Область техники, к которой относится изобретение
[0001] Настоящее изобретение относится к устройству обработки данных, системе обработки данных и способу обработки данных, которые формируют кодированные данные, в которых кодируется информация относительно конфигурации нейронной сети.
Уровень техники
[0002] Что касается способа для решения задач классификации (различения) и задач регрессии входных данных, предусмотрено машинное обучение. Для машинного обучения, предусмотрена технология, называемая "нейронной сетью", которая имитирует нейронную схему мозга (нейроны). В нейронной сети (далее называемой "NN" (neural network)), классификация (различение) или регрессия входных данных выполняется с использованием вероятностной модели (различающей модели или порождающей модели), представленной посредством сети, в которой нейроны взаимно соединяются.
[0003] Помимо этого, NN может достигать высокой производительности посредством оптимизации параметров NN по обучению с использованием большого объема данных. Тем не менее, следует отметить, что размер NN в последние годы растет, и имеется тенденция к увеличению размера данных NN, и вычислительная нагрузка на компьютер с использованием NN также увеличивается.
[0004] Например, непатентный документ 1 описывает технологию для скалярного квантования весовых коэффициентов ребер (включающих в себя значения смещения), которые представляют собой фрагменты информации, указывающие конфигурацию NN, и последующего кодирования весовых коэффициентов ребер. Посредством скалярного квантования весовых коэффициентов ребер и последующего кодирования весовых коэффициентов ребер, размер данных для данных относительно ребер сжимается.
Список библиографических ссылок
Непатентные документы
[0005] Непатентный документ 1. Vincent Vanhoucke Andrew Senior, Mark Z. Mao, "Improving the speed of neural networks on CPUs", Proc. Deep Learning and Unsupervised Feature Learning NIPS Workshop, 2011 год.
Сущность изобретения
Техническая задача
[0006] Предусмотрена система, имеющая множество клиентов, соединенных с сервером через сеть передачи данных, в которой кодируются данные, представляющие структуру NN, обученной на серверной стороне, и кодированные данные декодируются на клиентской стороне, за счет чего каждый из множества клиентов выполняет обработку данных с использованием NN, обученной посредством сервера. В традиционной системе, когда структура NN обновляется, в дополнение к информации относительно обновленного слоя, информация относительно слоя, который не обновлен, также передается клиентам. Следовательно, имеется проблема в том, что размер данных, которые должны передаваться, не может быть уменьшен.
[0007] Настоящее изобретение должно разрешать вышеописанную проблему, и задача настоящего изобретения заключается в том, чтобы получать устройство обработки данных, систему обработки данных и способ обработки данных, которые позволяют уменьшать размер данных для данных, представляющих структуру NN.
Решение задачи
[0008] Устройство обработки данных согласно настоящему изобретению включает в себя блок обработки данных для обучения NN; и блок кодирования для формирования кодированных данных, в которых кодируется информация заголовков моделей для идентификации модели NN, информация заголовков слоев для идентификации одного или более слоев NN и фрагменты информации весовых коэффициентов соответствующих ребер, принадлежащих каждому из одного или более слоев, идентифицированных посредством информации заголовков слоев, и блок кодирования кодирует информацию структуры слоев, указывающую структуру слоев нейронной сети.
Преимущества изобретения
[0009] Согласно настоящему изобретению, блок кодирования кодирует информацию структуры слоев, указывающую структуру слоев NN, и флаг нового слоя, указывающий то, является ли каждый слой, который должен кодироваться, слоем, который должен обновляться из соответствующего слоя опорной модели, или новым слоем. Из фрагментов данных, представляющих структуру NN, только информация относительно обновленного слоя кодируется и передается, и в силу этого размер данных фрагментов данных, представляющих структуру NN, может уменьшаться.
Краткое описание чертежей
[0010] Фиг. 1 является блок-схемой, показывающей конфигурацию системы обработки данных согласно первому варианту осуществления.
Фиг. 2 является схемой, показывающей примерную конфигурацию NN.
Фиг. 3 является блок-схемой, показывающей конфигурацию устройства обработки данных (кодера) согласно первому варианту осуществления.
Фиг. 4 является блок-схемой, показывающей конфигурацию устройства обработки данных (декодера) согласно первому варианту осуществления.
Фиг. 5 является блок-схемой последовательности операций способа, показывающей работу устройства обработки данных (кодера) согласно первому варианту осуществления.
Фиг. 6 является блок-схемой последовательности операций способа, показывающей работу устройства обработки данных (декодера) согласно первому варианту осуществления.
Фиг. 7 является схемой, показывающей пример кодированных данных в первом варианте осуществления.
Фиг. 8 является схемой, показывающей другой пример кодированных данных в первом варианте осуществления.
Фиг. 9 является схемой, показывающей пример процесса свертки для одномерных данных в первом варианте осуществления.
Фиг. 10 является схемой, показывающей пример процесса свертки для двумерных данных в первом варианте осуществления.
Фиг. 11 является схемой, показывающей матрицу поузловой информации весовых коэффициентов ребер в l-ом слое NN.
Фиг. 12 является схемой, показывающей матрицу шагов квантования для поузловой информации весовых коэффициентов ребер в l-ом слое NN.
Фиг. 13 является схемой, показывающей матрицу информации весовых коэффициентов ребер в сверточном слое.
Фиг. 14 является схемой, показывающей матрицу шагов квантования для информации весовых коэффициентов ребер в сверточном слое.
Фиг. 15 является блок-схемой, показывающей конфигурацию разновидности устройства обработки данных (кодера) согласно первому варианту осуществления.
Фиг. 16 является схемой, показывающей общее представление обновления кодированных данных в первом варианте осуществления.
Фиг. 17 является схемой, показывающей конфигурации сетевых моделей, соответствующих обновлению кодированных данных, показанных на фиг. 16.
Фиг. 18 является схемой, показывающей примеры информации структуры слоев, включенной в заголовок информации модели.
Фиг. 19 является схемой, показывающей примеры идентификационной информации слоев, соответствующей информации структуры слоев, включенной в заголовок информации модели.
Фиг. 20A является блок-схемой, показывающей аппаратную конфигурацию, которая реализует функции устройства обработки данных согласно первому варианту осуществления, и фиг. 20B является блок-схемой, показывающей аппаратную конфигурацию, которая выполняет программное обеспечение, которое реализует функции устройства обработки данных согласно первому варианту осуществления.
Подробное описание вариантов осуществления
[0011] Первый вариант осуществления
Фиг. 1 является блок-схемой, показывающей конфигурацию системы обработки данных согласно первому варианту осуществления. В системе обработки данных, показанной на фиг. 1, сервер 1 соединяется с клиентами 3-1, 3-2, …, 3-N через сеть 2 передачи данных. N является натуральным числом, большим или равным 2. Сервер 1 представляет собой устройство обработки данных, которое оптимизирует параметры NN (нейронной сети) посредством обучения с использованием большого объема данных, за счет этого создавая высокопроизводительную NN, и представляет собой первое устройство обработки данных, включенное в систему обработки данных, показанную на фиг. 1.
[0012] Сеть 2 передачи данных представляет собой сеть, через которую передаются данные, которыми обмениваются между сервером 1 и клиентами 3-1, 3-2, …, 3-N, и представляет собой Интернет или сеть intranet. Например, в сети 2 передачи данных, информация для создания NN передается из сервера 1 в клиенты 3-1, 3-2, …, 3-N.
[0013] Клиенты 3-1, 3-2, …, 3-N представляют собой устройства, которые создают NN, обученную посредством сервера 1, и выполняют обработку данных с использованием созданной NN. Например, клиенты 3-1, 3-2, …, 3-N представляют собой устройства, имеющие функцию связи и функцию обработки данных, такие как персональные компьютеры (PC), камеры или роботы. Каждый из клиентов 3-1, 3-2, …, 3-N представляет собой второе устройство обработки данных, включенное в систему обработки данных, показанную на фиг. 1.
[0014] В системе обработки данных, показанной на фиг. 1, размер данных модели и параметры NN и значение, указывающее соответствующую производительность, варьируются между клиентами 3-1, 3-2, …, 3-N. Следовательно, даже если модель и параметры NN кодируются с использованием технологии, описанной в непатентном документе 1, кодированные данные должны сжиматься до размера данных, подходящего для каждого из клиентов 3-1, 3-2, …, 3-N, и в силу этого нагрузка по обработке для кодирования увеличивается.
[0015] Следовательно, в системе обработки данных согласно первому варианту осуществления, сервер 1 формирует кодированные данные, в которых кодируется информация заголовков моделей для идентификации модели NN, информация заголовков слоев для идентификации слоя NN и информация относительно послойных весовых коэффициентов ребер, включающая в себя значения смещений (в дальнейшем, весовой коэффициент ребра включает в себя значение смещения, если не указано иное), и передает кодированные данные в каждый из клиентов 3-1, 3-2, …, 3-N через сеть 2 передачи данных. Каждый из клиентов 3-1, 3-2, …, 3-N может декодировать только информацию относительно требуемого слоя, из кодированных данных, передаваемых из сервера 1 через сеть 2 передачи данных. Таким образом, нагрузка по обработке для кодирования для сервера 1 снижается, и может достигаться уменьшение размера данных, передаваемых в сеть 2 передачи данных из сервера 1.
[0016] Ниже описывается конфигурация NN. Фиг. 2 является схемой, показывающей примерную конфигурацию NN. Как показано на фиг. 2, входные данные (x1, x2, …, xN1) обрабатываются посредством каждого слоя, включенного в NN, и результаты обработки (y1, …, yNL) выводятся. Nl (l=1, 2, …, L) указывает число узлов в l-ом слое, и L указывает число слоев в NN. Как показано на фиг. 2, NN включает в себя входной слой, скрытые слои и выходной слой, и она имеет такую структуру, в которой множество узлов соединяются с каждым из этих слоев посредством ребер. Выходное значение каждого из множества узлов может вычисляться из выходных значений узлов в предыдущем слое, которые соединяются с каждым из множества узлов посредством ребер, весовых коэффициентов ребер и функции активации, заданной для каждого слоя.
[0017] NN включают в себя, например, сверточную нейронную сеть (CNN), включающую в себя не только полностью соединенные слои, но также и сверточные слои и слои объединения в пул. CNN может создавать сеть, которая реализует обработку данных, отличную от классификации и регрессии, к примеру, сеть, которая реализует процесс фильтрации данных.
[0018] Например, при вводе изображения или аудио, CNN может реализовывать процесс фильтрации изображений или аудио, который достигает удаления шума или повышения качества входного сигнала, процесс высокочастотного восстановления для аудио с отсутствующими высокими частотами сжатого аудио, ретуширования дефектов для изображения, частичная область изображения которого отсутствует, или процесс на основе сверхразрешения для изображения. CNN также может конструировать NN, которая включает в себя комбинацию порождающей модели и различающей модели, и которая определяет то, являются или нет данные реальными, посредством использования различающей модели, причем различающая модель определяет то, формируются или нет данные посредством порождающей модели.
[0019] В последние годы, также предлагается новая NN, называемая "порождающей соперничающей сетью", которая обучается на основе соперничества таким образом, что различающая модель может отличать данные, сформированные посредством порождающей модели, от реальных данных, так что порождающая модель не формирует данные, которые могут отличаться, посредством различающей модели, от реальных данных. Эта NN может создавать высокоточную порождающую модель и различающую модель.
[0020] Фиг. 3 является блок-схемой, показывающей конфигурацию устройства обработки данных (кодера) согласно первому варианту осуществления. Устройство обработки данных, показанное на фиг. 3, представляет собой первое устройство обработки данных, которое обучает NN с использованием набора обучающих данных и набора оценочных данных, и формирует кодированные данные информации модели, указывающей конфигурацию NN (далее называемой "информацией модели"), и, например, представляет собой сервер 1, показанный на фиг. 1.
[0021] Устройство обработки данных, показанное на фиг. 3, включает в себя блок 10 обработки данных и блок 11 кодирования. Блок 10 обработки данных представляет собой первый блок обработки данных, который обучает NN, и включает в себя обучающий блок 101, блок 102 оценки и блок 103 управления. Блок 11 кодирования формирует кодированные данные, в которых кодируется информация заголовков моделей, которая идентифицирует модель NN, обученной посредством обучающего блока 101, информация заголовков слоев, которая идентифицирует слой NN, и информация послойных весовых коэффициентов ребер. Помимо этого, блок 11 кодирования кодирует информацию структуры слоев для слоя, который должен кодироваться (кодированного слоя), и кодирует флаг нового слоя. Информация структуры слоев представляет собой информацию, указывающую структуру слоев NN. Флаг нового слоя представляет собой информацию флага для идентификации того, является ли соответствующий слой слоем, который должен добавляться впервые, или слоем, полученным посредством обновления уже существующего слоя, и ниже описываются подробности флага нового слоя.
[0022] Обучающий блок 101 выполняет процесс обучения для NN с использованием набора обучающих данных, за счет этого формируя информацию модели обученной NN. Информация модели выводится в блок 102 оценки из обучающего блока 101. Кроме того, обучающий блок 101 имеет информацию модели кодирования, которая управляется посредством блока 103 управления, который описывается ниже, и выводит информацию модели кодирования в блок 11 кодирования, когда обучающий блок 101 принимает инструкцию завершения обучения из блока 103 управления. Блок 102 оценки создает NN с использованием информации модели и выполняет процесс логического вывода из набора оценочных данных, с использованием созданной NN. Значение индекса оценки, полученное в качестве результата процесса логического вывода, представляет собой результат оценки, и результат оценки выводится в блок 103 управления из блока 102 оценки. Индекс оценки задается в блоке 102 оценки и, например, представляет собой точность логического вывода или выходное значение функции потерь.
[0023] Блок 103 управления определяет то, следует или нет обновлять модель NN, обученной посредством обучающего блока 101, и то, может или нет обучающий блок 101 выполнять обучение NN, из значения оценки, полученного в качестве результата оценки посредством блока 102 оценки, и управляет обучающим блоком 101 на основе результатов определения. Например, блок 103 управления сравнивает значение оценки с критерием обновления модели и определяет то, следует или нет обновлять информацию модели в качестве информации модели кодирования, на основе результата сравнения. Помимо этого, блок 103 управления сравнивает значение оценки с критерием завершения обучения и, определяет то, следует или нет выполнять обучение NN посредством обучающего блока 101, на основе результата сравнения. Следует отметить, что эти критерии определяются из предыстории значений оценки.
[0024] Фиг. 4 является блок-схемой, показывающей конфигурацию устройства обработки данных (декодера) согласно первому варианту осуществления. Устройство обработки данных, показанное на фиг. 4, представляет собой второе устройство обработки данных, которое создает NN посредством декодирования кодированных данных, сформированных посредством блока 11 кодирования, показанного на фиг. 3, и выполняет процесс логического вывода для одного или более фрагментов оценочных данных с использованием созданной NN и соответствует, например, клиентам 3-1, 3-2, …, 3-N, показанным на фиг. 1.
[0025] Устройство обработки данных, показанное на фиг. 4, включает в себя блок 201 декодирования и блок 202 логического вывода. Блок 201 декодирования декодирует информацию модели из кодированных данных, сформированных посредством блока 11 кодирования. Например, блок 201 декодирования может декодировать только информацию, требуемую для устройства обработки данных, показанного на фиг. 4, из кодированных данных.
[0026] Блок 202 логического вывода представляет собой второй блок обработки данных, который создает NN с использованием информации модели, декодированной посредством блока 201 декодирования, и выполняет обработку данных, которая использует созданную NN. Например, обработка данных представляет собой процесс логического вывода для оценочных данных с использованием NN. Блок 202 логического вывода выполняет процесс логического вывода для оценочных данных с использованием NN и выводит результат логического вывода.
[0027] Далее описывается работа системы обработки данных согласно первому варианту осуществления. Фиг. 5 является блок-схемой последовательности операций способа, показывающей работу устройства обработки данных (кодера) согласно первому варианту осуществления, и показывает способ обработки данных, осуществляемый посредством устройства обработки данных, показанного на фиг. 3. Обучающий блок 101 обучает NN (этап ST1). Например, обучающий блок 101 обучает NN с использованием набора обучающих данных и выводит информацию модели, полученную посредством обучения, в блок 102 оценки.
[0028] Информация модели представляет собой информацию, указывающую конфигурацию модели NN, и выполнена с возможностью включать в себя информацию структуры слоев, указывающую структуру для каждого слоя, и информацию весовых коэффициентов каждого ребра, принадлежащего слою. Информация структуры слоев включает в себя информацию типов слоев, конфигурационную информацию относительно типа слоя и информацию, отличную от весовых коэффициентов ребер, которая требуется для того, чтобы формировать слой. Информация, отличная от весовых коэффициентов ребер, которая требуется для того, чтобы формировать слой, включает в себя, например, функцию активации. Информация типов слоев представляет собой информацию, указывающую тип слоя, и посредством ссылки на информацию типов слоев, может идентифицироваться тип слоя, к примеру, сверточный слой, слой объединения в пул или полностью соединенный слой.
[0029] Конфигурационная информация относительно типа слоя представляет собой информацию, указывающую конфигурацию слоя типа, соответствующего информации типов слоев. Например, когда тип слоя, соответствующий информации типов слоев, указывает сверточный слой, конфигурационная информация относительно типа слоя включает в себя фрагменты информации, указывающие число каналов, которые выполняют свертку, размер данных и форму сверточного фильтра (ядра), интервал (шаг) свертки, то, предусмотрено или нет дополнение на границах входных сигналов для процесса свертки, и способ для дополнения, когда дополнение предусмотрено. Помимо этого, когда тип слоя, соответствующий информации типов слоев, указывает слой объединения в пул, конфигурационная информация относительно типа слоя включает в себя фрагменты информации, указывающие способ объединения в пул, такой как объединение в пул по максимуму или объединение в пул по среднему, форму ядра, которое выполняет процесс объединения в пул, интервал (шаг) объединения в пул, то, имеется или нет дополнение на границах входных сигналов для процесса объединения в пул, и способ для дополнения, когда имеется дополнение.
[0030] Для информации, указывающей каждый весовой коэффициент ребра, весовые коэффициенты могут независимо задаваться для соответствующих ребер, аналогично полностью соединенному слою. С другой стороны, аналогично сверточному слою, весовой коэффициент ребра может быть общим в расчете на сверточный фильтр (ядро) (в расчете на канал), т.е. весовой коэффициент ребра может быть общим в одном фильтре.
[0031] Блок 102 оценки оценивает NN (этап ST2). Например, блок 102 оценки создает NN с использованием информации модели, сформированной посредством обучающего блока 101, и выполняет процесс логического вывода из набора оценочных данных, с использованием созданной NN. Результат оценки выводится в блок 103 управления из блока 102 оценки. Результат оценки, например, представляет собой точность логического вывода или выходное значение функции потерь.
[0032] Затем блок 103 управления определяет то, следует или нет обновлять информацию модели (этап ST3). Например, когда значение оценки, сформированное посредством блока 102 оценки, не удовлетворяет критерию обновления модели, блок 103 управления определяет необходимость не обновлять информацию модели кодирования, запоминаемую в обучающем блоке 101, а когда значение оценки удовлетворяет критерию обновления модели, блок 103 управления определяет необходимость обновлять информацию модели кодирования.
[0033] Что касается примера критерия обновления модели, когда значение оценки представляет собой выходное значение функции потерь, значение оценки, полученное посредством обучения на этот раз, может быть меньше минимального значения оценки в предыстории обучения, записываемой с начала обучения. Что касается другого примера, когда значение оценки представляет собой точность логического вывода, значение оценки, полученное посредством обучения в этот раз, может превышать максимальное значение оценки в предыстории обучения, записываемой с начала обучения.
[0034] Помимо этого, блок переключения предыстории обучения может представлять собой любой блок. Например, предполагается, что предыстория обучения предоставляется для каждого идентификационного номера (model_id) модели, который описывается ниже. В этом случае, когда модель не имеет идентификационного номера (reference_model_id) опорной модели, который описывается ниже, считается, что отсутствует предыстория обучения, и обучение начинается. А именно, на этапе ST3, выполняемом в первый раз, информация модели всегда обновляется. С другой стороны, когда модель имеет идентификационный номер опорной модели, ссылаются на предысторию обучения (предысторию A) модели, указываемой посредством идентификационного номера опорной модели. Как результат, при обучении модели, может предотвращаться обновление модели до модели, значение оценки которой является более плохим (более низкая точность логического вывода, большее значение функции потерь и т.д.), чем значение оценки для модели, указываемой посредством идентификационного номера опорной модели. В этом случае, когда идентификационный номер модели для модели является идентичным идентификационному номеру опорной модели, каждый раз, когда модель обучается, предыстория обучения (предыстория A), соответствующая идентификационному номеру опорной модели, обновляется. С другой стороны, когда идентификационный номер модели для модели отличается от идентификационного номера опорной модели, предыстория обучения (предыстория A), соответствующая идентификационному номеру опорной модели, копируется в качестве начального значения предыстории обучения (предыстории B) идентификационного номера модели для модели, и после этого каждый раз, когда модель обучается, предыстория обучения (предыстория B) модели обновляется.
[0035] Если блок 103 управления определяет необходимость обновлять информацию модели (этап ST3: "Да"), то обучающий блок 101 обновляет информацию модели кодирования на информацию модели (этап ST4). Например, блок 103 управления формирует информацию с инструкциями обновления модели, указывающую то, что предусмотрено обновление информации модели, и выводит управляющую информацию обучения, включающую в себя информацию с инструкциями обновления модели, в обучающий блок 101. Обучающий блок 101 обновляет информацию модели кодирования на информацию модели в соответствии с информацией с инструкциями обновления модели, включенной в управляющую информацию обучения.
[0036] С другой стороны, если определяется необходимость не обновлять информацию модели (этап ST3: "Нет"), то блок 103 управления формирует информацию с инструкциями обновления модели, указывающую то, что отсутствует обновление информации модели, и выводит управляющую информацию обучения, включающую в себя информацию с инструкциями обновления модели, в обучающий блок 101. Обучающий блок 101 не обновляет информацию модели кодирования в соответствии с информацией с инструкциями обновления модели, включенной в управляющую информацию обучения.
[0037] Затем блок 103 управления сравнивает значение оценки с критерием завершения обучения и определяет то, следует или нет выполнять обучение NN посредством обучающего блока 101, на основе результата сравнения (этап ST5). Например, что касается критерия завершения обучения, когда определяется то, достигает или нет значение оценки, сформированное посредством блока 102 оценки, конкретного значения, если значение оценки, сформированное посредством блока 102 оценки, удовлетворяет критерию завершения обучения, то блок 103 управления определяет то, что обучение NN посредством обучающего блока 101 завершено, а если значение оценки не удовлетворяет критерию завершения обучения, то блок 103 управления определяет то, что обучение NN посредством обучающего блока 101 не завершено. Альтернативно, например, когда критерий завершения обучения основан на последней предыстории обучения, например, определяется то, что обучение завершено, когда отсутствие обновления информации модели (этап ST3: "Нет") выбирается M раз в строке (M является предварительно определенным целым числом, большим или равным 1), если предыстория обучения не удовлетворяет критерию завершения обучения, то блок 103 управления определяет то, что обучение NN посредством обучающего блока 101 не завершено.
[0038] Если блок 103 управления определяет то, что обучение NN завершено (этап ST5: "Да"), то обучающий блок 101 выводит информацию модели кодирования в блок 11 кодирования, и обработка переходит к процессу на этапе ST6. С другой стороны, если блок 103 управления определяет то, что обучение NN не завершено (этап ST5: "Нет"), то обработка выполняется с этапа ST1.
[0039] Блок 11 кодирования кодирует информацию модели кодирования, введенную из обучающего блока 101 (этап ST6). Блок 11 кодирования кодирует информацию модели кодирования, сформированную посредством обучающего блока 101, на основе NN-слоя, за счет этого формируя кодированные данные, включающие в себя информацию заголовка, и послойные кодированные данные. Помимо этого, блок 11 кодирования кодирует информацию структуры слоев и кодирует флаг нового слоя.
[0040] Фиг. 6 является блок-схемой последовательности операций способа, показывающей операции устройства обработки данных (декодера) согласно первому варианту осуществления, и показывает операции устройства обработки данных, показанного на фиг. 4. Блок 201 декодирования декодирует информацию модели из кодированных данных, полученных посредством кодирования в блоке 11 кодирования (этап ST11). Затем блок 202 логического вывода создает NN из информации модели, декодированной посредством блока 201 декодирования (этап ST12). Блок 202 логического вывода выполняет процесс логического вывода для оценочных данных с использованием созданной NN и выводит результат логического вывода (этап ST13).
[0041] Далее подробно описывается кодирование информации модели посредством блока 11 кодирования на этапе ST6 по фиг. 5. Для кодирования информации модели посредством блока 11 кодирования, например, может использоваться способ (1) или (2) кодирования. Альтернативно, то, какое из кодирования (1) и (2) используется, может задаваться для каждого параметра. Например, посредством использования (1) для информации заголовка и (2) для данных весовых коэффициентов, в то время как декодер может легко анализировать информацию заголовка без выполнения декодирования на основе кода переменной длины для нее, декодер может реализовывать высокое сжатие посредством декодирования переменной длины для данных весовых коэффициентов, которые занимают значительную часть размера данных для кодированных данных, посредством которых может подавляться размер данных для всех кодированных данных.
(1) Данные, в которых непосредственно битовые строки, включающие в себя информацию заголовка, если информация заголовка присутствует, размещаются в предварительно установленном порядке, представляют собой кодированные данные. В каждой из битовых строк, параметр, включенный в каждый фрагмент информации, включенный в информацию модели, описывается с битовой точностью, заданной в параметре. Битовая точность представляет собой битовую точность, заданную в параметре, например, 8-битовое целое число или 32-битовое число с плавающей точкой.
(2) Данные, в которых непосредственно битовые строки, включающие в себя информацию заголовка, размещаются в предварительно установленном порядке, представляют собой кодированные данные. В каждой из битовых строк, параметр, включенный в каждый фрагмент информации, включенный в информацию модели, кодируется посредством способа кодирования переменной длины, заданного для каждого параметра.
[0042] Фиг. 7 является схемой, показывающей пример кодированных данных в первом варианте осуществления, и кодированные данные в вышеописанном (1) или (2) могут располагаться в порядке, показанном на фиг. 7. Кодированные данные, показанные на фиг. 7, включают в себя совокупность фрагментов данных, называемых "единицами данных", и единицы данных включают в себя единицу данных без слоя и единицу данных слоя. Единица данных слоя представляет собой единицу данных, которая сохраняет данные слоя, которые представляют собой послойные кодированные данные.
[0043] Данные слоя включают в себя начальный код, тип единиц данных, заголовок информации слоя и данные весовых коэффициентов. Заголовок информации слоя получается посредством кодирования информации заголовка слоя для идентификации слоя NN. Данные весовых коэффициентов получаются посредством кодирования информации весовых коэффициентов ребер, принадлежащих слою, указываемому посредством заголовка информации слоя. Следует отметить, что в кодированных данных, показанных на фиг. 7, порядок размещения единиц данных слоя не обязательно является идентичным порядку размещения слоев NN и представляет собой любой порядок. Причина для этого состоит в том, что идентификационный номер (layer_id) слоя, который описывается ниже, может идентифицировать то, слою какой позиции NN соответствует каждая из единиц данных слоя.
[0044] Единица данных без слоя представляет собой единицу данных, которая сохраняет данные, отличные от данных слоя. Например, единица данных без слоя сохраняет начальный код, тип единиц данных и заголовок информации модели. Заголовок информации модели получается посредством кодирования информации заголовка модели для идентификации модели NN.
[0045] Начальный код представляет собой код, сохраненный в начальной позиции единицы данных, чтобы идентифицировать начальную позицию единицы данных. Клиенты 3-1, 3-2, …, 3-N (далее называемые "стороной декодирования") могут идентифицировать начальную позицию единицы данных без слоя или единицы данных слоя посредством ссылки на начальный код. Например, когда 0×000001 задается как начальный код, данные, сохраненные в единице данных, отличной от начального кода, задаются таким образом, что 0×000001 не возникает. Как результат, начальная позиция единицы данных может идентифицироваться из начального кода.
[0046] Чтобы выполнять настройку таким образом, что 0×000001 не возникает, например, 03 вставляется в третий байт кодированных данных "0×000000-0×000003", в силу этого приводя к 0×00000300-0×00000303, и после декодирования, 0×000003 преобразуется в 0×0000, за счет чего данные могут возвращаться к исходным данным. Следует отметить, что при условии, что начальный код представляет собой битовую строку, которая может уникально идентифицироваться, битовая строка, отличная от 0×000001, может задаваться как начальный код. Помимо этого, при условии, что способ может идентифицировать начальную позицию единицы данных, начальный код не должен обязательно использоваться. Например, битовая строка, которая может идентифицировать конец единицы данных, может добавляться в конец единицы данных. Альтернативно, начальный код может добавляться только в начало единицы данных без слоя, и в качестве части заголовка информации модели, может кодироваться размер данных каждой единицы данных слоя. Следовательно, позиция разделения между любыми двумя смежными единицами данных слоя может идентифицироваться из вышеописанной информации.
[0047] Тип единиц данных представляет собой данные, сохраненные после начального кода в единице данных, чтобы идентифицировать тип единицы данных. Для типа единиц данных, значение задается для каждого типа единицы данных заранее. Посредством ссылки на тип единиц данных, сохраненный в единице данных, сторона декодирования может идентифицировать то, представляет единица данных собой единицу данных без слоя или единицу данных слоя, и дополнительно может идентифицировать то, какой вид из единицы данных без слоя или единицы данных слоя представляет собой единица данных.
[0048] Заголовок информации модели в единице данных без слоя включает в себя идентификационный номер (model_id) модели, число (num_layers) единиц данных слоя в модели и число (num_coded_layers) кодированных единиц данных слоя. Идентификационный номер модели представляет собой номер для идентификации модели NN. Таким образом, по существу, отдельные модели имеют номера, независимые друг от друга, но если устройство обработки данных (декодер) согласно первому варианту осуществления вновь принимает модель, имеющую идентификационный номер модели, идентичный идентификационному номеру модели для модели, принимаемой ранее, то предыдущая принимаемая модель, имеющая идентификационный номер модели, перезаписывается. Число единиц данных слоя в модели представляет собой число единиц данных слоя, включенных в модель, идентифицированную посредством идентификационного номера модели. Число кодированных единиц данных слоя представляет собой число единиц данных слоя, фактически присутствующих в кодированных данных. В примере по фиг. 7, предусмотрены единицы (1)-(n) данных слоя, и в силу этого число кодированных единиц данных слоя составляет n. Следует отметить, что число кодированных единиц данных слоя всегда меньше или равно числу единиц данных слоя в модели.
[0049] Заголовок информации слоя в единице данных слоя включает в себя идентификационный номер (layer_id) слоя и информацию структуры слоев. Идентификационный номер слоя представляет собой номер для идентификации слоя. Чтобы иметь возможность идентифицировать соответствующий слой посредством идентификационного номера слоя, то, как назначать значения идентификационных номеров слоев, фиксированно задается заранее. Например, номера назначаются в порядке от слоя, близкого к входному слою, к последующему слою, например, входному слою NN назначается 0, и последующему слою назначается 1. Информация структуры слоев представляет собой информацию, указывающую конфигурацию для каждого слоя NN, и включает в себя информацию типов слоев, конфигурационную информацию относительно типа слоя и информацию, отличную от весовых коэффициентов ребер, которая требуется для того, чтобы формировать слой. Информация структуры слоев включает в себя, например, информацию только соответствующей части слоя в model_structure_information и layer_id_information, которые описываются ниже. Кроме того, информация структуры слоев включает в себя weight_bit_length, указывающий битовую точность каждого весового коэффициента ребра соответствующего слоя. Например, когда weight_bit_length=8, это указывает то, что весовой коэффициент составляет 8-битовые данные. Таким образом, битовая точность весового коэффициента ребра может задаваться на послойной основе. Как результат, можно выполнять адаптивное управление, например, битовая точность изменяется на послойной основе, в зависимости от важности слоя (степени влияния, оказываемого посредством битовой точности на результат вывода).
[0050] Следует отметить, что хотя выше показан заголовок информации слоя, включающий в себя информацию структуры слое, заголовок информации модели может включать в себя все фрагменты информации (model_structure_information) структуры слоев, включенной в кодированные данные, и идентификационной информации (layer_id_information) слоев, соответствующей фрагментам информации структуры слоев. Сторона декодирования может идентифицировать конфигурации слоев с соответствующими идентификационными номерами слоев посредством ссылки на заголовок информации модели. Кроме того, в вышеописанном случае, поскольку конфигурации слоев с соответствующими идентификационными номерами слоев могут идентифицироваться посредством ссылки на заголовок информации модели, заголовок информации слоя может включать в себя только идентификационный номер слоя. Следовательно, когда размер данных единицы данных слоя превышает размер данных единицы данных без слоя, размер данных каждой единицы данных слоя может уменьшаться, за счет этого обеспечивая уменьшение максимального размера данных единиц данных в кодированных данных.
[0051] В единице данных слоя, данные весовых коэффициентов, которые кодируются на послойной основе, сохраняются после заголовка информации слоя. Данные весовых коэффициентов включают в себя ненулевые флаги и ненулевые данные весовых коэффициентов. Ненулевой флаг представляет собой флаг, указывающий то, равно или нет значение весового коэффициента ребра нулю, и задается для каждого из всех весовых коэффициентов ребер, принадлежащих соответствующему слою.
[0052] Ненулевые данные весовых коэффициентов представляют собой данные, которые задаются после ненулевых флагов в данных весовых коэффициентов. В ненулевых данных весовых коэффициентов, задается значение весового коэффициента, ненулевой флаг которого указывает ненулевой (значимый). На фиг. 7, данные (1) весовых коэффициентов - данные (m) весовых коэффициентов, указывающие ненулевое значение весового коэффициента, задаются в качестве ненулевых данных весовых коэффициентов. Число m фрагментов ненулевых данных весовых коэффициентов меньше или равно числу Ml всех весовых коэффициентов в соответствующем слое l. Следует отметить, что данные весовых коэффициентов относительно слоя, имеющего разреженные ребра с ненулевым значением весового коэффициента, имеют очень небольшой объем ненулевых данных весовых коэффициентов и включают в себя фактически только ненулевые флаги, и в силу этого размер данных для данных весовых коэффициентов значительно уменьшается.
[0053] Фиг. 8 является схемой, показывающей другой пример кодированных данных в первом варианте осуществления, и кодированные данные в вышеописанном (1) или (2) могут располагаться в порядке, показанном на фиг. 8. Кодированные данные, показанные на фиг. 8, отличаются от кодированных данных по фиг. 7 в конфигурации данных для данных весовых коэффициентов, и в ненулевых данных весовых коэффициентов, весовые коэффициенты всех ребер, принадлежащих соответствующему слою, совместно размещаются на основе каждой битовой плоскости в порядке от верхних битов. Кроме того, в заголовке информации слоя, задается идентификационная информация позиций данных битовой плоскости, указывающая начальную позицию каждого бита, указывающего весовой коэффициент ребра.
[0054] Например, когда битовая точность, заданная для весовых коэффициентов ребер, составляет X, весовые коэффициенты всех ребер, принадлежащих соответствующему слою, описываются с битовой точностью X. Из битовой строки этих весовых коэффициентов, блок 11 кодирования задает, в качестве каждых ненулевых данных весовых коэффициентов для первого бита, данные (1) весовых коэффициентов первого бита, данные (2) весовых коэффициентов первого бита, …, данные (m) весовых коэффициентов первого бита, которые представляют собой ненулевые данные весовых коэффициентов первого бита. Этот процесс повторяется для ненулевых данных весовых коэффициентов второго бита - ненулевых данных весовых коэффициентов X-ого бита. Следует отметить, что данные (1) весовых коэффициентов первого бита, данные (2) весовых коэффициентов первого бита, …, данные (m) весовых коэффициентов первого бита представляют собой фрагменты ненулевых данных весовых коэффициентов, которые формируют битовую плоскость первого бита.
[0055] Сторона декодирования идентифицирует требуемые кодированные данные из фрагментов послойных кодированных данных на основе идентификационной информации позиций данных битовой плоскости и может декодировать идентифицированные кодированные данные с любой битовой точностью. А именно, сторона декодирования может выбирать только требуемые кодированные данные из кодированных данных и декодировать информацию модели NN, подходящей для окружения на стороне декодирования. Следует отметить, что идентификационная информация позиций данных битовой плоскости может представлять собой любую информацию при условии, что позиция разделения между любыми двумя смежными фрагментами данных битовой плоскости может идентифицироваться, и может представлять собой информацию, указывающую начальную позицию каждого фрагмента данных битовой плоскости, либо может представлять собой информацию, указывающую размер данных каждого фрагмента данных битовой плоскости.
[0056] Когда полоса частот передачи сети 2 передачи данных не является достаточной для того, чтобы передавать все фрагменты кодированных данных, представляющих конфигурацию NN в сторону декодирования, блок 11 кодирования может ограничивать ненулевые данные весовых коэффициентов, которые должны передаваться из фрагментов кодированных данных, на основе полосы частот передачи сети 2 передачи данных. Например, в битовой строке информации весовых коэффициентов, описанной при 32-битовой точности, верхние 8 битов ненулевых данных весовых коэффициентов задаются в качестве цели передачи. Сторона декодирования может распознавать, из начального кода, расположенного после ненулевых данных весовых коэффициентов, то, что единица данных слоя, соответствующая следующему слою, размещается после ненулевых данных весовых коэффициентов 8-ого бита в кодированных данных. Помимо этого, сторона декодирования может надлежащим образом декодировать весовой коэффициент, значение которого равно нулю, посредством ссылки на ненулевой флаг в данных весовых коэффициентов.
[0057] Чтобы повышать, когда данные весовых коэффициентов декодируются с любой битовой точностью посредством стороны декодирования, точность логического вывода с битовой точностью, блок 11 кодирования может включать, в заголовок информации слоя, смещение, которое должно суммироваться с весовым коэффициентом, декодированным с каждой битовой точностью. Например, блок 11 кодирования суммирует смещение, которое является равномерным в расчете на слой, с битовой строкой весовых коэффициентов, описанных с битовой точностью, определяет смещение с наибольшей точностью и включает определенное смещение в заголовок информации слоя и выполняет кодирование.
[0058] Помимо этого, блок 11 кодирования может включать, в заголовок информации модели, смещения для весовых коэффициентов ребер во всех слоях, включенных в NN, и выполнять кодирование. Кроме того, блок 11 кодирования может задавать флаг, указывающий то, включается или нет смещение в заголовок информации слоя или в заголовок информации модели, и, например, только когда флаг указывает доступность смещения, смещение может включаться в кодированные данные.
[0059] Блок 11 кодирования может задавать разность между значением весового коэффициента ребра и конкретным значением, в качестве цели кодирования.
Конкретное значение включает в себя, например, непосредственно предыдущий весовой коэффициент в порядке кодирования. Помимо этого, соответствующий весовой коэффициент ребра, принадлежащий слою выше на один уровень (слою, близкому к входному слою), может использоваться в качестве конкретного значения, либо соответствующий весовой коэффициент ребра в модели до обновления может использоваться в качестве конкретного значения.
[0060] Кроме того, блок 11 кодирования имеет функции, показанные в (A), (B) и (C).
(A) Блок 11 кодирования имеет функцию масштабируемого кодирования, которая выполняет кодирование для базовых кодированных данных и улучшающих кодированных данных отдельно.
(B) Блок 11 кодирования имеет функцию кодирования разности относительно весового коэффициента ребра в опорной NN.
(C) Блок 11 кодирования имеет функцию кодирования, в качестве информации NN-обновления, только частичной информации (например, послойной информации) опорной NN.
[0061] В дальнейшем описывается пример (A).
Блок 11 кодирования квантует весовой коэффициент ребра с использованием способа квантования, который задается заранее для весового коэффициента ребра, задает данные, полученные посредством кодирования квантованного весового коэффициента, в качестве базовых кодированных данных, и задает данные, полученные посредством кодирования ошибки квантования, которая считается весовым коэффициентом, в качестве улучшающих кодированных данных. Весовой коэффициент в качестве базовых кодированных данных имеет более низкую битовую точность, чем весовой коэффициент до квантования, вследствие квантования, и в силу этого размер данных уменьшается. Когда полоса частот передачи, используемая для того, чтобы передавать кодированные данные в сторону декодирования, не является достаточной, устройство обработки данных согласно первому варианту осуществления передает только базовые кодированные данные в сторону декодирования. С другой стороны, когда полоса частот передачи, используемая для того, чтобы передавать кодированные данные в сторону декодирования, является достаточной, устройство обработки данных согласно первому варианту осуществления передает не только базовые кодированные данные, но также и улучшающие кодированные данные в сторону декодирования.
[0062] Могут использоваться два или более фрагмента улучшающих кодированных данных. Например, блок 11 кодирования задает квантованное значение, полученное, когда ошибка квантования дополнительно квантуется, в качестве первых улучшающих кодированных данных, и задает его ошибку квантования в качестве вторых улучшающих кодированных данных. Кроме того, квантованное значение, полученное посредством дополнительного квантования квантованной ошибки вторых улучшающих кодированных данных, его и квантованная ошибка могут отдельно кодироваться таким образом, что требуемое число фрагментов улучшающих кодированных данных получается. В связи с этим, посредством использования масштабируемого кодирования, может выполняться передача кодированных данных на основе полосы частот передачи и допустимого времени передачи сети 2 передачи данных.
[0063] Следует отметить, что блок 11 кодирования может кодировать верхние M битов ненулевых данных весовых коэффициентов, показанных на фиг. 8, в качестве базовых кодированных данных, и разделять оставшуюся битовую строку на один или более блоков и получать один или более фрагментов улучшающих кодированных данных. В этом случае, блок 11 кодирования сбрасывает ненулевой флаг для каждых из базовых кодированных данных и улучшающих кодированных данных. Весовой коэффициент, который равен 0 в улучшающих кодированных данных верхнего бита, всегда равен 0.
[0064] В дальнейшем описывается (B).
Когда предусмотрена модель NN перед переобучением посредством обучающего блока 101, блок 11 кодирования может кодировать разность между весовым коэффициентом ребра в модели NN после переобучения и соответствующим весовым коэффициентом ребра в модели перед переобучением. Следует отметить, что переобучение включает в себя обучение с переносом или дополнительное обучение. В системе обработки данных, когда конфигурация NN обновляется с высокой частотой, или изменение распределения обучающих данных для каждого переобучения является небольшим, разность между весовыми коэффициентами ребер является небольшой, и в силу этого размер данных для кодированных данных после переобучения уменьшается.
[0065] Блок 11 кодирования включает в себя, в заголовке информации модели, идентификационный номер (reference_model_id) опорной модели для идентификации модели перед обновлением, на которую необходимо ссылаться, в дополнение к идентификационному номеру модели. В примере (B), модель перед переобучением может идентифицироваться из вышеописанного идентификационного номера опорной модели. Кроме того, блок 11 кодирования может задавать флаг (reference_model_present_flag), указывающий то, имеют или нет кодированные данные опорный источник, в заголовке информации модели. В этом случае, блок 11 кодирования сначала кодирует флаг (reference_model_present_flag), и только когда флаг указывает кодированные данные для обновления модели, блок 11 кодирования дополнительно задает идентификационный номер опорной модели в заголовке информации модели.
[0066] Например, в системе обработки данных, показанной на фиг. 1, даже когда частота NN-обновления отличается между клиентами, либо клиенты выполняют обработку данных с использованием различных моделей NN, клиенты могут надлежащим образом идентифицировать то, кодированные данные какой модели служат для обновления, посредством ссылки на идентификационный номер опорной модели. Когда из идентификационного номера опорной модели идентифицируется то, что кодированные данные для обновления модели представляют собой кодированные данные для модели, которая не доступна на клиентской стороне, клиент может информировать сервер 1 в отношении этого факта.
[0067] В дальнейшем описывается пример (C).
Когда предусмотрена модель NN перед переобучением, например, для целей подстройки, обучающий блок 101 может фиксировать любой один или более слоев с самого верхнего уровня (стороны входного слоя) NN и переобучать только один или более слоев. В этом случае, блок 11 кодирования кодирует только информацию, указывающую конфигурацию слоя, обновленного посредством переобучения. Как результат, в обновлении NN, размер данных для кодированных данных, которые должны передаваться в сторону декодирования, уменьшается. Следует отметить, что число (num_coded_layers) кодированных единиц данных слоя в кодированных данных меньше или равно числу (num_layers) единиц данных слоя в модели. Сторона декодирования может идентифицировать слой, который должен обновляться, посредством ссылки на идентификационный номер опорной модели, включенный в заголовок информации модели, и идентификационный номер слоя, включенный в заголовок информации слоя.
[0068] Далее описывается обработка данных, выполняемая посредством обучающего блока 101, блока 102 оценки и блока 202 логического вывода.
Фиг. 9 является схемой, показывающей пример процесса свертки для одномерных данных в первом варианте осуществления, и показывает сверточные слои, которые выполняют процесс свертки для одномерных данных. Одномерные данные включают в себя, например, аудиоданные и данные временных рядов. Сверточные слои, показанные на фиг. 9, включают в себя девять узлов 10-1 - 10-9 в предыдущем слое и три узла 11-1 - 11-3 в последующем слое. Ребрам 12-1, 12-6 и 12-11 назначается идентичный весовой коэффициент, ребрам 12-2, 12-7 и 12-12 назначается идентичный весовой коэффициент, ребрам 12-3, 12-8 и 12-13 назначается идентичный весовой коэффициент, ребрам 12-4, 12-9 и 12-14 назначается идентичный весовой коэффициент, и ребрам 12-5, 12-10 и 12-15 назначается идентичный весовой коэффициент. Помимо этого, весовые коэффициенты ребер 12-1 - 12-5 могут иметь различные значения, либо множество весовых коэффициентов могут иметь идентичное значение.
[0069] Из девяти узлов 10-1 - 10-9 в предыдущем слое, пять узлов соединяются с одним узлом в последующем слое с вышеописанными весовыми коэффициентами. Размер K ядра равен 5, и ядро задается посредством комбинации этих весовых коэффициентов. Например, как показано на фиг. 9, узел 10-1 соединяется с узлом 11-1 через ребро 12-1, узел 10-2 соединяется с узлом 11-1 через ребро 12-2, узел 10-3 соединяется с узлом 11-1 через ребро 12-3, узел 10-4 соединяется с узлом 11-1 через ребро 12-4, и узел 10-5 соединяется с узлом 11-1 через ребро 12-5. Ядро задается посредством комбинации весовых коэффициентов ребер 12-1 - 12-5.
[0070] Узел 10-3 соединяется с узлом 11-2 через ребро 12-6, узел 10-4 соединяется с узлом 11-2 через ребро 12-7, узел 10-5 соединяется с узлом 11-2 через ребро 12-8, узел 10-6 соединяется с узлом 11-2 через ребро 12-9, и узел 10-7 соединяется с узлом 11-2 через ребро 12-10. Ядро задается посредством комбинации весовых коэффициентов ребер 12-6 - 12-10.
[0071] Узел 10-5 соединяется с узлом 11-3 через ребро 12-11, узел 10-6 соединяется с узлом 11-3 через ребро 12-12, узел 10-7 соединяется с узлом 11-3 через ребро 12-13, узел 10-8 соединяется с узлом 11-3 через ребро 12-14, и узел 10-9 соединяется с узлом 11-3 через ребро 12-15. Ядро задается посредством комбинации весовых коэффициентов ребер 12-11 - 12-15.
[0072] В процессе для входных данных с использованием CNN, обучающий блок 101, блок 102 оценки и блок 202 логического вывода выполняют, для каждого ядра, операцию свертки с интервалами в число шагов (на фиг. 9, S=2) с использованием комбинации весовых коэффициентов ребер сверточного слоя. Комбинация весовых коэффициентов ребер определяется для каждого ядра посредством обучения. Следует отметить, что в CNN, используемой для распознавания изображений, NN зачастую формируется с использованием сверточного слоя, включающего в себя множество ядер.
[0073] Фиг. 10 является схемой, показывающей пример процесса свертки для двумерных данных в первом варианте осуществления и показывает процесс свертки для двумерных данных, таких как данные изображений. В двумерных данных, показанных на фиг. 10, ядро 20 представляет собой блочную область, размер которой в направлении по оси Х составляет Kx, и размер которой в направлении по оси Y составляет Ky. Размер K ядра составляет K=Kx*Ky. Обучающий блок 101, блок 102 оценки или блок 202 логического вывода выполняет операцию свертки данных для двумерных данных на основе ядра 20, с интервалами в число Sx шагов в направлении по оси Х и с интервалами в числом Sy шагов в направлении по оси Y. Здесь, шаги Sx и Sy являются целыми числами, большими или равными 1.
[0074] Фиг. 11 является схемой, показывающей матрицу поузловой информации весовых коэффициентов ребер в l-ом слое (l=1, 2, …, L), который представляет собой полностью соединенный слой NN. Фиг. 12 является схемой, показывающей матрицу шагов квантования для поузловой информации весовых коэффициентов ребер в l-ом слое (l=1, 2, …, L), который представляет собой полностью соединенный слой NN.
[0075] В NN, комбинации весовых коэффициентов wij для каждого слоя, показанного на фиг. 11, представляют собой данные, которые формируют сеть. Следовательно, в многослойной NN, такой как глубокая нейронная сеть, объем данных, в общем, составляет несколько сотен мегабайт или более, и требуется большой размер запоминающего устройства; i является индексом узла, и i=1, 2, …, Nl; j является индексом ребра, и j=1, 2, …, Nl-1+1 (в том числе и смещение).
[0076] Следовательно, чтобы уменьшать объем данных информации весовых коэффициентов ребер, устройство обработки данных согласно первому варианту осуществления квантует информацию весовых коэффициентов. Например, как показано на фиг. 12, шаг qij квантования задается для каждого весового коэффициента wij ребра. Шаг квантования может быть общим для множества индексов узлов или множества индексов ребер либо общим для множества индексов узлов и индексов ребер. Как результат, информация квантования, которая должна кодироваться, уменьшается.
[0077] Фиг. 13 является схемой, показывающей матрицу информации весовых коэффициентов ребер в сверточном слое. Фиг. 14 является схемой, показывающей матрицу шагов квантования для информации весовых коэффициентов ребер в сверточном слое. В сверточном слое, весовой коэффициент ребра для одного ядра является общим для всех узлов, и посредством уменьшения числа ребер, соединенных в расчете на узел, т.е. размера K ядра, ядро может формироваться в небольшую область. Фиг. 13 является данными, в которых весовой коэффициент wi'j' ребра задается для каждого ядра, и фиг. 14 является данными, в которых шаг qi'j' квантования задается для каждого ядра. Следует отметить, что i' является индексом ядра, и i'=1, 2, …, Ml (l=1, 2, …, L); j' является индексом ребра, и j'=1, 2, …, Kl+1 (в том числе и смещение).
[0078] Шаг квантования может быть общим для множества индексов ядер, множества индексов ребер или множества индексов ядер и индексов ребер. Как результат, информация квантования, которая должна кодироваться, уменьшается. Например, все шаги квантования в слое могут представлять собой общий шаг квантования, и в силу этого один шаг квантования используется для одного слоя, или все шаги квантования в модели могут представлять собой общий шаг квантования, и в силу этого один шаг квантования может использоваться для одной модели.
[0079] Фиг. 15 является блок-схемой, показывающей конфигурацию разновидности устройства обработки данных (кодера) согласно первому варианту осуществления. Устройство обработки данных, показанное на фиг. 15, представляет собой первое устройство обработки данных, которое обучает NN с использованием набора обучающих данных и набора оценочных данных и формирует кодированные данные информации модели NN и, например, представляет собой сервер 1, показанный на фиг. 1. Устройство обработки данных, показанное на фиг. 15, включает в себя блок 10A обработки данных, блок 11 кодирования и блок 12 декодирования.
[0080] Блок 10A обработки данных представляет собой блок обработки данных, который создает и обучает NN, и включает в себя обучающий блок 101A, блок 102 оценки и блок 103 управления. Блок 11 кодирования кодирует информацию модели, сформированную посредством обучающего блока 101A, за счет этого формируя кодированные данные, включающие в себя информацию заголовка, и послойные кодированные данные. Блок 12 декодирования декодирует информацию модели из кодированных данных, сформированных посредством блока 11 кодирования. Помимо этого, блок 12 декодирования выводит декодированную информацию модели в обучающий блок 101A.
[0081] Аналогично обучающему блоку 101, обучающий блок 101A обучает NN с использованием набора обучающих данных и формирует информацию модели, указывающую конфигурацию обученной NN. Помимо этого, обучающий блок 101A создает NN с использованием декодированной информации модели и переобучает параметры созданной NN с использованием набора обучающих данных.
[0082] После вышеописанного переобучения, посредством выполнения переобучения с фиксированными некоторыми весовыми коэффициентами ребер, увеличение точности может достигаться, тогда как размер данных для кодированных данных поддерживается небольшим. Например, посредством выполнения переобучения с весовым коэффициентом, ненулевой флаг которого равен 0, фиксированно равным 0, оптимизация весовых коэффициентов является возможной, тогда как предотвращается превышение или равенство, посредством размера данных для кодированных данных, размеру данных для кодированных данных для весовых коэффициентов ребер перед переобучением.
[0083] Устройство обработки данных включает в себя блок 12 декодирования, и блок 10A обработки данных обучает NN с использованием информации, декодированной посредством блока 12 декодирования. Таким образом, например, даже когда блок 11 кодирования выполняет необратимое кодирование, посредством которого возникает искажение при кодировании, устройство обработки данных может создавать и обучать NN на основе фактических результатов декодирования кодированных данных и в силу этого может обучать NN таким образом, который минимизирует влияние ошибок кодирования, при обстоятельствах, при которых налагается ограничение на размер данных кодированных данных.
[0084] В системе обработки данных, которая имеет конфигурацию, идентичную конфигурации на фиг. 1, и включает в себя устройство обработки данных, показанное на фиг. 3 в качестве сервера 1, и включает себя устройства обработки данных, показанные на фиг. 4 в качестве клиентов 3-1, 3-2, …, 3-N, данные, выведенные из промежуточного слоя NN, могут использоваться в качестве одного или более признаков обработки данных для данных изображений и аудиоданных, например, извлечения или сопоставления изображений, описанного в нижеприведенном справочном документе 1.
Справочный документ 1. ISO/IEC JTC1/SC29/WG11/m39219, "Improved retrieval and matching with CNN feature for CDVA", Chengdu, China, октябрь 2016 года.
[0085] Например, когда выходные данные из промежуточного слоя NN используются в качестве признаков изображений для обработки изображений, такой как извлечение, согласование изображений или отслеживание объектов, замена или добавление признаков изображений выполняется для гистограммы ориентированных градиентов (HOG), масштабно-инвариантного преобразования признаков (SIFT) или ускоренных надежных признаков (SURF), которые представляют собой признаки изображений, используемые в вышеописанной традиционной обработке изображений. Как результат, посредством процедуры обработки, идентичной процедуре обработки изображений, которая использует традиционные признаки изображений, обработка изображений может реализовываться. В системе обработки данных согласно первому варианту осуществления, блок 11 кодирования кодирует информацию модели, указывающую конфигурацию части NN вплоть до промежуточного слоя, которая выводит признаки изображений.
[0086] Кроме того, устройство обработки данных, которое функционирует в качестве сервера 1, выполняет обработку данных, такую как извлечение изображения, с использованием признаков для вышеописанной обработки данных. Устройство обработки данных, которое функционирует в качестве клиента, создает NN вплоть до промежуточного слоя из кодированных данных и выполняет обработку данных, такую как извлечение изображений, с использованием, в качестве признаков, данных, выведенных из промежуточного слоя созданной NN.
[0087] В системе обработки данных, блок 11 кодирования кодирует информацию модели, указывающую конфигурацию NN вплоть до промежуточного слоя, в силу чего коэффициент сжатия данных параметров посредством квантования увеличивается, за счет этого обеспечивая уменьшение объема данных информации весовых коэффициентов перед кодированием. Клиент создает NN с использованием информации модели, декодированной посредством блока 201 декодирования, и выполняет обработку данных, которая использует, в качестве признаков, данные, выведенные из промежуточного слоя созданной NN.
[0088] Помимо этого, система обработки данных согласно первому варианту осуществления имеет конфигурацию, идентичную конфигурации на фиг. 1, и может включать в себя устройство обработки данных, показанное на фиг. 3 или 15 в качестве сервера 1, и включать себя устройства обработки данных, показанные на фиг. 4 в качестве клиентов 3-1, 3-2, …, 3-N. В системе обработки данных, имеющей эту конфигурацию, флаг (new_layer_flag) нового слоя задается в кодированных данных. Когда флаг нового слоя равен 0 ("ложь"), слой, соответствующий флагу нового слоя, представляет собой слой, который должен обновляться со ссылкой на опорный слой. Когда флаг нового слоя равен 1 ("истина"), слой, соответствующий флагу нового слоя, представляет собой слой, который должен добавляться впервые.
[0089] Когда флаг нового слоя равен 0 ("ложь"), флаг (channel_wise_update_flag) для идентификации того, обновляются или нет весовые коэффициенты ребер на поканальной основе, задается для слоя, соответствующего флагу нового слоя. Когда флаг равен 0 ("ложь"), весовые коэффициенты ребер для всех каналов кодируются. Когда флаг равен 1 ("истина"), флаг (channel_update_flag) обновления поканальных весовых коэффициентов задается. Этот флаг обновления представляет собой флаг, указывающий, для каждого канала, то, выполняется или нет обновление из опорного слоя. Когда флаг обновления равен 1 ("истина"), весовой коэффициент для соответствующего канала кодируется, и когда флаг обновления равен 0 ("ложь"), весовой коэффициент, идентичный весовому коэффициенту опорного слоя, задается.
[0090] Кроме того, в качестве заголовка информации слоя, задается информация (num_channels), указывающая число каналов в слое, и информация (weights_per_channels), указывающая число поканальных весовых коэффициентов ребер; weights_per_channels для данного слоя l указывает размер Kl+1 ядра или число ребер Nl-1+1 из слоя l-1, который представляет собой непосредственно предыдущий слой.
[0091] Посредством включения вышеуказанного флага нового слоя в кодированные данные, число каналов и число поканальных весовых коэффициентов могут идентифицироваться только из кодированных данных единицы данных слоя. Таким образом, в процессе декодирования для единицы данных слоя, флаг обновления поканальных весовых коэффициентов может декодироваться.
[0092] Помимо этого, случай, в котором флаг для идентификации того, обновляются или нет весовые коэффициенты на поканальной основе, задается равным 1 ("истина"), ограничен, когда число каналов является идентичным числу каналов опорного слоя. Причина для этого состоит в том, что, когда число каналов отличается от числа каналов опорного слоя, взаимосвязь соответствия между каналами является неизвестной между опорным слоем и слоем, соответствующим вышеописанному флагу.
[0093] Фиг. 16 является схемой, показывающей общее представление обновления кодированных данных в первом варианте осуществления. На фиг. 16, данные, показанные сверху, включают в себя единицу данных без слоя и единицы (1)-(4) данных слоя, и как показано на фиг. 7, кодирование выполняется по очереди из единицы (4) данных слоя. В единице данных без слоя, в качестве информации заголовков моделей, задается идентификационный номер (model_id) модели = 0, число (num_layers) единиц данных слоя в модели = 4, информация (model_structure_information) структуры слоев и идентификационная информация (layer_id_information) слоев, и флаг (reference_model_present_flag), указывающий то, имеют или нет кодированные данные опорный источник, задается равным 0 ("ложь").
[0094] В единице (1) данных слоя, идентификационный номер (layer_id) слоя задается равным 0, информация (num_channels), указывающая число каналов (фильтров или ядер) в слое, задается равной 32, и информация (weights_per_channels), указывающая число поканальных (пофильтровых или поядерных) весовых коэффициентов (включающих в себя значения смещения), задается равной 76. Помимо этого, в единице (2) данных слоя, идентификационный номер (layer_id) слоя задается равным 1, информация (num_channels), указывающая число каналов в слое, задается равной 64, и информация (weights_per_channels), указывающая число поканальных весовых коэффициентов, задается равной 289.
[0095] В единице (3) данных слоя идентификационный номер (layer_id) слоя задается равным 2, информация (num_channels), указывающая число каналов в слое, задается равной 128, и информация (weights_per_channels), указывающая число поканальных весовых коэффициентов, задается равной 577. Помимо этого, в единице (4) данных слоя, идентификационный номер (layer_id) слоя задается равным 3, информация (num_channels), указывающая число каналов в слое, задается равной 100, и информация (weights_per_channels), указывающая число поканальных весовых коэффициентов, задается равной 32769.
[0096] На фиг. 16, данные, показанные в нижней части, представляют собой данные, обновленные из данных, показанных сверху, с использованием информации структуры слоев, флага обновления слоя и флага нового слоя, и включают в себя единицу данных без слоя и единицы (1'), (2), (3), (5) и (4') данных слоя. Единица данных без слоя и единицы (1'), (5) и (4') данных слоя должны передаваться ("Должны передаваться") клиенту, которому переданы данные, показанные сверху, но единицы (2) и (3) данных слоя не обновляются и в силу этого не должны передаваться ("Не должны передаваться") клиенту.
[0097] В единице данных без слоя, показанной в нижней части по фиг. 16, в качестве информации заголовков моделей, задается идентификационный номер (model_id) модели = 10, число (num_layers) единиц данных слоя в модели = 5, информация (model_structure_information) структуры слоев и идентификационная информация (layer_id_information) слоев, и флаг (reference_model_present_flag), указывающий то, имеют или нет кодированные данные опорный источник, задается равным 1 ("истина"), идентификационный номер (reference_mode_id) опорной модели задается равным 0, и число (num_coded_layers) кодированных единиц данных слоя задается равным 3.
[0098] В единице (1') данных слоя, идентификационный номер (layer_id) слоя равен 0, флаг (new_layer_flag) нового слоя задается равным 0, информация (num_channels), указывающая число каналов в слое, задается равной 32, и информация (weights_per_channels), указывающая число поканальных весовых коэффициентов, задается равной 76. Помимо этого, флаг (channel_wise_update_flag) для идентификации того, обновляются или нет весовые коэффициенты на поканальной основе, задается равным 1 ("истина"), и в силу этого флаг (channel_update_flag) обновления поканальных весовых коэффициентов задается.
[0099] Единица (2) данных слоя, идентификационный номер (layer_id) слоя которой равен 1, и единица (3) данных слоя, идентификационный номер (layer_id) слоя которой равен 2, не представляют собой цели обновления и в силу этого не включаются в кодированные данные. Следовательно, в вышеописанной информации заголовков моделей, задается число (num_layers) единиц данных слоя в модели = 5, и число (num_coded_layers) кодированных единиц данных слоя = 3.
[0100] В единице (5) данных слоя, идентификационный номер (layer_id) слоя равен 4, и флаг (new_layer_flag) нового слоя задается равным 1 ("истина"). Помимо этого, информация (num_channels), указывающая число каналов в слое, задается равной 256, и информация (weights_per_channels), указывающая число поканальных весовых коэффициентов, задается равной 1153.
[0101] В единице (4') данных слоя, идентификационный номер (layer_id) слоя равен 3, флаг (new_layer_flag) нового слоя задается равным 0, информация (num_channels), указывающая число каналов в слое, задается равной 100, и информация (weights_per_channels), указывающая число поканальных весовых коэффициентов, задается равной 16385. Помимо этого, флаг (channel_wise_update_flag) для идентификации того, обновляются или нет весовые коэффициенты на поканальной основе, задается равным 0 ("ложь"), и отсутствует обновление поканальных весовых коэффициентов.
[0102] В данных, показанных в нижней части, единицы (1) и (4) данных слоя в данных, показанных сверху, обновляются на единицы (1') и (4') данных слоя, и кроме того, единица (5) данных слоя, идентификационный номер слоя которой равен 4, добавляется.
[0103] Фиг. 17 является схемой, показывающей конфигурации сетевых моделей, соответствующих обновлению кодированных данных, показанных на фиг. 16. На фиг. 17, сетевая модель, показанная слева, представляет собой сетевую модель, реализованную посредством декодирования данных, показанных поверх фиг. 16. Помимо этого, сетевая модель, показанная справа, представляет собой сетевую модель, реализованную посредством декодирования данных, показанных в нижней части по фиг. 16.
[0104] В единице (1') данных слоя, поскольку флаг (channel_wise_update_flag) для идентификации того, обновляются или нет весовые коэффициенты на поканальной основе, равен 1, весовые коэффициенты для нескольких каналов обновляются из единицы (1) данных слоя. Помимо этого, посредством добавления единицы (5) данных слоя и обновления единицы (4) данных слоя на единицу (4') данных слоя, в сетевой модели, показанной справа, двумерный сверточный слой и двумерный слой объединения в пул по максимуму добавляются перед полностью соединенным слоем.
[0105] Фиг. 18 является схемой, показывающей примеры информации структуры слоев, включенной в заголовок информации модели. Что касается всей информации (model_structure_information) структуры слоев, включенной в заголовок информации модели, может задаваться текстовая информация, такая как текстовая информация, показанная на фиг. 18. Текстовая информация, показанная на фиг. 18, представляет собой текстовую информацию, указывающую структуру слоев на основе модели по стандарту, описанному в справочном документе 2, называемому "форматом обмена данными в нейронных сетях (NNEF)".
Справочный документ 2. "Neural Network Exchange Format", рабочая группа NNEF Khronos, версия 1.0, исправление 3, 13.06.2018.
[0106] На фиг. 18, (A) сетевая модель с model_id = 0 представляет собой сетевую модель, соответствующую данным, показанным поверх фиг. 16 (сетевую модель, показанную слева по фиг. 17). (B) Сетевая модель с model_id = 10 представляет собой сетевую модель, соответствующую данным, показанным в нижней части по фиг. 16 (сетевую модель, показанную справа по фиг. 17).
[0107] Фиг. 19 является схемой, показывающей примеры идентификационной информации (layer_id_information) слоев, соответствующей информации структуры слоев, включенной в заголовок информации модели, и показывает идентификационную информацию слоев, в которой задаются идентификационные номера слоев, соответствующие информации структуры слоев по фиг. 18. На фиг. 19, (A) сетевая модель с model_id=0 имеет идентификационную информацию слоев, соответствующую сетевой модели, показанной слева по фиг. 17. (B) сетевая модель с model_id=10 имеет идентификационную информацию слоев, соответствующую сетевой модели, показанной справа по фиг. 17. Весовой коэффициент и значение смещения каждого слоя назначаются соответствующему идентификационному номеру слоя, и их значения соответствуют данным, показанным на фиг. 16.
[0108] В конфигурации кодированных данных, фрагментах файловых данных файла, в которых описываются model_structure_information, которая представляет собой информацию структуры всех слоев, и layer_id_information, которая представляет собой информацию, указывающую идентификационные номера слоев, соответствующие информации структуры всех слоев и т.д., включаются таким образом, что в заголовке информации модели, каждый из фрагментов файловых данных вставляется после информации, указывающей число байтов соответствующих одного из фрагментов файловых данных. Альтернативно, также можно приспосабливать другую конфигурацию, в которой универсальный указатель ресурса (URL-адрес), указывающий то, где расположены фрагменты файловых данных, включается в заголовок информации модели. Кроме того, чтобы иметь возможность выбирать любую из этих конфигураций, флаг, который идентифицирует то, какая конфигурация используется, может задаваться перед фрагментами файловых данных или URL-адреса в заголовке информации модели. Вышеописанный флаг идентификационных данных может быть общим для model_structure_information и layer_id_information либо может отдельно задаваться для model_structure_information и layer_id_information. В первом случае, объем информации заголовка информации модели может уменьшаться, а во втором случае, флаг идентификационных данных может независимо задаваться в зависимости от предварительного условия при использовании.
Кроме того, заголовок информации модели включает в себя информацию, указывающую формат вышеописанной текстовой информации. Например, информация указывает то, что NNEF имеет индекс 0, и другие форматы имеют индекс 1 или более. Как результат, то, в каком формате описывается текстовая информация, может идентифицироваться, и декодирование может выполняться надлежащим образом.
[0109] Следует отметить, что информация структуры слоев и информация, указывающая идентификационные номера слоев, соответствующие информации структуры слоев, которые указываются посредством соответствующих фрагментов текстовой информации, таких как фрагменты, показанные на фиг. 18 и 19, могут применяться ко всем системам, показанным в первом варианте осуществления. Кроме того, посредством model_structure_information и layer_id_information, то, данным какого слоя в модели соответствует каждая единица данных слоя, может идентифицироваться только из кодированных данных. Таким образом, когда модель обновляется (когда reference_model_present_flag является истинным), также можно задавать, в качестве опорной модели, модель, которая не создается из кодированных данных, показанных в настоящем варианте осуществления. А именно, посредством включения, в кодированные данные, показанные в настоящем варианте осуществления, model_structure_information и layer_id_information в качестве части заголовка информации модели, любая модель может задаваться в качестве опорной модели. Следует отметить, что в этом случае существует потребность в том, чтобы отдельно задавать ассоциирования между идентификационными номерами опорных моделей (reference_model_id) и соответствующими опорными моделями.
[0110] Далее описывается аппаратная конфигурация, которая реализует функции устройства обработки данных согласно первому варианту осуществления. Функции блока 10 обработки данных и блока 11 кодирования в устройстве обработки данных согласно первому варианту осуществления реализуются посредством схемы обработки. А именно, устройство обработки данных согласно первому варианту осуществления включает в себя схему обработки для выполнения процессов от этапа ST1 до этапа ST6 по фиг. 5. Схема обработки может представлять собой специализированные аппаратные средства, но может представлять собой центральный процессор (CPU), который выполняет программы, сохраненные в запоминающем устройстве.
[0111] Фиг. 20A является блок-схемой, показывающей аппаратную конфигурацию, которая реализует функции устройства обработки данных согласно первому варианту осуществления. На фиг. 20A, схема 300 обработки представляет собой специализированную схему, которая функционирует в качестве устройства обработки данных, показанного на фиг. 3. Фиг. 20B является блок-схемой, показывающей аппаратную конфигурацию, которая выполняет программное обеспечение, которое реализует функции устройства обработки данных согласно первому варианту осуществления. На фиг. 20B, процессор 301 и запоминающее устройство 302 соединяются между собой посредством сигнальной шины.
[0112] Когда вышеописанная схема обработки представляет собой специализированные аппаратные средства, показанные на фиг. 20A, схема 300 обработки соответствует, например, одной схеме, комбинированной схеме, программируемому процессору, параллельно программируемому процессору, специализированной интегральной схеме (ASIC), программируемой пользователем вентильной матрице (FPGA) либо комбинации вышеозначенного. Следует отметить, что функции блока 10 обработки данных и блока 11 кодирования могут реализовываться посредством различных схем обработки, или функции могут совместно реализовываться посредством одной схемы обработки.
[0113] Когда вышеописанная схема обработки представляет собой процессор, показанный на фиг. 20B, функции блока 10 обработки данных и блока 11 кодирования реализуются посредством программного обеспечения, микропрограммного обеспечения либо комбинации программного обеспечения и микропрограммного обеспечения. Программное обеспечение или микропрограммное обеспечение описывается как программы и сохраняется в запоминающем устройстве 302. Процессор 301 реализует функции блока 10 обработки данных и блока 11 кодирования посредством считывания и выполнения программ, сохраненных в запоминающем устройстве 302. А именно, устройство обработки данных согласно первому варианту осуществления включает в себя запоминающее устройство 302 для сохранения программ, которые, при выполнении посредством процессора 301, инструктируют последовательное выполнение процессов от этапа ST1 до этапа ST6, показанных на фиг. 5. Программы инструктируют компьютеру выполнять процедуры или способы, осуществляемые в блоке 10 обработки данных и блоке 11 кодирования. Запоминающее устройство 302 может представлять собой машиночитаемый носитель хранения данных, имеющий сохраненные программы для инструктирования компьютеру функционировать в качестве блока 10 обработки данных и блока 11 кодирования.
[0114] Запоминающее устройство 302 соответствует, например, энергонезависимому или энергозависимому полупроводниковому запоминающему устройству, такому как оперативное запоминающее устройство (RAM), постоянное запоминающее устройство (ROM), флэш-память, стираемое программируемое постоянное запоминающее устройство (EPROM) или электрически-EPROM (EEPROM), магнитный диск, гибкий диск, оптический диск, компакт-диск, минидиск или DVD.
[0115] Следует отметить, что некоторые функции блока 10 обработки данных и блока 11 кодирования могут реализовываться посредством специализированных аппаратных средств, и некоторые функции могут реализовываться посредством программного обеспечения или микропрограммного обеспечения. Например, функции блока 10 обработки данных могут реализовываться посредством схемы обработки, которая представляет собой специализированные аппаратные средства, и функция блока 11 кодирования может реализовываться посредством процессора 301, считывающего и выполняющего программу, сохраненную в запоминающем устройстве 302. В связи с этим, схема обработки может реализовывать каждую из вышеописанных функций посредством аппаратных средств, программного обеспечения, микропрограммного обеспечения либо комбинации вышеозначенного.
[0116] Следует отметить, что хотя описывается устройство обработки данных, показанное на фиг. 3, то же самое также применяется к устройству обработки данных, показанному на фиг. 4. Например, устройство обработки данных, показанное на фиг. 4, включает в себя схему обработки для выполнения процессов на этапах ST11-ST13 по фиг. 6. Схема обработки может представлять собой специализированные аппаратные средства, но может представлять собой CPU, который выполняет программы, сохраненные в запоминающем устройстве.
[0117] Когда вышеописанная схема обработки представляет собой специализированные аппаратные средства, показанные на фиг. 20A, схема 300 обработки соответствует, например, одной схеме, комбинированной схеме, программируемому процессору, параллельно программируемому процессору, ASIC, FPGA либо комбинации вышеозначенного. Следует отметить, что функции блока 201 декодирования и блока 202 логического вывода могут реализовываться посредством различных схем обработки, или функции могут совместно реализовываться посредством одной схемы обработки.
[0118] Когда вышеописанная схема обработки представляет собой процессор, показанный на фиг. 20B, функции блока 201 декодирования и блока 202 логического вывода реализуются посредством программного обеспечения, микропрограммного обеспечения либо комбинации программного обеспечения и микропрограммного обеспечения. Программное обеспечение или микропрограммное обеспечение описывается как программы и сохраняется в запоминающем устройстве 302. Процессор 301 реализует функции блока 201 декодирования и блока 202 логического вывода посредством считывания и выполнения программ, сохраненных в запоминающем устройстве 302. А именно, устройство обработки данных, показанное на фиг. 4, включает в себя запоминающее устройство 302 для сохранения программ, которые, при выполнении посредством процессора 301, инструктируют последовательное выполнение процессов на этапе ST11-ST13, показанных на фиг. 6. Программы инструктируют компьютеру выполнять процедуры или способы, осуществляемые в блоке 201 декодирования и блоке 202 логического вывода. Запоминающее устройство 302 может представлять собой машиночитаемый носитель хранения данных, имеющий сохраненные программы для инструктирования компьютеру функционировать в качестве блока 201 декодирования и блока 202 логического вывода.
[0119] Следует отметить, что одна из функций блока 201 декодирования и блока 202 логического вывода может реализовываться посредством специализированных аппаратных средств, и другая из функций может реализовываться посредством программного обеспечения или микропрограммного обеспечения. Например, функция блока 201 декодирования может реализовываться посредством схемы обработки, которая представляет собой специализированные аппаратные средства, и функция блока 202 логического вывода может реализовываться посредством процессора 301, считывающего и выполняющего программу, сохраненную в запоминающем устройстве 302.
[0120] Как описано выше, в устройстве обработки данных согласно первому варианту осуществления, когда блок 11 кодирования кодирует информацию структуры слоев и кодирует флаг обновления слоя, и флаг обновления слоя указывает обновление структуры слоев, флаг нового слоя кодируется. Из фрагментов данных, представляющих структуру NN, только информация относительно обновленного слоя кодируется и передается, и в силу этого размер данных фрагментов данных, представляющих структуру NN, может уменьшаться.
[0121] Помимо этого, блок 11 кодирования кодирует информацию, указывающую конфигурацию NN, за счет этого формируя кодированные данные, включающие в себя информацию заголовка и послойные кодированные данные. Поскольку только информация относительно слоя, требуемого для стороны декодирования, может кодироваться, нагрузка по обработке для кодирования информации относительно конфигурации NN уменьшается, и может достигаться уменьшение размера данных, которые должны передаваться в сторону декодирования.
[0122] В устройстве обработки данных согласно первому варианту осуществления, блок 11 кодирования кодирует информацию весовых коэффициентов ребер, принадлежащих слою NN, на основе каждой битовой плоскости с верхних битов. Таким образом, размер данных для кодированных данных, которые должны передаваться в сторону декодирования, может уменьшаться.
[0123] В устройстве обработки данных согласно первому варианту осуществления, блок 11 кодирования кодирует информацию относительно одного или более слоев, указываемых посредством информации заголовка. Таким образом, только информация относительно слоя, требуемого для стороны декодирования, кодируется, за счет этого обеспечивая уменьшение размера данных для кодированных данных, которые должны передаваться в сторону декодирования.
[0124] В устройстве обработки данных согласно первому варианту осуществления, блок 11 кодирования кодирует разность между значением весового коэффициента ребра, принадлежащего слою, указываемому посредством информации заголовка, и конкретным значением. Таким образом, размер данных для кодированных данных, которые должны передаваться в сторону декодирования, может уменьшаться.
[0125] В устройстве обработки данных согласно первому варианту осуществления, блок 11 кодирования кодирует информацию весовых коэффициентов ребер в качестве базовых кодированных данных и улучшающих кодированных данных отдельно. Таким образом, может реализовываться передача кодированных данных на основе полосы частот передачи и допустимого времени передачи сети 2 передачи данных.
[0126] Следует отметить, что настоящее изобретение не ограничено вышеописанными вариантами осуществления, и свободная комбинация вариантов осуществления, модификация любого компонента в каждом из вариантов осуществления либо опускание любого компонента в каждом из вариантов осуществления является возможным в пределах объема настоящего изобретения.
Промышленная применимость
[0127] Устройство обработки данных согласно настоящему изобретению может использоваться, например, для технологии распознавания изображений.
Список номеров ссылок
[0128] 1 - сервер, 2 - сеть передачи данных, 3-1 - 3-N - клиент, 10, 10A - блок обработки данных, 10-1 - 10-9, 11-1 - 11-3 - узел, 11 - блок кодирования, 12 - блок декодирования, 12-1 - 12-15 - ребро, 20 - ядро, 101, 101A - обучающий блок, 102 - блок оценки, 103 - блок управления, 201 - блок декодирования, 202 - блок логического вывода, 300 - схема обработки, 301 - процессор, 302 - запоминающее устройство.
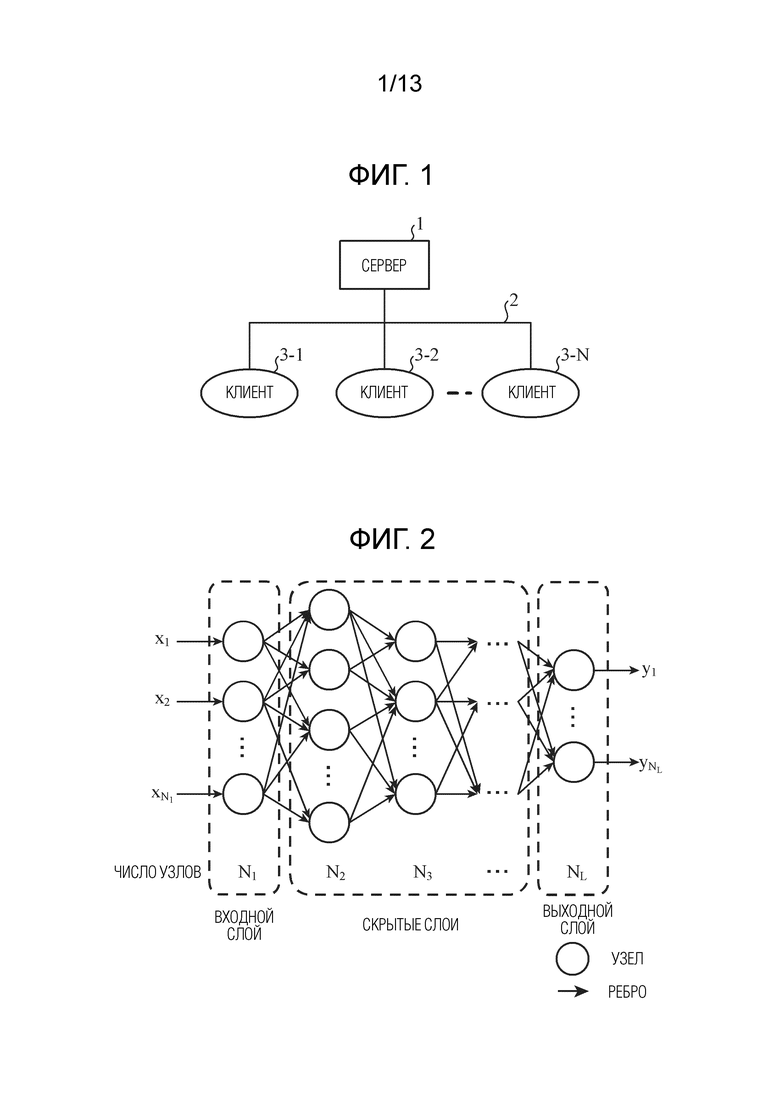
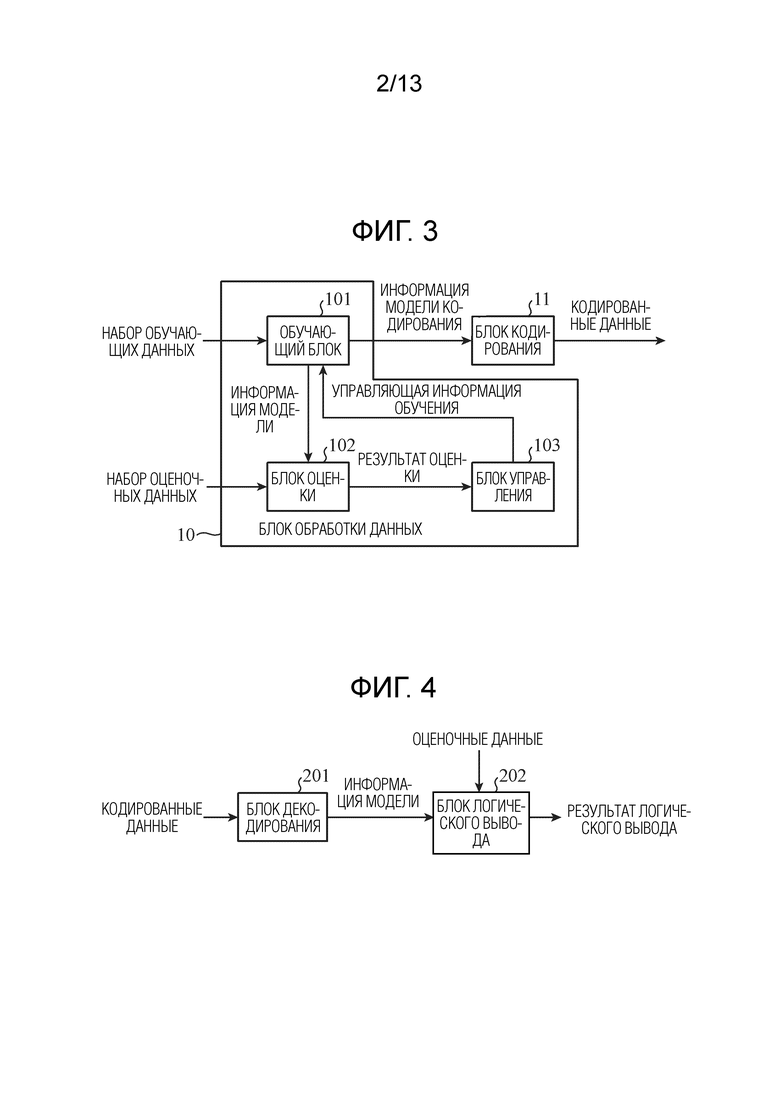
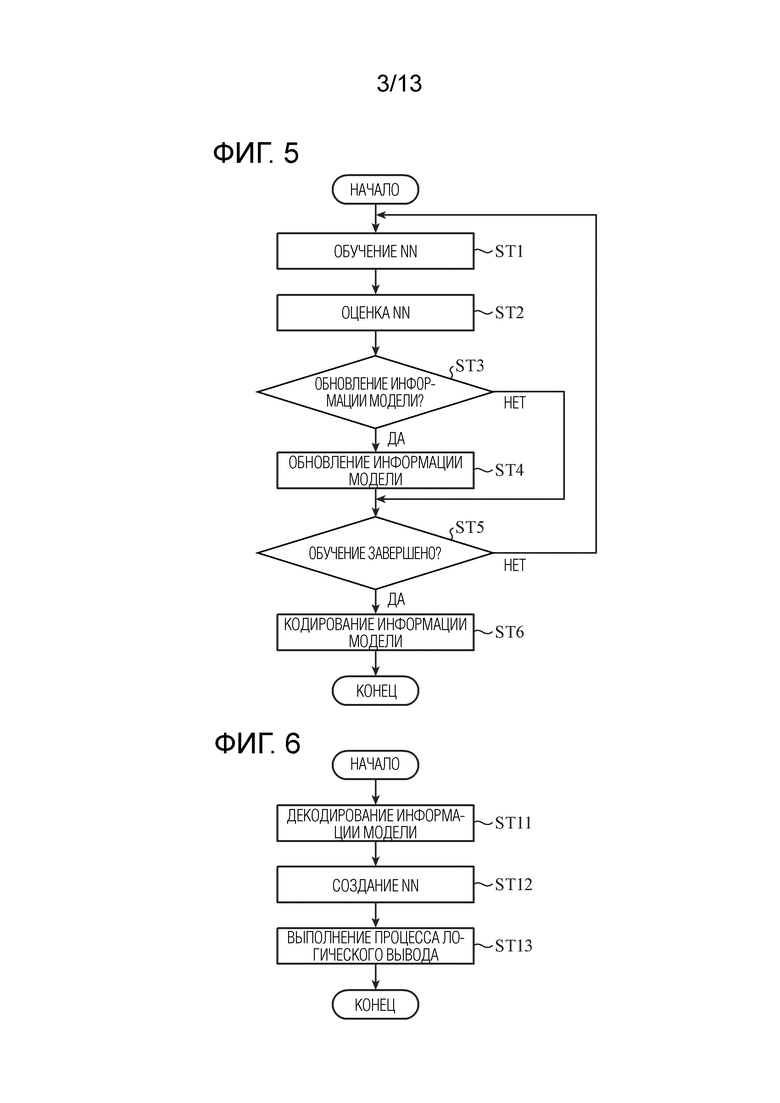
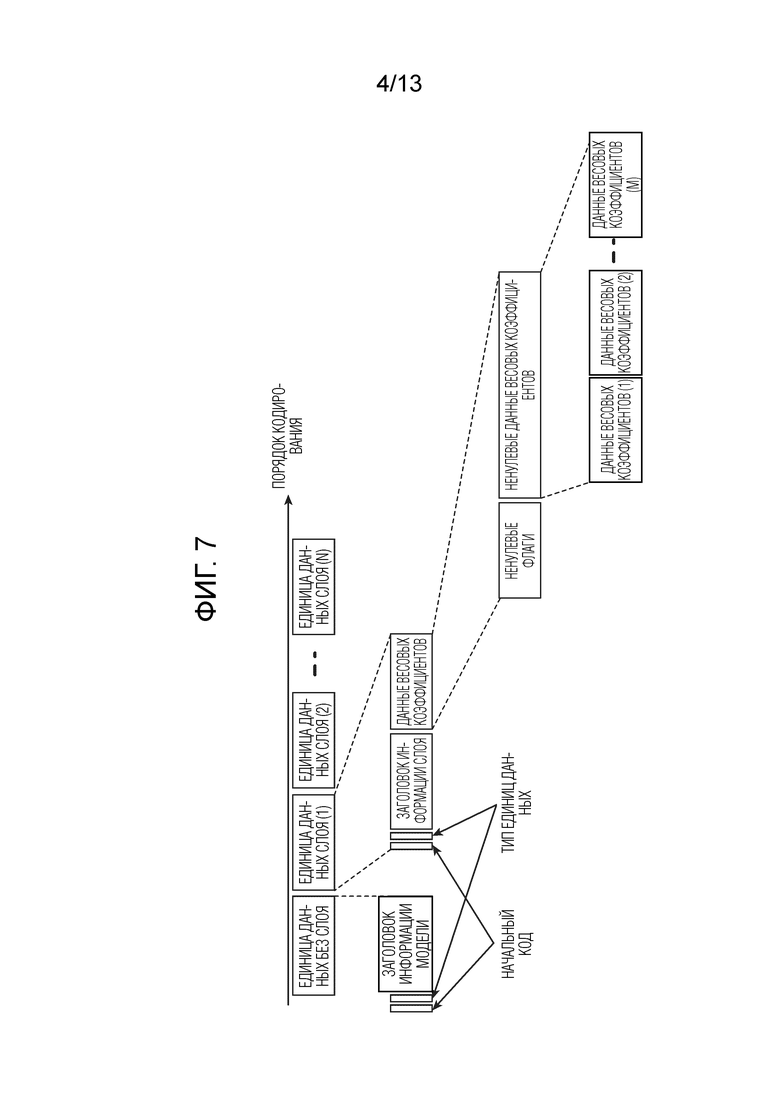
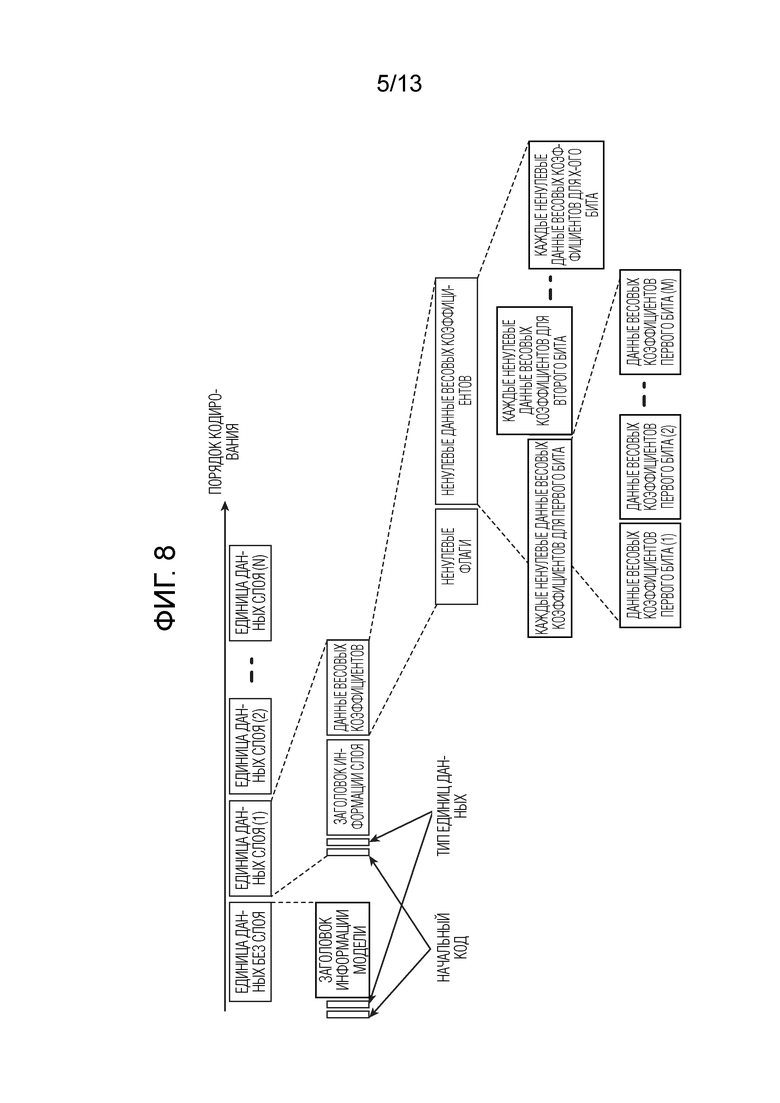
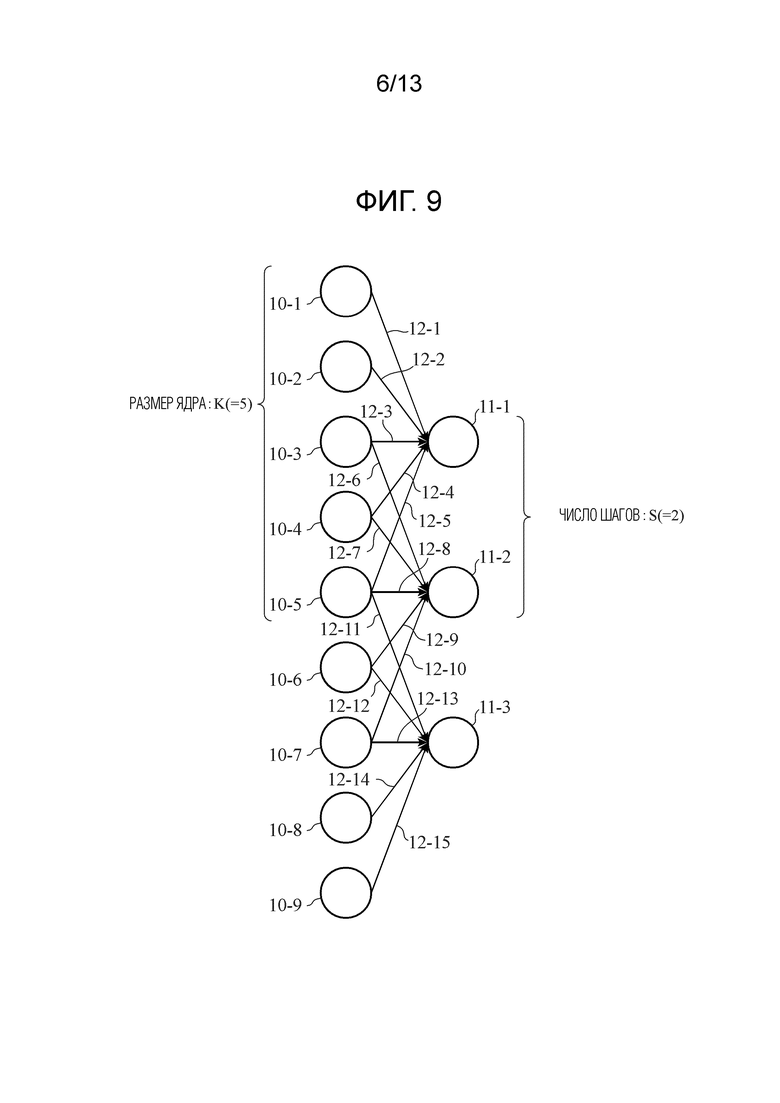
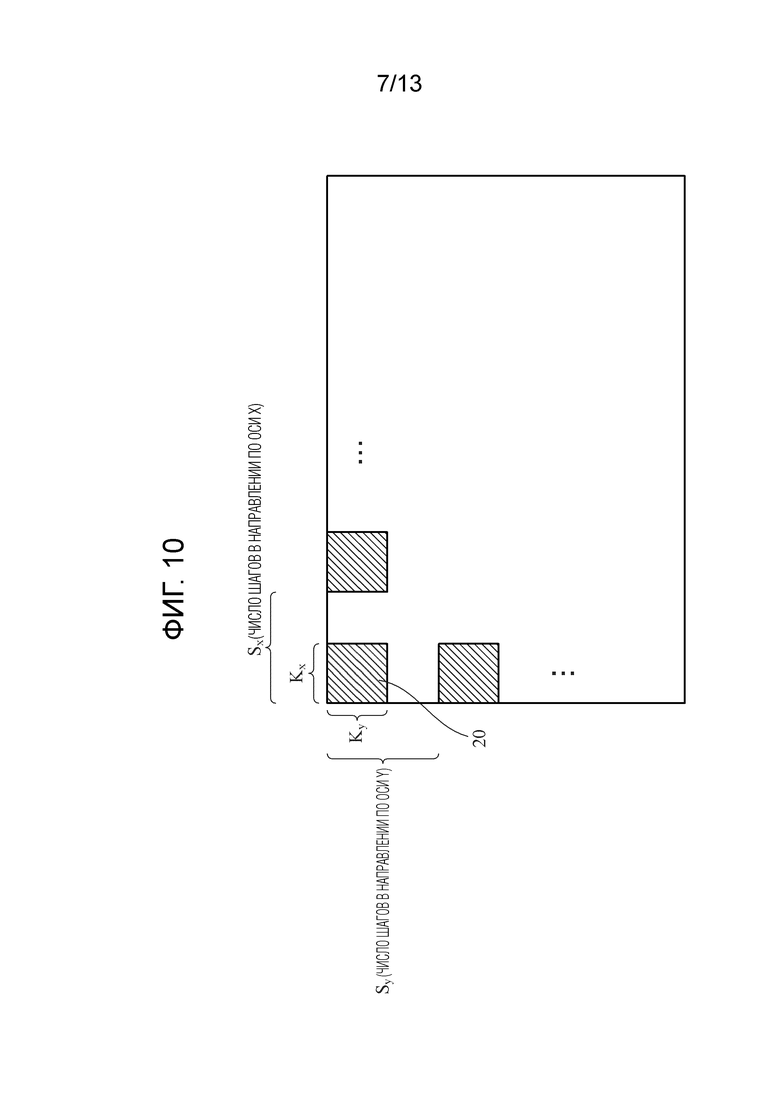
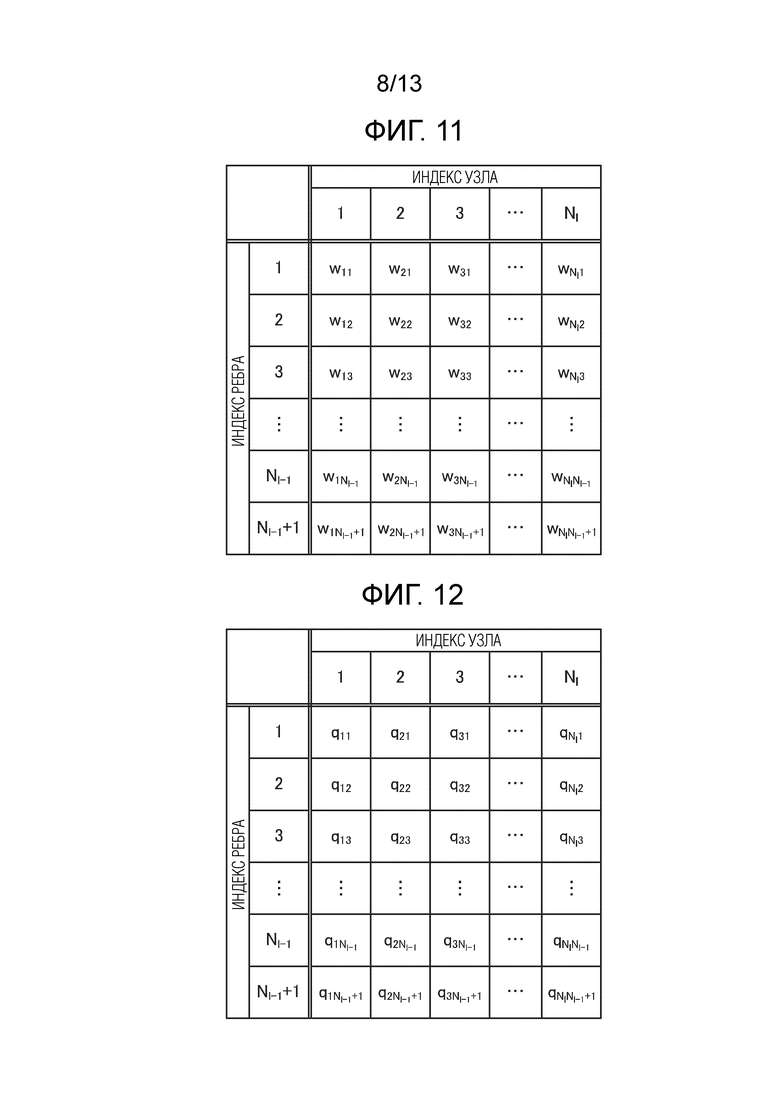
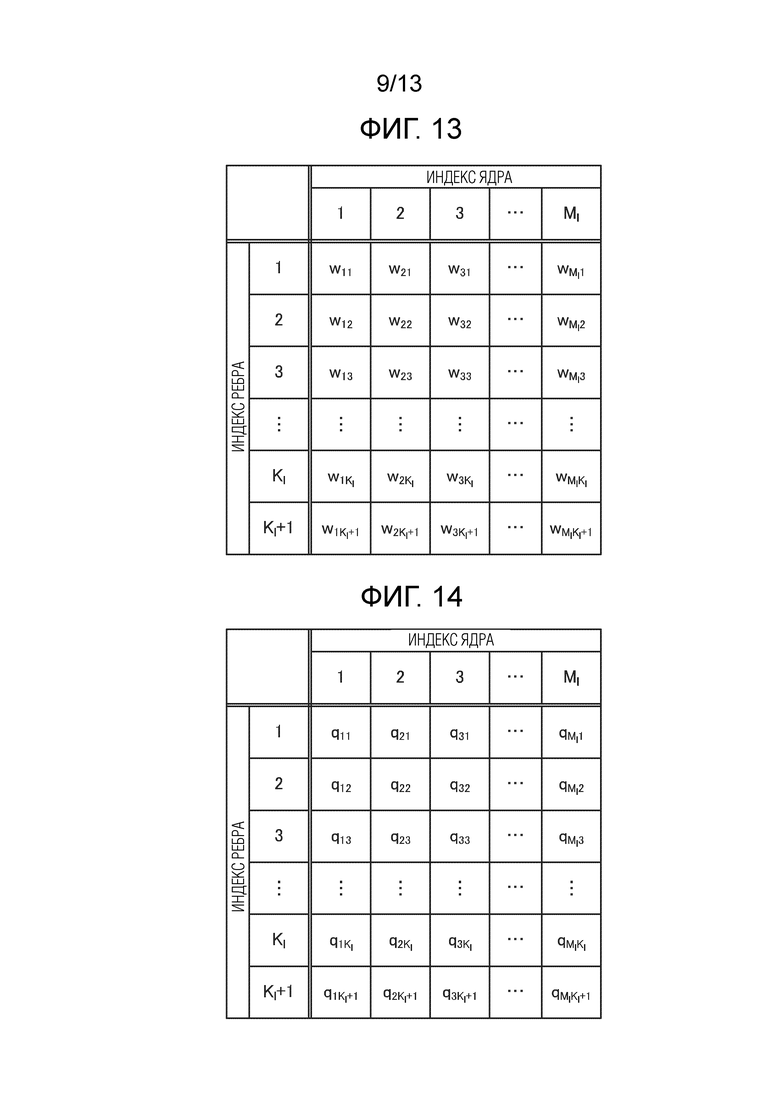
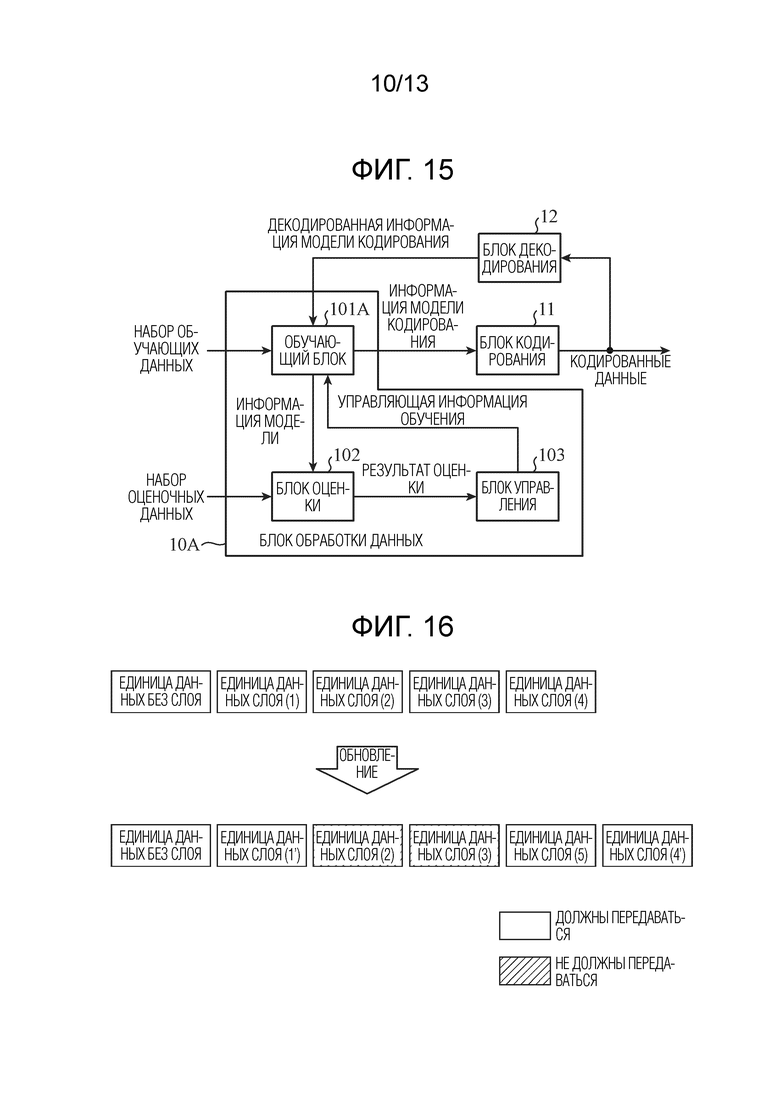

Изобретение относится к области вычислительной техники. Технический результат заключается в уменьшении размера данных, передаваемых на сервер, а также в снижении нагрузки по обработке данных для кодирования. Устройство обработки изображения или аудио данных, содержащее схему обработки данных для обучения нейронной сети с использованием набора обучающих данных и вывода информации модели обученной нейронной сети и схему обработки кодирования для формирования кодированных данных, в которых кодируется информация модели, включающая в себя информацию заголовка модели для идентификации модели нейронной сети, используемой для обработки изображения или аудио данных, информацию заголовков слоев для идентификации одного или более слоев нейронной сети и фрагменты информации весовых коэффициентов соответствующих ребер, принадлежащих каждому из одного или более слоев, идентифицированных посредством информации заголовков слоев, при этом схема обработки кодирования кодирует информацию структуры слоев, указывающую структуру слоев нейронной сети, причем информация структуры слоев включается в информацию модели и устройство обработки данных передает кодированные данные наружу. 3 н. и 6 з.п. ф-лы, 21 ил.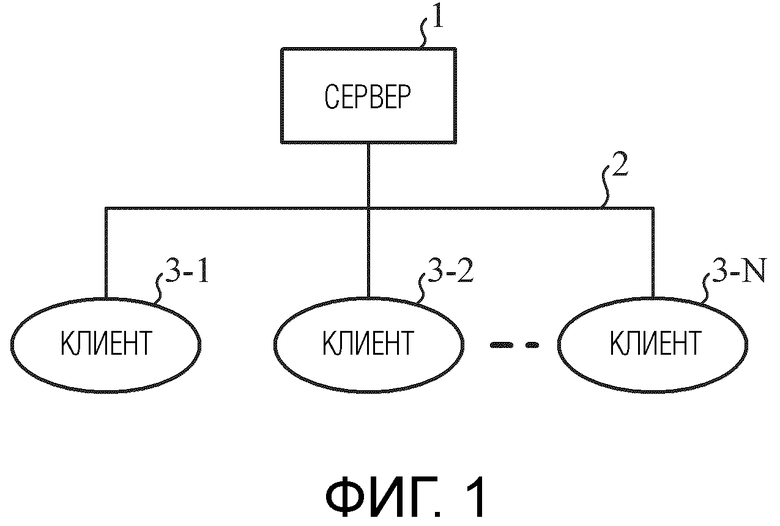
1. Устройство обработки изображения или аудио данных, содержащее:
- схему обработки данных для обучения нейронной сети с использованием набора обучающих данных и вывода информации модели обученной нейронной сети; и
- схему обработки кодирования для формирования кодированных данных, в которых кодируется информация модели, включающая в себя информацию заголовка модели для идентификации модели нейронной сети, используемой для обработки изображения или аудио данных, информацию заголовков слоев для идентификации одного или более слоев нейронной сети и фрагменты информации весовых коэффициентов соответствующих ребер, принадлежащих каждому из одного или более слоев, идентифицированных посредством информации заголовков слоев, при этом
схема обработки кодирования кодирует информацию структуры слоев, указывающую структуру слоев нейронной сети, причем информация структуры слоев включается в информацию модели, и
устройство обработки данных передает кодированные данные наружу.
2. Устройство обработки данных по п. 1, в котором схема обработки кодирования кодирует фрагменты информации весовых коэффициентов соответствующих ребер, принадлежащих каждому из одного или более слоев, на основе каждой битовой плоскости с верхних битов.
3. Устройство обработки данных по п. 1 или 2, в котором схема обработки кодирования кодирует фрагменты информации весовых коэффициентов соответствующих ребер, принадлежащих каждому из одного или более слоев, идентифицированных посредством информации заголовков слоев.
4. Устройство обработки данных по п. 1 или 2, в котором схема обработки кодирования кодирует разность между значением весового коэффициента ребра и конкретным значением.
5. Устройство обработки данных по п. 1 или 2, в котором схема обработки кодирования кодирует фрагменты информации весовых коэффициентов соответствующих ребер в качестве базовых кодированных данных и улучшающих кодированных данных отдельно,
причем базовые кодированные данные представляют собой данные, полученные посредством квантования весовых коэффициентов ребер и кодирования квантованных весовых коэффициентов, и
улучшающие кодированные данные представляют собой данные, полученные посредством кодирования ошибки квантования, которая считается соответствующим одним из весовых коэффициентов.
6. Устройство обработки данных по п. 1 или 2, содержащее схему обработки декодирования для декодирования кодированных данных, сформированных посредством схемы обработки кодирования, при этом:
схема обработки данных обучает нейронную сеть с использованием информации, декодированной посредством схемы обработки декодирования.
7. Система обработки изображения или аудио данных, содержащая:
- первое устройство обработки данных, включающее в себя:
первую схему обработки данных для обучения нейронной сети с использованием набора обучающих данных и вывода информации модели обученной нейронной сети; и
схему обработки кодирования для формирования кодированных данных, в которых кодируется информация модели, включающая в себя информацию заголовка модели для идентификации модели нейронной сети, используемой для обработки изображения или аудио данных, информацию заголовков слоев для идентификации одного или более слоев нейронной сети и фрагменты информации весовых коэффициентов соответствующих ребер, принадлежащих каждому из одного или более слоев, идентифицированных посредством информации заголовков слоев;
причем первое устройство обработки данных передает кодированные данные наружу; и
- второе устройство обработки данных, включающее в себя:
схему обработки декодирования для декодирования кодированных данных, сформированных посредством схемы обработки кодирования и передаваемых для получения только информации модели; и
вторую схему обработки данных для создания нейронной сети с использованием информации модели, декодированной посредством схемы обработки декодирования, и выполнения обработки изображения или аудио данных с использованием нейронной сети, при этом
схема обработки кодирования кодирует информацию структуры слоев, указывающую структуру слоев нейронной сети, причем информация структуры слоев включается в информацию модели.
8. Система обработки данных по п. 7, в которой:
- схема обработки кодирования кодирует информацию относительно части нейронной сети вплоть до промежуточного слоя, и
- второе устройство обработки данных выполняет обработку данных с использованием в качестве признака данных, выведенных из промежуточного слоя нейронной сети.
9. Способ обработки изображения или аудио данных, содержащий этапы, на которых:
- обучают нейронную сеть с использованием набора обучающих данных и выводят информацию модели обученной нейронной сети посредством схемы обработки данных; и
- формируют, посредством схемы обработки кодирования, кодированные данные, в которых кодируется информация модели, включающая в себя информацию заголовка модели для идентификации модели нейронной сети, используемой для обработки изображения или аудио данных, информацию заголовков слоев для идентификации одного или более слоев нейронной сети и фрагменты информации весовых коэффициентов соответствующих ребер, принадлежащих каждому из одного или более слоев, идентифицированных посредством информации заголовков слоев, и
- передают наружу кодированные данные, при этом
схема обработки кодирования кодирует информацию структуры слоев, указывающую структуру слоев нейронной сети, причем информация структуры слоев включается в информацию модели.
| Способ получения цианистых соединений | 1924 |
|
SU2018A1 |
| CN 108874914 A, 23.11.2018 | |||
| Станок для придания концам круглых радиаторных трубок шестигранного сечения | 1924 |
|
SU2019A1 |
| JP 2018206016 A, 27.12.2018 | |||
| Use cases and requirements for Compressed Representation of Neural Networks, ISO/IEC JTC1/SC29/WG11/N17924, опуб | |||
| Способ получения цианистых соединений | 1924 |
|
SU2018A1 |

