Изобретение относится к системам связи. Более конкретно, настоящее изобретение относится к новым, усовершенствованным способу и устройству, предназначенным для выполнения кодирования с линейным предсказанием, возбуждаемого кодом переменной скорости.
Передача речевых сигналов средствами цифровой техники получила широкое распространение, в частности, в системах большой дальности действия и в цифровых радиотелефонных системах. Это, в свою очередь, вызвало интерес в определении наименьшего объема информации, передаваемой по каналу, сохраняющему возможность различения воспроизводимой речи. Если речь передают с использованием дискретизации и преобразования в цифровую форму, для достижения качества речи обычного аналогового телефона требуется скорость передачи данных порядка 64 кбит/с. Однако, путем использования анализа речи с последующим соответствующим кодированием, передачей и повторным синтезом в приемном устройстве можно достичь значительного снижения скорости передачи данных.
Устройства, использующие способы сжатия вокализированной речи путем выделения параметров, относящихся к модели формирования человеческой речи, обычно называют вокодерами (устройствами кодирования речи). Такие устройства состоят из кодирующего устройства, которое анализирует поступающую речь для выделения соответствующих параметров, и декодирующего устройства, которое восстанавливает речь, используя параметры, которые оно принимает по каналу передачи. Для того, чтобы модель была точной, ее необходимо постоянно изменять. Таким образом, речь делится на временные блоки или анализируемые кадры, в течение которых рассчитываются параметры. Затем параметры обновляются для каждого нового кадра.
К одному из различных классов средств кодирования относятся возбуждаемое кодом кодирование с линейным предсказанием, стохастическое кодирование или кодирование речи с векторным возбуждением. Пример алгоритма кодирования для этого конкретного класса описан в работе "Возбуждаемое кодом устройство кодирования с линейным предсказанием со скоростью 4,8 кбит/с", Томаса И., Тремейна и др. , опубликованной в трудах Конференции по подвижным спутникам, 1988 г.
Функция вокодера заключается в сжатии преобразованного в цифровую форму речевого сигнала в сигнал с низкой скоростью передачи битов путем исключения всех естественных избыточностей, присущих речи. Речь обычно имеет кратковременную избыточность, обусловленную главным образом операцией фильтрации речевого тракта, и долговременную избыточность, обусловленную возбуждением речевого тракта голосовыми связками. В возбуждаемом кодом кодирующем устройстве с линейным предсказанием эти операции моделируются двумя фильтрами, формантным фильтром с малой постоянной времени и фильтром основного тона с большой постоянной времени. После того, как эти избыточности удалены, полученный в результате остаточный сигнал можно моделировать как белый гауссов шум, который также можно кодировать. Основа этого метода заключается в вычислении n параметров фильтра, называемого фильтром линейного кодирования с предсказанием (фильтром ЛКП), который осуществляет кратковременное предсказание речевого сигнала, используя модель тракта человеческого голоса. Кроме того, долговременные эффекты, связанные с основным тоном речи, моделируют путем расчета параметров фильтра основного тона, который главным образом моделирует голосовые связки человека. И наконец, эти фильтры должны возбуждаться, и это делается посредством определения того, какой из числа случайных сигналов возбуждения в кодовом словаре наиболее точно аппроксимирует первоначальную речь при возбуждении таким сигналом двух упомянутых фильтров. Таким образом, передаваемые параметры относятся к трем объектам: 1) фильтра ЛКП, 2) фильтра основного тона и 3) возбуждения кодового словаря.
Хотя использование методов кодирования речевых сигналов способствует снижению объема информации, посылаемой по каналу при сохранении качества восстанавливаемой речи, для достижения снижения необходимо применять другие методы. Одним из ранее использовавшихся методов снижения объема передаваемой информации является стробирование речевой активности. При этом методе во время пауз в речи информация не передается. Хотя этот метод позволяет уменьшить объем передаваемых данных, однако ему присущ ряд недостатков.
Во многих случаях качество речи снижается из-за отсечки начальных частей слова. Другая проблема, связанная со стробированием отключенного канала при отсутствии речевой активности, заключается в том, что пользователи системы ощущают отсутствие фонового шума, который обычно сопровождает речь, и оценивают качество канала как более низкое, чем при обычном телефонном разговоре. Следующая проблема, связанная со стробированием речевой активности, состоит в том, что внезапно появляющиеся время от времени шумы фона могут запускать передающее устройство при отсутствии речи, в результате чего в приемном устройстве появляются неприятные всплески шума.
При попытке улучшить качество синтезированной речи в системе стробирования речевой активности, в процессе декодирования добавляется синтезированный комфортный шум. Хотя от добавления комфортного шума достигается некоторое улучшение качества, это по существу не улучшает общего качества, поскольку комфортный шум не моделирует действительного фонового шума в кодирующем устройстве.
Предпочтительный способ осуществления сжатия данных для уменьшения количества информации, которую необходимо передать, заключается в осуществлении кодирования речевых сигналов с переменной скоростью. Поскольку речи внутренне присущи периоды молчания, то есть паузы, количество данных, требуемое для воспроизведения этих периодов, можно снизить. При кодировании речевых сигналов (вокодировании) переменной скорости данный факт используют наиболее эффективно посредством снижения скорости передачи данных в такие периоды молчания. Снижение скорости передачи данных, в противоположность полной остановке передачи данных в периоды молчания, преодолевает проблемы, связанные со стробированием речевой активности, способствуя тем самым уменьшению объема передаваемой информации.
В совместно поданной заявке на патент США сер. N 08/004.484 от 14 января 1993 г. на "Устройство кодирования речевых сигналов с переменной скоростью", принадлежащей тому же правопреемнику, что и настоящее изобретение, подробно описан алгоритм кодирования речевых сигналов упомянутого выше класса устройств кодирования речевых сигналов, в том числе возбуждаемого кодом линейного кодирования с предсказанием (ВКЛКП), стохастического кодирования или кодирования речи с векторным возбуждением. Метод ВКЛКП сам по себе обеспечивает значительное снижение объема данных, которые необходимы для представления речи таким образом, чтобы при восстановлении обеспечивалась речь высокого качества. Как упоминалось выше, параметры устройства кодирования речевых сигналов обновляют для каждого кадра. Вокодер, описанный в упомянутой заявке, обеспечивает переменную скорость выходных данных путем изменения частоты параметров модели. Алгоритм кодирования речевых сигналов, раскрытый в упомянутой выше заявке на патент, отличается наиболее заметно от прежних способов ВКЛКП тем, что обеспечивает переменную скорость выходных данных на основании речевой активности. Структура определяется таким образом, что параметры корректируются реже или с меньшей точностью во время пауз в речи. Этот метод позволяет еще больше снизить объем передаваемой информации. Явление, которое используется для снижения скорости передачи данных, представляет собой показатель речевой активности, который определяется средним процентом времени для данного абонента, в течение которого абонент действительно говорит во время разговора. Для обычных двусторонних телефонных переговоров средняя скорость передачи данных снижается в два или больше раз. Во время пауз в речи устройством кодирования речевых сигналов кодируется только фоновый шум. В эти периоды времени нет необходимости передавать некоторые параметры, относящиеся к модели речевого тракта человека.
Как упоминалось выше, известный подход для ограничения объема информации, передаваемой во время молчания, называется стробированием речевой активности. Это способ, при котором информация не передается в периоды времени молчания. На принимающей стороне эти периоды можно заполнять синтезированным "комфортным шумом". В противоположность этому, устройство кодирования речевых сигналов с переменной скоростью непрерывно передает данные, которые в раскрытом в упомянутой заявке варианте осуществления передаются при скоростях в пределах примерно от 8 кбит/с до 1 кбит/с. Устройство кодирования речевых сигналов, которое обеспечивает непрерывную передачу данных, исключает необходимость синтезирования "комфортного шума" при кодировании фонового шума, обеспечивающего более естественные характеристики для синтезируемой речи. Следовательно, изобретение, раскрытое в упомянутой выше заявке, обеспечивает существенное улучшение качества синтезируемой речи по сравнению с качеством стробирования речевой активности, благодаря обеспечению плавного перехода между речью и фоном.
Алгоритм кодирования речевых сигналов согласно вышеупомянутой заявке дает возможность детектировать короткие паузы в речи, реализуя снижение эффективного коэффициента речевой активности. Решение о скорости передачи можно принимать на покадровой основе без "затягивания", так что скорость передачи данных можно снижать в паузах в речи на величину длительности кадра, обычно равную 20 мс, следовательно - выделять паузы типа пауз между слогами. Этот способ снижает коэффициент речевой активности в большей степени, чем это имело место традиционно, поэтому можно кодировать при пониженных скоростях не только паузы больших длительностей между фразами, но также более короткие паузы.
Поскольку выбор скорости осуществляют на кадровой основе, не происходит отсечки начальной части слова, как это имеет место в системе стробирования речевой активности. Отсечка такого характера происходит в системе стробирования речевой активности из-за задержки между обнаружением речи и повторным запуском передачи данных. Принятие решения о выборе скорости на кадровой основе приводит в результате к восстановлению речи, в которой все переходы имеют естественное звучание.
В случае непрерывной передачи устройством кодирования речевых сигналов окружающий абонента фоновый шум будет непрерывно слышен на приемном конце, создавая таким образом более естественное звучание во время пауз в речи. Таким образом, настоящее изобретение обеспечивает плавный переход к фоновому шуму. То, что слышит слушатель как фон во время речи, внезапно не меняется на синтезируемый комфортный шум во время пауз, как в системе стробирования речевой активности.
Поскольку фоновый шум непрерывно кодируется для передачи, можно с полной ясностью передавать интересные события в фоне. В некоторых случаях интересующий фоновый шум можно даже кодировать на самой высокой скорости. Кодирование с максимальной скоростью может происходить, например, при наличии громкого разговора в составе фона или если автомашина скорой помощи проезжает мимо пользователя, стоящего на углу улицы. Однако, постоянный или медленно меняющийся фоновый шум должен кодироваться при низких скоростях.
Использование вокодирования переменной скорости позволяет более чем в два раза увеличить пропускную способность в системе цифровой сотовой телефонной связи с многостанционным доступом с кодовым разделением каналов (МДКРК). Режим МДКРК и вокодирование переменной скорости исключительно хорошо согласуется, поскольку в режиме МДКРК радиопомехи между каналами автоматически падают по мере уменьшения скорости передачи данных по какому-либо каналу. В противоположность этому рассмотрим системы с выделением интервалов передачи, такие как системы многостанционного доступа с временным разделением каналов (МДВРК) или многостанционного доступа с частотным разделением каналов (МДЧРК). Для того, чтобы такая система получила преимущество от уменьшения скорости передачи данных, требуется внешнее вмешательство для координирования нового назначения неиспользуемых временных интервалов другим пользователям. Внутренне присущая такой схеме задержка означает, что канал можно переназначить только во время длительных пауз в речи. Следовательно, нельзя в полной мере получить выгоды от использования показателя активности речи. Однако, при внешней координации функционирования системы кодирование речевых сигналов с переменной скоростью полезно и в системах, иных чем системы МДКРК, хотя и по другим упоминавшимся причинам.
В системе МДКРК качество речи может слегка снижаться в моменты времени, когда требуется дополнительная пропускная способность системы. Отвлеченно говоря, можно считать, что устройство кодирования речевых сигналов как бы состоит из множества вокодеров, которые работают на разных скоростях с разными результирующими качествами речи. Поэтому качества речи можно смешивать для дальнейшего понижения средней скорости передачи данных. Первоначальные эксперименты показали, что путем смешивания, например, кодированной при полной и половинной скорости речи, максимально допустимая скорость передачи данных изменяется на покадровой основе в пределах от 8 кбит/с до 4 кбит/с; полученная в результате речь имеет качество, которое лучше, чем при переменной половинной скорости, составляющей максимум 4 кбит/с, но не настолько хорошее, как при переменной полной скорости, составляющей 8 кбит/с.
Хорошо известно, что при большинстве телефонных разговоров одновременно говорит только один человек. В качестве дополнительной функции для полностью двусторонних телефонных линий связи можно обеспечить ведомую синхронизацию скорости. Если в одном направлении линии связи передача осуществляется при самой высокой скорости, то в другом направлении линии связи передача обеспечивается на самой низкой скорости. Такая синхронизация между двумя направлениями линии связи может гарантировать среднее использование каждого направления линии связи не более 50%. Тем не менее, когда канал отключен, например, при ведомой синхронизации в режиме стробирования активности, слушающий абонент не имеет возможности прервать говорящего абонента, чтобы взять на себя роль говорящего в разговоре. Соответствующий вышеупомянутой заявке на патент способ кодирования речевых сигналов легко обеспечивает возможность адаптивной синхронизации скорости с помощью управляющих сигналов, которые устанавливают скорость вокодирования.
В вышеупомянутой заявке на патент устройство кодирования речевых сигналов (вокодер) работает либо при полной скорости, когда присутствует речь, либо при восьмой части скорости, когда речь отсутствует. Работа алгоритма кодирования речевых сигналов при половинной скорости и четвертой части скорости резервируется для специальных условий перегруженной пропускной способности, или когда параллельно с речевыми данными следует передавать другие данные.
В совместно поданной заявке на патент США сер. N 08/118.473 от 8 сентября 1993 г. на "Способ и устройство, предназначенные для определения скорости передачи данных в системе связи коллективного пользования", принадлежащей тому же правопреемнику, что и настоящее изобретение, подробно описан способ, с помощью которого система связи в соответствии с измерениями пропускной способности системы ограничивает среднюю скорость передачи данных в кадрах, кодируемых с помощью вокодера переменной скорости. Система снижает скорость передачи данных, обеспечивая кодирование заранее определенных кадров в полноскоростной последовательности кадров при более низкой скорости, то есть при половинной скорости. Связанная со снижением скорости кодирования для кадров активной речи этим способом проблема заключается в том, что ограничение не соответствует каким-либо характеристикам входной речи и, таким образом, не оптимизирована в отношении качества сжатия речи.
Кроме того, в совместно поданной заявке на патент США сер. N 07/984.602 от 2 декабря 1992 г. на "Усовершенствованный способ определения скорости кодирования речи в вокодере переменной скорости", по которой выдан патент США N 5.341.456 23 августа 1994 г., принадлежащий тому же правопреемнику, что и настоящее изобретение, раскрыт способ отделения невокализированной речи от вокализированной речи. В раскрытом способе исследуется энергия речи и изменение уровня спектральных составляющих речи и используется упомянутое изменение уровня спектральных составляющих для отличия невокализированной речи от фонового шума.
Вокодеры переменной скорости, которые меняют скорость кодирования полностью на основании голосовой активности входной речи, не в состоянии реализовать эффективность сжатия кодирующего устройства с переменной скоростью, которое изменяет скорость кодирования на основании сложности или объема информации, который динамически изменяется при активной речи. За счет согласования скоростей кодирования со сложностью входного сигнала можно создать более эффективные устройства кодирования речи. Кроме того, системы, которые стремятся динамически регулировать скорость передачи выходных данных вокодеров переменной скорости, должны изменять скорости передачи данных в соответствии с характеристиками входной речи для достижения оптимального качества голоса для требуемой средней скорости передачи данных.
Настоящее изобретение относится к новым и усовершенствованным способу и устройству кодирования кадров активной речи при сниженной скорости передачи данных посредством кодирования речевых кадров при скоростях в диапазоне от заранее установленной максимальной скорости до заранее установленной минимальной скорости. Настоящее изобретение определяет набор режимов работы с активной речью. В примере осуществления настоящего изобретения имеются четыре режима работы с активной речью, в том числе речи при полной скорости, речи при половинной скорости, невокализированной речи при четвертой части скорости и вокализированной речи на четвертой части скорости.
Задачей настоящего изобретения является создание оптимизированного способа выбора режима кодирования, который обеспечивает эффективное по скорости кодирование поступающей на вход речи. Кроме того, задачей настоящего изобретения является идентифицировать набор параметров, идеально подходящих для этого выбора рабочего режима, и создать средство, предназначенное для вырабатывания этого набора параметров.
Изобретение позволяет обеспечить идентификацию двух раздельных условий кодирования при низкой скорости с минимальным ущербом для качества. Такими условиями являются наличие невокализированной речи и наличие временно маскированной речи. И, наконец, изобретение обеспечивает создание способа динамического регулирования средней скорости передачи выходных данных устройства кодирования речи с минимальным влиянием на качество речи.
Настоящее изобретение предусматривает набор критериев определения скорости, называемых критериями режима. Первым критерием режима является согласующееся по заданному значению отношение сигнал/шум от предыдущего кадра кодирования, который обеспечивает информацию о том, насколько хорошо синтезированная речь согласована с входной речью, или, другими словами, насколько хорошо выполнена модель кодирования. Вторым критерием режима является нормированная автокорреляционная функция, которая измеряет периодичность в речевом кадре. Третьим критерием режима является параметр пересечений нулевого уровня, который представляет собой недорогой с вычислительной точки зрения способ определения содержания высоких частот во входном речевом кадре. Четвертым критерием является прогнозируемый дифференциал усиления, определяющий, сохраняет ли модель ЛКП (линейное кодирование с предсказанием) свою эффективность предсказания. Пятым критерием является энергетический дифференциал, который сравнивает энергию в текущем кадре со средней энергией кадров.
В примере осуществления соответствующего настоящему изобретению алгоритма кодирования речевых сигналов используются пять перечисленных выше критериев режимов, с целью выбора режима кодирования для кадра активной речи. Соответствующая настоящему изобретению логика определения скорости сравнивает нормированную автокорреляционную функцию (АКФ) со значением первой пороговой величины, а пересечение нулевого уровня - со значением второй пороговой величины для определения, следует ли кодировать речь как невокализированную речь при четвертой части скорости.
Если определено, что кадр активной речи содержит вокализированную речь, то вокодер исследует энергетический дифференциал для определения, следует ли кодировать кадр речи как вокализированную речь при четвертой части скорости. Если определено, что речь не подлежит кодированию при четвертой части скорости, то вокодер исследует, можно ли кодировать речь при половинной скорости. Вокодер исследует значения упомянутых выше параметров согласованного по заданному значению отношения с/ш, прогнозируемого дифференциала усиления и нормированной АКФ для определения, можно ли кодировать речевой кадр при половинной скорости. Если он определил, что кадр активной речи нельзя кодировать при четвертой части или половинной скорости, то кадр кодируется при полной скорости.
Еще одной задачей является создание способа динамического изменения пороговых значений для обеспечения необходимой скорости. Путем изменения одного или более из пороговых значений выбора режима можно увеличить или уменьшить среднюю скорость передачи данных. Таким образом, с помощью динамического регулирования пороговых значений можно регулировать скорость на выходе.
Особенности, цели и преимущества настоящего изобретения станут более ясны из приведенного ниже подробного описания совместно с чертежами, на которых представлено следующее:
фиг. 1 - блок-схема соответствующего настоящему изобретению устройства определения скорости кодирования;
фиг. 2 - блок-схема, иллюстрирующая процедуру выбора скорости кодирования логической схемы определения скорости.
В приведенном для примера варианте осуществления изобретения кодируются речевые кадры из 160 речевых выборок. В этом варианте осуществления настоящего изобретения имеются четыре скорости передачи данных: полная скорость, половина скорости, четвертая часть скорости и восьмая часть скорости. Полная скорость соответствует выходной скорости передачи данных, равной 14,4 кбит/с. Половина скорости соответствует выходной скорости передачи данных 7,2 кбит/с. Четвертая часть скорости соответствует выходной скорости передачи данных 3,6 кбит/с. Одна восьмая часть скорости соответствует выходной скорости передачи данных 1,8 кбит/с и резервируется для передачи во время периодов молчания.
Следует отметить, что настоящее изобретение касается только кодирования кадров активной речи, т.е. кадров, которые детектируются для выделения содержащейся в них речи. Способ определения наличия речи описан в упомянутых выше заявках на патент США сер. N 08/004.484 и сер. N 07/984.602.
Как показано на фиг. 1, элемент 12 определения режимов измеряет значения пяти параметров, используемых логической схемой определения скорости 14 для выбора скорости кодирования кадров активной речи. В рассматриваемом варианте осуществления изобретения элемент 12 определения режимов определяет пять параметров, которые он посылает на логическую схему 14 определения скорости. На основании параметров, полученных элементом 12 определения режимов, логическая схема 14 определения скорости выбирает скорость кодирования из числа полной скорости, половины скорости и четвертой части скорости.
Логическая схема 14 определения скорости выбирает один из четырех режимов кодирования в соответствии с пятью вырабатываемыми параметрами. Четыре режима кодирования включают в себя режим на полной скорости, режим на половинной скорости, невокализированный режим на четвертой части скорости и вокализированный режим на четвертой части скорости. Вокализированный режим на четвертой части скорости и невокализированный режим на четвертой части скорости обеспечивают данные на одной и той же скорости, но с помощью разных способов кодирования. Режим на половинной скорости используется для кодирования стационарной, периодической, хорошо моделируемой речи. Режимы вокализированный на четвертой части скорости, невокализированный на четвертой части скорости и на половинной скорости удобны для участков речевого сигнала, которые не требуют высокой точности при кодировании кадра.
Невокализированный режим на четвертой части скорости используется при кодировании невокализированной речи. Вокализированный режим на четвертой части скорости используется при кодировании временно маскируемых речевых кадров. Большинство кодирующих речь возбуждаемых кодом устройств кодирования с линейным предсказанием используются при одновременной маскировке, при которой энергия речи на данной частоте маскирует энергию шума на тех же частоте и времени, делая шум неслышимым. Устройства кодирования речи при переменной скорости могут иметь преимущество временного маскирования, при котором низкоэнергетические кадры активной речи маскируются с помощью предшествующих высокоэнергетических кадров речи с подобным частотным спектром. Поскольку ухо человека объединяет энергию по времени в разных частотных диапазонах, низкоэнергетические кадры усредняются по времени с высокоэнергетическими кадрами, снижая таким образом требования к кодированию для низкоэнергетических кадров. Использование преимущества этого явления временного слухового маскирования позволяет устройству кодирования речи с переменной скоростью снизить скорость кодирования во время этого режима речи. Это психоакустическое явление подробно описано в журнале "Психология слухового восприятия" И. Цвикером и Х.Фестлом на стр. 56-101.
Элемент 12 определения режимов принимает четыре входных сигнала, с помощью которых он вырабатывает пять параметров режимов. Первый сигнал S (n), который принимает элемент 12 определения режимов, представляет собой некодированные входные речевые выборки. В рассматриваемом примере варианта осуществления речевые выборки обеспечиваются кадрами, содержащими 160 выборок речевого сигнала. Все речевые кадры, которые подаются на элемент 12 определения режимов, содержат активную речь. Во время периодов молчания соответствующая настоящему изобретению система определения скорости активной речи пассивна.
Второй сигнал  (n) синтезированной речи, который принимает элемент 12 определения режимов, представляет собой декодированную речь из декодера, возбуждаемого кодом устройства кодирования с линейным предсказанием с переменной скоростью. Декодер этого кодирующего устройства декодирует кадр кодированной речи для коррекции параметров фильтра и записей при анализе с помощью возбуждаемого кодом устройства кодирования с линейным предсказанием на основе синтеза. Конструкция таких декодеров хорошо известна в технике и подробно описана в вышеупомянутой заявке на патент США N 08/004.484.
(n) синтезированной речи, который принимает элемент 12 определения режимов, представляет собой декодированную речь из декодера, возбуждаемого кодом устройства кодирования с линейным предсказанием с переменной скоростью. Декодер этого кодирующего устройства декодирует кадр кодированной речи для коррекции параметров фильтра и записей при анализе с помощью возбуждаемого кодом устройства кодирования с линейным предсказанием на основе синтеза. Конструкция таких декодеров хорошо известна в технике и подробно описана в вышеупомянутой заявке на патент США N 08/004.484.
Третий сигнал, который принимает элемент 12 определения режима, представляет собой формантный остаточный сигнал e (n). Это речевой сигнал S (n), отфильтрованный фильтром ЛКП кодера, возбуждаемого кодом устройства кодирования с линейным предсказанием. Конструкция фильтров ЛКП и фильтрация сигналов с помощью таких фильтров в технике хорошо известны и подробно описаны в упомянутой выше заявке на патент США N 08/004.484. Четвертый входной сигнал элемента 12 определения режимов A (z) представляет значение сигнала на отводах перцептуально взвешивающего фильтра соответствующего устройства кодирования с линейным предсказанием. Формирование значений сигнала на отводах фильтра и операция фильтрации с помощью взвешивающего фильтра в технике хорошо известны и подробно описаны в заявке на патент США N 08/004.484.
Элемент 2 вычисления, согласующегося по заданному значению отношения с/ш, принимает синтезированный речевой сигнал  (n), речевые выборки S (n) и ряд значений A (z) сигнала на отводах перцептуально взвешивающего фильтра. Элемент 2 вычисления, согласующегося по заданному значению отношения с/ш, обеспечивает параметр, обозначенный TMSNR (СЗЗОСШ), который указывает, насколько хорошо речевая модель отслеживает входную речь. Элемент 2 вычисления, согласующегося по заданному значению с/ш (СЗЗОСШ), вырабатывает TMSNR в соответствии с уравнением (1):
(n), речевые выборки S (n) и ряд значений A (z) сигнала на отводах перцептуально взвешивающего фильтра. Элемент 2 вычисления, согласующегося по заданному значению отношения с/ш, обеспечивает параметр, обозначенный TMSNR (СЗЗОСШ), который указывает, насколько хорошо речевая модель отслеживает входную речь. Элемент 2 вычисления, согласующегося по заданному значению с/ш (СЗЗОСШ), вырабатывает TMSNR в соответствии с уравнением (1):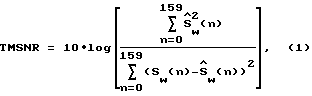
где подстрочный индекс w показывает, что сигнал отфильтрован с помощью перцептуально взвешивающего фильтра.
Отметим, что этот критерий рассчитывают для предыдущего кадра речи, тогда как NACF(НАКФ) (нормированная автокорреляционная функция), PGD (ПДУ - прогнозируемый дифференциал усиления), ED (ЭД - энергетический дифференциал), ZC (ПНУ - пересечение нулевого уровня) рассчитывают по текущему кадру речи. Значение TMSNR (СЗЗОСШ) рассчитывают для предыдущего кадра речи, поскольку он представляет функцию выбираемой скорости кодирования и, таким образом, по причинам сложности вычислений его рассчитывают по предыдущему кадру относительно кодированного кадра.
Конструкция и воплощение перцептуально взвешивающих фильтров в технике хорошо известны и подробно описаны в вышеупомянутой заявке на патент США N 08/004.484. Следует отметить, что перцептуальное взвешивание предпочтительно для взвешивания перцептуально значимых особенностей речевого кадра. Однако, очевидно, что измерение можно осуществлять без перцептуального взвешивания сигналов.
Элемент 4 вычисления нормализованной автокорреляции принимает остаточный сигнал форманта e (n). Функция элемента 4 вычисления нормированной АКФ заключается в обеспечении индикации периодичности выборок в речевом кадре. Элемент 4 вычисления нормированной АКФ вырабатывает параметр, обозначенный NACF (НАКФ - нормированная автокорреляционная функция) в соответствии с приведенным ниже уравнением (2):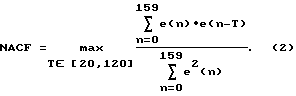
Следует отметить, что вырабатывание этого параметра требует запоминания формантного остаточного сигнала от кодирования предыдущего кадра. Это позволяет исследовать не только периодичность текущего кадра, но также исследовать периодичность текущего кадра с предыдущим кадром.
Причина, по которой в предпочтительном варианте осуществления используется формантный остаточный сигнал e (n) вместо речевых выборок S (n), которые можно использовать при генерировании NACF (НАКФ), заключается в том, чтобы устранить взаимодействие формантов речевого сигнала. Пропускание речевого сигнала через фильтр формантов служит для выравнивания речевой огибающей и, таким образом, отбеливания получающегося сигнала. Следует отметить, что величины задержки T в рассматриваемом примере осуществления изобретения соответствуют частотам основного тона между 66 Гц и 400 Гц для частоты выборок, равной 8000 выборок в секунду. Частота основного тона для данного значения задержки T рассчитывается по приведенному ниже уравнению (3):
fо.т.=fs/T, (3)
где fs - частота выборок.
Следует отметить, что частотный диапазон можно увеличить или уменьшить просто путем выбора другого набора величин задержки. Следует также отметить, что настоящее изобретение в равной степени применимо к любым частотам выборок.
Счетчик пересечений нулевого уровня 6 принимает выборки речи S (n) и подсчитывает количество периодов, когда выборки речи меняют знак. Это является недорогим с точки зрения вычисления способом определения высокочастотных составляющих в речевом сигнале. Этот счетчик можно реализовать программным средством с помощью цикла следующей формы:
cnt = 0 (счет = 0) (4)
for n = 0,158 (для n = 0,158) (5)
if (S(n)•S(n+1)<0) cnt++ (если) (6)
Цикл уравнений (4)-(6) перемножает последовательные речевые выборки и исследует, меньше ли нуля произведение, что показывает, что знак между двумя последовательными выборками отличается. Это предполагает, что в речевом сигнале нет составляющей постоянного тока. В технике хорошо известно, как исключить из сигнала постоянные составляющие.
Элемент 8 прогнозируемого дифференциала усиления принимает речевой сигнал S (n) и формантный остаточный сигнал e (n). Элемент 8 прогнозируемого дифференциала усиления вырабатывает параметр, обозначенный PGD (ПДУ - прогнозируемый дифференциал усиления), который определяет, сохраняет ли модель ЛКП свою эффективность предсказания. Элемент 8 прогнозируемого дифференциала усиления генерирует прогнозируемый коэффициент усиления Pg в соответствии с представленным ниже уравнением (7):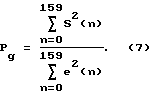
Затем прогнозируемый коэффициент усиления настоящего кадра сравнивается с прогнозируемым коэффициентом усиления предыдущего кадра при вырабатывании выходного параметра ПДУ с помощью следующего уравнения (8):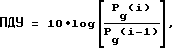 (8)
(8)
где i - номер кадра
В предпочтительном варианте осуществления изобретения элемент 8 прогнозируемого дифференциала усиления не вырабатывает значение прогнозируемого коэффициента усиления Pg. При вырабатывании коэффициента ЛКП побочным продуктом рекурсии Дарбина является прогнозируемый коэффициент усиления Pg, поэтому нет необходимости осуществлять повторное вычисление.
Элемент 10 определения энергетического дифференциала кадра принимает выборки речи S (n) текущего кадра и вычисляет энергию речевого сигнала в текущем кадре в соответствии со следующим выражением 9: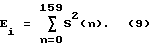
Энергия текущего кадра сравнивается со средней энергией предыдущих кадров Eave. В рассматриваемом примере осуществления изобретения среднюю энергию Eave вырабатывает квазиинтегратор формы:
Eave= α •Eave+(1- α)Ei, (10)
где 0 < α < 1.
Коэффициент α определяет диапазон кадров, которые относятся к данному вычислению. В данном примере осуществления α установлено равным 0,8825, что обеспечивает постоянную времени, равную 8 кадрам. Затем элемент 10 определения энергетического дифференциала кадров вырабатывает параметр ED (ЭД - энергетическая разность) в соответствии со следующим выражением: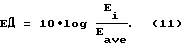
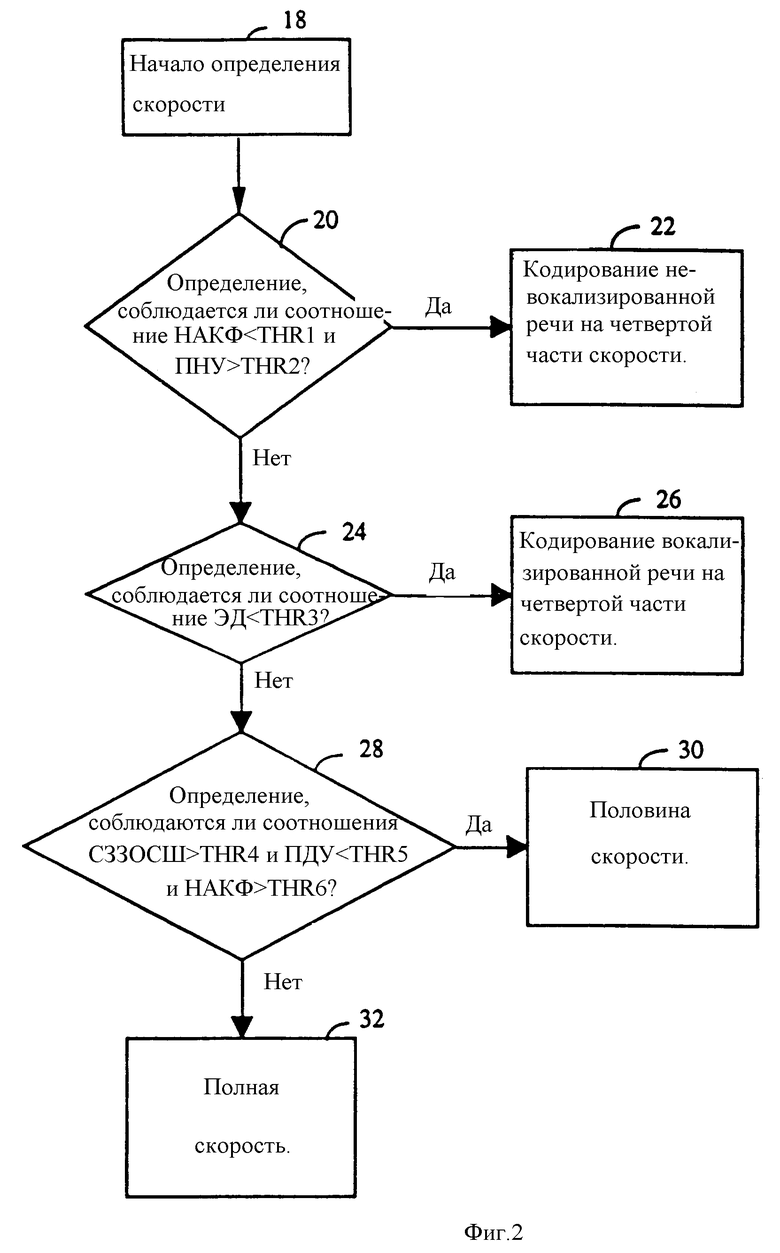
Пять параметров TMSNR (СЗЗОСШ), NACF (НАКФ), ZC (ПНУ), PGD (ПДУ) и ED (ЭД) поступают на логическую схему определения скорости 14. Логическая схема определения скорости 14 выбирает скорость кодирования для следующего кадра выборок в соответствии с параметрами и определенным заранее набором правил выбора. Рассмотрим теперь фиг. 2, которая иллюстрирует блок-схему процедуры выбора скорости логического элемента определения скорости 14.
Процедура определения скорости начинается в блоке 18. В блоке 20 выходной сигнал элемента 4 вычисления нормированной АКФ, NACF (НАКФ), сравнивается с заранее установленным пороговым значением THR1, а выходной сигнал счетчика пересечений нулевого уровня сравнивается со вторым заранее установленным пороговым уровнем THR2. Если NACF (НАКФ) меньше THR1, а ZC (ПНУ) больше THR2, то процедура обработки переходит к блоку 22, который кодирует речь как невокализированную речь при четвертой части скорости. Значение NACF (НАКФ) меньше, чем заранее установленное пороговое значение, показывает отсутствие периодичности речи, а значение ZC (ПНУ) больше, чем заранее установленное пороговое значение, указывает на высокочастотную составляющую в речи. Сочетание этих двух условий показывает, что кадр содержит невокализированную речь. В рассматриваемом варианте осуществления изобретения значение THR1 равно 0,35, а THR2 равно 50 пересечениям нулевого уровня. Если NACF (НАКФ) не меньше, чем THR, или ZC (ПНУ) не больше, чем THR2, то процедура обработки переходит к блоку 24.
В блоке 24 выходной сигнал элемента 10 энергетического дифференциала кадров ED(ЭД) сравнивается с третьим пороговым значением THR3. Если ED (ЭД) меньше THR3, то текущий речевой кадр будет кодироваться как вокализированная речь при четвертой части скорости в блоке 26. Если энергетический дифференциал текущего кадра меньше среднего значения на величину, превышающую пороговое значение, то это показывает режим временного маскирования речи. В примерном варианте осуществления изобретения значение THR3 равно 14 дБ. Если ED (ЭД) не превышает THR3, то процесс переходит к блоку 28.
В блоке 28 выходной сигнал элемента вычисления, согласующегося по заданному значению отношения с/ш 2, TMSNR (СЗЗОСШ) сравнивается с четвертым пороговым значением THR4; выходной сигнал элемента 8 прогнозируемого дифференциала усиления PGD (ПДУ) сравнивается с пятым пороговым значением THR5, а выходной сигнал элемента вычисления нормированной автокорреляции 4 NACF (НАКФ) сравнивается с шестым пороговым значением THR6. Если TMSNR (СЗЗОСШ) превышает THR4; PGD (ПДУ) меньше, чем THR5, а NACF (НАКФ) превышает THR6, то процедура обработки переходит в блок 30, и речь кодируется при половинной скорости. Превышение TMSNR (СЗЗОСШ) своего порогового уровня показывает, что модель и моделированная речь хорошо согласованы в предыдущем кадре. Если параметр PGD (ПДУ) меньше его заранее установленного порогового уровня, то это показывает, что модель ЛКП сохраняет свою эффективность прогнозирования. Превышение параметром NACF (НАКФ) своего заранее установленного порогового значения показывает, что кадр содержит периодическую речь, то есть периодическую с предыдущим кадром речи.
В рассматриваемом примере осуществления изобретения THR4 первоначально устанавливают на 10 дБ, THR5 устанавливают на значение 5 дБ, a THR6 - на значение 0,4. Если в блоке 28 TMSNR (СЗЗОСШ) не превышает значение THR4 или PGD (ПДУ) не превышает значение THR5, или NACF (НАКФ) не превышает значение THR6, то процесс переходит к блоку 32, а текущий речевой кадр будет кодироваться на полной скорости.
Путем динамического регулирования пороговых значений можно достичь произвольной общей скорости передачи данных. Общую среднюю скорость передачи данных активной речи R можно определить в отношении анализируемого окна W активных речевых кадров следующим образом: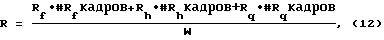
где Rf - скорость передачи данных для кадров, кодированных на полной скорости,
Rh - скорость передачи данных для кадров, кодированных на половине скорости,
Rq - скорость передачи данных для кадров, кодированных на четвертой части скорости, и
W = #Rf кадров + #Rh кадров + #Rq кадров.
Посредством перемножения каждой из скоростей кодирования на количество кадров, кодируемых при этой скорости, и затем деления на общее количество кадров в выборке, можно вычислить среднюю скорость передачи данных для выборки активной речи. Важно иметь размер выборки кадров W достаточно большой для предотвращения большой продолжительности невокализированной речи типа извлечения звуков "c" из искажения среднестатистического значения скорости. В примере осуществления изобретения размер выборки кадров W для вычисления средней скорости составляет 400 кадров.
Среднюю скорость передачи данных можно снизить путем повышения количества кадров, кодируемых при полной скорости, подлежащих кодированию при половинной скорости, и наоборот, среднюю скорость передачи данных можно увеличить путем увеличения количества кадров, закодированных при половинной скорости, подлежащих кодированию при полной скорости. В предпочтительном варианте осуществления изобретения пороговое значение, которое регулируют для выполнения этого изменения, является THR4. В примере осуществления запоминают гистограмму значений TMSNR (СЗЗОСШ). В примере осуществления изобретения запомненные значения TMSNR (СЗЗОСШ) разбивают на величины целых чисел децибелл из текущего значения THR4. С помощью сохранения гистограммы этого сорта можно легко оценить, как много кадров можно изменить в предыдущем блоке анализа из закодированных на полной скорости в кодируемые при половинной скорости, где THR4 подлежит уменьшению на целое число децибелл. И наоборот, оценка количества кадров, кодируемых при половинной скорости, которые можно кодировать при полной скорости, означает, что пороговое значение подлежит увеличению на целое число децибелл.
Выражение, предназначенное для определения количества кадров, которые следует изменить от кадров при половинной скорости на кадры при полной скорости, определяется следующим выражением: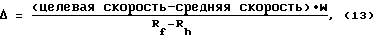
где Δ - количество кадров, кодируемых при половинной скорости, которые должны кодироваться при полной скорости для достижения целевой скорости;
W = #Rf кадров + #Rh кадров + #Rq кадров.
СЗЗОСШновое= СЗЗОСШстарое+(количество дБ от СЗЗОСШстарого для достижения разницы кадров, определяемой в вышеприведенном уравнении (13)).
Отметим, что первоначальное значение СЗЗОСШ является функцией требуемой целевой скорости. В примерном варианте осуществления с целевой скоростью 8,7 кбит/с в системе с Rf = 14,4 кбит/с, Rh = 7,2 кбит/с, Rq = 3,6 кбит/с, начальное значение СЗЗОСШ равно 10 дБ. Следует отметить, что разбиение значений СЗЗОСШ на целые числа для расстояния от порогового значения THR4 можно легко сделать мельче, например, половины или четвертой части децибелла, или можно сделать крупнее, например, полутора или двух децибелл.
Предполагается, что целевую скорость можно либо запоминать в запоминающем элементе логического элемента определения скорости 14, и в этом случае целевая скорость может представлять статическую величину, в соответствии с которой значение THR4 будет определяться динамическим путем. Предполагается, что в дополнение к этой начальной целевой скорости система связи может передавать сигнал управления скоростью на устройство выбора скорости кодирования, основываясь на условиях пропускной способности системы.
Сигнал управления скоростью может либо определять целевую скорость, либо может просто требовать увеличения или уменьшения средней скорости. Если в системе определяется целевая скорость, эта скорость будет использоваться при определении величины THR4 согласно уравнениям (12) и (13). Если только система определила, что пользователь должен передавать сообщения при более высокой или более низкой скорости, то логический элемент определения скорости 14 может реагировать посредством изменения величины THR4 на заранее установленное приращение, или может вычислить дифференциальное изменение в соответствии с заранее определенным дифференциальным увеличением или уменьшением скорости.
Блоки 22 и 26 показывают разницу в способе кодирования речи, основываясь на определении, соответствуют ли выборки речи вокализированной или невокализированной речи. Невокализированная речь является речью в форме фрикативных звуков и согласных звуков типа "ф", "с", "ш", "т", и "з". Вокализированная речь на четвертой части скорости представляет собой временно маскируемую речь, где речевой кадр низкой громкости следует за речевым кадром относительно высокой громкости аналогичного частотного содержания. Ухо человека не может слышать тонкие моменты речи в кадре с низкой громкостью, который следует за кадрами с высокой громкостью, так что разряды можно экономить, кодируя такую речь при четвертой части скорости.
В примерном варианте осуществления кодирования невокализированной речи при четвертой части скорости речевой кадр делится на четыре подкадра. Для каждого из четырех подкадров передается значение коэффициента усиления G и коэффициенты фильтра ЛКП A(z). В примере осуществления изобретения для представления коэффициента усиления в каждом подкадре передается пять двоичных разрядов. На декодирующем устройстве для каждого подкадра произвольно выбирается индекс кодового словаря. Произвольно выбранный вектор кодового словаря умножается на передаваемую величину коэффициента усиления и пропускается через фильтр ЛКП A(z) для генерирования синтезированной невокализированной речи.
При кодировании вокализированной речи при четвертой части скорости речевой кадр делится на два подкадра, а кодирующее устройство ВКЛП определяет индекс кодового словаря и коэффициент усиления для каждого из двух подкадров. В рассматриваемом примере осуществления назначаются пять двоичных разрядов для индикации индекса кодового словаря, а другие пять двоичных разрядов назначаются для определения соответствующего значения коэффициента усиления. В примере осуществления кодовый словарь, используемый для кодирования вокализированной речи при четвертой части скорости, представляет собой подмножество векторов кодового словаря, используемого для кодирования при половинной и полной скорости. В примере осуществления изобретения для определения индекса кодового словаря в режимах кодирования при полной и половинной скорости используются семь двоичных разрядов.
На фиг. 1 блоки можно представить как структурные блоки, предназначенные для выполнения определенных функций, или блоки могут представлять функции, выполняемые при программировании процессора цифровых сигналов (ПЦС) или интегральной схемы специального применения (ИССП). Описание функций настоящего изобретения обеспечивает возможность специалистам в данной области техники реализовать настоящее изобретение ПЦС или ИССП.
Вышеприведенное описание предпочтительных вариантов осуществления представлено для обеспечения возможности любому специалисту в данной области техники реализовать или использовать настоящее изобретение. Специалисты в данной области техники могут легко понять различные модификации этих вариантов осуществления, а определенные здесь основные принципы могут применять для других вариантов осуществления без дополнительного изобретательства. Таким образом, настоящее изобретение не ограничено описанными здесь вариантами осуществления, а должно соответствовать наиболее широкому объему, соответствующему раскрытым здесь принципам и признакам изобретения.
Изобретение относится к системе связи и предназначено для выполнения кодирования с линейным предсказанием, возбуждаемого кодом переменной скорости. Технический результат - обеспечение оптимизированного выбора режима кодирования для эффективного кодирования скорости входного речевого сигнала. Логическая схема 14 определения скорости выбирает скорость, при которой осуществляется кодирование речевого сигнала. Выбор скорости основан на согласующемся по заданному значению сигнал/шум, определенному элементом 12 определения режимов, нормализованной функции автокорреляции, вычисленной элементом 4 вычисления нормализованной автокорреляции, отсчете пересечений нулевого уровня, определенном счетчиком пересечений нулевого уровня 6, прогнозируемом дифференциале усиления, вычисляемом вычислительным элементом 8 прогнозируемого дифференциала усиления и энергетическом дифференциале между кадрами, вычисляемом элементом вычисления энергетического дифференциала кадров 10. 4 c. и 18 з.п. ф-лы, 2 ил.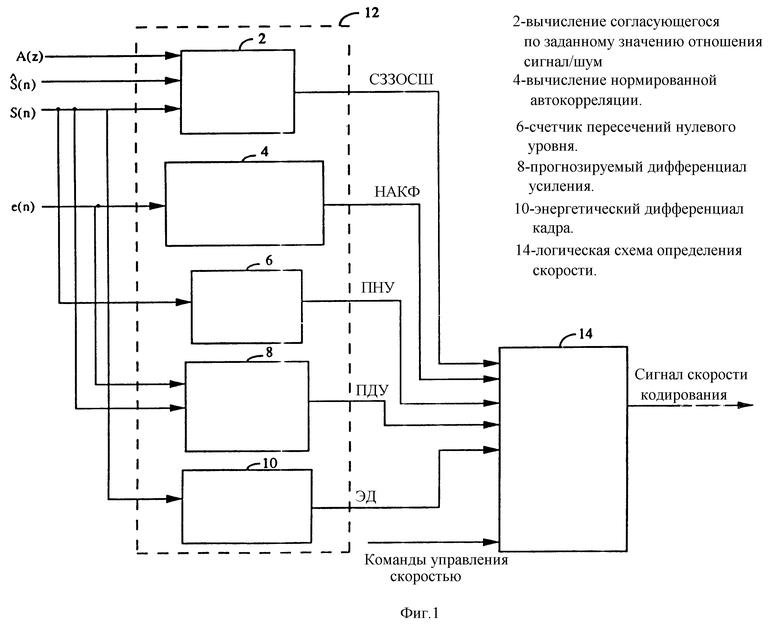
| Автоматический огнетушитель | 0 |
|
SU92A1 |
| АВТООПЕРАТОР | 1972 |
|
SU433015A1 |
| Облегченный тампонажный материал для низкотемпературных скважин | 1976 |
|
SU578436A1 |
| US 4589131 A, 13.05.86 | |||
| US 4852179 A, 25.07.89 | |||
| US 4860355 A, 22.08.89 | |||
| Цифровой предсказывающий вокодер | 1983 |
|
SU1088061A1 |
| Устройство анализа и синтеза речевого сигнала | 1981 |
|
SU980133A1 |
| Устройство кодирования речевого сигнала в системах вывода информации голосом | 1977 |
|
SU748498A1 |
