Изобретение относится в целом к области доверенного искусственного интеллекта, в частности, к вычислительным системам обработки естественного языка и применяется для определения тематической принадлежности текстов к заданному набору категорий с объяснением результатов. В соответствующей области техники эта задача носит название «классификация» или «рубрикация» текстов, а набор категорий называют «классификатором» или «рубрикатором».
Из уровня техники известны патенты RU 2413291, опубл. 27.02.2011, и RU 2487403, опубл. 10.07.2013, в которых предложены способы оценки семантического сходства между документами. В данных изобретениях реализованы методы оценки сходства между документами с использованием онтологий и явных ссылок, но отсутствуют объяснения результата рубрикации.
Известен способ по патенту RU 2678716, опубл. 31.01.2019, который включает создание с помощью вычислительной системы множества векторов признаков, обучение с использованием множества векторов признаков, автоэнкодера, представленного искусственной нейронной сетью, создание с использованием автоэнкодера результата скрытого слоя и обучение с использованием обучающей выборки данных классификатора текста. Также предложена система, включающая память и процессор, соединенный с запоминающим устройством, постоянный машиночитаемый носитель данных, включающий исполняемые команды, которые при исполнении их вычислительным устройством приводят к выполнению операций. Способ не содержит технического решения для объяснения результата рубрикации, что является его недостатком.
Известно техническое решение по патенту US10083230 B2, опубл. 25.09.2018, в котором для повышения скорости решения задачи применяются инвертированные индексы. Способы создания инвертированного индекса для объектов набора элементов данных, в котором каждый из элементов данных представлен вектором объектов, в котором инвертированный индекс при запросе с помощью объекта выводит один или более элементов данных, содержащих объект. Функции набора элементов данных ранжируются. Для каждого объекта в ранжированном списке запрашивается инвертированный индекс для элементов данных, имеющих объект и не имеющих ранее выбранного объекта, и создается кластер элементов данных на основе результатов, возвращенных в ответ на запрос. Данный способ не использует лингвистический анализ для выделения словосочетаний, в способе не применяется нормализация для словосочетаний, не реализуется процедура объяснений результата классификации, что приводит к неточностям и также является недостатком данного способа.
В патенте RU 2563148, опубл. 15.07.2013, представлена система и метод семантического поиска, в которой реализуются стадии лингвистического анализа: морфологический (включая снятие омонимии), синтаксический и семантический. Но полученные результаты лингвистического анализа применяются только для решения задачи информационного поиска без классификации, соответственно отсутствует и объяснение результатов классификации, что является недостатком данного способа.
Известен способ интерпретации искусственных нейронных сетей по патенту RU 2689818, опубл. 13.07.2018, который заключается в обучении некоторой нейронной сети для решения целевой задачи, а затем послойного построения для этой сети деревьев решений, действующих на входных данных аналогично соответствующему слою нейронной сети. Результат объяснения заключается в предоставлении упорядоченной последовательности номеров листьев, сформированных деревьев решений, и набора правил, предсказывающий последовательность номеров листьев по объекту. Наличие только лишь процедуры интерпретации цепочки принятия решений нейронной сетью без возможности объяснения исходных признаков (в понятной человеку форме) является недостатком способа.
В способе и системе для категоризации текстов с использованием онтологий по патенту US8782051B2, опубл. 15.07.2014, принятие решений об отнесении документа к рубрикам осуществляют на основе обнаружения в текстах терминов и понятий из онтологий соответствующих предметных областей. Недостатком способа является необходимость ручного формирования онтологий предметных областей, что существенно снижает применимость метода (ввиду невозможности построения универсальной онтологии).
В патенте на изобретение US 11176186 B2, опубл. 16.11.2021, представлен способ объяснения сходства между объектами различных множеств, в частности, между текстами. Для сопоставления сходства между объектами используется расстояние землекопа (Earth Mover's Distance ⎯ EMD, или метрика Васерштейна). В патенте представлена оценка сходства и визуализация семантически сходных (в смысле некоторой векторной языковой модели) фрагментов текстов, что обеспечивает технический результат, заключающийся в объяснимости результатов решения задач информационного поиска. К недостаткам изобретения можно отнести ограничение сопоставлением и объяснением сходства объектов одних уровней через другие уровни, а именно:
- для слов определяются семантически близкие слова,
- с использованием семантически близких слов для предложений определяются семантически близкие предложения,
- с использованием семантически близких предложений для абзацев определяются семантически близкие абзацы.
Недостатком этого способа является отсутствие использования морфологических и синтаксических методов анализа, при этом сопоставление значимых объектов разных уровней (например, слов и словосочетаний с рубриками, представленными подмножествами документов обучающей выборки) также не предусмотрено. Также способ не предоставляет способа объяснения (и соответствующей визуализации), на основе каких характеристик оказались семантически близкими два фрагмента текста.
Техническая проблема заключается в недостаточной полноте и точности систем автоматического определения тематики текстовых документов, наличии ошибок в результатах автоматического соотнесения текстов с рубриками и невозможности применения указанных систем в критических областях, требующих высокого уровня доверия, ввиду отсутствия у таких систем средств объяснения принятого решения об отнесении объекта классификации к той или иной рубрике в форме, пригодной для интерпретации человеком. Кроме того, проблема заключается в том, что системы искусственного интеллекта на основе машинного обучения подвержены атакам отравления обучающей выборки, при которых злоумышленник может осуществить внедрение в обучающую выборку некорректных с точки зрения решаемой задачи классификации примеров, что повлияет впоследствии на работу системы классификации. Объяснимая рубрикация текстов позволяет решить также и эту проблему за счёт предоставления эксперту возможности интерпретации результатов и выявления явных «смысловых» аномалий.
Технический результат состоит в обеспечении высокой точности, полноты и уровня достоверности результатов автоматической рубрикации за счёт способности объяснять принятые решения об отнесении объекта к некоторой рубрике путём автоматического формирования и предоставления пользователю системы набора смысловых признаков документа, обладающих важностью в контексте этой рубрики, в форме, пригодной для интерпретации человеком.
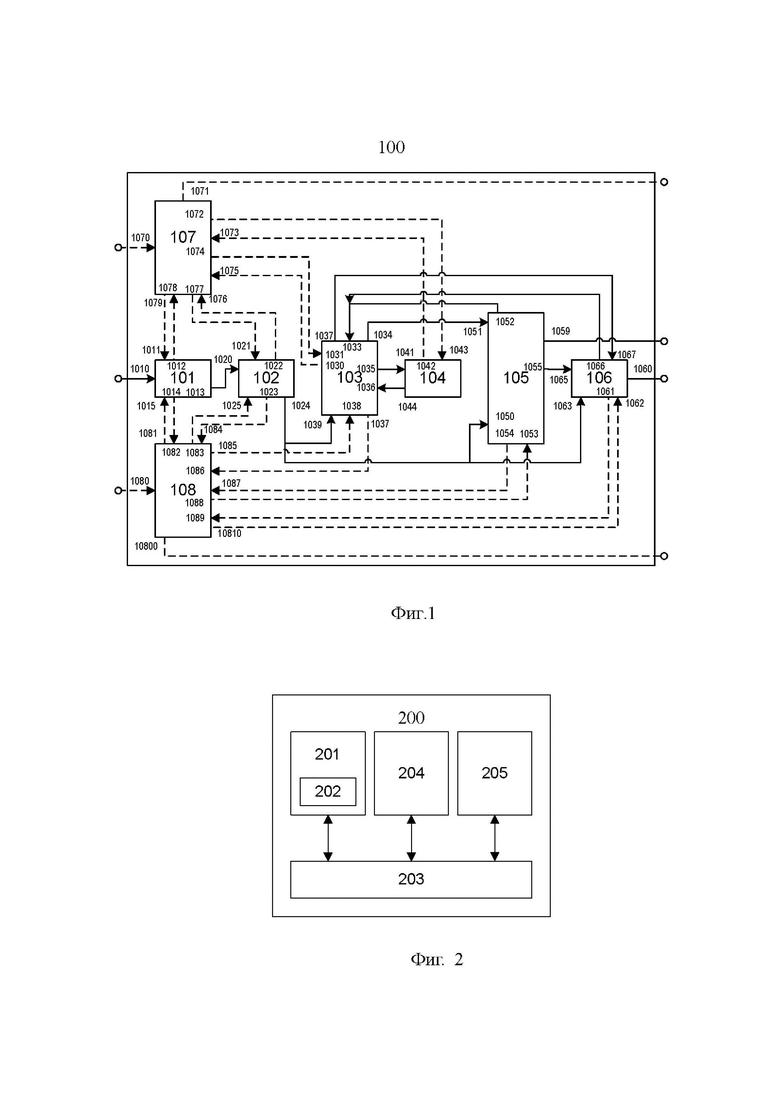
Техническая проблема решается и технический результат достигается за счет того, что система автоматического определения тематики текстовых документов на основе объяснимых методов искусственного интеллекта (100), представленная на Фиг. 1, содержит совокупность взаимосвязанных друг с другом модулей, взаимодействующих специальным образом.
Система (100) включает в себя следующие основные функциональные элементы (модули/подсистемы):
модуль предварительной обработки входных данных (101), для выделения и очистки текстового представления электронных документов;
модуль лингвистического анализа (102), включающий по меньшей мере стадии графематического, морфологического со снятием омонимии и синтаксического анализа;
базу данных слов и словосочетаний (103), предназначенную для хранения и выборки данных о словах и словосочетаниях, включая вносимые на этапе обучения текстовые представления нормальных форм и идентификаторы слов и словосочетаний обрабатываемых документов, если они встретились в процессе обучения впервые, в которой в качестве ключа выступает идентификатор и/или строковое представление нормальной формы каждого слова/словосочетания, а также список идентификаторов нормальных форм слов, составляющих словосочетание, причём на этапе обучения выполняется инкремент хранимых в базе данных числовых счётчиков встречаемости слов и словосочетаний в рубрикаторе в целом, а также для рубрик, к которым относится обрабатываемый документ обучающей выборки, а также расчётные величины значимости слов и словосочетаний как для рубрикатора в целом, так и для каждой из рубрик;
модуль оценки значимости слов и словосочетаний (104), реализующий расчёт величин значимости слов и словосочетаний как для всего классификатора, так и для каждой из рубрик;
модуль определения тематики (105), содержащий представление иерархии рубрик, получающий представление текста классифицируемого документа, являющееся результатом лингвистического анализа, с помощью запроса на выборку данных по значимым ловам и словосочетаниям рубрик, осуществляющий расчёт значения характеристики тематической значимости документа по отношению к каждой рубрике, а затем применяющий решающее правило;
модуль объяснения результата рубрикации (106), который получив результаты отнесения классифицируемого документа к некоторому подмножеству рубрик, а также значимые признаки текста, формирует объяснение в форме строковых представлений слов и словосочетаний и их значимости, а также в форме структурированной разметки фрагментов текста рубрицируемого документа, содержащих эти слова и словосочетания;
модуль управления процессом обучения (107), который реализует этапы процесса обучения системы;
модуль управления процессом рубрикации(108), который реализует этапы процесса определения соответствия тематики текста поступающих документов категориям рубрикатора,
причём модуль управления процессом обучения (107) содержит синхронизирующий вход (1070), являющийся первым синхронизирующим входом системы, принимающим сигнал о поступлении очередного документа обучающей выборки или о завершении процесса обучения,
и первый синхронизирующий выход (1071), являющийся первым синхронизирующим выходом системы, сигнализирующий вызывающей системе о состоянии завершения процесса обучения,
а также второй синхронизирующий выход (1079), соединённый с первым синхронизирующим входом (1011) модуля предварительной обработки входных данных (101) для передачи сигнала о начале обработки входного документа (из обучающей выборки),
причём первый синхронизирующий выход (1012) модуля предварительной обработки входных данных (101) соединён со вторым синхронизирующим входом (1078) модуля управления процессом обучения для целей передачи состояния завершения процесса обработки входного документа (из обучающей выборки), поступающего на первый информационный вход (1010) модуля предварительной обработки входных данных (101), являющийся также первым информационным входом системы, модулю управления процессом обучения (107),
в котором третий синхронизирующий выход (1077) соединён с первым синхронизирующим входом модуля лингвистического анализа (102) для передачи сигнала о начале обработки модулем лингвистического анализа (102) текста входного документа, поступающего на первый информационный вход (1020) модуля лингвистического анализа (102), соединённый с первым информационным выходом (1013) модуля предварительной обработки входных данных (101),
причём первый синхронизирующий выход (1022) модуля лингвистического анализа (102) соединён с третьим синхронизирующим входом (1076) модуля управления процессом обучения для целей передачи состояния завершения процесса обработки текста входного документа модулю управления процессом обучения (107),
в котором четвёртый синхронизирующий выход (1074) соединён с первым синхронизирующим входом базы данных слов и словосочетаний (103) для передачи сигнала на обработку базой данных слов и словосочетаний результата лингвистического анализа, поступающего на первый информационный вход (1039), соединённый с первым информационным выходом (1024) модуля лингвистического анализа (102),
а первый синхронизирующий выход (1030) базы данных слов и словосочетаний (103) соединён с четвёртым синхронизирующим входом модуля управления процессом обучения (1075) для целей передачи состояния завершения процесса обработки базой данных слов и словосочетаний (103) поступившего результата лингвистического анализа текста в модуль управления процессом обучения (1075),
в котором пятый синхронизирующий выход (1072) соединён с первым синхронизирующим входом (1043) модуля оценки значимости слов и словосочетаний (104) для передачи сигнала на расчёт значимости слов и словосочетаний, выполняемый на основе селекции опорных адресов частот встречаемости слов и словосочетаний, передаваемых на первый информационный вход (1041) модуля оценки значимости слов и словосочетаний (104), соединённый с первым информационным выходом (1035) базы данных слов и словосочетаний (103),
причём первый информационный выход (1044) модуля оценки значимости слов и словосочетаний (104) соединён со вторым информационным входом (1036) базы данных слов и словосочетаний (103), для кодирования по опорным адресам слов и словосочетаний соответствующих оценок значимости, полученным по результатам вычисления,
а первый синхронизирующий выход (1042) модуля оценки значимости слов и словосочетаний (104) соединён с пятым синхронизирующим входом модуля управления процессом обучения (1075) для целей передачи состояния завершения процесса оценки значимости слов и словосочетаний по базе данных слов и словосочетаний (103) в модуль управления процессом обучения (1075);
причём модуль управления процессом рубрикации(108) содержит
первый синхронизирующий вход (1080), являющийся вторым синхронизирующим входом системы, предназначенный для приёма сигнала о поступлении очередного документа для его анализа и определения соответствующей ему тематики,
первый синхронизирующий выход (10800), являющий вторым синхронизирующим выходом системы, сигнализирующий вызывающей системе о состоянии завершения процесса обработки поступившего документа,
а также второй синхронизирующий выход (1081), соединённый со вторым синхронизирующим входом (1015) модуля предварительной обработки входных данных (101) для передачи сигнала о начале обработки входного документа (для его рубрикации - определения тематики) в модуль предварительной обработки входных данных (101),
в котором второй синхронизирующий выход (1014) модуля предварительной обработки входных данных (101) соединён со вторым синхронизирующим входом (1082) модуля управления процессом рубрикации(108) для целей передачи состояния завершения процесса обработки входного документа, поступающего на первый информационный вход (1010) модуля предварительной обработки входных данных (101), являющийся также первым информационным входом системы, модулю управления процессом рубрикации(108),
в котором третий синхронизирующий выход (1083) соединён со вторым синхронизирующим входом модуля лингвистического анализа (102) для передачи сигнала о начале обработки модулем лингвистического анализа (102) текста входного документа, поступающего на первый информационный вход (1020) модуля лингвистического анализа (102), соединённый с первым информационным выходом (1013) модуля предварительной обработки входных данных (101), а также сигнала о предоставлении результата лингвистического анализа документа другим модулям через первый информационный выход (1024),
а второй синхронизирующий выход (1023) модуля лингвистического анализа (102) соединён с третьим синхронизирующим входом (1084) модуля управления процессом рубрикации(108) для целей передачи состояния завершения обработки входящих запросов модулю управления процессом рубрикации(108),
в котором четвёртый синхронизирующий выход (1088) соединён с первым синхронизирующим входом модуля определения тематики (105) для передачи управляющих сигналов начала обработки модулем определения тематики текущего документа и предоставлении результата рубрикации другим модулям через третий информационный выход (1055),
причём первый информационный вход (1050) модуля определения тематики (105) соединён с первым информационным выходом (1024) модуля лингвистического анализа (102) для получения результата лингвистического анализа текста рубрицируемого документа и выделения слов и словосочетаний, а первый синхронизирующий выход (1054) модуля определения тематики (105) соединён с четвёртым синхронизирующим входом (1087) модуля управления процессом рубрикации(108) для передачи сигнала о текущем состоянии обработки документа модулем определения тематики (105),
в котором первый информационный выход (1052) соединён со вторым информационным входом (1033) базы данных слов и словосочетаний (103)
а пятый синхронизирующий выход (1085) модуля управления процессом рубрикации(108) соединён со вторым синхронизирующим входом базы данных слов и словосочетаний (103), для целей передачи сигналов на обработку запросов, поступающих на второй информационный вход (1033), в частности для передачи сигналов, кодирующих набор слов и словосочетаний рубрицируемого документа в базу данных слов и словосочетаний (103) с целью формирования в последней опорных адресов ячеек, кодирующих величины оценок значимости этих слов и словосочетаний, передаваемых через второй информационный выход (1034) базы данных слов и словосочетаний (103), соединённый со вторым информационным входом (1051) модуля определения тематики (105),
в котором второй информационный выход (1059) является первым информационным выходом системы, представляющим кодированный результат рубрицирования документа во внешнюю систему,
а шестой синхронизирующий выход (10810) модуля управления процессом рубрикации(108) соединён с первым синхронизирующим входом (1062) модуля объяснения результата рубрикации (106) для передачи сигнала на обработку результата рубрицирования обрабатываемого документа,
а первый синхронизирующий выход модуля объяснения результата рубрикации (106) соединён с шестым синхронизирующим входом (1089) модуля управления процессом рубрикации(108) для передачи состояния выполнения объяснения результата рубрицирования документа,
причём первый информационный выход (1060) модуля объяснения результата рубрикации (106) является вторым информационным выходом системы, а первый информационный вход (1065) модуля объяснения результата рубрикации (106) соединён с третьим информационным выходом (1055) модуля определения тематики (105) для получения сведений о кодах значимых слов и словосочетаний, являвшихся признаками для отнесения документа к тем или иным рубрикам,
причём второй информационный выход (1066) модуля объяснения результата рубрикации (106) соединён со вторым информационным входом (1033) базы данных слов и словосочетаний (103), для передачи кодированных слов и словосочетаний обрабатываемого документа с целью получения из базы данных слов и словосочетаний кодированных строковых представлений слов и словосочетаний обрабатываемого документа, используемых в процессе объяснения, для чего второй информационный выход базы данных слов и словосочетаний (103) соединён со вторым информационным входом (1067) модуля объяснения результата рубрикации (106),
в котором третий информационный вход (1063) соединён с первым информационным выходом (1024) модуля лингвистического анализа (102) с целью получения кодированного результата лингвистического анализа для сопоставления значимых слов и словосочетаний рубрицированного документа с позициями их употреблений непосредственно в тексте.
При этом воплощение системы возможно с учётом следующих особенностей реализации.
Модуль предварительной обработки входных данных (101) реализует выделение текста, подлежащего дальнейшему анализу, тексты также могут быть очищены от служебной разметки и нетекстовой информации.
Модуль лингвистического анализа (102) реализует автоматический лингвистический анализ текста документа, включающий стадии графематического, морфологического (со снятием омонимии) и синтаксического анализа. При этом идентификаторы нормальной формы слова могут назначаться путём хэширования нормальной формы (например, по алгоритмы CRC32, CRC64, MurmurHash, ROT13 и др. ), либо на основе заданного идентификатора из внешнего словаря, либо путём автоматического инкремента порядкового номера. Синтаксические связи (зависимости) словоупотреблений в предложении могут представляться в формате универсальных зависимостей (Universal Dependencies) или составляющих (Constituent), а также подобных формализмах.
База данных слов и словосочетаний (103), обеспечивает сохранение и выборку данных о словах и словосочетаниях. На этапе обучения в неё заносятся текстовые представления нормальных форм и идентификаторы слов и словосочетаний обрабатываемых документов, если они встретились в процессе обучения впервые. В качестве ключа выступает идентификатор и/или строковое представление (нормальной формы) каждого слова / словосочетания, а также список идентификаторов нормальных форм слов, составляющих словосочетание. Аналогично отдельным словам, словосочетаниям назначаются числовые идентификаторы, получаемые, например, комбинацией хэшей нормальных форм слов в составе словосочетания (с учётом роли, «позиции» слова в словосочетании), либо путём автоматического инкремента порядкового номера слова в базе данных по мере появления ещё не встречавшихся в предшествующих документах обучающей выборки словосочетаний в обрабатываемых документах.
На этапе обучения выполняется инкремент в базе данных числовых счётчиков встречаемости слов и словосочетаний в рубрикаторе в целом, а также для рубрик, к которым относится обрабатываемый документ обучающей выборки. На этапе определения тематики эта информация выбирается из базы данных по идентификаторам слов и словосочетаний, встречающихся в тексте классифицируемого документа.
Модуль оценки значимости слов и словосочетаний (104) реализует расчёт величин значимости слов и словосочетаний как для всего классификатора, так и для каждой из рубрик. В качестве оценки значимости слов и словосочетаний может использоваться характеристика тематической значимости (ХТЗ) или мера наподобие BM-25 (компонента, аналогичная мере IDF). Рассчитанные значения сохраняются в базе данных слов и словосочетаний (103).
Модуль определения тематики (105), получив представление текста классифицируемого документа, являющееся результатом лингвистического анализа, отправляет запрос на выборку данных по значимым ловам и словосочетаниям рубрик, осуществляет расчёт значения характеристики тематической значимости документа по отношению к каждой рубрике, а затем применяет решающее правило для определения тематики.
Модуль объяснения результата рубрикации (106), получив результаты отнесения классифицируемого документа к некоторому подмножеству рубрик, а также значимые признаки текста, формирует объяснение в форме строковых представлений слов и словосочетаний и их значимости. Кроме того, модуль формирует набор текстовых представлений фрагментов (с весами значимости) классифицированного документа, содержащих слова и словосочетания, значимые в контексте каждой из рубрик, к которым отнесён документ, с указанием в этих фрагментах соответствующих слов и словосочетаний. Наряду с передачей этой информации в вызывающую систему, модуль объяснения результата рубрикации (106) может генерировать интерактивные формы для взаимодействия с ними пользователя (динамическое отображение фрагментов информации при выборе некоторого элемента) в форме облаков тегов, наборов предложений и фрагментов и т.п.. Эти формы могут быть описаны, например, на языке гипертекстовой разметки (HTML) и, соответственно, могут отображаться, например, на мониторе рабочей станции пользователя системы, в частности, с использованием веб-браузера. Конкретный частный способ представления результата пользователю зависит от программной реализации и не влияет на достижение технического эффекта настоящего изобретения.
Описанные выше элементы (модули) системы могут быть реализованы аппаратно или же программно-аппаратно, в том числе на серверной и персональной ЭВМ, причём они могут функционировать как на одном компьютерном устройстве, так и в распределённой компьютерной системе, в которой отдельные устройства соединены сетью передачи данных.
Конкретные реализации технического решения, построенного на основе описанных выше технических принципов, являются примером реализации (осуществления на практике) технического решения и не должны трактоваться как ограничивающие иные, частные примеры его воплощения, не выходящие за пределы испрашиваемой правовой охраны, которые являются очевидными для специалистов соответствующей области техники.
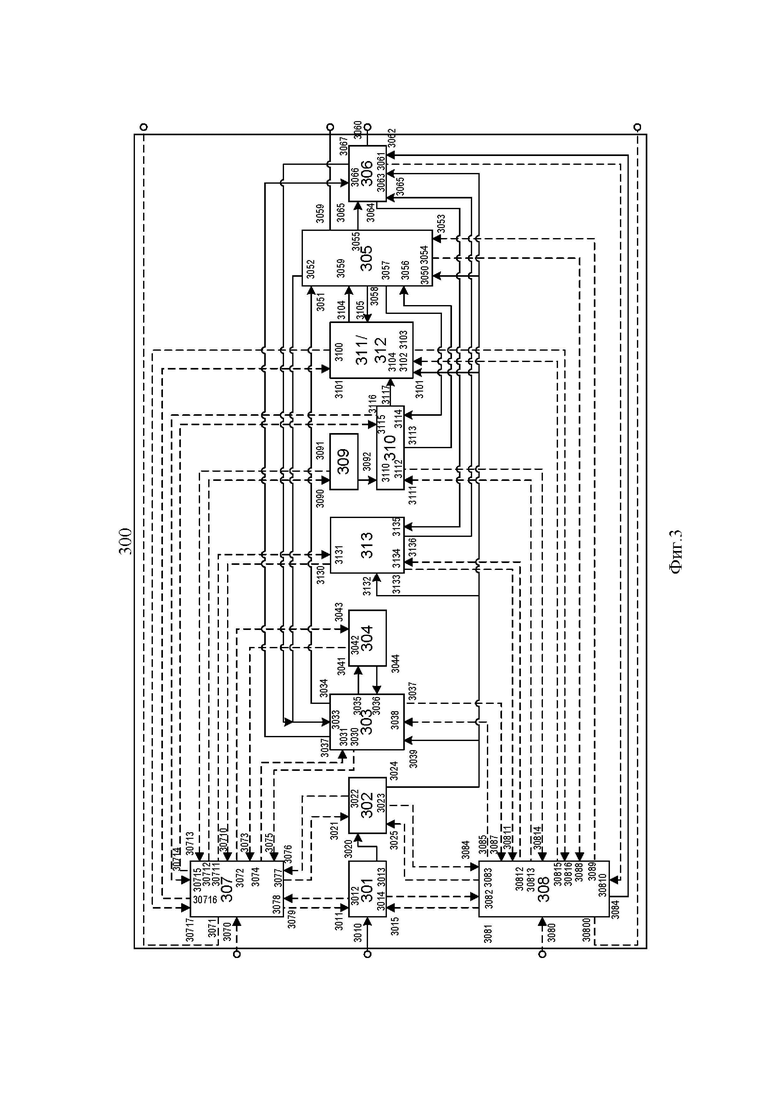
Приведём далее один из примеров такого воплощения. В компьютерной системе (200), представленной на Фиг. 2, воплощается раскрытое выше техническое решение путём передачи и обработки сигналов между следующими физическими компонентами: центральным процессором (201) (включая его кэш-память (202)), системной шиной (203), оперативной памятью (204), долговременной памятью (205). В ряде компьютерных систем дополнительно могут применяться компоненты в виде графического процессора (для повышения быстродействия при умножении матриц, которое на практике используется векторными языковыми моделями), а также сетевым устройством (сетевой картой), применяемой для отправки и получения данных в сеть передачи данных, объединяющую отдельные устройства при распределённом способе реализации настоящего изобретения.
Результат рубрикации документа вместе с объяснением этого результата в дальнейшем может быть передан в вызывающую систему, которая в свою очередь может маршрутизировать документ в зависимости от определённой тематики для дальнейшей обработки (как это происходит, например, при обработке обращений граждан в государственные органы в зависимости от темы вопроса) или непосредственно интерпретирован человеком-оператором.
Рассмотренное выше техническое решение может быть модифицировано для решения более широкого класса задач рубрикации текстовой информации с применением альтернативных технологий рубрикации, например, на основе комбинации методов ближайших соседей и дистрибутивно-семантических моделей. Для этой цели рассмотрим далее расширенную автоматическую систему определения тематики текстовых документов на основе объяснимых методов искусственного интеллекта (300), представленную на Фиг. 3, которая содержит модуль предварительной обработки входных данных (301), модуль лингвистического анализа (302), базу данных слов и словосочетаний (303), модуль оценки значимости слов и словосочетаний (304), модуль определения тематики (305), модуль объяснения результата рубрикации (306), модуль управления процессом обучения (307), модуль управления процессом рубрикации(308), а также следующие дополнительные модули: модуль представления векторной языковой модели (309), модуль дополнительного обучения векторной языковой модели (310), инвертированный индекс значимых слов и словосочетаний (311) или индексную базу данных векторных представлений (312), базу данных результатов лингвистического анализа (313), взаимодействующие следующим образом.
Модуль представления векторной языковой модели (310) используется для хранения по меньшей мере одной векторной языковой модели, применяемой на этапе обучения для порождения векторных представлений слов и словосочетаний документов обучающей выборки, а на этапе определения тематики - для порождения векторных представлений слов и словосочетаний классифицируемых документов,
для чего первый синхронизирующий вход (3111) модуля представления векторной языковой модели (310) соединён с седьмым синхронизирующим выходом (30813) модуля управления процессом рубрикации(308) с целью обмена сигнальными сообщениями о поступлении запросов на селекцию значений векторов признаков для передачи их модулю определения тематики (305), а первый синхронизирующий выход (3112) соединён с седьмым синхронизирующим входом (30814) модуля управления процессом рубрикации(308) для сигнализации о завершении процесса селекции значений векторов признаков и передачи их модулю определения тематики (305),
для чего, третий информационный выход (3057) модуля определения тематики (305) соединён с первым информационным входом (3114) модуля представления векторной языковой модели (310), обеспечивая получение кодированных данных о словах и словосочетаниях, для которых необходимо выполнить порождение векторных представлений слов и словосочетаний,
а первый информационный выход (3113) модуля представления векторной языковой модели (310) соединён с четвёртым информационным входом модуля определения тематики (305), обеспечивая передачу порожденных векторных представлений слов и словосочетаний модулю определения тематики (305).
Индексная база данных векторных представлений (312) используется для хранения векторных представлений слов и словосочетаний документов обучающей выборки, формируется на этапе обучения с использованием предобученной векторной языковой модели и применяется на этапе определения тематики для быстрого поиска ближайших соседей в векторном пространстве, для чего
первый синхронизирующий вход (3103) индексной базы данных векторных представлений (312) соединён с седьмым синхронизирующим выходом (30716) модуля управления процессом обучения (307), обеспечивая передачу управляющих сигналов в процессе формирования базы данных, включая сигнал о начале процесса индексации векторов, соответствующих слов и словосочетаний, поступающих из модуля представления векторной языковой модели (310),
а седьмой синхронизирующий вход (30717) модуля управления процессом обучения (307) соединён с первым синхронизирующим выходом (3100) индексной базы данных векторных представлений (312), обеспечивая передачу управляющих сигналов о завершении работы модуля в режиме индексации,
осуществляя индексацию набора векторов, соответствующих слов и словосочетаний из модуля представления векторной языковой модели (310), для чего второй информационный выход (3117) модуля представления векторной языковой модели (310) соединён со вторым информационным входом индексной базы данных векторных представлений (312), а первый информационный выход (3024) модуля лингвистического анализа (302) соединён с первым информационным входом (3101) индексной базы данных векторных представлений (312),
осуществляя быстрый поиск ближайших соседей в векторном пространстве за счёт того, что второй синхронизирующий вход (3102) индексной базы данных векторных представлений (312) соединён с восьмым синхронизирующим выходом (30815) модуля управления процессом рубрикации(308), обеспечивая сигнализацию о поступлении запроса на селекцию опорных адресов в регистрах, содержащих вектора слов и словосочетаний и кодирующих соответствующие им идентификаторы,
а восьмой синхронизирующим вход (30816) модуля управления процессом рубрикации(308) соединён со вторым синхронизирущим выходом (3103) индексной базы данных векторных представлений (312), обеспечивая сигнализацию о завершении процесса селекции опорных адресов в регистрах, содержащих вектора слов и словосочетаний и кодирующих соответствующие им идентификаторы, и готовности их передачи модулю определения тематики (305),
для чего второй информационный вход (3105) модуля индексной базы данных векторных представлений (312) соединён со вторым информационным выходом модуля определения тематики (305), осуществляя передачу кодированных идентификаторов слов и словосочетаний в качестве запроса для селекции опорных адресов в регистрах, содержащих близкие вектора слов и словосочетаний и кодирующих соответствующие им идентификаторы, а первый информационный выход (3104) модуля индексной базы данных векторных представлений (312) соединён с четвёртым информационным входом (3059) модуля определения тематики (305), обеспечивая передачу кодированных представлений найденных близких слов и словосочетаний.
Модуль дополнительного обучения векторной языковой модели (309) используется на предварительном этапе обучения для донастройки имеющейся в распоряжении (заранее обученной на репрезентативном корпусе) векторной языковой модели на документах обучающей выборки, для чего
второй синхронизирующий вход (3115) модуля представления векторной языковой модели (310) соединён с шестым синхронизирующим входом (30714) модуля управления процессом обучения (307), а второй синхронизирующий выход (3116) модуля представления векторной языковой модели (310) соединён с шестым синхронизирующим входом (30715) модуля управления процессом обучения (307), реализуя обмен сигналами о завершении процесса дообучения векторной языковой модели в модуле дополнительного обучения векторной языковой модели (309) с целью передачи дообученной модели из модуля дополнительного обучения векторной языковой модели (309) в модуль представления векторной языковой модели (310), для чего первый информационный выход (3092) дополнительного обучения векторной языковой модели (309) соединён со вторым информационным входом (3110) модуля представления векторной языковой модели (310).
База данных результата лингвистического анализа (313) применяется для хранения результата лингвистического анализа текстов документов обучающей выборки и расчёта величин значимости фрагментов текстов с целью определения значимых фрагментов документов соответствующей рубрики, используемая для хранения сопутствующей информации, включая идентификатор документа, а также идентификаторы рубрик, к которым относится документ обучающей выборки, так чтобы хранимые в ней данные использовались также на этапе определения тематики для объяснения результатов с помощью фрагментов текстов обучающей выборки, близких по смыслу к классифицируемому документу,
для чего первый синхронизирующий вход (3131) базы данных результата лингвистического анализа (313) соединён с седьмым синхронизирующим входом (30711) модуля управления процессом обучения (307), обеспечивая передачу сигналов о сохранении в опорных регистрах базы данных лингвистической информации очередного документа обучающей выборки, а первый синхронизирующий выход (3130) базы данных результата лингвистического анализа (313) соединён с седьмым синхронизирующим входом (30710) модуля управления процессом обучения (307), обеспечивая передачу сигнала о статусе операции сохранения в опорных регистрах базы данных лингвистической информации очередного документа обучающей выборки,
для чего первый информационный вход (3132) базы данных результата лингвистического анализа (313) соединён с первым информационным выходом (3024) модуля лингвистического анализа (302), обеспечивая приём результата лингвистического анализа очередного документа обучающей выборки для сохранения в опорных регистрах базы данных,
а второй синхронизирующий вход (3136) базы данных результата лингвистического анализа (313) соединён с девятым синхронизирующим выходом (30812) модуля управления процессом рубрикации(308), обеспечивая сигнализацию о поступлении запроса на выборку из опорных регистров базы данных лингвистической информации сведений о сохранённых там документах обучающих документах для их предоставления модулю объяснения результата рубрикации (306), а второй синхронизирующий выход (3133) модуля управления процессом рубрикации(308) соединён с девятым синхронизирующим входом (30811) модуля управления процессом рубрикации(308), обеспечивая сигнализацию о статусе обработки запроса на выборку из опорных регистров базы данных лингвистической информации сведений о сохранённых там документах обучающих документах для их предоставления модулю объяснения результата рубрикации (306),
для чего второй информационный вход (3135) базы данных результата лингвистического анализа (313) соединён с третьим информационным выходом (3057) модуля объяснения результата рубрикации (306), обеспечивая передачу запросов, содержащих кодированное представление идентификаторов документов обучающей выборки, тематически сходных с классифицируемым документом, для выборки из опорных регистров базы данных лингвистической информации сведений об этих документах, а второй информационный выход (3136) базы данных результата лингвистического анализа (313) соединён с третьим информационным входом (3056) модуля объяснения результата рубрикации (306), обеспечивая передачу выбранных сведений в модуль объяснения результата рубрикации (306).
В описанном выше техническом решении индексная база данных векторных представлений (312) выступает в качестве альтернативы инвертированному индексу значимых слов и словосочетаний (311) и используется для эффективной технической реализации метода поиска ближайших соседей в случае, когда для поиска близких документов используются векторные представления слов, словосочетаний, а также фрагментов текстов документов.
Инвертированный индекс значимых слов и словосочетаний (311) служит для эффективной технической реализации метода поиска ближайших соседей в случае, когда в качестве признаков для поиска близких документов используются непосредственно слова и словосочетания, а не их векторные представления.
В рассмотренных вычислительных (компьютерных) системах технический результат достигается за счёт описанных выше действий над материальными объектами - электрическими сигналами и состояниями ячеек памяти материальных носителей (энергонезависимая и энергозависимая, т.е. оперативная память), обеспечивающими системное представление обрабатываемых объектов (текстовых документов) и результата их обработки: присвоенных значений рубрик и объяснения принятого решения.
Представленные материалы заявки раскрывают предпочтительные примеры реализации технического решения и не должны трактоваться как ограничивающие иные, частные примеры его воплощения, не выходящие за пределы испрашиваемой правовой охраны, которые являются очевидными для специалистов соответствующей области техники.
Изобретение относится к области искусственного интеллекта. Технический результат заключается в обеспечении высокой точности, полноты и уровня достоверности результатов автоматической рубрикации. Система автоматического определения тематики текстовых документов на основе объяснимых методов искусственного интеллекта содержит совокупность взаимосвязанных друг с другом модулей, взаимодействующих путём обмена синхронизирующими сигналами через входы и выходы. В качестве модулей применены: модуль предварительной обработки входных данных, модуль лингвистического анализа, модуль оценки значимости слов и словосочетаний, модуль определения тематики, содержащий представление иерархии рубрик, модуль объяснения результата рубрикации, который, получив результаты отнесения классифицируемого документа к некоторому подмножеству рубрик, а также значимые признаки текста, формирует объяснение в форме строковых представлений слов и словосочетаний и их значимости, модуль управления процессом обучения, который реализует этапы процесса обучения системы, модуль управления процессом рубрикации, который реализует этапы процесса определения соответствия тематики текста поступающих документов категориям рубрикатора. 3 з.п. ф-лы, 3 ил.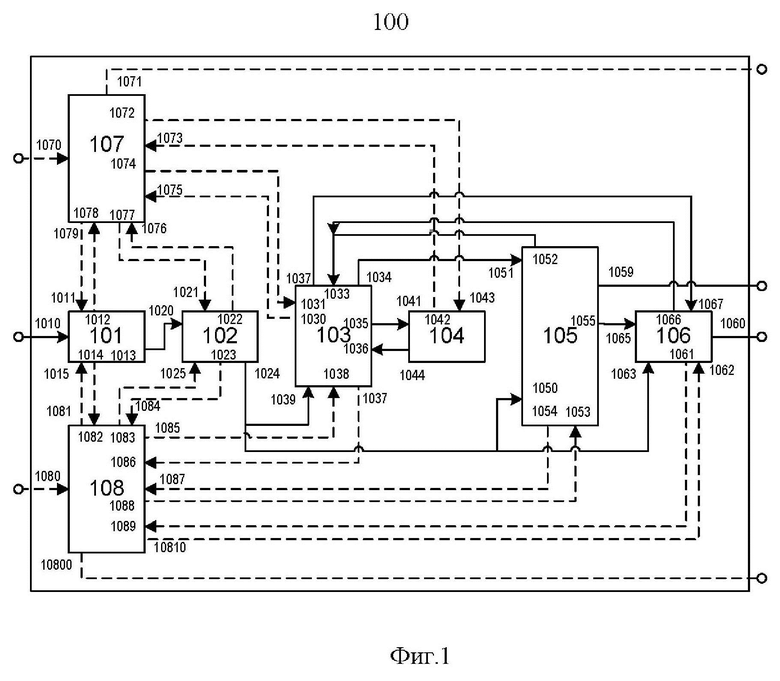
1. Система автоматического определения тематики текстовых документов на основе объяснимых методов искусственного интеллекта, содержащая следующие функциональные элементы:
модуль предварительной обработки входных данных, осуществляющий выделение и очистку текстового представления электронных документов;
модуль лингвистического анализа, включающий по меньшей мере стадии графематического, морфологического со снятием омонимии и синтаксического анализа;
базу данных слов и словосочетаний, обеспечивающую хранение и выборку данных о словах и словосочетаниях, включая вносимые на этапе обучения текстовые представления нормальных форм и идентификаторы слов и словосочетаний обрабатываемых документов, если они встретились в процессе обучения впервые, в которой в качестве ключа выступает идентификатор и/или строковое представление нормальной формы каждого слова/словосочетания, а также список идентификаторов нормальных форм слов, составляющих словосочетание, причём на этапе обучения выполняется инкремент хранимых в базе данных числовых счётчиков встречаемости слов и словосочетаний в рубрикаторе в целом, а также для рубрик, к которым относится обрабатываемый документ обучающей выборки, а также расчётные величины значимости слов и словосочетаний как для рубрикатора в целом, так и для каждой из рубрик;
модуль оценки значимости слов и словосочетаний, реализующий расчёт величин значимости слов и словосочетаний как для всего классификатора, так и для каждой из рубрик;
модуль определения тематики, содержащий представление иерархии рубрик, получающий представление текста классифицируемого документа, являющееся результатом лингвистического анализа, с помощью запроса на выборку данных по значимым ловам и словосочетаниям рубрик, осуществляющий расчёт значения характеристики тематической значимости документа по отношению к каждой рубрике, а затем применяющий решающее правило;
модуль объяснения результата рубрикации, который, получив результаты отнесения классифицируемого документа к некоторому подмножеству рубрик, а также значимые признаки текста, формирует объяснение в форме строковых представлений слов и словосочетаний и их значимости, а также в форме структурированной разметки фрагментов текста рубрицируемого документа, содержащих эти слова и словосочетания;
модуль управления процессом обучения, который путём обмена синхронизирующими сигналами с другими модулями реализует этапы процесса обучения системы;
модуль управления процессом рубрикации, который путём обмена синхронизирующими сигналами с другими модулями реализует этапы процесса определения соответствия тематики текста поступающих документов категориям рубрикатора,
реализующая процесс обучения системы за счёт того, что
модуль управления процессом обучения содержит синхронизирующий вход, являющийся первым синхронизирующим входом системы, принимающим сигнал о поступлении очередного документа обучающей выборки или о завершении процесса обучения,
и первый синхронизирующий выход, являющийся первым синхронизирующим выходом системы, сигнализирующий вызывающей системе о состоянии завершения процесса обучения,
а также второй синхронизирующий выход, соединённый с первым синхронизирующим входом модуля предварительной обработки входных данных для передачи сигнала о начале обработки входного документа (из обучающей выборки),
причём первый синхронизирующий выход модуля предварительной обработки входных данных соединён со вторым синхронизирующим входом модуля управления процессом обучения для целей передачи состояния завершения процесса обработки входного документа (из обучающей выборки), поступающего на первый информационный вход модуля предварительной обработки входных данных, являющийся также первым информационным входом системы, модулю управления процессом обучения,
в котором третий синхронизирующий выход соединён с первым синхронизирующим входом модуля лингвистического анализа для передачи сигнала о начале обработки модулем лингвистического анализа текста входного документа, поступающего на первый информационный вход модуля лингвистического анализа, соединённый с первым информационным выходом модуля предварительной обработки входных данных,
причём первый синхронизирующий выход модуля лингвистического анализа соединён с третьим синхронизирующим входом модуля управления процессом обучения для целей передачи состояния завершения процесса обработки текста входного документа модулю управления процессом обучения,
в котором четвёртый синхронизирующий выход соединён с первым синхронизирующим входом базы данных слов и словосочетаний для передачи сигнала на обработку базой данных слов и словосочетаний результата лингвистического анализа, поступающего на первый информационный вход, соединённый с первым информационным выходом модуля лингвистического анализа,
а первый синхронизирующий выход базы данных слов и словосочетаний соединён с четвёртым синхронизирующим входом модуля управления процессом обучения для целей передачи состояния завершения процесса обработки базой данных слов и словосочетаний поступившего результата лингвистического анализа текста в модуль управления процессом обучения,
в котором пятый синхронизирующий выход соединён с первым синхронизирующим входом модуля оценки значимости слов и словосочетаний для передачи сигнала на расчёт значимости слов и словосочетаний, выполняемый на основе селекции опорных адресов частот встречаемости слов и словосочетаний, передаваемых на первый информационный вход модуля оценки значимости слов и словосочетаний, соединённый с первым информационным выходом базы данных слов и словосочетаний,
причём первый информационный выход модуля оценки значимости слов и словосочетаний соединён со вторым информационным входом базы данных слов и словосочетаний для кодирования по опорным адресам слов и словосочетаний соответствующих оценок значимости, полученных по результатам вычисления,
а первый синхронизирующий выход модуля оценки значимости слов и словосочетаний соединён с пятым синхронизирующим входом модуля управления процессом обучения для целей передачи состояния завершения процесса оценки значимости слов и словосочетаний по базе данных слов и словосочетаний в модуль управления процессом обучения;
также реализующая процесс рубрикации за счёт того, что
модуль управления процессом рубрикации содержит
первый синхронизирующий вход, являющийся вторым синхронизирующим входом системы, предназначенный для приёма сигнала о поступлении очередного документа для его анализа и определения соответствующей ему тематики,
первый синхронизирующий выход, являющий вторым синхронизирующим выходом системы, сигнализирующий вызывающей системе о состоянии завершения процесса обработки поступившего документа,
а также второй синхронизирующий выход, соединённый со вторым синхронизирующим входом модуля предварительной обработки входных данных для передачи сигнала о начале обработки входного документа (для его рубрикации - определения тематики) в модуль предварительной обработки входных данных,
в котором второй синхронизирующий выход модуля предварительной обработки входных данных соединён со вторым синхронизирующим входом модуля управления процессом рубрикации для целей передачи состояния завершения процесса обработки входного документа, поступающего на первый информационный вход модуля предварительной обработки входных данных, являющийся также первым информационным входом системы, модулю управления процессом рубрикации,
в котором третий синхронизирующий выход соединён со вторым синхронизирующим входом модуля лингвистического анализа для передачи сигнала о начале обработки модулем лингвистического анализа текста входного документа, поступающего на первый информационный вход модуля лингвистического анализа, соединённый с первым информационным выходом модуля предварительной обработки входных данных, а также сигнала о предоставлении результата лингвистического анализа документа другим модулям через первый информационный выход,
а второй синхронизирующий выход модуля лингвистического анализа соединён с третьим синхронизирующим входом модуля управления процессом рубрикации для целей передачи состояния завершения обработки входящих запросов модулю управления процессом рубрикации,
в котором четвёртый синхронизирующий выход соединён с первым синхронизирующим входом модуля определения тематики для передачи управляющих сигналов начала обработки модулем определения тематики текущего документа и предоставлении результата рубрикации другим модулям через третий информационный выход,
причём первый информационный вход модуля определения тематики соединён с первым информационным выходом модуля лингвистического анализа для получения результата лингвистического анализа текста рубрицируемого документа и выделения слов и словосочетаний, а первый синхронизирующий выход модуля определения тематики соединён с четвёртым синхронизирующим входом модуля управления процессом рубрикации для передачи сигнала о текущем состоянии обработки документа модулем определения тематики,
в котором первый информационный выход соединён со вторым информационным входом базы данных слов и словосочетаний,
а пятый синхронизирующий выход модуля управления процессом рубрикации соединён со вторым синхронизирующим входом базы данных слов и словосочетаний для целей передачи сигналов на обработку запросов, поступающих на второй информационный вход, в частности для передачи сигналов, кодирующих набор слов и словосочетаний рубрицируемого документа, в базу данных слов и словосочетаний с целью формирования в последней опорных адресов ячеек, кодирующих величины оценок значимости этих слов и словосочетаний, передаваемых через второй информационный выход базы данных слов и словосочетаний, соединённый со вторым информационным входом модуля определения тематики,
в котором второй информационный выход является первым информационным выходом системы, представляющим кодированный результат рубрицирования документа во внешнюю систему,
а шестой синхронизирующий выход модуля управления процессом рубрикации соединён с первым синхронизирующим входом модуля объяснения результата рубрикации для передачи сигнала на обработку результата рубрицирования обрабатываемого документа,
а первый синхронизирующий выход модуля объяснения результата рубрикации соединён с шестым синхронизирующим входом модуля управления процессом рубрикации для передачи состояния выполнения объяснения результата рубрицирования документа,
причём первый информационный выход модуля объяснения результата рубрикации является вторым информационным выходом системы, а первый информационный вход модуля объяснения результата рубрикации соединён с третьим информационным выходом модуля определения тематики для получения сведений о кодах значимых слов и словосочетаний, являющихся признаками для отнесения документа к тем или иным рубрикам,
причём второй информационный выход модуля объяснения результата рубрикации соединён со вторым информационным входом базы данных слов и словосочетаний для передачи кодированных слов и словосочетаний обрабатываемого документа с целью получения из базы данных слов и словосочетаний кодированных строковых представлений слов и словосочетаний обрабатываемого документа, используемых в процессе объяснения, для чего второй информационный выход базы данных слов и словосочетаний соединён со вторым информационным входом модуля объяснения результата рубрикации,
в котором третий информационный вход соединён с первым информационным выходом модуля лингвистического анализа с целью получения кодированного результата лингвистического анализа для сопоставления значимых слов и словосочетаний рубрицированного документа с позициями их употреблений непосредственно в тексте.
2. Система по п. 1, отличающаяся тем, что дополнительно содержит:
модуль представления векторной языковой модели обеспечивающий хранение по меньшей мере одной векторной языковой модели, применяемой на этапе обучения для порождения векторных представлений слов и словосочетаний документов обучающей выборки, а на этапе определения тематики для порождения векторных представлений слов и словосочетаний классифицируемых документов,
для чего первый синхронизирующий вход модуля представления векторной языковой модели соединён с седьмым синхронизирующим выходом модуля управления процессом рубрикации с целью обмена сигнальными сообщениями о поступлении запросов на селекцию значений векторов признаков для передачи их модулю определения тематики, а первый синхронизирующий выход соединён с седьмым синхронизирующим входом модуля управления процессом рубрикации для сигнализации о завершении процесса селекции значений векторов признаков и передачи их модулю определения тематики,
для чего третий информационный выход модуля определения тематики соединён с первым информационным входом модуля представления векторной языковой модели, обеспечивая получение кодированных данных о словах и словосочетаниях, для которых необходимо выполнить порождение векторных представлений слов и словосочетаний,
а первый информационный выход модуля представления векторной языковой модели соединён с четвёртым информационным входом модуля определения тематики, обеспечивая передачу порожденных векторных представлений слов и словосочетаний модулю определения тематики;
индексную базу данных векторных представлений, обеспечивающую хранение векторных представлений слов и словосочетаний документов обучающей выборки, формируемую на этапе обучения с использованием предобученной векторной языковой модели и осуществляющую на этапе определения тематики быстрый поиск ближайших соседей в векторном пространстве за счёт того, что
первый синхронизирующий вход индексной базы данных векторных представлений соединён с седьмым синхронизирующим выходом модуля управления процессом обучения, обеспечивая передачу управляющих сигналов в процессе формирования базы данных, включая сигнал о начале процесса индексации векторов, соответствующих слов и словосочетаний, поступающих из модуля представления векторной языковой модели,
а седьмой синхронизирующий вход модуля управления процессом обучения соединён с первым синхронизирующим выходом индексной базы данных векторных представлений, обеспечивая передачу управляющих сигналов о завершении работы модуля в режиме индексации,
осуществляя индексацию набора векторов, соответствующих слов и словосочетаний из модуля представления векторной языковой модели, для чего второй информационный выход модуля представления векторной языковой модели соединён со вторым информационным входом индексной базы данных векторных представлений, а первый информационный выход модуля лингвистического анализа соединён с первым информационным входом индексной базы данных векторных представлений,
осуществляя быстрый поиск ближайших соседей в векторном пространстве за счёт того, что второй синхронизирующий вход индексной базы данных векторных представлений соединён с восьмым синхронизирующим выходом модуля управления процессом рубрикации, обеспечивая сигнализацию о поступлении запроса на селекцию опорных адресов в регистрах, содержащих вектора слов и словосочетаний и кодирующих соответствующие им идентификаторы,
а восьмой синхронизирующий вход модуля управления процессом рубрикации соединён со вторым синхронизирущим выходом индексной базы данных векторных представлений, обеспечивая сигнализацию о завершении процесса селекции опорных адресов в регистрах, содержащих вектора слов и словосочетаний и кодирующих соответствующие им идентификаторы, и готовности их передачи модулю определения тематики;
для чего второй информационный вход модуля индексной базы данных векторных представлений соединён со вторым информационным выходом модуля определения тематики, осуществляя передачу кодированных идентификаторов слов и словосочетаний в качестве запроса для селекции опорных адресов в регистрах, содержащих близкие вектора слов и словосочетаний и кодирующих соответствующие им идентификаторы, а первый информационный выход модуля индексной базы данных векторных представлений соединён с четвёртым информационным входом модуля определения тематики, обеспечивая передачу кодированных представлений найденных близких слов и словосочетаний,
базу данных результатов лингвистического анализа, обеспечивающую хранение результатов лингвистического анализа текстов документов обучающей выборки и расчёта величин значимости фрагментов текстов с целью определения значимых фрагментов документов соответствующей рубрики, используемую для хранения сопутствующей информации, включая идентификатор документа, а также идентификаторы рубрик, к которым относится документ обучающей выборки, так чтобы хранимые в ней данные использовались также на этапе определения тематики для объяснения результатов рубрикации с помощью фрагментов текстов обучающей выборки, близких по смыслу к классифицируемому документу,
для чего первый синхронизирующий вход базы данных результата лингвистического анализа соединён с седьмым синхронизирующим входом модуля управления процессом обучения, обеспечивая передачу сигналов о сохранении в опорных регистрах базы данных лингвистической информации очередного документа обучающей выборки, а первый синхронизирующий выход базы данных результата лингвистического анализа соединён с седьмым синхронизирующим входом модуля управления процессом обучения, обеспечивая передачу сигнала о статусе операции сохранения в опорных регистрах базы данных лингвистической информации очередного документа обучающей выборки,
для чего первый информационный вход базы данных результата лингвистического анализа соединён с первым информационным выходом модуля лингвистического анализа, обеспечивая приём результата лингвистического анализа очередного документа обучающей выборки для сохранения в опорных регистрах базы данных,
а второй синхронизирующий вход базы данных результата лингвистического анализа соединён с девятым синхронизирующим выходом модуля управления процессом рубрикации, обеспечивая сигнализацию о поступлении запроса на выборку из опорных регистров базы данных лингвистической информации сведений о сохранённых там обучающих документах для их предоставления модулю объяснения результата рубрикации, а второй синхронизирующий выход модуля управления процессом рубрикации соединён с девятым синхронизирующим входом модуля управления процессом рубрикации, обеспечивая сигнализацию о статусе обработки запроса на выборку из опорных регистров базы данных лингвистической информации сведений о сохранённых там обучающих документах для их предоставления модулю объяснения результата рубрикации,
для чего второй информационный вход базы данных результата лингвистического анализа соединён с третьим информационным выходом модуля объяснения результата рубрикации, обеспечивая передачу запросов, содержащих кодированное представление идентификаторов документов обучающей выборки, тематически сходных с классифицируемым документом, для выборки из опорных регистров базы данных лингвистической информации сведений об этих документах, а второй информационный выход базы данных результата лингвистического анализа соединён с третьим информационным входом модуля объяснения результата рубрикации, обеспечивая передачу выбранных сведений в модуль объяснения результата рубрикации.
3. Система по п. 2, отличающаяся тем, что вместо индексной базы данных векторных представлений содержит инвертированный индекс значимых слов и словосочетаний, обеспечивающий поиск ближайших соседей по текстам классифицируемых документов из числа документов обучающей выборки за счёт того, что
первый синхронизирующий вход инвертированного индекса значимых слов и словосочетаний соединён с седьмым синхронизирующим выходом модуля управления процессом обучения, обеспечивая передачу управляющих сигналов в процессе формирования базы данных, включая сигнал о начале процесса индексации текстов обучающей выборки, поступающих из модуля лингвистического анализа,
а седьмой синхронизирующий вход модуля управления процессом обучения соединён с первым синхронизирующим выходом инвертированного индекса значимых слов и словосочетаний, обеспечивая передачу управляющих сигналов о завершении работы модуля в режиме индексации,
осуществляя индексацию соответствующих слов и словосочетаний из модуля лингвистического анализа, для чего первый информационный выход модуля лингвистического анализа соединён с первым информационным входом инвертированного индекса значимых слов и словосочетаний,
осуществляя на этапе определения тематики текстов быстрый поиск ближайших соседей за счёт того, что второй синхронизирующий вход инвертированного индекса значимых слов и словосочетаний соединён с восьмым синхронизирующим выходом модуля управления процессом рубрикации, обеспечивая сигнализацию о поступлении запроса на селекцию опорных адресов в регистрах, содержащих кодированные представления слов и словосочетаний и кодирующих соответствующие им идентификаторы,
для чего второй информационный вход модуля инвертированного индекса значимых слов и словосочетаний соединён со вторым информационным выходом модуля определения тематики, осуществляя передачу кодированных идентификаторов слов и словосочетаний в качестве запроса для селекции опорных адресов в регистрах, содержащих сведения о текстах, содержащих переданные в качестве запроса вектора слов и словосочетаний и кодирующих соответствующие им идентификаторы, а первый информационный выход модуля индексной базы данных векторных представлений соединён с четвёртым информационным входом модуля определения тематики, обеспечивая передачу кодированных представлений найденных близких слов и словосочетаний,
обеспечивая селекцию с учётом семантической близости за счёт того, что восьмой синхронизирующий вход модуля управления процессом рубрикации соединён со вторым синхронизирущим выходом инвертированного индекса значимых слов и словосочетаний, обеспечивая сигнализацию о завершении процесса селекции опорных адресов в регистрах, содержащих кодированные представления слов и словосочетаний и кодирующих соответствующие им идентификаторы, и готовности их передачи модулю определения тематики, с учётом векторной языковой модели, для чего второй информационный выход модуля представления векторной языковой модели соединён со вторым информационным входом инвертированного индекса значимых слов и словосочетаний.
4. Система по любому из пп. 2, 3, отличающаяся тем, что дополнительно содержит
модуль дополнительного обучения векторной языковой модели, используемый на предварительном этапе обучения для донастройки имеющейся в распоряжении векторной языковой модели на документах обучающей выборки, для чего
второй синхронизирующий вход модуля представления векторной языковой модели соединён с шестым синхронизирующим входом модуля управления процессом обучения, а второй синхронизирующий выход модуля представления векторной языковой модели соединён с шестым синхронизирующим входом модуля управления процессом обучения, реализуя обмен сигналами о завершении процесса дообучения векторной языковой модели в модуле дополнительного обучения векторной языковой модели с целью передачи дообученной модели из модуля дополнительного обучения векторной языковой модели в модуль представления векторной языковой модели, для чего первый информационный выход дополнительного обучения векторной языковой модели соединён со вторым информационным входом модуля представления векторной языковой модели.
| ИСПОЛЬЗОВАНИЕ АВТОЭНКОДЕРОВ ДЛЯ ОБУЧЕНИЯ КЛАССИФИКАТОРОВ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2017 |
|
RU2678716C1 |
| СИСТЕМА И МЕТОД СЕМАНТИЧЕСКОГО ПОИСКА | 2013 |
|
RU2563148C2 |
| Способ использования системы определения тематики документов для целей информационной безопасности | 2018 |
|
RU2701990C1 |
| АЮШЕЕВА Н.Н | |||
| и др | |||
| Топка с несколькими решетками для твердого топлива | 1918 |
|
SU8A1 |
| US 10944863 B2, 09.03.2021 | |||
| US | |||

