ОБЛАСТЬ ТЕХНИКИ
Настоящее техническое решение относится к области вычислительной техники, в частности к системе генерации изображений в чате.
УРОВЕНЬ ТЕХНИКИ
В настоящее время известна компания Pandorabots, Inc. (https://www.pandorabots.com/mitsuku/бот), которая разработала бота Mitsuku, это многонациональный чат-бот, призванный развлекать пользователей чата и поддерживать с ними разговор. При этом данный бот на некоторые высказывания пользователя отвечает своим высказыванием, иллюстрированным картинкой. Данное решение основано на подборе картинки, релевантной ответу.
Однако данный бот не принимает во внимание вариации эмоционального состояния ответа и использует нейтральные картинки, непосредственно связанные со словом ответа. Например, на запрос «Do you like cats» генерируется ответ «Yes I love them. They seem a lot more independent than dogs» и вставляет картинку кота.
Также из уровня техники известен социальный чат-бот Microsoft, запущенный в Китае, и который общается почти по-человечески. Бот XiaoIce может работать в «полнодуплексном» режиме, то есть общаться в обоих направлениях одновременно, как во время телефонного звонка. Этим он отличается от чат-ботов «полудуплексного» режима, который больше похож на разговор по рации, когда говорить можно только по очереди. В данном боте реализовано новое обновление, которое Microsoft называет «полнодуплексной речью» (full duplex voice sense), что улучшает способность XiaoIce предсказывать, что собеседник скажет дальше. Это помогает принимать решения о том, как и когда реагировать на фразы собеседника.
Однако данный бот умеет принимать участие в диалоге с пользователем, но во время диалога не генерирует персонализированное изображение с текстом для пользователя на основе его эмоционального состояния.
Из уровня техники широко известны решения, в которых используют бота во время диалога в чате с пользователем, в части такие решения описаны в заявках: WO2019177485A1, опубл. 19.09.2019; US20180329993A1, опубл. 15.11.2018; US20180183735A1, опубл. 28.06.2018; KR101980727 В1, опубл. 21.05.2019.
Однако в данных решениях боты имеют ограниченную функциональность, они умеют принимать участие в диалоге с пользователем, но во время диалога не генерируют персонализированные изображения с текстом для пользователей на основе их эмоционального состояния.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Технической проблемой, на решение которой направлено заявленное техническое решение, является создание системы генерации изображений в чате, которая охарактеризована в независимом пункте формулы.
Технический результат заключается в возможности автоматически генерировать персонализированные изображения с текстом на основе проанализированного эмоционального состояния пользователя и включать результат естественным образом в диалог.
В предпочтительном варианте реализации заявлена система генерации изображений в чате, содержащая взаимосвязанные между собой:
- модуль формирования контекста диалога, осуществляющий прием и преобразование сообщения от пользователя на естественном языке в контекст диалог, при этом данный модуль принимает реплику как строку на входе от пользователя и преобразует ее в json-объект, включающий эту информацию и дополняющий контекст историей сообщений от данного пользователя;
- модуль классификации эмоций, осуществляющий анализ контекст диалога и определяющий эмоциональное состояние пользователя;
- модуль классификации состояния диалога, осуществляющий детектирование классов состояний в диалоге с пользователем;
- модуль генерации изображения, осуществляющий подбор из сформированной базы данных ранжированный список изображений, оцененных по близости контекста и сентимента реплики пользователя, и создающий персонализированное изображение на основе проанализированного эмоционального состояния пользователя;
- модуль оценки близости контекста, осуществляющий оценку близости контекста с сформированным персонализированным изображением;
- генератор фраз, осуществляющий создание фразы, которая проверяется на релевантность как наиболее подходящий текст ответа для диалога с пользователем и осуществляющий наложение текста ответа на подобранное изображение в результате чего получается персонализированное изображение с текстом.
ОПИСАНИЕ ЧЕРТЕЖЕЙ
Реализация изобретения будет описана в дальнейшем в соответствии с прилагаемыми чертежами, которые представлены для пояснения сути изобретения и никоим образом не ограничивают область изобретения. К заявке прилагаются следующие чертежи:
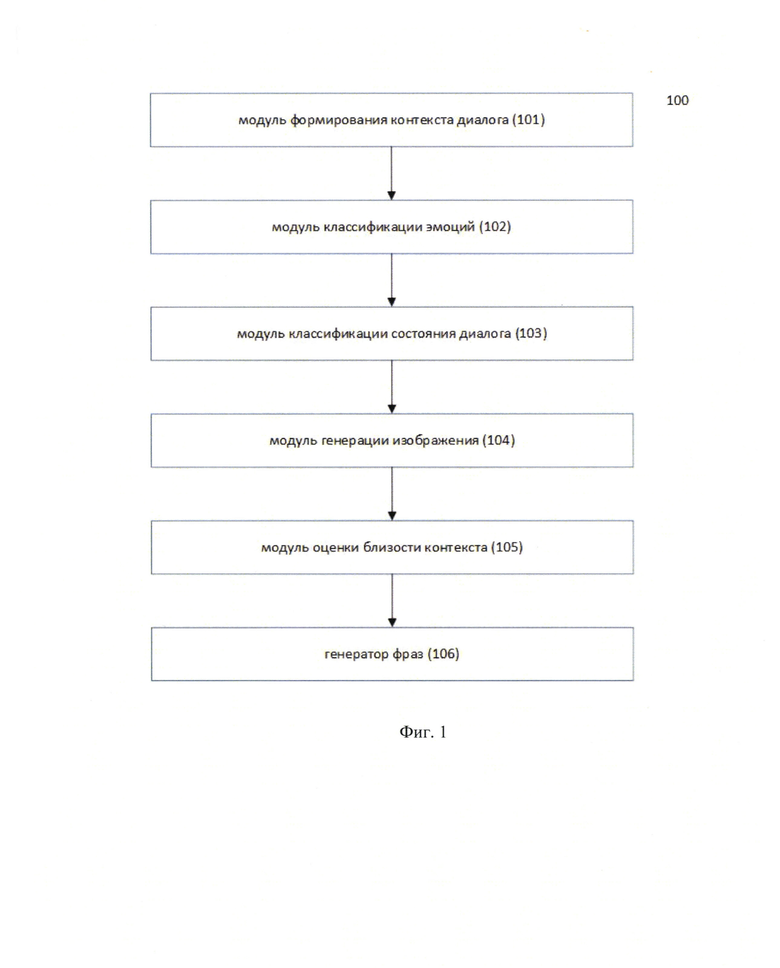
Фиг. 1 иллюстрирует блок-схему системы;
Фиг. 2 иллюстрирует сгенерированное изображение на основе диалога;
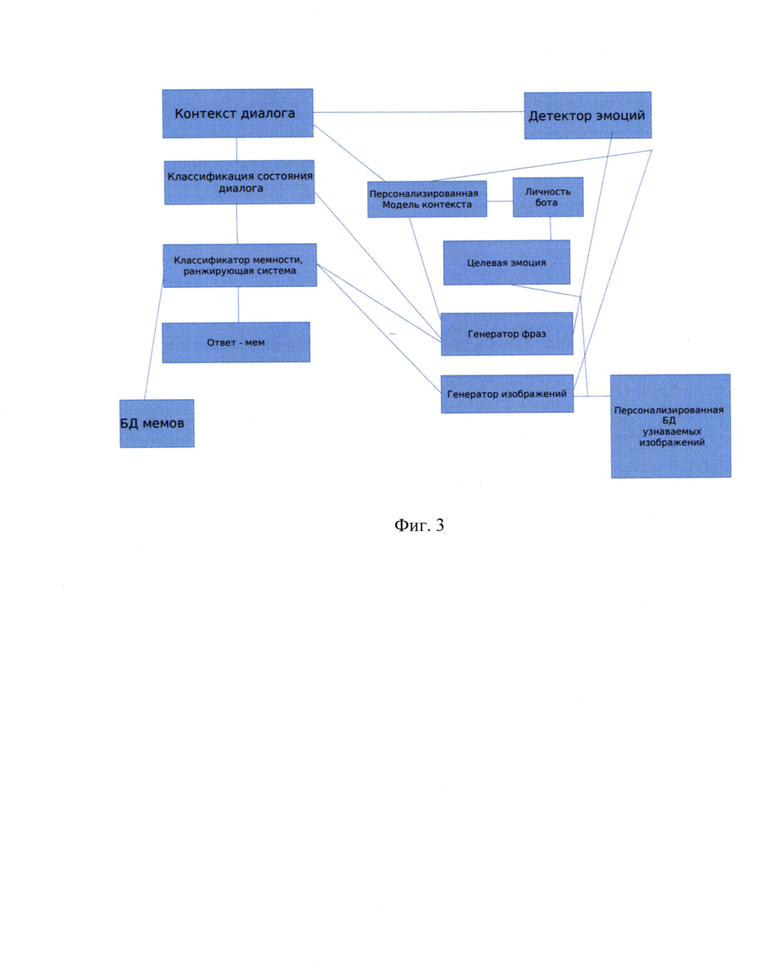
Фиг. 3 иллюстрирует блок-схему заявленного решения;
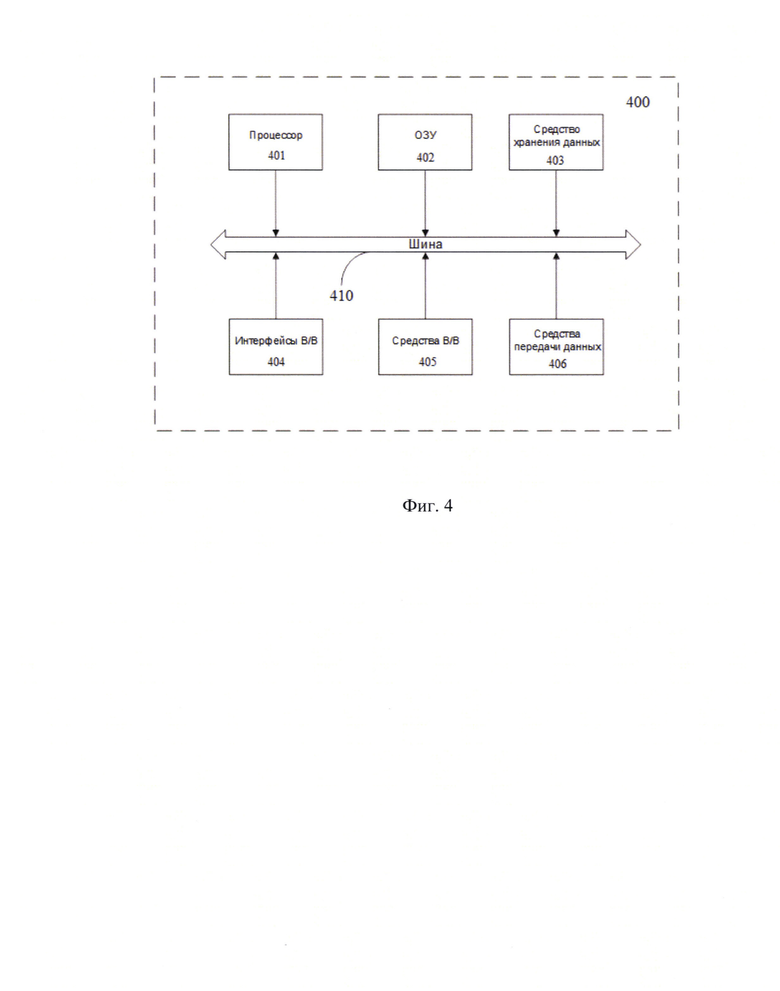
Фиг. 4 иллюстрирует пример общей схемы вычислительного устройства.
ДЕТАЛЬНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
В приведенном ниже подробном описании реализации изобретения приведены многочисленные детали реализации, призванные обеспечить отчетливое понимание настоящего изобретения. Однако, квалифицированному в предметной области специалисту, будет очевидно каким образом можно использовать настоящее изобретение, как с данными деталями реализации, так и без них. В других случаях хорошо известные методы, процедуры и компоненты не были описаны подробно, чтобы не затруднять излишне понимание особенностей настоящего изобретения.
Кроме того, из приведенного изложения будет ясно, что изобретение не ограничивается приведенной реализацией. Многочисленные возможные модификации, изменения, вариации и замены, сохраняющие суть и форму настоящего изобретения, будут очевидными для квалифицированных в предметной области специалистов.
Настоящее изобретение направлено на обеспечение системы генерации изображений в чате.
Как представлено на Фиг. 1, заявленная система генерации изображений в чате (100), состоит из следующих взаимосвязанных между собой модулей:
 модуля формирования контекста диалога (101). Данный модуль (101) осуществляет прием и преобразование сообщения от пользователя на естественном языке в контекст диалог, при этом данный модуль принимает реплику как строку на входе от пользователя и преобразует ее в json-объект, включает эту информацию и дополняет контекст историей сообщений от данного пользователя;
модуля формирования контекста диалога (101). Данный модуль (101) осуществляет прием и преобразование сообщения от пользователя на естественном языке в контекст диалог, при этом данный модуль принимает реплику как строку на входе от пользователя и преобразует ее в json-объект, включает эту информацию и дополняет контекст историей сообщений от данного пользователя;
 модуля классификации эмоций (102). Данный модуль (102) осуществляет анализ контекст диалога и определяет эмоциональное состояние пользователя;
модуля классификации эмоций (102). Данный модуль (102) осуществляет анализ контекст диалога и определяет эмоциональное состояние пользователя;
 модуль классификации состояния диалога (103). Данный модуль (103) осуществляет детектирование классов состояний в диалоге с пользователем;
модуль классификации состояния диалога (103). Данный модуль (103) осуществляет детектирование классов состояний в диалоге с пользователем;
 модуль генерации изображения (104). Данный модуль (104) осуществляет подбор из сформированной базы данных ранжированный список изображений, оцененных по близости контекста и сентимента реплики пользователя, и создает персонализированное изображение на основе проанализированного эмоционального состояния пользователя;
модуль генерации изображения (104). Данный модуль (104) осуществляет подбор из сформированной базы данных ранжированный список изображений, оцененных по близости контекста и сентимента реплики пользователя, и создает персонализированное изображение на основе проанализированного эмоционального состояния пользователя;
 модуль оценки близости контекста (105). Данный модуль (105) осуществляет оценку близости контекста с сформированным персонализированным изображением;
модуль оценки близости контекста (105). Данный модуль (105) осуществляет оценку близости контекста с сформированным персонализированным изображением;
 генератор фраз (106). Генератор (106) осуществляет создание фразы, которая проверяется на релевантность как наиболее подходящий текст ответа для диалога с пользователем и осуществляет наложение текста ответа на подобранное изображение в результате чего получается персонализированное изображение с текстом.
генератор фраз (106). Генератор (106) осуществляет создание фразы, которая проверяется на релевантность как наиболее подходящий текст ответа для диалога с пользователем и осуществляет наложение текста ответа на подобранное изображение в результате чего получается персонализированное изображение с текстом.
Персонализированное изображение с текстом - это созданный для пользователя во время диалога персонализированный мем.
Мем (англ. meme) - единица значимой для культуры информации.
Мем - информация в той или иной форме (медиаобъект, то есть объект, создаваемый электронными средствами коммуникации, фраза, концепция или занятие), как правило, остроумная и ироническая, спонтанно приобретающая популярность, распространяясь в Интернете разнообразными способами (посредством социальных сетей, форумов, блогов, мессенджеров и пр.). Обозначает также явление спонтанного распространения такой информации или фразы.
Мемами могут считаться как слова, так и изображения. Иначе говоря, это любые высказывания, картинки, видео или звукоряд, которые имеют значение и устойчиво распространяются во Всемирной паутине.
Сущность заявленного решения состоит в создании решения позволяющего end-to-end генерировать изображения (мемы), а именно сущности изображение + текст, обладающие свойствами мема, такими как:
1) Законченность идеи;
2) Узнаваемость и создание душевного переживания.
А также использовать это решение для целей ведения диалога и создания у собеседника впечатления ведения диалога человеком, а не ботом.
Для этой задачи не подходят существующие подходы в основном основанные на подборе изображения в том числе с помощью машинного обучения для матчинга с текстом, поскольку изображения (мемы) призваны создавать душевное переживание, а не просто являются иллюстрацией текста.
Также стоит более сложная задача, чем просто генерация персонализированного изображения с текстом (мема), а создание персонализированного изображения с текстом (мема), вызывающего душевное переживание нужного формата и находящегося в контексте.
Используется подбор из сформированной базы данных ранжированного списка изображений независимо от подбора текста, при этом изображение подбирается для создания нужного душевного переживания (целевой эмоции), а текст генерируется на основании состояния диалога, эмоции контекста, целевой эмоции, состояния диалога и модели контекста (а не самого контекста).
Заявленное решение не отвечает на контекст пользователя, а пытается создать нужное переживание относительно модели контекста используя личность бота.
Например:
Фраза пользователя (контекст) = «Ты любишь кошек?»
Модель эмоций = «Консерватизм»
Модель состояния = «вопрос о личности»
Личность бота - «Мне 20 лет. Я люблю животных. Я занимаюсь спортом»
Персональная модель контекста - матчинг личность и контекст - «Я люблю животных»
Модель целевая эмоций = «радость»
Как представлено на фиг. 2, на основе диалога сгенерировано изображение (животные и положительно).
Кошка, радость, хомячок, инопланетяне, радость.
Генератор фраз осуществляет создание фразы (Я люблю животных, нейтрально, вопрос, положительно) - «Мяу», «Хозяин я буду с тобой всегда».
Использование из сформированной базы данных (БД) изображений, размеченных относительно эмоций и объектов, позволяет поддерживать актуализированное состояние узнаваемости. То есть, не использовать старые мемы и изображения, что неизбежно случается при прямом подходе для машинного обучения на БД изображений и подборе персонажа обученной модели на старых мемах.
То есть система пытается понять «мемность» и использовать определение мемности вместо генерации похожих на существующие мемы или просто подбора картинки к фразе по контексту.
Матчинг контекста происходит только на последнем этапе путем выбора с помощью ранжирующей модели максимально релевантого контексту мема.
Описание процесса анализа и принятия решений
При получении сообщения от пользователя система формирует контекст диалога. Контекстная информация, включая последнюю реплику пользователя, отправляется в классификатор эмоций (анализ сентимента), результат сентимент анализа в дальнейшем исопльзуется генератором изображений для создания персонализированных изображений. Также контекст диалога проходит через классификатор состояния диалога для детектирования классов состояний в которых допустима реакция в виде персонализированного изображения с текстом (мема) (тексто-визуальный ответ). После анализа классификатором диалога информация проходит через ранжирующую систему, которая оценивает близость контекста к возможным персонализированным изображениям с текстом (мемам-ответам) из сформированной базы данных изображений (мемов). Когда ответ проанализирован ранжирующей системой и отобрано подмножество кандидатов ответов, система начинает фазу генерации персонализированного ответа, когда генераторы изображений и фраз формируют адаптированный ответ пользователю на базе подобранного ответа-мема.
Результаты генераторов параметризуются с помощью конфигурации целевой эмоции, которая является компонентом личности бота и позволяют боту не просто подбирать изображения (мем) под контекст, но и подталкивать пользователя к нужной эмоции (например, эмоции радости для вывода пользователя из эмоции горя (см. перечень классов в классификаторе эмоций)).
В начале беседы с новым пользователем у системы нет никакой информации о пользователе. По мере накопления беседы с пользователем у системы накапливается информация о сентиментах пользователя вокруг различных тем.
Контекст диалога = json файл с разметкой фраз «человек» - «бот» и размеченными предыдущими репликами относительно: состояний диалога, сентимента(эмоций)
Классификатор состояния диалога: Классификатор CNN модель. Реализация классификатора широко известна из уровня техники (например, https://github.com/ajinkyaT/CNN_Intent_Classification).
«Вопрос о личности» «Утверждение о личности» «Приветствие» «Прощание» «Извинение» «Подтверждение предыдущего высказывания» «Отрицание предыдущего высказывания» «Вопрос о факте» «Вопрос о суждении» «Суждение».
Классификация осуществляется на основе последней реплики пользователя и контекста диалога, включающего историю беседы с пользователем. В целом классификатор определяет эмоцию по характерным ключевым словам и фразам, отражающим эмоциональную окрашенность какого-то феномена в диалоге (например, «я ненавижу блины» - антагонизм детектируется благодаря фразе «ненавижу»)
Личность бота - Текстовое описание личности бота. Представляется как список предложений на естественном языке, перечисляющих факты, характеризующие индивидуальные особенности бота (что он любит, не любит, что его интересует и прочие афилляции).
Персонализированная модель контекста - поиск с помощью модели ODQA (Open domain question answering) в базе Текстовое описание личности бота + Значимые фразы из диалога с пользователем.
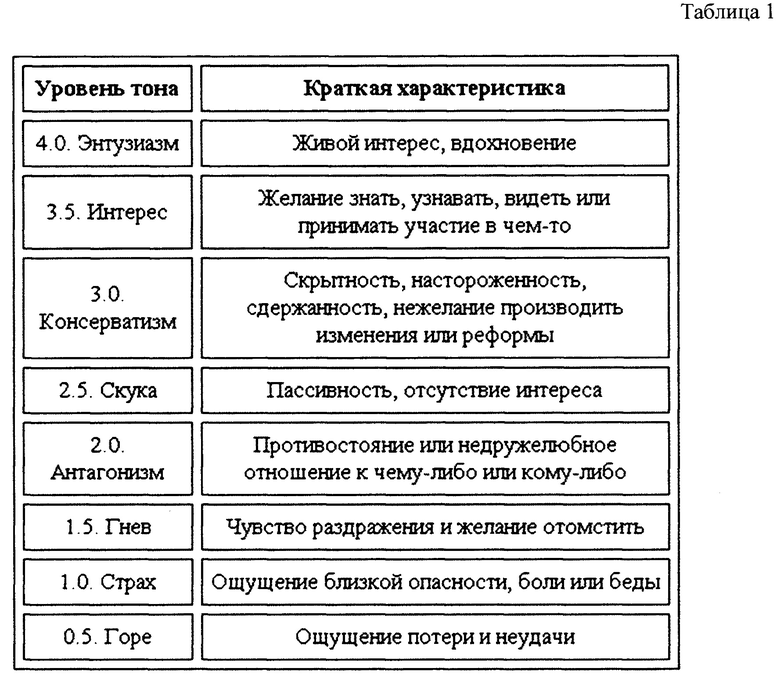
Детектор эмоций (модуль классификации эмоций, осуществляющий анализ контекста диалога и определение эмоционального состояния пользователя) - мультилейбловый классификатор на основе технологии CNN. Классы представлены ниже в таблице 1.
Детектор эмоций реализуется с помощью открытого решения для классификации сентимента на конволюционных нейронных сетях, например, https://keras.io/examples/imdb_cnn_lstm/.
Классификатор изображений (мемности) - дискриминатор GAN модели. Классификатор мемности не оценивает контекст мема.
Генератор фраз + модуль генерации изображения+сформированная БД изображений = генератор GAN модели. (Генеративно-состязательная сеть (англ. Generative adversarial network, сокращенно GAN) - алгоритм машинного обучения без учителя, построенный на комбинации из двух нейронных сетей, одна из которых (сеть G) генерирует образцы (см. Генеративная модель [en]), а другая (сеть D) старается отличить правильные («подлинные») образцы от неправильных)
Ранжирующая модель реализуется через оценку расстояния от эмбеддинга (текст + описание изображения) мема до эмбеддинга контекста диалога по L2-норме. Компонент осуществляющий преобразование текста в эмбединг: BERT, открытые реализации которого доступны из уровня техники: http://docs.deeppavlov.ai/eri/master/fearures/pretrained_vectors.htrnl#bert.
Модуль формирования контекста диалога (101), осуществляющий прием и преобразование сообщения от пользователя в контекст диалога.
Модуль (101) принимает реплику как строку на входе от некоторого пользователя и преобразует ее в json-объект, включающий эту информацию и дополняющий контекст историей сообщений от данного пользователя.
Модуль классификации эмоций (102), осуществляющий анализ контекста диалога и определение эмоционального состояния пользователя.
Модуль классификации состояния диалога (103) осуществляющий детектирование классов состояний в диалоге с пользователем.
Модуль генерации изображения (104), осуществляющий подбор из сформированной базы данных ранжированный список изображений, оцененных по близости контекста и сентимента реплики пользователя, и создающий персонализированное изображение на основе проанализированного эмоционального состояния пользователя
Модуль оценки близости контекста (105), осуществляющий оценку близости контекста с сформированным персонализированным изображением.
Генератор фраз (106), осуществляющий создание фразы, которая проверяется на релевантность как наиболее подходящий текст ответа для диалога с пользователем и осуществляющий наложение текста ответа на подобранное изображение, в результате чего получается персонализированное изображение с текстом.
На Фиг. 4 далее будет представлена общая схема вычислительного устройства (400), обеспечивающего обработку данных, необходимую для реализации заявленного решения.
В общем случае устройство (400) содержит такие компоненты, как: один или более процессоров (401), по меньшей мере одну память (402), средство хранения данных (403), интерфейсы ввода/вывода (404), средство В/В (405), средства сетевого взаимодействия (406).
Процессор (401) устройства выполняет основные вычислительные операции, необходимые для функционирования устройства (400) или функциональности одного или более его компонентов. Процессор (401) исполняет необходимые машиночитаемые команды, содержащиеся в оперативной памяти (402).
Память (402), как правило, выполнена в виде ОЗУ и содержит необходимую программную логику, обеспечивающую требуемый функционал.
Средство хранения данных (403) может выполняться в виде HDD, SSD дисков, рейд массива, сетевого хранилища, флэш-памяти, оптических накопителей информации (CD, DVD, MD, Blue-Ray дисков) и т.п. Средство (403) позволяет выполнять долгосрочное хранение различного вида информации, например, вышеупомянутых файлов с наборами данных пользователей, базы данных, содержащих записи измеренных для каждого пользователя временных интервалов, идентификаторов пользователей и т.п.
Интерфейсы (404) представляют собой стандартные средства для подключения и работы с серверной частью, например, USB, RS232, RJ45, LPT, COM, HDMI, PS/2, Lightning, FireWire и т.п.
Выбор интерфейсов (404) зависит от конкретного исполнения устройства (400), которое может представлять собой персональный компьютер, мейнфрейм, серверный кластер, тонкий клиент, смартфон, ноутбук и т.п.
В качестве средств В/В данных (405) в любом воплощении системы, реализующей описываемый способ, должна использоваться клавиатура. Аппаратное исполнение клавиатуры может быть любым известным: это может быть, как встроенная клавиатура, используемая на ноутбуке или нетбуке, так и обособленное устройство, подключенное к настольному компьютеру, серверу или иному компьютерному устройству. Подключение при этом может быть, как проводным, при котором соединительный кабель клавиатуры подключен к порту PS/2 или USB, расположенному на системном блоке настольного компьютера, так и беспроводным, при котором клавиатура осуществляет обмен данными по каналу беспроводной связи, например, радиоканалу, с базовой станцией, которая, в свою очередь, непосредственно подключена к системному блоку, например, к одному из USB-портов. Помимо клавиатуры, в составе средств В/В данных также может использоваться: джойстик, дисплей (сенсорный дисплей), проектор, тачпад, манипулятор мышь, трекбол, световое перо, динамики, микрофон и т.п.
Средства сетевого взаимодействия (406) выбираются из устройства, обеспечивающий сетевой прием и передачу данных, например, Ethernet карту, WLAN/Wi-Fi модуль, Bluetooth модуль, BLE модуль, NFC модуль, IrDa, RFID модуль, GSM модем и т.п.С помощью средств (405) обеспечивается организация обмена данными по проводному или беспроводному каналу передачи данных, например, WAN, PAN, ЛВС (LAN), Интранет, Интернет, WLAN, WMAN или GSM.
Компоненты устройства (400) сопряжены посредством общей шины передачи данных (410).
В настоящих материалах заявки было представлено предпочтительное раскрытие осуществления заявленного технического решения, которое не должно использоваться как ограничивающее иные, частные воплощения его реализации, которые не выходят за рамки испрашиваемого объема правовой охраны, и являются очевидными для специалистов в соответствующей области техники.
| название | год | авторы | номер документа |
|---|---|---|---|
| КОНВЕЙЕРНЫЙ НАКАПЛИВАЮЩИЙ СУММАТОР ПО МОДУЛЮ | 2023 |
|
RU2814657C1 |
| СИСТЕМА И СПОСОБ АВТОМАТИЗИРОВАННОЙ ОЦЕНКИ НАМЕРЕНИЙ И ЭМОЦИЙ ПОЛЬЗОВАТЕЛЕЙ ДИАЛОГОВОЙ СИСТЕМЫ | 2020 |
|
RU2762702C2 |
| СПОСОБ И СИСТЕМА УПРАВЛЕНИЯ ДИАЛОГОВЫМ АГЕНТОМ В КАНАЛЕ ВЗАИМОДЕЙСТВИЯ С ПОЛЬЗОВАТЕЛЕМ | 2019 |
|
RU2818036C1 |
| СПОСОБ УПРАВЛЕНИЯ ДИАЛОГОМ И СИСТЕМА ПОНИМАНИЯ ЕСТЕСТВЕННОГО ЯЗЫКА В ПЛАТФОРМЕ ВИРТУАЛЬНЫХ АССИСТЕНТОВ | 2020 |
|
RU2759090C1 |
| ИНТЕЛЛЕКТУАЛЬНОЕ РАБОЧЕЕ МЕСТО ОПЕРАТОРА И СПОСОБ ЕГО ВЗАИМОДЕЙСТВИЯ ДЛЯ ОСУЩЕСТВЛЕНИЯ ИНТЕРАКТИВНОЙ ПОДДЕРЖКИ СЕССИИ ОБСЛУЖИВАНИЯ КЛИЕНТА | 2020 |
|
RU2755781C1 |
| СПОСОБ И СИСТЕМА ДЛЯ ВЫСТРАИВАНИЯ ДИАЛОГА С ПОЛЬЗОВАТЕЛЕМ В УДОБНОМ ДЛЯ ПОЛЬЗОВАТЕЛЯ КАНАЛЕ | 2018 |
|
RU2688758C1 |
| СПОСОБ СОЗДАНИЯ МОДЕЛИ АНАЛИЗА ДИАЛОГОВ НА БАЗЕ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА ДЛЯ ОБРАБОТКИ ЗАПРОСОВ ПОЛЬЗОВАТЕЛЕЙ И СИСТЕМА, ИСПОЛЬЗУЮЩАЯ ТАКУЮ МОДЕЛЬ | 2019 |
|
RU2730449C2 |
| СИСТЕМА ИНТЕРАКТИВНЫХ РЕЧЕВЫХ СИМУЛЯЦИЙ | 2023 |
|
RU2807436C1 |
| СПОСОБ ОБУЧЕНИЯ ИНФОРМАЦИОННОЙ ДИАЛОГОВОЙ СИСТЕМЫ ПОЛЬЗОВАТЕЛЕМ | 2012 |
|
RU2530268C2 |
| СПОСОБ И СИСТЕМА ГЕНЕРАЦИИ ТЕКСТА ДЛЯ ЦИФРОВОГО АССИСТЕНТА | 2022 |
|
RU2796208C1 |

Изобретение относится к области вычислительной техники. Технический результат заключается в возможности автоматически генерировать персонализированные изображения с текстом на основе проанализированного эмоционального состояния пользователя. Система генерации изображений в чате, содержащая взаимосвязанные между собой модули: модуль формирования контекста диалога, осуществляющий прием и преобразование сообщения от пользователя на естественном языке в контекст диалога, при этом данный модуль принимает реплику как строку на входе от пользователя и преобразует ее в json-объект, включающий эту информацию и дополняющий контекст историей сообщений от данного пользователя, модуль классификации эмоций, модуль классификации состояния диалога, осуществляющий детектирование классов состояний в диалоге с пользователем, модуль генерации изображения, модуль оценки близости контекста, осуществляющий оценку близости контекста с сформированным персонализированным изображением, генератор фраз, осуществляющий создание фразы, которая проверяется на релевантность как наиболее подходящий текст ответа для диалога с пользователем и осуществляющий наложение текста ответа на подобранное изображение, в результате чего получается персонализированное изображение с текстом. 4 ил.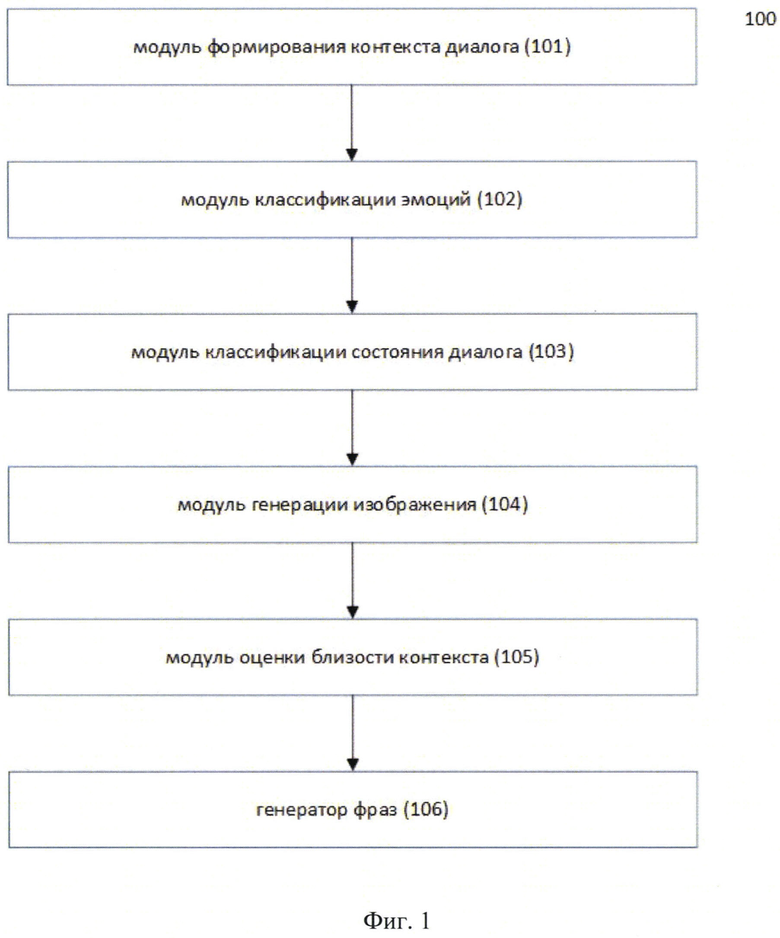
Система генерации изображений в чате, содержащая взаимосвязанные между собой модули:
- модуль формирования контекста диалога, осуществляющий прием и преобразование сообщения от пользователя на естественном языке в контекст диалога, при этом данный модуль принимает реплику как строку на входе от пользователя и преобразует ее в json-объект, включающий эту информацию и дополняющий контекст историей сообщений от данного пользователя;
- модуль классификации эмоций, осуществляющий анализ контекста диалога и определяющий эмоциональное состояние пользователя;
- модуль классификации состояния диалога, осуществляющий детектирование классов состояний в диалоге с пользователем, в которых допустима реакция в виде персонализированного изображения с текстом;
- модуль генерации изображения, осуществляющий подбор из сформированной базы данных, ранжированный список изображений, оцененных по близости контекста и сентимента реплики пользователя, и создающий персонализированное изображение на основе проанализированного эмоционального состояния пользователя;
- модуль оценки близости контекста, осуществляющий оценку близости контекста с сформированным персонализированным изображением;
- генератор фраз, осуществляющий создание фразы, которая проверяется на релевантность как наиболее подходящий текст ответа для диалога с пользователем и осуществляющий наложение текста ответа на подобранное изображение, в результате чего получается персонализированное изображение с текстом.
| US 20160163332 A1, 09.06.2016 | |||
| US 20190073197 A1, 07.03.2019 | |||
| US 20180089572 A1, 29.03.2018 | |||
| СПОСОБ ПОДГОТОВКИ РЕКОМЕНДАЦИЙ ДЛЯ ПРИНЯТИЯ РЕШЕНИЙ НА ОСНОВЕ КОМПЬЮТЕРИЗИРОВАННОЙ ОЦЕНКИ СПОСОБНОСТЕЙ ПОЛЬЗОВАТЕЛЕЙ | 2017 |
|
RU2672171C1 |
| ГЕНЕРИРОВАНИЕ ДИАЛОГОВЫХ РЕКОМЕНДАЦИЙ ДЛЯ ЧАТОВЫХ ИНФОРМАЦИОННЫХ СИСТЕМ | 2013 |
|
RU2637874C2 |
