Эта заявка на патент является частично продолжающей заявку на патент США N 08/172646 под названием "Способ и устройство параллельного кодирования и декодирования данных" от 23 декабря 1993 г., которая, в свою очередь, является частично продолжающей заявку на патент США N 08/016035 под названием "Способ и устройство параллельного декодирования и кодирования данных" от 10 февраля 1993 г.
Изобретение относится к системам уплотнения и разуплотнения данных, в частности к способу и устройству параллельного кодирования и декодирования данных в системах уплотнения-разуплотнения.
В настоящее время широко используется уплотнение данных, в частности, для хранения и передачи больших объемов данных. Из уровня техники известно много различных методов уплотнения данных. Методы уплотнения можно разделить на две категории: кодирование с потерями и кодирование без потерь. Кодирование с потерями включает в себя кодирование, приводящее в результате к потере информации, вследствие чего не гарантируется точное восстановление первоначальных данных. При уплотнении без потерь вся информация сохраняется, а данные уплотняются так, чтобы обеспечить точное восстановление.
При уплотнении без потерь входные символы преобразуются в выходные кодовые слова. Если уплотнение осуществлено успешно, кодовые слова представляются меньшим количеством двоичных разрядов, чем количество входных символов. Способы кодирования без потерь включают в себя словарные способы кодирования (например, способ Lempel-Ziv (Лемпел-Зива), кодирование неравномерным кодом, перечисляющим кодом и статистическим кодом.
К кодированию статистическим кодом относится любой способ кодирования без потерь, в котором стремятся уплотнить данные близко к предельной энтропии, используя известные или прогнозируемые вероятности символов. Статистические коды включают в себя коды Хаффмена, арифметические коды и двоичные статистические коды. Устройства кодирования двоичным статистическим кодом являются кодирующими устройствами без потерь, которые действуют на основе бинарных решений (да-нет), часто определяемых как наиболее вероятный символ (БВС) и наименее вероятный символ (МВС). Примеры бинарных статистических кодирующих устройств включают в себя Q-кодер фирмы IBM и кодирующее устройство, называемое B-кодером. Дополнительную информацию о B-кодере можно найти в патенте США N 5272478 на "Способ и устройство кодирования статистическим кодом", выданном Дж.Д.Аллену 21 декабря 1993 г. и принадлежащем тому же заявителю, что и настоящее изобретение (см. также работу М.Дж.Гормиша и Дж.Д. Аллена "Двоичное кодирование статистическим кодом конечного автомата", кратко изложенную в трудах Конференции по способам уплотнения данных, опубликованных 30 марта 1993 г. в г.Сноубид, штат Юта, с.449). B-кодер представляет собой устройство двоичного статистического кодирования, в котором для уплотнения используется конечный автомат (автомат с конечным числом состояний).
На фиг.1 показана блок-схема известной из уровня техники системы уплотнения и разуплотнения, в которой используется устройство двоичного статистического кодирования. Для кодирования данные вводят в контекстную модель 101 (КМ). КМ 101 преобразует входные данные в ряд или последовательность двоичных решений и обеспечивает контекстный элемент для каждого решения. Как последовательность двоичных решений, так и связанные с ними контекстные элементы выводятся из КМ 101 в модуль оценки вероятности (МОВ) 102. МОВ 102 принимает каждый контекстный элемент и вырабатывает оценку вероятности для каждого двоичного решения. Действительная оценка вероятности обычно представляется классом, обозначаемым P-классом. Каждый P-класс используется для диапазона вероятностей. МОВ 102, кроме того, определяет, находится ли двоичное решение (результат) в его наиболее вероятном состоянии или нет (то есть соответствует ли решение БВС). Модуль генератора последовательности бит (ГПБ) 103 принимает сигналы оценки вероятности (то есть P-класс) и определения того, насколько вероятно двоичное решение в качестве входных сигналов. В ответ на это модуль ГПБ 103 создает последовательность уплотненных данных, формируя на выходе нулевые или ненулевые биты для представления первоначальных входных данных.
Для декодирования КМ 104 обеспечивает для МОВ 105 контекстный элемент, а МОВ 105 на основании контекстного элемента обеспечивает класс вероятности (P-класс) для модуля ГПБ 106. Модуль ГПБ 106 подсоединен для приема класса вероятности. В ответ на класс вероятности и уплотненные данные модуль ГПБ 106 возвращает двоичный разряд, символизирующий, соответствует ли двоичное решение (то есть событие) в его наиболее вероятном состоянии или нет. МОВ 105 принимает этот двоичный разряд, обновляет оценку вероятности, основываясь на принятом двоичном разряде, и возвращает результат в КМ 104. КМ 104 принимает возвращаемый двоичный разряд и использует этот возвращенный двоичный разряд для генерирования исходных данных и обновления контекстного элемента для следующего двоичного решения.
Одна из проблем, возникающих при использовании декодеров двоичных статистических кодов, типа Q-кодера и B-кодера фирмы IBM, заключается в их низком быстродействии, даже при реализации аппаратными средствами. Их функционирование основано на использовании одной большой медленнодействующей цепи обратной связи. Чтобы повторно запустить процесс декодирования, в контекстной модели используются последние декодированные данные для создания контекста. В модуле оценки вероятности контекст используется для создания класса вероятности. В генераторе последовательности двоичных разрядов используются класс вероятности и уплотненные данные для определения, представляет ли следующий двоичный разряд вероятный или невероятный результат. В модуле оценки вероятности используется вероятный/невероятный результат для выработки двоичного разряда результата (и для обновления оценки вероятности контекста). Двоичный разряд результата используется в контекстной модели для обновления архива последних данных. Все эти этапы требуются для декодирования единственного двоичного разряда. Поскольку контекстная модель должна ожидать двоичного разряда результата для обновления ее архива данных, причем может обеспечить следующий контекст, необходимо ожидать декодирования следующего двоичного разряда. Желательно исключить ожидание замыкания петли обратной связи до декодирования следующего двоичного разряда. Другими словами, желательно одновременно декодировать более одного двоичного разряда или кодового слова для увеличения скорости декодирования уплотненных данных.
Другая проблема, связанная с декодерами двоичных статистических кодов, заключается в том, что нужно обрабатывать данные переменной длины. В большинстве систем декодируемые кодовые слова имеют переменные длины. Либо другие системы кодируют символы переменной длины (некодированные данные). При обработке данных переменной длины необходимо смещать данные на уровне двоичного разряда для обеспечения последующих корректных данных для операции декодирования или кодирования. Эти манипулирования на уровне двоичного разряда в потоке данных могут потребовать применения дорогостоящего и/или медленнодействующего аппаратного и/или программного обеспечения. Кроме того, в известных системах требуется, чтобы это смещение осуществлялось в петлях обратной связи, критичных к времени, что ограничивает эффективность декодирующего устройства. Также было бы желательно устранить манипулирование уровнем двоичного разряда потока данных из критичных к времени петель обратной связи, чтобы для увеличения быстродействия можно было использовать параллельную обработку.
Настоящее изобретение относится к системе уплотнения и разуплотнения без потерь. Кроме того, настоящее изобретение обеспечивает кодирующему и декодирующему устройствам, работающим в реальном масштабе времени, параллельное кодирование и декодирование данных соответственно. Соответствующие настоящему изобретению кодирующее и декодирующее устройства формируют сбалансированную параллельную энтропийную систему, в которой осуществляется как кодирование, так и декодирование в реальном масштабе времени с использованием аппаратных средств с высоким быстродействием и низкой стоимостью.
Предлагаются способ и устройство разуплотнения и уплотнения данных. Настоящее изобретение обеспечивает кодирующее устройство для использования в системе уплотнения, имеющей декодирующее устройство, предназначенное для декодирования информации, вырабатываемой кодирующим устройством. Соответствующее настоящему изобретению кодирующее устройство включает в себя кодер, предназначенный для формирования в ответ на данные информации кодовых слов. Кодирующее устройство включает в себя также блок переупорядочивания, который генерирует поток кодированных данных в ответ на поступающую из кодера информацию кодовых слов.
Переупорядочивающий блок содержит в себе блок переупорядочивания счета прогонов, предназначенный для расположения кодовых слов в порядке декодирования, и блок компоновки двоичных разрядов для объединения кодовых слов переменной длины в слова с чередованием фиксированной длины и для выдачи слов с чередованием фиксированной длины в требуемом декодирующим устройством порядке.
Настоящее изобретение будет более понятным из приведенного ниже подробного описания и прилагаемых чертежей различных вариантов осуществления изобретения, которые, однако, приведены не в качестве ограничения изобретения конкретными вариантами его осуществления, а только для объяснения и понимания.
Фиг. 1 представляет блок-схему известных двоичных статистических кодирующего и декодирующего устройств; фиг.2 представляет блок-схему соответствующей настоящему изобретению системы декодирования; фиг.3 представляет блок-схему возможного варианта осуществления соответствующей настоящему изобретению системы кодирования; фиг.4 представляет блок-схему возможного варианта осуществления соответствующей настоящему изобретению системы декодирования, в которой осуществляется параллельная обработка контекстных элементов кодированного сигнала; фиг.5 представляет блок-схему возможного варианта осуществления соответствующей настоящему изобретению декодирующей системы, в которой осуществляется параллельная обработка классов вероятности; фиг.6 иллюстрирует соответствующий настоящему изобретению поток с неперемежающимся кодом; фиг.7 иллюстрирует возможный вариант потока информации с перемежающимся кодом, полученного из примерного набора данных; фиг.8 представляет пример таблицы оценки вероятности и генератора последовательности двоичных разрядов для соответствующего изобретению R-кодера; фиг.9 представляет блок-схему возможного варианта осуществления соответствующего изобретению кодирующего устройства; фиг.10 представляет блок-схему возможного варианта осуществления соответствующего изобретению генератора двоичных разрядов; фиг.11 представляет блок-схему возможного варианта осуществления соответствующего изобретению переупорядочивающего блока; фиг. 12 представляет блок-схему возможного варианта осуществления соответствующего настоящему изобретению переупорядочивающего блока счета прогонов; фиг.13 представляет блок-схему другого варианта осуществления соответствующего настоящему изобретению переупорядочивающего блока счета прогонов; фиг. 14 представляет блок-схему возможного варианта осуществления соответствующего настоящему изобретению блока компоновки двоичных разрядов; фиг.15 представляет блок-схему возможного варианта осуществления соответствующей настоящему изобретению логической схемы компоновки; фиг.16 представляет блок-схему соответствующего настоящему изобретению генератора двоичных разрядов кодирующего устройства; фиг.17 представляет блок-схему возможного варианта осуществления соответствующей настоящему изобретению системы декодирования; фиг. 18 представляет блок-схему соответствующего настоящему изобретению декодирующего устройства; фиг. 19 представляет блок-схему возможного варианта осуществления соответствующей настоящему изобретению структуры обратного магазинного типа (FIFO); фиг.20 иллюстрирует возможный вариант осуществления соответствующей настоящему изобретению конвейерной обработки декодирования; фиг.21 иллюстрирует возможный вариант осуществления соответствующего настоящему изобретению декодирующего устройства; фиг.22 представляет блок-схему возможного варианта осуществления соответствующего настоящему изобретению сдвигающего устройства; фиг.23 представляет блок-схему другого варианта осуществления соответствующего настоящему изобретению сдвигающего устройства; фиг. 24 представляет блок-схему системы, имеющей внешнюю контекстную модель; фиг. 25 представляет блок-схему другой системы, имеющей внешнюю контекстную модель; фиг. 26 представляет блок-схему возможного варианта осуществления соответствующего настоящему изобретению декодирующего устройства; фиг.27 представляет блок-схему возможного варианта осуществления декодирующего устройства с отдельными генераторами двоичных разрядов; фиг.28 представляет блок-схему возможного варианта осуществления соответствующего настоящему изобретению генератора двоичных разрядов; фиг.29 представляет блок-схему возможного варианта осуществления настоящего изобретения блока длительного прогона; фиг. 30 представляет блок-схему возможного варианта осуществления настоящего изобретения блока короткого прогона; фиг.31 представляет блок-схему возможного варианта осуществления соответствующей настоящему изобретению логической схемы инициализации и управления; фиг.32 представляет блок-схему возможного варианта осуществления переупорядочивания данных с использованием декодирующего устройства слежения: фиг.33 представляет блок-схему другого варианта осуществления переупорядочивающего блока; фиг.34 представляет блок-схему другого варианта осуществления переупорядочивающего блока, в котором используется объединенная очередность; фиг.35 представляет блок-схему системы с широкой полосой, в которой используется настоящее изобретение; фиг. 36 представляет блок-схему системы согласования полос, в которой используется настоящее изобретение; фиг.37 представляет блок-схему телевизионной системы, работающей в реальном масштабе времени, в которой используется настоящее изобретение; фиг.38 иллюстрирует возможный вариант осуществления соответствующего настоящему изобретению запоминающего устройства кодированных данных; фиг.39 представляет соответствующую настоящему изобретению временную диаграмму декодирования.
Описываются способ и устройство для параллельного кодирования и декодирования данных. В нижеприведенном описании приведены многочисленные специальные детали, такие как определенные количества двоичных разрядов, количества кодеров, специфические вероятности, типы данных и так далее, для того, чтобы обеспечить полное понимание предпочтительных вариантов осуществления настоящего изобретения. Специалистам в данной области техники должно быть ясно, что настоящее изобретение можно осуществлять на практике без этих специфических деталей. Кроме того, известные схемы показаны в форме блок-схем, а не подробно, для большей ясности изложения настоящего изобретения.
Некоторые части последующего подробного описания представлены в виде алгоритмов и символических представлений операций с двоичными разрядами данных в памяти вычислительной машины. Эти алгоритмические описания и представления являются средствами, используемыми специалистами в технике обработки данных для более эффективного выражения сути их работы для других специалистов в этой области техники. Алгоритм рассматривается как последовательность этапов обработки, ведущих к требуемому результату. Эти этапы характеризуют собой физические операции над физическими объектами. Эти объекты могут принимать форму электрических или магнитных сигналов, которые можно запоминать, передавать, объединять, сравнивать и осуществлять другие операции. Иногда эти сигналы удобно называть двоичными разрядами, значениями, элементами, символами, знаками, терминами, числами или подобными понятиями.
Однако надо иметь в виду, что все эти и подобные им термины должны быть связаны с соответствующими физическими объектами и просто представляют удобные их обозначения. Если не оговорено особо, как очевидно из последующего описания, то следует понимать, что на всем протяжении настоящего изобретения обсуждения с использованием таких терминов, как "обработка", "вычисление", "расчет", "определение", "отображение" или подобных им, относятся к действию и процессам вычислительной системы или подобного электронного вычислительного устройства, которое манипулирует данными и преобразует данные, представляемые в виде физических (электронных) величин внутри регистров и запоминающих устройств вычислительной системы, в другие данные, подобным образом представляемые в виде физических величин в запоминающих устройствах или регистрах вычислительной системы или других таких запоминающих, передающих или отображающих информацию устройствах.
Настоящее изобретение касается также устройства, предназначенного для осуществления в нем операций. Это устройство может быть специально создано для требуемых целей или оно может содержать в себе универсальную вычислительную машину, избирательно приводимую в действие или реконфигурируемую с помощью компьютерной программы, хранящейся в вычислительной машине. Имеющиеся в нем алгоритмы и индикаторы по своей природе не связаны с какой-либо особой вычислительной машиной или другим устройством. Различные универсальные вычислительные машины можно использовать с программами в соответствии с излагаемыми здесь положениями или может оказаться удобным создание специализированного устройства для выполнения требуемых этапов этого способа. Из представленного ниже описания будет ясна необходимая структура этих различных вычислительных машин. Кроме того, настоящее изобретение описывается без ссылки на какой-либо конкретный язык программирования. Следует понимать, что можно использовать разнообразные языки программирования для осуществления изобретения.
Настоящее изобретение предусматривает систему параллельного статистического кодирования. Система включает в себя кодирующее устройство и декодирующее устройство. В одном варианте осуществления изобретения кодирующее устройство осуществляет кодирование данных в реальном масштабе времени. Подобно этому в одном варианте осуществления соответствующее настоящему изобретению декодирующее устройство осуществляет декодирование данных в реальном масштабе времени. Кодирующее и декодирующее устройства в реальном масштабе времени вместе образуют сбалансированную систему кодирования.
Настоящее изобретение относится к системе, которая декодирует без потерь параллельно закодированные данные. Данные декодируются параллельно с использованием множества ресурсов декодирования. Каждому из множества ресурсов декодирования выделяются данные (например, кодовые слова) из потока данных для декодирования. Выделение потока данных происходит непрерывно, ресурсы декодирования декодируют данные одновременно, осуществляя тем самым параллельное декодирование потока данных. Для того, чтобы обеспечить возможность такого выделения данных для эффективного использования ресурсов декодирования, поток данных упорядочивается. Этот процесс называется параллелизацией потока данных. Упорядочивание данных позволяет каждому ресурсу (средству) декодирования декодировать некоторые или все кодированные данные, не ожидая обратной связи от контекстной модели.
На фиг. 2 показана соответствующая настоящему изобретению система декодирования, не использующая медленнодействующую цепь обратной связи, известную из уровня техники. Входной буфер 204 принимает кодированные данные (то есть кодовые слова) и сигнал обратной связи с декодирующего устройства 205 и подает кодированные данные в заранее установленном порядке (например, в порядке контекстного элемента) в соответствующий настоящему изобретению декодер 205, который декодирует кодированные данные. Декодирующее устройство 205 включает в себя множество декодирующих блоков (например, 205A, 205B, 205C и так далее).
В одном варианте осуществления изобретения каждый из декодирующих блоков 205A, 205B, 205C и т.д. обеспечивается данными для группы контекстов. Каждый из декодирующих блоков в декодирующем устройстве 205 обеспечивается кодированными данными для каждого контекстного элемента дискретизации в его группе контекстов из входного буфера 204. Используя эти данные, каждый декодирующий блок 205A, 205B, 205C и т.д. формирует декодированные данные для его группы контекстных элементов. Контекстная модель не требуется для связывания кодированных данных с конкретной группой контекстных элементов.
Декодирующее устройство 205 посылает декодированные данные в накопитель декодированных данных 207 (например, 207A, 207B, 207C и т.д.). Отметим, что накопитель декодированных данных 207 может хранить промежуточные данные, которые не являются ни кодированными, ни некодированными, типа счетов прогонов. В этом случае накопитель декодированных данных 207 запоминает данные в сжатой, но не в закодированной статистическим кодом форме.
Работая независимо, контекстная модель 206 подсоединена для приема ранее декодированных данных из накопителя декодированных данных 207 (то есть 207A, 207B, 207C и т.д.) в ответ на сигналы обратной связи, которые она посылает в накопитель декодированных данных 207. Поэтому существуют две независимые цепи обратной связи; одна между декодирующим устройством 205 и входным буфером 204, а вторая между контекстной моделью 206 и накопителем декодированных данных 207. Поскольку большая цепь обратной связи устранена, декодеры в декодирующем устройстве 205 (например, 205A, 205B, 205C и т.д.) способны декодировать связанные с ними кодовые слова, как только они принимают их из входного буфера 204.
Контекстная модель обеспечивает участок памяти системы кодирования и делит набор данных (например, изображения) на различные категории (например, контекстные элементы кодирования данных) на основе запоминающего устройства. В настоящем изобретении контекстные элементы считаются независимыми упорядоченными наборами данных. В одном варианте осуществления каждая группа контекстных элементов кодированных данных имеет свою собственную модель оценки вероятности, а каждый контекстный элемент имеет свое собственное состояние (где модели оценки вероятности разделяются). Следовательно, каждый контекстный элемент кодированных данных может использовать иную модель оценки вероятности и/или генератор последовательности двоичных разрядов.
Таким образом, данные упорядочиваются или запараллеливаются, и данные из потока данных назначаются индивидуальным декодерам для декодирования.
Добавление параллелизма к классической модели статистического кодирования.
Для параллелизации потока данных данные можно разделить в соответствии с любой из последовательностей: контекстной, вероятностной, мозаичной, кодовых слов (основанной на кодовых словах) и т.д. Переупорядочивание потока кодированных данных не зависит от параллелизма, способа, используемого для параллелизма данных или вероятности в любой другой точке. На фиг. 3 показано устройство параллельного кодирования соответствующей настоящему изобретению системы кодирования, в которое поступают данные, дифференцированные контекстной моделью (КМ).
Как показано на фиг.3, параллельное зависимое от контекста кодирующее устройство содержит контекстную модель (КМ) 214, модули оценки вероятности (МОВ) 215-217 и генераторы последовательности бит (ГПБ) 218-220. КМ 214 подсоединена для приема кодированных входных данных. КМ 214 подсоединена также к модулям 215-217. МОВ 215-217, кроме того, связаны с ГПБ 218-220 соответственно, которые дают на выходе кодированные потоки 1, 2 и 3 соответственно. Каждая пара МОВ и ГПБ содержит кодер. Поэтому параллельное кодирующее устройство показано с тремя кодерами. Хотя показаны только три параллельных кодера, можно использовать любое их количество.
КМ 214 делит поток данных на разные контексты таким же образом, как обычная КМ, и посылает множество потоков в параллельные аппаратные средства кодирования. Отдельные контексты или группы контекстов направляются в раздельные модули оценки вероятности (МОВ) 215-217 и генераторы последовательности бит (ГПБ) 218-219. Каждый из ГПБ 218-220 дает на выходе поток кодированных данных.
На фиг. 4 представлена блок-схема одного варианта осуществления декодирующего устройства соответствующей настоящему изобретению системы декодирования. На фиг.4 показано зависимое от контекста параллельное декодирующее устройство, имеющее ГПБ 221-223, МОВ 224-226 и КМ 227. Кодированные потоки 1-3 подаются на ГПБ 221-223 соответственно. ГПБ 221-223 связаны также с МОВ 224-226 соответственно. МОВ 224-226 подсоединены к КМ 227, которая выдает на выходе реконструированные входные данные. Входной сигнал поступает из нескольких кодовых потоков, показанных в виде кодовых потоков 1-3. Один кодовый поток выделяется каждому МОВ и ГПБ. Каждый из ГПБ 221-223 возвращает двоичный разряд, представляющий выбор из двух альтернатив, в зависимости от того, находится ли в своем наиболее вероятном состоянии, которое МОВ 224-226 использует для возврата декодированных двоичных разрядов (например, выбор из двух альтернатив). Каждый из МОВ 224-226 связан с одним из ГПБ 221-223, показывая, какой код необходимо использовать для выработки потока данных из его входного кодового потока. КМ 227 создает поток декодированных данных путем отбора декодированных двоичных разрядов с генераторов потока бит в надлежащей последовательности, воссоздавая тем самым первоначальные данные. Таким образом, КМ 227 получает двоичный разряд разуплотненных данных из соответственных МОВ и ГПБ, фактически переупорядочивая данные в первоначальный порядок. Отметим, что управление этой схемой проходит в обратном направлении относительно потока данных. ГПБ и МОВ могут декодировать данные до того, как их потребует КМ 227, оставляя впереди один или больше двоичных разрядов. В качестве альтернативы КМ 227 может запрашивать (но не принимать) двоичный разряд с одного ГПБ и МОВ, а затем запрашивать один или больше двоичных разрядов с других ГПБ и МОВ до использования первоначально запрошенного двоичного разряда.
Показанная на фиг.4 конфигурация предусматривает жесткое соединение МОВ и ГПБ. Q-кодер 1ВМ является хорошим примером кодера, имеющего жестко соединенные МОВ и ГПБ. Локальные цепи обратной связи между этими двумя узлами не оказывают ограничивающего действия на характеристики системы.
В другом варианте конструкции МОВ могли бы дифференцировать данные и посылать их в параллельные блоки ГПБ. Таким образом, здесь может быть только одна КМ и один МОВ, а ГПБ дублируется. При таком способе можно использовать адаптированное кодирование Хаффмена и кодирование с использованием конечного автомата.
На фиг.5 показана аналогичная система декодирования, в которой используется МОВ для дифференцирования данных и посылки их в параллельные ГПБ. В этом случае классы вероятности обрабатываются параллельно, и каждый генератор последовательности бит (ГПБ) выделяется определенному классу вероятности и принимает сведения о результате. Как показано на фиг.5, потоки кодированных данных 1-3 поступают на соответствующие из множества генераторов последовательности бит (например, ГПБ 232, ГПБ 233, ГПБ 234 и т.д.), которые подсоединены для их приема. Каждый из генераторов последовательности бит подсоединен к МОВ 235. МОВ 235 подсоединен также к КМ 236. В этой конфигурации каждый из генераторов последовательности бит декодирует кодированные данные, а результаты декодирования выбираются МОВ 235 (вместо КМ 236). Каждый из генераторов последовательности бит принимает кодированные данные из источника, связанного с одним классом вероятности (то есть где кодированные данные могли быть из любого контекстного элемента). МОВ 235 выбирает генераторы последовательности бит, используя класс вероятности. Класс вероятности предписывает контекстным элементам кодированных данных, обеспечиваемым для него моделью КМ 236. Таким образом, декодированные данные получаются с помощью параллельной обработки классов вероятности.
Для соответствующих настоящему изобретению параллельных систем декодирования существуют многочисленные реализации. В одном варианте осуществления потоки кодированных данных, соответствующие многочисленным контекстным элементам кодированных данных, могут перемежаться в один поток, упорядоченный запросами различных кодеров. В одном варианте осуществления настоящего изобретения кодированные данные упорядочиваются таким образом, что каждый кодер постоянно получает данные, даже если кодированные данные подаются на декодер в одном потоке. Следует отметить, что настоящее изобретение оперирует со всеми типами данных, включая видеоданные.
При использовании малых простых кодеров, которые можно легко дублировать в интегральных схемах, кодированные данные можно быстро параллельно декодировать. В одном варианте осуществления изобретения кодеры выполняются на аппаратных средствах, используя кристаллы матриц логических элементов с эксплуатационным программированием (МЛЭЭП) или стандартный кристалл интегральных схем прикладной ориентации (ИСПО). Сочетание параллелизма и простых генераторов последовательности бит позволяет осуществлять декодирование кодированных данных со скоростью, превышающей скорости в существующих декодирующих устройствах, в то же время сохраняя или превышая эффективность уплотнения существующих декодирующих систем.
Канальное упорядочивание многочисленных потоков данных.
Существует множество различных конструктивных вопросов и проблем, влияющих на характеристики системы.
Некоторые из них будут упомянуты ниже. Однако в изображенных на фиг. 3 и 4 (и 5) вариантах осуществления используются многочисленные кодовые потоки. Можно представить системы с параллельными каналами, которые могут обеспечить этот вариант осуществления: линии с множеством телефонных аппаратов, множество головок на дисководах и т.д. В некоторых системах имеется или пригоден для использования только один канал. Фактически, если требуется много каналов, то может оказаться недостаточным использование полосы частот из-за пакетного характера отдельных кодовых потоков.
В одном варианте осуществления кодовые потоки конкатенируются (сочленяются) и непрерывным образом посылаются на декодирующее устройство. Начальный заголовок содержит указатели местоположения начального разряда каждого потока. На фиг. 6 показан возможный вариант упорядочения расположения этих данных. Как показано на фиг. 6, здесь три указателя 301-303 показывают начальное местоположение в сочлененном коде кодовых потоков 1, 2 и 3 соответственно. В буфере имеется полный файл уплотненных данных, представляемый для декодирующего устройства. При необходимости кодовые слова отыскиваются в надлежащем местоположении посредством надлежащего указателя. Затем указатель обновляется для следующего кодового слова в этом кодовом потоке.
Следует отметить, что этот способ требует запоминания в декодирующем устройстве и для практических целей в кодирующем устройстве полного закодированного кадра (блока данных). Если требуется система, работающая в реальном масштабе времени, или поток данных без пакетов, то для группирования можно использовать два кадровых буфера как в кодирующем, так и декодирующем устройствах.
Упорядоченность данных для упорядочения кодовых слов.
Отметим, что декодирующее устройство декодирует кодовые слова в заданном детерминированном порядке. При параллельном кодировании поток запросов кодового потока является детерминированным. Таким образом, если кодовые слова из параллельных кодовых потоков можно чередовать в правильном порядке в кодирующем устройстве, то оказывается достаточно одного кодового потока. Кодовые слова подаются в декодирующее устройство в таком же порядке на основе "строго вовремя". В кодирующем устройстве модель декодирующего устройства определяет порядок кодовых слов и компонует кодовые слова в один поток. Эта модель может представлять действительное декодирующее устройство.
Проблема в отношении подачи данных в параллельные декодирующие элементы возникает в том случае, если данные имеют переменную длину. Распаковка потока кодовых слов переменной длины требует использования регистра побитового сдвига для выравнивания кодовых слов. Регистры побитового сдвига часто бывают дорогостоящими и/или имеют низкое быстродействие, если они выполнены на аппаратных средствах. Управление регистром побитового сдвига зависит от размера конкретного кодового слова. Эта цепь управления обратной связи мешает быстрому осуществлению сдвига переменной длины. Положительные качества подачи одного потока на множество декодирующих устройств не могут быть реализованы, если процесс распаковки потока осуществляется в единственном регистре побитового сдвига, который не обладает достаточным быстродействием для того, чтобы работать совместно с множеством декодирующих устройств.
Решение, предлагаемое в этом изобретении, состоит в отделении проблемы распределения кодированных данных по параллельным кодерам от выравнивания кодовых слов переменной длины для декодирования. Кодовые слова в каждом независимом кодовом потоке компонуются в слова фиксированной длины, называемые словами с перемежением (чередованием). На декодирующем конце канала эти слова с перемежением могут быть распределены по параллельным блокам декодеров с быстродействующими линиями передачи данных на аппаратных средствах и с простой схемой управления.
Удобно выбрать длину перемежаемого слова больше максимальной длины кодового слова, чтобы в каждом перемежаемом слове содержалось по меньшей мере достаточное количество двоичных разрядов для целого одного кодового слова. Перемежаемые слова могут содержать возможные кодовые слова и части кодовых слов. На фиг.7 показано перемежение примерного набора параллельных кодовых потоков.
Эти слова перемежаются в соответствии с потребностями со стороны декодирующего устройства. Каждый независимый декодер принимает целое перемежаемое слово. Операция побитового смещения теперь осуществляется локально в каждом декодере, поддерживая параллелизм системы. Отметим, что на фиг.7 первое кодовое слово в каждом слове с перемежением представляет собой самое низшее оставшееся кодовое слово в наборе. Например, первые перемежаемые слова поступают из кодового потока 1, начинаясь с самого низшего кодового слова (т. е. N 1). За ним следует первое перемежаемое слово в кодовом потоке 2, а затем первое перемежаемое слово в кодовом потоке 3. Однако следующее самое низкое кодовое слово, не содержащееся полностью в уже упорядоченном перемежаемом слове, представляет N 7. Следовательно, следующее слово в потоке является вторым перемежаемым словом кодового потока 2.
В другом варианте осуществления изобретения порядок, в котором последующий набор перемежаемых слов (например, кодовое слово, начинающееся с кодового слова N 8 в потоке 1, кодовое слово, начинающееся с кодового слова N 7 в потоке 2, кодовое слово, начинающееся с кодового слова N 11 в потоке 3) вводится в перемежаемый кодовый поток, основывается на первом кодовом слове предыдущего набора перемежаемых слов (например, кодовое слово, начинающееся с кодового слова N 1 в потоке 1, кодовое слово, начинающееся с кодового слова N 2 в потоке 2, кодовое слово, начинающееся с кодового слова N 4 в потоке 3) и упорядочивается от перемежаемого слова с первым кодовым словом самого низкого номера до перемежаемого слова с первым кодовым словом наивысшего номера. Следовательно, в этом случае, поскольку первым было перемежаемое слово, начинающееся с кодового слова N 1, то следующее перемежаемое слово в потоке 1 является первым из второй группы перемежаемых слов, подлежащих введению в перемежаемый поток, за которым следует перемежаемое слово в потоке 2, а затем следующее перемежаемое слово в потоке 3. Следует отметить, что после введения второй группы перемежаемых слов в перемежаемый поток следующим перемежаемым словом в потоке 2 может быть следующее перемежаемое слово, введенное в поток, поскольку кодовое слово N 7 является самым низшим кодовым словом второго набора перемежаемых слов (с последующим кодовым словом N 8 в потоке 1 и затем кодовым словом N 11 в потоке 3).
Использование действительного декодера в качестве разработчика модели для потока данных учитывает все варианты построения и задержки при создании перемежаемого потока. Это не приводит к увеличению стоимости дуплексных систем, имеющих как кодирующие, так и декодирующие устройства. Следует отметить, что это можно обобщить для любого параллельного набора информационных слов переменной длины (или разных размеров), которые употребляются в детерминированном порядке.
Типы кодов и генераторов последовательности бит для параллельного декодирования.
В настоящем изобретении можно использовать в качестве элементов генерирования последовательности бит, которые дублируются параллельно, существующие кодеры, такие как Q-кодеры и B-кодеры. Однако можно использовать и другие коды и кодеры. Применяемые в настоящем изобретении кодеры и связанные с ними коды являются простыми кодирующими устройствами. В настоящем изобретении обеспечиваются преимущества использования генератора последовательности бит с простым кодом вместо сложного кода, типа арифметического кода, используемого в Q-кодере, или кодов с большим количеством состояний, используемых в B-кодере. Простой код имеет преимущество в том отношении, что реализация аппаратными средствами гораздо имеет значительно более высокое быстродействие, проще по конструкции и требует меньше кремниевых элементов, чем в случае сложного кода.
Другим преимуществом настоящего изобретения является то, что можно улучшить эффективность кодирования. Код, в котором используется ограниченное количество информации о состоянии, не может полностью соответствовать пределу энтропии Шеннона для каждой вероятности. В технике известны реализуемые аппаратными средствами коды, позволяющие одному генератору последовательности бит манипулировать многочисленными вероятностями или контекстами, но имеющие ограничения, снижающие эффективность кодирования. Устранение ограничений, требуемых для большого количества контекстов или классов вероятности, позволяет использовать коды, которые в большей степени соответствуют пределу энтропии Шеннона.
R-коды.
Код (и кодер), используемый в одном из вариантов осуществления настоящего изобретения, называется R-кодом. R-коды являются адаптивными кодами, которые преобразуют переменное количество идентичных входных символов в кодовое слово. В варианте осуществления изобретения R-коды параметризованы таким образом, что можно манипулировать большим количеством различных вероятностей с помощью единственного декодирующего устройства. Более того, соответствующие настоящему изобретению R-коды можно декодировать с помощью простого быстродействующего аппаратного средства.
В настоящем изобретении R-коды используются R-кодером для выполнения кодирования или декодирования. В одном варианте осуществления R-кодер представляет собой объединенные генератор последовательности бит и модуль оценки вероятности. Например, на фиг.1 R-кодер может включать в себя объединение модуля оценки вероятности 102 и генератора последовательности бит 103 и объединение модуля оценки вероятности 105 с генератором последовательности бит 106.
Кодовые слова представляют прогоны наиболее вероятного символа (БВС). БВС представляет результат принятия решения из двух альтернатив с вероятностью более 50%. С другой стороны, наименее вероятный символ (МВС) представляет результат принятия решения из двух альтернатив с вероятностью менее 50%. Следует отметить, что когда два результата равновероятны, неважно, который из них обозначается БВС или МВС, поскольку и кодирующее, и декодирующее устройства делают одинаковое обозначение. Результирующая последовательность двоичных разрядов в уплотненном файле показана в табл.1 для данного параметра, обозначенного MAXRUN (максимальное количество прогонов).
При кодировании количество БВС в прогоне подсчитывается простым счетчиком. Если этот счет равен величине счета MAXRUN, в кодовый поток направляется кодовое слово 0, и счетчик возвращается в исходное состояние. Если встречается МВС, то в кодовый поток посылается 1 с последующими N двоичными разрядами, которые однозначно описывают количество символов БВС перед МВС. (Следует отметить, что существует много способов назначения N двоичных разрядов для описания длины прогона.) Вновь счетчик устанавливается в исходное состояние. Следует отметить, что количество двоичных разрядов, необходимых для N, зависит от величины MAXRUN. Кроме того, отметим, что можно использовать дополнение до 1 кодовых слов.
При декодировании, если первый двоичный разряд в кодовом потоке представляет собой 0, то величина MAXRUN помещается в счетчике БВС, а показание МВС сбрасывается. Затем 0 двоичный разряд отбрасывается. Если первый двоичный разряд представляет собой 1, тогда следующие двоичные разряды исследуются для выделения N двоичных разрядов, и соответствующий счет (N) помещается в счетчике БВС, а индикатор МВС устанавливается. Затем отбрасываются двоичные разряды кодового потока, содержащие кодовое слово 1.
R-коды генерируются по приведенным в табл. 1 правилам. Следует отметить, что описание данного R-кода Rx(к) определяется параметром MAXRUN. Например:
MAXRUN для Rx(к) = х • 2к-1,
таким образом
MAXRUN для R2 (к) = 2 • 2к-1;
MAXRUN для R3(к) = 3 • 2к-1,
и т.д.
Отметим, что R-коды являются подмножеством кодов Голомба. Отметим также, что в кодах Райса используются только коды R2(*). Соответствующие настоящему изобретению R-коды позволяют использовать коды как R2(к), так и R3(к), а также другие коды Rn(к), если требуется. В одном варианте осуществления изобретения используются коды R2(к) и R3(к). Следует отметить, что Rn существует для n= 2 и n, равного любому нечетному числу (например, R2, R3, R5, R7, R9, R11, R13, R15). В одном варианте осуществления изобретения для кода R2(к) счет прогона r кодируется переменной N, счет прогона r описывается к двоичными разрядами, так что 1N представляется к + 1 двоичными разрядами. Еще в одном варианте осуществления изобретения для кода R3(к) N двоичных разрядов могут содержать 1 двоичный разряд для указания, если n < 2(к-1) или n ≥ 2(к-1) и либо к-1, либо к двоичных разрядов для отображения счета прогонов r, так что переменная N представляется общим количеством к или к+1 двоичных разрядов соответственно. В других вариантах осуществления изобретения в кодовом слове можно использовать дополнение до 1 величины N. В этом случае БВС имеет тенденцию создавать кодовые потоки с большим количеством 0-й, а МВС имеет тенденцию создавать кодовые потоки с большим количеством 1.
В табл. 2, 3, 4 и 5 изображены некоторые эффективные R-коды, используемые для одного варианта осуществления настоящего изобретения. Следует отметить, что в настоящем изобретении можно также использовать другие коды длительности прогона. Пример альтернативного кода длины прогона для R2(2) показан в табл. 6. В табл.7 и 8 показаны примеры кодов, используемых в варианте осуществления изобретения.
Модуль оценки вероятности для R-кодов.
В варианте осуществления изобретения код R2(0) не осуществляет кодирование: входной сигнал 0 кодируется в 0, а входной сигнал 1 кодируется в 1 (или наоборот) и является оптимальным для вероятностей, равных 60%. Код R2(1) предпочтительного в настоящее время варианта осуществления изобретения оптимален для вероятностей, близких к 0,707 (то есть 70,7%), a R3(1) оптимален для вероятности 0,794 (79,4%). Код оптимален для вероятности 0,841 (84,1%). Табл. 9 отображает близкий к оптимальному код длины прогона, где перекос вероятности определяется следующим выражением:
Перекос вероятности = -log2(MBC).
Отметим, что коды оказываются близкими к оптимальным в том смысле, что диапазон вероятностей, как показано перекосом вероятности, перекрывает интервал относительно равномерно, даже если оптимальные вероятности не дифференцируются так сильно при более высоких значениях к, как при более низких значениях к.
Ссылка делается на вероятность, при которой R-код оптимален. Фактически, только R2(2) соответствует кривой энтропии. Действительное соображение состоит в том, какой диапазон вероятностей представляет конкретный R-кодер лучше, чем все другие R-кодеры в данном классе. Последующие таблицы обеспечивают диапазоны вероятностей для класса кодов R2 и класса кодов R2 и R3.
Для класса кодов R2 от 0 до 12 диапазоны представлены в табл.10. Например, когда используются только коды R2, R2(0) оказывается лучше тогда, когда 0,50 ≤ вероятность ≤ 0,6180. Подобно этому R2(1) оказывается лучше, когда 0,6180 ≤ вероятность ≤ 0,7862.
Для класса кодов R2 и R3 решения представлены в табл.11. Например, когда используются коды R2 и R3, R2(1) оказывается лучше, когда 0,6180 ≤ вероятность ≤ 0,7549.
R2(к) для фиксированного к называется кодом длины прогона. Однако фиксированный к лучше только для диапазона вероятностей. Отмечается, что когда кодирование ведется вблизи оптимальной вероятности, в соответствующем настоящему изобретению R-коде используются кодовые слова "0" и "1N" с приблизительно одинаковой частотой. Другими словами, половину времени соответствующий настоящему изобретению R-кодер дает на выходе один код, а другую половину времени R-кодер дает на выходе другой код. С помощью исследования кодовых слов с номерами "0" и "1N" можно осуществить определение относительно того, лучший ли код используется. То есть, если на выходе слишком много кодовых слов "1N", то длина прогона слишком большая, с другой стороны, если на выходе слишком много кодовых слов 0, то длина прогона слишком маленькая.
Модель оценки вероятности, используемая Лангдоном, исследует первый двоичный разряд каждого кодового слова для определения, выше или ниже вероятность источника текущей оценки (см. работу Дж.Дж.Лангдона "Адаптивный алгоритм кодирования длины прогона", Бюллетень технических открытий IBM, том 26, N 7B, декабрь 1983 г). На основании этого определения к увеличивается или уменьшается. Например, если обнаруживается кодовое слово, указывающее БВС, оценка вероятности слишком низкая. Поэтому согласно Лангдону к увеличивают на 1 для каждого кодового слова 0. Если обнаруживается кодовое слово, показывающее меньше, чем MAXRUN БВС с последующим МВС (например, кодовое слово "1N"), оценка вероятности слишком высокая. Следовательно, согласно Лангдону к уменьшается на 1 для каждого кодового слова 1N.
Настоящее изобретение позволяет получить более сложную оценку вероятности, чем простое увеличение или уменьшение к на 1 каждого кодового слова. Настоящее изобретение включает в себя состояние (режим) модуля оценки вероятности, которое определяет код для использования. Много состояний (режимов) могут использовать один и тот же код. Коды назначаются состояниям с использованием таблицы состояний или конечного автомата.
В одном варианте осуществления настоящего изобретения оценка вероятности изменяет состояние каждого выходного слова. Таким образом, модуль оценки вероятности увеличивает или уменьшает оценку вероятности в зависимости от того, начинается ли кодовое слово с 0 или с 1. Например, если на выходе кодовое слово представляет "0", происходит увеличение оценки вероятности БВС. С другой стороны, если на выходе кодовое слово представляет "1", оценка вероятности БВС уменьшается.
В известном кодере Лангдона используются только коды R2(к) и производится увеличение или уменьшение к для каждого кодового слова. В качестве альтернативы в настоящем изобретении используются коды R2(к) и R3(к) вместе с таблицей состояний или конечным автоматом, что обеспечивает возможность настраивать скорость адаптации к применению. То есть, если имеется небольшое количество стационарных данных, адаптация должна происходить быстрее для получения более оптимального кодирования, а если имеется большее количество стационарных данных, время адаптации может быть больше, так что можно выбирать кодирование для достижения лучшего уплотнения остальной части данных. Отметим, в тех случаях, когда могут встречаться переменные количества изменений состояния, особые характеристики применений также могут влиять на скорость адаптации. Из-за характера R-кодов оценка R-кодов простая и требует небольшого технического обеспечения, в то же время она имеет очень высокую мощность. На фиг.40 показан этот график эффективности кодирования (длина кода нормирована относительно энтропии) в зависимости от вероятности БВС. На фиг. 40 показано, как некоторые из соответствующих настоящему изобретению R-кодов перекрывают интервал вероятности. В качестве примера на фиг.40 показано, что в случае вероятности БВС, равной примерно 0,55, эффективность кода R2(0) равна 1,01 (или на 1% хуже) предела энтропии. В противоположность этому код R2(1) имеет эффективность 1,09 (или на 9% хуже) предела энтропии. Этот пример показывает, что использование неверного кода для этого конкретного случая низкой вероятности приводит к потерям 8% эффективности кодирования.
Включение кодов R3(к) дает возможность перекрывать больший диапазон вероятности с более высокой эффективностью. На фиг. 8 показана соответствующая настоящему изобретению примерная таблица состояний оценки и вероятности. Рассмотрим фиг. 8, на которой в таблице состояний оценки вероятности показан как счетчик числа состояний, так и код, связанный с каждым из отдельных состояний в таблице. Следует отметить, что таблица включает в себя как положительные, так и отрицательные состояния. В таблице показано наличие 37 положительных состояний и 37 отрицательных состояний, включая нулевые состояния. Отрицательные состояния имеют значения БВС, отличные от положительных состояний. В одном варианте осуществления отрицательные состояния можно использовать, когда БВС равен 1, а положительные состояния можно использовать, когда БВС равен 0, или наоборот. Отметим, что показанная на фиг. 8 таблица является только примером и что другие таблицы могут иметь больше или меньше состояний и отличающееся расположение состояний.
В исходном положении кодер находится в состоянии 0, что означает код R2(0) (то есть нет кода) для оценки вероятности, равной 0,50. После каждой обработки кодового слова счетчик количества состояний получает положительное или отрицательное приращение в зависимости от первого двоичного разряда кодового слова. В одном варианте осуществления изобретения кодовое слово 0 увеличивает величину счетчика количества состояний, начало кодового слова с 1 уменьшает величину счетчика количества состояний. Поэтому каждое кодовое слово заставляет производить изменение состояния с помощью счетчика количества состояний. Другими словами, модуль оценки вероятности меняет состояние. Однако последовательные состояния могут быть связаны с одним и тем же кодом. В этом случае оценка вероятности совершается без изменения кодов с каждым кодовым словом. Другими словами, состояние изменяется с каждым кодовым словом; однако в определенные моменты состояние устанавливается на одни и те же вероятности. Например, все состояния от 5 до -5 используют код R2(0), тогда как состояния с 6 до 11 и с -6 до -11 используют код R2(1). Используя соответствующую настоящему изобретению таблицу состояний, оценка вероятности может оставаться в том же самом кодере нелинейным образом.
Следует отметить, что для более низких вероятностей включено больше состояний с одним и тем же R-кодом. Это сделано потому, что потеря эффективности при использовании неверного кода при низких вероятностях больше. Характер таблицы состояний кодов длины прогона заключается в переходе между состояниями после каждого кодового слова. В таблице состояний, составленной для изменения кодов с каждым изменением состояния, когда происходит переключение между состояниями на более низких вероятностях, код переключается между кодом, который очень близок к пределу энтропической эффективности, и кодом, который далек от предела энтропической эффективности. Таким образом, штраф (выраженный в количестве двоичных разрядов кодированных данных) может привести к переходу между состояниями. Существующие модули оценки вероятности типа модуля оценки вероятности Лангдона теряют свою характеристику из-за такого штрафа.
В кодах с более высокой вероятностью длины прогона штраф за использование неверного кода не такой большой. Поэтому в настоящем изобретении при более низких вероятностях добавляются дополнительные состояния, так что изменения в переключении между двумя правильными состояниями увеличиваются, снижая тем самым неэффективность кодирования.
Отметим, что в некоторых вариантах осуществления изобретения кодер может иметь первоначальное состояние оценки вероятности. Другими словами, кодер может начинать работать в заранее установленном одном из состояний, таком как состояние 18. В одном варианте осуществления можно использовать другую таблицу состояний, так что некоторые состояния можно использовать для первых нескольких символов с целью обеспечения быстрой адаптации. Вторую таблицу состояний можно использовать для оставшихся символов с целью медленной адаптации, чтобы обеспечить точную настройку оценки вероятности. Таким образом, кодер может иметь возможность скорее использовать более эффективный код в процессе кодирования. В другом варианте осуществления изобретения кодовый поток может устанавливать начальную оценку вероятности для каждого контекста. В одном варианте осуществления изобретения положительные и отрицательные приращения не производятся в соответствии с фиксированным числом (например, 1). Вместо этого состояние оценки вероятности может быть увеличено на переменное число в соответствии с количеством уже встречаемых данных или количеством изменения данных (стабильности). Примеры таких таблиц представлены в табл. 22 - 26.
Если таблица состояний симметричная, как показанная на фиг.8 примерная таблица, то необходимо запоминать или реализовать в аппаратном средстве только ее половину (включая нулевое состояние). В одном варианте осуществления изобретения количество состояний запоминается в форме дополнения величины знака (1) для получения преимущества от симметрии. Таким образом, можно использовать таблицу, принимая абсолютную величину числа дополнения до единицы для определения состояния и проверяя знак определения, равняется ли БВС 1 или 0. Это дает возможность уменьшить объем аппаратных средств, необходимых для положительного или отрицательного приращения состояния, поскольку для индексирования таблицы используется абсолютное значение состояния, а вычисление абсолютного значения числа дополнения до единицы оказывается тривиальным. В другом варианте осуществления изобретения для большей эффективности аппаратного средства таблицу состояний можно заменить жестко замонтированным или программируемым конечным автоматом. Жестко замонтированное состояние преобразователя кода характеризует собой одну из реализаций таблицы состояний.
Общая характеристика системы сбалансированного параллельного статистического кодирования.
Настоящее изобретение обеспечивает систему сбалансированного параллельного статистического кодирования. Система параллельного статистического кодирования включает в себя как кодирование в реальном масштабе времени, так и декодирование в реальном масштабе времени, выполняемые с помощью аппаратных средств с высоким быстродействием и низкой стоимостью. Настоящее изобретение можно использовать в многочисленных применениях кодирования без потерь, включая, но не ограничиваясь ими, уплотнение и разуплотнение в реальном масштабе времени данных на перезаписываемых оптических дисках или магнитных дисках, уплотнение и разуплотнение в реальном масштабе времени данных компьютерных сетей, уплотнение и разуплотнение в реальном масштабе времени данных изображения в памяти уплотненной группы данных в многофункциональной машине (например, в копировальном устройстве, факсимильной аппаратуре, сканирующем устройстве, печатающем устройстве и т.д.) и уплотнение и разуплотнение в реальном масштабе времени аудиоданных.
Некоторого внимания требует определение характеристик кодирующего устройства. Его проектирование и осуществление кодирования весьма просты, что позволяет достичь определенной скорости поступления исходных данных, выдаваемых в канал с достаточно быстрым кодированием данных. Однако во многих применениях задача состоит в том, чтобы кодирующее устройство эффективно использовало канал кодированных данных. На использование канала кодированных данных оказывает действие максимальная скорость передачи пакетов, интерфейса исходных данных, быстродействие кодирующего устройства и достигаемая степень уплотнения данных. Влияние этих воздействий необходимо рассматривать для некоторого локального количества данных, которое зависит от обеспечиваемой буферизации в кодирующем устройстве. Желательно иметь кодирующее устройство, эффективно использующее канал кодированных данных при сохранении быстродействия кодирующего устройства и высокого уплотнения, при этом обеспечивая максимальную скорость передачи пакетов.
В последующем описании раскрыто соответствующее настоящему изобретению кодирующее устройство. Описано также декодирующее устройство, которое можно использовать с кодирующим устройством.
Кодирование в реальном масштабе времени в настоящем изобретении.
На фиг. 9 представлена блок-схема соответствующей настоящему изобретению системы кодирования. В одном варианте осуществления изобретения соответствующее настоящему изобретению кодирующее устройство осуществляет кодирование в реальном масштабе времени. Показанная на фиг. 9 кодирующая система 600 включает в себя кодирующее устройство 602, подсоединенное к контекстной модели (КМ) и памяти состояния 603, предназначенное для генерирования кодированной информации в форме информации кодовых слов 604 в ответ на исходные данные 601. Информация кодовых слов 604 принимается переупорядочивающим блоком 606, который подсоединен к памяти переупорядочивания 607. В ответ на информацию кодовых слов 604 переупорядочивающий блок 606 совместно с памятью переупорядочивания 607 генерирует поток кодированных данных 608. Следует отметить, что система кодирования 600, соответствующая изобретению, не ограничивается оперированием с кодовыми словами, а может в других вариантах осуществления оперировать дискретными аналоговыми формами сигналов, комбинациями двоичных разрядов переменной длины, символами канала связи, алфавитами, событиями и т.д.
Кодирующее устройство 602 включает в себя контекстную модель (КМ), механизм оценки вероятности (MOB) и генератор последовательности бит (ГПБ). Контекстная модель и MOB (механизм оценки вероятности) в кодирующем устройстве 602 по существу идентичны элементам в декодирующем устройстве (за исключением направления потока данных). Генератор двоичных разрядов кодирующего устройства 602 аналогичен генератору двоичных разрядов декодирующего устройства и описывается ниже. Результат кодирования кодирующим устройством 602 представляет собой выходной сигнал из нуля или более двоичных разрядов, которые отображают исходные данные. В одном варианте осуществления изобретения выходной сигнал генератора последовательности бит, кроме того, включает в себя один или больше управляющих сигналов. Эти управляющие сигналы обеспечивают цепь управляющего воздействия на данные в последовательности двоичных разрядов. В одном варианте осуществления изобретения информация кодовых слов может содержать в себе индикацию начала прогона и индикацию окончания прогона, кодовое слово и индекс, идентифицирующий счет прогонов (как относящихся к контексту или к классу вероятности) для кодового слова. Ниже описан один вариант осуществления соответствующего настоящему изобретению генератора последовательности бит.
Переупорядочивающий блок 606 принимает двоичные разряды и управляющие сигналы, вырабатываемые генератором последовательности бит (если он вообще имеется) кодера 602, и вырабатывает кодированные данные. В одном варианте осуществления изобретения выходные кодированные данные переупорядочивающего блока 606 содержат в себе поток слов с чередованием.
В одном варианте осуществления изобретения переупорядочивающий блок 606 выполняет две функции. Переупорядочивающий блок 606 перемещает кодовые слова с конца прогонов, создаваемых кодирующим устройством, в начало прогонов, как это требуется для декодирующего устройства, и объединяет кодовые слова переменной длины в слова с чередованием, имеющие фиксированную длину, и передает их на выход в надлежащем порядке, требуемом для декодирующего устройства.
В переупорядочивающем блоке 606 используется временная переупорядочивающая память 607. В одном варианте осуществления изобретения, где кодирование осуществляется на автоматизированном рабочем месте, емкость временной памяти переупорядочивания может составлять более 100 мегабайтов. В соответствующей настоящему изобретению сбалансированной системе временная память переупорядочивания 607 имеет значительно меньшую емкость (например, приблизительно 1 килобайт) и является постоянной. Таким образом, в одном варианте осуществления изобретения кодирование в реальном масштабе времени осуществляется с использованием постоянного объема памяти, даже если это увеличивает память, необходимую декодирующему устройству или для скорости передачи бит (например, когда вывод осуществляется до завершения прогона). Соответствующее настоящему изобретению декодирующее устройство способно определять действия ограниченной памяти переупорядочивающего блока, используя, например, неявную, явную сигнализацию или сигнализацию внутри потока (как описывается ниже). Переупорядочивающий блок 606 имеет ограниченную память, используемую для переупорядочивания, но "необходимая" память не ограничена. Необходимо учитывать как влияние ограниченной памяти в отношении окончания прогона с целью начала очереди прогона, так и в отношении переупорядочивания перемежаемых слов.
В одном варианте осуществления изобретения соответствующая настоящему изобретению кодирующая система (и соответствующая декодирующая система) осуществляет кодирование (или декодирование), используя единственную интегральную микросхему. В другом варианте осуществления изобретения единственная интегральная схема содержит в себе соответствующую настоящему изобретению систему кодера, включая ее кодирующее и декодирующее устройства и память. Для обеспечения кодирования может быть дополнительно использовано отдельное внешнее запоминающее устройство. Многокристальный модуль или интегральная схема может содержать как аппаратные средства кодирования-декодирования, так и запоминающее устройство.
Соответствующая настоящему изобретению система кодирования может увеличить эффективную ширину полосы пропускания вплоть до величины, определяемой коэффициентом N. Если достигнутое уплотнение меньше, чем N:1, то канал кодирования данных будет полностью использован, но полученное увеличение эффективной ширины полосы пропускания равно только степени уплотнения. Если достигнутое уплотнение больше, чем N:1, то обеспечивается эффективная ширина полосы пропускания с дополнительной полосой пропускания с перезаписью. В обоих случаях достигаемое уплотнение должно обеспечиваться по всей локальной области данных, определяемой объемом буферизации, имеющейся в системе кодирования.
На фиг. 10 показан один вариант осуществления соответствующего настоящему изобретению генератора двоичных разрядов кодирующего устройства. Генератор двоичных разрядов 701 подсоединен для приема в качестве входных сигналов класса вероятности и некодированного двоичного разряда (например, индикации БВС или МВС). В ответ на входные сигналы генератор 701 выдает множество сигналов. Два из выходных сигналов представляют управляющие сигналы, указывающие начало прогона и окончание прогона (каждое кодовое слово представляет прогон), сигнал запуска 711 и сигнал окончания 712. Прогон можно запускать и оканчивать в одно и то же время. Когда прогон запускается или заканчивается, выходной сигнал "индекс" 713 содержит индикацию класса вероятности (или контекста) для некодированного двоичного разряда. В одном варианте осуществления изобретения выходной сигнал индекса 713 представляет объединение класса вероятности для двоичного разряда и идентификацию банка данных для систем, в которых каждый класс вероятности дублирован в нескольких банках данных запоминающего устройства. Выходной сигнал кодового слова 714 используется для вывода кодированного слова из генератора двоичных разрядов 701, когда заканчивается прогон.
Память 702 подсоединена к генератору двоичных разрядов 701 и содержит счет прогонов для данного класса вероятности. Во время генерации двоичных разрядов генератор двоичных разрядов 701 считывает из запоминающего устройства 702, используя индекс (например, класс вероятности). После считывания из памяти 702 генератор двоичных разрядов 701 осуществляет вырабатывание двоичных разрядов следующим образом. Во-первых, если счет прогонов равен нулю, выдается сигнал запуска 711, индицирующий начало прогона. Затем, если некодированный двоичный разряд равен МВС, то формируется сигнал окончания 712, указывающий на окончание прогона. Кроме того, если некодированный двоичный разряд равен наименее вероятному символу (МВС), то формируется выходное кодовое слово 714 для того, чтобы показать, что кодовое слово является кодовым словом "1N" и счет прогонов очищается, например устанавливается на ноль (поскольку это конец прогона). Если некодированный двоичный разряд не равен МВС, то счет прогонов получает положительное приращение, а проверка определяет, равен ли счет прогонов максимальному счету прогонов для кода. Если это так, то выдается сигнал окончания 712, выходной сигнал кодового слова 714 устанавливается на ноль, а счет прогонов очищается (например, счет прогонов устанавливается на ноль). Если в результате проверки определяется, что число прогонов не равно максимальному значению для кода, то счет прогонов получает положительное приращение. Отметим, что индексирующий сигнал 713 соответствует классу вероятности, принимаемому в качестве входного сигнала.
В настоящем изобретении срабатывание кодовых слов 1N осуществляется так, что их длину можно определять без какой-либо дополнительной информации. Табл. 12 иллюстрирует кодовые слова "1N", представляющие кодовые слова R3(2) для декодирующего и кодирующего устройств. Декодирующее устройство ожидает, что двоичный разряд "1" в кодовом слове "1N" будет МВС и что часть счета N оказывается в надлежащем порядке БВС...МВС. В порядке декодирования кодовое слово переменной длины не может отличаться от нулевого заполнения без знания того, какой конкретный код использован. В порядке кодирования кодовое слово реверсируется, и положение старшего разряда "1" показывает длину кодовых слов "1N". Для генерирования кодовых слов в порядке кодирования дополнение значения счета должно быть изменено на противоположное. Это можно выполнить путем реверсирования 13-разрядного счета и затем смещения его так, чтобы совместить его с МВС. Как описывается подробно ниже, блок компоновки двоичных разрядов реверсирует кодовые слова обратно, соответственно порядку декодирования. Однако это реверсирование кодовых слов не вызывает усложнения блока компоновки двоичных разрядов 606, поскольку он должен осуществлять сдвиг любым путем.
Для кодов R3 генерирование кодовых слов "N2" требует также, чтобы двоичный разряд, следующий за "1", указывал, присутствует ли короткий или длинный счет.
Используя многочисленные банки данных памяти, настоящее изобретение позволяет работать в конвейерном режиме. Например, в случае многопортового запоминающего устройства операция считывания осуществляется в запоминающем устройстве для некодированного двоичного разряда в то время, как операция записи осуществляется в запоминающем устройстве для предыдущего некодированного двоичного разряда.
Создание выборки Altera AHDL.
Один вариант осуществления соответствующего настоящему изобретению генератора двоичных разрядов кодирующего устройства включает в себя программируемую пользователем вентильную матрицу (ППВМ). При создании обрабатывают все коды R2 и R3 вплоть до R2(12). Ниже распечатан исходный код AHDL (язык описания аппаратного средства "Алтера").
Как показано на фиг. 16, эта схема содержит несколько частей. Первая часть EN СВG является основной частью схемы, в которой имеется логическая схема 1301 для осуществления запуска, окончания и продолжения прогона. Вторая часть KEXPAND 1302 используется для расширения класса вероятности на максимальную длину прогона, маску переменной длины и длину первого длинного кодового слова для кодов R3. Функция KEXPAND 1302 идентична функции декодирующего устройства с тем же названием. Третья часть LPSCW 1303 принимает в качестве входных сигналов величину счета и информацию о классе вероятности и вырабатывает надлежащее кодовое слово "1N".
В этой схеме используются два конвейерных каскада. Во время работы первого конвейерного каскада счет получает положительное приращение, класс вероятности расширяется и выполняется вычитание и сравнение длинных кодовых слов R3. Все другие операции осуществляются во время работы второго конвейерного каскада (см. табл.13).
На фиг. 11 представлена блок-схема одного варианта осуществления переупорядочивающего блока. Переупорядочивающий блок 606 содержит блок переупорядочивания счета прогонов 801 и блок уплотнения двоичных разрядов 802. Блок переупорядочивания счета прогонов 801 перемещает кодовые слова с конца прогонов, как это создается кодирующим устройством, к началу прогонов, как это необходимо для декодирующего устройства, в то время как блок компоновки двоичных разрядов 802 объединяет кодовые слова переменной длины в перемежаемые слова постоянной длины и выдает их на выходе в надлежащем порядке, требуемом декодирующим устройством.
В целях переупорядочивания для любого декодирующего устройства можно использовать "поисковое" декодирующее устройство, в котором декодирующее устройство включено в состав кодирующего устройства и обеспечивает запросы данных в том порядке, в котором кодовые слова будут необходимы для действительного декодирующего устройства. Для поддержки "поискового" декодирующего устройства можно осуществлять независимое переупорядочивание счетов прогонов для каждого потока. Для декодирующих устройств, которые легко можно смоделировать, в целях обеспечения возможности переупорядочивания можно использовать очереди с множеством отметок времени или единую объединенную очередность. В одном варианте осуществления изобретения переупорядочивание каждого кодового слова может выполняться с использованием очередеподобной структуры данных и независимо от использования множества потоков кодированных данных. Ниже приводится описание способа осуществления переупорядочивания.
Первая выполняемая в кодирующем устройстве операция переупорядочивания заключается в переупорядочивании каждого из счетов прогонов таким образом, что счет прогонов устанавливается в начале прогона (как этого требует декодирующее устройство для декодирования). Это переупорядочивание требуется потому, что кодирующее устройство до окончания прогона не определяет, какой имеется счет прогонов (и кодовое слово). Таким образом, получающийся в результате счет прогонов, выводимый из кодирования данных, переупорядочивается таким образом, что декодирующее устройство способно должным образом декодировать счеты прогонов обратно в поток данных.
Как показано на фиг. 11, соответствующий настоящему изобретению переупорядочивающий блок 606 включает в себя блок переупорядочивания счета прогонов 801 и блок компоновки двоичных разрядов 802. Переупорядочивающий блок счета прогонов 801 подсоединен для приема множества входных сигналов, которые включают в себя сигнал запуска 711, сигнал окончания 712, сигнал индекса 713 и кодовое слово 714. Эти сигналы будут описаны более подробно в связи с блоком переупорядочивания счета прогонов, показанным на фиг.12. В ответ на входные сигналы блок переупорядочивания счета прогонов 801 генерирует кодовое слово 803 и сигнал 804. Сигнал 804 указывает, когда счет прогонов необходимо возвращать в исходное состояние. Кодовое слово 803 принимается блоком компоновки двоичных разрядов 802. В ответ на кодовое слово 803 блок компоновки двоичных разрядов 802 вырабатывает перемежаемые слова 805.
Блок переупорядочивания счета прогонов 801 и блок компоновки двоичных разрядов 802 более подробно описаны ниже.
Блок переупорядочивания счета прогонов.
Как было описано выше, требуется, чтобы декодирующее устройство принимало кодовые слова в момент времени начала данных, кодируемых с помощью кодового слова. Однако кодирующее устройство не знает идентичности кодового слова до окончания данных, кодированных с помощью кодового слова.
Блок-схема одного варианта осуществления переупорядочивающего блока счета прогонов 801 показана на фиг. 12. Описываемый вариант осуществления обеспечивает четыре перемежаемых потока, в которых каждое перемежаемое слово содержит 16 двоичных разрядов, а длина кодового слова изменяется от одного до тринадцати двоичных разрядов. В этом случае переупорядочивающий блок 300 может быть конвейеризован для оперирования со всеми потоками. Более того, используется кодирующее устройство, которое связывает счета прогонов с классами вероятности, так что максимальное число счетов прогонов, которое можно активизировать в какое-либо время, мало и для данного варианта осуществления изобретения предполагается равным 25. Отметим, что настоящее изобретение не ограничивается четырьмя перемежаемыми потоками, перемежаемыми словами из 16 двоичных разрядов или длинами кодовых слов от 1 до 13 двоичных разрядов, а его можно использовать для большего или меньшего количества потоков с перемежаемыми словами длиной более или менее 16 двоичных разрядов и длинами кодовых слов в диапазоне от 1 двоичного разряда до более чем 13 двоичных разрядов.
Как показано на фиг. 12, запоминающее устройство указателя 901 подсоединено для приема входного сигнала индекса 713 и вырабатывает адресный выходной сигнал, который подается на один вход мультиплексора 902. Два других входа мультиплексора 902 подсоединены для приема адреса в форме головного указателя из головного счетчика 903 и адреса в форме хвостового указателя из хвостового счетчика 904. Выходным сигналом мультиплексора 902 является адрес, подаваемый в запоминающее устройство кодовых слов 908 и используемый для обращения к нему.
Входной сигнал индекса 713 подается также в качестве входного сигнала в мультиплексор 905. На другой вход мультиплексора 905 поступает входной сигнал кодовых слов 714. Выход мультиплексора 905 подсоединен к входу модуля выявления достоверности 906 и к шине данных 907. Шина данных 907 подсоединена к запоминающему устройству кодовых слов 908 и входу мультиплексора 905. Кроме того, к шине данных 907 подсоединен выход управляющего модуля 909. Входной сигнал запуска 711 и входной сигнал окончания 712 поступают на раздельные входы управляющего модуля 909. Выходные сигналы модуля выявления достоверности 906 содержат выходной сигнал кодовых слов 803 и сигнал 804 (фиг. 7). Переупорядочивающий блок счета прогонов 801 включает в себя также логическую схему управляющего устройства (не показана для исключения усложнения описания настоящего изобретения), предназначенную для координирования работы различных элементов переупорядочивающего блока счета прогонов 801.
Для повторения цикла обработки входной сигнал индекса 713 идентифицирует прогон. В одном варианте осуществления изобретения индекс указывает один из 25 классов вероятности. В таком случае для представления индекса необходимо пять двоичных разрядов. Отметим, что если используется множество банков данных для классов вероятности, то для определения конкретного банка данных могут потребоваться дополнительные двоичные разряды. В одном варианте осуществления изобретения входной сигнал индекса идентифицирует класс вероятности для счета прогонов. Входной сигнал кодовых слов 714 представляет собой кодовое слово, когда происходит окончание прогона, а в противном случае "не имеет значения". Входной сигнал запуска 711 и входной сигнал окончания 712 являются управляющими сигналами, которые указывают, начинается ли, заканчивается ли прогон или и то и другое. Прогон начинается и заканчивается в одно и то же время, когда прогон состоит из единственного некодированного двоичного разряда.
Переупорядочивающий блок счета прогонов 801 переупорядочивает счеты прогонов, вырабатываемые генератором двоичных разрядов в ответ на его входные сигналы. Запоминающее устройство кодовых слов 908 запоминает кодовые слова во время переупорядочивания. В одном варианте осуществления изобретения запоминающее устройство кодовых слов 908 больше, чем количество счетов прогонов, которые могут быть активированы в одно и то же время. Это ведет к лучшему уплотнению. Если запоминающее устройство кодовых слов меньше, чем количество счетов прогонов, которые могут быть активированы в одно и то же время, то это действительно может ограничивать количество активированных счетов прогонов количеством, которое может храниться в памяти. В системе, которая обеспечивает хорошее уплотнение, часто получается, что когда накапливаются данные для одного кодового слова с длинным счетом прогонов, то начинаются (возможно, также и оканчиваются) множество кодовых слов с короткими счетами прогонов. Это требует наличия большой памяти для исключения вытеснения длинного прогона до его полного завершения.
Запоминающее устройство указателя 901 запоминает адреса местоположений памяти кодовых слов для классов вероятности, которые находятся в середине прогона, и адресует запоминающее устройство кодовых слов 908 в режиме произвольной выборки. Запоминающее устройство указателей 901 имеет ячейку запоминающего устройства для адреса в запоминающем устройстве кодового слова 908 для каждого класса вероятности, который может быть в середине прогона. После того, как прогон завершится для конкретного класса вероятности, адрес, запомненный в запоминающем устройстве указателя 901 для этого класса вероятности, используется для выборки из запоминающего устройства кодовых слов 908, и завершенное кодовое слово записывается в запоминающее устройство кодовых слов 908 в этой ячейке. До этого времени эта ячейка в запоминающем устройстве кодовых слов 908 содержит недействительный элемент. Таким образом, запоминающее устройство указателя 901 запоминает местоположение ошибочного кодового слова для каждого счета прогона.
Головной счетчик 903 и хвостовой счетчик 904 обеспечивают также адреса для доступа в запоминающее устройство кодовых слов 908. Использование головного счетчика 903 и хвостового счетчика 904 позволяет адресовать запоминающее устройство кодовых слов 908 в качестве очереди или кольцевого буфера (например, запоминающее устройство обратного магазинного типа). Хвостовой счетчик 904 содержит адрес следующей имеющейся ячейки в запоминающем устройстве кодовых слов 908 для разрешения введения кодового слова в запоминающее устройство кодовых слов 908. Головной счетчик 903 содержит адрес в запоминающем устройстве кодовых слов 908 следующего подлежащего выведению кодового слова. Другими словами, головной счетчик 903 содержит адрес запоминающего устройства кодовых слов следующего кодового слова, подлежащего аннулированию из запоминающего устройства кодовых слов 908. Местоположение каждого возможного индекса (например, класса вероятности) в запоминающем устройстве указателя 901 используется для запоминания, где находился хвостовой указатель 904, когда был запущен прогон, чтобы в это местоположение в запоминающем устройстве кодовых слов 908 можно было поместить надлежащее кодовое слово при окончании прогона.
Управляющий модуль 909 вырабатывает сигнал достоверности в качестве части данных, запомненных в запоминающем устройстве кодовых слов 908 для того, чтобы показать, правильно ли запомнено содержимое данных кодовых слов или нет. Например, если двоичный разряд достоверности имеет логический уровень "1", то ячейка запоминающего устройства кодовых слов содержит достоверные данные. Однако если двоичный разряд достоверности представляет логический "0", то ячейка запоминающего устройства кодовых слов содержит недостоверные данные. Модуль выявления достоверности определяет, содержит ли ячейка в запоминающем устройстве правильное кодовое слово каждый раз, когда кодовое слово считывается из запоминающего устройства кодовых слов 908. В одном варианте осуществления изобретения модуль выявления достоверности 906 определяет, имеется ли в ячейке запоминающего устройства правильное кодовое слово или конкретный неверный код.
Когда запускается новый прогон, содержимое неверных данных вводится в запоминающее устройство кодовых слов 908. Ввод неверных данных действует в качестве держателей промежутка в потоке данных, хранящихся в запоминающем устройстве кодовых слов 908, чтобы при завершении прогона кодовое слово для прогона могло запоминаться в запоминающем устройстве в надлежащей ячейке (для надлежащего упорядочивания при моделировании декодирующего устройства). В одном варианте осуществления изобретения ввод неверных данных включает индекс посредством мультиплексора 905 и индикацию недостоверности (например, двоичный разряд недостоверности) из управляющего модуля 909. Адрес в запоминающем устройстве кодовых слов 908, под которым запоминается неверное содержимое, задается хвостовым указателем 904, а впоследствии запоминается в запоминающем устройстве указателя 901 в качестве напоминания о ячейке для счета прогонов в запоминающем устройстве кодовых слов 908. Остальные данные, которые появляются между головным указателем 903 и хвостовым указателем 904, запоминаются в запоминающем устройстве кодовых слов 908 в виде счетов завершенных прогонов (например, переупорядоченных счетов прогонов). Максимальные количества неверных ячеек запоминающего устройства равно от 0 до l-1, где l - количество счетов прогонов. Когда кодовое слово завершено в конце прогона, счет прогонов заполняется в запоминающем устройстве кодовых слов 908 с использованием адреса, хранящегося в запоминающем устройстве указателя 901.
Когда прогон запущен, индекс прогона запоминается в запоминающем устройстве кодовых слов 908, так что, если запоминающее устройство кодовых слов 908 заполнено, а прогон еще не завершен, индекс используется вместе с сигналом 804 для установления в исходное состояние соответствующего счетчика прогонов. В дополнение к запоминанию кодовых слов или индексов в запоминающем устройстве кодовых слов 908 один двоичный разряд используется для указания, который из этих двух типов данных запоминается.
Если нет запуска или окончания прогона, переупорядочивающий блок счета прогонов простаивает. Если произведен запуск прогона и нет окончания прогона и если запоминающее устройство заполнено, то из запоминающего устройства кодовых слов 908 выводится кодовое слово. Выводимое кодовое слово является кодовым словом, запомненным в адресе, содержащемся в головном указателе 903 для этого класса вероятности. Затем, если произведен запуск прогона и нет окончания прогона (независимо от того, заполнена ли память), входной сигнал индекса 713 записывается в запоминающее устройство кодовых слов 908 через мультиплексор 905 по адресу, определяемому хвостовым указателем 904. Затем хвостовой указатель 904 записывается в запоминающее устройство указателя 901 по адресу, определяемому данными во входном сигнале индекса 713 (например, в ячейке запоминающего устройства указателя 901 для класса вероятности). После записи хвостового указателя 904 хвостовой указатель 904 получает положительное приращение.
Если имеется окончание прогона и нет запуска прогона, то адрес, хранящийся в запоминающем устройстве указателя 901, соответствующий индексу (классу вероятности), считывается и используется в качестве ячейки в запоминающем устройстве кодовых слов для запоминания законченного кодового слова во входном сигнале кодового слова 714.
Если имеются запуск прогона и окончание прогона (то есть прогон начинается и заканчивается в одно и то же время), а память заполнена, то из запоминающего устройства кодовых слов 908 выводится кодовое слово. Затем, если произведены запуск прогона и окончание прогона (независимо от того, заполнена ли память), входной сигнал кодового слова 714 записывается в запоминающее устройство кодовых слов 908 по адресу, определяемому хвостовым указателем 904. Затем хвостовой указатель 904 получает положительное приращение для содержания следующей имеющейся ячейки (например, приращение на 1).
В настоящем изобретении переупорядочивающий блок счета прогонов 801 может выдавать кодовые слова в различные моменты времени. В одном варианте осуществления изобретения кодовые слова могут выдаваться, когда они верные или неверные. Кодовые слова могут выдаваться, когда они неверные, если существует состояние заполнения памяти, а прогон не завершен. Кроме того, неверные кодовые слова могут выдаваться для поддержания минимальной скорости (то есть для управления скоростью). Неверные кодовые слова могут выдаваться также для выключения из работы запоминающего устройства кодовых слов 908, когда все данные подверглись переупорядочиванию счета прогонов или когда в результате операции установки в исходное состояние переупорядочивающий блок счета прогонов переходит к середине запоминающего устройства кодовых слов 908. Отметим, что в таком случае декодирующее устройство должно быть уведомлено о том, что кодирующее устройство работает таким образом.
Как описано выше, кодовое слово выдается всякий раз, когда заполняется запоминающее устройство кодовых слов 908. После заполнения памяти всякий раз, когда осуществляется ввод (то есть запуск нового кодового слова) в запоминающее устройство кодовых слов 908, осуществляется вывод из запоминающего устройства кодовых слов 908. Отметим, что корректировка содержимого не вызывает вывода из запоминающего устройства кодовых слов 908, когда существует состояние заполнения памяти. То есть, завершение прогона с последующей записью полученного в результате кодового слова в заранее назначенную ему ячейку памяти не вызывает появления вывода из заполненной памяти. Аналогично этому, когда прогон окончен, а соответствующий адрес в запоминающем устройстве указателя 901 и адрес в головном счетчике 903 одни и те же, кодовое слово может быть выдано немедленно, а после этого головной счетчик 903 может получить положительное приращение без обращения в запоминающее устройство кодовых слов 908. В одном варианте осуществления изобретения состояние заполнения памяти происходит, когда хвостовой указатель 904 равен головному указателю 903 после того, как хвостовой счетчик получит положительное приращение. Следовательно, после того, как хвостовой указатель получит положительное приращение, логическая схема управляющего устройства в переупорядочивающем блоке счета прогонов 801 сравнивает хвостовой указатель 904 и головной указатель 903, и если они одинаковые, логическая схема управляющего устройства определяет, что запоминающее устройство кодовых слов 908 заполнено и что должно быть выдано кодовое слово. В другом варианте осуществления изобретения кодовые слова могут выдаваться до заполнения памяти. Например, если часть очереди, адресуемая заголовком, содержит верные кодовые слова, она может быть выдана. Для этого требуется, чтобы начало очереди неоднократно проверялось для определения состояния кодовых слов в ней. Отметим, что запоминающее устройство кодовых слов 908 в конце кодирования файла очищается.
Используя переупорядочивающий блок счета прогонов 801, кодовое слово выдается при первом считывании значения (например, данных) из запоминающего устройства кодовых слов 908 по адресу, определяемому головным указателем 903. Выводом кодовых слов управляет и координирует логическая схема управляющего устройства. Модуль выявления достоверности 906 осуществляет проверку с целью определения, является ли значение кодовым словом. Другими словами, модуль выявления достоверности 906 определяет, верное ли кодовое слово. В одном варианте осуществления изобретения модуль выявления достоверности 906 определяет достоверность любого содержимого путем проверки двоичного разряда достоверности, запомненного с каждым входным сообщением. Если значение является кодовым словом (то есть кодовое слово верное), то значение выдается как кодовое слово. С другой стороны, если значение не является кодовым словом (то есть кодовое слово неверное), то может быть выдано любое кодовое слово, которое имеет прогон символом БВС, по меньшей мере такой же длинный, как текущий счет прогонов. Кодовое слово "0" является одним кодовым словом, которое пока правильно представляет текущий прогон и может быть выдано. После осуществления выдачи головной указатель 903 получает положительное приращение для следующей ячейки в запоминающем устройстве кодовых слов 908. В качестве альтернативы, использование "1N" с самыми короткими возможными длинами прогона позволяет декодирующему устройству проверять, вытеснено ли только кодовое слово до выпуска МВС.
В одном варианте осуществления изобретения переупорядочивающий блок счета прогонов 801 работает с периодом времени двух циклов синхронизации. В первом цикле синхронизации входные сигналы принимаются в переупорядочивающий блок счета прогонов 801. Во втором цикле синхронизации происходит вывод сигнала из запоминающего устройства кодовых слов 908.
Хотя кодовые слова могут выводиться всякий раз, когда головной указатель 903 адресует правильное кодовое слово, может оказаться желательным в некоторых реализациях выдавать на выход кодовое слово только тогда, когда заполнен буфер. Это вызывает фиксированную задержку в системе в единицах количества кодовых слов вместо переменной задержки. Если запоминающее устройство 908 способно удерживать заранее установленное количество кодовых слов между моментом времени, когда прогон запускается и вводится и когда выводится, задержка составляет это количество кодовых слов, поскольку вывод не производится, пока оно не заполнится. Таким образом, существует постоянная задержка в кодовых словах. Отметим, что задержка переупорядочивания все еще остается переменной в других местах, например, в количестве кодированных или первоначальных данных. Позволяя запоминающему устройству 908 заполняться до осуществления вывода, на выходе вырабатывается кодовое слово за один цикл.
Отметим, что если ячейка запоминающего устройства кодовых слов маркируется как неверная, то можно использовать неиспользованные двоичные разряды для запоминания идентификации, для какого это счета прогона (то есть запоминается в ней контекстный элемент кодированного сигнала или класс вероятности, которые должны заполнять эту ячейку). Эта информация полезна для манипулирования в случае, когда память заполнена. В частности, информацию можно использовать для указания генератора двоичных разрядов, который не закончил кодовое слово для этой конкретной длины прогона, которое теперь должно быть закончено. В таком случае принимается решение вывести первое кодовое слово, которое может появиться из-за состояния заполненной памяти. Таким образом, когда система устанавливает в исходное состояние счетчик прогонов, информация, выраженная через генераторы двоичных разрядов и счеты прогонов, указывает, когда система начнет все сначала.
Что касается входного сигнала индекса, то по причинам конвейерного режима, когда используются банки классов вероятности, индекс может включать в себя идентификатор банка. То есть, здесь для конкретного класса вероятности может существовать множество счетов прогонов. Например, в случае 80-процентного кода можно использовать два счета прогонов, когда сначала используется один, потом другой.
Поскольку кодовые слова имеют переменную длину, они должны запоминаться в запоминающем устройстве кодовых слов 908 таким образом, который позволит установить их длину. Хотя было бы возможным запомнить размер в явном виде, это не минимизировало бы использование запоминающего устройства. В случае R-кодов запоминание значения нуля в памяти может индицировать одноразрядное кодовое слово "0", а кодовые слова "1N" могут запоминаться так, что для определения длины от первого двоичного разряда "1" можно использовать кодер приоритета.
Если запоминающее устройство кодовых слов 908 многопортовое (например, двухпортовое), эту конструкцию можно конвейеризировать для оперирования одним кодовым словом за один цикл синхронизации. Поскольку с большого количества портов можно осуществлять доступ к любой ячейке в запоминающем устройстве кодовых слов 908, в ячейке запоминающего устройства кодовых слов можно записывать, например, когда запоминается неверная информация или кодовое слово, в то время как другой участок можно считывать, например, когда кодовое слово выводится. Отметим, что в таком случае мультиплексоры могут быть модифицированы для обеспечения множества шин данных и адресов.
Всякий раз, когда кодирующее устройство дает на выходе кодовое слово "0" и устанавливает счетчик прогонов в исходное состояние, так как запоминающее устройство кодовых слов заполнено, декодирующее устройство должно делать то же самое. Это требует, чтобы декодирующее устройство моделировало очередь запоминающего устройства кодовых слов кодирующего устройства. Ниже будет описано, каким образом это выполняется.
Отметим, что для экономии энергии при реализациях комплементарных МОП-структур счетчики можно блокировать для кодовых слов "1N", когда кодовые слова "0" выводятся в отношении неверных прогонов. Это происходит потому, что декодируемое кодовое слово "1N" правильное, в то время как неверным может быть только кодовое слово "0".
Альтернативный вариант осуществления изобретения, основанный на контексте.
На фиг. 13 представлена блок-схема другого варианта осуществления переупорядочивающего блока счета прогонов, который переупорядочивает данные, принимаемые в соответствии с контекстом (в противоположность классу вероятности). Переупорядочивающий блок счета прогонов 1000 осуществляет переупорядочивание с использованием R-кодов. Рассматривая фиг.13, отметим, что переупорядочивающий блок 1000 включает в себя запоминающее устройство указателя 1001, головной счетчик 1002, хвостовой счетчик 1003, мультиплексор данных 1004, мультиплексор адреса 1005, блок вычисления длины 1006, блок выявления достоверности 1007 и запоминающее устройство кодовых слов 1008. Запоминающее устройство кодовых слов 1008 запоминает кодовые слова во время переупорядочивания. Запоминающее устройство указателя 1001 запоминает адреса ячеек запоминающего устройства кодовых слов для контекстных элементов кодированного сигнала, которые расположены в середине прогона. Головной счетчик 1002 и хвостовой счетчик 1003 позволяют адресовать запоминающее устройство кодовых слов 1008 в виде очереди или кольцевого буфера в дополнение к адресации методом произвольной выборки запоминающим устройством указателя 1001. В случае R-кодов запоминание значения нуля в памяти может указывать одноразрядное кодовое слово "0", а кодовые слова "1N" могут запоминаться так, что для определения длины от первого двоичного разряда "1" можно использовать кодер приоритета. Модуль вычисления длины 1006 функционирует подобно кодеру приоритета. (Если бы использовались другие неравномерные коды, то для точного запоминания длины было бы эффективнее в память добавлять двоичный разряд "1" с целью маркировки запуска кодового слова, чем добавлять log2 двоичных разрядов.) Переупорядочивающий блок счета прогонов 1000, кроме того, включает в себя логическую схему управляющего устройства обратными этапами для координирования и управления работой компонентов 1001-1008.
Функционирование переупорядочивающего блока счета прогонов 1000 очень похоже на функционирование переупорядочивающего блока счета прогонов, основанного на оценках вероятности. Если начинается новый прогон, то неверное содержимое, включающее в себя контекстный элемент кодированного сигнала, записывается в запоминающее устройство кодовых слов 1008 по адресу, указанному хвостовым указателем 1003. После этого адрес хвостового указателя 1003 запоминается в запоминающем устройстве указателя 1001 по адресу контекстного элемента кодированного сигнала текущего счета прогонов. Затем хвостовой указатель 1003 получает положительное приращение. При завершении указатель в запоминающем устройстве указателя 1001, соответствующий счету прогонов, считывается из запоминающего устройства указателя 1001, а кодовое слово параллельно записывается в запоминающее устройство кодовых слов 1008 в ячейке, указанной этим указателем. Если не происходит ни запуск, ни окончание прогона и если указанная адресом головного указателя 1002 ячейка в запоминающем устройстве кодовых слов 1008 не содержит неверных данных, то адресуемое головным указателем кодовое слово считывается и выводится. Затем головной указатель 1002 получает приращение. В том случае, если прогон начинается и заканчивается в одно и то же время, кодовое слово записывается в запоминающее устройство кодовых слов 1008 по адресу, указанному хвостовым указателем 1003, и после этого хвостовой указатель 1003 получает приращение.
Подобно этому, когда прогон заканчивается и соответствующий адрес в запоминающем устройстве указателя 1001 и адрес в головном счетчике 1002 одни и те же, кодовое слово может быть выведено немедленно, а значение в головном счетчике 1002 может получить приращение без обращения к запоминающему устройству кодовых слов 1008.
Для систем счета прогонов "с помощью контекста" каждый контекст требует ячейку памяти в запоминающем устройстве указателя 1001, так что емкость запоминающего устройства состояния генератора последовательности бит (ГПБ) и модуля оценки вероятности (MOB) можно увеличить с целью обеспечения этой памяти. Емкость запоминающего устройства указателя 1001 равна емкости, необходимой для адреса запоминающего устройства кодовых слов.
Количество ячеек в запоминающем устройстве кодовых слов 1008 может быть выбрано разработчиком при конкретной реализации. Ограниченная емкость этой памяти снижает эффективность уплотнения, так что существует компромисс между стоимостью и уплотнением. Емкость запоминающего устройства кодовых слов определяется размером самого большого кодового слова плюс один двоичный разряд для указания достоверности-недостоверности.
Для иллюстрации переупорядочивания будет представлен пример использования кода R2(2), показанный в табл. 14. В табл.15 показаны подлежащие переупорядочиванию данные /0 = БВС (наиболее вероятный символ); 1 = МВС (наименее вероятный символ)/, отмеченные контекстом. Имеются только два контекста. Указаны запуск и окончание прогонов, а кодовые слова показаны в конце прогонов.
Операция переупорядочивания переменных данных показана в табл. 16. Использовано запоминающее устройство кодовых слов с четырьмя ячейками 0-3, которые достаточно большие для исключения переполнения в этом примере. В каждой строке показано состояние системы после операции, которая представляет собой либо запуск, либо окончание прогона для некоторого контекста или вывода кодового слова. Символ "x" используется для указания ячеек памяти, которые "безразличны". В отношении некоторых некодированных двоичных разрядов прогон не запускается и не останавливается, так что переупорядочивающий блок счета прогонов простаивает. Для кодированных двоичных разрядов, у которых закончены прогоны, могут выдаваться одно или больше кодовых слов, что может вызывать несколько изменений в состоянии системы.
В соответствии c табл. 16 головной и хвостовой указатели устанавливаются в ноль, указывая, что в запоминающем устройстве кодовых слов ничего не содержится (например, очереди). Показано, что запоминающее устройство указателя имеет две ячейки памяти, по одной для каждого контекста. Каждая ячейка имеет "безразличные" значения до прихода разряда номер один. Показано запоминающее устройство кодовых слов с глубиной, равной четырем кодовым словам, которые все первоначально имеют "безразличные" значения.
В ответ на принятые данные для двоичного разряда номер 1 головной указатель сохраняет указание на ячейку 0 запоминающего устройства кодовых слов. Поскольку декодирующее устройство будет ожидать данные, следующая имеющаяся ячейка 0 запоминающего устройства кодовых слов назначается кодовому слову, а неверное значение записывается в ячейку памяти 0. Поскольку контекст равен нулю, адрес назначенной кодовому слову ячейки запоминающего устройства кодовых слов запоминается в ячейке запоминающего устройства указателя для нулевого контекста (ячейка 0 запоминающего устройства указателя). Таким образом, в ячейке 0 запоминающего устройства указателя запоминается "0". Хвостовой указатель получает приращение до следующей ячейки 1 запоминающего устройства кодовых слов.
В ответ на данные, соответствующие двоичному разряду номер 2, головной счетчик сохраняет указание на первую ячейку памяти (поскольку не было вывода, вызывающего приращение). Поскольку данные соответствуют второму контексту, то есть контексту 1, следующая ячейка запоминающего устройства кодовых слов назначается кодовому слову в качестве ячейки 1 запоминающего устройства кодовых слов, указываемой хвостовым указателем, а в ячейку записываются неверные данные. Адрес, то есть ячейка 1 кодового слова, записывается в ячейку запоминающего устройства указателя, соответствующую контексту 1. То есть, адрес второй ячейки запоминающего устройства кодового слова записывается в ячейку 1 запоминающего устройства указателя. После этого хвостовой указатель получает приращение.
В ответ на данные, соответствующие двоичным разрядам номер 3, переупорядочивающий блок простаивает, поскольку прогон не запускается и не оканчивается.
В ответ на соответствующие двоичному разряду номер 4 данные для контекста 1 указывается окончание прогона. Поэтому в ячейку запоминающего устройства кодовых слов, назначенную для контекста 1, записывается кодовое слово "101" (ячейка 1 запоминающего устройства кодовых слов), как указывает ячейка запоминающего устройства указателя для контекста 1. Головной и хвостовой указатели остаются теми же самыми, а значение в ячейке запоминающего устройства указателя для контекста 1 не будет использоваться снова, поэтому оно "безразлично".
В ответ на данные, соответствующие двоичному разряду номер 5, переупорядочивающий блок не занят, поскольку нет ни запуска, ни окончания прогона.
В ответ на данные, соответствующие двоичному разряду номер 6, происходит тот же тип операций, который описан выше для двоичного разряда номер 2.
В ответ на данные, соответствующие двоичному разряду номер 7, происходит окончание прогона кодового слова для контекста 0. В этом случае в ячейку запоминающего устройства кодовых слов (ячейка 0 запоминающего устройства кодовых слов) записывается кодовое слово "0", как указано ячейкой запоминающего устройства указателя для контекста 0 (ячейка 0 запоминающего устройства указателя). После этого значение в ячейке запоминающего устройства указателя не будет снова использоваться, так что оно оказывается "безразличным". Кроме того, ячейка запоминающего устройства кодового слова, обозначаемая головным указателем, содержит верные данные. Поэтому верные данные выводятся, а головной указатель получает приращение. Приращение головного указателя обуславливает указание им на другую ячейку запоминающего устройства кодовых слов, содержащую верное кодовое слово. Следовательно, это кодовое слово выводится, а головной указатель снова получает приращение. Отметим, что в этом примере кодовые слова выводятся тогда, когда они оказываются готовыми, в противоположность случаю, когда запоминающее устройство кодовых слов полностью заполнено.
Обработка некодированных двоичных разрядов продолжается в соответствии с приведенным выше описанием. Отметим, что ячейки запоминающего устройства кодовых слов не назначаются для использования конкретных контекстов, так что кодовые слова из любого контекста могут запоминаться в данной ячейке запоминающего устройства кодовых слов на всем протяжении кодирования файла данных.
Блок компоновки двоичных разрядов.
Компоновка двоичных разрядов иллюстрируется на фиг. 7, где показаны данные, обработанные с помощью переупорядочивающего блока до и после компоновки двоичных разрядов. На фиг. 7 показаны шестнадцать кодовых слов переменной длины, пронумерованные с 1 по 16 для указания порядка использования их декодирующим устройством. Каждое кодовое слово назначается одному из трех кодированных потоков. Данные в каждом кодированном потоке разбиваются на слова фиксированной длины, называемые перемежаемыми словами. (Отметим, что одно кодовое слово переменной длины может быть разбито на два перемежаемых слова. ) В этом примере перемежаемые слова упорядочены в одном перемежаемом потоке, так что порядок первого кодового слова переменной длины (или частичного кодового слова) в конкретном слове с чередованием (перемежением) определяет порядок слова с чередованием. Могут выполняться другие типы критериев упорядочивания. Преимущество чередования множества кодированных потоков заключается в том, что для передачи данных можно использовать один канал кодированных данных и что можно осуществлять сдвигание переменной длины для каждого потока параллельным или конвейерным образом.
Соответствующий настоящему изобретению блок компоновки двоичных разрядов 802 принимает кодовые слова переменной длины из переупорядочивающего блока счета прогонов 801 и компонует их в перемежаемые слова. Блок компоновки двоичных разрядов 802 содержит логическую схему для осуществления манипулирования кодовыми словами переменной длины и блок переупорядочивания типа объединенной очередности для вывода перемежаемых слов фиксированной длины в правильном порядке. В одном варианте осуществления изобретения кодовые слова принимаются из переупорядочивающего блока счета прогонов со скоростью вплоть до одного кодового слова за тактовый цикл. Блок-схема одного варианта осуществления блока компоновки двоичных разрядов 802 показана на фиг. 14. В следующем варианте осуществления изобретения используются четыре перемежаемых потока, каждое перемежаемое слово состоит из 16 разрядов, а длина кодового слова изменяется от одного до тридцати двоичных разрядов. В одном варианте осуществления изобретения для манипулирования всеми потоками конвейеризируется единственный блок компоновки двоичных разрядов. Если в соответствующем настоящему изобретению блоке компоновки двоичных разрядов 802 используется двухпортовое запоминающее устройство (или регистровый файл), оно может выдавать одно перемежаемое слово за тактовый цикл. Это может оказаться быстрее, чем требуется для согласования с остальной частью кодирующего устройства.
Как показано на фиг. 14, блок компоновки двоичных разрядов 802 включает в себя компонующую логическую схему 1101, счетчик потоков 1102, запоминающее устройство 1103, хвостовые указатели 1104 и головной счетчик 1105.
Компонующая логическая схема 1101 подсоединена для приема кодовых слов и подсоединена к счетчику потоков 1102. Счетчик потоков 1102 также подсоединен к запоминающему устройству 1103. К запоминающему устройству 1103, кроме того, подсоединены хвостовые указатели 1104 и головной счетчик 1105.
Счетчик потоков 1102 отслеживает перемежаемый поток, с которым связано текущее входное кодовое слово. В одном варианте осуществления изобретения счетчик потоков 1102 повторно считает потоки от 0 до N-1, где N - количество потоков. После того, как счетчик потоков 1102 достигнет величины N-1, он снова начинает считать с 0. В одном варианте осуществления изобретения счетчик потоков 1102 является двухразрядным счетчиком и считает от 0 до 3 (для четырех перемежаемых потоков). В этом варианте осуществления изобретения счетчик потоков устанавливается в ноль (например, посредством общего сброса в исходное состояние).
Компонующая логическая схема 1101 объединяет текущее входное кодовое слово с предыдущими входными кодовыми словами для формирования перемежаемых кодовых слов. Длина каждого из кодовых слов может меняться. Поэтому компонующая логическая схема 1101 компонует эти кодовые слова переменной длины в слова фиксированной длины. Созданные с помощью компонующей логической схемы 1101 перемежаемые кодовые слова выводятся в запоминающее устройство 1103 по порядку и хранятся в запоминающем устройстве 1103 до надлежащего времени для их вывода. В одном варианте осуществления изобретения запоминающее устройство 1103 представляет собой статистическое запоминающее устройство с произвольной выборкой (СЗУПВ) или регистровый файл с шестьюдесятью четырьмя 16-разрядными словами.
Перемежаемые слова запоминаются в запоминающем устройстве 1103. В настоящем изобретении емкость запоминающего устройства 1103 достаточно большая для манипулирования словами в двух случаях. Один случай нормальной работы, когда один перемежаемый поток имеет кодовые слова минимальной длины, а другие перемежаемые потоки имеют кодовые слова максимальной длины. Этот первый случай требует 3•13=39 ячеек памяти. Другой случай представляет собой случай инициализации, где опять один поток имеет кодовые слова минимальной длины, или короткие кодовые слова, а другие потоки имеют кодовые слова максимальной длины, или длинные кодовые слова. Для второго случая, хотя достаточно 2•3•13= 78 ячеек памяти, работа модуля MOB позволяет теснее связывать 56-ю ячейками.
Переупорядочение выполняет запоминающее устройство 1003 совместно со счетчиком потоков 1102 и хвостовыми указателями 1104. Счетчик потоков 1102 указывает текущий поток кодового слова, принимаемого запоминающим устройством 1103. Каждый из перемежаемых потоков связан по меньшей мере с одним хвостовым указателем. Хвостовые указатели 1104 и головной счетчик 1105 осуществляют переупорядочивание кодовых слов. Причина, по которой нужно иметь два хвостовых указателя на поток, следует из слова чередования N, запрашиваемого декодирующим устройством, когда данные в перемежаемом слове N-1 содержат запуск следующего кодового слова. Один хвостовой указатель определяет ячейку в запоминающем устройстве 1103 для запоминания следующего перемежаемого слова из данного перемежаемого потока. Другой хвостовой указатель определяет ячейку в запоминающем устройстве для запоминания слова с чередованием после следующего такого слова. Это позволяет определить ячейку слова N с чередованием, когда время запроса декодером слова N-1 с чередованием известно. В одном варианте осуществления изобретения указатели представляют собой восемь 6-разрядных регистров (два хвостовых указателя на поток).
В одном варианте осуществления изобретения в начале кодирования хвостовые указатели 1104 устанавливаются так, что первые восемь слов с чередованием (два из каждого потока) запоминаются в запоминающем устройстве 1103 в последовательности по одному из каждого потока. После инициализации всякий раз, когда компонующее логическое устройство 1101 начинает новое слово с чередованием для конкретного кодового потока, "следующий" хвостовой указатель устанавливают на значение "после следующего" хвостового указателя, а хвостовой указатель "после следующего" для кодового потока устанавливают на следующую имеющуюся ячейку памяти. Таким образом, для каждого потока имеются два хвостовых указателя. В другом варианте осуществления изобретения для каждого потока используют только один хвостовой указатель, и он указывает, где следующее перемежаемое слово следует запоминать в запоминающем устройстве 1103.
Головной счетчик 1105 используется для определения ячейки памяти для вывода следующего слова с чередованием из блока компоновки двоичных разрядов 802. В описываемом варианте осуществления изобретения головной счетчик 1105 содержит 6-разрядный счетчик, который получает приращение для вывода всего слова с чередованием сразу.
Запоминающее устройство 1103 в дополнение к использованию его для переупорядочивания можно также использовать в качестве буфера обратного магазинного типа (FIFO) между кодирующим устройством и каналом. Может оказаться желательным иметь запоминающее устройство с большей емкостью, чем требуется для переупорядочивания, поэтому для останова кодирующего устройства можно использовать сигнал почти заполненного FIFO, если канал не может поддерживать кодирующее устройство. Кодирующее устройство типа один двоичный разряд на цикл не может генерировать одно слово с чередованием за цикл. Когда кодирующее устройство хорошо согласовано с каналом, канал не принимает слово с чередованием на каждый цикл, и поэтому необходима некоторая FIFO-буферизация. Например, канал, который может принимать 16-разрядное слово с чередованием каждые 32 тактовых цикла, может представлять собой хорошо согласованный вариант для эффективного расширения полосы пропускания 2:1 или больше.
Блок-схема компонующей логической схемы показана на фиг. 15. Компонующая логическая схема 1101 состоит из размерного блока 1201, набора накапливающих сумматоров 1202, сдвигающего устройства 1203, мультиплексора 1204, набора регистров 1205 и логического вентиля ИЛИ 1206. Размерный блок 1201 подсоединен для приема кодовых слов и подсоединен к накапливающим сумматорам 1202. Накапливающие сумматоры подсоединены к сдвигающему устройству 1203, на который поступают также кодовые слова. Сдвигающее устройство 1203 подсоединено к мультиплексору 1204 и логическому вентилю ИЛИ 1206. Мультиплексор 1204 подсоединен также к регистрам 1205 и выходу логического вентиля ИЛИ 1206. Регистры, кроме того, подсоединены к логическому вентилю ИЛИ 1206.
В одном варианте осуществления изобретения кодовые слова вводятся в 13-разрядную шину с установленными на ноль неиспользованными разрядами. Эти установленные на ноль неиспользованные двоичные разряды находятся рядом с "1" в кодовых словах "1N", так что кодер приоритета в размерном блоке 1201 можно использовать для определения длины кодовых слов "1N" и вырабатывания размера кодовых слов "0".
Накапливающие сумматоры 1202 содержат множество накапливающих сумматоров, по одному для каждого потока с чередованием. Накапливающий сумматор для каждого потока с чередованием сохраняет запись количества двоичных разрядов уже в текущем слове с чередованием. В одном варианте осуществления изобретения каждый накапливающий сумматор содержит 4-разрядный сумматор (с завершением) и 4-разрядный регистр, используемый для каждого потока. В одном варианте осуществления изобретения выход сумматора является выходом накапливающего сумматора. В другом варианте выходной сигнал регистра представляет выходной сигнал накапливающего сумматора. Используя размер кодовых слов, принимаемых из размерного блока 1201, накапливающие сумматоры определяют количество разрядов для сдвигания с целью конкатенирования текущего кодового слова в регистр, содержащий текущее слово с чередованием для этого потока.
На основании текущего значения накапливающего сумматора сдвигающее устройство 1203 совмещает текущее кодовое слово так, чтобы оно надлежащим образом следовало за любыми предыдущими кодовыми словами в этом слове с чередованием. Таким образом, данные в кодирующем устройстве сдвигаются в порядок декодирования. Выходной сигнал сдвигающего устройства 1203 составляет 28 двоичных разрядов, что соответствует случаю, когда 13-разрядное кодовое слово должно добавляться к 15 двоичным разрядам в текущем слове с чередованием так, чтобы двоичные разряды из текущего кодового слова оканчивались в старших 12 двоичных разрядах из 28 выводимых двоичных разрядов. Отметим, что сдвигающее устройство 1203 работает без обратной связи и, следовательно, его можно конвейеризировать. В одном варианте осуществления изобретения сдвигающее устройство 1203 представляет собой многорегистровое циклическое сдвиговое устройство.
Регистры 1205 запоминают двоичные разряды в текущих словах с чередованием. В одном варианте осуществления изобретения 16-разрядный регистр для каждого перемежаемого потока удерживает предыдущие двоичные разряды текущего слова с чередованием.
Вначале кодовое слово потока принимается сдвигающим устройством 1203, в то время как размерный блок 1201 указывает размер кодового слова накапливающему сумматору, соответствующему потоку. Накапливающий сумматор имеет начальное значение, равное нулю, установленное посредством общего сброса в исходное состояние. Поскольку значение накапливающего сумматора равно нулю, кодовое слово не сдвигается и затем проходит в режиме ИЛИ с использованием логической схемы ИЛИ 1206 при содержимом регистра, соответствующем потоку. Однако в некоторых вариантах осуществления изобретения кодовые слова "1N" должны сдвигаться для надлежащего выравнивания даже в начале перемежаемого слова. Такой регистр установлен в нулевое состояние и, следовательно, результат операции ИЛИ заключается в помещении кодового слова в положения крайних правых разрядов выходного сигнала логической схемы ИЛИ 1206 и направлении по цепи обратной связи через мультиплексор 1204 в регистр для хранения до следующего кодового слова из потока. Таким образом, вначале сдвигающее устройство 1203 действует как транзитный проход. Отметим, что количество двоичных разрядов в первом кодовом слове теперь хранится в накапливающем сумматоре. При приеме следующего кодового слова для этого потока величина в накапливающем сумматоре посылается в сдвигающее устройство 1203, а кодовое слово сдвигается левее для объединения с ранее введенными двоичными разрядами в перемежаемом слове. Нули размещаются в других позициях двоичных разрядов в сдвигаемом слове. Двоичные разряды из регистра, соответствующего потоку, объединяются с двоичными разрядами из сдвигающего устройства 1203, используя для этого логическую схему ИЛИ 1206. Если накапливающий сумматор не дает индикацию завершения (например, сигнала), то требуется больше двоичных разрядов для завершения формирования текущего слова с чередованием, а данные, получаемые в результате операции ИЛИ, вводятся обратно в регистр через мультиплексор 1204. В одном варианте осуществления мультиплексор 1204 представляет собой мультиплексор 2:1. Когда накапливающий сумматор вырабатывает сигнал завершения, 16 двоичных разрядов, прошедших операцию ИЛИ данных из логической схемы ИЛИ 1206, представляют полное слово с чередованием и затем выводятся. Мультиплексор 1204 вызывает загрузку регистра любыми дополнительными двоичными разрядами (например, верхними 12 двоичными разрядами из 28 двоичных разрядов, выходящих из сдвигающего устройства 1203) после первых 16, а остальные заполняются нулями.
Управление мультиплексором 1204 и выводом слова с чередованием включает выдачу сигнала завершения из накапливающего сумматора. В одном варианте осуществления изобретения мультиплексор 1204 содержит шестнадцать мультиплексоров 2:1, четыре из которых имеют один вход, который всегда равен нулю.
Настоящее изобретение обеспечивает многочисленные варианты осуществления переупорядочивания данных. Например, в системе со множеством кодовых потоков кодовые потоки должны переупорядочиваться в перемежаемые слова, как показано на фиг. 7. Настоящее изобретение обеспечивает многочисленные пути выполнения переупорядочивания в перемежаемые слова.
Один способ переупорядочивания данных в перемежаемые слова заключается в использовании поискового декодирующего устройства, как показано на фиг. 32. Множество блоков переупорядочивания счетов прогонов 2501A-n подсоединены для приема информации кодовых слов наряду с потоком кодовых слов. Каждый из них вырабатывает на выходе кодовые слова и сигналы размеров. Отдельный блок логических схем компоновки двоичных разрядов (1101) типа блоков компоновки двоичных разрядов 2502A-n подсоединен для приема выходных сигналов кодовых слов и размеров от одного из блоков переупорядочивания счетов прогонов 2501A-n. Блоки логических схем компоновки двоичных разрядов 2502A-n выдают на выходе слова с чередованием, которые поступают как на мультиплексор 2503, так и на поисковое декодирующее устройство 2504. Декодирующее устройство 2504 обеспечивает селективный управляющий сигнал, который принимается мультиплексором 2503 и указывает мультиплексору 2503, которое из перемежаемых слов выводить в кодовый поток.
Каждый поток кодированных данных имеет блок переупорядочивания счета прогонов, содержащий блок переупорядочивания счета прогонов 801, изображенный на фиг. 11. Каждый блок компоновки двоичных разрядов объединяет кодовое слово переменной длины в слова с чередованием, имеющие фиксированную длину, возможно 8, 16 или 32 двоичных разряда в слове. Каждый блок компоновки двоичных разрядов содержит регистры и сдвигающую схему, как описано выше. Декодирующее устройство 2504 содержит полное операционное декодирующее устройство (включая ГПБ, MOB и КМ), которое имеет доступ к перемежающимся словам из всех блоков компоновки двоичных разрядов (либо по отдельным шинам, как показано на фиг. 32, либо через общую шину). Всякий раз, когда декодирующее устройство 2504 выбирает слово с чередованием с одного из блоков компоновки двоичных разрядов, это слово передается в кодовом потоке. Поскольку декодирующее устройство в конце приема требует данные в таком же порядке, как у идентичного поискового декодирующего устройства, перемежаемые слова передаются в надлежащем порядке.
Кодирующее устройство вместе с поисковым декодирующим устройством может быть приемлемым для использования в полудуплексной системе, поскольку поисковое декодирующее устройство также можно использовать, как нормальное декодирующее устройство. Преимущество использования метода поискового декодирующего устройства заключается в его применимости для любых детерминированных декодирующих устройств. В альтернативных решениях, описываемых ниже, независимо от поискового декодирующего устройства используются более простые модели декодирующего устройства для снижения стоимости аппаратного оборудования. Для декодирующих устройств, которые декодируют множество кодовых слов в одном и том же тактовом цикле, моделирование декодирующего устройства с использованием меньшего объема аппаратных средств, чем само декодирующее устройство, может оказаться невозможным, что неизбежно влечет за собой использование поискового декодирующего устройства. Как будет описано ниже, существуют более простые модели декодирующих устройств, которые декодируют самое большее только одно кодовое слово за цикл.
Другой технический прием переупорядочивания данных для конвейеризируемых систем декодирующих устройств заключается в том, что декодирование самое большее одного кодового слова за тактовый цикл основано на том, что информация, необходимая для моделирования запросов декодирующего устройства в отношении кодированных данных, заключается в том, чтобы знать порядок кодовых слов (учитывая все кодовые слова, а не независимые кодовые слова для потоков кодированных данных). Если временная метка связана с каждым кодовым словом, когда оно поступает в блок переупорядочивания счета прогонов, независимо от того, какое скомпонованное слово с чередованием имеет самую старшую временную метку, связанную с ним, оно представляет подлежащее выводу следующее слово с чередованием.
На фиг. 33 представлена блок-схема, изображающая примерный переупорядочивающий блок кодирующего устройства. Показанная здесь система кодирования такая же, как описанная со ссылкой на фиг. 32, за исключением того, что каждый блок переупорядочивания счета прогонов 2501A-n принимает также информацию временной метки. Эта информация временной метки также продвигается вперед в блоки компоновки двоичных разрядов 2502A-n. Блоки компоновки двоичных разрядов 2502A-n обеспечивают слова с чередованием для мультиплексора 2503, а связанные с ними временные метки - для логической схемы 2601. Логическая схема 2601 обеспечивает управляющий сигнал для мультиплексора 2503, предназначенный для выбора слова с чередованием, подлежащего выводу в кодовый поток.
В этом варианте осуществления изобретения поисковое декодирующее устройство заменяется простым сравнением, которое определяет, какой из блоков компоновки двоичных разрядов 2502A-n имеет кодовое слово (или часть кодового слова) с самой старшей временной меткой. Такая система выступает для мультиплексора 2503 в качестве множества очередей с временными метками. Логическая схема 2601 просто делает выбор между различными очередями. Логическая схема каждого из блоков переупорядочивания счета прогонов 2501A-n только слегка изменяет (из блока переупорядочивания счета прогонов 801) для записи временную метку, когда запускается прогон. Каждый блок переупорядочивания счета прогонов 2501A-n оборудован для запоминания временной метки в запоминающем устройстве кодовых слов. Запоминание временных меток с достаточным количеством двоичных разрядов для подсчета каждого слова из кодовых слов в потоке кодированных данных оказывается достаточным, но в некоторых вариантах осуществления изобретения может быть использовано меньшее количество двоичных разрядов.
Ниже представлено краткое описание этапов использования множества очередей с временными метками. Описание понятно для специалистов в данной области техники. Здесь представлены операции кодирующего устройства. Для случая, когда прогон начинается и заканчивается с помощью одного и того же кодового слова, упрощение не произведено. Операции можно проверить для каждого кодированного символа (хотя на практике не все проверки необходимо выполнять). Предположим, что перемежаемые слова имеют размер 32 двоичных разряда.
if (если нет текущего кодового слова для контекста):
размещение отметки времени в очередь (используемую для определения следующей очереди),
размещение указателя контекста в очередь,
размещение неверных данных в очередь,
указание контекста для ввода очереди,
обеспечение приращения хвостовому счету очереди,
if (если уже имеется кодовое слово и БВС):
обеспечение приращения счету прогонов контекста,
if (MAXRUN или МВС):
размещение верных данных в очередь,
(указатель контекста не нужен),
установка на нуль указателя и счет прогонов в запоминающем устройстве контекстов,
корректирование оценки вероятности в запоминающем устройстве контекстов,
if (достоверные данные в начале следующей очереди) (если):
размещение 32 двоичных разрядов данных на выходе,
очищение содержимого очереди,
обеспечение приращения головной части очереди,
while (в то время как любая очередь почти полная):
отыскание следующей очереди, которая должна поместить данные на выход,
в то время как менее чем 32 двоичных разряда достоверных данных,
использование указателя контекста для нахождения контекста,
установка на ноль указателя и счет прогонов в запоминающем устройстве контекстов,
размещение кодового слова MAXRUN в данные очереди.
Операции декодирующего устройства подобны, хотя нет необходимости кодовые слова сохранять в очереди. Однако необходимо сохранять временную метку кодовых слов в очереди.
Для запоминания информации о порядке кодовых слов используется описанная выше функция временных меток. Эквивалентный способ выражения той же концепции заключается в использовании одной очереди для всех кодовых слов, то есть объединенной очереди. В системе с объединенной очередью, как показано на фиг. 34, для всех перемежаемых потоков используется один блок переупорядочивания счета прогонов 2701. Блок переупорядочивания счета прогонов 2701 вырабатывает выходные сигналы кодового слова, размера и потока, поступающие в блоки компоновки двоичных разрядов 2502A-n, выходные перемежаемые слова для мультиплексора 2503 и информацию о позиции для логической схемы 2702, и эти сигналы мультиплексора 2503 предназначены для вывода в виде перемежаемых слов в виде части кодового потока.
В случае произвольных потоков запоминающее устройство переупорядочивания счета прогонов запоминает идентификацию перемежаемого потока для каждого кодового слова. Каждый перемежаемый поток имеет свой собственный головной указатель. Когда блоку компоновки двоичных разрядов требуется больше данных, используется соответствующий головной указатель для выборки такого количества кодовых слов, которое необходимо для формирования нового перемежаемого слова. Это может включать в себя просмотр большого количества ячеек памяти кодовых слов для определения, какие из них являются частью надлежащего потока. В качестве альтернативы это может повлечь за собой просмотр запоминающего устройства кодовых слов в отношении дополнительных полей для выполнения связного списка.
Другой способ перемежения потоков в настоящем изобретении заключается в использовании объединенной очереди с фиксированным распределением потоков. В этом способе используют единственный хвостовой указатель, как и в случае объединенной очередности, так что временные метки не требуются. Кроме того, многочисленные головные указатели используются как и в предыдущем случае, так что при выведении данных из конкретного потока непроизводительные издержки отсутствуют. Осуществление этого назначения кодовых слов в перемежаемые потоки в случае N потоков осуществляется согласно следующему правилу: кодовое слово M назначается потоку M по модулю N. Отметим, что в соответствии с данным способом перемежаемые потоки могут иметь кодовые слова из любого контекстного элемента, кодированного сигнала или класса вероятности. Если количество потоков соответствует показателю степени, равному двум, то M по модулю N можно вычислить посредством отбрасывания некоторых наиболее старших двоичных разрядов. Например, предположим, что запоминающее устройство переупорядочивания кодовых слов адресуется 12 двоичными разрядами и что используются четыре перемежаемых потока. Хвостовой указатель имеет длину 12 двоичных разрядов, а два самых младших двоичных разряда идентифицируют кодированный поток для следующего кодового слова. Четыре головных указателя с 10 двоичными разрядами, каждый из которых неявно назначается каждому из четырех возможных комбинаций двух самых младших двоичных разрядов. Как хвостовой, так и головной указатели получают приращение как обычные двоичные счетчики.
В декодирующем устройстве сдвигающее устройство имеет регистры для запоминания слов с чередованием. Сдвигающее устройство представляет выровненные надлежащим образом кодированные данные генератору двоичных разрядов. Когда генератор двоичных разрядов использует некоторые кодированные данные, он сообщает об этом сдвигающему устройству. Сдвигающее устройство представляет выровненные должным образом данные из следующего перемежаемого потока. Если количество потоков кодированных данных равно N, у сдвигающего устройства имеется N-1 тактовых циклов для сдвигания используемых данных и, возможно, запроса другого кодового слова с чередованием, прежде чем этот конкретный перемежаемый поток будет использован снова.
Настоящее изобретение включает в себя декодирующее устройство, которое поддерживает работу кодирующего устройства в реальном масштабе времени с ограниченной памятью переупорядочивания. В одном варианте осуществления декодирующее устройство характеризуется также уменьшенными требованиями в емкости и сложности благодаря сохранению счета прогонов для каждого класса вероятности вместо каждого контекстного сборника.
На фиг. 17 показана блок-схема одного варианта осуществления соответствующей настоящему изобретению системы аппаратных средств, реализующих декодирующее устройство. Система декодирующего устройства 1400 включает в себя структуру обратного магазинного типа (FIFO) 1401, декодирующие устройства 1402, запоминающее устройство 1403 и модель контекста 1404. Декодирующие устройства 1402 включают в себя множество декодеров. Кодированные данные 1410 подаются таким образом, чтобы их принимала структура обратного магазинного типа 1401. Структура обратного магазинного типа 1401 подсоединена для подачи кодированных данных на декодирующее устройство 1402. Декодирующие устройства 1402 подсоединены к запоминающему устройству 1403 и модели контекста 1404. Модель контекста 1404 также подсоединена к запоминающему устройству 1403. Один выход контекстной модели 1404 содержит декодированные данные 1411.
В системе 1400 кодированные данные 1410 поступают на вход структуры обратного магазинного типа 1401, упорядочиваются и перемежаются. Структура обратного магазинного типа 1401 содержит данные в надлежащем порядке. Потоки подаются на декодирующие устройства 1402. Декодирующие устройства 1402 запрашивают данные из этих потоков в последовательном и детерминированном порядке. Хотя порядок, в котором декодирующие устройства 1402 требуют кодированные данные, нетривиальный, он не произволен. С помощью упорядочивания кодовых слов в таком порядке в кодирующем устройстве вместо декодирующего устройства кодированные данные могут перемежаться в единый поток. В другом варианте осуществления изобретения кодированные данные 1410 могут содержать единственный поток неперемежаемых данных, где данные для каждого контекстного элемента кодированного сигнала, класса контекста и класса вероятности добавляются в поток данных. В этом случае структуру обратного магазинного типа 1401 заменяют на область памяти, предназначенную для приема всех кодированных данных прежде, чем направить данные дальше в декодирующие устройства 1402, так что данные могут быть сегментированы надлежащим образом.
Когда кодированные данные 1410 приняты структурой обратного магазинного типа 1401, контекстная модель 1404 определяет текущий контекстный сборник. В одном варианте осуществления изобретения контекстная модель 1404 определяет текущий контекстный сборник, основываясь на предыдущих элементах изображения и (или) двоичных разрядах. Хотя это не показано, но при контекстной модели 1404 может быть включена линейная буферизация. Линейная буферизация обеспечивает необходимые данные, или шаблон, с помощью которого контекстная модель 1404 определяет текущий контекстный сборник. Например, там, где контекст основан на значениях элементов изображения в окрестности текущего элемента изображения, линейная буферизация может использоваться для хранения значений тех элементов изображения в окрестностях, которые используются для обеспечения специального контекста.
В ответ на контекстный сборник система декодирующего устройства 1400 выбирает состояние декодирования из запоминающего устройства 1403 для текущего контекстного сборника. В одном варианте осуществления изобретения состояние декодера включает в себя состояние модуля оценки вероятности (МОВ) и состояние генератора двоичных разрядов. Состояние МОВ определяет, какой код надлежит использовать для декодирования новых кодовых слов. Состояние генератора двоичных разрядов поддерживает запись двоичных разрядов в текущем прогоне. Состояние для декодирующих устройств 1402 обеспечивается из запоминающего устройства 1403 в ответ на адрес, обеспечиваемый контекстной моделью 1404. Адрес выбирает ячейку в запоминающем устройстве 1403, которая хранит информацию, соответствующую контекстному сборнику.
После выбора из запоминающего устройства 1403 состояние декодирующего устройства для контекстного сборника система 1400 определяет следующий неуплотненный двоичный разряд и обрабатывает состояние декодирующего устройства. Затем декодирующие устройства 1402 декодируют новое кодовое слово, если это необходимо, и (или) обновляют счет прогонов. Если необходимо, то обновляется состояние МОВ, а также состояние генерации двоичных разрядов. После этого декодирующие устройства 1402 записывают новое состояние кодирующего устройства в запоминающее устройство 1403.
На фиг. 18 показан один вариант осуществления соответствующего настоящему изобретению декодирующего устройства. Декодирующее устройство включает в себя сдвигающую логическую схему 1431, генератор двоичных разрядов 1432, логическую схему "новое значение к" 1433, логическую схему обновления МОВ 1434, логическую схему новых кодовых слов 1435, блок состояния МОВ для логической схемы кэш 1436, логическую схему кодирования по шаблону 1437, логическую схему расширения кодирования по MaxP1, Шаблона и разбиения R3 1438, логическую схему декодирования 1439, мультиплексор 1440 и логическую схему обновления счета прогонов 1441. Сдвигающая логическая схема 1431 подсоединена для приема входных кодированных данных 1443, а также входного сигнала состояния 1442 (из запоминающего устройства). Выходной сигнал сдвигающей логической схемы 1431 поступает в качестве входного сигнала на логическую схему генерации двоичных разрядов 1432, логическую схему вырабатывания "нового значения к" 1433 и логическую схему обновления МОВ 1434. Логическая схема генерации двоичных разрядов 1432, кроме того, подсоединена для приема входного сигнала состояния 1442 и вырабатывает выходной сигнал декодированных данных для контекстной модели. Логическая схема "новое значение к" 1433 вырабатывает выходной сигнал, который подается на вход логической схемы кодирования по шаблону 1437. Логическая схема обновления МОВ 1434 также получает входной сигнал состояния 1442 и вырабатывает выходной сигнал состояния (подаваемый в запоминающее устройство). Входной сигнал состояния 1442, кроме того, подается на входы логической схемы новых кодовых слов 1435 и логической схемы состояния МОВ для кода 1436. Выходной сигнал логической схемы состояния МОВ для кода 1436 поступает для приема логической схемой расширения 1438. Выход логической схемы расширения 1438 подсоединен к логической схеме декодирования 1439 и логической схеме обновления счета прогонов 1441. Другой вход логической схемы декодирования подсоединен к выходу схемы кода по шаблону 1437. Выход логической схемы декодирования 1439 подсоединен к одному входу мультиплексора 1440. На другой вход мультиплексора 1440 поступает входной сигнал состояния 1442. Вход выбора мультиплексора 1440 подсоединен к выходу логической схемы новых кодовых слов 1435. Выходы мультиплексора 1440 и логической схемы расширения 1438 подсоединены к двум входам логической схемы обновления счета прогонов 1441 вместе с выходом логической схемы кода по шаблону 1437. Выходной сигнал логической схемы обновления счета прогонов 1441 включен в выходной сигнал состояния, подаваемый в запоминающее устройство.
Сдвигающая логическая схема 1431 сдвигает данные из потока кодовых данных. На основании входных кодированных данных и входного сигнала режима логическая схема генерирования двоичных разрядов 1432 вырабатывает декодированные данные для контекстной модели. Логическая схема "новое значение к" 1433 также использует сдвиг данных и входной сигнал состояния для вырабатывания новой величины к. В данном варианте осуществления изобретения логическая схема "новое значение к" 1433 использует состояние МОВ и первый разряд кодированных данных для вырабатывания нового значения к. На основании нового значения к логическая схема кодирования по шаблону 1437 вырабатывает шаблон R1Z для следующего кодового слова. Шаблон R1Z для следующего кодового слова посылается в логическую схему декодирования 1439 и логическую схему обновления счета прогонов 1441.
Логическая схема обновления МОВ 1434 обновляет состояние МОВ. В одном варианте осуществления изобретения состояние МОВ обновляется с использованием текущего состояния. Откорректированное состояние посылается в запоминающее устройство. Логическая схема новых кодовых слов 1435 определяет, нужно ли новое кодовое слово. Логическая схема состояния МОВ для кода 1436 определяет код для декодирования с использованием входного состояния 1442. Код вводится в логическую схему расширения 1438 для вырабатывания максимальной длины прогона текущего шаблона и величины расщепления R3. Логическая схема декодирования 1439 декодирует кодовое слово для производства выходного сигнала счета прогонов. Мультиплексор 1440 выбирает либо выходной сигнал логической схемы декодирования 1439, либо входной сигнал режима 1442 для логической схемы обновления счета прогонов 1441. Логическая схема обновления счета прогонов 1441 обновляет счет прогонов.
Соответствующая настоящему изобретению система декодирования 1400, включающая декодирующее устройство 1430, работает конвейерным способом. В одном варианте осуществления изобретения соответствующая настоящему изобретению декодирующая система 600 определяет контекстные сборники, оценивает вероятности, декодирует кодовые слова и генерирует двоичные разряды из счетов прогонов, все это выполняя конвейерным способом. Один вариант осуществления конвейерной структуры системы декодирования изображен на фиг. 20. Показанный на чертеже вариант осуществления конвейеризованного процесса декодирования содержит шесть ступеней 1-6.
На первой ступени определяется текущий контекстный сборник (1501). На второй ступени после определения элемента контекста происходит считывание запоминающего устройства (1502), при котором из запоминающего устройства выбирается текущее состояние декодирующего устройства для элемента контекста. Как установлено выше, состояние декодирующего устройства включает в себя режим МОВ и состояние генератора двоичных разрядов.
На третьей ступени соответствующего настоящему изобретению конвейеризованного процесса декодирования генерируется разуплотненный двоичный разряд (1503). Это создает возможность обеспечения пригодности двоичного разряда для контекстной модели. Две другие операции происходят в течение третьей ступени. Состояние МОВ преобразуется в тип кода (1504), а определение осуществляется относительно того, должно ли быть декодировано новое кодовое слово (1505), что также происходит на третьей ступени.
Во время четвертой ступени декодирующая система обрабатывает кодовое слово и (или) обновляет счет прогонов (1506). При обработке кодового слова и обновлении счета прогонов осуществляются несколько подопераций. Например, кодовое слово декодируют с целью определения следующего счета прогонов или счет прогонов обновляют для текущего кодового слова (1506). Если это необходимо, то при декодировании новых кодовых слов из входного сигнала устройства обратного магазинного типа выбираются дополнительные кодированные данные. Другая подоперация, происходящая на четвертой стадии, заключается в обновлении состояния МОВ (1507). И наконец, на четвертой стадии конвейера декодирования используется новое состояние МОВ для определения, какое кодовое слово нулевой длины прогона (описываемое ниже) подходит для следующего кода, если счет прогонов текущего кодового слова равен нулю (1508).
Во время пятого этапа соответствующего настоящему изобретению конвейера декодирования состояние декодирующего устройства вместе с обновленным состоянием МОВ записывается в запоминающее устройство (1509), и начинается сдвигание для следующего кодового слова (1510). На шестой ступени сдвигание к следующему кодовому слову завершается (1510).
Соответствующее настоящему изобретению конвейеризованное декодирование фактически начинается с решения относительно того, запускать ли процесс декодирования. Это определение основывается на том, достаточно ли имеется данных для представления их соответствующему настоящему изобретению декодирующему устройству. Если данных из устройства обратного магазинного типа не достаточно, система декодирования останавливается. В другом случае система декодирования может быть остановлена при вводе декодированных данных на периферийное устройство, которое не способно принимать все выходные данные декодирующего устройства, которые оно вырабатывает. Например, когда декодирующее устройство обеспечивает проработку выходного сигнала на интерфейс видеодисплея и связанные с ним телевизионные схемы, видеосигнал может иметь слишком низкую скорость, так что должен производиться останов декодирующего устройства для захвата видеосигнала.
После принятия решения на запуск процесса декодирования с помощью контекстной модели определяется текущий контекстный элемент. В настоящем изобретении текущий контекстный элемент устанавливается путем исследования предшествующих данных. Такие предшествующие данные могут храниться в строчных буферных устройствах и могут включать в себя данные из текущей строки и (или) предшествующих строк. Например, в шаблоне контекста для данного двоичного разряда двоичные разряды из строчного буферного устройства (буферных устройств) можно конструировать с использованием шаблона относительно предшествующих данных, так что контекстный элемент для текущих данных выбирается в соответствии с тем, согласуются ли проверяемые предшествующие данные с шаблоном. Эти строчные буферные устройства могут включать в себя регистры сдвига двоичных разрядов. Для каждой разрядной матрицы n-разрядного изображения можно использовать шаблон.
В одном варианте осуществления изобретения элемент кодированного сигнала контекста выбирают с помощью вывода адреса в запоминающее устройство в течение следующего конвейерного этапа. Адрес может включать в себя заранее установленное количество двоичных разрядов, например три бита, для идентификации разрядной матрицы. С помощью использования трех двоичных разрядов можно идентифицировать положение двоичных разрядов в данных элемента изображения. Используемый для определения контекста шаблон также может быть представлен в виде части адреса. Используемые для идентификации разрядной матрицы двоичные разряды и двоичные разряды, идентифицирующие шаблон, можно объединить с целью создания адреса для специальной ячейки в запоминающем устройстве, которое содержит информацию о режиме для элемента кодированного сигнала контекста, определяемого этими двоичными разрядами. Например, используя три двоичных разряда для определения позиции двоичных разрядов в контекстном элементе изображения и десять предыдущих двоичных разрядов в той же самой позиции в каждом из предшествующих элементов изображения в шаблоне, можно создать 13-разрядный адрес контекста.
Используя создаваемый с помощью контекстной модели адрес, запоминающее устройство (например, запоминающее устройство с произвольной выборкой, ЗУПВ) запрашивается для получения информации о состоянии. Состояние включает в себя состояние МОВ. Состояние МОВ включает в себя текущую оценку вероятности. Поскольку один и тот же код использует более одного состояния, состояние МОВ включает в себя не класс вероятности или обозначение кода, а скорее указатель на таблицу, типа таблицы, показанной на фиг. 8. Кроме того, при использовании таблицы типа изображенной на фиг. 8 состояние МОВ обеспечивает также наиболее вероятный символ (БВС) в качестве средства для идентификации того, соответствует ли текущее состояние МОВ положительной или отрицательной стороне таблицы. Состояние генерации двоичных разрядов может включать в себя величину счета и индикацию, имеется ли МВС (наименее вероятный символ). В одном варианте осуществления изобретения включена также величина БВС (наиболее вероятного символа) для текущего прогона для декодирования следующего кодового слова. В настоящем изобретении в целях снижения пространства, требуемого для счетчиков прогона, состояние генерирования двоичных разрядов хранится в запоминающем устройстве. Если стоимость пространства в системе, требуемого для счетчиков для каждого контекста, низкая, состояние генерирования двоичных разрядов не должно запоминаться в запоминающем устройстве.
После завершения четвертой ступени в запоминающее устройство записываются новое состояние генератора двоичных разрядов и состояние МОВ. Кроме того, на пятом этапе поток кодированных данных сдвигается к следующему кодовому слову. Операция сдвигания завершается на шестом этапе.
На фиг. 19 представлена блок-схема одного варианта осуществления соответствующей настоящему изобретению структуры обратного магазинного типа 1401, иллюстрирующая буферизацию слова с чередованием для двух декодирующих устройств. Отметим, что можно поддерживать любое количество декодирующих устройств, используя принципы настоящего изобретения. Как показано, входные данные и структура обратного магазинного типа имеют достаточную длину для размещения двух слов с чередованием. Структура обратного магазинного типа 1401 содержит структуру обратного магазинного типа 1460, регистры 1461 и 1462, мультиплексоры 1463 и 1464 и блок управления 1465. В качестве входных слов с чередованием подаются два входных кодовых слова. Выходы структуры обратного магазинного типа 1460 подсоединены к входам регистров 1461 и 1462. Входы мультиплексора 1463 подсоединены к выходам регистров 1461 и 1462. Блок управления 1465 подсоединен для обеспечения управляющих сигналов для структуры обратного магазинного типа 1460, регистров 1461 и 1462 и мультиплексоров 1463 и 1464. Слова с чередованием представляют собой выходные данные (выходные данные 1 и 2), обеспечиваемые для двух декодирующих устройств. Каждое декодирующее устройство использует сигнал запроса для индикации использования текущего слова и необходимости следующего нового слова. Сигналы запросов от декодирующих устройств подаются на входы блока управления 1465. Блок управления 1465 выдает сигнал запроса структуры обратного магазинного типа с целью запроса дополнительных данных из запоминающего устройства.
На начальной стадии структура обратного магазинного типа и регистры 1461 и 1462 заполнены данными, а в блоке управления 1465 установлено действительное состояние триггера. Всякий раз, когда появляется запрос, блок управления 1465 обеспечивает данные в соответствии с логикой, показанной в табл. 17.
На фиг. 21 показано другое конструктивное представление соответствующего настоящему изобретению декодирующего устройства. Рассматривая фиг. 21, отметим, что в декодирующее устройство вводятся (кодированные) данные переменной длины. Декодирующее устройство выдает сигнал, который подается обратно в качестве обратной связи с задержкой, которая принимается в качестве входного сигнала декодирующего устройства. В соответствующем настоящему изобретению декодирующем устройстве сдвиг переменной длины, используемый при декодировании, базируется на декодированных данных, которые имеются в наличии после некоторой задержки. Задержка обратной связи не снижает пропускную способность в декодирующих устройствах с допустимой задержкой.
Входные данные переменной длины делятся на слова с чередованием, имеющие фиксированную длину так, как описано в связи с фиг. 7. Декодирующее устройство использует слова фиксированной длины, как описано ниже со ссылкой на фиг. 22. Декодирующее устройство и задержка моделируют конвейерное декодирующее устройство, как описано в связи с фиг. 20, 21 и 39, или множество параллельных декодирующих устройств типа описанных в связи с фиг. 2-5. Таким образом, настоящее изобретение обеспечивает декодирующее устройство, не критичное к задержке. Соответствующие настоящему изобретению декодирующие устройства с допустимой задержкой позволяют параллельно манипулировать данными переменной длины.
Известные декодирующие устройства (например, декодирующие устройства Хаффмена) являются критичными к задержке. Для выполнения сдвига переменной длины, необходимого для декодирования следующего кодового слова, требуется информация, определяемая из декодирования всех предшествующих кодовых слов. В противоположность этому настоящее изобретение обеспечивает создание декодирующих устройств с допустимой задержкой.
Сдвиг в системе декодирования.
Соответствующее настоящему изобретению декодирующее устройство предусматривает сдвигающую логическую схему для сдвига слов с чередованием в соответствующий генератор двоичных разрядов для декодирования. Соответствующее настоящему изобретению сдвигающее устройство не требует никакого конкретного типа параллелизма "по контексту" или "по вероятности". Предполагается кодирующее устройство, которое назначает кодовое слово M по потоку M по модулю N (M%N на языке на основе языка Си), где N - количество потоков. В настоящем изобретении представляются кодированные данные из текущего потока до тех пор, пока не будет запрошено кодовое слово. Только после этого данные переключаются на следующий поток.
На фиг. 22 показан один вариант осуществления сдвигающего устройства для соответствующего настоящему изобретению декодирующего устройства. Сдвигающее устройство 1600 сконструировано для четырех потоков данных. Это обеспечивает четыре тактовых цикла для каждой операции сдвигания. Слова с чередованием состоят из 16 двоичных разрядов, а самое длинное кодовое слово состоит из 13 двоичных разрядов. Сдвигающее устройство 1600 включает в себя четыре регистра 1601-1604, подсоединенные для приема входных сигналов кодированных данных с чередованием. Выходы каждого из регистров 1601-1604 подсоединены к входам мультиплексора 1605. Выход мультиплексора 1605 подсоединен к входу многорегистрового циклического сдвигового устройства 1606. Выходной сигнал многорегистрового циклического сдвигового устройства 1606 подается в качестве входных сигналов на регистр 1607, мультиплексор и регистры 1608-1610 и размерный блок 1611. Выход размерного блока 1611 подсоединен к накапливающему сумматору 1612. Выходной сигнал накапливающего сумматора 1612 подается обратно и поступает на многорегистровое циклическое сдвиговое устройство 1606. Выходной сигнал регистра 1607 поступает в качестве входного сигнала на мультиплексор и регистр 1608. Выходной сигнал мультиплексора и регистра 1608 подается в качестве входного сигнала на мультиплексор и регистр 1609. Выходной сигнал мультиплексора и регистра 1609 подается в качестве входного сигнала на мультиплексор и регистр 1610. Выходной сигнал мультиплексора и регистра 1610 представляет собой выровненные кодированные данные. В одном варианте осуществления изобретения регистры 1601-1604 представляют собой 16-разрядные регистры, многорегистровое циклическое сдвиговое устройство 1606 - 32-13-разрядное многорегистровое циклическое сдвиговое устройство, а накапливающий сумматор 1612 представляет 4-разрядный накапливающий сумматор.
Регистры 1601-1604 принимают 16-разрядные слова из устройства обратного магазинного типа и посылают их на вход многорегистрового циклического сдвигового устройства 1606. В каждый момент времени по меньшей мере 32 двоичных разряда некодированных данных обеспечиваются для многорегистрового циклического сдвигового устройства 1606. Для начала четыре регистра 1601-1604 инициализируются двумя 16-разрядными словами кодированных данных. Это позволяет всегда иметь в наличии по меньшей мере одно новое кодовое слово для каждого потока.
Что касается R-кодов, то размерный блок кодовых слов 1611 определяет, присутствует ли кодовое слово "0" или "1N", и, если этим кодовым словом является "1N", то как много двоичных разрядов после символа "1" являются частью текущего кодового слова. Размерный блок, обеспечивающий такую же функцию, был описан фиг. 15. Для других кодов в технике хорошо известно определение размера кодового слова.
Сдвигающее устройство 1600 включает в себя устройство обратного магазинного типа, состоящее из четырех регистров, три из которых имеют мультиплексированные входы. Каждый из регистров 1607-1610 предназначен для размещения по меньшей мере одного кодового слова, так что длина регистров и мультиплексоров составляет 13 двоичных разрядов для размещения самого длинного возможного кодового слова. С каждым регистром связан также один управляющий мультивибратор (не показан), который показывает, содержит ли конкретный регистр кодовое слово или он ожидает подачи кодового слова от многорегистрового циклического сдвигового устройства 1606.
Устройство обратного магазинного типа никогда не бывает пустым. Можно использовать только одно кодовое слово за тактовый цикл и за временной цикл можно сдвигать одно кодовое слово. Задержка на выполнение сдвига компенсируется, поскольку система заранее запускает четыре кодовых слова. Как только каждое кодовое слово будет сдвинуто для обеспечения совмещения выходных кодированных данных, другие кодовые слова в регистрах 1607-1610 сдвигаются в сторону младших разрядов. Когда левое кодовое слово в устройстве обратного магазинного типа запоминается в регистре 1602, многорегистровое циклическое сдвигающее устройство 1606 вызывает считывание кодовых слов из регистров 1601-1604 через мультиплексор 1605 с тем, чтобы заполнить регистры 1607-1609. Отметим, что устройство обратного магазинного типа можно сконструировать таким образом, чтобы повторно заполнять регистр 1607 следующим кодовым словом, как только его кодовое слово будет сдвинуто в регистр 1608.
Многорегистровое циклическое сдвиговое устройство 1606, вычислительное устройство размера кодовых слов 1611 и выбранный накапливающий сумматор 1612 манипулируют сдвигом переменной длины. Накапливающий сумматор 1612 имеет четыре регистра, по одному для каждого потока кодированных данных, каждый из которых содержит выравненное текущее кодовое слово для каждого потока данных. Накапливающий сумматор 1612 представляет собой четырехразрядный накапливающий сумматор, используемый для управления многорегистровым циклическим сдвиговым устройством 1606. Накапливающий сумматор 1612 осуществляет приращение своего значения на значение входного сигнала, поступающего из размерного блока кодовых слов 1611. Когда накапливающий сумматор 1612 переполняется (например, каждый раз, когда счет сдвига равен 16 или больше), регистры 1601-1604 тактируются для сдвигания. Каждый другой сдвиг на 16 разрядов вызывает запрос нового 32-разрядного слова из устройства обратного магазинного типа. Входной сигнал накапливающего сумматора 1611 характеризует собой размер кодового слова, который определяется текущим кодом и первым одним или двумя разрядами текущего кодового слова. Отметим, что в некоторых вариантах осуществления изобретения регистры 1601-1604 должны инициализироваться кодированными данными до начала декодирования.
Когда система запрашивает кодовое слово, регистры в устройстве обратного магазинного типа тактируются так, что кодовые слова перемещаются к выходу. Когда многорегистровое циклическое сдвиговое устройство 1606 оказывается готовым выдать новое кодовое слово, оно мультиплексируется в первый незанятый регистр в устройстве обратного магазинного типа.
В этом варианте осуществления изобретения сигнал следующего кодового слова из генератора двоичных разрядов принимается до принятия решения на переключение потоков.
Если нельзя гарантировать, что сигнал следующего кодового слова с генератора двоичных разрядов будет принят до принятия решения о переключении потоков, можно использовать систему предварительного просмотра, иллюстрируемую фиг. 23. На чертеже показано в виде блок-схемы сдвигающее устройство 1620, использующее систему предварительного просмотра. Сдвигающее устройство 1620 включает в себя сдвигающее устройство 1600, которое производит выходные сигналы текущих кодированных данных и следующих кодированных данных. Текущие кодированные данные подают на вход логического блока предварительной обработки кодовых слов 1624. Следующие кодированные данные подаются на вход логического блока предварительной обработки кодированных слов 1622. Выходы обоих логических блоков предварительной обработки 1621 и 1622 подсоединены к входам мультиплексора 1623. Выход мультиплексора 1623 подсоединен к другому входу логического блока обработки кодовых слов 1624.
Логическое устройство, использующее кодовое слово, делится на две части: логическое устройство предварительной обработки кодовых слов и логическое устройство обработки кодовых слов. Два идентичных конвейерных блока предварительной обработки 1621 и 1622 работают до того, как можно будет сдвинуть перемежаемый поток. Один из блоков предварительной обработки 1621, 1622 вырабатывает надлежащую информацию в том случае, если поток переключается, а другой вырабатывает информацию, если поток не переключается. Когда поток переключается, выходной сигнал блока предварительной обработки соответствующих кодовых слов мультиплексируется с помощью мультиплексора 1623 в логическое устройство обработки кодовых слов 1624, которое завершает операцию с соответствующим кодовым словом.
Память и контекстные модели вне кристалла.
В одном варианте осуществления изобретения может оказаться желательным использовать множество кристаллов для внешнего запоминающего устройства или внешних контекстных моделей. В таких вариантах осуществления изобретения желательно снизить задержку между генерированием двоичного разряда и предоставлением двоичного разряда для контекстной модели, где используется множество интегральных схем.
На фиг. 24 показана блок-схема одного варианта осуществления системы с внешним кристаллом контекстной модели 1701 и кристаллом кодирующего устройства 1702 с запоминающим устройством для каждого контекста. Отметим, что на кристалле кодирующего устройства показаны только блоки, имеющие отношение к контекстной модели. Специалистам в данной области техники ясно, что кристалл кодирующего устройства 1702 содержит схемы генерирования двоичных разрядов, оценки вероятности и т.д. Кристалл кодирующего устройства 1702 включает в себя контекстную модель нулевого порядка 1703, контекстные модели 1704 и 1705, логическую схему выбора 1706, схему управления запоминающим устройством 1707 и запоминающее устройство 1708. Контекстная модель нулевого порядка 1703 и контекстные модели 1704 и 1705 вырабатывают выходные сигналы, которые подаются на входы логической схемы выбора 1706. Другой вход логической схемы выбора 1706 подсоединен к выходу внешнего кристалла контекстной модели 1701. Выход логической схемы выбора 1706 подсоединен к входу запоминающего устройства 1708. Кроме того, к входу запоминающего устройства 1708 подсоединен выход блока управления запоминающим устройством 1707.
Логическая схема выбора 1706 позволяет использовать либо внешнюю контекстную модель, либо внутреннюю контекстную модель (например, контекстную модель нулевого порядка 1703, контекстную модель 1704, контекстную модель 1705). Логическая схема выбора 1706 позволяет внутреннюю часть нулевого порядка контекстной модели 1703 использовать, даже когда используется внешняя контекстная модель 1701. Контекстная модель нулевого порядка 1703 обеспечивает один двоичный разряд или больше, в то время как внешний кристалл контекстной модели 1701 обеспечивает оставшуюся часть. Например, непосредственно предшествующие двоичные разряды могут представлять обратную связь и возвращаться обратно из контекстной модели нулевого порядка 1703, тогда как предшествующие двоичные разряды идут во внешнюю контекстную модель 1701. Таким образом, критическая по времени информация остается на кристалле. Это устраняет задержку на передачу информации вне кристалла для последних сформированных двоичных разрядов.
На фиг. 25 представлена блок-схема одной системы с внешней контекстной моделью 1801, внешним запоминающим устройством 1803 и кристаллом кодирующего устройства 1802. Некоторые адресные линии запоминающего устройства приводятся в действие внешней контекстной моделью 1801, тогда как другие приводятся в действие контекстной моделью "нулевого порядка" в кристалле кодирующего устройства 1802. То есть, контекст из только что прошедшего цикла декодирования приводится в действие контекстной моделью нулевого порядка. Это дает возможность кристаллу декодирующего устройства обеспечивать информацию контекста из только что прошедшего цикла с минимальной задержкой передачи информации. Кристалл контекстной модели 1802 опережает остальную часть информации, использующую двоичные разряды, декодированные более давно в прошлом, тем самым допуская задержку в передаче информации. Во многих случаях контекстная информация из только что прошедшего цикла характеризует собой состояние Маркова нулевого порядка, а контекстная информация из более отдаленного прошлого представляет состояние Маркова более высокого порядка. Показанный на фиг. 25 вариант осуществления изобретения устраняет задержку передачи информации, неизбежную при осуществлении модели нулевого порядка во внешнем кристалле контекстной модели 1802. Однако здесь все еще может быть определение контекстного элемента с целью задержки генерируемых двоичных разрядов, обусловленной кристаллом декодирующего устройства 1802 и запоминающим устройством 1803.
Следует отметить, что можно использовать другую архитектуру запоминающего устройства. Например, можно использовать систему с контекстной моделью и запоминающим устройством на одном кристалле, а кодирующее устройство - на другом кристалле. Кроме того, система может включать в себя кристалл кодирующего устройства с внутренним запоминающим устройством, которое используется для некоторых контекстов и внешнее запоминающее устройство, которое используется с другими контекстами.
На фиг. 26 показано декодирующее устройство с конвейеризированным генератором двоичных разрядов, использующим запоминающее устройство. Как показано на фиг. 26, декодирующее устройство 1900 включает в себя контекстную модель 1901, запоминающее устройство 1902, блок преобразования состояния МОВ в код 1903, конвейеризированный генератор двоичных разрядов 1905, запоминающее устройство 1904 и сдвигающее устройство 1906. Входной сигнал контекстной модели 1901 включает в себя декодированные данные с конвейеризированного генератора последовательности бит 1905. Входы сдвигающего устройства 1906 подсоединены для приема кодированных данных. Выход контекстной модели 1901 подсоединен к входу запоминающего устройства 1902. Выход запоминающего устройства 1902 подсоединен к блоку преобразования состояния МОВ в код 1903. Выход блока преобразования режима МОВ в код 1903 и выход выровненных кодированных данных со сдвигающего устройства 1906 подсоединены к входам генератора двоичных разрядов 1905. Запоминающее устройство 1904 также подсоединено к генератору двоичных разрядов 1905, используя двунаправленную шину. Выходной сигнал генератора двоичных разрядов 1905 представляет собой декодированные данные.
Под действием кодированных данных на входе контекстной модели 1901 на ее выходе появляется контекстный элемент. Элемент кодированного сигнала контекста используется в качестве адреса для обращения в запоминающее устройство 1902 на основании элемента кодированного сигнала контекста для получения вероятностного состояния, которое принимается модулем преобразования состояния МОВ в код 1903, который под действием вероятностного состояния вырабатывает класс вероятности. Затем класс вероятности используется в качестве адреса для обращения в запоминающее устройство 1904 для получения счета прогонов. После этого счет прогонов используется генератором двоичных разрядов 1905 для вырабатывания декодированных данных.
В одном варианте осуществления изобретения запоминающее устройство 1902 представляет собой память объемом 1024•7 двоичных разрядов (1024 - число различных контекстов), тогда как запоминающее устройство 1904 представляет собой память 25•14 двоичных разрядов (25 - число различных счетов прогонов).
Поскольку состояние генератора двоичных разрядов (счетов прогонов и т.д. ) связано с классами вероятности, а не с элементами кодированных сигналов контекста, имеется дополнительная конвейерная задержка перед тем, как двоичный разряд будет представлен для использования контекстной модели. Из-за того, что обновление состояния генератора двоичных разрядов занимает множество тактовых циклов (задержка на повторное обращение к памяти состояния генератора двоичных разрядов), для каждого класса вероятности будет использовано множество состояний генератора двоичных разрядов. Например, если конвейер занимает шесть тактовых циклов, то память состояний генератора двоичных разрядов имеет шесть входных сообщений на класс вероятности. Для выбора надлежащей ячейки памяти используется счетчик. Даже при большом количестве входных сообщений на класс вероятности размер памяти обычно бывает меньше, чем количество контекстов. Память может быть реализована либо в виде множества банков данных статистического запоминающего устройства с произвольной выборкой, либо в виде многопортового регистрового файла.
Поскольку один счет прогонов может быть связан со множеством контекстов, вариант осуществления изобретения должен обновлять состояние оценки вероятности одного или более контекстов. В одном варианте осуществления изобретения обновляется состояние МОВ контекста, который вызывает окончание прогона.
Вместо того, чтобы требовать считывание, модификацию и запись счета прогонов до того, как они могут быть считаны снова, счет прогонов снова можно использовать после завершения модификации. На фиг. 39 изображена временная диаграмма операции декодирования в одном варианте осуществления настоящего изобретения. Здесь показаны операции декодирования из трех циклов. Названия сигналов перечислены в левой колонке временной диаграммы. Достоверность сигнала во время любого одного цикла указана полосой в течение цикла (или его части). В некоторых случаях блок или логическая схема, ответственные за обеспечение достоверного сигнала, показаны рядом с индикацией достоверного сигнала в пунктирном прямоугольнике. Кроме того, приведены обозначения раскрытых здесь примеров конкретных элементов и блоков. Отметим, что любая часть сигнала, простирающаяся в другой цикл, индицирует достоверность сигнала только для того периода времени, который занят сигналом в этом другом цикле. Кроме того, некоторые сигналы показаны как отдельно достоверные более чем для одного цикла. Примером этого является временный сигнал счета прогонов, который достоверен в одной точке в конце второго цикла и затем вновь в течение третьего цикла. Отметим, что это указывает на то, что сигнал просто регистрируют в конце цикла. Перечень зависимостей также показан в табл. 18, показывающей зависимости от того же или предыдущего тактового цикла к текущему времени, и этот сигнал определяется достоверным.
В некоторых вариантах осуществления изобретения декодирующее устройство должно моделировать буфер ограниченного переупорядочивания кодирующего устройства. В одном варианте осуществления изобретения это моделирование осуществляется с неявной передачей сигналов (сигнализацией).
Как объяснялось выше относительно кодирующего устройства, когда кодовое слово запускается в кодирующем устройстве, в соответствующем буфере резервируется место для кодового слова в порядке кодовых слов, в котором они должны помещаться в канал. При резервировании в буфере последнего пространства для нового кодового слова некоторые кодовые слова помещаются в уплотненном потоке двоичных разрядов независимо от того, определены ли они полностью.
Если необходимо закончить неполное кодовое слово, то можно выбрать короткое кодовое слово и точно установить символы, принимаемые до сих пор. Например, в системе R-кодера, если необходимо преждевременно закончить кодовое слово для серии из 100 символов БВС в коде прогонов с максимальной длиной прогона, равной 128 символам, можно использовать слово для 128 символов БВС, поскольку это точно определяет первые 100 символов.
В качестве альтернативы можно использовать кодовое слово, которое определяет 100 символов БВС с последующим МВС. Когда кодовое слово закончено, его можно удалить из переупорядочивающего буфера и добавить к кодовому потоку. Это может дать возможность помещать в кодовом потоке также ранее завершенные кодовые слова. Если форсирование завершения одного неполного кодового слова приводит к удалению кодового слова из заполненного буфера, то кодирование может продолжаться. Если один буфер все еще полный, то следующее кодовое слово снова должно закончиться и добавиться к кодовому потоку. Этот процесс продолжается до тех пор, пока буферное устройство, которое было полным, больше не будет полным. Декодирующее устройство может моделировать кодирующее устройство для неявной передачи сигналов, используя счетчик для каждой ячейки памяти для информации о состоянии генератора двоичных разрядов.
В одном варианте осуществления изобретения каждый счетчик двоичных разрядов (в этом примере класса вероятности) имеет счетчик, у которого такой же размер, как у головных или хвостовых счетчиков в кодирующих устройствах (например, 6 двоичных разрядов). Каждый раз, когда запускается новый прогон (выбирается новое кодовое слово), соответствующий счет загружается вместе с размером памяти кодовых слов. Каждый раз, когда запускается прогон (выбирается новое кодовое слово), все счетчики получают отрицательное приращение. Любой счетчик, который достигает нуля, вызывает очищение соответствующего счета прогонов (и гасится признак наличия МВС).
Варианты сигнализации для конечной памяти.
Кодирование в реальном масштабе времени в настоящем изобретении требует, чтобы декодирующее устройство манипулировало прогонами символов БВС, после которых не следует МВС и которые не представляют максимальную длину прогона. Это происходит, когда кодирующее устройство начинает прогон символов БВС, но не имеет достаточного ограниченного переупорядочивающего устройства для того, чтобы дождаться завершения прогона. При этом условии требуется, чтобы новое кодовое слово декодировалось в следующий момент времени, когда используется этот контекстный элемент кодированного сигнала, и об этом состоянии должен быть послан сигнал в декодирующее устройство. Ниже описываются три потенциальных способа модификации декодирующего устройства.
Когда буфер заполнен, счет прогонов элемента кодированного сигнала контекста или класса вероятности, который вытесняется, должен быть установлен в исходное состояние. Для эффективного выполнения этого полезно запомнить в запоминающем устройстве кодовых слов элемент кодированного сигнала контекста или класс вероятности. Поскольку это необходимо только для прогонов, которые еще не имеют связанные с ними кодовые слова, можно совместно использовать запоминающее устройство, используемое для хранения кодового слова. Отметим, что в некоторых системах вместо вытеснения неполного кодового слова можно заставить двоичные разряды перейти в контекст и (или) класс вероятности кодового слова, которое задерживается в буфере, когда он заполняется. Декодирующее устройство определяет это и использует соответственный (неправильный) элемент кодированного сигнала контекста или класс вероятности.
При сигнализации в потоке используются кодовые слова для передачи сигнала в декодирующее устройство. В одном варианте осуществления изобретения определения кодов R2(к) и R3(к) изменяются с целью включения прогонов немаксимальной длины БВС, за которым не следует МВС. Это можно выполнить путем добавления одного двоичного разряда к кодовому слову, которое должно появляться с наименее вероятным символом. Это дает однозначно декодируемый префикс для счетов прогонов немаксимальной длины. В табл. 19 показана замена кодов R2(2), дающая возможность осуществлять сигнализацию в потоке. Недостатки этого способа заключаются в том, что необходимо изменить логику декодирования R-кода, и в том, что имеются затраты на уплотнение каждый раз, когда появляется кодовое слово с наименьшей вероятностью.
В некоторых вариантах осуществления изобретения декодирующее устройство выполняет неявную сигнализацию, используя временные отметки. Счетчик отслеживает текущее "время", давая приращение каждый раз, когда запрашивается кодовое слово. Кроме того, всякий раз, когда запускается кодовое слово, текущее "время" сохраняется в запоминающем устройстве, связанном с кодовым словом. Всегда после первого использования кодового слова соответствующее запомненное значение "времени" плюс размер переупорядочивающего буфера кодирующего устройства сравнивается с текущем "временем". Если текущее "время" больше, вырабатывается неявный сигнал, так что запрашивается новое кодовое слово. Таким образом моделируется ограниченное запоминающее устройство переупорядочивания в кодирующем устройстве. В одном варианте осуществления изобретения для обеспечения возможности перечисления всех кодовых слов используется достаточное количество двоичных разрядов для значений "времени".
Чтобы снизить требуемую емкость памяти, количество двоичных разрядов, используемых для временных меток, поддерживается минимальным. Если временные метки используют малое число двоичных разрядов, так что осуществляется повторное использование значений времени, следует обратить внимание на то, чтобы все прежние временные метки отмечались до того, как счетчик запустит повторно используемые значения времени. Допустим, что N - большее значение из количества адресных двоичных разрядов для очереди или памяти состояния генератора двоичных разрядов. Можно использовать временные метки с N+1 двоичными разрядами. Память состояний генератора двоичных разрядов должна обеспечивать множество обращений, например два считывания и две записи на декодированный двоичный разряд. Для циклирования памяти состояний генератора двоичных разрядов используется счетчик, дающий одно приращение на каждый декодируемый двоичный разряд. Любая достаточно "старая" ячейка памяти очищается, поэтому осуществляется выборка нового кодового слова при ее использовании в последующем. Это гарантирует проверку всех временных меток, прежде чем какое-либо значение времени будет использовано повторно.
Если память состояний генератора двоичных разрядов меньше, чем очередь, то можно уменьшить скорость счета (счетчика временных отметок) и требуемую ширину полосы памяти. Это объясняется тем, что каждая временная метка (одна на память состояний генератора двоичных разрядов) должна проверяться только один раз за множество циклов, требуемых для использования всей очереди. Кроме того, запоминание временных меток в отдельной памяти может уменьшить требуемую ширину полосы памяти. В системах, использующих кодовые слова "0" для парциальных прогонов, нет необходимости проверять временные метки для кодовых слов "1N". В системах, использующих кодовые слова "1N" для парциальных прогонов, временная метка должна проверяться только до генерирования МВС.
В некоторых вариантах осуществления изобретения неявная сигнализация выполняется очередью во время декодирования. Этот способ может быть полезен в полудуплексной системе, где при декодировании используются аппаратные средства кодирования. Функционирование очереди почти такое же, как и при кодировании. Когда запрашивается новое кодовое слово, его индекс помещается в очередь и маркируется как неверный. Когда данные из кодового слова заканчиваются, его содержимое в очереди маркируется как верное. Когда данные выводятся из очереди для того, чтобы обеспечить участок памяти для новых кодовых слов, то, если выведенные данные промаркированы как неверные, информация о состоянии генератора двоичных разрядов под этим индексом очищается. Эта операция очистки может потребовать, чтобы память состояний генератора двоичных разрядов обеспечивала поддержку дополнительной операции записи.
В противоположность этому явная сигнализация сообщает о переполнении буфера в виде уплотнения данных. Возможная реализация этого может состоять в том, чтобы иметь вспомогательный элемент контекста, который используется один раз для каждого нормального декодирования элемента контекста или один раз для каждого декодируемого кодового слова. Декодированные двоичные разряды из вспомогательного элемента контекста указывают, возникает ли условие необходимости нового кодового слова, и новое кодовое слово должно быть декодировано с учетом соответствующего нормального элемента контекста. В этом случае кодовые слова для этого специального контекста должны быть надлежащим образом переупорядочены. Поскольку использование этого контекста является до некоторой степени известной функцией для переупорядочивающего блока (обычно это используется один раз для каждого кодового слова), память, требуемую для переупорядочивания вспомогательного контекста, можно ограничить или неявно смоделировать. Кроме того, можно ограничить возможные коды, предоставляемые для этого вспомогательного контекста.
Неявная сигнализация моделирует ограниченный буфер кодирующего устройства при декодировании с целью вырабатывания сигнала, который показывает, что должно быть декодировано новое кодовое слово. В одном варианте осуществления изобретения временная метка сохраняется для каждого контекста. В одном варианте осуществления изобретения переупорядочивающий буфер ограниченного размера кодирующего устройства моделируется непосредственно. В полудуплексной системе, поскольку при декодировании используется переупорядочивающая схема кодирующего устройства, ее можно использовать для генерирования сигналов для декодирующего устройства.
Точное осуществление неявной сигнализации зависит от особенностей того, как кодирующее устройство распознает и оперирует состоянием полного буфера. В случае системы, использующей объединенную очередь с фиксированным размещением, использование множества головных указателей позволяет осуществлять выбор состояния, соответствующего "полному буферу". При наличии конкретного выполнения кодирующего устройства можно создать соответствующую модель.
Ниже описываются работа кодирующего устройства и модель для использования декодирующим устройством объединенной очередности с фиксированным распределением потоков параллельно системе вероятности. Для этого примера предположили, что переупорядочивающий буфер имеет 256 ячеек, используются 4 перемежаемых потока, а каждое перемежаемое слово состоит из 16 двоичных разрядов. Когда буфер содержит 256 входных сообщений, содержимое должно высылаться в устройство компоновки двоичных разрядов (например, блок компоновки двоичных разрядов) до того, как 257-е кодовое слово может быть помещено в очереди. При необходимости содержимое может быть вытеснено раньше.
В некоторых системах перемещение первого сообщения в буфере требует перемещения достаточного количества двоичных разрядов с целью завершения целого перемежаемого кодового слова. Поэтому, если возможны 1-разрядные кодовые слова, перемещение 0 кодового слова может потребовать также перемещения кодовых слов 4, 8, 12, ..., 52, 56, 60 для 16-разрядных перемежаемых слов. Для обеспечения того, чтобы введенные данные буфера представляли собой достоверные данные, формирование заполнения содержимого, поскольку память заполняется, может выполняться по адресам 64, 192 ячеек из ячейки, куда вводится новое кодовое слово (256-16•4=192).
В декодирующем устройстве имеется счетчик для каждой вероятности. Когда новое кодовое слово используется для запуска прогона, в счетчик загружается 192. В любое время, когда новое кодовое слово используется какой-либо вероятностью, все счетчики получают отрицательное приращение. Если какой-либо счетчик достигает нуля, длина прогона для этой вероятности устанавливается на ноль (и гасится признак наличия МВС).
Может оказаться удобным использовать многочисленные банки данных на ЗУПВ (многопортовая память, моделирование с быстродействующей памятью и т.д.), по одному банку данных для каждого потока кодированных данных. Это позволит всем блокам компоновки двоичных разрядов одновременно принимать данные, так что считывание многочисленных кодовых слов для конкретного потока не препятствует считыванию другими потоками.
В других системах множество блоков компоновки двоичных разрядов должны принимать решение для единственной памяти, основываясь на порядке кодовых слов, как они запомнены в буфере. В таких системах вывод содержимого из буфера может не завершить перемежаемое слово. Каждый блок компоновки двоичных разрядов обычно принимает некоторую часть перемежаемого слова в последовательности. Каждый блок компоновки двоичных разрядов принимает, как минимум, количество двоичных разрядов, равное длине самого короткого кодового слова (например, 1 бит), как максимум, количество двоичных разрядов, равное длине самого длинного кодового слова (например, 13 бит). Слова с чередованием не могут выпускаться до того, как они будут завершены, и должны выпускаться в порядке инициализации. В данном примере блок компоновки двоичных разрядов может иметь для буфера 13 слов с чередованием, это максимальное количество таких слов, которые могут быть завершены с кодовыми словами максимальной длины, в то время как другой поток имеет задержку слова с чередованием, то есть принимает кодовые слова минимальной длины.
Система, в которой каждое кодовое слово требует две записи и одно считывание памяти, может оказаться менее подходящей для осуществления их аппаратными средствами, чем система, обеспечивающая две записи и два считывания. Если бы потребовалась, например, система с четырьмя потоками, то блоки 1 и 2 компоновки двоичных разрядов могли бы совместно использовать один цикл считывания памяти, а блоки 1 и 3 компоновки двоичных разрядов могли бы совместно использовать другой цикл считывания (или любую другую произвольную комбинацию). Хотя это не обеспечило бы уменьшение необходимого размера буфера, однако позволило бы обеспечить более высокую скорость передачи в блок компоновки двоичных разрядов, что позволит блокам компоновки двоичных разрядов лучше использовать пропускную способность канала кодированных данных.
Системы с запоминающим устройством фиксированной емкости.
Одно из достоинств системы, имеющей множество состояний генератора двоичных разрядов на класс вероятности, заключается в том, что система может обеспечивать кодирование с потерями при переполнении запоминающего устройства фиксированной емкости. Это может оказаться полезным в случае уплотнения изображения для кадрового буфера и других применений, когда можно запомнить лишь ограниченное количество кодированных данных.
В случае систем с запоминающим устройством фиксированной емкости каждое из многочисленных состояний генератора двоичных разрядов для каждой вероятности назначается части данных. Например, каждое из восьми состояний можно назначить конкретной разрядной матрице для восьми разрядных данных. В этом случае каждой части данных назначается также сдвигающее устройство в противоположность сдвигающим устройствам, последовательно обеспечивающим следующее кодовое слово. Следует отметить, что нет необходимости делить данные посредством разрядной матрицы. Кроме того, в кодирующем устройстве не осуществляется перемежение, каждая часть данных просто компонуется по разрядам. Каждой части данных назначается запоминающее устройство.
Управление памятью кодированных данных предоставляется в случае систем, запоминающих все данные в запоминающем устройстве фиксированной емкости, и в случае систем, передающих данные в канал с максимальной допустимой шириной полосы. В обеих этих системах желательно постепенное сокращение возможностей системы с потерями. Для данных различной важности используются различные потоки данных, так что менее значимые потоки могут храниться или не передаваться, когда нет в наличии достаточной емкости памяти или пропускной способности.
При использовании памяти кодированные данные должны храниться так, чтобы можно было осуществлять такую выборку, когда можно отбрасывать менее важные потоки данных без потери способности декодировать важные потоки данных. Поскольку кодированные данные имеют переменную длину, можно использовать динамическое распределение памяти. На фиг. 38 показан пример блока динамического распределения памяти для трех потоков кодированных данных. Регистровый файл 3100 (или другое запоминающее устройство) содержит указатель для каждого потока плюс другой указатель для индикации следующей свободной ячейки памяти. Память 3101 делится на страницы фиксированной емкости.
В исходном положении каждый указатель, назначенный потоку, указывает начало страницы памяти, а свободный указатель - на следующую имеющуюся страницу памяти. Кодированные данные из конкретного потока запоминаются в ячейке памяти, адресованной соответственным указателем. Затем указатель получает приращение для следующей ячейки памяти.
Когда указатель достигает максимума для текущей страницы, происходит следующее. Адрес начала следующей свободной страницы (заполненный в свободном указателе) запоминается с текущей страницей. (Можно использовать либо часть памяти кодированных данных, либо отдельную память или регистровый файл. ) Текущий указатель устанавливается на следующую свободную страницу. Свободный указатель получает приращение. Эти действия назначают новую страницу памяти конкретному потоку и обеспечивают такую связь, что при декодировании можно определить порядок размещения.
Если все страницы памяти использованы, а в потоке еще имеются более важные данные, чем менее важные данные в памяти, можно действовать следующим образом. Во всех случаях память, выделенная менее значимым данным, предназначается потоку более важных данных и из потока менее значимых дополнительные данные не запоминаются.
Во-первых, страница, используемая в настоящий момент менее важным потоком, просто выделяется для более важных данных. Поскольку в более типичных устройствах кодирования статистическим кодом используется информация о внутреннем состоянии, теряются все ранее запомненные на этой странице менее важные данные.
Во-вторых, страница, используемая в данный момент менее важным потоком, просто выделяется для потока более важных данных. В отличие от предыдущего случая указатель устанавливается на конец страницы и, когда на странице записываются более важные данные, соответствующий указатель получает отрицательное приращение. Это имеет преимущество сохранения менее важных данных в начале страницы, если для потока более важных данных не требуется целая страница.
В-третьих, вместо текущей страницы переназначаемых менее важных данных можно переназначать любую страницу с менее важными данными. Это требует независимого кодирования кодируемых данных для всех страниц, что может снизить достигнутое уплотнение. Это также требует идентификацию некодированных данных, соответствующих началу всех страниц. Поскольку можно отбросить любую страницу менее важных данных, получается более высокая гибкость в постепенном сокращении возможностей кодирования с потерями.
Третий вариант может быть особенно привлекателен в системе, достигающей фиксированной степени уплотнения по всем областям изображения. Областям изображения можно назначать определенное количество страниц памяти. Сохраняются ли менее важные данные или нет, может зависеть от уплотнения, достигнутого в конкретной области. Память, назначенная области, может использоваться не полностью, если требуемое уплотнение без потерь меньше, чем емкость назначенной памяти. Достижение фиксированной степени уплотнения в области изображения может обеспечить произвольный доступ к областям изображения.
Для лучшего использования общей емкости, имеющейся в системе памяти, можно использовать возможность записывать данные в каждую страницу с обоих концов. Когда все страницы оказываются распределены, любую страницу, имеющую достаточную свободную область на конце, можно назначить для использования с конца. Возможность использования обоих концов страницы необходимо соотносить со стоимостью поддержания отслеживания местоположения, где встречаются два типа данных. (Это отличается от случая, когда один из типов данных не был важным и его можно было просто перезаписать).
Теперь рассмотрим систему, в которой данные передаются в канал вместо того, чтобы запоминаться в памяти. Используются страницы фиксированной емкости памяти, но необходима только одна страница на поток (или, возможно, две, если требуется пинг-понговое считывание, предназначенное для обеспечения амортизирования канала, так что при записи на одну страницу с другой можно считывать для вывода данных). Когда страница памяти заполняется, она передается в канал, и ячейку памяти можно использовать повторно, как только страница окажется переданной. В некоторых применениях емкость страницы памяти может представлять емкость пакетов данных, используемых в канале, или объем множества пакетов.
В некоторых системах связи, например с асинхронным режимом передачи (АРП), пакетам могут назначаться приоритеты. АРП имеет два уровня приоритетности: первичный и вторичный. Вторичные пакеты передаются только в том случае, если имеется достаточная ширина полосы. Для определения, который из пакетов первичный, а который вторичный, можно использовать пороговую величину. В другом способе можно использовать пороговую величину в кодирующем устройстве для того, чтобы не передавать потоки, которые оказались менее важными, чем порог.
На фиг. 27 представлена блок-схема системы с отдельными генераторами для каждого кода. Система декодирования 2000 включает в себя контекстную модель 2001, запоминающее устройство 2002, блок преобразования состояния МОВ в код 2003, декодирующее устройство 2004, генераторы двоичных разрядов 2005A-n и сдвигающее устройство 2006. Выход контекстной модели 2001 подсоединен к входу запоминающего устройства 2002. Выход запоминающего устройства 2002 подсоединен к входу блока преобразования состояния МОВ в код 2003. Выход блока преобразования состояния МОВ в код 2003 подсоединен к входу декодирующего устройства 2004. Выходной сигнал декодирующего устройства 2004 подается в качестве разрешающего сигнала на генераторы двоичных разрядов 2005A-n. Генераторы двоичных разрядов 2005A-n, кроме того, подсоединены для приема выходного сигнала кодированных данных со сдвигающего устройства 2006.
Контекстная модель 2001, запоминающее устройство 2002 и блок преобразования состояния МОВ в код 2003 работают подобно своим аналогам на фиг. 26. Контекстная модель 2001 вырабатывает элементы кодированных данных контекста. Запоминающее устройство 2002 выдает вероятностное состояние, основываясь на элементе контекста. Вероятностное состояние принимается блоком преобразования состояния МОВ в код 2003, который вырабатывает класс вероятности для каждого вероятностного состояния. Декодирующее устройство 2004 разблокирует один из генераторов двоичных разрядов 2005A-n на основании декодирования класса вероятности. (Отметим, что декодирующее устройство 2004 является схемой декодирующего устройства преобразования M в 2M подобно хорошо известному декодирующему устройству 74•138 3:8 - это не декодирующее устройство статистического кодирования). Отметим, что поскольку каждый код имеет отдельный генератор двоичных разрядов, некоторые генераторы двоичных разрядов могут использовать коды, отличающиеся от R-кодов. В частности, код для вероятностей порядка 60% может использоваться для лучшего перехода области вероятности между R2(0) и R2(1). Например, в табл. 20 показан такой код.
Если необходимо получить желательное быстродействие, то для обеспечения требуемой быстроты декодирования данных можно осуществить предварительное декодирование одного или больше двоичных разрядов. В некоторых вариантах осуществления изобретения во избежание необходимости обновления большого счета прогонов каждый тактовый цикл осуществляется расчленение как кодирования кодовых слов, так и подсчета прогонов для данных кодов.
Генератор двоичных разрядов для кодов R2(0) несложный. Кодовое слово запрашивается каждый раз, когда запрашивается двоичный разряд. Генерируемый двоичный разряд является просто кодовым словом (схема ИСКЛЮЧАЮЩЕЕ ИЛИ с МОВ).
Кодами для короткой длины прогона, например R2(1), R3(1), R2(2), R3(2), манипулируют следующим образом. Все двоичные разряды в кодовом слове декодируются и запоминаются в конечном автомате, который содержит малый счетчик (1, 2 или 3 двоичных разряда соответственно) и двоичный разряд наличия МВС. Счетчик и двоичный разряд наличия МВС функционируют как декодирующее устройство R-кода. В случае более длинных кодов, таких как R2(x), R3(к) для к>2, генераторы двоичных разрядов разделяются на два блока, как показано на фиг. 28. Здесь генератор двоичных разрядов для R2(к)-кодов, где к>2, показан состоящим из блока коротких прогонов 2101 и блока длинных прогонов 2102. Отметим, что хотя такая конструкция предназначена для использования с кодами R2(к>2), ее работа с кодами R3(к>2) будет такой же (и это ясно специалистам в данной области техники).
Блок коротких прогонов 2101 подсоединен для приема разблокирующего сигнала и кодового слова (0... 2) в качестве входных сигналов для генератора двоичных разрядов, а также сигнала "все нули" (на фиг. 28 "все единицы") и сигнала "нулевой счет" (указывающего счет нуля) из блока длинных прогонов 2102. В ответ на эти входные сигналы блок коротких прогонов 2101 выдает декодированный двоичный разряд и индикацию следующего сигнала, которая сигнализирует, что необходимо новое кодовое слово. Блок коротких прогонов 2101 вырабатывает также сигнал разблокирования счета, сигнал загрузки счета и сигнал максимального счета для блока длинных прогонов 2102. Блок длинных прогонов 2102 подсоединен также для приема кодового слова (к... 3) в качестве входного сигнала для генератора двоичных разрядов.
Блок коротких прогонов 2101 манипулирует прогонами длиной вплоть до 4 и подобен генератору двоичных разрядов R2(2). В одном варианте осуществления изобретения блок коротких прогонов 2101 одинаковый для всех кодов R2(к>2). Назначение блока длинных прогонов 2102 заключается в определении, когда необходимо выводить последний из 1-4 двоичных разрядов прогона. Блок длинных прогонов 2102 имеет входы, логическую схему И и счетчик, размер которого изменяется с изменением к.
Один вариант осуществления блока счета длинных прогонов 2102 показан на фиг. 29. Блок длинных прогонов 2102 содержит логическую схему И 2201, подсоединенную для приема кодового слова (к...3), и выдает сигнал "все единицы" в виде логической "1", если все двоичные разряды в кодовом слове представляют собой единицы, тем самым показывая, что кодовое слово представляет собой кодовое слово "1N" и что счет прогонов меньше 4. Логическая схема НЕ 2202 также подсоединена для приема кодового слова и инвертирует его. Выход логической схемы НЕ 2202 подсоединен к одному входу счетчика двоичных разрядов 2203. Счетчик двоичных разрядов 2203, кроме того, подсоединен для приема сигнала разблокирования счета, сигнала загрузки счета и сигнала максимума счета. В ответ на входные сигналы счетчик двоичных разрядов 2203 генерирует сигнал нулевого счета.
В одном варианте осуществления изобретения счетчик 2203 представляет собой счетчик к-2 разрядов и используется для разрыва счетов длинных прогонов на прогоны из четырех БВС и, возможно, некоторого остатка. Сигнал разблокирования счета показывает, что выведены четыре символа БВС и счетчик должен получить отрицательное приращение. Сигнал загрузки счета используется при декодировании кодовых слов "1N" и вызывает загрузку счетчика дополнением двоичных разрядов кодового слова от к до 3. Сигнал максимума счета используется при декодировании кодовых слов "0" и загружает счетчик их максимальным значением. Выходной сигнал нулевого счета индицирует, когда показание счетчика равно нулю.
Один вариант осуществления изобретения блока счета коротких прогонов 2101 показан на фиг. 30. Блок счета коротких прогонов содержит модуль управления 2301, двухразрядный счетчик 2302 и трехразрядный счетчик 2303. Модуль управления 2301 принимает разблокирующий сигнал, кодовое слово (0...2) и сигналы "все единицы" и "нулевой счет" с блока длинных прогонов. Двухразрядный счетчик используется для счета четырехразрядных прогонов символов БВС, являющихся частью более длинных прогонов. Счетчик R2(2) и двоичный разряд МВС (в сумме три двоичных разряда) 2303 используются для вырабатывания в конце прогона 1-4 двоичных разрядов. Разблокирующий входной сигнал указывает, что на выходе двоичных разрядов должен вырабатываться двоичный разряд. Нулевой счет поступает на вход, когда не подтверждены индикации, что прогон четырех символов БВС должен быть выдан. Всякий раз, когда счетчик БВС 2302 достигает нуля, формируется выходной сигнал разблокирования счета. Когда формируется входной сигнал нулевого счета, то либо используется счетчик R2(2) МВС, либо декодируется новое кодовое слово и формируется следующий выходной сигнал.
Когда декодируется новое кодовое слово, выполняемые действия определяются вводом кодового слова. Если на входе имеется кодовое слово "0", используется счетчик БВС 2302 и формируется выходной сигнал максимума счета. В случае новых слов "1N" первые три двоичных разряда кодового слова загружаются в счетчик R2(2) и МВС 2303 и формируется выходной сигнал загрузки счета. Если формируется входной сигнал всех единиц, то счетчик R2(2) и МВС 2303 используется для вырабатывания двоичных разрядов, в противном случае используется счетчик БВС до тех пор, пока не будет сформирован входной сигнал нулевого счета.
С точки зрения системы количество кодов должно быть небольшим для хорошей работы системы, обычно 25 или меньше. Емкость мультиплексора, необходимого для вывода двоичного разряда и следующего кодового слова, и декодирующего устройства, необходимого для разблокирования конкретного генератора двоичных разрядов, для быстрой работы должна быть ограничена. Кроме того, разветвление кодового слова от сдвигающего устройства должно быть не слишком высоким для высокоскоростной работы.
Отдельные генераторы двоичных разрядов для каждого кода обеспечивают возможность конвейерной обработки. Если все кодовые слова дали по меньшей мере два двоичных разряда, обработку кодовых слов можно конвейеризировать в два цикла вместо одного. Это могло бы удвоить быстродействие декодирующего устройства, если бы генераторы двоичных разрядов представляли ограничивающую часть системы. Один способ выполнения этого заключается в случае кодового слова нулевой длины прогона (кодовое слово указывает только МВС) с последующим одним двоичным разрядом, который является следующим некодированным двоичным разрядом. Их можно назвать кодами RN(k)+1, и они всегда могут кодировать по меньшей мере два двоичных разряда. Отметим, что кодовые слова R2(0) и, возможно, некоторые из других коротких кодовых слов не нуждаются в конвейеризации для повышения быстродействия.
Отдельные генераторы двоичных разрядов прибегают к использованию неявной сигнализации. Неявную сигнализацию, предназначенную для кодирования с конечным запоминающим устройством, можно выполнять следующим способом. Каждый генератор двоичных разрядов имеет счетчик, имеющий размер адреса очереди, например, 9 бит, когда используется очередность размером в 512 бит. Каждый раз, когда генератор двоичных разрядов использует новое кодовое слово, счетчик загружается максимальным значением. Всякий раз, когда какой-либо генератор запрашивает кодовое слово, счетчики всех генераторов двоичных разрядов получают отрицательное приращение. Всякий раз, когда счетчик достигает нуля, режим соответственного генератора двоичных разрядов очищается (например, очищаются счетчик БВС, счетчик R2(2) и МВС и счетчик длинных прогонов). Поскольку сбрасывание может происходить, даже если конкретный генератор двоичных разрядов не разблокирован, проблема со счетами состояний отсутствует.
Инициализация запоминающего устройства для каждого элемента контекста.
В случаях, когда запоминающее устройство для каждого элемента контекста содержит информацию об оценке вероятности, для очень быстрой инициализации декодирующего устройства (например, запоминающего устройства) может потребоваться дополнительная пропускная способность памяти. Быстрая инициализация декодирующего устройства может представлять проблему, когда декодирующее устройство имеет много контекстов и их все необходимо очищать. Когда декодирующее устройство обеспечивает много контекстов (1к или больше) и нельзя произвести полную очистку памяти, для очистки памяти потребуется неприемлемо большое количество тактовых циклов.
Для быстрой очистки контекстов в некоторых вариантах осуществления настоящего изобретения используется дополнительный двоичный разряд, называемый здесь двоичным разрядом инициализованного состояния, который запоминается с каждым контекстом. Таким образом, добавочный двоичный разряд запоминается вместе с состоянием МОВ (например, 8 бит) для каждого контекста.
На фиг. 31 показаны запоминающее устройство для каждого элемента контекста и логическая схема управления инициализацией. Запоминающее устройство контекста 2401 показано подсоединенным к регистру 2402. В одном варианте осуществления изобретения регистр 2402 включает в себя одноразрядный регистр, который указывает текущее надлежащее состояние для элемента инициализированного состояния. Регистр 2402 подсоединен к одному входу логической схемы ИСКЛЮЧАЮЩЕЕ ИЛИ 2403. Другой вход логической схемы ИСКЛЮЧАЮЩЕЕ ИЛИ 2403 подсоединен к выходу запоминающего устройства 2401. Выходной сигнал e логической схемы ИСКЛЮЧАЮЩЕЕ ИЛИ 2403 представляет собой достоверный сигнал и подается на вход логической схемы управления 2404. Другие входы логической схемы управления подсоединены к выходу счетчика 2405 и сигналу элемента дискретизации контекста. Выход логической схемы управления 2404 подсоединен к селективным входам мультиплексоров 2406 и 2407 и к входу счетчика 2405. Другой выход логической схемы управления 2404 подсоединен к селективному входу мультиплексора 2406. Входы мультиплексора 2406 подсоединены к выходу счетчика 2405 и сигналу индикации элемента дискретизации контекста. Выход мультиплексора 2406 подсоединен к запоминающему устройству 2401. Входы мультиплексора 2407 подсоединены к сигналу нового состояния МОВ и сигналу нуля. Выход мультиплексора 2407 подсоединен к одному входу запоминающего устройства 2401, выход запоминающего устройства 2401 и сигнал начального режима МОВ подсоединены к входу мультиплексора 2408. Выходной сигнал мультиплексора 2408 представляет собой выходной сигнал состояния МОВ.
Значение в регистре 2402 дополняется с каждым выполнением операции декодирования (то есть с каждым набором данных, а не с каждым декодированным двоичным разрядом). Логическая схема ИСКЛЮЧАЮЩЕЕ ИЛИ 2403 сравнивает достоверность каждой выбранной ячейки памяти со значением регистра для определения, достоверна ли выбранная ячейка памяти для данной операции декодирования. Это осуществляют с использованием логической схемы ИСКЛЮЧАЮЩЕЕ ИЛИ 2403, проверяя, совпадает ли двоичный разряд инициализированного состояния с надлежащим состоянием в регистре 2402. Если данные в запоминающем устройстве 2401 не достоверны, логическая схема управления 2404 вызывает пропускание данных логической схемой преобразования состояния в код и вместо этого использование начального состояния МОВ. Это выполняется с использованием мультиплексора 2408. Когда в запоминающее устройство записывается новое состояние МОВ, инициализированный двоичный разряд устанавливается на текущее значение регистра, так что при новом обращении это значение будет считаться достоверным.
Каждое содержимое запоминающего устройства элементов контекста должно иметь свой двоичный разряд инициализированного состояния, установленный на текущее значение регистра до того, как может начаться другая операция декодирования. Счетчик 2405 выполняет этапы по всем ячейкам памяти для гарантии, что они инициализированы. Всякий раз, когда используется элемент контекста, а его режим МОВ не скорректирован, неиспользованный цикл записи можно использовать для тестирования или коррекции ячейки памяти, указываемой счетчиком 2405. После завершения операции декодирования, если счетчик 2405 не достиг максимального значения, оставшиеся контексты инициализируются до начала следующей операции. Для операции управления используется следующая логика:
записать это = ложная;
счетчик = 0;
все инициализируемое = ложное;
хотя (счетчик < максимальный элемент кодирования данных контекста +1)
считывание режима МОВ из запоминающего устройства контекста
если ((счетчик = считыванию элемента кодирования данных контекста) и (записывание это))
запись это = ложная
счетчик = счетчик + 1
если (режим МОВ изменен)
записывание нового режима МОВ
еще если (записывание это)
записывание начального режима МОВ в ячейку памяти "счетчик"
счетчик = счетчик + 1
еще
считывание ячейки памяти "счетчик"
если (инициализированный двоичный разряд в считанной ячейке находится в ошибочном состоянии)
записывание это = истинная
еще
счетчик = счетчик + 1
все инициализированное = истинное;
хотя (декодирование)
считывание режима МОВ из запоминающего устройства контекста
если (состояние МОВ изменено)
записывание нового режима МОВ.
Используемый в настоящем изобретении модуль МОВ может включать в себя схему адаптации, которая позволяет быстрее адаптировать независимо от количества имеющихся данных. При ее использовании настоящее изобретение в качестве средства обеспечения более точной оценки позволит вначале быстрее адаптировать декодирование и гораздо медленнее адаптировать, когда имеется больше данных. Более того, МОВ может фиксироваться при реализации таблицы состояний / конечного автомата МОВ в программируемой пользователем вентильной матрице (ППВМ) или интегральных схемах прикладной ориентации (ИСПО).
В табл. 21-26 описан ряд конечных автоматов оценки вероятности. В некоторых таблицах не используются коды R3 и не используются длинные коды для пониженной цены аппаратного средства. Во всех таблицах, за исключением табл. 21, используются особые режимы "быстрой адаптации", используемые для быстрой адаптации при запуске кодирования до появления первого МВС. Эти режимы быстрой адаптации в таблицах показаны выделенным курсивом. Например, из табл. 22 видно, что когда начинается декодирование, текущее состояние представляет состояние 0. Если появляется БВС, декодирующее устройство переходит в состояние 35. Пока появляются символы БВС, декодирующее устройство переходит вверх по направлению от состояния 35, в конце концов переходя в состояние 28. Если в какое-то время появляется МВС, декодирующее устройство переходит из четко определенных режимов быстрой адаптации в режим, который представляет правильное состояние вероятности в отношении данных, которые были приняты до сих пор.
Отметим, что для каждой таблицы после приема определенного количества символов БВС декодирующее устройство выходит из режимов быстрого адаптирования. В желаемом варианте осуществления изобретения после выхода из режимов быстрой адаптации не существует механизма возвращения в них, за исключением повторного запуска процесса декодирования. В других вариантах осуществления таблицу состояний можно разработать так, чтобы повторно входить в эти режимы быстрой адаптации посредством обеспечения возможности более быстрого адаптирования, настоящее изобретение дает возможность декодирующему устройству быстрее вступить в более асимметричные коды, извлекая тем самым возможную пользу из улучшенного уплотнения. Отметим, что быструю адаптацию можно устранить для конкретной таблицы путем изменения содержимого таблицы для текущего состояния 0 таким образом, что таблица переходит только на одно состояние вверх или вниз в зависимости от входных данных.
Для всех этих таблиц данные для каждого состояния представляют код для этого состояния, следующего состояния при положительной коррекции (вверх) и следующего состояния при отрицательной коррекции (вниз). Звездочками указаны состояния, когда символы БВС должны измениться при отрицательной коррекции.
Добавление быстрой адаптации к оценке вероятности поможет только при запуске кодирования. Для улучшения адаптации во время кодирования можно использовать другие способы, когда статистические данные элементов контекста изменяются быстрее, чем могут отслеживать описанные выше таблицы состояния МОВ. Один способ сохранения быстрой адаптации на протяжении всего кодирования заключается в добавлении элемента ускорения к обновлению состояния МОВ. Это ускорение можно ввести в таблицу состояния МОВ путем повторения каждого кода постоянное количество раз (например, 8). Затем элемент ускорения M (например, положительное целое число) можно добавить или вычесть из текущего состояния при обновлении. Когда M равен 1, система работает так же, как без ускорения, и происходит наиболее медленная адаптация. Когда M больше 1, происходит более быстрая адаптация. Вначале M можно установить на некоторое значение, превышающее значение 1, обеспечивая начальную быструю адаптацию.
Один соответствующий настоящему изобретению способ обновления значения M основан на ряде последовательных кодовых слов. Например, если последовательно появляется заранее установленное количество кодовых слов, то значение M увеличивается. Например, если четыре последовательных кодовых слова представляют собой "0" "0" "0" "0" или "1N" "1N" "1N" "1N", то величина M увеличивается. С другой стороны, для уменьшения значения M можно использовать трафарет переключения между кодовыми словами "0" и "1N". Например, если четыре последовательных кодовых слова представляют собой "0" "1N" "0" "1N" или "1N" "0" "1N" "0", то величина M уменьшается.
В другом способе ускорения используют таблицы состояний, в которых каждый код повторяется S раз, где S - положительное целое число. S является обратной величиной параметра ускорения. Когда S равен единице, адаптация быстрая, а когда S больше, адаптация осуществляется медленнее. Значение S вначале можно установить равным 1 для обеспечения начальной быстрой адаптации. Используя способ, аналогичный описанному выше, значение S можно корректировать, когда четыре последовательных кодовых слова представляют собой "0" "0" "0" "0" или "1N" "1N" "1N" "1N". B таком случае величина S уменьшается. В противоположность этому, если четыре последовательных кодовых слова представляют собой "0" "1N" "0" "1N" или "1N" "0" "1N" "0", то значение S увеличивается.
Определение последовательных кодовых слов может иметь несколько значений. В системах "по контексту" последовательные кодовые слова могут относиться к последовательным словам в одном элементе контекста. В системе "по вероятности" последовательные кодовые слова могут относиться к последовательным кодовым словам в одном классе вероятности. В качестве альтернативы в одной системе последовательные кодовые слова могут относиться к последовательным кодовым словам в широком смысле (не относящимся к элементам контекста или классу вероятности). В случае этих трех примеров требуемые для сохранения архива кодовых слов двоичные разряды запоминания представляют собой 3 х количество элементов контекста, 3 х количество классов вероятности и 3 х соответственно. Сохранение ускорения для каждого элемента контекста может обеспечить лучшую адаптацию. Поскольку плохое отслеживание часто обусловлено общим изменением некодированных данных, хорошую адаптацию может обеспечить также определение общего ускорения.
Применения системы.
Одно из достоинств любой системы уплотнения заключается в снижении требований к объему памяти для совокупности данных. Соответствующую настоящему изобретению параллельную систему можно заменить для любого применения, осуществляемого в настоящее время, с помощью системы кодирования без потерь, и можно применять в системах, работающих с аудио-, текстовыми данными, базами данных, выполнимыми на вычислительных машинах, или другими цифровыми данными, сигналами или символами. Примеры систем кодирования без потерь включают в себя уплотнение факсимильной связи, уплотнение баз данных, уплотнение графических изображений побитовых отображений и уплотнение коэффициентов преобразования в стандартах изображения типа стандарта JPEG (рабочая группа по стандартам цифровых видео- и мультипликационных изображений) и стандарта MPEG (группа экспертов по движущимся изображениям - стандарт сжатия движущегося изображения). Настоящее изобретение обеспечивает возможность реализации небольшого эффективного аппаратного оборудования и реализаций сравнительно быстродействующих программных обеспечений, обеспечивая хороший выбор даже в случае применений, не требующих высокого быстродействия.
Преимущество, обеспечиваемое настоящим изобретением по сравнению с известным уровнем техники, заключается в возможности работы на очень высоких скоростях, особенно при декодировании. Таким образом, настоящее изобретение может обеспечивать полное использование дорогостоящих высокоскоростных каналов, таких как высокоскоростные сети вычислительных машин, спутниковые и наземные ретрансляционные каналы связи. На фиг. 35 показана такая система, в которой для декодирующей системы 2801 данные обеспечивает вещательная сеть или высокоскоростная сеть вычислительных машин. Система 2801 осуществляет параллельное кодирование данных при выработке выходных данных. Текущая энтропия аппаратного обеспечения (типа Q-кодера) может снизить пропускную способность этих систем. Все эти системы сконструированы так, что при высокой стоимости должны иметь большую пропускную способность. Счетчик выполнен так, что имеет декодирующее устройство, замедляющее пропускную способность. Соответствующая настоящему изобретению параллельная система не только обеспечивает эти высокие пропускные способности, она действительно увеличивает эффективную пропускную способность, поскольку данные можно передавать в сжатой форме.
Соответствующая настоящему изобретению параллельная система применима также для обеспечения более эффективной пропускной способности из-за умеренно быстрых каналов, подобных цифровой сети связи с интеграцией служб и комплексными услугами (ISDN), неперезаписываемых компакт-дисков (CD-ROM) и интерфейса малых вычислительных систем (SCSI). Такая система согласования пропускной способности показана на фиг. 36, тогда как данные от таких источников, как неперезаписываемый компакт-диск, этернет, интерфейс малых вычислительных систем или другого аналогичного источника, подаются на систему декодирования 2901, которая принимает и декодирует данные, с целью вырабатывания выходного сигнала. Эти каналы работают все еще быстрее, чем некоторые используемые в настоящее время кодирующие устройства. Часто эти каналы используются для обслуживания источника данных, которому требуется большая ширина полосы, чем для канала, например видеоизображение в реальном масштабе времени или компьютерная среда (мультимедиа). Соответствующая настоящему изобретению система может выполнять функцию согласования по ширине полосы.
Соответствующая настоящему изобретению система представляет собой переходный вариант для части кодирующего устройства статистического кода телевизионной системы, работающей в реальном масштабе времени, подобной стандартам телевидения высокой четкости (ТВВЧ) и телевидения группы экспертов по движущемуся изображению (MPEG). Такая система показана на фиг. 37. Телевизионная система, работающая в реальном масштабе времени, включает в себя систему декодирования 3001, на которую поступают уплотненные данные изображения. Система 3001 декодирует данные и выводит их в декодирующее устройство с потерями 3002. Декодирующее устройство с потерями 3002 может быть передающей, преобразующей цвет и субдискретизирующей частью декодирующего устройства телевидения высокой четкости стандарта сжатия движущегося изображения (MPEG). В качестве монитора 3003 можно использовать телевизионный или видеомонитор.
В то время как множество изменений и модификаций настоящего изобретения несомненно должны быть очевидны специалистам в данной области техники после прочтения описания, должно быть ясно, что конкретный вариант осуществления изобретения, показанный и описанный с помощью иллюстраций, не предназначен для того, чтобы считать его в качестве ограничения. Следовательно, ссылки на детали предпочтительного варианта осуществления изобретения не предназначены для ограничения объема формулы изобретения, в которой перечисляются только особенности, которые рассматриваются в виде сущности изобретения.
Таким образом, описаны способ и устройство, предназначенные для параллельного декодирования и кодирования.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И УСТРОЙСТВО СЖАТИЯ СИМВОЛОВ, СТОХАСТИЧЕСКИЙ КОДЕР (ВАРИАНТЫ) | 1995 |
|
RU2125765C1 |
| СПОСОБ И СИСТЕМА КОДИРОВАНИЯ И СПОСОБ И СИСТЕМА ДЕКОДИРОВАНИЯ | 1996 |
|
RU2154350C2 |
| ЭНТРОПИЙНОЕ КОДИРОВАНИЕ РАЗНОСТЕЙ ВЕКТОРОВ ДВИЖЕНИЯ | 2021 |
|
RU2776910C1 |
| ЭНТРОПИЙНОЕ КОДИРОВАНИЕ РАЗНОСТЕЙ ВЕКТОРОВ ДВИЖЕНИЯ | 2018 |
|
RU2758981C2 |
| ЭНТРОПИЙНОЕ КОДИРОВАНИЕ РАЗНОСТЕЙ ВЕКТОРОВ ДВИЖЕНИЯ | 2012 |
|
RU2658883C1 |
| ЭНТРОПИЙНОЕ КОДИРОВАНИЕ РАЗНОСТЕЙ ВЕКТОРОВ ДВИЖЕНИЯ | 2012 |
|
RU2615681C2 |
| ЭНТРОПИЙНОЕ КОДИРОВАНИЕ РАЗНОСТЕЙ ВЕКТОРОВ ДВИЖЕНИЯ | 2024 |
|
RU2839971C1 |
| ЭНТРОПИЙНОЕ КОДИРОВАНИЕ РАЗНОСТЕЙ ВЕКТОРОВ ДВИЖЕНИЯ | 2022 |
|
RU2820857C2 |
| ИНИЦИАЛИЗАЦИЯ КОНТЕКСТА ПРИ ЭНТРОПИЙНОМ КОДИРОВАНИИ | 2022 |
|
RU2839276C2 |
| ИНИЦИАЛИЗАЦИЯ КОНТЕКСТА ПРИ ЭНТРОПИЙНОМ КОДИРОВАНИИ | 2021 |
|
RU2779898C1 |






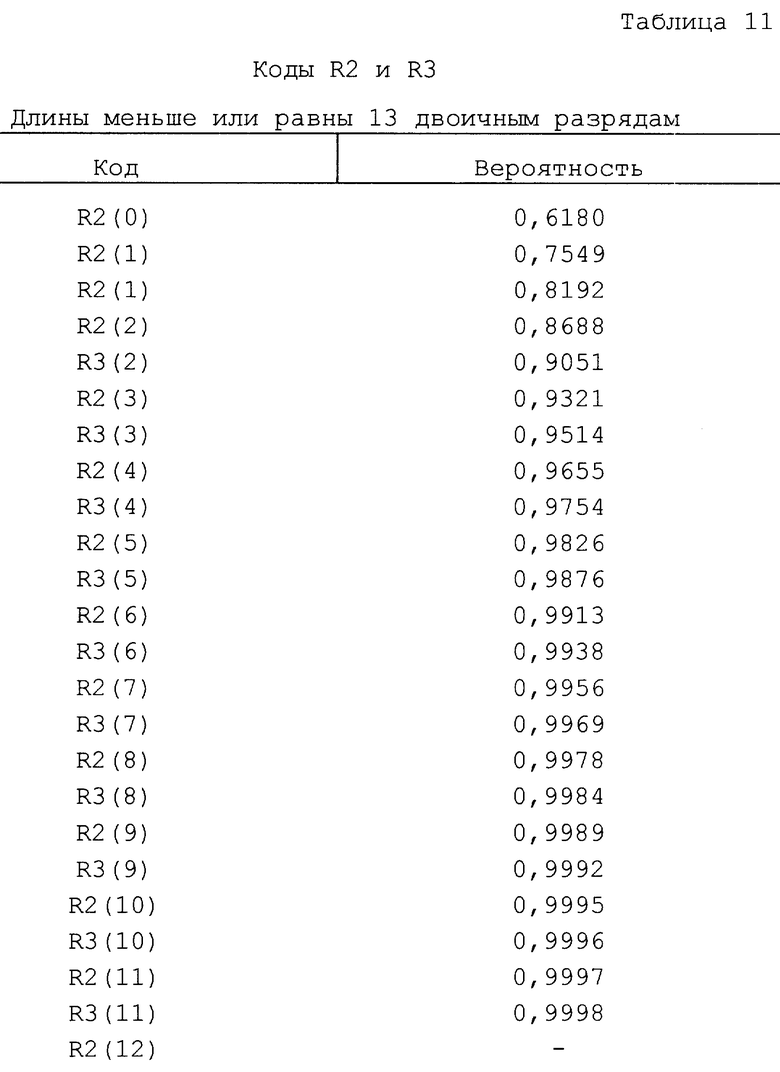
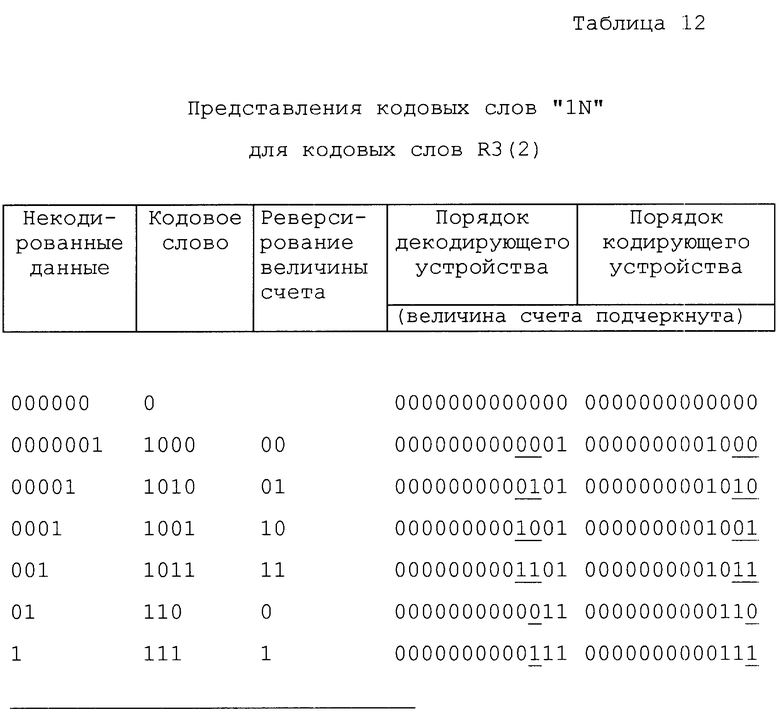







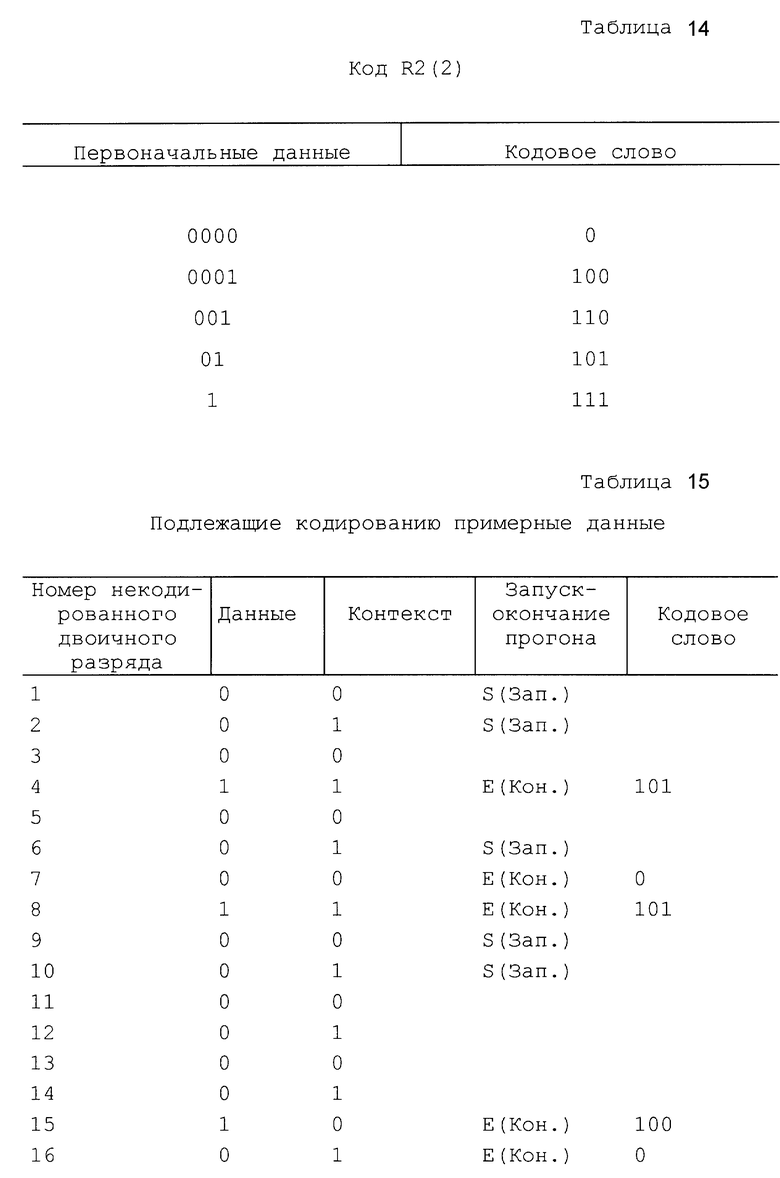




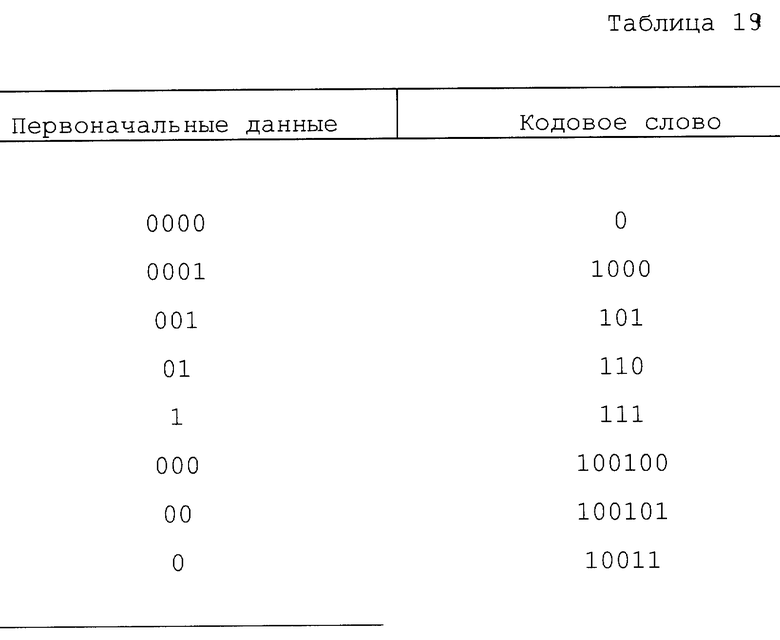

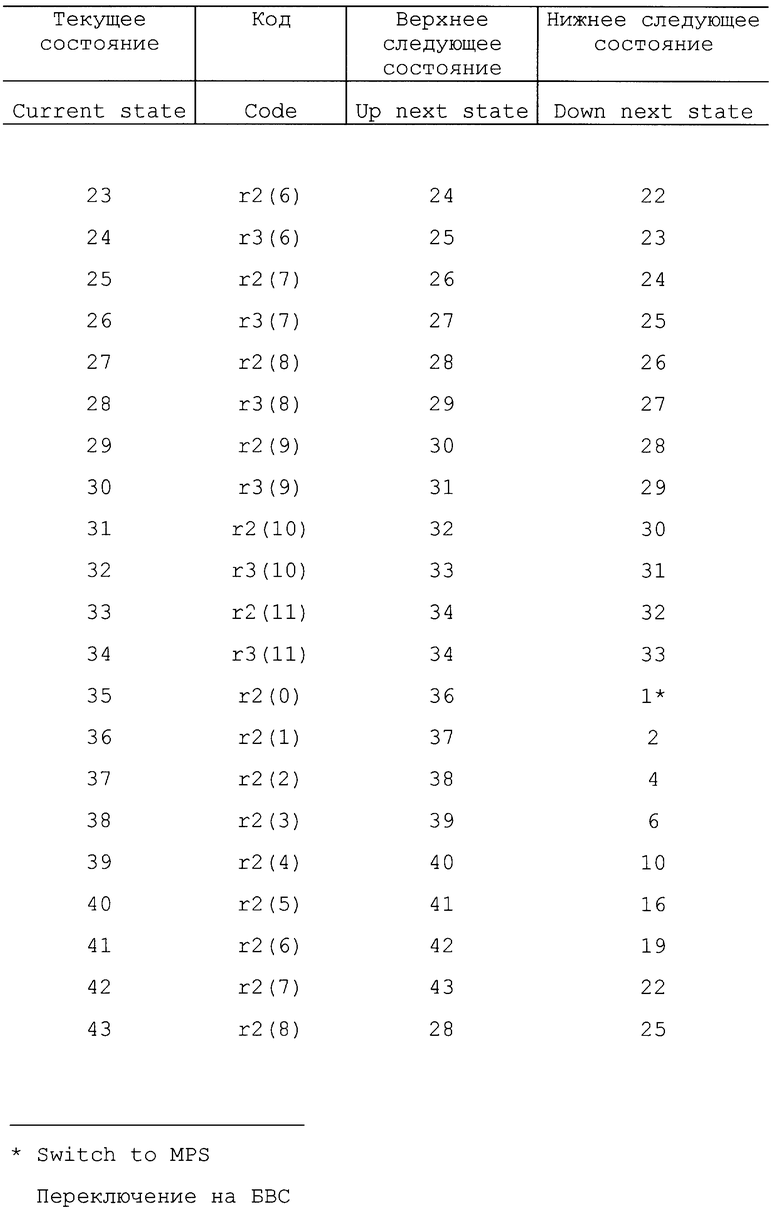
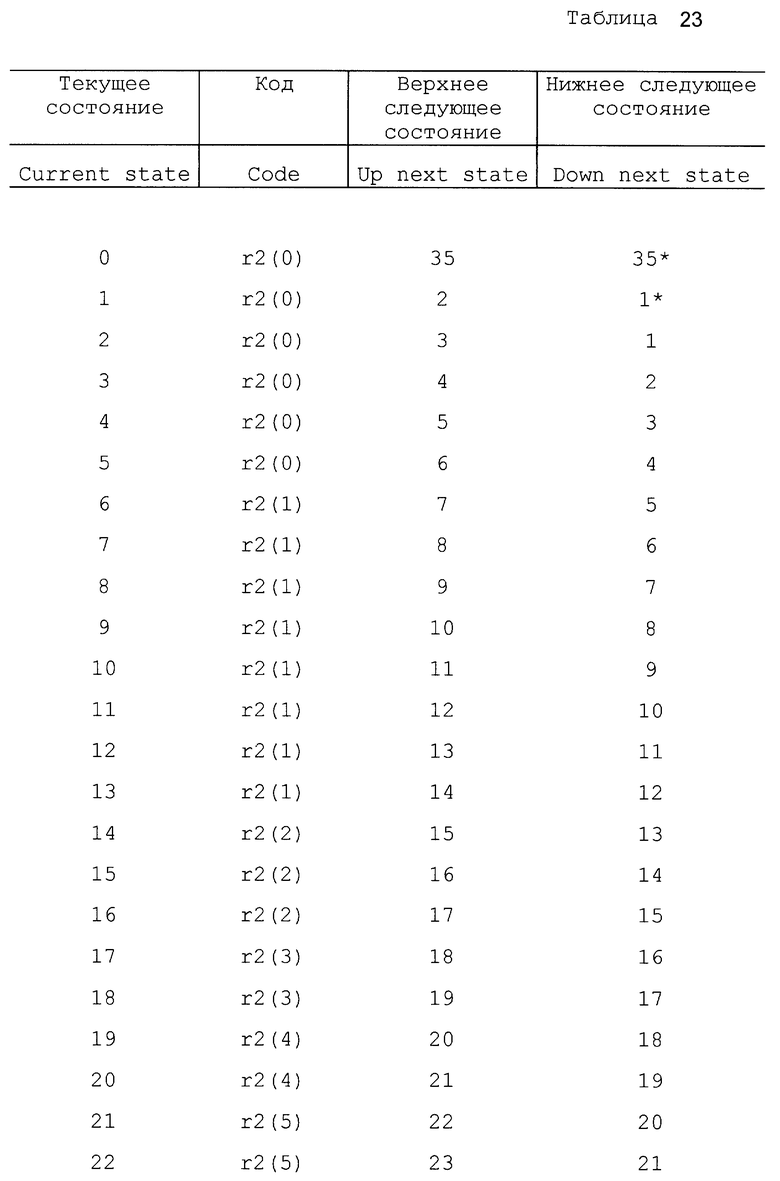
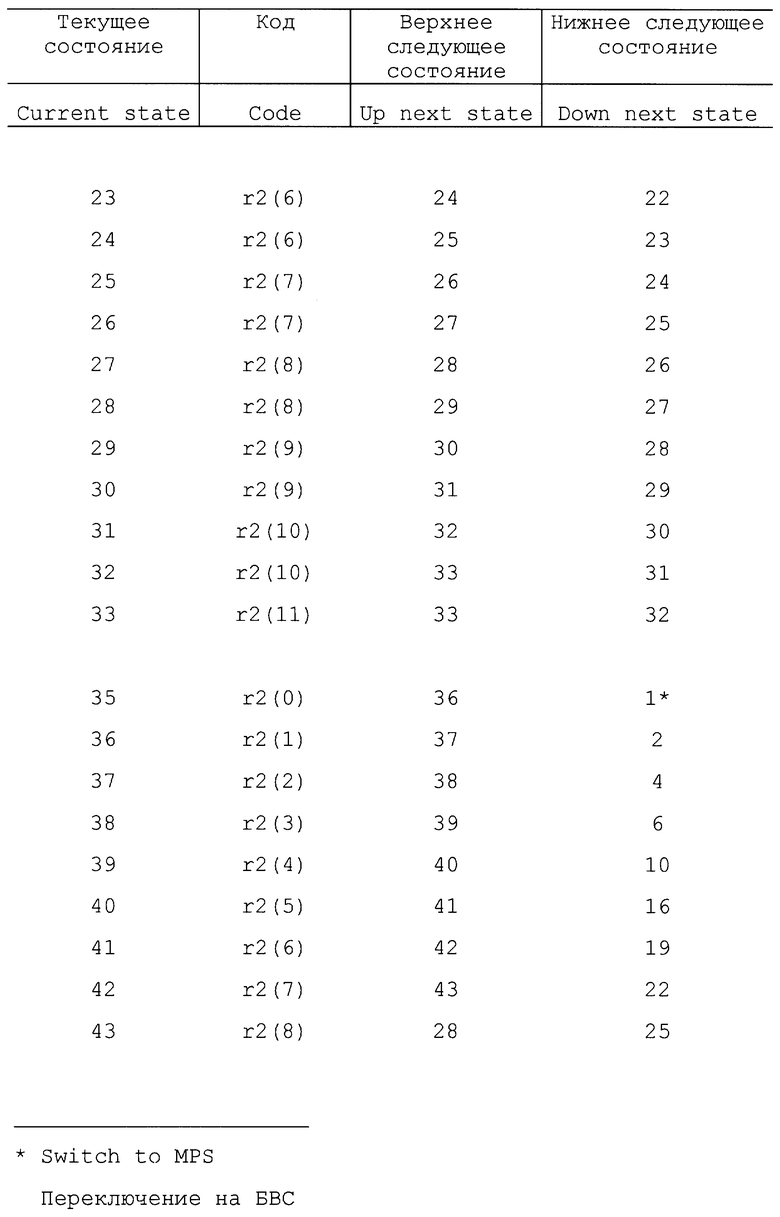

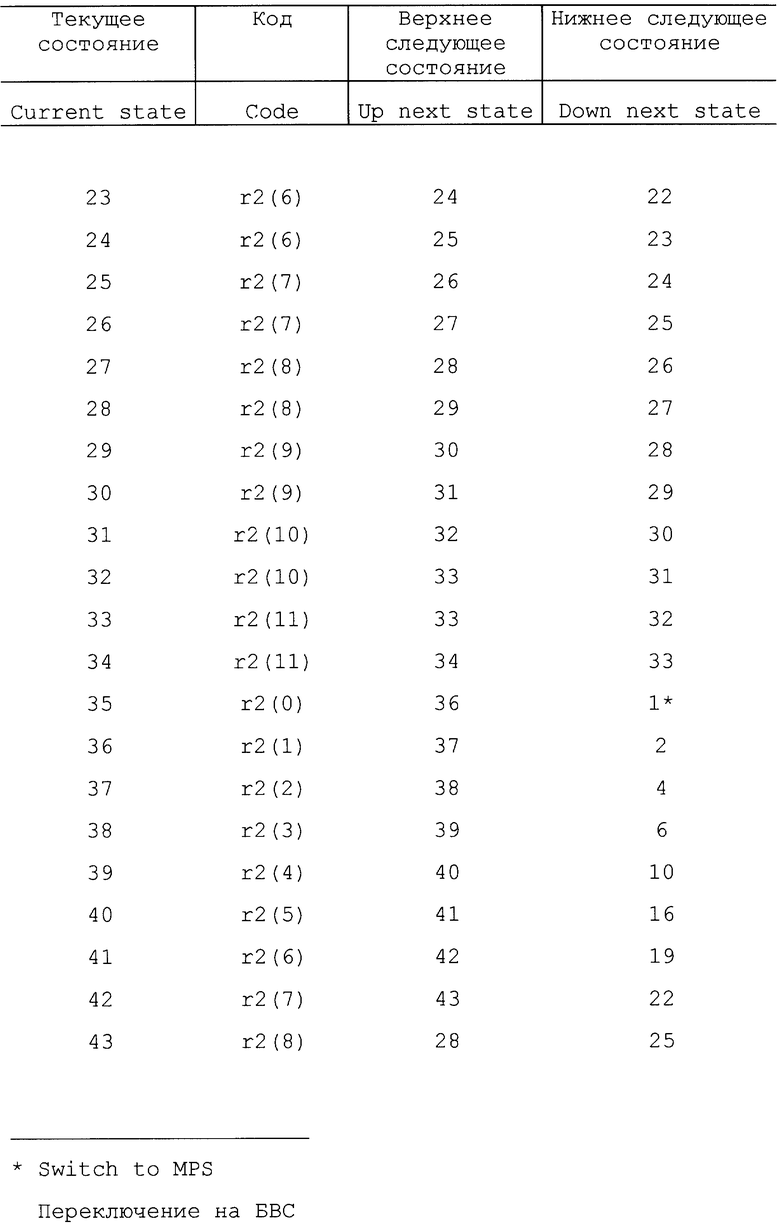
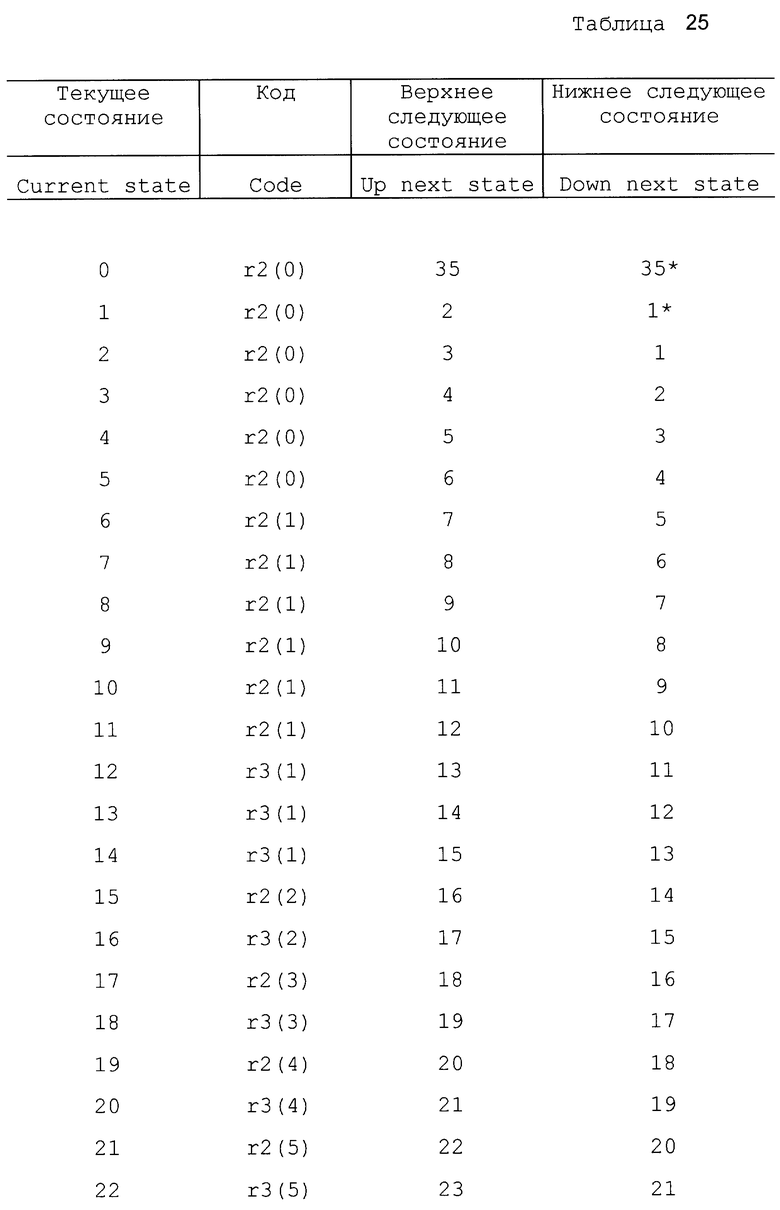
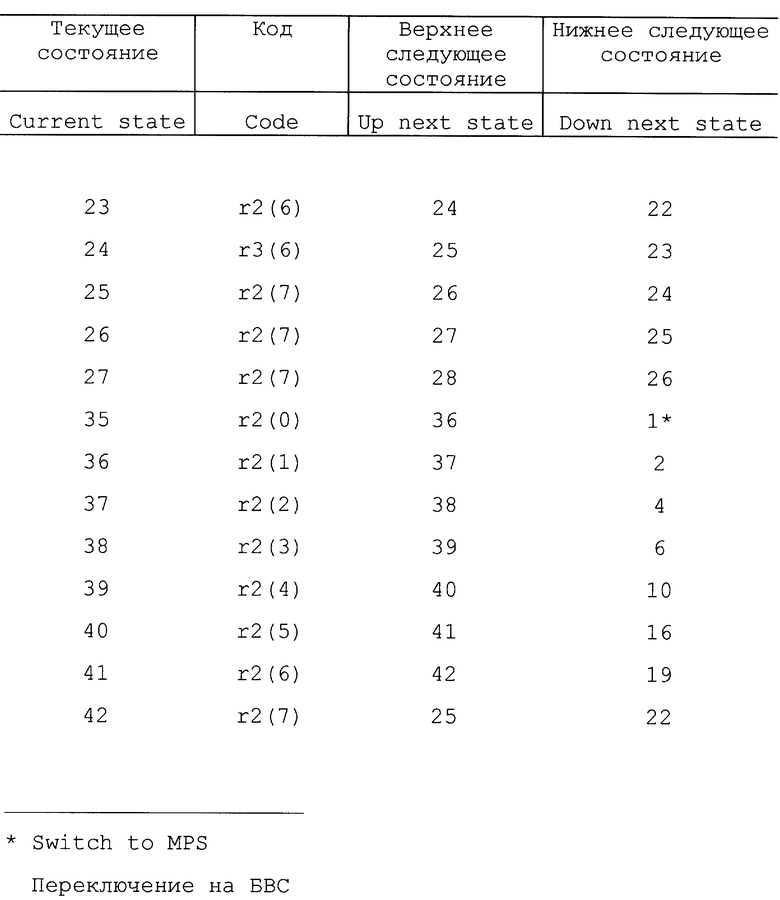
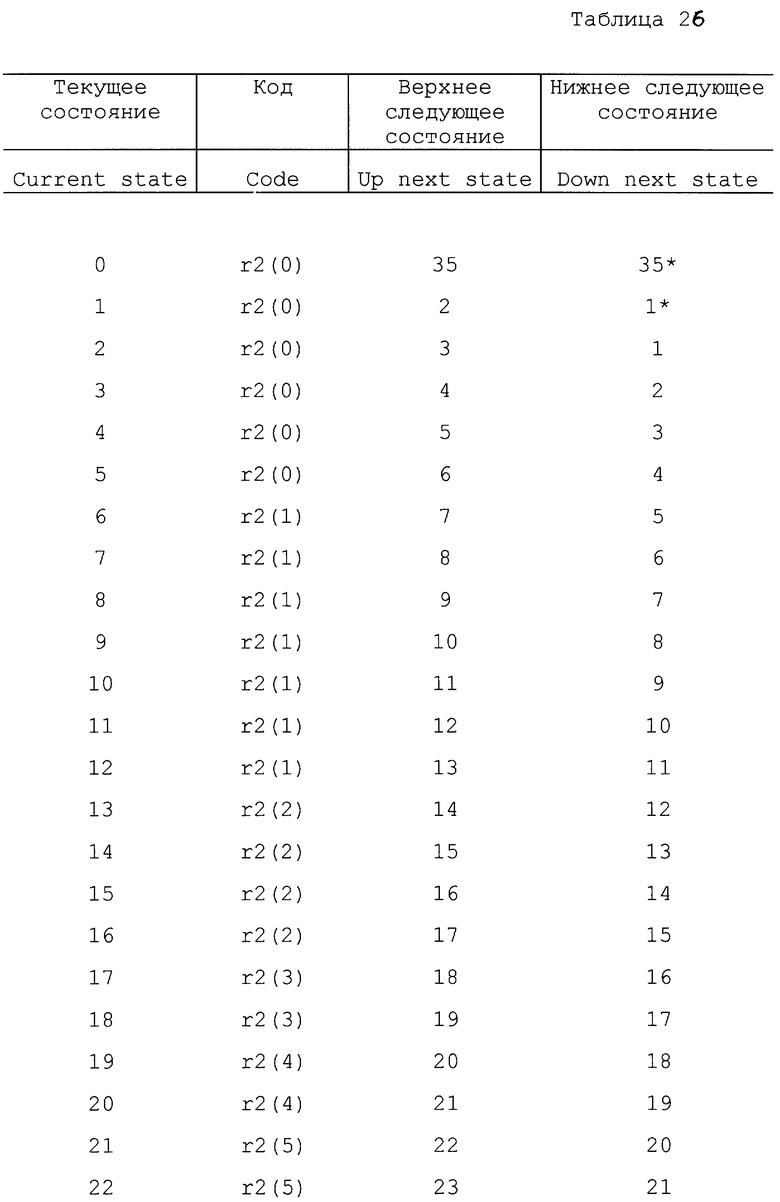
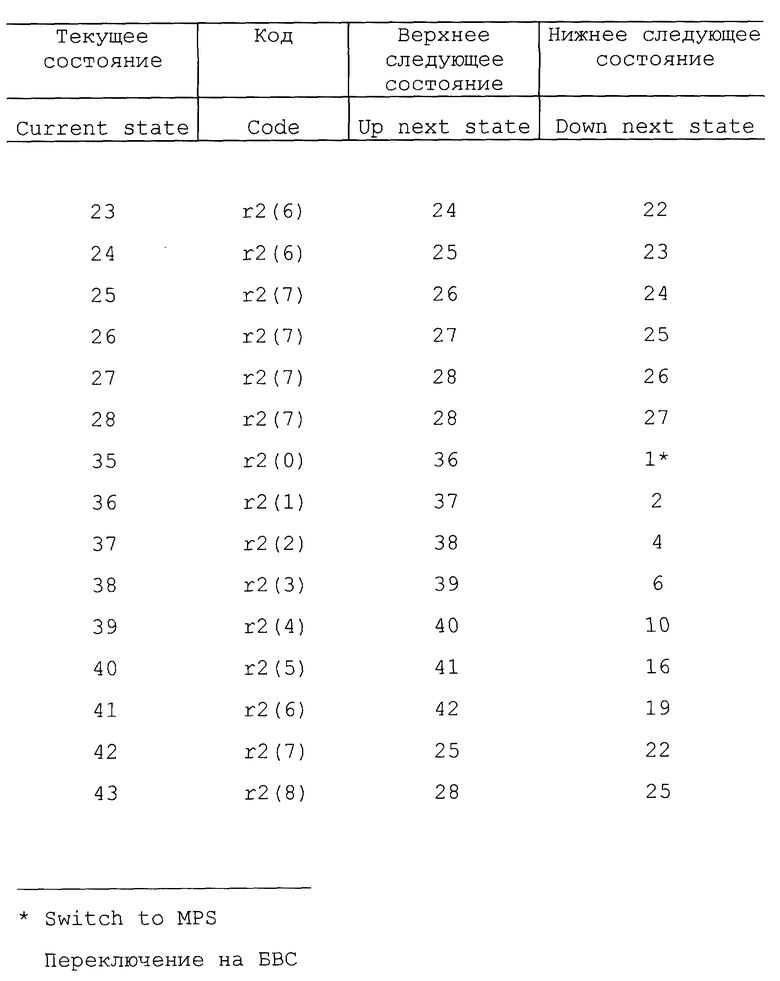
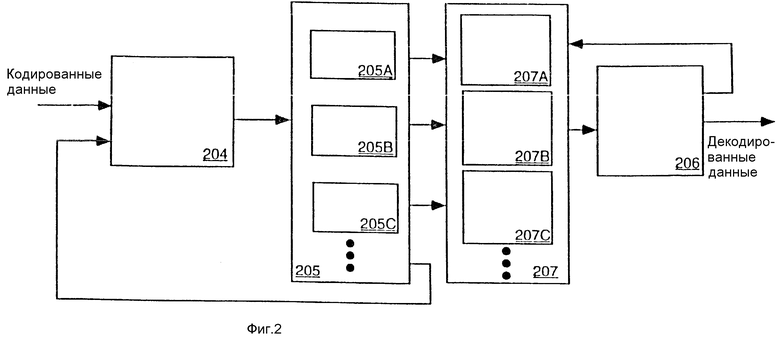
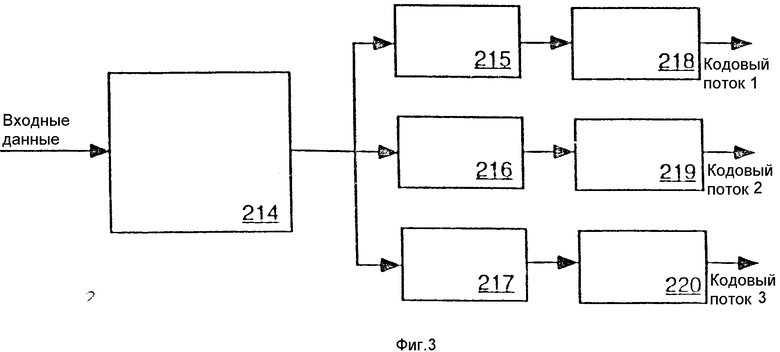

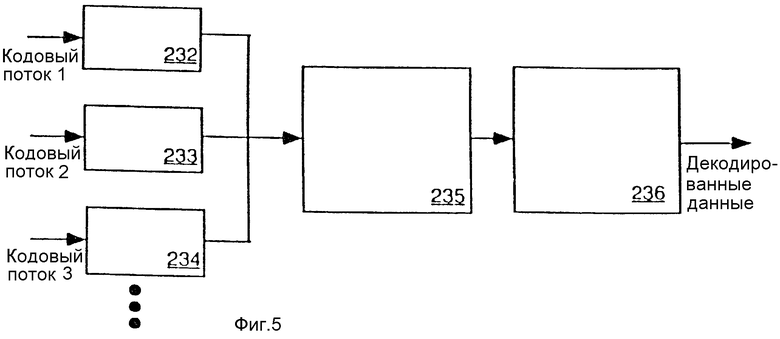

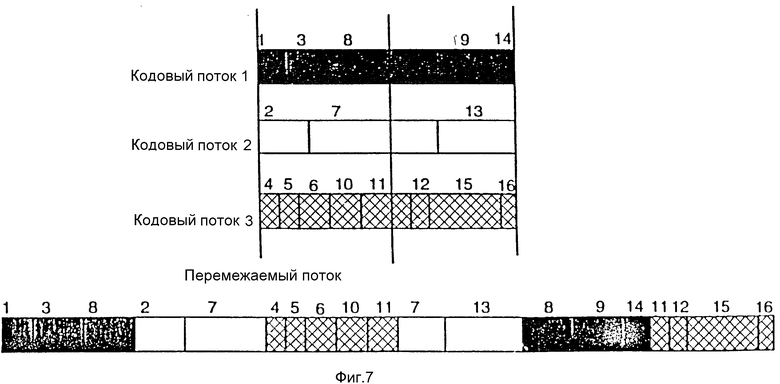
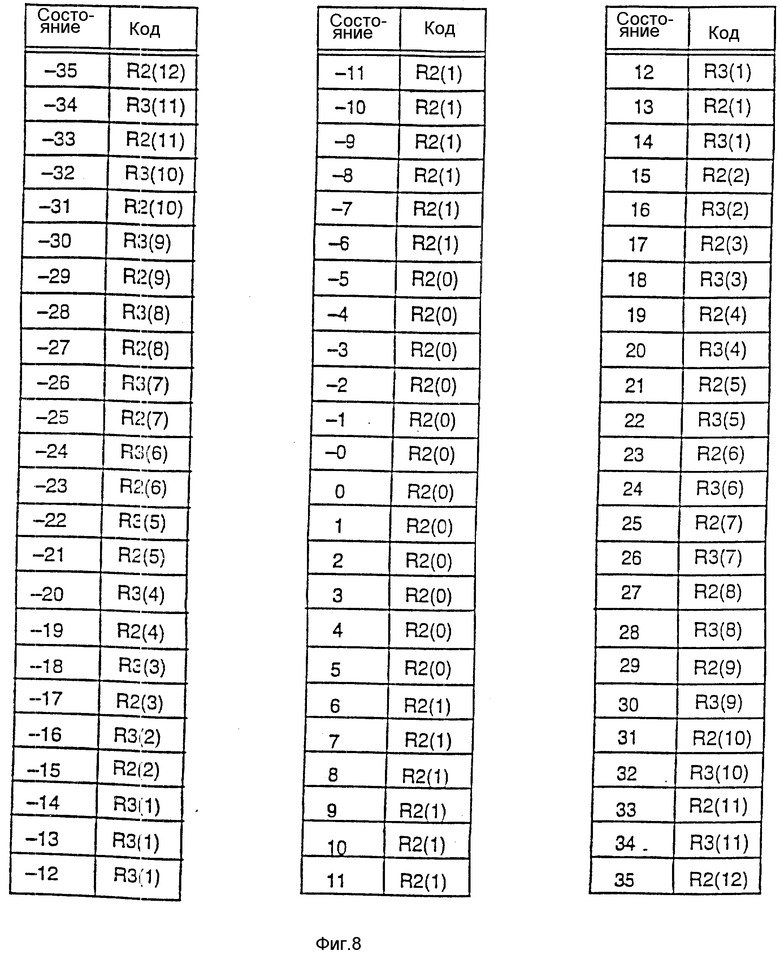
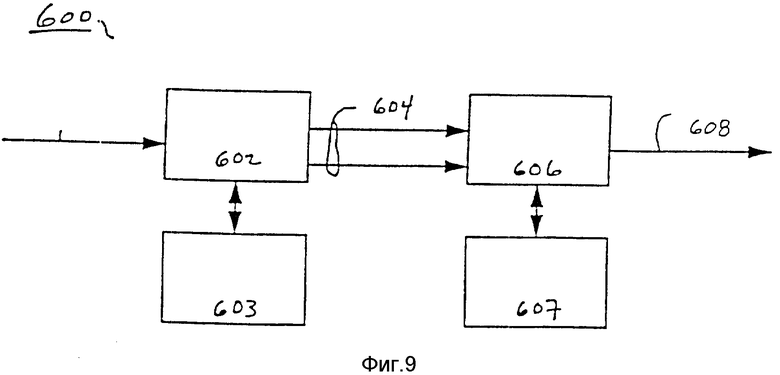

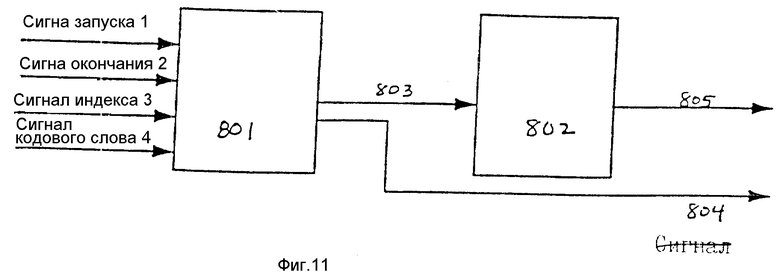
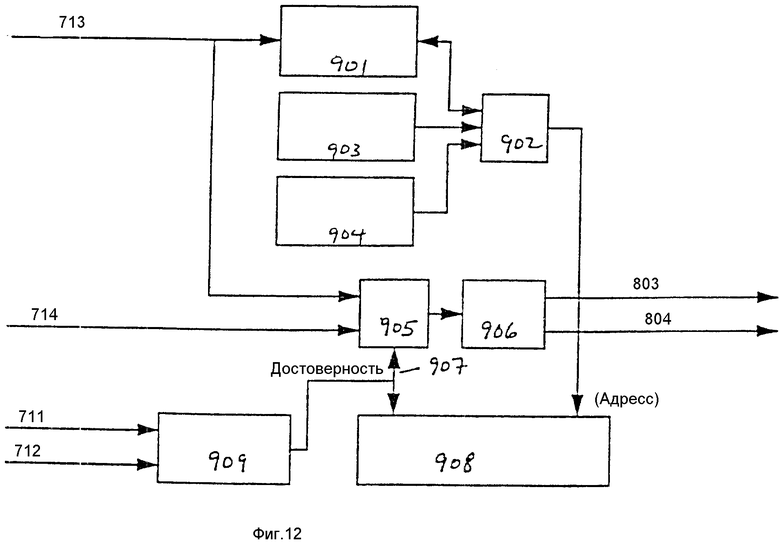
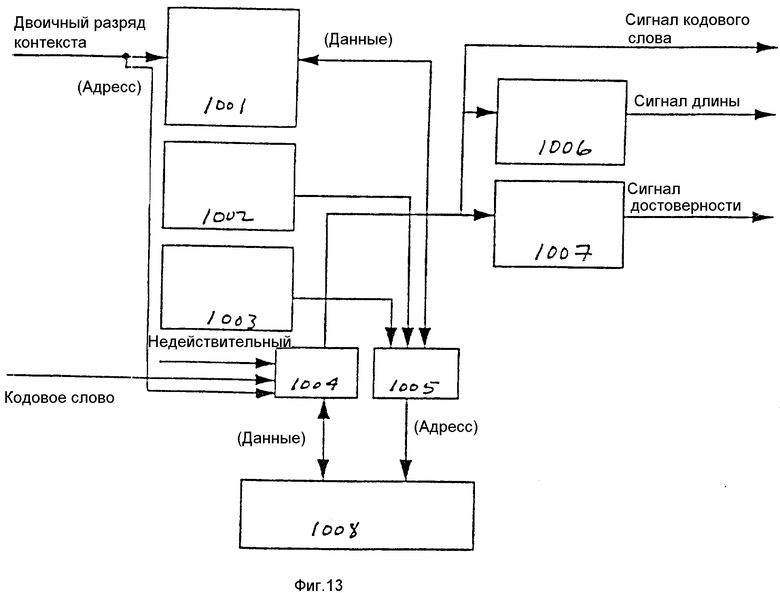

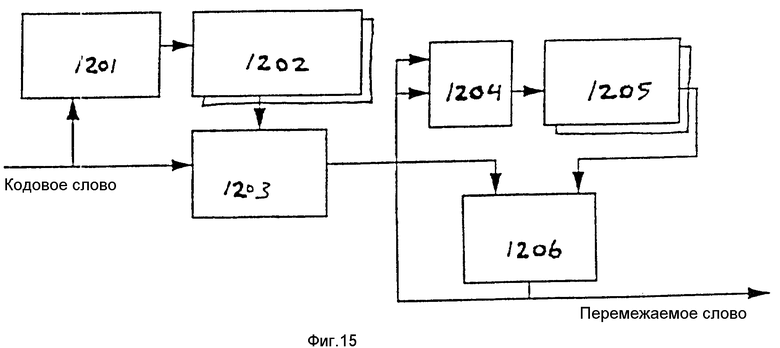
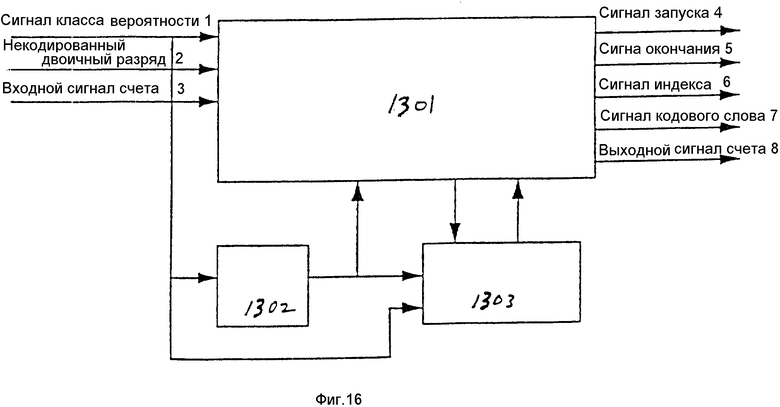

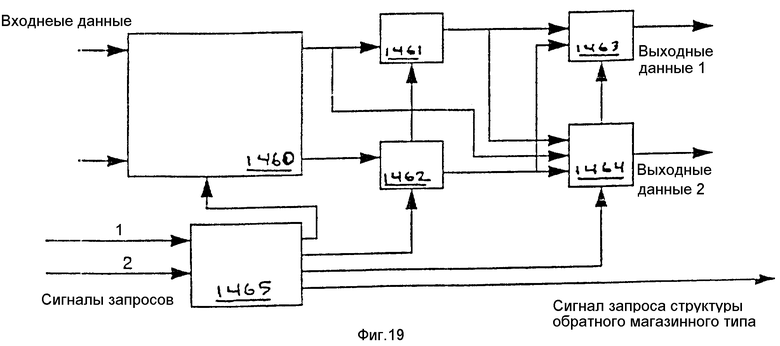



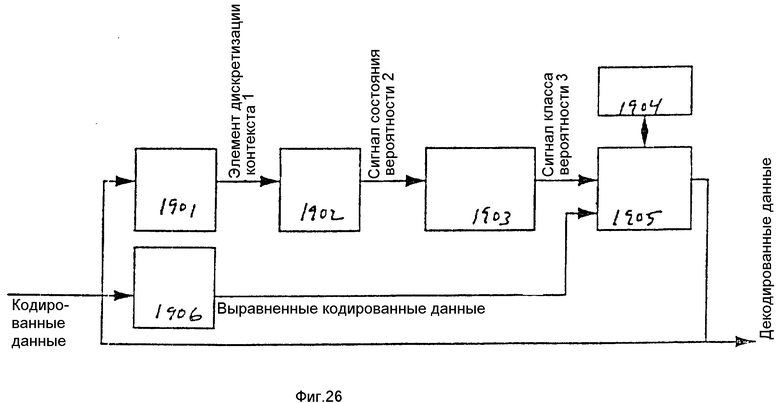

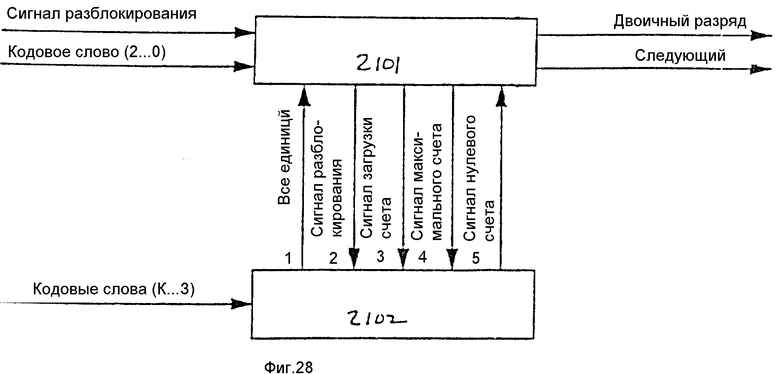

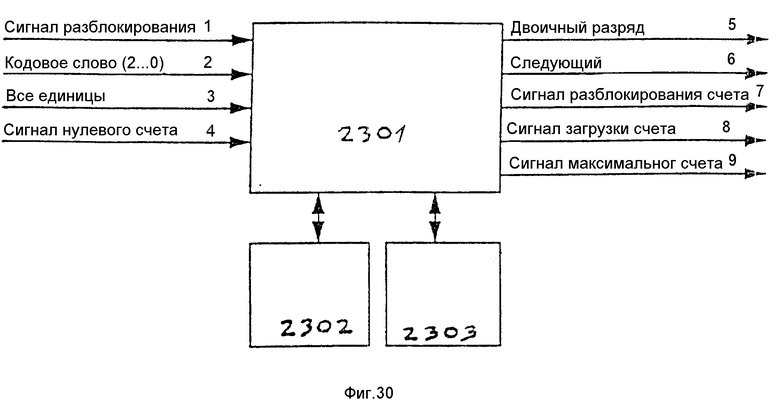


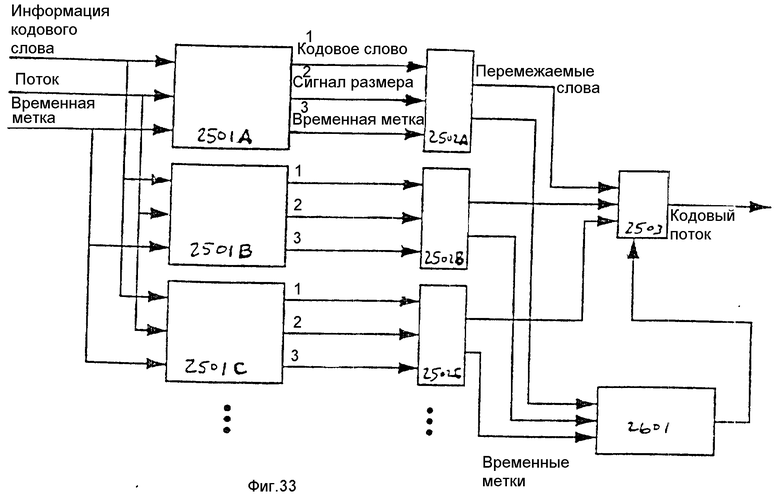


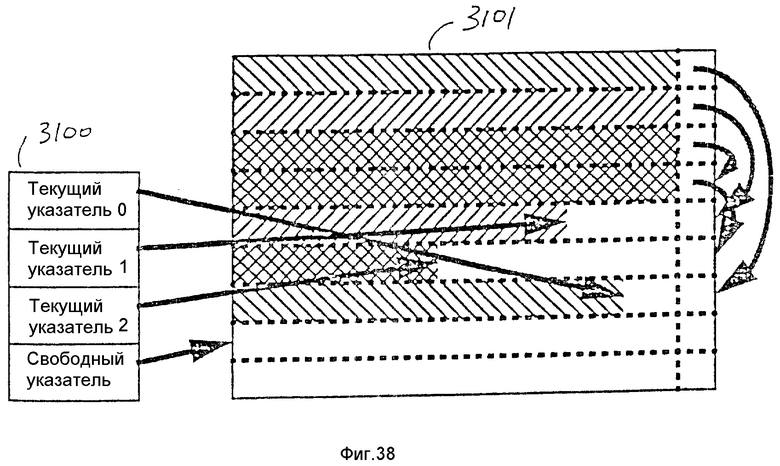


Описаны способ и устройство, предназначенные для разуплотнения и уплотнения данных. Настоящее изобретение относится к кодирующему устройству, предназначенному для использования в системах уплотнения, имеющих декодирующее устройство для декодирования информации, вырабатываемой кодирующим устройством. Соответствующее настоящему изобретению кодирующее устройство включает в себя кодер, предназначенный для генерирования информации кодовых слов в ответ на данные. Кодирующее устройство включает в себя также переупорядочивающий блок, который вырабатывает поток кодированных данных в ответ на информацию кодовых слов, поступающую с кодера. Переупорядочивающий блок включает в себя блок переупорядочивания счета прогонов, предназначенный для расположения кодовых слов в последовательность декодирования, и блок компоновки двоичных разрядов для объединения кодовых слов переменной длины в слова с чередованием фиксированной длины и для вывода этих слов фиксированной длины в последовательности, требуемой декодирующим устройством. Технический результат - обеспечение точного восстановления первоначальных данных. 21 с. и 100 з.п. ф-лы, 26 табл., 40 ил.
| SU, авторское свидетельство, 1566485, H 03 M 7/30, 1990 | |||
| US, патент, 5272478, H 03 M 7/30, 1993. |

