Область техники, к которой относится изобретение
Заявленное изобретение относится к области вычислительной обработки данных, в частности к методам обучения моделей классификации текстовой информации электронного вида на предмет наличия конфиденциальных данных и их комбинирования.
Уровень техники
а) Описание аналогов
Известен «Способ классификации документов по уровням конфиденциальности», (патент №20200342059 US класс G06F 17/27, заявл. от 01.05.2019).
В известном способе осуществляется применение к извлеченным информационным объектам документа набора правил классификации и связывание электронного документа с элементом метаданных, отражающих вычисленный уровень конфиденциальности, что обеспечивает классификацию документов по уровням конфиденциальности.
Недостатком данного способа является:
данный способ подходит для решения узкого круга задач и позволяет осуществлять классификацию конфиденциальных документов строго формализованного вида, что накладывает ограничения на его применение.
Известен «Способ классификации документов по уровням конфиденциальности», (патент №2665915 РФ класс G06F 40/10, заявл. 16.06.2017). В известном способе осуществляется классификация текстовой информации с помощью вычисления коэффициента плотности ключевых слов и в случае превышения порогового значения текст определяется как содержащий конфиденциальную информацию.
Недостатком данного способа является:
данный способ не учитывает зависимость точности классификации при работе с различными видами конфиденциальной информации и специфики деятельности организации, в отношении которой будет применяться данный способ, что накладывает ограничения на его применение в зависимости от конфиденциальной информации обрабатываемой в организации.
Известен «Способ классификации документов по уровню конфиденциальности», (патент №2015152418 РФ класс G06F 16/10, G06F 40/10, заявл. 13.06.2017). В известном способе осуществляется классификация текстовой информации на предмет наличия конфиденциальных данных, при помощи системы предикатов идентификации метки конфиденциальности в которую подставляются весовые коэффициенты словоформ, рассчитанные на этапе обучения системы.
Недостатком данного способа является:
данный способ подходит для решения узкого круга задач и позволяет осуществлять классификацию конфиденциальных документов строго формализованного вида, что накладывает ограничения на его применение.
б) описание ближайшего аналога (прототипа)
Наиболее близкой по своей технической сущности к заявленному способу является «Способ и система классификации данных для выявления конфиденциальной информации», (патент №2759786 РФ, класс G06F 16/906, заявл. 05.07.2019, опубл. 17.11.2021). Технический результат способа-прототипа заключается в том, что за счет обработки полученных данных при помощи ансамбля нейронных сетей, где каждая нейронная сеть из состава ансамбля обучена на выявление элементов текста, определяющих его конфиденциальность, осуществляется пометка тегом выявленных конфиденциальных данных. Помимо этого, способ усилен алгоритмом «Луна», позволяющим за счет определения контрольных разрядов выявлять данные, обладающие контрольным разрядом, такие как номера банковских карт, СНИЛС, ОКПО, ОГРН, ИНН, номер паспорта, номер телефона и т.д.
По сравнению с аналогами, способ-прототип за счет применения ансамбля нейронных сетей и усиления алгоритмом «Луна» способен выявлять более широкий круг конфиденциальной информации.
Недостатком прототипа является:
данный способ не учитывает зависимость точности классификации при работе с различными видами конфиденциальной информации и специфики деятельности организации, в отношении которой будет применяться данный способ, что накладывает ограничения на его применение в зависимости от конфиденциальной информации, обрабатываемой в организации. Использование алгоритма «Луна», как и процесс тегирования при помощи ансамбля нейронных сетей подразумевает применение данного способа с целью выявления персональных данных, что соответственно делает его неспособным выявлять другие виды конфиденциальной информации.
В настоящем изобретении предложен способ, позволяющий исправить выявленные недостатки.
Раскрытие изобретения (его сущность)
а) технический результат, на достижение которого направлено изобретение
Целью заявленного технического решения является разработка способа, позволяющего повысить точность классификации текстовой информации электронного вида, как формализованного, так и неформализованного вида, на предмет наличия конфиденциальных данных с учетом специфики деятельности организаций и видов конфиденциальной информации обрабатываемых в них.
Технический результат достигается тем, что за счет обучения моделей классификации, на основе «Байесовского алгоритма», алгоритмов «Decision tree», «Random Forest», «Логистической регрессии», «Градиентный бустинг», «Ada Boost», полносвязного нейросетевого алгоритма с одним скрытым слоем, метода опорных векторов, осуществляется их комбинирования и подбор комбинации, или модели производящей классификацию текстовой информации электронного вида на предмет наличия в ней конфиденциальных данных с учетом специфики деятельности организации и видов конфиденциальной информации, обрабатываемой в организации.
б) совокупность существенных признаков
Способ классификации текстовой информации электронного вида на предмет наличия конфиденциальных данных, выполняемый с помощью по меньшей мере одного процессора, одной памяти содержащей машиночитаемые инструкции, которые при их выполнении по меньшей мере одним процессором обеспечивают выполнение способа содержащего этапы получения на вход данных, представленных в виде текстовой информации электронного вида, предварительной обработки текстовой информации в объеме определенном экспертной группой, векторизации текстовой информации на основе данных, полученных в процессе извлечения признаков конфиденциальной информации.
Дополнительно в процесс обучения модели классификации текстовой информации электронного вида по степени конфиденциальности, которым обеспечивается выявление конфиденциальных данных в текстовой информации электронного вида, за счет внедрения цикла последовательного обучения моделей классификации на основе «Байесовского алгоритма», алгоритмов «Decision tree», «Random Forest», «Логистической регрессии», «Градиентный бустинг», «Ada Boost», полносвязного нейросетевого алгоритма с одним скрытым слоем, метода опорных векторов, что направлено на выявление наиболее подходящей модели классификации текстовой информации электронного вида на предмет наличия в них конфиденциальных данных обрабатываемых в организации вводится элемент, осуществляющий комбинирование прогнозов полученных в процессе тестирования каждой из обученных моделей, с целью исправления ошибок первого и второго рода при осуществлении классификации отдельно взятыми моделями классификации текстовой информации электронного вида на предмет наличия в них конфиденциальных данных, факт выявления которых на автоматизированном рабочем месте (далее - АРМ) пользователей не предназначенных для их обработки является предпосылкой к утечке конфиденциальной информации, а также элемент, осуществляющий оценку точности моделей классификации или их комбинации и определяющий наиболее подходящую модель классификации или их комбинацию, при этом данный процесс реализуется следующим образом: на вход алгоритма подается переменная corp, характеризующая собой корпус текстовой информации, состоящий как из текстов содержащих конфиденциальные данные так и из текстов не содержащих конфиденциальные данные, представленный в электронном виде без проставленных меток конфиденциальности в каждом отдельно взятом тексте, каждый элемент которой подвергается оценке экспертной группой на предмет наличия конфиденциальной информации с последующей разметкой по принадлежности к одному из классов переменной class которая заключается в проставлении символа «*» первым символом в тексте, содержащем конфиденциальную информацию, что является меткой принадлежности к классу с1, тогда как при отсутствии конфиденциальной информации в тексте метка «*» не проставляется, что свидетельствует об отсутствии необходимости контроля за данной информацией при ее обработке и означает принадлежность к классу с2, а также установкой экспертной группой порогового значения 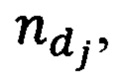 влияющего на размерность векторного представления текстовой информации электронного вида, после чего формируется переменная clear, в которую, в процессе предварительной обработки каждой текстовой информации электронного вида очищенной в объеме «стоп-слов» и специальных символов (за исключением символа «*»), приведения текста к нижнему регистру, токенизации и лемматизации словарных величин для сокращения размерности итогового словаря добавляются данные в виде кортежа, где каждый элемент кортежа есть предварительно обработанный текст, после чего формируется переменная label, в которую в результате работы цикла вносятся метки класса определяемые в переменной class на основании наличия или отсутствия символа «*», проставленного представителями экспертной группы в результате произведенной разметки элементов, составляющих корпус текстов по принципу наличия конфиденциальных данных, к которым принадлежат элементы множества clear после чего метка класса «*» должна быть удалена и переменная clear переопределяется, после чего производится расчет весовых коэффициентов каждой словарной величины, хранящихся в переменной vesa и формирование словаря, хранящегося в переменной slovar с полной синхронизацией по индексу словарной величины из переменной slovar с ее весовым коэффициентом из переменной vesa, с целью дальнейшей векторизации всей текстовой информации составляющей корпус с сохранением в переменную vector и разделения выборки, в случае соблюдения условия на предмет сбалансированности классов, либо генерации объектов меньшего класса в ином случае до достижения баланса классов с целью корректного обучения моделей и корректной оценки точности обученных моделей, на обучающую и тестовую, после чего осуществляется этап обучения вышеуказанных моделей, их последовательного тестирования каждой из обученных моделей, после чего производится расчет показателя точности для каждой из обученных моделей, с целью выявления наибольшего значения показателя точности, которое хранится в переменной accuracy а индекс, указывающий на модель modi из переменной model показавшую данную точность хранится в переменной count и перезаписывается как и значение accuracy на значение точности из переменной acc которое рассчитывается для каждой обученной модели в случае, если на последующей итерации цикла обучения моделей будет выявлена модель, с большим показателем точности, тогда как прогнозы обученных моделей, полученных в результате их тестирования по каждому элементу тестовой выборки записываются в переменную test в виде вектора и на следующем этапе поступают на вход комбинатора, формирующего все вариации комбинаций результатов тестирования по три элемента и хранящиеся в переменной comb, с целью выявления комбинации
влияющего на размерность векторного представления текстовой информации электронного вида, после чего формируется переменная clear, в которую, в процессе предварительной обработки каждой текстовой информации электронного вида очищенной в объеме «стоп-слов» и специальных символов (за исключением символа «*»), приведения текста к нижнему регистру, токенизации и лемматизации словарных величин для сокращения размерности итогового словаря добавляются данные в виде кортежа, где каждый элемент кортежа есть предварительно обработанный текст, после чего формируется переменная label, в которую в результате работы цикла вносятся метки класса определяемые в переменной class на основании наличия или отсутствия символа «*», проставленного представителями экспертной группы в результате произведенной разметки элементов, составляющих корпус текстов по принципу наличия конфиденциальных данных, к которым принадлежат элементы множества clear после чего метка класса «*» должна быть удалена и переменная clear переопределяется, после чего производится расчет весовых коэффициентов каждой словарной величины, хранящихся в переменной vesa и формирование словаря, хранящегося в переменной slovar с полной синхронизацией по индексу словарной величины из переменной slovar с ее весовым коэффициентом из переменной vesa, с целью дальнейшей векторизации всей текстовой информации составляющей корпус с сохранением в переменную vector и разделения выборки, в случае соблюдения условия на предмет сбалансированности классов, либо генерации объектов меньшего класса в ином случае до достижения баланса классов с целью корректного обучения моделей и корректной оценки точности обученных моделей, на обучающую и тестовую, после чего осуществляется этап обучения вышеуказанных моделей, их последовательного тестирования каждой из обученных моделей, после чего производится расчет показателя точности для каждой из обученных моделей, с целью выявления наибольшего значения показателя точности, которое хранится в переменной accuracy а индекс, указывающий на модель modi из переменной model показавшую данную точность хранится в переменной count и перезаписывается как и значение accuracy на значение точности из переменной acc которое рассчитывается для каждой обученной модели в случае, если на последующей итерации цикла обучения моделей будет выявлена модель, с большим показателем точности, тогда как прогнозы обученных моделей, полученных в результате их тестирования по каждому элементу тестовой выборки записываются в переменную test в виде вектора и на следующем этапе поступают на вход комбинатора, формирующего все вариации комбинаций результатов тестирования по три элемента и хранящиеся в переменной comb, с целью выявления комбинации 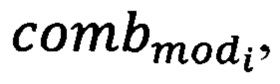 обеспечивающей наибольшую точность классификации хранящейся в переменной acc при реализации мажоритарного подхода среди элементов комбинации, который как и на предыдущем этапе обучения моделей в случае, если показатель точности acc превосходит показатель хранящийся в переменной accuracy, значение из переменной acc перезаписывается вместо значения из переменной accuracy а вместо значения count перезаписываются индексы моделей из переменной model участвующих в комбинации, и определяет модель или их комбинацию обеспечивающую наибольшую точность классификации текстовой информации электронного вида обрабатываемой в организации. На основе переменных slovar, vesa, modeli или полученных при выполнения вышеописанного алгоритма происходит процесс классификации текстовой информации электронного вида обрабатываемой на АРМ пользователей на предмет наличия конфиденциальных данных, который осуществляется следующим образом: на вход алгоритма поступает текстовая информация электронного вида обрабатываемая на АРМ пользователя хранящаяся в переменной text, данная текстовая информация проходит этап предварительной обработки, после чего каждая текстовая информация электронного вида прошедшая этап предварительной обработки вносится в переменную clear, после чего при помощи переменных slovar и vesa, полученных на этапе процесса обучения, осуществляется векторизация всей текстовой информации электронного вида обрабатываемой на АРМ пользователя, векторы которой хранятся в переменной vector, после чего каждый вектор из данной переменной поочередно подается на вход обученной модели mod или поочередно на вход каждой обученной модели из комбинации combmod с реализацией мажоритарного подхода, после чего формируется прогноз по наличию конфиденциальных данных в текстовой информации электронного вида хранящийся в переменной class, на основании которой осуществляется копирование исходных файлов, содержащих конфиденциальную текстовую информацию электронного вида, в каталог conƒ, доступ к которой имеет только специалист по обеспечению безопасности информации с целью дальнейшего ее анализа.
обеспечивающей наибольшую точность классификации хранящейся в переменной acc при реализации мажоритарного подхода среди элементов комбинации, который как и на предыдущем этапе обучения моделей в случае, если показатель точности acc превосходит показатель хранящийся в переменной accuracy, значение из переменной acc перезаписывается вместо значения из переменной accuracy а вместо значения count перезаписываются индексы моделей из переменной model участвующих в комбинации, и определяет модель или их комбинацию обеспечивающую наибольшую точность классификации текстовой информации электронного вида обрабатываемой в организации. На основе переменных slovar, vesa, modeli или полученных при выполнения вышеописанного алгоритма происходит процесс классификации текстовой информации электронного вида обрабатываемой на АРМ пользователей на предмет наличия конфиденциальных данных, который осуществляется следующим образом: на вход алгоритма поступает текстовая информация электронного вида обрабатываемая на АРМ пользователя хранящаяся в переменной text, данная текстовая информация проходит этап предварительной обработки, после чего каждая текстовая информация электронного вида прошедшая этап предварительной обработки вносится в переменную clear, после чего при помощи переменных slovar и vesa, полученных на этапе процесса обучения, осуществляется векторизация всей текстовой информации электронного вида обрабатываемой на АРМ пользователя, векторы которой хранятся в переменной vector, после чего каждый вектор из данной переменной поочередно подается на вход обученной модели mod или поочередно на вход каждой обученной модели из комбинации combmod с реализацией мажоритарного подхода, после чего формируется прогноз по наличию конфиденциальных данных в текстовой информации электронного вида хранящийся в переменной class, на основании которой осуществляется копирование исходных файлов, содержащих конфиденциальную текстовую информацию электронного вида, в каталог conƒ, доступ к которой имеет только специалист по обеспечению безопасности информации с целью дальнейшего ее анализа.
в) причинно-следственная связь между признаками и техническим результатом
Благодаря новой совокупности существенных признаков в заявленном способе расширяется функционал работы системы, осуществляющей обучение модели классификации текстовой информации электронного вида по степени конфиденциальности, путем последовательного обучения моделей классификации на основе «Байесовского алгоритма», алгоритмов «Decision tree», «Random Forest», «Логистической регрессии», «Градиентный бустинг», «Ada Boost», полносвязного нейросетевого алгоритма с одним скрытым слоем, метода опорных векторов и их комбинирования с целью исправления ошибок первого и второго рода при осуществлении классификации отдельно взятыми моделями классификации текстовой информации электронного вида на предмет наличия в них конфиденциальных данных, после чего на основании показателя значения точности определяется модель или комбинация моделей классификации текстовой информации электронного вида обрабатываемой в организации на предмет наличия конфиденциальных данных, с учетом специфики ее деятельности и видов конфиденциальной информации в ней обрабатываемой.
Проведенный анализ уровня техники позволил установить, что аналоги, имеющие совокупность признаков, описанных в предложенном способе, отсутствуют, что указывает на соответствие заявленного способа условию патентоспособности «новизна».
Результаты поиска известных решений в данной и смежных областях техники с целью выявления признаков, совпадающих с отличительными признаками предлагаемого способа, показали, что они не следуют явным образом из уровня техники. Также не выявлена известность отличительных признаков, обусловливающих тот же технический результат, который достигнут в заявленном способе. Следовательно, заявленное изобретение соответствует условию патентоспособности «изобретательский уровень». Краткое описание чертежей
Заявленный способ поясняется чертежами, на которых показаны:
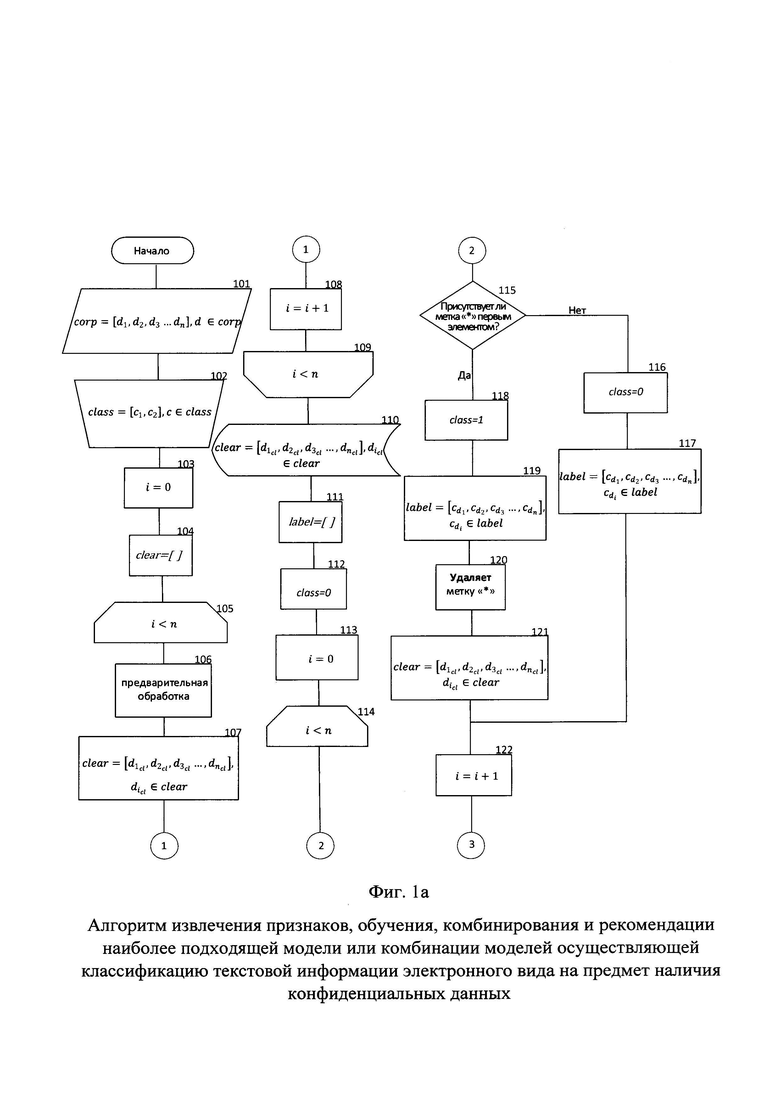
Фиг. 1а - Алгоритм извлечения признаков, обучения, комбинирования и рекомендации наиболее подходящей модели или комбинации моделей осуществляющей классификацию текстовой информации электронного вида на предмет наличия конфиденциальных данных.
Фиг. 1б - Алгоритм извлечения признаков, обучения, комбинирования и рекомендации наиболее подходящей модели или комбинации моделей осуществляющей классификацию текстовой информации электронного вида на предмет наличия конфиденциальных данных.
Фиг. 1в - Алгоритм извлечения признаков, обучения, комбинирования и рекомендации наиболее подходящей модели или комбинации моделей осуществляющей классификацию текстовой информации электронного вида на предмет наличия конфиденциальных данных.
Фиг. 1г - Алгоритм извлечения признаков, обучения, комбинирования и рекомендации наиболее подходящей модели или комбинации моделей осуществляющей классификацию текстовой информации электронного вида на предмет наличия конфиденциальных данных.
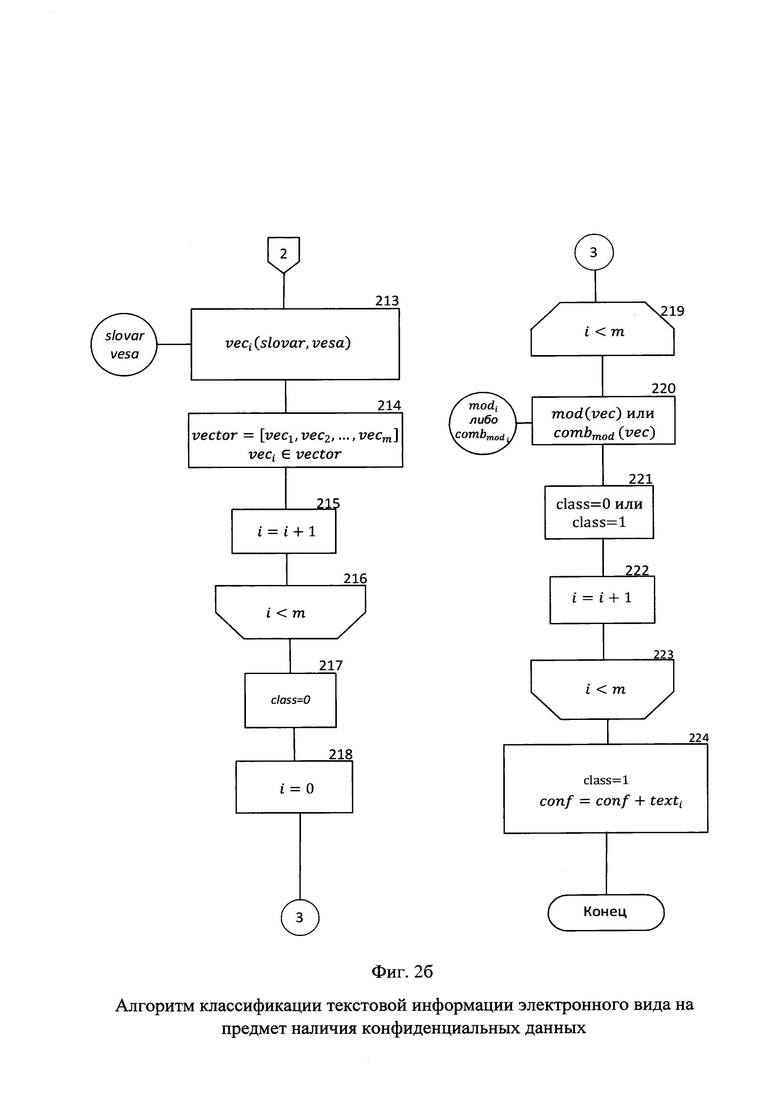
Фиг. 2а - Алгоритм классификации текстовой информации электронного вида на предмет наличия конфиденциальных данных.
Фиг. 2б - Алгоритм классификации текстовой информации электронного вида на предмет наличия конфиденциальных данных.
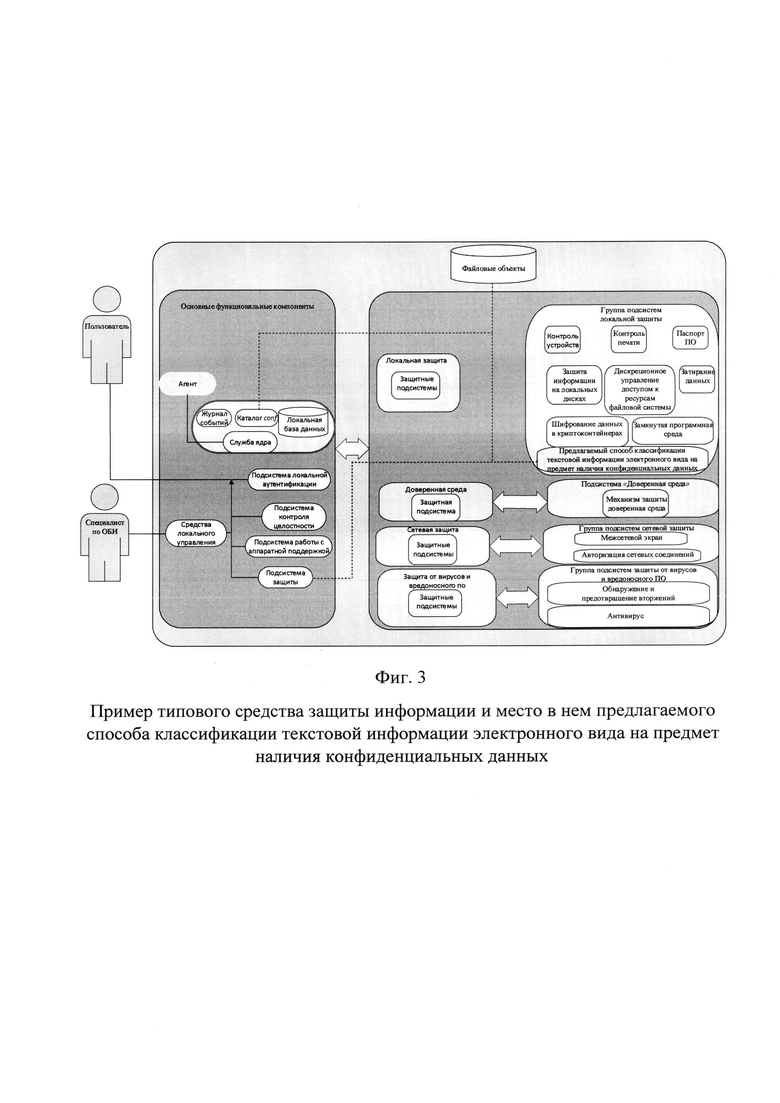
Фиг. 3 - Пример типового средства защиты информации и место в нем предлагаемого способа классификации текстовой информации электронного вида на предмет наличия конфиденциальных данных.
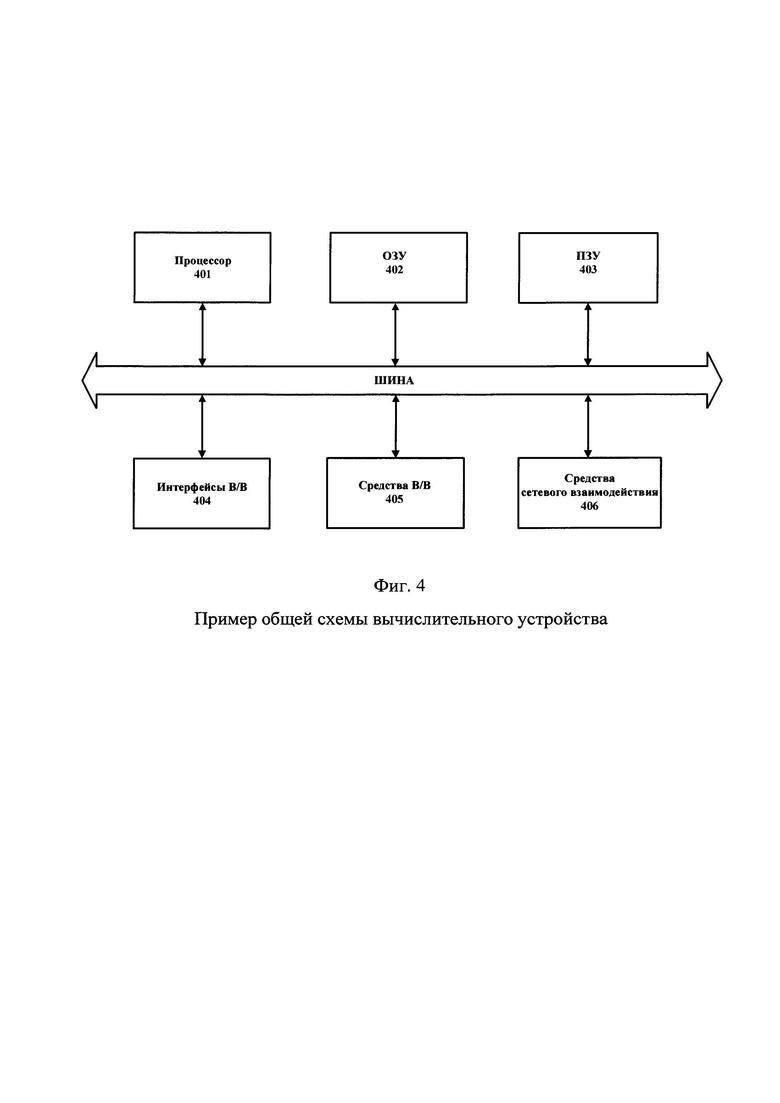
Фиг. 4 - Пример общей схемы вычислительного устройства.
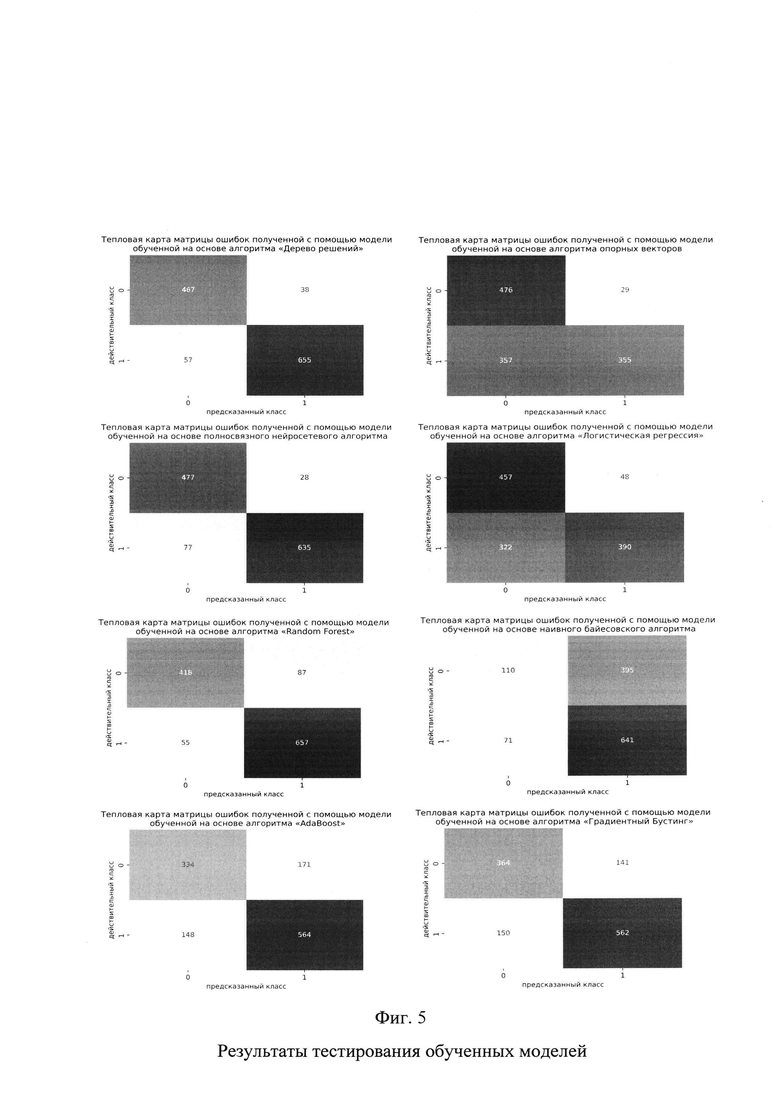
Фиг. 5 - Результаты тестирования обученных моделей.
Осуществление изобретения
Типичной практической задачей, возникающей перед специалистом по обеспечению безопасности информации, обрабатываемой в организации, является задача обеспечения контроля за обработкой конфиденциальных данных одним из направлений которой является обеспечение контроля за обработкой конфиденциальной текстовой информации электронного вида на АРМ пользователей, не предназначенных для ее обработки. Данный процесс контроля регламентирован должностными обязанностями администратора по обеспечению безопасности информации. Предлагаемые средства автоматизации контроля на сегодняшний день не учитывают специфику деятельности организаций, что не позволяет осуществлять полноценную проверку на предмет соблюдения правил обработки конфиденциальных данных, и в основном, направлены на контроль за персональными данными клиентов и сотрудников организаций. Ввиду этого специалисты по обеспечению безопасности информации осуществляют процесс контроля при помощи программных средств, работа которых основана на поиске конфиденциальных данных по ключевым словам, не реже чем раз в период, установленный в должностных инструкциях либо должностных обязанностях, что является довольно трудоемкой задачей, требующей от специалиста по обеспечению безопасности информации знаний о всех видах конфиденциальных данных обрабатываемых в организации а также специфику ее деятельности, позволяющих выявлять конфиденциальную информацию среди всей текстовой информации, обрабатываемой в организации.
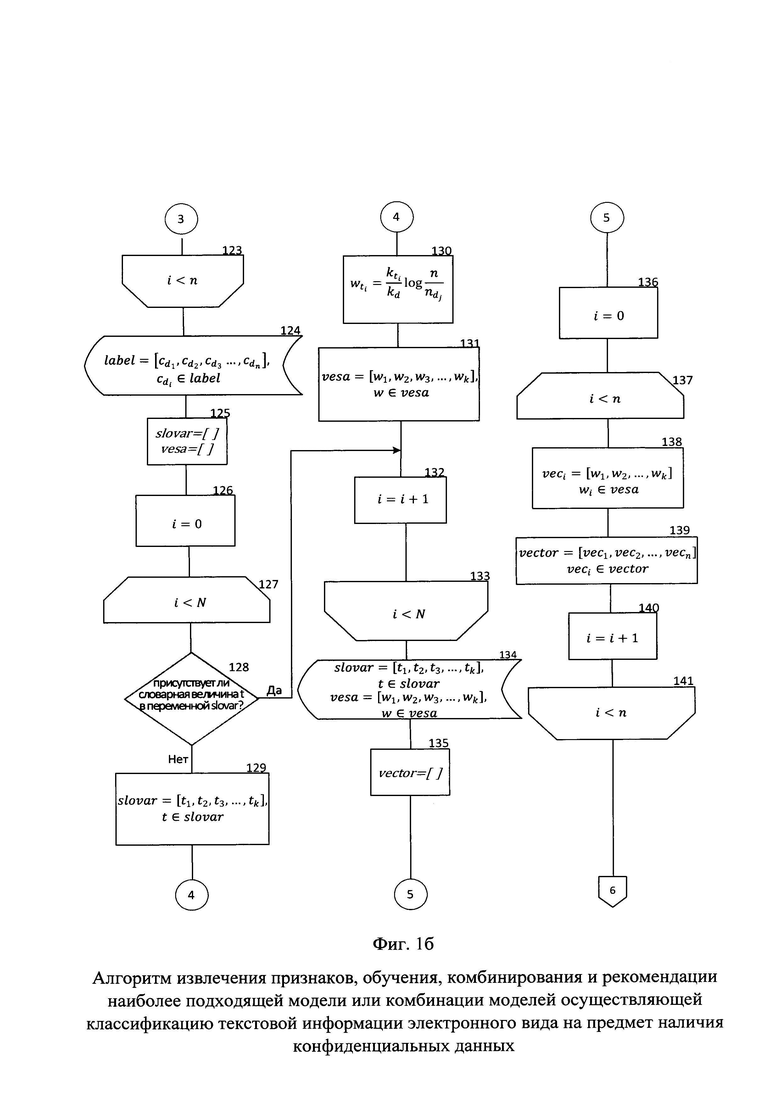
На фиг. №№1а, 1б, 1в, 1г представлен алгоритм извлечения признаков, обучения, комбинирования и рекомендации наиболее подходящей модели или комбинации моделей осуществляющей классификацию текстовой информации электронного вида на предмет наличия конфиденциальных данных.
Используемый в настоящем документе термин «текстовая информация электронного вида», может относиться к любой текстовой информации электронного вида, сохраненной в файле любого текстового формата, обработка которого может быть доступна для вычислительной системы, например DOC, DOCX, ТХТ и д.р.
Предполагается, что данный алгоритм реализуется на АРМ, обработка конфиденциальной информации на котором разрешена, так как процесс обучения моделей подразумевают наличие текстовой конфиденциальной информации электронного вида подлежащей контролю.
Ввиду того, что модели классификации являются довольно чувствительными к данным подаваемым на вход, их точность зависит от объема обучающей и тестовой выборок, видов конфиденциальной информации обрабатываемой в организации, специфики ее деятельности, нижеописанный алгоритм обучает и определяет модель, или их комбинацию, наиболее подходящую для осуществления классификации текстовой информации электронного вида на предмет наличия конфиденциальных данных и зависит от конфиденциальных данных, обрабатываемых в отдельно взятой организации, в интересах которой требуется осуществлять классификацию текстовой информации электронного вида на предмет наличия в ней конфиденциальных данных.
Алгоритм получает на вход корпус текстовой информации электронного вида состоящий как из текстовой информации, содержащей конфиденциальные данные, так и не содержащей (блок 101). Корпус представляет собой кортеж corp=[d1, d2, d3…dn], d∈corp, состоящий из элементов текстовой информации электронного вида, каждый из которых принадлежит к одному из двух классов, определяемых наличием в них конфиденциальной информации.
Каждый элемент кортежа corp размечается представителем экспертной группы на предмет наличия или отсутствия в нем конфиденциальной информации, что соответственно определяет необходимость контроля либо его отсутствие при дальнейшей обработке и принадлежность к одному из классов, class=[c1, с2], с∈С, d∈С (блок 102). Метка «*», проставленная представителем экспертной группы первым символом в тексте означает наличие в нем конфиденциальной информации и принадлежность к классу с1 тогда как отсутствие метки «*» определяет принадлежность текстовой информации к классу с2. Реквизиты, указывающие на наличие конфиденциальных данных в тексте должны быть удалены, за счет чего в процессе обучения фокусирование внимания обучаемых моделей сосредотачивается на содержательной части текстов.
Далее определяется переменная счетчика цикла i равная нулю (блок 103), которая переопределяется в процессе работы цикла и участвует в процессе проверки выхода из цикла по условию i<n, где n - числовое значение, определяемое количеством текстов, составляющих корпус текстовой информации электронного вида.
Определяется переменная clear, представляющая собой кортеж (блок 104), в которой сохраняется текстовая информация электронного вида прошедшая цикл предварительной обработки текстовой информации (блоки 105-109).
В блоке 106 цикла осуществляется процесс предварительной обработки текстовой информации, который включает в себя:
1) Приведение текста к нижнему или верхнему регистру (определяется экспертной группой);
2) Удаление специальных символов (за исключением символа «*»);
3) Удаление стоп-слов (объем определяется экспертной группой);
4) Токенизация текстовой информации;
5) Процесс лемматизации словарных величин.
Объемы предварительной обработки текстовой информации, определенные экспертной группой в пунктах 1-3 данного цикла, должны полностью отразиться в цикле предварительной обработки при эксплуатации модели или их комбинации определенной по итогу работы данного алгоритма.
После проведения процесса предварительной обработки, переменная clear переопределяется (блок 107), добавляя очередной очищенный текст, индекс которого определяется значением i.
Значение счетчика цикла i увеличивается на единицу (блок 108). При выполнении условия проверки выхода из цикла на этом этапе он завершается (блок 109).
В переменной clear осуществляется хранение предварительно обработанной текстовой информации электронного вида (блок 110), которая необходима для последующих расчетов.
Далее определяется переменная label (блок 111) представляющая собой кортеж, которая служит для хранения меток классов текстовой информации электронного вида с целью проведения в дальнейшем этапа машинного обучения.
Определяется переменная class (блок 112) представляющая собой числовое значение которой может быть ноль, что означает отсутствие конфиденциальной информации в тексте или единица, что означает наличию конфиденциальной информации в тексте. Данные значения присваиваются на основании символа «*», который был проставлен представителями экспертной группы (блок 102).
Переопределяется значение счетчика цикла i на нулевое значение (блок 113).
Далее следует цикл автоматического формирования меток класса (блоки 114-123) с внесением в переменную label с целью дальнейшего использования данной переменной на этапе машинного обучения.
Далее осуществляется проверка предварительно обработанной текстовой информации, на наличие первым символом «*» в элементе переменной clear. В том случае, если символ «*» не является первым символом в элементе переменной clear, значение переменной class переопределяется на нулевое (блок 116). Данное значение вносится в переменную label и переменная label переопределяется (блок 117).
В случае, если символ «*» является первым символом в элементе переменной clear, значение переменной class переопределяется на единицу (блок 118), добавляется в переменную label и переменная label переопределяется (блок 119). Далее символ «*» удаляется (блок 120), ввиду того, что данный символ был проставлен представителями экспертной группы и в реальных данных присутствовать не будет. После удаления метки «*» переменная clear переопределяется (блок 121).
Счетчик цикла i увеличивается на единицу (блок 122). При выполнении условия проверки выхода из цикла на этом этапе он завершается (блок 123).
Переменная label хранит метки классов каждого элемента из переменной corp (блок 124).
Инициализируется переменная slovar, представляющая собой кортеж, в которой осуществляется хранение всех словарных величин из всего корпуса текстовой информации в единичном экземпляре, в лемматизированной форме а также переменная vesa также представляющая собой кортеж, в которой осуществляется хранение весовых коэффициентов словарных величин из переменной slovar в строгом соответствии по индексу между словарной величиной и ее весовым коэффициентом (блок 125).
Переопределяется значение счетчика цикла i на нулевое значение (блок 126).
Далее, в цикле (блок 127-133), осуществляется формирование словаря хранящегося в переменной slovar и формирование переменной vesa с целью хранения весовых коэффициентов для каждой словарной величины из переменной slovar с проверкой условия выхода из цикла i<N, где N - количество словарных величин используемых во всем корпусе текстовой информации электронного вида после осуществления этапа предварительной обработки хранящихся в переменной clear.
Осуществляется проверка, присутствует ли словарная величина t в переменной slovar (блок 128). В случае, если словарная величина t присутствует в переменной slovar, счетчик цикла i увеличивается на единицу (блок 132) и осуществляется переход к проверке на наличие в переменной slovar следующей словарной величины.
В случае, если данной словарной величины нет в переменной slovar, словарная величина t добавляется в нее и переменная slovar переопределяется (блок 129). Для словарной величины t происходит расчет весового коэффициента, рассчитанного по алгоритму TF-IDF, при помощи формулы 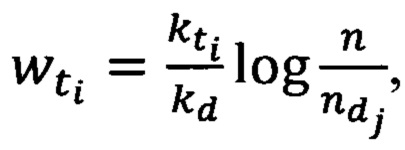 где
где 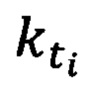 - количество раз, которое словарная величина t, встретилась в тексте, в котором она была встречена впервые, kd - количество всех словарных величин, составляющих данный текст, n - количество текстов составляющих корпус текстовой информации электронного вида,
- количество раз, которое словарная величина t, встретилась в тексте, в котором она была встречена впервые, kd - количество всех словарных величин, составляющих данный текст, n - количество текстов составляющих корпус текстовой информации электронного вида, 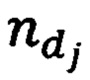 - количество текстов, в которых встречается данная словарная величина t (блок 130). Рассчитанный весовой коэффициент добавляется в переменную vesa, тем самым переопределяя ее (блок 131), счетчик цикла i увеличивается на единицу (блок 132), после чего осуществляется проверка по условию, что все словарные величины, используемые в корпусе текстовой информации, прошли проверку на факт присутствия в переменно slovar (блок 133). При выполнении условия проверки выхода из цикла на этом этапе он завершается. Размерность переменной slovar, определяет размерность вектора в которой представляется текстовая информация электронного вида. В свою очередь, размерность переменной slovar определяется АРМ пользователя, обладающим наименьшими вычислительными возможностями. К примеру процессор Intel Core i3-10100 и оперативная память 8 ГБ, способны обрабатывать вектор, состоящий не более чем из 17000 элементов. Размерность переменной slovar регулируется помимо стоп-слов, определяемых экспертной группой, установкой экспертной группой порогового значения
- количество текстов, в которых встречается данная словарная величина t (блок 130). Рассчитанный весовой коэффициент добавляется в переменную vesa, тем самым переопределяя ее (блок 131), счетчик цикла i увеличивается на единицу (блок 132), после чего осуществляется проверка по условию, что все словарные величины, используемые в корпусе текстовой информации, прошли проверку на факт присутствия в переменно slovar (блок 133). При выполнении условия проверки выхода из цикла на этом этапе он завершается. Размерность переменной slovar, определяет размерность вектора в которой представляется текстовая информация электронного вида. В свою очередь, размерность переменной slovar определяется АРМ пользователя, обладающим наименьшими вычислительными возможностями. К примеру процессор Intel Core i3-10100 и оперативная память 8 ГБ, способны обрабатывать вектор, состоящий не более чем из 17000 элементов. Размерность переменной slovar регулируется помимо стоп-слов, определяемых экспертной группой, установкой экспертной группой порогового значения 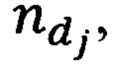 которое определяется количеством текстов, в которых встречается словарная величина. К примеру, если словарная величина встречается менее чем в пяти текстах из корпуса - она не добавляется в переменную slovar и для нее не рассчитывается весовой коэффициент. За счет увеличения или уменьшения данного значения как порогового, осуществляется регулирование размерности переменной slovar и соответственно размерности вектора, в виде которого может быть представлена любая текстовая информация электронного вида.
которое определяется количеством текстов, в которых встречается словарная величина. К примеру, если словарная величина встречается менее чем в пяти текстах из корпуса - она не добавляется в переменную slovar и для нее не рассчитывается весовой коэффициент. За счет увеличения или уменьшения данного значения как порогового, осуществляется регулирование размерности переменной slovar и соответственно размерности вектора, в виде которого может быть представлена любая текстовая информация электронного вида.
Переменные slovar и vesa подлежат обязательному сохранению ввиду дальнейшего их использования при осуществлении классификации текстовой информации электронного вида на предмет наличия в ней конфиденциальных данных обрабатываемой на АРМ пользователя (блок 134).
На следующем этапе инициализируется переменная vector, представляющая собой кортеж, с целью хранения векторизованной текстовой информации электронного вида составляющей корпус (блок 135).
Значение счетчика i переопределяется на нулевое, с целью осуществления проверки условия выхода из цикла (блок 136).
Далее осуществляется цикл векторизации текстовой информации электронного вида, прошедшей этап предварительной обработки и хранящейся в переменной clear с условием выхода из цикла i<n, где n количество элементов текстовой информации составляющей корпус (блок 137-141).
Осуществляется процесс векторизации каждого элемента переменной clear, который является текстовой информацией электронного вида прошедшей этап предварительной обработки (блок 138). Процесс векторизации осуществляется следующим образом - поочередно, с первого элемента проверяется, присутствует ли словарная величина из переменной slovar в векторизуемом тексте, хранящемся в переменной clear. В том случае, если данная словарная величина присутствует - в вектор текста добавляется ее весовой коэффициент из переменной vesa который синхронизирован по индексу. Векторизация, осуществляемая данным образом формирует векторы текстов единого размера, независимо от количества словарных величин применяемых в тексте, что в свою очередь расширяет перечень моделей машинного обучения пригодных для классификации текстовой информации электронного вида на предмет наличия в ней конфиденциальной информации, за счет чего в рамках одного алгоритма обучаются модели на основе «Байесовского алгоритма», алгоритмов «Decision tree», «Random Forest», «Логистической регрессии», «Градиентный бустинг», «Ada Boost», полносвязного нейросетевого алгоритма с одним скрытым слоем, метода опорных векторов.
Добавляя сформированный вектор текстовой информации электронного вида в переменную vector происходит ее переопределение (блок 139).
Значение счетчика цикла i увеличивается на единицу (блок 140).
Далее осуществляется проверка условия по выходу из цикла i<n. В случае, если данное условие не соблюдается - цикл прерывается (блок 141).
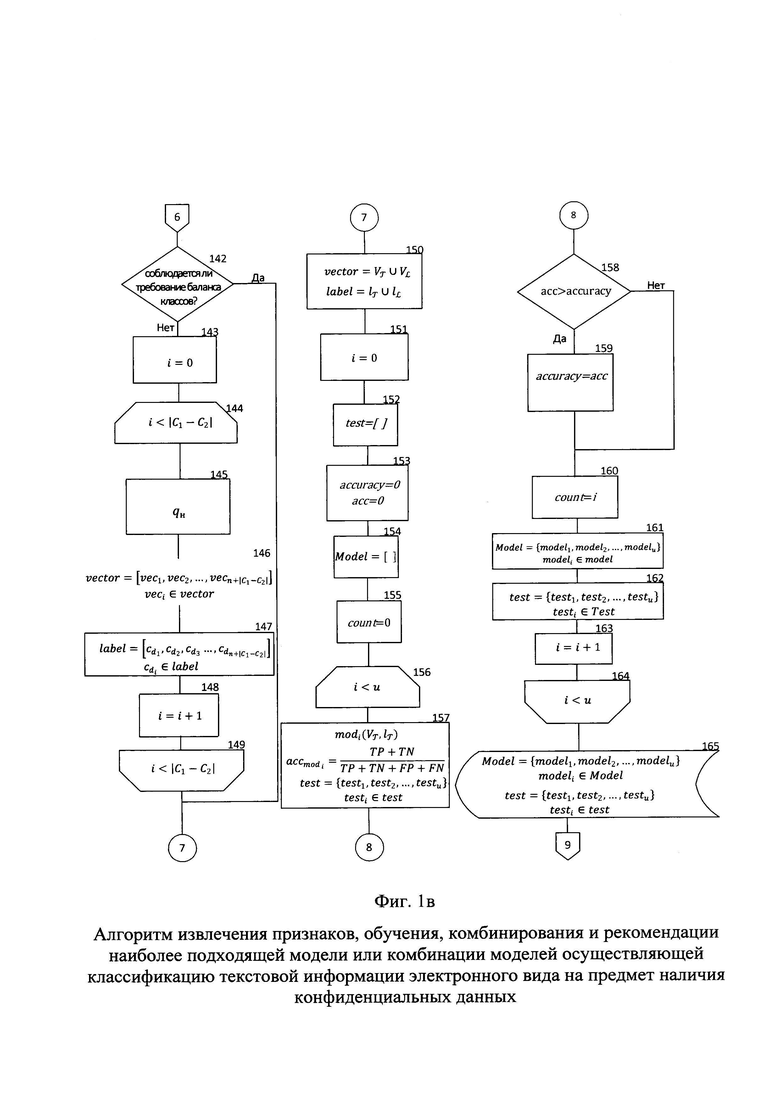
После того, как вся текстовая информация электронного вида была векторизована и сформированы переменные label и vector осуществляется проверка на сбалансированность выборки по классам с1 и с2 с целью дальнейшей объективной оценки показателей точности обученных моделей (блок 142).
В том случае, если баланс классов не соблюдается и с1≠с2, алгоритм запускает процесс аугментации данных для меньшего класса. Переопределяется переменная счетчика цикла i на значение равное нулю (блок 143), которая осуществляет проверку условия выхода из цикла i<|c1-c2|, где |c1-c2| значение, определяемое разницей классов по модулю (блок 144-149). Далее осуществляется процедура генерирования элемента qH новых данных недостающего класса (блок 145), которая заключается в случайном переставлении местами элементов вектора, составляющих один из векторов меньшего класса, определяемого случайным образом. Размерность сгенерированного вектора соответствует размерности переменной slovar. Вновь сгенерированный вектор добавляется в переменную vector, после чего она переопределяется соответственно (блок 146). Также в переменную label добавляется значение метки меньшего класса, тем самым переопределяя ее (блок 147). Значение переменной счетчика i увеличивается на единицу (блок 148). При выполнении условия выхода из цикла на этом этапе он завершается (блок 149).
Если условие по сбалансированности классов выборки соблюдается - алгоритм переходит к этапу разделения выборки на обучающую и тестовую (блок 150).
Далее происходит разделение переменных vector и label на обучающую выборку 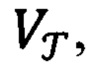 и метки их классов хранящихся в переменной
и метки их классов хранящихся в переменной 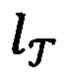 и тестовую выборку
и тестовую выборку 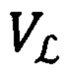 и метки их классов хранящихся в переменной
и метки их классов хранящихся в переменной 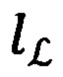 (блок 150) в строгом соответствии по индексу каждого элемента из переменной vector с каждым элементом из переменной label. При разделении выборки соблюдается пропорция 80/20, где 80% выборки является обучающей и 20% - тестовой.
(блок 150) в строгом соответствии по индексу каждого элемента из переменной vector с каждым элементом из переменной label. При разделении выборки соблюдается пропорция 80/20, где 80% выборки является обучающей и 20% - тестовой.
Значение счетчика i переопределяется на нулевое с целью осуществления проверки условия выхода из цикла i<u, где u значение, определяемое количеством обучаемых моделей классификации текстовой информации электронного вида на предмет наличия конфиденциальной информации (блок 151).
Определяется переменная test (блок 152), представляющая собой кортеж, с целью хранения векторов с результатами тестирования обученных моделей.
Определяется переменная accuracy (блок 153) с целью хранения значения точности обученной модели показавшей наибольшее значение точности, и переменная acc значение которой рассчитывается по результатам тестирования обученной модели при помощи формулы 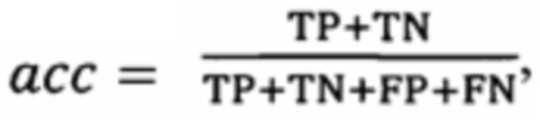 где TP - истинно положительное значение (верное предсказание о принадлежности текста к классу текстов, содержащих конфиденциальные данные), FP - ложно положительное значение (ошибка первого рода, текст предсказанный как принадлежащий к классу текстов, содержащих конфиденциальные данные фактически таковым не является), FN - ложно отрицательное значение (ошибка второго рода, текст предсказанный как не принадлежащий к классу текстов содержащих конфиденциальные данные фактически является таковым), TN - истинно отрицательное значение (верное предсказание о непринадлежности текста к классу текстов, содержащих конфиденциальные данные).
где TP - истинно положительное значение (верное предсказание о принадлежности текста к классу текстов, содержащих конфиденциальные данные), FP - ложно положительное значение (ошибка первого рода, текст предсказанный как принадлежащий к классу текстов, содержащих конфиденциальные данные фактически таковым не является), FN - ложно отрицательное значение (ошибка второго рода, текст предсказанный как не принадлежащий к классу текстов содержащих конфиденциальные данные фактически является таковым), TN - истинно отрицательное значение (верное предсказание о непринадлежности текста к классу текстов, содержащих конфиденциальные данные).
Определяется переменная model (блок 154), представляющая собой кортеж, с целью хранения обученных в результате выполнения цикла моделей.
Определяется переменная count (блок 155), представляющая собой кортеж, с целью хранения значения или последовательности значений, которое является индексом модели, показавшей наибольшую точность в результате тестирования или индексами нескольких моделей, участвующих в комбинации соответственно.
Далее осуществляется цикл обучения моделей классификации (блоки 156-164) на основе «Байесовского алгоритма», алгоритмов «Decision tree», «Random Forest», «Логистической регрессии», «Градиентный бустинг», «Ada Boost», полносвязного нейросетевого алгоритма с одним скрытым слоем, метода опорных векторов.
Представленные модели машинного обучения не требуют дополнительной настройки параметров и достаточным условием для их обучения является наличие векторизованной текстовой информации электронного вида хранящейся в переменной vector (блок 146), а также меток их классов хранящихся в переменной label (блок 147).
Осуществляется обучение модели modi классификации текстовой информации электронного вида на предмет наличия конфиденциальных данных до достижения наибольшего значения показателя точности acc, с формированием вектора прогнозов представленном в виде кортежа и состоящем из прогнозов по каждому элементу тестовой выборки (блок 157).
Далее осуществляется проверка, превышает ли значение точности модели acc, значение accuracy (блок 158). В том случае, если значение переменной acc превышает значение переменной accuracy - значение accuracy переопределяется на значение acc (блок 159). Данный показатель определяет модель, наиболее подходящую для осуществления классификации текстовой информации электронного вида на предмет наличия конфиденциальных данных. Также переопределяется значение count на показатель значения счетчика (блок 160). Показатель count указывает на индекс модели, показавшей наибольшее значение точности. В том случае, если значение точности обученной модели acc не превышает значение показателя accuracy - алгоритм переходит к переопределению переменной model, в которую сохраняется обученная модель (блок 161). Вектор результатов, представленный в виде кортежа, полученный в процессе произведенного тестирования обученной модели сохраняется в переменную test (блок 162). Счетчик цикла i увеличивается на единицу (блок 163). При выполнении условия проверки выхода из цикла i<u, на этом этапе он завершается (блок 164). Осуществляется хранение переменной test, с результатами тестирования каждой из обученных моделей и переменной Model с обученными моделями классификации текстовой информации на предмет наличия конфиденциальных данных (блок 165).
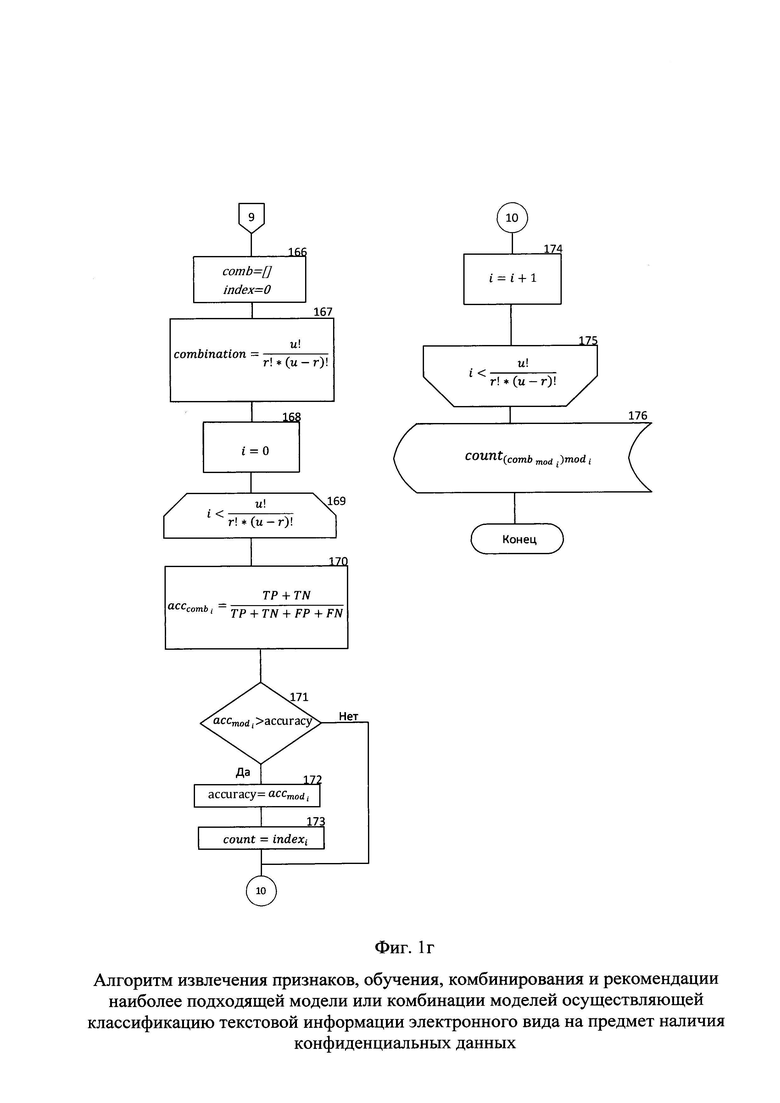
На следующем этапе определяется переменные comb и index представленные в виде кортежа (блок 166). Результаты тестирования обученных моделей комбинируются таким образом, чтобы из них были составлены все вариации комбинаций результатов тестирования по три элемента, в которых хранятся результаты тестирования обученных моделей классификации текстовой информации на предмет наличия конфиденциальных данных. Количество комбинаций определяется по формуле 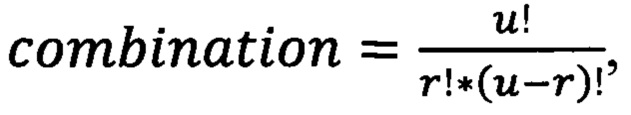 где u - количество ранее обученных моделей, а r - количество моделей участвующих в комбинации (блок 167). Таким образом значение combination = 56. Также в каждую из комбинаций добавляется вектор классов
где u - количество ранее обученных моделей, а r - количество моделей участвующих в комбинации (блок 167). Таким образом значение combination = 56. Также в каждую из комбинаций добавляется вектор классов 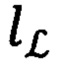 тестовой выборки, который был получен при разделении переменной label в процессе формирования обучающей и тестовой выборок (блок 150).
тестовой выборки, который был получен при разделении переменной label в процессе формирования обучающей и тестовой выборок (блок 150).
Значение счетчика i переопределяется на нулевое (блок 168). Далее осуществляется цикл расчета точности сформированных комбинаций с целью выявления комбинации моделей показывающей значение точности выше, чем отдельно взятая модель (блок 169-175).
Производится расчет значения точности комбинации 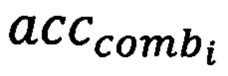 (блок 170). Далее осуществляется сравнение, превышает ли значение точности комбинации значение accuracy (блок 171). В том случае, если значение точности комбинации превышает значение accuracy значение accuracy переопределяется на значение (блок 172). Также переопределяется переменная count на значение indexi в котором хранятся индексы моделей, участвующих в комбинации (блок 173). В том случае, если значение точности acccomb не превышает значение accuracy происходит увеличение счетчика цикла i на единицу (блок 174). При не выполнении условия проверки выхода из цикла
(блок 170). Далее осуществляется сравнение, превышает ли значение точности комбинации значение accuracy (блок 171). В том случае, если значение точности комбинации превышает значение accuracy значение accuracy переопределяется на значение (блок 172). Также переопределяется переменная count на значение indexi в котором хранятся индексы моделей, участвующих в комбинации (блок 173). В том случае, если значение точности acccomb не превышает значение accuracy происходит увеличение счетчика цикла i на единицу (блок 174). При не выполнении условия проверки выхода из цикла 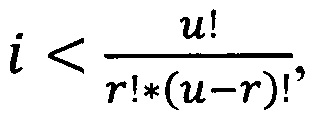 на этом этапе он завершается (блок 175).
на этом этапе он завершается (блок 175).
Осуществляется хранение модели, или их комбинации (блок 176), показавшей наибольшее значение точности классификации текстовой информации электронного вида на предмет наличия конфиденциальных данных определяемое на основании индекса или индексов комбинации, записанных в переменной count.
На основе данных, хранимых в блоках 134 и 176 при учете того, что полностью повторяется этап предварительной обработки информации, осуществляется классификация текстовой информации электронного вида на предмет наличия конфиденциальных данных на рабочих местах пользователей.
На фиг. №№2а, 2б представлен алгоритм классификации текстовой информации на предмет наличия конфиденциальных данных, который предлагается к реализации для осуществления контроля за конфиденциальной информацией на АРМ пользователей, не предназначенных для ее обработки, при помощи данных, полученных в результате алгоритма представленного на фиг. №№1а, 1б, 1в, 1г.
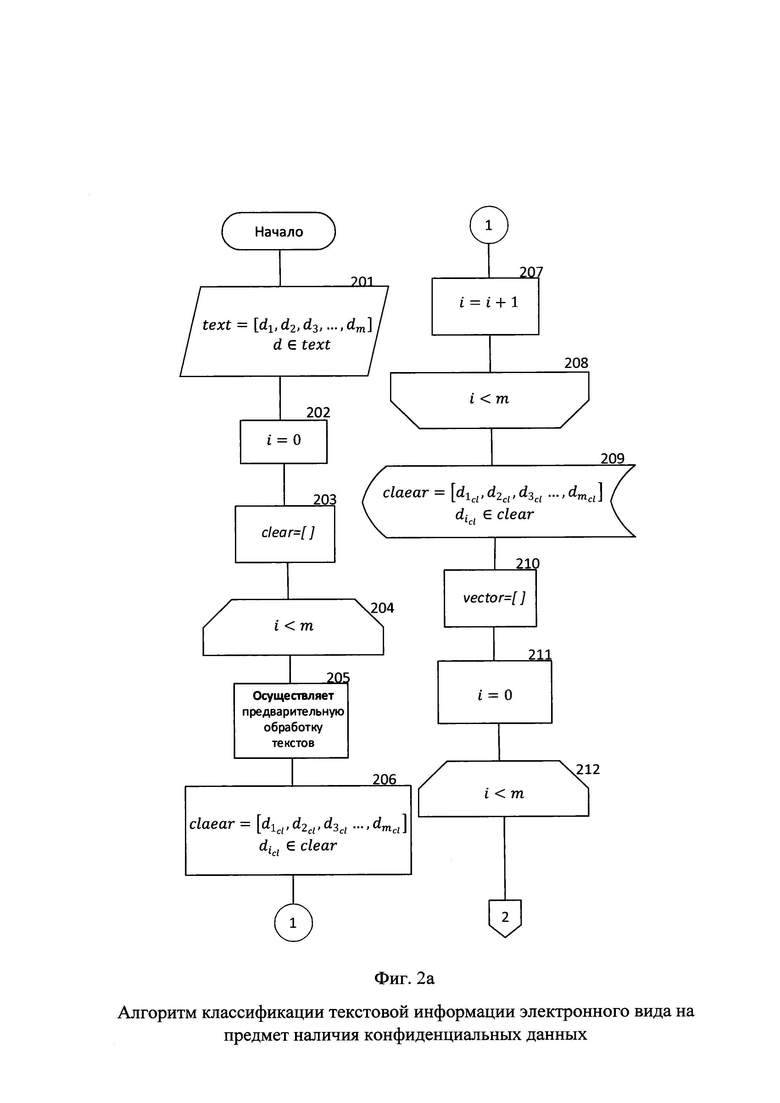
На вход поступает текстовая информация, обрабатываемая на АРМ пользователя хранящаяся в переменной text (блок 201).
Далее определяется значение счетчика цикла i равное нулю (блок 202), с целью осуществления проверки условия выхода из цикла i<m, где m количество файлов текстовой информации электронного вида обрабатываемых на АРМ.
Определяется переменная clear, представленная в виде кортежа, предназначенная для хранения предварительно обработанной текстовой информации электронного вида (блок 203).
Далее, в цикле (блок 204-208) осуществляется процесс предварительной обработки текстовой информации электронного вида. Цикл предварительной обработки текстовой информации электронного вида должен полностью совпадать с циклом предварительной обработки текстовой информации проведенном на этапе обучения, за исключение отсутствия необходимости в удалении стоп-слов, ввиду векторизации на основе уже сформированного ранее словаря и включает в себя (блок 205):
1) Приведение текста к нижнему или верхнему регистру (определено экспертной группой на этапе обучения моделей классификации);
2) Удаление специальных символов (объем определен экспертной группой на этапе обучения моделей классификации, включая удаление символа «*»);
3) Токенизация текстовой информации;
4) Лемматизирование словарных величин.
Текстовая информация электронного вида, прошедшая этап предварительной обработки добавляется в переменную clear, после чего данная переменная переопределяется (блок 206).
Значение счетчика цикла i увеличивается на единицу (блок 207).
При выполнении условия выхода из цикла на этом этапе он завершается (блок 208).
Предварительно обработанная текстовая информация хранится в переменной clear (блок 209).
Далее определяется переменная vector, с целью хранения векторизованной текстовой информации электронного вида обрабатываемой на АРМ пользователя (блок 210).
Переопределяется счетчик цикла i на нулевое значение (блок 211), с целью осуществления проверки условия выхода из цикла i<m. Осуществляется цикл векторизации каждого элемента кортежа, хранящегося в переменной clear (блоки 212-216). Процесс векторизации осуществляется следующим образом - поочередно, с первого элемента из переменной slovar проверяется, присутствует ли словарная величина, которая была сформирована на этапе обучения в векторизуемом тексте, хранящемся в переменной clear. В том случае, если данная словарная величина присутствует - в вектор текста добавляется ее весовой коэффициент из переменной vesa, который синхронизирован по индексу с переменной slovar и также была сформирована на этапе обучения. В случае, если словарная величина из словаря отсутствует в векторизуемом тексте - в вектор добавляется нулевое значение (блок 213). Сформированный вектор добавляется в переменную vector, после чего она переопределяется (блок 214). Далее значение счетчика цикла i увеличивается на единицу (блок 215). При выполнении условия проверки выхода из цикла на этом этапе он завершается (блок 216).
Далее определяется переменная class с целью хранения метки класса, представленной в виде целочисленного значения, которое будет определено в процессе классификации моделью или их комбинацией, векторизованной текстовой информации электронного вида (блок 217).
Переопределяется счетчик цикла i на нулевое значение (блок 218), с целью осуществления проверки условия выхода из цикла i<m.
Осуществляется цикл классификации векторизованной текстовой информации электронного вида (блоки 219-223).
Векторизованная текстовая информация электронного вида подается на вход обученной модели mod, или их комбинации combmod которые были получены в результате выполнения алгоритма обучения (блок 220). Спрогнозированный класс вносится в переменную class (блок 221), после чего данная переменная переопределяется. Значение счетчика цикла i увеличивается на единицу (блок 222). При выполнении условия проверки выхода из цикла на этом этапе он завершается (блок 223).
На основании переменной class в каталог conƒ копируются исходные файлы, содержащие текстовую конфиденциальную информацию (блок 224). Права доступа к данному каталогу предоставляются исключительно специалистам по обеспечению безопасности информации.
На фиг. 3 представлен пример типового средства защиты информации и место способа классификации текстовой информации электронного вида на предмет наличия конфиденциальных данных. Данное средство защиты информации является обязательным элементом в общей системе защиты информации организации. На сегодняшний день средство защиты информации не способно выявлять факт нарушения правил обработки конфиденциальной информации, вызванный превышением максимально допустимого уровня конфиденциальности обрабатываемой информации. Одним из возможных вариантов реализации данного способа является его применение в средстве защиты информации, за счет чего устраняется данный недостаток. Обученная модель или комбинация моделей классификации текстовой информации электронного вида на предмет наличия конфиденциальных данных, а также признаковое пространство, полученные в результате работы алгоритма (100), могут быть реализованы в составе группы подсистем локальной защиты. Пунктирными линиями обозначены связи с другими элементами средства защиты информации. Объекты файловой системы, имеющие формат хранения текстовой информации, классифицируются при помощи предлагаемого способа на предмет наличия в них конфиденциальных данных и в случае, если будут выявлен факт превышения максимально допустимого к обработке уровня конфиденциальности - данный объект копируется в каталог corp с целью дальнейшего анализа данной текстовой информации специалистом по обеспечению безопасности информации организации. Данный пример является одним из возможных вариантов реализации данного способа и не должен трактоваться как ограничивающий иные.
На фиг. 4 представлен пример общей схемы вычислительного устройства, которое обеспечивает реализацию заявленного способа. В общем случае устройство содержит такие компоненты, как: один или более процессоров (блок 401), средства памяти, такие как ОЗУ (блок 402) и ПЗУ (блок 403), интерфейсы ввода/вывода (блок 404), средства ввода/вывода (блок 405), и устройство для сетевого взаимодействия (блок 406).
Процессор (блок 401) (или несколько процессоров) может выбираться из ассортимента устройств, широко применяемых в настоящее время, например, таких производителей, как: Intel™, AMD™, Apple™, Samsung Exynos™, MediaTEK™, Qualcomm Snapdragon™. Под процессором или одним из используемых с целью реализации представленного способа также необходимо учитывать графический процессор, например, GPU NVIDIA или Graphcore, тип которых также является пригодным для полного или частичного выполнения представленного способа, а также может применяться для обучения и применения моделей машинного обучения.
Процессор задействуется на всех этапах работы алгоритма извлечения признаков, обучения, комбинирования и рекомендации наиболее подходящей модели или комбинации моделей осуществляющей классификацию текстовой информации электронного вида на предмет наличия конфиденциальных данных, а также работы алгоритма классификации текстовой информации на предмет наличия конфиденциальных данных. Особенно процессор задействуется на этапе обучения моделей (фиг. 1в, блок 157) а также на этапе классификации текстовой информации электронного вида (фиг. 2б, блок 220), когда происходят вычислительно сложные операции с большими объемами данных.
ОЗУ (блок 402) представляет собой оперативную память и предназначено для хранения исполняемых процессором (блок 401) машиночитаемых инструкций для выполнения необходимых операций по логической обработке данных. ОЗУ (блок 402), как правило, содержит исполняемые инструкции операционной системы и соответствующих программных компонент (приложения, программные модули). При этом в качестве ОЗУ (блок 402) может выступать доступный объем памяти графической карты или графического процессора.
Оперативная память используется на всех этапах этапах работы алгоритма извлечения признаков, обучения, комбинирования и рекомендации наиболее подходящей модели или комбинации моделей осуществляющей классификацию текстовой информации электронного вида на предмет наличия конфиденциальных данных а также работы алгоритма классификации текстовой информации на предмет наличия конфиденциальных данных для кратковременного хранения данных, моделей, промежуточных результатов вычислений и прочей информации для работы представленных алгоритмов.
ПЗУ (блок 403) представляет собой одно или более устройств постоянного хранения данных, например, жесткий диск (HDD), твердотельный накопитель данных (SSD), флэш-память (EEPROM, NAND), оптические носители информации (CD-R/RW, DVD-R/RW, BlueRay Disc, MD) и д.р.
ПЗУ используется на этапе предварительной обработки текстовой информации электронного вида, когда необходимо загрузить и сохранить большие объемы информации. Также ПЗУ используется для хранения модели или их комбинации, рекомендованной на этапе обучения как наиболее подходящей для осуществления классификации текстовой информации электронного вида на предмет наличия конфиденциальных данных. Данная модель также хранится на ПЗУ АРМ пользователя. Помимо этого на ПЗУ осуществляется хранение переменной slovar и переменной vesa.
Интерфейсы В/В (блок 404) представляют собой стандартные средства для подключения и работы с серверной частью и зависят от конкретного исполнения вычислительного устройства, не ограничиваясь, USB, RS232, RJ45, LPT, COM, HDMI, PS/2, Lightning, Fire Wire и т.п.
При помощи данных интерфейсов возможно осуществить ввод корпуса текстовой информации электронного вида на АРМ, на котором осуществляется извлечение признаков, обучение, комбинирование и рекомендации наиболее подходящей модели или комбинации моделей осуществляющей классификацию текстовой информации электронного вида на предмет наличия конфиденциальных данных. Также при помощи представленных интерфейсов возможно внести модель или их комбинацию, а также необходимые для работы представленного алгоритма данные, хранимые в переменной slovar и vesa на АРМ пользователя.
В качестве средства В/В данных (блок 405), в любом воплощении вычислительной системы, реализующей описываемый способ, должна использоваться клавиатура в любом ее аппаратном исполнении. Подключение при этом может быть, как проводным, при котором соединительный кабель клавиатуры подключен к порту PS/2, или USB, расположенному на системном блоке настольного компьютера, так и беспроводным, при котором клавиатура осуществляет обмен данными по каналу беспроводной связи, например, радиоканалу, с базовой станцией, которая, в свою очередь, непосредственно подключена к системному блоку, например, к одному из USB-портов. Помимо клавиатуры, в составе средств В/В данных также может использоваться: джойстик, дисплей (сенсорный дисплей), проектор, тачпад, манипулятор мышь, трекбол, сетевое перо, динамики, микрофон, и т.п.
Средства сетевого взаимодействия (блок 406) обеспечивает передачу данных посредством внутренней или внешней вычислительной сети, например, Интранет, Интернет, ЛВС и т.п. В качестве одного или более средств сетевого взаимодействия может использоваться, но не ограничиваться: Ethernet карта, GSM модем, GPRS модем, LTE модем, 5G модем, модуль спутниковой связи, NFC модуль, Bluetooth и/или BLE модуль, WI-FI модуль и д.р.
На фиг. 5 представлены результаты тестирования обученных моделей. Обучение и тестирование моделей классификации осуществлялось на реальных данных, содержащих и не содержащих конфиденциальную информацию, обрабатываемых в одной из организаций как формализованного, так и не формализованного вида. В данном случае наибольшее значение точности показала модель на основе алгоритма «Random Forest» с точностью 92%. В качестве элементов комбинации показавшей наибольшее значение точности были выявлены модели на основе следующих алгоритмов: модель на основе «полносвязного нейросетевого алгоритма», алгоритмов «Decision tree», «Random Forest». Точность данной комбинации составляет 91%. Соответственно представленный способ рекомендует модель на основе алгоритма «Random Forest», как наиболее подходящую для классификации текстовой информации электронного вида на предмет наличия конфиденциальных данных. Данный способ учитывает специфику деятельности организации в интересах которой осуществляется контроль за обрабатываемой в ней конфиденциальной информацией а также виды конфиденциальной информации в ней обрабатываемой, соответственно для осуществления классификации текстовой информации электронного вида на предмет наличия конфиденциальных данных обрабатываемых в другой организации, данный способ, вероятно, предложит иную модель машинного обучения или комбинацию моделей осуществляющих классификацию текстовой информации на предмет наличия конфиденциальных данных.
В настоящих материалах заявки было представлено предпочтительное раскрытие осуществления заявленного технического решения, которое не должно использоваться как ограничивающее иные, частные воплощения его реализации, которые не выходят за рамки испрашиваемого объема правовой охраны и являются очевидными для специалистов в соответствующей области техники.
Заявленное изобретение относится к области вычислительной техники для выявления текстовой информации электронного вида, содержащей конфиденциальные данные. Заявленный способ заключается в том, что после этапа предварительной обработки и векторизации корпуса текстовой информации осуществляется процедура разделения выборки на тестовую и обучающую. Затем происходит последовательное обучение моделей классификации. Обученные модели тестируются, производится расчет значений их точности, а результаты тестирования комбинируются с целью исправления ошибок первого и второго рода при осуществлении классификации отдельно взятыми моделями классификации текстовой информации электронного вида на предмет наличия в них конфиденциальных данных. Далее рассчитывается значение показателей точности для каждой сформированной комбинации моделей, среди которых выбирается наибольшее значение точности. Техническим результатом является повышение точности классификации текстовой информации электронного вида по степени конфиденциальности. 5 ил.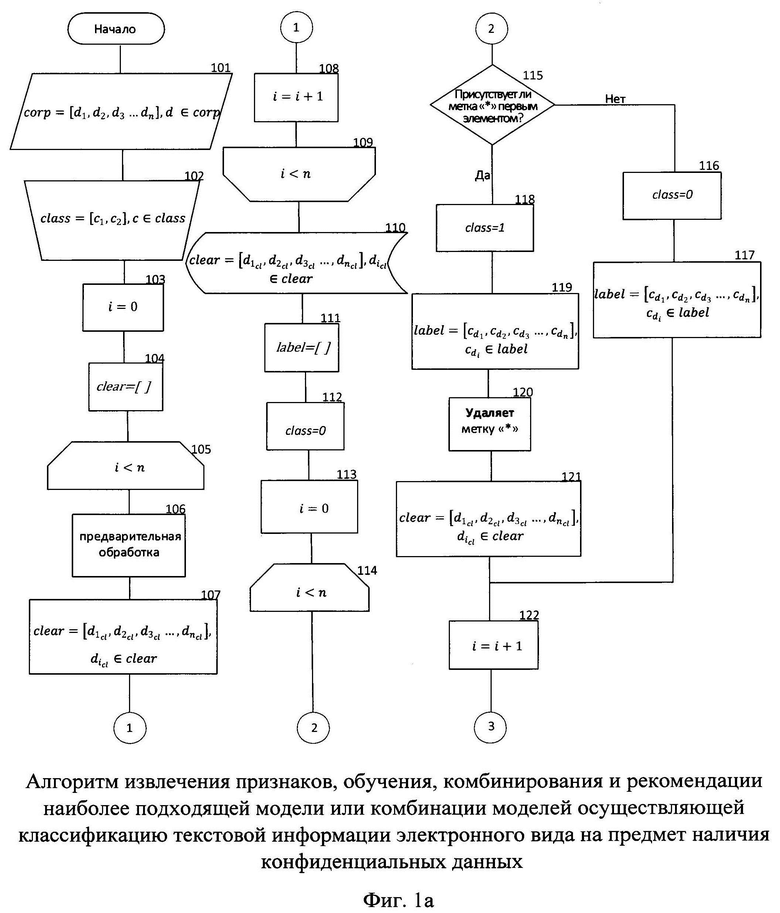
Способ классификации текстовой информации электронного вида на предмет наличия конфиденциальных данных, производящий автоматическую классификацию текстовой информации, содержащий процесс предварительной обработки текстовой информации в объеме, определенном экспертной группой, векторизации текстовой информации на основе данных, полученных в процессе извлечения признаков конфиденциальной информации, и отличающийся тем, что за счет внедрения цикла последовательного обучения моделей классификации на основе «Байесовского алгоритма», алгоритмов «Decision tree», «Random Forest», «Логистической регрессии», «Градиентный бустинг», «Ada Boost», полносвязного нейросетевого алгоритма с одним скрытым слоем, метода опорных векторов, что направлено на выявление наиболее подходящей модели классификации текстовой информации электронного вида на предмет наличия в них конфиденциальных данных, обрабатываемых в организации, вводится элемент, осуществляющий комбинирование прогнозов, полученных в процессе тестирования каждой из обученных моделей, с целью исправления ошибок первого и второго рода при осуществлении классификации отдельно взятыми моделями классификации текстовой информации электронного вида на предмет наличия в них конфиденциальных данных, факт выявления которых на автоматизированном рабочем месте (далее - АРМ) пользователей, не предназначенных для их обработки, является предпосылкой к утечке конфиденциальной информации, а также элемент, осуществляющий оценку точности моделей классификации или их комбинации и определяющий наиболее подходящую модель классификации или их комбинацию, при этом данный процесс реализуется следующим образом: на вход алгоритма подается переменная corp, характеризующая собой корпус текстовой информации, состоящий как из текстов, содержащих конфиденциальные данные, так и из текстов, не содержащих конфиденциальные данные, представленный в электронном виде без проставленных меток конфиденциальности в каждом отдельно взятом тексте, каждый элемент которой подвергается оценке экспертной группой на предмет наличия конфиденциальной информации с последующей разметкой по принадлежности к одному из классов переменной class, которая заключается в проставлении символа «*» первым символом в тексте, содержащем конфиденциальную информацию, что является меткой принадлежности к классу с1, тогда как при отсутствии конфиденциальной информации в тексте метка «*» не проставляется, что свидетельствует об отсутствии необходимости контроля за данной информацией при ее обработке и означает принадлежность к классу с2, а также установкой экспертной группой порогового значения 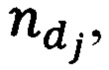 влияющего на размерность векторного представления текстовой информации электронного вида, после чего формируется переменная clear, в которую, в процессе предварительной обработки каждой текстовой информации электронного вида очищенной в объеме «стоп-слов» и специальных символов - за исключением символа «*», приведения текста к нижнему регистру, токенизации и лемматизации словарных величин для сокращения размерности итогового словаря, добавляются данные в виде кортежа, где каждый элемент кортежа есть предварительно обработанный текст, после чего формируется переменная label, в которую в результате работы цикла вносятся метки класса, определяемые в переменной class на основании наличия или отсутствия символа «*», проставленного представителями экспертной группы в результате произведенной разметки элементов, составляющих корпус текстов по принципу наличия конфиденциальных данных, к которым принадлежат элементы множества clear, после чего метка класса «*» должна быть удалена и переменная clear переопределяется, после чего производится расчет весовых коэффициентов каждой словарной величины, хранящихся в переменной vesa, и формирование словаря, хранящегося в переменной slovar с полной синхронизацией по индексу словарной величины из переменной slovar с ее весовым коэффициентом из переменной vesa, с целью дальнейшей векторизации всей текстовой информации, составляющей корпус, с сохранением в переменную vector и разделения выборки, в случае соблюдения условия на предмет сбалансированности классов, либо генерации объектов меньшего класса, в ином случае до достижения баланса классов с целью корректного обучения моделей и корректной оценки точности обученных моделей, на обучающую и тестовую, после чего осуществляется этап обучения вышеуказанных моделей, их последовательного тестирования каждой из обученных моделей, после чего производится расчет показателя точности для каждой из обученных моделей с целью выявления наибольшего значения показателя точности, которое хранится в переменной accuracy, а индекс, указывающий на модель modi из переменной model, показавшую данную точность, хранится в переменной count и перезаписывается как и значение accuracy на значение точности из переменной acc, которое рассчитывается для каждой обученной модели в случае, если на последующей итерации цикла обучения моделей будет выявлена модель с большим показателем точности, тогда как прогнозы обученных моделей, полученных в результате их тестирования по каждому элементу тестовой выборки, записываются в переменную test в виде вектора и на следующем этапе поступают на вход комбинатора, формирующего все вариации комбинаций результатов тестирования по три элемента и хранящиеся в переменной comb с целью выявления комбинации
влияющего на размерность векторного представления текстовой информации электронного вида, после чего формируется переменная clear, в которую, в процессе предварительной обработки каждой текстовой информации электронного вида очищенной в объеме «стоп-слов» и специальных символов - за исключением символа «*», приведения текста к нижнему регистру, токенизации и лемматизации словарных величин для сокращения размерности итогового словаря, добавляются данные в виде кортежа, где каждый элемент кортежа есть предварительно обработанный текст, после чего формируется переменная label, в которую в результате работы цикла вносятся метки класса, определяемые в переменной class на основании наличия или отсутствия символа «*», проставленного представителями экспертной группы в результате произведенной разметки элементов, составляющих корпус текстов по принципу наличия конфиденциальных данных, к которым принадлежат элементы множества clear, после чего метка класса «*» должна быть удалена и переменная clear переопределяется, после чего производится расчет весовых коэффициентов каждой словарной величины, хранящихся в переменной vesa, и формирование словаря, хранящегося в переменной slovar с полной синхронизацией по индексу словарной величины из переменной slovar с ее весовым коэффициентом из переменной vesa, с целью дальнейшей векторизации всей текстовой информации, составляющей корпус, с сохранением в переменную vector и разделения выборки, в случае соблюдения условия на предмет сбалансированности классов, либо генерации объектов меньшего класса, в ином случае до достижения баланса классов с целью корректного обучения моделей и корректной оценки точности обученных моделей, на обучающую и тестовую, после чего осуществляется этап обучения вышеуказанных моделей, их последовательного тестирования каждой из обученных моделей, после чего производится расчет показателя точности для каждой из обученных моделей с целью выявления наибольшего значения показателя точности, которое хранится в переменной accuracy, а индекс, указывающий на модель modi из переменной model, показавшую данную точность, хранится в переменной count и перезаписывается как и значение accuracy на значение точности из переменной acc, которое рассчитывается для каждой обученной модели в случае, если на последующей итерации цикла обучения моделей будет выявлена модель с большим показателем точности, тогда как прогнозы обученных моделей, полученных в результате их тестирования по каждому элементу тестовой выборки, записываются в переменную test в виде вектора и на следующем этапе поступают на вход комбинатора, формирующего все вариации комбинаций результатов тестирования по три элемента и хранящиеся в переменной comb с целью выявления комбинации 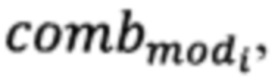 обеспечивающей наибольшую точность классификации хранящейся в переменной асе при реализации мажоритарного подхода среди элементов комбинации, который как и на предыдущем этапе обучения моделей в случае, если показатель точности асе превосходит показатель, хранящийся в переменной accuracy, значение из переменной acc перезаписывается вместо значения из переменной accuracy, а вместо значения count перезаписываются индексы моделей из переменной model, участвующих в комбинации, и определяет модель или их комбинацию, обеспечивающую наибольшую точность классификации текстовой информации электронного вида, обрабатываемой в организации. На основе переменных slovar, vesa, modeli или полученных при выполнения вышеописанного алгоритма, происходит процесс классификации текстовой информации электронного вида, обрабатываемой на АРМ пользователей, на предмет наличия конфиденциальных данных, который осуществляется следующим образом: на вход алгоритма поступает текстовая информация электронного вида, обрабатываемая на АРМ пользователя, хранящаяся в переменной text, данная текстовая информация проходит этап предварительной обработки, после чего каждая текстовая информация электронного вида, прошедшая этап предварительной обработки, вносится в переменную clear, после чего при помощи переменных slovar и vesa, полученных на этапе процесса обучения, осуществляется векторизация всей текстовой информации электронного вида, обрабатываемой на АРМ пользователя, векторы которой хранятся в переменной vector, после чего каждый вектор из данной переменной поочередно подается на вход обученной модели mod или поочередно на вход каждой обученной модели из комбинации combmod с реализацией мажоритарного подхода, после чего формируется прогноз по наличию конфиденциальных данных в текстовой информации электронного вида, хранящийся в переменной class, на основании которой осуществляется копирование исходных файлов, содержащих конфиденциальную текстовую информацию электронного вида, в каталог conƒ, доступ к которой имеет только специалист по обеспечению безопасности информации с целью дальнейшего ее анализа.
обеспечивающей наибольшую точность классификации хранящейся в переменной асе при реализации мажоритарного подхода среди элементов комбинации, который как и на предыдущем этапе обучения моделей в случае, если показатель точности асе превосходит показатель, хранящийся в переменной accuracy, значение из переменной acc перезаписывается вместо значения из переменной accuracy, а вместо значения count перезаписываются индексы моделей из переменной model, участвующих в комбинации, и определяет модель или их комбинацию, обеспечивающую наибольшую точность классификации текстовой информации электронного вида, обрабатываемой в организации. На основе переменных slovar, vesa, modeli или полученных при выполнения вышеописанного алгоритма, происходит процесс классификации текстовой информации электронного вида, обрабатываемой на АРМ пользователей, на предмет наличия конфиденциальных данных, который осуществляется следующим образом: на вход алгоритма поступает текстовая информация электронного вида, обрабатываемая на АРМ пользователя, хранящаяся в переменной text, данная текстовая информация проходит этап предварительной обработки, после чего каждая текстовая информация электронного вида, прошедшая этап предварительной обработки, вносится в переменную clear, после чего при помощи переменных slovar и vesa, полученных на этапе процесса обучения, осуществляется векторизация всей текстовой информации электронного вида, обрабатываемой на АРМ пользователя, векторы которой хранятся в переменной vector, после чего каждый вектор из данной переменной поочередно подается на вход обученной модели mod или поочередно на вход каждой обученной модели из комбинации combmod с реализацией мажоритарного подхода, после чего формируется прогноз по наличию конфиденциальных данных в текстовой информации электронного вида, хранящийся в переменной class, на основании которой осуществляется копирование исходных файлов, содержащих конфиденциальную текстовую информацию электронного вида, в каталог conƒ, доступ к которой имеет только специалист по обеспечению безопасности информации с целью дальнейшего ее анализа.
| СПОСОБ И СИСТЕМА КЛАССИФИКАЦИИ ДАННЫХ ДЛЯ ВЫЯВЛЕНИЯ КОНФИДЕНЦИАЛЬНОЙ ИНФОРМАЦИИ | 2019 |
|
RU2759786C1 |
| УСТРОЙСТВО ОБРАБОТКИ ИНФОРМАЦИИ, СПОСОБ ОБРАБОТКИ ИНФОРМАЦИИ И КОМПЬЮТЕРНАЯ ПРОГРАММА | 2006 |
|
RU2411572C2 |
| Способ автоматической классификации конфиденциальных формализованных документов в системе электронного документооборота | 2015 |
|
RU2647640C2 |
| Система и способ определения текста, содержащего конфиденциальные данные | 2017 |
|
RU2665915C1 |
| US 10348693 B2, 09.07.2019 | |||
| US 8752181 B2, 10.06.2014. | |||

