Варианты осуществления относятся к процессору для обработки аудиосигнала, содержащему буфер LTP и/или гармонический постфильтр. Дополнительные варианты осуществления относятся к соответствующему способу обработки аудиосигнала. Вышеуказанные варианты осуществления также могут быть реализуемыми компьютером. Следовательно, другой вариант осуществления относится к способу осуществления при выполнении на компьютере способа обработки аудиосигнала с использованием буферизации LTP и/или с использованием гармонической постфильтрации либо к способу декодирования и/или кодирования, включающему в себя одну из обработок. Другой вариант осуществления относится к кодеру. Другой вариант осуществления относится к декодеру. В общем, варианты осуществления направлены на повышение качества гармонических сигналов, кодированных в области MDCT.
Кодеки в области MDCT оптимально подходят для кодирования музыкальных сигналов, поскольку MDCT обеспечивает декорреляцию и уплотнение гармонических компонентов, обычно формируемых инструментами и поющим голосом. Тем не менее, это свойство MDCT ухудшается, если используются короткие окна взвешивания MDCT, либо если гармонические компоненты частотно или амплитудно модулированы. В качестве демонстрации значимых частотных и амплитудных модуляций, гласные в речевых сигналах являются очень сложными для кодеков MDCT.
Уровень техники уже раскрывает некоторые способы долговременного прогнозирования.
Способы долговременного прогнозирования (LTP) используют декодированные выборки из предыдущего кадра, доступного на стороне кодера и декодера, для прогнозирования выборки в текущем кадре. По сути, они увеличивают усиление при кодировании.
В [1] определяется основной тон, и сигнал прогнозирования конструируется в LTP с использованием основного тона и фильтрованных по нижним частотам декодированных выборок из предыдущих кадров. Поиск основного тона может выполняться в субкадрах. Сигнал LTP преобразуется через MDCT и вычитается из MDCT входного сигнала. Остаток кодируется и формируется с использованием передаваемой кривой маскирования. Только низкочастотные коэффициенты, в которых усиление для прогнозирования является высоким, вычитаются из входного MDCT. Сигнал LTP суммируется обратно с декодированным MDCT. Другой аналогичный способ, который работает в частотной области с использованием сигнала временной области, включает в себя [2-6]. Расширение для полифонических сигналов предлагается в [22].
В [7] предложен способ LTP, который полностью работает во временной области с применением MDCT для остатка LTP.
Также предусмотрены способы LTP, которые работают в области MDCT без необходимости обратного MDCT в кодере, например, [8], [9], [20], [21].
Способы гармонической постфильтрации (HPF), используемые в сочетании с кодеками в области MDCT, реализуют фильтрацию во временной области, которая уменьшает шум квантования между гармониками и/или увеличивает амплитуды гармоник. Иногда после постфильтра выполняется способ предварительной фильтрации, который уменьшает амплитуды гармоник в ожидании того, что кодеку области MDCT требуется меньшее число битов при кодировании предварительно фильтрованного сигнала.
В [10] адаптивный фильтр FIR 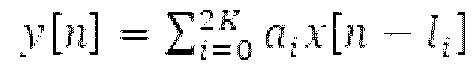 используется для улучшения речи. Параметры li задаются посредством периодов основного тона (из измерений гортанных перемещений акселерометра). Параметры ai являются фиксированными и задаются посредством функции оконного взвешивания (например, прямоугольной, Блэкмана).
используется для улучшения речи. Параметры li задаются посредством периодов основного тона (из измерений гортанных перемещений акселерометра). Параметры ai являются фиксированными и задаются посредством функции оконного взвешивания (например, прямоугольной, Блэкмана).
В [11] способ расширения и сжатия/уменьшения полосы пропускания, называемый «гармоническим масштабированием во временной области (TDHS)», используется для реализации изменяющегося во времени адаптивного гребенчатого фильтра, который фактически рассматривается в качестве другого способа реализации адаптивного фильтра FIR из [10] с конкретным окном взвешивания адаптивной длины в зависимости от основного тона.
В [12] описан подход на основе пред-/постфильтра разделяет кадр на неперекрывающиеся субкадры, при этом границы субкадров определяются таким образом, что чистая мощность сигналов минимизируется. Для каждого субкадра, получается информация основного тона. Постфильтры 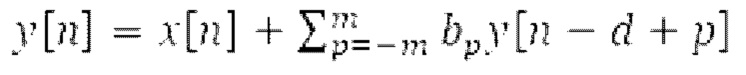 используются, где d представляет собой основной тон, оцененный в субкадре, и bp представляет собой коэффициенты прогнозирования, полученные с помощью поиска с замкнутым контуром.
используются, где d представляет собой основной тон, оцененный в субкадре, и bp представляет собой коэффициенты прогнозирования, полученные с помощью поиска с замкнутым контуром.
В [13] гармонический постфильтр (HPF) выполняется для декодированного сигнала, разделенного на субкадры фиксированной длины. Анализ основного тона возвращает корреляцию Y и основной тон Р0 в расчете на субкадр. Усиление g извлекается из корреляции у. HPF 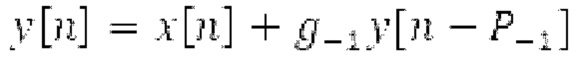 выполняется для каждого субкадра с g0, изменяющимся от 0 к g, и с g-1, изменяющимся от усиления в предыдущем субкадре к 0, где Р-1 равен основному тону в предыдущем субкадре.
выполняется для каждого субкадра с g0, изменяющимся от 0 к g, и с g-1, изменяющимся от усиления в предыдущем субкадре к 0, где Р-1 равен основному тону в предыдущем субкадре.
В [14], [15], гармонический фильтр с передаточной функцией:
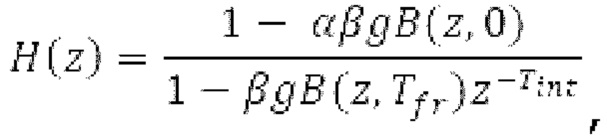
имеет коэффициенты, извлекаемые из значения запаздывания основного тона и усиления, которые являются сигнально-адаптивными. Значение g усиления вычисляется с использованием:
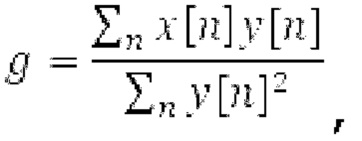
где х является входным сигналом, и Y является прогнозируемым сигналом. Значение g усиления затем ограничивается между 0 и 1. Параметры постфильтрации являются постоянными по кадру, при этом кадр задается посредством кодека. Разрывность на границах кадров удаляется с использованием регулятора плавного перехода или аналогичного способа.
Ниже приведен анализ уровня техники, показывающий эти недостатки, при этом идентификация недостатков представляет собой часть настоящего изобретения, поскольку усовершенствования, обеспечиваемые настоящим изобретением, по меньшей мере частично получены в результате анализа авторами изобретения недостатков уровня техники.
Использование длинных блоков MDCT повышает качество при кодировании гармонических сигналов даже для варьирующегося основного тона, при этом LTP, используемое в сигналах с варьирующимся основным тоном (например, в речевых), требует адаптации с варьирующейся скоростью, с тем чтобы достигать достаточно высокого усиления при кодировании. Развязывания частоты обновления LTP и кадра MDCT нелегко достичь в способах только на основе частоты из [8], [9], и до сих пор не предлагается решение.
При изменяющихся во времени характеристиках сигнала, требуется использовать самые новые доступные выборки в качестве ввода для LTP, и это является невозможным при использовании способов только во временной области из [7] в сочетании с перекрывающимися окнами взвешивания для преобразования частоты.
Разделение сигнала временной области в перекрывающихся субкадрах или сглаживание на границах субкадров и длина адаптивного фильтра в зависимости от основного тона представляют собой технологии, известные в фильтрации во временной области, но не применены в способах LTP, которые представляют собой суммирование/вычитание прогнозирования в частотной области.
В [1], [9] основной тон находится в расчете на субкадр, и если номер субкадра является высоким, множество битов может быть необходимо для кодирования информации основного тона.
Ни одна из известных технологий LTP не использует дополнительный неперекрывающийся вывод обратного MDCT, который доступен, если, например, используются способы из [16].
Фильтр FIR в [10] не моделирует амплитудные модуляции/изменения. Увеличение гармоничности, которую он вводит, является фиксированным и независимым от сигнала. Он использует перекрывающееся окно взвешивания фиксированного размера, охватывающее несколько периодов основного тона (в силу необходимости вследствие ограничения фильтра FIR), за счет этого также включающее в себя периоды с изменяющимися периодами основного тона в одном окне взвешивания. Проблема (быстро) изменяющегося периода основного тона называется «проблемой перегрузки» и решается посредством «выключения» адаптивного фильтра или эквивалентной вставки нулей в сигнал. Это уменьшает эффективность фильтра. Способ из [10] также требует обнаружения вокализованных/невокализовэнных частей.
Способ TDHS по [11] использует адаптивную длину окна взвешивания, но длина фильтра FIR охватывает по меньшей мере 4 периода основного тона, в силу чего также не позволяет моделировать быстрые изменения основного тона. Он также не моделирует амплитудные модуляции/изменения. Увеличение гармоничности, которую он вводит, также является фиксированным и является независимым от сигнала.
В [12] модуль прогнозирования дегармонизации уменьшает гармоническую часть в кодированном сигнале и в силу этого ограничивает качество кодированных гармонических компонентов и эффективность постфильтра. Все параметры постфильтра оцениваются для каждого субкадра и передаются, в силу этого значительно увеличивая скорость передачи битов. Способ также не рассматривает сглаживание на границах субкадров.
В [13] субкадры имеют постоянную длину, а не сигнально-адаптивную. Постфильтр в [13] не моделирует амплитудные модуляции/изменения, поскольку g0 является пропорциональным корреляции, ограниченной между 0 и 1.
Постфильтр LTP из [14], [15] не адаптируется достаточно быстро к изменениям сигнала, поскольку его адаптация привязывается к постоянному кадрированию кодека. Он также не моделирует хорошо амплитудные модуляции/изменения вследствие такого ограничения, что g≤1, и поскольку g появляется как в числителе (с прямой связью), так и в знаменателе (с обратной связью).
Основываясь на этом, существует потребность в усовершенствованном подходе.
Задача настоящего изобретения состоит в создании концепции повышения качества гармонического кодирования сигналов, в частности, в области MDCT.
Данная задача решается объектами независимых пунктов формулы изобретения.
Вариант осуществления предусматривает процессор для обработки кодированного аудиосигнала. Кодированный аудиосигнал или кодированный аудиосигнал временной области может содержать по меньшей мере кодированный параметр основного тона. Для полноты, следует отметить, что аудиосигнал также может иметь параметры, задающие выборки декодированного аудиосигнала (TD) временной области. Процессор содержит буфер LTP, модуль разделения/разбиения временных интервалов, средство вычисления, модуль прогнозирования и модуль преобразования в частотной области. Буфер LTP выполнен с возможностью приема выборок, извлекаемых из кадра кодированного аудиосигнала, модуль разделения/разбиения интервалов выполнен с возможностью разделения временного интервала, ассоциированного с последующим кадром (последующим относительно кадра) кодированного аудиосигнала, на субинтервалы в зависимости от кодированного параметра основного тона. Средство вычисления выполнено с возможностью извлечения параметров субинтервала из кодированного параметра основного тона в зависимости от положения субинтервалов во (временном) интервале, ассоциированном с последующим кадром кодированного аудиосигнала. Модуль прогнозирования выполнен с возможностью формирования сигнала прогнозирования из буфера LTP в зависимости от параметров субинтервала. Преобразование в частотной области выполнено с возможностью формирования спектра прогнозирования на основе сигнала прогнозирования.
Варианты осуществления этого аспекта изобретения основаны на таком принципе, что с точки зрения качества гармонического кодирования сигналов в области MDCT предпочтительно разбивать текущее окно взвешивания на перекрывающиеся субинтервалы, при этом, при необходимости, длины субинтервалов могут зависеть от основного тона. В каждом субинтервале прогнозируемый сигнал может конструироваться с использованием декодированного сигнала TD и фильтра, извлекаемого из контура основного тона в зависимости от положения субинтервала. Прогнозируемый сигнал подвергается оконному взвешиванию и преобразуется в частотную область, впоследствии. Таким образом, сконструированный прогнозируемый сигнал и LTP, применяемое в частотной области, обеспечивают плавную и быструю адаптацию без задержки к варьирующимся характеристикам сигналов на непостоянной частоте, отличающейся от частоты кадров кодера в частотной области. Согласно дополнительному варианту осуществления, прогнозируемый спектр может перцепционно сглаживаться, чтобы формировать извлечение спектра прогнозирования. Кроме того, следует отметить, что спектр прогнозирования или извлечение спектра прогнозирования может комбинироваться со спектром ошибки. Абсолютные величины, отстоящие от гармоник в прогнозируемом спектре, могут уменьшаться до нуля. Вследствие этого, в результате возникает следующее преимущество: прогнозируемый спектр дополнительно обрабатывается с использованием информации основного тона для удаления непрогнозируемых частей прогнозируемого спектра.
Относительно параметров основного тона, следует отметить, что может быть предусмотрено большее количество субинтервалов, чем отличающихся во времени кодированных параметров основного тона.
Согласно дополнительным вариантам осуществления, процессор дополнительно содержит модуль обратного преобразования в частотной области. Он может быть выполнен с возможностью формирования блока аудиосигнала (TD, временной области) с наложением спектров из извлечения спектра ошибки; дополнительно или в качестве альтернативы, процессор дополнительно содержит средство для формирования кадра аудиосигнала (TD) с использованием по меньшей мере двух блоков аудиосигнала (TD) с наложением спектров, при этом по меньшей мере некоторые части аудиосигнала (TD) с наложением спектров отличаются от аудиосигнала (TD) и принимаемых выборок, соответственно. Следует обратить внимание, что спектр прогнозирования получается из кадра кодированного аудиосигнала, и/или спектр ошибки получается из кадра кодированного аудиосигнала, последующего относительно кадра, и извлечение спектра ошибки проводится из спектра ошибки.
Следует обратить внимание, что кадр сигнала типично имеет временной интервал, ассоциированный с ним. Например: кодированный аудиосигнал разделяется на кадры. Блок аудиосигнала с наложением спектров может получаться из кадра кодированного аудиосигнала. Кадр выходного аудиосигнала временной области может получаться по меньшей мере из двух (последовательных и перекрывающихся) блоков аудио с наложением спектров.
Согласно дополнительным вариантам осуществления, процессор может содержать модуль объединения, выполненный с возможностью объединения по меньшей мере части извлечения спектра прогнозирования со спектром ошибки для формирования комбинированного спектра. Здесь извлечение спектра ошибки может проводиться, например, из комбинированного спектра.
Согласно вариантам осуществления, в каждом субинтервале прогнозируемый сигнал может конструироваться с использованием буфера LTP и/или с использованием декодированного аудиосигнала (TD) из буфера LTP и фильтра, параметры которого извлекаются из контура основного тона и положения субинтервала в кадре.
Согласно дополнительным вариантам осуществления, число прогнозируемых гармоник определяется на основе контура основного тона либо на основе скорректированного контура основного тона. Следует обратить внимание, что скорректированный контур основного тона извлекается из модифицированных параметров основного тона (см. ниже).
Согласно дополнительным вариантам осуществления, имеется большее количество отличающихся параметров субинтервала, чем отличающихся во времени кодированных параметров основного тона.
Согласно другому варианту осуществления, процессор дополнительно содержит средство для сглаживания множества субинтервалов по/на границах субинтервалов (границах субинтервалов). Сглаживание может выполняться, например, посредством плавного перехода или каскада изменяющихся во времени фильтров (например, каскадных фильтров в [19]).
Согласно дополнительным вариантам осуществления, процессор содержит средство для модификации прогнозируемого спектра (или производной прогнозируемого спектра) в зависимости от параметра, извлекаемого из кодированного параметра основного тона. Это направлено на формирование модифицированного прогнозируемого спектра.
Согласно дополнительным вариантам осуществления, процессор дополнительно содержит средство для извлечения модифицированного параметра основного тона из кодированного параметра основного тона в зависимости от содержимого буфера LTP. Например, прогнозируемый спектр может формироваться в зависимости от модифицированного параметра основного тона.
Согласно дополнительным вариантам осуществления, процессор дополнительно содержит средство для помещения всех выборок из блока аудиосигнала (TD) с наложением спектров, не отличающегося от аудиосигнала (TD), в буфер LTP. Эта процедура, согласно вариантам осуществления, в частности, затем выполняется, когда выборки одного блока аудиосигнала (TD) с наложением спектров используются для формирования двух отличающихся кадров аудиосигнала (TD).
Другой вариант осуществления согласно другим аспектам предусматривает процессор для обработки кодированного аудиосигнала. Процессор содержит средство для разбиения кадра, а также гармонический постфильтр. Средство для разбиения кадра выполнено с возможностью разбиения кадра аудиосигнала на множество (перекрывающихся) субинтервалов, имеющих соответствующие длины, и соответствующие длины множества (перекрывающихся) субинтервалов или по меньшей мере двух субинтервалов зависят от значения запаздывания основного тона. Соответствующая длина означает то, что длина различных субинтервалов может отличаться, т.е. каждый субинтервал имеет длину, заданную просто для субинтервала непосредственно всех из них. Гармонический постфильтр выполнен с возможностью фильтрации множества перекрывающихся субинтервалов, при этом гармонический постфильтр основан на передаточной функции, содержащей числитель и знаменатель. Здесь, числитель содержит гармоническое значение, при этом знаменатель содержит гармоническое значение и значение усиления и/или значение основного тона.
Следует обратить внимание, что кадр сигнала типично имеет временной интервал, ассоциированный с ним. Например: кодированный аудиосигнал разделяется на кадры. Блок аудиосигнала с наложением спектров может получаться из кадра кодированного аудиосигнала. Кадр выходного аудиосигнала временной области может получаться по меньшей мере из двух (последовательных перекрывающихся) блоков аудио с наложением спектров.
Варианты осуществления этого второго аспекта основаны на таких выявленных сведениях, что преимущественно, если изменяющийся основной тон, изменяющаяся гармоничность или амплитудная модуляция обнаруживается, так что текущий выходной кадр разбивается на перекрывающиеся субинтервалы длин в зависимости от основного тона, при этом этот основной тон получается из кодированных параметров основного тона, находится в обнаруженном сигнале временной области. В каждом субинтервале, декодированный (TD)-сигнал может фильтроваться с использованием адаптивных параметров, найденных в каждом субинтервале. Декодированный сигнал содержит достаточно информации для обнаружения варьирующейся характеристики сигналов для гармонического постфильтра (HPF), причем гармонический постфильтр может моделировать изменения основного тона и амплитуды. Здесь, частота обновления параметров гармонического постфильтра является независимой от частоты кадров кодера в частотной области.
Согласно дополнительным вариантам осуществления, значение гармоничности является пропорциональным требуемой интенсивности фильтра и/или независимым от изменений амплитуды в аудиосигнале.
Согласно вариантам осуществления, значение усиления зависит от изменения амплитуды в аудиосигнале.
Согласно дополнительным вариантам осуществления, гармоническое значение, значение усиления и значение запаздывания основного тона извлекаются с использованием вывода гармонического постфильтра, т.е. представляют результат предыдущего субинтервала/предыдущих субинтервалов.
Согласно дополнительным вариантам осуществления, гармонический постфильтр отличается в различном субинтервале во множествах субинтервалов.
Согласно дополнительным вариантам осуществления, процессор содержит средство для сглаживания множества субинтервалов по/на границе субинтервала (границах субинтервалов).
Следует отметить, что, согласно вариантам осуществления, в кадре имеется по меньшей мере два субинтервала. Дополнительно следует отметить, что соответствующие длины каждого субинтервала зависят от среднего основного тона. Например, средний основной тон получается из кодированного параметра основного тона.
Согласно вариантам осуществления, кодированный параметр основного тона может иметь более высокое временное разрешение, чем кадрирование кодека. Кроме того, кодированный параметр основного тона имеет более низкое временное разрешение, чем контур основного тона.
Согласно дополнительным вариантам осуществления, процессор содержит модуль преобразования области для преобразования на основе кадров представления в первой области аудиосигнала в представление во второй области аудиосигнала. Например, модуль преобразования области предусматривает для гармонической постфильтрации (HPF) сигнал во временной области.
Согласно дополнительным вариантам осуществления, модуль преобразования области выполнен с возможностью преобразования представления в области аудиосигнала в представление в частотной области аудиосигнала.
Согласно дополнительным вариантам осуществления, модуль обработки, принадлежащий первому аспекту, может комбинироваться с модулем обработки второго аспекта. Другими словами это означает то, что оба подхода (новый подход LTP и гармоническая постфильтрация (HPF)) могут комбинироваться и предпочтительно использоваться с кодеком MDCT. По сравнению с уровнем техники, задача нового способа состоит в лучшем моделировании частотных и амплитудных модуляций с минимальной необходимой или без необходимой вспомогательной информации.
Другой вариант осуществления предусматривает декодер для декодирования кодированного аудиосигнала, который содержит процессор согласно аспекту 1 и/или процессор согласно второму аспекту.
Согласно вариантам осуществления, декодер дополнительно содержит декодер в частотной области или декодер на основе кодека MDCT. Следует обратить внимание, что кодер в частотной области и декодер работают предпочтительно в частотной области в кадрах с перекрывающимися окнами взвешивания.
Другой вариант осуществления предусматривает кодер для кодирования аудиосигнала, содержащий процессор согласно первому аспекту.
Дополнительные варианты осуществления предусматривают способ обработки кодированного аудиосигнала. Способ содержит этапы:
- приема выборок, извлекаемых из кадра кодированного аудиосигнала, с использованием буфера LTP;
- разделения временного интервала, ассоциированного с последующим кадром кодированного аудиосигнала, на субинтервалы в зависимости от кодированного параметра основного тона;
- извлечения параметров субинтервала из кодированного параметра основного тона в зависимости от положения субинтервалов во временном интервале, ассоциированном с последующим кадром кодированного аудиосигнала;
- формирования сигнала прогнозирования из буфера LTP в зависимости от параметров субинтервала; и
- формирования спектра прогнозирования на основе сигнала прогнозирования.
Другой вариант осуществления предусматривает способ обработки аудиосигнала, содержащий этапы:
- разбиения кадра аудиосигнала на множество перекрывающихся субинтервалов, имеющих соответствующую длину, причем соответствующие длины множества перекрывающихся субинтервалов зависят от значения запаздывания основного тона;
- фильтрации множества перекрывающихся субинтервалов с использованием гармонического постфильтра, при этом гармонический постфильтр основан на передаточной функции, содержащей числитель и знаменатель, при этом числитель содержит гармоническое значение, и при этом знаменатель содержит значение запаздывания основного тона и гармоническое значение и/или значение усиления.
Дополнительные варианты осуществления предусматривают компьютерную программу для осуществления вышеописанного способа при выполнении на компьютере.
Ниже варианты осуществления настоящего изобретения поясняются с обращением к прилагаемым чертежам, на которых:
Фиг. 1а показывает схематичное представление базовой реализации процессора с использованием буферизации LTP согласно варианту осуществления первого аспекта;
Фиг. 1b показывает схематичное представление базовой реализации процессора с использованием гармонической постфильтрации согласно варианту осуществления второго аспекта;
Фиг. 2а показывает принципиальную блок-схему, иллюстрирующую кодер согласно варианту осуществления и декодер согласно другому варианту осуществления;
Фиг. 2b показывает принципиальную блок-схему, иллюстрирующую кодер согласно варианту осуществления;
Фиг. 2 с показывает принципиальную блок-схему, иллюстрирующую декодер согласно варианту осуществления;
Фиг. 3 показывает принципиальную блок-схему кодера сигналов для остаточного сигнала согласно вариантам осуществления;
Фиг. 4 показывает принципиальную блок-схему декодера, содержащего принцип заполнения нулями согласно дополнительным вариантам осуществления;
Фиг. 5 показывает принципиальную схему для иллюстрации принципа определения контура основного тона (см. контур основного тона межблочного интервала отсутствия сигнала) согласно вариантам осуществления;
Фиг. 6 показывает принципиальную блок-схему модуля импульсного извлечения с использованием информации относительно контура основного тона согласно дополнительным вариантам осуществления;
Фиг. 7 показывает принципиальную блок-схему модуля импульсного извлечения с использованием контура основного тона в качестве дополнительной информации согласно альтернативному варианту осуществления;
Фиг. 8 показывает принципиальную блок-схему, иллюстрирующую кодер импульсов согласно дополнительным вариантам осуществления;
Фиг. 9а-9b показывают принципиальные схемы для иллюстрации принципа спектрального сглаживания импульса согласно вариантам осуществления;
Фиг. 10 показывает принципиальную блок-схему кодера импульсов согласно дополнительным вариантам осуществления;
Фиг. 11a-11b показывают принципиальную схему,
иллюстрирующую принцип определения остаточного сигнала прогнозирования, начинающегося со сглаженного оригинала;
Фиг. 12 показывает принципиальную блок-схему кодера импульсов согласно дополнительным вариантам осуществления;
Фиг. 13 показывает принципиальную схему, иллюстрирующую остаточный сигнал и кодированные импульсы для иллюстрации вариантов осуществления;
Фиг. 14 показывает принципиальную блок-схему декодера импульсов согласно дополнительным вариантам осуществления;
Фиг. 15 показывает принципиальную блок-схему декодера импульсов согласно дополнительным вариантам осуществления;
Фиг. 16 показывает блок-схему, иллюстрирующую принцип оценки размера шага с использованием блока iBPC согласно вариантам осуществления;
Фиг. 17a-17d показывают принципиальные схемы для иллюстрации принципа долговременного прогнозирования согласно вариантам осуществления;
Фиг. 18a-18d показывают принципиальные схемы для иллюстрации принципа гармонической постфильтрации согласно дополнительным вариантам осуществления.
Ниже поясняются варианты осуществления настоящего изобретения с обращением к прилагаемым чертежам, на которых одинаковые ссылочные позиции используются для объектов, имеющих одинаковые или аналогичные функции, так что их описание является взаимно применимым и взаимозаменяемым.
Фиг. 1а показывает процессор 1000, который может представлять собой часть кодера для кодирования и/или декодера для декодирования кодированного аудиосигнала. Процессор 100 содержит, в своей базовой реализации, буфер 1010 LTP, модуль 1020 разделения интервалов/разбиения интервалов, модуль 1030 вычисления, а также элементы традиционного кодера/декодера, а именно, модуль 1040 прогнозирования и модуль 1050 преобразования в частотной области.
Аудиосигнал может представлять собой кодированный аудиосигнал, содержащий по меньшей мере кодированный параметр основного тона и при необходимости один или более параметров, задающих выборки декодированного аудиосигнала (TD) временной области. Следует обратить внимание, что кодированный аудиосигнал может состоять из «контура основного тона», "spect", "zfl", "tns", "sns" и «кодированных импульсов» (см. фиг.2а). Например, аудиосигнал может предварительно обрабатываться посредством модуля обратного преобразования в частотной области для формирования блока аудиосигнала TD с наложением спектров из производной спектра ошибки, при этом кадр аудиосигнала TD формируется с использованием по меньшей мере двух блоков аудиосигнала TD с наложением спектров таким образом, что по меньшей мере некоторые части аудиосигнала TD с наложением спектров отличаются от аудиосигнала TD. С другой точки зрения, это означает то, что аудиосигнал обрабатывается в частотной области. Следует обратить внимание, что производная спектра ошибки, например, представляет собой Хс (фиг.2а), поскольку Хс извлекается из комбинированного спектра (XDT), который извлекается (через модуль объединения) из спектра (XD) ошибки.
Этот аудиосигнал принимается посредством буфера 1010 и затем обрабатывается посредством тракта обработки, состоящего из элементов 1010, 1020 и 1030. Буфер 1010 буферизует/принимает выборки из кадра аудиосигнала TD. В качестве возможной реализации, вывод декодера в частотной области может использоваться в качестве буфера LTP, включающего в себя полную неперекрывающуюся часть декодированного сигнала.
В следующем объекте 1020, временной интервал текущей длины окна взвешивания кадра разбивается на перекрывающиеся субинтервалы (интервал, для которого формируется сигнал прогнозирования). Здесь, длины каждого субинтервала зависят от основного тона, например, зависят от среднего основного тона. Поскольку аудиосигнал содержит кодированные параметры основного тона, возможно то, что основной тон или информация основного тона получается из кодированного параметра основного тона. Согласно вариантам осуществления, основной тон определяется с использованием контура основного тона. Контур основного тона получается из кодированных параметров основного тона с использованием, например, интерполяции. Например, кодированный параметр основного тона может иметь более высокое временное разрешение, чем кодированное кадрирование, и/или может иметь более низкое временное разрешение, чем непосредственно контур основного тона. Следует отметить, что, согласно вариантам осуществления, может быть предусмотрено большее количество субинтервалов, чем отличающихся во времени кодированных параметров основного тона. Следующий объект 1030 принимает разделенный временной интервал, ассоциированный с кадром кодированного аудиосигнала, т.е. субинтервалы, и выполнен с возможностью извлечения параметров субинтервала из кодированного параметра основного тона в зависимости от положения субинтервала в сигнале прогнозирования. Это вычисление выполняется посредством объекта 1030. Следует отметить, что по меньшей мере в некоторых случаях, имеется большее количество отличающихся параметров субинтервала, чем отличающихся во времени кодированных параметров основного тона. Вследствие обработки сигнала прогнозирования /прогнозируемого спектра с использованием информации основного тона, можно анализировать непрогнозируемые части. После этой обработки выполняется конструирование прогнозируемого сигнала. Объект 1040 выполнен с возможностью конструирования прогнозируемого сигнала ХР* в каждом субинтервале, например, с использованием фильтра, параметры которого извлекаются из кодированного параметра основного тона/контура основного тона (следует обратить внимание, что контур основного тона извлекается из кодированных параметров основного тона, так что также можно указывать то, что параметры извлекаются из кодированных параметров основного тона) и положения субинтервала в окне взвешивания/во временном интервале, ассоциированном с кадром кодированного аудиосигнала. Следовательно, модуль 1040 прогнозирования конструирует/формирует сигнал прогнозирования, который представляет собой ХР*, зависимый от параметров субинтервала, выводимых посредством объекта 1030. Последующим относительно объекта 1040, модуль 1050 преобразования в частотной области может размещаться/конфигурироваться с возможностью формирования спектра ХР прогнозирования на основе сигнала ХР* прогнозирования. Здесь, прогнозируемый сигнал ХР* подвергается оконному взвешиванию и преобразуется в частотную область. Согласно вариантам осуществления, прогнозируемый спектр может при необходимости перцепционно сглаживаться для формирования сглаженного прогнозируемого спектра. Вследствие конструкции в расчете на субинтервал и применения LTP в частотной области, можно плавно, быстро и без дополнительной задержки адаптировать LTP к варьирующимся характеристикам сигналов на непостоянной частоте, отличающейся от частоты кадров кодера в частотной области.
Абсолютные величины, отстоящие от гармоник в (сглаженном) прогнозируемом спектре, уменьшаются до нуля, при этом местоположение гармоник извлекается из скорректированного контура основного тона.
Число прогнозируемых гармоник определяется в кодере на основе скорректированного контура основного тона, (сглаженного) прогнозируемого спектра и спектра, извлекаемого из входного сигнала. Согласно вариантам осуществления, часть сглаженного прогнозируемого спектра, соответствующая числу прогнозируемых гармоник, вычитается в частотной области в кодере. Согласно дополнительным вариантам осуществления, эта часть суммируется в частотной области в декодере и/или в кодере.
Следует отметить, что этот подход LTP может представлять собой часть кодера или декодера, как пояснено относительно фиг.2а. На фиг.2а буфер LTP составляет часть элемента 164 LTP.
Относительно фиг.1b, в дальнейшем поясняется другой вариант осуществления также с использованием разделения/разбиения аудиосигнала ус на перекрывающиеся субинтервалы в зависимости от информации основного тона.
Фиг. 1b показывает модуль 1100 гармонической постфильтрации (HPF), содержащий гармонический постфильтр 1120 после средства для разделения аудиосигнала Yc. Средство для разделения указано ссылочной позицией 1110. Модуль 1110 разделения выполнен с возможностью разделения/разбиения кадра аудиосигнала на множество перекрывающихся субинтервалов, имеющих соответствующие длины. Например, соответствующие длины двух или всех из множества субинтервалов или перекрывающихся субинтервалов зависят от значения запаздывания основного тона. Следует обратить внимание, что по меньшей мере в некоторых случаях, в кадре имеется по меньшей мере два субинтервала.
Гармонический постфильтр 1120 выполнен с возможностью фильтрации множества (перекрывающихся) субинтервалов. Фильтр 1120 использует функцию фильтра на основе передаточной функции, содержащей числитель и знаменатель. Числитель содержит значение гармоничности, тогда как знаменатель содержит значение гармоничности, значение усиления и значение запаздывания основного тона. Например, эта передаточная функция может задаваться посредством использования числителя, содержащего гармоническое значение, и знаменателя, содержащего гармоническое значение, значение усиления и значение запаздывания основного тона.
Фильтр, например, может быть описан на основе следующей передаточной функции:
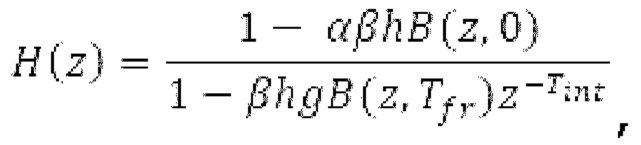
где сигнально-адаптивные параметры 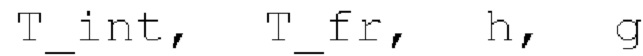 находятся в каждом субинтервале на основе декодированного сигнала временной области и уже доступных предыдущих субинтервалов выходного сигнала.
находятся в каждом субинтервале на основе декодированного сигнала временной области и уже доступных предыдущих субинтервалов выходного сигнала.
Согласно дополнительным вариантам осуществления, аудиосигнал принимается из модуля преобразования области для преобразования на основе кадров представления в первой области аудиосигнала во вторую область, предпочтительно, в представление во временной области аудиосигнала.
Согласно вариантам осуществления, значение гармоничности является пропорциональным требуемой интенсивности фильтра. Кроме того, оно может быть независимым от изменений амплитуды в аудиосигнале, при этом значение усиления может зависеть от изменений амплитуды. Результат заключается в том, что по меньшей мере в некоторых случаях, гармонический постфильтр отличается по меньшей мере в двух субинтервалах. Это также означает то, что если для одного кадра это условие задается, для некоторого другого кадра(ов), гармонический постфильтр может быть одинаковым во всех субинтервалах, либо если в некоторых случаях, предусмотрен только один субинтервал, равный временному интервалу, ассоциированному с полным кадром. Следует обратить внимание, что фильтр может иметь вид контура обратной связи таким образом, что значение гармоничности, значение усиления и значение запаздывания основного тона могут извлекаться с использованием уже доступного вывода гармонического фильтра в предыдущих субинтервалах и представления во второй области аудиосигнала (например, представление во второй области представляет собой временную область). Согласно дополнительным вариантам осуществления, в кадре может быть предусмотрено по меньшей мере два субинтервала. Здесь, могут быть предусмотрены некоторые другие кадры, в которых предусмотрен только один субинтервал, равный временному интервалу, ассоциированному с полным кадром.
Согласно вариантам осуществления, если изменяющийся основной тон, изменяющаяся гармоничность или амплитудная модуляция обнаруживается, временной интервал текущей длины выходного кадра разбивается на перекрывающиеся субинтервалы длин в зависимости от основного тона, причем основной тон получается из кодированных параметров основного тона или находится в декодированном сигнале временной области. Согласно вариантам осуществления, гармонический постфильтр 1100 выполнен с возможностью моделирования изменений основного тона и/или амплитуды. Согласно вариантам осуществления, частота обновления параметров HPF может быть независимой от частоты кадров кодера в частотной области.
Как показано относительно фиг.2а, объект 1100 HPF (см. фиг.1b) главным образом используется для стороны декодера. Объект 1100 HPF, указанный здесь позицией 214, размещается в конце тракта обработки, содержащего спектральный кодер 156. Все признаки, поясненные в контексте объекта 1100 HPF, также могут применяться к объекту 214 HPF.
Буфер LTP, включенный посредством процессора 1000, может использоваться для кодера 101, а также для декодера 201, которые поясняются относительно фиг.2а, 2b и 2 с. Здесь, объект 164 может содержать процессор 1000, содержащий буфер 1010 LTP, как пояснено в контексте фиг.1а. Все признаки, поясненные в контактах процессора 1000, также могут применяться к объекту 164 LTP.
В дальнейшем поясняется полное взаимодействие объектов 164 (LTP) и 214 (НРБ) относительно фиг.2а, при этом здесь упоминаются факультативные элементы.
Фиг. 2а показывает кодер 101 в комбинации с декодером 201.
Основные объекты кодера 101 указаны ссылочными позициями 110, 130, 151. Объект 110 выполняет импульсное извлечение, при котором импульсы р кодируются с использованием объекта 132 для импульсного кодирования.
Кодер 150 сигналов реализуется посредством множества объектов 152, 153, 154, 155, 156, 157, 158, 159, 160 и 161. Эти объекты 152-161 формируют основной тракт кодера 150, в котором, параллельно, могут размещаться дополнительные объекты 162, 163, 164, 165 и 166. Объект 162 (декодер zfl) соединяет информативно объекты 156 (iBPC) с объектом 158 (заполнение нулями). Объект 165 (получение TNS) соединяет информативно объект 153 (SNSE) с объектом 154, 158 и 159. Объект 166 (получение SNS) соединяет информативно объект 152 с объектами 153, 163 и 160. Объект 158 выполняет заполнение нулями и может содержать модуль 158 с объединения, который поясняется в контексте фиг.4. Следует обратить внимание, что может быть предусмотрена реализация, в которой объекты 159 и 160 не существуют, например, система с аналитической фильтрацией LP ввода MDCT и синтезирующей фильтрацией LP вывода MDCT. Таким образом, эти объекты 159 и 160 являются факультативными.
Объекты 163 и 164 (буфер LTP, например, как описано выше с обращением к модулю 1010) принимают контур основного тона из объекта 180 и аудиосигнал Yc временной области таким образом, чтобы сформировать прогнозируемый спектр ХР и/или перцепционно сглаженное прогнозирование XPS. Ниже описаны функциональность и взаимодействие различных объектов.
До пояснения функциональности кодера 101 и, в частности, кодера 150, приводится краткое описание декодера 201. Декодер 210 может содержать объекты 157, 162, 163, 164, 158, 159, 160, 161, а также конкретные для декодера объекты 214 (HPF), 23 (модуль объединения сигналов) и 22 (для конструирования формы сигнала, представляющей кодированные импульсы). Кроме того, декодер 201 содержит декодер 210 сигналов, при этом объекты 158, 159, 160, 161, 162, 163 и 164 формируют, вместе с объектом 214, декодер 210 сигналов. Объект 1100 может использоваться в качестве HPF 214. Кроме того, декодер 201 содержит модуль 23 объединения сигналов. Следует обратить внимание: Согласно вариантам осуществления, объект 156 просто частично используется посредством декодера. Таким образом, ссылочная позиция 201 не включает в себя объект 156, тогда как тракт 210 декодирования включает в себя его. Частичное использование 156 посредством декодера 210 проиллюстрировано посредством фиг.2 с, содержащего немного адаптированный объект 156'' для декодирования.
Импульсное извлечение 110 получает STFT входного аудиосигнала PCMi и использует спектрограмму нелинейной абсолютной величины и спектрограмму фазы STFT для нахождения и извлечения импульсов, причем каждый импульс имеет форму сигнала с характеристиками верхних частот. Остаточный импульсный сигнал ум получается посредством удаления импульсов из входного аудиосигнала. Импульсы кодируются посредством импульсного кодирования 132, и кодированные импульсы CP передаются в декодер 201.
Остаточный импульсный сигнал Yм подвергается оконному взвешиванию и преобразуется через MDCT 152, чтобы формировать Хм длины LM. Окна взвешивания выбираются из 3 окон взвешивания, как указано в [17]. Самое длинное окно взвешивания имеет длину в 30 миллисекунд с перекрытием в 10 миллисекунд в нижеприведенном примере, но могут использоваться любое другое окно взвешивания и длина перекрытия. Спектральная огибающая Хм перцепционно сглаживается через SNSE 153, получая XMS. При необходимости, формирование 154 временного шума (TNSE) применяется, чтобы сглаживать временную огибающую по меньшей мере в части спектра, формируя Хмт. По меньшей мере, один флаг φн тональности в части спектра (в Хм или XMS, или Хмт) может оцениваться и передаваться в декодер 201/210. При необходимости, долговременное прогнозирование 164 (LTP), которое выполняется после контура 180 основного тона, используется для конструирования прогнозируемого спектра ХР из предыдущих декодированных выборок, и перцепционно сглаженное прогнозирование XPS вычитается в области MDCT из Хмт, формируя остаток LTP XMR. Средняя гармоничность вычисляется для каждого кадра. Контур основного тона получается в блоке 180 получения контура основного тона для кадров с высокой средней гармоничностью и передается в декодер 201. Контур основного тона и гармоничность используются для направления множества частей кодека. В качестве альтернативы, контур основного тона может извлекаться из кодированных параметров основного тона, так что также можно указать, что параметры извлекаются из кодированных параметров основного тона.
Фиг. 2b показывает выдержку фиг.2а с акцентированием внимания на кодере 101', содержащем объекты 180, 110, 152, 153, 153, 155, 156, 165, 166 и 132. Следует обратить внимание, что 156 на фиг.2а является видом комбинации 156' на фиг.2b и 156'' на фиг.2 с. Следует обратить внимание, что объект 163 (на фиг.2а, 2 с) может быть одинаковым или сравнимым с 153 и является инверсией 160.
Согласно вариантам осуществления, кодер разбивает входной сигнал на кадры и выводит, например, для каждого кадра один или более следующих параметров:
- контур основного тона,
- вариант выбора окна взвешивания MDCT, 2 бита,
- параметры LTP,
- кодированные импульсы,
- sns, который представляет собой кодированную информацию для формирования спектра через SNS,
- tns, который представляет собой кодированную информацию для временного формирования через TNS,
- глобальное усиление gQo которое представляет собой глобальный размер шага квантования для кодека MDCT,
- spect, состоящий из энтропийно кодированного квантованного спектра MDCT,
- zfl, состоящий из параметрически кодированных нулевых частей квантованного спектра MDCT.
XPS представляет собой вывод 163 или 164, который также может требоваться в кодере, но показывается только в декодере.
Фиг. 2 с показывает выдержку фиг.2а с акцентированием внимания на декодере 201', содержащем объекты 156'', 162, 163, 164, 158, 159, 160, 161, 214, 23 и 2, которые пояснены в контексте фиг.2а касательно LTP 164. По существу, вследствие LTP, часть декодера (за исключением 214, 230, 222 и их выводов) также может использоваться/требоваться в кодере (как показано на фиг.2а) и называется «внутренним декодером». В реализациях без LTP в кодере не нужен внутренний декодер.
Пояснение для кодера MDCT: Вывод MDCT представляет собой Хм длины LM. Для примера, на входной частоте дискретизации в 48 кГц и для примерной длины кадра в 20 миллисекунд, LM равна 960. Кодек может работать на других частотах дискретизации и/или при других длинах кадров. Все другие спектры извлекаются из Хм: XMS, Хмт, XMR, XQ, XD, XDT, Xct, XCS, Xc, XP, XPS, XN, XNP, Xs также имеют равную длину LM, хотя в некоторых случаях только часть спектра может требоваться и использоваться. Спектр состоит из спектральных коэффициентов, также известных как спектральные элементы разрешения или частотные элементы разрешения. В случае спектра MDCT, спектральные коэффициенты могут иметь положительные и отрицательные значения. Можно сказать, что каждый спектральный коэффициент покрывает полосу пропускания. В случае частоты дискретизации в 48 кГц и длины кадра в 20 миллисекунд, спектральный коэффициент покрывает полосу пропускания в 25 Гц. Спектральные коэффициенты могут индексироваться от 0 до LM-1.
SNS-коэффициенты масштабирования, используемые в SNSE и SNSD, могут получаться из энергий в NSB=64 подполосах частот (иногда также называемых «полосами частот»), имеющих увеличивающиеся полосы пропускания, причем энергии получаются из спектра, разделенного на подполосы частот.Согласно примеру, границы подполос частот, выражаемые в Гц, могут задаваться равными 0, 50, 100, 150, 200, 250, 300, 350, 400, 450, 500, 550, 600, 700, 800, 900, 1000, 1100, 1200, 1300, 1400, 1500, 1600, 1700, 1800, 1900, 2050, 2200, 2350, 2500, 2650, 2800, 2950, 3100, 3300, 3500, 3700, 3900, 4100, 4350, 4600, 4850, 5100, 5400, 5700, 6000, 6300, 6650, 7000, 7350, 7750, 8150, 8600, 9100, 9650, 10250, 10850, 11500, 12150, 12800, 13450, 14150, 15000, 16000, 24000. Подполосы частот могут индексироваться от 0 до NSB-1. В этом примере, нулевая подполоса частот (от 0 до 50 Гц) содержит 2 спектральных коэффициента, одинаково с подполосами 1-11 частот, подполоса 62 частот содержит 40 спектральных коэффициентов, и подполоса 63 частот содержит 320 коэффициентов. Энергии в NSB=64 подполосах частот могут дискретизироваться с понижением до 16 значений, которые кодируются, причем кодированные значения обозначаются как "sns". 16 декодированных значений, полученных из "sns", интерполируются в SNS-коэффициенты масштабирования, причем, например, может быть предусмотрено 32, 64 или 128 коэффициентов масштабирования. Для получения дополнительных сведений относительно получения SNS, читателям следует обратиться к [22-26].
В блоках iBPC, «декодирования zfl» и/или «заполнения нулями», спектры могут разделяться на подполосы Bi частот варьирующейся длины LBi, причем подполоса частот начинается в jBi. Могут использоваться 64 границы подполос частот, одинаковые с границами, используемыми для энергий для получения SNS-коэффициентов масштабирования, но также может использоваться любое другое число подполос частот и любые другие границы подполос частот (независимо от SNS). Необходимо отметить, что может использоваться тот же принцип деления на подполосы частот, что и принцип деления на подполосы частот в SNS, но деление на подполосы частот в блоках iBPC, «декодирования zfl» и/или «заполнения нулями» является независимым от SNS и от блоков SNSE и SNSD. В вышеуказанном примере деления на подполосы частот, 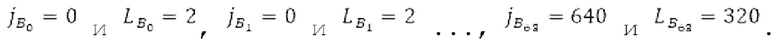
Следует обратить внимание, что еще в одном варианте осуществления подполосы частот (т.е. границы подполос частот) для iBPC, «декодирования zfl» и «заполнения нулями», могут извлекаться из положений нулевых спектральных коэффициентов в XD и XQ.
Кодирование XMR (остатка из LTP), выводимого посредством объекта 155, выполняется в интегральном кодере параметров для каждой полосы частот (iBPC), как пояснено относительно фиг.3.
Фиг. 3 показывает объект 156 iBPC, который может иметь подобъекты 156q, 156m, 156pc, 156sc и 156mu. Следует обратить внимание, что фиг.la показывает часть по фиг.3. Здесь, 1030 является сравнимым с 156а, 1010 является сравнимым с 156рс, 1020 является сравнимым с 156sc.
В выводе мультиплексора 156mu потоков битов, параметрический декодер 162 для каждой полосы частот размещается вместе со спектральным декодером 156sc. Объект 162 принимает сигнал zfl, а объект 156sc - сигнал spect, причем оба из них принимают глобальное усиление/размер gQ0 шага. Следует обратить внимание, что параметрический декодер 162 использует вывод XD спектрального декодера 156sc для декодирования zfl. Он альтернативно может использовать другой сигнал, выводимый из декодера 156sc. Исходная информация для указанного заключается в том, что спектральный декодер 156sc может содержать две части, а именно, спектральный декодер и деквантователь. Например, вывод квантователя может использоваться в качестве ввода для параметрического декодера 162.
XMR квантуется и кодируется, что включает в себя квантование и кодирование энергии для нулевых значений в (части) квантованном спектре XQ, при этом XQ является квантованной версией XMR. Квантование и кодирование XMR выполняется в интегральном параметрическом кодере 156 для каждой полосы частот (iBPC). В качестве одной из частей iBPC, квантование (квантователь 156q) вместе с адаптивным обнулением 156 т полос частот формирует, на основе оптимального размера gQ0 шага квантования, квантованный спектр XQ. iBPC 156 формирует кодированную информацию, состоящую из spect 156sc (который представляет XQ) и zfl 162 (который представляет энергию для нулевых значений в части XQ).
Объект 158 заполнения нулями, размещаемый в выводе объекта 157, проиллюстрирован посредством фиг.4.
Фиг. 4 показывает объект 158 заполнения нулями, принимающий сигнал Ев из объекта 162 и комбинированный спектр XDT из объекта 156sd при необходимости через элемент 157. Объект 158 заполнения нулями может содержать два подобъекта 158sc и 158sg, а также модуль 158 с объединения.
Spect декодируется для получения декодированного спектра XD (декодированного остатка LTP, спектра ошибки), эквивалентного квантованной версии XMR, представляющей собой XQ. Ев получается из zfl с учетом местоположения нулевых значений в XD (спектре ошибки). Ев может представлять собой сглаженную версию энергии для нулевых значений в XQ. Ев может иметь разрешение, отличное от разрешения zfl, предпочтительно более высокое разрешение, исходящее из сглаживания. После получения Ев (см. 162), перцепционно сглаженное прогнозирование XPS при необходимости суммируется с декодированным XD, формируя XDT. Заполнение Х3 нулями получается и комбинируется с XDT (например, с использованием суммирования 158 с) в «заполнении нулями», причем заполнение XG нулями состоит из заполнения XSBi нулями для каждой полосы частот, которое итеративно получается из спектра Х3 источника, состоящего из спектра XGBi источника для каждой полосы частот (см. 156sc), взвешенного на основе Ев. Хст представляет собой комбинацию для каждой полосы частот заполнения XG нулями и спектра XDT (158 с). Xs конструируется для каждой полосы частот (158sg выводит XG), и Хст получается для каждой полосы частот, начиная с наименьшей подполосы частот. Для каждой подполосы частот, спектр источника выбирается (см. 158sc), например, в зависимости от положения подполосы частот, флага (toi) тональности, спектра (pii) мощности, оцененного из XDT, Ев, информации основного тона и временной информации (tei). Следует обратить внимание, что спектр мощности, оцененный из XDT, может извлекаться из XDT или XD. В качестве альтернативы, вариант выбора спектра источника может получаться из потока битов. Наименьшие подполосы XSBl частот в Xs вплоть до начальной частоты fzFstart могут задаваться равными 0, что означает то, что в наименьших подполосах частот, Хст может представлять собой копию XDT; fZFStart может быть равна 0, что означает то, что спектр источника, отличающийся от нулей, может выбираться даже с начала спектра. Спектр источника для подполосы i частот, например, может представлять собой случайный шум или прогнозируемый спектр либо комбинацию уже полученной нижней части Хст, случайного шума и прогнозируемого спектра. Спектр Х3 источника взвешивается на основе Ев, чтобы получать заполнение XSBi нулями.
Взвешивание может выполняться посредством 158sg и иметь более высокое разрешение относительно деления на подполосы частот; оно может определяться даже на основе выборок, чтобы получать сглаженное взвешивание. XSBi суммируется с подполосой i частот XDT для формирования подполосы i частот Хст. После получения полного Хст, его временная огибающая при необходимости модифицируется через TNSD 159 (см. фиг.2а) таким образом, что она совпадает с временной огибающей XMS, формируя XCS. Спектральная огибающая Xcs затем модифицируется с использованием SNSD 160 таким образом, что она совпадает со спектральной огибающей Хм, формируя Хс.Сигнал ус временной области получается из Хс в качестве вывода IMDCT 161, при этом IMDCT 161 состоит из обратного MDCT, оконного взвешивания и суммирования с перекрытием; ус используется для обновления буфера 164 LTP (сравнимого либо с буфером 164 на фиг.2а и 2 с, либо с сочетанием 164+163) для следующего кадра. Гармонический постфильтр (HPF), который выполняется после контура основного тона, применяется к ус, чтобы уменьшать уровень шума между гармониками и выводить ун. Кодированные импульсы, состоящие из кодированных форм импульсного сигнала, декодируются, и сигнал уР временной области конструируется из декодированных форм импульсного сигнала; уР комбинируется с ун, чтобы формировать декодированный аудиосигнал (РСМ0). В качестве альтернативы, уР может комбинироваться с ус, и их комбинация может использоваться в качестве ввода в HPF, причем в этом случае вывод HPF 214 представляет собой декодированный аудиосигнал.
Объект 180 «получение контура основного тона» описан ниже с обращением к фиг.5.
Ниже поясняется процесс в блоке 180 «получение контура основного тона». Входной сигнал дискретизируется с понижением от полной частоты дискретизации до более низкой частоты дискретизации, например, в 8 кГц. Контур основного тона определяется посредством pitch_mid и pitch_end из текущего кадра и посредством pitch_start, который равен pitch_end из предыдущего кадра. Кадры примерно иллюстрируются посредством фиг. 5. Все значения, используемые в контуре основного тона, могут сохраняться в качестве запаздываний основного тона с дробной точностью. Значения запаздывания основного тона составляют между минимальным запаздыванием основного тона 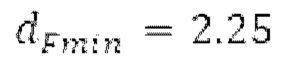 миллисекунды (соответствующим 4 44,4 Гц) и максимальным запаздыванием основного тона
миллисекунды (соответствующим 4 44,4 Гц) и максимальным запаздыванием основного тона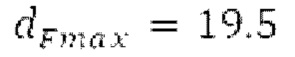 миллисекунд (соответствующим 51,3 Гц), при этом диапазон от
миллисекунд (соответствующим 51,3 Гц), при этом диапазон от  называется «полным диапазоном основного тона». Также может использоваться другой диапазон значений. Значения pitch_mid и pitch_end находятся посредством множества этапов. На каждом этапе, поиск основного тона выполняется в зоне дискретизированного с понижением сигнала либо в зоне входного сигнала.
называется «полным диапазоном основного тона». Также может использоваться другой диапазон значений. Значения pitch_mid и pitch_end находятся посредством множества этапов. На каждом этапе, поиск основного тона выполняется в зоне дискретизированного с понижением сигнала либо в зоне входного сигнала.
Поиск основного тона вычисляет нормализованную автокорреляцию своего ввода и задержанной версии ввода.
своего ввода и задержанной версии ввода.
Запаздывания dF составляют между началом dFstart поиска основного тона и концом dFend поиска основного тона. Начало dFstart поиска основного тона, конец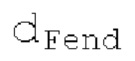 поиска основного тона, длина
поиска основного тона, длина 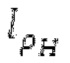 автокорреляции и предыдущий возможный вариант dFpast основного тона представляют собой параметры поиска основного тона. Поиск основного тона возвращает оптимальный основной тон dFoptim, в качестве запаздывания основного тона с дробной точностью и уровнем
автокорреляции и предыдущий возможный вариант dFpast основного тона представляют собой параметры поиска основного тона. Поиск основного тона возвращает оптимальный основной тон dFoptim, в качестве запаздывания основного тона с дробной точностью и уровнем 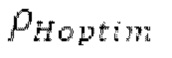 гармоничности, полученным из значения автокорреляции при оптимальном запаздывании основного тона.
гармоничности, полученным из значения автокорреляции при оптимальном запаздывании основного тона.
Диапазон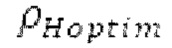 составляет между 0 и 1, при этом 0 означает отсутствие гармоничности, а 1 означает максимальную гармоничность.
составляет между 0 и 1, при этом 0 означает отсутствие гармоничности, а 1 означает максимальную гармоничность.
Местоположение абсолютного максимума в нормализованной автокорреляции представляет собой первый возможный вариант dF1 для оптимального запаздывания основного тона. Если 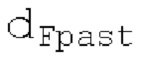 находится рядом с dFi, то второй возможный вариант dF2 для оптимального запаздывания основного тона составляет dFpast, в противном случае местоположение локального максимума рядом с dFpaBt представляет собой второй возможный вариант dF2. Поиск локального максимума не выполняется, если dFpast находится рядом с dF1, поскольку в таком случае dF1 должен выбираться снова для dF2.
находится рядом с dFi, то второй возможный вариант dF2 для оптимального запаздывания основного тона составляет dFpast, в противном случае местоположение локального максимума рядом с dFpaBt представляет собой второй возможный вариант dF2. Поиск локального максимума не выполняется, если dFpast находится рядом с dF1, поскольку в таком случае dF1 должен выбираться снова для dF2.  Если разность нормализованной автокорреляции в dF1 и dF2 составляет выше порогового значения τdF возможного варианта основного тона, то dFoptim задается равным dFi
Если разность нормализованной автокорреляции в dF1 и dF2 составляет выше порогового значения τdF возможного варианта основного тона, то dFoptim задается равным dFi 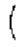
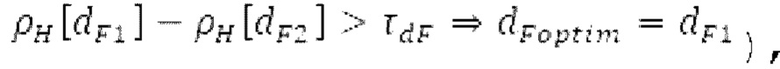 в противном случае dFoptim задается равным dF2; TdF адаптивно выбирается в зависимости от dF1, dF2 и
в противном случае dFoptim задается равным dF2; TdF адаптивно выбирается в зависимости от dF1, dF2 и 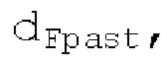 например,
например, 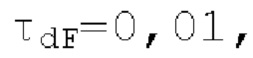 если
если 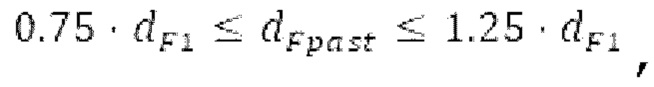 в противном случае
в противном случае 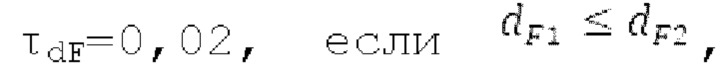 и
и 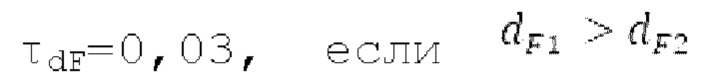 (для небольшого изменения основного тона проще переключаться на новое местоположение максимума, и если изменение является большим, то проще переключаться на меньшее запаздывание основного тона, чем на большее запаздывание основного тона).
(для небольшого изменения основного тона проще переключаться на новое местоположение максимума, и если изменение является большим, то проще переключаться на меньшее запаздывание основного тона, чем на большее запаздывание основного тона).
Местоположения зон для поиска основного тона относительно кадрирования и оконного взвешивания показаны на фиг.5. Для каждой зоны, поиск основного тона выполняется с длиной 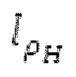 автокорреляции, заданной равной длине зоны. Во-первых, запаздывание start pitch ds основного тона и ассоциированная гармоничность start norm_corr ds вычисляются на более низкой частоте дискретизации с использованием
автокорреляции, заданной равной длине зоны. Во-первых, запаздывание start pitch ds основного тона и ассоциированная гармоничность start norm_corr ds вычисляются на более низкой частоте дискретизации с использованием 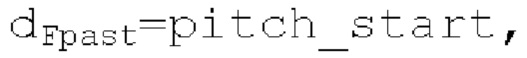
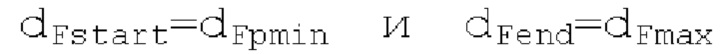 при выполнении поиска основного тона. После этого запаздывание avg pitch ds основного тона и ассоциированная гармоничность avg norm_corr ds вычисляются на более низкой частоте дискретизации с использованием dFpast=start pitch ds,
при выполнении поиска основного тона. После этого запаздывание avg pitch ds основного тона и ассоциированная гармоничность avg norm_corr ds вычисляются на более низкой частоте дискретизации с использованием dFpast=start pitch ds, 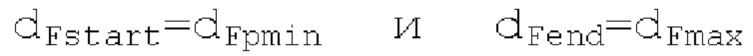 при выполнении поиска основного тона. Средняя гармоничность в текущем кадре задается равной max(start norm_corr ds, avg norm_corr ds). Запаздывания mid pitch ds и end pitch ds основного тона и ассоциированные гармоничности mid norm_corr ds и end norm_corr ds вычисляются на более низкой частоте дискретизации с использованием
при выполнении поиска основного тона. Средняя гармоничность в текущем кадре задается равной max(start norm_corr ds, avg norm_corr ds). Запаздывания mid pitch ds и end pitch ds основного тона и ассоциированные гармоничности mid norm_corr ds и end norm_corr ds вычисляются на более низкой частоте дискретизации с использованием 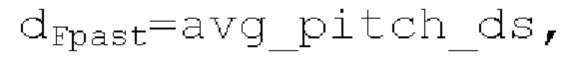
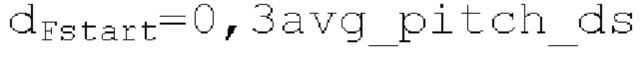 и
и 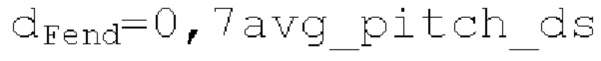 при выполнении поиска основного тона. Запаздывания pitch_mid и pitch_end основного тона и ассоциированные гармоничности norm_corr_mid и norm_corr_end вычисляются на полной частоте дискретизации с использованием
при выполнении поиска основного тона. Запаздывания pitch_mid и pitch_end основного тона и ассоциированные гармоничности norm_corr_mid и norm_corr_end вычисляются на полной частоте дискретизации с использованием 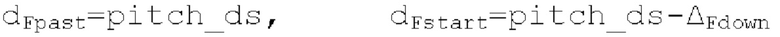 и
и 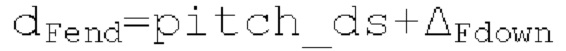 при выполнении поиска основного тона, при этом
при выполнении поиска основного тона, при этом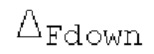 является отношением полной и более низкой частоты дискретизации, и pitch ds=mid pitch ds для pitch_mid и pitch ds=end pitch ds для pitch_end.
является отношением полной и более низкой частоты дискретизации, и pitch ds=mid pitch ds для pitch_mid и pitch ds=end pitch ds для pitch_end.
Если средняя гармоничность ниже 0,3, либо если norm_corr_end ниже 0,3, либо если norm_corr_mid ниже 0,6, то передается в служебных сигналах в потоке битов с помощью одного бита то, что в текущем кадре отсутствует контур основного тона. Если средняя гармоничность выше 0,3, контур основного тона кодируется с использованием абсолютного кодирования для pitch_end и дифференциального кодирования для pitch_mid. Pitch_mid кодируется дифференцированно в (pitch_start+pitch_end)/2 с использованием 3 битов, посредством использования кода для разности в (pitch_start+pitch_end)/2 из числа 8 заданных значений, который минимизирует автокорреляцию в зоне pitch_mid. Если имеется конец гармоничности в кадре, например, norm_corr_end<norm_corr_mid/2, то линейная экстраполяция из pitch_start и pitch_mid используется для pitch_end таким образом, что pitch_mid может кодироваться (например, norm_corr_mid>0,6 и norm_corr_end<0,3).
Если |pitch_mid-pitch_start| 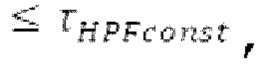 и |norm_corr_mid-norm_corr start|≤0,5, и ожидаемые усиления HPF в зоне pitch_start и pitch_mid составляют близко к 1 и сильно не изменяются, то передается в служебных сигналах в потоке битов то, что HPF должен использовать постоянные параметры.
и |norm_corr_mid-norm_corr start|≤0,5, и ожидаемые усиления HPF в зоне pitch_start и pitch_mid составляют близко к 1 и сильно не изменяются, то передается в служебных сигналах в потоке битов то, что HPF должен использовать постоянные параметры.
Согласно вариантам осуществления, контур основного тона обеспечивает dcontour, значение dcontour [i] запаздывания основного тона в каждой выборке i в текущем окне взвешивания и по меньшей мере в dFmax предыдущих выборок. Запаздывания основного тона контура основного тона получаются посредством линейной интерполяции pitch_mid и pitch_end из текущего, предыдущего и второго предыдущего кадра.
Среднее запаздывание  основного тона вычисляется для каждого кадра в качестве среднего pitch_start, pitch_mid и pitch_end.
основного тона вычисляется для каждого кадра в качестве среднего pitch_start, pitch_mid и pitch_end.
Коррекция запаздывания в половину основного тона также является возможной согласно дополнительным вариантам осуществления.
Буфер 164 LTP, который доступен как в кодере, так и в декодере, используется для проверки того, является ли запаздывание основного тона входного сигнала меньшим, чем dFmin. Обнаружение того, является ли запаздывание основного тона входного сигнала меньшим, чем dFmin, называется «обнаружением запаздывания в половину основного тона», и если упомянутое обнаружено, считается, что «обнаружено запаздывание в половину основного тона». Кодированные значения (pitch_mid, pitch_end) запаздывания основного тона кодируются и передаются в диапазоне от 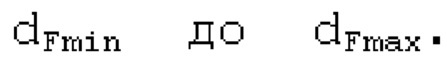 Из этик кодированный параметров, контур основного тона извлекается так, как задано выше. Если запаздывание в половину основного тона обнаруживается, предполагается, что кодированные значения запаздывания основного тона должны иметь значение, близкое к целому кратному
Из этик кодированный параметров, контур основного тона извлекается так, как задано выше. Если запаздывание в половину основного тона обнаруживается, предполагается, что кодированные значения запаздывания основного тона должны иметь значение, близкое к целому кратному 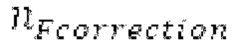 истинный значений запаздывания основного тона (эквивалентно, основной тон входного сигнала составляет около целого кратного
истинный значений запаздывания основного тона (эквивалентно, основной тон входного сигнала составляет около целого кратного 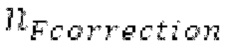 кодированного основного тона). Чтобы расширять диапазон запаздывания основного тона за пределы кодируемого диапазона, скорректированные значения (pitch_mid_corrected, pitch_end_corrected) запаздывания основного тона используются. Скорректированные значения (pitch_mid_corrected, pitch_end_corrected) запаздывания основного тона могут быть равными кодированным значениям (pitch_mid, pitch_end) запаздывания основного тона, если истинные значения запаздывания основного тона находятся в кодируемом диапазоне. Следует обратить внимание, что скорректированные значения запаздывания основного тона могут использоваться для получения скорректированного контура основного тона, аналогично тому, как контур основного тона извлекается из значений запаздывания основного тона. Другими словами, это позволяет расширять частотный диапазон контура основного тона за пределами частотного диапазона для кодированных параметров основного тона, формируя скорректированный контур основного тона.
кодированного основного тона). Чтобы расширять диапазон запаздывания основного тона за пределы кодируемого диапазона, скорректированные значения (pitch_mid_corrected, pitch_end_corrected) запаздывания основного тона используются. Скорректированные значения (pitch_mid_corrected, pitch_end_corrected) запаздывания основного тона могут быть равными кодированным значениям (pitch_mid, pitch_end) запаздывания основного тона, если истинные значения запаздывания основного тона находятся в кодируемом диапазоне. Следует обратить внимание, что скорректированные значения запаздывания основного тона могут использоваться для получения скорректированного контура основного тона, аналогично тому, как контур основного тона извлекается из значений запаздывания основного тона. Другими словами, это позволяет расширять частотный диапазон контура основного тона за пределами частотного диапазона для кодированных параметров основного тона, формируя скорректированный контур основного тона.
Обнаружение половины основного тона выполняется только в том случае, если основной тон считается постоянным в текущем окне взвешивания, и 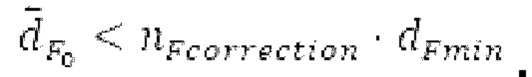 Основной тон считается постоянным в текущем окне взвешивания, если max (|pitch_mid-pitch_start|, |pitch_mid-pitch_endI) <
Основной тон считается постоянным в текущем окне взвешивания, если max (|pitch_mid-pitch_start|, |pitch_mid-pitch_endI) < 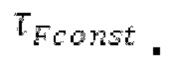 При обнаружении половины основного тона, для каждого
При обнаружении половины основного тона, для каждого 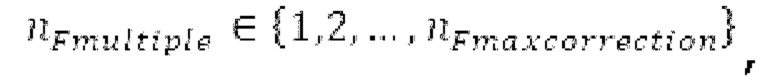 поиск основного тона выполняется с использованием
поиск основного тона выполняется с использованием 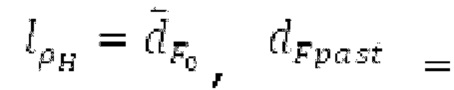
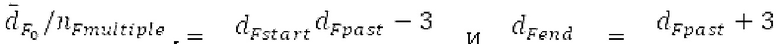 ;
;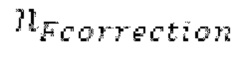 задается равным
задается равным 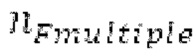 , который максимизирует нормализованную корреляцию, возвращаемую посредством поиска основного тона. Считается, что половина основного тона обнаруживается, если
, который максимизирует нормализованную корреляцию, возвращаемую посредством поиска основного тона. Считается, что половина основного тона обнаруживается, если 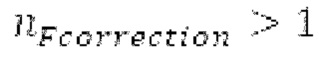 , и нормализованная корреляция, возвращаемая посредством поиска основного тона для
, и нормализованная корреляция, возвращаемая посредством поиска основного тона для 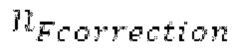 , выше 0,8 и на 0,02 выше нормализованной корреляции, возвращаемой посредством поиска основного тона для
, выше 0,8 и на 0,02 выше нормализованной корреляции, возвращаемой посредством поиска основного тона для 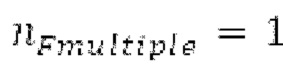 .
.
Если запаздывание в половину основного тона обнаруживается, то pitch_mid_corrected и pitch_end_corrected принимают значение, возвращаемое посредством поиска основного тона для 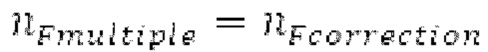 , в противном случае pitch_mid_corrected и pitch_end_corrected задаются равными pitch_mid и pitch_end, соответственно.
, в противном случае pitch_mid_corrected и pitch_end_corrected задаются равными pitch_mid и pitch_end, соответственно.
Среднее скорректированное запаздывание 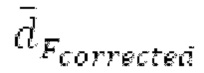 основного тона вычисляется как среднее pitch_start, pitch_mid_corrected и pitch_end_corrected после коррекции конечный октавных перескоков. Коррекция октавнык перескоков находит минимум из pitch_start, pitch_mid_corrected и pitch_end_corrected, и для каждого основного тона из pitch_start, pitch_mid_corrected и pitch_end_corrected находит основной тон /
основного тона вычисляется как среднее pitch_start, pitch_mid_corrected и pitch_end_corrected после коррекции конечный октавных перескоков. Коррекция октавнык перескоков находит минимум из pitch_start, pitch_mid_corrected и pitch_end_corrected, и для каждого основного тона из pitch_start, pitch_mid_corrected и pitch_end_corrected находит основной тон /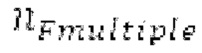 , ближайший к минимуму
, ближайший к минимуму 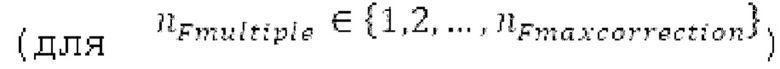 . Основной тон /
. Основной тон /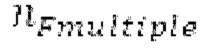 затем используется вместо исходного значения при вычислении средне го.
затем используется вместо исходного значения при вычислении средне го.
Ниже импульсное извлечение поясняется в контексте фиг.6. Фиг. 6 показывает модуль 110 импульсного извлечения, имеющий объекты 111hp, 112, 113с, 113р, 114 и 114m. Первый объект во вводе представляет собой используемый при необходимости фильтр верхних частот 111hp, который выводит сигнал в модуль 112 импульсного извлечения (извлекает импульсы и статистику).
В выводе размещаются два объекта 113с и 113р, которые взаимодействуют между собой и принимают в качестве ввода контур основного тона из объекта 180. Объект для 113 с выбора импульсов выводит импульсы Р непосредственно в другой объект 114, формирующий форму сигнала. Она представляет собой форму сигнала импульса и может вычитаться с использованием микшера 114m из сигнала РСМ таким образом, чтобы формировать остаточный сигнал R (остаток после извлечения импульсов).
Вплоть до 8 импульсов в расчете на кадр извлекаются и кодируются. В другом примере, может использоваться другое максимальное число импульсов. NPp импульсов из предыдущий кадров сохраняются и используются при извлечении и прогнозирующем кодировании 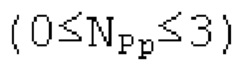 . В другом примере, другой предел может использоваться для
. В другом примере, другой предел может использоваться для 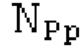 . «Получение 180 контура основного тона» обеспечивает
. «Получение 180 контура основного тона» обеспечивает 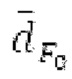 ; в качестве альтернативы, может использоваться
; в качестве альтернативы, может использоваться 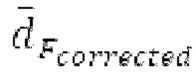 . Предполагается, что
. Предполагается, что 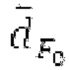 равен нулю для кадров с низкой гармоничностью.
равен нулю для кадров с низкой гармоничностью.
Частотно-временной анализ через кратковременное преобразование Фурье (STFT) используется для нахождения и извлечения импульсов (см. объект 112). В другом примере, могут использоваться другие частотно-временные представления. Сигнал PCMi может фильтроваться по верхним частотам (111hp) и подвергаться оконному взвешиванию с использованием возведенных в квадрат синусоидальных окон взвешивания длиной в 2 миллисекунды с 75%-м перекрытием и преобразовываться через дискретное преобразование Фурье (DFT) в частотную область (FD). В качестве альтернативы, фильтрация верхних частот может выполняться в FD (в 112s или в выводе 112s). Таким образом, в каждом кадре в 20 миллисекунд имеется 40 точек для каждой полосы частот, причем каждая точка состоит из абсолютной величины и фазы. Каждая полоса частот имеет ширину в 500 Гц, и учитываются только 49 полос частот для частоты дискретизации FS=48 кГц, поскольку оставшиеся 47 полос частот могут конструироваться через симметричное расширение. Таким образом, имеется 49 точек в каждый момент времени STFT и 40-49 точек в частотно-временной плоскости кадра. Размер STFT-перескока составляет Hp=0.0005FS.
На фиг.7, объект 112 показывается подробнее. В 112te, временная огибающая получается из спектрограммы логарифмической абсолютной величины посредством интеграции на частотной оси, т.е. для каждого момента времени STFT, логарифмические абсолютные величины суммируются для получения одной выборки временной огибающей.
Показанный объект 112 содержит объект 112s получения спектрограммы, выводящий фазу и/или спектрограмму абсолютной величины на основе сигнала PCMi. Спектрограмма фазы перенаправляется в модуль 112ре импульсного извлечения, тогда как спектрограмма абсолютной величины дополнительно обрабатывается. Спектрограмма абсолютной величины может обрабатываться с использованием модуля 112br удаления фона, модуля 112be оценки фона для оценки фонового сигнала, который должен удаляется. Дополнительно либо в качестве альтернативы, модуль 112te определения временной огибающей и модуль 112р1 определения местоположений импульсов обрабатывают спектрограмму абсолютной величины. Объекты 112pl и 112te позволяют определять эти местоположения импульсов, которые используются в качестве ввода для модуля 112ре импульсного извлечения и модуля 112be оценки фона. Модуль 112pl нахождения местоположений импульсов может использовать информацию контура основного тона. При необходимости, некоторые объекты, например, объект 112be и объект 112te, могут использовать алгоритмическое представление спектрограммы абсолютной величины, полученной посредством объекта 112lo.
Ниже поясняется функциональность. Сглаженная временная огибающая представляет собой фильтрованную по нижним частотам версию временной огибающей с использованием короткого симметричного фильтра FIR (например, фильтра четвертого порядка с FS=48 кГц).
Нормализованная автокорреляция временной огибающей вычисляется следующим образом:
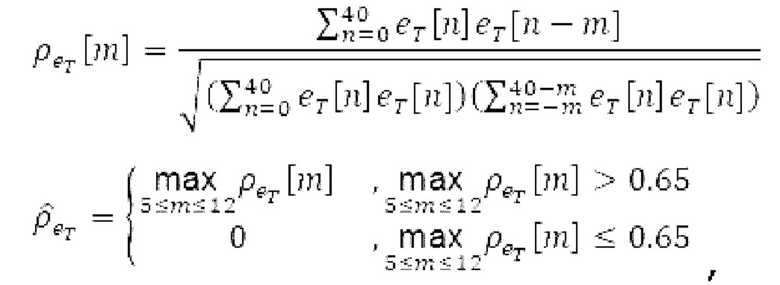
где ет является временной огибающей после удаления средних.
Точная задержка 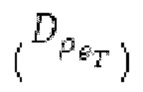 для максимума оценивается с использованием лагранжева полинома из 3 точек, формирующих пик в нормализованной автокорреляции.
для максимума оценивается с использованием лагранжева полинома из 3 точек, формирующих пик в нормализованной автокорреляции.
Ожидаемое среднее расстояние между импульсами может оцениваться из нормализованной автокорреляции временной огибающей и среднего запаздывания основного тона в кадре:
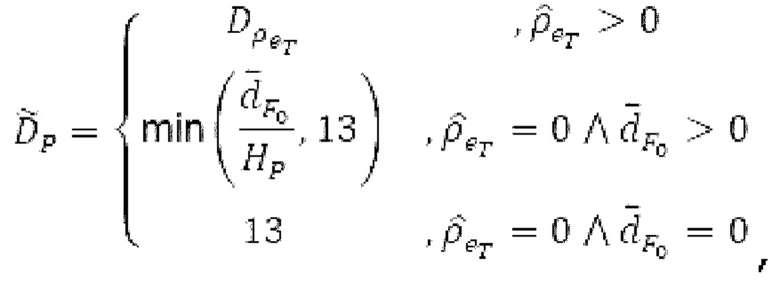
где, для кадров с низкой гармоничностью,  задается равным 13, что соответствует 6,5 миллисекундам.
задается равным 13, что соответствует 6,5 миллисекундам.
Положения импульсов представляют собой локальные пики в сглаженной временной огибающей с таким требованием, что пики должны находиться выше своих окрестностей. Окружение задается как фильтрованная по нижним частотам версия временной огибающей с использованием простого фильтра на основе скользящего среднего с адаптивной длиной; длина фильтра задается равной половине ожидаемого среднего расстояния  между импульсами. Точное положение
между импульсами. Точное положение 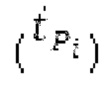 импульса оценивается с использованием лагранжева полинома из 3 точек, формирующих пик в сглаженной временной огибающей. Центральное положение
импульса оценивается с использованием лагранжева полинома из 3 точек, формирующих пик в сглаженной временной огибающей. Центральное положение 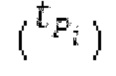 импульса представляет собой точное положение, округленное до моментов времени STFT, и в силу этого расстояние между центральными положениями импульсов является кратным 0,5 миллисекунды. Считается, что каждый импульс продолжается на 2 момента времени влево и на 2 вправо от своего центрального (временного) положения. Также может использоваться другое число моментов времени.
импульса представляет собой точное положение, округленное до моментов времени STFT, и в силу этого расстояние между центральными положениями импульсов является кратным 0,5 миллисекунды. Считается, что каждый импульс продолжается на 2 момента времени влево и на 2 вправо от своего центрального (временного) положения. Также может использоваться другое число моментов времени.
Вплоть до 8 импульсов в расчете на 20 миллисекунд находятся; если больше импульсов обнаруживается, то меньшие импульсы игнорируются. Число найденных импульсов обозначается как NPx; i-ый импульс обозначается как Р±. Среднее расстояние между импульсами задается следующим образом:
Абсолютные величины улучшаются на основе положений импульсов таким образом, что улучшенное STFT, также называемое «улучшенной спектрограммой», состоит только из импульсов. Фон импульса оценивается в качестве линейной интерполяции левого и правого фона, причем левый и правый фоны являются средним значением третьего-пятого моментов времени, отстоящего от центрального (временного) положения. Фон оценивается в области логарифмической абсолютной величины в 112be и удаляется посредством его вычитания в области линейной абсолютной величины в 112br. Абсолютные величины в улучшенном STFT задаются на линейной шкале. Фаза не модифицируется. Все абсолютные величины в моменты времени, не принадлежащие импульсу, задаются равными нулю.
Начальная частота импульса является пропорциональной инверсии среднего расстояния между импульсами (между близлежащими формами импульсного сигнала) в кадре, но ограничивается между 750 Гц и 7250 Гц:
Начальная частота 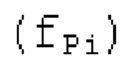 выражается как индекс STFT-полосы частот.
выражается как индекс STFT-полосы частот.
Изменение начальной частоты в последовательный импульсах ограничено 500 Гц (одной STFT-полосой частот). Абсолютные величины улучшенного STFT ниже начальной частоты задаются равными нулю в 112ре.
Форма сигнала каждого импульса получается из улучшенного STFT в 112ре. Форма импульсного сигнала является ненулевой в пределах 4 миллисекунд вокруг ее временного центра, и длина импульса составляет  (частота дискретизации формы импульсного сигнала равна частоте дискретизации Fs входного сигнала). Символ
(частота дискретизации формы импульсного сигнала равна частоте дискретизации Fs входного сигнала). Символ  представляет форму сигнала i-ого импульса.
представляет форму сигнала i-ого импульса.
Каждый импульс  уникально определяется центральным положением
уникально определяется центральным положением 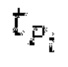 и формой
и формой 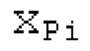 импульсного сигнала. Модуль 112ре импульсного извлечения выводит импульсы Pi, состоящие из центральных положений
импульсного сигнала. Модуль 112ре импульсного извлечения выводит импульсы Pi, состоящие из центральных положений 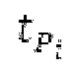 и формы
и формы 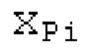 импульсного сигнала.
импульсного сигнала.
Импульсы совмещаются с сеткой STFT. В качестве альтернативы, импульсы могут не совмещаться с сеткой STFT, и/или точное положение 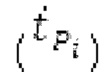 импульса может определять импульс вместо
импульса может определять импульс вместо 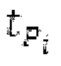 .
.
Признаки вычисляются для каждого импульса:
- процентная доля от локальной энергии в импульсе - 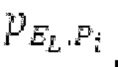 ,
,
- процентная доля от энергии кадра в импульсе - 
- процентная доля от полос частот с энергией импульса выше половины локальной энергии - 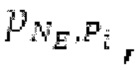
- корреляция 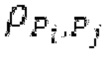 и расстояние
и расстояние 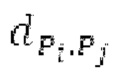 между каждой парой импульсов (из числа импульсов в текущем кадре и NPp последний кодированный импульсов из прошлый кадров),
между каждой парой импульсов (из числа импульсов в текущем кадре и NPp последний кодированный импульсов из прошлый кадров),
запаздывание основного тона в точном местоположении импульса - dPi.
Локальная энергия вычисляется из 11 моментов времени вокруг центра импульса в исходном STFT. Все энергии вычисляются только выше начальной частоты.
Расстояние 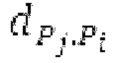 между парой импульсов получается из местоположения максимальной взаимной корреляции
между парой импульсов получается из местоположения максимальной взаимной корреляции 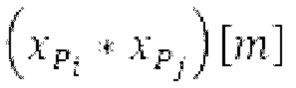 между импульсами. Взаимная корреляция подвергается оконному взвешиванию с прямоугольным окном взвешивания длиной в 2 миллисекунды и нормализуется посредством нормы импульсов (также подвергается оконному взвешиванию с прямоугольным окном взвешивания в 2 миллисекунды). Корреляция импульсов является максимумом нормализованной взаимной корреляции:
между импульсами. Взаимная корреляция подвергается оконному взвешиванию с прямоугольным окном взвешивания длиной в 2 миллисекунды и нормализуется посредством нормы импульсов (также подвергается оконному взвешиванию с прямоугольным окном взвешивания в 2 миллисекунды). Корреляция импульсов является максимумом нормализованной взаимной корреляции:
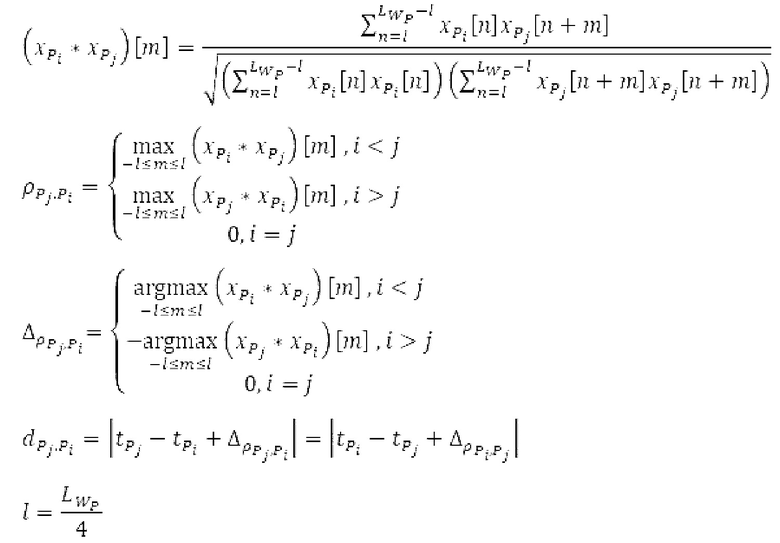
Значение 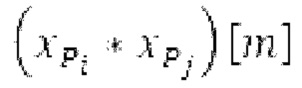 находится в диапазоне между 0 и 1.
находится в диапазоне между 0 и 1.
Ошибка между основным тоном и расстоянием между импульсами вычисляется следующим образом:
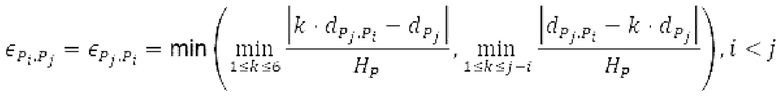
При введении кратного числа 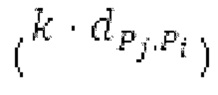 расстояния между импульсами, ошибки в оценке основного тона учитываются. Введение кратных чисел
расстояния между импульсами, ошибки в оценке основного тона учитываются. Введение кратных чисел 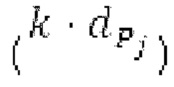 запаздывания основного тона разрешает пропущенные импульсы, возникающие в результате неидеальностей в цепочках импульсов: если импульс в цепочке искажается, или имеется переходная часть, не принадлежащая цепочке импульсов, которая запрещает обнаружение импульса, принадлежащего цепочке.
запаздывания основного тона разрешает пропущенные импульсы, возникающие в результате неидеальностей в цепочках импульсов: если импульс в цепочке искажается, или имеется переходная часть, не принадлежащая цепочке импульсов, которая запрещает обнаружение импульса, принадлежащего цепочке.
Вероятность того, что i-ый и j-ый импульс принадлежат цепочке импульсов (см. объект 113р):
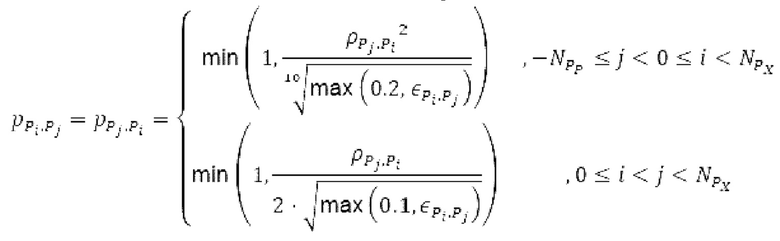
Вероятность импульса со взаимосвязью только с уже кодированными предыдущими импульсами задается следующим образом:
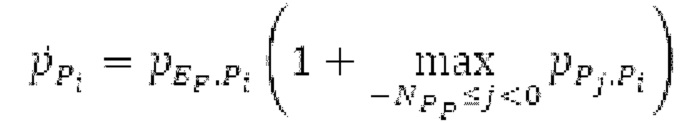
Вероятность 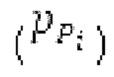 (см. объект 113р) импульса итеративно находится:
(см. объект 113р) импульса итеративно находится:
1. Все вероятности 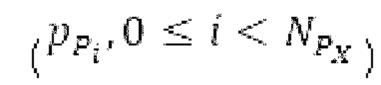 возникновения импульсов задаются равными 1.
возникновения импульсов задаются равными 1.
2. В порядке появления во времени импульсов, для каждого импульса, который по-прежнему является вероятным 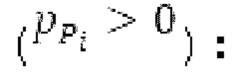
a. Вероятность импульса, принадлежащего цепочке импульсов в текущем кадре, вычисляется:
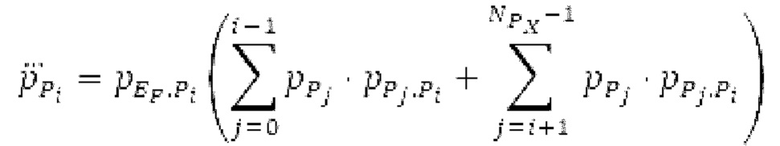
b. Начальная вероятность того, что он представляет собой истинный импульс, в таком случае является следующей:
37
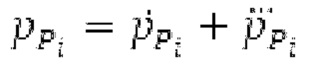
c. Вероятность увеличивается для импульсов с энергией во множестве полос частот выше половины локальной энергии:
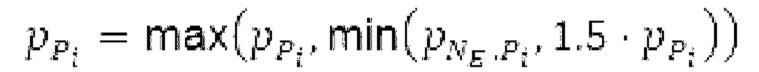
d. Вероятность ограничена посредством корреляции временных огибающих и процентной доли от локальной энергии в импульсе:
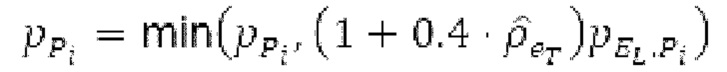
e. Если вероятность возникновения импульсов ниже порогового значения, то эта вероятность задается равной нулю, и она более не учитывается:
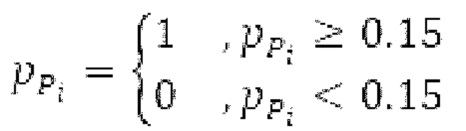
3. Этап 2 повторяется при условии, что имеется по меньшей мере одна 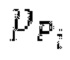 , заданная равной нулю в текущей итерации, либо до тех пор, пока все
, заданная равной нулю в текущей итерации, либо до тех пор, пока все 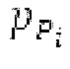 не задаются равными нулю.
не задаются равными нулю.
В конце этой процедуры, имеются NPc истинных импульсов с 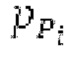 , равной единице. Все и только истинные импульсы составляют импульсную часть Р и кодируются в качестве СР. Из числа NPc истинных импульсов, вплоть до трех последних импульсов сохраняются в запоминающем устройстве для вычисления
, равной единице. Все и только истинные импульсы составляют импульсную часть Р и кодируются в качестве СР. Из числа NPc истинных импульсов, вплоть до трех последних импульсов сохраняются в запоминающем устройстве для вычисления 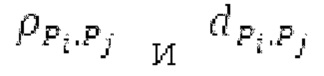 в следующих кадрах. Если имеется менее трех истинных импульсов в текущем кадре, некоторые импульсы уже в запоминающем устройстве сохраняются. Всего вплоть до трех импульсов сохраняются в запоминающем устройстве. Может быть предусмотрен другой предел для числа импульсов, сохраненных в запоминающем устройстве, например, 2 или 4. После того, как имеется три импульса в запоминающем устройстве, запоминающее устройство остается полным, при этом самые старые импульсы в запоминающем устройстве заменяются посредством новых найденных импульсов. Другими словами, число
в следующих кадрах. Если имеется менее трех истинных импульсов в текущем кадре, некоторые импульсы уже в запоминающем устройстве сохраняются. Всего вплоть до трех импульсов сохраняются в запоминающем устройстве. Может быть предусмотрен другой предел для числа импульсов, сохраненных в запоминающем устройстве, например, 2 или 4. После того, как имеется три импульса в запоминающем устройстве, запоминающее устройство остается полным, при этом самые старые импульсы в запоминающем устройстве заменяются посредством новых найденных импульсов. Другими словами, число 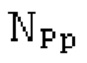 предыдущих импульсов, сохраненных в запоминающем устройстве, увеличивается в начале обработки до
предыдущих импульсов, сохраненных в запоминающем устройстве, увеличивается в начале обработки до 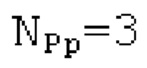 и сохраняется равным 3 в дальнейшем.
и сохраняется равным 3 в дальнейшем.
Ниже, относительно фиг.8, поясняется импульсное кодирование (сторона кодера, см. объект 132).
Фиг. 8 показывает кодер 132 импульсов, содержащий объекты 132fs, 132c и 132pc в основном тракте, при этом объект 132as выполнен с возможностью определения и передачи спектральной огибающей в качестве ввода в объект 132fs, выполненный с возможностью выполнения спектрального сглаживания. В основном тракте 132fs, 132с и 132рс, импульсы Р кодируются, чтобы определять кодированные спектрально сглаженные импульсы. Кодирование, выполняемое посредством объекта 132рс, выполняется для спектрально сглаженных импульсов. Кодированные импульсы CP на фиг.2а-с состоят из кодированных спектрально сглаженных импульсов и спектральной огибающей импульса. Ниже подробно поясняется кодирование множества импульсов относительно фиг.10. Импульсы кодируются с использованием параметров:
- число NPc импульсов в кадре,
- положение 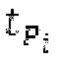 в кадре,
в кадре,
- начальная частота fPi импульсов,
- спектральная огибающая импульса,
усиление  для прогнозирования, и если
для прогнозирования, и если  не равно нулю:
не равно нулю:
-- индекс 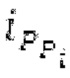 источника прогнозирования,
источника прогнозирования,
-- смещение 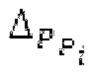 при прогнозировании,
при прогнозировании,
- инновационное усиление 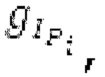
- инновация, состоящая из вплоть до 4 импульсов, причем каждый импульс кодируется посредством своего положения и знака.
Один кодированный импульс определяется посредством параметров:
- начальная частота 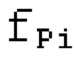 импульсов,
импульсов,
- спектральная огибающая импульса,
усиление 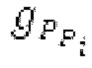 для прогнозирования, и если
для прогнозирования, и если 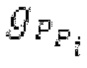 не равно нулю:
не равно нулю:
-- индекс 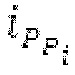 источника прогнозирования,
источника прогнозирования,
-- смещение 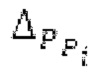 при прогнозировании,
при прогнозировании,
- инновационное усиление 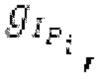
инновация, состоящая из вплоть до 4 импульсов, причем каждый импульс кодируется своим положением и знаком.
Из параметров, которые определяют один кодированный импульс, может конструироваться форма сигнала, которая представляет один кодированный импульс. В таком случае также можно сказать, что кодированная форма импульсного сигнала определяется посредством параметров одного кодированного импульса.
Число импульсов кодируется кодом Хаффмана.
Первое положение 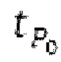 импульса кодируется абсолютно с использованием кодирования кодом Хаффмана. Для следующих импульсов, дельты
импульса кодируется абсолютно с использованием кодирования кодом Хаффмана. Для следующих импульсов, дельты 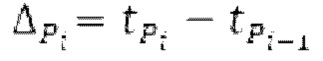 положений кодируются кодом Хаффмана. Предусмотрены различные коды Хаффмана в зависимости от числа импульсов в кадре и в зависимости от первого положения импульса.
положений кодируются кодом Хаффмана. Предусмотрены различные коды Хаффмана в зависимости от числа импульсов в кадре и в зависимости от первого положения импульса.
Первая начальная частота fP0 импульсов кодируется абсолютно с использованием кодирования кодом Хаффмана. Начальные частоты следующих импульсов дифференциально кодируются. Если имеется нулевая разность, то все следующие разности также являются нулевыми, в силу чего число ненулевых разностей кодируется. Все разности имеют одинаковый знак, в силу чего знак разностей может кодироваться с одним битом в расчете на кадр. В большинстве случаев, абсолютная разность составляет самое большее единицу, в силу чего один бит используется для кодирования, если максимальная абсолютная разность составляет единицу или более. В конце, только если максимальная абсолютная разность больше единицы, все ненулевые абсолютные разности должны кодироваться, и они унарно кодируются.
Спектральное сглаживание, например, выполняемое с
использованием STFT (см. объект 132fs по фиг.8), проиллюстрировано посредством фиг.9а и 9b, при этом фиг.9а показывает исходную форму импульсного сигнала по сравнению со сглаженной версией по фиг.9b. Следует обратить внимание, что спектральное сглаживание альтернативно может выполняться посредством фильтра, например, во временной области.
Все импульсы в кадре могут использовать равную спектральную огибающую (см. объект 132as), состоящую, например, из восьми полос частот. Частоты границ полос частот являются следующими: 1 кГц, 1,5 кГц, 2,5 кГц, 3,5 кГц, 4,5 кГц, 6 кГц, 8,5 кГц, 11,5 кГц, 16 кГц. Спектральное содержимое выше 16 кГц не кодируется явным образом. В другом примере, могут использоваться другие границы полос частот.
Спектральная огибающая в каждый момент времени импульса получается посредством суммирования абсолютный величин в полосах частот огибающей, причем импульс состоит из 5 моментов времени. Огибающие усредняются по всем импульсам в кадре. Точки между импульсами в частотно-временной плоскости не учитываются.
Значения сжимаются с использованием корня четвертой степени, и огибающие векторно квантуются. Векторный квантователь имеет 2 каскада, и второй каскад разбивается на 2 половины. Различные таблицы кодирования существуют для кадров с 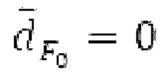 и
и 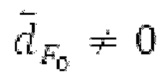 и для значений
и для значений 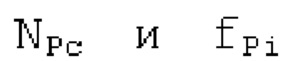 . Различные таблицы кодирования требуют различного числа битов.
. Различные таблицы кодирования требуют различного числа битов.
Квантованная огибающая может сглаживаться с использованием линейной интерполяции. Спектрограммы импульсов сглаживаются с использованием сглаженной огибающей (см. объект 132fs). Сглаживание достигается посредством деления абсолютных величин на огибающую (принимаемую из объекта 132as), которое является эквивалентным вычитанию в области логарифмической абсолютной величины. Значения фазы не изменяются. В качестве альтернативы, процессор фильтрации может быть выполнен с возможностью спектрального сглаживания абсолютных величин или импульсного STFT посредством фильтрации формы импульсного сигнала во временной области.
Форма YPi сигнала спектрально сглаженного импульса получается из STFT через обратное DFT, оконное взвешивание и суммирование с перекрытием в 132с.
Фиг. 10 показывает объект 132рс для кодирования одной спектрально сглаженной формы импульсного сигнала из множества спектрально сглаженных форм импульсного сигнала. Каждая одна кодированная форма импульсного сигнала выводится в качестве кодированного импульсного сигнала. С другой точки зрения, объект 132рс для кодирования одиночных импульсов по фиг.10 является одинаковым с объектом 132рс, выполненному с возможностью кодирования форм импульсного сигнала, как показано на фиг.8, но используется несколько раз для кодирования нескольких форм импульсного сигнала.
Объект 132рс по фиг.10 содержит кодер 132зрс импульсов, конструктор 132cpw для сглаженной формы импульсного сигнала и запоминающее устройство 132 т, размещаемые в качестве вида контура обратной связи. Конструктор 132cpw имеет ту же функциональность, что и 220cpw, а запоминающее устройство 132m - ту же функциональность, что и 229 на фиг.14. Каждый одиночный/текущий импульс кодируется посредством объекта 132spc на основе предыдущих импульсов с учетом сглаженной формы импульсного сигнала. Информация относительно предыдущих импульсов обеспечивается запоминающим устройством 132m. Следует обратить внимание, что предыдущие импульсы, кодированные посредством 132рс, подаются через конструктор 132cpw формы импульсного сигнала и запоминающее устройство 132 т.Это обеспечивает прогнозирование. Результат в силу использования такого подхода на основе прогнозирования проиллюстрирован посредством фиг.11. Здесь, фиг.11а указывает сглаженный оригинал вместе с прогнозированием и результирующим остаточным сигналом прогнозирования на фиг.11b.
Согласно вариантам осуществления, наиболее аналогичный ранее квантованный импульс находится из числа 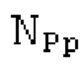 импульсов из предыдущих кадров и уже квантованных импульсов из текущего кадра. Корреляция
импульсов из предыдущих кадров и уже квантованных импульсов из текущего кадра. Корреляция 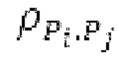 , заданная выше, используется для выбора наиболее аналогичного импульса. Если разности в корреляции ниже 0,05, более близкий импульс выбирается. Наиболее аналогичный предыдущий импульс представляет собой источник
, заданная выше, используется для выбора наиболее аналогичного импульса. Если разности в корреляции ниже 0,05, более близкий импульс выбирается. Наиболее аналогичный предыдущий импульс представляет собой источник 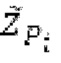 прогнозирования, и его индекс
прогнозирования, и его индекс 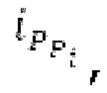 относительно текущего кодированного импульса, используется в импульсном кодировании. Вплоть до четырех относительных индексов
относительно текущего кодированного импульса, используется в импульсном кодировании. Вплоть до четырех относительных индексов 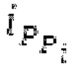 источников прогнозирования группируются и кодируются кодом Хаффмана. Группировка и коды Хаффмана зависят от
источников прогнозирования группируются и кодируются кодом Хаффмана. Группировка и коды Хаффмана зависят от 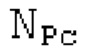 и от того, либо
и от того, либо 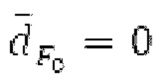 , либо
, либо 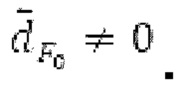
Смещение для максимальной корреляции представляет собой смещение  при импульсном прогнозировании. Оно кодируется абсолютно, дифференцированно или относительно оцененного значения, причем оценка вычисляется из запаздывания основного тона в точном местоположении импульса dPi. Число битов, требуемых для каждого типа кодирования, вычисляется, и тип кодирования с минимальным числом битов выбирается.
при импульсном прогнозировании. Оно кодируется абсолютно, дифференцированно или относительно оцененного значения, причем оценка вычисляется из запаздывания основного тона в точном местоположении импульса dPi. Число битов, требуемых для каждого типа кодирования, вычисляется, и тип кодирования с минимальным числом битов выбирается.
Усиление  которое максимизирует SNR, используется для масштабирования прогнозирования
которое максимизирует SNR, используется для масштабирования прогнозирования 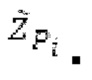 Усиление для прогнозирования неравномерно квантуется с 3-4 битами. Если энергия остатка прогнозирования не меньше по меньшей мере на 5% энергии импульса, прогнозирование не используется, и
Усиление для прогнозирования неравномерно квантуется с 3-4 битами. Если энергия остатка прогнозирования не меньше по меньшей мере на 5% энергии импульса, прогнозирование не используется, и 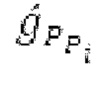 задается равным нулю.
задается равным нулю.
Остаток прогнозирования квантуется с использованием вплоть до четырех импульсов. В другом примере, может использоваться другое максимальное число импульсов. Квантованный остаток, состоящий из импульсов, называется  Это проиллюстрировано посредством фиг.12. Чтобы сокращать число битов, число импульсов уменьшается на единицу для каждого импульса, прогнозируемого из импульса в этом кадре. Другими словами: если усиление для прогнозирования является нулевым, либо если источник прогнозирования представляет собой импульс из предыдущих кадров, то четыре импульса квантуются, в противном случае число импульсов снижается по сравнению с источником прогнозирования.
Это проиллюстрировано посредством фиг.12. Чтобы сокращать число битов, число импульсов уменьшается на единицу для каждого импульса, прогнозируемого из импульса в этом кадре. Другими словами: если усиление для прогнозирования является нулевым, либо если источник прогнозирования представляет собой импульс из предыдущих кадров, то четыре импульса квантуются, в противном случае число импульсов снижается по сравнению с источником прогнозирования.
Фиг. 12 показывает тракт обработки, который должен использоваться в качестве блока 132spc обработки по фиг.10. Тракт обработки позволяет определять кодированные импульсы и может содержать три объекта 132bp, 132qi, 132се.
Первый объект 132bp для нахождения наилучшего прогнозирования использует предыдущий импульс(ы) и форму импульсного сигнала для определения iSOURCE, сдвига, GP' и остатка прогнозирования. Объект 132gi квантования импульсов квантует остаток прогнозирования и выводит GI' и импульсы. Объект 132се выполнен с возможностью вычисления и применения коэффициента коррекции. Вся эта информация вместе с формой импульсного сигнала принимается посредством объекта 132се для коррекции энергии таким образом, чтобы вывести кодированный импульс. Следующий алгоритм может использоваться согласно вариантам осуществления:
Для нахождения и кодирования импульсов, используется следующий алгоритм:
1. Абсолютная форма 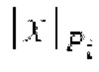 импульсного сигнала конструируется с использованием двухполупериодного выпрямления:
импульсного сигнала конструируется с использованием двухполупериодного выпрямления:
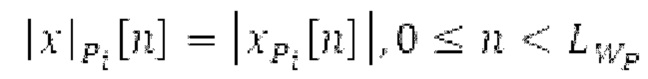
2. Вектор с числом 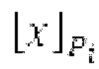 импульсов в каждом местоположении инициализируется с нулями:
импульсов в каждом местоположении инициализируется с нулями:
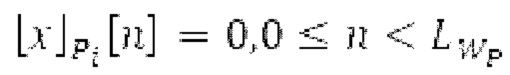
3. Местоположение максимума в 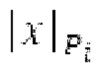 находится:
находится:
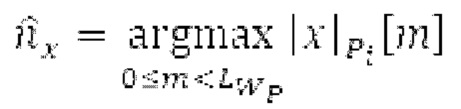
4. Вектор с числом импульсов увеличивается на единицу в местоположении 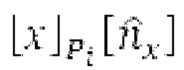 найденного максимума:
найденного максимума:
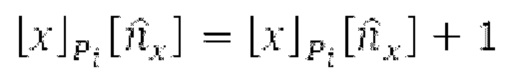
5. Максимум в 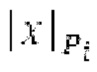 уменьшается:
уменьшается:
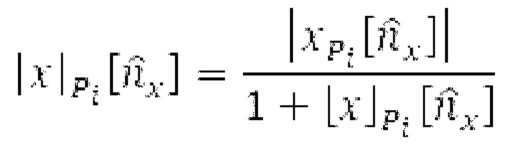
6. Этапы 3-5 повторяются до тех пор, пока не найдено требуемое число импульсов, при этом число импульсов равно 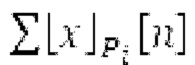
Следует отметить, что импульсы могут иметь одинаковое местоположение. Местоположения импульсов упорядочиваются посредством их расстояния от центра импульса. Местоположение первого импульса абсолютно кодируется. Местоположения следующих импульсов дифференциально кодируются с вероятностями в зависимости от положения предыдущего импульса. Кодирование кодом Хаффмана используется для местоположения импульса. Знак каждого импульса также кодируется. Если множество импульсов имеют одинаковое местоположение, то знак кодируется лишь однократно.
4 результирующих найденных и масштабированных импульса 15i остаточного сигнала 15r проиллюстрированы посредством фиг.13.
Подробно, импульсы, представленные посредством линий 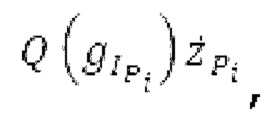 могут масштабироваться надлежащим образом, например, импульс +/- 1, умноженный на усиление
могут масштабироваться надлежащим образом, например, импульс +/- 1, умноженный на усиление 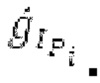
Усиление 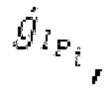 которое максимизирует SNR, используется для масштабирования инновации
которое максимизирует SNR, используется для масштабирования инновации 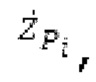 состоящей из импульсов. Инновационное усиление неравномерно квантуется с 2-4 битами, в зависимости от числа
состоящей из импульсов. Инновационное усиление неравномерно квантуется с 2-4 битами, в зависимости от числа 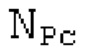 импульсов.
импульсов.
Первая оценка для квантования сглаженной формы 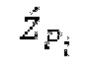 импульсного сигнала в таком случае является следующей:
импульсного сигнала в таком случае является следующей:
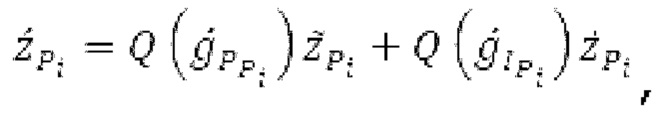
где  обозначает квантование.
обозначает квантование.
Поскольку усиления находятся посредством максимизации SNR, энергия 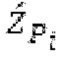 может быть гораздо ниже энергии исходного целевого
может быть гораздо ниже энергии исходного целевого  Чтобы компенсировать уменьшение энергии, коэффициент
Чтобы компенсировать уменьшение энергии, коэффициент  коррекции вычисляется:
коррекции вычисляется:
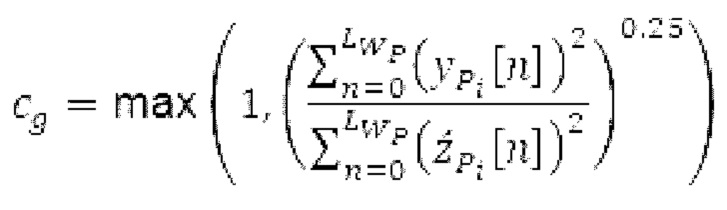
Конечные усиления затем являются следующими:
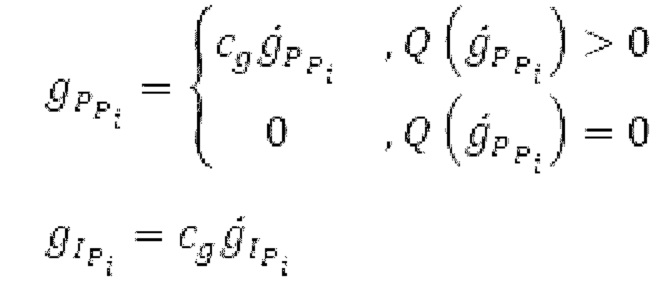
Запоминающее устройство для прогнозирования обновляется с использованием квантованной сглаженной формы импульсного сигнала:
импульсного сигнала:
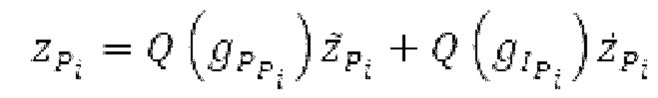
В конце кодирования 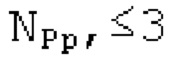 квантованных сглаженных форм импульсного сигнала сохраняются в запоминающем устройстве для прогнозирования в следующих кадрах.
квантованных сглаженных форм импульсного сигнала сохраняются в запоминающем устройстве для прогнозирования в следующих кадрах.
Ниже, обращаясь к фиг.14, поясняется подход для реконструкции импульсов.
Фиг. 14 показывает объект 220 для реконструкции формы сигнала одиночного импульса. Поясненный ниже подход для реконструкции формы сигнала одиночного импульса выполняется многократно для множества форм импульсного сигнала. Множество форм импульсного сигнала используются объектом 22' по фиг.15 для реконструкции формы сигнала, которая включает в себя множество импульсов. С другой точки зрения, объект 220 обрабатывает сигнал, состоящий из множества кодированных импульсов и множества спектральных огибающих импульса, и, для каждого кодированного импульса и ассоциированной спектральной огибающей импульса, выводит одну реконструированную форму импульсного сигнала таким образом, что в выводе объекта 220 предусмотрен сигнал, состоящий из множества реконструированных форм импульсного сигнала.
Объект 220 содержит множество подобъектов, например, объект 220cpw для конструирования спектрально сглаженной формы импульсного сигнала, объект 224 для формирования спектрограммы импульсов (спектрограммы фазы и абсолютной величины) спектрально сглаженной формы импульсного сигнала и объект 226 для спектрального формирования спектрограммы абсолютной величины импульсов. Этот объект 226 использует спектрограмму абсолютной величины, а также спектральную огибающую импульса. Вывод объекта 226 подается в модуль преобразования для преобразования спектрограммы импульсов в форму сигнала, который указан ссылочной позицией 228. Этот объект 228 принимает спектрограмму фазы, а также спектрально сформированную спектрограмму абсолютной величины импульсов, с тем чтобы реконструировать форму импульсного сигнала. Следует отметить, что объект 220cpw (выполненный с возможностью конструирования спектрально сглаженной формы импульсного сигнала) принимает во вводе сигнал, описывающий кодированный импульс. Конструктор 220cpw содержит вид контура обратной связи, включающего в себя запоминающее устройство 229 обновления. Это обеспечивает возможность того, что форма импульсного сигнала конструируется с учетом предыдущих импульсов. Здесь, ранее сконструированные формы импульсного сигнала возвращаются таким образом, что предыдущие импульсы могут использоваться посредством объекта 220cpw для конструирования следующей формы импульсного сигнала. Ниже поясняется функциональность этого модуля 220 реконструкции импульсов. Следует отметить, что на стороне декодера имеются только квантованные сглаженные формы импульсного сигнала (также называются «декодированными сглаженными формами импульсного сигнала» или «кодированными сглаженными формами импульсного сигнала»), и поскольку отсутствуют исходные формы импульсного сигнала на стороне декодера, используются сглаженные формы импульсного сигнала для называния квантованных сглаженных форм импульсного сигнала на стороне декодера и формы импульсного сигнала для называния квантованный форм импульсного сигнала (также называются «декодированными формами импульсного сигнала» или «кодированными формами импульсного сигнала», или «декодированными формами импульсного сигнала»).
Для реконструкции импульсов на стороне 220 декодера, квантованные сглаженные формы импульсного сигнала конструируются (см. объект 220cpw) после декодирования усилений  , импульсов/инновации, источника
, импульсов/инновации, источника  прогнозирования и смещения
прогнозирования и смещения 
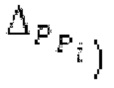 . Запоминающее устройство 229 для прогнозирования обновляется (аналогично кодеру в объекте 132m). STFT (см. объект 224) затем получается для каждой формы импульсного сигнала. Например, используются возведенные в квадрат синусоидальные окна взвешивания длиной в 2 миллисекунды с 75% перекрытием, равные окнам взвешивания при импульсном извлечении. Абсолютные величины STFT восстанавливаются в исходную форму с использованием декодированной и сглаженной спектральной огибающей и обнуляются ниже начальной частоты fPi импульсов. Простое умножение абсолютных величин на огибающую может использоваться для формирования STFT (см. объект 226). Фазы не модифицируются. Реконструированная форма сигнала импульса получается из STFT через обратное DFT, оконное взвешивание и суммирование с перекрытием (см. объект 228). Б качестве альтернативы, огибающая может формироваться через FIR или некоторый другой фильтр, исключая STFT.
. Запоминающее устройство 229 для прогнозирования обновляется (аналогично кодеру в объекте 132m). STFT (см. объект 224) затем получается для каждой формы импульсного сигнала. Например, используются возведенные в квадрат синусоидальные окна взвешивания длиной в 2 миллисекунды с 75% перекрытием, равные окнам взвешивания при импульсном извлечении. Абсолютные величины STFT восстанавливаются в исходную форму с использованием декодированной и сглаженной спектральной огибающей и обнуляются ниже начальной частоты fPi импульсов. Простое умножение абсолютных величин на огибающую может использоваться для формирования STFT (см. объект 226). Фазы не модифицируются. Реконструированная форма сигнала импульса получается из STFT через обратное DFT, оконное взвешивание и суммирование с перекрытием (см. объект 228). Б качестве альтернативы, огибающая может формироваться через FIR или некоторый другой фильтр, исключая STFT.
Фиг. 15 показывает объект 22 т, последующий относительно объекта 228, который принимает множество реконструированных форм сигналов импульсов, а также положений импульсов, таким образом, чтобы конструировать форму YP сигнала (см. фиг.2а, 2с). Этот объект 22' используется, например, в качестве последнего объекта в конструкторе 22 форм сигналов по 2а или 2с.
Реконструированные формы импульсного сигнала конкатенируются на основе декодированных положений 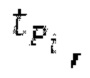 со вставкой нулей между импульсами в объекте 22' на фиг.15. Конкатенированная форма сигнала суммируется с декодированным сигналом (см. 23 на фиг.2а или фиг.2с либо 114m на фиг.6). Таким же способом исходные формы xPi импульсного сигнала конкатенируются (см. 6 114 на фиг.6) и вычитаются из ввода кодека на основе MDCT (см. фиг.6).
со вставкой нулей между импульсами в объекте 22' на фиг.15. Конкатенированная форма сигнала суммируется с декодированным сигналом (см. 23 на фиг.2а или фиг.2с либо 114m на фиг.6). Таким же способом исходные формы xPi импульсного сигнала конкатенируются (см. 6 114 на фиг.6) и вычитаются из ввода кодека на основе MDCT (см. фиг.6).
Реконструированные формы импульсного сигнала конкатенируются на основе декодированных положений 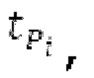 со вставкой нулей между импульсами. Конкатенированная форма сигнала суммируется с декодированным сигналом. Таким же способом исходные формы xPi импульсного сигнала конкатенируются и вычитаются из ввода кодека на основе MDCT.
со вставкой нулей между импульсами. Конкатенированная форма сигнала суммируется с декодированным сигналом. Таким же способом исходные формы xPi импульсного сигнала конкатенируются и вычитаются из ввода кодека на основе MDCT.
Реконструированная форма импульсного сигнала не является идеальными представлениями исходных импульсов. Удаление реконструированной формы импульсного сигнала из ввода в силу этого должно оставлять некоторые переходные части сигнала. Поскольку переходные сигналы не могут оптимально представляться с помощью кодека MDCT, шум, разбросанный по полному кадру, должен присутствовать, и преимущество отдельного кодирования импульсов должно уменьшаться. По этой причине, исходные импульсы удаляются из ввода.
Согласно вариантам осуществления, флаг 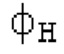 HF-тональности может задаваться следующим образом:
HF-тональности может задаваться следующим образом:
Нормализованная корреляция 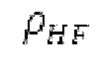 вычисляется для
вычисляется для 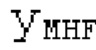 между выборками в текущем окне взвешивания и задержанной версией с задержкой
между выборками в текущем окне взвешивания и задержанной версией с задержкой 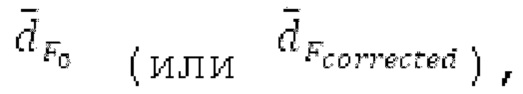 при этом
при этом 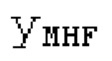 является фильтрованной по верхним частотам версией остаточного импульсного сигнала
является фильтрованной по верхним частотам версией остаточного импульсного сигнала 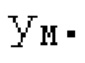 Для примера, может использоваться фильтр верхних частот с частотой перехода приблизительно в 6 кГц.
Для примера, может использоваться фильтр верхних частот с частотой перехода приблизительно в 6 кГц.
Для каждого частотного элемента MDCT разрешения выше указанной частоты, как указано в 5.3.3.2.5 по [18], определяется то, является либо нет частотный элемент разрешения тональным или шумоподобным. Общее число тональных частотных элементов 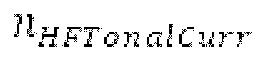 разрешения вычисляется в текущем кадре, и дополнительно сглаженное общее число тональных частот вычисляется как
разрешения вычисляется в текущем кадре, и дополнительно сглаженное общее число тональных частот вычисляется как 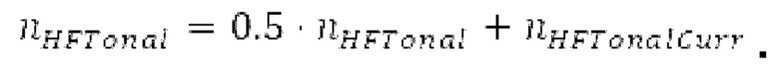
Флаг 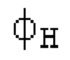 HF-тональности задается равным 1, если TNS является неактивным, и контур основного тона присутствует, и имеется тональность на высоких частотах, при этом тональность существует на высоких частотах, если
HF-тональности задается равным 1, если TNS является неактивным, и контур основного тона присутствует, и имеется тональность на высоких частотах, при этом тональность существует на высоких частотах, если 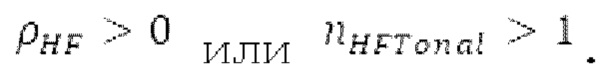
Относительно фиг.16, поясняется подход iBPC. Ниже поясняется процесс получения оптимального размера 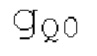 шага квантования. Процесс может представлять собой неотъемлемую часть iBPC блока. Следует обратить внимание, что iBPC по фиг.16 выводит на основе
шага квантования. Процесс может представлять собой неотъемлемую часть iBPC блока. Следует обратить внимание, что iBPC по фиг.16 выводит на основе 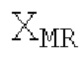 . В другом устройстве в качестве ввода могут использоваться
. В другом устройстве в качестве ввода могут использоваться 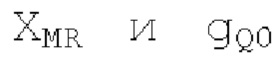 (для получения подробностей см. фиг. 3).
(для получения подробностей см. фиг. 3).
Фиг. 16 показывает блок-схему подхода для оценки размера шага. Процесс начинается с i=0, при этом далее, например, выполняются четыре этапа квантования, адаптивного обнуления полос частот, объединенного определения параметров для каждой полосы частот и спектра и определения того, является ли спектр кодируемым. Эти этапы указаны ссылочными позициями 301-304. В случае если спектр является кодируемым, размер шага снижается (см. этап 307), выполняется следующая итерация++i, см. ссылочную позицию 308. Это выполняется при условии, что i не равен максимальной итерации (см. этап 309 принятия решения). В случае если максимальная итерация достигается, размер шага выводится. В случае если максимальная итерация не достигается, выполняется следующая итерация.
В случае если спектр не является кодируемым, процесс, имеющий этапы 311 и 312 вместе с этапом 313 верификации (спектр теперь является кодируемым), применяется. После этого, размер шага увеличивается (см. 34 0) перед инициированием следующей итерации (см. этап 308).
Спектр 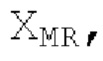 спектральная огибающая которого перцепционно сглаживается, скалярно квантуется с использованием одного размера
спектральная огибающая которого перцепционно сглаживается, скалярно квантуется с использованием одного размера 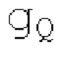 шага квантования по полной кодированной полосе пропускания и энтропийно кодируется, например, с помощью контекстного арифметического кодера, формирующего кодированный spect. Кодированная полоса пропускания спектра разделяется на подполосы Bi частот увеличивающейся ширины
шага квантования по полной кодированной полосе пропускания и энтропийно кодируется, например, с помощью контекстного арифметического кодера, формирующего кодированный spect. Кодированная полоса пропускания спектра разделяется на подполосы Bi частот увеличивающейся ширины  .
.
Оптимальный размер шага квантования, также называемый «глобальным усилением», итеративно находится, как пояснено выше в описании фиг.16.
На каждой итерации, спектр XMR квантуется в блоке квантования, чтобы формировать 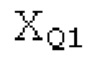 . Б блоке «адаптивного обнуления полос частот», отношение энергии нульквантованнык линий и исходной энергии вычисляется в подполосак
. Б блоке «адаптивного обнуления полос частот», отношение энергии нульквантованнык линий и исходной энергии вычисляется в подполосак 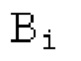 частот, и если отношение энергий выше адаптивного порогового значения
частот, и если отношение энергий выше адаптивного порогового значения 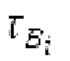 , полная подполоса частот в
, полная подполоса частот в 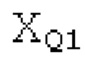 задается равной нулю. Пороговые значения
задается равной нулю. Пороговые значения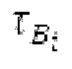 вычисляются на основе флага
вычисляются на основе флага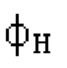 тональности и флагов
тональности и флагов  причем флаги
причем флаги  указывают, обнулена ли подполоса частот в предыдущем кадре:
указывают, обнулена ли подполоса частот в предыдущем кадре:
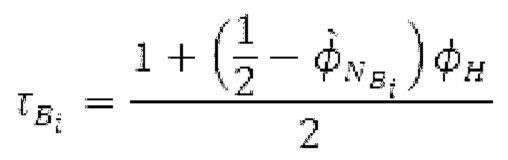
Для каждой обнуленной подполосы частот, флаг 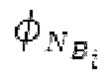 задается равным единице. В конце обработки текущего кадра,
задается равным единице. В конце обработки текущего кадра, 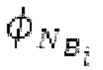 копируются в
копируются в 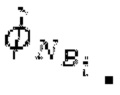 Б качестве альтернативы, может быть предусмотрено более одного флага тональности и преобразование из множества флагов тональности в тональность каждой подполосы частот, формируя значение
Б качестве альтернативы, может быть предусмотрено более одного флага тональности и преобразование из множества флагов тональности в тональность каждой подполосы частот, формируя значение 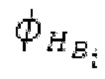 тональности для каждой подполосы частот. Значения
тональности для каждой подполосы частот. Значения 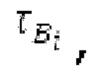 например, могут иметь значение из набора значений {-0,25, 0,5, 0,75}. Б качестве альтернативы, другое решение может использоваться для принятия решения на основе энергии нульквантованнык линий и исходной энергии и на основе содержимого
например, могут иметь значение из набора значений {-0,25, 0,5, 0,75}. Б качестве альтернативы, другое решение может использоваться для принятия решения на основе энергии нульквантованнык линий и исходной энергии и на основе содержимого 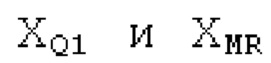 в отношении того, следует ли задать полную подполосу i частот в
в отношении того, следует ли задать полную подполосу i частот в 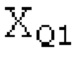 равной нулю.
равной нулю.
Частотный диапазон, в котором используется адаптивное обнуление полос частот, может ограничиваться выше определенной частоты 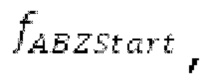 например, в 7000 Гц, расширяя адаптивное обнуление полос частот при условии, что наименьшая подполоса частот обнуляется, вниз до определенной частоты
например, в 7000 Гц, расширяя адаптивное обнуление полос частот при условии, что наименьшая подполоса частот обнуляется, вниз до определенной частоты 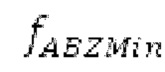 , например, в 700 Гц.
, например, в 700 Гц.
Отдельные уровни заполнения нулями (отдельный zfl) подполос частот 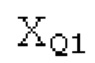 выше
выше 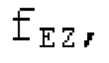 причем
причем 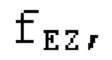 например, составляет 3000 Гц, которые полностью являются нулевыми, явно кодируются, и дополнительно один уровень
например, составляет 3000 Гц, которые полностью являются нулевыми, явно кодируются, и дополнительно один уровень 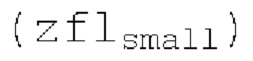 заполнения нулями для всех нулевых подполос частот ниже fEZ и всех нулевых подполос частот выше
заполнения нулями для всех нулевых подполос частот ниже fEZ и всех нулевых подполос частот выше 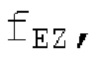 квантованных до нуля, кодируется. Подполоса частот XQ1 может быть полностью нулевой вследствие квантования в блоке квантования, даже если явно не задается равной нулю посредством адаптивного обнуления полос частот. Вычисляется требуемое число битов для энтропийного кодирования уровней заполнения нулями (zfl, состоящих из отдельного zfl и zflsmall) и спектральных линий в XQ1. Кроме того, число NQ спектральных линий, которые могут явно кодироваться с доступным битовым бюджетом, находится. NQ представляет собой неотъемлемую часть кодированного spect и используется в декодере, чтобы узнать, сколько битов используется для кодирования спектральных линий; могут использоваться другие способы нахождения числа битов для кодирования спектральных линий, например, с использованием специального символа EOF. При условии, что недостаточно битов для кодирования всех ненулевых линий, линии в XQ1 выше NQ задаются равными нулю, и требуемое число битов повторно вычисляется.
квантованных до нуля, кодируется. Подполоса частот XQ1 может быть полностью нулевой вследствие квантования в блоке квантования, даже если явно не задается равной нулю посредством адаптивного обнуления полос частот. Вычисляется требуемое число битов для энтропийного кодирования уровней заполнения нулями (zfl, состоящих из отдельного zfl и zflsmall) и спектральных линий в XQ1. Кроме того, число NQ спектральных линий, которые могут явно кодироваться с доступным битовым бюджетом, находится. NQ представляет собой неотъемлемую часть кодированного spect и используется в декодере, чтобы узнать, сколько битов используется для кодирования спектральных линий; могут использоваться другие способы нахождения числа битов для кодирования спектральных линий, например, с использованием специального символа EOF. При условии, что недостаточно битов для кодирования всех ненулевых линий, линии в XQ1 выше NQ задаются равными нулю, и требуемое число битов повторно вычисляется.
Для вычисления битов, необходимых для кодирования спектральных линий, вычисляются биты, необходимые для кодирования линий начиная снизу. Это вычисление необходимо только однократно, поскольку повторное вычисление битов, необходимых для кодирования спектральных линий, становится эффективным посредством сохранения числа битов, требуемых для кодирования n линий для каждого n≤NQ.
На каждой итерации, если требуемое число битов превышает число доступных битов, глобальное усиление снижается (307), в противном случае оно увеличивается (314). На каждой итерации, скорость изменения глобального усиления адаптируется. Для итеративной модификации глобального усиления может использоваться такая же модификация, что и модификации в контуре оптимизации искажения в зависимости от скорости передачи из EVS. В конце итеративного процесса, оптимальный размер шага квантования равен gQ, что формирует оптимальное кодирование спектра, например, с использованием критериев из EVS.
Вместо фактического кодирования, может использоваться оценка максимального числа битов, необходимых для кодирования. Вывод итеративного процесса представляет собой оптимальный размер шага квантования; вывод также может содержать кодированный spect и кодированные уровни заполнения шумом (zfl), поскольку они обычно уже доступны, с тем чтобы исключать повторяющуюся обработку при получении их снова.
Ниже подробно поясняется заполнение нулями.
Согласно вариантам осуществления, ниже поясняется блок «заполнения нулями», начиная с примера способа выбора спектра источника.
Для создания заполнения нулями, следующие параметры адаптивно находятся:
- оптимальное большое расстояние  перезаписи,
перезаписи,
- минимальное расстояние 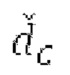 перезаписи,
перезаписи,
- минимальное начало 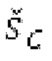 источника перезаписи,
источника перезаписи,
- сдвиг 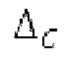 расстояния перезаписи.
расстояния перезаписи.
Оптимальное расстояние 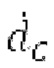 перезаписи определяет оптимальное расстояние, если спектр источника представляет собой уже полученную нижнюю часть XCT. Значение
перезаписи определяет оптимальное расстояние, если спектр источника представляет собой уже полученную нижнюю часть XCT. Значение 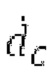 находится между минимальным
находится между минимальным 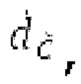 которое например, задается равным индексу, соответствующему 5600 Гц, и максимальным
которое например, задается равным индексу, соответствующему 5600 Гц, и максимальным 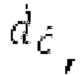 которое например, задается равным индексу, соответствующему 6225 Гц. Другие значения могут использоваться с ограничением
которое например, задается равным индексу, соответствующему 6225 Гц. Другие значения могут использоваться с ограничением 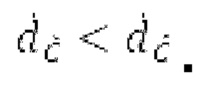
Расстояние 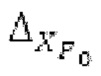 между гармониками вычисляется из среднего запаздывания
между гармониками вычисляется из среднего запаздывания 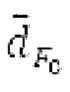 основного тона, причем среднее запаздывание
основного тона, причем среднее запаздывание 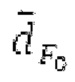 основного тона декодируется из потока битов или выводится из параметров из потока битов (например, pitch contour). В качестве альтернативы,
основного тона декодируется из потока битов или выводится из параметров из потока битов (например, pitch contour). В качестве альтернативы, 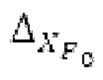 может получаться посредством анализа
может получаться посредством анализа 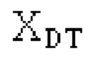 либо его производной (например, из сигнала временной области, полученного с использованием XDT). Расстояние
либо его производной (например, из сигнала временной области, полученного с использованием XDT). Расстояние 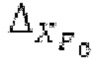 между гармониками не обязательно является целым числом. Если
между гармониками не обязательно является целым числом. Если 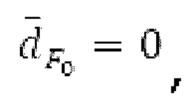 то
то 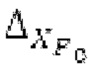 задается равным нулю, причем нуль представляет собой способ передачи в служебный сигналах того, что отсутствует значимое запаздывание основного тона.
задается равным нулю, причем нуль представляет собой способ передачи в служебный сигналах того, что отсутствует значимое запаздывание основного тона.
Значение 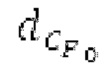 является минимальным кратным расстояния
является минимальным кратным расстояния 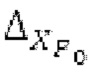 между гармониками, большего минимального оптимального расстояния
между гармониками, большего минимального оптимального расстояния 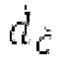 перезаписи:
перезаписи:
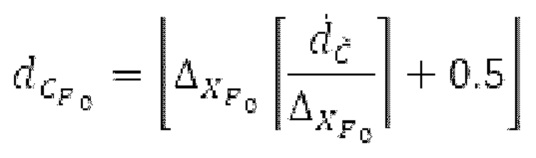
Если 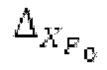 равно нулю, то
равно нулю, то 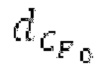 не используется.
не используется.
Начальная спектральная TNS-линия плюс TNS-порядок обозначается как  она, например, может составлять индекс, соответствующий 1000 Гц.
она, например, может составлять индекс, соответствующий 1000 Гц.
Если TNS является неактивным в кадре,  задается равным
задается равным 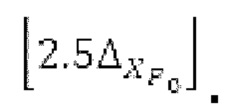 Если TNS является активным,
Если TNS является активным,  задается равным
задается равным  с дополнительным нижним ограничением посредством
с дополнительным нижним ограничением посредством 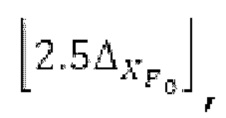 если HF являются тональными (например, если
если HF являются тональными (например, если 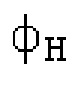 равен единице).
равен единице).
Спектр Zc абсолютной величины оценивается из декодированного spect XDT:
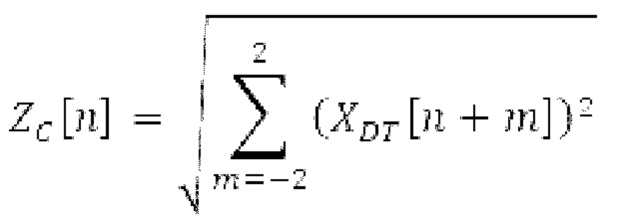
Нормализованная корреляция оцененного спектра абсолютной величины вычисляется следующим образом:
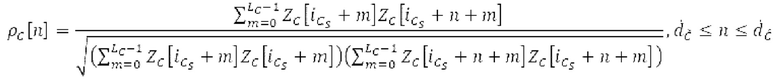
Длина Lc корреляции задается равной максимальному значению, разрешенному посредством доступного спектра, при необходимости ограниченному некоторым значением (например, длиной, эквивалентной 5000 Гц).
По существу, выполняется поиск n, которое максимизирует корреляцию между источником 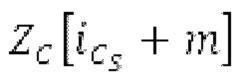 перезаписи и назначением
перезаписи и назначением 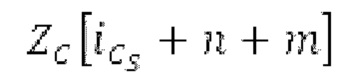 , где
, где 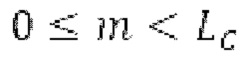
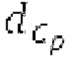 выбирается из n
выбирается из n 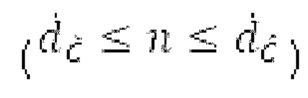 , при этом
, при этом 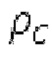 имеет первый пик и составляет выше среднего значения
имеет первый пик и составляет выше среднего значения 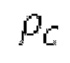 , т.е.:
, т.е.: 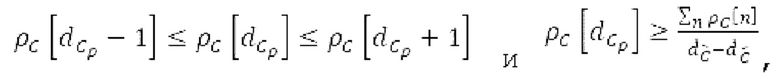 и для каждого
и для каждого 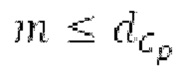 , не удовлетворяется то, что
, не удовлетворяется то, что 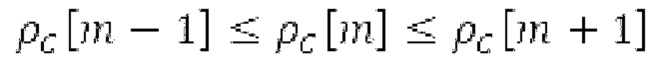 . Б другой реализации, можно выбирать
. Б другой реализации, можно выбирать 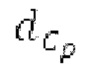 таким образом, что оно является абсолютным максимумом в диапазоне от
таким образом, что оно является абсолютным максимумом в диапазоне от  Любое другое значение в диапазоне от
Любое другое значение в диапазоне от  может выбираться для
может выбираться для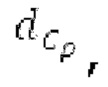 при этом оптимальное большое расстояние перезаписи ожидается.
при этом оптимальное большое расстояние перезаписи ожидается.
Если TNS является активным, можно выбирать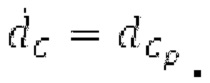
Если TNS является неактивным, 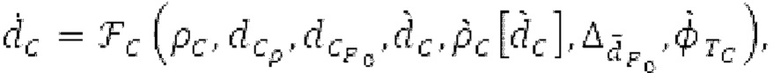 , где
, где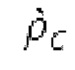 является нормализованной корреляцией, и
является нормализованной корреляцией, и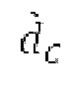 является оптимальным расстоянием в предыдущем кадре. Флаг
является оптимальным расстоянием в предыдущем кадре. Флаг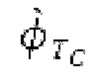 указывает, имеется ли изменение тональности в предыдущем кадре. Функция
указывает, имеется ли изменение тональности в предыдущем кадре. Функция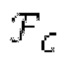 возвращает
возвращает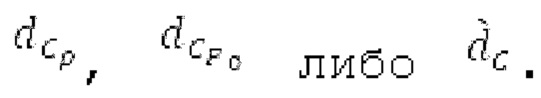 Решение в отношении того, какое значение следует возвращать в
Решение в отношении того, какое значение следует возвращать в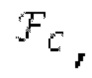 главным образом основано на значениях
главным образом основано на значениях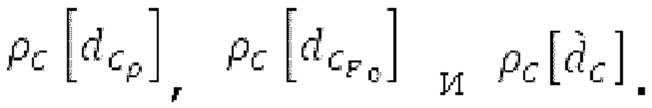 Если флаг
Если флаг 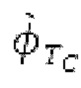 является истинным, и
является истинным, и 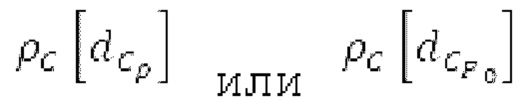 являются допустимыми, то
являются допустимыми, то 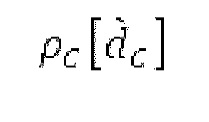 игнорируется. Значения
игнорируется. Значения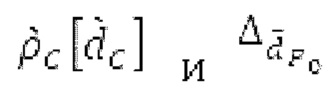 используются в редких случаях. В примере,
используются в редких случаях. В примере,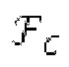 может задаваться с использованием следующих решений:
может задаваться с использованием следующих решений:
- 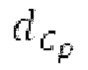 возвращается, если
возвращается, если 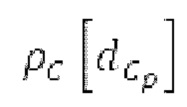 больше
больше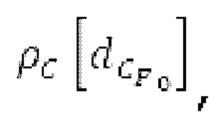 по меньшей мере для
по меньшей мере для и больше
и больше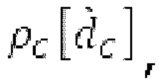 по меньшей мере для
по меньшей мере для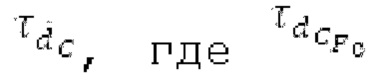 и
и 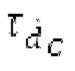 являются адаптивными пороговыми значениями, которые являются пропорциональными
являются адаптивными пороговыми значениями, которые являются пропорциональными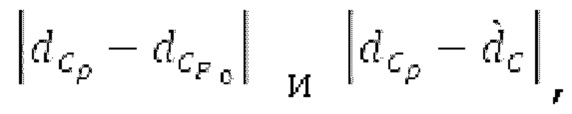 соответственно. Кроме того, может требоваться то, что
соответственно. Кроме того, может требоваться то, что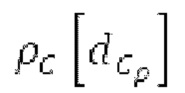 выше некоторого абсолютного порогового значения, например, 0,5,
выше некоторого абсолютного порогового значения, например, 0,5,
- в противном случае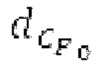 возвращается, если
возвращается, если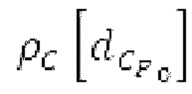 больше
больше 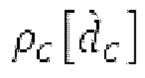 по меньшей мере для порогового значения, например, 0,2,
по меньшей мере для порогового значения, например, 0,2,
- в противном случае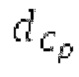 возвращается, если
возвращается, если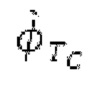 задается, и
задается, и 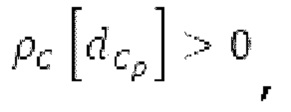
- в противном случае 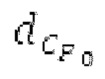 возвращается, если
возвращается, если 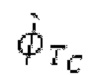 задается, и значение
задается, и значение 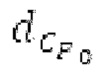 является допустимым, т.е. если возникает значимое запаздывание основного тона,
является допустимым, т.е. если возникает значимое запаздывание основного тона,
- в противном случае 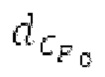 возвращается, если
возвращается, если 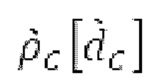 является небольшим, например, ниже 0,1, и значение
является небольшим, например, ниже 0,1, и значение 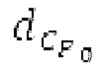 является допустимым, т.е. если возникает значимое запаздывание основного тона, и изменение запаздывания основного тона из предыдущего кадра является небольшим,
является допустимым, т.е. если возникает значимое запаздывание основного тона, и изменение запаздывания основного тона из предыдущего кадра является небольшим,
- в противном случае 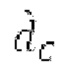 возвращается.
возвращается.
Флаг 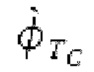 задается как истинный, если TNS является активным, либо если
задается как истинный, если TNS является активным, либо если 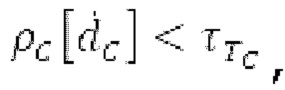 и тональность является низкой, при этом тональность является низкой, например, если
и тональность является низкой, при этом тональность является низкой, например, если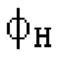 является ложью, либо если
является ложью, либо если 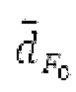 равно нулю;
равно нулю; 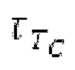 составляет значение меньше 1, например, 0,7. В следующем кадре используется значение, заданное равным
составляет значение меньше 1, например, 0,7. В следующем кадре используется значение, заданное равным 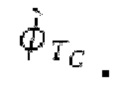
Также вычисляется процентное изменение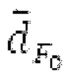 между предыдущим кадром и текущим кадром
между предыдущим кадром и текущим кадром 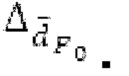
Сдвиг 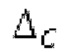 расстояния перезаписи задается равным
расстояния перезаписи задается равным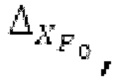 если оптимальное расстояние
если оптимальное расстояние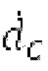 перезаписи не является эквивалентным
перезаписи не является эквивалентным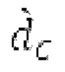 , и
, и (
(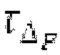 составляет заданное пороговое значение), причем в этом случае
составляет заданное пороговое значение), причем в этом случае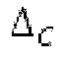 задается равным тому же значению, что и значение в предыдущем кадре, так что оно становится постоянным по последовательным кадрам;
задается равным тому же значению, что и значение в предыдущем кадре, так что оно становится постоянным по последовательным кадрам; представляет собой показатель изменения (например, процентного изменения)
представляет собой показатель изменения (например, процентного изменения) между предыдущим кадром и текущим кадром;
между предыдущим кадром и текущим кадром;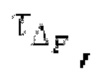 например, может задаваться равным 0,1, если
например, может задаваться равным 0,1, если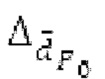 представляет собой перцепционное изменение
представляет собой перцепционное изменение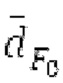 Если TNS является активным в кадре,
Если TNS является активным в кадре,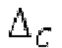 не используется.
не используется.
Минимальное начало 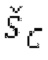 источника перезаписи, например, может задаваться равным
источника перезаписи, например, может задаваться равным 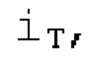 если TNS является активным, при необходимости с нижним ограничением посредством
если TNS является активным, при необходимости с нижним ограничением посредством  если HF являются тональными, либо, например, задаваться равным
если HF являются тональными, либо, например, задаваться равным  если TNS не является активным в текущем кадре.
если TNS не является активным в текущем кадре.
Минимальное расстояние 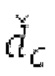 перезаписи, например, задается равным
перезаписи, например, задается равным 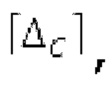 если TNS является неактивным. Если TNS является активным,
если TNS является неактивным. Если TNS является активным, 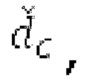 например, задается равным
например, задается равным 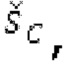 если HF не являются тональными, либо
если HF не являются тональными, либо 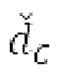 задается, например, равным
задается, например, равным 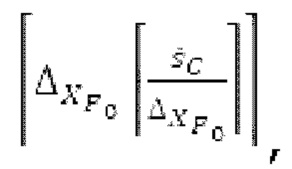 если HF являются тональными.
если HF являются тональными.
С использованием, например, 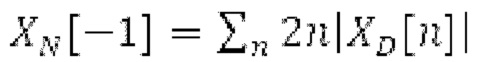 в качестве начального условия, случайный шумовой спектр
в качестве начального условия, случайный шумовой спектр 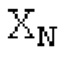 конструируется как
конструируется как 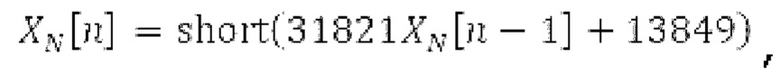 причем функция усекает результат до 16 битов. Любой другой генератор случайного шума и начальное условие могут использоваться. Случайный шумовой спектр XN затем задается равным нулю в местоположении ненулевых значений в XD, и при необходимости части в XN между местоположениями, заданными равными нулю, подвергаются оконному взвешиванию, чтобы уменьшать случайный шум около местоположений ненулевых значений в XD.
причем функция усекает результат до 16 битов. Любой другой генератор случайного шума и начальное условие могут использоваться. Случайный шумовой спектр XN затем задается равным нулю в местоположении ненулевых значений в XD, и при необходимости части в XN между местоположениями, заданными равными нулю, подвергаются оконному взвешиванию, чтобы уменьшать случайный шум около местоположений ненулевых значений в XD.
Для каждой подполосы 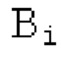 частот длины
частот длины 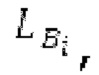 начиная с
начиная с 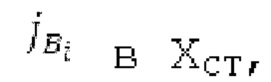 спектр источника для
спектр источника для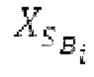 находится. Деление на подполосы частот может быть одинаковым с делением на подполосы частот, используемым для кодирования zfl, но также может отличаться, может быть более высоким или более низким.
находится. Деление на подполосы частот может быть одинаковым с делением на подполосы частот, используемым для кодирования zfl, но также может отличаться, может быть более высоким или более низким.
Для примера, если TNS не является активным, и HF не являются тональными, то случайный шумовой спектр XN используется в качестве спектра источника для всех подполос частот. В другом примере, XN используется в качестве спектра источника для подполос частот, в которых другие источники являются пустыми, либо для некоторых подполос частот, которые начинаются ниже минимального назначения перезаписи: 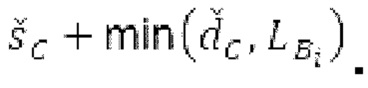
В другом примере, если TNS не является активным, и HF являются тональными, прогнозируемый спектр 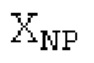 может использоваться в качестве источника для подполос частот, которые начинаются ниже
может использоваться в качестве источника для подполос частот, которые начинаются ниже 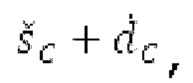 и в которых EB по меньшей мере на 12 дБ выше EB в соседних подполосах частот, причем прогнозируемый спектр получается из предыдущего декодированного спектра или из сигнала, полученного из предыдущего декодированного спектра (например, из декодированного TD-сигнала).
и в которых EB по меньшей мере на 12 дБ выше EB в соседних подполосах частот, причем прогнозируемый спектр получается из предыдущего декодированного спектра или из сигнала, полученного из предыдущего декодированного спектра (например, из декодированного TD-сигнала).
Для случаев, не содержащихся в вышеприведенных примерах, расстояние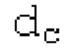 может находиться таким образом, что
может находиться таким образом, что 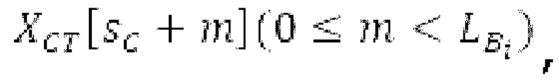 либо смесь
либо смесь 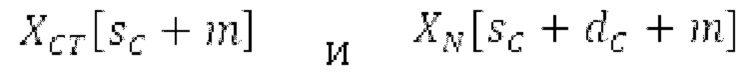 может использоваться в качестве спектра источника для
может использоваться в качестве спектра источника для 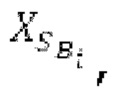 который начинается в
который начинается в 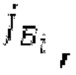 где
где 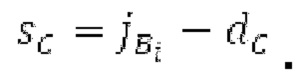 В одном примере, если TNS является активным, но начинается только на более высокой частоте (например, в 4500 Гц), и HF не являются тональными, смесь
В одном примере, если TNS является активным, но начинается только на более высокой частоте (например, в 4500 Гц), и HF не являются тональными, смесь 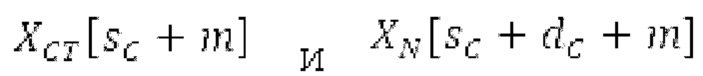 может использоваться в качестве спектра источника, если
может использоваться в качестве спектра источника, если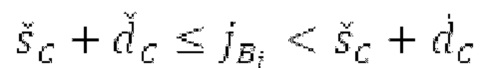 ; в еще одном другом примере, только
; в еще одном другом примере, только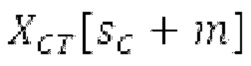 или спектр, состоящий из нулей, может использоваться в качестве источника. Если
или спектр, состоящий из нулей, может использоваться в качестве источника. Если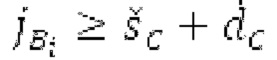 то
то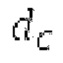 может задаваться равным
может задаваться равным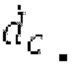 Если TNS является активным, то положительное целое число n может находиться таким образом, что
Если TNS является активным, то положительное целое число n может находиться таким образом, что 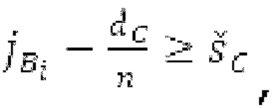 и
и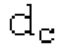 может задаваться равным
может задаваться равным 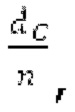 например, наименьшему такому целому числу п. Если TNS не является активным, другое положительное целое число n может находиться таким образом, что
например, наименьшему такому целому числу п. Если TNS не является активным, другое положительное целое число n может находиться таким образом, что 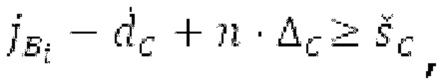 и
и 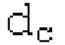 задается равным
задается равным 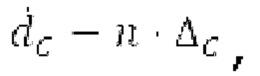 например, наименьшему такому целому числу n.
например, наименьшему такому целому числу n.
В другом примере, наименьшие подполосы 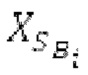 частот в
частот в 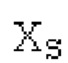 вплоть до начальной частоты
вплоть до начальной частоты 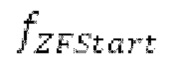 могут задаваться равными 0, что означает то, что в наименьших подполосах частот, Хст может представлять собой копию XDT.
могут задаваться равными 0, что означает то, что в наименьших подполосах частот, Хст может представлять собой копию XDT.
Ниже приводится пример взвешивания спектра источника на основе Ев в блоке «заполнения нулями».
В примере сглаживания EB, 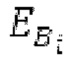 может получаться из zfl, причем каждое
может получаться из zfl, причем каждое 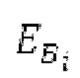 соответствует подполосе i частот в EB.
соответствует подполосе i частот в EB. 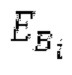 затем сглаживаются:
затем сглаживаются: 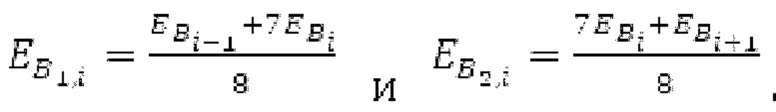
Коэффициент 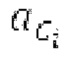 масштабирования вычисляется для каждой подполосы Bi частот в зависимости от спектра источника:
масштабирования вычисляется для каждой подполосы Bi частот в зависимости от спектра источника:
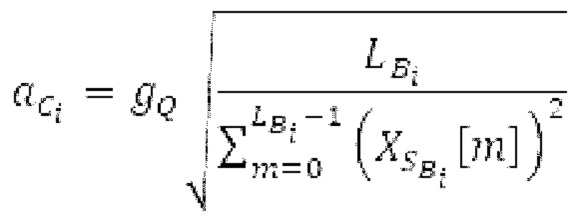
Кроме того, масштабирование ограничено с помощью коэффициента  вычисляемого следующим образом:
вычисляемого следующим образом:
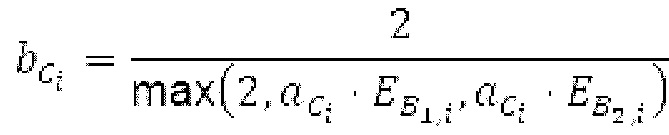
Полоса 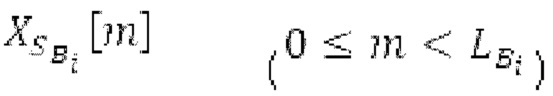 частот спектра источника разбивается на две половины, и каждая половина масштабируется, первая половина с
частот спектра источника разбивается на две половины, и каждая половина масштабируется, первая половина с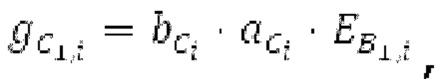 а вторая с
а вторая с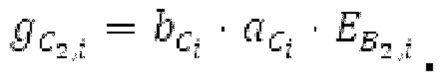
Масштабированная полоса 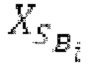 частот спектра источника, причем масштабированная полоса частот спектра источника составляет
частот спектра источника, причем масштабированная полоса частот спектра источника составляет 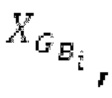 суммируется с
суммируется с 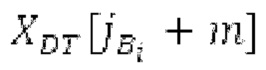 для получения
для получения 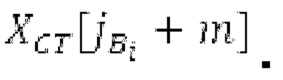
Ниже приводится пример квантования энергий нульквантованнык линий (в качестве части iBPC).
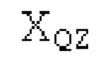 получается из
получается из 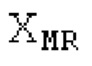 посредством задания ненулевых квантованных линий равными нулю. Например, так же, как и с XN, значения в местоположении ненулевых квантованных линий в XQ задаются равными нулю, и нулевые части между ненулевыми квантованными линиями подвергаются оконному взвешиванию в XHR, формируя
посредством задания ненулевых квантованных линий равными нулю. Например, так же, как и с XN, значения в местоположении ненулевых квантованных линий в XQ задаются равными нулю, и нулевые части между ненулевыми квантованными линиями подвергаются оконному взвешиванию в XHR, формируя 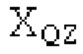
Энергия  в расчете на полосу i частот для нулевых линий вычисляется из
в расчете на полосу i частот для нулевых линий вычисляется из 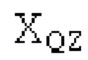 :
:
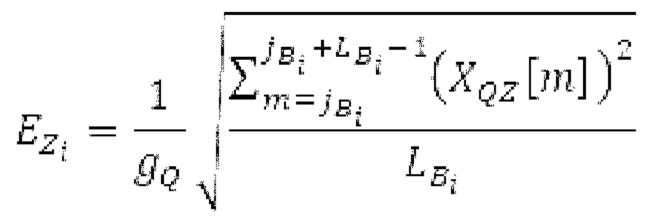
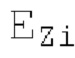 , например, квантуются с использованием размера шага в 1/8 и ограничены 6/8. Отдельные
, например, квантуются с использованием размера шага в 1/8 и ограничены 6/8. Отдельные 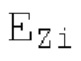 кодируются в качестве отдельного zfl только для подполос частот выше
кодируются в качестве отдельного zfl только для подполос частот выше 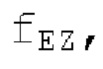 причем
причем 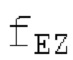 , например, составляет 3000 Гц, которые полностью квантуются до нуля. Кроме того, один энергетический уровень
, например, составляет 3000 Гц, которые полностью квантуются до нуля. Кроме того, один энергетический уровень 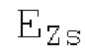 вычисляется как среднее значение всех
вычисляется как среднее значение всех 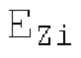 из нулевых подполос частот ниже
из нулевых подполос частот ниже 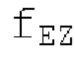 и из нулевых подполос частот выше
и из нулевых подполос частот выше 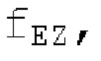 причем
причем 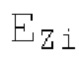 квантуется до нуля, при этом нулевая подполоса частот означает то, что полная подполоса частот квантуется до нуля. Низкий уровень
квантуется до нуля, при этом нулевая подполоса частот означает то, что полная подполоса частот квантуется до нуля. Низкий уровень 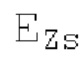 квантуется с размером шага в 1/16 и ограничивается 3/16. Энергия отдельных нулевых линий в ненулевых подполосах частот оценивается и не кодируется явно.
квантуется с размером шага в 1/16 и ограничивается 3/16. Энергия отдельных нулевых линий в ненулевых подполосах частот оценивается и не кодируется явно.
Долговременное прогнозирование (LTP)
Ниже поясняется блок LTP 164.
Сигнал ус временной области используется в качестве ввода в LTP, причем Yc получается из Хс в качестве вывода IMDCT. IMDCT состоит из обратного MDCT, оконного взвешивания и суммирования с перекрытием. Левая перекрывающаяся часть и неперекрывающаяся часть Yc в текущем кадре сохраняются в буфере LTP. Буфер LTP используется в следующем кадре в LTP, чтобы формировать прогнозируемый сигнал для всего окна взвешивания MDCT. Это проиллюстрировано посредством фиг.17а.
Если для правого перекрытия в текущем окне взвешивания используется меньшее перекрытие, например половинное перекрытие, то также неперекрывающаяся часть «разность перекрытия» сохраняется в буфере LTP. Таким образом, выборки в положении «разность перекрытия» (см. фиг.17b) также должны помещаться в буфер LTP вместе с выборками в положении между двумя вертикальными линиями перед «разностью перекрытия».
Неперекрывающаяся часть «разность перекрытия» выводится в декодере не в текущем кадре, а только в следующем кадре (см. фиг.17b и 17с).
Если для левого перекрытия в текущем окне взвешивания используется меньшее перекрытие, целая неперекрывающаяся часть вплоть до начала текущего окна взвешивания используется в качестве части буфера LTP для формирования прогнозируемого сигнала.
Прогнозируемый сигнал для целого окна взвешивания MDCT формируется из буфера ГТР. Временной интервал длины окна взвешивания разбивается на перекрывающиеся субинтервалы длины 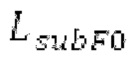 с размером перескока в
с размером перескока в 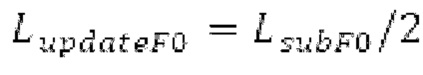 . Другие размеры перескока и взаимосвязи между длиной субинтервала и размером перескока могут использоваться. Длина перекрытия может составлять
. Другие размеры перескока и взаимосвязи между длиной субинтервала и размером перескока могут использоваться. Длина перекрытия может составлять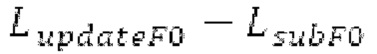 или меньше.
или меньше.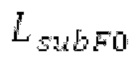 выбирается таким образом, что значимое изменение основного тона не ожидается в субинтервалак. Б примере,
выбирается таким образом, что значимое изменение основного тона не ожидается в субинтервалак. Б примере,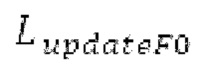 является целым числом, ближайшим к
является целым числом, ближайшим к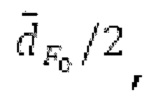 но не большим
но не большим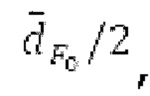 и
и 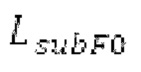 задается равным
задается равным 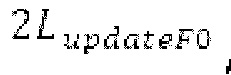 как проиллюстрировано посредством фиг.17d. В другом примере, дополнительно может требоваться то, что длина кадра или длина окна взвешивания делится на
как проиллюстрировано посредством фиг.17d. В другом примере, дополнительно может требоваться то, что длина кадра или длина окна взвешивания делится на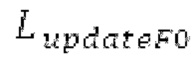 .
.
Ниже приводится пример «средства (1030) вычисления, выполненного с возможностью извлечения параметров субинтервала из кодированного параметра основного тона в зависимости от положения субинтервалов в интервале, ассоциированном с кадром кодированного аудиосигнала», а также пример «параметры извлекаются из кодированного параметра основного тона и положения субинтервала в интервале, ассоциированном с кадром кодированного аудиосигнала». Для каждого запаздывания основного тона в субинтервал в центре субинтервала, 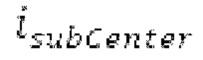 получается из контура основного тона. На первом этапе, запаздывание
получается из контура основного тона. На первом этапе, запаздывание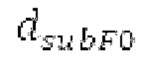 основного тона в субинтервал задается равным запаздыванию основного тона в положении центра
основного тона в субинтервал задается равным запаздыванию основного тона в положении центра 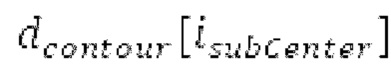 субинтервала. При условии, что расстояние
субинтервала. При условии, что расстояние 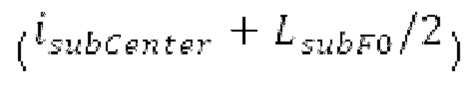 от конца субинтервала до начала окна взвешивания больше
от конца субинтервала до начала окна взвешивания больше 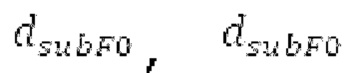 увеличивается для значения запаздывания основного тона из контура основного тона в положении
увеличивается для значения запаздывания основного тона из контура основного тона в положении 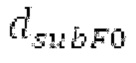 слева от центра субинтервала, которое составляет
слева от центра субинтервала, которое составляет  до
до 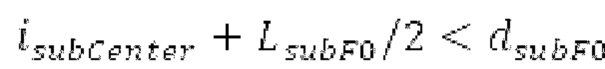 Расстояние
Расстояние 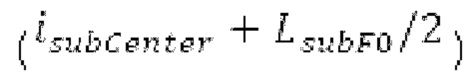 от конца субинтервала до начала окна взвешивания также может называться «концом субинтервала».
от конца субинтервала до начала окна взвешивания также может называться «концом субинтервала».
В каждом субинтервале, прогнозируемый сигнал конструируется с использованием буфера LTP и фильтра с передаточной функцией 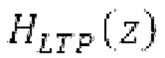 , при этом:
, при этом:
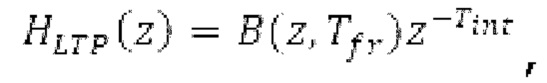
где 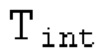 является целочисленной частью
является целочисленной частью 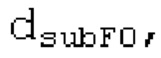 т.е.
т.е. 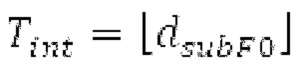 , и
, и 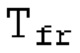 является дробной частью
является дробной частью 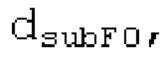 т.е.
т.е. 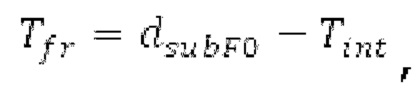 и B(z, Tfr) является фильтром с дробной задержкой. B(z, Tfr) может иметь характеристики нижних частот (либо он может компенсировать предыскажения высоких частот). Затем сигнал прогнозирования подвергается плавному переходу в перекрывающихся областях субинтервалов.
и B(z, Tfr) является фильтром с дробной задержкой. B(z, Tfr) может иметь характеристики нижних частот (либо он может компенсировать предыскажения высоких частот). Затем сигнал прогнозирования подвергается плавному переходу в перекрывающихся областях субинтервалов.
В качестве альтернативы, прогнозируемый сигнал может конструироваться с использованием способа с каскадными фильтрами, как описано в [19], с откликом при отсутствии входного сигнала (ZIR) фильтра на основе фильтра с передаточной функцией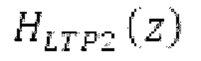 и буфера LTP, используемого в качестве начального вывода фильтра, причем:
и буфера LTP, используемого в качестве начального вывода фильтра, причем:
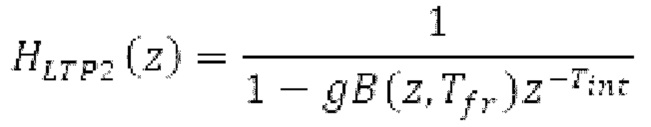
Примеры для 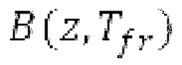 являются следующими:
являются следующими:

В примерах, 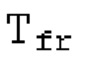 обычно округляется до ближайшего значения из списка значений, и для каждого значения в списке задается фильтр В.
обычно округляется до ближайшего значения из списка значений, и для каждого значения в списке задается фильтр В.
Прогнозируемый сигнал 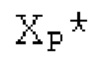 подвергается оконному взвешиванию с окном взвешивания, равным окну взвешивания, используемому формирования ХМ, и преобразуется через MDCT для получения ХР.
подвергается оконному взвешиванию с окном взвешивания, равным окну взвешивания, используемому формирования ХМ, и преобразуется через MDCT для получения ХР.
Ниже приводится пример средства для модификации прогнозируемого спектра или производной прогнозируемого спектра, в зависимости от параметра, извлекаемого из кодированного параметра основного тона. Абсолютные величины коэффициентов MDCT, отстоящие по меньшей мере на от гармоник в ХР, задаются равными нулю (или умножаются на положительный коэффициент меньше 1), причем
от гармоник в ХР, задаются равными нулю (или умножаются на положительный коэффициент меньше 1), причем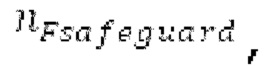 например, равно 10. В качестве альтернативы, окна взвешивания, отличные от прямоугольного окна взвешивания, могут использоваться для уменьшения абсолютный величин между гармониками. Считается, что гармоники в ХР находятся в местоположениях элементов разрешения, которые являются целыми кратными
например, равно 10. В качестве альтернативы, окна взвешивания, отличные от прямоугольного окна взвешивания, могут использоваться для уменьшения абсолютный величин между гармониками. Считается, что гармоники в ХР находятся в местоположениях элементов разрешения, которые являются целыми кратными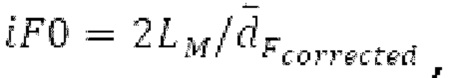 . где
. где 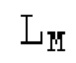 является длиной ХР, и
является длиной ХР, и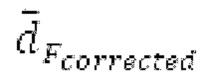 является средним скорректированным запаздыванием основного тона. Гармонические местоположения составляют
является средним скорректированным запаздыванием основного тона. Гармонические местоположения составляют 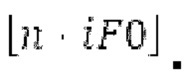 Это удаляет шум между гармониками, в частности, когда обнаруживается запаздывание в половину основного тона.
Это удаляет шум между гармониками, в частности, когда обнаруживается запаздывание в половину основного тона.
Спектральная огибающая ХР перцепционно сглаживается с помощью такого же способа, что и способ в отношении ХМ, например, через для получения
для получения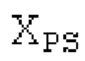 Ниже приводится пример «число прогнозируемых гармоник определяется на основе кодированного параметра основного тона». С использованием
Ниже приводится пример «число прогнозируемых гармоник определяется на основе кодированного параметра основного тона». С использованием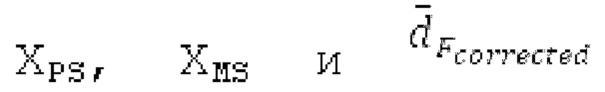 определяется число
определяется число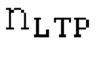 прогнозируемых гармоник;
прогнозируемых гармоник;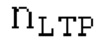 кодируется и передается в декодер. Вплоть до
кодируется и передается в декодер. Вплоть до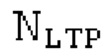 гармоник могут прогнозироваться, например, NLTP=8.
гармоник могут прогнозироваться, например, NLTP=8. 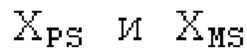 разделяются на
разделяются на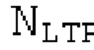 полос частот с длиной
полос частот с длиной 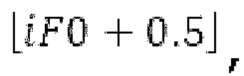 причем каждая полоса частот начинается в
причем каждая полоса частот начинается в 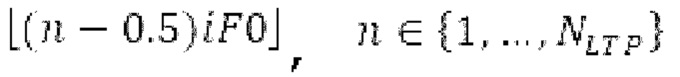 ;
; выбирается таким образом, что для всех
выбирается таким образом, что для всех  отношение энергии
отношение энергии  ниже порогового значения
ниже порогового значения  , например,
, например, 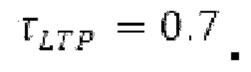 Если нет такого n, то nLTP=0, и LTP не является активным в текущем кадре. В служебных сигналах с помощью флага передается то, является ли LTP активным. Вместо
Если нет такого n, то nLTP=0, и LTP не является активным в текущем кадре. В служебных сигналах с помощью флага передается то, является ли LTP активным. Вместо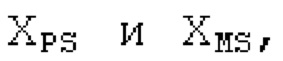 могут использоваться
могут использоваться 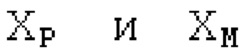 Вместо
Вместо 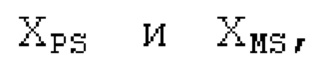 могут использоваться
могут использоваться  . В качестве альтернативы, число прогнозируемых гармоник может определяться на основе контура
. В качестве альтернативы, число прогнозируемых гармоник может определяться на основе контура основного тона.
основного тона.
Если LTP является активным, то первые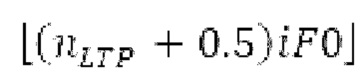 коэффициентов XPS, за исключением нулевого коэффициента, вычитаются из
коэффициентов XPS, за исключением нулевого коэффициента, вычитаются из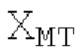 для формирования
для формирования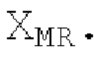 Нулевой коэффициент, а также коэффициенты выше
Нулевой коэффициент, а также коэффициенты выше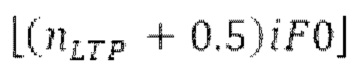 копируются из
копируются из
В процессе квантования, XQ получается из XMR, и XQ кодируется в качестве spect, и посредством декодирования, XD получается из spect.
Ниже приводится пример модуля (157) объединения, выполненного с возможностью объединения по меньшей мере части спектра (ХР) прогнозирования или части производной прогнозируемого спектра (XPS) со спектром (XD) ошибки. Если LTP является активным, то первые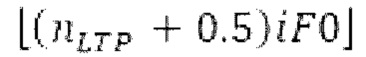 коэффициентов XPS, отличных от нулевого коэффициента, суммируются с XD, чтобы формировать XDT. Нулевой, а также коэффициенты выше
коэффициентов XPS, отличных от нулевого коэффициента, суммируются с XD, чтобы формировать XDT. Нулевой, а также коэффициенты выше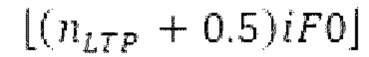 копируются из XD в XDT.
копируются из XD в XDT. указывает на использование функции минимального уровня.
указывает на использование функции минимального уровня.
Ниже поясняются факультативные признаки гармонической постфильтрации.
Сигнал Yc временной области получается из Хс в качестве вывода IMDCT, причем IMDCT состоит из обратного MDCT, оконного взвешивания и суммирования с перекрытием. Гармонический постфильтр (HPF), который выполняется после контура основного тона, применяется к Yc, чтобы уменьшать уровень шума между гармониками и выводить Yн. Вместо Yc, комбинация Yc и сигнала YP временной области, сконструированная из декодированных форм импульсного сигнала, может использоваться в качестве ввода в HPF,
Ввод HPF для текущего кадра к составляет . Также доступны предыдущие выходные выборки
. Также доступны предыдущие выходные выборки 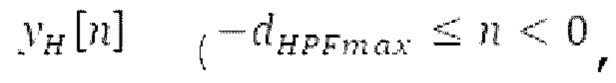 где
где 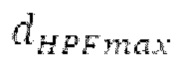 составляет по меньшей мере максимальное запаздывание основного тона). Также доступно
составляет по меньшей мере максимальное запаздывание основного тона). Также доступно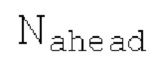 упреждающих выборок IMDCT, которые могут включать в себя подвергнутые временному наложению спектров части правой перекрывающейся области обратного вывода MDCT. Показывается пример, в котором временной интервал, к которому применяется HPF, равен текущему кадру, но могут использоваться различные интервалы. Местоположение текущего ввода-вывода HPF, предыдущего - вывода HPF и упреждения IMDCT относительно окон взвешивания MDCT/IMDCT проиллюстрировано посредством фиг.18а, также показывающего перекрывающуюся часть, которая может суммироваться как обычно, чтобы формировать суммирование с перекрытием.
упреждающих выборок IMDCT, которые могут включать в себя подвергнутые временному наложению спектров части правой перекрывающейся области обратного вывода MDCT. Показывается пример, в котором временной интервал, к которому применяется HPF, равен текущему кадру, но могут использоваться различные интервалы. Местоположение текущего ввода-вывода HPF, предыдущего - вывода HPF и упреждения IMDCT относительно окон взвешивания MDCT/IMDCT проиллюстрировано посредством фиг.18а, также показывающего перекрывающуюся часть, которая может суммироваться как обычно, чтобы формировать суммирование с перекрытием.
Если передается в служебных сигналах в потоке битов то, что HPF должен использовать постоянные параметры, сглаживание используется в начале текущего кадра, с дальнейшим выполнением HPF с постоянными параметрами для оставшейся части кадра. В качестве альтернативы, анализ основного тона может выполняться для Yc, чтобы принять решение в отношении того, должны ли использоваться постоянные параметры. Длина области, в которой используется сглаживание, может зависеть от параметров основного тона.
Когда постоянные параметры не передаются в служебных сигналах, ввод HPF разбивается на перекрывающиеся субинтервалы длины Lk с размером перескока в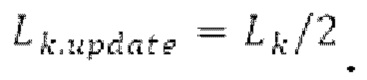 Другие размеры перескока могут использоваться. Длина перекрытия может составлять
Другие размеры перескока могут использоваться. Длина перекрытия может составлять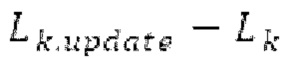 или меньше. Lk выбирается таким образом, что значимое изменение основного тона не ожидается в субинтервалах. В примере,
или меньше. Lk выбирается таким образом, что значимое изменение основного тона не ожидается в субинтервалах. В примере,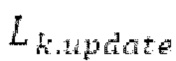 является целым числом, ближайшим к pitch_mid/2, но не большим pitch_mid/2, и Lk задается равной
является целым числом, ближайшим к pitch_mid/2, но не большим pitch_mid/2, и Lk задается равной . Вместо pitch_mid, некоторые другие значения могут использоваться, например, среднее значение pitch_mid и pitch_start либо значение, полученное из анализа основного тона для Yc, или, например, ожидаемое минимальное запаздывание основного тона в интервале для сигналов с варьирующимся основным тоном. В качестве альтернативы, фиксированное число субинтервалов может выбираться. В другом примере, дополнительно может требоваться то, что длина кадра делится на
. Вместо pitch_mid, некоторые другие значения могут использоваться, например, среднее значение pitch_mid и pitch_start либо значение, полученное из анализа основного тона для Yc, или, например, ожидаемое минимальное запаздывание основного тона в интервале для сигналов с варьирующимся основным тоном. В качестве альтернативы, фиксированное число субинтервалов может выбираться. В другом примере, дополнительно может требоваться то, что длина кадра делится на 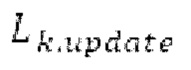 (см. фиг.18b).
(см. фиг.18b).
Считается, что число субинтервалов в текущем интервале к составляет Kk, в предыдущем интервале k-1 составляет Kk-1 и в следующем интервале k+1 составляет Kk+1. В примере на фиг.18b, Kk=6 и Kk-1=4.
В другом примере, возможно то, что текущий (временной) интервал разбивается на нецелое число субинтервалов, и/или то, что длина субинтервалов изменяется в текущем интервале, как показано посредством фиг.18с и 18d.
Для каждого субинтервала 1 в текущем интервале 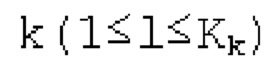 , запаздывание pk, х основного тона в субинтервал находится с использованием алгоритма поиска основного тона, который может быть таким же, что и поиск основного тона, используемый для получения контура основного тона, или отличным от него. Поиск основного тона для субинтервала 1 может использовать значения, извлеченные из кодированного запаздывания
, запаздывание pk, х основного тона в субинтервал находится с использованием алгоритма поиска основного тона, который может быть таким же, что и поиск основного тона, используемый для получения контура основного тона, или отличным от него. Поиск основного тона для субинтервала 1 может использовать значения, извлеченные из кодированного запаздывания  основного тона, с тем чтобы уменьшать сложность поиска и/или повышать стабильность значений
основного тона, с тем чтобы уменьшать сложность поиска и/или повышать стабильность значений 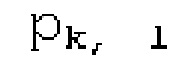 по субинтервалам, например, значения, извлеченные из кодированного запаздывания основного тона, могут быть значениями контура основного тона. Б другом примере, параметры, найденные посредством глобального анализа основного тона в полном интервале Yc, могут использоваться вместо кодированного запаздывания основного тона, с тем чтобы уменьшать сложность поиска и/или стабильность значений
по субинтервалам, например, значения, извлеченные из кодированного запаздывания основного тона, могут быть значениями контура основного тона. Б другом примере, параметры, найденные посредством глобального анализа основного тона в полном интервале Yc, могут использоваться вместо кодированного запаздывания основного тона, с тем чтобы уменьшать сложность поиска и/или стабильность значений 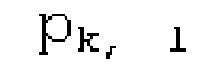 по субинтервалам. Б другом примере, при поиске запаздывания основного тона в субинтервал, предполагается, что промежуточный вывод гармонической постфильтрации для предыдущих субинтервалов доступен и используется в поиске основного тона (включающем в себя субинтервалы предыдущих интервалов).
по субинтервалам. Б другом примере, при поиске запаздывания основного тона в субинтервал, предполагается, что промежуточный вывод гармонической постфильтрации для предыдущих субинтервалов доступен и используется в поиске основного тона (включающем в себя субинтервалы предыдущих интервалов).
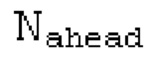 (потенциально подвергнутых временному наложению спектров) упреждающих выборок также могут использоваться для нахождения основного тона в субинтервалах, которые пересекают границу (временного) интервала/кадра, или, например, если упреждение не доступно, задержка может вводиться в декодере для обеспечения упреждения для последнего субинтервала в интервале. В качестве альтернативы, значение, извлеченное из кодированного запаздывания
(потенциально подвергнутых временному наложению спектров) упреждающих выборок также могут использоваться для нахождения основного тона в субинтервалах, которые пересекают границу (временного) интервала/кадра, или, например, если упреждение не доступно, задержка может вводиться в декодере для обеспечения упреждения для последнего субинтервала в интервале. В качестве альтернативы, значение, извлеченное из кодированного запаздывания  основного тона, может использоваться для
основного тона, может использоваться для 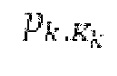 .
.
Для гармонической постфильтрации, может использоваться адаптивный к усилению гармонический постфильтр. Б примере, HPF имеет передаточную функцию:
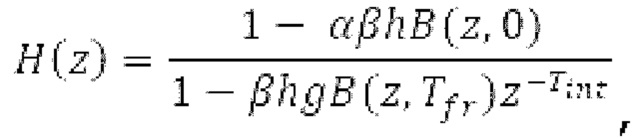
где B(z, Tfr) является фильтром с дробной задержкой. B(z, Tfr) может быть одинаковым с фильтрами с дробной задержкой, используемым в LTP, или отличным от них, поскольку вариант выбора является независимым. В HPF, QUOTE B(z, Ttr) также выступает в качестве нижний частот (или фильтра наклона, который компенсирует предыскажения высокий частот).
Пример для разностного уравнения для адаптивного к усилению гармонического постфильтра с передаточной функцией H(z) и bj (Tfr) в качестве коэффициентов B(z, Tfr) является следующим:
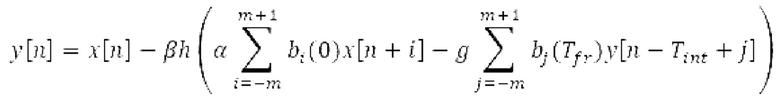
Вместо фильтра нижний частот с дробной задержкой, может использоваться фильтр тождественности, что дает B(z, Tfr) = 1 и разностное уравнение:
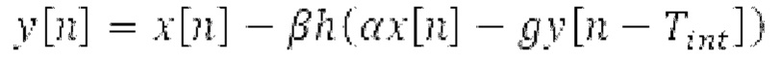
Параметр g является оптимальным усилением. Он моделирует изменение амплитуды (модуляцию) сигнала и является сигнально-адаптивным.
Параметр h является уровнем гармоничности. Он управляет требуемым увеличением гармоничности сигнала и является сигнально-адаптивным. Параметр β также управляет увеличением гармоничности сигнала и является постоянным либо зависит от частоты дискретизации и скорости передачи битов. Параметр β также может быть равным 1. Значение произведения βh должно составлять между 0 и 1, при этом 0 не вызывает изменение в гармоничности, а 1 максимально увеличивает гармоничность. На практике, обычно βh<0,75.
Часть с прямой связью гармонического постфильтра (которая представляет собой 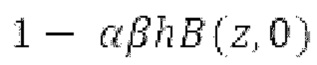 ) выступает в качестве верхних частот (или фильтра наклона, который компенсирует предыскажения низких частот). Параметр α определяет интенсивность фильтрации верхних частот (или другими словами, он управляет наклоном компенсации предыскажений) и имеет значение между 0 и 1. Параметр α является постоянным или зависит от частоты дискретизации и скорости передачи битов. Значение между 0,5 и 1 является предпочтительным в вариантах осуществления.
) выступает в качестве верхних частот (или фильтра наклона, который компенсирует предыскажения низких частот). Параметр α определяет интенсивность фильтрации верхних частот (или другими словами, он управляет наклоном компенсации предыскажений) и имеет значение между 0 и 1. Параметр α является постоянным или зависит от частоты дискретизации и скорости передачи битов. Значение между 0,5 и 1 является предпочтительным в вариантах осуществления.
Для каждого субинтервала, оптимальное усиление gk, i и уровень hk, i гармоничности находятся, либо, в некоторых случаях, они могут извлекаться из других параметров.
Для данного B(z, Tfr), функция для сдвига/фильтрации сигнала задается следующим образом:
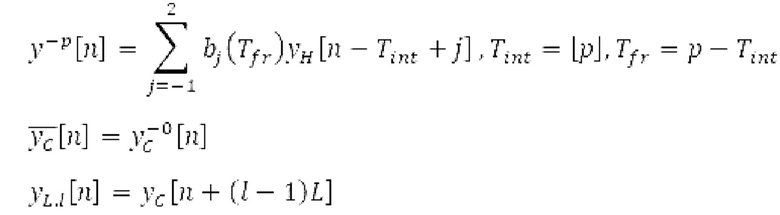
В этих определениях, 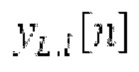 представляет, для
представляет, для  сигнал Yc в (суб-) интервале 1 с длиной L,
сигнал Yc в (суб-) интервале 1 с длиной L, 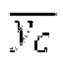 представляет фильтрацию Yc с B(z, 0),
представляет фильтрацию Yc с B(z, 0), 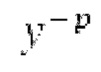 представляет сдвиг Yн для (возможно дробных) p выборок.
представляет сдвиг Yн для (возможно дробных) p выборок.
Нормализованная корреляция  сигналов Yc и Yн в (суб-) интервале 1 с длиной L и сдвигом p задается следующим образом:
сигналов Yc и Yн в (суб-) интервале 1 с длиной L и сдвигом p задается следующим образом:
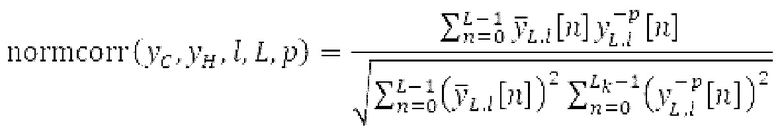
Альтернативное определение 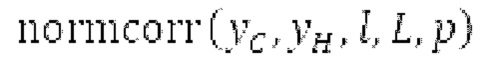 может быть следующим:
может быть следующим:
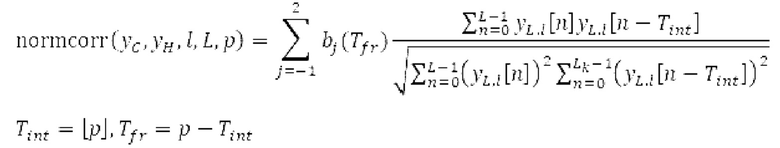
В альтернативном определении, 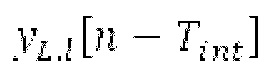 представляет ун в предыдущих субинтервалах для
представляет ун в предыдущих субинтервалах для 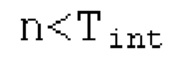
В вышеприведенных определениях, используется 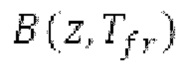 четвертого порядка. Может использоваться любой другой порядок, требующий изменения диапазона для j. В примере, в котором
четвертого порядка. Может использоваться любой другой порядок, требующий изменения диапазона для j. В примере, в котором 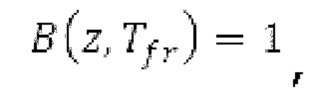 получаются
получаются 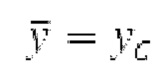 и
и 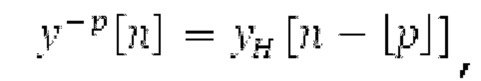 что может использоваться, если учитываются только целочисленные сдвиги.
что может использоваться, если учитываются только целочисленные сдвиги.
Нормализованная корреляция, заданная таким образом, обеспечивает возможность вычисления для дробных сдвигов p.
Параметры normcorr 1 и L задают окно взвешивания для нормализованной корреляции. В вышеуказанном определении, используется прямоугольное окно взвешивания. Вместо этого может использоваться любой другой тип окна взвешивания (например, Ханна, косинусоидальное), которое может задаваться как умножение 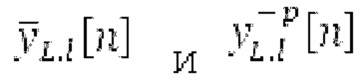 на w[n], где w[n] представляет окно взвешивания.
на w[n], где w[n] представляет окно взвешивания.
Чтобы получать нормализованную корреляцию в субинтервале, 1 должно задаваться равным номеру интервала, a L - равной длине субинтервала.
Вывод 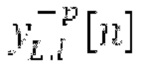 представляет ZIR адаптивного к усилению гармонического постфильтра H(z) для субкадра 1, где
представляет ZIR адаптивного к усилению гармонического постфильтра H(z) для субкадра 1, где 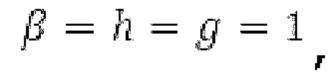 и
и 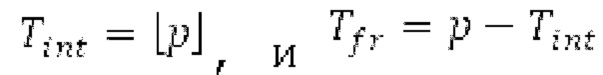
Оптимальное усиление gk, у моделирует изменение амплитуды (модуляцию) в субкадре 1. Например, оно может вычисляться в качестве корреляции прогнозируемого сигнала с фильтрованным по нижним частотам вводом, деленной на энергию прогнозируемого сигнала:
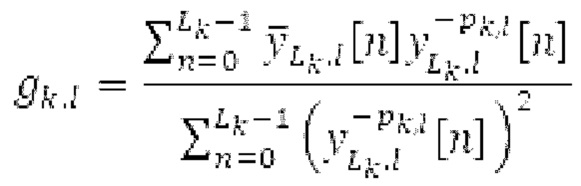
В другом примере, оптимальное усиление gk, 1 может вычисляться как энергия фильтрованного по нижним частотам ввода, деленная на энергию прогнозируемого сигнала:
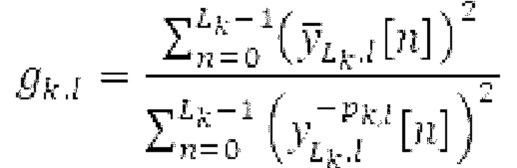
Уровень hk, 1 гармоничности управляет требуемым увеличением гармоничности сигнала и, например, может вычисляться в качестве квадрата нормализованной корреляции:
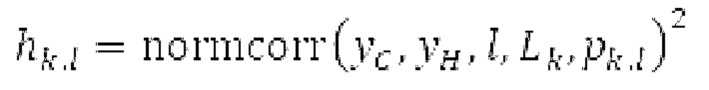
Обычно, нормализованная корреляция субинтервала уже доступна из поиска основного тона в субинтервале.
Уровень hk, 1 гармоничности также может модифицироваться в зависимости от LTP и/или в зависимости от декодированных спектральных характеристик. Например, можно задавать:
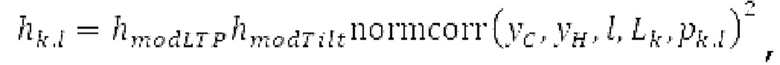
где 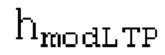 является значением между 0 и 1 и является пропорциональным числу гармоник, прогнозируемых посредством LTP, и
является значением между 0 и 1 и является пропорциональным числу гармоник, прогнозируемых посредством LTP, и 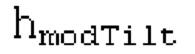 является значением между 0 и 1 и является обратно пропорциональным наклону ХС. В примере,
является значением между 0 и 1 и является обратно пропорциональным наклону ХС. В примере, 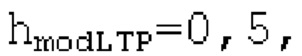 если nLTP равно нулю, в противном случае
если nLTP равно нулю, в противном случае 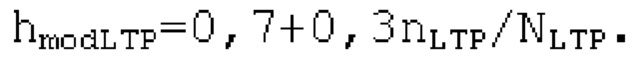 Наклон Хс может представлять собой отношение энергии первых 7 спектральных коэффициентов к энергии следующих 43 коэффициентов.
Наклон Хс может представлять собой отношение энергии первых 7 спектральных коэффициентов к энергии следующих 43 коэффициентов.
После того, как вычислены параметры для субинтервала l, можно формировать промежуточный вывод гармонической
постфильтрации для части субинтервала l, которая не перекрывается с субинтервалом l+1. Как указано выше, этот промежуточный вывод используется в нахождении параметров для последующих субинтервалов.
Каждый субинтервал является перекрывающимся, и операция сглаживания между двумя параметрами фильтрации используется. Может использоваться сглаживание, описанное в [3]. Ниже поясняются предпочтительные варианты осуществления.
Варианты осуществления предусматривают устройство для декодирования и кодирования аудиосигналов, причем кодированный аудиосигнал содержит по меньшей мере кодированные параметры основного тона и параметры, задающие спектр ошибки, причем устройство содержит: обратное преобразование в частотной области (например, обратное MDCT) для формирования блока аудиосигнала TD с наложением спектров из производной спектра ошибки; средство для формирования кадра аудиосигнала TD с использованием по меньшей мере двух блоков аудиосигнала TD с наложением спектров, при этом по меньшей мере некоторые части аудиосигнала TD с наложением спектров отличаются от аудиосигнала TD (при этом подавление наложения спектров во временной области (TDAC) возникает в результате оконного взвешивания и суммирования с перекрытием); средство для помещения выборок из кадра аудиосигнала TD в буфер LTP; средство для разделения сигнала прогнозирования на субинтервалы в зависимости от кодированных параметров основного тона, при этом по меньшей мере в некоторых случаях имеется большее количество субинтервалов, чем отличающихся во времени кодированных параметров основного тона; средство для извлечения параметров субинтервала из кодированных параметров основного тона в зависимости от положения субинтервала в сигнале прогнозирования, при этом по меньшей мере в некоторых случаях имеется большее количество отличающихся параметров субинтервала, чем отличающихся во времени кодированных параметров основного тона; средство для формирования сигнала прогнозирования из буфера LTP в зависимости от параметров субинтервала, включающего в себя сглаживание по/на границах субинтервалов; преобразование в частотной области для формирования спектра прогнозирования; средство объединения по меньшей мере части производной спектра прогнозирования со спектром ошибки для формирования комбинированного спектра (извлечение представляет собой перцепционное спектральное сглаживание или модификацию); при этом производная спектра ошибки извлекается из комбинированного спектра (причем извлечение включает в себя заполнение нулями, перцепционное формирование спектра и TNS).
Согласно другому варианту осуществления, предусмотрено устройство для декодирования кодированного аудиосигнала. Устройство содержит: обратное преобразование в частотной области для формирования блока аудиосигнала TD с наложением спектров из производной спектра ошибки; средство для формирования кадра аудиосигнала TD с использованием по меньшей мере двух блоков аудиосигнала TD с наложением спектров, при этом по меньшей мере некоторые части аудиосигнала TD с наложением спектров отличаются от аудиосигнала TD (при этом подавление наложения спектров во временной области (TDAC) возникает в результате оконного взвешивания и суммирования с перекрытием); средство для помещения выборок из кадра аудиосигнала TD в буфер LTP; средство для формирования сигнала прогнозирования из буфера LTP в зависимости от параметров, извлекаемых из кодированных параметров основного тона; преобразование в частотной области для формирования спектра прогнозирования из сигнала прогнозирования; средство для модификации спектра прогнозирования либо его производной, в зависимости от параметров, извлекаемых из кодированных параметров основного тона таким образом, чтобы сформировать модифицированный спектр прогнозирования (извлечение, например, представляет собой перцепционное спектральное сглаживание, модификация, например, представляет собой уменьшение абсолютной величины между гармониками или ограничение на число прогнозируемых гармоник); средство объединения по меньшей мере части производной модифицированного спектра прогнозирования со спектром ошибки для формирования комбинированного спектра (извлечение, например, представляет собой перцепционное спектральное сглаживание); при этом производная спектра ошибки извлекается из комбинированного спектра (причем извлечение включает в себя, например, заполнение нулями, перцепционное формирование спектра и TNS).
Другое устройство для декодирования кодированного аудиосигнала содержит: обратное преобразование в частотной области для формирования блока аудиосигнала TD с наложением спектров из производной спектра ошибки; средство для формирования кадра аудиосигнала TD с использованием по меньшей мере двух блоков аудиосигнала TD с наложением спектров, при этом по меньшей мере некоторые части аудиосигнала TD с наложением спектров отличаются от аудиосигнала TD (при этом подавление наложения спектров во временной области (TDAC) возникает в результате оконного взвешивания и суммирования с перекрытием); средство для помещения выборок из кадра аудиосигнала TD в буфер LTP; средство для извлечения модифицированных параметров основного тона из кодированных параметров основного тона в зависимости от содержимого буфера LTP (т.е. для расширения частотного диапазона кодированных параметров основного тона); средство для формирования спектра прогнозирования из буфера LTP в зависимости от модифицированных параметров основного тона (модифицированные параметры основного тона могут использоваться для формирования сигнала прогнозирования или модификации спектра прогнозирования); средство объединения по меньшей мере части производной спектра прогнозирования со спектром ошибки для формирования комбинированного спектра (извлечение, например, представляет собой перцепционное спектральное сглаживание); при этом производная спектра ошибки извлекается из комбинированного спектра (причем извлечение включает в себя, например, заполнение нулями, перцепционное формирование спектра и TNS).
Согласно вариантам осуществления, устройство дополнительно содержит средство для помещения всех выборок из блока аудиосигнала TD с наложением спектров, не отличающегося от аудиосигнала TD, в буфер LTP, даже когда выборки используются для формирования последующего кадра аудиосигнала TD (с использованием неперекрывающегося вывода IMDCT, когда перекрытие меньше максимального перекрытия). Например, часть соответствующих выборок, используемых посредством буфера LTP, может адаптироваться (например, таким образом, что часть выборок, используемых для LTP, увеличивается). Пример для увеличенной части, используемой для LTP, показывается посредством фиг.17с по сравнению с фиг.17а. Это означает то, что, согласно вариантам осуществления, один или более предыдущих кадров буферизуются посредством буфера LTP; буферизованные кадры могут использоваться для прогнозирования текущего кадра или последующего кадра. Например, используется всего один буферизованный кадр или множество буферизованных кадров либо просто часть (одна или более выборок) одного или более кадров. Выбор части соответствующих буферизованных кадров осуществляется динамически. Например, буферная часть выбирается таким образом, что она включает в себя выборки, которые должны выводиться в последующем кадре. В общем, она может содержать одну или более выборок одного или более кадров.
Другой вариант осуществления предусматривает аудиопроцессор для обработки аудиосигнала, имеющего ассоциированную информацию запаздывания основного тона, аудиопроцессор содержит модуль преобразования области для преобразования на основе кадров представления в первой области аудиосигнала в представление во второй области аудиосигнала; и средство для разделения аудиосигнала на перекрывающиеся субинтервалы в зависимости от информации основного тона, при этом по меньшей мере в некоторых случаях имеется по меньшей мере два субинтервала в кадре; гармонический постфильтр для фильтрации на основе субинтервалов представления во второй области аудиосигнала (включающей в себя сглаживание по/на границах субинтервалов), при этом гармонический постфильтр основан на передаточной функции, содержащей числитель и знаменатель, при этом числитель содержит значение гармоничности, и при этом знаменатель содержит значение гармоничности и значение усиления, и значение запаздывания основного тона, при этом значение гармоничности является пропорциональным требуемой интенсивности фильтра независимо от изменений амплитуды в аудиосигнале, и значение усиления зависит от изменений амплитуды в аудиосигнале, и по меньшей мере в некоторых случаях гармонический постфильтр отличается в различных субинтервалах.
Согласно вариантам осуществления, значение гармоничности, значение усиления и значение запаздывания основного тона извлекаются с использованием уже доступного вывода гармонического постфильтра в предыдущих субинтервалах и представления во второй области аудиосигнала. Исходная информация заключается в том, что гармонический постфильтр может изменяться между предыдущим субинтервалом и последующим субинтервалом, и что гармонический постфильтр использует уже доступный вывод в качестве своего ввода.
Другой вариант осуществления предусматривает сочетание как LTP, так и HPF с декодером в частотной области.
Хотя некоторые аспекты описаны в контексте устройства, очевидно, что эти аспекты также представляют описание соответствующего способа, при этом блок или устройство соответствует этапу способа либо признаку этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока или элемента, или признака соответствующего устройства. Некоторые или все этапы способа могут выполняться посредством (или с использованием) аппаратного устройства, такого как, например, микропроцессор, программируемый компьютер либо электронная схема. В некоторых вариантах осуществления, некоторые из одного или более самых важных этапов способа могут выполняться посредством этого устройства.
Кодированный аудиосигнал согласно изобретению может сохраняться на цифровом носителе данных либо может передаваться по среде передачи, такой как беспроводная среда передачи или проводная среда передачи, к примеру, Интернет.
В зависимости от определенных требований к реализации, варианты осуществления изобретения могут реализовываться в аппаратных средствах или в программном обеспечении. Реализация может выполняться с использованием цифрового носителя данных, например, гибкого диска, DVD, Blu-Ray, CD, ROM, PROM, E PROM, EEPROM или флэш-памяти, имеющего сохраненные считываемые электронными средствами управляющие сигналы, которые взаимодействуют (или допускают взаимодействие) с программируемой компьютерной системой таким образом, что осуществляется соответствующий способ. Следовательно, цифровой носитель данных может быть машиночитаемым.
Некоторые варианты осуществления согласно изобретению содержат носитель данных, имеющий считываемые электронными средствами управляющие сигналы, которые допускают взаимодействие с программируемой компьютерной системой таким образом, что осуществляется один из способов, описанных в данном документе.
В общем, варианты осуществления настоящего изобретения могут реализовываться как компьютерный программный продукт с программным кодом, при этом программный код выполнен с возможностью осуществления одного из способов, когда компьютерный программный продукт выполняется на компьютере. Программный код, например, может сохраняться на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для осуществления одного из способов, описанных в данном документе, сохраненную на машиночитаемом носителе.
Другими словами, таким образом, вариант осуществления способа согласно изобретению представляет собой компьютерную программу, имеющую программный код для осуществления одного из способов, описанных в данном документе, когда компьютерная программа выполняется на компьютере.
Следовательно, дополнительный вариант осуществления способов согласно изобретению представляет собой носитель данных (цифровой носитель данных или машиночитаемый носитель), содержащий записанную компьютерную программу для осуществления одного из способов, описанных в данном документе. Носитель данных, цифровой носитель данных или носитель с записанными данными обычно является материальным и/или постоянным.
Следовательно, дополнительный вариант осуществления способа согласно изобретению представляет собой поток данных или последовательность сигналов, представляющих компьютерную программу для осуществления одного из способов, описанных в данном документе. Поток данных или последовательность сигналов, например, может быть выполнена с возможностью передачи через соединение для передачи данных, например, через Интернет.
Дополнительный вариант осуществления содержит средство обработки, например, компьютер или программируемое логическое устройство, выполненное с возможностью осуществления одного из способов, описанных в данном документе.
Дополнительный вариант осуществления содержит компьютер, имеющий установленную компьютерную программу для осуществления одного из способов, описанных в данном документе.
Дополнительный вариант осуществления согласно изобретению содержит устройство или систему, выполненную с возможностью передачи (например, электронными или оптическими средствами) компьютерной программы для осуществления одного из способов, описанных в данном документе, в приемное устройство. Приемное устройство, например, может представлять собой компьютер, мобильное устройство, запоминающее устройство и т.п. Устройство или система может содержать, например, файловый сервер для передачи компьютерной программы в приемное устройство.
В некоторых вариантах осуществления, программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может использоваться для выполнения части или всех из функциональностей способов, описанных в данном документе. В некоторых вариантах осуществления, программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором, чтобы осуществлять один из способов, описанных в данном документе. В общем, способы предпочтительно осуществляются посредством любого аппаратного устройства.
Вышеописанные варианты осуществления являются лишь иллюстративными в отношении принципов настоящего изобретения. Следует понимать, что специалистам в данной области техники должны быть очевидными модификации и изменения конфигураций и подробностей, описанных в данном документе. Следовательно, подразумевается ограничение лишь объемом нижеприведенной формулы изобретения, а не конкретными подробностями, представленными в данном документе в порядке описания и пояснения вариантов осуществления.
[1] G. Cohen, Y. Cohen, D. Hoffman, H. Krupnik и A. Satt "Digital audio signal coding", US 6064954, 1998 год.
[2] К. Makino и J. Matsumoto "Hybrid audio coding for speech and audio below medium bit rate", in Consumer Electronics, 2000. ICCE. 2000 Digest of Technical Papers. International Conference on, 2000 год, стр. 264-265.
[3] J. Ojanpera "Method, apparatus and computer program to provide predictor adaptation for advanced audio coding (AAC) system", 2004 год.
[4] J. Ojanperaa "Method for improving the coding efficiency of the audio signal", 2007 год.
[5] J. Ojanpera "Method for improving the coding efficiency of the audio signal", 2008 год.
[6] J. Ojanpera, M. Vaananen и L. Yin "Long term predictor for transform domain perceptual audio coding", in Audio Engineering Society Convention 107, 1999 год.
[7] S. A. Ramprashad "A multimode transform predictive coder (MTPC) for speech and audio", in Speech Coding Proceedings, 1999 IEEE Workshop on, 1999 год, стр. 10-12.
[8] В. Edler, С.Helmrich, M. Neuendorf и В. Schubert "Audio Encoder, Audio Decoder, Method For Encoding An Audio Signal And Method For Decoding An Encoded Audio Signal", PCT/EP2016/054831, 2016 год.
[9] L. Villemoes, J. Klejsa и P. Hedelin "Speech coding with transform domain prediction", in 2017 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), 2017 год, стр. 324-328.
[10] R. H. Frazier "An adaptive filtering approach toward speech enhancement"., Citeseer, 1975 год.
[11] D. Malah и R. Cox "A generalized comb filtering technigue for speech enhancement", in Acoustics, Speech and Signal Processing, IEEE International Conference on ICASSP'82., 1982 год, том 7, стр. 160-163.
[12] J. Song, C.-H. Lee, H.-O. Oh и H.-G. Kang "Harmonic Enhancement in Low Bitrate Audio Coding Using the Efficient Long-Term Predictor", in EURASIP J. Adv. Signal Process. 2010, 2010 год.
[13] Т. Morii "Post Filter And Filtering Method", РСТ/JP2007/074044, 2007 год.
[14] E. Ravelli, C. Helmrich, G. Markovic, M. Neusinger, S. Disch, M. Jander и M. Dietz "Apparatus and Method for Processing the Audio Signal Using the Harmonic Post-Filter", PCT/EP2015/066998, 2015 год.
[15] 3rd Generation Partnership Project; Technical Specification Group Services and System Aspects; Codec for Enhanced Voice Services (EVS); Detailed algorithmic description, номер 26.445. 3GPP, 2019 год.
[16] С.Helmrich, J. Lecomte, G. Markovic, M. Schnell, B. Edler и S. Reuschl "Apparatus And Method For Encoding Or Decoding An Audio Signal Using A Transient-Location Dependent Overlap", PCT/EP2014/053293, 2014 год.
[17] С. Helmrich, J. Lecomte, G. Markovic, M. Schnell, B. Edler и S. Reuschl "Apparatus And Method For Encoding Or Decoding An Audio Signal Using A Transient-Location Dependent Overlap", PCT/EP2014/053293, 2014 год.
[18] 3rd Generation Partnership Project; Technical Specification Group Services and System Aspects; Codec for Enhanced Voice Services (EVS); Detailed algorithmic description, номер 26.445. 3GPP, 2019 год.
[19] G. Markovic, E. Ravelli, M. Dietz и В. Grill "Signal Filtering", РСТ/ЕР2018/080837, 2018 год.
[20] N. Guo и В. Edler "Encoder, Decoder, Encoding Method And Decoding Method For Freguency Domain Long-Term Prediction Of Tonal Signals For Audio Coding", PCT/EP2019/082802, 2019 год.
[21] N. Guo и В. Edler, "Frequency Domain Long-Term Prediction for Low Delay General Audio Coding", IEEE Signal Processing Letters, 2021 год.
[22] Т. Nanjundaswamy и К. Rose "Cascaded Long Term Prediction for Enhanced Compression of Polyphonic Audio Signals", IEEE/ACM Transactions On Audio, Speech and Language Processing, 2014 год.
[23] E. Ravelli, M. Schnell, C. Benndorf, M. Lutzky и M. Dietz "Apparatus And Method For Encoding And Decoding An Audio Signal Using Downsampling Or Interpolation Of Scale Parameters", патент (США) РСТ/EP2017/0789212017.
[24] E. Ravelli, M. Schnell, C. Benndorf, M. Lutzky, M. Dietz и S. Korse "Apparatus And Method For Encoding And Decoding An Audio Signal Using Downsampling Or Interpolation Of Scale Parameters", патент (США) РСТ/EP2018/0801372018.
[25] Low Complexity Communication Codec. Bluetooth, 2020 год.
[26] Digital Enhanced Cordless Telecommunications (DECT); Low Complexity Communication Codec plus (LC3plus), номер 103 634. ETSI, 2019 год.
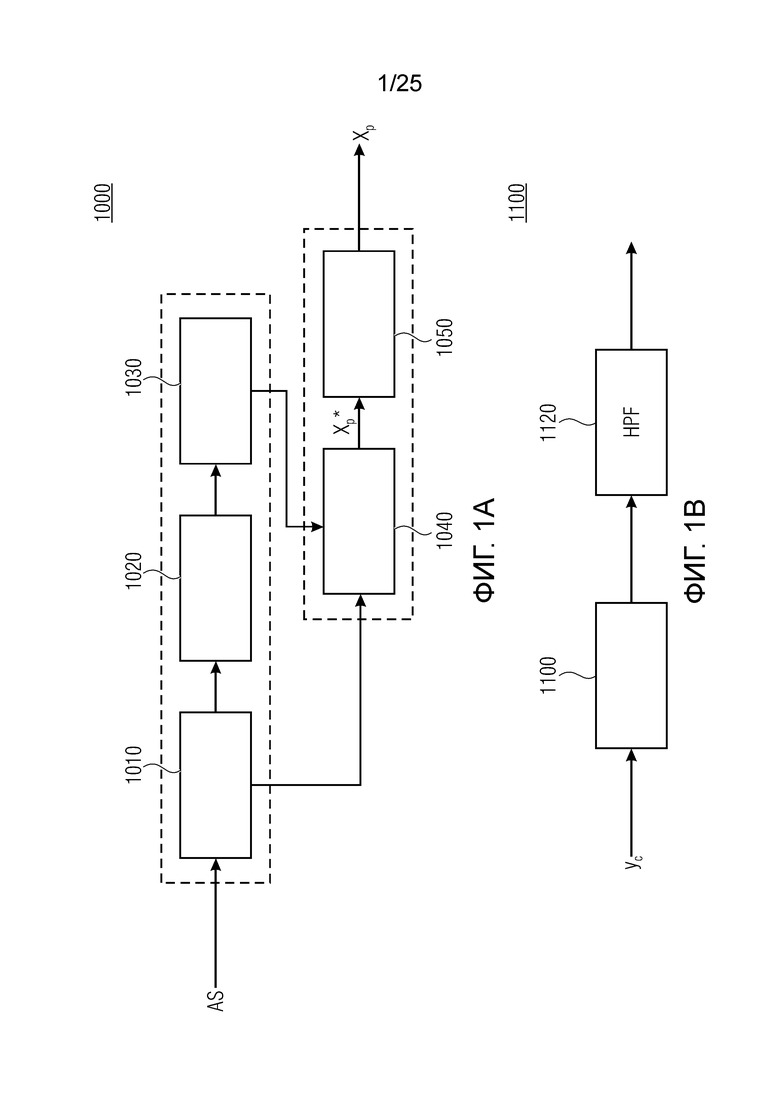
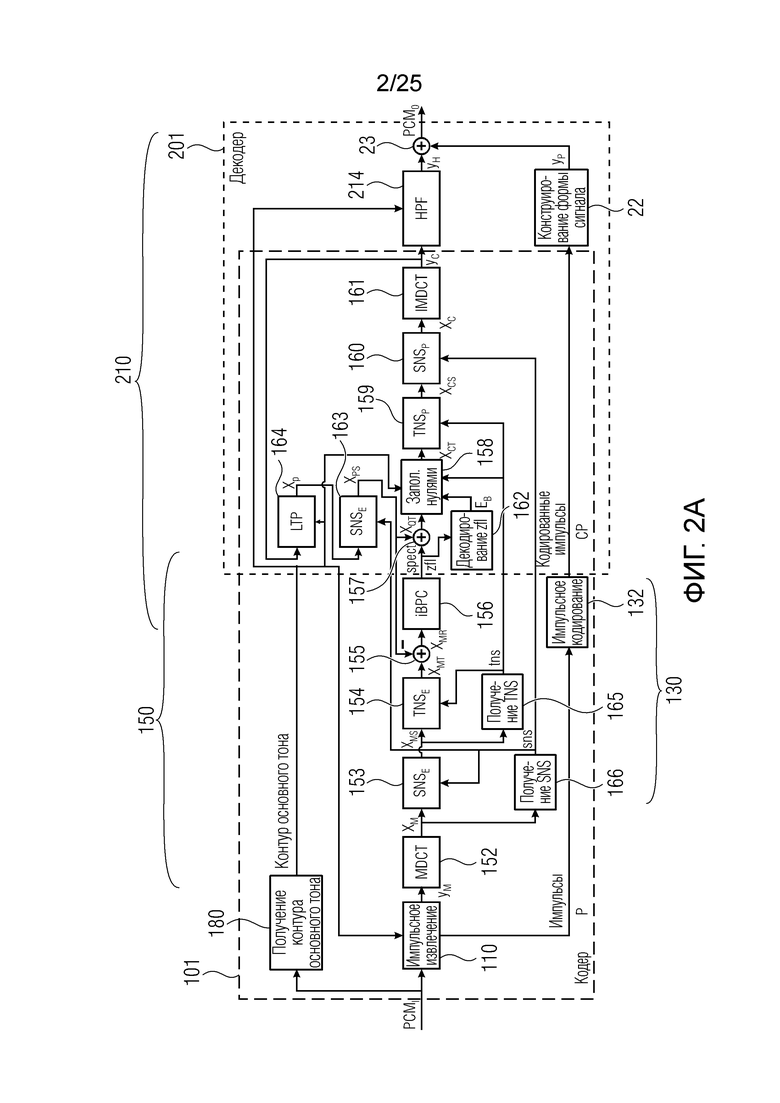
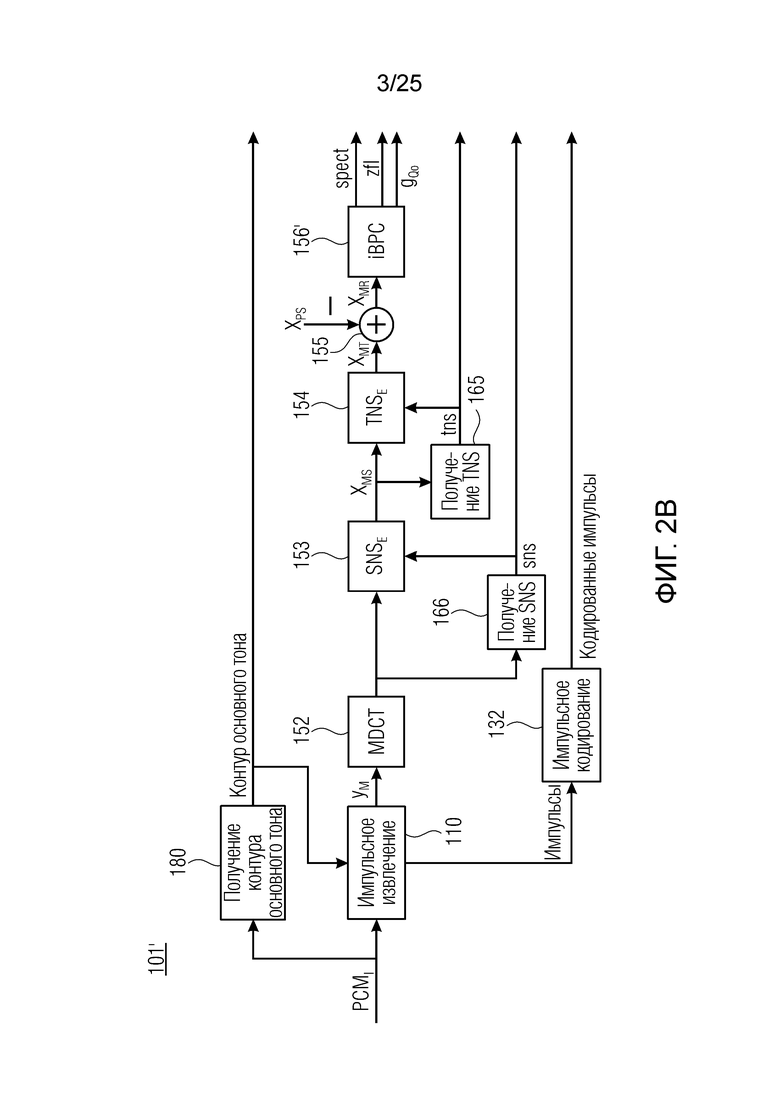
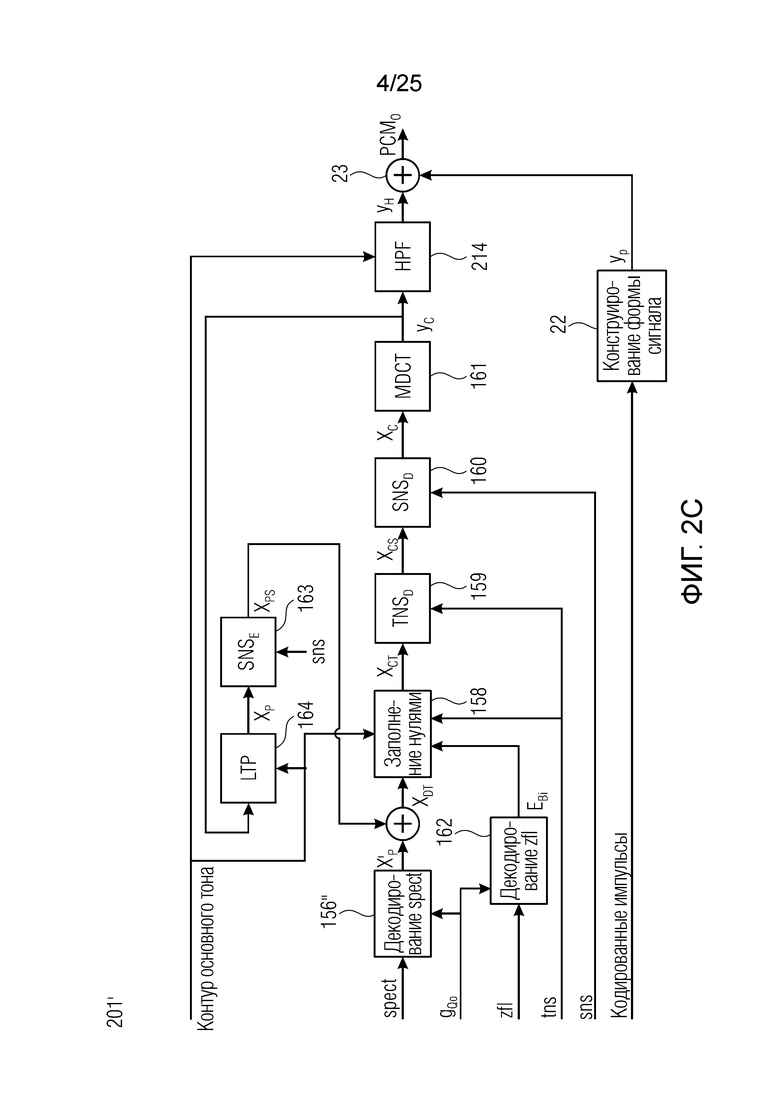
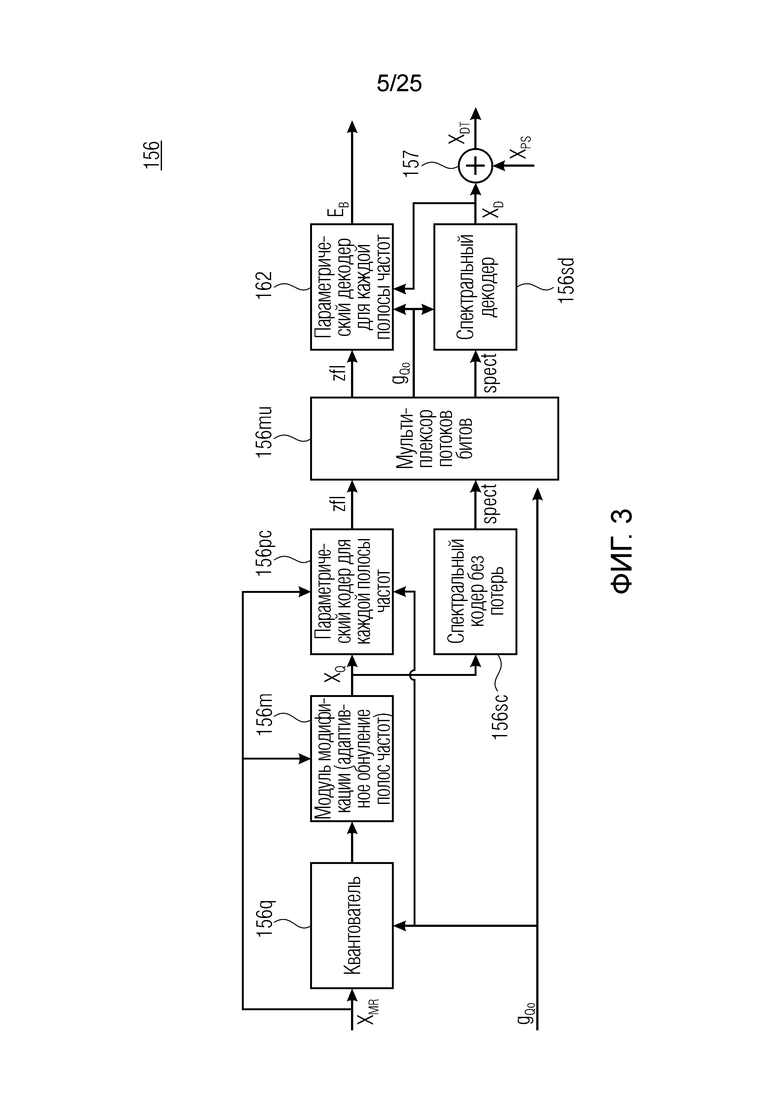
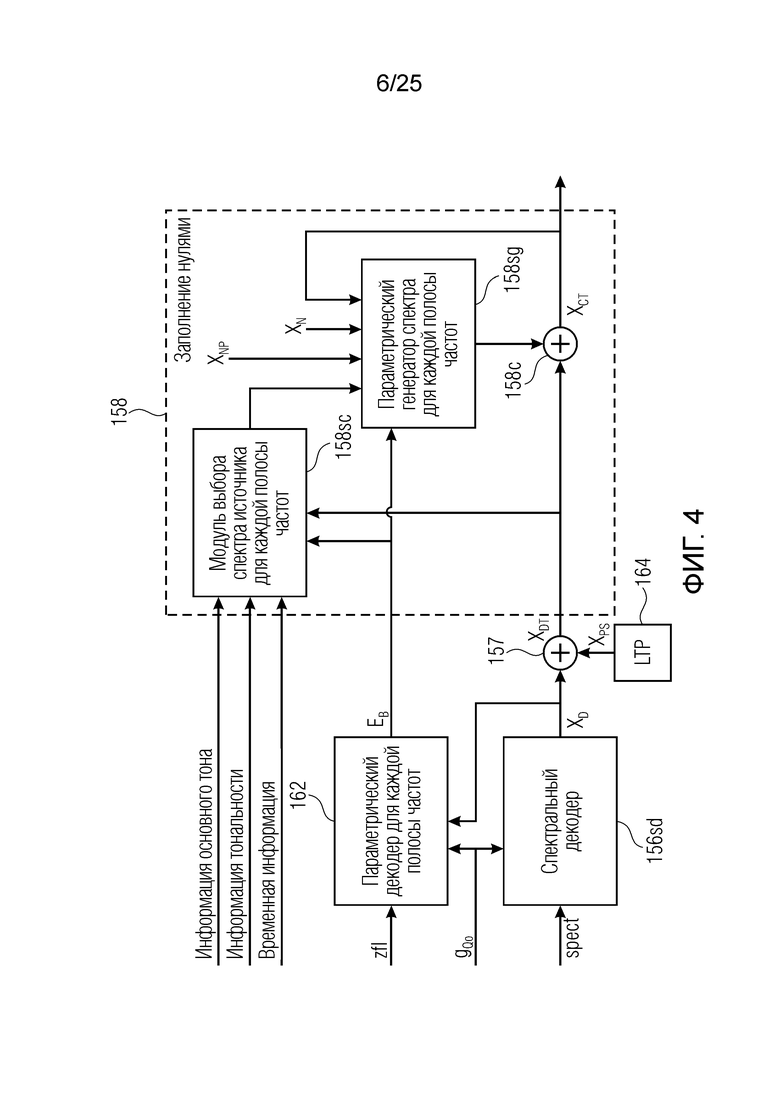
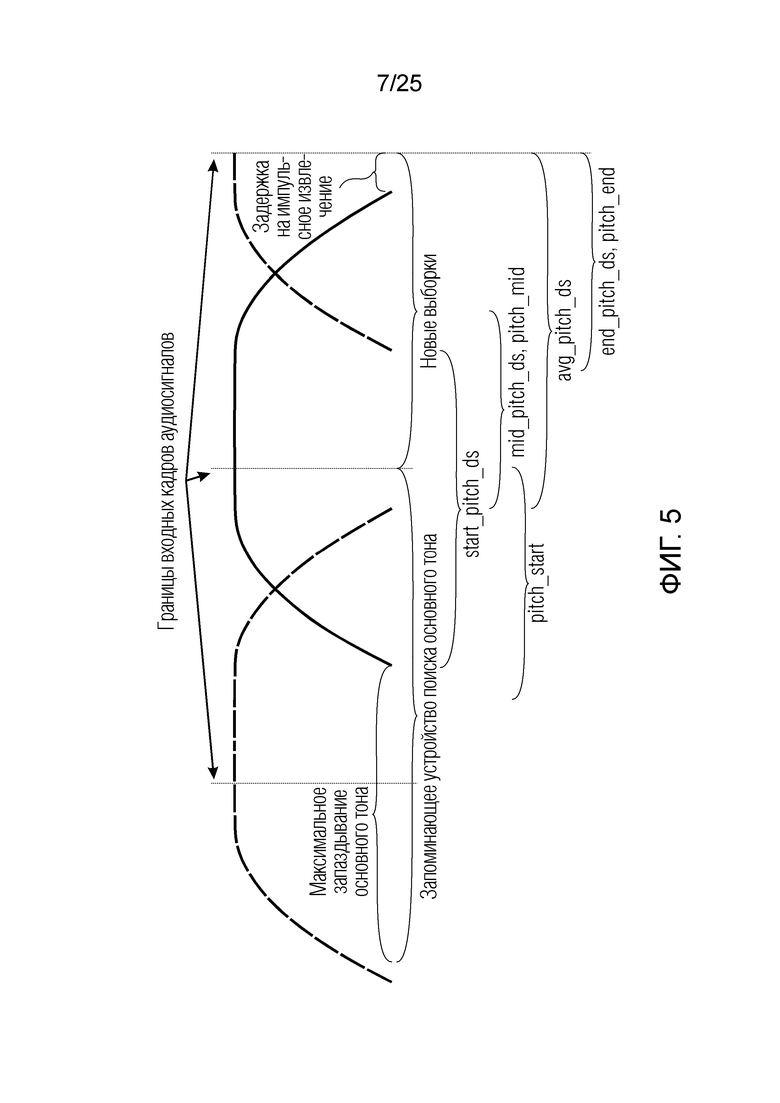
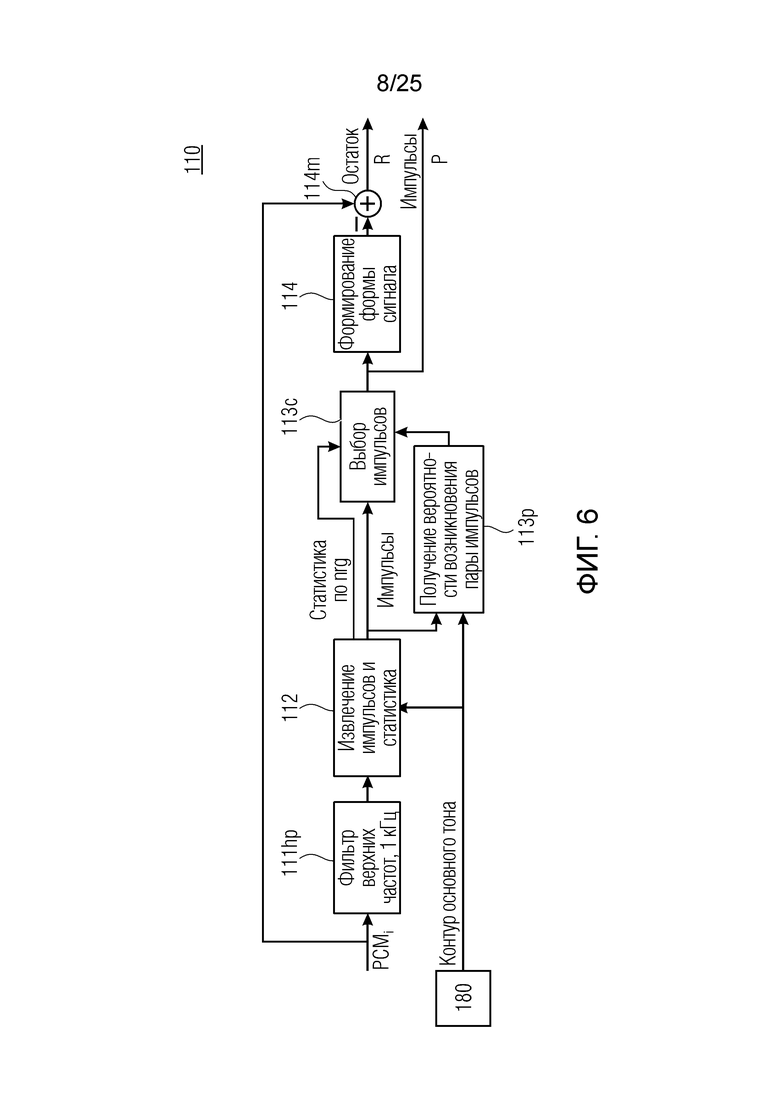
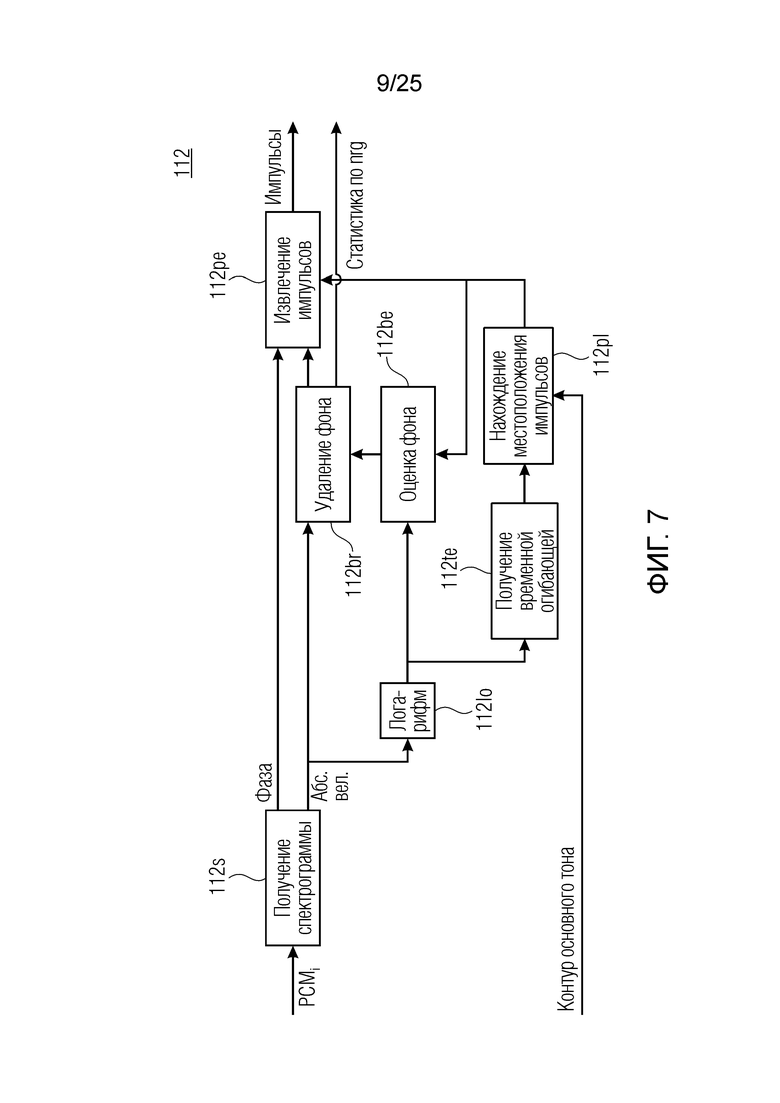
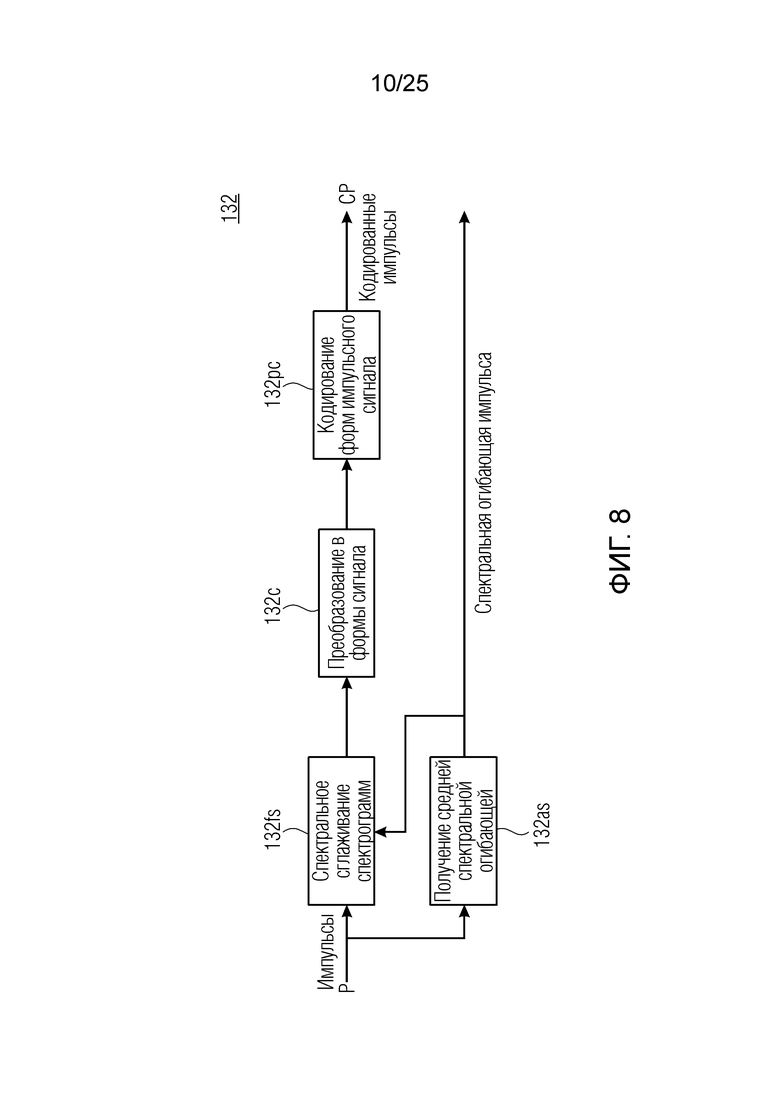
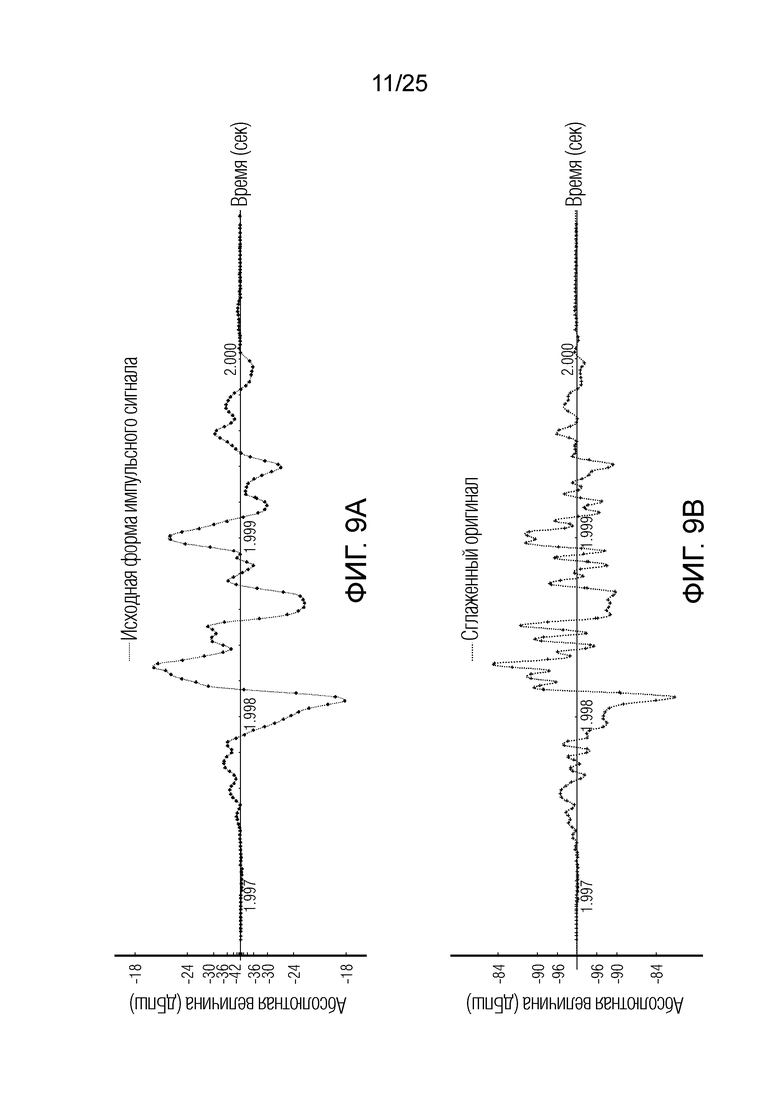
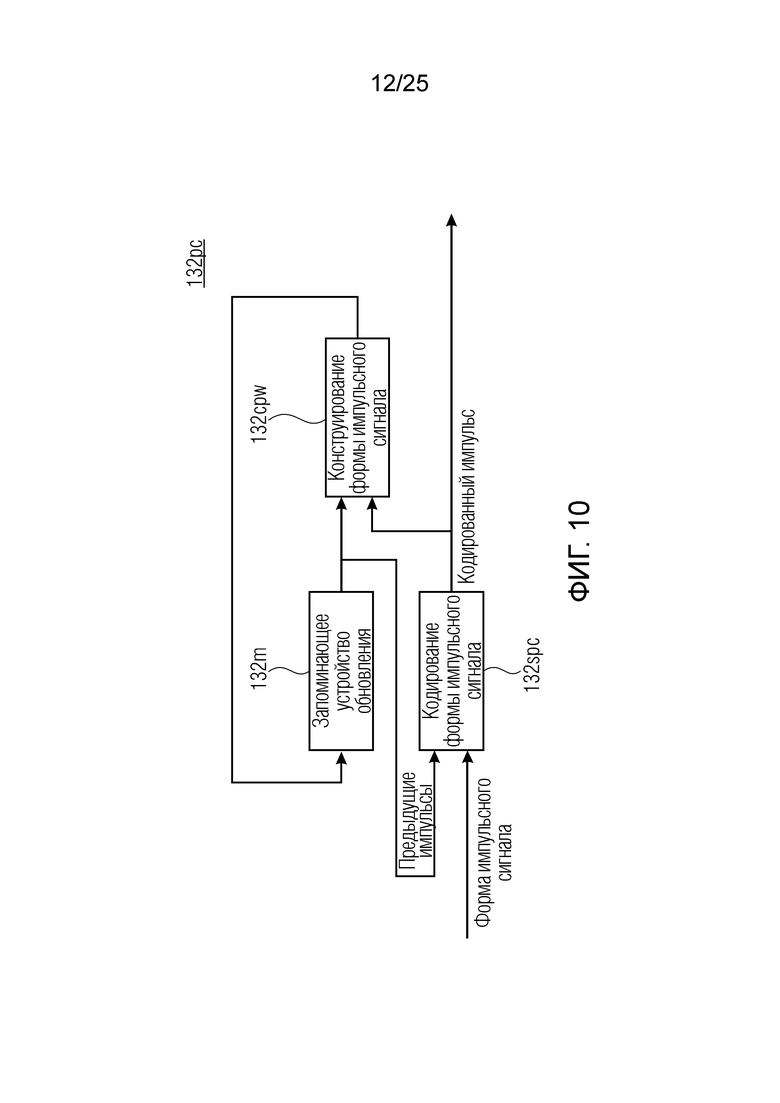

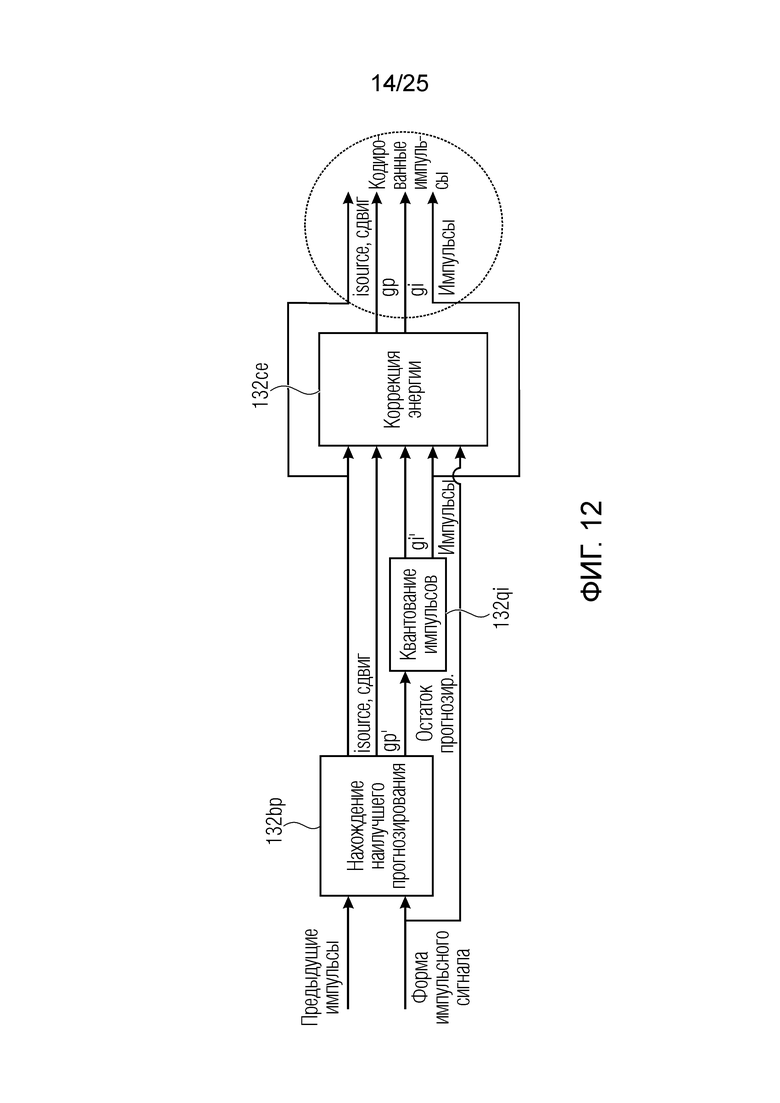
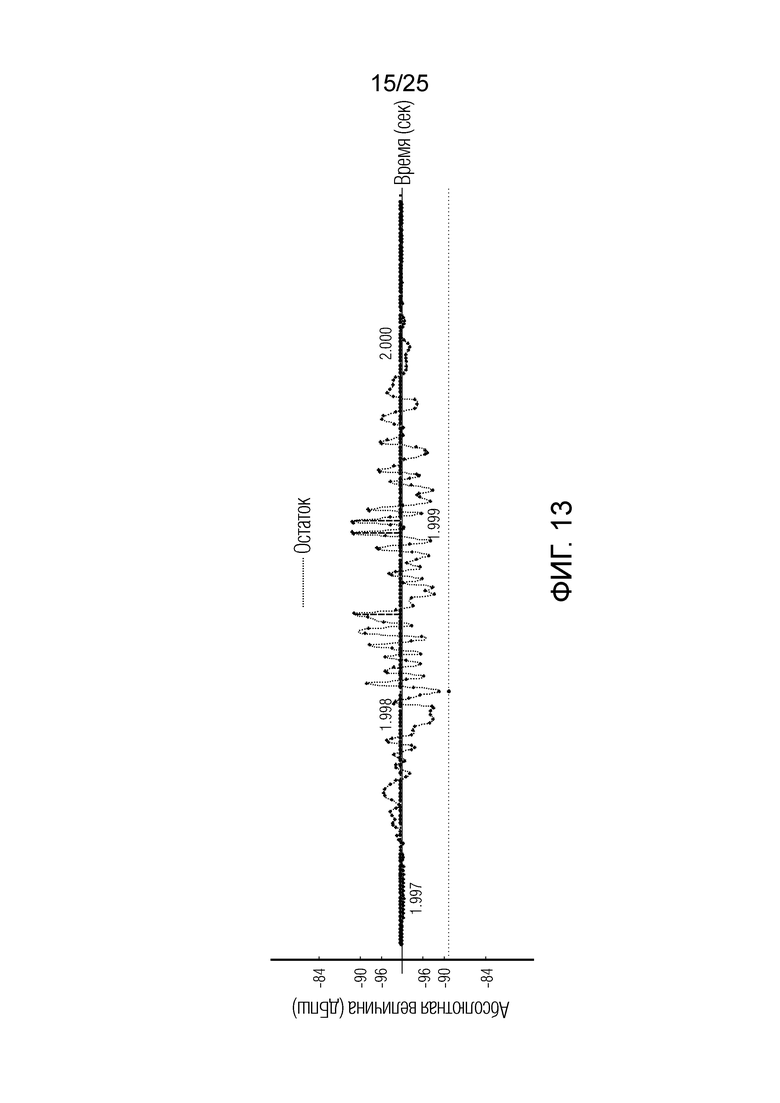
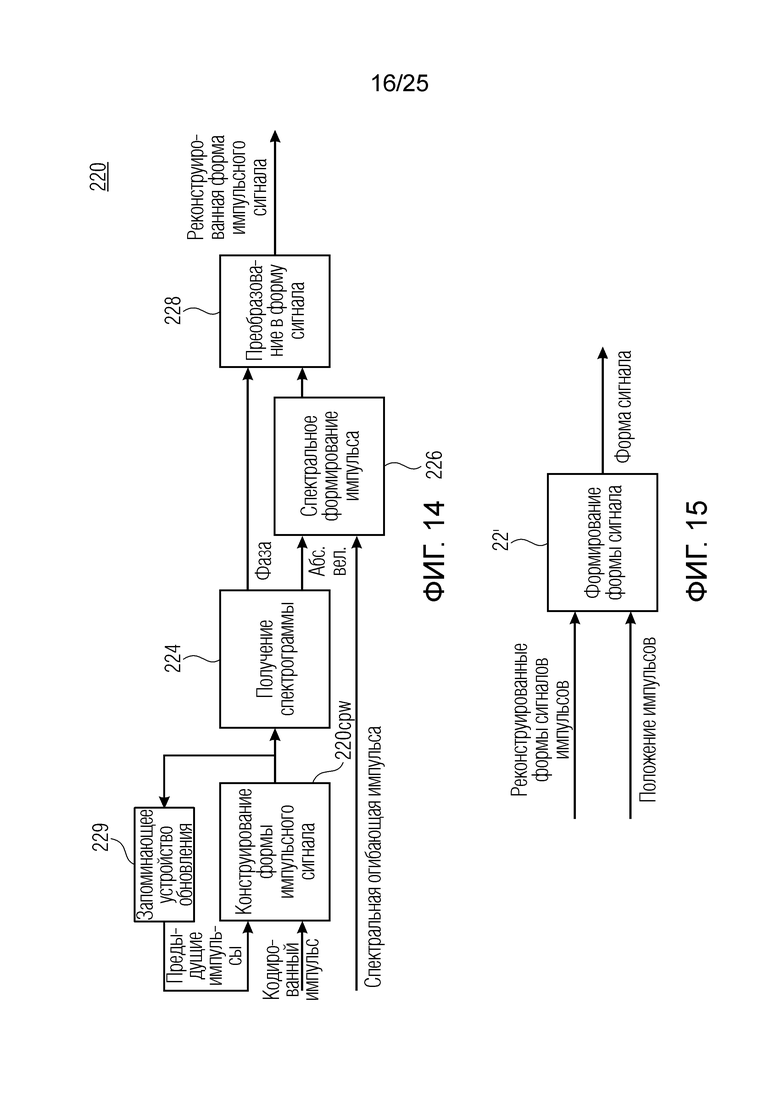
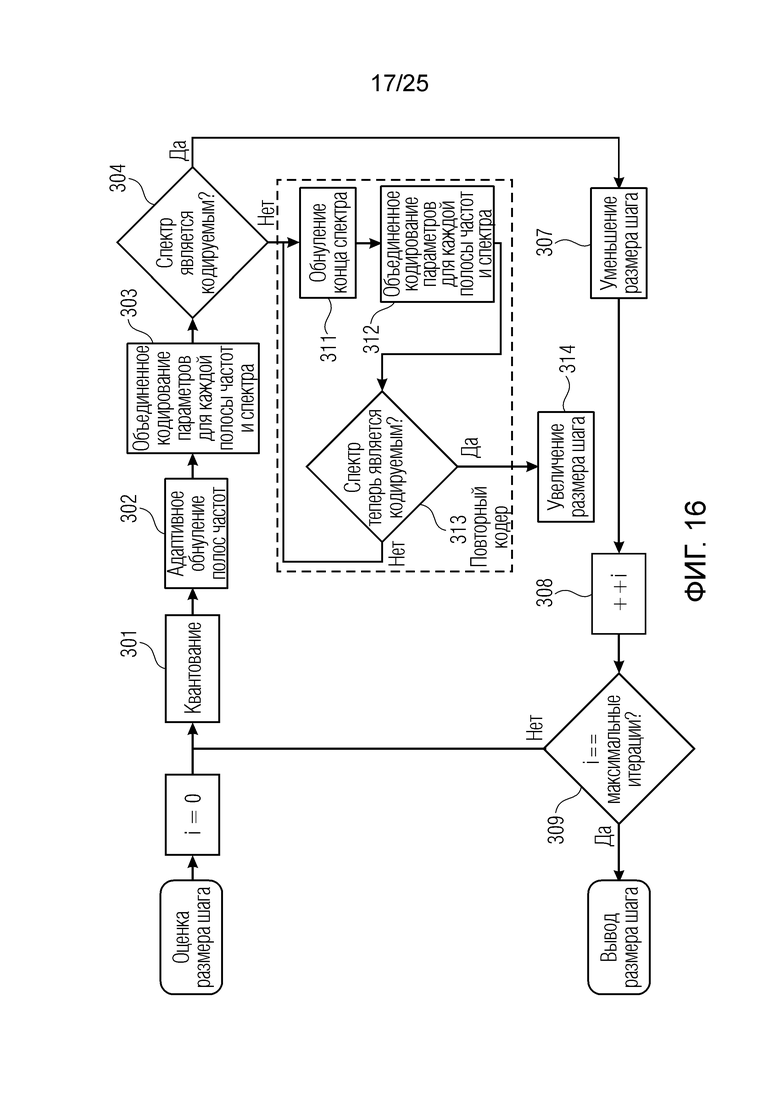
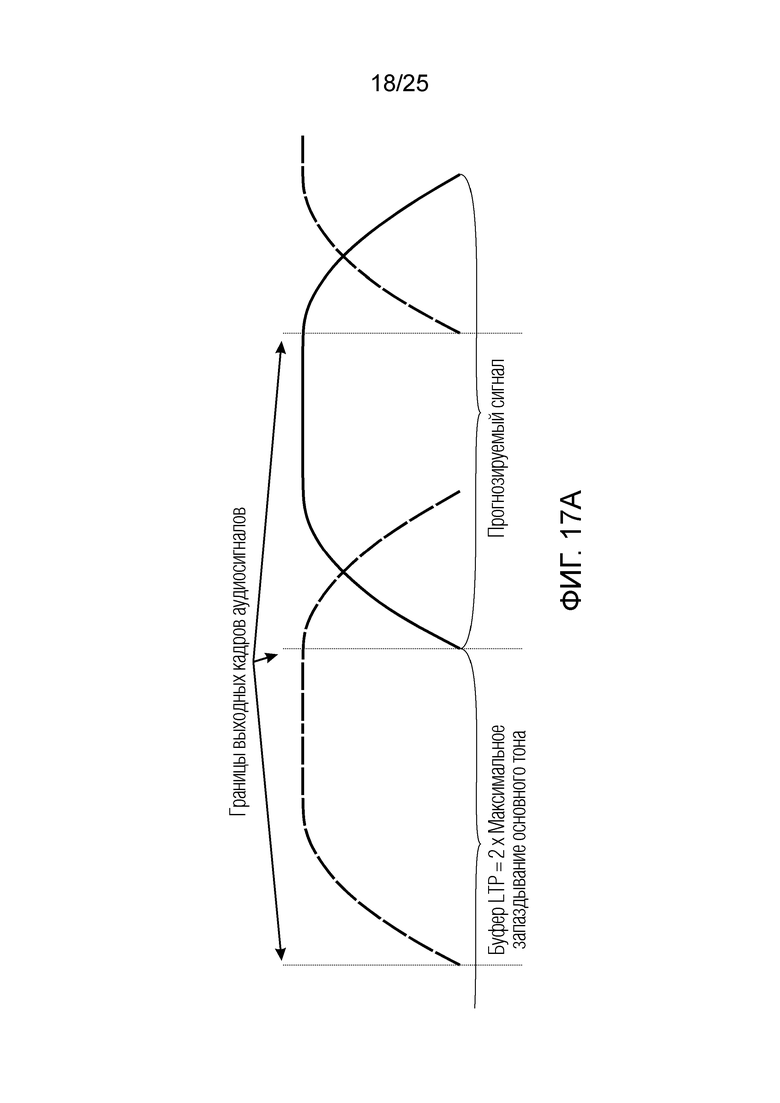
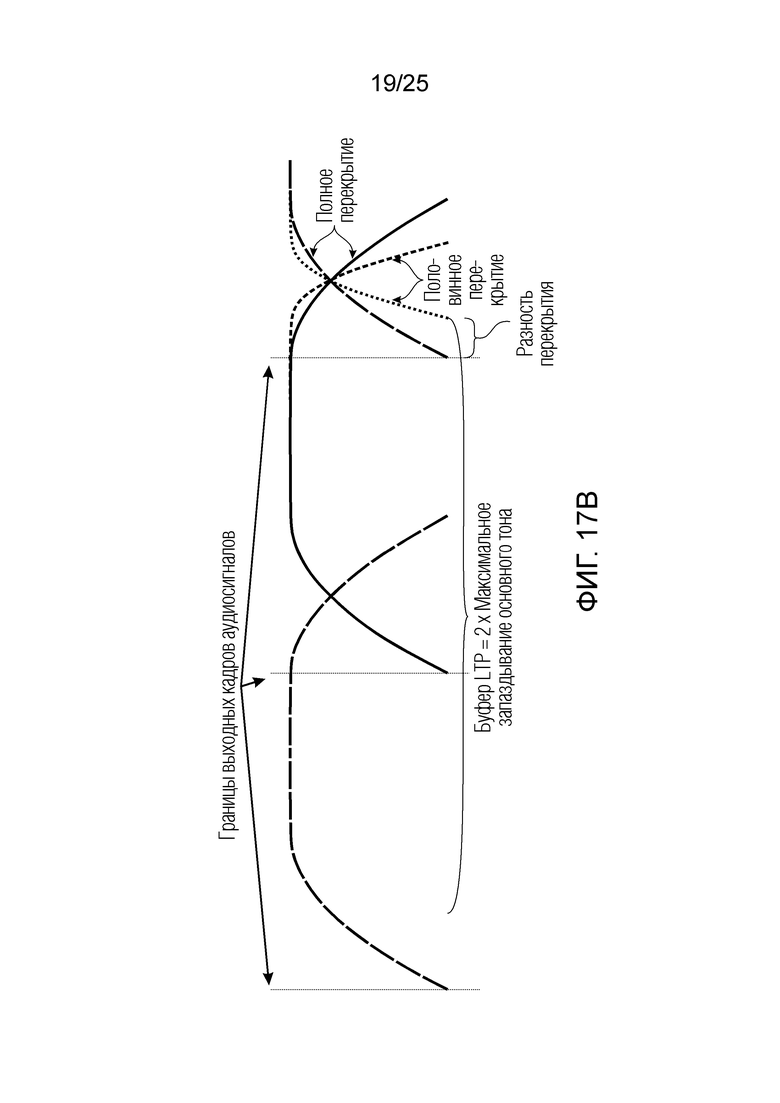
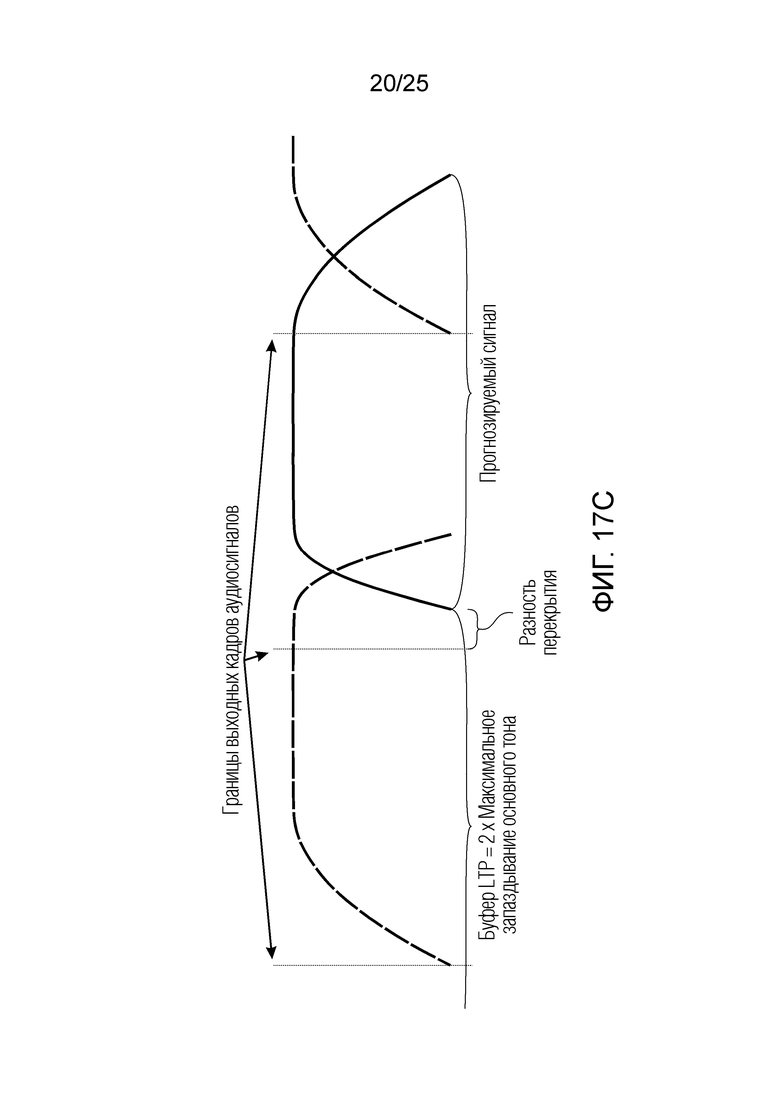
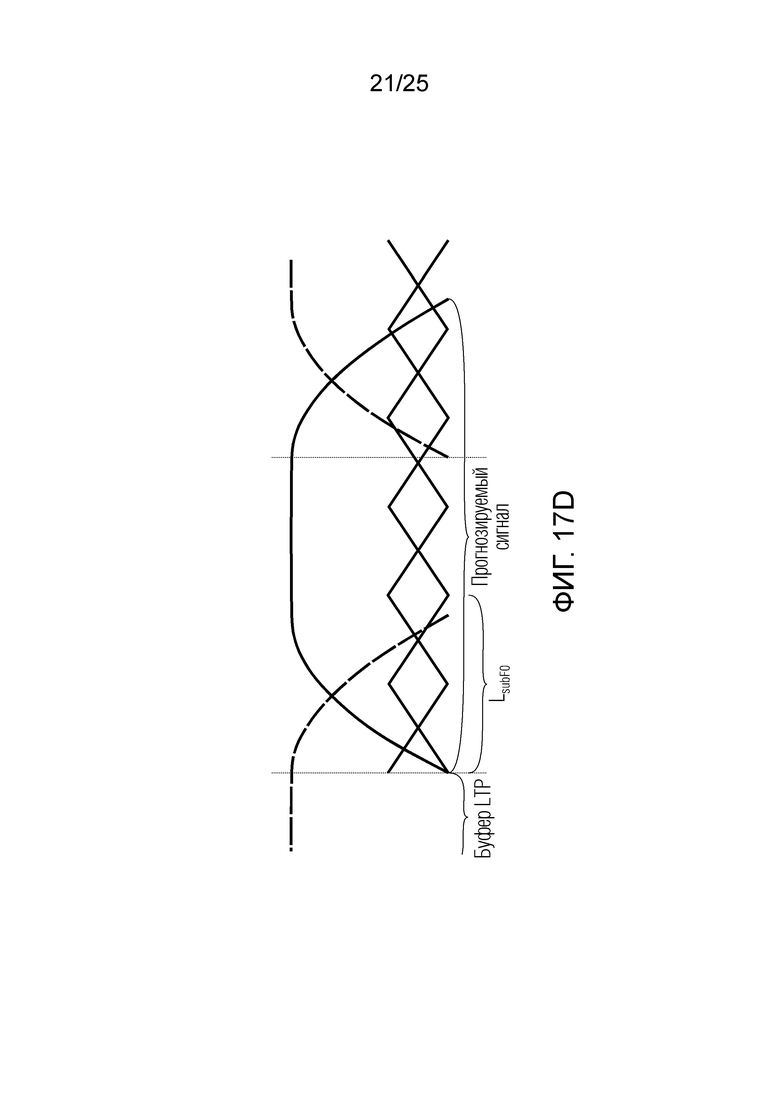
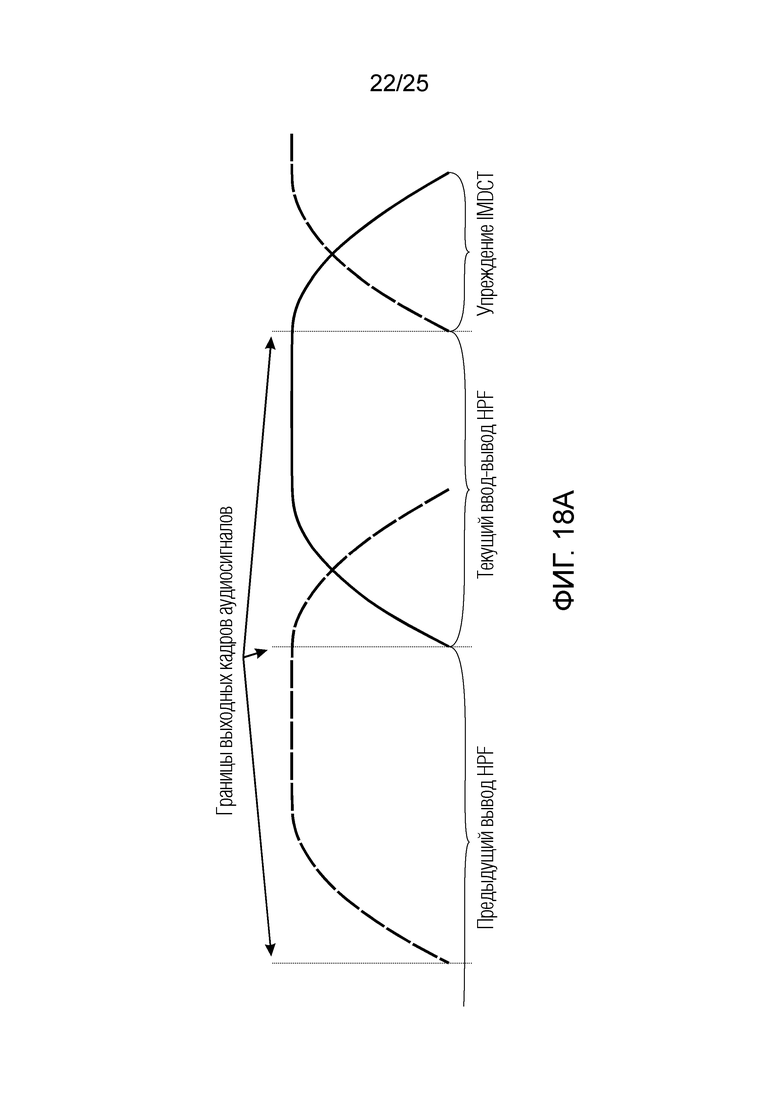
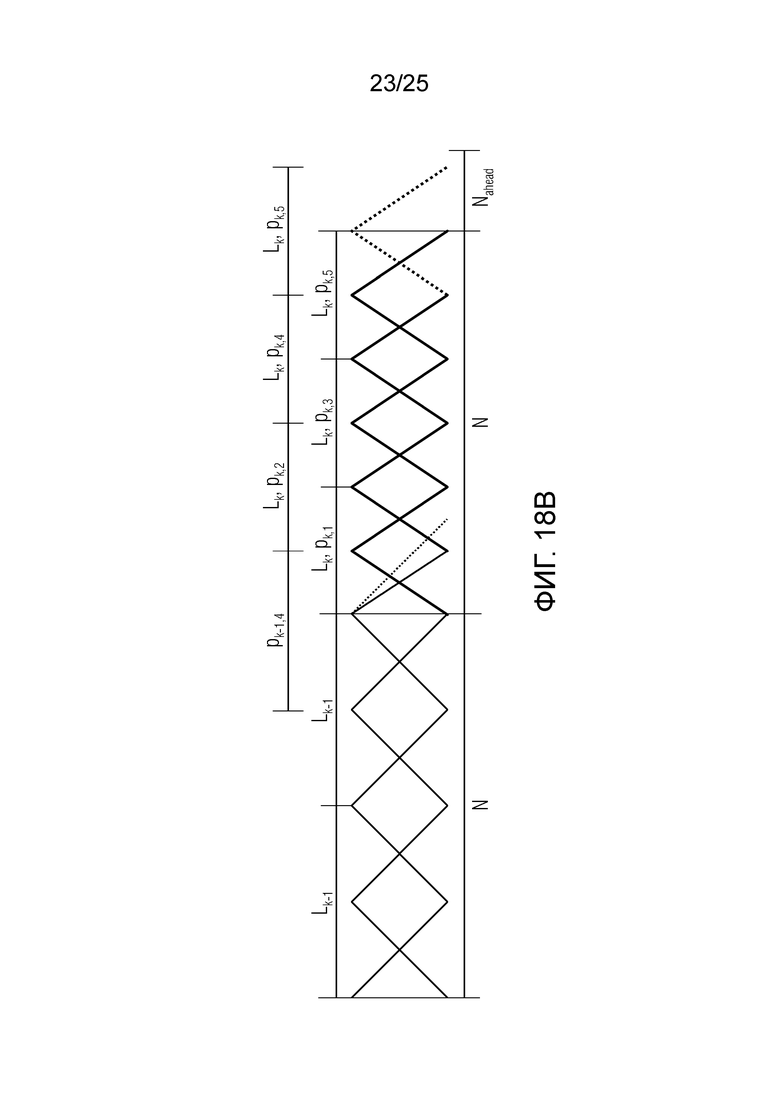
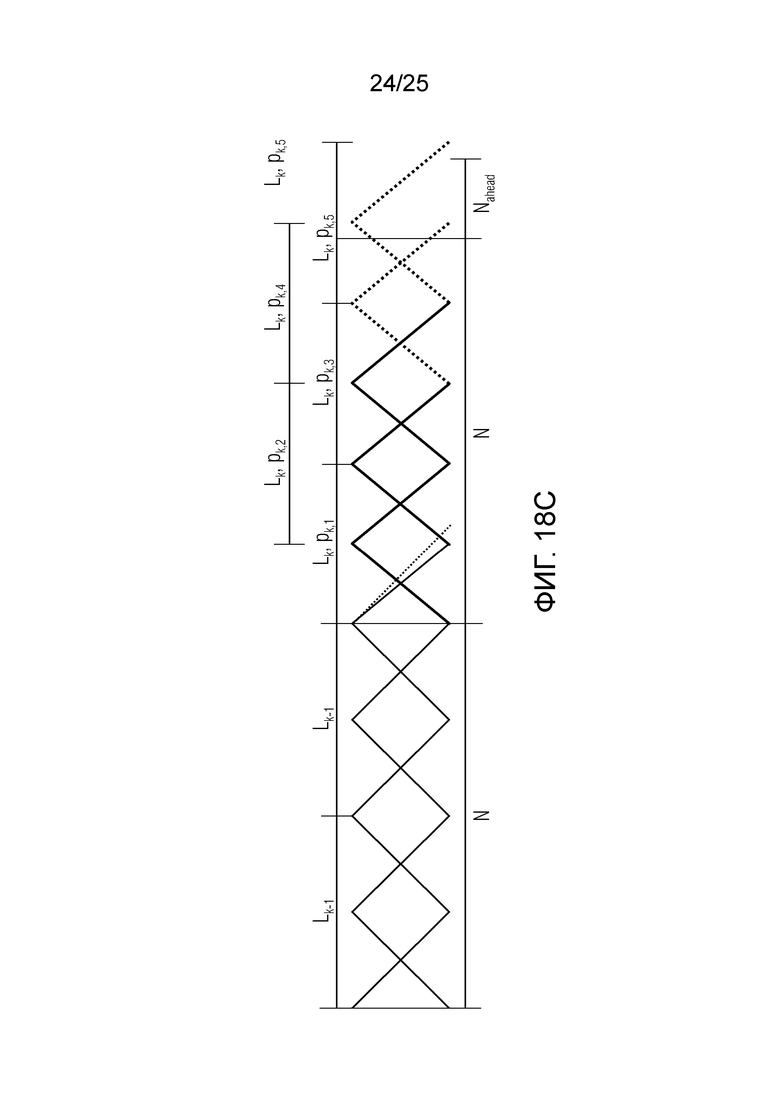
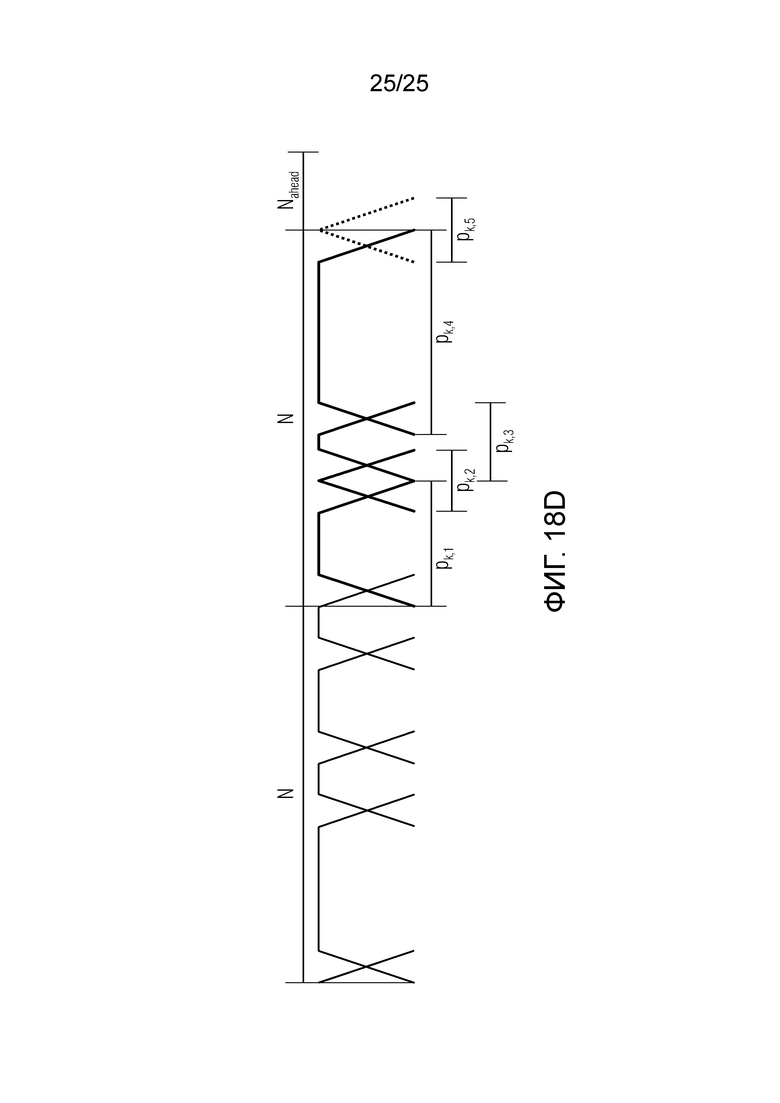
Изобретение относится к области вычислительной техники для обработки аудиоданных. Технический результат заключается в повышении качества гармонического кодирования сигналов. Технический результат достигается за счет этапов, на которых: принимают выборки (ус), извлекаемые из кадра кодированного аудиосигнала, с использованием буфера (1010) LTP; разделяют временной интервал, ассоциированный с последующим кадром кодированного аудиосигнала, последующего относительно кадра, на субинтервалы в зависимости от кодированного параметра основного тона; извлекают параметры субинтервала из кодированного параметра основного тона в зависимости от положения субинтервалов во временном интервале, ассоциированном с последующим кадром кодированного аудиосигнала; формируют сигнал прогнозирования из буфера (1010) LTP в зависимости от параметров субинтервала; и формируют спектр прогнозирования на основе сигнала прогнозирования. 9 н. и 20 з.п. ф-лы, 29 ил.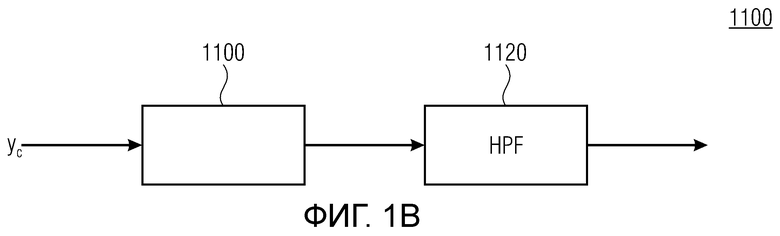
1. Процессор (1000, 164, 101, 201, 201') для обработки кодированного аудиосигнала, причем кодированный аудиосигнал содержит по меньшей мере кодированный параметр основного тона, причем процессор (1000) содержит:
- буфер (1010) LTP, выполненный с возможностью приема выборок (ус), извлекаемых из кадра кодированного аудиосигнала;
- модуль (1020) разбиения интервалов, выполненный с возможностью разделения временного интервала, ассоциированного с последующим кадром кодированного аудиосигнала, на субинтервалы в зависимости от кодированного параметра основного тона;
- средство (1030) вычисления, выполненное с возможностью извлечения параметров субинтервала из кодированного параметра основного тона в зависимости от положения субинтервалов во временном интервале, ассоциированном с последующим кадром кодированного аудиосигнала;
- модуль (1040) прогнозирования, выполненный с возможностью формирования сигнала прогнозирования из буфера (1010) LTP в зависимости от параметров субинтервала; и
- модуль (1050) преобразования в частотной области, выполненный с возможностью формирования спектра (ХР) прогнозирования на основе сигнала прогнозирования.
2. Процессор (1000, 164, 101, 201) по п. 1, в котором имеется большее количество субинтервалов, чем отличающихся во времени кодированных параметров основного тона; и/или
- в котором имеется большее количество отличающихся параметров субинтервала, чем отличающихся во времени кодированных параметров основного тона; и/или
- в котором имеется более одного отличающихся во времени кодированных параметров основного тона в кадре.
3. Процессор (101, 201) по одному из предшествующих пунктов, дополнительно содержащий модуль (157) объединения, выполненный с возможностью объединения по меньшей мере части извлечения спектра (XPS) прогнозирования со спектром (XD) ошибки для формирования комбинированного спектра (XDT); и/или
- при этом извлечение спектра (XPS) прогнозирования проводится из спектра (ХР) прогнозирования посредством перцепционного сглаживания прогнозируемого спектра (ХР).
4. Процессор (101, 201) по пп. 1, 2 или 3, при этом процессор (101, 201) дополнительно содержит модуль (161) обратного преобразования в частотной области; и/или
- при этом процессор (101, 201) дополнительно содержит модуль (161) обратного преобразования в частотной области, выполненный с возможностью формирования блока аудиосигнала временной области с наложением спектров из извлечения спектра (XC) ошибки, при этом спектр (ХР) прогнозирования получается из кадра кодированного аудиосигнала, и/или при этом спектр (XD) ошибки получается из последующего кадра кодированного аудиосигнала, последующего относительно кадра, и извлечение спектра (XC) ошибки проводится из спектра (XD) ошибки; или
- при этом процессор (101, 201) дополнительно содержит модуль (161) обратного преобразования в частотной области, выполненный с возможностью формирования блока аудиосигнала временной области с наложением спектров из извлечения спектра (XC) ошибки, при этом спектр (ХР) прогнозирования получается из кадра кодированного аудиосигнала, и/или при этом спектр (XD) ошибки получается из последующего кадра кодированного аудиосигнала, последующего относительно кадра, и извлечение спектра (XC) ошибки проводится из спектра (XD) ошибки; и дополнительно содержит средство для формирования кадра аудиосигнала (yc) временной области с использованием по меньшей мере двух блоков аудиосигнала временной области с наложением спектров, при этом по меньшей мере некоторые части аудиосигнала временной области с наложением спектров отличаются от аудиосигнала (ус) временной области и принимаемых выборок (ус), соответственно.
5. Процессор (101, 201) по п. 4, дополнительно содержащий объект (158), выполненный с возможностью заполнения нулями на основе сигнала (EB), принимаемого из параметрического декодера (162) для каждой полосы частот, и комбинированного спектра (XDT), с тем чтобы получать извлечение спектра (XC) ошибки, причем комбинированный спектр (XDT) получается на основе по меньшей мере части извлечения спектра (XPS) прогнозирования и спектра (XD) ошибки; и объект (160), выполненный с возможностью формирования спектра (SNSD) спектральной огибающей сигнала (XCS), модифицированного объектом, выполненным с возможностью временного формирования (TNSD) и с учетом кодированной информации (sns) для формирования спектра, таким образом, чтобы получить извлечение спектра (XC) ошибки, и объект (159), выполненный с возможностью временного формирования (TNSD) сигнала (XCT) с учетом кодированной информации (tns) для временного формирования таким образом, чтобы получить извлечение спектра (XC) ошибки.
6. Процессор (101, 201) по одному из предшествующих пунктов, дополнительно содержащий модуль (157) объединения, выполненный с возможностью объединения по меньшей мере части спектра ХР (ХР) прогнозирования со спектром XD (XD) ошибки для формирования комбинированного спектра XDT (XDT); и/или
- дополнительно содержащий модуль (157) объединения, выполненный с возможностью объединения по меньшей мере части спектра ХР (ХР) прогнозирования или по меньшей мере части извлечения спектра XPS (XPS) прогнозирования со спектром XD (XD) ошибки, при этом упомянутая часть определяется на основе кодированного параметра основного тона; и/или
- дополнительно содержащий модуль (157) объединения, выполненный с возможностью объединения по меньшей мере части спектра ХР (ХР) прогнозирования или по меньшей мере части извлечения спектра XPS (XPS) прогнозирования со спектром XD (XD) ошибки, при этом если буфер LTP является активным, то первые 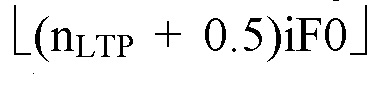 коэффициентов спектра (ХР) прогнозирования или извлечения спектра (XPS) прогнозирования, отличные от нулевого коэффициента, суммируются со спектром (XD) ошибки для формирования комбинированного спектра XDT (XDT); и/или при этом нулевой, а также коэффициенты выше копируются из спектра (XD) ошибки в комбинированный спектр (XDT), при этом
коэффициентов спектра (ХР) прогнозирования или извлечения спектра (XPS) прогнозирования, отличные от нулевого коэффициента, суммируются со спектром (XD) ошибки для формирования комбинированного спектра XDT (XDT); и/или при этом нулевой, а также коэффициенты выше копируются из спектра (XD) ошибки в комбинированный спектр (XDT), при этом  указывает использование функции минимального уровня;
указывает использование функции минимального уровня;
- при этом nLTP представляет собой параметр из кодированного аудиосигнала, и/или при этом nLTP является числом прогнозируемых гармоник; и
- при этом iF0 извлекается из кодированного параметра основного тона.
7. Процессор (1000) по одному из предшествующих пунктов, в котором в каждом субинтервале прогнозируемый сигнал конструируется с использованием буфера (1010) LTP и/или с использованием декодированного аудиосигнала из буфера (1010) LTP и фильтра, параметры которого извлекаются из кодированного параметра основного тона и положения субинтервала во временном интервале, ассоциированном с последующим кадром кодированного аудиосигнала.
8. Процессор (1000) по одному из предшествующих пунктов, в котором средство (1030) вычисления выполнено с возможностью извлечения параметров субинтервала из кодированного параметра основного тона, при этом параметры субинтервала содержат по меньшей мере параметр 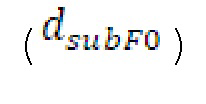 основного тона в субинтервал, следующим образом:
основного тона в субинтервал, следующим образом:
- получение запаздывания основного тона в субинтервал, ассоциированного с центром 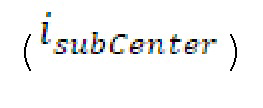 субинтервала, из контура
субинтервала, из контура  основного тона, при этом контур основного тона состоит из множества значений, имеющего один или более следующих подэтапов:
основного тона, при этом контур основного тона состоит из множества значений, имеющего один или более следующих подэтапов:
- задание запаздывания основного тона в субинтервал равным значению 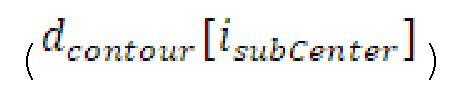 контура основного тона в положении центра субинтервала,
контура основного тона в положении центра субинтервала,
- определение конца 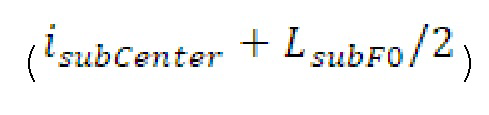 субинтервала,
субинтервала,
- сравнение запаздывания основного тона в субинтервал с концом 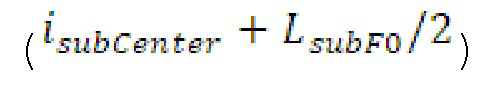 субинтервала, формируя результат сравнения,
субинтервала, формируя результат сравнения,
- адаптация запаздывания основного тона в субинтервал для значения контура основного тона в положении , извлекаемом из запаздывания основного тона в субинтервал, в зависимости от результата сравнения,
- и
- дополнительно содержащий средство вычисления, выполненное с возможностью извлечения контура основного тона из кодированного параметра основного тона; при этом контур основного тона получается из кодированных параметров основного тона с использованием интерполяции; или
- дополнительно содержащий средство вычисления, выполненное с возможностью извлечения контура основного тона из кодированного параметра основного тона; при этом контур основного тона получается из кодированных параметров основного тона с использованием интерполяции.
9. Процессор (1000) по одному из предшествующих пунктов, дополнительно содержащий средство для сглаживания сигнала прогнозирования по по меньшей мере двум субинтервалам из множества субинтервалов и/или на их границах, и/или
- дополнительно содержащий средство для сглаживания сигнала прогнозирования по по меньшей мере двум субинтервалам из множества субинтервалов и/или на их границах, при этом по меньшей мере упомянутые по меньшей мере два субинтервала перекрываются.
10. Процессор (1000) по одному из предшествующих пунктов, дополнительно содержащий средство для модификации прогнозируемого спектра или производной прогнозируемого спектра в зависимости от параметра, извлекаемого из кодированного параметра основного тона, с тем чтобы формировать модифицированный прогнозируемый спектр; и/или
- дополнительно содержащий средство для модификации прогнозируемого спектра (ХР) или производной прогнозируемого спектра (XPS), при этом средство для модификации выполнено с возможностью адаптации абсолютных величин коэффициентов MDCT, отстоящих по меньшей мере на 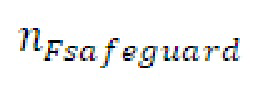 от гармоник в ХР или в XPS, посредством задания равными нулю или умножения на положительный коэффициент меньше 1, абсолютных величин коэффициентов MDCT; или дополнительно содержащий средство для модификации прогнозируемого спектра или производной прогнозируемого спектра, при этом средство для модификации выполнено с возможностью уменьшения абсолютных величин прогнозируемого спектра или абсолютных величин производной прогнозируемого спектра между гармониками.
от гармоник в ХР или в XPS, посредством задания равными нулю или умножения на положительный коэффициент меньше 1, абсолютных величин коэффициентов MDCT; или дополнительно содержащий средство для модификации прогнозируемого спектра или производной прогнозируемого спектра, при этом средство для модификации выполнено с возможностью уменьшения абсолютных величин прогнозируемого спектра или абсолютных величин производной прогнозируемого спектра между гармониками.
11. Процессор (1000) по одному из предшествующих пунктов, дополнительно содержащий средство для извлечения модифицированного параметра основного тона из кодированного параметра основного тона в зависимости от контента буфера (1010) LTP; или
- при этом прогнозируемый спектр формируется в зависимости от модифицированного параметра основного тона.
12. Процессор (1000) по одному из пп. 3-11, дополнительно содержащий средство для помещения всех выборок (ус) из блока аудиосигнала временной области с наложением спектров, не отличающегося от аудиосигнала, в буфер (1010) LTP; или
- дополнительно содержащий средство для помещения выборок (ус) из блока аудиосигнала временной области с наложением спектров, не отличающегося от аудиосигнала (ус) временной области, в буфер (1010) LTP, при этом выборки (ус) используются для формирования последующего кадра аудиосигнала; или
- дополнительно содержащий средство для помещения выборок (ус) из блока аудиосигнала временной области с наложением спектров, не отличающегося от текущего кадра, в буфер (1010) LTP, при этом выборки (ус) используются для формирования последующего кадра аудиосигнала (ус) временной области, при этом выбор части текущего кадра или выборок (ус), выбранных из блока аудиосигнала временной области с наложением спектров, адаптируется посредством средства для помещения выборок.
13. Процессор (1100, 214) для обработки аудиосигнала (ус), причем процессор (1100, 214) содержит:
- модуль (1110) разбиения, выполненный с возможностью разбиения временного интервала, ассоциированного с кадром аудиосигнала (ус), на множество субинтервалов, имеющих соответствующую длину, причем соответствующая длина множества субинтервалов зависит от значения запаздывания основного тона;
- гармонический постфильтр (1120), выполненный с возможностью фильтрации множества субинтервалов, при этом гармонический постфильтр (1120) основан на передаточной функции, содержащей числитель и знаменатель, при этом числитель содержит значение гармоничности, и при этом знаменатель содержит значение запаздывания основного тона в субинтервал и значение гармоничности и/или значение усиления;
- при этом ассоциированное значение гармоничности и/или значение запаздывания основного тона в субинтервал, и/или значение усиления отличаются по меньшей мере в двух различных субинтервалах из множества субинтервалов; при этом значение запаздывания основного тона в субинтервал, значение гармоничности и/или значение усиления получаются на основе аудиосигнала (ус) в каждом субинтервале из множества субинтервалов.
14. Процессор (1000, 1100, 214) по п. 13, в котором по меньшей мере два субинтервала или множество субинтервалов перекрываются.
15. Процессор (1100, 214) по п. 13 или 14, в котором значение гармоничности является пропорциональным требуемой интенсивности гармонического постфильтра и/или независимым от изменений амплитуды в аудиосигнале (ус); и/или
- при этом значение усиления зависит от изменений амплитуды в аудиосигнале (ус).
16. Процессор (1100, 214) по одному из пп. 13-15, в котором гармонический постфильтр изменяется между субинтервалом и последующим субинтервалом; и/или
- при этом значение гармоничности и/или значение усиления, и/или значение запаздывания основного тона в субинтервал в последующем субинтервале извлекаются с использованием вывода гармонического постфильтра (1120) в субинтервале.
17. Процессор (1100, 214) по одному из пп. 13-16, в котором гармонический постфильтр (1120) отличается по меньшей мере в двух различных субинтервалах из множества субинтервалов; или
- при этом гармонический постфильтр (1120) отличается по меньшей мере в двух различных субинтервалах из множества субинтервалов, или при этом ассоциированное значение гармоничности и/или значение запаздывания основного тона в субинтервал, и/или значение усиления отличаются по меньшей мере в двух различных субинтервалах из множества субинтервалов, причем по меньшей мере два различных субинтервала из множества субинтервалов принадлежат одинаковому кадру.
18. Процессор (1100, 214) по одному из пп. 13-17, дополнительно содержащий средство для сглаживания вывода гармонического постфильтра (1120) во множестве субинтервалов по субинтервалам и/или на их границах.
19. Процессор (1100, 214) по одному из пп. 13-18, в котором в кадре имеется по меньшей мере два субинтервала.
20. Процессор (1100, 214) по одному из пп. 13-19, в котором соответствующая длина зависит от среднего основного тона; и/или
- при этом средний основной тон получается из кодированного параметра основного тона; и/или
- при этом кодированный параметр основного тона имеет более высокое временное разрешение, чем кадрирование кодека, и/или при этом кодированный параметр основного тона имеет более низкое временное разрешение, чем контур основного тона.
21. Процессор (1100, 214) по одному из пп. 13-20, дополнительно содержащий модуль (161) преобразования области, выполненный с возможностью преобразования на основе кадров представления в первой области аудиосигнала (XC) в представление во второй области аудиосигнала (ус); или
- дополнительно содержащий модуль (161) преобразования области, выполненный с возможностью преобразования на основе кадров представления в частотной области аудиосигнала (XC) в представление во временной области аудиосигнала (ус).
22. Модуль обработки, содержащий процессор (1000, 164, 101, 201, 201') по одному из пп. 1-12 и процессор (1100, 214) по одному из пп. 13-21.
23. Декодер для декодирования кодированного аудиосигнала, который содержит процессор по одному из пп. 1-12 и/или процессор по одному из пп. 13-21.
24. Декодер по п. 23, дополнительно содержащий декодер в частотной области или декодер на основе обратного MDCT.
25. Кодер для кодирования аудиосигнала, содержащий процессор по одному из пп. 1-12.
26. Способ обработки кодированного аудиосигнала, причем кодированный аудиосигнал содержит по меньшей мере кодированный параметр основного тона, при этом способ содержит этапы, на которых:
- принимают выборки (ус), извлекаемые из кадра кодированного аудиосигнала, с использованием буфера (1010) LTP;
- разделяют временной интервал, ассоциированный с последующим кадром кодированного аудиосигнала, последующего относительно кадра, на субинтервалы в зависимости от кодированного параметра основного тона;
- извлекают параметры субинтервала из кодированного параметра основного тона в зависимости от положения субинтервалов во временном интервале, ассоциированном с последующим кадром кодированного аудиосигнала;
- формируют сигнал прогнозирования из буфера (1010) LTP в зависимости от параметров субинтервала; и
- формируют спектр прогнозирования на основе сигнала прогнозирования.
27. Способ обработки аудиосигнала (ус), при этом способ содержит этапы, на которых:
- разбивают временной интервал, ассоциированный с кадром аудиосигнала, на множество субинтервалов, имеющих соответствующую длину, причем соответствующие длины по меньшей мере двух из множества субинтервалов зависят от значения запаздывания основного тона;
- фильтруют множество субинтервалов с использованием гармонического постфильтра (1120), при этом гармонический постфильтр (1120) основан на передаточной функции, содержащей числитель и знаменатель, при этом числитель содержит значение гармоничности, и при этом знаменатель содержит значение запаздывания основного тона в субинтервал и значение гармоничности и/или значение усиления;
- при этом ассоциированное значение гармоничности и/или значение запаздывания основного тона в субинтервал, и/или значение усиления отличаются по меньшей мере в двух различных субинтервалах из множества субинтервалов; при этом значение запаздывания основного тона в субинтервал, значение гармоничности и/или значение усиления получаются на основе аудиосигнала (ус) в каждом субинтервале из множества субинтервалов.
28. Машиночитаемый носитель, на котором сохранена компьютерная программа для осуществления способа по п. 26 при ее выполнении на компьютере.
29. Машиночитаемый носитель, на котором сохранена компьютерная программа для осуществления способа по п. 27 при ее выполнении на компьютере.
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| СПОСОБ КОДИРОВАНИЯ АУДИОСИГНАЛА, СПОСОБ ДЕКОДИРОВАНИЯ АУДИОСИГНАЛА, УСТРОЙСТВО КОДИРОВАНИЯ, УСТРОЙСТВО ДЕКОДИРОВАНИЯ, СИСТЕМА ОБРАБОТКИ АУДИОСИГНАЛА, ПРОГРАММА КОДИРОВАНИЯ АУДИОСИГНАЛА И ПРОГРАММА ДЕКОДИРОВАНИЯ АУДИОСИГНАЛА | 2010 |
|
RU2482554C1 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ КОДИРОВАНИЯ, ОБРАБОТКИ И ДЕКОДИРОВАНИЯ ОГИБАЮЩЕЙ АУДИОСИГНАЛА ПУТЕМ МОДЕЛИРОВАНИЯ ПРЕДСТАВЛЕНИЯ СОВОКУПНОЙ СУММЫ С ИСПОЛЬЗОВАНИЕМ КВАНТОВАНИЯ И КОДИРОВАНИЯ РАСПРЕДЕЛЕНИЯ | 2014 |
|
RU2662921C2 |

