Область техники
Настоящее описание относится, в общем, к сжатию облака точек, а именно к способам и устройствам для кодирования/декодирования геометрических данных облака точек, обнаруженных при помощи по меньшей мере одного датчика.
Предпосылки создания изобретения
В последнее время, в качестве одного из форматов представления трехмерных данных, облака точек приобретают все большую популярность благодаря их универсальности и способности представлять любые типы физических объектов и сцен.
Виртуальная реальность (Virtual Reality, VR), дополненная реальность (Augmented Reality, AR) и технологии иммерсивного опыта в последнее время стали широко обсуждаемыми темами. Ожидается, что такие технологии придут на смену двумерному плоскому видео. Основная идея их заключается в погружении зрителя в окружающую среду, в отличие от обычного телевизора, дающего пользователям возможность лишь заглянуть в виртуальный мир, расположенный перед ними. Существуют различные степени иммерсивности, в зависимости от степеней свободы зрителя в окружении. Формат облаков точек являются многообещающим кандидатом для распространения VR/AR миров.
Сущность изобретения
В данном разделе представлено упрощенное общее описание по меньшей мере одного варианта осуществления изобретения, чтобы дать базовое понимание некоторых из его аспектов. Данный раздел не является исчерпывающим описанием одного из вариантов осуществления изобретения. Он не имеет целью указать на ключевые или критически важные элементы вариантов осуществления настоящего изобретения. В данном разделе лишь представлены некоторые из аспектов по меньшей мере одного из вариантов осуществления настоящего изобретения, в упрощенной форме, в качестве введения к более подробному описанию, приведенному в ином разделе данного документа.
В соответствии с первым аспектом предложен способ кодирования, в битовый поток, геометрических данных облака точек, представленных упорядоченными «грубыми» точками, занимающими часть дискретных местоположений из множества дискретных местоположений двумерного пространства. Способ включает получение по меньшей мере одних двоичных данных, являющихся представлением разности порядковых индексов, представляющих разность между порядковыми индексами двух последовательных занятых грубых точек, и кодирование всех из упомянутых по меньшей мере одних двоичных данных при помощи получения координат текущей грубой точки в двумерном пространстве; получение количества измерений на основе текущей грубой точки, при этом упомянутое количество измерений является представлением среднего количества последовательных измерений, необходимых для датчика, соответствующего текущей грубой точке, для обнаружения другой грубой точки; и энтропийное кодирование, в битовый поток, упомянутых двоичных данных на основе количества измерений.
В соответствии со вторым аспектом предложен способ декодирования, из битового потока, геометрических данных облака точек, представленных упорядоченными грубыми точками, занимающими часть дискретных местоположений из множества дискретных местоположений двумерного пространства. Способ включает получение по меньшей мере одних двоичных данных, являющихся представлением разности порядковых индексов, представляющих разность между порядковыми индексами двух последовательных занятых грубых точек, при помощи получения координат текущей грубой точки в двумерном пространстве; получение количества измерений на основе текущей грубой точки, при этом упомянутое количество измерений является представлением среднего количества последовательных измерений, необходимых для датчика, соответствующего текущей грубой точке, для обнаружения другой грубой точки; и энтропийное декодирование, из битового потока, упомянутых двоичных данных на основе количества измерений.
В некоторых из вариантов осуществления настоящего изобретения энтропийное кодирование или декодирование двоичных данных основано на количестве измерений, если количество измерений больше, чем пороговое значение активации, и оно основано по меньшей мере на разности координат между первой координатой, относящейся к текущей грубой точке, и одной первой координатой предыдущей кодированной или декодированной грубой точки с тем же индексом датчика, что и индекс датчика, соответствующий текущей грубой точке, если количество измерений не больше, чем пороговое значение активации.
В некоторых из вариантов осуществления настоящего изобретения энтропийное кодирование или декодирование двоичных данных основано на значении, которое зависит от индекса отсчета, индекса другого отсчета, соответствующего моменту времени измерения, в котором точка облака точек, представленная последней занятой грубой точкой, была обнаружена датчиком, соответствующим упомянутому индексу датчика, и на количестве измерений.
В некоторых из вариантов осуществления настоящего изобретения упомянутое значение ограничено двумя пороговыми значениями.
В некоторых из вариантов осуществления настоящего изобретения количество измерений зависит от радиуса и/или азимутального угла, соответствующих последней занятой грубой точке, являющейся представлением точки в облаке точек, обнаруженной датчиком, соответствующим текущей грубой точке.
В некоторых из вариантов осуществления настоящего изобретения количество измерений зависит от характеристического расстояния облака точек, определяющего среднее расстояние между точками облака точек, и от длины дуги, заданной в двумерной плоскости декартовых координат между двумя последовательными измерениями датчиком, соответствующим текущей грубой точке.
В некоторых из вариантов осуществления настоящего изобретения длина дуги зависит от радиуса, соответствующего последней занятой грубой точке, являющейся представлением точки в облаке точек, обнаруженной датчиком, соответствующим текущей грубой точке, и от азимутального смещения между двумя последовательными измерениями.
В некоторых из вариантов осуществления настоящего изобретения характеристическое расстояние облака точек кодируют в битовый поток.
В соответствии с третьим аспектом предложено устройство кодирования, в битовый поток, геометрических данных облака точек, представленных упорядоченными грубыми точками, занимающими часть дискретных местоположений из множества дискретных местоположений двумерного пространства. Устройство включает один или более процессоров, сконфигурированных для выполнения способа, соответствующего первому аспекту.
В соответствии с четвертым аспектом предложено устройство декодирования, из битового потока, геометрических данных облака точек, представленных упорядоченными грубыми точками, занимающими часть дискретных местоположений из множества дискретных местоположений двумерного пространства. Устройство включает один или более процессоров, сконфигурированных для выполнения способа, соответствующего второму аспекту.
В соответствии с пятым аспектом предложен компьютерный программный продукт, включающий инструкции, которые при исполнении программы одним или более процессорами обеспечивают выполнение, одним или более процессорами, способа в соответствии с первым аспектом.
В соответствии с шестым аспектом предложен носитель данных, содержащий инструкции программного кода для выполнения способа в соответствии с первым аспектом настоящего изобретения.
В соответствии с седьмым аспектом настоящего изобретения предложен компьютерный программный продукт, включающий инструкции, которые при исполнении программы одним или более процессорами обеспечивают выполнение, одним или более процессорами, способа в соответствии со вторым аспектом.
В соответствии с восьмым аспектом предложен носитель данных, содержащий инструкции программного кода для выполнения способа в соответствии со вторым аспектом я.
Особенности по меньшей мере одного из вариантов осуществления настоящего изобретения, а также другие цели, преимущества, признаки и возможные применения по меньшей мере одного из вариантов осуществления настоящего изобретения могут быть уяснены из приведенного ниже описания примеров, рассматриваемых в сочетании с приложенными чертежами.
Краткое описание чертежей
Далее для иллюстрации рассмотрим приложенные чертежи, где показаны варианты осуществления изобретения.
На фиг. 1 схематично проиллюстрирован вид сбоку измерительной головки и некоторые из ее параметров, в соответствии с по меньшей мере одним из вариантов осуществления.
На фиг. 2 схематично проиллюстрирован вид сверху измерительной головки и некоторые из ее параметров, в соответствии с по меньшей мере одним из вариантов осуществления.
На фиг. 3 схематично проиллюстрировано равномерное распределение данных, регистрируемых вращающейся измерительной головкой, в соответствии с по меньшей мере одним из вариантов осуществления.
На фиг. 4 схематично проиллюстрировано представление точки облака точек в трехмерном пространстве в соответствии с по меньшей мере одним из вариантов осуществления.
На фиг. 5 схематично проиллюстрирован пример измерительной головки, способной регистрировать реальную сцену, следуя программируемому пути измерений в соответствии с по меньшей мере одним из вариантов осуществления.
На фиг. 6 схематично проиллюстрирован пример измерительной головки, способной регистрировать реальную сцену, следуя программируемому пути измерений и с использованием различных частот измерения, в соответствии с по меньшей мере одним из вариантов осуществления.
На фиг. 7 схематично проиллюстрирован пример измерительной головки, способной регистрировать реальную сцену, следуя программируемому зигзагообразному пути измерений и с использованием различных частот измерения, в соответствии с по меньшей мере одним из вариантов осуществления.
На фиг. 8 схематично проиллюстрирован пример измерительной головки с одним датчиком, способной регистрировать реальную сцену, следуя программируемому зигзагообразному пути измерений и с использованием различных частот измерения.
На фиг. 9 схематично проиллюстрирован пример упорядоченных грубых точек, являющихся частью грубого представления, в соответствии по меньшей мере с одним из вариантов осуществления настоящего изобретения.
На фиг. 10 схематично проиллюстрирован пример упорядоченных грубых точек, являющихся частью грубого представления, измеренных при помощи головки с двумя датчиками, в соответствии по меньшей мере с одним из вариантов осуществления настоящего изобретения.
На фиг. 11 схематично показано представление упорядоченных грубых точек в пространстве двумерных координат (s, λ).
На фиг. 12 схематично проиллюстрированы упорядоченные грубые точки, являющиеся частью грубого представления, в соответствии по меньшей мере с одним из вариантов осуществления настоящего изобретения.
На фиг. 13 схематично проиллюстрирована блок-схема алгоритма, где показаны шаги способа 100 кодирования геометрических данных облака точек в битовый поток кодированных данных облака точек в соответствии по меньшей мере с одним вариантом осуществления настоящего изобретения.
На фиг. 14 схематично проиллюстрирован пример грубого представления с занятыми и незанятыми грубыми точками в соответствии по меньшей мере с одним из вариантов осуществления настоящего изобретения.
На фиг. 15 схематично проиллюстрирован пример грубого представления с занятыми и незанятыми грубыми точками в соответствии по меньшей мере с одним из вариантов осуществления настоящего изобретения.
На фиг. 16 схематично показано представление характеристического расстояния облака точек и расстояние между двумя последовательными измерениями одним и тем же датчиком в соответствии с одним из вариантов осуществления настоящего изобретения.
На фиг. 17 схематично проиллюстрирован пример разности Cj координат, вычисленной в одном из примеров конфигурации занятости окрестности.
На фиг. 18 схематично проиллюстрирован пример разности Cj координат, вычисленной в одном из примеров конфигурации занятости окрестности.
На фиг. 19 схематично проиллюстрирован пример разности Cj координат, вычисленной в одном из примеров конфигурации занятости окрестности.
На фиг. 20 схематично проиллюстрирован пример разности Cj координат, вычисленной в одном из примеров конфигурации занятости окрестности.
На фиг. 21 схематично проиллюстрирован пример разности между двумя индексами отсчетов, относящихся к двум различным моментам времени измерения, в которых две грубые точки были измерены одним и тем же датчиком, в соответствии с одним из вариантов осуществления настоящего изобретения.
На фиг. 22 схематично проиллюстрирована коррекция количества измерений в соответствии с одним из вариантов осуществления настоящего изобретения.
На фиг. 23 схематично проиллюстрирована блок-схема алгоритма для способа 200 декодирования геометрических данных облака точек из битового потока кодированных данных облака точек в соответствии по меньшей мере с одним вариантом осуществления настоящего изобретения.
На фиг. 24 схематично проиллюстрирована блок-схема алгоритма контекстно-адаптивного двоичного арифметического кодера в соответствии по меньшей мере с одним из вариантов осуществления настоящего изобретения.
На фиг. 25 показана структурная схема одного из примеров системы, в которой могут быть реализованы различные аспекты и варианты осуществления настоящего изобретения.
На различных чертежах аналогичные числовые обозначения могут обозначать аналогичные компоненты.
Подробное описание изобретения
Ниже будет более полно описан по меньшей мере один из вариантов осуществления настоящего изобретения, со ссылками на приложенные чертежи, на которых проиллюстрирован по меньшей мере один из вариантов осуществления настоящего изобретения. Однако варианты осуществления настоящего изобретения могут быть реализованы в множестве альтернативных форм, и их не следует считать ограниченными приведенными здесь иллюстрациями. Соответственно, нужно понимать, что варианты осуществления настоящего изобретения не следует считать ограниченными конкретными описанными формами. Напротив, настоящее описание подразумевает, что в сущность и объем настоящего раскрытия входят также все соответствующие модификации, эквиваленты и альтернативы.
В последнее время, в качестве одного из форматов представления трехмерных данных, облака точек приобретают все большую популярность благодаря их универсальности и способности представлять любые типы физических объектов и сцен. Облака точек могут применяться для различных задач, например, для объектов культурного наследия или зданий: статуи или здания сканируют и получают их трехмерное представление, позволяющее удаленно воспринимать пространственную конфигурацию объектов без их пересылки или посещения. Также это может быть одним из способов сохранения знаний об объектах в случае их физического уничтожения, например, храм, который может быть уничтожен землетрясением. Подобные облака точек являются, как правило, статическими, имеют цветовую информацию и огромны по объему.
Еще одним сценарием применения облаков точек может быть топография и картография, когда трехмерное представление позволяет карте не быть ограниченной плоскостью и включать также рельеф. Хорошим примеров трехмерной карты является сервис Google Maps, однако в нем применяются сетки, а не облака точек. Тем не менее облака точек подходят для применения в трехмерных картах, и такие облака точек являются, как правило, статическими, включают цветовую информацию и огромны по объему.
Виртуальная реальность (Virtual Reality, VR), дополненная реальность (Augmented Reality, AR) и технологии иммерсивного опыта в последнее время стали широко обсуждаемыми темами. Ожидается, что такие технологии придут на смену двумерному плоскому видео. Основная идея их заключается в погружении зрителя в окружающую среду, в отличие от обычного телевизора, дающего пользователям возможность лишь заглянуть в виртуальный мир, расположенный перед ними. Существуют различные степени иммерсивности, в зависимости от степеней свободы зрителя в окружении. Формат облаков точек являются многообещающим кандидатом для распространения VR/AR миров.
Еще одной сферой интенсивного применения облаков точек может быть автомобильная промышленность, а именно, беспилотные автомобили. Беспилотные автомобили должны уметь «зондировать» их окружение, чтобы принимать корректные решения при вождении на основе обнаруженного присутствия объектов, а также характера этих объектов и конфигурации дороги.
Облако точек представляет собой множество точек, расположенных в трехмерном (3D) пространстве. Опционально, к каждой из точек могут быть привязаны дополнительные значения. Такие дополнительные значения, как правило, называют атрибутами. Атрибутами могут быть, например, трехкомпонентный цвет, свойства материала, такие как отражающая способность, и/или двухкомпонентные векторы нормали, относящиеся к точке.
Облако точек, таким образом, представляет собой сочетание геометрических данных (местоположений точек в трехмерном пространстве, задаваемых, как правило, декартовыми координатами х, у и z) и атрибутов.
Облака точек могут формироваться при помощи устройств различных типов, например, массивов камер, датчиков глубины, лазеров (регистрирующих свет и измеряющих расстояния, также называемых лидарами), радарами, или могут формироваться при помощи компьютера (например, в послесъемочной обработке фильмов). В зависимости от сценария применения облака точек могут иметь от тысяч до миллиардов точек, в случае применения в картографии. В сыром, «необработанном», виде облака точек требуют очень большого количества битов на каждую точку, по меньшей мере 12 бит на каждую декартову координату х, у и z, и опционально, дополнительные биты для атрибутов, к примеру, три раза по 10 битов для цвета.
Во многих применениях важно либо иметь возможность доставлять облака точек конечному пользователю, либо хранить их на сервере, с использованием лишь ограниченного разумного битрейта или объема памяти, но с сохранением приемлемого (или, предпочтительно, очень высокого) качества восприятия. Чтобы транспортные сети для распределения множества иммерсивных миров могли быть реализованы на практике, критически важно иметь возможность эффективного сжатия облаков точек.
В случае доставки и визуализации у конечного пользователя, например, в AR/VR-очках или любых других устройств с 3D-функциями, такое сжатие может выполняться с потерями (аналогично видеосжатию). В других сценариях применения может требоваться сжатие без потерь, например, в медицине или беспилотных автомобилях, чтобы исключить влияние на решения, принимаемые при последующем анализе сжатых и переданных облаков точек.
До недавнего времени сжатие облаков точек (point cloud compression, РСС) не было востребовано на массовом потребительском рынке, и соответственно, не существовало стандартизированного кодека облаков точек. В 2017 году рабочая группа ISO/JCT1/SC29/WG11, также известная под именем «Группа экспертов по движущемуся изображению» (Moving Picture Experts Group, MPEG), инициировала работы по стандартизации сжатия облаков точек. В результате было предложено два стандарта, а именно:
MPEG-I часть 5 (ISO/IEC 23090-5), или сжатие облаков точек на основе видео (Video-based Point Cloud Compression, V-PCC);
MPEG-I часть 9 (ISO/IEC 23090-9), или сжатие облаков точек на основе геометрии (Geometry-based Point Cloud Compression, G-PCC).
В технологии кодирования V-PCC облако сжимают точек путем выполнения множества проекций трехмерного объекта с получением двумерных участков (патчей), которые упаковывают в изображение (или видео, при работе с динамическими облаками точек). Полученные изображения или видео затем сжимают с помощью существующих кодеков изображений/видео, что позволяет применять уже развернутые решения для работы с изображениями и видео. По своей природе технология V-PCC эффективна только для плотных и непрерывных облаков точек, поскольку кодеки изображений/видео не способны сжимать негладкие участки, которые могут возникать, например, в результате проецирования обнаруженных лидаром данных с рассеянной геометрией.
Метод G-PCC кодирования имеет две схемы сжатия обнаруженных данных с рассеянной геометрией.
Первая схема основана на дереве занятости, которое может быть, локально, любым из следующих типов, представляющих геометрию облака точек: октадеревом, квадродеревом или бинарным деревом. Занятые узлы (т.е. узлы, соответствующие кубу/кубоиду, содержащему по меньшей мере одной точек облака точек) разбивают на подветви до тех пор, пока не будет достигнут заданный размер, и занятые листы дерева содержат местоположения точек в трехмерном пространстве, как правило, в центре этих узлов. Информацию о занятости передают при помощи данных занятости (двоичных данных или флага), сигнализирующих о состоянии занятости каждого из дочерних узлов любого узла. С помощью методов предсказания на основе соседей в случае плотных облаков точек может быть достигнут высокий уровень сжатия данных занятости. Рассеянные облака точек также могут быть обработаны, при помощи непосредственного кодирования положения точки в узле с не-минимальным размером, и остановки построения дерева, когда в узлах находятся только изолированные точки; такой метод называют методом прямого кодирования (Direct Coding Mode, DCM).
Вторая схема основана на дереве предсказания, в котором каждый узел представляет собой местоположение точки в трехмерном пространстве, а отношения родитель/потомок между узлами представляет собой пространственное предсказание от родителя к потомку. Такой метод подходит только для рассеянных облаков точек и выгодно отличается низкими задержками и более простым декодированием, по сравнению с деревом занятости. Однако достижимая эффективность сжатия лишь незначительно выше при сложном, по сравнению с методом на основе занятости, кодировании, поскольку при построении дерева предсказаний кодеру необходимо выполнять тщательный поиск наилучшего предсказания (по длинному списку потенциальных предсказаний).
В обеих схемах (де)кодирование атрибутов выполняют после полного (де)кодирования геометрии, что практически означает кодирование в два прохода. Таким образом, низкие задержки для комбинации геометрии и атрибутов могут быть достигнуты за счет применения слайсов, разбивающих трехмерное пространство на независимо кодируемые частичные объемы (суб-объемы), без предсказания между частичными объемами. Это может оказывать сильное негативное влияние на эффективность сжатия, если количество используемых слайсов велико.
В существующих кодеках облаков точек до сих пор не удавалось решить задачу совмещения требований к простоте кодера и декодера, низких задержек и эффективности сжатия.
Одним из важных сценариев применения является передача рассеянных геометрических данных, обнаруженных при помощи по меньшей мере одного датчика, установленного на движущемся автомобиле. Как правило, это требует наличия на борту автомобиля простого кодера с низкими задержками. Простота необходима, поскольку кодер, вероятно, будет развернут на вычислительных блоках, которые параллельно выполняют обработку и других данных, например, при (частично-)беспилотном вождении, что ограничивает вычислительную мощность, доступную для кодера облаков точек. Низкие задержки при этом требуются для обеспечения быстрой передачи из автомобиля в облачную среду для наблюдения за дорожным движением в реальном времени, основанном на данных, получаемых от множества автомобилей, чтобы принимать быстрые и адекватные решения на основе информации о движении. Задержки при передаче могут быть достаточно малыми при использовании технологии 5G, соответственно, сам кодер не должен вносить слишком большие задержи при кодировании. Эффективность сжатия также является крайней важной, поскольку поток данных от миллионов автомобилей, передаваемый в облачное окружение, может иметь огромный объем.
Некоторые из уже существующих технологий, относящиеся к рассеянным геометрическим данным, захваченным при помощи вращающегося лидара, были применены в методе G-PCC и позволили очень значительно повысить степень сжатия.
Во-первых, в методе G-PCC применяют угол возвышения (относительно горизонтальной поверхности земли) для регистрации вращающейся головкой 10 лидара, в соответствии с иллюстрацией фиг. 1 и фиг. 2. Головка 10 лидара содержит набор датчиков 11 (например, лазеры), причем в данном примере показаны пять датчиков. Вращающаяся головка 10 лидара может поворачиваться вокруг вертикальной оси z для регистрации геометрических данных физических объектов. Обнаруженные лидаром геометрические данные затем представляют в сферических координатах (r3D,φ,θ), где r3D - расстояние от точки Р до центра головки лидара, φ - азимутальный угол поворота головки лидара относительно начала координат, а θ угол возвышения датчика k в головке лидара относительно опорной горизонтальной плоскости.
На фиг. 3 показано равномерное распределение по азимутальному углу, наблюдаемое в обнаруженных лидаром данных. Упомянутая равномерность используется в методе G-PCC для получения квази-одномерного представления облака точек, в котором, с точностью до шума, только радиус r3D принадлежит непрерывному диапазону значений, тогда как углы φ и θ принимают только набор дискретных значений φi; ∀i=0 до I-1, где I - количество азимутальных углов, используемых для обнаружения точек, and θj ∀j=0 до J-1, где K - количество датчиков во вращающейся лидарной головке 10. Фактически, в технологии G-PCC рассеянные геометрические данные, обнаруженные лидаром, представляют на двумерной плоскости дискретных углов (φ, θ), в соответствии с иллюстрацией фиг. 3, вместе со значением радиуса r3D для каждой точки. Это свойство квази-одномерности используют в G-PCC, и в дереве занятости, и в дереве предсказания, при помощи предсказания, в пространстве сферических координат, местоположения текущей точки на основе уже закодированной точки, с использованием дискретного характера углов.
А именно, в дереве занятости интенсивно применяют DCM и энтропийно кодируют непосредственные местоположения точек в узле с помощью контекстно-адаптивного энтропийного кодера. Контексты затем получают за счет локального преобразования местоположений точек в угловые координаты (φ, θ) и на основе местоположения этих угловых координат относительно дискретных угловых координат (φi, θj), полученных из ранее кодированных точек. В дереве предсказания непосредственно кодируют первую версию местоположения точки в угловых координатах (r2D, φ, θ), где r2D - проекция радиуса на горизонтальную ось ху, в соответствии с иллюстрацией, с использованием квазиодномерного характера (r2D, φi, θj), этого пространства угловых координат. Затем сферические координаты (r2D, φ, θ) преобразуют в трехмерные декартовы координаты (х, у, z), и ошибку xyz кодируют для компенсации погрешностей при преобразовании координат, аппроксимации угла возвышения и азимутального угла, а также возможного шума.
В G-PCC используют существующие технологии для работы с угловыми координатами для более эффективного кодирования рассеянных геометрических данных, регистрируемых при помощи лидара, однако не адаптируют структуру кодирования к последовательности измерений. В силу своих свойств дерево занятости должно быть закодировано до своей максимальной глубины, прежде чем может быть выдано значение хотя бы одной точки. Данные занятости кодируют в порядке «сначала в ширину»: сначала кодируют данные занятости корневого узла, и указывают его занятые дочерние узлы; затем кодируют данные занятости для каждого из занятых дочерних узлов, и указывают занятые внучатые узлы; и так далее по всей глубине дерева, пока не будут определены листовые узлы, и соответствующие точки будут переданы/выведены в приложение или в схему кодирования атрибутов. В дереве предсказания кодер свободен выбирать, как именно точки будут упорядочены в деревья, однако для высокой эффективности сжатия и оптимизации точности предсказания в стандарте G-PCC предложено кодирование по одному дереву для каждого датчика. Такой способ имеет тот же недостаток, что и использование одного слайса кодирования на каждый датчик, то есть неоптимальную эффективность датчиков, поскольку предсказание между различными датчиками невозможно, и не позволяет обеспечить низкие задержки в кодере. Что еще хуже, необходимо иметь отдельный процесс кодирования на каждый датчик, и количество базовых блоков кодирования должно быть равно количеству датчиков, а это непрактично.
Итак, в системах с вращающейся измерительной головкой, используемой для обнаружения данных облака точек с рассеянной геометрии, на существующем уровне техники нет средств решения задачи достижения одновременно простоты кодирования и декодирования, низких задержек и эффективности кодирования.
При этом регистрация геометрических данных рассеянного облака точек при помощи вращающейся измерительной головки имеет свои недостатки, и могут применяться другие типы измерительных головок.
Механические детали, обеспечивающие вращение (поворот) вращающейся измерительной головки являются дорогостоящими и подвержены отказам. Также, из-за конструктивных особенностей, угол обзора всегда равен 2π. Это не позволяет регистрировать выделенные области интереса с повышенной частотой. К примеру, измерения спереди автомобиля могут представлять больший интерес, чем сзади. На практике в большинстве случае, когда датчики устанавливают на автомобиль, большая часть из угла зрения, равного 2π, заслонена собственно автомобилем, и эту часть угла зрения регистрировать нет необходимости.
Недавно появились новые типы датчиков, допускающие более гибкий выбор измеряемой области. В наиболее современных системах датчик может перемещаться более гибко, и при помощи электронных средств (что позволяет избежать ломких механических деталей), что позволяет получать множество разнообразных путей измерения в трехмерной сцене, в соответствии с иллюстрацией фиг. 5. На фиг. 5 показан набор из четырех датчиков. Соответствующие им направления измерений, т.е. азимутальный угол и угол возвышения, зафиксированы относительно друг друга, однако они в целом могут регистрировать сцену, следуя программируемому пути измерения, показанному штриховой линией в двумерном пространстве угловых координат (φ,θ). Затем точки облака точек могут регистрироваться равномерно вдоль пути измерения. Некоторые измерительные головки могут также адаптировать свою частоту измерений, повышая ее, если обнаружена область R интереса, в соответствии с иллюстрацией фиг. 6. Область R интереса может соответствовать близкому объекту, движущемуся объекту или любому другом объекту (пешеходу, другому автомобилю и т.п.), который ранее был сегментирован, например, в предыдущем кадре, или из-за движения во время измерений. На фиг. 7 схематично показан еще один пример пути измерения (типовой зигзагообразный путь измерения), применяемый в измерительной головке, которая содержит два датчика, способных повышать частоту измерения, когда обнаружена область интереса (закрашенные или заштрихованные серым кружки). Зигзагообразный путь измерения, предпочтительно, используют для обнаружения в ограниченном (азимутальном) угловом секторе трехмерной сцены. Поскольку датчики могут быть установлены на автомобиле, их области зрения, представляющие интерес, по необходимости ограничены присутствием самого автомобиля, который заслоняет сцену, если только эти датчики не размещены на крыше автомобиля. Следовательно, датчики с ограниченным угловым сектором измерений имеют высокий потенциал применения, и их проще интегрировать в автомобиль.
В соответствии с иллюстрацией фиг. 8 может также применяться измерительная головка, имеющая один датчик, для измерения множества местоположений (два вертикальных местоположения на фиг. 8), к примеру, с помощью отражений в зеркалах, колеблющихся вращательно (в данном случае, с вертикальным поворотом). В таком случае вместо применения набора датчиков используют один датчик в различных угловых положениях (т.е. с различным углом возвышения на фиг. 8) вдоль пути измерения (в данном случае, зигзагообразного пути измерения), что имитирует измерения с использованием набора из множества датчиков.
Для простоты в приведенном ниже описании и в формуле изобретения под «измерительной головкой» понимают набор физических датчиков или также набор индексов возвышения для измерений, которые используют для имитации набора датчиков. Специалисты в данной области техники должны понимать, что под «датчиками» может также пониматься один датчик в различных положениях с различными индексами угла возвышения.
В существующих кодеках облаков точек до сих пор не удавалось решить задачу совмещения требований к простоте кодера и декодера, низких задержек и эффективности сжатия облаков точек, регистрируемых при помощи любых типов датчиков.
В соответствии с описанной задачей был предложен по меньшей мере вариант осуществления настоящего изобретения.
По меньшей мере один из аспектов настоящего изобретения относится, в общем, к кодированию и декодированию облака точек, еще один из аспектов настоящего изобретения относится, в общем, к передаче сформированного или кодированного битового потока, и еще один из аспектов настоящего изобретения относится к приему декодированного битового потока, или к доступу к декодированному битовому потоку.
При этом рассмотренные здесь аспекты настоящего изобретения не ограничены стандартами MPEG, например, частью 5 или частью 9 стандарта MPEG-I, относящегося к сжатию облаков точек, и могут применяться, к примеру, в других стандартах или рекомендациях, как существующих, так и будущих, а также в расширениях любых из подобных стандартов и рекомендаций (включая часть 5 и часть 9 MPEG-I). Если на обратное не указано прямо, или если для этого нет технических препятствий, аспекты, рассмотренные здесь, могут применяться как по отдельности, так и совместно.
Изобретение относится к кодированию/декодированию геометрических данных облака точек, представленных упорядоченными грубыми точками, соответствующими грубому представлению и занимающими часть дискретных местоположений из множества дискретных местоположений двумерного пространства.
К примеру, рабочая группа ISO/IEC JTC 1/SC 29/WG 7 по кодированию трехмерной графики предложила новый кодек, названный L3C2 (кодек низкой сложности с низкими задержками, Low-Latency Low-Compleхty Codec), который был призван обеспечить улучшенную, по сравнению с кодеком G-PCC, эффективность кодирования облаков точек, регистрируемых при помощи лидаров. Кодек L3C2 позволяет получить пример двумерного представления точек в облаке точек, а именно, грубое представление. Описание этого кодека может быть найдено в результирующем документе Рабочей группы N00167, ISO/IEC JTC 1/SC 29/WG 7, кодирование трехмерной графики MPEG, "Технологии, рассматриваемые для G-PCC", 31 августа 2021 года (N00167, ISO/IEC JTC 1/SC 29/WG 7, MPEG 3D Graphics Coding, "Technologies under Consideration in G-PCC").
В сущности, для каждой точки Pn в облаке точек получают индекс λn датчика, относящийся к датчику, зарегистрировавшему точку Pn и азимутальный угол φn, представляющий собой угол измерения упомянутого датчика, при помощи преобразования трехмерных декартовых координат (xn, yn, zn), представляющих местоположение измеренной точки Pn в трехмерном пространстве. Точки облака точек затем упорядочивают на основе азимутальных углов φn и индексов λn датчиков, например, сначала по индексу датчика и затем по азимутальному углу. Порядковый индекс о(Pn) точки Pn затем получают следующим образом:
о(Pn)=φn*K+λn
где K - количество датчиков.
На фиг. 9 схематично проиллюстрированы упорядоченные грубые точки, являющиеся частью грубого представления. Были обнаружены пять точек облака точек. Каждая из этих пяти точек приблизительно представлена грубой точкой (закрашенной черным) грубого представления: две грубые точки Pn и Pn+1 представляют собой две точки облака точек, измеренные в момент времени t1 с азимутальным углом φс (из углов φi;), а три другие грубые точки представляют собой три точки облака точек, измеренные в момент времени t2 с азимутальным углом φс+φΔ. Грубую точку, которая представляет обнаруженную точку облака точек, называют «занятой грубой точкой», а грубая точка, которая не представляет обнаруженную точку облака точек, называют «незанятой грубой точкой». Поскольку точки в облаке точек представлены занятыми грубыми точками грубого представления, порядковые индексы, относящиеся к точкам в облаке точек, также являются порядковыми индексами, соответствующим занятым грубым точкам.
Грубое представление геометрических данных облака точек может в этом случае быть задано в пространстве двумерных координат (φ, λ).
Грубое представление может быть также определено для любых типов измерительных головок, включая вращающуюся (поворотную) и не вращающиеся измерительные головки. Ее определение зависит от пути измерения, определяемого на основе характеристик датчика в пространстве двумерных угловых координат (φ,θ), включающим азимутальную координату φ, представляющую собой азимутальный угол, который является углом измерения датчика относительно начала координат, и координату θ возвышения, представляющую собой угол возвышения датчика относительно горизонтальной опорной плоскости. Путь измерения используют для регистрации точек облака точек в соответствии с упорядоченными грубыми точками, представляющими потенциальные местоположения обнаруженных точек облака точек. Каждую грубую точку определяют на основе одного индекса s отсчета, соответствующего моменту времени измерения вдоль пути измерения, и одного индекса λ датчика, соответствующего датчику.
На фиг. 10 применяют измерительную головку, имеющую два датчика. Измерительные пути, которым следуют два датчика, показаны штриховыми линиями. Для каждого индекса s отчета (каждого момента времени измерения) заданы две грубые точки. Грубые точки, относящиеся к первому датчику, показаны на фиг. 10 закрашенными черными кружками, а грубые точки, относящиеся ко второму датчику, - кружками с черной штриховкой. Каждая из этих двух точек принадлежит пути измерения датчика (штриховая линия), заданному на основе пути SP измерения. На фиг. 11 схематично показано представление упорядоченных грубых точек в пространстве двумерных координат (s, λ). Стрелками на фиг. 10 и 11 показаны линии соединения между двумя последовательными упорядоченными грубыми точками.
Порядковый индекс о(Р) поставлен в соответствие каждой грубой точке согласно положению этой грубой точки среди остальных упорядоченных грубых точек:
o(P)=λ+s*K
где K - количество датчиков в наборе датчиков или количество различных положений одного датчика с одним и тем же индексом отсчета, λ - порядковый индекс датчика, который обнаружил точку Р облака точек в момент s времени измерения.
На фиг. 12 показаны упорядоченные грубые точки грубого представления, причем показаны пять занятых грубых точек (закрашенные черным кружки): две грубые точки Pn и Pn+1 заняты двумя точками облака точек, обнаруженными в момент t1 времени измерения (соответствует индексу s1 отсчета), и три грубые точки заняты тремя точками облака точек, обнаруженными в момент t2 времени измерения (соответствует индексу s2 отсчета).
Грубое представление геометрических данных облака точек может в этом случае быть задано в пространстве двумерных координат (s, λ).
Независимо от двумерного пространства, в котором задано грубое представление геометрических данных облака точек, кодирование геометрических данных облака точек включает кодирование данных занятости занятых грубых точек грубого представления при помощи кодирования разностей Δо порядковых индексов, каждая из которых отражает разность между порядковыми индексами двух последовательных занятых грубых точек P-1 и Р:
Δо=о(Р)-o(P-1)
На фиг. 9, если допустить, что координаты первой занятой грубой точки Pn в пространстве двумерных координат (φ,λ) известны заранее, первую разность Δon+1 порядковых индексов получают как разность между порядковым индексом o(Pn+1), относящимся к занятой грубой точке Pn+1, и порядковым индексом о(Pn), соответствующим занятой грубой точке Рn. Вторую разность Δon+2 порядковых индексов получают как разность между порядковым индексом о(Pn+2), относящимся к другой занятой грубой точке Pn+2, и порядковым индексом o(Pn+1), соответствующим Pn+1 и т.п.
На фиг. 12, если допустить, что координаты первой занятой грубой точки Рn в пространстве двумерных координат (s, λ) известны заранее, первую разность Δon+1 порядковых индексов получают как разность между порядковым индексом o(Pn+1), относящимся к занятой грубой точке Pn+1, и порядковым индексом о(Pn), соответствующим занятой грубой точке Pn. В данном примере Δon+1=2, поскольку грубая точка не занята (пустой кружок). Вторую разность Δon+2 порядковых индексов получают как разность между порядковым индексом о(Pn+2), относящимся к другой занятой грубой точке Pn+2, и порядковым индексом o(Pn+1) занятой грубой точки Pn+1, и т.п.
Порядковый индекс o(P1) первой грубой точки, занятой первой обнаруженной точкой P1 облака точек, может непосредственно кодироваться в битовый поток. Это эквивалентно произвольному назначению нулевого значения порядковому индексу виртуальной нулевой точки, т.е. о(Р0)=0, при этом кодирование Δo1=o(P1) - о(Р0)=o(P1)
Если известен порядковый индекс o(P1) первой грубой точки, занятой первой обнаруженной точкой Pi облака точек, и разности Δо порядковых индексов, то можно рекурсивно восстановить порядковый индекс о(Р) любой занятой грубой точки, занятой обнаруженной точкой Р облака точек, при помощи следующего выражения:
о(Р)=o(P.i)+Δо
Ниже изобретение будет описано на примере рассмотрения грубого представления, заданного в пространстве двумерных координат (s,λ). Однако то же самое может быть описано для грубого представления, заданного в пространстве двумерных координат (φ,λ), поскольку вращающаяся измерительная головка, например, лидарная головка, представляет собой конкретное грубое представление, заданное в пространстве двумерных координат (s,λ), в котором в каждый момент времени датчики измерительной головки измеряют объект, а обнаруженные точки соответствуют занятым точкам представления.
Итак, способ кодирования включает получение по меньшей мере одних двоичных данных, являющихся представлением разности порядковых индексов Δо, представляющих разность между порядковыми индексами двух последовательных занятых грубых точек, и кодирование всех из упомянутых по меньшей мере одних двоичных данных fj описанным ниже образом. Упомянутые двоичные данные fj могут сигнализировать, равна ли разность порядковых индексов некоторому конкретному значению Vj, так что двоичные данные fj указывают на занятость текущей грубой точки Pj с порядковым индексом
o(Pj)=o(P-1)+Vj
где Р-1 - занятая грубая точка среди двух последовательных занятых грубых точек.
Сначала получают количество измерений на основе текущей грубой точки Pj, при этом упомянутое количество измерений является представлением среднего количества последовательных измерений, необходимых для датчика, соответствующего текущей грубой точке Pj, для обнаружения другой грубой точки; Затем двоичные данные fj энтропийно кодируют/декодируют на основе количества измерений.
Энтропийное кодирование/декодирования двоичных данных, представляющих разность порядковых индексов, может быть основано на геометрической информации, зависящей от геометрии грубого представления, например, индексов датчиков или значений индекса текущей грубой точки для двух занятых грубых точек. Такая геометрическая информация не зависит от измерительных характеристик датчиков. То есть, в ней может не хватать важной релевантной информации для предсказания занятости грубых точек грубого представления.
Количество измерений, используемое для энтропийного
кодирования/декодирования, является представлением среднего количества последовательных измерений, необходимых для датчика, соответствующего текущей грубой точке, для обнаружения другой грубой точки. Количество измерений дает такую информацию об измерительных характеристиках, как будет подробно показано ниже.
Энтропийное кодирование/декодирование двоичных данных может включать выбор контекста на основе количества измерений. Выбор контекстов на основе количества измерений позволяет получить лучшее предсказание, и следовательно, усовершенствовать энтропийное кодирование/декодирование кодируемых двоичных данных.
На фиг. 13 схематично проиллюстрирована блок-схема алгоритма, где показаны шаги способа 100 кодирования геометрических данных облака точек в битовый поток кодированных данных облака точек в соответствии по меньшей мере с одним вариантом осуществления настоящего изобретения.
На шаге 105 получают по меньшей мере одни двоичные данные fj, являющиеся представлением разности Δо порядковых индексов. Разность Δо порядковых индексов представляет собой разность между порядковыми индексами двух последовательных занятых грубых точек грубого представления.
В одном из вариантов осуществления шага 105, упомянутые по меньшей мере одни двоичные данные fj получают унарным кодированием разности Δо порядковых индексов.
К примеру, унарное представление разности Δо порядковых индексов, равное 8, может включать девять двоичных данных от f0 до f8, каждое из которых не равно значению PV (как правило, PV=1), за исключением f8, которое равно PV.
На шаге 110 рассматривают по меньшей мере одни из упомянутых по меньшей мере одних двоичных данных fj.
На шаге 120 получают координаты текущей грубой точки Pj в двумерном пространстве. Текущая грубая точка Pj имеет первую координату φj и вторую координату λj в пространстве двумерных координат (φ,λ), и первую координату sj и вторую координату λj в пространстве двумерных координат (s, λ).
На фиг. 14 незанятые грубые точки описаны штриховыми линиями, а закрашенные серым точки являются занятыми грубыми точками. Разность Δо порядковых индексов в проиллюстрированном примере равна 4, при этом она унарно кодируется тремя двоичными данными f0,…,f2, не равными PV, и одними двоичными данными f3, равными значению PV. Текущая грубая точка Pj (заштрихована на чертеже) расположена между занятой грубой точкой Р и следующей занятой грубой точкой P+1. Индекс j указывает на то, что текущая грубая точка Pj является j-й незанятой грубой точкой после занятой грубой точки Р. На фиг. 14 текущая грубая точка Pj является второй (j=2) грубой точкой после занятой точки Р, а на фиг. 15 текущая грубая точка Pj является третьей (j=3) грубой точкой после занятой точки Р. Вокруг текущей грубой точки Pj задают каузальную окрестность N. Каузальная окрестность N может меняться в зависимости от индекса j при кодировании всех двоичных данных fj, являющихся представлением разности порядковых индексов. Для кодирования каждых из упомянутых двоичных данных fj, показанных на фиг. 14 и 15, используют различные конфигурации занятости окрестности. Текущая грубая точка Pj является следующей занятой грубой точкой P+1, когда j=4 в данном конкретном неограничивающем примере. λj
На шаге 130 получают количество Nsens (sj,λj) измерений на основе текущей грубой точки Pj. Количество Nsens(sj,λj) измерений является представлением среднего количества последовательных измерений, необходимых для датчика λj, соответствующего текущей грубой точке Pj, для обнаружения другой грубой точки.
Иными словами, когда для грубого представления используют пространство двумерных координат (s,λ), количество измерений Nsens(sj,λj) является представлением количества отсчетов от s до s+Nsens(sj,λj) грубого представления, необходимых, чтобы покрыть расстояние между двумя точками, приблизительно равное характеристическому расстоянию LPC облака точек.
Пусть slast - это индекс отсчета, относящегося к моменту времени измерения, в котором точка облака точек, представленная последней занятой точкой Plast грубого представления, была обнаружена датчиком, соответствующим индексу λj (кратко, датчику λj), соответствующим текущей грубой точке Pj. В случае если Nsens(sj,λj)≤l, следующая грубая точка, обнаруженная тем же датчиком λj, ожидается при следующем индексе slast+1. В противном случае, когда Nsens(sj,λj)>l, следующая грубая точка, обнаруженная датчиком λj, ожидается около отсчета с индексом slast+Nsens(sj,λj).
Соответственно, чем ближе индекс sj отсчета текущей грубой точки Pj к slast+Nsens(sj,λj), тем более вероятно, что текущая грубая точка Pj будет занята.
Количество Nsens(sj,λj) измерений указывает, сколько «виртуальных измерений» необходимо, чтобы датчик λj смог увидеть следующую грубую точку. К примеру, если Nsens(sj,λj)=5, то ожидается, статистически, что для датчика λj будет присутствовать около одной занятой грубой точки среди каждых 5 грубых точек.
Ниже будет приведено определение характеристического расстояния LPC. При кодировании необработанных данных облака точек, регистрируемых датчиками, ожидается, что будут измерены все грубые точки грубого представления. Когда датчик зарегистрировал объект (как правило, когда измерено отражение лазерного луча от объекта), грубая точка является занятой, в противном случае она незанята. В таком случае данные о занятости грубых точек полностью зависят от измерения датчиком. Однако не все кодированные облака точек являются «сырыми» необработанными данными. К примеру, облако точек может быть обработано, с формированием пространственной дискретизации отсчетов, отвечающей некоторому минимальному расстоянию LPC между точками в пространстве трехмерных декартовых координат. Это происходит, когда необработанные пространственные данные облака точек, с плавающей точкой, преобразуют в целочисленные пространственные данные. Точность целых чисел, а именно, целых чисел, являющихся представлением трехмерных координат точки облака точек, задает пространственную дискретизацию облака точек. В таком случае шаг изменения одной из трехмерных координат точки может соответствовать пространственному шагу, равному минимальному расстоянию LPC в необработанных данных.
Помимо более простой реализации в случае целочисленного представления такая пространственная дискретизация позволяет также снизить объем облака точек за счет децимации слишком плотных областей. Такие плотные области, как правило, расположены очень близко к автомобилю (на котором установлена измерительная головка), поскольку плотность точек обычно уменьшается обратно пропорционально расстоянию robject между измерительной головкой и измеряемым объектом, если подразумевается измерение с постоянным углом. В большинстве сценариев применения, например, при беспилотном вождении, не требуется субмиллиметровая пространственная точность, и даже не требуется точность до долей сантиметра. На практике большинство измерительных систем не способны обеспечить такой точности. К примеру, допустим, что полезная точность равна около LPC=2 см в трехмерном декартовом пространстве, и измерительное устройство может измерять азимутальные углы с шагом Δφ=0.2°=0.2*2π/360 радиан (около 2000 измерений на оборот вращающегося лидара), тогда объекты на расстоянии (радиусе) rdense, меньшем
rdense=LPC/Δφ=2/(0.2*2π/360) ≈ 573 см ≈ 5 м
будут измерены измерительной системой с избыточной точностью. В этом примере угловой шаг Δφ, как правило, представляет собой азимутальное смещение между двумя измерениями, одним и тем же датчиком измерительной головки, применяемой для обнаружения объекта. Азимутальное смещение для вращающейся (лидарной) измерительной головки может является обычно является постоянными, однако может также меняться вдоль всего пути измерений, в соответствии с иллюстрацией фиг. 7. В любом случае азимутальное смещение Δφ может быть получено из информации, относящейся к характеристикам зондирующей схемы измерительного устройства.
Пространственное понижение частоты дискретизации (децимация) может достигаться квантованием трех декартовых координат (x,y,z) (с плавающей точкой или целочисленных) до требуемой точности (LPC), с получением целочисленных координат (x',y',z') отсчетов
(x',y',z')=LPC * round((x,y,z)/LPC)
и затем трехмерные дублированные точки, т.е. точки, имеющие одинаковые трехмерные координаты (x',y',z') отсчетов, могут быть объединены, чтобы оставить максимум одну точки для каждой координаты отсчета. Таким образом, точки облака точек расположены на трехмерной сетке с шагом, равным LPC, в соответствии с иллюстрацией фиг. 16.
Понижение пространственной частоты может также происходить вследствие ограниченной точности хранения трехмерных координат точек, ранее измеренных датчиком. В таком случае характеристическое расстояние LPC является максимальной точностью формата представления координат точек.
В одном из вариантов характеристическое расстояние LPC между точками не обязательно применимо к двумерной сетке. Вместо этого может применяться пространственное трехмерное сэмплирование по поверхностям (например, с использованием промежуточной сетки), в результате чего характеристическое расстояние LPC сохраняется между точками, не расположенными на сетке. И поэтому, в подобном случае, для занятой точки (закрашены черным, в плоскости ху), точки (незакрашенные) на фиг. 16 следует рассматривать как другие потенциальные точки, расположенные, как правило, не ближе, чем характеристическое расстояние LPC.
В одном из вариантов нижняя граница расстояния между точками, равная характеристическому расстоянию LPC, не считается обязательной для соблюдения, однако вместо этого является веским указанием на минимальное расстояния, т.е. две точки в пространстве трехмерных декартовых координат или на двумерной декартовой плоскости с большей вероятностью разделены по меньшей мере характеристическим расстоянием LPC, чем нет.
В случае объекта, расположенного на радиусе (расстоянии) robject от датчика, длина Larc в плоскости двумерных декартовых координат между двумя последовательными измерениями упомянутым датчиком равна:
Larc = robject * Δφ
Следовательно, если Larc<LPC, можно ожидать, что некоторые из грубых точек грубого представления не будут соответствовать ни одной точке облака точек. С другой стороны, если Larc>LPC, то вероятно, что большинство грубых точек грубого представления могут соответствовать точке облака точек.
На шаге 150 двоичные данные fj энтропийно кодируют на основе количества Nsens(sj,λj) измерений.
В способе кодирования выполняют переход к кодированию следующих двоичных данных fj из упомянутых по меньшей мере одних двоичных данных fj, являющихся представлением разности Δо порядковых индексов (шаг 160). Когда все двоичные данные fj из упомянутых по меньшей одних двоичных данных fj закодированы, по меньшей мере одни двоичные данные fj, являющиеся представлением другой разности порядковых индексов, представляющей собой разность между порядковыми индексами двух других последовательных занятых грубых точек, кодируют (шаг 170), при этом выполнение способа завершают, когда все занятые грубые точки рассмотрены.
Поскольку количество Nsens (λj,sj) измерений содержит немного информации, когда оно мало, например меньше или равно единице, в одном из вариантов осуществления шага 150 двоичные данные fj энтропийно кодируют на основе количества Nsens(sj,λj) измерений только тогда, когда количество Nsens(sj,λj) измерений превосходит пороговое значение thactivation активации. В противном случае двоичные данные fj энтропийно кодируют по меньшей мере на основе разности Cj координат и не на основе количества Nsens(sj,λj), или, в одном из вариантов, по меньшей мере на основе разности Cj,w координат окрестности (и опционально, на основе последовательности fj,n двоичных данных, указывающих на состояние занятости каждой из грубых точек, принадлежащих каузальной окрестности N), но не на основе количества Nsens(sj,λj) измерений.
Энтропийное кодирование двоичных данных fj на основе разности Cj координат (или на основе разности Cj,w координат окрестности) предпочтительно, поскольку разность Cj (или Cj,w) позволяет очень эффективно предсказывать значение двоичных данных fj, указывающих на данные о занятости j-й грубой точки. Это в особенности эффективно, когда Nsens(sj,λj) меньше или равно единице.
В одном из вариантов осуществления шага 150, разность Cj координат может быть получена между индексом sj отсчета и индексом sprec отсчета, соответствующего моменту времени измерения, в котором была обнаружена предыдущая кодированная или декодированная точка Pрrес с тем же индексом датчика, что и индекс λj датчика. Текущую грубую точку никогда не рассматривают среди множества уже закодированных точек, на основе которых определяют предшествующую уже закодированную точку Pprec:
Cj=sj-sprec
В одном из вариантов осуществления настоящего изобретения предшествующая занятая грубая точка Рргес является предпоследней занятой грубой точкой Ppenult.
На фиг. 17 и 18 показаны два примера двух конфигураций занятости окрестности, где предпоследняя занятая грубая точка Ppenult не принадлежит каузальной окрестности (ограничена пунктирной линией). В этом случае разность Cj координат не является избыточной информацией в дополнение к конфигурации занятости окрестности.
На фиг. 19 и 20 показаны два примера двух конфигураций занятости окрестности, где предпоследняя занятая грубая точка Ppenult принадлежит каузальной окрестности (ограничена пунктирной линией). На фиг. 19 разность Cj координат полностью содержится в конфигурации занятости окрестности. Однако на фиг. 20, когда предшествующая и предпоследняя грубые точки являются одной и той же, конфигурация занятости окрестности не позволяет обнаруживать дублирование точек. Можно заметить, что конфигурации занятости окрестности на фиг. 18 и 20 одинаковы, однако разности Cj координат отличаются.
Если ширина W каузальной окрестности N, заданной, например, от первой координаты текущей грубой точки (W=3 на фиг. 17), достаточно велика, чтобы гарантировать, что предпоследняя занятая грубая точка Ppenult принадлежит этой окрестности, то разность Cj координат уже содержится в конфигурации занятости окрестности.
В некоторых из примеров разность Cj координат вплоть до 6, 7 или даже 8 не обеспечивает надежного предсказания первых двоичных данных fj.
Высота окрестности (равная 5), включающая «линию» текущего датчика (грубые точки, соответствующие одному и тому же датчику с индексом λj) и две «линии» ниже (датчика с индексами λj-1 и λj-1), а также две линии выше (датчика с индексами λj+1 и λj+1) показала себя как адекватный размер для прогнозирования значения первых двоичных данных fj. Следовательно, чтобы гарантировать, что предпоследняя занятая грубая точка принадлежит каузальной окрестности, потребуется по меньшей мере 6*5+2=32 соседей, что дает 232=1 миллиард возможных конфигураций занятости окрестности.
В одном из вариантов осуществления настоящего изобретения разность координат Cj,w окрестности получают на основе сравнения разности Cj координат с шириной W окрестности, при этом первые двоичные данные fj энтропийно кодируют (шаг 150) на основе разности Cj,w координат в окрестности, заданной следующим выражением:
Cj,w=max(Cj, W).
Конфигурация занятости в каузальной окрестности N может быть представлена последовательностью (с индексом n) по меньшей мере одних вторых двоичных данных fj,n, указывающих на состояние занятости каждой из грубых точек, принадлежащих каузальной окрестности N. В одном из вариантов осуществления шага 150, первые двоичные данные fj энтропийно кодируют на основе последовательности из по меньшей мере одних вторых двоичных данных fj,n и разности Cj,w координат окрестности.
Использование Cj,w вместо Cj гарантирует, что случай, в котором предшествующая занятая грубая точка Рргес принадлежит окрестности N, будет распознан за счет того, что Cj,w будет равна W, и в этом случае, устраняется избыточность между разностью Cj координат и каузальной окрестностью N.
В одном из вариантов разность Cj,w координат окрестности равна определенному значению тогда и только тогда, когда предшествующая занятая грубая точка Pprec принадлежит каузальной окрестности N.
К примеру, разность Cj,w координат окрестности может определяться следующим выражением:
Cj,w=max(Cj, W)-W,
при этом предшествующая занятая грубая точка Рргес принадлежит каузальной окрестности N тогда и только тогда, когда Cj,w=0. Разность Cj,w координат окрестности, таким образом, содержится в заданной конфигурации занятости окрестности. В противном случае, когда разность координат окрестности Cj,w>0, разность Cj координат получают просто как Cj=Cj,w+W.
В одном из вариантов осуществления шага 150 двоичные данные fj энтропийно кодируют на основе значения Δj, зависящего от индекса sj отсчета текущей грубой точки Pj, индекса slast и количества Nsens(si,λi), заданного следующим выражением:
Δj=sj-slast-Nsens(sj,λj)
В одном из вариантов двоичные данные fj энтропийно кодируют на основе ограниченного значения Δj' на основе значения Δj, в соответствии со следующим выражением:
Δj'=max(thlow, min(thhigh, Δj))
где thlow и thhigh - два пороговых значения, и thhigh>thlow.
В одном из вариантов осуществления шага 130, показанном на фиг. 21, количество Nsens(sj,λj) получают на основе радиуса robject, соответствующего последней текущей занятой грубой точке Plast, обнаруженной датчиком с индексом λj датчика.
В одном из вариантов осуществления шага 130, показанном на фиг. 22, количество Nsens(sj,λj) измерений может корректироваться на основе азимутального угла φ.
Nsens(sj,λj)=floor(LPC'/Larc)
=floor(LPC*(|cos(φ)|+|sin(φ)|)/(robject * Δφ))
где LPC'=Lx+Ly=LPC*(|cos(φ)|+|sin(φ)|). Азимутальный угол φ означает измерение текущей грубой точки Pj и может быть получен при помощи индекса sj измерения или может быть получен на основе азимутального угла φlast последней занятой грубой точки Plast.
В одном из вариантов осуществления шага 130, если Larc<LPC, количество Nsens(sj,λj) измерений задано следующим выражением:
Nsens(sj,λj)=floor(LPC / Larc)=floor(LPC / (robject * Δφ))
Количество Nsens(sj,λj) измерений является локальным для двумерного представления, поскольку оно зависит от азимутального смещения Δφ, а радиус robject может одновременно зависеть от индекса λj датчика и от индекса sj отсчета.
Характеристическое расстояние LPC является характеристикой облака точек.
В одном из вариантов осуществления шага 130 характеристическое расстояние LPC может кодироваться в битовый поток, как правило, в набор параметров последовательности (Sequence Parameter Set, SPS) или в основной набор параметров (General Parameter Set, GPS).
В одном из вариантов осуществления шага 130 характеристическое расстояние LPC может зависеть от трехмерной или двумерной области пространства. В таком случае характеристическое расстояние LPC может кодироваться для каждой области.
В одном из вариантов осуществления настоящего изобретения количество Nsens(sj,λj) измерений равно числу N, так что длина Larc дуги, образованной между текущим отсчетом с текущим индексом s отсчета и будущим отсчетом с индексом s+N отсчета, приблизительно равна характеристическому расстоянию LPC:
Larc=robject*|φ_(s+N)-φ_s|≈LPC
Число N может быть получено итеративно подбором N=1, N=2 и т.п.
На фиг. 23 схематично проиллюстрирована блок-схема алгоритма способа 200 декодирования геометрических данных облака точек из битового потока кодированных данных облака точек в соответствии по меньшей мере с одним вариантом осуществления настоящего изобретения.
Способ 200 декодирования может быть напрямую выведен из способа 100 кодирования.
На шаге 210 получают координаты текущей грубой точки Pj в двумерном пространстве. Текущая грубая точка Pj имеет первую координату φj и вторую координату λj в пространстве двумерных координат (φ,λ), и первую координату sj и вторую координату λj в пространстве двумерных координат (s, λ).
Количество Nsens(sj,λj) измерений получают на шаге 130 в соответствии с предшествующим описанием.
На шаге 220 двоичные данные fj энтропийно декодируют из битового потока В на основе количества Nsens(sj,λj) измерений.
Затем в способе декодирования выполняют переход к декодированию следующих двоичных данных fj из упомянутых по меньшей мере одних двоичных данных fj, являющихся представлением разности Δо порядковых индексов. Когда все двоичные данные fj, являющиеся представлением разности Δо порядковых индексов, декодированы, декодируют другую разность порядковых индексов, представляющую еще одну разность между индексами двух последовательных занятых грубых точек, при этом способ завершается, когда рассмотрены все занятые грубые точки.
В одном из вариантов шага 220 двоичные данные fj энтропийно декодируют на основе количества Nsens(sj,λj) измерений, только если количество Nsens(sj,λj) измерений превосходит пороговое значение thactivation активации. В противном случае двоичные данные fj энтропийно декодируют по меньшей мере на основе разности Cj координат и не на основе количества Nsens(sj,λj), или, в одном из вариантов, по меньшей мере на основе разности Cj,w координат окрестности (и, опционально, на основе последовательности двоичных данных fj,n, указывающих состояние занятости каждой из грубых точек, принадлежащих каузальной окрестности N), но не на основе количества Nsens(sj,λj) измерений.
В одном из вариантов осуществления шага 150 двоичные данные fj энтропийно кодируют на основе значения Δj или Δj'.
В одном из вариантов шага 150, и соответственно, 220, двоичные данные fj кодируют, и соответственно, декодируют, при помощи двоичного арифметического кодера, и соответственно, декодера, с использованием вероятности pr того, что двоичные данные fj имеют значение «истина» (fj=l) на основе количества Nsens(sj,λj) измерений, или опционально, на разности Cj (Cw,j) координат и последовательности двоичных данных fj,n. В этом случае количество Nsens(sj,λj) измерений, или опционально, разность Cj (Cw,j) координат и последовательность fj,n двоичных данных, могут указывать на элемент таблицы Т вероятностей, так что pr=T[Nsens(sj,λj) или pr=T[Cj], или рг=T[Cw,j], или рr=T[Cw,j, fj,n]. Вероятность pr может обновляться после кодирования двоичных данных fj в зависимости их значения («истина» или «ложь», или же 0 или 1).
В одном из вариантов осуществления шага 150, или, соответственно, 220, показанном на фиг. 24, двоичные данные fj энтропийно кодируют, и соответственно декодируют, с контекстной адаптацией. Контекстно-адаптивное энтропийное кодирование, и соответственно, декодирование, может включать выбор контекста Ctx на основе количества Nsens(sj,λj) измерений, или опционально, на основе разности Cj (Cw,j) координат и на основе последовательности fj,n двоичных данных.
Контекст Ctx может выбираться из таблицы Т контекстов на основе по меньшей мере количества Nsens(sj,λj) измерений, или опционально,, на основе разности Cj (Cw,j) координат и на основе последовательности fj,n двоичных данных, так что Ctx=T[Nsens(sj,λj)] или Ctx=T[Cj], или Ctx=T[Cw,j] или Ctx=T[Cw,j, fj,n].
Первые двоичные данные fj энтропийно кодируют в зависимости от контекста в битовый поток В на основе выбранного контекста Ctx. Первые двоичные данные fj энтропийно декодируют в зависимости от контекста на основе выбранного контекста Ctx.
В одном из вариантов, показанном на фиг. 24, первые двоичные данные fj контекстно-адаптивно энтропийно кодируют или декодируют при помощи контекстно-адаптивного двоичного адаптивного кодера или декодера (САВАС).
Контекст Ctx может выбираться при помощи заданной процедуры выборы, по меньшей мере на основе количества Nsens(sj,λj) измерений, или опционально, на основе разности Cj (Cw,j) координат и на основе последовательности fj,n двоичных данных, в результате чего получают индекс ctxIdx контекста, соответствующий двоичным данным fj.
В таблице Tctx контекстов с Nctx записями, как правило, хранят вероятности, связанные с контекстами, и вероятности ctxIdx, полученные как ctxIdx-я запись в таблице контекстов. Контекст выбирают на основе индекса ctxIdx контекста при помощи следующего выражения:
Ctx=Tctx [ctxIdx].
К примеру, индекс ctxIdx контекста может соответствовать количеству Nsens(sj,λj) измерений, или опционально, разности Cj (Cw,j) координат и последовательности fj,n двоичных данных, в результате чего контекст Ctx выбирают следующим образом:
Ctx=Tctx[Nsens(sj,λj)] or Ctx=Tctx[Cj] or Ctx=T[Cw,j] or Ctx=T[Cw,j, fj,n].
Двоичные данные fj энтропийно кодируют в битовый поток, или соответственно, энтропийно декодируют из битового потока В, с использованием вероятности pctxIdx.
Энтропийные кодеры, как правило, являются арифметическими, однако могут быть также любым другим типом энтропийных кодеров, например, асимметричными системами счисления. В любом случае оптимальные кодеры добавляют -log2(pctxIdx) битов в битовый поток для кодирования fj=1 или- log2(1-pctxIdx) битов в битовый поток для кодирования fj=0. Когда двоичные данные fj закодированы (декодированы) вероятность pctxIdx обновляют при помощи блока обновления, который принимает на вход кодированные двоичные данные fj и pctxIdx; при этом обновление, как правило, выполняют при помощи обновленных таблиц. Обновленная вероятность заменяет ctxIdx-ю запись в таблице Tctx контекстов. Затем кодируют другие двоичные данные fj и т.д. Цикл обновления контекстной таблицы является узким горлом процесса кодирования, поскольку другой символ может кодироваться только после завершения обновления. По этой причине доступ к памяти таблицы контекстов должен быть как можно более быстрым, а минимизация размера таблицы упрощает ее аппаратную реализацию.
Контекстно-адаптивный двоичный арифметический декодер выполняет по существу те же операции, что и контекстно-адаптивный двоичный арифметический кодер, за исключением того, что кодированные двоичные данные fj декодируют из битового потока В при помощи энтропийного декодера с использованием вероятности pctxIdx.
Выбор подходящего контекста, т.е. вероятности pctxIdx, дающей наилучшую оценку шансов двоичных данных fj быть равными 1, критически важен для получения эффективного сжатия. Поэтому, чтобы получить подходящий контекст, для выбора контекста должны использоваться данные о занятости по меньшей мере для одной соседней грубой точки, принадлежащей каузальной окрестности текущей занятой грубой точки, а также корреляция между ними.
На фиг. 25 схематично проиллюстрирована блок-схема одного из примеров системы, в которой могут быть реализованы различные аспекты и примеры осуществления настоящего изобретения.
Система 300 может быть внедрена в виде одного или более устройств, включающих различные компоненты, описанные ниже. В различных вариантах осуществления настоящего изобретения система 300 может быть сконфигурирована для реализации одного или более из аспектов, описанных здесь.
Примеры оборудования, которые могут составлять систему 300 в целом, или ее часть, включают персональные компьютеры, портативные компьютеры, смартфоны, планшетные компьютеры, цифровые мультимедийные телеприставки, цифровые телеприемники, персональные системы видеозаписи, подключенные к Интернету бытовые приборы, подключенные к Интернету автомобили и их соответствующие системы обработки данных, устанавливаемые на голове дисплейные устройства или очки с прозрачными дисплеями (head mounted display devices, HMD), проекторы (мультимедийные), среды виртуальной реальности CAVE (системы со множеством дисплеев), серверы, видеокодеры, видеодекодеры, постпроцессоры, обрабатывающие выходные данные с видеодекодера, препроцессоры, подающие входные данные в видеокодер, веб-серверы, телеприставки или любые другие устройства для обработки облаков точек, видеоинформации, изображений или иные устройства связи. Элементы системы 300, по отдельности или в комбинации, могут быть реализованы в одной интегральной схеме (integrated circuit, IC), нескольких интегральные схемах и/или на дискретных компонентах. К примеру, по меньшей мере в одном из вариантов осуществления настоящего изобретения элементы обработки данных или кодера/декодера в системе 300 могут быть распределены среди нескольких интегральных схем и/или дискретных компонентов. В различных вариантах осуществления настоящего изобретения система 300 может быть соединена, с возможностью связи, с другими подобными системами или с другими электронными устройствами, например, при помощи шины связи или при помощи специальных портов ввода и/или вывода.
Система 300 может включать по меньшей мере один процессор 310, сконфигурированный для исполнения инструкций, загружаемых в него для реализации, к примеру, различных аспектов, описанных здесь. Процессор 310 может иметь встроенную память, интерфейс ввода-вывода и различные иные схемы, известные на существующем уровне техники. Система 300 может включать по меньшей мере одну память 320 (к примеру, энергозависимое запоминающее устройство и/или энергонезависимое запоминающее устройство). Система 300 может включать устройство 340 хранения, которое может включать энергонезависимую память и/или энергозависимую память, включая, без ограничения перечисленным, электрически перепрограммируемую память «только для чтения» (Electrically Erasable Programmable Read-Only Memory, EEPROM), память «только для чтения» (Read-Only Memory, ROM), программируемую память «только для чтения» (Programmable Read-Only Memory, PROM), память с произвольным доступом (Random Access Memory, RAM), динамическую память с произвольным доступом (Dynamic Random-Access Memory, DRAM), статическую память с произвольным доступом (Static Random-Access Memory, SRAM), флэш-память, привод магнитных дисков и/или привод оптических дисков. Устройство 340 хранения в качестве неограничивающих примеров может включать внутреннее устройство хранения, подключаемое устройство хранения и/или доступное по сети устройство хранения.
Система 300 может включать модуль 330 кодера/декодера, сконфигурированный, например, для обработки данных с целью получения кодированных/декодированных геометрических данных облака точек, при этом модуль 330 кодера/декодера может иметь собственные процессор и память. Модуль 330 кодера/декодера может представлять собой модуль (или модули), входящие в состав устройства для выполнения функций кодирования и/или декодирования. Как известно, устройство может содержать модуль кодирования, модуль декодирования или оба модуля одновременно. При этом модуль 330 кодера/декодера 330 может быть реализован в виде отдельного элемента 300 или может быть встроен в процессор 310 в виде комбинации аппаратного и программного обеспечения, что известных специалистам в данной области техники.
Программный код, загружаемый в процессор 310 или кодер/декодер 330 для выполнения различных аспектов, описанных здесь, может храниться в устройстве 340 хранения и впоследствии загружаться в память 320 для исполнения процессором 310. В соответствии с различными вариантами осуществления настоящего изобретения одно или более из следующего: процессор 310, память 320, устройство 340 хранения я модуль 330 кодера/декодера могут хранить один или более различных объектов при выполнении процедур, описанных здесь. Такие хранимые объекты включают, без ограничения перечисленным, кадр облака точек, геометрию/атрибуты кодируемых/декодируемых видео/изображений или фрагменты геометрии/атрибутов кодируемых/декодируемых видео/изображений, битовый поток, матрицы, переменные и промежуточные или окончательные результаты обработки уравнений, формул, операций и логики выполнения операций.
В некоторых из вариантов осуществления настоящего изобретения память внутри процессора 310 и/или модуля 330 кодера/декодера может использоваться для хранения инструкций и для использования в качестве рабочей памяти при обработке, которая может выполняться во время кодирования или декодирования.
В других вариантах осуществления настоящего изобретения, однако, для одной или более из подобных функций может применяться память, внешняя по отношению к устройству обработки данных (например, таким устройством обработки данных может быть процессор 310 или модуль 330 кодера/декодера). Внешней памятью может быть память 320 и/или устройство 340 хранения, к примеру, динамическая энергозависимая память и/или энергонезависимая флэш-память. В некоторых из вариантов осуществления настоящего изобретения внешняя энергонезависимая флэш-память может использоваться для хранения операционной системы телевизора. По меньшей мере в одном варианте осуществления настоящего изобретения быстрая внешняя динамическая энергозависимая память, например, RAM, может использоваться в качестве рабочей памяти для операций кодирования и декодирования видео, к примеру, для кодирования по стандартам MPEG-2 часть 2 (также называемому Рекомендация Н.262 ITU-T и ISO/IEC 13818-2, также называемому MPEG-2 Video), HEVC (High Efficiency Video coding, «высокоэффективное видеокодирование»), VVC (Versatile Video Coding, «универсальное видеокодирование»), или стандарту MPEG-I часть 5 или часть 9.
Входные данные в элементы системы 300 могут подаваться при помощи различных устройств ввода, показанных в блоке 390. Такие устройства ввода включают, без ограничения перечисленным: (i) радиочастотный узел, который может принимать радиочастотный сигнал, передаваемый, например, по радиоинтерфейсу передатчиком, (ii) входной терминал композитного интерфейса, (iii) входной терминал USB и/или (iv) входной терминал HDMI.
В различных вариантах осуществления настоящего изобретения устройства ввода в блоке 390 могут иметь соответствующие связанные с ними элементы обработки входных данных, известные на существующем уровне техники. К примеру, радиочастотный узел может быть связан с элементами, необходимым для следующего: (i) выбор необходимой частоты (это также называют выделением сигнала, или ограничением полосы частот до заданной полосы), (ii) преобразование выделенного сигнала с понижением частоты, (iii) повторное ограничение полосы частоты до более узкой для выделения (к примеру) полосы частот сигнала, которая может, в некоторых из вариантов осуществления настоящего изобретения, называться каналом, (iv) демодуляция преобразованного с понижением частоты и ограниченного по полосе частот сигнала, (v) выполнение исправления ошибок, и (vi) демультиплексирование для выделения требуемого потока пакетов данных. Радиочастотный узел в различных вариантах осуществления настоящего изобретения может включать один или более элементов для выполнения таких функций, к примеру, селекторы частоты, селекторы сигнала, ограничители полосы частот, селекторы канала, фильтры, понижающие преобразователи, демодуляторы, корректоры ошибок и демультиплексоры. Радиочастотный узел может включать устройство настройки, которое выполняет некоторые из подобных функций, включая, например, понижающее преобразование принятого сигнала до пониженной частоты (к примеру, промежуточной частоты или до близкой к основной полосе частот) или до основной полосы частот.
В одном из вариантов осуществления настоящего изобретения, представляющем собой телеприставку, радиочастотный узел и связанный с ним элемент обработки входных данных может принимать радиочастотный сигнал, передаваемый по проводному (например, кабельному) носителю. В этом случае радиочастотный узел может выполнять селекцию частоты, при помощи фильтрации, понижающего преобразования и повторной фильтрации, до требуемой полосы частот.
В различных вариантах осуществления настоящего изобретения описанные выше (и другие) элементы могут иметь иной порядок, некоторые из элементов могут быть удалены, и/или могут быть добавлены другие элементы, выполняющие сходные или отличающиеся функции.
Добавление элементов может включать введение элементов между существующими, к примеру, введение усилителей и аналого-цифрового преобразователя. В различных вариантах осуществления настоящего изобретения радиочастотный узел может иметь антенну.
При этом упомянутые терминалы USB и/или HDMI могут содержать соответствующие интерфейсные процессоры для соединения системы 300 с другими электронными устройствами по соединениям USB и/или HDMI. Нужно понимать, что различные аспекты обработки входных данных, к примеру, коррекция ошибок с помощью кодов Рида-Соломона, могут быть реализованы при помощи отдельной интегральной схемы обработки ввода или при внутри процессора 310, в зависимости от требований. Аналогично, аспекты обработки интерфейсов USB или HDMI могут быть реализованы в отдельных интерфейсных интегральных схемах или внутри процессора 310 в зависимости от требований. Демодулированный, с исправленными ошибками и демультиплексированный поток может быть подан в различные обрабатывающие элементы, включающие, например, процессор 310 и кодер/декодер 330, функционирующие в сочетании с элементами памяти и хранения, для обработки потока данных, необходимой для отображения на устройстве вывода.
Различные элементы системы 300 могут быть выполнены в интегральном корпусе. Внутри интегрального корпуса различные элементы могут быть связаны друг с другом и передавать друг другу данные с использованием подходящего соединительного механизма 390, например, внутренней шины, известной на существующем уровне техники, включая шину I2C, проводные соединения и печатные платы.
Система 300 может включать интерфейс 350 связи, которые обеспечивает возможность связи с другими устройствами по каналу 700 связи. Интерфейс 350 связи может включать, без ограничения перечисленным, приемопередатчик, сконфигурированный для передачи и приема данных по каналу 700 связи. Интерфейс 350 связи может включать, без ограничения перечисленным, модем или сетевую карту, при этом канал 700 связи может быть реализован, например, в проводной и/или беспроводной среде передачи.
Сигнал Wi-Fi в таких вариантах осуществления настоящего изобретения может приниматься по каналу 700 связи и интерфейсу 350 связи, которые приспособлены для связи по стандарту Wi-Fi. Канал 700 связи в таких вариантах осуществления настоящего изобретения, как правило, может быть связан с точкой доступа или маршрутизатором, который представляет доступ к внешним сетям, включая Интернет, давая возможность использовать стриминговые приложения и иную связь, поставляемую поверх сетевых услуг оператора связи (over-the-top, ОТТ).
В других вариантах осуществления настоящего изобретения потоковая передача данных в систему 300 может осуществляться с помощью телеприставки, которая подает данные по HDMI-соединению блока 390 ввода.
Также, в дополнительных вариантах осуществления настоящего изобретения потоковая передача данных в систему 300 может осуществляться с помощью радиочастотного соединения блока 390 ввода.
Передаваемый поток данных может использоваться как метод сигнализации информации, используемой в системе 300. Сигнализируемая информация может включать битовый поток В и/или такую информацию, как количество точек в облаке точек и/или конфигурационные параметры датчиков.
Нужно понимать, что сигнализация может выполняться множеством различных способов. К примеру, для сигнализации информации соответствующему декодеру в различных вариантах осуществления настоящего изобретения могут применяться один или более синтаксических элементов, флагов и т.п.
Система 300 может подавать выходной сигнал в различные устройства вывода, включая дисплей 400, громкоговорители 500 и иные периферийные устройства 600. Упомянутые иные периферийные устройства 600 могут включать в различных примерах осуществления настоящего изобретения одно или более из следующего: автономный DVR, проигрыватель дисков, стереосистему, систему освещения, а также другие устройства, выполняющие свои функции на основе выходных данных системы 300.
В различных вариантах осуществления настоящего изобретения между системой 300 и дисплеем 400, громкоговорителями 500 и иными периферийными устройствами 600 могут передаваться сигналы управления при помощи, например, такой сигнализации, как AV Link (Audio/Video Link, «аудио/видео линия»), СЕС (Consumer Electronics Control, «управление бытовой электроникой») или иных протоколов связи, обеспечивающих возможность управления между устройствами (device-to-device) с вмешательством пользователя или без него.
Устройства вывода могут быть соединены с системой 300, с возможностью связи, по специальным соединениям через соответствующие интерфейсы 360, 370 и 380.
Или, устройства вывода могут быть соединены с системой 300 при помощи канала 700 связи через интерфейс 350 связи. Дисплей 400 и громкоговорители 500 могут быть объединены в одном блоке с остальными компонентами системы 300 в составе электронного устройства, например, телевизора.
В различных вариантах осуществления настоящего изобретения дисплейный интерфейс 360 может включать дисплейный драйвер, к примеру, микросхему тайминг-контроллера (Т Con).
Дисплей 400 и громкоговоритель 500 могут быть отдельными от одного или более других компонентов, к примеру, если радиочастотный узел блок 390 ввода является частью отдельной телеприставки. В тех вариантах осуществления настоящего изобретения, где дисплей 400 и громкоговорители 500 являются внешними компонентами, выходной сигнал может подаваться по специальным выходным включая, к примеру, порты HDMI, порты USB или порты СОМР.
На фиг. 1-25 показаны различные способы, описанные в данном документе, при этом каждый способ включает один или более шагов, или операций, для реализации описанного способа. Если конкретный порядок выполнения шагов или операций не является необходимым для корректного выполнения способа, то порядок и/или использование каких-либо шагов, или операций, могут быть изменены, или они могут комбинироваться.
Некоторые из примеров были проиллюстрированы на примерах блок-схем и/или блок-схем алгоритмов. Каждый такой блок может представлять собой схемный элемент, модуль или фрагмент кода, который включает одну или более исполняемых инструкций для реализации заданной логической функции (или функций). Следует отметить, что в некоторых альтернативных реализациях, функции, отмеченные в блоке, могут выполняться в порядке, отличающемся от проиллюстрированного на чертеже. К примеру, два блока, показанные в виде последовательности, фактически могут исполняться по существу одновременно, или же, в некоторых случаях, блоки могут исполняться в обратном порядке, - в зависимости от используемой функциональности.
Реализации и аспекты, описанные в данном документе, могут быть реализованы, к примеру, в форме способа или процедуры, устройства, компьютерной программы, потока данных, битового потока или сигнала. Даже если реализация описана только в контексте одной формы (к примеру, только как способ), описанные отличительные признаки могут быть также реализованы и в других формах (к примеру, устройства или компьютерной программы).
Способы могут быть также реализованы, например, в форме процессора, что обобщенно подразумевает устройства обработки данных, например, компьютер, микропроцессор, интегральную схему или программируемое логическое устройство. Процессоры также включают устройства связи.
Также, способы могут быть реализованы за счет выполнения инструкций процессором, при этом такие инструкции (и/или значения данных, получаемые при выполнении) могут храниться на машиночитаемом носителе данных). Машиночитаемый носитель данных может принимать форму машиночитаемого программного продукта, воплощенного на одном или более машиночитаемых носителей и имеющего воплощенный на нем машиночитаемый программный код, который может исполняться компьютером. Под машиночитаемым носителем данных в настоящем документе понимают носитель данных, обладающий неотъемлемой способностью хранить в себе информацию, а также способностью обеспечивать извлечение информации из него. К примеру, машиночитаемый носитель данных может представлять собой, без ограничения перечисленным, электронную, магнитную, оптическую, электромагнитную, инфракрасную или полупроводниковую систему, оборудование или устройство, или же любую подходящую комбинацию перечисленного. Специалисты в данной области техники должны понимать, что перечисленное ниже, являясь конкретными примерами машиночитаемых носителей данных, в которых могут применяться варианты осуществления настоящего изобретения, является лишь иллюстративным и неисчерпывающим перечислением: портативная компьютерная дискета, жесткий диск, память "только для чтения" (ROM), перезаписываемая память "только для чтения" (EPROM) или флэш-память, портативная память "только для чтения" на компакт-диске (CD-ROM), оптическое запоминающее устройство, магнитное запоминающее устройство или любая комбинация перечисленного.
Инструкции могут образовывать прикладную программу, материально воплощенную на читаемом процессором носителе.
Инструкции могут, к примеру, иметь форму аппаратного обеспечения, микропрограммного обеспечения, программного обеспечения или их комбинации. Инструкции могут находиться, к примеру, в операционной системе, в отдельном приложении или в их комбинации. Процессор, соответственно, может быть определен, например, одновременно как устройство, сконфигурированное для выполнения процедуры, и как устройство, которое включает читаемый процессором носитель (например, запоминающее устройство) с инструкциями для выполнения процедуры. Также, на читаемом процессором носителе, в дополнение к инструкциям или вместо них, могут храниться значения данных, получаемых в результате исполнения.
Устройство может быть реализовано, к примеру, в форме подходящего аппаратного, программного и микропрограммного обеспечения. Примеры таких устройств могут включать персональные компьютеры, портативные компьютеры, смартфоны, планшетные компьютеры, цифровые мультимедийные телеприставки, цифровые телеприемники, персональные системы видеозаписи, подключенные к Интернету бытовые приборы, подключенные к Интернету автомобили и их соответствующие системы обработки данных, устанавливаемые на голове дисплейные устройства или очки с прозрачными дисплеями (HMD), проекторы (мультимедийные), среды виртуальной реальности CAVE (системы со множеством дисплеев), серверы, видеокодеры, видеодекодеры, постпроцессоры, обрабатывающие выходные данные с видеодекодера, препроцессоры, подающие входные данные в видеокодер, веб-серверы, телеприставки или любые другие устройства для обработки облаков точек, видеоинформации, изображений или иные устройства связи. Очевидно, такое оборудование может быть мобильным или даже установлено на подвижной транспортной платформе.
Компьютерное программное обеспечение может быть реализовано при помощи процессора 310 или при помощи аппаратного обеспечения, или с помощью комбинации программного и аппаратного обеспечения. В качестве неограничивающего примера варианты осуществления настоящего изобретения могут быть также реализованы при помощи одной или боле интегральных схем. Память 320 может быть любого типа, подходящего к техническому окружению, и может быть реализовано с помощью любой подходящей технологии хранения данных, к примеру, без ограничения перечисленным, оптических запоминающих устройств, магнитных запоминающих устройств, полупроводниковых запоминающих устройств, несъемной памяти или съемной памяти. Процессор 310 может быть любого типа подходящего к техническому окружению и может включать, без ограничения перечисленным, одно или более из следующего: микропроцессоры, компьютеры общего назначения, компьютеры специального назначения, а также процессоры, основанные на многоядерной архитектуре.
Специалистам в данной области техники должно быть очевидно, что реализации могут формировать множество различных сигналов, форматированных для содержания информации, которая, к примеру, может сохраниться или передаваться. Такая информация может включать, например, инструкции для выполнения способа или данные, получаемые в результате одной или более описанных реализаций. К примеру, некоторый сигнал может быть форматирован для содержания битового потока в соответствии с одним из описанных вариантов осуществления настоящего изобретения. Такой сигнал может быть форматирован, например, в форме электромагнитной волны (к примеру, с использованием радиочастотной области спектра) или в форме сигнала основной полосы частот. Форматирование может включать, например, кодирование потока данных и модуляцию несущий закодированным потоком данных. Информация, которую содержит сигнал, может быть, например, аналоговой или цифровой информацией. Сигнал, как известно, может передаваться по множеству различных проводных или беспроводных линий связи. Сигнал может храниться на читаемом процессором носителе данных.
Конкретная терминология в настоящем документе используется исключительно для описания конкретных вариантов его осуществления и не имеет целью ограничение настоящего изобретения. В настоящем описании, а также в приложенной формуле изобретения, такие выражения, как «один», «один из» и «упомянутый» в единственном числе могут также подразумевать включение означаемых во множественном числе, если только из контекста очевидно не следует обратное. Нужно также понимать, что выражения «включает/содержит» и/или «включающий/содержащий» в данном документе определяют присутствие перечисленных признаков, подсистем, шагов, операций, элементов и/или компонентов, но не исключают присутствие или добавление одного или боле других признаков, подсистем, шагов, операций, элементов, компонентов и/или их групп. При этом, когда элемент назван «реагирующим» на другой элемент, или «подключенным» к другому элементу, он может отвечать или быть подключенным непосредственно, или могут присутствовать промежуточные элементы. Напротив, если элемент описан как «непосредственно реагирующий» на другой элемент или «непосредственно подключенный» к другому элементом, промежуточные элементы отсутствуют.
Нужно понимать, что использование символа «/» или выражений «и/или» и «по меньшей мере одно из следующего», к примеру, в случае «А/В» «А и/или В» и «по меньшей мере одно из следующего: А и В» может подразумевать включение выбора только первой перечисленной опции (А) или выбор только второй перечисленной опции (В), или выбор обеих опций (А и В). В качестве еще одного примера, в случае: «А, В и/или С» и «по меньшей мере одно из следующего: А, В и С», такие выражения подразумевают включение выбора только первой перечисленной опции (А) или выбор только второй перечисленной опции (В), или выбор только третьей перечисленной опции (С), или выбор только первой и второй перечисленных опций (А и В), или выбор только первой и третьей перечисленных опций (А и С), или выбор только второй и третьей перечисленных опций (В и С), или выбор всех трех опций (А и В и С). Специалистам в данной области техники должно быть очевидно, что это может быть расширено на любое количество перечисленных элементов.
В настоящем описании могут использоваться множество различных числовых значений. Эти конкретные значения могут приводиться в качестве примера, и аспекты, описанные в данном документе, не ограничены этими конкретными значениями.
Для описания различных элементов в данном документе могли быть использованы термины «первый», «второй» и т.п., однако нужно понимать, что такие элементы не ограничены этими терминами. Данные термины используются исключительно в целях различения одних элементов от других. К примеру, первый элемент может быть назван вторым элементом, и аналогично, второй элемент может быть назван первым элементом, в пределах сущности и объема настоящего изобретения. Между первым и вторым элементами не предполагается никакого порядка предшествования.
Упоминание «варианта осуществления настоящего изобретения» или «одного из вариантов осуществления настоящего изобретения», или «одной реализации», или «одной из реализаций», а также вариаций этих выражений, используются зачастую для сообщения о том, что некоторый отличительный признак, структура, характеристика и т.п.(описанные в связи с вариантом осуществления настоящего изобретения или реализацией) включены по меньшей мере в один из вариантов осуществления или реализацию настоящего изобретения. То есть, фразы «в одном варианте осуществления настоящего изобретения» или «в одном из вариантов осуществления настоящего изобретения», или «в одной реализации», или «в одной из реализаций», а также их вариаций, в различных местах настоящей заявки не обязательно отсылают к одному и тому же варианту осуществления настоящего изобретения.
Аналогично, в данном документе выражение «в соответствии с одним из вариантов/примеров/реализаций» или «в одном из вариантов/примере/реализации», а также их вариации, используют зачастую для сообщения о том, что некоторый отличительный признак, структура, характеристика и т.п.(описанные в связи с проиллюстрированным вариантом/примером/реализацией) могут входить в состав по меньшей мере одного проиллюстрированного варианта/примера/реализации настоящего изобретения. Таким образом, появление выражений «в соответствии с одним из вариантов/примеров/реализаций» или «в одном из вариантов/примере/реализации» в различных местах настоящего описания не обязательно обозначает отсылку к одному и тому же варианту/примеру/реализации, а также не означает, что отдельные или альтернативные варианты/примеры/реализации должны исключать друг друга или другие проиллюстрированные варианты/примеры/реализации.
Числовые обозначения, приведенные в формуле изобретения, использованы исключительно для иллюстрации и не ограничивают объем формулы изобретения. Варианты и примеры осуществления настоящего изобретения могут применяться в любых комбинациях или суб-комбинациях, даже если они явно не описаны в данном документе.
Если чертеж является блок-схемой алгоритма, нужно понимать, что он также представляет блок-схему соответствующего устройства. Аналогично, когда чертеж является блок-схемой устройства, нужно понимать, что он также представляет блок-схему алгоритма соответствующего способа или процедуры.
На некоторых из блок-схем имеются стрелки на каналах связи, иллюстрирующие основное направление связи, однако нужно понимать, что связь может осуществляться и в противоположном стрелкам направлении.
В различных реализациях применяют декодирование. «Декодирование» в настоящей заявке может включать все процедуры (или их часть), выполняемые, например, над принятым кадром облака точек (включая, возможно, принятый битовый поток, где закодированы один или более кадров облака точек) для получения окончательных выходных данных, подходящих для отображения или для дальнейшей обработки в домене восстановленного облака точек. В различных вариантах осуществления настоящего изобретения такие процедуры включают одну или более процедуры, выполняемых, как правило, декодером. В различных вариантах осуществления настоящего изобретения такие процедуры также могут включать процедуры, выполняемые декодером, например, из различных реализаций, описанных в настоящей заявке.
В качестве дополнительных примеров, в одном из вариантов осуществления настоящего изобретения «декодирование» может означать только деквантование, в одном из вариантов осуществления настоящего изобретения «декодирование» может означать энтропийное декодирование, еще одном из вариантов осуществления настоящего изобретения «декодирование» может означать только дифференциальное декодирование, и в еще одном из вариантов осуществления настоящего изобретения «декодирование» может означать комбинации из деквантования, энтропийного декодирования и дифференциального декодирования. Что именно означает выражение «процедура декодирования», конкретное подмножество операций или, более общо, процедуру декодирования в целом, можно понять из контекста конкретного описания, - специалистам в данной области техники это должно быть очевидно.
В различных реализациях применяют кодирование. Аналогично приведенным выше рассуждениям о «декодировании», «кодирование» в настоящей заявки может включать все процедуры (или их часть), выполняемые, например, над входным кадром облака точек для получения кодированного битового потока. В различных вариантах осуществления настоящего изобретения такие процедуры включают одну или более процедуры, выполняемых, как правило, кодером. В различных вариантах осуществления настоящего изобретения такие процедуры также могут включать процедуры, выполняемые кодером из различных реализаций, описанных в настоящей заявке.
В качестве дополнительных примеров, в одном из вариантов осуществления настоящего изобретения «кодирование» может означать только квантование, в одном из вариантов осуществления настоящего изобретения «кодирование» может означать только энтропийное кодирование, в еще одном из вариантов осуществления настоящего изобретения «кодирование» может означать только дифференциальное кодирование, и в еще одном из вариантов осуществления настоящего изобретения «кодирование» может означать комбинации из квантования, дифференциального кодирования и энтропийного кодирования. Что именно означает выражение «процедура кодирования», конкретное подмножество операций или, более обобщенно, процедуру кодирования в целом, можно понять из контекста конкретного описания, - специалистам в данной области техники это должно быть очевидно.
Также в данной заявке может упоминаться «получение» различных элементов информации. Получение информации может включать, например, одно или более из следующего: оценка информации, вычисление информации, предсказание информации или извлечение информации из памяти.
Также в данной заявке может упоминаться «доступ» к различным элементам информации. Доступ к информации может включать, к примеру, одно или более из следующего: прием информации, излечение информации (например, из памяти), сохранение информации, перемещение информации, копирование информации, вычисление информации, определение информации, предсказание информации или оценку информации.
Также в данной заявке может упоминаться «прием» различных элементов информации. Прием, аналогично «доступу» следует понимать широко. Прием к информации может включать, к примеру, одно или более из следующего: доступ к информации или излечение информации (например, из памяти). При этом прием выполняют, как правило, так или иначе, во время таких операций, как сохранение информации, обработка информации, передачи информации, перемещение информации, копирование информации, стирание информации, вычисление информации, определение информации, предсказание информации или оценка информации.
Также в данном документе термин «сигнал» обозначает, помимо прочего, указание чего-то соответствующему декодеру. К примеру, в некоторых из вариантов осуществления настоящего изобретения кодер сигнализирует конкретную информацию, например, количество точек облака точек или координаты, или конфигурационные параметры датчика. Таким образом, в одном из вариантов осуществления настоящего изобретения один и тот же параметр может применяться как на стороне кодера, так и на стороне декодера. То есть, например, кодер может передавать (явно сигнализировать) конкретный параметр в декодер, в результате чего декодер может использовать этот конкретный параметр. И наоборот, если в декодере уже имеется конкретный параметр, среди прочих, то сигнализация может выполняться без передачи (явной сигнализации), просто чтобы уведомить декодер и выбрать конкретный параметр. Исключение передачи каких-либо фактических функций позволяет экономить биты в различных вариантах осуществления настоящего изобретения. Нужно понимать, что сигнализация может выполняться множеством различных способов. К примеру, для сигнализации информации соответствующему декодеру в различных вариантах осуществления настоящего изобретения могут применяться один или более синтаксических элементов, флагов и т.п. Предшествующее относится к глагольной форме «сигнализировать», однако «сигнализация» может также использоваться в данном документе как существительное.
Было рассмотрено несколько конкретных вариантов реализации настоящего изобретения. Однако нужно понимать, что в них могут быть выполнены множество различных модификаций. К примеру, элементы различных реализаций могут комбинироваться, дополняться, модифицироваться или удаляться, в результате чего могут быть получены другие реализации. При этом специалисты в данной области техники должны понимать, что вместо рассмотренных здесь могут применяться другие структуры или процедуры, и результирующие реализации будут выполнять по существу ту же функцию (или функции), по существу тем же методом (или методами), с получением по существу того же результата (или результатов), что и описанные реализации. Соответственно, подобные, а также другие реализации попадают в объем настоящей заявки.
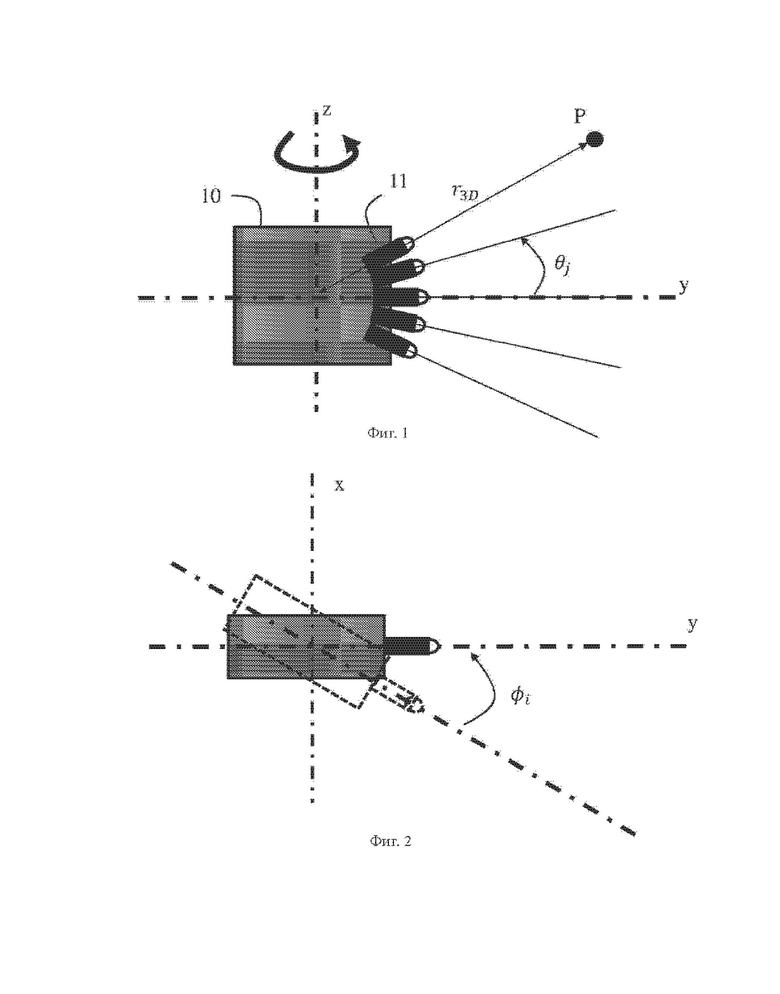
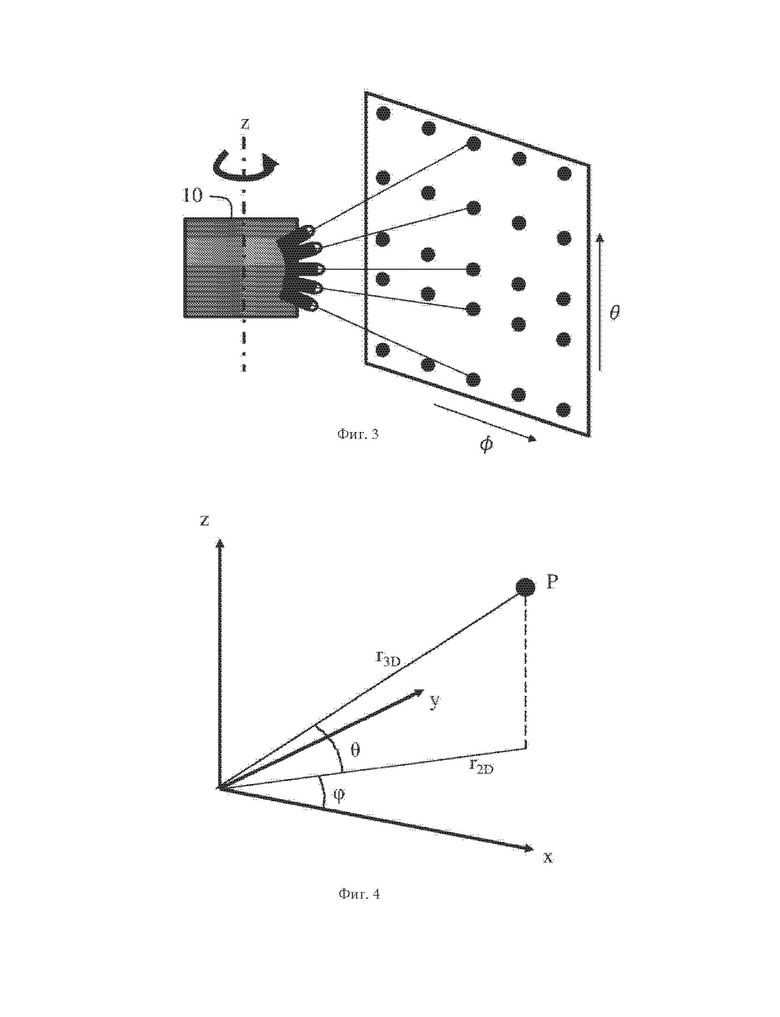
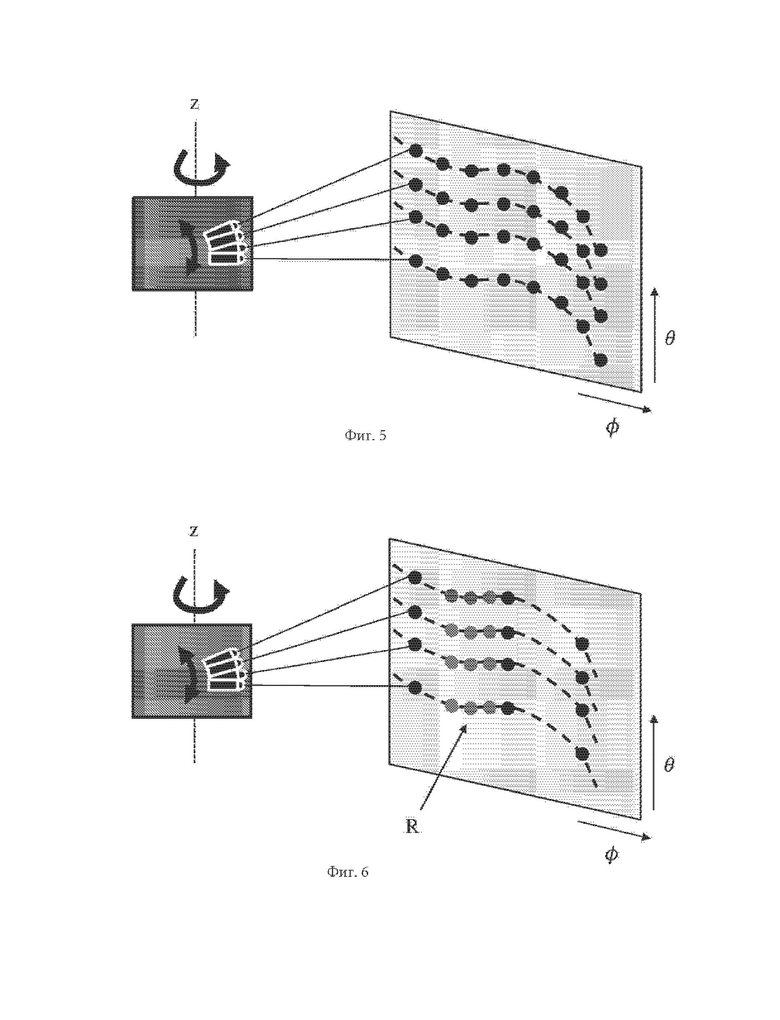
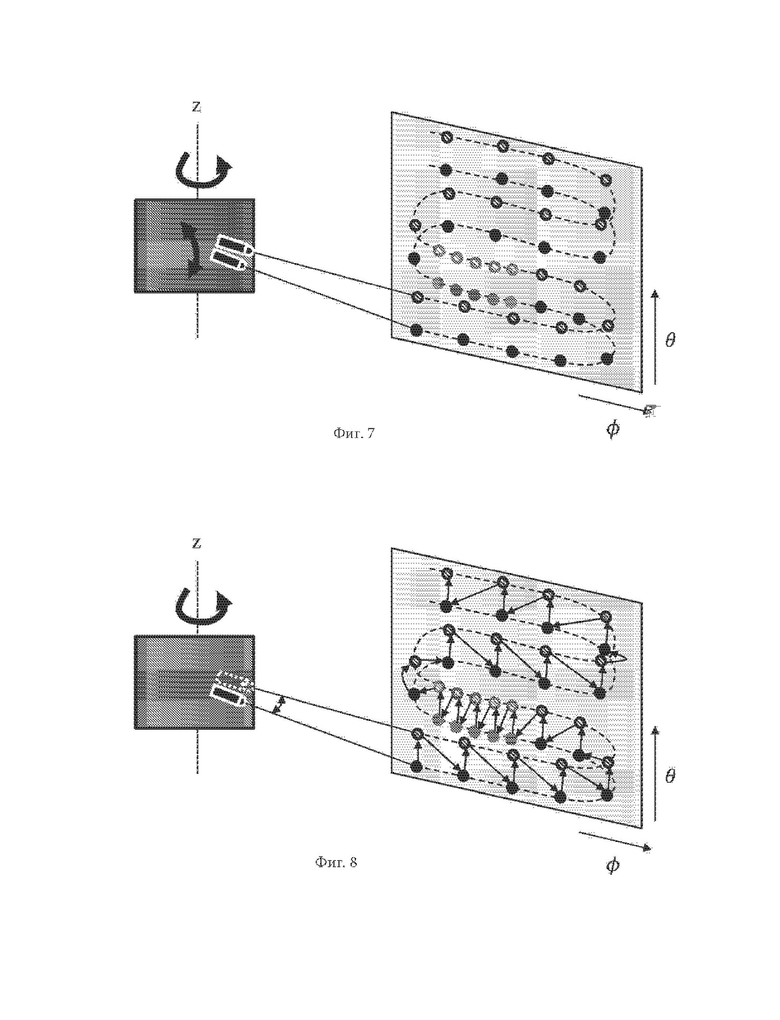
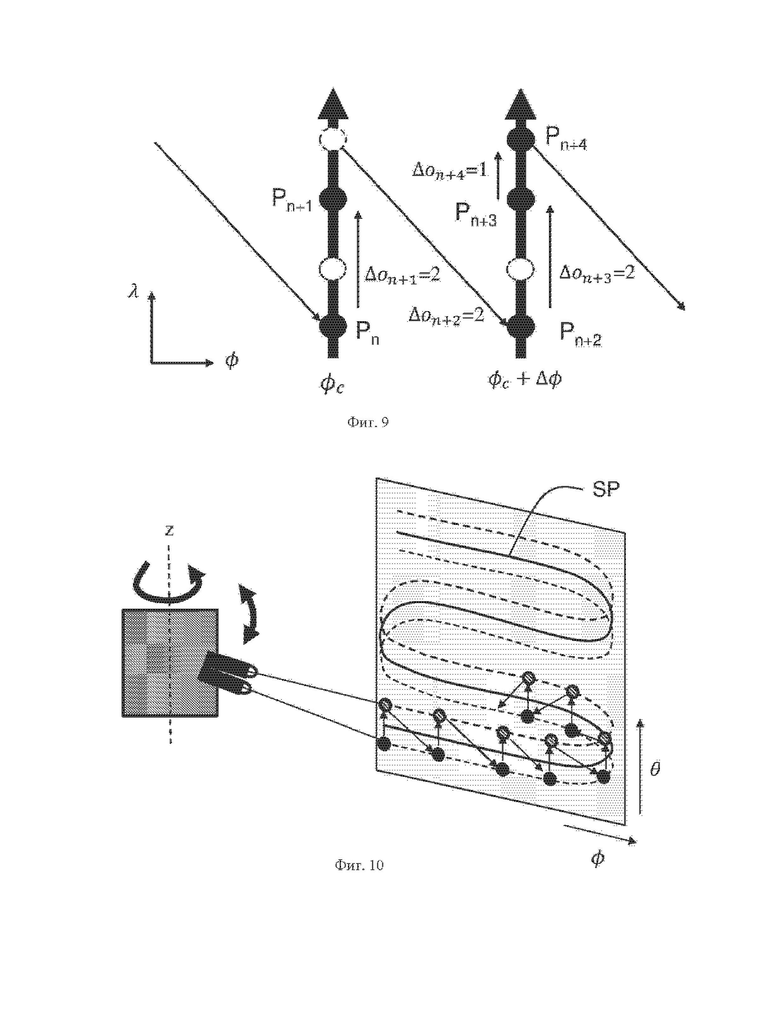
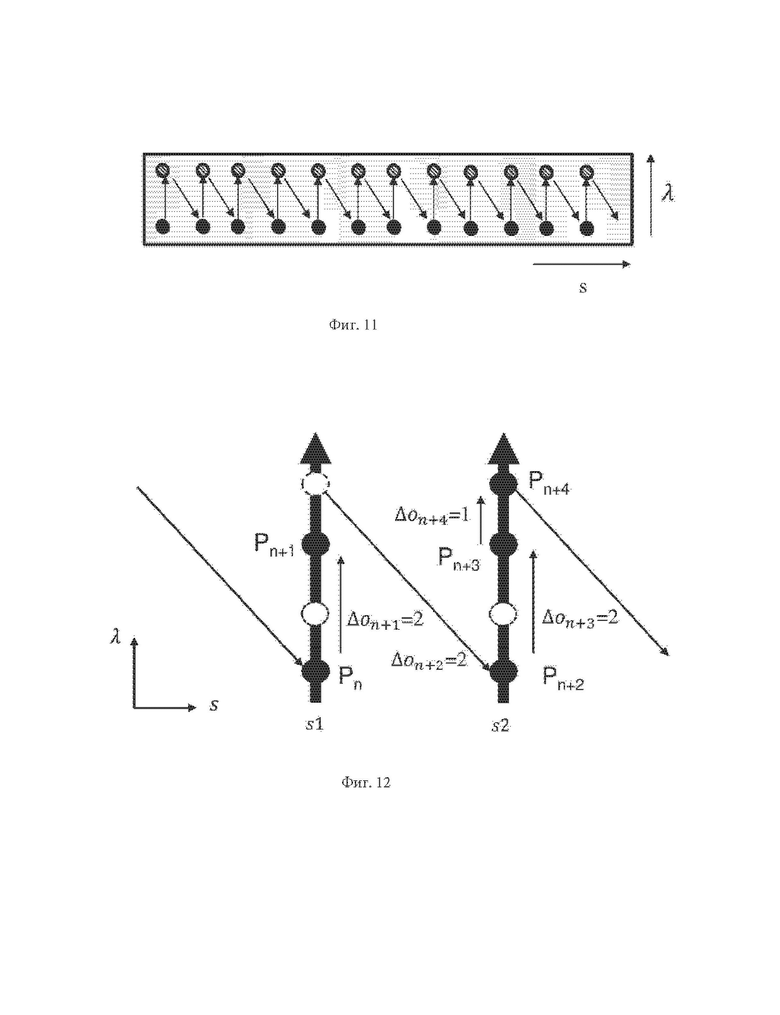
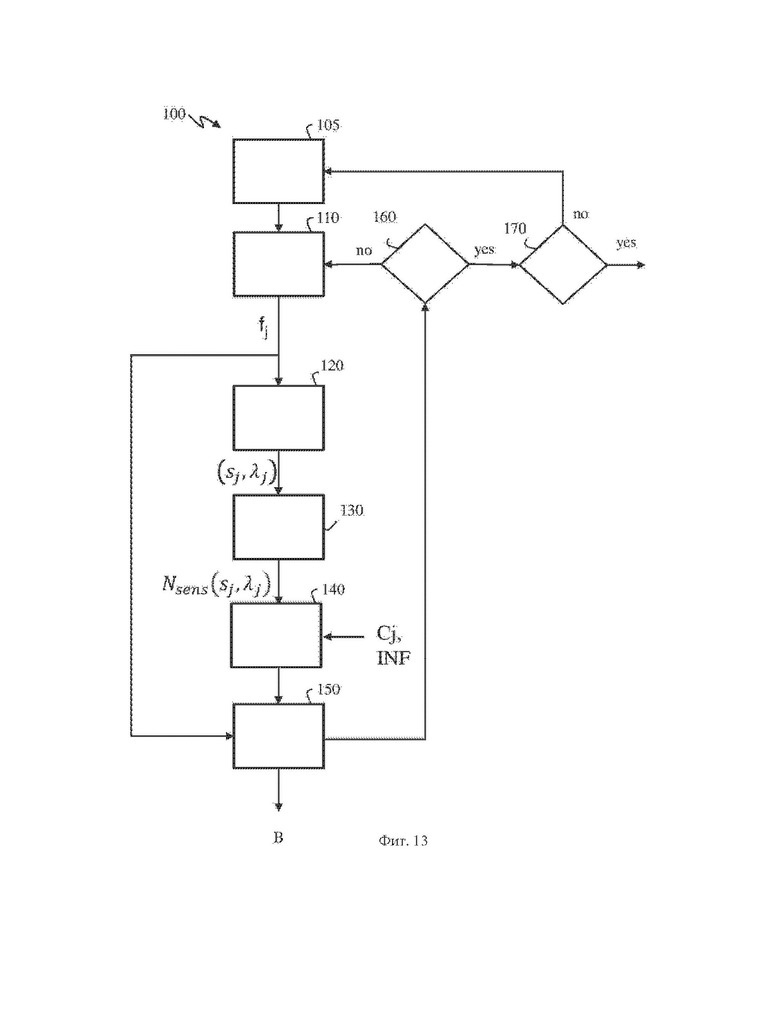
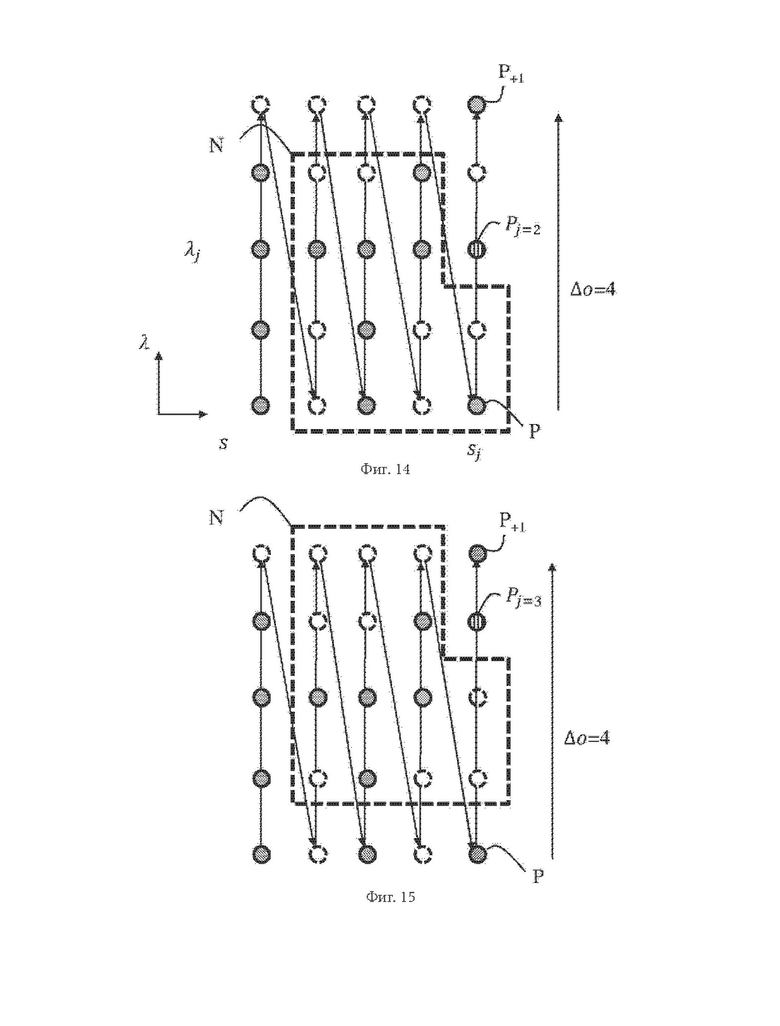
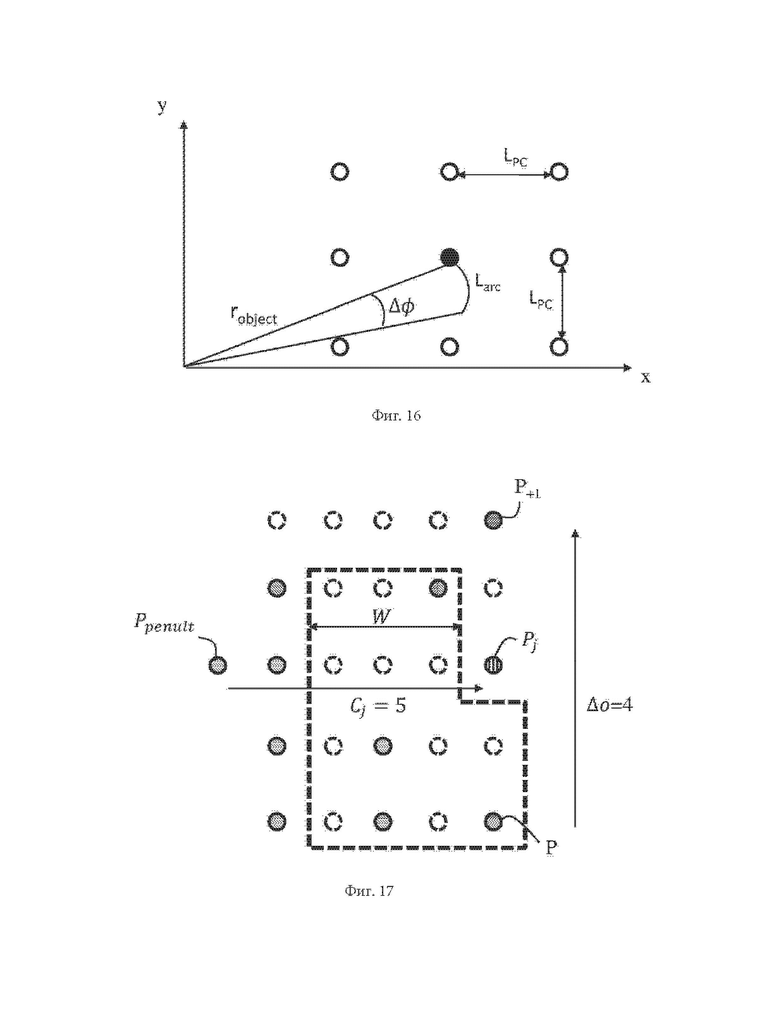
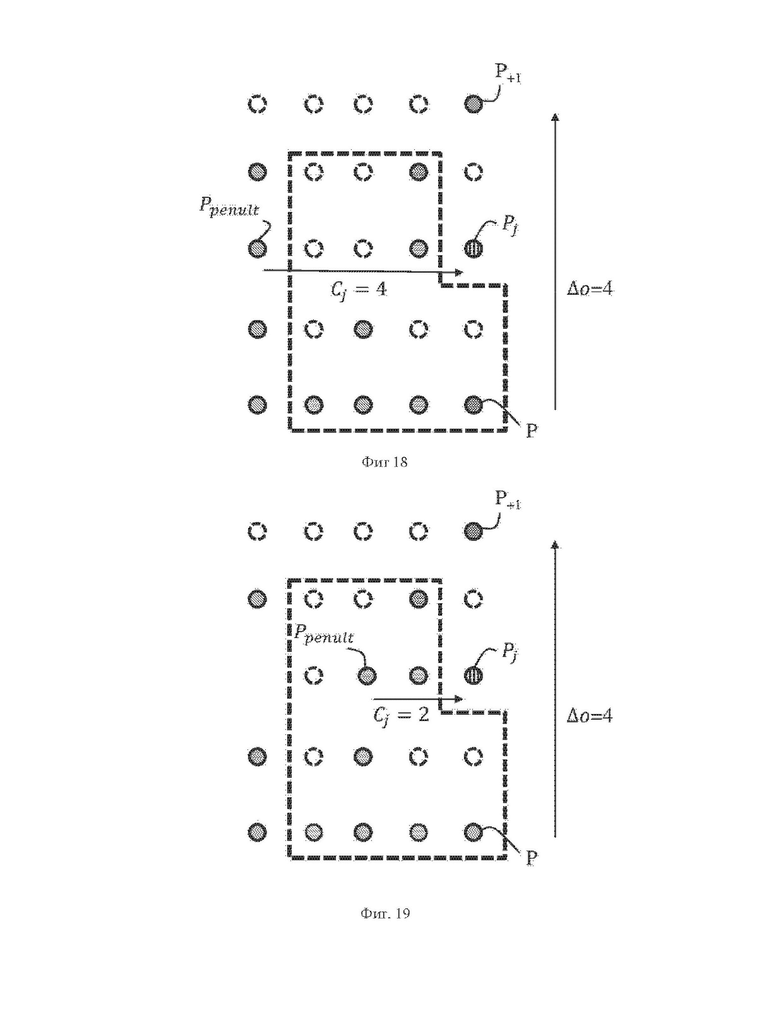
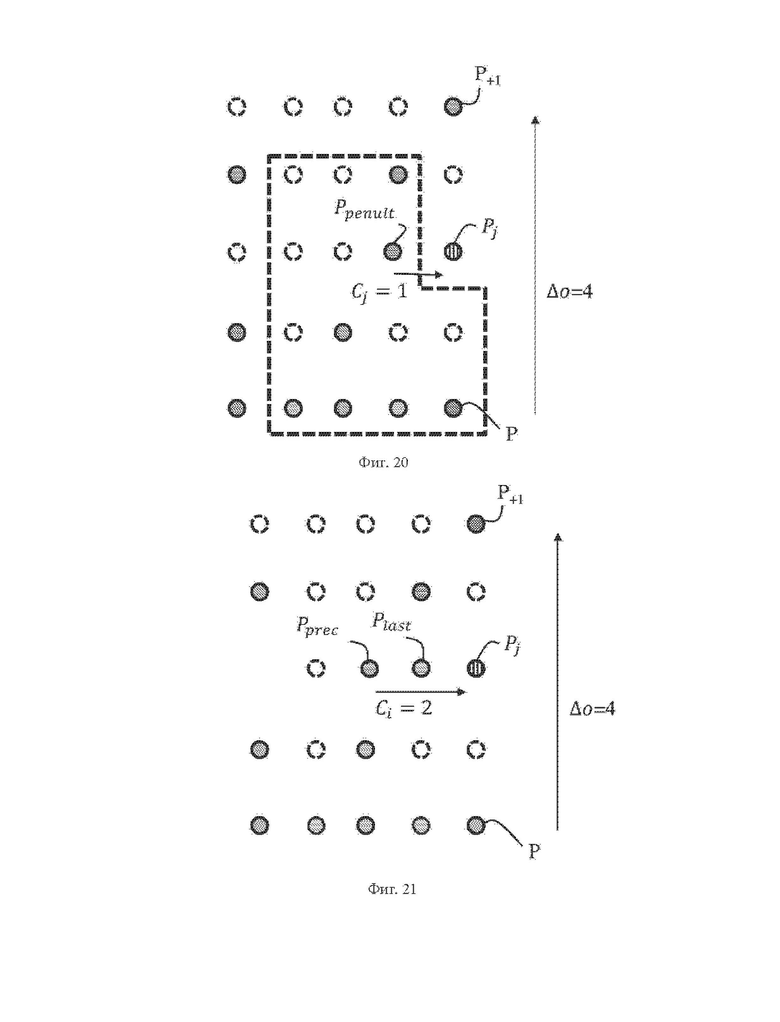
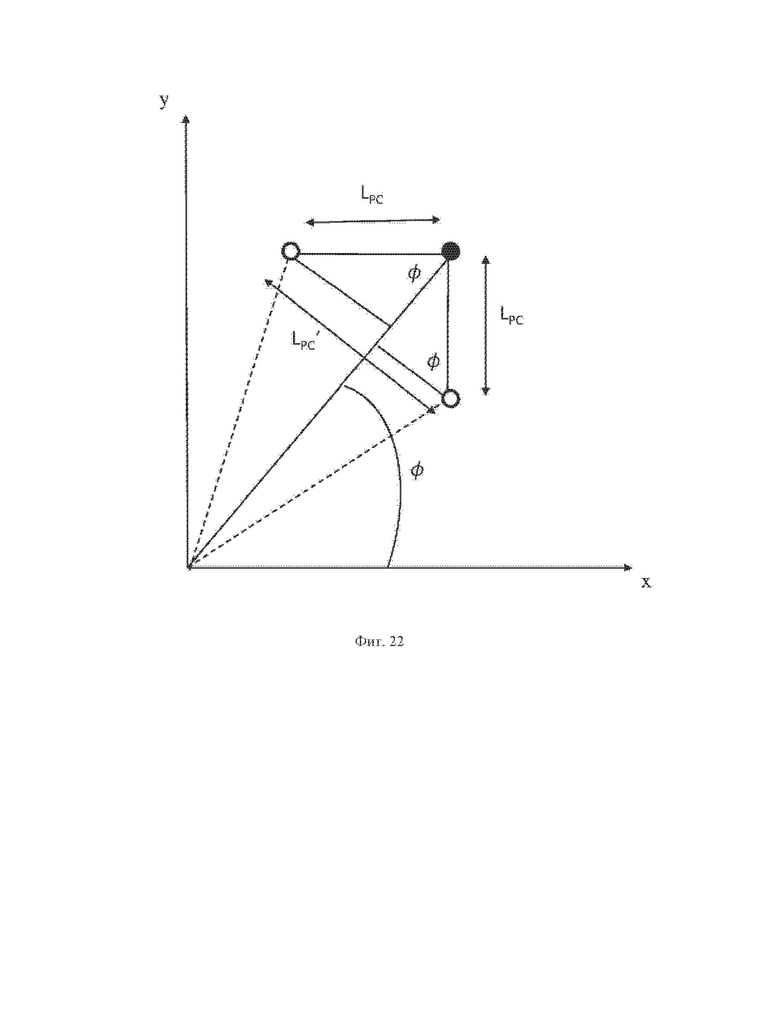
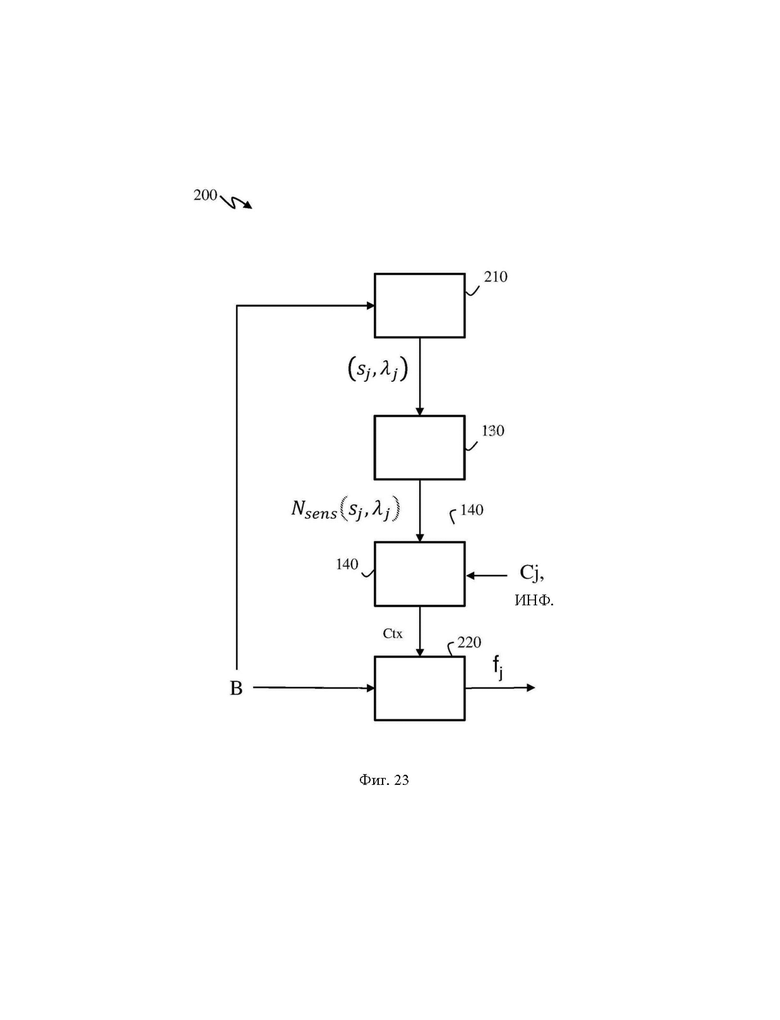
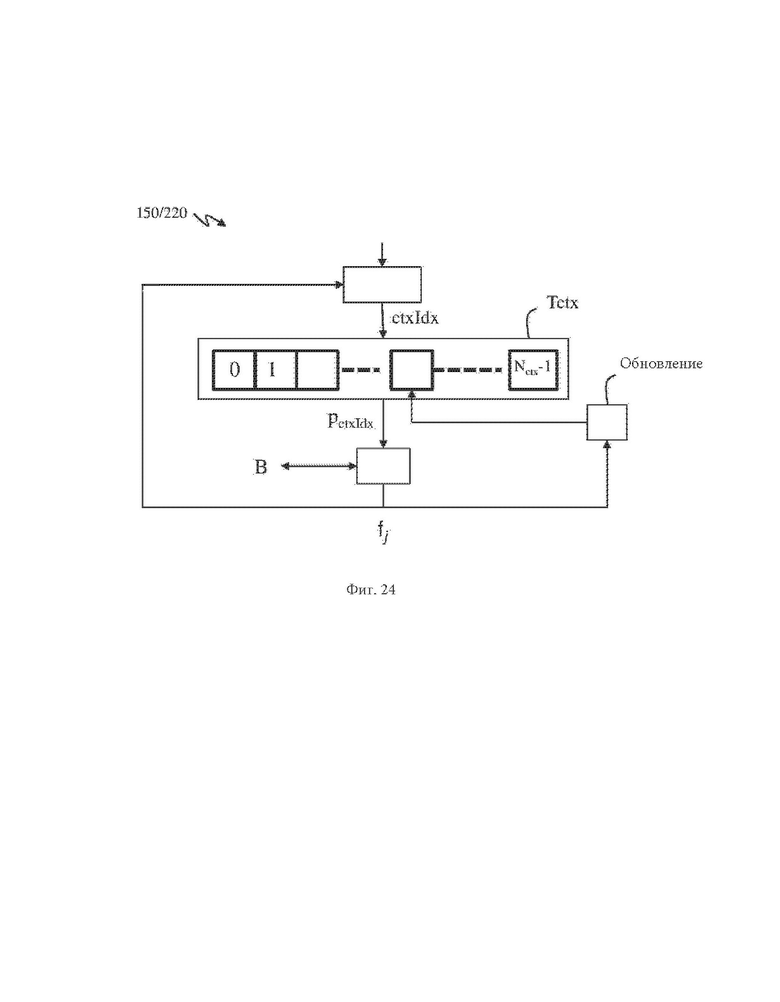
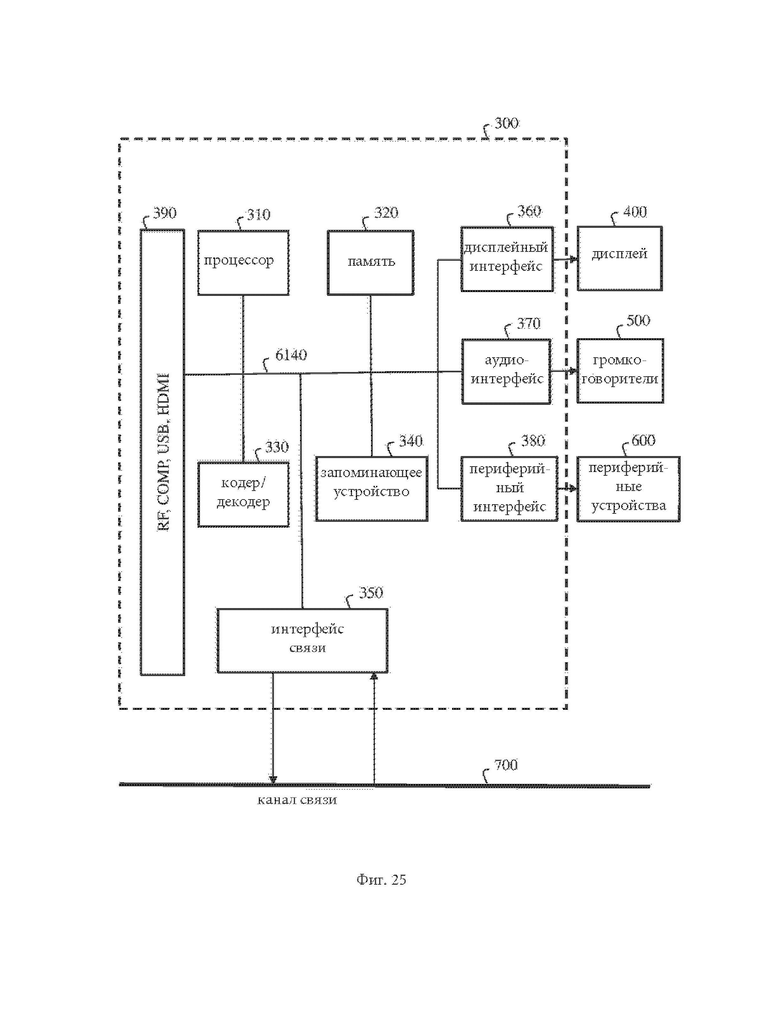
Изобретение относится к области вычислительной техники. Технический результат направлен на повышение точности определения местоположения. Способ кодирования/декодирования геометрических данных облака точек, представленных упорядоченными грубыми точками, которые занимают часть дискретных местоположений из множества дискретных местоположений двумерного пространства, включает получение по меньшей мере одних двоичных данных (fj), являющихся представлением разности порядковых индексов, представляющих разность между порядковыми индексами двух последовательных занятых грубых точек, и кодирование каждых из упомянутых по меньшей мере одних двоичных данных (fj) при помощи следующего: получение (120) координат (sj,λj) текущей грубой точки (Pj) в двумерном пространстве; получение (130) количества (Nsens(sj,λj)) измерений на основе текущей грубой точки (Pj), при этом упомянутое количество (Nsens(sj,λj)) измерений является представлением среднего количества последовательных измерений, необходимых датчику (λj), соответствующему текущей грубой точке (Pj), для обнаружения другой грубой точки; и энтропийное кодирование (150), в битовый поток, упомянутых двоичных данных (fj) на основе количества (Nsens(sj,λj)) измерений. 5 н. и 7 з.п. ф-лы, 25 ил.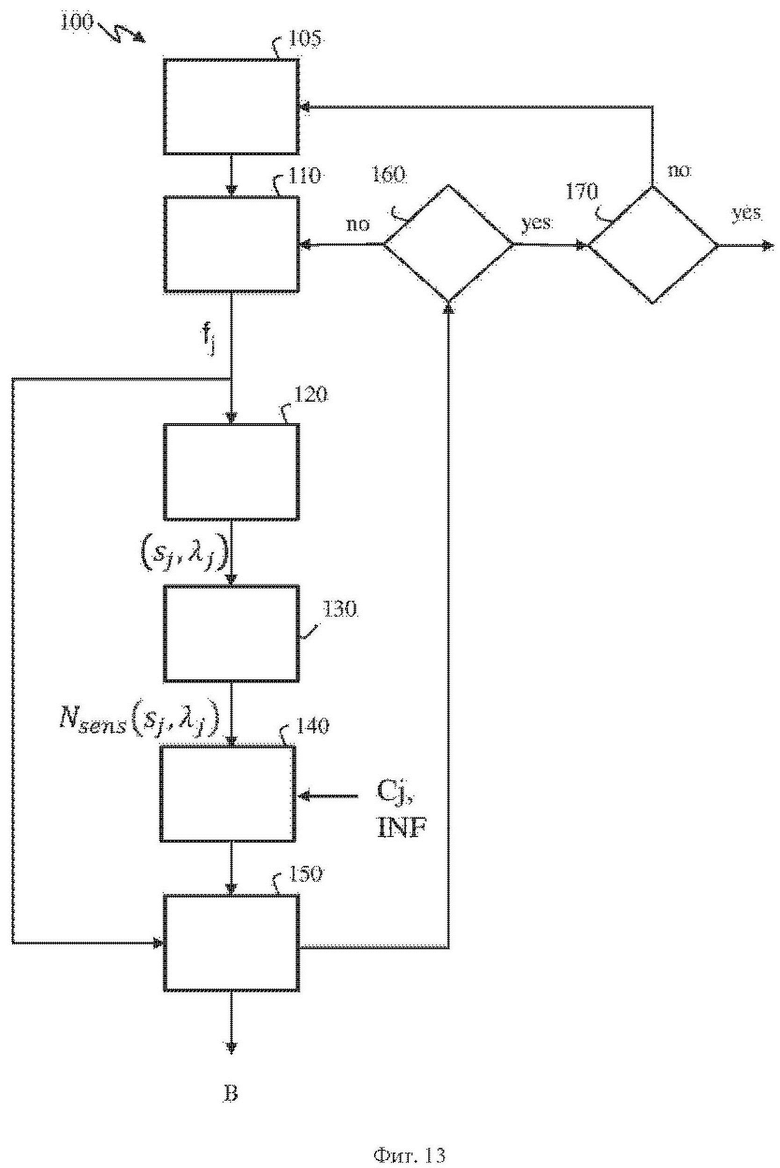
1. Способ кодирования, в битовый поток, геометрических данных облака точек, представленных упорядоченными грубыми точками, занимающими часть дискретных местоположений из множества дискретных местоположений двумерного пространства, при этом способ включает получение (105) по меньшей мере одних двоичных данных (fj), являющихся представлением разности порядковых индексов, представляющих разность между порядковыми индексами двух последовательных занятых грубых точек, и кодирование каждых из упомянутых по меньшей мере одних двоичных данных (fj) при помощи следующего:
- получение (120) координат (sj,λj) текущей грубой точки (Pj) в двумерном пространстве;
- получение (130) количества (Nsens(sj,λj)) измерений на основе текущей грубой точки (Pj), при этом упомянутое количество (Nsens(sj,Aj)) измерений является представлением среднего количества последовательных измерений, необходимых датчику (λj), соответствующему текущей грубой точке (Pj), для обнаружения другой грубой точки; и
- энтропийное кодирование (150), в битовый поток, упомянутых двоичных данных (fj) на основе количества (Nsens(sj,λj)) измерений.
2. Способ декодирования, из битового потока, геометрических данных облака точек, представленных упорядоченными грубыми точками, занимающими часть дискретных местоположений из множества дискретных местоположений двумерного пространства, при этом способ включает получение по меньшей мере одних двоичных данных (fj), являющихся представлением разности порядковых индексов, представляющих разность между порядковыми индексами двух последовательных занятых грубых точек, при помощи следующего:
- получение (210) координат текущей грубой точки (Pj) в двумерном пространстве;
- получение (130) количества (Nsens(sj,λj)) измерений на основе текущей грубой точки (Pj), при этом упомянутое количество (Nsens(sj,λj)) измерений является представлением среднего количества последовательных измерений, необходимых датчику (λj), соответствующему текущей грубой точке (Pj), для обнаружения другой грубой точки; и
- энтропийное декодирование (220), в битовый поток, упомянутых двоичных данных (fj) на основе количества (Nsens(sj,λj)) измерений.
3. Способ по п. 1 или 2, в котором энтропийное кодирование (150) или декодирование (220) двоичных данных (fj) основано на количестве (Nsens(sj,λj)) измерений, если количество Nsens(sj,λj) измерений превосходит пороговое значение активации (thactivation), и основано по меньшей мере на разности (Cj) координат между одной первой координатой, относящейся к текущей грубой точке (Pj), и одной первой координатой предыдущей кодированной или декодированной грубой точки (Рргес) с тем же индексом датчика, что и индекс датчика (λj), соответствующий текущей грубой точке, если количество Nsens(sj,λj) измерений не превосходит пороговое значение активации(thactivation).
4. Способ по п. 1 или 2, в котором энтропийное кодирование (150) или декодирование (220) двоичных данных (fj) основано на значении (Δj), которое зависит от индекса (sj) отсчета, индекса (slast) другого отсчета, соответствующего моменту времени измерения, в котором точка облака точек, представленная последней занятой грубой точкой (Plast), была обнаружена датчиком, соответствующим упомянутому индексу датчика (Δj), и количества (Nsens(sj,λj)) измерений.
5. Способ по п. 4, в котором упомянутое значение (Δj) ограничено двумя пороговыми значениями.
6. Способ по любому из пп. 1-5, в котором количество (Nsens(sj,λj)) измерений зависит от радиуса (robject) и/или азимутального угла (φlast), соответствующих последней занятой грубой точке (Plast), являющейся представлением точки в облаке точек, обнаруженной датчиком (λj), соответствующим текущей грубой точке (Pj).
7. Способ по любому из пп. 1-6, в котором количество (Nsens(sj,λj)) измерений зависит от характеристического расстояния (LPC) облака точек, определяющего среднее расстояние между точками облака точек, и от длины дуги (Larc), заданной на двумерной плоскости декартовых координат между двумя последовательными измерениями датчиком, соответствующим текущей грубой точке.
8. Способ по п. 7, в котором длина (Larc) дуги зависит от радиуса, соответствующего последней занятой грубой точке (Plast), являющейся представлением точки в облаке точек, обнаруженной датчиком, соответствующим текущей грубой точке, и от азимутального смещения между двумя последовательными измерениями.
9. Способ по п. 7 или 8, в котором характеристическое расстояние облака точек (LPC) кодируют в битовый поток.
10. Устройство кодирования, в битовый поток, геометрических данных облака точек, представленных упорядоченными грубыми точками, занимающими часть дискретных местоположений из множества дискретных местоположений двумерного пространства, при этом устройство включает по меньшей мере один процессор, сконфигурированный для выполнения способа по любому из пп. 1 или 3-9.
11. Устройство декодирования, из битового потока, геометрических данных облака точек, представленных упорядоченными грубыми точками, занимающими часть дискретных местоположений из множества дискретных местоположений двумерного пространства, при этом устройство включает по меньшей мере один процессор, сконфигурированный для выполнения способа по любому из пп. 2-9.
12. Машиночитаемый носитель данных, содержащий инструкции программного кода для выполнения способа по любому из пп. 1-9.
| WO 2021025251, 11.02.2021 | |||
| Способ восстановления спиралей из вольфрамовой проволоки для электрических ламп накаливания, наполненных газом | 1924 |
|
SU2020A1 |
| Способ регенерирования сульфо-кислот, употребленных при гидролизе жиров | 1924 |
|
SU2021A1 |
| СИСТЕМА И СПОСОБ ДЛЯ ДОПОЛНЕННОЙ И ВИРТУАЛЬНОЙ РЕАЛЬНОСТИ | 2012 |
|
RU2621633C2 |
| СПОСОБ И СИСТЕМА ДЛЯ АВТОМАТИЗИРОВАННОГО ПРЕДОХРАНЕНИЯ ОТ СТОЛКНОВЕНИЙ И СОХРАНЕНИЯ КОМПОЗИЦИИ КАМЕРЫ | 2018 |
|
RU2745828C1 |
| МЕХАНИЗМЫ ОБЕСПЕЧЕНИЯ БЕЗОПАСНОСТИ НА ОСНОВЕ КАМЕРЫ ДЛЯ ПОЛЬЗОВАТЕЛЕЙ УСТАНОВЛЕННЫХ НА ГОЛОВЕ ДИСПЛЕЕВ | 2014 |
|
RU2661857C2 |

