Изобретение касается способа идентификации подлинных серий изображений, например рекламных сообщений, в котором для отдельных изображений из серий изображений отбираются, переводятся в цифровую форму и сравниваются с эталонным образцом признаки их яркости.
Серии изображений, состоящие из множества образующих ряд и связанных между собой по смыслу отдельных кадров, должны идентифицироваться, например, в телевидении при каждой новой передаче. Такими сериями изображений могут быть рекламные сообщения, платные доклады, старые фильмы или видеоклипы и политические выступления, такие как, например, фрагменты предвыборной борьбы. Общим для всех перечисленных случаев является то, что распространение серий изображений ввиду оплаты, а также по правовым или статистическим причинам подлежит учету. Подлинность серий изображений означает при этом, что по своему содержанию эти изображения сохраняются в своем первоначальном виде, то есть все точки изображения по своей яркости и цветности являются уникальными и поэтому неизменными. При копировании на технически высококачественном оборудовании такое единственное в своем роде расположение не изменяется и не дополняется ни по одному параметру. Понятие "подлинный" относится, следовательно, и к скопированным сериям изображения.
Телевизионными станциями рекламные сообщения передаются, например, в такое время, которое представляет особый интерес для рекламодателей. Для рекламодателей важно убедиться, действительно ли его сообщение передавалось в назначенное время. Во время своего существования рекламное сообщение изменяет свой внешний вид, т.е. оно укорачивается, некоторые кадры изменяются или полностью заменяются. Такую новую серию изображений необходимо отличить от первоначальной версии.
Из заявки ФРГ 4309957 C1 известен способ идентификации подлинных серий изображений. При этом отдельные элементы изображения, так называемые точки изображения, формируются в группы или блоки, называемые кластерами, светимость или яркость которых преобразуется в цифровую форму и в качестве признаков сравнивается с признаками известных кадров или эталонных образцов.
В связи с необходимостью сжатия или уплотнения данных вероятность ошибочной идентификации относительно велика. Поэтому для снижения количества ошибочных идентификаций в известных способах производится сканирование нескольких, последовательно следующих кадров. При этом недостаток состоит в том, что следующие друг за другом кадры имеют, как правило, большое сходство, из-за чего обнаруженные признаки часто приводят к случайному сходству без наличия действительно схожих изображений. Эти, так называемые случайные ошибочные идентификации, правда, не обязательно отрицательно сказываются на идентификацию рекламного сообщения как такового, но ведут к большому объему данных, которые загружают вычислительное устройство.
Задачей настоящего изобретения является поэтому уменьшение объема данных и снижение числа ошибочных идентификаций.
Согласно изобретению эта задача решается за счет того, что признаки декоррелируются их квазистохастическим отбором через несколько кадров (изображений).
В результате того, что вместо отбора признаков соседних кадров признаки отбираются квазистохастическим способом, минуя несколько кадров, становится возможным пренебречь случайным сходством следующих друг за другом кадров, поскольку нарушаются связи последовательно следующих кадров. В результате снижается количество ошибочных идентификаций и связанный с ними и загружающий вычислительное устройство объем данных.
Согласно предпочтительному варианту осуществления изобретения выбранные признаки отдельных кадров записываются в упорядоченной последовательности в запоминающее устройство карусели изображений, выполненное в виде регистра сдвига, и считываются квазистохастическим способом при выборочном обращении. Обращение к признакам происходит при этом при максимальном пропуске изображений. Одновременно обращаются и к признакам с максимальным интервалом между кадрами. Благодаря такой мере обеспечивается декорреляция признаков, так как разрушаются временные и пространственные связи.
Согласно еще одному предпочтительному варианту осуществления изобретения проводится двухэтапная обработка способом, при котором осуществляют на первом этапе приблизительную и на втором точную идентификацию. По своему объему данных предварительная идентификация сокращена настолько, что она возможна в реальном масштабе времени. Она позволяет распознать рекламное сообщение без определения возможных искажений. Точная идентификация проводится лишь в том случае, когда в результате приблизительной идентификации серия изображений или рекламное сообщение будет соотнесено с имеющимся эталонным образцом. После этого точной идентификацией обеспечивается окончательная уверенность и вскрываются местные и временные искажения.
Согласно еще одному предпочтительному варианту осуществления способа для формирования признаков используют изменение яркости внутри кластера, образованного пространственно связанными точками изображения.
В этом случае кластеры подвергаются дискретному косинусоидальному преобразованию. Один из коэффициентов низкочастотного чередования сокращается до своего знака и используется в качестве признака. Серия изображений делится на кванты времени одинаковой длительности, причем каждый квант представляет собой самостоятельную, коррелируемую единицу. Таким образом кадры одного кванта времени кодируются при экстремальном уплотнении данных. Идентификация или точнее приблизительная идентификация рекламного сообщения происходит лишь в том случае, когда отдельные промежутки времени идентифицируются при их правильной последовательности и правильном временном интервале.
Изобретение касается также устройства для осуществления указанного способа.
Из заявки ФРГ 4309957 C1 известно устройство для осуществления способа идентификации подлинных серий изображений. Это устройство имеет тот недостаток, что возможен только разовый отбор признаков последовательно сменяющих друг друга кадров, в результате чего отобранные от кадров признаки коррелируются между собой и вызывают большое количество ошибочных идентификаций.
Поэтому еще одной задачей настоящего изобретения является создание устройства, обеспечивающего возможность квазистохастического отбора признаков.
Эта задача решается за счет того, что вход регистра сдвига, выполненного в виде запоминающего устройства, через преобразователь DCT (дискретного косинусоидального преобразования) подключен к видеодекодеру, содержащему конвертер растра/кластера, а выход подключен через коррелятор к опорной памяти с возможностью подачи серии изображений, поступающей с приемника на видеодекодер, на коррелятор в виде вектора признака и сравнения с эталонным образцом, хранимым в опорной памяти.
Благодаря применению регистра сдвига становится возможным простым способом производить квазистохастический отбор признаков, при этом декоррелируются признаки разных кадров (изображений).
Согласно еще одному предпочтительному варианту исполнения изобретения между преобразователем DCT и регистром сдвига предусмотрено ответвление в направлении к запоминающему устройству данных о точной идентификации, которое выполнено в виде регистра сдвига FIFO (first in, first out) (сначала ввод, сначала вывод) и в котором хранятся все признаки, характеризующие серию изображений.
Благодаря применению регистра сдвига FIFO возможно проводить точную идентификацию лишь после проведенной в масштабе реального времени приблизительной идентификации.
Другие подробные сведения об изобретении приводятся ниже в детальном описании и на приложенных чертежах, на которых наглядно представлены в качестве примера предпочтительные варианты осуществления изобретения.
На чертежах изображено:
фиг.1 блок-схема устройства идентификации подлинных серий изображения,
фиг. 2 схема рекламных сообщений в виде серий изображений с отдельной, разложенной на отрезки времени серией изображений,
фиг.3 схема отрезка времени с признаками (яркости),
фиг.4 вектор признаков отрезка времени на фиг.3 в виде двоичного потока,
фиг. 5 пример, иллюстрирующий искажение, при котором продукт лишился определения "новый",
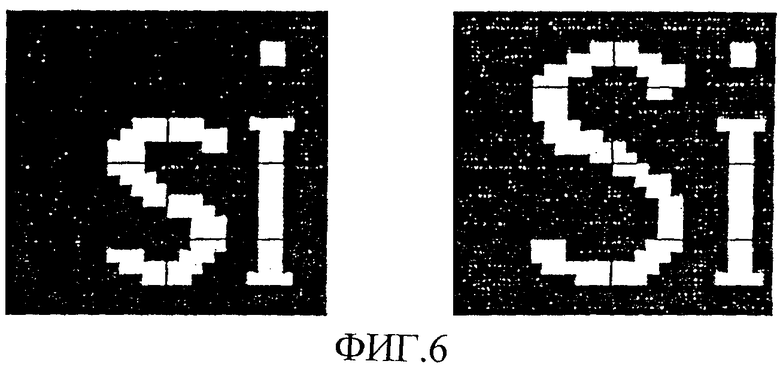
фиг. 6 пример, иллюстрирующий локальное искажение в пределах одного кадра, на котором изменено написание буквы (фрагмент),
фиг. 7 спектральные эталонные образцы в виде базисных изображений с минимально значимыми коэффициентами,
фиг. 8 варианты отдельных коэффициентов дискретного косинусоидального преобразования,
фиг.9 уплотнение данных о сигнале яркости в формате CCIR,
фиг. 10 плотность амплитудного распределения коэффициента любого кадра без Downsampling (сокращенная выборка),
фиг. 11 плотность амплитудного распределения коэффициента C01 любого кадра с Downsampling,
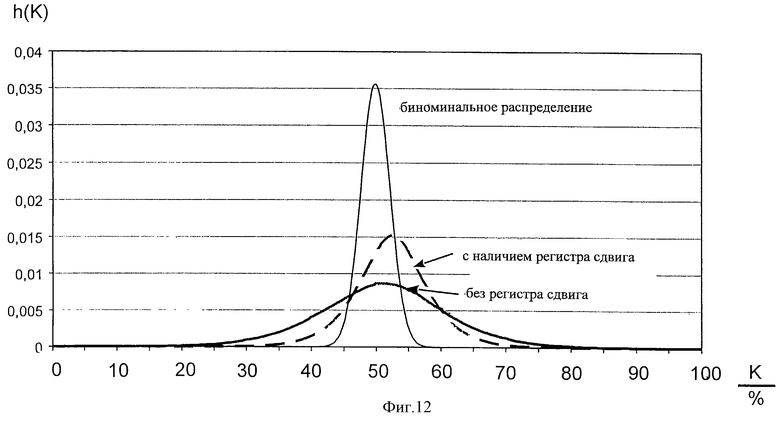
фиг. 12 величина случайных соответствий серий изображений с эталонными образцами в сравнении с теоретически ожидаемым биномиальным распределением,
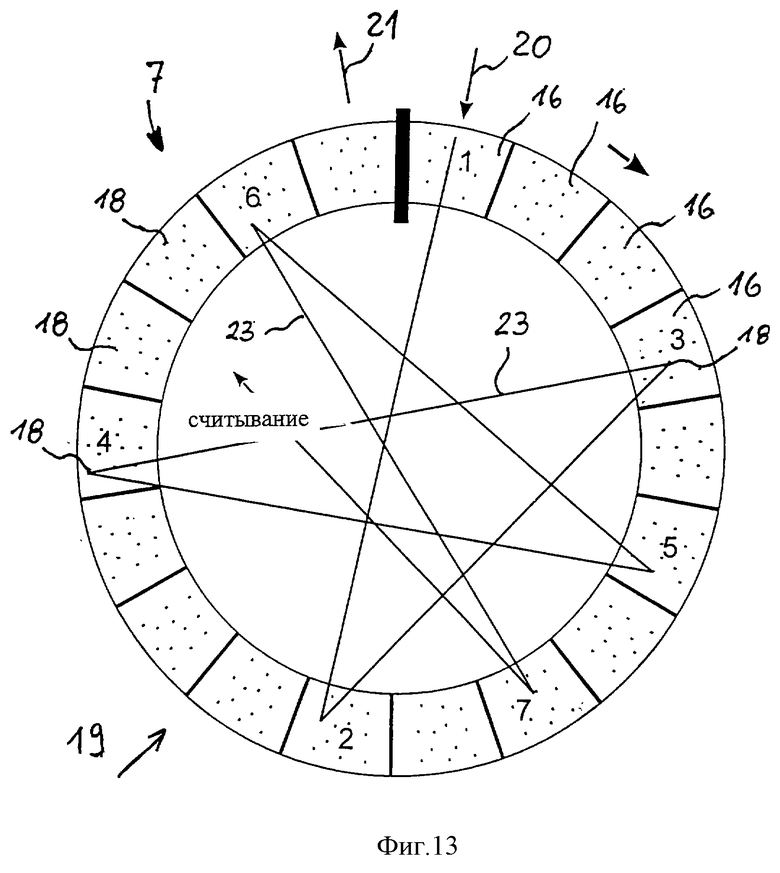
фиг.13 схема карусели изображений,
фиг.14 распределение случайных соответствий двоичных образцов при разных декоррелирующих действиях,
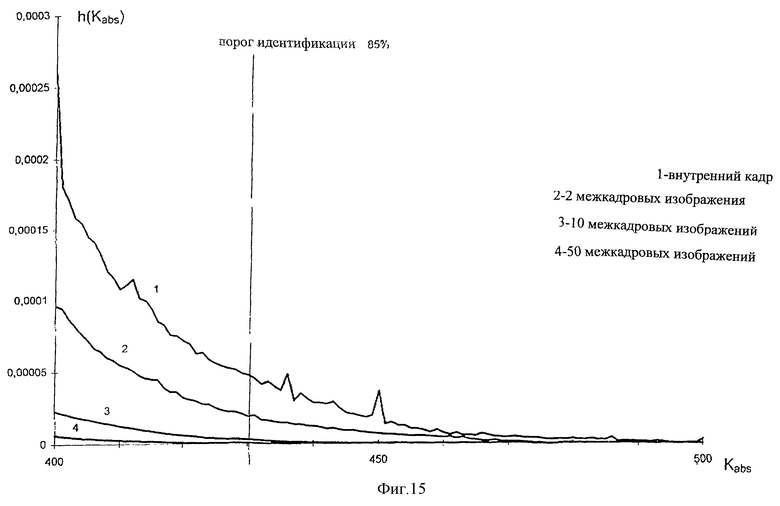
фиг. 15 эффект от декоррелирующих действий при превышении порога идентификации, фрагмент Фиг.14.
Устройство для идентификации подлинных серий изображений 1 состоит из видеодекодера 2 с конвертером для растра/кластера, который своим входом 3 соединен с видеовыходом приемника 4. Выход видеодекодера 2 соединен с входом преобразователя DСТ 5. Выход преобразователя DCT 5 соединен со входом 6 карусели 7 изображений. Регистр 7 сдвига изображений связан своим выходом 8 со входом коррелятора 9. Коррелятор 9 соединен с опорной памятью 10. Коррелятор 9 связан и с анализатором 11 приблизительной идентификации. Между преобразователем DCT 5 и регистром 7 сдвига располагается регистр сдвига FIFO 12, связанный с анализатором 13 точной идентификации. Анализатором 11 приблизительной идентификации выполняется на первом этапе обработки сигнала приблизительная идентификация. Если анализатором 11 будет обнаружена серия 14 изображений, имеющая большое сходство с хранимым в опорной памяти 10 эталонным образцом, и если при этом с большой вероятностью (например, с вероятностью >90%) обнаруживается искомое рекламное сообщение или искомая серия изображений 14, то анализатор 13 точной идентификации получает сигнал от анализатора 11 приблизительной идентификации и на втором этапе обработки вступает в действие, используя хранимые в регистре сдвига FIFO 12 данные. Точная идентификация гарантирует окончательную уверенность и обнаруживает локальные и временные искажения.
Из-за временного искажения (сокращения или изменения сцены) необходимо кодировать всю серию 14 изображений. Для этого целесообразно разбить серию 14 изображений на отрезки времени 15 длительностью, например, 2 секунды. Отрезки времени 15 представляют собой самостоятельные единицы, каждая из которых коррелируется отдельно. Идентификация (приблизительная) серии 14 изображений происходит в том случае, когда отдельные отрезки времени 15 идентифицируются при правильной последовательности и правильном временном интервале по отношению к анализатору 11, 13. При наличии временного искажения будут отсутствовать отдельные отрезки времени 15, в то время как остальные будут идентифицированы в ожидаемой последовательности. В ходе многочисленных опытов упомянутая продолжительность около 2 секунд была определена в качестве оптимальной, однако она может быть откорректирована с учетом того, что для рекламных сообщений или серий 14 изображений установлена предпочтительная продолжительность, и тогда отрезки времени 15 подбирают с таким расчетом, чтобы указанная продолжительность могла делиться без остатка на длительность этих отрезков. Пример: минимальная продолжительность рекламного сообщения 7 секунд, тогда продолжительность отдельного кванта времени 15 равна 1,75 секунды. В противном случае при корреляции останется без учета неделимый далее остаток.
Локальные искажения, т.е. изменения в пределах одного кадра 16 из серии 14 изображений, охватывают участок, выражаемый через точки изображения. На Фиг. 6 приведен пример, в котором изменено написание буквы (фрагмент). Значительные изменения занимают участок, равный 32x32 точки. При точной идентификации, т. е. при идентификации вероятно имеющихся локальных искажений, каждый кадр разбивается на участки примерно указанной величины, которые надлежит коррелировать (сравнивать) в обрабатывающем устройстве 13 в качестве самостоятельных единиц с соответствующими участками других кадров. Для кодирования одной группы точек изображения, т.е. одного кластера, используется переменная доля светимости или яркости в пределах одного кластера. Такая переменная доля указывает - совершенно в общем плане - на изменение яркости в пределах кластера в противоположность постоянной доле, яркость которой составляет среднюю величину. Изменение яркости может происходить разным образом: она может выступать как простой градиент с определенным направлением или как многократное чередование светлого с темным. Целесообразно, чтобы дискретное конусоидальное преобразование, выполняемое преобразователем DCT 5, использовалось для детектирования чередования светлого с темным. Такое дискретное косинусоидальное преобразование применяется также в известных алгоритмах уплотнения, например JPEG, MPEG, и поэтому встроено в высокоинтегрированные чипы, например Zoran 36050. При таких уплотнениях кадров кадр разбивается на кластеры (блоки) размером 8x8 точек (Raster to Clustar-Conversion)(преобразование растра/кластера), которые затем подвергаются двухразмерному дискретному косинусоидальному преобразованию. Таким способом получают частотный вид изображений.
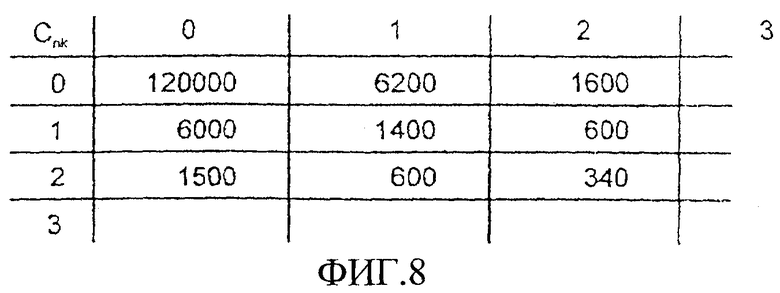
После этого уплотнение в принципе состоит в том, что высокочастотные удельные доли сильно уплотняют или даже опускают. Спектральные эталонные образцы для отдельных коэффициентов Cnk называют базисными кадрами, минимально значимые из которых представлены на фиг.7. Верхний левый базисный кадр (коэффициент C00) - при использовании в кластере 8x8 точек - обеспечивает постоянную долю, т.е. среднюю яркость кластера. Верхний правый базовый кадр (коэффициент C01) служит для проверки того, в какой степени показанная характеристика яркости присутствует в исследуемом кластере. Следовательно, он обеспечивает самую нижнюю спектральную линию видеоинформации в соответствии с постоянной долей. Остальные базовые кадры на фиг.7 обеспечивают соответствующую информацию в другом направлении кадра. Базовые кадры для коэффициентов DCT более высокого порядка не приводятся, так как для данного изобретения они не имеют значения. Дискретное косинусоидальное преобразование характеризуется свойством, при котором существенная информация, распределенная в зоне подлинника между всеми вспомогательными значениями, после преобразования оказывается сконцентрированной в немногих компонентах, т.е. значительные энергетические доли приходятся на так называемые коэффициенты DC (постоянная доля) и на нижние коэффициенты АС (доли низкочастотного чередования).
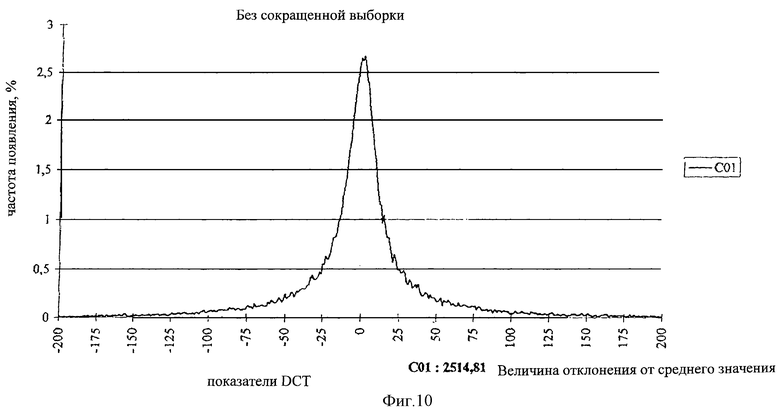
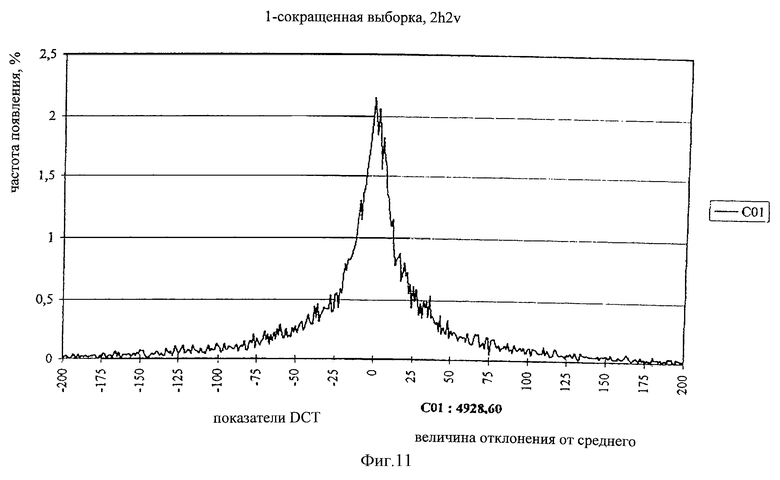
На фиг. 8 показано уменьшение энергии в коэффициентах АС более высокого порядка. Долю энергии, например, коэффициента C01 целесообразно приблизительно удвоить, если по горизонтали и вертикали проводится децимальное сокращение. Под этим следует понимать усредненное объединение четырех, квадратно расположенных точек изображения в одну новую точку. Этот способ еще называется Downsampling - субдискретизация. Таким способом кластер размером 16x16 точек приводится к размеру 8x8 точек, к которому затем снова применяют дискретное косинусоидальное преобразование. Полученные теперь коэффициенты Coi характеризуются, как правило, удвоенным эффектом по сравнению с коэффициентами, полученными из одного только подлинного кластера 8x8. Аппаратными средствами этот способ осуществляется частично обычным в телевидении пропуском строк, при котором изображения передаются полукадрами, строчками и в виде гребня. Если при этом рассматривать только полукадр, то будет присутствовать вертикальная субдискретизация. Горизонтальная субдискретизация может быть дополнительно получена при использовании чипов, имеющихся в продаже. На фиг.10 показана плотность амплитудного распределения коэффициента Coi для любого кадра 16 без Downsampling. На фиг.11 показана плотность амплитудного распределения коэффициента Coi на фиг.10 с Downsampling. Более широкая кривая на Фиг. 11 указывает в цифровом выражении почти на двойную величину отклонения от среднего значения по сравнению с кривой на фиг.10.
После того, как все кадры 16 отрезка времени 15 разложены на кластеры размером 8x8 точек - после децимального сокращения ими являются блоки изображений или кластеры размером 16x16 точек - и преобразованы в спектральную область, самый нижний коэффициент активного чередования - им является C01 или С10 каждого кластера - подвергается дальнейшему уплотнению данных в результате того, что в дальнейшем используется только его знак. Следовательно, кластер размером 8x8 точек представляют в виде бита, указывающего знак коэффициента чередования. Благодаря такому приему полученный массив данных для отрезка времени 15 имеет следующие существенные преимущества: вся серия изображений оказывается закодированной при экстремальном уплотнении данных. Каждый бит является локальным признаком, который не зависит от модуляции сигналов изображения и от отношения сигнал/шум.
Уплотнение данных о сигнале яркости формата CCIR, составляющего 768x576 точек, достигает сначала около 2•103. При длительности отрезка времени, равной, например, 2 секундам, объем данных составляет все еще около 11 кбайтов. При обработке в масштабе реального времени нескольких тысяч рекламных сообщений такой объем данных был бы слишком велик. Поэтому приблизительную идентификацию применяют в качестве пригодного для реального времени способа идентификации серий изображений без оценки возможно происшедших искажений. Точная идентификация накладывается затем на приблизительную, являясь непригодным для реального времени способом, подтверждает ее результаты и позволяет проанализировать искажения. Приблизительная идентификация возможна уже при наличии около 16 признаков 17, 18 яркости на каждый кадр 16. Под признаком 17, 18 яркости следует понимать знаковый бит коэффициента DCT. Таким образом по определенной схеме от 1728 знаковых битов одного (полу) кадра отбирают соответственно 16 бит, т.е. два байта. При двухсекундной длительности отрезка времени 15 это составит 100 байтов на отрезок времени 15. Схема отбора исключает пространственную связь коэффициентов. Видеообъекты имеют, как правило, протяженность, включающую много кластеров. Для этих кластеров действуют с большой вероятностью одинаковые коэффициенты DCT. Признаки 17, 18 яркости, отобранные у этих кластеров, следовательно, не являются независимыми друг от друга и не улучшают качества идентификации. Связи разрушаются, когда посредством квазистохастического способа отбирают от кластеров, пo-возможности удаленных друг от друга, 16 признаков 17, 18 яркости. В данном случае поступают аналогично в отношении каждого кадра 16, и получают в целом цепочку данных длиной, например, 16•50=800 битов. Если допустить независимость отдельных битов, тогда появляется вероятность случайного соответствия двух таких двоичных комбинаций в к битов из N, возможных согласно биноминальному распределению: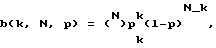
где р - вероятность появления признака 17, 18 яркости.
В рассматриваемых случаях р=0,5, т.е. 0 и 1, являясь знаковыми битами коэффициента, вероятны в одинаковой степени. Тогда биноминальное распределение сведется к
b(k, N, p) = (N)pN.
Если задать нижний предел идентификации, равный 85%,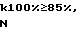
то все схожие элементы двух отрезков времени более 85% будут оцениваться как идентификация. Насколько такая идентификация действительно имеет отношение к подлинной идентификации серий изображений определяется контролем на достоверность, заложенным в программном обеспечении. В противном случае может иметь место случайное соответствие, так называемая ошибочная идентификация.
Для предупреждения ошибочных идентификаций предусмотрено наличие регистра 7 сдвига. Регистр 7 сдвига представляет собой запоминающее устройство 19 в виде регистра сдвига, в котором записываются выбранные признаки 17, 18 яркости кадров 16 в упорядоченной последовательности. Назначение регистра 7 сдвига изображений состоит в такой обработке нескольких кадров 16, при которой образцы создаются не по последовательности кадров, а по квазислучайному образцу через несколько кадров 16. Происходит так называемое межкадровое кодирование. На Фиг.14 изображено распределение случайного соответствия таких межкадровых кодирований, причем обработка производилась через 2, 10 и 50 изображений. Кривая 1 показывает так называемое межкадровое кодирование, при котором признаки обрабатываются в последовательности кадров. На Фиг.15 в увеличенном виде изображен участок, находящийся выше порога идентификации, равного 85%. Через 40 мс признаки 17, 18 яркости нового изображения 20 вводятся в запоминающее устройство 19, в то время как "самое старое" изображение 21 выводится наружу на конце запоминающего устройства 19. Между двумя операциями актуализации запоминающего устройства 19 считываются квазистохастическим способом при выборочном обращении N-признаки 17, 18 яркости отрезка времени и подаются в коррелятор 9 для сравнения с эталонным образцом. При этом действуют так, чтобы не происходило вторичного считывания кластера кадра 16 при его нахождении в регистре 7 сдвига изображений. Обращение к признакам 17, 18 яркости происходит при максимальном пропуске кадров 16 и одновременно при соблюдении максимального интервала между кадрами 16. Благодаря такому действию достигается декорреляция признаков 17, 18 яркости, так как разрушаются временные и пространственные связи. Способ может осуществляться посредством следующих операций:
а) Серии 14 изображений разделяются на отрезки времени 15 длительностью по 1,5-2 секунды (в соответствии с задачей идентификации).
б) Каждый кадр 16, согласно способу JPEG, разделяется на кластеры, причем предпочтительно применять вертикальную и горизонтальную субдискретизацию. Кластеры кадров подвергают дискретному косинусоидальному преобразованию и применяют знак минимально значимого коэффициента чередования в качестве признака 17, 18 яркости (предпочтительно C01 или C10).
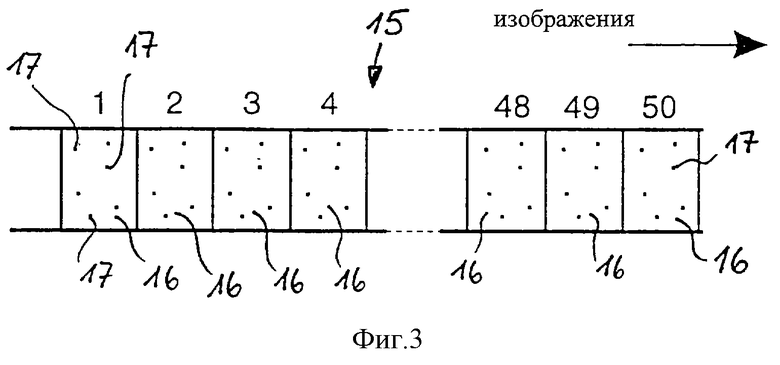
в) Из 1728 признаков 17, созданных согласно п.б) для каждого кадра 16, отбирается подмножество из около 800-1000 признаков 18 и для корреляции в реальном масштабе времени или точнее для приблизительной идентификации загружается в регистр 7 сдвига. Посредством декоррелирующего способа обращения отбирают около 800-1000 признаков 18 на 1 отрезок времени 15 и откладывают в виде вектора 22 признаков, присущих всему отрезку времени. Это соответствует приблизительно 16-32 битам на кадр.
г) Вектор признаков 22, полученный в п.в), обозначается как эталонный образец и впоследствии при работе сравнивается с тестовыми образцами, получаемыми непрерывно аналогичным образом на основе передаваемой программы, коррелятивно в виде связи EXNOR. При сходстве, превышающем заданное пороговое значение (например, 85%), идентификация принимается. Идентифицированные объекты, их степень сходства, заносятся вместе с точной отметкой времени кадра в банк данных, содержащий соответствующие зоны со всеми сравниваемыми эталонными образцами.
д) Банк данных постоянно контролируется соответствующими программными средствами на взаимосвязь отрезков времени 15, которые идентифицировались при соблюдении надлежащего интервала между кадрами и при наличии достаточного сходства. В случае идентификации большинства отрезков времени 25 серии 14 изображений вся серия изображений считается идентифицированной.
е) Процесс идентификации согласно пп. г), д) протекает в реальном масштабе времени, вследствие чего идентификация серии изображений может быть продемонстрирована непосредственно после передачи серии изображений или рекламного сообщения. Затем все признаки 17 кадра, например, при длительности отрезка времени 2 с - это 86400 битов=10,8 кбайтов -, которые временно хранятся в регистре сдвига FIFO 12, подаются на точную идентификацию. Здесь происходит корреляция всех, разделенных на области кадров 16 всех отрезков времени 15 серии 14 изображений. Такое сравнение может проводиться с предварительно выбранными эталонными образцами, так как идентификация серии изображений собственно произошла.
Подписи к фигурам
Фиг.2: 1 - рекламные сообщения, 2 - потеря Δt<2 c.
Фиг.3: 1- изображения.
Фиг.10: 1 - без сокращенной выборки (Downsampling), 2 - частота появления, %, 3 - показатели DCT, 4 - величина отклонения от среднего значения.
Фиг.11: 1 - сокращенная выборка, 2h2v, 2 - частота появления, %, 3 - показатели DCT, 4 - величина отклонения от среднего значения, 5 - коэффициент C01.
Фиг.12: 1- биномиальное распределение, 2 - с наличием карусели изображений, 3 - без карусели изображений.
Фиг.13: 1 - считывание.
Фиг.14: 1 - внутренний кадр, 2 - 2 межкадровых изображения, 3 - 10 межкадровых изображений, 4 - 50 межкадровых изображений.
Фиг.15: 1 - внутренний кадр, 2 - 2 межкадровых изображения, 3 - 10 межкадровых изображений, 4 - 50 межкадровых изображений, 5 - порог идентификации, 80%.





Изобретение относится к устройствам и способам идентификации подлинных серий изображений. Его применение при эксплуатации телевизионной техники позволяет получить технический результат в виде облегчения учета и хронометрирования рекламных сообщений, видеоклипов, политических выступлений и т.п. Этот результат достигается благодаря тому, что для отдельных изображений из серий изображений определяют признаки яркости, преобразуют их в цифровую форму и сравнивают с эталоном, при этом признаки яркости декоррелируют квазистохастическим отбором по множеству изображений. 2 с. и 30 з.п.ф-лы, 15 ил.
| SU 1835950 A1, 20.03.1996 | |||
| СПОСОБ ВЫДЕЛЕНИЯ ПРИЗНАКОВ ДЛЯ РАСПОЗНАВАНИЯ ОБЪЕКТА | 1990 |
|
RU2090929C1 |
| US 4736438, 05.04.1988 | |||
| УСТРОЙСТВО для ИЗМЕНЕНИЯ ДЛИНЫ ВРАЩАЮЩЕГОСЯ | 0 |
|
SU363828A1 |

