Изобретение относится к автоматике и вычислительной технике и может быть использовано для обработки символьной информации.
Известно устройство для лексического анализа программ, содержащее блок преобразования кода литер в код лексем, регистр, группу элементов ИЛИ, две группы элементов И, семь элементов И, пять элементов ИЛИ, четыре элемента задержки, одновибратор, два триггера, счетчик позиций, счетчик литер, дешифратор, элемент ИЛИ-НЕ. Устройство способно осуществлять лексический анализ текста, в результате которого на его выход поступают лексемы. Недостатком устройства являются узкие функциональные возможности, поскольку на текст налагаются существенные ограничения как на структурное представление, так и на представление отдельных элементов.
Известно устройство лексического анализа символьного текста, содержащее входной и выходной регистры, шифратор, три коммутатора, блок управления подстановкой, блок сравнения, блок памяти текстов подстановок, шифратор текста подстановок, блок синхронизации, элемент ИЛИ-НЕ, элемент ИЛИ. Данное устройство позволяет осуществить лексический анализ текста с произвольной структурой представления. Это достигается за счет разделения текста на элементы посредством трех специфических символов: разделитель, начало комментария; конец комментария. Символы, входящие в элементы, называются информационными. К недостаткам устройства следует отнести узкие функциональные возможности, связанные с ограничением на представление определенного типа элементов текста.
Известно устройство для лексического анализа метамикроассемблера, содержащее входной и выходной регистры, шифратор, коммутатор, генератор синхроимпульсов, блок памяти номера алфавита, дешифратор, триггер, два элемента И, элемент ИЛИ, шифратор типов лексем, буферный регистр, блок сравнения, два элемента НЕ. Устройство кроме функций, выполняемых указанными ранее устройствами, способно осуществлять лексический анализ текста с произвольным структурным представлением, который состоит из символов четырех типов: разделитель, начало комментария, конец комментария, информационный символ. Недостатком данного устройства являются ограниченные функциональные возможности, связанные с необходимостью сопровождения лексем идентификатором типа.
Наиболее близким по технической сущности к заявляемому устройству является устройство для лексического анализа метамикроассемблера, содержащее два регистра, инфомрационный вход первого из которых является информационным входом устройства, а выход второго является информационным выходом устройства, шифратор, коммутатор, блок памяти номера алфавита, блок управления, причем выход первого регистра соединен с первыми входами шифратора и коммутатора, выход шифратора соединен с входом блока управления, первый, второй, третий и четвертый выходы которого соединены соответственно с вторым и третьим выходами коммутатора, с первым входом второго регистра и с управляющим входом первого регистра, выход коммутатора соединен с вторым входом второго регистра, выход блока памяти номера алфавита соединен с вторым входом шифратора. Блок управления прототипа содержит три триггера, четыре элемента И, элемент ИЛИ, генератор синхроимпульсов, две группы элементов И, дешифратор, вход которого является входом блока, а первый, второй, третий и четвертый выходы соединены соответственно с первым и вторым входами первого триггера, с первым входом второго триггера и с первым входом первого элемента И, выход которого соединен с вторым входом второго триггера и с первым входом второго элемента И, причем выход второго триггера соединен с первым входом третьего элемента И и с входом третьего триггера, выход которого подключен к второму входу третьего элемента И, выход последнего соединен с вторым входом блока и с первым входом четвертого элемента И, выход которого соединен с первым входом элемента ИЛИ, выход последнего соединен с третьим входом блока, выход генератора синхроимпульсов соединен с четвертым входом блока и с вторыми входами второго и четвертого элементов И, выход второго элемента И соединен с вторым входом элемента ИЛИ, второй вход первого элемента И соединен с выходом первого триггера. В отличии от аналогов прототип позволяет выделять лексемы без определения их типа. К недостаткам прототипа относятся ограниченные функциональные возможности и, как следствие, ограниченная область применения, так как устройство не анализирует допустимость использования конкретных лексем в отдельных элементах текста, а также не способно кодировать лексемы и представлять заданный текст в закодированном виде.
Цель изобретения - расширение функциональных возможностей за счет анализа на допустимость использования лексем.
На фиг. 1 приведена функциональная схема устройства; на фиг. 2, 3 и 4 - функциональные схемы блока анализа лексем, блока кодирования лексем, преобразователя лексем соответственно; на фиг. 5, 6 - функциональные схемы узла поиска и узла настройки, входящих в состав блока анализа лексем, блока кодирования лексем и преобразователей лексем приведены соответственно; на фиг. 7 представлена схема тактирующего элемента; на фиг. 8 приведена функциональная схема узла формирования цепочки лексем, входящего в состав преобразователей, лексем; на фиг. 9 приведена схема элемент памяти, являющегося составной частью узла формирования цепочки лексем; на фиг. 10 и 11 представлены функциональные схемы блока постоянной памяти и блока координации лексем соответственно; на фиг. 12 и 13 приведены схемы блока идентификации лексем и операционного блока; на фиг. 14-16 приведен алгоритм работы операционного блока.
Устройство для обработки символьной информации содержит регистр 1, три триггера 2, 4, 5, два элемента И 3, 6, блок 7 постоянной памяти, блок 8 памяти, блок 9 идентификации лексем, блок 10 координации лексем, операционный блок 11, два преобразователя 12, 13 лексем, блок 14 анализа лексем, три блока 15, 16, 17 кодирования лексем, элемент ИЛИ 18 и имеет входы 19, 20, 25-32, 35-37 и выходы 21-24, 33, 34.
Блок 14 анализа лексем (фиг. 2) содержит узел 38 настройки, узел 39 поиска, схему 40 сравнения и имеет информационные входы 41, 42, управляющие входы 43, 44, группу информационных выходов 45 и управляющий выход 46.
Блок кодирования лексем (фиг. 3) содержит узел 47 настройки, узел 48 поиска, узел 49 памяти и имеет информационные входы 50, 51, управляющий вход 52, группу информационных выходов 53 и управляющий выход 54.
Преобразователь лексем (фиг. 4) содержит узел 55 формирования цепочки лексем, узел 56 настройки, узел 57 поиска и имеет информационные входы 58, 59, 60, управляющие входы 61, 62, информационный 63 и управляющий 64 выходы.
Узел поиска (фиг. 5) содержит мультиплексор 65, три элемента ИЛИ 66, 75, 76, элемент 67 памяти, две схемы 68, 71 сравнения, элемент И 69, счетчик 70, два триггера 72, 73, тактирующий элемент 74 и имеет информационные входы 77-80, управляющие входы 81, 82, выходы 83-85.
Узел настройки (фиг. 6) содержит элемент 86 памяти, элемент И 87, счетчик 88, элемент 89 задержки, мультиплексор 90 и имеет информационный вход 91, управляющие входы 92-94, настроечный вход 95, информационные выходы 96, 97, управляющий выход 98.
Тактирующий элемент (фиг. 7) содержит триггер 99 и элемент 100 и имеет входы 101-103 и выходы 104, 105.
Узел формирования цепочки лексем (фиг. 8) содержит элемент 106 памяти, три триггера 107, 108, 116, два тактирующих узла 109, 123, восемь элементов ИЛИ 110, 115, 117, 118, 126, 128, 129, 130, счетчик 111, шесть схем 112, 114, 120, 122, 124, 127 сравнения, элемент 113 постоянной памяти, элемент НЕ 119, два элемента И 121, 125 и имеет входы 131-136 и выходы 137-139.
Элемент памяти (фиг. 9) содержит счетчик 106.1, память 106.2, двадцать пять регистров 106.3-106.27 и двадцать пять триггеров 106.28-106.52.
Блок постоянной памяти (фиг. 10) содержит элемент 7.1 задержки, группу элементов И 7.2, элемент ИЛИ 7.3, счетчик 7.4, память 7.5 и n (n-7*a+b) байтовых регистров (7.11-7. N, где N = 11+n).
Блок координаций лексем (фиг. 11) содержит элемент 10.1 памяти, сумматор 10.2, регистр 10.3, элемент ИЛИ 10.5, схему 10.6 сравнения, элемент 10.7 задержки и элемент И 10.8.
Блок идентификации лексем (фиг. 12) содержит пять тактирующих узлов 9.1, 9.8, 9.11, 9.18, 9.20, триггер 9.3, восемь элементов И 9.4, 9.5, 9.9, 9.10, 9.19, 9.27, 9.28, 9.29, восемь элементов ИЛИ 9.2, 9.6, 9.7, 9.12, 9.16, 9.17, 9.21, 9.31, два счетчика 9.13, 9.22, две схемы 9.15, 9.24 сравнения, две памяти 9.14, 9.23, два элемента 9.25, 9.32 задержки и два элемента НЕ 9.26, 9.30.
Операционный блок (фиг. 13) содержит четыре элемента 11.21, 11.22, 11.26, 11.27 памяти, два элемента И 11.1, 11.3, три элемента ИЛИ 11.2, 11.4, 11.24, три коммутатора 11.25, 11.28, 11.29, счетчик 11.31, мультивибратор 11.5, сумматор 11.30, три элемента 11.23, 11.32, 11.33 задержки, пятнадцать триггеров 11.6-11.20. Работа устройства основана на рекурсивном принципе обработки символьной информации. Для использования данного принципа необходимо предварительное составление рекурсивного описания функции обработки символьной информации, т. е. разработка рекуррентных выражений, под лежащих реализации с помощью аппаратных блоков устройства. Работа устройства заключается в вычислении по рекуррентным соотношениям последующих значений функций для заданного аргумента при известном предыдущем значении функции.
В устройстве предусмотрен режим работы прототипа, а именно выделение последовательности лексем, разделенных внутренним разделителем.
Предлагаемое устройство спосоно выполнять кодирование программ, написан -ных на языке типа ассемблера. Рассмотрен пример с ориентацией на аналоговый микропроцессор к1813ве1. Для языка ассемблера к1813ве1 характерны следующие особенности. Исходный текст состоит из операторов, следующих друг за другом, оператор может быть командой микропроцессора, командой транслятора (псевдокомандой ПК) или строкой комментария. Первым оператором исходного текста является оператор, соответствующий заголовку, последним оператором - оператор конца. Операторы, находящиеся между начальным и конечным, объединяются в логические структуры двух типов (сегмент данных и программный сегмент). Каждый сегмент начинается оператором определения базового адреса и заканчивается оператором конца. Текст оператора состоит из базовых элементов языка, разделенных пробелами или другими разделителями. Обработка исходного текста заключается в последовательной обработке операторов. Обработка каждого оператора заключается в преобразовании его в цепочку лексем и дальнейшей параллельной обработке всех лексем цепочки.
Структура исходного текста приведена ниже.
Заголовок (ПК 'ТITL')
Определитель базы сегмента данных (ПК 'ORD')
Cегмент данных
Определитель конца сегмента данных (ПК 'END')
Определитель базы программного сегмента (ПК 'ORG')
Программный сегмент
Определитель конца программного сегмента (ПК 'END'
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Определитель конца программы (ПК 'END')
B исходном тексте допустимы следующие два формата операторов формат
Лексема 1 формируется из символа ': ' и последовательности информационных символов (является меткой оператора).
Лексема 2 формируется из последовательности информационных символов (является мнемоникой цифровой операции микропроцессора для ф1 или мнемоникой псевдокоманды для ф2.
Лексема 3 для ф1, формируется из символов, являющихся единицами или нулями (является операндом псевдокоманды).
Лексема 3, лексема 4 для ф2 формируются из символов, являющихся единицами и нулями или последовательностью информационных символов (является первым (3) или вторым (4) операндом цифровой операции.
Лексема 5, лексема 6 формируются из последовательности информационных символов (являются мнемоникой корректора масштаба (5) и аналоговой операции (6).
Если информативная часть лексемы меньше ее фиксированной длины, то оставшаяся справа часть заполняется пробелами.
Ниже приведен пример программы на языке ассемблера к1813ве1.
Функции обработки исходного текста приведены ниже. Используемые параметры и элементарные функции приведены в табл. 1 и 2 соответственно. Перечень всех функций с их краткой аннотацией приведен в табл. 3.
На вход устройства подается исходный текст, состоящий из операторов, представленных в соответствии с языком ассемблера к1813ве1. Далее каждый оператор преобразуется в стандартную структуру ассемблера - цепочку лексем (количество лексем в цепочке определяется форматом оператора). Далее каждая лексема из цепочки кодируется, что приводит к получению закодированной цепочки лексем. Закодированные цепочки лексем объединяются, что позволяет получить закодированный исходный текст.
Правила записи функций.
Рекурсивная функция определяется в виде рекурсивного процесса, который реализуется по шагам. На кадом шаге процесса происходит приращение аргумента, предварительно разделенного на части и занумерованного в соответсвтвии с выбранной нумерацией, рекурсивный процесс описывается тремя компонентами:
k( $) - определяет начальное значение;
k(p1, p2, . . . , m N) - определяет значение на каждом шаге рекурсии, где m определяет обработанную часть аргумента;
N определяет часть аргумента, соответствующую текущему шагу, значением является номер из выбранной системы нумерации;
р1, р2, . . . - параметры,
RA(k) - определяет завершение рекурсивного процесса (процесс завершается при единичном значении RA(k),
RA проверяется перед выполнением каждого шага рекурсивного процесса
Функция обработки исходного текста.
S является функцией обработки занумерованного исходного текста и представляет собой совокупность функций, имеющих одинаковые аргументы и выполняемых параллельно. В качестве аргумента выступает исходный текст, представленный в соответствии с языком ассемблера. Нумерация исходного текста заключается в разделении его на операторы языка ассемблера, которые естественным образом нумеруются в их последовательности. На каждом шаге рекурсивного процесса обрабатывается один оператор из последовательности. Результатом каждого шага является код текущего оператора. По завершении рекурсивного процесса закодирован весь исходный текст. Значение начального состояния S определяется совокупностью значений начальных состояний параллельно выполняемых функций. Завершение рекурсивного процесса осуществляется по достижении равенства текста на входе устройства и обработанного текста. S($) = St($)! Ssd($)! Sd($)! Ssk($)! Sk($)!
Ssm($)! Smm($)! Sma($)! Sse($)! Se($) S(w FL) = St(w FL)! Ssd(w FL)! Sd(w FL)! Ssk(w FL)! (1)
Sk(w FL)! Ssm(w FL)! Smm(w FL)! Sma(w FL)!
Sse(w FL)! Se(w FL)
RA(S) = Comp(St(w FL), St( $ )), где w - обработанная часть исходного текста;
FL - код цепочки лексем оператора исходного текста, соответствующего текущему шагу рекурсивного процесса (определяется через функцию FL);
St определяет значение состояния обработки исходного текста. Начальное значение соответствует нулю. Значение St на каждом шаге рекурсивного процесса определяется значением текущего состояния St, которое наращивается на величину, выбранную из табл. 4 (псс), в соответствии со сформированным указателем, который в свою очередь, зависит от результатов работы функции FL и текущего значения St.
St( $) = 0
St(w FL) = St(w) + Read(псс, (Comp(FL2p, KTIT)! !
Comp(FL2p, RORD)! ! Comp(FL2p, KORG)! ! (1.1)
Comp(FL2p, KEND)! ! Comp(St, KC3)! !
Comp(St, KC2)! ! Comp(St, KC1) ) ),
Ssd определяет значение указателя (счетчика) данных. Начальное значение соответствует нулю. Значение Ssd на кадом шаге рекурсивного процесса определяется текущим значением состояния Ssd и смысловым значением текущей части аргумента (оператор исходного текста), которое определяется значением FL2p и может быть одним из следующих: псевдокоманда задания начального адреса (ПК ODR), псевдокоманда определения значения данного (ПК DW), псевдокоманда наращивания указателя (счетчика) данных (ПК DS). При этом произведены следующие действия.
Текущее значение указателя (счетчика) устанавливается нулевым и к нулю добавляется значение операнда ПК ORD (FL3f), при этом учитывается возможность некорректности операнда (FL3c), в результате которой значение указателя (счетчика) остается нулевым.
Текущее значение указателя (счетчика) инкриментируется.
Текущее значение указателя (счетчика) наращивается на величину операнда ПК DS (FL3f), при этом учитывается возможность некорректности операнда (FL3c), в результате которой указатель (счетчик) остается в исходном состоянии. При других значениях FL2p значение указателя (счетчика) не изменяется.
Ssd( $ ) = 0
Ssd(w FL) = Ssd(w) + Comp(FL2p, KORD)*(_ Ssd(w) +
FL3f* _ FL3c) + Comp(FL2p, KDW) + (1.2)
Comp(FL2p, LDS)*FL3f*_ FL3c).
Sd формирует таблицу данных. Начальное значение нулевое. Значение Sd на каждом шаге рекурсивного процесса определяется текущим значением состояния таблицы данных, которая дополняется новой строкой. Указателем строки является значение функции Ssd. Значение, . заносимое в строку, определяется значением операнда ПК DW (FL3f). Если текущий операнд не является псевдокомандой DW (FL2p) или операнд ПК DW не корректен (FL3c), то значение соответствующей части строки не изменяется. Sd( $) = 0 Sd(w FL) = Sd(w) # Comp(FL2p, KDW) * Write(FL3f, Ssd)*_ FL3c (1.3)
Ssk определяет значение указателя (счетчика) команд. Начальное значение соответствует нулю. Значение Ssk на каждом шаге рекурсивного процесса определяется текущим значением Ssk и смысловым значением текущей части аргумента (оператор исходного текста), которое определяет значение FL2p и может быть одним из следующих: псевдокоманда задания начального адреса, команда микропроцессора. При этом произведены следующие действия.
Текущее значение указателя (счетчика) устанавливается нулевым и к нему добавляется значение операнда ПК ORG (FL3f), при этом учитывается возможность некорректности операнда (FL3c), при наличии которой состояние указателя (счетчика) остается нулевым.
Текущее значение указателя (счетчика) инкриментируется. При других значениях FL2p содержимое указателя (счетчика) не изменяется.
Ssk($ ) = 0
Ssk(w FL) = Ssk(w) + (_ Ssk(w) + FL3f*_ FL3c)* (1.4)
Comp(FL2p, KORG) + Comp(FL2p, кмп),
Sk формирует таблицу команд. Начальное значение таблицы нулевое. Значение Sk на каждом шаге рекурсивного процесса определяется текущим значением таблицы команд, которое дополняется новой строкой. Указаталем строки является значение функции Ssk(1.4). Значение, заносимое в строку, определяется смысловым значением текущего оператора исходного текста, а именно цифровой операцией (FL2f); значением операндов 1/2 (FL3f/FL4f), если они заданы кодом и корректны, на что указывает совокупность признаков (FL3c/FL4c, FL3p/FL4p), или значением, выбранным из таблицы адресов меток (тма) по указателю, сформированному посредством кодирования операнда (FL3f/FL4f), при условии, что таковая метка имеется (FL3c/FL4c, FL3p/FL4p); корректором масштаба (FL5f), если последний корректен (FL5c); аналоговой операцией (FL6f), если она корректна (FL6c). Вышеуказанные элементы определяют значения частей строки таблицы команд, которые объединяются посредством конкатенации. При некорректности какого-либо элемента значение соответствующей ему части остается нулевым. Если текущий оператор исходного текста не является командой микропроцессора (FL2c), значение строки таблицы не меняется.
Sk(w) = 0
Sk(w FL) = Sk(w) # Write({ FL2f! ! (FL3f*FL3c*
_ FL3p + FL3c*FL3p*Read(Sma(w), FL3f) )! !
(FL4f*FL4c*_ FL4p _ FL4c*FL4p* (1.5)
Read(Sma(w), FL4f) )! ! FL5fFL5c
FL6f*FL6c } , Ssk(w) ) * FL2c*comp(FL2p, кмп).
Ssm определяет значение указателя (счетчика) меток (для идентификации превышения допустимого колилчества меток). Начальное значение соответствует единице. Значение Ssm на каждом шаге рекурсивного процесса определяется смысловым значением оператора исходного текста. Если он содержит информацию о метке (FL1p), то значение указателя (счетчика) инкриментируется.
Ssm(w) = 1
Ssm(w FL) = Ssm(w) + FL1p. (1.6)
Smm формирует таблицу мнемоник меток (тмм). Начальное ее состояние следующее: первая строка соответствует значению метки, определяемой только пробелами (что интерпретируется в языке как отсутствие метки), остальные строки имеют нулевое значение. Значение Smm на каждом шаге рекурсивного процесса определяется текущим значением Smm, которое дополняется новой строкой таблицы. Указателем строки является значение функции FL1f(2.1.1). Знаение, заносимое в строку, определяется значением метки G(1, St(w)). Если текущий оператор не имеет метки (FL1p) или метка используется повторно, то значение строки таблицы не меняется.
Smm( $ ) = 0
Smm(w FL) = Smm(w) # FL1c*FL1p*Write(G(1, St, FL1f). (1.7)
Sma формирует таблицу указателей (адресов) меток (тма). Начальное ее состояние нулевое. Значение Sma на каждом шаге рекурсивного процесса определяется текущим состоянием Sma, которое дополняется новой строкой таблицы. Указателем строки является значение функции FL1f(2.1.1). Значение, заносимое в строку, определяется смысловым значением текущего оператора исходного текста, которое может быть одним из следующих: псевдокоманда DW, псевдокоманда EQU, при этом произведены следующие действия.
Строка таблицы принимает значение указателя (счетчика) данных (Ssd).
Строка таблицы принимает значение операнда ПК EQU (FL3f) при условии, что последний является корректным кодом (FL3c, FL3p).
Если текущий оператор не имеет метки (FL1p) или метка используется повторно (FL1c), то значение строки не меняется.
Sma( $ ) = 0
Sma(w FL) = Sma(w) # FL1c*FL1p*Write(Ssd*
Comp(FL2p, KDW) + FL3f*_ FL3c*_ FL3p* (1.8)
Comp(FL2p, KEQU} , FL1f)
Sse определяет значение указателя (счетчика) таблицы признаков. Начальное значение соответствует нулю. Состояние Sse на каждом шаге рекурсивного процесса определяется через инкриментирование текущего состояния.
Sse( $ ) = 0
Sse(w FL) = Sse(w) + 1. (1.9)
Se является функцией формирования таблицы признаков. Начальное состояние таблицы нулевое. Значение Se на кадом шаге рекурсивного процесса определяется текущим значением таблицы ошибок, которое дополняется новой строкой. Указателем строки является значение функции Sse(1.9). Значение, заносимое в строку, определяется результатом обработки текущего оператора исходного текста и состоит из элементов (FL1c, FL1p, FL2c, FL2p, FL3c, FL3p, FL4c, FL4p, FL5c, FL6c), объединенных посредством конкатенации.
Se( $ ) = 0
Se(w FL) = Se(w) # Write( { FL1c! ! FL1p! ! FL2c! !
FL2p! ! FL3c! ! FL3p! ! FL4c! ! (1.10)
FL4p! ! FL5c! ! FL6c } , Sse).
Функция кодирования цепочки лексем FL(2) представляет собой ряд параллельно выполняемых функций, кадая из которых реализует кодирование конкретной лексемы (FL1-лексемы 1, FL2-лексемы 2, FL3-лексемы 3, FL4-лексемы 4, FL5-лексемы 5, FL6-лексемы 6). Формирование цепочки лексем реализуется функцией L.
FL(L) = FL1! FL2! FL3! FL4! FL5! FL6, (2) где L - цепочка лексем оператора исходного текста (определяется через функцию L).
FL1 выполняет кодирование лексемы1 (метка) и является совокупностью параллельно выполняемых функций (FL1f, FL1c, FL1p). Перед выполнением FL1 осуществляется вызов функции FND (4), которая осуществляет поиск в таблице мнемоник меток Smm по аргументу, соответствующему лексеме1. В результате поиска в FNDf сформирован указатель на строке Smm, соответствующей либо первой незаполненной строке (искомая лексемF в таблице не найдена и FNDx = 0), либо строке Smm с искомой лексемой (FNDx = 1). FL1(FND(1, St, Smm)) = FL1f! FL1c! FL1p, (2.1)
FL1f соответствует указателю строки таблицы мнемоник меток Smm, по которому необходимо занести лексему1. Это действие выполнено функцией Smm(1.7).
FL1f = FNDf. (2.1.1)
FL1c идентифицирует корректность лексемы. Если в таблице мнемоник меток Smm уже зафиксирована метка, соответствующая лексеме1 (т. е. поиск завершился нахождением искомой мнемоники и FNDx = 1), то лексема1 соответствует повторной метке, что свидетельствует о некорректности.
FL1c = _ FNDx. (2.1.2)
FL1p идентифицирует наличие лексемы. Это связано с допустимостью (в рамках данного языка) отсутствия лексемы1 в операторе исходного текста. Для определения этой ситуации первая строка таблицы меток всегда содержит нулевые коды, соответствующие пустому значению лексемы1. Таким образом, соответствие полученного указателя (FNDf) первой строке таблицы мнемоник меток свидетельствует о том, что метка в текущем операторе исходного текста отсутствует.
FL1p = _ Comp(FL1f, 0). (2.1.3)
FL2 выполняет кодирование лексемы2 (мнемоника цифровой операции или псевдокоманды) и является совокупностью параллельно выполняемых функций (FL2f, FL2c, FL2p). Перед выполнением FL2 осуществляется вызов функции FND (4), которая осуществляет поиск в таблице лексемы2 кмл2 (табл. 5) по аргументу, соответствующему мнемонике лексемы 2. В результате поиска в FNDf сформирован указатель строки таблицы кмл2. Единичное значение FNDx свидетельствует о том, что искомая мнемоника в таблице найдена. Нулевое значение FNDx свидетельствует об обратном.
FL2(FND(2, St, KMл2) = FL2f! FL2c! FL2p. (2.2)
FL2f определяет код лексемы2, если ее мнемоника допустима (FNDx = 1). Код извлекается из таблицы кл2 (табл. 6) из части кл2n по указателю, соответствующему значению FNDf. Если текущий оператор является псевдокомандой, то в FL2f установлен нулевой код.
FL2f = Read(кл2, FNDf)*_ FNDx). (2.2.1)
FL2c идентифицирует корректность лексемы2. Нулевое значение свидетельствует о том, что мнемоника лексемы не допустима в рамках данного языка.
FL2c = FNDx. (2.2.2)
FL2p доопределяет содержимое лексемы2, если она корректна (FNDx = 1). Для этого из таблицы кл2 (табл. 6) из части кл2n указателю FNDf извлечено одно из следующих значений:
00000001 - соответствует
команде микро-
процессора
00000010 - соответствует ПК ЕQV
00000100 - ПК DS
00001000 - ПК DW
00010000 - ПК END
00100000 - ПК ORG
01000000 - ПК ORD
10000000 - ПК TIT
FL2p = Read(кл2n, FNDf)*_ FNDx. (2.2.3)
FL3/FL4 выполняет кодирование лексемы 3/4 (операнда 1/2) и является совокупностью параллельно выполняемых функций (FL3f/FL4f, FL3c/FL4c, FL3p/FL4p). Перед выполнением FL 3/4 осуществляется вызов функции p(3), которая формирует значение операнда.
FL3(P(3, St, G(3, St, L)) = FL3f! FL3c! FL3p; (2.3)
FL3f = Pf; (2.3.1)
FL3c = Pz; (2.3.2)
FL3p = Pd; (2.3.3)
FL4(P(4, St, G(4, St, L)) =
= FL4f FL4c FL4p; (2.4)
FL4f = Pf (2.4.1)
FL4c = Pz; (2.4.2)
FL4p = Pd. (2.4.3)
FL5/FL6 выполняет кодирование лексемы 5/6 (корректор масштаба/аналоговая операция) и является совокупностью параллельно выпоняемых подфункций (FL5f/LF6f, FL5c/FL6c). Перед выполнением FL5/FL6 осуществляется вызов функции FND (4), которая осуществляет поиск в таблице мнемоник лексемы 5/6 кмл5/кмл6 (табл. 7, табл. 9) по аргументу, соответствующему лексеме 5/6. В результате поиска в FNDf сформирован указатель соответствующей строки таблицы кмл5/кмл6. Нулевое значение FNDy свидетельствует о том, что искомая лексема в таблице не найдена, а единичное значение FNDx - об обратном.
FL5f/LF6f определяет код лексемы 5/6 в случае, если используемая мнемоника допустима (FNDx = 1). Код извлекается из таблицы кл5/мл6 (табл. 8/10) по указателю, соответствующему значению FNDf.
FL5c/FL6c идентифицирует корректность лексемы 5/6. Нулевое значение свидетельствует о том, что в рамках данного языка используемая мнемоника недопустима.
FL5(FND(5, St, КМл5) ) = FL5f FL5c (2.5)
FL5f = FNDx*Read(Кл5, FNDf); (2.5.1)
FL5c = FNDx; (2.5.2)
FL6(FND(6, St, КМл6) ) = FL6f FL6c (2.6)
FL6f = FNDx*Read(Кл6, FNDf); (2.6.1)
FL6c = FNDx (2.6.2)
Функция кодирования операнда.
Р выпоняет обработку лексемы 3 или 4. В зависимости от значения лексема может восприниматься как метка (первый символ лексемы не соответствует коду нуля или единицы) либо как значение адреса (в противном случае).
Для обработки метки инициируется функция FND, с ее помощью устанавливлается ссылка на таблицу адресов меток (Sma), где определена анализируемая метка. FND при этом реализует поиск в таблице мнемоник меток (Smm) по лексеме, определенной по номеру 1 и коду состояния процесса обработки. В этом случае результатом работы р будет соответствующая ссылка на строку таблицы адресов меток (Sma).
Обработка значения адреса заключается в преобразовании символьного представления в двоичный код с параллельным анализом каждого символа на корректность. В соответствии с нумерацией обрабатываемая лексема разделена на символы. На каждом шаге рекурсивного процесса осуществляется анализ и кодирование выбранного символа. Результатом каждого шага является двоичный код символа. По завершении рекурсивного процесса закодирован весь операнд.
Ps реализует функцию отслеживания размерности операнда (в сегменте данных 25 символов, в программном сегменте 6 символов для первого и второго операндов).
Pd идентифицирует вид задания операнда:
= 1 - метка; = 0 - код
pz определяет признак некорректности операнда;
= 0 - корректен; = 1 - не корректен.
Завершение процесса определяется установкой в единицу RA(P), что диктуется появлением одной из следующих ситуаций: операнд был задан меткой (FNDx = 1); логический конец лексемы (x = k''), физический конец лексемы (размерность лексемы исчерпана - определяется по табл. 12), в лексеме присутствует недопустимый символ (Pz = 1) лексемы).
Синтаксис функции р: p(l, C, F), где l - номер лексемы; С - значение состояния процесса обработки; F - значение лексемы.
P(l, C, $ ) = FND(l, C, Smm)! Pf( $ )! Ps( $ )! Pz( $ )!
Pd( $ );
P(l, C, f y) = Pf(f y)! Ps(f y)! Pz(f y)! Pd(f y); (3) RA(P) = FNDx + Cmp(Ps, Read (non, C) + Comp(Y, K'') + Pz
Pf( $ ) = 0;
Pf(f y) = SD(Pf(f) + Z(y)). (3.1)
Ps( $ ) = 0;
Ps(f y) = Ps(f) + 1. (3.2)
Pz( $ ) = 0; (3.3)
Pz(f y) = Pz(f) + _ (Comp(y, K1) + Comp(y, KO) + Comp(y, K'')).
Pd( $ ) = 1;
Pd(f y) = Pd(f)*FNDx. (3.4)
Функция поиска.
FND выполняет поиск искомой величины в таблице поиска. Искомая велилчина определяется через функцию G, которая из цепочки лексем, сформированной функцией L, выделяет конкретную лексему. Выбор лексемы определяется форматом (St) и номером лексемы в цепочке лексем. FND является совокупностью функций (FNDf, FNDx). В процессе ее работы используется функция G.
В соответствии с нумерацией таблица поиска разделена на строки. На каждом шаге рекурсивного процесса осуществляется анализ на равенство содержимого выделенной строки таблицы и выделенной лексемы. Результатом каждого шага является результат вышеописанного сравнения. По завершении рекурсивного процесса установлена ссылка на строку таблицы поиска. Ссылка может задавать строку, соответствующую искомой величине, логический конец таблицы поиска.
Синтаксис функции FND: FND(l, C, M), где l - номер лексемы, с которой идет работа; С - значение состояние процесса обработки; М - таблица поиска.
Функция FND реализуется следующим образом. Первоначально определяется точка, с которой идет поиск в таблице поиска М (начальное состояние FND). Далее осуществляется поэлементный просмотр таблицы М и сравнение с искомой величиной. Начальное состояние FND определяется исходя из таблицы границ тгп поиска части пнк (табл. 11). Процесс поиска завершается по двум причинам: найдена искомая лексема, вся таблица поиска М просмотрена.
Логический конец таблицы определяется исходя из таблицы границ поиска тгп части пкк (табл. 11).
FND(l, C, $ ) = G(l, C, L)! FNDf(l, C, $)! FNDx(l, C, $);
FND(l, C, M z) = FNDf(l, C, M z)! FNDx(l, C, M z) (4)
RA(FND) = FNDx + Comp(G, z).
FNDf(l, C, $ ) = Read(пнк(l), C);
FNDf(l, C, M z) = FND(l, C, M) + 1 (4.1)
FNDx(l, C, $ ) = 0;
FNDx(l, C, M z) = FNDx(l, C, M) + Comp(FNDf, Read(пкк(l), C). ) (4.2)
Функция формирования цепочки лексем.
L обеспечивает формирование цепочки лексем из набора символов т. Количество лексем в цепочке определяется исходя из текущего состояния обработки текста (табл. 12). Посредством функции D определяется наличие лексемы1. Каждая лексема формируется с помощью функции V.
L(St, 0) = Lf(St, 0)! Ls(0);
L(St, j+1) = Lf(St, j+1)! Ls(j+1);
RA(L) = Comp(Ls, Read(тф, St) );
Lf(St, 0) = 0;
Lf(St, j+1) = Lf(St, j) + Vf(St, Ls, T);
Ls(0) = 0+D(T);
Ls(j+1)= Ls(j) + 1.
V обеспечивает левостороннее представление лексемы (если длина ее меньше максимально допустимой). Длина определяется из таблицы тл в зависимости от текущего состояния обработки текста (St) и номера лексемы (1). Значение лексемы формируется с помощью функции М.
V(St, l, 0) = M(St, l, T)! Vf(0)! Vs(0);
V(St, l, k+1) = Vf(k+1)! Vs(k+1);
RA(V) = (Comp(Vs, Read(тл, (St! ! l)) ))*_ PR +Comp(k, 1)*PR;
Vf(0) = Mf;
Vf(k+1) = SD(Vf(k));
Vs(0) = Ms;
Vs(k+1) = Vs(k) + 1.
M обеспечивает формирование лексемы. Формирование завершается при появлении х, соответствующего управляющему символу (SL), или по достижении физического конца лексемы, который отслеживает функция MS. Длина лексемы определяется из таблицы тл (табл. 13) в зависимости от текущего состояния обработки текста (St) и номера лексемы (l).
M(St, l, 0) = Mf(0)! Ms(0);
M(St, l, T x) = Mf(T x)! Ms(T x);
RA(M) = Copm(f(x), SL) +
+ (Comp(Ms, Read(тл, (St! ! l)) ))*_ PR;
Mf(0) = 0;
Mf(T x) = SD(Mf(T)) + x;
Ms(0) = 0;
Ms(T x) = Ms(T) + 1.
D определяет наличие лексемы1 (метки) (D = 0 - есть метка, D = 1 - нет метки). Функция D также обеспечивает игнорирование символов комментария предыдущего оператора. D завершает свою работу при появлении информационного символа или символа ': ', определяющего наличие метки.
D(f( $ )) = 0;
D(T f(x)) = D(T) + Comp(f(x), l);
RA(D) = Copm(f(x), l) + Copm(f(x), U),
Примечания: 1 - строки, не указанные в таблицах, имеют нулевые значения; 2 - тгп содержит четыре подтаблицы.
Установим соответствие между рекурсивными соотношениями и отдельными структурными элементами устройства.
Для реализации функции S используются операционный блок 11 и блок 10 координации лексем. При этом значение функции St определяет состояние регистра 10.3 блока 10, от которого зависит состояние информационного выхода блока 10. Функции Ssk/Ssd определяют значение счетчика 11.31, Функции Sk, Sd определяют состояние линий 16-40, 41-64 второго информационного выхода блока 11. Функция Ssm определяет значения счетчиков 88 в блоках FA, FP1(12), FP2(13). Функция Sma описывает состояние двух элементов 11.26, 11.27 памяти операционного блока. Функция Smm описывает состояние элементов 67 памяти в блоках 14, 12, 13.
Функции FL1, FL2, FL3, FL4, FL5 и FL6 реализуются соответственно блокам 14 анализа лексем 14, первым блоком 15 кодирования лексем, первым 12 и вторым 13 преобразователями лексем, вторым 16 и третьим 17 блоками кодирования лексем. Функции FL1p, FL1f и FL1c описывают первую, вторую и третью группы информационного выхода соответствующего блока.
Для реализации функции L используются узел формирования цепочки лексем, блок 7 постоянной памяти, регистр 1, блок 8 памяти, три триггера 2, 4, 5 и два элемента И 3, 6. Значение L определяет состояние выхода блока 7.
Функция поиска FND реализуется с помощью узлов 39, 48, 57 поиска. Функция FNDf определяет выход А узла поиска, а функция FNDx - выход RA1.
Функция формирования операнда р реализуется с помощью узла 55 формирования цепочки лексем. Функция Ps определяет состояние счетчика 111. Функции Pd, Pf, Pz определяют состояние трех групп информационного выхода узла.
Устройство работает следующим образом.
Запуск устройства осуществляется посредством подачи импульса на вход 19. На информационный вход 20 устройства подается исходный текст, представляющий собой последовательность символов. Из этой последовательности в соответствии с языком ассемблера к1813ве1 формируются операторы, далее каждый оператор преобразуется в стандартную структуру ассемблера - цепочку лексем (количество лексем в цепочке определяется форматом оператора). Далее каждая лексема из цепочки кодируется, что приводит к получению закодированной цепочки лексем. Закодированные лексемы объединяются, что позволяет получить закодированный оператор. Вся совокупность закодированных операторов представляет собой закодированный исходный текст.
Основным координирующим блоком устройства является блок 10 координации лексем. Его работа описывается функцией St и обеспечивает запуск устройства (вход 19), прекращение его работы с выдачей соответствующего сигнала (выход 23) и организацию цикличепской работы устройства с помощью сигнала на выходе 22. На каждом цикле устройство обрабатывает один оператор исходного текста, блок координации лексем (фиг. 11) имеет следующие входы: 10.10 - запуск (соответствует входу 19 запуска всего устройства); 10.11 - признак завершения цикла обработки исходного текста (обработки оператора исходного текста); 10.9 - результат выполнения цикла (обработки оператора исходного текста) и следующие выходы: 10.14 - признак окончания обработки исходного текста (соответствует сигналу завершения работы всего устройства 23); 10.13 - запуск очередного цикла обработки; 10.12 - значение текущего состояния процесса обработки исходного текста.
Блок координации лексем работает следующим образом. Основным его элементом является регистр 10.3, состояние которого соответствует значению текущего состояния процесса обработки исходного текста. Смена состояния проихсодит при переходе к следующему циклу. Значение текущего состояния и данные на входе 10.9 (определяются результатом работы текущего цикла) объединяются и образуют адрес, по которому из элемента 10.1 памяти (табл. 4) выбрано приращение, обеспечивающее формирование значения следующего состояния. Для этого используется сумматор 10.2. Устройство обработки исходного текста может находиться в следующих состояниях: с0 - ожидание программы; с1 - ожидание сегмента или конца программы; с2 - ожидание конца сегмента данных; с3 - ожидание конца программного сегмента.
По значению текущего состояния настраиваются все остальные блоки (9, 14, 12, 13, 15, 16, 17, 11) на конкретный формат оператора. Завершение процесса обработки исходного текста определяется наличием состояния ожидания конца программы и приходом признака конца программы. Этот анализ обеспечивается схемой 10.6 сравнения.
Появление сигнала запуска цикла на выходе 22 приводит блок 7 в исходное состояние, а благодаря элементу ИЛИ 18 формируются сигнал, обеспечивающий ввод текущего символа в регистр 1, и сигнал запуска 30, блока 9 идентификации лексем. Информация с выхода регистра 1 поступает на вход 29 блока 7 и на вход блока 8 памяти. Последний обеспечивает идентификацию входного символа по его коду, т. е. устанавливает его принадлежность к одной из следующих групп: начало метки, управляющий, начало комментария, конец комментария, информационный. Код входного символа соответствует адресу. Содержимое ячейки памяти определяется следующим образом. Если входной символ соответствует началу метки (символ ': '), то содержимое ячейки - 00001. Если входной символ соответствует концу комментария (символ '. '), то содержимое ячейки памяти - 01000. Если входной символ соответствует началу комментария (символ '; '), то содержимое ячейки 10000. Если входной символ соответствует управляющему символу, то содержимое ячейки 00010. Если входной символ соответствует информационному символу, то содержимое ячейки 00100.
Код текущего символа соответствует адресу, по которому извлекаются признаки.
Элементы 2-6 выполняют следующие функции: формирование совокупности признаков на входе блока 9 (первый, второй и третий информационные входы): 100 - наличие метки, 010 - управляющий символ, 001 - информационный символ, 000 - текущий символ не подлежит обработке;
блокировку информационного признака для символов, относящихся к комментарию; блокировку признака управляющего символа, если последний приходит вслед за управляющим символом.
Триггер 2 предназначен для блокировки передачи через элемент И 3 признака информационного символа после прихода признака начала комментария и разблокировки этой передачи после прихода признака конца комментария. Триггер 5 имеет единичное начальное состояние и предназначен для блокировки прохода признака служебного символа через элемент И 6 в случае последовательности управляющих символов.
Работа блока 9 идентификации лексем описывается функцией L и выполняет следующие действия: выделяет из последовательности входных символов оператор исходного текста, преобразует оператор исходного текста в цепочку лексем.
Блок идентификации лексем (фиг. 12) имеет следующие входы: 9.37 - запуск; 9.38 - настройка, 9.33 - признак наличия метки, 9.34 - признак управляющего символа, 9.35 - признак информационного символа, 9.36 - код, соответствующий текущему состоянию процесса обработки текста и следующие выходы: 9.39 - запрос на ввод следующего входного символа, 9.40 - признак записи входного символа в текущую позицию накопителя, 9.41 - запрос на переход накопителя к следующей позиции; 9.42 - признак завершения формирования цепочки лексем.
Блок идентификации лексем работает следующим образом. На его вход поступают сформированные ранее признаки входного символа (входы 9.34, 9.35, 9.33) и текущее состояние обработки текста (вход 9.36). В соответствии с признаками блок 9 выполняет следующие функции: 000 - переход к следующей лексеме (при обработке лексемы1), 100 - текущий символ игнорируется, 010 - переход к следующей лексеме, 001 - анализ цепочки лексем и установка в нее текущего символа, 100 - текущий символ игнорируется.
После обработки каждого символа блок 9 активизирует следующие действия: ввод следующего символа через регистр 1 (при любых признаках), запись текущего символа в текущую позицию цепочки лексем (в блок 7) при информационном символе 001, переход к следующей позиции цепочки лексем (при управляющем 010 и информационном 001 символах), формирование сигнала на выходе 24 запуска обработки цепочки лексем (если сформирована цепочка лексем, соответствующая текущему оператору). Если длина текущей лексемы меньше максимально допустимой, то блок 9 обеспечивает переход к нужной позиции цепочки лексем.
По значению состояния обработки текста, поступающему на вход 9.36 из памяти 9.23 (табл. 12), устанавливающей соответствие между значением текущего состояния обработки текста и структурой текущего оператора исходного текста, извлекается информация, определяющая количество лексем для оператора текущей структуры. Исходный оператор может иметь одну из структур в соответствии с форматами операторов в исходном языке. Таким образом, память 9.23 совместно со счетчиком 9.22 обеспечивает отслеживание допустимого количества лексем в операторе установленного формата. Память 9.14 (табл. 13) содержит размерности каждой лексемы для всех возможных форматов. Таким образом, память 9.14 совместно со счетчиком 9.13 обеспечивает отслеживание количества символов в текущей лексеме. Наличие признака метки (вход 9.34) позволяет идентифицировать наличие в операторе лексемы1. При отсутствии этого признака обработка оператора начинается с второй лексемы. Как только все лексемы обработаны, блок 9 выдает соответствующий синал (выход 9.42). Каждая лексема формируется следующим образом. Если на вход поступает признак информационного символа, то блок 9 анализирует не достигнут ли конец лексемы (равенство значения счетчика 9.13 и выхода памяти 9.14). Если конец достигнут, то осуществляется переход к следующей лексеме. В противном случае на выходе блока 9 формируются признак записи входного символа в накопитель (выход 9.40) и признак перехода накопителя к следующей позиции (выход 9.41). Если на вход поступает признак управляющего символа, что свидетельствует о завершении текущей лексемы, то блок 9 проверяет соответствует ли текущая позиция накопителя последней позиции текущей лексемы. Если нет, то блок 9 выдает сигнал перехода к следующей позиции лексемы (выход 9.41) до тех пор, пока количество позиций в лексеме не будет исчерпано.
Блок 7 постоянной памяти (фиг. 10) работает в соответствии с функционированием блока 9 идентифицикации лексем. По окончании работы блока 9 в блоке 7 будет сформирована цепочка лексем. Блок 7 имеет следующие вход: А - код входного символа, В - признак записи входного символа в текущую позицию блока 7, С - признак перехода блока 7 к следующей позиции, R - установка блока 7 в исходное состояние.
Выход блока 7 представляет собой цепочку лексем и состоит из восьми групп. Первые шесть групп и восьмая группа включают в себя по 48 линий, а седьмая группа - восемь линий. Каждые восемь линий выхода представляют собой код символа. Первая группа линий определяет содержимое лексемы 1, вторая группа - лексемы 2. Остальные группы в зависимости от формата текущего оператора трактуются по разному. Для формата 1 группы с третьей по седьмую определяют содержимое лексемы 3. Для формата 2 третья группа определяет содержимое лексемы 3, четвертая группа - лексемы 4, паятая группа - лексемы 5, шестая группа - лексемы 6. Восьмая группа является вспомогательной.
Блок 7 работает следующим образом. Регистры 7.11-7. N (N = 49) являются позициями цепочки лексем. В них записываются коды текущих символов. Текущая позиция цепочки лексем определяется активным регистром (регистром, доступным на запись). Это определяется через память 7.5 в соответствии со значением счетчика 7.4. Память 7.5 обеспечивает преобразование десятичного кода, соответствующего адресу, в двоичный код, и, таким образом, реалиузется выбор соответствующего регистра (7.11-7. N(, т. е. текущей позции цепочки лексем.
После формирования цепочки лексем блок 9 выдает сигнал по выходу 24 запуска блока 14 анализа, двух преобразователей 12, 13 лексем и трех блоков 15, 16, 17 кодирования лексем. Работа каждого из этих блоков активизируется в соответствии с информационным выходом блока 10 (функция St), который подается на первые информационные входы (А) всех вышеуказанных блоков. Посредством этого входа происходит настройка блоков 12-17 на обработку соответствующего структурного модуля исходного текста (см. структуру программы и форматы операторов). Это связано с тем, что каждый из блоков 12-17 обрабатывает конкретную лексему: 12-лексему 3, 13-лексему 4, 14-лексему 1, 15-лексему 2, 16-лексему 5, 17-лексему 6. Таким образом, этап обработки цепочки лексем начинается настройкой операционного блока 11 по входу 32 и запуском конкретной совокупности блоков 12-17. Для обработки формата 1 запускаются блоки 12, 14, 15, а для обработки формата 2 - блоки 12, 13, 15, 16, 17.
Функция FL1 описывает работу блока 14, функции FL1p, FL1f и FL1c являются соответственно первой, второй и третьей группами информационного выхода 45 блока 14.
Функции FL2, FL5 и FL6 описывают работу соответственно первого 15, второго 16 и третьего 17 блоков кодирования лексем, фукнции FLp, FLf и FLc являютбся соответственно первой, второй и третьей группами информационного выхода 53 каждого блока кодирования лексем. Блоки 15 и 16 выхода FLp не имеют.
Функции FL3 и FL4 описывают работу первого 12 и второго 13 преобразователей лексем. При работе каждый преобразователь использует узел 55 формирования цепочки лексем, описываемый функцией Р и настроенный на использование в FL4 или FL3 посредством параметров. Функции FLp, FLf, FLc тождественны функциям Pf, Pz, Pd и являются тремя группами информационного выхода 137 узла 55. Функция Pf определяет значение второго информационного выхода элемента 106 данных. Функция Pd определяет выход триггера 116, а функция Pz - выход элемента ИЛИ 129.
В процессе работы всех функций типа FL используется узел поиска, описываемый функцией FND и настроенный через параметры функции FND, функции FNDf и FNDx описывают соответственно два выхода 83 и 84 узла поиска.
Работа блока 14 анализа лексем (фиг. 2) описывается функцией FL1 и осуществляет анализ и кодирование лексемы 1 (метка). Блок 14 имеет следующие входы: Y - активизирует работу анализатора, Х - обеспечивает дополнительную работу блока 14 по результатам работы операционного блока 11, которая заключается во включении лексемы 1 в таблицу мнемоник меток (Smm), А - определяет значние текущего состояния процесса трансляции (соответствует информационному выходу блока 10), В - определяет значение лексемы 1 и следующие выходы: 46 - признак завершения работы блока 14; 45 - ссылка на таблицу меток.
Блок анализа лексем содержит узел 38 настройки, узел 39 поиска и схему 40 сравнения. Узел 38 настройки настраивает узел 39 поиска на конкретные параметры и обеспечивает его запуск в зависимости от состояния процесса обработки текста (вход b). Узел 39 поиска осуществляет поиск или включение лексемы 1 в таблицу мнемоник меток (Smm). Схема 40 сравнения обеспечивает идентификацию отсутствия метки (пробелов). Информационный выход 45 состоит из трех частей, соответствующих функциям FL1p, FL1f, FL1c.
Работа первого 12 и второго 13 преобразователей лексем описывается соответственно функциями FL3, FL4 и заключается в анализ и кодировани лексем 3 и 4. Оба преобразователя лексем идентичны (фиг. 4) и имеют следующие входы: Y - обеспечивает активизацию работы преобразователя, Х - обеспечивает дополнительную работу преобразователя по результатам работы операционного блока 11, которая заключается во включении лексемы 3 или 4 в таблицу мнемоник меток (Smm), А - определяет текущее состояние процесса обработки текста (соответствует информационному выходу блока 10), В - определяет значение лексемы 3 или 4 для оператора формата ф1 или формата ф2, С - определяет значение лексемы 1 и следующие выходы: 64 - свидетельствует о завершении работы преобразователя, 63 - определяет сформированный код лексемы (если лексема задает адрес) или ссылку на таблицу мнемоник меток Smm (если лексема задает метку).
Каждый преобразователь лексем содержит узел 56 настройки, узел 57 поиска и узел 53 формирования цепочки лексем. Обрабатываемая лексема может задавать метку или адрес, идентификация которых осуществляется узлом 55. При задании адреса (первый символ не является нулем или единицей) узел 55 обеспечивает преобразование его из символьного представления в двоичный код. Если лексема задает метку, то обработка ее осуществляется блоком 57 поиска, который инициируется и настраивается через узел 56. Узел 57 обеспечивает поиск лексемы 3 или 4 в таблице мнемоник меток (Smm) и ее включение туда в случае отсутствия (это происходит при условии, что лексема задает метку). Узел 55 обеспечивает преобразование лексемы 3 или 4 в код (это происходит при условии что лексема задает адрес). Информационный выход преобразователя состоит из трех частей, соответствующих функциям Pf, Pz и Pd. Если лексема задавала метку, то эти функции соответствуют FL3/4p, FL3/4f, FL3/4c.
Работа первого 15, второго 16 и третьего 17 блоков кодирования лексем описывается соответственно функциями FL2, FL5 и FL6 и заключается в анализе и кодировании лексем 2, 5 и 6. Каждый блок кодирования лексем (фиг. 3) имеет следующие входы: Y - активизирует работу кодировщика; А - определяет текущее состояние процесса обработки текста, В - определяет значение лексемы 2, 5 или 6 и следующие выходы: 54 - свидетельствует о завершении работы кодировщика, 53 - определяет сформированный код лексемы. Каждый блок кодирования лексем содержит узел 47 настройки, узел 48 поиска и элемент 49 памяти. Узел настройки обеспечивает запуск узла 48 поиска и его настройку на работу с лексемой 2, 5 или 6. Узел поиска осуществляет просмотр таблицы поиска для нахождения строки, соответствующей искомому значению (значению лексемы с входа В). В результате поиска определен указатель, по которому из элемента 49 памяти извлекается соответствующий код. Содержимое элемента 49 памяти для блоков 15, 16, 17 разное и соответствует табл. 6, 8, 10. Первая группа выходов элемента памяти соответствует части таблицы клNn, вторая - клN.
Узел настройки выполняет следующие функции: инициализацию работы блока поиска и настройку работы блока поиска на текущее состояние обработки текста. Узел настройки (фиг. 6) имеет следующие входы: Y - активизирует работу узла настройки, А - определяет текущее состояние обработки исходного текста, N - настроечный, определяющий режим работы мультиплексора 90, R - установочный определяющий установку счетчика 88, входящего в состав узла настройки, в исходное состояние (единичное), Р - управляющий обеспечивающий инкремент счетчика 88, и следующие выходы: Y - сигнал запуска блока поиска, С - значение верхней границы поиска, D - значение нижней границы поиска.
Узел настройки работает следующим образом. Из элемента 86 памяти по адресу, соответствующему входу А, выделяется ячейка. Содержимое ячейки подразделяется на три группы: признак запуска процесса поиска, верхняя граница, нижняя граница. Единичное значение первой группы обеспечивает пропуск через элемент И 87 сигнала на выход Y, что обеспечивает запуск процесса поиска. Вторая группа обеспечивает на выходе С значение верхней границы процесса поиска. Третья группа подсоединена к входу N мультиплексора 90. К входу М этого мультиплексора подсоединен выход счетчика 88, соответствующий значению счетчика таблицы меток. Мультиплексор 90 обеспечивает пропуск на выход либо информации с выхода элемента 86 памяти (при С = 0), либо содержимого счетчика 88 (при С = 1). Для кодировщиков верхняя и нижняя границы поиска являются величинами постоянными. Для анализатора и преобразователей нижняя граница поиска величина динамическая, меняющаяся по мере изменения значения счетчика меток (счетчик 88). Для наращивания значения счетчика меток используется подача сигнала на счетный вход счетчика 88 (вход Р узла настройки).
Так как таблица меток является динамической, необходимо перед началом обработки исходного текста привести ее в начальное состояние путем установки счетчика 88 меток (вход R узла настройки) в единичное состояние.
Для каждого блока (12-17), в который входит узел настройки, содержимое элемента памяти имеет свое значение. Для блока 14 все ячейки памяти имеют нулевое значение, кроме ячейки с адресом 0, 1 и 2. Их содержимое 1 00000000 00000000. Для преобразователя 12 лексем все 1 аналогично блоку 14. Для преобразователя 13 лексем 2 ячейка с адресом 3 имеет значение 1 00000000 00000000, остальные ячейки имеют нулевое значение. Для блока 15 кодирования лексем 1 все ячейки нулевые, кроме следующих
Для блока 16 кодирования лексем 2 ячейка с адресом 3 имеет содержимое 1 00000000 00010000, остальные ячейки имеют нулевое значение. Для блока 17 кодирования лексем 3 ячейка с адресом 3 имеет содержимое 1 00000000 00100000, остальные ячейки имеют нулевое значение.
Узел поиска описывается функцией FND и осуществляет поиск информации в соответствии с заданными параметрами. Он (фиг. 5) имеет следующие входы: C и D - определяют верхнюю и нижнюю границы поиска, А - определяет значение данного, подлежащего включению в таблицу для поиска, Z - обеспечивает включение данного по входу А в таблице поиска по указателю, определяемому входом D, В - определяет искомую величину, Y - активизирует работу узла поиска и следующие выходы: 83 - определяет значение указателя, по которому в таблице поиска находится искомая величина или логический конец таблицы, 84 - указывает на завершение процесса поиска, 85 - указывает на то, что искомая величина найдена (= 0) и не найдена (= 1).
Узел поиска содержит элемент 67 памяти, который соответствует таблице поиска. Для каждого блока, в состав которого входит узел поиска, содержимое элемента памяти разное. Для блока 14 анализа лексем и преобразователей 12 и 13 оно соответствует таблицам мнемоник меток Smm. Для первого, второго и третьего блоков 15, 16 и 17 оно соответствует 5, 8 и 10. Узел поиска содержит счетчик 70, определяющий текущее значение указателя, по которому из таблицы поиска (элемент 67) производится выборка. Начальное состояние счетчика 70 определяется значением входа С при активизации узла поиска. Узел поиска включает схему 68 сравнения, на вход которой подаются информация, считываемая из таблицы поиска (элемент 67), и искомая величина (вход В). Результатом сравнения (выход схемы 68) будет признак найденности информации. Если искомая величина не соответствует значению, выбранному из таблицы поиска (элемент 67) в соответствии со значением указателя (счетчика 70), то осуществляется наращивание счетчика 70 и цикл поиска повторяется. Если искомая величина найдена, то поиск завершается и триггер 72 устанавливается в единицу (выход 84). Завершение поиска может наступить вследствие отсутствия в таблице поиска (элемент 67) искомой величины. Это определяется достижением указателем (счетчик 70) значения нижней границы. Для этого узел поиска содерит схему 71 сравнения, на вход которой поданы вход D узла поиска (нижняя граница поиска) и выхо счетчика 70. Выходом схемы сравнения является признак завершения поиска, по которому устанавливается в единичное состояние триггер 73.
Для организации циклической работы узла поиска используется тактирующий элемент 74 (фиг. 7). На вход Г тактирующего элемента подается сигнал с тактового генератора. Тактирующий сигнал пропускается (тактирующий элемент находится в активном состоянии) после установки (вход 101) триггера 99, входящего в состав тактирующего элемента, в нулевое состояние. При этом выход 104 имеет нулевое значение. Прекращение пропуска тактирующего сигнала (перевод элемента в пассивное состояние) происходит после установки триггера 99 в единицу (вход 103). При этом выход 104 имеет единичное значение.
Помимо поиска информации узел поиска выполняет функцию формирования таблицы поиска (элемент 67). Для этого предусмотрены вход Z, устанавливающий режим записи для элемента 67 памяти, вход данных, соответствующий входу А узла поиска, и вход адреса, соответствующий входу D узла поиска, который связан с адресным входом элемента 67 памяти через мультиплексор 65. Мультиплексор настраивается по входу С и пропускает либо значение счетчика 70, либо вход D. Для формирования таблицы меток используется вход Z. При подаче сигнала на этот вход данное с входа А записано в элемент 67 памяти по адресу, переданному через мультиплексор с входа D. В активном состоянии (процесс поиска) первый выход 104 тактирующего элемента имеет нулевое значение, мультиплексор 65 пропускает информацию с входа N. Когда производится запись в элемент 67 памяти, тактирующий элемент находится в пассивном состоянии и его первый выход имеет единичное значение. Мультиплексор 65 при этом пропускает информацию с входа М.
После того как все лексемы обработаны (т. е. все запущенные блоки выставляют сигнал готовности на управляющий вход блока 11, запускается операционный блок 11.
Работа операционного блока 11 описывается функциями Ssk, Sk, Ssd, Sd, Ssm, Smm, Sma, Sse, Se. Блок 11 формирует код обрабатываемой цепочки лексем. Этот код формируется по кодам лексем, получаемым с информационных выходов блоков 12-17. Операционный блок выполняет следующие функции: вырабатывает сигнал 33 завершения обработки текущего оператора, формирует для блока 10 координации лексем информацию (выход 34), от которой зависит смена состояния процесса обработки текста (выбор номера формата для следующего оператора), формирует код цепочки лексем (выход 21), формирует признак дополнительной работы (входы 35, 36, 37) блоков 12, 13, 14.
Необходимость доработки блоков 12, 13, 14 диктуется наличием в цепочке лексем лексемы 1. На эти же входы поступает и признак приведения таблиц мнемоник меток (Smm) в блоках 12-14 в исходное состояние (если блок 11 идентифицирует начало обработки текста).
Алгоритм работы операционного блока приведен на фиг. 14-16. На первый информационный вход 11.34 блока 11 подается значение состояния процесса обработки, настраивающее блок 11 на конкретный формат. Работа блока 11 организуется с помощью устройства управления, которое выполняет функцию дешифрирования логических условий и реализовано на двух элементах 11.21, 11.22 памяти. Структура второго информационного входа приведена в табл. 20. Логические условия представляют собой последовательность четырнадцати линий от второго информационного входа 1.36 операционного блока. Их смысловые значения приведены в табл. 16. В результате дешифрирования на выходе второго элемента 11.22 памяти появляется код, определяющий набор операций, выполнение которых необходимо при установленной информации на входе. Множество операций, которые соответствуют сигналам yi, приведены в табл. 17. В табл. 18 и 19 приведены соответственно прошивка первого элемента 11.21 памяти и части второго элемента 11.22, отражающей фрагменты алгоритма обработки команд, обработки ошибок и обработки псевдокоманды 'TIT' (для каждого фрагмента алгоритма, представленного на фиг. 14-16, выделены 64 ячейки 11.22 памяти). В табл. 20 приведена расшифровка кодов ошибок.
Блок 10, исходя из информации, полученной с выхода 34 (табл. 4), формирует новый код состояния обработки текста, передает его на вход 27 узла формирования цепочки лексем и выдает сигнал запуска нового цикла обработки исходного текста. Таким образом, повторяется процесс формирования и обработки следующего оператора. И так до тех пор, пока по признакам, приходящим с выхода 34, не будет ясно, что весь исходный текст обработан. Блок 10 выдает в этом случае сигнал 23 завершения обработки текста.
Рассмотрим пример обработки следующего исходного текста.
Запуск устройства осуществляется путем подачи импульса на вход 19. Исходный текст посимвольно поступает на информационный вход 20. Преобразование последовательности символов в операторы и далее в цепочку лексем осуществляет модуль IL. Ниже приведены результаты обработки операторов исходного текста.
П р и м е ч а н и я:
1. PR соответствует конкатенации признаков FL2p (1-4) из табл. Se и двоичного кода St и определяет адрес псс.
2. Пустые позиции лексемы соответствуют нулевому значению.
3. В колонке примечания всех таблиц указывается номер обрабатываемого оператора.
4. л1, л2. . . формируются посредством блока 9 из поданной на вход 20 устройства последовательности символов.
5. После выполнения каждого оператора формируется строка таблицы Se.
6. Обозначения: PR - рабочие признаки, St - состояние процесса обработки текста, Ssd - счетчик сегмента данных, Ssk - счетчик программного сегмента, Ssm - счетчик меток, Sse - счетчик таблицы признаков, Sd - таблица сегмента данных, Sk - таблица программного сегмента, Smm - таблица мнемоник меток, Sma - таблица адресов меток, Se - таблица признаков.
Исходное состояние:
PR = 000000, St = 0, Ssd = 0, Ssk = 0, Ssm = 1, Sse = 0, таблицы Sd, Sk, Smm, Sma, Se имеют произвольное значение (считают, что они обнулены).
1. Оператор 1 - TIT
Лексемы: л1 = 00h00h00h00h00h00h, л2 = 54h49h54h00h00h00h,
л3 = 00h00h00h00h00h00h00h00h00h00h00h00h00h00h
00h00h00h00h00h00h00h00h00h00h00h
Работают блоки 12, 14, 15.
Результат: FL1f = 00000000, FL2f = 000,
FL3f = 00000000000000000000000000,
PR = 100000, St = 0+1 = 1, Ssd = 0, Ssk = 0, Ssm = 1.
2. Оператор 2 - ORD 000001.
Лексемы: л1 = 00h00h00h00h00h00h, л2 = 4Fh52h44h00h00h00h,
л3 = 30h30h30h30h30h31h00h00h00h00h00h00h00h00h
00h00h00h00h00h00h00h00h00h00h00h
Работают блоки 12, 14, 15.
Результат:
FL1f = 00000000, FL2f = 000, FL3f = 0000010000000000000000000,
PR = 010001, St = 1+1 = 2, Ssd = 0+1 = 1, Ssk= 0, Ssm = 1,
3. Оператор 3 -- : K EQV 000000.
Лексемы: л1 = 4Bh00h00h00h00h00h, л2 = 45h51h56h00h00h00h,
л3 = 30h30h30h30h30h30h00h00h00h00h00h00h00h00h
00h00h00h00h00h00h00h00h00h00h00h.
Работают блоки 12, 14, 15.
Результат:
FL1f = 00000001, FL2f = 000,
FL3f = 0000000000000000000000000,
в таблицу меток по адресу Ssm = 1 записывается л1 в Smm и первые шесть бит FL3f в Sma,
PR = 000010, St = 2+0 = 2, Ssd = 1+0 = 1, Ssk = 0, Ssm = 1+1 = 2,
4. Оператор 4- : L EQV 000011, сегмент.
Лексемы: л1 = 4Ch00h00h00h00h00h, л2 = 45h51h56h00h00h00h,
л3 = 30h30h30h30h31h31h00h00h00h00h00h00h00h
00h00h00h00h00h00h00h00h00h00h00h.
Работают блоки 12, 14, 15.
Результат:
FL1f = 00000010, FL2f = 000.
FL3f = 0000110000000000000000000,
в таблицу меток по адресу Ssm = 2 записывается л1 в Smm и первые шесть бит FL3f в Sma,
PR = 000010, St = 2+0 = 2, Ssd = 1+0 = 1, Ssk = 0, Ssm = 2+1 = 3.
5. Оператор 5- DW 0
Лексемы: л1 = 00h00h00h00h00h00h, л2 = 44h57h00h00h00h00h,
л3 = 30h00h00h00h00h00h00h00h00h00h00h00h00h00h
00h00h00h00h00h00h00h00h00h00h00h,
Работаютб блоки 12, 14, 15.
Результат:
FL1f = 00000000, FL2f = 000,
FL3f = 0000000000000000000000000,
в таблицу кодов данных по адресу Ssd = 1 записывается FL3f, PR = 000010, St = 2+0 = 2, Ssd = 1+1 = 2, Ssk = 0, Ssm = 3.
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
6. Оператор 7- DS 000011.
Лексемы: л1 = 00h00h00h00h00h00h, л2 = 44h53h00h00h00h00h,
л3 = 30h30h30h30h31h31h00h00h00h00h00h00h00h00h,
00h00h00h00h00h00h00h00h00h00h00h.
Работают блоки 12, 14, 15.
Результат:
FL1f = 00000000, FL2f = 000, FL3f = 0000110000000000000000000,
PR = 000010, St = 2+0 = 2, Ssd = 2+3 = 5, Ssk = 0, Ssm = 4. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
7. Оператор 11- END
Лексемы: л1 = 00h00h00h00h00h00h, л2 = 45h4Eh44h00h00h00h, л3 = 00h00h00h00h00h00h00h00h00h00h00h00h00h00h
00h00h00h00h00h00h00h00h00h00h00h.
Работают блоки 12, 14, 15.
Результат:
FL1f = 00000000, FL2f = 000,
FL3f = 0000000000000000000000000, ,
PR = 000110, St = 2-1 = 1, Ssd = 10, Ssk = 0, Ssm = 6. .
8. Оператор 12- ORG 001100.
Лексемы: л1 = 00h00h00h00h00h00h, л2 = 4Fh52h46h00h00h00h,
л3 = 30h30h31h31h30h30h00h00h00h00h00h00h00h00h
00h00h00h00h00h00h00h00h00h00h00h,
Работают блоки 12, 14, 15.
Результат:
FL1f - 00000000, FL2f = 000,
FL3f = 0011000000000000000000000,
PR = 001001, St = 1+2 = 3, Ssd = 10, Ssk = 12, Ssm = 6.
9. Оператор 13- LDA 0, M ROO NOP, программный.
Лексемы л1 = 00h00h00h00h00h00h, л2 = 4Ch44h41h00h00h00h,
л3 = 30h00h00h00h00h00h, л4 = 4Dh00h00h00h00h00h,
л5 = 52h30h30h00h00h00h, л6 = 4Eh4Fh50h00h00h00h,
Работают блоки 12, 13, 15, 16, 17.
Результат:
FL2f = 111, FL3f = 000000, FL4f = 000011,
FL5f = 1111, FL6f = 10000,
PR = 000011, St = 3+0 = 3, Ssd = 10, Ssk = 12+1 = 13, Ssm = 6. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
10. Оператор 17- END.
Лексемы: л1 00h00h00h00h00h00h, л2 = 45h4Eh44h00h00h00h,
л3 = 00h00h00h00h00h00h, л4= 00h00h00h00h00h00h,
л5 = 00h00h00h00h00h00h, л6 = 00h00h00h00h00h00h,
Работают блоки 12, 13, 15, 16, 17.
Результат:
FL2f = 000, FL3f = 000000, FL4f = 000000,
FL5f = 0000, FL6f = 00000,
PR = 000111, St = 3-2 = 1, Ssd = 10, Ssk = 16, Ssm = 6.
11. Оператор 18- END.
Лексемы: л1 = 00h00h00h00h00h00h, л2 = 45h4Eh44h00h00h00h,
л3 = 00h00h00h00h00h00h00h00h00h00h00h00h00h00h
00h00h00h00h00h00h00h00h00h00h00h
Работают блоки 12, 14, 15.
Результат:
FL1f = 00000000, FL2f = 000,
FL3f = 0000000000000000000000000,
PR = 000101, St = 1-1 = 0, Ssd = 10, Ssk = 16, Ssm = 6.
Так как St приобрело нулевое значение, блок 10 формирует на выходе 23 сигнал завершения процесса трансляции.
В столбцах примечания находятся номера обрабатываемых операторов.
Рассмотрим более подробно процесс обработки оператора 4, имеющего следующий вид: : L EQV 000011 сегмент.
Перед началом обработки устройство находится в следующем состоянии:
St = 2, Ssd = 1, Ssk = 0, Ssm = 2, Sse = 4,
Sd, Sk, Se, Smm, Sma соответствуют частям таблиц, содержащих строки, в столбцах примечаний которых содержатся следующие номера операторов: 1, 2, 3 (остальные строки следует считать нулевыми).
Обработка оператора начинается по сигналу, появляющемуся на выходе 22 блока 10 координаций лексем, который устанавливает все регистры блока 7 в нулевое состояние и через элемент ИЛИ 18 обеспечивает ввод первого символа оператора ': ' в регистр 1 и активиризует блок 9 (подачей сигнала на вход 30). В результате блок 8 памяти на выходе имеет значение 00001, разряды которого распределяются следующим образом. Первый и второй поступают на первый и второй входы триггера 2, третий разряд поступает на вход элемента И 3, четвертый - на первый вход триггера 4, а пятый - на первый 31 информационный вход блока 9. Так как пятый разряд выхода блока 8 памяти равен единице, то на первый информационный вход блока 9 подано единичное значение. На втором и третьем информационных входах блока 9 нулевые значения. Таким образом, на входе блока 9 будет следующая совокупность признаков: 100, что свидетельствует о наличии в операторе лексемы 1 (метки). На выходе триггера 9.3 (табл. 12) в соответствии с текущим состоянием процесса обработки (St) устанавливается значение, соответствующее количеству лексем в текущем операторе. В данном случае оператор содержит три лексемы (в табл. 12 по адресу 2 находится значение, равное трем). Таким образом, после формирования трех лексем на выходе 9.42 блока 9 появляется сигнал, свидетельствующий о завершении формирования текущего оператора и инициирующий его дальнейшую обработку.
Информация на первых трех информационных входах блока 9 свидетельствует о наличии в операторе лексемы 1. Следовательно, значение счетчика 9.13 не инкриментировано и адрес, по которому из памяти 9.14 (табл. 13) выбирается размер лексемы (максимальное количество содержащихся в ней символов), будет следующим: 00100000, где первые четыре бита представляют собой двоичный код St, а последние четыре бита соответствуют значению счетчика 9.13. В данном случае размер соответствует шести и, следовательно лексема может содержать до шести символов (после обработки шестого символа формирование лексемы считается законченным).
По сформированной на входе (первые три информационных входа) совокупности признаков (100) блок 9 выполняет следующие действия: игнорирует текущий символ (не фиксирует его в блоке 7), выдает сигнал на выход 9.39 для инициации ввода следующего символа.
Следующий символ 'L' соответствует информационному и на выходе блока 8 памяти будет следующее значение 00100 (единица идет на вход элемента И 3). Так как триггер 2 находится в единичном состоянии (в нулевое состояние триггер переходит при появлении признака начала комментария, признак конца комментария возвращает триггер в единичное состояние), единица с выхода блока 8 памяти проходит через элемент И 3 и поступает на третий информационный вход блока 9, первый и второй информационные входы которого нулевые. По совокупности признаков (001) блок 9 выполняет следующие действия: фиксирует в текущей позиции блока 7 символ 'L' посредством сигнала на выходе 9.40, анализирует не достигло ли число символов (счетчик 9.13) в лексеме максимального количества (не исчерпан ли размер лексемы), переводит блок 7 к следующей позиции посредством выдачи сигнала на выход 9.41, увеличивает на единицу номер символа в лексеме (счетчик 9.13), инициирует ввод следующего символа посредством выдачи сигнала на выход 9.39.
Следующий символ '' соответствует управляющему и на выходе блока 8 памяти будет значение 00010. Единица идет на первый вход триггера 4 и на втором информационном входе блока 9 устанавливается единичное значение. На первом и третьем информационных входах блока 9 идентификации лексем нулевые значения. По совокупности признаков на входе (010) блок 9 фиксирует логический конец лексемы. Для полного формирования лексемы в блоке 7 необходимо пропустить еще пять позиций, что и будет организовано блоком 9 посредством пятиразовой выдачи сигнала на выход 9.41. Все остальные позиции блока 7 имеют нулевое значение.
Таким образом, значение счетчика 9.22 лексем инкриментировано и блок 9 переходит к обработке следующей лексемы. Размер ее соответствует знаению шесть, выбранному из памяти 9.14 (табл. 13) по адресу 00100001 (St = 2, счетчик 9.22= 1). Обработка следующей лексемы начинается с формирования сигнала на выходе 9.39 для ввода следующего символа.
Следующий символ '' соответствует управляющему и на выходе блока 8 памяти будет значение 00010. Но единица с выхода блока 8 памяти не проходит на вход блока 9 так как предыдущий управляющий символ сбросил триггер 5 в нулевое состояние. Таким образом, на первых трех информационных входах блока 9 нулевые значения. По совокупности признаков на входе (000) блок 9 идентификации лексем формирует признак на выходе 9.39 для ввода следующего символа. Описанная процедура повторяется до тех пор, пока на вход 20 устройства не поступит информационный символ. При появлении на входе 20 устройства информационного символа 'E' на выходе блока 8 памяти будет значение 001000. Единица с выхода блока памяти подается на третий информационный вход блока 9, а также устанавливает триггер 5 в единичное состояние, что разблокирует передачу признака управляющего символа на вход блока 9. Следующая лексема сформирована и значение счетчика 9.22 становится равным двум.
Обработка следующей лексемы начинается с появления на входе 20 устройства информационного символа 'O'. Размер ее соответствует 25-ти символам (табл. 13, адрес 00100010 (St= 2, счетчик 9.22= 2)). Формирование лексемы завершается после обработки шестого символа (так как достигнут логический конец лексемы).
Значение счетчика 9.22 теперь становится равным трем и блок 9 идентификации лексем фиксирует завершение формирования цепочки лекслем. В результате на выходе 9.42 блока 9 появляется единичный сигнал, что инициирует дальнейшую обработку оператора, сформированного на выходе блока 7 и разделенного на восемь групп.
Цепочка лексем при этом имеет следующее значение: L EKV 000011 --------------------------------------------------------------- 1 1 1 1 1 1 1 11
2 2 3 4 5 6 7 8
номер группы
В коде ASCII она имеет следующий вид:
4Ch00h00h00h00h00h45h4Bh56h00h00h00h30h30h30h30h31h31h
1 1 1 2 1 3 N группы.
00h00h00h00h00h00h00h00h00h00h00h00h00h00h00h00h00h00h
1 4 1 5 1 6
00h00h00h00h00h00h
17 1 8
Каждый символ представляет собой шестнадцатиричный код iih.
Напомним соответствие между лексемами и группами:
лексема1 - группа1, лексема2 - група 2, лексема3 - группы3, 4, 5, 6, 7 (для формата1), группа3 (для формата2), лексема4 - группа4, лексема5 - группа5, лексема6 - группа6.
Сигнал с выхода 9.42 блока 9 поступает на входы Y блока анализа лексем преобразователя лексем и блоков кодирования лексем. Распределение групп выхода блока 7 между этими блоками следующее: FP1 (12) вход В - группы 3, 4, 5, 6, 7, вход С - группа 1, FP2 (13) вход В - группы 4, 5, 6, 7, 8, вход С - группа 1, FA (14) вход В - группа 1, FK1 (15) вход В - группа 2, FK2 (16) вход В - группа 5, FK3 (17) вход В - группа 6. При этом конкретный блок работает только в том случае, если встроенный в него узел настройки в соответствии со значением состояния процесса обработки (вход А) прропускает сигнал Y на свой выход. В противном случе работа блока заблокирована. В конкретном случае работающими блоками будут блок 14 анализа лексем, преобразователь 13, первый блок 15 кодирования лексем.
Рассмотрим работу блока анализа лексем. Он имеет два управляющих (X, Y) и два информационных (А, В) входа. На вход Y поступает единичный импульс с выхода 9.42 блока 9. На вход Х сигнал не поступает. На входе А - значение, соответствующее St-00000010. На входе В - группа1.
Рассмотрим работу узла 48 настройки, входящего в блок анализа лексем. Из памяти 88 узла настройки по адресу, равному значению входа А (= 2), извлеена следующая информация: 1 00000000 00000000. Единица в первом разряде свидетельствует о том, что блок не заблокирован и на выходе Y узла настройки блока 14 появляется единичный импульс, инициирующий дальнейшую работу. Следующие восемь разрядов определяют верхнюю границу поиска, который реализован преобразователем лексем. Нижняя граница поиска задается значением счетчика 88 меток, так как на вход N узла настройки подан единичный сигнал, устанавливающий соответствующий режим работы мультиплексора 90. Счетчик 88 (соответствует Smm) в данный момент имеет значение, равное двум. Таким образом, на выходах блока 14 появляется следующая информация: Y-1, C-0, D-2, и далее посредством сигнала с выхода Y узла настройки запускается узел 39 поиска.
Узел поиска, входящий в блок 14 анализа лексем, реализует просмотр содержащейся в узле поиска таблицы мнемоник меток (Smm элемент 67) в пределах от верхней до нижней границы поиска (в данном случае 0-2) с целью нахождения в ней строки, соответствующей лексеме1 (L). Отметим, что таблица Smm на данный момент имеет только две заполненные строки. Остальные строки являются нулевыми. На входах узла поиска находится следующая информация: Y-1, C-0, D-2, A-0, Z-0, B-010001010000000000000000000000000000000000000000, что соответствует шестнадцатиричному коду 45h00h00h00h00h00h или символьному представлению L. Процесс поиска реализуется следующим образом. По сигналу запуска Y счетчик 70 устанавливается в значение верхней границы поиска (вход С= 0). Далее из элемента 67 памяти выбрано значение по адресу 0. Схема 68 сравнения реализует сравнение выбранного из памяти значения и значения на входе в узел поиска. В данном случае вход B(L) не равен выбранному из памяти значению, что влечет за собой инкриментирование счетчика 70 (теперь его значение равно единице) и цикл поиска повторяется. При этом из элемента 67 памяти выбрано значение по адресу 1 (k). Оно также не равно значению на входе В, поэтому счетчик 70 еще раз инкриментирован и его значение становится равным двум. При этом схема 71 сравнения фиксирует равенство значений счетчика 70 и вхоа D, что соответствует достижению процессом поиска нижней границы. Триггер 73 устанавливается в единичное состояние и процедура поиска завершается. При этом узел поиска на выходах имеет следующую информацию: 84-1, 85-2, что свидетельствует об отсутствии в Smm строки, соответствующей значению лексемы1. В результате работа блока 14 анализа лексем завершена и на его информационном выходе устанавливается следующая информация: FLp= 0, FLf= 00000010, FLc= 0. О завершении работы блока 14 свидетельствует единичный импульс на управляющем выходе 46 блока 14. Одновременно с блоком 14 аналогично запускаются первый блок 15 кодирования лексем и первый преобразователь 12.
Рассмотрим работу блока кодирования лексем. Он имеет один управляющий (Y) и два информационных (А, В) входа. На вход Y поступает единичный импульс с выхода 9.42 блока 9. На входе А - значение, соответствующее St= 00000010. На входе В - группа 2 выхода блока 7. После отработки встроенного в блок кодирования лексем узла настройки на выходах узла настройки следующая информация: Y-1, C-00000110, D-00001011 (на настроечный вход узла настройки подан нулевой сигнал, поэтому нижняя граница поиска определяется третьей группой выхода элемента 86 памяти). Таким образом, встроенный в блок кодирования лексем узел поиска реализует просмотр табл. 5 с целью нахождения в ней строки, соответствующей лексеме 2 в пределах адресов 6-11. Процесс поиска реализуется аналогичным (как в блоке 14) способом. Разница только в том, что когда счетчик 70 достигает значения 9, схема 68 сравнения фиксирует равенство значений строки табл. 5 по адресу 9 и лексемы2. Триггер 72 при этом устанавливается в единицу и поиск считается завершенным. На выходе узла поиска следующая информация: 84-1; 85-0.
Рассмотрим работу преобразователя лексем. Он имеет два упргавляющих (Y, X) и три инфомрационных (А, В, С) входа. На вход Y поступает единичный импульс с выхода 9.42 блока 9. На вход Х сигнал не поступает. На входе А - значение, соответствующее St= 00000010. На входе В - информация, значение которой соответствует совокупности групп 3, 4, 5, 6, 7. Преобразователь начинает свою работу с работы узла 55 формирования цепочки лексем, который посредством информации на входе С настраивается на текущий формат оператора. Если первый символ с входа В не соответствует коду нуля, единицы или коду пробела, то на выходе Y узла 55 появляется сигнал, запускающий узел 57 поиска. Сравнение обеспечивается схемами 114, 120, 122 и элементами 115, 120, 121. В противном случае узел 55 приступает к преобразованию информации с входа А (131) из символьного представления в двоичное. Преобразование реализуется с использованием элемента 106 памяти и в результате на его выходе S сформирован код лексемы3, поданной на вход С (60) преобразователя. Обрабатываемая в рассматриваемом примере лексема3 представляет собой последовательность нулей и единиц и на выходе S элемента памяти сформирован следующий код: 0000110000000000000000000, который в свою очередь является второй частью выхода А узла 55. Первой частью выхода А узла 55 является выход триггера 116, имеющий в данный момент нулевое значение, так как лексема3 не является меткой (о чем свидетельствует отсутствие единичного импульса на входе Y узла 55, указывающего на то, что работал узел поиска, запуск которого возможен только при условии, что лексема3 соответствует метке). Третьей частью выхода а (137) узла 55 является выход элемента ИЛИ 129. В рассматриваемом примере на указанном выходе, нулевое значение, так как лексема3 задана корректно. Единичное значение на этом выходе может появиться только в двух случаях, что обеспечивается элементом ИЛИ 129: когда лексема3 содержит внутри себя недопустимые символы (т. е. символы, не соответствующие коду нуля или коду единицы), что отслеживается схемами 124, 127 сравнения и элементом И 125, когда лексема3 задана меткой, которая не зафиксирована в таблице меток, на что указывает выход триггера 108. После того, как лексема 3 обработана, на выходе Х 139 узла 55 устанавливается единичное значение. Обработка лексемы3 может завершиться одной из четырех ситуаций, что обеспечивается элементом ИЛИ 126. Первый случай определяется достижением конца лексемы (размер лексемы определяется с использованием памяти 113, прошивка которой дана в таблице поп и отслеживается с использованием счетчика 111, подсчитывающего количество обрабатываемых символов, и схемы 117 сравнения. Второй случай определяется представлением лексемы как метки, поиск которой в таблице меток завершился успешно (о чем свидетельствует единичное значение на выходе триггера 107, установка которого реализуется подачей на его вход сигнала с выхода RA1 узла поиска). Третий и четвертый случаи свидетельствуют о некорректности лексемы3 и определяются выходами схемы И 125 или триггера 108. Выходы Х и А формирователя соответствуют выходам 64 и 63 преобразователя.
Блоки 13, 16 и 17 не работают, так как в памяти 86 их узлов настройки в ячейках с адресом St= 2 находится нулевая информация.
После того как блоки 12, 14, 15 на свои управляющие выходы выставят сигнал готовности, начинает работать операционный блок 11, настроенный на текущий формат посредством входа 32. На втором информационном входе блока 11 будет следующая информация: с выхода блока 12 (линии 1, 2, 3-27)- 0, 0, 0000110000000000000000000; с выхода блока 14 (линии 55, 56, 57-64) - 1,1,00000010; с выхода блока 15 (линии 65-72, 73-75) - 00000010,000. При этом входные признаки для устройства управления блока 11 имеют следующие значения: Х1= 0, Х2= 0, Х3= 1, Х4= 0, Х5= 0, Х6= 0, Х7= 0, Х8= 0, Х9= 0, Х10= 0, Х11= 0, Х12= 0, Х13= 0, Х14= 1. В соответствии со значениями Х8-Х14, Х7 из памяти 11.21 (табл. 17) по адресу 00000010 извлечено значение 00101. Самый крайний бит справа обеспечивает выборку следующей памяти 11.22. Остальные биты являются старшими четырьмя битами адреса, младшими битами которого являются признаки Х1, Х6, Х3, Х2, Х5, Х4. В результате из памяти 11.22 (табл. 18) по адресу 0010001000= 136 выбирается значение 100000000000000000010, которое соответствует Y0 и Y19. В результате выполнены следующие действия. В таблице адресов меток (элементы 11.26, 11.27 памяти) по адресу 00000010 (линии 57-64) зафиксировано значение лексемы3 (на настроечном входе С мультиплексора до узла настройки единичный сигнал и, следовательно, на выход пропущен вход М, соответствующий линиям 3-8 второго информационного входа блока 11 и, соответствует значению 000011). Дополнительно операционный блок выдает сигнал на доработку блоков 12, 13, 14, что связано с необходимостью зафиксировать текущую метку (лексема1) во всех таблицах мнемоник меток (на первую линию выхода 11.40 блока 11 выдан нулевой сигнал, так как он соответствует Х8, имеющему нулевое значение, а на вторую линию этого выхода выдан единичный сигнал с выхода элемента ИЛИ (11.24), так как на его входе появляется единичный Y19).
Таким образом, доработка блоков реализована посредством подачи на входы 35, 36, 37 значения 01, что обеспечивает появление на входах Z узлов поиска, входящих в блоки 12, 13, 14, единичного значения и, следовательно, запись в элемент 67 узла поиска информации с его входа А. Информация, поступающая на вход А узлов поиска, соответствует значению входа В блоков 12, 13, 14.
Параллельно с доработкой блоков инициируется работа блока координации лексем, что ведет к запуску следующего цикла функционирования устройства обработки символьной информации.
Следующий цикл начинается с обработки комментария от предыдущего оператора, так как последним символом, поданным на вход 20 устройства, был символ пробела, следующий за последней лексемой предыдущего оператора (см. исходный текст). Все дальнейшие символы пробела будут игнорированы, так как они являются управляющими символами и следуют друг за другом. Символ '; ' соответствует началу комментария, и на выходе блока 8 памяти будет следующее значение: 10000. Единица сбрасывает триггер 2 в нулевое состояние, в результате чего блокируется проход признака информационного символа через элемент И 3 до появления признака конца комментария. Таким образом, после подачи на вход 20 очередного символа на первых трех информационных входах блока 9 идентификации лексем нулевые знаения, что ведет к игнорированию текущего символа и выдаче от блока 9 запроса на ввод следующего символа. Эта процедура повторяется до тех пор, пока не появится признак конца комментария ' . ' , при котором выход блока 8 памяти имеет значение 01000. Единица с выхода блока 8 памяти идет на установочный вход триггера 2 и разблокирует передачу информационного символа. С появлением первого информационного символа или символа наличия метки начинается процесс формирования следующего оператора. (56) Авторское свидетельство СССР N 1182537, кл. G 06 F 15/04, 9/44, 1985.
Авторское свидетельство СССР N 1034043, кл. G 06 F 15/04, 9/44, 1983.
| название | год | авторы | номер документа |
|---|---|---|---|
| УСТРОЙСТВО ДЛЯ СИТУАЦИОННОГО КОНТРОЛЯ И УПРАВЛЕНИЯ | 1992 |
|
RU2041494C1 |
| УСТРОЙСТВО ДЛЯ КОНТРОЛЯ | 1991 |
|
RU2029986C1 |
| УСТРОЙСТВО ДЛЯ КОНТРОЛЯ ЦИФРОВЫХ БЛОКОВ | 1991 |
|
RU2065202C1 |
| ЦИФРОВОЙ ТЕРМОМЕТР | 1992 |
|
RU2039953C1 |
| УСТРОЙСТВО ДЛЯ АППРОКСИМАЦИИ ФУНКЦИЙ | 1992 |
|
RU2010324C1 |
| ЦИФРОВОЙ РЕГУЛЯТОР | 1992 |
|
RU2036502C1 |
| УСТРОЙСТВО ДЛЯ ФУНКЦИОНАЛЬНОГО ПРЕОБРАЗОВАНИЯ ШИРОТНО-ИМПУЛЬСНЫХ СИГНАЛОВ | 1991 |
|
RU2006935C1 |
| ЦИФРОВОЙ ИЗМЕРИТЕЛЬ АКТИВНОЙ МОЩНОСТИ | 1993 |
|
RU2074397C1 |
| СПОСОБ ЦВЕТОКОРРЕКЦИИ СИГНАЛА ИЗОБРАЖЕНИЯ | 1990 |
|
RU2024214C1 |
| УСТРОЙСТВО ДЛЯ ВЫЧИСЛЕНИЯ ЛОГАРИФМА | 1991 |
|
RU2006916C1 |

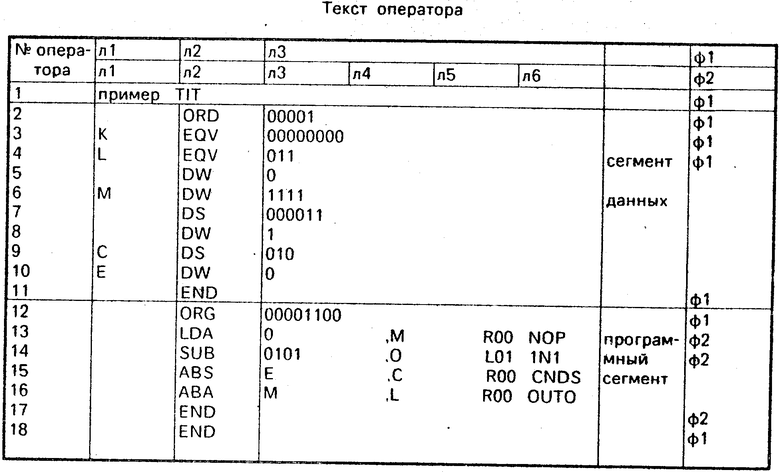
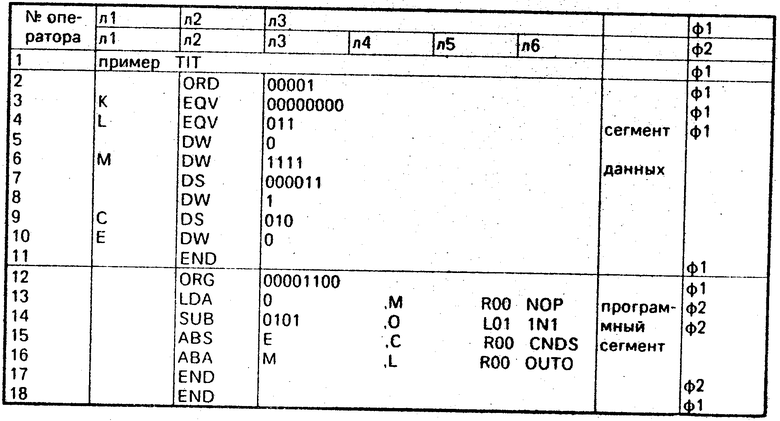
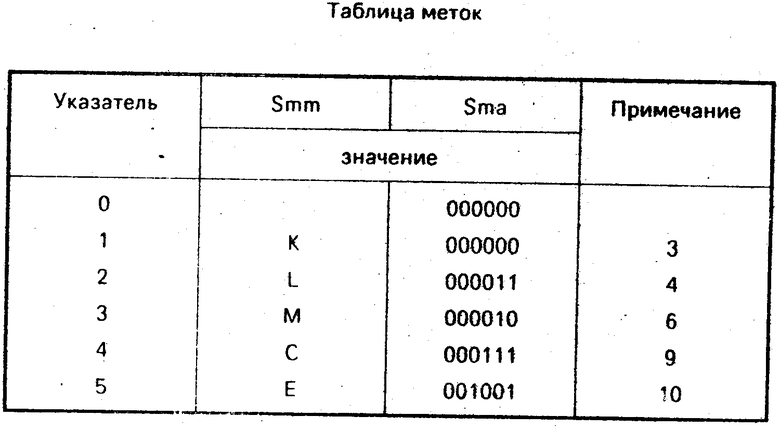
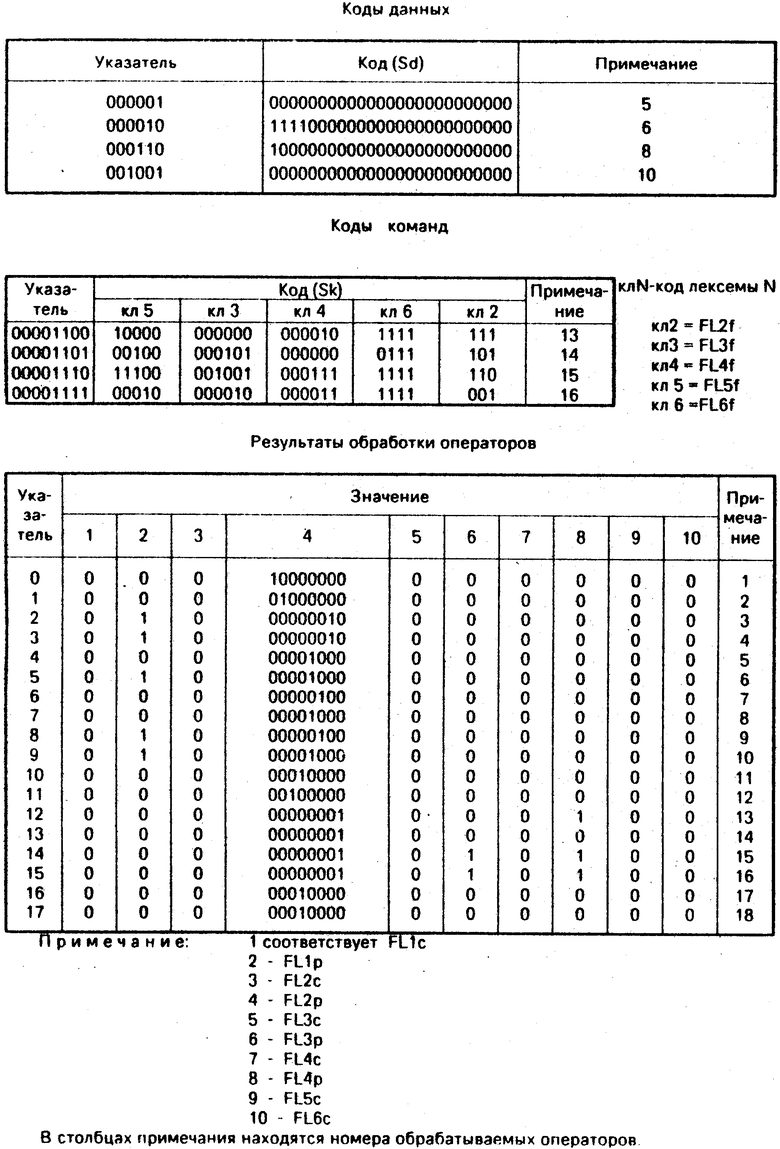



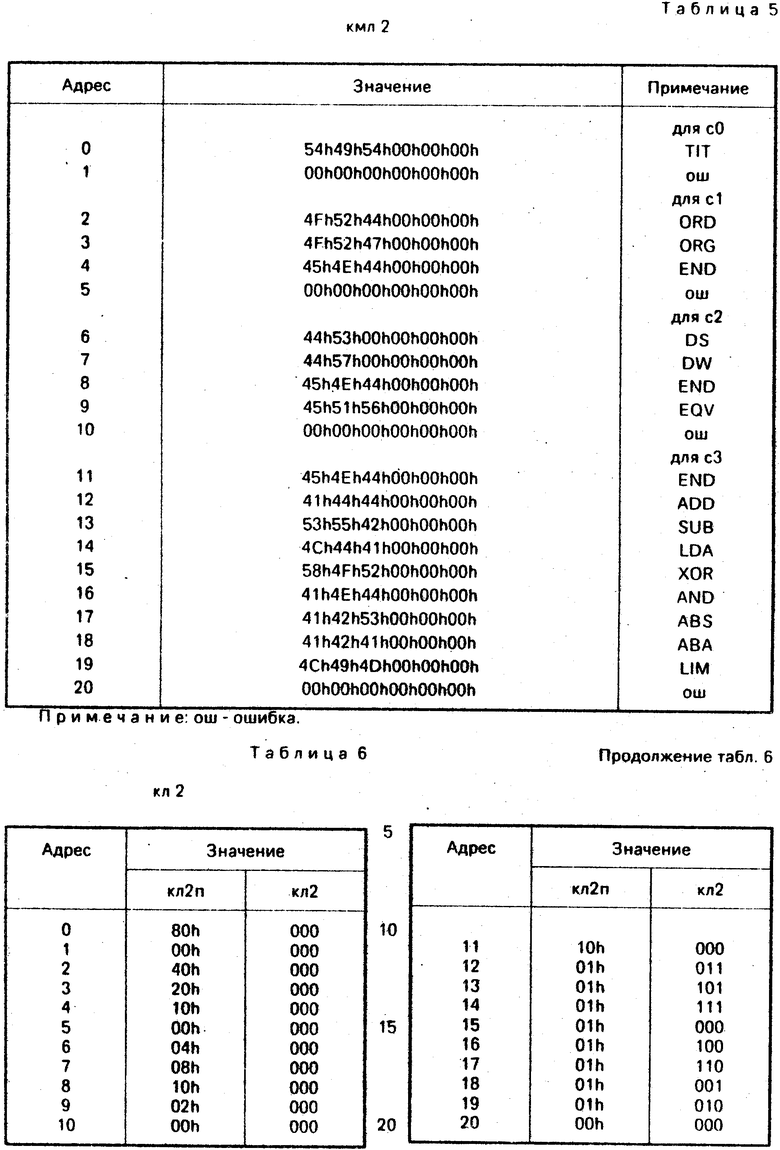
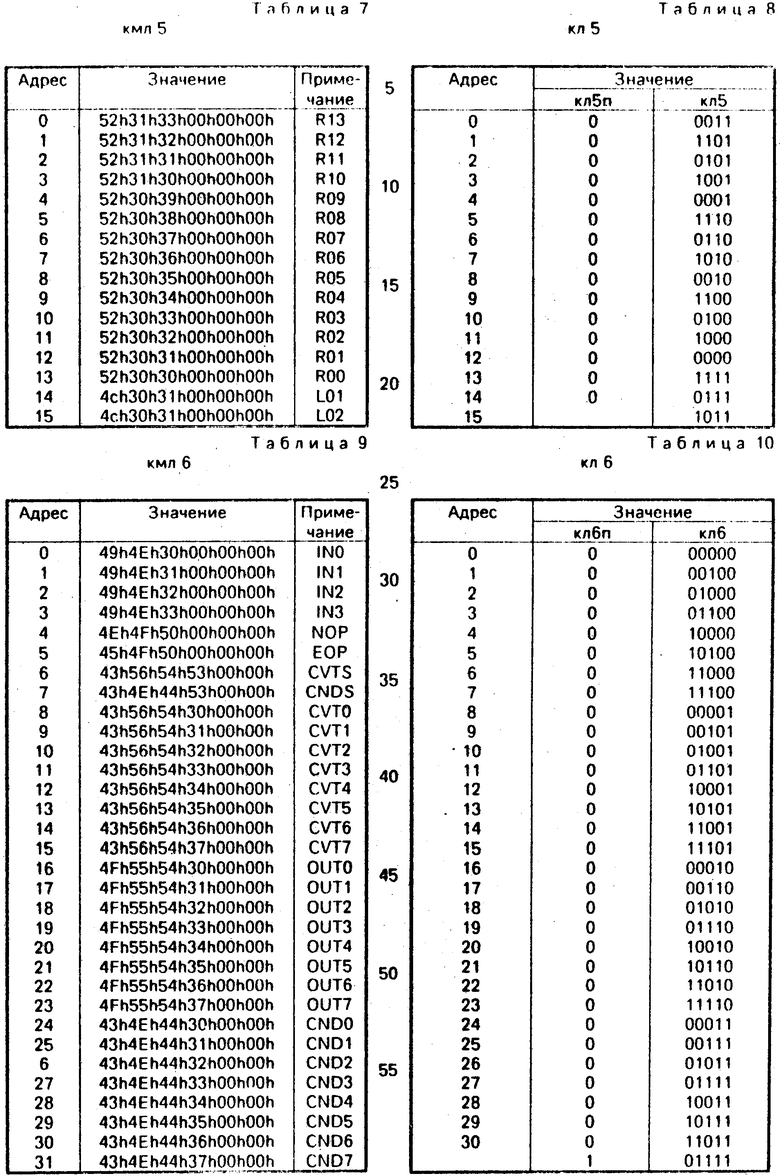
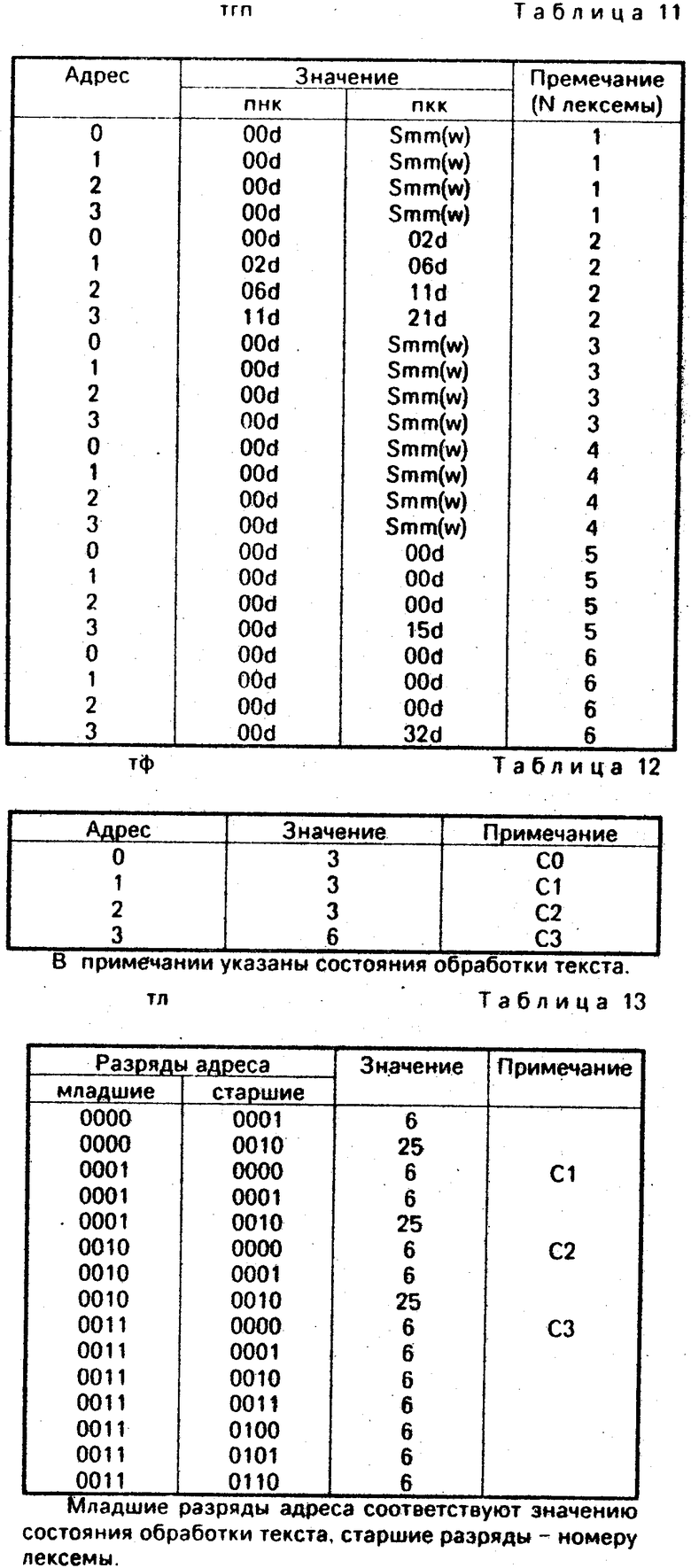

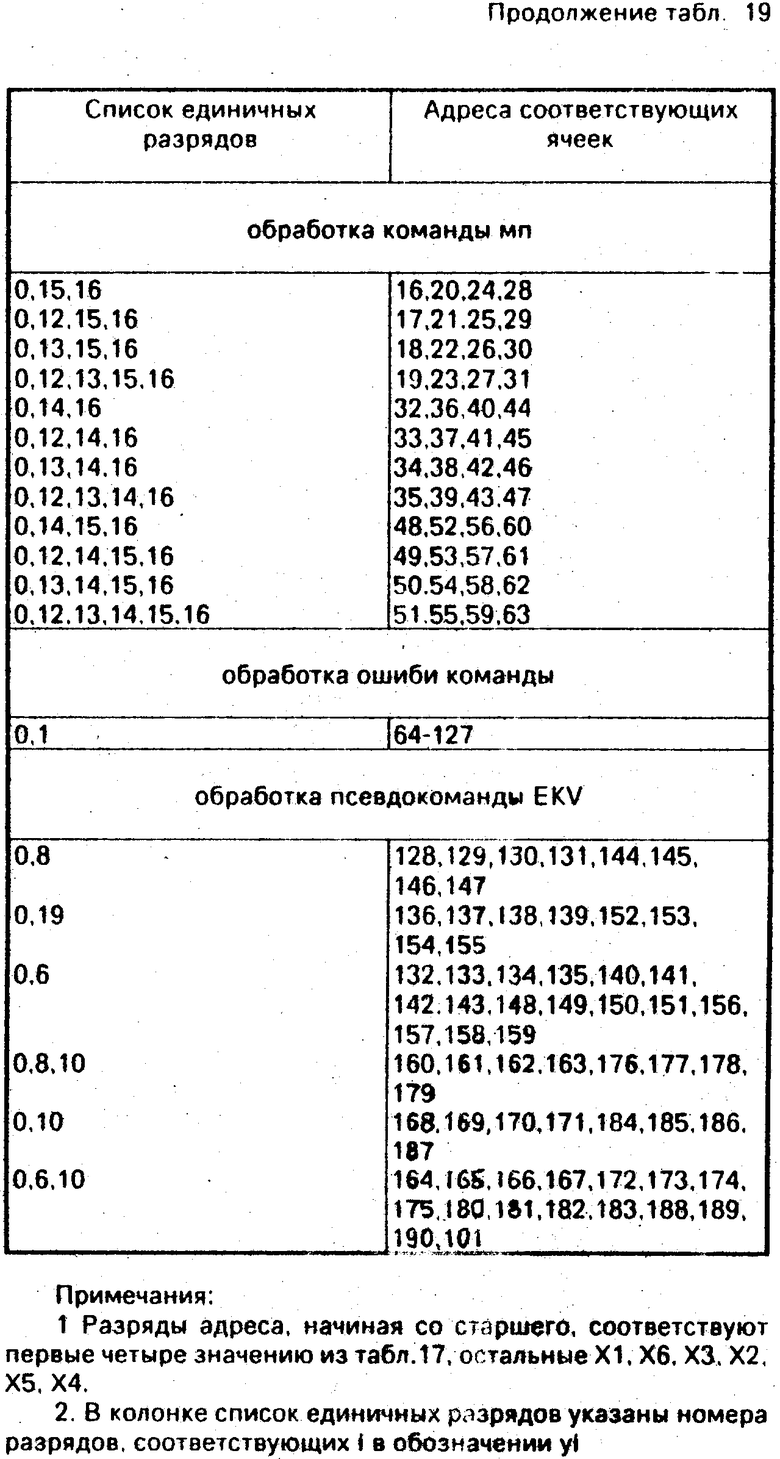
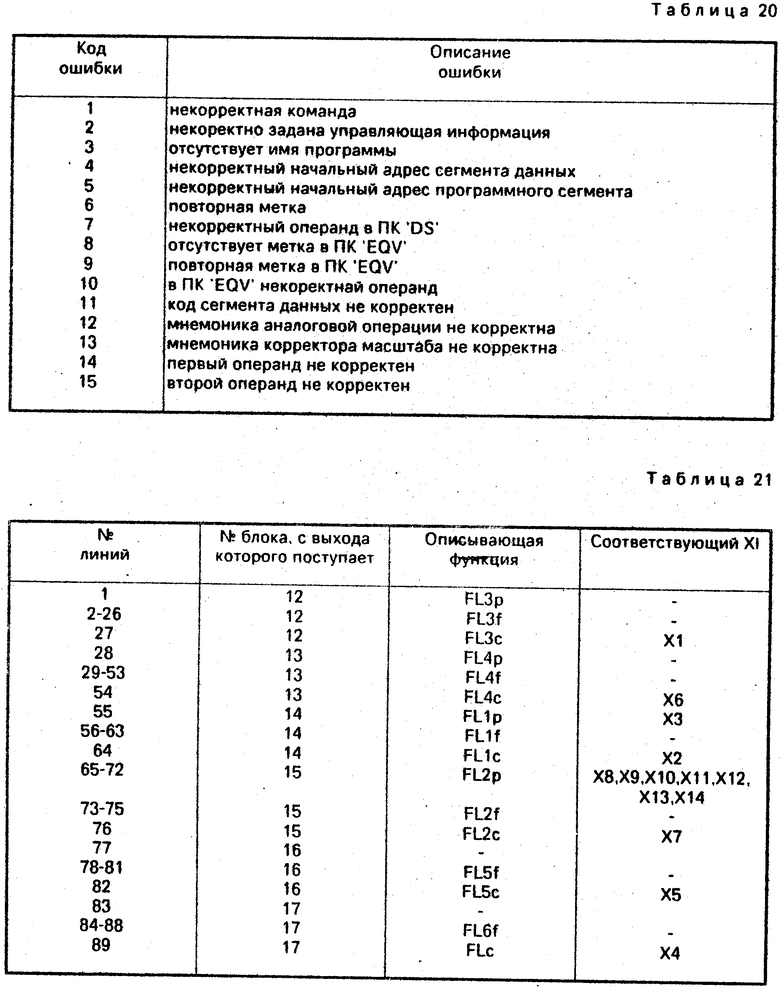
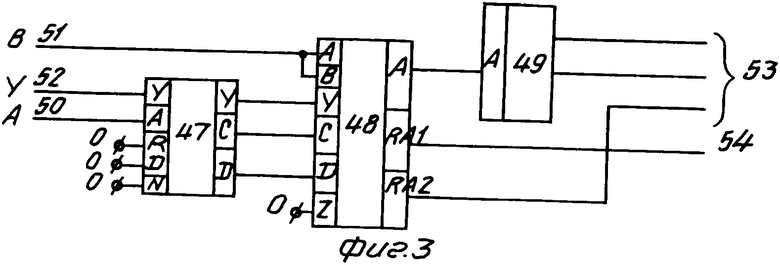
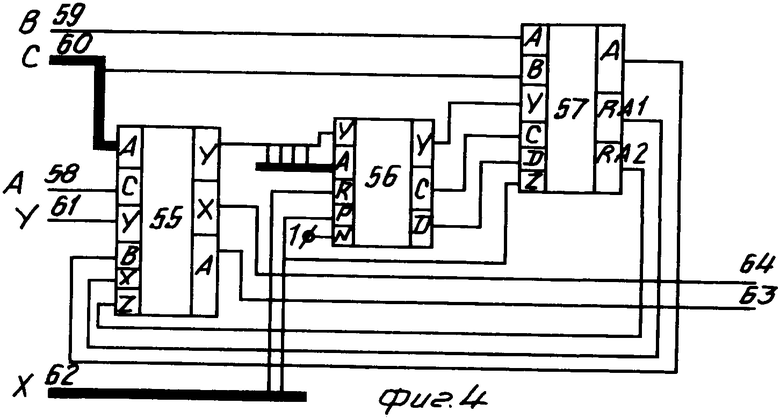
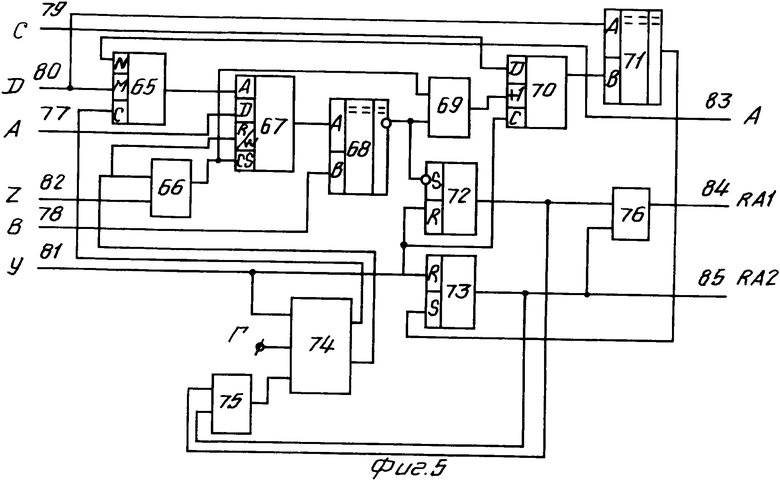
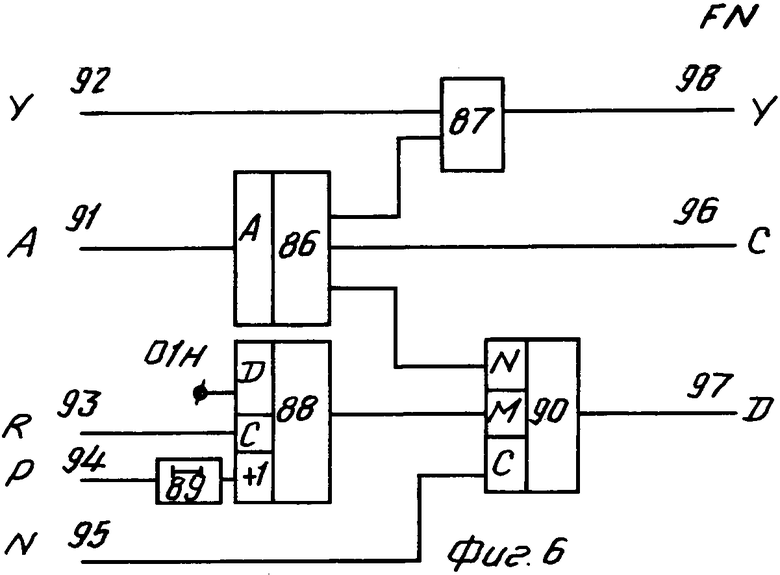
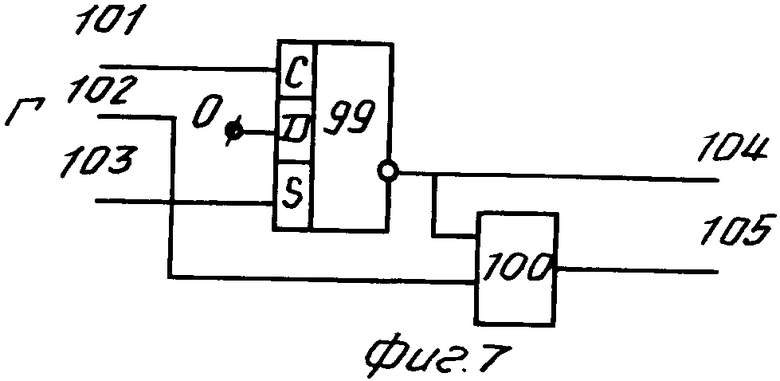
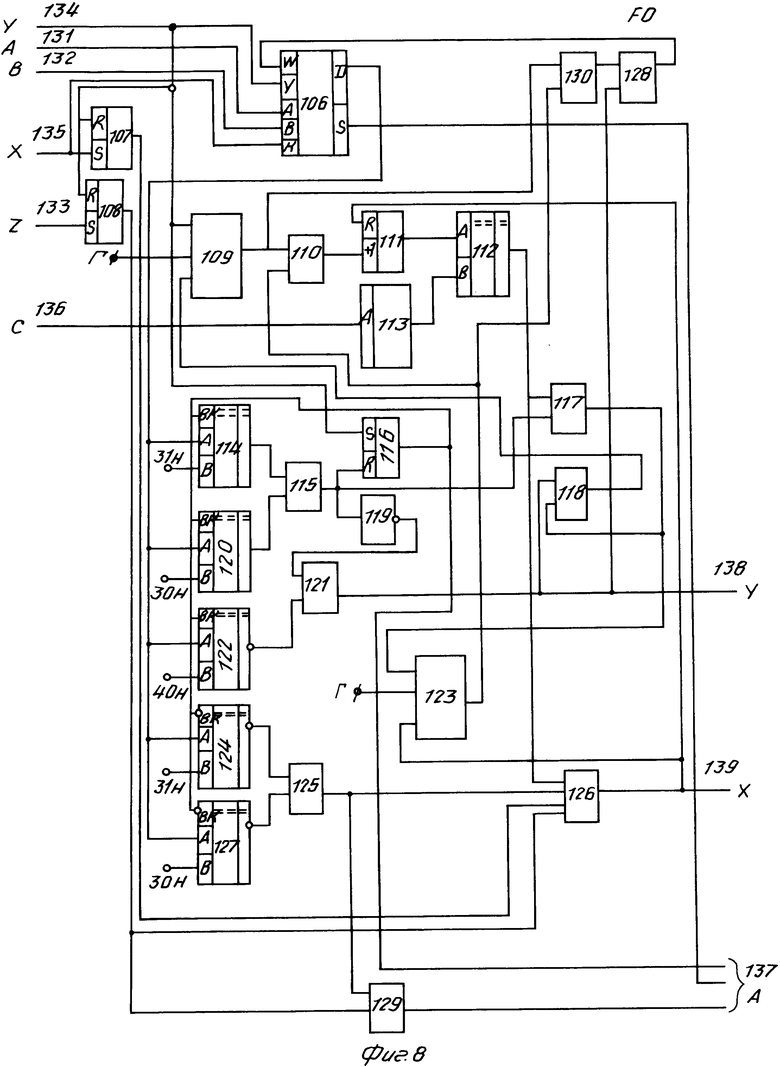
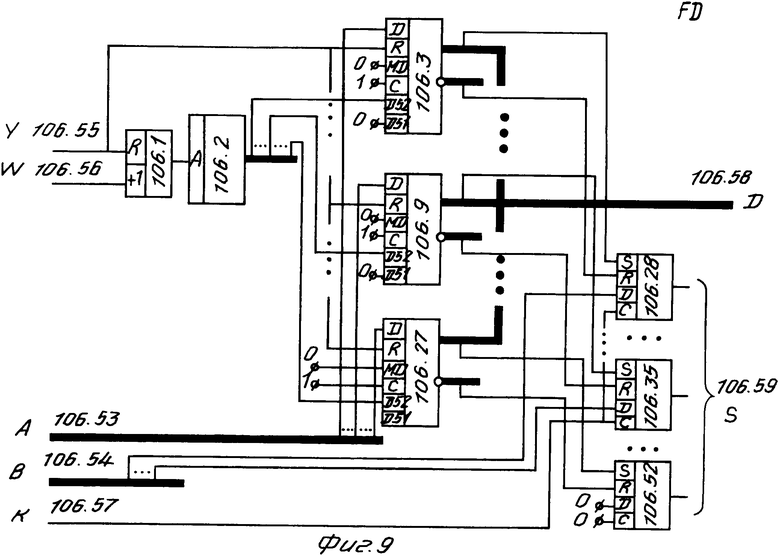
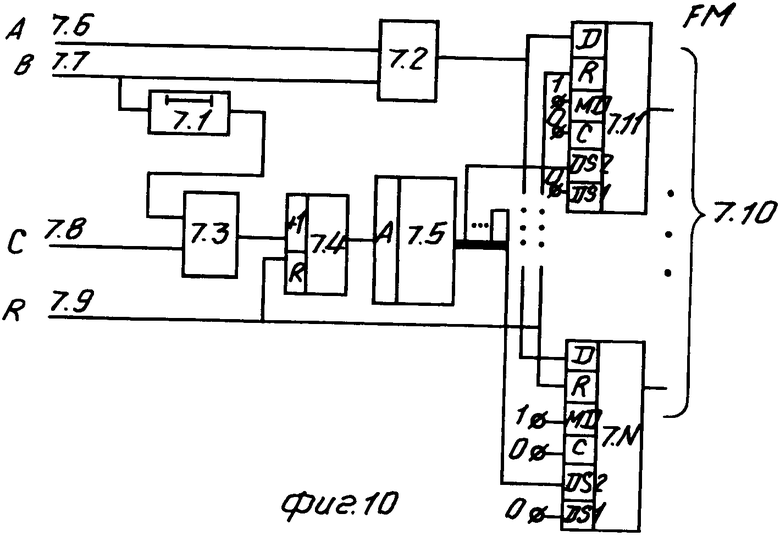
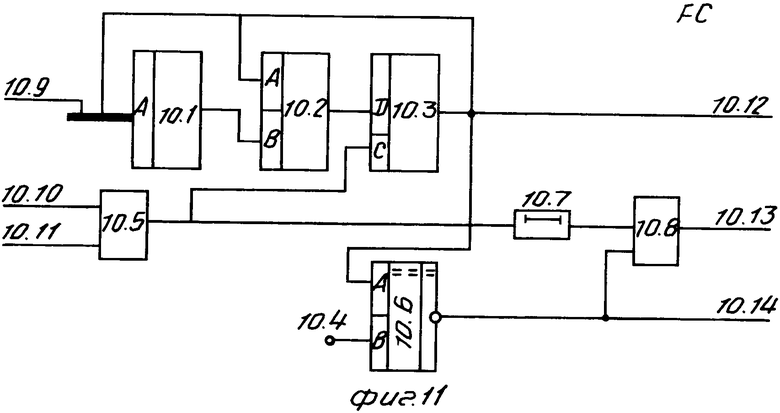
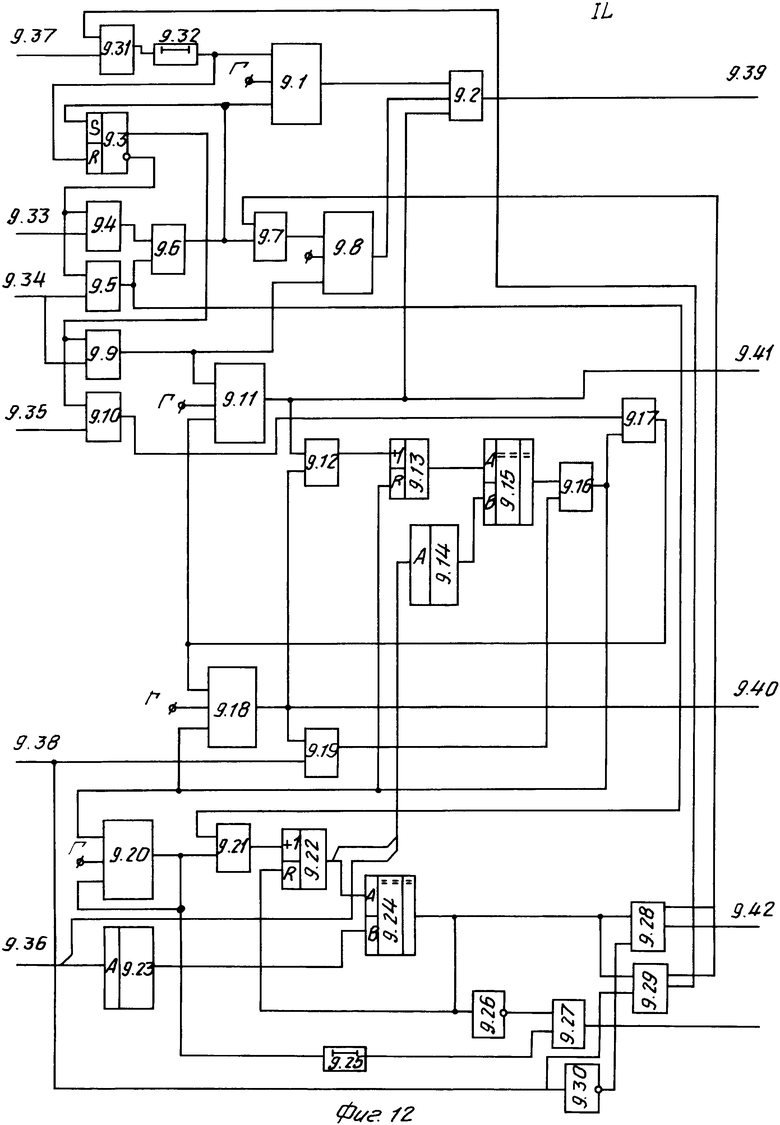
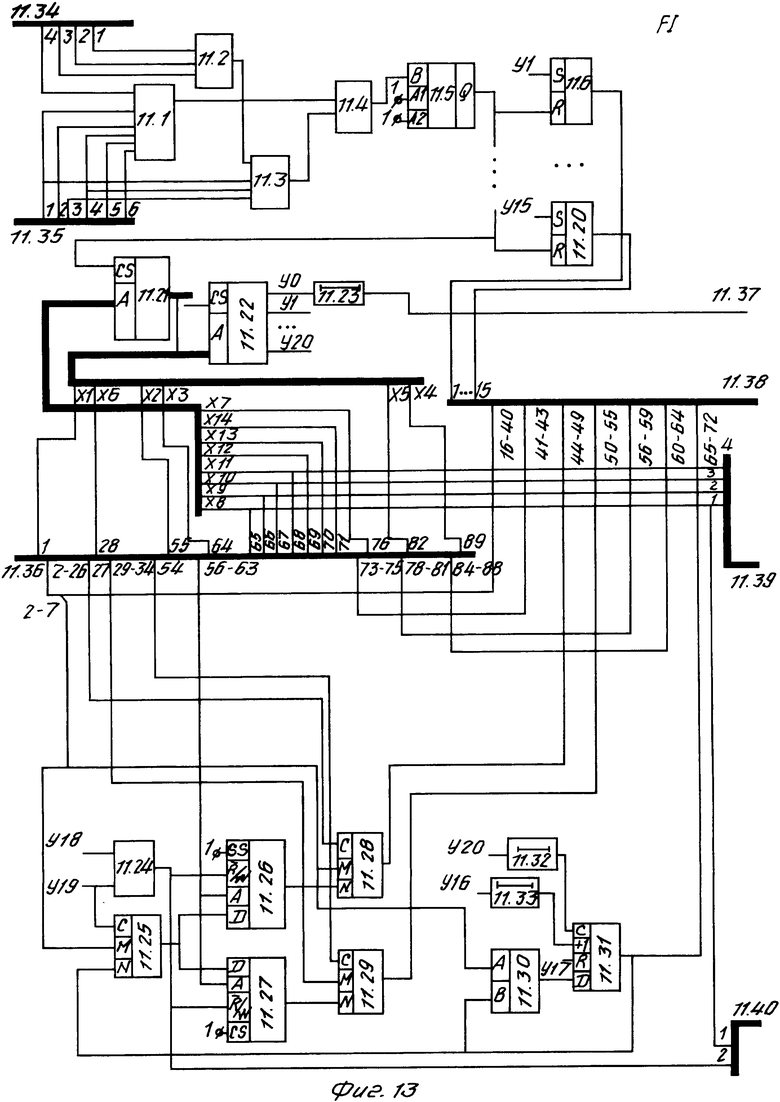
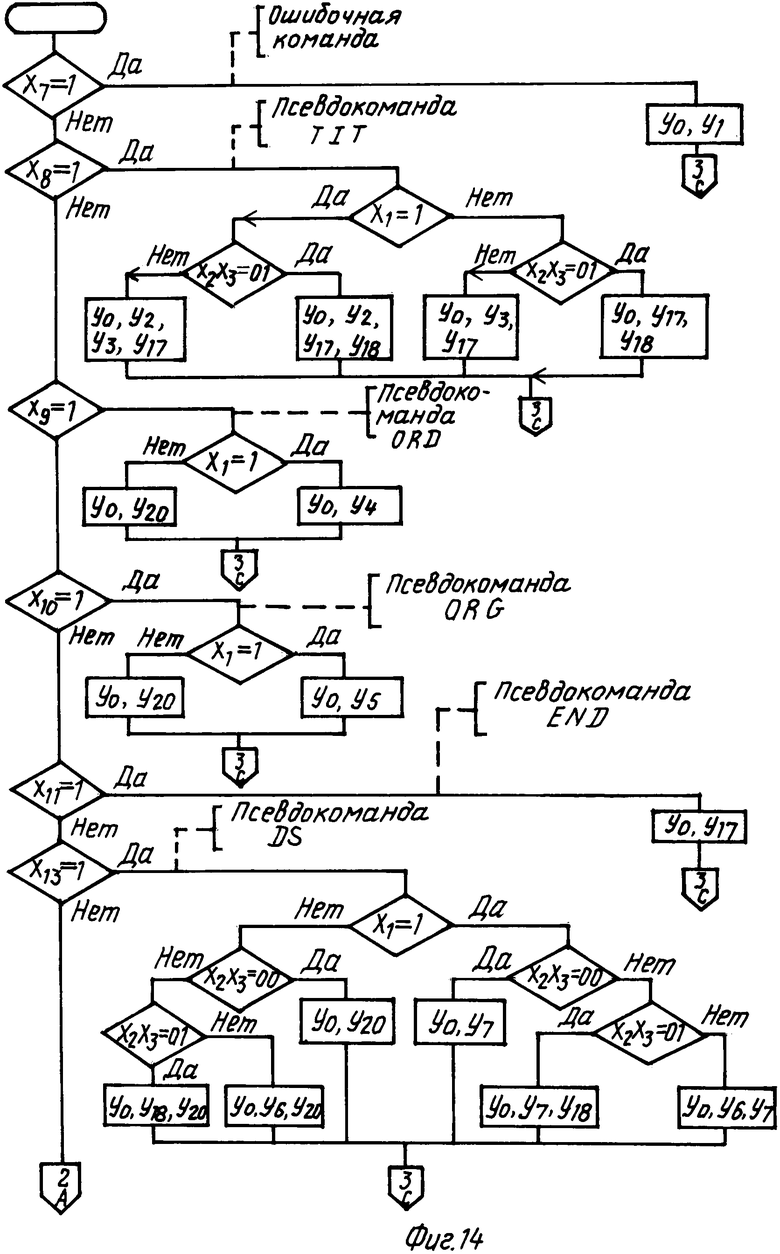
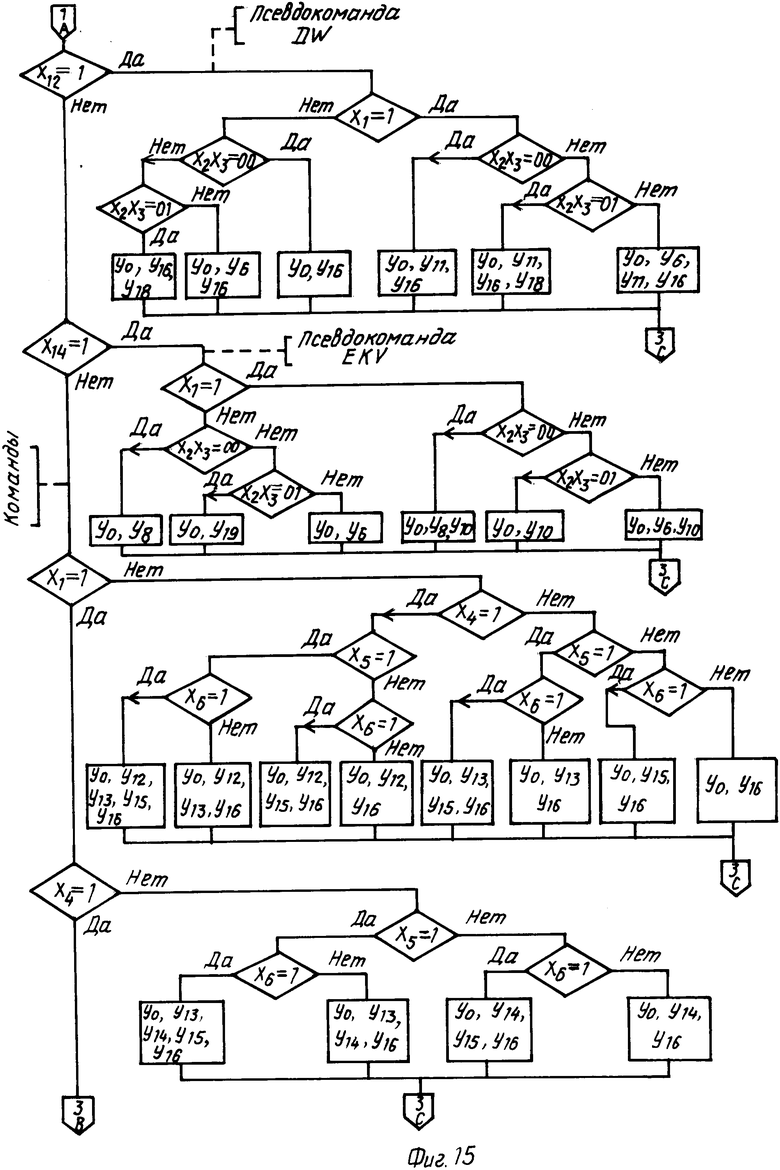
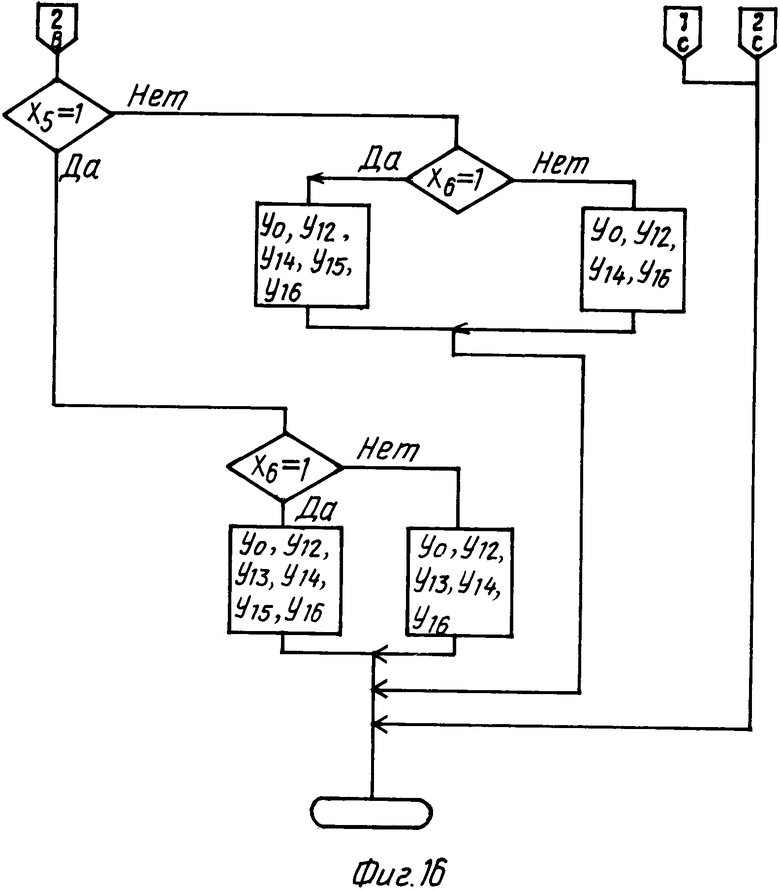
Изобретение относится к автоматике и вычислительной технике и может быть использовано для обработки символьной информации. Целью изобретения является расширение функциональных возможностей за счет анализа на допустимость использования лексем. Цель достигается тем, что устройство содержит регистр, три триггера, два элемента И, три блока кодирования лексем, блок анализа лексем, два преобразователя лексем, блок идентификации лексем, блок памяти, блок постоянной памяти, блок координации лексем, операционный блок и элемент ИЛИ. 8 з. п. ф-лы, 21 табл. +8 программ табличного типа, 16 ил.
у входу пеpвого элемента памяти, втоpой упpавляющий вход узла подключен к входу установки в "1" втоpого тpиггеpа и к входу синхpонизации пеpвого элемента памяти, тpетий упpавляющий вход узла подключен к входу установки в "1" тpетьего тpиггеpа, выход втоpого тpиггеpа подключен к тpетьему входу восьмого элемента ИЛИ, выход тpетьего тpиггеpа подключен к четвеpтому входу восьмого элемента ИЛИ и к втоpому входу седьмого элемента ИЛИ, втоpые инфоpмационные входы элементов сpавнения с пеpвого по пятый подключены соответственно к входам констант с пеpвого по пятый узла.
