ОБЛАСТЬ ТЕХНИКИ
[001] Настоящая заявка в целом относится к сжатию атрибутов точек облака точек, предпочтительно к способу кодирования и декодирования, а также кодеру и декодеру для улучшенного кодирования атрибутов облака точек.
УРОВЕНЬ ТЕХНИКИ
[002] В качестве формата для представления трехмерных (3D) данных в последнее время получили распространение облака точек, поскольку они универсальны в своих возможностях представления всех типов трехмерных объектов или сцен. Таким образом, многие варианты использования могут быть осуществлены с помощью облаков точек, среди которых
• постпроизводство фильма,
• 3D иммерсивное телеприсутствие в режиме реального времени или приложения VR/AR,
• видео с произвольной точки съемки (например, для просмотра спортивных состязаний),
• географические информационные системы (также известные как картография),
• культурное наследие (хранение сканов редких предметов в цифровом виде),
• автономное вождение, в том числе 3D-картографирование окружающей среды и сбор данных с помощью лидара в реальном времени.
[003] Облако точек представляет собой набор точек, расположенных в трехмерном пространстве, опционально с дополнительными значениями, прикрепленными к каждой из точек. Эти дополнительные значения обычно называются атрибутами точки. Следовательно, облако точек представляет собой комбинацию геометрии (трехмерного положения каждой точки) и атрибутов.
[004] Атрибутами могут быть, например, трехкомпонентные цвета, свойства материала, такие как отражательная способность и/или двухкомпонентные векторы нормали к поверхности, связанной с точкой.
[005] Облака точек могут быть захвачены различными типами устройств, таких как совокупность камер, датчиков глубины, лидаров, сканеров, или могут быть сгенерированы компьютером (например, при постпроизводстве фильма). В зависимости от вариантов использования облака точек могут содержать от тысяч до миллиардов точек, например, для картографических приложений.
[006] Необработанные представления облаков точек требуют очень большого количества битов на точку по меньшей мере дюжины битов на пространственный компонент X, Y или Z, и опционально больше битов для атрибута, например трижды по 10 битов для цвета. Практическое развертывание приложений на основе облаков точек требует технологий сжатия, которые позволяют хранить и распространять облака точек с помощью разумных инфраструктур хранения и передачи.
[007] Сжатие может осуществляться с потерями (как при сжатии видео) для распространения и визуализации конечным пользователем, например, на AR/VR-очках или любом другом устройстве с поддержкой 3D. Другие варианты использования требуют сжатия без потерь, например, в медицинских приложениях или автономном вождении, чтобы избежать изменения результатов решения, полученного в результате анализа сжатого и переданного облака точек.
[008] До недавнего времени сжатие облака точек (point cloud compression, также известное как РСС) не использовалось на массовом рынке, и стандартизированный кодек облака точек не был доступен. В 2017 году рабочая группа по стандартизации ISO/JCT1/SC29/WG11, также известная как Группа экспертов по движущимся изображениям (Moving Picture Experts Group), или MPEG, инициировала рабочие элементы по сжатию облаков точек. Это привело к появлению двух стандартов, а именно:
• MPEG-I часть 5 (ISO/IEC 23090-5) или сжатие облака точек на основе видео (Video-based Point Cloud Compression, V-PCC).
• MPEG-I часть 9 (ISO/IEC 23090-9) или сжатие облака точек на основе геометрии (Geometry-based Point Cloud Compression, G-PCC).
Стандарты V-PCC и G-PCC завершили свою первую версию в конце 2020 года и вскоре будут доступны на рынке.
[009] Способ кодирования V-PCC сжимает облако точек путем выполнения нескольких проекций трехмерного объекта для получения двухмерных фрагментов, которые упаковываются в изображение (или видео, когда речь идет о движущихся облаках точек). Полученные изображения или видео затем сжимаются с использованием уже существующих кодеков изображений/видео, что позволяет использовать уже развернутые решения для изображений и видео. По своей природе V-PCC эффективен только для плотных и непрерывных облаков точек, поскольку кодеки изображений/видео не способны сжимать негладкие участки, как это было бы получено при проецировании, например, разреженных геометрических данных, полученных с помощью лидара.
[010] Способ кодирования G-PCC имеет две схемы сжатия геометрии.
[011] Первая схема основана на представлении геометрии облака точек в виде дерева занятости (октодерева/квадродерева/двоичного дерева). Занятые узлы разбиваются до тех пор, пока не будет достигнут определенный размер, а занятые листовые узлы обеспечивают расположение точек, обычно в центре этих узлов. Используя способы прогнозирования на основе соседей, можно получить высокий уровень сжатия для плотных облаков точек. Решение по разреженным облакам точек также осуществляется путем прямого кодирования положения точки в узле неминимального размера, путем остановки построения дерева, когда в узле присутствуют только изолированные точки; этот способ известен как режим прямого кодирования (Direct Coding Mode, DCM).
[012] Вторая схема основана на прогнозирующем дереве, каждый узел представляет трехмерное местоположение одной точки, а связь между узлами представляет собой пространственное прогнозирование от родителя к дочерним элементам. Этот способ может работать только с разреженными облаками точек и предлагает преимущество более низкой задержки и более простого декодирования, чем дерево занятости. Однако производительность сжатия лишь незначительно лучше, а кодирование является сложным по сравнению с первым способом на основе занятости, требующим интенсивного поиска лучшего предиктора (среди длинного списка потенциальных предикторов) при построении дерева прогнозирования.
[013] В обеих схемах кодирование/декодирование атрибутов выполняется после полного кодирования/декодирования геометрии, что приводит к двухпроходному кодированию. Таким образом, низкая задержка достигается за счет использования срезов (slices), которые разлагают трехмерное пространство на подобъемы, которые кодируются независимо, без прогнозирования между подобъемами. Это может сильно повлиять на производительность сжатия при использовании большого количества срезов.
[014] Атрибуты точек кодируются на основе закодированных геометрических координат, которые используются для помощи в декорреляции информации атрибутов в соответствии с пространственными отношениями/расстояниями между точками. В G-PCC в основном существует два способа декорреляции и кодирования атрибутов: первый называется RAHT (region adaptive hierarchical transform) для адаптивного иерархического преобразования области, а второй использует один или несколько уровней детализации (level of details, LoD) и тогда иногда называется LoD или предлифт (predlift), поскольку его можно настроить для использования в качестве способа прогнозирующей декорреляции или в качестве способа декорреляции на основе лифтинга.
[015] При использовании схемы прогнозирования LoD прогнозирование значения атрибута (цвета трех каналов/компонентов или коэффициента отражения одного канала/компонента, прозрачности, например) текущей декодированной точки выполняется с использованием взвешенного прогнозирования на основе значений атрибутов k-ближайших (с использованием геометрических координат) предыдущих декодированных точек. Веса в прогнозе зависят от пространственного расстояния (согласно геометрическим координатам) между текущей точкой и каждой из ближайших предыдущих декодированных точек, используемых в прогнозировании.
[016] В текущем G-PCC прогнозирование атрибута выполняется между текущей точкой и ее k - ближайшими (с точки зрения манхэттенского расстояния) соседями в том же LoD (т.е. внутрикадровое предсказание LoD) и более высоких LoD (межкадровое предсказание LoD).
[017] Учитывая сложное распределение 3D-точек, выбор k-ближайших точек в качестве предикторов (т.е. использование расстояния в качестве единственного критерия) не всегда может быть оптимальным. Теоретически часто бывает, что k-ближайшие соседи (по расстоянию) не являются к-ближайшими соседями с точки зрения значений атрибутов.
[018] Целью настоящего изобретения является создание эффективного способа кодирования и декодирования, а также кодера и декодера для обеспечения улучшенного сжатия атрибутов облака точек.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[019] В одном из аспектов настоящего изобретения предложен способ кодирования в битовом потоке атрибутов точки, связанных с точкой облака точек. Способ включает в себя:
[020] Для точки Р, подлежащей кодированию в битовом потоке, определяют список предикторов из k точек-предикторов облака точек, включающий точки облака точек, ближайшие к точке Р, подлежащей кодированию, которые выбираются в соответствии с их положением относительно друг друга; и
[021] Кодирование атрибутов точки, связанных с точкой Р, подлежащей кодированию, для кодирования с предсказанием на основе атрибутов точек-предикторов из списка предикторов.
[022] Таким образом, для точки Р, атрибуты которой должны быть закодированы в битовый поток, определяется список предикторов из k точек-предикторов. Обычно к равно 3. При этом список предикторов включает в себя k точек облака точек, ближайших к точке Р, подлежащей кодированию, которые дополнительно выбираются на основе их относительного географического положения друг относительно друга вокруг точки Р, подлежащей кодированию. Таким образом, список предикторов может не включать в себя ближайшие к точек облака точек, но с помощью способа настоящего изобретения точка облака точек, находящаяся дальше от точки Р, подлежащей кодированию, может быть включена в список предикторов, что приводит к точкам-предикторам в списке предикторов, которые должны быть распределены вокруг или в достаточной мере вокруг точки Р, подлежащей кодированию. Таким образом, одна или несколько точек из к ближайших точек, находящихся ближе всего к точке Р, подлежащей кодированию, могут быть проигнорированы и заменены точками, которые находятся дальше (геометрически) в облаке точек, но обеспечивают улучшенное предсказание атрибутов точки Р.
[023] На следующем этапе атрибуты точки, связанные с точкой Р, подлежащей кодированию, кодируются посредством кодирования с предсказанием на основе атрибутов точек-предикторов из списка предикторов. Таким образом, список предикторов используется для кодирования с предсказанием атрибутов точки Р.
[024] При этом посредством выбранных точек списка предикторов может быть достигнуто лучшее предсказание атрибутов точки Р, тем самым уменьшая остаток, подлежащий кодированию, тем самым уменьшая размер битового потока.
[025] Предпочтительно, определение списка предикторов включает в себя:
[026] Определение исходного списка из k точек-предикторов Р0,…, P(k-l) облака точек, включающего k точек облака точек с ближайшими географическими координатами к точке Р, подлежащей кодированию;
[027] Определение выбора точек-предикторов исходного списка в качестве списка предикторов согласно их положению относительно друг друга. Таким образом, на первом этапе определяется исходный список из к точек-предикторов Р0,…,Р(k-1) облака точек, причем исходный список включает в себя к точек облака точек, ближайших к точке Р, подлежащей кодированию.. На последующем этапе точки-предикторы исходного списка выбираются на основе их относительного положения друг относительно друга относительно точки Р, подлежащей кодированию. Если расширение или распределение исходного списка достаточно, выбирается исходный список, т.е. к ближайших точек-предикторов облака точек, что приводит к достаточной точности предсказания атрибутов точки Р, подлежащей кодированию, во время кодирования с предсказанием атрибутов точка Р.
[028] Предпочтительно исходный список упорядочивается согласно расстоянию до точки Р, подлежащей кодированию, от ближайшей точки Р0 до самой дальней точки P(k-l).
[029] Предпочтительно способ включает в себя:
[030] Если точки-предикторы исходного списка не выбраны:
[031] Определение списка кандидатов из n точек-предикторов по k - k+n-1
ближайшим точкам Pk,…,Р(k+n-1) облака точек;
[032] Замена по меньшей мере одной точки-предиктора исходного списка на точку- предиктор из списка кандидатов для получения списка предикторов; и
[033] Выбор точек-предикторов полученного списка в качестве списка предикторов согласно их положению относительно друг друга.
[034] При этом предпочтительно n составляет от 1 до 10, более предпочтительно от 1 до 5 и наиболее предпочтительно n=3.
[035] Таким образом, по меньшей мере одна точка-предиктор исходного списка заменяется точкой-предиктором списка кандидатов для получения списка. При этом полученный список выбирается для использования для кодирования атрибутов точки, связанных с точкой Р, подлежащей кодированию посредством кодирования с предсказанием на основе географических координат точек-предикторов полученного списка относительно Друг друга. Таким образом, одна из k ближайших точек-предикторов исходного списка заменяется точкой-предиктором, которая находится дальше от точки, подлежащей кодированию, чтобы получить улучшенное предсказание атрибутов точки Р, подлежащей кодированию.
[036] Предпочтительно способ включает в себя:
[037] Если полученный список предикторов не выбран, итеративно заменяют по меньшей мере одну точку-предиктор поэтапно каждой точкой-предиктором из списка кандидатов для получения списка до тех пор, пока точки-предикторы соответствующего списка не будут выбраны на основе положений точек-предикторов полученного списка относительно друг друга.
[038] Таким образом, каждая точка-предиктор списка кандидатов последовательно рассматривается, может ли соответствующая точка-предиктор списка кандидатов увеличить расширение или распределение исходного списка, обеспечивая лучшие результаты прогнозирования для атрибутов точки Р, подлежащей кодированию. При этом процесс может быть остановлен, как только будет найдена одна точка-предиктор из списка кандидатов, так что будут выбраны точки-предикторы результирующего списка.
[039] Предпочтительно, точки-предикторы списков кандидатов упорядочены в соответствии с их расстоянием до точки Р, подлежащей кодированию, в порядке возрастания расстояния, при этом точка Pk является ближайшей точкой списка кандидатов (но еще дальше, поскольку последняя точка исходного списка) и P(k+n-1) - самая дальняя точка-предиктор списка кандидатов.
[040] Предпочтительно, заменяется только последняя точка-предиктор исходного списка. Таким образом, если точки-предикторы исходного списка не выбраны, только последняя точка-предиктор исходного списка заменяется одной из точек-предикторов списка кандидатов. В частности, также для полученного списка, полученного путем замены последней точки-предиктора исходного списка или, в итерационном процессе, путем замены последней точки-предиктора полученного списка предыдущего шага, только последняя точка-предиктор заменяется одной из точек-предикторов списка кандидатов.
[041] Предпочтительно, k равно 2 или больше и более предпочтительно равно 3. В частности, k=3 представляет собой достаточный компромисс между сложностью реализации для увеличения числа k и достаточной предсказуемостью, т.е. достаточным уменьшением соответствующих остатков при прогнозировании.
[042] Предпочтительно, пространство вокруг точки Р, подлежащей кодированию, разделяется на октанты вдоль осей X, Y и Z (используемых для географических положений/координат точек) кодирования/декодирования, при этом точки-предикторы выбираются, если по меньшей мере две точки-предиктора расположены в противоположных октантах, причем противоположные октанты имеют только общую точку Р, подлежащую кодированию.
[043] Таким образом, список точек-предикторов, являющийся исходным списком или списком предикторов, считается содержащим точки-предикторы, достаточно рассредоточенные или распределенные вокруг точки Р, подлежащей кодированию, и, таким образом, выбранные, если по меньшей мере две точки-предиктора из этого соответствующего списка точек-предикторов расположены в противоположных октантах. При этом при рассмотрении относительного положения друг относительно друга соответствующих точек-предикторов и выборе этих точек-предикторов из полученного списка предикторов или исходного списка определяется, содержит ли соответствующий список по меньшей мере две точки-предиктора, которые противоположны, т.е. расположены в противоположных октантах.
[044] Предпочтительно, пространство вокруг точки Р, подлежащей кодированию, разделено на октанты вдоль осей X, Y и Z кодирования/декодирования, при этом точки-предикторы выбираются, если по меньшей мере две точки-предиктора расположены в нестрого противоположных октантах, при этом нестрого противоположные октанты имеют только один общий край.
[045] Таким образом, список точек-предикторов, являющийся исходным списком или списком предикторов, считается содержащим точки-предикторы, достаточно рассредоточенные или распределенные вокруг точки Р, подлежащей кодированию, и, таким образом, выбранные, если по меньшей мере две точки-предиктора из этого соответствующего списка точек-предикторов расположены в нестрого противоположных октантах. При этом, при рассмотрении относительного положения друг относительно друга соответствующих точек-предикторов и выборе этих точек-предикторов из полученного списка предикторов или исходного списка, определяется, содержит ли соответствующий список по меньшей мере две точки-предиктора, которые расположены нестрого друг напротив друга, т.е. расположены в нестрого противоположных октантах.
[046] Предпочтительно, выбор точек-предикторов из исходного списка и/или списка предикторов включает в себя:
[047] определение того, расположены ли по меньшей мере две точки-предиктора исходного списка или списка предикторов в противоположных октантах, и последующее определение того, расположены ли по меньшей мере две точки-предиктора исходного списка или списка предикторов в нестрого противоположных октантах. В качестве альтернативы, для конкретной точки-предиктора списка кандидатов, заменяющей одну точку-предиктор из исходного списка, определяется, расположены ли по меньшей мере две точки-предиктора списка предикторов в противоположных октантах, и впоследствии определяется, расположены ли по меньшей мере две точки-предиктора исходного списка или списка предикторов в нестрого противоположных октантах. Впоследствии может быть рассмотрена следующая точка-предиктор списка кандидатов.
[048] Предпочтительно последующее определение того, расположены ли по меньшей мере две точки-предиктора исходного списка или списка предикторов в нестрого противоположных октантах, выполняется только тогда, когда последние две точки исходного списка находятся в одном и том же октанте.
[049] Предпочтительно, по меньшей мере одно пороговое значение Ti определяется как Ti=W х dist(P, Pi), с весом W>1 и Pi - точкой-предиктором из исходного списка, при этом точки-предикторы из списка кандидатов подходят для замены упомянутой по меньшей мере одной точки-предиктора исходного списка, если расстояние между точкой-предиктором списка кандидатов и точкой Р, подлежащей кодированию/декодированию, меньше Ti.
[050] Таким образом, только те точки-предикторы списка кандидатов рассматриваются для замены одной или более точек-предикторов исходного списка или любого прежнего полученного списка предикторов, если расстояние между соответствующей точкой-предиктором списка кандидатов до точки Р, подлежащей кодированию, меньше порога Ti. При этом отдельные пороговые значения Ti могут быть определены в соответствии с расстоянием между точкой Р и точкой Pi исходного списка, чтобы обеспечить возможность достаточного отбора кандидатов. При этом вес W предпочтительно фиксирован для определенного облака точек. Предпочтительно, W определяют согласно плотности точек облака точек, при этом для разреженного облака точек выбирается больший вес W.
[051] Предпочтительно, весовая информация W и/или n включена в битовый поток.
[052] Предпочтительно, битовый поток представляет собой битовый поток, совместимый с MPEG G-PCC, и информация о весе W и/или п присутствует в наборе параметров атрибутов (Attribute Parameter Set, APS) битового потока G-PCC.
[053] В одном из аспектов настоящего изобретения предложен способ декодирования из битового потока атрибутов точки, связанных с точкой облака точек, включающий в себя:
[054] Для точки Р, подлежащей декодированию в битовый поток, определение списка предикторов из k точек-предикторов облака точек, включающего точки облака точек, ближайшие к точке Р, подлежащей декодированию, которые выбираются в соответствии с их положением относительно друг друга; и
[055] Декодирование атрибутов точки, связанных с точкой Р, подлежащей декодированию посредством декодирования с предсказанием, на основе атрибутов точек-предикторов списка предикторов.
[056] Предпочтительно, способ декодирования дополнительно построен вместе с признаками, описанными выше в отношении способа кодирования. В частности, процесс кодирования и декодирования аналогичны. Те же этапы способа могут быть реализованы и для способа декодирования.
[057] В одном аспекте настоящего изобретения предложен кодер для кодирования в битовом потоке атрибутов точки, связанных с точкой облака точек, содержащий: процессор и запоминающее устройство, при этом в запоминающем устройстве хранятся инструкции, исполняемые процессором, которые при выполнении заставляют процессор выполнять способ кодирования, описанный выше.
[058] В одном аспекте настоящего изобретения предложен декодер для декодирования в битовом потоке атрибутов точки, связанных с точкой облака точек, содержащий: процессор и запоминающее устройство, причем в запоминающем устройстве хранятся инструкции, исполняемые процессором, которые при выполнении заставляют процессор выполнять способ, описанный выше.
[059] В одном аспекте настоящего изобретения предложен энергонезависимый машиночитаемый носитель данных, хранящий исполняемые процессором инструкции, которые при выполнении процессором заставляют процессор выполнять способ, как описано выше.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[060] Теперь в качестве примера будут сделаны ссылки на прилагаемые чертежи, на которых показаны примерные варианты осуществления настоящей заявки, и при этом на чертежах показано:
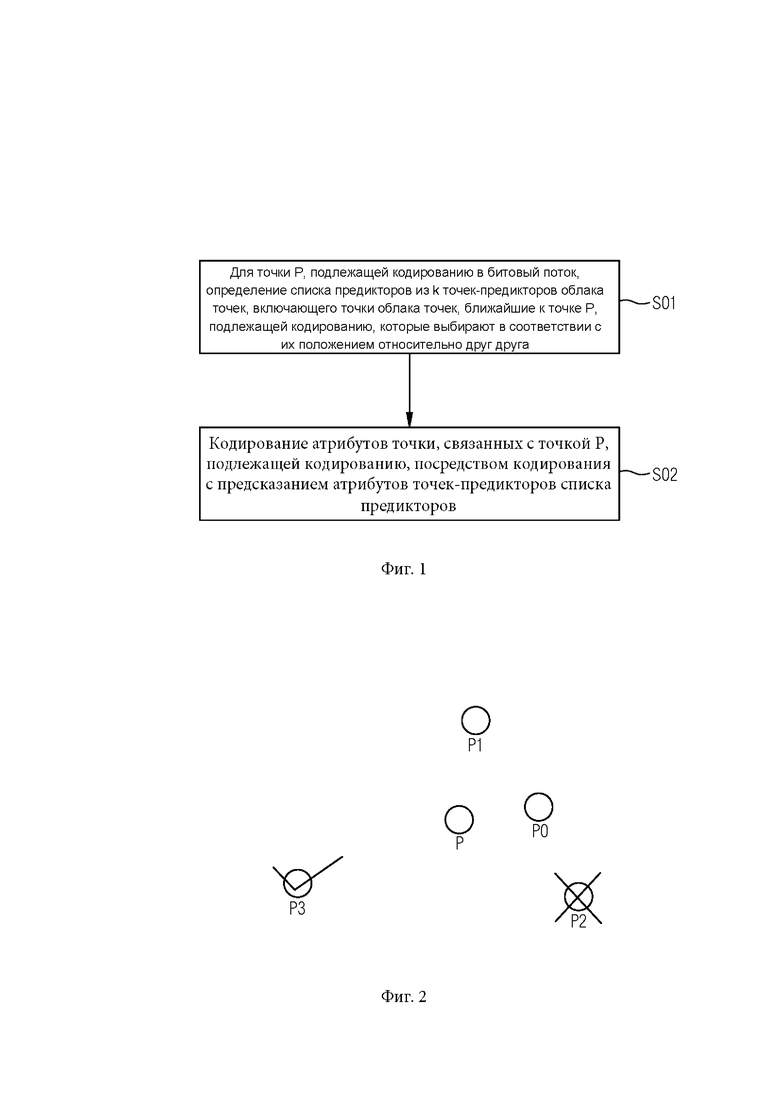
[061] Фиг. 1 иллюстрирует блок-схему способа кодирования согласно настоящему изобретению.
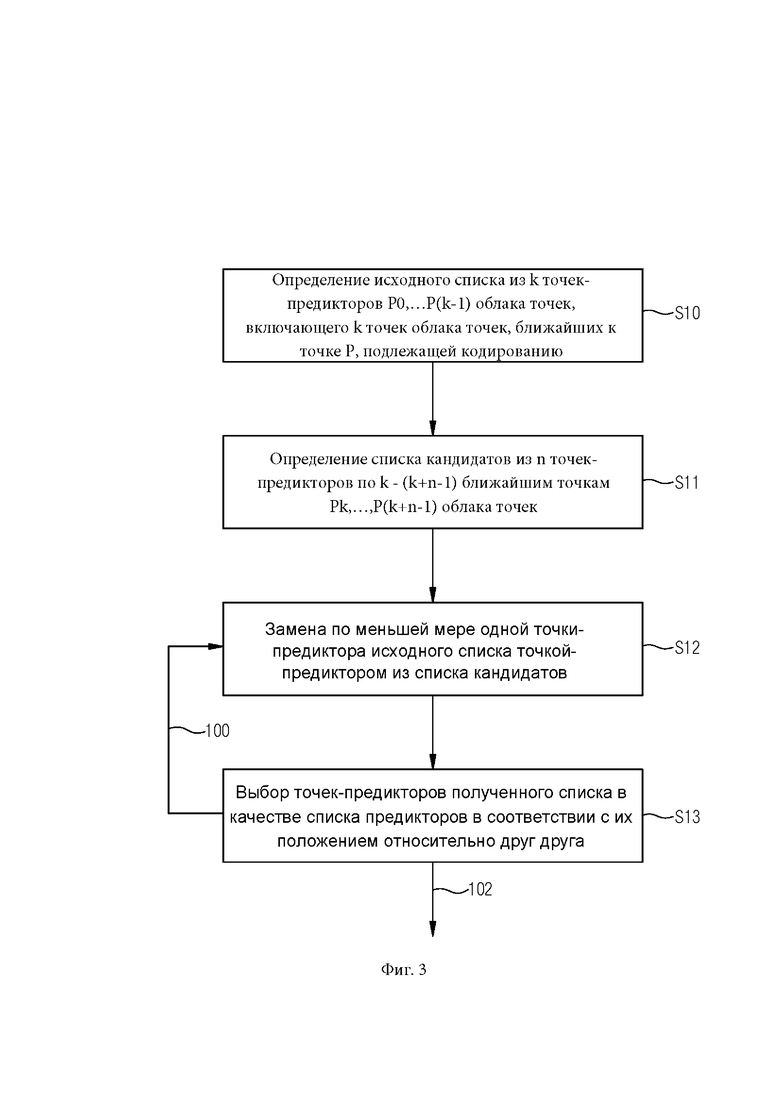
[062] Фиг. 2 иллюстрирует схематическое изображение точек-предикторов в облаке точек,
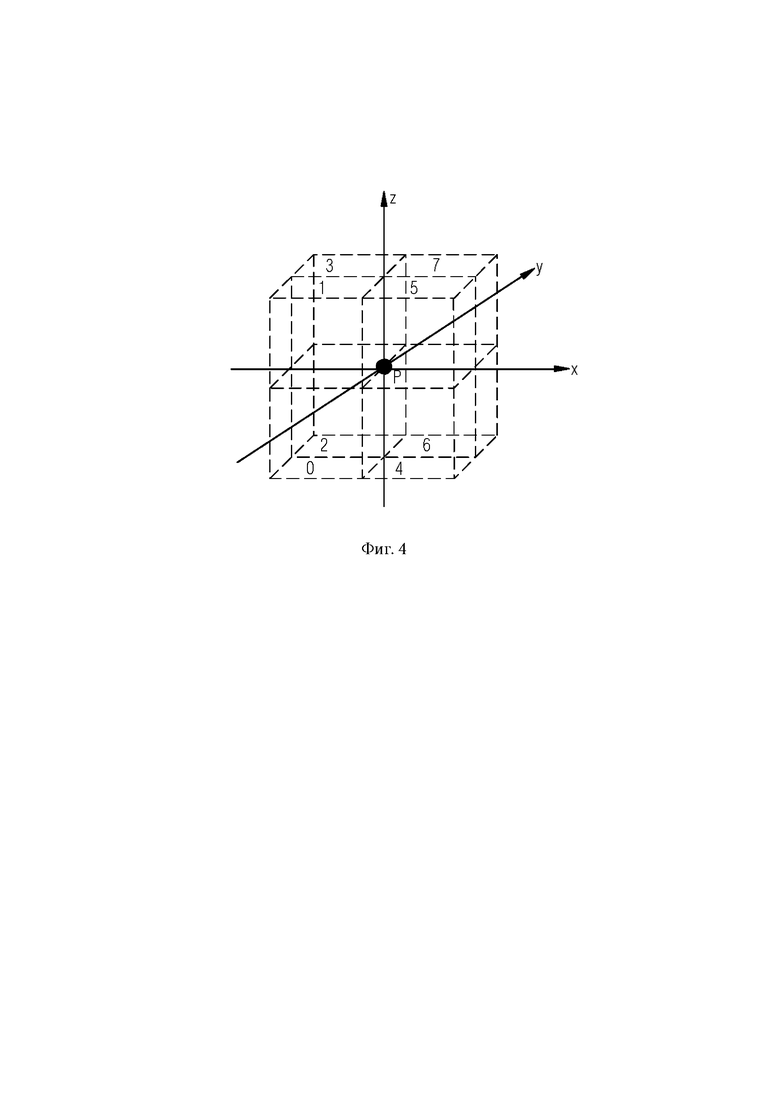
[063] Фиг. 3 иллюстрирует блок-схему другого варианта осуществления способа согласно настоящему изобретению.
[064] Фиг. 4 иллюстрирует особый порядок расположения вокруг точки Р, подлежащей кодированию,
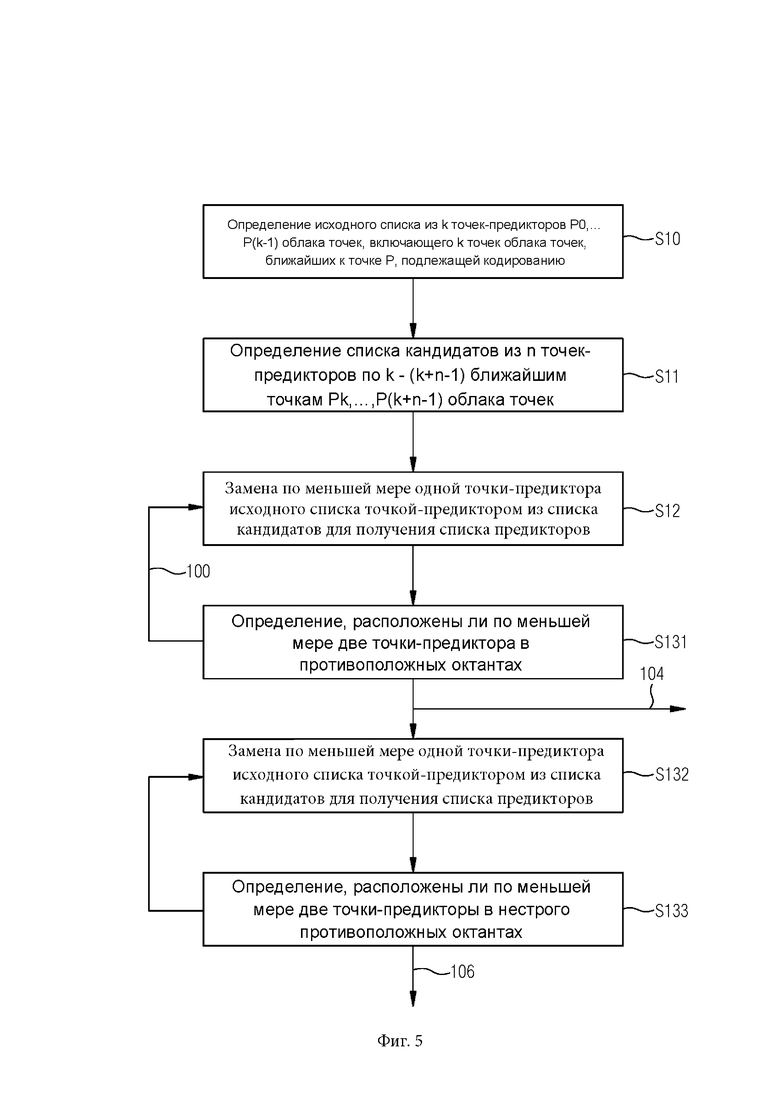
[065] Фиг. 5 иллюстрирует блок-схему еще одного варианта осуществления способа согласно настоящему изобретению.
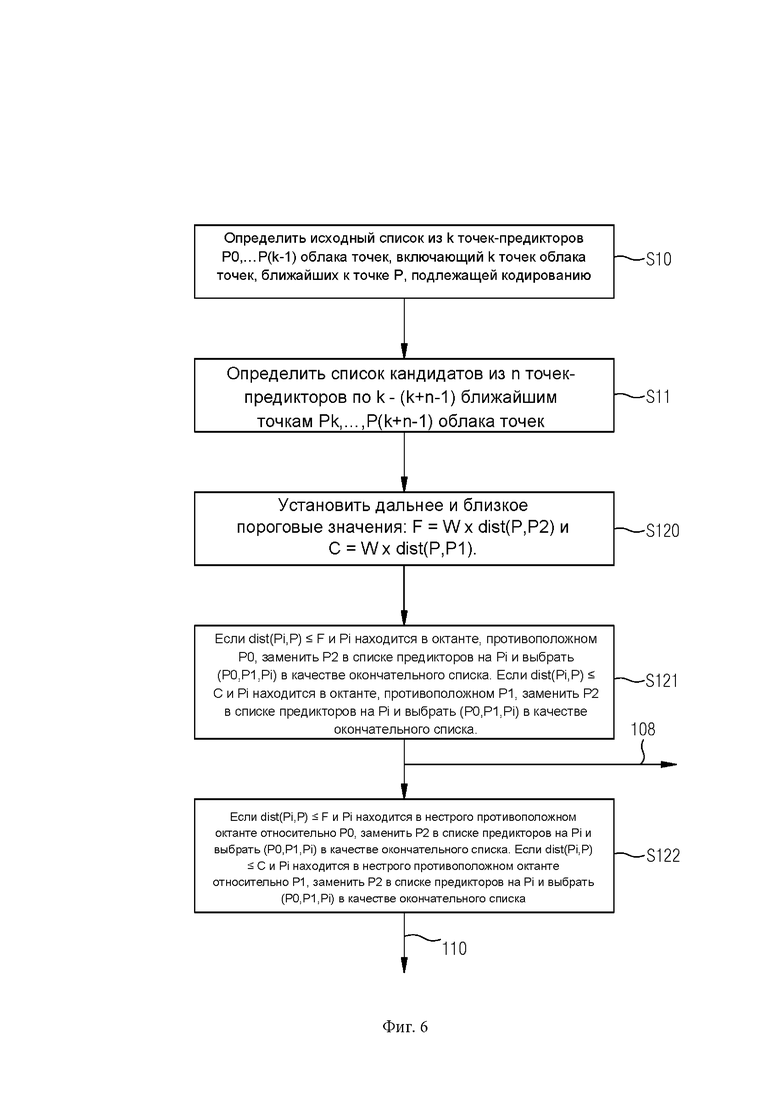
[066] Фиг. 6 иллюстрирует блок-схему еще одного варианта осуществления способа согласно настоящему изобретению.
[067] Фиг. 7 иллюстрирует блок-схему последовательности операций декодирования согласно настоящему изобретению.
[068] Фиг. 8 иллюстрирует кодер согласно настоящему изобретению и
[069] Фиг. 9 иллюстрирует декодер согласно настоящему изобретению.
ПОДРОБНОЕ ОПИСАНИЕ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ
[070] Настоящая заявка описывает способы кодирования и декодирования атрибутов точек в облаке точек, а также кодеры и декодеры для кодирования и декодирования атрибутов точек в облаке точек.
[071] Настоящее изобретение относится к способу кодирования в битовом потоке атрибутов точки, связанных с точкой облака точек, включающему в себя:
[072] Для точки Р, подлежащей кодированию в битовом потоке, определение списка предикторов из k точек-предикторов облака точек, включающего точки облака точек, ближайшие к точке Р, подлежащей кодированию, которые выбираются в соответствии с их положением относительно друг друга; и
[073] Кодирование атрибутов точки, связанных с точкой Р, подлежащей кодированию посредством кодирования с предсказанием на основе атрибутов точек-предикторов из списка предикторов.
[074] Кроме того, настоящее изобретение относится к способу декодирования из битового потока атрибутов точки, связанных с точкой облака точек, включающему в себя:
[075] Для точки Р, подлежащей декодированию в битовом потоке, определение списка предикторов из k точек-предикторов облака точек, включающего точки облака точек, ближайшие к точке Р, подлежащей декодированию, которые выбираются в соответствии с их положением относительно друг друга; и
[076] Декодирование атрибутов точки, связанных с точкой Р, подлежащей декодированию посредством декодирования с прогнозированием на основе атрибутов точек-предикторов списка предикторов.
[077] Другие аспекты и особенности настоящей заявки будут понятны специалистам в данной области техники из обзора следующего описания примеров в сочетании с сопроводительными чертежами.
[078] Облако точек представляет собой набор точек в трехмерной системе координат. Точки часто предназначены для обозначения внешней поверхности одного или нескольких объектов. Каждая точка имеет свое местоположение (положение) в трехмерной системе координат. Положение может быть представлено тремя координатами (X, Y, Z), которые могут быть декартовой или любой другой системой координат. Точки имеют дополнительные связанные атрибуты, такие как цвет, который в некоторых случаях также может быть трехкомпонентным значением, например R, G, В или Y, Cb, Cr. Другие связанные атрибуты могут включать в себя прозрачность, отражательную способность, вектор нормали и т.д., в зависимости от желаемого применения данных облака точек.
[079] Облака точек могут быть статическими или динамическими. Например, детальное сканирование или картография объекта или топографии могут представлять собой данные статического облака точек. Сканирование окружающей среды с помощью LiDAR для целей машинного зрения может быть динамическим, поскольку облако точек (по меньшей мере потенциально) меняется со временем, например, при каждом последующем сканировании объема. Таким образом, динамическое облако точек представляет собой упорядоченную по времени последовательность точек.
[080] Данные облака точек могут использоваться в ряде приложений, в том числе сохранение (сканирование исторических или культурных объектов), картографирование, машинное зрение (например, автономные или полуавтономные автомобили) и системы виртуальной реальности, указанные в качестве некоторых примеров. Данные динамического облака точек для таких приложений, как машинное зрение, могут сильно отличаться от данных статического облака точек, подобных тем, которые используются в целях сохранения. Например, автомобильное зрение обычно включает в себя бесцветные и высокодинамичные облака точек с относительно небольшим разрешением, полученные с помощью датчиков LiDAR (или аналогичных) с высокой частотой захвата. Целью таких облаков точек является не использование или просмотр человеком, а скорее обнаружение/классификация машинных объектов в процессе принятия решений. Например, типичные кадры LiDAR содержат порядка десятков тысяч точек, тогда как высококачественные приложения виртуальной реальности требуют нескольких миллионов точек. Можно ожидать, что со временем возникнет потребность в данных более высокого разрешения по мере увеличения скорости вычислений и поиска новых приложений.
[081] Хотя данные облака точек полезны, отсутствие эффективного и действенного сжатия атрибутов и геометрии такого облака точек, то есть процессов кодирования и декодирования, может препятствовать внедрению и развертыванию.
[082] Одним из наиболее распространенных механизмов кодирования данных облака точек является использование древовидных структур. В древовидной структуре ограничивающий трехмерный объем облака точек рекурсивно делится на подобъемы. Узлы дерева соответствуют подобъемам. Решение о том, следует ли дополнительно разделять подобъем, может быть основано на разрешении дерева и/или наличии каких-либо точек, содержащихся в подобъеме. Листовой узел может иметь флаг занятости, который указывает, содержит ли связанный с ним подобъем точку или нет. Флаги разделения могут сигнализировать о том, есть ли у узла дочерние узлы (т.е. был ли текущий объем дополнительно разделен на подобъемы). В некоторых случаях эти флаги могут быть закодированы энтропийно, а в некоторых случаях может использоваться кодирование с предсказанием. Обычно используемой древовидной структурой является октодерево. В этой структуре все объемы/подобъемы представляют собой кубы, и каждое разделение подобъема приводит к образованию восьми дополнительных подобъемов/подкубов.
[083] Основной процесс создания октодерева для кодирования облака точек может включать в себя:
Начните с ограничивающего объема (куба), содержащего облако точек в системе координат;
1. Разделите объем на 8 подобъемов (восемь подкубов);
2. Для каждого подобъема пометьте подобъем 0, если подобъем пуст, или 1, если в нем есть хотя бы одна точка;
3. Для всех подобъемов, отмеченных цифрой 1, повторите (2), чтобы разделить эти подобъемы, пока не будет достигнута максимальная глубина разделения; и
4. Для всех листовых подобъемов (подкубов) максимальной глубины пометьте листовой куб цифрой 1, если он непустой, и 0 в противном случае.
[084] Дерево может быть пройдено в заранее определенном порядке (сначала в ширину или сначала в глубину и в соответствии с схемой/порядком сканирования внутри каждого разделенного подобъема) для создания последовательности битов, представляющей схему занятости каждого узла.
[085] Как упоминалось выше, точки в облаке точек могут включать в себя атрибуты. Эти атрибуты кодируются независимо от кодирования геометрии облака точек. Таким образом, каждый занятый узел, т.е. узел, включающий в себя по меньшей мере одну точку облака точек, связан с одним или более атрибутами, чтобы дополнительно указать свойства облака точек.
[086] Настоящее изобретение предлагает способ кодирования атрибутов точек облака точек в битовом потоке. Способ показан на фиг. 1.
[087] На этапе S01, для точки Р, подлежащей кодированию в битовый поток, определяют список предикторов из k точек-предикторов облака точек, включающий точки облака точек, ближайшие к точке Р, подлежащей кодированию, которые выбираются в соответствии с их положением относительно друг друга.
[088] На этапе S02 кодируют атрибуты точки, связанные с точкой Р, подлежащей кодированию посредством кодирования с предсказанием на основе атрибутов точек-предикторов из списка предикторов.
[089] Настоящее изобретение представляет механизм, который позволяет как на стороне кодирования, так и на стороне декодирования заменять список из к ближайших предикторов для кодирования атрибута LoD другим списком из к предикторов, которые в конечном итоге обеспечивают лучшее предсказание (меньший остаток).
[090] Для этого настоящее изобретение рассматривает возможность замены одной или более из k ближайших точек-предикторов «дальними» точками, если их положение в пространстве более благоприятно, т.е. точки-предикторы более рассредоточены или распределены вокруг точки, подлежащей прогнозированию.
[091] Ссылаясь на фиг. 2, для кодирования атрибутов точки Р, может быть предпочтительнее использовать более дальнюю точку, обозначенную Р3 на фиг. 2, вместо более близкой точки Р2, поскольку точки-предикторы Р0, Р1 и РЗ лучше распределены или достаточно рассредоточены вокруг Р, чем три ближайшие точки-предикторы Р0, Р1 и Р2, и, таким образом, могут обеспечить лучший прогноз атрибутов точки Р.
[092] Ниже приводится пример, в котором 3 точки-предиктора используются для прогнозирования атрибутов точки Р, подлежащей кодированию, т.е. k=3. Конечно, настоящее изобретение не ограничивается этим количеством рассматриваемых точек-предикторов. Однако обычные приложения в соответствии со стандартом MPEG используют это количество предикторов в схемах прогнозирования LoD, поскольку оно обеспечивает хороший компромисс между сложностью реализации и точностью для уменьшения остатков в битовом потоке. Таким образом, в следующих примерах даны k=3.
[093] Обращаемся к фиг. 3, на которой показан другой вариант осуществления согласно настоящему изобретению.
[094] На этапе S10 определяют первоначальный список из к точек-предикторов облака точек, включающий в себя к точек Р0,…,Р(К-1) облака точек, ближайших к точке Р, подлежащей кодированию.
[095] На этапе S11 определяют список кандидатов из n точек-предикторов по k - (k+n-
1) ближайшим точкам Pk,…,Р(k+n-1) облака точек.
[096] На этапе S12 по меньшей мере одна точка-предиктор из исходного списка заменяется точкой-предиктором из списка кандидатов, чтобы получить список точек-предикторов.
[097] На этапе S13 выбирают точки-предикторы полученного списка в качестве списка предикторов в соответствии с их положением относительно друг друга.
[098] Таким образом, первоначальный список включал в себя те k точек облака точек, которые географически являются ближайшими к точке Р, подлежащей кодированию. Список кандидатов включает в себя n последующих точек, ближайших к точке Р, подлежащей кодированию. Список кандидатов включает в себя те точки-предикторы, которые можно рассматривать для получения окончательного списка предикторов, который используется для кодирования с предсказанием атрибутов точки Р. Например, k=3, таким образом, исходный список включает в себя Р0, Р1 и Р2. п может быть установлено равным 5, таким образом, список кандидатов включает точки Р3, Р4, Р5, Р6 и Р7, при этом от Р0 до Р7 упорядочены по возрастанию расстояния до точки Р, подлежащей кодированию, и являются восемью ближайшими точками облака точек до точки Р, подлежащей кодированию. Согласно этапу S12, по меньшей мере, одна точка-предиктор Р0, Р1 или Р2 заменяется одной из точек-предикторов списка кандидатов. Предпочтительно заменяется только одна точка-предиктор исходного списка. Предпочтительно последняя точка-предиктор исходного списка заменяется одной из точек-предикторов списка кандидатов. В приведенном выше примере Р2 может быть заменена одной из Р3-Р7, чтобы получить новый список точек-предикторов. После этого, согласно этапу S13, соответствующий список предикторов проверяется, распределены ли их точки-предикторы или достаточно ли они рассредоточены. Точки-предикторы нового списка выбираются в качестве списка предикторов согласно их положению относительно друг друга, и список предикторов рассматривается как окончательный список предикторов и согласно стрелке 102 на фиг. 3 используется для кодирования с предсказанием атрибутов точки Р. Если полученные предикторы из списка предикторов не выбираются, согласно стрелке 100 на фиг. 3, в итерационном процессе все предикторы из списка кандидатов обводятся кружком, и каждая проверяется, заменяется ли одна или несколько точек-предикторов исходного списка соответствующими точками-предикторами списка кандидатов, в результате получается список точек-предикторов, который выбирается на основе их относительного положения друг относительно друга и используется для кодирования с предсказанием 102 для улучшения предсказания атрибутов точки Р, подлежащей кодированию, на основе выбранных точек-предикторов. Например, на первом этапе точка Р2 заменяется на Р3 и проверяется, распределяется ли полученный список предикторов (Р0, Р1, Р3). Если нет, то на следующем этапе проверяется список предикторов (Р0, P1, Р4) и так далее, пока не будет найден список предикторов, который распределяется или не достигает конца списка кандидатов. В первом случае соответствующий список предикторов выбирается и используется для кодирования с предсказанием, тогда как во втором может использоваться исходный список.
[099] Обратимся к фиг. 4, изображающей пространство вокруг точки Р, подлежащей
кодированию, с осью в направлении X, Y и Z, совпадающей с направлением кодирования/декодирования. Таким образом, вокруг точки Р, обозначенной 0,…, 7, определяются восемь октантов. При этом список точек-предикторов выбирается, если по меньшей мере две точки из списка точек-предикторов противоположны друг другу.
[0100] Это означает, что строго противоположными октантами являются:
0 и 7;
1 и 6;
2 и 5;
3 и 4.
[0101] Если такие две точки-предиктора недоступны, то требование, чтобы по меньшей мере две точки-предиктора были противоположными, ослабляют в отношении точек-предикторов и выбирают по меньшей мере две точки-предиктора нестрого противоположными. При этом нестрого противоположные октанты определяют, если по меньшей мере две точки-предиктора расположены в нестрого противоположных октантах, при этом нестрого противоположные октанты имеют только один общий край. Это означает, что нестрого противоположными октантами являются:
0 и 3,5,6;
4 и 1,2,7;
1 и 2,4,7;
5 и 0,3,6;
2 и 1,4,7;
6 и 0,3,5;
3 и 0,5,6;
7 и 1,2,4.
[0102] Обратимся к фиг. 5. Здесь этапы S10-S12 такие же, как описано со ссылкой на фиг. 3.
[0103] На этапе S131 определяют, расположены ли по меньшей мере две точки-предиктора полученных списков предикторов в противоположных октантах.
[0104] Если это так, согласно стрелке 104, точки-предикторы полученного списка предикторов считаются достаточно распределенными вокруг точки Р, подлежащей кодированию, т.е. распределенными и выбранными для использования для кодирования с предсказанием.
[0105] В противном случае, согласно стрелке 100, итеративно каждый элемент списка кандидатов рассматривается, как описано выше относительно фиг. 3.
[0106] Если на этапах S12 и S131 не выбраны точки-предикторы, на этапе S132 по меньшей мере одна точка-предиктор из исходного списка заменяется точкой-предиктором из списка кандидатов для получения списка предикторов, аналогично этапу 12, описанному выше.
[0107] На этапе S133 определяют, расположены ли по меньшей мере две точки-предиктора полученных списков предикторов в нестрого противоположных октантах.
[0108] Если это так, согласно стрелке 106, точки-предикторы полученного списка предикторов считаются достаточно распределенными вокруг точки Р, подлежащей кодированию, т.е. распределенными и выбранными для использования для кодирования с предсказанием.
[0109] В противном случае итеративно каждый элемент списка кандидатов рассматривается на этапах S132 и S133, как описано выше.
[0110] На фиг. 5 показано, что сначала все точки-предикторы списка кандидатов проверяются, предоставляют ли они в полученном списке предикторов по меньшей мере две точки-предиктора, которые расположены в противоположных октантах, и если это не удается, то впоследствии все точки-предикторы в списки кандидатов снова проверяются на предмет того, могут ли они предоставить хотя бы две точки-предиктора, расположенные в нестрого противоположных октантах. Однако порядок этапов может быть изменен таким образом, что первая точка-предиктор списка кандидатов сначала проверяется, может ли этот кандидат обеспечить по меньшей мере две точки-предиктора, находящиеся в противоположных октантах, а затем одна и та же точка-предиктор списка кандидатов проверяется на предмет того, может ли она обеспечить по меньшей мере две точки-предиктора, находящиеся по меньшей мере в двух нестрого противоположных октантах.
[0111] Для примера k=3 этапами способа могут быть:
1. Он идентифицирует исходный список из 3 ближайших предикторов Р0, Р1 и Р2 и список кандидатов из n следующих ближайших предикторов от Р3 до Pn+2 к точке Р.
2. Если точки-предикторы исходного списка недостаточно распределены вокруг точки Р, каждый элемент списка кандидатов будет рассматриваться один за другим на предмет замены последнего элемента Р2 исходного списка до тех пор, пока все элементы первого списка не будут достаточно распределены около точки Р или больше нет кандидатов для оценки. Список предикторов считается достаточно распределенным, если хотя бы две точки-предиктора находятся в противоположных октантах друг другу.
3. Если процесс не может выбрать список достаточно распределенных элементов для исходного списка, весь процесс начинается снова, но на этот раз точки-предикторы списка кандидатов считаются пригодными для замены Р2, если хотя бы две точки-предиктора находятся в нестрого октантах, противоположных друг другу.
[0112] Обратимся к фиг. 6, иллюстрирующей случай k=3. Приемлемость точки-предиктора в списке кандидатов на замену Р2 определяется путем определения двух пороговых значений расстояния F (дальний порог) и С (близкий порог) и оценки положения в пространстве (противоположное направление, затем нестрого противоположное направление) соответствующей точки-предиктора списка кандидатов в отношении Р0 и Р1 до тех пор, пока она достаточно близка, т.е. ниже порога F для Р0 и порога С для Р1.
[0113] В предпочтительном варианте осуществления изобретения два пороговых значения выбираются следующим образом:
• F=W х dist(P,P2)
• C=Wx dist(P,Pl)
Где W - весовой коэффициент, влияющий на отбор кандидатов. Вес W может быть установлен заранее и фиксирован для конкретного облака точек. Поскольку один и тот же процесс принятия решения должен выполняться как на стороне кодера, так и на стороне декодера, и его результаты зависят от значения веса W, это значение также может сигнализироваться/передаваться вместе с закодированными данными в битовом потоке.
[0114] В предпочтительном варианте осуществления изобретения для примера k=3 на стороне кодирования выполняются следующие этапы:
[0115] Этапы S10 и S12 аналогичны описанным ранее, и избыточное описание здесь опущено.
[0116] На этапе S120 устанавливают дальнее пороговое значение F=W х dist(P,P2) и близкое пороговое значение С=W х dist(P,PI).
[0117] На дополнительном опциональном этапе, если Р1 и Р2 находятся в противоположных октантах, (Р0,Р1,Р2) уже хорошо распределены вокруг Р, тогда останавливают процесс и выбирают (Р0,Р1,Р2) в качестве окончательного списка предикторов.
[0118] На этапе S121 для каждой точки Pi в списке кандидатов, в порядке их расстояния до Р:
Если dist(Pi,P)≤ F и Pi находится в октанте, противоположном Р0, замените Р2 в списке предикторов на Pi и остановите процесс, выбрав (P0,P1,Pi) в качестве окончательного списка предикторов, как указано стрелкой 108.
b. Если dist(Pi,P)≤С и Pi находится в октанте, противоположном Р1, замените Р2 в списке предикторов на Pi и остановите процесс, выбрав (P0,P1,Pi) в качестве окончательного списка предикторов, как указано стрелкой 108.
[0119] На этапе S122, если по меньшей мере Р1 или Р2 находятся в том же направлении, что и Р0, для каждой точки Pi в списке кандидатов, в порядке их расстояния до Р:
a. Если dist(Pi,P)≤F и Pi находится в нестрого противоположном октанте относительно Р0, заменить Р2 в списке предикторов на Pi и остановить процесс, выбрав (P0,P1,Pi) в качестве окончательного списка предикторов.
b. Если dist(Pi,P)≤С и Pi находится в нестрого противоположном октанте относительно Р1, заменить Р2 в списке предикторов на Pi и остановить процесс, выбрав (P0,P1,Pi) в качестве окончательного списка предикторов.
[0120] В противном случае выберите (Р0,Р1,Р2) в качестве окончательного списка предикторов, поскольку лучшего кандидата найти невозможно.
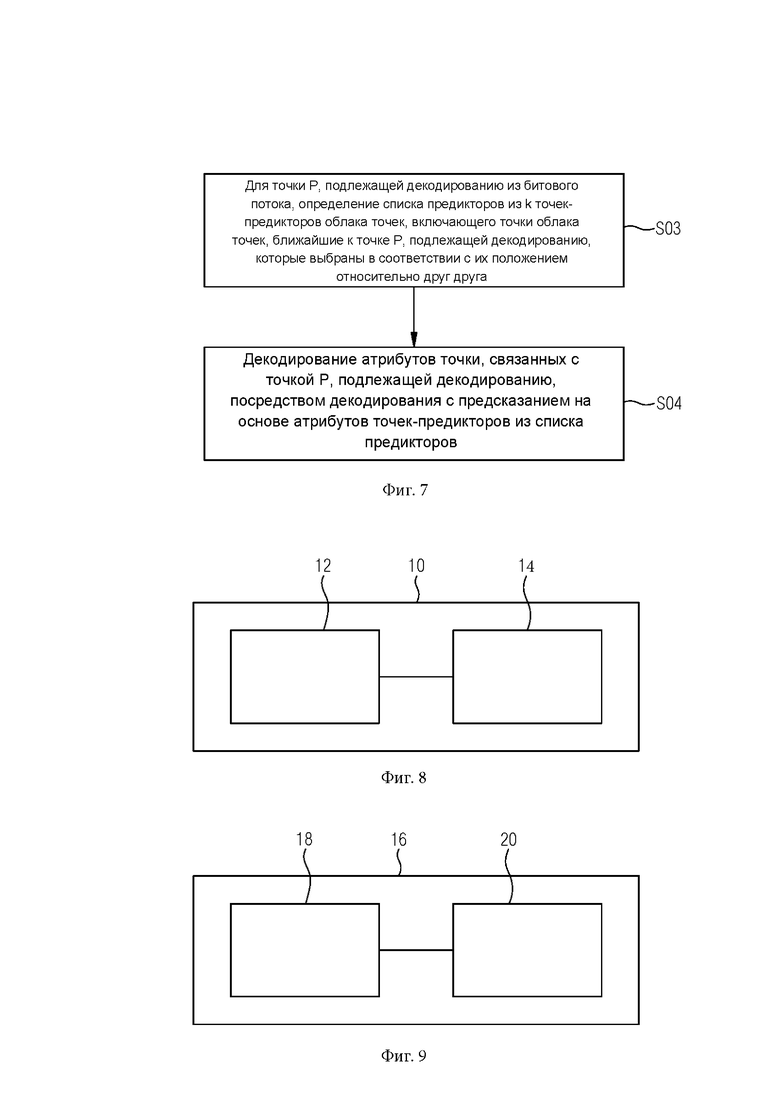
[0121] Настоящее изобретение дополнительно предлагает способ декодирования атрибутов точек облака точек в битовом потоке. Способ показан на фиг. 7. Ссылаясь на фиг. 7,
[0122] На этапе S03 для точки Р, подлежащей декодированию в битовый поток, определяют список предикторов из к точек-предикторов облака точек, включающий точки облака точек, ближайшие к точке Р, подлежащей декодированию, которые выбираются в соответствии с их положением относительно друг друга.
[0123] На этапе S04 атрибуты точки, связанные с точкой Р, декодируют посредством атрибутов декодирования с предсказанием точек-предикторов из списка предикторов.
[0124] При этом способ декодирования построен на основе признаков и этапов, описанных в отношении способа кодирования, подробно описанного выше.
[0125] Пока значения W и n совместно используются кодером и декодером, один и тот же процесс выбора точек-предикторов может выполняться с одинаковыми результатами с обеих сторон. Таким образом, способ декодирования имеет дополнительный этап считывания значений W (вес для приемлемости расстояния) и n (максимальное количество кандидатов) из кодированного битового потока облака точек. Следующие этапы идентичны способу кодирования, подробно описанному выше.
[0126] В предпочтительном варианте осуществления изобретения значения параметров веса W и n передаются в наборе параметров атрибутов (APS) облака точек, закодированного в формате MPEG G-PCC.
[0127] Теперь обратимся к фиг. 8, которая показывает упрощенную блок-схему примерного варианта осуществления кодера 10. Кодер 10 включает в себя процессор 12 и запоминающее устройство 14. Запоминающее устройство 14 может хранить компьютерную программу, или приложение, содержащее инструкции, которые при выполнении заставляют процессор 12 выполнять операции, такие как описанные здесь. Например, инструкции могут кодировать и выводить потоки битов, закодированные в соответствии с описанными здесь способами. Понятно, что инструкции могут храниться на энергонезависимом машиночитаемом носителе, таком как компакт-диск, устройство флэш-памяти, оперативное запоминающее устройство, жесткий диск и т.д. Когда команды выполняются, процессор 12 выполняет операции и функции, указанные в инструкциях, для работы в качестве процессора специального назначения, реализующего описанный(е) процесс(ы). В некоторых примерах такой процессор может называться «схемой процессора» или «совокупностью схем процессора».
[0128] Теперь также обратимся к фиг. 9, где показана упрощенная блок-схема примерного варианта осуществления декодера 16. Декодер 16 включает в себя процессор 18 и запоминающее устройство 20. Запоминающее устройство 20 может включать в себя компьютерную, программу или приложение, содержащее инструкции, которые при выполнении заставляют процессор 18 выполнять операции, такие как описанные здесь. Понятно, что инструкции могут храниться на машиночитаемом носителе, таком как компакт-диск, устройство флэш-памяти, оперативное запоминающее устройство, жесткий диск и т.д. Когда инструкции выполняются, процессор 18 выполняет операции и функции, указанные в инструкциях, для работы в качестве процессора специального назначения, реализующего описанные процессы и способы. В некоторых примерах такой процессор может называться «схемой процессора» или «совокупностью схем процессора».
[0129] Следует понимать, что декодер и/или кодер согласно настоящей заявке может быть реализован в ряде вычислительных устройств, в том числе, помимо прочего, серверов, соответствующим образом запрограммированных компьютеров общего назначения, системах машинного зрения и мобильных устройств. Декодер или кодер может быть реализован посредством программного обеспечения, содержащего инструкции для конфигурирования процессора или процессоров для выполнения описанных здесь функций. Инструкции программного обеспечения могут храниться в любой подходящей машиночитаемой памяти, в том числе компакт-дисках, ОЗУ, ПЗУ, флэш-памяти и т.д.
[0130] Понятно, что декодер и/или кодер, описанные в настоящем документе, и модуль, программа, процесс, поток или другой программный компонент, реализующий описанный способ/процесс для конфигурирования кодера или декодера, могут быть реализованы с использованием стандартных способов компьютерного программирования и языков. Настоящая заявка не ограничивается конкретными процессорами, компьютерными языками, соглашениями компьютерного программирования, структурами данных и другими подобными деталями реализации. Специалисты в данной области техники поймут, что описанные процессы могут быть реализованы как часть исполняемого компьютером кода, хранящегося в энергозависимой или энергонезависимой памяти, как часть специализированной интегрированной микросхемы (application-specific integrated chip, ASIC) и т.д.
[0131] Настоящая заявка также предлагает машиночитаемый сигнал, кодирующий данные, полученные посредством применения процесса кодирования в соответствии с настоящей заявкой.
[0132] Могут быть сделаны определенные адаптации и модификации описанных вариантов осуществления. Таким образом, рассмотренные выше варианты осуществления считаются иллюстративными, а не ограничивающими. В частности, варианты осуществления можно свободно комбинировать друг с другом.
Изобретение относится к сжатию атрибутов точек облака точек. Технический результат заключается в повышении эффективности кодирования и декодирования атрибутов точек облака точек. Такой результат обеспечивается за счет того, что для точки Р, подлежащей кодированию в битовый поток, осуществляют определение списка предикторов из k точек-предикторов облака точек, включающего точки облака точек, ближайшие к точке Р, подлежащей кодированию, которые выбираются в соответствии с их положением относительно друг друга; и кодируют атрибуты точки, связанные с точкой Р, подлежащей кодированию посредством кодирования с предсказанием на основе атрибутов точек-предикторов из списка предикторов. 4 н. и 8 з.п. ф-лы, 9 ил.
1. Способ кодирования в битовый поток атрибутов точки, связанных с точкой облака точек, включающий в себя:
определение, для точки P, подлежащей кодированию в битовый поток, списка предикторов из k точек-предикторов облака точек, включающего точки облака точек, ближайшие к точке P, подлежащей кодированию, которые выбирают согласно их положению относительно друг друга; и
кодирование атрибутов точки, связанных с точкой P, подлежащей кодированию, путем кодирования с предсказанием на основе атрибутов точек-предикторов из списка предикторов,
при этом определение списка предикторов включает в себя:
определение исходного списка из k точек-предикторов P0, …, P(k-1) облака точек, включающего k точек облака точек, ближайших к точке P, подлежащей кодированию; и
выбор точек-предикторов исходного списка в качестве списка предикторов в соответствии с их положением относительно друг друга,
при этом пространство вокруг точки P, подлежащей кодированию, разделяют на октанты вдоль осей X, Y и Z кодирования, и выбор точек-предикторов исходного списка в качестве списка предикторов в соответствии с их положением относительно друг друга содержит выбор k точек-предикторов из исходного списка, если по меньшей мере две точки-предикторы исходного списка расположены в противоположных октантах, при этом противоположные октанты имеют только общую точку P, подлежащую кодированию.
2. Способ декодирования из битового потока атрибутов точки, связанных с точкой облака точек, включающий в себя:
определение, для точки P, подлежащей декодированию из битового потока, списка предикторов из k точек-предикторов облака точек, включающего точки облака точек, ближайшие к точке P, подлежащей кодированию, которые выбраны согласно их положению относительно друг друга; и
декодирование атрибутов точки, связанных с точкой P, подлежащей декодированию, посредством декодирования с предсказанием на основе атрибутов точек-предикторов из списка предикторов,
при этом определение списка предикторов включает в себя:
определение исходного списка из k точек-предикторов P0, …, P(k-1) облака точек, включающего k точек облака точек, ближайших к точке P, подлежащей кодированию; и
выбор точек-предикторов исходного списка в качестве списка предикторов в соответствии с их положением относительно друг друга,
при этом пространство вокруг точки P, подлежащей кодированию, разделяют на октанты вдоль осей X, Y и Z декодирования, и выбор точек-предикторов исходного списка в качестве списка предикторов в соответствии с их положением относительно друг друга содержит выбор k точек-предикторов из исходного списка, если по меньшей мере две точки-предикторы исходного списка расположены в противоположных октантах, при этом противоположные октанты имеют только общую точку P, подлежащую кодированию.
3. Способ по п. 1, в котором, если отсутствуют по меньшей мере две точки-предикторы исходного списка, расположенные в противоположных октантах, способ включает:
определение списка кандидатов из n точек-предикторов по ближайшим, от k до k+n-1, точкам Pk, …, P(k+n-1) облака точек;
замену по меньшей мере одной точки-предиктора исходного списка на точку-предиктор из списка кандидатов для получения полученного списка предикторов с k точками-предикторами; и
выбор точек-предикторов полученного списка предикторов в качестве списка предикторов в соответствии с их положением относительно друг друга,
при этом выбор точек-предикторов полученного списка в качестве списка предикторов в соответствии с их положением относительно друг друга содержит выбор k точек-предикторов из полученного списка, если по меньшей мере две точки-предикторы полученного списка расположены в противоположных октантах.
4. Способ по п. 3, в котором,
если по меньшей мере две точки-предикторы полученного списка расположены в противоположных октантах, способ включает итеративную замену по меньшей мере одной точки-предиктора каждой точкой-предиктором из списка кандидатов для получения нового списка предикторов, до тех пор, пока k точек-предикторов не будут выбраны.
5. Способ по п. 3 или 4, в котором заменяют только последнюю точку-предиктор исходного списка и/или полученного списка предикторов.
6. Способ по любому из пп. 1-5, в котором k равно или больше 3.
7. Способ по п. 1 или 3, также содержащий:
если отсутствуют по меньшей мере две точки-предикторы списка, расположенные в противоположных октантах, определение, расположены ли по меньшей мере две точки-предикторы в нестрого противоположных октантах, при этом нестрого противоположные октанты имеют только один общий край.
8. Способ по любому из пп. 3-7, в котором по меньшей мере одно пороговое значение Ti определяют как Ti = W x dist(P, Pi), с весом W>1 и Pi – точкой-предиктором исходного списка, при этом точки-предикторы списка кандидатов пригодны для замены по меньшей мере одной точки-предиктора исходного списка, если расстояние между точкой-предиктором списка кандидатов и точкой P, подлежащей кодированию, меньше Ti.
9. Способ по п. 8, в котором вес W и/или n включают в битовый поток.
10. Способ по п. 8, в котором битовый поток представляет собой битовый поток, совместимый с MPEG G-PCC, и вес W и/или n присутствует в наборе атрибутивных параметров (APS) битового потока G-PCC.
11. Кодер для кодирования в битовый поток атрибутов точки, связанных с точкой облака точек, содержащий процессор и запоминающее устройство, при этом в запоминающем устройстве хранятся исполняемые процессором инструкции, которые при выполнении заставляют процессор выполнять способ по любому из пп. 1 и 10.
12. Декодер для декодирования из битового потока атрибутов точки, связанных с точкой облака точек, содержащий процессор и запоминающее устройство, причем в запоминающем устройстве хранятся исполняемые процессором инструкции, которые при выполнении заставляют процессор выполнять способ по п. 2.
| CN 109889840 A, 14.06.2019 | |||
| CN 111145090 A, 12.05.2020 | |||
| CN 110572655 A, 13.12.2019 | |||
| US 20190075320 A1, 07.03.2019 | |||
| WO 2020256244 A1, 24.12.2020 | |||
| WO 2020198180 A1, 01.10.2020 | |||
| WO 2021002594 A1, 07.01.2021 | |||
| RU 2018115810 A, 30.10.2019. |

