ОБЛАСТЬ ТЕХНИКИ
Изобретение относится к аудиоустройству, системе распределения аудио и способу их работы, в частности, но не исключительно, к их использованию для поддержки приложения для конференций в режиме дополненной/виртуальной реальности.
УРОВЕНЬ ТЕХНИКИ
Благодаря непрерывному развитию и введению новых услуг и способов использования и потребления аудиовизуального контента в последние годы произошел значительный рост разнообразия и диапазона восприятия такого контента. В частности, разрабатываются множество пространственных и интерактивных услуг, приложений и подходов к восприятию, чтобы обеспечить пользователям восприятие с более сильным вовлечением и погружением.
Примерами таких приложений являются приложения виртуальной реальности (Virtual Reality, VR) и дополненной реальности (Augmented Reality, AR), которые быстро становятся господствующими тенденциями, при этом ряд решений ориентирован на потребительский рынок. Кроме того, многими органами по стандартизации разрабатывается ряд стандартов. В рамках такой деятельности по стандартизации активно разрабатываются стандарты для различных аспектов систем VR/AR, включая, например, потоковую передачу, широковещание, преобразование для воспроизведения и т.д.
Приложения VR, как правило, обеспечивают восприятия пользователем, соответствующие нахождению пользователя в другом мире/окружающей среде/сцене, тогда как приложения AR (включая смешанную реальность, Mixed Reality (MR)), обычно обеспечивают восприятия пользователем, соответствующие нахождению пользователя в текущей окружающей среде, но с добавлением дополнительной информации либо виртуальных объектов или информации. Таким образом, приложения VR, как правило, обеспечивают полностью погружающие синтетически формируемые мир/сцену, тогда как приложения AR обычно обеспечивают частично синтетические мир/сцену, накладываемые на реальную сцену, в которой пользователь присутствует физически. Однако это термины часто используются взаимозаменяемо и имеют высокую степень перекрытия. Далее термин виртуальная реальность/VR будет использоваться для обозначения как виртуальной реальности, так и дополненной реальности.
В качестве примера, быстро набирающая популярность услуга заключается в предоставлении изображений и аудио таким образом, что пользователь в состоянии активно и динамически взаимодействовать с системой для изменения параметров преобразования для воспроизведения так, что изображения и аудио будут адаптироваться к перемещению и изменениям положения и ориентации пользователя. Весьма привлекательной особенностью многих приложений является возможность изменения действующего положения обзора и направления обзора зрителя, чтобы, например, зритель мог перемещаться и «осматриваться вокруг» в представляемой сцене.
Такая функция может, в частности, давать пользователю ощущение виртуальной реальности. Благодаря этому пользователь может (относительно) свободно передвигаться в виртуальной среде и динамически изменять свое положение и направление, в котором он смотрит. Как правило, такие приложения виртуальной реальности основаны на трехмерной модели сцены, причем модель динамически оценивается для обеспечения конкретного запрошенного вида. Данный подход хорошо известен, например, из игровых приложений для компьютеров и консолей, например, из категории игр-стрелялок от первого лица.
Также желательно, в частности, для приложений виртуальной реальности, чтобы представляемое изображение было трехмерным изображением. Действительно, для оптимизации погружения зрителя, как правило, предпочтительно, чтобы пользователь ощущал представленную сцену как трехмерную сцену. Ведь ощущение виртуальной реальности предпочтительно должно позволять пользователю выбирать свое собственное положение, точку обзора камеры и момент времени относительно виртуального мира.
Как правило, приложения виртуальной реальности по своей природе ограничены тем, что они основаны на заданной модели сцены и обычно на искусственной модели виртуального мира. В некоторых приложениях ощущение виртуальной реальности может быть обеспечено на основе захвата реального мира. Во многих случаях такой подход, как правило, основан на построении виртуальной модели реального мира из захватываемых данных реального мира. В таком случае ощущение виртуальной реальности формируется путем оценки этой модели.
Многие современные подходы, как правило, неоптимальные и часто имеют тенденцию предъявлять высокие требования к вычислительным и коммуникационным ресурсам и/или обеспечивать неоптимальное восприятие пользователем, например из-за пониженного качества или ограниченной свободы.
В качестве примера применения на рынке появились очки виртуальной реальности, которые позволяют зрителям воспринимать отснятое 360° (панорамное) или 180° видео. Такие 360° видео часто предварительно снимают с использованием многокамерной установки, в которой отдельные изображения сшиваются вместе в одно сферическое отображение. Обычные форматы стерео для 180° или 360° видео - сверху/снизу и слева/справа. Так же, как и в непанорамном стереоскопическом видео, изображения для левого глаза и правого глаза сжимают, например, как часть одного видеопотока стандарта H.264.
В добавление к визуальному воспроизведению большинство приложений VR/AR также обеспечивают соответствующее восприятие аудио. Во многих приложениях аудио предпочтительно обеспечивает пространственное восприятие звука, причем аудиоисточники воспринимаются как издающие звук из положений, которые соответствуют положениям соответствующих объектов в визуальной сцене. Таким образом, аудио- и видеосцены предпочтительно воспринимаются как согласованные, причем и те, и другие обеспечивают полное пространственное восприятие.
Что касается аудио, то до настоящего времени основной упор делали на воспроизведение через наушники с использованием технологии преобразования для воспроизведения бинаурального аудио. Во многих сценариях воспроизведение через наушники делает возможным персонализированное восприятие пользователем с высокой степенью погружения. С помощью отслеживания головы можно добиться реагирования преобразования для воспроизведения на движения головы пользователя, что значительно повышает ощущение погружения.
В последнее время, как на рынке, так и в ходе обсуждения стандартов, стали предлагать примеры использования, которые включают «социальный» или «общий» аспект VR (и AR), т.е. возможность обмена восприятием с другими людьми. Это могут быть люди в разных местах, но также люди в одном и том же месте (или сочетание и того, и другого). Например, у нескольких человек в одном и том же помещении может быть одно и то же общее восприятие виртуальной реальности с присутствием проекции (аудио или видео) каждого участника в контенте/сцене VR. Например, в игре с участием множества людей каждый игрок может иметь отличное от других местоположение в игровой сцене и, следовательно, отличную от других проекцию аудио- и видеосцены.
В качестве конкретного примера MPEG предпринимает попытки стандартизировать битовый поток и декодер для реалистических, погружающих восприятий AR/VR с шестью степенями свободы. Социальная VR является важной функцией и позволяет пользователям взаимодействовать в общей окружающей среде (игры, конференц-звонки, покупки в сети и т.д.). Концепция социальной VR также способствует тому, чтобы сделать виртуальную реальность более социальной деятельностью для пользователей, физически находящихся в одном и том же месте, но в том случае, например, когда установленный на голову дисплей или другая гарнитура VR обеспечивает изоляцию восприятия физической окружающей обстановки.
Конкретным примером приложений социальной VR являются приложения для конференций, в которых пользователи, находящиеся в разных местах, могут совместно использовать виртуальный «конференц-зал», причем пользователи, например, представлены аватарами. В качестве другого примера каждому пользователю может быть представлено представление других участников, виртуально преобразуемых для воспроизведения в собственной локальной окружающей среде пользователя, например, путем наложения реального мира с использованием очков AR на аватаров, соответствующих другим пользователям, таким образом, чтобы аватары создавали впечатление присутствия других пользователей в помещении. Кроме того, отдельному пользователю может быть предоставлена аудиосцена, которая содержит соответствующее аудио от всех участников, причем это аудио пространственно преобразуют для воспроизведения в соответствующих положениях воспринимаемых аудиоисточников. Это преобразование для воспроизведения видео и аудио выполняют так, что визуальные и звуковые положения для данного участника соответствуют друг другу.
Для обеспечения оптимального восприятия желательно тесное согласование восприятия аудио и видео, и, в частности, для приложений AR желательно также согласование со сценой реального мира. Однако зачастую этого трудно достичь, поскольку могут возникнуть ряд проблем, которые могут повлиять на восприятие пользователя. Например, на практике пользователь будет, как правило, использовать устройство в месте, где невозможно гарантировать полную тишину или темноту. Хотя гарнитуры могут пытаться блокировать свет и звук, обычно это будет достигается лишь частично. Кроме того, в приложениях AR в рамках восприятия пользователь часто может также воспринимать локальную окружающую среду, поэтому непрактично блокировать эту окружающую среду полностью.
Поэтому был бы полезен усовершенствованный подход к формированию аудио, в частности, для восприятия/приложения виртуальной/дополненной реальности, такого как, например, приложение для конференции в режиме VR/AR. В частности, был бы полезен подход, позволяющий улучшить работу, повысить гибкость, уменьшить сложность, облегчить реализацию, улучшить восприятие аудио, улучшить согласование восприятия аудио и визуальной сцены, уменьшить чувствительность к ошибкам в отношении источников в локальной окружающей среде, улучшить восприятие виртуальной реальности и/или улучшить рабочие характеристики и/или работу.
РАСКРЫТИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
Соответственно, настоящее изобретение направлено на предпочтительно ослабление, смягчение или устранение одного или более из вышеупомянутых недостатков по отдельности или в любой комбинации.
В соответствии с аспектом настоящего изобретения предложено аудиоустройство для системы распределения аудио, содержащей аудиосервер для приема входящего аудио от множества удаленных клиентов и для передачи аудио, полученного из входящего аудио, по меньшей мере некоторым из множества удаленных клиентов; при этом устройство содержит: приемник для приема данных, содержащих: аудиоданные для множества аудиокомпонентов, причем каждый аудиокомпонент представляет аудио от удаленного клиента из множества удаленных клиентов; данные о близости для по меньшей мере одного из аудиокомпонентов, причем данные о близости указывают физическую близость между удаленными клиентами в акустической окружающей среде реального мира; и генератор для формирования аудиосмеси множества аудиокомпонентов в ответ на данные о близости; при этом генератор выполнен с возможностью формирования первой аудиосмеси для первого удаленного клиента из множества удаленных клиентов, причем формирование первой аудиосмеси включает определение ослабления в первой аудиосмеси второго аудиокомпонента для второго удаленного клиента в ответ на данные о близости.
Изобретение может обеспечивать улучшенное восприятие пользователем во многих вариантах реализации и может, в частности, обеспечивать улучшенное распределение аудио во многих приложениях, таких как, в частности, приложения для конференций, основанные на подходе AR/VR. Данный подход может обеспечивать улучшенное восприятие аудио в сценариях, в которых пользователи/участники находятся, например в одном и том же помещении. Как правило, можно достичь улучшенного и более естественного восприятия аудиосцены, и во многих сценариях помехи и несогласованность, возникающее из-за находящихся в одном и том же месте пользователей/клиентов, могут быть ослаблены или уменьшены. Этот подход может быть, в частности, полезен для приложений виртуальной реальности, VR, (включая дополненную реальность, AR). Он может, например, обеспечивать улучшенное восприятие, например, для социальных приложений VR/AR, в которых в одном и том же месте присутствуют множество участников.
Данный подход может во многих вариантах реализации обеспечить улучшенные рабочие характеристики при сохранении низких сложности и использовании ресурсов.
Данные о близости могут быть, в частности, акустическими данными о близости. Данные о близости могут содержать указания близости для наборов (как правило, пар) удаленных клиентов. Указание близости для набора удаленных клиентов может указывать пространственное расстоянием между удаленными клиентами и/или связанными аудиоисточниками/пользователями, или может, например, указывать акустическое ослабление между удаленными клиентами и/или связанными аудиоисточниками/пользователями.
Аудиосмесь может быть набором аудиосигналов/аудиоканалов, (потенциально) содержащих вклады от множества аудиокомпонентов.
Данные о близости могут указывать имеющую место в реальном мире/абсолютную/физическую близость между удаленными клиентами. Данные о близости, в частности, отражают реальную физическую близость между удаленными клиентами в акустической окружающей среде реального мира.
Генератор выполнен с возможностью формирования первой аудиосмеси для первого удаленного клиента из множества удаленных клиентов, причем формирование первой аудиосмеси включает определение ослабления в первой аудиосмеси второго аудиокомпонента для второго удаленного клиента в ответ на данные о близости.
Это может обеспечить улучшенное восприятие пользователем и/или улучшенные рабочие характеристики восприятия аудио во многих сценариях. Это может, в частности, позволить улучшить адаптацию восприятия комбинированного аудио к потенциальным аудиопомехам между преобразованной для воспроизведения аудиосценой и аудиосценой реального мира. Ослабление в первой аудиосмеси второго аудиокомпонента для второго удаленного клиента может происходить в ответ на указание близости в данных о близости, причем указание близости указывает близость/расстояние меду первым удаленным клиентом и вторым удаленным клиентом.
В соответствии с необязательным признаком настоящего изобретения генератор выполнен с возможностью ослабления второго аудиокомпонента в первой аудиосмеси для данных о близости, удовлетворяющих критерию близости для первого удаленного клиента и второго удаленного клиента.
Это может обеспечить улучшенное восприятие пользователем и/или улучшенные рабочие характеристики восприятия аудио во многих сценариях. Генератор может быть выполнен с возможностью ослабления второго аудиокомпонента для данных о близости, указывающих меру расстояния между первым удаленным клиентом и вторым удаленным клиентом ниже порогового значения. Ослабление может быть бесконечным. В частности, генератор может быть выполнен с возможностью подавления/удаления/исключения второго аудиокомпонента для данных о близости, удовлетворяющих критерию близости для первого удаленного клиента и второго удаленного клиента.
В соответствии с необязательным признаком настоящего изобретения аудиоустройство является частью аудиосервера.
Это может обеспечить высокие рабочие характеристики и эффективную реализацию во многих вариантах реализации.
В соответствии с необязательным признаком настоящего изобретения аудиоустройство является частью удаленного клиента из множества удаленных клиентов.
Это может обеспечить высокие рабочие характеристики и эффективную реализацию во многих вариантах реализации.
В соответствии с необязательным признаком настоящего изобретения данные о близости содержат скалярное указание близости по меньшей мере для первого удаленного клиента и второго удаленного клиента, причем скалярное указание близости указывает акустическое ослабление от аудиоисточника второго удаленного клиента до элемента захвата первого удаленного клиента.
Это может обеспечить особенно эффективную работу во многих вариантах реализации. В некоторых вариантах реализации скалярное указание близости может быть двоичным указанием близости, указывающим, близки ли соответствующие удаленные клиенты или нет (например, в одном и том же помещении).
В соответствии с необязательным признаком настоящего изобретения данные о близости содержат указание близости первого удаленного клиента со вторым удаленным клиентом, которое отличается от близости второго удаленного клиента с первым удаленным клиентом.
Это может обеспечить эффективную работу во многих вариантах реализации. Данный подход может обеспечивать и поддерживать асимметричные указания близости, например, отражающие локальные акустические отличия (такие, как при использовании направленных микрофонов, или ношении участником закрытых наушников).
В соответствии с необязательным признаком настоящего изобретения приемник выполнен с возможностью приема данных о близости с динамической адаптацией к изменениям в положениях по меньшей мере одного из множества удаленных клиентов.
Это может обеспечить эффективную работу и может обеспечить подход, динамически адаптирующийся к движениям пользователя.
В соответствии с аспектом настоящего изобретения предложена система распределения аудио, содержащая: множество удаленных клиентов; аудиосервер для приема входящего аудио от множества удаленных клиентов и для передачи аудио, полученного из входящего аудио, по меньшей мере одному из множества удаленных клиентов; при этом по меньшей мере один из аудиосервера и одного из множества удаленных клиентов содержит: приемник для приема данных, содержащих: аудиоданные для множества аудиокомпонентов, причем каждый аудиокомпонент представляет аудио от удаленного клиента из множества удаленных клиентов; данные о близости для по меньшей мере одного из аудиокомпонентов, причем данные о близости указывают физическую близость между удаленными клиентами в акустической окружающей среде реального мира; генератор для формирования аудиосмеси множества аудиокомпонентов в ответ на данные о близости; при этом генератор выполнен с возможностью формирования первой аудиосмеси для первого удаленного клиента из множества удаленных клиентов, причем формирование первой аудиосмеси включает определение ослабления в первой аудиосмеси второго аудиокомпонента для второго удаленного клиента в ответ на данные о близости.
В соответствии с необязательным признаком настоящего изобретения система распределения аудио содержит детектор близости, выполненный с возможностью определения указания близости для первого удаленного клиента и второго удаленного клиента в ответ на сравнение первого аудиокомпонента для первого удаленного клиента и второго аудиокомпонента для второго удаленного клиента; и передатчик для передачи данных о близости, содержащих указание близости, приемнику.
Это может обеспечить особенно выгодные рабочие характеристики и низкую сложность во многих вариантах реализации.
В соответствии с необязательным признаком настоящего изобретения детектор близости является частью аудиосервера.
Это может обеспечить особенно выгодные рабочие характеристики и низкую сложность во многих вариантах реализации.
В соответствии с необязательным признаком настоящего изобретения первый удаленный клиент из множества удаленных клиентов содержит: вход для формирования сигнала микрофона, соответствующего аудио, захваченному набором микрофонов; детектор близости, выполненный с возможностью определения указания близости для первого удаленного клиента в ответ на сравнение сигнала микрофона и аудио, принятого с аудиосервера; и передатчик для передачи акустических аудиоданных, содержащих указание близости, аудиосерверу.
Это может обеспечить особенно выгодные рабочие характеристики и низкую сложность во многих вариантах реализации. В некоторых вариантах реализации набор микрофонов может содержать один микрофон или может содержать, например, множество микрофонов, такое как, например, микрофонный массив, например, используемый для формирования луча/направленного захвата.
В соответствии с необязательным признаком настоящего изобретения передатчик выполнен с возможностью передачи данных о близости, указывающих на то, что текущий активный удаленный клиент определен как близкий в ответ на определение первым детектором близости высокой корреляции между сигналом микрофона и аудио, принятым с аудиосервера.
Это может обеспечить особенно выгодные рабочие характеристики и низкую сложность во многих вариантах реализации.
В соответствии с аспектом настоящего изобретения предложен способ работы аудиоустройства для системы распределения аудио, содержащей аудиосервер для приема входящего аудио от множества удаленных клиентов и для передачи аудио, полученного из входящего аудио, по меньшей мере некоторым из множества удаленных клиентов; при этом способ включает: прием данных, содержащих: аудиоданные для множества аудиокомпонентов, причем каждый аудиокомпонент представляет аудио от удаленного клиента из множества удаленных клиентов; данные о близости для по меньшей мере одного из аудиокомпонентов, причем данные о близости указывают физическую близость между удаленными клиентами в акустической окружающей среде реального мира; и формирование аудиосмеси множества аудиокомпонентов в ответ на данные о близости; при этом формирование включает формирование первой аудиосмеси для первого удаленного клиента из множества удаленных клиентов, причем формирование первой аудиосмеси включает определение ослабления в первой аудиосмеси второго аудиокомпонента для второго удаленного клиента в ответ на данные о близости.
Эти и другие аспекты, признаки и/или преимущества настоящего изобретения станут очевидны из вариантов реализации, описанных далее в этом документе, и будут пояснены со ссылкой на варианты реализации.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Варианты реализации изобретения будут описаны только на примерах со ссылкой на чертежи, на которых:
на ФИГ. 1 показан пример системы распределения аудио;
на ФИГ. 2 показан пример системы распределения аудио;
на ФИГ. 3 показан пример системы распределения аудио для проведения аудиоконференций;
на ФИГ. 4 показан пример элементов аудиоустройства в соответствии с некоторыми вариантами реализации настоящего изобретения;
на ФИГ. 5 показан пример элементов системы распределения аудио в соответствии с некоторыми вариантами реализации настоящего изобретения; и
на ФИГ. 6 показан пример элементов удаленного клиента для системы распределения аудио в соответствии с некоторыми вариантами реализации настоящего изобретения.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
Виртуальные (включая дополненные) восприятия, позволяющие пользователю перемещаться в виртуальном или дополненном мире, становятся все более популярными, и для удовлетворения такого спроса разрабатывают услуги. Во многих таких подходах визуальные данные и аудиоданные могут быть сформированы динамически для отражения текущего положения пользователя (или владельца).
В данной области техники термины «расположение» и «поза» используются как общий термин для положения и/или направления/ориентации. Комбинация положения и направления/ориентации, например, объекта, камеры, головы или вида, может называться позой или расположением. Таким образом, указание расположения или позы может включать до шести значений/компонентов/степеней свободы, причем каждые значение/компонент/степень свободы описывают отдельное свойство положения/местоположения или ориентации/направления соответствующего объекта. Конечно, во многих ситуациях расположение или поза могут быть представлены с использованием меньшего числа компонентов, например, если один или более компонентов считают фиксированными или не относящимися к делу (например, если все объекты считают расположенными на одной и той же высоте и имеющими горизонтальную ориентацию, то полное представление позы объекта могут обеспечить четыре компонента). Далее термин «поза» используется для ссылки на положение и/или ориентацию, которые могут быть представлены от одного до шести значениями (соответствующими максимально возможным степеням свободы).
Многие приложения виртуальной реальности основаны на позе, имеющей максимум степеней свободы, т.е. по три степени свободы каждого из положений и ориентации, дающих в результате в общей сложности шесть степеней свободы. Таким образом, поза может быть представлена набором или вектором из шести значений, представляющих шесть степеней свободы и, следовательно, вектор позы может обеспечивать указание трехмерного положения и/или трехмерного направления. Однако понятно, что в других вариантах реализации поза может быть представлена меньшим количеством значений.
Систему или объект, основанные на обеспечении максимума степеней свободы для зрителя, обычно называют имеющими 6 степеней свободы. Многие системы и объекты обеспечивают только ориентацию или положение, и их обычно называют имеющими 3 степени свободы.
Как правило, приложение виртуальной реальности формирует трехмерные выходные данные в виде отдельных изображений вида для левого и правого глаз. Затем они могу быть представлены пользователю с помощью подходящих средств, обычно таких, как отдельные дисплеи для левого и правого глаз гарнитуры виртуальной реальности. В других вариантах реализации одно или более изображений вида могут быть, например, представлены на автостереоскопическом дисплее или, в действительности, в некоторых вариантах реализации может быть сформировано только одно двумерное изображение (например, с использованием обычного двумерного дисплея).
Аналогичным образом для данной позы зрителя/пользователя/слушателя может быть обеспечено аудиопредставление сцены. Аудиосцену обычно преобразуют для воспроизведения для обеспечения пространственного восприятия, в котором аудиоисточники воспринимаются как происходящие из требуемых положений. Аудиоисточники могут быть статичными в сцене, а изменения позы пользователя приведут к изменению относительного положения аудиоисточника относительно позы пользователя. Соответственно, пространственное восприятие аудиоисточника следует изменять для отражения нового положения относительно пользователя. Преобразование для воспроизведения аудио может быть, соответственно, адаптировано в зависимости от позы пользователя.
Во многих вариантах реализации преобразование для воспроизведения аудио является бинауральным преобразованием для воспроизведения с использованием передаточных функций головы (Head Related Transfer Function, HRTF) или бинауральных импульсных переходных характеристик помещения (Binaural Room Impulse Responses, BRIR) (или подобного) для обеспечения требуемого пространственного эффекта для пользователя, носящего наушники. Однако понятно, что в некоторых системах вместо этого аудио может быть преобразовано для воспроизведения с использованием системы громкоговорителей, а сигналы для каждого громкоговорителя могут быть преобразованы для воспроизведения так, что общий эффект возле пользователя соответствует требуемому пространственному восприятию.
Входные данные позы зрителя или пользователя могут быть определены разными путями в разных приложениях. Во многих вариантах реализации физическое движение пользователя может быть отслежено непосредственно. Например, камера, производящая съемку области пользователя, может обнаруживать и отслеживать голову (или даже глаза (отслеживание глаз)) пользователя. Во многих вариантах реализации пользователь может носить гарнитуру виртуальной реальности, которая может быть отслежена внешними и/или внутренними средствами. Например, гарнитура может содержать акселерометры и гироскопы, обеспечивающие информацию о перемещении и повороте гарнитуры и, следовательно, головы. В некоторых примерах гарнитура виртуальной реальности может передавать сигналы или содержать (например, визуальные) идентификаторы, которые позволяют внешнему датчику определять положение гарнитуры виртуальной реальности.
В некоторых системах поза зрителя может быть предоставлена с помощью ручных средств, например, пользователем, вручную управляющим джойстиком или аналогичным средством ввода вручную. Например, пользователь может вручную перемещать виртуального зрителя вокруг виртуальной сцены, управляя первым аналоговым джойстиком одной рукой, и управлять вручную направлением, в котором смотрит виртуальный зритель, двигая вручную второй аналоговый джойстик другой рукой.
В некоторых приложениях для формирования входной позы зрителя может быть использовано сочетание ручного и автоматизированного подходов. Например, гарнитура может отслеживать ориентацию головы, а перемещением/положением зрителя в сцене может управлять пользователь с помощью джойстика.
В некоторых системах приложение виртуальной реальности может быть предоставлено зрителю локально, например, с помощью автономного устройства, которое не использует какие-либо удаленные данные или обработку виртуальной реальности, или даже не имеет никакого доступа к ним. Например, устройство, такое как игровая консоль, может содержать хранилище для хранения данных сцены, вход для приема/формирования позы зрителя и процессор для формирования соответствующих изображений из данных сцены.
В других системах приложение виртуальной реальности может быть реализовано и выполнено удаленно от зрителя. Например, устройство, локальное для пользователя, может обнаруживать/принимать данные движения/позы, передаваемые удаленному устройству, которое обрабатывает данные для формирования позы зрителя. После этого удаленное устройство может формировать подходящие изображения вида для позы зрителя на основе данных сцены, описывающих сцену. Затем изображения вида передают на устройство, локальное для зрителя, где их представляют. Например, удаленное устройство может непосредственно формировать видеопоток (обычно поток стерео/3D-видео), который непосредственно представляют с помощью локального устройства. Аналогичным образом удаленное устройство может формировать аудиосцену, отражающую виртуальную окружающую аудиосреду. Во многих вариантах реализации это может быть сделано путем формирования аудиосигналов, которые соответствуют относительному положению разных аудиоисточников в виртуальной окружающей аудиосреде, например, путем применения бинауральной обработки к отдельным аудиокомпонентам, соответствующим их текущему положению относительно позы головы. Поэтому в таком примере локальное устройство может не выполнять никакой обработки виртуальной реальности за исключением передачи данных движения и представления принятых видео- и аудиоданных.
Аналогичным образом удаленное устройство VR может формировать аудиоданные, представляющие аудиосцену, и может передавать аудиокомпоненты/аудиообъекты, соответствующие разным аудиоисточниками в аудиосцене, вместе информацией о положении, указывающей положение этих источников (которая может быть, например, динамически изменена для движущихся объектов). После этого локальное устройство VR может преобразовать для воспроизведения сигналы соответствующим образом, например, путем применения надлежащей бинауральной обработки, отражающей относительное положение аудиоисточников для аудиокомпонентов.
Для аудиоучастника центральный сервер в некоторых вариантах реализации может соответственно формировать пространственную аудиосмесь, которая может быть преобразована для воспроизведения удаленным клиентским устройством. Например, центральный сервер может формировать пространственное аудио в виде ряда аудиоканалов для прямого преобразования для воспроизведения акустической системой окружающего звучания. Однако, чаще всего центральный сервер может формировать смесь посредством бинауральной обработки всех аудиосигналов в сцене, подлежащей преобразованию для воспроизведения, и затем объединять их в бинауральный стереосигнал, который может быть непосредственно преобразован для воспроизведения на клиентской стороне с использование наушников.
Во многих применениях центральный сервер может вместо этого предоставлять ряд аудиообъектов или аудиокомпонентов, каждый из которых соответствует, как правило, одному аудиоисточнику. После этого клиент может обработать такие объекты/компоненты для формирования требуемой аудиосцены. В частности, он может подвергнуть бинауральной обработке каждый аудиообъект на основе требуемого положения и объединить результаты.
В таких системах аудиоданные, передаваемые удаленному клиенту, могут содержать данные для множества аудиокомпонентов или аудиообъектов. Аудио может быть, например, представлено в виде кодированного аудио для данного аудиокомпонента, который нужно преобразовать для воспроизведения. Аудиоданные могут также содержать данные о положении, которые указывают положение источника аудиокомпонента. Позиционные данные могут, например, содержать данные об абсолютном положении, определяющие положение аудиоисточника в сцене. В таком варианте реализации локальное устройство может определять относительное положение аудиоисточника относительно текущей позы пользователя. Таким образом, принимаемые данные о положении могут быть независимыми от движений пользователя, а для отражения положения аудиоисточника относительно пользователя может быть локально определено относительное положение для аудиоисточников. Такое относительное положение может указывать относительное положение, из которого пользователь должен воспринимать источник звука, и, соответственно, будет меняться в зависимости от движений головы пользователя. В других вариантах реализации аудиоданные могут содержать данные о положении, которые непосредственно описывают относительное положение.
На ФИГ. 1 показан пример системы VR, в которой центральный сервер 101 поддерживает связь с рядом удаленных клиентов 103, например, через сеть 105, такую как Интернет. Центральный сервер 101 может быть выполнен с возможностью одновременной поддержки потенциально большого количества удаленных клиентов 103.
Такой подход может обеспечивать улучшенный компромисс, например, между сложностью и потребностью в ресурсах для разных устройств, требованиями к связи и т.д., во многих сценариях. Например, поза зрителя и соответствующие данные сцены могут передаваться с более длинными интервалами, при этом локальное устройство обрабатывает позу зрителя и принятые данные сцены локально для обеспечения восприятия в реальном времени с малым запаздыванием. Это может, например, существенно уменьшить требуемую полосу пропускания связи с обеспечением при этом восприятия с малой задержкой при возможности централизованного хранения, формирования и поддержания данных сцены. Это может, например, подойти для приложений, в которых восприятие виртуальной реальности обеспечивают на множестве удаленных устройств.
Особенно привлекательным приложением AR/VR является приложение для виртуальной телеконференции, в котором пользователи/участники могут находиться в разных местах. Пример такого приложения иллюстрирует ФИГ. 2, на которой показан центральный сервер 101, соответствующий центральному серверу, изображенному на ФИГ. 1, который поддерживает множество удаленных (аудио-) клиентов 103. Как можно увидеть, все удаленные клиенты 103 обмениваются данными непосредственно с центральным сервером 101, а не друг с другом. Таким образом, каждый удаленный клиент 103 может выгружать аудиокомпонент, соответствующий одному или более локальных аудиоисточников для удаленного клиента 103, на центральный сервер 101. Центральный сервер 101 может передавать отдельному удаленному клиенту 103 аудиоданные, которые представляют аудио от других удаленных клиентов 103. Как правило, каждый пользователь или участник будет иметь отдельное устройство, реализующее удаленный клиент 103, хотя, конечно, в некоторых вариантах реализации и сценариях удаленный клиент может совместно использоваться множеством пользователей/участников.
Однако, авторы изобретения поняли, что проблемой для многих таких практических систем и приложений является то, что на восприятие пользователем может влиять аудио в локальной окружающей среде. Обычно на практике трудно полностью подавить аудио в локальной окружающей среде, и действительно, даже при ношении наушников локальная окружающая среда вносит ощутимый вклад в воспринимаемое аудио. В некоторых случаях такие звуки могут быть подавлены с использованием активного шумоподавления. Однако это шумоподавление непрактично для аудиоисточников, которые имеют прямой аналог в сцене VR и часто имеет тенденцию быть неполным.
Действительно, проблема помех между звуками реальной окружающей среды и звуками аудиосцены остается открытой особенно для приложений, обеспечивающих восприятие VR, которое также отражает локальную окружающую среду, как, например, во многих случаях восприятия AR.
Например, осуществляются приложения, которые включают в себя «социальный» или «общий» аспект VR, при котором, например, множество людей в одной и той же локальной окружающей среде (например, помещении) имеют общее восприятие. Такие «социальные» или «общие» примеры использования предлагаются, например, в MPEG, и в настоящее время являются одним из основных классов восприятия для текущей деятельности по стандартизации MPEG-I. Примером такого применения является случай, когда несколько человек находятся в одном помещении и имеют одно и то же общее восприятие с присутствием проекции (аудио или видео) каждого участника в контенте VR.
При таком применении окружающая среда VR может содержать аудиоисточник, соответствующий каждому участнику, но в дополнение к этому пользователь может, например, из-за обычной проницаемости наушников, также слышать непосредственно других участников, если они присутствуют локально. Действительно, во многих ситуациях участник может преднамеренно носить открытые наушники, чтобы слышать локальную окружающую обстановку. Эта помеха может отрицательно сказаться на восприятии пользователем и может ослабить погружение участника. Однако выполнение шумоподавления на реальном звуковом компоненте является очень трудным и очень дорогостоящим с вычислительной точки зрения. Большинство типичных методов шумоподавления основаны на микрофоне внутри наушников вместе с контуром обратной связи для сведения к минимуму (предпочтительно, полному) любого компонента сигнала реального мира в сигнале микрофона (сигнал микрофона может рассматриваться как сигнал ошибки, приводящий в действие контур). Однако такой подход не реализуем, когда требуется фактическое присутствие аудиоисточника в воспринимаемом аудио.
Авторы изобретения поняли, что для системы проведения конференций, такой как система на ФИГ. 2, восприятие аудио может быть ухудшено, особенно когда разные пользователи/участники находятся в одном и том же физическом месте, и каждый пользователь имеет свой собственный микрофон и соединение с сервером конференций, т.е. когда разные находящиеся в одном месте пользователи используют разные удаленные клиенты. Сервер конференций может отправлять каждому удаленному клиенту уникальную смесь, содержащую все входящие сигналы от других удаленных клиентов. В случае, когда пользователи находятся в одном и том же физическом месте, они, как правило, акустически слышат других пользователей в этом месте (в зависимости от того, насколько акустически открыты наушники), а также через свои наушники, поскольку принимаемое аудио содержит аудиокомпонент от удаленного клиента другого пользователя. Задержка в таком конференц-соединении обычно достаточно большая, чтобы сделать восприятие весьма неприятным.
Данная проблема особенно значительна для AR/VR ввиду добавления визуального компонента. Если удаленный человек присоединяется к восприятию AR, этот человек также может быть преобразован для визуального воспроизведения, например, посредством аватара.
Даже если все пользователи носят достаточно закрытые наушники для уменьшения уровней внешних звуков для пользователя (наиболее вероятный случай использования для VR), все равно в сигналах микрофонов, которые записывают в общем месте, существует (прямой акустический) компонент речи каждого пользователя. Это может вызвать артефакты, поскольку речь поступает на разные микрофоны со слегка отличающимися задержками, и поэтому смешивается с немного разными задержками (и более ослабленными версиями) самой себя. Результатом может быть эффект, соответствующий применению гребенчатой фильтрации.
Таким образом, локальные источники звука могут создавать помехи как для восприятия пользователем аудио, преобразованного для воспроизведения аудиопространства, так и для захвата звука отдельного участника.
Хотя системы конференций могут приглушать или ослаблять пользователей с низким уровнем сигналов микрофона для улучшения разборчивости активной речи путем удаления шума или фоновых звуков из микрофонов участников, которые не говорят, это обычно не решает проблему полностью. Например, если микрофоны других участников улавливают речь с достаточно высоким уровнем, они не могут быть приглушены или ослаблены, что приводит к пониженному отношению сигнал/шум.
Эту проблему можно проиллюстрировать примером, приведенным на ФИГ. 3. Сценарий помещения A приводит к возможно сильным артефактам в нынешних системах конференций. При двух соединениях с сервером устройство пользователя A1 воспроизводит задержанную речь пользователя A2 и наоборот.
Как правило, для двух или более соединений, используемых в одном и том же помещении или по меньшей мере вблизи друг от друга, аудио каждого пользователя с сервера конференций будет исключать сигнал его собственного микрофона, но включать аудио от всех остальных пользователей с задержкой, определяемой кодеком конференции, системой и соединениями между пользователями и сервером и т.д. Для типичных систем конференций эти задержки будут менее 500 мс.
У этой ситуации несколько недостатков:
- Слышимость пользователем своей собственной речи с задержкой (задержанная слуховая обратная связь) очень раздражает и, как известно, вызывает нервно-психическое напряжение.
- Если пользователь A1 говорит, он будет отрицательно влиять на разборчивость речи для других людей в помещении, что увеличивает усилия на слушание и усталость.
- Если пользователь A1 говорит, задержанная речь от клиентских динамиков других пользователей в помещении также улавливается микрофоном пользователя A1, которая будет опять же воспроизводиться через динамики других пользователей и т.д., потенциально вызывая акустическую обратную связь («звон»).
- Если пользователь A1 говорит, он также будет улавливаться микрофонами всех других пользователей, что может вызвать проблемы для системы конференций, определяющей, какой человек говорит (предотвращая заглушение или ослабление системой других людей для управления отношением сигнал/шум), или вызвать нарастание уровня сигнала.
Далее будет описан подход, который может, как правило, смягчать такие эффекты и недостатки. Подход основан на формировании и распределении метаданных, указывающих акустическую/пространственную взаимосвязь между разными удаленными клиентами. Например, могут быть сформированы метаданные, которые указывают, какие удаленные клиенты (при наличии таковых) находятся в одном месте, и, в частности, указывают, находятся ли удаленные клиенты в одном и том же помещении (например, можно считать, что положение удаленного клиента соответствует положению захвата локального аудио, такой как, например, положение одного или более микрофонов, захватывающих локальное аудио). Метаданные могут быть распределены, например, центральному серверу или (другим) удаленным клиентам, где они могут быть использованы при формировании подходящего аудио (а также потенциально для других целей).
На ФИГ. 4 показаны примеры аудиоустройства для системы распределения аудио, которая содержит аудиосервер, обслуживающий множество удаленных клиентов и выполненный с возможностью приема и передачи аудио от удаленных клиентов/удаленным клиентам. Дальнейшее описание будет сосредоточено на системе распределения аудио в виде системы конференций в режиме VR и будет, в частности, ссылаться на систему, такую как система, изображенная на ФИГ. 1-3. Однако понятно, что общие подход и принципы не ограничиваются такой системой аудиоконференций, а могут быть применены к многим другим системам и приложениям распределения аудио, таким как другие услуги социальной AR.
Таким образом, далее центральный сервер 101 будет упоминаться как аудиосервер 101. Он, в частности, поддерживает приложение для аудиоконференций, и поэтому может рассматриваться как сервер конференций. Аналогичным образом, каждый из удаленных клиентов 103 представляет участника конференции/пользователя (или потенциально множество их) и выполняет функцию захвата/формирования аудиокомпонента, представляющего звук/аудио для участника и преобразования для воспроизведения комбинированной аудиосцены конференции пользователю. Каждый удаленный клиент также содержит функциональные возможности для формирования соответствующей визуальной сцены, например, путем формирования полностью виртуальной сцены с аватарами, представляющими других участников, или путем формирования визуальных наложений для гарнитуры AR. Аудиосцены и визуальные сцены формируют так, чтобы они были согласованными и обеспечивали интегрированное преобразование для воспроизведения подходящего сценария конференции.
Как правило, каждый удаленный клиент содержит по меньшей мере один микрофон, выполненный с возможностью захвата звука. Удаленный клиент также выполнен с возможностью формирования аудиокомпонента из захваченного сигнала микрофона, и этот аудиокомпонент может быть передан аудиосерверу 101.
Аудиосервер 101 принимает аудиокомпоненты от разных удаленных клиентов 103. После этого аудиосервер 101 передает каждому из удаленных клиентов 103 отражающие аудиокомпоненты, принимаемые от других удаленных клиентов 103. В некоторых вариантах реализации аудиосервер 101 может пересылать принимаемые аудиокомпоненты, так что удаленные клиенты 103 принимают аудиокомпоненты от других удаленных клиентов 103. В других вариантах реализации аудиосервер 101 может формировать комбинированное представление аудиосмеси (например, сигнал окружающего звука, бинауральные сигналы или моносигнал) путем объединения аудиокомпонентов для соответствующих удаленных клиентов 103. В таких вариантах реализации аудиосервер 101 может формировать конкретную аудиосмесь с понижающим микшированием для каждого удаленного клиента 103. Аудиосмесь может содержать аудиосигналы, представляющие аудиокомпоненты от множества удаленных клиентов 103.
Аудиоустройство на ФИГ. 2 содержит приемник 401, который выполнен с возможностью приема аудиоданных и связанных метаданных, содержащих данные о близости.
Приемник 401, в частности, выполнен с возможностью приема множества аудиокомпонентов, каждый из которых представляет звук от удаленного клиента. Таким образом, аудиоустройство принимает множество аудиокомпонентов, причем каждый из них связан с удаленным клиентом 103, от которого он принят. Каждый аудиокомпонент может, в частности, соответствовать аудио/звуку, захваченному набором микрофонов на удаленном клиенте 103.
Кроме того, приемник 401 принимает данные о близости по меньшей мере для одного и, как правило, некоторых или даже всех аудиокомпонентов. Данные о близости обеспечивают данные о взаимосвязи, которые предоставляют информацию об акустической/пространственной взаимосвязи между удаленными клиентами 103.
Данные о близости, в частности, указывают на близость между удаленными клиентами из множества удаленных клиентов. Указание близости от первого удаленного клиента до второго удаленного клиента может отражать акустическое ослабление (в реальном мире) (в частности, распространения звука посредством вибраций в воздухе или других средах) от аудиоисточника для этого первого удаленного клиента (такого, как говорящий участник, связанный с первым удаленным клиентом) до положения, связанного со вторым удаленным клиентом. Это положение может быть, в частности, положением микрофона первого удаленного клиента, захватывающего сигнал, из которого формируют аудиокомпонент для первого удаленного клиента, или может быть, например, положением пользователя (и, в частности, ушей пользователя) или пользователей.
Таким образом, данные о близости могут быть, в частности, акустическими данными о близости и могут содержать указания близости для удаленных клиентов, такие как указания близости для пар или наборов удаленных клиентов 103.
Данные о близости/указание близости могут соответственно отражать акустическую передаточную функцию/акустическое ослабление от положения первого удаленного клиента до положения второго удаленного клиента. Указание близости от первого удаленного клиента до второго удаленного клиента может отражать степень или уровень помех аудио, связанного со вторым удаленным клиентом, для аудио, связанного с первым удаленным клиентом.
Указание близости от первого удаленного клиента до второго удаленного клиента может, в частности, отражать величину аудио из аудиоисточника, связанного со вторым удаленным клиентом, которая захватывается в аудиокомпоненте первого удаленного клиента. В частности, указание близости может отражать, насколько аудио от первого динамика/участника для второго удаленного клиента захватывается первым удаленным клиентом.
Данные/указания близости во многих сценариях соответствуют непосредственно пространственной близости, и может быть использован термин «пространственная близость». Поэтому данные о близости могут указывать пространственную близость разных удаленных клиентов. Во многих вариантах реализации данные о близости могут обеспечивать информацию о том, какие удаленные клиенты находятся близко и, в частности, в одном месте. Удаленные клиенты могут рассматриваться как находящиеся в одном месте/близкие, если аудио, представленное аудиокомпонентом одного удаленного клиента, может быть также захвачено другим удаленным клиентом. В некоторых вариантах реализации удаленные клиенты могут считаться находящимися в одном месте/близкими, если положения удаленных клиентов удовлетворяют критерию расстояния, заключающемуся, например, в том, что пространственное расстояние меньше порогового значения, или что удаленные клиенты находятся в одном и том же помещении. В некоторых вариантах реализации в пороговое значение может быть встроен гистерезис во избежание переключения от одного решения к другому.
Данные о близости могут указывать близость в реальном мире между удаленными клиентами и, в частности, близость акустического/звукового распространения в реальном мире между удаленными клиентами. Указание близости может быть независимым от требуемых положений соответствующего аудио в формируемой аудиосцене аудиосмеси. Указание близости может быть независимым от положений виртуальной (аудио-) сцены. Указание/данные о близости могут указывать пространственные/акустические свойства в реальном мире. Таким образом, вместо отражения некоторой формы требуемой близости между аудио, подлежащим преобразованию для воспроизведения, данные о близости отражают некоторую форму фактической физической близости и акустическую окружающую среду между удаленными клиентами. Данные о близости не отражают некоторую форму воображаемой, теоретической, виртуальной или требуемой близости, например, некоторого нефизического мира, а отражают близость (обычно акустическую) в реальном мире.
В многих вариантах реализации указания близости могут быть симметричными, т.е. одни и те же указание/мера близости могут быть применены к близости от первого удаленного клиента до второго удаленного клиента, как и к близости от второго удаленного клиента до первого удаленного клиента. Однако в некоторых вариантах реализации могут быть применены асимметричные указания близости. Например, в случае удаленных клиентов, использующих направленные микрофоны, ослабление на втором удаленном клиенте динамика, связанного с первым удаленным клиентом, может отличаться от ослабления на первом удаленном клиенте динамика, связанного со вторым удаленным клиентом. Аналогичным образом, когда данные о близости содержат положение возле ушей участника/пользователя первого удаленного клиента, носящего наушники, ослабление зависит от акустического ослабления, оказываемого наушниками, и может отличаться от ослабления для ушей участника/пользователя второго удаленного клиента.
Таким образом, приемник 401 принимает данные о близости, которые могут представлять пространственные/акустические взаимосвязи между удаленными клиентами 103, и, в частности, могут указывать, что удаленные клиенты 103 находятся в одном месте/вблизи друг друга, например в одном помещении.
Приемник 401 соединен с генератором 403, который принимает аудиокомпоненты и данные о близости. Генератор выполнен с возможностью формирования аудиосмеси множества аудиокомпонентов в ответ на данные о близости. Аудиосмесь может содержать множество аудиокомпонентов от разных удаленных клиентов, объединенных в набор сигналов. По меньшей мере один из сигналов может содержать аудио из множества аудиокомпонентов/удаленных клиентов.
Например, генератор 403 может формировать окружающий звук с понижающим микшированием или бинауральный стереосигнал за счет объединения/понижающего микширования аудиокомпонента в каналы. Понижающее микширование также выполняют в зависимости от данных о близости таким образом, чтобы, например, уровень аудиокомпонентов зависел от данных о близости.
Генератор 403 может быть, в частности, выполнен с возможностью формирования аудиосигнала для одного конкретного удаленного клиента путем объединения всех аудиокомпонентов, за исключением аудиокомпонентов удаленных клиентов, которые указаны в данных о близости как находящиеся в одном месте с конкретным удаленным клиентом, для которого формируют аудиосигнал.
В системе метаданные, содержащие данные о близости, включают в битовые потоки системы распределения аудио, указывая, например, какие пользователя/клиенты находятся в одном и том же физическом месте. Метаданные могут быть, например, использованы для определения, какие сигналы воспроизводить возле каждого участника конференции. Например, аудиосигналы, воспроизводимые для участников, находящихся в одном и том же месте, могут включать не захваченные сигналы друг от друга, а только от удаленных пользователей, в то время как их речь отправляют удаленным пользователям. Этим можно, например, избежать нервно-психического напряжения, усталости и аудиоартефактов, обусловленных задержкой системы конференций, избежать акустической обратной связи и/или избежать снижения отношения сигнал/шум.
Вместо непосредственного исключения аудио для находящихся в одном и том же месте пользователей/удаленных клиентов, генератор 403 может обеспечивать более постепенное ослабление аудиокомпонента других пользователей, находящихся в том же самом месте.
Таким образом, во многих вариантах реализации генератор 403 может быть выполнен с возможностью формирования смеси для первого удаленного клиента, причем ослабление/взвешивание аудиокомпонента от второго удаленного клиента зависит от того, указывают ли данные о близости, что второй удаленный клиент находится близко к первому удаленному клиенту.
В некоторых вариантах реализации данные о близости могут содержать скалярное значение, указывающее расстояние между первым и вторым удаленными клиентами. Генератор 403 может быть в некоторых вариантах реализации выполнен с возможностью определения ослабления как монотонно убывающей функции от расстояния, так что чем ближе второй удаленный клиент к первому удаленному клиенту, тем ниже вес/выше ослабление аудиокомпонента. Если второй удаленный клиент находится очень близко к первому уделенному клиенту, первый удаленный клиент может соответствующим образом преобразовывать для воспроизведения аудиосцену, в которой аудио для второго удаленного клиента существенно ослаблено. Это может отражать то, что в таких ситуациях пользователь первого удаленного клиента сможет слышать пользователя второго удаленного клиента непосредственно. Однако чем дальше второй удаленный клиент, тем громче преобразуемое для воспроизведения аудио от него.
Это может обеспечить особенно привлекательные рабочие характеристики во многих вариантах реализации. Например, в ситуации, в которой приложение для аудиоконференций используется группой людей, некоторые из которых находятся на концерте в большом концертном зале, отдельным участникам, находящимся в концертном зале, может быть предоставлено сугубо индивидуальное преобразование аудио для воспроизведения, в котором других участников, не присутствующих в зале, преобразуют для воспроизведения при полной громкости, тогда как находящихся очень близко участников преобразуют для воспроизведения с очень низкой громкостью, а участников, находящихся в концертном зале, но на более дальних расстояниях, преобразуют для воспроизведения с промежуточной громкостью. Данный подход во многих ситуациях может обеспечить улучшенный баланс между аудио, принимаемым непосредственно за счет акустической передачи в локальной окружающей среде, и аудио, предоставляемого приложением для конференций.
В некоторых вариантах реализации генератор 403 может ослаблять аудиокомпонент, если данные о близости для двух удаленных клиентов удовлетворяют критерию близости. Ослабление может быть на заданную величину, которая во многих вариантах реализации может быть бесконечным ослаблением (соответствующим тому, что аудиокомпонент не преобразуют для воспроизведения или вообще не включают в сформированную аудиосмесь).
Во многих вариантах реализации критерий близости может включать требование о том, что указание близости для двух удаленных клиентов должно указывать расстояние ниже порогового значения. Если указание близости удовлетворяет этому требованию, генератор 403 может продолжать без выбора соответствующего аудиокомпонента для включения в формируемую аудиосмесь. Пороговое значение может быть установлено на низкое «безопасное» значение, указывающее по существу на отсутствие корреляции.
Данный подход во многих случаях может быть использован с двоичными указаниями близости, которые указывают, считаются ли пары удаленных клиентов находящимися в одном месте/близкими или нет (например, в одном и том же помещении). Если да, то при формировании аудиосигналов для отдельного удаленного клиента аудиокомпонент другого удаленного клиента не включают.
В некоторых вариантах реализации аудиоустройство на ФИГ. 4 может быть реализовано как часть аудиосервера 101. В некоторых вариантах реализации понижающее микширование аудиокомпонентов/аудиообъектов из множества удаленных клиентов 103 в объединенную аудиосмесь, содержащую аудиокомпоненты из множества удаленных клиентов 103, может быть выполнено на аудиосервере 101. В таких вариантах реализации удаленные клиенты 103 передают данные о близости на аудиосервер 101, который после этого может использовать их при формировании отдельных аудиосмесей для удаленных клиентов 103. Аудиосервер 101 может, в частности, формировать аудиосмесь для каждого из удаленных клиентов 103 путем объединения/понижающего микширования аудиокомпонентов, принимаемых от удаленных клиентов 103, с учетом данных о близости. В качестве конкретного примера аудиосервер 101 может формировать понижающим микшированием смеси, содержащие все аудиокомпоненты, за исключением тех, для которых данные о близости указывают, что соответствующий удаленный клиент находится в одном и том же месте с удаленным клиентом, для которого формируют аудиосмесь.
В некоторых вариантах реализации аудиоустройство на ФИГ. 4 может быть реализовано как часть удаленных клиентов 103, и в действительности такое аудиоустройство могут содержать все удаленные клиенты. В некоторых вариантах реализации понижающее микширование аудиокомпонентов/аудиообъектов из множества удаленных клиентов 103 в объединенную аудиосмесь, содержащую аудиокомпоненты из множества удаленных клиентов 103, может быть выполнена на удаленных клиентах 103. В таких вариантах реализации аудиосервер 101 может передавать как аудиокомпонент, так и данные о близости отдельным удаленным клиентам 103, которые после этого могут локально формировать аудиосмесь и преобразовать ее для воспроизведения пользователю. В некоторых таких вариантах реализации аудиосервер 101 может принимать аудиокомпоненты от разных удаленных клиентов 103 и пересылать все эти аудиокомпоненты отдельным удаленным клиентам 103. Кроме того, в некоторых вариантах реализации аудиосервер 101 может принимать данные о близости от удаленных клиентов 103 и распределять эти данные о близости другим удаленным клиентам 103. В других вариантах реализации аудиосервер 101 может принимать аудиокомпоненты от разных удаленных клиентов 103 и затем сам формировать данные о близости на основе аудиокомпонентов. Отдельный удаленный клиент может, например, формировать понижающим микшированием локальную смесь, содержащую все аудиокомпоненты, за исключением тех, для которых данные о близости указывают, что соответствующий удаленный клиент находится в одном и том же месте с удаленным клиентом, формирующим смесь.
Понятно, что в разных вариантах реализации могут быть использованы разные подходы к определению данных о близости. Во многих вариантах реализации данные о близости могут быть, в частности, определены путем сравнения разных аудиокомпонентов друг с другом. Система может содержать детектор близости, который определяет указание близости для двух удаленных клиентов путем сравнения друг с другом двух аудиокомпонентов от двух удаленных клиентов. Данные о близости могут быть, например, сформированы для отражения схожести между этими сигналами, и, в частности, может быть сформирована мера перекрестной корреляции с формированием указания близости на основе этой меры перекрестной корреляции. Например, значение перекрестной корреляции может быть использовано непосредственно, или, например, указание близости может быть установлено для указания того, что два удаленных клиента находятся в одном и том же месте, если максимальная мера перекрестной корреляции в пределах определенного диапазона запаздывания превышает данное пороговое значение. Тогда передатчик может формировать данные о близости, содержащие указание близости, и передавать их (как правило, вместе с аудиокомпонентом).
В вариантах реализации, в которых аудиоустройство реализуют в удаленных клиентах 103, на аудиосервере 101 может быть реализован детектор близости, который определяет значения перекрестной корреляции для всех пар аудиокомпонентов, и для каждой пары определяет указание близости. Могут быть сформированы данные о близости, содержащие все указания близости, и они могут быть переданы всем удаленным клиентам 103 или, например, удаленному клиенту могут быть переданы только данные о близости для этого удаленного клиента. Кроме того, аудиосервер 101 может передавать аудиокомпоненты, а клиент может приступать к локальному формированию аудиосмеси.
В вариантах реализации, в которых аудиоустройство реализуют на аудиосервере 101, детектор близости может быть реализован в удаленных клиентах 103. Каждый удаленный клиент может содержать детектор близости, который коррелирует, например, локальный аудиокомпонент с принимаемыми аудиокомпонентами от других удаленных клиентов 103. Указание близости может быть сформировано для каждого из принимаемых аудиокомпонентов и передано обратно на аудиосервер 101 вместе локальным аудиокомпонентом. После этого аудиосервер 101 может использовать данные о близости, принимаемые от всех удаленных клиентов, при формировании аудиосмесей для отдельных удаленных клиентов 103.
Таким образом, как показано на ФИГ. 5, первый объект 501 может содержать детектор 503 близости, который определяет значения перекрестной корреляции для одной или более пар аудиокомпонентов, и определяет указание близости для каждой пары. Например, первый объект 501 может содержать детектор 503 близости, который определяет указание близости для первого удаленного клиента и второго удаленного клиента в ответ на сравнение первого аудиокомпонента для первого удаленного клиента и второго аудиокомпонента для второго удаленного клиента. Он также содержит передатчик 505 данных, который выполнен с возможностью передачи данных о близости, содержащих указание близости для второго объекта 507, который содержит аудиоустройство, изображенное на ФИГ. 4. В дополнение к данным о близости передатчик 505 может передавать один или более аудиокомпонентов. Таким образом, передатчик 505 может, в частности, передавать данные о близости и данные аудиокомпонента на приемник 401 аудиоустройства. В некоторых вариантах реализации первой объект 501 может быть удаленным клиентом, а второй объект 507 может быть аудиосервером. В других вариантах реализации первый объект 501 может быть аудиосервером, а второй объект 507 может быть удаленным клиентом.
Таким образом, во многих вариантах реализации обработка сигнала аудиокомпонентов (например, соответствующих сигналам микрофона от удаленных клиентов) на аудиосервере 101 может обнаруживать, какие пользователи/удаленные клиенты находятся близко (например, в одном и том же помещении), и соответствующие метаданные будут отправлены удаленным клиентам 103.
Если, например, формируют матрицу корреляции со значениями максимальной перекрестной корреляции для всех пар аудиокомпонентов в матрице, то аудиокомпоненты для удаленных клиентов 103, которые находятся в одном и том же помещении (близко), будут иметь высокое значение максимальной перекрестной корреляции.
Например, аудиосервер 101 может вычислять для каждой уникальной комбинации из 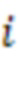 и
и 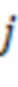 , при
, при 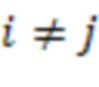 :
:
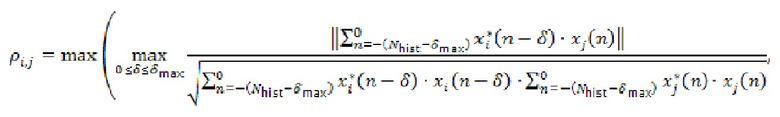
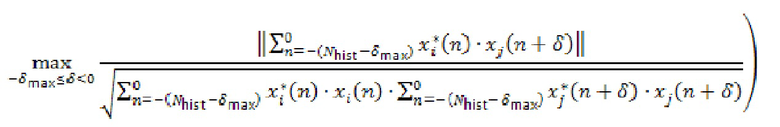

где 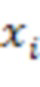 обозначает сигнал аудиокомпонента, который принимает сервер от удаленного клиента с индексом ,
обозначает сигнал аудиокомпонента, который принимает сервер от удаленного клиента с индексом , 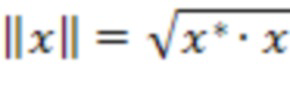 обозначает норму,
обозначает норму, 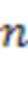 является индексом выборки из (истории) аудиокомпонента, причем
является индексом выборки из (истории) аудиокомпонента, причем 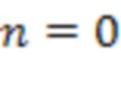 обозначает самую последнюю доступную выборку,
обозначает самую последнюю доступную выборку,  является количеством прошлых выборок, использованных в анализе, и
является количеством прошлых выборок, использованных в анализе, и 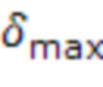 является максимальной поддерживаемой задержкой между аудиокомпонентами.
является максимальной поддерживаемой задержкой между аудиокомпонентами.
Например, 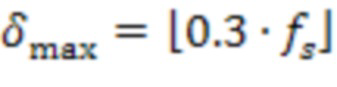 и
и 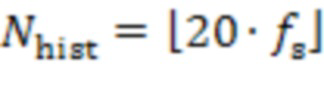 при частоте
при частоте 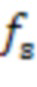 выборки сигналов микрофона и операции
выборки сигналов микрофона и операции 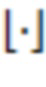 округления вниз. Типичное значение частоты выборки для речи составляет 16 кГц. В случае аудио часто используют более высокую частоту выборки, например 48 кГц. В частности, для данного подхода значение
округления вниз. Типичное значение частоты выборки для речи составляет 16 кГц. В случае аудио часто используют более высокую частоту выборки, например 48 кГц. В частности, для данного подхода значение 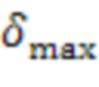 может быть выбрано достаточно большим, чтобы учитывать задержки между аудиокомпонентами, обусловленные разными длинами акустических путей между пользователями и микрофонами (в одном и том же помещении), и разницы в задержках при передаче от удаленных клиентов на аудиосервер 101.
может быть выбрано достаточно большим, чтобы учитывать задержки между аудиокомпонентами, обусловленные разными длинами акустических путей между пользователями и микрофонами (в одном и том же помещении), и разницы в задержках при передаче от удаленных клиентов на аудиосервер 101.
Если для определенной комбинации из и вышеупомянутая перекрестная корреляция высокая, например, 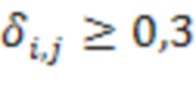 , удаленные клиенты и можно считать близкими и, в частности, находящимися в одном и том же помещении. Перекрестная корреляция может быть низкой, когда ни один из участников не говорит. Поэтому перекрестную корреляцию целесообразно вычислять только тогда, когда один из участников или активен.
, удаленные клиенты и можно считать близкими и, в частности, находящимися в одном и том же помещении. Перекрестная корреляция может быть низкой, когда ни один из участников не говорит. Поэтому перекрестную корреляцию целесообразно вычислять только тогда, когда один из участников или активен.
В качестве примера определение того, активен ли пользователь 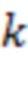 , может быть выполнено в соответствии с:
, может быть выполнено в соответствии с:
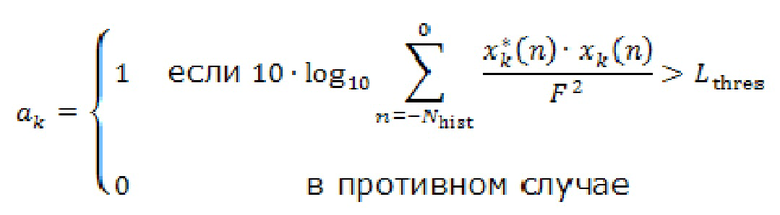
при, например, 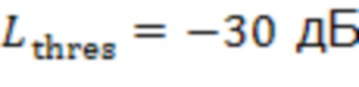 для сигналов
для сигналов 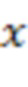 с полномасштабной амплитудой
с полномасштабной амплитудой 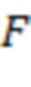 .
.
В альтернативном варианте реализации к сигналам может быть применен детектор речи.
Определение того, являются ли два удаленных клиента 103 близкими, как правило, оценивают только тогда, когда один из пользователей активен, и последнее определенное решение сохраняют, когда они не активны. Это предотвращает переключение метаданных в зависимости от того, активны ли динамики.
Для обеспечения надежности решения могут быть приняты дополнительные меры. Например, решение о том, находятся ли удаленные клиенты и в одном и том же помещении, может быть изменено только тогда, когда активный сигнал  в течение по меньшей мере 15 секунд приводит к другому сигналу.
в течение по меньшей мере 15 секунд приводит к другому сигналу.
В некоторых вариантах реализации аудиосервер 101 определяет, какие удаленные клиенты находятся в одном и том же помещении, и отправляет эту информацию в виде метаданных удаленным клиентам 103. В частности, данный вариант реализации обеспечивает преимущество, когда аудиосигналы пользователей не смешивают на аудиосервере 101 для каждого клиента, а посылают по отдельности. Например, приложения VR, в которых сигнал каждого пользователя преобразуют для воспроизведения для конкретного местоположения в виртуальной (или добавленной) реальности. В этом случае удаленные клиенты могут использовать метаданные, другие пользователи которых находятся, например, в том же самом помещении, для принятия решения не преобразовывать для воспроизведения или не воспроизводить соответствующие сигналы, принимаемые с сервера конференций.
В некоторых вариантах реализации детектор близости может, как упоминалось, находиться в удаленном клиенте. Пример элементов такого удаленного клиента показан на ФИГ. 6.
Удаленный клиент содержит вход 601, соединенный с микрофоном и выполненный с возможностью формирования сигнала микрофона, соответствующего аудио, захватываемому микрофоном. Сигнал микрофона подают на кодер 603, который кодирует сигнал для формирования аудиокомпонента (в некоторых вариантах реализации сигнал микрофона может быть использован непосредственно как аудиокомпонент).
Кодер соединен с интерфейсом 605, который выполнен с возможностью обмена данными с аудиосервером 101. Таким образом, интерфейс содержит передатчик для передачи данных на аудиосервер 101 и приемник для приема данных с аудиосервера 101. Интерфейс 605 получает данные аудиокомпонента и передает их на аудиосервер 101.
Кроме того, интерфейс 605 принимает аудиокомпоненты и данные о близости от других удаленных клиентов, и, в частности, интерфейс 605 может содержать приемник 401, показанный на ФИГ. 4.
Удаленный клиент также содержит преобразователь 607 для воспроизведения аудио, который может соответствовать непосредственно генератору 403, показанному на ФИГ. 4. Как описано ранее, генератор 403 может переходить к формированию локальной смеси для представления локальному пользователю.
В других вариантах реализации аудио, принимаемое с аудиосервера 101, может быть сформированным понижающим микшированием сигналом, т.е. генератор 409 может содержаться в аудиосервере 101, и передаваемое аудио может быть, например, бинауральным стереосигналом или сигналом окружающего звука. В таких вариантах реализации преобразователь 607 для воспроизведения может непосредственно преобразовывать для воспроизведения принимаемый сигнал.
Удаленный клиент на ФИГ. 6 также содержит детектор 607 близости, который выполнен с возможностью определения указания близости для первого удаленного клиента в ответ на сравнение сигнала микрофона (возможно, представленного аудиокомпонентом) и аудио, принимаемого с аудиосервера.
Например, если принимаемое аудио соответствует аудиокомпонентам от других удаленных клиентов, оно может быть непосредственно подано в детектор 609 близости, который затем может перейти к корреляции сигнала микрофона (возможно, представленного аудиокомпонентом) с принимаемыми аудиокомпонентами и формированию указания близости для каждого из принимаемых аудиокомпонентов. Указания близости могут быть поданы в интерфейс 605, который может передать данные о близости, содержащие указания близости, на аудиосервер 101.
В случае, когда принимаемое аудио соответствует аудиосмеси, содержащей множество аудиокомпонентов других удаленных клиентов, объединенных/микшированных в одни и те же аудиосигналы/аудиоканалы, детектор 609 близости может коррелировать сигнал микрофона с аудиосмесью.
Например, если аудиосмесь содержит только один сигнал, детектор 609 близости может коррелировать принимаемый сигнал с сигналом микрофона, и при обнаружении корреляции выше данного уровня может быть сформировано указание близости для указания того, что текущий активный удаленный клиент (для текущего активного динамика) является близким к текущему удаленному клиенту.
Если аудиосмесь содержит более одного канала/сигнала, они могут быть, например, объединены перед корреляцией, или корреляции могут быть выполнены для каждого сигнала канала и, например, учтена может быть только самая высокая корреляция.
В случаях, в которых идентичность текущего активного удаленного клиента/динамика известна удаленному клиенту (например, такая активность может быть обнаружена аудиосервером 101, и соответствующая информация может быть переслана удаленному клиенту), удаленный клиент может формировать указание близости, которое содержит эту идентификацию другого удаленного клиента, как находящегося близко.
В случаях, в которых такая информация может быть недоступна, удаленный клиент может просто передавать указание близости, указывающее, что текущий активный динамик/удаленный клиент является близким. В таком случае аудиосервер 101 может быть, например, выполнен с возможностью обнаружения текущего активного динамика (например, с использованием распознавания речи) и может определять соответствующий идентификатор удаленного клиента, который является близким к удаленному клиенту, передающему указание близости, как идентифицированного текущего активного динамика/удаленного клиента.
Таким образом, в некоторых вариантах реализации удаленные клиенты могут обнаруживать близких удаленных клиентов, сравнивая сигналы, принимаемые с аудиосервера 101, с сигналом своего локального микрофона (например, после подавления акустического эха, Acoustic Echo Cancelation (AEC)).
Например, клиент может определить перекрестную корреляцию между сигналами, принимаемыми с сервера, и сигналом микрофона удаленного клиента:
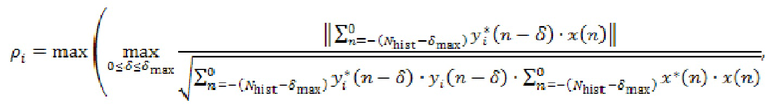
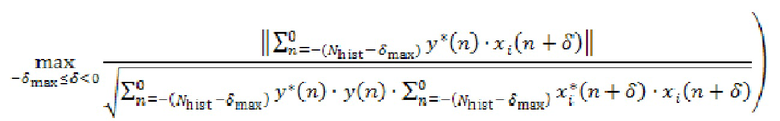
где 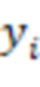 обозначает сигнал, принимаемый с аудиосервера, обозначает сигнал локального микрофона, обозначает норму, является индексом выборки из (истории) сигналов микрофона, причем обозначает самую последнюю доступную выборку,
обозначает сигнал, принимаемый с аудиосервера, обозначает сигнал локального микрофона, обозначает норму, является индексом выборки из (истории) сигналов микрофона, причем обозначает самую последнюю доступную выборку, 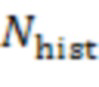 является количеством прошлых выборок, используемых в анализе, и является максимальной поддерживаемой задержкой между сигналами микрофона.
является количеством прошлых выборок, используемых в анализе, и является максимальной поддерживаемой задержкой между сигналами микрофона.
Например, 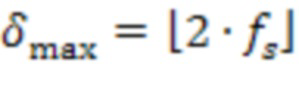 и при частоте выборки сигналов микрофона и операции округления вниз. В частности, для данного подхода значение должно быть достаточно большим, чтобы учитывать задержки между сигналом микрофона и сигналами, принимаемыми с аудиосервера, обусловленными задержками системы в (распределенной) системе из-за, например, кодирования, передачи (от клиента серверу), обработки на сервере, передачи (с сервера клиенту) и декодирования, а также из-за разных длин акустических путей между пользователями и микрофонами (в одном и том же помещении).
и при частоте выборки сигналов микрофона и операции округления вниз. В частности, для данного подхода значение должно быть достаточно большим, чтобы учитывать задержки между сигналом микрофона и сигналами, принимаемыми с аудиосервера, обусловленными задержками системы в (распределенной) системе из-за, например, кодирования, передачи (от клиента серверу), обработки на сервере, передачи (с сервера клиенту) и декодирования, а также из-за разных длин акустических путей между пользователями и микрофонами (в одном и том же помещении).
Если для определенного вышеупомянутая перекрестная корреляция высокая, например, 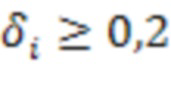 , пользователя можно считать находящимися в том же помещении (близким).
, пользователя можно считать находящимися в том же помещении (близким).
В альтернативном варианте реализации клиент может использовать сигнал микрофона, прежде чем применять к нему AEC. Он может сосредоточиться на задержках, превышающих, например, 15 мс, чтобы отделить акустическую обратную связь между динамиком и микрофоном в клиенте от большей задержки системы конференций. Клиент также может искать оба пика корреляции и предоставлять более короткую задержку для AEC.
Если один или более клиентов отправляют более одного аудиокомпонента, алгоритм может, например, выбрать самый громкий сигнал микрофона для анализа, вычислить понижающее микширование всех сигналов микрофона или выбрать конкретный сигнал микрофона.
Аналогичным образом, как и в подходе на стороне сервера, корреляция будет, как правило, вычисляться только тогда, когда пользователь говорит, и, в частности, когда активный динамик присутствует в одном из сигналов, принимаемых с сервера.
Аудиокомпоненты/аудиосигналы , принимаемые с аудиосервера 101, могут, как правило, представлять (по меньшей мере частично) других пользователей в конференц-вызове. Это позволяет удаленному клиенту определять, какие пользователи находятся в том же самом помещении, на основе того, какие сигналы имеют высокие корреляции. Сигналы некоторых пользователей могут быть не переданы ввиду того, что они приглушены или определены как неактивные аудиосервером.
Как упоминалось, в некоторых сигналах аудиокомпоненты могут быть объединены в аудиосмесь на аудиосервере 101. Когда сигналы представляют такую аудиосмесь, они могут представлять аудиоканалы, и сигналы некоторых пользователей могут быть представлены в множестве аудиоканалов. Поэтому анализ аудиоканалов по отдельности может не всегда приводить к особенно полезной дополнительной информации. Следовательно, может быть целесообразно микшировать с понижением сигналы и определять корреляцию результата с сигналом локального микрофона. Понижающее микширование можно вычислить по формуле:
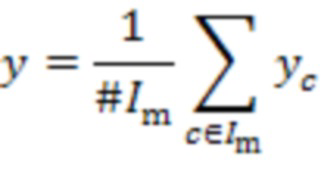
где 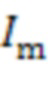 является набором индексов входных сигналов, относящихся к набору аудиосигналов, а
является набором индексов входных сигналов, относящихся к набору аудиосигналов, а 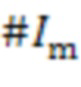 является количеством элементов набора .
является количеством элементов набора .
Результатом этого подхода является пониженная вычислительная сложность, что полезно для уменьшения использования ЦПУ в целом и/или повышения срока службы батареи в портативных устройствах.
Такой подход особенно выгоден, когда сигналы всех клиентов (по меньшей мере частично) предварительно микшируют или предварительно преобразовывают для воспроизведения на сервере, однако это может быть также применено для сигналов, которые не микшируют предварительно или не преобразовывают предварительно для воспроизведения.
В некоторых случаях, когда принимают аудиосмесь, может оказаться невозможно определить непосредственно, какие пользователи находятся в одном и том же помещении, поскольку может оказаться невозможно непосредственно различить аудиокомпоненты разных удаленных клиентов, когда они включены в одну и туже аудиосмесь. Однако клиент может отправлять метаданные, указывающие, что текущий активный пользователь (вероятно) находится в том же самом помещении. Аудиосервер 101 может учесть это, например, не включая при предварительном микшировании или предварительном преобразовании для воспроизведения сигнал активного пользователя в сигнал, который он отправляет клиенту, отправляющему метаданные, и наоборот.
Некоторые приложения для конференций отправляют информацию участников в вызове. В таких случаях это может быть использовано для определения того, какой пользователь активен на стороне клиента, когда обнаруживается высокая перекрестная корреляция, и удаленный клиент может отправить эту информацию серверу.
Сервер может выполнить последующую обработку принимаемых им метаданных для улучшения надежности. Например, может быть указано, что множество пользователей активны одновременно, в то время как третий клиент посылает метаданные, указывающие, что текущий активный пользователь находится в том же самом помещении. Затем аудиосервер может объединить это с информацией от этих двух пользователей, в которой один может также указывать, что текущий активный пользователь находится в том же самом помещении. В таком случае это может означать, что все трое находятся в одном и том же помещении. В альтернативном варианте реализации можно отметить флагом самого громкого из активных пользователей как находящегося в том же самом помещении, или увеличить значение правдоподобия для обоих активных пользователей. Когда значение правдоподобия больше определенного порогового значения, соответствующий пользователь может считаться находящимся в том же самом помещении. В альтернативном варианте реализации можно в предварительном микшировании уменьшить уровень пользователей в зависимости от возрастающего значения правдоподобия.
Различные способы, описанные выше, могут быть объединены для клиентов при получении как предварительно микшированных сигналов, так и отдельных сигналов, и/или при изменении свойств сигнала во времени (например, из-за изменения доступности полосы пропускания).
Аналогичным образом, как и в подходе на стороне сервера, с использованием тех же самых или подобных способов можно улучшить надежность в пределах клиентов.
В вариантах реализации, в которых выполняют перекрестную корреляцию между сигналами, она может быть осуществлена на сигналах полностью во временной области, как описано выше. В качестве альтернативы в некоторых вариантах реализации корреляция может быть выполнена на частотно-временном представлении (например, после банка квадратурных зеркальных фильтров (Quadrature Mirror Filter, QMF), кратковременного преобразование Фурье (Short-Term Fourier Transform, STFT) или анализа оконного модифицированного дискретного косинусного преобразования (Modified Discrete Cosine Transform, MDCT) или быстрого преобразования Фурье (Fast Fourier Transform, FFT)). В этих случаях каждая сумма в приведенных выше уравнениях корреляции становится двумерным суммированием по интервалам времени или кадрам во временном измерении () и полосам частот или элементам дискретизации в спектральном измерении ( ).
).
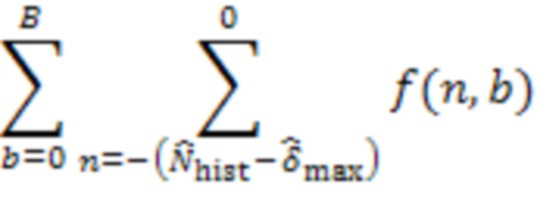
где 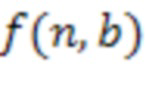 представляет соответствующую функцию от и/или
представляет соответствующую функцию от и/или  в уравнении корреляции, причем и принимают в качестве индекса временной области и в качестве индекса частотной области.
в уравнении корреляции, причем и принимают в качестве индекса временной области и в качестве индекса частотной области. 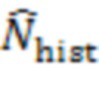 и
и 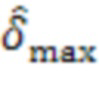 представляют собой, соответственно, и во временных интервалах или кадрах. Например,
представляют собой, соответственно, и во временных интервалах или кадрах. Например, 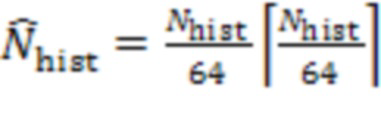 для банка фильтров QMF с коэффициентом понижающей дискретизации 64, или
для банка фильтров QMF с коэффициентом понижающей дискретизации 64, или 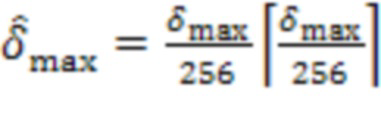 для оконного FFT с размером скачка 256 выборок с операцией
для оконного FFT с размером скачка 256 выборок с операцией  округления вверх.
округления вверх.
В качестве еще одного примера в некоторых вариантах реализации перекрестная корреляция может быть применена на свертке, профиле энергии или частотно-зависимом профиле энергии сигналов. Это выгодно для достижения пониженной вычислительной сложности и может быть полезно в случаях, когда сигналы реконструируют параметрически из меньшего количества сигналов понижающего микширования, и поэтому они с большей вероятностью имеют высокую корреляцию в локальной тонкой структуре реконструированных сигналов. В альтернативном варианте реализации в последнем случае корреляция также могла бы быть применена к параметрам реконструкции.
В случае вычислений частотно-зависимой корреляции в некоторых вариантах реализации может быть применено присвоение весовых коэффициентов определенным частотным элементам дискретизации/полосам, чтобы акцентировать типичные речевые частоты.
(Частотно-зависимый) профиль энергии может быть вычислен из сигналов следующим образом:
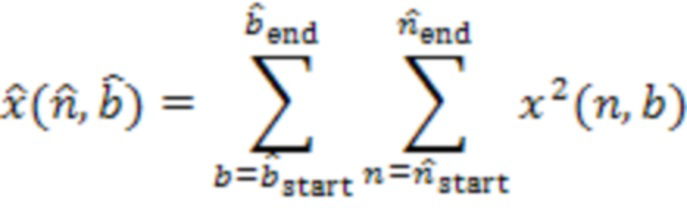
где каждое новое частотно-временное представление профиля  энергии является общей энергией всех частотно-временных ячеек в представлении
энергии является общей энергией всех частотно-временных ячеек в представлении 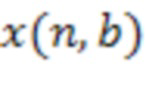 сигнала. Начальный и конечный элементы дискретизации для элемента дискретизации
сигнала. Начальный и конечный элементы дискретизации для элемента дискретизации  указаны как
указаны как 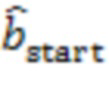 и
и 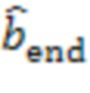 , соответственно, а начальный и конечный временные интервалы указаны как
, соответственно, а начальный и конечный временные интервалы указаны как 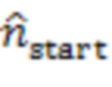 и
и 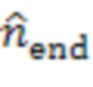 , соответственно. В случае сигналов чисто временной области (например, сигнал ИКМ) индекс и суммирование могут быть опущены.
, соответственно. В случае сигналов чисто временной области (например, сигнал ИКМ) индекс и суммирование могут быть опущены.
В некоторых вариантах реализации в качестве альтернативы или дополнительно могут быть использованы другие подходы к определению близости между удаленными клиентами 103.
Например, в некоторых вариантах реализации указания близости могут быть определены посредством прямой ручной конфигурации, например с использованием интерфейса отдельных удаленных клиентов. В других вариантах реализации может быть использована технология определения местоположения, такая как GPS, технологии определения местоположения внутри помещения, IP-адреса или идентификаторы сетей. В некоторых вариантах реализации удаленные клиенты отправляют такие данные на сервер, и он может затем оценить принятые данные для определения того, какие удаленные клиенты 103 находятся близко друг к другу.
Например, в качестве указания того, что удаленные клиенты являются близкими, могут быть использованы IP/MAC-адреса и/или времена задержки сетей. Например, тот факт, что удаленные клиенты 103 совместно используют одно и то же сетевое оборудование, указывает на нахождение в одном и том же месте.
В некоторых вариантах реализации близость двух удаленных клиентов может быть обнаружена путем обнаружения акустической обратной связи, и в этом случае система может перейти к предотвращению такой акустической обратной связи (например, путем изменения характеристик контура так, чтобы предотвратить положительную обратную связь).
Пример тестового процесса, который может быть использован для обнаружения близости путем обнаружения акустической обратной связи, может начинаться с заглушения всех микрофонов (или не предоставления клиентам обратной связи по аудиокомпонентам) для гарантирования отсутствия акустической обратной связи в данный момент. После этого можно включать микрофоны разных пар удаленных клиентов, и если это приводит к акустической обратной связи, то соответствующая пара удаленных клиентов считается близкой. Этот подход может прервать конференц-вызов на некоторое время, чтобы позволить обнаружить акустическую обратную связь в каждой паре клиентов.
Обнаружить акустическую обратную связь можно различными способами. Один подход с низкой сложностью заключается в том, чтобы определить, увеличиваются ли уровни множества клиентов, или обеспечивают ли один или более клиентских микрофонов экспоненциально возрастающий уровень. Учитывая среднюю двустороннюю задержку в системе, экспоненциальное возрастание среднеквадратического уровня может быть ступенчатым с периодичностью, аналогичной двусторонней задержке. В работе Devis Thomas, A.R. Jayan, Automated Suppression of Howling Noise Using Sinusoidal Model based Analysis/Synthesis, IEEE International Advance Computing Conference (IACC), ITM University, Gurgaon, India, с. 761-765, 2014, описано, что для обнаружения акустической обратной связи также может быть использована мера спектральной плоскостности (Spectral Flatness Measure, SFM). Другие подходы могут определять схожести в множестве сигналов микрофона от разных клиентов, такие как высокие корреляции между спектрами или спектрограммами. Еще одним примером является определение присутствия отсечения в сигналах микрофона.
Еще одним примером подхода к обнаружению того, какие клиенты, например, находятся в одном и том же месте, является добавление маркерного сигнала или водяного знака в аудиокомпонент каждого клиента. Этот маркер может быть выбран так, что он, как правило, не воспринимается людьми, и может быть выполнен с возможностью обнаружения в сигнале микрофона несмотря на искажения, накладываемые используемым кодеком и акустическим путем.
Например, сервер может вставлять эти маркеры в аудио, передаваемое клиентам. Часто выгодно, если клиент получает уникальный маркер. В дальнейшем в некоторых вариантах реализации сервер может анализировать принимаемые сигналы микрофона клиентов на предмет маркеров этих клиентов. В других вариантах реализации клиенты могут анализировать сигналы своих собственных микрофонов и передавать информацию о маркерах на сервер. Эта информация о маркерах может быть специально предназначенным идентификатором маркера, или она может сопоставить обнаруженный идентификатор маркера соответствующему клиенту в ответ на сопоставление метаданных, принимаемых им с сервера.
В вышеописанных примерах формирование аудиосмеси зависит от данных о близости. Однако понятно, что такие данные также могут быть использованы для других целей.
Например, в некоторых вариантах реализации данные о близости могут быть использованы для (например, пространственного) группирования пользователей в соответствии с тем, как они сгруппированы физически. В некоторых вариантах реализации, например, AR, данные о близости могут быть использованы для определения того, какие пользователи не присутствуют физически в помещении, и в таком случае вместо пользователя может быть представлен виртуальный аватар. В некоторых вариантах реализации данные о близости могут быть (дополнительно) использованы для преобразования для воспроизведения сигналов пользователей, не находящихся в физическом помещении в местах, которые не перекрываются с пользователями, находящимися в физическом помещении.
В некоторых вариантах реализации метаданные и/или анализ на стороне клиента могут быть использованы для синхронизации воспроизведения на разных устройствах так, чтобы достичь воспроизведения с малыми взаимными задержками.
В некоторых вариантах реализации данные о близости могут быть использованы для того, чтобы не преобразовывать для воспроизведения принимаемые с сервера сигналы, относящиеся к пользователям в одном и том же помещении, а в качестве альтернативы преобразовывать для воспроизведения сигнал, который захватывает локальный микрофон этих пользователей. Это может быть выгодно, когда пользователи носят наушники, которые могут блокировать или ослаблять акустические пути. За счет локального выполнения обработки можно устранить задержку системы конференций, что приводит к более хорошей синхронизации артикуляции.
В некоторых вариантах реализации первый удаленный клиент может передавать сформированный сигнал микрофона или аудиокомпонент второму удаленному клиенту, который обнаружен как находящийся в том же самом месте. Передача может осуществляться посредством прямой линии передачи данных (ЛВС/оптическая/РЧ) и может, в частности, исключать аудиосервер 101. Это может обеспечить линию связи/обмен данными с пониженной задержкой передачи. В таком случае второй удаленный клиент может использовать этот принимаемый напрямую сигнал для ослабления или подавления сигнала от аудиоисточника первого удаленного клиента. Такой подход может быть альтернативой к использованию акустического пути и выигрывает за счет более быстрой передачи (из-за разности в скорости света и звука). Благодаря чистому «опорному» аудио, своевременно доступному на втором удаленном клиенте, можно избежать ненужной сложной или подверженной ошибкам обработки аудио.
В некоторых вариантах реализации такая линия связи может быть использована для синхронизации воспроизведения аудиосмеси между удаленными клиентами, которые находятся в одном и том же помещении. В альтернативном варианте реализации такие метаданные синхронизации проходят через аудиосервер. В большинстве вариантов реализации синхронизация будет учитывать находящегося в том же самом месте клиента с наиболее высокой задержкой относительно данных, принимаемых с сервера, и задерживать воспроизведение аудиосмеси в других находящихся в том же месте клиентах для синхронизации. Этот непрерывный процесс синхронизации известен в данной области техники и может быть достигнут с использованием протоколов синхронизации, таких как протокол сетевого времени (Network Time Protocol, NTP) или протокол точного времени (Precision Time Protocol, PTP).
Как упоминалось ранее, акустическая близость может быть разной в направлении от первого удаленного клиента ко второму удаленному клиенту и в направлении от второго удаленного клиента к первому удаленному клиенту, что отражает тот факт, что акустическая передаточная функция может быть разной в этих двух направлениях. Соответственно, во многих вариантах реализации данные о близости могут содержать разные указания близости для пары удаленных клиентов 103 в зависимости от направления.
Например, данные о близости, предоставляемые аудиосервером 101 удаленному клиенту, могут содержать два значения для данного другого удаленного клиента, а локальное микширование аудио может соответственно выполняться в ответ на указание близости от этого другого удаленного клиента до данного удаленного клиента.
Использование асимметричных/направленных указаний близости может обеспечивать улучшенные рабочие характеристики во многих вариантах реализации, в том числе в конкретных ситуациях, в которых, например, один пользователь носит наушники, тогда как другой использует преобразование для воспроизведения акустической системой.
В некоторых вариантах реализации данные о близости могут быть сообщены/распределены при инициализации услуги/приложения, и эти данные о близости могут использоваться до завершения услуги/приложения. Например, при инициализации нового сеанса конференции данные о близости могут быть заменены и использоваться до завершения сеанса.
Однако в большинстве практических вариантов реализации система может быть выполнена с возможностью динамического определения/адаптации/распределения по меньшей мере некоторых данных о близости. Таким образом, приемник 401 обычно выполнен с возможностью приема данных о близости, динамически адаптирующихся к изменениям в положениях удаленных клиентов.
В частности, детектор(-ы) близости аудиосервера 101 и/или удаленных клиентов 103 могут непрерывно коррелировать соответствующие сигналы и определять указания близости на основе результатов корреляции. Тогда система может непрерывно распределять указания близости, например, путем непрерывной передачи метаданных, содержащих указания близости, вместе с распределением аудиокомпонентов.
Во многих вариантах реализации система может быть выполнена с возможностью передачи указаний близости для (по меньшей мере) первой пары удаленных клиентов с частотой обновления не менее одного раза в минуту и часто не менее одного раза в 30 секунд.
Такие динамические обновления могут обеспечивать эффективную и адаптивную систему, которая может адаптироваться к изменениям положений пользователей. Например, во многих вариантах реализации она может быстро адаптироваться к соединенному с помощью своего телефона участнику конференции, входящему в конференц-зал, где находится другой клиент. Например, часто можно предотвратить возникновение акустической обратной связи при входе участника в конференц-зал.
Понятно, что данные о близости могут быть переданы как метаданные множеством разных способов, и что конкретный используемый подход зависит от предпочтений и требований отдельного варианта реализации.
Точные структура, синтаксис и содержимое метаданных будут зависеть от конкретного варианта реализации. Таким образом, метаданные могут быть сконфигурированы и переданы различными способами, и предпочтительный подход может также зависеть от того, используется ли обнаружение на стороне клиента или обнаружение на стороне сервера (или их комбинация).
В случае обнаружения на стороне сервера метаданные обычно отправляют с сервера одному или более клиентам. Метаданные могут содержать информацию о том, какие пользователи/клиенты находятся в одном и том же месте. Например, может быть использовано указание индексов или имен клиентов, или битовая карта. Часть синтаксиса битовых потоков, отправляемых сервером клиентам, может быть, например, следующей:
Данный пример показывает синтаксис, который поддерживает разные способы отправки метаданных клиентам и выбирает способ в зависимости от предпочтительной настройки. Он обеспечивает всех клиентов информацией о имеющемся количестве уникальных местоположений (в качестве альтернативы о количестве местоположений с более чем 1 пользователем) и о том, какие пользователи в каком местоположении присутствуют.
В качестве другого примера соответствующие метаданные могут отправляться только пользователям, находящимся в одном и том же месте. Это показано в следующем примере синтаксиса:
В случае обнаружения на стороне клиента метаданные обычно отправляют на сервер, а сервер может, как правило, отправлять данные с аналогичной или производной информацией одному или более клиентам.
Клиент, например, может отправить флаг, который указывает, обнаруживается ли в данный момент времени высокая корреляция между выходным сигналом и сигналом микрофона (после AEC). Дополнительно или в качестве альтернативы он может отправить указание максимального значения корреляции.
В других вариантах реализации клиент может дополнительно использовать метаданные, указывающие, какие пользователи активны, и может передавать данные, указывающие одного или более конкретных пользователей, которые определены как находящиеся в том же самом месте. Это можно сделать с использованием синтаксиса, аналогичного описанному выше.
Кроме того, клиент может отправлять метаданные, описывающие, каким способом это было обнаружено, и/или какова задержка между прямым акустическим захватом и высокой корреляцией в аудиосигнале, принимаемом с сервера конференций.
Пример синтаксиса данных, отправляемых клиентом на сервер, следующий:
Пример определения метаданных способа обнаружения может быть следующим:
В ответ на подобные метаданные от одного или более клиентов сервер может отправить метаданные, аналогичные описанным выше. Сервер может объединять информацию, принимаемую от множества клиентов. Для этого он может объединять все указания о нахождении в одном и том же месте. Если, например, клиенты A и B указывают, что они находятся в том же месте, что и пользователь D, а клиент D указывает о нахождении в одном месте с пользователями A и C, сервер может указать, что пользователи A, B, C и D находятся в одном и том же месте.
В альтернативном варианте реализации он может указать, что пользователи A и D находятся в одном и том же месте, поскольку они взаимно указали совместно используемое место.
Понятно, что в вышеприведенном описании варианты реализации настоящего изобретения изложены для ясности со ссылкой на разные функциональные схемы, блоки и процессоры. Однако понятно, что может быть использовано любое подходящее распределение функциональных возможностей между разными функциональными схемами, блоками или процессорами без ущерба для настоящего изобретения. Например, показанные функциональные возможности, подлежащие осуществлению отдельными процессорами или контроллерами, могут быть осуществлены одним и тем же процессором или контроллерами. Поэтому ссылки на конкретные функциональные блоки или схемы должны рассматриваться только как ссылки на подходящие средства для обеспечения описываемых функциональных возможностей, а не как указание на строгую логическую или физическую структуру или организацию.
Настоящее изобретение может быть реализовано в любой подходящей форме, включая оборудование, программное обеспечение, встроенное программное обеспечение или любую их комбинацию. Настоящее изобретение необязательно может быть реализовано, по меньшей мере частично, в виде компьютерного программного обеспечения, выполняемого на одном или более процессорах и/или цифровых процессорах сигналов. Элементы и компоненты варианта реализации настоящего изобретения могут быть физически, функционально и логически реализованы любым подходящим образом. В действительности функциональные возможности могут быть реализованы в одном блоке, в множестве блоков или как часть других функциональных блоков. В силу этого настоящее изобретение может быть реализовано в одном блоке или может быть физически или функционально распределено между разными блоками, схемами и процессорами.
Хотя настоящее изобретение было описано в связи с некоторыми вариантами реализации, это не следует рассматривать как ограничение конкретной формой, изложенной в настоящем документе. Скорее, объем настоящего изобретения ограничен только прилагаемой формулой изобретения. Кроме того, хотя может показаться, что признак описан в связи с конкретными вариантами реализации, специалисту в данной области понятно, что различные признаки описанных вариантов реализации могут быть объединены в соответствии с настоящим изобретением. В формуле изобретения термин «содержащий/включающий» не исключает присутствия других элементов или этапов.
Кроме того, хотя множество средств, элементов, схем или этапов способа перечислены по отдельности, они могут быть реализованы, например, с помощью одной схемы, блока или процессора. Далее, хотя отдельные признаки могут быть включены в разные пункты формулы изобретения, они, возможно, могут быть эффективно объединены, а включение в разные пункты формулы изобретения не означает, что комбинация признаков является неосуществимой и/или невыгодной. Кроме того, включение признака в одну категорию пунктов формулы изобретения не означает ограничения этой категорией, а, скорее, указывает на то, что данный признак в равной степени может быть применен к другим категориям пунктов изобретения, когда это уместно. Кроме того, порядок признаков в формуле изобретения не означает конкретного порядка, в котором эти признаки должны прорабатываться, и, в частности, порядок отдельных этапов в формуле изобретения на способ, не означает, что этапы должны выполняться в данном порядке. Наоборот, этапы могут выполняться в любом подходящем порядке. Кроме того, упоминания в единственном числе не исключают множества. Поэтому ссылки с использованием средств указания единственного числа, числительных в единственном числе «первый», «второй» и т. д. не исключают множества. Ссылочные позиции в формуле изобретения приведены исключительно в качестве уточняющего примера и не должны трактоваться как ограничивающие объем формулы изобретения каким-либо образом.
| название | год | авторы | номер документа |
|---|---|---|---|
| Аудиоустройство и способ обработки аудио | 2019 |
|
RU2823573C1 |
| Аудиоустройство и способ обработки аудио | 2019 |
|
RU2815366C2 |
| Аудиоустройство и способ обработки аудио | 2019 |
|
RU2815621C1 |
| Аудиоустройство и способ обработки аудио | 2019 |
|
RU2798414C2 |
| АУДИОУСТРОЙСТВО И СПОСОБ ЕГО РАБОТЫ | 2019 |
|
RU2797362C2 |
| Аудиоустройство и способ для него | 2020 |
|
RU2804014C2 |
| Устройство и способ обработки аудиовизуальных данных | 2019 |
|
RU2805260C2 |
| УСТРОЙСТВО И СПОСОБ ФОРМИРОВАНИЯ СИГНАЛА РАССЕЯННОЙ РЕВЕРБЕРАЦИИ | 2021 |
|
RU2838375C1 |
| УСТРОЙСТВО И СПОСОБ КОДИРОВАНИЯ АУДИО | 2020 |
|
RU2823537C1 |
| ОПТИМИЗАЦИЯ ДОСТАВКИ ЗВУКА ДЛЯ ПРИЛОЖЕНИЙ ВИРТУАЛЬНОЙ РЕАЛЬНОСТИ | 2022 |
|
RU2801698C2 |
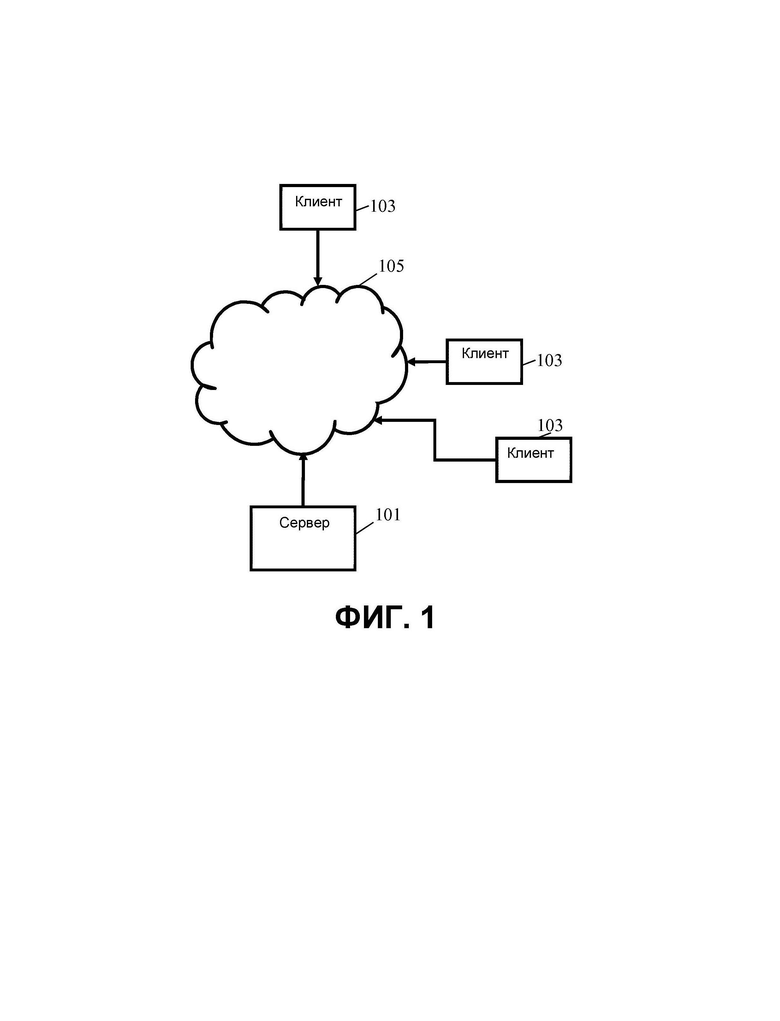
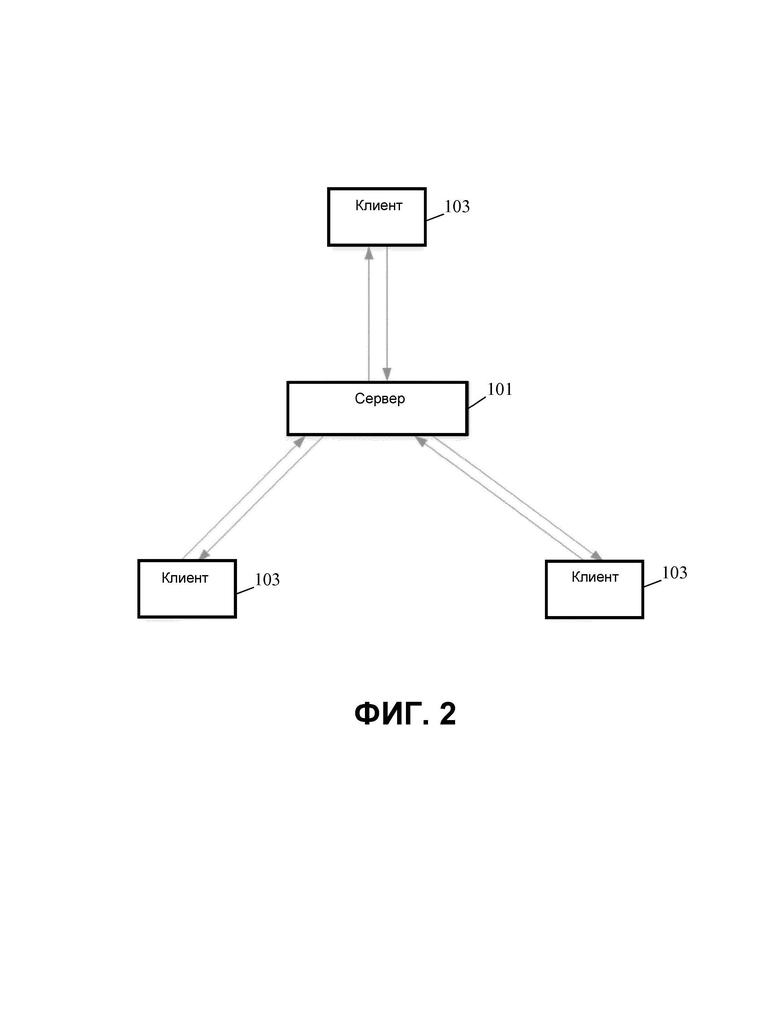
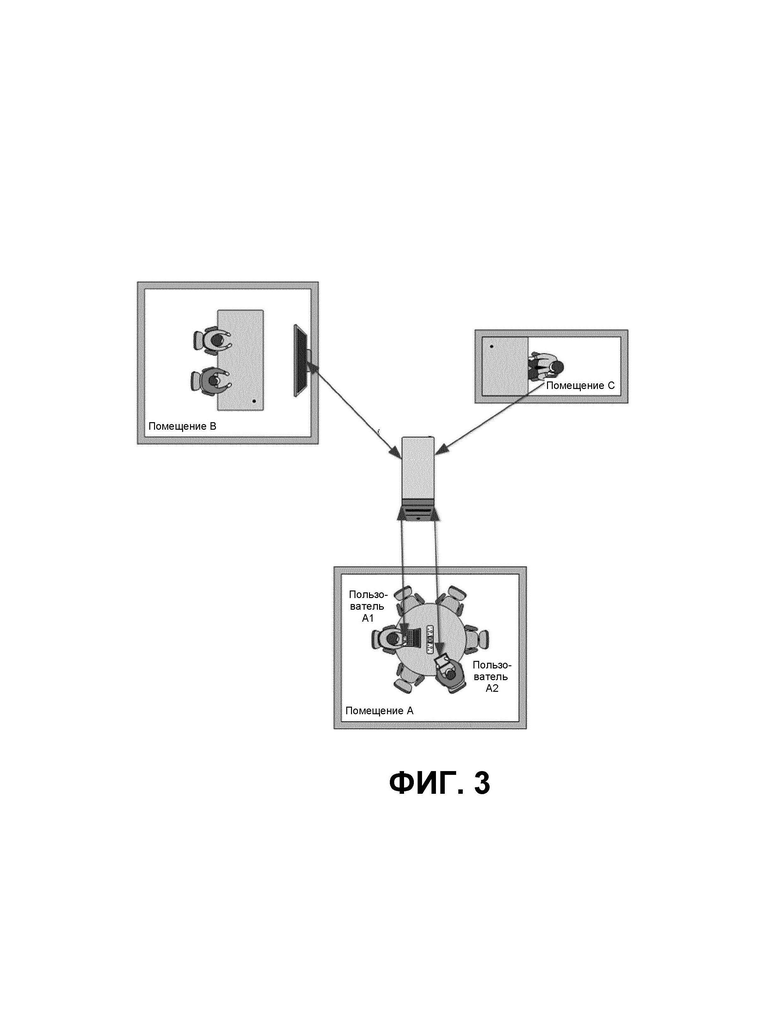
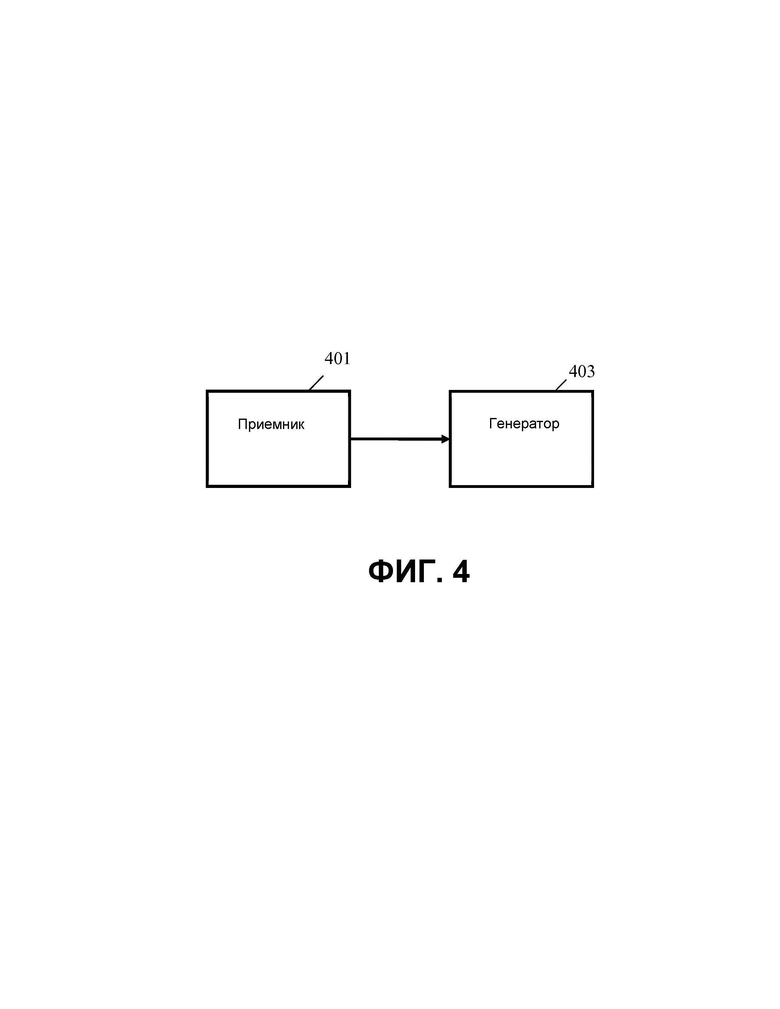
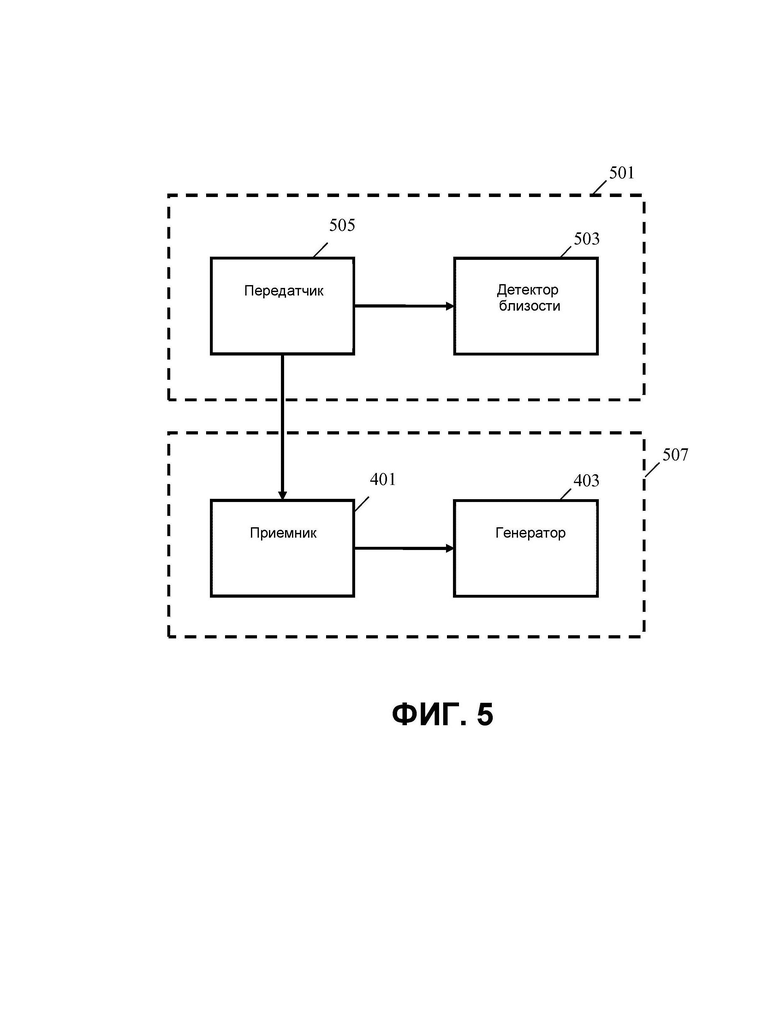

Изобретение относится к аудиоустройству, системе распределения аудио и способу их работы. Техническим результатом является повышение эффективности выравнивания аудио от удаленных клиентов в зависимости от физической близости между ними. Система распределения аудио содержит: множество удаленных клиентов; аудиосервер для приема входящего аудио от множества удаленных клиентов и для передачи аудио, получаемого из входящего аудио, по меньшей мере одному из множества удаленных клиентов, содержащий приемник для приема данных, содержащих: аудиоданные для множества аудиокомпонентов, причем каждый аудиокомпонент представляет аудио от удаленного клиента из множества удаленных клиентов; данные о близости по меньшей мере для одного из аудиокомпонентов; генератор для формирования аудиосмеси множества аудиокомпонентов в ответ на данные о близости, выполненный с возможностью формирования аудиосмеси для первого удаленного клиента из множества удаленных клиентов, включающей определение ослабления в первой аудиосмеси второго аудиокомпонента для второго удаленного клиента в ответ на данные о близости, при этом аудиосервер также содержит передатчик для передачи первой аудиосмеси первому удаленному клиенту. 3 н. и 8 з.п. ф-лы, 6 ил.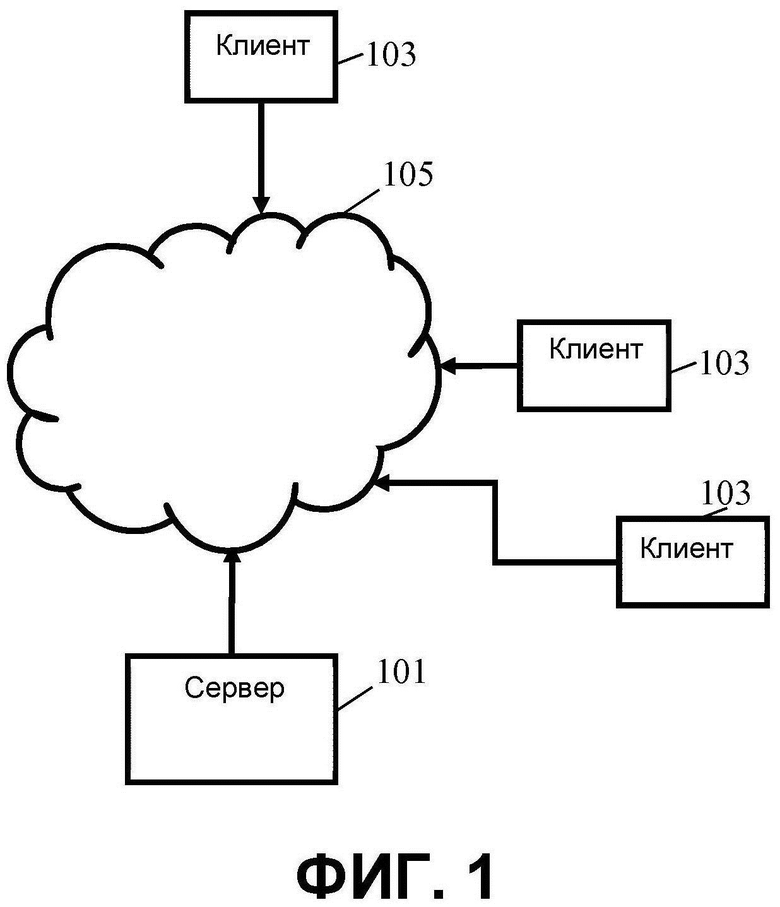
1. Аудиоустройство для системы распределения аудио, содержащей аудиосервер (101) для приема входящего аудио от множества удаленных клиентов (103) и для передачи аудио, получаемого из входящего аудио, по меньшей мере некоторым из множества удаленных клиентов (103); при этом устройство содержит:
приемник (401) для приема данных, содержащих:
аудиоданные для множества аудиокомпонентов, причем каждый аудиокомпонент представляет аудио от удаленного клиента из множества удаленных клиентов;
данные о близости по меньшей мере для одного из аудиокомпонентов, причем данные о близости указывают физическую близость между удаленными клиентами в акустической окружающей среде реального мира; и
генератор (403) для формирования аудиосмеси множества аудиокомпонентов в ответ на данные о близости,
причем аудиоустройство является частью аудиосервера (101), а генератор (403) выполнен с возможностью формирования первой аудиосмеси для первого удаленного клиента из множества удаленных клиентов, причем формирование первой аудиосмеси включает определение ослабления в первой аудиосмеси второго аудиокомпонента для второго удаленного клиента в ответ на данные о близости; при этом аудиоустройство также содержит передатчик для передачи первой аудиосмеси первому удаленному клиенту.
2. Аудиоустройство по п. 1, в котором генератор (403) выполнен с возможностью ослабления второго аудиокомпонента в первой аудиосмеси для данных о близости, удовлетворяющих критерию близости для первого удаленного клиента и второго удаленного клиента.
3. Аудиоустройство по любому предыдущему пункту, в котором данные о близости содержат скалярное указание близости для по меньшей мере первого удаленного клиента и второго удаленного клиента, причем скалярное указание близости указывает акустическое ослабление от аудиоисточника второго удаленного клиента до элемента захвата первого удаленного клиента.
4. Аудиоустройство по любому предыдущему пункту, в котором данные о близости содержат указание близости первого удаленного клиента со вторым удаленным клиентом, которое отличается от близости второго удаленного клиента с первым удаленным клиентом.
5. Аудиоустройство по п. 1, в котором приемник (401) выполнен с возможностью приема данных о близости с динамической адаптацией к изменениям в положениях по меньшей мере одного из множества удаленных клиентов (103).
6. Система распределения аудио, содержащая:
множество удаленных клиентов (103);
аудиосервер (101) для приема входящего аудио от множества удаленных клиентов (103) и для передачи аудио, получаемого из входящего аудио, по меньшей мере одному из множества удаленных клиентов (103); причем аудиосервер содержит:
приемник (401) для приема данных, содержащих:
аудиоданные для множества аудиокомпонентов, причем каждый аудиокомпонент представляет аудио от удаленного клиента из множества удаленных клиентов;
данные о близости по меньшей мере для одного из аудиокомпонентов, причем данные о близости указывают физическую близость между удаленными клиентами в акустической окружающей среде реального мира;
генератор (403) для формирования аудиосмеси множества аудиокомпонентов в ответ на данные о близости,
причем генератор (403) выполнен с возможностью формирования первой аудиосмеси для первого удаленного клиента из множества удаленных клиентов, причем формирование первой аудиосмеси включает определение ослабления в первой аудиосмеси второго аудиокомпонента для второго удаленного клиента в ответ на данные о близости, при этом аудиосервер также содержит передатчик для передачи первой аудиосмеси первому удаленному клиенту.
7. Система распределения аудио по п. 6, которая содержит детектор (503, 609) близости, выполненный с возможностью определения указания близости для первого удаленного клиента и второго удаленного клиента в ответ на сравнение первого аудиокомпонента для первого удаленного клиента и второго аудиокомпонента для второго удаленного клиента; и передатчик (505) для передачи данных о близости, содержащих указание близости, приемнику (401).
8. Система распределения аудио по п. 7, в которой детектор (503) является частью аудиосервера (101).
9. Система распределения аудио по п. 6, в которой первый удаленный клиент из множества удаленных клиентов содержит:
вход (601) для формирования сигнала микрофона, соответствующего аудио, захваченному набором микрофонов;
детектор (609) близости, выполненный с возможностью определения указания близости для первого удаленного клиента в ответ на сравнение сигнала микрофона и аудио, принятого с аудиосервера (101); и
передатчик (605) для передачи акустических аудиоданных, содержащих указание близости, на аудиосервер (101).
10. Система распределения аудио по п. 9, в которой передатчик (605) выполнен с возможностью передачи данных о близости, указывающих на то, что текущий активный удаленный клиент определен как близкий в ответ на определение первым детектором близости высокой корреляции между сигналом микрофона и аудио, принятым с аудиосервера.
11. Способ работы аудиоустройства для системы распределения аудио, содержащей аудиосервер (101) для приема входящего аудио от множества удаленных клиентов (103) и для передачи аудио, полученного из входящего аудио, по меньшей мере некоторым из множества удаленных клиентов (103); при этом способ включает выполнение аудиосервером следующих этапов:
прием данных, содержащих:
аудиоданные для множества аудиокомпонентов, причем каждый аудиокомпонент представляет аудио от удаленного клиента из множества удаленных клиентов;
данные о близости по меньшей мере для одного из аудиокомпонентов, причем данные о близости указывают физическую близость между удаленными клиентами в акустической окружающей среде реального мира; и
формирование аудиосмеси множества аудиокомпонентов в ответ на данные о близости,
причем формирование включает формирование первой аудиосмеси для первого удаленного клиента из множества удаленных клиентов, причем формирование первой аудиосмеси включает определение ослабления в первой аудиосмеси второго аудиокомпонента для второго удаленного клиента в ответ на данные о близости, при этом способ также включает передачу аудиосервером первой аудиосмеси первому удаленному клиенту.
| US 7379962 B1, 27.05.2008 | |||
| US 20160189726 A1, 30.06.2016 | |||
| WO 2017205986 A1, 07.12.2017 | |||
| US 20090097360 A1, 16.04.2009 | |||
| JP 2009115735 A, 28.05.2009 | |||
| СИСТЕМА И СПОСОБ ОСЛАБЛЕНИЯ ЗВУКА В ТРАНСПОРТНОМ СРЕДСТВЕ ДЛЯ ПРОСЛУШИВАНИЯ УКАЗАНИЙ ОТ МОБИЛЬНЫХ ПРИЛОЖЕНИЙ | 2014 |
|
RU2627127C2 |
| УСТРОЙСТВО ДЛЯ ОБРАБОТКИ ЗВУКОВЫХ СИГНАЛОВ | 2009 |
|
RU2542586C2 |

