ОБЛАСТЬ ТЕХНИКИ
[0001] Заявленное техническое решение в общем относится к области проектирования программно-аппаратных решений, а в частности к распределенной системе хранения данных.
УРОВЕНЬ ТЕХНИКИ
[0002] В настоящее время, с развитием информационных технологий, существует потребность в хранении больших объемов данных. Так, например, системы хранения данных широко используются для хранения больших объемов цифровых данных, создаваемых и используемых вычислительными системами, такими как облачные системы и т.д. Такие системы спроектированы с учетом мер защиты от повреждения или потери данных. Обычно данные хранятся в распределенных системах хранения данных. В таких системах файлы данных разбиваются на фрагменты и распределяются по различным узлам (серверам) в сети. Каждый сервер содержит только часть данных, и совместно все серверы создают единое хранилище. Это позволяет эффективно управлять большими объемами, обеспечивает отказоустойчивость и высокую скорость доступа. Кроме того, в таких системах существуют механизмы восстановления данных при повреждении какого-либо узла системы хранения данных. Однако, несмотря на вышесказанное, существующие подходы имеют ряд недостатков, связанных с производительностью и отказоустойчивостью.
[0003] Так, из уровня техники известны подходы, основанные на реализации систем хранения данных (СХД) в виде связки дисковой полки с контроллерами и парой вычислительных узлов. Отказоустойчивость таких СХД обеспечивается, как правило, за счет добавления второй пары вычислительных узлов и дисковой полки, т.е. как за счет дублирования аппаратного уровня, так и за счет вертикального масштабирования, т.е. увеличения производительности каждого вычислительного узла.
[0004] Однако, в таких СХД проблематично реализовать отказоустойчивость домена высокого уровня из-за необходимости дублирования большого количества аппаратных ресурсов, что в свою очередь, существенно снижает удельную производительность системы, повышает количество обращений к памяти при совершении действий, повышает стоимость конечной системы, требует высокой аппаратной интеграции и локализации размещения. Кроме того, СХД используют структуру виртуального диска с блоками данных достаточно крупного размера, например, данные блочного устройства обрабатывают на отдельной кэширующей системе или выделенном сервисе. Это значит, что существует проблема отказоустойчивости и скорости доступа к данным, которая зависит от структуры (однородности) полосы кодирования и ее глубины и упирается в производительность кэширующей системы/сервиса. Может возникнуть ситуация, когда для чтения или записи данных из долгосрочных хранилищ данных (холодные хранилища) одномоментно может быть задействован один член массива системы хранения данных или сервиса, т.е. возникает bottle neck (эффект "бутылочного горлышка") в виде единственного члена массива или высоконагруженного сервиса, работающего с однородными блоками данных.
[0005] Также, из уровня техники известны системы SDS (Software Defined Storage), которые используют структуру виртуального диска с блоками данных, наоборот, слишком маленького размера: объекты или страницы, каждая из которых распределена по кластеру. Распределение информации производится по PG (parity groups, группы размещений, см., например, найдено в Интернет по адресу: https://docs.ceph.com/en/mimic/rados/operations/placement-groups/) и аналогам, вследствие чего внутри таких систем разделен физический и логический уровни реализации. На физическом уровне SDS и аналоги оперируют объектами/страницами, отказоустойчивость хранения реализована на этом уровне. Представление данных на логическом уровне (блочный интерфейс, объектное хранение, и прочие интерфейсы) позволяет не привязываться к физическому уровню.
[0006] Недостатками таких решений является сложность вертикального масштабирования, сложность локализации доступов к данным для отдельного пользователя на уровне узлов хранения, и, соответственно, низкая производительность системы (ввиду проблематичной вертикальной масштабируемости). Например, физическая структура данных от одного пользователя будет максимально фрагментирована по разным PG без учета единой логики блочного устройства для обеспечения отказоустойчивости и, как следствие, пользовательские сценарии способны сильно "нагрузить" вычислительные ресурсы узлов хранения. Для решения проблемы нагрузки в таких системах используют горизонтальное (экстенсивное) масштабирование - увеличение числа вычислительных узлов (числа входящих в кластер вычислительных узлов, емкости кластера) с одновременным уменьшением размеров оперируемых блоков данных для ускорения параллелизации обработки данных. Однако, такое решение создает проблемы с равномерной утилизацией физических дисков в системе, поскольку вычислительных узлов в системе становится много, а нагрузка в облаке чаще всего неравномерная.
[0007] Общими недостатками существующих решений является отсутствие эффективной и высокопроизводительной распределенной системы хранения данных, обеспечивающей высокий уровень отказоустойчивости при сохранении того же уровня (малого количества) вычислительных ресурсов и их эффективного использования, высокую производительность операций ввода/вывода (I/O), и, как следствие, быстрое и эффективное кодирование данных. Также, такого рода решение, должно обеспечивать возможность оптимального хранения данных, горизонтальную масштабируемость, а также укрупненное оперирование на физическом уровне блоками данных без потери производительности. Кроме того, такого рода решение должно обеспечивать возможность локализации обработки подряд идущих блоков данных в горячих и долгосрочных хранилищах данных для локализации и ускорения процедуры кодирования данных.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[0008] В заявленном техническом решении предлагается новый подход к построению архитектуры распределенной программно-определяемой системы хранения данных, который обеспечивает повышение производительности системы и обеспечивает высокий уровень отказоустойчивости системы при сохранении возможности горизонтального масштабирования такой системы.
[0009] Таким образом, решается техническая проблема повышения отказоустойчивости и производительности распределенной системы хранения данных.
[0010] Техническим результатом, достигающимся при решении данной проблемы, является повышение производительности системы хранения данных, за счет повышения скорости чтения/записи данных.
[0011] Еще одним техническим результатом, проявляющимся при решении вышеуказанной проблемы, является повышение отказоустойчивости системы хранения данных.
[0012] Указанные технические результаты достигаются благодаря осуществлению распределенной системы хранения данных, содержащей:
• блочное хранилище, содержащее по меньшей мере одно виртуальное блочное устройство, выполненное с возможностью хранения данных структурами данных заданного размера и осуществления операций ввода/вывода;
• по меньшей мере два узла хранения данных, каждый из которых содержит:
 по меньшей мере один равноправный модуль хранения данных, выполненный с возможностью хранения блоков данных из структур данных по меньшей мере одного блочного устройства в по меньшей мере одном первом и втором хранилищах данных;
по меньшей мере один равноправный модуль хранения данных, выполненный с возможностью хранения блоков данных из структур данных по меньшей мере одного блочного устройства в по меньшей мере одном первом и втором хранилищах данных;
 по меньшей мере одно первое хранилище данных, выполненное с возможностью хранения блоков данных с высоким спросом;
по меньшей мере одно первое хранилище данных, выполненное с возможностью хранения блоков данных с высоким спросом;
 по меньшей мере одно второе хранилище данных, выполненное с возможностью хранения кодированных блоков данных;
по меньшей мере одно второе хранилище данных, выполненное с возможностью хранения кодированных блоков данных;
• модуль метаданных, хранящий карту размещений блоков данных, выполненный с возможностью определения местоположения блоков данных, составляющих по меньшей мере одно блочное устройство;
• модуль распределенных блокировок, выполненный с возможностью назначения режима доступа к блочному хранилищу;
• модуль перемещения данных, выполненный с возможностью кодирования и перемещения данных из по меньшей мере одного первого хранилища данных в по меньшей мере одно второе хранилище данных;
причем, система выполнена с возможностью определения по карте размещений местоположения и размещения модулями хранения данных блоков данных, которые поступают в блочное устройство, записи блоков данных в по меньшей мере одно первое хранилище данных и перемещения указанного блока в по меньшей мере одно второе хранилище данных в соответствии с картой размещений блоков данных на основе заданного события.
[0013] В одном из частных вариантов реализации блоки данных с высоким спросом реплицируются на множестве первых хранилищ данных.
[0014] В другом частном варианте реализации количество реплик блока данных с высоким спросом распределено на по меньшей мере два первых хранилища данных.
[0015] В другом частном варианте реализации кодирование данных выполняют алгоритмом кодирования стиранием.
[0016] В другом частном варианте реализации кодирование данных выполняют в процессе перемещения данных из по меньшей мере одного первого хранилища данных в по меньшей мере одно второе хранилище данных на основе заданного события.
[0017] В другом частном варианте реализации заданное событие представляет собой по меньшей мере одно из следующих событий:
• отсутствие чтения или записи данных в течение заданного времени;
• достижение порогового размера по меньшей мере одного первого хранилища данных;
• последовательное заполнение по меньшей мере одного первого хранилища данных путем формирования полосы кодирования внутри указанного хранилища данных.
[0018] В другом частном варианте реализации множество первых хранилищ данных узла хранения данных представляют собой горячие хранилища данных.
[0019] В другом частном варианте реализации множество вторых хранилищ данных узла хранения данных представляют собой долгосрочные хранилища данных.
[0020] В другом частном варианте реализации взаимодействие блочного устройства с по меньшей мере двумя узлами хранения данных осуществляется с помощью запросов с использованием RPC API.
[0021] В другом частном варианте реализации структура данных представляет собой последовательность блоков данных и/или последовательность блоков данных и блоков исправления ошибок.
[0022] В другом частном варианте реализации модуль перемещения данных дополнительно выполнен с возможностью удаления блока данных из по меньшей одного первого хранилища данных после перемещения указанного блока данных во второе хранилище данных.
[0023] В другом частном варианте реализации модуль метаданных, модуль распределенных блокировок, модуль перемещения данных представляют собой монолитный сервис и/или набор микросервисов.
[0024] В другом частном варианте реализации модуль метаданных дополнительно выполнен с возможностью хранения данных обо всех виртуальных блочных устройствах системы хранения данных.
[0025] В другом частном варианте реализации система дополнительно содержит модуль предоставления прав доступа.
[0026] В другом частном варианте реализации модуль предоставления прав доступа выполнен с возможностью разграничения доступа к блокам данных.
[0027] Кроме того, заявленные технические результаты достигаются за счет способа записи данных в распределенную систему хранения данных, содержащего этапы, на которых:
а) получают блок данных блочным хранилищем;
b) определяют модули хранения данных, связанные с виртуальным блочным устройством, и местоположение блоков данных на них из структуры данных виртуального блочного устройства, для размещения полученного блока данных;
c) определяют по карте размещения блоков данных управляющий модуль хранения данных из набора модулей хранения данных на узле хранения данных;
d) записывают управляющим модулем хранения данных блок данных в по меньшей мере одно первое хранилище данных;
e) выполняют управляющим модулем хранения данных реплицирование полученного блока данных в по меньшей мере одно первое хранилище данных;
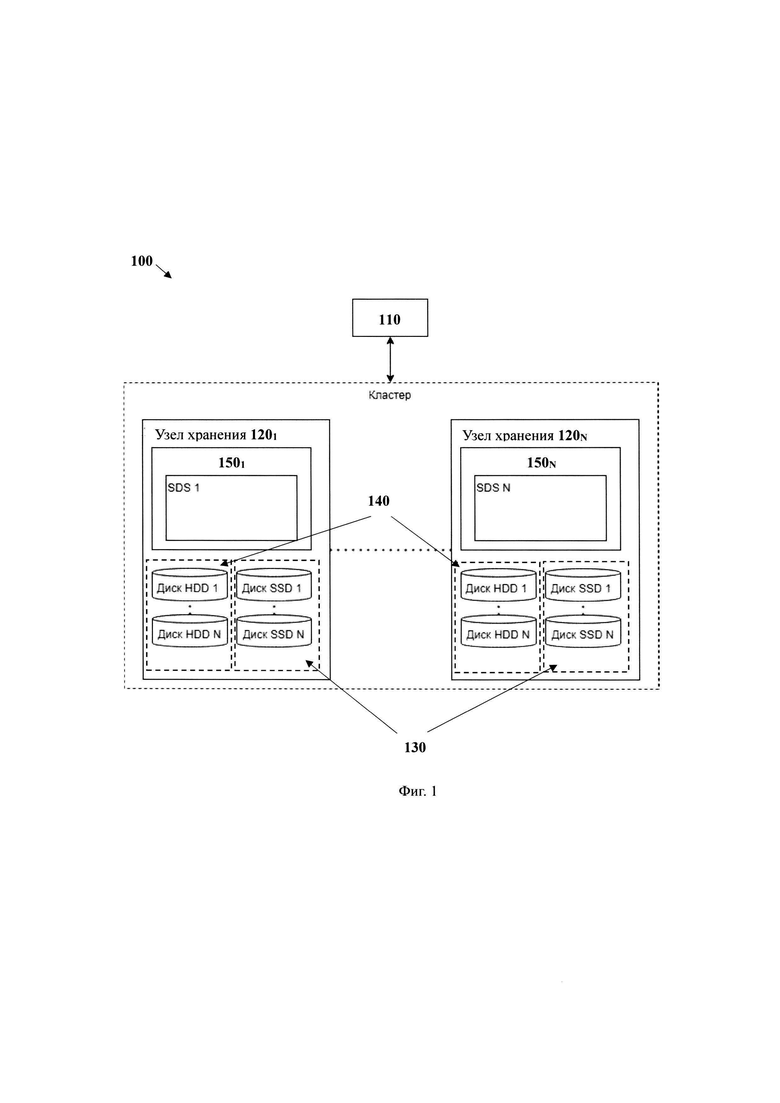
f) перемещают модулем перемещения блок данных из по меньшей мере одного первого хранилища данных в по меньшей мере одно второе хранилище данных, причем в процессе перемещения осуществляют кодирование данных.
g) осуществляют удаление по меньшей мере одного блока данных и реплик указанного блока данных из первых хранилищ, после перемещения указанного блока данных в по меньше мере одно второе хранилище данных.
[0028] В еще одном частном варианте осуществления способа реплицирование полученного блока данных выполняют заданное количество раз.
[0029] В другом частном варианте реализации способа количество реплицируемых блоков данных определяется в соответствии с заданными требованиями отказоустойчивости системы хранения данных.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0030] Признаки и преимущества настоящего изобретения станут очевидными из приводимого ниже подробного описания изобретения и прилагаемых чертежей.
[0031] Фиг. 1 иллюстрирует блок-схему общего вида заявленной системы.
[0032] Фиг. 2 иллюстрирует пример записи блока данных в системе хранения данных.
[0033] Фиг. 3 иллюстрирует блок-схему реализации заявленного способа.
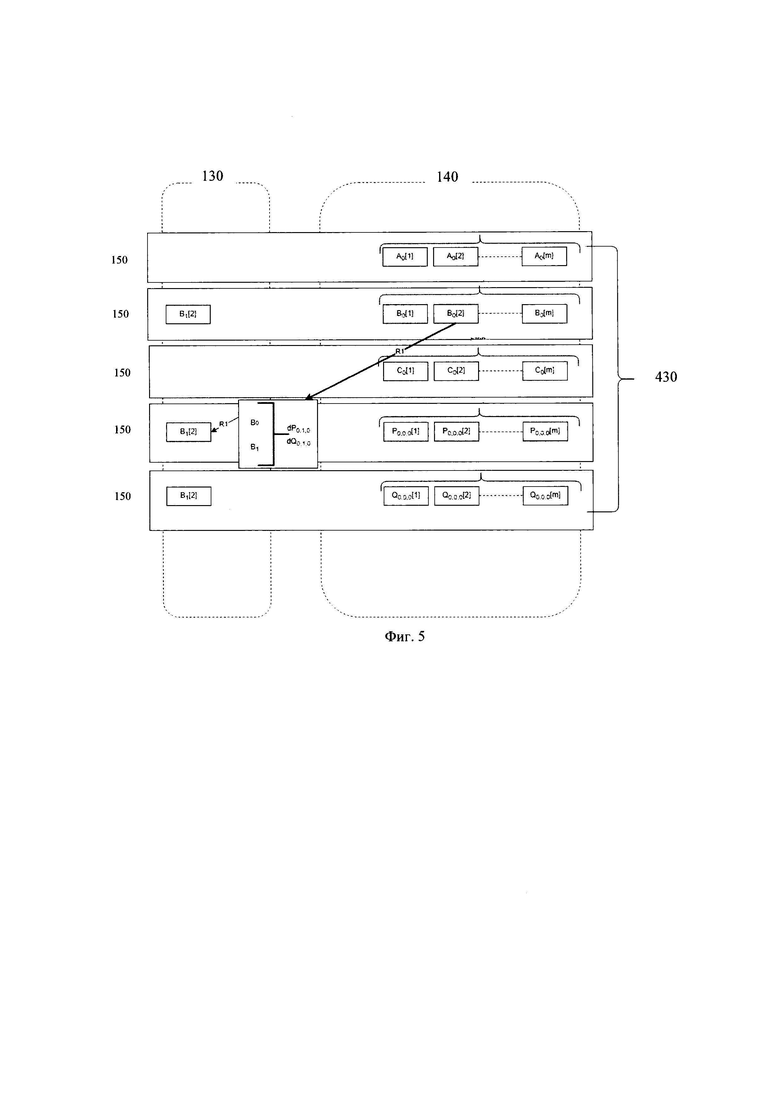
[0034] Фиг. 4 иллюстрирует пример кодирования стиранием при появлении измененного блока данных.
[0035] Фиг. 5 иллюстрирует пример кодирования с использованием дельт при появлении измененного блока данных.
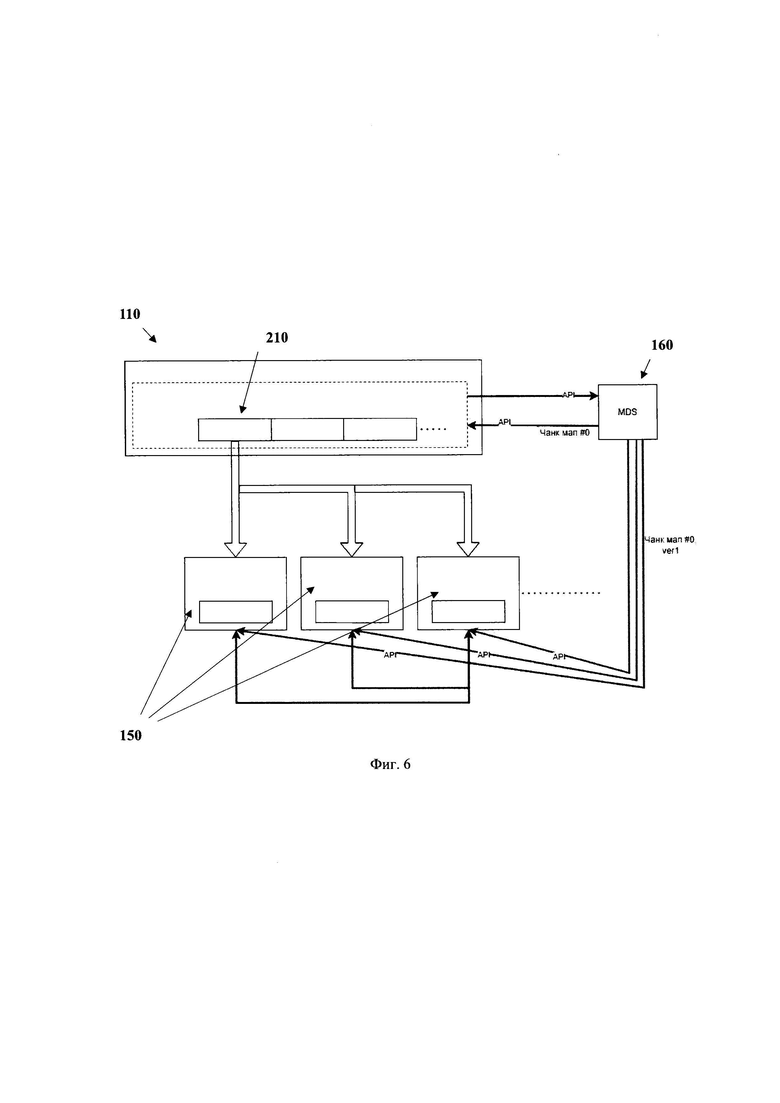
[0036] Фиг. 6 иллюстрирует принцип работы модуля метаданных.
[0037] Фиг. 7 иллюстрирует пример общего вида вычислительного устройства, которое обеспечивает реализацию элементов заявленного решения.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
[0038] Ниже будут описаны понятия и термины, необходимые для понимания данного технического решения.
[0039] Кодирование данных - процесс формирования на основе блоков данных - блоков исправления ошибок (error correction blocks) посредством алгоритма т.н. кодов стирания (кодирование стирания), в общем случае представляющих собой (включая, но не ограничиваясь) коды Рида-Соломона.
[0040] Код стирания (erasure code, кодирование стирания) - это процесс защиты и хранения данных, посредством которого объект данных разделяется на более мелкие компоненты / фрагменты, и каждый из этих фрагментов кодируется с избыточным заполнением данными для обеспечения возможности восстановления исходных данных в случае повреждения какой-либо части закодированных данных. Код стирания преобразует фрагменты объекта данных в более крупные фрагменты и использует первичный идентификатор объекта данных для восстановления каждого фрагмента.
[0041] Блок данных - единица хранения информации на блочном устройстве, но не конечный файл данных. Каждый блок имеет уникальный идентификатор (ID), который включает адрес, определяемый исходя из геометрии диска, для операций чтения/записи. Размер блоков данных определяется файловой системой и блочным устройством.
[0042] Распределенная система хранения данных (Distributed Storage) - это комплекс аппаратных и программных структур, в котором файлы разбиваются на фрагменты (состоящие из блоков) и распределяются по различным узлам (серверам), физически разнесенным в сети связи. Каждый сервер содержит только часть данных, и совместно все серверы создают единое хранилище. Это позволяет эффективно управлять большими объемами, обеспечивает отказоустойчивость и высокую скорость доступа. В одном частном варианте осуществления, распределенная система хранения данных может представлять программно-определяемую систему хранения данных (SDS), обеспечивающую распределение данных по нескольким узлам и управление хранилищем через программное обеспечение.
[0043] Тиринг данных (tiering data) - это технология многоуровневого хранения данных, с помощью которой система хранения данных может самостоятельно перераспределять данные по накопителям на основе частоты их использования и значимости.
[0044] Заявленное техническое решение предлагает новый подход в создании распределенных систем хранения данных, обеспечивающий повышение производительности и отказоустойчивости системы за счет архитектурных особенностей указанного решения. Так, заявленное решение обеспечивает эффективное распределение данных по всему кластеру, требует меньше вычислительных ресурсов и узлов для обеспечения отказоустойчивости и не привязано к конкретному типу оборудования. Кроме того, такое решение обеспечивает возможность горизонтального и вертикального масштабирования. Кроме того, ввиду того, что архитектурно сервисы (программное обеспечение) логически не отвязаны от физического уровня хранения данных (оперируют структурами данных и составляющими их блоками) и сервисы являются равными и взаимозаменяемыми между собой в использовании, обеспечивается возможность автоматизации контроля за состоянием кластера и динамично использовать сервера кластера для балансировки и подачи нагрузки на новые инстансы сервисов без участия человека. Также, еще одним преимуществом заявленной системы является возможность использования блоков крупного размера, что, соответственно, повышает эффективность кодирования данных.
[0045] Техническое решение также может быть реализовано в виде распределенной компьютерной системы или вычислительного устройства.
[0046] В данном решении под системой подразумевается компьютерная система, ЭВМ (электронно-вычислительная машина), ЧПУ (числовое программное управление), ПЛК (программируемый логический контроллер), компьютеризированные системы управления и любые другие устройства, способные выполнять заданную, четко определенную последовательность вычислительных операций (действий, инструкций).
[0047] Под устройством обработки команд подразумевается электронный блок либо интегральная схема (микропроцессор), исполняющая машинные инструкции (программы).
[0048] Устройство обработки команд считывает и выполняет машинные инструкции (программы) с одного или более устройства хранения данных, например, таких устройств, как оперативно запоминающие устройства (ОЗУ) и/или постоянные запоминающие устройства (ПЗУ). В качестве ПЗУ могут выступать, но, не ограничиваясь, жесткие диски (HDD), флэш-память, твердотельные накопители (SSD), оптические носители данных (CD, DVD, BD, MD и т.п.) и др.
[0049] Термин «инструкции», используемый в этой заявке, может относиться, в общем, к программным инструкциям или программным командам, которые написаны на заданном языке программирования для осуществления конкретной функции, такой как, например, кодирование данных, обращение к памяти узла хранения данных и т.п. Инструкции могут быть осуществлены множеством способов, включающих в себя, например, объектно-ориентированные методы. Например, инструкции могут быть реализованы, посредством языка программирования Python, С, С++, Java, Go, Rust различных библиотек (например, MFC; Microsoft Foundation Classes) и т.д. Инструкции, осуществляющие процессы, описанные в этом решении, могут передаваться как по проводным, так и по беспроводным каналам передачи данных, например, Wi-Fi, Bluetooth, USB, WLAN, LAN и т.п.
[0050] На фиг. 1 приведен общий вид распределенной системы хранения данных 100. Система 100 включает в себя основные функциональные элементы, такие как: блочное хранилище 110, состоящее из по меньшей мере одного блочного устройства 210, которое отображено на фиг. 2, множество узлов хранения данных 1201-120N, множество первых хранилищ данных 130, множество вторых хранилищ данных 140, по меньшей мере два равноправных модуля хранения данных 150, размещенных на разных узлах хранения данных соответственно, по меньшей мере одного модуля метаданных 160, показанного на фиг. 2, по меньшей мере одного модуля распределенных блокировок, по меньшей мере одного модуля перемещения данных.
[0051] Система 100 может представлять или являться системой хранения данных, содержащей по меньшей мере два узла хранения данных, таких как узлы 1201-120N, связанных между собой посредством сети связи, и обеспечивающей масштабируемое, отказоустойчивое и высокопроизводительное хранение данных за счет распределенной архитектуры, которая позволяет объединять несколько узлов (серверов) в кластер для обработки и хранения данных. Так, в одном частном варианте реализации, указанная система 100 может представлять собой аппаратно-программный комплекс, содержащий физический и логический слои для обеспечения высокой производительности системы и быстроты доступа к данным. Так, система 100 может обеспечивать создание сети хранения данных на неспециализированном оборудовании массового класса, как правило, группе серверных узлов под управлением операционных систем общего назначения. Управление инфраструктурой хранения может осуществляться посредством виртуализации функции хранения, отделяющей аппаратное обеспечение от программного. Кроме того, система 100 может представлять собой систему хранения данных (СХД) на базе комплекса аппаратных и программных средств, который предназначен для хранения и оперативной обработки данных. В качестве носителей данных используются жесткие диски, в основном SSD (системы All Flash Array), а также гибридные решения, сочетающие SSD- и HDD-накопители в одной СХД.
[0052] В еще одном частном варианте осуществления, размещение данных на системе 100 на физическом уровне выполняется с помощью разделения данных на т.н. горячее и холодное (долгосрочное хранение) хранилище (hot, cold), в зависимости от потребности в оперативном доступе к ним (tiering-a). Для данных с высоким спросом чтения-записи (hot-слой) предопределено высокоскоростное хранилище данных на базе дисков SSD. Для данных с низким спросом чтения-записи (cold-слой) может быть предопределено долгосрочное хранилище на базе дисков HDD и/или гибридное хранилище данных.
[0053] Система 100 может быть использована в качестве платформы облачных вычислений, обеспечивающей возможность использования удаленных серверов с получением высокой доступности и масштабируемости; системой хранения данных для массовых средств электронного обмена сообщениями (социальные сети, мессенджеры и т.д.) системой хранения данных для интернета вещей (IoT) и т.д.
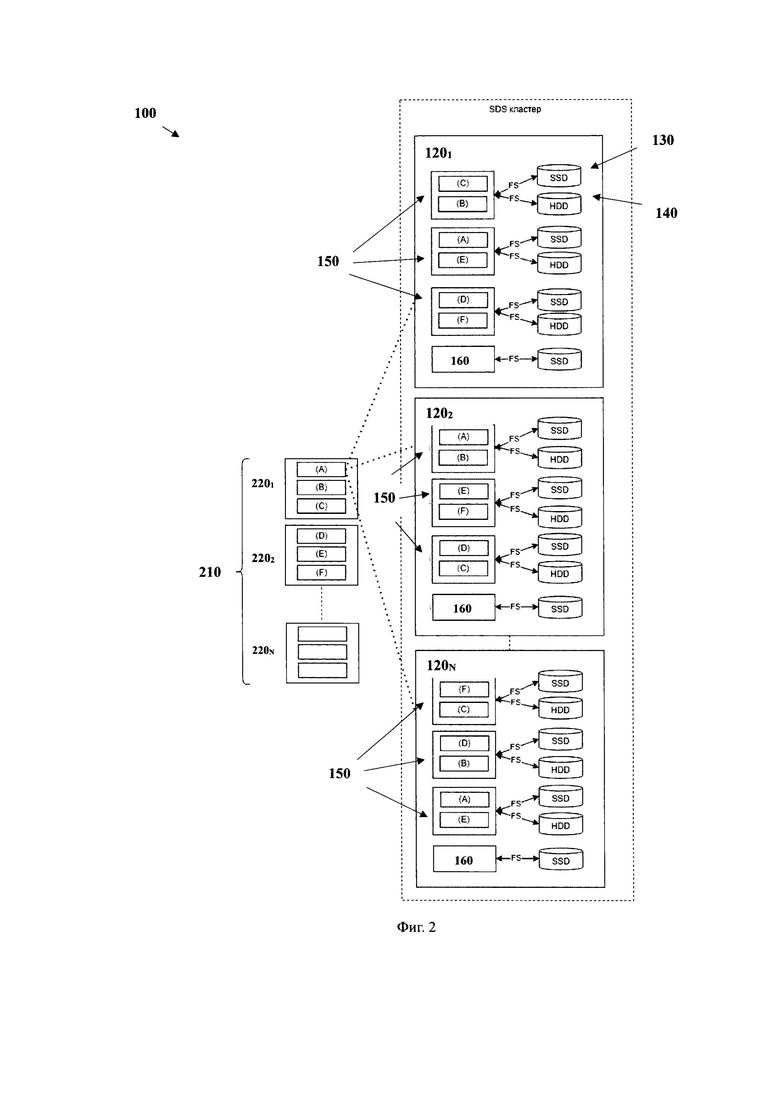
[0054] Блочное хранилище 110 может представлять собой единую точку входа для пользователей/протоколов для взаимодействия с системой 100. Так, в одном частном варианте осуществления блочное хранилище 110 может являться экземпляром библиотеки, которая транслирует запросы с использованием RPC API к модулю метаданных 160, расположенному, например, на узле хранения данных 120 и хранилищам данных (130 и 140), размещенным на множестве узлов 1201, 120N. Блочное хранилище 110 представляет собой по меньшей мере одно виртуальное блочное устройство 210, показанное на фиг. 2, выполненное с возможностью хранения данных структурами данных (2201, 2202, 220N) заданного размера и осуществления операций ввода/вывода. Другими словами, блочное хранилище 110 имитирует виртуальное блочное устройство для пользователя и осуществляет обращения (например, запись) в указанное по меньшей мере одно блочное устройство 210. Т.е. фактически, виртуальное блочное устройство 210 располагается в кластере, а блочное хранилище 110 - способ доступа к указанным блочным устройствам 210. Структура данных представляет собой последовательность блоков данных заданного размера. Соответственно, блочное хранилище 110 может содержать в себе множество блочных устройств 210, каждое из которых состоит из структур данных. Так, в одном частном варианте осуществления, блочное хранилище 110 состоит из множества блочных устройств, размером, например, 1 ГБ и т.д. Более наглядно, структура блочного устройства 210 показана на фиг. 2. Соответственно, блочное устройство 210 содержит структуры данных из блоков данных, к которым пользователь осуществляет обращения, например, операции ввода/вывода. Стоит отметить, что такая структура позволяет локализовать обработку подряд идущих блоков данных за счет совершения операций над ними в рамках хранилищ данных, связанных с определенными блочными устройствами, что, также, повышает скорость обработки данных системой 100. Блочное устройство 210, в свою очередь, может представлять собой виртуальный диск, представляющий собой логический слой хранения данных, размещенных на узлах 1201, 120N.
[0055] Также, стоит отметить, что использование такой архитектуры хранилища 110, обеспечивает возможность взаимодействия с крупными структурами данных, например, 1ГБ, что позволяет модулям хранения данных 150 узлов хранения данных 1201, 120N определять характер IO нагрузки пользователя и проводить эффективное кодирование, например, кодирование стиранием (ЕС). Кроме того, еще одним преимуществом является возможность отслеживать историю доступа к данным, кэшировать или предсказывать доступы и более эффективно выполнять дедупликацию данных.
[0056] Соответственно, блочные устройства 210 предназначены для обработки I/O и представляют собой логический слой хранения данных, которые расположены в хранилищах данных (130 и 140), управляемых модулями 150, узлов хранения данных 1201, 120N. Так, блоки данных блочного устройства 210, физически размещены модулем метаданных 160 (метадата-сервер (сервис), MDS) на разных узлах для повышения отказоустойчивости в случае отказа. Т.е. каждое блочное устройство 210 хранит структуру данных (2201, 2202, 220N). В свою очередь, структура данных представляет собой последовательные блоки данных и/или блоки данных и блоки исправления ошибок. Каждый модуль хранения 150 и/или группа таких модулей, обслуживающих одну структуру данных, хранят определенное количество последовательных логических блоков блочного устройства 210. При обращении к блокам данных блочного устройства, модули 150 предоставляют доступ на уровне блоков, что позволяет читать отдельные блоки с определенных модулей 150.
[0057] В одном частном варианте осуществления, устройство 210 может содержать интерфейс ввода/вывода, например, GUI и т.д., для получения запроса на изменение блока данных. В еще одном частном варианте осуществления, запрос на изменение блока данных может быть получен автоматически, например, посредством протоколов межмашинного взаимодействия.
[0058] В еще одном частном варианте осуществления, система 100 может дополнительно содержать модуль мониторинга статистики утилизации хранилища и производительности системы, а также состояния дисков, хостов и прочих аппаратных компонентов.
[0059] Множество узлов хранения данных 1201, 120N могут представлять собой сервера, каждый из которых содержит операционную систему и хранилища данных, такие как хранилища 130 и 140. Далее в настоящих материалах заявки, множество узлов хранения данных 1201-120N могут упоминаться как узлы хранения данных 120.
[0060] Как упоминалось выше, каждый узел 120 может представлять собой физический сервер, с программно-определяемой системой хранения данных (Software Defined Storage), представляющей собой набор микросервисов с разным ролевым участием, посредством которой образуется распределенный кластер. Т.е. множество узлов 120 образуют кластер данных, объединенный с помощью нескольких сетей, логических или физических, через коммутаторы - внутреннюю высокоскоростную сеть (Internal) для обслуживания трафика репликации/синхронизации/кодирования данных и пользовательскую сеть (Public) для пользовательского трафика. Стоит отметить, что пропускная способность Internal сети выше пропускной сети Public для обслуживания дополнительного служебного трафика.
[0061] Далее рассмотрим структуру каждого из множества узлов 120, из которых формируется по меньшей мере один кластер данных. Каждый узел 120 содержит в себе модуль 150 и/или множество модулей 150, которые хранят определенное количество последовательных логических блоков блочного устройства 210. При этом, модули 150 являются равноправными, что, соответственно, позволяет динамически задавать управляющий модуль, в зависимости от текущей нагрузки на узел или текущего состояния доступного модуля. Так, узел 120 выполнен с возможностью размещения данных на физическом уровне, посредством модулей 150, на разных уровнях хранилищ данных (первое хранилище данных 130 и второе хранилище данных 140). Так, в одном частном варианте осуществления разделение данных осуществляется на два уровня хранилищ данных (hot, cold), в зависимости от потребности в оперативном доступе к данным (tiering-а). Данные с высоким спросом чтения-записи содержатся в первом хранилище данных 130, которое может представлять краткосрочное или горячее хранилище данных (hot storage). Горячее хранилище данных обеспечивает высокоскоростной доступ к данным на базе дисков SSD. Для хранения данных с низким спросом чтения-записи применяется второе хранилище данных 140, такое как долгосрочное хранилище данных (cold storage) на базе дисков HDD или комбинации SSD и HDD, или только SSD для ультра высокой производительности (вариант хранилища - All Flash Array).
[0062] Скорость доступа к данным и отказоустойчивость данных в первых хранилищах 130 (горячее хранилище данных) обеспечивается за счет использования репликации, дающей большую скорость доступа и минимальную задержку, в сравнении с закодированными данными, однако, по мере падения спроса к данным на чтение-запись, данные могут проходить процедуру перемещения и кодирования во второе хранилище 140 (долгосрочное хранилище данных).
[0063] Хранение данных осуществляется посредством распределения поступающих на блочное хранилище 110 блоков данных по блочным устройствам 110, в которых блоки данных хранятся структурами данных, физически размещаемыми по карте размещения блоков данных на разных узлах 120 для повышения отказоустойчивости в случае отказа. Так, в одном частном варианте осуществления блочное хранилище является представлением единой структуры, которая посредством взаимодействия, например, посредством протоколов связи, с распределенной системой хранения 100, распределяется по указанной системе 100. В свою очередь, каждая структура данных состоит из полос кодирования (stripes), где одна полоса кодирования, например, состоит из трех блоков с данными и двух блоков исправления ошибок (erasure codes) и записывается обычно как схема кодирования 3+2. Для специалиста будет очевидно, что полоса кодирования может содержать иное количество блоков, определяемое в зависимости от применяемой схемы кодирования данных. Так, например, при использовании больших схем кодирования данных, полоса кодирования может содержать, например, двадцать блоков данных + два блока исправления ошибок и обозначаться как 20+2. Блоки исправления ошибок могут быть определены, например, по алгоритму Рида-Соломона на управляющем модуле, таком как один из модулей 150, а затем распределять полосу кодирования по разным вторым хранилищам 140 в соответствии со схемой отказоустойчивости.
[0064] В одном частном варианте осуществления, структура данных, расположенная на блочном устройстве 210, распределяется по множеству узлов 120, связанных с полосой кодирования указанной структуры данных. Указанное действие определяется посредством модуля метаданных 160 (MDS) при создании такой структуры данных. Модуль 160 отказоустойчиво хранит и обеспечивает консистентность метаданных между другими модулями 160. Внутри модуля 160 хранятся данные о конкретных хранилищах данных на каждом узле, метаданные (структура данных) и реализован механизм распределенных блокировок, работающий по таймауту, для назначения прав доступа на виртуальные диски (устройства 210).
[0065] Так, при запросе пользователем данных с виртуального блочного устройства 210 в режиме чтения данных, происходит процесс последовательного запроса месторасположения структуры данных, составляющих конкретное блочное устройство 210, в модуль метаданных 160, который предоставляет системе 100 карты размещений блоков данных из структуры данных, составляющих конкретное блочное устройство 210. В свою очередь, модуль 160 предоставляет по меньшей мере один модуль 150 или набор модулей 150, хранящих блоки данных из указанной структуры данных. Соответственно, при осуществлении записи данных выполняется кодирование данных (определение кода стирания) и распределение блоков данных по хранилищам данных.
[0066] По меньшей мере один модуль хранения данных 150 может представлять собой сервер с программными функциями, монолитный сервис, программно-аппаратный модуль и т.д. Так, указанный по меньшей мере один модуль может представлять собой сервис и/или набор микросервисов на физическом сервере по исполнению. Стоит отметить, что в данной заявке термин модуль и сервис могут использоваться взаимозаменяемо. Так, в одном частном варианте осуществления на каждом узле 120 может быть размещено множество равноправных модулей 150. Модуль 150 предназначен для управления поступающими на блочное устройство 210 блоками данных и их распределения по хранилищам данных узла 120. Так, в еще одном частном варианте осуществления модуль хранения 150 представляет собой сервер в составе узла хранения данных. В еще одном частном варианте осуществления, модуль 150 может представлять собой монолитный программный сервис или набор микросервисов, размещаемый в узле хранения данных 120.
[0067] Как указывалось выше, модуль хранения 150 выполнен с возможностью хранения структур данных 220 устройств 210 в хранилищах данных 130,140, обработки I/O от пользователя, управлением репликации блоков данных. Более подробно, структура блочного хранилища 110 состоит из блочных устройств 210 со структурами данных (chunks) 2201, 2202, 220N, состоящими из блоков данных, физически размещаемых модулем 160 на разных узлах хранения данных 120 для повышения отказоустойчивости в случае отказа.
[0068] Структура данных представляет собой последовательные блоки данных и/или последовательные блоки данных и блоки исправления ошибок. Каждый модуль хранения 150 и группа таких модулей обслуживают одну структуру данных, хранят определенное количество последовательных логических блоков блочного устройства 210, предоставляют доступ на уровне блоков, что позволяет читать отдельные блоки.
[0069] Модули хранения 150 не имеют информации о всей системе 100 в целом или о блочном хранилище 110. Определенные модули хранения 150 связаны только с конкретной (ограниченной) структурой данных, что делает все модули хранения 150 равными и взаимозаменяемыми. Т.е. каждый модуль хранения 150 и/или набор конкретных модулей хранения 150, связаны только с определенной структурой данной, размещенной в блочном устройстве 210. Соответственно, в одном узле хранения данных 120 может содержаться множество модулей хранения 150, каждый из которых может быть связан с определенным блочным устройством 210. Такой подход обеспечивает возможность повышения скорости чтения или записи данных за счет исключения «узких мест» в системе.
[0070] Также, распределение блоков по модулям хранения данных 150 описанным выше образом, позволяет модулю метаданных 160 выполнять балансировку и восстановление, заменяя неработающие модули 150 любыми другими, исходя из их загрузки, объема памяти, состояния оборудования и других параметров.
[0071] Также, еще одним преимуществом является возможность более быстрого добавления новых модулей хранения 150, по сравнению с известными SDS системами типа Ceph. Т.е. достаточно просто запустить новый модуль хранения 150, и модуль метаданных 160 начинает направлять на него нагрузку. Исключается необходимость вручную создавать или расширять группы размещения, пулы и прочие ручные операции. Кластер самостоятельно определяет свое состояние, количество работающих модулей хранения 150 и самостоятельно балансирует нагрузку, направляя ее на новые экземпляры модулей без участия человека.
[0072] При этом, в одном частном варианте осуществления, управляющий модуль хранения 150 из множества модулей 150, выбирается модулем 160 в соответствии с картой размещений. Т.е. при взаимодействии с блоком данных в узле 120, посредством модуля 160 гибко выбирается модуль, осуществляющий управление блоком. Таким образом, также повышается надежность системы 100.
[0073] Модуль метаданных 160 запрашивает динамическое состояние от хранилищ данных 130 и 140 в каждом узле хранения данных 120, виртуальных устройствах 210, управляющих модулях хранения 150, механизмах блокировок в модуле распределенных блокировок. Так, модуль 160 выполнен с возможностью сбора (опроса) у каждого модуля хранения данных 150 информации о фактическом свободном месте на каждом подконтрольном такому модулю 150 хранилище данных 130 и 140, т.к. каждый модуль хранения данных имеет динамическое состояние, т.е. наличие свободного места изменяется со временем. По меньшей мере один модуль метаданных 160 может представлять собой сервер с программными функциями, монолитный сервис, программно-аппаратный модуль и т.д. Так, указанный по меньшей мере один модуль метаданных 160 может представлять собой сервис и/или набор микросервисов на физическом сервере по исполнению. Стоит отметить, что в данной заявке термин модуль и сервис могут использоваться взаимозаменяемо. В одном частном варианте осуществления, модуль 160 представляет собой реплицируемую машину состояний (replicared state machine). Стоит отметить, что хотя описывается один модуль 160, система 100 может содержать множество взаимосвязанных модулей 160, например, на каждом узле 120. Взаимодействие между модулями 160 может происходить по алгоритму консенсуса в распределенной системе, например, RAFT, который обеспечивает консистентность метаданных между ними. Все изменения метаданных хранятся в персистентном слое хранения PebbleDB, основанном на LSM дереве (log structured merge tree). В еще одном частном варианте осуществления, взаимодействие с модулем 160 метаданных происходит посредством API. При изменении данных в системе 100, указанные изменения, например, через RAFT, распределяются на резервные модули 160, после успешной репликации, изменения применяются к реплицируемой машине состояния. В еще одном частном варианте осуществления сервер метаданных содержит несколько реплицируемых машин состояний - например данные о физических узлах (состояние, конфигурация и т.д.), количество модулей 160 метаданных в кластере, количество управляющих сервисов 150 и их состояние и т.д.
[0074] В одном частном варианте осуществления, модуль распределенных блокировок, может являться частью модуля 160 и/или быть взаимосвязанным с ним, например, посредством сети связи. Так, в еще одном частном варианте осуществления, модуль распределенных блокировок может представлять собой сервер с программным обеспечением для обеспечения возможности назначения режима доступа к блочному хранилищу 110. Указанный модуль предназначен для предоставления прав доступа на запись/чтение определенных блоков данных определенным модулям 150 в заданные моменты времени. Так, может возникнуть ситуация, когда два модуля 150 будут обрабатывать операцию с блоками данных из одного блочного устройства 210, или же, например, возможна попытка нелегитимно предоставить одно устройство 210 нескольким клиентам. Соответственно такая ситуация может привести к потере данных и ошибкам в кодировании данных (ввиду неактуальных версий блоков данных). Для решения указанной проблемы система 100 содержит модуль распределенных блокировок, обеспечивающий выдачу прав на совершение операции (запись данных) с блоком данных в заданные хранилища данных.
[0075] Возвращаясь к модулю 160, при запросе пользователем данных с виртуального диска (устройства 210), расположенного на хранилище 110 в режиме чтения данных, происходит процесс запроса актуальной чанк мапы (chunk maps) - карты размещений блоков данных, составляющих виртуальный диск - у модуля 160, с последующим последовательным запросом структур данных, таких как структуры 2201, 2202, 220N и их блоков данных, составляющих блочное устройство 210 из соответствующих модулей хранения 150.
[0076] Так, на фиг. 6 раскрывается более подробно принцип работы системы 100 посредством применения карты размещений блоков данных. Пользователь, при обращении к блочному хранилищу 110, взаимодействует с виртуальным диском в одном из блочных устройств 210. Для совершения действий (чтения блоков) система 100 должна определить список блоков данных, составляющих указанный диск. Стоит отметить, что виртуальный диск (блочное устройство 210) представляет собой набор последовательных структур данных 220, хранящихся в системе 100, и в хранилище 110 может быть расположено множество виртуальных дисков, т.е. блочных устройств 210 представляющих ту или иную часть данных, например, размером по 1 ГБ и т.д. Так, в представленном примере, структура данных, содержится в устройстве 210. Для взаимодействия с указанной структурой, система 100 запрашивает у модуля метаданных 160 посредством API карту размещений того или иного блока данных (в нашем случае блоков данных, составляющих структуру (наборы) данных), принадлежащего диску устройства 210. Так, модуль метаданных 160 опрашивает каждое хранилище данных, расположенное на одном из узлов 120, содержащее указанный блок данных и возвращает указанные блоки пользователю на последующее проведение IO-операций по актуальной карте размещений. После чего возможно проведение операций ввода-вывода (IO). Механизм распределенных блокировок может быть также реализован модулем метаданных 160. Так, указанный модуль 160 открывает и удерживает блокировку для запрашивающего хранилища 110 и выдает ему карту размещения блоков (чанк мапу). Если же блокировку уже удерживает какой-то другой экземпляр хранилища 110, то запрашивающий модуль карту не получит, соответственно не сможет продолжить никакие операции, хранилище 110 самостоятельно читает или пишет данные на модули 150 согласно карте размещения блоков.
[0077] Стоит отметить, что карта размещения блоков генерируется на этапе создания блочных устройств 210. Так, при создании блочного устройства 210, модуль метаданных 160 распределяет структуры данных 220 указанного блочного устройства 210 по модулям 150 в соответствии со схемой репликации и кодирования. Таким образом, для каждой структуры данных имеются модули 150, связанные с указанной структурой, при этом, модули 150 могут быть связаны с несколькими структурами. Так, на фиг. 4 представлен пример кодирования данных, который раскрывается более подробно ниже. На указанной фиг. 4, в частности, отображена структура узла хранения данных, где отражены модули 150. Соответственно, карта размещения блоков данных содержит информацию (метаданные) о всех модулях 150, их местоположении, и о том, какую часть структур данных 220 каждый модуль 150 обслуживает. Исходя из указанных данных, в карте размещений также может быть задан управляющий модуль 150 для каждой структуры данных. Все операции с блоками данных в системе 100 осуществляются исходя из указанной карты.
[0078] Модуль перемещения данных может представлять собой сервер с программными функциями, монолитный сервис, программно-аппаратный модуль и т.д. Так, указанный по меньшей мере один модуль может представлять собой сервис и/или набор микросервисов на физическом сервере по исполнению. Стоит отметить, что в данной заявке термин модуль и сервис могут использоваться взаимозаменяемо. В еще одном частном варианте осуществления модуль перемещения данных может являться частью модуля хранения данных 150.
[0079] Модуль перемещения данных выполнен с возможностью перемещения по меньшей мере одного блока данных из первого хранилища данных 130 во второе хранилище данных 140, и осуществления кодирования блока данных в процессе перемещения. Так, в ходе кодирования могут выполняться следующие этапы: чтение блока данных, записанного в первое хранилище данных 130 узла хранения данных 120; определение местоположения всех блоков данных из структуры данных, такой как структуры 220 к которой принадлежит блок данных из первого хранилища данных 130, чтение всех блоков данных, вычисление блоков исправления ошибок на основе указанных блоков данных.
[0080] Так, в одном частном варианте осуществления, при достижении определенного порогового события, система 100 осуществляет процесс кодирования и перемещения данных из первого хранилища данных 130 во второе хранилище данных 140. Так, событиями могут являться по меньшей мере следующие события: достижение порогового значения времени без перезаписи данных, достижение порогового значения времени без чтения данных, заполненность журнала событий, достижение порогового размера изменяемых данных, изменение состояния определенной последовательности блоков данных и блоков исправления ошибок и т.д. Очевидно, инициация переноса данных между хранилищами может выполняться в отложенном режиме в соответствии с наступлением определенного порогового события. Указанная особенность дополнительно обеспечивает повышение производительности системы 100.
[0081] Поскольку данные, в долгосрочном хранилище 140, хранятся вместе с блоками исправления ошибок для обеспечения отказоустойчивости системы 100 и более оптимального использования места под хранение по сравнению с хранением копиями реплик данных в первых хранилищах данных 130, то для перемещения блока данных в такое хранилище 140 требуется перекодировать всю полосу кодирования, т.е. заново определить блоки исправления ошибок для всей структуры данных, в которой появился измененный блок данных. Более подробно примеры кодирования данных раскрыты на фиг. 4 и фиг. 5.
[0082] На фиг. 2 представлен пример записи блока данных в системе хранения данных.
[0083] При обращении пользователя к системе 100, для выполнения операции с данными (I\O), пользователь обращается, посредством интерфейса взаимодействия к хранилищу 110. Как указывалось, выше, хранилище 110 содержит множество виртуальных дисков 210. Т.е. пользователь осуществляет обращение к хранилищу, как единой точке входа, и, соответственно, хранилище 110 на основе метаданных блока данных распределяет указанный блок к конкретному виртуальному диску для осуществления операции с блоком данных. После этого, происходит процесс последовательного запроса структуры данных, составляющей блочное устройство 210, в модуль 160 метаданных, который сверяет механизмы блокировок, например, посредством модуля распределенных блокировок, и выдает карту размещений блоков данных, составляющих виртуальный диск. Так, после определения месторасположения блоков данных и управляющего модуля 150 согласно полученной карте размещений, хранилище 110 выполняет требуемые операции ввода-вывода взаимодействуя напрямую с модулями хранения 150 из набора модулей 150 на узлах хранения данных 120, которые, соответственно, связаны с блочным устройством 210 к которому происходит обращение. Для обеспечения отказоустойчивости данных, а также обеспечения тиринга данных, запись данных происходит на управляющий модуль хранения 150, а сами данные воспринимаются как горячие и сохраняются в репликах, то есть располагаются в hot-storage. Это позволяет системе 110 иметь высокую производительность на запись, которая традиционно страдает в системах, использующих коды стирания. В дальнейшем, когда эти данные теряют спрос (остывают), например, их перестали перезаписывать и читать длительное время, управляющий модуль хранения 150 начинает процедуру перемещения данных, посредством, например, модуля перемещения данных, в ходе которой рассчитывает erasure codes, распределяет полосы кодирования по другим модулям хранения 150 согласно карте размещений структуры данных, к которой происходит обращение. После того, как управляющий модуль хранения 150 получает все подтверждения от других модулей 150 о том, что все блоки данных и блоки исправления ошибок сохранены, то указанный модуль 150 удаляет реплики, освобождая первые хранилища данных.
[0084] Стоит отметить, что в одном частном варианте осуществления, поступающие блоки данных в устройства 210, являются данными с высоким спросом. Соответственно, после появления заданного (порогового) события, данные теряют спрос и сохраняются в долгосрочное хранилище данных (перемещаются из первого хранилища во второе хранилище), при этом, для обеспечения отказоустойчивости и оптимального хранения, в процессе перемещения, данные кодируются.
[0085] Рассмотрим более подробно заданные события. Так, заданное событие может представлять следующие события: истечение заданного фиксированного интервала времени; отсутствие чтения или записи данных в течение заданного времени; достижение порогового размера первого блочного хранилища данных; получение последовательности блоков данных образующих целую полосу кодирования. Так, событие может представлять последовательное заполнение по меньшей мере одного первого хранилища данных путем формирования полосы кодирования внутри указанного хранилища данных.
[0086] Т.е. при появлении таких событий, система 100 осуществляет перемещение блока данных в по меньшей мере одно второе хранилище данных 140 в соответствии с картой размещений блоков данных. При этом, в процессе перемещения данных, с помощью модуля перемещения данных, осуществляется кодирование данных. В одном частном варианте осуществления, модуль перемещения данных может представлять собой контроллер, выполненный с возможностью кодирования данных и их дальнейшего сохранения во втором хранилище данных.
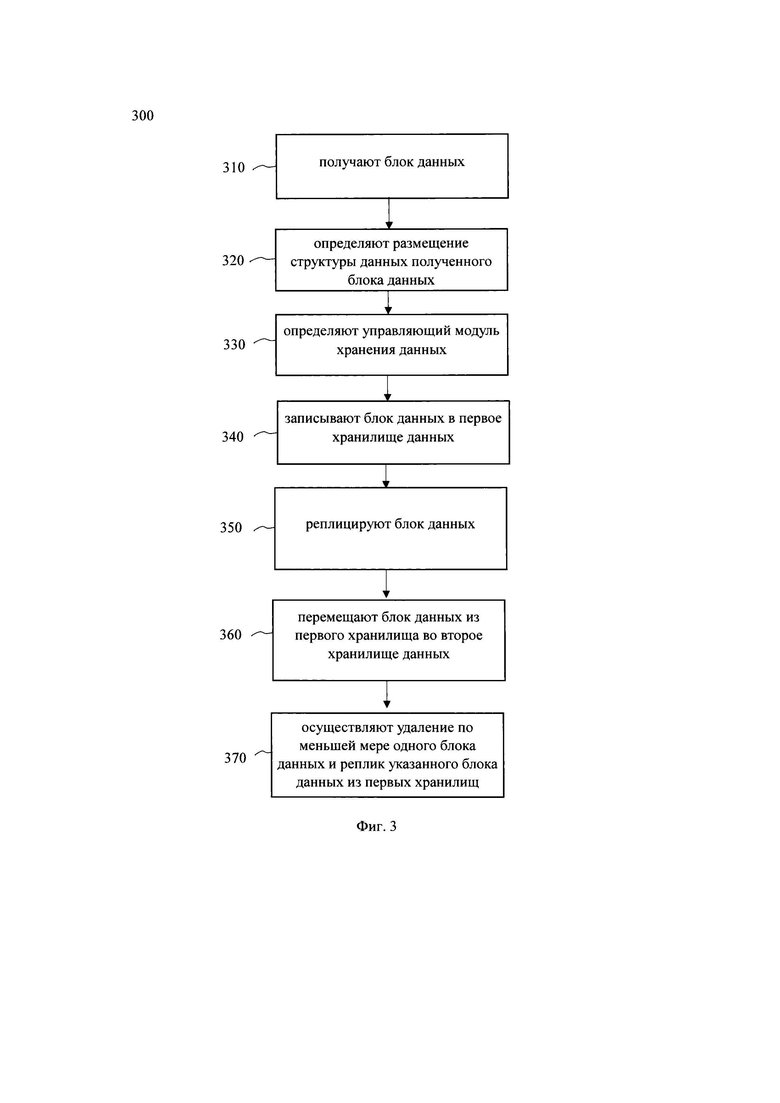
[0087] На фиг. 3 представлена блок схема способа 300 записи данных в распределенной системе хранения данных, такой как система 100, который раскрыт поэтапно более подробно ниже. Указанный способ 300 заключается в выполнении этапов, направленных на обработку различных цифровых данных.
[0088] На этапе 310 получают блок данных блочным хранилищем.
[0089] Так, на указанном этапе 310 в блочное хранилище 110 поступает блок данных.
[0090] Так, система 100, например, посредством хранилища 110 получает запрос на запись по меньшей мере одного блока данных в структуре данных. Запрос на запись блока данных содержит в себе измененный блок данных. Как указывалось выше, блок - это единица минимальной гранулярности, то есть нельзя изменить пол блока. Можно только перезаписать весь блок. Как указывалось, выше, запрос на запись блока данных может быть получен посредством RPC API. Указанный запрос поступает к управляющему модулю 150, расположенному, например, на одном из узлов хранения данных 120. Доступ к структуре данных осуществляется через виртуальное блочное устройство 210, связанное с соответствующей структурой данных. Т.е. На этапе 310 блочное хранилище 110 распределяет в конкретное блочное устройство 210 блок данных. Как указывалось выше, блочное хранилище, технически, представляет собой единую точку доступа к набору виртуальных блочных устройств 210 в кластере.
[0091] На этапе 320 хранилище 110 определяет размещение структуры данных виртуального блочного устройства 210, к которому принадлежит блок данных.
[0092] Так, на этапе 320, хранилище 110, посредством карты размещений блоков, предварительно полученной у модуля метаданных 160, определяет управляющий модуль 150, на который направляется запрос на запись блоков данных, составляющих устройство 210, к которому произошло обращение.
[0093] Управляющий модуль 150 назначается единожды при создании виртуального блочного устройства 210 и переназначается довольно редко (при поломке или переполнении), а дальше он просто читается из карты размещений каждый раз. Так, модули 150 обрабатывают исключительно блоки данных, соответственно, больше про эти блоки в системе 100 ни у кого нет информации. В карте размещений есть список модулей 150, роли этих модулей 150 и схема размещения блоков данных структуры данных.
[0094] Модуль метаданных 160 хранит данные о хранилищах данных 130 и 140 в каждом узле хранения данных 120, виртуальных дисках, всех модулях хранения 150, механизмах блокировок. Так, пользователь, при обращении к блочному устройству 110, взаимодействует с виртуальным диском. Для совершения действий (записи блоков) система 100 должна определить список блоков данных, составляющих указанный виртуальный диск. Для этого система 100 запрашивает у модуля 160 посредством API карту размещений того или иного блока данных (в нашем случае блоков данных, составляющих структуру данных блочного устройства 210), принадлежащего виртуальному диску (устройству 210). Так, модуль метаданных 160 формирует карту размещения блоков данных, определяет модули 150, обслуживающие каждую структуру данных данного виртуального диска, и назначает среди них управляющий модуль 150. Сервис метаданных 160 отслеживает доступность и состояние всех модулей 150. В случае необходимости (какой-то модуль 150 вышел из строя, либо его хранилище переполнено, либо он перегружен) модуль метаданных 160 формирует новую карту размещения, заменяя в ней один модуль 150 на другой, а затем рассылает новую версию карты размещения всем задействованным модулям 150.
[0095] Данный подход с назначением дает возможность выбрать из пула равнозначных модулей хранения любой и повысить его приоритет до координатора на определенном временном промежутке.
[0096] Далее, на этапе 340 записывают управляющим модулем 150 блок данных в по меньшей мере одно первое хранилище данных.
[0097] Так, на этапе 340 измененный блок данных записывается в первые хранилища данных 130. Как указывалось выше, для обеспечения доступности данных с высоким спросом чтения-записи, измененный блок данных вначале поступает в горячее хранилище данных 130 (hot storage). Горячее хранилище данных обеспечивает высокоскоростной доступ к данным на базе дисков SSD.
[0098] На этапе 350 выполняют управляющим модулем 150 реплицирование полученного блока данных в заданное местоположение по меньшей мере одного первого хранилища данных.
[0099] На указанном этапе 350, для обеспечения высокоскоростного доступа к данным, а также отказоустойчивости таких данных, измененный блок данных в структуре данных, размещается в виде реплик в хранилище данных 130 для обеспечения доступности данных. В еще одном частном варианте осуществления, количество реплик каждого блока данных равно двум или более, в зависимости от предустановленного уровня домена отказоустойчивости. Например, в одном из частных случаев это могут быть 3 реплики, одна из которых размещается в узле хранения на геоудаленном датацентре.
[0100] Далее, на этапе 360, перемещают модулем перемещения блок данных из по меньшей мере одного первого хранилища данных в по меньшей мере одно второе хранилище данных, причем в процессе перемещения осуществляют кодирование данных.
[0101] На этапе 360 осуществляют перемещение по меньшей мере одного измененного блока данных во второе хранилище данных, причем в процессе перемещения выполняют кодирование измененного блока данных, в ходе которого выполняют: чтение измененного блока данных, записанного в первое хранилище данных узла хранения данных; чтение изменяемого блока данных из второго хранилища данных узла хранения данных; определение дельты изменений данных между блоками; определение дельт блоков исправления ошибок.
[0102] Так, в одном частном варианте осуществления, на указанном этапе 360, при достижении определенного порогового события, система 100 осуществляет процесс кодирования и перемещения данных из первого хранилища данных 130 во второе хранилище данных 140. Так, событиями могут являться по меньшей мере следующие события: достижение порогового значения времени без перезаписи данных, достижение порогового значения времени без чтения данных, заполненность журнала событий, достижение порогового размера изменяемых данных, изменение состояния определенной последовательности блоков данных и блоков исправления ошибок и т.д. Так, изменение состояния блоков данных может представлять собой лог транзакций - запись всех изменений данных в журнал до того, как эти изменения будут применены непосредственно к данным. Очевидно, инициация переноса данных между хранилищами может выполняться в отложенном режиме в соответствии с наступлением определенного порогового события. Указанная особенность дополнительно обеспечивает повышение производительности системы 100.
[0103] Поскольку данные, в долгосрочном хранилище 140, хранятся вместе с блоками исправления ошибок для обеспечения отказоустойчивости системы 100, то для перемещения измененного блока данных в такое хранилище требуется перекодировать всю полосу кодирования, т.е. заново определить блоки исправления ошибок для всей структуры данных в которой появился измененный блок данных.
[0104] В одном частном варианте осуществления, процесс кодирования данных может представлять собой стирающее кодирование.
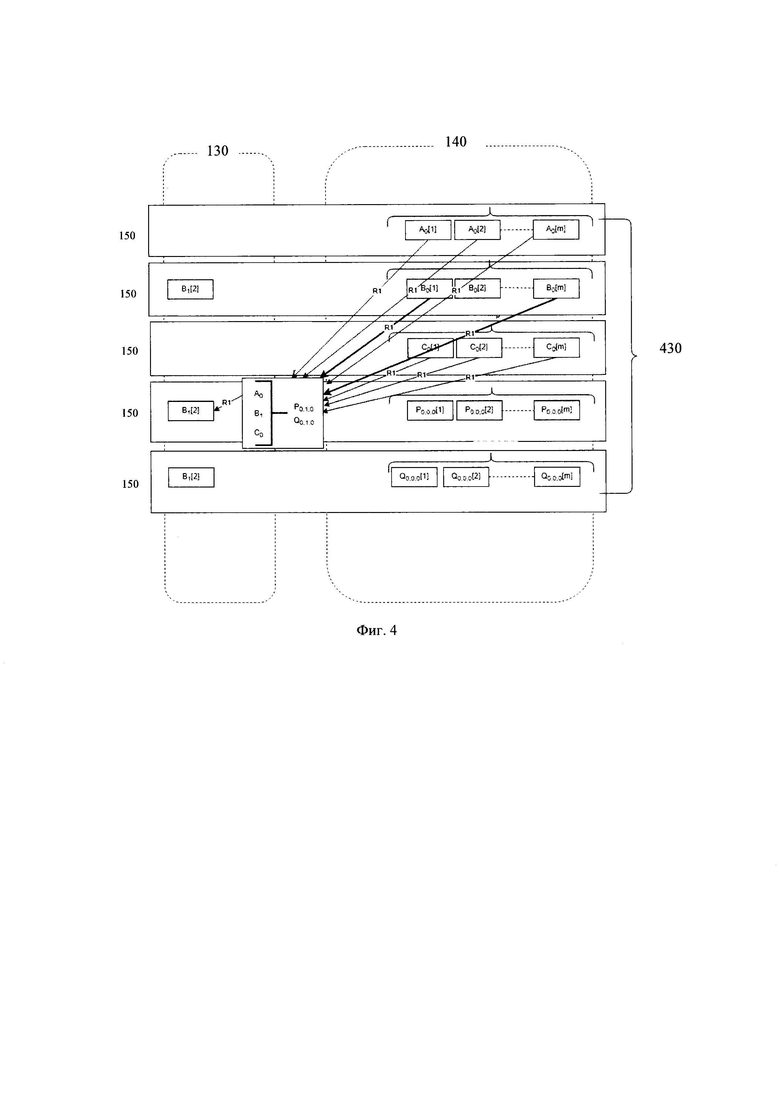
[0105] Так, на фиг. 4 изображен пример реализации стирающего кодирования данных одного измененного блока данных B1 в структуре данных A0B1C0.
[0106] Указанный пример отображает перемещение измененного блока данных B1 из первого хранилища данных 130 во второе хранилище данных 140 в разрезе одного узла хранения данных 120. Как упоминалось выше, структура данных делится на части, обычно кратные определенному размеру блока используемых для фактического хранения данных дисков, которые сохраняются последовательно на каждом долгосрочном хранилище данных, при этом непрерывные последовательные части в пределах конкретного хранилища данных называются стрипами (strip), т.е. это последовательности блоков вида А0[1]-А0[m] в пределах выделенного хранилища. Несколько подряд идущих частей, составляющих логически последовательную цепочку блоков данных (и блоков кодов стирания) - составляют страйп (stripe) и сама структура 3+2 (в нашем примере 3 стрипа данных + 2 стрипа исправления ошибок) называется полосой кодирования, такой как полоса кодирования 430 (stripe).
[0107] Так, при процессе кодирования стиранием, с учетом архитектурных особенностей системы 100, блок данных В1 появляется в общей структуре данных A0B1C0 на виртуальном диске в виде реплик на хранилищах 130. Для кодирования указанного блока данных и его перемещения в хранилище 140 выполняется вычитывание (получение) измененного блока операцией чтения R1, и вычитывание блоков данных А0В0С0 (где 0 - индексы старых версий данных) из хранилища 140 для последующего определения новых кодов стирания (блоков исправления ошибок) P0,1,0 и Q0,1,0 (где наборные версии 0,1,0 - упорядоченно нумерованные версии целевых блоков исправления ошибок для соответственных блоков данных А0 B1 С0). После вычисления новых кодов стирания, система 100, записывает новую версию блока данных B1 в хранилище 140, заменяя блок версии В0, а также новые блоки исправления ошибок P0,1,0 и Q0,1,0.
[0108] На Фиг. 5 изображен еще один пример кодирования данных, реализуемый в заявленной системе 100.
[0109] Так, при появлении в репликах (горячих хранилищах 130) соответствующих измененных блоков данных В1[2] вместо вычитки полной структуры данных (всех недостающих неизменяемых блоков стрипов) из второго хранилища данных 140, т.е. всех блоков данных из всех хранилищ данных, составляющих указанную полосу кодирования 430 (stripe 3+2) блоков данных предыдущего состояния для пересчета Р и Q, происходит только вычитка измененной части конкретного стрипа предыдущей версии В0[2] с конкретного хранилища данных. Это достигается за счет свойств линейности кодирования стирания с последующим вычислением дельт измененного стрипа.
[0110] Сначала вычисляется дельта изменений в данных, например, как разница между измененными блоками B1[2] и изменяемыми блоками В0[2]. А вместо полного перерасчета стирающих кодов, вычисляются соответствующие дельты изменений для стирающих кодов. В настоящем техническом решении может применяться набор коэффициентов кодирования для кодирования блоков данных в блоки исправления ошибок - Yij. Указанные коэффициенты выражают возможность каждого блока исправления ошибок быть закодированным путем вычисления линейной комбинации блоков данных, где все арифметические операции выполняются в поле Галуа над единицами кодирования. Таким образом, дельты стирающих кодов могут быть вычислены как произведение коэффициентов кодирования и дельт изменений в данных.
[0111] Свойство линейности кодирования со стиранием предоставляет альтернативу вычислению новых блоков исправления ошибок при обновлении некоторых блоков данных из структуры данных. Возвращаясь к настоящему примеру, при изменении блока данных В0[2], блок исправления ошибок Р может быть вычислен на основе предыдущего блока исправления ошибок и его дельты изменений (разности между измененным и старым блоком данных, помноженных на единый коэффициент кодирования). Таким образом, вместо суммирования по всем блокам данных мы вычисляем новые блоки исправления ошибок на основе изменений блоков данных.
[0112] Так, указанная операция, по сути, эквивалента алгоритму кодирования стирания, но применяемого для отдельных изменяемых данных, с хранением измененного состояния стрипа (включая, но не ограничиваясь) в журналах или, например, сразу накладываемого на изменяемый data-стрип.
[0113] Соответственно, в одном частном варианте осуществления, для кодирования данных, на этапе 360, посредством данных, определенных с помощью карты размещений, осуществляется вычитка (получение доступа системой 100) измененного блока данных (B1[2]), записанного в первое хранилище данных узла хранения данных и чтение изменяемого блока данных (В0[2]) из второго хранилища данных узла хранения данных. Принцип чтения данных был подробно описан выше.
[0114] Далее, в соответствии со схемой кодирования, осуществляется кодирование данных, для которого определяются дельты изменений данных между блоками, вычитанными блоками и определение дельт блоков исправления ошибок на основе определенной дельты. Т.е. существенно сокращается количество обращений к узлам системы и повышается производительность системы 100.
[0115] Кроме того, указанные изменения могут журналироваться, либо изменения данных могут накладываться сразу, а блоки исправления ошибок журналироваться, либо все изменения могут накладываться сразу с последующим удалением по меньшей мере одной реплики данных из первого хранилища данных.
[0116] Таким образом, на указанном этапе 360 осуществляется перемещение блока данных с кодированием указанных данных.
[0117] На этапе 370, в одном частном варианте осуществления осуществляют удаление измененного блока данных из первого хранилища данных и всех его реплик со всех других первых хранилищ данных. Т.е. на указанном этапе 370, после перемещения блока данных во второе хранилище и его кодирования, все копии блока данных в первых хранилищах удаляются.
[0118] Таким образом, в вышеприведенных материалах была описана система хранения данных, обеспечивающая высокую производительность и отказоустойчивость за счет архитектурных особенностей, описанных выше, также обеспечивающих снижение количества обращений к узлам системы и снижающий сетевой трафик внутри системы за счет локализации сервисов и блочных устройств.
[0119] На Фиг. 7 представлен пример общего вида вычислительной системы 700, которая обеспечивает реализацию заявленного способа или является частью компьютерной системы, например, хранилище 110, устройства 210, модулем перемещения данных, модулем распределенных блокировок, частью вычислительного кластера, обрабатывающим необходимые данные для осуществления заявленного технического решения.
[0120] В общем случае система 700 содержит такие компоненты, как: один или более процессоров 701, по меньшей мере одну память 702, средство хранения данных 703, интерфейсы ввода/вывода 704, средство В/В 705, средство сетевого взаимодействия 706, которые объединяются посредством универсальной шины.
[0121] Процессор 701 выполняет основные вычислительные операции, необходимые для обработки данных при выполнении способа 300. Процессор 701 исполняет необходимые машиночитаемые команды, содержащиеся в оперативной памяти 702.
[0122] Память 702, как правило, выполнена в виде ОЗУ и содержит необходимую программную логику, обеспечивающую требуемый функционал.
[0123] Средство хранения данных 703 может выполняться в виде HDD, SSD дисков, рейд массива, флэш-памяти, оптических накопителей информации (CD, DVD, MD, Blue-Ray дисков) и т.п. Средства 703 позволяют выполнять долгосрочное хранение различного вида информации, например, блоки данных, структура данных, метаданные и т.п.
[0124] Для организации работы компонентов системы 700 и организации работы внешних подключаемых устройств применяются различные виды интерфейсов В/В 704. Выбор соответствующих интерфейсов зависит от конкретного исполнения вычислительных устройств, которые могут представлять собой, не ограничиваясь: PCI, AGP, PS/2, IrDa, FireWire, LPT, COM, SATA, IDE, Lightning, USB (2.0, 3.0, 3.1, micro, mini, type C), TRS/Audio jack (2.5, 3.5, 6.35), HDMI, DVI, VGA, Display Port, RJ45, RS232 и т.п.
[0125] Выбор интерфейсов 704 зависит от конкретного исполнения системы 700, которая может быть реализована на базе широко класса устройств, например, персональный компьютер, мейнфрейм, ноутбук, серверный кластер, тонкий клиент, смартфон, сервер и т.п.
[0126] В качестве средств В/В данных 705 может использоваться: клавиатура, джойстик, дисплей (сенсорный дисплей), монитор, сенсорный дисплей, тачпад, манипулятор мышь, световое перо, стилус, сенсорная панель, трекбол, динамики, микрофон, средства дополненной реальности, оптические сенсоры, планшет, световые индикаторы, проектор, камера, средства биометрической идентификации (сканер сетчатки глаза, сканер отпечатков пальцев, модуль распознавания голоса) и т.п.
[0127] Средства сетевого взаимодействия 706 выбираются из устройств, обеспечивающих сетевой прием и передачу данных, например, Ethernet карту, WLAN/Wi-Fi модуль, Bluetooth модуль, BLE модуль, NFC модуль, IrDa, RFID модуль, GSM модем и т.п. С помощью средств 705 обеспечивается организация обмена данными между, например, системой 700, представленной в виде сервера и вычислительным устройством пользователя, на котором могут отображаться полученные данные по проводному или беспроводному каналу передачи данных, например, WAN, PAN, ЛВС (LAN), Интранет, Интернет, WLAN, WMAN или GSM.
[0128] Конкретный выбор элементов системы 700 для реализации различных программно-аппаратных архитектурных решений может варьироваться с сохранением обеспечиваемого требуемого функционала.
[0129] Представленные материалы заявки раскрывают предпочтительные примеры реализации технического решения и не должны трактоваться как ограничивающие иные, частные примеры его воплощения, не выходящие за пределы испрашиваемой правовой охраны, которые являются очевидными для специалистов соответствующей области техники. Таким образом, объем настоящего технического решения ограничен только объемом прилагаемой формулы.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ КОДИРОВАНИЯ ДАННЫХ И СИСТЕМА ХРАНЕНИЯ ДАННЫХ | 2023 |
|
RU2819584C1 |
| СПОСОБ И СИСТЕМА УПРАВЛЕНИЯ МЕТАДАННЫМИ В ВЫСОКОНАГРУЖЕННЫХ ОБЛАЧНЫХ СРЕДАХ | 2024 |
|
RU2829567C1 |
| Интегрированный программно-аппаратный комплекс | 2016 |
|
RU2646312C1 |
| Система и способ обеспечения отказоустойчивого взаимодействия узлов сети с хранилищем файлов | 2023 |
|
RU2811674C1 |
| СПОСОБ И СИСТЕМА ПЕРЕМЕЩЕНИЯ ДАННЫХ В ОБЛАЧНОЙ СРЕДЕ | 2023 |
|
RU2822554C1 |
| Система и способ контроля доступа к данным приложений для изоляции данных одного приложения от данных другого приложения | 2023 |
|
RU2816864C1 |
| СПОСОБ И СИСТЕМА УПРАВЛЕНИЯ ОБЪЕКТАМИ И ПРОЦЕССАМИ В ВЫЧИСЛИТЕЛЬНОЙ СРЕДЕ | 2023 |
|
RU2820753C1 |
| СПОСОБ МИГРАЦИИ ВИРТУАЛЬНЫХ УСТРОЙСТВ С СОХРАНЕНИЕМ ИХ ДИНАМИЧЕСКОГО СОСТОЯНИЯ | 2024 |
|
RU2835764C1 |
| СПОСОБ И УСТРОЙСТВО КЭШИРОВАНИЯ БЛОКОВ ДАННЫХ | 2023 |
|
RU2818670C1 |
| Способ формирования изображений с дополненной и виртуальной реальностью с возможностью взаимодействия внутри виртуального мира, содержащего данные виртуального мира | 2021 |
|
RU2764375C1 |
Изобретение относится к распределенным системам хранения данных и способам управления ими. Технический результат заключается в повышении производительности распределенной системы хранения данных. Технический результат достигается за счет того, что распределенная система хранения данных содержит: блочное хранилище, содержащее по меньшей мере одно виртуальное блочное устройство; по меньшей мере два узла хранения данных, каждый из которых содержит: по меньшей мере один равнозначный модуль хранения данных; по меньшей мере одно первое хранилище данных; по меньшей мере одно второе хранилище данных; модуль метаданных, хранящий карту размещений блоков данных; модуль распределенных блокировок; модуль перемещения данных. 2 н. и 16 з.п. ф-лы, 7 ил.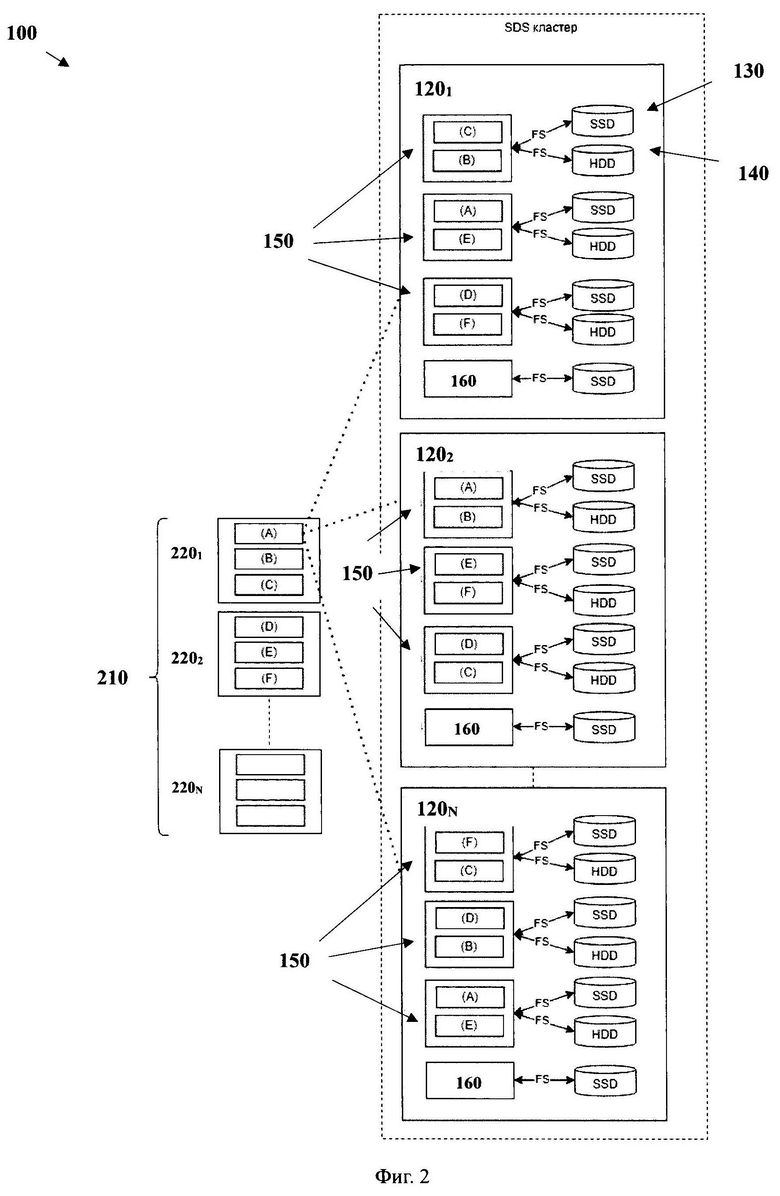
1. Распределенная система хранения данных, содержащая:
• блочное хранилище, содержащее по меньшей мере одно виртуальное блочное устройство, выполненное с возможностью хранения данных структурами данных заданного размера и осуществления операций ввода/вывода;
• по меньшей мере два узла хранения данных, каждый из которых содержит:
 по меньшей мере один равноправный модуль хранения данных, выполненный с возможностью хранения блоков данных из структур данных по меньшей мере одного блочного устройства в по меньшей мере одном первом и втором хранилищах данных;
по меньшей мере один равноправный модуль хранения данных, выполненный с возможностью хранения блоков данных из структур данных по меньшей мере одного блочного устройства в по меньшей мере одном первом и втором хранилищах данных;
по меньшей мере одно первое хранилище данных, выполненное с возможностью хранения блоков данных с высоким спросом;
по меньшей мере одно второе хранилище данных, выполненное с возможностью хранения кодированных блоков данных;
• модуль метаданных, хранящий карты размещений блоков данных, выполненный с возможностью определения местоположения блоков данных, составляющих по меньшей мере одно блочное устройство;
• модуль распределенных блокировок, выполненный с возможностью назначения режима доступа к блочному хранилищу;
• модуль перемещения данных, выполненный с возможностью кодирования и перемещения данных из по меньшей мере одного первого хранилища данных в по меньшей мере одно второе хранилище данных;
причем система выполнена с возможностью определения по карте размещений местоположения блоков данных, которые поступают в блочное устройство, записи блоков данных в по меньшей мере одно первое хранилище данных и перемещения указанного блока в по меньшей мере одно второе хранилище данных в соответствии с картой размещений блоков данных на основе заданного события.
2. Система по п. 1, характеризующаяся тем, что блоки данных с высоким спросом реплицируются на множестве первых хранилищ данных.
3. Система по п. 2, характеризующаяся тем, что количество реплик блока данных с высоким спросом распределено на по меньшей мере два первых хранилища данных.
4. Система по п. 1, характеризующаяся тем, что кодирование данных выполняют алгоритмом кодирования стиранием.
5. Система по п. 1, характеризующаяся тем, что кодирование данных выполняют в процессе перемещения данных из по меньшей мере одного первого хранилища данных в по меньшей мере одно второе хранилище данных на основе заданного события.
6. Система по п. 1, характеризующаяся тем, что заданное событие представляет собой по меньшей мере одно из следующих событий:
• отсутствие чтения или записи данных в течение заданного времени;
• достижение порогового размера по меньшей мере одного блочного устройства;
• последовательное заполнение по меньшей мере одного первого хранилища данных путем формирования полосы кодирования внутри указанного хранилища данных.
7. Система по п. 1, характеризующаяся тем, что множество первых хранилищ данных узла хранения данных представляют собой горячие хранилища данных.
8. Система по п. 1, характеризующаяся тем, что множество вторых хранилищ данных узла хранения данных представляют собой долгосрочные хранилища данных.
9. Система по п. 1, характеризующаяся тем, что взаимодействие блочного устройства с по меньшей мере двумя узлами хранения данных осуществляется с помощью запросов с использованием RPC API.
10. Система по п. 1, характеризующаяся тем, что структура данных представляет собой последовательность блоков данных и/или последовательность блоков данных и блоков исправления ошибок.
11. Система по п. 1, характеризующаяся тем, что модуль перемещения данных дополнительно выполнен с возможностью удаления блока данных из по меньшей одного первого хранилища данных после перемещения указанного блока данных во второе хранилище данных.
12. Система по п. 1, характеризующаяся тем, что модуль метаданных, модуль распределенных блокировок, модуль перемещения данных представляют собой монолитный сервис и/или набор микросервисов.
13. Система по п. 1, характеризующаяся тем, что модуль метаданных дополнительно выполнен с возможностью хранения данных о виртуальных блочных устройствах системы хранения данных.
14. Система по п. 1, характеризующаяся тем, что дополнительно содержит модуль предоставления прав доступа.
15. Система по п. 14, характеризующаяся тем, что модуль предоставления прав доступа выполнен с возможностью разграничения доступа к блокам данных.
16. Способ записи данных в распределенную систему хранения данных по любому из пп. 1-15, содержащий этапы, на которых:
a) получают блок данных блочным хранилищем;
b) определяют модули хранения данных, связанные с виртуальным блочным устройством и местоположение блоков данных на них из структуры данных виртуального блочного устройства, для размещения полученного блока данных;
c) определяют по карте размещения блоков данных управляющий модуль хранения данных из набора модулей хранения данных на узлах хранения данных;
d) записывают управляющим модулем хранения данных блок данных в по меньшей мере одно первое хранилище данных;
e) выполняют управляющим модулем хранения данных реплицирование полученного блока данных в по меньшей мере одно первое хранилище данных;
f) перемещают модулем перемещения блок данных из по меньшей мере одного первого хранилища данных в по меньшей мере одно второе хранилище данных, причем в процессе перемещения осуществляют кодирование данных;
g) осуществляют удаление по меньшей мере одного блока данных и реплик указанного блока данных из первых хранилищ, после перемещения указанного блока данных в по меньше мере одно второе хранилище данных.
17. Способ по п. 16, характеризующийся тем, что реплицирование полученного блока данных выполняют заданное количество раз.
18. Способ по п. 17, характеризующийся тем, что количество реплицируемых блоков данных определяется в соответствии с заданными требованиями отказоустойчивости системы хранения данных.
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| Способ получения цианистых соединений | 1924 |
|
SU2018A1 |
| Электромагнитный прерыватель | 1924 |
|
SU2023A1 |
| Система и способ передачи данных | 2018 |
|
RU2736141C1 |

