Часть описания содержит материалы, являющиеся предметом защиты авторским правом. Владелец авторских прав не возражает против ксерокопирования кем-либо патентного документа или описания патента в точно том виде, в котором оно появляется в патентных публикациях Ведомства по Патентам и Товарным знакам, но в ином случае оставляет за собой все авторские права.
Перекрестная ссылка на заявки, относящиеся к данной
Патент США N 5381145 A (Заявка на патент США N 08/016035, поданная 10 февраля 1993 года), названный "Способ и Устройство для параллельного декодирования и кодирования данных", права на которую принадлежат настоящему заявителю, включена сюда в качестве ссылки, как "ABSкодер".
Существующий уровень техники
Данное изобретение относится к области сжатия изображения, в частности к сжатию палитризованных изображений с использованием статистического кодера, а также с использованием параллельного статистического кодера.
Сжатие изображений в общем случае выполняется на оцифрованных изображениях. Для оцифровки изображение дискретизируется в различных точках на изображении, часто называемых пикселями. Каждый пиксель имеет положение в изображении и свой цвет. В одном примере изображение представлено двумерной матрицей 1024 х 768 пиекселей, где каждый пиксель может принимать одно 24-х разрядное значение. Каждое значение пикселя может представлять различные цвета, таким образом позволяя изображению быть представленным с использованием любого из 224, или 16777216, возможных цветов.
Во многих применениях каждое значение пикселя связано с конкретным цветом в изображении во время его оцифровки. С учетом этого цвет данного пикселя может определяться значением пикселя.
В других применениях цифровое изображение является палитризованным. В палитризованном изображении значение каждого пикселя не закреплено за цветом, но является указателем ко входу в таблицу палитры цветов. Когда палитризовнанное изображение подлежит показу, цвет пикселя находится путем использования значения пикселя как указателя в таблицу палитры цветов, которая поддерживает соотношение между каждым значением пикселя и цветом, назначенным для этого значения пикселя.
Палитризация является выбором нескольких цветов из набора всех возможных цветов, например 256(28) из 16777216 (224) цветов, и способом замещения произвольного цвета одним из нескольких выбранных цветов. В результате палитризованное изображение может эффективно храниться как кодовая книга со списком (в продолжение вышеупомянутого примера) для каждого из 256 указателей, полного 24-разрядного цветового описания выбранных цветов, дополненного 8-разрядным указателем каждого пикселя в изображении. Таким образом, экономится место за счет только однократного полного описания выбранных цветов и ссылки на каждый пиксель только указателем в кодовую книгу.
Сжатие изображения важно во многих изобразительных применениях из-за количества данных, нужных для представления изображения. В вышеупомянутом примере 24 х 1024 х 768, или 18874368 разрядов (2359296 байтов) необходимо для представления единичного несжатого изображения, или 8 х 1024 х 768 (6291456 разрядов) в случае палитризованного изображения. Сжатие даже более существенно для движущегося изображения, которое требует непрерывного потока изображений с высокой кадровой частотой, такой как 30 кадров в секунду.
Сжатие не только сберегает память для хранения изображений, сжатие также позволяет эффективно передавать изображения по каналам с ограниченным частотным диапазоном. Конечно, для таких применений, как подвижные изображения, изображения должны быть способны достаточно быстро растягиваться, чтобы быть показанными с кадровой частотой. В то время, как сжатие может выполняться заранее, применение часто требует растяжения в реальном масштабе времени. В выполнениях, где сжатие выполнено заранее, входным сигналом разуплотнителя является блок сжатия данных, которые могут храниться в запоминающем устройстве и растягиваться в любое время после сжатия.
Одной мерой того, насколько хорошо осуществляется сжатие, является коэффициент сжатия. Коэффициент сжатия является отношением размера несжатых данных к сжатым данным. Другой мерой качества сжатия является то, как быстро данные могут сжиматься и растягиваться. Во многих применениях скорость сжатия не так важна, как скорость растяжения, так как сжатие не обязательно выполнять в реальном масштабе времени.
Часто коэффициент сжатия улучшается в случае, когда больше известен характер данных. Нормальные цифровые изображения в общем случае являются результатом квантования колебаний, следовательно, они сохраняют многие отличительные признаки первоначального сигнала, такие как наличие относительной непрерывности значений цвета пикселей. В палитризованных изображениях эта непрерывность обычно не присутствует и не может быть использована непосредственно для улучшения коэффициента сжатия.
В палитризованных изображениях цветовой контраст между значениями двух пикселей не может быть с необходимостью выведен из значений пикселей, поскольку значения пикселей не представляют цветов пикселей. Вместо этого они только представляют указатели в таблицу кодов или таблицу значений цветов палитры. Проблема сжатых палитризованных изображений может быть обобщена как проблема сжатия последовательности входных символов, где каждый входной символ является символом М-ичного алфавита.
Y. Chin et al. , "Lossy Compression of Paletrized Images", ICASSP-93, vol. V, pp. 325 - 328, описывает пример сжатия с потерями палитризованных изображений. Хотя сжатие с потерями в общем случае проявляется в более хороших коэффициентах сжатия, многие применения не могут допустить искажения, которое появляется в результате сжатия с потерями, и поэтому требуют сжатия без потерь. При сжатии без потерь сигнал сжимается в сжатый сигнал, который может быть растянут для точного восстановления первоначального сигнала из сжатого сигнала, таким образом, никакие искажения не вносятся.
Из вышесказанного видно, что необходимы улучшенные способы и устройство для сжатия и растяжения палитризованных изображений.
Краткое описание изобретения
Улучшенное сжатие палитризованных изображений обеспечивается посредством данного изобретения, которое позволяет изображениям эффективно сжиматься и быстро растягиваться.
В одном выполнении настоящего изобретения входные символы являются символами в М-ичном алфавите и квантуются на два уровня на основании контекстной модели входных данных, где двухуровневое квантование выбрано для обеспечения хорошего сжатия двоичным кодом. Кодер преобразует входные символы в кодовые слова, тогда как декодер преобразует кодовые слова во входные символы. Конкретное двухуровневое квантование определяется из таблицы переиндексации, которая отображает каждый входной символ в некоторое двоичное число. Отображение определяется из подлежащих сжатию изображений и обычным образом передается со сжатыми изображениями как вставка.
Одним способом для создания отображения для таблицы переиндексации является присвоение индекса входному символу по одному. Индекс, присвоенный входному символу, является функцией разрядов индекса, распределения входных символов, контекстов входных символов, а также того, какие символы и индексы уже присвоены. Для конкретного входного символа из оставшихся неприсвоенных индексов присваивается индекс, который обеспечивает минимальную частичную поразрядную энтропию при данных уже присвоенных указателях и входных символах, которым назначены индексы. Хотя этот способ может не достигать глобальной минимальной поразрядной энтропии, возможной для данного набора распределений символов и контекстов, он обеспечивает хороший "локальный" минимум для выполнимого количества вычислений.
Переиндексированные входные данные затем проходят через разработчик контекстной модели, модуль оценки вероятности и генератор разрядов, выходом которого являются сжатые данные. Если необходимо, таблица переиндексации проходит от уплотнителя к разуплотнителю, как описано выше.
Таблица переиндексации не требуется там, где зафиксирована на будущее.
В другом аспекте данного изобретения разработчиком контекстной модели вырабатываются контекстные модели, которые используют небольшой объем памяти и все же обеспечивают хорошее сжатие для палитризованных изображений.
В другом аспекте настоящего изобретения сжатие и растяжение выполняются параллельно, и входной сигнал на уплотнитель буферизуется и переупорядочивается, чтобы поместить промежуток между разрядом, который закодирован, и разрядами, которые определяют контекст и кодирование закодированного разряда. Промежуток между разрядом и его контекстными разрядами выбран достаточным по задержке так, что контекстные разряды полностью декодируются, когда разуплотнитель достигает разряда, декодирование которого зависит от контекстных разрядов. Разуплотнитель включает в себя средства для выполнения противоположного переупорядочивания так, что входной сигнал разуплотнителя такой же, как и входной сигнал уплотнителя. В некоторых выполнениях выходной сигнал параллельных уплотнителей проходит по единичному каналу связи с очень небольшими вставками, необходимыми для разделения каналов во множестве параллельных разуплотнителей.
В специфических выполнениях входные символы выбираются из алфавита в 256 символов, процесс переиндексации выполняется соответственно программируемым цифровым компьютером, процесс сжатия выполняется не в реальном масштабе времени, а процесс растягивания выполняется в реальном масштабе времени. С 256 входными символами таблица переиндексации занимает 256 байтов.
В специфическом выполнении таблица переиндексации основана на распределениях вероятности входных символов на некотором наборе изображений или частей изображения, и новая таблица переиндексации передается с уплотнителя на разуплотнитель для каждого набора изображений или частей изображения.
Сущность изобретения иллюстрируется ссылкой на сопроводительные чертежи, в которых
фиг. 1 - блок-схема системы сжатия данных, показывающей уплотнитель и растягиватель;
фиг. 2 - блок-схема уплотнителя, показанного на фиг. 1;
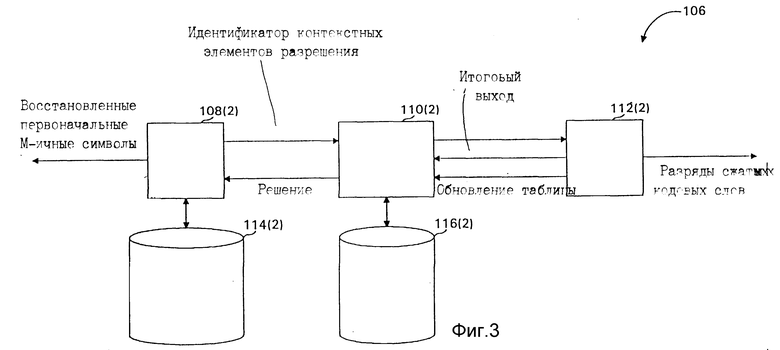
фиг. 3 - блок-схема разуплотнителя, показанного на фиг. 2;
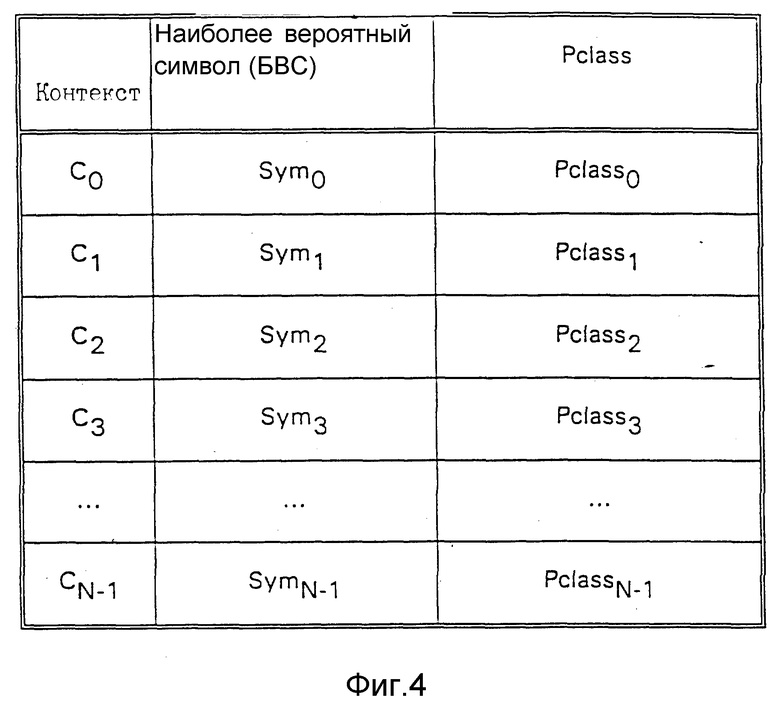
фиг. 4 - подробное представление хранения в памяти контекстной таблицы вероятностей элементов разрешения;
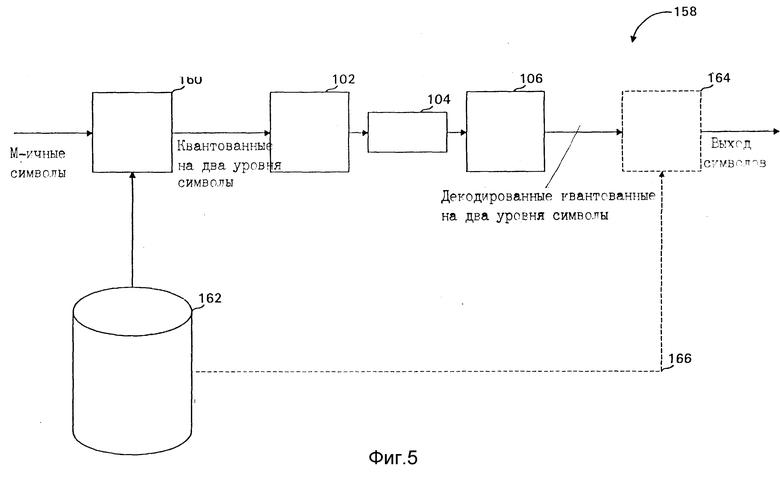
фиг. 5 - блок-схема системы сжатия данных, включающей в себя переиндексатор для переиндексации М-ичных символов в соответствии с таблицей переиндексации;
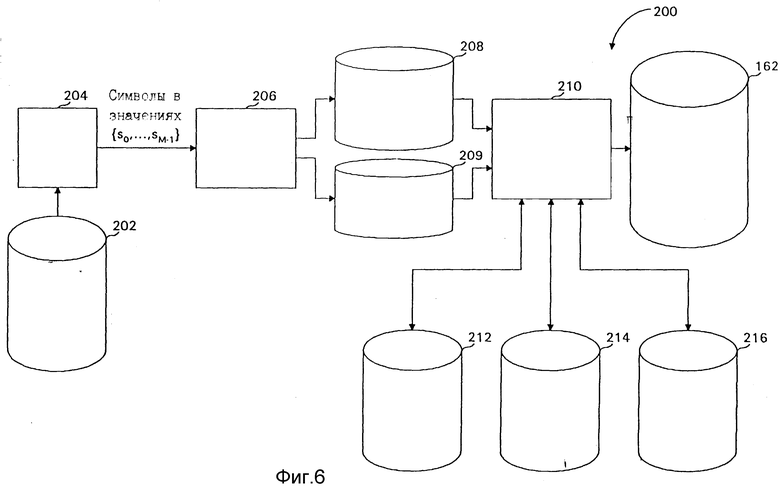
фиг. 6 - блок-схема индексного оптимизатора, который вырабатывает таблицу переиндексации, основанную на данных, содержащихся в подлежащем сжатию блоке данных;
фиг. 7 - блок-схема алгоритма процесса, выполняемого индексным оптимизатором для определения подходящей таблицы переиндексации;
фиг. 8 - иллюстрация различных контекстных моделей, выполненных разработчиками контекстных моделей по фиг. 2 и 3;
фиг. 9 - блок-схема системы параллельного сжатия;
фиг. 10 - блок-схема системы параллельного сжатия, использующей единичный канал;
фиг. 11 - блок-схема, иллюстрирующая работу переупорядочивающего буфера;
фиг. 12 - логическая схема записи, представляющая контекстные состояния;
фиг. 13 (a) и (b) - временные графы конвейерного кодера, который может одновременно обрабатывать более одного входного символа.
Описание предпочтительных вариантов выполнения изобретения
Нижеследующее описание разделено на несколько частей. Первая часть описывает стохастическое кодирование. Вторая часть описывает использование переиндексации для улучшения сжатия, когда используется стохастическое кодирование. Третья часть описывает, как контекстное моделирование может улучшить характеристики стохастического кодирования посредством более точной оценки вероятностей символов. Контекстное моделирование может использоваться с переиндексацией или без нее. Четвертая часть описывает, как параллельные уплотнители и разуплотнители используются для увеличения скоростей передачи данных. Наконец, пятая часть описывает, как буферизация используется для облегчения параллельных выполнений и поддержания тем не менее причинной связи, чтобы позволить данным растягиваться параллельно.
Стохастическое кодирование
Стохастические кодеры известны в технике сжатия данных. Стохастический кодер, который кодирует входные символы в выходные кодовые слова, является процессом без потерь, т.е. первоначальные входные символы могут быть выделены только из выходных кодовых слов. Стохастический кодер называется так потому, что он пытается достичь коэффициента сжатия, как можно более близкого к теоретической верхней границе, диктуемой энтропией входных символов. Кодер и декодер в общем случае разрабатываются так, чтобы декодер являлся инверсией кодера. Термин "кодер" относится к устройству, которое является либо кодером, либо декодером, либо ими обоими.
Здесь не будут описаны все детали стохастического кодера, а только определенные детали, имеющие отношение к данному изобретению. В стохастическом кодере входные символы считываются со входа, и один или более входных символов образуют выход кодового слова. Конкретные входной(ые) символ и выходные комбинации кодовых слов диктуются используемым кодом. Используемый код в оптимизированной системе выбирается на основе распределения вероятностей входных символов. В адаптивном стохастическом кодере используемый код может меняться с распределением вероятностей. Если распределение вероятностей оценено хорошо или точно известно и используются оптимизированные для этого распределения вероятностей коды, то будет получено хорошее сжатие.
Если входные символы являются битами (т.е. символ является 0 или 1), кодер является двоичным стохастическим кодером.
Двоичные стохастические кодеры предпочтительнее других стохастических кодеров, где важна конструктивная простота. ABS кодер является двоичным стохастическим кодером. В двоичном стохастическом кодере входные символы подаются на разрядный генератор, который принимает один или более разрядов на входе и выдает на выходе кодовое слово, для которого принимаются входные разряды. Если разрядный генератор снабжен индикацией распределения вероятностей нулей и единиц во входном потоке, то он может использовать эту информацию для выбора надлежащего кода для использования. Или же, разрядный генератор может быть лишь проинструктирован, каким кодом пользоваться, как определено модулем оценки вероятности. Коды могут сменяться, когда разрядный генератор определяет, что выходные кодовые слова, в среднем, слишком длины или коротки для действительного распределения вероятностей входных символов. Для дальнейших деталей см. ссылку на ABS кодер.
Важно, чтобы распределение вероятностей нулей и единиц было оценено хорошо. Если используется двоичный стохастический кодер, то необходимо, чтобы значения пикселей подлежащего сжатию изображения, которые являются символами из M-иячного алфавита, где M больше двух, прежде всего квантовались на два уровня. Когда это выполняется, в некоторых случаях конкретное выбранное двухуровневое квантование воздействует на энтропию потока разрядов, входящего в двоичный стохастический кодер и, как объяснено выше, энтропия задает пределы того, насколько сильно разрядный генератор может сжать входной поток разрядов. В тех случаях, где различение не ясно, используется "входной пиксельный символ" или "пиксельный символ" для ссылки на элемент подлежащих сжатию данных перед двухуровневым квантованием, который является входом уплотнителя, а также используется "двоичный входной символ" для ссылки на входной символ, который является входом разрядного генератора двоичного стохастического кодера.
Для данных непалитризованного изображения пиксельные символы могут быть квантованы на два уровня в соответствии с цветовой информацией, которая заключена в значении пикселя. Например, предположим, что значение пикселя принимает одно из 256 значений, и взятое значение индицирует цвет пикселя. В этом случае, если сходные цвета представлены сходными 8-разрядными значениями, можно смело предположить, что 00001100 и 00001101 более сходные по цвету, чем 00001100 и 11111111. В некоторых примерах, обсуждаемых здесь, M= 256, а символы в M-ичном алфавите представлены K-разрядным двухуровневым квантованием, где K=8. Понятно, что возможны другие значения M и K, включая значения M, которые не обязательно равны даже степеням двойки, единственное ограничение таково: K≥log2M.
Возвращаясь к примеру, поскольку в типичном изображении соседние пиксели часто имеют сходный цвет, число разрядов, требуемых для выражения каждого пикселя, может быть уменьшено путем представления каждого пикселя отличием в значении цвета пикселя между пикселем и соседним пикселем. Эта предварительная обработка данных в общем случае выразится в более хорошем сжатии, т. к. число разрядов, необходимых для представления значений, зависит от энтропии набора значений. Однако в случае пикселей в палитризованном изображении конкретное соотношение между двумя цветами не выводится из связи между разрядами таких 8-разрядных представлений. Например, в палитризованном изображении 00001100 и 00001101 могут быть очень разными цветами, а 00001100 и 11111111 могут быть почти одинаковыми цветами. Все зависит от палитры.
Таким образом, сжатие палитризованных изображений может улучшаться путем точной оценки распределения вероятностей потока разрядов и путем выбора двухуровневого квантования входных пиксельных символов, которые обеспечивают низкоэнтропийный поток разрядов на разрядный генератор. Решения первой задачи обсуждаются в нижеследующей части, названной "Контекстное моделирование", а решения второй задачи обсуждены в нижеследующей части, названной "Переиндексация".
Растяжение
Для разуплотнителя, для точного декодирования входных символов из выходных кодовых слов, требуется знать, какой код используется для каких кодовых слов, если кодер не является адаптивным кодером и не использует постоянный код. Поскольку вставки в посылаемых данных, индицирующих код, будут снижать эффективность сжатия, разуплотнитель должен быть способен выделять индикацию используемых кодов из кодовых слов. Это возможно, если используемый для данного двоичного входного символа код определяется оценкой вероятности, которая зависит только от разрядов, уже закодированных в кодовые слова. Если это вероятно, то разуплотнитель, используя цепь обратной связи и хранящуюся информацию о входных символах, когда они восстановлены, может определить, какой используется код, только лишь из данных, которые уже декодированы.
Контекстное моделирование
Чем более точны оценки вероятности, тем лучше используемые коды оптимизируются для сжатых данных. Одним путем к уточнению вероятностных оценок является поддерживание вероятностных оценок для множества контекстов. Здесь считается, что контекст входного пикселя является пикселем или пикселями в определенном соотношении ко входному пикселю. Например, в одной контекстной модели контекст входного пикселя определяется пикселем над входным пикселем. При определении контекста разряда в потоке разрядов на входе разрядного генератора контекст обеспечивается пикселями и/или разрядами в определенном соотношении ко входному разряду. Соотношение определяется контекстной моделью.
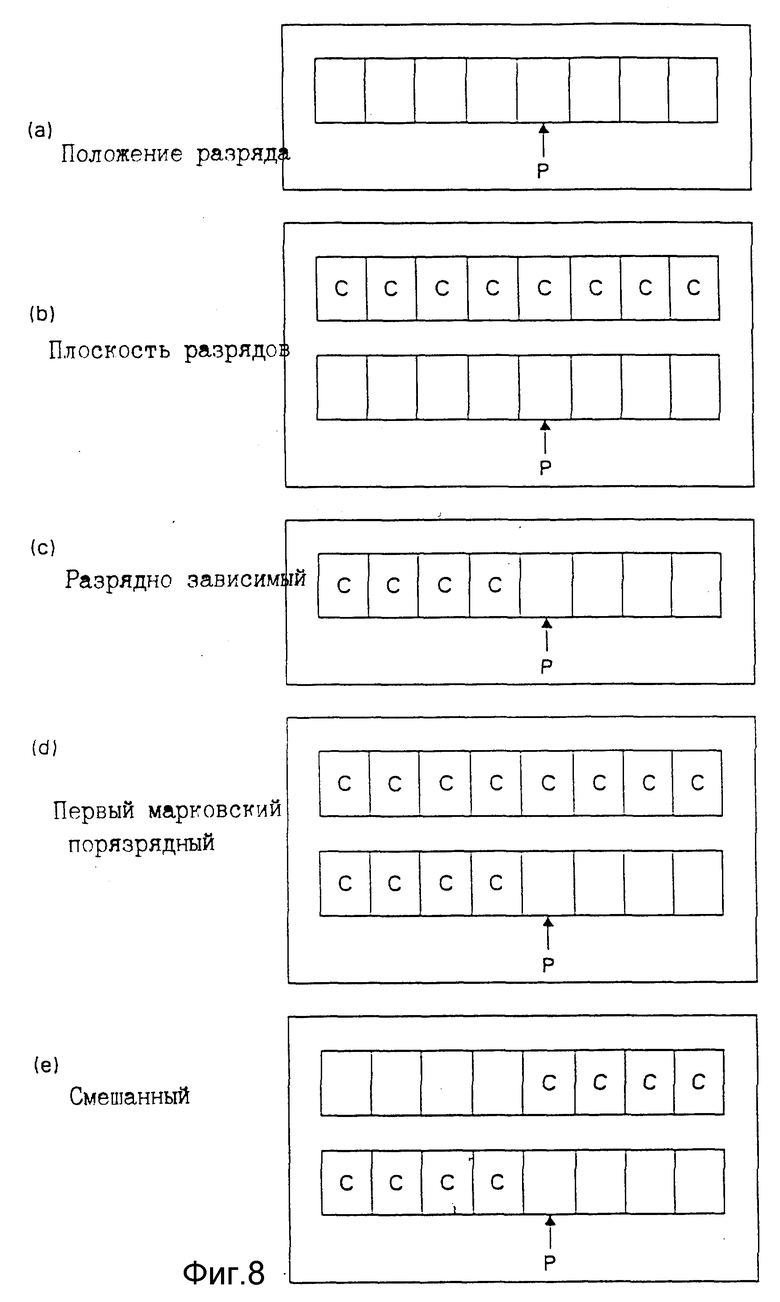
Фиг. 8 является графическим изображением пяти контекстных моделей. В каждой модели стрелка P показывает разрядное положение текущего входного разряда на разрядный генератор текущего входного символа, к которому относится контекст. Во всех показанных контекстах контекст извлекается из некоторого подмножества разрядов текущего входного символа, причем разрядное положение обозначено P, и из разрядов символа для пикселя в изображении над пикселем для текущего входного символа, который упоминается как символ "сверху". Понятно, что другие пиксели, такие как пиксель слева от текущего пикселя или другие, не показанные контекстные модели, могут работать также хорошо.
Каждая контекстная модель описывает, как определяется контекст, и число возможных контекстов может быть легко подсчитано. Для каждой контекстной модели сохраняется вероятностная оценка, и эта вероятностная оценка используется, когда появляется символ, имеющий этот контекст. Термин "контекстный элемент разрешения" часто используется для обозначения того, в какой контекст попадает символ.
Ссылаясь на фиг. 8, контекстная модель (a) является контекстной моделью разрядного положения. В этой модели только контекст является разрядным положением, которое требует K контекстных элементов разрешения. Если K=8, то это приемлемое число контекстных элементов разрешения.
Контекстная модель (b) является контекстной моделью разрядной матрицы, называемой так, потому что имеется набор из M контекстов для каждой разрядной матрицы. Таким образом, имеется MxK (2048 в случае M=256, K=8) контекстов. Одним признаком, который необходимо отметить, является то, что контексты текущего пикселя в моделях (a) и (b) независимы от разрядов, используемых для представления текущего пикселя.
Контекстная модель (c) является поразрядно зависимой контекстной моделью, где контекст определяется разрядным положением текущего разряда и предыдущих разрядов в текущем символе. В этой модели имеется 2К-1 контекстов (1 контекст, когда P находится в первом разряде, 2 контекста для следующего разряда и т. д.). При K=8 эта модель обеспечивает 255 контекстов. Заметим, что контекст разряда не основан на значениях еще не закодированных разрядов, так что декодер не нуждается в недекодированных разрядах для определения того, как декодировать разряд (фиг. 8 предлагает последовательность обработки сверху-вниз и справа-налево).
Контекстная модель (d) является хорошей контекстной моделью, принимающей в расчет все разряды верхнего пикселя и разряды входного пикселя, который предшествует текущему разряду. Эта контекстная модель объединяет информацию моделей (b) и (c) и таким образом обеспечивает Mx(2K-1) контекстов. Хотя эта контекстная модель могла бы обеспечить четкое разделение контекстов, память, необходимая для хранения контекстных значений, может быть запрещена в аппаратном выполнении уплотнителя и разуплотнителя. При M=256 и K=8 эта модель требует 65280 контекстов. Если каждый контекст требует 8 разрядов хранения, эта контекстная модель будет требовать 64K памяти только для этой цели. Тем не менее, одним преимуществом этой контекстной модели перед моделями (a) и (b) является то, что характеристики уплотнителя с использованием этой модели хороши, несмотря на использование квантования на два уровня, поскольку для определения контекстов используются предыдущие разряды текущего пикселя.
Контекстная модель (e) является смешанной контекстной моделью, которая показана как хороший компромисс между требованиями памяти и качеством контекстной модели. В этой модели контекстом являются P-1 предшествующих текущему входному символу разрядов и K-(P-1) последних разрядов символа сверху. Это требует 2K контекстов на разрядное положение (2048 контекстов для K=8).
Контекстная модель в общем случае фиксируется между уплотнителем и растягивателем, но нет ничего, чтобы предохранить уплотнитель и разуплотнитель от переключения контекстных моделей в случае, если они соглашаются на том, какая контекстная модель используется в любое данное время. Если разрешены различные контекстные модели, то для того, чтобы гарантировать, что контекстные модели одинаковы, должен существовать механизм, такой как вставки канала связи, обозначающие текущую контекстную модель.
Вышеприведенное обсуждение стохастического кодирования и контекстного моделирования приведено как основание для объяснения показанной на чертежах системы сжатия данных, которая теперь будет описана. На фиг. 1 показано выполнение системы 100 сжатия данных по данному изобретению, предназначенной для сжатия данных, содержащих символы в M-ичном алфавите, включающей в себя уплотнитель 102, канал 104 и разуплотнитель 106. Входной сигнал уплотнителя 102 является потоком входных пиксельных символов, представляющих каждый значение пикселя в изображении, хотя могут использоваться и другие типы данных.
Входные пиксельные символы преобразуются в сжатые кодовые слова уплотнителем 102, передаются по каналу 104 на разуплотнитель 106. Только из принятых кодовых слов и, возможно, знания принципа действия уплотнителя 102 и таблицы переиндексации (если она используется) разуплотнитель 106 восстанавливает первоначальные входные символы или их эквиваленты. В некоторых случаях первоначальные входные символы переводятся из одного представления в переиндексированное представление, и система сжатия данных манипулирует растянутыми символами без действительного выполнения инверсии переиндексации.
Одним преимуществом данного изобретения являются увеличенные коэффициенты сжатия для входных символов, которые являются значениями пикселей в палитризованном изображении. Поэтому сжатие, обеспечиваемое настоящим изобретением, полезно даже тогда, когда канал 104 имеет ограниченный частотный диапазон. Примеры канала 104 включают в себя каналы связи, как имеющиеся между памятью изображения и устройством представления или между устройством хранения и устройством, использующим хранящееся изображение. Канал 104 может также представлять передачу сжатых данных в форме устройств с памятью, как игровые картриджи, которые сжаты в одном месте и передаются в другое место, где они растягиваются.
В последней ситуации ограничение частотного диапазона канала 104 представляется как ограничение количества памяти, доступной в устройстве для хранения.
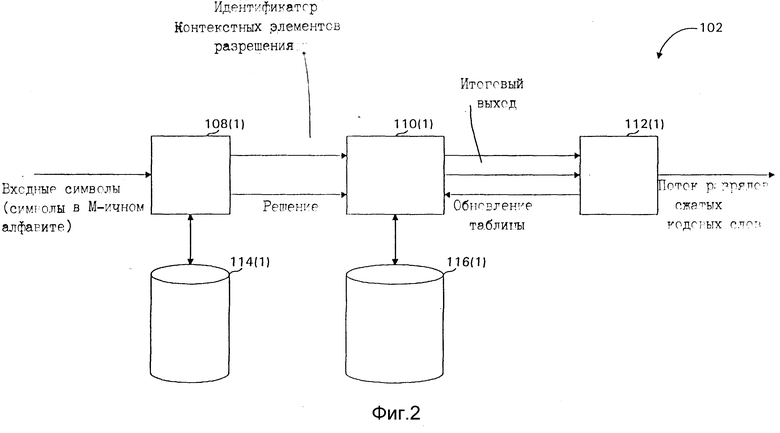
На фиг. 2 уплотнитель 102 включает в себя разработчик 108 (1) контекстных моделей, модуль 110 (1) оценки вероятности MOB (PEM), разрядный генератор 112 (1), контекстную память 114 (1) и память 116 (1) вероятности контекстного элемента разрешения. Заключенные в скобки цифры используются для разделения элементов, одинаково пронумерованных как в уплотнителе 102, так и в разуплотнителе 106. Ссылки на элемент, которые в общем случае применимы и к уплотнителю 102, и к разуплотнителю 106, показаны без взятых в скобки цифр. Хотя настоящее изобретение описывается в связи с конкретным уплотнителем 102, показанным на фиг. 2, другие уплотнители работают так же хорошо. Например, не все уплотнители требуют показанного подключения между MOB 110 и разрядным генератором 112, и MOB 110 может опираться на данные иные, нежели выработанные разрядным генератором 112 для обновления их оценок вероятности.
Разработчик 108 (1) контекстных моделей подключен ко входу уплотнителя 102 и поэтому принимает входные пиксельные символы. Если используется переиндексатор, то входным сигналом уплотнителя 102 является поток переиндексированных входных пиксельных символов. Разработчик 108 (1) контекстных моделей содержит два выхода: выход идентификатора 1D контекстного элемента разрешения и выход решения, которые оба являются входами MOB 110 (1). Полагая, что входной сигнал квантуется на два уровня для символа из K разрядов, разработчик 108 (1) контекстных моделей выдает K двоичных "решений" на входной пиксельный символ. Для каждого решения разработчик 108 (1) контекстных моделей также выдает один идентификатор контекстного элемента разрешения.
Разработчик 108 (1) контекстных моделей также выдает один идентификатор контекстного элемента разрешения.
Разработчик 108 (1) контекстных моделей также подключен к памяти 114 (1) для адресации в ней элементов данных и для считывания записи в ней данных, относящихся к появлению символов во входном потоке, как необходимо для определения контекста входного пиксельного символа, имеющегося на его входе. Конкретная компоновка элементов данных в памяти 114 (1) зависит от контекстной модели.
MOB 110 (1) принимает два выходных сигнала с разработчика 108 (1) контекстных моделей и имеет два выхода на разрядный генератор 112 (1), выход класса вероятности (Pclass) и итоговый выход. MOB 110 (1) также подключен к памяти 116 (1) для адресации в ней элементов данных и считывания и модифицирования значений этих элементов данных и к разрядному генератору 112 (1) для приема табличного обновленного сигнала. На каждый сигнал решения, поступающий на MOB 110 (1), MOB 110 (1) выдает один итоговый бит и одно значение класса вероятности Pclass. Итоговый разряд зависит от входного бита решения и наиболее вероятного символа (БВС) для контекстного элемента разрешения, связанных со входным битом решения. Итоговый бит показывает, является ли входной бит решения БВС или нет. Противоположностью БВС (который равен либо 0, либо 1, т.к. разрядный генератор кодирует двоичные символы) является наименее вероятный символ (MBC).
Разрядный генератор 112 (1) принимает поток итоговых битов и связанных с ними значений Pclass. Таким образом, разрядный генератор 112 (1) принимает K итоговых битов и связанных с ними значений Pclass для каждого входа пиксельного символа в разработчик 108 (1) контекстных моделей. Из этих двух входных потоков разрядный генератор 112 (1) зарабатывает поток сжатых кодовых слов, как объяснено в ссылке на ABS кодер. При должным образом разработанном разрядном генераторе поток итоговых битов может быть восстановлен из входных кодовых слов, и кодовые слова содержат меньше разрядов, чем входной поток разрядов. Значение Pclass используется для выбора кода для использования в кодировании потока разрядов. С другой стороны, MOB 110 (1) может хранить распределение вероятности БВС и МВС для каждого контекста и подавать значения вероятности на разрядный генератор.
Как показывает ссылка на ABS кодер, несколько двоичных кодов оптимизируются для конкретных вероятностей символов (нулей и единиц) во входном потоке. Например, если нули и единицы примерно одинаковы на входе разрядного генератора, то оптимальный код является кодом без сжатия, т.е. один разрядный выход для каждого входного разряда. Оптимальность кода определяется тем, насколько близко средняя длина кодового слова достигает теоретической энтропии входных разрядов.
Поскольку уплотнитель 102 работает по одному пиксельному символу, а MOB 110 и разрядный генератор 112 работают по одному разряду этого пикселя, понятия "текущего" пикселя и "текущего разряда" имеют значение и используются в последующем описании для объяснения работы уплотнителя 102 и разуплотнителя 106. Понятно, однако, что в комплексном уплотнителе символы могут обрабатываться не по одному, но понятие "текущего" символа тем не менее все же применимо. Также понятно, что элементы могут работать конвейерным образом, так что текущий символ для одной ступени может отличаться от текущего символа для другой ступени.
В операции сжатия уплотнитель 102 принимает каждый входной пиксельный символ в последовательности и выдает поток кодовых слов, хотя нет необходимости выдавать кодовое слово для фиксированного числа входных символов. В обработке одного пиксельного символа символ квантуется на два уровня и двухуровневое квантование является входом разработчика 108 (1) контекстных моделей. Разработчик 108 (1) контекстных моделей оценивает квантование на поразрядной основе, выдавая каждый разряд на выходе решения разработчика моделей вместе с идентификатором 1D контекстного элемента разрешения, идентифицирующим контекст разряда. Например, если используемая контекстная модель является контекстной моделью разрядного положения, то идентификатор 1D контекстного элемента разрешения только показывает положение разряда в двухуровневом квантовании входного пиксельного символа. Для контекста разрядного положения только указатель на текущий разряд нуждается в хранении, но для других контекстных моделей каждый пиксель, который воздействует на контекст другого пикселя, хранится в памяти 114. Если контекстная модель включает в себя пиксель над текущим пикселем, то это будет достаточным для хранения одной строки пикселей в памяти 114.
Там, где входные символы представляют цвета пикселей в двумерной матрице пикселей, формирующих изображение, порядок сканирования не столь важен по сравнению с блоком текста, где контекст в общем случае обеспечивается буквами около текущей буквы. Тем не менее, только для примера, это обсуждение предполагает, что двумерная матрица считывается в уплотнитель 102 в заранее заданном порядке, к примеру с верхней строки к нижней строке и слева направо в каждой строке. При этом порядке сканирования пиксель над текущим пикселем может использоваться для контекста, поскольку верхний пиксель будет уже декодирован во времени, что необходимо для обеспечения контекста для декодирования текущего пикселя и поскольку в типичном изображении пиксель прямо над текущим пикселем часто имеет цвет, который похож, чтобы быть подобранным в пару к цвету текущего пикселя.
Нет ничего особенного в контекстном пикселе над текущим пикселем, и хотя возможны многие контекстные модели, успешное растяжение без потерь из потока сжатых данных требует, чтобы контекстная модель текущего разряда не включала в себя разряды или символы, которые не декодированы во времени, в которое текущий разряд подлежит декодированию. Несколько примеров внесут ясность в этот вопрос.
Если контекстная модель является контекстом "разрядного положения", контекст текущего разряда является положением разряда в текущем входном пикселе, а идентификатор 1D контекста для этого контекста будет представлять текущий контекст, который, в случае К квантованных на два уровня разрядных символов, обеспечивает K контекстов. Однако, если контекст текущего разряда определяется используемым кодом для кодирования этого разряда, то контекст должен быть известен перед тем, как разряд может быть декодирован должным образом.
Для каждого разряда, выдаваемого из разработчика контекстных моделей на его выходе решения, MOB 110 (1) принимает решение и идентификатор 1D контекстного элемента разрешения для этого решения. Основываясь на этом решении, т. е. на БВС для контекстного элемента разрешения этого решения, MOB 110 (1) выдает итоговый бит и связанное с ним значение Pclass. То, как определяются БВС и значение Pclass, обсуждается ниже.
Значение Pclass является оценкой того, насколько вероятен БВС в потоке разрядов, выдаваемых разработчиком 108 (1) контекстных моделей на линию сигнала решения. Хотя распределения вероятностей БВС и МВС во входных данных могут быть определены путем сканирования всех входных данных, сжатие не должно зависеть от полного распределения вероятностей, поскольку это не будет доступно разуплотнителю декодирования кодовых слов. Поэтому используется оценка, которая зависит только от предварительно закодированных разрядов. Как объяснено в ссылке на ABS кодер, разрядный генератор 112 (1) использует значение Pclass для определения, какой код использовать для кодирования потока итоговых разрядов. Поскольку код оптимизируется по области распределений вероятностей, значение Pclass определяет область значений вероятностей, а следовательно, и класс вероятностей названий. Эти значения вероятности хранятся по одному на контексте в памяти 116. Память 116 также хранит БВС для каждого контекста. Фиг. 4 показывает размещение памяти 116. Вначале значение Pclass для каждого контекста является значением Pclass, которое показывает, что вероятность БВС равна 50% (и МВС равна 50%) и БВС может произвольно выбираться из 0 и 1.
Как указывает ссылка на ABS кодер, один способ сжатия данных в стохастическом кодере должен использовать код, который уменьшает длинные прогоны БВС до кодового слова, показывающего длину прогона. Первоначальный поток реконструируется путем выдачи числа разрядов БВС, обозначенных кодовым словом, за которыми следует МВС, кроме случая, где прогон разрядов БВС длиннее максимального прогона разбивается более чем на одно кодовое слово.
После выдачи кодового слова разрядный генератор 112 (1) сигнализирует на MOB 110 (1), появился или нет максимальный прогон БВС разрядов. Эта индикация обеспечивается на линии сигнала обновления таблицы. Если сталкиваются с максимальной длиной прогона, разрядный генератор 112 (1) сигнализирует на MOB 110 (1), чтобы обновить таблицу значений Pclass для индикации того, что БВС более вероятно, чем оценено предварительно. Если максимальная длина прогона не встречается, значение Pclass изменяется для индикации того, что БВС менее вероятно, чем оценено предварительно.
Растягивание является прямо противоположным процессом по отношению к сжатию: кодовые слова декодируются в поток итоговых разрядов, поток выходных разрядов преобразуется в поток разрядов решения и собирается в пиксельные символы, которые затем выдаются на выход. На фиг. 3 разуплотнитель 106 включает в себя разработчик 108 (2) контекстных моделей, MOB 110 (2), разрядный генератор 112 (2), память 114 (2) и память 116 (2). Подключения между модулями в разуплотнителе 106 инверсны по сравнению с уплотнителем 102 для потока разрядов, но имеют то же направление для информации о потоке разрядов, формируя таким образом две цепи обратной связи.
Одна цепь обратной связи определяет код, используемый для кодирования кодового слова. Знание используемых кодов позволяет разрядному генератору 112 (2) декодировать поток разрядов. Используемые коды определяются значением Pclass, выданным MOB 110 (2). Значение Pclass, как и в MOB 110 (1), определяется контекстом и сигналами с обновления линии таблицы. Контекст определяется из информации о предыдущих разрядах и пикселях, которая хранится в памяти 114 (2). Цепь обратной связи имеет определенную задержку, которая может быть измерена числом разрядов. Задержка может меняться в зависимости от принятых кодовых слов, и для большинства выполнений задержка может быть перекрыта на максимуме. Если максимум задержки составляет X разрядов, то контекст разряда не должен зависеть от X разрядов, которые предшествуют текущим разрядам в потоке разрядов решения. Это гарантирует, что текущий разряд может быть декодирован из информации, которая уже обработана разуплотнителем 106. Это требование представляет особые проблемы, которые решает настоящее изобретение, если данные должны быть растянутыми параллельно.
Переиндексация
Как обсуждено выше, двоичные стохастические кодеры могут сжимать данные до теоретического предела. Любое двухуровневое квантование палитризованных данных может использоваться для представления изображения так же легко, как и любое другое (путем изменения таблицы палитры цветов), тем не менее, оказывается, что некоторые двухуровневые квантования обеспечивают более низкую энтропию для некоторых контекстных моделей, чем другие. Это преимущественно может быть обеспечено путем добавления переиндексатора перед уплотнителем 102, где переиндексатор выбирает двухуровневое квантование, которое обеспечивает низкую энтропию для данных, подлежащих сжатию. Противоположность переиндексатора, деиндексатор, может быть размещен на выходе разуплотнителя 106, либо определение палитры цветов может изменяться для того, чтобы отвечать изменениям алфавитного промежутка из-за переиндексации. В некоторых выполнениях таблица переиндексации может быть зафиксирована перед сжатием и храниться и в уплотнителе, и в разуплотнителе.
Фиг. 5 показывает систему 158 сжатия переиндексированных данных, включающую в себя переиндексатор 160, подключенный ко входу уплотнителя 102, таблицу 162 переиндексации, которая является таблицей размером 2хM, и необязательный деиндексатор 164. Линия 166 сигнала показана для обозначения передачи от таблицы переиндексации на разуплотнитель 106, если переиндексация не зафиксирована. Поскольку таблица 162 переиндексации имеет размер только 2xM, ее передача со сжатыми данными не вносит значительных дополнительных затрат (на вставки).
Работа переиндексатора 160 и деиндексатора 164 прямо задается конкретной таблицей 162 переиндексации. Переиндексатор 160 индексирует в таблицу 162, используя пиксельные символы со своего входа, и считывает соответствующее переиндексированное значение. Это значение является выходом, когда квантованный на два уровня символ вводится на вход контекстного уплотнителя 102. Переиндексированные значения в таблице 162 таковы, что работа обратима, т.е. точно одно вхождение в таблице 162 переиндексации хранит любое данное переиндексированное значение. Таким образом, когда выход разуплотнителя 106, который имеет тот же вид, что и вход уплотнителя 102 с задержкой системы сжатия, подается на деиндексатор 164, если тот используется, деиндексатор 164 выполняет противоположное преобразование и выдает индекс, который содержит первоначальный M-ичный пиксельный символ. Как указано выше, если действительный первоначальный M-ичный символ не требуется и может использоваться известное двухуровневое квантование, деиндексатор 164 не требуется.
Фиг. 6 является блок-схемой генератора 200 таблицы переиндексации, который используется для выработки переиндексированных значений в таблице 162 из входного блока данных. Генератор 200 может выполняться либо в предназначенном для этого аппаратном обеспечении, либо в соответствующим образом запрограммированном цифровом компьютере.
Использование цифрового компьютера общего назначения часто менее дорого, особенно для однократных сжатий, хотя это ведет к замедлению по сравнению со специально предназначенным аппаратным обеспечением. Благоприятно, что большинство применений позволяют сжатию быть выполненным заранее, а не в реальном масштабе времени.
Входной сигнал генератора 200 является блоком пиксельных символов. Этот блок может быть всей совокупностью изображений, подлежащих сжатию, или несколькими выбранными подмножествами изображений, или даже частями изображений. Тем не менее, если сжатие может быть выполнено не в реальном масштабе времени, то в общем случае не является проблемой использование всего множества данных как входа в генератор 200. В некоторых выполнениях данные изображений объединяются в блоки из 16 или 256 изображений, и таблица переиндексации вырабатывается для каждого блока изображений.
Вновь обращаясь к фиг. 6, генератор 200 включает в себя модуль 204 фиксации порядка, аккумулятор 206 распределения условных вероятностей, таблицу 208 условных вероятностей для хранения значений Pc (Si) для i от 0 до M - 1 и c от 0 до N - 1, где Pc (Si) является вероятностью того, что входной символ Si появляется в контексте Cc, таблицу 209 контекстной вероятности для хранения значений P (Cc) для C от 0 до N - 1, где P (Cc) является вероятностью контекста Cc, появляющегося в блоке входных данных, стохастический минимизатор 210, подключенный к выходу таблицы 162 переиндексации, таблицу 212 частичной условной вероятности ("Таблица РСР") для хранения значений РСР (c) для c от 0 до N - 1, где РСР (c) является частичной условной вероятностью контекста Cc, как объяснено ниже, таблицу 214 частичной условной вероятности положения ("Таблица РРСР") для хранения значений РРСР (K, c) для K от 1 до K и c от 0 до N-1, где РРСР (K, c) является частичной условной вероятностью положения контекста Cc и разрядного положения K, как объяснено ниже, и таблицу 216 частичной поразрядовой энтропии для хранения значений PBE (j) для j от 1 до M-1, как объяснено ниже. Использование различных таблиц будет более понятным по прочтении описания, сопровождающего блок-схему алгоритма на фиг. 7.
Генератор 200 работает следующим образом. Модуль 204 фиксации порядка преобразует каждый символ из блока 202 данных в упорядоченный символ Si, где i меняется от 0 до M-1. Поскольку воздействием таблицы 162 переиндексации является переупорядочивание символов, конкретный используемый порядок имеет меньшую важность, чем работа остальной части системы. В одном возможном выполнении символы в блоке 202 данных уже хранятся как K-разрядные (K≥ log2 M) двоичные значения, и в этом случае модуль 204 не требуется. В другом выполнении S0 присвоено наиболее частому пиксельному символу в блоке 202 данных, S1 - следующему наиболее частому и т.д. до SM-1 для наименее частого пиксельного символа. Это иногда известно как распределение нулевого порядка частоты символов, или бесконтекстное распределение частоты символов.
Модуль 204, если он используется, считывает пиксельные символы из блока 202 данных и пропускает двоичное представление упорядоченных символов на аккумулятор 206, который аккумулирует вероятности в таблицы 208 и 209. Стохастический минимизатор 210 затем считывает содержимое таблиц 208 и 209, считывает значения из таблиц 212, 214 и 216 и записывает значения в таблицы 212, 214 и 216, чтобы выработать их основной выход, который становится содержимым таблицы 162. В некоторых выполнениях минимизатор 210 хранит внутреннюю таблицу, из которой присваиваются индексы таблицы 162, а в других выполнениях минимизатор 210 определяет, какие индексы присвоены, путем обращения к таблице 162.
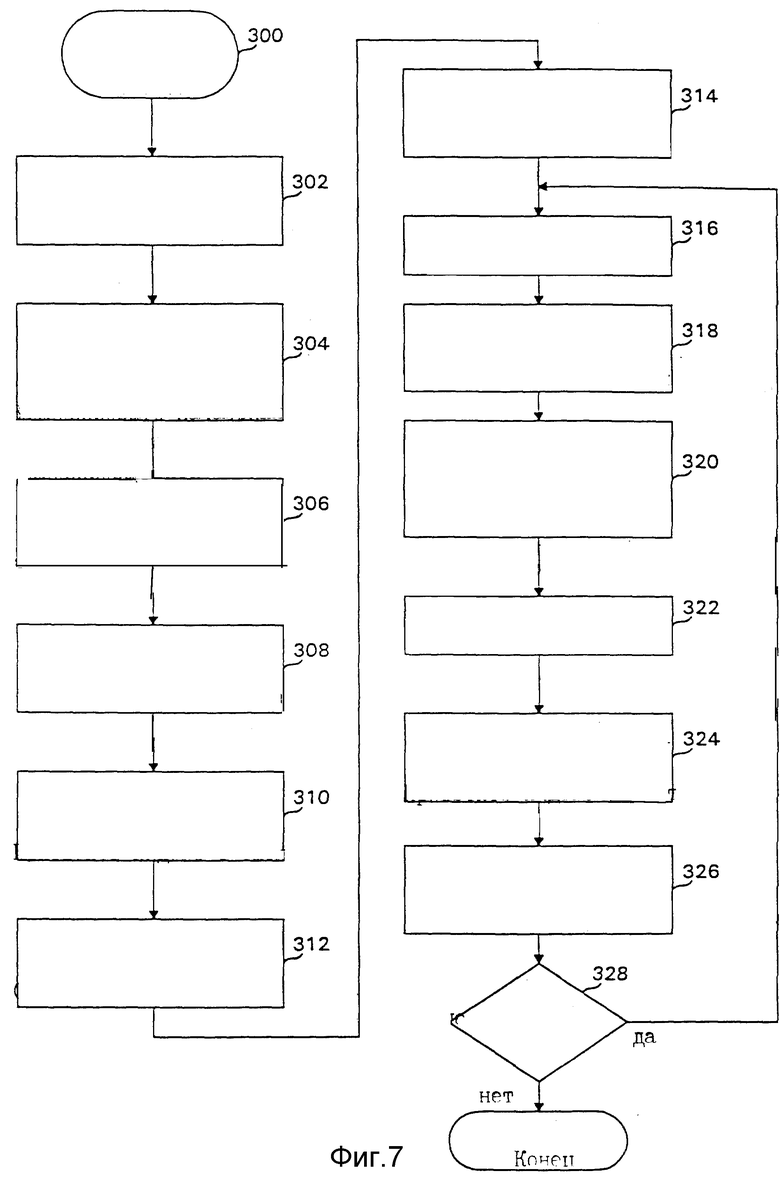
Работа генератора 200 таблицы переиндексации лучше всего понятна со ссылкой на блок-схему алгоритма, показанную на фиг. 7, в сочетании с фиг. 6. Блок-схема алгоритма показывает блоки 300, 302, 304, 306, 308, 310, 312, 314, 316, 318, 320, 322, 324, 326 и 328.
Блок 200 обозначает начало процесса выработки таблицы переиндексации из блока данных. Операции в блоках 302 и 306 обычно выполняются аккумулятором 206, операция в блоке 304 - модулем 204, а оставшаяся часть обычно выполняется стохастическим минимизатором 210. Процесс продолжается по порядку номеров блоков в блоках с 302 по 328, а с блока 328 или заканчивается, или зацикливается обратно на блок 316, как показано ниже.
В блоке 302 аккумулятор 206 очищает таблицы 208 и 209. В блоке 304 модуль 204, если он используется, упорядочивает символы в S0 - SM-1, а в блоке 306 аккумулятор 206 заполняет таблицы 208 и 209. После заполнения таблица 208 содержит вхождение для каждой комбинации контекста и входного символа, где вхождение (c, i) таблицы 208 обозначает вероятность появления символа Si при данном контексте Cc. После заполнения таблица 209 содержит вхождение для каждого контекста, где элемент с таблицы 209 показывает вероятность появления контекста Cc независимо от символа. Имеется N возможных значений для i и контексты равны {C0,..., CN-1}, давая N возможных контекстов. Таким образом, таблица 208 содержит M x N вхождений, а таблица 209 содержит M вхождений.
В одном выполнении контекст является символом для пикселя над пикселем, из которого взят Si, в этом случае N=M. В других выполнениях контекст является символом для пикселя слева (N=M) или контекст является двумя символами (N=M2). Тем не менее, использование двусимвольного контекста потребует M2 контекстов для каждого входного символа и, следовательно, таблицы 208 и 209 будут слишком большими для большинства значений M, в других выполнениях контекстов больше, чем M. Например, если все возможные символы сгруппированы в менее чем M групп и контекст для контекстного пикселя является группой, которая содержит пиксель над контекстным пикселем, то контекстов будет меньше, чем M. Например, если все символы сгруппированы в группы по четыре символа каждая, будет равно M/4. Конечно, для того, чтобы уменьшение в контекстах было полезным, должны использоваться некоторые разумные средства группировки символов.
В блоке 308 минимизатор 210 устанавливает циклическую переменную i в ноль и инициализирует таблицу 162 переиндексации, таблицу РСР (c) 212 и таблицу РРСР (K, c) 214. Хотя блок 308 показан после блока 306, их порядок может быть обратным, т.к. ни одна операция не зависит от результата другой. Таблица 162 переиндексации инициализируется посредством индикации с использованием флагов или других известных средств, так что все вхождения в таблице 162 пусты и им не присвоен ни один индекс. Таблица РСР инициализируется путем установки РСР (c) = 0 для всех c, а таблица РРСР инициализируется путем установки РРСР (K, c) = 0 для всех K и всех c.
В блоке 310 минимизатор 210 присваивает индекс o значению S0 и соответственно обновляет таблицу переиндексации.
В блоке 312 минимизатор 210 обновляет таблицу РСР (c) для добавленного индекса S0 путем установки РСР (c) = Pc(S0) для каждого c.
В блоке 314 минимизатор 210 модернизирует таблицу РРСР (c) для добавленного индекса S0 путем установки РРСР (K, c) = Pc (S0) для каждой пары (c, K), в которой K-ый разряд представления по основанию 2 присвоенного индекса равен 1. Эта операция не требуется, когда первый присвоенный индекс равен 0, т. к. ни один из разрядов индексов не равен 1, но эта операция необходима там, где первым присваивается ненулевой индекс.
В блоке 316 минимизатор 210 задает приращение переменной i, что при первом прохождении через блок 316 дает i = 1. Обработка блока 316 через блок 328 повторяется для каждого i между 0 и M-1 с присвоением по одному индексу в таблице переиндексации символу каждого цикла. Конечно, последний цикл, где i = M - 1, на деле не требуется, т.к. останется только один индекс в том месте, которому должен быть присвоен SM-1.
В блоке 318 таблица РСР обновляется для символа Si в соответствии с равенством РСР (c) = РСР (c) + Pc(Si). После этой операции при данных контексте Cc и алфавите из символов A' = {S0,...,Si} вероятность того, что принятый символ находится в алфавите A', равна РСР (c), т.е. c-ому вхождению таблицы РСР.
В блоке 320 значение частичной поразрядной энтропии ЧПЭ (РВЕ) вырабатывается для каждого неприсвоенного индекса. Неприсвоенные индексы (количество которых в этой точке равно M-i) находятся в таблице 162 или запомнены самим минимизатором 210. Частичная поразрадная энтропия для индекса j и символа Si, РВЕ (j; Si), если дано, что индексы от 0 до i - 1 уже присвоены, выражена в уравнениях 1 - 3: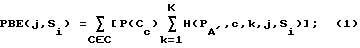
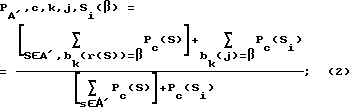
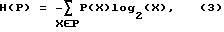
где A' является алфавитом из i уже присвоенных символов;
H(P) является энтропией распределения P вероятностей;
bK(x) является значением K-ого разряда представления по основанию 2 величины x;
r(S) является переиндексированным значением для символа S.
В блоке 322 минимизатор 210 выбирает минимальное значение РВЕ (j; Si) из всех вычисленных значений и устанавливает переменную X равной j из этого минимального значения.
В блоке 324 минимизатор 210 присваивает X, который должен быть переиндексирован значением для Si, и индицирует это присвоение в таблице 162.
В блоке 326 минимизатор 210 обновляет таблицу РРСР (c, K) для Si и X в соответствии с РРСР (c, K) = РРСР (c, K) + Pc (Si) для всех c и для всех K, где bК(x) = 1. После этой операции при данных контексте Cc и алфавите A′= {So...Si} вероятность того, что K-ый разряд переиндексированного значения для принятого символа равен 1 и принятый символ находится в алфавите A', равна РРСР (c, K).
В блоке 328 минимизатор 210 проверяет, не остались ли неприсвоенными два или более переиндексированных значений. Этот случай означает, если в этом блоке i = M - 2 или меньше, что уже присвоены M - 1 индексов. Последний индекс присваивается значению SM-1.
Знаменатель в уравнении 2 равен РСР (c), которая обновлена в блоке 318 путем добавления к ней Pc (Si) каждый раз, когда символ Si добавляется к алфавиту A'. Числитель в уравнении 2 равен РРСР (K, c), как это было бы, если бы j являлся индексом для Si. Поскольку обновленное значение РРСР (K, c) зависит от конкретного присвоения индекса j значению Si, РРСР (K, c) обновляется после выбора X = j в блоке 326. Конечно, так как H является функцией поразрядной энтропии, требуется только вычислить уравнение 2 или для β = 0, или β = 1, т. к. P(0) + P(1) = 1. Также, поскольку H является поразрядной энтропией, уравнение 3 в действительности упрощается до
H(x) = -x•log2x - (1 - x)•log2(1 - x).
Конечным результатом обработки, показанной на фиг. 7, является присвоение переиндексированных значений в таблице 162 переиндексации, что используется переиндексатором 160 для переиндексации входных пиксельных символов в двухуровневое квантование, что в общем случае выражается в лучшем сжатии, чем без переиндексации.
Параллельная обработка
Вышеперечисленные разделы описывали, как улучшить коэффициенты сжатия через использование адаптивного кодирования, контекстных моделей и переиндексации. В разуплотнителе адаптивное кодирование и контекстное моделирование требуют цепи обратной связи, так как способ, по которому разряд декодируется из потока кодовых слов, зависит от информации о предшествующих декодированных разрядах и символах. Если разуплотнителю требуется быстро декодировать поток кодовых слов в реальном масштабе времени, может использоваться параллельная обработка для обеспечения большей пропускной способности.
Одно такое воплощение параллельной обработки следующее.
При использовании контекстной модели расположения разряда (см. фиг. 8(а)) каждый разряд в значении пикселы обрабатывается одним из восьми параллельных кодеров, а каждый кодер закреплен за одним расположением разряда. При такой установке контекст разряда известен кодеру, поскольку расположение разряда является только контекстом; и контекст разряда известен кодеру, поскольку он является постоянным для частного кодера. Однако, когда используются другие контекстные модели для обеспечения лучшего сжатия, распараллеливание кодера не так просто.
Возьмем, например, поразрядно зависимую контекстную модель, показанную на фиг. 8(c). Если каждый разряд пикселя подается на отдельный кодер, разряды не могут быть декодированы параллельно, поскольку разряды слева от декодированного разряда должны декодироваться первыми для обеспечения необходимого контекста для декодированного разряда. Таким образом, использование некоторых контекстных моделей налагает ограничения на параллельную обработку.
В одном аспекте настоящего изобретения, чтобы разрешить использование предпочтительной контекстной модели, но также разрешить и параллельную обработку в кодере с использованием контекстных моделей, используется отдельный переупорядочивающий буфер.
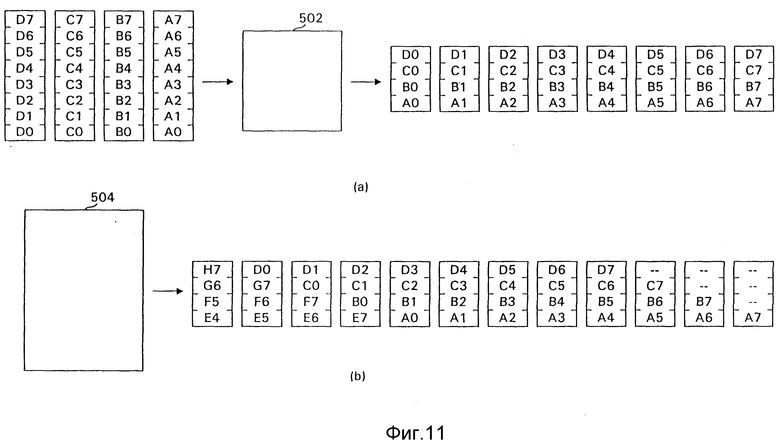
Фиг. 9 и 10 показывают, как переупорядочивающий буфер и его противоположность, разупорядочивающий буфер, подключены к параллельным кодерам, а фиг. 11 показывает работу переупорядочивающего буфера более подробно.
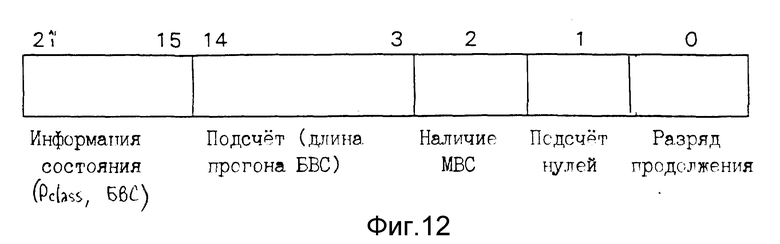
При данной предпочтительной контекстной модели на параллельный кодер накладываются два ограничения. Во-первых, если каждая ступень должна быть независимой, то среди множества разрядов, обрабатываемых в одном параллельном цикле, ни один из разрядов не должен влиять на контекст остальных разрядов. Во-вторых, если контекстные данные подлежат обновлению после того, как обработан каждый разряд, никакие два разряда во множестве разрядов, обработанных параллельно, не должны формировать контекст. Фиг. 12 показывает типичную контекстную запись, содержащую контекстные данные, которые должны быть обновлены, когда обрабатывается разряд, имеющий данный контекст. Эта запись может быть одной строкой в таблице, такой как память 116, показанная на фиг. 4.
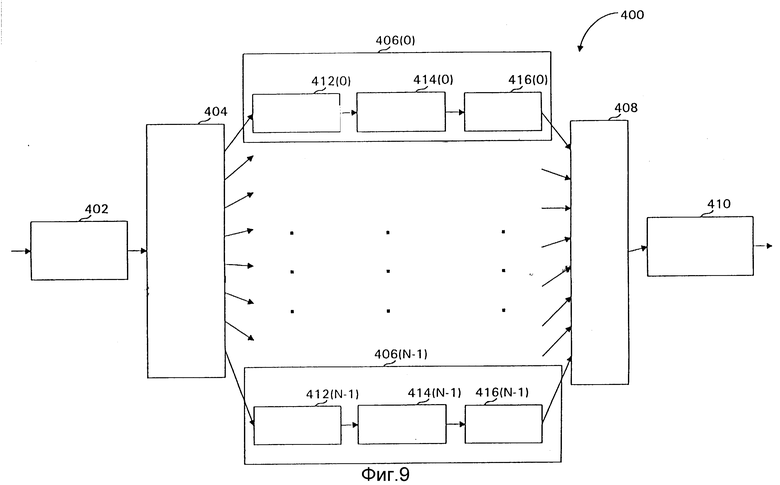
На фиг. 9 система 400 параллельного сжатия по настоящему изобретению показана с упорядочивающим буфером 402, демультиплексором 404, N параллельными цепями 406 (0,..., N - 1), мультиплексором 408 и разупорядочивающим буфером 410. Система 400 может использоваться с переупорядочением или без него. Каждая цепь 406 содержит уплотнитель 412, подобный уплотнителю 102, канал 414 и разуплотнитель 416, подобный разуплотнителю 106.
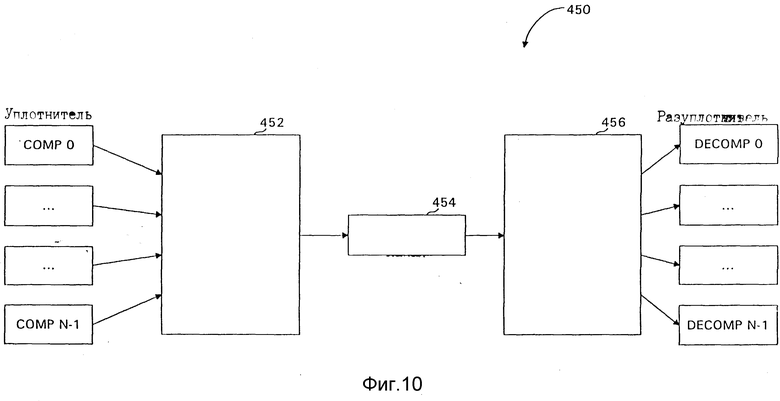
Фиг. 10 показывает другую конфигурацию 450, в которой используются перемножитель 452 для объединения рабочей нагрузки каналов 414 (0, ..., N - 1) на единичном канале 454 и деперемежитель 456, используемый для разделения рабочей нагрузки единичного канала 454 обратно в раздельные каналы для каждой цепи.
Вновь обращаясь к фиг. 9, вход потока символов в систему 400 буферизуется переупорядочивающим буфером 402. Переупорядочивающий буфер 402 принимает поток разрядов из K (K = 8 на фиг. 8) разрядов на символ, как подробно объяснено ниже, и выдает разряды на демультиплексор 404, который распределяет переупорядоченные разряды по параллельным кодерам. В i-ой параллельной цепи 406 (i) уплотнитель 412 (i) сжимает разряды, присвоенные цепи 406 (i), в кодовые слова, которые передаются по каналу 414 (i) и растягиваются разуплотнителем 416 (i). Выход всех цепей затем объединяется мультиплексором 408, который выдает их комбинацию на разупорядочивающий буфер 410, который выполняет противоположное переупорядочивающему буферу 402 действие. Хотя в показанном параллельном кодере каждая цепь присвоена единственному контексту, переупорядочивание обеспечивает гибкость для разделения параллельных цепей другими способами в соответствии с требованиями применения. Например, каждая цепь может быть присвоена значению Pclass, группе, содержащей множество контекстов, или к делению, специально разработанному для выравнивания рабочей нагрузки по различным цепям.
Фиг. 11 показывает переупорядочивающий буфер 502, который используется в параллельном кодере с четырьмя параллельными цепями и поразрядно зависимой контекстной моделью, хотя он также пригоден и с другими конфигурациями, к примеру с восемью или N параллельными цепями, с различным числом разрядов на пиксель или с различными контекстными моделями. Четыре входных байта (пиксели показаны слева) являются входами в буфер 502, и восемь четырехразрядных блоков показаны в качества выхода с буфера 502. Выходные блоки выдаются один на период параллельного кодирования на параллельный кодер, таким образом, каждый из выходных блоков представляет набор разрядов, обрабатываемых параллельно. Если входные разряды не переупорядочены, блоки, входящие в параллельный кодер, могут быть только четырьмя наиболее значимыми разрядами пикселя A (A7 - A4), за которыми следуют четыре менее значимых разряда пикселя A (A3-A0), затем четыре наиболее значимых разряда пикселя B (B7-B4) и т. д. Как ясно следует из вышеприведенного обсуждения, без переупорядочивания набор разрядов, обрабатываемых параллельно, не должен быть независимым, когда используется поразрядно зависимая модель, поскольку A4 берет свой контекст из его положения (4) и значений разрядов A7, A6, A5, которые находятся в том же наборе разрядов.
Для решения этой задачи буфер 502 переупорядочивает входные разряды, показанные выходящими из него, для пикселей A, B, C и D блоков (наборов разрядов, обрабатываемых параллельно) D7-C7-B7-A7, D6-C6-B6-A6 и т.д. При этом переупорядочивании ни один разряд не зависит от какого-либо другого разряда в их наборе для контекста. Однако, если есть два разряда, они уже могут формировать контекст.
Например, D7 и C7 могут формировать контекст в поразрядно зависимой контекстной модели, поскольку поразрядно зависимый контекст является положением разряда и разрядами слева. Для D7 и C7 разрядные положения одинаковы и нет разрядов слева (вверху на фиг. 11).
Это второе ограничение решается вместе с первым ограничением посредством переупорядочивающего буфера, показанного на фиг. 11 (b). В этом буфере разряды, сгруппированные в блоки, взяты из разных пикселей, но также взяты из разных разрядных положений. Если разрядное положение является частью контекста, то разряды с различными разрядными положениями будут иметь различные контексты. Таким образом, блоки (наборы разрядов, обрабатываемых параллельно), выдаваемые буфером 504, D7-C6-B5-A4, D6-C5-B4-A3 и т.д. до девятого блока H7-G6-F5-E4, каждый содержит разряды, которые не зависят от других разрядов в их блоке для контекста и не образуют контекст с любыми другими разрядами в их блоке. Входные пиксели E, F, G и H не показаны, но следуют за пикселем D.
На фиг. 11 (b) нет пикселей, предшествующих пикселю A, для иллюстрации состояния буфера после установки на нуль. В первой параллельной операции после установки буфера на нуль обрабатывается блок только с одним разрядом (от пикселя A). В следующей параллельной операции обрабатываются один разряд из пикселя A и один разряд из пикселя B. Хотя ступенчатое расположение разрядов во избежание контекстных столкновений означает, что не все параллельные уровни будут использоваться в первых нескольких блоках после установки на нуль, это недоиспользование незначительно для любого разумного размера изображения. В случае фиг. 11 (b) оно проявляется только в первых трех блоках.
Фиг. 13 (a) - (b) иллюстрируют ограничение контекстной модели, расположенной в конвейерных кодерах, сходное с ограничениями, налагаемыми на параллельные кодеры.
Фиг. 13 (a) и 13 (b) показывают улучшение обработки конвейерным кодером пикселей A - D, показанной на фиг. 11, причем фиг. 13 (a) показывает конвейерную обработку разрядов в неупорядоченном порядке, а фиг. 13 (b) показывает конвейерную обработку разрядов в переупорядоченном порядке. На обоих чертежах каждый столбец обозначен временем t и показывает обрабатываемый конвейерной ступенью разряд. Ступенями, показанными в этом примере, являются входная ступень, три промежуточных ступени (IS - 1, 1S - 2 и 1S - 3) и две выходных ступени.
В этом примере предполагается, что разряд обрабатывается и пригоден к определению контекста других разрядов в первой выходной ступени, но не раньше. Далее предполагается, что обработка ступени IS - 1 зависит от контекста обрабатываемого разряда, и используется поразрядно зависимая контекстная модель. При поразрядно зависимой контекстной модели контекст обведенного кружком разряда A2 зависит от A3, A4, A5, A6 и A7.
На фиг. 13 (a) это означает, что обработка разряда A2 в ступени IS - 1 не может произойти, по крайней мере пока разряды A3 и A4 не прошли весь путь до первой выходной ступени (разряды A5 - A7 уже прошли первую выходную ступень). Эта задержка уничтожает все преимущества конвейерной обработки.
Для решения этой задачи может использоваться переупорядочивающий буфер, такой как буфер 502, для действия, показанного на фиг. 13 (b). В этом примере обведенным кружком разрядом является B6, который берет свой контекст из разряда B7, который является выходом на первую выходную ступень в более ранний период, и поэтому он доступен, когда B6 подлежит обработке в ступени IS - 1.
Вышеприведенное описание является иллюстративным, а не ограничивающим. Многие варианты изобретения станут явными для специалистов по просмотре этого описания. Объем изобретения должен, следовательно, быть определен без ссылок на вышеприведенное описание, а вместо этого должен быть определен со ссылкой на приложенную формулу изобретения с ее полным объемом эквивалентов.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И УСТРОЙСТВО КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ ДАННЫХ | 1995 |
|
RU2117388C1 |
| СПОСОБ И СИСТЕМА КОДИРОВАНИЯ И СПОСОБ И СИСТЕМА ДЕКОДИРОВАНИЯ | 1996 |
|
RU2154350C2 |
| ИНИЦИАЛИЗАЦИЯ КОНТЕКСТА ПРИ ЭНТРОПИЙНОМ КОДИРОВАНИИ | 2019 |
|
RU2755020C2 |
| ИНИЦИАЛИЗАЦИЯ КОНТЕКСТА ПРИ ЭНТРОПИЙНОМ КОДИРОВАНИИ | 2018 |
|
RU2699677C2 |
| ИНИЦИАЛИЗАЦИЯ КОНТЕКСТА ПРИ ЭНТРОПИЙНОМ КОДИРОВАНИИ | 2012 |
|
RU2642373C1 |
| ИНИЦИАЛИЗАЦИЯ КОНТЕКСТА ПРИ ЭНТРОПИЙНОМ КОДИРОВАНИИ | 2022 |
|
RU2839276C2 |
| ИНИЦИАЛИЗАЦИЯ КОНТЕКСТА ПРИ ЭНТРОПИЙНОМ КОДИРОВАНИИ | 2021 |
|
RU2779898C1 |
| ИНИЦИАЛИЗАЦИЯ КОНТЕКСТА ПРИ ЭНТРОПИЙНОМ КОДИРОВАНИИ | 2012 |
|
RU2595934C2 |
| ЭНТРОПИЙНОЕ КОДИРОВАНИЕ РАЗНОСТЕЙ ВЕКТОРОВ ДВИЖЕНИЯ | 2012 |
|
RU2615681C2 |
| ЭНТРОПИЙНОЕ КОДИРОВАНИЕ РАЗНОСТЕЙ ВЕКТОРОВ ДВИЖЕНИЯ | 2012 |
|
RU2658883C1 |

Изобретение относится к области сжатия изображения, в частности к сжатию палитризованных изображений с использованием статистического кодера, а также с использованием параллельного статистического кодера. Технический результат - повышение точности восстановления первоначального сигнала из сжатого сигнала. Сущность способа и устройства для сжатия палитризованных изображений заключается в квантовании входных символов в М-ичном алфавите на два уровня на основе контекстной модели входных данных, где двухуровневое квантование выбирается для обеспечения хорошего сжатия двоичным кодером. Конкретное двухуровневое квантование определяется из таблицы переиндексации, которая отображает каждый входной символ в число двоичных значений. Отображение определяется из изображений, подлежащих сжатию, и обычно передается со сжатыми изображениями как вставка. Отображение является локальным минимумом поразрядной энтропии двухуровневого квантования. С переиндексацией входа или без нее символы могут быть параллельно преобразованы в сжатые, с разрядами входных символов, буферизованными и переупорядоченными, когда необходимо гарантировать, что разряды, требуемые для контекста декодированного разряда, доступны до того, как разуплотнитель декодирует декодируемый разряд. Разуплотнитель включает в себя средство для выполнения обратного переупорядочивания, так что выход разуплотнителя такой же, как и вход уплотнителя. 7 с. и 17 з.п.ф-лы, 13 ил.
| US, 5272478 A, 21.12.93 | |||
| US, 4875044 A, 03.10.89 | |||
| GB, 2164817 A, 28.03.86 | |||
| GB, 2152252 A, 31.07.85 | |||
| SU, 1566485 A, 23.05.90 | |||
| SU, 1561202 A, 30.04.90. |

