ОБЛАСТЬ ТЕХНИКИ
Изобретение относится к области обработки текстов на естественном языке (NLP, natural language processing), в частности к системе интерактивных речевых (коммуникативных) симуляций.
Настоящее изобретение может быть использовано, по меньшей мере, для обучения общению и улучшения межличностных навыков пользователей, в процессе обучения кадров, в сфере образования.
УРОВЕНЬ ТЕХНИКИ
В патенте US10896678B2, дата публикации 19.01.2021, раскрыто устройство устной коммуникации и платформа для обработки данных, которые предназначены для получения данных устных разговоров от людей и использования машинного обучения для получения интеллектуальных данных. Данное устройство реализовано в виде чат-бота, прогнозирования действий и событий и автоматического действия на основе этой вычисленной информации. При этом чат-бот предоставляет аудиоданные, которые отражают информацию, вычисленную платформой предоставления данных.
Однако в данном патенте отсутствует возможность интерактивного взаимодействия пользователя и системы, автоматического сбора данных пользователя с целью формирования вариативных интерактивных сценариев для пользователя на основании его поведения и обратной связи системы. Кроме того, в данном патенте отсутствует интерактивный диалоговый тренажер, который предоставляет гораздо большую функциональность по сравнению с чат-ботом и позволяет реализовывать коммуникативные симуляции с полным погружением пользователя в среду.
Технической задачей настоящего изобретения является создание системы интерактивных речевых (коммуникативных) симуляций с возможностью непрерывной оценки ответов человека в процессе проведения симуляции и изменения сценария симуляции в зависимости от ответов.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Техническим результатом заявляемого изобретения является повышение скорости и точности оценки ответов пользователя во время симуляции за счет автоматической обработки речи пользователя, текста, введенного пользователем, с применением NLP методов, а также обеспечение автоматической непрерывной оценки ответов пользователя во время симуляции с применением NLP методов, что позволяет создавать интерактивные речевые (коммуникативные) симуляции, повышает вариативность диалога между пользователем и персонажем во время симуляции.
Указанный технический результат достигается за счёт того, что:
система интерактивных речевых симуляций содержит:
редактор для создания по меньшей мере одной симуляции, причем с помощью указанного редактора создают по меньшей мере одну симуляцию, представляющую собой диалог между персонажем и пользователем, создают словарь стоп-слов, задают список возможных вариантов ответа пользователя, задают настройки по меньшей мере одной симуляции, добавляют основные сценарии, добавляют дополнительные сценарии, добавляют триггерные фразы основного сценария, по которым активируется переход на дополнительный сценарий;
плеер воспроизведения по меньшей мере одной симуляции, причем с помощью указанного плеера автоматически воспроизводят заданный в редакторе диалог между персонажем и пользователем в соответствии с заданными настройками симуляции, при этом автоматически выбирают сценарии диалога в процессе симуляции на основании настроек симуляции;
блок сбора пользовательских данных, причем с помощью указанного блока сбора пользовательских данных автоматически осуществляют сбор пользовательских данных в процессе симуляции, при этом пользовательские данные включают ответы пользователя, полученные во время симуляции, причем ответы пользователя включают аудиоданные, содержащие речь пользователя, и текстовые данные, содержащие текст, введенный пользователем;
блок автоматической непрерывной обработки пользовательских данных, собираемых в процессе симуляции, содержащий модуль распознавания речи пользователя в текст, связанный со следующими модулями: модулем семантического сравнения текстов, модулем сентиментного анализа текста, модулем словарей стоп-слов, причем с помощью модуля распознавания речи пользователя в текст осуществляют предобработку ответов пользователя в процессе симуляции для последующего анализа предобработанных ответов пользователя с помощью модулей семантического сравнения текстов, сентиментного анализа текста, словарей стоп-слов с целью непрерывной оценки ответов в процессе симуляции для автоматического изменения основного сценария в зависимости от ответа пользователя, для определения триггерных фраз в ответах пользователя для автоматической активации перехода на дополнительные сценарии и для определения итоговой оценки ответов пользователя.
В одном варианте реализации системы настройками одной или более симуляций являются, по меньшей мере, следующие: выбор персонажа, добавление рандомайзера действий персонажа, выбор метода обучения, выбор языка урока, выбор строгости распознавания речи, настройка словарей стоп-слов, настройка ключевых слов, включение/выключение записи видео, отображение отчета, содержащего оценку ответов пользователя, запрос авторизации пользователя, настройка стартового и финального сообщения урока, настройка фоновой картинки, настройка демонстрации мультимедиа.
В одном варианте реализации системы методом обучения является, по меньшей мере, обучение с помощью трех уровней, обучение с помощью двух уровней, обучение с помощью одного уровня, выбор вариантов ответов, интервью, квиз.
В одном варианте реализации системы дополнительные сценарии дополнительно используются с рандомайзером действий персонажа и активируются по фразе персонажа.
В одном варианте реализации системы дополнительно содержит модуль определения и выделения ключевых слов в тексте, при этом с помощью указанного модуля определяют ключевые слова в тексте с помощью редактора симуляции и в процессе симуляции выделяют ключевые слова в тексте, изменяют сценарии симуляции, если какое-либо из ключевых слов было задано как триггер, и показывают выделенные ключевые слова пользователю в качестве подсказки.
В одном варианте реализации системы с помощью модуля семантического сравнения текстов определяют семантическое сходство ответов пользователя с заранее заданными возможными вариантами ответов.
В одном варианте реализации системы с помощью модуля сентиментного анализа текста выявляют сентиментное настроение ответа пользователя и сравнение с наиболее вероятным заданным вариантом ответа.
В одном варианте реализации системы в соответствии с заданным словарем стоп-слов.
В одном варианте реализации системы активация перехода на дополнительные сценарии в процессе симуляции на основе триггерных фраз осуществляется в том случае, если пользователь произносит триггерную фразу целиком, система прерывает основной сценарий, который проходил пользователь и переносит пользователя в дополнительный сценарий, после того, как пользователь пройдет дополнительный сценарий до конца, система возвращает пользователя обратно к тому месту, на котором пользователь прервал основное прохождение.
В одном варианте реализации системы блок автоматической непрерывной обработки пользовательских данных, собираемых в процессе симуляции, дополнительно содержит модуль анализа аудиоданных, содержащих речь пользователя, при этом с помощью указанного модуля получают характеристики речи пользователя для предоставления пользователю в конце симуляции, характеристиками речи пользователя являются, по меньшей мере, скорость речи, диапазон интонации.
ОПИСАНИЕ ЧЕРТЕЖЕЙ
Реализация изобретения будет описана в дальнейшем в соответствии с прилагаемыми чертежами, которые представлены для пояснения сути изобретения и никоим образом не ограничивают область изобретения.
Заявляемое изобретение проиллюстрировано фигурами 1-8, на которых изображены:
Фиг. 1 – иллюстрирует вариант работы редактора для создания симуляций в виде блок-схемы.
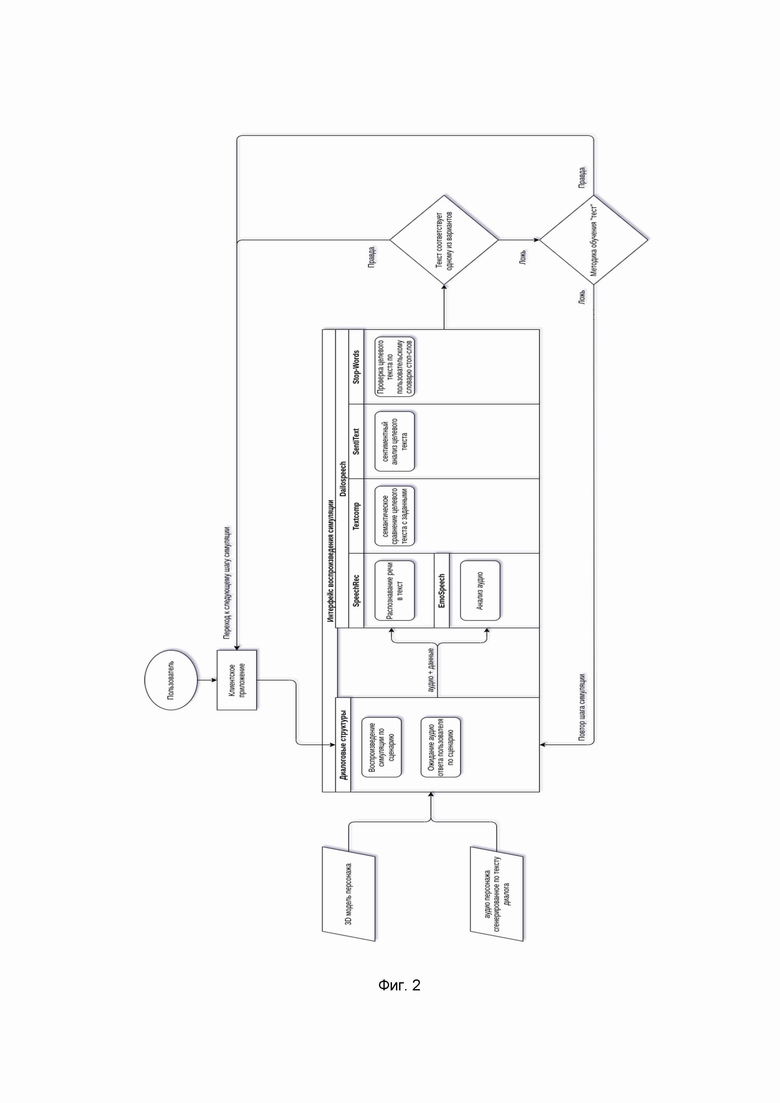
Фиг. 2 - иллюстрирует вариант работы плеера воспроизведения симуляции в виде блок-схемы.
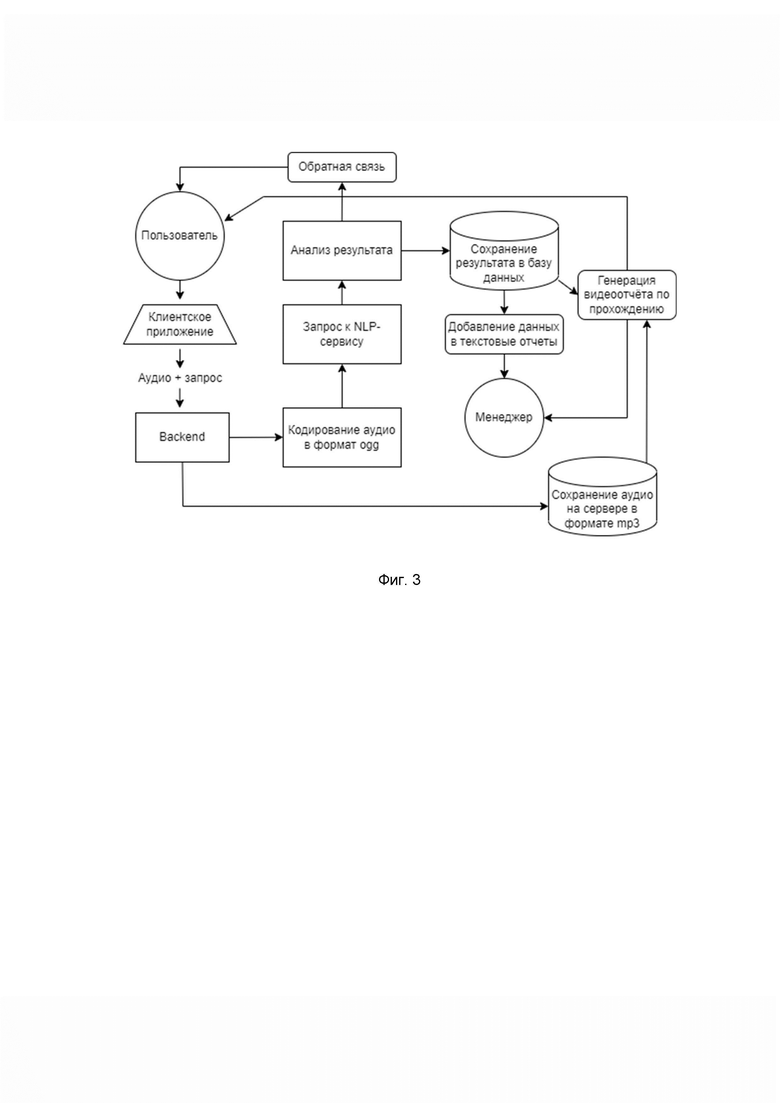
Фиг. 3 - иллюстрирует вариант работы системы в виде блок-схемы начиная от запроса пользователя до получения им обратной связи.
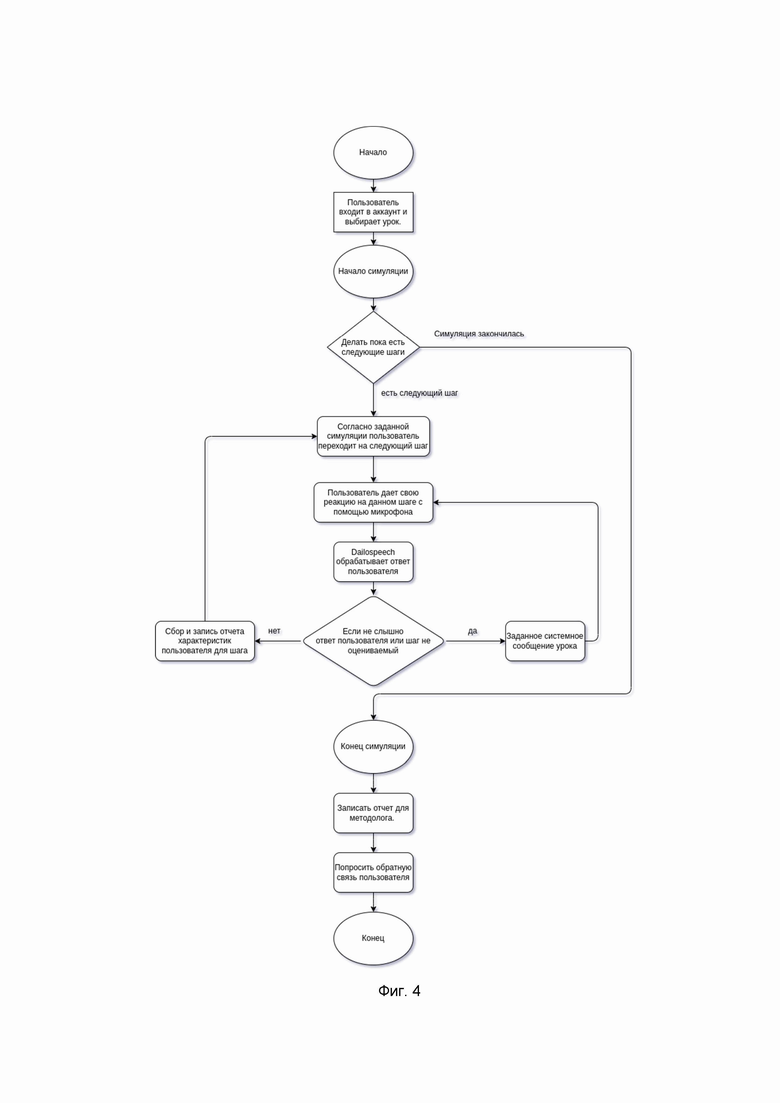
Фиг. 4 - иллюстрирует пример взаимодействия пользователя системы на этапе воспроизведения симуляции и основные внутренние процессы во время симуляции.
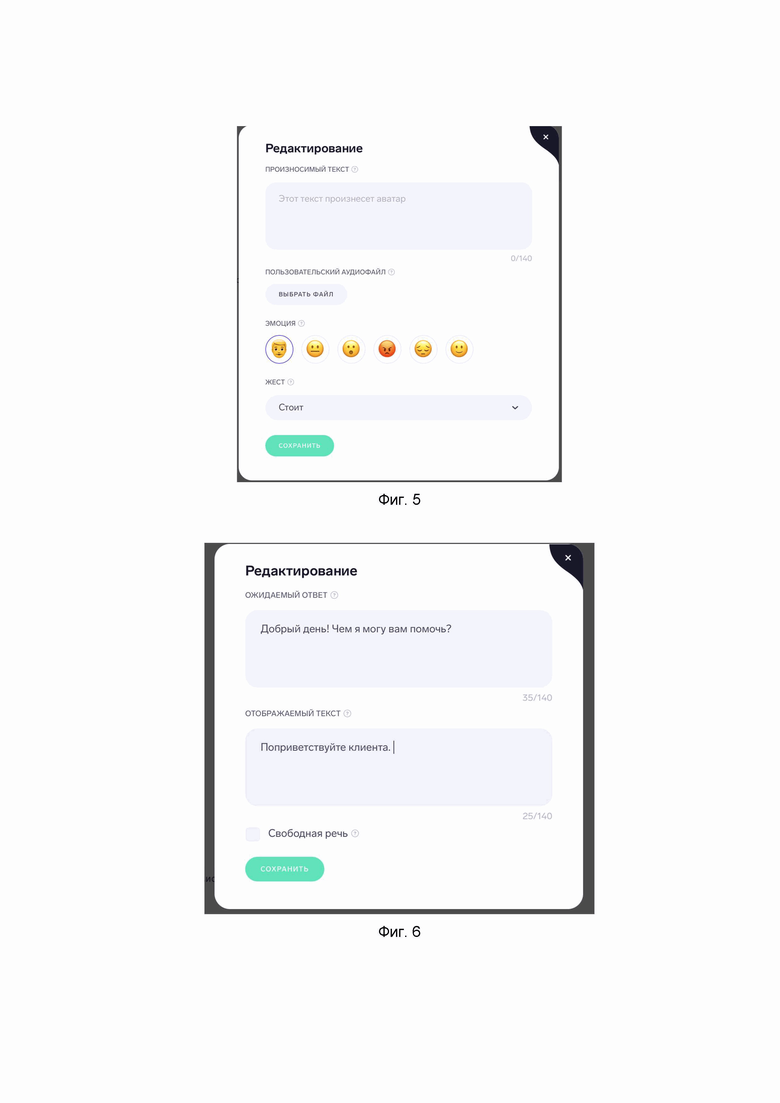
Фиг. 5, 6, 7, 8 - иллюстрируют примеры интерфейса редактора для создания симуляций.
ДЕТАЛЬНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
В приведенном ниже подробном описании реализации изобретения приведены многочисленные детали реализации, призванные обеспечить отчетливое понимание настоящего изобретения. Однако, квалифицированному в предметной области специалисту будет очевидно, каким образом можно использовать настоящее изобретение, как с данными деталями реализации, так и без них. В других случаях хорошо известные методы, процедуры и компоненты не были описаны подробно, чтобы не затруднять излишне понимание особенностей настоящего изобретения.
Кроме того, из приведенного изложения будет ясно, что изобретение не ограничивается приведенной реализацией. Многочисленные возможные модификации, изменения, вариации и замены, сохраняющие суть и форму настоящего изобретения, будут очевидными для квалифицированных в предметной области специалистов.
Настоящее изобретение представляет собой систему интерактивных речевых (коммуникативных) симуляций, которая позволяет непрерывно оценивать ответы пользователя во время симуляции, анализировать речь пользователя, текст, введенный пользователем с помощью методик обработки текста на естественном языке (NLP), а также изменять сценарии симуляции в зависимости от ответов пользователя. Пользователи получают обратную связь в режиме реального времени и могут улучшить свое поведение прямо в момент диалога.
Система интерактивных речевых симуляций содержит редактор для создания симуляций, с помощью которого создают симуляции, представляющую собой диалог между персонажем и пользователем, создают словарь стоп-слов, задают список возможных вариантов ответа пользователя, задают настройки по меньшей мере одной симуляции, добавляют основные сценарии, добавляют дополнительные сценарии, добавляют триггерные фразы основного сценария, по которым активируется переход на дополнительный сценарий; плеер воспроизведения по меньшей мере одной симуляции, с помощью которого автоматически воспроизводят заданный в редакторе диалог между персонажем и пользователем в соответствии с заданными настройками симуляции, при этом автоматически выбирают сценарии диалога в процессе симуляции на основании настроек симуляции; блок сбора пользовательских данных, с помощью которого автоматически осуществляют сбор пользовательских данных в процессе симуляции, при этом пользовательские данные включают ответы пользователя, полученные во время симуляции, причем ответы пользователя включают аудиоданные, содержащие речь пользователя, и текстовые данные, содержащие текст, введенный пользователем; блок автоматической непрерывной обработки пользовательских данных, собираемых в процессе симуляции, содержащий модуль распознавания речи пользователя в текст, связанный со следующими модулями: модулем семантического сравнения текстов, модулем сентиментного анализа текста, модулем словарей стоп-слов, причем с помощью модуля распознавания речи пользователя в текст осуществляют предобработку ответов пользователя в процессе симуляции для последующего анализа предобработанных ответов пользователя с помощью модулей семантического сравнения текстов, сентиментного анализа текста, словарей стоп-слов с целью непрерывной оценки ответов в процессе симуляции для автоматического изменения основного сценария в зависимости от ответа пользователя, для определения триггерных фраз в ответах пользователя для автоматической активации перехода на дополнительные сценарии и для определения итоговой оценки ответов пользователя.
Редактор для создания симуляций позволяет применять настройки к симуляции, например: выбрать персонаж; добавить рандомайзер действий персонажа; выбрать метод обучения (3 уровня, 2 уровня, 1 уровня, выбор вариантов ответов, интервью, квиз и т.д.); выбрать язык урока; выбрать строгость распознавания; настроить словари стоп-слов, при употреблении которых будет засчитываться ошибка; настроить отображение ключевых слов; настроить использование ключевых слов в качестве триггеров для изменения сценария; включить/выключить запись видео; показывать подробный отчет после урока, содержащий оценку ответов пользователя; запрашивать обязательную авторизацию для прохождения симуляции; настроить стартовое и финальное сообщения урока; настроить фоновую картинку симуляции, настройка демонстрации мультимедиа. В процессе создания урока в редакторе используют такие элементы, как например, фраза системы (закадровый голос), фраза персонажа, рандомная фраза персонажа (выбор из фраз), фраза пользователя, которую он должен сказать по подсказке или самостоятельно, выбор из фраз пользователя (выбор вариантов ответа для пользователя). К фразам системы и персонажа можно добавить аудиофайл, картинку или видео. Фиг. 1 иллюстрирует вариант работы редактора сценария.
Плеер воспроизведения симуляций представляет собой подсистему проигрывания диалога и воспроизведения всех примененных к симуляции настроек. Это заключается в воспроизведении диалога, заданного в редакторе, между аватаром (персонажем) и пользователем с учетом технологии обработки данных, методики обучения (с помощью трех, двух или одного шага, интервью или квиза), частных настроек, таких как фон или демонстрация мультимедиа и т.д. В процессе воспроизведения диалога плеер генерирует речь аватара и системы в виде произносимых фраз, а также выводит на экран рекомендуемый ответ для пользователя в виде полностью отображаемой фразы, частично отображаемой фразы или вариантов ответа. Фиг. 2 иллюстрирует вариант работы плеера воспроизведения симуляции.
Воспроизведение диалога заключается в проигрывании записанных в редакторе фраз аватара и ответов пользователя. Ответы пользователя записываются и распознаются системой, а затем анализируются и сравниваются с ожидаемым ответом с помощью подсистемы обработки семантических смыслов. В зависимости от результатов анализа, пользователь получает обратную связь, а также в зависимости от методики обучения ему могут начисляться баллы за прохождение, в зависимости от того, были ли смыслы сказанной и ожидаемой фразы похожи.
Сбор пользовательских данных осуществляется автоматически в процессе симуляции путем записи ответов пользователя для последующего анализа. Например, для записи речи пользователя используется микрофон, для ввода текста используется интерфейс ввода/вывода текста, например, предоставляемый с помощью клиентского приложения.
Блок автоматической обработки пользовательских данных представляет собой подсистему обработки семантических смыслов. С помощью модуля анализа аудиоданных, содержащих речь пользователя, получают характеристики речи пользователя. Характеристиками речи пользователя являются, по меньшей мере, скорость речи, диапазон интонации. С помощью модуля семантического сравнения текстов определяют семантическое сходство ответов пользователя с заранее заданными вариантами ответов. С помощью модуля сентиментного анализа текста выявляют сентиментное настроение ответа пользователя и сравнение с наиболее вероятным заданным вариантом ответа. С помощью модуля определения и выделения ключевых слов в тексте определяют и выделяют ключевые слова в ответах пользователя. С помощью модуля словарей стоп-слов проверяют наличие стоп-слов в ответах пользователя в соответствии с заданным словарем стоп-слов.
Подсистема обработки семантических смыслов реализована, например, в виде набора сервисов DailoSpeech для определения намерения пользователя на основании смыслового (семантического) сравнения двух текстов, для анализа действий (ответов) и реакций пользователя в процессе проведения симуляции для целей последующей оценки. DailoSpeech предназначена для проведения анализа и контроля ответов испытуемого. Подсистема реализована в виде отдельного сервиса. Интерфейс системы представлен в виде REST API сервера. Для функционирования подключаемого сервиса необходима среда разработки Python 3.10 и выше. В среде должен присутствовать интерпретатор упомянутого языка. Для работы сервиса требуется предустановленная объектно-реляционная система управления базами данных PostgreSQL. А также мультимедийный фреймворк для обработки аудиоданных “FFmpeg”. Подключаемый модуль принимает на вход подсистемы данные в соответствии с используемым методом в виде словаря или списка на языке программирования Python 3. После чего интерпретатор Python использует средства библиотеки requests, чтобы обратиться к системе DailoSpeech и получить соответствующий ответ. Сервер общается исключительно с доверенным сервером (back-end) посредством запросов REST. Он принимает на вход системы данные в соответствии с используемым http-запросом в виде словаря json. На выходе отдает ответ в виде данных в соответствии с используемым http-запросом в виде словаря json. Сервис работает с текстами на русском, английском и французском языках. Ожидаемая длина для каждого текста не превышает 768 символов. Значение семантического сходства указываются в промежутке значений от 0 до 1.
Ядро сервиса Core API реализует основную логику сервиса, обеспечивает работу с файлами конфигурации, механизмы сетевого взаимодействия и обмена данными, передачу информации между подпрограммами и модулями. А также работу с базой данных для хранения информации о запросах и результатах запросов в полном виде, взаимодействия с модуля пользовательских словарей стоп-слов с базой данных. Ядро включает в себя интерфейс программы (API). Интерфейс с помощью http-запросов позволяет проверить работоспособности сервиса, определять и выделять ключевые слова в тексте, распознавать аудио, анализировать аудио, определять семантическую близость, проводить сентиментный анализ текста, проверять работоспособность модуля для работы со словарями стоп-слов, создавать новые словари стоп-слов, удалять словари стоп-слов, обновлять словари стоп-слов, получать словари стоп-слов и т.д.
Фиг. 3 иллюстрирует вариант работы системы в виде блок-схемы начиная от запроса пользователя до получения им обратной связи и включает в себя варианты работы редактора и плеера.
Подсистема обработки семантических смыслов DailoSpeech включает в себя модули: модуль семантического сравнения текстов (Textcomp), модуль сентиментного анализа (SentiText), модуль распознавания речи в текст (SpeechRec), модуль анализа аудио (EmoSpeech), модуль определения и выделения ключевых слов (KeyXtract), модуль словарей стоп-слов (Stop-Words) (Фиг. 2).
Модуль семантического сравнения текстов (Textcomp) - это основная функция сервиса. Используется для анализа текста пользователя, определения семантического сходства текста с заранее заданными вариантами. На вход системе подается предобработанный текст пользователя и заведомо известные ожидаемые предложения. Система получает латентное представление каждого из предложений в виде векторов, оптимизированных для задачи семантической близости. Затем вектор текста пользователя ранжируется с векторами ожидаемых текстов по косинусной дистанции. Выбирается наибольшая метрика дистанции, что соответствует семантически ближайшему предложению, и проверяется по условию достижения определенного порога. Проверяется наличие или отсутствие общих стоп-слов. Если такие имеются, то метрика пользователя получает штраф. После чего происходит агрегирование собранных данных, выбранных групп и наиболее вероятный выбор отправляется в ответ пользователю в формате JSON.
С помощью модуля сентиментного анализа (SentiText) выявляют сентиментное настроение фразы пользователя и сравнивают с целевой фразой. Целевой фразой является наиболее вероятный вариант после обработки модулем семантического сравнения текстов по косинусной близости. Система получает латентное представление целевого и наиболее вероятного текстов в виде векторов. Вектора проходят через предобученную полносвязную нейронную сеть мультиклассификации для получения одного из трех сентиментных окрасов негативный, позитивный и нейтральный. Настроение целевого предложение сравнивается с настроением предложения пользователя. После чего происходит агрегирование данных, результат сравнения и сам полученный класс сентимента текста пользователя отправляются в ответ пользователю в формате JSON.
Модуль распознавания речи в текст (SpeechRec) позволяет распознавать текст в аудио в режиме офлайн и онлайн. Служит для предобработки запроса пользователя для дальнейшего анализа. Имеет в себе офлайн и онлайн распознавание аудио. Метод распознавания аудио заранее задан в запросе. После распознавания происходит постобработка текста. В зависимости от заданного языка в запросе происходит нормализация текста. Например, перевод чисел в из текстовой форму и транскрибация латиницы в кириллицу для заданного русского языка. Результатом работы модуля является нормализованный текст для дальнейшей обработки остальными модулями.
Модуль анализа аудио (EmoSpeech) анализирует аудиофайл для получения характеристик аудио. Предоставляет интерфейс для получения характеристик речи говорящего - интонационный диапазон и скорость речи. Характеристики речи используются для обратной связи пользователю в конце урока. По данным ставятся метки классов для данной записи. После чего происходит агрегирование данных и они отправляются в ответ пользователю в формате JSON.
Модуль определения и выделения ключевых слов в тексте (KeyXtract) предназначен для определения и выделения ключевых слов в предложении. Служит для определения и выделения ключевых слов в предложении. Это дополнительный метод ядра для отдельных запросов на выделение ключевых слов. Такие запросы требуются для двухуровневой или трехуровневой методик обучения. Во фразах пользователя можно выделить ключевые слова, которые будут отображаться на втором и третьем шаге. С помощью статического алгоритма система выбирает ключевые слова в предложении по заданному в запросе проценту ключевых слов и выделяет все такие слова фиксированными тегами, например <h> слово </h>. После чего данное обработанное предложение отправляется в ответ пользователю в формате JSON. Ключевые слова используются как подсказки для пользователя. При оценке ответов оценивается соответствие фразе целиком, ключевые слова помогают пользователю вспомнить фразу. Ключевые слова также используются для изменения сценариев симуляции, если какое-либо из ключевых слов было задано как триггер в редакторе симуляции.
Модуль словарей стоп-слов (Stop-Words) предназначен для работы с пользовательскими словарями стоп-слов. Использует базу данных для хранения словарей и обращения к ним. Использование модуля самим сервисом заключается в проверке текста по заранее заданному словарю стоп-слов. Имеет обособленные функции для сохранения, получения, обновления и удаления словарей из базы данных. Включен в ядро как ряд вышеописанных методов работы с стоп-словами посредством REST API, и как часть основного конвейера обработки основного запроса.
Комплексное решение представляет собой редактор для разработки симуляций, плеер для проигрывания обучения и сервис для определения намерения пользователя на основании смыслового (семантического) сравнения двух текстов (Dailospeech). Совокупность трех компонентов позволяет достичь интерактивности симуляций, так как Dailospeech анализирует и оценивает речь пользователя, а в редакторе есть функция настройки сценариев и речевой обратной связи системы. В результате за счет комбинации сервисов семантического анализа и редактора удается достичь высокой вариативности сценария, который изменяется на основании анализа речи пользователя, дает гибкую обратную связь для пользователя и предлагает различные варианты сценария для прохождения в зависимости от поведения пользователя. Фиг. 4 иллюстрирует пример взаимодействия пользователя системы на этапе воспроизведения симуляции и основные внутренние процессы во время симуляции.
Генерация интерактивного диалога с пользователем достигается с помощью следующих механик:
1. Вариативность ответов пользователя.
Это комбинированная система, а именно для ее реализации используются подсистемы: редактор, плеер и Dailospeech.
Описание на уровне пользовательского опыта: от того, как отвечает пользователь, зависит какую обратную связь дает аватар или система. Описание на уровне редактора сценариев: задается список возможных вариантов ответа пользователя. Описание на уровне плеера воспроизведения сценария: Dailospeech обрабатывает аудио пользователя с помощью подсистем SpeechRec, EmoSpeech, Textcomp, Stop-Words и список возможных вариантов подсистемой Textcomp. Система распознает аудио и сопоставляет результат с возможными вариантами. Если есть значительное соответствие с одним из вариантов, то он засчитывается системой как ответ. Если этот вариант отмечен как верный, то оценка за прохождение повышается на 100% / "общее кол-во вопросов". Если неверный, то остаётся той же. Если никакого соответствия с вариантами не найдено, то пользователю сообщается о том, что он сказал неверную фразу, пользователь пробует еще раз. Это не считается ошибкой только при условии, что тип урока "тест", в остальных случаях засчитывается ошибка в прохождении сценария данным пользователем, что отразится на итоговой оценке.
2. Рандомайзер действий персонажа.
Это комбинированная система, а именно для ее реализации используются подсистемы: редактор и плеер.
Описание на уровне пользовательского опыта: в определенный момент в сценарий добавляется рандомайзер, после чего сценарий может пойти по определенному количеству вариантов развития событий. Если метод обучения 2- или 3-уровневый, то последующие уровни используют ранее выпавшую случайным образом на 1 шаге фразу. При повторном прохождении сценария использованные ранее фразы будут исключены из пула возможных. Таким образом, система перебирает все варианты действий персонажа за N прохождений, где N - кол-во вариантов фраз персонажа, пока все возможные варианты не исчерпаются. Тогда процесс перезапускается и все фразы снова будут доступны при прохождении. Такая система обеспечивает уникальность каждого из прохождений вплоть до N прохождений, где N - кол-во вариантов фраз персонажа. Описание на уровне редактора сценариев: добавляются дополнительные действия персонажа. Для каждого действия устанавливается некоторое количество фраз аватара и для каждой из них своя вероятность выпадения в процентах. Описание на уровне воспроизведения сценария: при наличии вариативности фраз персонажа плеер воспроизведения симуляции с помощью генератора случайных чисел выбирает случайным образом следующую фразу персонажа, исходя из заранее заданной в редакторе сценариев вероятности фраз, метода обучения (1-, 2- или 3-уровневого) и использованных ранее вариантов в случае повторного прохождения.
3. Дополнительные сценарии.
a. Дополнительные сценарии по триггеру.
Это комбинированная система, а именно для ее реализации используются подсистемы: редактор, плеер и Dailospeech.
Описание на уровне пользовательского опыта: в зависимости от того, какую фразу сказал пользователь, сценарий может пойти по одному варианту развития событий или по-другому. Описание на уровне редактора сценариев: добавляются дополнительные сценарии и фразы-триггеры основного сценария, по которым активируется переход на дочерние. Фраз-триггеров может быть несколько. Список таких фраз уникален для каждого из дочерних сценариев. Описание на уровне воспроизведения сценария: с каждым пользовательским вводом система передает Dailospeech список триггерных фраз из урока, которые обрабатываются подсистемой Textcomp. Система проверяет, есть ли соответствие с любой из фраз. При соответствии Dailospeech возвращает порядковый номер триггерной фразы, которая была произнесена и плеер воспроизведения сценариев инициирует переход в дополнительный сценарий, связанный с этой триггерной фразой.
b. Дополнительные сценарии по фразе персонажа
Это комбинированная система, а именно для ее реализации используются подсистемы: редактор и плеер.
Описание на уровне пользовательского опыта: можно назначить дополнительному сценарию активацию по фразе персонажа. Данная функция системы может быть использована с “рандомайзером действий персонажа”. Таким образом можно реализовывать более живые уроки, в которых персонаж может повести себя по-разному и это будет влиять на содержание диалога.
Описание на уровне редактора сценариев: добавляются дополнительные сценарии и фразы персонажа основного сценария, по которым активируется переход на дочерние. Фраз персонажа и дополнительных сценариев может быть неограниченное количество. Список таких фраз персонажа уникален для каждого из дочерних сценариев. Подробный пример с описанием процесса и тонкостей добавления и связывания сценариев находится в разделе “Создание диалога”.
Описание на уровне воспроизведения сценария: при наличии вариативности фраз персонажа и, назначенных этим фразам дополнительных сценариев, плеер воспроизведения симуляции с помощью генератора случайных чисел выбирает случайным образом следующую фразу персонажа, исходя из заранее заданной в редакторе сценариев вероятности фраз, метода обучения (1-, 2- или 3-уровневого) и использованных ранее вариантов в случае повторного прохождения. Осуществляется переход в связанный с фразой персонажа дополнительный сценарий.
При комбинировании вышеописанных опций получается более 100 вариантов прохождения урока.
Для создания качественного диалога разработаны функции персонажа, системы и ответы пользователя
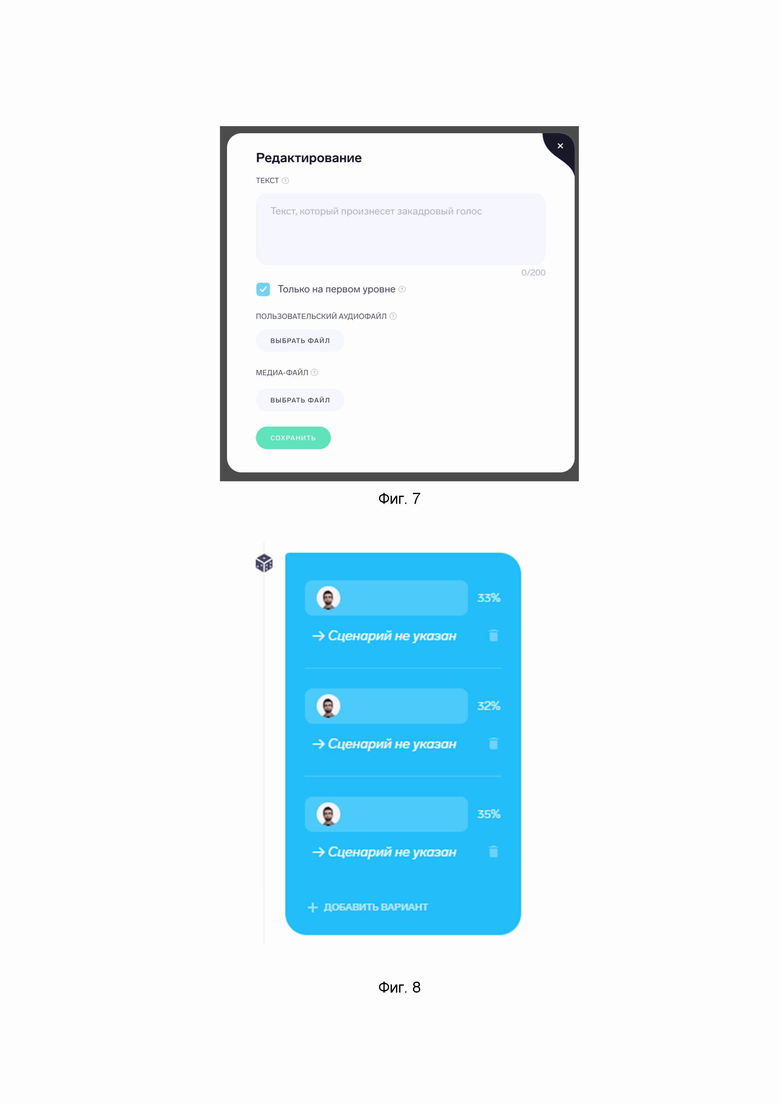
В настройках персонажа можно ввести фразу, которую будет произносить персонаж, выбранный пользователем в настройках урока. В данных настройках можно ввести текст для персонажа (Фиг. 5), выбрать эмоцию персонажа и его жест. По умолчанию система автоматически генерирует речь, однако пользователь может добавить собственный аудиофайл с записанной речью.
Для пользователя можно настроить фразу-действие, которую пользователь должен произнести голосом для дальнейшего обучения/тестирования. Во время обучения пользователь должен произнести фразу. По умолчанию «ожидаемый ответ» — фраза, которая одновременно отображается на экране у пользователя, и которую он должен произнести. Однако есть возможность разделить эти два действия, нажав на надпись «изменить отображаемый текст». Например, добавить в «отображаемый текст» — «Поприветствуйте клиента», а в «ожидаемый ответ» – «Добрый день! Чем я могу вам помочь?» (Фиг. 6).
Также можно выбрать поле «свободная речь», чтобы дать пользователю возможность говорить в свободной форме в течение заданного пользователем времени. На этой фразе распознавание речи не выполняется и соответственно, оценка урока от них не зависит. Рекомендуется не забывать задавать смысловую нагрузку в блоке «тема свободной речи». Например, когда вы хотите, чтобы пользователь ответил на какой-либо открытый вопрос.
Для системы можно настроить системную фразу, которая будет озвучена закадровым голосом. Это может быть вводная информация, теоретическая часть обучения или подсказка для пользователя. Например, «будьте доброжелательны и поддерживайте зрительный контакт с клиентом». По умолчанию, система автоматически генерирует речь, однако пользователь может добавить собственный аудиофайл с записанной речью (Фиг. 7). Также можно добавить изображение или видео.
Выбор из фраз пользователя можно настроить с помощью поля для заполнения нескольких вариантов ответа, из которых пользователь должен будет выбрать верный. При нажатии на «добавить вариант» появляется необходимое количество вариантов ответа. При нажатии на «изменить вариант ответа» перед пользователем появится поле редактирования, в котором можно выбрать, является ли этот вариант верным, неверным или прерывающим урок, а также ввести текст варианта ответа. При выборе неверного варианта ответа пользователь снова будет возвращаться к выбору, пока не выберет верный (верно для всех типов, кроме оцениваемого шага в типе «Тест с вариантами ответов (2 шага)».
Также можно добавить реакции (обратная связь, подсказка, или пояснение) для персонажа или системы к каждому варианту ответа. Это улучшит взаимодействие с пользователем. Например, «Неверно, попробуйте еще раз».
Настройка случайного действия персонажа позволяет добавить уроку вариативности. При попадании на данное действие для пользователя случайным образом проигрывается одна из фраз персонажа из списка. Пользователь может нажать на кнопку «добавить вариант» столько раз, сколько вариантов действия для персонажа планируется создать. Каждую фразу можно настроить точно так же, как если бы это было обычное линейное действие персонажа нажав на кнопку с иконкой персонажа.
Каждая из фраз может запустить переход на один из дополнительных сценариев урока. Так же редактор имеет возможность установить вероятность выпадения той или иной фразы в процентах. Сумма шансов всех фраз в действии не может превышать 100% и будет автоматически пересчитана при нарушении данного правила (Фиг. 8). Чтобы настроить переход на сценарий и шанс выпадения - необходимо нажать на кнопку со стрелкой под фразой персонажа.
Дополнительный сценарий редактируется так же, как и основной: добавляйте фразы персонажа, пользователя, системы. В правой панели управления вы можете изменить имя дополнительного сценария и добавить фразы-триггеры. Фразы-триггеры — слова, фразы или предложения, при произнесении которых запускается нужный сценарий. Чтобы добавить новые фразы-триггеры, впишите их в поле и нажмите кнопку сохранения.
Правила, по которым работают фразы-триггеры:
1. Пользователь произносит фразу-триггер целиком. Если пользователь произнесет часть фразы-триггера, система не засчитает ее, как фразу-триггер, и не перенесет пользователя в дополнительный сценарий.
2. Когда пользователь произносит фразу-триггер, система прерывает сценарий, который проходил пользователь и переносит пользователя в дополнительный сценарий.
3. После того, как пользователь пройдет дополнительный сценарий до конца, система вернет пользователя обратно к тому месту, на котором пользователь прервал основное прохождение.
Пользователь может создавать неограниченное количество дополнительных сценариев.
Система проверяет наличие фраз-триггеров в сценариях по порядку слева направо. Например, если пользователь добавил фразу-триггер «Расскажите подробнее» в дополнительный сценарий № 1, а потом в дополнительный сценарий № 2, то при произнесении фразы-триггера система будет отправлять пользователя в дополнительный сценарий № 1, так как он идет первым по счету.
Итоговая оценка урока
Оценкой урока является число, показывающее процент верных ответов пользователя по всему пройденному уроку. Принимает значения от 0% до 100%. Число подсчитывается и рассчитывается с помощью плеера воспроизведения симуляций для каждой отдельной сессии.
Если урок создан с методикой обучения квиз или интервью, то оценка составляет всегда 100%, т.е. эти методики не оцениваются. Если урок создан с методикой обучения 1- или 2-уровневый тест, то итоговая оценка считается как отношение количества верных ответов к общему количеству вопросов в процентах. Если урок создан с методикой обучения в 2 или 3 уровня, то в зачет идет первый ответ на каждом шаге. Ответ считается верным, если он совпадает на финальном уровне с ожидаемым текстом. Ответ считается ошибочным в следующих случаях: при использовании подсказки, если шаг пропущен пользователем, фраза на шаге симуляции произнесена верно не с первой попытки. Итоговая формула такая же: отношение количества верных ответов к общему количеству вопросов в процентах.
Специалисту в данной области техники должно быть очевидно, что все операции для обработки данных по настоящему изобретению могут быть реализованы с использованием по меньшей мере одного вычислительного устройства. Вычислительное устройство содержит по крайней мере один процессор, память и инструкции, хранимые в памяти и исполняемые процессором, с помощью которых осуществляют обработку данных для интерактивной речевой симуляции. Обработка данных может быть централизованной, например, с помощью одного вычислительного устройства, или распределенной, например, с помощью нескольких вычислительных устройств, распределенных по сети.
В общем случае вычислительное устройство, обеспечивающее обработку данных, необходимую для реализации заявленного решения, содержит такие компоненты, как: один или более процессоров, по меньшей мере одну память, средство хранения данных, интерфейсы ввода/вывода, средство В/В, средства сетевого взаимодействия.
Процессор устройства выполняет основные вычислительные операции, необходимые для функционирования устройства или функциональности одного или более его компонентов. Процессор исполняет необходимые машиночитаемые команды, содержащиеся в оперативной памяти. Память, как правило, выполнена в виде ОЗУ и содержит необходимую программную логику, обеспечивающую требуемый функционал. Средство хранения данных может выполняться в виде HDD, SSD дисков, рейд массива, сетевого хранилища, флеш-памяти, оптических накопителей информации (CD, DVD, MD, Blue-ray дисков) и т.п. Средство позволяет выполнять долгосрочное хранение различного вида информации. Интерфейсы представляют собой стандартные средства для подключения и работы с серверной частью, например, USB, RS232, RJ45, LPT, COM, HDMI, PS/2, Lightning, FireWire и т.п. Выбор интерфейсов зависит от конкретного исполнения устройства, которое может представлять собой персональный компьютер, мейнфрейм, серверный кластер, тонкий клиент, смартфон, ноутбук и т.п. В качестве средств В/В данных используется клавиатура. Помимо клавиатуры, в составе средств В/В данных также может использоваться: джойстик, дисплей (сенсорный дисплей), проектор, тачпад, манипулятор мышь, трекбол, световое перо, динамики, микрофон и т.п. Средства сетевого взаимодействия выбираются из устройств, обеспечивающих сетевой прием и передачу данных, например, Ethernet-карту, WLAN/Wi-Fi-модуль, Bluetooth-модуль, BLE-модуль, NFC-модуль, IrDa, RFID-модуль, GSM-модем и т.п. С помощью средств обеспечивается организация обмена данными по проводному или беспроводному каналу передачи данных, например, WAN, PAN, ЛВС (LAN), Интранет, Интернет, WLAN, WMAN или GSM, 3G, 4G, 5G, 6G и т.д. Компоненты вычислительного устройства сопряжены посредством общей шины передачи данных.
В настоящих материалах заявки представлено предпочтительное раскрытие осуществления заявленного технического решения, которое не должно использоваться как ограничивающее иные, частные воплощения его реализации, которые не выходят за рамки испрашиваемого объема правовой охраны и являются очевидными для специалистов в соответствующей области техники.
Специалисту в данной области техники должно быть понятно, что различные вариации заявляемого способа и системы не изменяют сущность изобретения, а лишь определяют его конкретные воплощения и применения.

Изобретение относится к области вычислительной техники для интерактивных речевых симуляций. Технический результат заключается в повышении скорости и точности оценки ответов пользователя во время речевой симуляции. Технический результат достигается за счет того, что система содержит: редактор для создания симуляций, с помощью которого создают симуляции, представляющие собой диалог между персонажем и пользователем, создают словарь стоп-слов, задают список возможных вариантов ответа пользователя, задают настройки симуляции, добавляют основные сценарии, добавляют дополнительные сценарии, добавляют триггерные фразы основного сценария, по которым активируется переход на дополнительный сценарий; плеер воспроизведения симуляций, с помощью которого автоматически воспроизводят заданный в редакторе диалог между персонажем и пользователем в соответствии с заданными настройками симуляции; блок сбора пользовательских данных, с помощью которого автоматически осуществляют сбор пользовательских данных в процессе симуляции; блок автоматической непрерывной обработки пользовательских данных, собираемых в процессе симуляции, содержащий модуль распознавания речи пользователя в текст, связанный со следующими модулями: семантического сравнения текстов, сентиментного анализа текста, словарей стоп-слов. 9 з.п. ф-лы, 8 ил.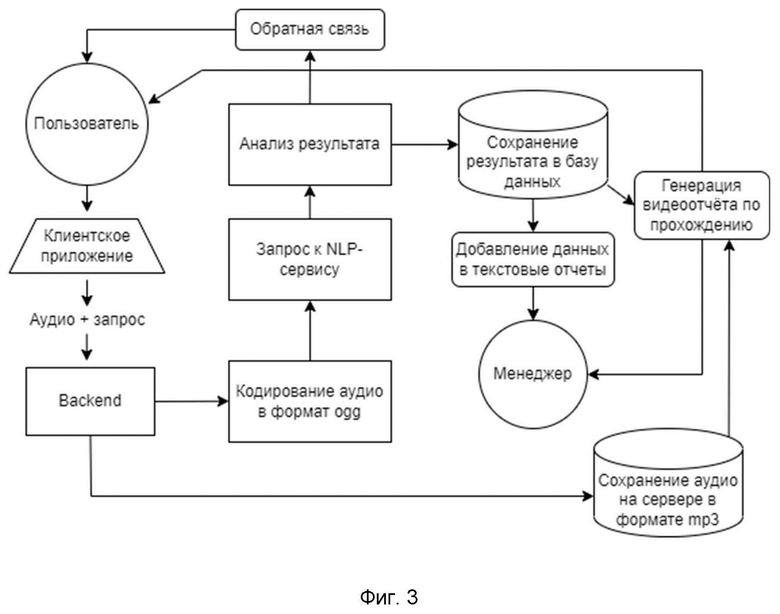
1. Система интерактивных речевых симуляций, содержащая:
редактор для создания по меньшей мере одной симуляции, причем с помощью указанного редактора создают по меньшей мере одну симуляцию, представляющую собой диалог между персонажем и пользователем, создают словарь стоп-слов, задают список возможных вариантов ответа пользователя, задают настройки по меньшей мере одной симуляции, добавляют основные сценарии, добавляют дополнительные сценарии, добавляют триггерные фразы основного сценария, по которым активируется переход на дополнительный сценарий;
плеер воспроизведения по меньшей мере одной симуляции, причем с помощью указанного плеера автоматически воспроизводят заданный в редакторе диалог между персонажем и пользователем в соответствии с заданными настройками симуляции, при этом автоматически выбирают сценарии диалога в процессе симуляции на основании настроек симуляции;
блок сбора пользовательских данных, причем с помощью указанного блока сбора пользовательских данных автоматически осуществляют сбор пользовательских данных в процессе симуляции, при этом пользовательские данные включают ответы пользователя, полученные во время симуляции, причем ответы пользователя включают аудиоданные, содержащие речь пользователя, и текстовые данные, содержащие текст, введенный пользователем;
блок автоматической непрерывной обработки пользовательских данных, собираемых в процессе симуляции, содержащий модуль распознавания речи пользователя в текст, связанный со следующими модулями: модулем семантического сравнения текстов, модулем сентиментного анализа текста, модулем словарей стоп-слов, причем с помощью модуля распознавания речи пользователя в текст осуществляют предобработку ответов пользователя в процессе симуляции для последующего анализа предобработанных ответов пользователя с помощью модулей семантического сравнения текстов, сентиментного анализа текста, словарей стоп-слов с целью непрерывной оценки ответов в процессе симуляции для автоматического изменения основного сценария в зависимости от ответа пользователя, для определения триггерных фраз в ответах пользователя для автоматической активации перехода на дополнительные сценарии и для определения итоговой оценки ответов пользователя.
2. Система по п. 1, характеризующаяся тем, что настройками одной или более симуляций являются по меньшей мере следующие: выбор персонажа, добавление рандомайзера действий персонажа, выбор метода обучения, выбор языка урока, выбор строгости распознавания речи, настройка словарей стоп-слов, настройка ключевых слов, включение/выключение записи видео, отображение отчета, содержащего оценку ответов пользователя, запрос авторизации пользователя, настройка стартового и финального сообщения урока, настройка фоновой картинки, настройка демонстрации мультимедиа.
3. Система по п. 2, характеризующаяся тем, что методом обучения являются по меньшей мере обучение с помощью трех уровней, обучение с помощью двух уровней, обучение с помощью одного уровня, выбор вариантов ответов, интервью, квиз.
4. Система по п. 2, характеризующаяся тем, что дополнительные сценарии дополнительно используются с рандомайзером действий персонажа и активируются по фразе персонажа.
5. Система по п. 2, характеризующаяся тем, что дополнительно содержит модуль определения и выделения ключевых слов в тексте, при этом с помощью указанного модуля определяют ключевые слова в тексте с помощью редактора симуляции и в процессе симуляции выделяют ключевые слова в тексте, изменяют сценарии симуляции, если какое-либо из ключевых слов было задано как триггер, и показывают выделенные ключевые слова пользователю в качестве подсказки.
6. Система по п. 1, характеризующаяся тем, что с помощью модуля семантического сравнения текстов определяют семантическое сходство ответов пользователя с заранее заданными возможными вариантами ответов, с целью непрерывной оценки ответов для возможности изменения сценария в зависимости от ответа пользователя и определения итоговой оценки.
7. Система по п. 1, характеризующаяся тем, что с помощью модуля сентиментного анализа текста выявляют сентиментное настроение ответа пользователя и сравнение с наиболее вероятным заданным вариантом ответа, с целью непрерывной оценки ответов для возможности изменения сценария в зависимости от ответа пользователя и определения итоговой оценки.
8. Система по п. 1, характеризующаяся тем, что с помощью модуля словарей стоп-слов проверяют наличие стоп-слов в ответах пользователя в соответствии с заданным словарем стоп-слов, с целью непрерывной оценки ответов для возможности изменения сценария в зависимости от ответа пользователя и определения итоговой оценки.
9. Система по п. 1, характеризующаяся тем, что активация перехода на дополнительные сценарии в процессе симуляции на основе триггерных фраз осуществляется в том случае, если пользователь произносит триггерную фразу целиком, система прерывает основной сценарий, который проходил пользователь и переносит пользователя в дополнительный сценарий, после того, как пользователь пройдет дополнительный сценарий до конца, система возвращает пользователя обратно к тому месту, на котором пользователь прервал основное прохождение.
10. Система по п. 1, характеризующаяся тем, что блок автоматической непрерывной обработки пользовательских данных, собираемых в процессе симуляции, дополнительно содержит модуль анализа аудиоданных, содержащих речь пользователя, при этом с помощью указанного модуля получают характеристики речи пользователя для предоставления пользователю в конце симуляции, характеристиками речи пользователя являются по меньшей мере скорость речи, диапазон интонации.
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ИЗУЧЕНИЯ ИНОСТРАННЫХ ЯЗЫКОВ | 2019 |
|
RU2718469C1 |

