Изобретение относится к преимплантационному генетическому тестированию моногенных заболеваний. В настоящее время в мире насчитывается более 350 миллионов людей, страдающих редким заболеванием (по данным RARE Project). Общее количество таких заболеваний по подсчетам European Organization for Rare Diseases (EURORDIS) варьируется от 5 до 7 тысяч. При этом около 80% редких заболеваний имеют генетическую причину. Известная генетическая основа заболевания позволяет с высокой точностью предсказать не только здоровье уже родившегося ребенка, но и оценить риск рождения такого ребенка при анализе генотипов родителей, а также провести генетическую диагностику на самых ранних этапах. Преимплантационное генетическое тестирование (ПГТ) моногенного заболевания становится мощным инструментом для профилактики таких заболеваний.
Настоящее изобретение относится к способу преимплантационного генетического тестирования синдрома Смита-Лемли-Опица. синдром Смита-Лемли-Опица- это наследственное заболевание, характеризующееся аутосомно-рецессивным типом наследования и широко вариабельной экспрессивностью, синдром Смита-Лемли-Опица встречается с частотой 1 на 20000-30000 новорожденных. Это заболевание приводит к нарушению холестеринового обмена, выраженной задержке физического и психомоторного развития, множеству аномалий развития - пороки сердца, аномалии развития головного мозга, микроцефалия, волчья пасть, гипоспадия, полидактилия, синдактилия 2-3 пальцев ног. При аутосомно-рецессивном типе наследования заболевания вероятность рождения ребенка с этим заболеванием в семье составляет 25%.
К заболеванию синдром Смита-Лемли-Опица могут приводить патогенные генетические варианты в гене DHCR7, располагающемся на хромосоме 11. [DeBarber, A. et al. (2011). Smith-Lemli-Opitz syndrome. Expert Reviews in Molecular Medicine, 13, E24.] Этот ген кодирует белок 7-дегидрохолестерин-редуктаза - фермент, который превращает предшественник холестерина - 7-дегидрохолестерин - в холестерин.
ПГТ синдрома Смита-Лемли-Опица проводится для семей, имеющих подтвержденную молекулярно-генетическую природу заболевания. Важно отметить, что обоснование патогенности и каузативности генетических вариантов происходит до проведения ПГТ моногенного заболевания и не входит ни в цели и задачи ПГТ моногенного заболевания, ни в комплекс мероприятий по проведению ПГТ моногенного заболевания. Оценку патогенности проводят по международному стандарту - по критериям, описанным в 2015 году Американским Колледжем Медицинской генетики и Геномики (American College of Medical Genetics and Genomics-Association for Molecular Pathology (ACMG-AMP)) в ходе поиска молекулярно-генетической причины заболевания. ПГТ рекомендуется семьям с высоким риском рождения ребенка с тяжелым (неизлечимым) наследственным заболеванием с установленными патогенными вариантами, обуславливающими этот риск. ПГТ позволяет выбрать из всех эмбрионов, полученных при ЭКО (экстракорпоральном оплодотворении), эмбрионы без патогенных вариантов в компаунд-гетерозиготе и, следовательно, без риска развития заболевания.
Основной проблемой при генетической диагностике эмбрионов является малое исходное количество биоматериала, так как биоптат содержит от одной до трех клеток. В этом случае для повышения эффективности и точности анализа важно как полностью исключить возможность контаминации, так и нивелировать возможный эффект неравномерной и/или неполной амплификации, а также деградации биоматериала. Это требует разработки тест-системы с особыми характеристиками. При этом тест-система разрабатывается с учетом возможности использовать биоматериал разного типа - тотальную дезоксирибонуклеиновую кислоту (ДНК), выделенную из разных тканей, продукт полногеномной амплификации (Whole Genome Amplification, WGA), а также единичные клетки. Сочетание универсальности по отношению к биоматериалу с поэтапной амплификацией целевых фрагментов позволяет проводить анализ нескольких патогенных вариантов для одного образца, в том числе на единичных клетках, а также выявить ситуацию неполной амплификации, контаминации или деградации образца. Еще одной особенностью ПГТ является отсутствие информации о биологических особенностях эмбриона: в отличие от взрослого человека, у эмбриона могут быть любые хромосомные аномалии, которые усложняют задачу оценки статуса эмбриона по конкретному генетическому варианту. Поэтому тест-система для ПГТ моногенного заболевания должна давать возможность выявить такие случаи и оценить их влияние на достоверность результата диагностики.
Наиболее близким техническим решением является проведение ПГТ синдрома Смита-Лемли-Опица предложенное Natesan, S. А. и коллегами [Natesan, S. A. et al, Reprod Biomed Online, 2014; 29(5),600-605] для детекции патогенного варианта в гене DHCR7 с помощью ПЦРв 1 раунд на единичных клетках, с помощью прямой детекции мутации и анализа наследования аллелей 3х полиморфных маркеров, сцепленных с геном. Важным преимуществом предлагаемого нами подхода является использование большего количества полиморфных маркеров(14) находящихся на расстоянии менее 3 Мб от гена, что снижает веротяность недостоверного результата из-за выпадения аллеля или рекомбинации, а также использование гнездовой и полугнездовой ПЦР для большей спецефичности и продуктивности реакций.
Представленный нами метод ПГТ синдрома Смита-Лемли-Опица решает задачу разработки более точного способа преимплантационного генетического тестирования этого моногенного заболевания без использования дорогостоящих приборов и реагентов, который можно было бы применять на биоматериале различного типа: ДНК, выделенную из разных тканей, продукт полногеномной амплификации (WGA), единичные клетки.
Техническим результатом стало создание тест-системы для диагностики патогенного варианта (номер нуклеотида в референсной последовательности геномной ДНК обозначен префиксом NC, номер нуклеотида в референсной последовательности кодирующего транскрипта обозначен префиксом NM): NC_000011.9:g.71152447C>T (NM_001360.2:c.452G>A, p.Trp151Ter) в гене DHCR7 с двойной системой детекции - прямой и косвенной. Данный вариант был описан в научной литературе как патогенный [Fitzky BU. et al. Mutations in the Delta7-sterol reductase gene in patients with the Smith-Lemli-Opitz syndrome. Proc Natl Acad Sci USA. 1998 Jul 7;95(14):8181-6] Двойная система детекции необходима при работе с малым количеством биоматериала, так как нестабильная амплификация может привести к потере информации или сниженной точности анализа. Прямая диагностика подразумевает анализ непосредственно наличия-отсутствия патогенного варианта. В данном случае для генетического варианта NC_000011.9:g.71152447C>T (NM_001360.2:c.452G>A, p.Trp151Ter) типа однонуклеотидный полиморфизм (ОНП, англ. Single nucleotide polymorphism SNP) были подобраны эндонуклеазы рестрикции, которые позволяют произвести детекцию патогенного варианта методом ПЦР-ПДРФ (полиморфизм длин рестриктных фрагментов), основанным на разнице последовательности в сайте рестрикции у различных аллелей. Косвенная диагностика заключается в анализе наследования молекулярно-генетических маркеров, сцепленных с мутацией, т.е. наследуемых вместе с ней. Для этого на расстоянии не более 3 мБ (что соответствует 3% кроссинговера в среднем) от гена DHCR7 в каждую сторону были выбраны полиморфные локусы, называемые STR (short tandem repeat - короткий тандемный повтор), с гетерозиготностью не менее 0,70 для обеспечения максимальной информативности косвенной диагностики. STR представляют собой повторы 2х и более нуклеотидов расположенные друг за другом (например пара аденин-цитозин (АЦ), повторяющаяся несколько раз подряд: АЦАЦАЦАЦ) и в большом количестве присутствуют в геноме человека. Количество повторов в каждом из них может варьироваться от индивидуума к индивидууму, а также может быть разным у одного и того же человека на 2х гомологичных хромосомах. Гетерозиготность выше 0,70 означает, что высока вероятность того, что у одного и того же человека количество повторов нуклеотидов в данном STR на одной хромосоме будет отличаться от количества повторов в этом же STR на гомологичной хромосоме, другими словами, аллели данного маркера у этого человека будут отличаться между собой по длине. При амплификации фрагмента, содержащего такой маркер, будут получены ампликоны двух разных длин. Проанализировав количество повторов в нескольких маркерах, окружающих патогенный вариант, и изучив то, как они наследуются в тестируемой семье, можно установить сцепление между аллелями маркеров и патогенным вариантом. Диагностическая ценность исследования количества повторов в данных маркерах у эмбрионов состоит в том, что по тому, какой аллель каждого из маркеров был унаследован эмбрионом, можно судить о том, унаследовал ли эмбрион ген DHCR7, несущий патогенный вариант, или же он унаследовал ген DHCR7 с другой, гомологичной хромосомы, не содержащий патогенный вариант. Для каждого из этих локусов были подобраны праймеры для амплификации по типу гнездовой или полугнездовой ПЦР в 2 раунда, позволяющей повысить точность и эффективность амплификации. В тест-систему были включены 14 STR локусов для гена DHCR7: D11S6816, D11S7047, D11S4139, D11S7053, D11S7064, D11S7067, D11S7079, D11S7175, D11S7200, D11S1314, D11S7267, D11S4184, D11S7304, D11S7315. Праймеры для амплификации фрагментов ДНК, содержащих STR локусы находятся на 11 хромосоме в районе координат 68165431-73154042 (в соответствии с hg19). Их последовательности перечислены в формуле изобретения в перечне SEQ ID NO 1-46. Важно отметить, что при подборе праймеров соблюдали ряд особенных требований: длина продукта с внешними праймерами для первого раунда ПЦР не должна превышать 500 п. н. (для наработки с фрагментов, получаемых при полногеномной амплификации), длина продукта с внутренних праймеров для второго раунда ПЦР от 120 до 350 п.н., высокая специфичность внешних праймеров, температура отжига не отличается более, чем на 1°С.
Подготовительный этап ПГТ
На подготовительном этапе проводится отработка тест-системы: подбор условий амплификации, оптимальных для работы праймеров, анализ эффективности и специфичности ПЦР-амплификации в обоих раундах, оценки универсальности тест-системы для биообразцов различного типа (ДНК, продукт WGA, единичные клетки). При отработке тест-системы были приготовлены стоковые разведения праймеров с концентрацией 100 mМ, и рабочие разведения комбинаций праймеров (комбинация пар праймеров для 1 и 2 раунда ПЦР) с концентрацией 10 mМ каждого праймера в растворе. Так как в рамках диагностики клинического материала могут быть использованы различные типы матриц, при отработке тест-системы были использованы две биопсии единичных клеток, находящихся в специальном лизирующем буфере (1xPCR Buffer, 0,1% Tween-20, 0,1% Triton Х-100, 1 мкг Proteinase К), два образца продуктов полногеномной амплификации биопсиий эмбриона (WGA), а также тотальной ДНК членов семьи, выделенной из крови, для составления родословной и выявления сцепления патогенного варианта с аллелями полиморфных маркеров.
В рамках гнездовой и полугнездовой ПЦР амплификация проводится в два этапа. На первом этапе проводится мультиплексная ПЦР со всеми внешними праймерами для всех локусов, входящих в тест-систему, для обогащения образца всеми целевыми фрагментами. На втором этапе проводится индивидуальная амплификация каждого фрагмента с внутренними праймерами.
Полугнездовая ПЦР
Для первого этапа были подобраны внешние высокоспецифичные праймеры для амплификации фрагментов от 300 до 500 п. н. Для второго этапа были подобраны праймеры для амплификации фрагментов длиной не более 350 пар оснований, а также были введены метки для детекции методом фрагментного анализа. Последовательности праймеров для амплификации фрагментов ДНК, содержащих STR локусы перечислены в формуле изобретения в перечне SEQ ID NO 1-46. ПЦР-смесь для первого раунда амплификации содержала 1хПЦР буфер с Mg2+ (Евроген, Россия), 0.1 mМ каждого деоксинуклеотида, 0.15 μМ каждого праймера, 2,5 U/μl ДНК полимеразы HsTaq (Евроген, Россия), 6% диметилсульфоксида (DMSO) и 1 мкл тотальной ДНК или 2,5 мкл WGA или 5 мкл лизирующего буфера с образцом в качестве матрицы. Первый этап амплификации проводился по следующему протоколу: этап денатурации 94°С в течение 2 минут, 30 циклов с понижением температуры отжига праймеров с 62 до 45°С в каждом, этап достройки всех матриц 72°С 10 минут. Далее продукты 1-ого этапа были разнесены в индивидуальные пробирки с одной парой праймеров на определенный локус.
В состав ПЦР смеси для второго этапа входили 1хПЦР буфер с Mg2+ (Евроген, Россия), 0.5xRediLoad™ загрузочный буфер (Thermo Fisher Scientific, USA), 0.2 mM каждого деоксинуклеотида, 0.2 μМ каждого праймера,1U/μl ДНК полимеразы HsTaq (Евроген, Россия), 6% диметилсульфоксида (DMSO) и 1 μl ПЦР-продукта первого этапа амплификации в качестве матрицы. Второй этап амплификации проводился по следующему протоколу: этап денатурации 95°С в течение 2 минут, 35 циклов: денатурация 95°С 30 секунд, отжиг праймеров - 57°С 30 секунд, синтез матрицы - 72°С 1 минута, этап достройки всех матриц 72°С 5 минут. Оценку эффективности и специфичности амплификации проводили с помощью электрофореза в 2% агарозном геле. Результат электрофореза в агарозном геле позволяет определить необходимую степень разведения продуктов амплификации для нанесения на фрагментный анализ (продукты амплификации ДНК членов семьи).
Фрагментный анализ продуктов амплификации проводили с помощью капиллярного электрофореза на приборе 3130x1 Genetic Analyzer (Applied Biosystems, USA). По результатам фрагментного анализа составляется родословная и отмечаются информативные полиморфные STR-локусы для каждой семьи, которые в дальнейшем будут использованы в клинической диагностике. Локусы делятся на неинформативные (носитель патогенного варианта гомозиготен по этому локусу), полуинформативные (на некоторых и родительских хромосом аллели по этому маркеру совпадают), информативные (на всех хромосомах родителей аллели этого маркера разные, что дает возможность отличить каждую из них при анализе генотипа эмбриона).
Полимеразная цепная реакция - полиморфизм длин рестрикционных фрагментов (ПЦР-ПДРФ)
Полиморфизм длин рестрикционных фрагментов (Restriction fragment length polymorphism, RFLP) - это способ исследования геномной ДНК, путем специфичного расщипления ДНК с помощью эндонуклеаз рестрикции и дальнейшего анализа размеров образующихся фрагментов (рестриктов) путем гель-электрофореза. При использовании данного метода наблюдаются фрагменты различной длины в зависимости от различий в последовательности нуклеотидов в сайте рестрикции, что позволяет детектировать однонуклеотидные варианты, если они располагаются в сайте рестрикции. Более точную детекцию патогенного варианта может обеспечить секвенирование по методу Сэнгера, однако в условиях ПГТ метод ПЦР-ПДРФ оказывается более эффективным из-за сниженной вероятность выпадения аллеля (allele drop out, ADO) и, как следствие, ошибочного результата по оценке статуса эмбриона по патогенному варианту.
Для детекции патогенного варианта NC_000011.9:g.71152447С>Т (NM_001360.2:c.452G>A, p.Trp151Ter) была разработана тест-система на основе ПЦР-ПДРФ. Стадия амплификации подробно описана в предыдущем разделе. Были использованы следующие праймеры:
Внешние: 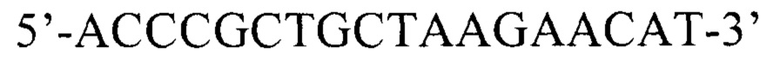 (прямой),
(прямой), 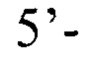
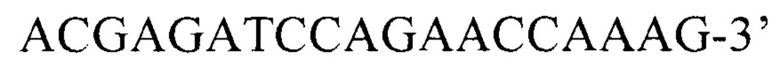 (обратный),
(обратный),
Внутренние для детекции аллеля гена DHCR7 дикого типа: 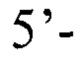
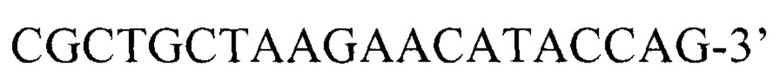 (прямой),
(прямой), 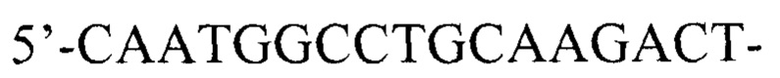
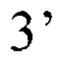 (обратный)
(обратный)
Внутренние для детекции мутантного аллеля гена DHCR7: 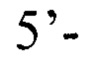
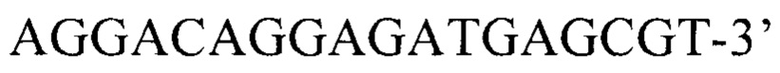 (прямой),
(прямой), 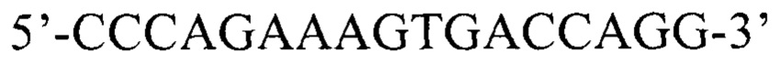 (обратный). Далее продукты амплификации с внутренних праймеров для детекции патогенного варианта использовали в реакции рестрикции. Эндонуклеаза BseNI разрезает только аллель дикого типа, эндонуклеаза FspBI разрезает только мутантный аллель варианта NC_000011.9:g.71152447C>T (NM__001360.2:c.452G>A, p.Trp151Ter). Детекция проводилась с помощью электрофореза в 12% полиакриламидном геле.
(обратный). Далее продукты амплификации с внутренних праймеров для детекции патогенного варианта использовали в реакции рестрикции. Эндонуклеаза BseNI разрезает только аллель дикого типа, эндонуклеаза FspBI разрезает только мутантный аллель варианта NC_000011.9:g.71152447C>T (NM__001360.2:c.452G>A, p.Trp151Ter). Детекция проводилась с помощью электрофореза в 12% полиакриламидном геле.
Пример 1
Пациенты А
В ЦГРМ Генетико обратилась семья А, в анамнезе которой было прерывание беременности плодом с заболеванием синдром Смита-Лемли-Опица с гомозиготным носительством патогенного варианта NC_000011.9:g.71152447C>T (NM_001360.2:c.452G>A, p.Trp151Ter) в гене DHCR7. Паре было рекомендовано проведение ПГТ заболевания синдром Смита-Лемли-Опица в рамках ЭКО для отбора эмбрионов, не унаследовавших заболевание.
Гаплотипирование семьи
На первом этапе был получен биоматериал (периферическая кровь) членов семьи для детекции патогенного варианта и выявления групп сцепления аллелей полиморфных маркеров. Было проанализировано 14 STR локусов. Фрагменты ДНК, содержащие STR локусы, амплифицировались с помощью праймеров, представленных в перечне SEQ ID NO 1-46 в формуле изобретения. Из них 11 оказались информативными по матери и/или отцу. Таким образом, образцы эмбрионов тестировались только на информативные маркеры.
Аллели, совпадающие у плода с заболеванием и родителя - носителя патогенного варианта NC_000011.9:g.711524470Т (NM_001360.2:c.452G>A, p.Trp151Ter) в гене DHCR7 признавались сцепленными друг с другом и с патогенным вариантом. Несовпадающие у родителя и ребенка с заболеванием аллели признавались сцепленными с друг другом и с нормальным аллелем гена DHCR7. Полученные результаты по информативным маркерам представлены в таблице 1. Аллели, указанные на одной строке, располагаются на одной хромосоме, то есть, представляют группу сцепления. Таким образом для каждого члена семьи представлено по 2 группы сцепления, соответствующие каждой из двух одиннадцатых хромосом человека. Вариант NC_000011.9:g.711524470Т (NM_001360.2:c.452G>A, p.Trp151Ter) в гене DHCR7 обозначен в таблице как DHCR7 c.452G>A. N в таблице обозначает аллель дикого типа (нормальный аллель), mut - мутантный аллель. Цифрами записаны длины ампликонов в парах нуклеотидов; их длины, зависят от количества повторов в маркере STR.
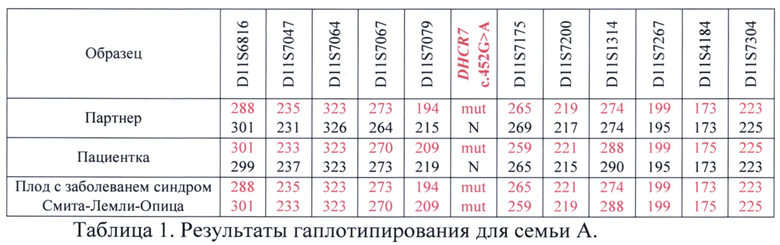
В результате гаплотипирования был сделан вывод, что у партнера пациентки с патогенным вариантом были сцеплены следующие аллели STR-маркеров: D11S6816 - 288, D11S7047 - 235, D11S7064 - 323, D11S7067 - 273, D11S7079- 194, D11S7175 - 265, D11S7200 - 219, D11S1314-274, D11S7267 - 199, D11S4184 - 173, D11S7304 - 223. У пациентки с патогенным вариантом были сцеплены следующие аллели STR-маркеров: D11S6816 - 301, D11S7047 - 233, D11S7064 - 323, D11S7067 - 270, D11S7079 - 209, D11S7175 -259, D11S7200 - 221, D11S1314 - 288, D11S7267 - 199, D11S4184 - 175, D11S7304-225.
Преимплантационное генетическое тестирование
В цикле ЭКО было получено 8 эмбрионов, проведена биопсия на 5 день развития (в клинике ЭКО), биоптат в буфере для WGA (lxPBS (Invitrogen, США), 1% поливинилпирролидона (PVP) (Fertipro, Бельгия)) направлен в лабораторию «Генетико». Для контроля контаминации на разных этапах работы с образцом в лаборатории разработана система контролей: контроль контаминации буфера для биопсии, контроль контаминации при транспортировке (одна пробирка с буфером не открывается эмбриологом), контроль контаминации каждого образца (проба среды из последней отмывочной капли биопсиийного материала). Все эти контроли вместе с образцами проходят этап полногеномной амплификации, после которого будет заметно малейшее количество ДНК, контаминировавшей контроли. Полногеномную амлификацию проводили с помощью коммерческого набора SurePlex (Illumina, США).
Продукт полногеномной амплификации, а также ДНК всех членов семьи амплифицировали на 1 этапе в мультиплексной ПЦР с праймерами для детекции патогенного варианта и праймерами для информативных для семьи А полиморфных маркеров в соответствии с разработанным в рамках подготовительного этапа протоколом для тест-системы. На 2 этапе амплификацию проводили для каждого маркера отдельно в соответствии с разработанным протоколом для тест-системы. Таким образом были установлены группы сцепления, унаследованные каждым эмбрионом. Полученные результаты:
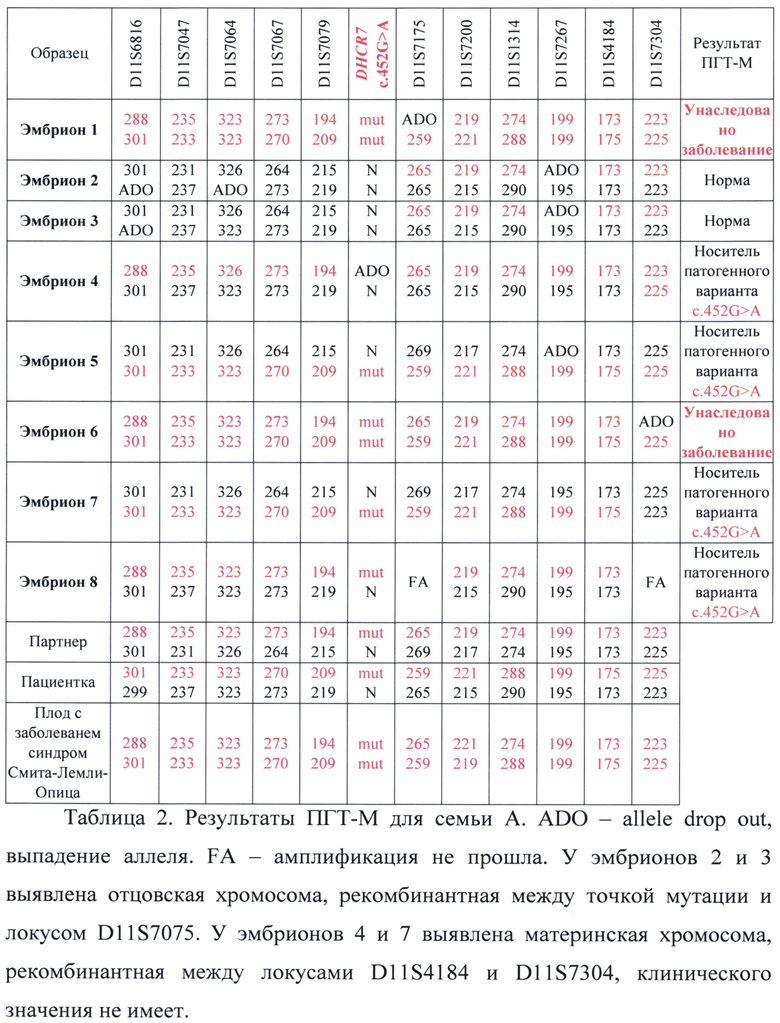
По результатам прямой и косвенной диагностики 6 эмбрионов не унаследовали заболевание, у 2 эмбрионов выявлен гаплотип, соответствующий унаследованному заболеванию. Так как у эмбрионов 2 и 3 произошла рекомбинация в отцовской хромосома между точной мутации и ближайшим к ней STR локусом, вывод о том, что эти эмбрионы не унаследовали патогенный вариант от отца (от партнера пациентки), был сделан на основе данных прямой диагностики. По запросу родителей для эмбрионов 2, 3, 4, 5 и 7 провели преимплантационный генетический скрининг хромосомных аномалий. По результатам всех проведенных анализов эмбрионы 2, 3, 4 и 5 были рекомендованы к переносу. Эмбрион 7 не был рекомендован в связи с анэуплоидией.
--->
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE ST26SequenceListing PUBLIC "-//WIPO//DTD Sequence Listing
1.3//EN" "ST26SequenceListing_V1_3.dtd">
<ST26SequenceListing dtdVersion="V1_3" fileName="Способ
преимплантационного генетического тестирования синдрома
Смита-Лемли-Опица.xml" softwareName="WIPO Sequence"
softwareVersion="2.2.0" productionDate="2023-11-02">
<ApplicantFileReference>Способ преимплантационного генетического
тестирования синдрома Смита-Лемли-Опица</ApplicantFileReference>
<ApplicantName languageCode="ru">Публичное акционерное общество
«Центр Генетики и Репродуктивной Медицины «ГЕНЕТИКО»</ApplicantName>
<ApplicantNameLatin>GENETICO PJSC</ApplicantNameLatin>
<InventionTitle languageCode="ru">Способ преимплантационного
генетического тестирования синдрома
Смита-Лемли-Опица</InventionTitle>
<SequenceTotalQuantity>46</SequenceTotalQuantity>
<SequenceData sequenceIDNumber="1">
<INSDSeq>
<INSDSeq_length>20</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..20</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>unassigned DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q2">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>unidentified</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>tcatttcgcttgtctgtgag</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="2">
<INSDSeq>
<INSDSeq_length>21</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..21</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>unassigned DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q4">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>unidentified</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>acgtgtttaaaggggagagtt</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="3">
<INSDSeq>
<INSDSeq_length>19</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..19</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>unassigned DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q6">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>unidentified</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>acttacagcgggagtgatg</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="4">
<INSDSeq>
<INSDSeq_length>19</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..19</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>unassigned DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q8">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>unidentified</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>taaaacaggggagggtagc</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="5">
<INSDSeq>
<INSDSeq_length>21</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..21</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>unassigned DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q10">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>unidentified</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>cttataaccccagcttgtcat</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="6">
<INSDSeq>
<INSDSeq_length>19</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..19</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>unassigned DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q12">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>unidentified</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>ccaagagaaaaggaccagg</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="7">
<INSDSeq>
<INSDSeq_length>18</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..18</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>unassigned DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q14">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>unidentified</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>ccaatgagctgaacaacg</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="8">
<INSDSeq>
<INSDSeq_length>19</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..19</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>unassigned DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q16">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>unidentified</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>gtgggctaactcgatttgt</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="9">
<INSDSeq>
<INSDSeq_length>21</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..21</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>unassigned DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q18">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>unidentified</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>caccacctatagacttcagcc</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="10">
<INSDSeq>
<INSDSeq_length>20</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..20</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>unassigned DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q20">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>unidentified</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>gtgggctaactcgatttgta</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="11">
<INSDSeq>
<INSDSeq_length>24</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..24</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>unassigned DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q22">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>unidentified</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>cttctcataggtctgtaaagagga</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="12">
<INSDSeq>
<INSDSeq_length>18</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..18</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>unassigned DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q24">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>unidentified</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>gtttgaccctcacctcca</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="13">
<INSDSeq>
<INSDSeq_length>20</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..20</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>unassigned DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q26">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>unidentified</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>agttaaagcgattctcctgc</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="14">
<INSDSeq>
<INSDSeq_length>22</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..22</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>unassigned DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q28">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>unidentified</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>tgaatagttcttgccagtatgc</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="15">
<INSDSeq>
<INSDSeq_length>17</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..17</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>unassigned DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q30">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>unidentified</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>caaaaacagggcaatgg</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="16">
<INSDSeq>
<INSDSeq_length>20</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..20</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>unassigned DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q32">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>unidentified</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>cctgagaacacgtagcaaac</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="17">
<INSDSeq>
<INSDSeq_length>22</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..22</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>unassigned DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q34">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>unidentified</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>ggattctactaaaagccagatg</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="18">
<INSDSeq>
<INSDSeq_length>19</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..19</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>unassigned DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q36">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>unidentified</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>tgaagctacgtggagcatc</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="19">
<INSDSeq>
<INSDSeq_length>22</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..22</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>unassigned DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q38">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>unidentified</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>ctgatatagggcgtacactcag</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="20">
<INSDSeq>
<INSDSeq_length>20</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..20</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>unassigned DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q40">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>unidentified</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>acaccgccatttttattgac</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="21">
<INSDSeq>
<INSDSeq_length>20</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..20</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>unassigned DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q42">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>unidentified</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>caacccttctcaattaacca</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="22">
<INSDSeq>
<INSDSeq_length>25</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..25</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>unassigned DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q44">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>unidentified</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>ttgtagatgtcagttacttaagcac</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="23">
<INSDSeq>
<INSDSeq_length>21</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..21</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>unassigned DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q46">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>unidentified</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>cccttctcaattaaccaactg</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="24">
<INSDSeq>
<INSDSeq_length>20</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..20</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>unassigned DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q48">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>unidentified</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>ctggaagttgatgggttctt</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="25">
<INSDSeq>
<INSDSeq_length>21</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..21</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>unassigned DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q50">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>unidentified</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>ccactccatctttgtagccta</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="26">
<INSDSeq>
<INSDSeq_length>20</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..20</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>unassigned DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q52">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>unidentified</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>ctgcacgttgagctgtagag</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="27">
<INSDSeq>
<INSDSeq_length>18</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..18</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>unassigned DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q54">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>unidentified</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>gcaatcaggaaccagacc</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="28">
<INSDSeq>
<INSDSeq_length>19</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..19</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>unassigned DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q56">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>unidentified</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>ttcactcttaccccactgc</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="29">
<INSDSeq>
<INSDSeq_length>20</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..20</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>unassigned DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q58">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>unidentified</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>tctggttgttagagggaggt</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="30">
<INSDSeq>
<INSDSeq_length>20</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..20</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>unassigned DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q60">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>unidentified</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>gtgtgtgaacccagtcctta</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="31">
<INSDSeq>
<INSDSeq_length>19</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..19</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>unassigned DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q62">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>unidentified</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>gggcttcgatcttaaaagg</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="32">
<INSDSeq>
<INSDSeq_length>18</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..18</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>unassigned DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q64">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>unidentified</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>gaaattgcggctcttttc</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="33">
<INSDSeq>
<INSDSeq_length>22</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..22</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>unassigned DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q66">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>unidentified</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>gccacacaaatacatattgcta</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="34">
<INSDSeq>
<INSDSeq_length>20</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..20</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>unassigned DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q68">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>unidentified</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>aattgcctggtttttatgct</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="35">
<INSDSeq>
<INSDSeq_length>19</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..19</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>unassigned DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q70">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>unidentified</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>cgacctcaagttcaccaat</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="36">
<INSDSeq>
<INSDSeq_length>21</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..21</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>unassigned DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q72">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>unidentified</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>agaccatctaagcctgtgaat</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="37">
<INSDSeq>
<INSDSeq_length>22</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..22</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>unassigned DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q74">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>unidentified</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>tctcaattattttcttgcttcg</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="38">
<INSDSeq>
<INSDSeq_length>21</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..21</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>unassigned DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q76">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>unidentified</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>agatagacatttcaacgcacc</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="39">
<INSDSeq>
<INSDSeq_length>23</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..23</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>unassigned DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q78">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>unidentified</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>tctgtgcttttaaaaccatcttc</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="40">
<INSDSeq>
<INSDSeq_length>25</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..25</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>unassigned DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q80">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>unidentified</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>ctgatgagcagaggtagaactatac</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="41">
<INSDSeq>
<INSDSeq_length>19</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..19</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>unassigned DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q82">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>unidentified</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>tggaaggagggtgcttaag</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="42">
<INSDSeq>
<INSDSeq_length>19</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..19</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>unassigned DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q84">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>unidentified</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>aaagcccagagattcatgc</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="43">
<INSDSeq>
<INSDSeq_length>20</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..20</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>unassigned DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q86">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>unidentified</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>cctgcccactgttaatgttc</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="44">
<INSDSeq>
<INSDSeq_length>20</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..20</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>unassigned DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q88">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>unidentified</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>gaagtgacagcttgaggaga</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="45">
<INSDSeq>
<INSDSeq_length>20</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..20</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>unassigned DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q90">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>unidentified</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>ggagggcaagaattatgtct</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="46">
<INSDSeq>
<INSDSeq_length>22</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..22</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>unassigned DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q92">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>unidentified</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>gcctttagttatgtgctcctaa</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
</ST26SequenceListing>
<---
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ преимплантационного генетического тестирования ахондроплазии | 2022 |
|
RU2795482C1 |
| Способ преимплантационного генетического тестирования синдрома Мартина-Белл | 2022 |
|
RU2796834C1 |
| Способ преимплантационного генетического тестирования болезни Гентингтона | 2024 |
|
RU2840728C1 |
| Способ преимплантационного генетического тестирования наследственной зонулярной катаракты | 2022 |
|
RU2799541C1 |
| Способ преимплантационного генетического тестирования спондилоэпифизарной дисплазии | 2022 |
|
RU2803650C1 |
| Способ преимплантационного генетического тестирования болезни Штаргардта | 2023 |
|
RU2831940C1 |
| Способ преимплантационного генетического тестирования Синдрома Марфана | 2023 |
|
RU2837158C1 |
| Способ преимплантационного генетического тестирования синдрома Альпорта | 2022 |
|
RU2795481C1 |
| Способ преимплантационного генетического тестирования лице-лопаточно-плечевой мышечной дистрофии | 2023 |
|
RU2808833C1 |
| Способ преимплантационного генетического тестирования остеопетроза 4 типа | 2022 |
|
RU2795483C1 |
Изобретение относится к области генетического тестирования. Описан способ преимплантационного генетического тестирования синдрома Смита-Лемли-Опица, предусматривающий выявление наследования патогенных вариантов NC_000011.9:g.711524470Т (NM_001360.2:c.452G>A, p.Trp151Ter) в гене DHCR7, включающий двойную систему детекции - прямую и косвенную. Техническим результатом является создание тест-системы для диагностики патогенного варианта NC_000011.9:g.71152447C>T (NM_001360.2:c.452G>A, p.Trp151Ter) в гене DHCR7 с двойной системой детекции - прямой и косвенной. 2 табл., 1 пр.
Способ преимплантационного генетического тестирования синдрома Смита-Лемли-Опица, предусматривающий выявление наследования патогенных вариантов NC_000011.9:g.711524470Т (NM_001360.2:c.452G>A, p.Trp151Ter) в гене DHCR7, включающий двойную систему детекции - прямую и косвенную, где прямую детекцию осуществляют с помощью следующих праймеров для амплификации:
Внешние: 5’-ACCCGCTGCTAAGAACAT-3’ (прямой), 5’-ACGAGATCCAGAACCAAAG-3’ (обратный),
Внутренние для детекции аллеля гена DHCR7 дикого типа: 5’-CGCTGCTAAGAACATACCAG-3’ (прямой), 5’-CAATGGCCTGCAAGACT-3’ (обратный),
Внутренние для детекции мутантного аллеля гена DHCR7: 5’-AGGACAGGAGATGAGCGT-3’ (прямой), 5’-CCCAGAAAGTGACCAGG-3’ (обратный),
а косвенную детекцию осуществляют с помощью праймеров для анализа наследования молекулярно-генетических маркеров типа STR, сцепленных с патогенными вариантами, выбранных из SEQ ID NO: 1-46, при этом используют праймеры, направленные на те STR, аллели которых разные на хромосомах хотя бы одного родителя-носителя мутации, где внешние праймеры обозначены как Fout (прямой праймер) и Rout (обратный праймер), а внутренние праймеры обозначены как Fin (прямой праймер) и Rin (обратный праймер), при этом диагностику проводят в два этапа полугнездовой ПЦР: на первом этапе проводят мультиплексную ПЦР с внешними праймерами, на втором этапе проводят индивидуальную ПЦР каждого фрагмента с внутренними праймерами для STR, а также проводят ПЦР-ПДРФ для определения патогенных вариантов в гене DHCR7.
| Natesan S.A., Handyside A.H., Thornhill A.R | |||
| et al | |||
| Live birth after PGD with confirmation by a comprehensive approach (karyomapping) for simultaneous detection of monogenic and chromosomal disorders | |||
| Печь-кухня, могущая работать, как самостоятельно, так и в комбинации с разного рода нагревательными приборами | 1921 |
|
SU10A1 |
| Reprod Biomed Online | |||
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| Способ преимплантационной генетической диагностики спинальной мышечной атрофии типа 1 | 2017 |
|
RU2671156C1 |
| Способ преимплантационной генетической диагностики анемии Фанкони | 2018 |
|
RU2697398C2 |
| DeBarber AE, Eroglu | |||

