Изобретение касается цифровых компьютеров и процессоров цифровых данных, цифровых компьютеров и процессоров данных, способных обрабатывать или выполнять две или больше команд параллельно или одновременно.
Эффективность традиционных компьютеров, которые выполняют команды по одной за один раз последовательным образом, значительно повышена в прошлом, главным образом, путем усовершенствования технологии схем. Такие компьютеры выполнения команд по одной за один раз иногда называется "скалярными" компьютерами или процессорами. Когда технология схем дошла до своего предела, конструкторы компьютеров разрабатывали другие средства для достижения значительного повышения эффективности.
Недавно были предложены так называемые "суперскалярные" компьютеры, которые пытаются повысить эффективность путем выполнения больше одной команды за один раз из потока одинарных команд. Такие предложенные суперскалярные вычислительные машины типично решают в течение периода выполнения команд, может ли данное число команд быть выполнено параллельно. Такое решение основывается на кодах операций (ОП-кодах) команд и зависимости от данных, которые могут существовать между смежными командами. ОП-коды определяют конкретные компоненты технических средств каждой из команд, которые будут использоваться для ее выполнения, вообще невозможно две или больше команд использовать в одном и том же компоненте технических средств в одно и то же время и невозможно выполнить команду, которая зависит от результатов предшествующей команды (зависимость от данных). Эти зависимости от технических средств и данных препятствуют выполнению некоторых комбинаций команд параллельно. В этом случае такие команды выполняются единолично, непараллельно с другими командами. Это, конечно, снижает эффективность суперскалярной вычислительной машины.
Предложенные суперскалярные компьютеры обеспечивают некоторые повышение эффективности, но также имеют недостатки, которые необходимо свести до минимума. С одной стороны, принятие решения в течение периода выполнения команд, какие команды могут выполняться параллельно, отнимает небольшое, но заметное количество времени, которое не может быть очень просто скрыто путем перекрывания его с другими нормальными операциями вычислительной машины. Этот недостаток становится более выраженным, когда сложность структуры набора команд увеличивается. Другой недостаток в том, что принятие решения должно проводиться повторно снова каждый раз, когда те же команды должны выполняться во второй или последующий раз.
Как показано в одновременно поданной заявке N 08/519.384 (по реестру IBM EN 9-90-020), один из принципов вычислительной машины для расширяемого набора составных команд (SCISM) состоит в следующем: не выносить решения с параллельном выполнении в течение периода выполнения. Делать это надо в более ранний момент в общем процессе обработки команд. Например, делать это перед буферами команд в этих вычислительных машинах, которые имеют буферные устройства команд или стековые запоминающие устройства (ЗУ) команд. В другом примере это надо делать до кэш-команд в этих вычислительных машинах, которые направляют команды в устройство кэш (кэш - быстродействующая буферная память большой емкости).
Другой принцип вычислительной машины SCISM состоит в записи результатов вынесения решения о параллельном выполнении, так что такие результаты в случае, когда те же самые команды используются во второй или последующий раз.
В одном варианте реализации настоящего изобретения запись вынесения решения о параллельном выполнении производится путем образования маркеров, которые добавляются или вставляются в индивидуальные команды в потоке команд. Эти маркеры говорят, могут ли команды выполняться параллельно или требуется их выполнять по одной за один раз. Этот процесс маркирования команд иногда именуется здесь как "объединение". Фактически он служит для объединения двух или более индивидуальных команд в одну составную команду для целей параллельной обработки.
В конкретном выгодном варианте реализации настоящего изобретения компьютер является таким, который содержит средства памяти или ЗУ кэш для временного хранения команд машины в их переходе из блока ЗУ более высокого уровня в компьютере в блоки выполнения команд компьютера, процесс маркирования объединения проводится между блоком ЗУ более высокого уровня и средством ЗУ кэш, так что в средство ЗУ кэш загружаются и команды и маркеры объединения команд. Как известно, использование хорошо спроектированного средства ЗУ кэш в машине и самом кэш служит для повышения общей эффективности (производительности) компьютера. И загрузка маркеров объединения в средство ЗУ кэш дает возможность использовать маркеры снова и снова так долго, как долго хранятся данные команды в средстве ЗУ кэш. Как известно, команды часто остаются в кэш достаточное время для возможности использования больше одного раза.
Для лучшего понимания настоящего изобретения вместе с другими и дальнейшими преимуществами и отличительными признаками его делается ссылка на нижеследующее описание совместно с прилагаемыми чертежами.
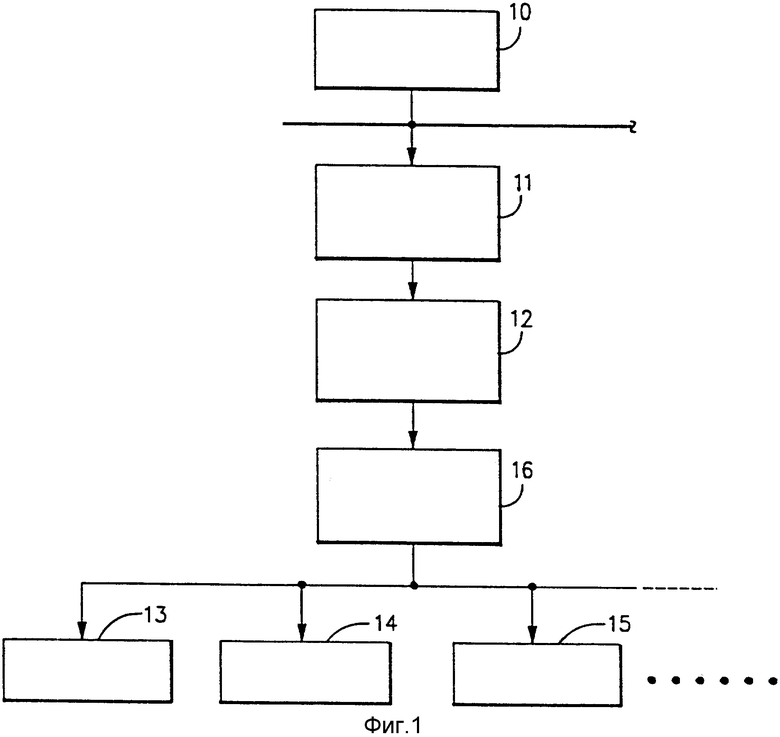
На фиг. 1 показан вариант реализации части цифровой компьютерной системы, выполненной в соответствии с настоящим изобретением; на фиг. 2 - вид длины потока команд, имеющих маркеры объединения или поля маркеров, связанные с командами; на фиг. 3 - более подробный вид внутренней конструкции репрезентативного варианта реализации блока объединения команд, который может использоваться в компьютерной системе на фиг. 1; на фиг. 4 - более подробный вид репрезентативной внутренней конструкции в отношении каждого из блоков анализатора объединения на фиг. 3; на фиг. 5 - вид примера логической схемы, которая может использоваться для реализации участков анализатора объединения и генератора маркеров на фиг. 3, которые образуют маркеры объединения в отношении первых трех команд в потоке команд; на фиг. 6 - таблица, используемая для пояснения функционирования примера на фиг. 5; на фиг. 7 - вид репрезентативного варианта реализации участка системы цифрового компьютера и используемого для пояснения, как составные или объединенные команды могут выполняться параллельно многофункциональными блоками обработки команд; на фиг. 8 - вид примера конкретной последовательности команд, которые могут обрабатываться компьютерной системой на фиг. 7; на фиг. 9 - таблица, используемая для пояснения обработки последовательности команд на фиг. 8 посредством компьютерной системы на фиг. 7.
На фиг. 1 показан репрезентативный вариант реализации части компьютерной системы и системы обработки цифровых данных, сконструированных в соответствии с настоящим изобретением. Эта компьютерная система способна обрабатывать две или больше команд параллельно. Она содержит первое средство ЗУ для хранения команд и данных, которые должны обрабатываться. Это средство ЗУ именуется как ЗУ 10 более высокого уровня. Это ЗУ 10 является средством ЗУ большой емкости, более медленного быстродействия и может быть, например, блоком ЗУ системы большой емкости или более нижней части обширной иерархической системы памяти или тому подобное.
Компьютерная система на фиг. 1 также может содержать средство объединения команд для приема команд от ЗУ 10 более высокого уровня и для взаимодействия с полями маркеров этих команд, которые указывают, какие их этих команд могут обрабатываться параллельно друг с другом. Это средство объединения команд представлено блоком 11 объединения команд. Этот блок 11 объединения команд анализирует поступающие команды для определения, какие из них могут обрабатываться параллельно. Далее блок 11 объединения команд образует для этих анализированных команд информацию маркера или поля маркера, которые указывают, какие команды могут обрабатываться параллельно друг с другом и какие команды не могут обрабатываться параллельно друг с другом.
Система на фиг. 1 далее содержит второе средство ЗУ, соединенное с блоком 11 объединения команд, для приема и хранения анализированных команд и их взаимодействующих полей маркеров. Это второе или дальнейшее средство ЗУ представлено в виде кэш 12 составных команд. Кэш 12 является меньшей емкости, с более быстродействующей памятью типа, обычно используемого для повышения быстродействия компьютерной системы путем снижения частоты наличия доступа к ЗУ 10 более низкого быстродействия.
Система на фиг. 1 далее содержит множество функциональных блоков обработки или выполнения команд, которые функционируют параллельно друг с другом. Эти функциональные блоки обработки команд представлены функциональными блоками 13, 14, 15 и т.д. Эти функциональные блоки 13 - 15 функционируют параллельно друг с другом одновременно, и каждый по своему может обрабатывать один или больше типов команд уровня машины. Примеры функциональных блоков, которые могут использоваться, следующие: общего назначения арифметико-логический блок (АЛУ), АЛУ типа образования адреса, АЛУ для устранения зависимости между данными (согласно одновременно поданной заявке N 07/504.910 (по реестру IBM EN 9-90-014), блок обработки команд перехода, блок сдвигового регистра данных, блок обработки плавающей запятой и т.д. Данная компьютерная система может содержать два или больше одинаковых этих типов функциональных блоков. Например, данная компьютерная система может содержать два или больше АЛУ общего назначения. Данной компьютерной системе не требуется также содержать каждый и каждого по одному из этих разных типов функциональных блоков. Конкретная конфигурация функциональных блоков будет зависеть от природы конкретной рассматриваемой компьютерной системы.
Компьютерная система на фиг. 1 также содержит средство выборки и выдачи команд, соединенное с кэш 12 составных команд, для подачи смежных команд, загруженных в него, на разные функциональные блоки 13 - 15 обработки команд, когда поля маркеров команд указывают, что они могут обрабатываться параллельно. Это средство представлено блоком 16 выборки и выдачи команд. Блок 16 выборки и выдачи команд выбирает команды из кэш 12, рассматривает их поля маркеров и поля кодов операций (ОП-кодов) и исходя из такого рассмотрения/анализа, посылает команды на соответствующие функциональные блоки 13 - 15.
Если требуемая команда находится в кэш 12 составных команд, соответствующий адрес посылается на кэш 12 для выборки из него требуемой команды. Это иногда именуется как "попадание на кэш". Если требуемая команда не находится в кэш 12, тогда она должна быть выбрана из ЗУ 10 более высокого уровня (по иерархии - прим. переводчика) и перенесена в кэш 12. Это иногда именуется как "пробел в кэш". Когда происходит пробел, адрес требуемой команды посылается в ЗУ 10 более высокого уровня. В ответ на это ЗУ 10 начинает передавать или считывать строку команд, которая содержит требуемую команду. Эти команды передаются на вход блока 11 объединения команд, который (блок) приступает к анализу этих поступающих команд и генерирует соответствующее поле маркера для каждой команды. Маркированные команды после этого посылаются в кэш 12 составных команд и загружаются в него для последующего использования, если это потребуется, функциональными блоками 13 - 15.
Анализ команды, проведенный в блоке 11 объединения команд, требует относительно небольшого определенного количества времени.
Однако анализ объединения команд проводится только в случае, когда происходит пробел в кэш командах, поэтому относительно нечасто.
На фиг. 2 показана часть потока объединенных или маркированных команд, как они могут появиться на выходе блока 11 объединения команд на фиг. 1. Как можно видеть, каждая команда (Команд.) имеет поле маркера, добавленное к ней блоком 11 объединения команд. Маркированные команды подобно показанным на фиг. 2 загружаются в кэш 12 составных команд. При необходимости маркированные команды в кэш 12 выбираются блоком 16 выборки и выдачи команд. Если маркированные команды приняты блоком 16 выборки и выдачи команд, их поля маркеров рассматриваются для определения, могут ли они обрабатываться параллельно, и рассматриваются их поля кодов операций (ОП-кодов) для определения, какие из возможных функциональных блоков наиболее соответствуют для их выполнения. Если поля маркеров указывают, что две или больше команд соответствуют для обработки параллельно, тогда они посылаются на соответствующий один из функциональных блоков в соответствии с кодированиями из полей ОП-кодов. Такие команды затем обрабатываются одновременно с одной (другой) командой им соответствующими функциональными блоками.
Когда встречается команда, которая не соответствует для параллельного выполнения, тогда она посылается на соответствующее функциональное устройство, как определено ее ОП-кодом, после этого обрабатывается единолично сама по себе выбранным функциональным блоком.
В наиболее удачном случае, когда множество команд обрабатывается параллельно, скорость выполнения команд компьютерной системы будет в 11 раз больше в случае, когда команды выполняются по одной за один раз, где 11 будет числом команд в группах, которые обрабатываются параллельно.
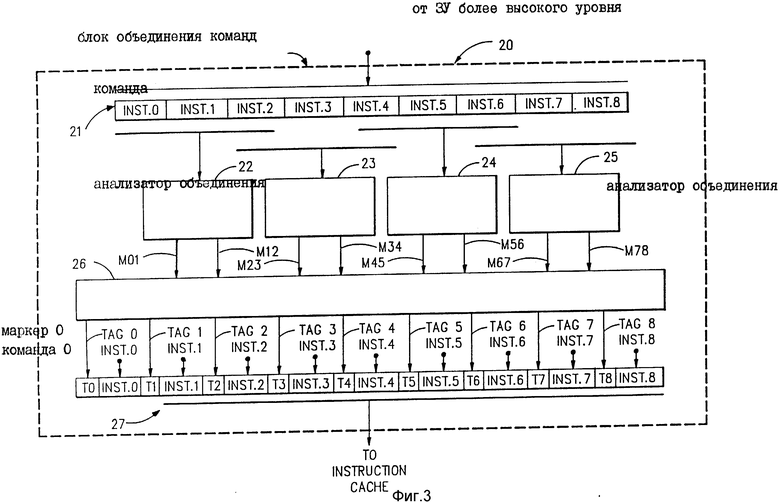
На фиг. 3 показано более подробно внутреннее построение репрезентативного варианта реализации блока объединения команд, выполненного в соответствии с настоящим изобретением. Этот блок объединения команд 20 соответствует для использования в качестве блока 11 объединения команд на фиг. 1. Блок 20 объединения команд на фиг. 3 выполнен для случая, когда максимально две команды за один раз могут обрабатываться параллельно. В этом случае используется поле маркера с одним битом (разрядом). Значение бита маркера "единица" означает, что команда является "первой". Значение бита маркера "ноль" означает, что команда является и может выполняться параллельно с предшествующей первой командой. Команда, имеющая значение бита маркера "единица", может выполняться либо единолично, либо одновременно и параллельно со следующей командой в зависимости от значения бита маркера в отношении такой следующей команды.
Каждое спаривание команд, в котором одна команда имеет значение бита маркера "единица", а последующая команда имеет значение бита маркера "ноль", образует составную команду для целей параллельного выполнения, т.е. команды в такой паре могут обрабатываться параллельно друг с другом. Когда биты маркеров в отношении двух последующих команд каждая имеют значение "единица", первая из этих команд выполняется сама по себе непараллельно в другой командой. В наихудшем возможном случае все команды в последовательности будут иметь значение бита маркера "единица". В этом наихудшем случае все команды будут выполняться по одной за один раз непараллельно.
Блок 20 объединения команд на фиг. 3 содержит регистр 21 команд для множества команд для приема множества последовательных команд от блока ЗУ 10 более высокого уровня. Блок 20 объединения команд также содержит множество средств анализатора команд на основе правил. Каждое такое средство анализатора команд анализирует разные пары смежных команд в регистре 21 и образует сигнал возможности или совместимости объединения, который указывает, могут или нет две команды в своей паре обрабатываться параллельно. На фиг. 3 показано множество блоков анализаторов объединения 22 - 25. Каждый из этих блоков 22 - 25 анализаторов объединения содержит два только что упомянутых средства анализатора команд. Таким образом, каждый из этих блоков анализатора 22 - 25 образует два сигнала совместимости объединения. Например, первый блок 22 анализатора объединения образует первый сигнал совместимости объединения М-01, который указывает, могут или нет команды 0 и 1 обрабатываться параллельно. Блок 22 анализатора объединения также образует второй сигнал совместимости объединения М12, который указывает, могут или нет команды 1 и 2 обрабатываться параллельно.
Аналогичным образом второй блок 23 анализатора объединения образует первый сигнал совместимости объединения М23, который указывает, могут или нет команды 2 и 3 обрабатываться параллельно, и второй сигнал совместимости объединения М34, который указывает, могут или нет команды 3 и 4 обрабатываться параллельно. Третий блок 24 анализатора объединения образует первый сигнал совместимости объединения М45, который указывает, могут или нет команды 4 и 5 обрабатываться параллельно, и второй сигнал совместимости объединения М56, который указывает, могут или нет команды 5 и 6 обрабатываться параллельно. Четвертый блок 25 анализатора объединения образует первый сигнал совместимости объединения М67, который указывает, могут или нет команды 6 и 7 обрабатываться параллельно, и второй сигнал совместимости объединения М78, который указывает, могут или нет команды 7 и 8 обрабатываться параллельно.
Блок 20 объединения команд далее содержит средство 26 генерирования маркеров, реагирующее на сигналы совместимости объединения, появляющиеся на выходах блоков 22 - 25 анализаторов, для генерирования индивидуальных полей маркеров для разных команд в регистре 21 команд. Эти поля маркеров Т0, Т1, Т2 и т.д. подаются на регистр 27 маркированных команд, как сами команды, которые (команды) поступают из регистра 21 входных команд. Благодаря этому в выходном регистре 27 блока объединения образуется поле маркера Т0 для команды 0, поле маркера Т1 для команды 1 и т.д.
В настоящем варианте реализации каждое поле маркера Т0, Т1, Т2 и т.д. состоит из одного двоичного разряда или бита. Значение бита маркера "единица" указывает, что непосредственно следующая команда, с какой он связан, является первой командой. Значение бита маркера "ноль" указывает, что непосредственно следующая команда является второй командой. Команды, имеющая значение бита маркера единицу, за которой следует команда, имеющая значение бита маркера ноль, указывает, что эти две команды могут выполняться параллельно друг с другом. Маркированные команды в выходном регистре 27 блока объединения подаются на вход кэш 12 составных команд на фиг. 1 и загружаются в такой кэш 12 составных команд.
Следует отметить, что количество средств регистра, показанных на фиг. 3, может быть сокращено путем загрузки составных команд непосредственно в кэш составных команд.
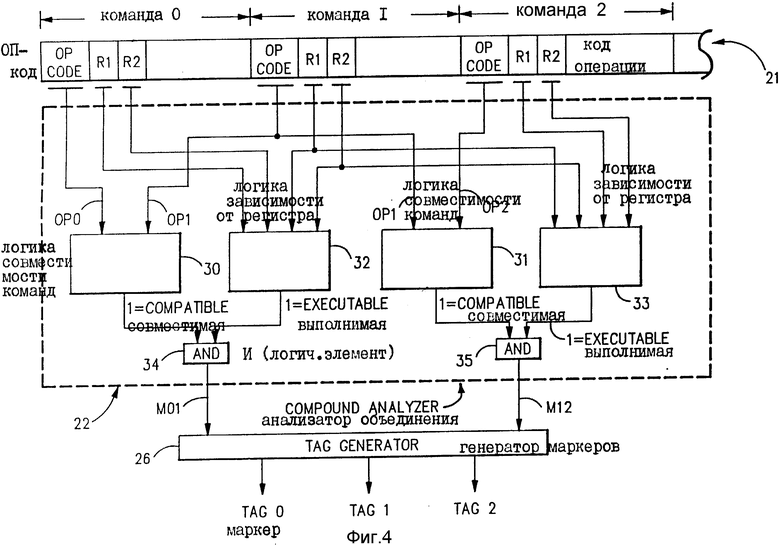
Обращаясь теперь к фиг. 4, на ней подробно показана внутренняя конструкция для блока 22 анализатора на фиг. 3. Остальные блоки 23 - 25 анализатора объединения аналогичны по конструкции. Как показано на фиг. 4, анализатор 22 объединения содержит логическую схему 30 совместимости команд для анализа ОП-кода команды О и ОП-кода команды 1 и для определения, совместимы ли эти два ОП-кода для целей параллельного выполнения. Логическая схема 30 выполнена в соответствии с заданными правилами для выбора, какие пары ОП-кодов совместимы для параллельного выполнения. Более конкретно логическая схема 30 содержит логическую схему для реализации правил, которые определяют, какие типы команд совместимы для параллельного выполнения в конкретной конфигурации технических средств, используемых для рассматриваемой компьютерной системы. Если ОП-коды команд 0 и 1 являются совместимыми, тогда логическая схема 30 образует на своем выходе сигнал уровня двоичной единицы. Если они несовместимы, логическая схема 30 образует значение двоичного нуля на своей выходной линии.
Анализатор 22 объединения далее содержит логическую схему 31 совместимости второй команды для анализа ОП-кодов команд 1 и 2 и для определения, являются ли они совместимыми для параллельного выполнения. Логическая схема 31 выполнена таким же образом, как логическая схема 30 в соответствии с теми же заданными правилами, используемыми для логической схемы 30, чтобы выбрать, какие пары ОП-кодов являются совместимыми для параллельного выполнения в случае команд 1 и 2. Таким образом, логическая схема 31 содержит логическую схему для реализации правил, которые определяют, какие типы команд совместимы для параллельного выполнения, причем эти правила те же самые, которые применяются в логической схеме 30. Если ОП-коды для команд 1 и 2 совместимы, тогда логическая схема 31 образует выход на уровне двоичной единицы. В противном случае она образует выход на уровне двоичного нуля.
Анализатор 22 объединений далее содержит первую логическую схему 32 зависимости от регистра для определения конфликтов при использовании регистров общего назначения, обозначенных полями R1 и R2 команд 0 и 1. Эти регистры общего назначения будут пояснены подробнее ниже. Наряду с другим логическая схема 32 зависимости может быть выполнена для определения появления условия зависимости от данных, в котором вторая команда (команда 1) нуждается в использовании результатов, полученных после выполнения предшествующей команды (команды 0). В этом случае либо вторая команда может быть выполнена с помощью технических средств устранения зависимости, тем самым выполняемый параллельно с первой командой, либо выполнение второй команды должно ждать завершения выполнения предшествующей команды, и поэтому она не может быть выполнена параллельно с предшествующей командой. (Следует отметить, что способ для обхода некоторых зависимостей от данных этого типа будет пояснен ниже). Если нет зависимости от регистра, которая препятствует выполнению команд 0 и 1 параллельно, тогда выходная линия логической схемы 32 принимает значение двоичной единицы. Если зависимость есть, тогда эта выходная линия принимает значение двоичного нуля.
Анализатор 22 объединений далее содержит вторую логическую схему 33 зависимости от регистра для обнаружения конфликтов при использовании регистров общего назначения, обозначенных полями R1 и R2 команд 1 и 2. Эта логическая схема 33 такой же конструкции, как ранее описанная логическая схема 32, и образует выход на уровне двоичной единицы, если нет зависимостей от регистров, или зависимости от регистров могут быть обработаны техническими средствами устранения зависимости от данных, в противном случае на выходе будет уровень двоичного нуля.
Выходные линии от логической схемы 30 совместимости команд и логической схемы 32 зависимости от регистра соединены с двумя входами логического элемента И 34. Выходная линия логического элемента И 34 имеет значение двоичной единицы, если два ОП-кода, которые были проанализированы, являются совместимыми для объединения, т.е. могут выполняться параллельно. Если, с другой стороны, выходная линия логического И 34 имеет двоичное значение нуля, тогда две команды несовместимы для объединения. Таким образом, на выходной линии логического элемента И 34 образуется первый сигнал совместимости объединения МО1, который указывает, могут или нет команды 0 и 1 обрабатываться параллельно. Этот сигнал МО1 подается на генератор 26 маркеров.
Выходные линии от второй логической схемы совместимости 31 и второй логической схемы 33 зависимости соединены с двумя входами логического элемента И 35. Логический элемент И 35 образует на своей выходной линии второй сигнал совместимости объединения М12, который имеет двоичное значения единицы, если два ОП-кода после их анализа оказались совестимыми и если нет зависимости от регистра у команд 1 и 2 или зависимость от регистра такова, что выполнение может производиться техническими средствами устранения зависимости данных. В противном случае выходная линия логического элемента И 35 будет иметь двоичное значение нуля. Выходная линия от логического элемента И 35 идет к второму входу генератора 26 маркеров.
Другие анализаторы 23 - 25 объединения, показанные на фиг.3, имеют ту же внутреннюю конструкцию, как показано на фиг.4 в отношении первого анализатора 22 объединений.
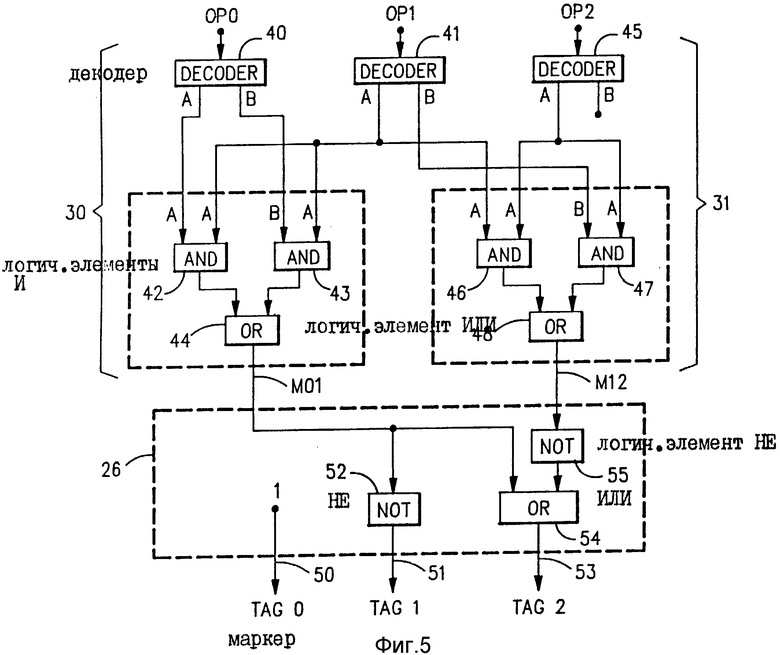
На фиг. 5 показан пример логической схемы, которая может использоваться для реализации анализатора 22 объединений и части генератора 26 маркеров, которая используется для генерирования первых трех маркеров: маркера 0, маркера 1 и маркера 2. В отношении примера на фиг.5 предполагается, что имеется две категории команд, которые обозначены как категория A и категория B. Правила в отношении объединения этих категорий команд предполагаются следующие:
1) A может всегда объединяться с A.
2) A никогда не может объединяться с B.
3) B никогда не может объединяться с B.
4) B может всегда объединяться с A.
5) Правила 4 имеет предпочтение по отношению к правилу 1.
Следует отметить, что эти правила чувствительны к порядку появления команд.
Далее предполагается, что эти правила таковы, что, когда они соблюдаются, то не будет проблем с зависимостями от регистров, потому что правила явно указывают, что в случае наличия взаимной блокировки, такая блокировка всегда может быть обработана техническими средствами устранения зависимости данных. Иначе говоря, в отношении примера на фиг.5 предполагается, что логические схемы 32 и 33 зависимости от регистра на фиг.4 не требуются. В таком случае логические элементы И 34 и 35 также не требуются и выход логической схемы 30 становится сигналом М01, а выход логической схемы 31 становится сигналов М11.
В отношении этих предположений фиг.5 показывает внутреннюю логическую схему, которая может использоваться для логики 30 совместимости команд и логики 31 совместимости команд на фиг.4. Со ссылкой на фиг.5 логика 30 совместимости команд содержит декодеры 40 и 41, логические элементы И 42 и 43 и логический элемент ИЛИ 44. Вторая логика 31 совместимости команды содержит декодеры 41 и 45, логические элементы И 46 и 47 и логический элемент ИЛИ 48. Средний декодер 41 используется совместно логическими схемами 30 и 31.
Первая логика 30 анализирует ОП-коды ОР0 и ОР1 команд 0 и 1 для определения их совместимости для целей параллельного выполнения, Это производится в соответствии с правилами 1 - 4, приведенными выше. Декодер 40 анализирует ОП-кода первой команды, если это ОП-код категории A, выходная линия A декодера 40 устанавливается на уровень единицы. Если ОР0 является ОП-кодом категории B, тогда выходная линия B декодера 40 устанавливается на уровень единицы. Если ОР0 не принадлежит ни к категории A, ни к категории B, тогда оба выхода декодера 40 будут на уровне двоичного нуля. Второй декодер 41 проводит такое же декодирование в отношении второго ОП-кода ОР1.
Логический элемент И 42 реализует правило 1, указанное выше. Если ОР0 является ОП-кодом категории A и ОР1 также является ОП-кодом категории A, тогда логический элемент И 42 образует выход на уровне единицы. В остальном выход логического элемента И 42 будет уровнем двоичного нуля. Логический элемент И 43 реализует правило 4, приведенное выше. Если первый ОП-код является ОП-кодом категории B, а второй ОП-код является ОП-кодом категории A, тогда логический элемент И 43 образует выход на уровне единицы. В остальном он образует выход на уровне нуля. Если или логический элемент И 42 или логический элемент И 43 образует выход на уровне единицы, это возбуждает логический элемент ИЛИ 44 на уровне единицы, в этом случает сигнал совместимости М01 будет иметь значение единицы. Это значение единицы указывает, что первая и вторая команды (команды 0 и 1) являются совместимыми при объединении для целей параллельного выполнения.
Если любая другая комбинация категорий ОП-кодом обнаруживается декодерами 40 и 41, тогда выходы логического элемента И 42 и логического элемента И 43 остаются на уровне нуля, а сигнал М01 совместимости объединения имеет значение нуля, указывающее на несовместимость. Таким образом, появление комбинаций, указанных правилами 2 и 3 выше, не удовлетворяет логические элементы И 42 и И 43, М01 остается на уровне нуля. Если имеются дальнейшие категории ОП-кодов дополнительно к категории A и B, их появление в потоке команд не возбуждает выходы декодеров 40 и 41. Поэтому они аналогичным образом ведут к сигналу совместимости объединения М01 на уровне нуля.
Вторая логическая схема 31 совместимости команд выполняет аналогичный тип анализа ОП-кода в отношении второй и третьей команд (команды 1 и 2). Если второй ОП-код ОР1 является ОП-кодом категории A, а третий ОП-код ОР2 является ОП-кодом категории A, тогда согласно правилу 1, логический элемент И 46 образует выход на уровне единицы, второй сигнал совместимости объединения М12 возбуждается до уровня двоичной единицы, указывающего на совместимость объединения. Если, с другой стороны, ОР1 является ОП-кодом категории B, ОР2 является ОП-кодом категории A, тогда согласно правилу 4 логический элемент И 47 возбуждается для образования уровня двоичной единицы и отношении второго сигнала совместимости объединения М12. В отношении других комбинаций ОП-кодов иного типа, чем те, которые изложены в правилах 1 и 4, сигнал М12 имеет значение нуля.
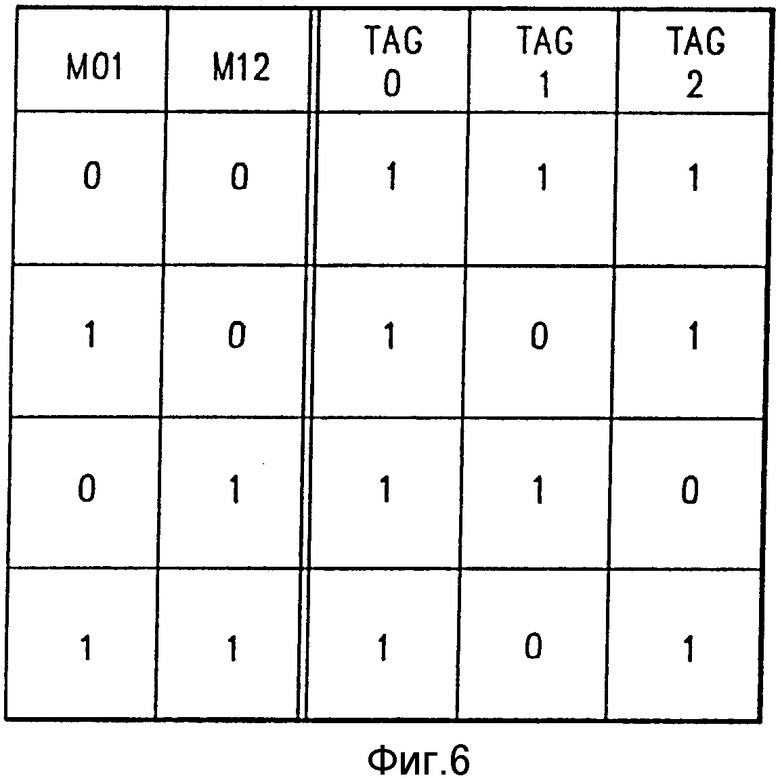
Сигналы совместимости объединения М01 и М12 подаются на генератор 26 маркеров. На фиг.5 показана логическая схема, которая может использоваться в генераторе 26 маркеров для реагирования на сигналы совместимости объединения М01 и М12, чтобы образовать требуемые значения бит маркеров в отношении маркеров 0, 1 и 2. Таблица на фиг.6 показывает логическую схему, которая реализуется генератором 26 маркеров в отношении маркеров 0, 1 и 2. Значение бита маркера "единица" указывает, что связанная с этим команда является первой командой для целей параллельного выполнения. Значение бита маркера "ноль" указывает, что связанная с этим команда является второй командой для параллельного выполнения. Единственные пары команд, которые объединяются и выполняются параллельно, это те, у которых первая команда в паре имеет значение бита маркера "единица", а вторая команда в паре имеет значение бита маркера "ноль". Любая команда, имеющая значение бита маркера "единица", за которой следует другая команда имеющая значение бита маркера "единица", выполняется сама по себе единолично, а не параллельно со следующей командой.
В отношении случая первого ряда на фиг.6 биты всех трех маркеров имеют значение "единица". Это означает, что каждая из команд 0 и 1 будет выполняться единолично, непараллельно с другой командой. В отношении второго ряда на фиг.6 команды 0 и 1 будут выполняться параллельно, так как маркер 0 имеет требуемое значение единицы, а маркер 1 имеет требуемое значение нуля. В отношении третьего ряда на фиг.6 команда 0 будет выполняться единолично, тогда как команды 1 и 2 будут выполняться параллельно друг с другом. В отношении четвертого ряда команды 0 и 1 будут выполняться параллельно друг с другом.
В отношении тех случаев, когда маркер 2 имеет двоичное значение единицы, состояние связанной с ним команды 2 зависит от двоичного значения маркера 3. Если маркер 3 имеет двоичное значение нуля, тогда команды 2 и 3 могут выполняться параллельно. Если, с другой стороны, маркер 3 имеет двоичное значение единицы, тогда команды 2 будет выполняться единолично, непараллельно с другой командой. Следует отметить, что логическая схема, реализованная в отношении генератора 26 маркеров, не дает возможности появления двух последовательных бит маркеров, имеющих двоичное значение нуля.
Рассмотрение фиг. 6 показывает логическую схему, необходимую для реализации частью генератора 26 маркеров, показанного на фиг.5. Как показано на фиг. 6, маркер 0 будет всегда иметь двоичное значение единицы. Это достигается путем образования постоянного двоичного значения единицы на выходной линии 50 маркерного генератора, которая составляет выходную линию маркера 0. Рассмотрение фиг.6 далее показывает, что значение бита для маркера 1 всегда противоположное значению бита сигнала совместимости объединения М01. Этот результат достигается путем соединения выходной линии 51 для маркера 1 с выходом логического элемента НЕ 52 вход которого соединен с линией сигнала М01.
Двоичный уровень на выходной линии 53 маркера 2 определяется логическим элементом ИЛИ 54 и логическим элементом НЕ 55. Один вход логического элемента ИЛИ 54 соединен с линией М01. Если М01 имеет значение "единица", тогда маркер 2 имеет значение "единица". Это определяет значения маркера 2 во втором и четвертом рядах на фиг.6. Другой вход логического элемента ИЛИ 54 соединен посредством логического элемента НЕ 55 с линией сигнала М12. Если М12 имеет двоичное значение нуля, это значение инвертируется логическим элементом НЕ 55 для подачи двоичного значения единицы на второй вход логического элемента ИЛИ 54. Это принуждает выходную линию 53 маркера 2 иметь значение двоичной единицы. Это определяет значение маркера 2 для ряда один фиг. 6. Следует отметить, что в отношении случая ряда 3 маркер 2 должен иметь значение нуля. Это будет происходить по той причине, что для этого случая М01 будет иметь значение нуля, а М12 будет иметь значение единицы, которое инвертируется логическим элементом НЕ 55 для образования нуля на втором входе логического элемента ИЛИ 54.
Явно в логической схеме на фиг.6 имеет место правило приоритезации в отношении случая ряда четыре, где каждый из М01 и М12 имеет двоичное значение единицы. Этот случай ряда четыре может быть создан последовательностью категорий команд BAA. Это может быть реализовано последовательностью маркеров 101, как показано на фиг.6, или альтернативно последовательностью маркеров 110. В настоящем варианте реализации выполняется правило 5, и последовательность 101, показанная на фиг.6, выбирается согласно этому правилу. Иначе говоря, спаривание ВА имеет предпочтение перед спариванием АА.
Образец 1, 1 в отношении М01 и М12 может также быть образован последовательностью ОП-кадров ААА. В этом случае последовательность маркеров 101 на фиг. 6 снова выбирается. Это лучше, потому что образует значение единицы для маркера 2, поэтому потенциально дает возможность команду 2 объединять с командой 3, если команда 2 совместима с командой 3.
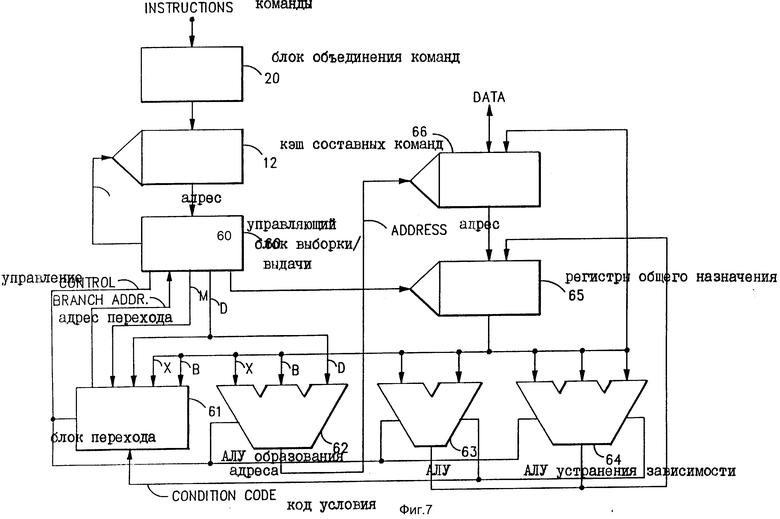
На фиг. 7 показан подробный пример, как компьютерная система может быть выполнена для использования маркеров объединения согласно настоящему изобретению для образования параллельной обработки команд компьютера на уровне машины. Блок 20 объединения команд, используемый на фиг.7, предположительно является типом, который описан на фиг.3, и как таковой он добавляет к каждой команде поле маркера в один бит. Эти поля маркеров используются для указания, какие пары команд могут выполняться параллельно. Эти маркированные команды подаются и загружаются в кэш 12 составных команд. Блок 60 управления выборкой/выдачей выбирает маркированные команды их кэш 12, если необходимо, и организует из обработку соответствующим одни или одними из множества функциональных блоков обработки команд 61, 62, 63 и 64. Блок 60 выборки/выдачи анализирует поля маркеров и поля ОП-кодов выбранных команд. Если поля маркеров указывают, что две последовательные команды могут быть обработаны параллельно, тогда блок 60 выборки/выдачи присваивает им соответствующие одни из функциональных блоков 61 - 64, как определено их ОП-кодами, и они обрабатываются параллельно выбранными функциональными блоками. Если поля маркеров указывают, что конкретная команда должна обрабатываться единолично, не параллельно с другой командой, тогда блок 60 выборки/выдачи придает ей соответствующий функциональный блок, как определено ее ОП-кодом, и она обрабатывается или выполняется сама по себе.
Первый функциональный блок 61 является блоком обработки команд перехода для обработки команд типа перехода (здесь "переход" в значении перехода выполнения от одной команды к другой в выбранной последовательности - прим. переводчика). Второй функциональный блок 62 является арифметико-логическим устройства (АЛУ) образования адресов, имеющим три входа, которое используется для вычисления адреса ЗУ (ячейки ЗУ) в отношении команд, которые передают операнды в ЗУ или из ЗУ. Третий функциональный блок 63 является арифметико-логическим устройством (АЛУ) общего назначения, которое используется для выполнения математических и логических операций. Четвертый функциональный блок 64 в настоящем примере является АЛУ для устранения зависимости данных типа, описанного в вышеупомянутой одновременно поданной заявке N 07/504.910 (по реестру IBM EN-9-90-014). Это АЛУ 64 устранения зависимости является АЛУ с тремя входами, способным выполнять две арифметико-логических операции за один машинный цикл.
Вариант реализации компьютерной системы на фиг.7 также содержит группу регистров 65 общего назначения для использования при выполнении некоторых команд на уровне машины. Типично эти регистры 65 общего назначения используются для временного хранения операндов данных и операндов адресов или используется как счетчики или для других целей обработки данных. В типовой компьютерной системе используется шестнадцать (16) таких регистров общего назначения. В настоящем варианте реализации регистров 65 общего назначения предполагаются многоканального типа, когда доступ к двум или больше регистрам может происходить одновременно.
Компьютерная система на фиг. 7 далее содержит быстродействующее ЗУ кэш данных 66 для хранения операндов данных, полученных от блока 10 ЗУ более высокого уровня. Данные в кэш 66 также могут переноситься обратно в блок 10 ЗУ более высокого уровня. Кэш 66 данных может быть известного типа и его функционирование относительно ЗУ 10 более высокого уровня может проводиться известным способом.
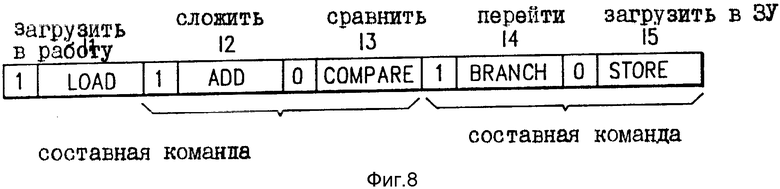
На фиг. 8 показан пример последовательности объединяемых или маркированных команд, которые могут обрабатываться компьютерной системой на фиг.7. Пример на фиг. 8 составлен из следующих команд в следующей последовательности: ЗАГРУЗИТЬ В РАБОТУ (LOAD). СЛОЖИТЬ (ADD), СРАВНИТЬ (COMPARE), ПЕРЕЙТИ ПО УСЛОВИЮ (BRANCH ON CONDITION) и ЗАГРУЗИТЬ В ПАМЯТЬ (STORE). Они идентифицированы как команды 11 - 15 соответственно. Биты маркеров в отношении этих команд 1, 1, 0, 1 и 0 соответственно. Исходя из организации вычислительной машины, показанной на фиг.7, команда ЗАГРУЗИТЬ В РАБОТУ обрабатывается единолично сама по себе. Команды СЛОЖИТЬ и СРАВНИТЬ трактуются как составная команда и обрабатываются параллельно друг с другом. Команды ПЕРЕЙТИ и ЗАГРУЗИТЬ В ПАМЯТЬ также трактуются как составная команда и также обрабатываются параллельно друг с другом.
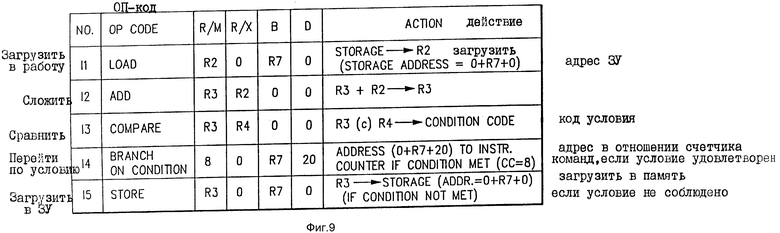
Таблица на фиг.9 дает дальнейшую информацию по каждой из этих команд на фиг. 8. Колонка R/M на фиг.9 указывает содержание первого поля в каждой команде, которое обычно используется для идентификации конкретного одного из регистров 65 общего назначения, который содержит первый операнд. Исключение составляет случай команды ПЕРЕХОДА ПО УСЛОВИЮ, в котором поле R/M содержит маску кода условия. Колонка R/M на фиг.9 указывает содержание второго поля в каждой команде, которое (поле) обычно используется для идентификации второго одного из регистров 65 общего назначения. Такой регистр может содержать второй операнд или может содержать значение индекса адреса (X). Колонка B на фиг.9 указывает содержание третьего возможного поля в каждой команде, которое (поле) может указывает конкретный один из регистров 65 общего назначения, который содержит значение адреса базы. Нуль в колонке B указывает на отсутствие поля B или отсутствие соответствующего компонента адреса в поле B. Поле D на фиг.9 указывает содержание дальнейшего поля в каждой команде, которое, когда используется для целей образования адреса, содержит значение перемещения адреса. Нуль в колонке D может также указывает на отсутствие соответствующего поля в данной команде, которая рассматривается, или альтернативно значение нуля перемещения адреса.
Рассматривая теперь обработку команды ЗАГРУЗИТЬ В РАБОТУ на фиг.8, управляющий блок 60 выборки/выдачи определяет из бит маркеров в отношении этой команды ЗАГРУЗИТЬ В РАБОТУ и следующей команды СЛОЖИТЬ, что команда ЗАГРУЗИТЬ В РАБОТУ должна обрабатываться единолично сама по себе. Действие, которое должно быть совершено этой командой ЗАГРУЗИТЬ В РАБОТУ, состоит в выборке операнда из ЗУ, в этом случае из кэш 66, и в размещении его (операнда) в регистре R2 общего назначения. Адрес ЗУ, из которого этот операнд был выбран, определяется сложением вместе значения индекса в регистре X, базового значения в регистре B и значения перемещения D. Управляющий блок 60 выборки/выдачи назначает эту операцию образования адреса АЛУ образования адреса. В этом случае АЛУ 62 складывает вместе значение индекса адреса в регистре X (значение нуля в настоящем примере), значение базового адреса, содержащееся в регистре R7 общего назначения, и значение адреса перемещения (значение нуля в настоящем примере), содержащееся в самой команде. Результирующий вычисленный адрес ЗУ, появляющийся на выходе АЛУ 62, подается на адресный вход кэш 66 данных для выборки требуемого операнда. Этот выбранный операнд загружается в регистр R2 общего назначена в группе регистров 65.
Рассматривая теперь обработку команд СЛОЖИТЬ и СРАВНИТЬ, эти команды выбираются управляющим блоком 60 выборки/выдачи. Управляющий блок 60 анализирует маркеры объединения в отношении этих двух команд и отмечает, что они могут выполняться параллельно. Как видно на фиг.9, команда СРАВНИТЬ имеет явную зависимость от данных команды СЛОЖИТЬ, так как СЛОЖЕНИЕ должно быть выполнено до того, как R3 может сравниваться. Однако эта зависимость может быть обработана АЛУ 64 устранения зависимости данных. Как следствие эти две команды могут быть обработаны параллельно в конфигурации на фиг.7. В частности, управляющий блок 60 назначает обработку команды СЛОЖИТЬ блоку АЛУ 63 и начинает обработку команды СРАВНИТЬ блоку АЛУ 64 устранения зависимости. АЛУ с 63 складывает содержания регистра общего назначения R2 с содержанием регистра общего назначения R3 и помещает результат сложения обратно в регистр общего назначения R3. Одновременно АЛУ 64 устранения зависимости выполняет следующую математическую операцию:
R2 + R2 - R4
Код условия в отношении результата этой операции посылается на регистр кода условия, расположенный в блоке 61 перехода. Зависимость данных устраняется, так как АЛУ 64 фактически вычисляет сумму R3 + R2, а затем сравнивает эту сумму с R4 для определения кода условия. Благодаря этому АЛУ 64 не должно ждать результатов от АЛУ 63, которое выполняет команды СЛОЖИТЬ. В этом конкретном случае числовые результаты, вычисленные АЛУ 64 и появившиеся на выходе АЛУ 64, не подаются обратно на регистры 65 общего назначения. В этом случае АЛУ 64 просто устанавливает код условия.
Рассмотрим теперь выполнение команды ПЕРЕЙТИ и команды ЗАГРУЗИТЬ В ПАМЯТЬ, показанные на фиг.8, эти команды выбираются из кэш 12 составных команд управляющим блоком 60 выборки/выдачи. Управляющий блок 60 определяет из бит маркеров в отношении этих команд, что они могут обрабатываться параллельно друг с другом. Он дальше определяет из ОП-кодов этих двух команд, что команда ПЕРЕЙТИ должна выполняться блоком 61 перехода, а команда ЗАГРУЗИТЬ В ПАМЯТЬ должна выполняться АЛУ 62 образования адреса. В соответствии с этим определением поле маски М и поле перемещения D команды ПЕРЕЙТИ подаются на блок 61 перехода. Аналогичным образом значение индекса адреса в регистре X и значение базы адреса в регистре B в отношении этой команды ПЕРЕЙТИ получают их регистров 65 общего назначения и подают на блок 61 перехода. В настоящем примере значение X является нулем, а базовое значение получают из регистра общего назначения R7. Значение перемещения D имеет шестнадцатиричное значение двадцати, тогда как поле маски М имеет значение положения маски восемь.
Блок 61 перехода начинает вычислять потенциальный адрес перехода (0 + R7 + 20) и одновременно сравнивает код условия, полученный от предшествующей команды сравнения, с маской кода условия М. Если значение кода условия такое же, как значение кода маски, необходимое условие перехода соблюдено, и адрес перехода, вычисленный блоком 61 перехода, после этого загружается в счетчик команд в управляющем блоке 60. Этот счетчик команд управляет выборкой команд из кэш 12. Если, с другой стороны, условие не удовлетворено (т.е. код условия, установленный предшествующей командой, не имеет значения восемь), тогда переход не производится, и адрес перехода не передается на счетчик команд в управляющем блоке 60.
В то же время, когда блок 61 перехода занят осуществлением своих действий в отношении команды ПЕРЕЙТИ, АЛУ 62 образования адреса занять вычислением адреса (0 + R7 + 0) для команды ЗАГРУЗИТЬ В ПАМЯТЬ. Адрес, вычисленный АЛУ 62, подается в кэш 66 данных. Если переход не предпринимается блоком 61 перехода, тогда команда ЗАГРУЗИТЬ В ПАМЯТЬ функционирует для загрузки операнда в регистре общего назначения R3 к кэш 66 данных с адресом, вычисленным АЛУ 62. Если, с другой стороны, условие перехода удовлетворительно, и переход предпринят, тогда содержание регистра общего назначения R3 не загружаются в кэш 66 данных.
Вышеизложенная последовательность команд на фиг.8 приведена только в качестве примера. Вариант реализации компьютерной системы на фиг.7 в равной степени способен обрабатывать разные и различные другие последовательности команд. Однако пример на фиг.8 ясно показывает полезность маркеров составных команд при определении, какие пары команд могут обрабатываться параллельно друг с другом.
Хотя здесь описано то, что в настоящий момент считается предпочтительными вариантами реализации этого изобретения, специалистам в этой области техники понятно, что могут иметь место различные изменения и модификации в этих вариантах без отклонения от изобретения, поэтому считается, что все такие изменения и модификации не выходят из рамок идеи и объема изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| ЦИФРОВОЙ КОМПЬЮТЕР С ВОЗМОЖНОСТЬЮ ПАРАЛЛЕЛЬНОГО ВЫПОЛНЕНИЯ ДВУХ И БОЛЕЕ КОМАНД | 1991 |
|
RU2109333C1 |
| ТРАНСФОРМАЦИЯ ПРЕРЫВИСТЫХ СПЕЦИФИКАТОРОВ КОМАНД В НЕПРЕРЫВНЫЕ СПЕЦИФИКАТОРЫ КОМАНД | 2012 |
|
RU2568241C2 |
| КОМАНДА ВЕКТОРНОГО ТИПА НА ПОЛЕ ГАЛУА ПЕРЕМНОЖЕНИЯ, СУММИРОВАНИЯ И НАКОПЛЕНИЯ | 2014 |
|
RU2613726C2 |
| КОМАНДА НА НЕТРАНЗАКЦИОННОЕ СОХРАНЕНИЕ | 2012 |
|
RU2568324C2 |
| БЛОК ДИАГНОСТИКИ ТРАНЗАКЦИЙ | 2012 |
|
RU2571397C2 |
| КОМАНДА ВЕКТОРНОГО ТИПА КОНТРОЛЬНОЙ СУММЫ | 2013 |
|
RU2608663C1 |
| УСТРОЙСТВО ДЛЯ ОПТИМИЗАЦИИ ОРГАНИЗАЦИИ ДОСТУПА К ОБЩЕЙ ШИНЕ ВО ВРЕМЯ ПЕРЕДАЧИ ДАННЫХ С ПРЯМЫМ ДОСТУПОМ К ПАМЯТИ | 1991 |
|
RU2110838C1 |
| СРАВНЕНИЕ И ЗАМЕНА ПОЗИЦИИ ТАБЛИЦЫ ДИНАМИЧЕСКОЙ ТРАНСЛЯЦИИ АДРЕСА | 2012 |
|
RU2550558C2 |
| КОНФИГУРАЦИЯ АРХИТЕКТУРНОГО РЕЖИМА В ВЫЧИСЛИТЕЛЬНОЙ СИСТЕМЕ | 2015 |
|
RU2664413C2 |
| ПЛАТА РАСШИРЕНИЯ ВЫЧИСЛИТЕЛЬНОЙ СИСТЕМЫ | 1990 |
|
RU2009539C1 |

Изобретение относится к цифровым компьютерным системам и предназначено для обработки двух и более команд параллельно. Схемное устройство содержит блок объединения команд, расположенный между блоком ЗУ и блоком КЭШ памяти, множество функциональных блоков обработки команд, которые функционируют параллельно друг другу. Команды, поданные на эти функциональные блоки, поступают из блока КЭШ памяти. 7 з.п. ф-лы, 9 ил.