Область техники, к которой относится изобретение
Изобретение относится, в общем, к компьютерам, а более конкретно к резервному копированию и восстановлению данных.
Уровень техники
Выполнение полного резервного копирования данных на компьютере представляет собой весьма затратную задачу управления данными. Обычно она включает в себя составление перечня всех файлов в файловой системе компьютера и резервное копирование каждого из этих файлов в индивидуальном порядке. По причине случайного характера разброса этих файлов по файловой системе и значительных непроизводительных издержек, вызванных извлечением метаданных, связанных с файлами, составление перечня всех файлов при выполнении резервного копирования имеет тенденцию осуществляться очень медленно. Несмотря на затраты, большинство организаций выполняет полное резервное копирование на еженедельной основе как с целью ограничить время, необходимое для восстановления данных после чрезвычайного происшествия, так и в силу необходимости хранить наборы данных, созданные посредством этого резервного копирования, в другом месте на случай выхода из строя центра обработки данных (например, при пожаре, наводнении, землетрясениях).
Между полными резервными копированиями может быть выполнено дифференциальное (основанное на фиксации различий) или инкрементное (основанное на фиксации приращений) резервное копирование для фиксации изменений, которые произошли между полными резервными копированиями. Наборы данных, созданные посредством как инкрементного, так и дифференциального резервного копирования, могут потреблять значительные ресурсы для сохранения различий между файловой системой в момент полного резервного копирования и в момент дифференциального резервного копирования. При инкрементном резервном копировании восстановление файлов на компьютере после чрезвычайного происшествия может занять существенно больше времени, поскольку может потребоваться восстановить набор данных, созданный посредством полного резервного копирования, а затем наборы данных, созданные посредством примененных к нему одного или более инкрементных резервных копирований.
Существует потребность в способе и системе, которые позволяли бы быстро и эффективно осуществлять полное резервное копирование файловой системы, не оказывая при этом серьезного воздействия на производительность компьютера. В идеальном варианте такие способ и система должны также предоставлять эффективный механизм для восстановления файлов для компьютера в случае частичного или полного повреждения файловой системы компьютера.
Раскрытие изобретения
Говоря коротко, настоящее изобретение предлагает способ и систему для резервного копирования и восстановления данных. Сначала выполняется полное резервное копирование для создания полного набора данных. После этого могут быть созданы инкрементные или дифференциальные наборы данных посредством инкрементного или дифференциального резервного копирования соответственно. Когда требуется новый полный набор данных, то вместо выполнения полного резервного копирования, предыдущий полный набор данных может быть объединен с последующими инкрементными или дифференциальными наборами данных, чем создается новый полный набор данных. Новый полный набор данных может быть создан на компьютере, отличном от компьютера, на котором размещены данные предыдущего полного набора данных. Новый полный набор данных может быть использован для хранения данных в другом месте или для быстрого восстановления данных в случае повреждения или порчи файловой системы компьютера.
Согласно одному аспекту изобретения наборы данных хранятся в работающем в режиме «он-лайн» запоминающем устройстве, таком как жесткий магнитный диск.
Согласно другому аспекту изобретения выполняется физическое резервное копирование, которое позволяет осуществить также резервное копирование «теневых» копий (точных дубликатов), содержащихся на томе.
Согласно другому аспекту изобретения наборы данных могут быть созданы с использованием дифференциального уплотнения, что позволяет эффективно сохранять множественные наборы данных на работающем в режиме «он-лайн» запоминающем устройстве.
Согласно другому аспекту изобретения фильтр файловой системы отслеживает, какие блоки или экстенты определенных файлов (например, больших файлов) в файловой системе изменились. При резервном копировании вместо того, чтобы копировать каждый большой файл, копируются только блоки или экстенты, которые изменились.
Согласно другому аспекту изобретения данные из набора данных могут быть считаны прикладной программой напрямую из набора данных, что делает возможным доступ к данным до или без восстановления набора данных.
Другие преимущества станут очевидны из нижеследующего подробного описания при рассмотрении его совместно с чертежами, перечень которых приводится ниже.
Краткий перечень чертежей
Фиг.1 - структурная схема, представляющая компьютерную систему, на которой может быть воплощено настоящее изобретение;
Фиг.2-4 - блок-схемы алгоритмов, представляющих в общем виде действия, которые могут происходить для выполнения синтетического (основанного на синтезе) полного резервного копирования в соответствии с различными аспектами данного изобретения;
Фиг. 5 - блок-схема, отражающая аспекты механизма «теневой» копии, который использует способ копирования при записи, в соответствии с различными аспектами данного изобретения;
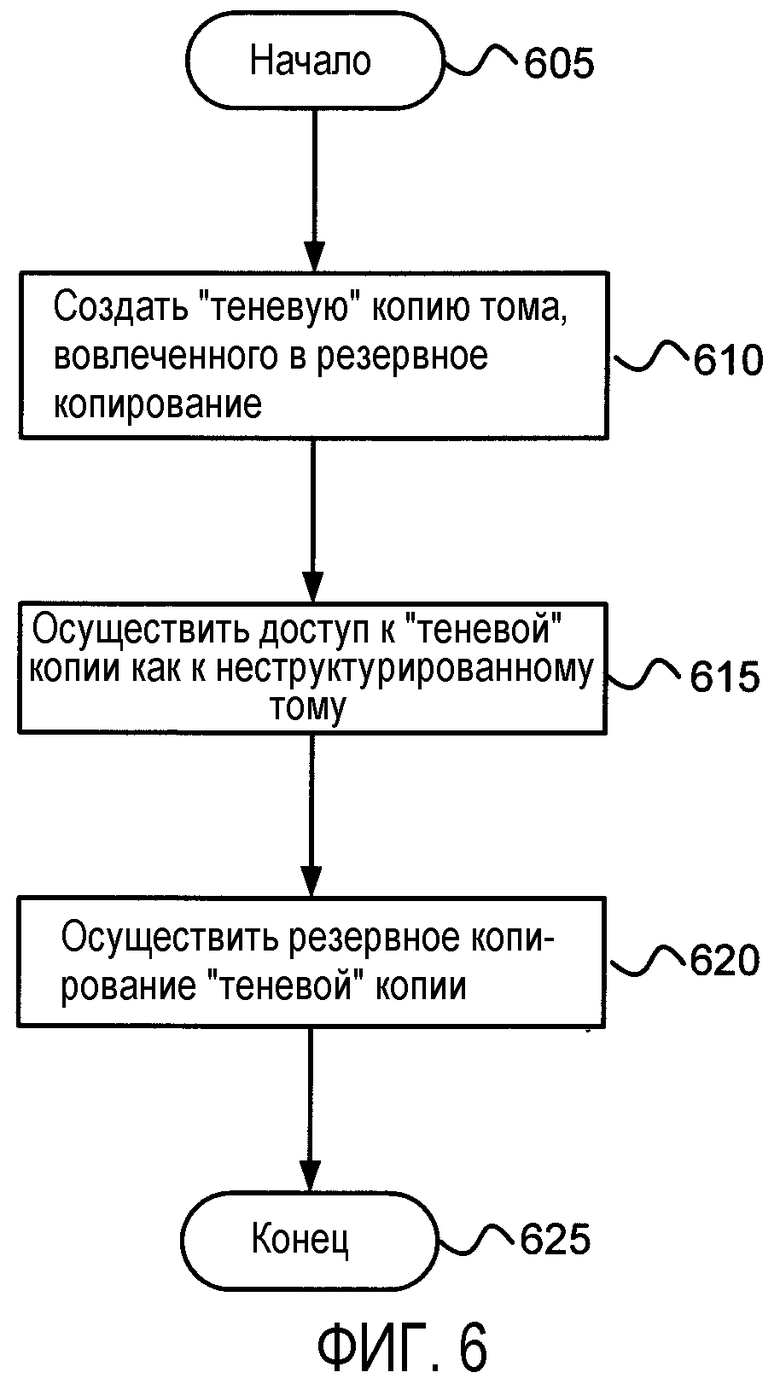
Фиг. 6 - блок-схема алгоритма, представляющего в общем виде действия, которые могут происходить для выполнения физического резервного копирования в соответствии с различными аспектами данного изобретения; и
Фиг. 7 - блок-схема, показывающая приводимую в качестве примера систему, в которой могут быть отслежены измененные экстенты, в соответствии с различными аспектами данного изобретения.
Осуществление изобретения
Иллюстративная операционная среда
На фиг.1 проиллюстрирован пример подходящей вычислительной системной среды (100), на которой может быть реализовано данное изобретение. Вычислительная системная среда (100) представляет собой только один пример подходящей вычислительной среды и не имеет своей целью предложить какое-либо ограничение в отношении объема использования или функциональных возможностей изобретения. Равным образом вычислительная среда (100) не должна толковаться как имеющая какую-либо зависимость или требование, относящиеся к какому-либо компоненту или сочетанию компонентов, проиллюстрированных в приводимой в качестве примера операционной среде (100).
Изобретение способно работать и с многочисленными другими вычислительными системами, средами или конфигурациями общего или специального назначения. Примерами хорошо известных вычислительных систем, сред и/или конфигураций, которые могут быть пригодны для использования с данным изобретением, включают в себя, но не в смысле ограничения, персональные компьютеры; компьютеры-серверы; переносные или портативные устройства; многопроцессорные системы; системы, основанные на микропроцессорах; блоки управления; программируемая бытовая радиоэлектронная аппаратура; сетевые персональные компьютеры (РС); мини-компьютеры; универсальные компьютеры; распределенные вычислительные среды, которые включают в себя любые из вышеописанных систем или устройств; и тому подобное.
Изобретение может быть описано в общем контексте машиноисполняемых команд, таких как программные модули, исполняемые компьютером. Обычно программные модули включают в себя процедуры, программы, объекты, компоненты, структуры данных и т.д., выполняющие конкретные задачи или реализующие определенные абстрактные типы данных. Изобретение также может быть практически реализовано в распределенных вычислительных средах, в которых задачи выполняются удаленными устройствами обработки данных, связанными через сеть связи. В распределенной вычислительной среде программные модули могут быть размещены как в локальных, так и в удаленных компьютерных носителях информации, включая запоминающие устройства.
Согласно фиг.1 приводимая в качестве примера система для реализации изобретения содержит вычислительное устройство общего назначения в виде компьютера (110). Компоненты компьютера (110) могут содержать, но не в ограничительном смысле, процессор (120), системную память (130) и системную шину (121), которая соединяет различные компоненты системы, включая системную память, с процессором (120). Системная шина (121) может относиться к любому из нескольких типов структур шины, включая шину памяти или контроллер памяти, периферийную шину и локальную шину, использующие любую из множества архитектур шины. В качестве примера, но не ограничения, такие архитектуры включают в себя шину архитектуры отраслевого стандарта (ISA), шину микроканальной архитектуры (МСА), усовершенствованную шину ISA (ЕISA), локальную шину Ассоциации по стандартам в области видеоэлектроники (VESA) и шину межсоединения периферийных компонентов (PCI), также известную как мезонинная шина.
Компьютер (110) обычно содержит разнообразные машиночитаемые носители информации. Машиночитаемые носители информации могут представлять собой любые доступные носители информации, к которым может осуществлять доступ компьютер (110), и включают в себя как энергозависимые, так и энергонезависимые носители информации, как съемные, так и несъемные носители информации. В качестве примера, но не ограничения, машиночитаемые носители информации могут включать в себя компьютерные носители информации и среды передачи данных. Компьютерные носители информации включают в себя энергозависимые и энергонезависимые, съемные и несъемные носители информации, реализованные любым способом или технологией для хранения информации, такой как машиночитаемые команды, структуры данных, программные модули или другие данные. Компьютерные носители информации включают в себя, но не в ограничительном смысле, оперативное запоминающее устройство (ОЗУ, RAM); постоянное запоминающее устройство (ПЗУ, ROM); электрически стираемое программируемое постоянное запоминающее устройство (ЭСППЗУ, EEPROM); флэш-память или память, использующую другую технологию; постоянное запоминающее устройство на компакт-диске (CD-ROM); универсальные цифровые диски (DVD) или другой оптический дисковый накопитель; магнитные кассеты; магнитную ленту; магнитный дисковый накопитель или другие магнитные запоминающие устройства; или любой другой носитель, который может быть использован для хранения необходимой информации и к которому может осуществлять доступ компьютер (100). Среды передачи данных обычно воплощают машиночитаемые команды, структуры данных, программные модули или другие данные в сигнале, модулированном данными, таком как несущая или другой механизм переноса информации, и включают в себя любые среды доставки информации. Термин «сигнал, модулированный данными», означает сигнал, одна или более характеристик которого устанавливается или изменяется таким образом, чтобы обеспечить кодирование информации в сигнале. В качестве примера, но не ограничения, среды передачи данных включают в себя проводные среды, такие как проводная сеть или прямое кабельное соединение, и беспроводные среды, такие как акустическая, радиочастотная, инфракрасная и другие беспроводные среды. Комбинации любых упомянутых выше сред также должны быть включены в диапазон машиночитаемых носителей информации.
Системная память (130) включает в себя компьютерные носители информации в виде энергозависимой и/или энергонезависимой памяти, такой как постоянное запоминающее устройство (ПЗУ, ROM) (131) и оперативное запоминающее устройство (ОЗУ, RAM) (132). Обычно в ПЗУ (131) хранится базовая система (133) ввода/вывода (BIOS), содержащая базовые процедуры, способствующие передаче информации между элементами внутри компьютера (110), например, при запуске. ОЗУ (132) обычно содержит данные и/или программные модули, к которым можно осуществить доступ немедленно и/или которыми в текущий момент оперирует процессор (120). В качестве примера, но не ограничения, на фиг.1 проиллюстрированы операционная система (134), прикладные программы (135), другие программные модули (136) и данные (137) программ.
Компьютер (110) также может содержать другие съемные/несъемные, энергозависимые/энергонезависимые компьютерные носители информации. Исключительно в качестве примера, на фиг.1 проиллюстрированы накопитель (140) на жестких магнитных дисках, который осуществляет считывание с несъемных энергонезависимых магнитных носителей информации или запись на них; дисковод (151) для магнитного диска, который осуществляет считывание со съемного энергонезависимого магнитного диска (152) или запись на него; и дисковод (155) для оптического диска, который осуществляет считывание со съемного энергонезависимого оптического диска (156), такого как компакт-диск CD-ROM, или других оптических носителей информации или запись на них. Другие съемные/несъемные, энергозависимые/энергонезависимые компьютерные носители информации, которые могут быть использованы в этой приводимой в качестве примера операционной среде, включают в себя, но не в ограничительном смысле, кассеты с магнитной лентой, карточки флэш-памяти, универсальные цифровые диски, цифровую видеомагнитофонную ленту, твердотельное ОЗУ, твердотельное ПЗУ и тому подобное. Накопитель (141) на жестких магнитных дисках обычно подсоединен к системной шине (121) посредством интерфейса несъемной памяти, такого как интерфейс (140), а дисковод (151) для магнитного диска и дисковод (155) для оптического диска обычно подсоединены к системной шине (121) посредством интерфейса съемной памяти, такого как интерфейс (150).
Дисководы и соответствующие им компьютерные носители информации, описанные выше и проиллюстрированные на фиг.1, обеспечивают хранение машиночитаемых команд, структур данных, программных модулей и других данных для компьютера (110). Например, на фиг.1 накопитель (141) на жестких магнитных дисках проиллюстрирован как хранящий операционную систему (144), прикладные программы (145), другие программные модули (146) и данные (147) программ. Следует отметить, что эти компоненты могут либо быть идентичными операционной системе (134), прикладным программам (135), другим программным модулям (136) и данным (137) программ, либо отличаться от них. Операционной системе (144), прикладным программам (145), другим программным модулям (146) и данным (147) программ даны здесь другие ссылочные позиции для того, чтобы проиллюстрировать тот факт, что, как минимум, они являются другими копиями. Пользователь может осуществлять ввод команд и информации в компьютер (20) посредством устройств ввода, таких как клавиатура (162), и координатно-указательное устройство (161), обычно обозначающее мышь, шаровой манипулятор или сенсорную панель. В число других устройств ввода (не показанных на чертеже) могут входить микрофон, джойстик, игровая панель, спутниковая антенна, сканер, сенсорный экран переносных персональных компьютеров (РС) или другой пишущий планшет или подобные им устройства. Часто эти и другие устройства ввода соединены с процессором (120) посредством интерфейса (160) пользовательского ввода, подсоединенного к системной шине, но они могут быть соединены с процессором посредством другого интерфейса и других структур шины, таких как параллельный порт, игровой порт или универсальная последовательная шина (USB). Также к системной шине (121) посредством интерфейса, такого как видеоинтерфейс (190), подсоединен монитор (191) или другой тип устройства отображения. В дополнение к монитору компьютеры могут также содержать другие периферийные устройства вывода, такие как громкоговорители (197) и принтер (196), который может быть подсоединен посредством периферийного интерфейса (190) вывода.
Компьютер (110) может функционировать в сетевой среде, используя логические соединения с одним или более удаленными компьютерами, такими как удаленный компьютер (180). Удаленный компьютер (180) может представлять собой персональный компьютер, сервер, маршрутизатор, сетевой персональный компьютер (РС), одноранговое устройство или другой узел общей сети, и обычно включает в себя многие или все элементы, описанные выше в отношении компьютера (110), хотя на фиг.1 проиллюстрировано только запоминающее устройство (181). Логические соединения, изображенные на фиг.1, включают в себя локальную сеть (LAN) (171) и глобальную сеть (WAN) (173), но могут также включать в себя и другие сети. Такие сетевые среды часто используются в офисах, компьютерных сетях масштаба предприятия, интрасетях и в сети Интернет.
При использовании в сетевой среде LAN компьютер (110) соединен с LAN (171) посредством сетевого интерфейса или адаптера (170). При использовании в сетевой среде WAN компьютер (110) обычно содержит модем (172) или другое средство для установления связи через сеть WAN (173), такую как сеть Интернет. Модем (172), который может быть внутренним или внешним, может быть подсоединен к системной шине (121) посредством интерфейса (160) пользовательского ввода или другого соответствующего механизма. В сетевой среде программные модули, изображенные в отношении компьютера (110), или их части могут храниться в удаленном запоминающем устройстве. В качестве примера, но не ограничения, фиг.1 изображает удаленные прикладные программы (185) как размещенные на запоминающем устройстве (181). Следует понимать, что показанные сетевые соединения приводятся в качестве примера и могут быть использованы и другие средства установления линии связи между компьютерами.
Синтетическое полное резервное копирование
Вместо того чтобы выполнять на периодической основе полное резервное копирование, полное резервное копирование может быть выполнено один раз, и после этого выполняется инкрементное или дифференциальное резервное копирование. Всякий раз, когда требуется новый полный набор данных (например, на еженедельной основе для сохранения данных в другом месте или в иных случаях), может быть выполнено синтетическое (основанное на синтезе) полное резервное копирование, использующее последний полный набор данных и либо дифференциальный набор данных, либо все инкрементные наборы данных, созданные после последнего полного набора данных. Синтетическое полное резервное копирование создает набор данных, который эквивалентен тому, что создало бы обыкновенное полное резервное копирование, если бы оно производилось в момент создания последнего набора данных, использованного для синтетического полного резервного копирования. Далее термин «полное резервное копирование» может относиться к обыкновенному полному резервному копированию и/или к синтетическому полному резервному копированию.
Термин «полный набор данных» относится к представлению данных источника данных в некоторый момент времени. Источник данных может включать в себя том (например, для файловых данных), базу данных (например, для данных, хранимых в комплексном хранилище данных) или некоторые их комбинации. Полный набор данных может быть создан посредством выполнения обыкновенного полного резервного копирования, синтетического полного резервного копирования или физического полного резервного копирования.
Дифференциальный набор данных создается посредством дифференциального резервного копирования и включает в себя различия между источником данных в момент последнего полного резервного копирования и источником данных в момент выполнения дифференциального резервного копирования. Инкрементный набор данных создается посредством инкрементного резервного копирования и включает в себя различия между источником данных в момент последнего резервного копирования (полного, дифференциального или инкрементного) и источником данных в момент выполнения инкрементного резервного копирования.
Ниже описывается алгоритм для осуществления слияния наборов данных, созданных посредством полного резервного копирования и дифференциального резервного копирования, в ходе синтетического полного резервного копирования. Этот алгоритм предполагает, что каждый набор данных отформатирован в ленточном формате Microsoft® (MTF), хотя данная методология применяется к наборам данных, отформатированным в любом формате, в котором имеется существующий или создаваемый каталог, перечисляющий содержимое наборов данных или, по меньшей мере, отклонения «дельта» от предыдущих полных, дифференциальных или инкрементных наборов данных.
В каждом наборе данных, созданных в формате MTF посредством полного, дифференциального или инкрементного резервного копирования, в заголовке набора данных появляется элемент для каждого файла или директории на томе. Далее для обозначения файла или директории или их обоих иногда используется термин «объект». В случае полного набора данных, созданного в формате MTF посредством полного резервного копирования, в полном наборе данных появляются все метаданные и данные для всех файлов и директорий на томе. В случае наборов данных, созданных в формате MTF посредством дифференциального или инкрементного резервного копирования, метаданные и данные для некоторого элемента могут появиться в наборе данных, созданных посредством дифференциального или инкрементного резервного копирования, только если объект был создан или изменен недавно по отношению к предыдущему набору данных, на котором основан этот дифференциальный или инкрементный набор данных. Формат MTF упорядочивает объекты в пределах набора данных в четко определенном порядке и гарантирует, что если некоторый объект F появляется в наборе данных, то все директории-предки (родители, прародители и т.д.) вплоть до корневой директории тома также перед этим появятся в этом наборе данных.
Данные, связанные с объектом, в том значении, в котором они здесь используются, включают в себя контент (информационно значимое содержимое), связанный с этим объектом, в то время как метаданные, связанные с объектом, включают в себя любые атрибуты или другие данные, связанные с этим объектом.
На фиг.2-4 приведены блок-схемы алгоритмов, представляющих в общем виде действия, которые могут происходить для выполнения полного синтетического резервного копирования в соответствии с различными аспектами данного изобретения. Согласно фиг. 2 на этапе 205 процесс начинается. На этапе 210 создается новый пустой набор данных. На этапе 215 указатели устанавливаются на первый элемент в каждом из наборов данных, которые вовлечены в слияние. Пусть В0 представляет собой указатель на самый поздний дифференциальный или инкрементный набор данных, указатели с В1 по ВN-1 представляют собой указатели на дифференциальные или инкрементные наборы данных, которые упорядочены во времени и являются непосредственно предшествующими более давними наборами данных, чем набор данных, указываемый указателем В0, а ВN представляет собой указатель, который указывает на последний полный набор данных. Алгоритм функционирует дальше следующим образом.
На этапе 215 указатель, связанный с каждым набором данных, присваивается первому элементу, связанному с этим набором данных. На этапе 220 каждый указатель продвигается, если это необходимо, пока элемент, связанный с указателем, не является либо равным, либо большим (по номеру), чем элемент, на который указывает указатель В0, что будет более подробно описано в связи с фиг. 3. Продвигать указатель может не требоваться в случае, если элемент, на который он уже указывает, больше чем или равен элементу, на который указывает указатель В0, или в случае, если указатель прошел последний элемент связанного с ним набора данных.
На этапе 225 в новый набор данных добавляется информация из первого набора данных, который содержит метаданные и данные, как это более подробно описано в связи с фиг. 4. На этапе 230 указатель В0 продвигается для исследования следующего элемента, обнаруженного в наборе данных. На этапе 235, если В0 показывает, что достигнут конец его набора данных, то обработка заканчивается; в противном случае обработка осуществляет условный переход на этап 220.
На фиг. 3 показана блок-схема алгоритма, представляющего в общем виде действия, которые корреспондируют этапу 220, показанному на фиг. 2, и которые могут происходить для продвижения указателей, указывающих на наборы данных, в соответствии с различными аспектами данного изобретения. Указатели, указывающие на каждый набор данных (не включая сюда указатель, связанный с В0), продвигаются, если это необходимо, пока они не больше или не равны элементу, указываемому указателем В0. Процесс начинается на этапе 305. На этапе 310 индексу (например, Х) присваивается значение «1» в качестве подготовки к выбору указателя В1. На этапе 315 выбирается указатель ВХ для исследования элемента, указываемого указателем ВХ. На этапе 320 производится определение того, является ли элемент в наборе данных, указываемом указателем ВХ, бóльшим или равным элементу в наборе данных, указываемом указателем В0, или указывает ли указатель ВХ на конец набора данных, связанного с ВХ. В случае если это так, обработка осуществляет условный переход на этап 330, на котором осуществляется приращение индекса для получения следующего указателя. В противном случае обработка осуществляет условный переход на этап 325, на котором указатель ВХ получает приращение с тем, чтобы указать следующий элемент из связанного с ним набора данных. Цикл, связанный с этапами 320 и 325, продолжает выполняться пока элемент, указываемый указателем ВХ, не больше или не равен элементу, указываемому указателем В0, или пока ВХ не укажет на конец набора данных, связанного с ВХ.
На этапе 335 производится определение того, больше ли индекс (например, Х), чем количество указателей (например, N). Если это так, то все указатели были исследованы и продвинуты, и обработка осуществляет условный переход на этап 340, на котором процесс возвращается к вызывающему процессу. Если же нет, то обработка осуществляет условный переход на этап 315, на котором выбирается следующий указатель.
На фиг. 4 показана блок-схема алгоритма, представляющего в общем виде действия, которые соответствуют этапу 225, показанному на фиг. 2, и которые могут выполняться для обнаружения самого позднего элемента набора данных для включения в новый набор данных в соответствии с различными аспектами изобретения. Процесс начинается на этапе 405. На этапе 410 индексу (например, Х) присваивается значение ноль в качестве подготовки к выбору указателя на набор данных, созданный посредством самого позднего резервного копирования. На этапе 415 выбирается указатель ВХ для исследования элемента, указываемого этим указателем. На этапе 420 производится определение того, содержит ли элемент, указываемый указателем ВХ, метаданные и данные для этого элемента. Если элемент, указываемый указателем ВХ, содержит метаданные и данные, то обработка осуществляет условный переход на этап 430, на котором этот элемент и метаданные и данные добавляются в новый набор данных. В противном случае обработка осуществляет условный переход на этап 425, где индекс (например, Х) получает приращение на этапе 425, и на этапе 415 выбирается следующий указатель. Действия, представленные на этапах 415-425, повторяются до тех пор, пока не найден самый поздний набор данных с элементом, содержащим данные и метаданные.
Следует отметить, что в случае формата MTF, если набор данных содержит элемент для объекта, но не содержит метаданных или данных, то это означает, что каждый предыдущий набор данных содержит такой элемент для этого объекта, пока некоторый набор данных не будет содержать также данные и метаданные для этого объекта.
Вышеописанный алгоритм может быть использован для
• слияния полного набора данных с наиболее поздним дифференциальным набором данных, основанным на этом полном наборе данных;
• слияния полного набора данных с каждым инкрементным набором данных, созданным после полного набора данных (например, для использования в случае, если выполняется только инкрементное резервное копирование); или
• слияния полного набора данных с наиболее поздним дифференциальным набором данных, основанным на этом полном наборе данных, и с каждым инкрементным набором данных, основанным на этом дифференциальном наборе данных (например, для использования в случае, если выполняются как дифференциальные, так и инкрементные резервные копирования).
Как было отмечено выше, вышеописанный алгоритм был рассмотрен на основе формата MTF. Следует, однако, признать, что этот алгоритм, не выходя за рамки сущности и объема настоящего изобретения, может быть легко модифицирован таким образом, чтобы учитывать и другие форматы в той мере, в какой каждый инкрементный или дифференциальный набор данных включает в себя способ определения того, какие объекты были удалены из предыдущего набора данных и какие объекты были изменены или добавлены в предыдущий набор данных.
Хотя описанный выше алгоритм может быть использован для слияния наборов данных, которые расположены либо на диске, либо на ленте, на практике он, возможно, наиболее эффективен в случае, когда все инкрементные/дифференциальные наборы данных и полный набор данных, слияние которых осуществляется, располагаются на диске.
Кроме того, описанный выше алгоритм может быть обобщен до многопроходного слияния, но непроизводительные издержки, связанные со множеством проходов, могут сделать этот алгоритм менее интересным для практического применения. Поскольку лента относится к носителям информации с последовательным доступом, то для того, чтобы все наборы данных были открытыми одновременно, может потребоваться сравнительно большое количество накопителей на магнитной ленте (например, один накопитель на набор данных), и это может быть реализовано наилучшим образом при отсутствии совместного расположения наборов данных (то есть один и только один подлежащий слиянию набор данных на носитель информации).
Наконец, чтобы разгрузить производственный компьютер от обработки слияний, для выполнения обработки слияний может быть использован отдельный компьютер для резервного копирования. Следует признать, что это имеет много преимуществ, включая освобождение производственного компьютера для производственных целей.
Физическое резервное копирование и восстановление
Одна из проблем, присущих существующей технологии выполнения полного резервного копирования, заключается в том, что отсутствует связь между логическими объектами, резервное копирование которых осуществляется, и физическим представлением этих объектов на диске. Эта проблема может быть решена посредством использования «теневой» копии. «Теневая» копия представляет собой «моментальный снимок» одного тома. В логическом плане «теневая» копия представляет собой точный дубликат тома в данный момент времени, даже если этот том при создании «теневой» копии может и не быть полностью скопированным (например, посредством способа копирования при записи). «Теневая» копия может рассматриваться операционной системой и любыми исполняемыми приложениями как отдельный том. Например, «теневая» копия может иметь атрибуты: устройство тома, имя тома, букву, обозначающую дисковод, точку установки и любые другие атрибуты реального тома. В дополнение к этому, «теневая» копия может экспонироваться через сетевой удаленный путь доступа, такой как сетевая доля (иногда именуемая просто «долей»), связанный с ней, который делает возможным доступ из сети к части или всем данным, содержащимся внутри «теневой» копии.
«Теневая» копия может быть создана посредством различных хорошо известных технологий, включая копирование при записи, расщепленное зеркальное копирование, специализированные аппаратные средства, которые создают копию самого диска, и другие способы и системы, известные специалистам в данной области техники.
Технология «теневой» копии может для реализации «теневых» копий способом копирования при записи использовать дифференциальную (фиксирующую различия) область. Дифференциальная область устанавливает соответствие блоков на томе с содержимым этих блоков на момент времени, когда была создана «теневая» копия. Технология различий в технологии «теневой» копии может функционировать на уровне физических блоков, а не на уровне объектов (файла или директории).
Например, согласно фиг. 5, в случае копирования при записи драйвер может разделить диск на экстенты. Экстент относится к ряду примыкающих друг к другу блоков на носителях информации и может различаться в зависимости от приложения. Например, одно приложение может разделить диск на экстенты, имеющие один размер, в то время как другое приложение может разделить диск на экстенты, имеющие другой размер.
Если некоторый блок на диске изменяется после создания «теневой» копии, то прежде чем блок будет изменен, экстент, содержащий этот блок (например, экстент (506)) копируется в место на запоминающем устройстве (например, экстент (507)), расположенное в дифференциальной области (515). Для конкретной «теневой» копии экстент копируется только первый раз, когда изменяется какой-либо блок внутри экстента. Когда принят запрос на информацию, содержащуюся в «теневой» копии, сначала проводится проверка, имеющая целью определить, изменился ли этот блок в оригинальном томе (например, посредством проверки того, имеется ли экстент, содержащий этот блок, в дифференциальной области (515)). Если блок не изменился, то извлекаются и возвращаются данные из оригинального тома. Если блок изменился, то извлекаются и возвращаются данные из дифференциальной области (515). Следует отметить, что если блок перезаписан теми же данными, то экстент, содержащий этот блок, не записывается в дифференциальную область (515).
Для того чтобы осуществить резервное копирование «теневой» копии, сохраняют схему соответствия физических блоков оригинального тома экстентам дифференциальной области. Один способ осуществления резервного копирования как тома, так и любых «теневых» копий, продолжающих существовать на нем, заключается в том, чтобы выполнить физическое (выполняемое на физическом (в отличие от логического) уровне) резервное копирование этого тома. Термин «физическое резервное копирование» относится к копированию физических блоков, связанных с томом, вместо выполнения пообъектного резервного копирования. Следует отметить, что блоки в пустых экстентах при физическом резервном копировании могут копироваться или могут не копироваться. Приложение, осуществляющее резервное копирование, может сохранять побитовое отображение или другое указание на то, какие экстенты были пусты, а какие не были пусты в наборе данных, созданном посредством резервного копирования. Следует признать, что отказ от копирования пустых экстентов обычно приводит к тому, что набор данных, созданный посредством физического резервного копирования, будет меньше.
Хотя различные аспекты изобретения были описаны в связи с технологиями получения «теневых» копий способом копирования при записи, могут также использоваться и другие технологии «теневых» копий, и это не выходит за рамки сущности или объема данного изобретения.
На фиг. 6 показана блок-схема алгоритма, представляющего в общем виде действия, которые могут происходить для выполнения физического резервного копирования в соответствии с различными аспектами данного изобретения. Всякий раз, когда дифференциальные области, используемые для продолжающих существовать «теневых» копий, располагаются совместно с оригинальным томом, выполнение физического резервного копирования будет сохранять эти «теневые» копии, также как и этот том. В этом случае резервное копирование может быть осуществлено следующим образом.
На этапе 605 процесс начинается. На этапе 610 создается резервная «теневая» копия тома, вовлеченного в резервное копирование. Эта резервная «теневая» копия может быть удалена, как только будет завершено резервное копирование. Следует отметить, что создание резервной «теневой» копии (вместо попытки скопировать блоки с тома напрямую) может быть выполнено с целью получения непротиворечивого и стабильного образа тома.
На этапе 615 «теневая» копия открывается как неструктурированный том, то есть как файл, представляющий физические блоки, лежащие в основе «теневой» копии.
На этапе 620 осуществляется резервное копирование «теневой» копии в порядке следования блоков.
Всякий раз, когда дифференциальные области, используемые для продолжающих существовать «теневых» копий, не располагаются совместно с оригинальным томом, резервное копирование как тома, содержащего дифференциальные области, так и оригинального тома осуществляется вместе. Это может быть выполнено посредством получения «теневых» копий обоих томов в одно и то же время и затем осуществления доступа к этим «теневым» копиям с целью создания набора данных. Приводимые в качестве примера способ и система для получения таких «теневых» копий описаны в патенте США № 6647473, права на который принадлежат правообладателю по настоящему изобретению и который включен в настоящее описание посредством ссылки.
Физическое резервное копирование имеет несколько важных атрибутов.
• Это резервное копирование будет, главным образом, выполняться как осуществляемое по спирали считывание диска. Некоторый произвольный доступ возможен к блокам, которые изменяются после того, как на этапе 610, описанном выше, создана «теневая» копия, но, в общем, резервное копирование будет существенно более быстрым, чем было бы возможно при осуществлении обыкновенного полного резервного копирования.
• Это резервное копирование не несет бремя описанных выше непроизводительных издержек по обработке файлов, связанных с получением объектов и связанных с ними метаданных. Таким образом, резервное копирование может требовать значительно меньше работы компьютера, резервирование данных которого осуществляется.
• При восстановлении набора данных, созданного посредством физического резервного копирования, восстановленный том будет иметь содержимое тома на момент времени, когда была выполнена (например, на этапе 610) «теневая» копия рассматриваемого тома, и всех продолжавших существовать «теневых» копий, которые были на томе на тот момент времени.
Набор данных, созданный посредством физического резервного копирования, может быть также использован для быстрого восстановления в сочетании с обычным чередованием резервного копирования, включающим в себя дифференциальное и/или инкрементное резервное копирование. Набор данных, созданный посредством физического резервного копирования, может рассматриваться как полный набор данных, и набор данных, созданный посредством дифференциального или инкрементного резервного копирования, может ссылаться на набор данных, созданный посредством физического резервного копирования. В этом случае последующий инкрементный или дифференциальный набор данных может быть восстановлен посредством восстановления сначала набора данных, созданного посредством физического резервного копирования, а затем применения любых последующих дифференциальных и инкрементных наборов данных.
В дополнение к этому, после применения каждого дифференциального или инкрементного набора данных могут быть созданы дополнительные «теневые» копии. Создание этих дополнительных «теневых» копий может позволить быстро вернуться к состоянию диска, представленному любой из этих «теневых» копий, так что том может быть восстановлен до состояния, имеющего столько же неиспорченных данных, сколько имелось в наличии на томе в момент, непосредственно предшествующий губительной утрате или порче тома.
Также следует отметить, что в случае, когда полный набор данных создан посредством физического полного резервного копирования, скорость восстановления может быть существенно более быстрой, чем в случае, когда восстанавливается набор данных, созданный посредством резервного копирования, отличного от физического, поскольку это восстановление может быть выполнено посредством записи блоков, осуществляемой по спирали, а не пообъектным способом.
Дифференциальное уплотнение полных наборов данных
Обычно источник данных от недели к неделе существенным образом не изменяется. Более того, имеются определенные типы источников данных, где ожидается возникновение очень небольших изменений. Эти источники данных включают в себя:
• Источники данных, связанные с операционной системой (ОС), которые включают в себя двоичные коды операционной системы и постоянное состояние системных служб.
• Источники данных, которые включают в себя доступные только для чтения базы данных или хранилища файлов, такие, как те, что используются для создания расписаний групповых мероприятий и для систем управления документооборотом, где осуществляется резервное копирование базы данных назначений, контактов и управления документооборотом. Эти источники данных меняются по мере того, как изменяются документы или определенные объекты (например, контакты, календарь и расписание).
Поскольку затраты на поддержание в режиме «он-лайн» полного набора данных относительно высоки (то есть примерно равны размеру тома, резервное копирование которого осуществляется), способность уплотнять полные наборы данных с тем, чтобы воспользоваться медленным характером их изменения, является полезной и может позволить, используя тот же объем памяти, поддерживать в режиме «он-лайн» намного больше полных наборов данных.
Для осуществления дифференциального (то есть основанного на фиксации различий) уплотнения при резервном копировании могут быть использованы две технологии:
• Использование для осуществления уплотнения технологии «теневой» копии, что будет более подробно описано ниже. Эта технология показывает очень хорошие результаты для наборов данных, где содержимое изменяется в блоках, которые обычно остаются в том же самом месте и позиционно не перемещаются по разным местам.
• Использование алгоритма дифференциального уплотнения, который способен находить различия в наборах данных, где одни и те же данные могут появляться в различное время в различных местах. Приводимые в качестве примера алгоритмы дифференциального уплотнения описаны в заявках на патенты США, имеющих порядковые номера 10/825753 и 10/844893, которые обе имеют своим правообладателем правообладателя по настоящему изобретению и включены в настоящее описание посредством ссылки.
При использовании технологии «теневой» копии в одном варианте осуществления изобретения новое полное резервное копирование может быть выполнено следующим образом:
1. Создание постоянной «теневой» копии тома, содержащего набор данных.
2. Перезапись на место оригинального набора данных на оригинальном томе нового полного набора данных или нового синтетического полного набора данных, которые описаны в связи с фиг.2-4.
3. Переименование оригинального набора данных в новый набор данных.
В другом варианте осуществления изобретения новое полное резервное копирование может быть выполнено следующим образом:
1. Создание постоянной "теневой" копии тома, содержащего набор данных.
2. Создание нового полного набора данных или нового синтетического полного набора данных, которые описаны в связи с фиг.2-4, на томе, отличном от тома, содержащего оригинальный том.
3. Перезапись на место оригинального набора данных нового набора данных.
4. Переименование оригинального набора данных в новый набор данных.
5. Удаление нового набора данных на другом томе.
При перезаписи на место оригинального набора данных нового набора данных описанная выше технология «теневой» копии помещает экстенты, содержащие блоки, содержимое которых изменилось (между оригинальным и новым наборами данных), в область различий. Изменение имени с имени оригинального набора данных на имя нового набора данных приводит к тому, что экстенты, содержащие блоки с метаданными, касающимися оригинального набора данных, изменяются и помещаются в область различий. Это позволяет программе осуществлять доступ к новому набору данных либо к оригинальному набору данных (через "теневую" копию). Следует признать, что при использовании технологии, описанной выше, дополнительное место на диске, необходимое для нового полного набора данных, может просто содержать экстенты, измененные между прошлым полным набором данных и новым полным набором данных.
Новое резервное копирование может быть выполнено с использованием удаленного дифференциального уплотнения следующим образом:
1. Создание нового синтетического полного набора данных, который описан в связи с фиг.2-4.
2. Применение одного из приводимых в качестве примера алгоритмов удаленного уплотнения, описанных выше, к оригинальному полному набору данных и синтетическому полному набору данных, созданному на этапе 1, с целью создания дифференциально уплотненного набора данных.
3. Удаление нового набора данных и переименование файла дифференциального уплотнения, дающее ему имя нового набора данных.
После того как с использованием удаленного дифференциального уплотнения создан дифференциально уплотненный набор данных, полный набор данных может быть получен посредством применения дифференциального уплотненного файла к предыдущему полному набору данных.
Вычисление дельты (отклонения) для резервного копирования больших файлов данных
Дифференциальное или инкрементное резервное копирование может быть выполнено посредством исследования каждого объекта, находящегося на запоминающем устройстве, с целью проверить, изменился ли данный объект с момента предыдущего резервного копирования, на котором основывается это дифференциальное или инкрементное резервное копирование. Определение того, изменился ли объект, может быть выполнено, например, посредством проверки времени последней модификации объекта. Если определено, что объект изменился, то в набор данных может быть скопирован весь объект. Копирование всего объекта в инкрементный или дифференциальный набор данных всякий раз, когда изменяется какая-либо часть этого объекта, может представлять собой затрату значительных ресурсов в случае больших объектов, таких как базы данных и хранилища электронной почты, которые часто изменяются, но в которых в действительности изменяется только малая часть объекта.
В одном варианте осуществления изобретения производится отслеживание тех экстентов в объекте, которые действительно изменились с момента последнего резервного копирования, таким образом, что может быть осуществлено их резервное копирование при выполнении инкрементного или дифференциального резервного копирования. Отслеживание этих экстентов может быть выполнено при помощи фильтра файловой системы, который отслеживает изменения в больших файлах (например, в любых файлах, размер которых превышает 16 мегабайтов) на томах в компьютере. Размер файлов, отслеживаемых фильтром файловой системы, может быть задан при предварительном конфигурировании или может выбираться.
Фильтр файловой системы может сохранять в постоянном хранилище, связанном с томом, следующую информацию:
• Путь доступа к объекту, который был изменен.
• Набор экстентов в объекте, которые изменились.
В одном варианте осуществления изобретения фильтр файловой системы отслеживает набор блоков, которые изменились в объекте, а не набор экстентов, которые изменились.
Фиг. 7 представляет собой блок-схему, показывающую приводимую в качестве примера систему, в которой могут быть отслежены измененные экстенты, в соответствии с различными аспектами данного изобретения. Операционная система (705) может принимать запросы на запись в файловую систему (715). Такие запросы передаются через фильтр (710) файловой системы. Если фильтр (710) файловой системы определяет, что любые изменения в экстентах некоторого файла должны быть отслежены, то он сохраняет информацию о том, какие экстенты изменились, в постоянном хранилище (720).
В случае схемы инкрементного резервного копирования постоянное хранилище, в котором отслеживаются эти экстенты, может возвращаться в исходное состояние всякий раз, когда выполнено инкрементное или полное резервное копирование, так, чтобы отслеживались изменения с момента каждого предыдущего резервного копирования. Если же используется схема дифференциального резервного копирования, то постоянное хранилище, в котором отслеживаются эти экстенты, может возвращаться в исходное состояние всякий раз, когда выполнено новое полное резервное копирование.
Дифференциальное или инкрементное резервное копирование может использовать это постоянное хранилище следующим образом. Если в постоянном хранилище появляется объект, то способом дифференциального или инкрементного резервного копирования может быть просто осуществлено резервное копирование:
списка экстентов в этом объекте, которые изменились; и
содержимого этих экстентов в том же порядке, в котором они появляются в списке.
Для воссоздания объекта на основе набора инкрементных наборов данных и полного набора данных или на основе дифференциального набора данных и полного набора данных могут быть выполнены следующие действия:
1. Проводимое для каждого экстента в этом объекте обнаружение наиболее позднего набора данных, имеющего этот экстент в своем списке экстентов, которые изменились, или имеющего полный набор данных этого объекта; и
2. Копирование этого экстента из этого набора данных и переход к следующему экстенту.
В одном варианте осуществления изобретения могут вестись два списка экстентов для того, чтобы поддерживать схему полного, дифференциального и инкрементного резервного копирования. Фильтр файловой системы производит отслеживание того, изменился ли каждый объект-кандидат (например, обладающий достаточным размером или другим критерием), в двух списках посредством:
• Ведения списка экстентов, которые изменились в этих объектах с того момента, когда было выполнено последнее полное резервное копирование; и
• Ведения списка экстентов, которые изменились в этих объектах с того момента, когда было выполнено последнее дифференциальное или инкрементное резервное копирование.
Дифференциальный набор данных может быть создан с использованием первого списка экстентов, в то время как инкрементный набор данных может быть создан с использованием второго списка экстентов. Второй список может обнуляться всякий раз, когда выполнено инкрементное или дифференциальное резервное копирование. Первый список может обнуляться, когда выполнено полное резервное копирование.
Считывание данных напрямую из набора данных
Многие приложения (например, электронная почта, управление документооборотом, активная директория и тому подобное) сохраняют объекты в базе данных. Часто представляется желательным восстановить конкретные наборы объектов из базы данных вместо того, чтобы восстанавливать всю базу данных. Так часто обстоит дело в случае, когда производится восстановление после ошибки пользователя, например, когда пользователь случайно удаляет документы или сообщения электронной почты, которые пользователь удалять не намеревался. Например, очень часто восстанавливается содержимое почтовых ящиков из базы данных электронной почты и индивидуальные документы из системы управления документооборотом.
Обычно эти виды объектов могут быть восстановлены посредством выделения места под всю базу данных, восстановления всей базы данных по состоянию на тот момент времени, когда объекты, подлежащие восстановлению, были в требуемом состоянии (например, не удаленными или не измененными), и использования затем приложения (например, системы электронной почты, системы управления документооборотом или другого подходящего приложения) для установки базы данных и извлечения из нее требуемых объектов.
При расположении набора данных на диске может отсутствовать необходимость восстанавливать этот набор данных на диске перед осуществлением доступа к требуемым объектам через соответствующие приложения. Вместо этого приложение может осуществлять доступ к файлам напрямую в том виде, в котором они хранятся в наборе данных. Если набор данных, созданный физическим резервным копированием, хранится в виде копии тома (в противоположность формату MTF), то набор данных может быть установлен непосредственно как том после удаления в этом наборе данных любого заголовка или завершающей части.
Если набор данных хранится в формате MTF (или в некотором другом архивном формате), то фильтр файловой системы может выполнить следующие действия:
• Экспонировать этот набор данных как том и разрешить доступ к этому тому. Дать этому тому другое имя или открыть доступ к нему через адрес, отличный от адреса оригинального тома в пространстве имен локального компьютера;
• Выполнить поиск с целью обнаружения соответствующего файла базы данных, содержащегося в этом наборе данных, при попытке приложения открыть этот файл базы данных через этот экспонируемый том. Следует отметить, что поскольку набор данных выглядит как том (например, благодаря использованию фильтра файловой системы), каждый файл и директория в этом томе (а следовательно, и в наборе данных) могут быть открыты напрямую;
• Позволить считывание метаданных напрямую из этого тома и позволить считывание данных объекта с использованием обыкновенных примитивов ввода/вывода файловой системы; и
• Сохранить свойство этого набора данных, заключающееся в его доступности только для чтения, посредством выполнения операций копирования при записи (в случае, когда приложение пытается записать данные в этот том) по отдельному адресу. Это может быть полезно для поддержки приложения, не поддерживающего установку с доступом только для чтения, такого как сервер или клиент электронной почты.
Фильтр файловой системы может использовать работающий в режиме «он-лайн» каталог, связанный с набором данных, который устанавливает соответствие каждого объекта в наборе данных и соответствующего смещения в созданном томе. Этот каталог может быть создан для наборов данных, которые не хранят в себе каталога. Например, когда открывают объект в томе, может быть произведен поиск этого объекта в работающем в режиме «он-лайн» каталоге, и может быть найдено смещение в наборе данных.
Заголовки, расположенные по адресу смещения, могут быть использованы для извлечения метаданных для объекта и для установления соответствия между смещениями, указывающими на объект, и смещениями, указывающими на данные для этого объекта. Любые операции чтения, производимые над объектом, могут иметь своим результатом соответствующую операцию чтения, производимую над набором данных по вычисленному адресу смещения, основанному на этом установленном соответствии.
Для наборов данных, хранящихся в формате MTF или в формате, отличном от MTF, в случае, если набор данных создан посредством инкрементного или дифференциального резервного копирования, фильтр файловой системы может рассматривать этот набор данных и любые другие наборы данных, на которых он основан, как устройство. Для получения информации, относящейся к объекту, может быть проведен поиск в этом устройстве с наборами данных с целью найти наиболее поздний набор данных, содержащий информацию. Перед разрешением доступа к тому, основанному на группе наборов данных, созданных посредством резервных копирований, может быть создан работающий в режиме «он-лайн» каталог для того, чтобы установить соответствие объектов с их соответствующими местами расположения в пределах наборов данных.
Как можно увидеть из вышеприведенного подробного описания, предлагается усовершенствованный способ и система для создания, восстановления и использования наборов данных, связанных с резервным копированием. Хотя изобретение допускает различные модификации и альтернативные конструкции, определенные иллюстративные варианты его осуществления показаны на чертежах и были подробно описаны выше. Следует понимать, однако, что не следует ограничивать изобретение конкретными описанными формами, но, напротив, подразумевается распространение его действия на все модификации, альтернативные конструкции и эквиваленты, соответствующие сущности и объему изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| ЭФФЕКТИВНОЕ СОЗДАНИЕ ЧАСТЫХ РЕЗЕРВНЫХ КОПИЙ ЦЕЛОСТНЫХ ДЛЯ ПРИЛОЖЕНИЙ | 2007 |
|
RU2433457C2 |
| Способ резервного копирования | 2017 |
|
RU2646309C1 |
| СПОСОБ И СИСТЕМА ГРАНУЛЯРНОГО ВОССТАНОВЛЕНИЯ РЕЗЕРВНОЙ КОПИИ БАЗЫ ДАННЫХ | 2024 |
|
RU2825077C1 |
| ЗАЩИЩЕННОЕ И КОНФИДЕНЦИАЛЬНОЕ ХРАНЕНИЕ И ОБРАБОТКА РЕЗЕРВНЫХ КОПИЙ ДЛЯ ДОВЕРЕННЫХ СЕРВИСОВ ВЫЧИСЛЕНИЯ И ДАННЫХ | 2010 |
|
RU2531569C2 |
| ПОЭТАПНАЯ, ОБЛЕГЧЕННАЯ СИСТЕМА РЕЗЕРВНОГО КОПИРОВАНИЯ | 2008 |
|
RU2483349C2 |
| КОНТРОЛЬНЫЕ ТОЧКИ ДЛЯ ФАЙЛОВОЙ СИСТЕМЫ | 2011 |
|
RU2554847C2 |
| СПОСОБЫ И УСТРОЙСТВО ДЛЯ ЭФФЕКТИВНОЙ РЕАЛИЗАЦИИ БАЗЫ ДАННЫХ, ПОДДЕРЖИВАЮЩЕЙ БЫСТРОЕ КОПИРОВАНИЕ | 2018 |
|
RU2740865C1 |
| ФАЙЛОВАЯ СИСТЕМА, ПРЕДСТАВЛЕННАЯ ВНУТРИ БАЗЫ ДАННЫХ | 2006 |
|
RU2398275C2 |
| СПОСОБЫ И УСТРОЙСТВО ДЛЯ ЭФФЕКТИВНОЙ РЕАЛИЗАЦИИ БАЗЫ ДАННЫХ, ПОДДЕРЖИВАЮЩЕЙ БЫСТРОЕ КОПИРОВАНИЕ | 2018 |
|
RU2785613C2 |
| СПОСОБ И СИСТЕМА РАСПРЕДЕЛЕННОГО ХРАНЕНИЯ ВОССТАНАВЛИВАЕМЫХ ДАННЫХ С ОБЕСПЕЧЕНИЕМ ЦЕЛОСТНОСТИ И КОНФИДЕНЦИАЛЬНОСТИ ИНФОРМАЦИИ | 2021 |
|
RU2777270C1 |





Изобретение относится к области резервного копирования и восстановления данных. Техническим результатом является повышение эффективности полного резервного копирования. Предлагается способ и система для резервного копирования и сохранения данных. Сначала выполняется полное резервное копирование с целью создать полный набор данных. После этого могут быть созданы инкрементные или дифференциальные наборы данных посредством инкрементного или дифференциального резервного копирования, соответственно. Когда требуется новый полный набор данных, то вместо выполнения полного резервного копирования предыдущий полный набор данных может быть объединен с последующими инкрементными или дифференциальными наборами данных, чем создается новый полный набор данных. Новый полный набор данных может быть создан на компьютере, отличном от компьютера, на котором размещены данные предыдущего полного набора данных. Новый полный набор данных может быть использован для хранения данных в другом месте или для быстрого восстановления данных в случае повреждения или порчи файловой системы компьютера. 4 н. и 24 з.п. ф-лы, 7 ил.
1. Способ полного резервного копирования файловой системы, при этом способ реализуется в вычислительной системе и содержит этапы, на которых:
выполняют обыкновенное полное резервное копирование файловой системы, причем файловая система включает в себя данные, и обыкновенное полное резервное копирование использует файловую систему с целью создать первый полный набор данных в момент времени создания, и упомянутое обыкновенное полное резервное копирование представляет собой первое полное резервное копирование;
вслед за выполнением обыкновенного полного резервного копирования выполняют частичное резервное копирование с целью создать второй набор данных после изменений в файловой системе, таких, что первый полный набор данных становится устаревшим, причем второй набор данных включает в себя только часть данных файловой системы, включающую части файловой системы, изменившиеся с момента обыкновенного полного резервного копирования, при этом выполнение частичного резервного копирования с целью создать второй набор данных содержит для файлов, размер которых превышает заданный размер, копирование измененных экстентов в файле, превышающем упомянутый заданный размер, таким образом, что во второй набор данных включаются не целый файл, а изменения в упомянутом файле; и
выполняют операцию синтетического полного резервного копирования путем объединения первого полного набора данных обыкновенного полного резервного копирования со вторым набором данных для создания первого синтетического полного набора данных файловой системы, причем первый синтетический полный набор данных является эквивалентом того, что создало бы обыкновенное полное резервное копирование, выполняемое в момент создания первого полного набора данных и синтетическое полное резервное копирование создает полный набор данных, основываясь на предыдущих резервных копированиях, а не на файловой системе;
периодически выполняют операцию синтетического полного резервного копирования для создания второго синтетического полного набора данных файловой системы с учетом любых изменений в ней и таким образом, что упомянутое первое полное резервное копирование представляет собой единственное обыкновенное резервное копирование, выполняемое для создания полного набора данных.
2. Способ по п.1, в котором выполнение обыкновенного полного резервного копирования включает в себя копирование данных на работающее в режиме «он-лайн» запоминающее устройство.
3. Способ по п.1, в котором работающее в режиме «он-лайн» запоминающее устройство содержит жесткий магнитный диск.
4. Способ по п.2, в котором данные содержат объекты, каждый из которых связан с метаданными, и в котором данные копируются на работающее в режиме «он-лайн» запоминающее устройство посредством получения метаданных, связанных с каждым объектом, и копирования объекта и связанных с ним метаданных на работающее в режиме «он-лайн» запоминающее устройство.
5. Способ по п.2, в котором файловая система содержит том и в котором копирование данных на работающее в режиме «он-лайн» запоминающее устройство включает в себя создание «теневой» копии тома и копирование "теневой" копии на работающее в режиме «он-лайн» запоминающее устройство.
6. Способ по п.5, в котором «теневая» копия сохраняется на указанном томе.
7. Способ по п.5, в котором «теневая» копия сохраняется на указанном томе и на другом томе.
8. Способ по п.2, в котором файловая система содержит том, включающий в себя «теневую» копию, и в котором данные, связанные с «теневой» копией, сохраняются во время каждого резервного копирования.
9. Способ по п.8, в котором данные, связанные с «теневой» копией, сохраняются посредством копирования физических блоков указанного тома при выполнении каждого резервного копирования.
10. Способ по п.8, дополнительно содержащий восстановление второго полного набора данных и данных, связанных с «теневой» копией, сохраненных в нем, осуществляемое таким образом, что «теневая» копия доступна обычным образом.
11. Способ по п.1, в котором данные хранятся в запоминающем устройстве, разделенном на блоки, и в котором первое резервное копирование и последующее резервное копирование выполняются посредством физического резервного копирования запоминающего устройства.
12. Способ по п.11, в котором физическое резервное копирование выполняется посредством открытия файла, в состав которого входят все блоки, подлежащие резервному копированию, и копирования блоков, подлежащих резервному копированию.
13. Способ по п.11, дополнительно содержащий восстановление первого полного набора данных посредством физического восстановления, включающего в себя открытие первого полного набора данных как файла и последовательное копирование блоков в первом полном наборе данных в запоминающее устройство восстановления.
14. Способ по п.13, дополнительно содержащий применение части данных файловой системы, включенных во второй набор данных, к содержимому запоминающего устройства восстановления.
15. Способ по п.1, в котором данные содержат блоки и в котором выполнение последующего резервного копирования включает в себя уплотнение части данных.
16. Способ по п.15, в котором уплотнение части данных включает в себя помещение любых блоков, данные в которых изменились, в область различий.
17. Способ по п.16, в котором блоки, данные в которых изменились, помещаются в область различий посредством действия механизма «теневой» копии.
18. Способ по п.17, в котором множественные полные наборы данных представлены на запоминающем устройстве как множественные «теневые» копии, созданные посредством механизма «теневой» копии.
19. Способ по п.15, в котором уплотнение части данных включает в себя применение алгоритма дифференциального уплотнения.
20. Способ по п.1, в котором выполнение частичного резервного копирования файловой системы с целью создать второй набор данных включает в себя копирование других объектов, которые изменились, но не отслеживаются, посредством копирования всех блоков, связанных с этими другими объектами, во второй набор данных.
21. Способ по п.1, в котором упомянутые данные представляют собой набор данных в ленточном формате Microsoft (MTF).
22. Способ по п.1, в котором выполнение частичного резервного копирования с целью создать второй набор данных содержит, если определено, что блок на диске должен быть изменен, копирование экстента, содержащего упомянутый блок, в дифференциальную область перед изменением упомянутого блока на диске.
23. Способ по п.1, в котором выполнение частичного резервного копирования с целью создать второй набор данных содержит этапы, на которых:
возвращают в исходное состояние постоянного хранилища фильтра каждый раз, когда выполняется частичное резервное копирование файловой системы;
определяют размер каждого файла в файловой системе;
для каждого файла в файловой системе, который имеет размер, меньший, чем упомянутый заданный размер, используют соответствующее время последнего изменения для определения, изменился ли данный объект;
для каждого файла в файловой системе, который имеет размер, меньший, чем упомянутый заданный размер, и который изменился, копируют весь объект во второй набор данных;
для каждого файла в файловой системе, который имеет размер, превышающий упомянутый заданный размер, отслеживают экстенты в файле, используя фильтр, который сохраняет в постоянном хранилище следующее:
путь к файлу, который был изменен;
список набора экстентов в упомянутом файле, которые изменились;
содержимое экстентов в упомянутом наборе экстентов в том порядке, в котором они встречаются в упомянутом списке набора экстентов.
24. Машиночитаемый носитель для использования в вычислительной среде, при этом упомянутый машиночитаемый носитель содержит машиночитаемые инструкции которые при выполнении их компьютером приводят к реализации компьютером способа по любому одному из пп.1-23.
25. Способ полного резервного копирования тома файловой системы, содержащий
создание и поддержание «теневой» копии тома, которая включает в себя первый полный набор данных, при этом «теневая» копия представляет собой логический дубликат этого тома по состоянию на некоторый момент времени;
создание второго полного набора данных этого тома;
перезапись на место первого полного набора данных второго полного набора данных при том, что «теневая» копия поддерживается;
удаление второго полного набора данных;
переименование первого полного набора данных во второй полный набор данных и
осуществление доступа к первому полному набору данных через «теневую» копию.
26. Способ по п.25, дополнительно содержащий осуществление доступа ко второму полному набору данных в томе.
27. Способ по п.25, дополнительно содержащий этап, на котором определяют различия между первым и вторым полными наборами данных, причем различия между первым и вторым полными наборами данных сохраняются в области различий, связанной с «теневой» копией.
28. Машиночитаемый носитель для использования в вычислительной среде, при этом упомянутый машиночитаемый носитель содержит машиночитаемые инструкции, которые при выполнении их компьютером приводят к реализации компьютером способа по любому одному из пп.25-27.
| US 20030149736 A1, 07.08.2003 | |||
| US 20020194523 A1, 19.12.2002 | |||
| СПОСОБ ОБРАЩЕНИЯ К ДАННЫМ, ХРАНИМЫМ В КОМПЬЮТЕРНОЙ СИСТЕМЕ, СПОСОБ АРХИВИРОВАНИЯ ДАННЫХ И КОМПЬЮТЕРНАЯ СИСТЕМА ДЛЯ ОСУЩЕСТВЛЕНИЯ СПОСОБОВ | 1995 |
|
RU2182360C2 |
| СИСТЕМА ПЕРЕМЕЩЕНИЯ ДАННЫХ В РЕАЛЬНОМ ВРЕМЕНИ И СПОСОБ ПРИМЕНЕНИЯ РАЗРЕЖЕННЫХ ФАЙЛОВ | 1996 |
|
RU2190248C2 |

