ОБЛАСТЬ ТЕХНИКИ
Заявленное техническое решение, в общем, относится к области вычислительной техники, а в частности к автоматизированному способу валидации обезличенных пользовательских данных.
УРОВЕНЬ ТЕХНИКИ
Из уровня техники известна облачная платформа для автоматизации маркетинга Mindbox, которая помогает собирать и обрабатывать данные о клиентах из онлайна и офлайна, автоматизировать коммуникации, управлять ими из одного окна и запускать омниканальные коммуникации, акции или рекламу (https://mindbox.ru/).
Другим примером платформы данных о клиентах является известная из уровня техники платформа Twilio Segment, которая осуществляет собор чистых, согласованных данных клиентов для получения аналитики в режиме реального времени. Twilio Segment позволяет группам по работе с данными легко подготавливать, обогащать и активировать имеющиеся данные в хранилище, что позволяет маркетологам быстро действовать с помощью персонализированной коммуникации.
Кроме того, из уровня техники известна технология HLR или Home Location Register, которая позволяет проверить телефонный номер абонента на активность: существует ли он и доступен ли.
Недостатком известных решений в данной области техники является то, что они обладают рядом ограничений в персонализации, динамической оптимизации и аналитике в реальном времени по сравнению с предлагаемым решением:
• Во-первых, Mindbox фокусируется преимущественно на автоматизации существующих коммуникационных каналов, но не обладает функционалом для динамической оптимизации времени и канала связи на основе цифрового портрета пользователя в реальном времени. Это может приводить к недостаточно персонализированным и менее эффективным кампаниям.
• Во-вторых, Twilio Segment предоставляет инструменты для сбора и обработки данных, однако интеграция данных и управление омниканальными коммуникациями требуют дополнительных ресурсов и технологий. Это решение не предоставляет встроенной системы анализа и рекомендаций по оптимизации времени отправки сообщений в зависимости от индивидуальных предпочтений пользователей, что снижает оперативность и персонализацию.
• Наконец, технология HLR ограничена проверкой активности телефонного номера, не предоставляя данных о предпочтениях пользователей и других характеристик цифрового портрета, что делает её узкоспециализированной и недостаточной для полноценной омниканальной стратегии.
Предлагаемое решение отличается от известных технологий возможностью глубокой персонализации, основанной на комплексном анализе цифрового профиля пользователя по обезличенным пользовательским данным, включающего его предпочтения, поведенческие данные и временные паттерны. Модель учитывает множество каналов связи (email, SMS, звонки и др.) и автоматически подбирает наиболее оптимальное время для коммуникации на основе собранных данных. Это позволяет значительно повысить точность и эффективность взаимодействий, сокращая расходы на коммуникацию и увеличивая отклик целевой аудитории.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
В заявленном техническом решении предлагается новый подход к валидации обезличенных пользовательских данных. В данном решении используются алгоритмы интеллектуальной валидации, скоринга и аналитики обезличенных пользовательских данных по номерам телефонов и адресам электронной почты.
Технический результат заключается в расширении арсенала технических средств решений такого назначения.
Дополнительным техническим результатом, достигающимся при решении данной проблемы, является обеспечение эффективности коммуникаций и повышения точности скоринга.
Заявленный технический результат достигается за счет осуществления способа валидации обезличенных пользовательских данных, включающий этапы, на которых:
a) в базе данных для записей, касающихся телефонных номеров пользователей, осуществляют сбор данных относительно успешных и неуспешных попыток связи за длительный период времени, определяют факторы, влияющие на успешность контакта, такие как: частота успешных звонков, время суток, когда пользователи чаще всего отвечают, предпочтения по каналам связи, анализируют данные, к чему привязан номер, осуществляют нормализацию и определение типа телефонных номеров, путем преобразования телефонного номера в строку, содержащую только последовательность цифр, а также путем удаления всех символов, кроме цифр, после чего проверяют преобразованный номер на соответствие международному стандарту с помощью заданного шаблона, определяют страну и тип телефонного номера с использованием базы данных всех международных кодов, и определяют номер телефона по-прежнему активен и принадлежит пользователю или неактивен;
b) в базе данных для записей, касающихся пользовательских адресов электронной почты: осуществляют нормализацию данных, путем преобразования записи адреса электронной почты в единый формат, а также путем исключения из записи адреса электронной почты сторонних символов и очистки формата записи; на основе нормализованных данных осуществляют проверку синтаксиса адреса электронной почты, путем проверки корректности написания записи с учетом заранее установленных правил формирования записи; осуществляют определение существования домена, к которому принадлежит адрес электронной почты, причем если домен существует, это свидетельствует о возможности отправки писем на этот адрес; осуществляют проверку существования электронного почтового ящика на указанном почтовом сервере, путем отправки запроса на указанный электронный почтовый сервер, для определения действительности указанного электронного почтового адреса; осуществляют проверку электронного почтового адреса на предмет регистрирования его на веб-ресурсах;
c) обновляют в базе данных каждую отдельную запись номера телефона и адреса электронной почты, с учетом выполненных операций по валидации на этапах a) и b).
ОПИСАНИЕ ЧЕРТЕЖЕЙ
Реализация изобретения будет описана в дальнейшем в соответствии с прилагаемыми чертежами, которые представлены для пояснения сути изобретения и никоим образом не ограничивают область изобретения. К заявке прилагаются следующие чертежи:
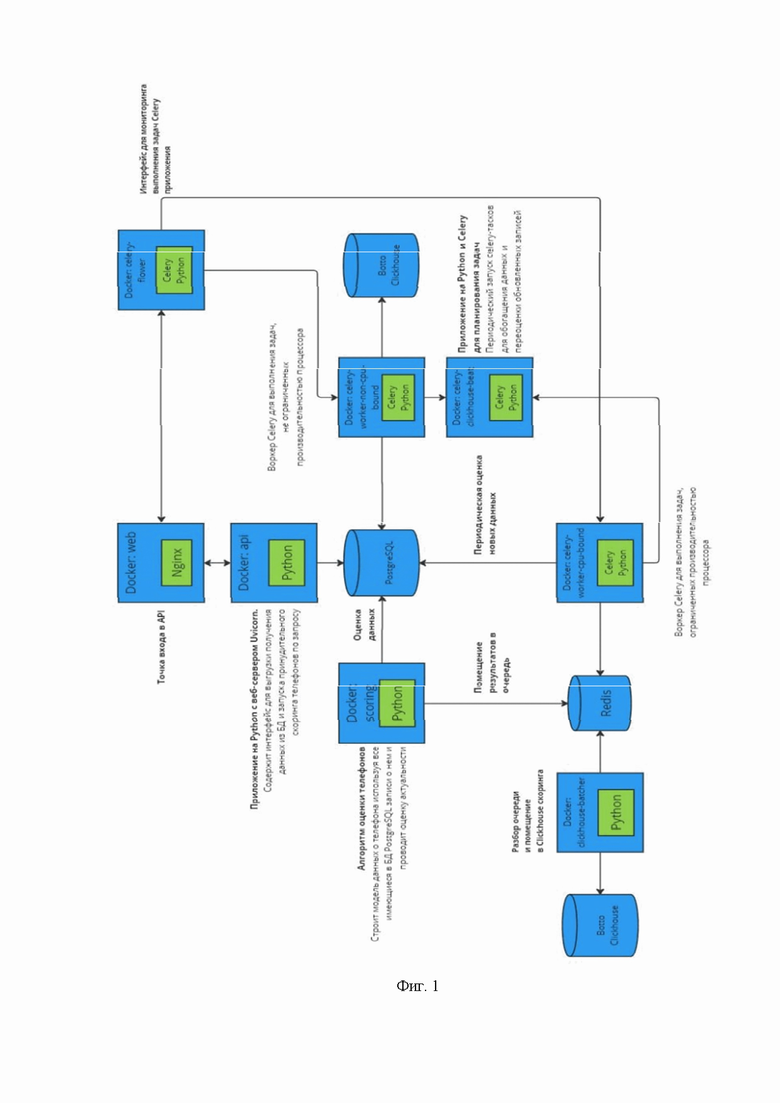
Фиг. 1 иллюстрирует схему валидации обезличенных пользовательских данных по телефонным номерам.
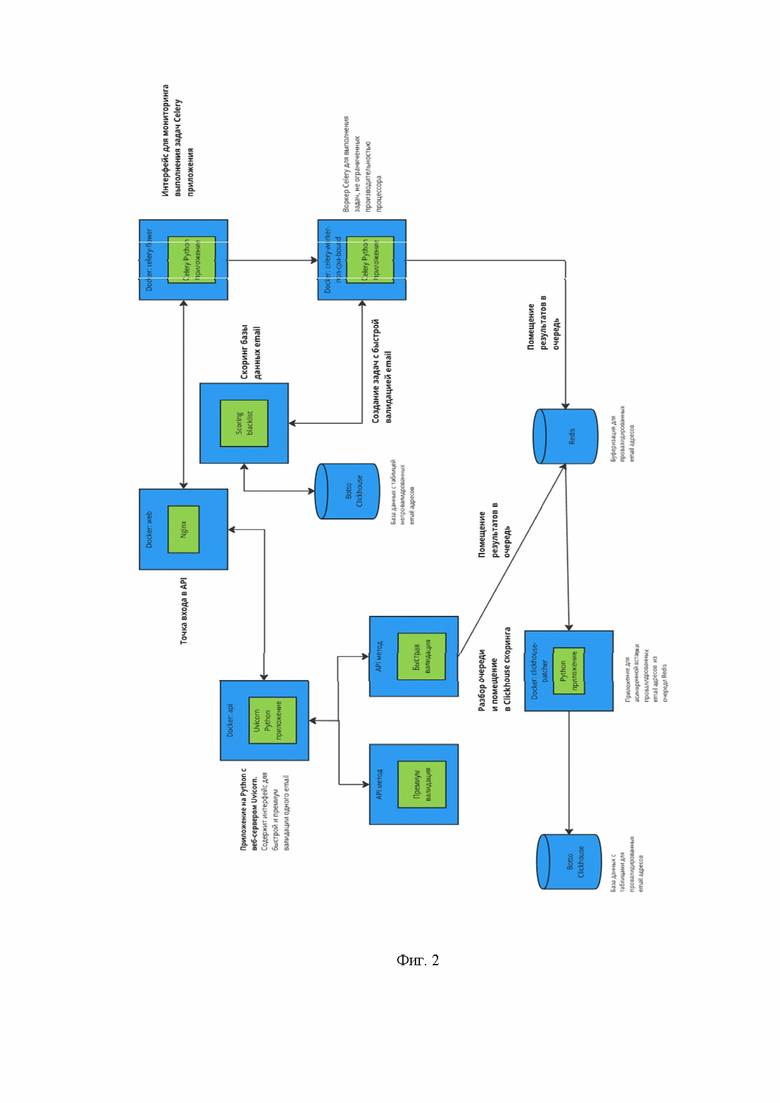
Фиг. 2 иллюстрирует схему валидации обезличенных пользовательских данных по электронным адресам.
ДЕТАЛЬНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
В приведенном ниже подробном описании реализации изобретения приведены многочисленные детали реализации, призванные обеспечить отчетливое понимание настоящего изобретения. Однако, квалифицированному в предметной области специалисту будет очевидно, каким образом можно использовать настоящее изобретение как с данными деталями реализации, так и без них. В других случаях хорошо известные методы, процедуры и компоненты не были описаны подробно, чтобы не затруднять понимание особенностей настоящего изобретения.
Кроме того, из приведенного изложения будет ясно, что изобретение не ограничивается приведенной реализацией. Многочисленные возможные модификации, изменения, вариации и замены, сохраняющие суть и форму настоящего изобретения, будут очевидными для квалифицированных в предметной области специалистов.
Ниже приведен подробный пример осуществления способа валидации обезличенных пользовательских данных.
Алгоритм интеллектуальной валидации и скоринга анализирует большой объем данных (Big Data) по коммуникациям с пользователями, а именно: звонки, мессенджеры и адреса электронных почт. В основе анализа лежат исторические данные взаимодействий за длительный период, принимая во внимание:
• Успешные и неуспешные попытки связи;
• Данные о предпочтениях пользователей, полученные из репозитория big data, включая профили в соцсетях, мессенджерах и историю e-mail взаимодействий;
• Сегментацию пользователей на основе поведенческих данных;
• Прогнозирование "живости" номера.
На первом этапе (фиг. 1) в заявленном решении осуществляют а) в базе данных для записей, касающихся телефонных номеров пользователей сбор данных относительно успешных и неуспешных попыток связи за длительный период времени, определяют факторы, влияющие на успешность контакта, такие как: частота успешных звонков, время суток, когда пользователи чаще всего отвечают, предпочтения по каналам связи, анализируют данные, к чему привязан номер, осуществляют нормализацию и определение типа телефонных номеров, путем преобразования телефонного номера в строку, содержащую только последовательность цифр, а также путем удаления всех символов, кроме цифр, после чего проверяют преобразованный номер на соответствие международному стандарту с помощью заданного шаблона, определяют страну и тип телефонного номера с использованием базы данных всех международных кодов, и определяют номер телефона по-прежнему активен и принадлежит пользователю или неактивен.
Указанный выше этап а) осуществляется с использованием ансамблевой модели, градиентного бустинга (XGBoost) для эффективной классификации структурированных данных и рекуррентных нейронных сетей (RNN) для анализа последовательностей временных рядов. Градиентный бустинг классифицирует структурированные данные (успех/неуспех связи), а RNN анализируют временные зависимости для выявления поведенческих паттернов, что позволяет учитывать временные аспекты взаимодействия с пользователем и повышает точность предсказаний по активности номера и эффективности выбранного канала связи. Такая модель, анализирует большой объем данных (Big Data) по коммуникациям с пользователями, например, звонки, мессенджеры, email. В основе анализа лежат исторические данные взаимодействий за длительный период. Модель обучается на этих данных для оценки вероятности успешности связи с абонентом, принимая во внимание:
• Успешные и неуспешные попытки связи;
• Сегментацию пользователей на основе поведенческих данных в коммуникациях.
Обучение модели включает несколько ключевых этапов:
• Сбор данных: на первом этапе собираются данные по коммуникациям с пользователями за длительный период. Эти данные включают успешные и неуспешные попытки связи по различным каналам (звонки, сообщения, e-mail и пр.), временные метки взаимодействий, и прочие поведенческие метрики.
• Предобработка данных: далее данные проходят предобработку, которая включает:
ο Нормализацию телефонных номеров для приведения их к единому формату;
ο Удаление дубликатов и пропусков в данных;
ο Категоризацию взаимодействий (успешные/неуспешные звонки, доставляемость сообщений, процент открытия в e-mail и т.д.);
ο Выделение временных паттернов взаимодействий.
• Создание фичей (feature engineering): на этапе feature engineering создаются признаки для модели, такие как частота успешных контактов, наиболее успешные временные промежутки (например, утро или вечер), канал связи с максимальной вероятностью выполнения целевого действия. Также добавляются временные метки для анализа изменений во времени.
• Тренировка модели: данные разбиваются на тренировочный и тестовый наборы. Модель обучается на тренировочных данных, используя градиентный бустинг для классификации успешных и неуспешных взаимодействий, а RNN для анализа последовательности временных событий. Для оценки качества модели применяют метрики precision, recall, F1-score и/или ROC-AUC.
• Валидация модели: после обучения модель тестируется на независимом наборе данных, который ранее не использовался в тренировке. Модель оценивает вероятность успешного контакта и сегментирует пользователей по временным паттернам, предоставляя результат в виде прогнозов, а применение кросс-валидации, позволяет минимизировать возможные ошибки переобучения и повысить устойчивость предсказаний.
Сегментация пользователей основывается на их поведении в разных каналах связи. Этот процесс включает несколько шагов:
• Анализ временных паттернов: в зависимости от времени суток, когда пользователи чаще всего реагируют на коммуникации (например, утром, днем или вечером), пользователи разделяются на сегменты по временному предпочтению.
• Анализ предпочтительных каналов связи: на основе успешных и неуспешных попыток связи выявляются каналы, через которые пользователи предпочитают получать информацию (например, одни пользователи отвечают на звонки быстрее, другие предпочитают мессенджеры или email). Таким образом, пользователи сегментируются по предпочтительным каналам.
• Поведенческая активность: учитывается частота взаимодействий. Пользователи, которые активно реагируют на сообщения, составляют один сегмент, а те, кто реже взаимодействует, - другой.
• Дополнительные поведенческие данные: важным аспектом является использование данных о прошлых взаимодействиях в социальных сетях и других платформах для создания более точных сегментов. Например, пользователи, которые активно взаимодействуют с рекламными предложениями в социальных сетях, могут быть выделены в отдельный сегмент для таргетированной коммуникации через эти каналы.
В результате сегментации пользователи группируются в кластеры, для каждого из которых подбирается оптимальная стратегия коммуникации по каналам, времени и содержанию сообщений, а также формирования групп пользователей с похожими характеристиками за счет K-means методов.
На основе анализа данных по успешным и неуспешным звонкам модель способна оценивать вероятность того, что номер телефона по-прежнему активен и принадлежит пользователю. Это критически важно для обеспечения эффективности коммуникаций, снижения затрат на недействительные контакты и повышения точности скоринга.
Модель постоянно обогащает данные, поступающие от микросервисов, с целью обновления цифровых портретов пользователей и повышения точности предсказаний. Это осуществляется за счет интеграции новых источников данных и постоянного самообучения модели на основе новых входных данных. Чем больше данных модель получает, тем точнее становятся ее предсказания относительно вероятности успешного контакта.
Ниже приведен пример работы алгоритма работы для скоринга номеров телефонов:
1. Сбор данных:
• Сбор и подготовка данных:
• - Исторические данные: собираются все взаимодействия с пользователями, включая успешные и неуспешные попытки связи.
• - Профили пользователей: информация из социальных сетей, мессенджеров и email анализируется для создания цифровых портретов. Модель изучает корреляции между различными факторами (время активности, предпочтения по каналам связи) и создает портрет пользователя, прогнозируя его поведение на основе этих данных.
• - Предварительная обработка: данные очищаются от пропусков (отсутствующих значений в данных, которые могут возникать из-за ошибок в сборе или передачи данных) и выбросов (аномально высоких или низких значений, которые могут исказить анализ), нормализуются для анализа путем очистки пропусков за счет удаления записей с пропусками или заполнение медианными/средними значениями, для удаления выбросов используются статистические методы (метод межквартильного размаха (IQR)).
• Моделирование и извлечение признаков:
• а) Выбор признаков: определение факторов, влияющие на успешность контакта, такие как:
• - Частота успешных звонков.
• - Время суток, когда пользователи чаще всего отвечают.
• - Предпочтения по каналам связи.
• б) Создание новых признаков с использованием методов:
• - One-hot encoding для категориальных данных по типам каналов связи с преобразованием их в численные признаки в алгоритмах машинного обучения - алгоритмы классифицируют данные, распределяя их по категориям (успешно/неуспешно, предпочтительные каналы и т.д.): логистическая регрессия для классификации успешных/неуспешных попыток связи; градиентный бустинг для выявления сложных зависимостей между каналами связи и результатами взаимодействий; деревья решений для определения ключевых факторов успеха коммуникаций).
• - Скользящее среднее для временных рядов для учета трендов в активности, используя взвешенное скользящее среднее (WMA), что придает большее значение недавним данным, но также учитывает прошлые значения с заданным весом или экспоненциальное скользящее среднее (EMA), которое более чувствительно к свежим данным, что позволяет лучше отслеживать недавние изменения поведения и активности. Оба метода помогают оперативно адаптировать модель к новым данным, что особенно важно в задачах анализа пользовательского поведения, где активность может быстро меняться под влиянием факторов, таких как акции, сезонность или новости.
• Обучение модели с использованием алгоритмов машинного обучения (после сбора данных, предварительной обработки и нормализации данных, разделения данных на тренировочную и тестовые выборки), таких как:
• - Логистическая регрессия для бинарной классификации (успех/неудача).
• - Регрессивное дерево, как средство поддержки принятия решений, и объединение алгоритмов-классификаторов в ансамбль для улучшения предсказательной силы.
• - Глубокое обучение с применением рекуррентных нейронных сетей (RNN) для более сложных паттернов, учитывающих последовательности данных таких как, поведение пользователя во времени. Сложные паттерны - это закономерности, которые не всегда очевидны и могут включать зависимости между многими параметрами данных: временные зависимости (RNN обрабатывают последовательности данных, сохраняя информацию о временных зависимостях чтобы сделать вывод о предпочтительных часах для связи с пользователями); многофакторные зависимости (зависимости между типом контента: информационные сообщения или рекламные, временем дня и каналом связи, для выявления предпочтений пользователя по типам коммуникаций и каналам связи в определенные часы). Паттерны могут включать реакцию на разные типы контента (реклама, информирование и прочее).
2. Анализ данных:
• Использование алгоритмов машинного обучения для обработки исторических данных: градиентный бустинг, логистическая регрессия, RNN, деревья решений для обработки временных рядов данных, таких как частота взаимодействий, реакция на определенные каналы связи, предпочтения по времени суток
• Применение методов классификации с логистической регрессией для определения вероятности успешного контакта на основе:
• - Частоты успешных и неуспешных попыток связи.
• - Профилей пользователей, включая информацию из социальных сетей и мессенджеров.
• - Сегментации пользователей по поведению в коммуникациях.
• На основе этих данных модель присваивает вероятность успешного контакта, обучаясь на исторических данных. Например, если пользователь чаще отвечает на звонки утром, модель будет предсказывать более высокую вероятность успеха утром.
3. Скоринг номера: каждый номер получает оценку на основе набора параметров:
• Успех/неудача связи: +1 балл за успешный контакт, -1 балл за неудачный.
• Достоверность источника: оценка по шкале (от 1 до 10 баллов в зависимости от достоверности источника данных; также достоверность источника определяется методом экспертных оценок (Delphi Method) и чистотой данных источника).
• Срок давности данных: большее количество баллов за более свежие данные.
• Суммирование баллов для формирования общего скоринга номера.
4. Прогнозирование активности:
Применение моделей для оценки вероятности активности номера на основе собранных данных и скоринга:
• Скоринговая модель: на основе обученных данных формируется модель назначения баллов записям в Big Data, которая присваивает баллы активности номеру, учитывая:
• - Историческую частоту успешных взаимодействий.
• - Данные о предпочтениях пользователей и их поведении.
• - Данные цифрового портрета.
• Оценка вероятности активности:
• - Логистическая регрессия для предсказания вероятности того, что номер активен. Модель анализирует входные данные и предсказывает вероятность на основе:
• - Успехов и неуспехов по каждому номеру.
• - Достоверности данных источника.
• Пороговая оценка: определяется порог (например, 0.7), выше которого номер считается активным (порог может динамически меняться на основе реальных результатов).
• Тестирование и валидация:
• - Кросс-валидация: модель проходит через кросс-валидацию для проверки ее точности и устойчивости.
• - Метрики: оцениваются показатели, такие как точность, полнота и F1-мера, для определения эффективности модели.
Преимущества:
• Оптимизация расходов на связи за счет повышения точности предсказаний.
• Улучшение пользовательского опыта за счет персонализированных предложений.
• Непрерывное самообучение и адаптация модели на основе новых данных.
Используемые технологии:
• Большие данные (Big Data) для анализа и построения предсказаний.
• Непрерывное обучение (Continuous Learning) для повышения точности предсказаний на основе поступающих данных.
• Микросервисы для гибкости и масштабируемости архитектуры.
Процесс нормализации телефонных номеров осуществляется следующим образом.
1. Полученная запись, содержащая телефонный номер, преобразуется в строку, содержащую только последовательность цифр. При этом удаляются все символы, кроме цифр. Это необходимо для унификации ввода данных и дальнейшей работы с номером в его стандартной форме.
2. Проверяют полученную запись на соответствие международному стандарту E.164 (это международный стандарт, который используется для телефонных номеров по всему миру, включая публичные сети) с помощью регулярного выражения ^\+[1-9]\d{1,14}$.
2.1 После первого шага по нормализации номера (удаления лишних символов), проверяем его на соответствие международному стандарту E.164, который задаёт формат телефонных номеров. Стандартом Е.164 определяется, что телефонный номер должен начинаться с символа "+", за которым следует код страны (от 1 до 3 цифр), и любой валидный телефонный номер может содержать до 15 цифр.
2.2. Для выполнения проверки используется регулярное выражение "^\+[1-9]\d{1,14}$":
- Проверяет, что номер начинается с символа "+";
- Проверяет, что первая цифра после "+" находится в диапазоне от 1 до 9 (код страны не может начинаться с 0);
- Ограничивает длину оставшейся части номера после символа "+" до 15 цифр.
2.3. Если номер не соответствует шаблону "^\+[1-9]\d{1,14}$" - он считается невалидным.
Пример:
- Введённый номер: "+123456789012345" соответствует стандарту E.164, так как начинается с "+" и содержит допустимое количество цифр.
- Введённый номер: "012345678901234" не соответствует, так как отсутствует символ "+" и начинается с недопустимой цифры "0".
3. В случае соответствия номера стандарту E.164, программным методом определяются страна и тип номера (мобильный стационарный и т.д.):
3.1. После успешной валидации номера по стандарту E.164, программными средствами определяется, к какой стране относится обрабатываемый номер. Это достигается путём анализа начальных цифр номера, которые соответствуют международному коду страны. Например:
- код "1" - для стран североамериканского плана нумерации (NANP), таких как: США и Канада и т.д.;
- "44" - для Великобритании;
- "7" - для России, Казахстана, Южной Осетии и Абхазии;
- "90" - для Турции;
- "998" - для Узбекистана и т.д.
3.2. Определение страны осуществляется с использованием базы данных всех международных кодов.
3.3. После определения страны программные средства проверяют тип номера: мобильный, стационарный или специальный (например, сервисные номера или платные номера) при помощи актуальных баз данных, содержащих информацию о выделении диапазонов номеров для каждой страны. Например, в некоторых странах мобильные номера начинаются с определённых префиксов (например, в Великобритании мобильные номера начинаются с "7" следующей за международным кодом Великобритании "44").
Пример:
- Номер "+12012031434" будет распознан как USA-FIXED_LINE_OR_MOBILE
- Номер "+5491120028197" будет распознан как Argentina-MOBILE
- Номер "+74955316650" будет распознан как Russian_Federation-FIXED_LINE и т.д.).
Следующим этапом заявленного способа (фиг. 2) является b) в базе данных для записей, касающихся пользовательских адресов электронной почты: осуществляют нормализацию данных, путем преобразования записи адреса электронной почты в единый формат, а также путем исключения из записи адреса электронной почты сторонних символов и очистки формата записи; на основе нормализованных данных осуществляют проверку синтаксиса адреса электронной почты, путем проверки корректности написания записи с учетом заранее установленных правил формирования записи; осуществляют определение существования домена, к которому принадлежит адрес электронной почты, причем если домен существует, это свидетельствует о возможности отправки писем на этот адрес; осуществляют проверку существования электронного почтового ящика на указанном почтовом сервере, путем отправки запроса на указанный электронный почтовый сервер, для определения действительности указанного электронного почтового адреса; осуществляют проверку электронного почтового адреса на предмет регистрирования его на веб-ресурсах.
В случае обработки данные электронных почт работает отдельная функция валидации и скоринга:
- Нормализация: Преобразование электронной почты в стандартный формат путем удаления лишних символов и исправления формата. Это позволяет исключить ошибки, вызванные неправильным написанием, и привести почту к читаемому и допустимому виду.
- Проверка синтаксиса: После нормализации почта проверяется на корректность написания с учетом всех правил формирования адреса электронной почты. Данный этап исключает адреса с недопустимыми символами или неправильным форматом и реализуется с помощью встроенных методов и регулярных выражений.
- MX-проверка: Определение существования домена, к которому принадлежит адрес. Если домен существует, это свидетельствует о возможности отправки писем на этот адрес.
- SMTP-проверка: Проверка наличия почтового ящика на указанном сервере. Система отправляет запрос на почтовый сервер, чтобы узнать, существует ли данный ящик. Это позволяет исключить несуществующие или заблокированные почты.
- Проверка статуса активности: Для почтовых сервисов, таких как Gmail и Mail.ru, функция позволяет узнать статус активности. Например, можно определить, когда последний раз менялась почта на Gmail, а также получить доступ к фотографии профиля и отзывам, оставленным пользователем. Для Mail.ru возможен доступ к информации о времени последнего входа, а также дополнительным данным о владельце, если такая информация есть (возраст, имя, страна, город).
- Проверка на регистрацию на веб-ресурсах: Определяют, зарегистрирован ли данный адрес электронной почты на различных веб-ресурсах. Эта функция полезна для маркетинга, безопасности и анализа пользовательской активности.
Следующим этапом является то, что с) обновляют в базе данных каждую отдельную запись номера телефона и адреса электронной почты, с учетом выполненных операций по валидации на этапах a) и b).
В заявленном решении модель постоянно обогащает данные, поступающие от микросервисов, с целью обновления репозитория и повышения точности предсказаний. Это осуществляется за счет интеграции новых источников данных и постоянного самообучения модели на основе новых входных данных. Чем больше данных модель получает, тем точнее становятся ее предсказания относительно предпочтений пользователей и вероятности успешного контакта.
Ниже представлен пример общего вида вычислительной системы, которая обеспечивает реализацию заявленного способа валидации обезличенных пользовательских данных или является частью компьютерной системы, например, сервером, персональным компьютером, частью вычислительного кластера, обрабатывающим необходимые данные для осуществления заявленного технического решения.
Вычислительная система, обеспечивающая обработку данных, необходимую для реализации заявленного решения, в общем случае содержит такие компоненты как: один или более процессоров, по меньшей мере, одну память, средство хранения данных, интерфейсы ввода/вывода, средство ввода, средства сетевого взаимодействия.
При исполнении машиночитаемых команд, содержащихся в оперативной памяти, конфигурируют процессор устройства для выполнения основных вычислительных операций, необходимых для функционирования устройства или функциональности одного, или более его компонентов.
Память, как правило, выполнена в виде ОЗУ, куда загружается необходимая программная логика, обеспечивающая требуемый функционал. При осуществлении работы предлагаемого решения выделяют объем памяти, необходимый для осуществления предлагаемого решения.
Средство хранения данных может выполняться в виде HDD, SSD дисков, рейд массива, сетевого хранилища, флэш-памяти и т.п. Средство позволяет выполнять долгосрочное хранение различного вида информации.
Интерфейсы представляют собой стандартные средства для подключения и работы периферийных и прочих устройств, например, USB, RS232, RJ45, COM, HDMI, PS/2, Lightning и т.п.
Выбор интерфейсов зависит от конкретного исполнения устройства, которое может представлять собой персональный компьютер, мейнфрейм, серверный кластер, тонкий клиент, смартфон, ноутбук и т.п.
В качестве средств ввода данных в любом воплощении системы, реализующей описываемый способ, может использоваться клавиатура. Аппаратное исполнение клавиатуры может быть любым известным: это может быть, как встроенная клавиатура, используемая на ноутбуке или нетбуке, так и обособленное устройство, подключенное к настольному компьютеру, серверу или иному компьютерному устройству. Подключение при этом может быть как проводным, при котором соединительный кабель клавиатуры подключен к порту PS/2 или USB, расположенному на системном блоке настольного компьютера, так и беспроводным, при котором клавиатура осуществляет обмен данными по каналу беспроводной связи, например, радиоканалу, с базовой станцией, которая, в свою очередь, непосредственно подключена к системному блоку, например, к одному из USB-портов. Помимо клавиатуры, в составе средств ввода данных также может использоваться: джойстик, дисплей (сенсорный дисплей), проектор, тачпад, манипулятор мышь, трекбол, световое перо, динамики, микрофон и т.п.
Средства сетевого взаимодействия выбираются из устройств, обеспечивающих сетевой прием и передачу данных, например, Ethernet карта, WLAN/Wi-Fi модуль, Bluetooth модуль, BLE модуль, NFC модуль, IrDa, RFID модуль, GSM модем и т.п. С помощью средств обеспечивается организация обмена данными по проводному или беспроводному каналу передачи данных, например, WAN, PAN, ЛВС (LAN), Интранет, Интернет, WLAN, WMAN или GSM.
Компоненты устройства сопряжены посредством общей шины передачи данных.
В настоящих материалах заявки было представлено предпочтительное осуществление заявленного технического решения, которое не должно использоваться как ограничивающее иные частные воплощения его реализации, которые не выходят за рамки испрашиваемого объема правовой охраны и являются очевидными для специалистов в соответствующей области техники.
Изобретение относится к области вычислительной техники. Технический результат заключается в повышении точности валидации обезличенных пользовательских данных. Технический результат достигается за счет этапов, на которых a) в базе данных для записей, касающихся телефонных номеров пользователей, осуществляют сбор данных относительно успешных и неуспешных попыток связи за длительный период времени, определяют факторы, влияющие на успешность контакта; b) в базе данных для записей, касающихся пользовательских адресов электронной почты: осуществляют нормализацию данных; на основе нормализованных данных осуществляют проверку синтаксиса адреса электронной почты; осуществляют определение существования домена, к которому принадлежит адрес электронной почты, причем если домен существует, это свидетельствует о возможности отправки писем на этот адрес; осуществляют проверку существования электронного почтового ящика на указанном почтовом сервере; осуществляют проверку электронного почтового адреса на предмет регистрирования его на веб-ресурсах; c) обновляют в базе данных каждую отдельную запись номера телефона и адреса электронной почты, с учетом выполненных операций по валидации на этапах a) и b). 2 ил.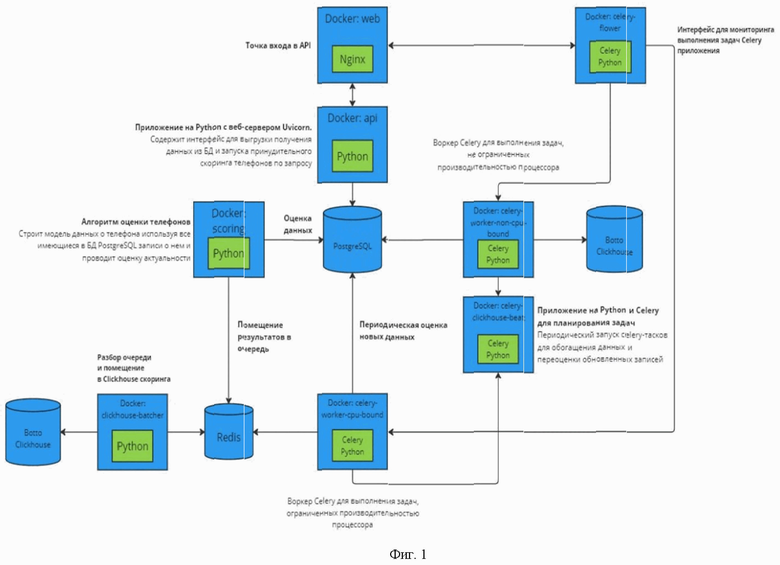
Способ валидации обезличенных пользовательских данных, включающий этапы, на которых:
a) в базе данных для записей, касающихся телефонных номеров пользователей, осуществляют сбор данных относительно успешных и неуспешных попыток связи за длительный период времени, определяют факторы, влияющие на успешность контакта, такие как: частота успешных звонков, время суток, когда пользователи чаще всего отвечают, предпочтения по каналам связи, анализируют данные, к чему привязан номер, осуществляют нормализацию и определение типа телефонных номеров путем преобразования телефонного номера в строку, содержащую только последовательность цифр, а также путем удаления всех символов, кроме цифр, после чего проверяют преобразованный номер на соответствие международному стандарту с помощью заданного шаблона, определяют страну и тип телефонного номера с использованием базы данных всех международных кодов, и определяют, номер телефона по-прежнему активен и принадлежит пользователю или неактивен;
b) в базе данных для записей, касающихся пользовательских адресов электронной почты: осуществляют нормализацию данных путем преобразования записи адреса электронной почты в единый формат, а также путем исключения из записи адреса электронной почты сторонних символов и очистки формата записи; на основе нормализованных данных осуществляют проверку синтаксиса адреса электронной почты путем проверки корректности написания записи с учетом заранее установленных правил формирования записи; осуществляют определение существования домена, к которому принадлежит адрес электронной почты, причем если домен существует, это свидетельствует о возможности отправки писем на этот адрес; осуществляют проверку существования электронного почтового ящика на указанном почтовом сервере, путем отправки запроса на указанный электронный почтовый сервер, для определения действительности указанного электронного почтового адреса; осуществляют проверку электронного почтового адреса на предмет регистрирования его на веб-ресурсах;
c) обновляют в базе данных каждую отдельную запись номера телефона и адреса электронной почты с учетом выполненных операций по валидации на этапах a) и b).
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| СТИРОЛ-БУТАДИЕНОВЫЙ КАУЧУК С ВЫСОКИМ СОДЕРЖАНИЕМ ЗВЕНЬЕВ СТИРОЛА И ВИНИЛА И УЗКИМ РАСПРЕДЕЛЕНИЕМ МОЛЕКУЛЯРНОГО ВЕСА И СПОСОБЫ ЕГО ПРИГОТОВЛЕНИЯ | 2012 |
|
RU2608041C2 |
| СПОСОБ И СИСТЕМА ОБЕЗЛИЧЕННОЙ ОЦЕНКИ КЛИЕНТОВ ОРГАНИЗАЦИЙ ДЛЯ ПРОВЕДЕНИЯ ОПЕРАЦИЙ МЕЖДУ ОРГАНИЗАЦИЯМИ | 2022 |
|
RU2795371C1 |
| КОМПЬЮТЕРИЗИРОВАННЫЙ СПОСОБ РАЗРАБОТКИ И УПРАВЛЕНИЯ МОДЕЛЯМИ СКОРИНГА | 2018 |
|
RU2680760C1 |

