Настоящая патентная заявка США соответствует нижеследующим одновременно поданным патентным заявкам США:
1) Заявка регистрационный N 07/519.384 (по реестру IBM EN 9-90-020), поданная 4 мая 1990 г. под названием "Структура вычислительной машины с расширяемым набором составных команд"; изобретателями являются Стаматис Вассилиадис и др.
2) Заявка регистрационный N 07/519.382 ( по реестру IBM EN 9-90-019), поданная 4 мая 1990 г. под названием "Средство объединения команд общего назначения для процессоров параллельной обработки на уровне команд"; изобретателями являются Ричард Дж.Айкемейер и др.
3) Заявка регистрационный N 07/504/910 (по реестру IBM EN 9-90-014), поданная 4 апреля 1990 г. под названием "Устройство технических средств для сокращения зависимости от данных", изобретателями являются Стаматис Вассилиадис и др., и
4) Заявка регистрационный N 07/522.291 (по реестру IBM EN 9-90-012), поданная 10 мая 1990 г. под названием "Процессор объединения команд для кэш", изобретателями являются Бартоломей Бленер и др.
Эти одновременно поданные заявки и настоящая заявка являются собственностью одного и того же правопреемника, именно "Интернейшнл бисзнес Машинз корпорейшн (IBM) оф Армонк", Нью-Йорк.
Описания, приведенные в этих одновременно поданных заявках, включены настоящим в настоящую заявку путем ссылки на них.
Изобретение касается цифровых компьютеров и процессоров цифровых данных и конкретно касается цифровых компьютеров процессоров данных, способных выполнять две и больше команд параллельно.
Традиционные компьютеры, которые принимают последовательность команд и выполняют последовательность по одной команде за один раз, известны. Команды, выполняемые этими компьютерами, имеют дело с однозначными объектами, и поэтому получили название "скалярные".
Операционная скорость традиционных скалярных компьютеров доведена до их предела усовершенствованиями в технологии схем, устройства компьютера и структуре компьютера. Однако при каждом новом поколении конкурирующих вычислительных машин новые средства ускорения должны быть найдены для традиционных скалярных вычислительных машин.
Недавнее усовершенствование в отношении ускорения скорости вычисления монопроцессоров нашло свое выражение в сокращенной структуре набора команд, которая использует ограниченный набор очень простых команд. Другое средство ускорения представляет собой структуру набора сложных команд, которая основана на минимальном наборе сложных многооперандных команд. Применение любой их этих структур к существующим скалярным компьютерам потребует фундаментального изменения структуры и набора команд вычислительной машины. Такая далеко идущая трансформация чревата расходами, временем простоя и начальным снижением надежности и доступности вычислительной машины.
В стремлениях применения к скалярным вычислительным машинам некоторых преимуществ, достигаемых с помощью сокращения набора команд, были разработаны так называемые "суперскалярные" компьютеры. Эти вычислительные машины являются по существу скалярными, эффективность которых увеличивается благодаря их адаптированию выполнять больше одной команды за один раз из потока команд, содержащего последовательность одинарных скалярных команд. Эти вычислительные машины типично решают во время выполнения команд, может ли быть выполнено параллельно две или больше команд в последовательности скалярных команд. Решение основывается на кодах операции (ОП-кодах) команд и зависимости от данных, которые могут находиться между командами. ОП-код определяет вычислительные технические средства компьютера, необходимые для команды. Вообще, невозможно одновременно выполнить две или больше команд, которые используют одно и то же техническое средство (зависимость от технических средств) или один и тот же операнд (зависимость от данных). Эти зависимости от технических средств и данных препятствуют параллельному выполнению некоторых комбинаций команд. В этих случаях находящиеся в такой зависимости команды выполняются последовательно. Это, конечно, снижает эффективность суперскалярной вычислительной машины.
Суперскалярные компьютеры имеют свои недостатки, которые необходимо снизить. Конкретное количество времени расходуется при решении в период времени выполнения команд, которые (команды) могут выполняться параллельно. Это время не может быть легко замаскировано путем перекрывания с другими операциями вычислительной машины. Этот недостаток становится более заметным, когда увеличивается сложность структуры набора команд. Решение о параллельном выполнении также должно выноситься повторно каждый раз, когда рассматриваются одни и те же команды.
Для увеличения полезного срока службы существующих скалярных компьютеров важно каждое средство ускорения выполнения. Однако ускорение посредством структуры сокращенного набора команд, структуры набора сложных команд или суперскалярных способов потенциально слишком дорогое и слишком невыгодное, чтобы применять к существующим скалярным машинам. Предпочитается ускорять скорость выполнения такого компьютера путем параллельного или одновременного выполнения команд в существующих наборах команд без необходимости изменения набора команд, изменения структуры вычислительной машины или увеличения времени, необходимого для выполнения команд.
В одновременно поданной патентной заявке N 07/519.384 (IBM реестр IN 9-90-020) предложена структура вычислительной машины для набора расширяемых составных команд (SCISM), в которой параллелизм на уровне команд достигается путем статического анализа последовательности скалярных команд в период времени, предшествующий выполнению команды, чтобы образовать составные команды, образованные смежными группами существующих команд в последовательности, которые могут быть выполнены параллельно. Соответствующая контрольная информация в форме маркеров добавляется в поток команд для индикации, где начинается составные команды, а также для индикации количества существующих команд, которые включены в составную команду. Соответственно, как здесь используется, термин "объединение" означает группирование команд, содержащихся в последовательности команд, группирование это для цели параллельного или одновременного выполнения сгруппированных или объединенных команд. Как минимум, объединение удовлетворяется "спариванием" двух команд для одновременного выполнения. Предпочтительно объединяемые команды не меняют своих форм, в каких они представлены для скалярного выполнения. Как пояснено ниже, объединяемые команды сопровождаются информацией маркера об объединении, т.е. битами, приложенными к сгруппированным командам, которые обозначают группу команд для параллельного выполнения.
В цифровой компьютерной системе, которая включает в себя средство для выполнения множества команд параллельно, конкретный выгодный вариант реализации изобретения основан на структуре памяти, которая обеспечивает объединение команд перед их выдачей и выполнением. Такая память является компонентом иерархической структуры памяти, которая обеспечивает команды для CPU (центральный обрабатывающий блок) компьютера. Типично такая структура включает в себя быстродействующую память кэш, содержащую часто выбираемые команды, менее быстродействующую основную память или первичную память, соединенную с кэш, и небыстродействующую большой емкости вспомогательную память. Типично кэш и основная память содержат команды, которые могут непосредственно касаться выполнения. Доступ к командам во вспомогательной памяти поддерживается через адаптер ввода/вывода (Вв/Выв), соединенный между основной памятью и вспомогательной памятью.
В скалярном компьютере, имеющем иерархическую организацию памяти, изобретение основывается на комбинации, включающей в себя интерфейс ввода/вывода для образования из вторичной памяти последовательности для выполнения, средство объединения команд, которое образует информацию маркера объединения в ответ на последовательность команд, причем эта информация маркера объединения указывает команды последовательности, которые могут быть выполнены параллельно, и основную память, соединенную с интерфейсом ввода/вывода и средством объединения команд, для запоминания (загрузки в память) последовательности команд с информацией маркера объединения.
Как известно, основная память обеспечивает место для данных и команд, которые сразу становятся доступными для CPU в отношении контроля для выполнения. Использование основной памяти в хорошо сконструированных системах иерархической памяти в ней самой и в системе служат для повышения общей эффективности действия скалярного компьютера. В изобретении запоминание информации маркера объединения в основной памяти дает возможность использовать информацию в течение всего времени и так долго, сколько команды остаются в основной памяти. Далее, команды ущемляют основную память, так как после того как поступили в кэш, часто остаются в кэш достаточно долго, чтобы использовать их больше одного раза.
Для лучшего понимания изобретения вместе с его преимуществами и отличительными признаками следует обратиться к нижеследующему описанию и описанным ниже чертежами, на которых изображено:
на фиг. 1 - вид варианта реализации части цифровой компьютерной системы, выполненной в соответствии с настоящим изобретением;
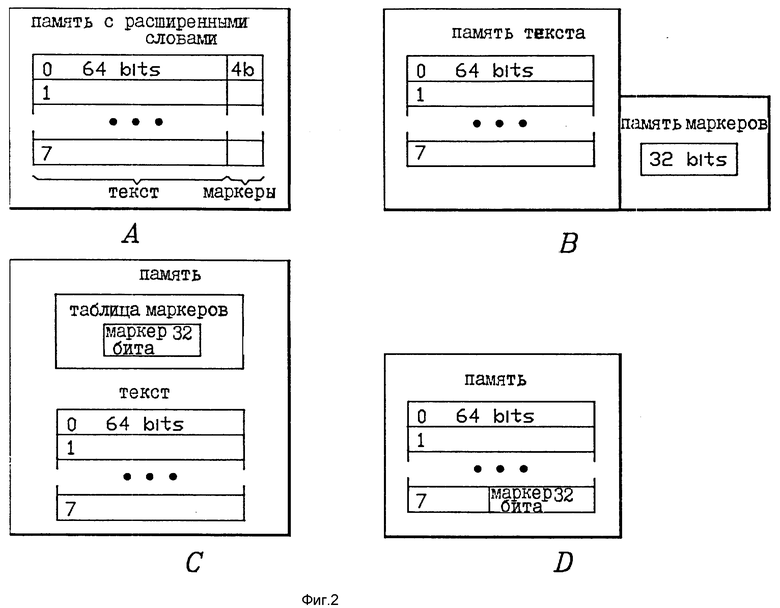
на фиг. 2,A - 2,D - иллюстрации альтернативных реализаций запоминающего устройства (ЗУ) для информации маркера объединения в основной памяти;
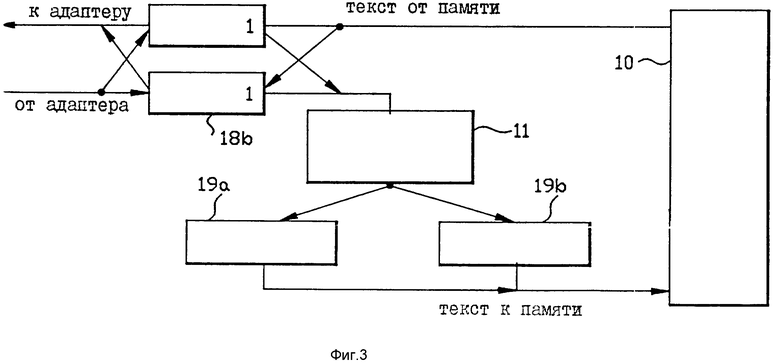
на фиг. 3 - вид в увеличенном масштабе структуры потока данных между адаптером Вв/Выв и основной памятью в компьютерной системе на фиг. 1;
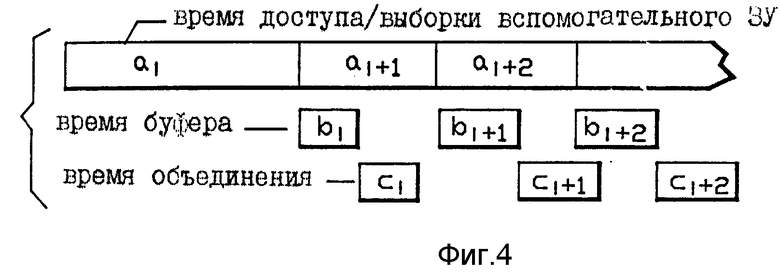
на фиг. 4 - временная схема передачи команд в структуре потока данных на фиг. 3;
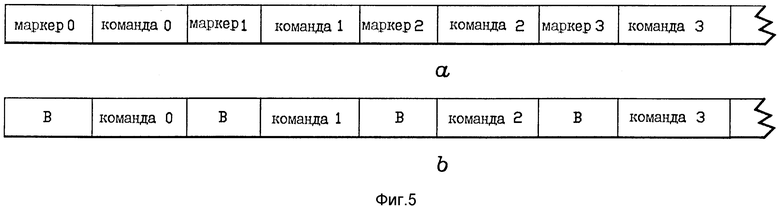
на фиг. 5, A - вид длины команд, имеющего маркеры объединения или поля маркеров, связанные с командами;
на фиг. 5, B - вид длины потока команд, имеющего поля границ команд, связанные с командами;
на фиг. 6 - вид с большими подробностями внутренней конструкции представленного варианта реализации блока объединения команд, который может использоваться в компьютерной системе на фиг. 1;
на фиг. 7 - вид с большими подробностями представленной внутренней конструкции в отношении каждого блока анализатора объединения на фиг. 3;
на фиг. 8 - пример логической схемы, которая может использоваться для реализации анализатора объединения и генератора маркеров на фиг. 6, которые образует маркеры объединения для первых трех команд в потоке команд;
на фиг. 9 - таблица, используемая для пояснения функционирования примера на фиг. 8;
на фиг. 10 - вид представленного варианта реализации части системы цифрового компьютера и используемой для пояснения, как составные команды могут обрабатываться параллельно многочисленными функциональными блоками обработки команд;
на фиг. 11 - пример конкретной последовательности команд, которая может обрабатываться компьютерной системой на фиг. 10, и на фиг. 12 - таблица, используемая для пояснения обработки последовательности команд на фиг. 11 компьютерной системой на фиг. 10.
На фиг. 1 показан иллюстративный вариант реализации части цифровой компьютерной системы или системы обработки цифровых данных, выполненной в соответствии с настоящим изобретением. Иллюстрируемая компьютерная система способна выполнять две или больше команд параллельно. Она включает в себя иерархически организованную систему памяти, в которой вспомогательные или вторичные запоминающие устройства соединяются с компьютером через шину Вв/Выв. Компьютер соединяется путем сопряжения с шиной Вв/Выв через адаптер, который также соединен с шиной памяти. Основная память и быстродействующая кэш соединены с шиной памяти.
Эта иерархия обычно дает возможность вычислительным компонентам компьютерной системы непосредственно делать выборку или обращаться к содержанию основной памяти и кэш, в то время как адаптер обеспечивает доступ к вспомогательному ЗУ. Команды и данные, которые должны быть выбраны или использованы для поддержки текущих операций компьютера, сохраняются в памяти. Когда они больше не требуются, они возвращаются во вспомогательную память через адаптер, тогда как новые команды и данные вводятся в основную память. Кэш поддерживает быстродействующую выборку со стороны CPU и используется для хранения команд и данных, которые в настоящее время используются или весьма вероятно будут использоваться CPU после текущей операции. Иерархические структуры памяти подробно описаны в главе 7 Операционных систем Дейтеля, второе издание, 1990.
На фиг. 1 показан иллюстративный вариант реализации цифровой компьютерной системы, имеющей иерархически организованную структуру памяти, согласно настоящему изобретению. Эта компьютерная система способна обрабатывать две и больше команд параллельно. Она включает в себя первое средство ЗУ для запоминания команд и данных, подлежащих обработке. Средство ЗУ идентифицировано как основная память 10. Основная память 10 соединена с шиной 9 памяти, имеющей шину 9a адресов и команд и шину 9b текста. Основная память 10 обменивается командами и данными по шине памяти через адаптер 8 Вв/Выв. Адаптер 8 Вв/Выв соединен с шиной 9 памяти и с шиной 7 Вв/Выв. Также предусмотрены одно или больше вспомогательных ЗУ (не показано), которые соединены с шиной 7 Вв/Выв. Адаптер 8 передает данные по шине 7 Вв/Выв путем загрузки информации программы во вспомогательные ЗУ и получения от них информации программы. Адаптер 8 также служит для обмена данными программы по шине 9 памяти с основной памятью 10 путем обеспечения команд и данных для и получения команд и данных от основной памяти по шине 9. Адаптер 8 буферизует команды и данные между шинами 7 и 9, которые имеют разные скорости и форматы. Наконец, адаптер 8 также содержит функции проверки и обнаружения ошибки. Адаптер Вв/Выв, соответствующий компоненту, обозначенному под цифровой позицией 8, является, например, канализованной подсистемой Вв/Выв системы компьютера модели 3080, выпускаемой "Корпорацией IBM", которая является правоприемником настоящей патентной заявки.
Основная память 10 имеет относительно большую емкость, средней скорости средство ЗУ, которое соединено посредством шины 9 памяти с быстродействующей кэш более низкой емкости. Эта кэш обозначена как кэш 12 составных команд.
Компьютерная система на фиг. 1 также содержит средство 11 объединения команд для приема команд от адаптера 8 и взаимодействия с той информацией маркеров составных команд в форме полей маркеров, которая указывает, какие их этих команд могут обрабатываться параллельно. Это средство объединения команд представлено блоком 11 объединения команд. Блок 11 объединения команд анализирует поступающие команды для определения, какие команды могут обрабатываться параллельно. Далее, блок 11 объединения команд образует для этих проанализированных команд маркерную информацию объединения в форме полей маркеров, которые указывают, какие команды могут обрабатываться параллельно друг с другом и какие команды не могут обрабатываться параллельно друг с другом. На фиг. 1 команды обеспечиваются для вычислительной системы из вспомогательного ЗУ посредством адаптера 8, блока 11 объединения команд и основной памяти 10. Основная память 10 принимает и запоминает анализированные команды и связанные с ними маркировочные поля. Основная память 10 обеспечивает затем анализированные команды и их взаимодействующие поля маркеров для кэш 12 составных команд. Кэш 12 имеет меньшую емкость и более высокое быстродействие, чем основная память 10, и является типом, обычно используемым для повышения скорости работы компьютерной системы путем сокращения частоты доступа к основной памяти 10.
Компьютерная система на фиг. 1 также содержит множество функциональных блоков обработки команд. Эти функциональные блоки обработки команд представлены функциональными блоками 13 - 15 и т.д. Эти функциональные блоки 13 - 15 функционируют параллельно друг с другом и одновременным образом, и каждый по своему способен обрабатывать один или больше типов команд на уровне вычислительной машины. Примеры функциональных блоков, которые могут использоваться, включают в себя общего назначения арифметические и логические устройства (АЛУ) и АЛУ типа генерирования адресов, АЛУ типа сокращения зависимости от данных, описанного в одновременно поданной заявке N 07/504.910 (по реестру IBM EN 9-90-014), блок обработки команды перехода, блок сдвига данных, блок обработки плавающей запятой и т.д. Данная компьютерная система может содержать два или больше некоторых этих типов функциональных блоков. Например, данная компьютерная система может два или больше общего назначения АЛУ. Данная компьютерная система может также содержать каждый и каждый по одному из этих разных типов функциональных блоков. Конкретная конфигурация функциональных блоков будет зависеть от природы предлагаемой конкретной компьютерной системы.
Компьютерная система на фиг. 1 также содержит средство выборки и выдача команд, связанное с кэш 12 составных команд, для подачи смежных команд, хранящихся в них, на разные функциональные блоки 13 - 15 обработки команд, когда поля маркеров команд указывают, что они должны быть обработаны параллельно. Это средство представлено блоком 16 выборки и выдачи команд. Блок 16 выборки и выдачи команд выбирает команды из кэш 12, рассматривает их поля маркеров и поля кода операции (ОП-кода) и, основываясь на этом рассмотрении, посылает команды на соответствующий один из функциональных блоков 13 - 15. Если требуемая команда находится в кэш 12 составных команд, соответствующий адрес посылается на кэш 12 для выборки из нее требуемой команды. Это иногда именуется как "ответ кэш". Если требуемая команда не находится в кэш 12, тогда она должна быть выбрана из основной памяти 10 и передана в кэш 12. Это иногда именуется как "пробел кэш". Когда происходит пробел, адрес требуемой команды посылается в основную память 10. В ответ на это основная память 10 начинает передавать или считывать строку команды, которая содержит запрашиваемую команду, вместе с полями маркеров команд в строке.
Пробел кэш принуждает обратиться к основной памяти 10 для определения, содержится ли требуемая команда в памяти 10. Команды обычно хранятся в основной памяти 10 в блоках, именуемых "страницы", и средство управления памятью (не показано) компьютерной системы способно определить из требуемой команды, находится ли страница, содержащая эту команду, в основной памяти. Если такая страница находится в основной памяти, строка, содержащая команду, передается или считывается из основной памяти 10 в кэш 12. Однако, если страница, содержащая запрашиваемую команду, не находится в основной памяти 10, происходит "ошибка из-за отсутствия страницы", что требует пропущенную страницу "выбрать" из вспомогательного ЗУ и поместить в основную память 10. Когда страница выбрана, идентификация пропущенной страницы посылается на адаптер 8, который отыскивает ее и затем обеспечивает ее по шине 9 памяти для хранения в основной памяти 10.
В изобретении страницы, которые выбраны для хранения в основной памяти 10, передаются на вход блока 11 объединения команд, который (блок 11) приступает к анализу этих поступающих команд и образует соответствующее поле маркера для каждой команды. Маркеры и команды после этого подаются на основную память 10 и хранятся в ней для последующего перемещения, если это требуется, в кэш 12 составных команд.
Хотя блок 11 объединения команд показан на фиг. 1 как соединенный между адаптером 8 и основной памятью 10, предполагается, что блок может быть отдельным средством анализа на шине 9 памяти или присоединен на входе к основной памяти 10.
Хранение составных команд в основной памяти 10 может быть реализовано разными способами, из которых некоторые показаны на фиг. 2,A - 2,D. Примеры на фиг. 2,A - 2,D предлагают шину 9b текста шириной 8 байтов плюс дополнительные линии для информации маркеров. Вообще считается, что передача основной памяти основной памятью 10 и кэш 12 составных команд включает в себя линию кэш 64 байта, с одним битом маркера для каждых двух байтов текста команды. Одна линия кэш показана в каждом примере на фиг. 2,A - 2,D. Вообще число маркерных бит определяется максимальным числом объединяемых команд и информацией, возможной для блока 11 объединения команд. Эти соображения изложены в одновременно поданных заявках NN 07/519.382 и 07/504.919 (по реестру IBM IN 9-90-019 и EN 9-90-014).
Простейшая реализация ЗУ маркера с точки зрения управления показана на фиг. 2,A. Если предлагается, что объединение ограничивается двумя командами, требуется минимум однобитный маркер для каждых двух байтов текста команды. Таким образом, для строки, загруженной в память на фиг. 2,A, каждые 64 бит (т. е. каждые восемь байтов) требуют четыре бит информации маркера объединения. Как показано на фиг. 2,A, ЗУ этой информации содержит расширение размера слова от 64 до 68 бит. Другие факультативные биты маркера будут увеличивать размер расширяемых слов.
Второе техническое решение, более совместимое с возможной технологией памяти показано на фиг. 2,B. На фиг. 2,B предусмотрены отдельные памяти текста и маркеров посредством ЗУ команд и информации, связанной с маркерами объединения. На фиг. 2, B память для маркеров функционирует параллельно с памятью для текста. Неявно в структуре памяти на фиг. 2,B есть требование в отношении дополнительного набора линий маркеров, образующих шину маркеров на шине 9 памяти образования параллельного функционирования памяти для текста и для маркеров. Это имеет несколько преимуществ по отношению к техническим решениям типа расширенного слова на фиг. 2A. Во-вторых, память для маркеров может охватывать только часть слов в основной памяти. Операционная система использует некоторые части памяти только в отношении страниц данных (в противоположность страницам команд), маркеры необязательно находятся во всех этих частях. Отличие между страницами данных и команд может быть осуществлено с помощью технических средств, программных средств или реализовано с помощью команд в память маркеров, которые указывают, что определенные страницы содержат только данные и поэтому не требуется адрес страницы в памяти переносить в адрес памяти маркеров в отношении этих страниц. Второе преимущество в том, что память для маркеров может быть устранена при желании для образования более дешевой системы. Это расширяет возможный диапазон эксплуатации в семействе компьютеров. Если требуется больше маркерных бит, как если бы требовалось для большего, чем двунаправленное объединение команд, новая память для маркеров будет заменять память для маркеров на фиг. 2,B без необходимости изменения конструкции основной памяти. Далее, каждая память может быть снабжена своей собственной коррекцией ошибок.
В отношении фиг. 2,A - 2,D следует отметить, что после образования блоком объединения результатов, маркеры объединения сопровождают поток команд в памяти, будь то вставлены в поток, приложены к секциям его или сохраняемые параллельно с ним.
Другие технические решения в отношении реализации ЗУ маркеров показаны на фиг. 2,C и 2,D. На фиг. 2,C первая секция основной памяти содержит таблицы маркеров, и второе ЗУ страницы текста команд. В этом примере требуется поддержка операционной системы, чтобы резервировать часть памяти для таблицы маркеров и пару страниц памяти со страницами маркеров. На фиг. 21 части каждой страницы резервированы для маркеров. Это требует способности в компилирующей программе в отношении конструкций страниц. Например, в случае строк кэш 64 байта компилирующая программа будет использовать 60 байтов для команд и 4 байта для маркеров. На фиг. 2,D маркеры объединены с байтами команд в кэш команд, когда это требует CPU.
Реализация компьютерной системы на фиг. 1 такова, что блок 11 объединения команд может составлять часть адаптера 8 шины. Таким образом, когда страница забирается из системы Вв/Выв, она подвергается неявно процессу объединения в блоке 11 и переводится по шине 9 памяти в основную память 10. Отсюда описание предлагает структуру страницы согласно фиг. 2,A, требующей, чтобы шина 9b текста была шириной 68 бит, и чтобы основная память имела структуру и управлялась для хранения таких страниц, как показано на фиг. 2, A. Конечно, кэш 12 составных команд имеет структуру и управляется с тем, чтобы принимать строки, содержащие расширенные слова, как показано на фиг. 2,A.
В случае ошибки из-за отсутствия страницы страница загружается в страничный буфер в адаптере 8 и обеспечивается для блока 11 объединения команд, как описано ниже. На фиг. 3 двухстраничные буферы 18a и 18b посылают последовательность страниц на блок 11 объединения команд, который предпринимает операции объединения путем добавления информации маркера объединения к командам страницы. Страницы, обработанные блоком 11 объединения, подаются в основную память 10 через буферы 19a и 19b объединенных страниц. Как показано на фиг. 4, блок объединения добавляет время ко времени, необходимому для выборки сегмента текста из вспомогательного ЗУ и вводит это в основную память 10. Однако добавленное время незначительно относительно всего времени, необходимого для операции в целом и не совпадает с CPU.
На фиг. 4 каждый сегмент i передается из вспомогательного ЗУ, такого как накопитель на дисках, на один из страничных буферов 18a или 18bi. Каждый из временных сегментов b указывает время, необходимое для передачи сегмента текста i из страничного буфера в основную память 10. Таким образом, текстовой сегмент i передается за время ai в один из страничных буферов 18a или 18b, вслед за чем текстовой сегмент i + I передается на другой из буферов. Без объединения текстовой сегмент i передается за время bi из страничного буфера, где он в данное время хранится, в основную память. Как показано на фиг. 4, это время существенно короче, чем время, необходимое для выборки страницы в одном из буферов 18a или 18b. При реализации этого изобретения время, необходимое для выполнения операции блока 11 объединения на текстовом сегменте в одном из страничных буферов, плюс время затраченное в буферах 19a или 19b объединения команд, представлено совокупным временем ci. Теперь, на фиг. 4 время bi является временем, которое требуется для передачи текстового сегмента i из страничного буфера в блок 11 объединения. Затем, время объединения с i затрачивается, когда текстовый сегмент подвергается обработке блоком 11 объединения. Как показано на фиг. 4, сумма времени bi и ci меньше, чем время aa. Следует напомнить, что суперскалярная вычислительная машина должна решать в течение времени выполнения команд, могут ли команды выполняться параллельно. Это решение представляет дискретную ступень в выполнении команды, тем самым значительно добавляя ко времени выполнения в суперскалярной вычислительной машине. В противоположность этому, как показано на фиг. 4, объединение в компьютерной системе на фиг. 1 не увеличивает значительно время, необходимое для выполнения операций компьютера. Таким образом, блок 11 объединения команд обеспечивает большую эффективность, чем компьютер, размещенный в блоке выполнения команд.
На фиг. 3 и 4 показаны два принципиальных преимущества объединения в основной памяти. Во-первых, объединение может быть сделано частью асинхронного процесса ошибки из-за отсутствия страницы без увеличения времени для завершения этого процесса. Во-вторых, объединение крупных блоков текста команд, таких как страницы, обеспечивает больший диапазон для выявления объединения, что может привести к более оптимизированному объединению. Последствие этого в том, что блок объединения команд в памяти, такой как показан на фиг. 1, будет обеспечивать преимущества эффективности, так как CPU, так как CPU будет всегда выполнять команды, которые объединены, и объединение может быть лучше оптимизировано, чем когда выполняется синхронно на меньшей секции текста команды.
Операция блока объединения команд будет теперь поясняться со ссылкой на фиг. 5, a. На фиг. 5,a показана часть потока объединенных или маркированных команд, как они могут появиться на выходе блока 11 объединения команд на фиг. 1. Как можно видеть, каждая команда (Коман.) имеет поле маркера, добавленное к ней блоком 11 объединения команд. Маркированные команды, подобно показанным на фиг. 5,a, загружаются в основную память в страничном блоке для страницы, содержащей команды. При необходимости маркированные команды в основном памяти 10 передаются в кэш 12, когда происходит "пробел". После этого маркированные команды в кэш 12 выбираются блоком выборки и выдачи команд 16. Если маркированные команды получены блоком 16 выборки и выдачи, их маркированные поля рассматриваются для определения, могут ли они обрабатываться параллельно, и их поля кода операции (ОП-кода) рассматриваются для определения, какие наличные функциональные блоки наиболее соответствуют для их обработки. Если маркерные поля указывают, что две или больше команд соответствуют для параллельной обработки, тогда они направляются на соответствующий один из функциональных блоков в соответствии с кодированием их полей ОП-кода. Такие команды затем обрабатываются одновременно друг с другом их соответствующими функциональными блоками.
Когда встречается команда, которая не соответствует для параллельной обработки, тогда она направляется на соответствующий функциональный блок, как определено ее ОП-кодом, и после этого обрабатывается единолично посредством самой себя и выбранным функциональным блоком.
В наилучшем случае, когда множество команд всегда обрабатывается параллельно, скорость выполнения команд компьютерной системой будет в N раз больше по сравнению со случаем, когда команды выполняются по одной за один раз, где N является числом команд в группах, которые обрабатываются параллельно.
Поток маркированных команд на фиг. 5,a легче обрабатывать блоком объединения команд, если существуют известные контрольные точки для индикации, где начинается команда. Такая контрольная точка будет обеспечивать точное знание, где проходит граница команды. Во многих компьютерных системах граница команд специально распознается только компилирующей программой во время компилирования и только CPU, когда выбираются команды. Контрольная точка границ неизвестна между временем компилирования и выборкой команд, если не адаптирована специальная контрольная схема границ. Такая схема показана на фиг. 5,b в виде бит B границ команд. Как показано на фиг. 5,b, биты границы могут быть вставлены в поток команд с помощью компилирующей программы во время компилирования для образования контрольной точки в отношении размещения команды непосредственно перед объединением. Вообще, патентные заявки, озаглавленные "Структура вычислительной машины для расширяемых наборов составных команд" и "Общего назначения устройство объединения команд для процессоров параллельной обработки на уровне команд" имеют дело с рассмотрением объединения с текстовыми потоками, в которых границы команд неопределенные. Конечно, когда границы команд могут быть определены из потока текста, если поток содержит только команды, и все команды одинаковой длины, определения границы не требуется.
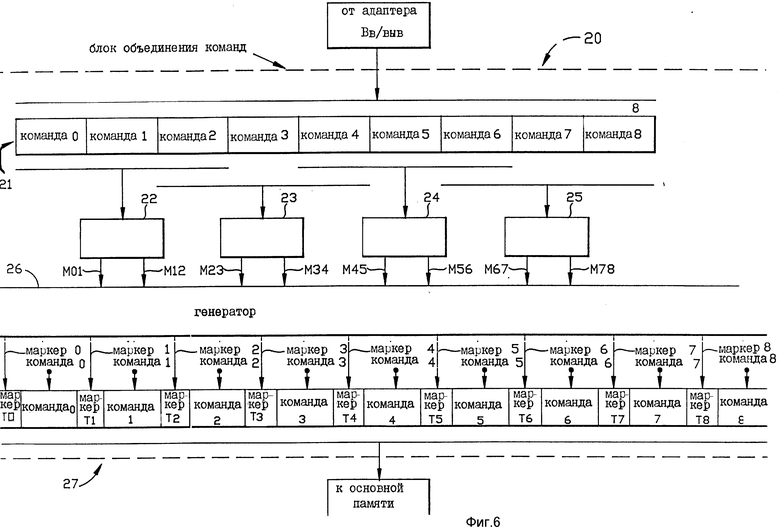
На фиг. 6 показана более подробно внутренняя конструкция иллюстративного варианта реализации блока объединения команд согласно настоящему изобретению. Этот блок 20 объединения команд соответствует для использования как блок 11 объединения команд на фиг. 1. Блок 20 объединения команд на фиг. 6 выполнен для случая, когда максимум две команды за один раз могут обрабатываться параллельно. Однако это не означает ограничения изобретения только объединением пары команд. В этом примере используется поле маркера 1-бит. Значение бита маркера "1" (один) означает, что команда является "первой" командой. Значение бита маркера "0" (ноль) означает, что команда является "второй" и может выполняться параллельно с предшествующей первой командой. Команда имеющая значение бита маркера 1, может выполняться либо сама по себе, либо одновременно и параллельно со следующей командой в зависимости от значения бита маркера в отношении такой следующей команды.
Каждая пара команд, имеющая значение бита маркера, единицу с последующей командой, имеющей значение бита маркера ноль, образует составную команду для целей параллельной обработки, т.е. команды в такой паре могут обрабатываться параллельно друг с другом. Когда биты маркера в отношении двух последовательных команд имеют каждый значение единица, первая из этих команд выполняется сама по себе непараллельно с другими командами. В наихудшем возможном случае все команды в последовательности будут иметь значение бита маркера единица. В этом наихудшем случае все команды будут выполняться поодиночке за каждый рабочий цикл обработки, непараллельно с другими командами.
На входе в блок 20 объединения команд блок размещения команд принимает от адаптера Вв/Выв поток команд, в котором должны быть произведены объединения. Поток команд может содержать двоичные биты B, как показано на фиг. 5, b. В этом случае размещение команд является просто вопросом определения бит границ и декодирования ОП-кодов команд. Как известно, в наборе команд IBM Система/370 ОП-коды содержат биты, которые дают длину команд в байтах или полусловах. Поэтому после того, как бит В границы идентифицирован в отношении команды, следующая команда может быть безошибочно идентифицирована путем вычисления количества байтов или полуслов от бита границы. Размещение команд не является отличительным признаком настоящего изобретения и должно быть понятно, что границы команд идентифицируются любым известным способом, включая использование двоичных бит.
Блок 20 объединения команд на фиг. 6 включает в себя регистр 21 команд для множества команд для приема множества последовательных команд от страничных буферов 18а и 18b адаптеров. Блок 20 объединения команд также содержит множество средства анализатора команд, которые (средства) основаны на правилах. Каждое такое средство анализатора команд анализирует другую пару смежных команд в регистре 21 команд и генерирует сигнал возможности объединения, который указывает, могут или нет две команды в его паре обрабатываться параллельно. На фиг. 6 показано множество блоков 22-25 анализаторов объединения. Каждый из этих блоков 22-25 анализаторов объединения содержит два упомянутых средства анализатора команд. Таким образом, каждый из этих блоков 22-25 анализаторов образует два сигнала возможности объединения. Например, первый блок 22 анализатора объединения образует первый сигнал возможности объединения M01, который указывает, могут или нет команды 0 и 1 обрабатываться параллельно. Блоки 22 анализаторов объединения также генерируют второй сигнал возможности объединения М12, который указывает, могут или нет команды 1 и 2 обрабатываться параллельно.
Аналогичным образом второй блок 23 анализатора объединения генерирует первый сигнал М23 возможности объединения, который указывает, могут или нет команды 2 и 3 обрабатываться параллельно, и второй сигнал М34 возможности объединения, который указывает, могут ли команды 3 и 4 обрабатываться параллельно. Третий анализатор 24 объединения генерирует первый сигнал возможности объединения М45, который указывает, могут или нет команды 4 и 5 обрабатываться параллельно, и второй сигнал возможности объединения М56, который указывает, могут или нет команды 5 и 6 обрабатываться параллельно. Четвертый анализатор 25 объединения генерирует первый сигнал возможности объединения М67, который указывает, могут или нет команды 6 и 7 обрабатываться параллельно и второй сигнал возможности объединения М78, который указывает, могут ли команды 7 и 8 обрабатываться параллельно.
Блок 20 объединения команд далее содержит средство 26 генерирования маркеров (маркерных знаков), реагирующее на сигналы возможности объединения, появляющиеся на выходах блоков анализатора 22-25, для генерирования индивидуальных полей маркеров для разных команд в регистре 21 команд. Эти маркерные поля Т0, Т1, Т2 и т.д. подаются на регистр 27 маркированных команд, как сами команды, причем последние поступают от входного регистра 21 команд. Таким образом в выходном регистре 27 блока объединения образуется маркерное поле Т0 для команды 0, маркерное поле Т1 для команды 1 и т.д.
В настоящем варианте реализации каждое поле маркера Т0, Т1, Т2 и т.д. состоит из одного двоичного бита (разряд). Значение бита маркера "один" указывает, что непосредственно следующая команда, к которой оно относится, является "первой" командой. Значение бита маркера "ноль" указывает, что непосредственно следующая команда является "второй" командой. Команда, имеющая значение бита маркера единица, следующая за командой, имеющей значение бита маркера ноль, указывает, что эти две команды могут быть выполнены параллельно друг с другом. Маркированные команды в выходном регистре 27 блока объединения подаются на вход основной памяти 10 на фиг. 1 через один или другой буфер объединения 19а или 19b на фиг. 3. Объединенные или составные команды загружаются в основную память 10.
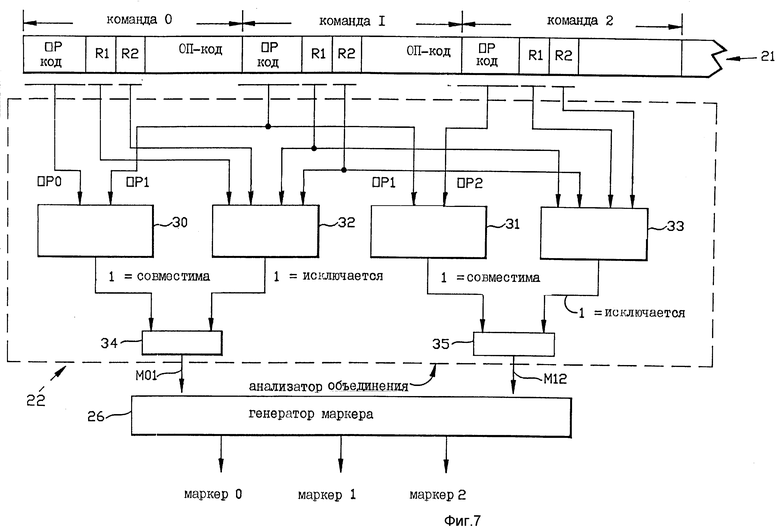
На фиг. 7, показана более подробно внутренняя конструкция, используемая в отношении блока 22 анализатора объединения на фиг. 6. Остальные блоки 23-25 анализатора объединения аналогичной конструкции. Как показано на фиг. 7, анализатор 22 соединения включает в себя логическую схему 30 возможности объединения команд для рассмотрения ОП-кода команды 0 и ОП-кода команды 1 и определения, совместимы ли эти два ОП-кода для целей параллельного выполнения. Логическая схема 30 выполнена в соответствии с заданными правилами для определения, какие пары ОП-кодов совместимы для параллельного выполнения. Более конкретно, логическая схема 30 включает в себя схему по реализации правил, которые определяют, какой тип команд является совместимым для параллельного выполнения в конкретной конфигурации технических средств, используемых в компьютерной системе, рассматриваемой в конкретном случае. Если ОП-коды в отношении команд 0 и 1 являются совместимыми, тогда логическая схема 30 образует на своем выходе сигнал уровня двоичной единицы. Если они несовместимы, логическая схема 30 образует величину двоичного нуля на своем выходе.
Анализатор 22 объединения далее включает в себя вторую логическую схему 31 совместимости команд для рассмотрения ОП-кодов команд 1 и 2 и определения, являются ли они совместимыми для параллельного выполнения. Логическая схема 31 выполнена так же как логическая схема 30 в соответствии с теми же заданными правилами, используемыми для логической схемы 30, для определения, какие пары ОП-кодов совместимы для параллельного выполнения для случая команд 1 и 2. Таким образом, логическая схема 31 включает в себя логическую схему для реализации правил, которые определяют, какие типы команд совместимы для параллельного выполнения; эти правила являются теми же, какие используются в логической схеме 30. Если ОП-коды в отношении команд 1 и 2 являются совместимыми, тогда логическая схема 31 образует выходной сигнал уровня двоичной единицы, в противном случае она образует выходной сигнал уровня двоичного нуля.
Анализатор 22 объединения далее включает в себя первую логическую схему 32 зависимости от регистра для определения конфликтов при использовании регистров общего назначения, определяемых полями R1 и R2 команд 0 и 1. Эти регистры общего назначения будут описаны подробнее здесь ниже. Наряду с другим логическая схема 32 зависимости может быть выполнена для определения ситуации зависимости от данных, при которой вторая команда (команда 1) должна использовать результаты, получаемые в результате выполнения предшествующей команды (команды 0). В этом случае либо вторая команда может выполняться с помощью технических средств сокращения зависимости, тем самым выполняясь параллельно с первой командой, либо выполнение второй команды должно ждать завершения выполнения предшествующей команды и поэтому не может выполняться параллельно с предшествующей командой. (Следует отметить, что способ преодоления некоторых зависимостей от данных типа будет пояснен здесь ниже.) Если нет зависимостей от регистров, которые (зависимости) препятствуют выполнению команд 0 и 1 параллельно, тогда выходная линия логической схемы 32 будет иметь двоичную величину единицу. Если есть зависимость, тогда в этой выходной линии будет двоичная величина ноль.
Анализатор 22 объединения далее включает в себя вторую логическую схему 33 зависимости от регистров для определения конфликтов в использовании регистров общего назначения, определяемых полями R1 и R2 команд 1 и 2. Эта логическая схема 33 такой же конструкции как ранее описанная схема 32, и образует выход уровня двоичной единицы, если нет зависимостей от регистров, или зависимости от регистров могут быть выполнены техническими средствами сокращения зависимости от данных и в остальных случаях выходным сигналом будет уровень двоичного нуля.
Выходные линии от логической схемы 30 совместимости команд и логическая схема 32 зависимости от регистров соединены с двумя входами логической схемы И 34. Выходная линия схемы И 34 имеет величину двоичной единицы, если рассматриваемые два ОП-кода являются совместимыми и если нет регистровых зависимостей. Эта двоичная величина единица на выходной линии схемы И 34 указывает, что две команды, которые рассматриваются, являются совместимыми, т. е. могут выполняться параллельно. Если, с другой стороны, выходная линия схемы И 34 имеет двоичную величину ноль, когда две команды являются несовместимыми. Таким образом, на выходной линии схемы И 34 образуется первый сигнал совместимости М01, который указывает, могут или нет команды 0 и 1 выполняться параллельно. Это сигнал М01 подается на генератор 26 маркеров.
Выходные линии от второй логической схемы 31 совместимости и второй логической схемы 33 зависимости соединены с двумя входами логического элемента И 35. Логический элемент И 35 образует на своей выходной линии второй сигнал М12 совместимости, который имеет двоичную величину единица, если два ОП-кода, которые рассматриваются (ОП-команд 1 и 2) являются совместимыми и если нет зависимостей от регистров у команд 1 и 2 или зависимостей от регистров, которые могут выполняться техническими средствами сокращения зависимости от данных. В остальном выходная линия логического элемента И 35 будет иметь логическую величину ноль. Выходная линия от логического элемента И 35 идет ко второму входу генератора 26 маркеров.
Остальные анализаторы 23-25 объединения, показанные на фиг. 6, являются такой же внутренней конструкции, как показано на фиг. 7 в отношении первого анализатора объединения.
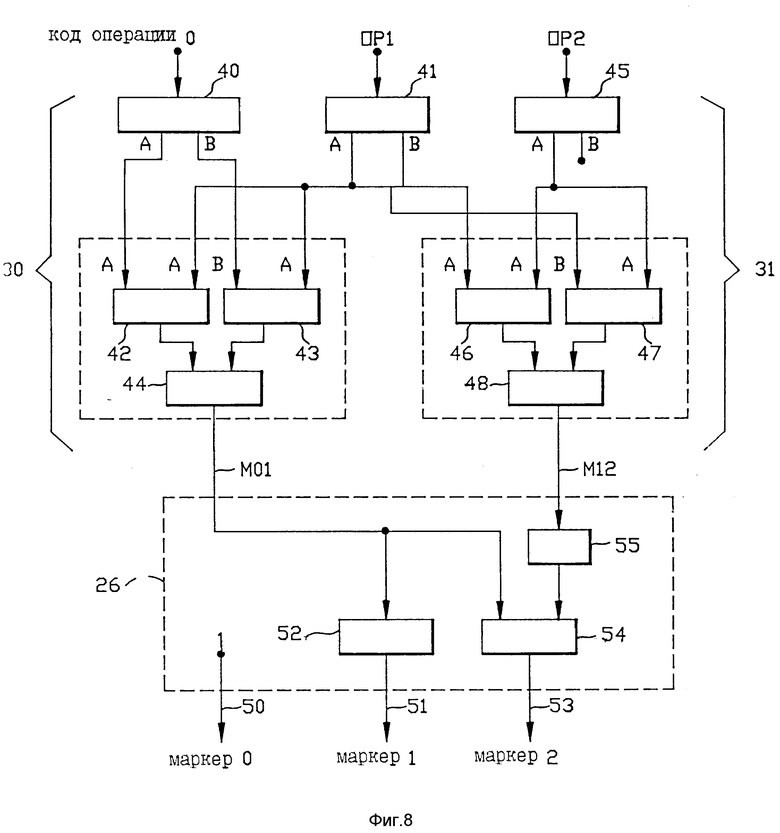
На фиг. 8 показан пример логической схемы, которая может использоваться для реализации анализатора 22 объединения, и часть генератора 26 маркеров, которая используется для генерирования первых трех маркеров, маркера 0, маркера 1 и маркера 2. В отношении примера на фиг. 5 предполагается, что имеется две категории команд, которые обозначены как категория А и категория В. Правила в отношении объединения этих категорий команд являются следующими:
1) А может всегда объединяться с A
2) A никогда не может объединяться с B
3) B никогда не может объединяться с B
4) B может всегда объединяться с A
5) правило (4) преобладает над правилом (1).
Следует отметить, что эти правила чувствительны к порядку появления команд.
Далее также предполагается, что эти правила являются такими, что когда они соблюдаются, то нет проблем с зависимостями от регистра, потому что правила явно указывают, что в случае, когда имеется взаимная блокировка, такая блокировка всегда может быть выполнена с помощью технических средств сокращения зависимости от данных. Иначе говоря, считается, что логические схемы 32 и 33 на фиг. 7 зависимости от регистров не требуются в случае примера на фиг. 8. В этом случае логические элементы И 34 и 35 также не требуются, и выходной сигнал логической схемы 30 становится сигналом М01, и выход логической схемы 31 становится сигналом М12.
В отношении этих предположения фиг. 8 показывает внутреннюю логическую схему, которая может использоваться для логической схемы 30 совместимости команд и логической схемы 31 совместимости команд на фиг. 7. Ссылаясь на фиг. 7, логическая схема 30 совместимости команд включает в себя декодеры 40 и 41, логические элементы И 42 и 43 и логический элемент ИЛИ 44. Вторая логическая схема 31 совместимости команд включает в себя декодеры 41 и 45, логические элементы И 46 и 47 и логический элемент ИЛИ 48. Средний декодер 41 используется совместно логическими схемами 30 и 31.
Первая логическая схема 30 рассматривает ОП-коды ОР0 и OP1 в отношении команд 0 и 1 для определения их совместимости для целей параллельного выполнения. Это производится в соответствии с правилами 1-4, изложенными выше. Декодер 40 рассматривает ОП-код первой команды, и если это ОП-код категории А, выходная линия А декодера 40 устанавливается на уровень единицы. Если ОР0 является ОП-кодом категории В, тогда выходная линия В декодера 40 устанавливается на уровень единицы. Если ОР0 не принадлежат к категории А, ни к категории B, тогда оба выхода декодера 40 находятся на уровне двоичного нуля. Вторая декодер 41 выполняет аналогичный тип декодирования в отношении второго ОП-кода OP1.
Логический элемент И 42 реализует правило 1. Если OP0 является ОП-кодом категории А, и OP1 также является ОП-кодом категории А, тогда логический элемент И 42 образует выход на уровне единицы. Логический элемент И 43 реализует правило 4. Если первый ОП-код является ОП-кодом категории B, и второй ОП-код является ОП-кодом категории А, тогда логический элемент И 43 производит выходной сигнал на уровне единицы. В остальном он образует выходной сигнал уровня ноль. Если любой из логических элементов И 42 или И 43 образует выходной сигнал на уровне единицы, это возбуждает выход логического элемента ИЛИ 44 на уровне единицы, и в этом случае сигнал М01 совместимости имеет величину единицы. Эта величина единицы указывает, что первая и вторая команды (команды 0 и 1) являются совместимыми для целей параллельного выполнения.
Если детектируется любая другая комбинация категорий ОП-кодов декодерами 40 и 41, тогда выходы логических элементов И 42 и 43 остаются на уровне нуля, и сигнал совместимости М01 значение нуля, указывающее на несовместимость. Таким образом, появлению комбинаций, указанных правилами 2 и 3, не удовлетворяют логические элементы И 42 и 43, и М01 остается на уровне нуля. Если имеются другие категории ОП-кодов дополнительно к категориям А и В, их появление в потоке команд не возбуждает выходы декодеров 40 и 42. Поэтому они аналогичным образом ведут к значению сигнала возможности объединения М01 ноль.
Вторая логическая схема 31 совместимости команд проводит аналогичного типа анализ ОП-кода в отношении второй и третьей команд (команды 1 и 2). Если второй ОП-код OP1 является ОП-кодом категории А, и третий ОП-код OP2 является ОП-кодом категории А, тогда согласно правилу 1 логический элемент И 46 образует выходной сигнал на уровне единицы, и второй сигнал М12 совместимости объединения возбуждается до уровня двоичной единицы, указывающий на совместимость объединения. Если OP1 является ОП-кодом категории B, и OP2 является ОП-кодом категории А, тогда согласно правилу 4 логический элемент И 47 возбуждается для образования уровня двоичной единицы в отношении второго сигнала совместимости объединения М 12. В отношении любой комбинации ОП-кодов иного типа, чем изложены в правилах 1 и 4, сигнал М 12 будет иметь величину ноль.
Сигналы совместимости объединения М01 и М12 подаются на генератор 26 маркеров. На фиг. 8 показана логическая схема, которая может использоваться в генераторе 26 маркеров в ответ на сигналы совместимости объединения М01 и М12 для образования требуемых значений бит маркера в отношении маркеров 0,1 и 2. Значение единицы бита маркера указывает, что взаимодействующая команда является "первой" командой для целей параллельного использования. Значение бита маркера ноль указывает, что взаимодействующая команда является "второй" командой для целей параллельного объединения. Одна только команда в паре имеет значение бита маркера ноль. Любая команда, имеющая значение бита маркера единица, за которой следует другая команда, имеющая значение бита маркера единица, выполняется сама по себе единолично, а не параллельно со следующей командой.
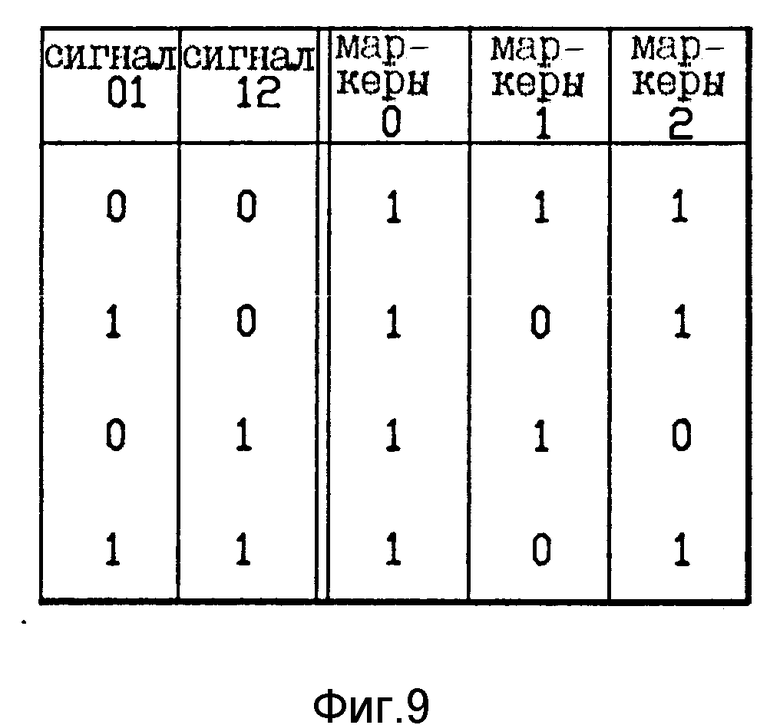
В отношении случая первого ряда на фиг. 9, все три бита маркеров имеют значение единица. Это означает, что каждая из команд 0 и 1 выполняется единолично, не параллельно с другой командой. В отношении второго ряда на фиг. 2, команды 0 и 1 будут выполняться параллельно, так как маркер 0 имеет требуемое значение единица, и маркер 1 имеет требуемое значение ноль. В отношении третьего ряда на фиг. 9, команда 0 будет выполняться единолично, в то время как команды 1 и 2 будут выполняться параллельно друг с другом. В отношении четвертого ряда, команды 0 и 1 будут выполняться параллельно друг с другом.
В отношении тех случаев, когда маркер 2 имеет двоичное значение единица, состояние его взаимодействующей команды 2 зависит от двоичного значения маркера 3. Если маркер 3 имеет двоичное значение ноль, тогда команды 2 и 3 могут выполняться параллельно. Если маркер 3 имеет двоичное значение единица, тогда команда 2 будет выполняться единолично, непараллельно с другой командой. Следует отметить, что логическая схема, реализованная в отношении генератора 26 маркеров, не дает возможности появления двух последовательных бит маркеров, имеющих двоичные значения нуля.
Рассмотрение фиг. 9 показывает логическую схему, необходимую для реализации частью генератора 26 маркеров, показанную на фиг. 8. Как показано на фиг. 9, маркер 0 всегда иметь двоичное значение единицы. Это достигается путем образования постоянного двоичного значения единицы на выходной линии 50 генератора маркеров, которая составляет выходную линию маркера 0. Рассмотрение фиг. 9 далее показывает, что значение бита в отношении маркера 1 всегда обратное значение бита сигнала совместимости объединения М01. Этот результата достигается путем соединения выходной линии 51 маркера 1 с выходом логического элемента НЕ 52, вход которого соединен с линией сигнала М01.
Двоичный уровень на выходной линии 53 маркера 2 определяется логическим элементом ИЛИ 54 и логическим элементом НЕ 55. Один вход элемента ИОИ 54 соединен с линией М01. Если М01 имеет значение единицы, тогда маркер 2 имеет значение единицы. Это определяет значения маркера 2 во втором и четвертом рядах на фиг. 9. Другой вход логического элемента ИЛИ 54 соединен посредством логического элемента НЕ 44 с линией сигнала М12. Если М12 имеет двоичное значение ноль, это значение инвертируется элементом НЕ 55 для подачи двоичного значения единицы на второй вход элемента ИЛИ 54. Это побуждает выходную линию 53 маркера 2 иметь двоичное значение единицы. Это определяет значение маркера 2 для ряда один на фиг. 9. Следует отметить, что в отношении случая ряда 3 маркер 2 должен иметь значение нуля. Это все будет происходить по той причине, что в отношении этого случая М01 будет иметь значение нуля, и М12 будет иметь значение единицы, которая инвертирована элементом НЕ 55 для образования нуля на втором входе элемента ИЛИ 54.
Явно в логической схема фиг. 9 имеет место правило приоритезации в случае четвертого ряда, где каждый М01 и М12 имеет двоичное значение единицы. Этот случай четвертого ряда может быть образован последовательностью категорий команд ВАА. Это может быть реализовано путем последовательности маркеров 101 как показано на фиг. 9 или альтернативно последовательностью маркеров 110. В настоящем варианте реализации соблюдается правило 5, и выбрана последовательность 101, показанная на фиг. 9. Иначе говоря, спаривание ВА имеет предпочтение по отношению к спариванию АА.
Образец 1, 1 в отношении 1101 и М12 может быть также образован на последовательности ОП-кода ААА. В этом случае последовательность маркера 102 на фиг. 9 снова выбирается. Это лучше, потому что образует значение единицы для маркера 2, и поэтому потенциально дает возможность объединить команду 2 с командой 3, если команда 2 совместима для выполнения с командой 3.
На фиг. 10 показан подробный пример, как компьютерная система может быть выполнена для использования маркеров объединения согласно настоящему изобретению для образования параллельной обработки команд компьютера на уровне машины. Блок 20 объединения команд, используемый на фиг. 10, предполагается быть типом, описанным на фиг. 6, и как таковой он добавляет к каждой команде поле маркера одного бита. Эти поля маркеров используются для идентификации, какие пары команд могут обрабатываться параллельно. Страницы, содержащие эти маркированные команды, подаются на и загружаются в основную память 10. Если маркированные команды требуются, они считываются или передаются в кэш 12. Управляющий блок 60 выборки/выдачи выбирает маркированные команды из кэш 12, когда требуется, и распределяет для их обработки соответствующим одним или одними из множества функциональных блоков обработки команд 61-64. Блок 60 выборки/выдачи рассматривает поля маркеров и поля ОП-кодов выбранных команд. Если поля маркеров указывают, что две последовательные команды могут быть обработаны параллельно, тогда блок 60 выборки/выдачи присваивает им соответствующие одни из функциональных блоков 61-64, как определено их ОП-кодами, и они обрабатываются параллельно выбранными функциональными блоками. Если поля маркеров указывают, что конкретная команда должна быть обработана единолично, непараллельно с другой командой, тогда блок выборки/выдачи 60 приписывает ее к конкретному функциональному блоку, как определено ее ОП-кодом, и она обрабатывается или выполняется сама по себе.
Первый функциональный блок 61 является блоком обработки команды перехода (ветвления) для обработки команд типа перехода. ("Переход" или "ветвление" в контексте оригинала означает переход от завершения выполнения одной команды к началу выполнения другой в данной последовательности команд - прим. переводчика). Второй функциональный блок 62 является арифметическим и логическим блоком образования трех входных адресов АЛУ), который используется для вычисления адресов памяти в отношении команд, которые передают операнды в или из ЗУ. Третий функциональный блок 63 является арифметическим и логическим блоком (АЛУ) общего назначения, который используется для выполнения операций арифметического и логического типа. Четвертый функциональный блок 64 в настоящем примере является АЛУ сокращения зависимости от данных типа, описанный в вышеназванной одновременно поданной заявке N 07/504.910 (по реестру IBM EN9-90-014). Это АЛУ сокращения зависимости 64 является трехвходным АЛУ, способным выполнять две арифметические/логические операции за один машинный цикл.
Вариант реализации компьютерной системы на фиг. 10 также включает в себя группу общего назначения регистров 65 для использования при выполнении некоторых из команд на уровне машины. Типично эти регистры 65 общего назначения используются для временной загрузки операнд данных и операнд адресов или используются как счетчики или для других целей обработки данных. В типовой компьютерной системе имеется шестнадцать (16) таких регистров общего назначения. В настоящем варианте реализации регистры 65 общего назначения считаются являющимися одним из многоканальных типов, в котором два или больше регистров могут иметь доступ для проведения выборки одновременно.
Компьютерная система на фиг. 10 далее включает в себя быстродействующее средство ЗУ кэш 66 для загрузки операнд данных, полученных от блока 10 ЗУ более высокого уровня. Данные в кэш 66 могут также использоваться для передачи обратно в основную память 10. Кэш 66 данных может быть известного типа, и его функционирование относительно основной памяти 10 может проводиться известным образом.
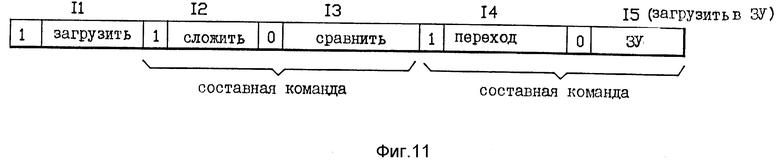
На фиг. 11 показан пример последовательности объединенных и маркированных команд, которая может быть обработана компьютерной системой на фиг. 10. пример на фиг. 11 составлен из следующих команд в следующей последовательности: загрузить в память, сложить, сравнить, перейти на условие и хранение. Они идентифицированы как команды 11-15 соответственно. Биты маркеров для этих команд есть 1,1,0,1 и 0 соответственно. Исходя из организации машины, показанной на фиг. 10, команда Загрузить выполняется единолично сама собой. Команды Сложить и Сравнить трактуются как составная команда и обрабатываются параллельно друг с другом. Команды Перейти и Сохранить в ЗУ также трактуются как составная команда и также выполняется параллельно друг с другом.
Таблица на фиг. 12 дает дальнейшую информацию по каждой из этих команд на фиг. 11. Колонка R/M на фиг. 12 указывает содержание первого поля в каждой команде, которая типично используется для идентификации конкретного одного из регистров 65 общего назначения, который содержит первый операнд. Исключением является случай команды Перехода на условие, в котором поле R/M содержит маску кода условия. Колонка R/X на фиг. 12 указывает содержание второго поля в каждой команде, которое (поле) типично используется для идентификации второго одного из регистров 65 общего назначения. Такой регистр может содержать второй операнд или может содержать значение индекса адреса (X). В колонке В на фиг. 12 указывается содержание третьего возможного поля в каждой команде, которое (поле) может идентифицировать конкретный один из регистров 65 общего назначения, который содержит значение адреса базы. Нуль в колонке В указывает на отсутствие поля В или отсутствие соответствующего адресного компонента в поле В. Поле D на фиг. 12 указывает содержание дальнейшего поля в каждой команде, которое, когда используется для цели образования адреса, включает в себя значение перемещения адреса. Нуль в колонке D может также указывать на отсутствие соответствующего поля в конкретной рассматриваемой команде или альтернативное значение перемещения адреса ноль.
Рассматривая теперь обработку команд Загрузить в память на фиг. 11, управляющий блок выборки/выдачи 60 определяет из бит маркеров для этой команды Загрузить и следующий команды Сложить, что команда Загрузить должна быть выполнена единолично сама собой. Операция выполняется этой командой Загрузить и состоит в выборке операнда из ЗУ, в этом случае кэш 66 данных и в размещении такого операнда в регистре общего назначения R2. Адресу ЗУ, из которого этот операнд был выбран, определяется путем сложения вместе индексных значений а регистре Х, т.е. базового значения в регистре В и значения перемещения D. Управляющий блок 60 выборки/выдачи приписывает эту операцию образования адреса АЛУ 62 образования адреса. В этом случае АЛУ 62 складывает вместе значение индекса адреса в регистре Х (значение ноль в настоящем примере), значение базового адреса, содержащегося в регистре R7 общего назначения, и значение адреса перемещения (значение нуля в настоящем примере), содержащееся в самой команде. Результирующий вычисленный адрес хранения, появляющийся на выходе АЛУ 62 подается на адресный вход кэш 66 данных для проведения доступа/выборки требуемого операнда. Этот выбранный операнд загружается в регистр Р2 общего назначения в группе регистров 65.
Рассматривая теперь выполнение команд Сложить и Сравнить, эти команды выбираются управляющим блоком 60 выборки/выдачи. Управляющий блок 60 рассматривает маркеры объединения в отношении этих двух команд и отмечает, что они могут быть выполнены параллельно. Как видно на фиг. 12, команда Сравнить имеет явную зависимость от данных команды Сложить, так как команда Сложить должна выполняться до выполнения сравнение Р3. Однако эта зависимость может быть обработана с помощью АЛУ 64 сокращения зависимости от данных. Как следствие, эти две команды могут обрабатываться параллельно в конфигурации на фиг. 10. В частности, управляющий блок 60 назначает обработку команды Сложить блоку АЛУ 63 и назначает обработку команды Сравнить блоку АЛУ 64 сокращения зависимости.
АЛУ 63 складывает содержания регистра R2 общего назначения с содержаниями регистра R3 общего назначения и помещает результат сложения обратно в регистр R3 общего назначения. В то же время АЛУ 64 сокращения зависимости выполняет следующую математическую операцию:
R3+R2-R4
Код условия в отношении результата этой операции посылается в регистр кодов условия, расположенный в блоке 61 перехода. Зависимость от данных сокращается, потому что АЛУ 64 фактически вычисляет сумму R3+R2 и затем сравнивает эту сумму с R4 для определения кода условия. Благодаря этому АЛУ 64 не должно ждать результатов от АЛУ 63, которое выполняет команду Сложить. В этом конкретном случае числовые результаты, вычисляемые АЛУ 64 и появляющиеся на выходе АЛУ 64, не посылаются обратно в регистры 65 общего назначения. В этом случае АЛУ 64 просто устанавливают код условия.
Рассматривая теперь выполнение команды Переход и команды Загрузить в ЗУ, показанное на фиг. 11, эти команды выбираются из кэш 12 составных команд управляющим блоком 60 выборки/выдачи. Управляющий блок 60 определяет из бит маркеров в отношении этих команд, что они могут выполняться параллельно друг с другом. Он далее определяет из ОП-кодов двух команд, что команда Переход должна быть выполнена блоком 61 перехода и команда Загрузить в ЗУ должна быть выполнена АЛУ 62 образования адреса. В соответствии с этим определением поле М маски и поле D перемещения команды Переход посылаются на блок 61 перехода. Аналогичным образом значение индекса адреса в регистре Х и значение базы адреса в регистре В в отношении этой команды Переход получают из регистров 65 общего назначения и подают на блок 61 перехода. В этом примере значение Х является нулем, и значение базы получают из регистра R7 общего назначения. Значение D перемещения имеет шестнадцатиричное значение двадцати, тогда как поле М маски имеет значение положения маски восемь.
Блок 61 перехода начинает вычислять потенциальный адрес перехода (0+R7+20) и в то же время сравнивает код условия, полученный из предшествующей команды Сравнить с маской М кода условия. Если значение кода условия то же самое, как значение кода маски, условие необходимого перехода удовлетворено, и адрес перехода, вычисленный блоком 62 перехода после этого загружается в счетчик команд в управляющем блоке 60. Этот счетчик команд управляет выборкой команд из кэш 12 составных команд. Если условие не удовлетворяется (т. е. код условия, установленный предшествующей командой, не имеет значение восемь) тогда переход на предпринимается, и адрес перехода не посылается на счетчик команд в управляющем блоке 60.
В то же время, когда блок 61 перехода занят осуществлением своих действий для обработки команды Переход, АЛУ 62 образования адреса занят вычислением адреса (0+R7+0) в отношении команды Загрузить в ЗУ. Вычисление адреса блоком АЛУ 62 посылается в кэш 66 данных. Если переход не предпринимается блоком 61 перехода, тогда команда Загрузить в ЗУ функционирует для загрузки операнда в регистре Р3 общего назначения в кэш 66 данных в адрес, вычисленный блоком АЛУ 62. Если условие перехода удовлетворено, и переход предпринят, тогда содержание регистра R3 общего назначения не загружается в кэш 66 данных.
Вышеприведенная последовательность команд на фиг. 11 приведена только как пример. Компьютерная система в варианте реализации на фиг. 10 также способна выполнять разные и различные другие последовательности команд. Однако пример на фиг. 11 четко показывает полезность маркеров составных команд при определении, какие пары команд могут выполняться параллельно друг с другом.
Каждое спаривание команды, имеющей значение бита маркера единицу с последующей командой, имеющей значение бита маркера ноль образует совокупную или составную команду для целей параллельного выполнения или обработки, т.е. команды, в которых пара может обрабатываться параллельно друг с другом. Когда биты маркера в отношении двух последовательных команд, каждая из которых имеет значение единицы, первая из этих команд выполняется как сама по себе, непараллельно с другой командой. В наихудшем возможном случае все команды в последовательности могут иметь значение бита маркера единицу. В этом наихудшем случае все команды будут выполняться по одной за один раз непараллельным образом.
Вышеприведенный пример технических средств в связи с предпочитаемым вариантом реализации этого изобретения объединяет в небольшом объеме. В этом отношении каждая пара смешной команды анализируется для определения, может ли пара быть выполнена параллельно. Фактически, объединение памяти представляет возможность анализа многих объединений свыше семи, два команды, и выбора наилучшего возможного группирования команд.
В вышеприведенных примерах используется способ, который предполагает значение, где начинаются команды. В общем случае границы команд могут быть идентифицированы компьютером, как сказано выше, или путем декодирования команд перед выполнением. Приводится ссылка на одновременно поданные заявки под названием "Структура вычислительной машины с расширяемым набором составных команд" и "Устройство объединения общего назначения для процессоров параллельной обработки на уровне команд".
Наконец, блок объединения команд иллюстрирован, в частности, как расположенный между адаптером Вв/Выв и шиной памяти. Этот пример не означает исключения других вариантов размещения в памяти, в которых может функционировать блок объединения команд. Например, он может быть включен в адаптер Вв/Выв, может функционировать как отдельный блок на шине 9 памяти (при таком расположении он может объединяться с основной памятью 10 или с кэш 12 составных команд), или может содержать блок, соединенный только с основной памятью через конкретный канал памяти, недоступный по шине 9 памяти. Средство объединения может также функционировать между основной памятью и кэш команд, как сказано в одновременно поданной заявке под названием "Предпроцессор объединения для кэш".
Хотя мы здесь описали предпочитаемый вариант реализации нашего изобретения, должно быть понятно, что модификации и адаптации его могут производиться специалистами в этой области техники. Поэтому патентная защита, представляемая нашему изобретению, должна ограничиваться только в соответствии с объемом нижеследующей формулы изобретения.


Изобретение относится к области цифровой вычислительной техники и предназначено для обработки двух или больше компьютерных команд параллельно. Цифровая компьютерная система, имеющая блок основной памяти для хранения блоков информации, содержащая компьютерные команды, включает в себя блок объединения команд для анализа команд и добавление к каждой команде поля маркера. Маркированные команды загружаются в основную память. Компьютерная система также включает в себя множество функциональных блоков обработки команд, которые функционируют параллельно друг с другом. Команды, поданные на функциональные блоки, поступают из памяти посредством блока ЗУ (КЭШ). В период времени подачи команды поля маркера команд рассматриваются, и те, которые маркированы для параллельной обработки, пересылаются в разные функциональные блоки в соответствии с кодами их полей кодов операций. 5 з.п.ф-лы, 12 ил.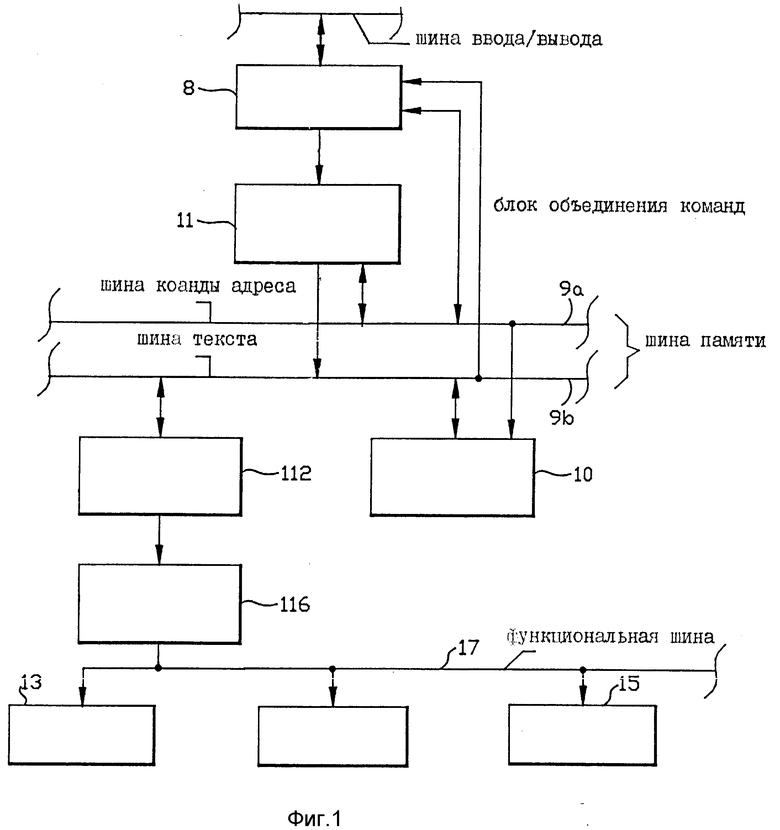
| US, патент, 4591972, кл | |||
| Приспособление для точного наложения листов бумаги при снятии оттисков | 1922 |
|
SU6A1 |
| SU, авторское свидетельство, 1295410, кл | |||
| Приспособление для точного наложения листов бумаги при снятии оттисков | 1922 |
|
SU6A1 |
| SU, авторское свидетельство, 1517035, кл | |||
| Приспособление для точного наложения листов бумаги при снятии оттисков | 1922 |
|
SU6A1 |
| Дейтель | |||
| Операционная система, 2-е изд-е, 1990, гл.7 | |||
| US, патент, 4873629, кл | |||
| Приспособление для точного наложения листов бумаги при снятии оттисков | 1922 |
|
SU6A1 |
| US, патент, 4200927, кл | |||
| Приспособление для точного наложения листов бумаги при снятии оттисков | 1922 |
|
SU6A1 |
