Изобретение главным образом имеет отношение к созданию систем обработки речевого сигнала и, в частности, касается создания систем с использованием постфильтрации.
Обработка речевого сигнала широко известна и часто применяется для сжатия поступающего речевого сигнала как для хранения, так и для последующей передачи. Обработка речевого сигнала обычно связана с делением входного речевого сигнала на блоки данных (кадры), с последующим анализом каждого блока данных для нахождения его компонентов. Затем полученные компоненты используются как для хранения, так и для последующей передачи.
Если есть желание восстановить исходный речевой сигнал, то каждый кадр декодируют и осуществляют операции синтеза, которые обычно в основном являются инверсией анализа. Полученная при этом синтезированная речь обычно не в полной мере аналогична исходной речи. Поэтому для "улучшения" звукового сигнала обычно осуществляют операции постфильтрации.
Одним из видов постфильтрации является постфильтрация основного тона, при которой информация основного тона, полученная на выходе кодирующего устройства, используется для фильтрации синтезированного сигнала. В известных ранее постфильтрах основного тона производится просмотр ранее полученных выборок участка синтезированного речевого сигнала p0, где p0 представляет собой значение основного тона. Субкадр ранее полученной речи, который наилучшим образом совпадает с текущим субкадром, комбинируется с текущим субкадром, обычно в соотношении 1 : 0,25 (то есть предшествующий сигнал ослабляется на три четверти).
К сожалению, речевые сигналы не всегда содержат основной тон. Это относится к случаю промежутка между словами; кроме того, в конце или в начале слова основной тон может изменяться. Так как в известных ранее постфильтрах основного тона производится комбинирование ранее полученной речи с текущим субкадром и так как основной тон ранее полученный речи не совпадает с основным тоном текущего субкадра, то на выходе такого постфильтра основного тона можно получить слабый выходной сигнал в начале слов. Аналогичное справедливо и для субкадра с окончаниями произнесенных слов. Если же большинство субкадров относится к молчанию или к шумам (например, если речь уже закончилась), то основной тон ранее полученного сигнала вообще не может быть использован.
Авторы данного изобретения обратили внимание на то, что декодеры речи обычно создают речевые кадры между их оперативными элементами, в то время как постфильтры основного тона оперируют только с субкадрами речевым сигналов.
Так, например для некоторых из субкадров имеется информация, касающаяся будущих речевых образов.
В связи с изложенным, задачей настоящего изобретения является создание постфильтра основного тона и способа, в которых используется будущая и предыдущая информация по меньшей мере для некоторых из субкадров.
В соответствии с предпочтительным вариантом осуществления настоящего изобретения, постфильтр основного тона получает кадр синтезированной речи, и для каждого субкадра, входящего в кадр синтезированной речи, вырабатывает сигнал, который является функцией субкадра и окон более ранней и более поздней синтезированной речи. Каждое окно используется только при его приемлемом совпадении с субкадром.
В частности, в соответствии с предпочтительным вариантом осуществления настоящего изобретения, постфильтр основного тона осуществляет проверку совпадения окна более ранней синтезированной речи с субкадром и затем принимает (допускает) это окно более ранней синтезированной речи только в том случае, если ошибка между субкадром и взвешенной версией окна мала. Если имеется достаточный промежуток более поздней синтезированной речи, то постфильтр основного тона осуществляет также проверку совпадения окна более поздней синтезированной речи с субкадром и затем принимает (допускает) это окно, если ошибка мала. В этом случае выходной сигнал является функцией субкадра и окон более ранней и более поздней синтезированной речи, если они были приняты.
Далее, в соответствии с предпочтительным вариантом осуществления настоящего изобретения, оценка совпадения предусматривает определение более раннего и более позднего усиления соответственно для окон более ранней и более поздней синтезированной речи.
Кроме того, в соответствии с предпочтительным вариантом осуществления настоящего изобретения, функция для выходного сигнала является суммой субкадра, более раннего окна синтезированной речи, взвешенного более ранним усилением и первым разрешающим весом, и более позднего окна синтезированной речи, взвешенного более поздним усилением и вторым разрешающим весом.
Наконец, также в соответствии с предпочтительным вариантом осуществления настоящего изобретения, первый и второй разрешающие веса зависят от результатов шагов приятия решения (о совпадении).
Настоящее изобретение может быть более полно понятно и оценено из последующего подробного его описания, приведенного со ссылкой на чертежи.
На фиг. 1 показана структурная схема системы, которая включает в себя постфильтр в соответствии с настоящим изобретением; на фиг. 2 - схема, позволяющая лучше понять работу постфильтра в соответствии с фиг. 1; на фиг. 3 - блок-схема операций постфильтра в соответствии с фиг.1.
Обратимся теперь к рассмотрению фиг. 1, 2 и 3, которые позволяют понять работу постфильтра в соответствии с настоящим изобретением.
Как показано на фиг. 1, постфильтр основного тона, обозначенный позицией 10, в соответствии с настоящим изобретением получает кадры синтезированной речи от синтезирующего фильтра 12, такого как синтезирующий фильтр с коэффициентом линейного прогнозирования (LPC). Постфильтр основного тона 10 получает также значение основного тона, которое было получено ранее в декодере речи. Постфильтр основного тона 10 не должен быть обязательно первым постфильтром; он может также получать постфильтрованные кадры синтезированной речи. Постфильтр основного тона 10 включает в себя буферное устройство (буфер) текущего кадра 25, буфер предшествующего кадра 26, детерминатор (устройство определения) опережения/запаздывания 27 и постфильтр 28. Буфер текущего кадра 25 запоминает текущий кадр синтезированной речи и его разбивание на субкадры. Буфер предшествующего кадра 26 запоминает предшествующие кадры синтезированной речи. Детерминатор опережения/запаздывания 27 определяет указанные ранее показатели опережения и запаздывания относительно значения основного тона p0. Постфильтр 28 получает субкадр s [n] и будущее окно s [n + LEAD] от буфера текущего кадра 25 и вырабатывает из них постфильтрованный сигнал.
Следует иметь в виду, что синтезирующий фильтр 12 синтезирует кадры синтезированной речи и подает их на постфильтр основного тона 10. Аналогично известным ранее постфильтрам основного тона, постфильтр в соответствии с настоящим изобретением оперирует с субкадрами синтезированной речи. Однако, так как заявители настоящего изобретения поняли, что при обработке субкадров на буфере текущего кадра 25 имеется полный кадр синтезированной речи, то постфильтр основного тона 10 в соответствии с настоящим изобретением также использует будущую информацию по меньшей мере для некоторых из субкадров.
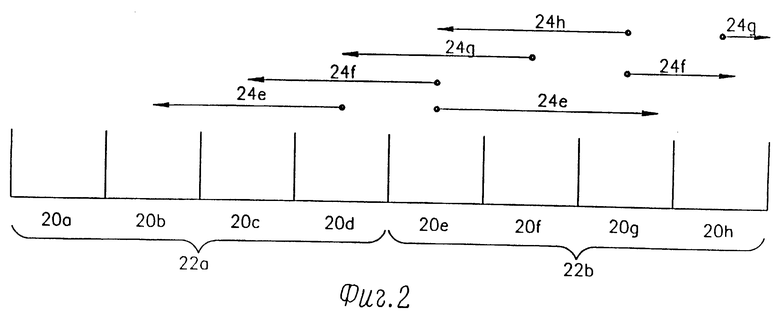
Это показано на фиг.2, где изображены восемь субкадров 20a - 20h двух кадров 22a и 22b, которые запоминаются соответственно в буфере текущего кадра 25 и в буфере предыдущего кадра 26. Показаны также местоположения, из которых могут быть взяты аналогичные субкадры данных для более поздних субкадров 20e - 20h. Как показывает стрелка 24e, для первого субкадра 20e данные могут быть взяты из предыдущих субкадров 20d, 20e и 20b, а также из будущих субкадров 20e, 20f и 20g. Как показывает стрелка 24f, для второго субкадра 20f данные могут быть взяты из предыдущих субкадров 20e, 20d и 20c, а также из будущих субкадров 20f, 20g и 20h. Следует иметь в виду, что для более поздних субкадров 20g и 20h имеется меньше будущих данных, которые могли бы быть использованы (так как при этом субкадр 20h отсутствует), однако при этом имеется некоторое количество прошлых данных, которое может быть использовано.
Детерминатор опережения/запаздывания 27 в соответствии с настоящим изобретением производит поиск в прошлом и будущем сигналов синтезированной речи, раздельно определяет для них положение выборок запаздывания и опережения или соответственно показатель, в соответствии с которым окна длины субкадра прошедшего и будущего сигналов, начинающиеся соответственно при выборах запаздывания и опережения, наиболее полно совпадают с текущим субкадром. Если совпадение плохое, то окно не используется. Обычно поиск проводят в пределах 20 - 146 выборок раньше и позже текущего субкадра, как это показано стрелками 24. Диапазон поиска сокращен для будущих данных (то есть для субкадров 20g и 20h).
После этого постфильтр 28 производит постфильтрацию сигнала синтезированной речи с использованием любого или обоих совпавших окон.
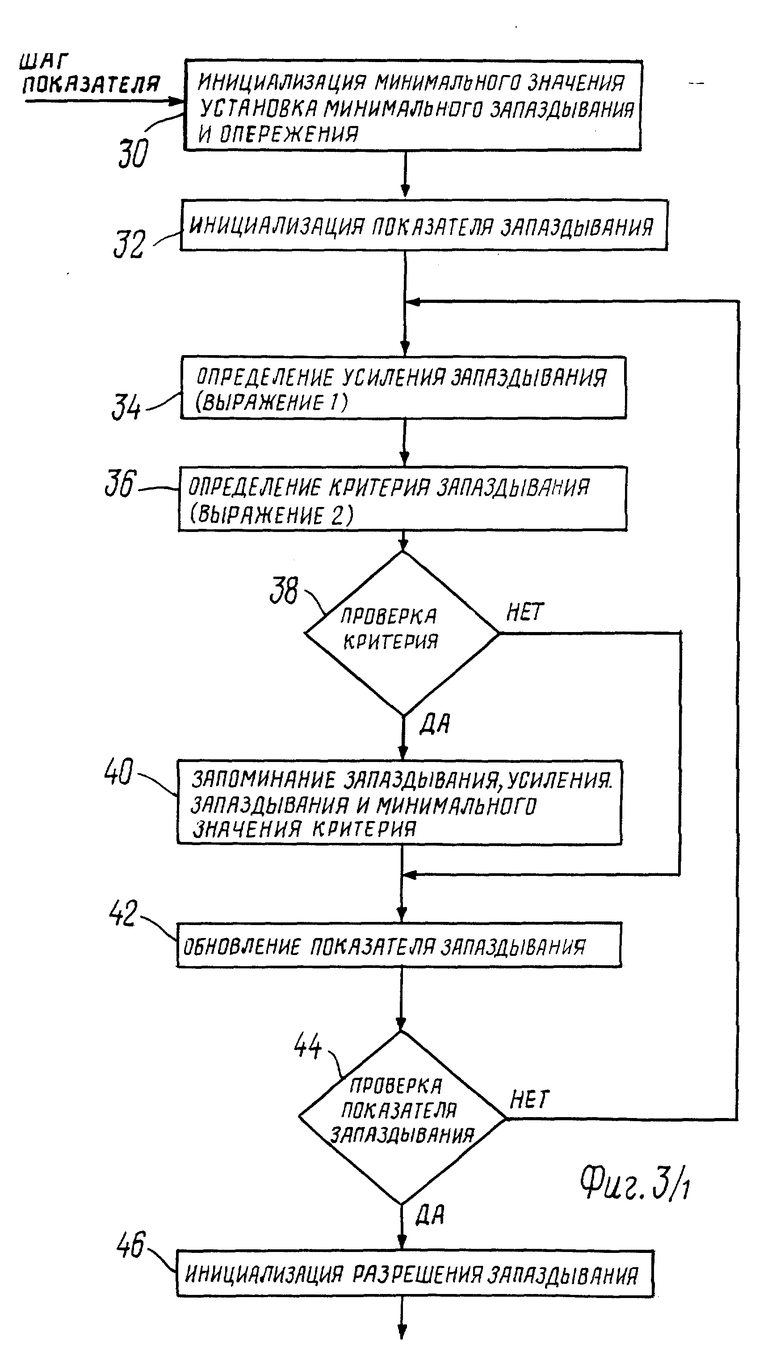
Один из вариантов построения постфильтра в соответствии с настоящим изобретением иллюстрируется фиг. 3, на которой приведена блок-схема его операций для одного субкадра. Операции 30 - 74 осуществляются при помощи детерминатора опережения/запаздывания 27, а операции 76 и 78 осуществляются при помощи постфильтра 28.
Операции способа в соответствии с настоящим изобретением начинаются с инициализации (шаг 30), при которой устанавливают в качестве величины минимального критерия минимальные и максимальные значения опережения/запаздывания. В соответствии с этим вариантом, минимальным опережением/запаздыванием является минимальный (основной тон - дельта, 20), а максимальным опережением/запаздыванием является (максимальный (основной тон + дельта, 146). В соответствии с этим вариантом дельта равняется трем.
При проведении операций 34 - 44 определяют значение опережения, а при проведении операций 60 - 70 определяют значение запаздывания, если они имеются. Обе секции осуществляют одинаковые операции, при этом предыдущие данные запоминают в буфере предшествующего кадра 26, а будущие данные запоминают в буфере текущего кадра 25. Поэтому операции будут описаны ниже только для одной из секций. Однако полученные уравнения являются разными, как это указано далее.
При проведении операции 32 устанавливают минимальную величину показателя запаздывания M_g, а при проведении операций 34 и 36 с показателем запаздывания M_g объединяют усиление g_g и определяют критерий E_g для этого показателя запаздывания. Усиление g_g является отношением кросс-корреляция субкадра s [n] и предыдущего окна s[n-M_g] с автокорреляцией предыдущего окна s[n-M_ g] в соответствии с выражением
g_g = Σs[n]*s[n-M_g]/Σs2[n-M_g], 0 ≤ n ≤ 59. (1)
Критерий E_ g представляет собой энергию сигнала ошибки s[n] - g_g * s[n-M _g] в соответствии с выражением
E_g = Σ(s[n]-g_g*s[n-M_g])2, 0 ≤ n ≤ 59. (2)
Если результирующий критерий меньше ранее определенного минимального значения (операция 38), то производят запоминание текущего показателя запаздывания M_g и условия g_g, а также устанавливают минимальное значение текущего усиления (операция 40). Показатель запаздывания увеличивают на единицу (операция 42) и процесс повторят до достижения максимального значения показателя запаздывания.
При проведении операций 46 - 50 результат определения запаздывания принимают только в том случае, если усиление запаздывания, которое найдено при проведении операций 34 - 44, больше заданной величины порога или равно ей, причем порог, например, может быть равен 0,625. При проведении операции 46 признак разрешения запаздывания устанавливают на 0, а при проведении операции 48 проверяют порог усиления запаздывания g _ g. При проведении операции 50 принимают результат установкой признака разрешения запаздывания на 1. Таким образом, для предыдущего речевого сигнала, который не аналогичен текущему субкадру, например, если в текущем субкадре имеется речь, а в предыдущем ее нет, данные для предыдущего субкадра использоваться не будут.
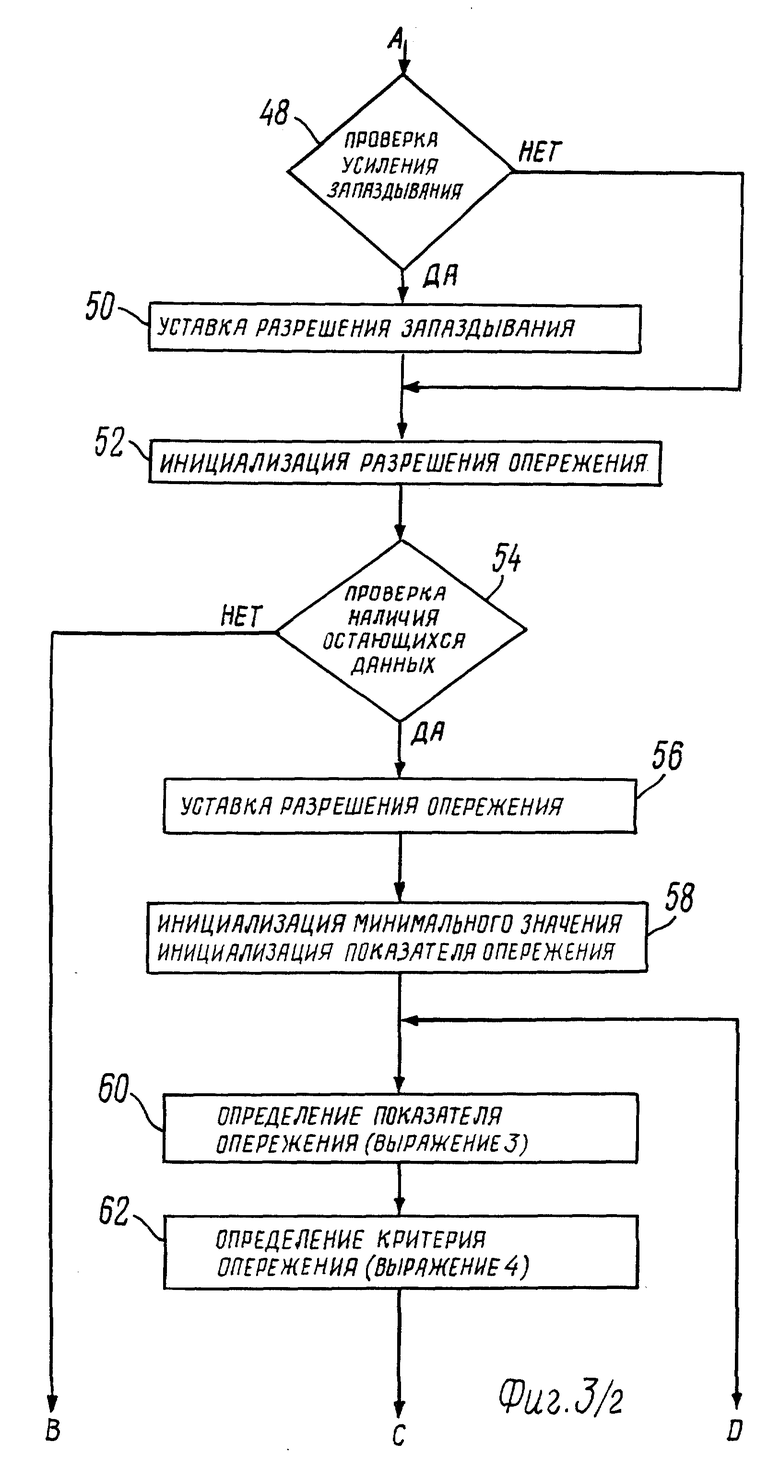
При проведении операций 52 - 56 признак разрешения опережения устанавливают только в том случае, когда сумма текущего положения N, длительность субкадра (длина которого обычно составляет 60 выборок) и максимального значения запаздывания/опережения, составляет меньше длительности кадра (длина которого обычно составляет 240 выборок). Таким образом, будущие данные используют только тогда, когда они имеются в достаточном количестве. При проведении операции 52 признак разрешения опережения устанавливают на 0, а при проведении операции 54 производят проверку приемлемости суммы, и, если она приемлема, то при проведении операции 56 признак разрешения опережения устанавливают на 1.
При проведении операции 58 повторно инициализируют минимальное значение и показатель опережения устанавливают на минимальное значение опережения. Как уже упоминалось ранее, операции 60 - 70 аналогичны операциям 34 - 44; при их проведении определяют показатель опережения, который наилучшим образом совпадает с представляющим интерес субкадром. Опережение обозначают M _ d, усилие обозначают g _ d, а критерий обозначают E _ d; они определены уравнениями 3 и 4 в следующем виде:
g_d = Σs[n]*s[n-M_d]/Σs2[n-M_d], 0 ≤ n ≤ 59; (3)
E_d = Σ(s[n]-g_d*s[n-M_d])2, 0 ≤ n ≤ 59. (4)
При проведении операции 60 находят усилие g_d, при проведении операции 62 находят критерий E_d, при проведении операции 64 проверяют, что критерий E_ d меньше, чем минимальное значение, а при проведении операции 66 производят запоминание опережения M_d и усиление опережения g_d, а также обновляют минимальное значение E_d. При проведении операции 68 увеличивают показатель опережения на единицу, а при проведении операции 70 определяют, превышает или нет показатель опережения значение максимального показателя опережения.
При проведении операций 72 и 74 признак разрешения опережения блокируют (операция 74), если усиление опережения, которое найдено при проведении операций 60 - 70, является слишком низким (например, ниже заданного порога), причем эту проверку осуществляют при проведении операции 72.
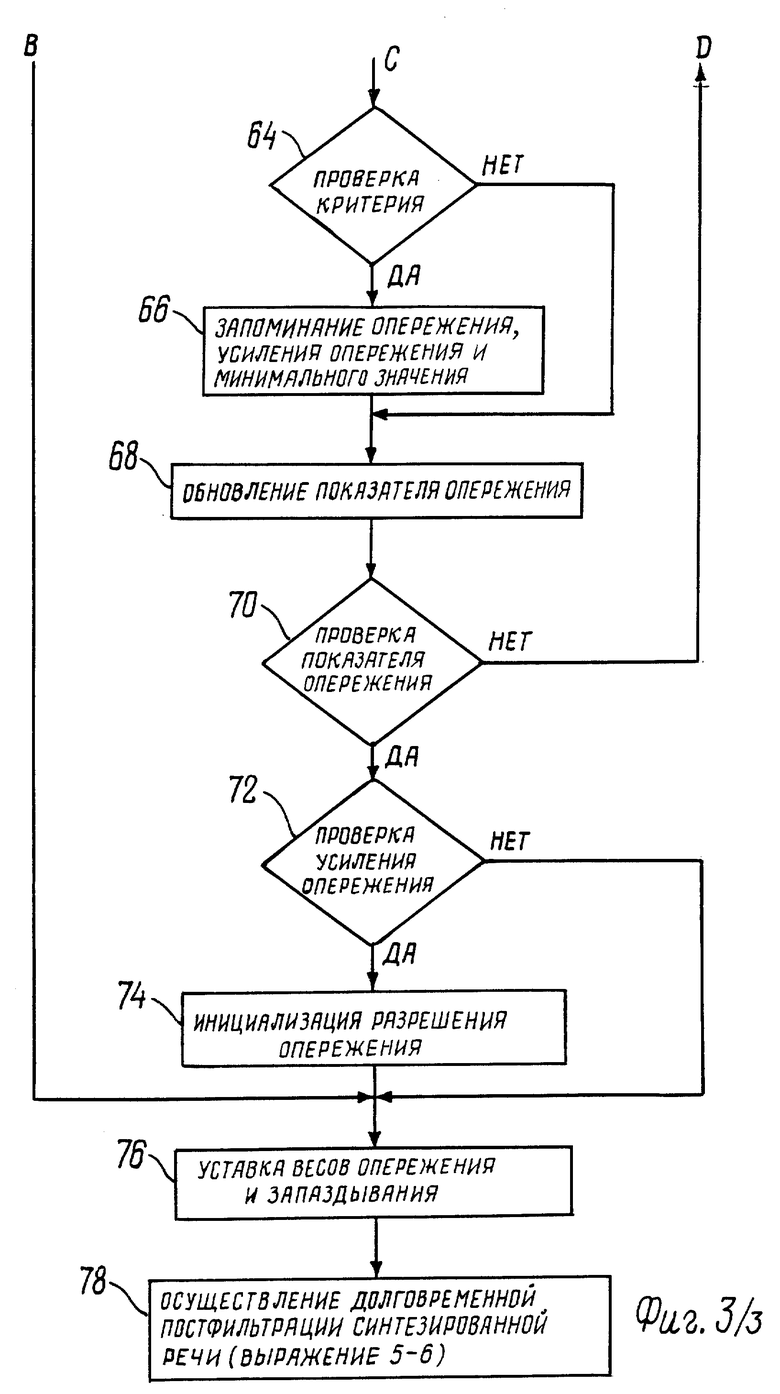
При проведении операции 76 определяют веса запаздывания w_g и опережения w_ d соответственно из признаков разрешения запаздывания и опережения. Веса w_g и w_d определяют вклады, если они есть, будущих и предыдущих данных.
В соответствии с этим вариантом вес запаздывания w_g представляет собой максимум выражения (разрешение запаздывания - (0,5* разрешение опережения)) и 0, умноженного на 0,25. Вес опережения w_d представляет собой максимум выражения (разрешение опережения - (0,5* разрешение запаздывания)) и 0, умноженного на 0,25. Другими словами, веса запаздывания w_g и опережения w_d оба равны 0,125 в том случае, когда имеются как будущие, так и предшествующие данные, которые совпадают с текущим субкадром; равны 0,25 в том случае, когда только один из этих весов совпадает с текущим субкадром; равны 0, когда нет совпадения.
При проведении операции 78 получают выходной сигнал p[n], который является функцией сигнала s[n], более раннего окна s[n-M_g] и более позднего окна s[n -M_d]. Величина M_g и M_d представляет собой соответственно показатели запаздывания и опережения, которые хранятся в памяти. Функция сигнала p[n] для данного варианта может быть определена в соответствии со следующими выражениями 5 и 6:
p[n]=g_p*{s[n]+w_g*g_g*s[n-M_g]+w_d* g_d*s[n-M_d]}= g_p*p'[n];
g_p = sqrt(Σs2[n]/Σp′2[n]), 0 ≤ n ≤ 59. (6)
Операции 30 - 78 повторяют для каждого субкадра.
Следует иметь в виду, что настоящее изобретение включает в себя все постфильтры основного тона, в которых используется как будущая, так и предшествующая информация.
Несмотря на то, что был описан предпочтительный вариант осуществления изобретения, совершено ясно, что в него специалистами в данный области могут быть внесены изменения и дополнения, которые не выходят однако из рамки приведенной далее формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СИСТЕМА И СПОСОБ ОБРАБОТКИ РЕЧЕВОГО СИГНАЛА | 1995 |
|
RU2121172C1 |
| КОДИРОВАНИЕ СИГНАЛА С ИСПОЛЬЗОВАНИЕМ КОДИРОВАНИЯ С РЕГУЛЯРИЗАЦИЕЙ ОСНОВНЫХ ТОНОВ И БЕЗ РЕГУЛЯРИЗАЦИИ ОСНОВНЫХ ТОНОВ | 2011 |
|
RU2470384C1 |
| СИСТЕМЫ И СПОСОБЫ ДЛЯ ИЗМЕНЕНИЯ ОКНА С КАДРОМ, АССОЦИИРОВАННЫМ С АУДИО СИГНАЛОМ | 2007 |
|
RU2418323C2 |
| ПРОЦЕССОР ДЛЯ ФОРМИРОВАНИЯ СПЕКТРА ПРОГНОЗИРОВАНИЯ НА ОСНОВЕ ДОЛГОСРОЧНОГО ПРОГНОЗИРОВАНИЯ И/ИЛИ ГАРМОНИЧЕСКОЙ ПОСТФИЛЬТРАЦИИ | 2022 |
|
RU2826967C2 |
| ИЗБИРАТЕЛЬНЫЙ БАСОВЫЙ ПОСТФИЛЬТР | 2016 |
|
RU2642553C2 |
| ИЗБИРАТЕЛЬНЫЙ БАСОВЫЙ ПОСТФИЛЬТР | 2016 |
|
RU2599338C1 |
| ИЗБИРАТЕЛЬНЫЙ БАСОВЫЙ ПОСТФИЛЬТР | 2011 |
|
RU2562422C2 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ ОБРАБОТКИ ЗВУКОВОГО СИГНАЛА С ИСПОЛЬЗОВАНИЕМ ГАРМОНИЧЕСКОГО ПОСТФИЛЬТРА | 2015 |
|
RU2665259C1 |
| СИСТЕМЫ И СПОСОБЫ ДЛЯ ВКЛЮЧЕНИЯ ИДЕНТИФИКАТОРА В ПАКЕТ, АССОЦИАТИВНО СВЯЗАННЫЙ С РЕЧЕВЫМ СИГНАЛОМ | 2007 |
|
RU2421828C2 |
| ИЗБИРАТЕЛЬНЫЙ БАСОВЫЙ ПОСТФИЛЬТР | 2023 |
|
RU2802659C1 |
В соответствии с настоящим изобретением синтезированную речь пропускают через постфильтр, который производит вычисления на основании будущих и предшествующих данных. Кадры данных разделены на субкадры для назначения точек вычисления. Технический результат заключается в улучшении соответствия синтезированной и исходной речи. 2 с. и 8 з.п. ф-лы. 3 ил.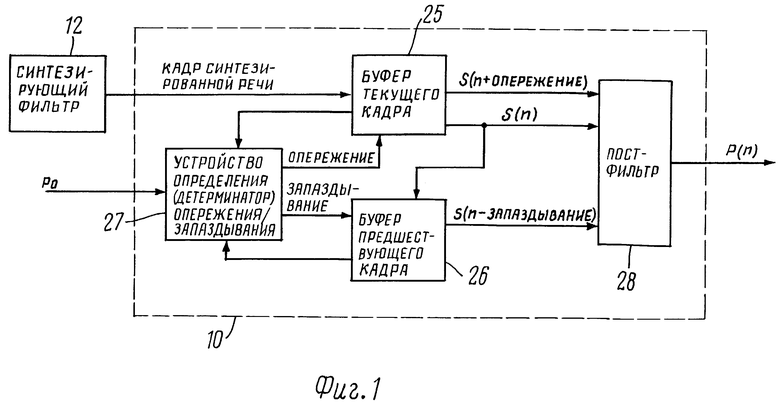
| US 4969192 A (CHE N et al.) 06.11.90 | |||
| US 5307441 A (TZENG) 26.04.94 | |||
| US 5293449 A (TZENG) 08.03.94 | |||
| Способ анализа и синтеза речи и устройство для его осуществления | 1986 |
|
SU1316030A1 |
| акад | |||
| Н.П | |||
| Способ восстановления хромовой кислоты, в частности для получения хромовых квасцов | 1921 |
|
SU7A1 |
