Изобретение относится к средствам интерактивной разметки текстовых данных.
Известна интерактивная система машинного обучения для автоматизированной разметки информации в тексте [US 2005027664 А1, опублик. 03.02.2005], предназначенная для обучения разметке текстовых данных в интерактивном режиме. Система и способ основываются на множестве начальных обучающих данных (частично размеченных или неразмеченных) и множестве примеров данных, представляющих собой результат обучения. Посредством итеративных интерактивных (с участием пользователя) сеансов обучения на размеченных данных система обучает модули разметки, которые, в свою очередь, используются для обнаружения большего количества примеров-кандидатов для разметки. После завершения процедуры разметки всех (или значительного объема) текстовых данных, на усмотрение пользователя возможно обучение итогового модуля (модулей) разметки, который может быть в дальнейшем экспортирован и использован для разметки новых текстовых данных. По мере итеративного процесса обучения для принятия пользователем соответствующих решений, интерфейс системы выборочно предоставляет пользователю экземпляры размеченных данных, обеспечивая возможность проверки размеченных данных и (при необходимости) внесения исправлений.
Недостатком данного изобретения является отсутствие средств статистического языкового моделирования, представляемых, в том числе, посредством языковых моделей глубокого обучения. Отсутствие средств языкового моделирования сказывается на возможности эффективно обрабатывать контекст размечаемых фрагментов текста и ведет к выделению сущностей на основе неполной информации в условиях семантической неоднозначности текста.
Известен сервис для разметки данных на основе замкнутого цикла активного обучения [US 11048979 В1, опублик. 29.06.2023], где описаны методы разметки данных на основе активного обучения. Сервис разметки данных на основе активного обучения позволяет пользователю создавать большие наборы данных высокой точности и управлять ими для использования в различных системах машинного обучения. Схемы на основе машинного обучения могут использоваться для автоматизации разметки и управления наборами данных, повышая эффективность разметки и сокращая сопутствующие временные затраты. В вариантах реализации данных схем используются методы активного обучения для уменьшения размера данных, разметка которых производится вручную. По мере разметки подмножеств исходного набора данных, размеченные данные используются для обучения модели, которая далее способна самостоятельно идентифицировать необходимые объекты в наборе данных. Процесс может продолжаться итеративно до сходимости модели; данная схема обеспечивает разметку данных без необходимости привлечения ручной разметки для каждого объекта.
Недостатком данного изобретения является определение оценки качества размеченных данных в соответствии с заданным порогом, без возможности проверки результатов разметки экспертом, а также помещение результатов автоматической разметки (AUTO LABELING) во множество размеченных данных (LABEL STORE) в отсутствие надежного механизма проверки размеченных данных.
Наиболее близким аналогом является система и методы глубокого обучения для классификации данных с учетом содержания и контекста [US 20200279105 А1, опублик. 09.03.2020], где описана система и методы глубокого обучения для классификации данных по бизнес-категориям и уровню конфиденциальности, с учетом содержания и контекста. Система глубокого обучения включает модуль выделения признаков, модуль классификации и разметки, модуль выделения признаков извлекает из документов контекстные признаки и признаки документа, настройка модуля классификации и разметки предусматривает классификацию документов по содержанию и контексту при помощи нейросетевых моделей с учетом бизнес-категорий и уровня конфиденциальности данных.
Недостатками изобретения являются ограниченное количество уровней (тегов), связанных с уровнем конфиденциальности данных, отсутствие политики распределения ролей и проверки результатов разметки экспертом.
Задачей заявляемого изобретения является создание интерактивного способа разметки данных, обеспечивающего экономию времени на разметку данных, с сохранением возможности проверки результатов разметки.
Техническим результатом изобретения является обеспечение экономии времени на разметку данных за счет автоматического отбора данных для разметки на основе метрик неуверенности с сохранением возможности проверки результатов разметки за счет контроля данных для обучения на каждой итерации.
Технический результат достигается следующим образом.
Способ разметки и верификации текстовых данных реализуется в несколько последовательных этапов, при этом на первом этапе осуществляют предварительное обучение языковой модели глубокого обучения на подготовленном корпусе данных, включающем в себя коллекции текстов широкой тематической направленности, на втором этапе осуществляют разметку релевантных решаемой задаче текстовых данных при помощи программного интерфейса путем выделения фрагментов текста произвольной длины, присвоения размеченным данным различных произвольно определяемых пользователем категорий, которые используют в качестве дополнительной обучающей выборки для языковой модели, на третьем этапе осуществляют предварительную обработку размеченных данных, на четвертом этапе осуществляют обучение языковой модели с учетом вновь размеченных данных и векторизацию размеченных данных, на пятом этапе производят предсказание категорий на множестве неразмеченных данных при помощи модели классификатора, сопряженного с языковой моделью, при этом формируют метрики, отражающие степень неуверенности модели для каждой категории, используют стратегию отбора объектов из выборки, каждому объекту на основе метрик присваивают степень информативности, после чего для экспертной оценки выбирают наиболее информативные объекты, при этом в качестве метрик неуверенности используют максимальную энтропию и минимальную уверенность, а также метрику "дубли категорий", отражающую степень неуверенности при отнесении данных, принадлежащих одной категории к другой категории, при этом расчет данной метрики производят при помощи расчета средней уверенности модели для одного типа категорий по разметке для другого типа категорий, после чего последовательность действий со второго по пятый этапы повторяют до достижения консенсуса между оценкой эксперта и метриками неуверенности по всем предоставляемым для оценки объектам и их предсказанным категориям, при этом выбор момента консенсуса определяет эксперт.
Кроме того, осуществляют произвольное определение категорий, например, «юр. лицо», «реквизиты», «условие», «мера ответственности» и др. со стороны пользователя, при этом состав определяемых категорий устанавливают в зависимости от стилистической принадлежности размечаемого текста и особенностей бизнес-задачи, для решения которой производится разметка данных.
К тому же выделяют фрагменты текста с произвольной глубиной вложенности, т.е. выделяют подсущности в составе сущностей, при этом в рамках данной иерархии в качестве подсущностей выбирают словосочетания, входящие в границы предложения - сущности, а также слова, входящие в границы словосочетания - сущности.
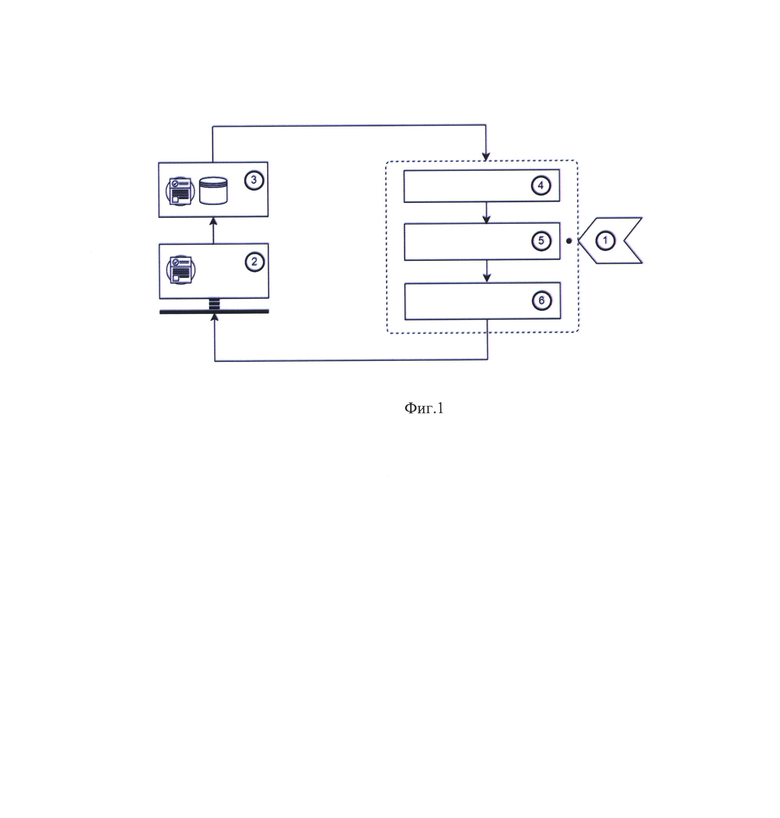
Изобретение поясняется чертежом, где на фигуре 1 представлена структурная схема способа, где 1 - базовый цикл обучения языковой модели (предварительное обучение); 2 - разметка данных пользователем (соответствие "фрагмент текста" - категория"); 3 - добавление размеченных данных в обучающую выборку; 4 - предварительная обработка размеченных данных (токенизация, удаление стоп-слов, лемматизация, приведение к нижнему регистру, сохранение форматирования оригинального фрагмента текста); 5 - цикл обучения языковой модели (с учетом размеченных данных), формирующий векторизованное представление текстовых фрагментов; 6 - модель классификации категорий, формирующая метрики неуверенности для каждой категории.
Заявленный способ реализуют следующим образом в несколько шагов:
Предварительное обучение языковой модели глубокого обучения на основе архитектуры Transformer (реализация RoBERTa) (1).
Разметка данных пользователем (2); в ходе разметки осуществляется выделение пользователем произвольных фрагментов текста, обладающих различной синтаксической организацией (слов, словосочетаний, предложений, абзацев и т.п.) и представляющих интерес с точки зрения поставленной бизнес-задачи.
Добавление размеченных данных в обучающую выборку (3); на данной стадии предусмотрена возможность экспертной оценки размеченных данных; по результатам оценки возможна передача размеченных данных на доработку (повторную разметку).
Предварительная обработка размеченных данных (токенизация, удаление стоп-слов, лемматизация, приведение к нижнему регистру, сохранение форматирования оригинального фрагмента текста) (4).
Векторизация размеченных текстовых фрагментов (фрагментов текста с тегом в виде названия категории) при помощи языковой модели; в ходе дополнительного обучения размеченные данные и контекстное окружение размеченных фрагментов позволяют языковой модели формировать необходимое признаковое описание для решения задачи поиска и предсказания категорий (5)
Предсказание категорий на множестве неразмеченных данных при помощи модели классификатора на основе градиентного бустинга, сопряженного с языковой моделью (6). Для каждой категории формируются метрики, отражающие степень неуверенности модели для каждой категории (в качестве метрик неуверенности используют максимальную энтропию и минимальную уверенность); на основе метрик определяется степень информативности, после чего для экспертной оценки выбираются наиболее информативные объекты. Дополнительно вычисляется метрика "дубли категорий", отражающая степень неуверенности при отнесении данных, принадлежащих одной категории, к другой категории; расчет данной метрики производится при помощи расчета средней уверенности модели для одного типа категорий по разметке для другого типа категорий.
Указанные шаги повторяются до достижения консенсуса между оценкой эксперта и метриками неуверенности по всем предоставляемым для оценки объектам и их категориям; выбор момента консенсуса определяет эксперт.
Промышленное применение заявленного технического решения возможно с использованием известных технических и технологических средств.
В качестве примера приводятся результаты на каждом шаге реализации способа:
(1) - языковая модель глубокого обучения предварительно обучена;
(2) - в случае решения задачи по выделению условий об ответственности в договорной документации, в качестве данных для разметки (на усмотрение пользователя) могут выступать следующие фрагменты текста и правила их совместного расположения в тексте документа:
- "… нести полную ответственность";
- "… общая сумма штрафных санкций...не должна превышать…";
- "… единственной мерой ответственности";
- "… за каждый факт нарушения";
Наличие словосочетания "штраф/неустойку в размере" и отсутствие словосочетания "за каждый/ое/ые/ую" (маркер ограниченной ответственности). Разметка соответствующего текстового фрагмента пользователем может означать определение для данного фрагмента категории «Ограниченная ответственность» или любой другой категории (на усмотрение пользователя).
(3) - в обучающую выборку добавлены размеченные данные;
(4) - размеченные данные прошли процедуру предварительной обработки;
(5) - получено векторное представление (массив числовых векторов) размеченных текстовых фрагментов;
(6) - получено предсказание категорий на множестве неразмеченных данных.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ УПРАВЛЕНИЯ АВТОМАТИЗИРОВАННОЙ СИСТЕМОЙ ПРАВОВЫХ КОНСУЛЬТАЦИЙ | 2019 |
|
RU2718978C1 |
| ВЫДЕЛЕНИЕ ВРЕМЕННЫХ ВЫРАЖЕНИЙ ДЛЯ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2014 |
|
RU2595489C2 |
| Система автоматического определения тематики текстовых документов на основе объяснимых методов искусственного интеллекта | 2023 |
|
RU2823436C1 |
| Автоматическое извлечение именованных сущностей из текста | 2014 |
|
RU2665239C2 |
| Способ атрибутизации частично структурированных текстов для формирования нормативно-справочной информации | 2020 |
|
RU2750852C1 |
| СПОСОБ УПРАВЛЕНИЯ ДИАЛОГОМ И СИСТЕМА ПОНИМАНИЯ ЕСТЕСТВЕННОГО ЯЗЫКА В ПЛАТФОРМЕ ВИРТУАЛЬНЫХ АССИСТЕНТОВ | 2020 |
|
RU2759090C1 |
| СЕГМЕНТАЦИЯ ТЕКСТА | 2017 |
|
RU2666277C1 |
| ОБУЧЕНИЕ КЛАССИФИКАТОРОВ, ИСПОЛЬЗУЕМЫХ ДЛЯ ИЗВЛЕЧЕНИЯ ИНФОРМАЦИИ ИЗ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2018 |
|
RU2691855C1 |
| ОБУЧЕНИЕ КЛАССИФИКАТОРОВ, ИСПОЛЬЗУЕМЫХ ДЛЯ ИЗВЛЕЧЕНИЯ ИНФОРМАЦИИ ИЗ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2018 |
|
RU2681356C1 |
| СПОСОБ ПОЛУЧЕНИЯ НИЗКОРАЗМЕРНЫХ ЧИСЛОВЫХ ПРЕДСТАВЛЕНИЙ ПОСЛЕДОВАТЕЛЬНОСТЕЙ СОБЫТИЙ | 2020 |
|
RU2741742C1 |
Изобретение относится к способу разметки и верификации текстовых данных. Технический результат заключается в возможности более точной разметки текстового документа. В способе на первом этапе осуществляют предварительное обучение языковой модели глубокого обучения на подготовленном корпусе данных, включающем в себя коллекции текстов широкой тематической направленности, на втором этапе осуществляют разметку релевантных решаемой задаче текстовых данных при помощи программного интерфейса путем выделения фрагментов текста произвольной длины, присвоения размеченным данным различных произвольно определяемых пользователем категорий, которые используют в качестве дополнительной обучающей выборки для языковой модели, на третьем этапе осуществляют предварительную обработку размеченных данных, на четвертом этапе осуществляют обучение языковой модели с учетом вновь размеченных данных и векторизацию размеченных данных, на пятом этапе производят предсказание категорий на множестве неразмеченных данных при помощи модели классификатора, сопряженного с языковой моделью, при этом формируют метрики, отражающие степень неуверенности модели для каждой категории, используют стратегию отбора объектов из выборки, каждому объекту на основе метрик присваивают степень информативности, после чего для экспертной оценки выбирают наиболее информативные объекты, при этом в качестве метрик неуверенности используют максимальную энтропию и минимальную уверенность, а также метрику "дубли категорий", отражающую степень неуверенности при отнесении данных, принадлежащих одной категории, к другой категории, при этом расчет данной метрики производят при помощи расчета средней уверенности модели для одного типа категорий по разметке для другого типа категорий, после чего последовательность действий со второго по пятый этапы повторяют до достижения консенсуса между оценкой эксперта и метриками неуверенности по всем предоставляемым для оценки объектам и их предсказанным категориям, при этом выбор момента консенсуса определяет эксперт. 2 з.п. ф-лы, 1 ил.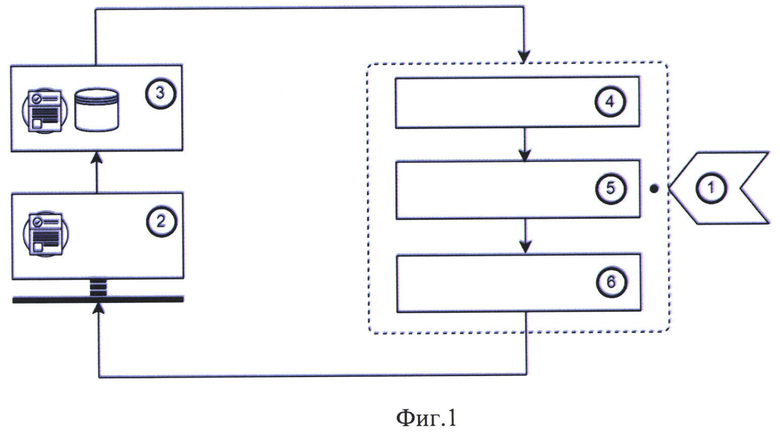
1. Способ разметки и верификации текстовых данных реализуется в несколько последовательных этапов, при этом
на первом этапе осуществляют предварительное обучение языковой модели глубокого обучения на подготовленном корпусе данных, включающем в себя коллекции текстов широкой тематической направленности,
на втором этапе осуществляют разметку релевантных решаемой задаче текстовых данных при помощи программного интерфейса путем выделения фрагментов текста произвольной длины, присвоения размеченным данным различных произвольно определяемых пользователем категорий, которые используют в качестве дополнительной обучающей выборки для языковой модели,
на третьем этапе осуществляют предварительную обработку размеченных данных,
на четвертом этапе осуществляют обучение языковой модели с учетом вновь размеченных данных и векторизацию размеченных данных,
на пятом этапе производят предсказание категорий на множестве неразмеченных данных при помощи модели классификатора, сопряженного с языковой моделью, при этом формируют метрики, отражающие степень неуверенности модели для каждой категории, используют стратегию отбора объектов из выборки, каждому объекту на основе метрик присваивают степень информативности, после чего для экспертной оценки выбирают наиболее информативные объекты, при этом в качестве метрик неуверенности используют максимальную энтропию и минимальную уверенность, а также метрику "дубли категорий", отражающую степень неуверенности при отнесении данных, принадлежащих одной категории к другой категории, при этом расчет данной метрики производят при помощи расчета средней уверенности модели для одного типа категорий по разметке для другого типа категорий,
после чего последовательность действий со второго по пятый этапы повторяют до достижения консенсуса между оценкой эксперта и метриками неуверенности по всем предоставляемым для оценки объектам и их предсказанным категориям, при этом выбор момента консенсуса определяет эксперт.
2. Способ разметки и верификации текстовых данных по п. 1, отличающийся тем, что осуществляют произвольное определение категорий, например «юр. лицо», «реквизиты», «условие», «мера ответственности» и др., со стороны пользователя, при этом состав определяемых категорий устанавливают в зависимости от стилистической принадлежности размечаемого текста и особенностей бизнес-задачи, для решения которой производится разметка данных.
3. Способ разметки и верификации текстовых данных по п. 1, отличающийся тем, что выделяют фрагменты текста с произвольной глубиной вложенности, т.е. выделяют подсущности в составе сущностей, при этом в рамках данной иерархии в качестве подсущностей выбирают словосочетания, входящие в границы предложения-сущности, а также слова, входящие в границы словосочетания-сущности.
| Система автоматического определения тематики текстовых документов на основе объяснимых методов искусственного интеллекта | 2023 |
|
RU2823436C1 |
| ОБУЧЕНИЕ КЛАССИФИКАТОРОВ, ИСПОЛЬЗУЕМЫХ ДЛЯ ИЗВЛЕЧЕНИЯ ИНФОРМАЦИИ ИЗ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2018 |
|
RU2691855C1 |
| АВТОМАТИЧЕСКОЕ ОПРЕДЕЛЕНИЕ НАБОРА КАТЕГОРИЙ ДЛЯ КЛАССИФИКАЦИИ ДОКУМЕНТА | 2018 |
|
RU2701995C2 |
| ИЗВЛЕЧЕНИЕ ИНФОРМАЦИОННЫХ ОБЪЕКТОВ С ИСПОЛЬЗОВАНИЕМ КОМБИНАЦИИ КЛАССИФИКАТОРОВ, АНАЛИЗИРУЮЩИХ ЛОКАЛЬНЫЕ И НЕЛОКАЛЬНЫЕ ПРИЗНАКИ | 2018 |
|
RU2686000C1 |
| ВОССТАНОВЛЕНИЕ ТЕКСТОВЫХ АННОТАЦИЙ, СВЯЗАННЫХ С ИНФОРМАЦИОННЫМИ ОБЪЕКТАМИ | 2017 |
|
RU2665261C1 |
| US 20200279105 A1, 03.09.2020 | |||
| KR 102069621 B1, 23.01.2020 | |||
| US 20210065041 A1, 04.03.2021. | |||

