В среде виртуальной реальности (VR), или также в средах дополненной реальности (AR) либо смешанной реальности (MR), или в средах панорамного (360 градусов) видео пользователь может визуализировать полный панорамный контент с использованием, например, наголовного дисплея (HMD) и слушать его через наушники (или также через громкоговорители, включая правильное выведение в зависимости от его положения).
В простом варианте использования контент создается таким образом, что в некоторый момент времени воспроизводится только одна аудио/видеосцена (то есть панорамное видео). У аудио/видеосцены постоянное местоположение (например, сфера с пользователем в центре), и пользователь не может перемещаться по сцене, а может только поворачивать голову в различных направлениях (поворот, продольный крен, поперечный крен). В этом случае пользователю воспроизводится разное видео и аудио (отображаются разные поля видимости) на основе ориентации его головы.
Контент для аудио одинаков для всей сцены, тогда как контент для видео доставляется для всей панорамной сцены вместе с метаданными для описания процесса выведения (например, информация о сшивке, проекционное наложение и т.п.) и выбирается на основе текущего поля видимости пользователя. На основе метаданных аудиоконтент приспосабливается к текущему полю видимости пользователя (например, аудиообъект выводится по-разному на основе информации о поле видимости/ориентации пользователя). Следует отметить, что панорамный контент относится к любому типу контента, который содержит больше одного угла обзора в один и тот же момент времени, из которых пользователь может выбирать (например, с помощью ориентации головы или с использованием устройства дистанционного управления).
В более сложном сценарии, когда пользователь может перемещаться по VR-сцене или "перепрыгивать" от одной сцены к следующей, аудиоконтент также мог бы меняться (например, аудиоисточники, которые не слышны в одной сцене, можно услышать в следующей сцене - "дверь открывается"). В существующих системах законченные аудиосцены могут кодироваться в один поток и, при необходимости, в дополнительные потоки (зависимые от главного потока). Такие системы известны как аудиосистемы следующего поколения (например, MPEG-H 3D Audio). Примеры таких вариантов использования могут содержать:
Пример 1: пользователь выбирает вход в новую комнату, и меняется вся аудио/видеосцена;
Пример 2: пользователь перемещается по VR-сцене, открывает дверь и проходит в нее, что предполагает необходимый переход аудио от одной сцены к следующей сцене.
С целью описания этого сценария предлагается идея "дискретных точек наблюдения в пространстве" в качестве дискретного местоположения в пространстве (или в VR-среде), для которых доступен разный аудио/видеоконтент.
Решение "в лоб" состоит в наличии кодера в реальном масштабе времени, который меняет кодирование (число аудиоэлементов, пространственную информацию и т. д.) на основе обратной связи касательно положения/ориентации пользователя от воспроизводящего устройства. Это решение, например, в среде потоковой передачи подразумевало бы очень сложную связь между клиентом и сервером:
- клиенту (который обычно предполагают использующим только простую логику) потребовались бы продвинутые механизмы для передачи не только запросов разных потоков, но также сложной информации о подробностях кодирования, которая обеспечила бы обработку правильного контента на основе положения пользователя;
- медиа-сервер обычно заранее заполняется разными потоками (форматированными определенным образом, что допускает "посегментную" доставку), и основная функция сервера - предоставлять информацию о доступных потоках и порождать их доставку при запросе. Чтобы обеспечить сценарии, которые допускают кодирование на основе обратной связи от воспроизводящего устройства, медиа-серверу потребовались бы развитые линии связи с несколькими медиа-кодерами прямого эфира и способность оперативно создавать всю сигнальную информацию (например, Описание представления мультимедиа), которая могла бы меняться в реальном масштабе времени.
Хотя и можно представить себе такую систему, ее сложность и вычислительные требования выходят за функциональные возможности и особенности оборудования и доступных сегодня систем или даже тех, что будут разработаны в следующих десятилетиях.
В качестве альтернативы всегда можно доставлять контент, представляющий собой законченную VR-среду ("совершенный мир"). Это решило бы проблему, но потребовало бы гигантской скорости передачи битов (битрейта), которая превышает пропускную способность доступных линий связи.
Это сложно для среды в реальном масштабе времени, и чтобы обеспечить такие варианты использования с использованием доступных систем, предлагаются альтернативные решения, которые обеспечивают эти функциональные возможности при низкой сложности.
Терминология и определения
В данной области техники используется следующая терминология:
- аудиоэлементы: аудиосигналы, которые можно представить, например, в виде аудиообъектов, аудиоканалов, сценового аудио (амбиофония высшего порядка - HOA) или любого их сочетания;
- видимая область (ROI): одна область видеоконтента (или отображенной либо имитированной среды), которая интересна пользователю в один момент времени. Обычно это область на сфере, например, или многоугольная выборка из 2-мерной карты. ROI идентифицирует определенную область для конкретной цели, задавая границы исследуемого объекта;
- информация о положении пользователя: информация о местоположении (например, координаты x, y, z), информация об ориентации (поворот, продольный крен, поперечный крен), направление и скорость перемещения и т.п.;
- поле видимости: часть сферического видео, которое в настоящее время отображается и наблюдается пользователем;
- точка наблюдения: центральная точка поля видимости;
- панорамное видео (также известное как видео с эффектом присутствия или сферическое видео): применительно к этому документу представляет собой видеоконтент, который содержит более одного вида (то есть поля видимости) в одном направлении в один и тот же момент времени. Такой контент можно создать, например, с использованием всенаправленной камеры или совокупности камер. Во время воспроизведения зритель управляет направлением наблюдения;
- Описание представления мультимедиа (MPD) является синтаксисом, например XML, содержащим информацию о медиасегментах, их взаимосвязях и информацию, необходимую для выбора между ними;
- адаптационные наборы содержат медиапоток или набор медиапотоков. В самом простом случае один адаптационный набор содержит все аудио и видео для контента, но для уменьшения полосы пропускания каждый поток можно разделить на разный адаптационный набор. Общий случай - наличие одного адаптационного набора видео и нескольких адаптационных наборов аудио (один для каждого поддерживаемого языка). Адаптационные наборы также могут содержать субтитры или произвольные метаданные;
- представления позволяют адаптационному набору содержать одинаковый контент, кодированный по-разному. В большинстве случаев представления будут предоставляться в нескольких скоростях передачи битов. Это позволяет клиентам запрашивать контент наивысшего качества, который они могут воспроизводить без ожидания буферизации. Представления также могут кодироваться разными кодеками, допуская поддержку клиентов с разными поддерживаемыми кодеками.
Применительно к данной заявке идеи адаптационных наборов используются универсальнее, иногда фактически относясь к представлениям. Также медиапотоки (аудио/видеопотоки) в целом заключаются сначала в медиасегменты, которые являются фактическими медиафайлами, воспроизводимыми клиентом (например, DASH-клиентом). Для медиасегментов можно использовать различные форматы, например ISO Base Media File Format (ISOBMFF), который аналогичен формату контейнера MPEG-4, или транспортный поток (TS) MPEG-2. Заключение в медиасегменты и в разные представления/адаптационные наборы не зависит от описанных здесь способов, эти способы применяются ко всем различным вариантам.
Более того, описание способов в этом документе сосредоточено на связи сервер-клиент DASH, но способы являются достаточно универсальными для работы с другими средами доставки, например MMT, TS MPEG-2, DASH-ROUTE, форматом файла для воспроизведения файлов и т.п.
Вообще говоря, адаптационный набор находится на более высоком уровне относительно потока и может содержать метаданные (например, ассоциированные с положениями). Поток может содержать множество аудиоэлементов. Аудиосцена может ассоциироваться с множеством потоков, доставляемых как часть множества адаптационных наборов.
Современные решения
Современными решениями являются:
[1]. ISO/IEC 23008-3:2015, Information technology - High efficiency coding and media delivery in heterogeneous environments - Part 3: 3D audio
[2]. N16950, Study of ISO/IEC DIS 23000-20 Omnidirectional Media Format
Современные решения ограничены в предоставлении независимого VR-восприятия в одном постоянном местоположении, что позволяет пользователю менять ориентацию, но не перемещаться в VR-среде.
Сущность изобретения
В соответствии с вариантом осуществления система для среды виртуальной реальности, VR, дополненной реальности, AR, смешанной реальности, MR, или панорамного видео может быть выполнена с возможностью принимать видео- и аудиопотоки для воспроизведения в мультимедийном устройстве, причем система может содержать: по меньшей мере один медиа-декодер видео, выполненный с возможностью декодировать видеосигналы из видеопотоков для представления пользователю сцен среды VR, AR, MR или панорамного видео, и по меньшей мере один декодер аудио, выполненный с возможностью декодировать аудиосигналы по меньшей мере из одного аудиопотока, причем система может быть выполнена с возможностью запрашивать у сервера по меньшей мере один аудиопоток, и/или один аудиоэлемент в аудиопотоке, и/или один адаптационный набор на основе по меньшей мере текущего поля видимости пользователя, и/или ориентации головы, и/или данных перемещения, и/или метаданных взаимодействия, и/или данных виртуального положения.
В соответствии с аспектом система может быть выполнена с возможностью предоставлять серверу текущее поле видимости пользователя, и/или ориентацию головы, и/или данные перемещения, и/или метаданные взаимодействия, и/или данные виртуального положения, чтобы получить от сервера по меньшей мере один аудиопоток, и/или один аудиоэлемент аудиопотока, и/или один адаптационный набор.
Вариант осуществления может конфигурироваться так, что по меньшей мере одна сцена ассоциируется по меньшей мере с одним аудиоэлементом, при этом каждый аудиоэлемент ассоциируется с положением и/или областью в визуальной среде, где слышен аудиоэлемент, чтобы разные аудиопотоки предоставлялись для разных положений пользователя, и/или полей видимости, и/или ориентаций головы, и/или данных перемещения, и/или метаданных взаимодействия, и/или данных виртуального положения в сцене.
В соответствии с другим аспектом система может быть выполнена с возможностью решать, нужно ли воспроизводить по меньшей мере один аудиоэлемент аудиопотока и/или один адаптационный набор для текущего поля видимости пользователя, и/или ориентации головы, и/или данных перемещения, и/или метаданных взаимодействия, и/или виртуального положения в сцене, и при этом система может быть выполнена с возможностью запрашивать и/или принимать по меньшей мере один аудиоэлемент в текущем виртуальном положении пользователя.
В соответствии с аспектом система может быть выполнена с возможностью прогнозировать, станет ли релевантным и/или слышимым по меньшей мере один аудиоэлемент аудиопотока и/или один адаптационный набор, на основе по меньшей мере текущего поля видимости пользователя, и/или ориентации головы, и/или данных перемещения, и/или метаданных взаимодействия, и/или данных виртуального положения, и при этом система может быть выполнена с возможностью запрашивать и/или принимать по меньшей мере один аудиоэлемент, и/или аудиопоток, и/или адаптационный набор в конкретном виртуальном положении пользователя до предсказанного перемещения и/или взаимодействия пользователя в сцене, причем система может быть выполнена с возможностью воспроизводить, при приеме, по меньшей мере один аудиоэлемент и/или аудиопоток в конкретном виртуальном положении пользователя после перемещения и/или взаимодействия пользователя в сцене.
Вариант осуществления системы может быть выполнен с возможностью запрашивать и/или принимать по меньшей мере один аудиоэлемент с более низкой скоростью передачи битов и/или уровнем качества в виртуальном положении пользователя до перемещения и/или взаимодействия пользователя в сцене, причем система может быть выполнена с возможностью запрашивать и/или принимать по меньшей мере один аудиоэлемент с более высокой скоростью передачи битов и/или уровнем качества в виртуальном положении пользователя после перемещения и/или взаимодействия пользователя в сцене.
В соответствии с аспектом система может быть выполнена так, что по меньшей мере один аудиоэлемент ассоциируется по меньшей мере с одной сценой, при этом каждый аудиоэлемент ассоциируется с положением и/или областью в визуальной среде, ассоциированной со сценой, причем система может быть выполнена с возможностью запрашивать и/или принимать потоки с более высокой скоростью передачи битов и/или качеством для аудиоэлементов ближе к пользователю, чем для аудиоэлементов, более отдаленных от пользователя.
В соответствии с аспектом в системе по меньшей мере один аудиоэлемент может ассоциироваться по меньшей мере с одной сценой, при этом по меньшей мере один аудиоэлемент ассоциируется с положением и/или областью в визуальной среде, ассоциированной со сценой, причем система может быть выполнена с возможностью запрашивать разные потоки с разными скоростями передачи битов и/или уровнями качества для аудиоэлементов на основе их релевантности и/или уровня слышимости в каждом виртуальном положении пользователя в сцене, где система может быть выполнена с возможностью запрашивать аудиопоток с более высокой скоростью передачи битов и/или уровнем качества для аудиоэлементов, которые более релевантны и/или лучше слышны в текущем виртуальном положении пользователя, и/или аудиопоток с более низкой скоростью передачи битов и/или уровнем качества для аудиоэлементов, которые менее релевантны и/или хуже слышны в текущем виртуальном положении пользователя.
В варианте осуществления в системе по меньшей мере один аудиоэлемент может ассоциироваться со сценой, при этом каждый аудиоэлемент ассоциируется с положением и/или областью в визуальной среде, ассоциированной со сценой, где система может быть выполнена с возможностью периодически отправлять серверу текущее поле видимости пользователя, и/или ориентацию головы, и/или данные перемещения, и/или метаданные взаимодействия, и/или данные виртуального положения, чтобы: для первого положения от сервера предоставлялся поток с более высокой скоростью передачи битов и/или качеством, а для второго положения от сервера предоставлялся поток с более низкой скоростью передачи битов и/или качеством, где первое положение ближе по меньшей мере к одному аудиоэлементу, чем второе положение.
В варианте осуществления системы может задаваться множество сцен для нескольких визуальных сред, например смежных и/или соседних сред, чтобы предоставлялись первые потоки, ассоциированные с первой текущей сценой, и чтобы в случае перехода пользователя ко второй, дальней сцене предоставить потоки, ассоциированные с первой сценой, и вторые потоки, ассоциированные со второй сценой.
В варианте осуществления системы может задаваться множество сцен для первой и второй визуальных сред, при этом первая и вторая среды являются смежными и/или соседними средами, где от сервера предоставляются первые потоки, ассоциированные с первой сценой, для воспроизведения первой сцены, если положение или виртуальное положение пользователя находится в первой среде, ассоциированной с первой сценой, от сервера предоставляются вторые потоки, ассоциированные со второй сценой, для воспроизведения второй сцены, если положение или виртуальное положение пользователя находится во второй среде, ассоциированной со второй сценой, и предоставляются первые потоки, ассоциированные с первой сценой, и вторые потоки, ассоциированные со второй сценой, если положение или виртуальное положение пользователя находится в переходном положении между первой сценой и второй сценой.
В варианте осуществления системы может задаваться множество сцен для первой и второй визуальных сред, которые являются смежными и/или соседними средами, причем система выполнена с возможностью запрашивать и/или принимать первые потоки, ассоциированные с первой сценой, ассоциированной с первой средой, для воспроизведения первой сцены, если виртуальное положение пользователя находится в первой среде, причем система может быть выполнена с возможностью запрашивать и/или принимать вторые потоки, ассоциированные со второй сценой, ассоциированной со второй средой, для воспроизведения второй сцены, если виртуальное положение пользователя находится во второй среде, и при этом система может быть выполнена с возможностью запрашивать и/или принимать первые потоки, ассоциированные с первой сценой, и вторые потоки, ассоциированные со второй сценой, если виртуальное положение пользователя находится в переходном положении между первой средой и второй средой.
В соответствии с аспектом система может быть выполнена так, что первые потоки, ассоциированные с первой сценой, получаются с более высокой скоростью передачи битов и/или качеством, когда пользователь находится в первой среде, ассоциированной с первой сценой, тогда как вторые потоки, ассоциированные со второй сценой, ассоциированной со второй средой, получаются с более низкой скоростью передачи битов и/или качеством, когда пользователь находится в начале переходного положения от первой сцены ко второй сцене, и первые потоки, ассоциированные с первой сценой, получаются с более низкой скоростью передачи битов и/или качеством, а вторые потоки, ассоциированные со второй сценой, получаются с более высокой скоростью передачи битов и/или качеством, когда пользователь находится в конце переходного положения от первой сцены ко второй сцене, где более низкая скорость передачи битов и/или качество ниже более высокой скорости передачи битов и/или качества.
В соответствии с аспектом система может быть выполнена так, что может задаваться множество сцен для нескольких сред, например смежных и/или соседних сред, чтобы система могла получать потоки, ассоциированные с первой текущей сценой, ассоциированной с первой текущей средой, и если расстояние положения или виртуального положения пользователя от границы сцены меньше заранее установленной пороговой величины, то система может дополнительно получать аудиопотоки, ассоциированные со второй, смежной и/или соседней средой, ассоциированной со второй сценой.
В соответствии с аспектом система может быть выполнена так, что может задаваться множество сцен для нескольких визуальных сред, чтобы система запрашивала и/или получала потоки, ассоциированные с текущей сценой, с более высокой скоростью передачи битов и/или качеством, и потоки, ассоциированные со второй сценой, с более низкой скоростью передачи битов и/или качеством, где более низкая скорость передачи битов и/или качество ниже более высокой скорости передачи битов и/или качества.
В соответствии с аспектом система может быть выполнена так, что может задаваться множество из N аудиоэлементов, и если расстояние пользователя до положения или области этих аудиоэлементов больше заранее установленной пороговой величины, то обрабатываются N аудиоэлементов для получения меньшего числа M аудиоэлементов (M<N), ассоциированных с положением или областью, близкой к положению или области N аудиоэлементов, чтобы предоставить системе по меньшей мере один аудиопоток, ассоциированный с N аудиоэлементами, если расстояние пользователя до положения или области N аудиоэлементов меньше заранее установленной пороговой величины, либо предоставить системе по меньшей мере один аудиопоток, ассоциированный с M аудиоэлементами, если расстояние пользователя до положения или области N аудиоэлементов больше заранее установленной пороговой величины.
В соответствии с аспектом система может быть выполнена так, что по меньшей мере одна сцена визуальной среды ассоциируется по меньшей мере с одним множеством из N аудиоэлементов (N>=2), при этом каждый аудиоэлемент ассоциируется с положением и/или областью в визуальной среде, где по меньшей мере одно множество из N аудиоэлементов предоставляется по меньшей мере в одном представлении с высокой скоростью передачи битов и/или уровнем качества, и где по меньшей мере одно множество из N аудиоэлементов предоставляется по меньшей мере в одном представлении с низкой скоростью передачи битов и/или уровнем качества, где по меньшей мере одно представление получается путем обработки N аудиоэлементов, чтобы получить меньшее число M аудиоэлементов (M<N), ассоциированных с положением или областью, близкой к положению или области N аудиоэлементов, причем система может быть выполнена с возможностью запрашивать представление с более высокой скоростью передачи битов и/или уровнем качества для аудиоэлементов, если аудиоэлементы более релевантны и/или лучше слышны в текущем виртуальном положении пользователя в сцене, причем система может быть выполнена с возможностью запрашивать представление с более низкой скоростью передачи битов и/или уровнем качества для аудиоэлементов, если аудиоэлементы менее релевантны и/или хуже слышны в текущем виртуальном положении пользователя в сцене.
В соответствии с аспектом система может быть выполнена так, что если расстояние пользователя, и/или релевантность, и/или уровень слышимости, и/или угловая ориентация меньше заранее установленной пороговой величины, то получаются разные потоки для разных аудиоэлементов.
В варианте осуществления система может быть выполнена с возможностью запрашивать и/или получать потоки на основе ориентации пользователя, и/или направления перемещения пользователя, и/или взаимодействий пользователя в сцене.
В варианте осуществления системы поле видимости может ассоциироваться с положением, и/или виртуальным положением, и/или данными перемещения, и/или головой.
В соответствии с аспектом система может быть выполнена так, что разные аудиоэлементы предоставляются в разных полях видимости, причем система может быть выполнена с возможностью запрашивать и/или принимать первый аудиоэлемент с более высокой скоростью передачи битов, чем второй аудиоэлемент, который не входит в поле видимости, если один первый аудиоэлемент входит в поле видимости.
В соответствии с аспектом система может быть выполнена с возможностью запрашивать и/или принимать первые аудиопотоки и вторые аудиопотоки, где первые аудиоэлементы в первых аудиопотоках более релевантны и/или лучше слышны, чем вторые аудиоэлементы во вторых аудиопотоках, где первые аудиопотоки запрашиваются и/или принимаются с более высокой скоростью передачи битов и/или качеством, чем скорость передачи битов и/или качество у вторых аудиопотоков.
В соответствии с аспектом система может быть выполнена так, что задаются по меньшей мере две сцены визуальной среды, где по меньшей мере один первый и второй аудиоэлементы ассоциируются с первой сценой, ассоциированной с первой визуальной средой, и по меньшей мере один третий аудиоэлемент ассоциируется со второй сценой, ассоциированной со второй визуальной средой, причем система может быть выполнена с возможностью получать метаданные, описывающие, что по меньшей мере один второй аудиоэлемент дополнительно ассоциируется со второй сценой визуальной среды, и причем система может быть выполнена с возможностью запрашивать и/или принимать по меньшей мере первый и второй аудиоэлементы, если виртуальное положение пользователя находится в первой визуальной среде, и при этом система может быть выполнена с возможностью запрашивать и/или принимать по меньшей мере второй и третий аудиоэлементы, если виртуальное положение пользователя находится во второй сцене визуальной среды, и при этом система может быть выполнена с возможностью запрашивать и/или принимать по меньшей мере первый, второй и третий аудиоэлементы, если виртуальное положение пользователя находится в переходе между первой сценой визуальной среды и второй сценой визуальной среды.
Вариант осуществления системы может конфигурироваться так, что по меньшей мере один первый аудиоэлемент предоставляется по меньшей мере в одном аудиопотоке и/или адаптационном наборе, и по меньшей мере один второй аудиоэлемент предоставляется по меньшей мере в одном втором аудиопотоке и/или адаптационном наборе, и по меньшей мере один третий аудиоэлемент предоставляется по меньшей мере в одном третьем аудиопотоке и/или адаптационном наборе, и где по меньшей мере первая сцена визуальной среды описывается метаданными как законченная сцена, которая требует по меньшей мере первого и второго аудиопотоков и/или адаптационных наборов, и при этом вторая сцена визуальной среды описывается метаданными как незаконченная сцена, которая требует по меньшей мере третьего аудиопотока и/или адаптационного набора и по меньшей мере второго аудиопотока и/или адаптационных наборов, ассоциированных по меньшей мере с первой сценой визуальной среды, причем система содержит процессор метаданных, выполненный с возможностью работать с метаданными, чтобы разрешить соединение второго аудиопотока, принадлежащего первой визуальной среде, и третьего аудиопотока, ассоциированного со второй визуальной средой, в новый единый поток, если виртуальное положение пользователя находится во второй визуальной среде.
В соответствии с аспектом система содержит процессор метаданных, выполненный с возможностью работать с метаданными по меньшей мере в одном аудиопотоке по меньшей мере перед одним декодером аудио, на основе текущего поля видимости пользователя, и/или ориентации головы, и/или данных перемещения, и/или метаданных взаимодействия, и/или данных виртуального положения.
В соответствии с аспектом процессор метаданных может быть выполнен с возможностью включать и/или отключать по меньшей мере один аудиоэлемент по меньшей мере в одном аудиопотоке по меньшей мере перед одним декодером аудио на основе текущего поля видимости пользователя, и/или ориентации головы, и/или данных перемещения, и/или метаданных взаимодействия, и/или данных виртуального положения, причем процессор метаданных может быть выполнен с возможностью отключать по меньшей мере один аудиоэлемент по меньшей мере в одном аудиопотоке по меньшей мере перед одним декодером аудио, если система решает, что аудиоэлемент больше не нужно воспроизводить как следствие текущего поля видимости, и/или ориентации головы, и/или данных перемещения, и/или метаданных взаимодействия, и/или данных виртуального положения, и причем процессор метаданных может быть выполнен с возможностью включать по меньшей мере один аудиоэлемент по меньшей мере в одном аудиопотоке по меньшей мере перед одним декодером аудио, если система решает, что аудиоэлемент нужно воспроизводить как следствие текущего поля видимости пользователя, и/или ориентации головы, и/или данных перемещения, и/или метаданных взаимодействия, и/или данных виртуального положения.
В соответствии с аспектом система может быть выполнена с возможностью отключать декодирование аудиоэлементов, выбранных на основе текущего поля видимости пользователя, и/или ориентации головы, и/или данных перемещения, и/или метаданных, и/или виртуального положения.
В соответствии с аспектом система может быть выполнена с возможностью соединять по меньшей мере один первый аудиопоток, ассоциированный с текущей аудиосценой, по меньшей мере с одним потоком, ассоциированным с соседней, смежной и/или будущей аудиосценой.
В соответствии с аспектом система может быть выполнена с возможностью получать и/или собирать статистические или агрегированные данные о текущем поле видимости пользователя, и/или ориентации головы, и/или данные перемещения, и/или метаданные, и/или данные виртуального положения, чтобы передавать серверу запрос, ассоциированный со статистическими или агрегированными данными.
В соответствии с аспектом система может быть выполнена с возможностью отключать декодирование и/или воспроизведение по меньшей мере одного потока на основе метаданных, ассоциированных по меньшей мере с одним потоком, и на основе текущего поля видимости пользователя, и/или ориентации головы, и/или данных перемещения, и/или метаданных, и/или данных виртуального положения.
В соответствии с аспектом система может быть выполнена с возможностью: работать с метаданными, ассоциированными с группой выбранных аудиопотоков, на основе по меньшей мере текущего или предполагаемого поля видимости пользователя, и/или ориентации головы, и/или данных перемещения, и/или метаданных, и/или данных виртуального положения, чтобы: выбирать, и/или включать, и/или активировать аудиоэлементы, составляющие воспроизводимую аудиосцену; и/или обеспечивать соединение всех выбранных аудиопотоков в единый аудиопоток.
В соответствии с аспектом система может быть выполнена с возможностью управлять запросом у сервера по меньшей мере одного потока на основе расстояния положения пользователя от границ соседних и/или смежных сред, ассоциированных с разными сценами, или других показателей, ассоциированных с положением пользователя в текущей среде или предсказаниями о будущей среде.
В соответствии с аспектом системная информация может предоставляться от серверной системы для каждого аудиоэлемента или аудиообъекта, причем эта информация включает в себя описательную информацию о местоположениях, в которых звуковая сцена или аудиоэлементы активны.
В соответствии с аспектом система может быть выполнена с возможностью выбирать между воспроизведением одной сцены и составлением, или смешиванием, или мультиплексированием, или наложением, или объединением по меньшей мере двух сцен на основе текущего или будущего поля видимости, и/или ориентации головы, и/или данных перемещения, и/или метаданных, и/или виртуального положения, и/или выбора пользователя, при этом две сцены ассоциированы с разными соседними и/или смежными средами.
В соответствии с аспектом система может быть выполнена с возможностью создавать или использовать по меньшей мере адаптационные наборы, чтобы: некоторое количество адаптационных наборов ассоциировалось с одной аудиосценой; и/или предоставлялась дополнительная информация, которая соотносит каждый адаптационный набор с одной точкой наблюдения, или одной аудиосценой; и/или предоставлялась дополнительная информация, которая может включать в себя: информацию о границах одной аудиосцены, и/или информацию о взаимосвязи между одним адаптационным набором и одной аудиосценой (например, аудиосцена кодируется в три потока, которые заключаются в три адаптационных набора), и/или информацию о связи между границами аудиосцены и несколькими адаптационными наборами.
В соответствии с аспектом система может быть выполнена с возможностью: принимать поток для сцены, ассоциированной с соседней или смежной средой; запускать декодирование и/или воспроизведение потока для соседней или смежной среды при обнаружении перехода границы между двумя средами.
В соответствии с аспектом система может быть выполнена с возможностью работать в качестве клиента и сервера, сконфигурированных для доставки видео- и аудиопотоков для воспроизведения в мультимедийном устройстве.
В соответствии с аспектом система может быть выполнена с возможностью: запрашивать и/или принимать по меньшей мере один первый адаптационный набор, содержащий по меньшей мере один аудиопоток, ассоциированный по меньшей мере с одной первой аудиосценой; запрашивать и/или принимать по меньшей мере один второй адаптационный набор, содержащий по меньшей мере один второй аудиопоток, ассоциированный по меньшей мере с двумя аудиосценами, включая по меньшей мере одну первую аудиосцену; и обеспечивать соединение по меньшей мере одного первого аудиопотока и по меньшей мере одного второго аудиопотока в новый аудиопоток для декодирования на основе метаданных, доступных касательно текущего поля видимости пользователя, и/или ориентации головы, и/или данных перемещения, и/или метаданных, и/или данных виртуального положения, и/или информации, описывающей ассоциацию по меньшей мере одного первого адаптационного набора по меньшей мере с одной первой аудиосценой и/или ассоциацию по меньшей мере одного второго адаптационного набора по меньшей мере с одной первой аудиосценой.
В соответствии с аспектом система может быть выполнена с возможностью принимать информацию о текущем поле видимости пользователя, и/или ориентацию головы, и/или данные перемещения, и/или метаданные, и/или данные виртуального положения, и/или любую информацию, описывающую изменения, вызванные действиями пользователя; и принимать информацию о доступности адаптационных наборов и информацию, описывающую ассоциацию по меньшей мере одного адаптационного набора по меньшей мере с одной сценой, и/или точкой наблюдения, и/или полем видимости, и/или положением, и/или виртуальным положением, и/или данными перемещения, и/или ориентацией.
В соответствии с аспектом система может быть выполнена с возможностью решать, нужно ли воспроизводить по меньшей мере один аудиоэлемент по меньшей мере из одной аудиосцены, встроенной по меньшей мере в один поток, и по меньшей мере один дополнительный аудиоэлемент по меньшей мере из одной дополнительной аудиосцены, встроенной по меньшей мере в один дополнительный поток; и вызывать, при положительном решении, операцию соединения, или составления, или мультиплексирования, или наложения, или объединения по меньшей мере одного дополнительного потока дополнительной аудиосцены по меньшей мере с одним потоком по меньшей мере одной аудиосцены.
В соответствии с аспектом система может быть выполнена с возможностью работать с метаданными аудио, ассоциированными с выбранными аудиопотоками, на основе по меньшей мере текущего поля видимости пользователя, и/или ориентации головы, и/или данных перемещения, и/или метаданных, и/или данных виртуального положения, чтобы: выбирать, и/или включать, и/или активировать аудиоэлементы, составляющие аудиосцену, выбранную для воспроизведения; и обеспечивать соединение всех выбранных аудиопотоков в единый аудиопоток.
В соответствии с аспектом может обеспечиваться сервер для доставки аудио- и видеопотоков клиенту для среды виртуальной реальности, VR, дополненной реальности, AR, смешанной реальности, MR, или панорамного видео, при этом видео- и аудиопотоки должны воспроизводиться в мультимедийном устройстве, причем сервер может содержать кодер для кодирования и/или хранилище для хранения видеопотоков, чтобы описывать визуальную среду, при этом визуальная среда ассоциирована с аудиосценой; причем сервер может дополнительно содержать кодер для кодирования и/или хранилище для хранения множества потоков, и/или аудиоэлементов, и/или адаптационных наборов для доставки клиенту, при этом потоки, и/или аудиоэлементы, и/или адаптационные наборы ассоциированы по меньшей мере с одной аудиосценой, причем сервер выполнен с возможностью: выбирать и доставлять видеопоток на основе запроса от клиента, при этом видеопоток ассоциирован со средой; выбирать аудиопоток, и/или аудиоэлемент, и/или адаптационный набор на основе запроса от клиента, при этом запрос ассоциирован по меньшей мере с текущим полем видимости пользователя, и/или ориентацией головы, и/или данными перемещения, и/или метаданными взаимодействия, и/или данными виртуального положения и с аудиосценой, ассоциированной со средой; и доставки аудиопотока клиенту.
В соответствии с аспектом потоки могут заключаться в адаптационные наборы, при этом каждый адаптационный набор включает в себя множество потоков, ассоциированных с разными представлениями с разной скоростью передачи битов и/или качеством одного и того же аудиоконтента, причем выбранный адаптационный набор выбирается на основе запроса от клиента.
В соответствии с аспектом система может работать как клиент и сервер.
В соответствии с аспектом система может включать в себя сервер.
В соответствии с аспектом может предоставляться способ для среды виртуальной реальности, VR, дополненной реальности, AR, смешанной реальности, MR, или панорамного видео, выполненный с возможностью принимать видео- и аудиопотоки для воспроизведения в мультимедийном устройстве (например, воспроизводящем устройстве), содержащий: декодирование видеосигналов из видеопотоков для представления пользователю сцен среды VR, AR, MR или панорамного видео, и декодирование аудиосигналов из аудиопотоков, запрос и/или получение от сервера по меньшей мере одного аудиопотока на основе текущего поля видимости пользователя, и/или данных о положении, и/или ориентации головы, и/или данных перемещения, и/или метаданных, и/или данных виртуального положения, и/или метаданных.
В соответствии с аспектом может предоставляться компьютерная программа, содержащая команды, которые при исполнении процессором побуждают процессор выполнять вышеупомянутый способ.
Краткое описание чертежей
Фиг. 1.1-1.8 показывают патентоспособные примеры.
Фиг. 2-6 показывают патентоспособные сценарии.
Фиг. 7A-8B показывают патентоспособные способы.
Осуществление изобретения
Ниже в этом документе (например, фиг. 1.1 и последующие) раскрываются примеры систем в соответствии с патентоспособными аспектами.
Примеры патентоспособной системы (которую можно воплотить в разных раскрытых ниже примерах) вместе указываются ссылкой 102. Система 102 может быть клиентской системой, например, так как может получать от серверной системы (например, 120) аудио- и/или видеопотоки для представления пользователю аудиосцен и/или визуальных сред. Клиентская система 102 также может принимать от серверной системы 120 метаданные, которые предоставляют, например, дополнительную и/или вспомогательную информацию об аудио- и/или видеопотоках.
Система 102 может ассоциироваться (или содержать в некоторых примерах) с мультимедийным устройством (MCD), которое фактически воспроизводит пользователю аудио- и/или видеосигналы. В некоторых примерах пользователь может надевать MCD.
Система 102 может выполнять запросы к серверной системе 120, при этом запросы ассоциируются по меньшей мере с одним текущим полем видимости пользователя, и/или ориентацией головы, (например, угловой ориентацией), и/или данными перемещения, и/или метаданными взаимодействия, и/или данными 110 виртуального положения (могут предоставляться несколько показателей). Поле видимости, и/или ориентация головы, и/или данные перемещения, и/или метаданные взаимодействия, и/или данные 110 виртуального положения могут предоставляться в обратной связи от MCD к клиентской системе 102, которая может, в свою очередь, предоставлять запрос серверной системе 120 на основе этой обратной связи.
В некоторых случаях запрос (который указывается ссылкой 112) может содержать текущее поле видимости пользователя, и/или ориентацию головы, и/или данные перемещения, и/или метаданные взаимодействия, и/или данные 110 виртуального положения (или указание либо его обработанную версию). На основе текущего поля видимости пользователя, и/или ориентации головы, и/или данных перемещения, и/или метаданных взаимодействия, и/или данных 110 виртуального положения серверная система 120 предоставит необходимые аудио- и/или видеопотоки и/или метаданные. В этом случае серверная система 120 может знать о положении пользователя (например, в виртуальной среде) и может ассоциировать правильные потоки с положениями пользователя.
В других случаях запрос 112 от клиентской системы 102 может содержать явные запросы конкретных аудио- и/или видеопотоков. В этом случае запрос 112 может основываться на текущем поле видимости пользователя, и/или ориентации головы, и/или данных перемещения, и/или метаданных взаимодействия, и/или данных 110 виртуального положения. Клиентская система 102 знает об аудио- и видеосигналах, которые нужно вывести пользователю, даже если клиентская система 102 не хранит необходимые потоки. Клиентская система 102 в примерах может обращаться к конкретным потокам в серверной системе 120.
Клиентская система 102 может быть системой для среды виртуальной реальности, VR, дополненной реальности, AR, смешанной реальности, MR, или панорамного видео, выполненной с возможностью принимать видео- и аудиопотоки для воспроизведения в мультимедийном устройстве,
причем система 102 содержит:
по меньшей мере один медиа-декодер видео, выполненный с возможностью декодировать видеосигналы из видеопотоков для представления пользователю сцен среды VR, AR, MR или панорамного видео, и
по меньшей мере один декодер 104 аудио, выполненный с возможностью декодировать аудиосигналы (108) по меньшей мере из одного аудиопотока 106,
причем система 102 выполнена с возможностью запрашивать 112 у сервера 120 по меньшей мере один аудиопоток 106, и/или один аудиоэлемент в аудиопотоке, и/или один адаптационный набор на основе по меньшей мере текущего поля видимости пользователя, и/или ориентации головы, и/или данных перемещения, и/или метаданных взаимодействия, и/или данных 110 виртуального положения.
Нужно отметить, что в средах VR, AR, MR может подразумеваться, что пользователь 140 находится в конкретной среде (например, в конкретной комнате). Среда описывается видеосигналами, которые кодируются, например, на стороне сервера (сторона серверной системы 120, что не обязательно включает в себя серверную систему 120, но может содержать другой кодер, который ранее кодировал видеопотоки, которые после этого были сохранены в хранилище сервера 120). В некоторых примерах в каждый момент пользователь может получать только некоторые видеосигналы (например, поле видимости).
Вообще говоря, каждая среда может ассоциироваться с конкретной аудиосценой. Аудиосцену можно понимать как совокупность всех звуков, которые нужно воспроизвести для пользователя в конкретной среде и за конкретный период времени.
Традиционно среды понимали как дискретное число. Соответственно, количество сред понималось как конечное. По тем же причинам количество аудиосцен понималось как конечное. Поэтому на известном уровне техники системы VR, AR, MR спроектированы так, что:
- пользователь должен находиться в одной-единственной среде в каждый момент; поэтому для каждой среды:
- клиентская система 102 запрашивает у серверной системы 120 только видеопотоки, ассоциированные с одной средой;
- клиентская система 102 запрашивает у серверной системы 120 только аудиопотоки, ассоциированные с одной сценой.
Этот подход привел к неудобствам.
Например, все аудиопотоки должны доставляться клиентской системе 102 вместе для каждой сцены/среды, а совсем новые аудиопотоки нужно доставлять, когда пользователь перемещается в другую среду (например, когда пользователь проходит в дверь, подразумевая передачу сред/сцен).
Кроме того, в некоторых случаях появлялось неестественное восприятие: например, когда пользователь находится рядом со стеной (например, виртуальной стеной виртуальной комнаты), он должен воспринимать звуки, идущие с другой стороны стены. Однако это восприятие в традиционных средах невозможно: очевидно, что совокупность аудиопотоков, ассоциированных с текущей сценой, не содержит никакой поток, ассоциированный со смежными средами/сценами.
С другой стороны, восприятие пользователя обычно улучшается, когда увеличивается скорость передачи битов у аудиопотоков. Это может вызвать дополнительные проблемы: чем выше скорость передачи битов, тем больше полезная нагрузка, которую серверной системе нужно доставлять в клиентскую систему 102. Например, когда аудиосцена содержит несколько аудиоисточников (передаваемых в виде аудиоэлементов), причем некоторые из них расположены возле положения пользователя, а другие - далеко от него, то расположенные далеко источники звука будут слышны меньше. Поэтому доставка всех аудиоэлементов с одинаковой скоростью передачи битов или уровнем качества может приводить к очень высоким скоростям передачи битов. Это означает неэффективную доставку аудиопотока. Если серверная система 120 доставляет аудиопотоки с наивысшей возможной скоростью передачи битов, то получается неэффективная доставка, так как звуки с низким уровнем слышимости или низкой релевантностью к общей аудиосцене все же потребовали бы высокой скорости передачи битов аналогично релевантным звукам, сформированным ближе к пользователю. Поэтому, если бы все аудиопотоки одной сцены доставлялись с наивысшей скоростью передачи битов, то связь между серверной системой 120 и клиентской системой 102 излишне увеличила бы полезную нагрузку. Если все аудиопотоки одной сцены доставляются с более низкой скоростью передачи битов, то восприятие пользователя не будет удовлетворительным.
Проблемы связи усиливают рассмотренное выше неудобство: когда пользователь проходит в дверь, предполагается, что он немедленно меняет среду/сцену, что потребовало бы от серверной системы 120 немедленное предоставление всех потоков клиентской системе 102.
Поэтому традиционно было невозможно решить рассмотренные выше проблемы.
Однако эти проблемы можно решить с помощью данного изобретения: клиентская система 102 предоставляет запрос серверной системе 120, который также может основываться на текущем поле видимости пользователя, и/или ориентации головы, и/или данных перемещения, и/или метаданных взаимодействия, и/или данных виртуального положения (а не только на среде/сцене). Соответственно, серверная система 120 может предоставлять для каждого момента аудиопотоки, которые нужно вывести, например, для каждого положения пользователя.
Например, если пользователь никогда не ходит близко к стене, то клиентской системе 102 не нужно запрашивать потоки соседней среды (например, они могут запрашиваться клиентской системой 102, только когда пользователь подходит к стене). Кроме того, потоки снаружи стены могут обладать уменьшенной скоростью передачи битов, так как они могут звучать на малой громкости. Примечательно, что более релевантные потоки (например, потоки от аудиообъектов в текущей среде) могут доставляться серверной системой 120 клиентской системе 102 с наивысшей скоростью передачи битов и/или наивысшим уровнем качества (в результате того, что менее релевантные потоки передаются с более низкой скоростью передачи битов и/или уровнем качества, оставляя поэтому свободную полосу для более релевантных потоков).
Более низкий уровень качества можно получить, например, путем уменьшения скорости передачи битов или путем обработки аудиоэлементов таким образом, что сокращаются необходимые данные для передачи, тогда как используемая скорость передачи битов по каждому аудиосигнала остается постоянной. Например, если 10 аудиообъектов располагаются в разных положениях далеко от пользователя, то эти объекты можно смешать в меньшее число сигналов на основе положения пользователя:
- в положениях, очень удаленных от положения пользователя (например, больше первой пороговой величины) объекты смешиваются в 2 сигнала (возможны другие числа на основе их пространственного положения и семантики) и доставляются как 2 "виртуальных объекта";
- в положениях ближе к положению пользователя (например, меньше первой пороговой величины, но больше второй пороговой величины, которая меньше первой пороговой величины) объекты смешиваются в 5 сигналов (на основе их пространственного положения и семантики) и доставляются как 5 (возможны другие числа) "виртуальных объектов";
- в положениях очень близко к положениям пользователя (меньше первой и второй пороговых величин) 10 объектов доставляются как 10 аудиосигналов с наивысшим качеством.
Хотя для наивысшего качества все аудиосигналы могут считаться очень важными и слышимыми, пользователь может отдельно определять местонахождение каждого объекта. Для более низких уровней качества в удаленных положениях некоторые аудиообъекты могут становиться менее релевантными или менее слышимыми, поэтому пользователь никак не смог бы отдельно определить местонахождение аудиосигналов в пространстве, и поэтому снижение уровня качества для доставки этих аудиосигналов не привело бы ни к какому снижению качества восприятия для пользователя.
Другой пример про то, когда пользователь выходит за дверь: в переходном положении (например, на границе между двумя разными средами/сценами) серверная система 120 предоставит оба потока обоих сцен/сред, но с более низкими скоростями передачи битов. Причина в том, что пользователь будет воспринимать звуки из двух разных сред (звуки могут соединяться из разных аудиопотоков, первоначально ассоциированных с разными сценами/средами), и не возникает потребности в наивысшем уровне качества у каждого источника звука (или аудиоэлемента).
В связи с вышеизложенным изобретение позволяет превзойти традиционный подход с дискретным числом визуальных сред и аудиосцен, но может позволить постепенное представление разных сред/сцен, создавая более реалистичное восприятие у пользователя.
В этом документе считается, что каждая визуальная среда (например, виртуальная среда) ассоциируется с аудиосценой (атрибуты сред также могут быть атрибутами сцены). Каждая среда/сцена может ассоциироваться, например, с геометрической системой координат (которая может быть виртуальной геометрической системой координат). Среда/сцена может иметь границы, чтобы получалась другая среда/сцена, когда положение пользователя (например, виртуальное положение) выходит за границы. Границы могут основываться на используемой системе координат. Среда может содержать аудиообъекты (аудиоэлементы, источники звука), которые могут располагаться в некоторых конкретных координатах среды/сцены. Например, по отношению к относительному положению и/или ориентации пользователя относительно аудиообъектов (аудиоэлементов, источников звука) клиентская система 102 может запрашивать разные потоки, и/или серверная система 120 может предоставлять разные потоки (например, с более высокими/более низкими скоростями передачи битов и/или уровнями качества в соответствии с расстоянием и/или ориентацией).
В общих чертах клиентская система 102 может запрашивать и/или получать от серверной системы 120 разные потоки (например, разные представления одних и тех же звуков с разными скоростями передачи битов и/или уровнями качества) на основе их слышимости и/или релевантности. Слышимость и/или релевантность может определяться, например, на основе по меньшей мере текущего поля видимости пользователя, и/или ориентации головы, и/или данных перемещения, и/или метаданных взаимодействия, и/или данных виртуального положения.
В нескольких примерах существует возможность соединения разных потоков. В нескольких случаях имеется возможность составления, или смешивания, или мультиплексирования, или наложения, или объединения по меньшей мере двух сцен. Существует, например, возможность использования смесителя и/или блока вывода (который может использоваться, например, после нескольких декодеров, декодирующих по меньшей мере один аудиопоток) либо выполнение операции мультиплексирования потоков, например, перед декодированием потоков. В других случаях может быть возможность декодирования разных потоков и их вывода при разных настройках громкоговорителей.
Нужно отметить, что настоящее изобретение не обязательно отвергает концепцию визуальной среды и аудиосцены. В частности, с помощью изобретения аудио- и видеопотоки, ассоциированные с конкретной сценой/средой, могут доставляться от серверной системы 120 клиентской системе 102, когда пользователь входит в среде/сцену. Тем не менее, в одной и той же среде/сцене можно запрашивать, обращаться и/или доставлять разные аудиопотоки, и/или аудиообъекты, и/или адаптационные наборы. В частности, может быть так, что:
- по меньшей мере некоторые видеоданные, ассоциированные с визуальной средой, доставляются от сервера 120 клиенту 102 при входе пользователя в сцену; и/или
- по меньшей мере некоторые аудиоданные (потоки, объекты, адаптационные наборы, …) доставляются клиентской системе 102 только на основе текущего (или будущего) поля видимости, и/или ориентации головы, и/или данных перемещения, и/или метаданных, и/или виртуального положения, и/или выбора/взаимодействия пользователя; и/или
- (в некоторых случаях): некоторые аудиоданные доставляются клиентской системе 102 на основе текущей сцены (независимо от текущего или будущего положения, или поля видимости, и/или ориентации головы, и/или данных перемещения, и/или метаданных, и/или виртуального положения, и/или выбора пользователя), тогда как оставшиеся аудиоданные доставляются на основе текущего или будущего поля видимости, и/или ориентации головы, и/или данных перемещения, и/или метаданных, и/или виртуального положения, и/или выбора пользователя.
Нужно отметить, что различные элементы (серверная система, клиентская система, MCD и т.п.) могут представлять собой элементы в разных аппаратных устройствах или даже в одних и тех же устройствах (например, клиент и MCD можно реализовать как часть одного мобильного телефона, или аналогичным образом клиент может находиться в ПК, подключенном к вспомогательному экрану, который содержал бы MCD).
Примеры
Один вариант осуществления системы 102 (клиента), как показано на фиг. 1.1, выполнен с возможностью принимать (аудио) потоки 106 на основе заданного положения в некой среде (например, виртуальной среде), которую можно понимать как ассоциированную с видео- и аудиосценой (в дальнейшем называемой сценой 150). Разные положения в одной и той же сцене 150 обычно подразумевают разные потоки 106 или разные метаданные, ассоциированные с потоками 106, которые нужно предоставить декодеру 104 аудио в системе 102 (например, от медиа-сервера 120). Система 102 подключается к мультимедийному бытовому прибору (MCD), от которого принимает обратную связь, ассоциированную с положением и/или виртуальным положением пользователя в той же среде. В дальнейшем положение пользователя в среде может ассоциироваться с конкретным полем видимости, которое нравится пользователю (предполагаемое поле видимости, например, поверхность, предполагаемую в виде прямоугольной поверхности, проецируемой на сферу, которая представляется пользователю).
В примерном сценарии, когда пользователь перемещается по сцене 150 VR, AR и/или MR, аудиоконтент можно представить как виртуально формируемый одним или более аудиоисточниками 152, которые могут меняться. Аудиоисточники 152 можно понимать как виртуальные аудиоисточники в том смысле, что они могут относиться к положениям в виртуальной среде: выведение каждого аудиоисточник приспосабливается к положению пользователя (например, в упрощенном пояснении уровень аудиоисточника выше, когда пользователь находится ближе к положению аудиоисточника, и ниже, когда пользователь более отдален от аудиоисточника). Каждый аудиоэлемент (аудиоисточник), тем не менее, кодируется в аудиопотоки, которые предоставляются декодеру. Аудиопотоки могут ассоциироваться с различными положениями и/или областями в сцене. Например аудиоисточники 152, которые не слышны в одной сцене, можно услышать в следующей сцене, например, когда открывается дверь в сцену 150 VR, AR и/или MR. Тогда пользователь может решить войти в новую сцену/среду 150 (например, комнату), и меняется вся аудиосцена. С целью описания этого сценария термин "дискретные точки наблюдения в пространстве" может использоваться в качестве дискретного местоположения в пространстве (или в VR-среде), для которого доступен разный аудиоконтент.
Вообще говоря, медиа-сервер 120 может предоставлять потоки 106, ассоциированные с конкретной сценой 150, на основе положения пользователя в сцене 150. Потоки 106 могут кодироваться по меньшей мере одним кодером 154 и предоставляться медиа-серверу 120. Медиа-сервер 120 может передавать потоки 113 с помощью связей 113 (например, по сети связи). Предоставление потоков 113 может основываться на запросах 112, поданных системой 102 на основе положения 110 пользователя (например, в виртуальной среде). Положение 110 пользователя также можно понимать как ассоциируемое с полем видимости, которое нравится пользователю (так как для каждого положения имеется один-единственный прямоугольник, который представляется), и с точкой наблюдения (так как точка наблюдения является центром поля видимости). Поэтому предоставление поля видимости в некоторых примерах может быть таким же, как предоставление положения.
Система 102, как показано на фиг. 1.2, выполнена с возможностью принимать (аудио) потоки 113 на основе другой конфигурации на стороне клиента. В этой примерной реализации на кодирующей стороне предоставляется множество медиа-кодеров 154, которое может использоваться для создания одного или более потоков 106 для каждой доступной сцены 150, ассоциированной с одной частью звуковой сцены у одной точки наблюдения.
Медиа-сервер 120 может хранить несколько адаптационных наборов аудио и (не показано) видео, содержащих разные кодирования одних и тех же аудио- и видеопотоков с разными скоростями передачи битов. Более того, медиа-сервер может содержать описательную информацию обо всех адаптационных наборах, которая может включать в себя доступность всех созданных адаптационных наборов. Адаптационные наборы могут включать в себя также информацию, описывающую ассоциацию одного адаптационного набора с одной конкретной аудиосценой и/или точкой наблюдения. Таким образом, каждый адаптационный набор может ассоциироваться с одной из доступных аудиосцен.
Кроме того, адаптационные наборы могут включать в себя информацию, описывающую границы каждой аудиосцены и/или точки наблюдения, которая может содержать, например, законченную аудиосцену или только отдельные аудиообъекты. Границы одной аудиосцены могут задаваться, например, в виде геометрических координат сферы (например, центр и радиус).
Система 102 на стороне клиента может принимать информацию о текущем поле видимости, и/или ориентации головы, и/или данные перемещения, и/или метаданные взаимодействия, и/или о виртуальном положении пользователя, или любую информацию, описывающую изменения, вызванные действиями пользователя. Кроме того, система 102 также может принимать информацию о доступности всех адаптационных наборов и информацию, описывающую ассоциацию одного адаптационного набора с одной аудиосценой и/или точкой наблюдения; и/или информацию, описывающую "границы" каждой аудиосцены и/или точки наблюдения (которая может содержать, например, законченную аудиосцену или только отдельные объекты). Например, в случае среды доставки DASH такая информация может предоставляться как часть синтаксиса XML Описания представления мультимедиа (MPD).
Система 102 может предоставлять аудиосигнал мультимедийному устройству (MCD), используемому для потребления контента. Мультимедийное устройство также отвечает за сбор информации о местоположении пользователя, и/или ориентации, и/или направлении перемещения (или любой информации, описывающей изменения, вызванные действиями пользователя) в виде данных 110 о положении и переходе.
Процессор 1232 поля видимости может быть выполнен с возможностью принимать от мультимедийного устройства упомянутые данные 110 о положении и переходе. Процессор 1232 поля видимости также может принимать информацию о ROI, сигнализированную в метаданных, и всю информацию, доступную на принимающей стороне (система 102). Тогда процессор 1232 поля видимости может на основе всей информации, принятой и/или выведенной из принятых и/или доступных метаданных, решать, какую точку наблюдения аудио ему следует воспроизводить в некоторый момент времени. Например, процессор 1232 поля видимости может решить, что нужно воспроизвести одну законченную аудиосцену, одну новую аудиосцену 108 нужно создать из всех доступных аудиосцен, например, только некоторые аудиоэлементы из нескольких аудиосцен нужно воспроизвести, тогда как другие оставшиеся аудиоэлементы из этих аудиосцен воспроизводить не нужно. Процессор 1232 поля видимости также может решить, нужно ли воспроизводить переход между двумя или более аудиосценами.
Выборная часть 1230 может предоставляться для выбора на основе информации, принятой от процессора 1232 поля видимости, одного или более адаптационных наборов из доступных адаптационных наборов, которые сигнализированы в информации, принятой принимающей стороной; при этом выбранные адаптационные наборы полностью описывают аудиосцену, которую следует воспроизводить в текущем местоположении пользователя. Эта аудиосцена может быть законченной аудиосценой, которая задана на кодирующей стороне, или может потребоваться создать новую аудиосцену из всех доступных аудиосцен.
Более того, в случае, когда на основе указания от процессора 1232 поля видимости предстоит переход между двумя или более аудиосценами, выборная часть может быть выполнена с возможностью выбирать один или более адаптационных наборов из доступных адаптационных наборов, которые сигнализированы в информации, принятой принимающей стороной; при этом выбранные адаптационные наборы полностью описывают аудиосцену, которую может потребоваться воспроизвести в ближайшем будущем (например, если пользователь идет в направлении следующей аудиосцены с некоторой скоростью, то можно предсказать, что потребуется следующая аудиосцена, и она выбирается перед воспроизведением).
Более того, сначала можно выбрать некоторые адаптационные наборы, соответствующие соседним местоположениям, с более низкой скоростью передачи битов и/или более низким уровнем качества, например представление, кодированное с более низкой скоростью передачи битов, выбирается из доступных представлений в одном адаптационном наборе, и на основе изменений положения качество увеличивается путем выбора более высокой скорости передачи битов для тех определенных адаптационных наборов, например представление, кодированное с более высокой скоростью передачи битов, выбирается из доступных представлений в одном адаптационном наборе.
Может предоставляться загружающая и переключающая часть 1234 для запроса у медиа-сервера одного или более адаптационных наборов из доступных адаптационных наборов на основе указания, принятого от выборной части, конфигурируемая для приема одного или более адаптационных наборов из доступных адаптационных наборов от медиа-сервера и извлечения метаданных из всех принятых аудиопотоков.
Процессор 1236 метаданных может предоставляться для приема от загружающей и переключающей части информации о принятых аудиопотоках, которая может включать в себя метаданные аудио, соответствующие каждому принятому аудиопотоку. Процессор 1236 метаданных также может быть выполнен с возможностью обрабатывать метаданные аудио, ассоциированные с каждым аудиопотоком 113, на основе принятой от процессора 1232 поля видимости информации, которая может включать в себя информацию о местоположении пользователя, и/или ориентации, и/или направлении 110 перемещения, чтобы выбирать/включать необходимые аудиоэлементы 152, составляющие новую аудиосцену, которая указана процессором 1232 поля видимости, и разрешать соединение всех аудиопотоков 113 в единый аудиопоток 106.
Мультиплексор/устройство 1238 соединения потоков может быть выполнено с возможностью соединять все выбранные аудиопотоки в один аудиопоток 106 на основе принятой от процессора 1236 метаданных информации, которая может включать в себя измененные и обработанные метаданные аудио, соответствующие всем принятым аудиопотокам 113.
Медиа-декодер 104 выполнен с возможностью принимать и декодировать по меньшей мере один аудиопоток для воспроизведения новой аудиосцены, которая указана процессором 1232 поля видимости, на основе информации о местоположении пользователя, и/или ориентации, и/или направлении перемещения.
В другом варианте осуществления система 102, как показано на фиг. 1.7, может быть выполнена с возможностью принимать аудиопотоки 106 с разными скоростями передачи битов и/или уровнями качества аудио. Аппаратная конфигурация этого варианта осуществления аналогична конфигурации из фиг. 1.2. По меньшей мере одна сцена 152 визуальной среды может ассоциироваться по меньшей мере с одним множеством из N аудиоэлементов (N>=2), при этом каждый аудиоэлемент ассоциируется с положением и/или областью в визуальной среде. По меньшей мере одно множество из N аудиоэлементов 152 предоставляется по меньшей мере в одном представлении с высокой скоростью передачи битов и/или уровнем качества, и где по меньшей мере одно множество из N аудиоэлементов 152 предоставляется по меньшей мере в одном представлении с низкой скоростью передачи битов и/или уровнем качества, где по меньшей мере одно представление получается путем обработки N аудиоэлементов 152, чтобы получить меньшее число M аудиоэлементов 152 (M<N), ассоциированных с положением или областью, близкой к положению или области N аудиоэлементов 152.
Обработка N аудиоэлементов 152 могла быть, например, простым сложением аудиосигналов, или могла быть активным понижающим микшированием на основе их пространственного положения 110, или выведением аудиосигналов с использованием их пространственного положения в новом виртуальном положении, расположенном между аудиосигналами. Система может быть выполнена с возможностью запрашивать представление с более высокой скоростью передачи битов и/или уровнем качества для аудиоэлементов, если аудиоэлементы более релевантны и/или лучше слышны в текущем виртуальном положении пользователя в сцене, причем система выполнена с возможностью запрашивать представление с более низкой скоростью передачи битов и/или уровнем качества для аудиоэлементов, если аудиоэлементы менее релевантны и/или хуже слышны в текущем виртуальном положении пользователя в сцене.
Фиг. 1.8 показывает пример системы (которая может быть системой 102), показывающий систему 102 для среды виртуальной реальности, VR, дополненной реальности, AR, смешанной реальности, MR, или панорамного видео, сконфигурированную для приема видеопотоков 1800 и аудиопотоков 106 для воспроизведения в мультимедийном устройстве,
причем система 102 может содержать:
по меньшей мере один медиа-декодер 1804 видео, выполненный с возможностью декодировать видеосигналы 1808 из видеопотоков 1800 для представления пользователю среды VR, AR, MR или панорамного видео, и
по меньшей мере один декодер 104 аудио, выполненный с возможностью декодировать аудиосигналы 108 по меньшей мере из одного аудиопотока 106.
Система 102 может быть выполнена с возможностью запрашивать (112) у сервера (например, 120) по меньшей мере один аудиопоток 106, и/или один аудиоэлемент в аудиопотоке, и/или один адаптационный набор на основе по меньшей мере текущего поля видимости пользователя, и/или ориентации головы, и/или данных перемещения, и/или метаданных взаимодействия, и/или данных 110 виртуального положения (например, предоставленных в качестве обратной связи от мультимедийного устройства 180).
Система 102 может быть такой же, как система 102 из фиг. 1.1-1.7, и/или получать сценарии из фиг. 2a и последующих.
Настоящие примеры также относятся к способу для среды виртуальной реальности, VR, дополненной реальности, AR, смешанной реальности, MR, или панорамного видео, сконфигурированному для приема видео- и аудиопотоков для воспроизведения в мультимедийном устройстве [например, воспроизводящем устройстве], содержащему:
декодирование видеосигналов из видеопотоков для представления пользователю сцен среды VR, AR, MR или панорамного видео, и
декодирование аудиосигналов из аудиопотоков,
запрос и/или получение от сервера по меньшей мере одного аудиопотока на основе текущего поля видимости пользователя, и/или данных о положении, и/или ориентации головы, и/или данных перемещения, и/или метаданных, и/или данных виртуального положения, и/или метаданных.
Случай 1
Разные сцены/среды 150 обычно подразумевают прием разных потоков 106 от сервера 120. Однако потоки 106, принимаемые декодером 104 аудио, также могут быть обусловлены положением пользователя в одной и той же сцене 150.
В первый (начальный) момент (t=t1), показанный на фиг. 2a, пользователь располагается, например, в сцене 150 с первым заданным положением в VR-среде (или AR-среде, или MR-среде). В декартовой системе XYZ (например, горизонтальной) первое поле 110’ видимости (положение) пользователя ассоциируется с координатами x’u и y’u (ось Z здесь ориентирована выходящей из листа). В этой первой сцене 150 располагаются два аудиоэлемента 152-1 и 152-1 с соответствующими координатами x’1 и y’1 для аудиоэлемента 1 (152-1) и x’2 и y’2 для аудиоэлемента 2 (152-2). Расстояние d’1 от пользователя до аудиоэлемента 1 (152-1) меньше расстояния d’2 (152-1) от пользователя до аудиоэлемента 2. Все данные о положении пользователя (поле видимости) передаются от MCD в систему 102.
Во второй примерный момент (t=t2), показанный на фиг. 2b, пользователь располагается, например, в той же сцене 150, но во втором, отличном положении. В декартовой системе XY второе поле 110” видимости (положение) пользователя ассоциируется с новыми координатами x”u и y”u (ось Z здесь ориентирована выходящей из листа). Теперь расстояние d”1 пользователя от аудиоэлемента 1 (152-1) больше расстояния d”2 пользователя от аудиоэлемента 2 (152-2). Все данные о положении пользователя (поле видимости) опять передаются от MCD в систему 102.
Пользователь, оснащенный упомянутым MCD для визуализации некоторого поля видимости в панорамной среде, может слушать, например, через наушники. Пользователю может нравиться воспроизведение разных звуков для разных положений, изображенных на фиг. 2a и 2b, одной и той же сцены 150.
Любое положение, и/или любой переход, и/или поле видимости, и/или виртуальное положение, и/или ориентация головы, и/или данные перемещения в сцене, например, от фиг. 2a к 2b, могут передаваться периодически (например, в обратной связи) от MCD в систему 102 (клиент) в виде сигнала 110. Клиент может повторно передавать данные 110’ или 110” о положении и переходе (например, данные поля видимости) серверу 120. Клиент 102 либо сервер 120 на основе данных 110’ или 110” о положении и переходе (например, данных поля видимости) может решать, какие аудиопотоки 106 необходимы для воспроизведения правильной аудиосцены в текущем положении пользователя. Клиент мог бы выбирать и передавать запрос 112 соответствующего аудиопотока 106, тогда как сервер 120 может быть выполнен с возможностью доставлять соответственно поток (потоки) 106 в зависимости от информации о положении, предоставленной клиентом (системой 102). В качестве альтернативы сервер 120 мог бы выбирать и доставлять соответственно поток (потоки) 106 в зависимости от информации о положении, предоставленной клиентом (системой 102).
Клиент (система 102) может запрашивать передачу потоков, которые нужно декодировать для представления сцены 150. В некоторых примерах система 102 может передавать информацию о наивысшем уровне качества для воспроизведения на MCD (в других примерах это делает сервер 120, который выбирает уровень качества для воспроизведения на MCD на основе положения пользователя в сцене). В ответ сервер 120 может выбрать одно из множества представлений, ассоциированных с представляемой аудиосценой, чтобы доставить по меньшей мере один поток 106 в соответствии с положением 110’ или 110” пользователя. Поэтому клиент (система 102) может быть выполнен с возможностью доставлять аудиосигнал 108 пользователю, например посредством декодера 104 аудио, чтобы воспроизвести звук, ассоциированный с фактическим (действующим) положением 110’ или 110”. (Можно использовать адаптационные наборы 113: разные варианты одних и тех же потоков, например, с разными скоростями передачи битов, можно использовать для разных положений пользователя).
Потоки 106 (которые могут предварительно обрабатываться или оперативно формироваться) могут передаваться клиенту (системе 102) и могут конфигурироваться для множества точек наблюдения, ассоциированных с некоторыми звуковыми сценами.
Отмечалось, что разные качества (например, разные скорости передачи битов) могут предоставляться для разных потоков 106 в соответствии с конкретным положением (например, 110’ или 110”) пользователя в среде (например, виртуальной). Например: в случае множества аудиоисточников 152-1 и 152-2 каждый аудиоисточник 152-1 и 152-2 может ассоциироваться с конкретным положением в сцене 150. Чем ближе положение 110’ или 110’ пользователя к первому аудиоисточнику 152-1, тем больше необходимое разрешение и/или качество потока, ассоциированного с первым аудиоисточником 152-2. Этот примерный случай может применяться к аудиоэлементу 1 (152-1) на фиг. 2a, а также к аудиоэлементу 2 (152-2) на фиг. 2b. Чем больше удалено положение 110 пользователя от второго аудиоисточника 152-2, тем меньше необходимое разрешение потока 106, ассоциированного со вторым аудиоисточником 152-2. Этот примерный случай может применяться к аудиоэлементу 2 (152-2) на фиг. 2a, а также к аудиоэлементу 1 (152-1) на фиг. 2b.
Фактически, первый, близкий аудиоисточник должен звучать на более высоком уровне (и поэтому предоставляться с более высокой скоростью передачи битов), тогда как второй, дальний аудиоисточник должен звучать на более низком уровне (что может позволить требовать меньшего разрешения).
Поэтому на основе положения 110’ или 110” в среде, которое предоставлено клиентом 102, сервер 120 может предоставлять разные потоки 106 с разными скоростями передачи битов (или другим качеством). На основе того, что аудиоэлементы, которые находятся далеко, не требуют высоких уровней качества, сохраняется общее качество восприятия пользователя, даже если они доставляются с более низкой скоростью передачи битов или уровнем качества.
Поэтому для некоторых аудиоэлементов в разных положениях пользователя могут использоваться разные уровни качества, сохраняя при этом качество восприятия.
Без этого решения серверу 120 следует предоставлять все потоки 106 клиенту с наивысшей скоростью передачи битов, что увеличило бы полезную нагрузку в канале связи от сервера 120 клиенту.
Случай 2
Фиг. 3 (случай 2) показывает вариант осуществления с другим примерным сценарием (представленным на вертикальной плоскости XZ в пространстве XYZ, где ось Y представляется входящей в лист), где пользователь перемещается в первой сцене A VR, AR и/или MR (150A), открывает дверь и проходит в нее (переход 150AB), подразумевая переход аудио от первой сцены 150A в момент t1 через переходное положение (150AB) в момент t2 к следующей (второй) сцене B (150B) в момент t3.
В момент времени t1 пользователь может находиться в положении x1 в направлении x первой сцены VR, AR и/или MR. В момент времени t3 пользователь может находиться в другой, второй сцене B VR, AR и/или MR (150B) в положении x3. В момент t2 пользователь может находиться в переходном положении 150AB, пока он открывает дверь (например, виртуальную дверь) и проходит в нее. Поэтому переход подразумевает переход аудиоинформации от первой сцены 150A ко второй сцене 150B.
В этом смысле пользователь меняет положение 110, например из первой VR-среды (отличающейся первой точкой (A) наблюдения, как показано на фиг. 1.1) во вторую VR-среду (отличающуюся второй точкой (B) наблюдения, как показано на фиг. 1.1). В конкретном случае, например, во время перехода через дверь, расположенную в положении x2 в направлении x, некоторые аудиоэлементы 152A и 152B могут присутствовать в обеих точках наблюдения (положения A и B).
Пользователь (оснащенный MCD) меняет положение 110 (x1-x3) по отношению к двери, что может подразумевать, что аудиоэлементы в переходном положении x2 принадлежат первой сцене 150A и второй сцене 150B. MCD передает новое положение и данные 110 о переходе клиенту, который повторно передает их медиа-серверу 120. Пользователь может слушать подходящие аудиоисточники, заданные промежуточным положением x2 между первым и вторым положениями x1 и x3.
Любое положение и любой переход из первого положения (x1) во второе положение (x3) теперь периодически (например, постоянно) передается от MCD к клиенту. Клиент 102 может повторно передать данные 110 о положении и переходе (x1-x3) медиа-серверу 120, который выполнен с возможностью доставлять соответственно один специальный элемент, например, из нового набора предварительно обработанных потоков 106 в виде актуализированного адаптационного набора 113’, в зависимости от принятых данных 110 о положении и переходе (x1-x3).
Медиа-сервер 120 может выбирать одно из множества представлений, ассоциированных с вышеупомянутой информацией, не только касательно способности MCD отображать наивысшую скорость передачи битов, но также касательно данных 110 о положении и переходе (x1-x3) пользователя во время его перемещения из одного положения в другое. (В этом смысле можно использовать адаптационные наборы: медиа-сервер 120 может решать, какой адаптационный набор 113’ оптимально представляет виртуальный переход пользователя, не мешая способности выведения у MCD).
Поэтому медиа-сервер 120 может доставлять специальный поток 106 (например, в виде нового адаптационного набора 113’) в соответствии с переходом положений. Клиент 102 может быть выполнен с возможностью соответственно доставлять аудиосигнал 108 пользователю 140, например, посредством медиа-декодера 104 аудио.
Потоки 106 (сформированные оперативно и/или предварительно обработанные) могут передаваться клиенту 102 в периодически (например, постоянно) актуализируемом адаптационном наборе 113’.
Когда пользователь проходит в дверь, сервер 120 может передавать потоки 106 первой сцены 150A и потоки 106 второй сцены 150B. Это происходит для того, чтобы смешивать, или мультиплексировать, или составлять, или воспроизводить эти потоки 106 одновременно, чтобы обеспечить пользователю подлинное впечатление. Поэтому на основе положения 110 пользователя (например, "положение, соответствующее двери") сервер 120 передает клиенту разные потоки 106.
Даже в этом случае, так как разные потоки 106 должны звучать одновременно, они могут обладать разными разрешениями и могут передаваться от сервера 120 клиенту с разными разрешениями. Когда пользователь завершил переход и находится во второй сцене (положении) 150A (и закрыл дверь за собой), у сервера 120 будет возможность сокращения или отказа от передачи потоков 106 первой сцены 150 (если сервер 120 уже предоставил клиенту 102 потоки, то клиент 102 может решить не использовать их).
Случай 3
Фиг. 4 (случай 3) показывает вариант осуществления с другим примерным сценарием (представленным на вертикальной плоскости XZ в пространстве XYZ, где ось Y представляется входящей в лист), где пользователь перемещается в сцене 150A VR, AR и/или MR, подразумевая переход аудио из одного первого положения в момент t1 во второе положение также в первой сцене 150A в момент t2. Пользователь в первом положении может находиться далеко от стены в момент t1 на расстоянии d1 от стены; и может находиться близко к стене в момент t2 на расстоянии d2 от стены. Здесь d1> d2. Хотя на расстоянии d1 пользователь слышит только источник 152A сцены 150A, он также может слышать источник 152B сцены 150B за стеной.
Когда пользователь находится во втором положении (d2), клиент 102 отправляет серверу 120 данные касательно положения 110 пользователя (d2) и принимает от сервера 120 не только аудиопотоки 106 первой сцены 150A, но также аудиопотоки 106 второй сцены 150B. На основе метаданных, предоставленных сервером 120, клиент 102 запустит воспроизведение, например посредством декодера 104, потоков 106 второй сцены 150B (за стеной) на малой громкости.
Даже в этом случае скорость передачи битов (качество) потоков 106 второй сцены 150B может быть низкой (низким), поэтому требуя уменьшенной полезной нагрузки передачи от сервера 120 клиенту. Примечательно, что положение 110 (d1, d2) клиента (и/или поле видимости) задает аудиопотоки 106, которые предоставляются сервером 120.
Например, система 102 может быть выполнена с возможностью получать потоки, ассоциированные с первой текущей сценой (150A), ассоциированной с первой, текущей средой, и если расстояние положения пользователя или виртуального положения от границы сцены (например, соответствующей стене) меньше заранее установленной пороговой величины (например, когда d2<dthreshold), то система 102 дополнительно получает аудиопотоки, ассоциированные со второй, смежной и/или соседней средой, ассоциированной со второй сценой (150B).
Случай 4
Фиг. 5a и 5b показывают вариант осуществления с другим примерным сценарием (представленным на горизонтальной плоскости XY в пространстве XYZ, где ось Z представляется выходящей из листа), где пользователь располагается в одной и той же сцене 150 VR, AR и/или MR, но в разные моменты на разных расстояниях, например до двух аудиоэлементов.
В первый момент t=t1, показанный на фиг. 5a, пользователь располагается, например, в первом положении. В этом первом положении первый аудиоэлемент 1(152-1) и второй аудиоэлемент 2 (152-2) располагаются (например, виртуально) на расстояниях d1 и соответствующем d2 от пользователя, оснащенного MCD. Оба расстояния d1 и d2 в этом случае могут быть больше заданного порогового расстояния dthreshold, и поэтому система 102 выполнена с возможностью группировать оба аудиоэлемента в один-единственный виртуальный источник 152-3. Положение и свойства (например, пространственная протяженность) одного виртуального источника могут вычисляться, например, на основе положений двух исходных источников таким образом, чтобы он как можно лучше имитировал исходное звуковое поле, сформированное двумя источниками (например, два хорошо локализованных точечных источника можно воспроизвести посередине расстояния между ними как один источник). Данные 110 о положении пользователя (d1, d2) могут передаваться от MCD системе 102 (клиенту) и впоследствии серверу 120, который может решить отправить подходящий аудиопоток 106, который серверной системе 120 нужно вывести (в других вариантах осуществления это клиент 102, который решает, какие потоки нужно передать от сервера 120). Группируя оба аудиоэлемента в один-единственный виртуальный источник 152-3, сервер 120 может выбрать одно из множества представлений, ассоциированных с вышеупомянутой информацией. (Например, можно доставить специальный поток 106 с адаптационным набором 113’, соответственно ассоциированным, например, с одним-единственным каналом.) Поэтому пользователь посредством MCD может принимать аудиосигнал как передаваемый от одного виртуального аудиоэлемента 152-3, расположенного между настоящими аудиоэлементами 1 (152-1) и 2 (152-2).
Во второй момент t=t2, показанный на фиг. 5b, пользователь располагается, например, в той же сцене 150 со вторым заданным положением в той же VR-среде, как и на фиг. 5a. В этом втором положении два аудиоэлемента 152-1 и 152-2 располагаются (например, виртуально) на расстояниях d3 и соответствующем d4 от пользователя. Оба расстояния d3 и d4 могут быть меньше порогового расстояния dthreshold, и поэтому группирование аудиоэлементов 152-1 и 152-2 в один-единственный виртуальный источник 152-3 больше не используется. Данные о положении пользователя передаются от MCD в систему 102 и впоследствии серверу 120, который может решить отправить другой подходящий аудиопоток 106, который серверной системе 120 нужно вывести (в других вариантах осуществления это решение принимается клиентом 102). Избегая группировки аудиоэлементов, сервер 120 может выбирать разное представление, ассоциированное с вышеупомянутой информацией, для доставки соответственно специального потока 106 с адаптационным набором 113’, соответственно ассоциированным с разными каналами для каждого аудиоэлемента. Поэтому пользователь посредством MCD может принимать аудиосигнал 108 как передаваемый от двух разных аудиоэлементов 1 (152-1) и 2 (152-2). Следовательно, чем ближе положение 110 пользователя к аудиоисточникам 1 (152-1) и 2 (152-2), тем выше нужно выбирать необходимый уровень качества потока, ассоциированного с аудиоисточниками.
Фактически, чем ближе располагаются аудиоисточники 1 (152-1) и 2 (152-2) относительно пользователя, как изображено на фиг. 5b, тем выше нужно поднимать уровень, и поэтому аудиосигналы 108 можно выводить с более высоким уровнем качества. В отличие от этого удаленные аудиоисточники 1 и 2, представленные на фиг. 5b, должны звучать на более низком уровне как воспроизводимые одним виртуальным источником, а поэтому выводимые, например, с более низким уровнем качества.
В аналогичной конфигурации множество аудиоэлементов может располагаться перед пользователем, при этом все они расположены на расстояниях больше порогового расстояния от пользователя. В одном варианте осуществления две группы по пять аудиоэлементов могут объединяться в два виртуальных источника. Данные о положении пользователя передаются от MCD в систему 102 и впоследствии серверу 120, который может решить отправить подходящий аудиопоток 106, который серверной системе 120 нужно вывести. Группируя все 10 аудиоэлементов только в два виртуальных источника, сервер 120 может выбирать одно из множества представлений, ассоциированных с вышеупомянутой информацией, для доставки специального потока 106 с адаптационным набором 113’, соответственно ассоциированным, например, с двумя одиночными аудиоэлементами. Поэтому пользователь посредством MCD может принимать аудиосигнал как передаваемый от двух отдельных виртуальных аудиоэлементов, расположенных в той же области с настоящими аудиоэлементами.
В последующий момент времени пользователь приближается к множеству (из десяти) аудиоэлементов. В этой последующей сцене все аудиоэлементы располагаются на расстояниях меньше порогового расстояния dthreshold, и поэтому система 102 выполнена с возможностью завершать группирование аудиоэлементов. Новые данные о положении пользователя передаются от MCD в систему 102 и впоследствии серверу 120, который может решить отправить другой подходящий аудиопоток 106, который серверной системе 120 нужно вывести. Не группируя аудиоэлементы, сервер 120 может выбирать разное представление, ассоциированное с вышеупомянутой информацией, для доставки соответственно специального потока 106 с адаптационным набором 113’, соответственно ассоциированным с разными каналами для каждого аудиоэлемента. Поэтому пользователь посредством MCD может принимать аудиосигнал как передаваемые от десяти разных аудиоэлементов. Следовательно, чем ближе положение 110 пользователя к аудиоисточникам, тем выше нужно выбирать необходимое разрешение потока, ассоциированного с аудиоисточниками.
Случай 5
Фиг. 6 (случай 5) изображает пользователя 140, расположенного в одном положении одной-единственной сцены 150, с мультимедийным бытовым прибором (MCD), который может быть направлен в трех примерных разных направлениях (каждое ассоциировано с разным полем 160-1, 160-2, 160-3 видимости). Эти направления, как показано на фиг. 6, могут обладать ориентацией (например, угловой ориентацией) в полярной системе координат и/или декартовой системе XY, указывая на первую точку 801 наблюдения, расположенную, например, под углом 180° в нижней части фиг. 6, на вторую точку 802 наблюдения, расположенную, например, под углом 90° с правой стороны фиг. 6, и на третью точку 803 наблюдения, расположенную, например, под углом 0° в верхней части фиг. 6. Каждая из этих точек наблюдения ассоциируется с ориентацией пользователя 140 с мультимедийным бытовым прибором (MCD), при этом пользователь расположен в центре, предлагаемом определенным полем видимости, отображенным MCD, выводящим соответствующий аудиосигнал 108 в соответствии с ориентацией MCD.
В этой конкретной VR-среде первый аудиоэлемент s1 (152) располагается в первом поле 160-1 видимости поблизости от точки наблюдения, расположенной, например, под углом 180°, а второй аудиоэлемент s2 (152) располагается в третьем поле 160-3 видимости поблизости от точки наблюдения, расположенной, например, под углом 180°. Перед изменением ориентации пользователь 140 в первой ориентации к точке 801 наблюдения (поле 160-1 видимости) воспринимает звук, ассоциированный с фактическим (действующим) положением, громче от аудиоэлемента s1, чем от аудиоэлемента s2.
Меняя ориентацию, пользователь 140 во второй ориентации к точке 802 наблюдения может воспринимать звук, ассоциированный с фактическим положением 110, почти на той же громкости сбоку от обоих аудиоэлементов s1 и s2.
В конечном счете, меняя ориентацию, пользователь 140 в третьей ориентации к точке 801 наблюдения (поле 160-3 видимости) может воспринимать звук, ассоциированный с аудиоэлементом 2, громче звука, ассоциированного с аудиоэлементом s1 (фактически, звук от аудиоэлемента 2 приходит спереди, тогда как звук от аудиоэлемента 1 приходит сзади).
Поэтому разные поля видимости, и/или ориентации, и/или данные о виртуальном положении можно ассоциировать с разными скоростями передачи битов и/или качествами.
Другие случаи и примеры
Фиг. 7A показывает вариант осуществления способа для приема аудиопотоков системой в виде последовательности этапов на схеме. В любой момент пользователь системы 102 ассоциируется с текущим полем видимости, и/или ориентацией головы, и/или данными перемещения, и/или метаданными взаимодействия, и/или виртуальным положением. В некоторый момент система на этапе 701 из фиг. 7A может определить аудиоэлементы для воспроизведения на основе текущего поля видимости, и/или ориентации головы, и/или данных перемещения, и/или метаданных взаимодействия, и/или виртуального положения. Поэтому на следующем этапе 703 может определяться релевантность и уровень слышимости для каждого аудиоэлемента. Как описано выше на фиг. 6, у VR-среды могут быть разные аудиоэлементы, расположенные в конкретной сцене 150 либо поблизости от пользователя, либо дальше от него, но также с определенной ориентацией в 360-градусном окружении. Все эти факторы определяют релевантность и уровень слышимости для каждого упомянутого аудиоэлемента.
На следующем этапе 705 система 102 может запросить у медиа-сервера 120 аудиопотоки в соответствии с определенной релевантностью и уровнем слышимости для каждого из аудиоэлементов.
На следующем этапе 707 система 102 может принять аудиопотоки 113, соответственно подготовленные медиа-сервером 120, где потоки с разными скоростями передачи битов могут отражать релевантность и уровень слышимости, которые определены на предшествующих этапах.
На следующем этапе 709 система 102 (например, декодер аудио) может декодировать принятые аудиопотоки 113, чтобы на этапе 711 воспроизводилась конкретная сцена 150 (например, посредством MCD) в соответствии с текущим полем видимости, и/или ориентацией головы, и/или данными перемещения, и/или метаданными взаимодействия, и/или виртуальным положением.
Фиг. 7B изображает взаимодействие между медиа-сервером 120 и системой 102 в соответствии с вышеописанной последовательностью из схемы работы. В некоторый момент медиа-сервер может передать аудиопоток 750 с более низкой скоростью передачи битов в соответствии с вышеупомянутой определенной более низкой релевантностью и уровнем слышимости релевантных аудиоэлементов вышеупомянутой сцены 150. В последующий момент 752 система может определить, что происходит взаимодействие или изменение данных о положении. Такое взаимодействие может возникать, например, либо из-за изменения данных о положении в той же сцене 150, либо, например, приведения в действие дверной ручки, пока пользователь пытается войти во вторую сцену, отделенную от первой сцены дверью, снабженной дверной ручкой.
Изменение текущего поля видимости, и/или ориентации головы, и/или данных перемещения, и/или метаданных взаимодействия, и/или виртуального положения может привести к запросу 754, отправленному системой 102 медиа-серверу 120. Этот запрос может отражать более высокую релевантность и уровень слышимости релевантных аудиоэлементов, определенных для той последующей сцены 150. В качестве ответа на запрос 754 медиа-сервер может передать поток 756 с более высокой скоростью передачи битов, обеспечивающей правдоподобное и реалистичное воспроизведение сцены 150 системой 102 в любом текущем виртуальном положении пользователя.
Фиг. 8A показывает другой вариант осуществления способа для приема аудиопотоков системой также в виде последовательности этапов на схеме. В некоторый момент 801 может выполняться определение первого текущего поля видимости, и/или ориентации головы, и/или данных перемещения, и/или метаданных взаимодействия, и/или виртуального положения. В утвердительном случае система 102 может подготовить запрос потоков, ассоциированных с первым положением, заданным низкой скоростью передачи битов, и передать его на этапе 803.
В последующий момент может выполняться этап 805 определения с тремя разными результатами. Одна или две заданных пороговых величины могут быть релевантны на этом этапе для определения, например, предсказывающего решения о последующем поле видимости, и/или ориентации головы, и/или данных перемещения, и/или метаданных взаимодействия, и/или виртуального положения. Поэтому может выполняться сравнение с первой и/или второй пороговой величиной касательно вероятности изменения второго положения, приводящее, например, к выполнению трех разных последующих этапов.
При результате, отражающем, например, очень низкую вероятность (например, ассоциированную с вышеупомянутым сравнением с первой заранее установленной пороговой величиной), выполнялся бы новый этап 801 сравнения.
При результате, отражающем низкую вероятность (например, больше первой заранее установленной пороговой величины, но меньше второй заранее установленной пороговой величины, которая больше первой пороговой величины), это может привести на этапе 809 к запросу аудиопотоков 113 с низкой скоростью передачи битов.
При результате, отражающем высокую вероятность (например, больше второй заранее установленной пороговой величины), на этапе 807 может выполняться запрос аудиопотоков 113 с высокой скоростью передачи битов. Поэтому последующим этапом, который нужно выполнить после исполнения этапов 807 или 809, опять мог бы быть этап 801 определения.
Фиг. 8B изображает взаимодействие между медиа-сервером 120 и системой 102 в соответствии только с одной вышеописанной последовательностью из схемы работы. В некоторый момент медиа-сервер может передать аудиопоток 850 с низкой скоростью передачи битов в соответствии с вышеупомянутой определенной низкой релевантностью и уровнем слышимости аудиоэлементов вышеупомянутой сцены 150. В последующий момент 852 система может определить, что вероятно произойдет взаимодействие. Предсказывающее изменение текущего поля видимости, и/или ориентации головы, и/или данных перемещения, и/или метаданных взаимодействия, и/или виртуального положения может привести к подходящему запросу 854, отправленному системой 102 медиа-серверу 120. Этот запрос может отражать один из вышеописанных случаев касательно высокой вероятности прихода во второе положение, ассоциированное с высокой скоростью передачи битов в соответствии с уровнем слышимости аудиоэлементов, который необходим для соответствующей последующей сцены 150. В качестве ответа медиа-сервер может передать поток 856 с более высокой скоростью передачи битов, обеспечивающей правдоподобное и реалистичное воспроизведение сцены 150 системой 102 в любом текущем виртуальном положении пользователя.
Система 102, как показано на фиг. 1.3, выполнена с возможностью принимать аудиопотоки 113 на основе другой конфигурации на стороне клиента, при этом архитектура системы может использовать дискретные точки наблюдения на основе решения, использующего несколько декодеров 1320, 1322 аудио. На стороне клиента система 102 может воплощать, например, части системы, описанной на фиг. 1.2, которые дополнительно или в качестве альтернативы содержат несколько декодеров 1320, 1322 аудио, которые могут быть выполнены с возможностью декодировать отдельные аудиопотоки, которые указаны процессором 1236 метаданных, например, с некоторым количеством отключенных аудиоэлементов.
В системе 102 может предоставляться смеситель/блок 1238 вывода, конфигурируемый для воспроизведения итоговой аудиосцены на основе информации о местоположении пользователя, и/или ориентации, и/или направлении перемещения, то есть некоторые аудиоэлементы, которые не слышны в определенном местоположении, следует отключить или не выводить.
Нижеследующие варианты осуществления, показанные на фиг. 1.4, 1.5 и 1.6, основываются на независимых адаптационных наборах для дискретных точек наблюдения с гибкими адаптационными наборами. В случае, когда пользователь перемещается в VR-среде, аудиосцена может постоянно меняться. Для обеспечения хорошего восприятия аудио все аудиоэлементы, составляющие аудиосцену в некоторый момент времени, может потребоваться сделать доступными медиа-декодеру, который может применить информацию о положении для создания итоговой аудиосцены.
Если контент предварительно кодируется для некоторого количества предопределенных местоположений, то система может обеспечить точное воспроизведение аудиосцен в этих конкретных местоположениях при допущении, что эти аудиосцены не перекрываются, и пользователь может "перепрыгивать/переключаться" с одного местоположения на следующее.
Но в случаях, когда пользователь "идет" из одного местоположения в следующее, аудиоэлементы из двух (или более) аудиосцен можно услышать одновременно. Решение для этих вариантов использования было предоставлено в предыдущих примерах систем, где независимо от механизмов, предусмотренных для декодирования нескольких аудиопотоков (либо с использованием мультиплексора с одним медиа-декодером, либо с несколькими медиа-декодерами и дополнительным смесителем/блоком вывода), клиенту нужно предоставлять аудиопотоки, которые описывают законченные аудиосцены.
Ниже предоставляется оптимизация путем предложения идеи общих аудиоэлементов между несколькими аудиопотоками.
Обсуждение аспектов и примеров
Решение 1: Независимые адаптационные наборы для дискретных местоположений (точек наблюдения).
Одним из способов решения описанной проблемы является использование законченных независимых адаптационных наборов для каждого местоположения. Для лучшего понимания решения фиг. 1.1 используется в качестве примерного сценария. В этом примере три разных дискретных точки наблюдения (содержащие три разных аудиосцены) используются для создания законченной VR-среды, в которой должен перемещаться пользователь. Поэтому:
- несколько независимых или перекрывающихся аудиосцен кодируются в некоторое количество аудиопотоков. Для каждой аудиосцены может использоваться один главный поток либо, в зависимости от варианта использования, один главный поток и дополнительные вспомогательные потоки (например, некоторые аудиообъекты, содержащие разные языки, могут кодироваться в независимые потоки для эффективной доставки). В предоставленном примере аудиосцена A кодируется в два потока (A1 и A2), аудиосцена B кодируется в три потока (B1, B2 и B3), тогда как аудиосцена C кодируется в три потока (C1, C2 и C3). Нужно отметить, что аудиосцена A и аудиосцена B совместно используют некоторое количество общих элементов (в этом примере два аудиообъекта). Поскольку каждая сцена должна быть законченной и независимой (для независимого воспроизведения, например на воспроизводящих устройствах без VR), общие элементы приходится кодировать дважды для каждой сцены;
- все аудиопотоки кодируются с разными скоростями передачи битов (то есть разными представлениями), что допускает эффективную адаптацию скорости передачи битов в зависимости от сетевого соединения (то есть для пользователей, использующих высокоскоростное соединение, доставляется кодированная с высокой скоростью передачи битов версия, тогда как для пользователей с менее скоростным сетевым соединением доставляется версия с более низкой скоростью передачи битов);
- аудиопотоки сохраняются на медиа-сервере, где для каждого аудиопотока разные кодирования с разными скоростями передачи битов (то есть разными представлениями) группируются в один адаптационный набор с подходящими данными, сигнализирующими доступность всех созданных адаптационных наборов;
- дополнительно к адаптационным наборам медиа-сервер принимает информацию о "границах" местоположения у каждой аудиосцены и их взаимосвязь с каждым адаптационным набором (который может содержать, например, законченную аудиосцену или только отдельные объекты). Таким образом, каждый адаптационный набор может ассоциироваться с одной из доступных аудиосцен. Границы одной аудиосцены могут задаваться, например, в виде геометрических координат сферы (например, центр и радиус);
- каждый адаптационный набор содержит также описательную информацию о местоположениях, в которых активна звуковая сцена или аудиоэлементы. Например, если один вспомогательный поток содержит один или более объектов, то адаптационный набор мог бы содержать такую информацию, как местоположения, где слышны объекты (например, координаты центра сферы и радиус);
- медиа-сервер предоставляет клиенту, например клиенту DASH, информацию о "границах" местоположения, ассоциированных с каждым адаптационным набором. Например, в случае среды доставки DASH ее можно встроить в синтаксис XML Описания представления мультимедиа (MPD);
- клиент принимает информацию о местоположении пользователя, и/или ориентации, и/или направлении перемещения (или любую информацию, описывающую изменения, вызванные действиями пользователя);
- клиент принимает информацию о каждом адаптационном наборе, и на ее основе и местоположения пользователя, и/или ориентации, и/или направления перемещения (или любой информации, описывающей изменения, вызванные действиями пользователя, например содержащей координаты x, y, z и/или значения поворота, продольного крена, поперечного крена) клиент выбирает один или более адаптационных наборов, полностью описывающих аудиосцену, которую следует воспроизвести в текущем местоположении пользователя;
- клиент запрашивает один или более адаптационных наборов;
- кроме того, клиент может выбрать больше адаптационных наборов, полностью описывающих более одной аудиосцены, и использовать аудиопотоки, соответствующие более одной аудиосцене, для создания новой аудиосцены, которую следует воспроизвести в текущем местоположении пользователя. Например, если пользователь идет в VR-среде и в некоторый момент времени располагается между ними (или в местоположении, расположенном в месте, где у двух аудиосцен есть слышимые эффекты);
- как только доступны аудиопотоки, можно использовать несколько медиа-декодеров для декодирования отдельных аудиопотоков и дополнительный смеситель/блок 1238 вывода для воспроизведения итоговой аудиосцены на основе информации о местоположении пользователя, и/или ориентации, и/или направлении перемещения (то есть, например, некоторые аудиоэлементы, которые не слышны в определенном местоположении, следует отключить или не выводить);
- в качестве альтернативы процессор 1236 метаданных может использоваться для работы с метаданными аудио, ассоциированными со всем аудиопотоками, на основе информации о местоположении пользователя, и/или ориентации, и/или направлении перемещения, чтобы:
- выбрать/включить необходимые аудиоэлементы 152, составляющие новую аудиосцену;
- и обеспечить соединение всех аудиопотоков в единый аудиопоток;
- медиа-сервер доставляет необходимые адаптационные наборы;
- в качестве альтернативы клиент предоставляет информацию о местоположении пользователя медиа-серверу, а медиа-сервер предоставляет указание о необходимых адаптационных наборах.
Фиг. 1.2 показывает другую примерную реализацию такой системы, содержащей:
- на кодирующей стороне
- множество медиа-кодеров, которые могут использоваться для создания одного или более аудиопотоков для каждой доступной аудиосцены, ассоциированной с одной частью звуковой сцены у одной точки наблюдения;
- множество медиа-кодеров, которые могут использоваться для создания одного или более видеопотоков для каждой доступной видеосцены, ассоциированной с одной частью видеосцены у одной точки наблюдения. На чертеже видеокодеры не представлены для простоты;
- медиа-сервер, который хранит несколько адаптационных наборов аудио и видео, содержащих разные кодирования одних и тех же аудио- и видеопотоков с разными скоростями передачи битов (то есть разные представления). Более того, медиа-сервер содержит описательную информацию про все адаптационные наборы, которая может включать в себя:
- доступность всех созданных адаптационных наборов;
- информацию, описывающую ассоциацию одного адаптационного набора с одной аудиосценой и/или точкой наблюдения; Таким образом, каждый адаптационный набор может ассоциироваться с одной из доступных аудиосцен;
- информацию, описывающую "границы" каждой аудиосцены и/или точки наблюдения (которая может содержать, например, законченную аудиосцену или только отдельные объекты). Границы одной аудиосцены могут задаваться, например, в виде геометрических координат сферы (например, центр и радиус);
- на стороне клиента систему (клиентскую систему), которая может содержать в любой из:
- принимающей стороны, которая может принимать:
- информацию о местоположении пользователя, и/или ориентации, и/или направлении перемещения (или любую информацию, описывающую изменения, вызванные действиями пользователя);
- информацию о доступности всех адаптационных наборов и информацию, описывающую ассоциацию одного адаптационного набора с одной аудиосценой и/или точкой наблюдения; и/или информацию, описывающую "границы" каждой аудиосцены и/или точки наблюдения (которая может содержать, например, законченную аудиосцену или только отдельные объекты). Например, в случае среды доставки DASH такая информация может предоставляться как часть синтаксиса XML Описания представления мультимедиа (MPD);
- стороны мультимедийного устройства, используемой для потребления контента (например, на основе HMD). Мультимедийное устройство также отвечает за сбор информации о местоположении пользователя, и/или ориентации, и/или направлении перемещения (или любой информации, описывающей изменения, вызванные действиями пользователя);
- процессор 1232 поля видимости, который может быть выполнен с возможностью
- принимать от мультимедийного устройства информацию о текущем поле видимости, которая может содержать местоположение пользователя, и/или ориентацию, и/или направление перемещения (или любую информацию, описывающую изменения, вызванные действиями пользователя);
- принимать информацию о ROI, сигнализированную в метаданных (поля видимости видео, сигнализированные в виде спецификации OMAF);
- принимать всю информацию, доступную на принимающей стороне;
- решать, какую точку наблюдения аудио/видео следует воспроизводить в некоторый момент времени, на основе всей информации, принятой и/или выведенной из принятых и/или доступных метаданных. Например, процессор 1232 поля видимости может решить, что:
- нужно воспроизвести одну законченную аудиосцену;
- нужно создать одну новую аудиосцену из всех доступных аудиосцен (например, нужно воспроизводить только некоторые аудиоэлементы из нескольких аудиосцен, тогда как другие оставшиеся аудиоэлементы из этих аудиосцен воспроизводить не нужно);
- нужно воспроизвести переход между двумя или более аудиосценами;
- выборная часть 1230, выполненная с возможностью выбирать на основе информации, принятой от процессора 1232 поля видимости, один или более адаптационных наборов из доступных адаптационных наборов, которые сигнализированы в информации, принятой принимающей стороной; при этом выбранные адаптационные наборы полностью описывают аудиосцену, которую следует воспроизводить в текущем местоположении пользователя. Эта аудиосцена может быть законченной аудиосценой, которая задана на кодирующей стороне, или нужно создать новую аудиосцену из всех доступных аудиосцен;
- более того, в случае, когда на основе указания от процессора 1232 поля видимости предстоит переход между двумя или более аудиосценами, выборная часть 1230 может быть выполнена с возможностью выбирать один или более адаптационных наборов из доступных адаптационных наборов, которые сигнализированы в информации, принятой принимающей стороной; при этом выбранные адаптационные наборы полностью описывают аудиосцену, которую может потребоваться воспроизвести в ближайшем будущем (например, если пользователь идет в направлении следующей аудиосцены с некоторой скоростью, то можно предсказать, что потребуется следующая аудиосцена, и она выбирается перед воспроизведением);
- более того, сначала можно выбрать некоторые адаптационные наборы, соответствующие соседним местоположениям, с более низкой скоростью передачи битов (то есть представление, кодированное с более низкой скоростью передачи битов, выбирается из доступных представлений в одном адаптационном наборе), и на основе изменений положения качество увеличивается путем выбора более высокой скорости передачи битов для тех определенных адаптационных наборов (то есть представление, кодированное с более высокой скоростью передачи битов, выбирается из доступных представлений в одном адаптационном наборе);
- загружающая и переключающая часть, которая может быть выполнена с возможностью:
- запрашивать у медиа-сервера 120 один или более адаптационных наборов из доступных адаптационных наборов на основе указания, принятого от выборной части 1230;
- принимать от медиа-сервера 120 один или более адаптационных наборов (то есть одного представления из всех представлений, доступных внутри каждого адаптационного набора) из доступных адаптационных наборов;
- извлекать метаданные из всех принятых аудиопотоков;
- процессор 1236 метаданных, который может быть выполнен с возможностью:
- принимать от загружающей и переключающей части информацию о принятых аудиопотоках, которая может включать в себя метаданные аудио, соответствующие каждому принятому аудиопотоку;
- обрабатывать метаданные аудио, ассоциированные с каждым аудиопотоком, на основе принятой от процессора 1232 поля видимости информации, которая может включать в себя информацию о местоположении пользователя, и/или ориентации, и/или направлении перемещения, чтобы:
- выбрать/включить необходимые аудиоэлементы 152, составляющие новую аудиосцену, которая указана процессором 1232 поля видимости;
- обеспечить соединение всех аудиопотоков в единый аудиопоток;
- мультиплексор/устройство 1238 соединения потоков, которое может быть выполнено с возможностью соединения всех выбранных аудиопотоков в один аудиопоток на основе принятой от процессора 1236 метаданных информации, которая может включать в себя измененные и обработанные метаданные аудио, соответствующие всем принятым аудиопотокам;
- медиа-декодер, выполненный с возможностью принимать и декодировать по меньшей мере один аудиопоток для воспроизведения новой аудиосцены, которая указана процессором 1232 поля видимости, на основе информации о местоположении пользователя, и/или ориентации, и/или направлении перемещения.
Фиг. 1.3 показывает систему, содержащую на стороне клиента систему (клиентскую систему), которая может воплощать, например, части системы, описанной на фиг. 1.2, которые дополнительно или в качестве альтернативы содержат:
- несколько медиа-декодеров, которые могут быть выполнены с возможностью декодировать отдельные аудиопотоки, которые указаны процессором 1236 метаданных (например, с некоторым количеством отключенных аудиоэлементов);
- смеситель/блок 1238 вывода, который может быть выполнен с возможностью воспроизводить итоговую аудиосцену на основе информации о местоположении пользователя, и/или ориентации, и/или направлении перемещения (то есть некоторые аудиоэлементы, которые не слышны в определенном местоположении, следует отключить или не выводить).
Решение 2
Фиг. 1.4, 1.5 и 1.6 относятся к примерам в соответствии с решением 2 из изобретения (которое может быть вариантами осуществления примеров из фиг. 1.1, и/или 1.2, и/или 1.3): независимые адаптационные наборы для дискретных местоположений (точек наблюдения) с гибкими адаптационными наборами.
В случае, когда пользователь перемещается в VR-среде, аудиосцена 150 может постоянно меняться. Для обеспечения хорошего восприятия аудио все аудиоэлементы 152, составляющие аудиосцену 150 в некоторый момент времени, может потребоваться сделать доступными медиа-декодеру, который может применить информацию о положении для создания итоговой аудиосцены.
Если контент предварительно кодируется для некоторого количества предопределенных местоположений, то система может обеспечить точное воспроизведение аудиосцен в этих конкретных местоположениях при допущении, что эти аудиосцены не перекрываются, и пользователь может "перепрыгивать/переключаться" с одного местоположения на следующее.
Но в случаях, когда пользователь "идет" из одного местоположения в следующее, аудиоэлементы 152 из двух (или более) аудиосцен 150 можно услышать одновременно. Решение для этих вариантов использования было предоставлено в предыдущих примерах систем, где независимо от механизмов, предусмотренных для декодирования нескольких аудиопотоков (либо с использованием мультиплексора с одним медиа-декодером, либо с несколькими медиа-декодерами и дополнительным смесителем/блоком 1238 вывода), клиенту/системе 102 нужно предоставлять аудиопотоки, которые описывают законченные аудиосцены 150.
Ниже предоставляется оптимизация путем предложения идеи общих аудиоэлементов 152 между несколькими аудиопотоками.
Фиг. 1.4 показывает пример, в котором разные сцены совместно используют по меньшей мере один аудиоэлемент (аудиообъект, источник звука, …). Поэтому клиент 102 может принимать, например, один главный поток 106A, ассоциированный только с одной сценой A (например, ассоциированной со средой, где пользователь находится в настоящее время) и ассоциированный с объектами 152A, и один вспомогательный поток 106B, совместно используемый другой сценой B (например, поток на границе между сценой A, в которой пользователь находится в настоящее время, и соседний или смежный поток B, совместно использующий объекты 152B) и ассоциированный с объектами 152B.
Поэтому, как показано на фиг. 1.4:
- несколько независимых или перекрывающихся аудиосцен кодируются в некоторое количество аудиопотоков. Аудиопотоки 106 создаются таким образом, что:
- для каждой аудиосцены 150 можно создать один главный поток, содержащий только аудиоэлементы 152, которые являются частью соответствующей аудиосцены, но не частью никакой другой аудиосцены; и/или
- для всех аудиосцен 150, которые совместно используют аудиоэлементы 152, общие аудиоэлементы 152 могут кодироваться только во вспомогательные аудиопотоки, ассоциированные только с одной из аудиосцен, и создаются подходящие метаданные, указывающие ассоциацию с другими аудиосценами. Или, другими словами, дополнительные метаданные указывают возможность того, что некоторые аудиопотоки можно использовать вместе с несколькими аудиосценами; и/или
- в зависимости от варианта использования можно создать дополнительные вспомогательные потоки (например, некоторые аудиообъекты, содержащие разный языки, могут кодироваться в независимые потоки для эффективной доставки).
- В предоставленном варианте осуществления:
- аудиосцена A кодируется в:
- главный аудиопоток (A1, 106A);
- вспомогательный аудиопоток (A2, 106B);
- метаданные, которые могут указывать, что некоторые аудиоэлементы 152B из аудиосцены A не кодируются в этот аудиопоток A, а во вспомогательный поток A2 (106B), принадлежащий другой аудиосцене (аудиосцене B);
- аудиосцена B кодируется в:
- главный аудиопоток (B1, 106C);
- вспомогательный аудиопоток (B2);
- вспомогательный аудиопоток (B3);
- метаданные, которые могут указывать, что аудиоэлементы 152B из аудиопотока B2 являются общими аудиоэлементами 152B, которые принадлежат также аудиосцене A;
- аудиосцена C кодируется в три потока (C1, C2 и C3);
- аудиопотоки 106 (106A, 106B, 106C, …) могут кодировать с разными скоростями передачи битов (то есть разными представлениями), что допускает эффективную адаптацию скорости передачи битов в зависимости от сетевого соединения (то есть для пользователей, использующих высокоскоростное соединение, доставляется кодированная с высокой скоростью передачи битов версия, тогда как для пользователей с менее скоростным сетевым соединением доставляется версия с более низкой скоростью передачи битов);
- аудиопотоки 106 сохраняются на медиа-сервере 120, где для каждого аудиопотока разные кодирования с разными скоростями передачи битов (то есть разными представлениями) группируются в один адаптационный набор с подходящими данными, сигнализирующими доступность всех созданных адаптационных наборов. (В одном адаптационном наборе может присутствовать несколько представлений потоков, ассоциированных с одними и теми же аудиосигналами, но с разными скоростями передачи битов, и/или качествами, и/или разрешениями);
- дополнительно к адаптационным наборам медиа-сервер 120 может принимать информацию о "границах" местоположения у каждой аудиосцены и их взаимосвязь с каждым адаптационным набором (который может содержать, например, законченную аудиосцену или только отдельные объекты). Таким образом, каждый адаптационный набор может ассоциироваться с одной или более доступными аудиосценами 150. Границы одной аудиосцены могут задаваться, например, в виде геометрических координат сферы (например, центр и радиус);
- каждый адаптационный набор может содержать также описательную информацию о местоположениях, в которых активна звуковая сцена или аудиоэлементы 152. Например, если один вспомогательный поток (например, A2, 106B) содержит один или более объектов, то адаптационный набор мог бы содержать такую информацию, как местоположения, где слышны объекты (например, координаты центра сферы и радиус);
- дополнительно или в качестве альтернативы каждый адаптационный набор (например, адаптационный набор, ассоциированный со сценой B) может содержать описательную информацию (например, метаданные), которая может указывать, что аудиоэлементы (например, 152B) из одной аудиосцены (например, B) кодируются (также или дополнительно) в аудиопотоки (например, 106B), принадлежащие другой аудиосцене (например, A);
- медиа-сервер 120 может предоставлять системе 102 (клиенту), например клиенту DASH, информацию о "границах" местоположения, ассоциированных с каждым адаптационным набором. Например, в случае среды доставки DASH ее можно встроить в синтаксис XML Описания представления мультимедиа (MPD);
- система 102 (клиент) может принимать информацию о местоположении пользователя, и/или ориентации, и/или направлении перемещения (или любую информацию, описывающую изменения, вызванные действиями пользователя);
- система 102 (клиент) может принимать информацию о каждом адаптационном наборе, и на ее основе и/или местоположения пользователя, и/или ориентации, и/или направления перемещения (или любой информации, описывающей изменения, вызванные действиями пользователя, например содержащей координаты x, y, z и/или значения поворота, продольного крена, поперечного крена) система 102 (клиент) может выбрать один или более адаптационных наборов, полностью или частично описывающих аудиосцену 150, которую следует воспроизвести в текущем местоположении пользователя 140;
- система 102 (клиент) может запрашивать один или более адаптационных наборов:
- кроме того, система 102 (клиент) может выбрать один или более адаптационных наборов, полностью или частично описывающих более одной аудиосцены 150, и использовать аудиопотоки 106, соответствующие более одной аудиосцене 150, для создания новой аудиосцены 150 для воспроизведения в текущем местоположении пользователя 140;
- на основе метаданных, указывающих, что аудиоэлементы 152 являются частью нескольких аудиосцен 150, общие аудиоэлементы 152 можно запросить только один раз для создания новой аудиосцены вместо запрашивания их дважды, по одному разу для каждой законченной аудиосцены;
- как только аудиопотоки доступны клиентской системе 102, в примерах можно использовать один или более медиа-декодеров (104) для декодирования отдельных аудиопотоков и/или дополнительный смеситель/блок вывода для воспроизведения итоговой аудиосцены на основе информации о местоположении пользователя, и/или ориентации, и/или направлении перемещения (то есть, например, некоторые аудиоэлементы, которые не слышны в определенном местоположении, следует отключить или не выводить);
- в качестве альтернативы или дополнительно процессор метаданных может использоваться для работы с метаданными аудио, ассоциированными со всем аудиопотоками, на основе информации о местоположении пользователя, и/или ориентации, и/или направлении перемещения, чтобы:
- выбрать/включить необходимые аудиоэлементы 152 (152A-152c), составляющие новую аудиосцену; и/или
- обеспечить соединение всех аудиопотоков в единый аудиопоток;
- медиа-сервер 120 может доставить необходимые адаптационные наборы;
- в качестве альтернативы система 102 (клиент) предоставляет информацию о местоположении пользователя 140 медиа-серверу 120, а медиа-сервер предоставляет указание о необходимых адаптационных наборах.
Фиг. 1.5 показывает другую примерную реализацию такой системы, содержащей:
- на кодирующей стороне
- множество медиа-кодеров 154, которые могут использоваться для создания одного или более аудиопотоков 106, встраивающих аудиоэлементы 152 из одной или более доступных аудиосцен 150, ассоциированных с одной частью звуковой сцены у одной точки наблюдения;
- для каждой аудиосцены 150 можно создать один главный поток, содержащий только аудиоэлементы 152, которые являются частью соответствующей аудиосцены 150, но не частью никакой другой аудиосцены;
- для той же аудиосцены можно создать дополнительные вспомогательные потоки (например, некоторые аудиообъекты, содержащие разные языки, могут кодироваться в независимые потоки для эффективной доставки);
- можно создать дополнительные вспомогательные потоки, которые содержат:
- аудиоэлементы 152, общие более чем для одной аудиосцены 150;
- метаданные, указывающие ассоциацию этого вспомогательного потока со всеми другими аудиосценами 150, которые совместно используют общие аудиоэлементы 152. Или, другими словами, метаданные указывают возможность того, что некоторые аудиопотоки можно использовать вместе с несколькими аудиосценами;
- множество медиа-кодеров, которые могут использоваться для создания одного или более видеопотоков для каждой доступной видеосцены, ассоциированной с одной частью видеосцены у одной точки наблюдения. На чертеже видеокодеры не представлены для простоты;
- медиа-сервер 120, который хранит несколько адаптационных наборов аудио и видео, содержащих разные кодирования одних и тех же аудио- и видеопотоков с разными скоростями передачи битов (то есть разные представления). Более того, медиа-сервер 120 содержит описательную информацию про все адаптационные наборы, которая может включать в себя
- доступность всех созданных адаптационных наборов;
- информацию, описывающую ассоциацию одного адаптационного набора с одной аудиосценой и/или точкой наблюдения; Таким образом, каждый адаптационный набор может ассоциироваться с одной из доступных аудиосцен;
- информацию, описывающую "границы" каждой аудиосцены и/или точки наблюдения (которая может содержать, например, законченную аудиосцену или только отдельные объекты). Границы одной аудиосцены могут задаваться, например, в виде геометрических координат сферы (например, центр и радиус);
- информацию, указывающую ассоциацию одного адаптационного набора более чем с одной аудиосценой, которые совместно используют по меньшей мере один общий аудиоэлемент;
- на стороне клиента систему (клиентскую систему), которая может содержать в любой из:
- принимающей стороны, которая может принимать:
- информацию о местоположении пользователя, и/или ориентации, и/или направлении перемещения (или любую информацию, описывающую изменения, вызванные действиями пользователя);
- информацию о доступности всех адаптационных наборов и информацию, описывающую ассоциацию одного адаптационного набора с одной аудиосценой и/или точкой наблюдения; и/или информацию, описывающую "границы" каждой аудиосцены и/или точки наблюдения (которая может содержать, например, законченную аудиосцену или только отдельные объекты). Например, в случае среды доставки DASH такая информация может предоставляться как часть синтаксиса XML Описания представления мультимедиа (MPD);
- информацию, указывающую ассоциацию одного адаптационного набора более чем с одной аудиосценой, которые совместно используют по меньшей мере один общий аудиоэлемент;
- стороны мультимедийного устройства, используемой для потребления контента (например, на основе HMD). Мультимедийное устройство также отвечает за сбор информации о местоположении пользователя, и/или ориентации, и/или направлении перемещения (или любой информации, описывающей изменения, вызванные действиями пользователя);
- процессор 1232 поля видимости, который может быть выполнен с возможностью
- принимать от мультимедийного устройства информацию о текущем поле видимости, которая может содержать местоположение пользователя, и/или ориентацию, и/или направление перемещения (или любую информацию, описывающую изменения, вызванные действиями пользователя);
- принимать информацию о ROI, сигнализированную в метаданных (поля видимости видео, сигнализированные в виде спецификации OMAF);
- принимать всю информацию, доступную на принимающей стороне;
- решать, какую точку наблюдения аудио/видео следует воспроизводить в некоторый момент времени, на основе всей информации, принятой и/или выведенной из принятых и/или доступных метаданных. Например, процессор 1232 поля видимости может решить, что:
- нужно воспроизвести одну законченную аудиосцену;
- нужно создать одну новую аудиосцену из всех доступных аудиосцен (например, нужно воспроизводить только некоторые аудиоэлементы из нескольких аудиосцен, тогда как другие оставшиеся аудиоэлементы из этих аудиосцен воспроизводить не нужно);
- нужно воспроизвести переход между двумя или более аудиосценами;
- выборная часть 1230, выполненная с возможностью выбирать на основе информации, принятой от процессора 1232 поля видимости, один или более адаптационных наборов из доступных адаптационных наборов, которые сигнализированы в информации, принятой принимающей стороной; при этом выбранные адаптационные наборы полностью или частично описывают аудиосцену, которую следует воспроизводить в текущем местоположении пользователя. Эта аудиосцена может быть законченной или частично законченной аудиосценой, которая задана на кодирующей стороне, или нужно создать новую аудиосцену из всех доступных аудиосцен;
- более того, в случае аудиоэлементов 152, принадлежащих более одной аудиосцене, по меньшей мере один из адаптационных наборов выбирается на основе информации, указывающей ассоциацию по меньшей мере одного адаптационного набора более чем с одной аудиосценой, которые содержат те же аудиоэлементы 152;
- более того, в случае, когда на основе указания от процессора 1232 поля видимости предстоит переход между двумя или более аудиосценами, выборная часть 1230 может быть выполнена с возможностью выбирать один или более адаптационных наборов из доступных адаптационных наборов, которые сигнализированы в информации, принятой принимающей стороной; при этом выбранные адаптационные наборы полностью описывают аудиосцену, которую может потребоваться воспроизвести в ближайшем будущем (например, если пользователь идет в направлении следующей аудиосцены с некоторой скоростью, то можно предсказать, что потребуется следующая аудиосцена, и она выбирается перед воспроизведением);
- более того, сначала можно выбрать некоторые адаптационные наборы, соответствующие соседним местоположениям, с более низкой скоростью передачи битов (то есть представление, кодированное с более низкой скоростью передачи битов, выбирается из доступных представлений в одном адаптационном наборе), и на основе изменений положения качество увеличивается путем выбора более высокой скорости передачи битов для тех определенных адаптационных наборов (то есть представление, кодированное с более высокой скоростью передачи битов, выбирается из доступных представлений в одном адаптационном наборе);
- загружающая и переключающая часть, которая может быть выполнена с возможностью:
- запрашивать у медиа-сервера 120 один или более адаптационных наборов из доступных адаптационных наборов на основе указания, принятого от выборной части 1230;
- принимать от медиа-сервера 120 один или более адаптационных наборов (то есть одно представление из всех представлений, доступных внутри каждого адаптационного набора) из доступных адаптационных наборов;
- извлекать метаданные из всех принятых аудиопотоков;
- процессор 1236 метаданных, который может быть выполнен с возможностью:
- принимать от загружающей и переключающей части информацию о принятых аудиопотоках, которая может включать в себя метаданные аудио, соответствующие каждому принятому аудиопотоку;
- обрабатывать метаданные аудио, ассоциированные с каждым аудиопотоком, на основе принятой от процессора 1232 поля видимости информации, которая может включать в себя информацию о местоположении пользователя, и/или ориентации, и/или направлении перемещения, чтобы:
- выбрать/включить необходимые аудиоэлементы 152, составляющие новую аудиосцену, которая указана процессором 1232 поля видимости;
- обеспечить соединение всех аудиопотоков в единый аудиопоток;
- мультиплексор/устройство 1238 соединения потоков, которое может быть выполнено с возможностью соединять все выбранные аудиопотоки в один аудиопоток на основе принятой от процессора 1236 метаданных информации, которая может включать в себя измененные и обработанные метаданные аудио, соответствующие всем принятым аудиопотокам;
- медиа-декодер, выполненный с возможностью принимать и декодировать по меньшей мере один аудиопоток для воспроизведения новой аудиосцены, которая указана процессором 1232 поля видимости, на основе информации о местоположении пользователя, и/или ориентации, и/или направлении перемещения.
Фиг. 1.6 показывает систему, содержащую на стороне клиента систему (клиентскую систему), которая может воплощать, например, части системы, описанной на фиг. 5, которые дополнительно или в качестве альтернативы содержат:
- несколько медиа-декодеров, которые могут быть выполнены с возможностью декодировать отдельные аудиопотоки, которые указаны процессором 1236 метаданных (например, с некоторым количеством отключенных аудиоэлементов);
- смеситель/блок 1238 вывода, который может быть выполнен с возможностью воспроизводить итоговую аудиосцену на основе информации о местоположении пользователя, и/или ориентации, и/или направлении перемещения (то есть некоторые аудиоэлементы, которые не слышны в определенном местоположении, следует отключить или не выводить).
Обновления форматов файлов для воспроизведения
Для варианта использования формата файла несколько главных и вспомогательных потоков можно заключить в виде отдельных дорожек в одном файле ISOBMFF. Одна дорожка такого файла представляла бы один аудиоэлемент, как упоминалось ранее. Поскольку не доступно MPD, которое содержит необходимую информацию для правильного воспроизведения, информацию нужно предоставлять на уровне формата файла, например путем предоставления/введения определенного контейнера формата файла или определенных контейнеров формата файла на уровне дорожки и фильма. В зависимости от варианта использования есть разная информация, необходимая для правильного представления заключенных аудиосцен, однако следующий набор информации является основополагающим и поэтому всегда должен присутствовать:
- информация о включенных аудиосценах, например "границы местоположения";
- информация обо всех доступных аудиоэлементах, в особенности о том, какой аудиоэлемент заключается в какую дорожку;
- информация о местоположении заключенных аудиоэлементов;
- список всех аудиоэлементов, принадлежащих одной аудиосцене, при этом аудиоэлемент может принадлежать нескольким аудиосценам;
С помощью этой информации все упомянутые варианты использования, включая вариант с дополнительным процессором метаданных и совместно используемым кодированием, также должны работать в файловой среде.
Дополнительные соображения по вышеприведенным примерам
В примерах (например, по меньшей мере среди фиг. 1.1-6) по меньшей мере одна сцена может ассоциироваться по меньшей мере с одним аудиоэлементом (аудиоисточником 152), при этом каждый аудиоэлемент ассоциируется с положением и/или областью в визуальной среде, где слышен аудиоэлемент, чтобы разные аудиопотоки предоставлялись от серверной системы 120 клиентской системе 102 для разных положений пользователя, и/или полей видимости, и/или ориентаций головы, и/или данных перемещения, и/или метаданных взаимодействия, и/или данных виртуального положения в сцене.
В примерах клиентская система 102 может быть выполнена с возможностью решать, нужно ли воспроизводить по меньшей мере один аудиоэлемент 152 аудиопотока (например, A1, A2) и/или один адаптационный набор при наличии текущего поля видимости пользователя, и/или ориентации головы, и/или данных перемещения, и/или метаданных взаимодействия, и/или виртуального положения в сцене, причем система 102 выполнена с возможностью запрашивать и/или принимать по меньшей мере один аудиоэлемент в текущем виртуальном положении пользователя.
В примерах клиентская система (например, 102) может быть выполнена с возможностью прогнозировать, станет ли релевантным и/или слышимым по меньшей мере один аудиоэлемент (152) аудиопотока и/или один адаптационный набор, на основе по меньшей мере текущего поля видимости пользователя, и/или ориентации головы, и/или данных перемещения, и/или метаданных взаимодействия, и/или данных (110) виртуального положения, и при этом система выполнена с возможностью запрашивать и/или принимать по меньшей мере один аудиоэлемент, и/или аудиопоток, и/или адаптационный набор в конкретном виртуальном положении пользователя до предсказанного перемещения и/или взаимодействия пользователя в сцене, причем система выполнена с возможностью воспроизводить, при приеме, по меньшей мере один аудиоэлемент и/или аудиопоток в конкретном виртуальном положении пользователя после перемещения и/или взаимодействия пользователя в сцене. См., например, фиг. 8A и 8B выше. В некоторых примерах по меньшей мере одна из операций системы 102 или 120 может выполняться на основе прогнозных, и/или статистических, и/или агрегатных данных.
В примерах клиентская система (например, 102) может быть выполнена с возможностью запрашивать и/или принимать по меньшей мере один аудиоэлемент (например, 152) с более низкой скоростью передачи битов и/или уровнем качества в виртуальном положении пользователя до перемещения и/или взаимодействия пользователя в сцене, причем система выполнена с возможностью запрашивать и/или принимать по меньшей мере один аудиоэлемент с более высокой скоростью передачи битов и/или уровнем качества в виртуальном положении пользователя после перемещения и/или взаимодействия пользователя в сцене. См., например, фиг. 7B.
В примерах по меньшей мере один аудиоэлемент может ассоциироваться по меньшей мере с одной сценой, при этом по меньшей мере один аудиоэлемент ассоциируется с положением и/или областью в визуальной среде, ассоциированной со сценой, причем система выполнена с возможностью запрашивать разные потоки с разными скоростями передачи битов и/или уровнями качества для аудиоэлементов на основе их релевантности и/или уровня слышимости в каждом виртуальном положении пользователя в сцене, причем система выполнена с возможностью запрашивать аудиопоток с более высокой скоростью передачи битов и/или уровнем качества для аудиоэлементов, которые более релевантны и/или лучше слышны в текущем виртуальном положении пользователя, и/или аудиопотока с более низкой скоростью передачи битов и/или уровнем качества для аудиоэлементов, которые менее релевантны и/или хуже слышны в текущем виртуальном положении пользователя. В общих чертах см. фиг. 7A. См. также фиг. 2a и 2b (где более релевантные и/или слышимые источники могут быть ближе к пользователю), фиг. 3 (где более релевантный и/или слышимый источник является источником сцены 150a, когда пользователь находится в положении x1, и более релевантный и/или слышимый источник является источником сцены 150b, когда пользователь находится в положении x3), фиг. 4 (где в момент t2 времени более релевантные и/или слышимые источники могут быть источниками первой сцены), фиг. 6 (где более слышимые источники могут быть источниками, которые пользователь наблюдает перед собой).
В примерах по меньшей мере один аудиоэлемент (152) ассоциируется со сценой, при этом каждый аудиоэлемент ассоциируется с положением и/или областью в визуальной среде, ассоциированной со сценой, где клиентская система 102 выполнена с возможностью периодически отправлять серверной системе 120 текущее поле видимости пользователя, и/или ориентацию головы, и/или данные перемещения, и/или метаданные взаимодействия, и/или данные (110) виртуального положения, чтобы: для положения ближе по меньшей мере к одному аудиоэлементу (152) от сервера предоставлялся поток с более высокой скоростью передачи битов и/или качеством, а для положения дальше по меньшей мере от одного аудиоэлемента (152) от сервера предоставлялся поток с более низкой скоростью передачи битов и/или качеством. См., например, фиг. 2a и 2b.
В примерах может задаваться множество сцен (например, 150A, 150B) для нескольких визуальных сред, например смежных и/или соседних сред, чтобы предоставлялись первые потоки, ассоциированные с первой текущей сценой (например, 150A), и чтобы в случае перехода пользователя (150AB) ко второй, дальней сцене (например, 150B) предоставить потоки, ассоциированные с первой сценой, и вторые потоки, ассоциированные со второй сценой. См., например, фиг. 3.
В примерах задается множество сцен для первой и второй визуальных сред, при этом первая и вторая среды являются смежными и/или соседними средами, где от сервера предоставляются первые потоки, ассоциированные с первой сценой, для воспроизведения первой сцены, если виртуальное положение пользователя находится в первой среде, ассоциированной с первой сценой, от сервера предоставляются вторые потоки, ассоциированные со второй сценой, для воспроизведения второй сцены, если виртуальное положение пользователя находится во второй среде, ассоциированной со второй сценой, и предоставляются первые потоки, ассоциированные с первой сценой, и вторые потоки, ассоциированные со второй сценой, если виртуальное положение пользователя находится в переходном положении между первой сценой и второй сценой. См., например, фиг. 3.
В примерах первые потоки, ассоциированные с первой сценой, получаются с более высокой скоростью передачи битов и/или качеством, когда пользователь находится в первой среде, ассоциированной с первой сценой, тогда как вторые потоки, ассоциированные со второй сценой, ассоциированной со второй средой, получаются с более низкой скоростью передачи битов и/или качеством, когда пользователь находится в начале переходного положения от первой сцены ко второй сцене, и первые потоки, ассоциированные с первой сценой, получаются с более низкой скоростью передачи битов и/или качеством, а вторые потоки, ассоциированные со второй сценой, получаются с более высокой скоростью передачи битов и/или качеством, когда пользователь находится в конце переходного положения от первой сцены ко второй сцене. Это может быть случай, например, из фиг. 3.
В примерах задается множество сцен (например, 150A, 150B) для нескольких визуальных сред (например, смежных сред), чтобы система 102 могла запрашивать и/или получать потоки, ассоциированные с текущей сценой, с более высокой скоростью передачи битов и/или качеством, а потоки, ассоциированные со второй сценой, с более низкой скоростью передачи битов и/или качеством. См., например, фиг. 4.
В примерах задается множество из N аудиоэлементов, и если расстояние пользователя до положения или области этих аудиоэлементов больше заранее установленной пороговой величины, то обрабатываются N аудиоэлементов для получения меньшего числа M аудиоэлементов (M<N), ассоциированных с положением или областью, близкой к положению или области N аудиоэлементов, чтобы предоставить системе по меньшей мере один аудиопоток, ассоциированный с N аудиоэлементами, если расстояние пользователя до положения или области N аудиоэлементов меньше заранее установленной пороговой величины, либо предоставить системе по меньшей мере один аудиопоток, ассоциированный с M аудиоэлементами, если расстояние пользователя до положения или области N аудиоэлементов больше заранее установленной пороговой величины. См., например, фиг. 1.7.
В примерах по меньшей мере одна сцена визуальной среды ассоциируется по меньшей мере с одним множеством из N аудиоэлементов (N>=2), при этом каждый аудиоэлемент ассоциируется с положением и/или областью в визуальной среде, где по меньшей мере одно множество из N аудиоэлементов может предоставляться по меньшей мере в одном представлении с высокой скоростью передачи битов и/или уровнем качества, и где по меньшей мере одно множество из N аудиоэлементов предоставляется по меньшей мере в одном представлении с низкой скоростью передачи битов и/или уровнем качества, где по меньшей мере одно представление получается путем обработки N аудиоэлементов, чтобы получить меньшее число M аудиоэлементов (M<N), ассоциированных с положением или областью, близкой к положению или области N аудиоэлементов, где система выполнена с возможностью запрашивать представление с более высокой скоростью передачи битов и/или уровнем качества для аудиоэлементов, если аудиоэлементы более релевантны и/или лучше слышны в текущем виртуальном положении пользователя в сцене, причем система выполнена с возможностью запрашивать представление с более низкой скоростью передачи битов и/или уровнем качества для аудиоэлементов, если аудиоэлементы менее релевантны и/или хуже слышны в текущем виртуальном положении пользователя в сцене. См., например, фиг. 1.7.
В примерах, если расстояние пользователя, и/или релевантность, и/или уровень слышимости, и/или угловая ориентация меньше заранее установленной пороговой величины, то получаются разные потоки для разных аудиоэлементов. См., например, фиг. 1.7.
В примерах разные аудиоэлементы предоставляются в разных полях видимости, чтобы, если один первый аудиоэлемент входит в текущее поле видимости, первый аудиоэлемент получался с более высокой скоростью передачи битов, чем второй аудиоэлемент, который не входит в поле видимости. См., например, фиг. 6.
В примерах задаются по меньшей мере две сцены визуальной среды, где по меньшей мере один первый и второй аудиоэлементы ассоциируются с первой сценой, ассоциированной с первой визуальной средой, и по меньшей мере один третий аудиоэлемент ассоциируется со второй сценой, ассоциированной со второй визуальной средой, причем система 102 выполнена с возможностью получать метаданные, описывающие, что по меньшей мере один второй аудиоэлемент дополнительно ассоциируется со второй сценой визуальной среды, и при этом система выполнена с возможностью запрашивать и/или принимать по меньшей мере первый и второй аудиоэлементы, если виртуальное положение пользователя находится в первой визуальной среде, и при этом система выполнена с возможностью запрашивать и/или принимать по меньшей мере второй и третий аудиоэлементы, если виртуальное положение пользователя находится во второй сцене визуальной среды, и при этом система выполнена с возможностью запрашивать и/или принимать по меньшей мере первый, второй и третий аудиоэлементы, если виртуальное положение пользователя находится в переходе между первой сценой визуальной среды и второй сценой визуальной среды. См., например, фиг. 1.4. Это также может применяться к фиг. 3.
В примерах по меньшей мере один первый аудиоэлемент может предоставляться по меньшей мере в одном аудиопотоке и/или адаптационном наборе, и по меньшей мере один второй аудиоэлемент предоставляется по меньшей мере в одном втором аудиопотоке и/или адаптационном наборе, и по меньшей мере один третий аудиоэлемент предоставляется по меньшей мере в одном третьем аудиопотоке и/или адаптационном наборе, и где по меньшей мере первая сцена визуальной среды описывается метаданными как законченная сцена, которая требует по меньшей мере первого и второго аудиопотоков и/или адаптационных наборов, и где вторая сцена визуальной среды описывается метаданными как незаконченная сцена, которая требует по меньшей мере третьего аудиопотока и/или адаптационного набора и по меньшей мере второго аудиопотока и/или адаптационных наборов, ассоциированных по меньшей мере с первой сценой визуальной среды, где система содержит процессор метаданных, выполненный с возможностью работать с метаданными, чтобы разрешить соединение второго аудиопотока, принадлежащего первой визуальной среде, и третьего аудиопотока, ассоциированного со второй визуальной средой, в новый единый поток, если виртуальное положение пользователя находится во второй визуальной среде. См., например, фиг. 1.2-1.3, 1.5 и 1.6.
В примерах система 102 может содержать процессор метаданных (например, 1236), выполненный с возможностью работать с метаданными по меньшей мере в одном аудиопотоке по меньшей мере перед одним декодером аудио, на основе текущего поля видимости пользователя, и/или ориентации головы, и/или данных перемещения, и/или метаданных взаимодействия, и/или данных виртуального положения.
В примерах процессор метаданных (например, 1236) может быть выполнен с возможностью включать и/или отключать по меньшей мере один аудиоэлемент по меньшей мере в одном аудиопотоке по меньшей мере перед одним декодером аудио на основе текущего поля видимости пользователя, и/или ориентации головы, и/или данных перемещения, и/или метаданных взаимодействия, и/или данных виртуального положения, причем процессор метаданных может быть выполнен с возможностью отключать по меньшей мере один аудиоэлемент по меньшей мере в одном аудиопотоке по меньшей мере перед одним декодером аудио, если система решает, что аудиоэлемент больше не нужно воспроизводить как следствие текущего поля видимости, и/или ориентации головы, и/или данных перемещения, и/или метаданных взаимодействия, и/или данных виртуального положения, и при этом процессор метаданных может быть выполнен с возможностью включать по меньшей мере один аудиоэлемент по меньшей мере в одном аудиопотоке по меньшей мере перед одним декодером аудио, если система решает, что аудиоэлемент нужно воспроизводить как следствие текущего поля видимости пользователя, и/или ориентации головы, и/или данных перемещения, и/или метаданных взаимодействия, и/или данных виртуального положения.
Серверная сторона
Вышеизложенное также относится к серверу (120) для доставки аудио- и видеопотоков клиенту для среды виртуальной реальности, VR, дополненной реальности, AR, смешанной реальности, MR, или панорамного видео, при этом видео- и аудиопотоки должны воспроизводиться в мультимедийном устройстве, причем сервер (120) содержит кодер для кодирования и/или хранилище для хранения видеопотоков, чтобы описывать визуальную среду, при этом визуальная среда ассоциирована с аудиосценой; причем сервер дополнительно содержит кодер для кодирования и/или хранилище для хранения множества потоков, и/или аудиоэлементов, и/или адаптационных наборов для доставки клиенту, при этом потоки, и/или аудиоэлементы, и/или адаптационные наборы ассоциированы по меньшей мере с одной аудиосценой, причем сервер выполнен с возможностью:
выбирать и доставлять видеопоток на основе запроса от клиента, при этом видеопоток ассоциирован со средой;
выбирать аудиопоток, и/или аудиоэлемент, и/или адаптационный набор на основе запроса от клиента, при этом запрос ассоциирован по меньшей мере с текущим полем видимости пользователя, и/или ориентацией головы, и/или данными перемещения, и/или метаданными взаимодействия, и/или данными виртуального положения и с аудиосценой, ассоциированной со средой; и
доставлять аудиопоток клиенту.
Дополнительные варианты осуществления и разновидности
В зависимости от некоторых требований к реализации примеры можно реализовать в аппаратных средствах. Реализация может выполняться с использованием цифрового носителя информации, например гибкого диска, универсального цифрового диска (DVD), диска Blu-Ray, компакт-диска (CD), постоянного запоминающего устройства (ROM), программируемого постоянного запоминающего устройства (PROM), стираемого и программируемого постоянного запоминающего устройства (EPROM), электрически стираемого программируемого постоянного запоминающего устройства (EEPROM) или флэш-памяти, с сохраненными на нем электронно считываемыми управляющими сигналами, которые взаимодействуют (или допускают взаимодействие) с программируемой компьютерной системой, так что выполняется соответствующий способ. Поэтому цифровой носитель информации может быть машиночитаемым.
Как правило, примеры можно реализовать как компьютерный программный продукт с программными командами, причем программные команды действуют для выполнения одного из способов, когда компьютерный программный продукт выполняется на компьютере. Программные команды могут храниться, например, на машиночитаемом носителе.
Другие примеры выполнены в виде компьютерной программы для выполнения одного из описанных в этом документе способов, сохраненной на машиночитаемом носителе. Другими словами, пример способа поэтому является компьютерной программой с программными командами для выполнения одного из описанных в этом документе способов, когда компьютерная программа выполняется на компьютере.
Дополнительный пример способов поэтому является носителем информации (или цифровым носителем информации, или машиночитаемым носителем), содержащим записанную на нем компьютерную программу для выполнения одного из описанных в этом документе способов. Носитель информации, цифровой носитель информации или записанный носитель являются материальными и/или постоянными в отличие от сигналов, которые являются неосязаемыми и временными.
Дополнительный пример выполнен в виде блока обработки, например, компьютера, или программируемого логического устройства, выполняющего один из описанных в этом документе способов.
Дополнительный пример выполнен в виде компьютера с установленной на нем компьютерной программой для выполнения одного из описанных в этом документе способов.
Дополнительный пример выполнен в виде устройства или системы, передающих приемнику (например, электронно или оптически) компьютерную программу для выполнения одного из описанных в этом документе способов. Приемник может быть, например, компьютером, мобильным устройством, запоминающим устройством или т.п. Устройство или система могут, например, содержать файл-сервер для передачи компьютерной программы приемнику.
В некоторых примерах программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может использоваться для выполнения некоторых или всех функциональных возможностей описанных в этом документе способов. В некоторых примерах программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором, чтобы выполнить один из способов, описанных в этом документе. Как правило, способы могут выполняться любым подходящим аппаратным устройством.
Вышеописанные примеры поясняют рассмотренные выше принципы. Подразумевается, что будут очевидны модификации и изменения компоновок и подробностей, описанных в этом документе. Поэтому есть намерение ограничиться только объемом предстоящей формулы изобретения, а не определенными подробностями, представленными посредством описания и объяснения примеров в этом документе.
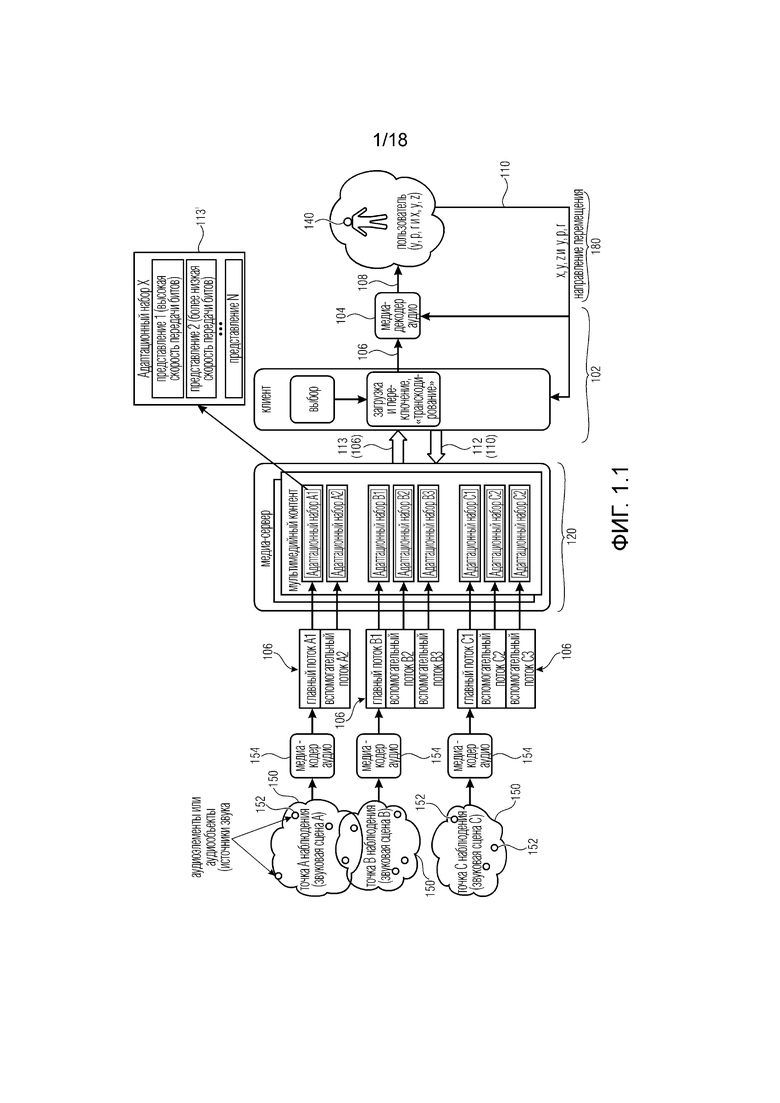
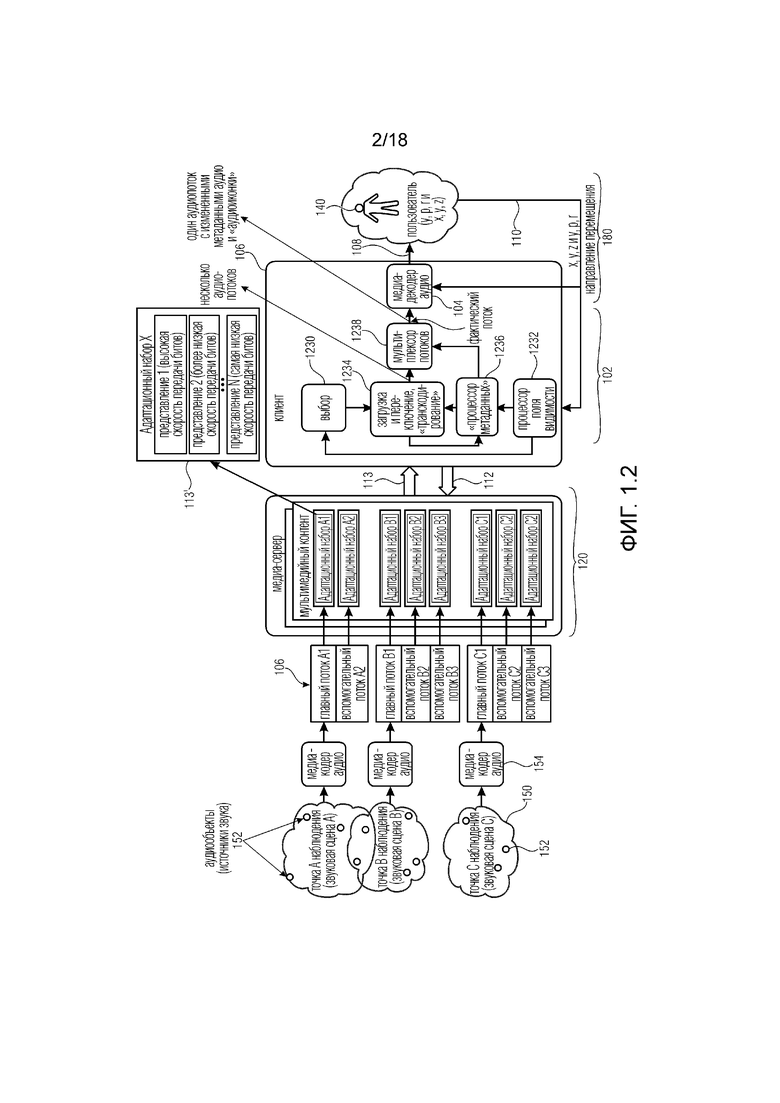
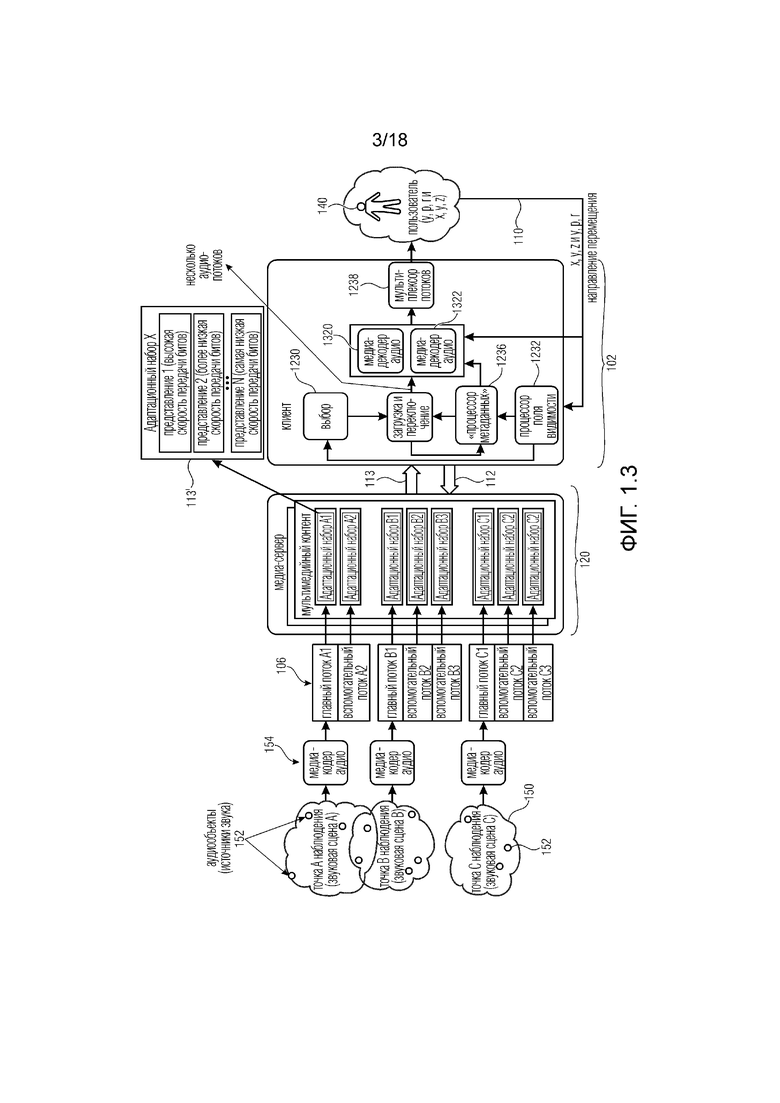
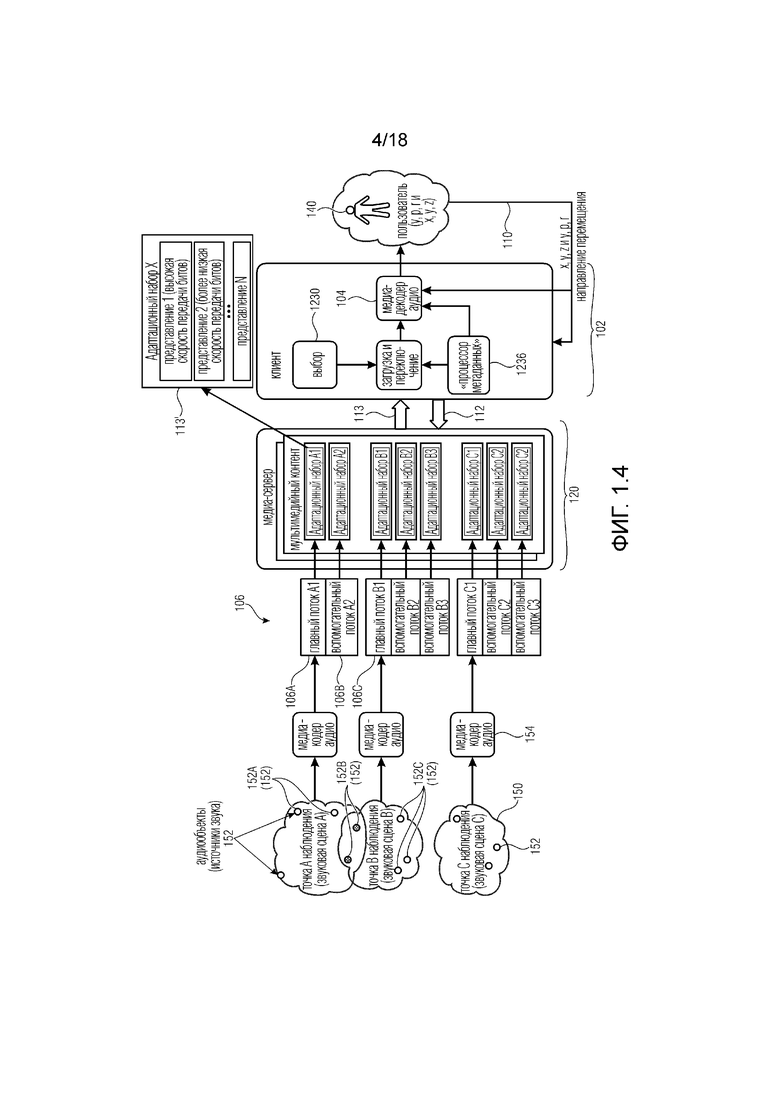
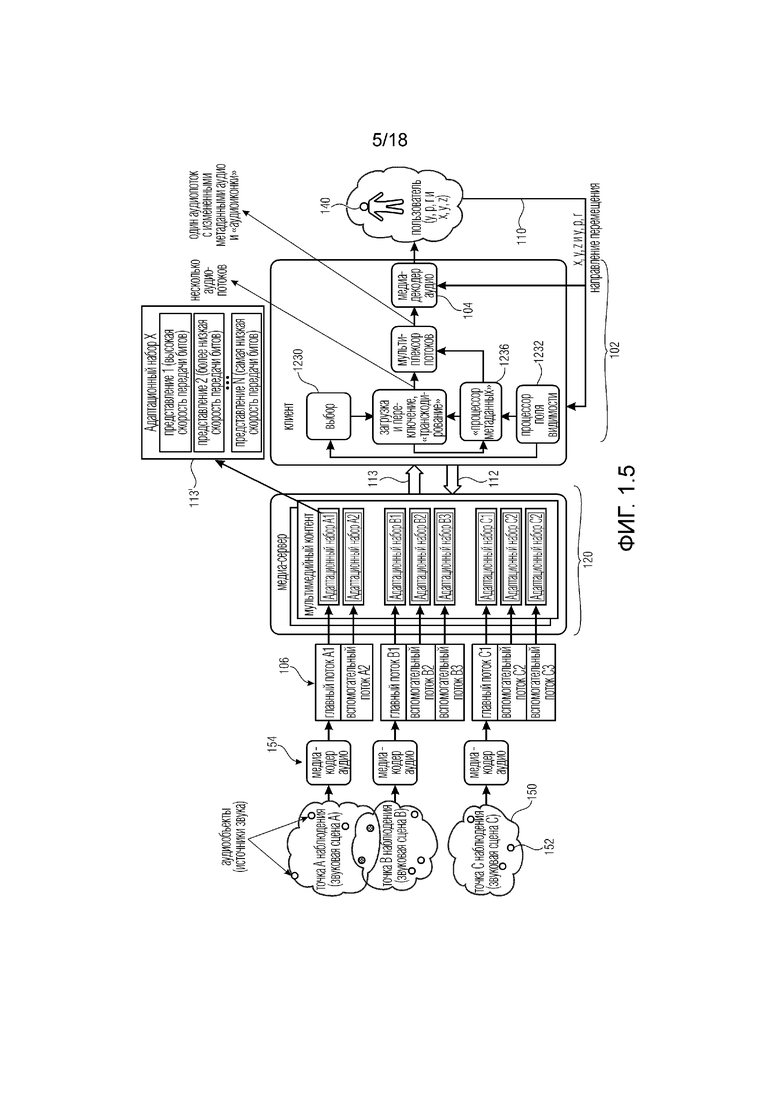
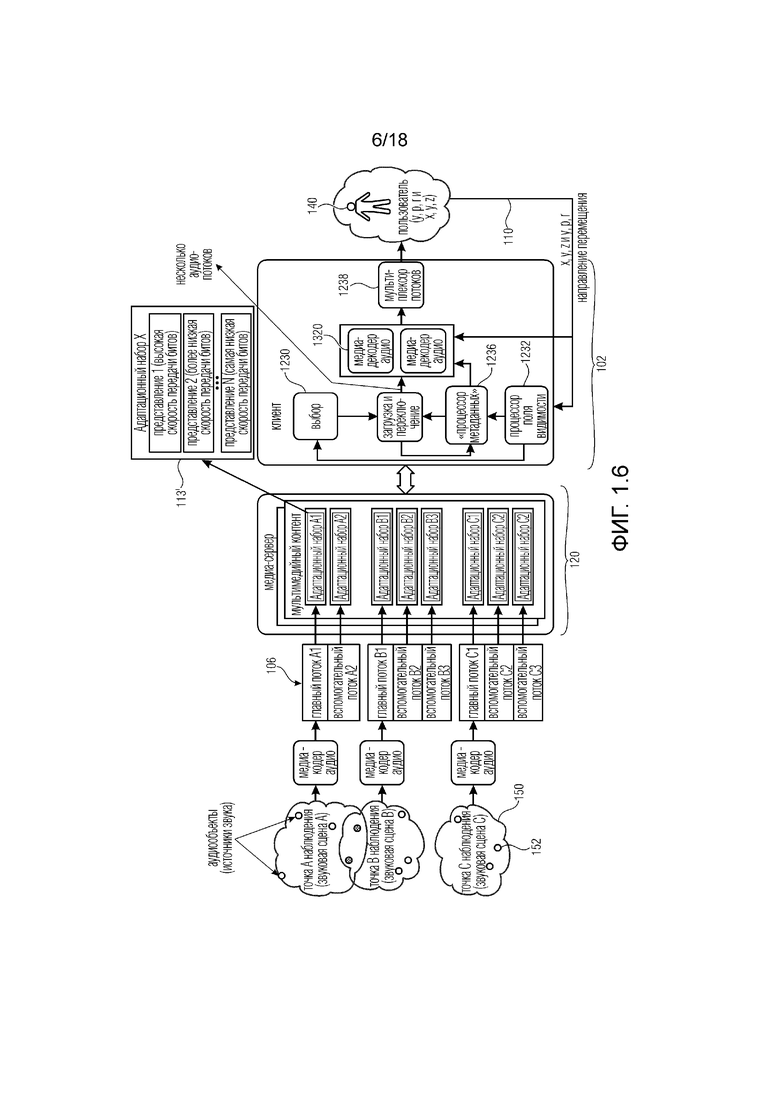
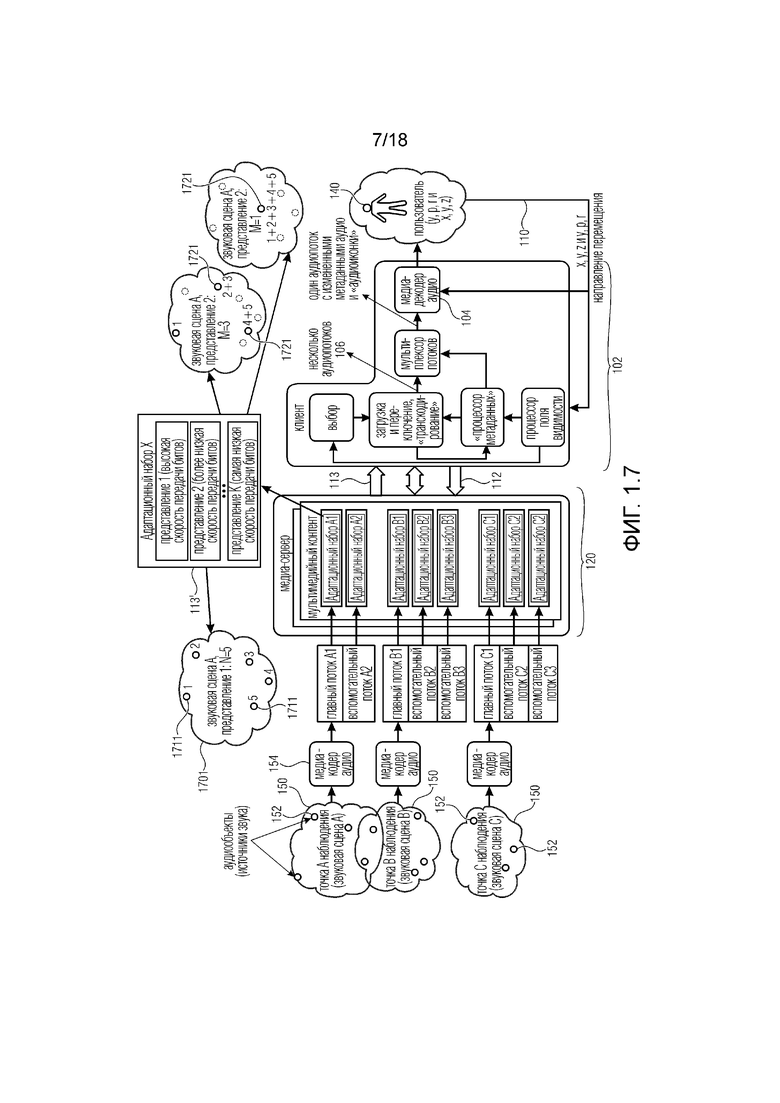
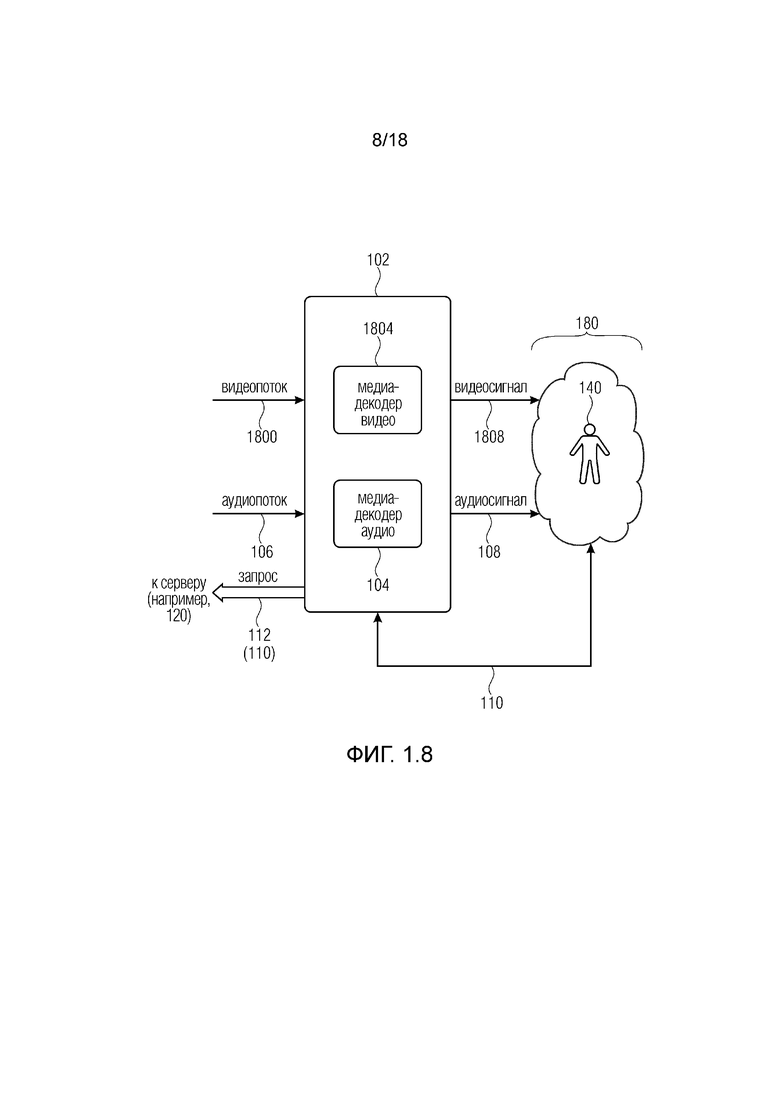
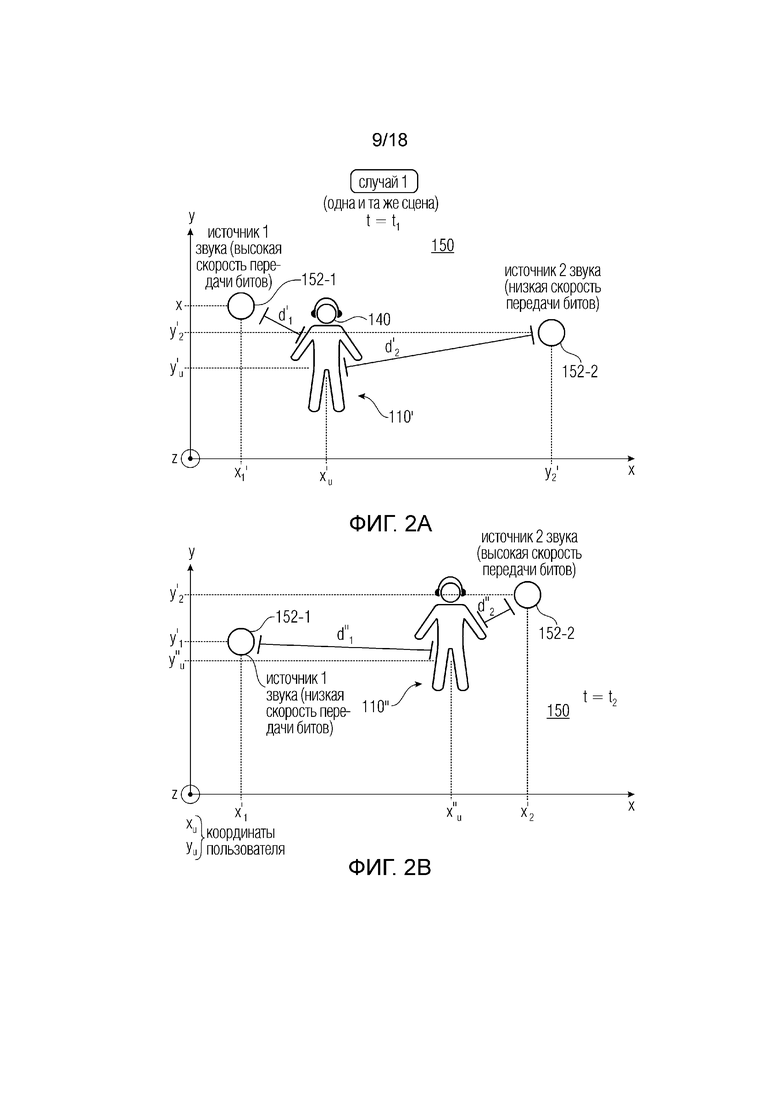
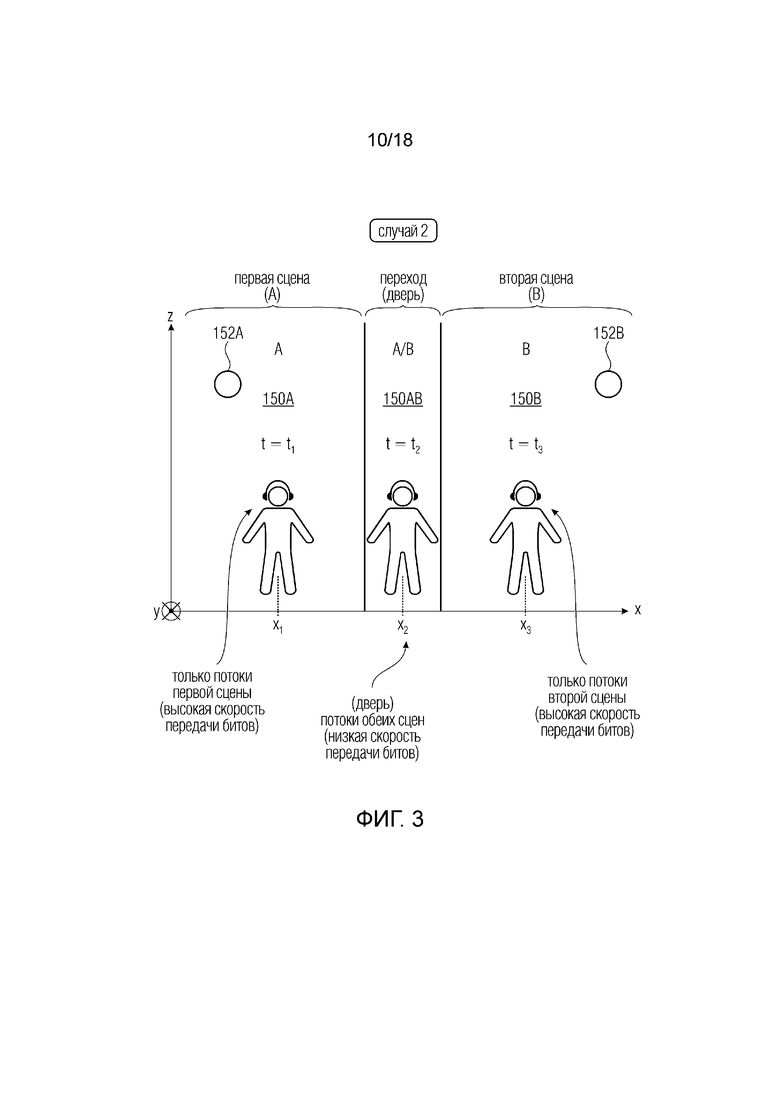
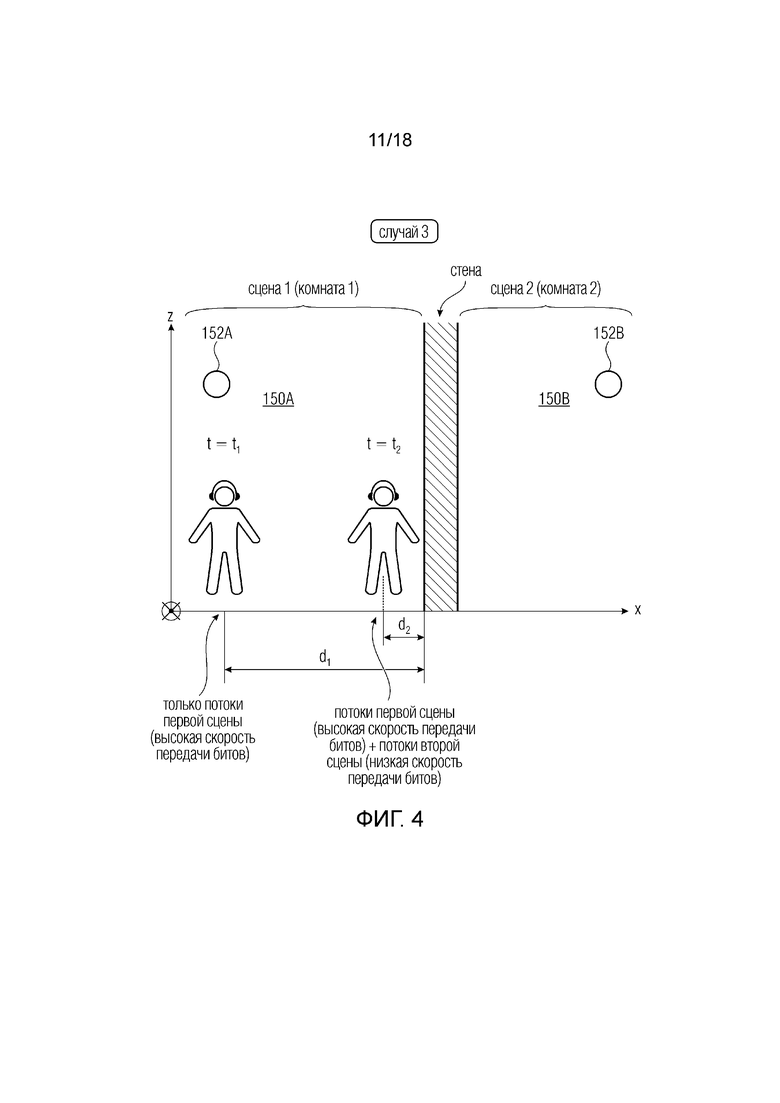
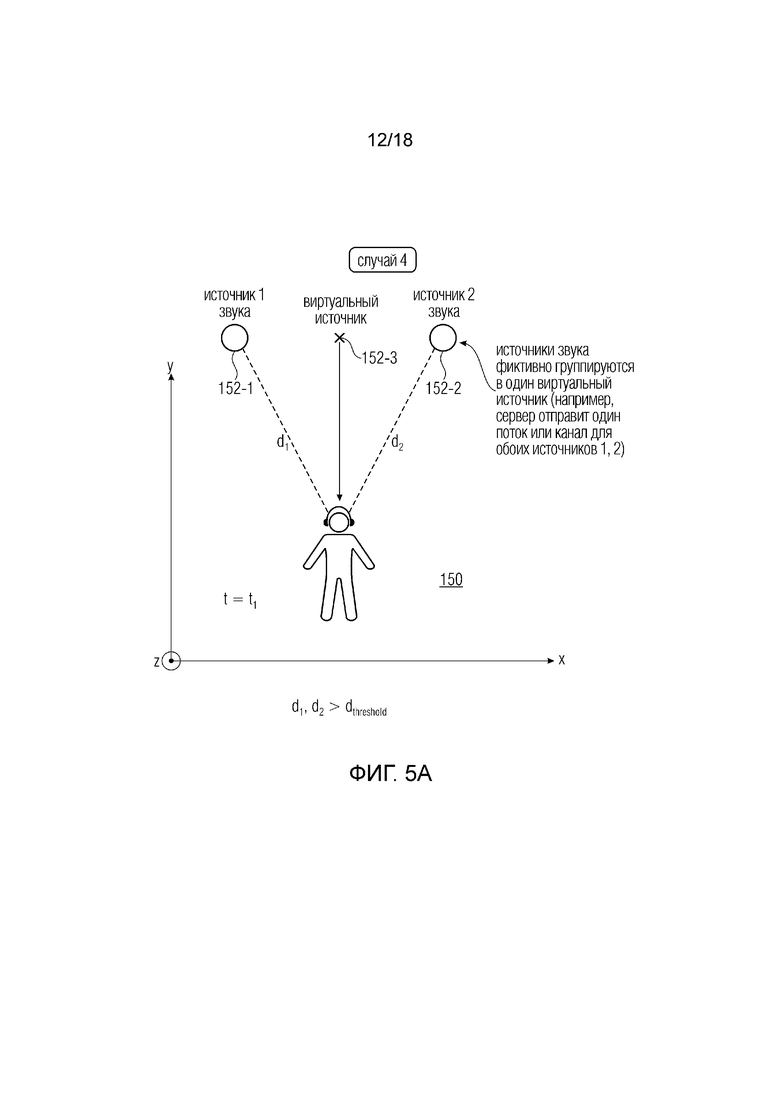
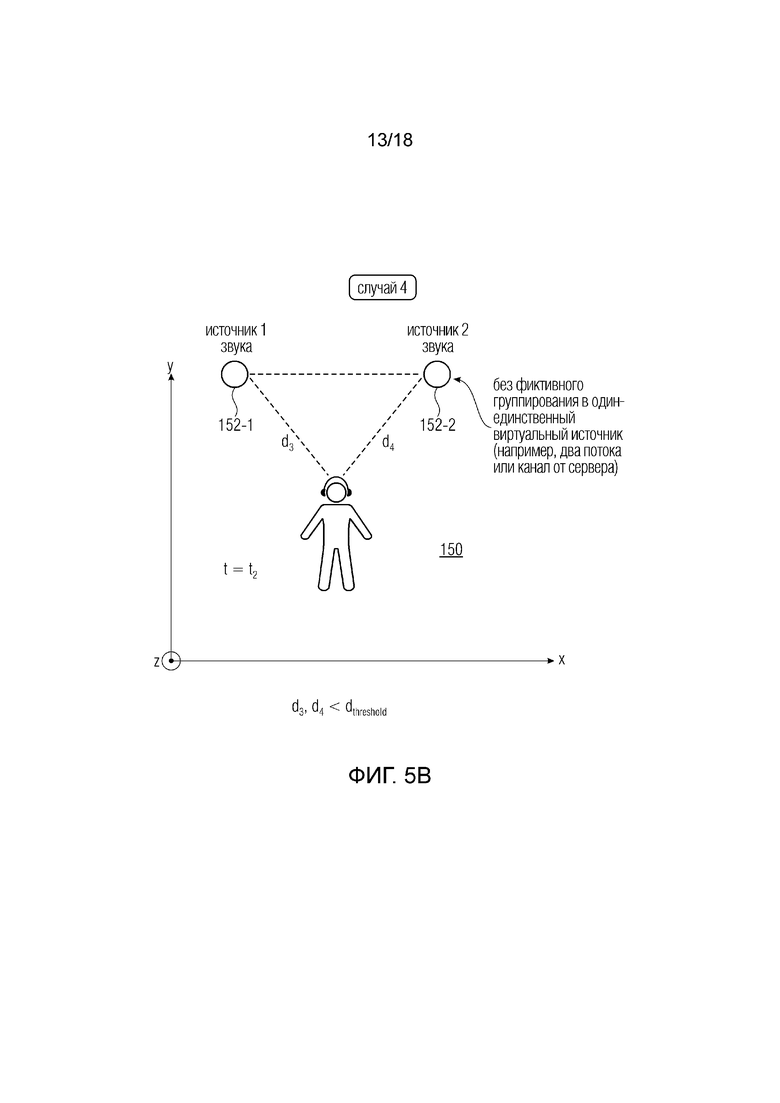
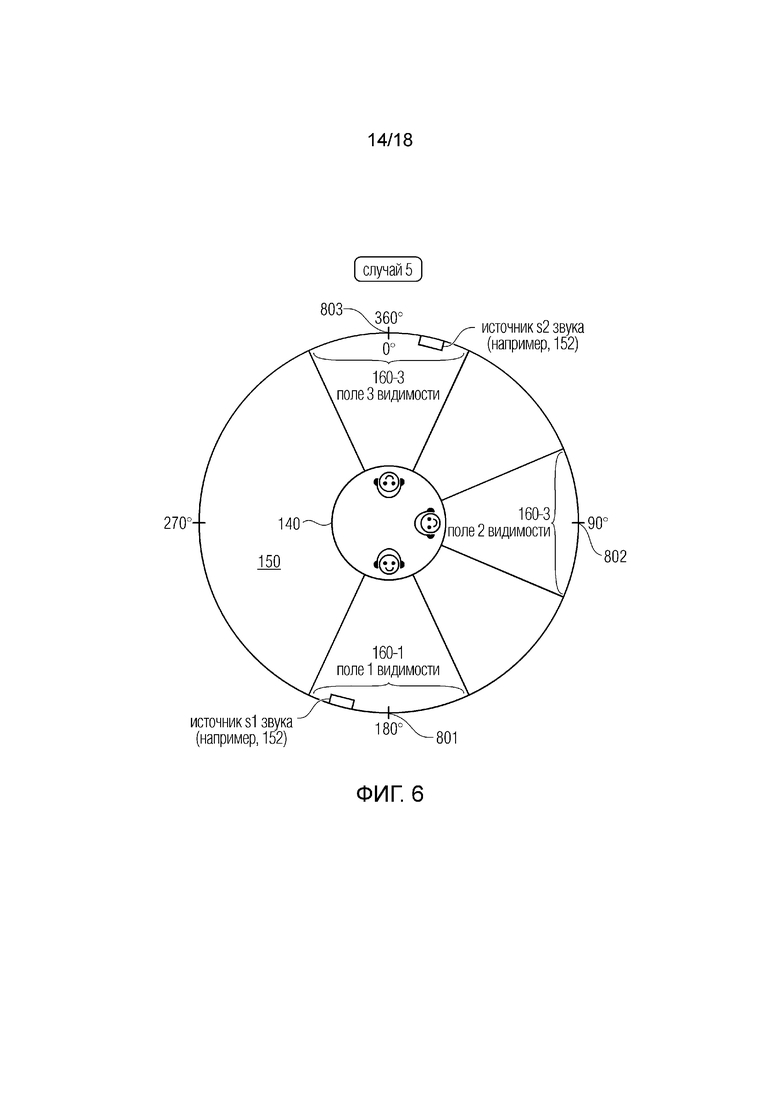
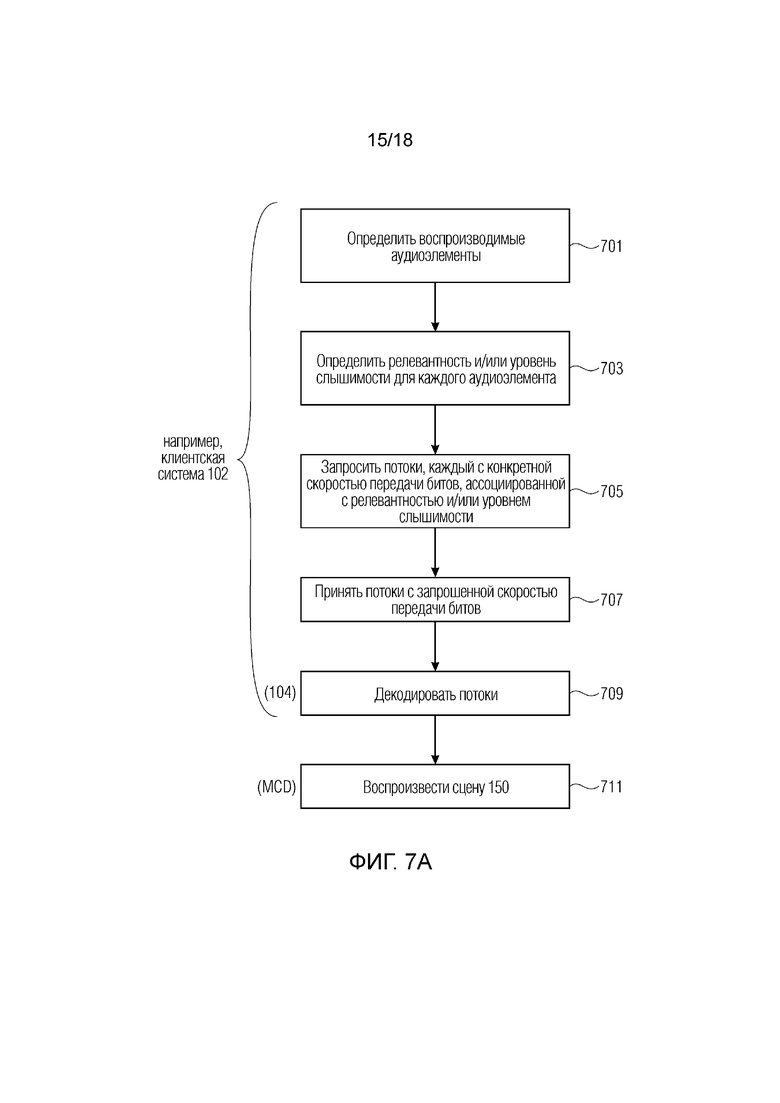
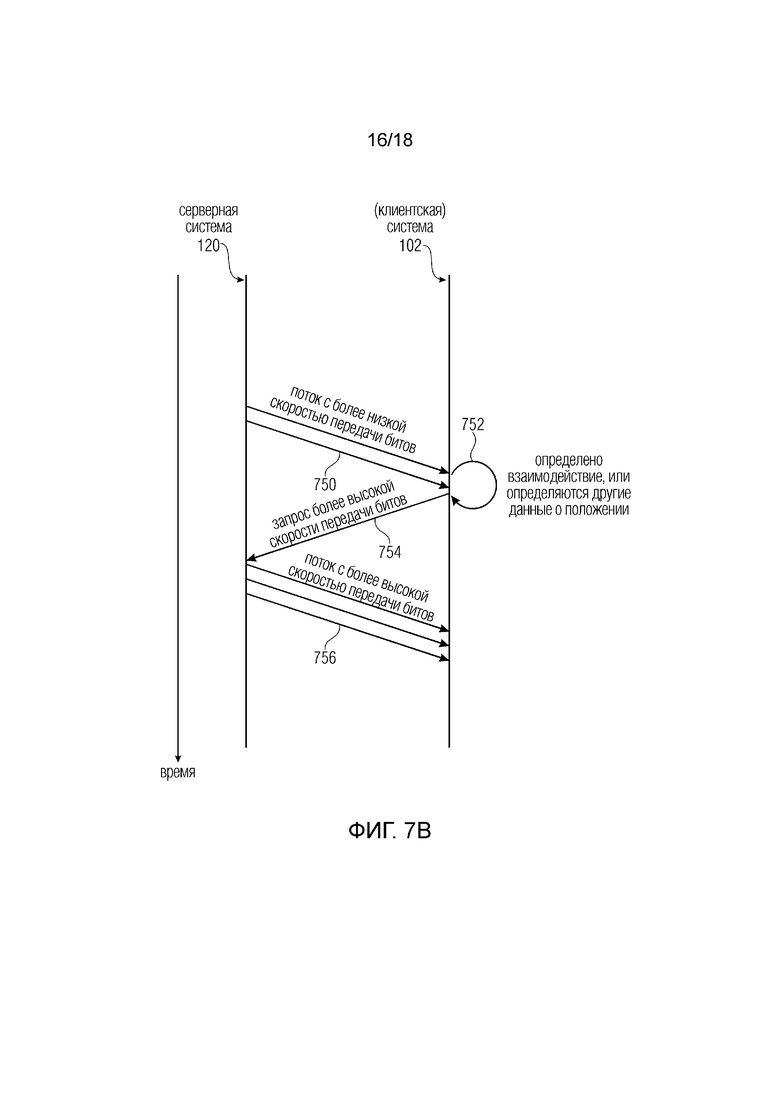
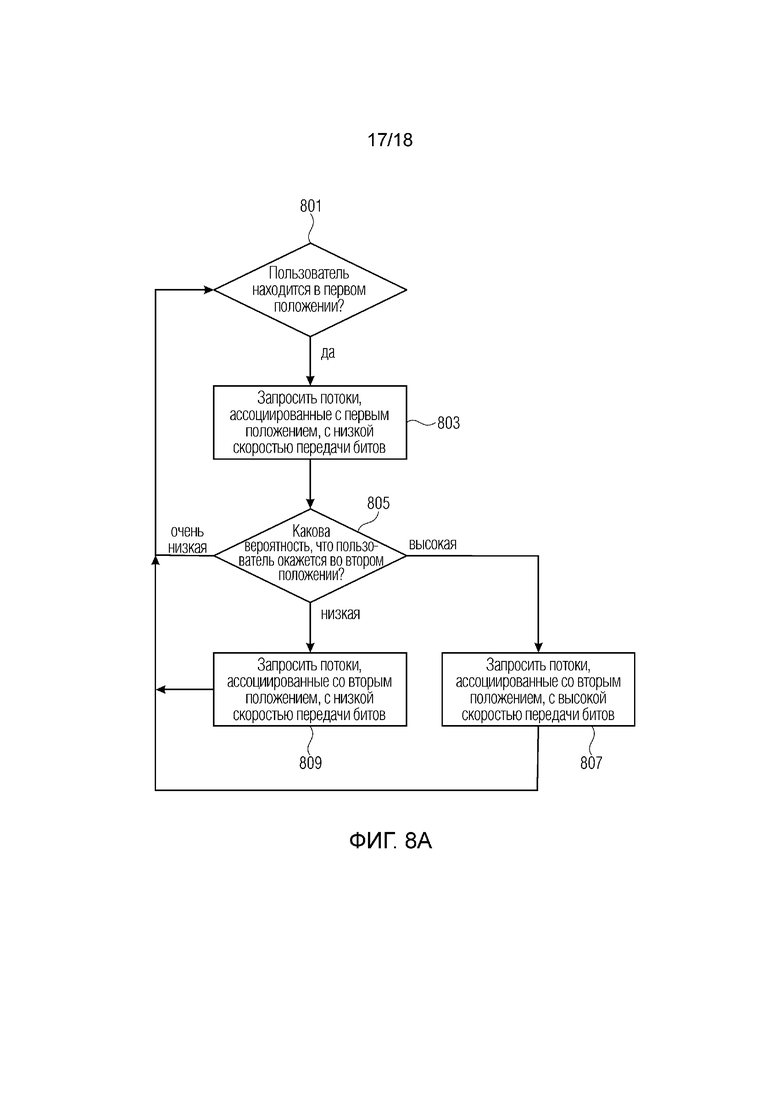
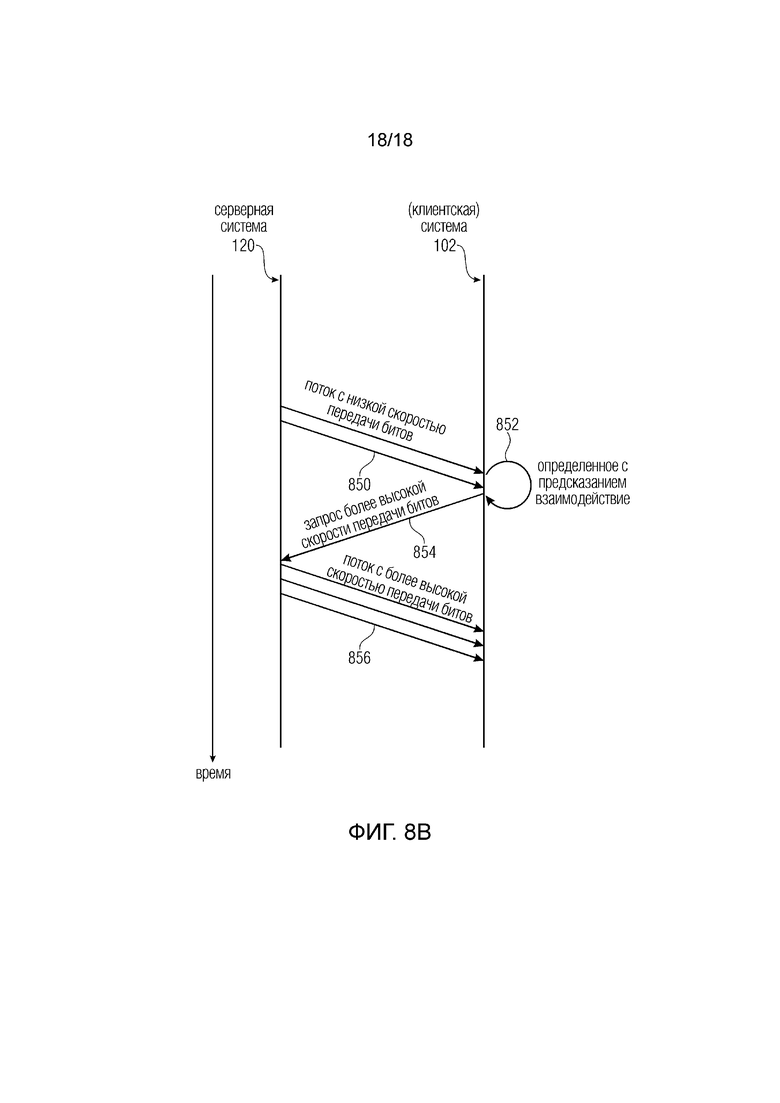
Изобретение относится к средствам для аудиокодирования. Технический результат заключается в повышении эффективности аудиокодирования. Запрашивают по меньшей мере один аудиопоток, и/или один аудиоэлемент в аудиопотоке, и/или один адаптационный набор на основе, по меньшей мере, текущей ориентации головы пользователя, и/или данных перемещения пользователя, и/или метаданных взаимодействия пользователя. По меньшей мере одна сцена ассоциирована с по меньшей мере одним множеством из N аудиоэлементов, N≥2, при этом каждый аудиоэлемент ассоциируется с положением и/или областью в среде. Упомянутое по меньшей мере одно множество из N аудиоэлементов предоставляется в по меньшей мере одном представлении с высоким битрейтом и/или уровнем качества. Упомянутое по меньшей мере одно множество из N аудиоэлементов предоставляется в по меньшей мере одном представлении с низким битрейтом и/или уровнем качества, где данное по меньшей мере одно представление получается путем обработки N аудиоэлементов, чтобы получить меньшее число M аудиоэлементов (M<N), ассоциированных с положением или областью, близкой к положению или области N аудиоэлементов. Запрашивают представление с более высоким уровнем качества для аудиоэлементов, если аудиоэлементы более релевантны в текущем виртуальном положении пользователя в сцене. 3 н. и 47 з.п. ф-лы, 19 ил.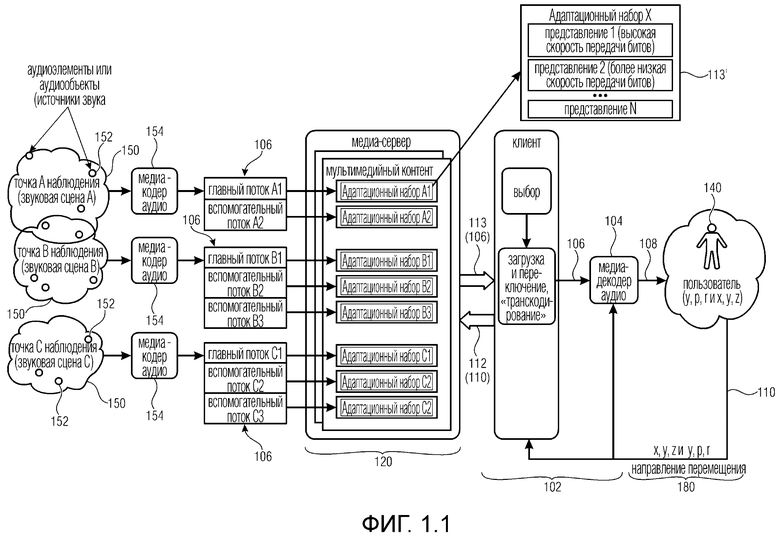
1. Система (102) для приема аудиопотоков, которые должны воспроизводиться в мультимедийном устройстве,
при этом система (102) содержит по меньшей мере один декодер (104) аудио, выполненный с возможностью декодировать аудиосигналы (108) из по меньшей мере одного аудиопотока (106),
причем система (102) выполнена с возможностью запрашивать (112) по меньшей мере один аудиопоток (106), и/или один аудиоэлемент в аудиопотоке, и/или один адаптационный набор на основе, по меньшей мере, текущей ориентации головы пользователя, и/или данных перемещения пользователя, и/или метаданных взаимодействия пользователя,
при этом система выполнена с возможностью соединять по меньшей мере один первый аудиопоток, ассоциированный с текущей аудиосценой, с по меньшей мере одним потоком, ассоциированным с соседней, смежной и/или будущей аудиосценой.
2. Система по п.1, выполненная с возможностью предоставлять серверу (120) текущую ориентацию головы пользователя, и/или данные перемещения пользователя, и/или метаданные взаимодействия пользователя, чтобы получить от сервера (120) по меньшей мере один аудиопоток (106), и/или один аудиоэлемент аудиопотока, и/или один адаптационный набор.
3. Система по п.1 или 2, при этом по меньшей мере одна сцена ассоциирована с по меньшей мере одним аудиоэлементом (152), причем каждый аудиоэлемент ассоциируется с положением и/или областью в среде, где слышен этот аудиоэлемент, чтобы разные аудиопотоки предоставлялись для разных положений пользователя, и/или ориентаций головы пользователя, и/или данных перемещения пользователя, и/или метаданных взаимодействия пользователя в упомянутой сцене.
4. Система по любому из предшествующих пунктов, при этом упомянутый по меньшей мере один аудиопоток заключен в аудиосегменты согласно MPEG-2 или MPEG-4.
5. Система по любому из предшествующих пунктов, выполненная с возможностью решать, нужно ли воспроизводить по меньшей мере один аудиоэлемент аудиопотока и/или один адаптационный набор для текущей ориентации головы пользователя, и/или данных перемещения пользователя, и/или метаданных взаимодействия пользователя, и/или виртуального положения пользователя в сцене, при этом система выполнена с возможностью запрашивать и/или принимать этот по меньшей мере один аудиоэлемент в текущем виртуальном положении пользователя.
6. Система по любому из предшествующих пунктов,
при этом система выполнена с возможностью прогнозировать, станет ли релевантным и/или слышимым по меньшей мере один аудиоэлемент (152) аудиопотока и/или один адаптационный набор, на основе, по меньшей мере, текущей ориентации головы пользователя, и/или данных перемещения пользователя, и/или метаданных взаимодействия пользователя,
причем система выполнена с возможностью запрашивать и/или принимать этот по меньшей мере один аудиоэлемент, и/или аудиопоток, и/или адаптационный набор в конкретном виртуальном положении пользователя до предсказанного перемещения и/или взаимодействия пользователя в сцене, и
при этом система выполнена с возможностью воспроизводить данный по меньшей мере один аудиоэлемент и/или аудиопоток, по его приему, в упомянутом конкретном виртуальном положении пользователя после перемещения и/или взаимодействия пользователя в сцене.
7. Система по любому из предшествующих пунктов, выполненная с возможностью запрашивать и/или принимать по меньшей мере один аудиоэлемент (152) с более низким битрейтом и/или уровнем качества в виртуальном положении пользователя до перемещения и/или взаимодействия пользователя в сцене, причем система выполнена с возможностью запрашивать и/или принимать этот по меньшей мере один аудиоэлемент с более высоким битрейтом и/или уровнем качества в виртуальном положении пользователя после упомянутого перемещения и/или взаимодействия пользователя в сцене.
8. Система по любому из предшествующих пунктов, при этом по меньшей мере один аудиоэлемент (152) ассоциирован с по меньшей мере одной сценой, каждый аудиоэлемент ассоциируется с положением и/или областью в среде, ассоциированной со сценой, причем система выполнена с возможностью запрашивать и/или принимать потоки с более высоким битрейтом и/или уровнем качества для аудиоэлементов ближе к пользователю, чем для аудиоэлементов, более отдаленных от пользователя.
9. Система по любому из предшествующих пунктов, при этом по меньшей мере один аудиоэлемент (152) ассоциируется с по меньшей мере одной сценой, причем этот по меньшей мере один аудиоэлемент ассоциируется с положением и/или областью в среде, ассоциированной с упомянутой сценой,
при этом система выполнена с возможностью запрашивать разные потоки с разными битрейтами и/или уровнями качества для аудиоэлементов на основе их релевантности и/или уровня слышимости в каждом виртуальном положении пользователя в упомянутой сцене,
причем система выполнена с возможностью запрашивать аудиопоток с более высоким битрейтом и/или уровнем качества для аудиоэлементов, которые более релевантны и/или лучше слышны в текущем виртуальном положении пользователя, и/или аудиопоток с более низким битрейтом и/или уровнем качества для аудиоэлементов, которые менее релевантны и/или хуже слышны в текущем виртуальном положении пользователя.
10. Система по любому из предшествующих пунктов, при этом по меньшей мере один аудиоэлемент (152) ассоциируется со сценой, причем каждый аудиоэлемент ассоциируется с положением и/или областью в среде, ассоциированной с данной сценой, при этом система выполнена с возможностью периодически отправлять на сервер текущую ориентацию головы пользователя, и/или данные перемещения пользователя, и/или метаданные взаимодействия пользователя, чтобы:
для первого положения с сервера предоставлялся поток с более высоким битрейтом и/или уровнем качества, а
для второго положения с сервера предоставлялся поток с более низким битрейтом и/или уровнем качества,
причем первое положение ближе к упомянутому по меньшей мере одному аудиоэлементу (152), чем второе положение.
11. Система по любому из предшествующих пунктов, в которой задается множество сцен (150A, 150B) для нескольких сред, например, смежных и/или соседних сред, с тем чтобы предоставлялись первые потоки, ассоциированные с первой, текущей сценой, и, в случае перехода пользователя ко второй, дальней сцене, предоставлялись как потоки, ассоциированные с первой сценой, так и вторые потоки, ассоциированные со второй сценой.
12. Система по любому из предшествующих пунктов, в которой задается множество сцен (150A, 150B) для первой и второй сред, при этом первая и вторая среды являются смежными и/или соседними средами,
причем с сервера предоставляются первые потоки, ассоциированные с первой сценой, для воспроизведения первой сцены, если положение или виртуальное положение пользователя находится в первой среде, ассоциированной с первой сценой,
с сервера предоставляются вторые потоки, ассоциированные со второй сценой, для воспроизведения второй сцены, если положение или виртуальное положение пользователя находится во второй среде, ассоциированной со второй сценой, и
предоставляются как первые потоки, ассоциированные с первой сценой, так и вторые потоки, ассоциированные со второй сценой, если положение или виртуальное положение пользователя находится в переходном положении между первой сценой и второй сценой.
13. Система по любому из предшествующих пунктов, в которой задается множество сцен (150A, 150B) для первой и второй сред, которые являются смежными и/или соседними средами,
причем система выполнена с возможностью запрашивать и/или принимать первые потоки, ассоциированные с первой сценой (150A), ассоциированной с первой средой, для воспроизведения первой сцены, если виртуальное положение пользователя находится в первой среде,
причем система выполнена с возможностью запрашивать и/или принимать вторые потоки, ассоциированные со второй сценой (150B), ассоциированной со второй средой, для воспроизведения второй сцены, если виртуальное положение пользователя находится во второй среде, и
при этом система выполнена с возможностью запрашивать и/или принимать как первые потоки, ассоциированные с первой сценой, так и вторые потоки, ассоциированные со второй сценой, если виртуальное положение пользователя находится в переходном положении (150AB) между первой средой и второй средой.
14. Система по любому из пп.11-13, при этом
первые потоки, ассоциированные с первой сценой, получаются с более высоким битрейтом и/или уровнем качества, когда пользователь находится в первой среде, ассоциированной с первой сценой,
тогда как вторые потоки, ассоциированные со второй сценой, ассоциированной со второй средой, получаются с более низким битрейтом и/или уровнем качества, когда пользователь находится в начале переходного положения от первой сцены ко второй сцене, и
первые потоки, ассоциированные с первой сценой, получаются с более низким битрейтом и/или уровнем качества, а вторые потоки, ассоциированные со второй сценой, получаются с более высоким битрейтом и/или уровнем качества, когда пользователь находится в конце переходного положения от первой сцены ко второй сцене,
причем упомянутый более низкий битрейт и/или уровень качества ниже упомянутого более высокого битрейта и/или уровня качества.
15. Система по любому из предшествующих пунктов, при этом
система выполнена с возможностью, в начале перехода от первой аудиосцены ко второй аудиосцене, принимать и/или запрашивать:
с более высоким битрейтом, первые аудиопотоки или первые адаптационные наборы, ассоциированные с первой аудиосценой, и
с более низким битрейтом, вторые аудиопотоки или вторые адаптационные наборы, ассоциированные со второй аудиосценой; и
система выполнена с возможностью, в конце перехода от первой аудиосцены ко второй аудиосцене, принимать и/или запрашивать:
с более высоким битрейтом, первые аудиопотоки или первые адаптационные наборы, ассоциированные со второй аудиосценой, и
с более низким битрейтом, вторые аудиопотоки или вторые адаптационные наборы, ассоциированные с первой аудиосценой.
16. Система по любому из предшествующих пунктов, дополнительно выполненная с возможностью соединять два аудиопотока перед по меньшей мере одним декодером (104) аудио.
17. Система по любому из пп.1-13, дополнительно содержащая смеситель, выполненный с возможностью смешивания разных аудиосигналов, декодированных из разных аудиопотоков.
18. Система по любому из предшествующих пунктов, в которой задается множество сцен (150A, 150B) для нескольких сред, например, смежных и/или соседних сред, так что система выполнена с возможностью получать потоки, ассоциированные с первой, текущей сценой, ассоциированной с первой, текущей средой, и
если расстояние положения или виртуального положения пользователя от границы сцены меньше заранее установленной пороговой величины, то система дополнительно получает аудиопотоки, ассоциированные со второй, смежной и/или соседней средой, ассоциированной со второй сценой.
19. Система по любому из предшествующих пунктов, в которой задается множество сцен (150A, 150B) для нескольких сред, чтобы система запрашивала и/или получала потоки, ассоциированные с текущей сценой, с более высоким битрейтом и/или уровнем качества, а потоки, ассоциированные со второй сценой, - с более низким битрейтом и/или уровнем качества, причем упомянутый более низкий битрейт и/или уровень качества ниже упомянутого более высокого битрейта и/или уровня качества.
20. Система по любому из предшествующих пунктов, в которой задается множество из N аудиоэлементов, и если расстояние пользователя до положения или области этих аудиоэлементов больше заранее установленной пороговой величины, то обрабатываются N аудиоэлементов для получения меньшего числа M аудиоэлементов (M<N), ассоциированных с положением или областью, близкой к положению или области N аудиоэлементов, чтобы
предоставить системе по меньшей мере один аудиопоток, ассоциированный с N аудиоэлементами, если расстояние пользователя до положения или области N аудиоэлементов меньше заранее установленной пороговой величины, либо
предоставить системе по меньшей мере один аудиопоток, ассоциированный с M аудиоэлементами, если расстояние пользователя до положения или области N аудиоэлементов больше заранее установленной пороговой величины.
21. Система (102) для приема аудиопотоков, которые должны воспроизводиться в мультимедийном устройстве,
при этом система (102) содержит по меньшей мере один декодер (104) аудио, выполненный с возможностью декодировать аудиосигналы (108) из по меньшей мере одного аудиопотока (106),
причем система (102) выполнена с возможностью запрашивать (112) по меньшей мере один аудиопоток (106), и/или один аудиоэлемент в аудиопотоке, и/или один адаптационный набор на основе, по меньшей мере, текущей ориентации головы пользователя, и/или данных перемещения пользователя, и/или метаданных взаимодействия пользователя, и
при этом по меньшей мере одна сцена ассоциирована с по меньшей мере одним множеством из N аудиоэлементов, N≥2, при этом каждый аудиоэлемент ассоциируется с положением и/или областью в среде,
причем по меньшей мере упомянутое по меньшей мере одно множество из N аудиоэлементов предоставляется в по меньшей мере одном представлении с высоким битрейтом и/или уровнем качества,
при этом по меньшей мере упомянутое по меньшей мере одно множество из N аудиоэлементов предоставляется в по меньшей мере одном представлении с низким битрейтом и/или уровнем качества, где данное по меньшей мере одно представление получается путем обработки N аудиоэлементов, чтобы получить меньшее число M аудиоэлементов (M<N), ассоциированных с положением или областью, близкой к положению или области N аудиоэлементов,
причем система выполнена с возможностью запрашивать представление с более высоким битрейтом и/или уровнем качества для аудиоэлементов, если аудиоэлементы более релевантны и/или лучше слышны в текущем виртуальном положении пользователя в сцене,
причем система выполнена с возможностью запрашивать представление с более низким битрейтом и/или уровнем качества для аудиоэлементов, если аудиоэлементы менее релевантны и/или хуже слышны в текущем виртуальном положении пользователя в сцене.
22. Система по п.20 или 21, в которой, если расстояние пользователя, и/или релевантность, и/или уровень слышимости, и/или угловая ориентация ниже заранее установленной пороговой величины, то разные потоки получаются для разных аудиоэлементов.
23. Система по любому из предшествующих пунктов, при этом система выполнена с возможностью запрашивать и/или получать потоки на основе ориентации пользователя, и/или направления перемещения пользователя, и/или взаимодействия пользователя в сцене.
24. Система по любому из предшествующих пунктов, в которой разные аудиоэлементы предоставляются в разных положениях, причем система выполнена с возможностью запрашивать и/или принимать, в случае когда один первый аудиоэлемент (S1) входит в положение (160-1), этот первый аудиоэлемент с более высоким битрейтом, чем второй аудиоэлемент (S2), который не входит в эти положения.
25. Система по любому из предшествующих пунктов, выполненная с возможностью запрашивать и/или принимать первые аудиопотоки или первые адаптационные наборы и вторые аудиопотоки или вторые адаптационные наборы, причем первые аудиоэлементы в первых аудиопотоках или первых адаптационных наборах более релевантны и/или лучше слышны, чем вторые аудиоэлементы во вторых аудиопотоках или вторых адаптационных наборах, при этом первые аудиопотоки запрашиваются и/или принимаются с более высоким битрейтом и/или уровнем качества, чем битрейт и/или уровень качества вторых аудиопотоков.
26. Система по п.25, в которой одни из первых и вторых аудиопотоков, либо первых и вторых адаптационных наборов запрашиваются или принимаются на основе текущей аудиосцены независимо от данных перемещения пользователя, тогда как другие из первых и вторых аудиопотоков запрашиваются или принимаются на основе данных перемещения пользователя.
27. Система по п.25 или 26, выполненная с возможностью определять слышимость аудиоэлементов в текущей аудиосцене, причем первыми аудиоэлементами являются аудиоэлементы с лучшей слышимостью, чем у вторых аудиоэлементов.
28. Система по п.25, или 26, или 27, выполненная с возможностью определять релевантность аудиоэлементов в текущей аудиосцене, причем первыми аудиоэлементами являются аудиоэлементы с большей релевантностью, чем у вторых аудиоэлементов.
29. Система по любому из пп.25-28, при этом изначально запрашиваются или принимаются вторые аудиопотоки или вторые адаптационные наборы с более низким битрейтом, и, после приема данных перемещения пользователя, отражающих более высокую релевантность или слышимость элементов в аудиосцене, система отправляет запрос на передачу вторых аудиопотоков или вторых адаптационных наборов с более высоким битрейтом, с тем чтобы впоследствии принимать первые аудиопотоки или первые адаптационные наборы с более высоким битрейтом.
30. Система по любому из предшествующих пунктов, в которой задаются по меньшей мере две сцены среды, причем по меньшей мере один первый и второй аудиоэлементы ассоциируются с первой сценой, ассоциированной с первой средой, и по меньшей мере один третий аудиоэлемент ассоциируется со второй сценой, ассоциированной со второй средой,
причем система выполнена с возможностью получать метаданные, описывающие, что по меньшей мере один второй аудиоэлемент дополнительно ассоциируется со сценой второй среды,
при этом система выполнена с возможностью запрашивать и/или принимать по меньшей мере первый и второй аудиоэлементы, если виртуальное положение пользователя находится в первой среде, и
причем система выполнена с возможностью запрашивать и/или принимать по меньшей мере второй и третий аудиоэлементы, если виртуальное положение пользователя находится в сцене второй среды, и
при этом система выполнена с возможностью запрашивать и/или принимать по меньшей мере первый, второй и третий аудиоэлементы, если виртуальное положение пользователя находится в переходе между сценой первой среды и сценой второй среды.
31. Система по п.30, в которой по меньшей мере один первый аудиоэлемент предоставляется в по меньшей мере одном аудиопотоке и/или адаптационном наборе, по меньшей мере один второй аудиоэлемент предоставляется в по меньшей мере одном втором аудиопотоке и/или адаптационном наборе, и по меньшей мере один третий аудиоэлемент предоставляется в по меньшей мере одном третьем аудиопотоке и/или адаптационном наборе, при этом по меньшей мере сцена первой среды описывается метаданными как законченная сцена, которая требует по меньшей мере первого и второго аудиопотоков и/или адаптационных наборов, причем сцена второй среды описывается метаданными как незаконченная сцена, которая требует по меньшей мере третьего аудиопотока и/или адаптационного набора и по меньшей мере второго аудиопотока и/или адаптационных наборов, ассоциированных с по меньшей мере сценой первой среды,
причем система содержит процессор метаданных, выполненный с возможностью работать с метаданными для обеспечения возможности соединения второго аудиопотока, принадлежащего первой среде, и третьего аудиопотока, ассоциированного со второй средой, в новый единый поток, если виртуальное положение пользователя находится во второй среде.
32. Система по любому из предшествующих пунктов, причем система содержит процессор метаданных, выполненный с возможностью работать с метаданными в по меньшей мере одном аудиопотоке перед по меньшей мере одним декодером аудио на основе текущей ориентации головы пользователя, и/или данных перемещения пользователя, и/или метаданных взаимодействия пользователя.
33. Система по п.32, в которой процессор метаданных выполнен с возможностью включать и/или отключать по меньшей мере один аудиоэлемент в по меньшей мере одном аудиопотоке перед по меньшей мере одним декодером аудио на основе текущей ориентации головы пользователя, и/или данных перемещения пользователя, и/или метаданных взаимодействия пользователя, причем
процессор метаданных выполнен с возможностью отключать по меньшей мере один аудиоэлемент в по меньшей мере одном аудиопотоке перед по меньшей мере одним декодером аудио, если система решает, что этот аудиоэлемент больше не нужно воспроизводить как следствие текущей ориентации головы, и/или данных перемещения, и/или метаданных взаимодействия, и при этом
процессор метаданных выполнен с возможностью включать по меньшей мере один аудиоэлемент в по меньшей мере одном аудиопотоке перед по меньшей мере одним декодером аудио, если система решает, что этот аудиоэлемент нужно воспроизводить как следствие текущей ориентации головы пользователя, и/или данных перемещения пользователя, и/или метаданных взаимодействия пользователя.
34. Система по любому из предшествующих пунктов, выполненная с возможностью отключать декодирование аудиоэлементов, выбранных на основе текущей ориентации головы пользователя, и/или данных перемещения пользователя, и/или метаданных пользователя, и/или виртуального положения пользователя.
35. Система по любому из предшествующих пунктов, выполненная с возможностью работать с метаданными аудио, ассоциированными с выбранными аудиопотоками, основываясь на по меньшей мере текущей ориентации головы пользователя, и/или данных перемещения пользователя, и/или метаданных пользователя, чтобы:
выбирать и/или включать и/или активировать аудиоэлементы, составляющие аудиосцену, которую решено воспроизводить; и
обеспечивать соединение всех выбранных аудиопотоков в единый аудиопоток.
36. Система по любому из предшествующих пунктов, выполненная с возможностью получать и/или собирать статистические или агрегированные данные о текущей ориентации головы пользователя, и/или данных перемещения пользователя, и/или метаданных пользователя, чтобы передавать запрос, ассоциированный с этими статистическими или агрегированными данными.
37. Система по любому из предшествующих пунктов, выполненная с возможностью отключать декодирование и/или воспроизведение по меньшей мере одного потока на основе метаданных, ассоциированных с этим по меньшей мере одним потоком, и на основе текущей ориентации головы пользователя, и/или данных перемещения пользователя, и/или метаданных пользователя.
38. Система по любому из предшествующих пунктов, дополнительно выполненная с возможностью работать с метаданными, ассоциированными с группой выбранных аудиопотоков, на основе по меньшей мере текущей или предполагаемой ориентации головы пользователя, и/или данных перемещения пользователя, и/или метаданных пользователя, чтобы:
выбирать и/или включать и/или активировать аудиоэлементы, составляющие аудиосцену для воспроизведения; и/или
обеспечивать соединение всех выбранных аудиопотоков в единый аудиопоток.
39. Система по любому из предшествующих пунктов, выполненная с возможностью управлять запросом по меньшей мере одного потока на основе расстояния положения пользователя от границ соседних и/или смежных сред, ассоциированных с разными сценами, либо других метрик, ассоциированных с положением пользователя в текущей среде, или предсказаний касаемо будущей среды.
40. Система по любому из предшествующих пунктов, в которой предоставляется информация для каждого аудиоэлемента или аудиообъекта, каковая информация включает в себя описательную информацию о местоположениях, в которых активны звуковая сцена или аудиоэлементы.
41. Система по любому из предшествующих пунктов, выполненная с возможностью выбирать между воспроизведением одной сцены и составлением, или смешиванием, или мультиплексированием, или наложением, или объединением по меньшей мере двух сцен на основе текущей или будущей ориентации головы, и/или данных перемещения, и/или метаданных, и/или виртуального положения, и/или выбора со стороны пользователя, причем эти две сцены ассоциированы с разными соседними и/или смежными средами.
42. Система по любому из предшествующих пунктов, выполненная с возможностью создавать или использовать по меньшей мере адаптационные наборы, чтобы:
множество адаптационных наборов ассоциировалось с одной аудиосценой; и/или
предоставлялась дополнительная информация, которая соотносит каждый адаптационный набор с одной точкой наблюдения или одной аудиосценой; и/или
предоставлялась дополнительная информация, которая может включать в себя:
- информацию о границах одной аудиосцены, и/или
- информацию о взаимосвязи между одним адаптационным набором и одной аудиосценой (например, аудиосцена кодируется в три потока, которые заключаются в три адаптационных набора), и/или
- информацию о связи между границами аудиосцены и множеством адаптационных наборов.
43. Система по любому из предшествующих пунктов, выполненная с возможностью:
принимать поток для сцены, ассоциированной с соседней или смежной средой;
запускать декодирование и/или воспроизведение потока для соседней или смежной среды при обнаружении перехода границы между двумя средами.
44. Система по любому из предшествующих пунктов,
при этом по меньшей мере одна сцена ассоциирована с по меньшей мере одним множеством из N аудиоэлементов, N≥2, при этом каждый аудиоэлемент ассоциируется с положением и/или областью в среде,
причем по меньшей мере упомянутое по меньшей мере одно множество из N аудиоэлементов предоставляется в по меньшей мере одном представлении с высоким битрейтом и/или уровнем качества, и
при этом по меньшей мере упомянутое по меньшей мере одно множество из N аудиоэлементов предоставляется в по меньшей мере одном представлении с низким битрейтом и/или уровнем качества, где данное по меньшей мере одно представление получается путем обработки N аудиоэлементов, чтобы получить меньшее число M аудиоэлементов (M<N), ассоциированных с положением или областью, близкой к положению или области N аудиоэлементов,
причем система выполнена с возможностью запрашивать представление с более высоким битрейтом и/или уровнем качества для аудиоэлементов, если аудиоэлементы более релевантны и/или лучше слышны в текущем виртуальном положении пользователя в сцене,
причем система выполнена с возможностью запрашивать представление с более низким битрейтом и/или уровнем качества для аудиоэлементов, если аудиоэлементы менее релевантны и/или хуже слышны в текущем виртуальном положении пользователя в сцене.
45. Система по любому из предшествующих пунктов, дополнительно выполненная с возможностью:
запрашивать и/или принимать по меньшей мере один первый адаптационный набор, содержащий по меньшей мере один аудиопоток, ассоциированный с по меньшей мере одной первой аудиосценой;
запрашивать и/или принимать по меньшей мере один второй адаптационный набор, содержащий по меньшей мере один второй аудиопоток, ассоциированный с по меньшей мере двумя аудиосценами, включая упомянутую по меньшей мере одну первую аудиосцену; и
обеспечивать соединение по меньшей мере одного первого аудиопотока и по меньшей мере одного второго аудиопотока в новый аудиопоток для декодирования, основываясь на метаданных, доступных касаемо текущей ориентации головы пользователя, и/или данных перемещения пользователя, и/или метаданных пользователя, и/или информации, описывающей ассоциацию по меньшей мере одного первого адаптационного набора с по меньшей мере одной первой аудиосценой и/или ассоциацию по меньшей мере одного второго адаптационного набора с по меньшей мере одной первой аудиосценой.
46. Система по любому из предшествующих пунктов, выполненная с возможностью:
принимать информацию о текущей ориентации головы пользователя, и/или данных перемещения пользователя, и/или метаданных пользователя, и/или любой информации, описывающей изменения, вызванные действиями пользователя; и
принимать информацию о доступности адаптационных наборов и информации, описывающей ассоциацию по меньшей мере одного адаптационного набора с по меньшей мере одной сценой, и/или точкой наблюдения, и/или положением, и/или виртуальным положением, и/или данными перемещения, и/или ориентацией.
47. Система по любому из предшествующих пунктов, выполненная с возможностью:
решать, нужно ли воспроизводить по меньшей мере один аудиоэлемент из по меньшей мере одной аудиосцены, встроенной в по меньшей мере один поток, и по меньшей мере один дополнительный аудиоэлемент из по меньшей мере одной дополнительной аудиосцены, встроенной в по меньшей мере один дополнительный поток; и
вызывать, при положительном решении, операцию соединения, или составления, или мультиплексирования, или наложения, или объединения упомянутого по меньшей мере одного дополнительного потока дополнительной аудиосцены с упомянутым по меньшей мере одним потоком по меньшей мере одной аудиосцены.
48. Система по любому из предшествующих пунктов, дополнительно содержащая декодер видео.
49. Система по п.48, в которой декодер видео выполнен с возможностью декодировать видеосигналы из видеопотоков для представления пользователю сцен сред виртуальной реальности (VR), дополненной реальности (AR), смешанной реальности (MR) или панорамного видео.
50. Способ приема аудиопотоков для воспроизведения в мультимедийном устройстве, содержащий этапы, на которых:
декодируют аудиосигналы из аудиопотоков; и
запрашивают и/или принимают по меньшей мере один аудиопоток на основе текущей ориентации головы пользователя, и/или данных перемещения пользователя, и/или метаданных пользователя;
при этом способ включает в себя этап, на котором соединяют по меньшей мере один первый аудиопоток, ассоциированный с текущей аудиосценой, с по меньшей мере одним потоком, ассоциированным с соседней, смежной и/или будущей аудиосценой.
| EP 3065406 A1, 07.09.2016 | |||
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| СИСТЕМА И СПОСОБ ДЛЯ ДОПОЛНЕННОЙ И ВИРТУАЛЬНОЙ РЕАЛЬНОСТИ | 2012 |
|
RU2621633C2 |
