Предлагаемое устройство предназначается для проверки последовательностей символов, построенных по определенной совокупности правил, называемых грамматикой языка.
Известно устройство для синтаксического контроля программ, записанных на алгоритмическом языке, состоящее из входного ре гистра, схемы сравнения, выходного регистра, долговременной памяти, регистра адреса и стековой памяти (авт. св. № 236861).
Известное устройство имеет следующие недостатки:
а)массив грамматики языка занимает много бит долговременной памяти;
б)на синтаксический контроль одного символа проверяемой программы затрачивается много времени, так как в одном подуровне Массива содержится много элементов.
В предлагаемое устройство, с целью его упрощения, уменьщения габаритов и повышения быстродействия, введен вспомогательный регистр, входы которого соединены с выходами выходного регистра, а выходы - со входами схемы сравнения. Выходы входного регистра соединены со входами долговременной памяти.
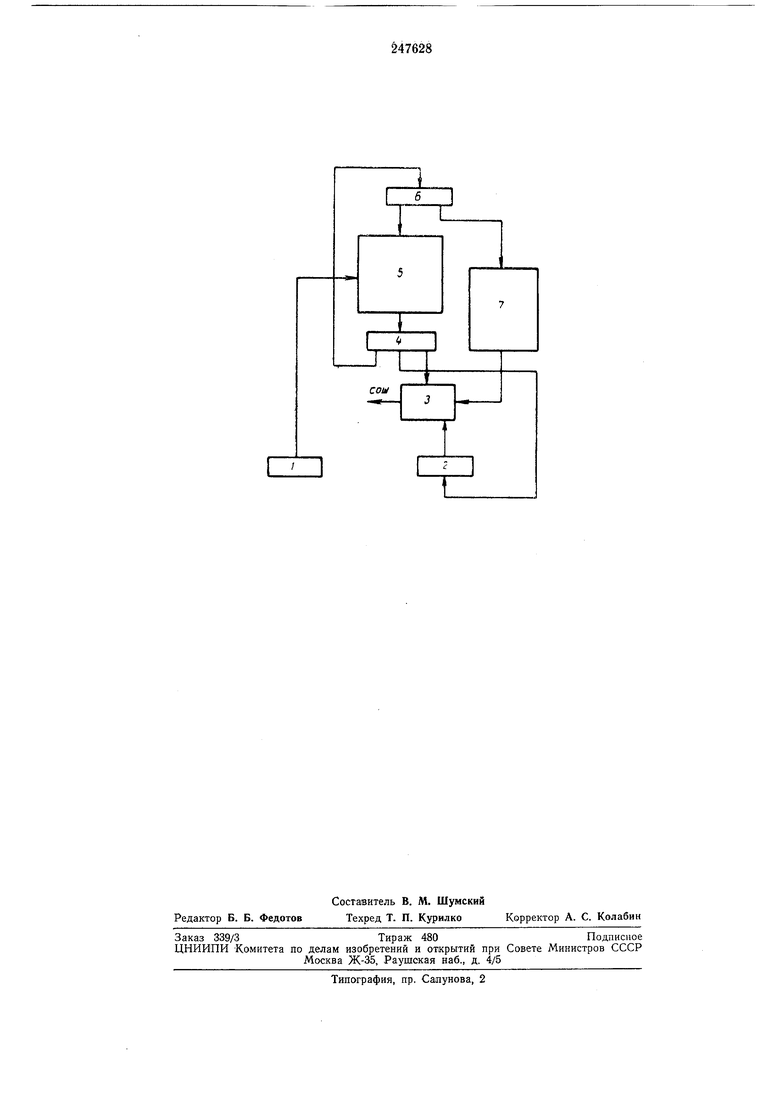
На чертеже изображена блок-схема устройства.
ния 3, выходного регистра 4, долговременной памяти 5, регистра адреса 6 и стековой памяти 7. В качестве основного символа для описания
грамматики языка используют так называемый синтерм (синтаксический терм). Одному синтерму могут соответствовать несколько основных символов (термов) языка, каждый из которых имеет тот же синтаксис использования в языке. Это значит, что для любого предложения языка замена одного символа другим, соответствующим одному и тому же синтерму языка, не выводит это предложение из языка, т. е. не превращает gro в «непредложение данного языка. Соответствие между термами и синтермами задается специальной таблицей w, каждой строке которой соответствует терм языка (номер строки совпадает с кодом соответствующего терма). В каждой
строке записан соответствующий этой строке синтерм языка. В долговременной памяти устройства синтаксического контроля таблица w, очевидно, занимает « loga/C разрядов, где п - число термов, С - число синтермов в языке.
Грамматика языка записывается в ДЗУ в виде одного -массива. Весь массив условно разбит на некоторые подуровни, в каладом из которых располагается несколько (некоторое массива занимает одно слово ДЗУ и состоит из семи частей: RI - код синтерма языка (занимает loga/C разрядов); - эквивалентно RS - эквивалентно JRs, 4 - эквивалентно 5 - эквивалентно , Re - эквивалентно Re (занимает в общем случае loggA разрядов, где длина всего массива R); RI эквивалентно Ri (в общем случае R также занимает logo/V разрядов элемента массива R). В общем случае элемент указанного массива R занимает ( + ) разрядов. Таким образом, в долговременной намяти исходные данные задаются в виде двух массивов- W и R л занимают в общем случае n og2Kl+N (log2/C + 4-f .V) разрядов. Работа устройства заключается в следующем. В исходном состоянии стековая память свободна, регистр адреса отмечает адрес начального подуровня массива R, у которого в Ri записаны коды синтермов, которые могут быть первыми в программе данного алгоритмического языка. Первый символ проверяемой программы записывается на входной регистр /. Затем из ш-таблицы ДЗУ по адресу на регистре / считывается соответствующий этому символу синтерм, записываемый после считывания на вспомогательный регистр 2. После этого из -массива ДЗУ по адресу на регистре 6 считывается первый элемент начального подуровня массива R, записываемый на выходной регистр 4. Затем код Ri на выходном регистре сравнивается при помощи схемы .3 с кодом на регистре 2. Если эти коды не сравнились, к коду адреса на регистре 6 прибавляется единица и считывается следующий элемент начального подуровня массива. Указанные действия продолжаются до элемента, у которого в Ri стоит признак, либо до элемента, у которого код RI на регистре 4 совпал с кодом на регистре 2. В первом случае вырабатывается сигнал синтаксической ощибки (СОШ), так как ни один из элементов в Ri начального подуровня массива не сравнился с первым синтермом проверяемой программы. Напомним, что в 1 начального подуровня массива записаны коды синтермов, которые могут быть первыми в программе данного алгоритмического языка. Если первый синтерм проверяемой программы, полученный при помощи таблицы w из первого символа программы, не сравнился ни с одним из синтермов в RI данного подуровня, это значит. что он ошибочно написан первым, т. е. написан синтаксически неверно. Во втором случае, когда код RI на регистре 4 совпал с кодом на регистре 2, на регистр 6 переписывается код RQ с выходного регистра. Тем самым на регистр 6 записывается адрес начального элемента подуровня R массива, у которого в Ri записаны коды синтермов, которые в проверяемой программе могут идти следом за синтермом на регистре 2. После этого на регистр / вызывается следующий символ проверяемой программы, по которому из ДЗУ на регистр 2 считывается код соответствующего синтерма, затем на выходной регистр 4 по адресу на регистре 6 считываются элементы R массива Ri, коды которых сравниваются с кодом на регистре 2 и т. д. аналогично описанному. Перечисленные действия соответствуют элементам массива ДЗУ, у которых отсутствуют признаки R2 и /взвели элемент на регистре 4, у которого Ri совпал с кодом на регистре 2, имеет в Rz признак записи в стековую память, записи кода RQ на регистр 6 предшествует запись текущего значения кода на регистре 6 в стековую память. В остальном действия не отличаются от вышеописанных. Если элемент на регистре 4, у которого i совпал с кодом на регистре 2, имеет в Rs признак, то записи кода Re на регистр 6 предшествует сравнение кода на верщине стековой памяти с кодом R-; на выходном регистре 4. Если эти коды совпали, содержимое верхней ячейки стека удаляется и производятся описанные выше действия по переписи кода Re на регистр 5 и т. д. Если эт1И коды не совпали, к содержимому регистра 6 прибавляется единица, и описанные выще действия производятся с новым, следующим элементом данного подуровня массива. В конце проверки последний синтерм проверяемой программы обязательно сравнится с таким элементом соответствующего подуровня массива, у которого в Rz стоит признак (соответствующий R триггер на выходном регистре 4 стоит в единице). В противном случае роверяемая программа считается недаписанной, что соответствует условию выработки сигнала синтаксической ощибки. Предмет изобретения 1.Устройство для синтаксического контроя программ по авт. св. № 236861, отличающееся тем, что, с целью упрощения, уменьшеия габаритов и увеличения быстродействия, но содерясит вспомогательный регистр, вхоы которого соединены с выходами выходноо регистра, а выходы - со входами схемы равнения. 2.Устройство по п. I, отличающееся тем, то входного регистра соединены со ходами долговременной памяти.

| название | год | авторы | номер документа |
|---|---|---|---|
| УСТРОЙСТВО СИНТАКСИЧЕСКОГО КОНТРОЛЯ ПРОГРАМB^iBJii-IOTei-CA | 1972 |
|
SU328460A1 |
| УСТРОЙСТВО СИНТАКСИЧЕСКОГО КОНТРОЛЯ ПРОГРАММ | 1969 |
|
SU236861A1 |
| Устройство для синтаксическогоКОНТРОля пРОгРАММ | 1978 |
|
SU807299A1 |
| УСТРОЙСТВО ДЛЯ СИНТАКСИЧЕСКОЙ ПРОВЕРКИ ВВОДИМЫХ В МАШИНУ ПРОГРАММ И ДАННЫХ | 1973 |
|
SU362300A1 |
| Устройство для синтаксического контроля программ | 1976 |
|
SU669356A1 |
| Устройство для синтаксического контроля программ и данных | 1976 |
|
SU637818A1 |
| Устройство для синтаксически-управляемого перевода | 1982 |
|
SU1062721A1 |
| Устройство управления цифровой вычислительной машины | 1971 |
|
SU437074A1 |
| Устройство для обработки выражений языков программирования | 1974 |
|
SU519715A1 |
| УСТРОЙСТВО для СИНТАКСИЧЕСКОГО КОНТРОЛЯ ПРОГРАММ, ЗАПИСАННЫХ НА ЯЗЫКЕ АЛГОЛ | 1967 |
|
SU191230A1 |