Изобретение относится к вычислительной технике, в частности к трансляторам языков программирования, и может быть использовано в вычислительных системах с диалоговым режимом отладки и выполнения программ.
Целью изобретения является расширение функциональных возможностей устройства путем обработки входных текстов программ, лексические единицы которых не имеют строгих позиций во входной записи, нейтрализации лексических ошибок, а также увеличения типов распознаваемых терминальных слоев при одновременном упрощении устройства и повышении его быстродействия за счет исключения записи во временную таблицу конструкций, которые были ранее в нее записаны.
Сущность изобретения состоит в
следующем.
В процессе лексического анализа программ из отдельных литер (букв,. цифр, разделителей, специальных символов) обычно собираются простые синтаксические конструкции (простые
нетерминальные символы): идентифика- 30 В качестве меры схожести А и В приторы, целые, целые с основанием и вещественные числа, зарезервированные слова языка (операторы), например declare, loop, when, do, go to, begin и т.п., одно-дву-и трахлитер- ные разделители, которые при синтаксическом анализе и других этапах трансляции рассматриваются как неделимые. При этом осуществляется построение временных таблиц входных слов (в соответствии с их типами) и частичный лексический контроль, а также подавление всех незначащих литер программы.
Введение блока нейтрализации ошибок и определяемых им связей позволяет с заведомо определенной степенью, точности заменять зарезервированные слова с лексичес1{ими ошибками на эквивалентные из временных таблиц Данный блок позволяет нейтрализовать следующие типы ошибок: пропуск одного символа, искажеьше символа, перестановка двух соседних символов и вставка лишнего символа. К данным типам относятся до 80% всех лексических ошибок.
Сущность алгоритма нейтрализации лексических ошибок состоит в следующем. Входное слово представляется как В (Ь, Ь...Ь„), а слово из вре- мё нных таблиц А (а, а,...а,), где Ь и а. - символы этих слов. Из А и Б вьщеляются такие подписки (участки сравниваемых слов) d ... of и /3, .../3, для которых выполняются условия
и d:
5
. ,, i 1,
UJ.1 , предшествует rfj
m
(1) (2)
u, . предшествует ,9|j., соответственно в списках (словахM и В. Иначе говоря, если (a;,a .j
i.r(ai, то
i2 ij.
.а .а
.11 fi h е2
), ),
(3)
i1+l1 i 12. Разбиение A и В на подписке, удовлетворяющее условиям (1)-(3), может быть произведено любыми способами. Естественно, что из всех воз- можных вариантов разбиений должно быть выбрано разбиение, дающее максимальную величину суммы
ct,. (.
нимается коэффициент списковой кор15еляции
35
- (7А777в7Т
- 1
UJ max (
R
d,
где R - множество вариантов разбиений, удовлетворяющих условиям (1)-(3).
Кроме того, предлагаемое устройство наряду с обработкой позиционных
программ может обрабатывать произвольные тексты программ, так как в большинстве языков высокого уровня позиционирования не применяется, но оно применяется в языке ассемблера, который используется наряду с другими языками.. Наряду с нейтрализацией ошибок блок совместно с введенным мультиплексором позволяет производить сравнение всех входных констРУкций с эталонами из таблиц, что позволяет, в отличие от известного устройства, записывать во временные таблицы входные слова в качестве эталонов только один раз, что зна
типа ti
чительно экономит память, а также процессорное время и другие ресурсы ЭВМ.
Таким образом, по сравнению с известным предлагаемое устройство позволяет осуществлять выдачу лексем идентификатор, целое число, целое число с основанием, вещественное число с целью формирования временных таблиц, используемых на последующих этапах трансляции и при нейтрализации лексических ошибок в конструкциях этих типовJ осуществлять лексический контроль входных терминальных слов и производить, с заведомо определенной степенью точности, нейтрализацию лексических ошибок путем замены ошибочного слова .на эквивалентное из временных таб-. лиц; осуществлять обработку позиционированных программ и произвольные тексты программ; осуществлять построение временных таблиц как в процессе лексического анализа всего текста программ, так и, при соответствующей организации входных программ, в процессе просмотра описаний идентификаторов и чисел, используемых в программе; исключить запись во временные таблицы конструкций, которые были ранее записаны в данную таблицу.
Устройство работает в режиме Запрос - Ответ с другими частями транслятора и внешним устройством.
На фиг. 1 изображена функциональная схема устройства для лексического анализа; на фиг. 2 (а,б) - функциональная схема блока нейтрализации ошибок; на фиг. 3 (а,б,в,г) - блок-схема алгоритма обработки зарезервированного слова (оператора), содержащего ошибку; на фиг. 4 - блок схема алгоритма обработки идентификатора и всех типов чисел, для случая ,когда нейтрализация ошибок в этих конструкциях не производится; на фиг. 5 (а,б,в,г) - блок-схема алгоритма обработки идентификаторов и чисел с возможностью нейтрализации ошибок в конструкциях данных типов.
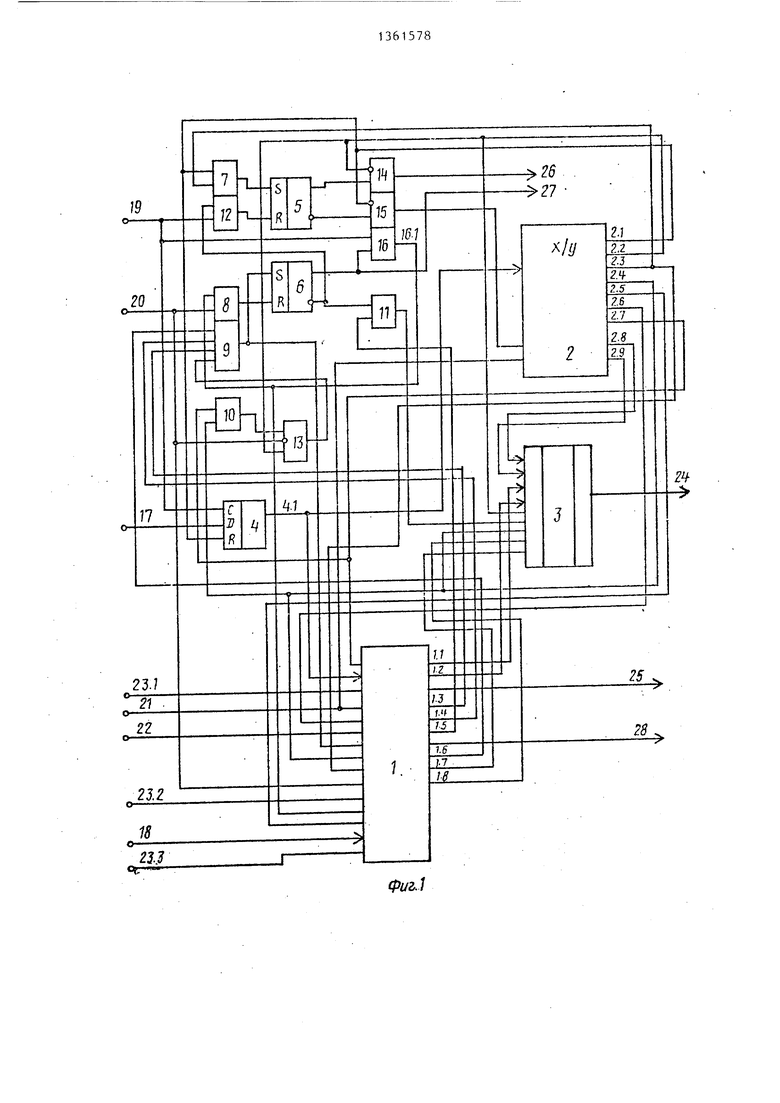
Устройство для лексического анализа (фиг. 1) содержит блок 1 нейтрализации ошибок с информационными выходами 1.1, 1.2 и управляющими выходами 1.3-1.8, блок 2 формирования лексемы с управляющими выходами 2.1-2.7 и информационными выходами
1361578
2.8 и 2,
9, мультиплексор 3 лексемы.
0
5
0
регистр 4 литеры с выходами 4.1, триггер 5 пуска, триггер 6 эталона, элементы ИЛИ 7-11, элементы И 12-16, информационные входы 17 устройства и 18 коэффициента,, вход 19 ответа, вход 20 сравнения, вход 21 вьщачи, вход 22 завершения просмотра, вход 23.1 организации, вход 23.2 начальной установки, вход 23.3 блокировки, выходы 24 лексемы, выход 25 терминального слова, выход 26 запроса, выход 27 вызова и выход 28 готовности.
Блок 1 нейтрализации ошибок предназначен для нейтрализации лексических ошибок, допущенных при написании операторов, поиска в таблицах слова, эквивалентного входному, принятому в стек, формирование значения выходных лексем по входным идентификаторам, числам и ошибочным операторам и передачи в таблицы входных слов
5 (идентификаторов и чисел), которые не встречались ранее в программе.
Блок 2 формирования лексемы предназначен для распознавания литер входного текста программы, формироQ вания типа и значения выходной лексемы и инициирования управляющих сигналов в процессе анализа. Работа блока 2 формирования лексемы сводится к дешифрации комбинации кодов входных литер по управляющему сиг налу, щифрации кодов типа и значения лексем по ним и вьщачи соответствующих управляюш;их сигналов.
Блок 2 формирования лексемы работает следуюш 1М образом.
0
5
0
5
В исходном состоянии на информационные входы поступает код входной литеры, по сигналу на первом управляющем входе производится запоминание и обработка поступившего кода. Далее на информационные входы поступает код второй входной литеры и по управляющему сигналу на первом входе производится запоминание и обработка поступившего кода. Если в соответствии с синтаксисом входного языка эти две литеры могут принадлежать одной лексической конструкции, то производится запоминание и обработка следующей литеры и так далее до тех пор, пока не будет, запомнена литера, которая не может принадлежать обрабатываемой конструкции. После запоминания такой литеры на выходе 2.2 формируется сигнал Расхождение типа, единичный сигнал формируется таклсе на выходе 2.4, если обработан идентификатор или число, на выходе 2.5, если обработан оператор (зарезервированное слово), и на выходе 2.6, если обработан разделитель, отличный от случая выработки сигнала на выходе 2.1 и от пробела.
Если обрабатываемая конструкция является оператором и в ней допущена ошибка, то единичный сигнал формируется также на выходе 2.7.
Б случае, когда обрабатывается разделитель, идентифицирующий начало комментария, то единичный сигнал формируется на выходе 2.1, который блокирует реакцию блока 2 формирования литеры на все литеры, отличные от разделителя, идентифицирующего завершения комментария. После запоминания такого разделителя сигнал на выходе 2.1 снимается и инициируется сигнал на выходе 2.3, который формируется в случае обработки пробела.
Если на второй управляющий вход поступает единичный сигнал, то на выходах 2.8 формируется код типа выходной лексемы, а если обрабатывался разделитель или оператор, не содержащий ошибок, то на выходах 2.9 формируется и код значения выходной лексемы. Через время, необходимое для выдачи кодов с выходов 2.8 и 2.9 через мультиплексор 3 на выходы 24 устройства, блок 2 формирования лексемы переходит в исходное состояние.
Мультиплексор 3 лексемы предназначен для вьщачи адреса эталона и выходной лексемь; на выходы 24 устройства.
Регистр 4 литеры предназначен для приема и хранения очередной литеры входной цепочки.
Триггер 5 пуска предназначен для формирования сигнала Запрос, идентифицирующего готовность устройства к обработке следующей литеры (прямой выход), на выходе 26 устройства и сигнала, инициирующего анализ входной литеры блоком 2 формировани лексемы (инверсный выход) .
Триггер 6 зталона предназначен для формирования сигнала Вызов, обеспечивающего выдачу зталона для
0
5
нейтрализации ошибки или поиска соответствующего слова в таблице.
Прочие элементы И и ИЛИ предназначены для разнесения во времени несовместимых микроопераций, реализуемых в течение одного такта.
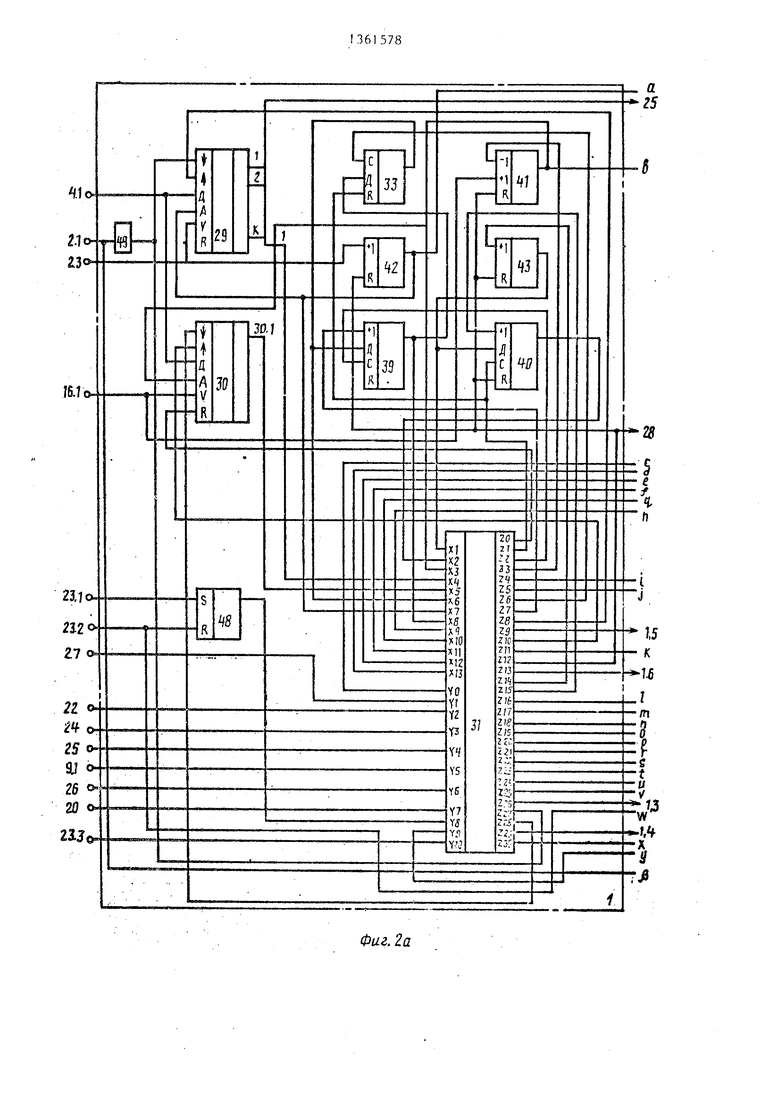
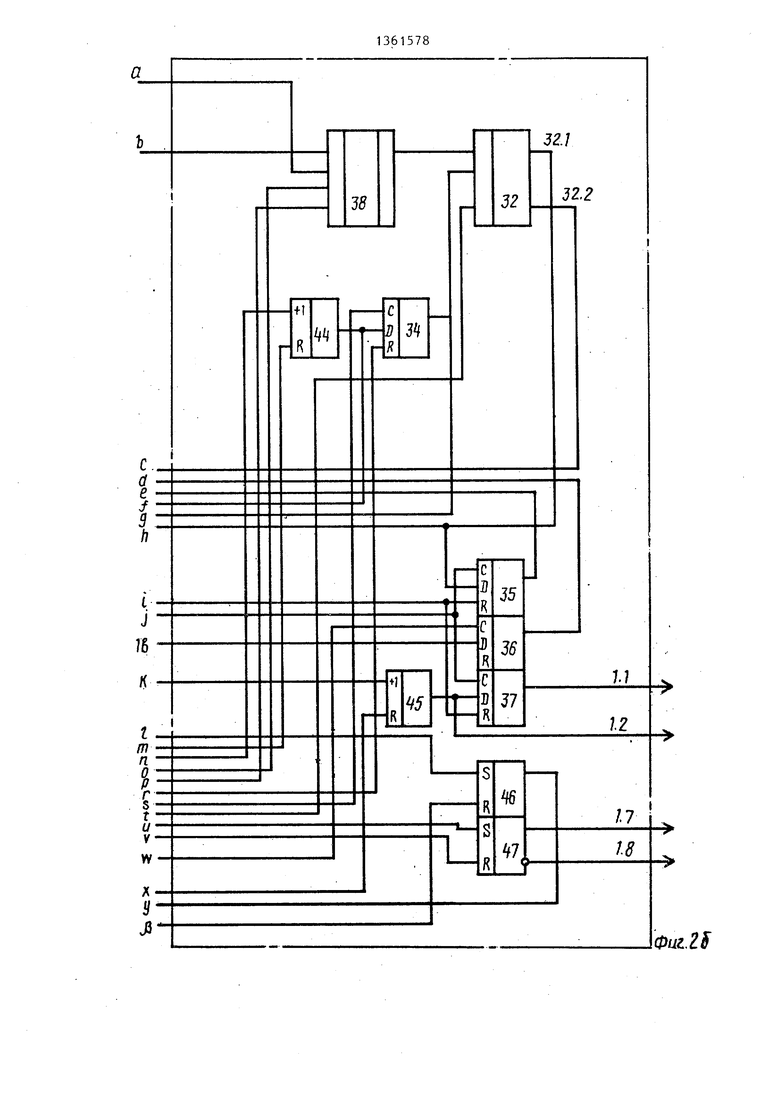
Блок 1 нейтрализации ошибок (фиг. 2) содержит блоки 29 и 30 стековой памяти с информационными выходами 29.1-29.К и 30.1 соответственно, причем выходы 29.1-29.К одновременно являются выходами 25 терминального слова устройства, блок 31 f. признаков с выходами 31 .ZO-31 .Z30, причем выход 31.Z12 одновременно является выходом 28 готовности устройства, блок 32 коэффициента с информационными выходами 32.1 и управляющим выходом 32.2, регистр 33, регистр 34 совпадений, регистр 35 коэффициента, регистр 36 ограничения, регистр 37 значения, мультиплексор 38, счетчик 39 входного маркера, счетчик 40 эталонного маркера, счетчик 41 литер эталона, счетчик 42 входных литер, счетчик 43 разбиений, счетчик 44 совпадений, счетчик 45 адреса эталона, триггеры 46 и 47, триггер 48 режима и элемент 49 задержки.
Блок 29 бтековой памяти предназначен для приема и хранения до К литер входного слова, передачи их для сравнения в блок 31 признаков 5 и выдачи по выходам 25 в таблицы, соответствующие типам входных конструкций.
Блок 30 стековой памяти предна- 0 значен для приема и хранения до К литер эталонного слова и политерной передачи их для сравнения в блок 31 признаков.
Блок 31 признаков предназначен 5 для формирования управляющих сигналов, обеспечивающих функционирование блока 1 нейтрализации ошибок в соответствии с алгоритмами (фиг. 3-5). Работа блока 31 сводится к формирова- 0 нию управляющих сигналов на выходах 31.ZO-31.Z30 в зависимости от поступающих управляющих сигналов на входы 31.Y-31.Y9 и от информации, поступающей на входы 31.XI-31.x 13.
0
Рассмотрим системы логических уравнений процесса функционирования блока 31 признаков в соответствии с предназначенными алгоритмами.
Алгоритм 1 обработка оператора, содержащего лексические ошибки (фиг. 3).
. Г31Л5М31Л4 лС31Л13 31..,
31Л7 31..Z14J;
31..ХЗ 31.Z1 ;
31..X3 31..Z7r,
(С31.Х8.31.Х7)/ (С31. .X5) 31..,
(31.Х8.Г31.Х7)/(С31.Х4 31.Х53) 31..Z153H 31.Z7 .Z18j;
(31...X7)v{ 31.X8 J. .X7D Л (Г31.Х4 31.Х5)Л A(t31..X7J)} 31.Z15JЛ .Z10J ,
а31..ХЗ)А(Г31.Х113 31.X10)C31.
(t 31..X3J) Л (C31.X11. .31.X10)31. 31...,
31.X9 t31..Z53-,
( 31 .X9 31 .XI2 )И t 31 .Y2l 31.ZO /ir31...Z273;
(Г31.Х9 31.Х123). Л(С31..Х13) 31.Z243-.
(31.X9 4 31.Х12). Л(31..Х13) 31.
31.Y9 31..Z4.
Алгоритм 2 - обработка идентификаторов и чисел, в случае,когда нейтрализация ошибок в данных конструкциях не производится (фиг. 4):
31.53/1С31..в t31..Z53;
(31.ХЗ 31.Х7) Л (31.Х4 31.Х5) 31.. .
(С31.ХЗ 0) r31..Z12
(31.ХЗЗ 0 )Л(31.Х4 31.X5)31...
(31.ХЗ 7 0) А (31.Х4 31.Х5)Л 31.Y2 I31.Z12J ;
(ЗПХЗЗэЬ 0 ) Л(Г31 .Х4 31 .X5J )А .У2 31..,
(31.ХЗ 31.Х7) Л(31.Х4 .Х53)ЛС31.2 31.,
(31..Х73)Л(31.Х43 31.X51).Y2 31..Z53;
31.Y9j 31..Z4l ..
Алгоритм 3 - обработка идентификаторов и чисел с возможностью нейтрализации лексических ошибок (фиг. 5)
31...Z1llA 31. - (31..X7) .Y2 31. D1.
5
0
5
0
5
0
(31..X7j).Y2 31.Z30j-,
31..., (31.X3J 31.X7J)A(r31.X4J
31.x5) 3i..zio:iA 3i.z3j;
(31.X3J 31.X7) л (31.X4 5 .X5)..,
(Г31.ХЗ Р1.Х7) Л(31.Х43 31.Х5)Л 31.Y2 r31..Z5Ji
(31.X3J(Z ) 31.(31. )A(C31.X43it 31.X5J) 31...Z33(C31.X3 0)Л(31.Х4 .X5 ..
(31.)Л (Г31.Х41 ГЗКХФА .Y23 31..Z53 ;
(Г31. 31.XI) r31.Zl3 f
(31..X1) r31.
(31..X33) t31.Z2 3 .Z7Ji
(31..X3l)A(31 .X11J 31.X10})31.
(31..X3)A(31.X1l3-f
-..xioj) 31.Z14J(31..X73) 31.Z15jA .,
(31 .XBJi 31 .X7J )/ (ГЗ 1 . эь .X5j) r31.Z73A 31.Z83,
(31..X5)A(31.X8 31.X73)31..
(31..X5l)A(31.X83. .31.X7) 31..(;31.Z7JA 31.Z183;.
(31..X12) 31.Z53;
(31..Xl2J)A(31,. .X13j) 31..Z123i
(31.X9J.C31 .X12J)A(31.X123 .Х133) 31.Z253At31.Z123-,
31.Y9J 31..Z43 .
В случае поступления единичного сигнала на вход 31.Y10 блока 31 производится блокировка выдачи всех
сигналов на выходах 31.ZO-31.Z30 независимо от сигналов и информации на входах 31 .YO-31 .Y9 и 31 .Х1-31 .Х13, за исключением сигнала на выходе 31.Z12.
В общем случае составление обобщенной системы логических уравнений, характеризующей работу блока 31 признаков без привязки к конкретным алгоритмам, является тривиальной задачей и поэтому в описании не приводится .
Блок 32 определения коэффициента предназначен для вычисления коэффици 91
ента схожести (КС) входного и эталонного слов. Данный блок представляет собой электронный узел, позволяющий реализовать вычисление
КС
2 W
тахиКА77 7кв7)
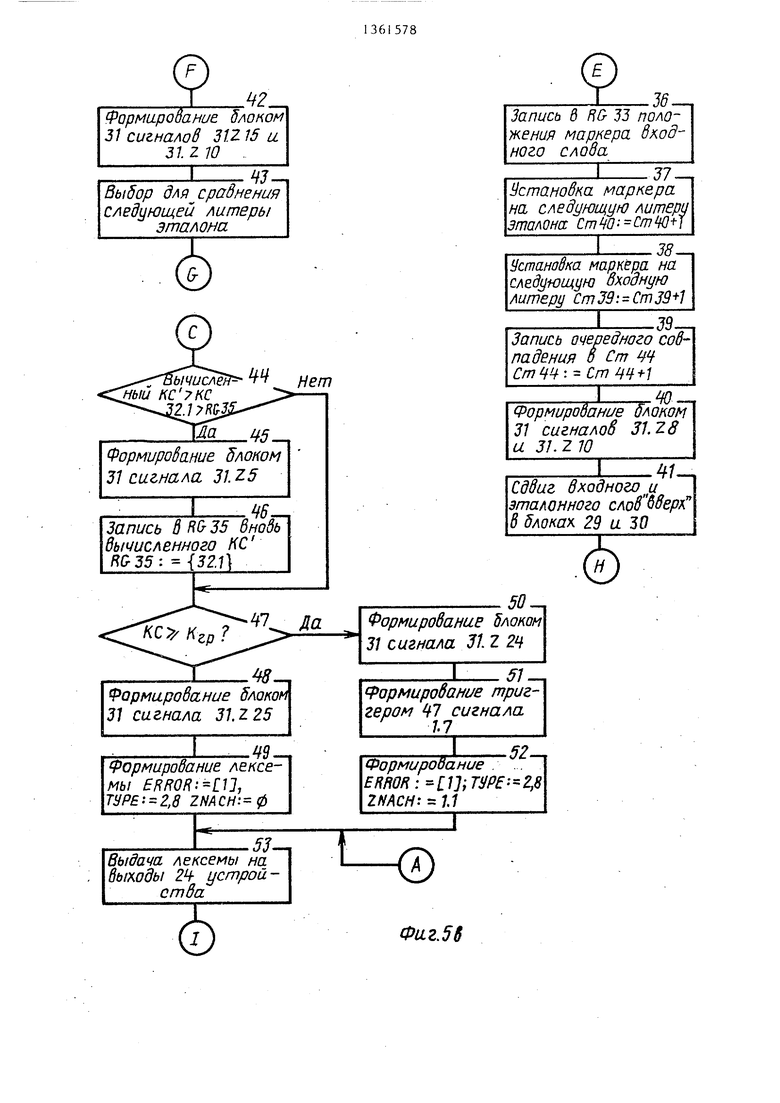
Схема такого блока представляет собой арифметическое устройство, позвляющее производить элементарные арифметические преобразования над двумя операндами. Синтез блока 32 определения коэффициента может быть произведен при помощи современных ВИС для выполнения арифметических операций, поэтому функциональная схема блока 32 также не рассматривается.
Регистр 33 предназначен для хранения позиции сравниваемой литеры входного слова, регистр 34 совпадения - для хранения максимального числа совпадений (для всех разбиений) при сравнении входного слова с эталонным, регистр 35 коэффициента - для хранения максимального коэффициента схожести КС для сравниваемых эталонов, регистр 36 ограничения - для хранения граничного коэффициента (), который определяет минимальное значение коэффициента КС, а регистр 37 значения - для хранения адреса считываемого эталона и, в случае совпадения (или определения эквивалентности в процессе нейтрализации), вьщачи значения выходной лексемы.
Мультиплексор 38 предназначен для выдачи в блок 32 максимального значения длин входного и эталонного слов.
Счетчик 39 служит для определения позиции сравниваемой литеры входного слова, счетчик 40 - для определения позиции сравниваемой литеры эталонного слова, счетчик 41 литер эталона - для определения количества литер эталонного слова (его длины), счетчик 42 входных литер - для определения количества входных литер (определения длины входного слова), счетчик 43 разбиений - для перебора всех разбиений для данного эталона в процессе нейтрализации, счетчик 44 совпадений. - для подсчета всех совпадений в одном разбиении, счетчик 45 адреса эталона - для формирования адрес эталона, необходимого для выборки.
10
15
0
25
61578 0
Триггер 46 предназначен для формирования сигнала Лексема готова на выходе 28 устройства в случае обработки идентификаторов и чисел
5 нейтрализации ошибок, триггер 47 - для управления формированием значения лексемы в лроцессе нейтрализации ошибок, триггер 48 режима - для установления режима работы блока 1 нейтрализации ошибок. Если триггер 48 находится в единичном состоянии, то производится нейтрализация ошибок во всех конструкциях (кроме разделителей) . Если триггер 48 находится в нулевом состоянии, нейтрализация производится только над ошибочными операторами.
Элемент 49 задержки предназначен для обеспечения обнуления блока 29 стековой памяти после выдачи результатов анализа.
В исходном положении все блоки, узлы и элементы блока 1 нейтрализации ошибок находятся в нулевом состоянии, а на информационные входы 18 поступает код коэффициента К. (граничный коэффициент схожести слов). Сигнал с входа 23.2 строби- рует запись данного коэффициента- в регистр 36 ограничения, одновременно данный сигнал обнуляет триггер 48 режима. В зависимости от структуры программы сигнал с входа 23.1 переводит в единичное состоя35 ние триггер 48 (если в программе производится нейтрализация ошибок во всех конструкциях) или данньш сигнал не поступает (если нейтрализация производится.только в ключе вых словах - операторах).
Входные литеры поступают на информационные входы блоков 29 и 30 стековой памяти, одновременно на счетный вход счетчика 42 поступает
45 единичньй сигнал, который инициирует формирование адреса записи входных литер и, поступая на V-вход блока 29, стробирует запись литер входного слова в ячейку блока 29, со50 отвётствующую адресу, сформированному счетчиком-42. Данный процесс повторяется до тех пор, пока все литеры одной и той же конструкции не будут записаны в блок 29. После
55 записи последней литеры обрабатывае- 1мой конструкции на вход 9.1 блока 1 нейтрализации ошибок, а далее на вход 31.Y5 блока 31 признаков поступает сигнал Расхождение типа.
30
Далее процесс функционирования блока 1 нейтрализации ошибок зависит от типа обрабатываемого входного слова и структуры входной программы поэтому целесообразно рассмотреть работу блока в соответствии с подмножествами его состояний.
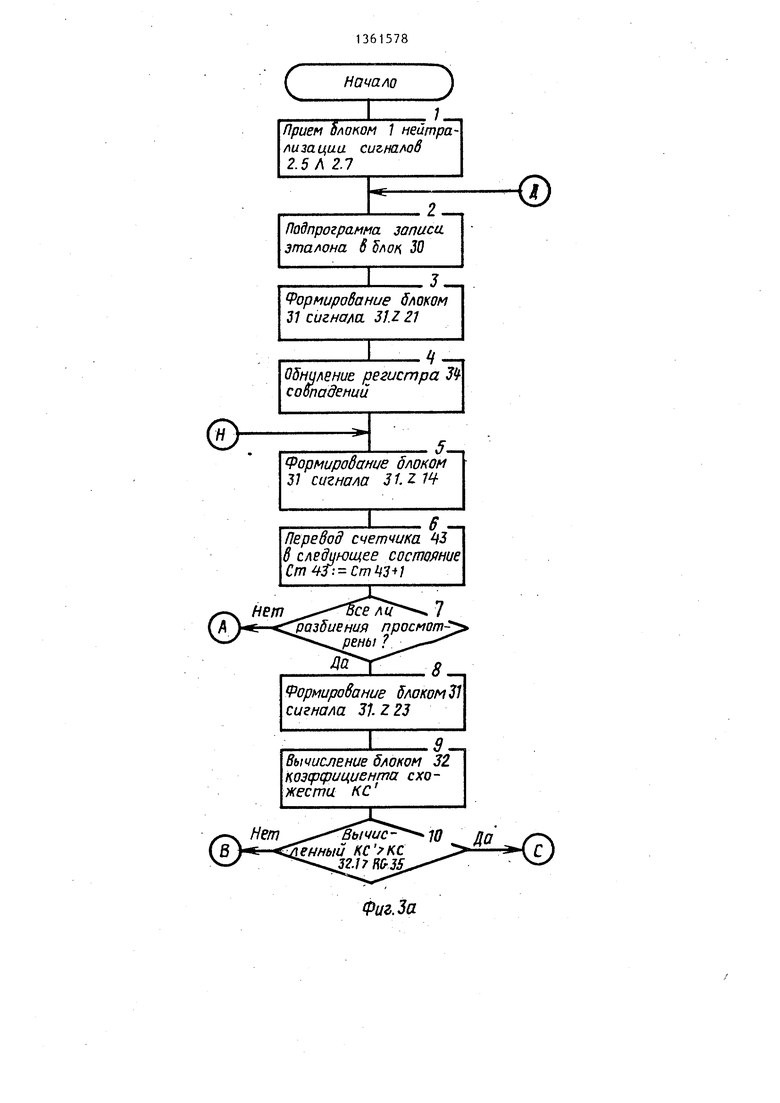
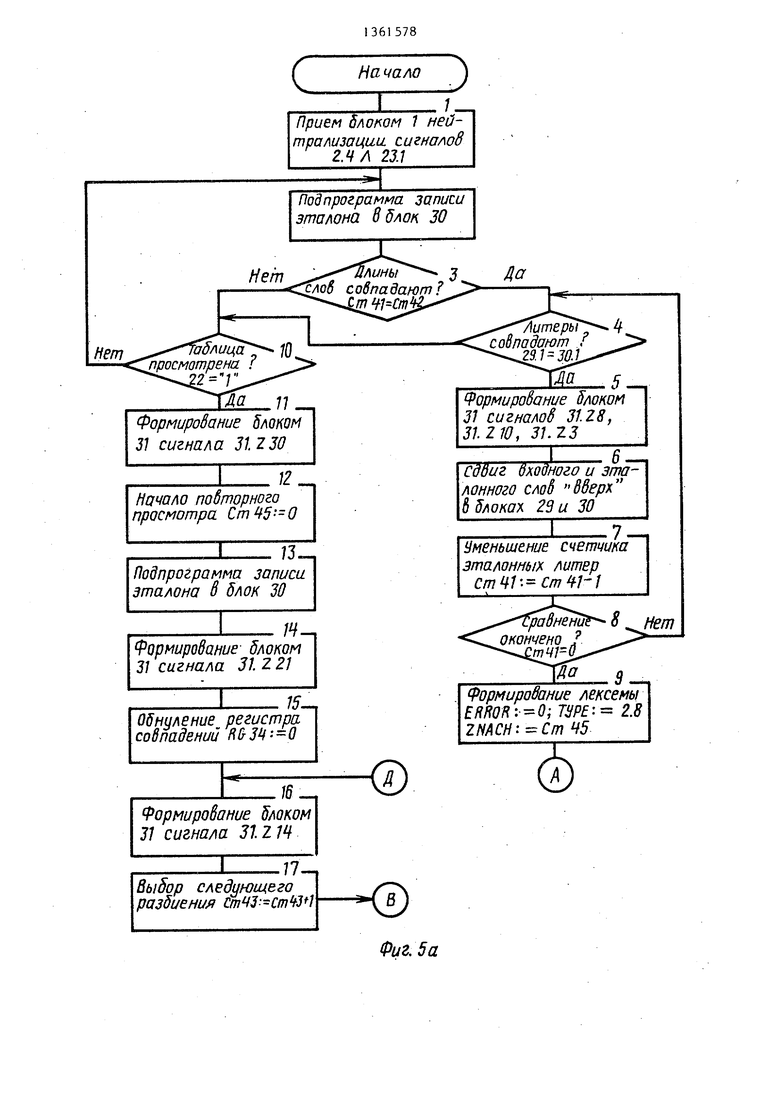
Подмножество 1 - обработка ключевых слов (операторов, содержащих ошибку). Процесс функционирования блока 1 нейтрализации ошибок в рассматриваемом подмножестве не зависит от структуры входной программы и представлен блок-схемой алгоритма (фиг. 3.).
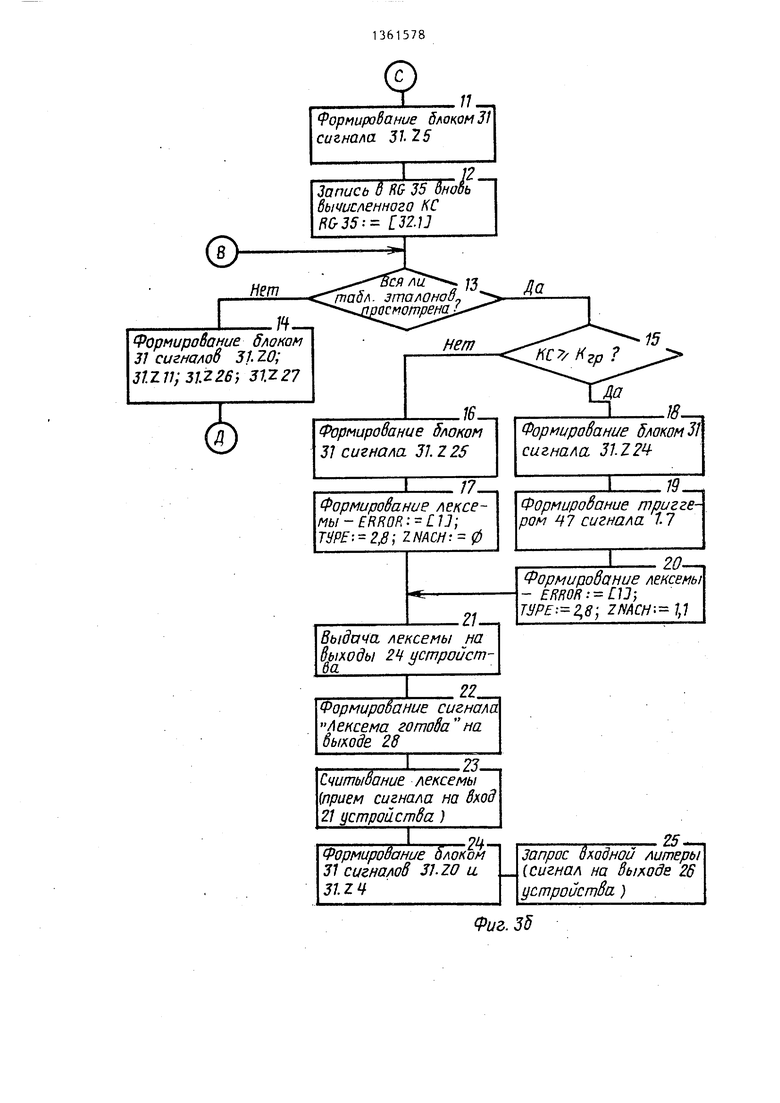
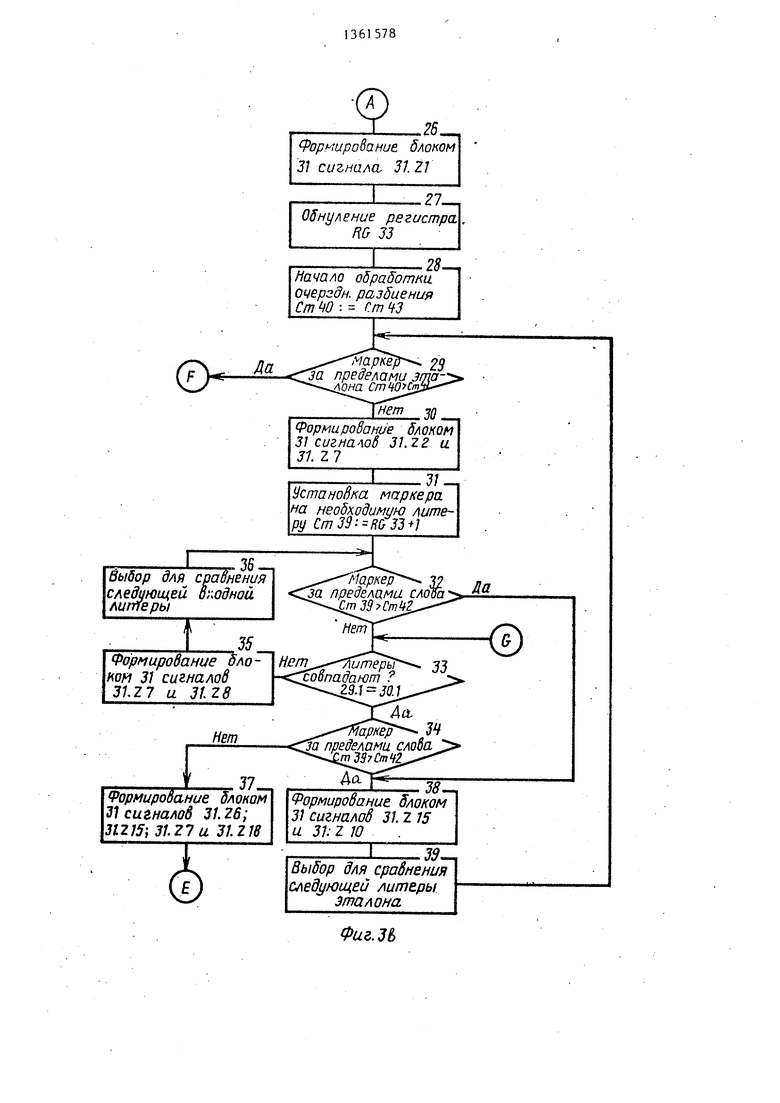
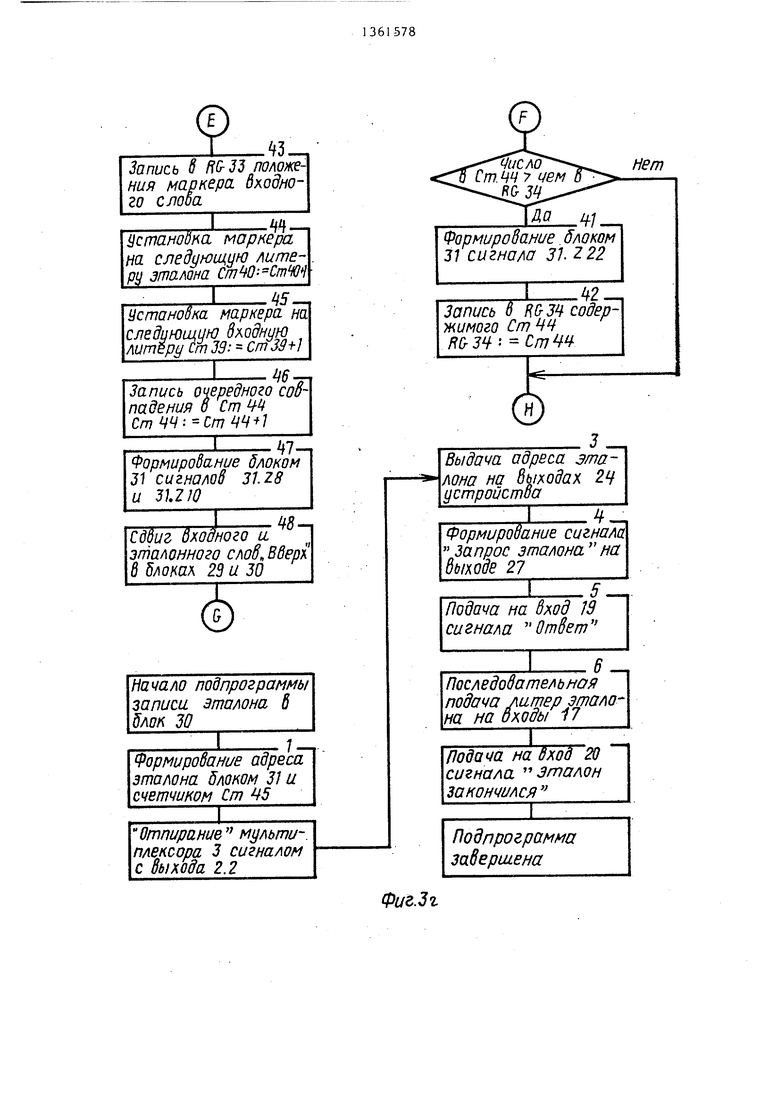
Одновременно с сигналом Расхождение типа, который поступает на вход 31.Y5 блока 31 признаков, на , входы 31.Y4 и 31.Y1 поступают сигналы (блок 1 алгоритма, фиг. За). Данная последовательность сигналов инициирует выборку из таблиц и запись в блок 30 стековой памяти эталонного слова (фиг. Зг). Далее производится обнуление регистра 34 совпадений (блоки 3 и 4 алгоритма) и выбор варианта разбиения эталона (блоки 5 и 6 алгоритма). Затем блок 31 признаков анализирует все ли варианты разбие.ний просмотрены. Данная операция производится путем сравнения содержимого счетчиков 41 и 43 (блок 7 алгоритма). Если не все варианты разбиений просмотрены (Ст43 ), то инициируется обработка очередного варианта разбиения (блоки 26-28 алгоритма). В следующем такте работы блок 31 анали-зируе. положение сравниваемой литеры эталонного слова, если литеры эталонного слова не все сравнивались ( Ст41) (блок 29 алгоритма), то во входном слове для сравнения выбирается литера, следующая после последней совпадающей (блоки 30 и 31 алг-оритма). Далее блок 31 анализирует все пи входное слово просмотрено (блок 32 алгоритма), если нет (Ст39 : Ст423), то блок 31 сравнивает литеры входного и эталонного слов, которые уже выбраны для сравнения (блок 33 алгоритма), если литеры не совпадают, то для сравнения выбирается следующая входная литера методом сдвига входного слова в блоке 29 (блоки 35 и 36 алгоритма) и, если ( (блок 32 алгоритма) , снова производится сравне
ние литер, если литеры не совпадают, процесс повторяется до тех пор, пока не просмотрены все литеры входного слова. Если литеры совпадают, то производится проверка все ли
литеры входного слова сравнивались, если нет ( ГСт42 |), то производится запоминание последней сравниваемой литеры входного слова и сдвиг для просмотра следующих литер эталонного и входного слов в блоках 30 и 29 (блоки 37, 43-48 алгоритма) и снова литеры сравниваются, в дальнейшем, если указанные условия выполняются
(Ст39 ЛСт42) ,
0
0
5
то процесс повторяется.
В случае сравнения всех литер входного слова (блоки 32 и 34 алгоритма) , т.е. если ( Ст39 7 ;Ст42) , то для сравнения выбирается следую-
5 щая литера эталона (блоки 38 и 39
алгоритма). Далее выполняется, проверка все ли литеры эталона сравнивались (блок 29 алгоритма), если нет, т.е. (), то блок 31 признаков инициирует повторное выполнение микроопераций, описанных блоками 30-39 и 43-48 алгоритма. Если сравнивались все литеры эталона, т.е. (ССт40 Ст413), то в регистр 34 совпадений помещается число совпадений в данном разбиении, если оно превышает количество совпадений других разбиений (блоки 40-42 алгоритма) .
Затем производится выбор следующего варианта разбиения (блоки 5 и 6 алгоритма) , если последний существу- -ет, то указанный процесс повторяется. Если все варианты разбиения
5 рассмотрены, то блок 31 инициирует определение в блоке 32 коэффициента (КС ) для данного эталона (блоки 7 и 8 алгоритма) и, если вновь вычисленный коэффициент (КС ) больше коэффициента для ранее обработанного эталона (или безусловно, если обрабатывается первый эталон), то он записывается в регистр 35 коэффициента (блоки 10-12 алгоритма). Далее блок 31 анализирует вся ли таблица . эталонов просмотрена. Если нет (от- .сутствует сигнал от внешнего устройства на входе 22 завершения просмотра) , то формируется адрес следующего эта-
0
0
5
пона и инициируется его вызов из внешнего устройства и запись в блок 30 стековой памяти, а также производится установка в исходное положение входного слова (сдвиг вниз на длину данного слова - сигнал 31.Z27) После записи нового эталона процесс повторяется до полного просмотра таблицы эталонов зарезервированных слов (операторов).
По окончании просмотра всей таблицы в блоке 31 вычисленный коэффициент схожести сравнивается с граничным значением данного коэффициента, т.е. сравнивается содержимое регистров 35 и 36. Если вычисленный коэффициент меньше граничного значения, то выходная лексема формируется следующим образом: в поле ошибки записывается 1 -ERROR 1, в поле типа записывается код оператора, сгенерированный кодопреобразователем 2 - ТУРЕ: 2,8, в поле значения записывается последовательность ф -тл - ZNACH: - 0 . Если вычисленный коэффициент больше или равен граничному значению, то выходная лексема отличается от описанной формы полем значения, которому присваивается адрес в таблице эталонного слова со значени- .ем коэффициента схожести KC-ZNACH: 1.1 и в поле ошибки записывается 9i-ERROR: Далее производился выдача лексемы на выходы устройства и считывание ее внешним устройством (блоки 21-25 алгоритма).
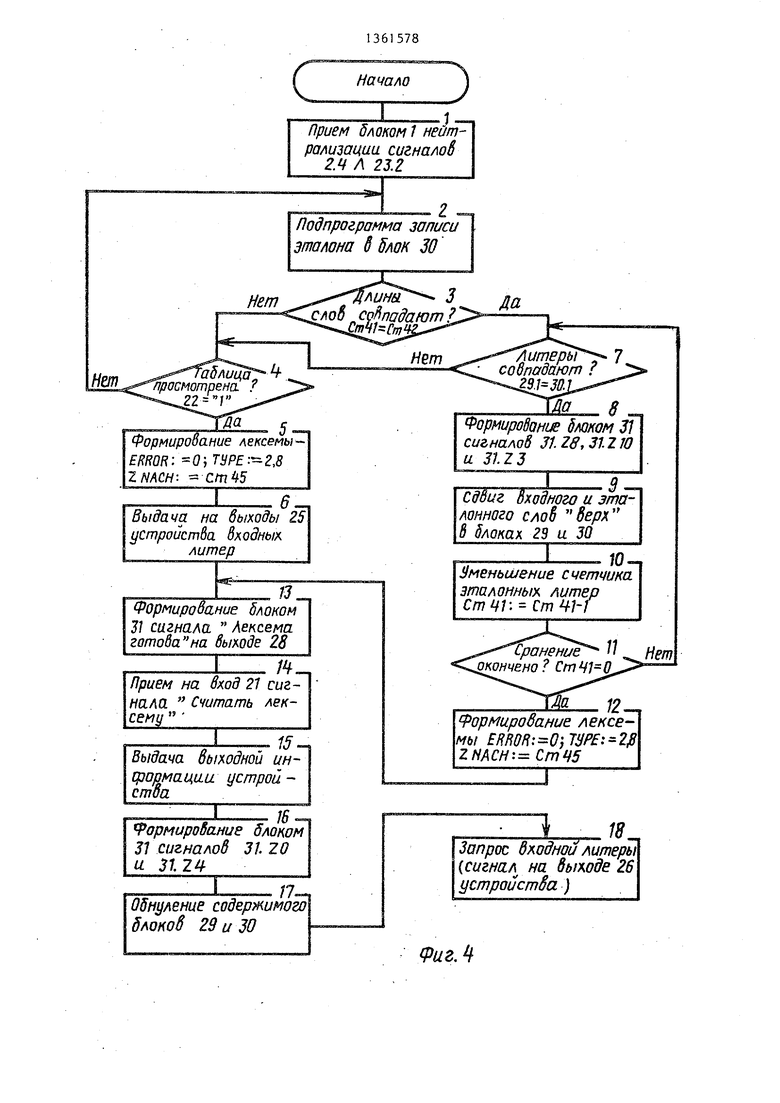
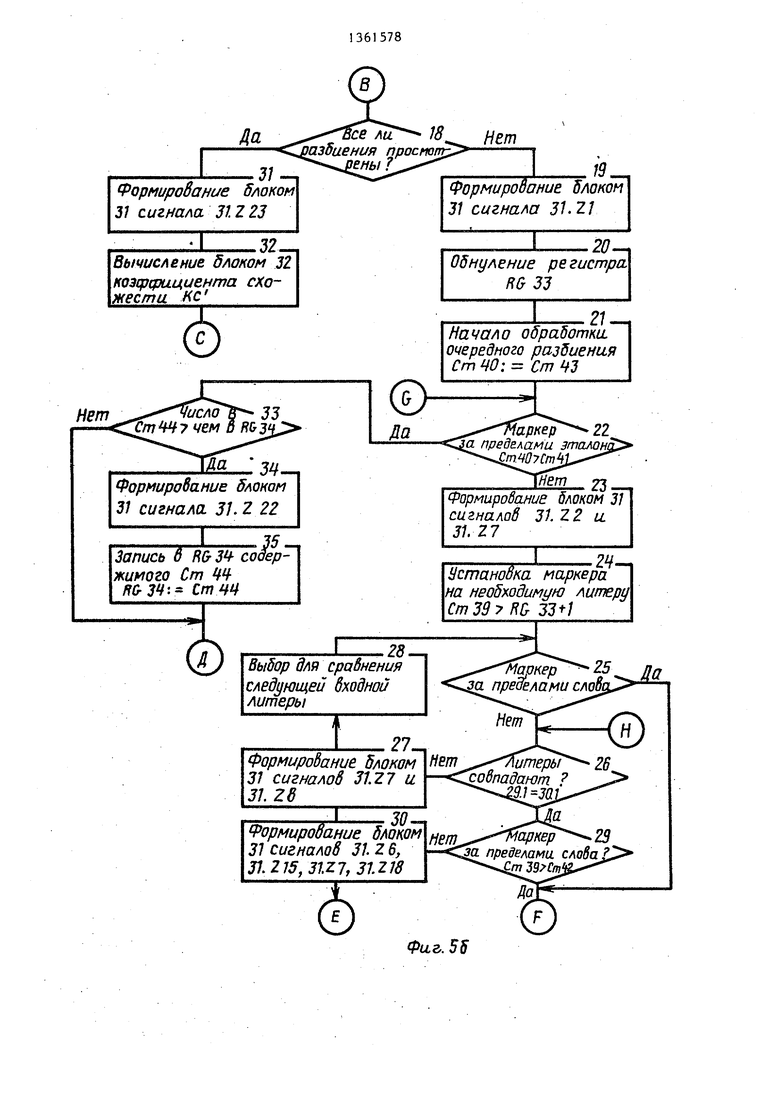
Подмножество 2 - распознавание чисел и идентификаторов и построение таблиц данных конструкций в процессе просмотра программы (т.е. описани чисел и идентификаторов перед телом программы не производится и нейтрализация ошибок в данных конструкциях не осуш;ествляется) .
В одном такте работы блока на его входы 9.1, 2.4 и 23.2 поступают единичные сигналы Расхождение типа (алгоритм фиг, 4), сигнал, идентифицирующий тип входной конструкции 2.4, и сигнал 23,2 начальной установки, включающий нейтрализацию ошибок в конструкциях, отличных от оператора. Последовательность указ-а ных сигналов инициирует запись эталона из таблиц в блок 30 стековой памяти (фиг, 32). После записи эталона в блок 30, о чем идентифицирует сиг
5
0
5
0
нал 20 на входе 31.Y7 блока 31, данный блок сравнивает длины входного и эталонного слов (совпадают ли значения счетчиков 41 и 43), если длины не совпадают (Ст41 Ст433), то блок 31 проверяет есть ли сигнал завершения просмотра на его входе 31.Y2, т.е., просмотрена ли таблица эталонов, если нет, то инициируется запись очередного эталона в блок 30. Данный процесс повторяется либо до совпадения длин анализируемых слов, либо до окончания просмотра таблицы. Если длины слов совпадают (Гст41 ГСт43), то
блок 31 анализирует идентичность первых литер анализируемых слов, если литеры не совпадают, то анализ данного эталона завершается и производится проверка на окончание просмотра таблицы (блок 4 алгоритма), и, если сигнал завершения просмотра отсутствует, в блок 30 записывается новый эталон и процесс повторяется, если первые литеры совпадают, то производится последовательный анализ следующих литер слов, если какие- либо литеры не совпадают, анализ прекращается и выбирается новое слово, если совпали литеры (т.е. данная конструкция встречалась ранее в программе и уже записана в таблицу), то выходная лексема формируется сле- 5 дующим образом: полю ошибки присваивается О - ERROR: О, полю типа присваивается значение, выдаваемое кодопреобразователем 2 по выходам 2.8-TYPE 2.8, а полю значения присваивается адрес эталона, совпавшего с входным словом, который хранится в счетчике 45 блока 1 нейтрализации ошибок ZNACH: Ст45. После формирования лексемы производится выдача ее внешнему устройству по его запросу (блоки 13-18 алгоритма). Если в процессе обработки входного слова в таблице эталонов не найден эталон, соответствующий данному входному слову, то выходная лексема формируется также, как- и в предыдущем случае, только полю значения присвоен адрес (N+1) в таблице символов, если в таблице уже записано N эталонов, а само входное слово выдается параллельным кодом на выходы 25 устройства и записывается в таблицу эталонов в соответствии с его типом по адресу (N+1). Сформированная лексе0
5
0
5
ма выдается в соответствии с алгоритмом (блоки 13-18 алгоритма).
20
25
30
Подмножество 3 - распознавание чисел и идентификаторов и нейтрали- 5 зация ошибок при их возникновении в рассматриваемых конструкциях (при условии, что перед телом программ описываются все идентификаторы и числа, используемые в данных про- Ю граммах).
Таблицы входных лексических конструкций при такой структуре программ строятся следующим образом. На вход 31.Y10 блока 31 признаков по- ступает сигнал с входа 23.3 блокировки устройства и блокирует вьщачу управляющих сигналов на входах 31,ZOT31.Z30 блока 31, за исключением сигнала 31.Z12, независимо от сигналов и информации, поступающей на входы 31.YOT31.Y9, 31.X1431.X13. Литеры входного слова накапливаются в блоке 29 стековой памяти и по сигналу Расхождение ±ипа с выхода 22 блока 2 формирования лексемы вьздают- ся на выходы 25 устройства и помеща- ются в таблицу в соответствии с кодом типа входной конструкции, выдаваемым на выходе 24 устройства по первому свободному адресу в данной таблице, данный процесс повторяется до окончательнЬго формирования таблиц входных конструкций, после чего сигнал на входе 31.Y10 блока 31 сни- 35 мается.
По окончании формирования таблиц входных конструкций блок 1 нейтрализации .ошибок функционирует следующим образом (фиг. 5). Если обрабатывае- 40 мая конструкция не содержит ошибок (т.е. записана в таблицу в соответг ствии с типом), то процесс функционирования аналогичен работе блока 1 нейтрализации ошибок в соответствии 45 с состоянием подмножества 2. В-случае обнаружения ошибок (входное слово не обнаружено в таблице эталонов) блок 1 нейтрализации ошибок функционирует в соответствии с состоянием 50 подмножества 1.
Устройство для лексического анализа работает следующим образом.
В исходном положении элементы и
блоки устройства находятся в нуле- gg
BOM состоянии, а триггер 5 пуска - в единичном, причем последний инициирует на выходе 26 устройства единичный сигнал Запрос, на выходы 18
1361578
16
0
5
0
5
0 5 0
g
поступает значение граничного коэффициента К|. , а на вход 23.2 - сигнал Начальная установка, строби- рующий запись кода граничного коэффициента в регистр 36. В зaвиcимoctи от структуры входной программы на входах 23.1 и 23.3 устройства присутствуют или отсутствуют единичные сигналы Спец.структура и Блокировка. Сигнал Запрос вызывает подачу от внешнего устройства (не показано) единичного сигнала Ответ на вход 19 ответа и литеру входной записи на информационные входы 17 устройства. Сигнал Ответ стробиру- ет запись входной литеры в регистр 4 литеры и через открытый элемент И 12 устанавливает триггер 5 пуска в нулевое состояние, обеспечивая, снятие сигнала Запрос. Одновременно сигнал с инверсного выхода триггера 5 пуска через открытый элемент И 15 инициирует распознавание кодопреобразователем 2 литеры, записанной в регистр 4 литеры, код которой поступает на информационные входы блока 2 формирования лексемы после распознавания входной литеры, если она относится к ранее считанной конструкции, на выходе 2.3 блока 2 формирования лексемы формируется единичный сигнал. Данный сигнал, поступая на одноименный вход блока 1 нейтрализации ошибок, инициирует перезапись .входной литеры из регистра. 4 литеры в блок 29 стековой памяти, одновременно сигнал с выхода 2,3 через элемент ИЛИ 7 устанавливает триггер 5 пуска в единичное состояние. Сигнал с прямого выхода триггера 5 пуска через открытый элемент И 14 формирует на выходе 26 устройства сигнал Запрос, по которому на выходы 17 поступает следующая литера, и процесс повторяется до тех пор, пока в регистр 4 литеры не будет записана литера, не принадлежащая к обрабатываемой конструкции. После записи в регистр 4 литеры, не принадлежащей к конструкции, литеры которой обработаны ранее, блок 2 формирования лексемы разпознает данную литеру и в результате анализа формирует на выходе 2.2 единичный сигнал Расхождение типа.
Далее процесс функционирования зависит от типа обрабатываемой входной конструкции, поэтому целесообразно рассмотреть работу устройства в следующих состояниях..
Состояние 1: обрабатываемая конструкция - оператор (зарезервированное слово), не содержащий лексических ошибок. В данном состоянии блок 2 формирования лексемы формирует коды типа и значения выходной лексемы и сигнал Оператор на выходе 2.5. Сигнал Оператор поступает на двенадцатьй управляющий вход блока 1 нейтрализации ошибок и инициирует формирование этим блоком еди- ночного сигнала Лексема готова на выходе 28 устройства. По данному сигналу внешнее устройство (не показано) устанавливает на вход 21 выдачи единичный сигнал, который поступает на второй управляющий вход блока 22 формирования лексемы и инициирует снятие сигнала Расхождение типа с выхода 2.2 и вьщачу данным блоком 2 формирования лексемы кодов типа на выходы 2.8 и кодов значения выходной лексемы на выходы 2.9. Коды типа и значения лексемы поступают на первые и вторые информационные входы мультиплексора 3 лексемы, где под действием сигнала на втором управляющем входе окончательно формируется лексема. Сформированная лексема выдается на входы мультиплексора 3 лексемы, которые одновременно ;Являются выходами- 24 устройства. Од- |новременно сигнал с входа 21 приво- дит в исходное состояние блок 2 фор- :мирования лексемы и через время задержки, равное вьщачи лексемы во внешнее устройство, инициирует распознавание литеры, записанной в регистре 4 литеры, и процесс накопления литер одной входной конструкции в блоке 29 стековой памяти повторяется до формирования блоком 2 формирования лексемы единичного сигнала на выходе 2.2.
Состояние 1а: обрабатываемая конструкция - оператор, содержащий лексические ошибки. При обработке данной конструкции блок 2 формирования лексемы совместно с кодом типа и сигналом Расхождение типа формирует сигналы Оператор и Ошибка на выходах 2.5 и 2.7 соответственно.
Данные сигналы инициируют работу блока Т нейтрализации ошибок в соответствии с алгоритмом (фиг. 3). Сигнал Ошибка через элементы. ИЛИ 10,
И 13 и ИЛИ 9 устанавливает триггер 6 эталона в единичное состояние. Сигн ал с прямого выхода триггера 6 эталона формирует единичный сигнал Вызов эталона на выходе 27 устройства. По данному сигналу внешнее устройство устанавливает единичный сигнал на вход 19 устройства и последовательно подает литеры эталона на входы 17 устройства. Сигнал с входа 19 через элемент И 16 поступает на одиннадцатый управляющий вход блока 1 нейтрализации ошибки и иниg циирует запись литер эталона в блок 30 стековой памяти, этот же сигнал через элемент ИЛИ 8 устанавливает триггер 6 эталона в нулевое состояние, при этом сигнал Вызов эталона
Q с вькода 27 снимается. Сигнал с нулевого выхода триггера 6 эталона через элемент ИЛИ 11 поступает на второй управляющий вход мультиплексора 3 лексемы, но формирование лексемы
5 не происходит, так как данный сигнал блокирован сигналом Расхождение типа, поступающим на первый управ- ляющий вход мультиплексора 3 лексемы. После завершения работы блока I0 нейтрализация ошибки по алгоритму
(фиг. 3) устройство переводится в исходное состояние.
Состояние 2: обрабатываемая конструкция - разделитель. Блок 2 формирования лексемы формирует значение выходной лексемы и сигнал Разделитель на выходе 2.6. По данному сигналу устройство начинает функционировать аналогично функционированию в
Q состоянии 1 под воздействием сигнала Оператор, однако выходная лексема формируется в соответствии с результатами анализа разделителя.
Состояние 3: обрабатьшаемая кон5 струкция - число (идентификатор), а структура программы не предусматривает нейтрализации лексических ошибок в идентификаторах и числах любого класса. В данном состоянии блок
о 2 формирования лексемы формирует единичный сигнал .на выходе 2.4, которьй поступает на одноименный вход блока 1 нейтрализации ошибок и совместно с сигналом с входа 23.2 инициирует запуск работы блока 1 нейтрализации ошибок по алгоритму (фиг. 4). Одновременно сигнал с выхода 2.4 поступает на третий управляющий вход мультиплексора 3 лексемы, но он бло5
5
кнруется сигналом Расхождение типа После завершения работы блока нейтрализации ошибок по алгоритму устройство переходит в исходное состояние, обрабатывает литеру из регистра 4 литеры и процесс повторяется.
Состояние Д: обрабатываемая конструкция - число (идентификатор), а структура программы позволяет произ- водить нейтрализацию ошибок в рассматриваемых конструкциях. В данном состоянии устройство по сигналу на входе 23.3 блокировки формирует временные таблицы рассматриваемых кон- струкций, т.е. производится накопление входных литер блоком 1 нейтрализации ошибок и по сигналу Расхождение типа на выходе 2.2 кодопреобразователя 2 записанное слово- выдается на выходы 25 устройства, а на выходы 24 устройства блока 2 формирования лексемы через мультиплексор 3 лексемы выдается код типа обработанного входного слова. Далее внешнее устройство по этим данным формирует временные таблицы. После завершения процесса формирования таблиц сигнал с входа 23.3 устройства снимается и по сигналам 2.4 и 23.1 блок нейтрализации начинает функционировать в соответствии с алгоритмом (фиг. 5).
Формула изобретения
Устройство для лексического анализа, содержащее блок формирования лексемы, регистр литеры, триггер пуска, триггер эталона, пять элементов И и пять элементов ИЛИ, причем инфор мационный вход регистра литеры является информационным входом устройства, выход регистра литеры соединен с информационным входом блока формирования лексемы, первый управляющий выход которого соединен с первым входом первого элемента И, первым входом первого элемента ИЛИ и входом асинхронной установки в О регистра литеры, второй управляющий выход бло ка формирования лексемы соединен с первыми входами второго и третьего элементов И, третий управляющий выход блока формирования лексемы соединен с вторым входом первого элемен- та ИЛИ, четвертый и пятый управляющие выходы блока формирования лексемы соединены с первым и вторым входами второго элемента ИЛИ соответ
0
5
g
0 5 0 g
0
5
ственно, первый управляющий вход блока формирования лексемы соединен с выходом второго э-лемента И, второй управляющий вход блока формирования лексемы является входом выдачи устройства, выход второго элемента .И является выходом запроса устройства, прямой выход триггера эталона соединен с первым входом четвертого элемента И и является выходом вызова устройства, выход четвертого элемента И соединен с первым входом третьего элемента ИЛИ, второй вход которого является входом сравнения устройства и соединен с вторым входом третьего элемента И, выход которого подключен к первому входу четвертого элемента ИЛИ, выход которого соединен с входом установки единицы триггера эталона, вход установки поля которого подключен к выходу третьего элемента ИЛИ, инверсный выход триггера эталона соединен с первыми входами пятьпс элементов И и ИЛИ, входы установки поля и единицы триггера пуска подключены к выходам первого элемента ИЛИ и пятого элемента И соответственно, инверсный и прямой выходы триггера пуска соединены с вторыми входами первого и второго элементов И соответственно, второй вход пятого элемента И является входом ответа устройства и соединен с вторым входом четвертого элемента И и входом синхронизации
регистра литеры, выход второго элемента ИЛИ соединен с третьим входом третьего элемента И, отличающееся тем, что, с целью расширения функциональньдх возможностей путем обработки входных тестов программ, лексические единицы которых не имеют строгих позиций по входной записи, нейтрализации лексических ошибок, а также увеличения типов распознаваемых терминальных слов при одновременном упрощении устройства и повьщ ении его быстродействия эа счет исключения записи во временную таблицу конструкций, которые были ранее в нее записаны в процессе лексического анализа, в устройство введены блок нейтрализации ошибок и мультиплексор лексемы, причем первый и второй информационные вькоды блока формирования лексемы соединены соответственно с первым и вторым информационными входами мультиплексора лексемы, третий
и четвертый информационные входы которого соединены соответственно с первым и вторым информационными выходами блока нейтрализации ошибок, третий информационный выход которого является выходом терминального слова устройства, первый управляющий вход мультиплексора лексемы соединен с вторым управляющим выходом блока формирования лексемы, второй управляющий вход мультиплексора лексемы соединен с выxoдo 4 пятого элемента ИЛИ, третий управляющий вход мультиплексора лексег ы соединен с четвертым управляющим выходом блока формирования лексемы, первый и второй управляющие выходы блока нейтрализации ошибок соединены соответственно с четвертым и пятым управляющими входами мультиплексора лексемы, выход которого является выходом лексемы устройства, третий, четвертый и пятый управляющие выходы блока нейтрализации ошибок соединены с вторым, третьим и четвертым входами четвертого элемента ИЛИ соответственно, шестой управляющий выход блока нейтрализации ошибок является выходом готовности устройства, седьмой управляющий выход блока нейтрализации ошибок соединен с вторым входом пятого элемента ШШ, первый информацио гный вход блока нейтрализации ошибок соединен с выходом регистра литеры, второй информационный вход
блока нейтрализации ошибок является входом коэффициента поправки устройства, первый управляющий вход блока нейтрализации ошибок соединен с пятым управляющим выходом блока формирования лексемы, второй управляющий вход блока нейтрализации ошибок соединен с вторым управляющим входом блока формирования лексемы, третий, четвертый, пятый и шестой управляющие входы блока нейтрализации ошибок образуют соответственно входы организации, завершения просмотра, начальной установки и блокировки устройства, седьмой управляющий вход
блока нейтрализации ошибок .соединен с выходом четвертого элемента ИЛИ, восьмой управляющий вход блока нейтрализации ошибок соединен с вторым входом третьего элемента И, девятый
управляющий вход блока нейтрализации ошибок соединен с первьм входом третьего элемента И, десятый, одиннадцатый, двенадцатый и тринадцатый управляющие входы блока нейтрализации ошибок соединены соответственно с третьим, четвертым, шестым и седьмым управляющими вьтходами блока формирования лексемы.
Фиг. 2а
С
Начало
I
.
Прием блоком 1 нейтрализации сигналов 2.5/ г
2-.
Подпрограмма записи, эталона S 5лог 30
I
J
Нормирование блоком 31 сигна/ а. 31.Z 21
If
Одниление (зегистра 3 соопадений
Формиробание блоком 31 сигнала
м
-п
I
-,
Перевод счетчика 3 8 следующее состояние Стч :-СтЦз- 1
нет /i7 7 разбиения просмотр 3ew6/
Да
-8
Нормирование блоком 31 сигнала 31. Z23
I
- 9
Вычисление блоком 32 коз(р(рициента схожести КС
Фиг. За
/7 РормироВание блоком 31 сигнала 3125
1
т
Запись 6 К& 35 бнооь 8ы цс/ енного КС / C-J5: 32.1J
1
т
& 35 бнооь го КС 32.1J
Нет
ся ли . /5 Тпадл. ,
IП
Нормирование блоком 31 сигналов 31-20; 31277; 31226f 317.27
Да
18Формирование 5Аоком31 сигнала 3122
I
17
Формирование лексе- Mbi-ERf OR: lJ; ТУРЕ: 2NACH: 0
г
Выдача лексемы на выходы 24 устройст1
п.
Формиробание сигнал а
Лексема готова на бымде 28
1
.2J-,
Считывание, лексемы (прием сигнала на 8мд 21 дстройс/пба)
I
2
Формиробание 5локом 31 сигналов 31.20 и, 31Z Ч
I
- 75
Формиробание триггерам щ сигнала 7.7
1
20Нормирование лексемы - /i W/r: r J; 1PE.2,8 Zyy/lW: 7,7
1
п.
ние сигнал
, /п
,
25.
.«
Запрос литеры (сигнал на выводе 26 устройства)
иг. 35
-.5
Лорнирование блоком
31 сигнала 31.21
Обнуление регистра / 33
.27 cmpa
Начало обработки, очергдн. раз5иенир Cm 43
I
е регистра 33
.27 cmpal
, р
28
. .7/7
(рориирование SAOKQM 31 сигналов 31Z2 и 31.21
I
., Л
Устаноока маркера, на нБобходимцю ру CmJ3 - K&33 J
1 g
Выбор для сраонЕния следующей о угодной литеры
I
Рорииробание 5ло AOW Л сигналов 31Z7 и 3128
Нет
:i::-J.
Нормирование блоком
71 f.i iiififr R 11 1C
T-u/.i4ijfjvuunuc.
31 сигналоб 31.2 15 31:2 Ю
1-J -,
Выбор для срабнения следующей литеры эталона
Фuz. П









| название | год | авторы | номер документа |
|---|---|---|---|
| Устройство для лексического анализа программ | 1984 |
|
SU1238103A1 |
| Устройство для лексического анализа программ | 1987 |
|
SU1418757A1 |
| Устройство для лексического анализа метатранслятора | 1983 |
|
SU1153329A1 |
| УСТРОЙСТВО ДЛЯ ОБРАБОТКИ СИМВОЛЬНОЙ ИНФОРМАЦИИ | 1991 |
|
RU2010319C1 |
| Устройство для лексического анализа метамикроассемблера | 1982 |
|
SU1034043A1 |
| Устройство для ввода данных | 1976 |
|
SU564630A1 |
| Устройство для обучения иностранным языкам | 1989 |
|
SU1741154A1 |
| УСТРОЙСТВО ДЛЯ РЕАЛИЗАЦИИ УПОРЯДОЧИВАЮЩИХ ПОДСТАНОВОК | 1992 |
|
RU2067315C1 |
| Адаптивное устройство для обучения языкам | 1987 |
|
SU1441445A1 |
| Устройство для лексического анализа | 1976 |
|
SU690497A1 |
Изобретение относится к вычислительной технике и может быть использовано в вычислительных системах с диалоговым режимом отладки и выполнения программ. Цель изобретения расширение функциональных возможностей путем обработки входных текстов программ, лексические единицы которых не имеют строгих позиций во входной записи, нейтрализации лексических ошибок, а также увеличения типов распознаваемых терминальных слов при одновременном упрощении устройства и повышении его быстродействия за счет исключения записи во временную таблицу конструкций, которые были ранее в нее записаны. Для достижения указанной цели в устройство дополнительно введены блок нейтрализации ошибок и мульти- плексор лексемы. 5 ил. S
Фиг.3г
,-.- t
прием блоком 1 нейтрализации сигналов 2М Л 23.2
Начало
подпрограмма записи эталона 5 5лок 30
Формирование лексемы-
.5 2NACH: Ст45
Выдача на выходы 25 устройства бходньк литер
0
Формирование блоком 31 сигнала Лексема гот оба на вымде 28
I
- / прием на вход 21 сигнала. Считать лек- сеиу
Выдача
Срормацаи стой
15-Од1}(ОдНОй инуcm рой Формирован1Л §Аомм J/ сигналоб 31.28,31.2 Ю и. 31.23
I
5
Сдвиг Входного и эталонного берх S блоках 29 и 30
I
Уменьшение счетчика зталонныу литер
С/77 7: С/77 /-Г
CpaneHLfe П Hgfjj окончено С т 41 О
чи
Нормирование лексемы 8f OK: Ojfm: 2f 2НАСН СтЧ5
L
- 1В Ч ормирооание блоком 31 сигналов 3120 и 31.2
П
Обнуление содержимого
длокоб 29 и 30
±
1В
Запрос буозднои латерм (сигнал на дымде 26 устройства)
Фиг,
I
/
Прием 5ло(.ом 1 нейтрализации, сигналов гм Л 23.1
±L
Подпрограмма записи эталона 6 длок 30
На чало
±L
Нет ,„... 00 совпадают 1т
Формирование 5локом 31 сигнала 31.230
/2
Начало побторного просмотри СтЧ5 0
I
- П
Подпрограмма записи, эталона в блок 30
fia
| шмм вамм внмя в мв1 ш1 «м|вм11н| яя
Нормирование блоком 31 сигналоб 31.28, 31210, 31.23
5
I
Сддаг входного и зта- лонного слое 86ерх 8 блоках 29 и 30
I
Уменьшение сяетчика эталонные, литер Cm 41 -Cm 1-1
7 Щ-,
Формиробание блоког 31 сигнала 31. 2 21
I
- 15 Обнуление регистра со8падений
Нет
3
Нормирование лексемы ERHOR .Q , ТИРЕ - 2.8 2NACH: Cm 45
/б-,
Нормирование блоком 31 сигнала 312 Щ
I
- 7 Выбор следующего раз5иенил cm43- cm iJ l
Фиг, 5а
Формирование блоком 31 сигнала 31.223
19
Формиробание блоком
31 сигнала 31.21
I
- 32-, Вычисление блоком 32 козсрсрициен/па схо- жеста КС
1
- 2/7-. Обнуление регистра,
R& 33
I
21 -
Начало обработки, очередного разбиения Cm ЦО: Cm д
нет
Форииробание ёлоном 31 сигнала 3L2 22
,. 1 -.55-.
Запись о К& 3 соаержииого Cm ЧЧ- RG-ЗЧ: СП1Ц14
23-1
Формиробание блоком 31 сигналов 31.22 и. 31.27
I
Устаноока маркера на нео5мдимуш литеру Cm 3d У
1
Вы5ор для срабнения
бходной литеры
25
I
-27-,
Формирование Ьлоком 31 сигналов 31.27 и. 31 26
1
Рормирование блоком ЗТ сигналов 31.26, 31.215,312.7,31.218
я
25-,
Фиг. 5S
Рорми.роШние SAOKOM 31 сигналов 31.215 и. 31 Z 10 ..
.36,
Запись в HG- 5J положения маркера 8мд- ного слова
1
- Н7 Выбор для сравнения следующей литеры эталона
I
J7-n Устаноока маркера
на. следс/ющую ли терц эталона
,J(,
Устанойка маркёра на следующую входную литерд С т
Нет
Ч5-.
Формирование блоком 31 сигнала 31. 5
-.
Запись в RG- 35 бнодь вь исленного КС КС- 35 : {32.1}
Нормирование блоком 31 сигнала 31.225
I
J5
Запись очеоедного со8- падения о Cm ЧЧ- СтЧЧ- Ст +1
I
Формиродание 31 сигналов и J7. Z 10
I
4/-,
Сддиг входно а и. эталонного ( в блоках 29 и. 30
50-,
Формародание блоком 31 сагнала. Л. Z 2
I
,Я-.
f opMupoouHue триггером 47 сигнала 7.7
I
3Формирование лексемы E8ROR LU, ТУ РЕ:-2,8 ZNACH-0
I
Фор/жирование . .
ЕКМК: 11 ;ТУРе- 2,8 2НАСН: - 7.7
Выдача лексемы на выкоды 2 устройства
Фа г. 6
Ф.
.
Нормирование сигнала Аексёма готова на вымое 28
I
„,
СчитыБание лексемы
(прием сигнала на 6мд21 устройства
Редактор И.Николайчук
Составитель И,Поливода Техред А.Кравчук
Заказ.6293/50Тираж 671Подписное
ВНИИПИ Государственного комитета СССР
по делам изобретений и открытий 113035, Москва, Ж-35, Раушская наб., д. 4/5
Производственно-полиграфическое предприятие, г. Ужгород, ул. Проектная, 4
1
Формирование блоком 31 сигналов 3120 и
3124
4--г- 7Запрос вмдной лите- ры сигнал ну, 6ы;(оде
26 устройсг7 8а)
(риг,. 5г
Корректор А.Зимокосов
| Устройство для лексического анализа метамикроассемблера | 1982 |
|
SU1034043A1 |
| Приспособление для точного наложения листов бумаги при снятии оттисков | 1922 |
|
SU6A1 |
| Устройство для лексического анализа программ | 1984 |
|
SU1238103A1 |
| Приспособление для точного наложения листов бумаги при снятии оттисков | 1922 |
|
SU6A1 |
