ОБЛАСТЬ ТЕХНИКИ
[0001] Настоящее изобретение относится к области компьютерной техники, в частности к решениям для реализации диалоговых систем для автоматизированной оценки намерений и эмоций пользователя.
УРОВЕНЬ ТЕХНИКИ
[0002] Определение намерений и эмоций пользователя - информацию способная существенно повысить качество обработки сообщений в диалоговых системах. Подобные механизмы анализа сейчас присутствуют во многих популярных чат-ботах, например, Gunrock (Chen С.Y. et al. Gunrock: Building A Human-Like Social Bot By Leveraging Large Scale Real User Data. - 2018. https://pdfs.semanticscholar.org/b402/b85ad45e3ac51flda8ee718373082ce24f47.pdf)
[0003] Архитектура диалоговой системы включает в себя субмодули, отвечающие за классификацию и извлечение заданных команд от пользователя (intent), эмоций (sentiment), выделения тематик разговора пользователя (topic modelling). Система показывает высокие метрики качества, однако оперирует только заданными наборами эмоций, команд, тематик, тогда как поведение пользователей не детерминировано и потенциально может покрывать неограниченное количество тематик.
[0004] Другим примером такого рода систем является решение Xiaoice (Zhou L. et al. The design and implementation of Xiaoice, an empathetic social chatbot //arXiv preprint arXiv: 1812.08989. - 2018. https://arxiv.org/abs/1812.08989). Данная диалоговая система также оперирует субмодулями, отвечающие за классификацию команд от пользователя (intent), эмоций (sentiment), выделения тематик разговора пользователя (topic modelling), выделения заданного набора намерений/диалоговых актов (dialog acts). Она также обладает специальной системой хранения мнений пользователя и связанных с ним объектов.
[0005] Система показывает высокие метрики качества и регулярно обновляет архитектуру за счет большого количества обратной связи от пользователей. Однако также оперирует только заданными наборами эмоций, команд, тематик, тогда как поведение пользователей не детерминировано и потенциально может покрывать неограниченное количество тематик.
[0006] При этом существуют нейросетевые модели с открытым набором возможных выводов (в том числе потенциально - намерений, эмоций), в частности, модель Event2Mind (Rashkin Н. et al. Event2mind: Commonsense inference on events, intents, and reactions //arXiv preprint arXiv: 1805.06939. - 2018. https://arxiv.org/abs/1805.06939). Данная система решает задачу логического вывода и генерирует возможные эмоциональные состояния человека (открытый список) соотносимые с событиями, описанными в тексте на естественном языке.
[0007] На вход системе дается текст с описанием какого-то события (например, Персона X пьет утром кофе), - система генерирует намерения, либо причину события (Персона X хочет взбодриться/проснуться или Персона X засыпает) и психоэмоциональное состояние и реакции субъектов события (Персона X чувствует себя усталым). Потенциально обученная система способна соотносить высказанные эмоции и состояния с субъектом и объектом (если они присутствуют в сообщении). Авторы данного решения собрали датасет для английского языка, в котором содержится около 25.000 событий и соответствующим им реакций и намерений участников событий. Система способна генерировать релевантный ответ и показывает высокие метрики качества на тестовой выборке. Однако для русского языка подобного набора данных не существует, также, морфология русского языка богаче, что потенциально может вызвать проблемы для генерации.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0008] Для решения существующей технической проблемы предлагается заявленная архитектура системы и способа ее функционирования, которая способна в реальном времени проанализировать сообщение от пользователя на предмет не только фактического смысла высказывания, но и эмоций, субэмоций, причин событий в высказывании, открытого списка намерений, и на основании данной информации отвечать поддерживать разговор с пользователем более валидно и эмпатично.
[0009] Техническим результатом является обеспечение в реальном времени автоматизированного анализа сообщений пользователя для выбора наиболее релевантной реакции для автоматического ответа со стороны диалоговой системы.
[0010] Заявленный результат достигается с помощью системы автоматизированной оценки намерений и эмоций пользователей диалоговой системы, которая содержит:
по меньшей мере один процессор;
по меньшей мере одно средство памяти;
модуль препроцессинга текста, выполненный с возможностью обработки входных данных, при которой осуществляется очистка, нормализация и токенизация текстовых данных;
модуль векторизации, обеспечивающий формирование вектора предложений на основании токенов, передаваемых от модуля препроцессинга текста;
модуль анализа тональности, выполненный с возможностью определения типа предложения на основании получаемого вектора с помощью модели машинного обучения, при этом тип предложения представляет собой: негативный, позитивный, нейтральный или разговорный;
модуль извлечения диалоговых актов, выполненный с возможностью определения общего намерения в поступающих предложениях с помощью обработки упомянутого вектора предложения моделью машинного обучения;
модуль обработки событий, выполненный с возможностью
обработки токенов предложений на предмет выявления по меньшей мере одного из: субъект, объект, действие, или их сочетания, в каждом предложении;
определение конкретного намерения и/или причины, а также эмоций объекта и субъекта на основании обработки упомянутых токенов предложения.
[0011] В одном из частных примеров реализации системы при токенизации входные данные разбиваются на слова, числа и/или знаки препинания.
[0012] В другом частном примере реализации системы разбиение предложений осуществляется по пробелам и знакам препинания, с учетом сокращений и инициалов.
[0013] В другом частном примере реализации системы при очистке данных удаляются токены, не являющиеся буквами алфавита, знаками препинания и/или цифрами.
[0014] В другом частном примере реализации системы модуль препроцессинга текста в ходе нормализации выполняет исправление опечаток в токенах.
[0015] В другом частном примере реализации системы модуль препроцессинга текста в ходе нормализации выполняет лемматизацию токенов.
[0016] В другом частном примере реализации системы модуль препроцессинга текста в ходе нормализации осуществляет построение синтаксического графа для каждого предложения для определения бинарных отношений управления, согласования и примыкания между словами предложений.
[0017] Заявленный технический результат достигается также с помощью способа автоматизированной оценки намерений и эмоций пользователей диалоговой системы, который выполняется с помощью процессора и содержит этапы, на которых:
выполняют обработку входных текстовых данных, при которой осуществляется
очистка, нормализация и токенизация данных;
формируют по меньшей мере один вектор предложения на основании получаемых токенов данных;
осуществляют анализ тональности, при котором определяют тип предложения на основании упомянутых векторов предложений с помощью их обработки моделью машинного обучения, при этом тип предложения представляет собой: негативный, позитивный, нейтральный или разговорный;
выполняют извлечение диалоговых актов, при котором определяют общее намерение в поступающих предложениях с помощью обработки упомянутого вектора предложения моделью машинного обучения;
выполняют обработку упомянутых токенов предложений на предмет выявления по меньшей мере одного из: субъект, объект, действие, или их сочетания, в каждом предложении; и
определяют конкретное намерение и/или причину, а также эмоции объекта и субъекта на основании обработки упомянутых токенов предложения.
[0018] В одном из частных примеров реализации способа при токенизации входные данные разбиваются на слова, числа и/или знаки препинания.
[0019] В другом частном примере реализации способа разбиение предложений осуществляется по пробелам и знакам препинания, с учетом сокращений и инициалов.
[0020] В другом частном примере реализации способа при очистке данных удаляются токены, не являющиеся буквами алфавита, знаками препинания и/или цифрами.
[0021] В другом частном примере реализации способа в ходе нормализации текста выполняется исправление опечаток в токенах.
[0022] В другом частном примере реализации способа в ходе нормализации текста выполняется морфологический анализ и лемматизация токенов.
[0023] В другом частном примере реализации способа в ходе нормализации текста осуществляется построение синтаксического графа для каждого предложения для определения бинарных отношений управления, согласования и примыкания между словами предложений.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
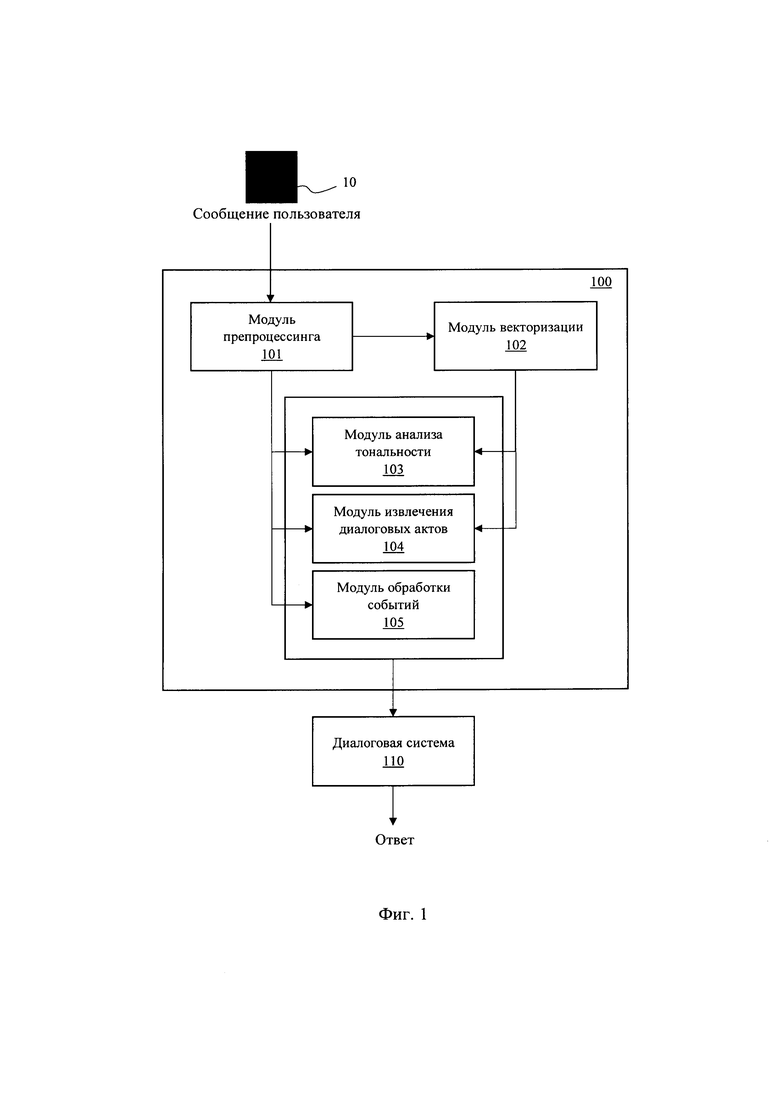
[0024] Фиг. 1 иллюстрирует общий вид заявленной системы.
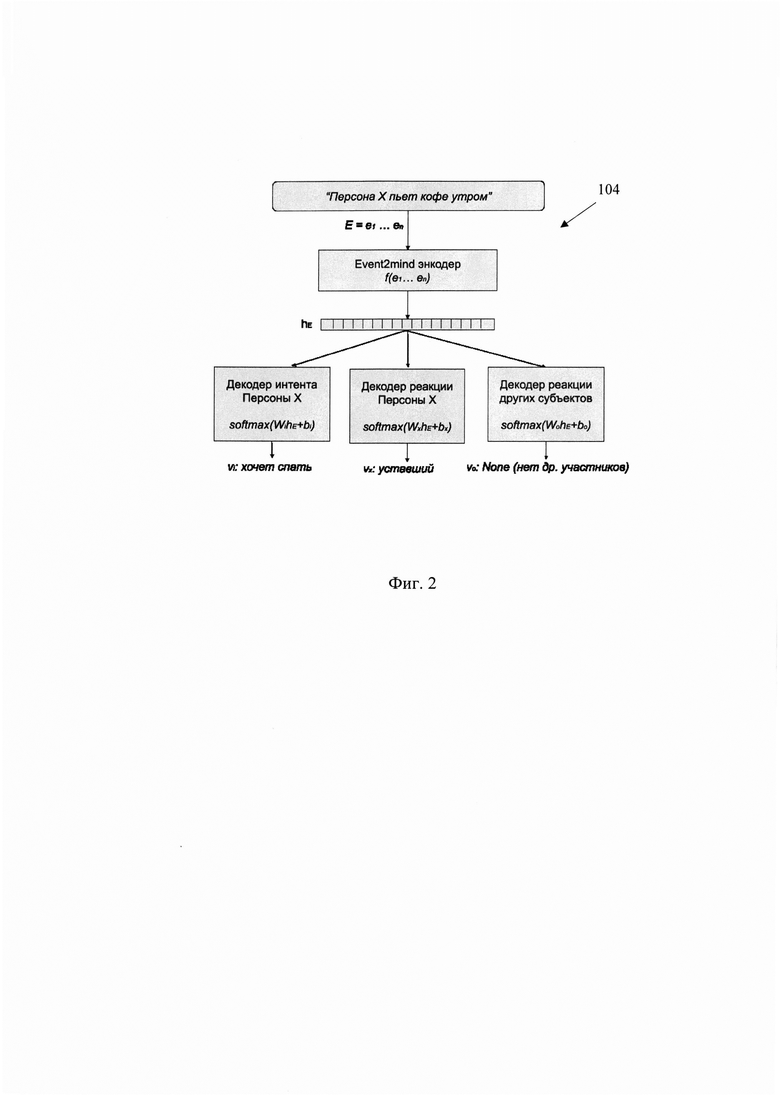
[0025] Фиг. 2 иллюстрирует архитектуру модуля обработки событий.
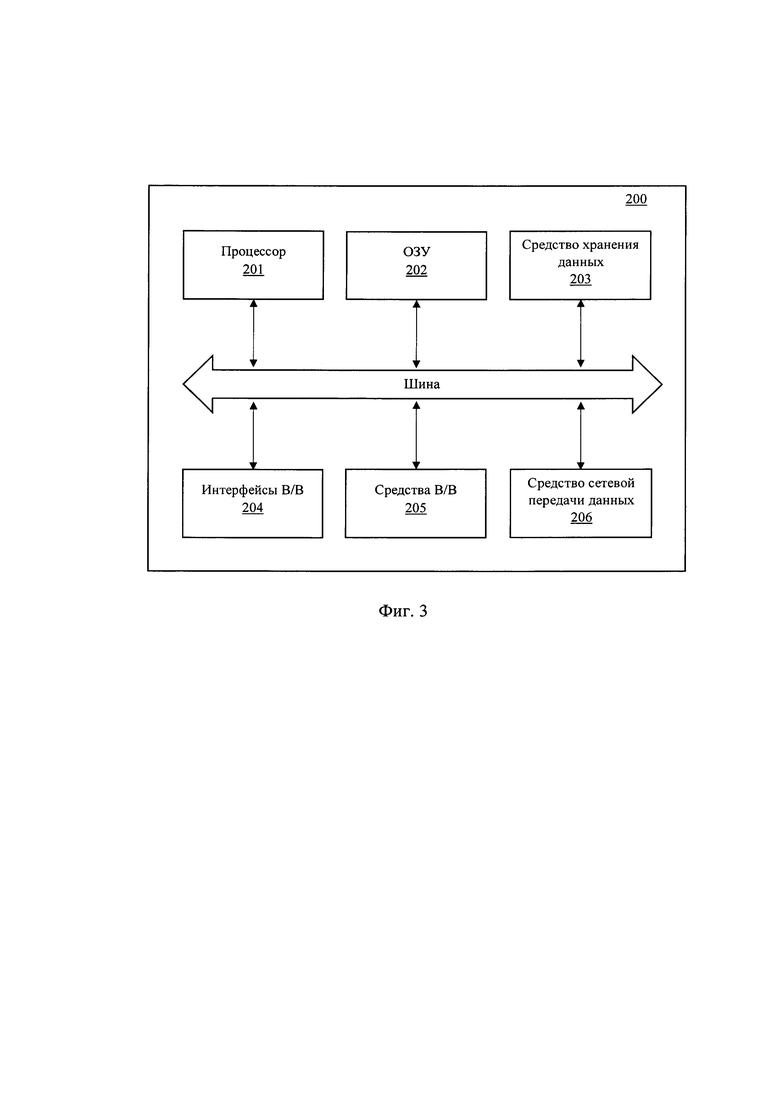
[0026] Фиг. 3 иллюстрирует общий вид вычислительного устройства.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
[0027] На Фиг. 1 представлена архитектура заявленной системы (100) автоматизированной оценки намерений и эмоций пользователей диалоговой системы, которая может быть реализована на базе вычислительного устройства, например, персонального компьютера, сервера и т.п. Система (100) содержит совокупность модулей обеспечивающий обработки поступающих реплик от пользователя (10), который выполняет взаимодействие с диалоговой системой (110).
[0028] Модуль препроцессинга текста (101) является модулем выполняющим первичную обработку обращений пользователя, в частности, выполняет обязательные последовательные процедуры очистки и подготовки входящего текста из диалоговой системы при ведении беседы с пользователем. Модуль препроцессинга (101) осуществляет деление входящего текста на предложения и их токенизацию. Под токенизацией понимается разбиение текста на минимально функциональные единицы, токены, которыми являются слова, числа и знаки пунктуации.
[0029] Входные данные подаются на вход модуля (101) в формате txt. Пользователь (10) может взаимодействовать с диалоговой системой (110) с помощью голосовых команд, например, если голосовая система (110) представляет собой голосового. В этом случае голосовые команды пользователя (10) преобразовываются в текстовый формат с помощью известных решений в уровне техники, например, Google Speech-to-Text. С помощью открытых библиотек на языке python3, производится деление полученного текста на предложения(при помощи https://pypi.org/project/rusenttokenize/) и деление предложений на токены с помощью разбивки предложений по пробелам и отделения от них знаков препинания.
[0030] После первичной обработки текста модулем (101) формируется предложений, в котором списки токенов предложения.
Пример:
"Все люди смертны. Сократ - человек. Следовательно, Сократ смертен." □ [["все", "люди", "смертны", "."], ["Сократ", "-", "человек", "."], ["Следовательно", ",", "Сократ", "смертен", "."]].
В данной системе токен считается не типом данных string, а объектом класса Token, у которого определены следующие атрибуты:
asis - здесь хранится текст токена «как есть»
morph - результат морфологического анализа токена (нормальная форма слова, часть речи, падеж и т.д.)
spellcheck - результат спеллчекинга (от англ. Spellcheck - проверка правописания) токена.
Если модуль спеллчекинга не выявил ошибку, этот атрибут будет пустым, если же выявил - будет содержать самое вероятное исправление.
Start_index, end_index - порядковый номер в тексте первого и последнего символа в токене Coref - поле для кореференции (связи токена с другими в пределах текста, если токен является местоимением). По умолчанию поле пустое.
Псевдокод:

[0031] Далее с помощью модуля (101) осуществляется очистка текста от спецсимволов. В ходе упомянутой процедуры выполняется фильтрация входящих токенов от спецсимволов, не входящих в список кириллических и латинских букв, чисел и символов со стандартной 105-клавишной клавиатуры.
[0032] После очистки текста от спецсимволов модуль (101) выполняет исправление опечаток. На данном этапе происходит проверка входящих токенов на опечатки и их исправление. Используются открытые технологии - модель на основе расстояния Damerau Levenshtein 1 (Модель из репозитория DeepPavlov Damerau Levenshtein 1 + lm). При осуществлении процедуры исправления опечаток выполняется обработка списка объектов класса Token, для которых по итогу проверки заполняется атрибут spellcheck у тех токенов, где возможна опечатка.
[0033] После этого модулем (101) осуществляется определение частей речи (морфологический анализ), при которой выполняется нормализация токенов. При нормализации происходит приведение токенов к форме именительного падежа единственного числа у существительных, инфинитива у глаголов и т.д., а также фиксация морфологических характеристик формы токена (падеж, число, лицо, род и т.д.). Анализ осуществляется при помощи открытой технологий - библиотеки RnnMorph на рекуррентных нейросетях https://pypi.org/project/rnnmorph/. Данная нейросетевая архитектура обеспечивает наилучшее качество анализа для русского языка. По результатам анализа для каждого токена сохраняется следующая информация:
• Часть речи (POS, part of speech);
• Морфологические характеристики (fulltag);
• Нормальная форма лемматизации (lemma).
Пример анализа:
Asis
"токены"
Morph:
[{ "grammar": {'POS'i'NOUN', 'fulltag':'Case=Nom|Gender=Masc|Number=Plur', 'wordform': 'токены', 'lemma':'токен'}].
[0034] Далее с помощью модуля (101) осуществляется синтаксический анализ. В ходе данного этапа выполняется более высокоуровневый анализ входящего текста - осуществляет построение синтаксического графа на каждом предложении, определяя бинарные отношения управления, согласования и примыкания между словами. Для синтаксического анализа используется открытая библиотека Udpipe https://pypi.org/project/ufal.udpipe/. В ходе анализа формируются списки вершин и ребер синтаксического графа для предложения, собираемого из передаваемого на вход списка токенов. По итогам обработки формируется построчная матрица ребер синтаксического графа на исходном списке токенов, String. Информация о синтаксическом разборе может использоваться дополнительно и сохраняется в привязки к списку токенов предложения.
[0035] Модуль векторизации (102) получает на вход текст, обработанный модулем (101), и выполняет его преобразование в вектор при помощи модели ELMo. Модель ELMO обеспечивает формирование вектора для предложений русского языка. Полученный вектор, содержащий контекстную информацию о порядке слов в тексте и их важности, передается затем на вход модулей (103) и (104).
[0036] Модель векторизации текста ELMo (https://allennlp.org/elmo) для русского языка предобучена на огромных корпусах данных и представляет собой архитектуру, хранящую многоуровневую информацию о языке - символьную, лексическую и семантическую (информацию о контексте). За счет этого возможно делать высокоуровневые обобщения о свойствах входящих фраз даже при отсутствии большого количества примеров при обучении классификатора.
[0037] Модуль анализа тональности (103) выполняется на основе нейросетевой модели классификатора, обученную определять эмоции сообщения. Определение выполняется по заданному списку классов, распознаваемых моделью модуля (103). Применения модуля (102) позволяет более эмпатично отвечать на сообщения пользователя в ходе его взаимодействия с диалоговой системой, накапливать его мнения о различных вопросах, менять тональность сообщения в ответ, воздействовать на негатив, стараясь перевести на более позитивные аспекты и т.д. В одном из примеров реализации системы (100) может применяться модель анализа тональности из открытого репозитория DeepPavlov (https://github.eom/deepmipt/DeepPavlov/blob/0.2.0/deeppavlov/configs/classifiers/rusentiment_elmo.json).
[0038] Сверточная нейросеть модуля (103) обучена приписывать вектору предложения определенный класс, выбираемый из группы: 'positive', 'negative', 'neutral', 'speech', 'skip'.
• Positive, neutral, negative - для выраженно позитивных, нейтральных и негативных эмоций
• Speech - для нейтральных разговорных фраз ("Привет, пока, спасибо")
• Skip - для случаев, неявных для модели (для которых невозможно осуществить классификацию).
[0039] Модель на основе нейронной сети в модуле (103) обучена на данных из открытого источника RuSentiment (содержит тексты социальных медиа на русском языке). Так как модель работает с векторами целых предложений и коротких текстов, то обобщающая способность модели позволяет ей воспринимать текст целиком, а не привязываться к конкретным словам, так как их значение в контексте может сильно изменяться: теплый (позитивный сентимент) + пиво (нейтральный сентимент) = теплое пиво (негативный сентимент).
[0040] Модуль извлечения диалоговых актов (104) представляет собой также нейросетевую архитектуру классификатора, который может определить на сообщении от 1 до 13 различных диалоговых актов, то есть классов, определяющих намерения в сообщении пользователя - информативный вопрос, вопрос о мнении, личное мнение, причина, следствие, аргумент, согласие, несогласие, извинение, ответ на извинение, благодарность, ответ на благодарность, приветствие, прощание и т.д. Модуль (104) принимает на вход предложение векторизованное с помощью модуля (102). Далее векторизованное предложение обрабатывается классификатором для распознавания общего намерения пользователя в поступающих предложениях.
[0041] Модель классификатора модуля (104) работает на основе сверточной нейронной сети, обученной приписывать вектору предложения от 1 до 13 меток класса (они не являются взаимоисключающими, multiclass labelling).
[0042] Модель обучена на примерах пользовательских диалогов, накопленных во время тестирования диалоговых систем и открытых данных диалогов из OpenSubtitles, размеченных правилами и обученными разметчиками. По итогам обработки вектора предложений модулем (104) формируется список меток предложения.
[0043] Модуль извлечения диалоговых актов (104) позволяет точнее обрабатывать информацию о прагматике высказывания (с точностью 92%) и корректном ответе на сообщение пользователя. Например, высказывание «сколько этот телефон стоит?» требует точного ответа, высказывание «да сколько же такой телефон может стоить?» требует оценочного суждения в ответ (в том числе о характеристиках телефона, а не о цене), а высказывание «да что же это такое, что телефоны столько стоят!» требует реакции на негатив. На приведенных примерах модель классификатора модуля (104) дает различные классы - информативный вопрос, вопрос о мнении, личное мнение.
[0044] Модуль обработки событий (105), построенный на архитектуре модели event2mind, выделяет событие из текста и генерирует релевантное описание причин события и психоэмоциональное состояние участников события в моменте. На Фиг. 2 представлен пример архитектуры упомянутого модуля.
[0045] Модуль (105) по факту обработки токенов предложений пользователя (10) способен определить конкретное намерение и/или причину, а также эмоции объекта и субъекта предложения. События выделяются с помощью синтаксического парсера (UDPipe модель для русского, обученная на синтагрусе http://ufal.mff.cuni.cz/udpipe), по шаблонам вида "субъект" (subj) + "действие" (глагол - verb) + "объект" (obj). Такого типа события («Я хочу кофе» → «X (subj) усталый») вычленяются из текста пользователя и подаются в нейросеть модуля (105). Получая на вход текст события, модель нацелена на генерацию трех прагматических выводов: намерение/причины события, реакция Персоны X и реакции других участников события (Персоны Y).
[0046] Работа нейросети модуля (105) выглядит следующим образом: 1) на вход подается описание событие в виде текста; 2) событие кодируется в векторное представление hE автоэнкодером; 3) далее используются несколько RNN декодеров, которые принимают векторное представление события на вход и генерируют текстовые сущности. Например, последовательность намерения/причины события (vi=vi^(0) vi^(1) …) высчитывается следующим образом: vi^(t+1) = softmax(Wi RNN(vi^(t), hi,dec^(t))+bi).
[0047] Модуль обработки событий (105) позволяет как брать в виде признаков для обучения результаты работы модулей (103) и (104), так и автономно генерировать новые реплики, отражающие эмоциональное состояние пользователя (10). Для работы модуля (105) необходим размеченный датасет для русского языка с описанием событий и прагматических выводов из них. Модель нейронного енкодера-декодера показала, что может успешно составлять векторные представления ранее не присутствующих в обучающей выборке событий и генерировать вероятностные намерения и реакции участников события.
[0048] Система (100) может получать на вход не только предобработанный текст пользователя (10), но и контекст - предыдущие сообщения в беседе. Существует возможность реализовать как ответ напрямую, через модуль обработки событий (105), уточняющий эмоциональное состояние человека (эмпатичное сообщение), так и использовать полученную информацию при работе модулей (103) - (105) для более корректного выбора ответа, реализации различных модулей проактивности в диалоговой системе (110), накопления знаний о событиях в жизни пользователя и т.д.
[0049] Потенциально заявленная система (100) может быть встроена в современные архитектуры диалоговых систем (110) и дополнять и улучшать их качество работы; система также может работать автономно и ее данные по результатам анализа большого массива отзывов пользователей могут быть полезны для аналитики, отслеживания трендов, помощи операторам колл-центров и др.
[0050] В качестве диалоговой системы (110) могут выступать различные решения, например, голосовые помощники, чат-боты, роботизированные колл-центры, и иные технологии, воплощающие автоматизированный процесс общения с пользователем.
[0051] На Фиг. 3 представлен общий вид вычислительного устройства (200). На базе устройства (200) может быть реализовано устройство пользователя для формирования процесса общения с диалоговой системой (110), система (100) для реализации заявленного решения и иные непредставленные устройства, которые могут участвовать в общей информационной архитектуре заявленного решения.
[0052] В общем случае, вычислительное устройство (200) содержит объединенные общей шиной информационного обмена один или несколько процессоров (201), средства памяти, такие как ОЗУ (202) и ПЗУ (203), интерфейсы ввода/вывода (204), устройства ввода/вывода (205), и устройство для сетевого взаимодействия (206).
[0053] Процессор (201) (или несколько процессоров, многоядерный процессор) могут выбираться из ассортимента устройств, широко применяемых в текущее время, например, компаний Intel™, AMD™, Apple™, Samsung Exynos™, MediaTEK™, Qualcomm Snapdragon™ и т.п. Процессор (201) может включать в себя также графический процессор или работать в совокупности с графическим ускорителем, например, Nvidia, AMD Radeon и др., которые могут применяться для осуществления вычислительных операций при выполнении алгоритмов машинного обучения.
[0054] ОЗУ (202) представляет собой оперативную память и предназначено для хранения исполняемых процессором (201) машиночитаемых инструкций для выполнение необходимых операций по логической обработке данных. ОЗУ (202), как правило, содержит исполняемые инструкции операционной системы и соответствующих программных компонент (приложения, программные модули и т.п.).
[0055] ПЗУ (203) представляет собой одно или более устройств постоянного хранения данных, например, жесткий диск (HDD), твердотельный накопитель данных (SSD), флэш-память (EEPROM, NAND и т.п.), оптические носители информации (CD-R/RW, DVD-R/RW, BlueRay Disc, MD) и др.
[0056] Для организации работы компонентов устройства (200) и организации работы внешних подключаемых устройств применяются различные виды интерфейсов В/В (204). Выбор соответствующих интерфейсов зависит от конкретного исполнения вычислительного устройства, которые могут представлять собой, не ограничиваясь: PCI, AGP, PS/2, IrDa, FireWire, LPT, COM, SATA, IDE, Lightning, USB (2.0, 3.0, 3.1, micro, mini, type C), TRS/Audio jack (2.5, 3.5, 6.35), HDMI, DVI, VGA, Display Port, RJ45, RS232 и т.п.
[0057] Для обеспечения взаимодействия пользователя с вычислительным устройством (200) применяются различные средства (205) В/В информации, например, клавиатура, дисплей (монитор), сенсорный дисплей, тач-пад, джойстик, манипулятор мышь, световое перо, стилус, сенсорная панель, трекбол, динамики, микрофон, средства дополненной реальности, оптические сенсоры, планшет, световые индикаторы, проектор, камера, средства биометрической идентификации (сканер сетчатки глаза, сканер отпечатков пальцев, модуль распознавания голоса) и т.п.
[0058] Средство сетевого взаимодействия (206) обеспечивает передачу данных устройством (200) посредством внутренней или внешней вычислительной сети, например, Интранет, Интернет, ЛВС и т.п. В качестве одного или более средств (206) может использоваться, но не ограничиваться: Ethernet карта, GSM модем, GPRS модем, LTE модем, 5G модем, модуль спутниковой связи, NFC модуль, Bluetooth и/или BLE модуль, Wi-Fi модуль и др.
[0059] Дополнительно могут применяться также средства спутниковой навигации в составе устройства (300), например, GPS, ГЛОНАСС, BeiDou, Galileo.
[0060] Представленные материалы заявки раскрывают предпочтительные примеры реализации технического решения и не должны трактоваться как ограничивающие иные, частные примеры его воплощения, не выходящие за пределы испрашиваемой правовой охраны, которые являются очевидными для специалистов соответствующей области техники.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ УПРАВЛЕНИЯ АВТОМАТИЗИРОВАННОЙ СИСТЕМОЙ ПРАВОВЫХ КОНСУЛЬТАЦИЙ | 2019 |
|
RU2718978C1 |
| СИСТЕМА И СПОСОБ АУГМЕНТАЦИИ ОБУЧАЮЩЕЙ ВЫБОРКИ ДЛЯ АЛГОРИТМОВ МАШИННОГО ОБУЧЕНИЯ | 2020 |
|
RU2758683C2 |
| Способ распознавания речевых эмоций при помощи 3D сверточной нейронной сети | 2023 |
|
RU2816680C1 |
| СПОСОБ И СИСТЕМА ДЛЯ ВЫСТРАИВАНИЯ ДИАЛОГА С ПОЛЬЗОВАТЕЛЕМ В УДОБНОМ ДЛЯ ПОЛЬЗОВАТЕЛЯ КАНАЛЕ | 2018 |
|
RU2688758C1 |
| СПОСОБ И СИСТЕМА ИЗВЛЕЧЕНИЯ ИМЕНОВАННЫХ СУЩНОСТЕЙ | 2020 |
|
RU2760637C1 |
| СПОСОБ И СИСТЕМА ГЕНЕРАЦИИ ТЕКСТА ДЛЯ ЦИФРОВОГО АССИСТЕНТА | 2022 |
|
RU2796208C1 |
| СПОСОБ И СИСТЕМА ГЕНЕРАЦИИ ТЕКСТА | 2023 |
|
RU2817524C1 |
| СПОСОБ И СИСТЕМА РАСПОЗНАВАНИЯ ИНФОРМАЦИИ, СОСТАВЛЯЮЩЕЙ КОММЕРЧЕСКУЮ ТАЙНУ | 2024 |
|
RU2841161C1 |
| СИСТЕМА И МЕТОДИКА АВТОМАТИЧЕСКОГО ОБУЧЕНИЯ ЯЗЫКАМ НА ОСНОВЕ ЧАСТОТНОСТИ СИНТАКСИЧЕСКИХ МОДЕЛЕЙ | 2015 |
|
RU2632656C2 |
| СПОСОБ И СИСТЕМА ПЕРЕФРАЗИРОВАНИЯ ТЕКСТА | 2023 |
|
RU2814808C1 |
Изобретение относится к области компьютерной техники. Технический результат - обеспечение в реальном времени автоматизированного анализа сообщений пользователя для выбора наиболее релевантной реакции для автоматического ответа со стороны диалоговой системы. Такой результат достигается тем, что выполняют обработку входных текстовых данных, при которой осуществляется очистка, нормализация и токенизация данных; формируют по меньшей мере один вектор предложения на основании получаемых токенов данных; осуществляют анализ тональности, при котором определяют тип предложения на основании упомянутых векторов предложений с помощью их обработки моделью машинного обучения, при этом тип предложения представляет собой: негативный, позитивный, нейтральный или разговорный; выполняют извлечение диалоговых актов, при котором определяют общее намерение в поступающих предложениях с помощью обработки упомянутого вектора предложения моделью машинного обучения; выполняют обработку упомянутых токенов предложений, полученных по итогу анализа тональности и диалоговых актов, на предмет выявления по меньшей мере одного из: субъект, объект, действие или их сочетания в каждом предложении и определяют конкретное намерение и/или причину, а также эмоции объекта и субъекта на основании обработки упомянутых токенов предложения. 2 н. и 12 з.п. ф-лы, 3 ил.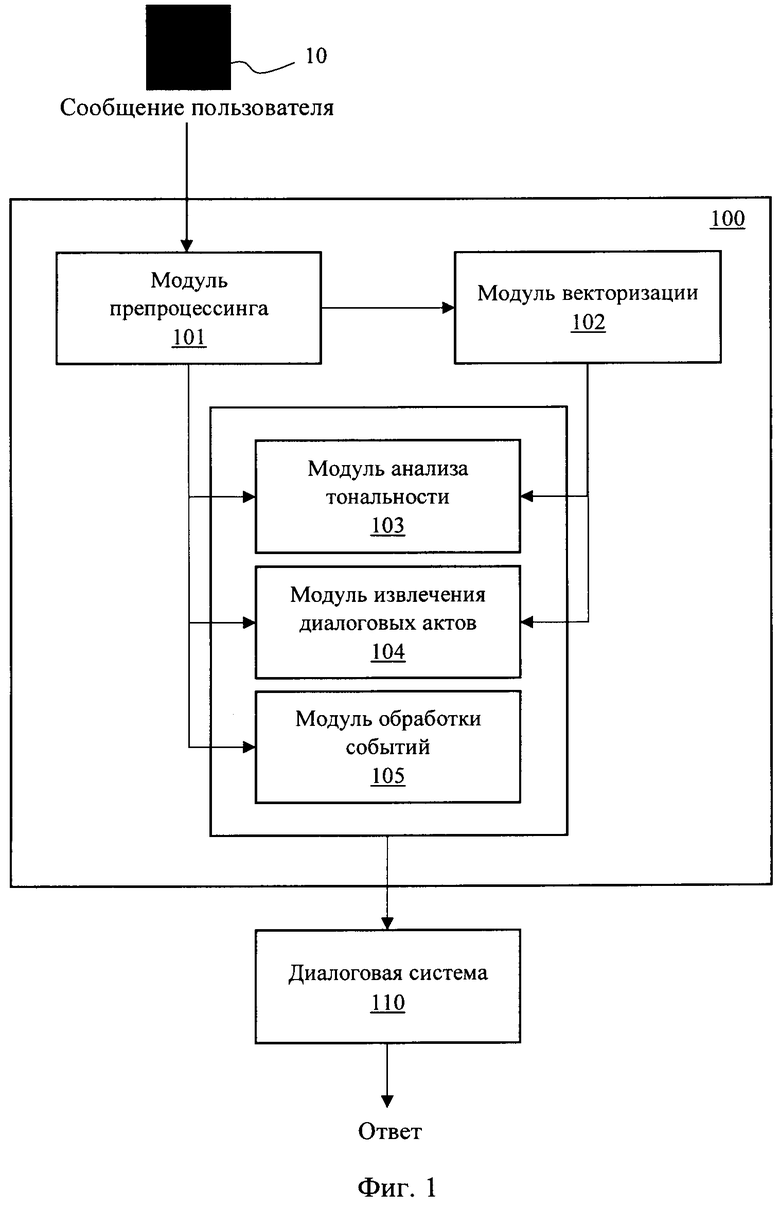
1. Система автоматизированной оценки намерений и эмоций пользователей диалоговой системы, содержащая
по меньшей мере один процессор;
по меньшей мере одно средство памяти;
модуль препроцессинга текста, выполненный с возможностью обработки входных данных, при которой осуществляется очистка, нормализация и токенизация текстовых данных;
модуль векторизации, обеспечивающий формирование вектора предложений на основании токенов, передаваемых от модуля препроцессинга текста;
модуль анализа тональности, выполненный с возможностью определения типа предложения на основании получаемого вектора с помощью модели машинного обучения, при этом тип предложения представляет собой: негативный, позитивный, нейтральный или разговорный;
модуль извлечения диалоговых актов, выполненный с возможностью определения общего намерения в поступающих предложениях с помощью обработки упомянутого вектора предложения моделью машинного обучения;
модуль обработки событий, выполненный с возможностью
обработки токенов предложений, получаемых от модуля анализа тональности и модуля извлечения диалоговых актов, на предмет выявления по меньшей мере одного из: субъект, объект, действие или их сочетания в каждом предложении;
определения конкретного намерения и/или причины, а также эмоций объекта и субъекта на основании обработки упомянутых токенов предложения.
2. Система по п. 1, характеризующаяся тем, что при токенизации входные данные разбиваются на слова, числа и/или знаки препинания.
3. Система по п. 2, характеризующаяся тем, что разбиение предложений осуществляется по пробелам и знакам препинания с учетом сокращений и инициалов.
4. Система по п. 1, характеризующаяся тем, что при очистке данных удаляются токены, не являющиеся буквами алфавита, знаками препинания и/или цифрами.
5. Система по п. 1, характеризующаяся тем, что модуль препроцессинга текста в ходе нормализации выполняет исправление опечаток в токенах.
6. Система по п. 1, характеризующаяся тем, что модуль препроцессинга текста в ходе нормализации выполняет лемматизацию токенов.
7. Система по п. 1, характеризующаяся тем, что модуль препроцессинга текста в ходе нормализации осуществляет построение синтаксического графа для каждого предложения для определения бинарных отношений управления, согласования и примыкания между словами предложений.
8. Способ автоматизированной оценки намерений и эмоций пользователей диалоговой системы, выполняемый с помощью процессора и содержащий этапы, на которых:
выполняют обработку входных текстовых данных, при которой осуществляется очистка, нормализация и токенизация данных;
формируют по меньшей мере один вектор предложения на основании получаемых токенов данных;
осуществляют анализ тональности, при котором определяют тип предложения на основании упомянутых векторов предложений с помощью их обработки моделью машинного обучения, при этом тип предложения представляет собой: негативный, позитивный, нейтральный или разговорный;
выполняют извлечение диалоговых актов, при котором определяют общее намерение в поступающих предложениях с помощью обработки упомянутого вектора предложения моделью машинного обучения;
выполняют обработку упомянутых токенов предложений, полученных по итогу анализа тональности и диалоговых актов, на предмет выявления по меньшей мере одного из: субъект, объект, действие или их сочетания в каждом предложении и
определяют конкретное намерение и/или причину, а также эмоции объекта и субъекта на основании обработки упомянутых токенов предложения.
9. Способ по п. 8, характеризующийся тем, что при токенизации входные данные разбиваются на слова, числа и/или знаки препинания.
10. Способ по п. 9, характеризующийся тем, что разбиение предложений осуществляется по пробелам и знакам препинания с учетом сокращений и инициалов.
11. Способ по п. 8, характеризующийся тем, что при очистке данных удаляются токены, не являющиеся буквами алфавита, знаками препинания и/или цифрами.
12. Способ по п. 8, характеризующийся тем, что в ходе нормализации текста выполняется исправление опечаток в токенах.
13. Способ по п. 8, характеризующийся тем, что в ходе нормализации текста выполняется лемматизация токенов.
14. Способ по п. 8, характеризующийся тем, что в ходе нормализации текста осуществляется построение синтаксического графа для каждого предложения для определения бинарных отношений управления, согласования и примыкания между словами предложений.
| СПОСОБЫ И ЭЛЕКТРОННЫЕ УСТРОЙСТВА ДЛЯ ОПРЕДЕЛЕНИЯ НАМЕРЕНИЯ, СВЯЗАННОГО С ПРОИЗНЕСЕННЫМ ВЫСКАЗЫВАНИЕМ ПОЛЬЗОВАТЕЛЯ | 2018 |
|
RU2711153C2 |
| CN 109992671 A, 09.07.2019 | |||
| СПОСОБ И СИСТЕМА ДЛЯ ВЫСТРАИВАНИЯ ДИАЛОГА С ПОЛЬЗОВАТЕЛЕМ В УДОБНОМ ДЛЯ ПОЛЬЗОВАТЕЛЯ КАНАЛЕ | 2018 |
|
RU2688758C1 |
| СЕНТИМЕНТНЫЙ АНАЛИЗ НА УРОВНЕ АСПЕКТОВ И СОЗДАНИЕ ОТЧЕТОВ С ИСПОЛЬЗОВАНИЕМ МЕТОДОВ МАШИННОГО ОБУЧЕНИЯ | 2016 |
|
RU2635257C1 |
| ТЕМАТИЧЕСКИЕ МОДЕЛИ С АПРИОРНЫМИ ПАРАМЕТРАМИ ТОНАЛЬНОСТИ НА ОСНОВЕ РАСПРЕДЕЛЕННЫХ ПРЕДСТАВЛЕНИЙ | 2018 |
|
RU2719463C1 |
| US 20100131260 A1, 27.05.2010 | |||
| US 20190164551 A1, 30.05.2019 | |||
| CN 106775665 A, 31.05.2017 | |||
| CN 104538043 A, 22.04.2015. | |||

