Область техники, к которой относится изобретение
Варианты осуществления согласно изобретению относятся к многоканальному аудиодекодеру для предоставления, по меньшей мере, двух выходных аудиосигналов на основе кодированного представления.
Дополнительные варианты осуществления согласно изобретению относятся к многоканальному аудиокодеру для предоставления кодированного представления на основе, по меньшей мере, двух входных аудиосигналов.
Дополнительные варианты осуществления согласно изобретению относятся к способу для предоставления, по меньшей мере, двух выходных аудиосигналов на основе кодированного представления.
Дополнительные варианты осуществления согласно изобретению относятся к способу для предоставления кодированного представления на основе, по меньшей мере, двух входных аудиосигналов.
Дополнительные варианты осуществления согласно изобретению относятся к компьютерной программе для осуществления одного из упомянутых способов.
Дополнительные варианты осуществления согласно изобретению относятся к кодированному аудиопредставлению.
Вообще говоря, варианты осуществления согласно настоящему изобретению относятся к принципу декорреляции для систем многоканального параметрического кодирования аудиообъектов с понижающим микшированием/повышающим микшированием.
Уровень техники
В последние годы, спрос на хранение и передачу аудиоконтента постоянно растет. Кроме того, также постоянно растут требования к качеству для хранения и передачи аудиоконтента. Соответственно, совершенствуются принципы для кодирования и декодирования аудиоконтента.
Например, разработано так называемое "усовершенствованное кодирование аудио" (AAC), которое описывается, например, в международном стандарте ISO/IEC 13818-7:2003. Кроме того, созданы некоторые пространственные расширения, такие как, например, так называемый принцип "на основе стандарта объемного звучания MPEG", который описывается, например, в международном стандарте ISO/IEC 23003-1:2007. Кроме того, дополнительные улучшения для кодирования и декодирования пространственной информации аудиосигналов описываются в международном стандарте ISO/IEC 23003-2:2010, который относится к так называемому "пространственному кодированию аудиообъектов".
Кроме того, принцип переключаемого кодирования/декодирования аудио, который предоставляет возможность кодировать как общие аудиосигналы, так и речевые сигналы с хорошей эффективностью кодирования и обрабатывать многоканальные аудиосигналы, задается в международном стандарте ISO/IEC 23003-3:2012, который описывает так называемый принцип "стандартизированного кодирования речи и аудио".
Кроме того, дополнительные традиционные принципы описываются в ссылочных материалах, которые упоминаются в конце настоящего описания.
Тем не менее, желательно предоставлять еще более усовершенствованный принцип для эффективного кодирования и декодирования трехмерных аудиосцен.
Сущность изобретения
Вариант осуществления согласно изобретению создает многоканальный аудиодекодер для предоставления, по меньшей мере, двух выходных аудиосигналов на основе кодированного представления. Многоканальный аудиодекодер выполнен с возможностью осуществлять рендеринг множества декодированных аудиосигналов, которые получаются на основе кодированного представления, в зависимости от одного или более параметров рендеринга, чтобы получать множество представленных посредством рендеринга аудиосигналов. Многоканальный аудиодекодер выполнен с возможностью извлекать один или более декоррелированных аудиосигналов из представленных посредством рендеринга аудиосигналов. Кроме того, многоканальный аудиодекодер выполнен с возможностью комбинировать представленные посредством рендеринга аудиосигналы или их масштабированную версию с одним или более декоррелированными аудиосигналами для того, чтобы получать выходные аудиосигналы.
Этот вариант осуществления согласно изобретению основан на таких выявленных сведениях, что качество звука может повышаться в многоканальном аудиодекодере посредством извлечения одного или более декоррелированных аудиосигналов из представленных посредством рендеринга аудиосигналов, которые получаются на основе множества декодированных аудиосигналов, и посредством комбинирования представленных посредством рендеринга аудиосигналов или их масштабированной версии с одним или более декоррелированными аудиосигналами для того, чтобы получать выходные аудиосигналы. Обнаружено, что более эффективно регулировать характеристики корреляции или характеристики ковариантности выходных аудиосигналов посредством суммирования декоррелированных сигналов после рендеринга по сравнению с суммированием декоррелированных сигналов перед рендерингом или во время рендеринга. Обнаружено, что этот принцип является более эффективным в общих случаях, в которых предусмотрено большее число декодированных аудиосигналов, которые вводятся в рендеринг, чем представленных посредством рендеринга аудиосигналов, поскольку большее число декорреляторов требуется в том случае, если декорреляция выполняется перед рендерингом или во время рендеринга. Кроме того, обнаружено, что зачастую предоставляются артефакты, когда декоррелированные сигналы суммируются с декодированными аудиосигналами перед рендерингом, поскольку рендеринг типично способствует комбинации декодированных аудиосигналов. Соответственно, принцип согласно настоящему варианту осуществления изобретения превосходит традиционные подходы, в которых декоррелированные сигналы суммируются перед рендерингом. Например, можно непосредственно оценивать требуемые характеристики корреляции или характеристики ковариантности представленных посредством рендеринга сигналов и адаптировать инициализацию декоррелированных аудиосигналов к фактически представленным посредством рендеринга сигналам, что приводит к лучшему компромиссу между эффективностью и качеством звука и зачастую даже приводит к повышенной эффективности и лучшему качеству одновременно.
В предпочтительном варианте осуществления, многоканальный аудиодекодер выполнен с возможностью получать декодированные аудиосигналы, которые представляются посредством рендеринга, чтобы получать множество представленных посредством рендеринга аудиосигналов, с использованием параметрического восстановления. Обнаружено, что принцип согласно настоящему изобретению способствует преимуществам в комбинации с параметрическим восстановлением аудиосигналов, при этом параметрическое восстановление, например, основано на вспомогательной информации, описывающей сигналы объектов и/или взаимосвязь между сигналами объектов (при этом сигналы объектов могут составлять декодированные аудиосигналы). Например, может быть сравнительно большое число сигналов объектов (декодированных аудиосигналов) в таком принципе, и обнаружено, что применение декорреляции на основе представленных посредством рендеринга аудиосигналов является очень эффективным и исключает артефакты в таком сценарии.
В предпочтительном варианте осуществления, декодированные аудиосигналы представляют собой восстановленные сигналы объектов (например, параметрически восстановленные сигналы объектов), и многоканальный аудиодекодер выполнен с возможностью извлекать восстановленные сигналы объектов из одного или более сигналов понижающего микширования с использованием вспомогательной информации. Соответственно, комбинация представленных посредством рендеринга аудиосигналов с одним или более декоррелированными аудиосигналами, которые основаны на представленных посредством рендеринга аудиосигналах, предоставляет возможность эффективного восстановления характеристик корреляции или характеристик ковариантности в выходных аудиосигналах, даже если предусмотрено сравнительно большое число восстановленных сигналов объектов (которое может превышать число представленных посредством рендеринга аудиосигналов или выходных аудиосигналов).
В предпочтительном варианте осуществления, многоканальный аудиодекодер может быть выполнен с возможностью извлекать коэффициенты обратного микширования из вспомогательной информации и применять коэффициенты обратного микширования, чтобы извлекать (параметрически) восстановленные сигналы объектов из одного или более сигналов понижающего микширования с использованием коэффициентов обратного микширования. Соответственно, входные сигналы для рендеринга могут извлекаться из вспомогательной информации, которая, например, может быть связанной с объектами вспомогательной информацией (такой как, например, информация межобъектной корреляции или информация разности уровней объектов, при этом идентичный результат может получаться посредством использования абсолютных энергий).
В предпочтительном варианте осуществления, многоканальный аудиодекодер может быть выполнен с возможностью комбинировать представленные посредством рендеринга аудиосигналы с одним или более декоррелированными аудиосигналами для того, чтобы, по меньшей мере, частично достигать требуемых характеристик корреляции или характеристик ковариантности выходных аудиосигналов. Обнаружено, что комбинация представленных посредством рендеринга аудиосигналов с одним или более декоррелированными аудиосигналами, которые извлекаются из представленных посредством рендеринга аудиосигналов, предоставляет возможность регулирования (или восстановления) требуемых характеристик корреляции или характеристик ковариантности. Кроме того, обнаружено, что важно для слухового впечатления иметь надлежащие характеристики корреляции или характеристики ковариантности в выходном аудиосигнале, и что это может достигаться лучше всего посредством модификации представленных посредством рендеринга аудиосигналов с использованием декоррелированных аудиосигналов. Например, все ухудшения, вызываемые на предыдущих стадиях обработки, также могут учитываться при комбинировании представленных посредством рендеринга аудиосигналов и декоррелированных аудиосигналов на основе представленных посредством рендеринга аудиосигналов.
В предпочтительном варианте осуществления, многоканальный аудиодекодер может быть выполнен с возможностью комбинировать представленные посредством рендеринга аудиосигналы с одним или более декоррелированными аудиосигналами для того, чтобы, по меньшей мере, частично компенсировать энергетические потери во время параметрического восстановления декодированных аудиосигналов, которые представляются посредством рендеринга, чтобы получать множество представленных посредством рендеринга аудиосигналов. Обнаружено, что применение для пострендеринга декоррелированных аудиосигналов дает возможность корректировать дефекты сигналов, которые вызываются посредством обработки перед рендерингом, например, посредством параметрического восстановления декодированных аудиосигналов. Следовательно, необязательно восстанавливать характеристики корреляции или характеристики ковариантности декодированных аудиосигналов, которые вводятся в рендеринг, с высокой точностью. Это упрощает восстановление декодированных аудиосигналов и, следовательно, способствует высокой эффективности.
В предпочтительном варианте осуществления, многоканальный аудиодекодер выполнен с возможностью определять требуемые характеристики корреляции характеристик ковариантности выходных аудиосигналов. Кроме того, многоканальный аудиодекодер выполнен с возможностью регулировать комбинацию представленных посредством рендеринга аудиосигналов с одним или более декоррелированными аудиосигналами для того, чтобы получать выходные аудиосигналы, так что характеристики корреляции или характеристики ковариантности полученных выходных аудиосигналов аппроксимируют или равны требуемым характеристикам корреляции или требуемым характеристикам ковариантности. Посредством вычисления (или определения) требуемых характеристик корреляции или характеристик ковариантности выходных аудиосигналов (которые должны быть достигнуты после комбинирования представленных посредством рендеринга аудиосигналов с декоррелированными аудиосигналами), можно регулировать характеристики корреляции или характеристики ковариантности на последующей стадии обработки, что, в свою очередь, обеспечивает возможность относительно точного восстановления. Соответственно, пространственное впечатление от прослушивания выходных аудиосигналов хорошо адаптировано к требуемому впечатлению от прослушивания.
В предпочтительном варианте осуществления, многоканальный аудиодекодер может быть выполнен с возможностью определять требуемые характеристики корреляции или требуемые характеристики ковариантности в зависимости от информации рендеринга, описывающей рендеринг множества декодированных аудиосигналов, которые получаются на основе кодированного представления, чтобы получать множество представленных посредством рендеринга аудиосигналов. Посредством учета процесса рендеринга в определении требуемых характеристик корреляции или требуемых характеристик ковариантности, можно достигать точной информации для регулирования комбинации представленных посредством рендеринга аудиосигналов с одним или более декоррелированными аудиосигналами, что способствует возможности иметь выходные аудиосигналы, которые совпадают с требуемым впечатлением от прослушивания.
В предпочтительном варианте осуществления, многоканальный аудиодекодер может быть выполнен с возможностью определять требуемые характеристики корреляции или требуемые характеристики ковариантности в зависимости от информации корреляции объектов или информации ковариантности объектов, описывающей характеристики множества аудиообъектов и/или взаимосвязь между множеством аудиообъектов. Соответственно, можно восстанавливать характеристики корреляции или характеристики ковариантности, которые адаптированы к аудиообъектам, на последней стадии обработки, а именно, после рендеринга. Соответственно, уменьшается сложность для декодирования аудиообъектов. Кроме того, посредством учета характеристик корреляции или характеристик ковариантности аудиообъектов после рендеринга, может исключаться негативное влияние рендеринга, и характеристики корреляции или характеристики ковариантности могут быть восстановлены с хорошей точностью.
В предпочтительном варианте осуществления, многоканальный аудиодекодер выполнен с возможностью определять информацию корреляции объектов или информацию ковариантности объектов на основе вспомогательной информации, включенной в кодированное представление. Соответственно, принцип может быть хорошо адаптирован к подходу на основе пространственного кодирования аудиообъектов, который использует вспомогательную информацию.
В предпочтительном варианте осуществления, многоканальный аудиодекодер выполнен с возможностью определять фактические характеристики корреляции или характеристики ковариантности представленных посредством рендеринга аудиосигналов и регулировать комбинацию представленных посредством рендеринга аудиосигналов с одним или более декоррелированными аудиосигналами для того, чтобы получать выходные аудиосигналы в зависимости от фактических характеристик корреляции или характеристик ковариантности представленных посредством рендеринга аудиосигналов. Соответственно, можно добиться того, что могут учитываться неидеальности на более ранних стадиях обработки, такие как, например, энергетические потери при восстановлении аудиообъектов или неидеальности, вызываемые посредством рендеринга. Таким образом, комбинация представленных посредством рендеринга аудиосигналов с одним или более декоррелированными аудиосигналами может очень точно регулироваться согласно потребностям таким образом, что комбинация фактических представленных посредством рендеринга аудиосигналов с декоррелированными аудиосигналами приводит к требуемым характеристикам.
В предпочтительном варианте осуществления, многоканальный аудиодекодер может быть выполнен с возможностью комбинировать представленные посредством рендеринга аудиосигналы с одним или более декоррелированными аудиосигналами, при этом представленные посредством рендеринга аудиосигналы взвешены с использованием первой матрицы P микширования, и при этом один или более декоррелированных аудиосигналов взвешены с использованием второй матрицы M микширования. Это предоставляет возможность простого извлечения выходных аудиосигналов, при этом выполняется операция линейного комбинирования, которая описывается посредством матрицы P микширования, которая применяется к представленным посредством рендеринга аудиосигналам, и матрицы M микширования, которая применяется к одному или более декоррелированным аудиосигналам.
В предпочтительном варианте осуществления, многоканальный аудиодекодер выполнен с возможностью регулировать, по меньшей мере, одну из матрицы P микширования и матрицы M микширования таким образом, что характеристики корреляции или характеристики ковариантности полученных выходных аудиосигналов аппроксимируют или равны требуемым характеристикам корреляции или требуемым характеристикам ковариантности. Таким образом, предусмотрен способ регулировать одну или более матриц микширования, что типично возможно с небольшими усилиями и хорошими результатами.
В предпочтительном варианте осуществления, многоканальный аудиодекодер выполнен с возможностью объединенно вычислять матрицу P микширования и матрицу M микширования. Соответственно, можно получать матрицы микширования таким образом, что характеристики корреляции или характеристики ковариантности полученных выходных аудиосигналов могут задаваться таким образом, чтобы аппроксимировать или быть равными требуемым характеристикам корреляции или требуемым характеристикам ковариантности. Кроме того, при объединенном вычислении матрицы P микширования и матрицы M микширования, типично доступны определенные степени свободы, так что можно обеспечивать наилучшее соответствие матрицы P микширования и матрицы M микширования требованиям.
В предпочтительном варианте осуществления, многоканальный аудиодекодер выполнен с возможностью получать комбинированную матрицу F микширования, которая содержит матрицу P микширования и матрицу M микширования, так что ковариационная матрица полученных выходных аудиосигналов равна требуемой ковариационной матрице.
В предпочтительном варианте осуществления, комбинированная матрица микширования может вычисляться в соответствии с уравнениями, описанными ниже.
В предпочтительном варианте осуществления, многоканальный аудиодекодер может быть выполнен с возможностью определять комбинированную матрицу F микширования с использованием матриц, которые определяются с использованием разложения по сингулярным значениям первой ковариационной матрицы, которая описывает представленный посредством рендеринга аудиосигнал и декоррелированный аудиосигнал, и второй ковариационной матрицы, которая описывает требуемые характеристики ковариантности выходных аудиосигналов. Использование такого разложения по сингулярным значениям составляет численно эффективное решение для определения комбинированной матрицы микширования.
В предпочтительном варианте осуществления, многоканальный аудиодекодер выполнен с возможностью задавать матрицу P микширования как единичную матрицу или ее кратное и вычислять матрицу M микширования. Это исключает микширование различных представленных посредством рендеринга аудиосигналов, что помогает сохранять требуемое пространственное впечатление. Кроме того, уменьшается количество степеней свободы.
В предпочтительном варианте осуществления, многоканальный аудиодекодер может быть выполнен с возможностью определять матрицу M микширования таким образом, что разность между требуемой ковариационной матрицей и ковариационной матрицей представленных посредством рендеринга аудиосигналов аппроксимирует или равна ковариантности одного или более декоррелированных сигналов после микширования с матрицей M микширования. Таким образом, предусмотрен вычислительно простой принцип для получения матрицы M микширования.
В предпочтительном варианте осуществления, многоканальный аудиодекодер может быть выполнен с возможностью определять матрицу WI микширования с использованием матриц, которые определяются с использованием разложения по сингулярным значениям разности между требуемой ковариационной матрицей и ковариационной матрицей представленных посредством рендеринга аудиосигналов и ковариационной матрицы одного или более декоррелированных сигналов. Оно представляет собой вычислительно очень эффективный подход для определения матрицы M микширования.
В предпочтительном варианте осуществления, многоканальный аудиодекодер выполнен с возможностью определять матрицы P, M микширования в соответствии с таким ограничением, что данный представленный посредством рендеринга аудиосигнал микшируется только с декоррелированной версией самого данного представленного посредством рендеринга аудиосигнала. Этот принцип ограничивается небольшой модификацией (например, при наличии неидеальных декорреляторов) или предотвращает модификацию характеристик взаимной корреляции или характеристик взаимной ковариантности (например, в случае идеальных декорреляторов) и может, следовательно, требоваться в некоторых случаях, чтобы исключать изменение воспринимаемой позиции объекта. Тем не менее, при наличии неидеальных декорреляторов, значения автокорреляции (или значения автоковариации) явно модифицируются, и изменения перекрестных членов игнорируются.
В предпочтительном варианте осуществления, многоканальный аудиодекодер выполнен с возможностью комбинировать представленные посредством рендеринга аудиосигналы с одним или более декоррелированными аудиосигналами таким образом, что только значения автокорреляции или значения автоковариации представленных посредством рендеринга аудиосигналов модифицируются, в то время как характеристики взаимной корреляции или характеристики взаимной ковариантности остаются немодифицированными или модифицированными с небольшим значением (например, при наличии неидеальных декорреляторов). С другой стороны, может исключаться ухудшение воспринимаемой позиции аудиообъектов. Кроме того, может уменьшаться вычислительная сложность. Тем не менее, например, значения взаимной ковариантности модифицируются как следствие модификации энергий (значений автокорреляции), но значения взаимной корреляции остаются немодифицированными (они представляют нормализованную версию значений взаимной ковариантности).
В предпочтительном варианте осуществления, многоканальный аудиодекодер выполнен с возможностью задавать матрицу P микширования как единичную матрицу или ее кратное и вычислять матрицу M микширования в соответствии с таким ограничением, что M является диагональной матрицей. Таким образом, модификация характеристик взаимной корреляции или характеристик взаимной ковариантности может исключаться или ограничиваться небольшим значением (например, при наличии неидеальных декорреляторов).
В предпочтительном варианте осуществления, многоканальный аудиодекодер выполнен с возможностью комбинировать представленные посредством рендеринга аудиосигналы с одним или более декоррелированными аудиосигналами для того, чтобы получать выходной аудиосигнал, при этом диагональная матрица M применяется к одному или более декоррелированным аудиосигналам W. В этом случае, многоканальный аудиодекодер выполнен с возможностью вычислять диагональные элементы матрицы M микширования таким образом, что диагональные элементы ковариационной матрицы выходных аудиосигналов равны требуемым энергиям. Соответственно, энергетические потери, которые могут получаться посредством операции рендеринга и/или посредством восстановления аудиообъектов на основе одного или более сигналов понижающего микширования и вспомогательной пространственной информации, могут компенсироваться. Таким образом, может достигаться надлежащая интенсивность выходных аудиосигналов.
В предпочтительном варианте осуществления, многоканальный аудиодекодер может быть выполнен с возможностью вычислять элементы матрицы M микширования в зависимости от диагональных элементов требуемой ковариационной матрицы, диагональных элементов ковариационной матрицы представленных посредством рендеринга аудиосигналов и диагональных элементов ковариационной матрицы одного или более декоррелированных сигналов. Внедиагональные элементы матрицы WI микширования могут задаваться равными нулю, и требуемая ковариационная матрица может вычисляться на основе матрицы рендеринга, используемой для операции рендеринга и ковариационной матрицы объектов. Кроме того, пороговое значение может использоваться для того, чтобы ограничивать величину декорреляции, суммируемой с сигналами. Этот принцип предусматривает очень вычислительно эффективное определение элементов матрицы M микширования.
В предпочтительном варианте осуществления, многоканальный аудиодекодер может быть выполнен с возможностью учитывать характеристики корреляции или характеристики ковариантности декоррелированных аудиосигналов при определении того, как комбинировать представленные посредством рендеринга аудиосигналы или их масштабированную версию с одним или более декоррелированными аудиосигналами. Соответственно, могут учитываться неидеальности декорреляции.
В предпочтительном варианте осуществления, многоканальный аудиодекодер может быть выполнен с возможностью микшировать представленные посредством рендеринга аудиосигналы и декоррелированные аудиосигналы, так что данный выходной аудиосигнал предоставляется на основе двух или более представленных посредством рендеринга аудиосигналов и, по меньшей мере, одного декоррелированного аудиосигнала. Посредством использования этого принципа, характеристики взаимной корреляции могут эффективно регулироваться без необходимости вводить большие количества декоррелированных сигналов (что может ухудшать слуховое пространственное впечатление).
В предпочтительном варианте осуществления, многоканальный аудиодекодер может быть выполнен с возможностью переключаться между различными режимами, в которых различные ограничения применяются для определения того, как комбинировать представленные посредством рендеринга аудиосигналы или их масштабированную версию с одним или более декоррелированными аудиосигналами для того, чтобы получать выходные аудиосигналы. Соответственно, сложность и характеристики обработки могут регулироваться для сигналов, которые обрабатываются.
В предпочтительном варианте осуществления, многоканальный аудиодекодер может быть выполнен с возможностью переключаться между первым режимом, в котором разрешается микширование между различными представленными посредством рендеринга аудиосигналами при комбинировании представленных посредством рендеринга аудиосигналов или их масштабированной версии с одним или более декоррелированными аудиосигналами, вторым режимом, в котором не разрешается микширование между различными представленными посредством рендеринга аудиосигналами при комбинировании представленных посредством рендеринга аудиосигналов или их масштабированной версии с одним или более декоррелированными аудиосигналами, и в котором разрешается комбинирование данного декоррелированного сигнала, с идентичным или различным масштабированием, с множеством представленных посредством рендеринга аудиосигналов или их масштабированной версией, чтобы регулировать характеристики взаимной корреляции или характеристики взаимной ковариантности выходных аудиосигналов, и третьим режимом, в котором не разрешается микширование между различными представленными посредством рендеринга аудиосигналами при комбинировании представленных посредством рендеринга аудиосигналов или их масштабированной версии с одним или более декоррелированными аудиосигналами, и в котором не разрешается комбинирование данного декоррелированного сигнала с представленными посредством рендеринга аудиосигналами, за исключением представленного посредством рендеринга аудиосигнала, из которого извлекается данный декоррелированный сигнал. Таким образом, как сложность, так и характеристики обработки могут регулироваться согласно типу аудиосигнала, который в данный момент представляется посредством рендеринга. Модификация только характеристик автокорреляции или характеристик автоковариантности и отсутствие явной модификации характеристик взаимной корреляции или характеристик взаимной ковариантности, например, могут быть полезными, если пространственное впечатление аудиосигналов ухудшается посредством такой модификации, при этом, тем не менее, желательно регулировать интенсивность выходных аудиосигналов. С другой стороны, возникают случаи, в которых желательно регулировать характеристики взаимной корреляции или характеристики взаимной ковариантности выходных аудиосигналов. Многоканальный аудиодекодер, упомянутый здесь, предоставляет возможность такого регулирования, при котором в первом режиме, можно комбинировать представленные посредством рендеринга аудиосигналы таким образом, что величина (или интенсивность) декоррелированных компонентов сигналов, которая требуется для регулирования характеристик взаимной корреляции или характеристик взаимной ковариантности, является сравнительно небольшой. Таким образом, "локализуемые" компоненты сигналов используются в первом режиме, чтобы регулировать характеристики взаимной корреляции или характеристики взаимной ковариантности. Напротив, во втором режиме, декоррелированные сигналы используются для того, чтобы регулировать характеристики взаимной корреляции или характеристики взаимной ковариантности, что естественно способствует различному впечатлению от прослушивания. Соответственно, посредством предоставления трех различных режимов, аудиодекодер может быть хорошо адаптирован к обрабатываемому аудиоконтенту.
В предпочтительном варианте осуществления, многоканальный аудиодекодер выполнен с возможностью оценивать элемент потока битов кодированного представления, указывающего то, какой из трех режимов для комбинирования представленных посредством рендеринга аудиосигналов или их масштабированной версии с одним или более декоррелированными аудиосигналами должен использоваться, и выбирать режим в зависимости от упомянутого элемента потока битов. Соответственно, аудиокодер может сигнализировать надлежащий режим в зависимости от своих знаний аудиоконтента. Таким образом, максимальное качество выходных аудиосигналов может достигаться при любых обстоятельствах.
Вариант осуществления согласно изобретению создает многоканальный аудиокодер для предоставления кодированного представления на основе, по меньшей мере, двух входных аудиосигналов. Многоканальный аудиокодер выполнен с возможностью предоставлять один или более сигналов понижающего микширования на основе, по меньшей мере, двух входных аудиосигналов. Кроме того, многоканальный аудиокодер выполнен с возможностью предоставлять один или более параметров, описывающих взаимосвязь, по меньшей мере, между двумя входными аудиосигналами. Помимо этого, многоканальный аудиокодер выполнен с возможностью предоставлять параметр способа декорреляции, описывающий то, какой режим декорреляции из множества режимов декорреляции должен использоваться на стороне аудиокодера. Соответственно, многоканальный аудиокодер может управлять аудиодекодером, чтобы использовать надлежащий режим декорреляции, который хорошо адаптирован к типу аудиосигнала, который в данный момент кодируется. Таким образом, многоканальный аудиокодер, описанный здесь, хорошо адаптирован для взаимодействия с многоканальным аудиодекодером, поясненным выше.
В предпочтительном варианте осуществления, многоканальный аудиокодер выполнен с возможностью избирательно предоставлять параметр способа декорреляции для того, чтобы сигнализировать один из следующих трех режимов для работы аудиодекодера: первый режим, в котором разрешается микширование между различными представленными посредством рендеринга аудиосигналами при комбинировании представленных посредством рендеринга аудиосигналов или их масштабированной версии с одним или более декоррелированными аудиосигналами, второй режим, в котором не разрешается микширование между различными из представленных посредством рендеринга аудиосигналов при комбинировании представленных посредством рендеринга аудиосигналов или их масштабированной версии с одним или более декоррелированными аудиосигналами, и в котором разрешается комбинирование данного декоррелированного аудиосигнала, с идентичным или различным масштабированием, с множеством представленных посредством рендеринга аудиосигналов или их масштабированной версией, чтобы регулировать характеристики взаимной корреляции или характеристики взаимной ковариантности выходных аудиосигналов, и третий режим, в котором не разрешается микширование между различными из представленных посредством рендеринга аудиосигналов при комбинировании представленных посредством рендеринга аудиосигналов или их масштабированной версии с одним или более декоррелированными аудиосигналами, и в котором не разрешается комбинирование данного декоррелированного аудиосигнала с представленными посредством рендеринга аудиосигналами, за исключением представленного посредством рендеринга аудиосигнала, из которого извлекается данный декоррелированный аудиосигнал. Таким образом, многоканальный аудиокодер может переключать многоканальный аудиодекодер через вышеописанные три режима в зависимости от аудиоконтента, при этом режим, в котором работает многоканальный аудиодекодер, может быть хорошо адаптирован посредством многоканального аудиокодера к типу текущего кодированного аудиоконтента. Тем не менее, в некоторых вариантах осуществления, могут использоваться (или могут быть доступными) только один или два из вышеуказанных трех режимов для работы аудиодекодера.
В предпочтительном варианте осуществления, многоканальный аудиокодер выполнен с возможностью выбирать параметр способа декорреляции в зависимости от того, содержат входные аудиосигналы сравнительно высокую корреляцию или сравнительно более низкую корреляцию. Таким образом, адаптация декорреляции, которая используется в декодере, может выполняться на основе важной характеристики аудиосигналов, которые в данный момент кодируются.
В предпочтительном варианте осуществления, многоканальный аудиокодер выполнен с возможностью выбирать параметр способа декорреляции для того, чтобы обозначать первый режим или второй режим, если корреляция или ковариантность между входными аудиосигналами является сравнительно высокой, и выбирать параметр способа декорреляции для того, чтобы обозначать третий режим, если корреляция или ковариантность между входными аудиосигналами является сравнительно более низкой. Соответственно, в случае сравнительно небольшой корреляции или ковариантности между входными аудиосигналами, выбирается режим декодирования, в котором отсутствует коррекция характеристик взаимной ковариантности или характеристик взаимной корреляции. Обнаружено, что это представляет собой эффективный выбор для сигналов, имеющих сравнительно низкую корреляцию (или ковариантность), поскольку такие сигналы являются практически независимыми, что исключает необходимость адаптации взаимных корреляций или взаимных ковариантностей. Наоборот, регулирование взаимных корреляций или взаимных ковариантностей для практически независимых входных аудиосигналов (имеющих сравнительно небольшую корреляцию или ковариантность) типично должно ухудшать качество звука и одновременно увеличивать сложность декодирования. Таким образом, этот принцип предоставляет возможность обоснованной адаптации многоканального аудиодекодера к сигналу, вводимому в многоканальный аудиокодер.
Вариант осуществления согласно изобретению создает способ для предоставления, по меньшей мере, двух выходных аудиосигналов на основе кодированного представления. Способ содержит рендеринг множества декодированных аудиосигналов, которые получаются на основе кодированного представления, в зависимости от одного или более параметров рендеринга, чтобы получать множество представленных посредством рендеринга аудиосигналов. Способ также содержит извлечение одного или более декоррелированных аудиосигналов из представленных посредством рендеринга аудиосигналов и комбинирование представленных посредством рендеринга аудиосигналов или их масштабированной версии с одним или более декоррелированными аудиосигналами для того, чтобы получать выходные аудиосигналы. Этот способ основан на соображениях, идентичных соображениям для вышеописанного многоканального аудиодекодера. Кроме того, способ может дополняться посредством любых из признаков и функциональностей, поясненных выше относительно многоканального аудиодекодера.
Другой вариант осуществления согласно изобретению создает способ для предоставления кодированного представления на основе, по меньшей мере, двух входных аудиосигналов. Способ содержит предоставление одного или более сигналов понижающего микширования на основе, по меньшей мере, двух входных аудиосигналов, предоставление одного или более параметров, описывающих взаимосвязь, по меньшей мере, между двумя входными аудиосигналами, и предоставление параметра способа декорреляции, описывающего то, какой режим декорреляции из множества режимов декорреляции должен использоваться на стороне аудиодекодера. Этот способ основан на соображениях, идентичных соображениям для вышеописанного многоканального аудиокодера. Кроме того, способ может дополняться посредством любых из признаков и функциональностей, описанных в данном документе относительно многоканального аудиокодера.
Другой вариант осуществления согласно изобретению создает компьютерную программу для осуществления одного или более способов, описанных выше.
Другой вариант осуществления согласно изобретению создает кодированное аудиопредставление, содержащее кодированное представление сигнала понижающего микширования, кодированное представление одного или более параметров, описывающих взаимосвязь, по меньшей мере, между двумя входными аудиосигналами, и кодированный параметр способа декорреляции, описывающий то, какой режим декорреляции из множества режимов декорреляции должен использоваться на стороне аудиодекодера. Это кодированное аудиопредставление дает возможность сигнализировать надлежащий режим декорреляции и, следовательно, помогает реализовывать преимущества, описанные относительно многоканального аудиокодера и многоканального аудиодекодера.
Краткое описание чертежей
Далее описываются варианты осуществления согласно настоящему изобретению со ссылкой на прилагаемые чертежи, на которых:
Фиг. 1 показывает принципиальную блок-схему многоканального аудиодекодера, согласно варианту осуществления настоящего изобретения;
Фиг. 2 показывает принципиальную блок-схему многоканального аудиокодера, согласно варианту осуществления настоящего изобретения;
Фиг. 3 показывает блок-схему последовательности операций способа для предоставления, по меньшей мере, двух выходных аудиосигналов на основе кодированного представления, согласно варианту осуществления изобретения;
Фиг. 4 показывает блок-схему последовательности операций способа для предоставления кодированного представления на основе, по меньшей мере, двух входных аудиосигналов, согласно варианту осуществления настоящего изобретения;
Фиг. 5 показывает схематичное представление кодированного аудиопредставления, согласно варианту осуществления настоящего изобретения;
Фиг. 6 показывает принципиальную блок-схему многоканального декоррелятора, согласно варианту осуществления настоящего изобретения;
Фиг. 7 показывает принципиальную блок-схему многоканального аудиодекодера, согласно варианту осуществления настоящего изобретения;
Фиг. 8 показывает принципиальную блок-схему многоканального аудиокодера, согласно варианту осуществления настоящего изобретения;
Фиг. 9 показывает блок-схему последовательности операций способа для предоставления множества декоррелированных сигналов на основе множества входных сигналов декоррелятора, согласно варианту осуществления настоящего изобретения;
Фиг. 10 показывает блок-схему последовательности операций способа для предоставления, по меньшей мере, двух выходных аудиосигналов на основе кодированного представления, согласно варианту осуществления настоящего изобретения;
Фиг. 11 показывает блок-схему последовательности операций способа для предоставления кодированного представления на основе, по меньшей мере, двух входных аудиосигналов, согласно варианту осуществления настоящего изобретения;
Фиг. 12 показывает схематичное представление кодированного представления, согласно варианту осуществления настоящего изобретения.
Фиг. 13 показывает схематичное представление, которое предоставляет общее представление принципа параметрического понижающего микширования/повышающего микширования на основе MMSE;
Фиг. 14 показывает геометрическое представление для принципа ортогональности в трехмерном пространстве;
Фиг. 15 показывает принципиальную блок-схему системы параметрического восстановления с декорреляцией, применяемой к представленному посредством рендеринга выводу, согласно варианту осуществления настоящего изобретения;
Фиг. 16 показывает принципиальную блок-схему модуля декорреляции;
Фиг. 17 показывает принципиальную блок-схему модуля декорреляции с меньшей сложностью, согласно варианту осуществления настоящего изобретения;
Фиг. 18 показывает табличное представление позиций громкоговорителей, согласно варианту осуществления настоящего изобретения;
Фиг. 19a-19g показывают табличные представления коэффициентов предварительного микширования для N=22 и K между 5 и 11;
Фиг. 20a-20d показывают табличные представления коэффициентов предварительного микширования для N=10 и K между 2 и 5;
Фиг. 21a-21c показывают табличные представления коэффициентов предварительного микширования для N=8 и K между 2 и 4;
Фиг. 21d-21f показывают табличные представления коэффициентов предварительного микширования для N=7 и K между 2 и 4;
Фиг. 22a и 22b показывают табличные представления коэффициентов предварительного микширования для N=5 и K=2 или K=3;
Фиг. 23 показывает табличное представление коэффициентов предварительного микширования для N=2 и K=1;
Фиг. 24 показывает табличное представление групп сигналов каналов;
Фиг. 25 показывает синтаксическое представление дополнительных параметров, которые могут быть включены в синтаксис SAOCSpecifigConfig() или, эквивалентно, SAOC3DSpecificConfig();
Фиг. 26 показывает табличное представление различных значений для переменной bsDecorrelationMethod потока битов;
Фиг. 27 показывает табличное представление числа декорреляторов для различных уровней декорреляции и выходных конфигураций, указываемых посредством переменной bsDecorrelationLevel потока битов;
Фиг. 28 показывает, в форме принципиальной блок-схемы, общее представление касательно трехмерного аудиокодера;
Фиг. 29 показывает, в форме принципиальной блок-схемы, общее представление касательно трехмерного аудиодекодера; и
Фиг. 30 показывает принципиальную блок-схему структуры преобразователя форматов;
Фиг. 31 показывает принципиальную блок-схему процессора понижающего микширования, согласно варианту осуществления настоящего изобретения;
Фиг. 32 показывает таблицу, представляющую режимы декодирования для различного числа объектов SAOC-понижающего микширования; и
Фиг. 33 показывает синтаксическое представление элемента SAOC3DSpecificConfig потока битов.
Подробное описание вариантов осуществления
1. Многоканальный аудиодекодер согласно фиг. 1
Фиг. 1 показывает принципиальную блок-схему многоканального аудиодекодера 100 согласно варианту осуществления настоящего изобретения.
Многоканальный аудиодекодер 100 выполнен с возможностью принимать кодированное представление 110 и предоставлять, на его основе, по меньшей мере, два выходных аудиосигнала 112, 114.
Многоканальный аудиодекодер 100 предпочтительно содержит декодер 120, который выполнен с возможностью предоставлять декодированные аудиосигналы 122 на основе кодированного представления 110. Кроме того, многоканальный аудиодекодер 100 содержит модуль 130 рендеринга, который выполнен с возможностью осуществлять рендеринг множества декодированных аудиосигналов 122, которые получаются на основе кодированного представления 110 (например, посредством декодера 120) в зависимости от одного или более параметров 132 рендеринга, чтобы получать множество представленных посредством рендеринга аудиосигналов 134, 136. Кроме того, многоканальный аудиодекодер 100 содержит декоррелятор 140, который выполнен с возможностью извлекать один или более декоррелированных аудиосигналов 142, 144 из представленных посредством рендеринга аудиосигналов 134, 136. Кроме того, многоканальный аудиодекодер 100 содержит модуль 150 комбинирования, который выполнен с возможностью комбинировать представленные посредством рендеринга аудиосигналы 134, 136 или их масштабированную версию с одним или более декоррелированными аудиосигналами 142, 144, чтобы получать выходные аудиосигналы 112, 114.
Тем не менее, следует отметить, что другая аппаратная структура многоканального аудиодекодера 100 может быть возможной при условии, что предоставлены функциональности, описанные выше.
Относительно функциональности многоканального аудиодекодера 100 следует отметить, что декоррелированные аудиосигналы 142, 144 извлекаются из представленных посредством рендеринга аудиосигналов 134, 136, и что декоррелированные аудиосигналы 142, 144 комбинированы с представленными посредством рендеринга аудиосигналами 134, 136, чтобы получать выходные аудиосигналы 112, 114. Посредством извлечения декоррелированных аудиосигналов 142, 144 из представленных посредством рендеринга аудиосигналов 134, 136 может достигаться очень эффективная обработка, поскольку число представленных посредством рендеринга аудиосигналов 134, 136 типично является независимым от числа декодированных аудиосигналов 122, которые вводятся в модуль 130 рендеринга. Таким образом, усилия по декорреляции являются типично независимыми от числа декодированных аудиосигналов 122, что повышает эффективность реализации. Кроме того, применение декорреляции после рендеринга исключает введение артефактов, которые могут вызываться посредством модуля рендеринга при комбинировании нескольких декоррелированных сигналов в случае, если декорреляция применяется перед рендерингом. Кроме того, характеристики представленных посредством рендеринга аудиосигналов могут учитываться при декорреляции, выполняемой посредством декоррелятора 140, что типично приводит к выходным аудиосигналам хорошего качества.
Кроме того, следует отметить, что многоканальный аудиодекодер 100 может дополняться посредством любых из признаков и функциональностей, описанных в данном документе. В частности, следует отметить, что отдельные улучшения, как описано в данном документе, могут вводиться в многоканальный аудиодекодер 100, чтобы за счет этого даже повышать эффективность обработки и/или качество выходных аудиосигналов.
2. Многоканальный аудиокодер согласно фиг. 2
Фиг. 2 показывает принципиальную блок-схему многоканального аудиокодера 200, согласно варианту осуществления настоящего изобретения. Многоканальный аудиокодер 200 выполнен с возможностью принимать два или более входных аудиосигналов 210, 212 и предоставлять, на их основе, кодированное представление 214. Многоканальный аудиокодер содержит модуль 220 предоставления сигналов понижающего микширования, который выполнен с возможностью предоставлять один или более сигналов 222 понижающего микширования на основе, по меньшей мере, двух входных аудиосигналов 210, 212. Кроме того, многоканальный аудиокодер 200 содержит модуль 230 предоставления параметров, который выполнен с возможностью предоставлять один или более параметров 232, описывающих взаимосвязь (например, взаимную корреляция, взаимную ковариантность, разность уровней и т.п.), по меньшей мере, между двумя входными аудиосигналами 210, 212.
Кроме того, многоканальный аудиокодер 200 также содержит модуль 240 предоставления параметров способа декорреляции, который выполнен с возможностью предоставлять параметр 242 способа декорреляции, описывающий то, какой режим декорреляции из множества режимов декорреляции должен использоваться на стороне аудиодекодера. Один или более сигналов 222 понижающего микширования, один или более параметров 232 и параметр 242 способа декорреляции включены, например, в кодированной форме, в кодированное представление 214.
Тем не менее, следует отметить, что аппаратная структура многоканального аудиокодера 200 может отличаться при условии, что удовлетворяются функциональности, как описано выше. Другими словами, распределение функциональностей многоканального аудиокодера 200 в отдельные блоки (например, в модуль 220 предоставления сигналов понижающего микширования, в модуль 230 предоставления параметров и в модуль 240 предоставления параметров способа декорреляции) должно рассматриваться только в качестве примера.
Относительно функциональности многоканального аудиокодера 200 следует отметить, что один или более сигналов 222 понижающего микширования и один или более параметров 232 предоставляются традиционным способом, например, как в многоканальном SAOC-аудиокодере или в многоканальном USAC-аудиокодере. Тем не менее, параметр 242 способа декорреляции, который также предоставляется посредством многоканального аудиокодера 200 и включен в кодированное представление 214, может использоваться для того, чтобы адаптировать режим декорреляции к входным аудиосигналам 210, 212 или к требуемому качеству воспроизведения. Соответственно, режим декорреляции может быть адаптирован к различным типам аудиоконтента. Например, различные режимы декорреляции могут быть выбраны для типов аудиоконтента, в которых входные аудиосигналы 210, 212 сильно коррелируются, и для типов аудиоконтента, в которых входные аудиосигналы 210, 212 являются независимыми. Кроме того, различные режимы декорреляции, например, могут сигнализироваться посредством параметра 242 режима декорреляции для типов аудиоконтента, в которых пространственное восприятие является очень важным, и для типов аудиоконтента, в которых пространственное впечатление является менее важным или даже имеет второстепенную важность (например, по сравнению с воспроизведением отдельных каналов). Соответственно, многоканальный аудиодекодер, который принимает кодированное представление 214, может управляться посредством многоканального аудиокодера 200 и может задаваться в режим декодирования, который способствует наилучшему компромиссу между качеством воспроизведения и сложностью декодирования.
Кроме того, следует отметить, что многоканальный аудиокодер 200 может дополняться посредством любых из признаков и функциональностей, описанных в данном документе. Следует отметить, что возможные дополнительные признаки и улучшения, описанные в данном документе, могут добавляться в многоканальный аудиокодер 200 по отдельности или в комбинации, чтобы за счет этого улучшать (или совершенствовать) многоканальный аудиокодер 200.
3. Способ для предоставления, по меньшей мере, двух выходных аудиосигналов согласно фиг. 3
Фиг. 3 показывает блок-схему последовательности операций способа 300 для предоставления, по меньшей мере, двух выходных аудиосигналов на основе кодированного представления. Способ содержит рендеринг 310 множества декодированных аудиосигналов, которые получаются на основе кодированного представления 312, в зависимости от одного или более параметров рендеринга, чтобы получать множество представленных посредством рендеринга аудиосигналов. Способ 300 также содержит извлечение 320 одного или более декоррелированных аудиосигналов из представленных посредством рендеринга аудиосигналов. Способ 300 также содержит комбинирование 330 представленных посредством рендеринга аудиосигналов или их масштабированной версии с одним или более декоррелированными аудиосигналами для того, чтобы получать выходные аудиосигналы 332.
Следует отметить, что способ 300 основан на соображениях, идентичных соображениям для многоканального аудиодекодера 100 согласно фиг. 1. Кроме того, следует отметить, что способ 300 может дополняться посредством любых из признаков и функциональностей, описанных в данном документе (по отдельности или в комбинации). Например, способ 300 может дополняться посредством любых из признаков и функциональностей, описанных относительно многоканальных аудиодекодеров, описанных в данном документе.
4. Способ для предоставления кодированного представления согласно фиг. 4
Фиг. 4 показывает блок-схему последовательности операций способа 400 для предоставления кодированного представления на основе, по меньшей мере, двух входных аудиосигналов. Способ 400 содержит предоставление 410 одного или более сигналов понижающего микширования на основе, по меньшей мере, двух входных аудиосигналов 412. Способ 400 дополнительно содержит предоставление 420 одного или более параметров, описывающих взаимосвязь, по меньшей мере, между двумя входными аудиосигналами 412, и предоставление 430 параметра способа декорреляции, описывающего то, какой режим декорреляции из множества режимов декорреляции должен использоваться на стороне аудиодекодера. Соответственно, предоставляется кодированное представление 432, которое предпочтительно включает в себя кодированное представление одного или более сигналов понижающего микширования, одного или более параметров, описывающих взаимосвязь, по меньшей мере, между двумя входными аудиосигналами, и параметра способа декорреляции.
Следует отметить, что способ 400 основан на соображениях, идентичных соображениям для многоканального аудиокодера 200 согласно фиг. 2, так что вышеприведенные пояснения также применимы.
Кроме того, следует отметить, что порядок этапов 410, 420, 430 может гибко варьироваться, и что этапы 410, 420, 430 также могут выполняться параллельно, насколько это является возможным в среде выполнения для способа 400. Кроме того, следует отметить, что способ 400 может дополняться посредством любых из признаков и функциональностей, описанных в данном документе по отдельности или в комбинации. Например, способ 400 может дополняться посредством любых из признаков и функциональностей, описанных в данном документе относительно многоканальных аудиокодеров. Тем не менее, также можно вводить признаки и функциональности, которые соответствуют признакам и функциональностям многоканальных аудиодекодеров, описанных в данном документе, которые принимают кодированное представление 432.
5. Кодированное аудиопредставление согласно фиг. 5
Фиг. 5 показывает схематичное представление кодированного аудиопредставления 500 согласно варианту осуществления настоящего изобретения.
Кодированное аудиопредставление 500 содержит кодированное представление 510 сигнала понижающего микширования, кодированное представление 520 одного или более параметров, описывающих взаимосвязь, по меньшей мере, между двумя аудиосигналами. Кроме того, кодированное аудиопредставление 500 также содержит кодированный параметр 530 способа декорреляции, описывающий то, какой режим декорреляции из множества режимов декорреляции должен использоваться на стороне аудиодекодера. Соответственно, кодированное аудиопредставление дает возможность сигнализировать режим декорреляции из аудиокодера в аудиодекодер. Соответственно, можно получать режим декорреляции, который хорошо адаптирован к характеристикам аудиоконтента (который описывается, например, посредством кодированного представления 510 одного или более сигналов понижающего микширования и посредством кодированного представления 520 одного или более параметров, описывающих взаимосвязь, по меньшей мере, между двумя аудиосигналами (например, по меньшей мере, между двумя аудиосигналами, которые микшированы с понижением в кодированное представление 510 одного или более сигналов понижающего микширования)). Таким образом, кодированное аудиопредставление 500 предоставляет возможность рендеринга аудиоконтента, представленного посредством кодированного аудиопредставления 500, с очень хорошим слуховым пространственным впечатлением и/или очень хорошим компромиссом между слуховым пространственным впечатлением и сложностью декодирования.
Кроме того, следует отметить, что кодированное представление 500 может дополняться посредством любых из признаков и функциональностей, описанных относительно многоканальных аудиокодеров и многоканальных аудиодекодеров, по отдельности или в комбинации.
6. Многоканальный декоррелятор согласно фиг. 6
Фиг. 6 показывает принципиальную блок-схему многоканального декоррелятора 600, согласно варианту осуществления настоящего изобретения.
Многоканальный декоррелятор 600 выполнен с возможностью принимать первый набор из N входных сигналов 610a-610n декоррелятора и предоставлять, на их основе, второй набор из N' выходных сигналов 612a-612n' декоррелятора. Другими словами, многоканальный декоррелятор 600 выполнен с возможностью предоставления множества (по меньшей мере, приблизительно) декоррелированных сигналов 612a-612n' на основе входных сигналов 610a-610n декоррелятора.
Многоканальный декоррелятор 600 содержит предварительный микшер 620, который выполнен с возможностью предварительно микшировать первый набор из N входных сигналов 610a-610n декоррелятора во второй набор из K входных сигналов 622a-622k декоррелятора, где K меньше N (причем K и N являются целыми числами). Многоканальный декоррелятор 600 также содержит ядро 630 декорреляции (или декоррелятора), которое выполнено с возможностью предоставлять первый набор из K' выходных сигналов 632a-632k' декоррелятора на основе второго набора из K входных сигналов 622a-622k декоррелятора. Кроме того, многоканальный декоррелятор содержит постмикшер 640, который выполнен с возможностью повышающе микшировать первый набор из K' выходных сигналов 632a-632k' декоррелятора во второй набор из N' выходных сигналов 612a-612n' декоррелятора, где N' превышает K' (при этом N' и K' являются целыми числами).
Тем не менее, следует отметить, что данная структура многоканального декоррелятора 600 должна рассматриваться только в качестве примера, и что необязательно подразделять многоканальный декоррелятор 600 на функциональные блоки (например, на предварительный микшер 620, ядро 630 декорреляции или декоррелятора и постмикшер 640) при условии, что функциональность, описанная в данном документе, предоставляется.
Относительно функциональности многоканального декоррелятора 600, также следует отметить, что принцип выполнения предварительного микширования, чтобы извлекать второй набор из K входных сигналов декоррелятора из первого набора N входных сигналов декоррелятора, и выполнения декорреляции на основе (предварительно микшированного или "микшированного с понижением") второго набора из K входных сигналов декоррелятора способствует уменьшению сложности, по сравнению с принципом, в котором фактическая декорреляция применяется, например, непосредственно к N входных сигналов декоррелятора. Кроме того, второй (повышающе микшированный) набор из N' выходных сигналов декоррелятора получается на основе первого (исходного) набора выходных сигналов декоррелятора, которые являются результатом фактической декорреляции, на основе постмикширования, которое может выполняться посредством повышающего микшера 640. Таким образом, многоканальный декоррелятор 600 эффективно (при просмотре извне) принимает N входных сигналов декоррелятора и предоставляет, на их основе, N' выходных сигналов декоррелятора, в то время как фактическое ядро 630 декоррелятора работает только для меньшего числа сигналов (а именно, K микшированных с понижением входных сигналов 622a-622k декоррелятора из второго набора из K входных сигналов декоррелятора). Таким образом, сложность многоканального декоррелятора 600 может быть существенно уменьшена, по сравнению с традиционными декорреляторами, посредством выполнения понижающего микширования или "предварительного микширования" (которое предпочтительно может представлять собой линейное предварительное микширование без функциональности декорреляции) на входной стороне ядра 630 декорреляции (или декоррелятора) и посредством выполнения повышающего микширования или "постмикширования" (например, линейного повышающего микширования без дополнительной функциональности декорреляции) на основе (исходных) выходных сигналов 632a-632k' ядра 630 декорреляции (декоррелятора).
Кроме того, следует отметить, что многоканальный декоррелятор 600 может дополняться посредством любых из признаков и функциональностей, описанных в данном документе относительно многоканальной декорреляции, а также относительно многоканальных аудиодекодеров. Следует отметить, что признаки, описанные в данном документе, могут добавляться в многоканальный декоррелятор 600 по отдельности или в комбинации, чтобы за счет этого улучшать или совершенствовать многоканальный декоррелятор 600.
Следует отметить, что многоканальный декоррелятор без уменьшения сложности может извлекаться из вышеописанного многоканального декоррелятора для K=N (и возможно K'=N' или даже K=N=K'=N').
7. Многоканальный аудиодекодер согласно фиг. 7
Фиг. 7 показывает принципиальную блок-схему многоканального аудиодекодера 700, согласно варианту осуществления изобретения.
Многоканальный аудиодекодер 700 выполнен с возможностью принимать кодированное представление 710 и предоставлять, на его основе, по меньшей мере, два выходных сигнала 712, 714. Многоканальный аудиодекодер 700 содержит многоканальный декоррелятор 720, который может быть практически идентичным многоканальному декоррелятору 600 согласно фиг. 6. Кроме того, многоканальный аудиодекодер 700 может содержать любые из признаков и функциональностей многоканального аудиодекодера, которые известны для специалистов в данной области техники или которые описываются в данном документе относительно других многоканальных аудиодекодеров.
Кроме того, следует отметить, что многоканальный аудиодекодер 700 содержит, в частности, высокую эффективность, по сравнению с традиционными многоканальными аудиодекодерами, поскольку многоканальный аудиодекодер 700 использует высокоэффективный многоканальный декоррелятор 720.
8. Многоканальный аудиокодер согласно фиг. 8
Фиг. 8 показывает принципиальную блок-схему многоканального аудиокодера 800, согласно варианту осуществления настоящего изобретения. Многоканальный аудиокодер 800 выполнен с возможностью принимать, по меньшей мере, два входных аудиосигнала 810, 812 и предоставлять, на их основе, кодированное представление 814 аудиоконтента, представленного посредством входных аудиосигналов 810, 812.
Многоканальный аудиокодер 800 содержит модуль 820 предоставления сигналов понижающего микширования, который выполнен с возможностью предоставлять один или более сигналов 822 понижающего микширования на основе, по меньшей мере, двух входных аудиосигналов 810, 812. Многоканальный аудиокодер 800 также содержит модуль 830 предоставления параметров, который выполнен с возможностью предоставлять один или более параметров 832 (например, параметров взаимной корреляции или параметров взаимной ковариантности, или параметров межобъектной корреляции, и/или параметров разности уровней объектов) на основе входных аудиосигналов 810, 812. Кроме того, многоканальный аудиокодер 800 содержит модуль 840 предоставления параметров сложности декорреляции, который выполнен с возможностью предоставлять параметр 842 сложности декорреляции, описывающий сложность декорреляции, которая должна использоваться на стороне аудиодекодера (который принимает кодированное представление 814). Один или более сигналов 822 понижающего микширования, один или более параметров 832 и параметр 842 сложности декорреляции включены в кодированное представление 814, предпочтительно в кодированной форме.
Тем не менее, следует отметить, что внутренняя структура многоканального аудиокодера 800 (например, присутствие модуля 820 предоставления сигналов понижающего микширования, модуля 830 предоставления параметров и модуля 840 предоставления параметров сложности декорреляции) должна рассматриваться только в качестве примера. Различные структуры являются возможными при условии, что функциональность, описанная в данном документе, достигается.
Относительно функциональности многоканального аудиокодера 800 следует отметить, что многоканальный кодер предоставляет кодированное представление 814, при этом один или более сигналов 822 понижающего микширования и один или более параметров 832 могут быть аналогичными или равными сигналам и параметрам понижающего микширования, предоставленным посредством традиционных аудиокодеров (таких как, например, традиционные SAOC-аудиокодеры или USAC-аудиокодеры). Тем не менее, многоканальный аудиокодер 800 также выполнен с возможностью предоставлять параметр 842 сложности декорреляции, который дает возможность определять сложность декорреляции, которая применяется на стороне аудиодекодера. Соответственно, сложность декорреляции может быть адаптирована к аудиоконтенту, который в данный момент кодируется. Например, можно сигнализировать требуемую сложность декорреляции, которая соответствует достижимому качеству звука в зависимости от знаний на стороне кодера относительно характеристик входных аудиосигналов. Например, если обнаружено, что пространственные характеристики являются важными для аудиосигнала, более высокая сложность декорреляции может сигнализироваться, с использованием параметра 842 сложности декорреляции, по сравнению со случаем, в котором пространственные характеристики не являются настолько важными. Альтернативно, использование высокой сложности декорреляции может сигнализироваться с использованием параметра 842 сложности декорреляции, если обнаружено, что прохождение аудиоконтента или всего аудиоконтента является таким, что декорреляция с высокой сложностью требуется на стороне аудиодекодера по другим причинам.
Если обобщать, многоканальный аудиокодер 800 предоставляет возможность управлять многоканальным аудиодекодером таким образом, чтобы использовать сложность декорреляции, которая адаптирована к характеристикам сигналов или требуемым характеристикам воспроизведения, которые могут задаваться посредством многоканального аудиокодера 800.
Кроме того, следует отметить, что многоканальный аудиокодер 800 может дополняться посредством любых из признаков и функциональностей, описанных в данном документе относительно многоканального аудиокодера, по отдельности или в комбинации. Например, некоторые или все признаки, описанные в данном документе относительно многоканальных аудиокодеров, могут добавляться в многоканальный аудиокодер 800. Кроме того, многоканальный аудиокодер 800 может быть выполнен с возможностью взаимодействия с многоканальными аудиодекодерами, описанными в данном документе.
9. Способ для предоставления множества декоррелированных сигналов на основе множества входных сигналов декоррелятора, согласно фиг. 9
Фиг. 9 показывает блок-схему последовательности операций способа 900 для предоставления множества декоррелированных сигналов на основе множества входных сигналов декоррелятора.
Способ 900 содержит предварительное микширование 910 первого набора из N входных сигналов декоррелятора во второй набор из K входных сигналов декоррелятора, где K меньше N. Способ 900 также содержит предоставление 920 первого набора из K' выходных сигналов декоррелятора на основе второго набора из K входных сигналов декоррелятора. Например, первый набор из K' выходных сигналов декоррелятора может предоставляться на основе второго набора из K входных сигналов декоррелятора с использованием декорреляции, которая может выполняться, например, с использованием ядра декоррелятора или с использованием алгоритма декорреляции. Способ 900 дополнительно содержит постмикширование 930 первого набора из K' выходных сигналов декоррелятора во второй набор из N' выходных сигналов декоррелятора, где N' превышает K' (при этом N' и K' являются целыми числами). Соответственно, второй набор из N' выходных сигналов декоррелятора, которые являются выводом способа 900, может предоставляться на основе первого набора N входных сигналов декоррелятора, которые являются вводом в способ 900.
Следует отметить, что способ 900 основан на соображениях, идентичных соображениям для многоканального декоррелятора, описанного выше. Кроме того, следует отметить, что способ 900 может дополняться посредством любых из признаков и функциональностей, описанных в данном документе относительно многоканального декоррелятора (и также относительно многоканального аудиокодера, если применимо), по отдельности или в комбинации.
10. Способ для предоставления, по меньшей мере, двух выходных аудиосигналов на основе кодированного представления, согласно фиг. 10
Фиг. 10 показывает блок-схему последовательности операций способа 1000 для предоставления, по меньшей мере, двух выходных аудиосигналов на основе кодированного представления.
Способ 1000 содержит предоставление 1010, по меньшей мере, двух выходных аудиосигналов 1014, 1016 на основе кодированного представления 1012. Способ 1000 содержит предоставление 1020 множества декоррелированных сигналов на основе множества входных сигналов декоррелятора в соответствии со способом 900 согласно фиг. 9.
Следует отметить, что способ 1000 основан на соображениях, идентичных соображениям для многоканального аудиодекодера 700 согласно фиг. 7.
Кроме того, следует отметить, что способ 1000 может дополняться посредством любых из признаков и функциональностей, описанных в данном документе относительно многоканальных декодеров, по отдельности или в комбинации.
11. Способ для предоставления кодированного представления на основе, по меньшей мере, двух входных аудиосигналов, согласно фиг. 11
Фиг. 11 показывает блок-схему последовательности операций способа 1100 для предоставления кодированного представления на основе, по меньшей мере, двух входных аудиосигналов.
Способ 1100 содержит предоставление 1110 одного или более сигналов понижающего микширования на основе, по меньшей мере, двух входных аудиосигналов 1112, 1114. Способ 1100 также содержит предоставление 1120 одного или более параметров, описывающих взаимосвязь, по меньшей мере, между двумя входными аудиосигналами 1112, 1114. Кроме того, способ 1100 содержит предоставление 1130 параметра сложности декорреляции, описывающего сложность декорреляции, которая должна использоваться на стороне аудиодекодера. Соответственно, кодированное представление 1132 предоставляется на основе, по меньшей мере, двух входных аудиосигналов 1112, 1114, при этом кодированное представление типично содержит один или более сигналов понижающего микширования, один или более параметров, описывающих взаимосвязь, по меньшей мере, между двумя входными аудиосигналами, и параметр сложности декорреляции в кодированной форме.
Следует отметить, что этапы 1110, 1120, 1130 могут выполняться параллельно или в другом порядке в некоторых вариантах осуществления согласно изобретению. Кроме того, следует отметить, что способ 1100 основан на соображениях, идентичных соображениям для многоканального аудиокодера 800 согласно фиг. 8, и что способ 1100 может дополняться посредством любых из признаков и функциональностей, описанных в данном документе относительно многоканального аудиокодера, в комбинации или по отдельности. Кроме того, следует отметить, что способ 1100 может быть выполнен с возможностью соответствовать многоканальному аудиодекодеру и способу для предоставления, по меньшей мере, двух выходных аудиосигналов, описанными в данном документе.
12. Кодированное аудиопредставление согласно фиг. 12
Фиг. 12 показывает схематичное представление кодированного аудиопредставления, согласно варианту осуществления настоящего изобретения. Кодированное аудиопредставление 1200 содержит кодированное представление 1210 сигнала понижающего микширования, кодированное представление 1220 одного или более параметров, описывающих взаимосвязь, по меньшей мере, между двумя входными аудиосигналами, и кодированный параметр 1230 сложности декорреляции, описывающий сложность декорреляции, которая должна использоваться на стороне аудиодекодера. Соответственно, кодированное аудиопредставление 1200 дает возможность регулировать сложность декорреляции, используемую посредством многоканального аудиодекодера, что способствует повышенной эффективности декодирования и возможно повышенному качеству звука или улучшенному компромиссу между эффективностью кодирования и качеством звука. Кроме того, следует отметить, что кодированное аудиопредставление 1200 может предоставляться посредством многоканального аудиокодера, как описано в данном документе, и может использоваться посредством многоканального аудиодекодера, как описано в данном документе. Соответственно, кодированное аудиопредставление 1200 может дополняться посредством любых из признаков, описанных относительно многоканальных аудиокодеров и относительно многоканальных аудиодекодеров.
13. Система обозначений и базовые соображения
В последнее время, параметрические технологии для эффективной по скорости передачи битов передачи/хранения аудиосцен, содержащих несколько аудиообъектов, предложены в области техники кодирования аудио (см., например, ссылочные материалы [BCC], [АО], [SAOC], [SAOC1], [SAOC2]) и информированного разделения источников (см., например, ссылочные материалы [ISS1], [ISS2], [ISS3], [ISS4], [ISS5], [ISS6]). Эти технологии направлены на восстановление требуемой выходной аудиосцены или исходного аудиообъекта на основе дополнительной вспомогательной информации, описывающей передаваемую/сохраненную аудиосцену и/или исходные объекты в аудиосцене. Это восстановление осуществляется в декодере с использованием схемы параметрического информированного разделения источников. Кроме того, также следует обратиться к так называемому принципу "на основе стандарта объемного звучания MPEG", который описывается, например, в международном стандарте ISO/IEC 23003-1:2007. Кроме того, также следует обратиться к так называемому "пространственному кодированию аудиообъектов", которое описывается в международном стандарте ISO/IEC 23003-2:2010. Кроме того, следует обратиться к так называемому принципу "стандартизированного кодирования речи и аудио", который описывается в международном стандарте ISO/IEC 23003-3:2012. Принципы из этих стандартов могут использоваться в вариантах осуществления согласно изобретению, например, в многоканальных аудиокодерах, упомянутых в данном документе, и в многоканальных аудиодекодерах, упомянутых в данном документе, при этом могут требоваться некоторые адаптации.
Далее описывается некоторая исходная информация. В частности, общее представление схем параметрического разделения предоставляется с использованием примера технологии пространственного кодирования аудиообъектов (SAOC) по стандарту MPEG (см., например, ссылочный материал [SAOC]). Рассматриваются математические свойства этого способа.
13.1. Система обозначений и определения
Следующая система математических обозначений применяется в текущем документе:
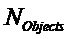
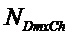
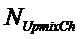
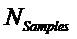
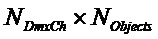
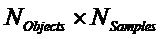
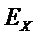
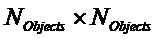
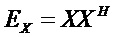
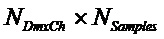
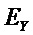
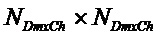
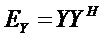
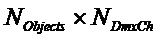
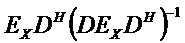
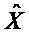
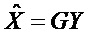
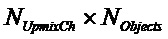
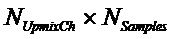
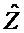
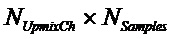
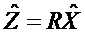
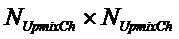
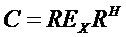
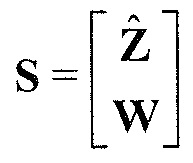 , размер
, размер 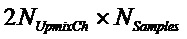
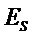
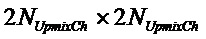
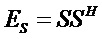
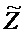
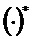

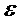
13.2. Системы параметрического разделения
Общие системы параметрического разделения нацелены на оценку числа аудиоисточников из смеси сигналов (понижающего микширования) с использованием вспомогательной информации параметров (такой как, например, информация значений межканальной корреляции, значений межканальной разности уровней, значений межобъектной корреляции и/или разности уровней объектов). Стандартное решение этой задачи основано на применении алгоритмов оценки на основе минимальной среднеквадратической ошибки (MMSE). SAOC-технология является одним примером таких систем параметрического кодирования/декодирования аудио.
Фиг. 13 показывает общий принцип архитектуры SAOC-кодера/декодера. Другими словами, фиг. 13 показывает, в форме принципиальной блок-схемы, общее представление принципа параметрического понижающего микширования/повышающего микширования на основе MMSE.
Кодер 1310 принимает множество сигналов 1312a, 1312b-1312n объектов. Кроме того, кодер 1310 также принимает параметры D микширования, 1314, которые, например, могут представлять собой параметры понижающего микширования. Кодер 1310 предоставляет, на их основе, один или более сигналов 1316a, 1316b понижающего микширования и т.д. Кроме того, кодер предоставляет вспомогательную информацию 1318. Один или более сигналов понижающего микширования и вспомогательная информация, например, могут предоставляться в кодированной форме.
Кодер 1310 содержит микшер 1320, который типично выполнен с возможностью принимать сигналы 1312a-1312n объектов и комбинировать (например, микшировать с понижением) сигналы 1312a-1312n объектов в один или более сигналов 1316a, 1316b понижающего микширования в зависимости от параметров 1314 микширования. Кроме того, кодер содержит модуль 1330 оценки вспомогательной информации, который выполнен с возможностью извлекать вспомогательную информацию 1318 из сигналов 1312a-1312n объектов. Например, модуль 1330 оценки вспомогательной информации может быть выполнен с возможностью извлекать вспомогательную информацию 1318 таким образом, что вспомогательная информация описывает взаимосвязь между сигналами объектов, например, взаимную корреляцию между сигналами объектов (которая может обозначаться как "межобъектная корреляция (IOC)"), и/или информацию, описывающую разность уровней между сигналами объектов (которая может обозначаться как "информация разности уровней объектов (OLD)").
Один или более сигналов 1316a, 1316b понижающего микширования и вспомогательная информация 1318 могут сохраняться и/или передаваться в декодер 1350, что указывается по ссылке с номером 1340.
Декодер 1350 принимает один или более сигналов 1316a, 1316b понижающего микширования и вспомогательную информацию 1318 (например, в кодированной форме) и предоставляет, на их основе, множество выходных аудиосигналов 1352a-1352n. Декодер 1350 также может принимать информацию 1354 пользовательского взаимодействия, которая может содержать один или более параметров R рендеринга (которые могут задавать матрицу рендеринга). Декодер 1350 содержит модуль 1360 разделения параметрических объектов, процессор 1370 вспомогательной информации и модуль 1380 рендеринга. Процессор 1370 вспомогательной информации принимает вспомогательную информацию 1318 и предоставляет, на ее основе, управляющую информацию 1372 для модуля 1360 разделения параметрических объектов. Модуль 1360 разделения параметрических объектов предоставляет множество сигналов 1362a-1362n объектов на основе сигналов 1360a, 1360b понижающего микширования и управляющей информации 1372, которая извлекается из вспомогательной информации 1318 посредством процессора 1370 вспомогательной информации. Например, модуль разделения объектов может выполнять декодирование кодированных сигналов понижающего микширования и разделение объектов. Модуль 1380 рендеринга представляет посредством рендеринга восстановленные сигналы объектов 1362a-1362n, чтобы за счет этого получать выходные аудиосигналы 1352a-1352n.
Далее поясняется функциональность принципа параметрического понижающего микширования/повышающего микширования на основе MMSE.
Общая обработка параметрического понижающего микширования/повышающего микширования выполняется частотно-временным избирательным способом и может описываться как последовательность следующих этапов:
- В "кодер" 1310 предоставляются входные "аудиообъекты" x и "параметры D микширования". "Микшер" 1320 микширует с понижением "аудиообъекты" x в число "сигналов Y понижающего микширования" с использованием "параметров D микширования" (например, усилений при понижающем микшировании). "Модуль оценки вспомогательной информации" извлекает вспомогательную информацию 1318, описывающую характеристики входных "аудиообъектов" x (например, свойства ковариантности).
- "Сигналы Y понижающего микширования" и вспомогательная информация передаются или сохраняются. Эти аудиосигналы понижающего микширования дополнительно могут сжиматься с использованием аудиокодеров (таких как MPEG-1/2 уровня II или III, усовершенствованное кодирование аудио (AAC) по стандарту MPEG-2/4, стандартизированное кодирование речи и аудио (USAC) MPEG и т.д.). Вспомогательная информация также может быть представлена и кодирована эффективно (например, в качестве кодированных без потерь отношений мощностей объектов и коэффициентов корреляции объектов).
- "Декодер" 1350 восстанавливает исходные "аудиообъекты" из декодированных "сигналов понижающего микширования" с использованием передаваемой вспомогательной информации 1318. "Процессор 1370 вспомогательной информации" оценивает коэффициенты 1372 обратного микширования, которые должны применяться к "сигналам понижающего микширования" в "модуле 1360 разделения параметрических объектов", чтобы получать восстановление параметрических объектов x. Восстановленные "аудиообъекты" 1362a-1362n представляются посредством рендеринга в (многоканальную) целевую сцену, представленную посредством выходных каналов Z, посредством применения "параметров R 1354 рендеринга".
Кроме того, следует отметить, что функциональности, описанные относительно кодера 1310 и декодера 1350, могут использоваться в других аудиокодерах и аудиодекодерах, описанных в данном документе также.
13.3. Принцип ортогональности оценки на основе минимальной среднеквадратической ошибки
Принцип ортогональности является одним главным свойством модулей MMSE-оценки. Рассмотрим два гильбертовых пространства W и V, при этом V охватывается посредством набора векторов yi, и вектор 
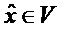
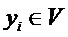
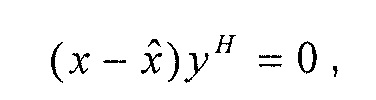
Как следствие, ошибка оценки и сама оценка являются ортогональными:
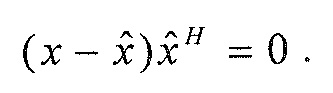
Геометрически можно визуализировать это посредством примеров, показанных на фиг. 14.
Фиг. 14 показывает геометрическое представление для принципа ортогональности в трехмерном пространстве. Как можно видеть, векторное пространство охватывается посредством векторов y1, y2. Вектор x равен сумме вектора 
Соответственно, вектор 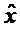
13.4. Ошибка параметрического восстановления
При задании матрицы, содержащей N сигналов (x), и обозначении ошибки оценки как 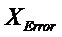
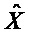
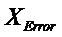
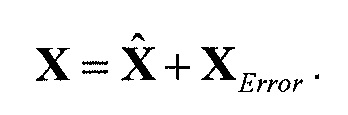
Вследствие принципа ортогональности, ковариационная матрица 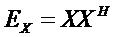
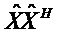
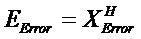
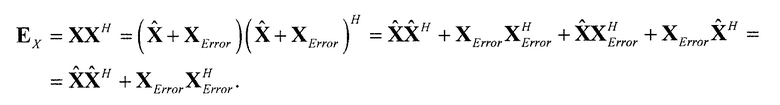
Когда входные объекты x не находятся в пространстве, охватываемом посредством каналов понижающего микширования (например, число каналов понижающего микширования меньше числа входных сигналов), и входные объекты не могут представляться как линейные комбинации каналов понижающего микширования, алгоритмы на основе MMSE вводят неточность 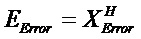
13.5. Межобъектная корреляция
В слуховой системе, взаимная ковариантность (когерентность/корреляция) тесно связана с восприятием огибания как окружения посредством звука, а также с воспринимаемой шириной источника звука. Например, в системах на основе SAOC параметры межобъектной корреляции (IOC) используются для определения характеристик этого свойства:
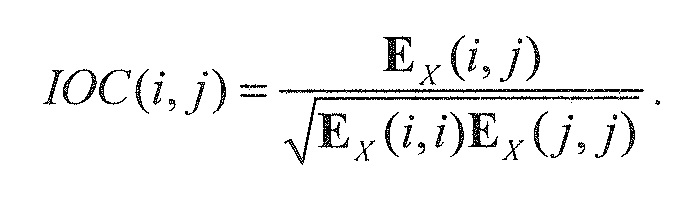
Рассмотрим пример воспроизведения источника звука с использованием двух аудиосигналов. Если значение IOC является близким к единице, звук воспринимается как хорошо локализованный точечный источник. Если значение IOC является близким к нулю, воспринимаемая ширина источника звука увеличивается, и для крайних случаев, он может даже восприниматься как два различных источника [Blauert, глава 3].
13.6. Компенсация неточности восстановления
В случае неидеального параметрического восстановления выходной сигнал может демонстрировать более низкую энергию по сравнению с исходными объектами. Ошибка в диагональных элементах ковариационной матрицы может приводить к звуковым разностям уровней и ошибке во внедиагональных элементах в искаженном пространственном звуковом изображении (по сравнению с идеальным опорным выводом). Предложенный способ имеет цель разрешать эту проблему.
В стандарте объемного звучания MPEG (MPS), например, эта проблема исследуется только для некоторых конкретных сценариев канальной обработки, а именно, для моно/стереопонижающего микширования и ограниченных статических выходных конфигураций (например, моно, стерео, 5.1, 7.1 и т.д.). В объектно-ориентированных технологиях, таких как SAOC, которая также использует моно/стереопонижающее микширование, эта проблема исследуется посредством применения рендеринга с MPS-постобработкой только для выходной 5.1-конфигурации.
Существующие решения ограничены стандартными выходными конфигурациями и фиксированным числом входных/выходных каналов. А именно, они реализованы в качестве последовательного применения нескольких блоков, реализующих просто способы канальной декорреляции "моно-в-стерео" (или "стерео-в-три").
Следовательно, требуется общее решение (например, способ коррекции свойств энергетического уровня и корреляции) для компенсации неточности параметрического восстановления, которое может применяться для гибкого числа каналов понижающего микширования/выходных каналов и произвольных выходных конфигурационных компоновок.
13.7. Заключения
В качестве вывода, предоставлено общее представление в отношении системы обозначений. Кроме того, описана система параметрического разделения, на которой основаны варианты осуществления согласно изобретению. Кроме того, указано то, что принцип ортогональности применяется к оценке на основе минимальной среднеквадратической ошибки. Кроме того, предоставлено уравнение для вычисления ковариационной матрицы  , которое применяется при наличии ошибки
, которое применяется при наличии ошибки 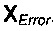 восстановления. Кроме того, предоставлена взаимосвязь между так называемыми значениями межобъектной корреляции и элементами ковариационной матрицы
восстановления. Кроме того, предоставлена взаимосвязь между так называемыми значениями межобъектной корреляции и элементами ковариационной матрицы 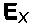 , которая может применяться, например, в вариантах осуществления согласно изобретению, чтобы извлекать требуемые характеристики ковариантности (или характеристики корреляции) из значений межобъектной корреляции (которые могут быть включены в параметрическую вспомогательную информацию) и возможно формировать разности уровней объектов. Кроме того, указано то, что характеристики восстановленных сигналов объектов могут отличаться от требуемых характеристик вследствие неидеального восстановления. Кроме того, указано то, что существующие решения для разрешения проблемы ограничены некоторыми конкретными выходными конфигурациями и основываются на конкретной комбинации стандартных блоков, что делает традиционные решения негибкими.
, которая может применяться, например, в вариантах осуществления согласно изобретению, чтобы извлекать требуемые характеристики ковариантности (или характеристики корреляции) из значений межобъектной корреляции (которые могут быть включены в параметрическую вспомогательную информацию) и возможно формировать разности уровней объектов. Кроме того, указано то, что характеристики восстановленных сигналов объектов могут отличаться от требуемых характеристик вследствие неидеального восстановления. Кроме того, указано то, что существующие решения для разрешения проблемы ограничены некоторыми конкретными выходными конфигурациями и основываются на конкретной комбинации стандартных блоков, что делает традиционные решения негибкими.
14. Вариант осуществления согласно фиг. 15
14.1. Общее представление принципа
Варианты осуществления согласно изобретению расширяют способы параметрического MMSE-восстановления, используемые в схемах параметрического аудиоразделения с решением по декорреляции для произвольного числа каналов понижающего микширования/повышающего микширования. Варианты осуществления согласно изобретению, такие как, например, изобретаемое устройство и изобретательский способ, могут компенсировать энергетические потери во время параметрического восстановления и восстанавливать свойства корреляции оцененных объектов.
Фиг. 15 предоставляет общее представление принципа параметрического понижающего микширования/повышающего микширования с интегрированным трактом декорреляции. Другими словами, фиг. 15 показывает, в форме принципиальной блок-схемы, систему параметрического восстановления с декорреляцией, применяемую для представленного посредством рендеринга вывода.
Система согласно фиг. 15 содержит кодер 1510, который является практически идентичным кодеру 1310 согласно фиг. 13. Кодер 1510 принимает множество сигналов 1512a-1512n объектов и предоставляет, на их основе, один или более сигналов 1516a, 1516b понижающего микширования, а также вспомогательную информацию 1518. Сигналы 1516a, 1515b понижающего микширования могут быть практически идентичными сигналам 1316a, 1316b понижающего микширования и может обозначаться как Y. Вспомогательная информация 1518 может быть практически идентичной вспомогательной информации 1318. Тем не менее, вспомогательная информация, например, может содержать параметр режима декорреляции или параметр способа декорреляции, или параметр сложности декорреляции. Кроме того, кодер 1510 может принимать параметры 1514 микширования.
Система параметрического восстановления также содержит передачу и/или хранение одного или более сигналов 1516a, 1516b понижающего микширования и вспомогательной информации 1518, при этом передача и/или хранение обозначены с помощью 1540, и при этом один или более сигналов 1516a, 1516b понижающего микширования и вспомогательная информация 1518 (которая может включать в себя параметрическую вспомогательную информацию) могут кодироваться.
Кроме того, система параметрического восстановления согласно фиг. 15 содержит декодер 1550 1550, который выполнен с возможностью принимать передаваемые или сохраненные один или более (возможно кодированных) сигналов 1516a, 1516b понижающего микширования и передаваемую или сохраненную (возможно кодированную) вспомогательную информацию 1518 и предоставлять, на их основе, выходные аудиосигналы 1552a-1552n. Декодер 1550 (который может рассматриваться как многоканальный аудиодекодер) содержит модуль 1560 разделения параметрических объектов и процессор 1570 вспомогательной информации. Кроме того, декодер 1550 содержит модуль 1580 рендеринга, декоррелятор 1590 и микшер 1598.
Модуль 1560 разделения параметрических объектов выполнен с возможностью принимать один или более сигналов 1516a, 1516b понижающего микширования и управляющую информацию 1572, которая предоставляется посредством процессора 1570 вспомогательной информации на основе вспомогательной информации 1518, и предоставлять, на их основе, сигналы 1562a-1562n объектов, которые также обозначены с X и которые могут рассматриваться как декодированные аудиосигналы. Управляющая информация 1572, например, может содержать коэффициенты обратного микширования, которые должны применяться к сигналам понижающего микширования (например, к декодированным сигналам понижающего микширования, извлекаемым из кодированных сигналов 1516a, 1516b понижающего микширования) в модуле разделения параметрических объектов, чтобы получать восстановленные сигналы объектов (например, декодированные аудиосигналы 1562a-1562n). Модуль 1580 рендеринга представляет посредством рендеринга декодированные аудиосигналы 1562a-1562n (которые могут быть восстановленными сигналами объектов и которые, например, могут соответствовать входным сигналам 1512a-1512n объектов), чтобы за счет этого получать множество представленных посредством рендеринга аудиосигналов 1582a-1582n. Например, модуль 1580 рендеринга может учитывать параметры R рендеринга, которые, например, могут предоставляться посредством пользовательского взаимодействия и которые, например, могут задавать матрицу рендеринга. Тем не менее, альтернативно параметры рендеринга могут извлекаться из кодированного представления (которое может включать в себя кодированные сигналы 1516a, 1516b понижающего микширования и кодированную вспомогательную информацию 1518).
Декоррелятор 1590 выполнен с возможностью принимать представленные посредством рендеринга аудиосигналы 1582a-1582n и предоставлять, на их основе, декоррелированные аудиосигналы 1592a-1592n, которые также обозначены с помощью W. Микшер 1598 принимает представленные посредством рендеринга аудиосигналы 1582a-1582n и декоррелированные аудиосигналы 1592a-1592n и комбинирует представленные посредством рендеринга аудиосигналы 1582a-1582n и декоррелированные аудиосигналы 1592a-1592n, чтобы за счет этого получать выходные аудиосигналы 1552a-1552n. Микшер 1598 также может использовать управляющую информацию 1574, которая извлекается посредством процессора 1570 вспомогательной информации из кодированной вспомогательной информации 1518, как описано ниже.
14.2. Функция декоррелятора
Далее описываются некоторые подробности относительно декоррелятора 1590. Тем не менее, следует отметить, что могут использоваться другие принципы декоррелятора, некоторые из которых описываются ниже.
В варианте осуществления, функция 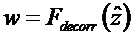
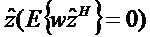
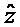
В случае нескольких входных сигналов, предпочтительно, если функция декорреляции формирует несколько выводов, которые являются взаимно ортогональными (т.е. 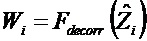
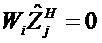
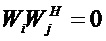
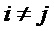
Точное подробное описание для реализации функции декоррелятора находится за рамками объема этого описания. Например, декорреляторы на основе гребенки из нескольких фильтров с бесконечной импульсной характеристикой (HR), указываемые в стандарте объемного звучания MPEG, могут быть использованы в целях декорреляции [MPS].
Общие декорреляторы, описанные в этом описании, предположительно являются идеальными. Это подразумевает то, что (в дополнение к перцепционным требованиям) вывод каждого декоррелятора является ортогональным для своего ввода и для вывода всех других декорреляторов. Следовательно, для данного ввода 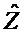
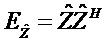
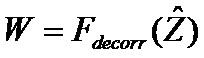
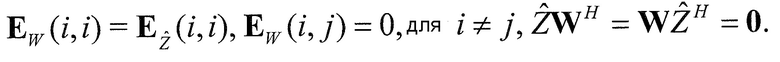
Из этих взаимосвязей следует, что:
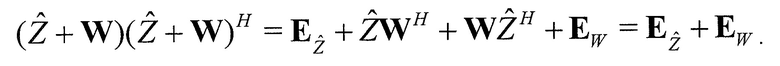
Вывод W декоррелятора может использоваться для того, чтобы компенсировать неточность прогнозирования в модуле MMSE-оценки (следует напомнить, что ошибка прогнозирования является ортогональной к прогнозированным сигналам) посредством использования прогнозированных сигналов в качестве вводов.
При этом следует отметить, что ошибки прогнозирования в общем случае не являются ортогональными между собой. Таким образом, одна цель идеи изобретения (например, способа) состоит в том, чтобы создавать смесь "сухого" (т.е. входного декоррелятора) сигнала (например, представленных посредством рендеринга аудиосигналов 1582a-1582n) и "мокрого" (т.е. выходного декоррелятора) сигнала (например, декоррелированных аудиосигналов 1592a-1592n), так что ковариационная матрица результирующей смеси (например, выходных аудиосигналов 1552a-1552n) становится аналогичной ковариационной матрице требуемого вывода.
Кроме того, следует отметить, что может использоваться уменьшение сложности для модуля декорреляции, которое подробно описывается ниже и которое может способствовать некоторым неидеальностям декоррелированного сигнала, которые, тем не менее, могут быть приемлемыми.
14.3. Коррекция выходной ковариантности с использованием декоррелированных сигналов
Далее описывается принцип для того, чтобы регулировать характеристики ковариантности выходных аудиосигналов 1552a-1552n, чтобы получать достаточно хорошее впечатление от прослушивания.
Предложенный способ для коррекции ошибок выходной ковариантности составляет выходной сигнал 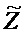
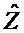
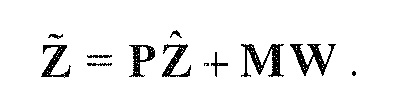
Тем не менее, следует отметить, что это уравнение может считаться самым общим формулированием. К вышеприведенной формуле необязательно может применяться изменение, которое является (или которое может задаваться) допустимым для всех "упрощенных способов", описанных в данном документе.
Матрицы P микширования, применяемая к прямому сигналу 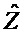
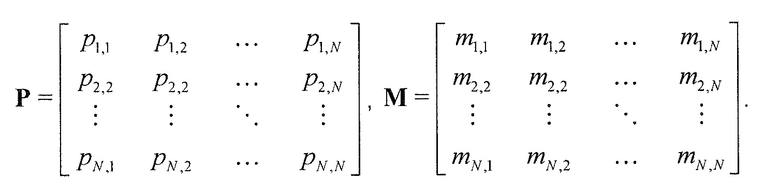
При применении обозначения для комбинированной матрицы 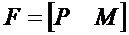
 в результате получается:
в результате получается:

Тем не менее, альтернативно может применяться уравнение:
 ,
,
как подробнее описано ниже.
С использованием этого представления, ковариационная матрица 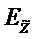
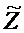

Целевая ковариация C идеальной созданной представленной посредством рендеринга выходной сцены задается следующим образом:
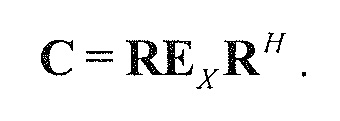
Матрица F микширования вычисляется таким образом, что ковариационная матрица 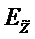
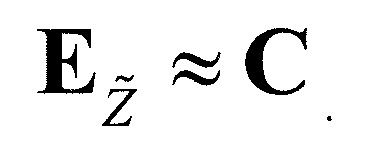
Матрица F микширования вычисляется, например, в качестве функции известных величин 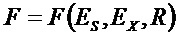
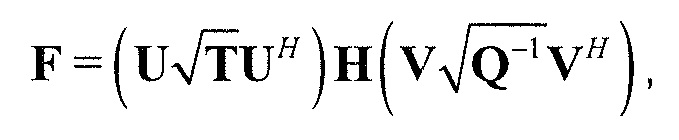
где матрицы U, T и V, Q могут определяться, например, с использованием разложения по сингулярным значениям (SVD) ковариационных матриц 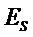
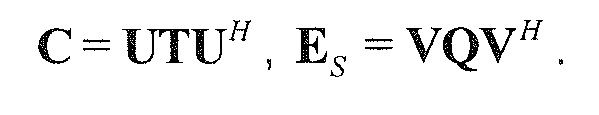
Прототипная матрица H может быть выбрана согласно требуемым взвешиваниям для трактов передачи прямых и декоррелированных сигналов.
Например, возможная прототипная матрица H может определяться следующим образом:
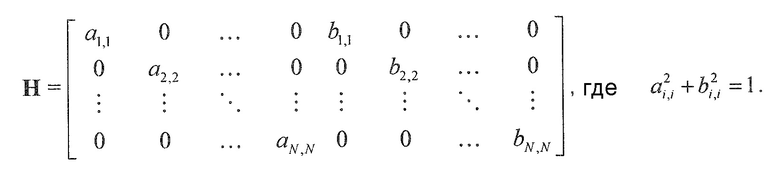
Далее предоставляются некоторые математические извлечения для общей структуры матрицы F.
Другими словами, ниже описывается извлечение матрицы F микширования для общего решения.
Ковариационные матрицы 
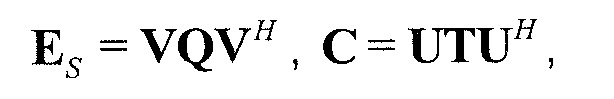
где T и Q являются диагональными матрицами с сингулярными значениями C и 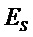
Следует отметить, что применение триангуляции Шура или разложения по собственным значениям (вместо SVD) приводит к аналогичным результатам (или даже идентичным результатам, если диагональные матрицы Q и T ограничены положительными значениями).
При применении этого разложения к требованию 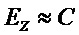
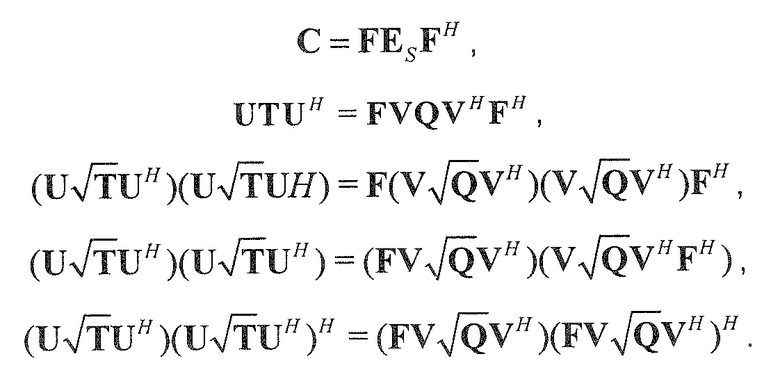
Чтобы следить за размерностью ковариационных матриц, в некоторых случаях требуется регуляризация. Например, может применяться прототипная матрица H размера 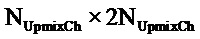
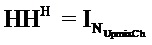
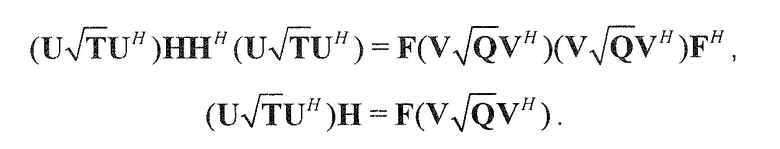
Из этого следует, что матрица F микширования может определяться следующим образом:
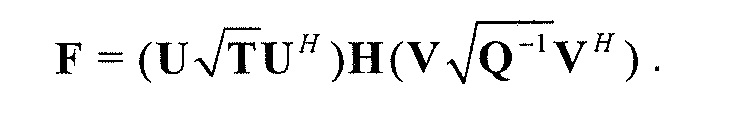
Прототипная матрица H выбрана согласно требуемым взвешиваниям для трактов передачи прямых и декоррелированных сигналов. Например, возможная прототипная матрица H может определяться следующим образом:
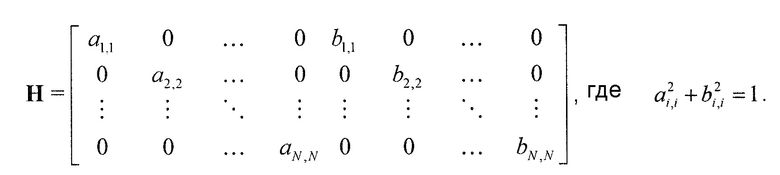
В зависимости от состояния ковариационной матрицы 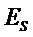
В качестве вывода, описан принцип для того, чтобы извлекать выходные аудиосигналы (представленные посредством матрицы 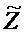
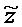
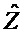
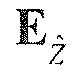 выходных аудиосигналов 1552a-1562n аппроксимирует или равна требуемой ковариантности C (также обозначаемой как "целевая ковариантность"). Требуемая ковариационная матрица C, например, может извлекаться на основе знаний матрицы R рендеринга (которые могут предоставляться, например, посредством пользовательского взаимодействия) и на основе знаний ковариационной матрицы
выходных аудиосигналов 1552a-1562n аппроксимирует или равна требуемой ковариантности C (также обозначаемой как "целевая ковариантность"). Требуемая ковариационная матрица C, например, может извлекаться на основе знаний матрицы R рендеринга (которые могут предоставляться, например, посредством пользовательского взаимодействия) и на основе знаний ковариационной матрицы 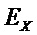
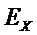
Тем не менее, альтернативно процессор 1570 вспомогательной информации также может непосредственно предоставлять матрицу F микширования в качестве информации 1574 в микшер 1598.
Кроме того, описано правило вычисления для матрицы F микширования, которое использует разложение по сингулярным значениям. Тем не менее, следует отметить, что имеются определенные степени свободы, поскольку могут быть выбраны записи 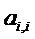
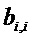
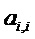
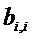
14.4. Упрощенные способы для коррекции выходной ковариантности
В этом разделе, описываются две альтернативных структуры для упомянутой выше матрицы F микширования вместе с примерными алгоритмами для определения ее значений. Две альтернативы разработаны для различного входного контента (например, аудиоконтента):
Способ регулирования ковариантности для высококоррелированного контента (например, канального ввода с высокой корреляцией между различными канальными парами).
Способ энергетической компенсации для независимых входных сигналов (например, объектно-ориентированного ввода, обычно предполагаемого независимым).
14.4.1. Способ (A) регулирования ковариантности
С учетом того, что сигнал 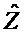
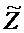
Если обрабатывается только смесь декоррелированных сигналов W, матрица P микширования может уменьшаться до единичной матрицы (или ее кратного). Таким образом, этот упрощенный способ может описываться посредством задания следующего:
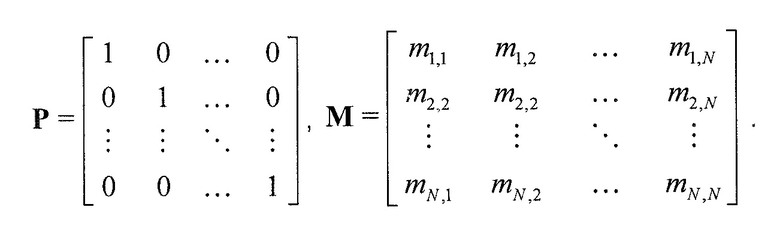
Конечный вывод системы может представляться следующим образом:
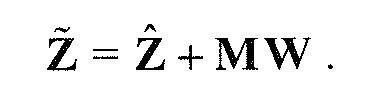
Следовательно, конечная выходная ковариантность системы может представляться следующим образом:
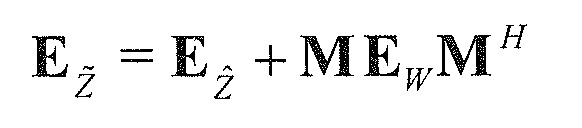
Разность 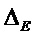
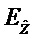
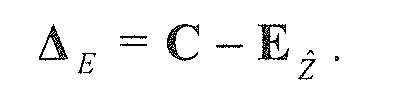
Следовательно, матрица M микширования определяется таким образом, что:
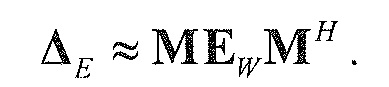
Матрица M микширования вычисляется таким образом, что ковариационная матрица микшированных декоррелированных сигналов MW равна или аппроксимирует разность ковариантности между требуемой ковариантностью и ковариантностью сухих сигналов (например, представленных посредством рендеринга аудиосигналов). Следовательно, ковариантность конечного вывода аппроксимирует целевую ковариантность 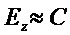
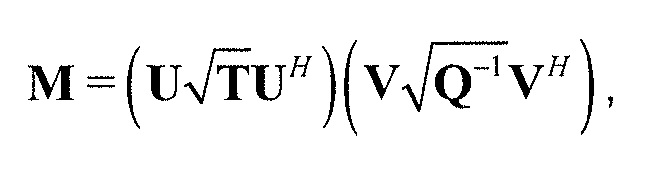
где матрицы U, T и V, Q могут определяться, например, с использованием разложения по сингулярным значениям (SVD) ковариационных матриц 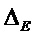
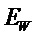
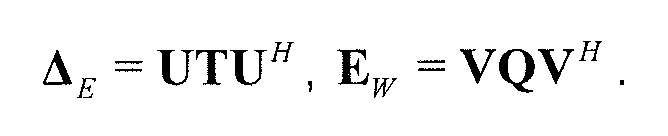
Этот подход обеспечивает хорошее восстановление взаимной корреляции, максимизирующее использование сухого вывода (например, представленных посредством рендеринга аудиосигналов 1582a-1582n), и использует только свободу микширования декоррелированных сигналов. Другими словами, не разрешается микширование между различными представленными посредством рендеринга аудиосигналами при комбинировании представленных посредством рендеринга аудиосигналов (или их масштабированной версии) с одним или более декоррелированными аудиосигналами. Тем не менее, разрешается то, что данный декоррелированный сигнал комбинирован, с идентичным или различным масштабированием, с множеством представленных посредством рендеринга аудиосигналов или их масштабированной версией, чтобы регулировать характеристики взаимной корреляции или характеристики взаимной ковариантности выходных аудиосигналов. Комбинация задается, например, посредством матрицы M, как задано здесь.
Далее предоставляются некоторые математические извлечения для ограниченной структуры матрицы F.
Другими словами, поясняется извлечение матрицы M микширования для упрощенного способа A.
Ковариационные матрицы 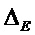
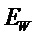
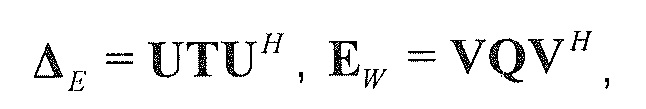
где T и Q являются диагональными матрицами с сингулярными значениями
Следует отметить, что применение триангуляции Шура или разложения по собственным значениям (вместо SVD) приводит к аналогичным результатам (или даже идентичным результатам, если диагональные матрицы Q и T ограничены положительными значениями).
При применении этого разложения к требованию 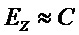
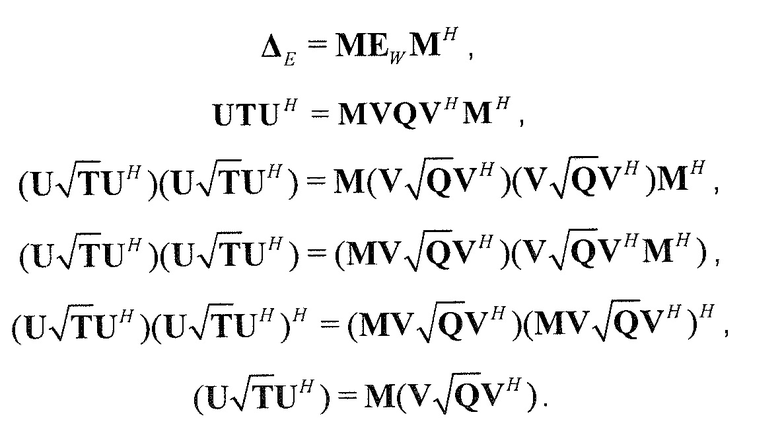
При этом отметим, что обе стороны уравнения представляют квадрат матрицы, отбрасывается возведение в квадрат и находится решение для полной матрицы M.
Из этого следует, что матрица M микширования может определяться следующим образом:
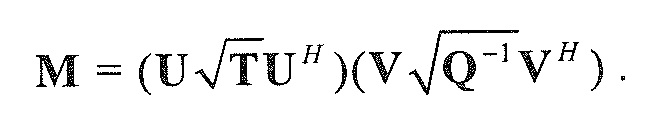
Этот способ может извлекаться из общего способа посредством задания прототипной матрицы H следующим образом:

В зависимости от состояния ковариационной матрицы 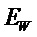
14.4.2. Способ (B) энергетической компенсации
Иногда (в зависимости от сценария применения) нежелательно разрешать микширование параметрических восстановлений (например, представленных посредством рендеринга аудиосигналов) или декоррелированных сигналов, а по отдельности микшировать каждый параметрически восстановленный сигнал (например, представленный посредством рендеринга аудиосигнал) только с собственным декоррелированным сигналом.
Чтобы достигать этого требования, дополнительное ограничение должно вводиться в упрощенный способ A. Теперь, матрица M микширования мокрых сигналов (декоррелированных сигналов) должна иметь диагональную форму:
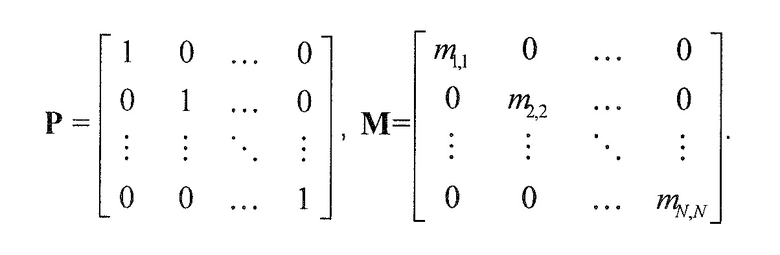
Основная цель этого подхода состоит в том, чтобы использовать декоррелированные сигналы для того, чтобы компенсировать потери энергии в параметрическом восстановлении (например, в представленном посредством рендеринга аудиосигнале), тогда как внедиагональная модификация ковариационной матрицы выходного сигнала игнорируется, т.е. отсутствует прямая обработка взаимных корреляций. Следовательно, взаимная утечка между выходными объектами/каналами (например, между представленными посредством рендеринга аудиосигналами) не вводится при применении декоррелированных сигналов.
Как результат, только главная диагональ целевой ковариационной матрицы (или требуемая ковариационная матрица) может быть достигнута, а не-диагонали полностью зависят от точности параметрического восстановления и суммированных декоррелированных сигналов. Этот способ является самым подходящим для только объектно-ориентированных вариантов применения, в которых сигналы могут считаться декоррелированными.
Конечный вывод способа (например, выходные аудиосигналы) задается посредством 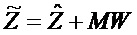
C может определяться так, как пояснено выше для общего случая.
Например, матрица M микширования может непосредственно извлекаться посредством деления требуемых энергий сигналов компенсации (разностей между требуемыми энергиями (которые могут описываться посредством диагональных элементов взаимной ковариационной матрицы C) и энергий параметрических восстановлений (которые могут определяться посредством аудиодекодера)) на энергии декоррелированных сигналов (которые могут определяться посредством аудиодекодера):
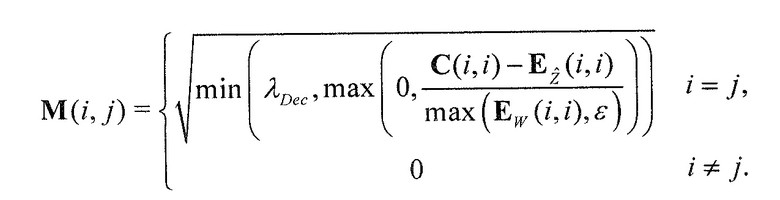
где 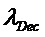
Следует отметить, что энергии могут быть восстановлены параметрически (например, с использованием OLD, IOC и коэффициентов рендеринга) или могут быть фактически вычислены посредством декодера (что типично является более вычислительно затратным).
Этот способ может извлекаться из общего способа посредством задания прототипной матрицы H следующим образом:

Этот способ максимизирует использование сухих представленных посредством рендеринга выводов явно. Способ является эквивалентным упрощению A, когда ковариационные матрицы не имеют внедиагональных записей.
Этот способ имеет уменьшенную вычислительную сложность.
Тем не менее, следует отметить, что способ энергетической компенсации необязательно подразумевает то, что члены взаимной корреляции не модифицируются. Это справедливо только в том случае, если используются идеальные декорреляторы, и отсутствует уменьшение сложности для модуля декорреляции. Идея способа состоит в том, чтобы восстанавливать энергию и игнорировать модификации в перекрестных членах (изменения перекрестных членов не модифицируют существенно свойства корреляции и не влияют на полное пространственное впечатление).
14.5. Требования для матрицы F микширования
Далее, поясняется то, что матрица F микширования, извлечение которой описано в разделах 14.3 и 14.4, удовлетворяет требованиям, чтобы исключать ухудшения.
Во избежание ухудшений в выводе, любой способ для компенсации ошибок параметрического восстановления должен формировать результат со следующим свойством: если матрица рендеринга равна матрице понижающего микширования, то выходные каналы должны быть равными (или, по меньшей мере, аппроксимировать) каналы понижающего микширования. Предложенная модель удовлетворяет этому свойству. Если матрица рендеринга равна матрице понижающего микширования, R=D, параметрическое восстановление задается следующим образом:
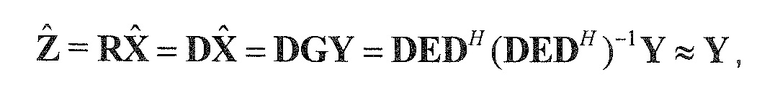
и требуемая ковариационная матрица является следующей:
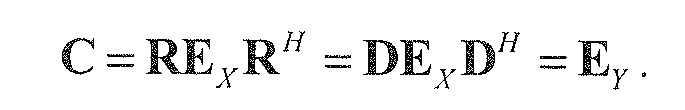
Следовательно, уравнение, которое должно быть решено для получения матрицы F микширования, следующее:
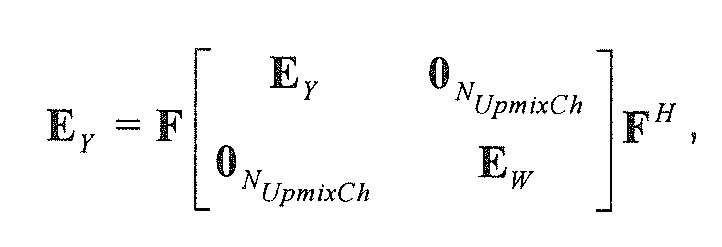
где 

Это означает то, что декоррелированные сигналы имеют нулевой весовой коэффициент в суммировании, и конечный вывод задается посредством сухих сигналов, которые являются идентичными с сигналами понижающего микширования:

Как результат, в этом сценарии рендеринга удовлетворяется данное требование для равенства системного вывода сигналу понижающего микширования.
14.6. Оценка ковариационной матрицы Es сигналов
Для того, чтобы получать матрицу F микширования, знание ковариационной матрицы 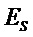
В принципе, можно оценивать ковариационную матрицу 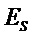
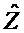
Хотя этот подход может приводить к более точным результатам, он может не быть практичным вследствие ассоциированной вычислительной сложности. Предложенные способы используют параметрические аппроксимации ковариационной матрицы
Общая структура ковариационной матрицы
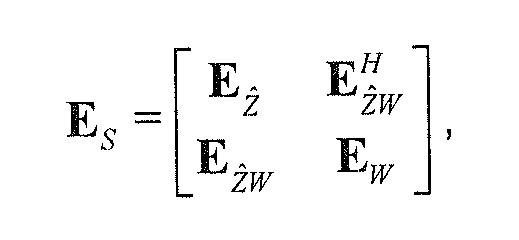
где матрица 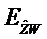
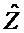
При условии, что декорреляторы являются идеальными (т.е. сохраняющими энергию, причем выводы являются ортогональным к вводам, и все выводы являются взаимно ортогональными), ковариационная матрица Es может выражаться с использованием упрощенной формы следующим образом:
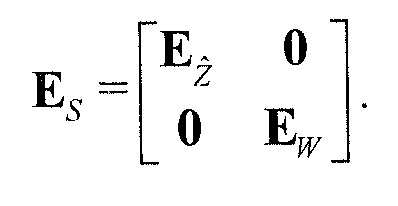
Ковариационная матрица 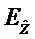
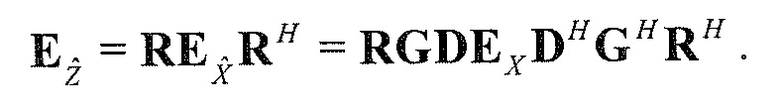
Ковариационная матрица 
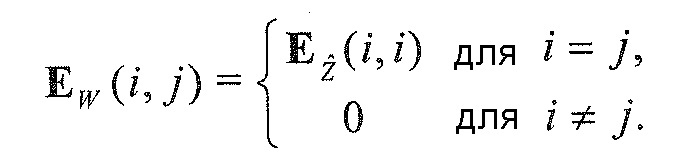
Если допущение в отношении взаимной ортогональности и/или сохранении энергии нарушается (например, в случае, когда число доступных декорреляторов меньше числа сигналов, которые должны быть декоррелированы), то ковариационная матрица
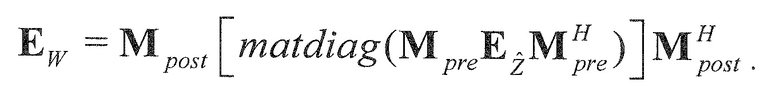
14.7. Необязательное улучшение: коррекция выходной ковариантности с использованием декоррелированных сигналов и модуля энергетического регулирования
Далее описывается сверхпреимущественный принцип, который может быть комбинирован с другими принципами, описанными в данном документе.
Предложенный способ для коррекции ошибок выходной ковариантности составляет выходной сигнал в качестве взвешенной суммы параметрически восстановленного сигнала 

При применении обозначения для комбинированной матрицы:
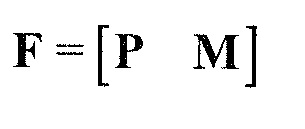
и сигнала:
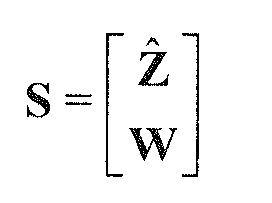
это дает в результате:

Тем не менее, следует отметить, что это уравнение может считаться самым общим формулированием. К вышеприведенной формуле необязательно может применяться изменение, которое является допустимым для всех "упрощенных способов", описанных в данном документе.
Далее описывается функциональность, которая может выполняться, например, посредством модуля энергетического регулирования.
Во избежание введения артефактов в конечном выводе, в крайних случаях, различные ограничения могут налагаться на матрицу F микширования (или матрицу микширования 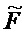
Способ, описанный в этом разделе, предлагает достигать этого посредством добавления этапа энергетического регулирования в блоке конечного выходного микширования. Цель такого этапа обработки состоит в том, чтобы обеспечивать то, что после этапа микширования с матрицей F (или "модифицированной" матрицей 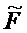
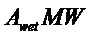
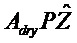
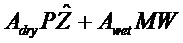
Эта дополнительная функциональность может достигаться посредством модификации определения комбинированной матрицы F микширования таким образом, что она представляет собой следующее:
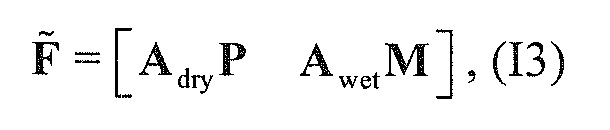
где две квадратных (или диагональных) матрицы 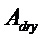
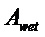
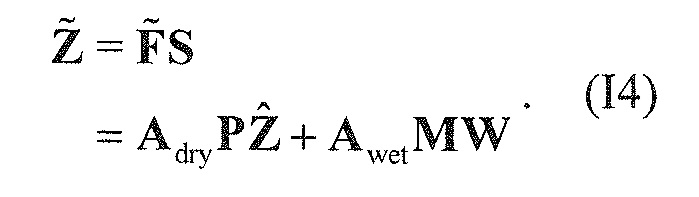
Сухие и мокрые матрицы 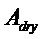
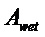
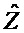
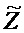
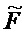
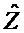
Сухие и мокрые матрицы 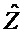
Одно возможное решение задается посредством следующих выражений:
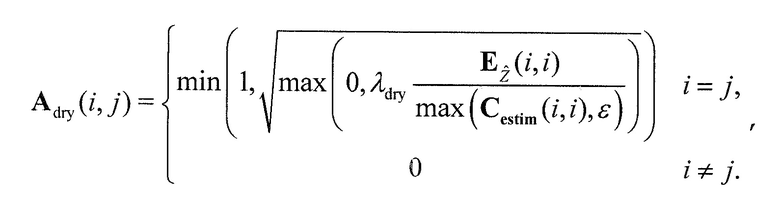
и:
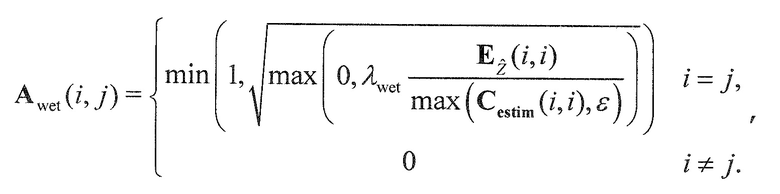
где 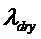
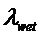
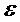
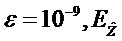
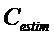
В вышеприведенных уравнениях, операция "max(.)" в знаменателе, которая предоставляет максимальное значение аргументов 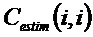
Например, 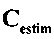 может задаваться следующим образом:
может задаваться следующим образом:
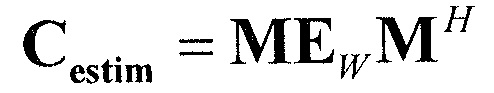 - оценка ковариационной матрицы мокрых сигналов после этапа микширования с матрицей M.
- оценка ковариационной матрицы мокрых сигналов после этапа микширования с матрицей M.
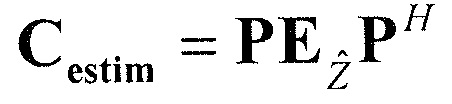 - оценка ковариационной матрицы сухих сигналов после этапа микширования с матрицей P.
- оценка ковариационной матрицы сухих сигналов после этапа микширования с матрицей P.
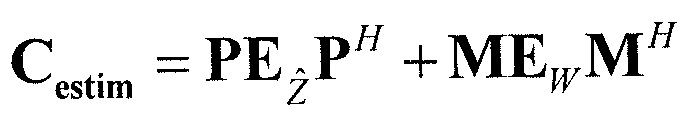 - оценка ковариационной матрицы выходных сигналов после этапа микширования с матрицей F.
- оценка ковариационной матрицы выходных сигналов после этапа микширования с матрицей F.
Далее описываются некоторые дополнительные упрощения. Другими словами, описываются упрощенные способы для коррекции выходной ковариантности.
С учетом того, что сигналы Z являются уже оптимальными в отношении MMSE, обычно нежелательно модифицировать параметрические восстановления 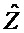
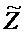
Если обрабатывается только смесь декоррелированных (мокрых) сигналов W, матрица P микширования может уменьшаться до единичной матрицы. В этом случае, матрица энергетического регулирования, соответствующая параметрически восстановленным (сухим) сигналам, также может уменьшаться до единичной матрицы. Таким образом, этот упрощенный способ может описываться посредством задания следующего:
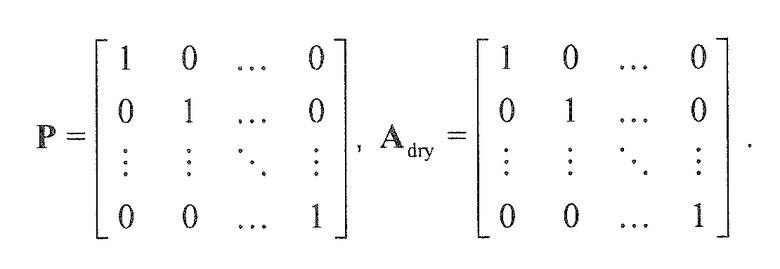
Конечный вывод системы может представляться следующим образом:
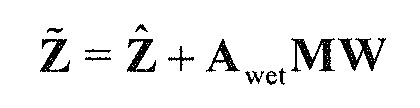
15. Уменьшение сложности для модуля декорреляции
Далее описывается то, как может уменьшаться сложность декорреляторов, используемых в вариантах осуществления согласно настоящему изобретению.
Следует отметить, что реализация функции декоррелятора зачастую является вычислительно сложной. В некоторых вариантах применения (например, в решениях для портативных декодеров), ограничения на число декорреляторов, возможно, должны вводиться вследствие ограниченных вычислительных ресурсов. Этот раздел предоставляет описание средств для уменьшения сложности модуля декорреляции посредством управления числом применяемых декорреляторов (или декорреляций). Интерфейс модуля декорреляции проиллюстрирован на фиг. 16 и 17.
Фиг. 16 показывает принципиальную блок-схему простого (традиционного) модуля декорреляции. Модуль 1600 декорреляции согласно фиг. 6 выполнен с возможностью принимать N входных сигналов 1610a-1610n декоррелятора, таких как, например, представленные посредством рендеринга аудиосигналы 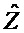
Тем не менее, фиг. 17 показывает принципиальную блок-схему модуля 1700 декорреляции с меньшей сложностью. Модуль 1700 декорреляции с меньшей сложностью выполнен с возможностью принимать N входных сигналов 1710a-1710n декоррелятора и предоставлять, на их основе, N выходных сигналов 1712a-1712n декоррелятора. Например, входные сигналы 1710a-1710n декоррелятора могут представлять собой представленные посредством рендеринга аудиосигналы
Декоррелятор 1700 содержит предварительный микшер 1720 (или эквивалентно, функциональность предварительного микширования), который выполнен с возможностью принимать первый набор из N входных сигналов 1710a-1710n декоррелятора и предоставлять, на их основе, второй набор из K входных сигналов 1722a-1722k декоррелятора. Например, предварительный микшер 1720 может выполнять так называемое "предварительное микширование" или "понижающее микширование", чтобы извлекать второй набор из K входных сигналов 1722a-1722k декоррелятора на основе первого набора N входных сигналов 1710a-1710n декоррелятора. Например, K сигналов второго набора из K входных сигналов 1722a-1722k декоррелятора могут быть представлены с использованием матрицы 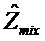
Модуль 1700 декорреляции также содержит постмикшер 1740, который выполнен с возможностью принимать K выходных сигналов 1732a-1732k декоррелятора из первого набора выходных сигналов декоррелятора и предоставлять, на их основе, N сигналов 1712a-1712n из второго набора выходных сигналов декоррелятора (которые составляют "внешние" выходные сигналы декоррелятора).
Следует отметить, что предварительный микшер 1720 предпочтительно может выполнять операцию линейного микширования, которая может описываться посредством матрицы Mpre предварительного микширования. Кроме того, постмикшер 1740 предпочтительно выполняет операцию линейного микширования (или повышающего микширования), которая может быть представлена посредством матрицы Mpost постмикширования, чтобы извлекать N выходных сигналов 1712a-1712n декоррелятора из второго набора выходных сигналов декоррелятора из первого набора из K выходных сигналов 1732a-1732k декоррелятора (т.е. из выходных сигналов ядра 1730 декоррелятора).
Основная идея предложенного способа и устройства состоит в том, чтобы сокращать число входных сигналов в декорреляторы (или в ядро декоррелятора) с N до k посредством следующего:
- Предварительное микширование сигналов (например, представленных посредством рендеринга аудиосигналов) в меньшее число каналов с помощью:
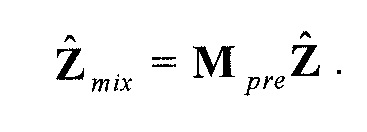
- Применение декорреляции с использованием доступных K декорреляторов (например, ядра декоррелятора) с помощью:
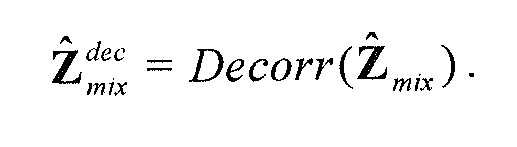
- Повышающее микширование декоррелированных сигналов обратно в N каналов с помощью:
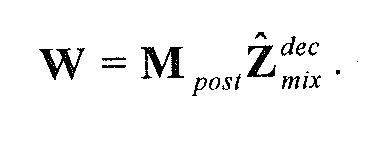
Матрица Mpre предварительного микширования может составляться на основе информации понижающего микширования/рендеринга/корреляции/и т.д. таким образом, что матричное произведение (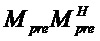
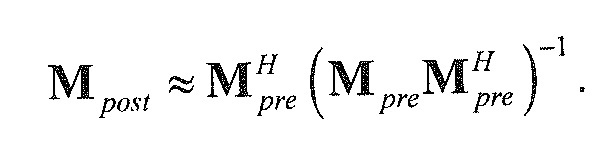
Даже если ковариационная матрица промежуточных декоррелированных сигналов 
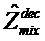
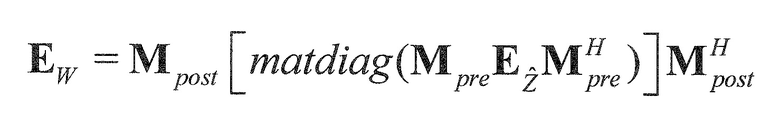
Число используемых декорреляторов (или отдельных декорреляций), k, не указывается и зависит от требуемой вычислительной сложности и доступных декорреляторов. Его значение может варьироваться от N (наибольшая вычислительная сложность) до 1 (наименьшая вычислительная сложность).
Число входных сигналов в модуль декорреляции, N, является произвольным, и предложенный способ поддерживает любое число входных сигналов, независимо от конфигурации рендеринга системы.
Например, в вариантах применения с использованием трехмерного аудиоконтента, с высоким числом выходных каналов, в зависимости от выходной конфигурации одно возможное выражение для матрицы предварительного микширования Mpre описывается ниже.
Далее описывается то, как предварительное микширование, которое выполняется посредством предварительного микшера 1720 (и следовательно, постмикширование, которое выполняется посредством постмикшера 1740), регулируется, если модуль 1700 декорреляции используется в многоканальном аудиодекодере, при этом входные сигналы 1710a-1710n декоррелятора из первого набора входных сигналов декоррелятора ассоциированы с различными пространственными позициями аудиосцены.
С этой целью, фиг. 18 показывает табличное представление позиций громкоговорителей, которые используются для различных выходных форматов.
В таблице 1800 по фиг. 18, первый столбец 1810 описывает числовой индекс громкоговорителя. Второй столбец 1820 описывает метку громкоговорителя. Третий столбец 1830 описывает азимутальную позицию соответствующего громкоговорителя, и четвертый столбец 1832 описывает азимутальный допуск позиции громкоговорителя. Пятый столбец 1840 описывает подъем позиции соответствующего громкоговорителя, и шестой столбец 1842 описывает соответствующий допуск по подъему. Седьмой столбец 1850 указывает, какие громкоговорители используются для выходного формата 0-2.0. Восьмой столбец 1860 показывает то, какие громкоговорители используются для выходного формата 0-5.1. Девятый столбец 1864 показывает то, какие громкоговорители используются для выходного формата 0-7.1. Десятый столбец 1870 показывает то, какие громкоговорители используются для выходного формата 0-8.1, одиннадцатый столбец 1880 показывает то, какие громкоговорители используются для выходного формата 0-10.1, и двенадцатый столбец 1890 показывает то, какие громкоговорители используются для выходного формата 0-22.2. Как можно видеть, два громкоговорителя используются для выходного формата 0-2.0, шесть громкоговорителей используются для выходного формата 0-5.1, восемь громкоговорителей используются для выходного формата 0-7.1, девять громкоговорителей используются для выходного формата 0-8.1, 11 громкоговорителей используются для выходного формата 0-10.1, и 24 громкоговорителя используются для выходного формата 0-22.2.
Тем не менее, следует отметить, что один громкоговоритель с низкочастотным эффектом используется для выходных форматов 0-5.1, 0-7.1, 0-8.1 и 0-10.1, и что два громкоговорителя (LFE1, LFE2) с низкочастотным эффектом используются для выходного формата 0-22.2. Кроме того, следует отметить, что в предпочтительном варианте осуществления, один представленный посредством рендеринга аудиосигнал (например, один из представленных посредством рендеринга аудиосигналов 1582a-1582n) ассоциирован с каждым из громкоговорителей, за исключением одного или более громкоговорителей с низкочастотным эффектом. Соответственно, два представленных посредством рендеринга аудиосигнала ассоциированы с двумя громкоговорителями, используемыми согласно формату 0-2.0, пять представленных посредством рендеринга аудиосигналов ассоциированы с пятью громкоговорителями без низкочастотного эффекта, если используется формат 0-5.1, семь представленных посредством рендеринга аудиосигналов ассоциированы с семью громкоговорителями без низкочастотного эффекта, если используется формат 0-7.1, восемь представленных посредством рендеринга аудиосигналов ассоциированы с восемью громкоговорителями без низкочастотного эффекта, если используется формат 0-8.1, десять представленных посредством рендеринга аудиосигналов ассоциированы с десятью громкоговорителями без низкочастотного эффекта, если используется формат 0-10.1, и 22 представленных посредством рендеринга аудиосигнала ассоциированы с 22 громкоговорителями без низкочастотного эффекта, если используется формат 0-22.2.
Тем не менее, часто желательно использовать меньшее число (отдельных) декорреляторов (ядра декоррелятора), как упомянуто выше. Далее описывается то, как число декорреляторов может гибко уменьшаться, когда выходной формат 0-22.2 используется посредством многоканального аудиодекодера, так что предусмотрено 22 представленных посредством рендеринга аудиосигнала 1582a-1582n (которые могут быть представлены посредством матрицы 
Фиг. 19a-19g представляют различные варианты для предварительного микширования представленных посредством рендеринга аудиосигналов 1582a-1582n при допущении, что имеется N=22 представленных посредством рендеринга аудиосигнала. Например, фиг. 19a показывает табличное представление записей матрицы Mpre предварительного микширования. Строки, помеченные 1-11 на фиг. 19a, представляют строки матрицы Mpre предварительного микширования, и столбцы, помеченные 1-22, ассоциированы со столбцами матрицы Mpre предварительного микширования. Кроме того, следует отметить, что каждая строка матрицы Mpre предварительного микширования ассоциирована с одним из K входных сигналов 1722a-1722k декоррелятора из второго набора входных сигналов декоррелятора (т.е. с входными сигналами ядра декоррелятора). Кроме того, каждый столбец матрицы Mpre предварительного микширования ассоциирован с одним из N входных сигналов 1710a-1710n декоррелятора из первого набора входных сигналов декоррелятора, и, следовательно, с одним из представленных посредством рендеринга аудиосигналов 1582a-1582n (поскольку входные сигналы 1710a-1710n декоррелятора из первого набора входных сигналов декоррелятора типично являются идентичными представленным посредством рендеринга аудиосигналам 1582-1582n в варианте осуществления). Соответственно, каждый столбец матрицы Mpre предварительного микширования ассоциирован с конкретным громкоговорителем, и, следовательно, поскольку громкоговорители ассоциированы с пространственными позициями, с конкретной пространственной позицией. Строка 1910 указывает то, с каким громкоговорителем (и следовательно, с какой пространственной позицией) ассоциированы столбцы матрицы Mpre предварительного микширования (при этом метки громкоговорителей задаются в столбце 1820 таблицы 1800).
Далее подробнее описывается функциональность, заданная посредством предварительного микширования Mpre по фиг. 19a. Как можно видеть, представленные посредством рендеринга аудиосигналы, ассоциированные с динамиками (или, эквивалентно, позициями динамиков) "CH_M_000" и "CH_L_000", комбинированы с возможностью получать первый входной сигнал декоррелятора из второго набора входных сигналов декоррелятора (т.е. первый микшированный с понижением входной сигнал декоррелятора), который указывается посредством значений в "1" в первом и втором столбце первой строки матрицы предварительного микширования Mpre Аналогично, представленные посредством рендеринга аудиосигналы, ассоциированные с динамиками (или, эквивалентно, позициями динамиков) "CH_U_000" и "CH_T_000" комбинированы с возможностью получать второй микшированный с понижением входной сигнал декоррелятора (т.е. второй входной сигнал декоррелятора из второго набора входных сигналов декоррелятора). Кроме того, можно видеть, что матрица Mpre предварительного микширования по фиг. 19a задает одиннадцать комбинаций из двух представленных посредством рендеринга аудиосигналов, так что одиннадцать микшированных с понижением входных сигналов декоррелятора извлекаются из 22 представленных посредством рендеринга аудиосигналов. Также можно видеть, что четыре центральных сигнала комбинированы с возможностью получать два микшированных с понижением входных сигнала декоррелятора (см. столбцы 1-4 и строки 1 и 2 матрицы предварительного микширования). Кроме того, можно видеть, что другие микшированные с понижением входные сигналы декоррелятора получены посредством комбинирования двух аудиосигналов, ассоциированных с идентичной стороной аудиосцены. Например, третий микшированный с понижением входной сигнал декоррелятора, представленный посредством третьей строки матрицы предварительного микширования, получается посредством комбинирования представленных посредством рендеринга аудиосигналов, ассоциированных с азимутальной позицией +135° ("CH_M_L135"; "CH_U_L135"). Кроме того, можно видеть, что четвертый входной сигнал декоррелятора (представленный посредством четвертой строки матрицы предварительного микширования) получается посредством комбинирования представленных посредством рендеринга аудиосигналов, ассоциированных с азимутальной позицией -135° ("CH_M_R135"; "CH_U_R135"). Соответственно, каждый из микшированных с понижением входных сигналов декоррелятора получается посредством комбинирования двух представленных посредством рендеринга аудиосигналов, ассоциированных с идентичной (или аналогичной) азимутальной позицией (или, эквивалентно, горизонтальной позицией), при этом типично предусмотрена комбинация сигналов, ассоциированных с различным подъемом (или, эквивалентно, вертикальной позицией).
Обратимся теперь к фиг. 19b, который показывает коэффициенты предварительного микширования (записи матрицы Mpre предварительного микширования) для N=22 и K=10. Структура таблицы по фиг. 19b является идентичной структуре таблицы по фиг. 19a. Тем не менее, как можно видеть, матрица Mpre предварительного микширования согласно фиг. 19b отличается от матрицы Mpre предварительного микширования по фиг. 19a тем, что первая строка описывает комбинацию четырех представленных посредством рендеринга аудиосигналов, имеющих идентификаторы каналов (или позиции) "CH_M_000", "CH_L_000", "CH_U_000" и "CH_T_000". Другими словами, четыре представленных посредством рендеринга аудиосигнала, ассоциированные с вертикально смежными позициями, комбинированы в предварительное микширование, чтобы сокращать число требуемых декорреляторов (десять декорреляторов вместо одиннадцати декорреляторов для матрицы согласно фиг. 19a).
Если обратиться теперь к фиг. 19c, который показывает коэффициенты предварительного микширования (записи матрицы Mpre предварительного микширования) для N=22 и K=9, можно видеть, что матрица Mpre предварительного микширования согласно фиг. 19c содержит только девять строк. Кроме того, из второй строки матрицы Mpre предварительного микширования по фиг. 19c можно видеть, что представленные посредством рендеринга аудиосигналы, ассоциированные с идентификаторами каналов (или позициями) "CH_M_L135", "CH_U_L135", "CH_M_R135" и "CH_U_R135", комбинированы (в предварительном микшере, сконфигурированном согласно матрице предварительного микширования по фиг. 19c) с возможностью получать второй микшированный с понижением входной сигнал декоррелятора (входной сигнал декоррелятора из второго набора входных сигналов декоррелятора). Как можно видеть, представленные посредством рендеринга аудиосигналы, которые комбинированы в отдельные микшированные с понижением входные сигналы декоррелятора посредством матриц предварительного микширования согласно фиг. 19a и 19b, микшированы с понижением в общий микшированный с понижением входной сигнал декоррелятора согласно фиг. 19c. Кроме того, следует отметить, что представленные посредством рендеринга аудиосигналы, имеющие идентификаторы каналов "CH_M_L135" и "CH_U_L135", ассоциированы с идентичными горизонтальными позициями (или азимутальными позициями) на идентичной стороне аудиосцены и пространственно смежными вертикальными позициями (или подъемами), и что представленные посредством рендеринга аудиосигналы, имеющие идентификаторы каналов "CH_M_R135" и "CH_U_R135", ассоциированы с идентичными горизонтальными позициями (или азимутальными позициями) на второй стороне аудиосцены и пространственно смежными вертикальными позициями (или подъемами). Кроме того, можно сказать, что представленные посредством рендеринга аудиосигналы, имеющие идентификаторы каналов "CH_M_L135", "CH_U_L135", "CH_M_R135" и "CH_U_R135", ассоциированы с горизонтальной парой (или даже горизонтальной четверкой) пространственных позиций, содержащих левостороннюю позицию и правостороннюю позицию. Другими словами, во второй строке матрицы Mpre предварительного микширования по фиг. 19c можно видеть, что два из четырех представленных посредством рендеринга аудиосигналов, которые комбинированы для декорреляции с использованием одного данного декоррелятора, ассоциированы с пространственными позициями в левой стороне аудиосцены, и что два из четырех представленных посредством рендеринга аудиосигналов, которые комбинированы для декорреляции с использованием идентичного данного декоррелятора, ассоциированы с пространственными позициями в правой стороне аудиосцены. Кроме того, можно видеть, что левосторонние представленные посредством рендеринга аудиосигналы (из упомянутых четырех представленных посредством рендеринга аудиосигналов) ассоциированы с пространственными позициями, которые являются симметричными, относительно центральной плоскости аудиосцены, с пространственными позициями, ассоциированными с правосторонними представленными посредством рендеринга аудиосигналами (из упомянутых четырех представленных посредством рендеринга аудиосигналов), так что "симметричная" четверка представленных посредством рендеринга аудиосигналов комбинирована посредством предварительного микширования для декорреляции с использованием одного (отдельного) декоррелятора.
Если обратиться к фиг. 19d, 19e, 19f и 19g, можно видеть, что все большее число представленных посредством рендеринга аудиосигналов комбинированы с сокращением числа (отдельных) декорреляторов (т.е. со снижением K). Как можно видеть на фиг. 19a-19g, типично представленные посредством рендеринга аудиосигналы, которые микшированы с понижением в два отдельных микшированных с понижением входных сигнала декоррелятора, комбинированы при сокращении числа декорреляторов посредством 1. Кроме того, можно видеть, что типично комбинируются такие представленные посредством рендеринга аудиосигналы, которые ассоциированы с "симметричной четверкой" пространственных позиций, при этом, для сравнительно высокого числа декорреляторов, комбинируются только представленные посредством рендеринга аудиосигналы, ассоциированные с равными или, по меньшей мере, аналогичными горизонтальными позициями (или азимутальными позициями), тогда как для сравнительно меньшего числа декорреляторов, также комбинируются представленные посредством рендеринга аудиосигналы, ассоциированные с пространственными позициями на противоположных сторонах аудиосцены.
Если обратиться теперь к фиг. 20a-20d, 21a-21c, 22a-22b и 23, следует отметить, что аналогичные принципы также могут применяться для различного числа представленных посредством рендеринга аудиосигналов.
Например, фиг. 20a-20d описывают записи матрицы Mpre предварительного микширования для N=10 и для K между 2 и 5.
Аналогично, фиг. 21a-21c описывают записи матрицы Mpre предварительного микширования для N=8 и K между 2 и 4.
Аналогично, фиг. 21d-21f описывают записи матрицы Mpre предварительного микширования для N=7 и K между 2 и 4.
Фиг. 22a и 22b показывают записи матрицы предварительного микширования для N=5 и K=2 и K=3.
В завершение, фиг. 23 показывает записи матрицы предварительного микширования для N=2 и K=1.
Если обобщать, матрицы предварительного микширования согласно фиг. 19-23 могут использоваться, например, переключаемым способом, в многоканальном декорреляторе, который является частью многоканального аудиодекодера. Переключение между матрицами предварительного микширования может выполняться, например, в зависимости от требуемой выходной конфигурации (которая типично определяет число N представленных посредством рендеринга аудиосигналов), а также в зависимости от требуемой сложности декорреляции (которая определяет параметр K и которая может регулироваться, например, в зависимости от информации сложности, включенной в кодированное представление аудиоконтента).
Если обратиться теперь к фиг. 24, подробнее описывается уменьшение сложности для выходного 22.2-формата. Как уже указано выше, одно возможное решение для составления матрицы предварительного микширования и матрицы постмикширования состоит в том, чтобы использовать пространственную информацию схемы размещения для воспроизведения, чтобы выбирать каналы, которые должны микшироваться, и вычислять коэффициенты микширования. На основе их позиции, геометрически связанные громкоговорители (и, например, представленные посредством рендеринга аудиосигналы, ассоциированные кроме того) группируются между собой, с рассмотрением вертикальных и горизонтальных пар, как описано в таблице по фиг. 24. Другими словами, фиг. 24 показывает, в форме таблицы, группировку позиций громкоговорителей, которые могут быть ассоциированы с представленными посредством рендеринга аудиосигналами. Например, первая строка 2410 описывает первую группу позиций громкоговорителей, которые находятся в центре аудиосцены. Вторая строка 2412 представляет вторую группу позиций громкоговорителей, которые пространственно связаны. Позиции громкоговорителей "CH_M_L135" и "CH_U_L135" ассоциированы с идентичными азимутальными позициями (или эквивалентно горизонтальными позициями) и смежными позициями подъема (или эквивалентно, вертикально смежными позициями). Аналогично, позиции "CH_M_R135" и "CH_U_R135" содержат идентичный азимут (или, эквивалентно, идентичную горизонтальную позицию) и аналогичный подъем (или, эквивалентно, вертикально смежную позицию). Кроме того, позиции "CH_M_L135", "CH_U_L135", "CH_M_R135" и "CH_U_R135" формируют четверку позиций, в которой позиции "CH_M_L135" и "CH_U_L135" являются симметричными позициям "CH_M_R135" и "CH_U_R135" относительно осевой плоскости аудиосцены. Кроме того, позиции "CH_M_180" и "CH_U_180" также содержат идентичную азимутальную позицию (или, эквивалентно, идентичную горизонтальную позицию) и аналогичный подъем (или, эквивалентно, смежную вертикальную позицию).
Третья строка 2414 представляет третью группу позиций. Следует отметить, что позиции "CH_M_L030" и "CH_L_L045" являются пространственно смежными позициями и содержат аналогичный азимут (или, эквивалентно, аналогичную горизонтальную позицию) и аналогичный подъем (или, эквивалентно, аналогичную вертикальную позицию). То же справедливо для позиций "CH_M_R030" и "CH_L_R045". Кроме того, позиции третьей группы позиций формируют четверку позиций, в которой позиции "CH_M_L030" и "CH_L_L045" являются пространственно смежными и симметричными относительно осевой плоскости аудиосцены позициям "CH_M_R030" и "CH_L_R045".
Четвертая строка 2416 представляет четыре дополнительных позиции, которые имеют аналогичные характеристики, по сравнению с первыми четырьмя позициями второй строки, и которые формируют симметричную четверку позиций.
Пятая строка 2418 представляет другую четверку симметричных позиций "CH_M_L060", "CH_U_L045", "CH_M_R060" и "CH_U_R045".
Кроме того, следует отметить, что представленные посредством рендеринга аудиосигналы, ассоциированные с позициями различных групп позиций, могут быть комбинированы все в большем числе с сокращением числа декорреляторов. Например, при наличии одиннадцати отдельных декорреляторов в многоканальном декорреляторе, представленные посредством рендеринга аудиосигналы, ассоциированные с позициями в первом и втором столбце, могут быть комбинированы для каждой группы. Помимо этого, представленные посредством рендеринга аудиосигналы, ассоциированные с позициями, представленными в третьем и четвертом столбце, могут быть комбинированы для каждой группы. Кроме того, представленные посредством рендеринга аудиосигналы, ассоциированные с позициями, показанными в пятом и шестом столбце, могут быть комбинированы для второй группы. Соответственно, могут получаться одиннадцать входных сигналов декоррелятора понижающего микширования (которые вводятся в отдельные декорреляторы). Тем не менее, если требуется иметь меньше отдельных декорреляторов, представленные посредством рендеринга аудиосигналы, ассоциированные с позициями, показанными в столбцах 1-4, могут быть комбинированы для одной или более групп. Кроме того, представленные посредством рендеринга аудиосигналы, ассоциированные со всеми позициями второй группы, могут быть комбинированы, если требуется дополнительно сокращать число отдельных декорреляторов.
Если обобщать, сигналы, подаваемые в выходную схему размещения (например, в динамики), имеют горизонтальные и вертикальные зависимости, которые должны сохраняться во время процесса декорреляции. Следовательно, коэффициенты микширования вычисляются таким образом, что каналы, соответствующие различным группам громкоговорителя, не микшируются.
В зависимости от числа доступных декорреляторов или требуемого уровня декорреляции, в каждой группе сначала микшируются вертикальные пары (между средним уровнем и верхним уровнем или между средним уровнем и нижним уровнем). Во-вторых, микшируются горизонтальные пары (между левым и правым) или оставшиеся вертикальные пары. Например, в группе три, сначала микшируются каналы в левой вертикальной паре ("CH_M_L030" и "CH_L_L045") и в правой вертикальной паре ("CH_M_R030" и "CH_L_R045"), за счет этого сокращая число требуемых декорреляторов для этой группы с четырех до двух. Если требуется сокращать еще больше число декорреляторов, полученная горизонтальная пара микширована с понижением только в один канал, и число требуемых декорреляторов для этой группы уменьшается с четырех до одного.
На основе представленных правил микширования, вышеупомянутые таблицы (например, показанные на фиг. 19-23) извлекаются для разных уровней требуемой декорреляции (или для разных уровней требуемой сложности декорреляции).
16. Совместимость со вторичным внешним модулем рендеринга/преобразователем форматов
В случае, когда SAOC-декодер (или, если обобщать, многоканальный аудиодекодер) используется вместе с внешним вторичным модулем рендеринга/преобразователем форматов, могут использоваться следующие изменения предложенного принципа (способа или устройства):
- внутренняя матрица R рендеринга (например, модуля рендеринга) задается равной идентификатору 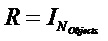
- число декорреляторов уменьшается с использованием способа, описанного в разделе 15, с матрицей Mpre предварительного микширования, вычисленной на основе информации обратной связи, принимаемой из модуля рендеринга/преобразователя форматов (например, 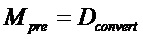

С использованием внешнего преобразователя форматов, внутренний модуль SAOC-рендеринга должен предварительно осуществлять рендеринг в промежуточную конфигурацию (например, конфигурацию с наибольшим числом громкоговорителей).
В качестве вывода, в некоторых вариантах осуществления информация относительно того, какие из выходных аудиосигналов микшируются во внешнем модуле рендеринга или преобразователе форматов, используется для того, чтобы определять матрицу Mpre предварительного микширования, так что матрица предварительного микширования задает комбинацию таких входных сигналов декоррелятора (первого набора входных сигналов декоррелятора), которые фактически комбинированы во внешнем модуле рендеринга. Таким образом, информация, принимаемая из внешнего модуля рендеринга/преобразователя форматов (который принимает выходные аудиосигналы многоканального декодера), используется для того, чтобы выбирать или регулировать матрицу предварительного микширования (например, когда внутренняя матрица рендеринга многоканального аудиодекодера задается равной идентификатору или инициализируется с коэффициентами микширования, извлекаемыми из промежуточной конфигурации рендеринга), и внешний модуль рендеринга/преобразователь форматов соединен, чтобы принимать выходные аудиосигналы, как упомянуто выше относительно многоканального аудиодекодера.
17. Поток битов
Далее описывается то, какая дополнительная служебная информация может использоваться в потоке битов (или эквивалентно, в кодированном представлении аудиоконтента). В вариантах осуществления согласно изобретению, способ декорреляции может сигнализироваться в потоке битов для обеспечения требуемого уровня качества. Таким образом, пользователь (или аудиокодер) имеет большую гибкость в том, чтобы выбирать способ на основе контента. С этой целью, синтаксис MPEG SAOC-потока битов, например, может быть расширен на два бита для указания используемого способа декорреляции и/или два бита для указания конфигурации (или сложности).
Фиг. 25 показывает синтаксическое представление элементов bsDecorrelationMethod и bsDecorrelationLevel потока битов, которые могут добавляться, например, в часть SAOCSpecifigConfig() или SAOC3DSpecificConfig() потока битов. Как можно видеть на фиг. 25, два бита могут использоваться для элемента bsDecorrelationMethod потока битов, и два бита могут использоваться для элемента bsDecorrelationLevel потока битов.
Фиг. 26 показывает, в форме таблицы, ассоциирование между значениями переменной bsDecorrelationMethod потока битов и различными способами декорреляции. Например, три различных способа декорреляции могут сигнализироваться посредством различных значений упомянутой переменной потока битов. Например, коррекция выходной ковариантности с использованием декоррелированных сигналов, как описано, например, в разделе 14.3, может сигнализироваться в качестве одного из вариантов. В качестве другого варианта, может сигнализироваться способ регулирования ковариантности, например, как описано в разделе 14.4.1. В качестве еще одного другого варианта, может сигнализироваться способ энергетической компенсации, например, как описано в разделе 14.4.2. Соответственно, три различных способа для восстановления характеристик сигналов выходных аудиосигналов на основе представленных посредством рендеринга аудиосигналов и декоррелированных аудиосигналов могут выбираться в зависимости от переменной потока битов.
Режим энергетической компенсации использует способ, описанный в разделе 14.4.2, режим ограниченного регулирования ковариантности использует способ, описанный в разделе 14.4.1, а режим общего регулирования ковариантности использует способ, описанный в разделе 14.3.
Если обратиться теперь к фиг. 27, который показывает, в форме табличного представления, как различные уровни декорреляции могут сигнализироваться посредством переменной bsDecorrelationLevel потока битов, описывается способ для выбора сложности декорреляции. Другими словами, упомянутая переменная может оцениваться посредством многоканального аудиодекодера, содержащего многоканальный декоррелятор, описанный выше, чтобы определять то, какая сложность декорреляции используется. Например, упомянутый параметр потока битов может сигнализировать различные "уровни" декорреляции, которые могут быть обозначены с помощью значений: 0, 1, 2 и 3.
Пример конфигураций декорреляции (которые, например, могут обозначаться как "уровни декорреляции") приведен в таблице по фиг. 27. Фиг. 27 показывает табличное представление числа декорреляторов для различных "уровней" (например, уровней декорреляции) и выходных конфигураций. Другими словами, фиг. 27 показывает число K входных сигналов декоррелятора (второго набора входных сигналов декоррелятора), которые используются посредством многоканального декоррелятора. Как можно видеть в таблице по фиг. 27, число (отдельных) декорреляторов, используемых в многоканальном декорреляторе, переключается между 11, 9,7 и 5 для выходной 22.2-конфигурации в зависимости от того, какой "уровень декорреляции" сигнализируется посредством параметра bsDecorrelationLevel потока битов. Для выходной 10.1-конфигурации, выбор осуществляется между 10, 5, 3 и 2 отдельными декорреляторами, для 8.1-конфигурации, выбор осуществляется между 8, 4, 3 или 2 отдельными декорреляторами, и для выходной 7.1-конфигурации, выбор осуществляется между 7, 4, 3 и 2 декорреляторами в зависимости от "уровня декорреляции", сигнализируемого посредством упомянутого параметра потока битов. В выходной 5.1-конфигурации, предусмотрено только три допустимых варианта для чисел отдельных декорреляторов, а именно, 5, 3 или 2. Для выходной 2.1-конфигурации, предусмотрен только выбор между двумя отдельными декорреляторами (уровень 0 декорреляции) и одним отдельным декоррелятором (уровень 1 декорреляции).
Если обобщать, способ декорреляции может определяться на стороне декодера на основе вычислительной мощности и доступного числа декорреляторов. Помимо этого, выбор числа декорреляторов может осуществляться на стороне кодера и сигнализироваться с использованием параметра потока битов.
Соответственно, как способ того, как применяются декоррелированные аудиосигналы, чтобы получать выходные аудиосигналы, так и сложность для инициализации декоррелированных сигналов может управляться со стороны аудиокодера с использованием параметров потока битов, показанных на фиг. 25 и подробнее заданных на фиг. 26 и 27.
18. Области применения для изобретаемой обработки
Следует отметить, что одна из целей введенных способов заключается в том, чтобы восстанавливать сигнальные аудиометки, которые имеют большую важность для человеческого восприятия аудиосцены. Варианты осуществления согласно изобретению повышают точность восстановления свойств энергетического уровня и корреляции и, следовательно, увеличивают перцепционное качество звучания конечного выходного сигнала. Варианты осуществления согласно изобретению могут применяться для произвольного числа каналов понижающего микширования/повышающего микширования. Кроме того, способы и устройства, описанные в данном документе, могут быть комбинированы с существующими алгоритмами разделения параметрических источников. Варианты осуществления согласно изобретению дают возможность управлять вычислительной сложностью системы посредством задания ограничений на число применяемых функций декоррелятора. Варианты осуществления согласно изобретению могут приводить к упрощению алгоритмов объектно-ориентированного параметрического составления, таких как SAOC, посредством удаления этапа MPS-транскодирования.
19. Окружение кодирования/декодирования
Далее описывается окружение кодирования/декодирования аудио, в котором могут применяться принципы согласно настоящему изобретению.
Система трехмерных аудиокодеков, в которой могут использоваться принципы согласно настоящему изобретению, основана на MPEG-D USAC-кодеке для кодирования сигналов каналов и объектов, чтобы повышать эффективность для кодирования большого количества объектов. Адаптирована MPEG SAOC-технология. Три типа модулей рендеринга выполняют задачи рендеринга объектов в каналы, рендеринга каналов в наушники или рендеринга каналов в различные компоновки громкоговорителей. Когда сигналы объектов явно передаются или параметрически кодируются с использованием SAOC, соответствующая информация метаданных объектов сжимается и мультиплексируется в трехмерный аудиопоток.
Фиг. 28, 29 и 30 показывают различные алгоритмические блоки трехмерной аудиосистемы.
Фиг. 28 показывает принципиальную блок-схему такого аудиокодера, а фиг. 29 показывает принципиальную блок-схему такого аудиодекодера. Другими словами, фиг. 28 и 29 показывают различные алгоритмические блоки трехмерной аудиосистемы.
Если обратиться теперь к фиг. 28, который показывает принципиальную блок-схему трехмерного аудиокодера 2900, поясняются некоторые подробности. Кодер 2900 содержит необязательный модуль 2910 предварительного рендеринга/микшер, который принимает один или более сигналов 2912 каналов и один или более сигналов 2914 объектов и предоставляет, на их основе, один или более сигналов 2916 каналов, а также один или более сигналов 2918, 2920 объектов. Аудиокодер также содержит USAC-кодер 2930 и необязательно SAOC-кодер 2940. SAOC-кодер 2940 выполнен с возможностью предоставлять один или более транспортных SAOC-каналов 2942 и вспомогательную SAOC-информацию 2944 на основе одного или более объектов 2920, предоставленных для SAOC-кодера. Кроме того, USAC-кодер 2930 выполнен с возможностью принимать сигналы 2916 каналов, содержащие каналы и предварительно представленные посредством рендеринга объекты, из модуля 2910 предварительного рендеринга/микшера, принимать один или более сигналов 2918 объектов из модуля 2910 предварительного рендеринга/микшера и принимать один или более транспортных SAOC-каналов 2942 и вспомогательную SAOC-информацию 2944 и предоставлять, на их основе, кодированное представление 2932. Кроме того, аудиокодер 2900 также содержит кодер 2950 метаданных объектов, который выполнен с возможностью принимать метаданные 2952 объектов (которые могут оцениваться посредством модуля 2910 предварительного рендеринга/микшера) и кодировать метаданные объектов, чтобы получать кодированные метаданные 2954 объектов. Кодированные метаданные также приняты посредством USAC-кодера 2930 и использованы для того, чтобы предоставлять кодированное представление 2932.
Ниже описываются некоторые подробности относительно отдельных компонентов аудиокодера 2900.
Если обратиться теперь к фиг. 29, описывается аудиодекодер 3000. Аудиодекодер 3000 выполнен с возможностью принимать кодированное представление 3010 и предоставлять, на его основе, многоканальный сигнал 3012 громкоговорителя, сигналы 3014 наушников и/или сигналы 3016 громкоговорителей в альтернативном формате (например, в 5.1-формате). Аудиодекодер 3000 содержит USAC-декодер 3020, который предоставляет один или более сигналов 3022 каналов, один или более предварительно представленных посредством рендеринга сигналов 3024 объектов, один или более сигналов 3026 объектов, один или более транспортных SAOC-каналов 3028, вспомогательную SAOC-информацию 3030 и информацию 3032 сжатых метаданных объектов на основе кодированного представления 3010. Аудиодекодер 3000 также содержит модуль 3040 рендеринга объектов, который выполнен с возможностью предоставлять один или более представленных посредством рендеринга сигналов 3042 объектов на основе одного или более сигналов 3026 объектов и информацию 3044 метаданных объектов, при этом информация 3044 метаданных объектов предоставляется посредством декодера 3050 метаданных объектов на основе информации 3032 сжатых метаданных объектов. Аудиодекодер 3000 также содержит, необязательно, SAOC-декодер 3060, который выполнен с возможностью принимать транспортный SAOC-канал 3028 и вспомогательную SAOC-информацию 3030 и предоставлять, на их основе, один или более представленных посредством рендеринга сигналов 3062 объектов. Аудиодекодер 3000 также содержит микшер 3070, который выполнен с возможностью принимать сигналы 3022 каналов, предварительно представленные посредством рендеринга сигналы 3024 объектов, представленные посредством рендеринга сигналы 3042 объектов и представленные посредством рендеринга сигналы 3062 объектов и предоставлять, на их основе, множество микшированных сигналов 3072 каналов, которые, например, могут составлять многоканальные сигналы 3012 громкоговорителей. Аудиодекодер 3000, например, может также содержать модуль 3080 бинаурального рендеринга, который выполнен с возможностью принимать микшированные сигналы 3072 каналов и предоставлять, на их основе, сигналы 3014 наушников. Кроме того, аудиодекодер 3000 может содержать преобразование 3090 формата, которое выполнено с возможностью принимать микшированные сигналы 3072 каналов и информацию 3092 схемы размещения для воспроизведения и предоставлять, на их основе, сигнал 3016 громкоговорителя для альтернативной компоновки громкоговорителей.
Далее описываются некоторые подробности относительно компонентов аудиокодера 2900 и аудиодекодера 3000.
19.1. Модуль предварительного рендеринга/микшер
Модуль 2910 предварительного рендеринга/микшер необязательно может быть использован для того, чтобы преобразовывать входную сцену каналов плюс объектов в сцену каналов перед кодированием. Функционально, он может быть идентичным, например, модулю рендеринга объектов/микшеру, описанному ниже.
Предварительный рендеринг объектов, например, может обеспечивать детерминированную энтропию сигналов на входе кодера, которая по существу является независимой от числа одновременно активных сигналов объектов.
При предварительном рендеринге объектов, не требуется передача метаданных объектов.
Сигналы дискретных объектов представляются посредством рендеринга в схему размещения каналов, которую кодер выполнен с возможностью использовать, весовые коэффициенты объектов для каждого канала получаются из ассоциированных метаданных 1952 объектов (OAM).
19.2. Базовый USAC-кодек
Базовый кодек 2930, 3020 для сигналов каналов громкоговорителя, сигналов дискретных объектов, сигналов понижающего микширования объектов и предварительно представленных посредством рендеринга сигналов основан на MPEG-D USAC-технологии. Он обрабатывает декодирование множества сигналов посредством создания информации преобразования каналов и объектов на основе геометрической и семантической информации назначения входных каналов и объектов. Эта информация преобразования описывает то, как входные каналы и объекты преобразуются в канальные USAC-элементы (CPE, SCE, LFE), и соответствующая информация передается в декодер.
Все дополнительные рабочие данные, такие как SAOC-данные или метаданные объектов, проходят через расширенные элементы и учитываются при управлении скоростью кодеров. Декодирование объектов является возможным различными способами, в зависимости от требований по искажению в зависимости от скорости передачи и требований по интерактивности для модуля рендеринга. Возможны следующие варианты кодирования объектов:
- Предварительно представленные посредством рендеринга объекты: сигналы объектов представляются посредством рендеринга и микшируются в 22.2-канальные сигналы перед кодированием. Последующая цепочка кодирования видит 22.2-канальные сигналы.
- Формы сигналов дискретных объектов: объекты, применяемые в качестве монофонических форм сигнала для кодера. Кодер использует одноканальные элементы (SCE) для того, чтобы передавать объекты в дополнение к сигналам каналов. Декодированные объекты представляются посредством рендеринга и микшируются на стороне приемного устройства. Информация сжатых метаданных объектов передается в приемное устройство/модуль рендеринга совместно.
- Формы сигналов параметрических объектов: свойства объектов и их взаимосвязь между собой описываются посредством SAOC-параметров. Понижающее микширование сигналов объектов кодируется с помощью USAC. Параметрическая информация передается совместно. Число каналов понижающего микширования выбирается в зависимости от числа объектов и полной скорости передачи данных. Информация сжатых метаданных объектов передается в модуль SAOC-рендеринга.
19.3. SAOC
SAOC-кодер 2940 и SAOC-декодер 3060 для сигналов объектов основаны на MPEG SAOC-технологии. Система допускает повторное создание, модификацию и рендеринг определенного числа аудиообъектов на основе меньшего числа передаваемых каналов и дополнительных параметрических данных (разностей уровней объектов (OLD), межобъектных корреляций (IOC), усилений при понижающем микшировании (DMG)). Дополнительные параметрические данные демонстрируют значительно более низкую скорость передачи данных, чем требуется для передачи всех объектов по отдельности, что делает декодирование очень эффективным. SAOC-кодер принимает в качестве ввода сигналы объектов/каналов в качестве монофонических форм сигнала и выводит параметрическую информацию (которая пакетирована в трехмерный поток 2932, 3010 аудиобитов) и транспортные SAOC-каналы (которые кодируются с использованием одноканальных элементов и передаются). SAOC-декодер 3000 восстанавливает сигналы объектов/каналов из декодированных транспортных SAOC-каналов и 3028 параметрической информации 3030 и формирует выходную аудиосцену на основе схемы размещения для воспроизведения, информации распакованных метаданных объектов и необязательно на основе информации пользовательского взаимодействия.
19.4. Кодек метаданных объектов
Для каждого объекта, ассоциированные метаданные, которые указывают геометрическую позицию и объем объекта в трехмерном пространстве, эффективно кодируются посредством квантования свойств объектов во времени и пространстве. Сжатые метаданные 2954, 3032 объектов (cOAM) передаются в приемное устройство в качестве вспомогательной информации.
19.5. Модуль рендеринга объектов/микшер
Модуль рендеринга объектов использует распакованные метаданные 3044 объектов (OAM) для того, чтобы формировать формы сигналов объектов согласно данному формату воспроизведения. Каждый объект представляется посредством рендеринга в определенные выходные каналы согласно своим метаданным. Вывод этого блока получается в результате суммы частичных результатов.
Если декодируются как канальный контент, так и дискретные/параметрические объекты, канальные формы сигналов и представленные посредством рендеринга формы сигналов объектов микшируются перед выводом результирующих форм сигналов (или перед их подачей в модуль постпроцессора, такой как модуль бинаурального рендеринга или модуль рендеринга громкоговорителей).
19.6. Модуль бинаурального рендеринга
Модуль 3080 бинаурального рендеринга формирует бинауральное понижающее микширование многоканального аудиоматериала таким образом, что каждый входной канал представлен посредством виртуального источника звука. Обработка осуществляется покадрово в QMF-области. Бинаурализация основана на измеренных бинауральных импульсных характеристиках в помещении.
19.7. Модуль рендеринга громкоговорителей/преобразование формата
Модуль 3090 рендеринга громкоговорителей преобразует между конфигурацией передаваемых каналов и требуемым форматом воспроизведения. Таким образом, далее он называется "преобразователем форматов". Преобразователь форматов выполняет преобразования в меньшие числа выходных каналов, т.е. он создает понижающего микширования. Система автоматически формирует оптимизированные матрицы понижающего микширования для данной комбинации входных и выходных форматов и применяет эти матрицы в процессе понижающего микширования. Преобразователь форматов обеспечивает возможность стандартных конфигураций громкоговорителей, а также случайных конфигураций с нестандартными позициями громкоговорителей.
Фиг. 30 показывает принципиальную блок-схему преобразователя форматов. Другими словами, фиг. 30 показывает структуру преобразователя форматов.
Как можно видеть, преобразователь 3100 форматов принимает выходные сигналы 3110 микшера, например, микшированные сигналы 3072 каналов и предоставляет сигналы 3112 громкоговорителей, например, сигналы 3016 динамиков. Преобразователь форматов содержит процесс 3120 понижающего микширования в QMF-области и конфигуратор 3130 понижающего микширования, при этом конфигуратор понижающего микширования предоставляет конфигурационную информацию для процесса 3020 понижающего микширования на основе информации 3032 схемы размещения выходов микшера и информации 3034 схемы размещения для воспроизведения.
19.8. Общие примечания
Кроме того, следует отметить, что принципы, описанные в данном документе, например, аудиодекодер 100, аудиокодер 200, многоканальный декоррелятор 600, многоканальный аудиодекодер 700, аудиокодер 800 или аудиодекодер 1550, могут использоваться в аудиокодере 2900 и/или в аудиодекодере 3000. Например, вышеупомянутые аудиокодеры/декодеры могут использоваться в качестве части SAOC-кодера 2940 и/или в качестве части SAOC-декодера 3060. Тем не менее, принципы, упомянутые выше, также могут использоваться в других позициях трехмерного аудиодекодера 3000 и/или аудиокодера 2900.
Естественно, способы, упомянутые выше, также могут использоваться в принципах для кодирования или декодирования аудиоинформации согласно фиг. 28 и 29.
20. Дополнительный вариант осуществления
20.1. Введение
Далее описывается другой вариант осуществления согласно настоящему изобретению.
Фиг. 31 показывает принципиальную блок-схему процессора понижающего микширования, согласно варианту осуществления настоящего изобретения.
Процессор 3100 понижающего микширования содержит обратный микшер 3110, модуль 3120 рендеринга, модуль 3130 комбинирования и многоканальный декоррелятор 3140. Модуль рендеринга предоставляет представленные посредством рендеринга аудиосигналы 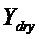
Модуль 3130 рендеринга, например, может применять матрицу R для рендеринга, предварительный микшер, например, может применять матрицу Mpre для предварительного микширования, постмикшер, например, может применять матрицу Mpost для постмикширования, и модуль комбинирования, например, может применять матрицу P для комбинирования.
Следует отметить, что процессор 3100 понижающего микширования либо его отдельные компоненты или функциональности могут использоваться в аудиодекодерах, описанных в данном документе. Кроме того, следует отметить, что процессор понижающего микширования может дополняться посредством любых из признаков и функциональностей, описанных в данном документе.
20.2. Трехмерная SAOC-обработка
Применяется гибридная гребенка фильтров, описанная в 23003-1:2007 ISO/IEC. Деквантование параметров DMG, OLD, IOC соответствует правилам, идентичным правилам, заданным в 7.1.2 23003-2:2010 ISO/IEC.
20.2.1. Сигналы и параметры
Аудиосигналы задаются для каждого временного кванта n и каждой гибридной подполосы k частот. Соответствующие трехмерные SAOC-параметры задаются для каждого параметрического временного кванта и полосы m частот обработки. Последующее преобразование между гибридной и параметрической областью указывается посредством таблицы 31 23003-1:2007 ISO/IEC. Следовательно, все вычисления выполняются относительно определенного времени/индексов полос частот, и соответствующие размерности подразумеваются для каждой введенной переменной.
Доступные данные в трехмерном SAOC-декодере состоят из многоканального сигнала X понижающего микширования, ковариационной матрицы E, матрицы R рендеринга и матрицы D понижающего микширования.
20.2.1.1. Параметры объектов
Ковариационная матрица E размера N×N с элементами ei,j представляет аппроксимацию ковариационной матрицы 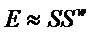
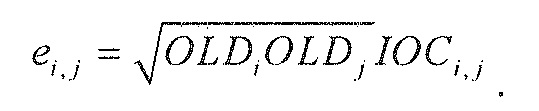
Здесь, деквантованные параметры объектов получаются следующим образом:
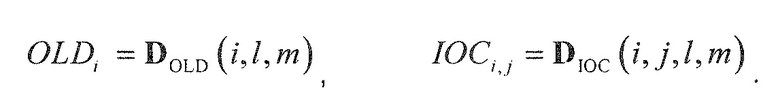
20.2.1.3. Матрица понижающего микширования
Матрица D понижающего микширования, применяемая к входным аудиосигналам S, определяет сигнал понижающего микширования в качестве X=DS. Матрица D понижающего микширования размера 
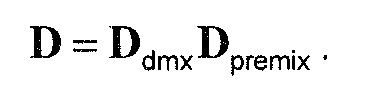
Матрица 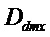

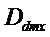
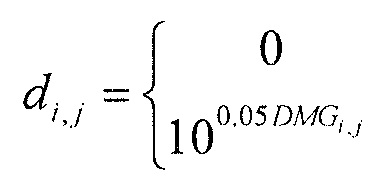
Здесь, деквантованные параметры понижающего микширования получаются следующим образом:
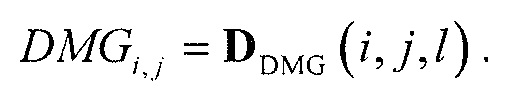
20.2.1.3.1. Прямой режим
В случае прямого режима, не используется предварительное микширование. Матрица 
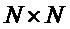
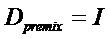
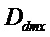
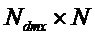
20.2.1.3.2. Режим предварительного микширования
В случае режима предварительного микширования, матрица 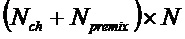
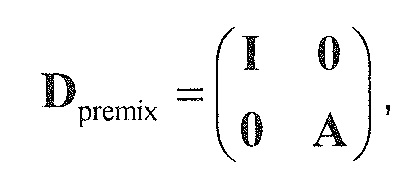
где матрица предварительного микширования размера 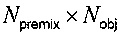 принимается как ввод в трехмерный SAOC-декодер из модуля рендеринга объектов.
принимается как ввод в трехмерный SAOC-декодер из модуля рендеринга объектов.
Матрица 
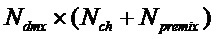
20.2.1.4. Матрица рендеринга
Матрица R рендеринга, применяемая к входным аудиосигналам S, определяет целевой представленный посредством рендеринга вывод в качестве Y=RS. Матрица R рендеринга размера 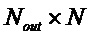
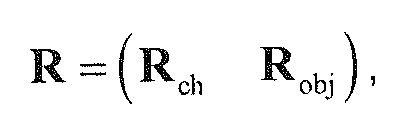
где 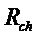
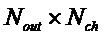
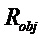
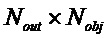
20.2.1.4. Целевая выходная ковариационная матрица
Ковариационная матрица C размера 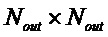
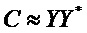
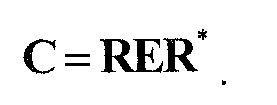
20.2.2. Декодирование
Описывается способ для получения выходного сигнала с использованием трехмерных SAOC-параметров и информации рендеринга. Трехмерный SAOC-декодер, например, может состоять из процессора трехмерных SAOC-параметров и процессора трехмерного SAOC-понижающего микширования.
20.2.2.1. Процессор понижающего микширования
Выходной сигнал процессора понижающего микширования (представленный в гибридной QMF-области) подается в соответствующую гребенку синтезирующих фильтров, как описано в ISO/IEC 23003-1:2007, что дает в результате конечный вывод трехмерного SAOC-декодера. Подробная структура процессора понижающего микширования проиллюстрирована на фиг. 31.
Выходной сигнал 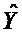
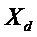
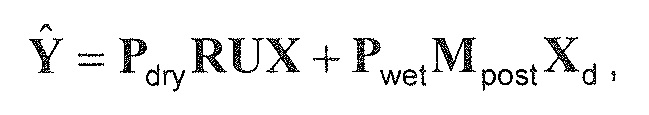
где U представляет матрицу параметрического обратного микширования и задается в 20.2.2.1.1 и 20.2.2.1.2.
Декоррелированный многоканальный сигнал
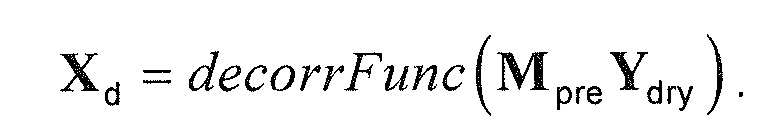
Матрица 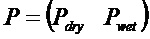
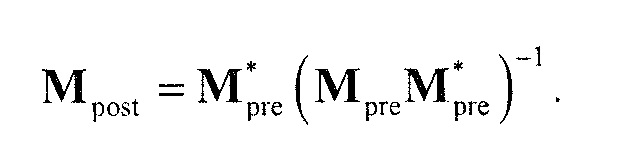
Режим декодирования управляется посредством элемента bsNumSaocDmxObjects потока битов, как показано на фиг. 32.
20.2.2.1.1. Комбинированный режим декодирования
В случае комбинированного режима декодирования, матрица U параметрического обратного микширования задается следующим образом:
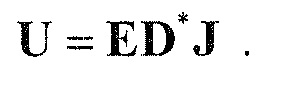
Матрица J размера 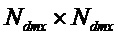
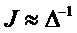
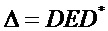
20.2.2.1.2. Независимый режим декодирования
В случае независимого режима декодирования, матрица U обратного микширования задается следующим образом:
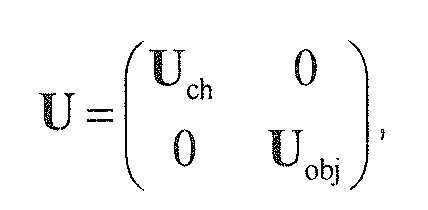
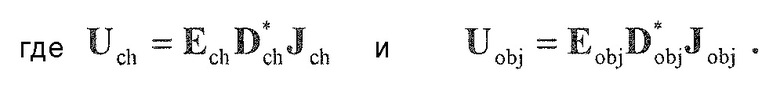
Канальная ковариационная матрица 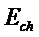
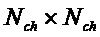
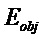
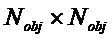
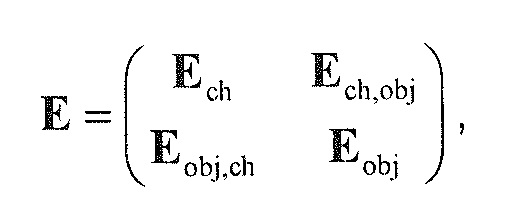
где матрица 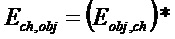
Канальная матрица 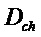
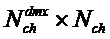
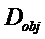
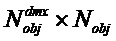
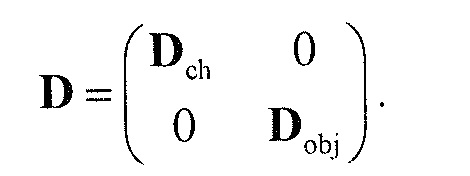
Матрица 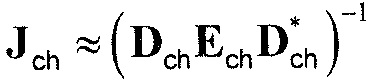 размера
размера 
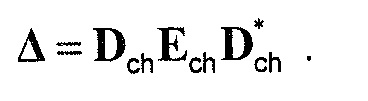
Матрица 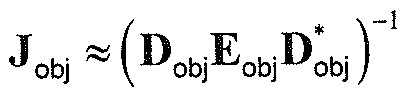 размера
размера 
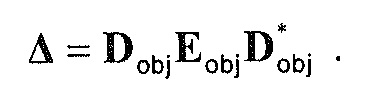
20.2.2.1.4. Вычисление матрицы J
Матрица 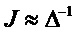
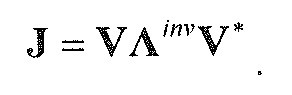
Здесь сингулярный вектор V матрицы 
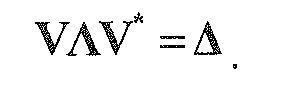
Регуляризованная инверсия 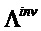
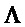

Относительный скаляр 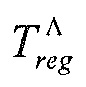 регуляризации определяется с использованием абсолютного порогового значения
регуляризации определяется с использованием абсолютного порогового значения 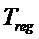
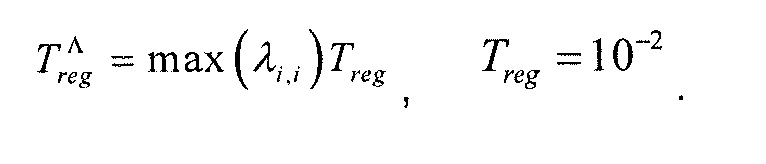
20.2.3. Декорреляция
Декоррелированные сигналы Xd созданы из декоррелятора, описанного в 6.6.2 23003-1:2007 ISO/IEC, с bsDecorrConfig==0 и индексом декоррелятора, x, согласно таблицам на фиг. 19-24. Следовательно, decorrFunc() обозначает процесс декорреляции:
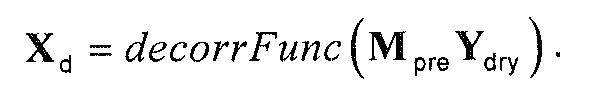
20.2.4. Матрица P микширования - первый вариант
Вычисление матрицы 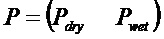
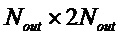
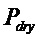
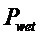
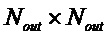
20.2.4.1. Режим энергетической компенсации
Режим энергетической компенсации использует декоррелированные сигналы для того, чтобы компенсировать потери энергии в параметрическом восстановлении. Матрицы
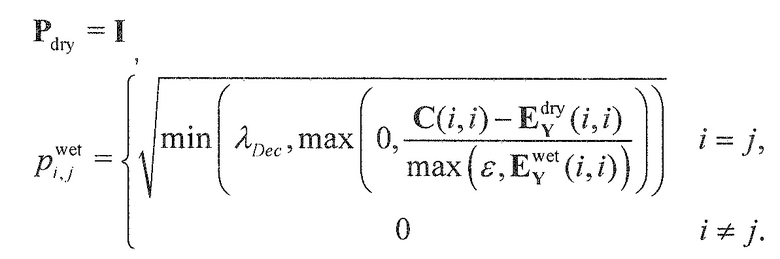
где 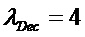
20.2.4.2. Режим ограниченного регулирования ковариантности
Режим ограниченного регулирования ковариантности обеспечивает то, что ковариационная матрица 
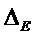
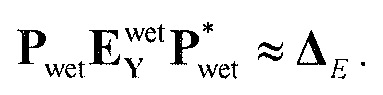
Матрицы
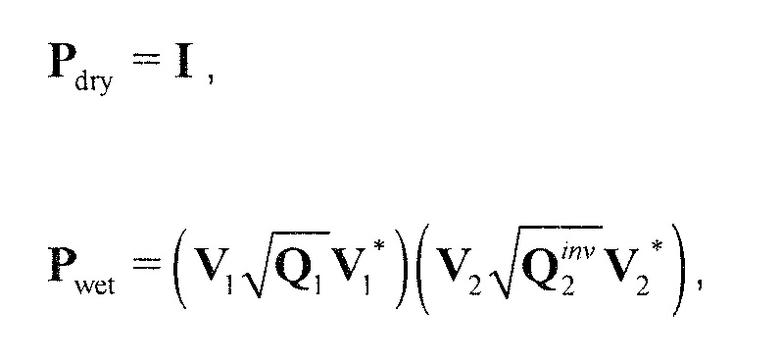
при этом регуляризованная инверсия 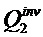
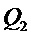

Относительный скаляр 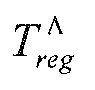 регуляризации определяется с использованием абсолютного порогового значения
регуляризации определяется с использованием абсолютного порогового значения 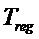
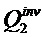
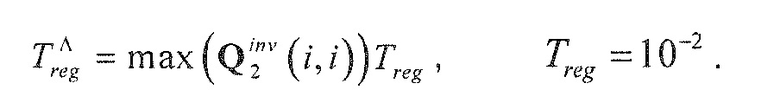
Матрица 
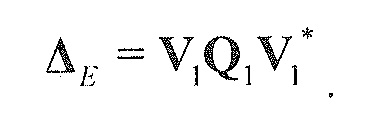
Ковариационная матрица 
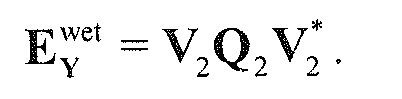
20.2.4.3. Режим общего регулирования ковариантности
Режим общего регулирования ковариантности обеспечивает то, что ковариационная матрица 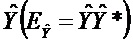
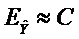
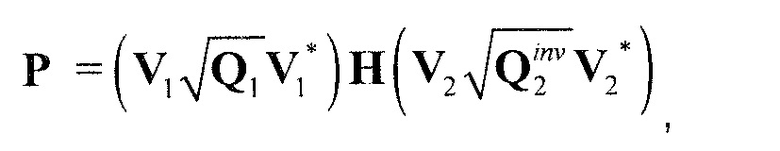
при этом регуляризованная инверсия 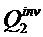
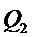

Относительный скаляр 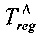 регуляризации определяется с использованием абсолютного порогового значения
регуляризации определяется с использованием абсолютного порогового значения 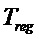
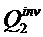
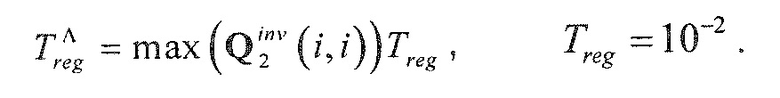
Целевая ковариационная матрица C разлагается с использованием разложения по сингулярным значениям следующим образом:
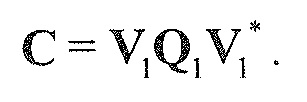
Ковариационная матрица 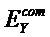
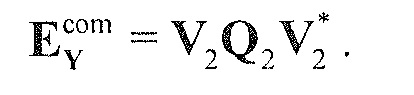
Матрица H представляет прототипную матрицу весовых коэффициентов размера 
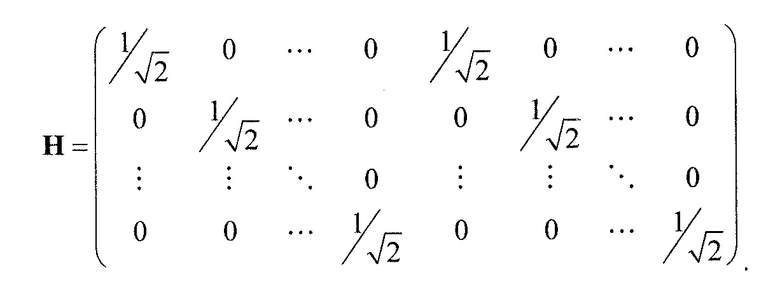
20.2.4.4. Введенные ковариационные матрицы
Матрица 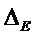
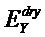
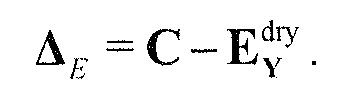
Матрица 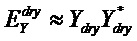

Матрица 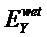
При рассмотрении сигнала 
ковариационная матрица
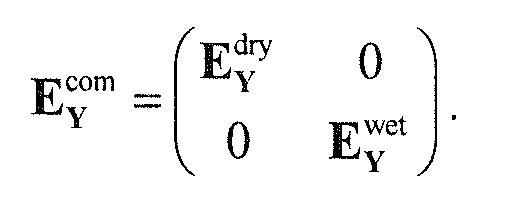
Матрица 
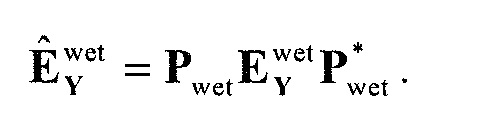
20.2.5. Матрица P микширования - второй вариант
Вычисление матрицы 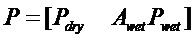
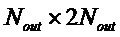
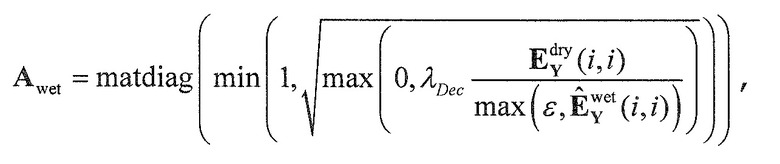
где ковариационные матрицы 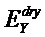
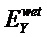
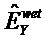
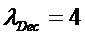
20.2.5.1. Режим энергетической компенсации
Режим энергетической компенсации использует декоррелированные сигналы для того, чтобы компенсировать потери энергии в параметрическом восстановлении. Матрицы 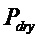
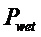

20.2.5.2. Дополнительные принципы и подробности
Относительно дополнительных принципов и дополнительных подробностей, также следует обратиться к разделам 20.2.4.2-20.2.4.4.
20.3. Примечания относительно системы обозначений
Следует отметить, что различные системы обозначений используются в настоящей заявке. Тем не менее, из контекста очевидно то, какая система обозначений применяется к конкретному уравнению.
Например, матрица микширования обозначена с помощью F или 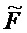
Кроме того, компонент матрицы микширования, который должен применяться к сухому сигналу (или к сухим сигналам), обозначен с помощью P в некоторых частях описания и с помощью 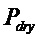
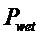
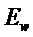
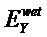
21. Альтернативы реализации
Хотя некоторые аспекты описаны в контексте устройства, очевидно, что эти аспекты также представляют описание соответствующего способа, при этом блок или устройство соответствует этапу способа либо признаку этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока или элемента, или признака соответствующего устройства. Некоторые или все этапы способа могут быть выполнены посредством (или с использованием) устройства, такого как, например, микропроцессор, программируемый компьютер либо электронная схема. В некоторых вариантах осуществления, некоторые из одного или более самых важных этапов способа могут выполняться посредством этого устройства.
Изобретаемый кодированный аудиосигнал может быть сохранен на цифровом носителе хранения данных или может быть передан по среде передачи, такой как беспроводная среда передачи или проводная среда передачи, к примеру, Интернет.
В зависимости от определенных требований к реализации, варианты осуществления изобретения могут быть реализованы в аппаратных средствах или в программном обеспечении. Реализация может выполняться с использованием цифрового носителя хранения данных, например, гибкого диска, DVD, Blu-Ray, CD, ROM, PROM, EPROM, EEPROM или флэш-памяти, имеющего сохраненные электронно считываемые управляющие сигналы, которые взаимодействуют (или допускают взаимодействие) с программируемой компьютерной системой, так что осуществляется соответствующий способ. Следовательно, цифровой носитель хранения данных может быть машиночитаемым.
Некоторые варианты осуществления согласно изобретению содержат носитель данных, имеющий электронночитаемые управляющие сигналы, которые допускают взаимодействие с программируемой компьютерной системой таким образом, что осуществляется один из способов, описанных в данном документе.
В общем, варианты осуществления настоящего изобретения могут быть реализованы как компьютерный программный продукт с программным кодом, при этом программный код выполнен с возможностью осуществления одного из способов, когда компьютерный программный продукт работает на компьютере. Программный код, например, может быть сохранен на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для осуществления одного из способов, описанных в данном документе, сохраненную на машиночитаемом носителе.
Другими словами, следовательно, вариант осуществления изобретаемого способа представляет собой компьютерную программу, имеющую программный код для осуществления одного из способов, описанных в данном документе, когда компьютерная программа работает на компьютере.
Следовательно, дополнительный вариант осуществления изобретаемых способов представляет собой носитель хранения данных (цифровой носитель хранения данных или машиночитаемый носитель), содержащий записанную компьютерную программу для осуществления одного из способов, описанных в данном документе. Носитель данных, цифровой носитель хранения данных или носитель с записанными данными типично является материальным и/или энергонезависимым.
Следовательно, дополнительный вариант осуществления изобретаемого способа представляет собой поток данных или последовательность сигналов, представляющих компьютерную программу для осуществления одного из способов, описанных в данном документе. Поток данных или последовательность сигналов, например, может быть выполнена с возможностью передачи через соединение для передачи данных, например, через Интернет.
Дополнительный вариант осуществления содержит средство обработки, например, компьютер или программируемое логическое устройство, выполненное с возможностью осуществлять один из способов, описанных в данном документе.
Дополнительный вариант осуществления содержит компьютер, имеющий установленную компьютерную программу для осуществления одного из способов, описанных в данном документе.
Дополнительный вариант осуществления согласно изобретению содержит устройство или систему, выполненную с возможностью передавать (например, электронно или оптически) компьютерную программу для осуществления одного из способов, описанных в данном документе, в приемное устройство. Приемное устройство, например, может представлять собой компьютер, мобильное устройство, запоминающее устройство и т.п. Устройство или система, например, может содержать файловый сервер для передачи компьютерной программы в приемное устройство.
В некоторых вариантах осуществления, программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может быть использовано для того, чтобы выполнять часть или все из функциональностей способов, описанных в данном документе. В некоторых вариантах осуществления, программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором, чтобы осуществлять один из способов, описанных в данном документе. В общем, способы предпочтительно осуществляются посредством любого устройства.
Вышеописанные варианты осуществления являются просто иллюстративными в отношении принципов настоящего изобретения. Следует понимать, что модификации и изменения компоновок и подробностей, описанных в данном документе, должны быть очевидными для специалистов в данной области техники. Следовательно, они подразумеваются как ограниченные только объемом нижеприведенной формулы изобретения, а не конкретными подробностями, представленными посредством описания и пояснения вариантов осуществления в данном документе.
Библиографический список
[BCC] C. Faller и F. Baumgarte "Binaural Cue Coding - Part II: Schemes and applications", IEEE Trans, on Speech and Audio Proc, издание 11, номер 6, ноябрь 2003 года.
[Blauert] J. Blauert "Spatial Hearing - The Psychophysics of Human Sound Localization", Revised Edition, The MIT Press, Лондон, 1997 год.
[JSC] C. Faller, "Parametric Joint-Coding of Audio Sources", 120th AES Convention, Париж, 2006 год.
[ISS1] M. Parvaix и L. Girin: "Informed Source Separation of underdetermined instantaneous Stereo Mixtures using Source Index Embedding", IEEE ICASSP, 2010 год.
[ISS2] M. Parvaix, L. Girin, J.-M. Brossier: "A watermarking-based method for informed source separation of audio signals with the single sensor", IEEE Transactions on Audio, Speech and Language Processing, 2010 год.
[ISS3] A. Liutkus и J. Pinel и R. Badeau и L. Girin и G. Richard: "Informed source separation through spectrogram coding and data embedding", Signal Processing Journal, 2011 год.
[ISS4] A. Ozerov, A. Liutkus, R. Badeau, G. Richard: "Informed source separation: source coding meets source separation", IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, 2011 год.
[ISS5] S. Zhang и L. Girin: "An Informed Source Separation System for Speech Signals", INTERSPEECH, 2011 год.
[ISS6] L. Girin и J. Pinel: "Informed Audio Source Separation from Compressed Linear Stereo Mixtures", AES 42nd International Conference: Semantic Audio, 2011 год.
[MPS] ISO/IEC, "Information technology - MPEG audio technologies - Part 1: MPEG Surround", ISO/IEC JTC1/SC29/WG11 (MPEG) international Standard 23003-1:2006.
[OCD] J. Vilkamo, T. Backstrom и A. Kuntz "Optimized covariance domain framework for time-frequency processing of spatial audio", Journal of the Audio Engineering Society, 2013 год, в печати.
[SAOC1] J. Herre, S. Disch, J. Hilpert, O. Hellmuth: "From SAC To SAOC - Recent Developments in Parametric Coding of Spatial Audio", 22nd Regional UK AES Conference, Cambridge, UK, апрель 2007 года.
[SAOC2] J. Engdegard, B. Resch, C. Falch, O. Hellmuth, J. Hilpert, A. Holzer, L. Terentiev, J. Breebaart, J. Koppens, E. Schuijers и VV. Oomen: "Spatial Audio Object Coding (SAOC) - The Upcoming MPEG Standard on Parametric object Based Audio Coding", 124th AES Convention, Амстердам, 2008 год.
[SAOC] ISO/IEC "MPEG audio technologies - Part 2: Spatial Audio Object Coding (SAOC)", ISO/IEC JTC1/SC29/WG11 (MPEG) International Standard 23003-2.
Международный Патент № WO/2006/026452, "MULTICHANNEL DECORRELATION IN SPATIAL AUDIO CODING", выданный 9 марта 2006 года.
| название | год | авторы | номер документа |
|---|---|---|---|
| МНОГОКАНАЛЬНЫЙ ДЕКОРРЕЛЯТОР, МНОГОКАНАЛЬНЫЙ АУДИОДЕКОДЕР, МНОГОКАНАЛЬНЫЙ АУДИОКОДЕР, СПОСОБЫ И КОМПЬЮТЕРНАЯ ПРОГРАММА С ИСПОЛЬЗОВАНИЕМ ПРЕДВАРИТЕЛЬНОГО МИКШИРОВАНИЯ ВХОДНЫХ СИГНАЛОВ ДЕКОРРЕЛЯТОРА | 2014 |
|
RU2666640C2 |
| МНОГОКАНАЛЬНЫЙ АУДИОДЕКОДЕР, МНОГОКАНАЛЬНЫЙ АУДИОКОДЕР, СПОСОБЫ И КОМПЬЮТЕРНАЯ ПРОГРАММА С ИСПОЛЬЗОВАНИЕМ РЕГУЛИРОВАНИЯ ДОЛИ ДЕКОРРЕЛИРОВАННОГО СИГНАЛА НА ОСНОВАНИИ ОСТАТОЧНЫХ СИГНАЛОВ | 2014 |
|
RU2676233C2 |
| УПРАВЛЯЕМОЕ МОДУЛЕМ РЕНДЕРИНГА ПРОСТРАНСТВЕННОЕ ПОВЫШАЮЩЕЕ МИКШИРОВАНИЕ | 2014 |
|
RU2659497C2 |
| ПРИНЦИП ДЛЯ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ АУДИО ДЛЯ АУДИОКАНАЛОВ И АУДИООБЪЕКТОВ | 2014 |
|
RU2641481C2 |
| ДЕКОДЕР АУДИОСИГНАЛА, СПОСОБ ДЕКОДИРОВАНИЯ АУДИОСИГНАЛА И КОМПЬЮТЕРНАЯ ПРОГРАММА С ИСПОЛЬЗОВАНИЕМ СТУПЕНЕЙ КАСКАДНОЙ ОБРАБОТКИ АУДИООБЪЕКТОВ | 2010 |
|
RU2558612C2 |
| БИНАУРАЛЬНАЯ ВИЗУАЛИЗАЦИЯ МУЛЬТИКАНАЛЬНОГО ЗВУКОВОГО СИГНАЛА | 2009 |
|
RU2512124C2 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ УЛУЧШЕННОГО ПРОСТРАНСТВЕННОГО КОДИРОВАНИЯ АУДИООБЪЕКТОВ | 2014 |
|
RU2660638C2 |
| УСТРОЙСТВО И СПОСОБ ОБРАБОТКИ КОДИРОВАННОГО АУДИОСИГНАЛА | 2016 |
|
RU2678136C1 |
| УСТРОЙСТВО, СПОСОБ И КОМПЬЮТЕРНАЯ ПРОГРАММА ДЛЯ КОДИРОВАНИЯ ЗВУКОВОГО СИГНАЛА ИЛИ ДЛЯ ДЕКОДИРОВАНИЯ КОДИРОВАННОЙ АУДИОСЦЕНЫ | 2021 |
|
RU2809587C1 |
| УМЕНЬШЕНИЕ АРТЕФАКТОВ ГРЕБЕНЧАТОГО ФИЛЬТРА ПРИ МНОГОКАНАЛЬНОМ ПОНИЖАЮЩЕМ МИКШИРОВАНИИ С АДАПТИВНЫМ ФАЗОВЫМ СОВМЕЩЕНИЕМ | 2014 |
|
RU2678161C2 |
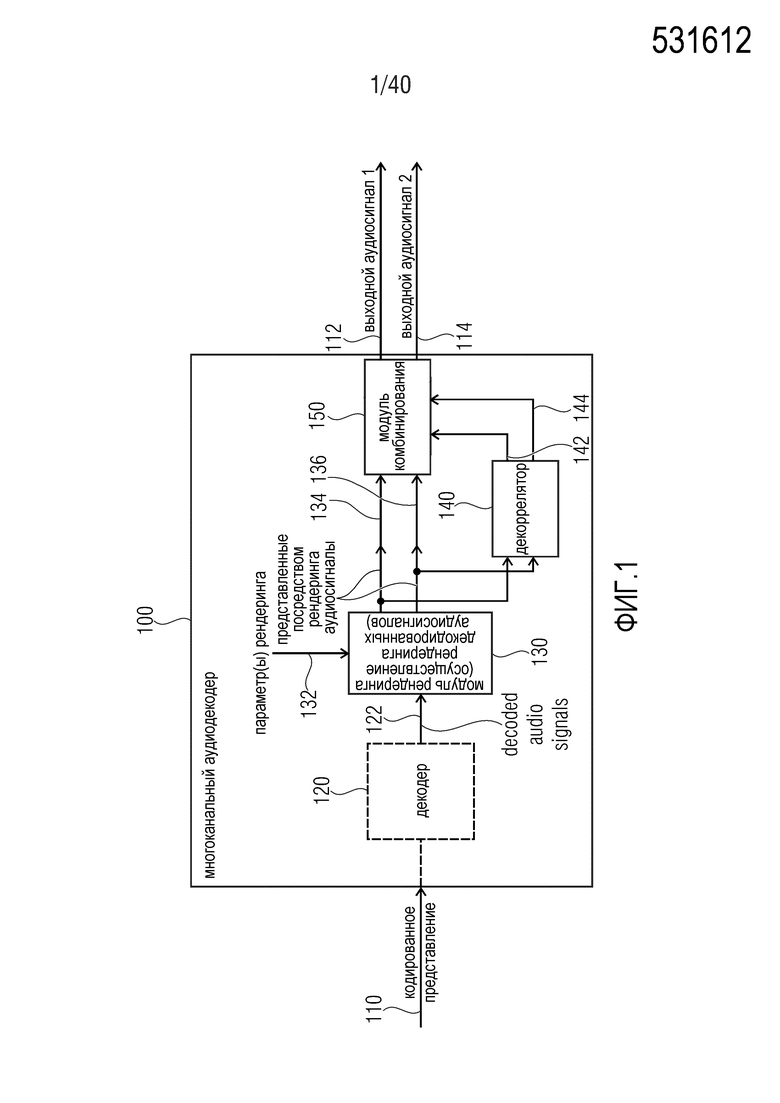
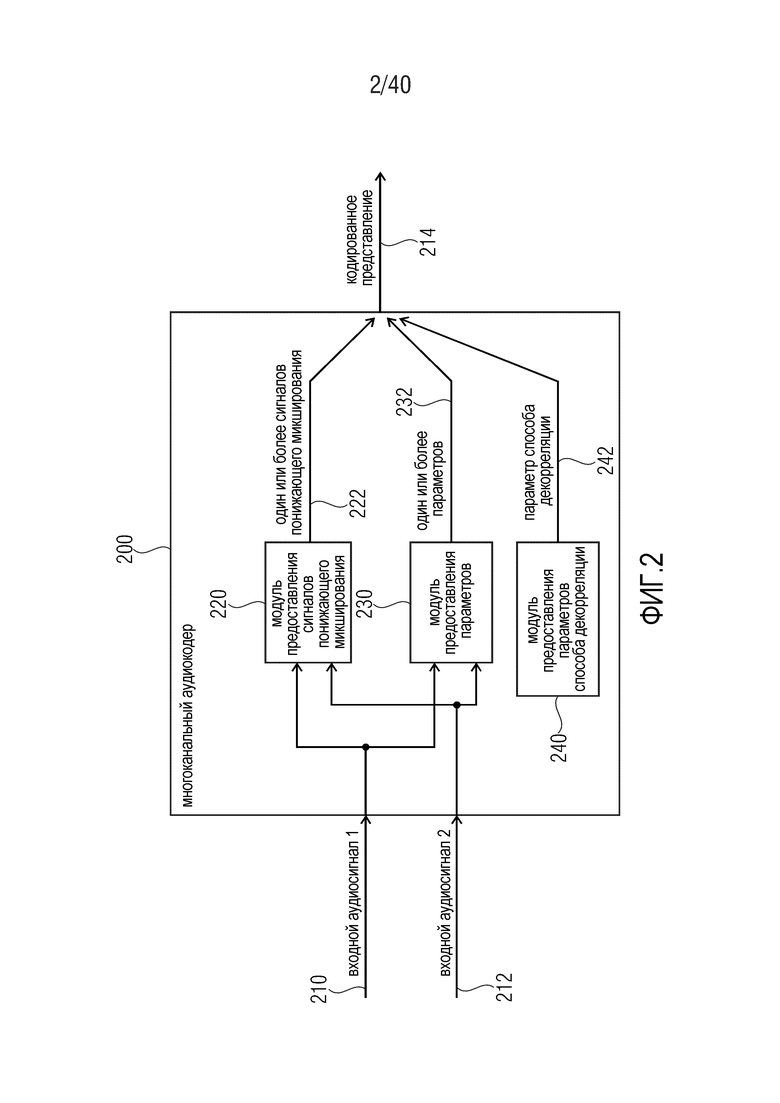
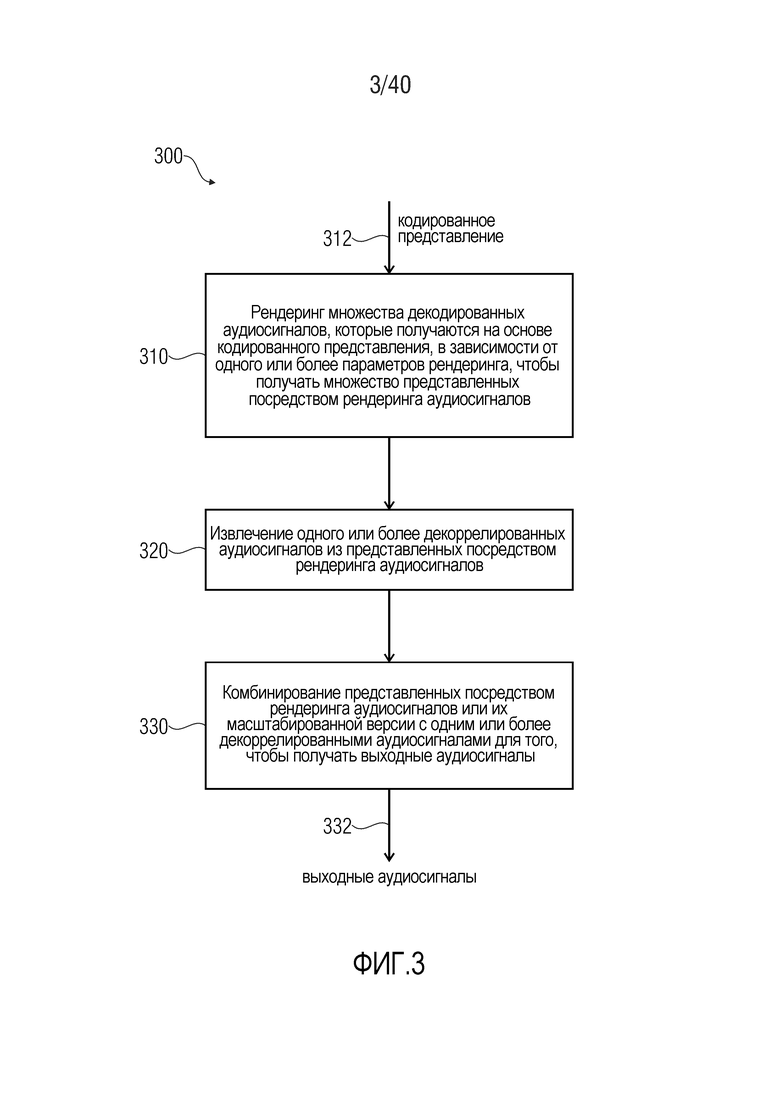
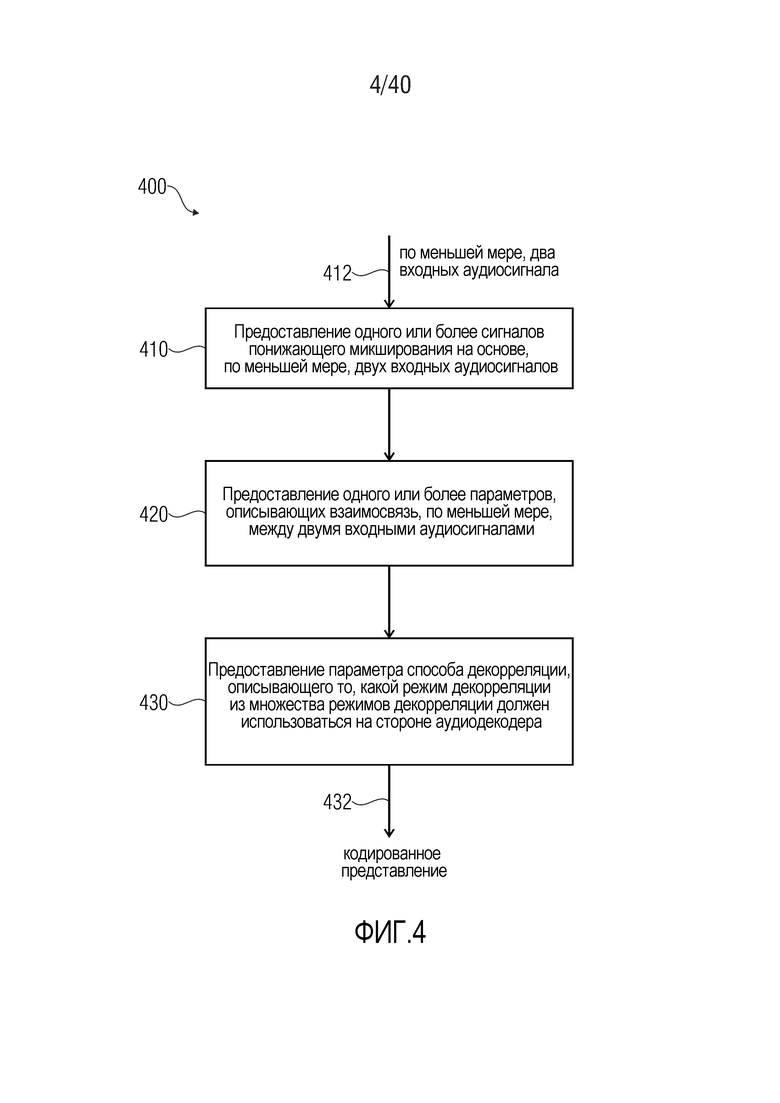
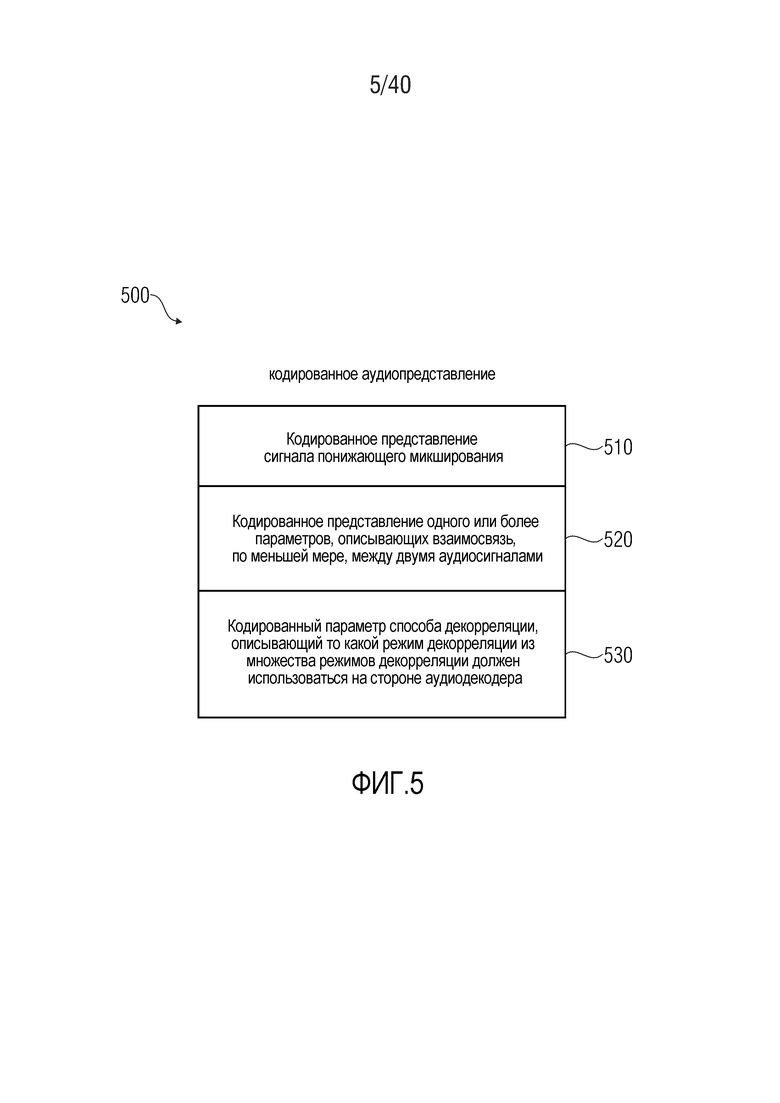
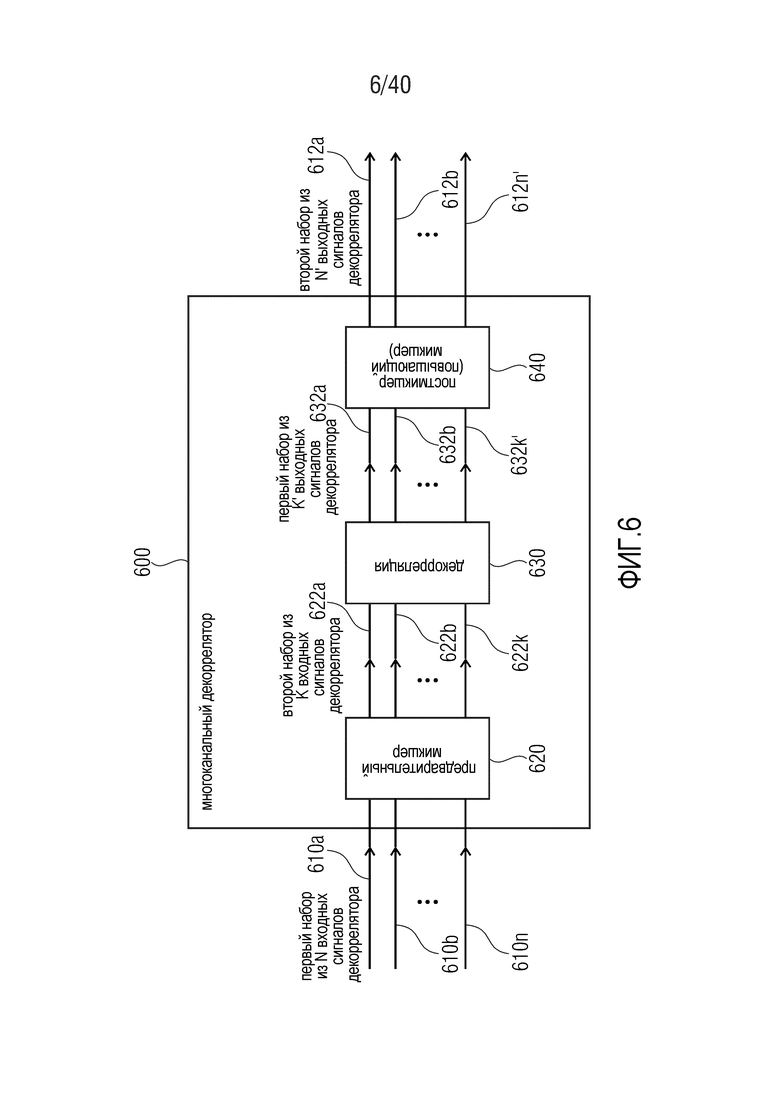
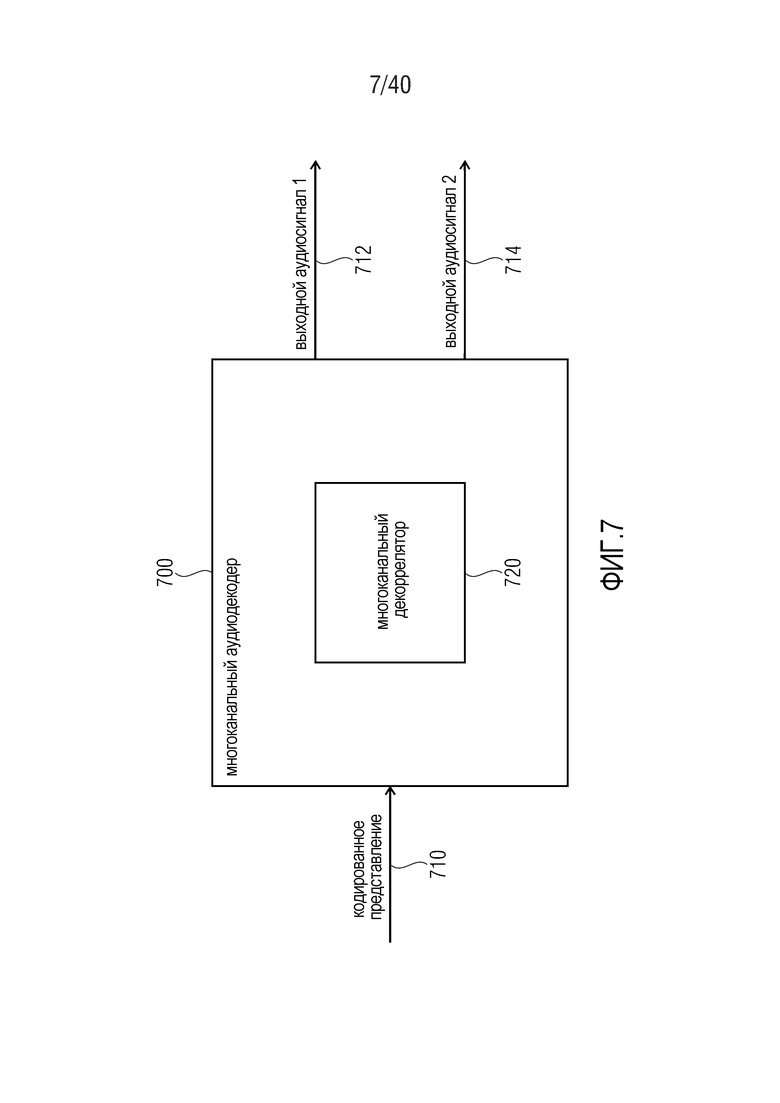
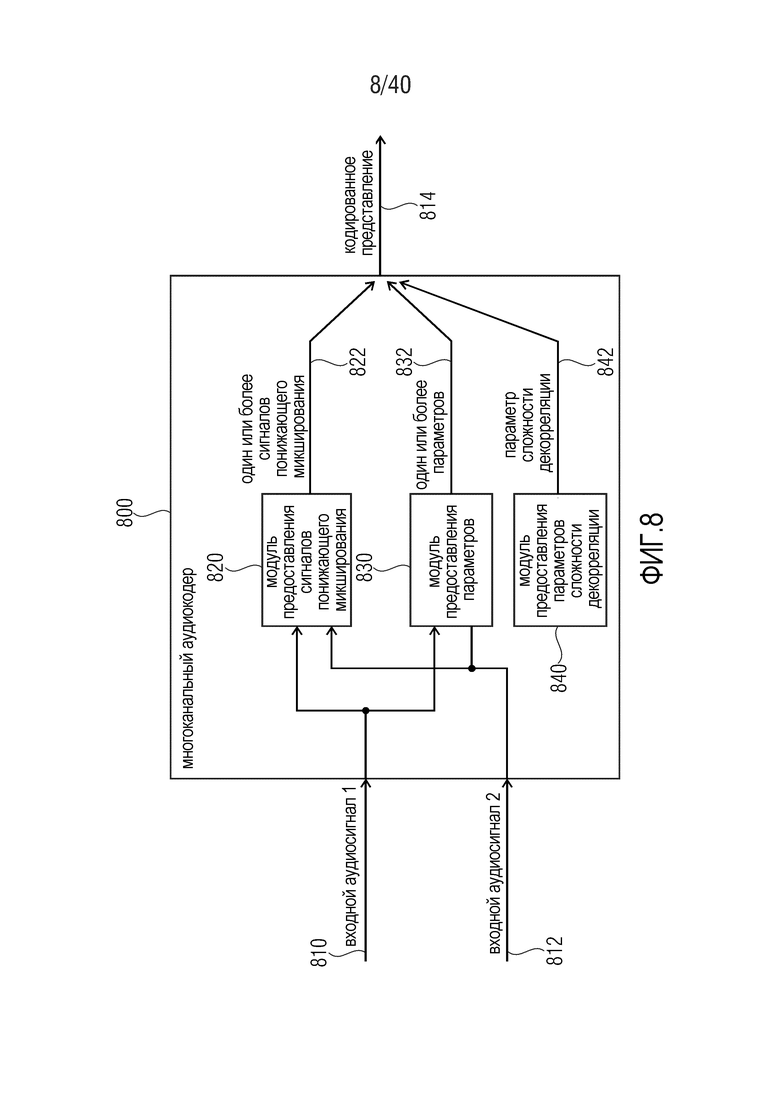
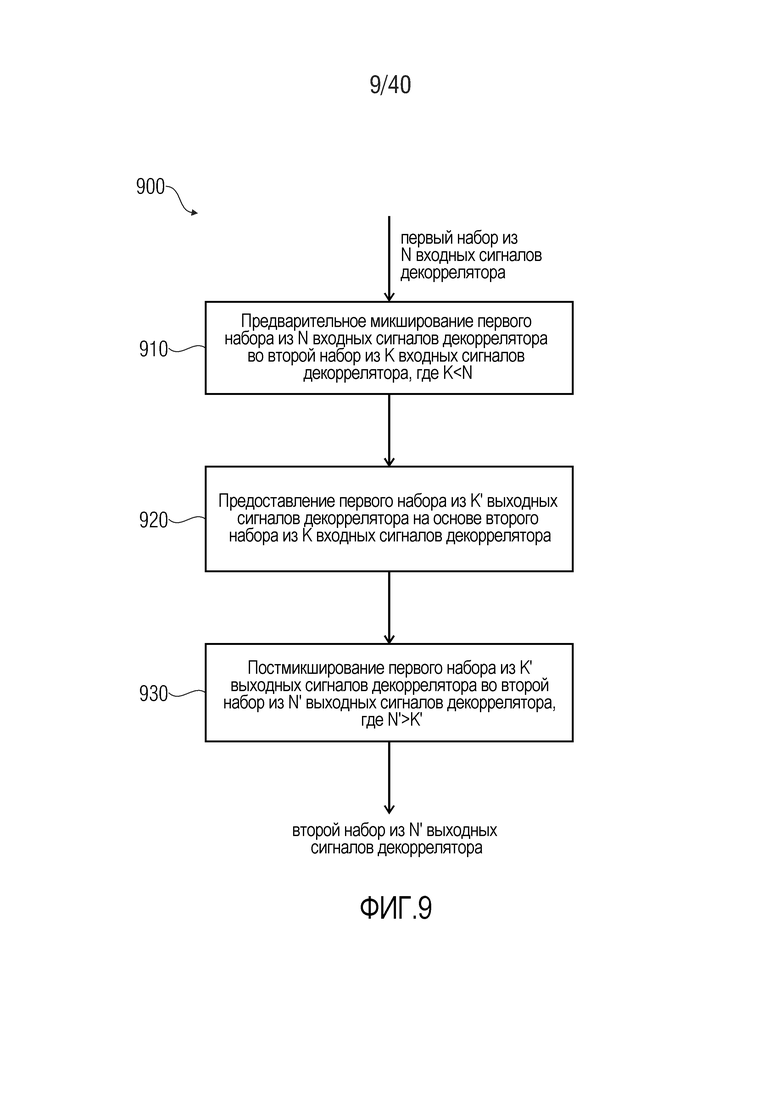
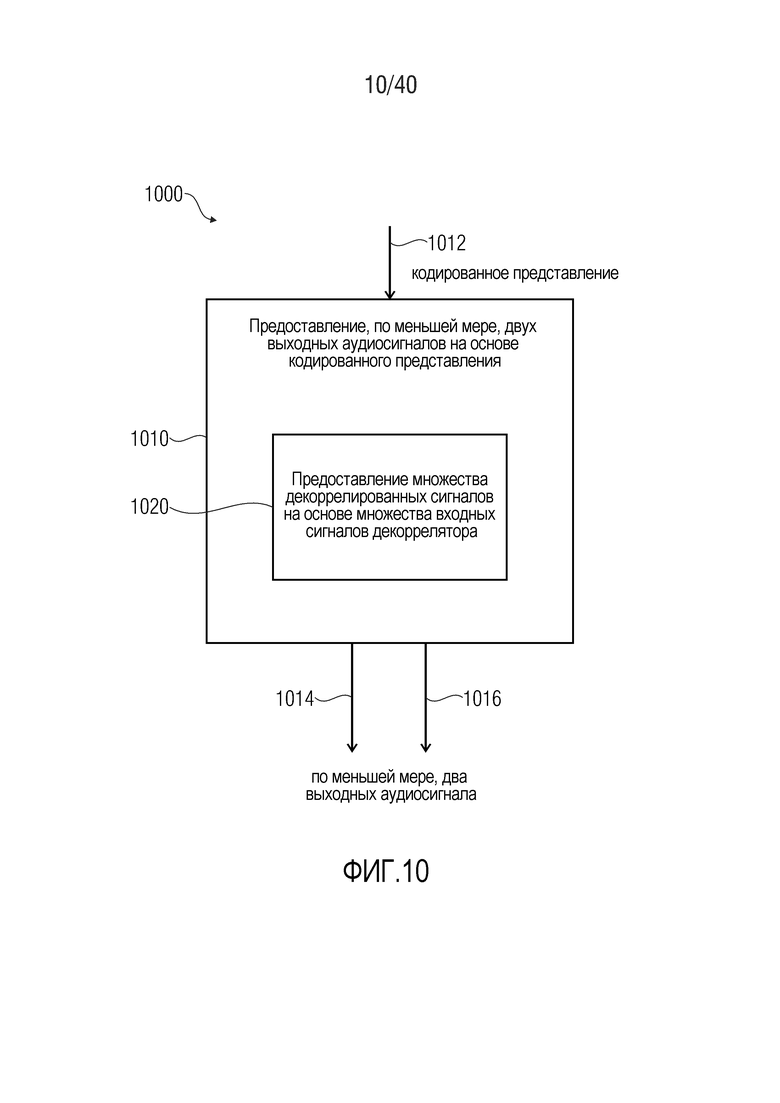
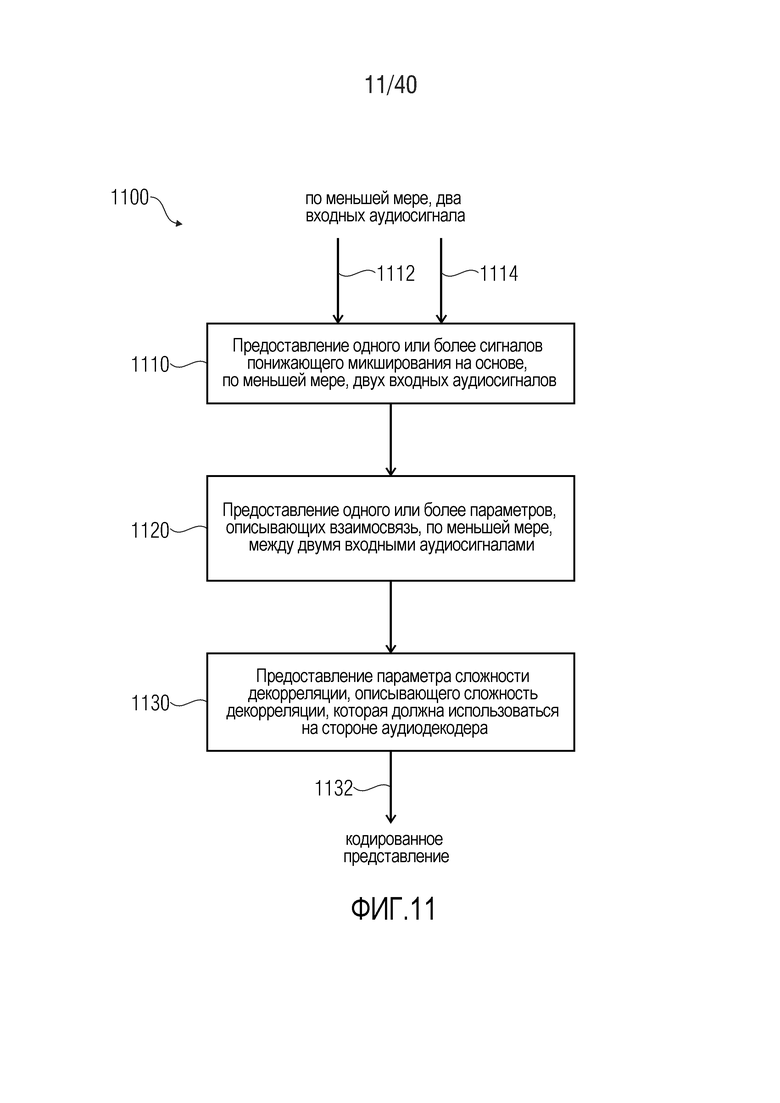
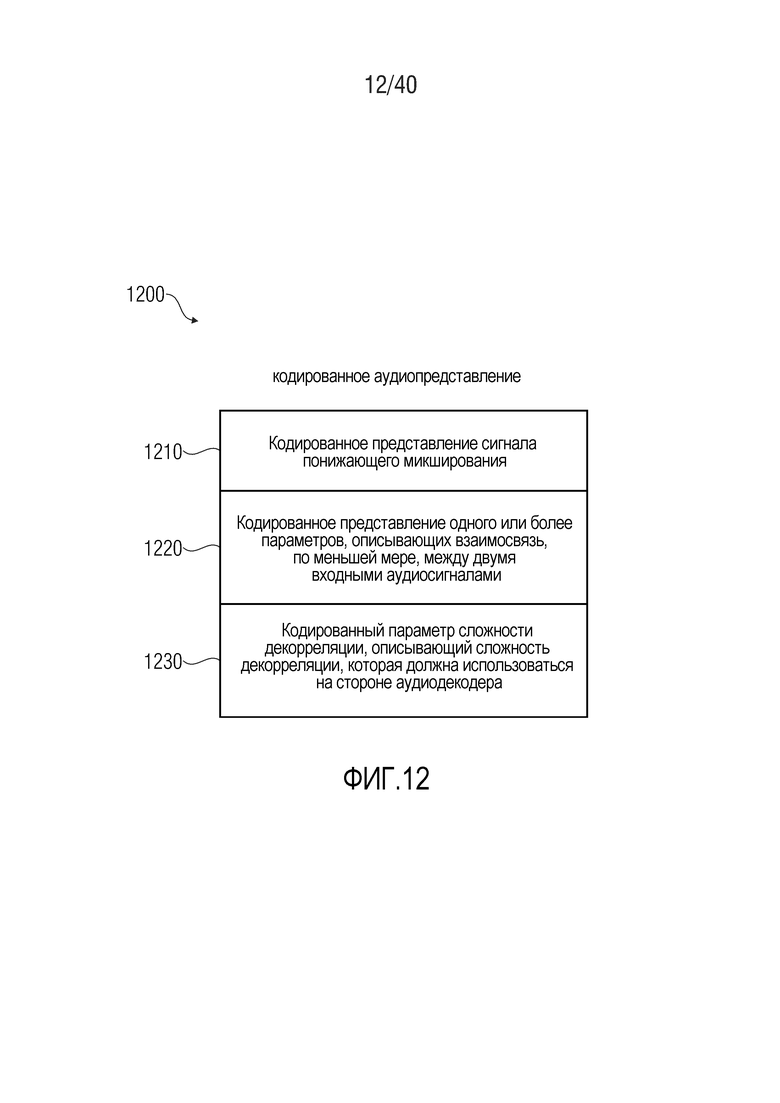
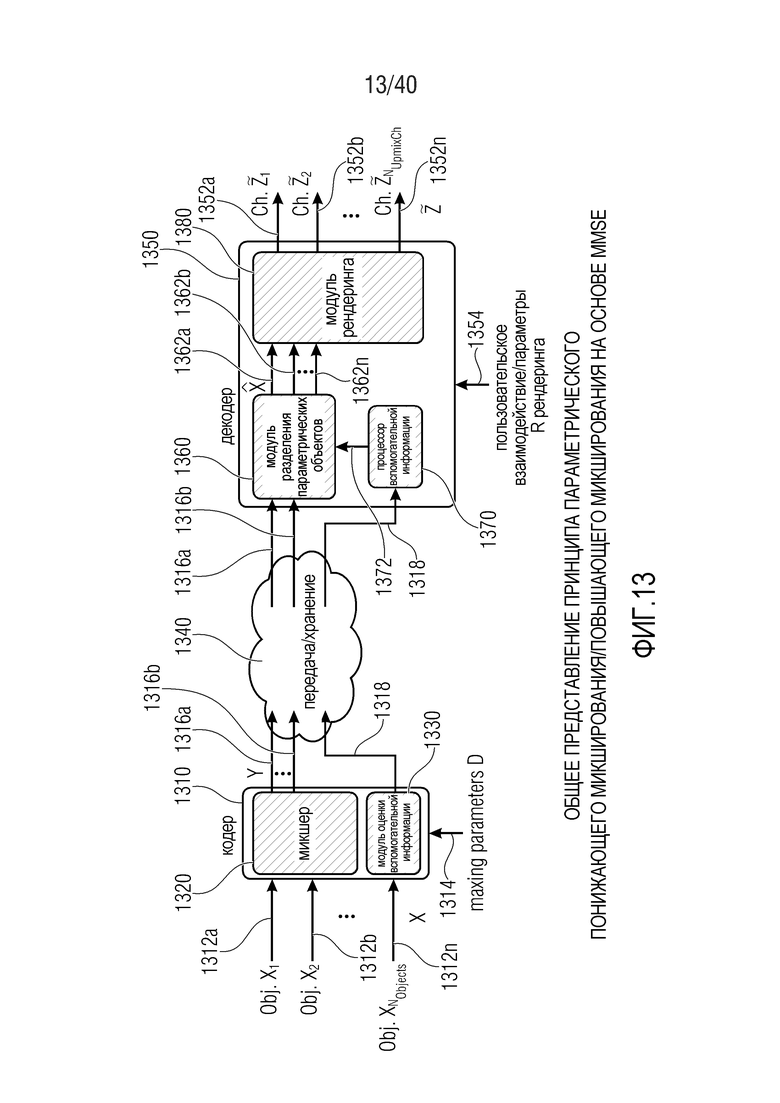
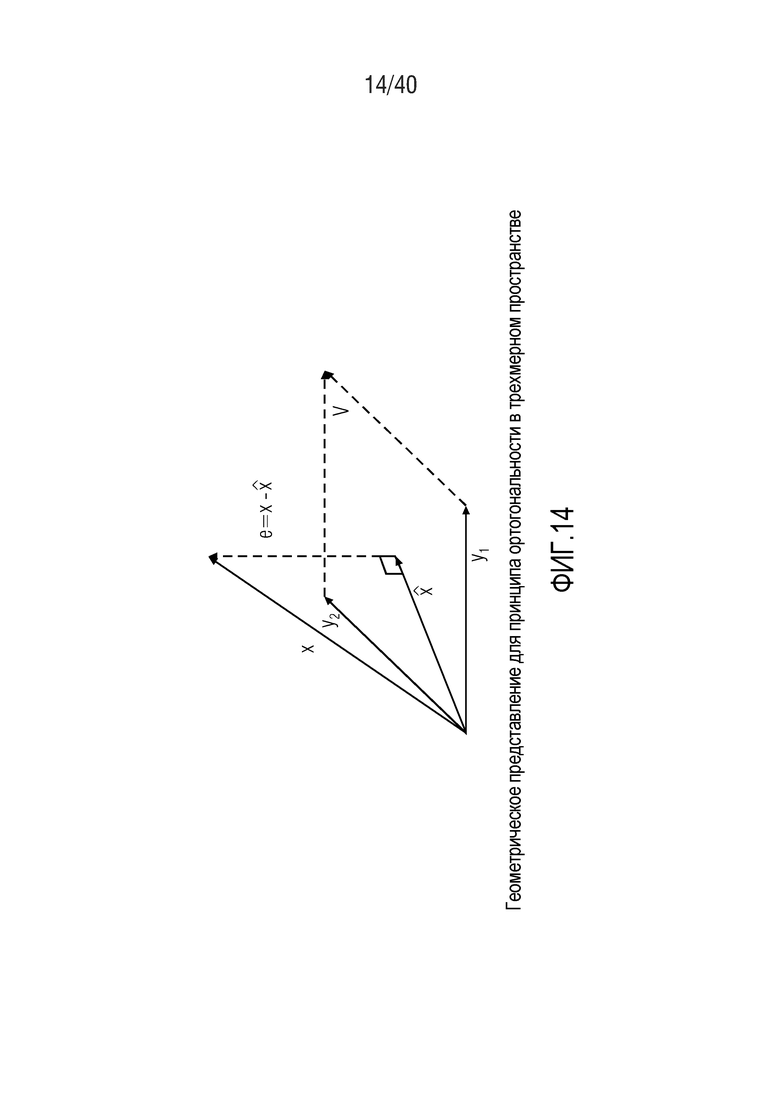
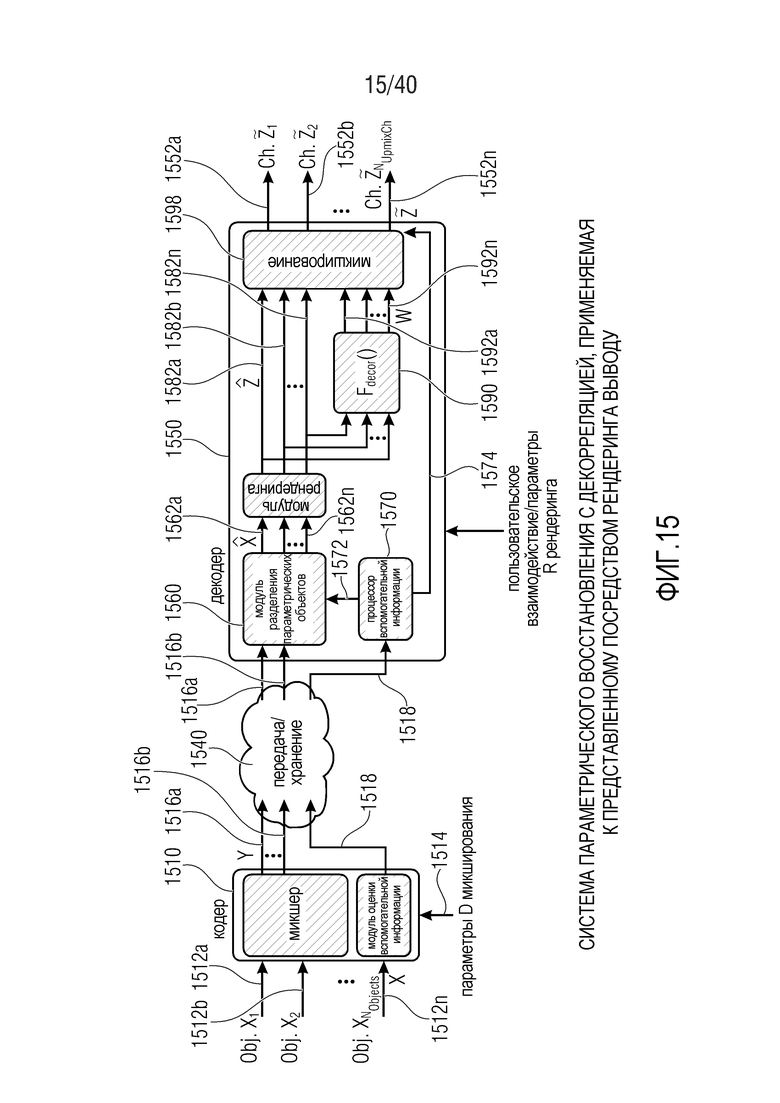
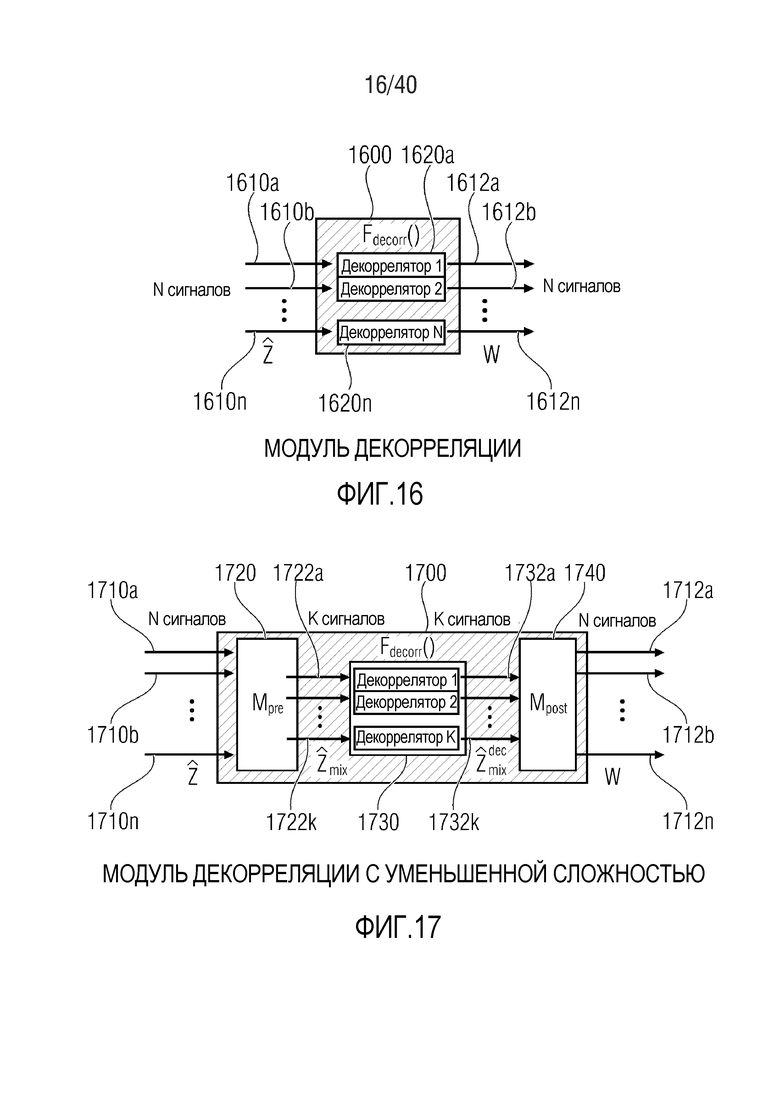
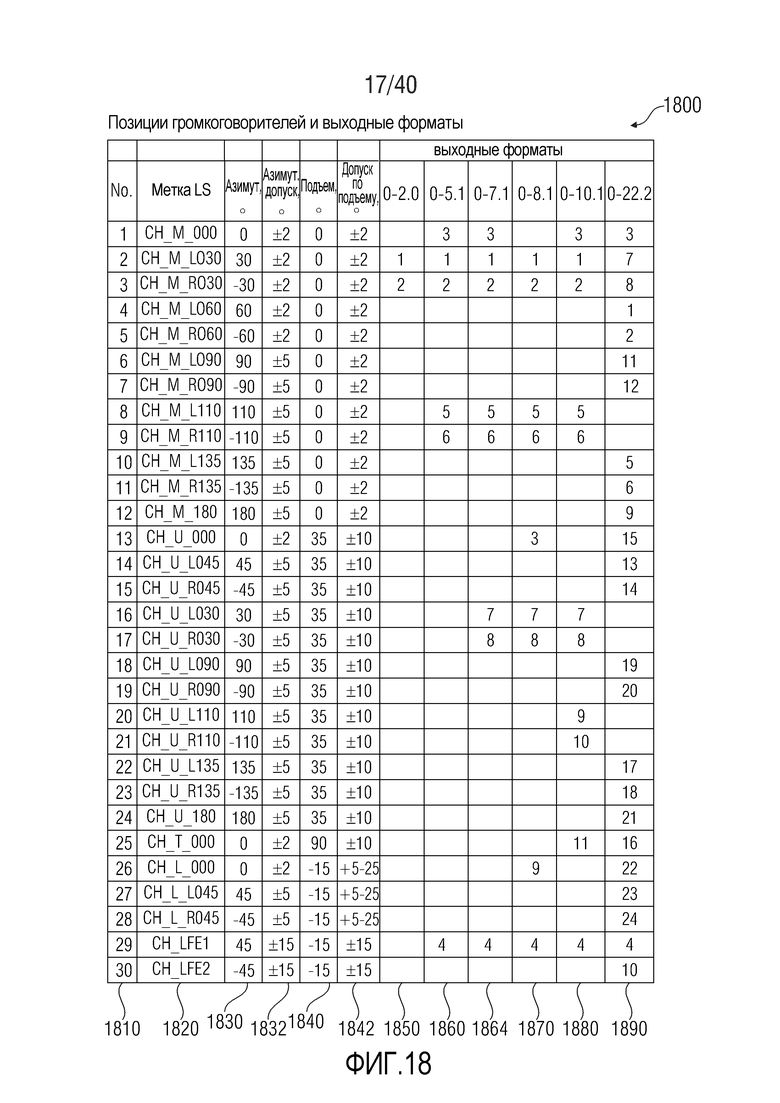
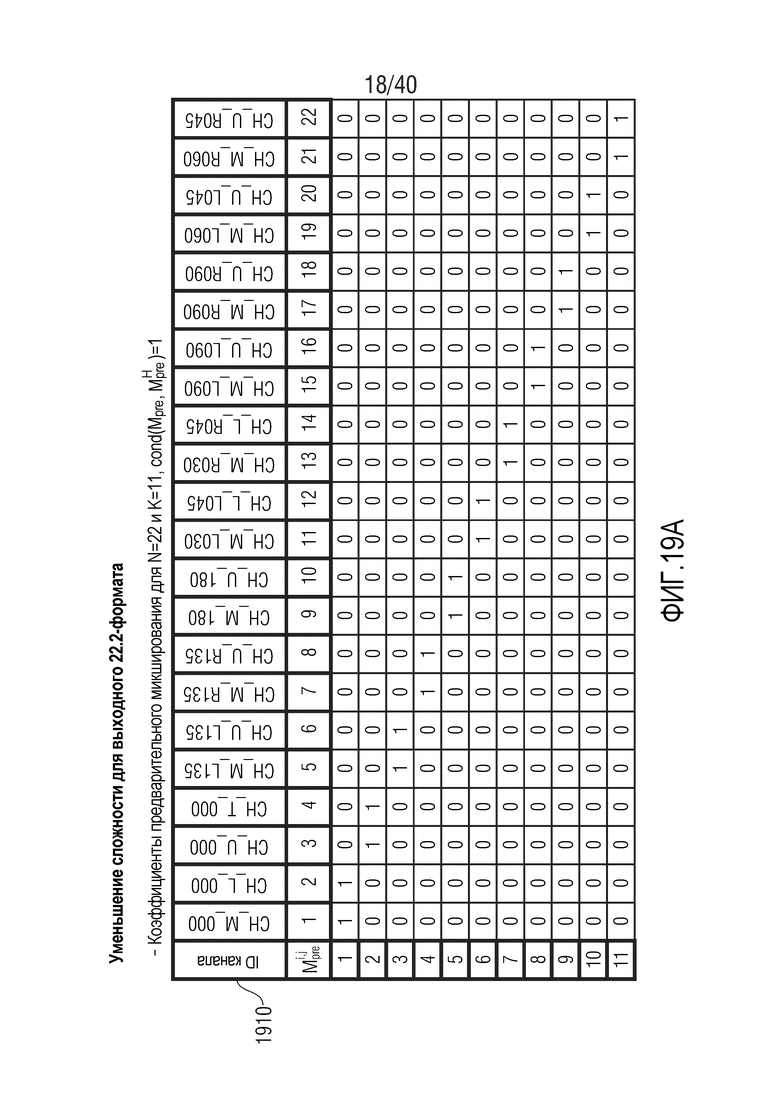
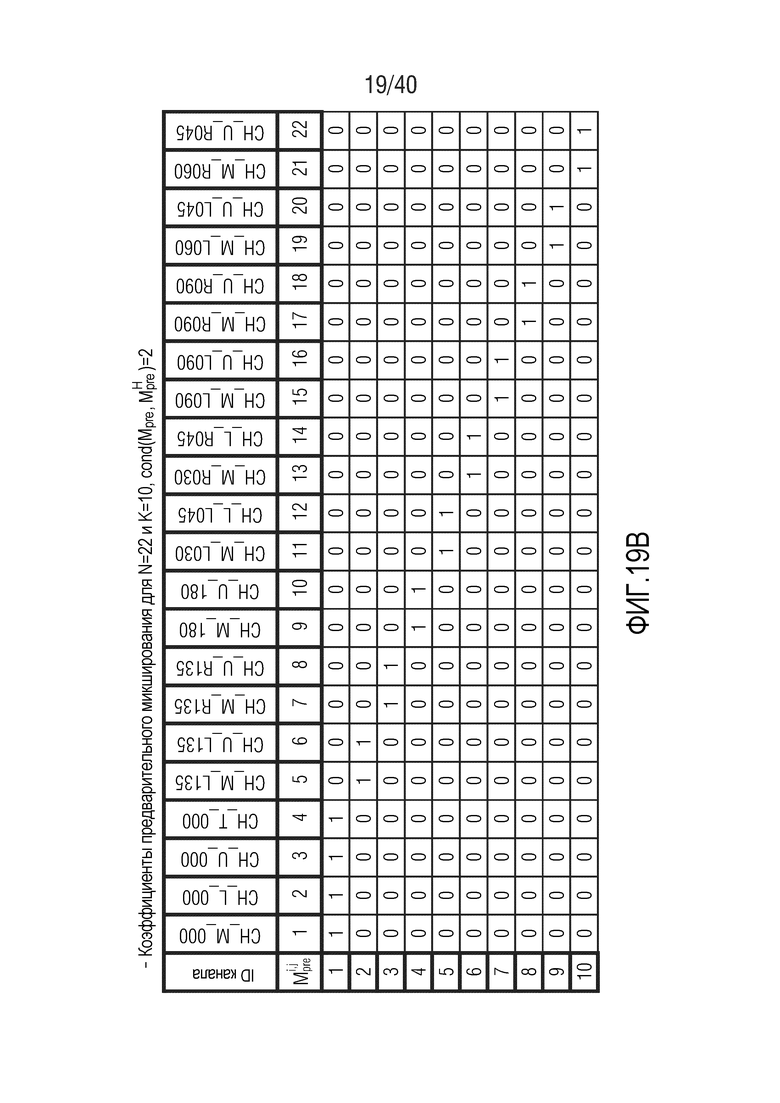
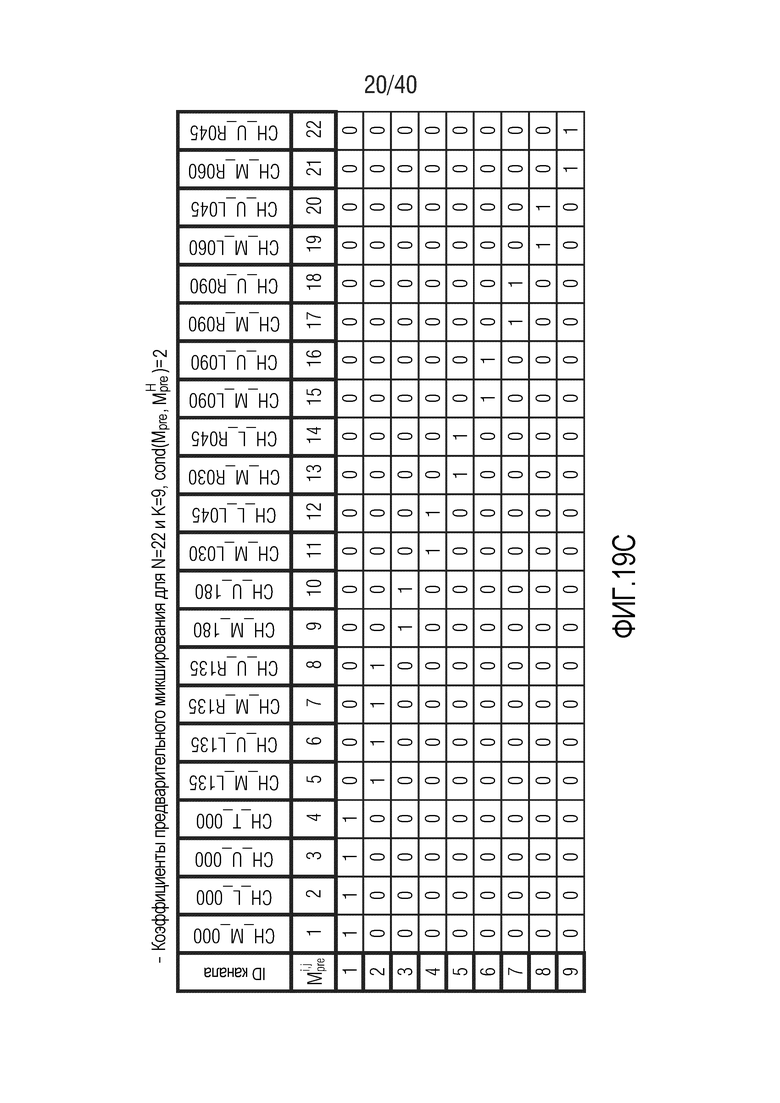
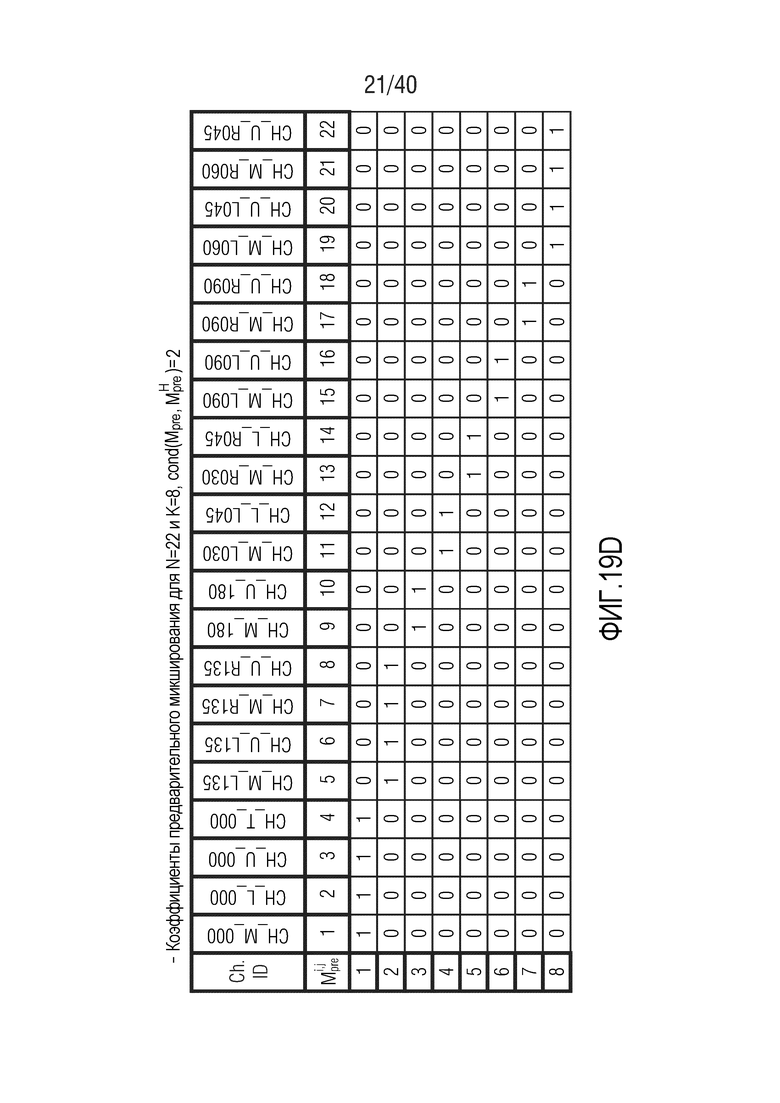
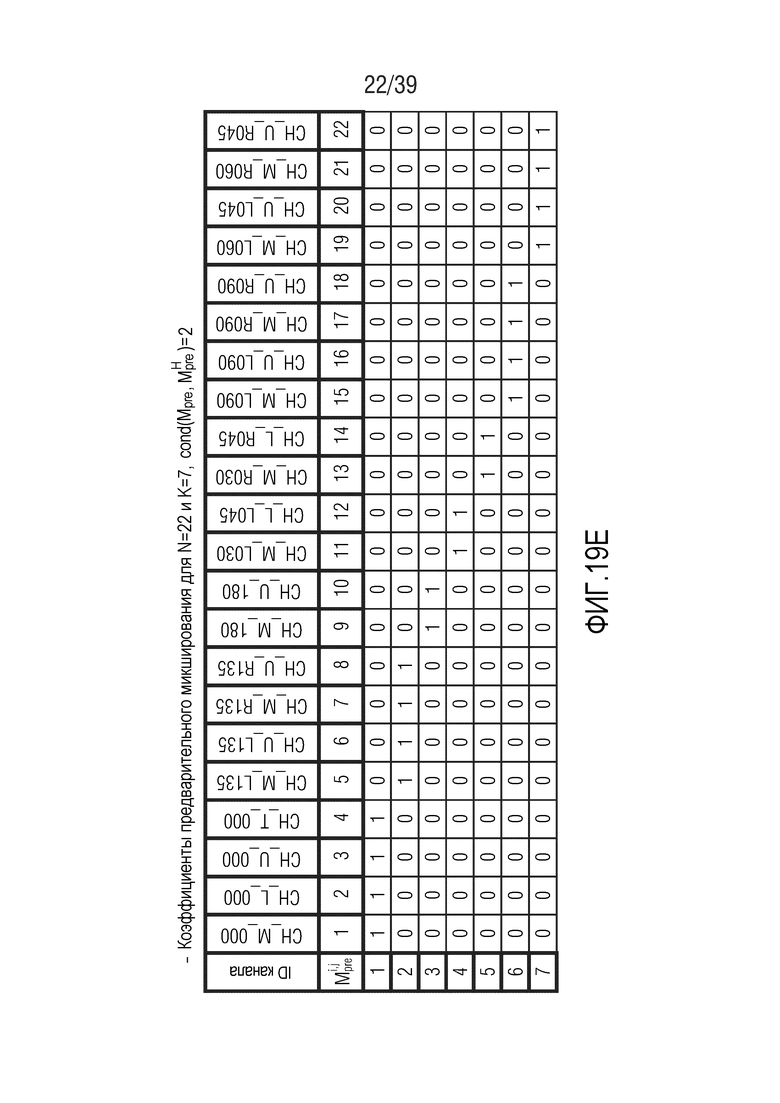
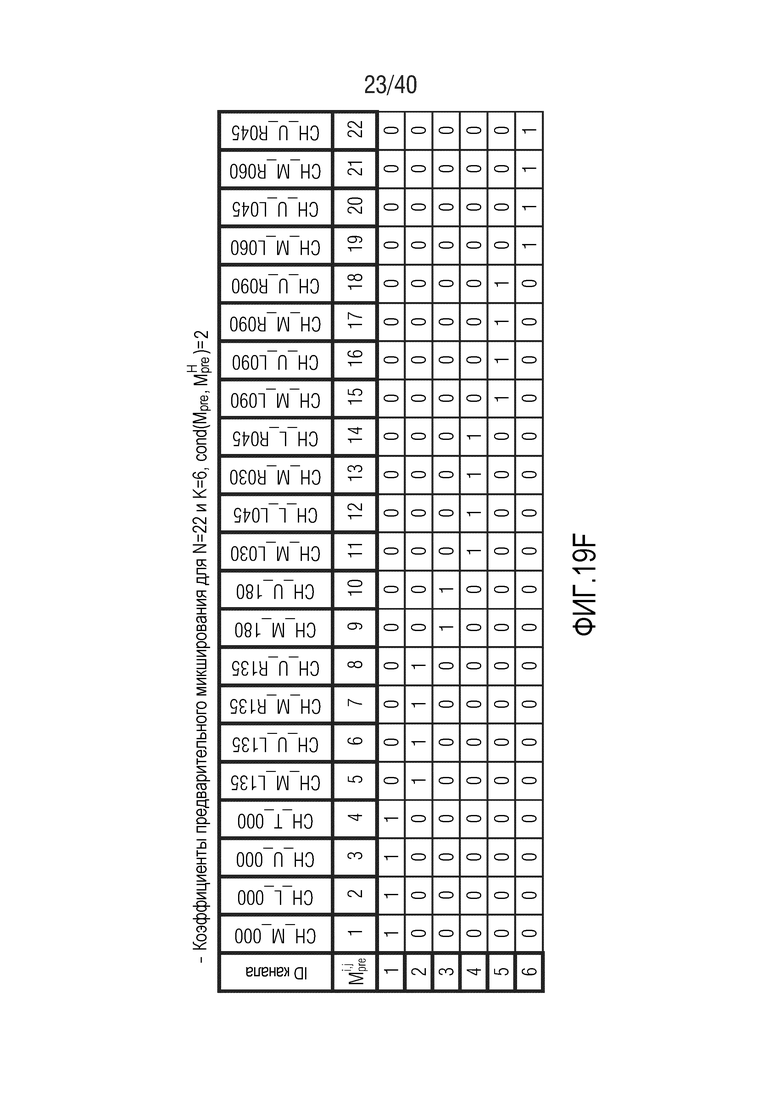
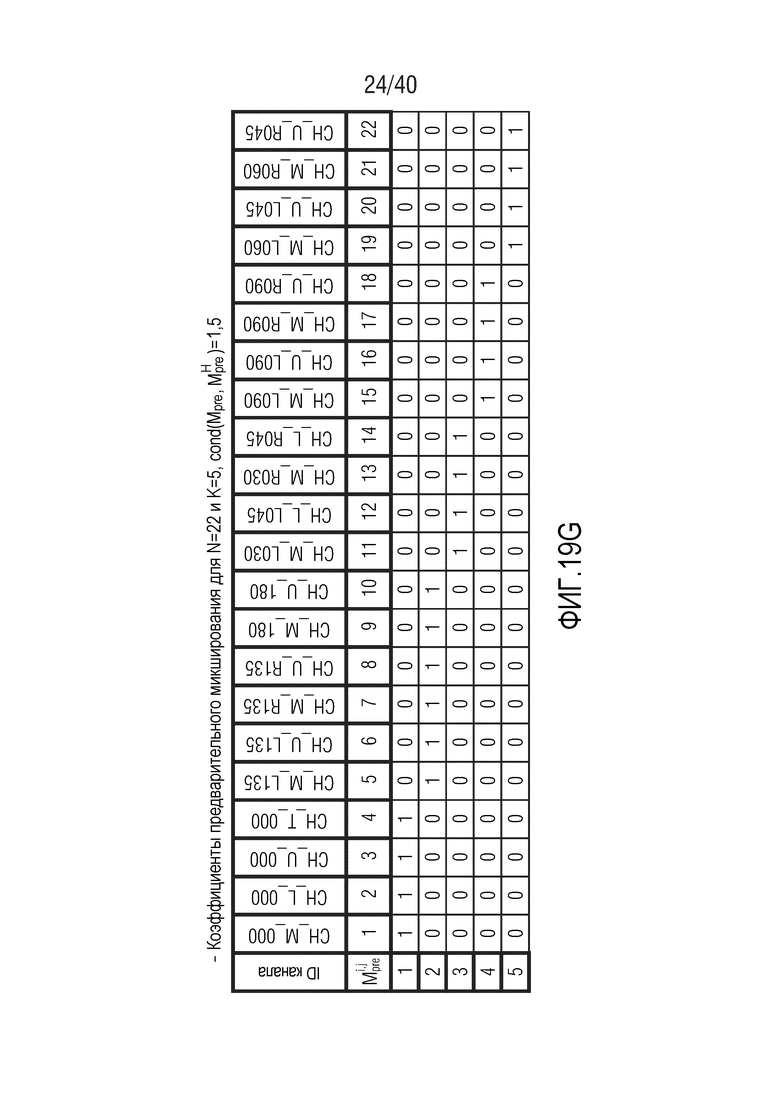

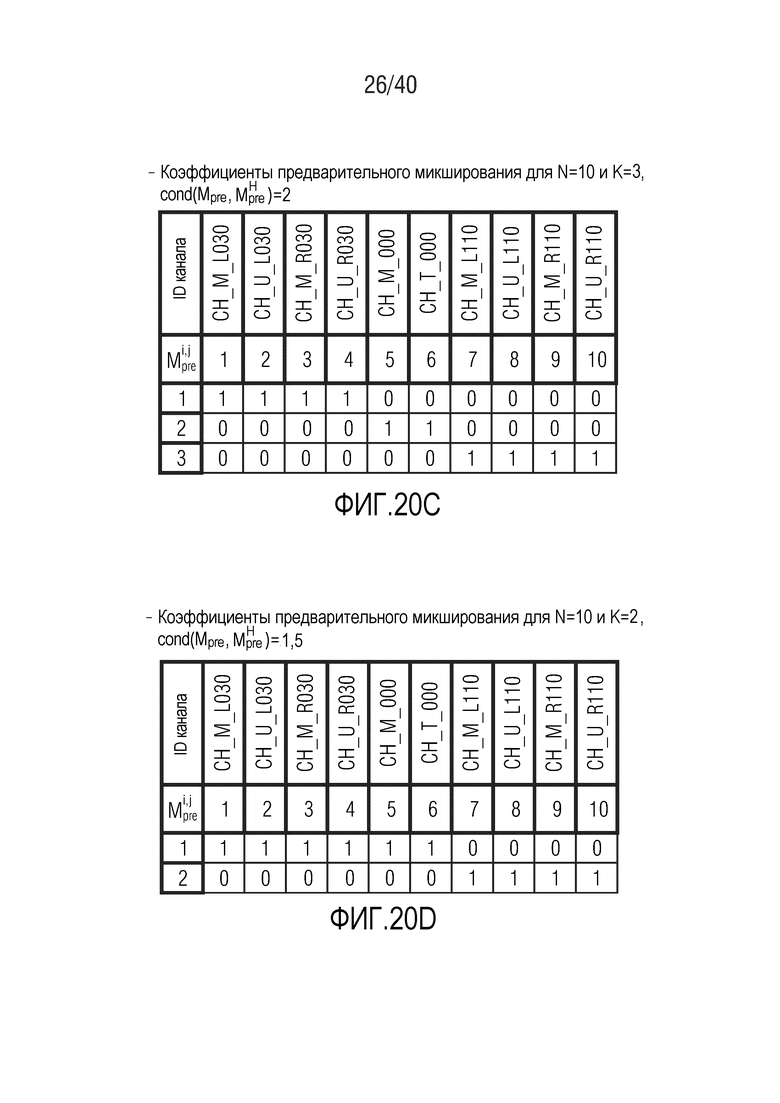
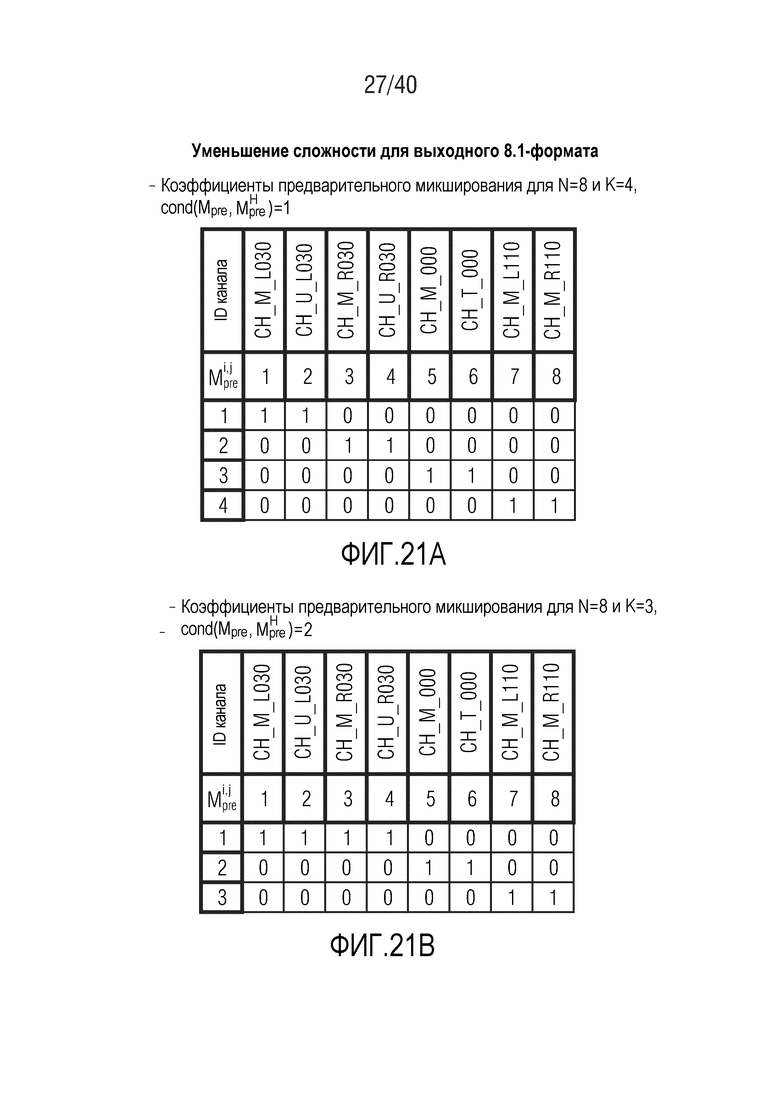

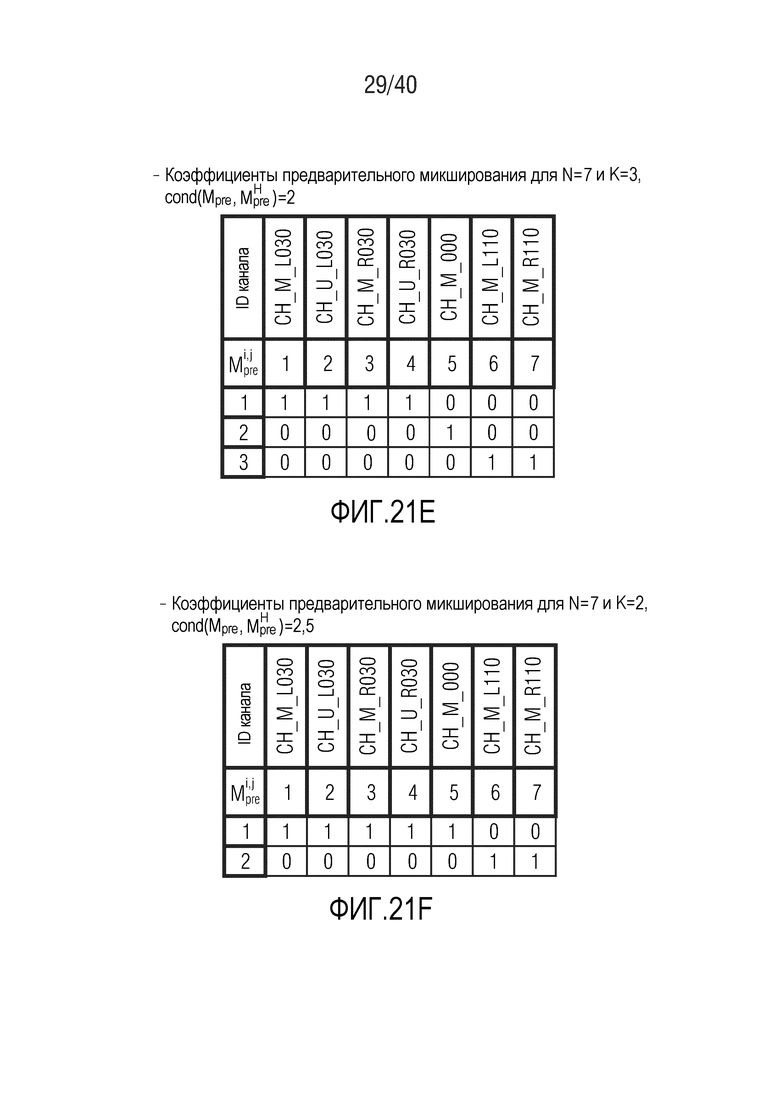
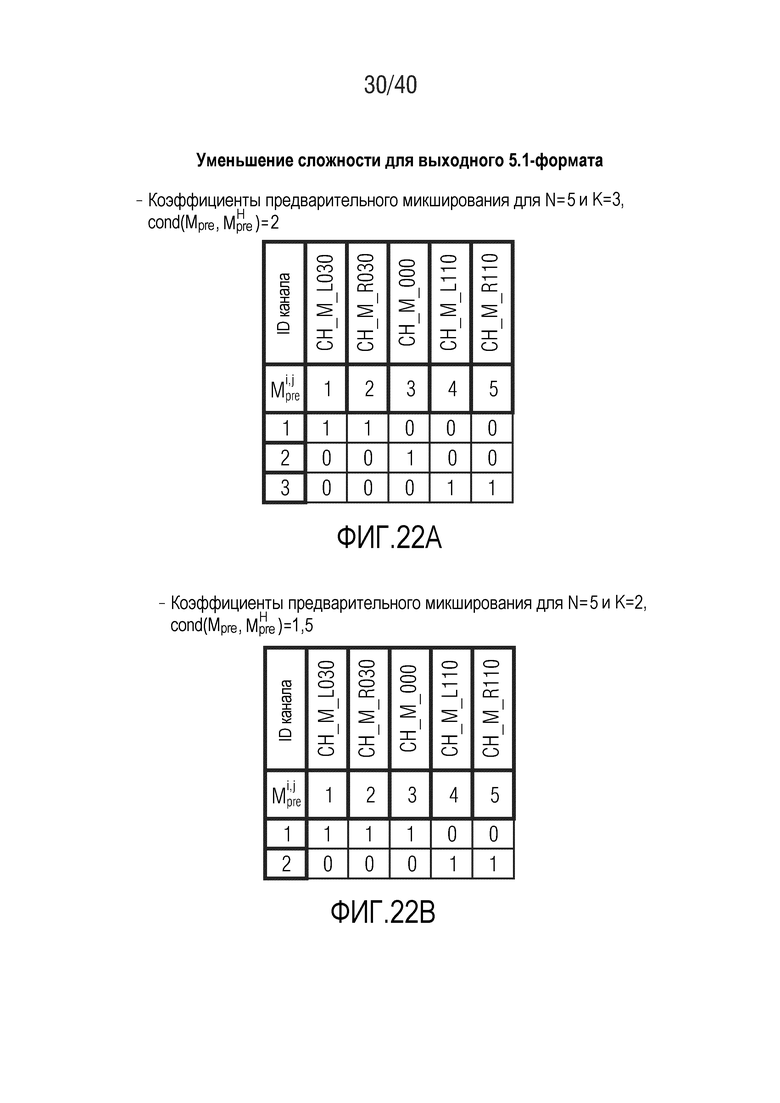

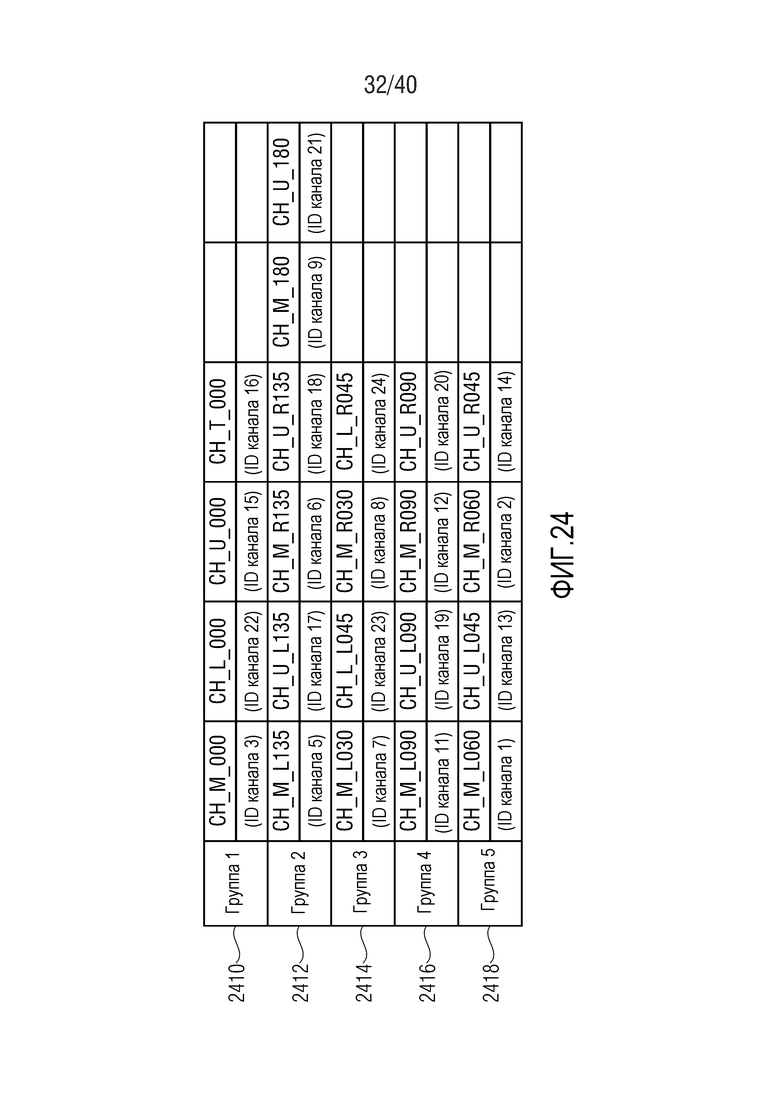

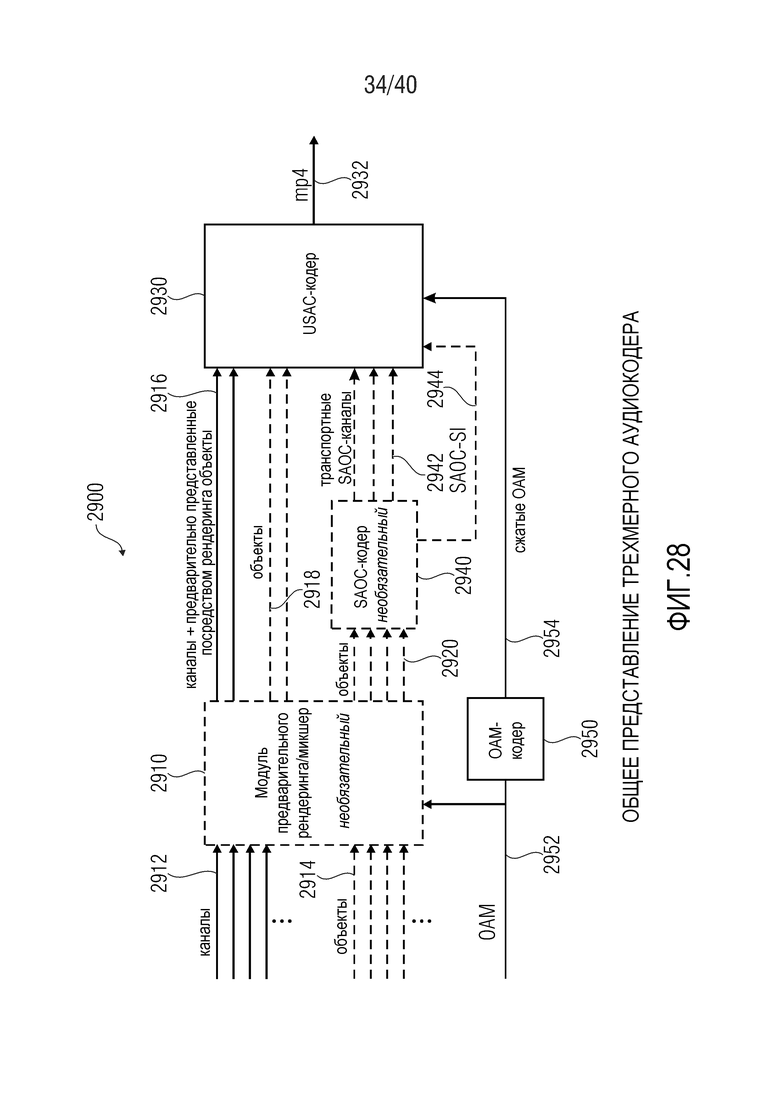
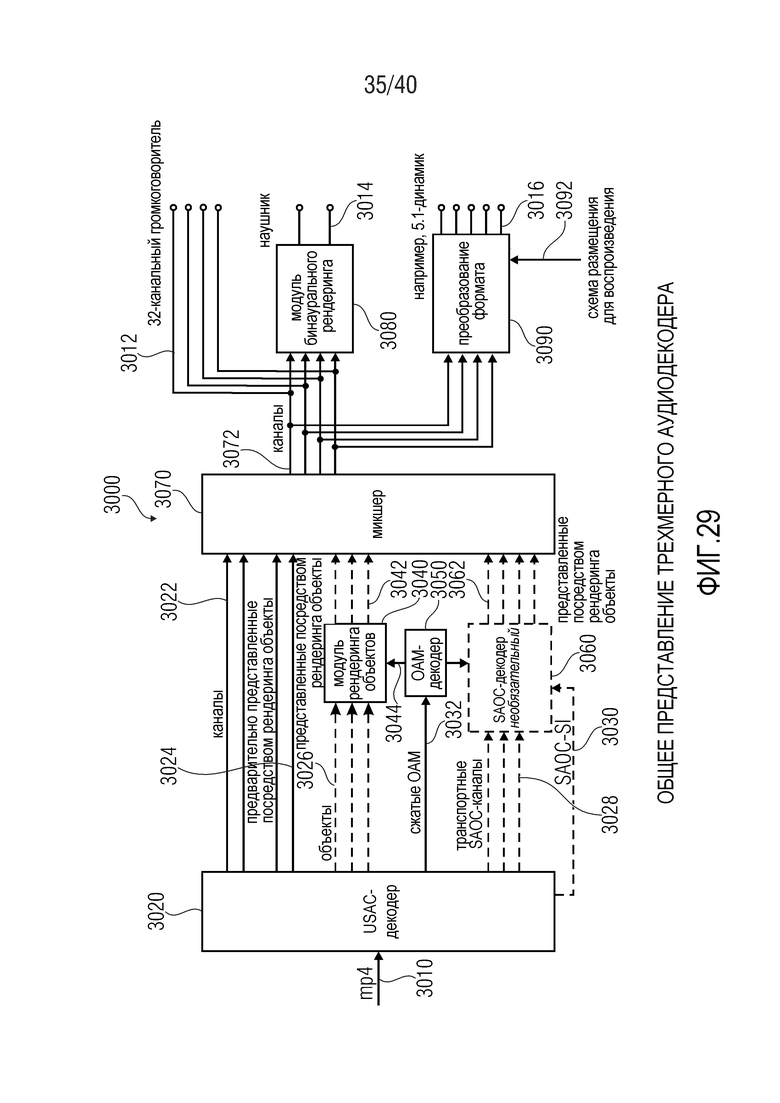
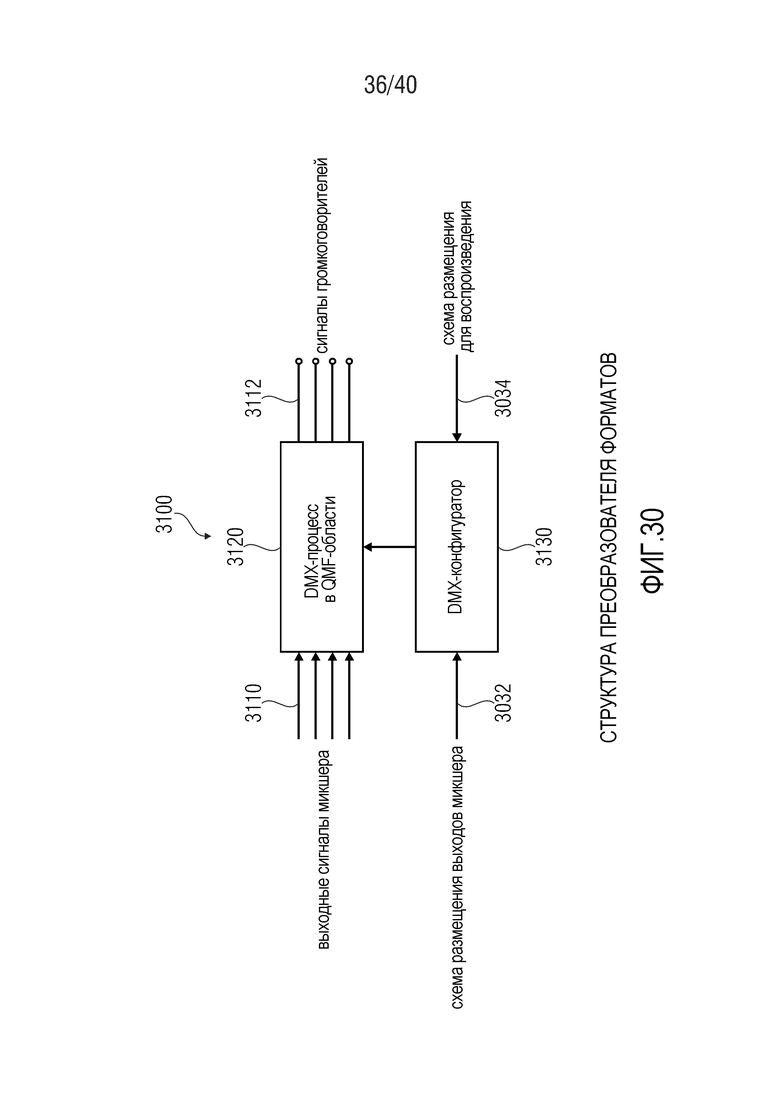
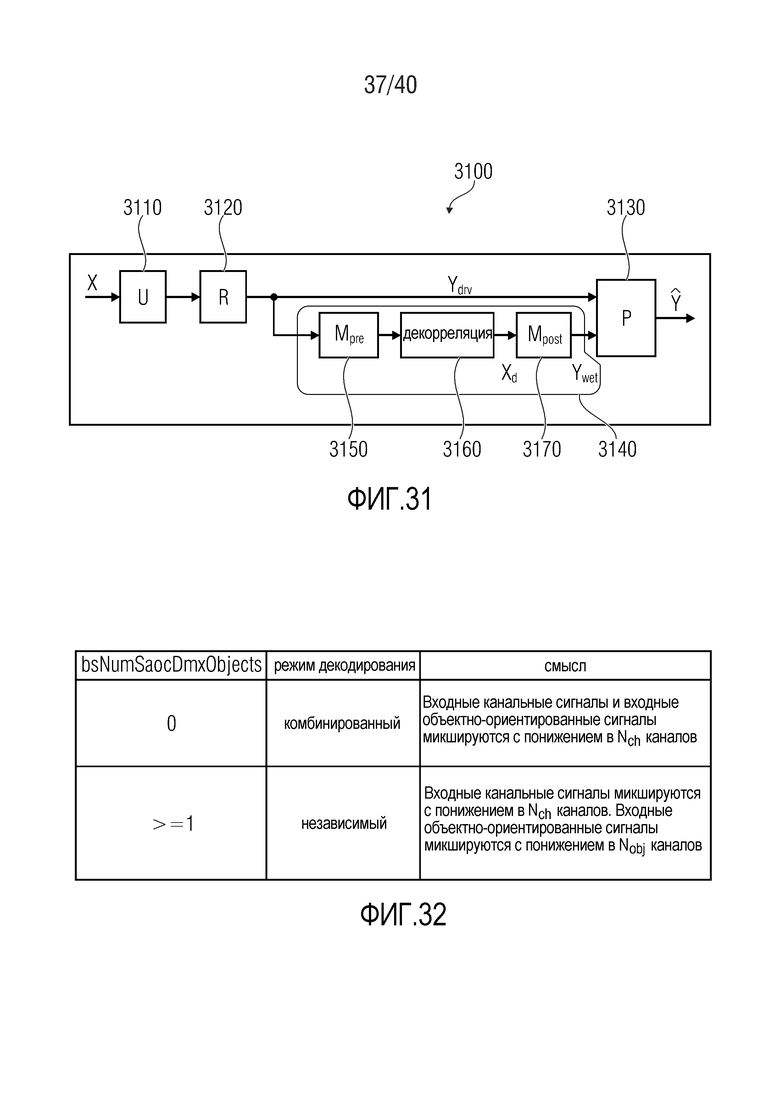



Изобретение относится к средствам для кодирования аудиосигналов. Технический результат заключается в повышении эффективности кодирования трехмерных аудиосцен. Предоставляют один или более сигналов понижающего микширования на основе, по меньшей мере, двух входных аудиосигналов. Предоставляют один или более параметров, описывающих взаимосвязь между входными аудиосигналами. Предоставляют параметр способа декорреляции, описывающий то, какой режим декорреляции должен использоваться на стороне аудиодекодера. Избирательно предоставляют параметр способа декорреляции для того, чтобы сигнализировать один из трех режимов работы аудиодекодера. Первый режим, в котором разрешается микширование между различными представленными посредством рендеринга аудиосигналами при комбинировании этих аудиосигналов или их масштабированной версии с одним или более декоррелированными аудиосигналами. Второй режим, в котором не разрешается микширование между различными представленными посредством рендеринга аудиосигналами при комбинировании этих аудиосигналов или их масштабированной версии с декоррелированными аудиосигналами. 10 н. и 38 з.п. ф-лы, 50 ил.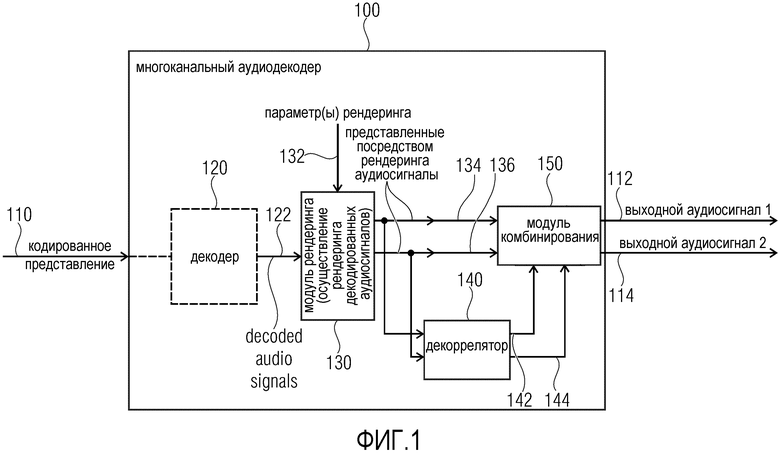
1. Многоканальный аудиодекодер (100; 700; 1550; 3000) для предоставления, по меньшей мере, двух выходных аудиосигналов (112, 114; 712, 714; 1552a-1552n; 3012) на основе кодированного представления (110; 710; 1516a, 1516b, 1518),
- при этом многоканальный аудиодекодер выполнен с возможностью осуществлять рендеринг (130; 1580) множества декодированных аудиосигналов (122; 1562a-1562n, 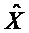
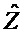
- при этом многоканальный аудиодекодер выполнен с возможностью извлекать (140; 1590) один или более декоррелированных аудиосигналов (142, 144; 1592a-1592n) из представленных посредством рендеринга аудиосигналов, и
- при этом многоканальный аудиодекодер выполнен с возможностью комбинировать (150; 1598) представленные посредством рендеринга аудиосигналы или их масштабированную версию с одним или более декоррелированными аудиосигналами для того, чтобы получать выходные аудиосигналы;
- при этом многоканальный аудиодекодер выполнен с возможностью получать декодированные аудиосигналы, которые представляются посредством рендеринга, чтобы получать множество представленных посредством рендеринга аудиосигналов, с использованием параметрического восстановления (120; 1560);
- при этом декодированные аудиосигналы представляют собой восстановленные сигналы объектов, и
- при этом многоканальный аудиодекодер выполнен с возможностью извлекать восстановленные сигналы объектов из одного или более сигналов (1516a, 1516b) понижающего микширования с использованием вспомогательной информации (1518).
2. Многоканальный аудиодекодер по п.1, при этом многоканальный аудиодекодер выполнен с возможностью извлекать коэффициенты обратного микширования из вспомогательной информации и применять коэффициенты обратного микширования, чтобы извлекать восстановленные сигналы объектов из одного или более сигналов понижающего микширования с использованием коэффициентов обратного микширования.
3. Многоканальный аудиодекодер по п.1, при этом многоканальный аудиодекодер выполнен с возможностью комбинировать представленные посредством рендеринга аудиосигналы с одним или более декоррелированными аудиосигналами для того, чтобы, по меньшей мере, частично достигать требуемых характеристик корреляции или характеристик ковариантности выходных аудиосигналов.
4. Многоканальный аудиодекодер по п.1, при этом многоканальный аудиодекодер выполнен с возможностью комбинировать представленные посредством рендеринга аудиосигналы с одним или более декоррелированными аудиосигналами для того, чтобы, по меньшей мере, частично компенсировать энергетические потери во время параметрического восстановления (120; 1560) декодированных аудиосигналов (122; 1562a-1562n), которые представляются посредством рендеринга, чтобы получать множество представленных посредством рендеринга аудиосигналов.
5. Многоканальный аудиодекодер по п.1, при этом многоканальный аудиодекодер выполнен с возможностью определять требуемые характеристики корреляции или требуемые характеристики ковариантности выходных аудиосигналов, и
- при этом многоканальный аудиодекодер выполнен с возможностью регулировать комбинацию (150; 1598) представленных посредством рендеринга аудиосигналов с одним или более декоррелированными аудиосигналами для того, чтобы получать выходные аудиосигналы, так что характеристики корреляции или характеристики ковариантности полученных выходных аудиосигналов аппроксимируют или равны требуемым характеристикам корреляции или требуемым характеристикам (C) ковариантности.
6. Многоканальный аудиодекодер по п.5, при этом многоканальный аудиодекодер выполнен с возможностью определять требуемые характеристики корреляции или требуемые характеристики (C) ковариантности в зависимости от информации (R) рендеринга, описывающей рендеринг (130; 1560) множества декодированных аудиосигналов (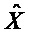
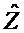
7. Многоканальный аудиодекодер по п.5, при этом многоканальный аудиодекодер выполнен с возможностью определять требуемые характеристики корреляции или требуемые характеристики (C) ковариантности в зависимости от информации корреляции объектов или информации 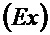
8. Многоканальный аудиодекодер по п.7, при этом многоканальный аудиодекодер выполнен с возможностью определять информацию корреляции объектов или информацию
9. Многоканальный аудиодекодер по п.5, при этом многоканальный аудиодекодер выполнен с возможностью определять фактические характеристики корреляции или характеристики (ES) ковариантности представленных посредством рендеринга аудиосигналов и одного или более декоррелированных аудиосигналов, и
- регулировать комбинацию (150; 1598) представленных посредством рендеринга аудиосигналов с одним или более декоррелированными аудиосигналами для того, чтобы получать выходные аудиосигналы, в зависимости от фактических характеристик корреляции или характеристик (ES) ковариантности представленных посредством рендеринга аудиосигналов и одного или более декоррелированных аудиосигналов.
10. Многоканальный аудиодекодер по п.1,
- при этом многоканальный аудиодекодер выполнен с возможностью комбинировать представленные посредством рендеринга аудиосигналы 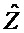
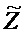
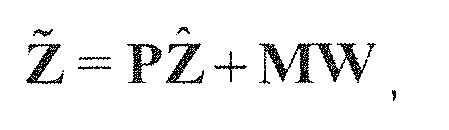
- где P является матрицей микширования, которая применяется к представленным посредством рендеринга аудиосигналам
- где M является матрицей микширования, которая применяется к одному или более декоррелированным аудиосигналам W.
11. Многоканальный аудиодекодер по п.10,
- при этом многоканальный аудиодекодер выполнен с возможностью регулировать, по меньшей мере, одну из матрицы P микширования и матрицы M микширования таким образом, что характеристики корреляции или характеристики 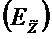
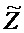
12. Многоканальный аудиодекодер по п.10,
- при этом многоканальный аудиодекодер выполнен с возможностью получать комбинированную матрицу F микширования с помощью:
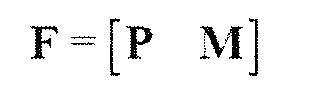 ,
,
так что ковариационная матрица 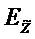
13. Многоканальный аудиодекодер по п.13,
- при этом многоканальный аудиодекодер выполнен с возможностью определять комбинированную матрицу F микширования таким образом, что ковариационная матрица:
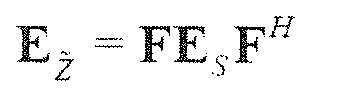
равна требуемой ковариационной матрице:
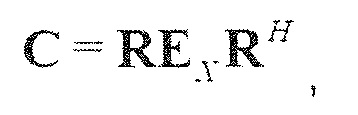
- где ES является ковариационной матрицей сигнала S, комбинирующего представленные посредством рендеринга аудиосигналы 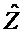
 , и
, и
- где EX является ковариационной матрицей объектов.
14. Многоканальный аудиодекодер по п.1,
- при этом многоканальный аудиодекодер выполнен с возможностью комбинировать представленные посредством рендеринга аудиосигналы 
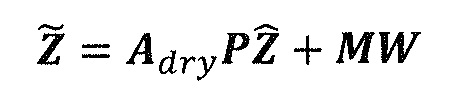 ,
,
или согласно следующему:
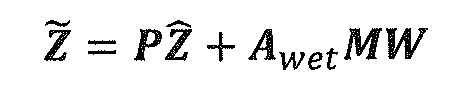 ,
,
или согласно следующему:
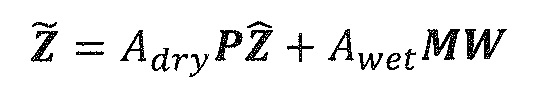 ,
,
- где P является матрицей микширования, которая применяется к представленным посредством рендеринга аудиосигналам 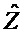
- где M является матрицей микширования, которая применяется к одному или более декоррелированным аудиосигналам W,
- где Adry является первой матрицей коррекции или первой матрицей регулирования, где Awet является второй матрицей коррекции или второй матрицей регулирования.
15. Многоканальный аудиодекодер по п.14,
- при этом многоканальный аудиодекодер выполнен с возможностью регулировать, по меньшей мере, одну из матрицы P микширования и матрицы M микширования таким образом, что характеристики корреляции или характеристики
16. Многоканальный аудиодекодер по п.14,
- при этом многоканальный аудиодекодер выполнен с возможностью получать комбинированную матрицу F микширования с помощью:
F=[P M],
так что ковариационная матрица 
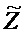
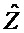
17. Многоканальный аудиодекодер по п.16,
- при этом многоканальный аудиодекодер выполнен с возможностью определять комбинированную матрицу F микширования таким образом, что ковариационная матрица:
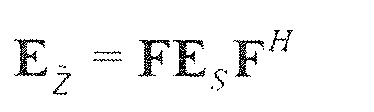
равна требуемой ковариационной матрице:
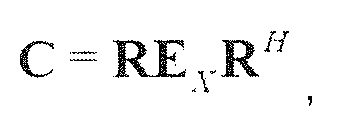
- где ES является ковариационной матрицей сигнала S, комбинирующего представленные посредством рендеринга аудиосигналы 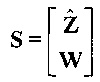 , и
, и
- где EX является ковариационной матрицей объектов.
18. Многоканальный аудиодекодер по п.14,
- при этом многоканальный аудиодекодер выполнен с возможностью определять первую матрицу коррекции таким образом, что вклад представленных посредством рендеринга аудиосигналов в выходные аудиосигналы ограничен, и/или
- при этом многоканальный аудиодекодер выполнен с возможностью определять вторую матрицу коррекции таким образом, что вклад декоррелированных аудиосигналов в выходные аудиосигналы ограничен.
19. Многоканальный аудиодекодер по п.14,
- при этом многоканальный аудиодекодер выполнен с возможностью определять первую матрицу коррекции в зависимости от свойств представленных посредством рендеринга аудиосигналов, и/или в зависимости от свойств декоррелированных аудиосигналов, и/или в зависимости от свойств требуемых выходных аудиосигналов, и/или в зависимости от оцененных свойств микшированных представленных посредством рендеринга аудиосигналов, и/или в зависимости от оцененных свойств микшированных декоррелированных аудиосигналов таким образом, что вклад представленных посредством рендеринга аудиосигналов в выходные аудиосигналы ограничен, и/или
- при этом многоканальный аудиодекодер выполнен с возможностью определять вторую матрицу коррекции в зависимости от свойств представленных посредством рендеринга аудиосигналов, и/или в зависимости от свойств декоррелированных аудиосигналов, и/или в зависимости от свойств требуемых выходных аудиосигналов, и/или в зависимости от оцененных свойств микшированных представленных посредством рендеринга аудиосигналов, и/или в зависимости от оцененных свойств микшированных декоррелированных аудиосигналов таким образом, что вклад декоррелированных аудиосигналов в выходные аудиосигналы ограничен.
20. Многоканальный аудиодекодер по п.19, в котором свойства представленных посредством рендеринга аудиосигналов, и/или декоррелированных аудиосигналов, и/или требуемых выходных аудиосигналов, и/или микшированных представленных посредством рендеринга аудиосигналов, и/или микшированных декоррелированных аудиосигналов являются энергетическими свойствами, или свойствами корреляции, или свойствами ковариантности.
21. Многоканальный аудиодекодер по п.1,
- при этом многоканальный аудиодекодер выполнен с возможностью комбинировать представленные посредством рендеринга аудиосигналы 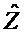
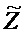
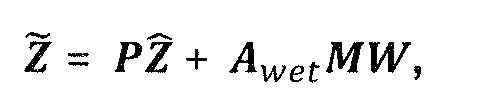
- при этом многоканальный аудиодекодер выполнен с возможностью предоставлять матрицу Awet коррекции таким образом, что Awet является диагональной матрицей, и таким образом, что записи Awet(i,i) матрицы Awet коррекции приводятся, по сравнению с нормальными, неприведенными диагональными записями матрицы Awet коррекции, если отношение между интенсивностью 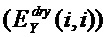
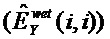
22. Многоканальный аудиодекодер по п.21, в котором пороговое значение является предварительно определенным постоянным пороговым значением или в котором пороговое значение является изменяющимся во времени и/или изменяющимся по частоте в зависимости от свойств сигналов, например энергетических свойств, свойств корреляции и/или свойств ковариантности.
23. Многоканальный аудиодекодер по п.1,
- при этом многоканальный аудиодекодер выполнен с возможностью комбинировать представленные посредством рендеринга аудиосигналы 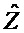
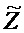
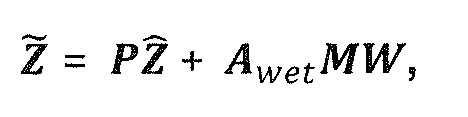
- где P = Pdry, где M = Pwet,
- где 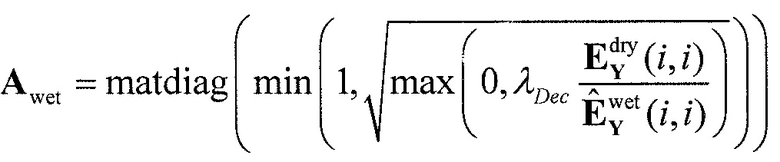 ,
,
- где 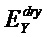
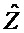
- где 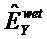
λDec - значение порога.
24. Многоканальный аудиодекодер по п.14, при этом многоканальный аудиодекодер выполнен с возможностью определять комбинированную матрицу F микширования согласно следующему:
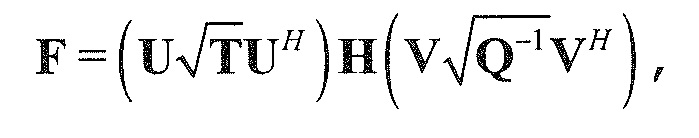
где матрицы U, T, V и Q определяются с использованием разложения по сингулярным значениям ковариационных матриц ES и C, что дает в результате:

и:
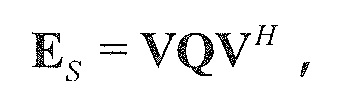
- где матрица H задается следующим образом:
 ,
,
- где 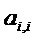
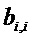
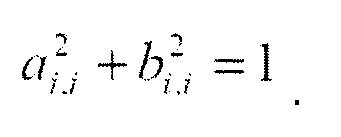
25. Многоканальный аудиодекодер по п.10,
- при этом многоканальный аудиодекодер выполнен с возможностью задавать матрицу P микширования как единичную матрицу или ее кратное и вычислять матрицу M микширования.
26. Многоканальный аудиодекодер по п.25, при этом многоканальный аудиодекодер выполнен с возможностью определять матрицу WI микширования таким образом, что разность ΔE между требуемой ковариационной матрицей C и ковариационной матрицей 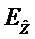
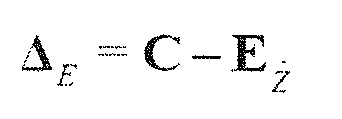 ,
,
равна или аппроксимирует ковариантность:
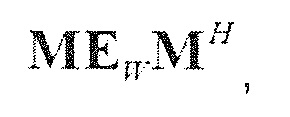
- где требуемая ковариационная матрица C задается следующим образом:
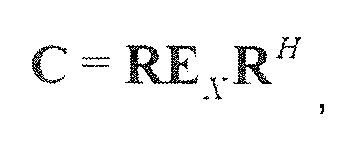
- где R является матрицей рендеринга,
- где EX является ковариационной матрицей объектов, и
- где EW является ковариационной матрицей одного или более декоррелированных сигналов, и
- где 
27. Многоканальный аудиодекодер по п.26,
- при этом многоканальный аудиодекодер выполнен с возможностью определять матрицу M микширования согласно следующему:
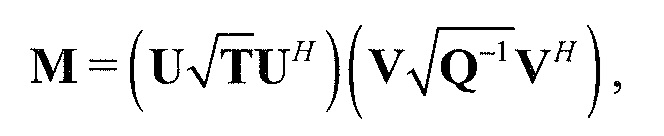
где матрицы U, T, V и Q определяются с использованием разложения по сингулярным значениям ковариационных матриц ΔE и EW, что дает в результате:
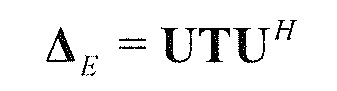
и:
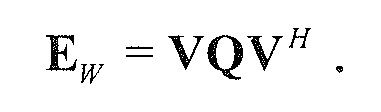
28. Многоканальный аудиодекодер по п.10,
- при этом многоканальный аудиодекодер выполнен с возможностью определять матрицы P, M микширования в соответствии с таким ограничением, что данный представленный посредством рендеринга аудиосигнал микшируется только с декоррелированной версией самого данного представленного посредством рендеринга аудиосигнала.
29. Многоканальный аудиодекодер по п.10,
- при этом многоканальный аудиодекодер выполнен с возможностью комбинировать представленные посредством рендеринга аудиосигналы с одним или более декоррелированными аудиосигналами таким образом, что только значения автокорреляции или значения автоковариации представленных посредством рендеринга аудиосигналов модифицируются, в то время как значения взаимной корреляции или значения взаимной ковариантности остаются неизменными.
30. Многоканальный аудиодекодер по п.10,
- при этом многоканальный аудиодекодер выполнен с возможностью задавать матрицу P микширования как единичную матрицу или ее кратное и вычислять матрицу M микширования в соответствии с таким ограничением, что WI является диагональной матрицей.
31. Многоканальный аудиодекодер по п.28, при этом многоканальный аудиодекодер выполнен с возможностью комбинировать представленные посредством рендеринга аудиосигналы 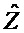
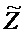
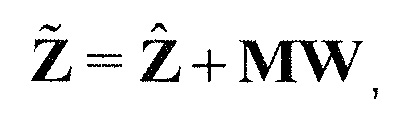
- где M является диагональной матрицей микширования, которая применяется к одному или более декоррелированным аудиосигналам W, и
- при этом многоканальный аудиодекодер выполнен с возможностью вычислять диагональные элементы матрицы M микширования таким образом, что диагональные элементы ковариационной матрицы выходных аудиосигналов равны требуемым энергиям.
32. Многоканальный аудиодекодер по п.31, при этом многоканальный аудиодекодер выполнен с возможностью вычислять элементы матрицы M микширования согласно следующему:
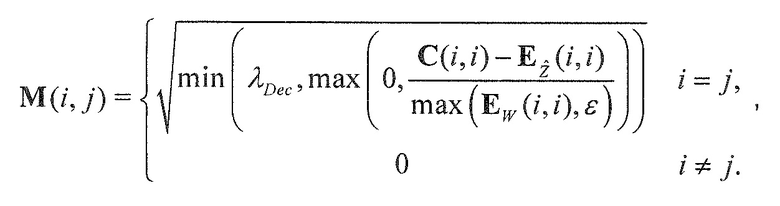
- где требуемая ковариационная матрица C задается следующим образом:
- где R является матрицей рендеринга,
- где EX является ковариационной матрицей объектов,
- где EW является ковариационной матрицей одного или более декоррелированных сигналов, и
- где 
- где 
33. Многоканальный аудиодекодер по п.1, при этом многоканальный аудиодекодер выполнен с возможностью учитывать характеристики корреляции или характеристики ковариантности декоррелированных аудиосигналов при определении того, как комбинировать представленные посредством рендеринга аудиосигналы или их масштабированную версию с одним или более декоррелированными аудиосигналами.
34. Многоканальный аудиодекодер по п.1, при этом многоканальный аудиодекодер выполнен с возможностью микшировать представленные посредством рендеринга аудиосигналы и декоррелированные аудиосигналы, так что данный выходной аудиосигнал предоставляется на основе двух или более представленных посредством рендеринга аудиосигналов и, по меньшей мере, одного декоррелированного аудиосигнала.
35. Многоканальный аудиодекодер по п.1, при этом многоканальный аудиодекодер выполнен с возможностью переключаться между различными режимами, в которых различные ограничения применяются для определения того, как комбинировать представленные посредством рендеринга аудиосигналы или их масштабированную версию с одним или более декоррелированными аудиосигналами для того, чтобы получать выходные аудиосигналы.
36. Многоканальный аудиодекодер по п.1, при этом многоканальный аудиодекодер выполнен с возможностью переключаться между:
- первым режимом, в котором разрешается микширование между различными представленными посредством рендеринга аудиосигналами при комбинировании представленных посредством рендеринга аудиосигналов или их масштабированной версии с одним или более декоррелированными аудиосигналами,
- вторым режимом, в котором не разрешается микширование между различными представленными посредством рендеринга аудиосигналами при комбинировании представленных посредством рендеринга аудиосигналов или их масштабированной версии с одним или более декоррелированными аудиосигналами и в котором разрешается комбинирование данного декоррелированного сигнала, с идентичным или различным масштабированием, с множеством представленных посредством рендеринга аудиосигналов или их масштабированной версией, чтобы регулировать характеристики взаимной корреляции или характеристики взаимной ковариантности выходных аудиосигналов, и
- третьим режимом, в котором не разрешается микширование между различными представленными посредством рендеринга аудиосигналами при комбинировании представленных посредством рендеринга аудиосигналов или их масштабированной версии с одним или более декоррелированными аудиосигналами и в котором не разрешается комбинирование данного декоррелированного сигнала с представленными посредством рендеринга аудиосигналами, за исключением представленного посредством рендеринга аудиосигнала, из которого извлекается данный декоррелированный сигнал.
37. Многоканальный аудиодекодер по п.35, при этом многоканальный аудиодекодер выполнен с возможностью оценивать элемент потока битов кодированного представления, указывающего то, какой из трех режимов для комбинирования представленных посредством рендеринга аудиосигналов или их масштабированной версии с одним или более декоррелированными аудиосигналами должен использоваться, и выбирать режим в зависимости от упомянутого элемента потока битов.
38. Многоканальный аудиокодер (200; 1510; 2900) для предоставления кодированного представления (214; 1516a, 1516b, 1518; 2932) на основе, по меньшей мере, двух входных аудиосигналов (210, 212; 1512a-1512n; 2912, 2914),
- при этом многоканальный аудиокодер выполнен с возможностью предоставлять (220) один или более сигналов (222; 1516a, 1516b) понижающего микширования на основе, по меньшей мере, двух входных аудиосигналов, и
- при этом многоканальный аудиокодер выполнен с возможностью предоставлять (230) один или более параметров (232; 1518), описывающих взаимосвязь, по меньшей мере, между двумя входными аудиосигналами, и
- при этом многоканальный аудиокодер выполнен с возможностью предоставлять (240) параметр (242; 1518) способа декорреляции, описывающий то, какой режим декорреляции из множества режимов декорреляции должен использоваться на стороне аудиодекодера;
- при этом многоканальный аудиокодер выполнен с возможностью избирательно предоставлять параметр способа декорреляции для того, чтобы сигнализировать один из следующих трех режимов для работы аудиодекодера:
- первый режим, в котором разрешается микширование между различными представленными посредством рендеринга аудиосигналами при комбинировании представленных посредством рендеринга аудиосигналов или их масштабированной версии с одним или более декоррелированными аудиосигналами,
- второй режим, в котором не разрешается микширование между различными представленными посредством рендеринга аудиосигналами при комбинировании представленных посредством рендеринга аудиосигналов или их масштабированной версии с одним или более декоррелированными аудиосигналами и в котором разрешается комбинирование данного декоррелированного сигнала, с идентичным или различным масштабированием, с множеством представленных посредством рендеринга аудиосигналов или их масштабированной версией, чтобы регулировать характеристики взаимной корреляции или характеристики взаимной ковариантности выходных аудиосигналов, и
- третий режим, в котором не разрешается микширование между различными представленными посредством рендеринга аудиосигналами при комбинировании представленных посредством рендеринга аудиосигналов или их масштабированной версии с одним или более декоррелированными аудиосигналами и в котором не разрешается комбинирование данного декоррелированного сигнала с представленными посредством рендеринга аудиосигналами, за исключением представленного посредством рендеринга аудиосигнала, из которого извлекается данный декоррелированный сигнал.
39. Многоканальный аудиокодер по п.38, при этом многоканальный аудиокодер выполнен с возможностью выбирать параметр способа декорреляции в зависимости от корреляции входных аудиосигналов.
40. Многоканальный аудиокодер по п.38, при этом многоканальный аудиокодер выполнен с возможностью выбирать параметр способа декорреляции для того, чтобы обозначать первый режим или второй режим, если корреляция между входными аудиосигналами является сравнительно высокой, и
- при этом многоканальный аудиокодер выполнен с возможностью выбирать параметр способа декорреляции для того, чтобы обозначать третий режим, если корреляция между входными аудиосигналами является сравнительно более низкой.
41. Способ (300) для предоставления, по меньшей мере, двух выходных аудиосигналов на основе кодированного представления, при этом способ содержит этапы, на которых:
- представляют посредством рендеринга (310) множество декодированных аудиосигналов, которые получаются на основе кодированного представления, в многоканальную целевую сцену в зависимости от одного или более параметров рендеринга, которые задают матрицу рендеринга, чтобы получать множество представленных посредством рендеринга аудиосигналов,
- извлекают (320) один или более декоррелированных аудиосигналов из представленных посредством рендеринга аудиосигналов, и
- комбинируют (330) представленные посредством рендеринга аудиосигналы или их масштабированную версию с одним или более декоррелированными аудиосигналами для того, чтобы получать выходные аудиосигналы;
- при этом декодированные аудиосигналы, которые представляются посредством рендеринга, чтобы получать множество представленных посредством рендеринга аудиосигналов, получаются с использованием параметрического восстановления (120; 1560);
- при этом декодированные аудиосигналы представляют собой восстановленные сигналы объектов; и
- при этом восстановленные сигналы объектов извлекаются из одного или более сигналов (1516a, 1516b) понижающего микширования с использованием вспомогательной информации (1518).
42. Способ (400) для предоставления кодированного представления на основе, по меньшей мере, двух входных аудиосигналов, при этом способ содержит этапы, на которых:
- предоставляют (410) один или более сигналов понижающего микширования на основе, по меньшей мере, двух входных аудиосигналов,
- предоставляют (420) один или более параметров, описывающих взаимосвязь, по меньшей мере, между двумя входными аудиосигналами, и
- предоставляют (430) параметр способа декорреляции, описывающий то, какой режим декорреляции из множества режимов декорреляции должен использоваться на стороне аудиодекодера;
- при этом способ содержит этап, на котором избирательно предоставляют параметр способа декорреляции для того, чтобы сигнализировать один из следующих трех режимов для работы аудиодекодера:
- первый режим, в котором разрешается микширование между различными представленными посредством рендеринга аудиосигналами при комбинировании представленных посредством рендеринга аудиосигналов или их масштабированной версии с одним или более декоррелированными аудиосигналами,
- второй режим, в котором не разрешается микширование между различными представленными посредством рендеринга аудиосигналами при комбинировании представленных посредством рендеринга аудиосигналов или их масштабированной версии с одним или более декоррелированными аудиосигналами и в котором разрешается комбинирование данного декоррелированного сигнала, с идентичным или различным масштабированием, с множеством представленных посредством рендеринга аудиосигналов или их масштабированной версией, чтобы регулировать характеристики взаимной корреляции или характеристики взаимной ковариантности выходных аудиосигналов, и
- третий режим, в котором не разрешается микширование между различными представленными посредством рендеринга аудиосигналами при комбинировании представленных посредством рендеринга аудиосигналов или их масштабированной версии с одним или более декоррелированными аудиосигналами и в котором не разрешается комбинирование данного декоррелированного сигнала с представленными посредством рендеринга аудиосигналами, за исключением представленного посредством рендеринга аудиосигнала, из которого извлекается данный декоррелированный сигнал.
43. Носитель данных, содержащий компьютерную программу для осуществления способа по п.41, когда компьютерная программа работает на компьютере.
44. Носитель данных, содержащий компьютерную программу для осуществления способа по п.42, когда компьютерная программа работает на компьютере.
45. Кодированное аудиопредставление (500), содержащее:
- кодированное представление (510) сигнала понижающего микширования;
- кодированное представление (520) одного или более параметров, описывающих взаимосвязь, по меньшей мере, между двумя входными аудиосигналами, и
- кодированный параметр (530) способа декорреляции, описывающий то, какой режим декорреляции из множества режимов декорреляции должен использоваться на стороне аудиодекодера;
- при этом параметр способа декорреляции сигнализирует один из следующих трех режимов для работы аудиодекодера:
- первый режим, в котором разрешается микширование между различными представленными посредством рендеринга аудиосигналами при комбинировании представленных посредством рендеринга аудиосигналов или их масштабированной версии с одним или более декоррелированными аудиосигналами,
- второй режим, в котором не разрешается микширование между различными представленными посредством рендеринга аудиосигналами при комбинировании представленных посредством рендеринга аудиосигналов или их масштабированной версии с одним или более декоррелированными аудиосигналами и в котором разрешается комбинирование данного декоррелированного сигнала, с идентичным или различным масштабированием, с множеством представленных посредством рендеринга аудиосигналов или их масштабированной версией, чтобы регулировать характеристики взаимной корреляции или характеристики взаимной ковариантности выходных аудиосигналов, и
- третий режим, в котором не разрешается микширование между различными представленными посредством рендеринга аудиосигналами при комбинировании представленных посредством рендеринга аудиосигналов или их масштабированной версии с одним или более декоррелированными аудиосигналами и в котором не разрешается комбинирование данного декоррелированного сигнала с представленными посредством рендеринга аудиосигналами, за исключением представленного посредством рендеринга аудиосигнала, из которого извлекается данный декоррелированный сигнал.
46. Многоканальный аудиодекодер (100; 700; 1550; 3000) для предоставления, по меньшей мере, двух выходных аудиосигналов (112, 114; 712, 714; 1552a-1552n; 3012) на основе кодированного представления (110; 710; 1516a, 1516b, 1518),
- при этом многоканальный аудиодекодер выполнен с возможностью осуществлять рендеринг (130; 1580) множества декодированных аудиосигналов (122; 1562a-1562n, 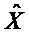
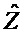
- при этом многоканальный аудиодекодер выполнен с возможностью извлекать (140; 1590) один или более декоррелированных аудиосигналов (142, 144; 1592a-1592n) из представленных посредством рендеринга аудиосигналов, и
- при этом многоканальный аудиодекодер выполнен с возможностью комбинировать (150; 1598) представленные посредством рендеринга аудиосигналы или их масштабированную версию с одним или более декоррелированными аудиосигналами для того, чтобы получать выходные аудиосигналы;
- при этом многоканальный аудиодекодер выполнен с возможностью переключаться между:
- первым режимом, в котором разрешается микширование между различными представленными посредством рендеринга аудиосигналами при комбинировании представленных посредством рендеринга аудиосигналов или их масштабированной версии с одним или более декоррелированными аудиосигналами,
- вторым режимом, в котором не разрешается микширование между различными представленными посредством рендеринга аудиосигналами при комбинировании представленных посредством рендеринга аудиосигналов или их масштабированной версии с одним или более декоррелированными аудиосигналами и в котором разрешается комбинирование данного декоррелированного сигнала, с идентичным или различным масштабированием, с множеством представленных посредством рендеринга аудиосигналов или их масштабированной версией, чтобы регулировать характеристики взаимной корреляции или характеристики взаимной ковариантности выходных аудиосигналов, и
- третьим режимом, в котором не разрешается микширование между различными представленными посредством рендеринга аудиосигналами при комбинировании представленных посредством рендеринга аудиосигналов или их масштабированной версии с одним или более декоррелированными аудиосигналами и в котором не разрешается комбинирование данного декоррелированного сигнала с представленными посредством рендеринга аудиосигналами, за исключением представленного посредством рендеринга аудиосигнала, из которого извлекается данный декоррелированный сигнал.
47. Способ (300) для предоставления, по меньшей мере, двух выходных аудиосигналов на основе кодированного представления, при этом способ содержит этапы, на которых:
- представляют посредством рендеринга (310) множество декодированных аудиосигналов, которые получаются на основе кодированного представления, в зависимости от одного или более параметров рендеринга, чтобы получать множество представленных посредством рендеринга аудиосигналов,
- извлекают (320) один или более декоррелированных аудиосигналов из представленных посредством рендеринга аудиосигналов, и
- комбинируют (330) представленные посредством рендеринга аудиосигналы или их масштабированную версию с одним или более декоррелированными аудиосигналами для того, чтобы получать выходные аудиосигналы;
- при этом способ содержит этап, на котором переключаются между:
- первым режимом, в котором разрешается микширование между различными представленными посредством рендеринга аудиосигналами при комбинировании представленных посредством рендеринга аудиосигналов или их масштабированной версии с одним или более декоррелированными аудиосигналами,
- вторым режимом, в котором не разрешается микширование между различными представленными посредством рендеринга аудиосигналами при комбинировании представленных посредством рендеринга аудиосигналов или их масштабированной версии с одним или более декоррелированными аудиосигналами и в котором разрешается комбинирование данного декоррелированного сигнала, с идентичным или различным масштабированием, с множеством представленных посредством рендеринга аудиосигналов или их масштабированной версией, чтобы регулировать характеристики взаимной корреляции или характеристики взаимной ковариантности выходных аудиосигналов, и
- третьим режимом, в котором не разрешается микширование между различными представленными посредством рендеринга аудиосигналами при комбинировании представленных посредством рендеринга аудиосигналов или их масштабированной версии с одним или более декоррелированными аудиосигналами и в котором не разрешается комбинирование данного декоррелированного сигнала с представленными посредством рендеринга аудиосигналами, за исключением представленного посредством рендеринга аудиосигнала, из которого извлекается данный декоррелированный сигнал.
48. Носитель данных, содержащий компьютерную программу для осуществления способа по п.47, когда компьютерная программа работает на компьютере.
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| ИЗНОСОСТОЙКАЯ СТАЛЬ | 2002 |
|
RU2225893C1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| JP 2012505575 A, 01.03.2012 | |||
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ СИНТЕЗИРОВАНИЯ ВЫХОДНОГО СИГНАЛА | 2008 |
|
RU2439719C2 |

