Данный документ относится, в числе прочего, к устройству для формирования кодированной аудиосцены и к устройству для декодирования и/или обработки кодированной аудиосцены. Документ также относится к соответствующим способам и к постоянным блокам хранения, сохраняющим инструкции, которые при выполнении процессором предписывают процессору осуществлять соответствующий способ.
В данном документе поясняются способы для режима прерывистой передачи (DTX) и формирования комфортного шума (CNG) для аудиосцен, для которых пространственное изображение параметрически кодировано посредством парадигмы на основе направленного кодирования аудио (DirAC) либо передано в пространственном аудиоформате на основе метаданных (MASA).
Варианты осуществления относятся к прерывистой передаче параметрически кодированного пространственного аудио, такой как режим DTX для DirAC и MASA.
Варианты осуществления настоящего изобретения относятся к эффективной передаче и рендерингу разговорной речи, например, захватываемой с помощью микрофонов в звуковом поле. Таким образом, захваченный аудиосигнал называется в общем «трехмерным аудио», поскольку звуковые события могут быть локализованы в трехмерном пространстве, что усиливает иммерсивность и улучшает как разборчивость, так и пользовательское восприятие.
Передача аудиосцены, например, в трех измерениях требует обработки нескольких каналов, что обычно вызывает большой объем данных, которые следует передавать. Например, технология направленного кодирования аудио (DirAC) [1] может использоваться для уменьшения высокой исходной скорости передачи данных. DirAC считается эффективным подходом для анализа аудиосцены и ее параметрического представления. Он перцепционно обуславливается и представляет звуковое поле с помощью направления поступления (DoA) и рассеянности, измеренных в расчете на полосу частот. Это базируется на допущении, что в один момент времени и для одной критической полосы частот, пространственное разрешение слуховой системы ограничено декодированием одной сигнальной метки для направления, а другой - для интерауральной когерентности. Пространственный звук затем воспроизводится в частотной области посредством плавного перехода двух потоков: ненаправленного рассеянного потока и направленного нерассеянного потока.
Более того, в типичном разговоре, каждый говорящий молчит примерно шестьдесят процентов времени. Посредством отличения кадров аудиосигнала, которые содержат речь («активных кадров»), от кадров, содержащих только фоновый шум или молчание («неактивных кадров»), речевые кодеры могут существенно снижать скорость передачи данных. Неактивные кадры типично воспринимаются как переносящие небольшой или нулевой объем информации, и речевые кодеры обычно выполнены с возможностью уменьшения своей скорости передачи битов для таких кадров или даже отсутствия передачи информации. В таком случае, кодеры работают в так называемом режиме прерывистой передачи (DTX), который представляет собой эффективный способ радикально уменьшать скорость передачи кодека связи в отсутствие голосового ввода. В этом режиме, большинство кадров, которые определяются как состоящие только из фонового шума, отбрасываются из передачи и заменяются посредством некоторого формирования комфортного шума (CNG) в декодере. Для этих кадров, очень низкоскоростное параметрическое представление сигнала передается посредством кадров дескриптора вставки молчания (SID), отправляемых регулярно, но не в каждом кадре. Это обеспечивает возможность CNG в декодере формировать искусственный шум, напоминающий фактический фоновый шум.
Варианты осуществления настоящего изобретения относятся к системе DTX и, в частности, к SID и CNG для трехмерных аудиосцен, захваченных, например, посредством микрофона в звуковом поле, и которые могут кодироваться параметрически посредством схемы кодирования на основе парадигмы DirAC и одинаково. Настоящее изобретение обеспечивает возможность радикального уменьшения потребности по скорости передачи битов для передачи разговорной иммерсивной речи.
Описание уровня техники
[1] V. Pulkki, M.-V. Laitinen, J. Vilkamo, J. Ahonen, T. Lokki и Т. Pihlajamäki "Directional audio coding - perception-based reproduction of spatial sound", International Workshop on the Principles and Application on Spatial Hearing, ноябрь 2009 года, Зао; Мияги, Япония.
[2] 3GPP TS 26.194; Voice Activity Detector (VAD); - 3GPP technical specification Retrieved on 2009-06-17.
[3] 3GPP TS 26.449 "Codec for Enhanced Voice Services (EVS); Comfort Noise Generation (CNG) Aspects".
[4] 3GPP TS 26.450 "Codec for Enhanced Voice Services (EVS); Discontinuous Transmission (DTX)".
[5] A. Lombard, S. Wilde, E. Ravelli, S. Döhla, G. Fuchs и M. Dietz "Frequency-domain Comfort Noise Generation for Discontinuous Transmission in EVS", 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Брисбен, QLD, 2015 год, стр. 5893-5897, DOI: 10.110 9/ICASSP.2 015.717 9102.
[6] V. Pulkki "Virtual source positioning using vector base amplitude panning", J. Audio Eng. Soc, 45 (6): 456-466, июнь 1997 года.
[7] J. Ahonen и V. Pulkki "Diffuseness estimation using temporal variation of intensity vectors", in Workshop on Applications of Signal Processing to Audio and Acoustics WASPAA, Mohonk Mountain House, Нью-Палц, 2009 год.
[8] Т. Hirvonen, J. Ahonen и V. Pulkki "Perceptual compression methods for metadata in Directional Audio Coding applied to audiovisual teleconference", AES 126th Convention, 2009 год, 7-10 мая, Мюнхен, Германия.
[9] Vilkamo, Juha и Backstrom, Tom и Kuntz, Achim (2013) "Optimized Covariance Domain Framework for Time-Frequency Processing of Spatial Audio", Journal of the Audio Engineering Society, 61.
[10] M. Laitinen и V. Pulkki "Converting 5.1 audio recordings to B-format for directional audio coding reproduction", 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Прага, 2011 год, стр. 61-64, DOI: 10.1109/ICASSP.2011.5946328.
Раскрытие изобретения
В соответствии с аспектом, предусмотрено устройство для формирования кодированной аудиосцены из аудиосигнала, имеющего первый кадр и второй кадр, содержащее:
генератор параметров звукового поля для определения первого представления параметров звукового поля для первого кадра из аудиосигнала в первом кадре и второго представления параметров звукового поля для второго кадра из аудиосигнала во втором кадре;
- детектор активности для анализа аудиосигнала, чтобы определять, в зависимости от аудиосигнала, то, что первый кадр представляет собой активный кадр, и второй кадр представляет собой неактивный кадр;
- кодер аудиосигналов для формирования кодированного аудиосигнала для первого кадра, представляющего собой активный кадр, и для формирования параметрического описания для второго кадра, представляющего собой неактивный кадр; и
- формирователь кодированных сигналов для составления кодированной аудиосцены посредством объединения первого представления параметров звукового поля для первого кадра, второго представления параметров звукового поля для второго кадра, кодированного аудиосигнала для первого кадра и параметрического описания для второго кадра.
Генератор параметров звукового поля может быть выполнен с возможностью формирования первого представления параметров звукового поля или второго представления параметров звукового поля таким образом, что первое представление параметров звукового поля или второе представление параметров звукового поля содержит параметр, указывающий характеристику аудиосигнала относительно положения слушателя.
Первое или второе представление параметров звукового поля может содержать один или более параметров направления, указывающих направление звука относительно положения слушателя в первом кадре, либо один или более параметров рассеянности, указывающих часть рассеянного звука относительно прямого звука в первом кадре, либо один или более параметров отношения энергий, указывающих отношение энергий прямого звука и рассеянного звука в первом кадре, либо параметр межканальной когерентности/когерентности объемного звучания в первом кадре.
Генератор параметров звукового поля может быть выполнен с возможностью определения из первого кадра или второго кадра аудиосигнала множества отдельных источников звука и определения параметрического описания для каждого источника звука.
Генератор звукового поля может быть выполнен с возможностью разложения первого кадра или второго кадра на множество частотных элементов разрешения, причем каждый частотный элемент разрешения представляет отдельный источник звука, и определения для каждого частотного элемента разрешения по меньшей мере одного параметра звукового поля, причем параметр звукового поля примерно содержит параметр направления, параметр направления поступления, параметр рассеянности, параметр отношения энергий либо любой параметр, представляющий характеристику звукового поля, представленного посредством первого кадра аудиосигнала относительно положенияи слушателя.
Аудиосигнал для первого кадра и второго кадра может содержать входной формат, имеющий множество компонентов, представляющих звуковое поле относительно слушателя,
- при этом генератор параметров звукового поля выполнен с возможностью вычисления одного или более транспортных каналов для первого кадра и второго кадра, например, с использованием понижающего микширования множества компонентов и анализа входного формата для определения первого представления параметров, связанного с одним или более транспортными каналами, или
- при этом генератор параметров звукового поля выполнен с возможностью вычисления одного или более транспортных каналов, например, с использованием понижающего микширования множества компонентов, и
- при этом детектор активности выполнен с возможностью анализа одного или более транспортных каналов, извлекаемых из аудиосигнала во втором кадре.
Аудиосигнал для первого кадра или второго кадра может содержать входной формат, имеющий для каждого кадра из первого и второго кадров один или более транспортных каналов и метаданные, ассоциированные с каждым кадром,
- при этом генератор параметров звукового поля выполнен с возможностью считывания метаданных из первого кадра и второго кадра и использования или обработки метаданных для первого кадра в качестве первого представления параметров звукового поля и обработки метаданных второго кадра для получения второго представления параметров звукового поля, при этом обработка для получения второго представления параметров звукового поля является такой, что количество информационных единиц, требуемое для передачи метаданных для второго кадра, уменьшается относительно количества, требуемого перед обработкой.
Генератор параметров звукового поля может быть выполнен с возможностью обработки метаданных для второго кадра для сокращения числа информационных элементов в метаданных, либо повторной дискретизации информационных элементов в метаданных до более низкого разрешения, например, временного разрешения или частотного разрешения, либо повторного квантования информационных единиц метаданных для второго кадра до более приблизительного представления относительно ситуации перед повторным квантованием.
Кодер аудиосигналов может быть выполнен с возможностью определения описания информации молчания для неактивного кадра в качестве параметрического описания,
- при этом описание информации молчания примерно содержит связанную с амплитудой информацию, такую как энергия, мощность или уровень громкости для второго кадра, и информацию формирования, такую как информация формирования спектра, или связанную с амплитудой информацию для второго кадра, такую как энергия, мощность или уровень громкости и параметры линейного прогнозного кодирования (LPC) для второго кадра или параметры масштабирования для второго кадра с варьирующимся ассоциированным частотным разрешением таким образом, что различные параметры масштабирования связаны с полосами частот с различными ширинами.
Кодер аудиосигналов может быть выполнен с возможностью кодирования аудиосигнала для первого кадра с использованием режима кодирования во временной области или в частотной области, причем кодированный аудиосигнал содержит, например, кодированные выборки временной области, кодированные выборки спектральной области, кодированные выборки области LPC и вспомогательную информацию, полученную из компонентов аудиосигнала либо полученную из одного или более транспортных каналов, извлекаемых из компонентов аудиосигнала, например, посредством операции понижающего микширования.
Аудиосигнал может содержать входной формат, представляющий собой амбиофонический формат первого порядка, амбиофонический формат высшего порядка, многоканальный формат, ассоциированный с данной компоновкой громкоговорителей, такой как 5.1, или 7.1, или 7.1+4, или с одним или более аудиоканалами, представляющими один или более различных аудиообъектов, локализованных в пространстве, как указано посредством информации, включенной в ассоциированные метаданные, либо входной формат, представляющий собой ассоциированное с метаданными пространственное аудиопредставление,
- при этом генератор параметров звукового поля выполнен с возможностью определения первого представления параметров звукового поля и второго представления звукового поля таким образом, что параметры представляют звуковое поле относительно заданного положения слушателя, или
- при этом аудиосигнал содержит сигнал микрофона, снимаемый посредством реального микрофона или виртуального микрофона, либо синтетически созданный сигнал микрофона, например, имеющий амбиофонический формат первого порядка или амбиофонический формат высшего порядка.
Детектор активности может быть выполнен с возможностью обнаружения фазы неактивности за второй кадр и один или более кадров после второго кадра, и
- при этом кодер аудиосигналов выполнен с возможностью формирования дополнительного параметрического описания для неактивного кадра только для дополнительного третьего кадра, который отделен относительно временной последовательности кадров от второго кадра по меньшей мере на один кадр, и
- при этом генератор параметров звукового поля выполнен с возможностью определения дополнительного представления параметров звукового поля только для кадра, для которого кодер аудиосигналов определяет параметрическое описание, или
- при этом детектор активности выполнен с возможностью определения неактивной фазы, содержащей второй кадр и восемь кадров после второго кадра, и при этом кодер аудиосигналов выполнен с возможностью формирования параметрического описания для неактивного кадра только в каждом восьмом кадре, и при этом генератор параметров звукового поля выполнен с возможностью формирования представления параметров звукового поля для каждого восьмого неактивного кадра, или
- при этом генератор параметров звукового поля выполнен с возможностью формирования представления параметров звукового поля для каждого неактивного кадра, даже когда кодер аудиосигналов не формирует параметрическое описание для неактивного кадра, или
- при этом генератор параметров звукового поля выполнен с возможностью определения представления параметров с более высокой частотой кадров, чем кодер аудиосигналов формирует параметрическое описание для одного или более неактивных кадров.
Генератор параметров звукового поля может быть выполнен с возможностью определения второго представления параметров звукового поля для второго кадра:
- с использованием пространственных параметров для одного или более направлений в полосах частот и ассоциированных отношений энергий в полосах частот, соответствующих отношению одного направленного компонента в полной энергии, или
- определения параметра рассеянности, указывающего отношение рассеянного звука или прямого звука, или
- определения информации направления с использованием более приблизительной схемы квантования по сравнению с квантованием в первом кадре, или
- с использованием усреднения направления во времени или по частоте для получения более приблизительного временного или частотного разрешения, или
- определения представления параметров звукового поля для одного или более неактивных кадров с частотным разрешением, равным частотному разрешению первого представления параметров звукового поля для активного кадра, и с возникновением по времени, которое меньше возникновения по времени для активных кадров относительно информации направления в представлении параметров звукового поля для неактивного кадра, или
- определения второго представления параметров звукового поля, имеющего параметр рассеянности, причем параметр рассеянности передается с равным временным или частотным разрешением с активными кадрами, но с более приблизительным квантованием, или
- квантования параметра рассеянности для второго представления звукового поля с первым числом битов, и при этом только второе число битов каждого индекса квантования передается, причем второе число битов меньше первого числа битов, или
- определения для второго представления параметров звукового поля межканальной когерентности, если аудиосигнал имеет входные каналы, соответствующие каналам, расположенным в пространственной области, либо межканальные разности уровней, если аудиосигнал имеет входные каналы, соответствующие каналам, расположенным в пространственной области, или
- определения когерентности объемного звучания, определяемой как отношение рассеянной энергии, когерентное в звуковом поле, представленном посредством аудиосигнала.
В соответствии с аспектом, предусмотрено устройство для обработки кодированной аудиосцены, содержащей, в первом кадре, первое представление параметров звукового поля и кодированный аудиосигнал, при этом второй кадр представляет собой неактивный кадр, причем устройство содержит:
- детектор активности для обнаружения того, что второй кадр представляет собой неактивный кадр;
- синтезатор синтетических сигналов для синтезирования синтетического аудиосигнала для второго кадра с использованием параметрического описания для второго кадра;
- аудиодекодер для декодирования кодированного аудиосигнала для первого кадра; и
- блок пространственного рендеринга для пространственного рендеринга аудиосигнала для первого кадра с использованием первого представления параметров звукового поля и с использованием синтетического аудиосигнала для второго кадра либо транскодер для формирования выходного формата на основе метаданных, содержащего аудиосигнал для первого кадра, первое представление параметров звукового поля для первого кадра, синтетический аудиосигнал для второго кадра и второе представление параметров звукового поля для второго кадра.
Кодированная аудиосцена может содержать, для второго кадра, второе описание параметров звукового поля, и при этом устройство содержит процессор параметров звукового поля для извлечения одного или более параметров звукового поля из второго представления параметров звукового поля, и при этом блок пространственного рендеринга выполнен с возможностью использования для рендеринга синтетического аудиосигнала для второго кадра одного или более параметров звукового поля для второго кадра.
Устройство может содержать процессор параметров для извлечения одного или более параметров звукового поля для второго кадра,
- при этом процессор параметров выполнен с возможностью сохранения представления параметров звукового поля для первого кадра и синтеза одного или более параметров звукового поля для второго кадра с использованием сохраненного первого представления параметров звукового поля для первого кадра, при этом второй кадр идет после первого кадра во времени, или
- при этом процессор параметров выполнен с возможностью сохранения одного или более представлений параметров звукового поля для нескольких кадров, возникающих во времени перед вторым кадром или возникающих во времени после второго кадра, чтобы экстраполировать или интерполировать с использованием по меньшей мере двух представлений параметров звукового поля из одного или более представлений параметров звукового поля для нескольких кадров, чтобы определять один или более параметров звукового поля для второго кадра, и
- при этом блок пространственного рендеринга выполнен с возможностью использования для рендеринга синтетического аудиосигнала для второго кадра одного или более параметров звукового поля для второго кадра.
Процессор параметров может быть выполнен с возможностью выполнения размывания с направлениями, включенными по меньшей мере в два представления параметров звукового поля, возникающие во времени до или после второго кадра при экстраполяции или интерполяции, для определения одного или более параметров звукового поля для второго кадра.
Кодированная аудиосцена может содержать один или более транспортных каналов для первого кадра,
- при этом генератор синтетических сигналов выполнен с возможностью формирования одного или более транспортных каналов для второго кадра в качестве синтетического аудиосигнала, и
- при этом блок пространственного рендеринга выполнен с возможностью пространственного рендеринга одного или более транспортных каналов для второго кадра.
Генератор синтетических сигналов может быть выполнен с возможностью формирования для второго кадра множества синтетических компонентных аудиосигналов для отдельных компонентов, связанных с выходным аудиоформатом блока пространственного рендеринга, в качестве синтетического аудиосигнала.
Генератор синтетических сигналов может быть выполнен с возможностью формирования по меньшей мере для каждого поднабора по меньшей мере из двух отдельных компонентов, связанных с выходным аудиоформатом, отдельного синтетического компонентного аудиосигнала,
- при этом первый отдельный синтетический компонентный аудиосигнал декоррелируется относительно второго отдельного синтетического компонентного аудиосигнала, и
- при этом блок пространственного рендеринга выполнен с возможностью рендеринга компонента выходного аудиоформата с использованием комбинации первого отдельного синтетического компонентного аудиосигнала и второго отдельного синтетического компонентного аудиосигнала.
Блок пространственного рендеринга может быть выполнен с возможностью применения способа на основе ковариации.
Блок пространственного рендеринга может быть выполнен с возможностью неиспользования обработки декоррелятора или управления обработкой декоррелятора таким образом, что только количество декоррелированных сигналов, сформированных посредством обработки декоррелятора, указанной посредством способа на основе ковариации, используется при формировании компонента выходного аудиоформата.
Генератор синтетических сигналов представляет собой генератор комфортного шума.
Генератор синтетических сигналов может содержать генератор шума, и первый отдельный синтетический компонентный аудиосигнал формируется посредством первой дискретизации генератора шума, и второй отдельный синтетический компонентный аудиосигнал формируется посредством второй дискретизации генератора шума, при этом вторая дискретизация отличается от первой дискретизации.
Генератор шума может содержать таблицу шумов, и при этом первый отдельный синтетический компонентный аудиосигнал формируется посредством обращения к первой части таблицы шумов, и при этом второй отдельный синтетический компонентный аудиосигнал формируется посредством обращения ко второй части таблицы шумов, при этом вторая часть таблицы шумов отличается от первой части таблицы шумов, или
- при этом генератор шума содержит генератор псевдошума, и при этом первый отдельный синтетический компонентный аудиосигнал формируется посредством использования первого посевного числа для генератора псевдошума, и при этом второй отдельный синтетический компонентный аудиосигнал формируется с использованием второго посевного числа для генератора псевдошума.
Кодированная аудиосцена может содержать, для первого кадра, два или более транспортных каналов, и
- при этом генератор синтетических сигналов содержит генератор шума и выполнен с возможностью формирования первого транспортного канала с использованием параметрического описания для второго кадра посредством дискретизации генератора шума и второго транспортного канала посредством дискретизации генератора шума, при этом первый и второй транспортные каналы, определенные посредством дискретизации генератора шума, взвешиваются с использованием одинакового параметрического описания для второго кадра.
Блок пространственного рендеринга может быть выполнен с возможностью работы:
- в первом режиме для первого кадра с использованием микширования прямого сигнала и рассеянного сигнала, сформированного посредством декоррелятора из прямого сигнала под управлением первого представления параметров звукового поля, и
- во втором режиме для второго кадра с использованием микширования первого синтетического компонентного сигнала и второго синтетического компонентного сигнала, при этом первый и второй синтетические компонентные сигналы формируются посредством синтезатора синтетических сигналов посредством различных реализаций шумового процесса или псевдошумового процесса.
Блок пространственного рендеринга может быть выполнен с возможностью управления микшированием во втором режиме посредством параметра рассеянности, параметра распределения энергии или параметра когерентности, извлекаемого для второго кадра посредством процессора параметров.
Генератор синтетических сигналов может быть выполнен с возможностью формирования синтетического аудиосигнала для первого кадра с использованием параметрического описания для второго кадра, и
- при этом блок пространственного рендеринга выполнен с возможностью выполнения комбинирования со взвешиванием аудиосигнала для первого кадра и синтетического аудиосигнала для первого кадра до или после пространственного рендеринга, при этом при комбинировании со взвешиванием интенсивность синтетического аудиосигнала для первого кадра уменьшается относительно интенсивности синтетического аудиосигнала для второго кадра.
Процессор параметров может быть выполнен с возможностью определения для второго неактивного кадра когерентности объемного звучания, определяемой как отношение рассеянной энергии, когерентное в звуковом поле, представленном посредством второго кадра, при этом блок пространственного рендеринга выполнен с возможностью перераспределения энергии между прямыми и рассеянными сигналами во втором кадре на основе звуковой когерентности, при этом энергия звуковых когерентных компонентов объемного звучания удаляется из рассеянной энергии, которая должна перераспределяться в направленные компоненты, и при этом направленные компоненты панорамируются в пространстве воспроизведения.
Устройство может содержать выходной интерфейс для преобразования выходного аудиоформата, сформированного посредством блока пространственного рендеринга, в транскодированный выходной формат, такой как выходной формат, содержащий число выходных каналов, выделенных для громкоговорителей, которые должны быть размещены в заданных положениях, либо транскодированный выходной формат, содержащий данные FOA или НОА, или
- при этом, вместо блока пространственного рендеринга, предусмотрен транскодер для формирования выходного формата на основе метаданных, содержащего аудиосигнал для первого кадра, первые параметры звукового поля для первого кадра и синтетический аудиосигнал для второго кадра и второе представление параметров звукового поля для второго кадра.
Детектор активности может быть выполнен с возможностью обнаружения того, что второй кадр представляет собой неактивный кадр.
В соответствии с аспектом, предусмотрен способ формирования кодированной аудиосцены из аудиосигнала, имеющего первый кадр и второй кадр, содержащий:
- определение первого представления параметров звукового поля для первого кадра из аудиосигнала в первом кадре и второго представления параметров звукового поля для второго кадра из аудиосигнала во втором кадре;
- анализ аудиосигнала для определения в зависимости от аудиосигнала того, что первый кадр представляет собой активный кадр, и второй кадр представляет собой неактивный кадр;
- формирование кодированного аудиосигнала для первого кадра, представляющего собой активный кадр, и формирование параметрического описания для второго кадра, представляющего собой неактивный кадр; и
- составление кодированной аудиосцены посредством объединения первого представления параметров звукового поля для первого кадра, второго представления параметров звукового поля для второго кадра, кодированного аудиосигнала для первого кадра и параметрического описания для второго кадра.
В соответствии с аспектом, предусмотрен способ обработки кодированной аудиосцены, содержащей, в первом кадре, первое представление параметров звукового поля и кодированный аудиосигнал, при этом второй кадр представляет собой неактивный кадр, при этом способ содержит:
- обнаружение того, что второй кадр представляет собой неактивный кадр, и обеспечение параметрического описания для второго кадра;
- синтезирование синтетического аудиосигнала для второго кадра с использованием параметрического описания для второго кадра;
- декодирование кодированного аудиосигнала для первого кадра; и
- пространственный рендеринг аудиосигнала для первого кадра с использованием первого представления параметров звукового поля и с использованием синтетического аудиосигнала для второго кадра или формирование выходного формата на основе метаданных, содержащего аудиосигнал для первого кадра, первое представление параметров звукового поля для первого кадра, синтетический аудиосигнал для второго кадра и второе представление параметров звукового поля для второго кадра.
Способ может содержать обеспечение параметрического описания для второго кадра.
В соответствии с аспектом, предусмотрена кодированная аудиосцена, содержащая:
- первое представление параметров звукового поля для первого кадра;
- второе представление параметров звукового поля для второго кадра;
- кодированный аудиосигнал для первого кадра; и
- параметрическое описание для второго кадра.
В соответствии с аспектом, предусмотрена компьютерная программа для осуществления, при выполнении на компьютере или процессоре, вышеприведенного или нижеприведенного способа.
Чертежи
Фиг. 1 (который разделяется между фиг. 1а и фиг. 1b) показывает пример согласно предшествующему уровню техники, который может использоваться для анализа и синтеза согласно примерам.
Фиг. 2 показывает пример декодера и кодера согласно примерам.
Фиг. 3 показывает пример кодера согласно примеру.
Фиг. 4 и 5 показывают примеры компонентов. Фиг. 5 показывает пример компонента согласно примеру.
Фиг. 6-11 показывают примеры декодеров.
Осуществление изобретения
Сначала будет приведено некоторое пояснение известных парадигм (DTX, DirAC, MASA и т.д.) с описанием технологий, некоторые из которых могут быть реализованы в примерах изобретения по меньшей мере в некоторых случаях.
DTX
Генераторы комфортного шума обычно используются в прерывистой передаче (DTX) речи. В таком режиме, речь сначала классифицируется на активные и неактивные кадры посредством детектора голосовой активности (VAD). Пример VAD содержится в [2]. На основе VAD-результата, только активные речевые кадры кодируются и передаются с номинальной скоростью передачи битов. В течение длинных пауз, в которых присутствует только фоновый шум, скорость передачи битов понижается или обнуляется, и фоновый шум кодируется эпизодически и параметрически. Средняя скорость передачи битов в таком случае значительно уменьшается. Шум формируется в течение неактивных кадров на стороне декодера посредством генератора комфортного шума (CNG). Например, речевые кодеры AMR-WB [2] и 3GPP EVS [3, 4] имеют возможность работать в режиме DTX. Пример эффективного CNG приводится в [5].
Варианты осуществления настоящего изобретения расширяют этот принцип таким способом, что он применяет тот же принцип к иммерсивной разговорной речи с пространственной локализацией звуковых событий.
DirAC
DirAC представляет собой перцепционно обусловленное воспроизведение пространственного звука. Предполагается, что в один момент времени и для одной критической полосы частот, пространственное разрешение слуховой системы ограничено декодированием одной сигнальной метки для направления, а другой - для интерауральной когерентности.
На основе этих допущений, DirAC представляет пространственный звук в одной полосе частот посредством плавного перехода двух потоков: ненаправленного рассеянного потока и направленного нерассеянного потока. Обработка DirAC выполняется в двух фазах: анализ и синтез, проиллюстрированных на фиг. 1 (причем фиг. 1а показывает синтез, фиг. 1b показывает анализ).
В каскаде DirAC-анализа, совпадающий микрофон первого порядка в В-формате рассматривается как ввод, и рассеянность и направление поступления звука анализируются в частотной области.
В каскаде DirAC-синтеза, звук разделяется на два потока, нерассеянный поток и рассеянный поток. Нерассеянный поток воспроизводится в качестве точечных источников с использованием амплитудного панорамирования, которое может выполняться посредством использования векторного амплитудного панорамирования (VBAP) [6]. Рассеянный поток, в общем, отвечает за ощущение огибания и формируется посредством передачи в громкоговорители взаимно декоррелированных сигналов.
Параметры DirAC, также далее называемые «пространственными метаданными» или «метаданными DirAC», состоят из кортежей рассеянности и направления. Направление может представляться в сферической координате посредством двух углов, азимута и подъема, тогда как рассеянность может представлять собой скалярный множитель между 0 и 1.
Определенная работа проведена для уменьшения размера метаданных для обеспечения возможности использования парадигмы DirAC для пространственного кодирования аудио и в сценариях на основе телеконференций [8].
Насколько известно авторам изобретения, система DTX вообще не создавалась или не предлагалась в связи с параметрическим пространственным аудиокодеком, и тем более на основе парадигмы DirAC. В этом состоит предмет вариантов осуществления настоящего изобретения.
MASA
Пространственное аудио на основе метаданных (MASA) представляет собой пространственный аудиоформат, извлеченный из принципа DirAC, который может непосредственно вычисляться из необработанных сигналов микрофона и передаваться в аудиокодек без необходимости проходить через промежуточный формат, такой как амбиофония. Набор параметров, который может состоять из параметра направления, например, в полосах частот, и/или параметра отношения энергий, например, в полосах частот (например, указывающего пропорцию звуковой энергии, которая является направленной), также может использоваться в качестве пространственных метаданных для аудиокодека или блока рендеринга. Эти параметры могут оцениваться из захваченных из массива микрофонов аудиосигналов; например, моно- или стереосигнал может формироваться из сигналов массива микрофонов, которые должны передаваться с пространственными метаданными. Моно- или стереосигнал может кодироваться, например, с помощью базового кодера, такого как 3GPP EVS либо его производная. Декодер может декодировать аудиосигналы в и обрабатывать звук в полосах частот (с использованием передаваемых пространственных метаданных), чтобы получать пространственный вывод, который может представлять собой бинауральный вывод, многоканальный сигнал громкоговорителя или многоканальный сигнал в амбиофоническом формате.
Обуславливание
Иммерсивная речевая связь представляет собой новую область исследования, и существует очень небольшое число систем; кроме того, системы DTX не проектируются для такого варианта применения.
Тем не менее, проще всего комбинировать существующие решения. Можно, например, применять независимо DTX к каждому отдельному многоканальному сигналу. Этот упрощенный подход сталкивается с несколькими проблемами. Для этого, следует передавать дискретно каждый отдельный канал, который является несовместимым с ограничениями при связи с низкой скоростью передачи битов и в силу этого практически несовместимым с DTX, которая проектируется для случаев связи с низкой скоростью передачи битов. Кроме того, в таком случае требуется синхронизировать решение VAD между каналами, чтобы исключать странности и эффекты демаскирования, а также полностью использовать уменьшение скорости передачи битов системы DTX. Фактически, для прерывания передачи и извлечения выгоды из этого, следует удостоверяться, что решения по голосовой активности синхронизируются между всеми каналами.
Другая проблема возникает на стороне приемного устройства, при формировании отсутствующего фонового шума в течение неактивных кадров посредством генератора (ов) комфортного шума. Для иммерсивной связи, в частности, при прямом применении DTX к отдельным каналам, требуется один генератор в расчете на один канал. Если эти генераторы, которые типично дискретизируют случайный шум, используются независимо, то когерентность между каналами должна быть равна нулю или близкой к нулю и может отклоняться перцепционно от исходного звукового ландшафта. С другой стороны, если используется только один генератор, и результирующий комфортный шум копируется во все выходные каналы, то когерентность должна быть очень высокой, и иммерсивность должна радикально уменьшаться.
Эти проблемы могут частично разрешаться посредством применения DTX не непосредственно к входным или выходным каналам системы, а вместо этого после схемы параметрического пространственного кодирования аудио, такой как DirAC, для результирующих транспортных каналов, которые обычно представляют собой микшированную с понижением или уменьшенную версию исходного многоканального сигнала. В этом случае, необходимо задавать то, как неактивные кадры параметризуются и затем получают пространственную форму посредством системы DTX. Это не является тривиальным и представляет собой предмет вариантов осуществления настоящего изобретения. Пространственное изображение должно быть согласованным между активными и неактивными кадрами и должно быть максимально возможно перцепционно достоверным для исходного фонового шума.
Фиг. 3 показывает кодер 300 согласно примеру. Кодер 300 может формировать кодированную аудиосцену 304 из аудиосигнала 302.
Аудиосигнал 304 (поток битов) или аудиосцена 304 (а также другие аудиосигналы, раскрытые ниже) может разделяться на кадры (например, он может представлять собой последовательность кадров). Кадры могут быть ассоциированы с временными квантами, которые в дальнейшем могут задаваться вместе (в некоторых примерах, предшествующий аспект может перекрываться с последующим кадром). Для каждого кадра, значения во временной области (TD) или в частотной области (FD) могут записываться в поток 304 битов. В TD могут быть обеспечены значения для каждой выборки (при этом каждый кадр имеет, например, дискретную последовательность выборок). В FD могут быть обеспечены значения для каждого частотного элемента разрешения. Как поясняется ниже, каждый кадр может классифицироваться (например, посредством детектора активности) в качестве либо активного кадра 306 (например, непустого кадра), либо неактивного кадра 308 (например, пустых кадров или кадров молчания либо исключительно шумовых кадров). Различные параметры (например, активные пространственные параметры 316 или неактивные пространственные параметры 318) также могут быть введены в ассоциации в активный кадр 306 и неактивный кадр 308 (в случае отсутствия данных, ссылочная позиция 319 показывает, что данные не вводятся).
Аудиосигнал 302, например, может представлять собой многоканальный аудиосигнал (например, с двумя каналами или более). Аудиосигнал 302, например, может представлять собой стереоаудиосигнал. Аудиосигнал 302, например, может представлять собой амбиофонический сигнал, например, в А-формате или В-формате. Аудиосигнал 302 может иметь, например, формат MASA (пространственный аудиоформат на основе метаданных). Аудиосигнал 302 может иметь входной формат, представляющий собой амбиофонический формат первого порядка, амбиофонический формат высшего порядка, многоканальный формат, ассоциированный с данной компоновкой громкоговорителей, такой как 5.1, или 7.1, или 7.1+4, или с одним или более аудиоканалами, представляющими один или более различных аудиообъектов, локализованных в пространстве, как указано посредством информации, включенной в ассоциированные метаданные, либо входной формат, представляющий собой ассоциированное с метаданными пространственное аудиопредставление. Аудиосигнал 302 может содержать сигнал микрофона, снимаемый посредством реальных микрофонов или виртуальных микрофонов. Аудиосигнал 302 может содержать синтетически созданный сигнал микрофона (например, находиться в амбиофоническом формате первого порядка или амбиофоническом формате высшего порядка).
Аудиосцена 304 может содержать по меньшей мере одно либо комбинацию следующего:
- первое представление 316 параметров звукового поля (например, активный пространственный параметр) для первого кадра 306;
- второе представление 318 параметров звукового поля (например, неактивный пространственный параметр) для второго кадра 308;
- кодированный аудиосигнал 346 для первого кадра 306; и
- параметрическое описание 34 8 для второго кадра 308 (в некоторых примерах, неактивный пространственный параметр 318 может быть включен в параметрическое описание 348, но параметрическое описание 348 также может включать в себя другие параметры, которые не представляют собой пространственные параметры).
Активные кадры 306 (первые кадры) могут представлять собой такие кадры, которые содержат речь (либо, в некоторых примерах, также другие аудиозвуки, отличающиеся от чистого шума). Неактивные кадры 308 (вторые кадры) могут пониматься как представляющие собой такие кадры, которые не содержат речь (либо, в некоторых примерах, также другие аудиозвуки, отличающиеся от чистого шума), и могут пониматься как содержащие уникально шум.
Анализатор 310 аудиосцен (генератор параметров звукового поля) может быть предусмотрен, например, для формирования версии 324 транспортного канала (подразделенной между 326, и 328) аудиосигнала 302. Здесь можно обратиться к транспортному каналу(ам) 326 каждого первого кадра 306 и/или к транспортному каналу(ам) 328 каждого второго кадра 308 (например, транспортный канал(ы) 328 может пониматься как обеспечивающий параметрическое описание молчания или шума). Транспортный канал(ы) 324 (326, 328) может представлять собой микшированную с понижением версию входного формата 302. В общих чертах, каждый из транспортных каналов 326, 328, например, может представлять собой один отдельный канал, если входной аудиосигнал 302 представляет собой стереоканал. Если входной аудиосигнал 302 имеет более двух каналов, микшированная с понижением версия 324 входного аудиосигнала 302 может иметь меньшее количество каналов, чем входной аудиосигнал 302, но по-прежнему более одного канала в некоторых примерах (например, если входной аудиосигнал 302 имеет четыре канала, микшированная с понижением версия 324 может иметь один, два или три канала).
В качестве дополнения или альтернативы, анализатор 310 аудиосигналов может обеспечивать параметры звукового поля (пространственные параметры), указанные позицией 314. В частности, параметры 314 звукового поля могут включать в себя активные пространственные параметры 316 (первые пространственные параметры или первое представление пространственных параметров), ассоциированные с первым кадром 306, и неактивные пространственные параметры 318 (вторые пространственные параметры или второе представление пространственных параметров), ассоциированные со вторым кадром 308. Каждый активный пространственный параметр 314 (316, 318) может содержать (например, представлять собой) параметр, указывающий пространственную характеристику аудиосигнала (302), например, относительно положения слушателя. В некоторых других примерах, активный пространственный параметр 314 (316, 318) может содержать (например, представлять собой) по меньшей мере частично параметр, указывающий характеристику аудиосигнала 302 относительно положения громкоговорителей. В некоторых примерах, активный пространственный параметр 314 (316, 318) может содержать (например, представлять собой) может по меньшей мере частично содержать характеристики аудиосигнала, извлеченные из источника сигналов.
Например, пространственные параметры 314 (316, 318) могут включать в себя параметры рассеянности: например, один или более параметров рассеянности, указывающих отношение «рассеянный звук к сигналу» относительно звука в первом кадре 306 и/или во втором кадре 308, либо один или более параметров отношения энергий, указывающих отношение энергий прямого звука и рассеянного звука в первом кадре 306 и/или во втором кадре 308, либо параметры межканальной когерентности/когерентности объемного звучания в первом кадре 306 и/или во втором кадре 308, либо отношения мощностей когерентного сигнала и рассеянного звука в первом кадре 306 и/или во втором кадре 308, либо отношения «сигнал к рассеянному звуку» в первом кадре 306 и/или во втором кадре 308.
В примерах, активный пространственный параметр(ы) 316 (первое представление параметров звукового поля) и/или неактивный пространственный параметр(ы) 318 (второе представление параметров звукового поля) могут получаться из входного сигнала 302 в полноканальной версии либо в ее поднаборе, таком как компонент первого порядка амбиофонического входного сигнала высшего порядка.
Устройство 300 может включать в себя детектор 320 активности. Детектор 320 активности может анализировать входной аудиосигнал (в его входной версии 302 либо в его микшированной с понижением версии 324), чтобы определять, в зависимости от аудиосигнала (302 или 324), то, представляет кадр собой активный кадр 306 или неактивный кадр 308, в силу чего выполняя классификацию для кадра. Как видно из фиг. 3, активный детектор 320 может предполагаться как управляющий (например, через контроллер 321) первым блоком 322 отклонения и вторым блоком 322а отклонения. Первый блок 322 отклонения может выбирать между активным пространственным параметром 316 (первым представлением параметров звукового поля) и неактивными пространственными параметрами 318 (вторым представлением параметров звукового поля). Следовательно, детектор 320 активности может определять то, должны выводиться (например, передаваться в служебных сигналах в потоке 304 битов) активные пространственные параметры 316 или неактивные пространственные параметры 318. Тот же контроллер 321 может управлять вторым блоком 322а отклонения, который может выбирать между выводом первого кадра 326 (306) в транспортном канале 324 или втором кадре 328 (308) (например, параметрическим описанием) в транспортном канале 326. Действия первого и второго блоков 322 и 322а отклонения координируются друг с другом: когда активные пространственные параметры 316 выводятся, затем транспортные каналы 326 первого кадра 306 также выводятся, и когда неактивные пространственные параметры 318 выводятся, затем транспортные каналы 328 первого кадра 306, транспортные каналы выводятся. Это обусловлено тем, что активные пространственные параметры 316 (первое представление параметров звукового поля) описывают пространственные характеристики первого кадра 306, тогда как неактивные пространственные параметры 318 (второе представление параметров звукового поля) описывают пространственные характеристики второго кадра 308.
В силу этого детектор 320 активности по существу может определять, какой из первого кадра 306 (326, 346) и его связанных параметров (316) и второго кадра 308 (328, 348) и его связанных параметров (318) следует выводить. Детектор 320 активности также может управлять кодированием некоторой передачи служебных сигналов в потоке битов, которая передает в служебных сигналах то, является ли кадр активным или неактивным (могут использоваться другие технологии).
Детектор 320 активности может выполнять обработку для каждого кадра 306/308 входного аудиосигнала 302 (например, посредством измерения энергии в кадре, например, во всех или по меньшей мере во множестве частотных элементов разрешения конкретных кадров аудиосигнала) и может классифицировать конкретный кадр в качестве первого кадра 306 или второго кадра 308. В общих чертах, детектор 320 активности может определять один отдельный результат классификации для одного отдельного, целого кадра, без различения между различными частотными элементами разрешения и различными выборками того же кадра. Например, один результат классификации может представлять собой «речь» (которая должна составлять первый кадр 306, 326, 346, пространственно описанный посредством активных пространственных параметров 316) или «молчание» (которое должно составлять второй кадр 308, 328, 348, пространственно описанный посредством неактивных пространственных параметров 318). Следовательно, согласно классификации, применяемой посредством детектора 320 активности, блоки 322 и 322а отклонения могут выполнять переключение, и их результат в принципе является допустимым для всех частотных элементов разрешения (и выборок) классифицированного кадра.
Устройство 300 может включать в себя кодер 330 аудиосигналов. Кодер 330 аудиосигналов может формировать кодированный аудиосигнал 344. Кодер 330 аудиосигналов может, в частности, обеспечивать кодированный аудиосигнал 34 6 для первого кадра (306, 326), например, сформированного посредством транспортного канального кодера 340, который может представлять собой часть кодера 330 аудиосигналов. Кодированный аудиосигнал 34 4 может представлять собой или включать в себя параметрическое описание 34 8 молчания (например, параметрическое описание шума) и может формироваться посредством дескриптора 350 SI в транспортные каналы, который может представлять собой часть кодера 330 аудиосигналов. Сформированный второй кадр 348 может соответствовать по меньшей мере одному второму кадру 308 исходного входного аудиосигнала 302 и по меньшей мере одному второму кадру 328 сигнала 324 понижающего микширования и может пространственно описываться посредством неактивных пространственных параметров 318 (второго представления параметров звукового поля). В частности, кодированный аудиосигнал 344 (либо 346 или 348) также может находиться в транспортном канале (и в силу этого может представлять собой сигнал 324 понижающего микширования). Кодированный аудиосигнал 344 (либо 346 или 348) может сжиматься таким образом, чтобы уменьшить его размер.
Устройство 300 может включать в себя формирователь 37 0 кодированных сигналов. Формирователь 370 кодированных сигналов может записывать кодированную версию по меньшей мере кодированной аудиосцены 304. Формирователь 370 кодированных сигналов может работать посредством объединения первого (активного) представления 316 параметров звукового поля для первого кадра 306, второго (неактивного) представления 318 параметров звукового поля для второго кадра 308, кодированного аудиосигнала 346 для первого кадра 306 и параметрического описания 348 для второго кадра 308. Соответственно, аудиосцена 304 может представлять собой поток битов, который может передаваться или сохраняться (либо и то, и другое) и использоваться посредством общего декодера для формирования аудиосигнала, который должен выводиться, который представляет собой копию исходного входного сигнала 302. В аудиосцене 304 (потоке битов), последовательность из «первых кадров»/«вторых кадров» в силу этого может получаться для разрешения воспроизведения входного сигнала 306.
Фиг. 2 показывает пример кодера 300 и декодера 200. Кодер 300 может быть таким же (либо измененным) по сравнению с кодером по фиг. 3 в некоторых примерах (в некоторых других примерах, они могут представлять собой различные варианты осуществления). Кодер 300 может иметь во вводе аудиосигнал 302 (который, например, может быть в В-формате), и может иметь первый кадр 306 (который, например, может представлять собой активный кадр) и второй кадр 308 (который, например, может представлять собой неактивный кадр). Аудиосигнал 302 может вводиться в качестве сигнала 324 (например, в качестве кодированного аудиосигнала 326 для первого кадра и кодированного аудиосигнала 328 или параметрического представления, для второго кадра) в кодер 330 аудиосигналов после выбора, внутреннего в блоке 320 выбора (который может включать в себя аудио, ассоциированное с блоками 322 и 322а отклонения). В частности, блок 320 также может иметь возможности формирования понижающего микширования из входного сигнала 302 (306, 308) в транспортные каналы 324 (326, 328). По существу, блок 320 (блок формирования диаграммы направленности/выбора сигналов) может пониматься как включающий в себя функциональности активного детектора 320 по фиг. 3, но некоторые другие функциональности (такие как формирование пространственных параметров 316 и 318), которые на фиг. 3 выполняются посредством блока 310, могут выполняться посредством «блока 310 анализа DirAC» по фиг. 2. Следовательно, канальный сигнал 324 (326, 328) может представлять собой микшированную с понижением версию исходного сигнала 302. Тем не менее, в некоторых случаях, также может быть возможно то, что понижающее микширование не выполняется для сигнала 302, и сигнал 324 представляет собой просто выбор между первым и вторым кадрами. Кодер 330 аудиосигналов может включать в себя по меньшей мере один из блоков 340 и 350, как пояснено выше. Вывод кодера 330 аудиосигналов может выводить аудиосигнал 344 кодера для первого кадра 346 либо для второго кадра 348. Фиг. 2 не показывает формирователь 370 кодированных сигналов, который, тем не менее, может присутствовать.
Как показано, блок 310 может включать в себя блок анализа DirAC (либо, если обобщать, генератор 310 параметров звукового поля). Блок 310 (генератор параметров звукового поля) может включать в себя анализ 390 на основе гребенки фильтров. Анализ 390 на основе гребенки фильтров может подразделять каждый кадр входного сигнала 302 на множество частотных элементов разрешения, которые могут представлять собой вывод 391 анализа 390 на основе гребенки фильтров. Блок 392а оценки рассеянности может обеспечивать параметры 314а рассеянности (которые могут представлять собой один параметр рассеянности активного пространственного(ых) параметра(ов) 316 для активного кадра 306 либо один параметр рассеянности в неактивном пространственном(ых) параметре(ах) 318 для неактивного кадра 308), например, для каждого частотного элемента разрешения из множества частотных элементов 391 разрешения, выведенных посредством анализа 390 на основе гребенки фильтров. Генератор 310 параметров звукового поля может включать в себя блок 392b оценки направления, вывод 314b которого может представлять собой параметр направления (который может представлять собой один параметр направления активного пространственного(ых) параметра(ов) 316 для активного кадра 306 либо один параметр направления в неактивном пространственном(ых) параметре(ах) 318 для неактивного кадра 308), например, для каждого частотного элемента разрешения из множества частотных элементов 391 разрешения, выведенных посредством анализа 390 на основе гребенки фильтров.
Фиг. 4 показывает пример блока 310 (генератора параметров звукового поля). Генератор 310 параметров звукового поля может быть таким же, что и генератор 310 параметров звукового поля по фиг. 2, и/или может быть таким же или по меньшей мере реализовывать функциональности блока 310 по фиг. 3, несмотря на тот факт, что блок 310 по фиг. 3 также допускает выполнение понижающего микширования входного сигнала 302, хотя это не показывается (или не реализуется) в генераторе 310 параметров звукового поля по фиг. 4.
Генератор 310 параметров звукового поля по фиг. 4 может включать в себя блок 390 анализа на основе гребенки фильтров (который может быть таким же, что и блок 390 анализа на основе гребенки фильтров по фиг. 2). Блок 390 анализа на основе гребенки фильтров может обеспечивать информацию 391 частотной области для каждого кадра и для каждого пучка (частотного мозаичного элемента). Информация 391 частотной области может вводиться в блок 392а анализа рассеянности и/или блок 392b анализа направления, которые могут представлять собой блоки, показанные на фиг. 3. Блок 392а анализа рассеянности и/или блок 392b анализа направления могут обеспечивать информацию 314а рассеянности и/или информацию 314b направления. Она может обеспечиваться для каждого первого кадра 306 (346) и для каждого второго кадра 308 (348). Комплексно, информация, обеспечиваемая блоком 392а и 392b, считается параметрами 314 звукового поля, которые охватывают как первые параметры 316 звукового поля (активные пространственные параметры), так и вторые параметры 318 звукового поля (неактивные пространственные параметры). Активные пространственные параметры 316 могут вводиться в кодер 396 активных пространственных метаданных, и неактивные пространственные параметры 318 могут вводиться в кодер 398 неактивных пространственных метаданных. В результате получаются первое и второе представления (316, 318, комплексно указываемые с помощью 314) параметров звукового поля, которые могут кодироваться в потоке 304 битов (например, через формирователь 37 0 сигналов кодера) и сохраняться для последующего воспроизведения посредством декодера. Независимо от того, кодер 396 активных пространственных метаданных или неактивные пространственные параметры 318 должны кодировать кадр, это может управляться посредством контроллера, такого как контроллер 321 на фиг. 3 (блок 322 отклонения не показан на фиг. 2), например, через классификацию, осуществляемую посредством детектора активности. (Следует отметить, что кодеры 396, 398 также могут выполнять квантование, в некоторых примерах).
Фиг. 5 показывает другой пример возможного генератора 310 параметров звукового поля, который может быть альтернативным генератору 310 параметров звукового поля по фиг. 4 и который также может реализовываться в примерах по фиг. 2 и 3. В этом примере, входной аудиосигнал 302 может уже быть в формате MASA, в котором пространственные параметры уже представляют собой часть входного аудиосигнала 302 (например, в качестве пространственных метаданных), например, для каждого частотного элемента разрешения из множества частотных элементов разрешения. Соответственно, нет необходимости в наличии блока анализа рассеянности и/или направленного блока, и они могут заменяться посредством считывателя 390М MASA. Считыватель 390М MASA может считывать конкретные поля данных в аудиосигнале 302, которые уже содержат такую информацию, как активный пространственный параметр(ы) 316 и неактивный пространственный параметр(ы) 318 (согласно тому факту, представляет кадр сигнала 302 собой первый кадр 306 или второй кадр 308). Примеры параметров, которые могут кодироваться в сигнале 302 (и которые могут считываться посредством -считывателя 390М) MASA, могут включать в себя по меньшей мере одно из направления, отношения энергий, когерентности объемного звучания, когерентности разброса и т.д. Ниже считывателя 390М MASA могут быть предусмотрены кодер 396 активных пространственных метаданных (например, такой как кодер 396 активных пространственных метаданных по фиг. 4) и кодер 398 неактивных пространственных метаданных (например, такой как кодер 398 неактивных пространственных метаданных по фиг. 4) для вывода первого представления 316 параметров звукового поля и второго представления 318 параметров звукового поля, соответственно. Если входной аудиосигнал 302 представляет собой сигнал MASA, то детектор 320 активности может реализовываться как элемент, который считывает определенное поле данных во входном сигнале 302 MASA и классифицирует в качестве активного кадра 306 или неактивного кадра 308 на основе значения, кодированного в поле данных. Пример по фиг. 5 может обобщаться для аудиосигнала 302, который имеет уже кодированную пространственную информацию, которая может кодироваться как активный пространственный параметр 316 или неактивный пространственный параметр 318.
Варианты осуществления настоящего изобретения применяются в системе пространственного кодирования аудио, например, проиллюстрированной на фиг. 2, на котором проиллюстрированы пространственный аудиокодер и декодер на основе DirAC. Далее здесь приводится пояснение означенного.
Кодер 300 может обычно анализировать пространственную аудиосцену в В-формате. В качестве альтернативы, анализ DirAC может регулироваться для анализа различные аудиоформаты, такие как аудиообъекты или многоканальные сигналы, либо сочетание любых пространственных аудиоформатов.
Анализ DirAC (например, выполняемый в любом из каскадов 392а, 392b) может извлекать параметрическое представление 304 из входной аудиосцены 302 (входного сигнала). Направление 314b поступления (DoA) и/или рассеянность 314а, измеренные в расчете на частотно-временную единицу, формируют параметр(ы) 316, 318. Анализ DirAC (например, выполняемый в любом из каскадов 392а, 392b) может осуществляться посредством кодера пространственных метаданных (например, 396 и/или 398), который может квантовать и/или кодировать параметры DirAC, чтобы получать параметрическое представление с низкой скоростью передачи битов (на чертежах, параметрические представления 316, 318 с низкой скоростью передачи битов указываются с теми же ссылочными позициями, что и параметрические представления выше кодеров 396 и/или 398 пространственных метаданных).
Наряду с параметрами 316 и/или 318, сигнал 324 (326) понижающего микширования, извлекаемый из различных источников (например, различных микрофонов), либо входные аудиосигналы 302 (например, различные компоненты многоканального сигнала) могут кодироваться (например, для передачи и/или для хранения) посредством традиционного базового аудиокодера. В предпочтительном варианте осуществления, аудиокодер EVS (например, 330, фиг. 2) может быть предпочтительным для кодирования сигнала 324 (326, 328) понижающего микширования, но варианты осуществления изобретения не ограничены этим базовым кодером и могут применяться к любому базовому аудиокодеру. Сигнал 324 (326, 328) понижающего микширования может состоять, например, различных каналов, также называемых «транспортными каналами»: сигнал 324, например, может представлять собой или содержать четыре сигнала коэффициентов, составляющие сигнал в В-формате, стереопару или монофоническое понижающее микширование, в зависимости от целевой скорости передачи битов. Кодированные пространственные параметры 328 и кодированный поток 326 аудиобитов могут мультиплексироваться до передачи по каналу связи (или сохранения).
В декодере (см. ниже), транспортные каналы 344 декодируются посредством базового декодера, в то время как метаданные DirAC (например, пространственные параметры 316, 318) могут сначала декодироваться до передачи с декодированными транспортными каналами в синтез DirAC. Синтез DirAC использует декодированные метаданные для управления воспроизведением прямого звукового потока и его смешения с рассеянным звуковым потоком. Воспроизведенное звуковое поле может воспроизводиться при произвольной схеме размещения громкоговорителей или может формироваться в амбиофоническом формате (HOA/FOA) с произвольным порядком.
Оценка параметров DirAC
Здесь поясняется неограничивающая технология для оценки пространственный параметров 316, 318 (например, рассеянности 314а, направления 314b). Приведем пример В-формата.
В каждой полосе частот (например, полученной из анализа 390 на основе гребенки фильтров), может оцениваться направление 314а поступления звука вместе с рассеянностью 314b звука. Из частотно-временного анализа входных компонентов 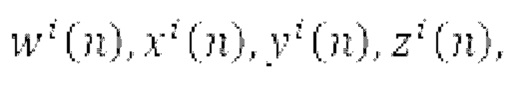 в В-формате, векторы давления и скорости могут определяться следующим образом:
в В-формате, векторы давления и скорости могут определяться следующим образом:
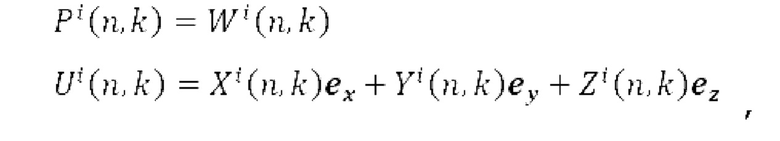
где i является индексом ввода 302, и k и n являются временными и частотными индексами частотно-временной плитки, и ех, еу, ez представляют единичные декартовы векторы. Р(n, k) и U(n, k) могут быть необходимыми, в некоторых примерах, для вычисления параметров (316, 318) DirAC, а именно DOA 314а и рассеянности 314а, например, через вычисление вектора интенсивности:
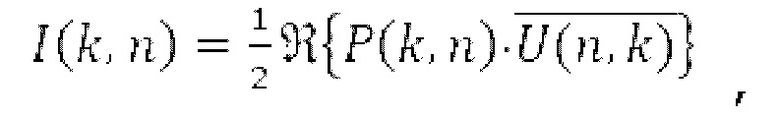
где  обозначает комплексное сопряжение. Рассеянность комбинированного звукового поля задается следующим образом:
обозначает комплексное сопряжение. Рассеянность комбинированного звукового поля задается следующим образом:
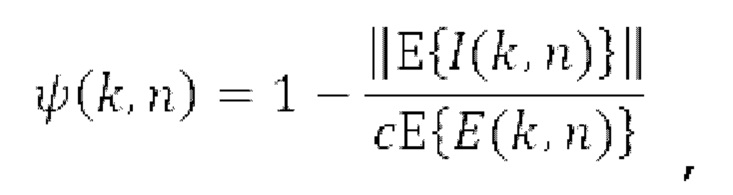
где  обозначает оператор временного усреднения, с является скоростью звука, и Е(k, n) является энергией звукового поля, заданной следующим образом:
обозначает оператор временного усреднения, с является скоростью звука, и Е(k, n) является энергией звукового поля, заданной следующим образом:
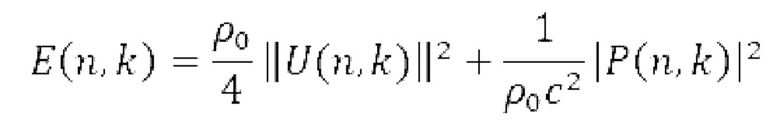
Рассеянность звукового поля задается как отношение между интенсивностью звука и плотностью энергии, имеющее значения между 0 и 1.
Направление поступления (DoA) выражается посредством единичного вектора direction(n, k), заданного следующим образом:
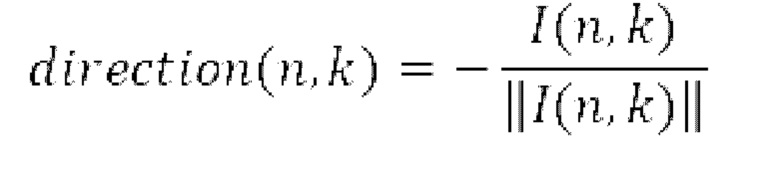
Направление 314b поступления может определяться посредством энергетического анализа (например, в 392b) входного сигнала 302 в B-формате и может задаваться как противоположное направление вектора интенсивности. Направление задается в декартовых координатах, но, например, может легко преобразовываться в сферические координаты, заданные посредством единичного радиуса, угла азимута и угла подъема.
В случае передачи, параметры 314а, 314b (316, 318) должны передаваться в сторону приемного устройства (например, сторону декодера) через поток битов (например, 304). Для более надежной передачи по сети с ограниченной пропускной способностью, предпочтительным или даже необходимым является поток битов с низкой скоростью передачи битов, который может достигаться посредством проектирования эффективной схемы кодирования для параметров 314а, 314b DirAC (316, 318). Он может использовать, например, такие технологии, как группировка полос частот, посредством усреднения параметров по различным полосам частот и/или единицам времени, прогнозирование, квантование и энтропийное кодирование. В декодере, передаваемые параметры могут декодироваться для каждой частотно-временной единицы (k, n) в случае, если ошибки не возникают в сети. Тем не менее, если характеристики сети не являются достаточно хорошими для обеспечения надлежащей передачи пакетов, пакет может теряться во время передачи. Варианты осуществления настоящего изобретения направлены на обеспечение решения во втором случае.
Декодер
Фиг. 6 показывает пример устройства 200 декодера. Оно может представлять собой устройство для обработки кодированной аудиосцены (304), содержащей, в первом кадре (346), первое представление (316) параметров звукового поля и кодированный аудиосигнал (346), при этом второй кадр (348) представляет собой неактивный кадр. Устройство 200 декодера может содержать по меньшей мере одно из следующего:
- детектор (2200) активности для обнаружения того, что второй кадр (348) представляет собой неактивный кадр, и для обеспечения параметрического описания (328) для второго кадра (308);
- синтезатор (210) синтетических сигналов для синтезирования синтетического аудиосигнала (228) для второго кадра (308) с использованием параметрического описания (348) для второго кадра (308);
- аудиодекодер (230) для декодирования кодированного аудиосигнала (346) для первого кадра (306); и
- блок (240) пространственного рендеринга для пространственного рендеринга аудиосигнала (202) для первого кадра (306) с использованием первого представления (316) параметров звукового поля и с использованием синтетического аудиосигнала (228) для второго кадра (308).
В частности, детектор (2200) активности может применять команду 221', которая может определять то, классифицируется входной кадр в качестве активного кадра 346 или неактивного кадра 348. Детектор 2200 активности может определять классификацию входного кадра, например, из информации 221, которая передается ли в служебных сигналах или определяется из длины полученного кадра.
Синтезатор (210) синтетических сигналов, например, может формировать шум 228, например, с использованием информации (например, параметрической информации), полученной из параметрического представления 348. Блок 220 пространственного рендеринга может формировать выходной сигнал 202 таким образом, что неактивные кадры 228 (полученные из кодированных кадров 348) обрабатываются через неактивный пространственный параметр(ы) 318, чтобы добиваться того, что слушатель-человек имеет трехмерное пространственное впечатление источника шума.
Следует отметить, что на фиг. 6, позиции 314, 316, 318, 344, 346, 348 являются одинаковыми с позициями по фиг. 3, поскольку они соответствуют получению из потока 304 битов. Несмотря на это, имеется вероятность того, что будут иметь место некоторые незначительные различия (например, вследствие квантования).
Фиг. 6 также показывает контроллер 221', который может управлять блоком 224' отклонения таким образом, что сигнал 226 (выведенный посредством синтезатора 210 синтетических сигналов) или аудиосигнал 228 (выведенный посредством аудиодекодера 230) может выбираться, например, через классификацию, осуществляемую посредством детектора 220 активности. В частности, сигнал 224 (либо 226 или 228) по-прежнему может представлять собой сигнал понижающего микширования, который может вводиться в блок 220 пространственного рендеринга таким образом, что блок пространственного рендеринга формирует выходной сигнал 202 через активные или неактивные пространственные параметры 314 (316, 318). В некоторых примерах, сигнал 224 (либо 226 или 228), тем не менее, может микшироваться с повышением, так что число каналов сигнала 224 увеличивается относительно кодированной версии 344 (346, 348). В некоторых примерах, несмотря на повышающее микширование, число каналов сигнала 22 4 может быть меньше числа каналов выходного сигнала 202.
Ниже приведены другие примеры устройства 200 декодера. Фиг. 7-10 показывают примеры устройства 700, 800, 900, 1000 декодера, которое может осуществлять устройство 200 декодера.
Даже если на фиг. 7-10 некоторые элементы показаны как внутренние по отношению к блоку 220 пространственного рендеринга, тем не менее, они могут находиться за пределами блока 220 пространственного рендеринга в некоторых примерах. Например, синтетический синтезатор 210 может быть частично или полностью внешним по отношению к блоку 220 пространственного рендеринга.
В этих примерах, может быть включен процессор 275 параметров (который может быть внутренним или внешним по отношению к блоку 220 пространственного рендеринга). Процессор 275 параметров также может считаться присутствующим в декодере по фиг. 6, хотя и не показан.
Процессор 275 параметров по любому из фиг. 7-10 может включать в себя, например, декодер 278 неактивных пространственных параметров для обеспечения неактивных кадров, которые могут представлять собой интеллектуальные параметры 318 (например, полученные из передачи служебных сигналов в потоке 304 битов), и/или блок 279 («декодер восстановления пространственных параметров в непередаваемых кадрах»), который обеспечивает неактивные пространственные параметры, которые не считываются в потоке 304 битов, но которые получаются (например, восстанавливаются, реконструируются, экстраполируются, логически выводятся и т.д.), например, посредством экстраполяции или синтетически формируются.
Следовательно, второе представление параметров звукового поля также может представлять собой сформированный параметр 219, который не присутствует в потоке 304 битов. Как поясняется ниже, восстановленные (реконструированные, экстраполированные, логически выведенные и т.д.) пространственные параметры 219 могут получаться, например, через «стратегию запоминания», «стратегию экстраполяции направления» и/или через «размывание направления» (см. ниже). Процессор 275 параметров в силу этого может экстраполировать либо так или иначе получать пространственные параметры 219 из предыдущих кадров. Как можно видеть на фиг. 6-9, переключатель 275' может выбирать между неактивными пространственными параметрами 318, передаваемыми в служебных сигналах в потоке 304 битов, и восстановленными пространственными параметрами 219. Как пояснено выше, кодирование кадров 348 молчания (SID) (а также неактивных пространственных параметров 318) обновляется с более низкой скоростью передачи битов, чем кодирование первых кадров 346: неактивные пространственные параметры 318 обновляются с меньшей частотой относительно активных пространственных параметров 316, и некоторые стратегии выполняются посредством процессора 275 (1075) параметров для восстановления непередаваемых в служебных сигналах пространственных параметров 219 для непередаваемых неактивных кадров. Соответственно, переключатель 275' может выбирать между передаваемыми в служебных сигналах неактивными пространственными параметрами 318 и непередаваемыми в служебных сигналах (но восстановленными или иным образом реконструированными) неактивными пространственными параметрами 219. В некоторых случаях, процессор 275' параметров может сохранять одно или более представлений 318 параметров звукового поля для нескольких кадров, возникающих перед вторым кадром или возникающих во времени после второго кадра, чтобы экстраполировать (или интерполировать) параметры 219 звукового поля для второго кадра. В общих чертах, блок 220 пространственного рендеринга может использовать, для рендеринга синтетического аудиосигнала 202 для второго кадра 308, один или более параметров 318 звукового поля для второго кадра 219. Помимо этого или в качестве альтернативы, процессор 275 параметров может сохранять представления 316 параметров звукового поля для активных пространственных параметров (показаны на фиг. 10) и синтезировать параметры 219 звукового поля для второго кадра (неактивного кадра) с использованием сохраненного первого представления 316 параметров звукового поля (активных кадров), чтобы формировать восстановленный пространственный параметр 319. Как показано на фиг. 10 (но также реализуется на любом из фиг. 6-9), также можно включать декодер 276 активных пространственных параметров, из которого активные пространственные параметры 316 могут получаться из потока 304 битов. Это позволяет выполнять размывание с направлениями, включенными по меньшей мере в два представления параметров звукового поля, возникающие во времени до или после второго кадра (308) при экстраполяции или интерполяции, чтобы определять один или более параметров звукового поля для второго кадра (308).
Синтезатор 210 синтетических сигналов может быть внутренним по отношению к блоку 220 пространственного рендеринга или может быть внешним, либо, в некоторых случаях, он может иметь внутреннюю часть и внешнюю часть. Синтетический синтезатор 210 может работать с каналами понижающего микширования транспортных каналов 228 (которых меньше, чем выходных каналов) (здесь следует отметить, что М является числом каналов понижающего микширования, и N является числом выходных каналов). Генератор 210 синтетических сигналов (другое название для синтезатора синтетических сигналов) может формировать, для второго кадра, множество синтетических компонентных аудиосигналов (по меньшей мере, в одном из каналов транспортного сигнала или по меньшей мере в одном отдельном компоненте выходного аудиоформата) для отдельных компонентов, связанных с внешним форматом блока пространственного рендеринга, в качестве синтетического аудиосигнала. В некоторых случаях, он может находиться в каналах сигнала 228 понижающего микширования, и в некоторых случаях он может находиться в одном из внутренних каналов пространственного рендеринга.
Фиг. 7 показывает пример, в котором по меньшей мере K каналов 228а, полученных из синтетического аудиосигнала 228 (например, в его версии 228b ниже анализа 720 на основе гребенки фильтров), могут декоррелироваться. Это получается, например, когда синтетический синтезатор 210 формирует синтетический аудиосигнал 228 по меньшей мере в одном из М каналов синтетического аудиосигнала 228. Эта обработка 730 корреляции может применяться к сигналу 228b (либо по меньшей мере к одному или некоторым его компонентам) ниже блока 720 анализа на основе гребенки фильтров, так что могут получаться по меньшей мере K каналов (где K≥М и/или K≤N, при этом N является числом выходных каналов). Затем, K декоррелированных каналов 228а и/или М каналов сигнала 228b могут вводиться в блок 740 для формирования усилений при микшировании/матриц микширования, который, через пространственные параметры 218, 219 (см. выше), может обеспечивать микшированный сигнал 742. Микшированный сигнал 742 может подвергаться обработке в блоке 746 синтеза на основе гребенки фильтров для получения выходного сигнала в N выходных каналов 202. По существу, ссылочная позиция 228а по фиг. 7 может представлять отдельный синтетический компонентный аудиосигнал, который декоррелируется относительно отдельного синтетического компонентного аудиосигнала 228b, так что блок пространственного рендеринга (и блок 740) использует комбинацию компонента 228а и компонента 228b. Фиг. 8 показывает пример, в котором все каналы 228 формируются в K каналов.
Кроме того, на фиг. 7, декоррелятор 730 применяется к K декоррелированных каналов 228b ниже блока 720 анализа на основе гребенки фильтров. Это может выполняться, например, для рассеянного поля. В некоторых случаях, М каналов сигнала 228b находятся ниже блока 720 анализа с обратной связью и могут вводиться в блок 744, формирующий усиления при микшировании/матрицы микширования. Способ на основе ковариации может использоваться для уменьшения проблем с декорреляторами 730, например, посредством масштабирования каналов 228b на значение, ассоциированное со значением, комплементарным ковариации между различными каналами.
Фиг. 8 показывает пример синтезатора 210 синтетических сигналов, который находится в частотной области. Способ на основе ковариации может использоваться для синтетического синтезатора 210 (810) по фиг. 8. В частности, синтетический аудиосинтезатор 210 (810) вводит свой вывод 228с в K каналов (с K≥М), тогда как транспортный канал 228 должен находиться в М каналов.
Фиг. 9 показывает пример декодера 900 (варианта осуществления декодера 200), который может пониматься как использующий гибридную технологию декодера 800 по фиг. 8 и декодера 700 по фиг. 7. Как можно видеть здесь, синтезатор 210 синтетических сигналов включает в себя первую часть 210 (710), которая формирует синтетический аудиосигнал 228 в М каналов сигнала 228 понижающего микширования. Сигнал 228 может вводиться в блок 730 анализа на основе гребенки фильтров, который может обеспечивать вывод 228b, в котором несколько полос частот фильтра отличаются друг от друга. В это время, каналы 228b могут декоррелироваться, чтобы получать декоррелированный сигнал 228а в K каналов. Между тем, вывод 228b анализа на основе гребенки фильтров в М каналов передается в блок 740 для формирования матриц усиления при микшировании, которые могут обеспечивать микшированную версию микшированного сигнала 742. Микшированный сигнал 742 может по-прежнему учитывать неактивные пространственные параметры 318 и/или восстановленные (реконструированные) пространственные параметры для неактивных кадров 219. Следует отметить, что вывод 228а декоррелятора 730 также может суммироваться, в сумматоре 920, с выводом 228d второй части 810 синтезатора 210 синтетических сигналов, который вводит синтетический сигнал 228d в K каналов. Сигнал 228d может суммироваться в блоке 920 суммирования с декоррелированным сигналом 228а для обеспечения суммированного сигнала 228е в блок 740 микширования. Следовательно, можно выполнять рендеринг конечного выходного сигнала 202 посредством использования комбинации компонента 228b и компонента 228е, которая приводит в соответствие как декоррелированные компоненты 228а, так и сформированные компоненты 228d. Компоненты 228b, 228а, 228d, 228е (если присутствуют) по фиг. 8 и 7 могут пониматься, например, как рассеянные и нерассеянные компоненты синтетического сигнала 228. В частности, обращаясь к декодеру 900 по фиг. 9, по существу полосы низких частот сигнала 228е могут получаться из транспортного канала 710 (и получаются из 228а), и полосы высоких частот сигнала 228е могут формироваться в синтезаторе 810 (и находятся в каналах 228d), при этом их суммирование в сумматоре 920 позволяет иметь обе из них в сигнале 228е.
В частности, на вышеописанных фиг. 7-10 не показан транспортный канальный декодер для активных кадров.
Фиг. 10 показывает пример декодера 1000 (варианта осуществления декодера 200), в котором показаны как аудиодекодер 230 (который обеспечивает декодированные каналы 226), так и синтезатор 210 синтетических сигналов (здесь считающийся разделенным между первой внешней частью 710 и второй внутренней частью 810). Показывается переключатель 224', который может быть аналогичным переключателю по фиг. 6 (например, управляемому посредством контроллера или команды 221', выданной детектором 220 активности). По существу, можно выбирать между режимом, в котором декодированная аудиосцена 226 вводится в блок 220 пространственного рендеринга, и другим режимом, в котором обеспечивается синтетический аудиосигнал 228. Сигнал 224 (226, 228) понижающего микширования находится в М каналов, что, в общем, меньше, чем N выходных каналов выходного сигнала 202.
Сигнал 224 (226, 228) может вводиться в блок 720 анализа на основе гребенки фильтров. Вывод 228b анализа 720 на основе гребенки фильтров (во множестве частотных элементов разрешения) может вводиться на блок 750 суммирования при повышающем микшировании, который также может вводиться посредством сигнала 228d, обеспеченного второй частью 810 синтезатора 210 синтетических сигналов. Вывод 228f блока 750 суммирования при повышающем микшировании может вводиться в обработку 730 коррелятора. Вывод 228а обработки 730 декоррелятора может вводиться вместе с выводом 228f блока 750 суммирования при повышающем микшировании в блок 740 для формирования усилений при микшировании и матриц микширования. Блок 750 суммирования при повышающем микшировании, например, может увеличивать число каналов с М до K (и, в некоторых случаях, он может масштабировать их, например, посредством умножения на постоянные коэффициенты) и может суммировать K каналов с K каналов 228d, сформированных посредством синтезатора 210 синтетических сигналов (например, второй внутренней части 810). Для рендеринга первого (активного) кадра блок 740 микширования может рассматривать по меньшей мере одно из активных пространственных параметров 316, обеспечиваемых в потоке 304 битов, восстановленных (реконструированных) пространственных параметров 210, экстраполированных или полученных иным способом (см. выше).
В некоторых примерах, вывод блока 720 анализа на основе гребенки фильтров может находиться в М каналов, но может учитывать различные полосы частот. Для первых кадров (и переключателя 224' и переключателя 222', расположенных таким образом, как указано на фиг. 10), декодированный сигнал 226 (по меньшей мере в двух каналах) может вводиться в анализ 720 на основе гребенки фильтров и может в силу этого взвешиваться в блоке 750 суммирования при повышающем микшировании через K шумовых каналов 228d (каналов передачи синтетических сигналов) для получения сигнала 228f в K каналов. Следует напомнить, что K≥М и может содержать, например, рассеянный канал и направленный канал. В частности, рассеянный канал может декоррелироваться посредством декоррелятора 730, чтобы получать декоррелированный сигнал 228а. Соответственно, декодированный аудиосигнал 224 может взвешиваться (например, в блоке 750) с синтетическим аудиосигналом 228d, который может маскировать переход между активными и неактивными кадрами (первыми кадрами и вторыми кадрами). После этого, вторая часть 810 синтезатора 210 синтетических сигналов используется не только для активных кадров, но также и для неактивных кадров.
Фиг. 11 показывает другой пример декодера 200, который может содержать, в первом кадре (346), первое представление (316) параметров звукового поля и кодированный аудиосигнал (346), при этом второй кадр (348) представляет собой неактивный кадр, причем устройство содержит детектор активности (220) для обнаружения того, что второй кадр (348) представляет собой неактивный кадр, и для обеспечения параметрического описания (328) для второго кадра (308); синтезатор (210) синтетических сигналов для синтезирования синтетического аудиосигнала (228) для второго кадра (308) с использованием параметрического описания (348) для второго кадра (308); аудиодекодер (230) для декодирования кодированного аудиосигнала (346) для первого кадра (306); и блок (240) пространственного рендеринга для пространственного рендеринга аудиосигнала (202) для первого кадра (306) с использованием первого представления (316) параметров звукового поля и с использованием синтетического аудиосигнала (228) для второго кадра (308) либо транскодер для формирования выходного формата на основе метаданных, содержащего аудиосигнал (346) для первого кадра (306), первое представление (316) параметров звукового поля для первого кадра (306), синтетический аудиосигнал (228) для второго кадра (308) и второе представление (318) параметров звукового поля для второго кадра (308).
Обращаясь к синтезатору 210 синтетических сигналов в вышеприведенных примерах, как пояснено выше, он может содержать (или даже представлять собой) генератор шума (например, генератор комфортного шума). В примерах, генератор (210) синтетических сигналов может содержать генератор шума, и первый отдельный синтетический компонентный аудиосигнал формируется посредством первой дискретизации генератора шума, и второй отдельный синтетический компонентный аудиосигнал формируется посредством второй дискретизации генератора шума, при этом вторая дискретизация отличается от первой дискретизации.
Помимо этого или в качестве альтернативы, генератор шума содержит таблицу шумов, и при этом первый отдельный синтетический компонентный аудиосигнал формируется посредством обращения к первой части таблицы шумов, и при этом второй отдельный синтетический компонентный аудиосигнал формируется посредством обращения ко второй части таблицы шумов, при этом вторая часть таблицы шумов отличается от первой части таблицы шумов.
В примерах, генератор шума содержит генератор псевдошума, и при этом первый отдельный синтетический компонентный аудиосигнал формируется посредством использования первого посевного числа для генератора псевдошума, и при этом второй отдельный синтетический компонентный аудиосигнал формируется с использованием второго посевного числа для генератора псевдошума.
В общих чертах, блок 220 пространственного рендеринга, в примерах по фиг. 6, 7, 9, 10 и 11, может работать в первом режиме для первого кадра (306) с использованием микширования прямого сигнала и рассеянного сигнала, сформированного посредством декоррелятора (730) из прямого сигнала под управлением первого представления (316) параметров звукового поля, и во втором режиме для второго кадра (308) с использованием микширования первого синтетического компонентного сигнала и второго синтетического компонентного сигнала, при этом первый и второй синтетические компонентные сигналы формируются посредством синтезатора (210) синтетических сигналов посредством различных реализаций шумового процесса или псевдошумового процесса.
Как пояснено выше, блок (220) пространственного рендеринга может быть выполнен с возможностью управления микшированием (740) во втором режиме посредством параметра рассеянности, параметра распределения энергии или параметра когерентности, извлекаемого для второго кадра (308) посредством процессора параметров.
Вышеприведенные примеры также относятся к способу формирования кодированной аудиосцены из аудиосигнала, имеющего первый кадр (306) и второй кадр (308), содержащему: определение первого представления (316) параметров звукового поля для первого кадра (306) из аудиосигнала в первом кадре (306) и второго представления (318) параметров звукового поля для второго кадра (308) из аудиосигнала во втором кадре (308); анализ аудиосигнала, чтобы определять, в зависимости от аудиосигнала, то, что первый кадр (306) представляет собой активный кадр, и второй кадр (308) представляет собой неактивный кадр; формирование кодированного аудиосигнала для первого кадра (306), представляющего собой активный кадр, и формирование параметрического описания (348) для второго кадра (308), представляющего собой неактивный кадр; и составление кодированной аудиосцены посредством объединения первого представления (316) параметров звукового поля для первого кадра (306), второго представления (318) параметров звукового поля для второго кадра (308), кодированного аудиосигнала для первого кадра (306) и параметрического описания (348) для второго кадра (308).
Вышеприведенные примеры также относятся к способу обработки кодированной аудиосцены, содержащей, в первом кадре (306), первое представление (316) параметров звукового поля и кодированный аудиосигнал, при этом второй кадр (308) представляет собой неактивный кадр, при этом способ содержит: обнаружение того, что второй кадр (308) представляет собой неактивный кадр, и обеспечение параметрического описания (348) для второго кадра (308); синтезирование синтетического аудиосигнала (228) для второго кадра (308) с использованием параметрического описания (348) для второго кадра (308); декодирование кодированного аудиосигнала для первого кадра (306); и пространственный рендеринг аудиосигнала для первого кадра (306) с использованием первого представления (316) параметров звукового поля и с использованием синтетического аудиосигнала (228) для второго кадра (308) или формирование выходного формата на основе метаданных, содержащего аудиосигнал для первого кадра (306), первое представление (316) параметров звукового поля для первого кадра (306), синтетический аудиосигнал (228) для второго кадра (308) и второе представление (318) параметров звукового поля для второго кадра (308).
Также предусмотрена кодированная аудиосцена (304), содержащая: первое представление (316) параметров звукового поля для первого кадра (306); второе представление (318) параметров звукового поля для второго кадра (308); кодированный аудиосигнал для первого кадра (306); и параметрическое описание (348) для второго кадра (308).
В вышеприведенных примерах, имеется вероятность того, что пространственные параметры 316 и/или 318 передаются для каждой полосы (подполосы) частот.
Согласно некоторым примерам, это параметрическое описание 348 молчания может содержать этот частичный параметр 318, который может в силу этого представлять собой часть SID 348.
Пространственный параметр 318 для неактивных кадров может быть допустимым для каждой подполосы частот (либо полосы частот или частоты).
Пространственные параметры 316 и/или 318, поясненные выше, передаваемые или кодированные, в ходе активной фазы 346 и в SID 348 могут иметь различное частотное разрешение, и помимо этого или в качестве альтернативы, пространственные параметры 316 и/или 318, поясненные выше, передаваемые или кодированные, в ходе активной фазы 346 и в SID 348 могут иметь различное временное разрешение, и помимо этого или в качестве альтернативы, пространственные параметры 316 и/или 318, поясненные выше, передаваемые или кодированные, в ходе активной фазы 346 и в SID 348 могут иметь различное разрешение квантования.
Следует отметить, что устройство декодирования и устройство кодирования могут представлять собой такие устройства, как CELP или DCX или блоки расширения полосы пропускания.
Также можно использовать и схему кодирования на основе MDCT (модифицированного дискретного косинусного преобразования).
В настоящих примерах устройства 200 декодера (в любом из его вариантов осуществления, например, в вариантах осуществления по фиг.6-11), можно заменять аудиодекодер 230 и блок 240 пространственного рендеринга транскодером для формирования выходного формата на основе метаданных, содержащего аудиосигнал для первого кадра, первое представление параметров звукового поля для первого кадра, синтетический аудиосигнал для второго кадра и второе представление параметров звукового поля для второго кадра.
Пояснение
Варианты осуществления настоящего изобретения предлагают способ расширять DTX на параметрическое пространственное кодирование аудио. В силу этого предлагается применять традиционную DTX/CNG к каналам понижающего микширования/транспортным каналам (например, 324, 224) и расширять ее с пространственными параметрами (далее называемыми «пространственным SID»), например, 316, 318, и пространственным рендерингом для неактивных кадров (например, 308, 328, 348, 228) на стороне декодера. Для восстановления исходной версии пространственного изображения неактивных кадров (например, 308, 328, 348, 228), SID 326, 226 в транспортные каналы изменяется с некоторыми пространственными параметрами 319 (или 219) (пространственными SID), специально спроектированными и релевантными для иммерсивных фоновых шумов. Варианты осуществления настоящего изобретения (поясненные ниже и/или выше) охватывают по меньшей мере два аспекта:
- Расширение SID в транспортные каналы для пространственного рендеринга. Для этого, дескриптор изменяется с пространственными параметрами 318, например, извлекаемыми из парадигмы DirAC или формата MASA. По меньшей мере один из параметров 318, таких как рассеянность 314а и/или направление 314b поступления, и/или межканальная когерентность(и)/когерентность(и) объемного звучания, и/или отношения энергий, может передаваться наряду с SID 328 (348) в транспортные каналы. В определенных случаях и при определенных допущениях, некоторые параметры 318 могут отбрасываться. Например, если предполагается, что фоновый шум полностью рассеивается, можно отбрасывать передачу направлений 314b, которые в таком случае являются незначащими.
- Придание пространственной формы на стороне приемного устройства неактивным кадрам посредством рендеринга CNG в транспортных каналах в пространстве. Принцип на основе синтеза DirAC либо одна из его производных может использоваться со стимуляцией посредством передаваемых в конечном счете пространственных параметров 318 в пространственном SID-дескрипторе фонового шума. Существуют по меньшей мере два варианта, которые даже могут комбинироваться: формирование комфортного шума в транспортных каналах может формироваться только для транспортных каналов 228 (это имеет место на фиг. 7, на котором комфортный шум 228 формируется посредством синтезатора 710 синтетических сигналов); или CNG в транспортных каналах также может формироваться для транспортных каналов, как и для дополнительных каналов, используемых в блоке рендеринга для повышающего микширования (это имеет место на фиг. 9, на котором некоторый комфортный шум 228 формируется посредством первой части 710 синтезатора синтетических сигналов, но некоторый другой комфортный шум 228d формируется посредством второй части 810 синтезатора синтетических сигналов). В последнем случае, вторая CNG-часть 710, например, дискретизация случайного шума 22 8d с другим посевным числом, может автоматически декоррелировать сформированные каналы 228d и минимизировать использование декорреляторов 730, которые могут представлять собой источники типичных артефактов. Кроме того, CNG также может использоваться (как показано на фиг. 10) в активных кадрах, но, в некоторых примерах, с уменьшенной интенсивностью для сглаживания перехода между активными и неактивными фазами (кадрами), а также для маскировки конечных артефактов от транспортного канального кодера и параметрической парадигмы DirAC.
Фиг. 3 иллюстрирует общее представление вариантов осуществления устройства 300 кодера. На стороне кодера, сигнал может анализироваться посредством анализа DirAC. DirAC может анализировать сигналы, такие как В-формат или амбиофония первого порядка (FOA). Тем не менее, также можно расширять принцип на амбиофонию высшего порядка (НОА) и даже на многоканальные сигналы, ассоциированные с данной компоновкой громкоговорителей, такой как 5.1 или 7.1, или 7.1+4, как предложено в [10]. Входной формат 302 также может представлять собой отдельные аудиоканалы, представляющие один или более различных аудиообъектов, локализованных в пространстве посредством информации, включенной в ассоциированные метаданные. В качестве альтернативы, входной формат 302 может представлять собой ассоциированное с метаданными пространственное аудио (MASA). В этом случае, пространственные параметры и транспортные каналы непосредственно передаются в устройство 300 кодера. Анализ аудиосцен (например, как показано на фиг. 5) в таком случае может пропускаться, и только конечное (повторное) квантование и повторная дискретизация пространственных параметров должны выполняться для неактивного набора пространственных параметров 318 либо для активного и неактивного наборов пространственных параметров 316, 318.
Анализ аудиосцен может быть проводиться для активных и неактивных кадров 306, 308 и формировать два набора пространственных параметров 316, 318. Первый набор 316 в случае активного кадра 308 и другой (318) в случае неактивного кадра 308. Можно не иметь неактивных пространственных параметров, но в предпочтительном варианте осуществления изобретения, неактивных пространственных параметров 318 меньше по числу, и/или они квантуются более приблизительно, чем активные пространственные параметры 316. После этого, две версии пространственных параметров (также называемые «метаданными DirAC») могут быть доступными. Что важно, варианты осуществления настоящего изобретения могут быть главным образом направлены на пространственные представления аудиосцены с точки зрения слушателя. В силу этого рассматриваются пространственные параметры, такие как параметры 318, 316 DirAC, включающие в себя одно или более направлений наряду с конечным коэффициентом рассеянности или отношением(ями) энергий. В отличие от межканальных параметров, эти пространственные параметры с точки зрения слушателя имеют существенное преимущество того, что они являются агностическими относительно системы захвата и воспроизведения звука. Эта параметризация не является конкретной для любого конкретного массива микрофонов или схемы размещения громкоговорителей.
Детектор 320 голосовой активности (либо, если обобщать, детектор активности) затем может применяться к входному сигналу 302 и/или транспортным каналам 326, сформированным посредством анализатора аудиосцен. Транспортные каналы меньше числа входных каналов; обычно понижающее мономикширование, понижающее стереомикширование, А-формат или амбиофонический сигнал первого порядка. На основе решения VAD, обрабатываемый текущий кадр задается как активный (306, 326) или неактивный (308, 328). В случае активных кадров (306, 326), выполняется традиционное кодирование речи или аудио транспортных каналов. Результирующие кодовые данные затем комбинируются с активными пространственными параметрами 316. В случае неактивных кадров (308, 328), описание 328 информации молчания транспортных каналов 324 формируется эпизодически, обычно с регулярными кадровыми интервалами в ходе неактивной фазы, например, каждые 8 активных кадров (306, 326, 346). SID (328, 348) в транспортные каналы затем может изменяться в мультиплексоре 370 (формирователе кодированных сигналов) с неактивными пространственными параметрами. В случае если неактивные пространственные параметры 318 являются нулевыми, только SID 348 в транспортные каналы затем передается. Полный SID может обычно представлять собой описание с очень низкой скоростью передачи битов, которая, например, составляет всего 2,4 или 4,25 Кбит/с. Средняя скорость передачи битов еще более уменьшается в неактивной фазе, поскольку большую часть времени передача не выполняется, и данные не отправляются.
В предпочтительном варианте осуществления изобретения, SID 348 в транспортные каналы имеет размер в 2,4 Кбит/с, и полный SID, включающий в себя пространственные параметры, имеет размер в 4,25 Кбит/с. Вычисление неактивных пространственных параметров описывается на фиг. 4 для DirAC, имеющего в качестве ввода многоканальный сигнал, такой как FOA, который может непосредственно извлекаться из высшего порядка амбиофонии (НОА), на фиг. 5 для входного формата MASA. Как описано выше, неактивные пространственные параметры 318 могут извлекаться параллельно с активными пространственными параметрами 316, с усреднением и/или повторным квантованием уже кодированных активных пространственных параметров 318. В случае многоканального сигнала, такого как FOA в качестве входного формата 302, анализ на основе гребенки фильтров многоканального сигнала 302 может выполняться до вычисления пространственных параметров, направления и рассеянности, для каждой временной и частотной плитки. Кодеры 396, 398 метаданных могут усреднять параметры 316, 318 по различным полосам частот и/или временным квантам до применения квантователя и кодирования квантованных параметров. Дополнительный кодер неактивных пространственных метаданных может наследоваться из некоторых квантованных параметров, извлекаемых в кодере активных пространственных метаданных, чтобы использовать их непосредственно в неактивных пространственных параметрах либо повторно квантовать их. В случае формата MASA (например, фиг. 5), сначала входные метаданные могут считываться и передаваться в кодеры 396, 398 метаданных при данном частотно-временном разрешении и разрешении по битовой глубине. Кодер(ы) 396, 398 метаданных, например, после этого должен дополнительно обрабатывать посредством конечного преобразования некоторых параметров, адаптации их разрешения (т.е. понижения разрешения, например, их усреднения) и их повторного квантования перед их кодированием посредством схемы энтропийного кодирования.
На стороне декодера, как проиллюстрировано, например, на фиг. 6, информация 221 VAD (например, то, классифицируется кадр в качестве активного или неактивного) сначала восстанавливается, посредством обнаружения размера передаваемого пакета (например, кадра) либо посредством обнаружения отсутствия передачи пакета. В активных кадрах 348, декодер работает в активном режиме, и рабочие данные транспортного канального кодера декодируются, как и активные пространственные параметры. Блок 220 пространственного рендеринга (синтез DirAC) затем микширует с повышением/придает пространственную форму декодированным транспортным каналам с использованием декодированных пространственных параметров 316, 318 в выходном пространственном формате. В неактивных кадрах, комфортный шум может формироваться в транспортных каналах посредством части 810 CNG в транспортных каналах (например, на фиг. 10). CNG стимулируется посредством SID в транспортные каналы обычно для регулирования энергии и спектральной формы (например, через коэффициенты масштабирования, применяемые в частотной области, или коэффициенты линейного прогнозирующего кодирования, применяемые через фильтр синтеза во временной области). Комфортный(е) шум(ы) 228d, 228а и т.д. затем рендерируются/получают пространственную форму в блоке 740 пространственного рендеринга (синтеза DirAC), со стимуляцией в этот раз посредством неактивных пространственных параметров 318. Выходной пространственный формат 202 может представлять собой бинауральный сигнал (2 канала), многоканальный сигнал для данной схемы размещения громкоговорителей или многоканальный сигнал в амбиофоническом формате. В альтернативном варианте осуществления, выходной формат может представлять собой пространственное аудио на основе метаданных (MASA), что означает то, что декодированные транспортные каналы или комфортные шумы в транспортных каналах непосредственно выводятся наряду с активными или неактивными пространственными параметрами, соответственно, для рендеринга посредством внешнего устройства.
Кодирование и декодирование неактивных пространственных параметров
Неактивные пространственные параметры 318 могут состоять из одного из нескольких направлений в полосах частот и ассоциированных отношений энергий в полосах частот, соответствующих отношению одного направленного компонента в полной энергии. В случае одного направления, аналогично предпочтительному варианту осуществления, отношение энергий может заменяться посредством рассеянности, которая является комплементарной отношению энергии, и затем придерживаться исходного набора параметров DirAC. Поскольку направленный компонент(ы), в общем, предположительно должен быть менее релевантным, чем рассеянная часть в неактивных кадрах, он также может передаваться в меньшем числе битов с использованием более приблизительной схемы квантования, например, в активных кадрах и/или посредством усреднения направления во времени или по частоте для получения более приблизительного временного и/или частотного разрешения. В предпочтительном варианте осуществления, направление может отправляться каждые 20 мс вместо 5 мс для активных кадров, но с использованием равного частотного разрешения в 5 неравномерных полос частот.
В предпочтительном варианте осуществления, рассеянность 314а может передаваться в одинаковое время/на равной частоте с активными кадрами, но в меньшем числе битов, что приводит к минимальному индексу квантования. Например, если рассеянность 314а квантуется в 4 битах в активных кадрах, она затем передается только в 2 битах, с исключением передачи исходных индексов от 0 до 3. Декодированный индекс в таком случае должен суммироваться со смещением в+4.
Также можно полностью исключать отправку направления 314b или альтернативно исключать отправку рассеянности 314а и заменять ее в декодере на значение по умолчанию или оцененное значение, в некоторых примерах.
Кроме того, можно рассматривать возможность передавать межканальную когерентность, если входные каналы соответствуют каналам, расположенным в пространственной области. Межканальные разности уровней также представляют собой альтернативу направлениям.
Более релевантной является отправка когерентности объемного звучания, которая задается как отношение рассеянной энергии, которое является когерентным в звуковом поле. Оно может использоваться в блоке пространственного рендеринга (синтеза DirAC), например, посредством перераспределения энергии между прямыми и рассеянными сигналами. Энергия когерентных компонентов объемного звучания удаляется из рассеянной энергии, которая должна перераспределяться в направленные компоненты, которые затем панорамируются более равномерно в пространстве.
Естественно, любые комбинации вышеперечисленных параметров могут рассматриваться для неактивных пространственных параметров. Также может быть предусмотрена возможность, для целей сокращения числа битов, вообще не отправлять параметры в неактивной фазе.
Ниже приводится примерный псевдокод кодера неактивных пространственных метаданных:



Ниже приводится примерный псевдокод декодера неактивных пространственных метаданных:


Восстановление пространственного параметра в случае отсутствия передачи на стороне декодера
В случае SID в ходе неактивной фазы, пространственные параметры могут полностью или частично декодироваться и затем использоваться для последующего синтеза DirAC.
В случае отсутствия передачи данных, либо если пространственные параметры 318 не передаются наряду с SID 348 в транспортные каналы, пространственные параметры 219, возможно, должны восстанавливаться в исходной версии. Это может достигаться посредством синтетического формирования отсутствующих параметров 219 (например, фиг. 7-10) с учетом предыдущих принимаемых параметров (например, 316 и/или 318). Нестабильное пространственное изображение может восприниматься как неприятное, в частности, в фоновом шуме, считающемся устойчивым, а не быстро развивающимся. С другой стороны, строго постоянное пространственное изображение может восприниматься как неестественное. Могут применяться различные стратегии.
Стратегия запоминания
В общем, можно с уверенностью считать, что пространственное изображение должно быть относительно стабильным во времени, что может истолковываться для параметров DirAC, т.е. для DOA и рассеянности таким образом, что они сильно не изменяются между кадрами. По этой причине, простой, но эффективный подход заключается в том, чтобы сохранять, в качестве восстановленных пространственных параметров 219, последние принимаемые пространственные параметры 316 и/или 318. Он представляет собой очень надежный подход по меньшей мере для рассеянности, которая имеет долговременную характеристику. Тем не менее, для направления могут предусматриваться различные стратегии, как перечислено ниже.
Экстраполяция направления
В качестве альтернативы или дополнения, может быть предусмотрена возможность оценки траектории звуковых событий в аудиосцене и затем пытаться экстраполировать оцененную траекторию. Это является, в частности, релевантным, если звуковое событие хорошо локализуется в пространстве в качестве точечного источника, который отражается в модели DirAC посредством низкой рассеянности. Оцененная траектория может вычисляться из наблюдений предыдущий направлений и подгонки кривой между этими точками, что может разворачивать интерполяцию или сглаживание. Также может использоваться регрессионный анализ. Экстраполяция параметра 219 затем может выполняться посредством оценки подогнанной кривой за пределами диапазона наблюдаемых данных (например, включающего в себя предыдущие параметры 316 и/или 318). Тем не менее, этот подход в результате может быть менее релевантным для неактивных кадров 348, в которых фоновый шум является бесполезным и предположительно должен быть рассеянным в значительной степени.
Размывание направления
Когда звуковое событие является более рассеянным, что, в частности, имеет место для фонового шума, направления являются менее значимыми и могут считаться реализацией стохастического процесса. Размывание в таком случае может помогать делать более естественным и более приятным рендерируемое звуковое поле за счет введения случайного шума в предыдущие направления перед его использованием для непереданных кадров. Вводимый шум и его дисперсия могут представлять собой функцию рассеянности.
Например, дисперсии σazi и σe1e введенных шумов в азимуте и подъеме могут придерживаться простои модельной функции рассеянности, например, следующим образом:

Формирование комфортного шума и придание пространственной формы (сторона декодера)
Ниже поясняются некоторые примеры, приведенные выше.
В первом варианте осуществления, генератор 210 (710) комфортного шума выполняется в базовом декодере, как проиллюстрировано на фиг. 7. Результирующие комфортные шумы вводятся в транспортные каналы и затем получают пространственную форму в синтезе DirAC с помощью передаваемых неактивных пространственных параметров 318 либо, в случае отсутствия передачи, с использованием пространственных параметров 219, выведенных так, как описано выше. Придание пространственной формы затем может реализовываться способом, описанным выше, например, посредством формирования двух потоков, направленных и ненаправленных, которые извлекаются из декодированных транспортных каналов и, в случае неактивных кадров, из комфортных шумов в транспортных каналах. Два потока затем микшируются с повышением и микшируются между собой в блоке 740 в зависимости от пространственных параметров 318.
Кроме того, комфортный шум либо его часть может непосредственно формироваться в рамках синтеза DirAC в области гребенки фильтров. Фактически, DirAC может управлять когерентностью восстановленной в исходной версии сцены с помощью транспортных каналов 224, пространственных параметров 318, 316, 319 и некоторых декорреляторов (например, 730). Декорреляторы 730 могут уменьшать когерентность синтезированного звукового поля. Пространственное изображение затем воспринимается с большей шириной, глубиной, рассеянием, реверберацией или реализацией в конкретной форме в случае воспроизведения в наушниках. Тем не менее, декорреляторы зачастую подвержены типичным слышимым артефактам, и желательно сокращать их использование. Это может достигаться, например, посредством так называемого способа ковариационного синтеза [5] посредством использования уже существующего некогерентного компонента транспортных каналов. Тем не менее, этот подход может иметь ограничения, в частности, в случае монофонического транспортного канала.
В случае комфортного шума, сформированного посредством случайного шума, преимущественно формировать, для каждого из выходных каналов или по меньшей мере их поднабора, выделенный комфортный шум. Более конкретно, преимущественно применять формирование комфортного шума не только для транспортных каналов, но также и к промежуточным аудиоканалам, используемым в блоке 220 пространственного рендеринга (синтеза DirAC) (и в блоке 740 микширования). Декорреляция рассеянного поле затем должна непосредственно обеспечиваться путем использования различных генераторов шума вместо использования декорреляторов 730, что позволяет снижать количество артефактов, а также общую сложность. Фактически, различные реализации случайного шума по определению декоррелируются. Фиг. 8 и 9 иллюстрируют два способа для достижения этого, посредством формирования комфортного шума полностью или частично в блоке 220 пространственного рендеринга. На фиг. 8, CN выполняется в частотной области, как описано в [5], он может непосредственно формироваться с областью гребенки фильтров блока пространственного рендеринга, исключающей как анализ 720 на основе гребенки фильтров, так и декорреляторы 730. Здесь, K, число каналов, для которых формируется комфортный шум, равно или больше М, числа транспортных каналов, и меньше или равно N, числа выходных каналов. В простейшем случае, K=N.
Фиг. 9 иллюстрирует другую альтернативу, которая включает формирование 810 комфортного шума в блок рендеринга. Формирование комфортного шума разбивается между внутренней частью (в 710) и наружной частью (в 810) блока 220 пространственного рендеринга. Комфортный шум 228d в блоке 220 рендеринга суммируется (в сумматоре 92 0) с конечным выводом 228а декоррелятора. Например, полоса низких частот может формироваться в наружной части в той же области, что и область в базовом кодере, с тем, чтобы иметь возможность легко обновлять необходимые запоминающие устройства. С другой стороны, формирование комфортного шума может выполняться непосредственно в блоке рендеринга для высоких частот.
Кроме того, формирование комфортного шума также может применяться в течение активных кадров 346. Вместо полного отключения формирования комфортного шума в течение активных кадров 346, оно может поддерживаться активным за счет уменьшения его интенсивности. В таком случае оно служит для маскирования перехода между активными и неактивными кадрами, а также маскирования артефактов и неидеальностей как базового кодера, так и параметрической пространственной аудиомодели. Это предложено в [11] для монофонического кодирования речи. Тот же принцип может расширяться на пространственное кодирование речи. Фиг. 10 иллюстрирует реализацию. На этот раз, формирования комфортного шума в блоке 220 пространственного рендеринга переключаются для активной и неактивной фазы. В неактивной фазе 348, оно является комплементарным формированию комфортного шума, выполняемому в транспортных каналах. В блоке рендеринга, комфортный шум задается для K каналов, равных или больших М транспортных каналов, с целью сокращения использования декорреляторов. Формирование комфортного шума в блоке 220 пространственного рендеринга добавляется в микшированную с повышением версию 228f транспортных каналов, что может достигаться за счет простой копии М каналов в K каналов.
Аспекты для кодера:
1. Устройство (300) аудиокодера для кодирования пространственного аудиоформата, имеющего несколько каналов либо один или более аудиоканалов с метаданными, описывающими аудиосцену, содержащее по меньшей мере одно из следующего:
a. аудиоанализатор (310) сцен пространственного входного аудиосигнала (302), выполненный с возможностью формирования первого набора или первого и второго наборов пространственных параметров (318, 319), описывающих пространственное изображение, и микшированную с понижением версию (326) входного сигнала (202), содержащую один или более транспортных каналов, причем число транспортных каналов меньше числа входных каналов;
b. устройство (340) транспортного канального кодера, выполненное с возможностью формирования кодированных данных (346) посредством кодирования микшированного с понижением сигнала (326), содержащего транспортные каналы в активной фазе (306);
c. дескриптор (350) вставки молчания в транспортные каналы, чтобы формировать дескриптор (348) вставки молчания для фонового шума транспортных каналов (328) в неактивной фазе (308);
d. мультиплексор (370) для комбинирования первого набора пространственных параметров (318) и кодированных данных (344) в поток (304) битов в ходе активных фаз (306) и для отправки «без данных» или для отправки дескриптора (348) вставки молчания либо для комбинирования отправки дескриптора (348) вставки молчания и второго набора пространственных параметров (318) в ходе неактивных фаз (308).
2. Аудиокодер по п. 1, в котором аудиоанализатор (310) сцен придерживается принципа направленного кодирования аудио (DirAC).
3. Аудиокодер по п. 1, в котором аудиоанализатор (310) сцен интерпретирует входные метаданные наряду с одним или более транспортными каналами (348).
4. Аудиокодер по п. 1, в котором аудиоанализатор (310) сцен извлекает один или два набора параметров (316, 318) из входных метаданных и извлекает транспортные каналы из одного или более входных аудиоканалов.
5. Аудиокодер по п. 1, в котором пространственные параметры представляют собой либо одно или более направлений (314b) поступления (DOA), либо рассеянность (314а), либо одну или более когерентностей.
6. Аудиокодер по п. 1, в котором пространственные параметры извлекаются для различных подполос частот.
7. Аудиокодер по п. 1, в котором устройство транспортного канального кодера придерживается CELP-принципа или представляет собой схему кодирования на основе MDCT либо осуществляет переключаемую комбинацию двух схем.
8. Аудиокодер по п. 1, в котором активные фазы (306) и неактивные фазы (308) определяются посредством детектора (320) голосовой активности, выполняемого в транспортных каналах.
9. Аудиокодер по п. 1, в котором первый и второй наборы пространственных параметров (316, 318) отличаются по временному или частотному разрешению либо разрешению квантования, либо характеру параметров.
10. Аудиокодер по п. 1, в котором пространственный входной аудиоформат (202) находится в амбиофоническом формате или В-формате либо представляет собой многоканальный сигнал, ассоциированный с данной компоновкой громкоговорителей, или многоканальный сигнал, извлекаемый из массива микрофонов или набора отдельных аудиоканалов наряду с метаданными или пространственным аудио на основе метаданных (MASA).
11. Аудиокодер по п. 1, в котором пространственный входной аудиоформат состоит более чем из двух аудиоканалов.
12. Аудиокодер по п. 1, в котором число транспортного канала(ов) равно 1, 2 или 4 (другие числа могут выбираться).
Для декодера:
1. Устройство (200) аудиодекодера для декодирования потока (304) битов таким образом, чтобы формировать из него пространственный выходной аудиосигнал (202), причем поток (304) битов содержит по меньшей мере активную фазу (306), после которой идет по меньшей мере неактивная фаза (308), при этом поток битов имеет кодированный по меньшей мере кадр (348) дескриптора вставки молчания (SID), который описывает фоновые шумовые характеристики транспортных каналов/каналов (228) понижающего микширования и/или информацию пространственных изображений, причем устройство (200) аудиодекодера содержит по меньшей мере одно из следующего:
a. декодер (210) дескрипторов вставки молчания, выполненный с возможностью декодирования SID (348) молчания таким образом, чтобы реконструировать фоновый шум в транспортных каналах/каналах (228) понижающего микширования;
b. устройство (230) декодирования, выполненное с возможностью реконструкции транспортных каналов/каналов (226) понижающего микширования из потока (304) битов в ходе активной фазы (306);
с. устройство (220) пространственного рендеринга, выполненное с возможностью реконструкции (740) выходного пространственного сигнала (202) из декодированных транспортных каналов/каналов (224) понижающего микширования и передаваемых пространственных параметров (316) в ходе активной фазы (306) и из реконструированного фонового шума в транспортных каналах/каналах (228) понижающего микширования в ходе неактивной фазы (308).
2. Аудиодекодер по п. 1, в котором пространственные параметры (316), передаваемые в активной фазе, состоят из рассеянности или направления поступления, или когерентности.
3. Аудиодекодер по п. 1, в котором пространственные параметры (316, 318) передаются посредством подполос частот.
4. Аудиодекодер по п. 1, в котором дескриптор (348) вставки молчания содержит пространственные параметры (318), помимо фоновых шумовых характеристик транспортных каналов/каналов (228) понижающего микширования.
5. Аудиодекодер по п. 4, в котором параметры (318), передаваемые в SID (348), могут состоять из рассеянности или направления поступления, или когерентности.
6. Аудиодекодер по п. 4, в котором пространственные параметры (318), передаваемые в SID (348), передаются посредством подполос частот.
7. Аудиодекодер по п. 4, в котором пространственные параметры (316, 318), передаваемые или кодированные в ходе активной фазы (346) и в SID (348), имеют различное частотное разрешение или временное разрешение, или разрешение квантования.
8. Аудиодекодер по п. 1, в котором блок (220) пространственного рендеринга может состоять из следующего:
a. декоррелятор (730) для получения декоррелированной версии (228b) декодированных транспортных каналов/каналов (226) понижающего микширования и/или реконструированного фонового шума (228);
b. повышающий микшер для извлечения выходных сигналов из декодированных транспортных каналов/каналов (226) понижающего микширования или реконструированного фонового шума (228) и их декоррелированной версии (228b) и из пространственных параметров (348).
9. Аудиодекодер по п. 8, в котором повышающий микшер блока пространственного рендеринга включает в себя:
а. по меньшей мере два генератора (710, 810) шума для формирования по меньшей мере двух декоррелированных фоновых шумов (228, 228а, 228d) с характеристиками, описанными в дескрипторах (448) молчания и/или заданными посредством оценки шума, применяемой в активной фазе (346).
10. Аудиодекодер по п. 9, в котором сформированный декоррелированный фоновый шум в повышающем микшере микшируется с декодированными транспортными каналами или реконструированным фоновым шумом в транспортных каналах, с учетом пространственных параметров, передаваемых в активной фазе, и/или пространственных параметров, включенных в SID.
11. Аудиодекодер по одному из предшествующих аспектов, в котором устройство декодирования содержит речевой кодер, такой как CELP, либо общий аудиокодер, такой как ТСХ или блок расширения полосы пропускания.
Дополнительная характеризация чертежей:
Фиг. 1: Анализ DirAC и синтез из [1].
Фиг. 2: Подробная блок-схема анализа DirAC и синтеза в трехмерном аудиокодере с низкой скоростью передачи битов.
Фиг. 3: Блок-схема декодера.
Фиг. 4: Блок-схема анализатора аудиосцен в режиме DirAC.
Фиг. 5: Блок-схема анализатора аудиосцен для входного формата MASA.
Фиг. 6: Блок-схема декодера.
Фиг. 7: Блок-схема блока пространственного рендеринга (синтеза DirAC), с CNG в транспортных каналах, находящемся за пределами блока рендеринга.
Фиг. 8: Блок-схема блока пространственного рендеринга (синтеза DirAC), с CNG, выполняемым непосредственно в области гребенки фильтров блока рендеринга для K каналов, K>=М транспортных каналов.
Фиг. 9: Блок-схема блока пространственного рендеринга (синтеза DirAC), с CNG, выполняемым во внутренней части и в наружной части относительно блока пространственного рендеринга.
Фиг. 10: Блок-схема блока пространственного рендеринга (синтеза DirAC), с CNG, выполняемым во внутренней части и в наружной части относительно блока пространственного рендеринга и также включенным для активных и неактивных кадров.
Преимущества
Варианты осуществления настоящего изобретения обеспечивают возможность расширения DTX на параметрическое пространственное кодирование аудио эффективным способом. Оно позволяет восстанавливать исходную версию с высокой перцепционной точностью воспроизведения фонового шума даже для неактивных кадров, для которых передача может прерываться для экономии полосы пропускания линий связи.
Для этого, SID транспортных каналов расширяется посредством неактивных пространственных параметров, релевантных для описания пространственного изображения фонового шума. Сформированный комфортный шум применяется в транспортных каналах до получения пространственной формы посредством блока рендеринга (синтеза DirAC). В качестве альтернативы, для повышения качества CNG может применяться к большему количеству каналов, чем количество транспортных каналов в рамках рендеринга. Это обеспечивает возможность снижения сложности и уменьшения раздражения вследствие артефактов декоррелятора.
Другие аспекты
Здесь следует отметить, что все альтернативы или аспекты, поясненные выше, и все аспекты, заданные посредством независимых аспектов в нижеприведенных аспектах, могут использоваться отдельно, т.е. без альтернатив или целей, отличных от предполагаемой альтернативы, цели или независимого аспекта. Тем не менее, в других вариантах осуществления, две или более из альтернатив или аспектов либо независимых аспектов могут комбинироваться друг с другом, и, в других вариантах осуществления, все аспекты или альтернативы и все независимые аспекты могут комбинироваться друг с другом.
Кодированный сигнал согласно изобретению может сохраняться на цифровом носителе данных или на постоянном носителе данных либо может передаваться по передающей среде, такой как беспроводная среда передачи или проводная среда передачи, например, Интернет.
Хотя некоторые аспекты описаны в контексте устройства, очевидно, что эти аспекты также представляют описание соответствующего способа, при этом блок или устройство соответствует этапу способа либо признаку этапа способа. Аналогичным образом, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока или элемента, или признака соответствующего устройства.
В зависимости от определенных требований к реализации, варианты осуществления изобретения могут реализовываться в аппаратных средствах или в программном обеспечении. Реализация может выполняться с использованием цифрового носителя данных, например, гибкого диска, DVD, CD, ROM, PROM, EPROM, EEPROM или флеш-памяти, имеющего сохраненные считываемые электронными средствами управляющие сигналы, которые взаимодействуют (или допускают взаимодействие) с программируемой компьютерной системой таким образом, что осуществляется соответствующий способ.
Некоторые варианты осуществления согласно изобретению содержат носитель данных, имеющий считываемые электронными средствами управляющие сигналы, которые допускают взаимодействие с программируемой компьютерной системой таким образом, что осуществляется один из способов, описанных в данном документе.
В общем, варианты осуществления настоящего изобретения могут реализовываться как компьютерный программный продукт с программным кодом, при этом программный код выполнен с возможностью осуществления одного из способов, когда компьютерный программный продукт работает на компьютере. Программный код, например, может сохраняться на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для осуществления одного из способов, описанных в данном документе, сохраненную на машиночитаемом носителе или на постоянном носителе данных.
Другими словами, вариант осуществления способа согласно изобретению в силу этого представляет собой компьютерную программу, имеющую программный код для осуществления одного из способов, описанных в данном документе, когда компьютерная программа работает на компьютере.
Следовательно, дополнительный вариант осуществления способов согласно изобретению представляет собой носитель данных (цифровой носитель данных или машиночитаемый носитель), содержащий записанную компьютерную программу для осуществления одного из способов, описанных в данном документе.
Следовательно, дополнительный вариант осуществления способа согласно изобретению представляет собой поток данных или последовательность сигналов, представляющих компьютерную программу для осуществления одного из способов, описанных в данном документе. Поток данных или последовательность сигналов, например, может быть выполнена с возможностью передачи через соединение для передачи данных, например, через Интернет.
Дополнительный вариант осуществления содержит средство обработки, например, компьютер или программируемое логическое устройство, выполненное с возможностью осуществления одного из способов, описанных в данном документе.
Дополнительный вариант осуществления содержит компьютер, имеющий установленную компьютерную программу для осуществления одного из способов, описанных в данном документе.
В некоторых вариантах осуществления, программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может использоваться для выполнения части или всех из функциональностей способов, описанных в данном документе. В некоторых вариантах осуществления, программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором, чтобы осуществлять один из способов, описанных в данном документе. В общем, способы предпочтительно осуществляются посредством любого аппаратного устройства.
Вышеописанные варианты осуществления являются просто иллюстративными в отношении принципов настоящего изобретения. Следует понимать, что модификации и изменения компоновок и подробностей, описанных в данном документе, должны быть очевидными для специалистов в данной области техники. Следовательно, они подразумеваются как ограниченные только посредством объема нижеприведенных аспектов патента, а не посредством конкретных подробностей, представленных посредством описания и пояснения вариантов осуществления в данном документе.
Последующие заданные аспекты для первого набора вариантов осуществления и второго набора вариантов осуществления могут комбинироваться таким образом, что определенные признаки одного набора вариантов осуществления могут быть включены в другой набор вариантов осуществления.
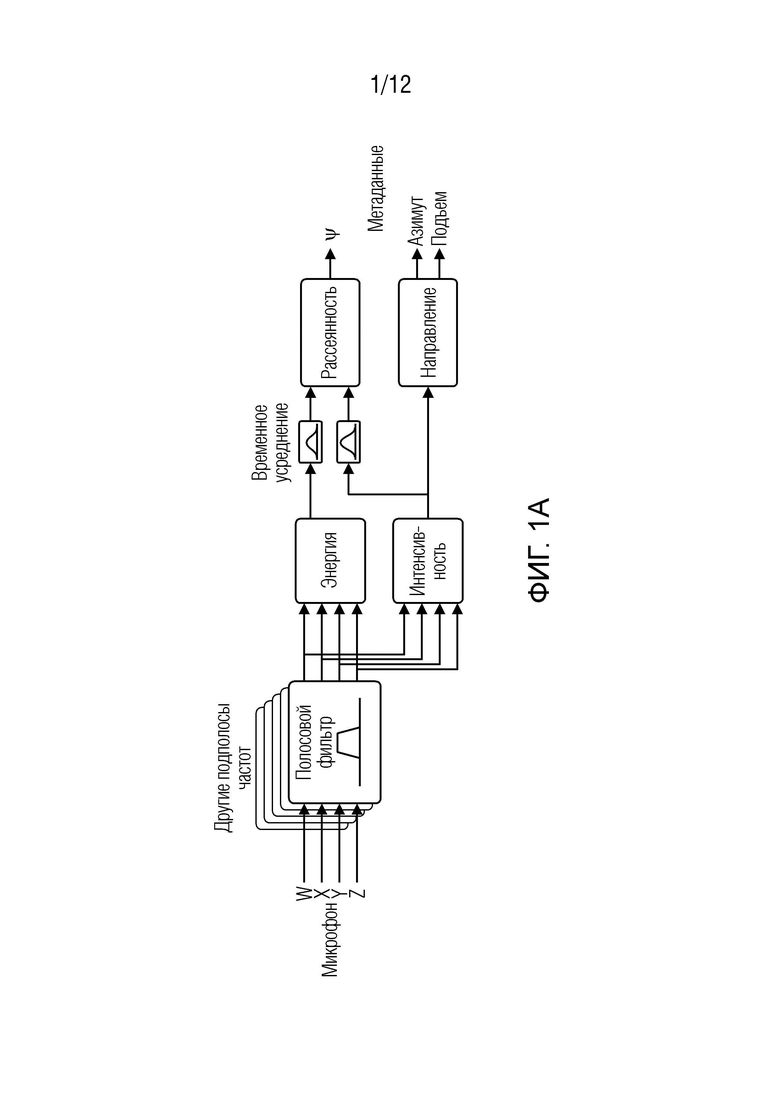
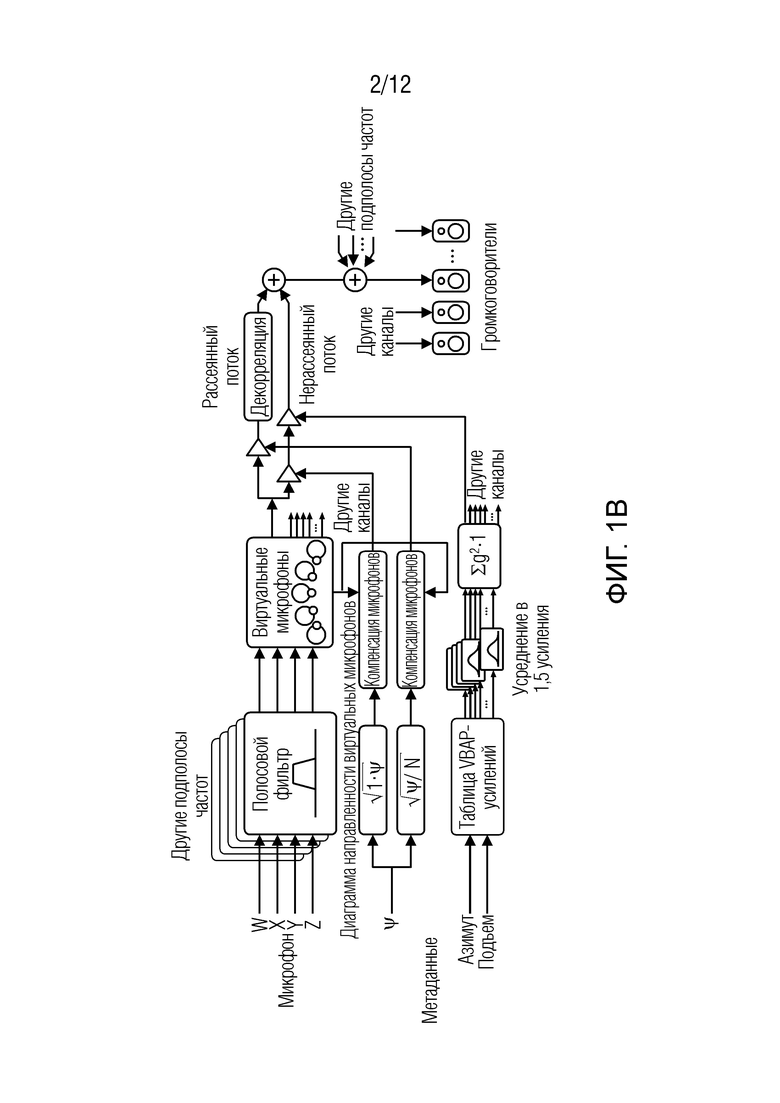
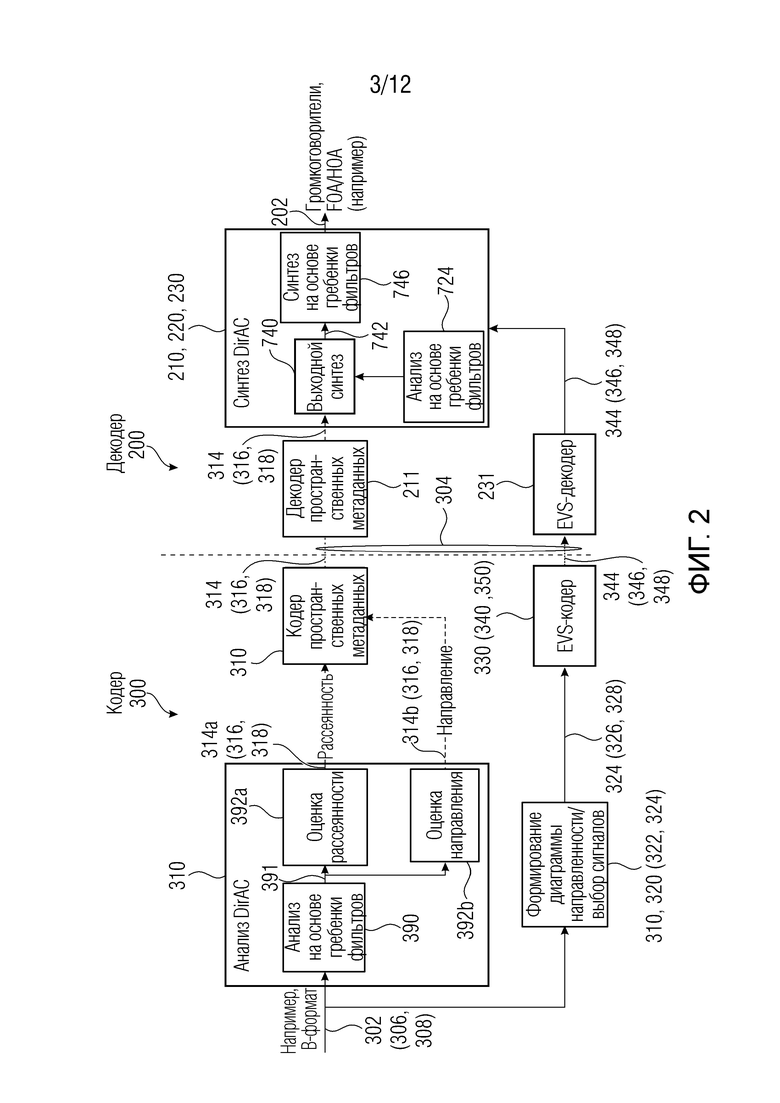
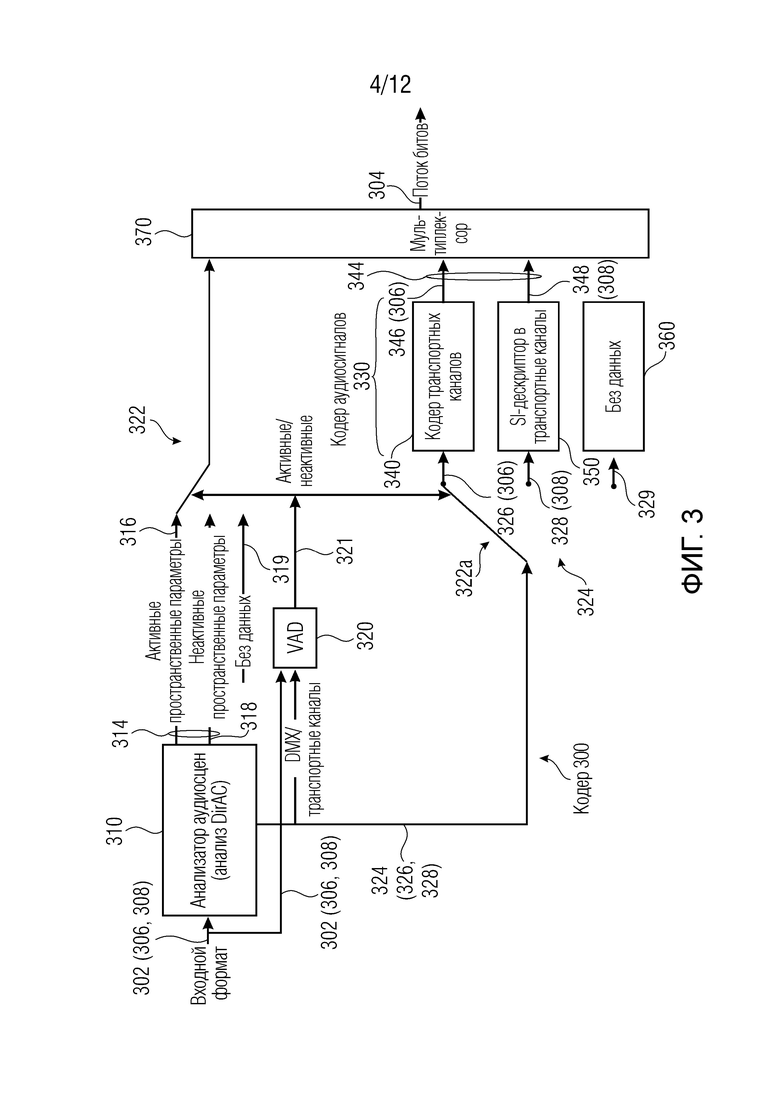
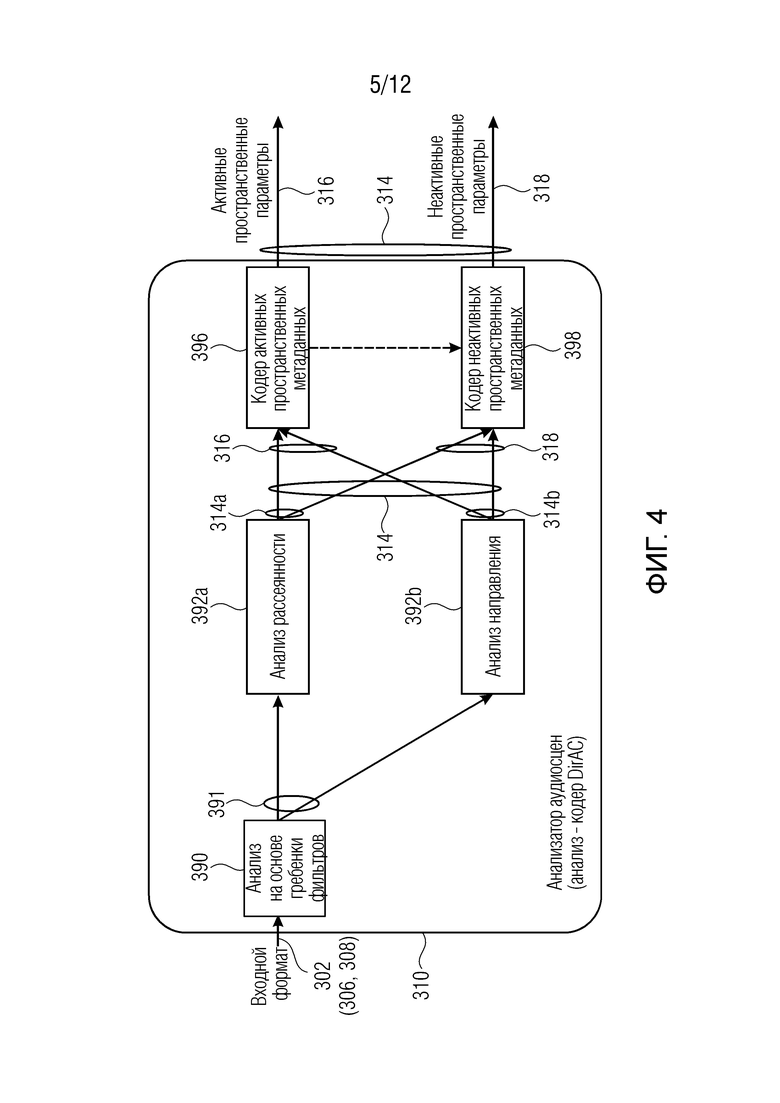
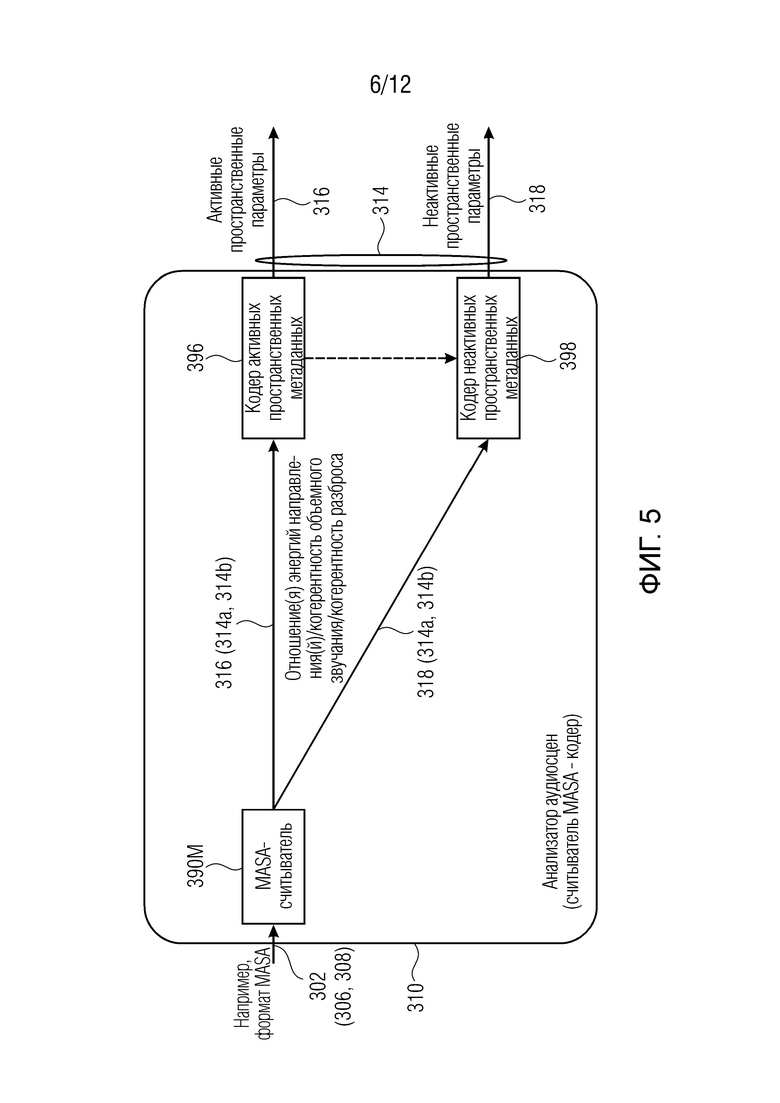
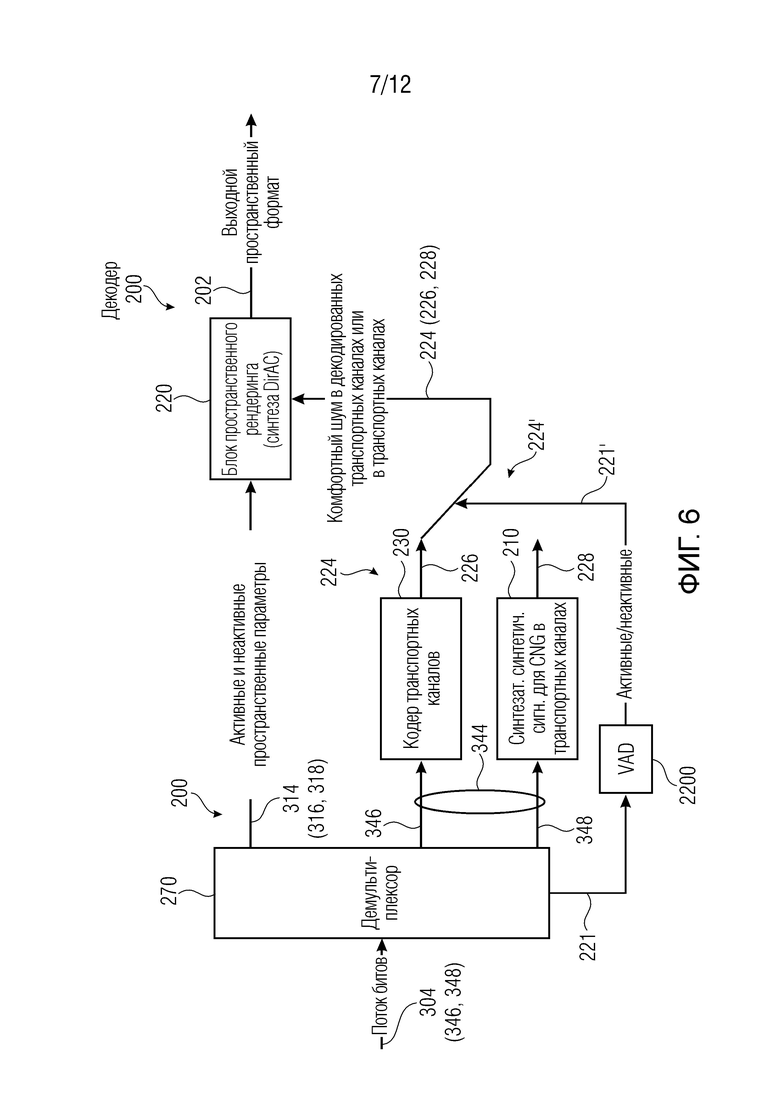
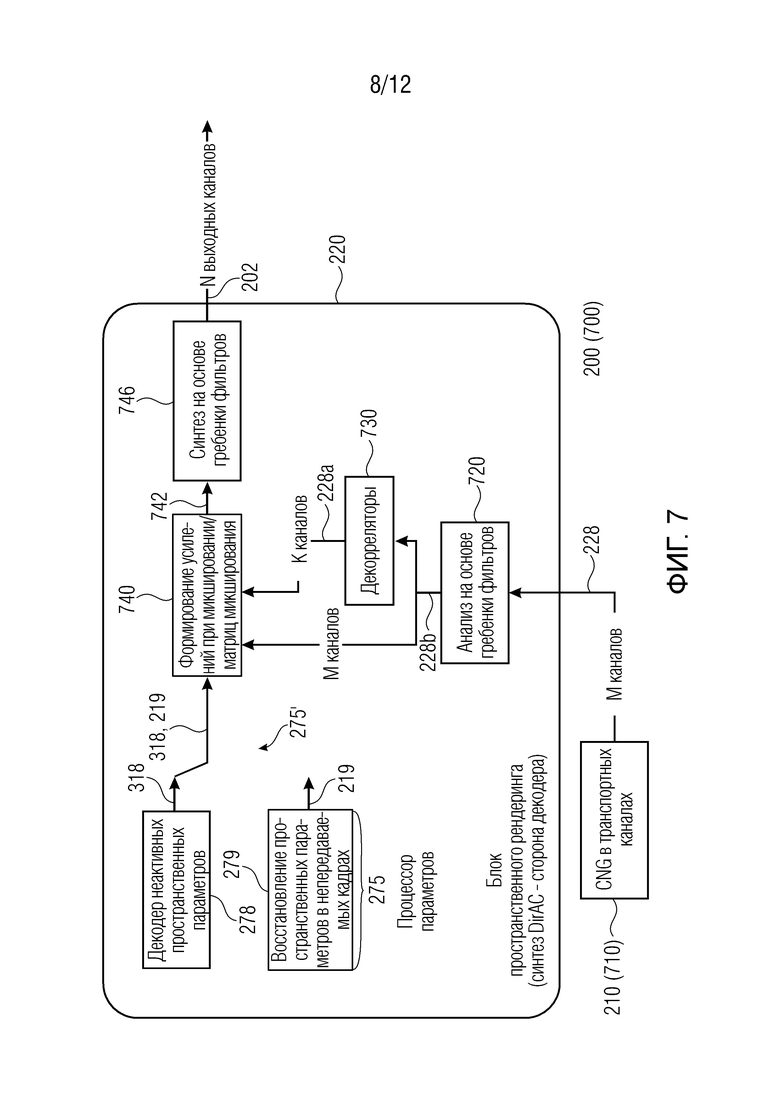
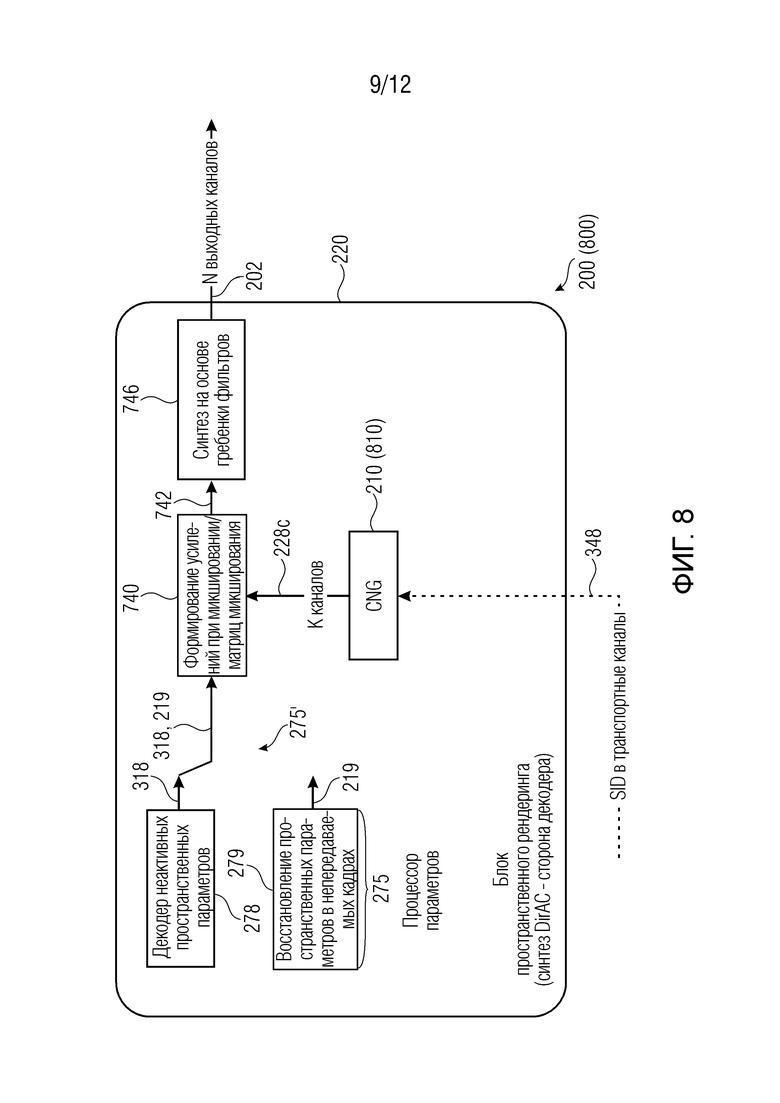
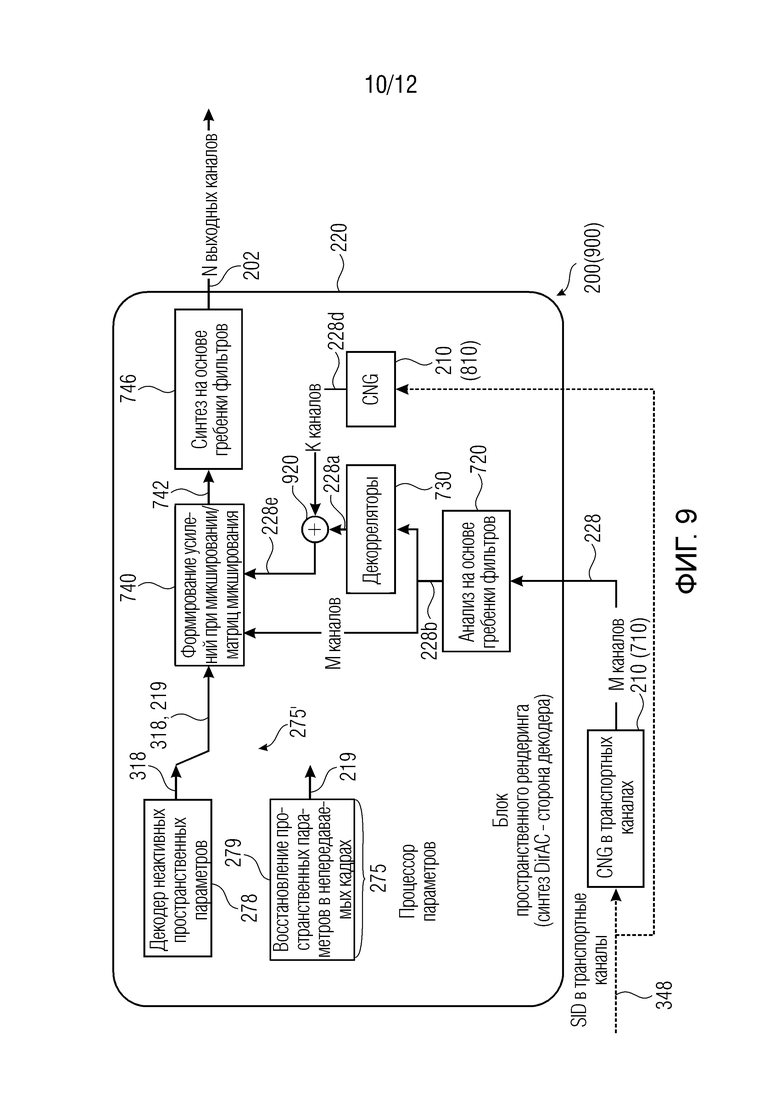
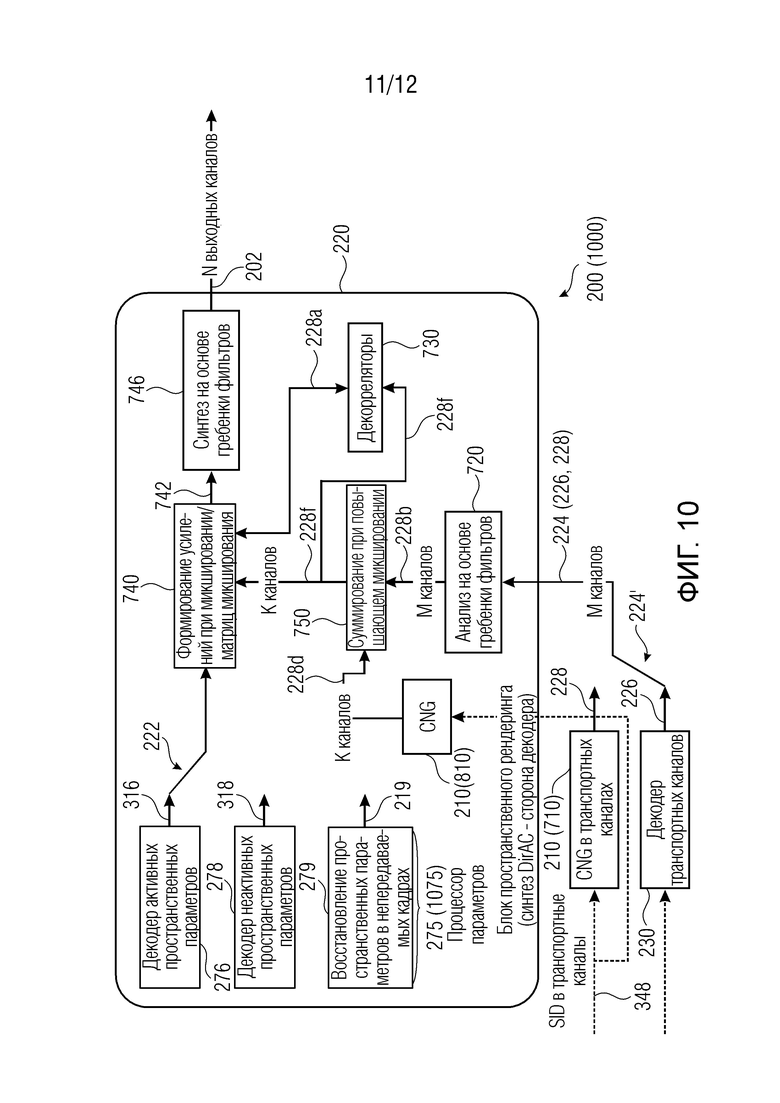
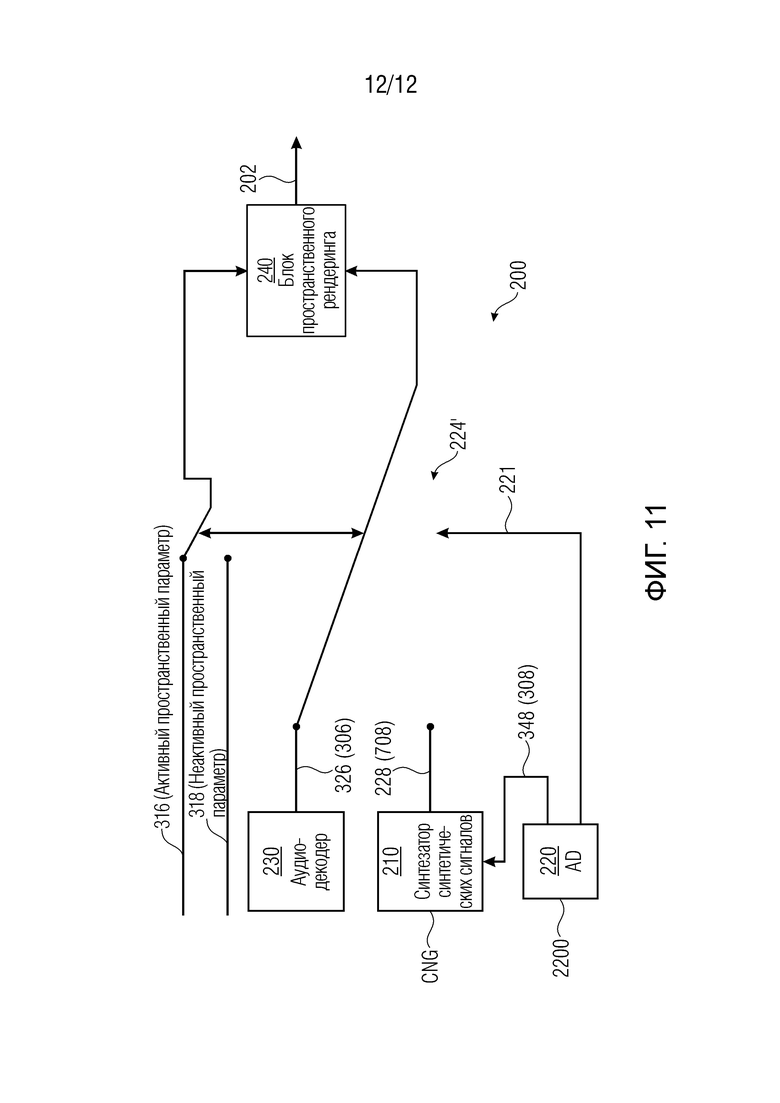
Изобретение относится к области вычислительной техники для обработки аудиоданных. Технический результат заключается в уменьшении потребности по скорости передачи битов для передачи разговорной иммерсивной речи. Технический результат достигается за счет определения первого представления параметров звукового поля для первого кадра из аудиосигнала в первом кадре и второго представления параметров звукового поля для второго кадра (308) из аудиосигнала во втором кадре; и анализа аудиосигнала, чтобы определять, в зависимости от аудиосигнала, то, что первый кадр представляет собой активный кадр, и второй кадр представляет собой неактивный кадр формирования кодированного аудиосигнала, причем кодированный аудиосигнал обеспечивает кодированный аудиосигнал для первого кадра, представляющего собой активный кадр, и параметрическое описание для второго кадра, представляющего собой неактивный кадр; и составления кодированной аудиосцены посредством объединения первого представления параметров звукового поля для первого кадра, второго представления параметров звукового поля для второго кадра, кодированного аудиосигнала для первого кадра и параметрического описания для второго кадра. 7 н. и 43 з.п. ф-лы, 12 ил.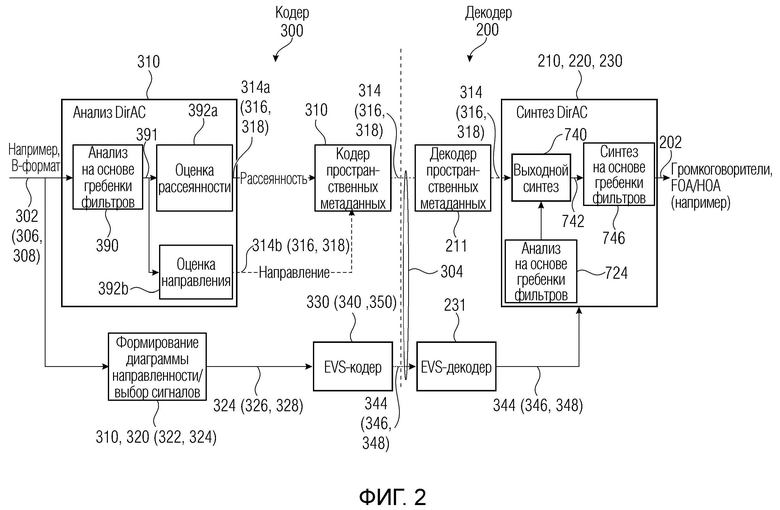
1. Устройство (300) для формирования кодированной аудиосцены (304) из аудиосигнала (302), имеющего первый кадр (306) и второй кадр (308), содержащее:
генератор (310) параметров звукового поля для определения первого представления (316) параметров звукового поля для первого кадра (306) из аудиосигнала (302) в первом кадре (306) и второго представления (318) параметров звукового поля для второго кадра (308) из аудиосигнала (302) во втором кадре (308); и
детектор (320) активности для анализа аудиосигнала (302), чтобы определять, в зависимости от аудиосигнала (302), то, что первый кадр представляет собой активный кадр (306), и второй кадр представляет собой неактивный кадр (308),
при этом генератор (310) параметров звукового поля выполнен с возможностью определения из второго кадра (308) аудиосигнала отдельного(ых) источника(ов) звука и определения для каждого источника звука параметрического описания (328) для второго кадра,
при этом генератор (310) параметров звукового поля
выполнен с возможностью разложения второго кадра (308) на частотный(е) элемент(ы) разрешения, причем каждый частотный элемент разрешения представляет отдельный источник звука из отдельного(ых) источника(ов) звука, и определения для каждого частотного элемента разрешения по меньшей мере одного неактивного пространственного параметра в качестве второго представления (318) параметров звукового поля для второго кадра (308), причем по меньшей мере один неактивный пространственный параметр содержит параметр направления, параметр направления поступления, параметр рассеянности или параметр отношения энергий,
причем устройство дополнительно содержит:
кодер (330) аудиосигналов для формирования кодированного аудиосигнала (344), причем кодированный аудиосигнал (344) обеспечивает кодированный аудиосигнал (346) для первого кадра, представляющего собой активный кадр (306), и параметрическое описание (348) для второго кадра, представляющего собой неактивный кадр (308); и
формирователь (370) кодированных сигналов для составления кодированной аудиосцены (304) посредством объединения первого представления (316) параметров звукового поля для первого кадра (306), второго представления (318) параметров звукового поля для второго кадра (308), кодированного аудиосигнала (346) для первого кадра (306) и параметрического описания (348) для второго кадра (308).
2. Устройство по п. 1, в котором генератор (310) параметров звукового поля выполнен с возможностью определения из второго кадра (308) аудиосигнала множества отдельных источников звука и определения для каждого источника звука параметрического описания (328) для второго кадра, причем каждый частотный элемент разрешения представляет отдельный источник звука из множества отдельных источников звука.
3. Устройство по п. 1 или 2, в котором генератор (310) параметров звукового поля выполнен с возможностью формирования второго представления (318) параметров звукового поля таким образом, что второе представление (318) параметров звукового поля содержит параметр, указывающий характеристику аудиосигнала (302) относительно положения слушателя.
4. Устройство по п. 1, или 2, или 3, в котором первое представление (316) параметров звукового поля содержит один или более параметров направления, указывающих направление звука относительно положения слушателя в первом кадре (306), либо один или более параметров рассеянности, указывающих часть рассеянного звука относительно прямого звука в первом кадре (306), либо один или более параметров отношения энергий, указывающих отношение энергий прямого звука и рассеянного звука в первом кадре (306), либо параметр межканальной когерентности/когерентности объемного звучания в первом кадре (306).
5. Устройство по одному из предшествующих пунктов, в котором аудиосигнал для первого кадра (306) и второго кадра (308) содержит входной формат, имеющий множество компонентов, представляющих звуковое поле относительно слушателя,
при этом генератор (310) параметров звукового поля выполнен с возможностью вычисления одного или более транспортных каналов (324, 326, 328) для первого кадра (306) и второго кадра (308) с использованием понижающего микширования множества компонентов и анализа входного формата для определения первого представления параметров, связанного с одним или более транспортными каналами, или
при этом генератор (310) параметров звукового поля выполнен с возможностью вычисления одного или более транспортных каналов (324, 326, 328), с использованием понижающего микширования множества компонентов, и
при этом детектор (320) активности выполнен с возможностью анализа одного или более транспортных каналов (328), извлекаемых из аудиосигнала во втором кадре (308).
6. Устройство по одному из предшествующих пунктов, в котором аудиосигнал для первого кадра (306) или второго кадра (308) содержит входной формат, имеющий, для каждого кадра из первого и второго кадров, один или более транспортных каналов и метаданные, ассоциированные с каждым кадром,
при этом генератор (310) параметров звукового поля выполнен с возможностью считывания метаданных из первого кадра (306) и второго кадра (308) и использования или обработки метаданных для первого кадра (306) в качестве первого представления (316) параметров звукового поля и обработки метаданных второго кадра (308) для получения второго представления (318) параметров звукового поля,
при этом обработка для получения второго представления (318) параметров звукового поля является такой, что количество информационных единиц, требуемое для передачи метаданных для второго кадра (308), уменьшается относительно количества, требуемого перед обработкой.
7. Устройство по п. 6, в котором генератор (310) параметров звукового поля выполнен с возможностью обработки метаданных для второго кадра (308) для сокращения числа информационных элементов в метаданных, либо повторной дискретизации информационных элементов в метаданных до более низкого разрешения, например, временного разрешения или частотного разрешения, либо повторного квантования информационных единиц метаданных для второго кадра (308) до более приблизительного представления относительно ситуации перед повторным квантованием.
8. Устройство по одному из предшествующих пунктов, в котором кодер (330) аудиосигналов выполнен с возможностью определения описания информации молчания для неактивного кадра в качестве параметрического описания (348), при этом описание информации молчания содержит связанную с амплитудой информацию, такую как энергия, мощность или уровень громкости для второго кадра (308), и информацию формирования, такую как информация формирования спектра, или связанную с амплитудой информацию для второго кадра (308), такую как энергия, мощность или уровень громкости и параметры линейного прогнозного кодирования (LPC) для второго кадра (308) или параметры масштабирования для второго кадра (308) с варьирующимся ассоциированным частотным разрешением таким образом, что различные параметры масштабирования связаны с полосами частот с различными ширинами.
9. Устройство по одному из предшествующих пунктов, в котором кодер (330) аудиосигналов выполнен с возможностью кодирования аудиосигнала для первого кадра (306) с использованием режима кодирования во временной области или в частотной области, причем кодированный аудиосигнал содержит кодированные выборки временной области, кодированные выборки спектральной области, кодированные выборки области LPC и вспомогательную информацию, полученную из компонентов аудиосигнала либо полученную из одного или более транспортных каналов, извлекаемых из компонентов аудиосигнала посредством операции понижающего микширования.
10. Устройство по одному из предшествующих пунктов, в котором аудиосигнал (302) содержит входной формат, представляющий собой амбиофонический формат первого порядка, амбиофонический формат высшего порядка, многоканальный формат, ассоциированный с данной компоновкой громкоговорителей, такой как 5.1, или 7.1, или 7.1 + 4, или с одним или более аудиоканалами, представляющими один или более различных аудиообъектов, локализованных в пространстве, как указано посредством информации, включенной в ассоциированные метаданные, либо входной формат, представляющий собой ассоциированное с метаданными пространственное аудиопредставление, при этом генератор (310) параметров звукового поля выполнен с возможностью определения первого представления (316) параметров звукового поля и второго представления звукового поля таким образом, что параметры представляют звуковое поле относительно заданного положения слушателя.
11. Устройство по одному из предшествующих пунктов, в котором аудиосигнал (302) содержит входной формат, представляющий собой амбиофонический формат первого порядка, амбиофонический формат высшего порядка, многоканальный формат, ассоциированный с данной компоновкой громкоговорителей, такой как 5.1, или 7.1, или 7.1 + 4, или с одним или более аудиоканалами, представляющими один или более различных аудиообъектов, локализованных в пространстве, как указано посредством информации, включенной в ассоциированные метаданные, либо входной формат, представляющий собой ассоциированное с метаданными пространственное аудиопредставление,
при этом аудиосигнал содержит сигнал микрофона, снимаемый посредством реального микрофона или виртуального микрофона, либо синтетически созданный сигнал микрофона, например, имеющий амбиофонический формат первого порядка или амбиофонический формат высшего порядка.
12. Устройство по одному из предшествующих пунктов, в котором детектор (320) активности выполнен с возможностью обнаружения фазы неактивности за второй кадр (308) и один или более кадров после второго кадра (308), и при этом детектор (320) активности выполнен с возможностью определения неактивной фазы, содержащей второй кадр (308) и восемь кадров после второго кадра (308), и при этом кодер (330) аудиосигналов выполнен с возможностью формирования параметрического описания для неактивного кадра только в каждом восьмом кадре, и при этом генератор (310) параметров звукового поля выполнен с возможностью формирования представления параметров звукового поля для каждого восьмого неактивного кадра.
13. Устройство по одному из пп. 1-11, в котором детектор (320) активности выполнен с возможностью обнаружения фазы неактивности за второй кадр (308) и один или более кадров после второго кадра (308), и
при этом генератор (310) параметров звукового поля выполнен с возможностью формирования представления параметров звукового поля для каждого неактивного кадра, даже когда кодер (330) аудиосигналов не формирует параметрическое описание для неактивного кадра.
14. Устройство по одному из пп. 1-11, в котором генератор (310) параметров звукового поля выполнен с возможностью определения представления параметров с более высокой частотой кадров, чем кодер (330) аудиосигналов формирует параметрическое описание для одного или более неактивных кадров.
15. Устройство по одному из предшествующих пунктов, в котором генератор (310) параметров звукового поля выполнен с возможностью определения второго представления (318) параметров звукового поля для второго кадра (308):
с использованием пространственных параметров для одного или более направлений в полосах частот и ассоциированных отношений энергий в полосах частот, соответствующих отношению одного направленного компонента в полной энергии.
16. Устройство по одному из пп. 1-14, в котором генератор (310) параметров звукового поля выполнен с возможностью определения второго представления (318) параметров звукового поля для второго кадра (308) для:
определения параметра рассеянности, указывающего отношение рассеянного звука или прямого звука.
17. Устройство по одному из пп. 1-14, в котором генератор (310) параметров звукового поля выполнен с возможностью определения второго представления (318) параметров звукового поля для второго кадра (308) для:
определения информации направления с использованием более приблизительной схемы квантования по сравнению с квантованием в первом кадре (306).
18. Устройство по одному из пп. 1-14, в котором генератор (310) параметров звукового поля выполнен с возможностью определения второго представления (318) параметров звукового поля для второго кадра (308):
с использованием усреднения направления во времени или по частоте для получения более приблизительного временного или частотного разрешения.
19. Устройство по одному из пп. 1-14, в котором генератор (310) параметров звукового поля выполнен с возможностью определения второго представления (318) параметров звукового поля для второго кадра (308) для:
определения представления параметров звукового поля для одного или более неактивных кадров с частотным разрешением, равным частотному разрешению первого представления (316) параметров звукового поля для активного кадра, и с возникновением по времени, которое меньше возникновения по времени для активных кадров относительно информации направления в представлении параметров звукового поля для неактивного кадра.
20. Устройство по одному из пп. 1-14, в котором генератор (310) параметров звукового поля выполнен с возможностью определения второго представления (318) параметров звукового поля для второго кадра (308) для:
определения второго представления (318) параметров звукового поля, имеющего параметр рассеянности, причем параметр рассеянности передается с равным временным или частотным разрешением по сравнению с активными кадрами, но с более приблизительным квантованием.
21. Устройство по одному из пп. 1-14, в котором генератор (310) параметров звукового поля выполнен с возможностью определения второго представления (318) параметров звукового поля для второго кадра (308) для:
квантования параметра рассеянности для второго представления звукового поля с первым числом битов, и при этом только второе число битов каждого индекса квантования передается, причем второе число битов меньше первого числа битов.
22. Устройство по одному из пп. 1-14, в котором генератор (310) параметров звукового поля выполнен с возможностью определения второго представления (318) параметров звукового поля для второго кадра (308) для:
определения для второго представления (318) параметров звукового поля межканальной когерентности, если аудиосигнал имеет входные каналы, соответствующие каналам, расположенным в пространственной области, либо межканальные разности уровней, если аудиосигнал имеет входные каналы, соответствующие каналам, расположенным в пространственной области.
23. Устройство по одному из пп. 1-14, в котором генератор (310) параметров звукового поля выполнен с возможностью определения второго представления (318) параметров звукового поля для второго кадра (308) для:
определения когерентности объемного звучания, определяемой как отношение рассеянной энергии, когерентное в звуковом поле, представленном посредством аудиосигнала.
24. Способ формирования кодированной аудиосцены (304) из аудиосигнала (302), имеющего первый кадр (306) и второй кадр (308), содержащий этапы, на которых:
определяют первое представление (316) параметров звукового поля для первого кадра (306) из аудиосигнала в первом кадре (306) и второе представление (318) параметров звукового поля для второго кадра (308) из аудиосигнала во втором кадре (308); и
анализируют аудиосигнал (302), чтобы определять, в зависимости от аудиосигнала, то, что первый кадр (306) представляет собой активный кадр, и второй кадр (308) представляет собой неактивный кадр,
при этом определение первого представления параметров звукового поля включает в себя этап, на котором определяют, из второго кадра (308) аудиосигнала, для каждого источника звука, параметрическое описание (328) для второго кадра (308),
при этом определение первого представления параметров звукового поля включает в себя этап, на котором разлагают второй кадр (308) на частотный(ые) элемент(ы) разрешения, причем каждый частотный элемент разрешения представляет отдельный источник звука, и определяют, для каждого частотного элемента разрешения по меньшей мере один неактивный пространственный параметр в качестве второго представления (318) параметров звукового поля для второго кадра (308), причем по меньшей мере один неактивный пространственный параметр содержит параметр направления, параметр направления поступления, параметр рассеянности или параметр отношения энергий,
причем способ дополнительно содержит этапы, на которых:
формируют кодированный аудиосигнал (344), причем кодированный аудиосигнал (344) обеспечивает кодированный аудиосигнал (346) для первого кадра, представляющего собой активный кадр (306), и параметрическое описание (348) для второго кадра, представляющего собой неактивный кадр (308); и
составляют кодированную аудиосцену (304) посредством объединения первого представления (316) параметров звукового поля для первого кадра (306), второго представления (318) параметров звукового поля для второго кадра (308), кодированного аудиосигнала (346) для первого кадра (306) и параметрического описания (348) для второго кадра (308).
25. Способ по п. 24, в котором определяют из второго кадра (308) аудиосигнала множество отдельных источников звука, и для каждого источника звука определяют параметрическое описание (328) для второго кадра (308), при этом определение первого представления параметров звукового поля включает в себя этап, на котором разлагают второй кадр (308) на множество частотных элементов разрешения, причем каждый частотный элемент разрешения представляет отдельный источник звука.
26. Устройство (200) для обработки кодированной аудиосцены (304), содержащей, в первом кадре (346), первое представление (316) параметров звукового поля и кодированный аудиосигнал (346), при этом второй кадр (308) представляет собой неактивный кадр, причем устройство содержит:
детектор (2200) активности для обнаружения того, что второй кадр (308) представляет собой неактивный кадр;
синтезатор (210) синтетических сигналов для синтезирования синтетического аудиосигнала (228) для второго кадра (308) с использованием параметрического описания (348) для второго кадра (308);
аудиодекодер (230) для декодирования кодированного аудиосигнала (346) для первого кадра (306); и
транскодер для формирования выходного формата на основе метаданных, содержащего аудиосигнал (346) для первого кадра (306), первое представление (316) параметров звукового поля для первого кадра (306), синтетический аудиосигнал (228) для второго кадра (308) и второе представление (318) параметров звукового поля для второго кадра (308).
27. Устройство (200) для обработки кодированной аудиосцены (304), содержащей, в первом кадре (346), первое представление (316) параметров звукового поля и кодированный аудиосигнал (346), и во втором кадре, неактивный кадр, причем второй кадр разлагается на частотный(ые) элемент(ы) разрешения, и причем, для каждого частотного элемента разрешения по меньшей мере один неактивный пространственный параметр определяется в качестве второго представления (318) параметров звукового поля для второго кадра (308), причем по меньшей мере один неактивный пространственный параметр содержит параметр направления, параметр направления поступления, параметр рассеянности или параметр отношения энергий, причем устройство содержит:
детектор (2200) активности для обнаружения того, что второй кадр (348) представляет собой неактивный кадр;
синтезатор (210) синтетических сигналов для синтезирования синтетического аудиосигнала (228) для второго кадра (308) с использованием параметрического описания (348) для второго кадра (308);
аудиодекодер (230) для декодирования кодированного аудиосигнала (346) для первого кадра (306); и
блок (220) пространственного рендеринга для пространственного рендеринга аудиосигнала (202) для первого кадра (306) с использованием первого представления (316) параметров звукового поля и с использованием синтетического аудиосигнала (228) и второго представления (318) параметров звукового поля для второго кадра (308),
при этом генератор (210) синтетических сигналов выполнен с возможностью формировать один или более транспортных каналов (228) для второго кадра (308) в качестве синтетического аудиосигнала (228), и
при этом блок (220) пространственного рендеринга выполнен с возможностью пространственного рендеринга одного или более транспортных каналов (228) для второго кадра (308).
28. Устройство по п. 27, в котором определяется, для второго кадра (308) аудиосигнала, отдельный источник(и) звука, и определяется, для каждого источника звука, параметрическое описание для второго кадра, причем каждый частотный элемент разрешения представляет отдельный источник звука.
29. Устройство по п. 27 или 28, в котором кодированная аудиосцена (304) содержит, для второго кадра (308), второе описание (318) параметров звукового поля, и при этом устройство содержит процессор (275, 1075) параметров для извлечения одного или более параметров (219, 318) звукового поля из второго представления (318) параметров звукового поля, и при этом блок (220) пространственного рендеринга выполнен с возможностью использования для рендеринга синтетического аудиосигнала (228) для второго кадра (308) одного или более параметров звукового поля для второго кадра (308).
30. Устройство по п. 27, или 28, или 29, в котором процессор (275, 1075) параметров выполнен с возможностью сохранения одного или более представлений параметров звукового поля для нескольких кадров, возникающих во времени перед вторым кадром (308) или возникающих во времени после второго кадра (308), чтобы экстраполировать или интерполировать с использованием по меньшей мере двух представлений параметров звукового поля из одного или более представлений параметров звукового поля для нескольких кадров для определения одного или более параметров звукового поля для второго кадра (308), и
при этом блок пространственного рендеринга выполнен с возможностью использования для рендеринга синтетического аудиосигнала (228) для второго кадра (308) одного или более параметров звукового поля для второго кадра (308).
31. Устройство по п. 30, в котором процессор (275) параметров выполнен с возможностью выполнения размывания с направлениями, включенными по меньшей мере в два представления параметров звукового поля, возникающие во времени до или после второго кадра (308) при экстраполяции или интерполяции для определения одного или более параметров звукового поля для второго кадра (308).
32. Устройство по любому из пп. 27-31, в котором генератор (210) синтетических сигналов выполнен с возможностью формирования для второго кадра (308) множества синтетических компонентных аудиосигналов для отдельных компонентов, связанных с выходным аудиоформатом блока пространственного рендеринга, в качестве синтетического аудиосигнала (228).
33. Устройство по п. 32, в котором генератор (210) синтетических сигналов выполнен с возможностью формирования по меньшей мере для каждого поднабора по меньшей мере из двух отдельных компонентов (228a, 228b), связанных с выходным аудиоформатом (202), отдельного синтетического компонентного аудиосигнала, при этом первый отдельный синтетический компонентный аудиосигнал (228a) декоррелируется относительно второго отдельного синтетического компонентного аудиосигнала (228b), и
при этом блок (220) пространственного рендеринга выполнен с возможностью рендеринга компонента выходного аудиоформата (202) с использованием сочетания первого отдельного синтетического компонентного аудиосигнала (228a) и второго отдельного синтетического компонентного аудиосигнала (228b).
34. Устройство по п. 33, в котором блок (220) пространственного рендеринга выполнен с возможностью применения способа на основе ковариации.
35. Устройство по п. 34, в котором блок (220) пространственного рендеринга выполнен с возможностью неиспользования обработки декоррелятора или управления обработкой (730) декоррелятора таким образом, что только количество декоррелированных сигналов (228a), сформированных посредством обработки (730) декоррелятора, указанной посредством способа на основе ковариации, используется при формировании компонента выходного аудиоформата (202).
36. Устройство по одному из пп. 27-35, в котором генератор (210, 710, 810) синтетических сигналов представляет собой генератор комфортного шума.
37. Устройство по одному из пп. 33-36, в котором генератор (210) синтетических сигналов содержит генератор шума, и первый отдельный синтетический компонентный аудиосигнал формируется посредством первой дискретизации генератора шума, и второй отдельный синтетический компонентный аудиосигнал формируется посредством второй дискретизации генератора шума, при этом вторая дискретизация отличается от первой дискретизации.
38. Устройство по п. 37, в котором генератор шума содержит таблицу шумов, и при этом первый отдельный синтетический компонентный аудиосигнал формируется посредством обращения к первой части таблицы шумов, и при этом второй отдельный синтетический компонентный аудиосигнал формируется посредством обращения ко второй части таблицы шумов, при этом вторая часть таблицы шумов отличается от первой части таблицы шумов.
39. Устройство по п. 37, в котором генератор шума содержит генератор псевдошума, и при этом первый отдельный синтетический компонентный аудиосигнал формируется посредством использования первого посевного числа для генератора псевдошума, и при этом второй отдельный синтетический компонентный аудиосигнал формируется с использованием второго посевного числа для генератора псевдошума.
40. Устройство по одному из пп. 27-39, в котором кодированная аудиосцена (304) содержит, для первого кадра (306), два или более транспортных каналов (326), и
при этом генератор (210, 710, 810) синтетических сигналов содержит генератор (810) шума и выполнен с возможностью формирования первого транспортного канала с использованием параметрического описания (348) для второго кадра (308) посредством дискретизации генератора (810) шума и второго транспортного канала посредством дискретизации генератора (810) шума, при этом первый и второй транспортные каналы, определенные посредством дискретизации генератора (180) шума, взвешиваются с использованием того же параметрического описания (348) для второго кадра (308).
41. Устройство по одному из пп. 27-40, в котором блок (220) пространственного рендеринга выполнен с возможностью работы в первом режиме для первого кадра (306) с использованием микширования прямого сигнала и рассеянного сигнала, сформированного посредством декоррелятора (730) из прямого сигнала под управлением первого представления (316) параметров звукового поля, и во втором режиме для второго кадра (308) с использованием микширования первого синтетического компонентного сигнала и второго синтетического компонентного сигнала, при этом первый и второй синтетические компонентные сигналы формируются посредством синтезатора (210) синтетических сигналов посредством различных реализаций шумового процесса или псевдошумового процесса.
42. Устройство по п. 41, в котором блок (220) пространственного рендеринга выполнен с возможностью управления микшированием (740) во втором режиме посредством параметра рассеянности, параметра распределения энергии или параметра когерентности, извлекаемого для второго кадра (308) посредством процессора параметров.
43. Устройство по одному из пп. 27-42, в котором генератор (210) синтетических сигналов выполнен с возможностью формирования синтетического аудиосигнала (228) для первого кадра (306) с использованием параметрического описания (348) для второго кадра (308), и
при этом блок пространственного рендеринга выполнен с возможностью выполнения комбинирования со взвешиванием аудиосигнала для первого кадра (306) и синтетического аудиосигнала (228) для первого кадра (306) до или после пространственного рендеринга, при этом при комбинировании со взвешиванием интенсивность синтетического аудиосигнала (228) для первого кадра (306) уменьшается относительно интенсивности синтетического аудиосигнала (228) для второго кадра (308).
44. Устройство по одному из пп. 27-43, в котором процессор (275, 1075) параметров выполнен с возможностью определения для второго неактивного кадра (308) когерентности объемного звучания, определяемой как отношение рассеянной энергии, когерентное в звуковом поле, представленном посредством второго кадра (308), при этом блок пространственного рендеринга выполнен с возможностью перераспределения энергии между прямыми и рассеянными сигналами во втором кадре (308) на основе звуковой когерентности, при этом энергия звуковых когерентных компонентов объемного звучания удаляется из рассеянной энергии, которая должна перераспределяться в направленные компоненты, и при этом направленные компоненты панорамируются в пространстве воспроизведения.
45. Устройство по одному из пп. 27-44, дополнительно содержащее выходной интерфейс для преобразования выходного аудиоформата, сформированного посредством блока пространственного рендеринга, в транскодированный выходной формат, такой как выходной формат, содержащий число выходных каналов, выделенных для громкоговорителей, которые должны быть размещены в заданных положениях, либо транскодированный выходной формат, содержащий данные FOA или HOA.
46. Устройство по одному из пп. 27-45, дополнительно содержащее процессор (275, 1075) параметров, выполненный с возможностью извлечения одного или более вторых параметров (219, 318) звукового поля для второго кадра (308), при этом процессор (275, 1075) параметров выполнен с возможностью сохранения первого представления параметров звукового поля для первого кадра (306) и синтеза одного или более вторых параметров звукового поля для второго кадра (308) с использованием сохраненного первого представления (316) параметров звукового поля для первого кадра (306), при этом второй кадр (308) идет после первого кадра (306) во времени.
47. Способ обработки кодированной аудиосцены, содержащей, в первом кадре (306), первое представление (316) параметров звукового поля и кодированный аудиосигнал, и во втором кадре (308), неактивный кадр, причем кодированная аудиосцена (304) содержит один или более транспортных каналов (326) для первого кадра (306), причем второй кадр разлагается на частотный(ые) элемент(ы) разрешения, и причем, для каждого частотного элемента разрешения по меньшей мере один неактивный пространственный параметр определяется в качестве второго представления (318) параметров звукового поля для второго кадра (308), при этом способ содержит этапы, на которых:
обнаруживают то, что второй кадр (308) представляет собой неактивный кадр;
синтезируют синтетический аудиосигнал (228) для второго кадра (308) с использованием параметрического описания (348) для второго кадра (308);
декодируют кодированный аудиосигнал для первого кадра (306); и
выполняют пространственный рендеринг аудиосигнала для первого кадра (306) с использованием первого представления (316) параметров звукового поля и с использованием синтетического аудиосигнала (228) для второго кадра (308) и синтетического аудиосигнала (228) для второго кадра (308),
причем способ дополнительно содержит этап, на котором формируют один или более транспортных каналов (228) для второго кадра (308) в качестве синтетического аудиосигнала (228) и выполняют пространственный рендеринг одного или более транспортных каналов (228) для второго кадра (308),
причем способ дополнительно содержит этап, на котором извлекают один или более вторых параметров (219, 318) звукового поля для второго кадра (308), при этом процессор (275, 1075) параметров выполнен с возможностью сохранения первого представления параметров звукового поля для первого кадра (306) и синтеза одного или более вторых параметров звукового поля для второго кадра (308) с использованием сохраненного первого представления (316) параметров звукового поля для первого кадра (306), при этом второй кадр (308) идет после первого кадра (306) во времени.
48. Способ по п. 47, дополнительно содержащий этап, на котором обеспечивают параметрическое описание (348) для второго кадра (308).
49. Постоянный блок хранения, сохраняющий инструкции, которые при выполнении на компьютере или в процессоре реализуют способ по п. 24.
50. Постоянный блок хранения, сохраняющий инструкции, которые при выполнении на компьютере или в процессоре реализуют способ по п. 47.
| Станок для придания концам круглых радиаторных трубок шестигранного сечения | 1924 |
|
SU2019A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| УКАЗАНИЕ ВОЗМОЖНОСТИ ПОВТОРНОГО ИСПОЛЬЗОВАНИЯ ПАРАМЕТРОВ КАДРА ДЛЯ КОДИРОВАНИЯ ВЕКТОРОВ | 2015 |
|
RU2689427C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ КОДИРОВАНИЯ И ОПТИМАЛЬНОЙ РЕКОНСТРУКЦИИ ТРЕХМЕРНОГО АКУСТИЧЕСКОГО ПОЛЯ | 2009 |
|
RU2533437C2 |
| СИСТЕМА И СПОСОБ ДЛЯ ГЕНЕРИРОВАНИЯ, КОДИРОВАНИЯ И ПРЕДСТАВЛЕНИЯ ДАННЫХ АДАПТИВНОГО ЗВУКОВОГО СИГНАЛА | 2012 |
|
RU2617553C2 |

