Перекрестная ссылка на родственные заявки
[0001] По данной заявке испрашивается приоритет на основании предварительной заявки на патент США №63/228,732, поданной 3 августа 2021 г., предварительной заявки на патент США №63/171,404, поданной 6 апреля 2021 г., и предварительной заявки на патент США №63/120,365, поданной 2 декабря 2020 г., все из которых включены в настоящий документ путем ссылки.
Область техники, к которой относится изобретение
[0002] Данное изобретение относится в общем к кодированию и декодированию битовых потоков аудиоданных.
Уровень техники
[0003] Разработка стандартов для голосовых и аудио кодеров/декодеров («кодеков») в последнее время была сосредоточена на разработке кодека для иммерсивных голосовых и аудиослужб (IVAS). Ожидается, что IVAS будет поддерживать диапазон характеристик служб передачи аудио, включающих, но не ограничиваясь, повышающее микширование из моно в стерео и кодирование, декодирование и рендеринг полностью иммерсивного аудио. IVAS предназначен для поддержки широкого диапазона устройств, конечных точек и сетевых узлов, включая, но не ограничиваясь: мобильными телефонами и смартфонами, электронными планшетами, персональными компьютерами, конференц-телефонами, конференц-залами, устройствами виртуальной реальности (VR) и дополненной реальности (AR), устройствами домашних кинотеатров и другими подходящими устройствами.
[0004] Кодек IVAS эффективно кодирует N-канальный многоканальный вход, включая амбисонический вход, путем понижающего микширования ввода в N_dmx каналов (где N_dmx <= N) и формирования дополнительной информации (пространственных метаданных), затем эти N_dmx каналов кодируются одним или более экземплярами базовых кодеков. Затем биты базового кодека вместе с кодированной дополнительной информацией передаются в декодер IVAS. Декодер IVAS декодирует N_dmx каналов понижающего микширования, используя один или более экземпляров базовых кодеков, а затем реконструирует многоканальный вход из N_dmx каналов, используя переданную дополнительную информацию и один или более экземпляров декорреляторов.
[0005] При разных скоростях передачи битов может быть кодировано различное количество N_dmx, например, при 32 кбит/с может быть кодирован только 1 канал понижающего микширования. Один из N_dmx каналов понижающего микширования является представлением доминирующего собственного сигнала (W') N-канального входа (далее также называемого «основным каналом понижающего микширования»), а остальные каналы понижающего микширования могут быть получены как функция от W' и многоканального входа. В IVAS доступны две схемы понижающего микширования: схема пассивного понижающего микширования и схема активного понижающего микширования. В схеме пассивного понижающего микширования доминирующий собственный сигнал (W') является задержанной версией центрального канала или основного входного канала (канала W в случае амбисонического входа). В схеме активного понижающего микширования собственный сигнал (W') получается путем масштабирования и добавления одного или более каналов к N-канальному входу. Например, для амбисонического входа первого порядка (FoA) W'=s0W+s1Y+s2X+s3Z, где s0-3 - коэффициенты усиления входного понижающего микширования. Таким образом, схему пассивного понижающего микширования можно рассматривать как частный случай схемы активного понижающего микширования, в которой s0=1, s1=0, s2=0 и s3=0.
Раскрытие изобретения
[0006] Реализации раскрыты для кодирования IVAS со стратегиями адаптивного понижающего микширования, при этом адаптивное понижающее микширование является либо пассивным понижающим микшированием, либо активным понижающим микшированием, либо комбинацией пассивного и активного понижающего микширования. В варианте осуществления способ кодирования аудиосигнала, который использует стратегию кодирования понижающего микширования, применяемую в кодере, которая отличается от стратегии декодирования повторного понижающего микширования или повышающего микширования, применяемой в декодере, содержит: получение по меньшей мере одним процессором входного аудиосигнала, при этом входной аудиосигнал является входной аудиосценой и содержит основной входной аудиоканал и дополнительные каналы; определение по меньшей мере одним процессором типа схемы кодирования понижающего микширования на основе входного аудиосигнала; а основе типа схемы кодирования понижающего микширования: вычисление по меньшей мере одним процессором одного или более входных коэффициентов усиления понижающего микширования, которые должны быть применены к входному аудиосигналу для конструирования основного канала понижающего микширования, при этом входные коэффициенты усиления понижающего микширования определяются для минимизации общей ошибки прогнозирования на дополнительных каналах; определение по меньшей мере одним процессором одного или более коэффициентов усиления масштабирования понижающего микширования для масштабирования основного канала понижающего микширования, при этом коэффициенты усиления масштабирования понижающего микширования определяются путем минимизации разности энергий между реконструированным представлением входной аудиосцены из основного канала понижающего микширования и входным аудиосигналом; формирование по меньшей мере одним процессором коэффициентов усиления прогнозирования на основе входного аудиосигнала, входных коэффициентов усиления понижающего микширования и коэффициентов усиления масштабирования понижающего микширования; определение по меньшей мере одним процессором одного или более остаточных каналов из дополнительных каналов во входном аудиосигнале путем использования основного канала понижающего микширования и коэффициентов усиления прогнозирования для формирования прогнозирований дополнительных каналов, а затем вычитания прогнозирований дополнительных каналов из дополнительных каналов; определение по меньшей мере одним процессором коэффициентов усиления декорреляции на основе энергии в остаточных каналах; кодирование по меньшей мере одним процессором основного канала понижающего микширования, ноль или более остаточных каналов и дополнительной информации в битовый поток, при этом дополнительная информация содержит коэффициенты усиления прогнозирования и коэффициенты усиления декорреляции, соответствующие одному или более остаточным каналам; и отправку по меньшей мере одним процессором битового потока на декодер.
[0007] В варианте осуществления способ дополнительно содержит: вычисление по меньшей мере одним процессором входной ковариации на основе входного аудиосигнала; и определение по меньшей мере одним процессором общей ошибки прогнозирования с использованием входной ковариации.
[0008] В варианте осуществления вычисление коэффициентов усиления масштабирования понижающего микширования дополнительно содержит: определение по меньшей мере одним процессором коэффициентов усиления масштабирования повышающего микширования как функцию от дополнительной информации, передаваемой в декодер; формирование по меньшей мере одним процессором представления входной аудиосцены из основного канала понижающего микширования и нуля или более остаточных каналов путем применения коэффициентов усиления масштабирования повышающего микширования к основному каналу понижающего микширования таким образом, чтобы общая энергия входной аудиосцены сохранялась; определение по меньшей мере одним процессором коэффициентов усиления масштабирования понижающего микширования путем решения замкнутой формы решения многочлена для сохранения энергии входной аудиосцены, где коэффициенты усиления масштабирования понижающего микширования определяются при сравнении энергии реконструированной входной аудиосцены с энергией входной аудиосцены.
[0009] В варианте осуществления коэффициенты усиления масштабирования повышающего микширования для реконструирования представления входной аудиосцены из основного канала понижающего микширования и нуля или более остаточных каналов являются функцией коэффициентов усиления прогнозирования и коэффициентов усиления декорреляции, передаваемых в дополнительной информации в декодер, так, что реконструированное представление основных входных аудиосигналов совпадает по фазе с основным каналом понижающего микширования, а многочлен является квадратичным многочленом.
[0010] В варианте осуществления коэффициенты усиления масштабирования повышающего микширования для реконструирования представления входной аудиосцены из основного канала понижающего микширования являются функцией коэффициентов усиления прогнозирования и коэффициентов усиления декорреляции, передаваемых в декодер, так, что коэффициенты усиления масштабирования понижающего микширования, полученные путем решения квадратичного многочлена, масштабируют коэффициенты усиления прогнозирования и коэффициенты усиления декорреляции в пределах заданного диапазона квантования.
[0011] В варианте осуществления описанный выше способ дополнительно содержит: в кодере: вычисление по меньшей мере одним процессором кодера комбинации входных коэффициентов усиления понижающего микширования, которые должны быть применены к входному аудиосигналу для формирования основного канала понижающего микширования, и коэффициентов усиления масштабирования понижающего микширования, при этом входные коэффициенты усиления понижающего микширования вычисляются как функция входной ковариации входного аудиосигнала; формирование по меньшей мере одним процессором кодера основного канала понижающего микширования на основе входного аудиосигнала и входных коэффициентов усиления понижающего микширования; формирование процессором кодера коэффициентов усиления прогнозирования на основе входного аудиосигнала и входных коэффициентов усиления понижающего микширования; определение по меньшей мере одним процессором кодера остаточных каналов из дополнительных каналов во входном аудиосигнале с использованием основного канала понижающего микширования и коэффициентов усиления прогнозирования для формирования прогнозирований дополнительных каналов, а затем вычитание прогнозирований дополнительных каналов из дополнительных каналов во входном аудиосигнале; определение по меньшей мере одним процессором кодера коэффициентов усиления декорреляции на основе энергии в остаточных каналах; определение по меньшей мере одним процессором кодера коэффициентов усиления масштабирования понижающего микширования для масштабирования основного канала понижающего микширования, коэффициентов усиления прогнозирования и коэффициентов усиления декорреляции, так, что коэффициенты усиления прогнозирования или коэффициенты усиления декорреляции или и те, и другие находятся в заданном диапазоне квантования; кодирование по меньшей мере одним процессором кодера основного канала понижающего микширования, нуля или более остаточных каналов и дополнительной информации, включающей в себя масштабированные коэффициенты усиления прогнозирования и масштабированные коэффициенты усиления декорреляции, в битовый поток; отправку по меньшей мере одним процессором кодера битового потока в декодер; в декодере: декодирование по меньшей мере одним процессором декодера основного канала понижающего микширования, нуля или более остаточных каналов и дополнительной информации, включающей в себя масштабированные коэффициенты усиления прогнозирования и масштабированные коэффициенты усиления декорреляции; установку по меньшей мере одним процессором декодера коэффициентов усиления масштабирования повышающего микширования как функции от коэффициентов усиления прогнозирования и коэффициентов усиления декорреляции; формирование по меньшей мере одним процессором декодера декоррелированных сигналов, которые декоррелированы по отношению к основному каналу понижающего микширования; и применение по меньшей мере одним процессором декодера коэффициентов усиления масштабирования повышающего микширования к комбинации основного канала понижающего микширования, нуля или более остаточных каналов и декоррелированных сигналов для реконструирования представления входной аудиосцены таким образом, чтобы общая энергия входной аудиосцены сохранялась.
[0012] В варианте осуществления входные коэффициенты усиления понижающего микширования, которые должны применяться к входному аудиосигналу для формирования основного канала понижающего микширования, вычисляются как функция нормированной входной ковариации, так, что числитель функции является первой константой, умноженной на ковариацию между основным входным аудиоканалом и дополнительными каналами, а знаменатель функции является максимумом второй константы, умноженным на отклонение основного входного аудиоканала и сумму отклонений дополнительных каналов входного аудиосигнала; и формированием по меньшей мере одним процессором кодера линейного многочлена путем минимизации ошибки прогнозирования для прогнозирований дополнительного канала и решение для коэффициентов усиления прогнозирования.
[0013] В варианте осуществления входные коэффициенты усиления понижающего микширования, которые должны применяться к входному аудиосигналу для формирования основного канала понижающего микширования, соответствуют схеме кодирования пассивного понижающего микширования, так, что основной канал понижающего микширования является либо тем же самым, что и основной входной аудиосигнал, либо задержанной версией основного входного аудиосигнала, и входные коэффициенты усиления понижающего микширования, которые должны применяться к входному аудиосигналу для формирования основного канала понижающего микширования, вычисляются, как функция коэффициентов усиления прогнозирования.
[0014] В варианте осуществления вычисление входных коэффициентов усиления понижающего микширования, которые должны применяться к входному аудиосигналу для конструирования основного канала понижающего микширования, содержит: определение по меньшей мере одним процессором корреляции между основным аудиосигналом и дополнительными каналами входного аудиосигнала; и выбор по меньшей мере одним процессором схемы вычисления входного коэффициента усиления понижающего микширования на основе корреляции.
[0015] В варианте осуществления вычисление входных коэффициентов усиления понижающего микширования, которые должны применяться к входному аудиосигналу для конструирования основного канала понижающего микширования, дополнительно содержит: на кодере определение по меньшей мере одним процессором кодера набора коэффициентов усиления пассивного прогнозирования на основе схемы кодирования пассивного понижающего микширования; сравнение по меньшей мере одним процессором кодера набора коэффициентов усиления пассивного прогнозирования с первым пороговым значением; определение по меньшей мере одним процессором кодера, является ли набор коэффициентов усиления пассивного прогнозирования меньшим или равным первому пороговому значению, и, если это так, то вычисление первого набора входных коэффициентов усиления понижающего микширования; формирование по меньшей мере одним процессором кодера первого набора коэффициентов усиления прогнозирования на основе входного аудиосигнала и входных коэффициентов усиления понижающего микширования; определение по меньшей мере одним процессором кодера, превышает ли первый набор коэффициентов усиления прогнозирования второе пороговое значение, и, если это так, то вычисление второго набора входных коэффициентов усиления понижающего микширования; формирование по меньшей мере одним процессором кодера второго набора коэффициентов усиления прогнозирования на основе входного аудиосигнала и входных коэффициентов усиления понижающего микширования; определение по меньшей мере одним процессором кодера остаточных каналов из дополнительных каналов во входном аудиосигнале с использованием основного канала понижающего микширования и второго набора коэффициентов усиления прогнозирования; определение по меньшей мере одним процессором кодера коэффициентов усиления декорреляции на основе энергии остаточного канала, которая не передана в декодер; определение по меньшей мере одним процессором кодера коэффициентов усиления масштабирования понижающего микширования для масштабирования основного канала понижающего микширования, второго набора коэффициентов усиления прогнозирования и коэффициентов усиления декорреляции таким образом, чтобы коэффициенты усиления прогнозирования или коэффициенты усиления декорреляции или и те, и другие находились в заданном диапазоне квантования; кодирование по меньшей мере одним процессором кодера основного канала понижающего микширования, нуля или более остаточных каналов и дополнительной информации, включающей в себя масштабированные коэффициенты усиления прогнозирования и масштабированные коэффициенты усиления декорреляции, в битовый поток; отправку по меньшей мере одним процессором кодера битового потока в декодер; в декодере: декодирование по меньшей мере одним процессором декодера основного канала понижающего микширования, нуля или более остаточных каналов и дополнительной информации, включающей в себя масштабированные коэффициенты усиления прогнозирования и масштабированные коэффициенты усиления декорреляции; определение по меньшей мере одним процессором декодера коэффициентов усиления масштабирования повышающего микширования как функции коэффициентов усиления прогнозирования и коэффициентов усиления декорреляции; формирование по меньшей мере одним процессором декодера декоррелированных сигналов, которые декоррелированы по отношению к основному каналу понижающего микширования; и применение по меньшей мере одним процессором декодера коэффициентов усиления масштабирования повышающего микширования к комбинации основного канала понижающего микширования, нуля или более остаточных каналов и декоррелированных сигналов для реконструирования представления входной аудиосцены таким образом, чтобы общая энергия входной аудиосцены сохранялась.
[0016] В варианте осуществления первый набор входных коэффициентов усиления понижающего микширования соответствует схеме кодирования пассивного понижающего микширования.
[0017] В варианте осуществления первый набор входных коэффициентов усиления понижающего микширования соответствует схеме активного понижающего микширования, в которой первый набор входных коэффициентов усиления понижающего микширования, подлежащий применению к входному аудиосигналу для формирования основного канала понижающего микширования, вычисляется как функция нормированной входной ковариации, так, что числитель в функции является первой константой, умноженной на ковариацию основного входного аудиоканала и дополнительных каналов, а знаменатель в функции является максимумом второй константы, умноженным на отклонение основного входа аудиоканал и суммы отклонений дополнительных каналов.
[0018] В варианте осуществления второй набор входных коэффициентов усиления понижающего микширования соответствует схеме кодирования активного понижающего микширования, при этом основной канал понижающего микширования получают путем применения второго набора входных коэффициентов усиления понижающего микширования к основному входному аудиоканалу и дополнительным каналам, а затем объединения каналов вместе.
[0019] В варианте осуществления второй набор входных коэффициентов усиления понижающего микширования является коэффициентами квадратичного многочлена.
[0020] В варианте осуществления пороговое значение, с которым сравниваются коэффициенты усиления прогнозирования, вычисляется таким образом, что коэффициенты усиления прогнозирования находятся в заданном диапазоне квантования.
[0021] В варианте осуществления вычисление входных коэффициентов усиления понижающего микширования, которые должны применяться к входному аудиосигналу для формирования канала понижающего микширования, содержит: вычисление коэффициента масштабирования для масштабирования основного входного аудиосигнала; вычисление ковариации масштабированного основного входного аудиосигнала; выполнение собственного анализа ковариации масштабированного основного входного аудиосигнала; выбор собственного вектора, соответствующего наибольшему собственному значению, в качестве входных коэффициентов усиления понижающего микширования таким образом, чтобы основной канал понижающего микширования положительно коррелировал с основным входным аудиоканалом; и вычисление коэффициентов усиления масштабирования понижающего микширования для масштабирования основного канала понижающего микширования и дополнительной информации таким образом, чтобы общая энергия входной аудиосцены сохранялась.
[0022] В варианте осуществления вычисление входных коэффициентов усиления понижающего микширования, применяемых к входному аудиосигналу для конструирования основного канала понижающего микширования, содержит: вычисление коэффициента масштабирования для масштабирования основного входного аудиоканала; вычисление входных коэффициентов усиления понижающего микширования на основе масштабированного основного входного аудиоканала путем установки входных коэффициентов усиления понижающего микширования как функции коэффициентов усиления прогнозирования масштабированного основного входного аудиоканала; и вычисление коэффициентов усиления масштабирования понижающего микширования для масштабирования основного канала понижающего микширования и дополнительной информации таким образом, чтобы общая энергия входной аудиосцены сохранялась.
[0023] В варианте осуществления коэффициент масштабирования для масштабирования основного входного аудиоканала является соотношением отклонения основного входного аудиоканала и квадратного корня из суммы отклонений дополнительных каналов.
[0024] В варианте осуществления вычисление входных коэффициентов усиления понижающего микширования, применяемых к входному аудиосигналу для формирования основного канала понижающего микширования, дополнительно содержит: определение по меньшей мере одним процессором кодера коэффициентов усиления прогнозирования на основе схемы кодирования пассивного понижающего микширования; вычисление по меньшей мере одним процессором кодера первых коэффициентов усиления масштабирования для масштабирования основного канала понижающего микширования и дополнительной информации таким образом, чтобы общая энергия входной аудиосцены сохранялась в реконструированном представлении входной аудиосцены; определение по меньшей мере одним процессором кодера, являются ли первые коэффициенты усиления масштабирования понижающего микширования меньшими или равными первому пороговому значению, и в результате вычисление первого набора входных коэффициентов усиления понижающего микширования; определение по меньшей мере одним процессором кодера, превышают ли первые коэффициенты усиления масштабирования понижающего микширования второе пороговое значение, и в результате вычисление второго набора входных коэффициентов усиления понижающего микширования; и формирование по меньшей мере одним процессором кодера второго набора коэффициентов усиления прогнозирования на основе входного аудиосигнала и первых или вторых входных коэффициентов усиления понижающего микширования; в декодере: декодирование по меньшей мере одним процессором декодера основного канала понижающего микширования и дополнительной информации, включающей в себя масштабированный второй набор коэффициентов усиления прогнозирования и масштабированные коэффициенты усиления декорреляции; определение по меньшей мере одним процессором декодера коэффициентов усиления масштабирования повышающего микширования, как функции от второго набора коэффициентов усиления прогнозирования и коэффициентов усиления декорреляции; формирование по меньшей мере одним процессором декодера декоррелированных сигналов, которые декоррелированы по отношению к основному каналу понижающего микширования; и применение по меньшей мере одним процессором декодера коэффициентов усиления масштабирования повышающего микширования к комбинации основного канала понижающего микширования и декоррелированных сигналов для реконструирования представления входной аудиосцены таким образом, чтобы общая энергия входной аудиосцены сохранялась.
[0025] В варианте осуществления первый набор входных коэффициентов усиления понижающего микширования соответствует схеме кодирования пассивного понижающего микширования.
[0026] В варианте осуществления второй набор входных коэффициентов усиления понижающего микширования соответствует схема кодирования активного понижающего микширования, при этом основной канал понижающего микширования получают путем применения входных коэффициентов усиления понижающего микширования к основному входному аудиоканалу и дополнительным каналам и последующего суммирования каналов вместе.
[0027] В варианте осуществления система содержит: один или более процессоров; и постоянный машиночитаемый носитель, на котором сохранены инструкции, исполнение которых одним или более процессорами побуждает один или более процессоров выполнить операции согласно способам, описанным выше.
[0028] В варианте осуществления постоянный машиночитаемый носитель, на котором сохранены инструкции, которые при выполнении одним или более процессорами побуждают один или более процессоров выполнить операции согласно способам, описанным выше.
[0029] Другие реализации изобретения, раскрытые здесь, относятся к системе, устройству и машиночитаемому носителю. Подробности раскрытых реализаций изобретения изложены на прилагаемых чертежах и в описании ниже. Другие особенности, цели и преимущества очевидны из описания, чертежей и формулы изобретения. Частные случаи реализации, раскрытые в данном документе, обеспечивают одно или более из следующих преимуществ. Стратегии активного понижающего микширования реализованы в декодере IVAS для улучшения качества декодированных аудиосигналов, таких как четыре канала FoA. Раскрытые способы активного понижающего микширования могут использоваться в конфигурациях одноканальных или многоканальных каналов понижающего микширования. Схема кодирования активного понижающего микширования по сравнению со схемой пассивного понижающего микширования предлагает дополнительный масштабирующий член для реконструирования канала W в декодере, который можно использовать для обеспечения лучшей оценки параметров, используемых для реконструкции каналов FoA (например, пространственных метаданных).
[0030] Кроме того, раскрыты потенциальные улучшения для одноканальных и многоканальных случаев понижающего микширования. В варианте осуществления схема кодирования активного понижающего микширования работает адаптивно, при этом одной возможной рабочей точкой является схема кодирования пассивного понижающего микширования.
Краткое описание чертежей
[0031] На чертежах, конкретные компоновки или упорядочения схематичных элементов, к примеру, элементов, которые представляют устройства, модули, блоки обработки инструкций и элементы данных, показаны для простоты описания. Тем не менее, специалисты в данной области техники должны понимать, что конкретное упорядочение или компоновка схематичных элементов на чертежах не имеют намерение подразумевать то, что требуется конкретный порядок или последовательность обработки или разделение процессов. Кроме того, включение схематичного элемента на чертеже не имеет намерение подразумевать то, что такой элемент требуется во всех вариантах осуществления, или то, что в некоторых реализациях признаки, представленные таким элементом, могут не быть включены или могут быть объединены с другими элементами.
[0032] Кроме того, на чертежах, на которых соединительные элементы, такие как сплошные или пунктирные линии либо стрелки, используются для иллюстрации соединения, взаимосвязи или ассоциации между двумя или более других схематичных элементов, отсутствие таких соединительных элементов не имеет намерение подразумевать то, что соединение, взаимосвязь или ассоциирование не может существовать. Другими словами, некоторые соединения, взаимосвязи или ассоциирования между элементами не показаны на чертежах с тем, чтобы не затруднять понимание изобретения. Помимо этого, для простоты иллюстрации, для представления множества соединений, взаимосвязей или ассоциаций между элементами используется один соединительный элемент. Например, если соединительный элемент представляет обмен сигналами, данными или инструкциями, специалисты в данной области техники должны понимать, что такой элемент представляет один или более трактов передачи сигналов, в зависимости от необходимости для осуществления связи.
[0033] Фиг. 1 иллюстрирует варианты использования для кодека IVAS согласно варианту осуществления.
[0034] Фиг. 2 является блок-схемой системы для кодирования и декодирования битовых потоков IVAS согласно варианту осуществления.
[0035] Фиг. 3 является блок-схемой процесса кодирования аудио согласно варианту осуществления.
[0036] Фиг. 4А и 4В является блок-схемой процесса кодирования и декодирования аудио согласно варианту осуществления.
[0037] Фиг. 5 является блок-схемой декодера SPAR FOA, работающего в режиме одноканального понижающего микширования со схемой адаптивного понижающего микширования, согласно варианту осуществления.
[0038] Фиг. 6 является блок-схемой кодера SPAR FOA, работающего в режиме одноканального понижающего микширования с адаптивной схемой понижающего микширования, согласно варианту осуществления.
[0039] Фиг. 7 является блок-схемой примерной архитектуры устройства, согласно варианту осуществления.
[0040] Одинаковые ссылочные позиции, используемые на различных чертежах, указывают на аналогичные элементы.
Осуществление изобретения
[0041] В нижеприведенном подробном описании приведено множество конкретных подробностей для обеспечения полного понимания различных описанных вариантов осуществления. Специалистам в данной области техники должно быть очевидным, что различные описанные реализации могут осуществляться на практике без этих конкретных подробностей. В других случаях, хорошо известные способы, процедуры, компоненты и схемы не описаны подробно, чтобы не затруднять понимание аспектов вариантов осуществления. Ниже описано множество признаков, которые могут использоваться независимо друг от друга либо с любым сочетанием других признаков. Терминология
[0042] При использовании в данном документе термин «включает в себя» и его разновидности следует читать как неисключающие термины, которые означают «включает в себя, не ограничиваясь». Термин «или» следует читать как «и/или», если контекст явным образом не указывает иное. Термин «на основе» следует трактовать как «по меньшей мере частично на основе». Термин «одна примерная реализация» и «примерная реализация» следует читать как «по меньшей мере одна примерная реализация». Термин «другая реализация» следует читать как «по меньшей мере одна другая реализация». Термины «определенный», «определяет» или «определение» следует читать как получение, прием, вычисление, расчет, оценка, прогнозирование или вывод. Помимо этого, в нижеприведенном описании и в формуле изобретения, если не указано иное, все технические и научные термины, используемые в данном документе, имеют тот же смысл, в котором их обычно понимают специалисты в той области техники, к которой относится данное изобретение.
Примеры вариантов использования IVAS
[0043] Фиг. 1 иллюстрирует варианты 100 использования для кодека 100 IVAS согласно одной или более реализациям. В некоторых реализациях, различные устройства обмениваются данными через сервер 102 вызовов, который выполнен с возможностью приема аудиосигналов, например, из коммутируемой телефонной сети общего пользования (PSTN) или наземной сети мобильной связи общего пользования (PLMN), проиллюстрированной посредством PSTN/другой PLMN 104. Варианты 100 использования поддерживают ранее созданные устройства 106, которые выполняют рендеринг и захватывают только аудио в моно, включая, но не ограничиваясь: устройства, которые поддерживают улучшенные голосовые службы (EVS), стандарт широкополосного адаптивного многоскоростного кодирования (AMR-WB) и стандарт узкополосного адаптивного многоскоростного кодирования (AMR-NB). Варианты 100 использования также поддерживают абонентское устройство 108, 114 (UE), которое захватывает и выполняет рендеринг стерео аудиосигналов, или UE 110, которое захватывает и выполняет бинауральный рендеринг моносигналов в многоканальные сигналы. Варианты 100 использования также поддерживают иммерсивные и стереосигналы, захваченные и подготовленные посредством рендеринга посредством систем 116, 118 в видеоконференц-залах, соответственно. Варианты 100 использования также поддерживают стереозахват и иммерсивный рендеринг стерео аудиосигналов для систем 120 домашнего кинотеатра и компьютера 112 и монозахват и иммерсивный рендеринг аудиосигналов для гарнитуры 122 системы виртуальной реальности (VR) и модуля 124 поглощения иммерсивного содержимого.
Примерный кодек IVAS
[0044] Фиг. 2 является блок-схемой кодека 200 IVAS для кодирования и декодирования битовых потоков IVAS согласно варианту осуществления. Кодек 200 IVAS включает в себя кодер и декодер на дальнем конце. Кодер IVAS включает в себя модуль 202 пространственного анализа и понижающего микширования, модуль 203 квантования и энтропийного кодирования, модуль 206 базового кодирования и модуль 207 управления режимом/скоростью передачи битов. Декодер IVAS включает в себя модуль 204 квантования и энтропийного декодирования, модуль 208 базового декодирования, модуль 209 пространственного синтеза/рендеринга и модуль 211 декоррелятора.
[0045] Модуль 202 пространственного анализа и понижающего микширования принимает N-канальный входной аудиосигнал 201, представляющий аудиосцену. Входной аудиосигнал 201 включает в себя, но не ограничивается: моносигналы, стереосигналы, бинауральные сигналы, пространственные аудиосигналы (например, многоканальные пространственные аудиообъекты), FoA, Амбисоники более высокого порядка (НоА) и любые другие аудиоданные. N-канальный входной аудиосигнал 201 микшируется с понижением количества каналов до заданного количества каналов понижающего микширования (N_dmx) модулем 202 пространственного анализа и понижающего микширования. В этом примере N_dmx является <= N. Модуль 202 пространственного анализа и понижающего микширования также формирует дополнительную информацию (например, пространственные метаданные), которая может использоваться декодером IVAS на дальнем конце для синтеза N-канального входного аудиосигнала 201 из N_dmx каналов понижающего микширования, пространственных метаданных и сигналов декорреляции, сформированных декодером. В некоторых вариантах осуществления модуль 202 пространственного анализа и понижающего микширования реализует улучшенную сложную связь (CACPL) для анализа/понижающего микширования аудиосигналов стерео/FoA и/или пространственную реконструкцию (SPAR) для анализа/понижающего микширования аудиосигналов FoA. В других вариантах осуществления модуль 202 пространственного анализа и понижающего микширования реализует другие форматы.
[0046] N_dmx каналы кодируются N_dmx экземплярами моно или одного или более многоканальных базовых кодеков, включенных в модуль 206 базового кодирования (например, модуль базового кодирования EVS), а дополнительная информация (например, пространственные метаданные (MD)) квантуется и кодируется модулем 203 квантования и энтропийного кодирования. Кодированные биты затем упаковываются вместе в битовый поток(и) (например, битовый поток(и) IVAS) и отправляются в декодер IVAS. Хотя в этом примерном варианте осуществления и в последующих вариантах осуществления может быть описан кодек EVS, но любой моно, стерео или многоканальный кодек может быть использован в качестве базового кодека в кодеке 200 IVAS.
[0047] В некоторых вариантах осуществления квантование может включать в себя несколько уровней все более приблизительного квантования (например, точное, среднее, приблизительное и сверхприблизительное квантование), а энтропийное кодирование может включать в себя кодирование кодом Хаффмана или арифметическое кодирование.
[0048] В некоторых вариантах осуществления, модуль 206 базового кодирования EVS соответствует 3GPP TS 26.445 и обеспечивает широкий диапазон функциональностей, к примеру, повышенное качество и эффективность кодирования для узкополосных (EVS-NB) и широкополосных (EVS-WB) речевых служб, повышенное качество с использованием сверхширокополосной (EVS-SWB) речи, повышенное качество для микшированного содержимого и музыки в разговорных вариантах применения, устойчивость к потерям пакетов и дрожанию времени задержки и обратную совместимость с кодеком AMR-WB.
[0049] В некоторых вариантах осуществления, модуль 206 базового кодирования EVS включает в себя модуль 207 предварительной обработки и управления режимом/скоростью передачи битов, который выбирает между речевым кодером для кодирования речевых сигналов и перцепционным кодером для кодирования аудиосигналов при указанной скорости передачи битов на основе выхода от модуля 207 управления режимом/скоростью передачи битов. В некоторых вариантах осуществления, речевой кодер является улучшенным вариантом линейного прогнозирования с возбуждением по алгебраическому коду (ACELP), расширенного со специализированными режимами на основе линейного прогнозирования (LP) для различных речевых классов. В некоторых вариантах осуществления, перцепционный кодер является кодером на основе модифицированного дискретного косинусного преобразования (MDCT) с повышенной эффективностью при низкой задержке/низких скоростях передачи битов и проектируется с возможностью выполнения прозрачного и надежного переключения между речевыми и аудиокодерами.
[0050] В декодере N_dmx каналов декодируются соответствующими экземплярами N_dmx монокодеков, включенными в модуль 208 базового декодирования, а дополнительная информация декодируется модулем 204 квантования и энтропийного декодирования. Основной канал понижающего микширования (например, канал W в формате сигнала FoA) подается на модуль 211 декоррелятора, который формирует N-N_dmx декоррелированных каналов. N_dmx каналов понижающего микширования, N-N_dmx декоррелированных каналов и дополнительная информация подаются в модуль 209 пространственного синтеза/рендеринга, который использует эти входные данные для синтеза или регенерации исходного N-канального входного аудиосигнала. В варианте осуществления N_dmx каналов декодируются монокодеками, отличными от монокодеков EVS. В других вариантах осуществления N_dmx каналов декодируются комбинацией одного или более многоканальных модулей базового кодирования и одного или более одноканальных модулей базового кодирования.
Кодирование IVAS с стратегиями активного понижающего микширования
1.0 Введение
[0051] Нижеследующее раскрытие описывает стратегии активного понижающего микширования для улучшения качества декодированных каналов FoA. Предложенные способы активного понижающего микширования могут использоваться в конфигурациях одноканальных или многоканальных каналов понижающего микширования. Схема кодирования активного понижающего микширования по сравнению со схемой пассивного понижающего микширования предлагает дополнительный масштабирующий член для реконструирования W канала в декодере, который можно использовать для обеспечения лучшей оценки параметров, используемых для реконструкции каналов FoA (например, пространственных метаданных).
[0052] Кроме того, исследована схема кодирования активного понижающего микширования и предлагаются потенциальные улучшения для одноканальных и многоканальных случаев понижающего микширования. В варианте осуществления схема активного понижающего микширования может выполняться адаптивно, при этом одной возможной рабочей точкой является схема кодирования пассивного понижающего микширования.
2.0 Терминология и постановка задачи
2.1. Примерная реализации пассивного понижающего микширования со SPAR с входом FoA
[0053] Кодер SPAR при работе с входом FoA преобразует входной аудиосигнал FoA, представляющий аудиосцену, в набор каналов понижающего микширования и пространственных параметров, используемых для регенерации входного сигнала в декодере SPAR. Сигналы понижающего микширования могут варьироваться от 1 до 4 каналов, и параметры включают в себя параметры прогнозирования Р, параметры перекрестного прогнозирования С и параметры декорреляции d. Эти параметры рассчитываются из входной ковариационной матрицы кодированного со взвешиванием входного аудиосигнала в заданном количестве частотных диапазонов (например, 12 частотных диапазонов).
[0054] Примерное представление извлечения параметров SPAR выглядит следующим образом:
[0055] 1. Прогнозирование всех дополнительных сигналов (Y, Z, X) из основного аудиосигнала W с использованием уравнения [1]:
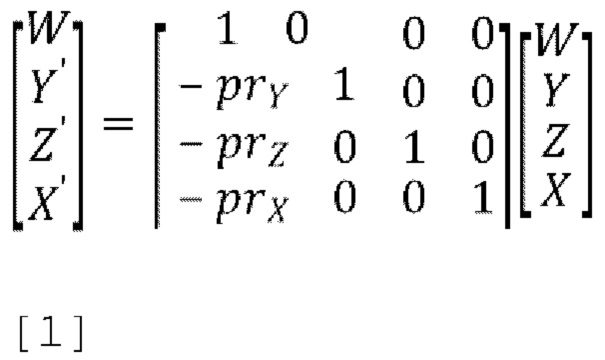
где, в качестве примера, коэффициент усиления прогнозирования для прогнозированного канала Y' рассчитывается, как показано в уравнении [2]:

[0056] Здесь normscale является коэффициентом масштабирования нормализации и является константой между 0 и 1, a RYW=cov (Y, W) - элементы входной ковариационной матрицы, соответствующие каналам Y и W. Точно так же остаточные каналы Z' и X' имеют соответствующие параметры prZ и prX. Р является вектором параметров прогнозирования Р=[prY,prZ,prX]T, также называемый [p1,p2,p3]T в некоторых вариантах осуществления. Упомянутое выше понижающее микширование так же называется пассивное понижающее микширование W, в котором W либо вообще не изменяется, либо просто задерживается во время процесса понижающего микширования.
[0057] 2. Повторное микширование канала W и прогнозированных (Y', Z', X') каналов от наиболее акустически релевантных к наименее релевантным, где повторное микширование включает в себя переупорядочивание или перекомбинацию каналов на основе некоторой методологии, как показано в уравнении [4]:
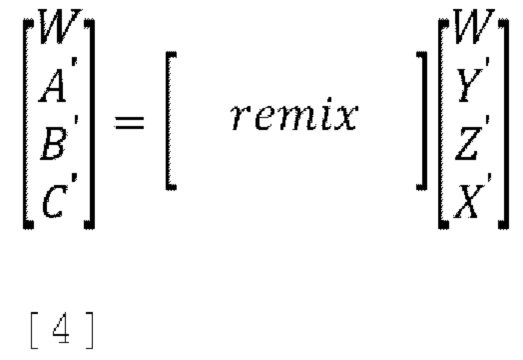
[0058] Следует отметить, что один вариант осуществления повторного микширования может быть переупорядочением входных каналов в W, Y', X', Z', при таком допущении, что сигнальные аудиометки слева и справа более важные, чем спереди назад и, наконец, сигнальные метки вверх и вниз.
[0059] 3. Расчет ковариации четырехканального пост-прогнозирования и понижающего микширования с повторным микшированием, как показано в уравнениях [5] и [6]:

где dd представляет дополнительные каналы понижающего микширования за пределами W (например, каналы со 2-го по N-dmx-й), а и представляет каналы, которые необходимо полностью переформировать (например, от (N_dmx+1)-го до 4-го каналов).
[0060] Для примера понижающего микширования WABC с 1-4 каналами понижающего микширования d и u представляют следующие каналы, при этом переменные-заполнители А, В, С могут быть любой комбинацией каналов X, Y, Z в FoA):

[0061] 4. Из этих вычислений определяем, возможно ли перекрестное прогнозирование какой-либо оставшейся части полностью параметрических каналов из отправляемых остаточных каналов. Требуемые дополнительные коэффициенты С:
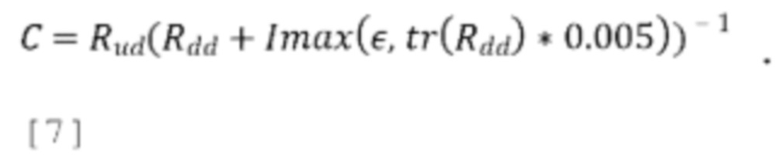
[0062] Таким образом, С имеет форму (1×2) для 3-канального понижающего микширования и (2×1) для 2-канального понижающего микширования. Одна реализация пространственного зашумления не требует этих параметров С, и эти параметры могут быть установлены в 0. Альтернативная реализация пространственного зашумления может также включать в себя параметры С.
[0063] 5. Расчет оставшейся энергии в параметризованных каналах, которые должны быть заполнены декорреляторами. Остаточная энергия в каналах повышающего микширования Resuu является разницей между фактической энергией Ruu (пост-прогнозирования) и регенерированной энергией перекрестного прогнозирования Reguu:
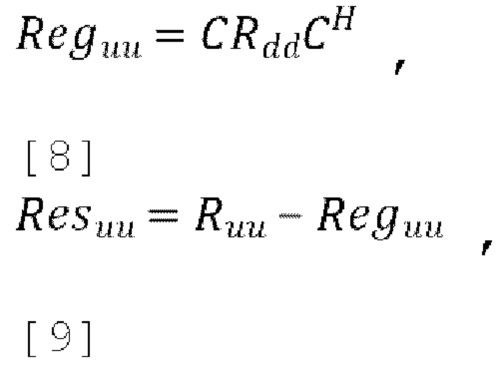

где scale - коэффициент масштабирования нормализации. Scale может быть широкополосным значением (например, scale = 0,01) или частотно зависимым и может принимать разные значения в разных частотных диапазонах (например, scale = linspace (0.5, 0.01, 12)), когда спектр разделен на 12 диапазонов). Параметры в d в уравнении [11] предписывают, сколько декоррелированных компонентов W используется для воссоздания каналов А, В и С до отмены прогнозирования и отмены понижающего микширования.
[0064] В конфигурации с 1-канальным пассивным понижающим микшированием только канал W, параметры Р (p1, p2, p3) и параметры d (d1, d2, d3) кодируются и отправляются в декодер.
[0065] В схеме кодирования пассивного понижающего микширования дополнительные каналы Y, X, Z прогнозируются в декодере из переданного понижающего микширования W с использованием трех параметров прогнозирования Р. Недостающая энергия в дополнительных каналах восполняется путем добавления масштабированных версий декоррелированного понижающего микширования D(W) с использованием параметров декорреляции d. Для пассивного понижающего микширования реконструкция входа FoA выполняется следующим образом:
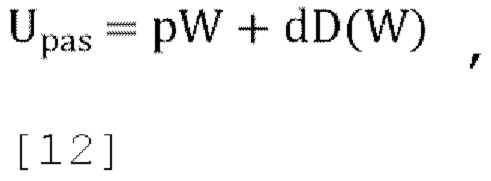
где p=[1 p1 p2 p3]T и d=[0 d1 d2 d3]T a D(W) описывает выходы декоррелятора с каналом W в качестве входа для блока декоррелятора. Следует отметить, что, предполагая идеальные декорреляторы и отсутствие квантования параметров прогнозирования и декоррелятора, эта схема достигает идеального реконструирования с точки зрения входной ковариационной матрицы.
[0066] Пассивное понижающее микширование часто не может реконструировать входную сцену на выходе декодера с более низкой конфигурацией канала понижающего микширования из-за несовершенных декорреляторов и ограниченного диапазона квантования, доступных для параметров прогнозирования и параметров декоррелятора. Таким образом, желательно, чтобы схема активного понижающего микширования уменьшала общую ошибку прогнозирования за счет формирования лучших оценок коэффициентов усиления прогнозирования, которые находятся в пределах желаемого диапазона квантования.
2.2 Схема кодирования активного понижающего микширования
[0067] Ниже описано решение для активного понижающего микширования. Это решение направлено на формирование представления доминирующего собственного сигнала путем масштабирования и добавления входных каналов W, X, Y, Z. Матрица прогнозирования или матрица понижающего микширования задается уравнением (13) как:
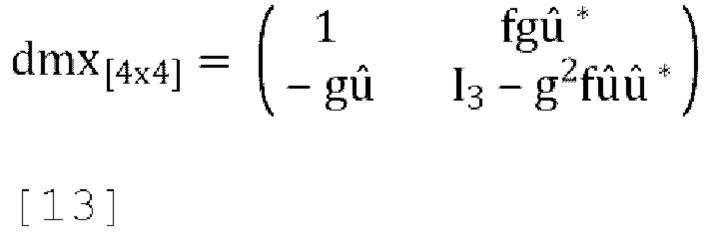
[0068] Каналы понижающего микширования W вычисляются как:
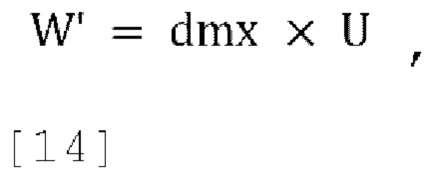
где U - входной сигнал FoA, задается как:
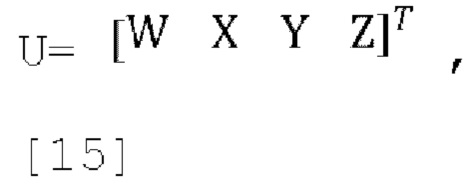
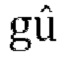 являются параметрами прогнозирования [p1, p2, p3], которые кодируются и отправляются в декодер,
являются параметрами прогнозирования [p1, p2, p3], которые кодируются и отправляются в декодер, 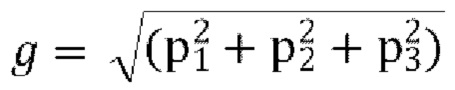 ,
, 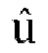 является единичным вектором, f является константой (например, 0,5), известной как кодеру, так и декодеру. Для понижающего микширования одиночного канала канал W'=W+fp1X+fp2Y+fp3Z кодируется и отправляется в декодер вместе с параметрами прогнозирования и параметрами декорреляции d.
является единичным вектором, f является константой (например, 0,5), известной как кодеру, так и декодеру. Для понижающего микширования одиночного канала канал W'=W+fp1X+fp2Y+fp3Z кодируется и отправляется в декодер вместе с параметрами прогнозирования и параметрами декорреляции d.
Декодер применяет матрицу повышающего микширования к W', заданную как:
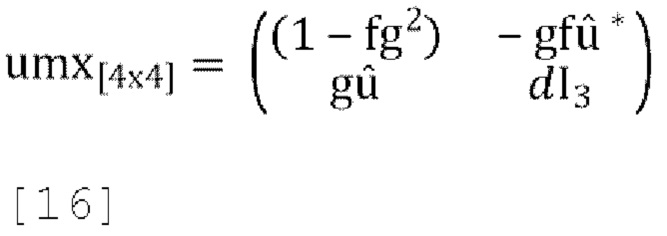
где d являются параметрами декорреляции (d1, d2, d3), а реконструированный сигнал FoA задается как:
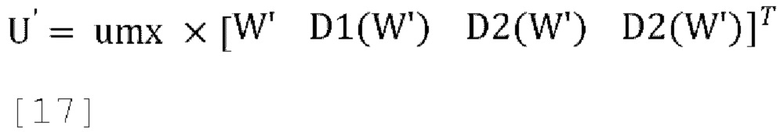
где D1(W'), D2(W') и D3(W') - три выхода блока декоррелятора.
[0069] Это решение в общем обеспечивает более точные оценки параметров прогнозирования по сравнению со схемой пассивного понижающего микширования, приводит параметры прогнозирования в желаемый диапазон квантования и уменьшает общую ошибку прогнозирования. Однако, решение опирается на выходы декоррелятора для реконструирования канала W из понижающего микширования W', что может приводить к аудиоартефактам. Кроме того, учитывая, что входные коэффициенты усиления понижающего микширования 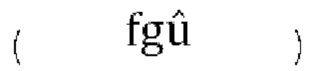 прямо пропорциональны параметрам прогнозирования, было замечено, что это решение обеспечивает оценки параметров прогнозирования более высокие, чем требуется, и может приводить к пространственным искажениям в реконструированном выходе FoA.
прямо пропорциональны параметрам прогнозирования, было замечено, что это решение обеспечивает оценки параметров прогнозирования более высокие, чем требуется, и может приводить к пространственным искажениям в реконструированном выходе FoA.
2.3 Примерные осуществления предлагаемых схем кодирования адаптивного понижающего микширования
2.3.1 Схема кодирования адаптивного понижающего микширования
[0070] Цель описанных ниже стратегий адаптивного понижающего микширования (здесь также называемых стратегиями адаптивного активного понижающего микширования) состоит в том, чтобы обеспечить лучшую оценку параметров прогнозирования р путем вычисления входных коэффициентов усиления понижающего микширования (здесь также называемых коэффициентами активного понижающего микширования) 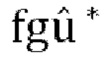 заданных в [13] различными способами.
заданных в [13] различными способами.
[0071] В некоторых вариантах осуществления входные коэффициенты усиления понижающего микширования вычисляются таким образом, что суммарная квадратичная ошибка прогнозирования минимизирована, при этом ошибка формы сигнала прогнозирования задается как:
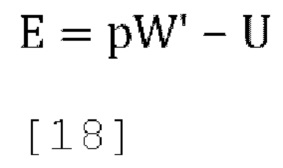
а среднеквадратические ошибки прогнозирования (ошибки прогнозирования на сигнал) (4×1) задаются как:
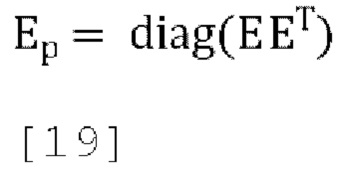
где общая квадратичная ошибка прогнозирования задается как:
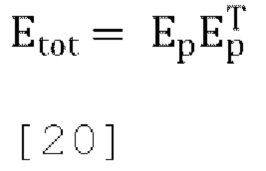
где р - матрица обратного прогнозирования.
[0072] В некоторых вариантах осуществления входные коэффициенты усиления понижающего микширования вычисляются таким образом, чтобы ковариация пост-прогнозирования была минимальна.
[0073] В некоторых вариантах осуществления входные коэффициенты усиления понижающего микширования вычисляются таким образом, чтобы параметры прогнозирования находились в требуемом диапазоне квантования.
[0074] Было замечено, что для конфигураций канала с низким понижающим микшированием качество аудио при SPAR-кодировании с раскрытой схемой кодирования активного понижающего микширования лучше, чем с текущей схемой кодирования пассивного понижающего микширования. Однако для некоторого аудиоконтента качество лучше со схемой пассивного понижающего микширования, что предполагает адаптивную работу схемы кодирования активного понижающего микширования.
[0075] На основе вышеописанных наблюдений ниже раскрыта схема адаптивного понижающего микширования, которая вычисляет входные коэффициенты усиления понижающего микширования в зависимости от свойств сигнала. Это зависящее от сигнала вычисление входных коэффициентов усиления понижающего микширования может быть включено в каждую обрабатываемую полосу частот и аудиокадр или во все частотные диапазоны в аудиокадре.
2.3.1.1 Выбор входных коэффициентов усиления понижающего микширования на основе минимальной ошибки
[0076] В варианте осуществления выбор фактора «f» во входных коэффициентах понижающего микширования 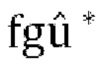 заданных в [13], может быть получен путем расчета общей ошибки прогнозирования (уравнение [20]) для каждого возможного f и выбора одной с наименьшей общей ошибкой прогнозирования. Следует отметить, что как только входная ковариация R станет доступной, общая ошибка прогнозирования может быть эффективно вычислена в ковариационной области.
заданных в [13], может быть получен путем расчета общей ошибки прогнозирования (уравнение [20]) для каждого возможного f и выбора одной с наименьшей общей ошибкой прогнозирования. Следует отметить, что как только входная ковариация R станет доступной, общая ошибка прогнозирования может быть эффективно вычислена в ковариационной области.
2.3.1.2 Схема адаптивного понижающего микширования на основе речевой активности
[0077] Было замечено, что для речевых сигналов высокое значение f может ухудшить характеристики пространственного комфортного шума во время передачи данных. Фоновый шум в речевых сигналах обычно рассеивается, и агрессивная активная W схема может привести к тому, что канал понижающего микширования W будет забирать больше энергии из остаточных каналов X, Y и Z, чем хотелось бы. При полностью параметризированном кодировании декодер решения для комфортного шума формирует 4 некоррелированных канала комфортного шума с той же спектральной формой, что и канал W активного понижающего микширования. Затем эти некоррелированные каналы формируются с использованием параметров SPAR. Учитывая чрезвычайно низкую скорость передачи битов, приблизительное квантование параметров SPAR и полностью параметризированную реконструкцию во время прерывистого режима передачи (DTX) кадров, где для текущей параметризированной реконструкции дополнительная энергия в активном канале W никогда не удаляется, а выходной канал W пространственно сжимается, высокая энергия делает шум комфортным.
[0078] Также желательно, чтобы реконструированный фоновый шум в декодере звучал непрерывно во время активных кадров обнаружения речевой активности (VAD) и неактивных кадров VAD. В варианте осуществления схема пассивного понижающего микширования во время неактивных кадров VAD и схема активного во время активных кадров VAD могут ухудшить общую производительность кодека IVAS. Однако при субъективных оценках было замечено, что уменьшенное значение f (например, 0,25) в целом хорошо работает для неактивных кадров, в то время как высокое значение f (например, 0,5) хорошо работает для активных кадров. Такое условное применение f также помогает поддерживать плавный переход между активными и неактивными кадрами.
[0079] В варианте осуществления SPAR в активной конфигурации W динамически выбирает различные значения f на основе решения VAD, где VAD принимает на вход сигнал FoA. Высокое значение f можно выбрать, когда VAD активный, а низкое значение f можно выбрать, когда VAD неактивный.
2.3.1.3 Схема кодирования адаптивного понижающего микширования на основе желаемого диапазона параметров прогнозирования
Первый вариант способа IVAS
[0080] В варианте осуществления, если f=0, декодирование возвращается к описанной выше схеме пассивного понижающего микширования, что приводит к проблеме, заключающейся в том, что параметры прогнозирования «g» могут быть неограниченными. Устанавливая для f большее значение (например, f=0,5), диапазон положительного действительного значения «g» в уравнении [17] можно ограничить до 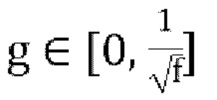 . Имеются некоторые свидетельства того, что стабильность стратегии активного понижающего микширования можно улучшить, сохраняя f малым и используя большее значение f только тогда, когда необходимо предотвратить слишком большое значение g.
. Имеются некоторые свидетельства того, что стабильность стратегии активного понижающего микширования можно улучшить, сохраняя f малым и используя большее значение f только тогда, когда необходимо предотвратить слишком большое значение g.
[0081] В варианте осуществления потенциальный вариант стратегии активного понижающего микширования состоит в том, чтобы устанавливать f=0 всегда, когда это возможно, при условии что это сохраняет g<g', где g' - желаемый диапазон для параметров прогнозирования, в противном случае выбирать f так, чтобы g=g'. Если это приводит к чрезмерно большому значению g (если g>g'), устанавливать g=g' в уравнении (17), и затем решать квадратное уравнение Q(f)=(βg'3)f2+(2αg'2-βg')f+wg'-α чтобы найти f, устанавливая = gg' и решая для f:
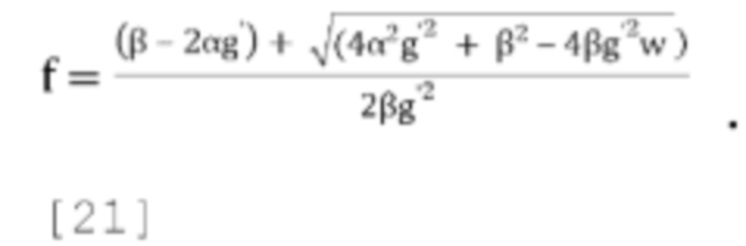
[0082] Чтобы гарантировать, что квадратное уравнение всегда имеет по меньшей мере одно действительное решение и что наибольшее действительное решение находится в диапазоне 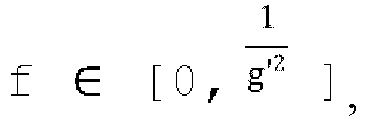 замечено, что:
замечено, что:
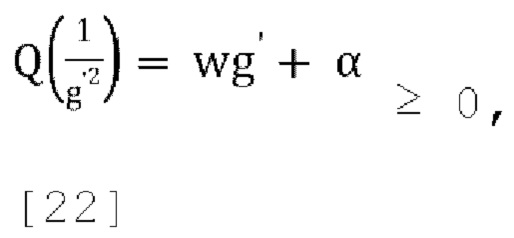
где α≥0, ω≥0 и g'≥0, Q(0)=wg'-α<0 поскольку 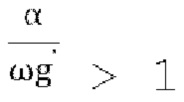 , и где существует положительное пересечение нуля в диапазоне
, и где существует положительное пересечение нуля в диапазоне 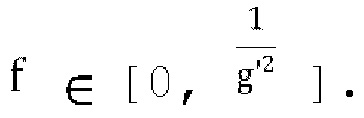
[0083] Некоторые примерные значения g' могут быть 1,0 (f [от 0 до 1]), 1,414 (f [от 0 до 0,5]) и 2 (f [от 0 до 0,25]). Приведенные выше наблюдения можно обобщить, как показано в уравнениях [23] и [24]:
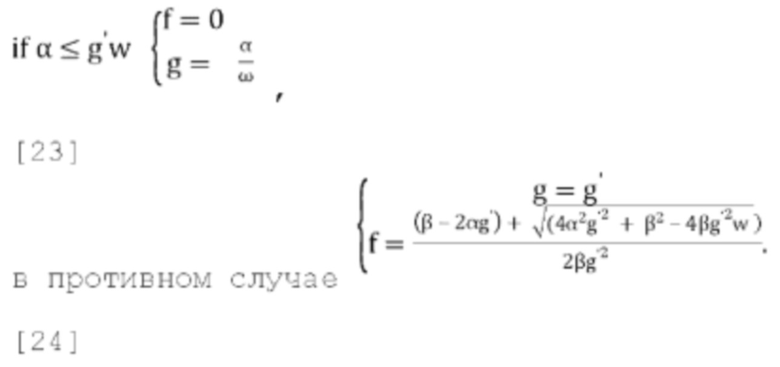
[0084] Следует отметить, что приведенные выше уравнения [23] и [24] могут потребовать передачи дополнительных метаданных в декодер. Отправка дополнительных метаданных для указания значения «f» можно избежать, используя способ масштабирования, описанный в разделе 2.3.1.4.
Второй вариант способа IVAS
[0085] Замечено, что малое значение f желательно, когда g мало, и большее значение f может дать лучшие результаты, когда g велико. Между f и g может существовать некоторая линейная зависимость, которую можно использовать для получения оптимальных результатов во всех случаях. Например, если f=kg, где k - это константа ≤1,0 (обычно 0,5),
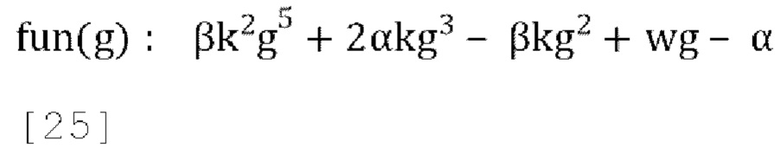
и эта функция хорошо себя ведет, когда
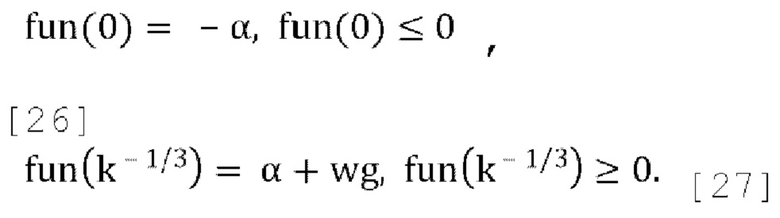
Соответственно, есть хотя бы один корень между 0 и k-1/3. Производная этой функции:
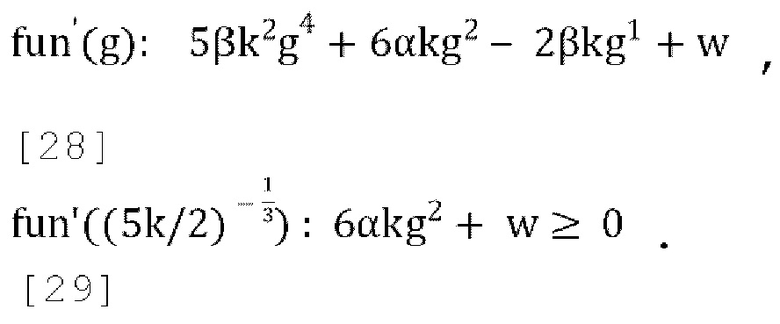
[0086] Производная этого многочлена монотонно возрастает после 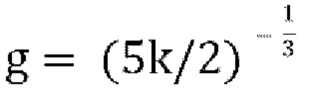 . Если
. Если 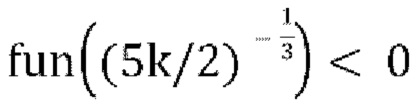 , то между
, то между 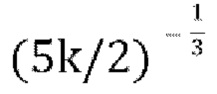 и
и 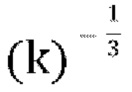 существует только один корень, который является наибольшим корнем, что упрощает способу Ньютона Рафсона, или другому подходящему решателю, схождение к нужному корню, если начальное условие установлено соответствующим образом. Если
существует только один корень, который является наибольшим корнем, что упрощает способу Ньютона Рафсона, или другому подходящему решателю, схождение к нужному корню, если начальное условие установлено соответствующим образом. Если 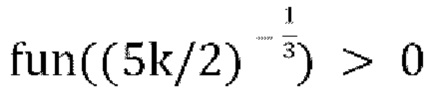 , то наибольший корень находится между g=0 and
, то наибольший корень находится между g=0 and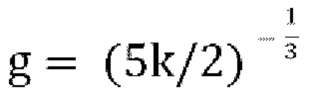 , и в таких случаях может быть несколько корней между g=0 и
, и в таких случаях может быть несколько корней между g=0 и 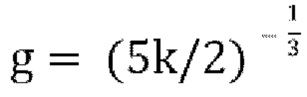 . В варианте осуществления для нахождения наибольшего корня способ Ньютона Рафсона можно инициализировать с помощью
. В варианте осуществления для нахождения наибольшего корня способ Ньютона Рафсона можно инициализировать с помощью 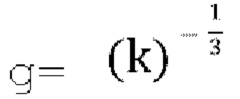 или
или 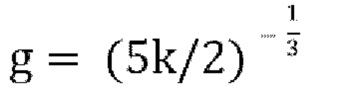 , а количество итераций можно увеличить, а скорость обучения настроить таким образом, что расходимости удается избежать, и способ Ньютона-Рафсона медленно сходится к наибольшему корню. Следует отметить, что при k=0,5, g будет находиться в диапазоне от 0 до 1,26,
, а количество итераций можно увеличить, а скорость обучения настроить таким образом, что расходимости удается избежать, и способ Ньютона-Рафсона медленно сходится к наибольшему корню. Следует отметить, что при k=0,5, g будет находиться в диапазоне от 0 до 1,26, 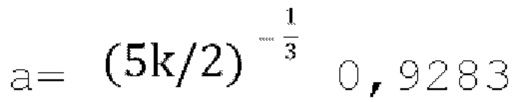 . Отправки дополнительных метаданных для указания значения «f» можно избежать, используя способ масштабирования, описанный в разделе 2.3.1.4.
. Отправки дополнительных метаданных для указания значения «f» можно избежать, используя способ масштабирования, описанный в разделе 2.3.1.4.
2.3.1.4 Кодирование активного понижающего микширования с масштабированием
Вариант способа IVAS
[0087] Обратное прогнозирование задается как:
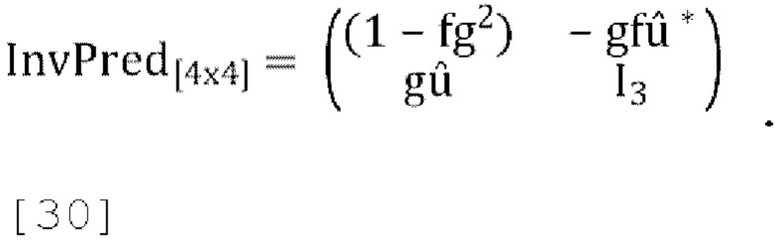
[0088] С помощью этой матрицы обратного прогнозирования основной канал W может быть реконструирован из W', Y', X' и Z', где W', Y', X' и Z' являются каналами понижающего микширования после прогнозирования. Но в случае параметрической реконструкции есть только Ndmx каналов понижающего микширования, где Ndmx меньше 4. В этом случае отсутствующий канал понижающего микширования параметрически реконструируется с использованием диапазонных ценок энергии в полосе частот канала, микшированного с понижением количества каналов, и декоррелированного сигнала W'. При параметрической реконструкции матрица обратного прогнозирования, приведенная в [30], может быть не в состоянии реконструировать W из W' и может еще больше исказить W.
[0089] В варианте осуществления способ решения этой проблемы проиллюстрирован ниже для 1-канального понижающего микширования.
[0090] Модифицированная матрица обратного прогнозирования задается следующим образом:
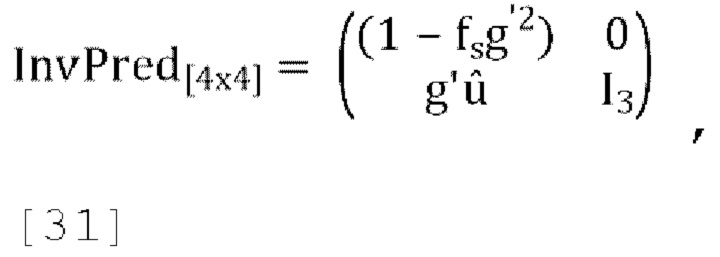
где g' является g/r, где r - коэффициент масштабирования, применяемый к W' таким образом, что выход обратного прогнозирования канала W соответствует по энергии входу канала W в матрицу прогнозирования, fs является константой.
[0091] В варианте осуществления значение «fs» в матрице обратного прогнозирования, заданной уравнением [31], является постоянным значением, которое не зависит от значения фактора «f», используемого в кодере при вычислении входных коэффициентов усиления понижающего микширования. В этом варианте осуществления входные коэффициенты усиления понижающего микширования с уменьшением числа каналов могут быть вычислены без отправки каких-либо дополнительных метаданных в декодер.
[0092] Новая матрица прогнозирования задается следующим образом:
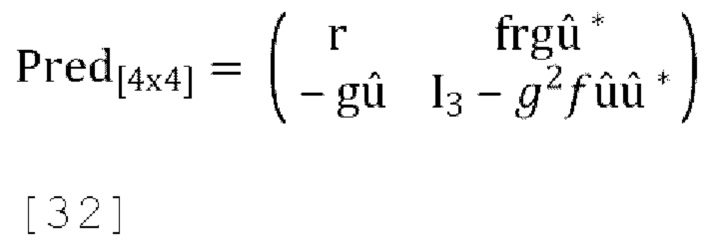
[0093] Матрица пост-прогнозирования и матрица обратного пост-прогнозирования (также называемая выходной ковариационной матрицей) могут быть вычислены как:
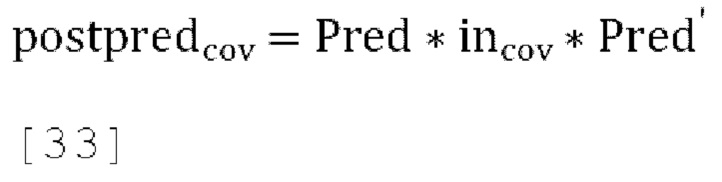
где «Pred» - матрица прогнозирования, заданная в уравнении [32], a incov - ковариационная матрица входных каналов. Выходная ковариационная матрица задается как:
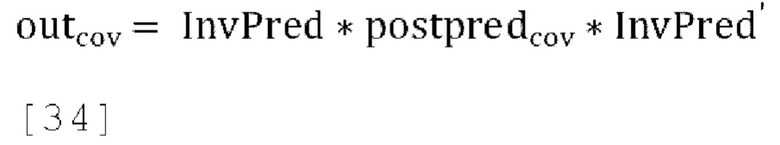
где «InvPred» - матрица обратного прогнозирования, заданная в уравнении [31].
[0094] Пусть w=incov(1, 1) (т.е. отклонение входного канала W) m=postpredcov(1, 1) (т.е. отклонение пост-прогнозированного канала W), когда r=1.
[0095] Замена «Pred» из уравнения [32] и «InvPred» из уравнения [31] в уравнение [33] и уравнение [34] дает:
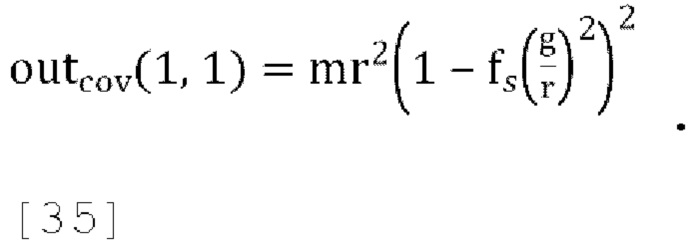
[0096] Чтобы соответствовать отклонению outcov(1, 1)=w
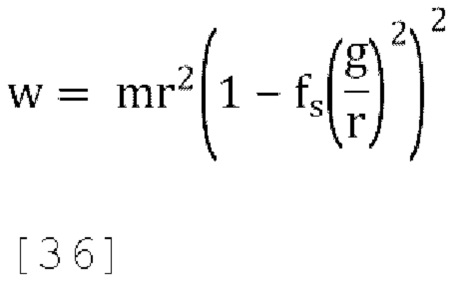
которое может быть решено для r, чтобы получить:
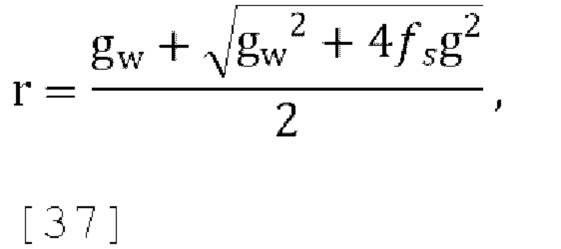
Где 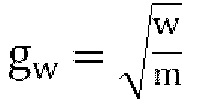 , a g вычисляется путем использования любого способа, упомянутого в различных вариантах осуществления.
, a g вычисляется путем использования любого способа, упомянутого в различных вариантах осуществления.
[0097] После прогнозирования каналы понижающего микширования X', Y' и Z' указывают остаточные каналы, содержащие сигнал, который не может быть прогнозирован из W'. В случае параметрического повышающего микширования один или более остаточных каналов могут не передаваться в декодер; вместо этого в декодер кодируется и отправляется представление их энергетических уровней (также называемых Pd или параметрами декорреляции). Декодер параметрически регенерирует эти отсутствующие остаточные каналы, используя W', блок декоррелятора и параметры Pd.
[0098] Параметры d можно вычислить следующим образом:
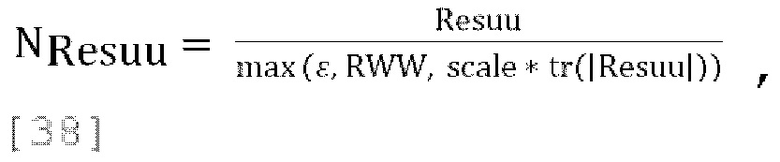
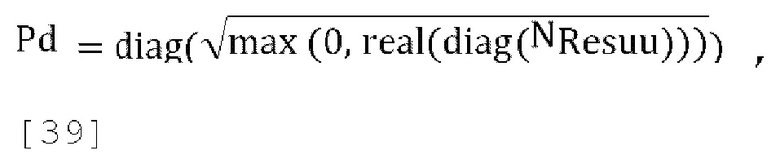
где параметр «scale» является коэффициент масштабирования нормализации. В варианте осуществления scale может быть широкополосным значением (например, scale = 0,01) или частотно зависимым и может принимать разные значения в разных частотных диапазонах (например, scale = linspace (0,5, 0,01, 12), где спектр разделен на 12 диапазонов), RWW=mr2=postpredcov(1, 1) согласно уравнению [33], a Resuu является ковариационной матрицей остаточных каналов, которые должны быть параметрически микшированы с повышением количества каналов в декодере. Для 1-канального понижающего микширования Resuu является ковариационной матрицей 3×3, задаваемой через Resuu=postpredcov(2:4, 2:4)
[0099] В некоторых реализациях коэффициент масштабирования понижающего микширования  может быть функцией и от параметров прогнозирования, и от параметров декорреляции, где параметры декорреляции для понижающего микширования одного канала определены в уравнении [39]. Для 1-канального понижающего микширования с улучшенным масштабированием матрица обратного прогнозирования принимает вид:
может быть функцией и от параметров прогнозирования, и от параметров декорреляции, где параметры декорреляции для понижающего микширования одного канала определены в уравнении [39]. Для 1-канального понижающего микширования с улучшенным масштабированием матрица обратного прогнозирования принимает вид:
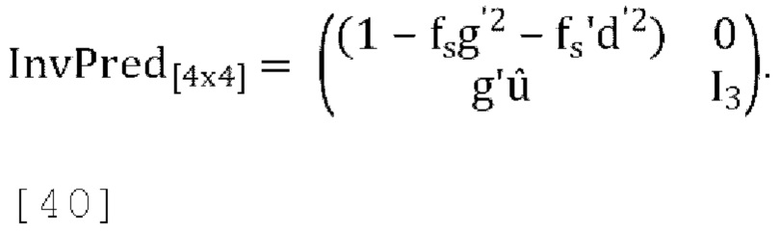
[00100] Где fs и fs' константы, например, для, fs=fs'=0,5,  где r=f(g, d), d=sqrt(sum(diag(Pd))) и Pd вычисляется согласно уравнению [39].
где r=f(g, d), d=sqrt(sum(diag(Pd))) и Pd вычисляется согласно уравнению [39].
[00101] Решение для r с использованием уравнений [33] и [34],
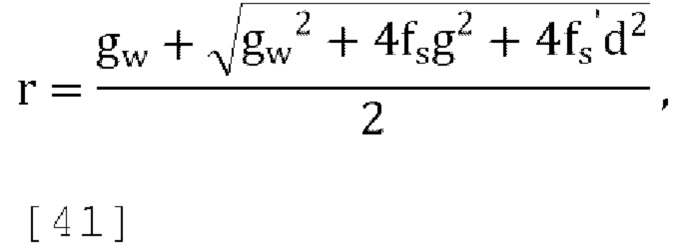
где 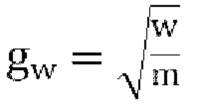 , a g вычисляется путем использования любого способа, упомянутого в различных вариантах осуществления. Pd'=Diag(Pd/r) и
, a g вычисляется путем использования любого способа, упомянутого в различных вариантах осуществления. Pd'=Diag(Pd/r) и 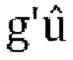 квантуются и отправляются в декодер, а масштабирование гарантирует, что неквантованные и масштабированные параметры декорреляции и прогнозирования находятся в желаемом диапазоне.
квантуются и отправляются в декодер, а масштабирование гарантирует, что неквантованные и масштабированные параметры декорреляции и прогнозирования находятся в желаемом диапазоне.
[00102] Окончательный декодированный/микшированный с повышением количества каналов вывод задается как:
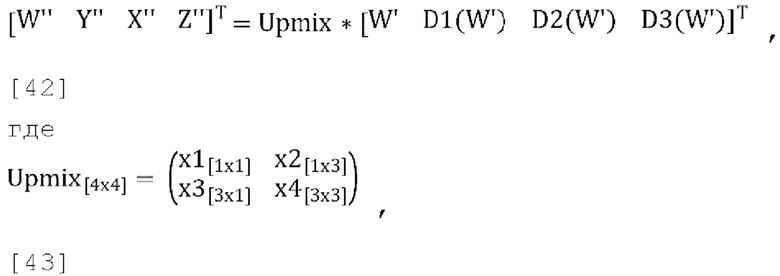
где 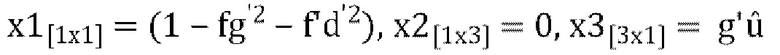 , и
, и 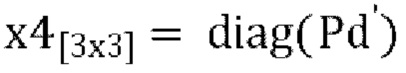 , W' - это пост-прогнозированный и масштабированный канал понижающего микширования, D1(W'), D2(W') and D3(W') - декоррелированные выходы W', a W'', Y'', X'', Z'' - декодированные каналы FoA.
, W' - это пост-прогнозированный и масштабированный канал понижающего микширования, D1(W'), D2(W') and D3(W') - декоррелированные выходы W', a W'', Y'', X'', Z'' - декодированные каналы FoA.
2.3.1.5 Кодирование пассивного понижающего микширования с масштабированием
[00103] В способе пассивного понижающего микширования существует проблема, заключающаяся в том, что 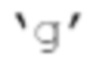 , например, вектор параметров прогнозирования, может быть неограниченным. Это приводит к пространственным искажениям с параметрическими конфигурациями повышающего микширования. При низких скоростях передачи битов количество каналов понижающего микширования может быть меньше 4, а оставшиеся каналы параметрически микшируются с повышением количества каналов в декодере. При квантовании становится ограниченным, что приводит к несовершенным оценкам прогнозирования, а повышающее микширование полагается на большую энергии декоррелятора для параметрической регенерации каналов Y, X или Z. Проблема решается с помощью описанной ниже модифицированной пассивной схемы, которая применяет динамическое масштабирование к каналу W во время процесса понижающего микширования. Масштабирование рассчитывается таким образом, что никогда не выходит за пределы допустимого диапазона, и во время параметрического повышающего микширования больше энергии извлекается из доступного представления канала W, а не из декоррелированных сигналов.
, например, вектор параметров прогнозирования, может быть неограниченным. Это приводит к пространственным искажениям с параметрическими конфигурациями повышающего микширования. При низких скоростях передачи битов количество каналов понижающего микширования может быть меньше 4, а оставшиеся каналы параметрически микшируются с повышением количества каналов в декодере. При квантовании становится ограниченным, что приводит к несовершенным оценкам прогнозирования, а повышающее микширование полагается на большую энергии декоррелятора для параметрической регенерации каналов Y, X или Z. Проблема решается с помощью описанной ниже модифицированной пассивной схемы, которая применяет динамическое масштабирование к каналу W во время процесса понижающего микширования. Масштабирование рассчитывается таким образом, что никогда не выходит за пределы допустимого диапазона, и во время параметрического повышающего микширования больше энергии извлекается из доступного представления канала W, а не из декоррелированных сигналов.
[00104] Ниже приведена примерная реализация схемы кодирования пассивного понижающего микширования с 1-канальным микшированием.
[00105] Вход FoA задается как U=[W X Y Z]T. Ковариационная матрица (4×4) входного сигнала: R=UUT. Параметры прогнозирования пассивной схемы по-умолчанию вычисляются как 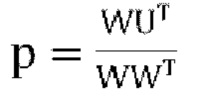 , где Р=[1 p1 p2 p3]Т. Матрица прогнозирования понижающего микширования задается как:
, где Р=[1 p1 p2 p3]Т. Матрица прогнозирования понижающего микширования задается как:
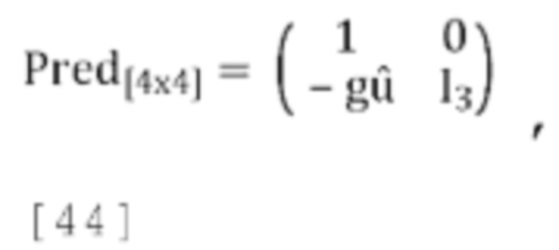
где 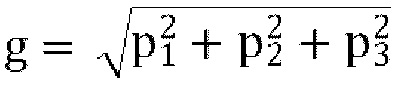 , и
, и 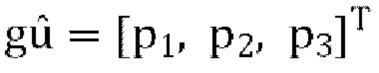 , передаваемые в декодер параметры прогнозирования являются квантованными p1, p2, p3. Обратное прогнозирование повышающего микширования в схеме пассивного кодирования задается как:
, передаваемые в декодер параметры прогнозирования являются квантованными p1, p2, p3. Обратное прогнозирование повышающего микширования в схеме пассивного кодирования задается как:
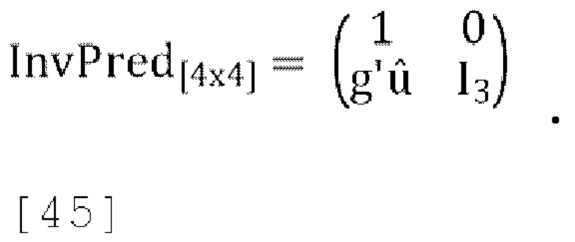
[00106] При масштабировании матрица прогнозирования понижающего микширования изменяется на:
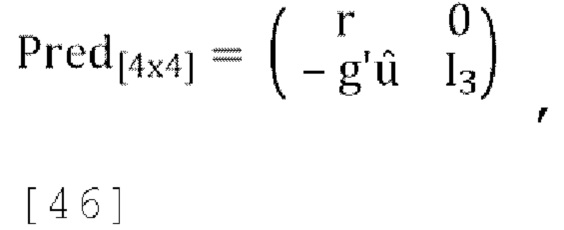
где 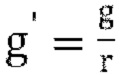 и r - коэффициент масштабирования, а матрица обратного прогнозирования повышающего микширования изменяется на:
и r - коэффициент масштабирования, а матрица обратного прогнозирования повышающего микширования изменяется на:
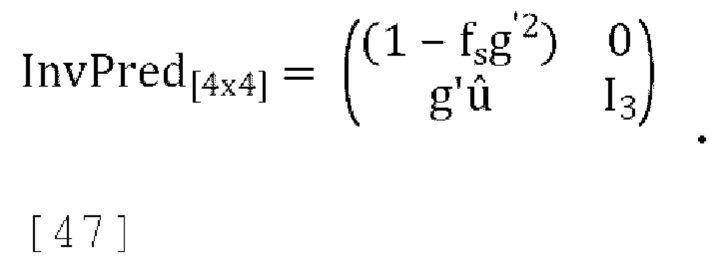
где fs - константа (например, 0,5).
[00107] Подставляя эти значения в уравнения [33] и [34] и приравнивая outcov(1, 1)=W получаем:
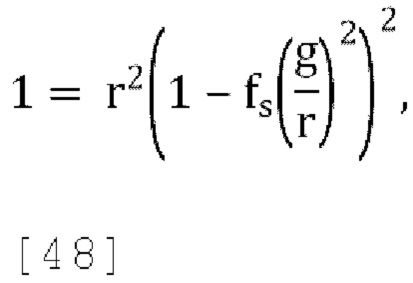
где решая для r получаем:
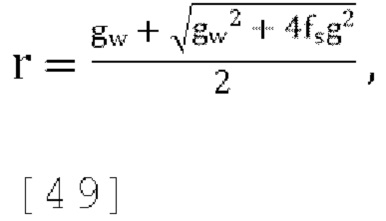 где gw=1.
где gw=1.
[00108] В схеме масштабированного пассивного понижающего микширования передаваемые в декодер параметры прогнозирования квантуются как p1/r, р2/r, р3/r. Поскольку коэффициент масштабирования 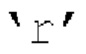 является функцией параметров прогнозирования, то он увеличивает энергию в W в достаточной степени, чтобы быть уверенными, что параметры прогнозирования находятся в желаемом диапазоне. Коэффициент масштабирования может быть диапазонным или широкополосным значением.
является функцией параметров прогнозирования, то он увеличивает энергию в W в достаточной степени, чтобы быть уверенными, что параметры прогнозирования находятся в желаемом диапазоне. Коэффициент масштабирования может быть диапазонным или широкополосным значением.
[00109] Как показано в уравнении [41], в некоторых реализациях коэффициент масштабирования 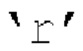 может быть функцией как параметров прогнозирования, так и параметров декорреляции. Для пассивного понижающего микширования этот коэффициент масштабирования принимает вид:
может быть функцией как параметров прогнозирования, так и параметров декорреляции. Для пассивного понижающего микширования этот коэффициент масштабирования принимает вид:
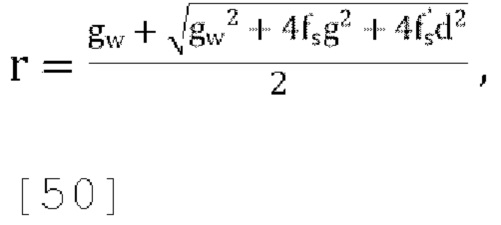 где gw=1.
где gw=1.
2.3.1.6 Кодирование адаптивного понижающего микширования с масштабированием
[00110] Замечено, что способ кодирования понижающего микширования масштабированного активного W лучше всего работает в условиях, когда имеется высокая корреляция между W и каналами X, Y, Z, в то время как способ кодирования понижающего микширования масштабированного пассивного W работает лучше всего, когда корреляция низкая. Следовательно, в некоторых реализациях более надежное решение может быть получено путем соответствующего переключения между схемами кодирования масштабируемого пассивного и активного W.
[00111] В варианте осуществления способ кодирования понижающего микширования активного W может быть основан либо на решениях, описанных в разделе 2.3.1.2. Масштабирование способа кодирования понижающего микширования активного W выполняется в соответствии с решением, описанным в разделе 2.3.1.4, а масштабирование способа кодирования понижающего микширования пассивного W может быть выполнено в соответствии с решением, описанным в разделе 2.3.1.5. Ниже описана примерная реализация адаптивного понижающего микширования с масштабированием.
[00112] Вход FoA задается как U=[W X Y Z]T. Ковариационная матрица (4×4) входного сигнала: R=UUT. Вычисляем фактор коэффициента пассивного прогнозирования gpred, где 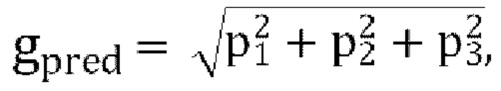
где площади p1, р2 and р3 рассчитываются следующим образом:
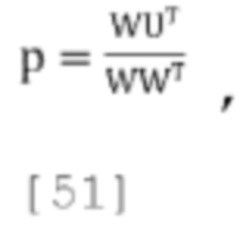 где Р=[1 p1 p2 p3]Т.
где Р=[1 p1 p2 p3]Т.
[00113] Если gpred≥thresh, то вычисляем параметры прогнозирования 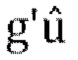 активного W, коэффициент масштабирования
активного W, коэффициент масштабирования  , матрицу прогнозирования, матрицу обратного прогнозирования, матрицы понижающего и повышающего микширования в соответствии с уравнениями [31]-[41] в разделе 2.3.1.4.
, матрицу прогнозирования, матрицу обратного прогнозирования, матрицы понижающего и повышающего микширования в соответствии с уравнениями [31]-[41] в разделе 2.3.1.4.
[00114] Если gpred<thresh, то вычисляем параметры прогнозирования 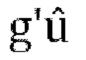 пассивного W, коэффициент масштабирования
пассивного W, коэффициент масштабирования 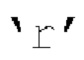 , матрицу прогнозирования, матрицу обратного прогнозирования, матрицы понижающего и повышающего микширования в соответствии с уравнениями [44]-[50] в разделе 2.3.1.5.
, матрицу прогнозирования, матрицу обратного прогнозирования, матрицы понижающего и повышающего микширования в соответствии с уравнениями [44]-[50] в разделе 2.3.1.5.
[00115] Поскольку, как показано в уравнении [31] и уравнении [47], матрица обратного прогнозирования на стороне декодера одинакова для способов кодирования понижающего микширования масштабированных пассивных и активных W, то не требуется никакой другой дополнительной информации, чтобы сигнализировать о том, кодировано ли понижающее микширование способом кодирования понижающего микширования для масштабированного активного или пассивного W. Другой подход основан на максимальном коэффициенте масштабирования г, как описано в разделе 2.3.1.7.
2.3.1.7 Мягкое переключение между активным и пассивным масштабированным понижающим микшированием
[00116] В этом варианте осуществления масштабированная версия сигнала W (например, без вкладов от сигналов Y, X, Z) используется в качестве понижающего микширования в способе кодирования активного понижающего микширования до тех пор, пока требуемый коэффициент масштабирования r не превышает верхний предел. Адаптивное масштабирование выдвигает параметры прогнозирования и декоррелятора в хороший диапазон для квантования, а отсутствие микширования вкладов сигналов Y, X, Z в понижающее микширование позволяет избежать артефактов для некоторых типов сигналов. С другой стороны, большие вариации коэффициента масштабирования r понижающего микширования также могут привести к артефактам. Следовательно, если максимальный коэффициент масштабирования на полосу частот превышает верхний предел (например, обычно 2,5), то описанный ниже примерный итеративный процесс может использоваться для определения коэффициентов усиления понижающего микширования с вкладами сигналов Y, X, Z таким образом, что коэффициент масштабирования r находится в пределах максимального предела. По сравнению с исходным алгоритмом активного W, дополнительный коэффициент масштабирования r позволяет использовать оптимальные коэффициенты усиления прогнозирования.
[00117] Упомянутый выше примерный итеративный процесс описывается следующим образом:
1. определяются коэффициенты усиления понижающего микширования: A=[1 0 0 0],
2. вычисляются параметры прогнозирования, используя 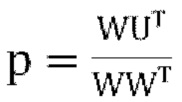 ,
,
3. вычисляются параметры декоррелятора, используя 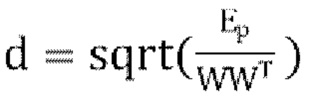 , где Ер вычислен согласно уравнению [19],
, где Ер вычислен согласно уравнению [19],
4. вычисляется коэффициент масштабирования понижающего микширования, используя r=r1 из уравнения [49],
5. масштабируются параметры прогнозирования и декоррелятора на 1/r, масштабируется понижающее микширование как W'=r*W
6. определяется единичный вектор 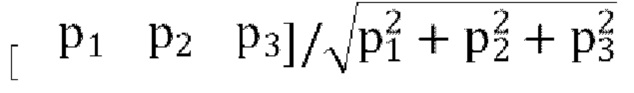
7. определяется масштабирование единичного вектора h=0,1 и максимальный коэффициент масштабирования r_max=2,5,
8. пока (r>r_max && h <= 0,5)
а. определяются коэффициенты усиления понижающего микширования A=[1 hU]
b. Вычисляется основной канал понижающего микширования М без масштабирования,
c. вычисляются параметры прогнозирования, используя 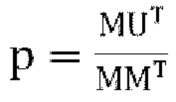
d. вычисляются параметры декоррелятора, используя 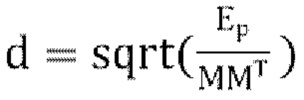 ’
’
e. вычисляется коэффициент масштабирования понижающего микширования, используя r=r1 из уравнения [37],
f. масштабируются параметры прогнозирования и декоррелятора на 1/r, масштабируется понижающее микширование как W'=r*M, и
д. инкрементируется масштабирование единичного вектора: h=h+0,1
2.3.1.8 Схема кодирования активного понижающего микширования на основе собственного сигнала
[00118] Для этого варианта осуществления терминология определяется следующим образом: входной сигнал в кодер = [W X Y Z]T, сигнал кодера, который должен быть передан в кодер EVS=[W' X' Y' Z']T (некоторые каналы могут быть отброшены перед кодированием EVS), выход из декодера EVS перед прогнозированием, установленным в декодере = [W'' X'' Y'' Z'']T (если кодер отбросил некоторые каналы, то будет существовать только подмножество этого вектора) и выход из декодера = [Wout Xout Yout Zout]T.
[00119] Если предположить, что «базовый кодер» IVAS работает, отбрасывая каналы X', Y', Z' и EVS кодирование канала W', тогда:
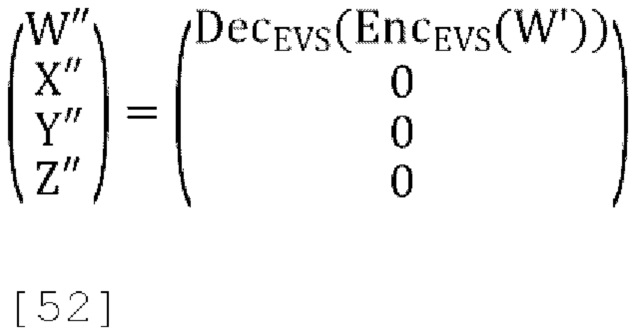
[00120] Если существует полная свобода выбора параметров, используемых в декодере для формирования выходных сигналов из W, тогда в варианте осуществления оптимальное решение способом наименьших квадратов находится путем реализации кодера Е1 типа Канаде-Лукас-Томази (KLT). В альтернативном варианте осуществления цель системы прогнозирования активного W формулируется следующим образом: добавить некоторые ограничения к способу KLT, чтобы уменьшить часто возникающие проблемы прерывистости, и свести ограничения к минимуму, чтобы максимально приблизиться к оптимальной производительности, которая достигается способом KLT.
[00121] Способы прогнозирования (как пассивные, так и активные) обычно основаны на представлении о том, что сигнал понижающего микширования (W') должен иметь достаточно большую положительную корреляцию с исходным сигналом W. Потенциальным способом достижения этого является применение способа KLT к набору каналов с усиленным W (например, набору из 4 каналов, где канал W был усилен коэффициентом масштабирования h), именуемый в дальнейшем как «усиленный KLT» способ. Пусть вектор Т представляет этот усиленный сигнал W:
[00122]
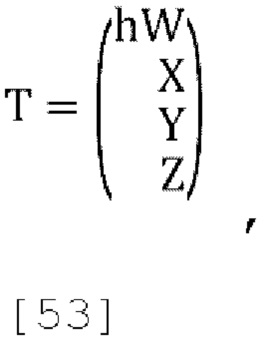
и пусть Q будет наибольшим собственным вектором Т×Т*:
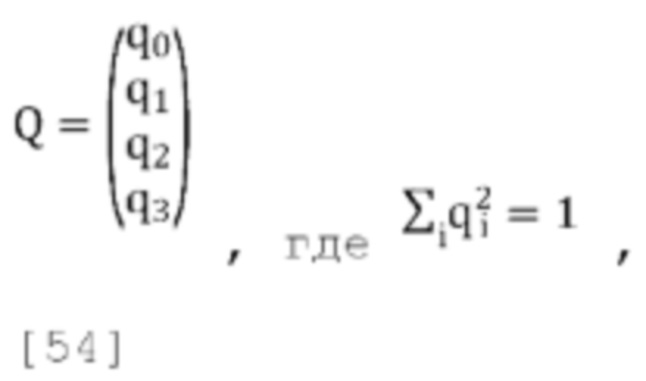
где собственный вектор выбирается таким образом, чтобы 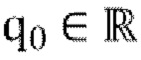 и q0>=0 (таким образом обеспечивается положительная корреляция нашего сигнала понижающего микширования с W, если это возможно).
и q0>=0 (таким образом обеспечивается положительная корреляция нашего сигнала понижающего микширования с W, если это возможно).
[00123] Следует отметить, что необходимость выбора собственного вектора из набора кандидатов проистекает из того факта, что если Q является собственным вектором, то таким же является и λQ, где λ - любой комплексный коэффициент масштабирования единичной величины, и выбор делается путем выбора значения λ такого, которое делает q0 неотрицательной действительной величиной. Акт выбора λ может быть источником прерывистости в поведении кодека, и этого неустойчивого поведения можно избежать, обеспечив q0 не близким к нулю, и сделав коэффициент h усиления большим настолько, что усиленный сигнал hW достаточно велик, чтобы сформировать значительный компонент сигнала E1.
[00124] E1 образуется как:
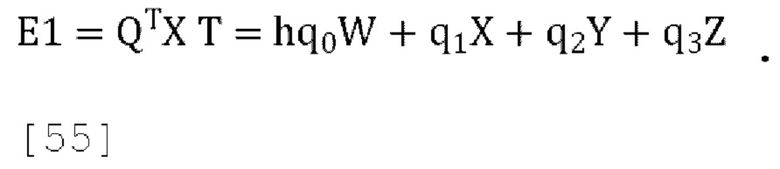
[00125] В декодере наилучшая оценка Т по способу наименьших квадратов реконструируется с использованием собственного вектора Q, и затем выход может быть образован путем отмены повышения усиления h^:

[00126] Однако, уравнение [56] может быть реализовано с использованием переданных параметров прогнозирования (p1, p2 и p3) и константы fs, путем применения коэффициента масштабирования r к Е1 (этот коэффициент масштабирования будет применен в кодере):
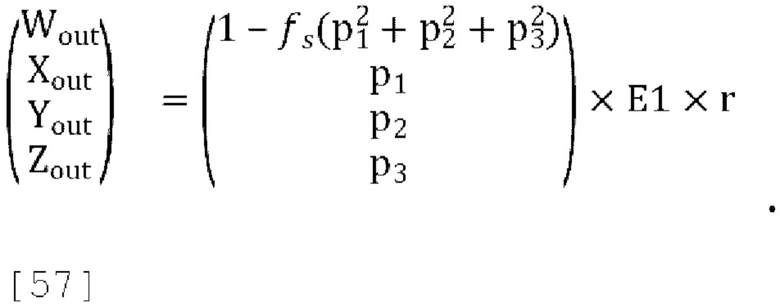
[00127] Желаемое поведение «усиленного KLT» из уравнения [56] может быть достигнуто способом из уравнения [57], если r выбран в соответствии с:
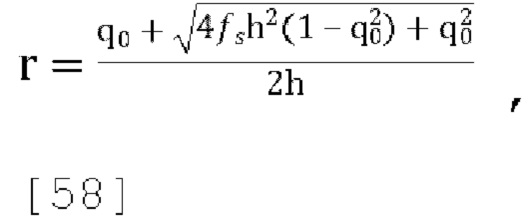
и затем вычислены:
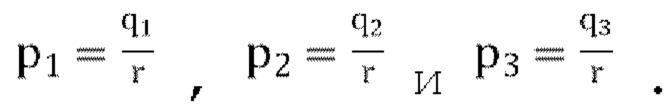
[00128] Вариант осуществления, описанный выше, может быть обобщен следующим образом.
Этап кодирования 1:
[00129] Учитывая Ковариацию входных сигналов CovU, используем диагональные члены (W2, X2, Y2 и Z2) чтобы определить 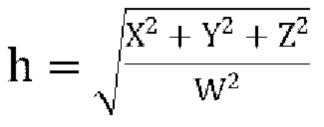 (но ограничивая h диапазоном 1≤h<10)
(но ограничивая h диапазоном 1≤h<10)
Этап кодирования 2:
[00130] Формируем ковариацию усиленного сигнала W: CovT=diag[h,1,1,1]×CovU×diag[h,1,1,1]
Этап кодирования 3:
[00131] Определяем доминирующий собственный вектор: Q=[q0,q1,q2,q3]T, таким образом, что 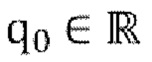 и q0≥0.
и q0≥0.
Этап кодирования 4:
[00132] Предполагая 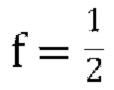 вычисляем
вычисляем 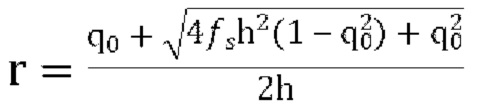 , и, следовательно, вычисляем параметры прогнозирования декодера:
, и, следовательно, вычисляем параметры прогнозирования декодера: 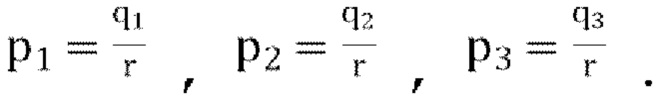
Этап кодирования 5:
[00133] Из сигнала понижающего микширования W'=r(hq0W+q1X+q2Y+q3Z).
Этап кодирования 6:
[00134] Определяем коэффициенты усиления декорреляции d1, d2 и d3 согласно уравнению [39]
Декодирование:
[00135] Учитывая выход EVS W'', предполагая , и учитывая метаданные  вычисляем сигналы выхода:
вычисляем сигналы выхода:
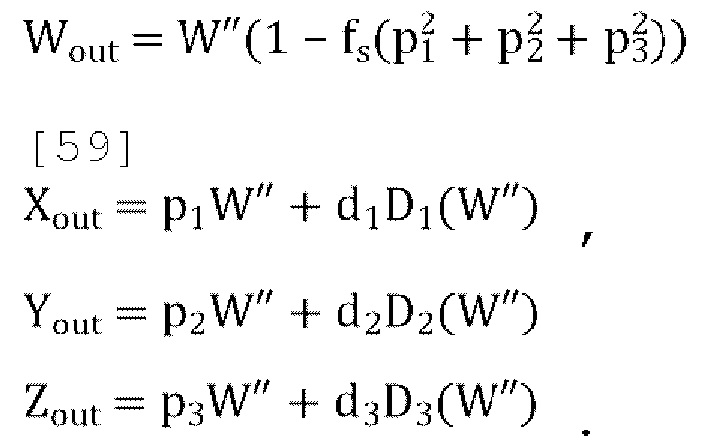
2.3.1.9 Схема кодирования масштабированного активного понижающего микширования на основе предварительного масштабирования канала W.
[00136] При создании представления доминирующего собственного сигнала с активным прогнозированием (т.е. микшируя компоненты из X, Y и Z в W) одной из трудностей является получение сглаженного/непрерывного представления доминирующего собственного сигнала по частотному спектру и по границам кадра во временной области. В то время как описанные ранее подходы к активному прогнозированию пытаются решить эту проблему, все еще есть некоторые случаи, когда степень вращения (или микширования) каналов X, Y и Z в W либо слишком агрессивна, что вызывает прерывистость (или другие аудиоартефакты), либо вращения вообще отсутствует (пассивное прогнозирование), что не позволяет дать оптимальное прогнозирование и больше полагается на декорреляторы для заполнения непрогнозируемой энергии. Соответственно, подходы, описанные выше, могут обеспечивать прогнозирование, которое является слишком агрессивным или слишком слабым. В варианте осуществления W масштабируется перед выполнением активного прогнозирования. Идея этого варианта осуществления заключается в том, что предварительное масштабирование канала W гарантирует, что канал W после активного прогнозирования (или представление доминирующего собственного сигнала) содержит большую часть исходного W. Это означает, что уменьшается количество X, Y и Z для микширования с W, и, следовательно, это приводит к менее агрессивному активному прогнозированию, но тем не менее приводит к более верному прогнозированию по сравнению с пассивными (или масштабированными пассивными) подходами, описанными выше. Величина предварительного масштабирования определяется как функция отклонения W и каналов X, Y, Z таким образом, что W становится близким к доминирующему сигналу энергии перед выполнением активного прогнозирования.
[00137] Ниже приведена примерная реализация схемы кодирования активного предсказания понижающего микширования предварительно масштабированного W с понижающим микшированием с 1 канала. Пусть вход FoA задан как U=[W X Y Z]T, а ковариационная матрица (4×4) входного сигнала имеет вид:
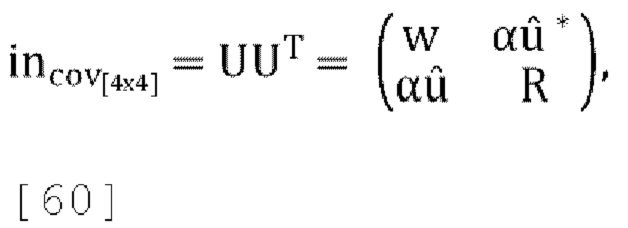
где  единичный вектор 3×1, a R - ковариационная матрица 3×3 каналов X, Y и Z, a w - отклонение канала W.
единичный вектор 3×1, a R - ковариационная матрица 3×3 каналов X, Y и Z, a w - отклонение канала W.
[00138] Теперь предварительно масштабируем канал W перед выполнением активного прогнозирования. Коэффициент предварительного масштабирования «h» является функцией отклонения X, Y, Z и W и вычисляется следующим образом:
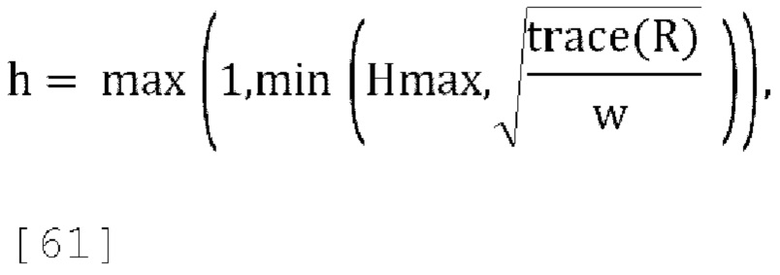
где h - коэффициент предварительного масштабирования, Hmax - константа (например, 4), которая устанавливает верхнюю границу предварительного масштабирования.
[00139] Матрица предварительного масштабирования задается как:
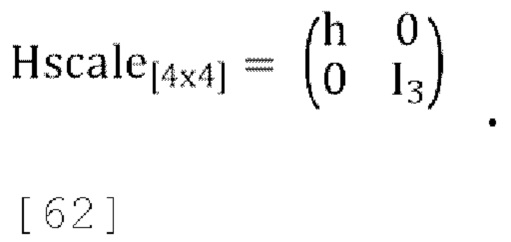
[00140] Затем вычисляем параметры активного прогнозирования на основе приведенной ниже масштабированной ковариационной матрицы 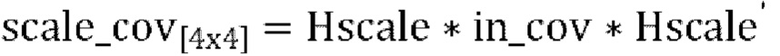 и решаем для «g» на основе масштабированных результатов входной ковариации в cubic(g) следующим образом:
и решаем для «g» на основе масштабированных результатов входной ковариации в cubic(g) следующим образом:
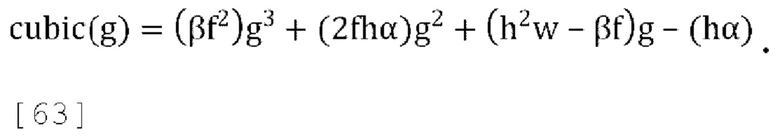
[00141] В качестве альтернативы можно решить для g и f следующим образом:
если 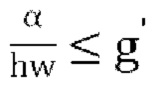 тогда
тогда 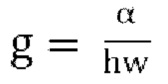 , иначе устанавливаем g=g' и решаем для f, тогда
, иначе устанавливаем g=g' и решаем для f, тогда
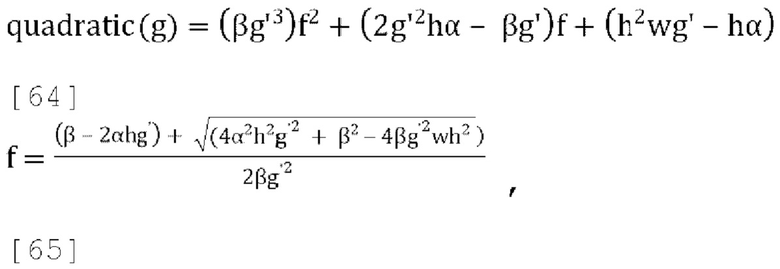
или
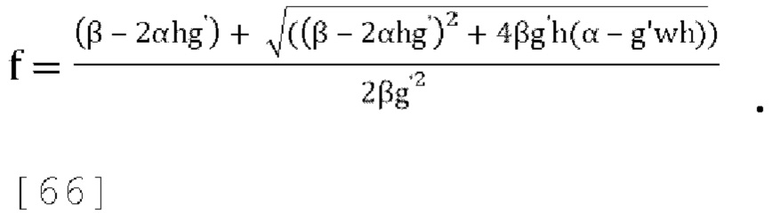
[00142] Поскольку 4βg'h(α-g'wh)>0, так как α>g'wh f может быть записан как:
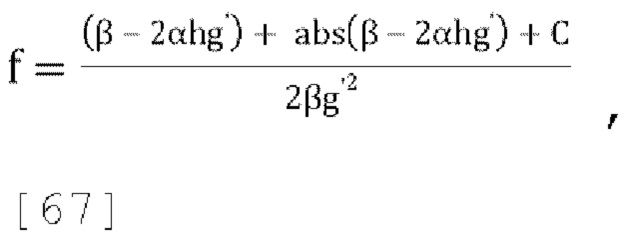
где С - положительная константа, и учитывая, что (β-2αhg')+abs(β-2αhg') будет либо равно 0, либо всегда будет уменьшаться по мере его увеличения.
[00143] Также известно, что С уменьшается, если 4βg'h(α-g'wh) уменьшается, 4βg'h(α-g'wh) уменьшается по мере увеличения h, если α<g'w(2h+δ), где δ - приращение значения h.
[00144] Следовательно, общее значение «f» должно уменьшаться с увеличением значения «h», если только входная ковариация не слишком высока, но в этом случае контроль микширования X, Y, Z с W может так или иначе не потребоваться.
[00145] Теперь, с предварительно прогнозирующим масштабированием «h» и масштабированием пост-прогнозирующим масштабированием «r», матрица прогнозирования вычисляется следующим образом:
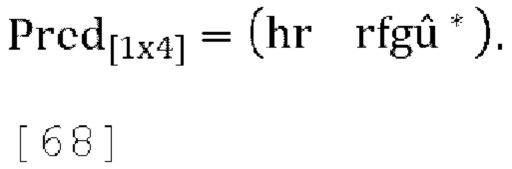
[00146] Это приводит к пост-прогнозированному сигналу W как:
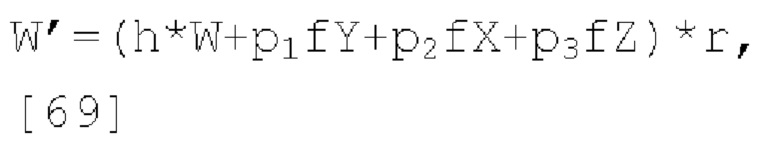
где g 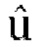 (или [p1, p2, p3]) - вектор 3×1, представляющий параметры прогнозирования, r - коэффициент масштабирования для масштабирования пост-прогнозированного W, таким образом, что энергия W, микшированного с повышением количества каналов, совпадает с входным W.
(или [p1, p2, p3]) - вектор 3×1, представляющий параметры прогнозирования, r - коэффициент масштабирования для масштабирования пост-прогнозированного W, таким образом, что энергия W, микшированного с повышением количества каналов, совпадает с входным W.
[00147] Вычисление пост-прогнозирующего коэффициента масштабирования «r» такое же, как указано в разделе 2.3.1.4, уравнение [37]:
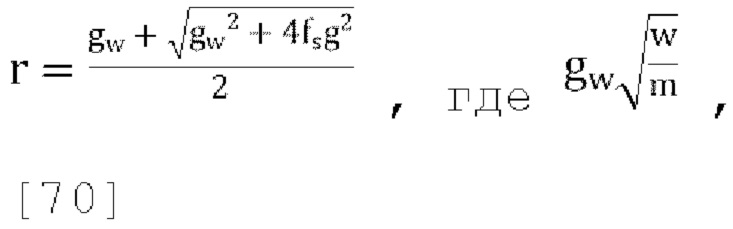
а g вычисляется с использованием любого способа, раскрытого в вышеприведенных вариантах выполнения.
[00148] Теперь масштабированные параметры прогнозирования вычисляются как:
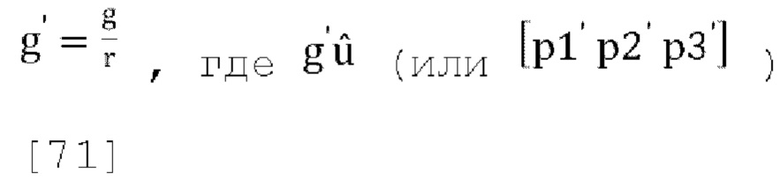
Параметры декорреляции
[00149] В варианте осуществления изменчивость микшированного с понижением количества каналов (или пост-прогнозированного) канала W задается как:
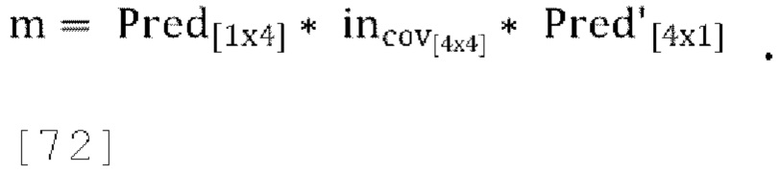
[00150] Параметры декорреляции вычисляются как нормализованная некоррелированная (или непрогнозируемая) энергия в каналах Y, X и Z по отношению к пост-прогнозированному каналу W. В примерной реализации параметры декорреляции (параметры Pd) с схемой кодирования активного понижающего микширования предварительно масштабированного W могут быть вычислены из масштабированной ковариации, масштабированной в соответствии с уравнением [62], и матрицы активного понижающего микширования, заданной как

[00151] Здесь уравнение [77] задает параметры декорреляции (матрица 3×1 Pd или параметры d1, d2 и d3) для кодирования и отправки в декодер. А «m» - это отклонение, указанное в уравнении [72], scale - это константа между 0 и 1.
Декодер
[00152] В варианте осуществления декодер принимает кодированный РСМ канал W (заданный уравнением [69]), кодированные параметры прогнозирования (заданные уравнением [71]) и кодированные параметры декорреляции (заданные уравнением [77]). Декодер моноканала (например, EVS) декодирует канал W' (например, пусть декодированный канал будет W''), затем декодер SPAR применяет матрицу обратного прогнозирования к каналу W'', чтобы реконструировать представление исходного канала W и элементы X, Y и Z, которые можно прогнозировать по каналу W''.
[00153] В варианте осуществления матрица обратного прогнозирования задается следующим образом:
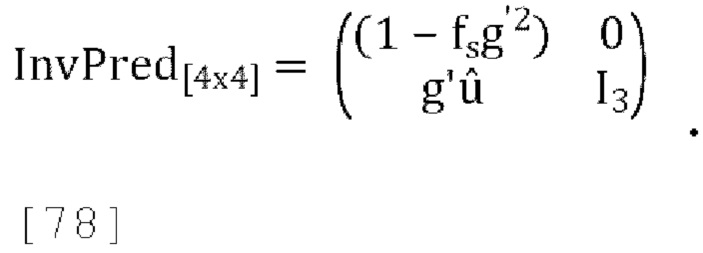
[00154] SPAR применяет матрицу обратного прогнозирования и параметры декорреляции для реконструирования представления исходного сигнала FoA, где реконструкция сигнала FoA задается следующим образом:
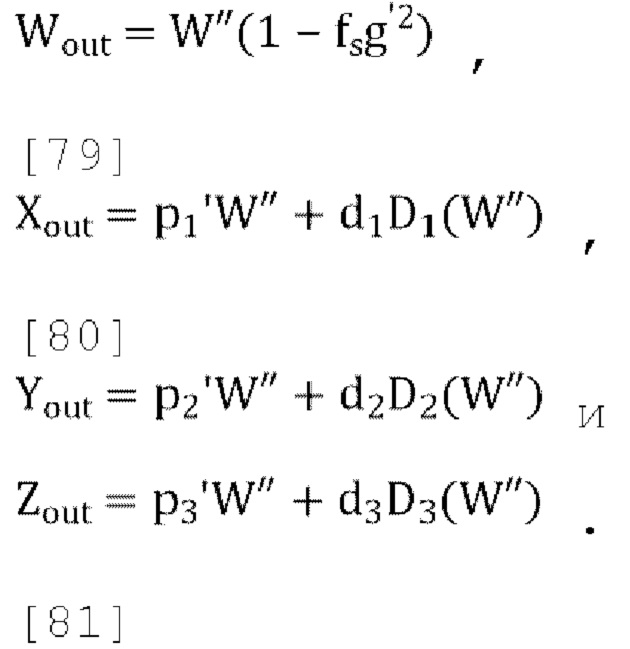
[00155] Здесь d1, d2 and d3 - параметры декорреляции, а D1(W''), D2(W''), D3(W'') - три декоррелированных канала по отношению к каналу W''.
2.3.1.10 Масштабированная схема активного понижающего микширования на основе нормализованной ковариации
[00156] Другой вариант осуществления для создания представления доминирующего собственного сигнала заключается во вращении входа FoA как функции нормализованной ковариации каналов WX, WY и WZ. Этот вариант осуществления гарантирует, что только коррелированные компоненты в каналах X, Y и Z микшируются в канал W, таким образом уменьшая артефакты, которые могут возникнуть из-за агрессивного вращения (или микширования) ранее описанными способами, особенно при работе с параметрическим повышающим микшированием. поскольку нет возможности отменить несовершенное микширование X, Y, Z в W на стороне декодера. Еще одним преимуществом этого подхода является то, что он упрощает вычисление «g» (фактора коэффициента активного прогнозирования), что приводит к линейному уравнению относительно «g».
[00157] Ниже приведена примерная реализации кодирования активного предсказания понижающего микширования с понижающим микшированием 1 канала, где представление доминирующего собственного сигнала образуется путем выполнения вращения (которое является функцией коэффициента нормализованной ковариации) для входного сигнала FoA.
[00158] Пусть вход FoA задан как U=[W X Y Z]T, ковариационная матрица (4×4) входного сигнала:
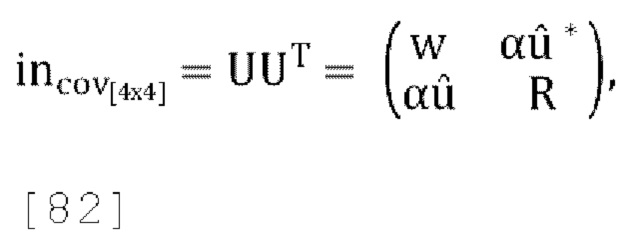
где 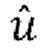 единичный вектор 3×1, R - ковариационная матрица 3×3 между каналами X, Y и Z, a w - отклонение канала W.
единичный вектор 3×1, R - ковариационная матрица 3×3 между каналами X, Y и Z, a w - отклонение канала W.
[00159] Пусть «F» будет функцией нормализованного «α» которая дает количество микширования, которое необходимо выполнить из X, Y, Z в канал W, чтобы сформировать представление доминирующего собственного сигнала. Затем матрица активного прогнозирования может быть представлена следующим образом:
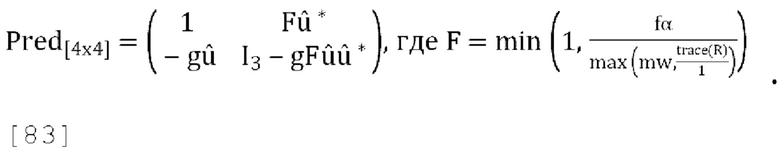
[00160] В варианте осуществления нормировочный член при вычислении «F» выбирают таким образом, что это приводит к оптимальному микшированию X, Y, Z в W даже в крайних случаях, когда энергия в W слишком мала или слишком велика по сравнению с каналами X, Y и Z.
[00161] В уравнении [83] «f» и «m» являются константами, такими, что f <= 1, a m >= 1 (например, f>0,5, а m=3), и может оказаться желательно иметь более низкое значение F, когда отклонение W уже велико по сравнению с отклонениями каналов X, Y и Z, и, таким образом, в этих случаях коэффициент «m» помогает достигать желаемой нормализации.
[00162] В варианте осуществления, после применения матрицы прогнозирования в уравнении [83] к входным данным, матрица пост-прогнозирования задается как:
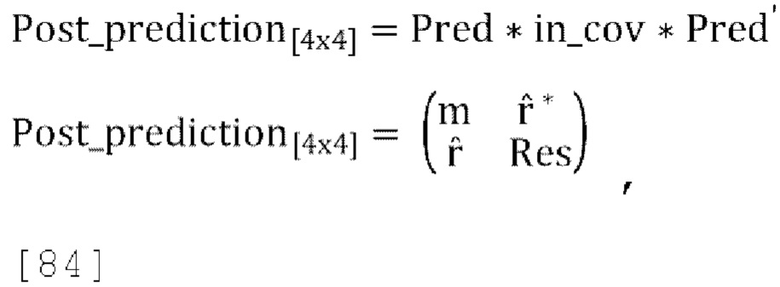
где 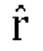 минимизируется путем установки
минимизируется путем установки 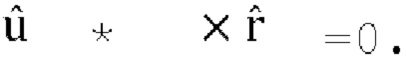 Это приводит к линейному уравнению относительно g:
Это приводит к линейному уравнению относительно g:
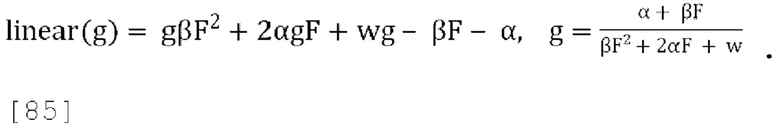
[00163] Если вращения нет (т.е. F=0), тогда g=α/w, что совпадает с фактором коэффициента пассивного прогнозирования.
[00164] Когда корреляция между W и каналами X, Y, Z очень низкая, такая, что α≈0, тогда результатом является F≈0, что означает нулевое (или близкое к 0) количество микширования, которое должно быть выполнено из X, Y и Z в W. И наоборот, когда существует высокая корреляция между W и каналами X, Y, Z и отклонение W ниже, чем каналы X, Y и Z, то это приводит к желаемому высокому значению F. После активного прогнозирования все еще может быть желательно выполнить масштабирование пост-прогнозированного W, чтобы гарантировать, что отклонение микшированного с повышением количества каналов W будет таким же, как входной W, а также, чтобы гарантировать, что параметры прогнозирования находятся в желаемом диапазоне.
[00165] В варианте осуществления фактическая матрица прогнозирования для 1-канального понижающего микширования после масштабирования задается как:
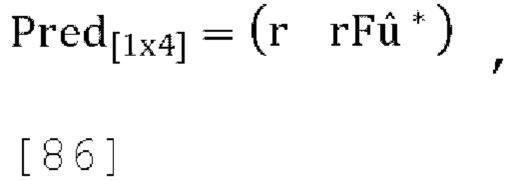
где r - коэффициент масштабирования пост-прогнозирования.
[00166] Что приводит к пост-прогнозированному сигналу W':
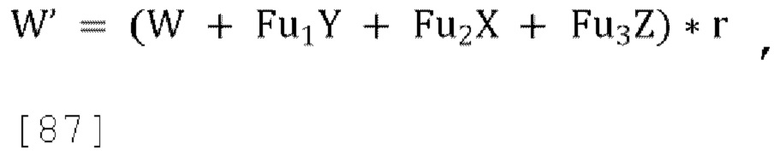
где F задан в уравнении [83], (u1, u2, u3) - единичный вектор, заданный через  в уравнении [82].
в уравнении [82].
[00167] Вычисление коэффициента масштабирования пост-прогнозирования «r» такое же, как указано в Уравнении (37) раздела 2.3.1.4, с использованием матрицы обратного прогнозирования, приведенной в уравнении [31], и матрицы прогнозирования, приведенной в уравнении [86], и подстановки их в уравнение [33] и уравнение [34]:
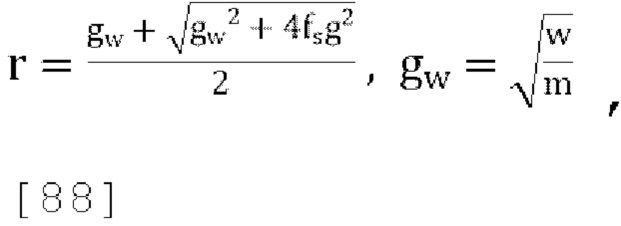
где m - отклонение пост-прогнозированного W с r=1 согласно уравнению [33].
[00168] Масштабированные параметры прогнозирования задаются следующим образом:
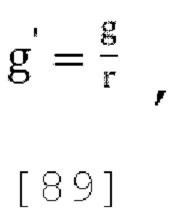
и 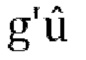 (или [p1, р2, р3]) - вектор параметров прогнозирования 3×1, который должен быть кодирован и отправлен в декодер.
(или [p1, р2, р3]) - вектор параметров прогнозирования 3×1, который должен быть кодирован и отправлен в декодер.
Параметры декорреляции
[00169] Из уравнений [82] и [86] отклонение канала W, микшированного с понижением количества каналов (или пост-прогнозированного), задается как:
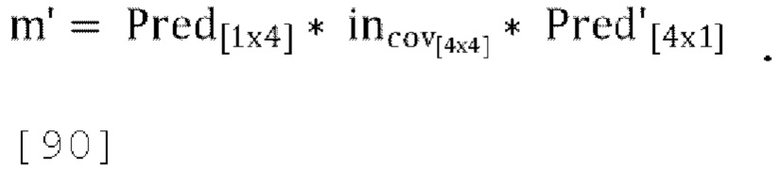
[00170] В варианте осуществления параметры декорреляции вычисляются как нормализованная некоррелированная (или непрогнозируемая) энергия в каналах Y, X и Z по отношению к пост-прогнозированному каналу W.
[00171] В варианте осуществления параметры декорреляции (параметры Pd) могут быть вычислены из Post_prediction[4×4], вычисленного по уравнению [84]:

[00172] Здесь уравнение [93] дает параметры декорреляции (матрица 3×1 Pd или параметры d1, d2 и d3) для кодирования и отправки в декодер. A «m'» - это отклонение, указанное в уравнении [90], «scale» - это константа между 0 и 1.
Декодер
[00173] В варианте осуществления декодер принимает кодированный РСМ канал W' (задаваемый уравнением [87]), кодированные параметры прогнозирования (задаваемые уравнением [89]) и кодированные параметры декорреляции (задаваемые уравнением [93]).
[00174] В варианте осуществления декодер моноканала (например, EVS) декодирует канал W' (пусть декодированный канал будет W''), а затем декодер SPAR применяет матрицу обратного прогнозирования к каналу W'', чтобы реконструировать представление исходного канала W и элементов X, Y и Z, которые можно прогнозировать по каналу W''.
[00175] Матрица обратного прогнозирования такая же, как и в уравнении [31]:
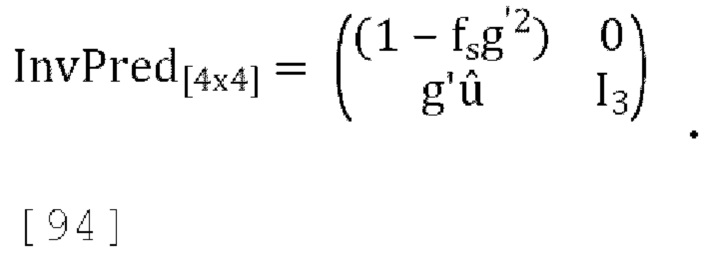
[00176] В варианте осуществления SPAR применяет матрицу обратного прогнозирования и параметры декорреляции для реконструирования представления исходного сигнала FoA, где реконструкция сигнала FOA задается следующим образом:
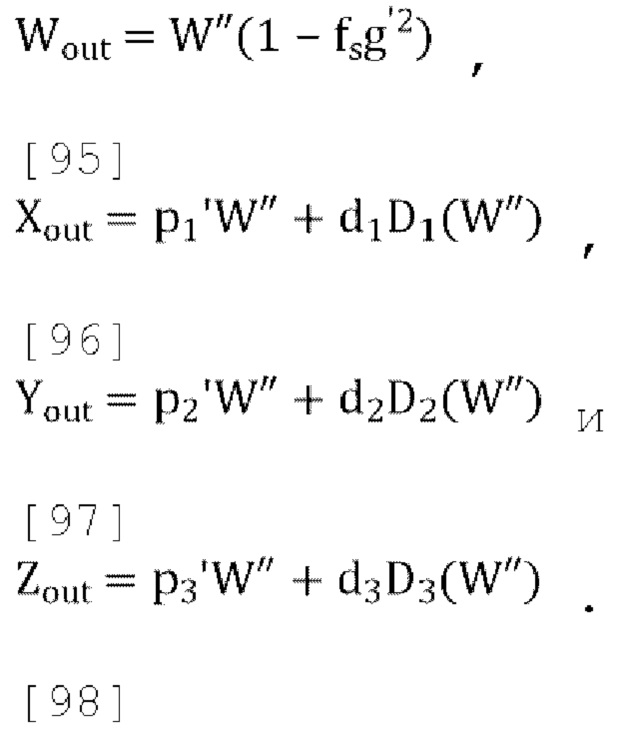
[00177] Здесь d1, d2 и d3 - параметры декорреляции, а D1(W''), D2(W''), D3(W'') - три декоррелированных канала по отношению к каналу W''.
2.3.2 Схема кодирования пассивного понижающего микширования
[00178] В схеме кодирования пассивного понижающего микширования для передачи может быть выбрано любое понижающее микширование, что обеспечивает наилучшую возможную реконструкцию сигналов FoA с использованием N (например, N=3) параметров прогнозирования и М (например, М=3) параметров декоррелятора. Для схемы кодирования пассивного понижающего микширования передается исходный W, например, операция понижающего микширования не выполняется. Преимущество такого подхода состоит в том, что сигнал понижающего микширования не подвержен каким-либо проблемам нестабильности, которые могут быть вызваны адаптивным понижающим микшированием сигнала. Недостатком является то, что реконструкция (прогнозирование) сигналов FoA X, Y, Z неоптимальна. Поэтому ниже описаны различные стратегии понижающего микширования, что уменьшает ошибку формы сигнала реконструирования для сигналов FoA по сравнению с передачей W. Во всех случаях сигналы FoA X, Y, Z прогнозируются с помощью одного параметра прогнозирования каждый, а понижающее микширование представляет W. Понижающее микширование масштабируется таким образом, что энергия понижающего микширования соответствует энергии W. Стратегии понижающего микширования, описанные ниже, можно также применять в схеме кодирования активного понижающего микширования.
2.3.2.1 Предложение стратегий адаптивного понижающего микширования
2.3.2.1.1 Сглаживание
[00179] Для всех стратегий адаптивного понижающего микширования существует риск внесения временных нестабильностей (артефактов), когда коэффициенты усиления понижающего микширования или коэффициент масштабирования изменяются слишком быстро (во времени) или во всех частотных диапазонах. Кроме того, если понижающее микширование выполняется в области блока фильтров с понижающей дискретизацией, то слишком резкое изменение сигналов может увеличить искажение наложения спектров в синтезе. Следовательно, коэффициенты должны меняться относительно гладко по времени и частоте. Предлагается сглаживать коэффициенты усиления понижающего микширования во времени с помощью фильтра IIR первого порядка или фильтра FIR. Сглаживание по частотным диапазонам может быть выполнено с помощью фильтра FIR со скользящим средним значением без задержки.
[00180] В качестве альтернативы, адаптивное понижающее микширование может быть широкополосным понижающим микшированием, например, коэффициенты адаптивного понижающего микширования во временном интервале идентичны для всех частотных диапазонов, в то время как параметры прогнозирования и декоррелятора зависят от полосы частот.
2.3.2.1.2 Стабилизированный собственный сигнал
[00181] В варианте осуществления доминирующий собственный сигнал, который получается из собственного вектора с наибольшим собственным значением на основе входной ковариации R, передается в декодер. Проблема в том, что собственный сигнал может быть нестабильным во времени. Эту проблему можно смягчить путем передачи «усиленного» собственного сигнала с принудительно доминирующим W (усиленным до получения собственного вектора) в соответствии с уравнением [55] в разделе 2.3.1.7, таким образом, что
A=[hq0 q1 q2 q3] с дополнительной энергией (W), сохраняющей коэффициент масштабирования r.
2.3.2.1.3 Специальное эвристическое правило понижающего микширования
[00182] Этот подход основан на наблюдении, что понижающее микширование должно быть до некоторой степени коррелировано с сигналами для прогнозирования. Это особенно верно, если энергия целевого сигнала велика и, следовательно, важна для восприятия. Поскольку мы допускаем отрицательные значения параметров прогнозирования, мы должны позаботиться о когерентном добавлении сигналов понижающего микширования X, Y, Z к W (например, с правильным знаком).
[00183] Эти соображения приводят к следующему правилу понижающего микширования (нотация Matlab):
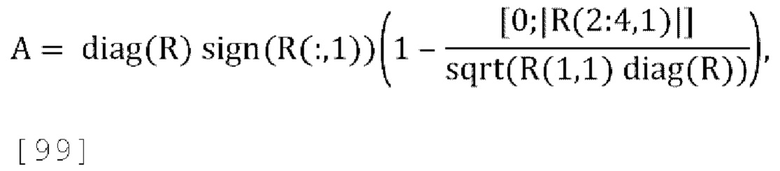
с масштабированием энергии согласно уравнению [87]. В экспериментах общая ошибка прогнозирования с этой стратегией понижающего микширования значительно меньше, чем для стандартного пассивного понижающего микширования.
2.3.2.1.4 Статические коэффициенты усиления понижающего микширования
[00184] Менее подверженным артефактам нестабильности является эмпирически полученное понижающее микширование с фиксированными начальными коэффициентами. Одним из возможных понижающих микширований может быть:
А=[1 0.3 0.2 0.1].
[00185] Следует отметить, что даже несмотря на то, что коэффициенты фиксированы, при масштабировании по отношению к энергии W понижающее микширование становится адаптивным.
2.3.2.1.5 Итеративная корректировка
[00186] Эта стратегия итеративно уменьшает общую ошибку прогнозирования, добавляя вклады сигналов к W, который формирует наибольшую измеренную за итерацию ошибку прогнозирования в соответствии с уравнением [86]. Ограничение квантования параметров прогнозирования можно учитывать при расчете общей ошибки прогнозирования. В варианте осуществления применяется следующая итеративная обработка:
- Инициализируем А=[1,0,0,0], константа настройки k=0,2
- Запускаем итерационный цикл (несколько раз, например, 1, 2, 3 или 4)
- рассчитываем ошибку прогнозирования на сигнал Ep по уравнению [91]
- Вариант 1
- Находим сигнал (id) с самой высокой ошибкой прогнозирования
- Инкрементируем коэффициент усиления понижающего микширования: 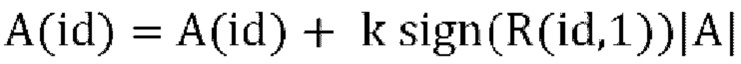
Вариант 2 (инкрементируем все коэффициенты за один этап за итерацию)
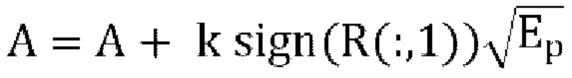
- Применяем масштабирование к коэффициентам усиления понижающего микширования (сохраняем энергию W)
- Рассчитываем параметры прогнозирования, уравнение [84]
- Ограничиваем параметры прогнозирования диапазоном квантования
[00187] Фиг. 3 является блок-схемой процесса 300 кодирования аудиосигнала, в котором используется стратегия кодирования понижающего микширования, применяемая в кодере, которая отличается от стратегии декодирования понижающего микширования, применяемой в декодере. Процесс 300 может быть реализован, например, системой 700, как описано с обращением к Фиг. 7.
[00188] Процесс 300 включает в себя этапы получения входного аудиосигнала, представляющего входную аудиосцену и содержащего основной входной аудиоканал и дополнительные каналы (301), определение типа схемы кодирования понижающего микширования на основе входного аудиосигнала (302), на основе тип схемы кодирования понижающего микширования: вычисление одного или более входных коэффициентов усиления понижающего микширования, которые должны быть применены к входному аудиосигналу для конструирования основного канала (303) понижающего микширования, при этом входные коэффициенты усиления понижающего микширования определяются, чтобы минимизировать общую ошибку прогнозирования в дополнительных каналах, определение одного или более коэффициентов усиления масштабирования понижающего микширования для масштабирования основного канала (304) понижающего микширования, при этом коэффициенты усиления масштабирования понижающего микширования определяются путем минимизации разности энергий между реконструированным представлением входной аудиосцены из основного канала понижающего микширования и входным аудиосигналом, формирование коэффициентов усиления прогнозирования на основе входного аудиосигнала, входных коэффициентов усиления понижающего микширования и коэффициентов (305) усиления масштабирования понижающего микширования; определение одного или более остаточных каналов из дополнительных каналов во входном аудиосигнале, путем использования основного канала понижающего микширования и коэффициентов усиления прогнозирования для формирования прогнозирований дополнительных каналов, а затем вычитание прогнозирования дополнительных каналов из дополнительных каналов (306); определение коэффициентов усиления декорреляции на основе энергии в нуле или более остаточных каналов (307); кодирование основного канала понижающего микширования, нуля или более остаточных каналов и дополнительной информации в битовый поток, при этом дополнительная информация содержит коэффициенты усиления прогнозирования и коэффициенты (308) усиления декорреляции; и отправка битового потока в декодер (309). Каждый из этих этапов был подробно описан в предыдущих разделах.
[00189] Фиг. 4А и 4В являются блок-схемой процесса 400 кодирования и декодирования аудио согласно варианту осуществления. Процесс 400 может быть реализован, например, системой 700, как описано с обращением к Фиг. 7.
[00190] Обращаясь к Фиг. 4А, в кодере процесс 400 включает в себя этапы: вычисление комбинации входных коэффициентов усиления понижающего микширования, которые должны быть применены к входному аудиосигналу для формирования основного канала понижающего микширования и коэффициентов усиления масштабирования понижающего микширования, при этом входные коэффициенты усиления понижающего микширования вычисляются как функция входной ковариации входного аудиосигнала (401); формирование основного канала понижающего микширования на основе входного аудиосигнала и входных коэффициентов усиления понижающего микширования (402); формирование коэффициентов усиления прогнозирования на основе входного аудиосигнала и входных коэффициентов усиления понижающего микширования (403); определение остаточных каналов из дополнительных каналов во входном аудиосигнале путем использования основного канала понижающего микширования и коэффициентов усиления прогнозирования для формирования прогнозирований дополнительных каналов, а затем вычитания прогнозирований дополнительных каналов из дополнительных каналов во входном аудиосигнале (406); определение коэффициентов усиления декорреляции на основе энергии в остаточных каналах (407); определение коэффициентов усиления масштабирования понижающего микширования для масштабирования основного канала понижающего микширования, коэффициентов усиления прогнозирования и коэффициентов усиления декорреляции, таким образом, что коэффициенты усиления прогнозирования, или коэффициенты усиления декорреляции, или и те, и другие находятся в заданном диапазоне квантования (408); кодирование основного канала понижающего микширования, нуля или более остаточных каналов и дополнительной информации, включающей в себя масштабированные коэффициенты усиления прогнозирования и масштабированные коэффициенты усиления декорреляции, в битовый поток (409); отправка битового потока в декодер (410).
[00191] Обращаясь к Фиг. 4В, в декодере процесс 400 продолжается путем декодирования основного канала понижающего микширования, нуля или более остаточных каналов и дополнительной информации, включающей в себя масштабированные коэффициенты усиления прогнозирования и масштабированные коэффициенты усиления декорреляции (411); установки коэффициентов усиления масштабирования повышающего микширования, как функции от масштабированных коэффициентов усиления прогнозирования и масштабированных коэффициентов усиления декорреляции (412); формирования декоррелированных сигналов, которые декоррелированы по отношению к основному каналу понижающего микширования (413); и применения коэффициентов усиления масштабирования повышающего микширования к комбинации основного канала понижающего микширования, нуля или более остаточных каналов и декоррелированных сигналов для реконструирования представления входной аудиосцены таким образом, что общая энергия входной аудиосцены сохраняется (414).
[00192] Фиг. 5 является блок-схемой декодера SPAR FOA, работающего в одноканальном режиме понижающего микширования с адаптивной схемой понижающего микширования, согласно варианту осуществления. Декодер 500 SPAR принимает на вход битовый поток SPAR и реконструирует представление входного сигнала FoA на выходе декодера, при этом входной сигнал FoA содержит основной канал W и дополнительные каналы Y, Z и X, а декодированный вывод обеспечивается каналами W'', Y'', Z'' и X''. Битовый поток SPAR распаковывается в биты базового кодирования и биты дополнительной информации. Биты базового кодирования отправляются в модуль 501 базового декодирования, который реконструирует основной канал W' понижающего микширования. Биты дополнительной информации отправляются в модуль 502 декодирования дополнительной информации, который декодирует и обратно квантует биты дополнительной информации, которые содержат коэффициенты усиления прогнозирования (p1, p2, p3) и коэффициенты усиления декорреляции (d1, d2, d3).
[00193] Основной канал понижающего микширования W' подается на модуль 503 декоррелятора, который формирует 3 выхода, которые декоррелированы по отношению к W'. Прогнозирования каналов Y, Z и X вычисляются путем масштабирования канала W' с коэффициентами прогнозирования (p1, p2, p3), а оставшиеся некоррелированные компоненты сигнала каналов Y, Z и X вычисляются путем масштабирования декоррелированных выходов модуля 503 с коэффициентами декорреляции (d1, d2 и d3). Компоненты прогнозирования и декоррелированные компоненты складываются вместе для получения выходных каналов Y'', Z'' и X'' на выходе декодера 500.
[00194] Выход основного канала понижающего микширования W' модуля 501 и выход декодированной дополнительной информации модуля 502 подаются в модуль 504 вычисления масштабирования, который вычисляет коэффициент масштабирования повышающего микширования для масштабирования канала W' для получения канала W'' таким образом, чтобы энергия канала W'' была такой же, как энергия входного канала кодера W. В варианте осуществления реконструкция сигнала FoA в декодере задается следующим образом:
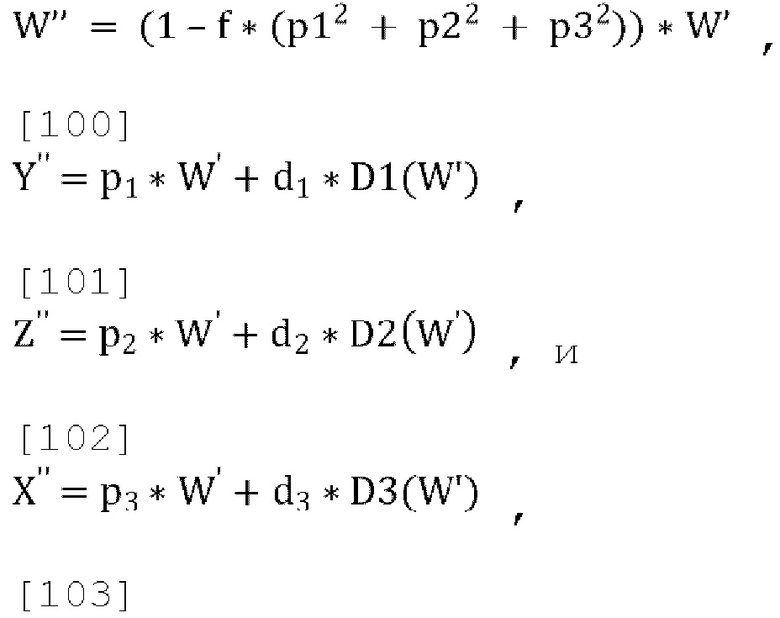
где f является константой (например, f=0,5), a D1(W'), D2(W') и D3(W') являются выходами модуля 503 декоррелятора. В примерном варианте осуществления модуль 501 базового декодирования является декодером EVS, а биты базового кодирования содержат битовый поток EVS. В других вариантах осуществления модулем 501 базового декодирования может быть любой моноканальный кодек.
[00195] Фиг. 6 является блок-схемой кодера 600 SPAR FOA, работающего в одноканальном режиме понижающего микширования с адаптивной схемой понижающего микширования, согласно варианту осуществления. Кодер 600 SPAR принимает сигнал FoA в качестве входа и формирует кодированный битовый поток, который может быть декодирован декодером 500 SPAR, описанным на Фиг. 5, при этом вход FoA задается каналами W, Y, Z и X. Вход FoA подается в модуль 601 пространственного анализа/формирования дополнительной информации и квантования, который анализирует вход FoA, формирует входные оценки ковариации и на основе оценок ковариации вычисляет входные коэффициенты усиления понижающего микширования (s0, s1, s2 and s3) и коэффициента усиления масштабирования понижающего микширования (r). В варианте осуществления входной коэффициент усиления понижающего микширования s0 равен 1.
[00196] Модуль 601 пространственного анализа/формирования дополнительной информации и квантования вычисляет коэффициенты усиления прогнозирования и коэффициенты усиления декорреляции на основе входных оценок ковариации, входных коэффициентов усиления понижающего микширования и коэффициентов усиления масштабирования понижающего микширования таким образом, что коэффициенты усиления прогнозирования и коэффициенты усиления декорреляции находятся в пределах заданного диапазона квантования, а затем квантует их. Квантованная дополнительная информация, содержащая коэффициенты усиления прогнозирования и коэффициенты усиления декорреляции, затем отправляется в модуль 603 кодирования дополнительной информации, который кодирует дополнительную информацию в битовый поток. Вход FoA, входные коэффициенты усиления понижающего микширования и коэффициент масштабирования понижающего микширования подаются в модуль 602 понижающего микширования, который формирует одноканальное понижающее микширование W (также называемое основным понижающим микшированием или представлением доминирующего собственного сигнала) путем применения входных коэффициентов усиления понижающего микширования и коэффициента усиления масштабирования понижающего микширования к входу FoA. Выход W модуля 602 понижающего микширования затем подается в модуль 604 базового кодирования, который кодирует канал W' в битовый поток базового кодирования. Выход модуля 604 базового кодирования и модуля 603 кодирования дополнительной информации упаковываются в битовый поток SPAR с помощью модуля 605 упаковки битов.
[00197] В варианте осуществления модуль 601 пространственного анализа/формирования дополнительной информации и квантования вычисляет оценку энергии выхода декодера W'' декодера 500 и приравнивает ее к оценке энергии входа кодера W кодера 600, при этом вычисляя коэффициент масштабирования понижающего микширования, коэффициенты усиления прогнозирования и коэффициенты усиления декорреляции, тем самым сохраняя энергию. В примерном варианте осуществления модуль 604 базового кодирования является кодером EVS, а биты базового кодирования содержат битовый поток EVS. В других вариантах осуществления модулем 604 базового кодирования может быть любой моноканальный кодек.
Примерная архитектура системы
[00198] Фиг. 7 показывает блок-схему примерной системы 700, подходящей для реализации примерных вариантов осуществления настоящего изобретения. Система 800 включает в себя один или более серверных компьютеров либо любое клиентское устройство, включающее в себя, не ограничиваясь, любые из устройств, показанных на фиг. 1, таких как сервер 102 вызовов, ранее созданные устройства 106, абонентское устройство 108, 114, системы 116, 118 в конференц-залах, системы домашнего кинотеатра, гарнитура 122 VR и модуль 124 поглощения иммерсивного содержимого. Система 700 включает в себя любые бытовые устройства, включающие в себя, не ограничиваясь: смартфоны, планшетные компьютеры, носимые компьютеры, компьютеры в транспортных средствах, игровые консоли, системы объемного звучания, киоски.
[00199] Как показано, система 700 включает в себя центральный процессор 701 (CPU), который допускает выполнение различных процессов в соответствии с программой, сохраненной, например, в постоянном запоминающем устройстве 702 (ROM), или с программой, загружаемой, например, из модуля 708 хранения в оперативное запоминающее устройство 703 (RAM). В RAM 703, также сохраняются данные, требуемые, когда CPU 701 выполняет различные процессы, по мере необходимости. CPU 701, ROM 702 и RAM 703 соединяются между собой через шину 704. Интерфейс 705 ввода-вывода также соединяется с шиной 704.
[00200] Следующие компоненты соединяются с интерфейсом 705 ввода-вывода: модуль 706 ввода, который может включать в себя клавиатуру, мышь и т.п.; модуль 707 вывода, который может включать в себя дисплей, такой как жидкокристаллический дисплей (ЖК-дисплей) и один или более динамиков; модуль 708 хранения, включающий в себя жесткий диск или другое подходящее устройство хранения данных; и модуль 709 связи, включающий в себя сетевую интерфейсную плату, к примеру, сетевую плату (например, проводную или беспроводную).
[00201] В некоторых реализациях, модуль 706 ввода включает в себя один или более микрофонов в различных позициях (в зависимости от хост-устройства), обеспечивающих захват аудиосигналов в различных форматах (например, в моно-, стерео-, пространственном, иммерсивном и других подходящих форматах).
[00202] В некоторых реализациях, модуль 707 вывода включает в себя системы с различным числом динамиков. Как проиллюстрировано на фиг. 1, модуль 707 вывода (в зависимости от характеристик хост-устройства) может выполнять рендеринг аудиосигналов в различных форматах (например, в моно-, стерео-, иммерсивном, бинауральном и других подходящих форматах).
[00203] Модуль 709 связи выполнен с возможностью обмена данными с другими устройствами (например, через сеть). Накопитель 710 также соединяется с интерфейсом 705 ввода-вывода по мере необходимости. Съемный носитель 711, такой как магнитный диск, оптический диск, магнитооптический диск, флэш-накопитель или другой подходящий съемный носитель, монтируется на накопителе 710 таким образом, что компьютерная программа, считываемая с него, устанавливается в модуль 708 хранения по мере необходимости. Специалисты в данной области техники должны понимать, что, хотя система 700 описана как включающая в себя вышеописанные компоненты, в реальных вариантах применения, можно добавлять, удалять и/или заменять некоторые из этих компонентов, и все эти модификации или изменения попадают в пределы объема настоящего изобретения.
[00204] В соответствии с примерными вариантами осуществления настоящего изобретения, процессы, описанные выше, могут быть реализованы в виде программ, реализованных в форме компьютерного программного обеспечения, либо на машиночитаемом носителе данных. Например, варианты осуществления настоящего изобретения включают в себя компьютерный программный продукт, включающий в себя компьютерную программу, материально реализованную на машиночитаемом носителе, причем компьютерная программа включает в себя программный код для осуществления способов. В таких вариантах осуществления, компьютерная программа может загружаться и монтироваться из сети через модуль 709 связи и/или устанавливаться со съемного носителя 711, как показано на фиг. 7.
[00205] В общем случае, различные примерные варианты осуществления настоящего изобретения могут быть реализованы в аппаратных средствах или специализированных схемах (например, в схеме управления), в программном обеспечении, в логике либо в любом их сочетании. Например, модули, поясненные выше, могут выполняться посредством схемы управления (например, CPU в комбинации с другими компонентами по фиг. 7) таким образом, что схема управления может выполнять действия, описанные в данном описании. Некоторые аспекты могут быть реализованы в аппаратных средствах, тогда как другие аспекты могут быть реализованы в микропрограммном обеспечении или программном обеспечении, которое может выполняться посредством контроллера, микропроцессора или другого вычислительного устройства (например, схемы управления). Хотя различные аспекты примерных вариантов осуществления настоящего изобретения проиллюстрированы и описаны в виде блок-схем, блок-схем способов или с использованием некоторого другого графического представления, следует учитывать, что блоки, устройства, системы, технологии или способы, описанные в данном документе, могут быть реализованы, в качестве неограничивающих примеров, в аппаратных средствах, в программном обеспечении, в микропрограммном обеспечении, в специализированных схемах или в логике, в аппаратных средствах общего назначения или в контроллере, или в других вычислительных устройствах, или в некотором их сочетании.
[00206] Кроме того, различные блоки, показанные на блок-схемах, могут рассматриваться в качестве этапов способа и/или в качестве операций, которые получаются в результате операции компьютерного программного кода, и/или в качестве множества соединенных логических схемных элементов, сконструированных с возможностью выполнения ассоциированной функции. Например, варианты осуществления настоящего изобретения включают в себя компьютерный программный продукт, включающий в себя компьютерную программу, материально реализованную на машиночитаемом носителе, причем компьютерная программа содержит программные коды, выполненные с возможностью осуществления способов, описанных выше.
[00207] В контексте изобретения, машиночитаемый носитель может представлять собой любой материальный носитель, который может содержать или сохранять программу для использования посредством или в связи с системой, устройством или устройством выполнения инструкций. Машиночитаемый носитель может представлять собой машиночитаемую среду передачи сигналов или машиночитаемый носитель данных. Машиночитаемый носитель может быть постоянным и может включать в себя, не ограничиваясь, электронную, магнитную, оптическую, электромагнитную, инфракрасную или полупроводниковую систему, устройство или устройство либо любое подходящее их сочетание. Более конкретные примеры машиночитаемого носителя данных должны включать в себя электрическое соединение, имеющее один или более проводов, портативную компьютерную дискету, жесткий диск, оперативное запоминающее устройство (RAM), постоянное запоминающее устройство (ROM), стираемое программируемое постоянное запоминающее устройство (EPROM или флэш-память), оптоволокно, портативное постоянное запоминающее устройство на компакт-дисках (CD-ROM), оптическое устройство хранения данных, магнитное устройство хранения данных либо любое подходящее их сочетание.
[00208] Компьютерный программный код для осуществления способов настоящего изобретения может быть написан на любом сочетании одного или более языков программирования. Эти компьютерные программные коды могут передаваться в процессор компьютера общего назначения, компьютер специального назначения или другое программируемое устройство обработки данных, которое имеет схему управления, таким образом, что программные коды, при выполнении посредством процессора компьютера или другого программируемого устройства обработки данных, предписывают реализацию функций/операций, указываемых на блок-схемах способов и/или на блок-схемах. Программный код может выполняться полностью на компьютере, частично на компьютере, в качестве автономного программного пакета, частично на компьютере и частично на удаленном компьютере или полностью на удаленном компьютере или сервере, либо может быть распределен по одному или более удаленным компьютерам и/или серверам.
[00209] Хотя данный документ содержит множество конкретных сведений по реализации, они должны истолковываться не в качестве ограничений на объем того, что может быть заявлено в качестве формулы изобретения, а напротив - в качестве описания признаков, которые могут относиться к конкретным вариантам осуществления. Определенные признаки, которые поясняются в этом подробном описании в контексте отдельных вариантов осуществления, также могут быть реализованы объединенно в одном варианте осуществления. Наоборот, различные признаки, которые описан в контексте одного варианта осуществления, также могут быть реализованы во множестве вариантах осуществления по отдельности либо в любом подходящем подсочетании. Кроме того, хотя признаки могут быть описаны выше как работающие в определенных сочетаниях и даже первоначально определяться в формуле изобретения как таковые, один или более признаков из заявленного сочетания в некоторых случаях могут быть исключены из сочетания, и заявленное сочетание может относиться к подсочетанию или вариантам подсочетания. Логические последовательности операций, проиллюстрированные на чертежах, не требуют конкретного показанного порядка или последовательного порядка для достижения требуемых результатов. Помимо этого, могут быть предусмотрены другие этапы, или этапы могут исключаться из описанных процессов, и другие компоненты могут добавляться или удаляться из описанных систем. Соответственно, другие реализации находятся в пределах объема прилагаемой формулы изобретения.
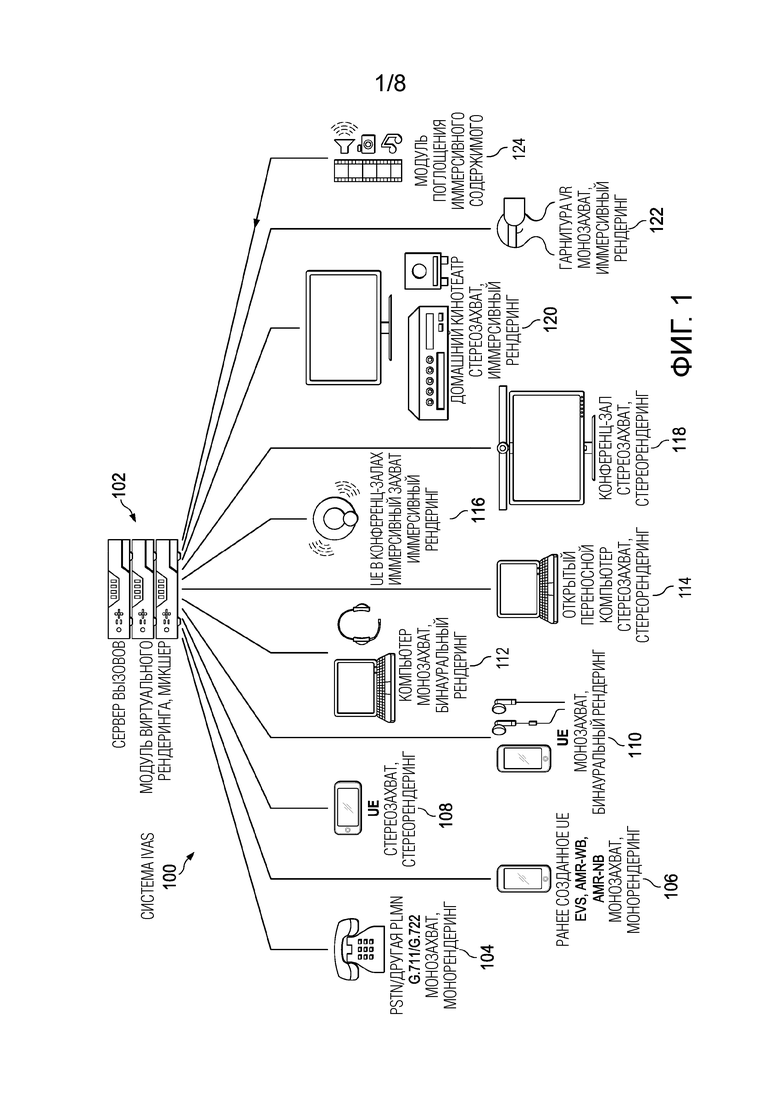
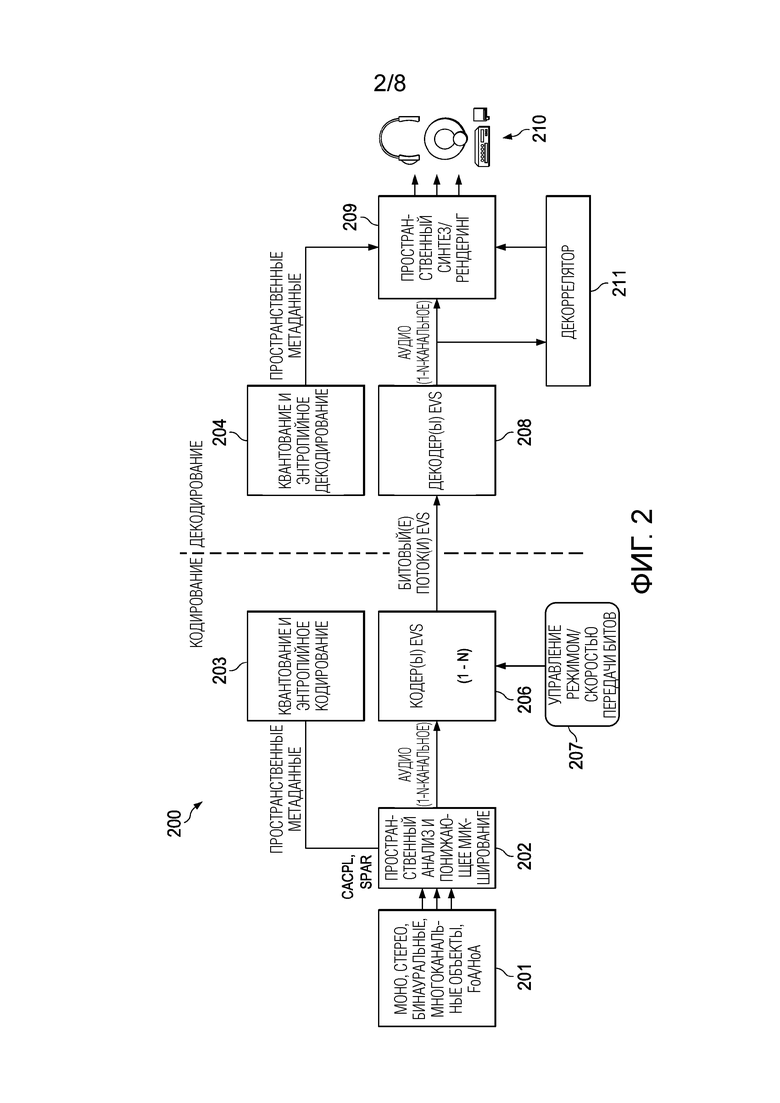
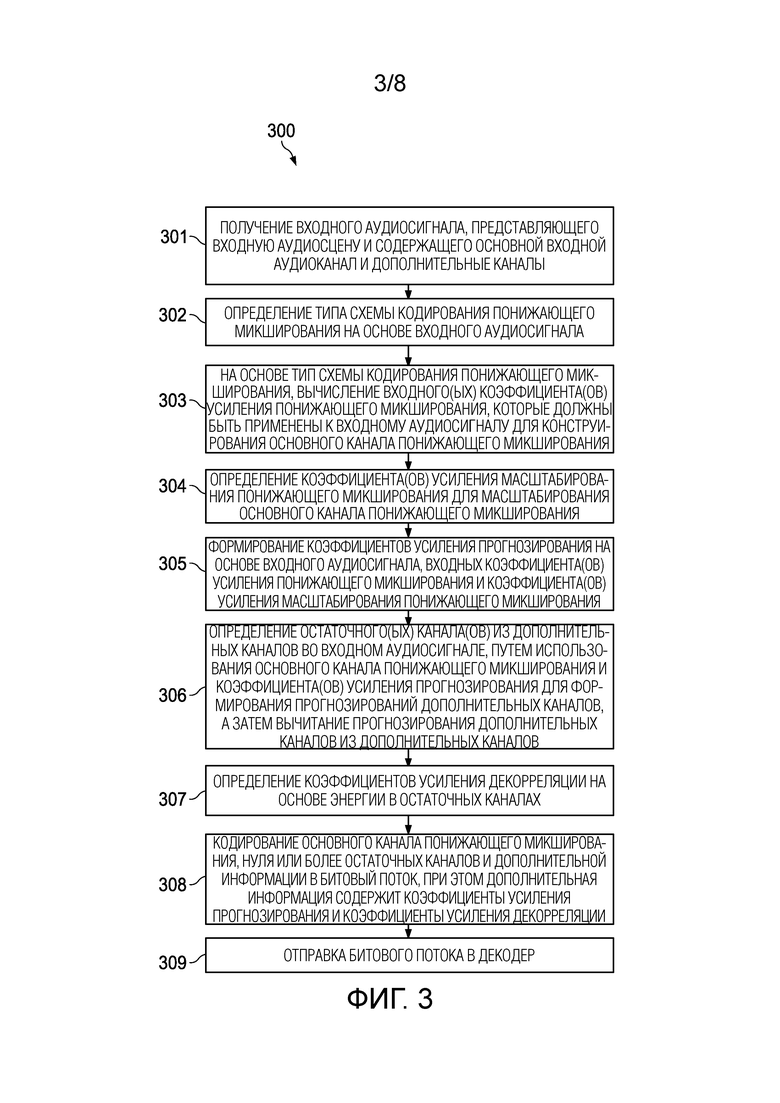
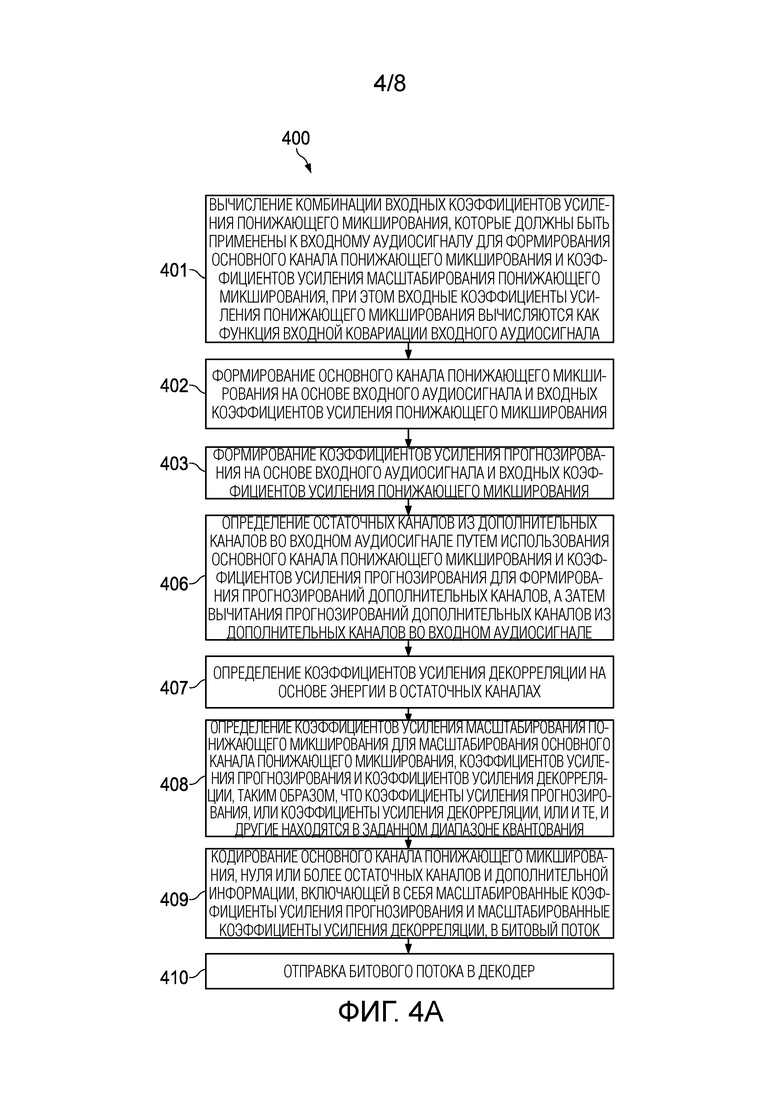
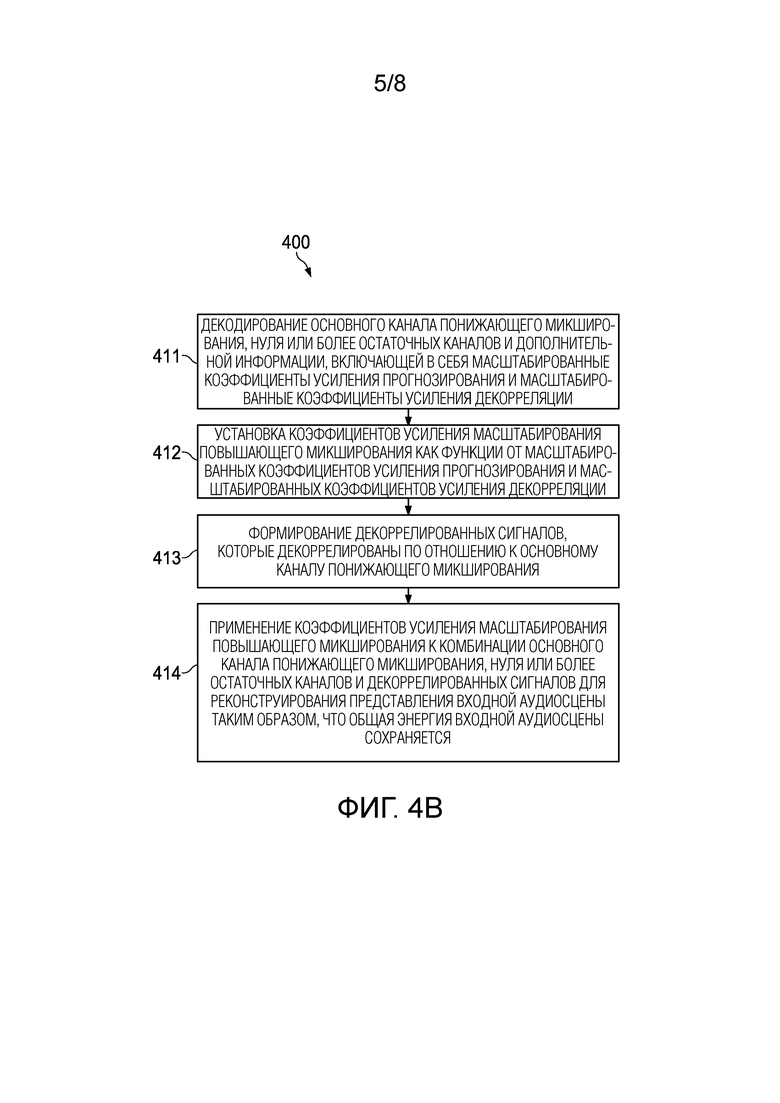
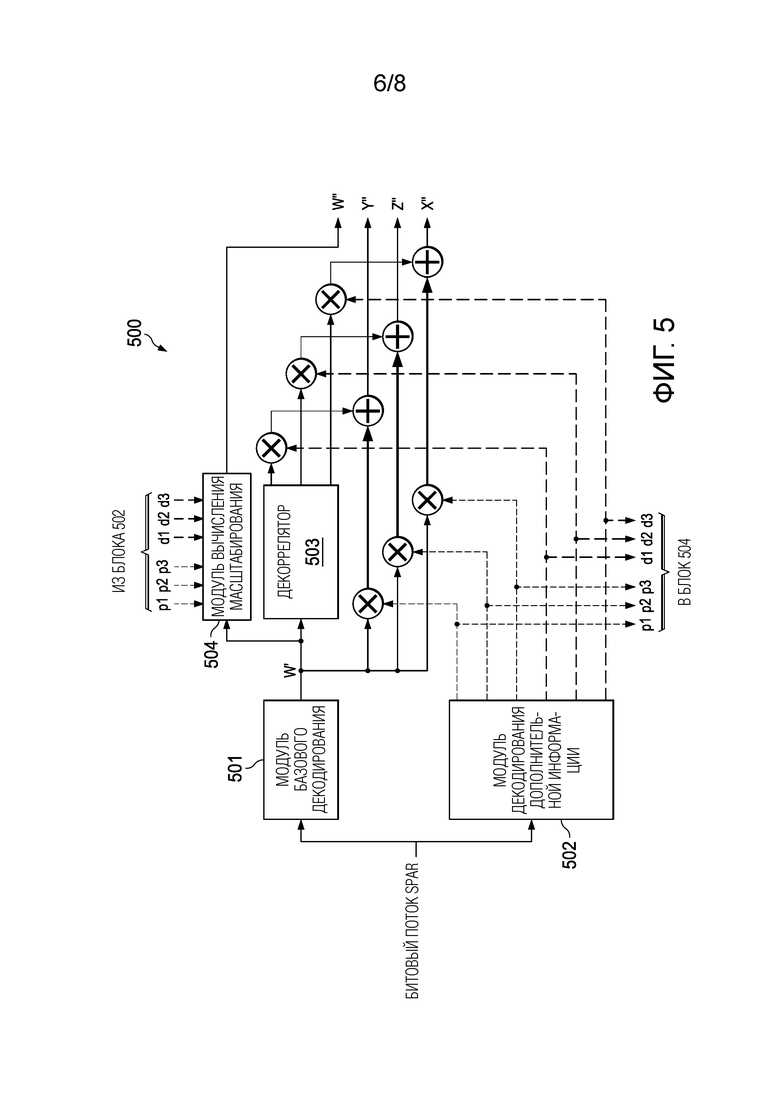
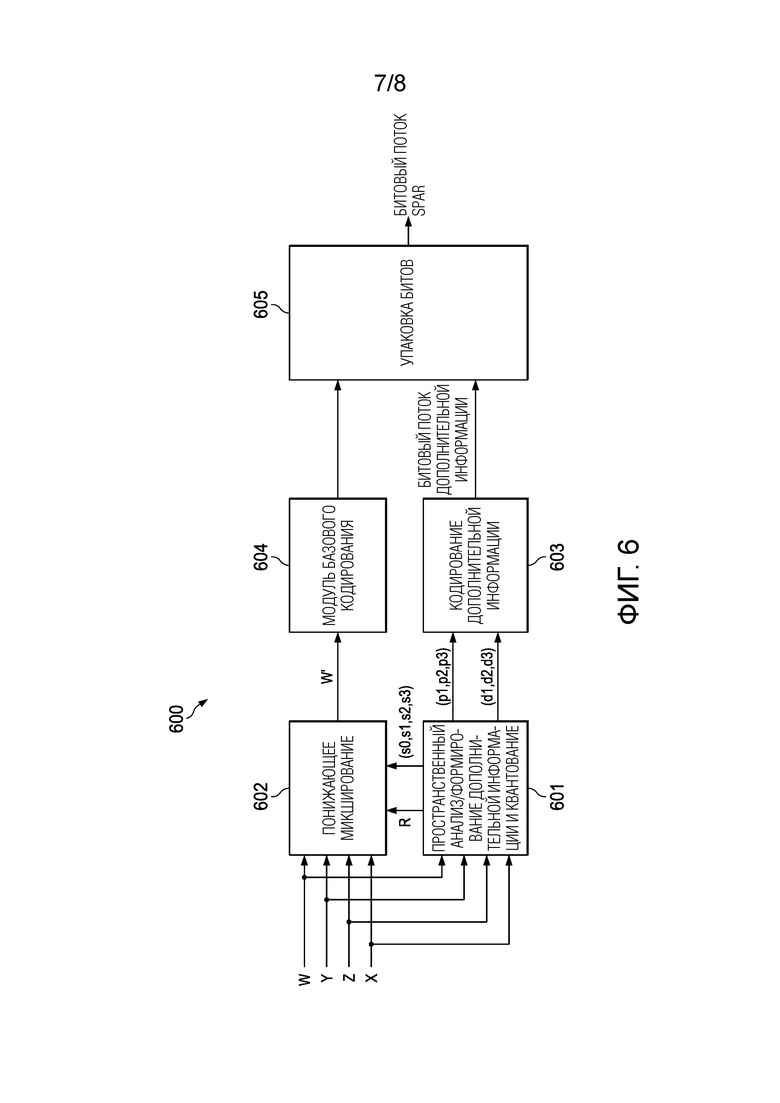
Изобретение относится к средствам для кодирования и декодирования аудиосигнала. Технический результат заключается в повышении эффективности кодирования аудиосигнала. Входной аудиосигнал представляет входную аудиосцену и содержит основной входной аудиоканал и дополнительные каналы. Определяют тип схемы кодирования понижающего микширования на основе входного аудиосигнала. На основе типа схемы кодирования понижающего микширования вычисляют один или более входных коэффициентов усиления понижающего микширования, которые должны быть применены к входному аудиосигналу для конструирования основного канала понижающего микширования. Входные коэффициенты усиления понижающего микширования определяются для минимизации общей ошибки прогнозирования на дополнительных каналах. Определяют один или более коэффициентов усиления масштабирования понижающего микширования для масштабирования основного канала понижающего микширования. Коэффициенты усиления масштабирования понижающего микширования определяются путем минимизации разности энергий между реконструированным представлением входной аудиосцены из основного канала понижающего микширования и входным аудиосигналом. 2 н. и 21 з.п. ф-лы, 8 ил.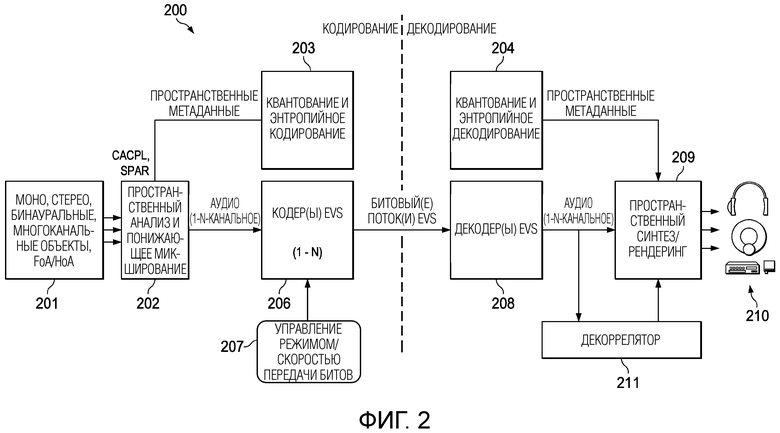
1. Способ кодирования аудиосигнала, который использует стратегию кодирования понижающего микширования, применяемую в кодере, которая отличается от стратегии декодирования повторного микширования или повышающего микширования, применяемой в декодере, при этом способ содержит этапы, на которых:
получают по меньшей мере одним процессором входной аудиосигнал, при этом входной аудиосигнал представляет входную аудиосцену и содержит основной входной аудиоканал и дополнительные каналы;
определяют по меньшей мере одним процессором тип схемы кодирования понижающего микширования на основе входного аудиосигнала;
на основе типа схемы кодирования понижающего микширования: вычисляют по меньшей мере одним процессором один или более входных коэффициентов усиления понижающего микширования, которые должны быть применены к входному аудиосигналу для конструирования основного канала понижающего микширования, при этом входные коэффициенты усиления понижающего микширования определяются для минимизации общей ошибки прогнозирования на дополнительных каналах;
определяют по меньшей мере одним процессором один или более коэффициентов усиления масштабирования понижающего микширования для масштабирования основного канала понижающего микширования, при этом коэффициенты усиления масштабирования понижающего микширования определяются путем минимизации разности энергий между реконструированным представлением входной аудиосцены из основного канала понижающего микширования и входным аудиосигналом;
формируют по меньшей мере одним процессором коэффициенты усиления прогнозирования на основе входного аудиосигнала, входных коэффициентов усиления понижающего микширования и коэффициентов усиления масштабирования понижающего микширования;
определяют по меньшей мере одним процессором один или более остаточных каналов из дополнительных каналов во входном аудиосигнале путем использования основного канала понижающего микширования и коэффициентов усиления прогнозирования для формирования прогнозирований дополнительных каналов, а затем вычитания прогнозирований дополнительных каналов из дополнительных каналов;
определяют по меньшей мере одним процессором коэффициенты усиления декорреляции на основе энергии в остаточных каналах;
кодируют по меньшей мере одним процессором основной канал понижающего микширования, ноль или более остаточных каналов и дополнительную информацию в битовый поток, при этом дополнительная информация содержит коэффициенты усиления прогнозирования и коэффициенты усиления декорреляции, соответствующие одному или более остаточным каналам; и
отправляют по меньшей мере одним процессором битовый поток на декодер.
2. Способ по п. 1, дополнительно содержащий этапы, на которых:
вычисляют по меньшей мере одним процессором входную ковариацию на основе входного аудиосигнала; и
определяют по меньшей мере одним процессором общую ошибку прогнозирования с использованием входной ковариации.
3. Способ по п. 2, в котором вычисление коэффициентов усиления масштабирования понижающего микширования дополнительно содержит этапы, на которых:
определяют по меньшей мере одним процессором коэффициенты усиления масштабирования повышающего микширования как функцию от дополнительной информации, передаваемой в декодер;
формируют по меньшей мере одним процессором представление входной аудиосцены из основного канала понижающего микширования и нуля или более остаточных каналов путем применения коэффициентов усиления масштабирования повышающего микширования к основному каналу понижающего микширования таким образом, чтобы общая энергия входной аудиосцены сохранялась;
определяют по меньшей мере одним процессором коэффициенты усиления масштабирования понижающего микширования путем решения замкнутой формы решения многочлена для сохранения энергии входной аудиосцены, где коэффициенты усиления масштабирования понижающего микширования определяются при сравнении энергии реконструированной входной аудиосцены с энергией входной аудиосцены.
4. Способ по п. 3, в котором коэффициенты усиления масштабирования повышающего микширования для реконструирования представления входной аудиосцены из основного канала понижающего микширования и нуля или более остаточных каналов являются функцией коэффициентов усиления прогнозирования и коэффициентов усиления декорреляции, передаваемых в дополнительной информации в декодер, таким образом, что реконструированное представление основных входных аудиосигналов совпадает по фазе с основным каналом понижающего микширования, а многочлен является квадратичным многочленом.
5. Способ по п. 4, в котором коэффициенты усиления масштабирования повышающего микширования для реконструирования представления входной аудиосцены из основного канала понижающего микширования являются функцией коэффициентов усиления прогнозирования и коэффициентов усиления декорреляции, передаваемых в декодер, таким образом, что коэффициенты усиления масштабирования понижающего микширования, полученные путем решения квадратичного многочлена, масштабируют коэффициенты усиления прогнозирования и коэффициенты усиления декорреляции в пределах заданного диапазона квантования.
6. Способ по п. 5, дополнительно содержащий этапы, на которых:
в кодере:
вычисляют по меньшей мере одним процессором кодера комбинацию входных коэффициентов усиления понижающего микширования, которые должны быть применены к входному аудиосигналу для формирования основного канала понижающего микширования, и коэффициентов усиления масштабирования понижающего микширования, при этом входные коэффициенты усиления понижающего микширования вычисляются как функция входной ковариации входного аудиосигнала;
формируют по меньшей мере одним процессором кодера основной канал понижающего микширования на основе входного аудиосигнала и входных коэффициентов усиления понижающего микширования;
формируют процессором кодера коэффициенты усиления прогнозирования на основе входного аудиосигнала и входных коэффициентов усиления понижающего микширования;
определяют по меньшей мере одним процессором кодера остаточные каналы из дополнительных каналов во входном аудиосигнале путем использования основного канала понижающего микширования и коэффициентов усиления прогнозирования для формирования прогнозирований дополнительных каналов и последующего вычитания прогнозирований дополнительных каналов из дополнительных каналов во входном аудиосигнале;
определяют по меньшей мере одним процессором кодера коэффициенты усиления декорреляции на основе энергии в остаточных каналах;
определяют по меньшей мере одним процессором кодера коэффициенты усиления масштабирования понижающего микширования для масштабирования основного канала понижающего микширования, коэффициентов усиления прогнозирования и коэффициентов усиления декорреляции таким образом, что коэффициенты усиления прогнозирования или коэффициенты усиления декорреляции или и те и другие находятся в заданном диапазоне квантования;
кодируют по меньшей мере одним процессором кодера основной канал понижающего микширования, ноль или более остаточных каналов и дополнительную информацию, включающую в себя масштабированные коэффициенты усиления прогнозирования и масштабированные коэффициенты усиления декорреляции, в битовый поток;
отправляют по меньшей мере одним процессором кодера битовый поток в декодер;
в декодере:
декодируют по меньшей мере одним процессором декодера основной канал понижающего микширования, ноль или более остаточных каналов и дополнительную информацию, включающую в себя масштабированные коэффициенты усиления прогнозирования и масштабированные коэффициенты усиления декорреляции;
устанавливают по меньшей мере одним процессором декодера коэффициенты масштабирования повышающего микширования как функцию от масштабированных коэффициентов усиления прогнозирования и масштабированных коэффициентов усиления декорреляции;
формируют по меньшей мере одним процессором декодера декоррелированные сигналы, которые декоррелированы по отношению к основному каналу понижающего микширования; и
применяют по меньшей мере одним процессором декодера коэффициенты усиления масштабирования повышающего микширования к комбинации основного канала понижающего микширования, нуля или более остаточных каналов и декоррелированных сигналов для реконструирования представления входной аудиосцены таким образом, чтобы общая энергия входной аудиосцены сохранялась.
7. Способ по п. 6, в котором входные коэффициенты усиления понижающего микширования, которые должны применяться к входному аудиосигналу для формирования основного канала понижающего микширования, вычисляются как функция нормированной входной ковариации таким образом, что числитель функции является первой константой, умноженной на ковариацию между основным входным аудиоканалом и дополнительными каналами, а знаменатель функции является максимумом второй константы, умноженным на отклонение основного входного аудиоканала и сумму отклонений дополнительных каналов входного аудиосигнала; и
формируют по меньшей мере одним процессором кодера линейный многочлен путем минимизации ошибки прогнозирования для прогнозирований дополнительного канала и решения для коэффициентов усиления прогнозирования.
8. Способ по любому из пп. 6, 7, в котором входные коэффициенты усиления понижающего микширования, которые должны применяться к входному аудиосигналу для формирования основного канала понижающего микширования, соответствуют схеме кодирования пассивного понижающего микширования так, что основной канал понижающего микширования является либо тем же самым, что и основной входной аудиосигнал, либо задержанной версией основного входного аудиосигнала.
9. Способ по любому из пп. 6-8, в котором входные коэффициенты усиления понижающего микширования, которые должны применяться к входному аудиосигналу для формирования основного канала понижающего микширования, вычисляются как функция коэффициентов усиления прогнозирования.
10. Способ по любому из пп. 6-9, в котором вычисление входных коэффициентов усиления понижающего микширования, которые должны применяться к входному аудиосигналу для конструирования основного канала понижающего микширования, содержит этапы, на которых:
определяют по меньшей мере одним процессором корреляцию между основным аудиосигналом и дополнительными каналами входного аудиосигнала; и
выбирают по меньшей мере одним процессором схему вычисления входного коэффициента усиления понижающего микширования на основе корреляции.
11. Способ по любому из пп. 6-10, в котором вычисление входных коэффициентов усиления понижающего микширования, которые должны применяться к входному аудиосигналу для конструирования основного канала понижающего микширования, дополнительно содержит этапы, на которых:
в кодере:
определяют по меньшей мере одним процессором кодера набор коэффициентов усиления пассивного прогнозирования на основе схемы кодирования пассивного понижающего микширования;
сравнивают по меньшей мере одним процессором кодера набор коэффициентов усиления пассивного прогнозирования с первым пороговым значением;
определяют по меньшей мере одним процессором кодера, является ли набор коэффициентов усиления пассивного прогнозирования меньшим или равным первому пороговому значению, и, если это так, вычисляют первый набор входных коэффициентов усиления понижающего микширования;
формируют по меньшей мере одним процессором кодера первый набор коэффициентов усиления прогнозирования на основе входного аудиосигнала и входных коэффициентов усиления понижающего микширования;
определяют по меньшей мере одним процессором кодера, превышает ли первый набор коэффициентов усиления прогнозирования второе пороговое значение, и, если это так, вычисляют второй набор входных коэффициентов усиления понижающего микширования;
формируют по меньшей мере одним процессором кодера второй набор коэффициентов усиления прогнозирования на основе входного аудиосигнала и входных коэффициентов усиления понижающего микширования;
определяют по меньшей мере одним процессором кодера остаточные каналы из дополнительных каналов во входном аудиосигнале с использованием основного канала понижающего микширования и второго набора коэффициентов усиления прогнозирования;
определяют по меньшей мере одним процессором кодера коэффициенты усиления декорреляции на основе энергии остаточного канала, которая не передана в декодер;
определяют по меньшей мере одним процессором кодера коэффициенты усиления масштабирования понижающего микширования для масштабирования основного канала понижающего микширования, второго набора коэффициентов усиления прогнозирования и коэффициентов усиления декорреляции таким образом, чтобы коэффициенты усиления прогнозирования или коэффициенты усиления декорреляции или и те и другие находились в заданном диапазоне квантования;
кодируют по меньшей мере одним процессором кодера основной канал понижающего микширования, ноль или более остаточных каналов и дополнительную информацию, включающую в себя масштабированные коэффициенты усиления прогнозирования и масштабированные коэффициенты усиления декорреляции, в битовый поток;
отправляют по меньшей мере одним процессором кодера битовый поток в декодер;
в декодере:
декодируют по меньшей мере одним процессором декодера основной канал понижающего микширования, ноль или более остаточных каналов и дополнительную информацию, включающую в себя масштабированные коэффициенты усиления прогнозирования и масштабированные коэффициенты усиления декорреляции;
определяют по меньшей мере одним процессором декодера коэффициенты усиления масштабирования повышающего микширования как функцию масштабированных коэффициентов усиления прогнозирования и масштабированных коэффициентов усиления декорреляции;
формируют по меньшей мере одним процессором декодера декоррелированные сигналы, которые декоррелированы по отношению к основному каналу понижающего микширования; и
применяют по меньшей мере одним процессором декодера коэффициенты усиления масштабирования повышающего микширования к комбинации основного канала понижающего микширования, нуля или более остаточных каналов и декоррелированных сигналов для реконструирования представления входной аудиосцены таким образом, чтобы общая энергия входной аудиосцены сохранялась.
12. Способ по любому из пп. 6-11, в котором входные коэффициенты усиления понижающего микширования соответствуют схеме кодирования пассивного понижающего микширования.
13. Способ по п. 7 или 11, в котором первый набор входных коэффициентов усиления понижающего микширования соответствует схеме активного понижающего микширования, в которой первый набор входных коэффициентов усиления понижающего микширования, подлежащий применению к входному аудиосигналу для формирования основного канала понижающего микширования, вычисляется как функция нормированной входной ковариации таким образом, что числитель в функции является первой константой, умноженной на ковариацию основного входного аудиоканала и дополнительных каналов, а знаменатель в функции является максимумом второй константы, умноженным на отклонение основного входа аудиоканал и суммы отклонений дополнительных каналов.
14. Способ по п. 11, в котором второй набор входных коэффициентов усиления понижающего микширования соответствует схеме кодирования активного понижающего микширования, при этом основной канал понижающего микширования получают путем применения второго набора входных коэффициентов усиления понижающего микширования к основному входному аудиоканалу и дополнительным каналам, а затем объединения каналов вместе.
15. Способ по п. 11 или 14, в котором второй набор входных коэффициентов усиления понижающего микширования представляет собой коэффициенты квадратичного многочлена.
16. Способ по п. 11, в котором пороговое значение, с которым сравниваются коэффициенты усиления прогнозирования, вычисляется таким образом, что коэффициенты усиления прогнозирования находятся в заданном диапазоне квантования.
17. Способ по п. 6, в котором вычисление входных коэффициентов усиления понижающего микширования, которые должны применяться к входному аудиосигналу для формирования канала понижающего микширования, содержит этапы, на которых:
вычисляют коэффициент масштабирования для масштабирования основного входного аудиосигнала;
вычисляют ковариацию масштабированного основного входного аудиосигнала;
выполняют собственный анализ ковариации масштабированного основного входного аудиосигнала;
выбирают собственный вектор, соответствующий наибольшему собственному значению, в качестве входных коэффициентов усиления понижающего микширования таким образом, чтобы основной канал понижающего микширования положительно коррелировал с основным входным аудиоканалом; и
вычисляют коэффициенты усиления масштабирования понижающего микширования для масштабирования основного канала понижающего микширования и дополнительной информации таким образом, чтобы общая энергия входной аудиосцены сохранялась.
18. Способ по п. 6, в котором вычисление входных коэффициентов усиления понижающего микширования, применяемых к входному аудиосигналу для конструирования основного канала понижающего микширования, содержит этапы, на которых:
вычисляют коэффициент масштабирования для масштабирования основного входного аудиоканала;
вычисляют входные коэффициенты усиления понижающего микширования на основе масштабированного основного входного аудиоканала путем установки входных коэффициентов усиления понижающего микширования как функции коэффициентов усиления прогнозирования масштабированного основного входного аудиоканала; и
вычисляют коэффициенты усиления масштабирования понижающего микширования для масштабирования основного канала понижающего микширования и дополнительной информации таким образом, чтобы общая энергия входной аудиосцены сохранялась.
19. Способ по п. 17 или 18, в котором коэффициент масштабирования для масштабирования основного входного аудиоканала является соотношением отклонения основного входного аудиоканала и квадратного корня из суммы отклонений дополнительных каналов.
20. Способ по п. 11, в котором вычисление входных коэффициентов усиления понижающего микширования, применяемых к входному аудиосигналу для формирования основного канала понижающего микширования, дополнительно содержит этапы, на которых:
определяют по меньшей мере одним процессором кодера коэффициенты усиления прогнозирования на основе схемы кодирования пассивного понижающего микширования;
вычисляют по меньшей мере одним процессором кодера коэффициент масштабирования для масштабирования основного канала понижающего микширования и дополнительной информации таким образом, чтобы общая энергия входной аудиосцены сохранялась в реконструированном представлении входной аудиосцены;
определяют по меньшей мере одним процессором кодера, является ли коэффициент масштабирования понижающего микширования меньшим или равным первому пороговому значению, и в результате вычисляют первый набор входных коэффициентов усиления понижающего микширования;
определяют по меньшей мере одним процессором кодера, превышает ли коэффициент масштабирования понижающего микширования второе пороговое значение, и в результате вычисляют второй набор входных коэффициентов усиления понижающего микширования; и
формируют по меньшей мере одним процессором кодера второй набор коэффициентов усиления прогнозирования на основе входного аудиосигнала и первого набора или второго набора входных коэффициентов усиления понижающего микширования;
определяют по меньшей мере одним процессором кодера остаточные каналы из дополнительных каналов во входном аудиосигнале с использованием основного канала понижающего микширования и второго набора коэффициентов усиления прогнозирования;
определяют по меньшей мере одним процессором кодера коэффициенты усиления декорреляции на основе энергии остаточного канала, которая не передается в декодер;
кодируют по меньшей мере одним процессором кодера основной канал понижающего микширования, ноль или более остаточных каналов и дополнительную информацию, включающую в себя второй набор коэффициентов усиления прогнозирования и коэффициенты усиления декорреляции, в битовый поток;
отправляют по меньшей мере одним процессором кодера битовый поток в декодер;
в декодере:
декодируют по меньшей мере одним процессором декодера основной канал понижающего микширования, ноль или более остаточных каналов и дополнительную информацию, включающую в себя второй набор коэффициентов усиления прогнозирования и коэффициенты усиления декорреляции;
определяют по меньшей мере одним процессором декодера коэффициенты усиления масштабирования повышающего микширования как функции от второго набора коэффициентов усиления прогнозирования и коэффициентов усиления декорреляции;
формируют по меньшей мере одним процессором декодера декоррелированные сигналы, которые декоррелированы по отношению к основному каналу понижающего микширования; и
применяют по меньшей мере одним процессором декодера коэффициенты усиления масштабирования повышающего микширования к комбинации основного канала понижающего микширования, нуля или более остаточных каналов и декоррелированных сигналов для реконструирования представления входной аудиосцены таким образом, чтобы общая энергия входной аудиосцены сохранялась.
21. Способ по п. 8 или 20, в котором первый набор входных коэффициентов усиления понижающего микширования соответствует схеме кодирования пассивного понижающего микширования.
22. Способ по любому из пп. 14-16 или 20, в котором второй набор входных коэффициентов усиления понижающего микширования соответствует схеме кодирования активного понижающего микширования, при этом основной канал понижающего микширования получают путем применения входных коэффициентов усиления понижающего микширования к основному входному аудиоканалу и дополнительным каналам и последующего суммирования каналов вместе.
23. Постоянный машиночитаемый носитель, на котором сохранены инструкции, которые при выполнении одним или более процессорами побуждают один или более процессоров выполнить операции по любому из пп. 1-22.
| EP 3079379 B1, 01.07.2020 | |||
| Станок для придания концам круглых радиаторных трубок шестигранного сечения | 1924 |
|
SU2019A1 |
| МНОГОКАНАЛЬНЫЙ ДЕКОРРЕЛЯТОР, МНОГОКАНАЛЬНЫЙ АУДИОДЕКОДЕР, МНОГОКАНАЛЬНЫЙ АУДИОКОДЕР, СПОСОБЫ И КОМПЬЮТЕРНАЯ ПРОГРАММА С ИСПОЛЬЗОВАНИЕМ ПРЕДВАРИТЕЛЬНОГО МИКШИРОВАНИЯ ВХОДНЫХ СИГНАЛОВ ДЕКОРРЕЛЯТОРА | 2014 |
|
RU2666640C2 |
| US 9584912 B2, 28.02.2017 | |||
| US 9848272 B2, 19.12.2017 | |||
| US 10448185 B2, 15.10.2019. | |||

