Изобретение относится к области методов (способов) оценки действительности документа при помощи локализации на цифровом изображении документа и оптического распознавания текста оттиска печати/штампа.
Из уровня техники известны различные методы/способы оценки действительности документа, например, которые могут сопоставляться: с некоторыми не зависящими от конкретного документа эталонными значениями или с другими (полученными оптическим распознаванием содержания документа) реквизитами документа.
Например, известны устройство и способ для автоматической идентификации и проверки документа (см. заявку US 20050229010 А1, опубл. 13.10.2005). При этом используются общие принципы систем распознавания с использованием «поиска цветов или других характеристик в определенных местах документа». Существенным недостатком заявки является отсутствие пригодных для реализации методов выявления конкретных характеристик изображений документов, которые могут использоваться для проверки документов.
Из патента US 9576272 В2 (опубл. 21.02.2017), известен способ захвата изображения и проверки подлинности документа на основе сравнения некоторых или всех извлеченных при помощи методов оптического распознавания текста (OCR) данных, представляющих интерес, со справочной информацией. Таким образом, суть изобретения состоит в использовании результатов распознавания для проверки подлинности документа, при этом конкретные особенности распознаваемого текста, как и методы достижения достаточного для потребителя качества распознавания не рассматриваются. Поскольку известно, что методы оптического распознавания текста существенным образом опираются на базовые предположения о геометрических, яркостных и цветовых характеристиках изображений исходного текста, то существенное отличие геометрических и цветовых характеристик текста на печати приводит к невозможности его распознавания обычными средствами оптического распознавания текста.
Из патента US 6351550 В1 (опубл. 26.02.2002), известно устройство для локализации и проверки цифрового изображения цветного оттиска печати на рыночных ценных бумагах, таких как векселя или чеки, для проведения проверки оттиска печати при помощи сравнения с зарегистрированным эталонным изображением. Для детектирования области оттиска печати на изображении используется заранее сохраненная информация о цвете и размере печати. При этом метод допускает наличие находящейся в пределах предварительно определенного порогового значения степень отличия по этим характеристикам. Задетектированная область изображения документа сравнивается с эталонным изображениям при помощи масок с учетом возможной деградации оттиска на документе.
Из патента RU 2556461 С2 (опубл. 10.07.2015), известен способ автоматизированного поиска на цифровом изображении заранее заданных эталонных круглых печатей. Способ включает в себя использование каскадных классификаторов и предусматривает выполнение следующих операций: сбор коллекции различных изображений как содержащих круглые печати, так и не содержащих круглые печати; обучение каскадных классификаторов на собранных коллекциях изображений; преобразование в заранее заданный формат всех изображений эталонных печатей, заданных пользователем; сохранение преобразованных изображений печатей на запоминающем устройстве; выявление областей в электронном файле анализируемого документа, где предположительно может располагаться печать; сравнение найденных областей с заранее заданными эталонами; формирование результата, состоящего из эталонов, найденных в анализируемом документе. Алгоритм состоит из двух основных шагов: 1. детекция - на изображении документа ищутся области (заданные окнами - ограничивающими квадратами), похожие на круглую печать; 2. классификация - найденные «подозрительные» области сравниваются с загруженными пользователем эталонами печатей. Поскольку сравнивать напрямую результат детекции и эталонные изображения нельзя (оттиск печати может быть повернут, а также слегка смещен и отмасштабирован), поэтому для оценки близости двух изображений используется преобразование Фурье-Меллина.
Описываемые в патентах US 6351550 В1 и RU 2556461 С2 устройства предназначены для локализации положения оттиска печати на изображении документа и сравнения изображения в локализованной области с заранее известным эталонным изображением. Данный подход не подходит в ситуации, когда сбор образцов изображений всех проверяемых печатей затруднителен или невозможен. Существенный недостаток данных устройств состоит в обязательном требовании наличия эталонного изображения оттиска печати для проверяемою документа.
Из документа CN 105631447 А (опубл. 01.06.2015), известен метод для извлечения текстового содержимого из изображения круглой печати для повышения эффективности идентификации печатей и обработки документов. Основные шаги метода: локализация печати в виде минимального охватывающего прямоугольника; уточнение центра и радиуса круга при помощи преобразования Хафа; бинаризация зоны печати: вырезание и "распрямление" отдельных иероглифов; оптическое распознавание при помощи универсального модуля отдельных нормализованных изображений иероглифов. Описываемый метод оптического распознавания текста на круглых печатях опираются на определение геометрических характеристик изображения круглого оттиска печати (центр и радиус описанной окружности). Вычисленные параметры используются для геометрической трансформации изображения оттиска печати к такому виду, в котором написанные по дугам окружностей символы "выпрямляются" в горизонтально ориентированные "строки". Изображения строк передаются в универсальный модуль оптического распознавания текста (OCR). Описание изобретения предполагает дальнейшее использование извлеченного из изображения оттиска печати наименования предприятия для повышения эффективности автоматизации бизнес-процессов обработки документов. Существенный недостаток данных методов состоит в использовании бинаризованных изображений на этапах "выпрямления" изображений текстовых строк и оптического распознавания текста. Известно, что для выполненных методами защищенной полиграфии документов фон бланка сильно текстурирован, а методы бинаризации плохо справляются с отделением пикселей оттиска печати от пикселей фона.
Из патента RU 2560789 С1 (опубл. 20.08.2015), известно, что для распознавания и идентификации оттиска печати в изображении документа используют метод преобразования растрового изображения оттиска в характеристический вектор признаков и установление идентичность изображения объекта одной из эталонных печатей путем распознавания на основе метода опорных векторов. Существенный недостаток описываемого в источнике подхода состоит в том, что для изображения исследуемого оттиска с применением метода опорных векторов производят классифицирование ЦИ печатей на Ζ классов-эталонов. Таким образом, в обязательном требованием этого подхода является наличия полного набора эталонных изображений оттиска печати для проверяемого документа.
Все перечисленные выше технические решения не могут быть использованы для проверки действительности документа путем сверки текстового содержания печати с эталонными текстовыми значениями, поскольку не содержат описания требующихся для такой проверки этапов получения эталонных текстовых значений и непосредственно самой процедуры сверки.
Задача заявленного способа заключается в устранении недостатков известного уровня техники. Заявленный способ оценки действительности документа при помощи оптического распознавания текста на изображении круглого оттиска печати/штампа на цифровом изображении документа описывает конкретный способ метод оценки действительности документа при помощи локализации на цифровом изображении документа и оптического распознавания текста оттиска печати/штампа и позволяет достигать необходимых технологических и пользовательских характеристик за счет совокупности методов и приемов, не описанных в таком сочетании в других источниках.
Технический результат заключается в обеспечении способа оценки действительности документа при помощи оптического распознавания текста на изображении круглого оттиска печати/штампа на цифровом изображении документа, который обладает высоким быстродействием, повышенным качеством результатов оптического распознавания и повышенной надежностью.
Заявленный способ включает следующие этапы.
1. Захват изображения документа.
Источником изображения может являться сканер, мобильное устройство, web-камера или иное устройство, использующее сканирующее устройство или малоформатную цифровую камеру для получения изображения документа.
Результатом этапа является захваченное цветное или серое изображение документа.
2. Классификация документа и нормализация его изображения.
Определяются факт наличия, тип документа и положение документа на захваченном изображении. Исходя из найденного положения документа в соответствии с его типом проводится геометрическая нормализацию изображения документа. Одновременно с исправлением геометрических искажений, могут нормализоваться яркостные, цветовые и иные искажения, появившиеся в процессе съемки и оцифровки.
Результатами этапа являются: 1. описание тина документа; 2. нормализованное (в соответствии с типом документа) изображение документа (его страницы).
Если захваченное изображение не содержит изображения документа известного типа и/или проведение процедуры нормализации не представляется возможным, то завершение работы.
3. Локализация оттиска печати.
На нормализованном изображении документа детектируется точное положение изображения оттиска печати. Например, для круглых печатей положение может описываться минимальным охватывающим прямоугольником или центром и радиусом окружности.
В качестве метода детекции точного положения печати могут использоваться следующие подходы:
1. Обобщенное преобразование Хафа. Для каждой точки на изображении существует конечное множество окружностей, которым она может принадлежать. Тогда, т.к. окружность задается тремя параметрами (координатами центра и радиусом), введя трехмерный массив (аккумулятор), можно провести процедуру голосования, где каждая точка голосует за все окружности, которым она может принадлежать, победителей которой можно объявить истинными окружностями, соответствующими положениям печатей.
2. Метод Виолы-Джонса. Данный метод позволяет с помощью техники машинного обучения построить бинарный классификатор, который с помощью метода скользящего окна используется для решения задачи локализации искомого объекта.
3. Аппроксимация компонент связности краев изображения фигурами искомой формы. На бинарном изображении, являющемся результатом работы детектора Канни, можно выделить группы пикселей, транзитивно соседствующих друг с другом по одному из 8-ми направлений. Такие множества будем называть треками. Если на исходном изображении были печати, то соответствующие треки будут похожи на дугу окружности. Поиск и анализ таких треков позволяет локализовать печати на исходном изображении.
Результатом этапа является описание геометрического положения оттиска печати на нормализованном изображении документа.
Если область оттиска печати не найдена, то завершение работы.
4. Оптическое распознавание содержания печати.
4.1. Нормализация изображения текстовой строки.
Для применения методов оптического распознавания текста к изображению печати зона текста геометрически нормализуется: происходит "разворот'' круглой (круговой) полосы печати на изображении В в прямоугольник (см. фиг.1, 2, 3).
Пусть заданы предполагаемый радиус печати R_pred, желаемый отступ от края печати indent, ширина вырезаемой полосы strip и необходимая высота итогового "развернутого" прямоугольника H_unwrap, координаты центра C_stamp (С_(х),С_у).
Ширина "развернутого" прямоугольника рассчитывается так (в соответствии с длиной окружности радиуса (R_pred-indent): W_unwrap=2*π*(R_pred-indent).
Далее для каждой точки "развернутого" изображения рассчитывается соответствуюшая ей точка исходного. Пусть идет расчет координат точки Ρ_src соответствующей точке "развернутого" изображения Ρ_dst (row,col). Порядок вычислений следующий:
Вычисляют расстояние от P_src до внешней окружности вырезаемой полосы:
distance2strip_border=strip*(1.0 - row/H_unwrap)
Вычисляют расстояние от P_src до внешней окружности печати:
distance2stamp_border=indent+distance2strip_border
Вычисляют расстояние от P_src до центра печати C_stamp
distance2center=R_pred-distance2stamp_border
Вычисляют угол между горизонталью и отрезком 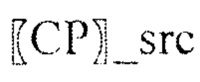 по часовой стрелке:
по часовой стрелке:
α=2*π*(1 - coI/W_unwrap)
Вычисляют координаты сдвиги Ρ_src посчитав сдвиги вдоль осей координат Ρ_src от центра печати:
x=С_(x) - distance2center*cos(α)
у=С_(у) - distance2center*sin(α)
Таким образом, точке P_dst (row,col) соответствует точка P_src (х,у).
Результатом является изображение С.
4.2. Поиск области кода подразделения.
Поиск области кода подразделения по шаблону ХХХ-ХХХ с помощью алгоритма Виола-Джонса на изображении С.Формула Результатом являются координаты прямоугольника кода подразделения. Вырезание этого прямоугольника и получение изображения D.
Если область кода подразделения не найдена, соединяем концы изображения С и обрезаем. Результатом является изображения Е.
с) Повторный поиск области кода подразделения по шаблону с помощью алгоритма Виола-Джонса на изображении Е. Результатом являются координаты прямоугольника кода подразделения. Вырезание этого прямоугольника и получение изображения F.
Если область кода подразделения не найдена, то выход из алгоритма.
4.3. Распознавание кода подразделения.
Распознавание кода подразделения на изображении производят с помощью оптического распознавания символов. Результатом является текстовая строка с альтернативами и оценками распознавания, также называемая матрицей альтернатив или АΡ-цепь. Происходит следующим образом: распознаваемая зона (строка) обладает массивом точек разрезания x0, x1, …, xΝ. Для каждой из пар точек xi и xj образ символа распознается методом, дающим штрафную оценку r(xi, xj). Для путей τ, являющихся подмножеством исходного набора отрезков разрезания, подсчитывается мера m(τ) как наименьшая из оценок пар соседних точек разрезания r(xi, xi+1). Целью является нахождение пути с максимальной оценкой m(τ). Оптимальный путь определяется с помощью динамического программирования, опирающегося в каждом отрезке на уже построенные оптимальные пути в промежуточные точки, этим достигается построение оптимального пути, ведущего из начальной точки зоны сегментации в ее конечную точку за один проход.
На фиг.4 отображен пример матрицы альтернатив (АР-цепи), соответствующей изображению номера.
4.4. Постпроцессинг полученного результата.
Для распознаваемой строки предварительно по ее шаблону задается синтаксическая диаграмма. Далее ищется оптимальный путь на АР-цепи. Результатом является текстовое значение Т собранное из текстовых значений приписанных вершинам оптимального пути.
На фиг.5 отображен пример синтаксической диаграммы соответствующая искомому коду подразделения на паспорте РФ.
4.5. Приведение текстового значения к стандартной заданной форме.
Результатом является финальная текстовая строка кода подразделения в заданном формате.
5. Оптическое распознавание содержания документа.
В соответствии с типом документа и его описанием производится оптическое распознавание содержания документа.
Результатом является текстовое содержание реквизитов.
6. Оценка соответствия текста печати реквизитам документа.
В соответствии с типом документа и его описанием производят сопоставление текстовою содержания печати (получено в п. 4) с текстовым содержимым документа (получено в п. 5). Результатами этапа являются: 1. оценка соответствия текста печати и содержимого документа с точки зрения достоверности документа; 2. уровень достоверности такой оценки.
7. Вывод результата.
Обрабатывают результаты проверки действительности документа по его изображению в соответствии с логикой и настройками прикладной системы, совершив необходимые действия.
Например, по результатам сравнения итоговой интегральной оценки действительности документа с пороговым значением производят сигнализацию пользователю о действительности или недействительности документа.
| название | год | авторы | номер документа |
|---|---|---|---|
| ВЫЯВЛЕНИЕ СНИМКОВ ЭКРАНА НА ИЗОБРАЖЕНИЯХ ДОКУМЕНТОВ | 2014 |
|
RU2595557C2 |
| СПОСОБ РАСПОЗНАВАНИЯ ТЕКСТА НА ИЗОБРАЖЕНИЯХ ДОКУМЕНТОВ | 2021 |
|
RU2768544C1 |
| КЛАССИФИКАЦИЯ ИЗОБРАЖЕНИЙ ДОКУМЕНТОВ НА ОСНОВАНИИ КОНТЕНТА | 2014 |
|
RU2571545C1 |
| СПОСОБ ФАКСИМИЛЬНОГО РАСПОЗНАВАНИЯ И ВОСПРОИЗВЕДЕНИЯ ТЕКСТА ПЕЧАТНОЙ ПРОДУКЦИИ | 2003 |
|
RU2260208C2 |
| СРАВНЕНИЕ ДОКУМЕНТОВ С ИСПОЛЬЗОВАНИЕМ ДОСТОВЕРНОГО ИСТОЧНИКА | 2014 |
|
RU2597163C2 |
| УСТРОЙСТВО И СПОСОБ ПОИСКА РАЗЛИЧИЙ В ДОКУМЕНТАХ | 2013 |
|
RU2571378C2 |
| ВВОД ДАННЫХ ИЗ СЕРИИ ИЗОБРАЖЕНИЙ, СООТВЕТСТВУЮЩИХ ШАБЛОННОМУ ДОКУМЕНТУ | 2016 |
|
RU2634192C1 |
| АВТОМАТИЗИРОВАННЫЕ СПОСОБЫ И СИСТЕМЫ ВЫЯВЛЕНИЯ НА ИЗОБРАЖЕНИЯХ, СОДЕРЖАЩИХ ДОКУМЕНТЫ, ФРАГМЕНТОВ ИЗОБРАЖЕНИЙ ДЛЯ ОБЛЕГЧЕНИЯ ИЗВЛЕЧЕНИЯ ИНФОРМАЦИИ ИЗ ВЫЯВЛЕННЫХ СОДЕРЖАЩИХ ДОКУМЕНТЫ ФРАГМЕНТОВ ИЗОБРАЖЕНИЙ | 2016 |
|
RU2647670C1 |
| СПОСОБ ИДЕНТИФИКАЦИИ ПЕЧАТИ НА ЦИФРОВОМ ИЗОБРАЖЕНИИ | 2014 |
|
RU2560789C1 |
| Сохранение контента в конвертированных документах | 2014 |
|
RU2648636C2 |


Изобретение относится к оптическому распознаванию текста. Технический результат - повышение быстродействия, качества и надежности оптического распознавания оттиска печати/штампа. Зона текста в изображении геометрически нормализуется: происходит "разворот" круглой полосы печати на изображении В в прямоугольник, получают изображение С, где производят поиск области кода подразделения по шаблону ХХХ-ХХХ с помощью алгоритма Виола-Джонса, получают координаты прямоугольника кода подразделения, производят его вырезание, получают изображения D, если область кода подразделения не найдена, соединяют концы изображения С и обрезают, получают изображения Н, производят повторный поиск области кода подразделения, получают координаты прямоугольника кода подразделения, производят его вырезание, получают изображения F, распознавание кода подразделения производят с помощью оптическою распознавания символов, результатом является текстовая строка с альтернативами и оценками распознавания, при постпроцессинге полученного результата для распознаваемой строки предварительно по ее шаблону задают синтаксическую диаграмму, далее ищут оптимальный путь на АР-цепи, результатом является текстовое значение Τ, собранное из текстовых значений приписанных вершинам оптимального пути. 5 ил.
Способ оценки действительности документа при помощи оптического распознавания текста на изображении круглого оттиска печати/штампа на цифровом изображении документа, заключающийся в том, что производят захват изображения документа, получают захваченное цветное или серое изображение документа,
производят классификацию документа и нормализацию его изображения, при этом определяют факт наличия, тип документа и положение документа на захваченном изображении исходя из найденного положения документа в соответствии с его типом проводят геометрическую нормализацию изображения документа,
производят локализацию оттиска печати, при этом на нормализованном изображении документа детектируют точное положение изображения оттиска печати,
производят оптическое распознавание содержания печати, которое включает нормализацию изображения текстовой строки, поиск области кода подразделения, распознавание кода подразделения, постпроцессинг полученного результата, приведение текстовою значения к стандартной заданной форме,
при этом при нормализации изображения текстовой строки для применения методов оптическою распознавания текста к изображению печати, зона текста геометрически нормализуется: происходит "разворот" круглой (круговой) полосы печати на изображении В в прямоугольник и в результатом получают изображение С,
при этом при поиске области кода подразделения по шаблону ХХХ-ХХХ производят с помощью алгоритма Виола-Джонса на изображении С, результатом являются координаты прямоугольника кода подразделения, производят вырезание этого прямоугольника и получение изображения D, при этом если область кода подразделения не найдена, соединяют концы изображения С и обрезают, результатом является изображения Е, производят повторный поиск области кода подразделения по шаблону с помощью алгоритма Виола-Джонса на изображении Е, результатом являются координаты прямоугольника кода подразделения, производят вырезание этого прямоугольника и получают изображения F,
при этом распознавание кода подразделения на изображении производят с помощью оптического распознавания символов, результатом является текстовая строка с альтернативами и оценками распознавания,
при этом при постпроцессинге полученного результата, для распознаваемой строки предварительно по ее шаблону задают синтаксическую диаграмму, далее ищут оптимальный путь на АР-цепи, результатом является текстовое значение Т, собранное из текстовых значений, приписанных вершинам оптимального пути,
при этом при приведении текстового значения к стандартной заданной форме, результатом является финальная текстовая строка кода подразделения в заданном формате,
производят оптическое распознавание содержания документа в соответствии с типом документа и его описанием, результатом является текстовое содержание реквизитов,
производят оценку соответствия текста печати реквизитам документа, при этом в соответствии с типом документа и его описанием производят сопоставление ранее полученного текстового содержания печати с ранее полученным текстовым содержимым документа,
при этом результатами являются: оценка соответствия текста печати и содержимого документа с точки зрения достоверности документа и уровень достоверности такой оценки,
производят вывод результата посредством обработки результатов проверки действительности документа по его изображению.
| CN 105631447 B, 15.02.2019 | |||
| CN 102646193 A, 22.08.2012 | |||
| CN 101162506 A, 16.04.2008 | |||
| CN 111401372 A, 10.07.2020 | |||
| US 9576272 B2, 21.02.2017 | |||
| US 6351550 B1, 26.02.2002 | |||
| СПОСОБ АВТОМАТИЗИРОВАННОГО ПОИСКА ЭТАЛОННЫХ ПЕЧАТЕЙ | 2013 |
|
RU2556461C2 |
| СПОСОБ ИДЕНТИФИКАЦИИ ПЕЧАТИ НА ЦИФРОВОМ ИЗОБРАЖЕНИИ | 2014 |
|
RU2560789C1 |

