ОБЛАСТЬ ТЕХНИКИ
[0001] Настоящее изобретение в целом относится к вычислительным системам, а точнее - к системам и способам обработки естественного языка.
УРОВЕНЬ ТЕХНИКИ
[0002] Различные задачи обработки естественного языка могут включать классификацию текстов на естественном языке. К примерам таких задач относятся выявление семантических сходств, ранжирование результатов поиска, определение авторства текста, фильтрация спама, выбор текстов для контекстной рекламы и т.д.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[0003] В соответствии с одним или более вариантами реализации настоящего изобретения пример способа использования автоэнкодера для обучения классификатора текстов на естественном языке может включать: создание, с помощью вычислительной системы, множества векторов признаков, таких что каждый вектор признаков представляет текст или корпус текстов на естественном языке, где корпус текстов содержит первое множество аннотированных текстов на естественном языке и второе множество неаннотированных текстов на естественном языке; обучение, с использованием множества векторов признаков, автоэнкодера, представленного искусственной нейронной сетью; создание, с использованием автоэнкодера, результата скрытого слоя, путем обработки обучающей выборки данных, включающей первое множество аннотированных текстов на естественном языке; и обучение, с использованием обучающей выборки данных, классификатора текста, который получает входной вектор, содержащий результат скрытого слоя и выдает степень связанности с определенной категорией текстов естественного языка, использованной для получения результата скрытого слоя.
[0004] В соответствии с одним или более вариантами реализации настоящего изобретения пример системы классификации текстов на естественном языке может включать: память и процессор, соединенный с запоминающим устройством, при этом процессор выполнен с возможностью: получения вычислительной системой текста на естественном языке; обработки текста на естественном языке автоэнкодером, представленным искусственной нейронной сетью; подачи в классификатор текстов входного вектора, содержащего результат скрытого слоя; и определения, с помощью классификатора текстов, степени связанности текста на естественном языке с определенной категорией текстов.
[0005] В соответствии с одним или более вариантами реализации настоящего изобретения пример постоянного машиночитаемого носителя данных может включать исполняемые команды, которые при исполнении их вычислительным устройством приводят к выполнению вычислительным устройством операций, включающих: создание множества векторов признаков, таких что каждый вектор признаков представляет текст или корпус текстов на естественном языке, где корпус текстов содержит первое множество аннотированных текстов на естественном языке и второе множество неаннотированных текстов на естественном языке; обучение, с использованием множества векторов признаков, автоэнкодера, представленного искусственной нейронной сетью; создание, с использованием автоэнкодера, результата скрытого слоя, путем обработки обучающей выборки данных, включающей первое множество аннотированных текстов на естественном языке; и обучение, с использованием обучающей выборки данных, классификатора текста, который получает входной вектор, содержащий результат скрытого слоя и выдает степень связанности с определенной категорией текстов естественного языка, использованной для получения результата скрытого слоя. Технический результат от использования автоэнкодеров для классификации текстов состоит в достижении высокой точности классификации при обучении классификатора на обучающих выборках относительно небольшого объема посредством использования результата скрытого слоя автоэнкодера для дообучения классификатора.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0006] Настоящее изобретение иллюстрируется с помощью примеров, а не способом ограничения, и может быть лучше понято при рассмотрении приведенного ниже описания предпочтительных вариантов реализации в сочетании с чертежами, на которых:
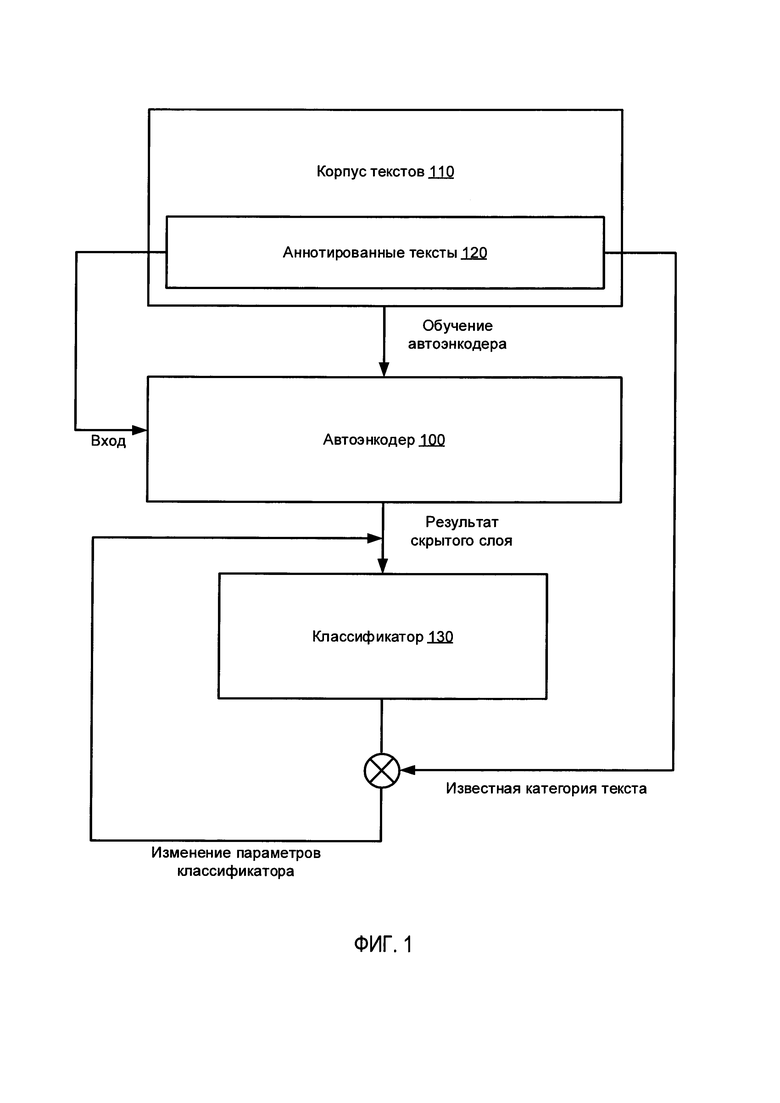
[0007] На Фиг. 1 схематически иллюстрируется пример процесса, используемого автоэнкодером для обучения классификатора текста на естественном языке в соответствии с одним или более вариантами реализации настоящего изобретения;
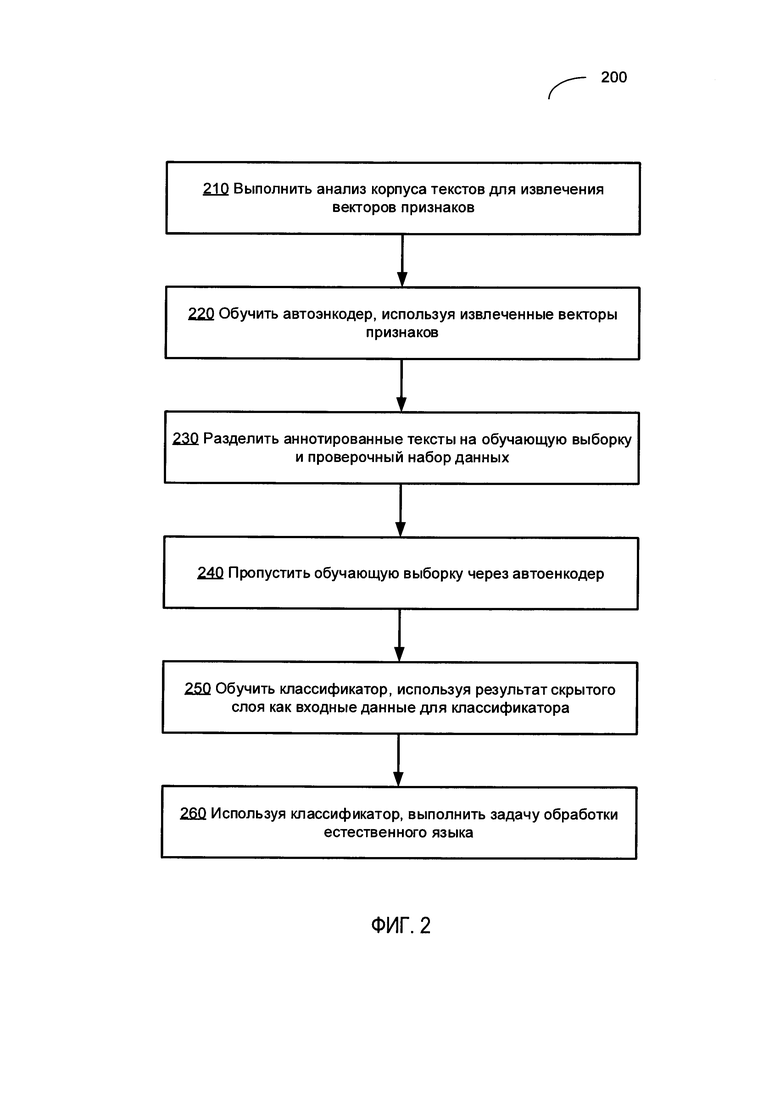
[0008] На Фиг. 2 приведена блок-схема одного из иллюстративных примеров использования автоэнкодера для обучения классификатора текста на естественном языке в соответствии с одним или более вариантами реализации настоящего изобретения;
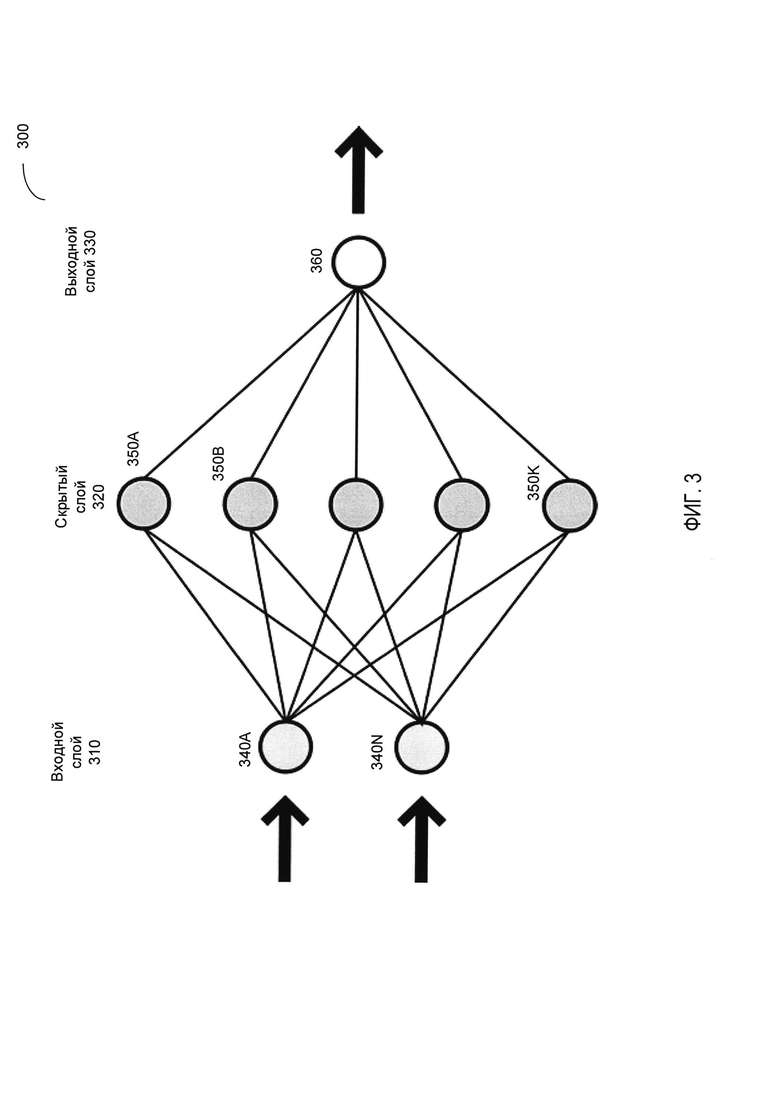
[0009] На Фиг. 3 схематически иллюстрируется пример структуры нейронной сети, работающей в соответствии с одним или более вариантами реализации настоящего изобретения;
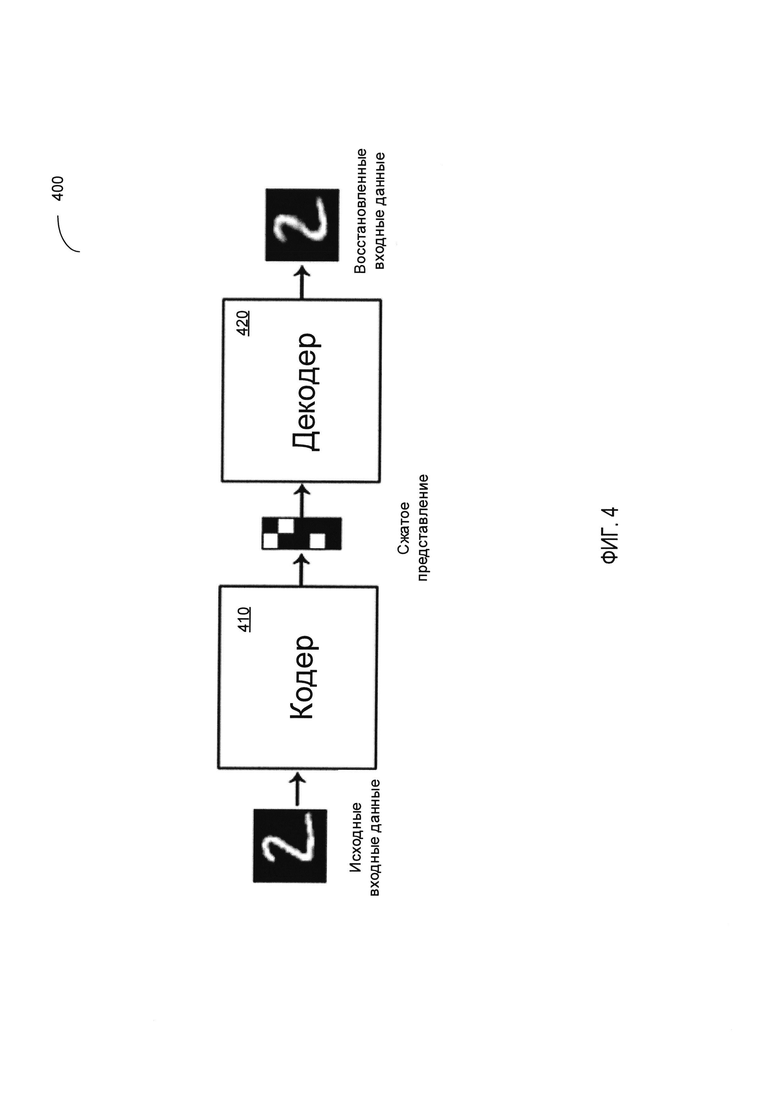
[00010] На Фиг. 4 схематически иллюстрируется пример работы автоэнкодера в соответствии с одним или более вариантами реализации настоящего изобретения;
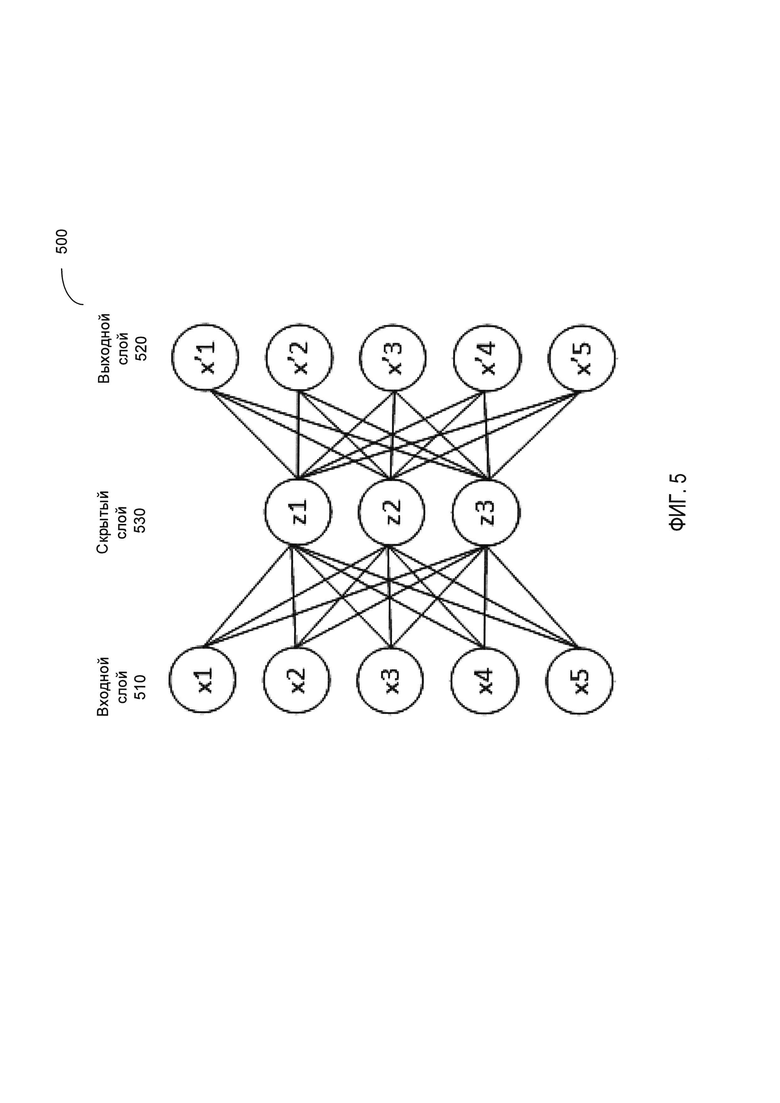
[00011] На Фиг. 5 схематически иллюстрируется структура автоэнкодера, работающего в соответствии с одним или более вариантами реализации настоящего изобретения;
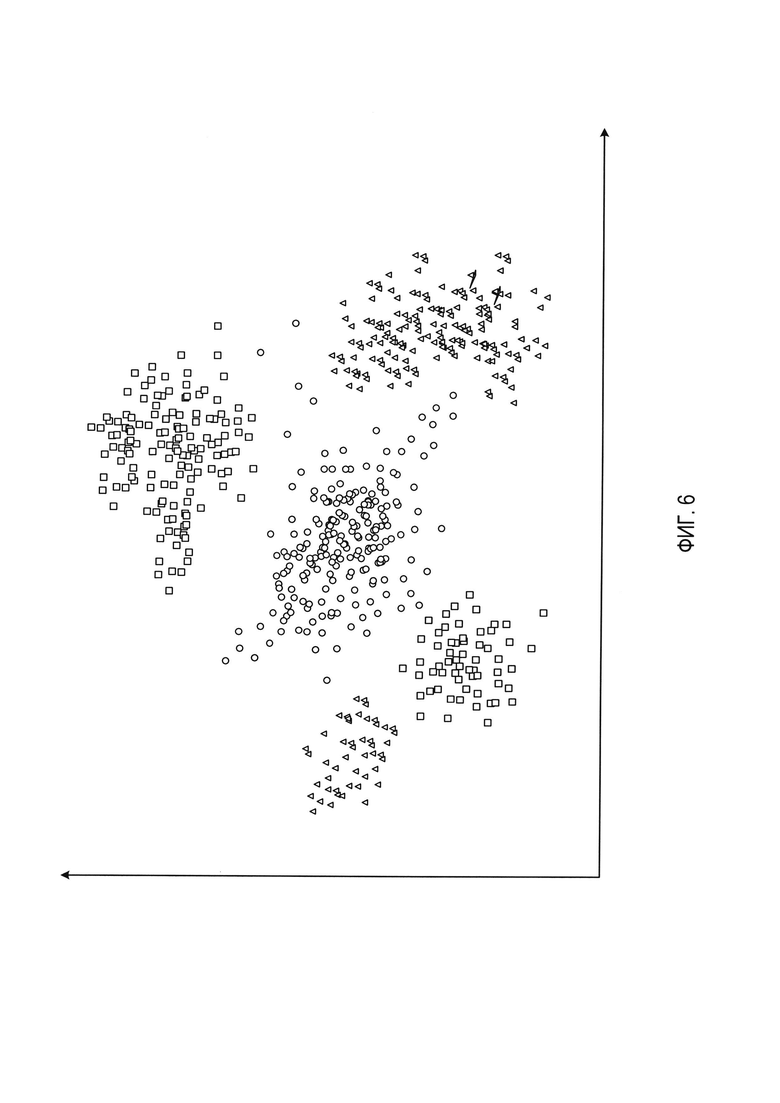
[00012] На Фиг. 6 схематически иллюстрируется выход скрытого слоя автоэнкодера, обрабатывающего типовую выборку данных в соответствии с одним или более вариантами реализации настоящего изобретения;
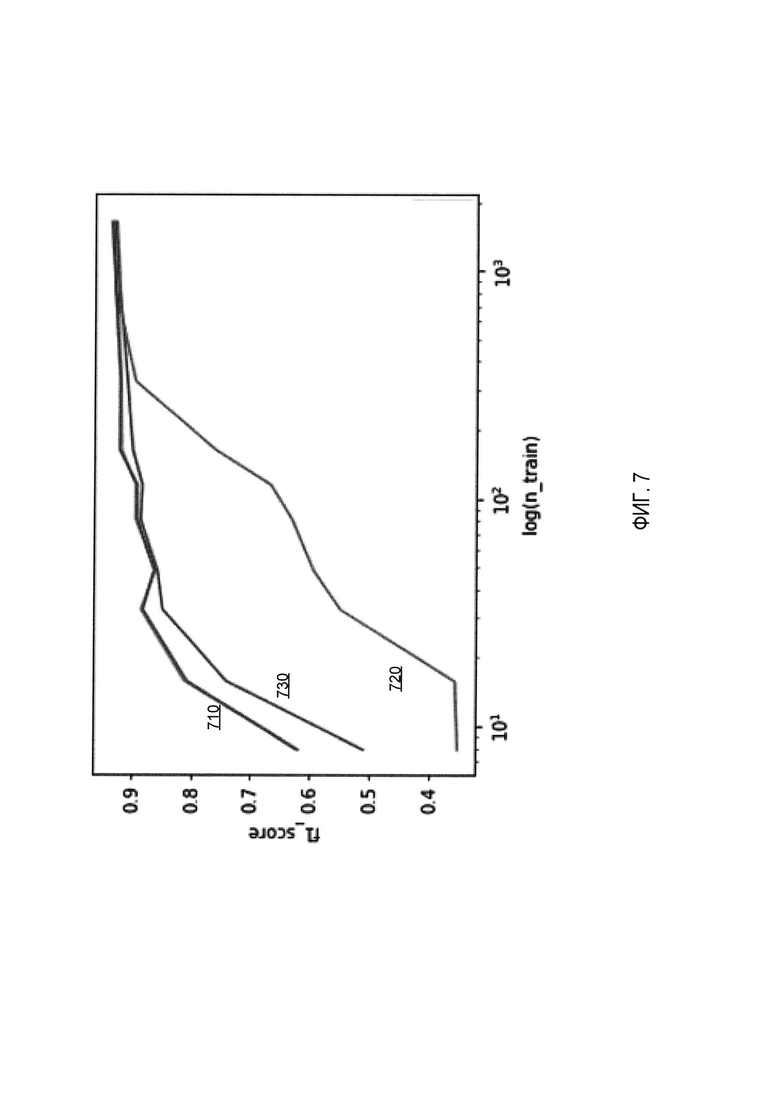
[00013] На Фиг. 7 схематически иллюстрируется точность классификации текста классификаторами текста, обрабатывающими объединенные входные векторы, содержащие текстовые признаки и выход автоэнкодера, в соответствии с одним или более вариантами реализации настоящего изобретения, и классификаторами текста, обрабатывающими только мешки слов;
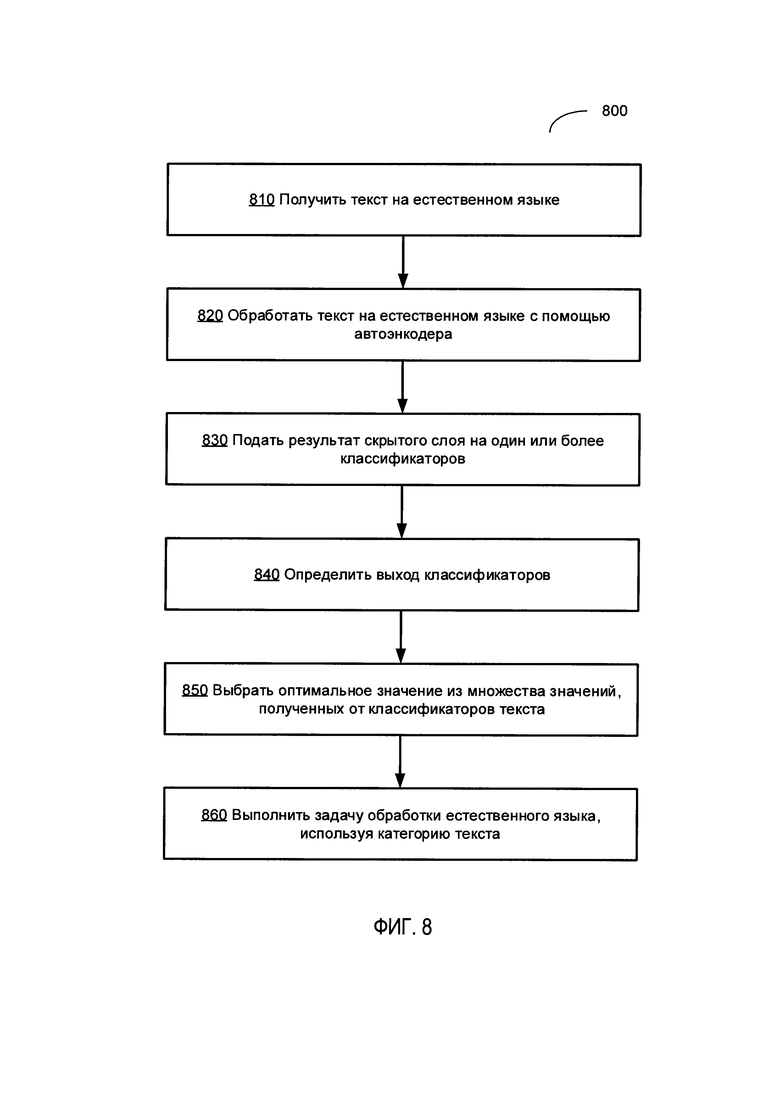
[00014] На Фиг. 8 приведена блок-схема одного иллюстративного примера способа классификации текста на естественном языке в соответствии с одним или более вариантами реализации настоящего изобретения; и
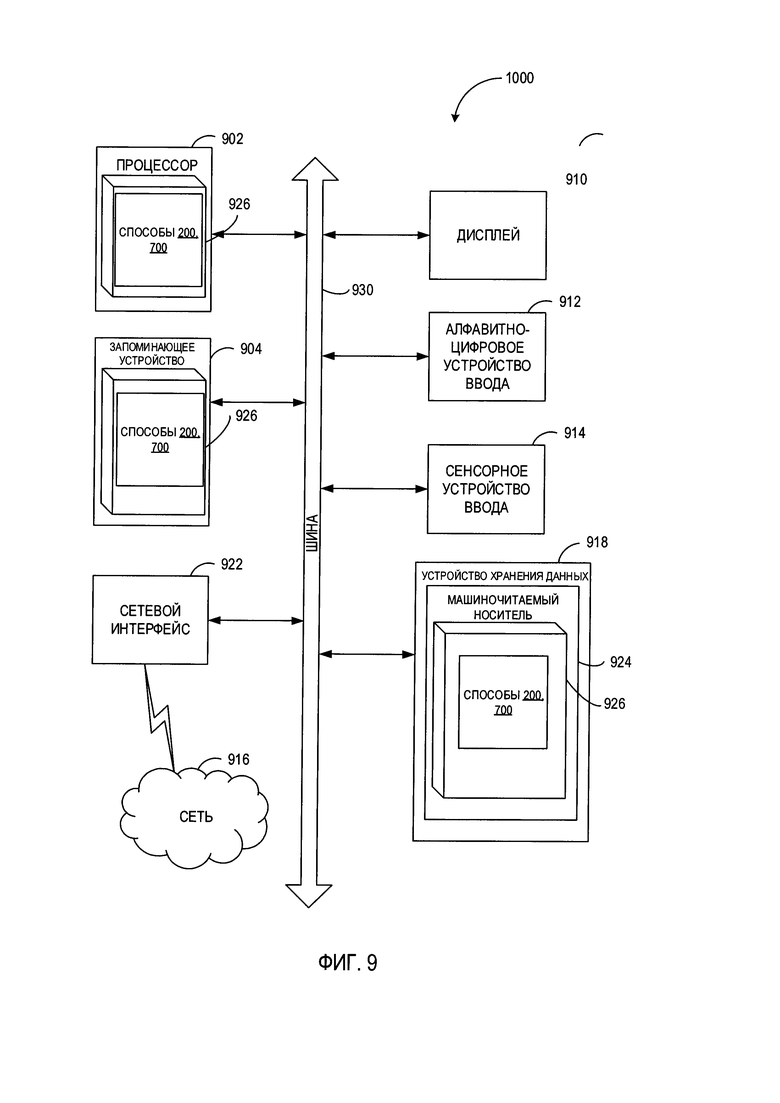
[00015] На Фиг. 9 показана схема примера вычислительной системы, реализующей методы настоящего изобретения.
ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНЫХ ВАРИАНТОВ РЕАЛИЗАЦИИ
[00016] В настоящем документе описываются способы и системы использования автоэнкодеров для обучения классификаторов естественных языков. Классификация текстов на естественном языке может подразумевать соотнесение заданного текста на естественном языке, который может быть представлен, например, по меньшей мере, частью документа, с одной или более категориями из определенного набора категорий. В некоторых вариантах осуществления набор категорий может быть определен заранее (например, "спам" и "разрешенные сообщения" для классификации сообщений электронной почты). Вместо этого набор категорий может быть выявлен на ходу во время выполнения классификации путем анализа корпуса текстов на естественном языке или документов (например, множества заметок из ленты новостей).
[00017] В настоящем документе термин "вычислительная система" означает устройство обработки данных, оснащенное универсальным процессором, запоминающим устройством и по меньшей мере одним интерфейсом связи. Примерами вычислительных систем, которые могут использовать описанные в этом документе методы, являются, в частности, настольные компьютеры, ноутбуки, планшетные компьютеры и смартфоны.
[00018] При автоматической классификации текста каждый текст на естественном языке может быть представлен точкой в многомерном пространстве, такой, что координаты этой точки представлены значениями признаков. Поэтому выполнение классификации текстов может включать определение параметров одной или более разделительных гипер-плоскостей, которые разделяют многомерное пространство на сектора, представляющие категории классификации.
[00019] Классификация текста может выполняться путем вычисления функции классификации, также известной как классификатор, которая может быть представлена как функция множества признаков текста, которая отражает степень соотнесения классифицируемого текста с определенной категорией из множества категорий классификации (например, вероятность соотнесения текста с определенной категорией). Классификация текста может включать оценку выбранной функции классификации для каждой категории из множества категорий классификации, а также связывание текста на естественном языке с категорией, соответствующей оптимальному (максимальному или минимальному) значению функции классификации.
[00020] В некоторых вариантах осуществления каждый текст на естественном языке может быть представлен вектором признаков, содержащим множество числовых значений, описывающих признаки соответствующего текста. В иллюстративном примере каждый элемент вектора может содержать значение, отражающее определенные частотные характеристики слова, определяемого индексом элемента, как более подробно будет описано ниже.
[00021] Значения одного или более параметров классификатора могут определяться с помощью метода обучения с учителем, метод может включать итеративное изменение значений параметров, исходя из анализа обучающей выборки данных, включающей тексты на естественном языке с известными категориями классификации, для оптимизации функции качества, отражающей отношение числа текстов на естественном языке в наборе проверочных данных, которые были правильно классифицированы с использованием определенных значений параметров классификатора, к общему числу текстов на естественном языке в наборе проверочных данных.
[00022] Фактически, количество доступных аннотированных текстов, которые могут быть включены в обучающую выборку или набор проверочных данных, может быть относительно невелико, поскольку создание этих аннотированных текстов может включать получение информации от пользователя, определяющего категорию классификации для каждого текста. Обучение с учителем на основе относительно небольших обучающих выборок и наборов проверочных данных может привести к малой эффективности классификаторов.
[00023] Настоящее изобретение служит для устранения этого и других ограничений известных способов классификации текста за счет использования автоэнкодеров для извлечения информации из больших, чаще всего неаннотированных корпусов текстов, так что извлеченная информация может затем использоваться в процессе обучения классификатора. Термин "автоэнкодер" в настоящем документе означает искусственную нейронную сеть, которая используется для обучения и сжатия наборов данных без учителя, обычно с целью уменьшения размерности. Автоэнкодер может быть реализован в виде трехслойной искусственной нейронной сети, в которой размерность векторов на входе и выходе совпадает, а размерность скрытого промежуточного слоя значительно меньше, чем размерность входного и выходного слоев, как более подробно будет описано ниже. Обучение автоэнкодера без учителя включает обработку тестовой выборки данных для определения значений одного или более параметров автоэнкодера, чтобы свести к минимуму ошибку в результатах, соответствующую разнице между входным и выходным векторами. Поскольку размерность скрытого слоя значительно ниже размерности входного и выходного слоев, автоэнкодер сжимает входной вектор во входном слое, а затем восстанавливает его в выходном слое, таким образом обнаруживая некоторые внутренние или скрытые признаки входной выборки данных.
[00024] На Фиг. 1 схематически иллюстрируется пример процесса, используемого автоэнкодером для обучения классификатора текста на естественном языке в соответствии с одним или более вариантами реализации настоящего изобретения. Как показано на Фиг. 1, автоэнкодер 100, обученный на корпусе 110 текстов на естественном языке, может использоваться для обработки обучающей выборки, представленной аннотированным подмножеством 120 текстового корпуса 110. Поскольку автоэнкодер 100 был обучен на всем корпусе 110, выход скрытого слоя автоэнкодера 100, обрабатывающего аннотированный текст из обучающей выборки данных 120, будет, предположительно, отражать не только признаки текста, извлеченные из аннотированного текста, но и информацию, собранную автоэнкодером 100 из всего текстового корпуса 110 при обучении автоэнкодера. Таким образом, классификатор 130, обрабатывая результат скрытого слоя автоэнкодера 100, будет давать более точные результаты, чем классификатор, непосредственно обрабатывающий признаки текста, извлеченные из текста. Классификатор 130, обрабатывающий выход скрытого слоя автоэнкодера 100, может обучаться с использованием аннотированного текста, включающего обучающую выборку данных 120. Неаннотированные тексты текстового корпуса 110 и/или другие аналогичные тексты затем могут классифицироваться в ходе двухстадийного процесса, который включает использование автоэнкодера для получения выхода скрытого слоя с последующей подачей этого выхода на вход обученного классификатора, как более подробно будет описано ниже.
[00025] Различные аспекты упомянутых выше способов и систем подробно описаны ниже в этом документе с помощью примеров, не с целью ограничения.
[00026] На Фиг. 2 приведена блок-схема одного иллюстративного примера использования автоэнкодера для обучения классификатора текста на естественном языке в соответствии с одним или более вариантами реализации настоящего изобретения. Способ 200 и/или каждая из его отдельных функций, программ, подпрограмм или операций могут выполняться одним или более процессорами вычислительной системы (например, вычислительной системы 1000 на Фиг. 9), реализующими этот способ. В некоторых реализациях способ 200 может быть реализован в одном потоке обработки. В качестве альтернативы способ 200 может быть реализован с помощью двух или более потоков обработки, при этом каждый поток выполняет одну или более отдельных функций, стандартных программ, подпрограмм или операций данного способа. В иллюстративном примере реализующие способ 200 потоки обработки могут быть синхронизированы (например, с помощью семафоров, критических секций и (или) других механизмов синхронизации потоков). В качестве альтернативы реализующие способ 200 потоки обработки могут выполняться асинхронно по отношению друг к другу.
[00027] На шаге 210 блок-схемы вычислительная система, реализующая этот способ, может анализировать корпус текстов на естественном языке для получения, для каждого текста на естественном языке, вектора признаков, представляющего соответствующий текст. Этот корпус может содержать тексты, имеющие общую или сходную структуру (например, новостные заметки или сообщения электронной почты) и представлять несколько категорий классификации (например, авторство различных людей, спам и разрешенные сообщения электронной почты, новостные заметки о внешней политике, науке и спорте, и т.д.). Возможно, что относительно небольшое подмножество корпуса текстов будет аннотировано, то есть будет включать тексты, имеющие известную категорию классификации (такое как авторство литературного произведения, классификация сообщений электронной почты как спама, тема новостной заметки и т.д.). Отметим, что системы и способы настоящего изобретения особенно пригодны для обработки несбалансированных обучающих выборок, то есть обучающих выборок, в которых количество текстов, соответствующих одной категории классификации, может значительно отличаться от количества текстов, соответствующих другой категории классификации.
[00028] Векторы признаков, представляющие соответствующие тексты корпуса, могут комбинироваться в матрицу, представляющую текстовых корпус, так что каждая строка матрицы представляет вектор признаков текста, определяемого индексом строки, а каждый столбец матрицы представляет некоторый признак текста, например, наличие слова, определяемый индексом столбца.
[00029] В качестве иллюстративного примера каждый текст может быть представлен "мешком слов", то есть неупорядоченным или упорядоченным набором слов, содержащихся в тексте. Таким образом, каждая ячейка матрицы может хранить целое значение, отражающее количество вхождений слова, ассоциированного со столбцом, в документе, определяемом строкой.
[00030] Для снижения уровня шума, который может быть вызван отдельными часто встречающимися словами, которые не определяют категорию документа (например, артикли, предлоги, вспомогательные слова и т.д.), каждый текст на естественном языке может быть представлен вектором значений частоты использования слов - обратной частоты документа (TF-IDF).
[00031] Частота использования слов (TF) представляет собой частоту встречаемости данного слова в документе:
[00032] tƒ(t,d)=nt/∑nk
где t - это идентификатор слова,
d- идентификатор документа,
nt - количество появлений слова t в документе d, и
∑nk - общее количество слов в документе d.
[00033] Обратная частота документа (IDF) определяется как логарифмическое отношение количества текстов в корпусе к количеству документов, содержащих данное слово:
[00034] idƒ(t, D)=log[|D|/|{di∈D|t∈di}|]
где D - идентификатор текстового корпуса,
|D| - количество документов в корпусе, и
{di∈D|t∈di} - количество документов в корпусе D, содержащих слово t.
[00035] Таким образом, TF-IDF можно определить как произведение частоты использования слов (TF) и обратной частоты документа (IDF):
tƒ-idƒ(t, d, D)=tƒ(t, d)*idƒ(t, D)
[00036] TF-IDF будет давать большие значения для слов, которые чаще встречаются в одном документе, чем в других документах корпуса. Соответственно, текстовый корпус может быть представлен матрицей, в каждой ячейке которой хранится значение TF-IDF слова, определяемого индексом столбца, в документе, определяемом индексом строки.
[00037] В различных альтернативных вариантах реализации изобретения для классификации текста системами и способами в соответствии с настоящим изобретением могут использоваться другие типы признаков, которые могут быть извлечены из текстов на естественном языке, включая морфологические, синтаксические и/или семантические признаки, в дополнение или вместо описанных выше значений TF-IDF.
[00038] На шаге 220 вычислительная система может использовать векторы признаков, представляющие тексты на естественном языке, для обучения методом "без учителя" автоэнкодера, который затем будет использован для использования как вход классификатора. В иллюстративном примере автоэнкодер может быть представлен трехслойной искусственной нейронной сетью.
[00039] Нейронная сеть представляет собой вычислительную модель, основанную на многоэтапном алгоритме, который применяет набор заранее определенных функциональных преобразований ко множеству входных данных (например, вектору признаков, представляющему документ), а затем использует преобразованные данные для выполнения извлечения информации, распознавания образов и т.д. В иллюстративном примере нейронная сеть может содержать множество искусственных нейронов, которые получают входные данные, изменяют свое внутреннее состояние в соответствии с этими входными данными и функцией активации, и создают выходные данные, которые зависят от входных данных и активированного внутреннего состояния. Нейронная сеть может формироваться путем соединения выхода отдельных нейронов со входом других нейронов с формированием направленного взвешенного графа, в котором нейроны представляют собой узлы, а связи между нейронами представляют взвешенные направленные ребра. В ходе процесса обучения веса и параметры функции активации могут изменяться.
[00040] На Фиг. 3 схематически иллюстрируется пример структуры нейронной сети, работающей в соответствии с одним или более вариантами реализации настоящего изобретения. Как показано на Фиг. 3, нейронная сеть 300 может содержать входной слой 310, скрытый слой 320 и выходной слой 330. Входной слой 310 может содержать один или более нейронов 340A-340N, которые могут быть связаны с одним или более нейронами 350А-350K скрытого слоя 320. Нейроны скрытого слоя 350A-350K могут, в свою очередь, быть связаны с одним или более нейронами 360 выходного слоя 330.
[00041] Как отмечено выше в настоящем документе, трехслойная искусственная нейронная сеть, в которой размерности входного и выходного слоев совпадают, а размерность скрытого слоя значительно ниже, чем размерность входного или выходного слоя, может реализовывать автоэнкодер, который может использоваться для обучения кодировке наборов данных без учителя, обычно с целью уменьшения размерности.
[00042] Фиг. 4 схематически иллюстрирует работу примера автоэнкодера в соответствии с одним или более вариантами реализации настоящего изобретения. Как показано на Фиг. 4, пример автоэнкодера 400 может содержать этап 410 кодера и этап 420 декодера. Стадия кодера 410 автоэнкодера может получать входной вектор х и отображать его в скрытое представление z, размерность которого значительно ниже, чем размерность входного вектора:
[00043] z=σ(Wx+b),
где σ - функция активации, которая может быть представлена сигмоидной функцией или блоком линейного сглаживания,
W - матрица весов, и
b - вектор смещения.
[00044] Этап декодера 420 автоэнкодера может отображать скрытое представление z на восстановленный вектор х', имеющий ту же размерность, что и входной вектор х:
[00045] X'=σ'(W'z+b').
[00046] Автоэнкодер можно обучить сводить к минимуму ошибку восстановления:
[00047] L(х, х')=||х-х'||2=||х-σ' (W'(σ(Wx+b))+b')||2,
[00048] где x может быть усреднено по обучающей выборке данных.
[00049] Поскольку размерность скрытого слоя значительно ниже размерности входного и выходного слоев, автоэнкодер сжимает входной вектор в входном слое, а затем восстанавливает его в выходном слое, таким образом обнаруживая некоторые внутренние или скрытые признаки входной выборки данных.
[00050] На Фиг. 5 схематически иллюстрируется структура примера автоэнкодера, работающего в соответствии с одним или более вариантами реализации настоящего изобретения. Как показано на Фиг. 5, автоэнкодер 500 может быть представлен нейронной сетью с прямой связью без повторений, содержащей входной слой 510, выходной слой 520 и один или более скрытых слоев 530, соединяющих входной слой 510 с выходным слоем 520. Выходной слой 520 может иметь то же количество узлов, что и входной слой 510, так что сеть 500 может быть обучена, в ходе обучения без учителя, восстанавливать собственные входные данные.
[00051] В некоторых реализациях изобретения функция активации скрытого слоя автоэнкодера может быть представлена блоком линейного сглаживания (ReLU), который можно описать следующей формулой:
σ(x)=max(0, х).
[00052] В некоторых реализациях изобретения функция активации выходного слоя автоэнкодера может быть представлена блоком линейного сглаживания(ReLU), который можно описать следующей формулой:
σ(x)=1/(1+е-х).
[00053] Обучение автоэнкодера без учителя может включать для каждого входного вектора x прямую передачу сигнала для получения выхода х', измерение ошибки выхода, описываемой функцией потерь L(x, x'), и обратное распространение ошибки выхода по сети для обновления размерности скрытого слоя, весов и (или) параметров функции активации. В иллюстративном примере функция потерь может быть представлена бинарной функцией перекрестной энтропии. Процесс обучения может повторяться, пока ошибка выхода не станет ниже заранее определенного порогового значения.
[00054] На Фиг. 2 на шаге 230 вычислительная система может разделить аннотированное подмножество текстового корпуса на обучающую выборку данных и набор проверочных данных. В некоторых вариантах осуществления к корпусу текстов на естественном языке может быть применен способ перекрестной проверки (cross-validation) с помощью k-свертки. Этот способ может включать случайное разделение аннотированных текстов на k подмножеств одинакового размера, одно из которых затем используется в качестве набора проверочных данных, а оставшиеся k-1 наборов составляют обучающую выборку данных. Процесс перекрестной проверки может быть повторен k раз, таким образом, чтобы каждое из k подмножеств использовалось один раз в качестве набора проверочных данных.
[00055] На шаге 240 вычислительная система использует обученный автоэнкодер для обработки выявленной обучающей выборки данных для получения выхода скрытого слоя автоэнкодера. Поскольку автоэнкодер был обучен на всем корпусе текстов, включая неаннотированные и аннотированные тексты, выход скрытого слоя автоэнкодера, обрабатывающего аннотированный текст из обучающей выборки данных, будет, предположительно, отражать не только признаки текста, извлеченные из конкретного аннотированного текста, но и информацию, собранную автоэнкодером из всего корпуса тестов при обучении автоэнкодера.
[00056] На шаге 250 вычислительная система может обучать классификатор, используя результат, полученный скрытым слоем автоэнкодера, в качестве входных данных классификатора. В некоторых вариантах реализации изобретения классификатор может быть представлен линейным классификатором на основе метода опорных векторов (LinearSVC). Обучение классификатора может включать итеративное нахождение значений определенных параметров модели классификатора текста для оптимизации выбранной функции качества. В одном из иллюстративных примеров функция качества может отражать число текстов на естественном языке в проверочном наборе данных, которые должны быть правильно классифицированы при использовании определенных значений параметров классификатора. В одном из иллюстративных примеров функция качества может быть представлена F-мерой, которая определяется как взвешенное гармоническое среднее точности и полноты:
[00057] F=2*P*R/(P+R),
где Р - точность - количество правильных положительных результатов, деленное на количество всех положительных результатов, и
R - полнота - количество правильных положительных результатов, деленное на количество положительных результатов, которое должно быть получено.
[00058] На шаге 260 вычислительная система может использовать обученный классификатор для выполнения задачи обработки естественного языка. К примерам задач обработки естественного языка относятся выявление семантических сходств, ранжирование результатов поиска, определение авторства текста, фильтрация спама, выбор текстов для контекстной рекламы и т.д. После завершения операций, указанных в блоке 260, выполнение способа может быть завершено.
[00059] В иллюстративном примере обученный классификатор может использоваться для классификации неаннотированного текста из текстового корпуса 110 и/или других подобных текстов. Процесс классификации может включать использование автоэнкодера для получения выхода скрытого слоя с последующей передачей его обученному классификатору. Классификация текста может включать оценку выбранной функции классификации для каждой категории из множества категорий классификации, а также связывание текста на естественном языке с категорией, соответствующей оптимальному (максимальному или минимальному) значению функции классификации, как подробнее описано выше в настоящем документе, как более подробно будет описано ниже со ссылкой на Фиг. 7.
[00060] Для относительно малых обучающих выборок данных классификаторы, обученные на результатах автоэнкодера, могут показывать более высокую точность, чем классификаторы, непосредственно обрабатывающие признаки, извлеченные из аннотированного текста. На Фиг. 6 схематически иллюстрируется результат скрытого слоя автоэнкодера, обрабатывающего типовую выборку данных. Каждая точка, изображенная фигурой в пространстве признаков, соответствует тексту на естественном языке, так что тексты, классифицированные как относящиеся к одной категории, представлены фигурами одного типа. Как показано на Фиг. 6, результат скрытого слоя автоэнкодера демонстрирует явно заметную кластеризацию даже после трансформации, путем уменьшения числа независимых координат от количества, равного размерности скрытого слоя автоэнкодера, до двух независимых координат, при выполнении двумерной визуализации.
[00061] Фактически текстовый корпус может изначально содержать только малое подмножество аннотированных документов, но их число может увеличиваться за счет получения, классификации и подтверждения классификации новых документов (например, путем запроса и получения ввода через пользовательский интерфейс подтверждающего или изменяющего категорию документа, выданного классификатором текстов). Таким образом, в некоторых вариантах реализации для определенных текстовых корпусов выход скрытого слоя может быть объединен с вектором признаков, извлеченным из текста на естественном языке, и полученный объединенный вектор может быть подан на вход классификатора для обучения классификатора.
[00062] На Фиг. 7 схематически иллюстрируется точность классификации текста классификаторами текста, обрабатывающими объединенные входные векторы, содержащие признаки текста, и выход автоэнкодера, и классификаторами текста, обрабатывающими только мешки слов. Как показано на Фиг. 7, точность примера текстового классификатора 710, который обрабатывает объединенные входные векторы, содержащие признаки текста и выход автоэнкодера, превышает, при малых объемах обучающих выборок данных, как точность линейного классификатора 720, который обрабатывает только мешки слов, так и точность классификатора на основе метода случайного леса (random forest) 730.
[00063] На Фиг. 8 приведена блок-схема одного иллюстративного примера способа классификации текста на естественном языке в соответствии с одним или более вариантами реализации настоящего изобретения. Способ 800 и/или каждая из его отдельных функций, процедур, подпрограмм или операций может выполняться с помощью одного или более процессоров вычислительной системы (например, устройства обработки 1000 на Фиг. 9), реализующей этот способ. В некоторых реализациях способ 800 может быть реализован в одном потоке обработки. При альтернативном подходе способ 800 может осуществляться с использованием двух или более потоков обработки, при этом в каждом потоке реализована одна или более отдельных функций, процедур, подпрограмм или действий этого способа. В иллюстративном примере потоки обработки, реализующие способ 800, могут быть синхронизированы (например, с помощью семафоров, критических секций и/или других механизмов синхронизации потоков). Кроме того, потоки обработки, реализующие способ 800, могут выполняться асинхронно друг относительно друга.
[00064] На шаге 810 вычислительное устройство, в котором реализован этот способ, может получить текст на естественном языке, подлежащий классификации на принадлежность к категории заранее определенного множества категорий.
[00065] На шаге 820 вычислительная система может использовать автоэнкодер, который был заранее обучен на большом текстовом корпусе, для обработки полученного текста на естественном языке и получения выхода скрытого слоя автоэнкодера, как подробнее описано выше в настоящем документе.
[00066] На шаге 830 вычислительная система может подать выход скрытого слоя автоэнкодера в один или более классификаторов, которые были предварительно обучены на аннотированном подмножестве текстового корпуса, как подробнее описано выше в настоящем документе.
[00067] На шаге 840 каждый классификатор может определить степень соответствия классифицируемого текста соответствующей категории из множества категорий классификации, как подробнее описано выше в настоящем документе.
[00068] На шаге 850 вычислительная система может выбрать оптимальное (т.е. минимальное или максимальное) значение из значений, полученных классификаторами, и связать текст на естественном языке с категорией, соответствующей классификатору, который выдал выбранное оптимальное значение.
[00069] На шаге 860 вычислительная система может использовать найденную категорию текста для выполнения задачи обработки естественного языка. К примерам задач обработки естественного языка относятся выявление семантических сходств, ранжирование результатов поиска, определение авторства текста, фильтрация спама, выбор текстов для контекстной рекламы и т.д. После завершения операций, указанных на шаге 280, выполнение способа может быть завершено.
[00070] На Фиг. 9 показан иллюстративный пример вычислительной системы 1000, которая может исполнять набор команд, которые вызывают выполнение вычислительной системой любого отдельно взятого или нескольких способов настоящего изобретения. Вычислительная система может быть соединена с другой вычислительной системой по локальной сети, корпоративной сети, сети экстранет или сети Интернет. Вычислительная система может работать в качестве сервера или клиента в сетевой среде «клиент/сервер» либо в качестве однорангового вычислительного устройства в одноранговой (или распределенной) сетевой среде. Вычислительная система может быть представлена персональным компьютером (ПК), планшетным ПК, телевизионной приставкой (STB), карманным ПК (PDA), сотовым телефоном или любой вычислительной системой, способной выполнять набор команд (последовательно или иным образом), определяющих операции, которые должны быть выполнены этой вычислительной системой. Кроме того, несмотря на то что показана только одна вычислительная система, термин «вычислительная система» также может включать любую совокупность вычислительных систем, которые отдельно или совместно выполняют набор (или более наборов) команд для выполнения одной или более методик, обсуждаемых в настоящем документе.
[00071] Пример вычислительной системы 1000 включает процессор 902, основное запоминающее устройство 904 {например, постоянное запоминающее устройство (ПЗУ) или динамическое оперативное запоминающее устройство (ДОЗУ)) и устройство хранения данных 918, которые взаимодействуют друг с другом по шине 930.
[00072] Процессор 902 может быть представлен одной или более универсальными вычислительными системами, например, микропроцессором, центральным процессором и т.д. В частности, процессор 902 может представлять собой микропроцессор с полным набором команд (CISC), микропроцессор с сокращенным набором команд (RISC), микропроцессор с командными словами сверхбольшой длины (VLIW), процессор, реализующий другой набор команд или процессоры, реализующие комбинацию наборов команд. Процессор 902 также может представлять собой одну или более вычислительных систем специального назначения, например, заказную интегральную микросхему (ASIC), программируемую пользователем вентильную матрицу (FPGA), процессор цифровых сигналов (DSP), сетевой процессор и т.п. Процессор 902 реализован с возможностью выполнения команд 926 для осуществления рассмотренных в настоящем документе операций и функций.
[00073] Вычислительная система 1000 может дополнительно включать устройство сетевого интерфейса 922, устройство визуального отображения 910, устройство ввода символов 912 (например, клавиатуру), и устройство ввода в виде сенсорного экрана 914.
[00074] Устройство хранения данных 918 может содержать машиночитаемый носитель данных 924, в котором хранится один или более наборов команд 926, реализующих один или несколько из методов или функций настоящего изобретения. Команды 926 во время выполнения их в вычислительной системе 1000, также могут находиться полностью или по меньшей мере частично в основном запоминающем устройстве 904 и (или) в процессоре 902, при этом оперативное запоминающее устройство 904 и процессор 902 также составляют машиночитаемый носитель данных. Команды 926 дополнительно могут передаваться или приниматься по сети 916 через устройство сетевого интерфейса 922.
[00075] В некоторых вариантах реализации инструкции 926 могут включать инструкции способов 200, 700 обучения классификатора текста и классификации текстов на естественном языке, в соответствии с одним или более вариантами реализации настоящего изобретения. Хотя машиночитаемый носитель данных 924, показанный в примере на Фиг. 9, является единым носителем, термин "машиночитаемый носитель" может включать один носитель или несколько носителей {например, централизованную или распределенную базу данных и/или соответствующие кэши и серверы), в которых хранится один или несколько наборов команд. Термин «машиночитаемый носитель данных» также может включать любой носитель, который может хранить, кодировать или содержать набор команд для выполнения машиной и который обеспечивает выполнение машиной любой одной или более методик настоящего изобретения. Поэтому термин «машиночитаемый носитель данных» относится, помимо прочего, к твердотельным запоминающим устройствам, а также к оптическим и магнитным носителям.
[00076] Способы, компоненты и функции, описанные в этом документе, могут быть реализованы с помощью дискретных компонентов оборудования либо они могут быть встроены в функции других компонентов оборудования, например, ASICS (специализированная заказная интегральная схема), FPGA (программируемая логическая интегральная схема), DSP (цифровой сигнальный процессор) или аналогичных устройств. Кроме того, способы, компоненты и функции могут быть реализованы с помощью модулей встроенного программного обеспечения или функциональных схем аппаратного обеспечения. Способы, компоненты и функции также могут быть реализованы с помощью любой комбинации аппаратного обеспечения и программных компонентов либо исключительно с помощью программного обеспечения.
[00077] В приведенном выше описании изложены многочисленные детали. Однако любому специалисту в этой области техники, ознакомившемуся с этим описанием, должно быть очевидно, что настоящее изобретение может быть осуществлено на практике без этих конкретных деталей. В некоторых случаях хорошо известные структуры и устройства показаны в виде блок-схем без детализации, чтобы не усложнять описание настоящего изобретения.
[00078] Некоторые части описания предпочтительных вариантов реализации изобретения представлены в виде алгоритмов и символического представления операций с битами данных в запоминающем устройстве компьютера. Такие описания и представления алгоритмов представляют собой средства, используемые специалистами в области обработки данных, что обеспечивает наиболее эффективную передачу сущности работы другим специалистам в данной области. В контексте настоящего описания, как это и принято, алгоритмом называется логически непротиворечивая последовательность операций, приводящих к желаемому результату. Операции подразумевают действия, требующие физических манипуляций с физическими величинами. Обычно, хотя и необязательно, эти величины принимают форму электрических или магнитных сигналов, которые можно хранить, передавать, комбинировать, сравнивать и выполнять другие манипуляции. Иногда удобно, прежде всего для обычного использования, описывать эти сигналы в виде битов, значений, элементов, символов, терминов, цифр и т.д.
[00079] Однако следует иметь в виду, что все эти и подобные термины должны быть связаны с соответствующими физическими величинами и что они являются лишь удобными обозначениями, применяемыми к этим величинам. Если явно не указано обратное, принимается, что в последующем описании термины «определение», «вычисление», «расчет», «получение», «установление», «определение», «изменение» и т.п. относятся к действиям и процессам вычислительной системы или аналогичной электронной вычислительной системы, которая использует и преобразует данные, представленные в виде физических (например, электронных) величин в реестрах и устройствах памяти вычислительной системы, в другие данные, также представленные в виде физических величин в устройствах памяти или реестрах вычислительной системы или иных устройствах хранения, передачи или отображения такой информации.
[00080] Настоящее изобретение также относится к устройству для выполнения операций, описанных в настоящем документе. Такое устройство может быть специально сконструировано для требуемых целей, либо оно может представлять собой универсальный компьютер, который избирательно приводится в действие или дополнительно настраивается с помощью программы, хранящейся в памяти компьютера. Такая компьютерная программа может храниться на машиночитаемом носителе данных, например, помимо прочего, на диске любого типа, включая дискеты, оптические диски, CD-ROM и магнитно-оптические диски, постоянные запоминающие устройства (ПЗУ), оперативные запоминающие устройства (ОЗУ), СППЗУ, ЭППЗУ, магнитные или оптические карты и носители любого типа, подходящие для хранения электронной информации.
[00081] Следует понимать, что приведенное выше описание призвано иллюстрировать, а не ограничивать сущность изобретения. Специалистам в данной области техники после прочтения и уяснения приведенного выше описания станут очевидны и различные другие варианты реализации изобретения. Исходя из этого область применения изобретения должна определяться с учетом прилагаемой формулы изобретения, а также всех областей применения эквивалентных способов, на которые в равной степени распространяется формула изобретения.
Группа изобретений относится к вычислительным системам и способам обработки естественного языка. Технический результат состоит в достижении высокой точности классификации при обучении классификатора на обучающих выборках относительно небольшого объема посредством использования результата скрытого слоя автоэнкодера для дообучения классификатора. Для достижения технического результата предложен способ, который включает создание, с помощью вычислительной системы, множества векторов признаков, обучение, с использованием множества векторов признаков, автоэнкодера, представленного искусственной нейронной сетью, создание, с использованием автоэнкодера, результата скрытого слоя и обучение, с использованием обучающей выборки данных, классификатора текста. Также предложена система, включающая память и процессор, соединенный с запоминающим устройством. И предложен постоянный машиночитаемый носитель данных, включающий исполняемые команды, которые при исполнении их вычислительным устройством приводят к выполнению вычислительным устройством операций. 3 н. и 17 з.п. ф-лы, 9 ил.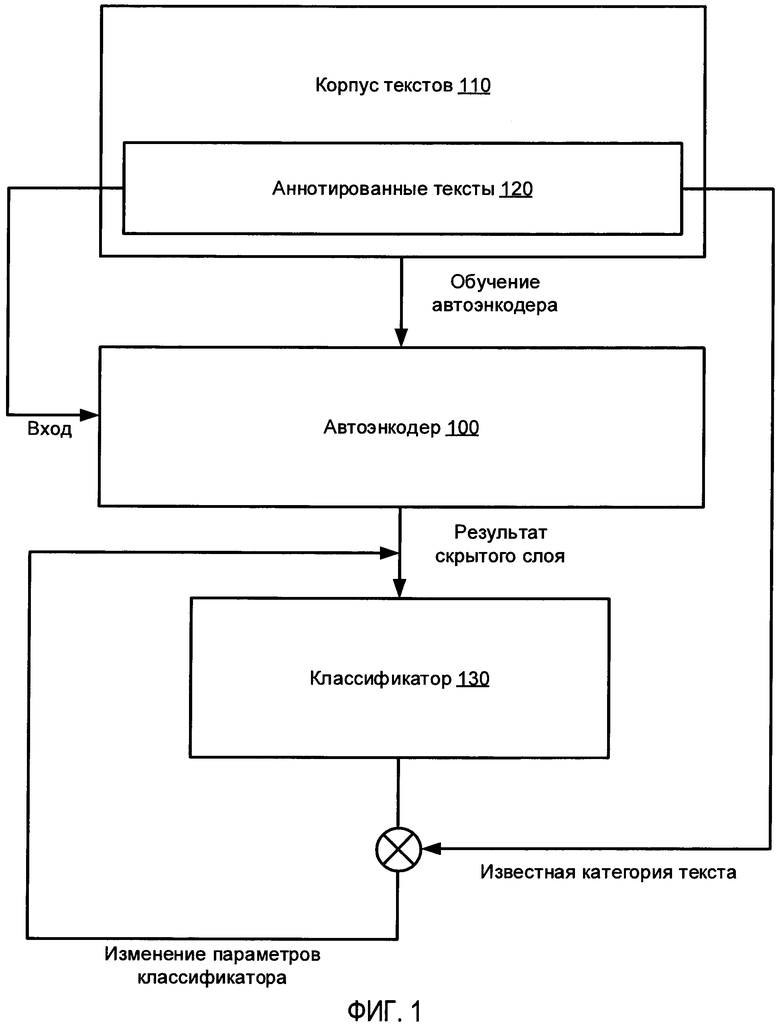
1. Способ классификации текстов на естественном языке, включающий:
создание, с помощью вычислительной системы, множества векторов признаков, таких что каждый вектор признаков представляет текст из корпуса текстов на естественном языке, где корпус текстов содержит первое множество аннотированных текстов на естественном языке и второе множество неаннотированных текстов на естественном языке;
обучение, с использованием множества векторов признаков, автоэнкодера, представленного искусственной нейронной сетью;
создание, с использованием автоэнкодера, результата скрытого слоя, путем обработки обучающей выборки данных, включающей первое множество аннотированных текстов на естественном языке; и
обучение, с использованием обучающей выборки данных, классификатора текста, который получает входной вектор, содержащий результат скрытого слоя и выдает степень связанности с определенной категорией текстов на естественном языке, использованной для получения результата скрытого слоя.
2. Способ по п. 1, отличающийся тем, что автоэнкодер содержит входной слой, скрытый слой и выходной слой;
причем первая размерность входного слоя равна второй размерности выходного слоя и больше третьей размерности скрытого слоя.
3. Способ по п. 1, отличающийся тем, что автоэнкодер содержит скрытый слой, имеющий функцию активации, предоставляемую блоком линейного сглаживания.
4. Способ по п. 1, отличающийся тем, что обучение автоэнкодера дополнительно включает:
определение значения весового параметра автоэнкодера для сведения к минимуму ошибки в результатах, соответствующей разнице между входом и выходом автоэнкодера.
5. Способ по п. 1, отличающийся тем, что обучение автоэнкодера дополнительно включает:
определение значения функции активации автоэнкодера для сведения к минимуму ошибки в результатах, соответствующей разнице между входом и выходом автоэнкодера.
6. Способ по п. 1, отличающийся тем, что обучение автоэнкодера дополнительно включает:
определение размерности скрытого слоя автоэнкодера для сведения к минимуму ошибки в результатах, соответствующей разнице между входом и выходом автоэнкодера.
7. Способ по п. 1, отличающийся тем, что обучение классификатора текста дополнительно включает:
определение набора значений множества параметров классификатора текста для оптимизации функции качества, отражающей число текстов на естественном языке в наборе проверочных данных, которые были правильно классифицированы классификатором текста с использованием этого набора значений.
8. Способ по п. 1, отличающийся тем, что каждый вектор признаков содержит множество значений частоты использования слов - обратной частоты документа (TF-IDF), и каждое значение отражает частотную характеристику слова, определяемого индексом значения в векторе признаков.
9. Способ по п. 1, дополнительно включающий:
получение классифицируемого текста на естественном языке;
обработку текста на естественном языке автоэнкодером;
подачу результата скрытого слоя в классификатор текста; и
определение, с использованием классификатора текста, степени связанности текста на естественном языке с определенной категорией текста.
10. Способ по п. 1, дополнительно включающий:
использование классификатора текста для выполнения задачи обработки естественного языка.
11. Система классификации текстов на естественном языке, включающая:
запоминающее устройство;
процессор, соединенный с запоминающим устройством, при этом процессор выполнен с возможностью:
получения вычислительной системой текста на естественном языке;
обработки текста на естественном языке автоэнкодером, представленным искусственной нейронной сетью;
подачи в классификатор текстов входного вектора, содержащего результат скрытого слоя; и
определения, с использованием классификатора текста, степени связанности текста на естественном языке с определенной категорией текста.
12. Система по п. 11, отличающаяся тем, что первая размерность входного слоя равна второй размерности выходного слоя и больше третьей размерности скрытого слоя.
13. Система по п. 11, дополнительно включающая:
получение вектора признаков, содержащего множество значений частоты использования слов - обратной частоты документа (TF-IDF), таких что каждое значение отражает частоту встречаемости в тексте на естественном языке слова, определяемого индексом значения в векторе признаков; и
получение входного вектора путем объединения выхода скрытого слоя и вектора признаков.
14. Система по п. 11, дополнительно включающая:
создание множества векторов признаков, таких что каждый вектор признаков представляет текст или корпус текстов на естественном языке, где корпус текстов содержит первое множество аннотированных текстов на естественном языке и второе множество неаннотированных текстов на естественном языке;
обучение автоэнкодера с использованием множества векторов признаков.
15. Система по п. 11, дополнительно включающая:
создание множества входных векторов классификатора, таких что каждый входной вектор классификатора включает результат скрытого слоя; и
обучение классификатора текста с использованием множества входных векторов классификатора, таких что каждый входной вектор классификатора связан с известной категорией текстов на естественном языке, использованных для получения результата скрытого слоя.
16. Система по п. 11, дополнительно включающая:
создание множества входных векторов классификатора, таких что каждый входной вектор классификатора включает объединение вектора признаков, представляющего текст на естественном языке, и результат скрытого слоя, полученный при обработке текста на естественном языке; и
обучение классификатора текста с использованием множества входных векторов классификатора, таких что каждый входной вектор классификатора связан с известной категорией текстов на естественном языке, использованных для получения результата скрытого слоя.
17. Система по п. 11, дополнительно включающая:
выполнение, исходя из степени связанности, задачи обработки естественного языка.
18. Постоянный машиночитаемый носитель данных, содержащий исполняемые команды, которые при выполнении заставляют вычислительную систему:
создавать множество векторов признаков, таких что каждый вектор признаков представляет текст или корпус текстов на естественном языке, где корпус текстов содержит первое множество аннотированных текстов на естественном языке и второе множество неаннотированных текстов на естественном языке;
обучать, с использованием множества векторов признаков, автоэнкодер, представленный искусственной нейронной сетью;
создавать, с использованием автоэнкодера, результат скрытого слоя, путем обработки обучающей выборки данных, включающей первое множество аннотированных текстов на естественном языке; и
обучать, с использованием обучающей выборки данных, классификатор текста, который получает входной вектор, содержащий результат скрытого слоя и выдает степень связанности с определенной категорией текстов естественного языка, использованной для получения результата скрытого слоя.
19. Постоянный машиночитаемый носитель данных по п. 18, отличающийся тем, что автоэнкодер содержит входной слой, скрытый слой и выходной слой; и
причем первая размерность входного слоя равна второй размерности выходного слоя и больше третьей размерности скрытого слоя.
20. Постоянный машиночитаемый носитель данных по п. 18, отличающийся тем, что обучение классификатора текста дополнительно включает:
определение набора значений множества параметров классификатора текста для оптимизации функции качества, отражающей число текстов на естественном языке в наборе проверочных данных, которые были правильно классифицированы классификатором текста с использованием этого набора значений.
| СЕНТИМЕНТНЫЙ АНАЛИЗ НА УРОВНЕ АСПЕКТОВ И СОЗДАНИЕ ОТЧЕТОВ С ИСПОЛЬЗОВАНИЕМ МЕТОДОВ МАШИННОГО ОБУЧЕНИЯ | 2016 |
|
RU2635257C1 |
| СПОСОБ ИЗВЛЕЧЕНИЯ ФАКТОВ ИЗ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2016 |
|
RU2637992C1 |
| ПРИКЛАДНОЙ ПРОГРАММНЫЙ ИНТЕРФЕЙС ДЛЯ ИЗВЛЕЧЕНИЯ И ПОИСКА ТЕКСТА | 2005 |
|
RU2412476C2 |
| CN 101566998 A, 28.10.2009 | |||
| CN 106991085 A, 28.07.2017. | |||

