ПЕРЕКРЕСТНАЯ ССЫЛКА НА РОДСТВЕННУЮ ЗАЯВКУ
По этой заявке испрашивается приоритет согласно европейской патентной заявке ЕР 20306673.3, поданной 23 декабря 2020 г., содержание которой полностью включено в настоящее описание посредством ссылки.
ОБЛАСТЬ ТЕХНИКИ
Настоящая заявка в целом относится к сжатию облака точек и, в частности, к способам и устройству для энтропийного кодирования/декодирования данных геометрии облака точек, захваченных вращающейся головкой датчиков.
ПРЕДПОСЫЛКИ СОЗДАНИЯ ИЗОБРЕТЕНИЯ
Настоящий раздел предназначен для ознакомления читателя с различными аспектами области техники, которые могут быть связаны с различными аспектами по меньшей мере одного примера осуществления настоящей заявки, который описан и/или заявлен ниже. Предполагается, что это обсуждение полезно для предоставления читателю исходной информации, чтобы способствовать лучшему пониманию различных аспектов настоящей заявки.
В качестве формата представления 3D-данных, облака точек недавно получили распространение, поскольку они универсальны в своих возможностях для представления всех типов физических объектов или сцен. Облака точек могут использоваться для различных целей, например для сохранения культурного наследия/здания, при этом такие объекты, как статуи или здания, сканируются в 3D, для совместного использования пространственной конфигурации объекта без его передачи или посещения. Кроме того, это способ обеспечить сохранение знаний об объекте на случай его уничтожения; например, храм землетрясением. Такие облака точек обычно являются статичными, цветными и огромными.
Другой вариант использования - топография и картография, где использование 3D-представлений позволяет создавать карты, которые не ограничены плоскостью и могут включать рельеф. Карты Google теперь являются хорошим примером 3D-карт, но вместо облаков точек используют сетки. Тем не менее, облака точек могут быть подходящим форматом данных для 3D-карт, и такие облака точек обычно являются статичными, цветными и огромными.
Виртуальная реальность (VR, Virtual Reality), дополненная реальность (AR, Augmented Reality) и иммерсивные миры в последнее время стали горячей темой и многими предвидятся как будущее плоского 2D-видео. Основная идея заключается в погружении зрителя в окружающую среду, в отличие от стандартного телевизора, который позволяет зрителю только смотреть на виртуальный мир перед ним. Существует несколько градаций иммерсивности в зависимости от свободы зрителя в окружающей среде. Облако точек - хороший кандидат на формат для распространения миров VR/AR.
Автомобильная промышленность и, в частности, предполагаемые автономные автомобили также представляют области, в которых могут интенсивно использоваться облака точек. Автономные автомобили должны иметь возможность «прощупывать» свое окружение, чтобы принимать правильные решения о вождении на основе обнаруженного присутствия и характера ближайших объектов и конфигурации дороги.
Облако точек - это набор точек, расположенных в трехмерном (3D) пространстве, при необходимости с дополнительными значениями, связанными с каждой из точек. Эти дополнительные значения обычно называются атрибутами. Атрибутами могут быть, например, трехкомпонентные цвета, свойства материала, такие как коэффициент отражения, и/или двухкомпонентные векторы нормали к поверхности, связанной с точкой.
Таким образом, облако точек представляет собой комбинацию геометрии (расположение точек в трехмерном пространстве, обычно представленное трехмерными декартовыми координатами х, у и z) и атрибутов.
Облака точек могут быть захвачены различными типами устройств, такими как массив камер, датчики глубины, лазеры (для обнаружения света и определения дальности, также известные как лидары), радары, или могут быть сгенерированы компьютером (например, при постпроизводстве фильма). В зависимости от вариантов использования облака точек могут иметь от тысяч до миллиардов точек для картографических приложений. Для необработанных представлений облаков точек требуется очень большое количество битов на точку, по меньшей мере дюжина битов на декартову координату х, у или z, и, возможно, больше битов для атрибута(ов), например, трижды по 10 битов для цвета.
Во многих приложениях важно иметь возможность либо распространять облака точек среди конечных пользователей, либо хранить их на сервере, потребляя разумный объем битрейта или дискового пространства и сохраняя при этом приемлемое (или, желательно, очень хорошее) качество восприятия. Эффективное сжатие этих облаков точек является ключевым моментом для реализации на практике распространения многих иммерсивных миров.
Сжатие может быть с потерями (как при сжатии видео) для распространения и визуализации конечным пользователем, например, в очках AR/VR или на любом другом устройстве с поддержкой 3D. Другие варианты использования требуют сжатия без потерь, например медицинские приложения или автономное вождение, чтобы избежать изменения результатов решения, полученного в результате последующего анализа сжатого и переданного облака точек.
До недавнего времени сжатие облака точек (РСС, point cloud compression) не использовалось на массовом рынке, и стандартизированный кодек облака точек не был доступен. В 2017 году рабочая группа по стандартизации ISO/JCT1/SC29/WG11, также известная как Группа экспертов по движущимся изображениям или MPEG (Moving Picture Experts Group), инициировала работу по сжатию облака точек. Это привело к двум стандартам, а именно:
• MPEG-I часть 5 (ISO/IEC 23090-5) или сжатие облака точек на основе видео (V-PCC, Video-based Point Cloud Compression)
• MPEG-I часть 9 (ISO/IEC 23090-9) или сжатие облака точек на основе геометрии (G-PCC, Geometry-based Point Cloud Compression)
Способ кодирования V-PCC сжимает облако точек путем выполнения нескольких проекций 3D-объекта для получения 2D-участков (patch), упакованных в изображение (или видео при работе с динамическими облаками точек). Полученные изображения или видео затем сжимаются с использованием уже существующих кодеков изображений/видео, что позволяет использовать уже существующие решения для изображений и видео. По самой своей природе V-PCC эффективен только для плотных и непрерывных облаков точек, потому что кодеки изображения/видео не могут сжимать негладкие участки, которые можно получить, например, при проецировании разреженных данных геометрии, полученных лидаром.
Способ кодирования G-PCC имеет две схемы сжатия захваченных разреженных данных геометрии.
Первая схема основана на дереве занятости, которое локально представляет собой любой тип дерева из октодерева, квадрадерева или бинарного дерева, представляющих геометрию облака точек. Занятые узлы разбиваются до тех пор, пока не будет достигнут определенный размер, а занятые конечные узлы обеспечивают трехмерное расположение точек, обычно в центре этих узлов. Информация о занятости переносится флагами занятости, сигнализирующими о состоянии занятости каждого из дочерних узлов для узлов. Используя способы предсказания на основе соседей, можно получить высокий уровень сжатия флагов занятости для плотных облаков точек. Разреженные облака точек также решаются посредством прямого кодирования положения точки в узле с неминимальным размером путем остановки построения дерева, когда в узле присутствуют только изолированные точки; этот способ известен как режим прямого кодирования (DCM, Direct Coding Mode).
Вторая схема основана на дереве предсказания, в котором каждый узел представляет трехмерное местоположение одной точки, а отношение родитель/потомок между узлами представляет собой пространственное предсказание от родителя к дочерним элементам. На фиг. 1 показана часть дерева предсказания, в котором точки (узлы) представлены черными кружками, а взаимосвязи между родительскими и дочерними точками представлены стрелками. Одна дочерняя точка имеет уникальную родительскую точку. Таким образом, текущая точка Pn-1 имеет уникальную родительскую точку, уникальную точку прародителя и уникальную точку прапрародителя. Пространственные предикторы для текущей точки строятся с использованием этих точек-предков, например, предиктор может быть самой родительской точкой, линейным предсказанием от прародителя к родителю, как показано на фиг. 2, или параллелограммным предсказанием от трех предков, как показано на фиг. 3. Затем строится остаток путем вычитания предиктора до текущей точки. Этот остаток кодируется в битовый поток с использованием классических способов бинаризации и энтропийного кодирования. Этот способ может работать только с разреженными облаками точек и предлагает преимущество меньшей задержки и более простого декодирования по сравнению с деревом занятости. Однако производительность сжатия лишь незначительно выше, а кодирование является сложным по сравнению с первым способом, основанным на занятости, поскольку кодер должен интенсивно искать лучший предиктор (среди длинного списка потенциальных предикторов) при построении дерева предсказания.
В обеих схемах атрибутное (де)кодирование выполняется после (де)кодирования полной геометрии, что практически приводит к двухпроходному кодированию. Таким образом, совместная низкая задержка для геометрии/атрибутов достигается за счет использования слайсов, которые разделяют трехмерное пространство на подобъемы, кодируемые независимо, без предсказания между подобъемами. Это может сильно повлиять на производительность сжатия, когда используется много слайсов.
Сочетание требований к простоте кодера и декодера, низкой задержке и производительности сжатия по-прежнему является проблемой, которая не была удовлетворительно решена существующими кодеками облака точек.
Важным вариантом использования является передача разреженных данных геометрии, полученных вращающимся лидаром, установленным на движущемся транспортном средстве. Обычно для этого необходим простой встроенный кодер с малой задержкой. Требуется простота, поскольку кодер, вероятно, будет использоваться на вычислительных устройствах, которые параллельно выполняют другую обработку, например при (полу)автономном вождении, что ограничивает вычислительную мощность, доступную для кодера облака точек. Также требуется низкая задержка для обеспечения быстрой передачи данных из автомобиля в облако, чтобы иметь представление о местном трафике в режиме реального времени на основе захвата нескольких транспортных средств и принимать адекватные быстрые решения на основе информации о дорожном движении. Хотя задержка передачи может быть достаточно низкой при использовании 5G, сам кодер не должен создавать слишком большую задержку из-за кодирования. Кроме того, чрезвычайно важна производительность сжатия, поскольку ожидается, что поток данных от миллионов автомобилей в облако будет очень большим.
Конкретные априорные данные, связанные с вращением разреженных данных геометрии, полученных лидаром, уже использовались в G-PCC и привели к очень значительному увеличению степени сжатия.
Во-первых, G-PCC использует угол наклона (относительно горизонтальной поверхности земли) захвата с вращающейся головки лидара, как показано на фиг. 4 и 5. Головка 10 лидара содержит набор датчиков 11 (лазеров), здесь представлены пять лазеров. Головка 10 лидара может вращаться вокруг вертикальной оси z для захвата данных геометрии физического объекта. Захваченные лидаром данные геометрии затем представляются в сферических координатах (r3D, φ, θ), где r3D - расстояние точки Р от центра головки лидара, φ - азимутальный угол вращения головки лидара относительно опорного положения, а θ - угол наклона датчика k головки лидара относительно горизонтальной опорной плоскости.
Регулярное распределение по азимутальному углу наблюдалось для данных, захваченных лидаром, как показано на фиг. 6. Эта регулярность используется в G-PCC для получения квазиодномерного представления облака точек, где с точностью до шума только радиус r3D принадлежит непрерывному диапазону значений, а углы φ и θ принимают дискретное число значений ∀i=0 до I-1, где I - количество азимутальных углов, используемых для захвата точек, и θk ∀k=0 до K-1, где K - количество датчиков головки 10 лидара. По сути, G-PCC представляет разреженные данные геометрии, полученные с помощью лидара, на двумерной дискретной плоскости углов (φ, θ), как показано на фиг. 6, вместе со значением радиуса r3D для каждой точки.
Это квазиодномерное свойство использовалось в G-PCC как в дереве занятости, так и в дереве предсказания путем предсказания в пространстве сферических координат местоположения текущей точки на основе уже закодированной точки с использованием дискретной природы углов.
Точнее, дерево занятости интенсивно использует DCM и энтропийное кодирование прямого местоположения точек внутри узла с помощью контекстно-адаптивного энтропийного кодера. Затем контексты получают из локального преобразования местоположений точек в угловые координаты (φ, θ) и из расположения этих угловых координат относительно дискретных угловых координат (φi, θk), полученных из ранее закодированных точек. Дерево предсказания напрямую кодирует первую версию местоположения точки в угловых координатах (r2D, φ, θ), где r2D - радиус проекции на горизонтальную плоскость ху, как показано на фиг .7, с использованием квазиодномерной природы (r2D, φi, θk) этого координатного пространства. Затем угловые координаты (r2D, φ, θ) преобразуются в трехмерные декартовы координаты (х, у, z), а остаток xyz кодируется для устранения ошибок преобразования координат, аппроксимации углов наклона и азимута и потенциального шума.
G-PCC использует угловые априорные данные для лучшего сжатия разреженных данных геометрии, полученных вращающимся лидаром, но не адаптирует структуру кодирования к порядку захвата. По самой своей природе дерево занятости должно быть закодировано до последней глубины перед выводом точки. Эта занятость кодируется в так называемом порядке в ширину: сначала кодируется занятость корневого узла с указанием его занятых дочерних узлов; затем кодируется занятость для каждого из занятых дочерних узлов с указанием занятости внучатых дочерних узлов; и так далее по глубине дерева до тех пор, пока не будут определены листовые узлы и соответствующие точки не будут предоставлены/выведены в приложение или в схему кодирования атрибута(ов). Что касается дерева предсказания, кодер может свободно выбирать порядок точек в дереве, но для получения хорошей производительности сжатия для оптимизации точности предсказания G-PCC предлагает кодировать одно дерево для каждого лазера, как показано на фиг .8. Это в основном имеет тот же недостаток, что и использование одного слайса кодирования для каждого лазера, т.е. неоптимальные характеристики сжатия, поскольку предсказание между лазерами (датчиками) не допускается и не обеспечивает низкую задержку кодера. Хуже того, на каждый лазер (датчик) должна быть одна обработка кодирования, а количество основных единиц кодирования должно равняться количеству воспринимающих лазеров; это не практично.
Вкратце, в рамках вращающейся головки датчиков, используемой для захвата разреженных данных геометрии облака точек, предшествующий уровень техники не решает проблему сочетания простоты кодирования и декодирования, малой задержки и производительности сжатия.
По меньшей мере один пример осуществления настоящей заявки был разработан с учетом вышеизложенного.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
В этом разделе представлено упрощенное описание по меньшей мере одного примера осуществления изобретения, чтобы обеспечить базовое понимание некоторых аспектов настоящей заявки. Этот раздел не является подробным обзором примера осуществления изобретения. Он не предназначен для идентификации ключевых или критических элементов варианта осуществления изобретения. Следующее краткое изложение просто представляет некоторые аспекты по меньшей мере одного из иллюстративных вариантов осуществления изобретения в упрощенной форме в качестве введения к более подробному описанию, приведенному в другом месте документа.
Согласно первому аспекту настоящей заявки предоставляется способ кодирования облака точек в битовый поток кодированных данных облака точек, представляющих физический объект, причем точки облака точек упорядочены на основе азимутальных углов, представляющих углы захвата датчиков, и индексов датчиков, связанных с датчиками. Способ включает кодирование в битовый поток по меньшей мере одной разности порядковых индексов, представляющей разность между порядковыми индексами двух последовательных упорядоченных точек, посредством: получения по меньшей мере одних двоичных данных путем бинаризации по меньшей мере одной разности порядковых индексов; и, для каждых двоичных данных, выбора контекста на основе расстояния между азимутальным углом, связанным с двоичными данными, и азимутальным углом уже закодированной точки, и основанного на контексте энтропийного кодирования двоичных данных в битовый поток на основе выбранного контекста.
Согласно примеру осуществления изобретения уже закодированная точка является предпоследней уже закодированной точкой с тем же индексом датчика, что и индекс датчика, связанный с двоичными данными.
Битовый поток, полученный в настоящей заявке, может передаваться быстро для получения малой задержки при получении высокого уровня сжатия.
Согласно примеру осуществления изобретения способ также включает: передачу битового потока в облако.
Согласно второму аспекту настоящей заявки предоставляется способ декодирования облака точек из битового потока кодированных данных облака точек, представляющих физический объект. Способ включает декодирование по меньшей мере одной разности порядковых индексов, представляющей разность между порядковыми индексами двух последовательных упорядоченных точек на основе по меньшей мере одних двоичных данных, декодированных из битового потока, причем каждые двоичные данные декодируют посредством: выбора контекста на основе расстояния между азимутальным углом, связанным с двоичными данными, и азимутальным углом уже декодированной точки; основанного на контексте энтропийного декодирования упомянутых по меньшей мере одних двоичных данных на основе выбранного контекста и информации о вероятности относительно двоичных данных, декодированных из битового потока; и декодирования разности порядковых индексов из по меньшей мере одних двоичных данных, декодированных посредством основанного на контексте энтропийного декодирования.
Согласно примеру осуществления изобретения уже декодированная точка является предпоследней уже декодированной точкой с тем же индексом датчика, что и индекс датчика, связанный с двоичными данными.
Согласно примеру осуществления изобретения контекст для декодирования двоичных данных выбирают из таблицы контекстов, индексированной индексом контекста, и индекс контекста для двоичных данных равен расстоянию между азимутальным углом, связанным с двоичными данными, и азимутальным углом уже декодированной точки.
Согласно примеру осуществления изобретения контекст для декодирования двоичных данных выбирают из таблицы контекстов, индексированной индексом контекста, при этом индекс контекста для двоичных данных зависит от конкретного ранга упомянутых двоичных данных в последовательности двоичных данных, представляющих разность порядковых индексов.
Согласно примеру осуществления изобретения контекст для декодирования двоичных данных выбирают из таблицы контекстов, индексированной индексом контекста, и при этом индекс контекста для двоичных данных зависит от индекса датчика, связанного с двоичными данными.
В соответствии с примером осуществления изобретения контекст для декодирования двоичных данных выбирают из таблицы контекстов, индексированной индексом контекста, и индекс контекста для двоичных данных зависит от групп датчиков, содержащих датчики с близкими углами наклона.
Согласно примеру осуществления изобретения способ также включает получение битового потока из облака.
Согласно примеру осуществления изобретения способ также включает получение битового потока от автомобиля.
В соответствии с третьим аспектом настоящей заявки предоставляется устройство для кодирования облака точек в битовый поток кодированных данных облака точек, представляющих физический объект. Устройство содержит один или более процессоров, сконфигурированных для выполнения способа согласно первому аспекту настоящей заявки.
В соответствии с четвертым аспектом настоящей заявки предоставляется устройство для декодирования облака точек из битового потока кодированных данных облака точек, представляющих физический объект. Устройство содержит один или более процессоров, сконфигурированных для выполнения способа согласно второму аспекту настоящей заявки.
В соответствии с пятым аспектом настоящей заявки предоставляется битовый поток кодированных данных облака точек, представляющих физический объект. Битовый поток содержит информацию о вероятности относительно по меньшей мере одних двоичных данных, представляющих разность порядковых индексов, представляющую разность между порядковыми индексами двух последовательных упорядоченных точек облака точек.
В соответствии с шестым аспектом настоящей заявки предоставляется компьютерный программный продукт, включающий инструкции, которые, когда программа выполняется одним или более процессорами, обеспечивают выполнение одним или более процессорами способа в соответствии с первым аспектом настоящей заявки.
В соответствии с седьмым аспектом настоящей заявки предоставляется носитель данных, содержащий инструкции программного кода для выполнения способа в соответствии с первым аспектом настоящей заявки.
В соответствии с восьмым аспектом настоящей заявки предоставляется компьютерный программный продукт, содержащий инструкции, которые, когда программа выполняется одним или более процессорами, обеспечивают выполнение одним или более процессорами способа согласно второму аспекту настоящей заявки.
В соответствии с девятым аспектом настоящей заявки предоставляется носитель данных, содержащий инструкции программного кода для выполнения способа в соответствии со вторым аспектом настоящей заявки.
Конкретный характер по меньшей мере одного из иллюстративных вариантов осуществления изобретения, а также другие цели, преимущества, особенности и использование упомянутого по меньшей мере одного из иллюстративных вариантов осуществления изобретения станут очевидными из последующего описания примеров, рассматриваемых вместе с прилагаемыми чертежами.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Теперь в качестве примера будет сделана ссылка на прилагаемые чертежи, на которых показаны примеры осуществления настоящей заявки:
фиг. 1 иллюстрирует часть дерева предсказания, используемого для кодирования облака точек в соответствии с предшествующим уровнем техники;
фиг. 2 иллюстрирует линейное предсказание в части дерева предсказания, используемого для кодирования облака точек в соответствии с предшествующим уровнем техники;
фиг. 3 иллюстрирует параллелограммное предсказание в части дерева предсказания, используемого для кодирования облака точек в соответствии с предшествующим уровнем техники;
фиг. 4 иллюстрирует вид сбоку головки датчиков и некоторые ее параметры в соответствии с предшествующим уровнем техники;
фиг. 5 иллюстрирует вид сверху головки датчиков и некоторые ее параметры в соответствии с предшествующим уровнем техники;
фиг. 6 иллюстрирует регулярное распределение данных, захваченных вращающейся головкой датчиков в соответствии с предшествующим уровнем техники;
фиг. 7 иллюстрирует представление точки в трехмерном пространстве в соответствии с предшествующим уровнем техники;
фиг. 8 иллюстрирует кодирование дерева предсказания в соответствии с предшествующим уровнем техники;
фиг. 9 иллюстрирует блок-схему этапов способа 100 кодирования облака точек в битовый поток кодированных данных облака точек, представляющих физический объект, в соответствии по меньшей мере с одним примером осуществления изобретения;
фиг. 10 иллюстрирует пример кодированных упорядоченных точек в соответствии с одним примером осуществления настоящей заявки;
фиг. 11 иллюстрирует пример упорядоченной захваченной точки, представленной в двумерном пространстве, в соответствии с одним примером осуществления настоящей заявки;
фиг. 12 иллюстрирует другой пример упорядоченной захваченной точки, представленной в двумерном пространстве, в соответствии с одним примером осуществления настоящей заявки;
фиг. 13 иллюстрирует пример захваченных точек в соответствии с одним примером осуществления настоящей заявки;
фиг. 14 иллюстрирует пример упорядоченных и квантованных захваченных точек в соответствии с одним примером осуществления настоящей заявки;
фиг. 15 иллюстрирует блок-схему этапов способа 200 декодирования облака точек из битового потока кодированных данных облака точек, представляющих физический объект, в соответствии по меньшей мере с одним примером осуществления изобретения;
фиг. 16 иллюстрирует блок-схему этапов способа 800 энтропийного кодирования разностей порядковых индексов в соответствии по меньшей мере с одним примером осуществления изобретения;
фиг. 17 иллюстрирует блок-схему контекстно-адаптивного арифметического кодера в соответствии по меньшей мере с одним примером осуществления изобретения;
фиг. 18 иллюстрирует недостатки при использовании расстояния между азимутальным углом, связанным с двоичными данными, и азимутальным углом последней уже закодированной точки;
фиг. 19 иллюстрирует недостатки при использовании расстояния между азимутальным углом, связанным с двоичными данными, и азимутальным углом последней уже закодированной точки;
фиг. 20 иллюстрирует блок-схему этапов способа 900 энтропийного декодирования разности порядковых индексов в соответствии по меньшей мере с одним примером осуществления изобретения; и
фиг. 21 иллюстрирует структурную схему примера системы, в которой реализованы различные аспекты и примеры осуществления изобретения.
Аналогичные ссылочные позиции могут использоваться на разных чертежах для обозначения аналогичных компонентов.
ОПИСАНИЕ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ ИЗОБРЕТЕНИЯ
По меньшей мере один из иллюстративных вариантов осуществления изобретения описан более подробно ниже со ссылкой на прилагаемые чертежи, на которых проиллюстрированы примеры по меньшей мере одного из иллюстративных вариантов осуществления изобретения. Однако иллюстративный вариант осуществления изобретения может быть реализован во многих альтернативных формах и не должен рассматриваться как ограниченный приведенными здесь примерами. Соответственно, следует понимать, что иллюстративные варианты осуществления изобретения не ограничены конкретными раскрытыми формами. Напротив, раскрытие предназначено для охвата всех модификаций, эквивалентов и альтернатив в пределах сущности изобретения.
Когда чертеж представлен в виде блок-схемы, следует понимать, что он также обеспечивает структурную схему соответствующего устройства. Точно так же, когда чертеж представлен в виде структурной схемы, следует понимать, что он также обеспечивает блок-схему соответствующего способа/процесса.
По меньшей мере один из аспектов обычно относится к кодированию и декодированию облака точек, и по меньшей мере один другой аспект обычно относится к передаче сгенерированного или закодированного битового потока.
Более того, настоящие аспекты не ограничиваются стандартами MPEG, такими как MPEG-I, часть 5 или часть 9, которые относятся к сжатию облака точек, и могут применяться, например, к другим стандартам и рекомендациям, существующим или разработанным в будущем, а также к расширениям любых таких стандартов и рекомендаций (включая части 5 и 9 MPEG-I). Если не указано иное или технически не исключено, аспекты, описанные в настоящей заявке, могут использоваться по отдельности или в комбинации.
Фиг. 9 иллюстрирует блок-схему этапов способа 100 кодирования облака точек в битовый поток кодированных данных облака точек, представляющих физический объект, в соответствии по меньшей мере с одним примером осуществления изобретения.
Данные геометрии облака точек, представляющие трехмерное расположение точек облака точек, захватываются вращающейся головкой датчиков.
Вращающаяся головка датчиков может представлять собой вращающуюся головку 10 лидара, содержащую несколько лазеров (датчиков), как пояснено выше. Но объемраскрытия не ограничивается вращающейся головкой лидара и может применяться к любой головке датчиков, способной вращаться вокруг оси и захватывать точки трехмерного местоположения, представляющие физический объект, для каждого углового угла захвата. Датчиками могут быть камеры, датчики глубины, лазеры, лидары или сканеры.
Захваченные 3D-место положения представлены в системе 2D-координат (φ, λ), как показано на фиг. 7, вместе со значениями радиуса r2D или r3D. Координата φ - азимутальный угол вращения головки датчиков, дискретные значения которого обозначаются φi(∀i=0 до I-1). Координата λ является индексом датчика, дискретные значения которого обозначаются λk (∀k=0 до K-1). Радиус r2D или r3D принадлежит непрерывному диапазону значений.
Из-за регулярного вращения (поворота) головки датчиков и непрерывного захвата с фиксированным интервалом времени азимутальное расстояние между двумя точками, зондируемыми одним и тем же датчиком, кратно элементарному азимутальному сдвигу Δφ, как показано на фиг. 11. Затем, например, в первый захваченный момент времени t1 пять точек P1(t1),…, Pk(t1),… Р5(t1) исследуются пятью датчиками головки 10 лидара на фиг. 4 с азимутальным углом φ1, во второе время захвата t2 пять точек P1(t2),…, Pk(t2),… P5(t2) зондируются датчиками головки 10 лидара с азимутальным углом φ2=φ1+Δφ и т.д. Следовательно, дискретное значение φ1 можно рассматривать как квантованное значение азимутальных углов φ точек P1(t1),…, Pk(t1),… Р5(t1); квантование получено посредством шага квантования Δφ. Сходным образом, дискретное значение φ2 можно рассматривать как квантованное значение азимутальных углов φ точек P1(t2),…, Pk(t2),… P5(t2).
На этапе 110 для каждой точки Pn облака точек получают индекс датчика λk(n) (среди набора индексов датчиков λk (∀k=0 до K-1)), связанный с датчиком, который захватил точку Pn, азимутальный угол φi(n) (среди набора дискретных углов φi (∀i=0 до I-1)), представляющий собой угол захвата указанного датчика, и значение радиуса rn сферических координат точки Pn. Для простоты λk(n) и индекс i(n) в дальнейшем будут соответственно обозначаться λn и φn. Следовательно, φn - это не угол, а индекс i (∀i=0 до I-1), указывающий на угол φi. Тем не менее, поскольку существует однозначная связь между индексом φn и канонически связанным азимутальным углом φi(n)=φφn, величина φn по-прежнему называется азимутальным углом.
Согласно примеру осуществления этапа 110 индекс датчика λn и азимутальный угол φn получают путем преобразования трехмерных декартовых координат (xn,yn,zn), представляющих трехмерное местоположение захваченной точки Pn. Эти трехмерные декартовы координаты (xn,yn,zn) могут выводиться головкой датчиков.
На этапе 120 точки облака точек упорядочивают на основе азимутальных углов φn и индексов датчиков λn.
Согласно примеру осуществления этапа 120 точки упорядочивают в соответствии с лексикографическим порядком на основе сначала азимутального угла, а затем индекса датчика. Вернемся к фиг.11, упорядоченные захваченные точки: P1(t1),…, Pk(t1),… Р5(t1), P1(t2),…, Pk(t2),… P5(t2),…, P1(tn),…, Pk(tn),… P5(tn). Порядковый индекс o(Pn) точки Pn получают следующим образом:
о(Pn)=φn*K+λn
Согласно другому примеру осуществления этапа 120, показанному на фиг. 12, точки упорядочивают в соответствии с лексикографическим порядком на основе сначала индекса датчика, а затем азимутального угла.
Порядковый индекс о(Pn) точки Pn получают следующим образом:
о(Pn)=λn*I+φn
На этапе 130 разности Δon порядковых индексов, каждая из которых представляет разность между порядковыми индексами двух последовательных точек Pn-1 и Pn (для n=2 до N), получают следующим образом:
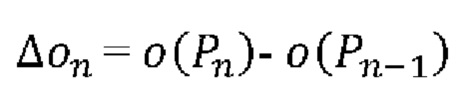
Кодирование упорядоченных точек в битовый поток В может включать кодирование по меньшей мере одной разности Δon порядковых индексов. Опционально, оно также может включать кодирование значений радиуса rn (по существу представляющего либо r2D или r3D точки Pn), декартовых остатков (xres,n, yres,n, zres,n) трехмерных декартовых координат упорядоченных точек и углового остатка φres,n.
Порядковый индекс о(Р1) первой точки Р1 может непосредственно кодироваться в битовый поток В. Это эквивалентно произвольной установке порядкового индекса виртуальной нулевой точки в ноль, т.е. о(Р0)=0, и кодированию Δо1=о(P1)-о(Р0)=о(Р1).
Зная порядковый индекс о(Р1) первой точки и порядковые разности Δon, можно рекурсивно восстановить порядковый индекс о(Pn) любой точки Pn следующим образом:
о(Pn)=о{Pn-1)+Δо
Затем индексы датчиков λn и азимутальный угол φn получают следующим образом:
λn=o(Pn) modulo K (1)
φn=о(Pn)/K (2)
где деление /K - целочисленное деление (также известное как евклидово деление). Следовательно, о(Р1) и Δon являются альтернативным представлением λn и φn.
На этапе 140 порядковый индекс о(Pn), связанный с упорядоченными точками, кодируют в битовый поток В путем кодирования (N-1) разностей порядковых индексов Δon (∀n=2 до N), где N - количество упорядоченных точек. Каждый порядковый индекс о(Pn) представляет собой разность между порядковыми индексами, связанными с двумя последовательными упорядоченными точками. На фиг. 10 представлены пять упорядоченных точек (черные кружки): две точки Pn и Pn+1 были захвачены во время t1 с угловым углом φс (среди φi) и три точки были захвачены во время t2 с угловым углом φс+Δφ. Предполагая, что координаты первой точки Pn в двумерной системе координат (φ, λ) известны заранее, первую разность Δon+1 порядковых индексов получают как разность между порядковым индексом о(Pn+1), связанным с точкой Pn+1, и порядковым индексом о(Pn), связанным с точкой Pn.. Вторую разность Δon+2 порядковых индексов получают как разность между порядковым индексом о(Pn+2), связанным с другой упорядоченной точкой Pn+2, и порядковым индексом о(Pn+1), связанным с Pn+1, и т.д.
Упорядочивание захваченных точек обеспечивает взаимодействие между точками, захваченными разными датчиками вращающейся головки датчиков. Таким образом, для кодирования этих упорядоченных точек требуется одно кодирование, что приводит к очень простому кодированию с малой задержкой.
Для восстановления точек по разностям Δon порядковых индексов требуется такая информация, как число N точек облака точек, порядковый индекс о(Р1) первой точки в системе двумерных координат (φ, λ) и параметры настройки датчика, такие как элементарный азимутальный сдвиг Δφ или угол наклона θn, связанный с каждым датчиком. Эта информация также может кодироваться в битовый поток В или передаваться другим способом или может быть заранее известна декодеру.
Разности Δon порядковых индексов энтропийно кодируют, как поясняется ниже со ссылкой на фиг. 16.
Опционально, способ также включает на этапе 150 кодирование в битовый поток В значений rn радиуса сферических координат, связанных с упорядоченными точками облака точек.
Согласно примеру осуществления этапа 150 значения rn радиуса квантуют.
Согласно примеру осуществления этапа 150 значения rn радиуса квантуют.
Согласно примеру осуществления этапа 150 значения rn радиуса квантуют и энтропийно кодируют.
Согласно примеру осуществления этапа 150 значения rn радиуса представляют собой радиус r3D.
В соответствии с примером осуществления этапа 150 значения rn радиуса представляют спроецированный радиус r2D на горизонтальной плоскости ху, как показано на фиг. 7.
Опционально, способ также включает на этапе 160 кодирование остатков (xres,n,yres,n,zres,n) трехмерных декартовых координат упорядоченных точек Pn на основе их трехмерных декартовых координат (xn,yn,zn), декодированных азимутальных углов φdec,n, декодированных значений радиуса rdec,n, полученных из значений rn радиуса, и индексов датчиков λn.
В соответствии с примером осуществления этапа 160 остатки (xresn,yres;n, zresn) представляют собой разности между трехмерными декартовыми координатами (xn,yn,zn) точек облака точек и расчетными трехмерными координатами (xestim,n,yestim,n,zestim,n).
Согласно примеру осуществления этапа 160 остатки (xresn,yres;n,zres;n) задают следующим образом:
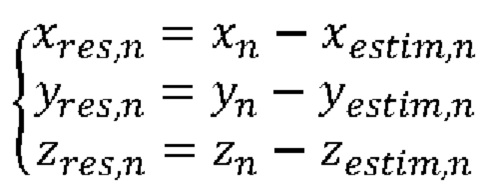
Согласно примеру осуществления этапа 160 расчетные координаты (xestim,n,yestim,n), связанные с упорядоченной точкой Pn, основаны на декодированных азимутальных углах φdec,n и декодированных значениях rdec,n радиуса, связанных с точкой Pn.
Согласно примеру осуществления этапа 160 остатки (xresn,yres,n,zres,n) энтропийно кодируют.
Согласно примеру осуществления этапа 160 расчетные координаты (xestim,n,yestim,n) задают следующим образом:
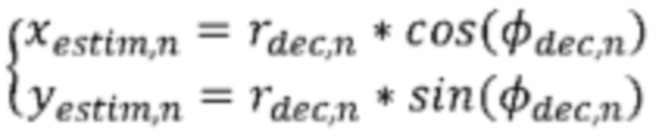
Согласно примеру осуществления этапа 160 расчетная координата (zestim,n), связанная с упорядоченной точкой, основана на декодированном значении радиуса rdec,n, связанном с точкой, и угле наклона θn датчика, который захватил точку.
Согласно примеру осуществления этапа 160 расчетные координаты (zestim,n) также основаны на индексах датчиков λn.
Согласно примеру осуществления этапа 160 расчетные координаты (zestim,n) задают следующим образом:
zestim,n=rdec,ntanθn
Опционально, способ также включает на этапе 170 кодирование в битовый поток В остаточных азимутальных углов φres,n, связанных с упорядоченными точками. Согласно примеру осуществления этапа 170 азимутальные углы φn квантуют следующим образом:
φn=round(φ(Pn)/Δφ)
где φ(Pn) - исходный азимутальный угол точки Pn.В этом случае множество дискретных углов φi (0≤i≤I) по существу определяют как φi=i* Δφ и получают φi(n)=φn* Δφ.
Таким образом, порядковый индекс о(Pn) точки Pn определяют как:
о(Pn)=φn* K+λn=round(φ(Pn)/Δφ)*K+λn
Остаточные азимутальные углы φres,n определяют по формуле:
φres,n=φ(Pn)-φn* Δφ (3)
Этот пример осуществления этапа 170 обеспечивает преимущества, поскольку иногда на практике не все точки захватываются в каждый момент времени захвата, потому что может быть зафиксирован шум, или потому что не все датчики могут быть идеально выровнены, или потому что по меньшей мере один лазерный луч головки датчиков лидара может не отражаться. Тогда захваченные точки могут выглядеть так, как показано на фиг. 13. Квантование азимутальных углов φ(Pn) приводит к более легкому дискретному представлению точек в системе 2D-координат (φ, λ), как показано на фиг. 14, что позволяет упростить путь для упорядочивания точек облака точек.
Остаточные азимутальные углы φres,n кодируют в битовый поток В предпочтительно путем квантования и/или энтропийного кодирования.
Этот пример осуществления этапа 170 также уменьшает динамику угловых углов, которые должны быть закодированы в битовом потоке, поскольку кодируют только остаток, а не значение полного диапазона. Достигается высокая производительность сжатия.
Опционально способ также включает, на этапе 180, получение декодированных азимутальных углов φdec,n на основе азимутального угла φn.
В соответствии с вариантом осуществления этапа 180 декодированные азимутальные углы φdec,n задают следующим образом:
φdec,n=φn*Δφ
Согласно варианту осуществления этапа 180 декодированные азимутальные углы φdec,n получают на основе азимутального угла φn, элементарного азимутального сдвига Δφ и остаточных азимутальных углов φres,n.
В соответствии с вариантом осуществления этапа 180 декодированные азимутальные углы φdec,n задают следующим образом:
φdec,n=φn*Δφ+φres,n
Согласно варианту осуществления этапа 180 декодированные азимутальные углы φdec,n получают на основе азимутального угла φn, элементарного азимутального сдвига Δφ и декодированного углового остатка φdec,res,n, полученного путем деквантования квантованного остаточного азимутального угла φres,n, заданного уравнением 3.
В соответствии с вариантом осуществления этапа 180 декодированные азимутальные углы φdec,n задают следующим образом:
φdec,n=φn* Δφ+φdec,res,n
Опционально, на этапе 190 декодированные значения rdec,n радиуса получают на основе кодированных значений rn радиуса.
Согласно примеру осуществления изобретения на этапе 190 декодированные значения rdec,n радиуса получают путем деквантования квантованных значений rn радиуса.
Фиг. 15 иллюстрирует блок-схему этапов способа 200 декодирования облака точек из битового потока кодированных данных облака точек, представляющих физический объект, в соответствии по меньшей мере с одним примером осуществления изобретения.
Для декодирования точек облака точек из битового потока В требуется информация, такая как количество N точек облака точек, порядковый индекс о(Р1) первой точки в системе 2D-координат (φ, λ) и параметры настройки датчика, такие как элементарный азимутальный сдвиг Δφ или угол наклона θk, связанный с каждым датчиком k. Эта информация также может быть декодирована из битового потока В или получена любым другим способом, или может быть заранее известна декодеру.
N точек облака точек декодируют рекурсивно.
На этапе 210 по меньшей мере одну разность Δon (n=2 до N) порядковых индексов декодируют из битового потока В. Каждую разность Δon порядковых индексов декодируют для текущей точки Pn.
На этапе 220 порядковый индекс о(Pn) получают для текущей точки Pn следующим образом:
о(Pn)=о(Pn-1)+Δon
Разность Δon порядковых индексов представляет собой разность между порядковым индексом, связанным с текущей точкой Pn, и другим порядковым индексом о(Pn-1), связанным с (уже) ранее декодированной точкой Pn-1.
На этапе 230 индекс датчика λn, связанный с датчиком, который захватил текущую точку Pn, и азимутальный угол φn, представляющий угол захвата указанного датчика, получают из порядкового индекса о(Pn).
Согласно примеру осуществления этапа 230 индекс датчика λn и азимутальные углы φn получают с помощью уравнений (1) и (2).
Опционально, на этапе 240 декодированный азимутальный угол φdec,n получают на основе азимутального угла φn.
Согласно варианту осуществления этапа 240 декодированные азимутальные углы φdec,n получают на основе азимутального угла φn и элементарного азимутального сдвига Δφ.
В соответствии с вариантом осуществления этапа 240 декодированный азимутальный угол φdec,n определяют следующим образом:
φdec,n=φn*Δφ
В соответствии с вариантом осуществления этапа 240 декодированный азимутальный угол φdec,n получают на основе остаточного азимутального угла φres,n, декодированного из битового потока В.
В соответствии с вариантом осуществления этапа 240 декодированный азимутальный угол φdec,n определяют следующим образом:
φdec,n=φn*Δφ+φres,n
Опционально, на этапе 250 значение радиуса rn сферических координат текущих точек Pn декодируют из битового потока В.
Согласно примеру осуществления этапа 250 значения радиуса rn деквантуют для получения декодированных значений радиуса rdec,n.
Согласно примеру осуществления этапа 250 значения радиуса rn подвергают энтропийному декодированию и деквантованию для получения декодированных значений радиуса rdec,n.
Опционально, на этапе 260 остаток (xresn, yres,n, zres,n) трехмерных декартовых координат текущей точки Pn декодируют из битового потока В.
Согласно примеру осуществления этапа 260 остаток (xresn, yres,n, zres,n) подвергают энтропийному декодированию.
Опционально, на этапе 270 трехмерные декартовы координаты (x,y,z) текущей точки Pn декодируют на основе декодированного остатка (xresn, yres,n, zres,n) трехмерных декартовых координат текущей точки Pn, значения радиуса rn, декодированного азимутального угла φdec,n и индекса датчика λт.
Согласно примеру осуществления этапа 270 трехмерные декартовы координаты (x,y,z) текущей точки Pn представляют собой суммы остатков (xresn, yres,n, zres,n) и расчетных трехмерных координат (xestim, yestim, zestim):
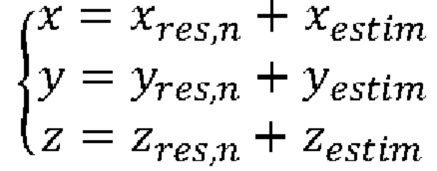
Согласно примеру осуществления этапа 270 расчетные координаты (xestim, yestim), связанные с текущей точкой Pn, основаны на азимутальном угле φn и значении радиуса rn.
Согласно примеру осуществления этапа 270 расчетные координаты (xestim, yestim) задают следующим образом:
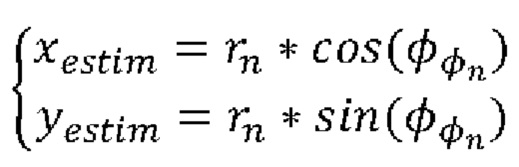
В соответствии с другим примером осуществления этапа 270 расчетные координаты (xestim, yestim) задают следующим образом:
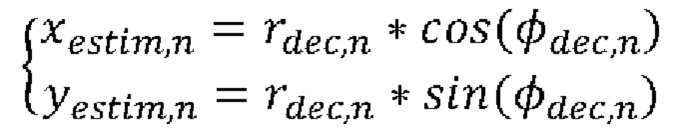
где rdec,n - декодированные значения радиуса, полученные из значений радиуса rn. Например, декодированные значения радиуса rdec,n могут быть получены путем деквантования значений радиуса rn.
Согласно примеру осуществления этапа 270 расчетная координата (zestim), связанная с текущей точкой Pn, основана на значении радиуса rn, связанном с текущей точкой Pn, и угле наклона θk датчика k, который захватил текущую точку Pn.
Согласно примеру осуществления этапа 270 расчетные координаты (zestim) задают следующим образом:
zestim=rntanθk
Согласно примеру осуществления этапа 270 расчетные координаты (zestim) также основаны на индексе датчика Δn.
Согласно примеру осуществления этапа 270 расчетные координаты (zestim) задают следующим образом:
zestim=rntanθλn
На фиг. 16 показана блок-схема этапов способа 800 энтропийного кодирования разности Δon порядковых индексов в соответствии по меньшей мере с одним примером осуществления изобретения.
На этапе 810 по меньшей мере одни двоичные данные fj получают путем бинаризации по меньшей мере одной разности Δon порядковых индексов.
Для каждых двоичных данных fj выбирают контекст (этап 820) на основе расстояния Cj между азимутальным углом φj, связанным с двоичными данными fj, и азимутальным углом уже закодированной точки, и каждые двоичные данные fj кодируют контекстно-адаптивным энтропийным кодированием (830) в битовый поток В на основе выбранного контекста. Как будет разъяснено ниже, подобно величине φn, величина φj именуется азимутальным углом, даже если это индекс между 0 и I-1, указывающий на конкретный дискретный угол среди φi.
Контекстно-адаптивное энтропийное кодирование разности порядковых индексов обеспечивает эффективную производительность сжатия по сравнению с другими способами кодирования, такими как способ кодирования с помощью дерева предсказания, поскольку такой способ кодирования на основе предсказания не учитывает внутреннюю структуру представления (φ, λ) местоположений точек. Такая структура учитывается в вариантах осуществления настоящей заявки путем выбора контекстов и энтропийного кодирования разности порядковых индексов на основе выбранного контекста.
В соответствии с примером осуществления этапа 810 бинаризацию разности Δon порядковых индексов выполняют с помощью последовательности двоичных данных fj, для j≥0. Двоичные данные fj равны конкретному значению PV (например, fj=1), чтобы указать, равно ли Δon j и не равно указанному конкретному значению PV в противном случае (например, fj=0). Затем кодируют первые двоичные данные f0. Например, если f0=PV, кодирование Δon завершают, поскольку Δon=0 было закодировано; в противном случае, если f0≠PV, то кодируют вторые двоичные данные f1. Если f1≠PV, то кодируют третьи двоичные данные f2 и т.д. По сути, это унарное кодирование Δon.
Согласно примеру осуществления этапа 810, когда точки упорядочены в соответствии с лексикографическим порядком на основе сначала азимутального угла, а затем индекса датчика (фиг. 11), азимутальный угол ≠φj, связанный с двоичными данными fj, представляет собой азимутальный угол φn-1, связанный с текущей точкой Pn-1, если j+с<K, где с - индекс текущей точки по модулю K (или, что то же самое, с - индекс датчика λn-1 текущей точки); в противном случае азимутальный угол φj, связанный с двоичными данными fj, является азимутальным углом
φj=φn+s
где s - целое число, такое, что sK≤j+с<(s+1)K. Каждым двоичным данным fj также соответствует индекс датчика λj, который соответствует индексу датчика, который захватил бы следующую упорядоченную точку Pn, если бы fj было равно PV, т.е. λj=λn-1+j mod K.
На фиг. 11 разность Δon порядковых индексов равна 8 и бинарно преобразуется в девять двоичных данных от f0 до f8, не равных PV, за исключением последнего f8, которое равно PV. Азимутальные углы от φ0 до φ6, соответственно связанные с двоичными данными от f0 до f6, равны азимутальному углу φn-1, а азимутальные углы φ7 и φ8 соответственно, связанные с f7 и f8, равны φn.
Согласно примеру осуществления этапа 810, когда точки упорядочены в соответствии с лексикографическим порядком на основе сначала индекса датчика, а затем азимутального угла (фиг. 12), азимутальные углы φj, связанные с двоичными данными fj, задают следующим образом:
φj=φn-1+j
Каждым двоичным данным fj также соответствует индекс датчика λj, который соответствует индексу датчика, который захватил бы следующую упорядоченную точку Pn, если бы fj было равно PV, т.е. λj=λn-1.
На фиг. 12 разность Δon порядковых индексов равна 4 и бинарно преобразуется в пять двоичных данных от f0 до f4, не равных PV, за исключением последнего f4, которое равно PV. Азимутальные углы от φ0 до φ4 соответственно, связанные с двоичными данными от f0 до f4, соответственно равны φn-1, φn-1+1, φn-1+2, φn-1+3 и φn-1+4=φn.
Опционально, на этапе 840 остаток R получают как разность между разностью Δon порядковых индексов и максимальным количеством двоичных данных (верхней границей) Nflag. Затем, если двоичные данные fNflag-1 достигнуты и не равны PV, то обязательно Δon≥Nflag, а остаток R определяют как R=Δon-Nflag.
Максимальное количество флагов Nflag устанавливают для ограничения количества арифметически закодированной двоичной информации на точку и ограничения задержки для получения следующей точки.
В соответствии с вариантом осуществления этапа 840 остаток R кодируют с использованием кода exp-Golomb.
Согласно примеру осуществления этапа 810 двоичные данные fj являются флагом, и PV=1.
Согласно примеру осуществления этапа 830 двоичные данные fj энтропийно кодируют контекстно-адаптивным двоичным арифметическим кодером (подобным САВАС).
На фиг. 17 схематично показана структурная схема контекстно-адаптивного двоичного арифметического кодера.
Во-первых, контекст выбирают посредством некоторого процесса выбора на основе уже закодированной информации, чтобы обеспечить индекс контекста ctxIdx, связанный с каждыми двоичными данными fj (двоичным символом). Таблица контекстов с записями Nctx хранит вероятности, связанные с контекстами, и вероятность pctxIdx получают как ctxIdx-ю запись таблицы контекстов. Двоичный символ fj кодируют в битовый поток с помощью энтропийного кодера с использованием вероятности pctxIdx.
Энтропийные кодеры обычно являются арифметическими кодерами, но могут быть любым другим типом энтропийных кодеров, например, асимметричными системами счисления. В любом случае оптимальные кодеры добавляют -log2(pctxIdx) битов в битовый поток для кодирования fj=1 или -log2(1- pctxIdx) битов в битовый поток для кодирования fj=0. Как только символ fj закодирован, вероятность pctxIdx обновляется с использованием процесса обновления, принимающего fj и pctxIdx в качестве входных данных; процесс обновления обычно выполняется с использованием таблиц обновления. Обновленная вероятность заменяет ctxIdx-ю запись таблицы контекстов. Затем можно кодировать другой символ и т.д. Цикл обновления обратно в таблицу контекстов является узким местом в рабочем процессе кодирования, поскольку другой символ может кодироваться только после выполнения обновления. По этой причине доступ к памяти для таблицы контекстов должен быть как можно более быстрым, а минимизация размера таблицы контекстов помогает упростить ее аппаратную реализацию.
Контекстно-адаптивный двоичный арифметический декодер выполняет по существу те же операции, что и контекстно-адаптивный двоичный арифметический кодер, за исключением того, что закодированный символ fj декодируется из битового потока энтропийным декодером с использованием вероятности pctxIdx.
Выбор адекватного контекста, т.е. вероятности pctxIdx, которая наилучшим образом оценивает вероятность того, что двоичные данные fj будут равны PV, важен для получения хорошего сжатия. Следовательно, выбор контекста должен использовать соответствующую уже закодированную информацию и корреляцию для получения этого адекватного контекста.
Согласно примеру осуществления этапа 820 расстояние Cj, связанное с двоичными данными fj, зависит от азимутального угла φj, связанного с двоичными данными fj, и (индекса) азимутального угла φpenult связанного с предпоследней уже закодированной точкой Ppenult с тем же индексом датчика, что и индекс датчика λj, связанный с двоичными данными fj. Текущая точка Pn-1 никогда не рассматривается в наборе уже кодированных точек, из которых определяется предпоследняя уже закодированная точка Ppenult.
Согласно примеру осуществления этапа 820 расстояние Cj, связанное с двоичными данными fj, задают следующим образом:
Cj=φj-φpenult,j (13)
Напомним, что две величины φj и φpenult,j являются индексами, указывающими на дискретные углы в наборе дискретного числа значений φi (t=0 до I-1).
На фиг. 11 расстояние Со=0, так как последняя и предпоследняя уже закодированные точки с индексом датчика, равным λ0=λn-1=2, находятся в одном и том же угловом положении φ0=φn-1, что и текущая точка Pn-1; это может произойти в какой-то конкретной конфигурации датчика. Затем C1=4, так как разность между азимутальными углами φpenult,3, связанными с предпоследней уже закодированной точкой (серый кружок) с индексом датчика λ1=λn-1+1=3, ассоциированным с f1, с одной стороны, и φ1=φn-1, с другой стороны, равна 4. Затем С2=3, так как разность между азимутальными углами φpenult,4, связанными с предпоследней уже закодированной точкой с индексом датчика λ2=λn-1+2=4, связанным с f2, и φ2=φn-1 равна 3 и т.д. Далее, С7=3, так как разность между азимутальными углами φpenult,0, связанными с предпоследней уже закодированной точкой с индексом датчика λ7=λn-1+7=9=0 mod K (здесь K=9), связанным с f7, и φ7=φn-1+1 равна 3. Наконец, C8=2, поскольку разность между азимутальными углами φpenult,1 связанными с предпоследней уже закодированной точкой с индексом датчика λ8=λn-1+8=10=1 mod K, связанным с f8, и φ8=φn-1 равна 2.
На фиг. 12 все двоичные данные fj связаны с одним и тем же индексом датчика λj=λn-1. Расстояние С0=2, потому что разность между азимутальным углом 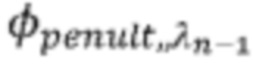 , связанным с предпоследней уже закодированной точкой (серый кружок), и φ0=φn-1 равна 2. Расстояние C1=3, так как разность между азимутальными углами , связанными с предпоследней уже закодированной точкой, и φ1=φn-1+1 равна 3 и т.д.
, связанным с предпоследней уже закодированной точкой (серый кружок), и φ0=φn-1 равна 2. Расстояние C1=3, так как разность между азимутальными углами , связанными с предпоследней уже закодированной точкой, и φ1=φn-1+1 равна 3 и т.д.
Зависимость расстояния Cj от предпоследней уже закодированной точки Ppenult обеспечивает преимущества по сравнению с другими альтернативными зависимостями, такими как зависимость с последней, третьей перед последней или любой другой уже закодированной точкой перед последней по следующим причинам, приведенным в связи с фиг. 18 и 19.
При зондировании физического объекта зондирующий лазер обычно обеспечивает отраженный сигнал для нескольких последовательных захваченных углов. В этом случае, когда точки упорядочиваются в соответствии с лексикографическим порядком, основанным сначала на индексе датчика, а затем на азимутальном угле (фиг. 12), можно ожидать получить несколько последовательных разностей Δon индексов, равных единице, как показано на фиг. 18.
В верхнем ряду показаны точки Pn, расположенные под углом φ=φ(Pn), а в нижнем ряду показаны те же точки после квантования φ в φс=φi(n)=φn * Δφ. Каждый интервал квантования занят одной-единственной точкой, что приводит к последовательной разности порядковых индексов Δon=+1. Однако при добавлении шума считывания некоторые точки могут перескакивать с одного интервала на соседний, как показано на фиг. 19, где вторая точка немного сместилась влево. Следовательно, шаблон Δon изменился с +1 +1 +1 +1 на+1 0 +2 +1. Аналогично, он может также измениться на +1 +2 +0 +1, если точка перемещается вправо.
Расстояние Cj (уравнение 13) может обнаружить этот шаблон и предвидеть следующую Δon. В принципе, если Cj равно 2 (получено из шаблонов +1 +1,+2 0 или +0 +2), вероятно, что точка, соответствующая fj=PV, присутствует, и контекст, соответствующий Cj=2, обеспечит высокую вероятность кодирования PV как значения для fj. С другой стороны, если Cj равно 1 (получено из +1 +0), ожидается компенсация «опоздания» и более вероятно, что точка, соответствующая fj=PV, отсутствует и контекст, соответствующий Cj=1, обеспечит низкую вероятность кодирования PV как значения для fj.
Ясно (это также подтверждают тесты), что расстояние Cj, заданное как φj - φlast,j, означает, что использование последней точки вместо предпоследней точки менее эффективно для предсказания Δon. Например, либо а+1, либо 0 могут следовать за а+2 в шаблонах +1 0 +2 +1 и +1 +2 0 +1.
Тесты проводились на одном кадре тестовой последовательности QNX и тестовой последовательности Форда, взятой из набора тестов MPEG для G-PCC. Азимутальные углы и индексы датчиков, представляющие точки, захваченные вращающейся головкой датчиков, кодировались посредством 1) кодирования облака точек G-PCC с двумерным входным облаком точек, сформированным азимутальными углами и индексами датчиков, 2) кодирования азимутальных углов и индексов датчиков с помощью разностей Δon порядковых индексов энтропийного кодирования с контекстами, которые не зависят от расстояния Cj, и 3) кодирования азимутальных углов и индексов датчиков с помощью разностей Δon порядковых индексов энтропийного кодирования с контекстами, зависящими от расстояния Cj. Как в 2), так и в 3) бинаризация Δon выполнялась, как описано выше, с использованием fj и R.
В таблице 1 показаны полученные степени сжатия, когда точки упорядочены в соответствии с лексикографическим порядком, основанным сначала на азимутальном угле, а затем на индексе датчика (фиг. 11), а в таблице 2 показаны полученные степени сжатия, когда точки упорядочены в соответствии с лексикографическим порядком, основанным сначала на индексе датчика, а затем на азимутальном угле (фиг. 12). Результаты представлены в битах на точку (bpp) для сжатия без потерь для обоих лексикографических порядков. Более низкие значения bpp указывают на лучшее сжатие. 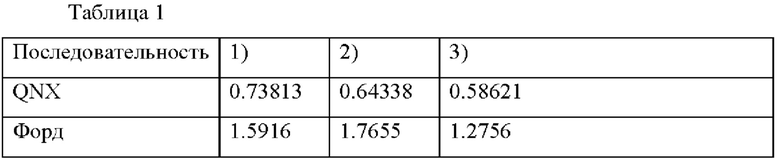

Решение 3) обеспечивает прирост сжатия от 5% до 30% и явно превосходит решение 1 (G-PCC).
Реализация зависимости расстояния Cj требует доступа к азимутальным углам φpenult, связанным с предпоследней уже закодированной точкой Ppenult с тем же индексом датчика, что и индекс датчика λj двоичных данных fj. Реализация такой зависимости с использованием скользящего буфера приводит к упрощению кодирования/декодирования.
Например, скользящий буфер может быть двумерным массивом, в первом столбце которого хранятся K значений φpenult(k) (∀k=0 до K-1) предпоследних кодированных точек с индексом датчика, равным k, а в другом столбце значения K φlast(k) (∀k=0 до K-1) последних кодированных точек с индексом датчика, равным k. Когда расстояние Cj должно быть вычислено для двоичных данных fj, азимутальный угол φ penult(λj) для индекса датчика λj (связанного с fj) непосредственно получают из буфера скользящих данных. После каждого (де)кодирования разности Δon порядковых индексов получают азимутальный угол φn, и буфер перекатывается следующим образом
φ penult(k)=φlast(k) и φlast(k)=φn
где φn - азимутальный угол следующей точки Pn, порядковый индекс которой равен о(Pn)=о(Pn-1)+Δon.
Согласно примеру осуществления этапа 820 расстояние Cj, связанное с двоичными данными fj, зависит от азимутального угла φj, связанного с двоичными данными fj, и (индекса) азимутального угла φal, связанного с любой из уже закодированных точек, не обязательно зондированных тем же индексом датчика, что и индекс датчика текущей точки Pn-1.
Согласно примеру осуществления этапа 820 расстояние Ci, связанное с двоичными данными fj, определяют следующим образом:
Cj=φj-φal
Согласно примеру осуществления этапа 820 индекс контекста ctxIdx таблицы контекстов, связанной с двоичными данными fj, равен расстоянию Cj.
Согласно примеру осуществления этапа 320 индекс контекста ctxIdx ограничивают порогом th1 для ограничения количества контекстов:
ctxIdx=min(Cj, th1)
Например, th1 может быть равно 6.
Ограничение количества контекстов важно для упрощения реализации, ограничения использования памяти, а также для обеспечения статистической релевантности вероятностей pctxIdx, поскольку высокие значения j не могут часто посещаться.
В соответствии с примером осуществления этапа 820 индекс контекста ctxIdx для двоичных данных fj зависит от ранга j упомянутых двоичных данных в последовательности двоичных данных, представляющих разность Δon порядковых индексов.
Поскольку статистика двоичных данных fj имеет тенденцию к слабой зависимости от ранга j при высоком j, можно воспользоваться этой слабой зависимостью, чтобы ограничить количество контекстов.
Более того, зависимость между индексом контекста ctxIdx и значением j дает преимущества по следующим причинам: статистика каждого бинарного флага fj равна PV или не зависит от индекса j. Обычно вероятность P(fj=PV | f0 до fj-1≠4PV) уменьшается с увеличением j. Следовательно, можно получить лучшие вероятности pctxIdx, сделав индекс ctxIdx зависимым от j.
В соответствии с примером осуществления этапа 820 индекс контекста ctxIdx задают следующим образом:
ctxIdx=min(Cj, th1)*(th2+l)+min(j,th2)
где th2 - это второй порог, такой как наличие (th1+l)*(th2+1) контекстов. Например, можно взять th2 равным 3.
Согласно примеру осуществления этапа 820 индекс контекста ctxIdx зависит от индекса датчика, связанного с двоичными данными fj.
Статистика каждых двоичных данных fj, равных или не равных PV, также зависит от индекса датчика (лазера), определяющего местоположение следующей точки, если двоичные данные fj равны PV. Например, датчики, направленные на землю, почти всегда что-то исследуют (в основном дорогу), а датчики, направленные в небо, как правило, реже исследуют больше объектов, таких как здания или деревья. Но зависимость между индексом контекста ctxIdx и индексом датчика λj, связанным с двоичными данными fj, умножает количество контекстов на K (количество датчиков) и, вероятно, обеспечивает очень большое количество контекстов, поскольку типичная головка лидара имеет 16, 32 или даже 64 лазерных луча.
Согласно примеру выполнения этапа 820 датчики с близкими углами наклона группируют вместе в группы, поскольку все датчики одной и той же группы обычно зондируют сходные объекты.
Каждый датчик с индексом λ имеет соответствующий индекс группы λpack(λ), а двоичные данные fj, связанные с индексом датчика λj, имеют соответствующий индекс группы с индексом группы λj,pack.
Группировка датчиков в группы ограничивает количество контекстов.
Согласно примеру осуществления этапа 820 индекс контекста ctxIdx задают следующим образом:
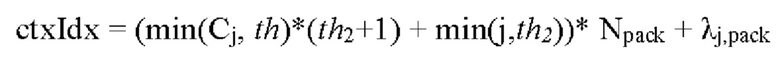
где Npack - количество групп.
Количество контекстов становится (th+1)*(th2+l)*Npack.
В варианте индекс группы λj,pack задают следующим образом:
λj,pack=floor(λj*Npack/K)
так что λj,pack принадлежит [0, Npack-1].
Затем количество контекстов можно отрегулировать, установив соответствующие значения для th1, и/или th2, и/или Npack. Эти значения могут быть закодированы в битовом потоке В. Например, с соответствующими значениями 6, 3 и 4 получается 7*4*4=112, что является приемлемым количеством контекстов.
На фиг .20 показана блок-схема этапов способа 900 энтропийного декодирования разности Δon порядковых индексов в соответствии по меньшей мере с одним примером осуществления изобретения.
Декодирование из битового потока В точки Pn облака точек, представляющего физический объект, включает декодирование из битового потока В разности Δon порядковых индексов, представляющей разность между порядковым индексом о(Pn), связанным с точкой Pn, и другим порядковым индексом о(Pn-1), связанным с текущей точкой Pn-1.
Декодирование разности Δon порядковых индексов включает декодирование по меньшей мере одних двоичных данных fj из битового потока В. Для каждых двоичных данных fj способ выбирает (этап 910) контекст на основе расстояния Cj между азимутальным углом φj, связанным с двоичными данными fj, и азимутальным углом (φpenult или φal) уже декодированной точки. Затем способ на основе контекста энтропийно декодирует (этап 920) указанные по меньшей мере одни двоичные данные fj на основе выбранных контекстов и информации о вероятности относительно двоичных данных fj и декодирует их из битового потока В. Затем получают разность Δon порядковых индексов (этап 930) двоичных данных fj, декодированных посредством основанного на контексте энтропийного декодирования.
Опционально, на этапе 930, если двоичные данные fNflag-1 достигнуты и не равны PV, то остаток R также декодируют из битового потока В, и разность Δon порядковых индексов получают с помощью Δon=R+Nflag.
Согласно варианту осуществления изобретения на этапе 930 остаток R декодируют с использованием кода exp-Golomb.
Выбор контекста на этапах 820 и 910 одинаков. Следовательно, все примеры осуществления и варианты этапа 820 применимы к этапу 910.
Согласно примеру осуществления этапа 920 двоичные данные fj подвергают энтропийному декодированию с помощью контекстно-адаптивного двоичного арифметического декодера (подобного САВАС). Основанное на контексте энтропийное декодирование (этап 920) двоичных данных fj на основе выбранного контекста по существу такое же, как основанное на контексте энтропийное кодирование на фиг. 17.
По сути, энтропийные декодеры декодируют -log2(pctxIdx) битов из битового потока В, чтобы декодировать двоичное значение fj=1 или -log2(1-pctxIdx) битов из битового потока В, чтобы декодировать fj=0. Как только символ fj декодирован, вероятность pctxIdx обновляется с использованием процесса обновления, принимающего fj и pctxIdx в качестве входных данных; процесс обновления обычно выполняется с использованием таблиц обновления. Обновленная вероятность заменяет ctxIdx-ю запись таблицы контекстов. Затем можно декодировать другой символ и т.д. Цикл обновления обратно в таблицу контекстов является узким местом в рабочем процессе кодирования, поскольку другой символ может быть декодирован только после выполнения обновления. По этой причине доступ к памяти для таблицы контекстов должен быть как можно более быстрым, а минимизация размера таблицы контекстов помогает упростить ее аппаратную реализацию.
Согласно варианту осуществления изобретения на этапе 930 разность Δon порядковых индексов декодируют посредством унарного декодирования по меньшей мере одних декодированных двоичных данных fj.
Например, если первые данные f0=PV, декодирование завершается, когда декодировано Δon=0; в противном случае, если f0≠PV, то декодируют вторые двоичные данные f1, в противном случае Δon=1, и декодирование завершается. Если f1≠PV, то декодируют третьи двоичные данные f2 и т.д.
На фиг. 21 показана схематическая структурная схема, иллюстрирующая пример системы, в которой реализованы различные аспекты и примеры осуществления изобретения.
Система 300 может быть представлена в виде одного или более устройств, включающих различные компоненты, описанные ниже. В различных вариантах осуществления изобретения система 300 может быть сконфигурирована для реализации одного или нескольких аспектов, описанных в настоящей заявке.
Примеры оборудования, которое может полностью или частично формировать систему 300, включают персональные компьютеры, ноутбуки, смартфоны, планшетные компьютеры, цифровые мультимедийные приставки, цифровые телевизионные приемники, персональные системы видеозаписи, подключенные бытовые приборы, подключенные транспортные средства и связанные с ними системы обработки данных, головные устройства отображения (HMD, прозрачные очки), проекторы (излучатели), «пещеры» (системы, включающие несколько дисплеев), серверы, видеокодеры, видеодекодеры, постпроцессоры, обрабатывающие выходные данные видеодекодера, препроцессоры, обеспечивающие входные данные для видеокодера, веб-серверы, телевизионные приставки и любое другое устройство для обработки облака точек, видео или изображения или другие устройства связи. Элементы системы 300 по отдельности или в комбинации могут быть реализованы в одной интегральной схеме (IC, integrated circuit), нескольких IC и/или с помощью дискретных компонентов. Например, по меньшей мере в одном варианте осуществления изобретения элементы обработки и кодера/декодера системы 300 могут быть распределены по нескольким IC и/или дискретным компонентам. В различных вариантах осуществления изобретения система 300 может быть связана с другими подобными системами или с другими электронными устройствами, например, через шину связи или через выделенные порты ввода и/или вывода.
Система 300 может включать по меньшей мере один процессор 310, сконфигурированный для выполнения загруженных в него инструкций для реализации, например, различных аспектов, описанных в настоящей заявке. Процессор 310 может включать встроенную память, интерфейс ввода-вывода и различные другие схемы, известные в данной области техники. Система 300 может включать по меньшей мере одно запоминающее устройство 320 (например, энергозависимое запоминающее устройство и/или энергонезависимое запоминающее устройство). Система 300 может включать запоминающее устройство 340, которое может включать энергонезависимую память и/или энергозависимую память, включая, помимо прочего, электрически стираемое программируемое постоянное запоминающее устройство (EEPROM, Electrically Erasable Programmable Read-Only Memory), постоянное запоминающее устройство (ROM, Read-Only Memory), программируемое постоянное запоминающее устройство (PROM, Programmable Read-Only Memory), оперативную память (RAM, Random Access Memory), динамическую оперативную память (DRAM, Dynamic Random-Access Memory), статическую оперативную память (SRAM, Static Random Access Memory), флэш-память, дисковод на магнитных и/или оптических дисках. Запоминающее устройство 340 может включать внутреннее запоминающее устройство, подключенное запоминающее устройство и/или доступное по сети запоминающее устройство, в качестве неограничивающих примеров.
Система 300 может включать модуль 330 кодера/декодера, сконфигурированный, например, для обработки данных для предоставления кодированных/декодированных данных геометрии облака точек, а модуль 330 кодера/декодера может включать собственный процессор и память. Модуль 330 кодера/декодера может представлять собой модуль(и), которые могут быть включены в устройство для выполнения функций кодирования и/или декодирования. Как известно, устройство может включать один или оба модуля кодирования и декодирования. Кроме того, модуль 330 кодера/декодера может быть реализован как отдельный элемент системы 300 или может быть встроен в процессор 310 в виде комбинации аппаратного и программного обеспечения, как известно специалистам в данной области техники.
Программный код, подлежащий загрузке в процессор 310 или кодер/декодер 330 для выполнения различных аспектов, описанных в настоящей заявке, может храниться в запоминающем устройстве 340 и впоследствии загружаться в память 320 для выполнения процессором 310. В соответствии с различными вариантами осуществления изобретения одно или более из процессора 310, памяти 320, запоминающего устройства 340 и модуля 330 кодера/декодера могут сохранять один или более различных элементов во время выполнения процессов, описанных в настоящей заявке. Такие сохраненные элементы могут включать, помимо прочего, кадр облака точек, кодированные/декодированные видео/изображения геометрии/атрибутов или части кодированных/декодированных видео/изображений геометрии/атрибутов, битовый поток, матрицы, переменные и промежуточные или окончательные результаты обработки уравнений, формул, операций и операционной логики.
В некоторых вариантах осуществления изобретения память внутри процессора 310 и/или модуля 330 кодера/декодера может использоваться для хранения инструкций и предоставления рабочей памяти для обработки, которая может выполняться во время кодирования или декодирования.
Однако в других вариантах осуществления изобретения для одной или более из этих функций может использоваться память, внешняя по отношению к устройству обработки (например, устройством обработки может быть либо процессор 310, либо модуль 330 кодера/декодера). Внешней памятью может быть память 320 и/или запоминающее устройство 340, например динамическая энергозависимая память и/или энергонезависимая флэш-память. В некоторых вариантах осуществления изобретения внешняя энергонезависимая флэш-память может использоваться для хранения операционной системы телевизора. По меньшей мере в одном варианте осуществления изобретения быстрая внешняя динамическая энергозависимая память, такая как RAM, может использоваться в качестве рабочей памяти для операций кодирования и декодирования видео, например, для MPEG-2, часть 2 (также известной как Рекомендация МСЭ-Т Н.262 и ISO/IEC 13818-2, также известна как MPEG-2 Video), HEVC (High Efficiency Video coding, высокоэффективное кодирование видео), VVC (Versatile Video Coding, универсальное кодирование видео) или MPEG-I часть 5 или часть 9.
Ввод в элементы системы 300 может обеспечиваться через различные устройства ввода, как указано в блоке 390. Такие устройства ввода включают, но не ограничиваются этим, (i) радиочастотную часть, которая может принимать радиочастотный сигнал, передаваемый, например, в эфире вещательной компанией, (ii) композитный входной разъем, (iii) входной разъем USB и/или (iv) входной разъем HDMI.
В различных вариантах осуществления изобретения устройства ввода блока 390 могут иметь соответствующие элементы обработки ввода, как известно в данной области техники. Например, радиочастотная часть может быть связана с элементами, необходимыми для (i) выбора желаемой частоты (также называемого выбором сигнала или ограничением полосы частот сигнала), (ii) преобразования выбранной частоты с понижением частоты выбранного сигнала, (iii) ограничения полосы до более узкой полосы частот для выбора (например) полосы частот сигнала, которая может называться каналом в некоторых вариантах осуществления изобретения, (iv) демодуляции преобразованного с понижением частоты и ограниченного по полосе сигнала, (v) выполнения исправления ошибок и (vi) демультиплексирования для выбора желаемого потока пакетов данных. Радиочастотная часть различных вариантов осуществления изобретения может включать один или более элементов для выполнения этих функций, например, селекторы частоты, селекторы сигналов, ограничители полосы, селекторы каналов, фильтры, преобразователи с понижением частоты, демодуляторы, корректоры ошибок и демультиплексоры. Радиочастотная часть может включать тюнер, который выполняет различные из этих функций, включая, например, преобразование с понижением частоты принятого сигнала до более низкой частоты (например, промежуточной частоты или частоты, близкой к основной полосе частот) или до основной полосы частот.
В одном варианте осуществления телевизионной приставки РЧ-часть и связанный с ней элемент обработки ввода могут принимать РЧ-сигнал, передаваемый по проводной среде (например, кабелю). Затем радиочастотная часть может выполнять выбор частоты путем фильтрации, преобразования с понижением частоты и повторной фильтрации до требуемой полосы частот.
Различные варианты осуществления изобретения изменяют порядок вышеописанных (и других) элементов, удаляют некоторые из этих элементов и/или добавляют другие элементы, выполняющие аналогичные или отличные функции.
Добавление элементов может включать вставку элементов между существующими элементами, например, вставку усилителей и аналого-цифрового преобразователя. В различных вариантах осуществления изобретения радиочастотная часть может включать антенну.
Кроме того, разъемы USB и/или HDMI могут включать соответствующие интерфейсные процессоры для подключения системы 300 к другим электронным устройствам через соединения USB и/или HDMI. Следует понимать, что различные аспекты обработки ввода, например исправление ошибок Рида-Соломона, могут быть реализованы, например, в отдельной IC обработки ввода или в процессоре 310 при необходимости. Точно так же аспекты обработки интерфейсов USB или HDMI могут быть реализованы в отдельных интерфейсных IC или в процессоре 310 при необходимости. Демодулированный, с исправлением ошибок, и демультиплексированный поток может подаваться на различные элементы обработки, включая, например, процессор 310 и кодер/декодер 330, работающие в сочетании с элементами памяти и хранения, для обработки потока данных по мере необходимости для представления на устройство вывода.
Различные элементы системы 300 могут быть размещены внутри интегрированного корпуса. Внутри интегрированного корпуса различные элементы могут быть соединены между собой и передавать данные между собой с использованием подходящего соединительного устройства 390, например, внутренней шины, известной в данной области техники, включая шину I2C, проводку и печатные платы.
Система 300 может включать интерфейс 350 связи, который обеспечивает связь с другими устройствами через канал 700 связи. Интерфейс 350 связи может включать, не ограничиваясь этим, приемопередатчик, сконфигурированный для передачи и приема данных по каналу 700 связи. Интерфейс 350 связи может включать, не ограничиваясь этим, модем или сетевую карту, а канал 700 связи может быть реализован, например, в проводной и/или беспроводной среде.
Данные могут передаваться в систему 300 в различных вариантах осуществления изобретения с использованием сети Wi-Fi, такой как IEEE 802.11. Сигнал Wi-Fi этих вариантов осуществления изобретения может быть принят по каналу 700 связи и интерфейсу 350 связи, которые приспособлены для связи Wi-Fi. Канал 700 связи в этих вариантах осуществления изобретения обычно может быть подключен к точке доступа или маршрутизатору, который обеспечивает доступ к внешним сетям, включая Интернет, для обеспечения возможности потоковой передачи приложений и других видов связи.
Другие варианты осуществления изобретения могут предоставлять потоковые данные в систему 300 с использованием телевизионной приставки, которая доставляет данные через соединение HDMI блока 390 ввода.
Другие варианты осуществления изобретения могут предоставлять потоковые данные в систему 300 с использованием радиочастотного соединения блока 390 ввода.
Потоковые данные могут использоваться как способ передачи информации сигнализации, используемой системой 300. Информация сигнализации может включать битовый поток В и/или информацию, такую как количество точек облака точек, координаты или порядок o(P1) первой точки в системе 2D-координат (φ, λ) и/или параметры настройки датчика, такие как элементарное азимутальное смещение Δφ или угол наклона θk, связанный с датчиком головки 10 лидара.
Следует принимать во внимание, что сигнализация может осуществляться различными способами. Например, один или более синтаксических элементов, флагов и т.д. могут использоваться для передачи информации соответствующему декодеру в различных вариантах осуществления изобретения.
Система 300 может подавать выходной сигнал на различные устройства вывода, включая дисплей 400, динамики 500 и другие периферийные устройства 600. Другие периферийные устройства 600 могут включать, в различных примерах осуществления изобретения, одно или более из автономного цифрового видеорегистратора, проигрывателя дисков, стереосистемы, системы освещения и других устройств, обеспечивающих работу на основе выходных данных системы 300.
В различных вариантах осуществления изобретения управляющие сигналы могут передаваться между системой 300 и дисплеем 400, динамиками 500 или другими периферийными устройствами 600 с использованием сигнализации, такой как AV.Link (аудио/видео связь), СЕС (Consumer Electronics Control, управление бытовой электроникой) или других протоколов связи, которые позволяют осуществлять управление между устройствами с участием пользователя или без него.
Устройства вывода могут быть связаны с системой 300 посредством выделенных соединений через соответствующие интерфейсы 360, 370 и 380.
Альтернативно, устройства вывода могут быть подключены к системе 300 с использованием канала 700 связи через интерфейс 350 связи. Дисплей 400 и динамики 500 могут быть интегрированы в единый блок с другими компонентами системы 300 в электронном устройстве, таком как телевизор.
В различных вариантах осуществления изобретения интерфейс 360 дисплея может включать драйвер дисплея, такой как, например, микросхема контроллера синхронизации (Т Con).
В качестве альтернативы дисплей 400 и динамик 500 могут быть отделены от одного или более других компонентов, например, если радиочастотная часть ввода 390 является частью отдельной телевизионной приставки. В различных вариантах осуществления изобретения, в которых дисплей 400 и динамики 500 могут быть внешними компонентами, выходной сигнал может подаваться через специальные выходные соединения, включая, например, порты HDMI, порты USB или выходы СОМР.
На фиг. 1-21 описаны различные способы, и каждый из способов включает один или более этапов или действий для осуществления описанного способа. Если для правильной работы способа не требуется определенный порядок этапов или действий, порядок и/или использование конкретных этапов и/или действий можно изменить или комбинировать.
Некоторые примеры описаны в отношении структурных схем и/или операционных блок-схем. Каждый блок представляет собой элемент схемы, модуль или часть кода, которая включает одну или более исполняемых инструкций для реализации указанной логической функции (функций). Следует также отметить, что в других реализациях функции, указанные в блоках, могут выполняться не в указанном порядке. Например, два блока, показанные последовательно, могут фактически выполняться по существу одновременно, или иногда блоки могут выполняться в обратном порядке, в зависимости от задействованной функциональности.
Описанные здесь реализации и аспекты могут осуществляться, например, в способе или процессе, устройстве, компьютерной программе, потоке данных, битовом потоке или сигнале. Даже если это обсуждается только в контексте одной формы реализации (например, обсуждается только как способ), реализация обсуждаемых признаков также может осуществляться в других формах (например, в виде устройства или компьютерной программы).
Способы могут быть реализованы, например, в процессоре, который относится в общем к устройствам обработки, включая, например, компьютер, микропроцессор, интегральную схему или программируемое логическое устройство. К процессорам также относятся устройства связи.
Кроме того, способы могут быть реализованы с помощью инструкций, выполняемых процессором, и такие инструкции (и/или значения данных, полученные при реализации) могут быть сохранены на машиночитаемом носителе данных. Машиночитаемый носитель данных может иметь форму машиночитаемого программного продукта, воплощенного на одном или более машиночитаемых носителях и имеющего хранимый на нем машиночитаемый программный код, который может выполняться компьютером. Машиночитаемый носитель данных, используемый в данном документе, может считаться постоянным носителем данных, с учетом присущей ему способности хранить информацию, а также присущей ему способности обеспечивать извлечение из него информации. Машиночитаемый носитель информации может быть, например, электронной, магнитной, оптической, электромагнитной, инфракрасной или полупроводниковой системой, оборудованием или устройством, или любой подходящей комбинацией вышеперечисленного. Следует понимать, что, хотя ниже будут представлены более конкретные примеры машиночитаемых носителей данных, к которым могут быть применены настоящие варианты осуществления изобретения, они представляют просто иллюстративный, а не исчерпывающий список, что легко поймут специалисты в данной области техники: переносная компьютерная дискета; жесткий диск; постоянное запоминающее устройство (ROM); стираемая программируемая постоянная память (EPROM или флэш-память); портативный компакт-диск постоянного запоминающего устройства (CD-ROM); оптическое запоминающее устройство; магнитное запоминающее устройство; или любая подходящая комбинация вышеперечисленного.
Инструкции могут формировать прикладную программу, материально воплощенную на считываемом процессором носителе.
Инструкции могут быть, например, в аппаратном обеспечении, встроенном программном обеспечении, программном обеспечении или их комбинации. Инструкции можно найти, например, в операционной системе, в отдельном приложении или в их комбинации. Таким образом, процессор можно охарактеризовать, например, как устройство, сконфигурированное для выполнения процесса, так и как устройство, которое включает считываемый процессором носитель (такой как запоминающее устройство), содержащий инструкции для выполнения процесса. Кроме того, считываемый процессором носитель может хранить в дополнение к инструкциям или вместо них значения данных, созданные при реализации.
Устройство может быть реализовано, например, в соответствующих аппаратных средствах, программном обеспечении и встроенном программном обеспечении. Примеры таких устройств включают персональные компьютеры, ноутбуки, смартфоны, планшетные компьютеры, цифровые мультимедийные приставки, цифровые телевизионные приемники, персональные системы видеозаписи, подключенную бытовую технику, головные устройства отображения (HMD, прозрачные очки), проекторы (видеопроекторы), «пещеры» (системы, включающие несколько дисплеев), серверы, видеокодеры, видеодекодеры, постпроцессоры, обрабатывающие выходные данные видеодекодера, препроцессоры, обеспечивающие ввод для видеокодера, веб-серверы, телевизионные приставки и любое другое устройство для обработки облака точек, видео или изображения или другие средства связи. Как должно быть понятно, оборудование может быть мобильным и может даже устанавливаться в подвижном транспортном средстве.
Компьютерное программное обеспечение может быть реализовано процессором 310 или аппаратным обеспечением, или комбинацией аппаратного обеспечения и программного обеспечения. В качестве неограничивающего примера, варианты осуществления изобретения также могут быть реализованы с помощью одной или более интегральных схем. Память 320 может быть любого типа, соответствующего технической среде, и может быть реализована с использованием любой подходящей технологии хранения данных, такой как оптические запоминающие устройства, магнитные запоминающие устройства, полупроводниковые запоминающие устройства, стационарная память и съемная память, в качестве неограничивающих примеров. Процессор 310 может быть любого типа, соответствующего технической среде, и может включать один или более микропроцессоров, компьютеров общего назначения, компьютеров специального назначения и процессоров на основе многоядерной архитектуры, в качестве неограничивающих примеров.
Как будет очевидно специалисту в данной области техники, реализации могут генерировать различные сигналы, отформатированные для переноса информации, которая может быть, например, сохранена или передана. Информация может включать, например, инструкции по выполнению способа или данные, полученные в одной из описанных реализаций. Например, сигнал может быть отформатирован для переноса битового потока описанного варианта осуществления изобретения. Такой сигнал может быть отформатирован, например, как электромагнитная волна (например, с использованием радиочастотной части спектра) или как сигнал основной полосы частот. Форматирование может включать, например, кодирование потока данных и модуляцию несущей кодированным потоком данных. Информация, которую несет сигнал, может быть, например, аналоговой или цифровой информацией. Как известно, сигнал может передаваться по различным проводным или беспроводным каналам связи. Сигнал может быть сохранен на считываемом процессором носителе.
Используемая здесь терминология предназначена только для описания конкретных вариантов осуществления изобретения и не предназначена для ограничения изобретения. Используемые здесь формы единственного числа могут также означать включение форм множественного числа, если в контексте явно не указано иное. Далее будет понятно, что термины «включает/содержит» и/или «включающий/содержащий» при использовании в данном описании могут указывать на наличие, например, заявленных признаков, целых чисел, этапов, операций, элементов и/или компонентов, но не исключают наличия или добавления одного или более других признаков, целых чисел, этапов, операций, элементов, компонентов и/или их групп. Более того, когда элемент упоминается как «отвечающий» или «подключенный» к другому элементу, он может быть непосредственно отвечающим или связанным с другим элементом, или могут присутствовать промежуточные элементы. Напротив, когда элемент упоминается как «непосредственно отвечающий» или «непосредственно связанный» с другим элементом, промежуточные элементы отсутствуют.
Следует понимать, что использование любого символа/термина «/», «и/или» и «по меньшей мере один из», например, в случаях «А/В», «А и/или В» и «по меньшей мере один из А и В» могут означать выбор только первого из перечисленных вариантов (А), или только выбор второго из перечисленных вариантов (В), или выбор обоих вариантов (А и В). В качестве еще одного примера, в случаях «А, В и/или С» и «по меньшей мере один из А, В и С» такая формулировка предназначена для охвата выбора только первого из перечисленных вариантов (А), или выбор только второго из перечисленных вариантов (В), или выбор только третьего из перечисленных вариантов (С), или выбор только первого и второго из перечисленных вариантов (А и В), или выбор только первого и третьего из перечисленных вариантов (А и С), либо выбор только второго и третьего из перечисленных вариантов (В и С), либо выбор всех трех вариантов (А и В и С). Это может быть расширено, как ясно любому специалисту в этой области и смежных областях, на столько предметов, сколько перечислено.
В настоящей заявке могут использоваться различные числовые значения. Конкретные значения могут быть использованы для примера, и описанные аспекты не ограничиваются этими конкретными значениями.
Следует понимать, что, хотя термины «первый», «второй» и т.д. могут использоваться здесь для описания различных элементов, эти элементы не ограничиваются этими терминами. Эти термины используются только для того, чтобы отличить один элемент от другого. Например, первый элемент можно было бы назвать вторым элементом, и аналогично второй элемент можно было бы назвать первым элементом, в пределах сущности изобретения. Порядок между первым элементом и вторым элементом не подразумевается.
Ссылка на «один пример осуществления изобретения» или «пример осуществления изобретения», или «один вариант реализации изобретения», или «вариант осуществления изобретения», а также другие их варианты часто используется для обозначения того, что конкретный признак, структура, характеристика и т.д. (описанные в связи с вариантом осуществления/реализацией изобретения) включен по меньшей мере в один вариант осуществления/реализации изобретения. Таким образом, появление фразы «в одном примере осуществления изобретения» или «в примере осуществления изобретения», или «в одной реализации изобретения», или «в реализации изобретения», а также любые другие варианты, встречающиеся в различных местах в этой заявке, не обязательно относятся к одному и тому же варианту.
Аналогичным образом ссылка в данном документе на «в соответствии с примером осуществления/примером/реализацией изобретения» или «в примере осуществления/примере/реализации изобретения», а также их другие варианты часто используется для обозначения того, что конкретный признак, структура или характеристика (описанный в связи с примером осуществления/примером/реализацией изобретения) может быть включен по меньшей мере в один пример осуществления/пример/реализацию изобретения. Таким образом, выражения «в соответствии с примером осуществления/примером/реализацией изобретения» или «в примере осуществления/примере/реализации изобретения» в различных местах описания не обязательно все относятся к одному и тому же примеру осуществления/примеру/реализации изобретения, а также отдельные или альтернативные иллюстративные варианты осуществления/примеры/реализации изобретения не обязательно исключают другие из иллюстративных вариантов осуществления/примеров/реализации изобретения.
Ссылочные позиции, встречающиеся в формуле изобретения, приведены только в качестве примера и не ограничивают объем формулы изобретения. Хотя это и не описано явно, настоящие варианты осуществления/примеры изобретения и варианты могут быть использованы в любой комбинации или подкомбинации.
Когда чертеж представлен в виде блок-схемы, следует понимать, что он также обеспечивает структурную схему соответствующего устройства. Точно так же, когда чертеж представлен в виде структурной схемы, следует понимать, что он также обеспечивает блок-схему соответствующего способа/процесса.
Хотя некоторые из диаграмм содержат стрелки на путях связи, чтобы показать основное направление связи, следует понимать, что связь может происходить в направлении, противоположном показанным стрелкам.
Различные реализации включают декодирование. «Декодирование», используемое в данной заявке, может охватывать все или часть процессов, выполняемых, например, над принятым кадром облака точек (включая, возможно, принятый битовый поток, в котором кодированы один или более кадров облака точек) для получения конечного результата, подходящего для отображения или дальнейшей обработки в области реконструированного облака точек. В различных вариантах осуществления изобретения такие процессы включают один или более процессов, обычно выполняемых декодером. Например, в различных вариантах осуществления изобретения такие процессы также или альтернативно включают процессы, выполняемые декодером различных реализаций, описанных в данной заявке.
В качестве дополнительных примеров, в одном варианте осуществления изобретения «декодирование» может относиться только к деквантованию, в одном варианте осуществления изобретения «декодирование» может относиться к энтропийному декодированию, в другом варианте осуществления изобретения «декодирование» может относиться только к дифференциальному декодированию, а в другом варианте осуществления изобретения «декодирование» может относиться к комбинациям деквантования, энтропийного декодирования и дифференциального декодирования. Может ли фраза «процесс декодирования» предназначаться для обозначения конкретно подмножества операций или в целом более широкого процесса декодирования, будет ясно на основании контекста конкретного описания и считается хорошо понятным специалистам в данной области техники.
Различные реализации включают кодирование. Аналогично приведенному выше обсуждению «декодирования», «кодирование», используемое в данной заявке, может охватывать все или часть процессов, выполняемых, например, над входным кадром облака точек для создания кодированного битового потока. В различных вариантах осуществления изобретения такие процессы включают один или более процессов, обычно выполняемых кодером. В различных вариантах осуществления изобретения такие процессы также или альтернативно включают процессы, выполняемые кодером различных реализаций, описанных в этой заявке.
В качестве дополнительных примеров, в одном варианте осуществления изобретения «кодирование» может относиться только к квантованию, в одном варианте осуществления изобретения «кодирование» может относиться только к энтропийному кодированию, в другом варианте осуществления изобретения «кодирование» может относиться только к дифференциальному кодированию, а в другом варианте осуществления изобретения «кодирование» может относятся к комбинациям квантования, дифференциального кодирования и энтропийного кодирования. Может ли фраза «процесс кодирования» предназначаться для обозначения конкретно подмножества операций или в целом более широкого процесса кодирования, будет ясно на основе контекста конкретного описания и считается хорошо понятным специалистам в данной области техники.
Кроме того, эта заявка может относиться к «определению» различных фрагментов информации. Определение информации может включать, например, одно или более из оценки информации, вычисления информации, предсказания информации или извлечения информации из памяти.
Кроме того, эта заявка может относиться к «доступу» к различным частям информации. Доступ к информации может включать одно или более действий, например получение информации, извлечение информации (например, из памяти), сохранение информации, перемещение информации, копирование информации, вычисление информации, определение информации, предсказание информации или оценку информации.
Кроме того, эта заявка может относиться к «получению» различных фрагментов информации. Получение, как и «доступ», должно быть широким термином. Прием информации может включать одно или более действий, например, доступ к информации или извлечение информации (например, из памяти). Кроме того, «получение» обычно так или иначе связано с такими операциями, как, например, сохранение информации, обработка информации, передача информации, перемещение информации, копирование информации, стирание информации, вычисление информации, определение информации, предсказание информации или оценка информации.
Кроме того, используемое здесь слово «сигнал» относится, среди прочего, к указанию соответствующему декодеру. Например, в некоторых вариантах осуществления изобретения кодер передает конкретную информацию, такую как по меньшей мере одни двоичные данные fj, остаток R, количество точек облака точек или координаты или порядок o(P1) первой точки в системе двумерных координат (φ, λ), параметры настройки датчика, такие как элементарный азимутальный сдвиг Δφ или угол наклона θk, связанный с датчиком k. Таким образом, в варианте осуществления изобретения один и тот же параметр может использоваться как на стороне кодера, так и на стороне декодера. Таким образом, например, кодер может передать (явная сигнализация) конкретный параметр декодеру, чтобы декодер мог использовать тот же самый конкретный параметр. И наоборот, если декодер уже имеет конкретный параметр, а также другие, тогда сигнализация может использоваться без передачи (неявная сигнализация), чтобы просто позволить декодеру узнать и выбрать конкретный параметр. Избегая передачи каких-либо фактических функций, в различных вариантах осуществления изобретения достигается экономия битов. Следует принимать во внимание, что сигнализация может осуществляться различными способами. Например, один или более синтаксических элементов, флагов и т.д. используются для передачи информации соответствующему декодеру в различных вариантах осуществления изобретения. Хотя предыдущее относится к глаголам от слова «сигнал», здесь также может использоваться существительное «сигнал».
Описан ряд реализаций. Тем не менее, следует понимать, что могут быть сделаны различные модификации. Например, элементы различных реализаций могут быть объединены, дополнены, изменены или удалены для создания других реализаций. Кроме того, специалисту будет понятно, что раскрытые конструкции и процессы могут быть заменены другими, и полученные реализации будут выполнять по меньшей мере по существу те же функции по меньшей мере по существу тем же способом (способами) для достижения по меньшей мере по существу того(тех) же результата(ов), что и раскрытые реализации. Соответственно, эти и другие реализации охватываются данной заявкой.
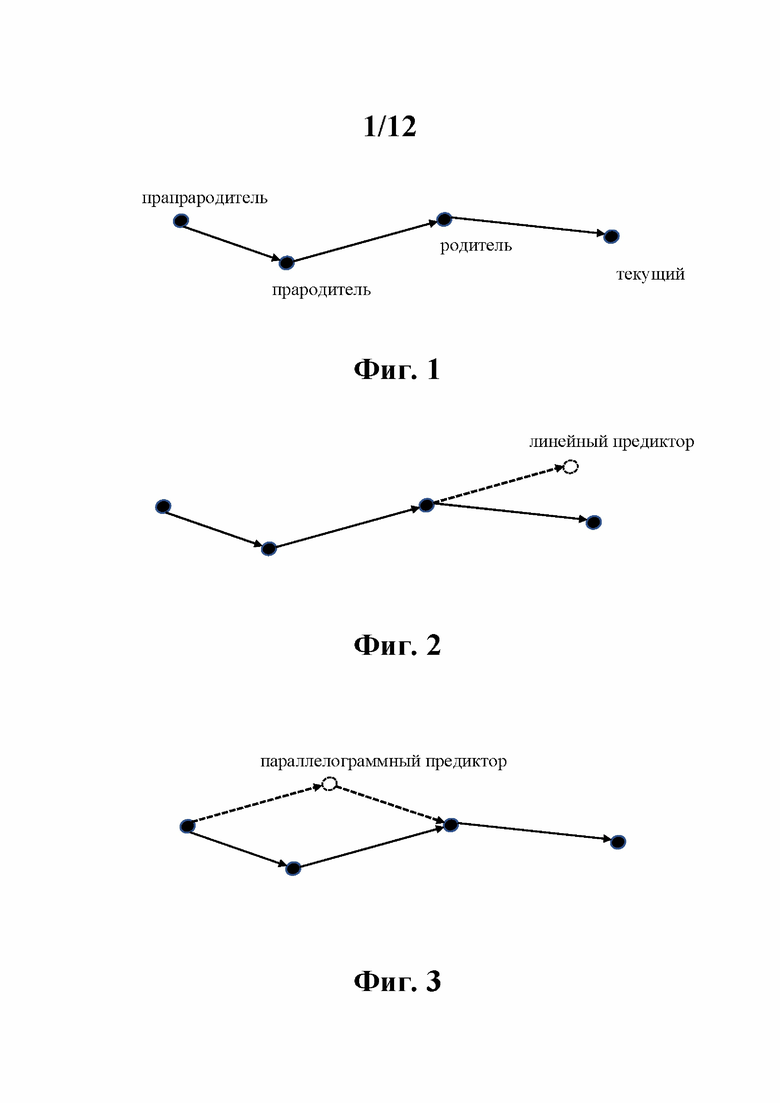
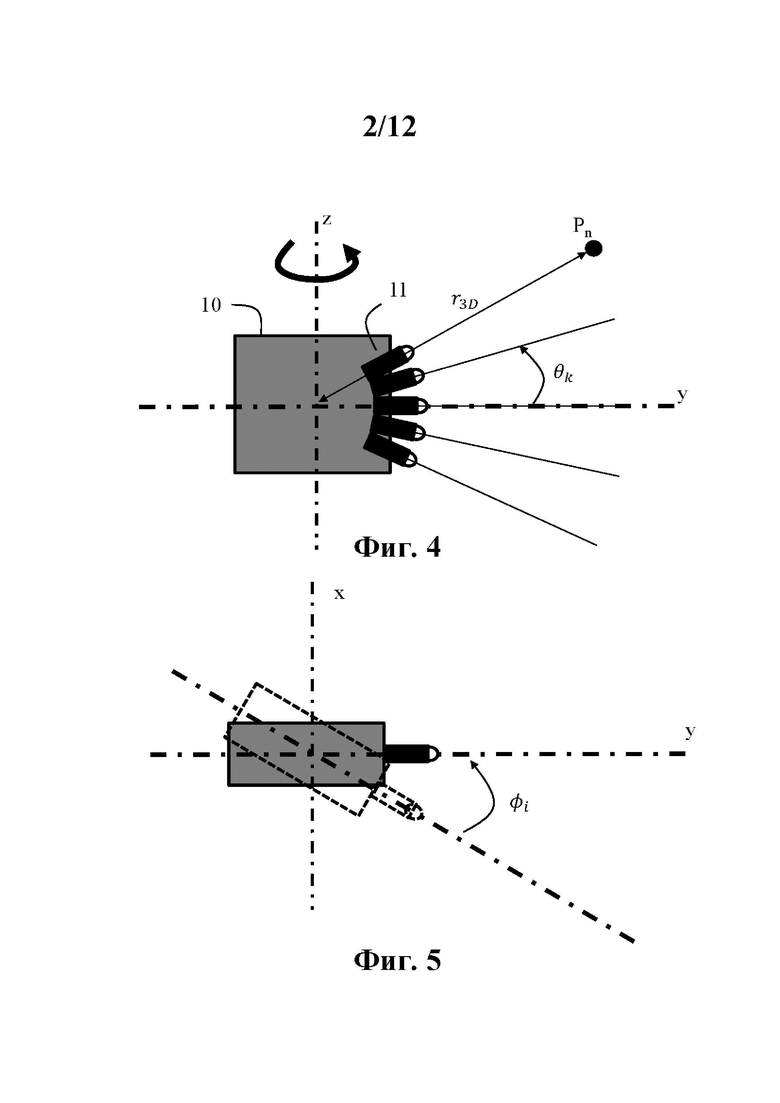
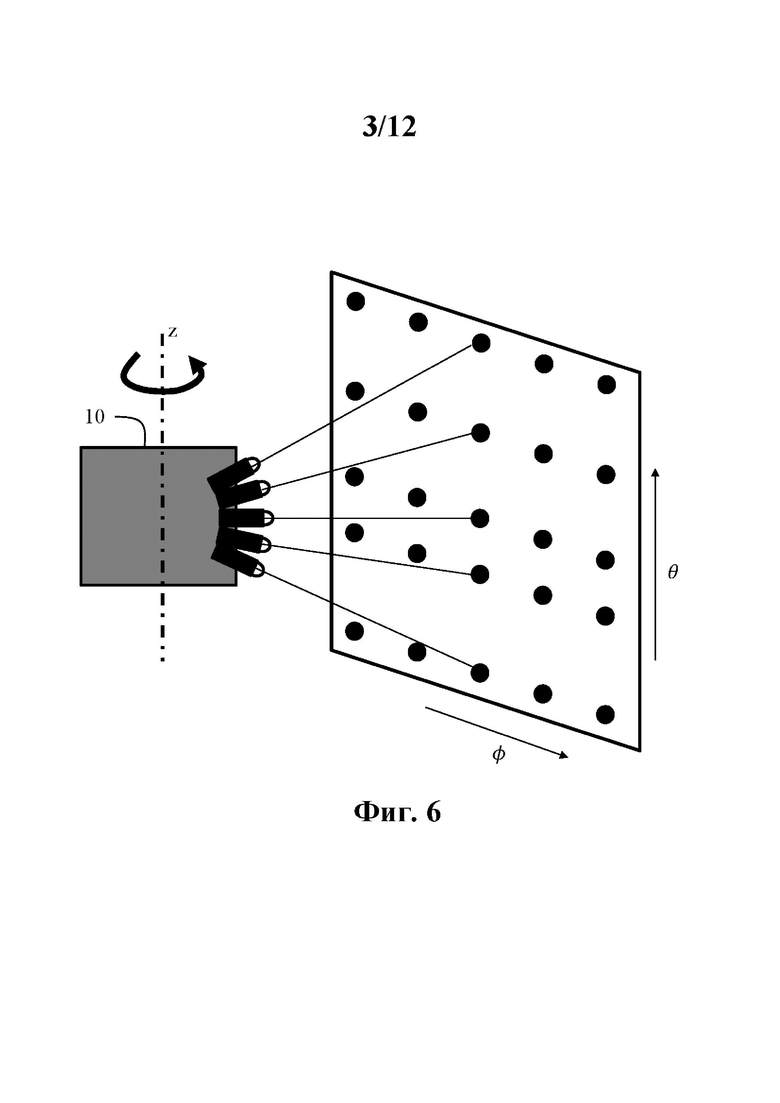
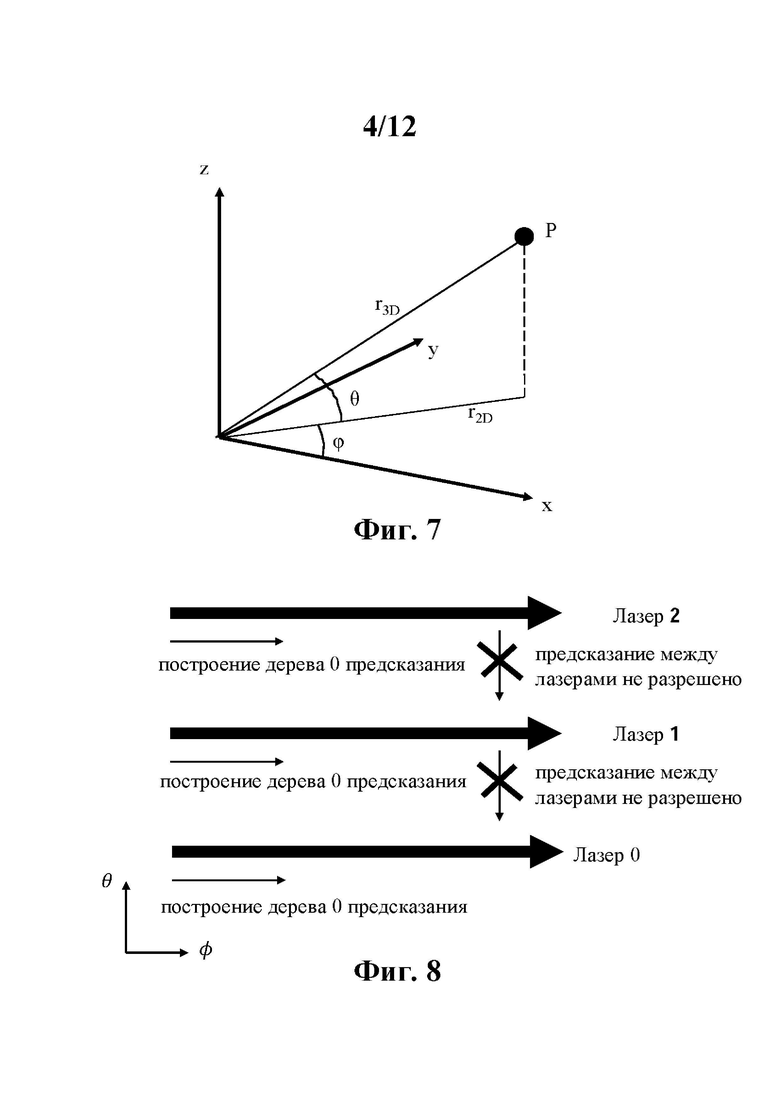
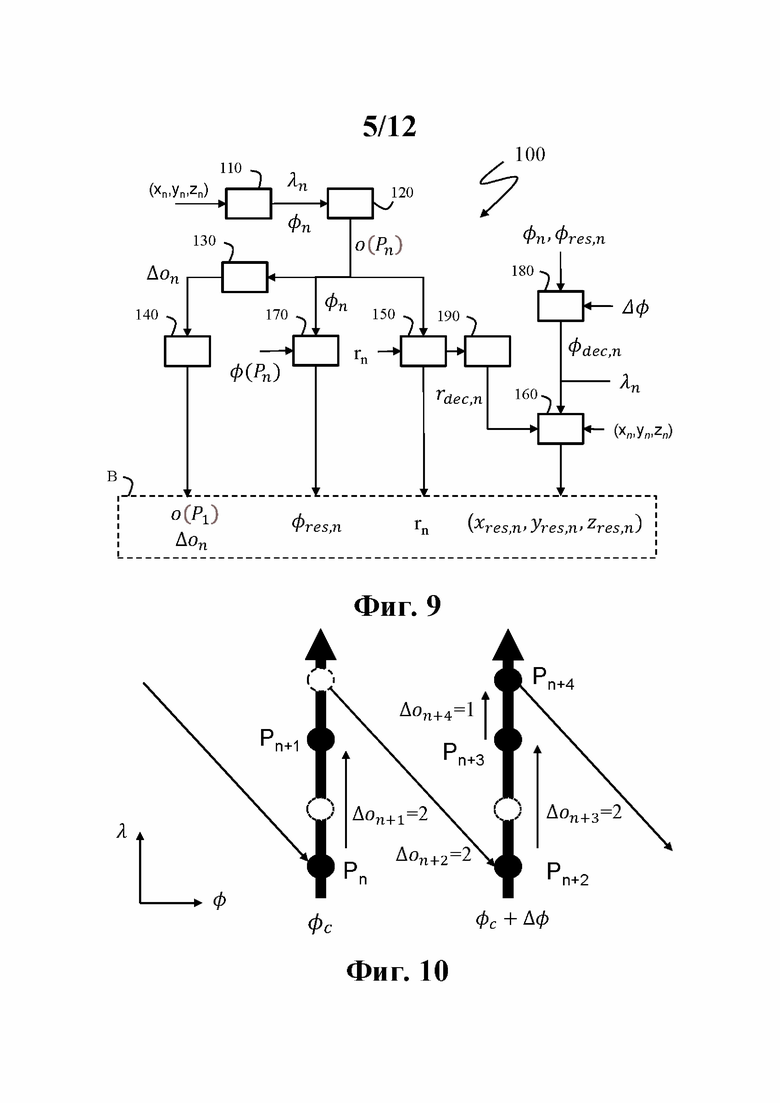
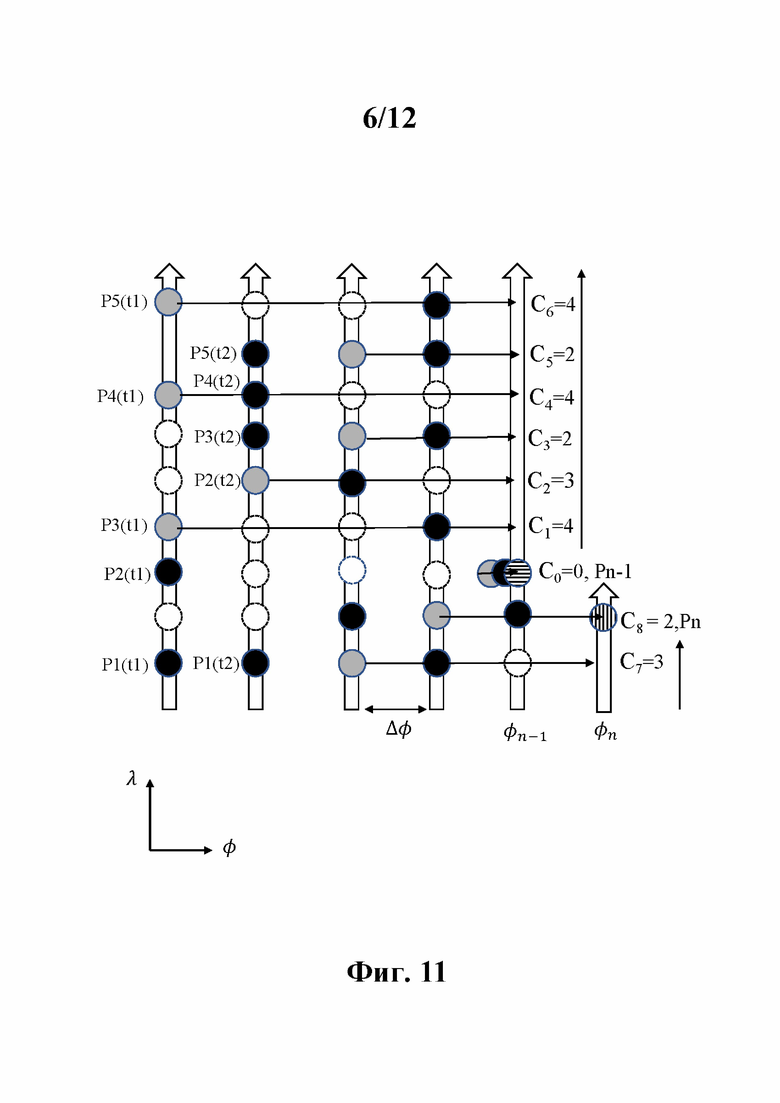
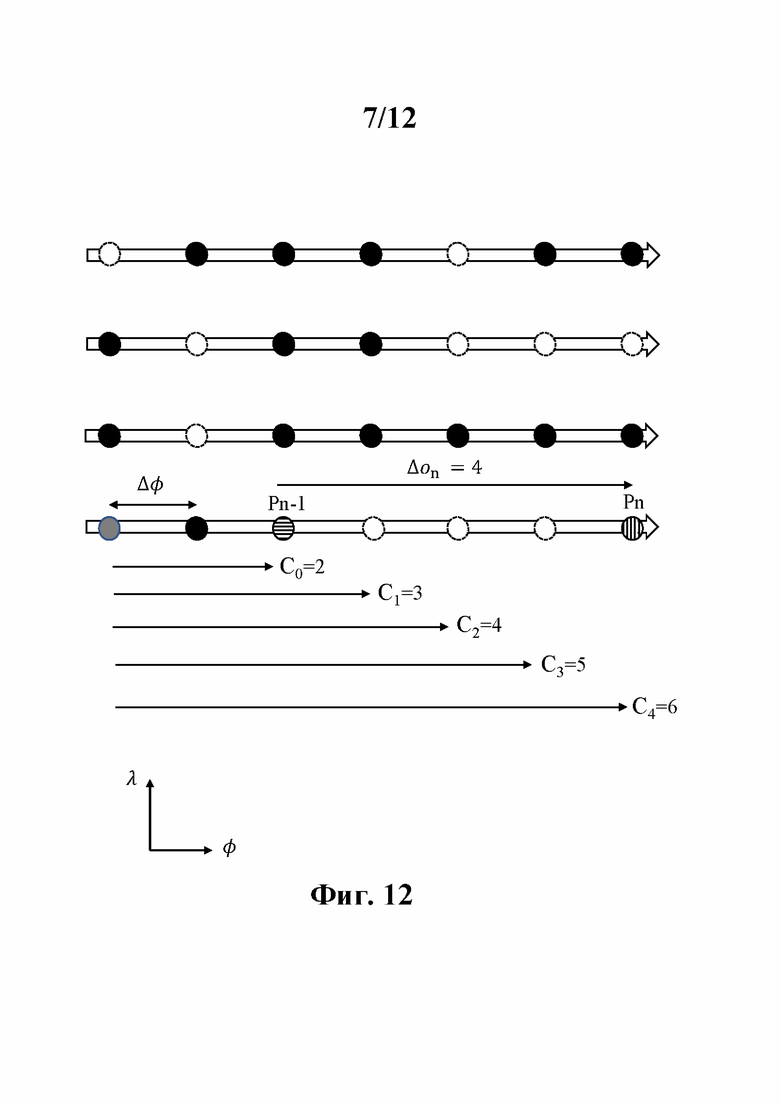
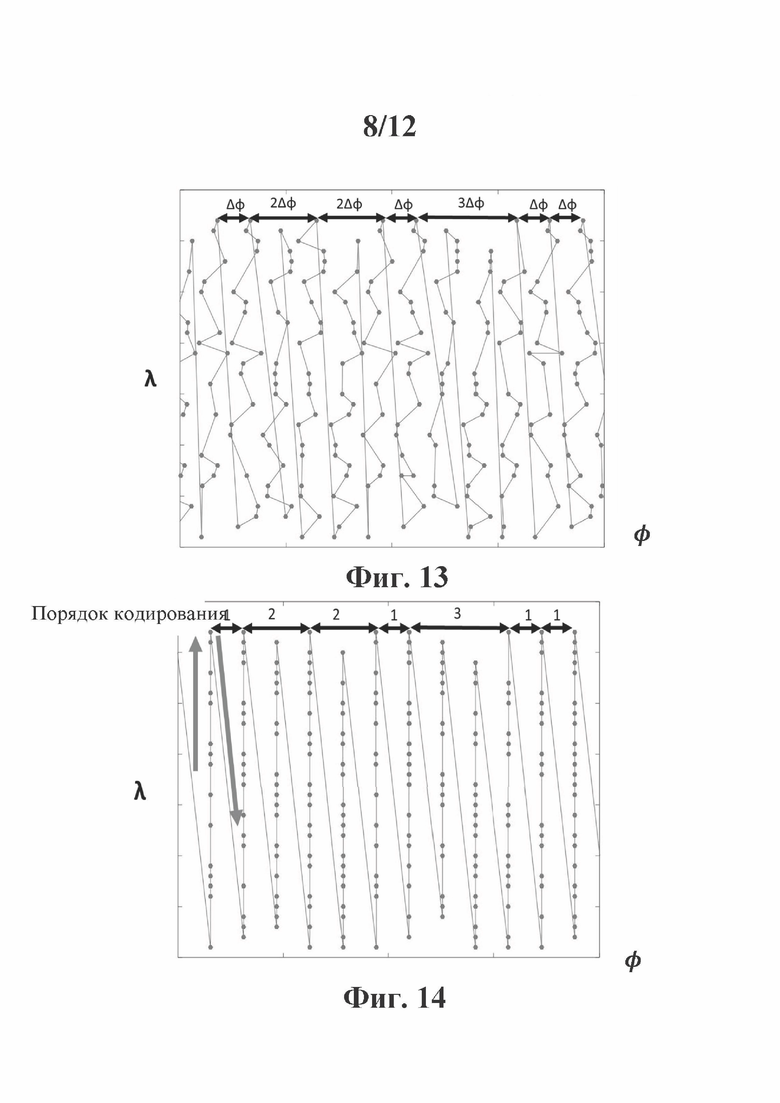
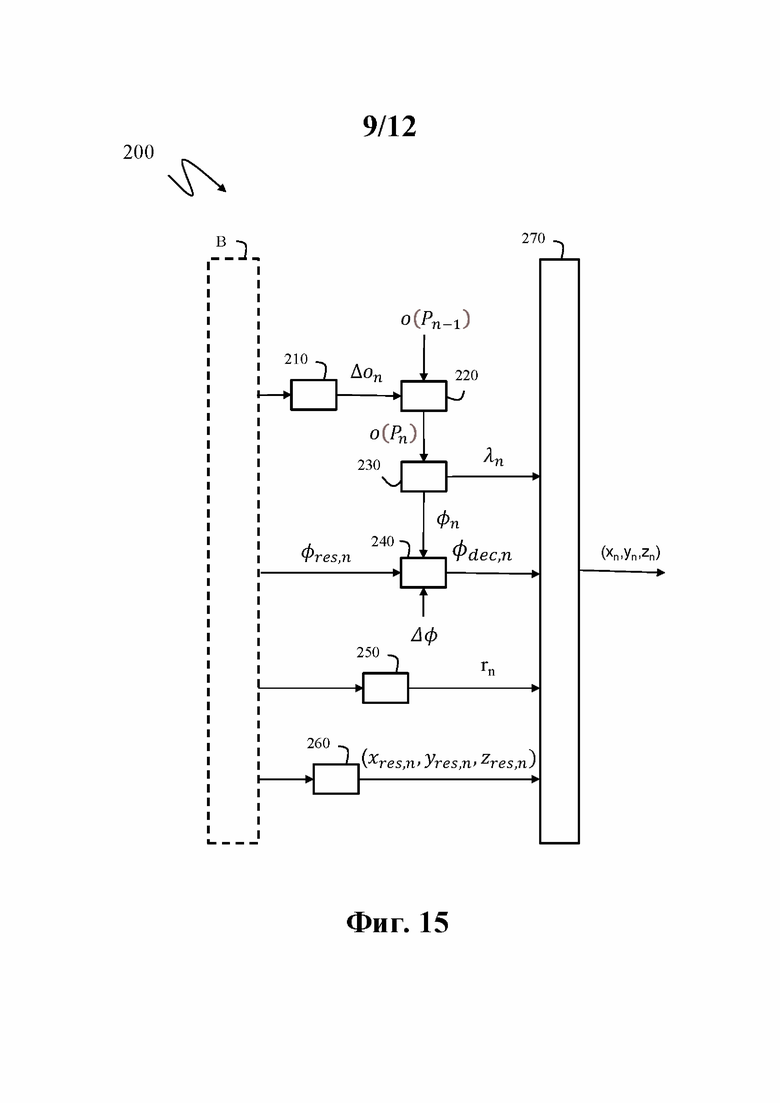
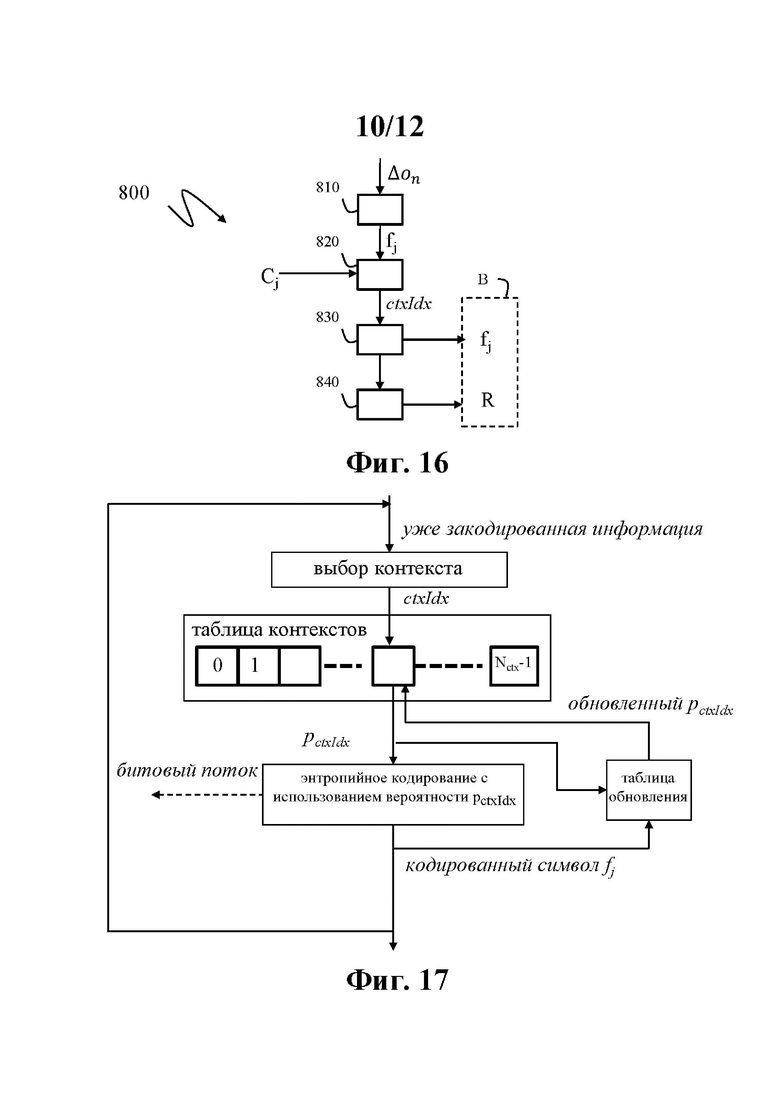
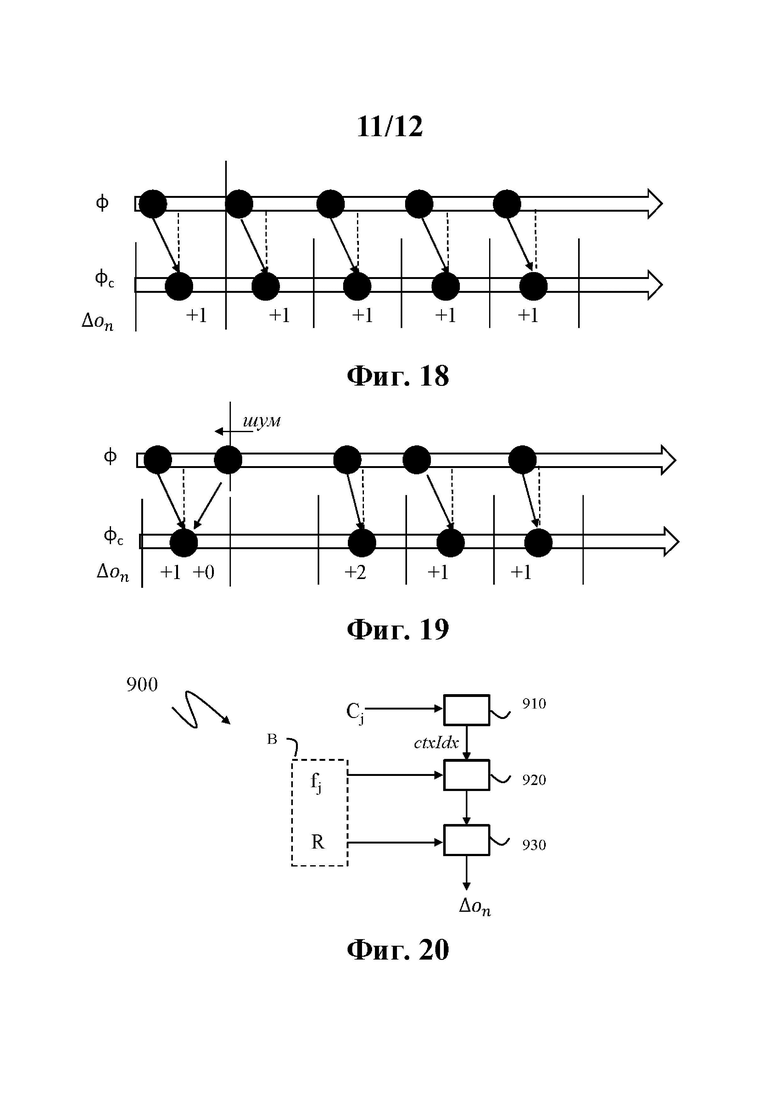
Изобретение относится к сжатию облака точек, в частности к способам и устройству для энтропийного кодирования/декодирования данных геометрии облака точек, захваченных вращающейся головкой датчиков. Техническим результатом является повышение производительности сжатия. Результат достигается тем, что точки облака точек упорядочены на основе азимутальных углов, представляющих углы захвата датчиков, и индексов датчиков, связанных с датчиками. При этом способ кодирования включает кодирование в битовый поток по меньшей мере одной разности порядковых индексов, представляющей разность между порядковыми индексами двух последовательных упорядоченных точек, посредством: получения по меньшей мере одних двоичных данных путем бинаризации по меньшей мере одной разности порядковых индексов и, для каждых двоичных данных, выбора контекста на основе расстояния между азимутальным углом, связанным с двоичными данными, и азимутальным углом уже закодированной точки и основанного на контексте энтропийного кодирования двоичных данных в битовый поток на основе выбранного контекста. 5 н. и 6 з.п. ф-лы, 21 ил., 2 табл.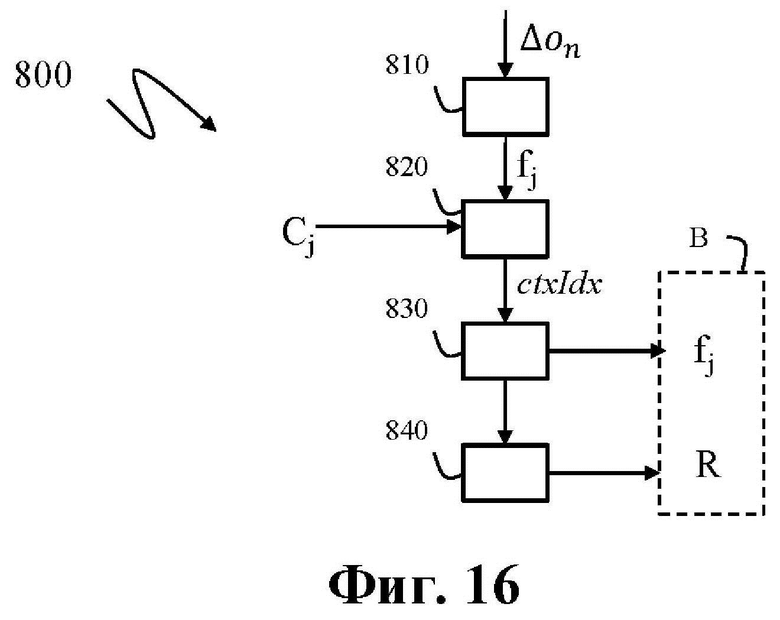
1. Способ кодирования облака точек в битовый поток кодированных данных облака точек, представляющих физический объект, причем точки облака точек упорядочены на основе азимутальных углов (φn), представляющих углы захвата датчиков, и индексов датчиков (λn), связанных с датчиками, при этом способ включает кодирование в битовый поток по меньшей мере одной разности (Δon) порядковых индексов, представляющей разность между порядковыми индексами двух последовательных упорядоченных точек посредством:
получения (810) по меньшей мере одних двоичных данных (fj) путем бинаризации по меньшей мере одной разности (Δon) порядковых индексов; и,
для каждых двоичных данных, выбора (820) контекста на основе расстояния (Cj) между азимутальным углом (φj), связанным с двоичными данными, и азимутальным углом (φpenult, φal) уже закодированной точки, и основанного на контексте энтропийного кодирования (830) двоичных данных в битовый поток на основе выбранного контекста.
2. Способ по п. 1, в котором уже закодированная точка является предпоследней уже закодированной точкой (Ppenult) с тем же индексом датчика, что и индекс датчика (λj), связанный с двоичными данными (fj).
3. Способ декодирования облака точек из битового потока кодированных данных облака точек, представляющих физический объект, при этом способ включает декодирование по меньшей мере одной разности (Δon) порядковых индексов, представляющей разность между порядковыми индексами двух последовательных упорядоченных точек на основе по меньшей мере одних двоичных данных (fj), декодированных из битового потока, причем каждые двоичные данные (fj) декодируют посредством:
выбора (910) контекста на основе расстояния (Cj) между азимутальным углом (φj), связанным с двоичными данными (fj), и азимутальным углом (φpenult, φal) уже декодированной точки;
основанного на контексте энтропийного декодирования (920) упомянутых по меньшей мере одних двоичных данных на основе выбранного контекста и информации о вероятности относительно двоичных данных, декодированных из битового потока; и
декодирования (930) разности (Δon) порядковых индексов из по меньшей мере одних двоичных данных (fj), декодированных посредством основанного на контексте энтропийного декодирования.
4. Способ по п. 3, в котором уже декодированная точка является предпоследней уже декодированной точкой (Ppenult) с тем же индексом датчика, что и индекс датчика (λj), связанный с двоичными данными (fj).
5. Способ по п. 3, в котором контекст для декодирования двоичных данных выбирают из таблицы контекстов, индексированной индексом контекста (ctxIdx), и при этом индекс контекста для двоичных данных (fj) равен расстоянию (Cj) между азимутальным углом (φj), связанным с двоичными данными (fj), и азимутальным углом (φpenult, φal) уже декодированной точки.
6. Способ по п. 3, в котором контекст для декодирования двоичных данных выбирают из таблицы контекстов, индексированной индексом контекста (ctxIdx), и при этом индекс контекста (ctxIdx) для двоичных данных (fj) зависит от ранга (j) упомянутых двоичных данных в последовательности двоичных данных, представляющих разность (Δon) порядковых индексов.
7. Способ по п. 3, в котором контекст для декодирования двоичных данных выбирают из таблицы контекстов, индексированной индексом контекста (ctxIdx), и при этом индекс контекста (ctxIdx) для двоичных данных (fj) зависит от индекса датчика (λj), связанного с двоичными данными (fj).
8. Способ по п. 3, в котором контекст для декодирования двоичных данных выбирают из таблицы контекстов, индексированной индексом контекста (ctxIdx), а индекс контекста (ctxIdx) для двоичных данных (fj) зависит от групп датчиков, содержащих датчики с близкими углами наклона.
9. Устройство кодирования для кодирования облака точек в битовый поток кодированных данных облака точек, представляющих физический объект, причем точки облака точек упорядочены на основе азимутальных углов, представляющих углы захвата датчиков, и индексов датчиков, связанных с датчиками, при этом устройство содержит один или более процессоров, сконфигурированных для кодирования в битовый поток по меньшей мере одной разности порядковых индексов, представляющей разность между порядковыми индексами двух последовательных упорядоченных точек, посредством:
получения по меньшей мере одних двоичных данных путем бинаризации по меньшей мере одной разности порядковых индексов; и,
для каждых двоичных данных, выбора контекста на основе расстояния между азимутальным углом, связанным с двоичными данными, и азимутальным углом уже закодированной точки, и основанного на контексте энтропийного кодирования двоичных данных в битовый поток на основе выбранного контекста.
10. Устройство для декодирования из битового потока точки облака точек, представляющего физический объект, при этом устройство содержит один или более процессоров, сконфигурированных для декодирования по меньшей мере одной разности порядковых индексов, представляющей разность между порядковыми индексами двух последовательных упорядоченных точек на основе по меньшей одних двоичных данных, декодированных из битового потока, причем каждые двоичные данные декодируются посредством:
выбора контекста на основе расстояния между азимутальным углом, связанным с двоичными данными, и азимутальным углом уже декодированной точки;
основанного на контексте энтропийного декодирования упомянутых по меньшей мере одних двоичных данных на основе выбранного контекста и информации о вероятности относительно двоичных данных, декодированных из битового потока; и
декодирования разности порядковых индексов из по меньшей мере одних двоичных данных, декодированных посредством основанного на контексте энтропийного декодирования.
11. Носитель данных, содержащий инструкции программного кода для выполнения способа кодирования облака точек в битовый поток кодированных данных облака точек, представляющих физический объект, причем точки облака точек упорядочены на основе азимутальных углов, представляющих углы захвата датчиков, и индексов датчиков, связанных с датчиками, при этом способ включает кодирование в битовый поток по меньшей мере одной разности порядковых индексов, представляющей разность между порядковыми индексами двух последовательных упорядоченных точек, посредством:
получения по меньшей мере одних двоичных данных путем бинаризации по меньшей мере одной разности порядковых индексов; и,
для каждых двоичных данных, выбора контекста на основе расстояния между азимутальным углом, связанным с двоичными данными, и азимутальным углом уже закодированной точки, и основанного на контексте энтропийного кодирования двоичных данных в битовый поток на основе выбранного контекста.
| US 2020175725 A1, 2020.06.04 | |||
| WO 2019140510 A1, 2019.07.25 | |||
| US 2020394822 A1, 2020.12.17 | |||
| US 10796457 B2, 2020.10.06 | |||
| US 2018053324 A1, 2018.02.22 | |||
| WO 2020119487 A1, 2020.06.18 | |||
| US 2019116372 A1, 2019.04.18 | |||
| US 2020302237 A1, 2020.09.24 | |||
| US 2020374505 A1, 2020.11.26 | |||
| СПОСОБ И УСТРОЙСТВО ДЛЯ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ ИЗОБРАЖЕНИЯ С ИСПОЛЬЗОВАНИЕМ КРУПНОЙ ЕДИНИЦЫ ПРЕОБРАЗОВАНИЯ | 2010 |
|
RU2543519C2 |

