Область техники
Настоящее изобретение относится к способу и системе кодирования и/или декодирования данных и, в частности к способу и системе кодирования и к способу и системе декодирования, подходящим для сжатия и декомпрессии компьютерных данных и программного обеспечения игр.
Уровень техники
Система JBIG (Объединенная группа двухуровневого изображения) была предложена в качестве нового способа кодирования двухуровневого изображения, который подходит не только для обмена твердыми копиями, например, обмена факсимильными сообщениями, но также и для обмена копиями программ, например, обмена данными компьютерных изображений.
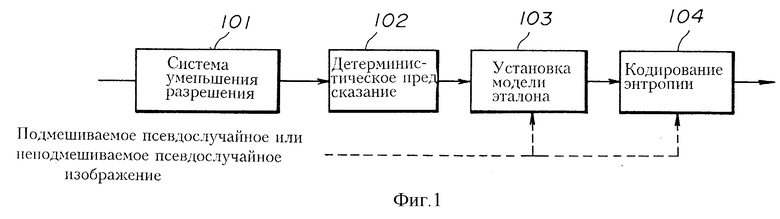
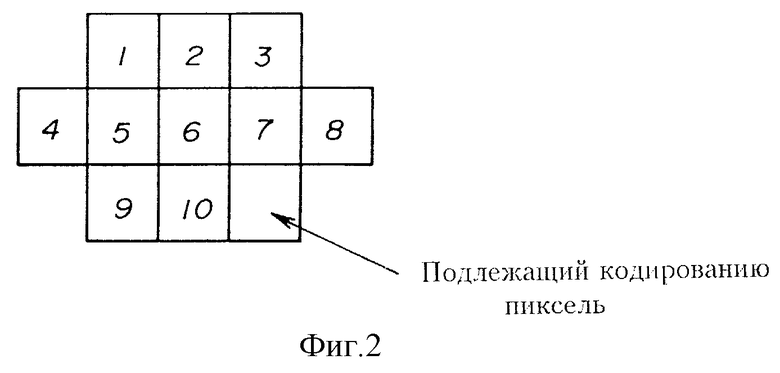
Фиг. 1 изображает блок-схему, изображающую стандартную систему JBIG. Первый блок 101 является электрической схемой, которая использует PRES (Схему прогрессивного сокращения) в качестве системы снижения разрешения изображения. Второй блок 102 является электрической схемой для выполнения DP (детерминистического предсказания). DP используется для предсказания детерминистически значения пикселя, которое кодируется исходя из значений окружающих пикселей, которые уже закодированы. Используя DP, возможно улучшить эффективность кодирования. Третий блок представляет собой электрическую схему для установки эталона модели. Эталон является опорным пиксельным образцом, который должен быть использован при кодировании. Фиг. 2 изображает пример такого эталона. В данном примере эталон включает в себя 10 пикселей "1" - "10", окружающие пиксель, который должен быть закодирован. Используя такой эталон, выполняется кодирование с применением модели Маркова порядка M1 к изображению с максимально уменьшенным разрешением. В особенности, M1 уже закодированных пикселей в окрестности каждого пикселя, который должен быть закодирован, используются в качестве опорных пикселей эталона. Количество возможных состояний (комбинаций) значений опорных пикселей равно 2M1 состояний. Для каждого одного из таких состояний задается соответствующая заданная условная вероятность символа. Используя таким образом заданные вероятности символа для подлежащего кодированию пикселя и действительные значения (символы), выполняется кодирование энтропии. Четвертый блок 104 является схемой кодирования энтропии и использует JBIG QM кодер. (JBIG QM кодер является QM кодером, используемым в JBIG. Обычно арифметический кодировщик называется QM кодером. JBIG является общим названием стандарта кодирования двухуровневых данных в ITU ((International Telecommunication Union - Международный телекоммуникационный союз). В JBIG используется QM кодер для кодирования двухуровневых данных).
В качестве системы кодирования такого типа ранее были предложены система, в которой эталон является фиксированным, адаптивная эталонная система (см. Yasuhiro Yamazaki, Humitaka Ono, Tadashi Yoshida and Toshiaki Endo, Progressive Buildup Coding Scheme for Bi-level Images - JBIG Algorithm., - 1991, Vol. 20, N 1, Image Eltctronic Society Journal), и система, в которой эталон выбирается в соответствии с типом данных (например, см. выложенную заявку на патент Японии N 6-261214). Дополнительно о системах JBIG см. также ITU-T (Telecommunication Standartization Sector of ITU), Т.82 (03/93), Terminal Equipment and Protocols for Telematic Services, Information Technology - Coded Representation of Picture and Audio Information - Progressive Bi-Level Image Compression.
В системе, в которой эталон фиксирован, на основании статистик степени сжатия в системе определяется эталон, имеющий наивысшую степень сжатия, и используется в качестве фиксированного эталона. В такой системе схема сжатия может быть упрощена. Однако в такой системе при кодировании данных, которые имеют характеристики, значительно отличающиеся от средних характеристик статистик, степень сжатия снижается.
В упомянутой выше адаптивной эталонной системе во время сжатия данных всегда определено, какой эталон приводит к наивысшей степени сжатия, и, таким образом, используемый эталон динамически изменяется. В такой системе всегда определяются статистики, и используемый эталон изменяется в соответствии с результатом статистик. Поэтому эта система является подходящей для случая, когда кодируются длинные данные, и характеристики данных начинают изменяться при положении данных. Однако, если обрабатываются короткие данные, то время, требуемое для адаптивного изменения эталона, который должен использоваться, составляет значительную часть от всего периода обработки сжатия, и, таким образом, эта система может не быть эффективной системой сжатия. К тому же, так как всегда определяется, какой эталон будет оптимальным, то схема устройства кодирования/декодирования будет сложной.
В системе, в которой эталон выбирается в соответствии с типом данных, предоставляется соответствующий эталон, который должен использоваться для сжатия каждого из множества типов данных. Например, когда сжимается цветное изображение, то, так как каждый пиксель состоит из множества битов, то используют индивидуальные эталоны для множества битовых плоскостей. Однако, так как в этом способе эталон для каждой из множества битовых плоскостей фиксирован, система не является достаточно удовлетворительной по причине, аналогичной той, которая отмечена для вышеописанной системы, в которой применяется фиксированный эталон.
К тому же известна система, которая обрабатывает цветные изображения способом, в котором множество битов (множество битовых плоскостей), назначенные для одного пикселя, является переменным, т.е. изменяется, например, так, как в описанной выше системе, в которой обрабатывается цветное изображение. Однако способ кодирования в предшествующем уровне техники может быть применен только к системе, в которой фиксированы несколько битовых плоскостей. Поэтому, невозможно применить способ кодирования с использованием эталона к такой системе, которая обрабатывает цветные изображения способом, в котором множество битовых плоскостей, назначенных для одного пикселя, изменяется.
Сущность изобретения
Настоящее изобретение было сделано в результате рассмотрения вышеописанных обстоятельств, и задачей настоящего изобретения является создание способа и системы кодирования и способа и системы декодирования, в которых эталон, соответствующий конкретным данным, определяется при кодировании, а высокая степень сжатия может быть сохранена без усложнения схем устройства кодирования/декодирования. Другой задачей настоящего изобретения является применение способа кодирования, использующего эталон, к системе, которая обрабатывает цветные изображения способом, в котором множество битов, назначенных для одного пикселя, изменяются.
Способ кодирования согласно настоящему изобретению содержит следующие этапы
подготовка возможного эталона кодирования,
кодирование и, таким образом, сжатие подлежащих сжатию данных каждый раз, когда используется один из множества эталонов,
сравнение степеней сжатия кодированных данных друг с другом, причем кодированные данные закодированы каждый раз, когда используют соответствующий один из множества эталонов,
определение для каждого файла подлежащих кодированию данных оптимального эталона, обеспечивающего наивысшую степень сжатия,
выдача кодированных данных, имеющих наивысшую степень сжатия и идентификационную информацию используемого эталона, когда получают кодированные данные, имеющие наивысшую степень сжатия.
Другой способ кодирования согласно настоящему изобретению содержит следующие этапы
разделение подлежащих сжатию данных на множество битовых плоскостей данных,
кодирование и, таким образом, сжатие каждой битовой плоскости данных каждый раз, когда используют соответствующий один из множества эталонов,
сравнение для каждой битовой плоскости данных степеней сжатия кодированных данных друг с другом, причем кодированные данные кодируют каждый раз, когда используют соответствующий один из множества эталонов,
для каждой битовой плоскости данных выдачу кодированных данных, имеющих наивысшую степень сжатия, и идентификационной информации используемого эталона, когда получают кодированные данные, имеющие наивысшую степень сжатия.
Другой способ кодирования согласно настоящему изобретению содержит следующие этапы:
разделение подлежащих сжатию данных на множество битовых плоскостей данных, причем количество указанного множества битовых плоскостей данных является переменным,
кодирование и, таким образом, сжатие каждой битовой плоскости данных.
Способ декодирования согласно настоящему изобретению содержит следующие этапы:
выбор эталона из множества эталонов, который должен быть использован при декодировании кодированных данных, используя идентификационную информацию эталона, причем используемый эталон получают во время кодирования данных, имеющих наивысшую степень сжатия,
декодирование кодированных данных, используя выбранный при декодировании кодированных данных эталон.
Другой способ декодирования согласно настоящему изобретению содержит следующие этапы
для каждой битовой плоскости кодированных данных выбирают эталон из множества эталонов, который должен быть использован при декодировании кодированных данных, используя идентификационную информацию эталона, используемый эталон получают во время кодирования кодированных данных, имеющих наивысшую степень сжатия, и
декодирования кодированных данных для каждой битовой плоскости кодированных данных, используя выбранный при декодировании кодированных данных эталон.
Другой способ декодирования согласно настоящему изобретению содержит следующие этапы
прием кодированных данных, которые содержат множество битовых плоскостей данных, причем количество множества битовых плоскостей данных является переменным, когда множество битовых плоскостей данных получают в результате разделения подлежащих сжатию данных, и
декодирование каждой битовой плоскости данных множества битовых плоскостей данных.
Другие задачи и дополнительные признаки настоящего изобретения станут более понятны из следующего подробного описания совместно с сопроводительными чертежами.
Краткое описание чертежей
В дальнейшем изобретение поясняется наилучшими вариантами его воплощения со ссылками на сопроводительные чертежи, на которых:
фиг. 1 изображает блок-схему стандартной JBIG системы;
фиг. 2 изображает эталон;
фиг. 3 изображает блок-схему первого воплощения настоящего изобретения;
фиг. 4 изображает блок-схему работы, выполняемой системой, изображенной на фиг. 3;
фиг. 5 изображает структуру закодированных данных, выдаваемых системой, изображенной на фиг. 3;
фиг. 6 изображает функциональную схему части устройства для выполнения этапа кодирования, изображенного на фиг. 4;
фиг. 7 изображает блок-схему второго воплощения настоящего изобретения;
фиг. 8 изображает структуру данных изображения, обрабатываемую третьим воплощением настоящего изобретения;
фиг. 9 изображает блок-схему третьего воплощения настоящего изобретения;
фиг. 10 изображает структуру закодированных данных, выдаваемых системой кодирования в третьем воплощении; и
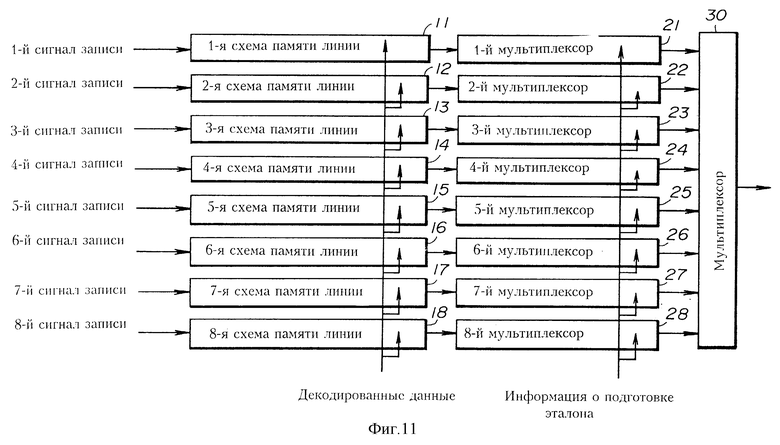
фиг. 11 изображает часть блок-схемы четвертого воплощения настоящего изобретения.
Наилучшие варианты воплощения настоящего изобретения
Ниже будут описаны предпочтительные варианты воплощения настоящего изобретения со ссылками на чертежи.
Фиг. 3 изображает блок-схему устройства кодирования при первом варианте воплощения системы кодирования и способа в настоящем изобретении. Фиг. 4 изображает блок-схему работы при операции кодирования, выполняемой устройством кодирования, изображенным на фиг. 3. Фиг. 5 изображает структуру кодированных данных, которые подаются устройством кодирования, изображенным на фиг. 3.
Операция кодирования выполняется центральным процессором ЦП 51, изображенным на фиг. 3, над поданными исходными данными, используя программное обеспечение, предварительно хранимое в памяти 52 только для считывания (ROM). ЦП 51 выполняет операцию, изображенную на фиг. 4, в результате выполнения программ программного обеспечения. ЦП 51 выполняет операцию кодирования и, таким образом, выдает кодированные данные, которые записываются в память 53 со случайным доступом (RAM). Кодированные данные, записанные в памяти 53 RAM, используются для хранения тех же самых данных, что и в ROM, которая подсоединена к устройству декодирования, которое декодирует кодированные данные, хранимые в ROM.
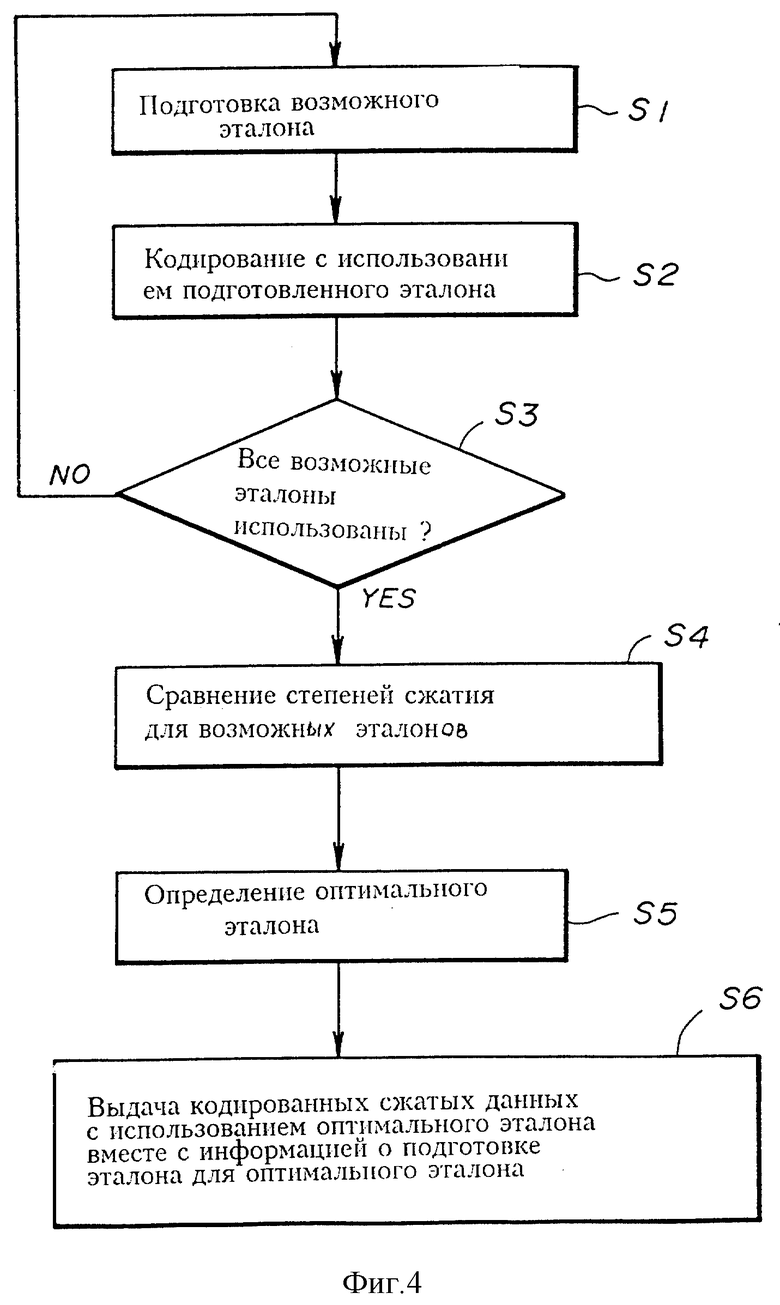
Возможный эталон (фиг. 4) подготавливается в S1. По существу, например, см. фиг. 2, возможный эталон получается с помощью выбора шести пикселей из десяти 1-10, изображенных на чертеже, для подлежащего кодированию пикселя. С помощью этого способа возможно C10 6 комбинаций и, таким образом, производятся C10 6 возможных эталонов. Дополнительно с помощью этого способа возможно получить различные формы эталонов.
В блоке S2 файл подлежащих кодированию данных (подлежащих сжатию) кодируется (сжимается), используя возможный эталон, подготовленный в S1. В блоке S3 определяется, все или не все возможные эталоны (все C10 6 возможных эталонов) использованы для кодирования подлежащих кодированию данных. Если нет, то в блоке S1 производится другой возможный эталон и используется для кодирования тех же самых подлежащих кодированию данных в S2. Эта операция повторяется до тех пор, пока все возможные эталоны не будут использованы для кодирования одних и тех же подлежащих кодированию данных.
Если использованы все возможные эталоны, то в блоке S4 сравниваются друг с другом степени сжатия для каждого всех возможных эталонов. Посредством этого в блоке S5 определяется оптимальный эталон, который должен иметь наивысшую степень сжатия. Затем в блоке 6 кодированные данные, полученные при использовании оптимального эталона, выдаются вместе с информацией о подготовке эталона, которая является идентификационными данными эталона, и используются устройством декодирования при декодировании кодированных данных для подготовки того же самого эталона. Выходные данные записываются в RAM 53.
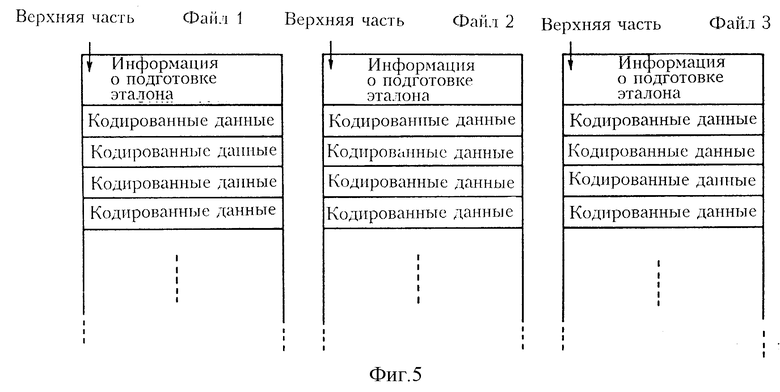
Таким образом, выходные данные для файлов подлежащих кодированию данных имеют структуру данных, изображенную на фиг. 4. Каждая структура данных из структур данных включает в себя группу кодированных данных, которые являются выходными кодированными данными из ЦП 51 для соответствующего файла подлежащих кодированию данных. Каждая структура данных дополнительно включает в себя вышеупомянутую информацию о подготовке эталона, которая добавляется в верхнюю часть группы кодированных данных, как изображено на чертеже.
Так как файлы поданных подлежащих кодированию данных могут иметь различные характеристики, то эталон, который используется для кодирования файла подлежащих кодированию данных и в результате обеспечивает наивысшую степень сжатия, может отличаться от эталона, который используется для кодирования другого файла подлежащих кодированию данных и в результате обеспечивает наивысшую степень сжатия. Поэтому в устройстве кодирования в первом воплощении настоящего изобретения определяется оптимальный эталон для каждого файла подлежащих кодированию данных. В случае кодирования программного обеспечения видеоигр файлы подлежащих кодированию данных могут включать в себя фоновое изображение, изображение символа (человека, животного и т.п.) и т.д. В случае такого программного обеспечения видеоигр, вообще говоря, каждый файл подлежащих кодированию данных имеет малое количество данных. Поэтому, вышеописанный способ имеет преимущество, так как операция, изображенная на фиг. 4, является очень простой и не требует длительного времени на выполнение.
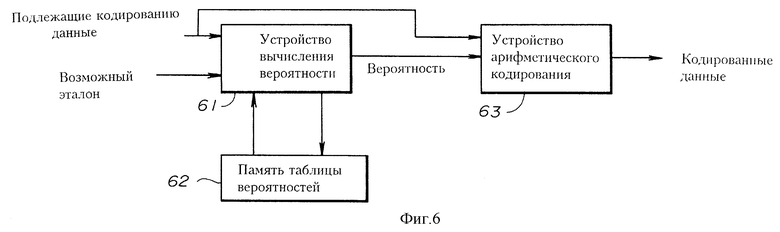
Фиг. 6 изображает функциональную схему части системы кодирования, изображенной на фиг. 3, причем эта часть выполняет этап кодирования S2, изображенный на фиг. 4. Подлежащие кодированию данных и информация возможного эталона подаются на устройство 61 вычисления вероятности. Устройство 61 вычисления вероятности получает значения 6 опорных пикселей возможного эталона для подлежащего кодированию пикселя и подает полученные значения 6 пикселей в память 62 таблицы вероятности в качестве адреса. В памяти 62 таблицы вероятности соответствующая вероятность хранится для каждого из 26 состояния (которые называются "контекстами") по соответствующему адресу. Такая вероятность является вероятностью, что подлежащий кодированию пиксель имеет значение предварительно заданного символа (обычно, MPS "О"). В этом случае 6 опорных пикселей используются в качестве шестой модели Маркова, и возможные 26 состояний определяются в качестве контекстов (которые представлены целыми числами). Память 62 таблицы вероятности принимает 6 значений пикселя в качестве адреса и выдает соответствующую вероятность на арифметическое устройство 63 кодирования. Арифметическое устройство 63 кодирования выполняет арифметическое кодирование (которое является одним из способов кодирования энтропии), используя вероятность и действительное значение подлежащего кодированию пикселя.
Вообще говоря, в кодировании энтропии, например, арифметическом кодировании, степень сжатия может быть увеличена, когда предсказание значения подлежащего кодированию пикселя улучшается. То есть, так как действительная вероятность того, что подлежащий кодированию пиксель имеет символ, который был предварительно предсказан, выше, то результирующая степень сжатия может быть увеличена. Для того, чтобы увеличить вероятность, требуется эталон, соответствующий характеристикам конкретного файла подлежащих кодированию данных.
Любая известная система кодирования, использующая эталон, например, та, которая изображена на фиг. 1, может быть использована для реализации системы кодирования, изображенной на фиг. 3. В случае, когда используется система кодирования, изображенная на фиг. 1, этап кодирования S2, изображенный на фиг. 4, выполняется схемой 104 кодирования энтропии. В третьем блоке 103 выполняется подготовка возможного эталона, выполняемая на этапе S1, изображенном на фиг. 4. Вышеупомянутые M1 опорных пикселей эталона являются шестью опорными пикселями эталона. Затем выполняется кодирование энтропии, аналогичное кодированию энтропии, выполняемому в блоке 104, изображенному на фиг. 1, с помощью средства кодирования энтропии (которое может быть осуществлено ЦП 51 с помощью программ) аналогично блоку 104, повторяясь для каждого из всех вышеупомянутых возможных эталонов.
Ниже будут описаны способ декодирования и система при втором воплощении настоящего изобретения. В этом способе соответствующий эталон готовится, используя вышеупомянутую информацию о подготовке эталона, сопровождающую каждый файл кодированных данных. Подготовленный эталон используется для декодирования файла кодированных данных.
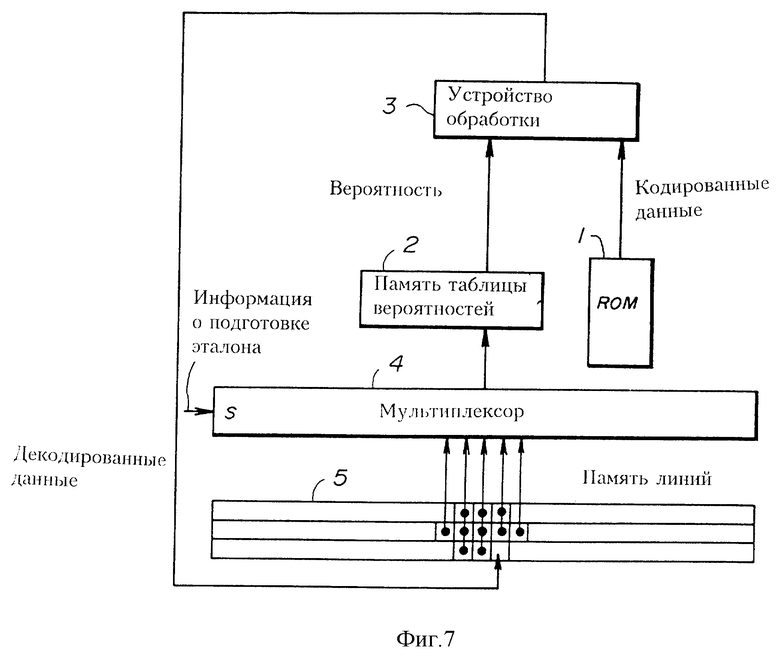
Фиг. 7 изображает общую блок-схему системы с ROM-картриджами при втором воплощении настоящего изобретения. ROM-картридж (ROM 1 изображен на данном чертеже), содержащий программу видеоигры в форме закодированных данных изображения, подсоединяется к такой системе с ROM-картриджами, которая декодирует кодированные данные изображения. Кодированные данные изображения могут быть файлом кодированных данных, который подается кодирующей системой в первом воплощении настоящего изобретения, изображенном на фиг. 3.
Устройство 5 памяти линий сохраняет три линии данных, которые получены в результате декодирования кодированных данных изображения. Посредством средства считывания из памяти (на чертеже не изображено) 10 пикселей декодированных данных, расположенных в десяти пикселях 1-10, изображенных на фиг. 2 для подлежащего кодированию пикселя, считываются из устройства 5 памяти линий. Считанные декодированные данные подаются на мультиплексор 4.
Мультиплексор 4 выбирает 6 пикселей данных из поданных 10 пикселей декодированных данных согласно информации о подготовке эталона. Информация эталона хранится в ROM 1 и сопровождает файл кодированных данных в ROM 1, как изображено на фиг. 5. Информация об эталоне считывается из ROM 1 при декодировании файла закодированных данных, и подается на мультиплексор 4 через буферную память (на чертеже не изображена). Мультиплексор 4 подает выбранные 6 пикселей данных на память 2 таблицы вероятности в качестве адреса, причем память таблицы вероятности идентична памяти 62 таблицы вероятности, изображенной на фиг. 1.
Память 2 таблицы вероятности принимает 6 пикселей данных, использует их в качестве адреса данных и выдает вышеупомянутую вероятность появления символа, хранимую по этому адресу.
Устройство 3 обработки использует кодированные данные, считанные из ROM 1, и данные вероятности, считанные из памяти 2 таблицы вероятности, и затем получает декодированный бит в качестве результата такого декодирования кодированных данных. Полученный декодированный бит затем подается на устройство 5 памяти линий и сохраняется там. Затем, когда декодирован последующий пиксель, 10 пикселей данных, поданных из памяти линий на мультиплексор, сдвигаются на один пиксель вправо на фиг. 7, и далее выполняется операция, аналогичная описанной выше, для текущего подлежащего кодированию пикселя.
В способе и системе кодирования и способе и системе декодирования согласно настоящему изобретению, описанные выше, после того, как декодирование выполнено для нескольких возможных эталонов над подлежащими сжатию данными, определяется эталон, имеющий наивысшую степень сжатия, и выдаются сжатые данные, полученные с помощью такого эталона. Поэтому, возможно значительно увеличить степень сжатия по сравнению с указанными выше системой с фиксированным эталоном и системой, в которой эталон выбирается в соответствии с типом данных, но эталон фиксирован для каждого типа данных. Далее, в настоящем изобретении не выполняется присутствующая всегда операция определения, какой эталон является оптимальным во время сжатия. Поэтому структура схемы кодирования/декодирования не будет сложной.
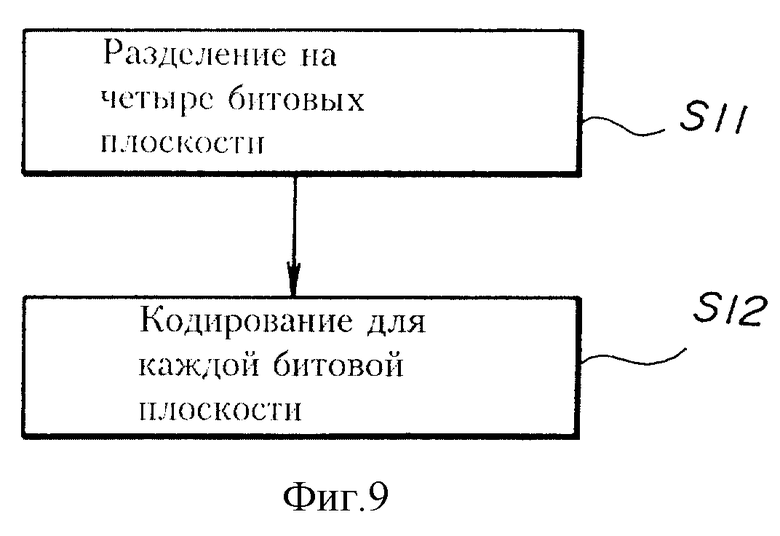
Далее описывается третье воплощение настоящего изобретения. В этом варианте воплощения данные изображения разделяются на множество битовых плоскостей данных изображения, и кодирование выполняется для каждой битовой плоскости. Количество битовых плоскостей является переменным. Система кодирования в третьем варианте воплощения имеет аппаратную конструкцию такую же, как и аппаратная конструкция системы в первом варианте воплощения, изображенном на фиг. 3.
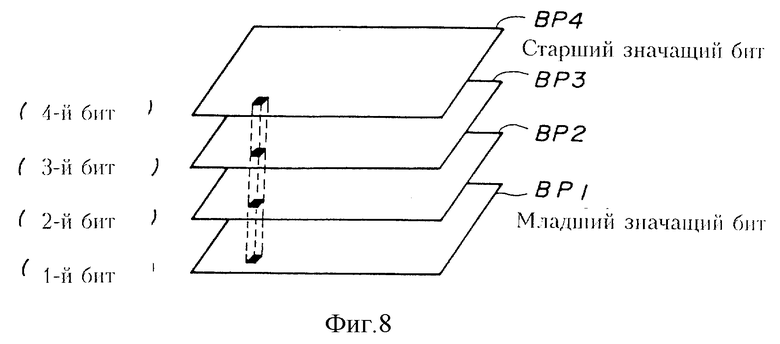
Когда кодируются данные многоуровневого изображения, в котором пиксель имеет четырехбитовый код, например, на этапе S11, изображенном на фиг. 9, данные многоуровневого изображения разделяются на четыре битовые плоскости BP1, BP2, BP3 и BP4, как изображено на фиг. 8. Биты, находящиеся в одинаковом месте четырехместных битов пикселей, содержатся в соответствующей одной из четырех битовых плоскостей.
В блоке S12, изображенном на фиг. 9, кодирование выполняется над данными изображения для каждой битовой плоскости. В S12 эталон, включающий 10 пикселей 1 - 10, изображенных на фиг. 2, используется в качестве опорных пикселей для каждого подлежащего кодированию пикселя. Затем определяется состояние Маркова для 10 пиксельных значений опорных пикселей, и определяется вероятность появления символа для определенного состояния Маркова для подлежащего кодированию пикселя способом, аналогичным способу, описанном выше, используя память 62 таблицы вероятности, изображенной на фиг. 6. Затем, подлежащий кодированию пиксель кодируется способом, аналогичным способу, описанному выше с использованием устройства 63 арифметического кодирования, изображенного на фиг. 6.
Возможно также, как в вышеописанном первом воплощении, что подходящие 6 пикселей выбраны из 10 пикселей, изображенных на фиг. 2, для эталона. В таком случае кодирование выполняется с использованием нескольких возможных эталонов, а кодированные данные с наивысшей степенью сжатия выдаются для каждой битовой плоскости.
Для того, чтобы сделать несколько битовых плоскостей переменными, готовится ряд эталонов для максимального количества (например, четырех) битовых плоскостей. Затем, когда кодируются конкретные многоуровневые данные изображения, в которых каждый пиксель имеет два бита, используются несколько (в данном примере - два) эталонов из подготовленного количества (в данном примере - четырех) эталонов. В случае, когда оптимальный эталон выбирается из нескольких возможных эталонов для каждого битовой плоскости, как отмечено выше, аналогично случаю в первом воплощении, например, б подходящих пикселей выбираются из 10 пикселей для каждого возможного эталона. В данном случае, как изображено на фиг. 10, информация о подготовке эталона четвертой битовой плоскости, третьей битовой плоскости, второй битовой плоскости и первой битовой плоскости сопровождает кодированные данные четвертой (битового места) битовой плоскости, третьей (битового места) битовой плоскости, второй (битового места) битовой плоскости и первой (битового места) битовой плоскости и указывает эталоны, каждый эталон из которых использован для кодирования и, таким образом, получают кодированные данные соответствующей одной из четырех (битовых мест) битовых плоскостей.
Ниже описываются способ и система декодирования четвертого воплощения настоящего изобретения. Такая система кодирования может декодировать данные многоуровневого изображения, имеющее множество битовых плоскостей, причем это количество отличается от количества битовых плоскостей других данных многоуровневого изображения, которое также может быть декодировано в той же системе. В этом способе декодирования, аналогичном описанному выше для первого варианта воплощения, эталон, подходящий для декодирования кодированных данных, устанавливается, используя информацию о подготовке эталона, сопровождающую кодированные данные, и декодирование выполняется с использованием установленного эталона.
Система декодирования в четвертом варианте воплощения, реализующая способ декодирования, имеет общую конструкцию, аналогичную общей конструкции системы декодирования во втором варианте воплощения, изображенном на фиг. 7. В системе декодирования в четвертом воплощении вместо устройства 5 памяти линий и мультиплексора 4 во втором варианте воплощения используются восемь устройств 11-18 памяти линий, восемь мультиплексоров 21-28, и другой мультиплексор 30. Фиг. 11 изображает общую блок-схему этой части системы декодирования.
Эта система в четвертом варианте воплощения может обрабатывать данные многоуровневого изображения, имея максимум 8 битовых плоскостей. Восемь устройств памяти линий, начиная с первого устройства 11 памяти линий до восьмого устройства 18 памяти линий предназначены для 8 битовых плоскостей соответственно. Каждая память линий имеет структуру, аналогичную структуре устройства 3 памяти линий во втором варианте воплощения, изображенном на фиг. 7. Операции записи данных в устройствах 11 - 18 памяти линий управляются восемью сигналами записи, начиная с первого сигнала записи до восьмого сигнала записи, соответственно. Например, когда обрабатываются данные многоуровневого изображения, имеющие две битовые плоскости, операции записи данных на первом и втором устройствах 11 и 12 памяти линий выполняются поочередно. Когда обрабатываются данные многоуровневого изображения, имеющего четыре битовых плоскости, то поочередно выполняются операции записи данных в устройства 11-14 памяти линий последовательно с первого по четвертое. Когда обрабатываются данные многоуровневого изображения, имеющего восемь битовых плоскостей, то поочередно выполняются операции записи данных в устройства 11 - 18 памяти линий последовательно с первого по восьмое. Управление сигналами записи может быть легко осуществлено с использованием счетчика для выполнения описанной выше последовательной поочередной записи.
Восемь мультиплексоров, с первого мультиплексора 21 по восьмой мультиплексор 28, соединены с восемью устройства 11 - 18 памяти линий соответственно. Ряд из восьми мультиплексоров 21 - 28 устанавливает эталоны для битовых плоскостей с использованием информации о подготовке эталона, подаваемой для битовых плоскостей. Этот ряд мультиплексоров является мультиплексорами, соединенными с рядом устройств памяти линий из восьми устройств памяти линий, это количество соответствует количеству битовых плоскостей данных заданного многоуровневого изображения. Другой мультиплексор 30 последовательно выбирает один из выходных сигналов вышеописанного ряда мультиплексоров и подает выбранный выходной сигнал на память таблицы вероятности (не изображенную на чертеже) в качестве адреса. Память таблицы вероятности идентична памяти 2 таблицы вероятности во втором варианте воплощения, изображенном на фиг. 7. Оставшаяся часть операции декодирования аналогична операции декодирования системы декодирования во втором варианте воплощения, изображенном на фиг. 7. В системе декодирования в четвертом варианте воплощения декодирование выполняется последовательно поочередно для нескольких битовых плоскостей.
Таким образом, согласно настоящему изобретению описанное выше кодирование и декодирование с использованием эталона могут быть применены для системы обработки изображения, которая обрабатывает данные многоуровневого изображения, в которой количество битов каждого одного пикселя может изменяться, то есть данные многоуровневого изображения, в которых количество битовых плоскостей может изменяться. Например, когда обрабатываются данные изображения программного обеспечения видео игр, файл данных фонового изображения имеет четыре битовых плоскости, в то время как файл данных изображения символа (человека, животного и т.п.) имеет две битовые плоскости. Создав конструкцию, такую как изображена на фиг. 11, возможно, что одна система декодирования сможет декодировать и файл фонового изображения с четырьмя битовыми плоскостями и файл изображения символа с двумя битовыми плоскостями.
Возможно также, что каждое из вышеописанных второго воплощения со ссылкой на фиг. 7 и четвертого воплощения, описанного со ссылкой на фиг. 11, реализуются схемой аппаратуры, такой как изображена на фиг. 3. В этом случае вся операция выполняется в результате выполнения центральным процессором соответствующего программного обеспечения.
Настоящее изобретение не ограничивается описанными выше воплощениями различные изменения, и модификации могут быть сделаны без отрыва от сущности настоящего изобретения.
Промышленная применимость
Таким образом, согласно настоящему изобретению могут быть созданы система и способ кодирования и система и способ декодирования, в которых эталон, соответствующий конкретным данным, определяется при кодировании, и высокая степень сжатия может быть сохранена без усложнения схем устройств кодирования/декодирования. Кроме того, способ кодирования, использующий эталон, может быть применен к системе, которая обрабатывает цветные изображения способом, в котором количество битов, назначенных одному пикселю, изменяется. Поэтому, настоящее изобретение особенно полезно при применении к системе и способу кодирования и способу и системе декодирования для сжатия и декомпрессии компьютерных данных и программного обеспечения игр.

Способ кодирования, согласно которому подготавливают возможный эталон кодирования, кодируют и, таким образом, сжимают подлежащие сжатию данные каждый раз, когда используют соответствующий один возможный из множества эталонов, сравнивают степени кодированных данных друг с другом, причем кодированные данные кодируют каждый раз, когда используют соответствующий один возможный из множества эталонов, определяют для каждого файла подлежащих кодированию данных оптимальный эталон, обеспечивающий наивысшую степень сжатия идентификационную информацию используемого эталона, когда получают указанные кодированные данные, имеющие наивысшую ступень сжатия. 12 с. и 4 з.п. ф-лы, 11 ил.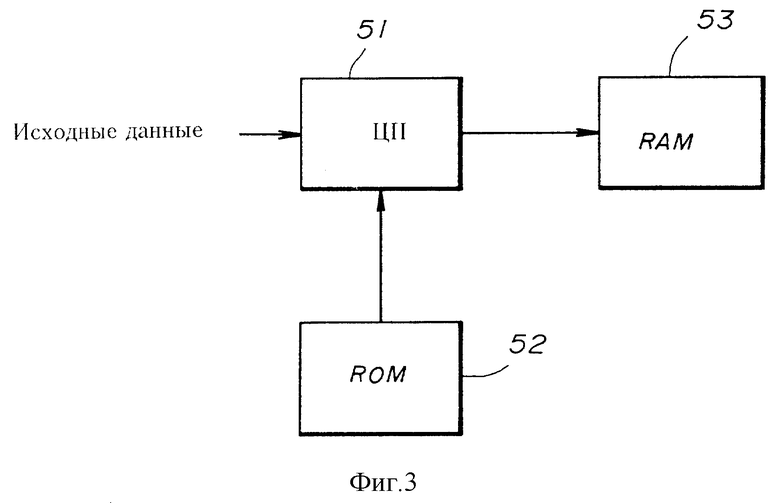
Приоритет по пунктам:
20.06.95 по пп.1 - 13;
05.09.95 по пп.14 - 21.
| Устройство сжатия факсимильных сигналов | 1980 |
|
SU1107339A1 |
| Приводной торцевой гаечный ключ | 1930 |
|
SU33014A1 |
| СПОСОБ ОПРЕДЕЛЕНИЯ АКТИВНОСТИ ТЕЛОМЕРАЗЫ МЕТОДОМ ДВОЙНОЙ АМПЛИФИКАЦИИ ТЕЛОМЕРНЫХ ПОВТОРОВ В РЕАЛЬНОМ ВРЕМЕНИ | 2017 |
|
RU2681165C1 |
| Способ получения борида алюминия а1в 12 | 1966 |
|
SU266748A1 |

