ОБЛАСТЬ ТЕХНИКИ
Настоящее изобретение относится к способу и устройству для кодирования аудио и, в частности, но не исключительно, для кодирования аудио для динамических приложений, таких как приложения виртуальной реальности.
УРОВЕНЬ ТЕХНИКИ
Разнообразие и диапазон аудио- и видеоприложений в последние годы значительно выросли, поскольку постоянно разрабатываются и внедряются новые сервисы и способы использования и потребления аудио, изображений и видео.
Например, одним из все более популярных сервисов является предоставление аудио и изображений таким образом, чтобы зритель мог активно и динамически взаимодействовать с системой для изменения параметров преобразования для воспроизведения (рендеринга, rendering). Весьма привлекательной функцией во многих приложениях является возможность изменения эффективного положения просмотра/прослушивания. Такая функция может, в частности, предоставлять пользователю ощущение виртуальной реальности.
Тенденция заключается в предоставлении большей гибкости, которая обеспечивает возможность адаптации сцены со стороны преобразования для воспроизведения. Для обеспечения повышенной гибкости стороны преобразования для воспроизведения для преобразования для воспроизведения аудиосцены был предложен ряд подходов к кодированию аудио и распределению, в которых аудиосцена может быть представлена комбинациями различных элементов аудио. Например, элементы аудио могут представлять собой отдельные источники звука, например, собственные динамики и т. д. В некоторых подходах все элементы аудио являются однотипными, но все чаще разрабатываются системы, которые обеспечивают возможность одновременного использования и поддержки нескольких различных типов аудио. Например, некоторые элементы аудио могут быть аудиоканалами, другие могут быть отдельными аудиообъектами, а третьи могут быть основаны на сцене, например, амбисоническими элементами аудио и т.д. Во многих системах метаданные могут быть предоставлены вместе с аудиоданными, которые представляют элементы аудио. Такие метаданные могут, например, указывать номинальное положение в сцене для аудиоисточника элемента аудио.
Такие подходы могут обеспечить высокий уровень настройки и адаптации со стороны клиента/преобразования для воспроизведения. Например, аудиосцена может быть локально адаптирована к изменениям виртуального положения слушателей в аудиосцене или к конкретным предпочтениям конкретного слушателя.
В качестве конкретного примера, консорциум 3GPP в настоящее время разрабатывает так называемый кодек иммерсивных голосовых и аудиосервисов (Immersive Voice and Audio Services, IVAS). Этот кодек сможет обеспечить возможность кодировки аудиоконтента в различных конфигурациях, таких как конфигурации на основе канала, объекта или сцены (в частности, амбисонической). Назначение кодирования состоит в том, чтобы передать аудиоинформацию с минимальным объемом данных.
Кроме того, кодек IVAS должен содержать преобразователь для воспроизведения, чтобы переводить различные потоки аудио в вид, пригодный для воспроизведения на принимающем конце. Например, аудио может отображаться на конфигурацию известной акустической системы, или аудио может быть преобразовано в бинауральный формат для воспроизведения через наушники.
В сфере применения кодека IVAS 3GPP продолжается работа по сбору возможных вариантов использования. Для этого предполагается, что кодек должен обеспечивать интерактивность для управления преобразованием для воспроизведения. Например, возможно, аудио в наушниках должно быть преобразовано для воспроизведения независимо от положения и перемещения головы, что означает, что оно должно быть скомпенсировано для движений головы. В качестве другого примера пользователю может быть предоставлена возможность пространственного позиционирования элементов аудио, например (повторного) позиционирования объектов, передающих аудио участников виртуального собрания.
Преобразователь для воспроизведения считается частью рабочего элемента кодека IVAS 3GPP и рассматривается как внутренний по отношению к кодеку IVAS. Однако было предложено, чтобы кодек также включал режим сквозной передачи. Этот режим обеспечил бы возможность представления элементов аудио на выходе декодера в той же конфигурации (конфигурациях), в которой они были введены на входе кодера (т.е. как элементы аудио на основе канала, объекта и сцены в соотношении 1:1). Посредством выделенного внешнего интерфейса преобразования для воспроизведения внешний преобразователь для воспроизведения может иметь доступ к этим элементам и может реализовать альтернативное преобразование для воспроизведения к внутреннему преобразователю IVAS для воспроизведения.
Такой подход может обеспечить дополнительную гибкость и расширить возможности для настройки и адаптации на принимающем конце. Однако данный подход может также иметь сопутствующие недостатки. Например, существует компромисс между гибкостью и качеством аудио и сложностью. Обычно может быть полезно ограничить свободу, тем самым позволяя поставщику контента сохранять некоторый контроль над преобразованием для воспроизведения на стороне клиента. Это может не только способствовать преобразованию для воспроизведения и обеспечить преобразованную для воспроизведения аудиосцену, которая является более реалистичной, но также может обеспечить возможность сохранения поставщиком контента некоторого контроля над восприятием, предоставляемым пользователю. Например, это может препятствовать генерированию преобразователем для воспроизведения аудиосцены, которая является нереалистичной, и которая может негативно отразиться на контенте и поставщике контента.
Предусмотрено, что кодированные элементы аудио могут быть дополнены метаданными, которые ограничивают то, как преобразователю для воспроизведения разрешено выполнять преобразование для воспроизведения элементов аудио. Во многих ситуациях это может позволить добиться лучшего компромисса между различными требованиями. Однако это может быть оптимальным не во всех ситуациях и может, например, потребовать увеличенной передачи данных, и может привести к снижению гибкости и/или качества преобразованной для воспроизведения аудиосцены.
Поэтому был бы желателен усовершенствованный подход. В частности, был бы полезен подход, который позволяет улучшить работу, повысить гибкость, упростить реализацию, упростить работу, снизить стоимость, снизить сложность, снизить скорость передачи данных, улучшить воспринимаемое качество аудио, улучшить управление преобразованием для воспроизведения, улучшить компромиссы и/или повысить производительность.
РАСКРЫТИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
Соответственно, настоящее изобретение предпочтительно направлено на ослабление, смягчение или устранение одного или более из вышеуказанных недостатков по отдельности или в любой комбинации.
Согласно одному аспекту настоящего изобретения предложено устройство для кодирования аудио, содержащее: аудиоприемник для приема множества элементов аудио, представляющих аудиосцену; приемник метаданных для приема входных метаданных представления для множества элементов аудио, причем входные метаданные представления описывают ограничения представления для преобразования для воспроизведения множества элементов аудио, ограничивающие параметр преобразования для воспроизведения, который может быть адаптирован при преобразовании для воспроизведения элементов аудио, при этом ограничения представления содержат по меньшей мере одно ограничение из группы, состоящей из: ограничения реверберации, ограничения усиления и ограничения управлением динамическим диапазоном; аудиокодер для генерирования кодированных аудиоданных для аудиосцены путем кодирования множества элементов аудио, причем кодирование выполняется в ответ на входные метаданные представления посредством включения в объединяющий блок (215) для генерирования объединенного элемента аудио путем объединения по меньшей мере первого элемента аудио и второго элемента аудио из множества элементов аудио в ответ на входные метаданные представления для первого элемента аудио и входные метаданные представления для второго элемента аудио, и указанный аудиокодер (205) выполнен с возможностью генерирования объединенных данных устройство для кодирования аудио для первого и второго элемента аудио путем кодирования объединенного элемента аудио и включения объединенных данных устройство для кодирования аудио в кодированные аудиоданные; схему метаданных для генерирования выходных метаданных представления из входных метаданных представления, причем выходные метаданные представления содержат данные для кодированных элементов аудио, которые величину, на которую возможно адаптирование адаптируемого параметра преобразования для воспроизведения может быть адаптирован при преобразовании для воспроизведения кодированных элементов аудио; схему вывода для генерирования потока кодированных аудиоданных, содержащего кодированные аудиоданные и выходные метаданные представления.
Настоящее изобретение может обеспечить улучшенное и/или более гибкое кодирование во многих сценариях. Данный подход может во многих вариантах осуществления обеспечить возможность генерирования потока кодированных аудиоданных, который обеспечивает улучшенное соотношение качества к скорости передачи данных. Поток кодированных аудиоданных может быть сгенерирован для обеспечения некоторой гибкости преобразования для воспроизведения, а также для обеспечения определенного управления преобразованием для воспроизведения со стороны источника/кодирования.
Метаданные представления для элемента аудио могут ограничивать по меньшей мере одно из пространственного параметра и параметра громкости для преобразования для воспроизведения элемента аудио, включая, например, ограничение положения преобразования для воспроизведения, уровня усиления, уровня сигнала, пространственного распределения или свойства реверберации.
Аудиокодер может быть выполнен с возможностью адаптации кодирования элемента аудио на основе входных метаданных представления и, в частности, на основе входных метаданных представления для элемента аудио. Адаптация может адаптировать сжатие битов/данных (скорость) для кодирования элемента аудио. Битрейт, полученный в результате кодирования элемента аудио, может быть адаптирован на основе входных метаданных представления.
Входные метаданные представления могут описывать ограничения представления/преобразования для воспроизведения для принятого множества элементов аудио. Кодированные аудиоданные могут содержать аудиоданные для множества кодированных элементов аудио. Множество кодированных элементов аудио может быть сгенерировано путем кодирования принятого множества элементов аудио. Выходные метаданные представления описывают ограничения представления/преобразования для воспроизведения для преобразования для воспроизведения множества кодированных элементов аудио.
Ограничение воспроизведения может быть ограничением преобразования для воспроизведения и может ограничивать параметр преобразования для воспроизведения для элемента аудио. Параметр преобразования для воспроизведения может быть параметром процесса преобразования для воспроизведения и/или свойством преобразованного для воспроизведения сигнала.
Выходные метаданные представления могут, в частности, представлять собой любые данные, ассоциированные/связанные/предоставленные для кодированных элементов аудио, сгенерированных аудиокодером, которые ограничивают степень, в которой один или более адаптируемых/переменных аспектов/свойств/параметров представления/преобразования для воспроизведения могут/в состоянии быть адаптированы при преобразовании для воспроизведения кодированных элементов аудио.
Выходные метаданные представления, и в частности данные для кодированных элементов аудио, которые ограничивают степень, в которой адаптируемый параметр преобразования для воспроизведения может быть адаптирован при преобразовании для воспроизведения кодированных элементов аудио, могут быть сгенерированы схемой метаданных в ответ на ограничения представления, ограничивающие параметр преобразования для воспроизведения, который может быть адаптирован при преобразовании для воспроизведения множества элементов аудио.
Аудиокодер может генерировать кодированные аудиоданные для включения множества кодированных элементов аудио (путем кодирования множества элементов аудио).
Аудиокодер содержит объединяющий блок для генерирования объединенного элемента аудио путем объединения по меньшей мере первого элемента аудио и второго элемента аудио из множества элементов аудио в ответ на входные метаданные представления для первого элемента аудио и входные метаданные представления для второго элемента аудио, и аудиокодер выполнен с возможностью генерирования объединенных данных кодирования аудио для первого и второго элемента аудио путем кодирования объединенного элемента аудио, и включения объединенных данных кодирования аудио в кодированные аудиоданные.
Это может обеспечить особенно эффективное кодирование и/или гибкость во многих вариантах осуществления. Во многих вариантах осуществления это может, в частности, обеспечить эффективное сжатие битрейта с уменьшенным ухудшением восприятия.
В соответствии с используемым при необходимости признаком настоящего изобретения объединяющий блок выполнен с возможностью выбора первого элемента аудио и второго элемента аудио из множества элементов аудио в ответ на входные метаданные представления для первого элемента аудио и для второго элемента аудио.
Это может обеспечить особенно эффективное кодирование и/или гибкость во многих вариантах осуществления.
В соответствии с используемым при необходимости признаком настоящего изобретения объединяющий блок выполнен с возможностью выбора первого элемента аудио и второго элемента аудио в ответ на определение того, что по меньшей мере некоторые входные метаданные представления для первого элемента аудио и входные метаданные представления для второго элемента аудио соответствуют критерию сходства.
Это может обеспечить особенно эффективное кодирование и/или гибкость во многих вариантах осуществления. Критерий сходства может включать требование о том, что ограничения преобразования для воспроизведения для параметра преобразования для воспроизведения, ограниченного метаданными представления, удовлетворяют критерию сходства.
В соответствии с используемым при необходимости признаком настоящего изобретения входные метаданные представления для первого элемента аудио и входные метаданные представления для второго элемента аудио содержат по меньшей мере одно из ограничения усиления и ограничения положения.
Это может обеспечить особенно эффективную работу во многих вариантах осуществления.
В соответствии с используемым при необходимости признаком настоящего изобретения аудиокодер дополнительно выполнен с возможностью генерирования объединенных метаданных представления для объединенного элемента аудио в ответ на входные метаданные представления для первого элемента аудио и входные метаданные представления для второго элемента аудио и включения объединенных метаданных представления в выходные метаданные представления.
Это может обеспечить улучшенное функционирование во многих вариантах осуществления и, в частности, во многих вариантах осуществления может позволить кодеру обрабатывать объединенные элементы аудио и кодированные входные элементы аудио таким же образом и, по сути, без знания того, является ли отдельный элемент аудио объединенным элементом аудио или нет.
В соответствии с используемым при необходимости признаком настоящего изобретения аудиокодер выполнен с возможностью генерирования по меньшей мере некоторых объединенных метаданных представления для отражения ограничения параметра воспроизведения для объединенного элемента аудио, причем ограничение определено как ограничение, удовлетворяющее как ограничению для первого элемента аудио, указанному входными метаданными представления для первого элемента аудио, так и ограничению для второго элемента аудио, указанному входными метаданными представления для второго элемента аудио.
Это может обеспечить повышенную эффективность во многих сценариях и приложениях.
В соответствии с используемым при необходимости признаком настоящего изобретения аудиокодер выполнен с возможностью адаптации сжатия первого элемента аудио в ответ на входные метаданные представления для второго элемента аудио.
Данный подход, как правило, может обеспечить улучшенное сжатие и кодирование элемента аудио. Сжатие может представлять собой уменьшение битрейта, и увеличение сжатия может привести к уменьшению скорости передачи данных кодированного элемента аудио. Сжатие может представлять собой уменьшение битрейта/сжатие . Кодирование аудио может быть таким, что кодированный элемент аудио, представляющий один или более входных элементов аудио, представлен меньшим количеством битов, чем один или более входных элементов аудио.
В соответствии с используемым при необходимости признаком настоящего изобретения аудиокодер выполнен с возможностью оценки эффекта маскирования на первый элемент аудио от второго элемента аудио в ответ на входные метаданные представления для второго элемента аудио, и с возможностью адаптации сжатия первого элемента аудио в ответ на эффект маскирования.
Это может обеспечить особенно эффективную работу и улучшенные характеристики во многих вариантах осуществления.
В соответствии с используемым при необходимости признаком настоящего изобретения аудиокодер выполнен с возможностью оценки эффекта маскирования для первого элемента аудио от второго элемента аудио в ответ по меньшей мере на одно из ограничения усиления и ограничения положения для второго элемента аудио, указанного входными метаданными представления для второго элемента аудио.
Это может обеспечить особенно эффективную работу и улучшенные характеристики во многих вариантах осуществления.
В соответствии с используемым при необходимости признаком настоящего изобретения аудиокодер дополнительно выполнен с возможностью адаптации сжатия первого элемента аудио в ответ на входные метаданные представления для первого элемента аудио.
Это может обеспечить особенно эффективную работу и/или рабочие характеристики во многих вариантах осуществления.
В соответствии с используемым при необходимости признаком настоящего изобретения входные метаданные представления содержат приоритетные данные по меньшей мере для некоторых элементов аудио, и кодер выполнен с возможностью адаптации сжатия для первого элемента аудио в ответ на указание приоритета для первого элемента аудио во входных метаданных представления.
Это может обеспечить особенно эффективную работу и/или рабочие характеристики во многих вариантах осуществления.
В соответствии с используемым при необходимости признаком настоящего изобретения аудиокодер выполнен с возможностью генерирования данных адаптированного кодирования, указывающих на то, как кодирование адаптируется в ответ на входные метаданные представления, и с возможностью включения данных адаптированного кодирования в поток кодированных аудиоданных.
Это может обеспечить особенно эффективную работу и/или рабочие характеристики во многих вариантах осуществления. Это может, в частности, позволить улучшить адаптацию декодером для соответствия процессу кодирования.
Согласно одному аспекту настоящего изобретения предложен способ кодирования аудио, включающий: прием множества элементов аудио, представляющих аудиосцену; прием входных метаданных представления для множества элементов аудио, причем входные метаданные представления описывают ограничения представления для преобразования для воспроизведения множества элементов аудио, причем ограничения представления ограничивают параметр преобразования для воспроизведения, который может быть адаптирован при преобразовании для воспроизведения элементов аудио при этом ограничения представления содержат по меньшей мере одно ограничение из группы, состоящей из: ограничения реверберации, ограничения усиления и ограничения управлением динамическим диапазоном; генерирование кодированных аудиоданных для аудиосцены путем кодирования множества элементов аудио, причем кодирование выполняется в ответ на входные метаданные представленияпосредством включения в объединяющий блок (215) для генерирования объединенного элемента аудио путем объединения по меньшей мере первого элемента аудио и второго элемента аудио из множества элементов аудио в ответ на входные метаданные представления для первого элемента аудио и входные метаданные представления для второго элемента аудио, и указанный аудиокодер (205) выполнен с возможностью генерирования объединенных данных устройство для кодирования аудио для первого и второго элемента аудио путем кодирования объединенного элемента аудио и включения объединенных данных устройство для кодирования аудио в кодированные аудиоданные; генерирование выходных метаданных представления из входных метаданных представления, причем выходные метаданные представления содержат данные для кодированных элементов аудио, которые ограничивают величину, на которую адаптируемый параметр преобразования для воспроизведения может быть адаптирован при преобразовании для воспроизведения кодированных элементов аудио; и генерирование потока кодированных аудиоданных, содержащего кодированные аудиоданные и выходные метаданные представления.
Эти и другие аспекты, признаки и/или преимущества настоящего изобретения станут очевидны из вариантов осуществления, описанных далее в настоящем документе, и будут пояснены со ссылкой на вариант(ы) осуществления.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Варианты осуществления изобретения будут описаны только посредством примера со ссылкой на чертежи, на которых:
на фиг. 1 показан пример элементов системы распределения аудио согласно некоторыми вариантами осуществления настоящего изобретения;
на фиг. 2 показан пример элементов устройства кодирования аудио согласно некоторым вариантам осуществления настоящего изобретения; и
на фиг. 3 показан пример элементов устройства декодирования аудио согласно некоторым вариантам осуществления настоящего изобретения.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
В следующем описании основное внимание будет уделено системе кодирования и декодирования аудио, которая может быть совместима с кодеком 3GPP Immersive Voice and Audio Services (IVAS), но следует понимать, что описанные принципы и концепции могут быть использованы во многих других приложениях и вариантах осуществления.
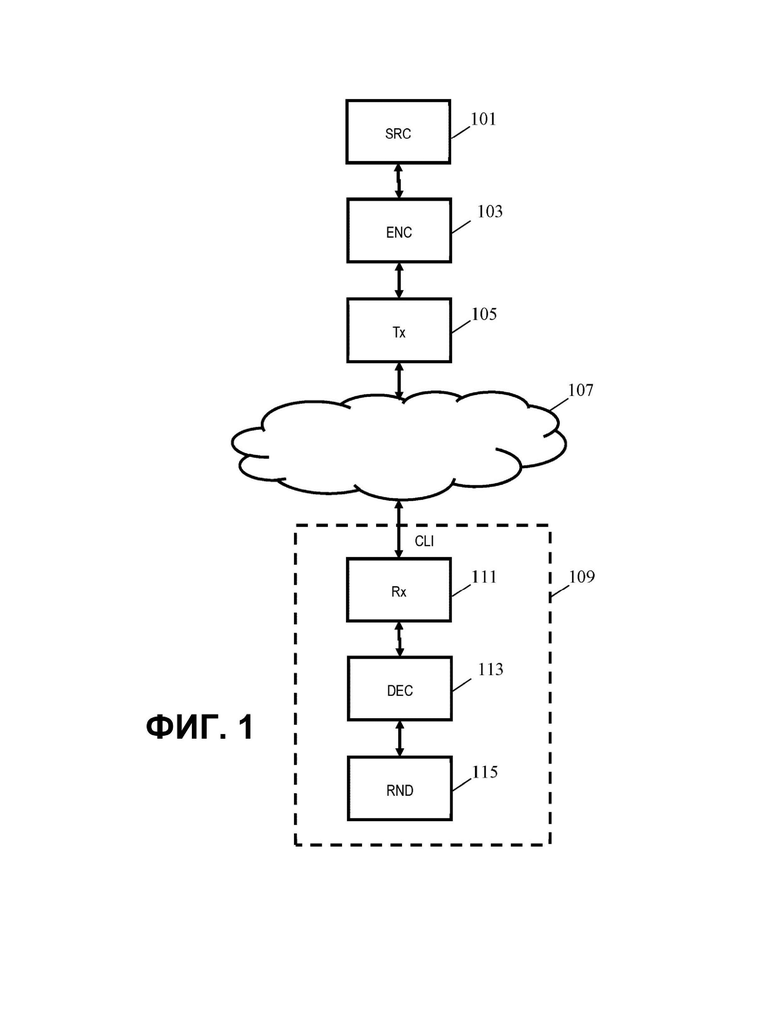
На фиг. 1 показан пример системы кодирования аудио. В системе аудиоисточник 101 предоставляет аудиоданные в блок 103 аудиокодера. Аудиоданные содержат аудиоданные для множества элементов аудио, которые представляют собой аудио аудиосцены. Элементы аудио могут быть предоставлены в виде различных типов, включая, в частности:
Элементы аудио на основе канала: Для таких элементов аудио 1D (монауральный), 2D или 3D пространственный аудиоконтент, как правило, представлен в виде дискретных сигналов, предназначенных для воспроизведения через акустические системы в заданных положениях относительно слушателя. Хорошо известными настройками акустических систем являются, например, двухканальный стерео (также известный как "2.0") или 5 каналов вокруг слушателя плюс канал низкочастотных эффектов (также называемый ‘5.1’). Также бинауральным аудио обычно считается аудио на основе канала, состоящего из двух каналов аудиосигнала, предназначенных для представления непосредственно соответствующим ушам слушателя (обычно через наушники).
Элементы аудио на основе объектов: Для таких элементов аудио для представления локальных источников аудио обычно используются отдельные аудиосигналы. Эти источники звука часто относятся к реальным объектам или лицам, например участникам телеконференции. Сигналы обычно являются монофоническими, но могут использоваться и другие варианты представления. Аудиосигналы на основе объектов часто сопровождаются метаданными, описывающими дополнительные свойства, такие как величина (пространственная скорость), направленность или рассеяние аудиосигнала объекта.
Элементы аудио на основе сцены: Для таких элементов аудио исходная двумерная или трехмерная пространственная аудиосцена обычно представлена в виде ряда аудиосигналов, относящихся к определенным сферическим гармоникам. Путем объединения этих аудиосигналов, на основе сцены, воспроизводимые аудиосигналы могут быть построены в произвольных двухмерных или трехмерных положениях, например, в положении реальной акустической системы в конфигурации воспроизведения аудиосигнала. Примером реализации аудио на основе сцены является Ambisonics. Аудио на основе сцены использует технологию звукового поля, называемую «амбисоникой более высокого порядка» (higher-order ambisonics, HOA), для создания целостных описаний как захваченных в реальном времени, так и художественно созданных аудиосцен, которые не зависят от конкретных компоновок акустических устройств.
В дополнение к аудиоданным, аудиоисточник может предоставлять метаданные представления для элементов аудио. Метаданные представления могут описывать ограничения представления для преобразования для воспроизведения аудиосцены и, таким образом, могут содержать ограничения представления/преобразования для воспроизведения для множества элементов аудио.
Метаданные представления могут описывать ограничение того, как преобразователь для воспроизведения должен выполнять преобразование для воспроизведения элементов аудио. Метаданные представления могут определять ограничение одного или более параметров/свойств преобразования для воспроизведения. Параметр/свойство может, в частности, влиять на на свойство восприятия преобразования для воспроизведения элемента аудио. Ограничение может быть ограничением, которое влияет на пространственное восприятие и/или (относительный) уровень сигнала элемента аудио в сцене. Метаданные представления могут, в частности, ограничивать пространственный параметр и/или параметр усиления/уровня сигнала для одного или более элементов аудио. Метаданные могут, например, представлять собой ограничение положения и/или усиления для каждого элемента аудио.
Метаданные могут, например, описывать диапазон или набор допустимых значений для одного или более параметров одного или более элементов аудио. Преобразование для воспроизведения элемента аудио(ов) может свободно выполняться в пределах ограничения, т.е. преобразование для воспроизведения может быть таким, что ограниченные параметры имеют любое из указанных допустимых значений, но не могут быть такими, что ограниченный параметр не имеет этого значения.
В качестве примера, метаданные представления могут для одного или более элементов аудио описывать область и/или (относительный) диапазон усиления. Затем элемент аудио должен быть преобразован для воспроизведения с учетом воспринимаемого положения в пределах области и/или с усилением в пределах диапазона усиления.
Таким образом, метаданные представления могут ограничивать преобразование для воспроизведения при сохранении некоторой гибкости для адаптации и настройки локального преобразования для воспроизведения.
Примеры ограничений параметров или свойств преобразования для воспроизведения, которые могут быть предоставлены метаданными представления, включают:
Ограничение положения для одного или более элементов аудио. Это может, например, определять пространственную область или громкость в аудиосцене, из которой элемент аудио должен быть преобразован для воспроизведения.
Ограничение реверберации для одного или более элементов аудио. Это может, например, определять минимальное или максимальное время реверберации. Ограничение может, например, гарантировать, что элемент аудио преобразован для воспроизведения с требуемыи уровнем диффузности. Например, может потребоваться, чтобы преобразование для воспроизведения элемента аудио, представляющего общий окружающий фоновый звук, осуществлялось с минимальной степенью реверберации, в то время как для элемента аудио, представляющего основной динамик, может потребоваться преобразование для воспроизведения с меньшим порогом реверберации, чем заданный.
Ограничение усиления. Преобразование для воспроизведения элемента аудио может быть адаптирован преобразователем для воспроизведения, чтобы быть громче или тише в соответствии с конкретными настройками процесса преобразования для воспроизведения. Например, в некоторых случаях усиление для динамика по отношению к фоновым звукам окружающей среды может быть увеличено или уменьшено в зависимости от предпочтений слушателей. Однако ограничение усиления может ограничивать то, насколько, например, может меняться усиление, тем самым гарантируя, что динамик всегда может быть услышан через окружающий шум.
Ограничение громкости. Преобразование для воспроизведения элемента аудио может быть адаптирован преобразователем для воспроизведения, чтобы быть более громкой или более тихой в соответствии с конкретными предпочтениями процесса преобразования для воспроизведения. Например, усиление для участников телеконференции в некоторых случаях может быть увеличено или уменьшено в зависимости от предпочтений слушателя. Тем не менее, ограничение громкости может ограничивать то, насколько может быть изменена воспринимаемая громкость определенных участников, тем самым гарантируя, что, например, ведущего собрания всегда можно услышать достаточно громко в присутствии других выступающих или фонового шума.
Ограничение управления динамическим диапазоном. Динамический диапазон элемента аудио может быть адаптирован преобразователем для воспроизведения, чтобы быть более громким, например, он может быть уменьшен таким образом, чтобы аудио было слышно также в периоды более низкого уровня при наличии фонового шума в положении слушателей. Например, звук скрипки может автоматически делаться громче на низких уровнях. Однако ограничение управления динамическим диапазоном может ограничивать то, насколько динамический диапазон может быть уменьшен, тем самым, например, обеспечивая достаточно естественное восприятие нормального звучания скрипки.
Метаданные представления, описывающие ограничения представления для преобразования для воспроизведения множества элементов аудио, могут, в частности, представлять собой данные, предоставляющие ограничения на параметр или свойство преобразования для воспроизведения, которые могут быть адаптированы при преобразовании для воспроизведения элементов аудио (для которых предоставляются метаданные представления). Параметр или свойство преобразования для воспроизведения может быть параметром/свойством операции преобразования для воспроизведения и/или параметром или свойством сгенерированного преобразованнного/воспроизведенного сигнала и/или аудио.
Входные метаданные представления могут, в частности, представлять собой любые данные, ассоциированные/связанные/предоставленные для входных элементов аудио для аудиокодера 205, которые ограничивают величину, на которую один или более адаптируемых/переменных аспектов/свойств/параметров представления/преобразования для воспроизведения способен/может быть адаптирован при преобразовании для воспроизведения входных элементов аудио.
Блок 103 аудиокодера выполнен с возможностью генерирования потока кодированных аудиоданных, который содержит кодированные аудиоданные для аудиосцены. Кодированные аудиоданные генерируются путем кодирования элементов аудио (т.е. принятых аудиоданных, представляющих элементы аудио). Кроме того, блок 103 аудиокодера генерирует выходные метаданные представления для кодированных элементов аудио и включает эти метаданные в поток кодированных аудиоданных. Выходные метаданные представления описывают ограничения преобразования для воспроизведения для кодированных элементов аудио.
Выходные метаданные представления могут, в частности, представлять собой любые данные, ассоциированные/связанные/предоставленные для кодированных элементов аудио, сгенерированных аудиокодером 205, которые ограничивают величину, на которую один или более адаптируемых/переменных аспектов/свойств/параметров представления/преобразования для воспроизведения способен/может быть адаптирован при преобразовании для воспроизведения кодированных элементов аудио.
Выходные метаданные представления и, в частности, данные для кодированных элементов аудио, которые ограничивают величину, на которую адаптируемый параметр преобразования для воспроизведения может быть адаптирован при преобразовании для воспроизведения кодированных элементов аудио, могут быть сгенерированы схемой метаданных в ответ на (входные) ограничения представления, ограничивающие параметр преобразования для воспроизведения, который может быть адаптирован при преобразовании для воспроизведения множества (входных) элементов аудио.
Блок 103 аудиокодера соединен с передатчиком 105, в который подается поток кодированных аудиоданных. В примере передатчик 105 выполнен с возможностью передачи/распределения потока кодированных аудиоданных одному или более клиентам, которые могут воспроизводить аудиосцену на основе потока кодированных аудиоданных.
В этом примере поток кодированных аудиоданных распределяется посредством сети 107, которая, в частности, может быть или может включать в себя Интернет. Передатчик 105 может быть выполнен с возможностью одновременной поддержки потенциально большого количества клиентов, и аудиоданные могут распределяться множеству клиентов в целом.
В конкретном примере поток кодированных аудиоданных может быть передан одному или более преобразующим устройствам 109. Преобразующее устройство 109 может содержать приемник 111, который принимает поток кодированных аудиоданных из сети 107.
Следует понимать, что передатчик 105 и приемник 111 могут осуществлять связь в любой подходящей форме и с использованием любого подходящего протокола, стандарта, способа и функциональности связи. В данном примере передатчик 105 и приемник 111 могут содержать соответствующую функциональность сетевого интерфейса, но следует понимать, что в других вариантах осуществления передатчик 105 и/или приемник 111 могут, например, включать в себя функциональность радиосвязи, функциональность волоконно-оптической связи и т.д.
Приемник 111 соединен с декодером 113, в который подается принятый поток кодированных аудиоданных. Декодер 113 выполнен с возможностью декодирования потока кодированных аудиоданных для воссоздания элементов аудио. Декодер 113 может дополнительно декодировать метаданные представления из потока кодированных аудиоданных.
Декодер 113 соединен с преобразователем 115 для воспроизведения, в который подаются декодированные аудиоданные для элементов аудио и метаданные представления. Преобразователь 115 для воспроизведения может преобразовывать аудиосцену путем преобразования для воспроизведения элементов аудио на основе принятых метаданных представления. Преобразование для воспроизведения с помощью преобразователя 115 может быть предназначен для конкретной используемой системы воспроизведения аудио. Например, для системы объемного звучания 5.1 могут генерироваться аудиосигналы для отдельных каналов, для системы наушников могут генерироваться бинауральные сигналы с использованием, например, фильтров HRTF и т.д. Следует понимать, что известно множество различных возможных алгоритмов и методов аудиопреобразования для воспроизведения и что может быть использован любой подходящий подход без отклонения от настоящего изобретения.
Преобразователь 115 для воспроизведения может, в частности, генерировать выходные аудиосигналы для воспроизведения, так что объединенное воспроизведение обеспечивает восприятие аудиосцены при восприятии слушателем. Преобразователь для воспроизведения обычно обрабатывает различные элементы аудио раздельно и по-разному в зависимости от конкретных характеристик отдельного элемента аудио, а затем объединяет компоненты полученного сигнала для каждого выходного канала. Например, для элемента аудио аудиообъекта компоненты сигнала могут генерироваться для каждого выходного канала в зависимости от желаемой позиции в аудиосцене для аудиоисточника, соответствующего аудиообъекту. Элемент аудио аудиоканала может быть, например, преобразован для воспроизведения путем генерирования компонента сигнала для соответствующего выходного канала воспроизведения или, например, посредством множества каналов воспроизведения, если он точно не соответствует одному из каналов воспроизведения (например, с использованием методов панорамирования или микширования, если это необходимо).
Представление аудиосцены несколькими, как правило, различными типами элементов аудио может обеспечивать преобразователю 115 для воспроизведения высокий уровень гибкости и адаптивности при преобразовании для воспроизведения сцены. Это может, например, быть использовано преобразователем для воспроизведения, чтобы адаптированть и настраивать преобразуемую для воспроизведения аудиосцену. Например, относительное усиление и/или положение различных аудиообъектов может быть адаптировано, частотное содержание элементов аудио может быть изменено, динамический диапазон элементов аудио может быть управляемым, свойства реверберации могут быть изменены и т.д. Таким образом, преобразователь 115 для воспроизведения может генерировать выход, в котором аудиосцена адаптирована к конкретным предпочтениям для текущего применения/преобразования, включая адаптацию к конкретной используемой системе воспроизведения и/или к личным предпочтениям слушателя. Данный подход может, например, также обеспечивать возможность эффективной локальной адаптации преобразованной для воспроизведения аудиосцены к изменениям в виртуальном положении прослушивания в аудиосцене. Например, для поддержки приложения виртуальной реальности преобразователь 115 для воспроизведения может динамически и непрерывно принимать ввод данных о положении пользователя и адаптировать преобразование для воспроизведения в ответ на изменения указанного виртуального положения пользователя в аудиосцене.
Преобразователь 115 для воспроизведения выполнен с возможностью преобразования для воспроизведения элементов аудио на основе принятых метаданных представления. В частности, метаданные представления могут указывать ограничения на переменный аспект/свойство/параметр преобразования для воспроизведения кодированных/декодированных элементов аудио, и преобразователь 115 для воспроизведения может соответствовать этим ограничениям при преобразовании для воспроизведения.
Выходные аудиосигналы от преобразователя 115/преобразующего устройства 109 являются результатом операции преобразования для воспроизведения, применяемой к декодированным элемента аудиом, генерируемым декодером 113 из принятого кодированного потока аудио данных. Операция преобразования для воспроизведения может иметь некоторые параметры, которые могут быть адаптированы внешне или локально, и которые влияют на восприятие (аспекты) преобразованного для воспроизведения выводимого аудио. Метаданные представления, описывающие ограничения представления для преобразования для воспроизведения, могут быть, в частности, данными, которые ограничивают набор (т.е. для непрерывно адаптируемых параметров диапазон значений, или для перечисляемых параметров набор дискретных значений), с помощью которого параметры преобразования для воспроизведения могут быть адаптированы при преобразовании для воспроизведения.
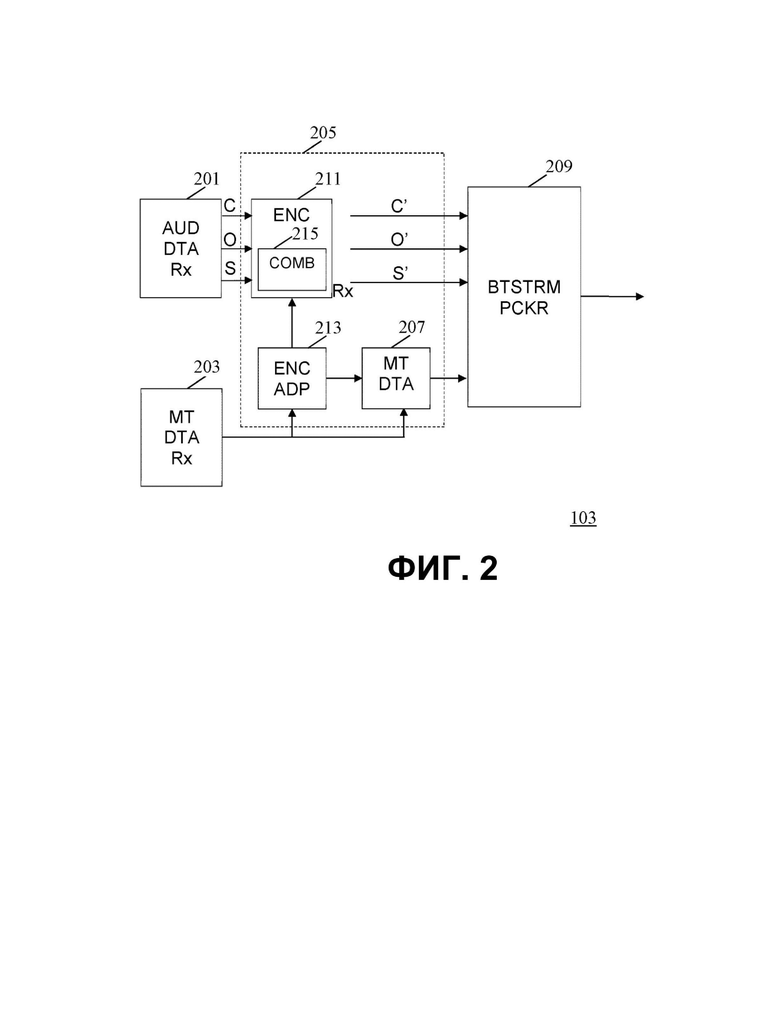
На фиг .2 более подробно показан пример элементов блока 103 аудиокодера. В примере блок 103 аудиокодера содержит аудиоприемник 201, который принимает входные аудиоданные, описывающие сцену. В настоящем примере аудиосцена представлена тремя различными типами аудиоданных, а именно элементами аудио C на основе канала, элементами аудио O на основе объекта и элементами аудио S на основе сцены. Элементы аудио предоставляются аудио данными, которые могут быть в любой подходящей форме. Аудиоданные могут, например, предоставлять элементы аудио в виде необработанных WAV-файлов или в виде аудио, кодированных в соответствии с любым подходящим форматом. Как правило, входные элементы аудио будут иметь высокое качество аудио и высокую скорость передачи данных.
Блок 103 аудиокодера дополнительно содержит приемник 203 метаданных, который выполнен с возможностью приема метаданных представления для входных элементов аудио. Как было описано выше, метаданные представления могут содержать ограничения на преобразование для воспроизведения элементов аудио.
Аудиоприемник 201 и приемник 203 метаданных соединены с аудиокодером 205, который выполнен с возможностью генерирования кодированных аудиоданных для аудиосцены путем кодирования принятых элементов аудио. Аудиокодер 205 в данном примере, в частности, генерирует кодированные элементы аудио, т.е. элементы аудио, представленные кодированными аудиоданными. Что касается входных элементов аудио, выходные/кодированные элементы аудио также могут быть элементами аудио разных типов, и в конкретном примере могут быть, в частности, элементами аудио C’ на основе канала, элементами аудио O’ на основе объекта и элементами аудио S’ на основе сцены.
Один, некоторые или все из кодированных элементов аудио могут быть сгенерированы путем независимого кодирования входных элементов аудио, т.е. кодированный элемент аудио может быть кодированным входным элементом аудио. Однако в некоторых сценариях один или более кодированных элементов аудио могут быть сгенерированы для представления множества входных элементов аудио или входной элемент аудио может быть представлен в множестве/посредством множества кодированных элементов аудио.
Следует понимать, что известно много алгоритмов и методов кодирования, и что может быть использован любой подходящий алгоритм, стандарт и подход. Кроме того, следует понимать, что для различных элементов аудио могут быть использованы различные алгоритмы и методы. Например, элемент аудио, соответствующий музыке, может быть кодирован, применяя подход кодирования с использованием адаптивного кодирования аудио (Adaptive Audio Coding, AAC), элемент аудио, соответствующий речи, может быть кодирован, применяя подход кодирования с линейным предсказанием с кодовым возбуждением (Code Excited Linear Prediction, CELP) и т.д. Для элементов аудио, которые уже приняты в кодированном формате, кодирование с помощью аудиокодера 205 может быть перекодированием в другой формат кодирования, или может быть, например, просто преобразованием скорости передачи данных (например, путем изменения уровней квантования и/или отсечения). Как правило, кодирование включает сжатие битрейта, и кодированные элементы аудио представлены меньшим количеством бит, чем входные элементы аудио.
Блок 103 аудиокодера также содержит схему 207 метаданных, которая выполнена с возможностью генерирования выходных метаданных представления для кодированных элементов аудио. Схема 207 метаданных представления выполнена с возможностью генерирования этих выходных метаданных представления из принятых входных метаданных представления. Фактически, для многих элементов аудио выходные метаданные представления могут быть такими же, как входные метаданные представления. Для одного или более элементов аудио выходные метаданные представления могут быть изменены, как будет описано более подробно ниже.
Аудиокодер 205 и схема 207 метаданных соединены с схемой 209 вывода, которая выполнена с возможностью генерирования потока кодированных аудиоданных, который содержит кодированные аудиоданные и выходные метаданные представления. Схема 209 вывода может быть, в частности, упаковщиком битового потока, который генерирует поток кодированных аудиоданных, содержащий как кодированные аудиоданные, так и выходные метаданные. Поток кодированных аудиоданных может быть сгенерирован в соответствии со стандартным форматом, что позволяет интерпретировать его целым рядом приемников.
Таким образом, схема 209 вывода работает как упаковщик битового потока, который принимает элементы аудио с уменьшенным/кодированным битрейтом и выходные метаданные представления, и объединяет их в битовый поток, который может передаваться по подходящему каналу связи, такому как, например, сеть 5G.
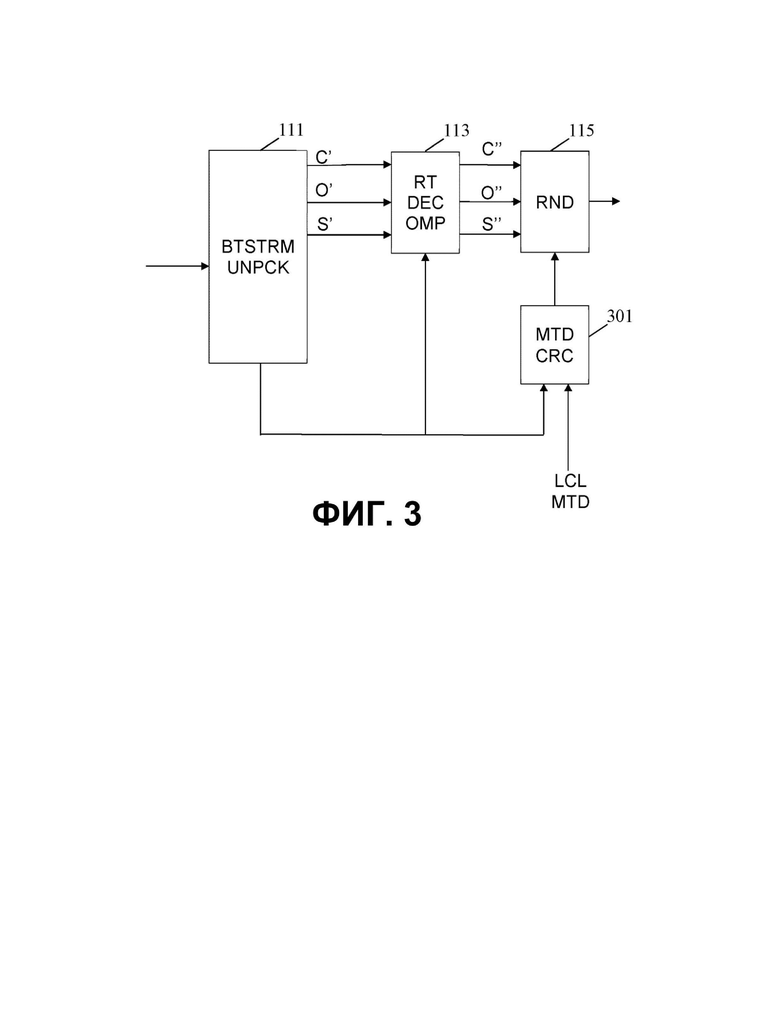
На фиг. 3 показан конкретный пример элементов преобразующего устройства 109, которое может принимать и обрабатывать поток кодированных аудиоданных от блока 103 аудиокодера. Преобразующее устройство 109 содержит приемник 111 в виде распаковщика битового потока, который принимает поток кодированных аудиоданных от блока 103 аудиокодера и который отделяет различные данные от принятого потока данных. В частности, приемник 111 может выделять отдельные аудиоданные для кодированных элементов аудио и подавать их на декодер 113.
Декодер 113, в частности, выполнен с возможностью декодирования принятых кодированных элементов аудио для генерирования, как правило, некодированных представлений элементов аудио на основе канала, объекта и сцены.
Для многих элементов аудио декодер 113 может реверсировать кодирование, выполняемое аудиокодером 205. Для других элементов аудио декодирование может, например, только частично реверсировать операцию кодирования. Например, если аудиокодер 205 объединил элементы аудио в один объединенный элемент аудио, декодер 113 может декодировать только объединенный элемент аудио и не полностью генерировать отдельные элементы аудио. Следует понимать, что в зависимости от конкретных предпочтений и требований отдельного варианта осуществления может быть использован любой подходящий алгоритм и способ декодирования.
Декодированные элементы аудио подают на преобразователь 115 для воспроизведения, который выполнен с возможностью преобразования для воспроизведения аудиосцены путем преобразования для воспроизведения элементов аудио, как описано ранее, например, в виде бинаурального сигнала или сигнала объемного звука.
Преобразующее устройство 109 также содержит контроллер/схему 301 метаданных, в которую из приемника 111 подаются метаданные представления. В данном примере контроллер 301 метаданных может также принимать локальные метаданные представления, которые, например, могут отражать локальные предпочтения или требования, такие как, например, индивидуальные пользовательские предпочтения или свойства используемой системы воспроизведения.
Таким образом, в дополнение к метаданным воспроизведения аудио, распакованным из принятого битового потока, преобразующее устройство 109 также может принимать локальные метаданные представления аудио, которые, например, могут быть предоставлены с помощью одного или более входных интерфейсов. Эти данные могут предоставлять информацию о контексте, в котором должно быть представлено аудио, которое недоступно на стороне кодера, такую как, например:
- желаемую конфигурацию воспроизведения (акустической системы);
- предпочтения пользователя (например, уровни звука и ориентация звука участников на виртуальной встрече);
- свойства местной акустики, такие как, например, реверберация помещения. Это может может обеспечивать преобразователю для воспроизведения возможность определения, какие эффекты и свойства окружающей среды применять к элемента аудиом;
- локальные аудиосигналы (например, для учета при выборе усиления для элементов аудио;
- местополождение слушателя и
- ориентация головы слушателя.
Контроллер 301 метаданных может объединять принятые и локальные метаданные вместе и предоставлять их преобразователю 115 для воспроизведения, который может приступать к преобразованию для воспроизведения элементов аудио согласно ограничениями метаданных представления.
Преобразователь 115 для воспроизведения может объединять элементы аудио C’’, O’’ и S’’, генерируемые декодером 113, в воспроизводимое аудио требуемой конфигурации воспроизведения (например, бинауральный или объемный звук).
Преобразователь 115 для воспроизведения может, в частности, генерировать представление аудио в соответствии с метаданными, полученными от контроллера 301 метаданных, и при этом преобразованное для воспроизведения аудио ограничено пределами принятых метаданных представления, т.е. ограничено со стороны кодера. Это обеспечивает управление стороны источника/поставщика контента над преобразованием для воспроизведения аудио и представленной аудиосценой, при этом обеспечивая некоторую гибкость на стороне клиента. Это может быть использовано, например, для предоставления услуги или приложения, в котором автор контента сохраняет контроль над иммерсивным приложением, которое было разработано для обеспечения определенного ограниченного контроля для конечного пользователя и т.д.
Более подробно, контроллер 301 метаданных может обрабатывать полученные метаданные, например, подавление элементов аудио, соответственно, локальные метаданные. Контроллер 301 метаданных может, например, ограничивать локальные метаданные, например, диапазон вращения или высоту, соответственно, принятые метаданные.
В некоторых вариантах осуществления преобразователь 115 для воспроизведения может быть устройством или функциональным объектом, отличающимся от преобразующего устройства 109. Например, стандарт, такой как предполагаемый кодек 3GPP IVAS, может предписывать декодера 113 работу, но обеспечивать возможность того, чтобы преобразователь 115 для воспроизведения был индивидуально изготовленным и более свободно адаптируемым. В некоторых вариантах осуществления контроллер 301 метаданных может быть частью другого устройства или функционального объекта.
В таком варианте осуществления внешний преобразователь для воспроизведения, таким образом, обязан обрабатывать и интерпретировать декодированные элементы аудио O’’, C’’, S’’ и полученные метаданные представления. Операция преобразования для воспроизведения внешним преобразователем для воспроизведения должна по-прежнему соответствовать ограничениям, предусмотренным метаданными представления.
Таким образом, метаданные представления могут быть данными, которые используются стороной источника/поставщиком контента для управления операцией преобразования для воспроизведения на клиентах. Преобразование для воспроизведения должно быть адаптировано/ограничено в соответствии с метаданными представления.
Однако, в дополнение к метаданным воспроизведения, используемым для управления преобразованием для воспроизведения преобразователем 115 для воспроизведения стороны клиента, аудиокодер 205 блока 103 аудиокодера также выполнен с возможностью адаптации кодирования в ответ на входные метаданные представления. Входные метаданные представления подаются в аудиокодер 205 и это может изменить кодирование одного или более элементов аудио на основе метаданных представления (обычно для этого одного или более элементов аудио). Таким образом, аудиокодер 205 представляет собой адаптируемый кодер, который выполнен с возможностью реагирования на метаданные представления, полученные с помощью элементов аудио.
Аудиокодер 205, в частности, содержит схему 211 кодирования, выполненную с возможностью осуществления кодирования элементов аудио, и кодирующий адаптер 213, выполненный с возможностью адаптации кодирования посредством схемы 211 кодирования на основе метаданных представления.
Кодирующий адаптер 213 может быть выполнен с возможностью установки параметра кодирования для данного элемента аудио на основании метаданных представления для этого элемента аудио. Например, он может быть выполнен с возможностью установки распределения/цели битрейта, уровня квантования, порога маскирования, диапазона частот и т.д. для кодирования на основании, например, диапазона усиления или диапазона положения, указанного метаданными представления, которые являются допустимыми для элемента аудио.
Во многих вариантах осуществления схема 211 кодирования представляет собой компрессор битрейта, который выполнен с возможностью кодирования элементов аудио с уменьшенным количеством битов по сравнению с принятыми входными элементами аудио. Соответственно, кодирование может представлять собой сжатие битрейта, что позволяет генерировать более эффективный и легкий для распределения поток кодированных аудиоданных. В таких вариантах осуществления кодирующий адаптер 213 может адаптировать уменьшение битрейта схемы 211 кодирования на основе метаданных представления (таким образом, чтобы оптимизировать качество преобразованного для воспроизведения аудио в соответствии с подходящим критерием/алгоритмом оптимизации).
Кодирующий адаптер 213 может, например, выполнять процесс анализа кодирования, который анализирует метаданные представления и принимает решения о том, как наилучшим образом выполнить снижение битрейта различных входных элементов аудио. Примеры операций и адаптации, которые могут быть выполнены кодирующим адаптером 213, включают:
- Сигнализацию (минимальных) уровней маскирования для схемы 211 кодирования, которые должны соблюдаться для уменьшения битрейта. Кодирующий адаптер 213 содержит информацию, относящуюся к тому, какие элементы аудио совместно представлены, на каких уровнях и в какой ориентации. Это может обеспечить ему возможность адаптации уровня маскирования для отдельных элементов аудио с уровнями маскирования, которые затем используются кодировкой.
- Преобразование элементов аудио, например, перемещение аудиообъектов в аудио на основе канала или сцены.
- Выбор элементов аудио для понижающего микширования (с соответствующими параметрами повышающего микширования), где понижающее микширование может быть повышено для реконструкции иммерсивного аудио на стороне декодера, обеспечивая при этом, чтобы артефакты параметрического кодирования понижающего микширования были достаточно замаскированы различными элементами аудио, которые представлены вместе. В качестве дополнительных уточнений кодирующий адаптер 213 может:
- оптимизировать усиление понижающего/повышающего микширования для максимальной эффективности / минимальных артефактов;
- выбирать параметры повышающего микширования с оптимальными временными/частотными характеристиками;
- необратимо объединять элементы аудио в объединенные элементы аудио, которые затем могут быть преобразованы для воспроизведения в виде одного элемента аудио преобразователем 115 для воспроизведения. Это может использовать тот факт, что нет внутренней необходимости в том, чтобы вся аудиоинформация была доступна отдельно на стороне преобразования для воспроизведения. Например, если отдельная адаптация некоторых входных элементов аудио не разрешена (например, может потребоваться, чтобы они были преобразованы для воспроизведения в одном и том же положении), отсутствует необходимость в том, чтобы элементы аудио были доступны по отдельности. Например, несколько входных аудиообъектов со схожими ограничениями ориентации и адаптации усиления могут быть объединены в один элемент аудио на основе сцены, где во время преобразования для воспроизведения усиление и ориентация для всей сцены все еще могут быть адаптированы, но первые объекты будут иметь фиксированные относительные уровни аудио и фиксированные относительные положения в сцене;
- распределение различных ресурсов битрейта для различных элементов аудио в зависимости от метаданных представления для элементов аудио. Например, битрейт может быть назначен элемента аудиом на основании объема немаскированной информации, которую каждый из них представляет.
Схема 211 кодирования может затем использовать кодирование элементов аудио в соответствии с данными управления кодированием, генерируемыми кодирующим адаптером 213. Например, схема 211 кодирования может генерировать уменьшенные по битрейту (например, квантованные, параметризованные...) версии некоторых элементов аудио на основе канала, объекта и сцены. Кроме того, благодаря, например, объединению или преобразованию как части кодирования различных элементов аудио, по меньшей мере некоторые из кодированных элементов аудио могут предоставлять иную аудиоинформацию, чем входные элементы аудио, т.е. может отсутствовать прямое соответствие между входными элементами аудио и кодированными элементами аудио.
В некоторых вариантах осуществления изобретения аудиокодер 205 может, в частности, содержать объединяющий блок 215, который выполнен с возможностью объединения входных элементов аудио в один или более объединенных элементов аудио. Объединяющий блок 215 может, в частности, объединять первый и второй входной элемент аудио в объединенный элемент аудио. Затем объединенный элемент аудио может быть кодирован для создания объединенного кодированного элемента аудио, и этот объединенный кодированный элементы аудио может быть включен в поток кодированных аудиоданных, обычно заменяя первый и второй элементы аудио. Таким образом, вместо отдельного кодирования первого и второго элементов аудио, объединяющий блок 215 может объединять их в один кодированный элемент аудио, который затем включается в состав потока кодированных аудиоданных, в то время как отдельные кодированные аудиоданные не включаются для первого или второго элементов аудио соответственно.
Объединение элементов аудио выполняется в ответ на принятые метаданные представления. Во многих вариантах осуществления элементы аудио, выбранные для объединения, выбираются на основе метаданных представления. Например, кодирующий адаптер 213 может выбирать элементы аудио для объединения в ответ на критерий, включающий требование, чтобы ограничения для элементов аудио соответствовали критерию сходства.
Например, может потребоваться, чтобы для элементов аудио которые должны быть объединены, ограничения для элементов аудио, указанные в метаданных представления, не должны быть противоречивыми, т.е. должна существовать возможность выполнения обоих ограничений. Таким образом, может потребоваться, чтобы ограничения, указанные метаданными представления, не противоречили друг другу, и, например, чтобы ограничения имели по меньшей мере перекрытие, так что существует по меньшей мере одно значение параметра преобразования для воспроизведения, которое позволяет выполнять ограничения преобразования для воспроизведения для обоих (или всех) объединенных элементов аудио. Кодирующий адаптер 213 может требовать, чтобы метаданные представления не описывали несовместимые ограничения для общего параметра преобразования для воспроизведения.
Например, метаданные представления могут описывать ограничения для положения элементов аудио в аудиосцене. В таком случае может потребоваться, чтобы ограничения положения были перекрывающимися и чтобы существовали некоторые общие допустимые положения.
Выбор объединяемых элементов аудио может быть основан на метаданных представления для элементов аудио. Таким образом, выбор первого и второго элемента аудио для объединения может основываться на метаданных представления для первого и второго элемента аудио. Например, как упоминалось выше, может потребоваться, чтобы метаданные представления для первого и второго элементов аудио не определяли конфликтующие ограничения.
В некоторых вариантах осуществления первый и второй элементы аудио могут, например, быть выбраны как элементы аудио, которые имеют ограничения для одного и того же параметра, которые, например, являются наиболее похожими. Например, могут быть выбраны элементы аудио, которые имеют по существу одинаковые ограничения положения.
В частности, мера сходства для двух элементов аудио может быть определена для отображения перекрытия между допустимыми положениями. Например, мера сходства может быть сгенерирована как отношение между объемом области перекрывающихся допустимых положений относительно суммы объемов отдельных допустимых положений для двух элементов аудио.
В качестве другого примера, несколько аудиообъектов, удовлетворяющих критерию подобия для их ограничений адаптации положения, даже если соответствующие диапазоны положения или пространственные объемы могут не перекрываться, могут быть объединены в элемент аудио на основе сцены, где аудиоисточники будут иметь фиксированную относительную ориентацию друг к другу в аудио на основе сцены (т.е. не могут быть адаптированы по отдельности), но их ориентации все еще могут быть адаптированы вместе как единое целое.
В качестве другого примера, мера подобия может быть сгенерирована для отображения размера перекрывающегося диапазона усиления для двух элементов аудио. Чем больше общий допустимый диапазон усиления, тем больше сходство.
Кодирующий адаптер 213 может оценивать такие показатели сходства для различных пар элементов аудио и выбирать, например, пары, для которых показатели сходства выше, чем данное пороговое значение. Затем эти элементы аудио могут быть объединены в единые объединенные элементы аудио.
Во многих вариантах осуществления кодирующий адаптер 213 также выполнен с возможностью генерирования объединенных метаданных представления для объединенного элемента аудио из входных метаданных представления. Затем эти метаданные представления подают на упаковщик 209 битового потока, который включает их в поток выходных кодированных аудиоданных.
Схема 207 метаданных может, в частности, генерировать объединенные метаданные представления, которые связаны с объединенным элементом аудио, и которые содержат ограничения преобразования для воспроизведения для объединенных метаданных представления. Тогда сгенерированный объединенный элемент аудио с соответствующими объединенными метаданными представления может рассматриваться как любой другой элемент аудио, и в действительности клиент/декодер/преобразователь для воспроизведения может даже не знать, что объединенный элемент аудио действительно сгенерирован путем объединения входных элементов аудио аудиокодером 205. В значительной степени объединенный элемент аудио и связанные с ним метаданные представления могут быть для стороны клиента неотличимы от входных элементов аудио и связанных с ними метаданных представления и могут быть преобразованы для воспроизведения как любой другой элемент аудио.
Во многих вариантах осуществления объединенные метаданные представления могут, например, генерироваться, чтобы отражать ограничение параметра воспроизведения для объединенного элемента аудио. Ограничение может быть определено таким образом, что оно удовлетворяет отдельным ограничениям для объединяемых элементов аудио, как указано входными метаданными представления для этих элементов аудио. В частности, ограничение для объединенного элемента аудио для первого и второго элемента аудио может быть определено как ограничение, удовлетворяющее как ограничению для первого элемента аудио, указанному входными метаданными представления для первого элемента аудио, так и ограничению для второго элемента аудио, указанному входными метаданными представления для второго элемента аудио. Таким образом, объединенные метаданные представления генерируются для обеспечения одного или более ограничений, которые гарантируют выполнение отдельных ограничений для отдельных элементов аудио при условии выполнения объединенного ограничения.
Например, для первого элемента аудио, являющегося аудиообъектом, входные метаданные представления могут указывать на то, что он должен быть преобразован для воспроизведения с относительным усилением в диапазоне, например, от -6 дБ до 0 дБ и в положении в пределах координатного объема (азимут, высота, радиус), например, ([0, 100], [-40,60], [0,5, 1,5]). Для второго элемента аудио, являющегося аудиообъектом, входные метаданные представления могут указывать на то, что он должен быть преобразован для воспроизведения с относительным усилением в диапазоне от, например, -3 дБ до 3 дБ и в положении в пределах координатного объема (азимут, высота, радиус), например, ([-100, 80], [-20, 70], [0,2, 1,0]). В этом случае объединенные метаданные представления могут быть сгенерированы для указания того, что объединенный элемент аудио, представляющий собой аудиообъект, должен быть преобразован для воспроизведения с относительным усилением в диапазоне от, например, -3 дБ до 0 дБ и в положении в пределах объема координат (азимут, высота, радиус), например, ([0, 80], [-20, 60], [-0,5, 1,0]). Это гарантирует, что объединенный элемент аудио будет преобразован для воспроизведения способом, который был бы приемлем как для первого, так и для второго элемента аудио.
В некоторых вариантах осуществления устройство 205 кодирования аудио может быть выполнено с возможностью адаптации сжатия одного элемента аудио на основе метаданных представления для другого элемента аудио.
В качестве примера низкой сложности сжатие одного элемента аудио может зависеть от близости и усиления/уровня для другого элемента аудио. Например, если метаданные представления для текущего элемента аудио указывают диапазон положения и диапазон уровня, это можно сравнить с диапазоном положения и диапазоном уровня для второго элемента аудио. Если второй элемент аудио вынужден располагаться рядом с первым элементом аудио и должен быть преобразован для воспроизведения на существенно более высоком уровне, чем первый элемент аудио, то первый элемент аудио, скорее всего, будет восприниматься слушателем лишь незначительно. Соответственно, кодирование первого элемента аудио может быть с более высоким снижением сжатия/битрейта, чем при отсутствии другого элемента аудио. В частности, распределение битрейта для кодирования первого элемента аудио может зависеть от расстояния до и уровня одного или более других элементов аудио.
В некоторых вариантах осуществления кодирующий адаптер 213 может быть выполнен с возможностью оценки эффекта маскирования второго элемента аудио на первый элемент аудио. Эффект маскирования может быть представлен мерой маскирования, которая указывает уровень маскирования, введенный в первый элемент аудио из преобразования для воспроизведения второго элемента аудио. Таким образом, мера маскирования указывает на воспринимаемую значимость первого элемента аудио в присутствии второго элемента аудио.
Мера маскирования может конкретно генерироваться как указание уровня принятого звука от второго элемента аудио относительно уровня принятого звука от первого элемента аудио, когда второй элемент аудио преобразован для воспроизведения в соответствии с ограничениями, указанными метаданными представления.
Например, эффект маскирования первого элемента аудио с наименьшим коэффициентом усиления для второго элемента аудио с наибольшим коэффициентом усиления может быть использован для оценки уровня маскирования второго элемента, и наоборот.
В качестве еще одного примера может определяться самое дальнее (или, например, среднее) расстояние между первым и вторым элементами аудио и оцениваться затухание между ними. Затем эффект маскирования может быть оценен на основе относительной разности уровней после компенсации затухания.
В качестве другого примера, если система использует номинальное положение прослушивания, уровень сигнала в положении прослушивания от, соответственно, первого и второго элементов аудио может определяться на основе относительных уровней усиления или уровней сигнала и разницы в ослаблении от положений источников звука. Позиции элемента аудио могут быть выбраны из допустимых положений, например, таким образом, чтобы свести к минимуму эффект маскирования (ближайшее допустимое положение для первого элемента аудио и наиболее удаленное положение для второго элемента аудио).
Таким образом, кодирующий адаптер 213 может оценивать эффект маскирования для первого элемента аудио от второго элемента аудио на основании ограничения усиления/уровня и ограничения положения для второго элемента аудио, указанного входными метаданными представления для второго элемента аудио; и часто также на основании ограничения усиления/уровня и ограничения положения для первого элемента аудио, указанного входными метаданными представления для первого элемента аудио.
В некоторых вариантах осуществления кодирующий адаптер 213 может непосредственно определять порог маскирования для первого элемента аудио на основании метаданных представления для второго элемента аудио, а схема 211 кодирования может продолжать кодирование первого элемента аудио с использованием определенного порога маскирования.
В некоторых вариантах осуществления адаптация кодирования с помощью аудиокодера 205 может представлять собой внутренний процесс, при этом никакая другая функция не адаптируется соответствующим образом. Например, необратимое объединение множества элементов аудио в объединенный элемент аудио может быть выполнено с объединенным элементом аудио, включенным в поток кодированных аудиоданных, и без указания способа создания объединенного элемента аудио, т.е. без преобразующего устройства, выполняющего какую-либо конкретную обработку объединенного элемента аудио.
Однако во многих вариантах осуществления изобретения аудиокодер 205 может генерировать данные адаптированного кодирования, которые указывают на то, как кодирование адаптируется в ответ на входные метаданные представления. Затем эти данные адаптированного кодирования могут быть включены в поток кодированных аудиоданных. В этом подходе преобразующее устройство 109 соответственно может иметь информацию об адаптации кодирования и может быть выполнено с возможностью соответствующей адаптации декодирования и/или преобразования для воспроизведения.
Например, аудиокодер 205 может генерировать данные, указывающие на то, какие элементы аудио данных акустической среды являются фактически объединенными элементами аудио. Это может дополнительно указывать на некоторые параметры объединения, и, действительно, во многих вариантах осуществления они могут позволить преобразующему устройству 109 генерировать представления исходных элементов аудио, которые были объединены. Фактически, в некоторых вариантах осуществления объединенный элемент аудио может быть сгенерирован в виде понижающего микширования входных элементов аудио и аудиокодер 205 может генерировать параметрические данные повышающего микширования и включать их в поток кодированных аудиоданных, тем самым позволяя преобразующему устройству выполнять надлежащее повышающее микширование.
В качестве еще одного примера, декодирование как таковое может быть не адаптировано, но информация может быть использована во взаимодействии с слушателем/конечным пользователем. Например, множество аудио объектов, которые считаются «близкими» по своим адаптационным ограничениям, могут быть объединены кодером в один элемент аудио на основе сцены, в то время как их существование в качестве «виртуальных объектов» сигнализируется декодеру в данных адаптированного кодирования. Затем пользователю может быть предоставлена эта информация, и ему может быть предложено вручную управлять «виртуальными источниками звука» (хотя только в целом, поскольку они были объединены в аудио на основе сцены), а не быть информированным/осведомленным о аудио на основе сцены в качестве носителя для виртуальных объектов.
В некоторых вариантах осуществления метаданные представления могут содержать приоритетные данные для одного или более элементов аудио, а аудиокодер 205 может быть выполнен с возможностью адаптации сжатия для первого элемента аудио в ответ на указание приоритета для первого элемента аудио.
Индикация приоритета может быть индикацией приоритета преобразования для воспроизведения, которая указывает на перцептивную значимость или важность элемента аудио в аудиосцене. Например, он может использоваться для указания того, что элемент аудио, представляющий основной динамик, является более существенным, чем элемент аудио, представляющий, скажем, щебетание птиц в фоновом режиме.
Преобразователь 115 для воспроизведения может адаптировать преобразование для воспроизведения на основе указаний приоритета. Например, для слушателей с ослабленным слухом преобразователь 115 для воспроизведения может увеличивать коэффициент усиления для основного диалога с высоким приоритетом по сравнению с фоновым шумом с низким приоритетом, тем самым делая речь более разборчивой.
Кроме того, аудиокодер 205 может увеличивать сжатие для уменьшения приоритета. Например, для объединения элементов аудио может потребоваться, чтобы уровни приоритета были ниже заданного уровня. В качестве другого примера, аудиокодер 205 может объединять все элементы аудио, для которых уровень приоритета ниже заданного уровня.
В некоторых вариантах осуществления распределение битов для каждого элемента аудио может зависеть от уровня приоритета. Например, распределение битов для различных элементов аудио может быть основано на алгоритме или формуле, которая учитывает множество параметров, включая приоритет. Распределение битов для данного элемента аудио может увеличиваться монотонно с увеличением приоритета.
Следует понимать, что в вышеприведенном описании варианты осуществления настоящего изобретения изложены для ясности со ссылкой на разные функциональные схемы, блоки и процессоры. Однако очевидно, что может быть использовано любое подходящее распределение функциональных возможностей между разными функциональными схемами, блоками или процессорами без ущерба для настоящего изобретения. Например, показанные функциональные возможности, подлежащие осуществлению отдельными процессорами или контроллерами, могут быть осуществлены одним и тем же процессором или контроллерами. Поэтому ссылки на конкретные функциональные блоки или схемы должны рассматриваться только как ссылки на подходящее средство для обеспечения описываемых функциональных возможностей, а не как указание на строгую логическую или физическую структуру или организацию.
Настоящее изобретение может быть реализовано в любой подходящей форме, включая оборудование, программное обеспечение, встроенное программное обеспечение или любую их комбинацию. Настоящее изобретение при необходимости может быть реализовано, по меньшей мере частично, в виде компьютерного программного обеспечения, выполняемого на одном или более процессорах и/или цифровых процессорах сигналов. Элементы и компоненты варианта осуществления настоящего изобретения могут быть физически, функционально и логически реализованы любым подходящим способом. В действительности, функциональные возможности могут быть реализованы в одном блоке, в множестве блоков или в виде части других функциональных блоков. В силу этого настоящее изобретение может быть реализовано в одном блоке или может быть физически или функционально распределено между разными блоками, схемами и процессорами.
Как правило, примеры устройства аудиокодера, способа аудиокодера и компьютерного программного продукта, реализующего способ, обозначены нижеприведенными вариантами осуществления.
Хотя настоящее изобретение было описано в связи с некоторыми вариантами осуществления, это не следует рассматривать как ограничение конкретной формой, изложенной в настоящем документе. Напротив, объем настоящего изобретения ограничен только прилагаемой формулой изобретения. Кроме того, хотя может показаться, что признак описан в связи с конкретными вариантами осуществления, специалисту в данной области следует понимать, что различные признаки описанных вариантов осуществления могут быть объединены в соответствии с настоящим изобретением. В формуле изобретения термин «содержащий/включающий» не исключает наличия других элементов или этапов.
Кроме того, хотя множество средств, элементов, схем или этапов способа перечислены по отдельности, они могут быть реализованы, например, с помощью одной схемы, блока или процессора. Кроме того, хотя отдельные признаки могут быть включены в различные пункты формулы изобретения, они, возможно, могут быть эффективно объединены, и включение в различные пункты формулы изобретения не означает, что комбинация признаков является неосуществимой и/или невыгодной. Кроме того, включение признака в одну категорию пунктов формулы изобретения не означает ограничения этой категорией, а наоборот, указывает на то, что данный признак в равной степени может быть применен к другим категориям пунктов изобретения, когда это уместно. Кроме того, порядок признаков в формуле изобретения не означает конкретного порядка, в котором эти признаки должны прорабатываться, и, в частности, порядок отдельных этапов в пункте формулы изобретения способа не означает, что этапы должны выполняться в данном порядке. Напротив, этапы могут выполняться в любом подходящем порядке. Кроме того, упоминания в единственном числе не исключают множества. Поэтому ссылки с использованием средств указания единственного числа, прилагательных в единственном числе «первый», «второй» и т.д. не исключают множества. Ссылочные позиции в формуле изобретения приведены исключительно в качестве уточняющего примера и не должны трактоваться как ограничивающие объем формулы изобретения каким-либо образом.
| название | год | авторы | номер документа |
|---|---|---|---|
| Аудиоустройство и способ для него | 2020 |
|
RU2804014C2 |
| АУДИОУСТРОЙСТВО И СПОСОБ ЕГО РАБОТЫ | 2019 |
|
RU2797362C2 |
| УСТРОЙСТВО, СПОСОБ И КОМПЬЮТЕРНАЯ ПРОГРАММА ДЛЯ КОДИРОВАНИЯ, ДЕКОДИРОВАНИЯ, ОБРАБОТКИ СЦЕНЫ И ДРУГИХ ПРОЦЕДУР, ОТНОСЯЩИХСЯ К ОСНОВАННОМУ НА DirAC ПРОСТРАНСТВЕННОМУ АУДИОКОДИРОВАНИЮ | 2018 |
|
RU2759160C2 |
| Устройство и способ обработки аудиовизуальных данных | 2019 |
|
RU2805260C2 |
| ОПТИМИЗАЦИЯ ДОСТАВКИ ЗВУКА ДЛЯ ПРИЛОЖЕНИЙ ВИРТУАЛЬНОЙ РЕАЛЬНОСТИ | 2018 |
|
RU2750505C1 |
| Аудиоустройство и способ обработки аудио | 2019 |
|
RU2823573C1 |
| Аудиоустройство и способ обработки аудио | 2019 |
|
RU2815366C2 |
| ОПТИМИЗАЦИЯ ДОСТАВКИ ЗВУКА ДЛЯ ПРИЛОЖЕНИЙ ВИРТУАЛЬНОЙ РЕАЛЬНОСТИ | 2022 |
|
RU2801698C2 |
| Аудиоустройство и способ обработки аудио | 2019 |
|
RU2815621C1 |
| Аудиоустройство, система распределения аудио и способ их работы | 2019 |
|
RU2816884C2 |
Изобретение относится к способу и устройству для кодирования аудио и, в частности, для кодирования аудио для динамических приложений, таких как приложения виртуальной реальности. Техническим результатом является обеспечение возможности улучшенного и/или более гибкого кодирования во многих сценариях, генерирования потока кодированных аудиоданных, который обеспечивает улучшенное соотношение качества к скорости передачи данных. Заявленный способ реализуется устройством для кодирования аудио, которое содержит аудиоприемник (201), принимающий элементы аудио, представляющие аудиосцену, и приемник (203) метаданных, принимающий входные метаданные представления для элементов аудио, описывающие ограничения представления для преобразования для воспроизведения элементов аудио. Ограничения представления ограничивают параметр преобразования для воспроизведения, который может быть адаптирован при преобразовании для воспроизведения элементов аудио. Аудиокодер (205) генерирует кодированные аудиоданные для аудиосцены путем кодирования множества элементов аудио, причем кодирование адаптируется в ответ на входные метаданные представления. Схема (207) метаданных генерирует выходные метаданные представления из входных метаданных представления. Выходные метаданные представления содержат данные для кодированных элементов аудио, которые ограничивают величину, на которую адаптируемый параметр преобразования для воспроизведения может быть адаптирован при преобразовании для воспроизведения кодированных элементов аудио. Вывод (209) генерирует поток кодированных аудиоданных, содержащий кодированные аудиоданные и выходные метаданные представления. 2 н. и 11 з.п. ф-лы, 3 ил.
1. Устройство для кодирования аудио, содержащее:
аудиоприемник (201) для приема множества элементов аудио, представляющих аудиосцену;
приемник (203) метаданных для приема входных метаданных представления для множества элементов аудио, причем входные метаданные представления описывают ограничения представления для преобразования для воспроизведения множества элементов аудио, ограничивающие параметр преобразования для воспроизведения, который может быть адаптирован при преобразовании для воспроизведения множества элементов аудио, при этом ограничения представления содержат по меньшей мере одно ограничение из группы, состоящей из:
ограничения реверберации,
ограничения усиления и
ограничения управления динамическим диапазоном;
аудиокодер (205) для генерирования кодированных аудиоданных для аудиосцены путем кодирования множества элементов аудио, причем кодирование выполняется в ответ на входные метаданные представления посредством наличия объединяющего блока (215) для генерирования объединенного элемента аудио путем объединения по меньшей мере первого элемента аудио и второго элемента аудио из множества элементов аудио в ответ на входные метаданные представления для первого элемента аудио и входные метаданные представления для второго элемента аудио, и указанный аудиокодер (205) выполнен с возможностью генерирования объединенных данных кодирования аудио для первого и второго элемента аудио путем кодирования объединенного элемента аудио и включения объединенных данных кодирования аудио в кодированные аудиоданные;
схему (207) метаданных для генерирования метаданных выходного воспроизведения из входных метаданных представления, причем выходные метаданные представления содержат данные для кодированных элементов аудио, которые ограничивают величину, на которую возможно адаптирование адаптируемого параметра преобразования для воспроизведения при преобразовании для воспроизведения кодированных элементов аудио; и
схему (209) вывода для генерирования потока кодированных аудиоданных, содержащего кодированные аудиоданные и выходные метаданные представления.
2. Устройство для кодирования аудио по п. 1, в котором объединяющий блок (215) выполнен с возможностью выбора первого элемента аудио и второго элемента аудио из множества элементов аудио в ответ на входные метаданные представления для первого элемента аудио и для второго элемента аудио.
3. Устройство для кодирования аудио по п. 1 или 2, в котором объединяющий блок (215) выполнен с возможностью выбора первого элемента аудио и второго элемента аудио в ответ на определение того, что по меньшей мере некоторые входные метаданные представления для первого элемента аудио и входные метаданные представления для второго элемента аудио соответствуют критерию сходства.
4. Устройство для кодирования аудио по пп. 1-3, в котором входные метаданные представления для первого элемента аудио и входные метаданные представления для второго элемента аудио содержат по меньшей мере одно из ограничения усиления и ограничения положения.
5. Устройство для кодирования аудио по любому предыдущему пункту 1-4, в котором аудиокодер (205) дополнительно выполнен с возможностью генерирования объединенных метаданных представления для объединенного элемента аудио в ответ на входные метаданные представления для первого элемента аудио и входные метаданные представления для второго элемента аудио и включения объединенных метаданных представления в выходные метаданные представления.
6. Устройство для кодирования аудио по п. 5, в котором аудиокодер (205) выполнен с возможностью генерирования по меньшей мере некоторых объединенных метаданных представления для отображения ограничения параметра воспроизведения для объединенного элемента аудио, причем ограничение определено как ограничение, удовлетворяющее как ограничению для первого элемента аудио, указанному входными метаданными представления для первого элемента аудио, так и ограничению для второго элемента аудио, указанному входными метаданными представления для второго элемента аудио.
7. Устройство для кодирования аудио по любому предыдущему пункту, в котором аудиокодер (205) выполнен с возможностью адаптации сжатия первого элемента аудио в ответ на входные метаданные представления для второго элемента аудио.
8. Устройство для кодирования аудио по п. 7, в котором аудиокодер (205) выполнен с возможностью оценки эффекта маскирования для первого элемента аудио от второго элемента аудио в ответ на входные метаданные представления для второго элемента аудио, и с возможностью адаптации сжатия первого элемента аудио в ответ на эффект маскирования.
9. Устройство для кодирования аудио по п. 8, в котором аудиокодер (205) выполнен с возможностью оценки эффекта маскирования на первый элемент аудио от второго элемента аудио в ответ по меньшей мере на одно из ограничения усиления и ограничения положения для второго элемента аудио, указанного входными метаданными представления для второго элемента аудио.
10. Устройство для кодирования аудио по любому предыдущему пункту 7-9, в котором аудиокодер (205) также выполнен с возможностью адаптации сжатия первого элемента аудио в ответ на входные метаданные представления для первого элемента аудио.
11. Устройство для кодирования аудио по любому предыдущему пункту, в котором входные метаданные представления содержат данные о приоритете по меньшей мере для некоторых элементов аудио, а кодер выполнен с возможностью адаптации сжатия для первого элемента аудио в ответ на указание приоритета для первого элемента аудио во входных метаданных представления.
12. Устройство для кодирования аудио по любому предыдущему пункту, в котором аудиокодер (205) выполнен с возможностью генерирования данных адаптированного кодирования, указывающих на то, как кодирование адаптируется в ответ на входные метаданные представления, и включения данных адаптированного кодирования в поток кодированных аудиоданных.
13. Способ кодирования аудио, включающий:
прием множества элементов аудио, представляющих аудиосцену;
прием входных метаданных представления для множества элементов аудио, входные метаданные представления, описывающие ограничения представления для преобразования для воспроизведения множества элементов аудио, ограничения представления, ограничивающие параметр преобразования для воспроизведения, который может быть адаптирован при преобразовании для воспроизведения элементов аудио, при этом ограничения представления содержат по меньшей мере одно ограничение из группы, состоящей из:
ограничения реверберации,
ограничения усиления и
ограничения управления динамическим диапазоном;
генерирование кодированных аудиоданных для аудиосцены путем кодирования множества элементов аудио, причем кодирование выполняется в ответ на входные метаданные представления посредством генерирования объединенного элемента аудио путем объединения по меньшей мере первого элемента аудио и второго элемента аудио из множества элементов аудио в ответ на входные метаданные представления для первого элемента аудио и входные метаданные представления для второго элемента аудио, и генерирования объединенных данных кодирования аудио для первого и второго элемента аудио путем кодирования объединенного элемента аудио и включения объединенных данных кодирования аудио в кодированные аудиоданные;
генерирование выходных метаданных представления из входных метаданных представления, причем выходные метаданные представления содержат данные для кодированных элементов аудио, которые ограничивают величину, на которую возможно адаптирование адаптируемого параметра преобразования для воспроизведения при преобразовании для воспроизведения кодированных элементов аудио; и
генерирование потока кодированных аудиоданных, содержащего кодированные аудиоданные и выходные метаданные представления.
| US 2015332680 A1, 19.11.2015 | |||
| WO 2018047667 A1, 15.03.2018 | |||
| TSINGOS N., GALLO E., DRETTAKIS G | |||
| Perceptual audio rendering of complex virtual environments // ACM Transactions on Graphics, 01.08.2004, Vol | |||
| Прибор для равномерного смешения зерна и одновременного отбирания нескольких одинаковых по объему проб | 1921 |
|
SU23A1 |
| Переносная печь для варки пищи и отопления в окопах, походных помещениях и т.п. | 1921 |
|
SU3A1 |
| Трансляция, предназначенная для телефонирования быстропеременными токами | 1921 |
|
SU249A1 |
| US 2014297296 A1, 02.10.2014 | |||
| WO 2018180531 A1, 04.10.2018 | |||
| RU 2018104812 A, 26.02.2019 | |||
| АППАРАТУРА И МЕТОД МНОГОКАНАЛЬНОГО ПАРАМЕТРИЧЕСКОГО ПРЕОБРАЗОВАНИЯ | 2007 |
|
RU2431940C2 |
| RU | |||

