ПЕРЕКРЕСТНАЯ ССЫЛКА НА РОДСТВЕННЫЕ ЗАЯВКИ
[0001] По настоящей заявке испрашивается приоритет предварительной заявки на патент США № 62/760262, поданной 13 ноября 2018; предварительной заявки на патент США № 62/795248, поданной 22 января 2019; предварительной заявки на патент США № 62/828038, поданной 2 апреля 2019; и предварительной заявки на патент США № 62/926719, поданной 28 октября 2019, содержание которых включено в настоящей описание посредством ссылки.
ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
[0002] Настоящее раскрытие в целом относится к кодированию звуковой сцены, содержащей звуковые объекты. В частности, оно относится к способам, системам, компьютерным программным продуктам и форматам данных для представления пространственного звука и ассоциированным с ними кодировщику, декодировщику и средству рендеринга для кодирования, декодирования и представления пространственного звука.
УРОВЕНЬ ТЕХНИКИ
[0003] Внедрение высокоскоростного беспроводного доступа к телекоммуникационным сетям 4G/5G в сочетании с доступностью все более мощных аппаратных платформ обеспечило основу для более быстрого и простого развертывания передовых услуг связи и мультимедиа, чем когда-либо прежде.
[0004] Кодек расширенных голосовых услуг (EVS) в рамках проекта партнерства третьего поколения (3GPP) обеспечил весьма значительное улучшение пользовательского опыта благодаря введению сверхширокополосного (SWB) и полнополосного (FB) кодирования речи и звука вместе с повышенной устойчивостью к потере пакетов. Тем не менее, расширенная полоса пропускания звука является лишь одним из параметров, необходимых для действительно полного эффекта погружения. Поддержка, выходящая за рамки моно и мульти-моно, которые в настоящее время предлагает EVS, в идеале необходима для погружения пользователя в убедительный виртуальный мир эффективным в отношении использования ресурсов способом.
[0005] Кроме того, определенные в настоящее время аудиокодеки в 3GPP обеспечивают подходящее качество и сжатие для стереоконтента, но не имеют диалоговых функций (например, достаточно низкой задержки), необходимых для разговорной речи и телеконференций. Этим кодировщикам также не хватает многоканальной функциональности, необходимой для иммерсивных сервисов, таких как потоковое вещание, виртуальная реальность (VR) и иммерсивная телеконференция.
[0006] Расширение кодека EVS было предложено для иммерсивных голосовых и аудиосервисов (IVAS), чтобы заполнить этот технологический пробел и удовлетворить растущий спрос на многофункциональные мультимедийные услуги. Кроме того, приложения для телеконференций через 4G/5G выиграют от использования кодека IVAS в качестве улучшенного диалогового кодировщика, поддерживающего многопоточное кодирование (например, звука на основе каналов, объектов и сцен). Сценарии использования этого кодека следующего поколения включают, помимо прочего, голос при разговоре, многопоточную телеконференцию, диалоговую виртуальную реальность и создаваемую пользователями потоковую передачу контента в реальном времени и не в реальном времени.
[0007] Хотя цель состоит в разработке единого кодека с привлекательными функциями и производительностью (например, отличное качество звука, низкая задержка, поддержка пространственного кодирования звука, подходящий диапазон скоростей передачи данных, высококачественная устойчивость к ошибкам, сложность практической реализации), в настоящее время отсутствует окончательное соглашение о формате звукового входа кодека IVAS. Формат пространственного звука с поддержкой метаданных (MASA) был предложен в качестве одного из возможных форматов звукового входа. Однако обычные параметры MASA делают определенные идеалистические предположения, например, что захват звука выполняется в одной точке. Однако в реальном сценарии, когда мобильный телефон или планшет используется в качестве устройства для захвата звука, такое предположение о захвате звука в одной точке может не выполняться. Скорее, в зависимости от форм-фактора конкретного устройства, различные микрофоны устройства могут быть расположены на некотором расстоянии друг от друга, и разные захваченные сигналы микрофонов могут не быть полностью синхронизированы по времени. Это особенно верно, когда также учитывается, каким образом источник звука может перемещаться в пространстве.
[0008] Другое предположение, лежащее в основе формата MASA, состоит в том, что все каналы микрофонов предоставлены на одинаковом уровне и что между ними нет различий в частотной и фазовой характеристиках. Опять же, в реальном сценарии каналы микрофонов могут иметь разные частотные и фазовые характеристики, зависящие от направления, и которые также могут зависеть от времени. Можно предположить, например, что устройство захвата звука временно удерживается таким образом, что один из микрофонов закрыт или что поблизости от телефона находится какой-то объект, который вызывает отражения или дифракции приходящих звуковых волн. Таким образом, существует множество дополнительных факторов, которые необходимо учитывать при определении того, какой формат звука подходит для использования с кодеком, таким как кодек IVAS.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0009] Типовые варианты осуществления теперь будут описаны со ссылкой на прилагаемые чертежи, на которых:
[0010] Фиг. 1 представляет собой блок-схему способа представления пространственного звука согласно типовым вариантам осуществления;
[0011] Фиг. 2 представляет собой схематичную иллюстрацию устройства захвата звука и направленных и диффузных источников звука, соответственно, согласно типовым вариантам осуществления;
[0012] На фиг. 3A показана таблица (таблица 1A) с описанием того, каким образом значение параметра канального бита указывает, сколько каналов используется для формата MASA, согласно типовым вариантам осуществления.
[0013] На фиг. 3B показана таблица (таблица 1B) структуры метаданных, которая может использоваться для представления плоскостного FOA и захвата FOA с понижающим микшированием в два канала MASA согласно типовым вариантам осуществления;
[0014] На фиг. 4 показана таблица (таблица 2) значений компенсации задержки для каждого микрофона и для каждой TF ячейки согласно типовым вариантам осуществления;
[0015] На фиг. 5 показана таблица (таблица 3) структуры метаданных, которая может использоваться для указания, какой набор значений компенсации применяется к какой TF ячейке, согласно типовым вариантам осуществления;
[0016] На фиг. 6 показана таблица (таблица 4) структуры метаданных, которая может использоваться для представления настройки усиления для каждого микрофона согласно типовым вариантам осуществления;
[0017] На фиг. 7 показана система, которая включает в себя устройство захвата звука, кодировщик, декодировщик и средство рендеринга, согласно типовым вариантам осуществления.
[0018] На фиг. 8 показано устройство захвата звука согласно типовым вариантам осуществления.
[0019] На фиг. 9 показаны декодировщик и средство рендеринга согласно типовым вариантам осуществления.
[0020] Все фигуры являются схематичными и обычно показывают только те части, которые необходимы для пояснения раскрытия, тогда как другие части могут быть опущены или их наличие может просто предполагаться. Если не указано иное, одинаковые цифровые обозначения относятся к одинаковым частям на разных фигурах.
ПОДРОБНОЕ ОПИСАНИЕ
[0021] Ввиду вышеизложенного, целью является предоставление способов, систем и компьютерных программных продуктов и формата данных для улучшенного представления пространственного звука. Также предоставляются кодировщик, декодировщик и средство рендеринга для пространственного звука.
I. Обзор - пространственное представление звука
[0022] Согласно первому аспекту предоставлены способ, система, компьютерный программный продукт и формат данных для представления пространственного звука.
[0023] Согласно типовым вариантам осуществления предоставлен способ представления пространственного звука, при этом пространственный звук является комбинацией направленного звука и рассеянного звука, включающий в себя:
- создание одноканального или многоканального звукового сигнала понижающего микширования посредством понижающего микширования входных звуковых сигналов от множества микрофонов в блоке захвата звука, захватывающем пространственный звук;
- определение параметров первых метаданных, ассоциированных со звуковым сигналом понижающего микширования, при этом параметры первых метаданных указывают одно или более из: значения относительной временной задержки, значения усиления и значения фазы, ассоциированных с каждым входным звуковым сигналом; и
- объединение созданного звукового сигнала понижающего микширования и параметров первых метаданных в представление пространственного звука.
[0024] С помощью вышеупомянутой схемы может быть достигнуто улучшенное представление пространственного звука с учетом различных свойств и/или пространственного положения множества микрофонов. Более того, использование метаданных на последующих этапах обработки кодирования, декодирования или рендеринга может способствовать достоверному представлению и восстановлению захваченного звука при представлении звука в эффективной относительно скорости передачи данных кодированной форме.
[0025] Согласно типовым вариантам осуществления, объединение созданного звукового сигнала понижающего микширования и параметров первых метаданных в представление пространственного звука может дополнительно включать в себя включение параметров вторых метаданных в представление пространственного звука, при этом параметры вторых метаданных указывают на конфигурацию понижающего микширования для входных звуковых сигналов.
[0026] Преимущество указанного заключается в том, что оно позволяет восстановить (например, посредством операции повышающего микширования) входные звуковые сигналы в декодировщике. Кроме того, в результате предоставления вторых метаданных дополнительное понижающее микширование может выполняться отдельным блоком перед кодированием представления пространственного звука в битовый поток.
[0027] Согласно типовым вариантам осуществления, параметры первых метаданных могут быть определены для одной или более полос частот входных звуковых сигналов микрофона.
[0028] Преимущество указанного заключается в том, что оно позволяет индивидуально настраивать задержку, коэффициент усиления и/или параметры настройки фазы, например, с учетом различных частотных характеристик для различных диапазонов частот сигналов микрофона.
[0029] Согласно типовым вариантам осуществления понижающее микширование для создания одноканального или многоканального звукового сигнала понижающего микширования x может быть описано следующим образом:
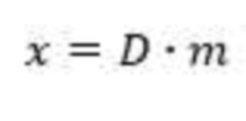
где:
D представляет собой матрицу понижающего микширования, содержащую коэффициенты понижающего микширования, задающие веса для каждого входного звукового сигнала от множества микрофонов, и
M представляет собой матрицу, представляющую входные звуковые сигналы от множества микрофонов.
[0030] Согласно типовым вариантам осуществления, коэффициенты понижающего микширования могут быть выбраны для выбора входного звукового сигнала микрофона, имеющего в текущий момент наилучшее отношение сигнал/шум по отношению к направленному звуку, и для отбрасывания входных звуковых сигналов от любых других микрофонов.
[0031] Преимущество указанного заключается в том, что оно позволяет достичь хорошего качества представления пространственного звука при сниженной сложности вычислений в блоке захвата звука. В этом варианте осуществления выбирается только один входной звуковой сигнал для представления пространственного звука в конкретном аудиокадре и/или частотно-временной ячейке. Следовательно, снижается вычислительная сложность операции понижающего микширования.
[0032] Согласно типовым вариантам осуществления выбор может быть определен на основе частотно-временных (TF) ячеек.
[0033] Преимущество указанного заключается в том, что оно позволяет улучшить операцию понижающего микширования, например, с учетом разных частотных характеристик для разных полос частот микрофонных сигналов.
[0034] Согласно типовым вариантам осуществления, выбор может быть сделан для конкретного аудиокадра.
[0035] Преимущество указанного заключается в том, что оно обеспечивает возможность настройки в отношении изменяющихся во времени сигналов захвата микрофона и, в свою очередь, в отношении улучшения качества звука.
[0036] Согласно типовым вариантам осуществления, коэффициенты понижающего микширования могут быть выбраны для максимизации отношения сигнал/шум по отношению к направленному звуку при объединении входных звуковых сигналов от разных микрофонов.
[0037] Преимущество указанного заключается в том, что оно позволяет повысить качество понижающего микширования за счет ослабления нежелательных компонентов сигнала, которые не исходят от направленных источников.
[0038] Согласно типовым вариантам осуществления, максимизация может выполняться для конкретной полосы частот.
[0039] Согласно типовым вариантам осуществления, максимизация может выполняться для конкретного аудиокадра.
[0040] Согласно типовым вариантам осуществления, определение параметров первых метаданных может включать в себя анализ одного или более из следующего: характеристик задержки, усиления и фазы входных звуковых сигналов от множества микрофонов.
[0041] Согласно типовым вариантам осуществления, параметры первых метаданных могут быть определены на основе частотно-временной (TF) ячейки.
[0042] Согласно типовым вариантам осуществления по меньшей мере часть понижающего микширования может происходить в блоке захвата звука.
[0043] Согласно типовым вариантам осуществления по меньшей мере часть понижающего микширования может происходить в кодировщике.
[0044] Согласно типовым вариантам осуществления, при обнаружении более одного источника направленного звука первые метаданные могут быть определены для каждого источника.
[0045] Согласно типовым вариантам осуществления, представление пространственного звука может включать в себя по меньшей мере один из следующих параметров: индекс направления, отношение прямой энергии к общей; когерентность распространения; время прихода, усиление и фаза для каждого микрофона; отношение рассеянной энергии к общей; объемная когерентность; отношение остатка к общей энергии; и расстояние.
[0046] Согласно типовым вариантам осуществления параметр метаданных параметров вторых или первых метаданных может указывать, генерируется ли созданный звуковой сигнал понижающего микширования из: левых и правых стереосигналов, плоскостных амбиофонических сигналов первого порядка (FOA) или компонентных сигналов FOA.
[0047] Согласно типовым вариантам осуществления, представление пространственного звука может содержать параметры метаданных, организованные в поле определения и поле селектора, при этом в поле определения задан по меньшей мере один набор параметров компенсации задержки, ассоциированный с множеством микрофонов, и в поле селектора задан выбор набора параметров компенсации задержки.
[0048] Согласно типовым вариантам осуществления, в поле селектора может быть указано, какой набор параметров компенсации задержки применяется к произвольной заданной частотно-временной ячейке.
[0049] Согласно типовым вариантам осуществления, значение относительной временной задержки может находиться в приблизительном интервале [-2,0 мс, 2,0 мс].
[0050] Согласно типовым вариантам осуществления, параметры метаданных в представлении пространственного звука могут дополнительно включать в себя поле, задающее применяемую настройку усиления, и поле, задающее настройку фазы.
[0051] Согласно типовым вариантам осуществления, настройка усиления может находиться в приблизительном интервале [+10 дБ, -30 дБ].
[0052] Согласно типовым вариантам осуществления по меньшей мере части элементов первых и/или вторых метаданных определяют в устройстве захвата звука с использованием сохраненных справочных таблиц.
[0053] Согласно типовым вариантам осуществления по меньшей мере части элементов первых и/или вторых метаданных определяют в удаленном устройстве, подключенном к устройству захвата звука.
II. Обзор - система
[0054] Согласно второму аспекту, предоставлена система для представления пространственного звука.
[0055] Согласно типовым вариантам осуществления, предоставлена система для представления пространственного звука, содержащая:
компонент приема, сконфигурированный для приема входных звуковых сигналов от множества микрофонов в блоке захвата звука, захватывающем пространственный звук;
компонент понижающего микширования, сконфигурированный для создания одноканального или многоканального звукового сигнала понижающего микширования посредством понижающего микширования принятых звуковых сигналов;
компонент определения метаданных, сконфигурированный для определения параметров первых метаданных, ассоциированных со звуковым сигналом понижающего микширования, при этом параметры первых метаданных указывают на одно или более из: значения относительной временной задержки, значения усиления и значения фазы, ассоциированных с каждым входным звуковым сигналом; и
компонент объединения, сконфигурированный для объединения созданного звукового сигнала понижающего микширования и параметров первых метаданных в представление пространственного звука.
III. Обзор - формат данных
[0056] Согласно третьему аспекту, предоставлен формат данных для представления пространственного звука. Формат данных может с выгодой использоваться в сочетании с физическими компонентами, относящимися к пространственному звуку, такими как устройства захвата звука, кодировщики, декодировщики, средства рендеринга и т.д., а также с различными типами компьютерных программных продуктов и другого оборудования, которое используется для передачи пространственного звука между устройствами и/или местоположениями.
[0057] Согласно типовым вариантам осуществления, формат данных содержит:
звуковой сигнал понижающего микширования, полученный в результате понижающего микширования входных звуковых сигналов от множества микрофонов в блоке захвата звука, захватывающем пространственный звук; и
параметры первых метаданных, указывающие одно или более из: конфигурации понижающего микширования для входных звуковых сигналов, значения относительной временной задержки, значения усиления и значения фазы, ассоциированных с каждым входным звуковым сигналом.
[0058] Согласно одному из примеров, формат данных хранится в энергонезависимой памяти.
IV. Обзор - кодировщик
[0059] Согласно четвертому аспекту, предоставлен кодировщик для кодирования представления пространственного звука.
[0060] Согласно типовым вариантам осуществления, предоставлен кодировщик, сконфигурированный для:
приема представления пространственного звука, при этом представление содержит:
одноканальный или многоканальный звуковой сигнал понижающего микширования, созданный посредством понижающего микширования входных звуковых сигналов от множества микрофонов в блоке захвата звука, захватывающем пространственный звук, и
параметры первых метаданных, ассоциированные со звуковым сигналом понижающего микширования, при этом параметры первых метаданных указывают одно или более из: значения относительной временной задержки, значения усиления и значения фазы, ассоциированных с каждым входным звуковым сигналом; и
кодирования одноканального или многоканального звукового сигнала понижающего микширования в битовый поток с использованием первых метаданных, или
кодирования одноканального или многоканального звукового сигнала понижающего микширования и первых метаданных в битовый поток.
V. Обзор - декодировщик
[0061] Согласно пятому аспекту, предоставлен декодировщик для декодирования представления пространственного звука.
[0062] Согласно типовым вариантам осуществления, предоставлен декодировщик, сконфигурированный для:
приема битового потока, указывающего кодированное представление пространственного звука, при этом представление содержит:
одноканальный или многоканальный звуковой сигнал понижающего микширования, созданный посредством понижающего микширования входных звуковых сигналов от множества микрофонов в блоке захвата звука, захватывающем пространственный звук, и
параметры первых метаданных, ассоциированные со звуковым сигналом понижающего микширования, при этом параметры первых метаданных указывают одно или более из: значения относительной временной задержки, значения усиления и значения фазы, ассоциированных с каждым входным звуковым сигналом; и
декодирования битового потока в аппроксимацию пространственного звука посредством использования параметров первых метаданных.
VI. Обзор - средство рендеринга
[0063] Согласно шестому аспекту, предоставлено средство рендеринга для выполнения рендеринга представления пространственного звука.
[0064] Согласно типовым вариантам осуществления, предоставлено средство рендеринга, сконфигурированное для:
приема представления пространственного звука, при этом представление содержит:
одноканальный или многоканальный звуковой сигнал понижающего микширования, созданный посредством понижающего микширования входных звуковых сигналов от множества микрофонов в блоке захвата звука, захватывающем пространственный звук, и
параметры первых метаданных, ассоциированные со звуковым сигналом понижающего микширования, при этом параметры первых метаданных указывают одно или более из: значения относительной временной задержки, значения усиления и значения фазы, ассоциированных с каждым входным звуковым сигналом; и
рендеринга пространственного звука с использованием первых метаданных.
VII. Обзор - общее описание
[0065] Аспекты со второго по шестой могут в целом обладать теми же характеристиками и преимуществами, что и первый аспект.
[0066] Другие цели, характеристики и преимущества настоящего изобретения станут очевидными из приведенного ниже подробного описания, из прилагаемых зависимых пунктов формулы изобретения, а также из чертежей.
[0067] Этапы любого раскрытого в настоящем описании способа не обязательно должны выполняться точно в раскрытом порядке, если явно не указано иное.
VIII. Примеры вариантов осуществления
[0068] Как описано выше, захват и представление пространственного звука имеют определенный набор проблем относительного того, чтобы захваченный звук мог быть точно воспроизведен на принимающей стороне. Различные варианты осуществления настоящего изобретения, описанные в настоящем раскрытии, решают различные аспекты этих проблем путем включения различных параметров метаданных вместе со звуковым сигналом понижающего микширования при передаче звукового сигнала понижающего микширования.
[0069] Изобретение будет описано посредством примера и со ссылкой на аудиоформат MASA. Однако важно понимать, что общие принципы изобретения применимы к широкому диапазону форматов, которые могут использоваться для представления звука, и приведенное в настоящем раскрытии описание не ограничивается MASA.
[0070] Кроме того, следует понимать, что параметры метаданных, которые описаны ниже, не являются полным списком параметров метаданных, но могут иметься дополнительные параметры метаданных (или меньшее подмножество параметров метаданных), которые могут использоваться для передачи данных о звуковом сигнале понижающего микширования на различные устройства, применяемые при кодировании, декодировании и рендеринге звука.
[0071] Кроме того, хотя примеры в настоящем раскрытии будут описаны в контексте кодировщика IVAS, следует отметить, что он является только одним из типов кодировщиков, в котором могут применяться общие принципы изобретения, и что может существовать множество других типов кодировщиков, декодировщиков и средств рендеринга, которые могут применяться вместе с различными вариантами осуществления, описанными в настоящем раскрытии.
[0072] Наконец, следует отметить, что хотя термины «повышающее микширование» и «понижающее микширование» используются в настоящем раскрытии, они не обязательно могут означать увеличение и уменьшение, соответственно, количества каналов. Хотя это часто может иметь место, следует понимать, что любой термин может относиться либо к уменьшению, либо к увеличению количества каналов. Таким образом, оба термина подпадают под более общее понятие «микширование». Точно так же, термин «звуковой сигнал понижающего микширования» будет использоваться везде в описании, но следует понимать, что иногда могут использоваться другие термины, такие как «канал MASA», «транспортный канал» или «канал понижающего микширования», все из которых имеют по существу то же значение, что и «звуковой сигнал понижающего микширования».
[0073] Обратимся теперь к фиг. 1; описан способ 100 представления пространственного звука в соответствии с одним из вариантов осуществления. Как видно на фиг. 1, способ начинается с захвата пространственного звука с применением устройства захвата звука, этап 102. На фиг. 2 показан схематический вид звуковой среды 200, в которой устройство 202 захвата звука, такое как сотовый телефон или планшетный компьютер, например, захватывает звук от диффузного источника 204 окружающей среды и направленного источника 206, такого как говорящий. В проиллюстрированном варианте осуществления устройство 202 захвата звука имеет три микрофона m1, m2 и m3, соответственно.
[0074] Направленный звук исходит из направления прихода (DOA), представленного углами азимута и подъема. Предполагается, что диффузный звук окружающей среды является всенаправленным, то есть, пространственно инвариантным или пространственно однородным. В последующем обсуждении также рассматривается возможность появления второго источника направленного звука, который не показан на фиг. 2.
[0075] Затем сигналы от микрофонов подвергаются понижающему микшированию с целью создания одноканального или многоканального звукового сигнала с понижающим микшированием, этап 104. Существует множество причин для распространения только монофонического звукового сигнала с понижающим микшированием. Например, могут присутствовать ограничения скорости передачи данных или намерение сделать высококачественный монофонический звуковой сигнал с понижающим микшированием, доступный после внесения определенных патентованных улучшений, таких как формирование пучка и коррекция или подавление шума. В других вариантах осуществления понижающее микширование дает многоканальный звуковой сигнал понижающего микширования. Как правило, количество каналов в звуковом сигнале понижающего микширования меньше, чем количество входных звуковых сигналов, однако в некоторых случаях количество каналов в звуковом сигнале понижающего микширования может быть равно количеству входных звуковых сигналов, а цель понижающего микширования состоит скорее в том, чтобы добиться повышенного отношения сигнал/шум или уменьшить объем данных в результирующем звуковом сигнале понижающего микширования по сравнению с входными звуковыми сигналами. Это более подробно рассматривается ниже.
[0076] Распространение соответствующих параметров, используемых во время понижающего микширования, на кодек IVAS как часть метаданных MASA может дать возможность восстановить стереосигнал и/или пространственный звуковой сигнал понижающего микширования с наилучшей возможной точностью.
[0077] В этом сценарии единственный канал MASA получают с помощью следующей операции понижающего микширования:
, где
 и
и

[0078] Сигналы m и x могут во время различных этапов обработки не обязательно быть представлены как полнополосные временные сигналы, но, возможно, также как компонентные сигналы различных поддиапазонов во временной или частотной области (TF ячейки). В этом случае они в конечном итоге будут перекомпонованы и, потенциально, преобразованы во временную область, прежде чем будут распространены на кодек IVAS.
[0079] Системы кодирования/декодирования звука обычно разделяют частотно-временное пространство на частотные/временные ячейки, например, посредством применения подходящих блоков фильтров к входным звуковым сигналам. Под частотной/временной ячейкой обычно подразумевается часть частотно-временного пространства, соответствующая полосе частот и временному интервалу. Временной интервал обычно может соответствовать продолжительности временного кадра, используемого в системе кодирования/декодирования звука. Полоса частот представляет собой часть всего диапазона частот звукового сигнала/объекта, который кодируется или декодируется. Полоса частот обычно может соответствовать одной или более смежным полосам частот, задаваемым блоком фильтров, используемым в системе кодирования/декодирования. В случае, если полоса частот соответствует нескольким смежным полосам частот, заданным посредством блока фильтров, это позволяет иметь неоднородные полосы частот в процессе декодирования звукового сигнала понижающего микширования, например, более широкие полосы частот для более высоких частот звукового сигнала понижающего микширования.
[0080] В реализации, использующей один канал MASA, есть по меньшей мере два варианта того, как может быть определена матрица понижающего микширования. Один из вариантов состоит в выборе сигнала микрофона, который имеет наилучшее соотношение сигнал/шум (SNR) в отношении направленного звука. В конфигурации, показанной на фиг. 2, вполне вероятно, что микрофон m1 захватывает наилучший сигнал, поскольку он направлен на направленный источник звука. Тогда сигналы от других микрофонов можно было бы отбросить. В этом случае матрица понижающего микширования может быть следующей:
D = (1 0 0)
[0081] Пока источник звука перемещается относительно устройства захвата звука, можно выбрать другой более подходящий микрофон, чтобы в качестве результирующего канала MASA использовался либо сигнал m2, либо сигнал m3.
[0082] При переключении сигналов микрофонов важно убедиться, что сигнал канала MASA не страдает от каких-либо потенциальных разрывов. Разрывы могут возникать из-за разного времени прихода направленного источника звука на разные микрофоны или из-за разного усиления или фазовых характеристик акустического тракта от источника до микрофонов. Следовательно, отдельные характеристики задержки, усиления и фазы различных микрофонных входов должны быть проанализированы и скомпенсированы. Таким образом, фактические сигналы микрофона могут подвергаться определенной настройке задержки и фильтрации перед понижающим микшированием MASA.
[0083] В другом варианте осуществления коэффициенты матрицы понижающего микширования устанавливают таким образом, чтобы SNR канала MASA по отношению к направленному источнику являлся максимальным. Это может быть достигнуто, например, путем добавления различных сигналов микрофона с правильно отрегулированными весами κ1,1, κ1,2, κ1,3. Для того, чтобы выполнить эту работу эффективным образом, необходимо снова проанализировать и компенсировать индивидуальные характеристики задержки, усиления и фазы различных микрофонных входов, что также можно понимать как формирование акустического пучка в направлении направленного источника.
[0084] Регулировки усиления/фазы можно понимать как операцию частотно-избирательной фильтрации. По существу, соответствующие настройки также могут быть оптимизированы для достижения сокращения акустического шума или усиления направленных звуковых сигналов, например, в соответствии с подходом Винера.
[0085] В качестве дополнительной вариации можно привести пример с тремя каналами MASA. В этом случае матрица понижающего микширования может быть определена следующей матрицей 3 на 3:

[0086] Следовательно, теперь существует три сигнала x1, x2, x3 (вместо одного в первом примере), которые могут быть закодированы с помощью кодека IVAS.
[0087] Первый канал MASA может быть сгенерирован в соответствии с описанным в первом примере. Второй канал MASA может использоваться для передачи второго направленного звука, если он присутствует. Коэффициенты матрицы понижающего микширования затем могут быть выбраны в соответствии с принципами, аналогичными принципам для первого канала MASA, однако, таким образом, чтобы SNR второго направленного звука было максимальным. Коэффициенты матрицы понижающего микширования κ3,1, κ3,2, κ3,3 для третьего канала MASA могут быть настроены для извлечения компонента диффузного звука при минимизации направленных звуков.
[0088] Обычно может выполняться стереозахват доминирующих направленных источников в присутствии некоторого фонового окружающего звука, как показано на фиг. 2 и описано выше. Это может часто происходить в определенных вариантах применения, например, в телефонии. В соответствии с различными вариантами осуществления, описанными в настоящем раскрытии, параметры метаданных также определяют в связи с понижающим микшированием, этап 104, и они впоследствии будут добавляться и распространяться вместе с единичным монофоническим звуковым сигналом понижающего микширования.
[0089] В одном из вариантов осуществления три основных параметра метаданных ассоциированы с каждым захваченным звуковым сигналом: значение относительной временной задержки, значение усиления и значение фазы. В соответствии с общим подходом MASA-канал получают в результате следующих операций:
настройка задержки каждого сигнала микрофона mi (i=1,2) на величину τi= Δτi+τref.
настройка усиления и фазы каждого частотно-временного (TF) компонента/ячейки каждого микрофонного сигнала с регулируемой задержкой с помощью параметра регулировки усиления и фазы, α и φ, соответственно.
[0090] Элемент настройки задержки τi в приведенном выше выражении можно интерпретировать как время прихода плоской звуковой волны со стороны направленного источника, и, таким образом, его также удобно выразить как время прихода относительно времени прихода звуковой волны в контрольной точке τref, например, в геометрическом центре звукового устройства захвата 202, хотя может быть использована любая контрольная точка. Например, при использовании двух микрофонов настройку задержки можно сформулировать как разницу между τ1 и τ2, что эквивалентно перемещению контрольной точки в положение второго микрофона. В одном из вариантов осуществления параметр времени прихода позволяет моделировать относительное время прихода в интервале [-2,0 мс, 2,0 мс], что соответствует максимальному смещению микрофона относительно исходной точки, составляющему около 68 см.
[0091] Что касается регулировок усиления и фазы, в одном из вариантов осуществления они параметризуются для каждой ячейки TF, так что изменения усиления можно моделировать в диапазоне [+10 дБ, -30 дБ], а изменения фазы могут быть представлены в диапазоне [-Pi, +Pi].
[0092] В базовом случае только с одним доминирующим направленным источником, таким как источник 206, показанный на фиг. 2, настройка задержки обычно постоянна по всему частотному спектру. Поскольку положение направленного источника 206 может изменяться, два параметра настройки задержки (по одному для каждого микрофона) будут меняться со временем. Таким образом, параметры настройки задержки зависят от сигнала.
[0093] В более сложном случае, когда может присутствовать несколько источников 206 направленного звука, один источник из первого направления может быть доминирующим в определенной полосе частот, в то время как другой источник из другого направления может доминировать в другой полосе частот. В таком сценарии настройка задержки вместо этого предпочтительно выполняется для каждой полосы частот.
[0094] В одном из вариантов осуществления это может быть сделано путем компенсации задержки сигналов микрофона в заданной частотно-временной (TF) ячейке относительно направления звука, которое оказывается доминирующим. Если в TF ячейке не обнаружено доминирующего направления звука, компенсация задержки не выполняется.
[0095] В другом варианте осуществления сигналы микрофона в заданной TF ячейке могут быть скомпенсированы по задержке с целью максимизации отношения сигнал/шум (SNR) по отношению к направленному звуку, захваченному всеми микрофонами.
[0096] В одном из вариантов осуществления подходящее ограничение числа различных источников, для которых может выполняться компенсация задержки, составляет три. Это дает возможность выполнить компенсацию задержки в TF ячейке либо по отношению к одному из трех доминирующих источников, либо вообще ее не выполнять. Соответствующий набор значений компенсации задержки (набор применяется ко всем микрофонным сигналам), таким образом, может сигнализироваться только двумя битами на TF ячейку. Это охватывает наиболее актуальные на практике сценарии захвата и имеет преимущество, заключающееся в том, что объем метаданных или их скорость передачи остаются низкими.
[0097] Другой возможный сценарий заключается в захвате и микшировании, например, в один канал MASA амбиофонических сигналов первого порядка (FOA), а не стереосигналов. Концепция FOA хорошо известна специалистам в данной области техники, но может быть кратко описана как способ записи, микширования и воспроизведения трехмерного звука на 360 градусов. Основной подход амбиофонии состоит в том, чтобы рассматривать звуковую сцену как полную 360-градусную сферу звука, исходящего с разных направлений вокруг центральной точки, где размещается микрофон во время записи или где находится «зона наилучшего восприятия» слушателя во время воспроизведения.
[0098] Захват плоскостного FOA и FOA с понижающим микшированием в один канал MASA являются относительно простыми расширениями случая стереозахвата, описанного выше. Случай плоскостного FOA характеризуется тремя микрофонами, как показано на фиг. 2, выполняющими захват до понижающего микширования. В последнем случае захват FOA осуществляется четырьмя микрофонами, расположение или направленность которых распространяется на все три пространственных измерения.
[0099] Параметры компенсации задержки, настройки амплитуды и фазы могут использоваться для восстановления трех или, соответственно, четырех исходных сигналов захвата и для обеспечения более точного пространственного рендеринга с использованием метаданных MASA, чем было бы возможно только на основе монофонического сигнала понижающего микширования. В качестве альтернативы, параметры компенсации задержки, настройки амплитуды и фазы могут использоваться для создания более точного (плоскостного) представления FOA, которое приближается к тому, которое было бы получено с помощью регулярной микрофонной сетки.
[00100] В еще одном сценарии плоскостной FOA или FOA может быть захвачен и подвергнут понижающему микшированию в два или более каналов MASA. Этот случай является расширением предыдущего случая с той разницей, что захваченные три или четыре микрофонных сигнала микшируются с понижением до двух, а не только до одного канала MASA. Те же принципы применяются, когда целью обеспечения компенсации задержки, параметров настройки амплитуды и фазы является обеспечение наилучшего восстановления исходных сигналов перед понижающим микшированием.
[00101] Как будет понятно специалисту, для того, чтобы приспособиться ко всем этим сценариям использования, представление пространственного звука должно включать метаданные не только о задержке, усилении и фазе, но также и о параметрах, которые указывают конфигурацию понижающего микширования для звукового сигнала понижающего микширования.
[00102] Возвратимся теперь к фиг. 1; определенные параметры метаданных объединяют со звуковым сигналом понижающего микширования в представление пространственного звука, этап 108, который завершает процесс 100. Ниже приведено описание того, как эти параметры метаданных могут быть представлены в соответствии с одним из вариантов осуществления изобретения.
[00103] Для поддержки описанных выше вариантов применения с понижающим микшированием в один или множество каналов MASA используются два элемента метаданных. Один из элементов метаданных представляет собой метаданные конфигурации, не зависящие от сигнала, которые указывают понижающее микширование. Этот элемент метаданных описывается ниже в связи с фиг. 3A-3B. Другой элемент метаданных связан с понижающим микшированием. Этот элемент метаданных описан ниже в связи с фиг. 4-6 и может быть определен в соответствии с описанным выше в связи с фиг. 1. Этот элемент требуется при передаче сигнала понижающего микширования.
[00104] В таблице 1A, показанной на фиг. 3A, представлена структура метаданных, которая может использоваться для указания количества каналов MASA, от одного (моно) канала MASA, и двух (стерео) каналов MASA до максимум четырех каналов MASA, представленных значениями битов канала 00, 01, 10 и 11, соответственно.
[00105] Таблица 1B, показанная на фиг. 3B содержит значения битов канала из таблицы 1A (в данном конкретном случае для иллюстративных целей показаны только значения канала «00» и «01») и показывает, как может быть представлена конфигурация захвата микрофона. Например, как можно увидеть в таблице 1B для одиночного (моно) канала MASA, в сигнале может передаваться информация о том, являются ли конфигурации захвата моно, стерео, плоскостным FOA или FOA. Как можно также видеть в таблице 1B, конфигурация захвата микрофона кодируется как 2-битное поле (в столбце с названием «битовое значение»). Таблица 1B также включает дополнительное описание метаданных. Дополнительная независимая от сигнала конфигурация может, например, представлять, что звук исходит из микрофонной сетки смартфона или аналогичного устройства.
[00106] В случае, когда метаданные понижающего микширования зависят от сигнала, необходимы некоторые дополнительные детали, как будет описано ниже. Как указано в таблице 1B для конкретного случая, когда транспортный сигнал представляет собой монофонический сигнал, полученный посредством понижающего микширования сигналов с нескольких микрофонов, эти детали предоставляются в поле метаданных, зависящих от сигнала. Информация, представленная в этом поле метаданных, описывает примененную настройку задержки (с возможной целью формирования акустического пучка в направлении направленных источников) и фильтрацию сигналов микрофона (с возможной целью выравнивания/подавления шума) перед понижающим микшированием. В результате предлагается дополнительная информация, которая может помочь при кодировании, декодировании и/или рендеринге.
[00107] В одном из вариантов осуществления метаданные понижающего микширования содержат четыре поля, поле определения и селектора для сигнализации о применяемой компенсации задержки, за которыми следуют два поля, сигнализирующие о применяемых настройках усиления и фазы, соответственно.
[00108] Количество микрофонных сигналов n, подвергнутых понижающему микшированию, указывается в поле «битовое значение» в таблице 1В, то есть n=2 для стереофонического понижающего микширования ('битовое значение=01'), n=3 для плоскостного понижающего микширования FOA ('битовое значение=10') и n=4 для понижающего микширования FOA ('битовое значение=11').
[00109] До трех различных наборов значений компенсации задержки для максимум n микрофонных сигналов могут быть определены и сигнализированы для каждой TF ячейки. Каждый набор соответствует направлению направленного источника. Определение наборов значений компенсации задержки и сигнализация, какой набор применяется к какой TF ячейке, выполняется с помощью двух отдельных полей (определение и селектор).
[00110] В одном из вариантов осуществления поле определения представляет собой матрицу nx3 с 8-битовыми элементами Bi, j, кодирующими применяемую компенсацию задержки. Эти параметры соответствуют тому набору, к которому они принадлежат, то есть, соответствуют направлению направленного источника (j=1…3). Кроме того, элементы Bi, j соответствуют микрофону захвата (или соответствующему сигналу захвата) (i=1…n, n≤4). Это схематически проиллюстрировано в таблице 2, показанной на фиг. 4.
[00111] Фиг. 4 в сочетании с фиг. 3, таким образом, показывает вариант осуществления, в котором представление пространственного звука содержит параметры метаданных, которые организованы в поле определения и поле селектора. Поле определения задает по меньшей мере один набор параметров компенсации задержки, ассоциированный с множеством микрофонов, а поле селектора определяет выбор набора параметров компенсации задержки. Преимущество такого представления значения относительной временной задержки между микрофонами заключается в том, что оно является компактным и, таким образом, требует меньшей скорости передачи данных при передаче на следующий кодировщик или тому подобное.
[00112] Параметр компенсации задержки представляет относительное время прихода предполагаемой плоской звуковой волны со стороны источника по сравнению с приходом волны в (произвольную) геометрическую центральную точку устройства 202 захвата звука. Кодирование этого параметра с помощью 8-битного целочисленного кодового слова B выполняется в соответствии со следующим уравнением:
 . Уравнение № (1)
. Уравнение № (1)
[00113] В результате получают линейную квантификацию относительной задержки в интервале [-2,0 мс, 2,0 мс], что соответствует максимальному смещению микрофона относительно исходной точки около 68 см. Это, конечно, является всего лишь одним примером, и другие характеристики квантования и разрешения также могут быть рассмотрены.
[00114] Сигнализация того, какой набор значений компенсации задержки применяется к какой TF ячейке, выполняется с использованием поля селектора, представляющего 4*24 TF ячеек в кадре 20 мс, что предполагает наличие 4 подкадров в кадре 20 мс и 24 полосы частот. Каждый элемент поля содержит 2-битный набор кодировок 1…3 значений компенсации задержки с соответствующими кодами «01», «10» и «11». Запись «00» используется, если для TF ячейки не применяется компенсация задержки. Это схематично проиллюстрировано в таблице 3, показанной на фиг. 5.
[00115] Настройка усиления сигнализируется в 2-4 полях метаданных, по одному для каждого микрофона. Каждое поле представляет собой матрицу 8-битных кодов Bα настройки усиления, соответствующих 4*24 TF ячейкам в кадре 20 мс. Кодирование параметров настройки усиления с помощью целочисленного кодового слова выполняется в соответствии со следующим уравнением:
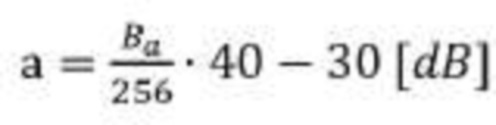 . Уравнение № (2)
. Уравнение № (2)
[00116] 2-4 поля метаданных для каждого микрофона организованы, как показано в таблице 4, показанной на фиг. 6.
[00117] Настройка фазы передается аналогично настройке усиления в 2-4 полях метаданных, по одному для каждого микрофона. Каждое поле представляет собой матрицу 8-битных кодов настройки фазы Bφ, соответствующих 4*24 TF ячейкам в кадре 20 мс. Кодирование параметров настройки фазы с помощью целочисленного кодового слова Bφ выполняется в соответствии со следующим уравнением:
 . Уравнение № (3)
. Уравнение № (3)
[00118] 2-4 поля метаданных для каждого микрофона организованы, как показано в таблице 4, с той лишь разницей, что элементы поля являются кодовыми словами настройки фазы Bφ.
[00119] Такое представление сигналов MASA, которые включают в себя связанные метаданные, затем может использоваться кодировщиками, декодировщиками, средствами рендеринга и другими типами звукового оборудования, которое будет применяться для передачи, приема и достоверного восстановления записанной пространственной звуковой среды. Методики выполнения указанного хорошо известны специалистам в данной области техники и могут быть легко адаптированы для соответствия описанному в настоящем раскрытии представлению пространственного звука. Следовательно, в данном контексте нет необходимости в дальнейшем обсуждении этих конкретных устройств.
[00120] Как понятно специалисту, элементы метаданных, описанные выше, могут постоянно хранить или определять различными способами. Например, метаданные могут быть определены локально на устройстве (таком как устройство захвата звука, устройство кодирования и т.д.), могут быть получены иным образом из других данных (например, из облака или другой удаленной службы) или могут храниться в таблице предварительно заданных значений. Например, на основе настройки задержки между микрофонами значение компенсации задержки (фиг. 4) для микрофона может быть определено с помощью справочной таблицы, хранящейся в устройстве захвата звука, или принято от удаленного устройства на основе вычисления настройки задержки, сделанного в устройстве захвата звука, или принято от такого удаленного устройства на основе вычисления настройки задержки, выполняемого в этом удаленном устройстве (то есть, на основе входных сигналов).
[00121] На фиг. 7 показана система 700 в соответствии с типовым вариантом осуществления, в которой могут быть реализованы описанные выше характеристики изобретения. Система 700 включает в себя устройство 202 захвата звука, кодировщик 704, декодировщик 706 и средство 708 рендеринга. Различные компоненты системы 700 могут обмениваться данными друг с другом через проводное или беспроводное соединение, или любую их комбинацию, и данные обычно пересылаются между блоками в форме битового потока. Устройство 202 захвата звука было описано выше и со ссылкой на фиг. 2, и сконфигурировано для захвата пространственного звука, который представляет собой комбинацию направленного звука и рассеянного звука. Устройство 202 захвата звука создает одноканальный или многоканальный звуковой сигнал понижающего микширования посредством понижающего микширования входных звуковых сигналов от множества микрофонов в блоке захвата звука, захватывающем пространственный звук. Затем устройство 202 захвата звука определяет параметры первых метаданных, ассоциированные со звуковым сигналом понижающего микширования. Это будет дополнительно проиллюстрировано ниже в связи с фиг. 8. Параметры первых метаданных указывают значение относительной временной задержки, значение усиления и/или значение фазы, ассоциированные с каждым входным звуковым сигналом. Устройство 202 захвата звука, наконец, объединяет звуковой сигнал понижающего микширования и параметры первых метаданных в представление пространственного звука. Следует отметить, что хотя в текущем варианте осуществления весь захват и объединение звука выполняется в устройстве 202 захвата звука, также могут иметься альтернативные варианты осуществления, в которых определенные части операций создания, определения и объединения выполняются в кодировщике 704.
[00122] Кодировщик 704 принимает представление пространственного звука от устройства 202 захвата звука. То есть, кодировщик 704 принимает формат данных, содержащий одноканальный или многоканальный звуковой сигнал понижающего микширования, полученный в результате понижающего микширования входных звуковых сигналов от множества микрофонов в блоке захвата звука, захватывающем пространственный звук, и параметры первых метаданных, указывающие конфигурацию понижающего микширования для входных звуковых сигналов, значение относительной временной задержки, значение усиления и/или значение фазы, ассоциированные с каждым входным звуковым сигналом. Следует отметить, что формат данных может храниться в энергонезависимой памяти до/после того, как он будет принят кодировщиком. Кодировщик 704 затем кодирует одноканальный или многоканальный звуковой сигнал понижающего микширования в поток битов, используя первые метаданные. В некоторых вариантах осуществления кодировщик 704 может являться кодировщиком IVAS, как описано выше, но, как будет понятно квалифицированному специалисту, другие типы кодировщиков 704 могут иметь аналогичные возможности и также могут быть использованы.
[00123] Закодированный битовый поток, который указывает на кодированное представление пространственного звука, затем принимается декодировщиком 706. Декодировщик 706 декодирует битовый поток в аппроксимацию пространственного звука, используя параметры метаданных, которые включены в битовый поток от кодировщика 704. Наконец, средство рендеринга 708 принимает декодированное представление пространственного звука и осуществляет рендеринг пространственного звука с использованием метаданных, чтобы создать точное воспроизведение пространственного звука на принимающей стороне, например, с помощью одного или более громкоговорителей.
[00124] На фиг. 8 показано устройство 202 захвата звука согласно некоторым вариантам осуществления. Устройство 202 захвата звука может в некоторых вариантах осуществления содержать память 802 с хранящимися в ней справочными таблицами для определения первых и/или вторых метаданных. Устройство 202 захвата звука в некоторых вариантах осуществления может быть подключено к удаленному устройству 804 (которое может быть размещено в облаке или являться физическим устройством, подключенным к устройству 202 захвата звука), которое может содержать память 806 с хранящимися в ней справочными таблицами для определения первых и/или вторых метаданных. Устройство захвата звука может в некоторых вариантах осуществления выполнять необходимые вычисления/обработку (например, с использованием процессора 803), например, для определения значения относительной временной задержки, значения усиления и значения фазы, ассоциированных с каждым входным звуковым сигналом, и передавать такие параметры на удаленное устройство для получения первых и/или вторых метаданных от этого устройства. В других вариантах осуществления устройство 202 захвата звука передает входные сигналы на удаленное устройство 804, которое выполняет необходимые вычисления/обработку (например, с использованием процессора 805) и определяет первые и/вторые метаданные для передачи обратно на устройство захвата звука 202. В еще одном варианте осуществления удаленное устройство 804, которое выполняет необходимые вычисления/обработку, передает параметры обратно в устройство 202 захвата звука, которое определяет первые и/или вторые метаданные локально на основе принятых параметров (например, с использованием памяти 806 с хранящимися в ней справочными таблицами).
[00125] На фиг. 9 показан декодировщик 706 и средство рендеринга 708 (каждое из них содержит процессор 910, 912 для выполнения различной обработки, например, декодирования, рендеринга и т.д.) согласно вариантам осуществления. Декодировщик и средство рендеринга могут являться отдельными устройствами или одним и тем же устройством. Процессор(-ы) 910, 912 может(-гут) совместно использоваться декодировщиком и средством рендеринга, или могут являться отдельными процессорами. Аналогично описанному со ссылкой на фиг. 8, интерпретация первых и/или вторых метаданных может быть выполнена с использованием справочной таблицы, хранящейся либо в памяти 902 в декодировщике 706, либо в памяти 904 в средстве рендеринга 708, либо в памяти 906 на удаленном устройстве 905 (содержащем процессор 908), подключенном либо к декодировщику, либо к средству рендеринга.
Эквиваленты, расширения, альтернативы и прочее
[00126] Дополнительные варианты осуществления настоящего раскрытия станут очевидными для специалиста в данной области техники после изучения приведенного выше описания. Несмотря на то, что настоящее описание и чертежи раскрывают варианты осуществления и примеры, раскрытие не ограничивается этими конкретными примерами. Могут быть выполнены многочисленные модификации и изменения, не выходящие за пределы объема настоящего раскрытия, который определяется в прилагаемой формуле изобретения. Любые цифровые обозначения, фигурирующие в пунктах формулы изобретения, не следует понимать, как ограничивающие их объем.
[00127] Кроме того, изменения раскрытых вариантов осуществления могут быть поняты и осуществлены квалифицированным специалистом, применяющим раскрытие на практике, на основе изучения чертежей, раскрытия и прилагаемой формулы изобретения. В формуле изобретения слово «содержащий» не исключает других элементов или этапов, а единственное число не исключает множественности. Тот факт, что определенные меры изложены во взаимно различных зависимых пунктах формулы изобретения, не означает, что комбинация этих мер не может быть использована с выгодой.
[00128] Системы и способы, раскрытые выше, могут быть реализованы как программное обеспечение, встроенное программное обеспечение, аппаратное обеспечение, или комбинация указанного. В аппаратной реализации разделение задач между функциональными блоками, упомянутыми в приведенном выше описании, не обязательно соответствует разделению на физические блоки; напротив, один физический компонент может иметь несколько функций, а одна задача может выполняться несколькими физическими компонентами совместно. Некоторые компоненты или все компоненты могут быть реализованы как программное обеспечение, выполняемое процессором цифровых сигналов или микропроцессором, или реализованы как аппаратные средства или как специализированная интегральная схема. Такое программное обеспечение может распространяться на машиночитаемых носителях, которые могут включать в себя компьютерные носители данных (или энергонезависимые носители) и средства связи (или энергозависимые носители). Как хорошо известно специалистам в данной области техники, термин «компьютерные носители данных» включает в себя как энергозависимые, так и энергонезависимые, съемные и несъемные носители, реализованные посредством любых способов или технологий для хранения информации, такие как машиночитаемые инструкции, структуры данных, программные модули или другие данные. Компьютерные носители данных включают, помимо прочего, RAM, ROM, EEPROM, флэш-память или другую технологию памяти, CD-ROM, универсальные цифровые диски (DVD) или другое хранилище оптических дисков, магнитные кассеты, магнитную ленту, хранилище на магнитных дисках или другие магнитные запоминающие устройства, или любой другой носитель, который можно использовать для хранения желаемой информации и к которому может получить доступ компьютер. Кроме того, специалисту в данной области хорошо известно, что среда связи обычно воплощает машиночитаемые инструкции, структуры данных, программные модули или другие данные в модулированном сигнале данных, таком как несущая волна или другой транспортный механизм, и включает в себя любые среды доставки информации.
Все фигуры являются схематичными и обычно показывают только те части, которые необходимы для пояснения раскрытия, тогда как другие части могут быть опущены или их наличие может просто предполагаться. Если не указано иное, одинаковые цифровые обозначения относятся к одинаковым частям на разных фигурах.





Изобретение относится к акустике. Предлагается способ представления пространственного звука, при этом пространственный звук представляет собой комбинацию направленного звука и рассеянного звука, при этом упомянутый способ включает в себя: создание одноканального или многоканального звукового сигнала понижающего микширования посредством понижающего микширования входных звуковых сигналов от множества микрофонов (m1, m2, m3) в блоке захвата звука, захватывающем пространственный звук, при этом понижающее микширование для создания одноканального или многоканального звукового сигнала x понижающего микширования описывается следующим образом:
 ,
,
где D представляет собой матрицу понижающего микширования, содержащую коэффициенты понижающего микширования, задающие веса для каждого входного звукового сигнала от множества микрофонов, и m представляет собой матрицу, представляющую входные звуковые сигналы от множества микрофонов; определение параметров первых метаданных, ассоциированных со звуковым сигналом понижающего микширования, при этом параметры первых метаданных указывают одно или более из: значения относительной временной задержки, значения усиления и значения фазы, ассоциированных с каждым входным звуковым сигналом; и объединение созданного звукового сигнала понижающего микширования и параметров первых метаданных в представление пространственного звука. Технический результат – улучшение представления пространственного звука. 6 н. и 29 з.п. ф-лы, 9 ил.
1. Способ представления пространственного звука, при этом пространственный звук представляет собой комбинацию направленного звука и рассеянного звука, при этом упомянутый способ включает в себя:
создание одноканального или многоканального звукового сигнала понижающего микширования посредством понижающего микширования входных звуковых сигналов от множества микрофонов (m1, m2, m3) в блоке захвата звука, захватывающем пространственный звук, при этом понижающее микширование для создания одноканального или многоканального звукового сигнала x понижающего микширования описывается следующим образом:
 ,
,
где D представляет собой матрицу понижающего микширования, содержащую коэффициенты понижающего микширования, задающие веса для каждого входного звукового сигнала от множества микрофонов, и
m представляет собой матрицу, представляющую входные звуковые сигналы от множества микрофонов;
определение параметров первых метаданных, ассоциированных со звуковым сигналом понижающего микширования, при этом параметры первых метаданных указывают одно или более из: значения относительной временной задержки, значения усиления и значения фазы, ассоциированных с каждым входным звуковым сигналом; и
объединение созданного звукового сигнала понижающего микширования и параметров первых метаданных в представление пространственного звука.
2. Способ по п. 1, в котором объединение созданного звукового сигнала понижающего микширования и параметров первых метаданных в представление пространственного звука дополнительно включает в себя:
включение параметров вторых метаданных в представление пространственного звука, при этом параметры вторых метаданных указывают конфигурацию понижающего микширования для входных звуковых сигналов.
3. Способ по п. 1 или 2, в котором параметры первых метаданных определяют для одной или более полос частот входных звуковых сигналов микрофона.
4. Способ по п. 3, в котором коэффициенты понижающего микширования выбирают для выбора входного звукового сигнала микрофона, имеющего в настоящее время наилучшее отношение сигнал/шум по отношению к направленному звуку, и для отбрасывания входных звуковых сигналов от любых других микрофонов.
5. Способ по п. 4, в котором выбор выполняют для каждой частотно-временной (TF) ячейки.
6. Способ по п. 4, в котором выбор выполняют для всех полос частот конкретного аудиокадра.
7. Способ по п. 3, в котором коэффициенты понижающего микширования выбирают таким образом, чтобы максимизировать отношение сигнал/шум по отношению к направленному звуку при объединении входных звуковых сигналов от различных микрофонов.
8. Способ по п. 7, в котором максимизацию выполняют для конкретной полосы частот.
9. Способ по п. 7, в котором максимизацию выполняют для конкретного аудиокадра.
10. Способ по любому из пп. 1-9, в котором определение параметров первых метаданных включает в себя анализ одного или более из следующего: характеристик задержки, усиления и фазы входных звуковых сигналов от множества микрофонов.
11. Способ по любому из пп. 1-10, в котором параметры первых метаданных определяют для каждой частотно-временной (TF) ячейки.
12. Способ по любому из пп. 1-11, в котором по меньшей мере часть понижающего микширования происходит в блоке захвата звука.
13. Способ по любому из пп. 1-11, в котором по меньшей мере часть понижающего микширования происходит в кодировщике.
14. Способ по любому из пп. 1-13, дополнительно включающий в себя:
в ответ на обнаружение более одного источника направленного звука определение первых метаданных для каждого источника.
15. Способ по любому из пп. 1-14, в котором представление пространственного звука включает в себя по меньшей мере один из следующих параметров: индекс направления, отношение прямой энергии к общей; когерентность распространения; время прихода, усиление и фаза для каждого микрофона; отношение рассеянной энергии к общей; объемная когерентность; отношение остатка к общей энергии; и расстояние.
16. Способ по любому из пп. 1-15, в котором параметр метаданных параметров вторых или первых метаданных указывает, генерируется ли созданный звуковой сигнал понижающего микширования из: левых и правых стереофонических сигналов, плоскостных амбиофонических сигналов первого порядка (FOA) или компонентных амбиофонических сигналов первого порядка.
17. Способ по любому из пп. 1-16, в котором представление пространственного звука содержит параметры метаданных, организованные в поле определения и поле селектора, при этом поле определения задает по меньшей мере один набор параметров компенсации задержки, ассоциированный с множеством микрофонов, и поле селектора задает выбор набора параметров компенсации задержки.
18. Способ по п. 17, в котором поле селектора задает, какой набор параметров компенсации задержки применяется к любой заданной частотно-временной ячейке.
19. Способ по любому из пп. 1-18, в котором значение относительной временной задержки находится приблизительно в интервале [-2,0 мс, 2,0 мс].
20. Способ по п. 17, в котором параметры метаданных в представлении пространственного звука дополнительно содержат поле, задающее применяемую настройку усиления, и поле, задающее настройку фазы.
21. Способ по п. 20, в котором настройка усиления находится приблизительно в интервале [+ 10 дБ, -30 дБ].
22. Способ по любому из пп. 1-21, в котором по меньшей мере части элементов первых и/или вторых метаданных определяют в устройстве захвата звука с использованием справочных таблиц, хранящихся в памяти.
23. Способ по любому из пп. 1-21, в котором по меньшей мере части элементов первых и/или вторых метаданных определяют на удаленном устройстве, подключенном к устройству захвата звука.
24. Система для представления пространственного звука, содержащая:
компонент приема, сконфигурированный для приема входных звуковых сигналов от множества микрофонов (m1, m2, m3) в блоке захвата звука, захватывающем пространственный звук;
компонент понижающего микширования, сконфигурированный для создания одноканального или многоканального звукового сигнала понижающего микширования посредством понижающего микширования принятых звуковых сигналов, при этом понижающее микширование для создания одноканального или многоканального звукового сигнала x понижающего микширования описывается следующим образом:
,
где D представляет собой матрицу понижающего микширования, содержащую коэффициенты понижающего микширования, задающие веса для каждого входного звукового сигнала от множества микрофонов, и
m представляет собой матрицу, представляющую входные звуковые сигналы от множества микрофонов;
компонент определения метаданных, сконфигурированный для определения параметров первых метаданных, ассоциированных со звуковым сигналом понижающего микширования, при этом параметры первых метаданных указывают одно или более из: значения относительной временной задержки, значения усиления и значения фазы, ассоциированных с каждым входным звуковым сигналом; и
компонент объединения, сконфигурированный для объединения созданного звукового сигнала понижающего микширования и параметров первых метаданных в представление пространственного звука.
25. Система по п. 24, в которой компонент объединения дополнительно сконфигурирован для включения параметров вторых метаданных в представление пространственного звука, при этом параметры вторых метаданных указывают конфигурацию понижающего микширования для входных звуковых сигналов.
26. Машиночитаемый носитель, на котором хранятся инструкции, которые заставляют процессор выполнять способ по любому из пп. 1-23.
27. Кодировщик пространственного звука, сконфигурированный для:
приема представления пространственного звука, содержащего:
одноканальный или многоканальный звуковой сигнал понижающего микширования, созданный посредством понижающего микширования входных звуковых сигналов от множества микрофонов (m1, m2, m3) в блоке захвата звука, захватывающем пространственный звук, при этом понижающее микширование для создания одноканального или многоканального звукового сигнала x понижающего микширования описывается следующим образом:
,
где D представляет собой матрицу понижающего микширования, содержащую коэффициенты понижающего микширования, задающие веса для каждого входного звукового сигнала от множества микрофонов, и
m представляет собой матрицу, представляющую входные звуковые сигналы от множества микрофонов, и
параметры первых метаданных, ассоциированные со звуковым сигналом понижающего микширования, при этом параметры первых метаданных указывают одно или более из: значения относительной временной задержки, значения усиления и значения фазы, ассоциированных с каждым входным звуковым сигналом; и
выполнения одного из:
кодирования одноканального или многоканального звукового сигнала понижающего микширования в битовый поток с использованием первых метаданных, и
кодирования одноканального или многоканального звукового сигнала понижающего микширования и первых метаданных в битовый поток.
28. Кодировщик по п. 27, в котором:
представление пространственного звука дополнительно включает в себя параметры вторых метаданных, указывающие конфигурацию понижающего микширования для входных звуковых сигналов; и
кодировщик сконфигурирован для кодирования одноканального или многоканального звукового сигнала понижающего микширования в битовый поток с использованием параметров первых и вторых метаданных.
29. Кодировщик по п. 27, в котором часть понижающего микширования происходит в блоке захвата звука, и часть понижающего микширования происходит в кодировщике.
30. Декодировщик пространственного звука, сконфигурированный для:
приема битового потока, указывающего кодированное представление пространственного звука, при этом упомянутое представление включает в себя:
одноканальный или многоканальный звуковой сигнал понижающего микширования, созданный посредством понижающего микширования входных звуковых сигналов от множества микрофонов (m1, m2, m3) в блоке захвата звука (202), захватывающего пространственный звук, при этом понижающее микширование для создания одноканального или многоканального звукового сигнала x понижающего микширования описывается следующим образом:
,
где D представляет собой матрицу понижающего микширования, содержащую коэффициенты понижающего микширования, задающие веса для каждого входного звукового сигнала от множества микрофонов, и
m представляет собой матрицу, представляющую входные звуковые сигналы от множества микрофонов, и
параметры первых метаданных, ассоциированные со звуковым сигналом понижающего микширования, при этом параметры первых метаданных указывают одно или более из: значения относительной временной задержки, значения усиления и значения фазы, ассоциированных с каждым входным звуковым сигналом; и
декодирования битового потока в аппроксимацию пространственного звука с использованием параметров первых метаданных.
31. Декодировщик по п. 30, в котором:
представление пространственного звука дополнительно включает в себя параметры вторых метаданных, указывающие конфигурацию понижающего микширования для входных звуковых сигналов; и
декодировщик сконфигурирован для декодирования битового потока в аппроксимацию пространственного звука с использованием параметров первых и вторых метаданных.
32. Декодировщик по п. 30 или 31, дополнительно включающий:
использование параметра первых метаданных для восстановления межканальной разницы во времени или для настройки величины или фазы декодированного выходного звука.
33. Декодировщик по п. 31, дополнительно включающий:
использование параметра вторых метаданных для определения матрицы повышающего микширования для восстановления сигнала направленного источника или восстановления сигнала окружающего звука.
34. Средство рендеринга пространственного звука, сконфигурированное для:
приема представления пространственного звука, причем упомянутое представление включает в себя:
одноканальный или многоканальный звуковой сигнал понижающего микширования, созданный посредством понижающего микширования входных звуковых сигналов от множества микрофонов (m1, m2, m3) в блоке захвата звука, захватывающем пространственный звук, при этом понижающее микширование для создания одноканального или многоканального звукового сигнала x понижающего микширования описывается следующим образом:
,
где D представляет собой матрицу понижающего микширования, содержащую коэффициенты понижающего микширования, задающие веса для каждого входного звукового сигнала от множества микрофонов, и
m представляет собой матрицу, представляющую входные звуковые сигналы от множества микрофонов, и
параметры первых метаданных, ассоциированные со звуковым сигналом понижающего микширования, при этом параметры первых метаданных указывают одно или более из: значения относительной временной задержки, значения усиления и значения фазы, ассоциированных с каждым входным звуковым сигналом; и
рендеринга пространственного звука с использованием первых метаданных.
35. Средство рендеринга по п. 34, в котором:
представление пространственного звука дополнительно включает в себя параметры вторых метаданных, указывающие конфигурацию понижающего микширования для входных звуковых сигналов; и
средство рендеринга сконфигурировано для рендеринга пространственного звука с использованием параметров первых и вторых метаданных.
| WO 2017182714 A1, 26.10.2017 | |||
| US 2011208528 A1, 25.08.2011 | |||
| US 2012082319 A1, 05.04.2012 | |||
| US 2009325524 A1, 31.12.2009. |
