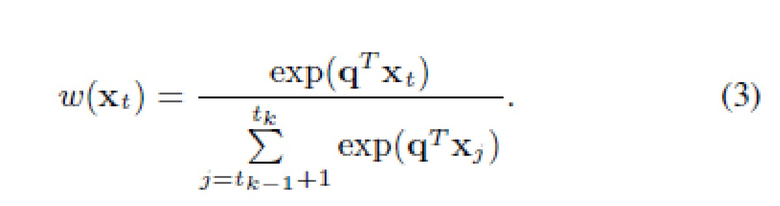
Здесь q - обучаемый D-мерный вектор весов. Плотный (полносвязный) слой присоединяют к результирующему дескриптору x(k), и всю нейронную сеть (фиг. 2) обучают сквозным образом с использованием предоставленного обучающего набора из N≥1 альбомов. Класс события, предсказанный данной сетью в блоке "Нейронная модель внимания" (фиг. 1), присваивается всем фотографиям 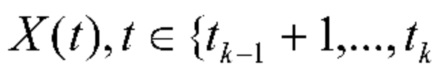 }.
}.
Полные процедуры классификация и обучения представлены в алгоритме 1 и алгоритме 2, соответственно. Для простоты следует отметить, что во втором алгоритме на шаге 17 вызывается алгоритм 1 классификации событий. Однако для ускорения вычислений рекомендуется предварительно вычислить матрицу попарного сходства между оценками уверенности всех обучающих фотографий, чтобы во время обучения модели не потребовалось извлечение векторных представлений (шаги 3-4 в алгоритме 1) и вычисление подобия.
В настоящем изобретении реализован весь конвейер (фиг. 1) в общедоступном демонстрационном приложении для Android (https: drive.google.comopen?id=laYN0ZwU90T8ZruacvND01hbIaJS4EZLI) (фиг. 3), разработанный ранее для извлечения пользовательских предпочтений путем обработки всех фотографий из галереи в фоновом потоке [26]. Схожие события, найденные на фотографиях, сделанных в один день, объединяются в высокоуровневые записи для наиболее важных событий. Отображаются только те сцены/события, для которых существует как минимум две фотографии и средняя оценка прогнозов сцены/события для всех фотографий этого дня превышает определенный порог. Этот порог устанавливается автоматически во время процедуры обучения (шаги 16-22 в алгоритме 2). На фиг. 3а показан пример скриншота основного пользовательского интерфейса. Можно нажать на любой столбец на этой гистограмме, чтобы отобразить новую форму с подробными категориями (фиг. 3в). Если нажать на конкретную категорию, появится форма "display", содержащая список всех фотографий из галереи данной категории (фиг. 3с). В этом списке события сгруппированы по дате и имеется возможность выбрать конкретный день.
Алгоритм 2. Процедура обучения согласно предлагаемому подходу
1: для каждого альбома n∈{1,…, N} повторить
2: для каждого изображения l∈{1,…, Ln} повторить
3: Подать изображение Xn(l) в CNN и вычислить векторные представления xn(l)
4: закончить для
5: закончить для
6: Обучить классификатор С, используя развернутую обучающую выборку X векторных представлений
7: Обучить сеть внимания (2)-{3), используя подмножества с фиксированным размером S всех обучающих выборок признаков {xn(l)}
8: для каждого альбома n∈{1,…,N} повторить
9: для каждого изображения l∈{1,…,Ln} повторить
10: Предсказать оценки степени уверенности рn(l) для векторных представлений хn(l), используя классификатор С
11: закончить для
12: закончить для
13: Выполнить случайную перестановку всех индексов {1,…,N} для получения последовательности (ni,…,nN)
14: Развернуть все обучающие векторные представления, используя эту перестановку: 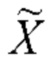 ={Xn1(1),…,X1(Ln1),…,XnN(1),…,XnN(LnN)}
={Xn1(1),…,X1(Ln1),…,XnN(1),…,XnN(LnN)}
15: Присвоить ρ:=0, α*:=0
16: для каждого потенциального порога с повторить
17: Вызвать алгоритм 1 с параметрами , С и порогом с
18: Вычислить точность б, используя прогнозы для всех обучающих изображений
19:если α*<α, то
20: Присвоить α*:=α, ρ0:=ρ
21: закончить, если
22: закончить для
23: возвратить классификатор C, сеть внимания, порог с0
Распознавание событий на отдельных фотографиях
Задачу распознавания события на отдельных фотографиях можно сформулировать как обычную задачу распознавания изображения. Необходимо поставить в соответствие каждой фотографии X из галереи одну из С>1 категорий событий (классов). Для обучения классификатора доступна обучающая выборка N≥1 фотографий X={Xn|n∈{1,…,N}} с известными метками событий сn∈{l,…,C}. Иногда обучающие фотографии одного и того же события ассоциированы с альбомом [5, 33]. В этом случае обучающие альбомы разворачиваются в набор X, так что метка уровня коллекции альбома присваивается меткам каждой фотографии из данного альбома. У этой задачи есть несколько характеристик, чрезвычайно усложняющих ее по сравнению с распознаванием событий на основе альбома. Одной из этих характеристик является наличие нерелевантных или несущественных фотографий, которые можно ассоциировать с любым событием [1]. Эти фотографии можно выявить с помощью моделей на основе внимания, когда имеется весь альбом [13], однако качество распознавания событий на отдельных фотографиях может значительно пострадать.
Так как N обычно довольно мало, может применить перенос обучения [11]. Сначала обучают глубокую CNN на большом наборе данных, например, ImageNet или Places [38]. Затем эту CNN подвергают тонкой настройке (дообучению) на обучающее множество X, то есть последний слой заменяют на новый с активациями Softmax и выходами С. Каждую входную фотографию X классифицируют путем ее подачи в дообученную CNN для вычисления С выходов выходного слоя, т.е. оценок апостериорных вероятностей для всех категорий событий. Эту процедуру можно модифицировать путем извлечения глубоких векторных представлений фотографий, используя выходы одного из последних слоев предварительно обученной CNN. Фотографии X и Xn подаются на вход CNN, а выходы предпоследнего слоя используются в качестве D-мерных векторов векторные представления X=[x1,…,xD] и Xn=[xn;1,…,xn;D], соответственно. Такие блоки извлечения векторных представлений на базе глубокого обучения позволяют обучать общий классификатор Cemb, например, k-ближайший сосед, случайный лес (RF), машину опорных векторов (SVM) или градиентный бустинг. C-мерный вектор pemb=Cemb(x) оценок степеней уверенности предсказывается с учетом входной фотографии в обоих случаях дообученной сети с последним слоем Softmax в роли классификатора Cemb и извлечением векторных представлений с помощью общего классификатора. См. фиг. 4. Окончательное решение может быть принято в пользу класса с максимальной уверенностью.
В настоящем изобретении используется другой подход к распознаванию событий, основанный на генеративных моделях и составлении подписи к изображению. Предложенный подход для распознавания событий на основе составления подписи к изображению представлен на фиг. 4. Следует отметить, что все описанные блоки могут быть реализованы программными и/или аппаратными средствами.
В блоке "Извлечение векторных представлений (CNN)" выполняется следующее: извлекаются визуальные векторные представления (векторные представления) путем подачи RGB-представления фотографии из галереи на вход предварительно обученной сверточной нейронной сети для вычисления выходов одного из ее последних слоев (обычно предпоследнего слоя).
В блоке "Генерация подписи" выполняется следующее: извлеченные визуальные векторные представления и последовательность ранее сгенерированных слов подаются в RNN (рекуррентную нейронную сеть), чтобы спрогнозировать следующее слово в текстовом описании фотографии. Эта последовательность ранее сгенерированных слов изначально содержит только одно специальное слово <START>. Пока предсказанное слово не равно специальному слову <END>, оно добавляется в эту последовательность ранее сгенерированных слов и извлеченные визуальные векторные представления и эта последовательность подаются на вход той же самой RNN.
В блоке "Словарь" выполняется следующее: так как вышеупомянутая RNN оперирует со словами, представленными числами, необходимо отобразить номера, сгенерированные RNN, в реальные слова из словаря.
В блоке "Предварительная обработка подписи" выполняется следующее: выбирается подмножество словаря путем выбора наиболее часто встречающихся слов в обучающей выборке с необязательным исключением стоп-слов. Далее, каждая фотография представляется в виде разреженного вектора с использованием унитарного кодирования: v-й компонент вектора равен 1, только если хотя бы одно слово в сгенерированной подписи равно v-му слову из словаря.
Блок "Обучающая выборка" содержит набор обучающих фотографий с известным типом события.
В блоке "Классификация векторных представлений" выполняется следующее: вычисляются оценки степени уверенности для всех типов событий для фотографии путем подачи ее векторных представлений в любой классификатор. Этот классификатор должен быть предварительно обучен распознавать события в обучающей выборке, где каждая фотография из обучающей выборки представлена собственными визуальными векторными представлениями, извлеченными с помощью процедуры из блока "Извлечение векторных представлений (CNN)".
В блоке "Текстовая классификация" выполняется следующее: вычисляются оценки степени уверенности для всех типов событий для фотографии путем подачи разреженного вектора унитарно кодированного текстового описания в любой классификатор. Этот классификатор должен быть предварительно обучен распознавать события в обучающей выборке, где каждая фотография из обучающей выборки представлена ее собственными визуальными векторными представлениями, извлеченными с помощью процедуры из блока "Предварительная обработка подписи".
В блоке "Ансамбль": выходы классификаторов для векторных представлений и текстов объединяются в ансамбле на основе простого голосования с мягким агрегированием. В частности, агрегированные степени уверенности вычисляются как взвешенная сумма оценок степеней уверенности, вычисленных в блоках "Классификация векторных представлений" и "Текстовая классификация". Решение принимается в пользу класса с максимальной агрегированной степенью уверенностью.
Сначала выполняется обычное извлечение векторных представлений x с помощью предварительно обученной CNN. Затем эти визуальные векторные представления и словарь V подаются в специальную нейронную сеть (генератор) на основе RNN, которая создает подпись, описывающую каждую входную фотографию. Подпись представляется в виде последовательности L>0 слов из словаря (tl∈V, l∈{0,…,L}). Она генерируется последовательно, слово за словом, начиная со специального слова t0=<START>, до тех пор, пока не будет создано специальное слово tL=<END> [6]. См. фиг. 4.
Сгенерированная подпись t подается в классификатор событий. Для обучения его параметров каждую n-ю фотографию из обучающей выборки подают в одну и ту же сеть составления подписи к изображению, чтобы создать подпись tn={tn;0,tn;;1…,tn;Ln+1}. Так как количество слов Ln не одинаково для всех фотографий, необходимо либо обучить последовательный классификатор на базе RNN, либо преобразовывать все подписи в векторы векторного представления с одинаковой размерностью. Поскольку количество обучающих экземпляров N не очень велико, было определено экспериментальным путем, что последний подход является таким же точным, как и первый, при значительно меньшем времени обучения. Поэтому было решено использовать унитарное кодирование последовательностей t и {tn} в векторы 0 и 1, как описано в [7]. В частности, формируется подмножество словаря 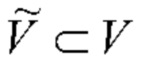 путем выбора наиболее часто встречающихся слов в обучающих данных {tn} с необязательным исключением стоп-слов. Затем каждую входную фотографию представляют как |
путем выбора наиболее часто встречающихся слов в обучающих данных {tn} с необязательным исключением стоп-слов. Затем каждую входную фотографию представляют как | 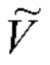 |- мерный разреженный вектор
|- мерный разреженный вектор 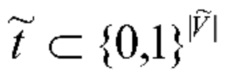 , где | | - размер сокращенного словаря , а v-й компонент вектора
, где | | - размер сокращенного словаря , а v-й компонент вектора 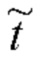 равен 1, только если хотя бы одно из L слов в подписи t равно v-му слову из словаря . Это будет означать, например, превращение последовательности {1,5,10,2} в -мерный разреженный вектор, состоящий из всех нулей, за исключением индексов 1, 2, 5 и 10, значения которых будут единицами [7]. Такая же процедура используется для описания каждой n-й обучающей фотографии с -мерным разреженным вектором
равен 1, только если хотя бы одно из L слов в подписи t равно v-му слову из словаря . Это будет означать, например, превращение последовательности {1,5,10,2} в -мерный разреженный вектор, состоящий из всех нулей, за исключением индексов 1, 2, 5 и 10, значения которых будут единицами [7]. Такая же процедура используется для описания каждой n-й обучающей фотографии с -мерным разреженным вектором 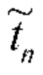 . После этого можно использовать произвольный классификатор Ctxt таких текстовых представлений, подходящий для разреженных данных, чтобы предсказать С оценок степени уверенности Ptxt=Ctxt( ). В [7] было продемонстрировано, что такой подход даже более точен, чем традиционные классификаторы на основе RNN (включающие в себя один слой LSTM) для набора данных IMDB.
. После этого можно использовать произвольный классификатор Ctxt таких текстовых представлений, подходящий для разреженных данных, чтобы предсказать С оценок степени уверенности Ptxt=Ctxt( ). В [7] было продемонстрировано, что такой подход даже более точен, чем традиционные классификаторы на основе RNN (включающие в себя один слой LSTM) для набора данных IMDB.
В общем, не ожидается, что классификация коротких текстовых описаний будет более точной, чем традиционные методы распознавания изображений. Однако существует уверенность, что наличие подписей к фотографиям в ансамбле классификаторов может значительно улучшить его диверсификацию. Кроме того, поскольку подписи генерируются на базе извлеченного вектора x векторных представлений, требуется всего один вывод CNN, если объединенный обычный общий классификатор векторных представлений из отдельных классификаторов объединяется в простом голосовании с мягким агрегированием.
В частности, агрегированные уверенности вычисляются как взвешенная сумма выходов отдельного классификатора:
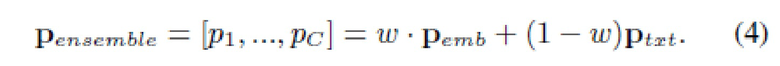
Решение принимается в пользу класса с максимальной уверенностью:
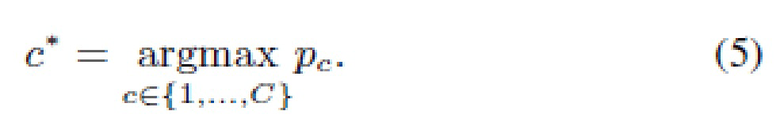
Вес w∈[0,1] в (4) можно выбрать, используя специальное контрольное подмножество для достижения максимальной точности критерия (5).
Приведем качественные примеры для использования описанного подхода (фиг. 4). На фиг. 5 представлены результаты (корректного) распознавания событий с использованием ансамбля. Первая строка заголовка содержит сгенерированную подпись фотографии. Кроме того, в заголовке отображаются результаты распознавания события с использованием подписей t (вторая строка), векторных представлений xemb (третья строка) и всего ансамбля (последняя строка). Как можно заметить, единая классификация подписей не всегда корректна. Однако этот ансамбль способен выдать достоверное решение, даже если отдельные классификаторы принимают неверные решения.
ЭКСПЕРИМЕНТАЛЬНОЕ ИССЛЕДОВАНИЕ
Распознавание событий в галерее фотографий
Для распознавания событий в личных коллекциях фотографий имеется только ограниченное количество наборов данных [1]. Поэтому в этой области рассматриваются два основных набора данных, а именно:
1. PEC [5], содержащий 61 364 фотографий из 807 коллекций 14 классов общественных мероприятий (день рождения, свадьба, выпускной и т.д.). Использовалось выполненное его авторами разделение: обучающая выборка, содержащая 667 альбомов (50 279 фотографий), и тестовая выборка, содержащая 140 альбомов (11 085 фотографий).
2. ML-CUFED [33], содержащий 23 распространенных типа событий. Каждый альбом связан с несколькими событиями, т.е. решается задача мультиклассовой классификации. Использовалось обычное разделение на обучающую выборку (75 377 фотографий, 1507 альбомов) и тестовую выборку (376 альбомов с 19 420 фотографиями).
Векторные представления извлекались с помощью моделей распознавания сцен (Inception v3 и MobileNet v2 с a=1 и a=1.4), предварительно обученных на наборе данных Places2 [38]. Для получения окончательного дескриптора набора фотографий использовались два метода, а именно: (1) простое усреднение векторных представлений отдельных фотографий в наборе (AvgPool), и (2) реализация нейронного механизма внимания (2)-(3) для L2-нормированных векторных представлений. В первом случае в качестве С использовался линейный классификатор SVM из библиотеки scikit-learn, так как он имеет более высокую точность, чем RF, k-NN и RBF SVM. Во втором случае обучались веса основанной на внимании сети (фиг. 2) с использованием наборов из S=10 произвольно выбранных фотографий из всех альбомов для создания идентичной формы входных тензоров. В результате было получено 667 обучающих подмножеств и 1507 подмножеств с S=10 фотографиями для PEC и ML-CUFED, соответственно. Так как ML-CUFED содержит множество меток на каждый альбом, используются сигмоидные активации и потеря двоичной кросс-энтропии. Для PEC применяются обычные активации Softmax и категорическая кросс-энтропия. Эта модель обучалась с использованием оптимизатора ADAM (скорость обучения 0,001) для 10 эпох с ранним остановом в среде Keras 2.3 с бэкэндом TensorFlow 1.15.
Таблица 1: Точность (%) распознавания событий в наборе изображений (альбоме)
Внимание
89.29
84.04
Внимание
87.36
84.31
Внимание
87.86
84.84
Агрегация репрезентативных признаков |34]
87.9
84.5
Агрегация репрезентативных признаков |34]
89.1
83.4
В таблице 1 представлены показатели точности распознавания предобученной CNN. В данном случае вычисляется мультиклассовая точность для ML-CUFED, поэтому предполагается, что предсказанное событие верно, если оно соответствует любой метке, ассоциированной с альбомом. В таблице представлены наиболее известные результаты для указанных наборов данных [33, 34].
При этом во всех случаях основанная на внимании агрегация точнее на 1-3%, чем классификация средних векторных представлений. Можно заметить, что предлагаемая реализация механизма внимания достигает самых высоких на сегодняшний день результатов, хотя используются гораздо более быстрые сверточные сети (MobileNet и Inception, а не AlexNet и ResNet-101) и не учитывается последовательный характер фотографий в альбом в сети на основе внимания (фиг. 2). Наиболее примечательным фактом в данном случае является то, что наилучшие результаты для PEC достигаются для самой простой модели (MobileNet v2, a=1.0), что можно объяснить отсутствием обучающих данных для этого конкретного набора данных.
Как отмечалось выше, информация об альбомах в галерее вообще отсутствует. Поэтому событие должно присваиваться всем фотографиям индивидуально. В следующем эксперименте каждой фотографии, содержащейся в обоих наборах данных, непосредственно присваивается первая метка уровня коллекции и для распознавания событий просто используется сама фотография без какой-либо метаинформации. В дополнение к базовому подходу (подраздел 3.1) используется иерархическая агломерационная кластеризация всей тестовой галереи. Показаны только результаты, достигнутые средней связной кластеризацией векторных представлений xt, извлеченных предобученной CNN, и оценки степени уверенности pt. В первом случае используются как евклидово расстояние (L2), так и расстояние хи-квадрат (X2). Поскольку оценки степени уверенности, возвращаемые функцией принятия решения для LinearSVC, не всегда неотрицательны, для них используется только евклидово расстояние. Результаты представлены в таблице 2.
Таблица 2: Точность (%) распознавания событий в одном изображении.
MobileNet2, б = 1.4
Inception v3
60.34
61.82
61.25
64.19
61.92
64.22
60.58
61.97
MobiLeNet2, б = 1.4
Inception v3
53.54
57.26
54.97
59.19
55.98
60.12
54.03
57.87
При этом, во-первых, точность распознавания событий на отдельных фотографиях на 25-30% ниже, чем точность классификации по альбомам (таблица 1). Во-вторых, кластеризация оценок степеней уверенности на выходе лучшего классификатора не оказывает существенного влияния на общую точность. В-третьих, иерархическая кластеризация с расстоянием хи-квадрат приводит к чуть более точным результатам, чем обычная евклидова метрика. И наконец, предварительная кластеризация векторных представлений снижает частоту ошибок базового подхода всего на 1,2-2%, даже если при кластеризации был тщательно подобран порог подобия.
Продемонстрируем, как предположение о последовательно упорядоченных фотографиях в альбоме может повысить точность распознавания событий. Чтобы усложнить задачу, была 10 раз проведена следующая трансформация порядка тестовых фотографий. Последовательность альбомов случайным образом перемешивалась, и также перемешивались фотографии в каждом альбоме. В дополнение к сопоставлению оценок уверенности от решающей функции linearSVC выполнялась их L2-нормализация. Кроме того, CNN дообучали с помощью развернутой обучающей выборки X следующим образом. Сначала замораживались веса в базовой части CNN и изучался новый головной элемент (полносвязный слой с С выходами и активацией Soft-max) в течение 10 эпох. Затем изучались веса во всей CNN в течение 3 эпох с 10-кратным снижением скорости обучения.
В таблицах 3 и 4 представлены результаты (средняя точность ± ее стандартное отклонение) предложенных алгоритмов 1, 2 для PEC и ML-CUFED, соответственно. При этом механизм внимания в большинстве случаев снижает уровень ошибок на 8%. Примечательно, что сопоставление сходства между L2-нормированными уверенностями значительно улучшает общую точность модели внимания для PEC (таблица 3), хотя представленные эксперименты не показали каких-либо улучшений в традиционной кластеризации по сравнению с предыдущим экспериментом (таблица 2). Очевидно, что дообученные сети CNN приводят к наиболее точному решению, но разница (0,1-1,6%) с лучшими результатами предварительно обученных моделей довольно мала. Однако последние не требуют дополнительного вывода в существующих моделях распознавания сцены, поэтому реализация распознавания событий в альбоме будет очень быстрой, если сцены необходимо дополнительно классифицировать, например, для более детального моделирования пользователем [26]. Удивительно, что вычисление сходства между оценками степеней уверенности классификаторов (с(Pt, Pt-1)) снижает вероятность ошибки традиционного сопоставления векторных представлений (с(Xt, Xt-1)) на 2-7%. Следует напомнить, что обычная кластеризация векторных представлений была на 1-2% более точной при сравнении с оценками классификатора (таблица 2). По видимому, в этом конкретном случае порог с0 можно оценить (алгоритм 2) более надежно, когда большинство фотографий одного и того же события сопоставляются в процедуре предсказания (алгоритм 1). И наконец, самый важный вывод состоит в том, что предлагаемый подход имеет на 9-20% более высокую точность по сравнению с базовым подходом. Более того, этот алгоритм на 13-16% точнее, чем классификация групп фотографий, полученных с помощью иерархической кластеризации (таблица 2).
Таблица 3: Точность (%) предложенного подхода, PEC.
Внимание
54.43
68.51±0.41
70.65±1.20
74.49±0.70
80.48±1.01
Внимание
55.36
70.53±0.79
71.16±0.72
78.20±1.47
81.27±0.81
Внимание
61.55
-
-
78.77±0.49
81.33±0.69
-
Внимание
56.94
72.38±1.13
71.36±0.67
76.76±0.70
-
80.17±1.14
(дообученная), оценки
Внимание
62.91
-
-
81.03±0.77
81.95±1.11
-
Таблица 4: Точность (%) предложенного подхода, ML-CUFED.
подход
Внимание
51.05
68.71±0.71
68.55±0.61
71.44±0.82
-
71.61±0.69
Внимание
51.12
68.34±0.68
68.62±0.50
70.79±0.75
-
71.78±0.74
Внимание
56.09
-
-
72.90±0.59
73.46±0.58
-
(предобученная), векторные представления
Внимание
50.89
69.30±0.47
68.52±0.89
72.73±0.72
-
73.00±0.65
(дообученная), оценки
Внимание
57.29
-
-
73.06±0.74
73.92±0.81
-
Распознавание событий на отдельных фотографиях
Кроме PEC и ML-CUFED исследовалась база веб-изображений для распознавания событий WIDER (Web Image Dataset for Event Recognition) [35], содержащая 50 574 фотографий и С=61 категорий событий (парад, танцы, встречи, пресс-конференции и т.д.). Использовалось стандартное разделение на обучение/тестирование для всех наборов данных, предложенных их разработчиками. В PEC и ML-CUFED метка уровня коллекции присваивалась непосредственно каждой фотографии, содержащейся в данной коллекции. Любые метаданные, например, временная информация, полностью игнорировались, за исключением самой фотографии, так же, как и в статье [32].
Чтобы сосредоточиться на возможности реализовать автономное распознавание событий на мобильных устройствах [26] в целях сравнения предлагаемого подхода с традиционными классификаторами, использовались сети CNN MobileNet v2 с а=1 [23] и Inception v4 [28]. Сначала их обучали на наборе данных Places2 [38] для извлечения векторных представлений. Использовался линейный классификатор SVM из библиотеки scikit-learn, так как он имеет более высокую точность, чем другие классификаторы из этой библиотеки (RF, k-NN и RBF SVM). Кроме того, эти CNN дообучались с использованием предоставленной обучающей выборки следующим образом. Сначала фиксировались веса в базовой части CNN и обучался новый классификатор (полносвязный слой с С выходами и активацией Softmax) с использованием оптимизатора ADAM (скорость обучения 0,001) для эпох с ранним остановом в среде Keras 2.2 с бэкэндом TensorFlow 1.15. Затем обучались веса во всей CNN в течение 5 эпох, используя ADAM. И наконец, CNN обучалась с использованием SGD в течение 3 эпох с 10-кратным снижением параметра скорости обучения.
Кроме того, использовались векторные представления из моделей обнаружения объектов, которые типичны для распознавания событий [35, 26]. Поскольку многие фотографии одного и того же события иногда содержат идентичные объекты (например, мяч в футболе), их можно обнаружить с помощью современных методов на основе CNN, например, SS-DLite [23] или Faster R-CNN [21]. Эти методы определяют положение нескольких объектов на входной фотографии и прогнозируют оценки каждого класса из заданного набора К>1 типов. Для каждого типа объекта извлекается разреженный K-мерный вектор оценок. Если имеется несколько объектов одного типа, максимальная оценка сохраняется в данном векторе векторные представления [20]. Этот вектор векторные представления либо классифицируется линейным SVM, либо используется для обучения нейронной сети прямого распространения с двумя скрытыми слоями, содержащими 32 нейрона каждый. Оба классификатора обучались с использованием обучающей выборки из каждого набора данных событий. В этом исследовании рассматривается SSD с архитектурой MobileNet и Faster R-CNN с архитектурами InceptionResNet. Модели, предварительно обученные на наборе данных Open Photos v4 (K=601 объектов), были взяты из TensorFlow Object Detection Model Zoo.
Предварительное экспериментальное исследование с предварительно обученными моделями составления подписи к изображению, которые обсуждались в разделе 2, продемонстрировало, что лучшее качество для набора данных составления подписей MS COCO достигается моделью AR-Net[6]. Поэтому в этом эксперименте использовалась модель кодера/декодера ARNet. Однако его можно заменить любым другим методом составления подписи к изображению без изменения алгоритма распознавания событий. ARNet обучали на наборе данных концептуальных подписей Conceptual Captions Dataset, который содержит более 3,3 млн пар фото-URL и подписей в обучающей выборке и около 15 тысяч пар в тестовой выборке. Извлечение векторных представлений в кодировщике реализуется не только теми же CNN (Inception и MobileNet v2). Было извлечено |  |=5000 наиболее часто встречающихся слова, за исключением специальных слов <START> и <END>. Их классифицировали либо линейным SVM, либо нейронной сетью с прямым распространением с той же архитектурой, что и в случае обнаружения объекта. Эти классификаторы также обучались с нуля на каждом предоставленной обучающей выборке событий. Этот же набор использовался для оценки веса w в ансамбле (уравнение 1).
|=5000 наиболее часто встречающихся слова, за исключением специальных слов <START> и <END>. Их классифицировали либо линейным SVM, либо нейронной сетью с прямым распространением с той же архитектурой, что и в случае обнаружения объекта. Эти классификаторы также обучались с нуля на каждом предоставленной обучающей выборке событий. Этот же набор использовался для оценки веса w в ансамбле (уравнение 1).
В таблицах 5, 6, 7 представлены результаты облегченных мобильных (MobileNet и детектор объектов SSD) и глубоких моделей (Inception и Faster R-CNN) для PEC, WIDER и ML-CUFED, соответственно. В них добавлены самые известные результаты за 24 года для тех же экспериментальных протоколов.
Таблица 5: Точность распознавания событий (%), PEC
Объекты
Тексты
Предлагаемый ансамбль (4),(5)
42.18
43.77
60.56
47.83
47.24
62.87
Объекты
Тексты
Предлагаемый ансамбль (4),(5)
40.17
43.52
63.38
47.42
46.84
65.12
Мультимножество подсобытий [5]
SHMM[5]
Перенос обучения на базе инициализации [32]
Перенос обучения данных и знаний [321
51.4
55.7
60.6
62.2
Таблица 6: Точность распознавания событий (%), WIDER
Объекты
Тексты
Предлагаемый ансамбль (4),(5)
19.91
26.38
48.91
28.66
31.89
51.59
CNN
Объекты
Тексты
Предлагаемый ансамбль (4),(5)
12.91
23.93
49.80
21.27
30.91
51.84
Глубокий синтез каналов [35]
Перенос обучения на базе инициализации [32]
Передача обучения данных и знаний [32]
42.4
50.8
53.0
Конечно, предлагаемое распознавание подписей к фотографиям не так точно, как с обычными векторными представлениями на основе CNN. Однако классификация текстовых описаний намного лучше, чем случайное предположение с точностью 100%/14≈7,14%, 100%/6l≈1,64% и 100%/23≈4,35% для PEC, WIDER и ML-CUFED, соответственно. Важно подчеркнуть, что в большинстве случаев этот подход дает более низкую частоту ошибок, чем классификация векторных представлений на базе обнаружения объектов. Это улучшение особенно заметно на облегченных моделях SSD, точность которых на 1,5-13% ниже, чем в предлагаемой классификации подписей к фотографиям, из-за ограничений моделей на основе SSD при обнаружении небольших объектов (продуктов питания, домашних животных, модных аксессуаров и т.п.). Векторные представления, обнаруженные Faster R-CNN, можно классифицировать более точно, но Faster R-CNN с архитектурой InceptionResNet дает в несколько раз более медленный вывод, чем декодирование в ARNet (6-10 секунд против 0,5-2 секунд в MacBook Pro 2015).
Таблица 7. Точность распознавания событий (%), ML-CUFED
Объекты
Тексты
Предлагаемый ансамбль (4),(5)
34.21
37.24
55.26
40.94
41.52
58.86
Объекты
Тексты
Предлагаемый ансамбль (4),(5)
32.05
36.74
57.94
40.12
41.35
60.01
И наконец, наиболее подходящим способом использования составления подписей изображений при классификации событий является их слияние с обычными CNN. В таком случае предыдущая известная наилучшая точность для PEC увеличивается с 62,2% [32] даже для облегченных моделей (63,38%), если в ансамбле используются дообученные CNN. Представленная модель на основе Inception еще лучше (точность 65,12%). Самый высокий на сегодня уровень точности 53% [32] для набора данных WIDER все еще не достигнут, хотя лучшая точность (51,84%) на 9% выше по сравнению с лучшими результатами (42,4%) из оригинальной статьи [35]. Представленный экспериментальный протокол для набора данных ML-CUFED изучался в этой работе впервые, так как этот набор данных разработан главным образом для распознавания событий на основе альбома.
На практике предпочтительно использовать предварительно обученную CNN в качестве блока извлечения векторных представлений, чтобы исключить дополнительный проход по дообученной CNN, когда она расходится с кодером в модели подписи изображений. К сожалению, точность SVM для векторных представлений предварительно обученной CNN ниже на 1,5-3% по сравнению с дообученными моделями для PEC и ML-CUFED. В этом случае можно допустить дополнительный вывод. Тем не менее, разница в частоте возникновения ошибок между предварительно обученными и дообученными моделями для набора данных WIDER несущественна, так что в данном случае определенно стоит использовать предварительно обученные CNN.
Описанные выше варианты осуществления изобретения являются примерами, и их не следует рассматривать как ограничивающие. Кроме того, описание примерных вариантов осуществления предназначено для иллюстрации, а не для ограничения объема формулы изобретения, и для специалистов в данной области техники будут очевидны многие альтернативы, модификации и варианты.
ЛИТЕРАТУРА
[1] Kashif Ahmad and Nicola Conci, 'How deep features have improved event recognition in multimedia: A survey', ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM), 15(2), 39(2019).
[2] Kashif Ahmad, Nicola Conci, Giulia Boato, and Francesco GB De Natale, 'Event recognition in personal photo collections via multiple instance learning-based classification of multiple images', Journal of Electronic Imaging, 26(6), 060502, (2017).
[3] Wesam M Ashour, Riham Z Muqat, Alaaeddin В AlQazzaz, and Saeb R AbdElnabi, 'Improve basic sequential algorithm scheme using ant colony algorithm', in Proceedings of the 7th Palestinian International Conference on Electrical and Computer Engineering (PICECE), pp. 1-6. IEEE, (2019).
[4] Siham Bacha, Mohand Said Allili, and Nadjia Benblidia, 'Event recognition in photo albums using probabilistic graphical models and feature relevance', Journal of Visual Communication and Image Representation, 40, 546-558, (2016).
[5] Lukas Bossard, Matthieu Guillaumin, and Luc Van Gool, 'Event recognition in photo collections with a stopwatch HMM', in Proceedings of the International Conference on Computer Vision (ICCV), pp. 1193-1200. IEEE, (2013).
[6] Xinpeng Chen, Lin Ma, Wenhao Jiang, Jian Yao, and Wei Liu, 'Regularizing rnns for caption generation by reconstructing the past with the present', in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2018).
[7] Francois Chollet, Deep learning with Python, Manning Publications Company, 2017.
[8] Minh-Son Dao, Due-Tien Dang-Nguyen, and Francesco GB De Natale, 'Signature-image-based event analysis for personal photo albums', in Proceedings of the 19th International Conference on Multimedia (ACM MM), pp. 1481-1484. ACM, (2011).
[9] Sergio Escalera, Junior Fabian, Pablo Pardo, Xavier Baro, Jordi Gonzalez, Hugo J Escalante, Dusan Misevic, Ulrich Steiner, and Isabelle Guyon, 'Chalearn looking at people 2015: Apparent age and cultural event recognition datasets and results', in Proceedings of the International Conference on Computer Vision Workshops (ICCVW), pp. 1-9,(2015).
[10] Ming Geng, Yukun Li, and Fenglian Liu, 'Classifying personal photo collections: an event-based approach', in Proceedings of the Asia- Pacific Web (APWeb) and Web-Age Information Management (WAIM) Joint International Conference on Web and Big Data, pp. 201-215. Springer, (2018).
[11] Ian Goodfellow, Yoshua Bengio, and Aaron Courville, Deep learning, MIT Press, 2016.
[12] Ivan Grechikhin and Andrey V Savchenko, 'User modeling on mobile device based on facial clustering and object detection in photos and videos', in Proceedings of the Iberian Conference on Pattern Recognition and Image Analysis, pp. 429-440. Springer, (2019).
[13] Cong Guo, Xinmei Tian, and Tao Mei, 'Multigranular event recognition of personal photo albums', IEEE Transactions on Multimedia, 20(7), 1837-1847, (2017).
[14] MD Hossain, Ferdous Sohel, Mohd Fairuz Shiratuddin, and Hamid Laga, 'A comprehensive survey of deep learning for image captioning', ACM Computing Surveys (CSUR), 51(6), 118, (2019).
[15] Andrew G Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, and Hartwig Adam, 'MobileNets: Efficient convolutional neural networks for mobile vision applications', arXivpreprint arXiv: 1704.04861,(2017).
[16] Dmitry Kuzovkin, Tania Pouli, Olivier Le Meur, Remi Cozot, Jonathan Kervec, and Kadi Bouatouch, 'Context in photo albums: Understanding and modeling user behavior in clustering and selection', ACM Transactions on Applied Perception (TAP), 16(2), 11,(2019).
[17] Stefan Lonn, Petia Radeva, and Mariella Dimiccoli, 'Smartphone picture organization: A hierarchical approach', Computer Vision and Image Understanding, 187, 102789, (2019).
[18] Jiasen Lu, Jianwei Yang, Dhruv Batra, and Devi Parikh, 'Neural baby talk', in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2018).
[19] Junhua Mao, Wei Xu, Yi Yang, Jiang Wang, and Alan L. Yuille, 'Deep captioning with multimodal recurrent neural networks (m-RNN)', in Proceedings of the International Conference on Learning Representations (ICLR), (2015).
[20] Alexandr Rassadin and Andrey Savchenko, 'Scene recognition in user preference prediction based on classification of deep embeddings and object detection', in Proceedings of the International Symposium on Neural Networks (ISNN), volume 11555, pp. 422-430. Springer, (2019).
[21] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun, 'Faster R- CNN: Towards real-time object detection with region proposal networks', in Advances in Neural Information Processing Systems (NIPS), pp. 91-99, (2015).
[22] Mark Sandier, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, and Liang-Chieh Chen, 'MobilenetV2: Inverted residuals and linear bottlenecks', in Proceedings of the International Conference on Computer Vision and Pattern Recognition (CVPR), pp. 4510-4520, (2018).
[23] Mark Sandier, Andrew G. Howard, Menglong Zhu, Andrey Zhmoginov, and Liang-Chieh Chen, 'Mobilenetv2: Inverted residuals and linear bottlenecks', in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, June 18-22, 2018, pp. 4510-4520, (2018).
[24] Andrey V. Savchenko, 'Efficient facial representations for age, gender and identity recognition in organizing photo albums using multi-output ConvNet', PeerJ Computer Science, 5(el97), (2019).
[25] Andrey V. Savchenko, 'Sequential three-way decisions in multi-category image recognition with deep features based on distance factor', Information Sciences, 489, 18-36, (2019).
[26] Andrey V Savchenko, Kirill V Demochkin, and Ivan S Grechikhin, 'User preference prediction in visual data on mobile devices', arXiv preprint arXiv: 1907.04519, (2019).
[27] Anastasiia D Sokolova, Angelina S Kharchevnikova, and Andrey V Savchenko, 'Organizing multimedia data in video surveillance systems based on face verification with convolutional neural networks', in Proceedings of the International Conference on Analysis of Images, Social Networks and Texts (AIST), pp. 223-230. Springer, (2017).
[28] Christian Szegedy, Sergey Ioffe, Vincent Vanhoucke, and Alex A. Alemi, 'Inception-v4, Inception-ResNet and the impact of residual connections on learning', in Proceedings of the International Conference on Learning Representations (ICLR) Workshop, (2016).
[29] Shen-Fu Tsai, Thomas S Huang, and Feng Tang, 'Album-based object-centric event recognition', in Proceedings of the International Conference on Multimedia and Expo, pp. 1-6. IEEE, (2011).
[30] Nivetha Vijayaraju, 'Image retrieval using image captioning', Master's Projects, 687, (2019).
[31] O. Vinyals, A. Toshev, S. Bengio, and D. Erhan, 'Show and tell: Lessons learned from the 20 mscoco image captioning challenge', IEEE Transactions on Pattern Analysis and Machine Intelligence, 39(4), 652-663, (2017).
[32] Limin Wang, Zhe Wang, Yu Qiao, and Luc Van Gool, 'Transferring deep object and scene representations for event recognition in still images', International Journal of Computer Vision, 126(2-4), 390-409, (2018).
[33] Yufei Wang, Zhe Lin, Xiaohui Shen, Radomir Mech, Gavin Miller, and Garrison W Cottrell, 'Recognizing and curating photo albums via event-specific image importance', in Proceedings of British Conference on Machine Vision (BMVC), (2017).
[34] Zifeng Wu, Yongzhen Huang, and Liang Wang, 'Learning representative deep features for image set analysis', IEEE Transactions on Multimedia, 17(11), 1960-1968, (2015).
[35] Yuanjun Xiong, Kai Zhu, Dahua Lin, and Xiaoou Tang, 'Recognize complex events from static images by fusing deep channels', in Proceedings of the International Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1600-1609, (2015).
[36] Kelvin Xu, Jimmy Lei Ba, Ryan Kiros, Kyunghyun Cho, Aaron Courville, Ruslan Salakhutdinov, Richard S. Zemel, and Yoshua Bengio, 'Show, attend and tell: Neural image caption generation with visual Внимание', in Proceedings of the
International Conference on International Conference on Machine Learning (ICML), pp. 2048-2057, (2015).30
[37] J. Yang, P. Ren, D. Zhang, D. Chen, F. Wen, H. Li, and G. Hua, 'Neural aggregation network for video face recognition', in Proceedings of the International Conference on Computer Vision and Pattern Recognition (CVPR), pp. 5216-5225. IEEE, (2017).
[38] Bolei Zhou, Agata Lapedriza, Aditya Khosla, Aude Oliva, and Antonio Torralba, 'Places: A million image database for scene recognition', IEEE Transactions on Pattern Analysis and Machine Intelligence, 40(6), 1452-1464, (2018).
| название | год | авторы | номер документа |
|---|---|---|---|
| ОДНОВРЕМЕННОЕ РАСПОЗНАВАНИЕ АТРИБУТОВ ЛИЦ И ИДЕНТИФИКАЦИИ ЛИЧНОСТИ ПРИ ОРГАНИЗАЦИИ ФОТОАЛЬБОМОВ | 2018 |
|
RU2710942C1 |
| СПОСОБ ПОЛУЧЕНИЯ НИЗКОРАЗМЕРНЫХ ЧИСЛОВЫХ ПРЕДСТАВЛЕНИЙ ПОСЛЕДОВАТЕЛЬНОСТЕЙ СОБЫТИЙ | 2020 |
|
RU2741742C1 |
| ВЫЧИСЛИТЕЛЬНО ЭФФЕКТИВНОЕ МНОГОКЛАССОВОЕ РАСПОЗНАВАНИЕ ИЗОБРАЖЕНИЙ С ИСПОЛЬЗОВАНИЕМ ПОСЛЕДОВАТЕЛЬНОГО АНАЛИЗА НЕЙРОСЕТЕВЫХ ПРИЗНАКОВ | 2019 |
|
RU2706960C1 |
| СПОСОБ И СИСТЕМА ИЗВЛЕЧЕНИЯ ИМЕНОВАННЫХ СУЩНОСТЕЙ | 2020 |
|
RU2760637C1 |
| СПОСОБЫ И СЕРВЕРЫ ДЛЯ ОБУЧЕНИЯ МОДЕЛИ ОБНАРУЖЕНИЮ СМЕНЫ ДИКТОРА | 2024 |
|
RU2841235C1 |
| Способ получения набора объектов трехмерной сцены | 2019 |
|
RU2803287C1 |
| СПОСОБ И СИСТЕМА ДЛЯ ОПРЕДЕЛЕНИЯ СИНТЕТИЧЕСКИ ИЗМЕНЕННЫХ ИЗОБРАЖЕНИЙ ЛИЦ НА ВИДЕО | 2021 |
|
RU2768797C1 |
| СПОСОБ СОЗДАНИЯ КОМБИНИРОВАННЫХ КАСКАДОВ НЕЙРОННЫХ СЕТЕЙ С ЕДИНЫМИ СЛОЯМИ ИЗВЛЕЧЕНИЯ ПРИЗНАКОВ И С НЕСКОЛЬКИМИ ВЫХОДАМИ, КОТОРЫЕ ОБУЧАЮТСЯ НА РАЗНЫХ ДАТАСЕТАХ ОДНОВРЕМЕННО | 2021 |
|
RU2779408C1 |
| СПОСОБ ОБРАБОТКИ ИЗОБРАЖЕНИЙ С ИСПОЛЬЗОВАНИЕМ АДАПТИВНЫХ ТЕХНОЛОГИЙ НА ОСНОВЕ НЕЙРОСЕТЕЙ И КОМПЬЮТЕРНОГО ЗРЕНИЯ | 2020 |
|
RU2744769C1 |
| СЕГМЕНТАЦИЯ ТКАНЕЙ ЧЕЛОВЕКА НА КОМПЬЮТЕРНОМ ИЗОБРАЖЕНИИ | 2017 |
|
RU2654199C1 |


Изобретение относится к способам обработки и анализа изображений и может быть использовано для организации фотогалереи в мобильных системах. Техническим результатом является обеспечение улучшения точности распознавания событий посредством объединения последовательно снятых фотографий в альбомы со сходным содержанием с последующей классификацией каждого альбома на основе нейронного механизма внимания. Предложен способ распознавания событий на фотографиях с автоматическим выделением альбомов. Согласно способу автоматически присваивают границы альбомов, оценивая сходство между степенями уверенности для каждой пары последовательных фотографий в галерее, при этом сходство между фотографиями вычисляют как расстояние между степенями уверенности для каждого типа события, оцененного с помощью классификации каждой фотографии, или сходство между фотографиями вычисляют как сумму сходств между степенями уверенности для каждого типа события, оцененного на основе классификации каждой фотографии, и сходства между их местоположениями, если данные EXIF (Exchangeable Photo File Format) этих фотографий содержат информацию о местоположении. 2 н. и 9 з.п. ф-лы, 5 ил., 7 табл.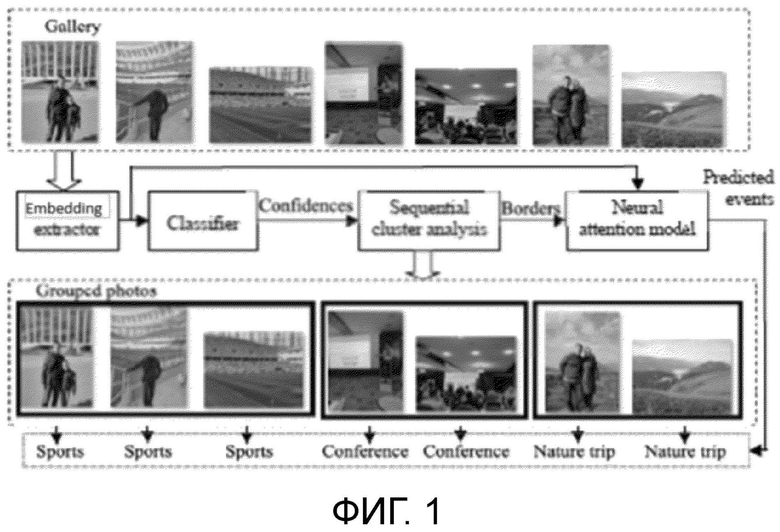
1. Способ распознавания событий на фотографиях с автоматическим выделением альбомов, заключающийся в том, что:
автоматически присваивают границы альбомов, оценивая сходство между степенями уверенности для каждой пары последовательных фотографий в галерее, при этом сходство между фотографиями вычисляют как расстояние между степенями уверенности для каждого типа события, оцененного с помощью классификации каждой фотографии, или сходство между фотографиями вычисляют как сумму сходств между степенями уверенности для каждого типа события, оцененного на основе классификации каждой фотографии, и сходства между их местоположениями, если данные EXIF (Exchangeable Photo File Format) этих фотографий содержат информацию о местоположении;
группируют последовательные фотографии из галереи в альбомы;
вычисляют дескриптор каждого альбома с помощью механизма внимания нейронной модели внимания, которая предсказывает один класс событий для набора фотографий, при этом предсказанный класс присваивается всем фотографиям между упомянутыми границами;
распознают тег типа события каждого альбома путем подачи его дескриптора на вход классификатора;
распознают событие на фотографиях в галерее путем присвоения соответствующего тега типа события всем фотографиям в каждом альбоме.
2. Способ по п.1, причем оценивают, если сходство не превышает заданный порог, то обе фотографии включают в один и тот же альбом.
3. Способ по п.2, в котором заданный порог вычисляют автоматически во время процедуры предварительного обучения, используя предоставленный обучающий набор альбомов.
4. Способ распознавания события на фотографии с ее представлением в текстовой области, заключающийся в том, что:
вычисляют векторные представления фотографии путем подачи ее RGB (красный-зеленый-синий) представления на вход сверточной нейронной сети;
автоматически составляют подписи к изображению для генерации текстовых описаний фотографии на основе ее векторных представлений, при этом текстовое описание фотографии генерируют следующим образом: подают извлеченные векторные представления и последовательность ранее сгенерированных слов в рекуррентную нейронную сеть (RNN) для прогнозирования следующего слова в текстовом описании фотографии;
выбирают подмножество словаря путем выбора наиболее часто встречающихся слов в обучающих данных с необязательным исключением стоп-слов;
кодируют сгенерированную подпись;
подают сгенерированные текстовые описания на вход классификатора событий;
распознают событие путем присвоения выхода классификатора событий тегу соответствующей фотографии.
5. Способ по п.4, в котором сгенерированную подпись кодируют как разреженный вектор с помощью унитарного кодирования текстового описания фотографии: v-й компонент вектора равен 1, только если сгенерированная подпись содержит по меньшей мере одно v-е слово из словаря.
6. Способ по п.5, в котором дополнительно объединяют выходы классификатора для сгенерированных текстовых описаний и традиционного классификатора векторных представлений в ансамбль для повышения точности распознавания событий.
7. Способ по п.6, в котором выходы классификаторов получают следующим образом:
вычисляют оценки степени уверенности для всех типов событий для фотографии путем подачи ее векторных представлений в произвольный классификатор;
вычисляют оценки степени уверенности для всех типов событий для фотографии путем подачи разреженного вектора унитарно кодированного текстового описания в произвольный классификатор;
объединяют выходы классификаторов для векторных представлений и текстов в ансамбле на основе простого голосования с мягким агрегированием.
8. Способ по п.4, в котором дополнительно добавляют спрогнозированное слово в эту последовательность ранее сгенерированных слов и подают извлеченные визуальные векторные представления и эту последовательность в одну и ту же RNN.
9. Способ по п.4, в котором обучающая выборка представляет собой набор фотографий с известным типом события.
10. Способ по п.6, в котором следует предварительно обучить традиционный классификатор распознаванию событий в обучающей выборке, в которой каждая фотография представлена вместе с ее извлеченными визуальными векторными представлениями.
11. Способ по п.7, в котором, в частности, агрегированные степени уверенности вычисляют как взвешенную сумму оценок степеней уверенности и решение принимают в пользу класса с максимальной агрегированной степенью уверенности.
| US 10452905 B2, 22.10.2019 | |||
| US 6324532 B1, 27.11.2001 | |||
| CN 110168573 A, 23.08.2019 | |||
| Станок для придания концам круглых радиаторных трубок шестигранного сечения | 1924 |
|
SU2019A1 |
| АВТОМАТИЧЕСКОЕ ГЕНЕРИРОВАНИЕ ТЕГА НА ОСНОВАНИИ СОДЕРЖАНИЯ ИЗОБРАЖЕНИЯ | 2012 |
|
RU2608261C2 |
| ПОИСК ИЗОБРАЖЕНИЙ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2015 |
|
RU2688271C2 |

