Область техники, к которой относится изобретение
Изобретение относится к области информационных технологий, а именно к обработке информационных естественно-языковых текстовых материалов, и может быть использовано для упорядочивания и накопления информации по конкретно заданным предметным областям, а также для графического отображения смысла обрабатываемых текстов в виде когнитивных карт.
Уровень техники
Известен способ автоматизированной обработки информационных материалов, преимущественно текстовых, для идентификации объектов по их описаниям, заключающийся в том, что преобразуют тексты естественного языка в заданных областях знаний в сигналы, пригодные для машинной обработки, формируют соответствующие тезаурусы текста путем машинной обработки сигналов, преобразованных из каждого упомянутого текста, в системе хранения и обработки информации, осуществляют статистическую обработку слов в тезаурусах каждого текста, объединяют тезаурусы текстов в соответствующие базы данных в системе хранения и обработки информации, при идентификации конкретного объекта в упомянутых областях знаний формируют запрос к выбранной базе данных путем указания выборки желательных слов, характеризующих упомянутый конкретный объект, сравнивают упомянутую выборку слов из сформированного запроса с тезаурусами текстов в выбранной базе данных, по результатам этого сравнения принимают решение об идентификации упомянутого конкретного объекта, отличающийся тем, что в процессе формирования тезаурусов каждого текста осуществляют лингвистическую сортировку всех слов этого текста по заранее заданным кластерам, упомянутую статистическую обработку слов осуществляют для каждого кластера данного текста, осуществляют лингвистическую сортировку всех слов из выборки слов сформированного запроса, аналогичную лингвистической сортировке слов при формировании тезаурусов текстов, в процессе упомянутого сравнения вычисляют статистическую меру совпадения тезаурусов для выборки слов из сформированного запроса и текстов из выбранной базы данных, решение об идентификации упомянутого конкретного объекта принимают на основе сопоставления вычисленных статистических мер совпадения для различных текстов. (Патент РФ №2167450, МПК 7 G 06 F 17/30, 2001(аналог)).
Наиболее близким по технической сущности к заявляемому является способ автоматизированной обработки информационных материалов, при котором выявляют наличие в обрабатываемых информационных материалах сведений, могущих быть описанными с точки зрения их содержания элементами характеристики информационной потребности пользователя, фиксируют факт наличия таких сведений и соответствующие им элементы характеристики информационной потребности пользователя и используют эти элементы и их сочетания при представлении пользователю содержания обрабатываемых материалов, при этом обработку ведут в интерактивном режиме, причем последовательно демонстрируют отдельные смысловые фрагменты, на которые подразделены обрабатываемые информационные материалы, в форме, соответствующей их виду, с демонстрацией в визуальной или аудиовизуальной форме элементов характеристики информационной потребности пользователя и в случае выявления смысловой связи между содержанием данного фрагмента и теми или иными из элементов характеристики информационной потребности пользователя фиксируют наличие такой связи путем формирования индивидуального признака для каждого из упомянутых элементов, с которым выявлена связь данного смыслового фрагмента, при выявлении различной степени связи данного смыслового фрагмента с разными элементами характеристики информационной потребности пользователя формируют признаки принадлежности этих элементов разным уровням в соответствии с количеством выявленных градаций связи, после чего осуществляют формирование образа локальной структуры данного смыслового фрагмента, представляющей собой помеченный связный неориентированный граф, вершинам которого поставлены в соответствие те элементы характеристики информационной потребности пользователя, для которых сформированы признаки наличия связи с содержанием данного смыслового фрагмента, указанный граф является полносвязным, если ни один из упомянутых элементов характеристики информационной потребности пользователя не является доминирующим, а если сформированы признаки принадлежности элементов характеристики информационной потребности пользователя разным уровням в соответствии с выявленными различиями тесноты их связи с содержанием данного смыслового фрагмента, то каждая из вышерасположенных вершин графа связана со всеми нижерасположенными, причем в случае наличия более одной вершины на самом верхнем уровне каждая из таких вершин связана также с остальными, по окончании формирования образа локальной структуры для последнего из смысловых фрагментов обрабатываемых информационных материалов формируют образ интегрального графа путем логического суммирования всех графов локальных структур при одинаковых кратностях их ребер и отображают результат обработки в визуально воспринимаемом виде с заменой кратных ребер геометрическими образами, размеры или цвет которых соответствуют их кратности, и цифровой индикацией кратности ребер полученного интегрального графа в целом или отдельных его компонент в качестве показателей степени взаимосвязанности проблем, соотносимых с элементами характеристики информационной потребности пользователя, которым соответствуют вершины интегрального графа. (Патент РФ №2096824, МПК G 06 F 15/16, 17/60, 1997 (прототип)).
Сущность изобретения
При создании изобретения решалась задача расширения арсенала способов автоматизированной обработки информационных текстовых материалов.
Технический результат заключается как в создании нового способа автоматизированной обработки информационных текстовых материалов на основе выделения смысловых категорий в текстах на естественном языке с графическим представлением смысла всего текста в виде когнитивной карты, так и в повышении эффективности подготовки обрабатываемых информационных текстовых материалов к аналитической их обработке в условиях персонализированного информационного обеспечения.
Указанный технический результат достигается благодаря тому, что в способе автоматизированной обработки информационных текстовых материалов, при котором выявляют наличие в обрабатываемых информационных текстовых материалах сведений, могущих быть описанными с точки зрения их содержания элементами характеристики информационной потребности пользователя, фиксируют факт наличия таких сведений и соответствующие им элементы характеристики информационной потребности пользователя и используют эти элементы и их сочетания при графическом представлении пользователю содержания обрабатываемых материалов, при этом обработку информационного текстового материала ведут в интерактивном режиме, формируют образ структуры графического представления информационного текстового материала, представляющей собой граф с вершинами и связями, по окончании обработки информационного текстового материала формируют когнитивную карту последнего, согласно изобретению, предварительно информационные потребности пользователя по определенной тематике формируют в виде ориентированного графа, при этом в вершинах графа располагают типы интересующих пользователя объектов, а на дугах - интересующие его типовые отношения между этими типами объектов, и для каждой вершины построенного графа и каждой дуги, связывающей пары вершин, строят отдельное множество логических конструкций, каждая из которых содержит в левой части шаблон поиска примеров типов объектов и/или примеров типовых отношений между ними, а в правой части - операторы фиксации в тексте найденных по шаблону примеров типов объектов и/или примеров типовых отношений между ними, а процесс обработки текстового информационного материала ведут путем последовательного осуществления фазы препроцессии, включающей этап морфологического анализа обрабатываемого информационного текстового материала с фиксацией морфологической пометы, присвоенной каждому его слову по результатам морфологического анализа, этап поиска устойчивых словосочетаний в обрабатываемом информационном текстовом материале с фиксацией семантической пометы, присвоенной каждому словосочетанию по результатам поиска, и этап сегментации обрабатываемого информационного текстового материала на предложения, состоящий в выделении знаков препинания, соответствующих концам предложения с фиксацией пометы конца предложения, фазы процессии, включающей этап выделения примеров типовых отношений, состоящий в поиске глагольных групп в обрабатываемом информационном текстовом материале путем сравнения слов, имеющих морфологическую помету, соответствующую глагольным группам, с шаблонами левых частей множества логических конструкций и фиксации фрагмента обрабатываемого информационного текстового материала, содержащего совпадающую с шаблоном глагольную группу, с помощью операторов, заданных в правой части соответствующей шаблону логической конструкции, сравнения совпадающих с шаблонами найденных глагольных групп с названиями дуг графа образа структуры информационной потребности пользователя, и фиксации их в виде списка примеров типовых отношений при обнаружении дуг, названия которых соответствуют найденным глагольным группам, а в случае отсутствия дуг, названия которых соответствуют глагольным группам обрабатываемого информационного текстового материала, дальнейшую обработку последнего прекращают и этап выделения примеров типов объектов, который осуществляют путем поиска в обрабатываемом информационном текстовом материале примеров, соответствующих объектам тех вершин графа, которые соединены дугами, названия которых идентичны найденным глагольным группам, с последующей фиксацией в списке примеров объектов данного типа с одновременной фиксацией тех типов объектов, к которым они относятся, а в случае отсутствия в обрабатываемом информационном текстовом материале примеров типов объектов, соответствующих шаблонам, дальнейшую обработку информационного текстового материала прекращают, и фазы постпроцессии, которую выполняют как последовательность этапа формирования из списка примеров типовых отношений и списка примеров типов объектов элементарных графов, каждый из которых имеет структуру вида “вершина - дуга - вершина”, в вершинах которого располагают примеры соответствующих типов объектов, а на дуге - пример соответствующего типового отношения, связывающего выбранные вершины, с фиксацией списка элементарных графов и этапа слияния элементарных графов в когнитивную карту обработанного информационного текстового материала.
При этом согласно изобретению, образ структуры графического представления информационных потребностей пользователя по заданной теме формируют люди-эксперты, трансформируя в ориентированный граф информационную потребность пользователя по определенной тематике путем отбора и фиксации существенных для данной темы типов объектов и типовых отношений между объектами.
При этом согласно изобретению, типовые отношения между типами объектов делят на общие и специализированные.
При этом согласно изобретению, перечень общих отношений является фиксированный и неизменным, а перечень специализированных отношений является открытым для пополнения и изменений.
При этом согласно изобретению, к общим типовым отношениям относят отношения, фиксирующие иерархию типов объектов “потомок - предок”.
При этом согласно изобретению, к общим типовым отношениям относят отношение “БЫТЬ ПРИМЕРОМ”.
При этом согласно изобретению, к специализированным типовым отношениям относят отношения, специфичные для выбранной темы.
При этом согласно изобретению, каждое множество логических конструкций используют в качестве правил поиска в тексте примеров типов объектов и примеров типовых отношений между ними.
При этом согласно изобретению, в качестве общего словаря используют словари русского языка, а в качестве специализированных словарей используют составленные и пополняемые пользователями словари.
При этом согласно изобретению, в качестве отдельных единиц выделяют слова, как последовательности букв от пробела до пробела, и/или знаки препинания, и/или специальные символы, и/или даты, и/или числа.
При этом согласно изобретению, этап морфологического анализа обрабатываемого текста осуществляют путем выделения окончания каждого слова обрабатываемого текста, сравнения оставшейся части слова с соответствующими словами общего словаря, после чего приводят слово из обрабатываемого текста к нормальной форме с одновременным приписыванием ей морфологических признаков, причем приведением существительного к нормальной форме признают фиксацию слова в соответствующем роде, именительном падеже и в единственном числе, приведением глаголов к нормальной форме - фиксацию глагола в неопределенной форме.
При этом согласно изобретению, в качестве морфологических признаков для существительного используют род, число, падеж, а для глаголов - вид, лицо и время.
При этом согласно изобретению, этап поиска устойчивых словосочетаний в обрабатываемом информационном текстовом материале осуществляют после этапа морфологического анализа.
При этом согласно изобретению, в качестве устойчивых словосочетаний используют элементы специализированных словарей по тематике информационных потребностей пользователя.
При этом согласно изобретению, этап поиска устойчивых словосочетаний в обрабатываемом информационном текстовом материале осуществляют путем поиска в обрабатываемом информационном текстовом материале слов и словосочетаний, которые представлены в специализированных словарях, и фиксации для каждого найденного устойчивого словосочетания семантической пометы из соответствующего словаря.
При этом согласно изобретению, этап сегментации обрабатываемого информационного текстового материала осуществляют путем выявления его части, начинающейся либо с большой буквы, либо начинающейся после одной и более пустых строк и заканчивающейся одним из знаков препинания, которым присвоены пометы “КОНЕЦ-ПРЕДЛ”.
При этом согласно изобретению, при поиске глагольных групп на этапе выделения примеров типовых отношений выделяют слова или словосочетания, имеющих морфологическую помету “глагол”, или помету “причастие”, или помету “отглагольное существительное”, приписанную на стадии морфологического анализа.
При этом согласно изобретению, на этапе выделения примеров объектов по найденным дугам находят типы объектов, расположенные в вершинах графа, соединенных этими дугами, и фиксируют найденные типы объектов в виде списка, затем для каждого зафиксированного типа объектов выбирают соответствующее ему множество логических конструкций, каждую из которых используют для выделения в информационном текстовом материале примеров соответствующего типа объектов путем сравнения слов или словосочетаний из обрабатываемого текста с шаблоном из левой части соответствующей логической конструкции и при положительном результате такого сравнения найденный в обрабатываемом информационном текстовом материале пример фиксируют в списке примеров объектов данного типа с одновременной фиксацией тех типов объектов, к которым они относятся, а в случае отсутствия в обрабатываемом информационном текстовом материале примеров типов объектов, соответствующих шаблонам, дальнейшую обработку информационного текстового материала прекращают.
При этом согласно изобретению, в случаях, когда типы объектов и/или типовых отношений в образе структуры графического представления информационной потребности описаны дополнительными характеристиками, для выделения которых из информационного текстового материала предварительно созданы соответствующие логические конструкции, обработку информационного текстового материала продолжают путем поиска в последнем конкретных фрагментов, соответствующих описанным дополнительным характеристикам, и фиксацией этих фрагментов в списках типов объектов и/или типовых отношений.
При этом согласно изобретению, этап формирования элементарных графов содержит стадию формирования элементарных графов для примеров типовых отношений из списка примеров типовых отношений и стадию поиска и обработки синонимов.
При этом согласно изобретению, для формирования элементарных графов для примеров типовых отношений из списка примеров типовых отношений сначала для каждого из элементов списка примеров типовых отношений выбирают соответствующую ему дугу из графа образа структуры графического представления информационной потребности и по ней выбирают вершины, которые связаны этой дугой, затем из списка типов объектов выбирают примеры объектов, соответствующие выбранным вершинам, и для каждой такой тройки формируют элементарный граф, имеющий структуру вида “вершина - дуга - вершина”, причем в вершинах элементарного графа располагают примеры соответствующих типов объектов, а на дуге - пример соответствующего типового отношения, связывающего выбранные вершины.
При этом согласно изобретению, стадию поиска и обработки синонимов осуществляют путем сравнения названия каждого из примеров типов объектов из списка типов объектов с элементами словаря синонимов или с помощью эвристического алгоритма, заключающегося в том, что синонимами считают два примера одного типового объекта, если представление одного из них в исходном тексте является частью второго из них в исходном тексте или если представление в исходном тексте обоих примеров полностью совпадает, и в случае выявления синонимов для каждой пары формируют элементарный граф, имеющий структуру вида “вершина -дуга - вершина”, первая вершина которого соответствует примеру типового объекта, вторая - его синониму, а дуга - отношению с именем “СИНОНИМ”, полученный элементарный граф фиксируют в общем списке элементарных графов.
При этом согласно изобретению, этап формирования элементарных графов дополнительно включает стадию формирования элементарных графов для неопределенных отношений.
При этом согласно изобретению, стадию формирования элементарных графов для неопределенных отношений осуществляют для примеров тех типов объектов, которые остались неиспользованными, но находятся в пределах одного предложения путем формирования из множества неиспользованных элементов из списка примеров типов объектов всех возможных их пар и формирования для каждой такой пары элементарного графа, тоже имеющего структуру вида “вершина - дуга - вершина”, причем первая вершина этого элементарного графа соответствует первому примеру объекта из выделенной пары, вторая - второму примеру объекта из выделенной пары, а дуга - неопределенному отношению с именем “???”, полученный элементарный граф фиксируют в общем списке элементарных графов.
При этом согласно изобретению, этап слияния элементарных графов в когнитивную карту обработанного информационного текстового материала осуществляют путем наложения одинаковых вершин построенных элементарных графов и исключения дублирующихся дуг.
При этом согласно изобретению, в когнитивную карту обработанного информационного текстового материала элементарные графы с дугами, имеющими в качестве имени неопределенное отношение “???”, вливают только после подтверждения необходимости этой операции пользователем.
При этом согласно изобретению, этап формирования когнитивной карты для совокупности обработанных информационных текстовых материалов осуществляют после обработки последнего из информационных текстовых материалов из заданной совокупности путем наложения одинаковых вершин всех построенных когнитивных карт и исключения дублирующихся дуг.
При этом согласно изобретению, каждый из типов объектов и/или типовых отношений имеет единичные или множественные характеристики.
При этом согласно изобретению, характеристики могут быть числовыми, строковыми или ссылочными.
Перечень фигур чертежей и иных материалов
Изобретение поясняется описанием конкретного примера его выполнения и прилагаемыми чертежами, где на:
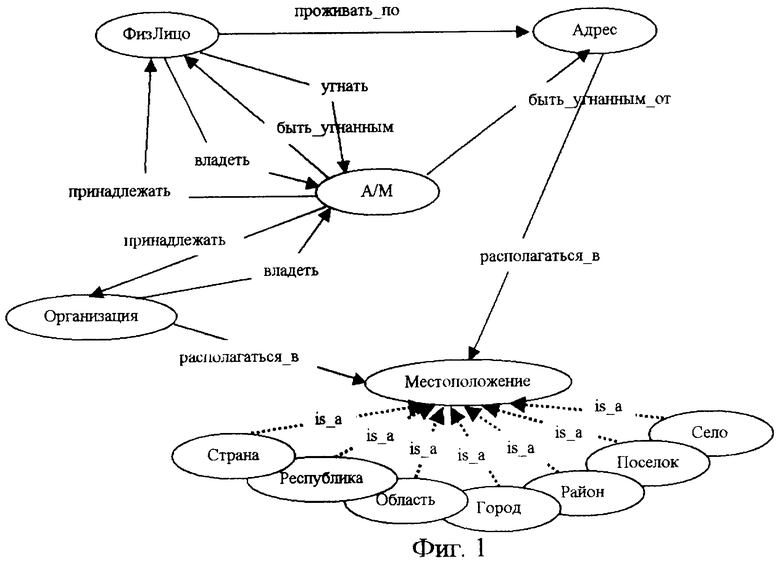
фиг.1 изображен образ структуры графического представления информационной потребности пользователя по тематике “Сводки об угонах машин” в виде ориентированного графа;
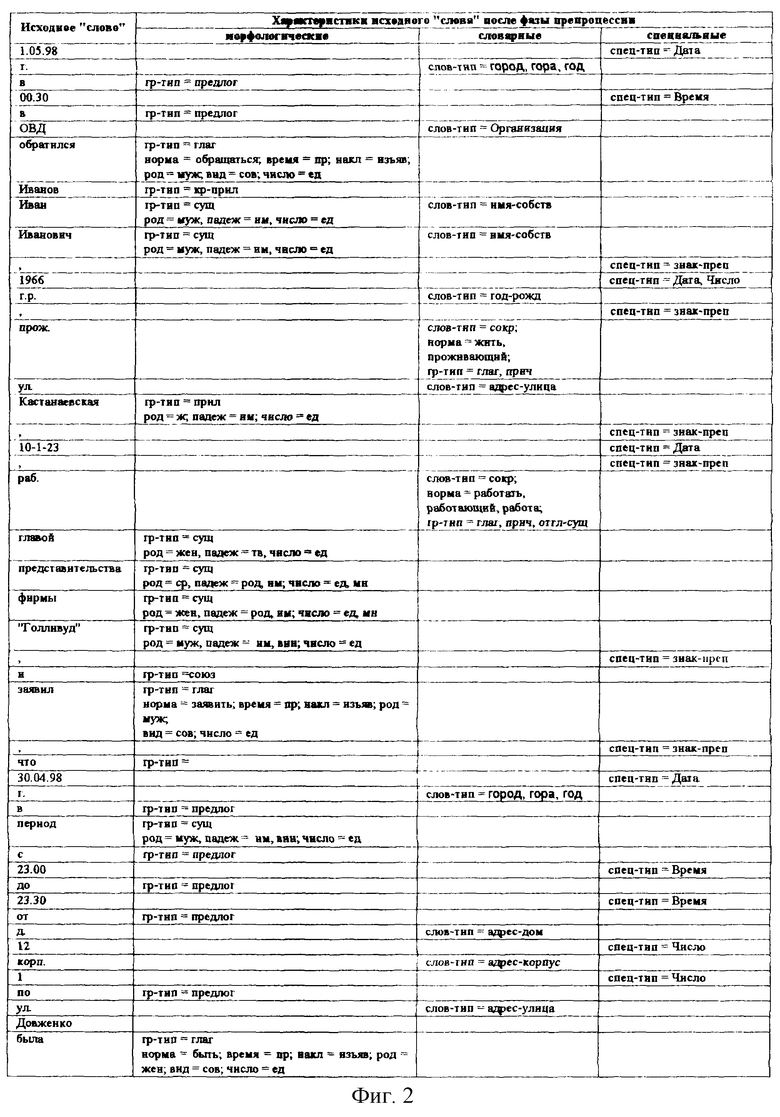
фиг.2 - вид информационного текстового материала после фазы препроцессии;
фиг.3 - список примеров типовых отношений, полученный в результате выполнения этапа выделения примеров типовых отношений;
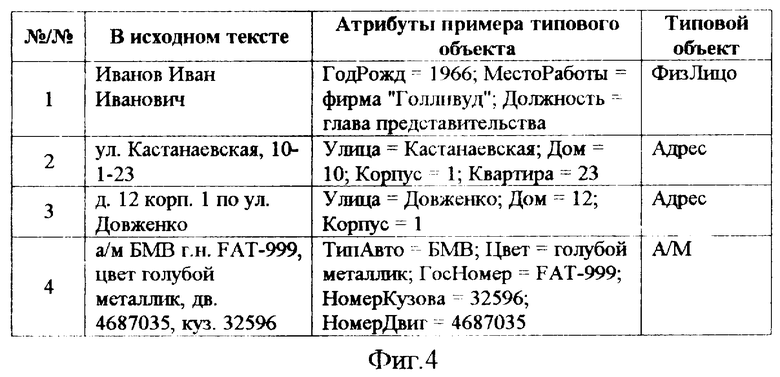
фиг.4 - список примеров типов объектов, полученный в результате выполнения этапа выделения примеров типов объектов;
фиг.5 - список элементарных графов, полученный в результате выполнения стадии формирования элементарных графов для примеров типовых отношений;
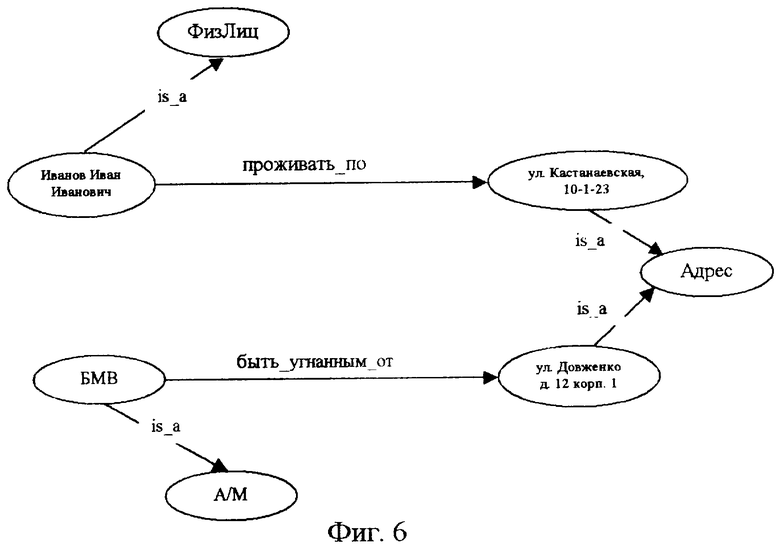
фиг.6 - когнитивная карта сводки об угоне автомобиля у гражданина Иванова;
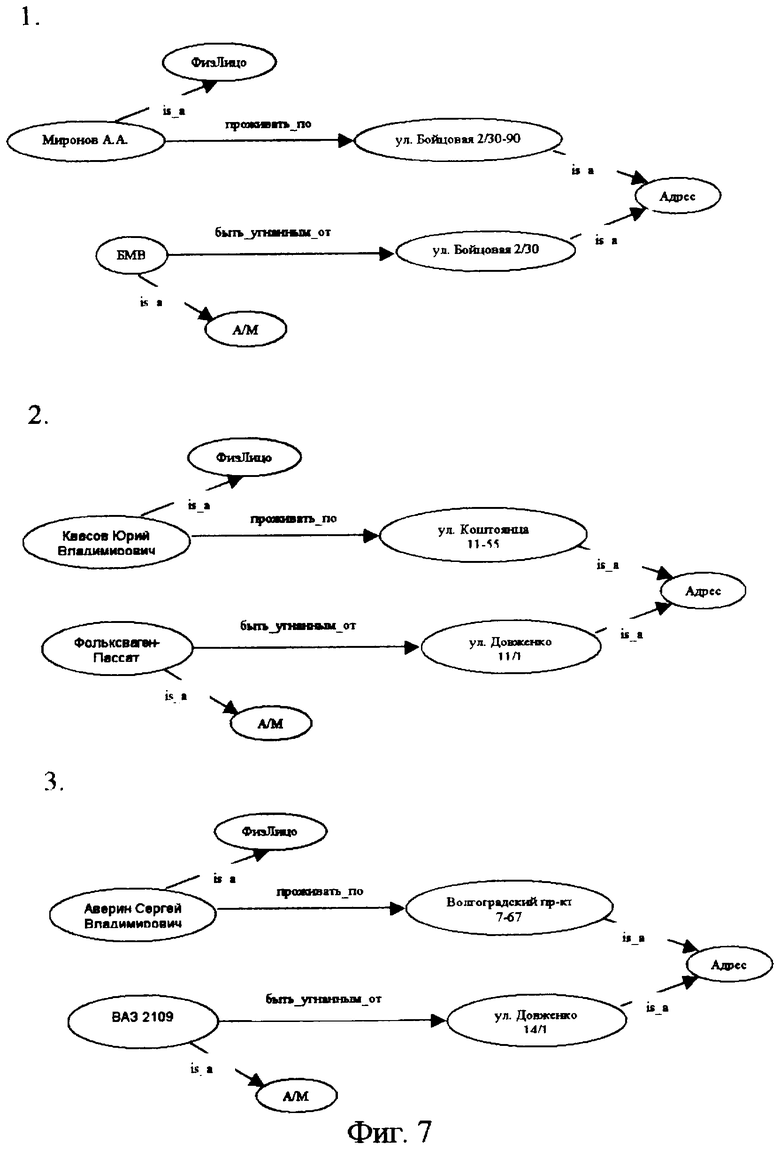
фиг.7 - примеры когнитивных карт каждого из дополнительных информационных текстовых материалов об угонах автомашин;
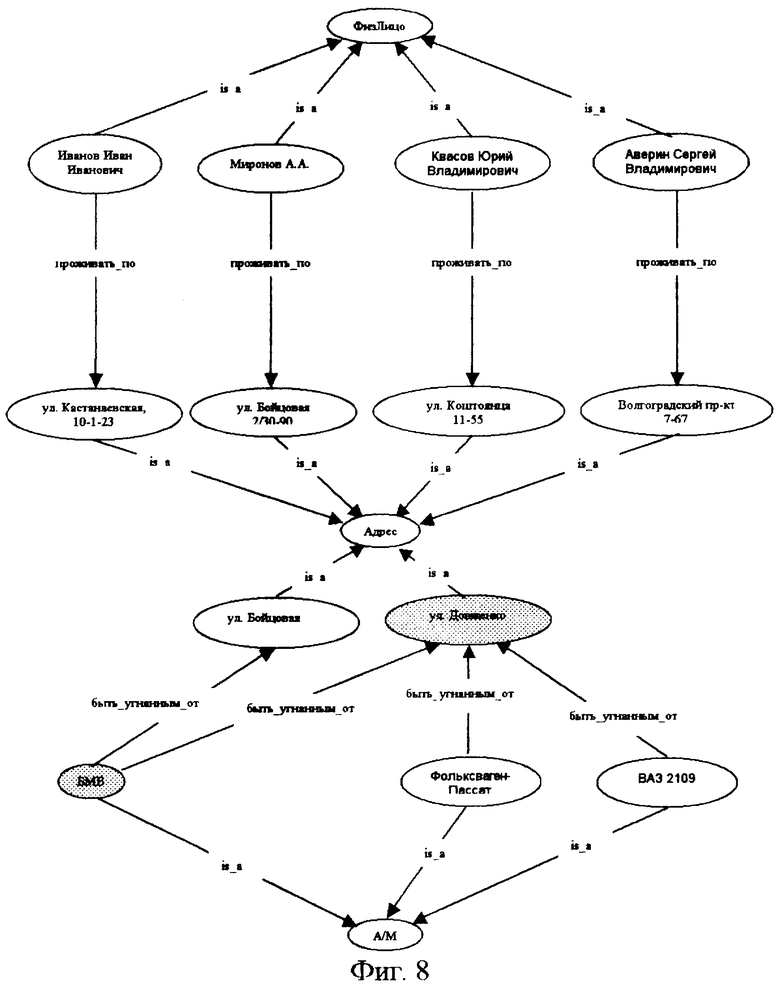
фиг.8 - когнитивная карта совокупности текстовых материалов об угонах автомашин по г.Москве.
Сведения, подтверждающие возможность осуществления изобретений
Способ осуществляют в следующей последовательности:
Предлагаемый способ предназначен для автоматизированной обработки текстовых информационных материалов, которые могут быть представлены на естественном языке как в виде отдельных документов по определенной теме, так и в виде совокупности документов (например, сообщений, статей, аналитических материалов и т.п.), связанных одной, быть может многоаспектной тематикой.
Документы должны быть представлены в виде планарных, т.е. не содержащих управляющих форматных символов, текстовых файлов, и храниться в машинно-читаемом виде, причем указанные текстовые файлы могут быть получены любым известным способом: из сети Интернет, по электронной почте или факсу, отсканированы с бумажных носителей или набраны на клавиатуре пользователем.
Под “элементами характеристики информационной потребности пользователя” следует понимать смысловые элементы, которыми описаны те или иные события во взаимосвязи. В зависимости от информационной потребности элементами могут быть понятия (синоним: типовые объекты), примеры этих понятий (синонимы: экземпляры объектов, примеры объектов), типовые отношения между понятиями, примеры этих типовых отношений, которые в общем случае выражаются в тексте словами или словосочетаниями на естественном языке.
Типы объектов - категории объектов, содержащие характерные, обобщенные черты экземпляров объектов. Например, “ЧЕЛОВЕК” - это понятие или типовой объект, а “Иванов Иван Иванович” - это пример или экземпляр данного понятия.
Типовые отношения - отношения между типами объектов, содержащие характерные, обобщенные черты экземпляров отношений. Например, “БЫТЬ РОДСТВЕННИКОМ” - это типовое отношение, а “БЫТЬ СЕСТРОЙ” или “БЫТЬ МУЖЕМ” - это экземпляры данного отношения.
Каждый тип объекта и/или типовое отношение, помимо имени, могут иметь атрибуты (характеристики), которые в свою очередь могут быть числовыми, строковыми или ссылочными (единичными или множественными). Соответственно каждый экземпляр объекта и/или экземпляр отношения может иметь только те атрибуты, которые имеют их “родители” (тип объекта и/или типовое отношение), но конкретизируют эти атрибуты за счет присваивания им определенных значений. Например, у типа объекта “ЧЕЛОВЕК” может быть атрибут “ВОЗРАСТ”, который выражается целым числом, тогда у экземпляра этого объекта “Иванов Иван Иванович” атрибут “ВОЗРАСТ” может иметь значение “33”, которое является конкретизацией данного атрибута, описанного в объекте - “родителе”.
Устойчивые словосочетания в обрабатываемом информационном текстовом материале - это последовательности слов, всегда имеющих один и тот же смысл в пределах определенной тематики. Так, для тематики, связанной с кадровыми назначениями, типичными примерами устойчивых словосочетаний являются названия организаций (ООО “Салют”, ф-ка “Красный Октябрь” и т.п.) и названия должностей (главный бухгалтер, заместитель директора, менеджер и т.п.).
Проведение всей обработки информационного текстового материала именно с позиции характеристики информационной потребности пользователя, представленной в виде образа структуры ее графического представления, и определяет заявленный способ как способ обработки для персонализированного использования по заданной теме.
Примерный состав технических средств, с помощью которых может быть реализован заявленный способ автоматизированной обработки информационных текстовых материалов, включает в себя традиционное вычислительное оборудование: процессор, компьютерный монитор с клавиатурой и графическим манипулятором, например, типа “мышь”, носители файлов обрабатываемых информационных текстовых материалов и графического представления информационной потребности пользователя, причем может быть использован любой компьютер, который обеспечивает функционирование под управлением операционной системы Windows.
Осуществление заявленного способа автоматизированной обработки информационных текстовых материалов выполняют в интерактивном режиме с последовательным отображением текущей и итоговой информации с выводом на экран монитора персонального компьютера.
Предварительно по заданной теме люди-эксперты формируют образ структуры графического представления информационных потребностей пользователя по определенной тематике в виде ориентированного графа путем отбора и фиксации существенных для данной темы типов объектов и типовых отношений между ними, при этом в вершинах графа располагают типы интересующих пользователя объектов, а на дугах - интересующие его типовые отношения между этими типами объектов. Затем для каждой вершины построенного графа и каждой пары вершин, связанных дугами, строят отдельное множество логических конструкций, каждая из которых содержит в левой части шаблон поиска примеров типов объектов и/или примеров типовых отношений между ними, а в правой части - операторы фиксации в тексте найденных по шаблону примеров типов объектов и/или примеров типовых отношений между ними.
Люди-эксперты в данной области информационные потребности пользователей по определенной тематике трансформируют в образ структуры графического представления этих потребностей на основе своих знаний и опыта. Люди-эксперты в области лингвистики на основе своих знаний строят отдельное множество логических конструкций, определяющих правила поиска в тексте примеров типов объектов и примеров типовых отношений между ними.
С помощью указанных выше логических конструкций в обрабатываемых информационных текстовых материалах выявляют соответствующие описанным в виде ориентированного графа информационных потребностей пользователя конкретные сведения, а факт наличия таких сведений и соответствующие им элементы характеристики информационных потребностей фиксируют. Эти элементы и их сочетания используют при графическом представлении пользователю содержания обрабатываемых материалов.
Процесс обработки информационного текстового материала ведут путем последовательного осуществления фазы препроцессии, фазы процессии и фазы постпроцессии.
Фаза препроцессии включает этап морфологического анализа обрабатываемого информационного текстового материала с фиксацией морфологической пометы, присвоенной каждой выделенной текстовой единице по результатам морфологического анализа, этап поиска устойчивых словосочетаний в обрабатываемом информационном текстовом материале с фиксацией семантической пометы, присвоенной каждому выделенному словосочетанию по результатам поиска в специальных словарях, и этап сегментации обрабатываемого информационного текстового материала на предложения, состоящий в выделении знаков препинания, соответствующих концам предложения с фиксацией пометы конца предложения, например, типа КОНЕЦ-ПРЕДЛ.
Таким образом, на фазе препроцессии сначала осуществляют морфологическую разметку слов обрабатываемого информационного текстового материала. В качестве “слов” в рамках настоящего изобретения выделяют последовательности букв от пробела до пробела; знаки препинания, специальные символы, например обозначения валют, даты; числа и т.п. единицы. Алгоритмы такого выделения общеизвестны, неоднократно описаны и реализованы (например, в системе, разработанной в Шеффилдском университете Великобритании).
В качестве отдельных единиц выделяют слова как последовательности букв от пробела до пробела, и/или знаки препинания, и/или специальные символы, и/или даты, и/или числа.
Собственно приписывание выделенным единицам морфологической информации осуществляют на этапе морфологического анализа “слов”. Для этого каждое “слово” анализируют справа-налево. В процессе такого анализа в рамках настоящего изобретения выделяют окончания, список которых для всех широко распространенных естественных языков уже известен и исчерпывающе описан в общедоступной литературе, а для оставшейся части слова производят поиск в общем словаре, после чего приводят “слово” к нормальной форме: для существительных это, например, мужской род, именительный падеж, единственное число; для глаголов - неопределенная форма; и т.д., с одновременным приписыванием полученной нормальной форме ее морфологических признаков (род-число-падеж для существительных; вид-лицо-время - для глаголов; и т.д.). При этом учитывают все омонимы анализируемого слова. (Омонимы - слова с одинаковым написанием, но с разным смыслом. Например, слово СТЕКЛО это существительное среднего рода, единственного числа, именительного или винительного падежа и одновременно глагол прошедшего времени, третьего лица, совершенного вида).
Алгоритмы морфологического анализа слов русского языка общедоступны и неоднократно описаны.
Таким образом, этап морфологического анализа обрабатываемого текста осуществляют путем выделения окончания каждого слова обрабатываемого текста, сравнения оставшейся части слова с соответствующими словами общего словаря, после чего приводят слово из обрабатываемого текста к нормальной форме с одновременным приписыванием ее морфологических признаков, причем приведением существительного к нормальной форме признают фиксацию слова в соответствующем роде, именительном падеже и в единственном числе, приведением глаголов к нормальной форме - фиксацию глагола в неопределенной форме.
При этом в качестве морфологических признаков для существительного используют род, число, падеж, а для глаголов - вид, лицо и время.
В результате морфологического анализа всем “словам” обрабатываемого текста, для которых это возможно и/или целесообразно (например, невозможно приписать морфологическую информацию сокращениям и нецелесообразно ее приписывать, например, датам) приписывают морфологические пометы, возможно, неоднозначные.
По завершении морфологического анализа фрагмента информационного текстового материала осуществляют этап поиска устойчивых словосочетаний в обрабатываемом информационном текстовом материале с фиксацией семантической пометы, присвоенной каждому выделенному словосочетанию по результатам поиска в специальных словарях, т.е. осуществляют разметку текста по специальным словарям. Для русского языка принципиально, что этот этап проводят после морфологической разметки, так как в русском языке специальные слова и словосочетания (имена собственные, географические названия, названия фирм) могут изменяться, например, по родам, числам и падежам (Москва-Москвы-Москве и т.д.). Для других естественных языков, например для английского, где не такое богатое словоизменение, порядок применения вышеуказанных этапов не столь важен, но и здесь (для единообразия предлагаемого способа) разметку по словарям производят после морфологической разметки. Алгоритм разметки прост - в тексте ищут слова и словосочетания, которые представлены в специальных словарях, и каждому найденному приписывают информацию из соответствующего словаря (например, словосочетанию <ф-ка “Красный Октябрь”> будет приписана помета ОРГАНИЗАЦИЯ, а словосочетанию <Южная Америка> - помета ГЕОГР-НАЗВАНИЕ). В процессе разметки текста по специальным словарям также возможна омонимия, которую учитывают, однако, в отличие от омонимии на этапе морфологического анализа, эта омонимия, как правило, семантическая (например, сокращение <г.> может получить три семантические пометы - ГОРОД ГОРА и ГОД). Алгоритмы разметки текста по специальным словарям тоже общеизвестны и опубликованы, а разные реализации отличаются лишь эффективностью поиска словосочетаний в специальных словарях. В результате обрабатываемый текст получит дополнительно к морфологическим семантические пометы, которые используют на дальнейших этапах.
Этап сегментации обрабатываемого информационного текстового материала на предложения завершает фазу препроцессии и состоит в выделении знаков препинания, соответствующих концам предложения с фиксацией пометы конца предложения, например “КОНЕЦ-ПРЕДЛ”. Алгоритм выполнения этого этапа основан на следующих общеизвестных эвристиках: каждое предложение, как правило, начинают с большой буквы и заканчивают точкой, вопросительным или восклицательным знаком или многоточием, т.е. каким-либо “сильным” знаком препинания; абзац, как правило, начинает новое предложение; одна или несколько пустых строк, как правило, начинают новый абзац и, следовательно, новое предложение, которые не гарантируют абсолютно точного выделения границ предложений, но, как показал анализ разных текстов, позволяют сделать это в большинстве случаев. В результате выполнения любой программы, реализующей вышеуказанный этап, часть знаков препинания получит специальные пометы, например “КОНЕЦ-ПРЕДЛ”. Таким образом, этап сегментации обрабатываемого информационного текстового материала осуществляют путем выявления его части, начинающейся либо с большой буквы, либо начинающейся после одной и более пустых строк и заканчивающейся каким-либо знаком препинания, которому присвоена помета “КОНЕЦ-ПРЕДЛ”.
Результатом выполнения фазы препроцессии является обрабатываемый текстовый информационный материал, слова в котором имеют морфологические пометы, устойчивые словосочетания - семантические пометы, а знаки препинания, соответствующие концам предложения, - специальные пометы, например, “КОНЕЦ-ПРЕДЛ”.
Фаза процессии, согласно данному изобретению, включает этап выделения примеров отношений, состоящий в поиске в обрабатываемом информационном текстовом материале глагольных групп и в обработке найденных глагольных групп путем сравнения последних с названиями дуг уже построенного ориентированного графа образа структуры информационной потребности пользователя по определенной тематике с последующей фиксацией идентичных таким дугам найденных глагольных групп и этап выделения примеров объектов, который осуществляют путем поиска в обрабатываемом информационном текстовом материале примеров, соответствующих типам объектов тех вершин графа, которые соединены дугами, названия которых идентичны найденным глагольным группам, т.е. с зафиксированными на предыдущем этапе, с последующей фиксацией в списке примеров объектов данного типа с одновременной фиксацией тех типов объектов, к которым они относятся, а в случае отсутствия в обрабатываемом информационном текстовом материале примеров типов объектов дальнейшую обработку информационного текстового материала прекращают. Оба этапа выполняют с использованием соответствующих логических конструкций, определяющих правила поиска в тексте примеров типовых отношений, примеров типов объектов и примеров типовых отношений между примерами типов объектов, причем каждая логическая конструкция содержит в левой части шаблон поиска примеров объектов и/или примеров отношений между ними, а в правой части - операторы фиксации в тексте найденных по шаблону примеров объектов и/или примеров отношений между ними.
Таким образом, фазу процессии начинают с этапа выделения примеров отношений, который осуществляют путем поиска в обрабатываемом информационном текстовом материале глагольных групп, отражающих смысл отношений, представленных в образе структуры графического представления информационных потребностей, под управлением которой осуществляется вся обработка. Для этого в тексте выделяют слова, грамматический тип которых имеет одну из следующих помет: “глагол”, “причастие” или “отглагольное существительное”, приписанных на стадии морфологического анализа, и каждое из таких слов сравнивают с шаблонами левых частей соответствующих логических конструкций. При совпадении проверяемого слова или словосочетания с шаблоном соответствующий фрагмент текстового информационного материала фиксируют с помощью операторов, заданных в правой части соответствующей логической конструкции, а затем сравнивают с дугами предварительно построенного людьми-экспертами ориентированного графа образа структуры информационной потребности пользователя. При обнаружении дуг, которые соответствуют найденным глагольным группам, т.е. идентичных найденным в текста глагольным группам, их фиксируют в виде списка примеров типовых отношений с одновременным указанием тех типовых отношений, к которым они относятся. Если интересующие нас дуги не найдены, дальнейшая обработка информационного текстового материала нецелесообразна и процесс останавливают.
На этапе выделения примеров объектов по найденным в соответствии с вышеуказанным алгоритмом дугам находят типы объектов, расположенные в вершинах графа, соединенных этими дугами, и фиксируют найденные типы объектов в виде списка. Для каждого зафиксированного типа объектов выбирают соответствующее ему множество предварительно построенных людьми-экспертами логических конструкций, каждую из которых используют для выделения в обрабатываемом информационном текстовом материале примеров соответствующего типа объектов путем сравнения слов или словосочетаний из текста с шаблоном из левой части соответствующей логической конструкции и при положительном результате такого сравнения найденный в тексте обрабатываемого информационного материала пример фиксируют в списке примеров объектов данного типа с одновременной фиксацией тех типов объектов, к которым они относятся. Если интересующие нас примеры типовых объектов не найдены, дальнейшая обработка информационного текстового материала нецелесообразна и процесс останавливают.
В тех случаях, когда типы объектов и/или типовые отношения в образе структуры графического представления информационной потребности описывают дополнительными атрибутами (характеристиками), для выделения которых из информационного текстового материала людьми-экспертами предварительно также созданы соответствующие логические конструкции, эти атрибуты вовлекают в обработку путем поиска в информационном текстовом материале конкретных фрагментов, им соответствующих, и фиксации этих фрагментов в вышеуказанных списках.
Результатом выполнения фазы процессии являются списки примеров типовых отношений и примеров типов объектов, выделенных в тексте обрабатываемого информационного материала, с указаниями на их типовые отношения и типы объектов и, возможно, конкретные значения атрибутов примеров типовых отношений и примеров типов объектов.
Фаза постпроцессии включает этап формирования элементарных графов для обработанного на предыдущих фазах информационного текстового материала, этап слияния элементарных графов для обработанного информационного текстового материала в когнитивную карту и этап формирования когнитивной карты для совокупности обработанных информационных текстовых материалов, который включают в общий процесс обработки по желанию пользователя.
Этап формирования элементарных графов для обработанного информационного текстового материала выполняют на фазе постпроцессии первым. Он включает стадию формирования элементарных графов для примеров типовых отношений, которую можно осуществлять, например, и программным путем, на основе использования списков примеров отношений и примеров объектов, зафиксированных на предыдущей фазе, следующим образом: для каждого примера отношения из первого списка выбирают соответствующую ему дугу из образа структуры графического представления информационной потребности и по ней выбирают вершины, которые связаны этой дугой, затем из второго списка выбирают примеры объектов, соответствующие выбранным вершинам, и для каждой такой тройки формируют элементарный граф, имеющий структуру вида “вершина - дуга - вершина”, причем в вершинах располагают примеры соответствующих типов объектов, а на дуге - пример соответствующего типового отношения, связывающего выбранные вершины с фиксацией полученного элементарного графа в списке элементарных графов, стадию поиска и обработки синонимов объектов путем сравнения названия каждого из найденных в обрабатываемом информационном текстовом материале примеров объектов для каждого типа объектов из графа образа структуры информационной потребности пользователя с элементами словаря синонимов или, например, с помощью эвристического алгоритма, заключающегося в следующем: синонимами считают два объекта, если представление в исходном тексте первого из них полностью “вкладывается” в представление в исходном тексте второго из них или их представления в исходном тексте полностью совпадают, например синонимами будут объекты “Иванов” и “Иванов Иван Иванович”, с последующей фиксацией найденных синонимов и формированием для каждого из них элементарных графов, каждый из которых имеет ту же структуру вида “вершина - дуга - вершина”, что и в предыдущем случае, но первая вершина этого элементарного графа соответствует примеру объекта, вторая - уже зафиксированному его синониму из словаря синонимов, а дуга -специальному отношению с именем “СИНОНИМ” с фиксацией полученного элементарного графа в том же списке элементарных графов, стадию формирования элементарных графов для неопределенных отношений, которая введена нами в силу возможной неполноты множества логических конструкций для лингвистической обработки текста, построенных предварительно людьми-экспертами, возможной многозначности получаемых при этом результатов, а также в силу следующих эвристических соображений: не все примеры объектов, выделенные на предыдущей фазе, могут быть уже использованы при построении элементарных графов на предыдущих стадиях фазы постпроцессии, поэтому примеры тех объектов, которые остались неиспользованными, но находятся в пределах одного предложения, обрабатывают путем формирования для каждой пары таких примеров объектов элементарного графа, тоже имеющего структуру вида “вершина - дуга - вершина”, причем первая вершина этого элементарного графа соответствует первому примеру объекта из выделенной пары, вторая - второму примеру объекта из выделенной пары, а дуга - неопределенному отношению с именем “???>> с фиксацией полученного элементарного графа в том же списке элементарных графов.
Этап слияния элементарных графов в когнитивную карту обработанного информационного текстового материала осуществляют, например, вручную или программно, путем обработки построенного на предыдущем этапе списка элементарных графов за счет наложения одинаковых вершин и исключения дублирующихся дуг, при этом элементарные графы с дугами, имеющими в качестве имени неопределенное отношение “???”, вводят в когнитивную карту только после подтверждения необходимости этой операции пользователем.
Результат слияния элементарных графов в когнитивную карту обработанного информационного текстового материала представляется пользователю на экране монитора в визуально воспринимаемом виде. Полученная когнитивная карта может редактироваться пользователем с помощью графического редактора, а результат такого редактирования может быть сохранен на машинном носителе для последующего использования.
Этап формирования когнитивной карты для совокупности обработанных информационных текстовых материалов включают в общий процесс обработки по желанию пользователя. Его осуществляют путем слияния одинаковых вершин всех когнитивных карт совокупности информационных текстовых материалов и исключения дублирующих дуг. Полученную когнитивную карту совокупности информационных текстовых материалов пользователь также может редактировать вручную или программно с помощью графического редактора, а результат такого редактирования также может быть сохранен на машинном носителе для последующего использования.
Таким образом, в результате обработки информационных текстовых материалов сформированы когнитивные карты, в которых присутствуют выделенные из обработанных информационных текстовых материалов примеры объектов, связанные примерами отношений из образа структуры графического представления информационных потребностей пользователя и, возможно, неопределенными отношениями.
Полученные когнитивные карты отражают смысл обработанных под управлением образа структуры графического представления информационных потребностей пользователя информационных текстовых материалов и могут быть использованы для визуализации результатов информационного поиска, для последующей аналитической обработки документов по заданной тематике, для последующего разбиения множества таких информационных текстовых материалов на классы, в каждом из которых представлены близкие по смыслу документы, а также для последующей визуальной оценки смысла обрабатываемых информационных текстовых материалов по их когнитивным картам.
Пример
Для иллюстрации осуществления заявленного способа автоматизированной обработки информационных текстовых материалов рассмотрим следующий пример: пусть имеется совокупность русских текстов, сформированная из сводок об угонах автомобилей по г.Москве, присылаемых из районных отделов УВД. Типичным примером таких текстов является следующее сообщение: “1.05.98 г. в 00.30 в ОВД обратился Иванов Иван Иванович, 1966 г.р., прож. ул. Кастанаевская, 10-1-23, раб. главой представительства фирмы “Голливуд”, и заявил, что 30.04.98 г. в период с 23.00 до 23.30 от д.12 корп.1 по ул. Довженко была угнана а/м БМВ г.н. FAT-999, цвет голубой металлик, дв. 4687035, куз. 32596”.
В соответствии с заявленным способом для обработки информационных текстовых материалов по теме “Сводки об угонах машин” используют предварительно созданный образ структуры графического представления информационных потребностей пользователя по данной теме в виде ориентированного графа, в вершинах которого располагают типы интересующих пользователя объектов, а на дугах - интересующие его типовые отношения между этими типами объектов (фиг.1).
В нашем примере типами объектов являются “ФизЛицо”, “Адрес”, “А/М”, “Организация”, “Местоположение”, “Страна”, “Республика”, “Область”, “Город”, “Район”, “Поселок”, “Село”. Типовые отношения между ними делятся на два класса - общие, характерные для любых тем, например, в нашем примере это отношение “БЫТЬ ПРИМЕРОМ”, которое далее на чертежах обозначено как “is a” в силу ограниченности пространства, фиксирующее иерархию объектов типа “потомок-предок”, и специальные - специфичные для выбранной темы, например в нашем случае это типовые отношения “проживать по”, “работать в”, “угнать”, “быть угнанным”, “быть угнанным от”, “владеть”, “принадлежать” и “располагаться в”.
Перечень общих отношений является фиксированным и неизменным, т.е. не может быть изменен ни экспертами, ни пользователями, а перечень специальных отношений является открытым для пополнения и изменения экспертами и частично пользователями.
В соответствии с заявленным способом людьми-экспертами предварительно построены и множества логических конструкций, причем каждая логическая конструкция содержит в левой части шаблон поиска примеров объектов и/или примеров отношений между ними, а в правой части - операторы фиксации в тексте найденных по шаблону примеров объектов и/или примеров отношений между ними. С помощью таких логических конструкций, подготовленных людьми-лингвистами, в обрабатываемых информационных текстовых материалах выявляют соответствующие описанным в виде определенного выше графа образа структуры графического представления информационных потребностей пользователей конкретные сведения.
Кроме графа образа структуры графического представления информационных потребностей пользователей и логических конструкций в соответствии с изложенным выше способом требуются словари общей и специальной лексики.
В качестве общего словаря в нашем случае может быть использован, например, словарь русского языка Ожегова, а специальные словари могут быть представлены следующим набором: словарь сокращений, характерных для предметной области (готовится пользователями), словарь имен физических лиц (в качестве начального словаря в нашем случае используется словарь романских имен, подготовленный на основании словаря имен собственных Успенского и пополняемый людьми-экспертами по результатам обработки представительного множества текстов), словарь улиц Москвы (в качестве начального словаря в нашем случае используется словарь, подготовленный на основании справочника и пополняемый людьми-экспертами по результатам обработки представительного множества текстов), словарь географических названий (в качестве начального словаря в нашем случае используется словарь, подготовленный на основании справочника и пополняемый людьми-экспертами по результатам обработки представительного множества текстов), и словарь наименований организаций (в качестве начального словаря в нашем случае используют словарь, подготовленный на основании реестра организаций и пополняемый людьми-экспертами по результатам обработки представительного множества текстов).
В соответствии с заявленным способом автоматизированной обработки приведенного выше информационного текстового материала по теме “Сводки об угонах машин” сначала осуществляют фазу препроцсссии, которую, в свою очередь, выполняют как последовательность этапов морфологического анализа с выделением в тексте отдельных “слов” и приписывания выделенным единицам морфологической пометы из общего словаря, этапа поиска устойчивых словосочетаний в обрабатываемом информационном текстовом материале с фиксацией семантической пометы, присвоенной каждому выделенному словосочетанию по результатам поиска в специальных словарях, и этапа сегментации обрабатываемого информационного текстового материала на предложения с фиксацией пометы конца предложения (КОНЕЦ-ПРЕДЛ.). В результате выполнения фазы препроцессии обрабатываемый информационный текстовый материал будет приведен к виду, представленному на фиг.2.
В соответствии с заявленным способом фазу процессии начинают с выполнения этапа выделения примеров отношений, состоящего из поиска в обрабатываемом информационном текстовом материале глагольных групп, отражающих семантику отношений, представленных в ориентированном графе образа структуры информационной потребности пользователя по теме “Сводки об угонах машин”. В данном случае в тексте вышеприведенной сводки присутствуют глагольные группы “обратился”, “прож.”, “раб.”, “заявил” и “была угнана”, которые идентифицируют по морфологическим пометам отдельных слов, полученным после фазы препроцессии. Эти глагольные группы фиксируют в отдельном списке, элементы которого затем сравнивают с дугами предварительно построенного ориентированного графа образа структуры информационной потребности пользователя по теме “Сводки об угонах машин”. Идентичные дугам глагольные группы фиксируют в виде списка примеров типовых отношений с указанием для каждого из них типового отношения, примерами которых они являются.
Для нашего случая глагольной группе “была угнана” поставлена в соответствие дуга “быть угнанным”, сокращениям “прож.” и “раб.” - дуги “проживать по” и “работать в” соответственно, а для глагольных групп “обратился” и “заявил” соответствия с дугами предварительно построенного ориентированного графа образа структуры информационной потребности пользователя по теме “Сводки об угонах машин” не найдено, что приведет к исключению их из дальнейшего рассмотрения. Таким образом, в результате выполнения этапа выделения примеров типовых отношений формируют их список, представленный на фиг.3.
Следующим на фазе процессии выполняют этап выделения примеров объектов, осуществляемый путем последовательной обработки элементов из списка примеров типовых отношений, полученного на предыдущем этапе, с целью формирования промежуточного списка типов объектов, которые соединены типовыми отношениями в ориентированном графе образа структуры информационной потребности пользователя по теме “Сводки об угонах машин”, которые, в свою очередь, являются предками примеров отношений из обрабатываемого списка.
Для нашего случая по типовому отношению “быть угнанным” из графа образа структуры информационной потребности будут выбраны типы объектов “А/М” и “ФизЛицо”, по типовому отношению “проживать по” - типы объектов “ФизЛицо” и “Адрес”, а по типовому отношению “работать в” - типы объектов “ФизЛицо” и “Организация”. После удаления из сформированного промежуточного списка дубликатов и пополнения его атрибутами оставшихся типов объектов для нашего случая будет получен следующий список типов объектов и их атрибутов, примеры которых должны быть выделены в обрабатываемом информационном текстовом материале: “ГодРождения” и “Должность” для типов объектов “ФизЛицо”; “ТипАвто”, “Цвет”, “ГосНомер”, “ГодВыпуска”, “НомерКузова” и “НомерДвиг” - для типов объектов “А/М”; “Улица”, “Дом”, “Корпус” и “Квартира” - для типов объектов “Адрес”. Собственно выделение примеров объектов для каждого типа объекта из сформированного выше промежуточного списка осуществляют согласно данному изобретению путем использования множеств логических конструкций, соответствующих определенному типу объекта. В нашем случае для выделения в информационном текстовом материале примеров типа объекта “ФизЛицо” и их обработки имеется логическая конструкция, например, левая часть которой задает шаблон вида:
((ИМЯ) (ОТЧЕСТВО)? (СЛОВО С БОЛЬШОЙ БУКВЫ)): физ лицо,
что позволяет найти в обрабатываемом информационном текстовом материале фрагменты “Иван Иванович Иванов”, “Петр Иванов” и аналогичные им фрагменты, а правая часть - последовательность операторов для фиксации выделенного с помощью этого шаблона примера типа объекта “ФизЛицо” вида
{
границы понятия=найти в обрабатываемом тексте границы понятия (“ФизЛицо”);
характеристики=создать пустое множество характеристик ();
физ лицо=получить языковое выражение понятия из текста
(информационный материал, границы понятия);
характеристики=+пополнить множество характеристик (“имя”, физ лицо);
характеристики=+пополнить множество характеристик (“тип”, “ФизЛицо”);
сформировать понятие (границы, “ФизЛицо”, характеристики);
},
выполнение которых приводит к формированию в нашем случае следующего примера типа объекта “ФизЛицо”:
[“Иванов Иван Иванович” БЫТЬ ПРИМЕРОМ “ФизЛицо”].
Аналогичные логические конструкции, предварительно подготовленные людьми-экспертами по лингвистике, используют для выделения в обрабатываемом информационном текстовом материале по теме “Угоны автомашин” примеров, соответствующих указанным выше 4 типам объектов и 7 атрибутам.
В нашем случае примерами типов объектов являются “Иванов Иван Иванович” (“ФизЛицо”), “ул. Кастанаевская, 10-1-23” (“Адрес”), “д. 12 корп.1 по ул. Довженко” (“Адрес”), “а/м БМВ г.н.FAT-999, цвет голубой металлик, дв. 4687035, куз. 32596” (“А/М”), “фирма "Голливуд"” (“Организация”), а примеры атрибутов - 1966 (“ГодРождения”), глава представительства (“Должность”), БМВ (“ТипАвто”), голубой металлик (“Цвет”), FAT-999 (“ГосНомер”), 32596 (“НомерКузова”) и 4687035 (“НомерДвиг”).
Таким образом, в результате выполнения этапа выделения примеров объектов формируют список примеров объектов, представленный на фиг.4, а общим результатом выполнения фазы процессии являются два списка: примеры типовых отношений и примеры типов объектов, выделенные в тексте обрабатываемого информационного материала, с указаниями на их типовые отношения и типы объектов и, возможно, конкретные значения атрибутов примеров типовых отношений и примеров типов объектов.
В соответствии с заявленным способом автоматизированную обработку приведенного выше информационного текстового материала по теме “Угоны автомашин” завершают фазой постпроцессии, которую, в свою очередь, выполняют как последовательность этапа формирования элементарных графов из списков, полученных на фазе процессии, этапа слияния элементарных графов в когнитивную карту и этапа формирования когнитивной карты для совокупности обработанных информационных текстовых материалов, причем последний этап включают в общий процесс после обработки всех информационных текстовых материалов из заданной совокупности по желанию пользователя.
В свою очередь, согласно данному изобретению, этап формирования элементарных графов включает:
- стадию формирования элементарных графов для примеров типовых отношений из списка примеров типовых отношений, полученного в результате выполнения фазы процессии;
- стадию поиска и обработки синонимов;
- стадию формирования элементарных графов для неопределенных отношений.
Стадию формирования элементарных графов для примеров типовых отношений из списка примеров типовых отношений осуществляют путем выполнения для нашего примера следующих действий: для каждого элемента списка примеров типовых отношений выбирают соответствующую ему дугу из графа образа структуры графического представления информационной потребности и по ней выбирают вершины, которые связаны этой дутой, затем из списка типов объектов выбирают примеры объектов, соответствующие выбранным вершинам, и для каждой такой тройки формируют элементарный граф, имеющий структуру вида “вершина - дуга - вершина”. В вершинах элементарного графа располагают примеры соответствующих типов объектов, а на дуге - пример соответствующего типового отношения, связывающего выбранные вершины. Полученный элементарный граф фиксируют в списке элементарных графов.
Так, для примера типового отношения “была угнана” выбирают дугу, соответствующую типовому отношению “быть угнанным” и по ней из графа образа структуры графического представления информационной потребности выбирают вершины, которые связаны этой дугой. Для нашего случая это типы объектов “ФизЛицо” и “А/М”, затем для типа объекта “ФизЛицо” из списка примеров типов объектов выбирают элемент “Иванов Иван Иванович”, а для типа объекта “А/М” - элемент “а/м БМВ г.н.FAT-999, цвет голубой металлик, дв. 4687035, куз. 32596” и из полученных трех элементов формируют элементарный граф вида: “а/м БМВ г.H.FAT-999, цвет голубой металлик, дв. 4687035, куз. 32596”, “быть угнанным”, “Иванов Иван Иванович”.
Сформированный элементарный граф фиксируют в списке элементарных графов. После завершения вышеуказанных действий для всех элементов списка примеров отношений сформирован список элементарных графов, представленный на фиг.5.
Стадию поиска и обработки синонимов осуществляют путем сравнения названия каждого из примеров типов объектов из списка типов объектов, сформированного на фазе процессии, с элементами словаря синонимов или, например, с помощью эвристического алгоритма, заключающегося в том, что синонимами считают два объекта, если представление в исходном тексте первого из них полностью “вкладывается” в представление в исходном тексте второго из них или их представления в исходном тексте полностью совпадают. Например, синонимами считаются объекты “Иванов” и “Иванов Иван Иванович”.
Для каждой пары найденных синонимов формируют элементарный граф, имеющий ту же структуру вида “вершина - дуга - вершина”, что и в предыдущем случае, но первая вершина этого элементарного графа соответствует примеру типового объекта, вторая - его синониму, а дуга - специальному отношению с именем “СИНОНИМ”. Полученный элементарный граф фиксируют в общем списке элементарных графов.
Для нашего примера информационного текстового материала данная стадия не дает новых элементарных графов, однако, если бы в этом тексте присутствовал фрагмент вида “… была угнана принадлежащая Иванову а/м БМВ…”, триада вида “Иванов Иван Иванович”, “СИНОНИМ”, “Иванов”, была бы добавлена в список элементарных графов.
Стадию формирования элементарных графов для неопределенных отношений вводят согласно данному изобретению в силу возможной неполноты множества логических конструкций для лингвистической обработки текста, возможной многозначности получаемых при этом результатов, а также в силу того, что не все примеры объектов, выделенные на предыдущей фазе, могут быть уже использованы при построении элементарных графов на предыдущих стадиях фазы постпроцессии.
Поэтому примеры тех типов объектов, которые остались неиспользованными, но находятся в пределах одного предложения, на данной стадии обрабатывают путем формирования из множества неиспользованных на предыдущих стадиях фазы постпроцессии элементов из списка примеров типов объектов всех возможных их пар и формирования для каждой такой пары элементарного графа, тоже имеющего структуру вида “вершина - дуга - вершина”, причем первая вершина этого элементарного графа соответствует первому примеру объекта из выделенной пары, вторая - второму примеру объекта из выделенной пары, а дуга - неопределенному отношению с именем “???”. Полученный элементарный граф фиксируют в общем списке элементарных графов.
В случае нашего примера информационного текстового материала данная стадия, как и предыдущая, не дает новых элементарных графов, однако, если бы в этом тексте присутствовал фрагмент вида “…и заявил следователю Петрову п.П. и оперуполномоченному Сидорову С.С… что…”, триада вида “Сидоров С.С.”, “???”, “Петров П.П.”, была бы добавлена в список элементарных графов.
Следующим этапом фазы постпроцессии, согласно данному изобретению, является этап слияния элементарных графов в когнитивную карту обработанного информационного текстового материала.
Этап слияния элементарных графов в когнитивную карту обработанного информационного текстового материала осуществляют путем наложения одинаковых вершин, построенных на предыдущем этапе элементарных графов, и исключения дублирующихся дуг. При этом элементарные графы с дугами, имеющими в качестве имени неопределенное отношение “???”, вливают в общий граф только после подтверждения необходимости этой операции пользователем.
Для обсуждаемого примера информационного текстового материала список элементарных графов представлен на фиг.5, а результат наложения одинаковых вершин и исключения дублирующихся дуг в виде когнитивной карты, т.е. графическом виде, показан на фиг.6. Таким образом, смыслом обработанного информационного текстового материала сводки об угоне автомобиля у гражданина Иванова в контексте образа структуры графического представления информационной потребности пользователя, представленной на фиг.1, является когнитивная карта, представленная на фиг.6.
Полученная когнитивная карта может редактироваться пользователем с помощью графического редактора, а результат такого редактирования может быть сохранен на машинном носителе для последующего использования.
Понятно, что тексты сводок об угонах, рассматриваемые независимо, не всегда дают достаточно информации, действительно интересной для пользователя. Однако если использовать заявленный способ для обработки не одной сводки, а совокупности сводок об угонах автомашин, например, по г.Москве за определенный период времени, ситуация существенно изменяется.
Предположим, что в дополнение к рассмотренному примеру сводки с помощью предлагаемого способа обрабатываются и сводки вида:
1. “В ночь на 01.05.98 от д. 2/30 по ул. Бойцовая была угнана а/м БМВ фиолетовый металлик, 1996 г.в., г.н. М 456ОК77, куз. Т1767898, дв. 1890223, принадлежащая Миронову А.А., прож: ул. Бойцовая 2/30-90.”;
2. “1.05.1998 г. в 9.45 с заявлением обратился гр-н Квасов Юрий Владимирович, 1965 г/р, прож: ул. Коштоянца, 11-55, не работает, о том, что в период с 22.00 30.04 до 9.00 1.05.1998 г. от д.11 к.1 по ул. Довженко неизвестными лицами была угнана принадлежащая ему а/м "Фольксваген-Пассат″, г/н P895TB77rus, двиг. №ААМО72658, кузов №Е074347, г/в 1992 г., белого цвета.”;
3. “1.05.1998 г. в 22.30 с заявлением обратился гр-н Аверин Сергей Владимирович, 1977 г/р, прож: Волгоградский пр-т, 7-67, работает: кладовщиком ТОО ″Маг-Видео", о том, что в период с 21.00 30.04 до 15.00 01.05.1998 г. от д.14/1 по ул. Довженко неизвестными лицами была угнана принадлежащая ему а/м ВАЗ 21063, г/н Г8719MM, двиг. №9368164, кузов №Н1658322, 1987 г/в, желтого цвета”.
Результаты обработки каждой из них представлены на фиг.7.
Теперь всю совокупность когнитивных карт, полученных в результате обработки отдельных информационных текстовых материалов согласно изложенному выше способу, можно обработать с помощью действий, составляющих этап формирования когнитивной карты для совокупности информационных текстовых материалов, который осуществляют после обработки последнего из информационных текстовых материалов из заданной совокупности путем наложения одинаковых вершин всех построенных когнитивных карт и исключения дублирующихся дуг.
Для приведенной выше совокупности информационных текстовых материалов результирующая когнитивная карта представлена на фиг.8.
Такая обобщенная когнитивная карта в отличие от частных когнитивных карт явным образом представляет криминогенную ситуацию в области угонов автомобилей и активно помогает пользователю, которым может быть, например, эксперт-криминалист, в анализе данного вида преступлений. При этом визуализация, предлагаемая в рамках данного способа, акцентирует внимание эксперта на критических точках (в нашем случае это район угона и типы угнанных автомашин).
Полученная когнитивная карта совокупности информационных текстовых материалов, как и отдельные когнитивные карты, может редактироваться пользователем с помощью графического редактора, а результат такого редактирования может быть сохранен на машинном носителе для последующего использования.
Все рассмотренные выше фазы, этапы, стадии и операции заявленного способа обработки информационных текстовых материалов могут быть выполнены с помощью общеизвестных программных операций и их последовательностей, например сравнения символов и слов на совпадение, вычисления номеров позиций символов и слов в тексте, циклов по словарным статьям общих и специальных словарей, считывания и записи элементов списков и т.п., и не являются предметом патентных притязаний заявителя. Конкретный вид соответствующих программ определяется конкретным видом аппаратного обеспечения и конкретной операционной системой, установленной на выбранном оборудовании, например все программы, реализующие заявленный способ обработки информационных текстовых материалов, могут быть выполнены на персональных ЭВМ с процессором Интел-Пентиум, с оперативной памятью не менее 256 мегабайт, с объемом свободной памяти на магнитных дисках не менее 500 мегабайт, функционирующих под управлением, например, операционной системы Windows 2000/NT, и являются стандартными.
Таким образом, из приведенного описания следует, что заявленное изобретение позволяет обрабатывать информационные текстовые материалы и их совокупности по заданной тематике и формировать визуальные представления их смысла в виде когнитивных карт, т.е. создан новый способ автоматизированной обработки информационных текстовых материалов на основе выделения смысловых категорий в текстах на естественном языке с графическим представлением смысла всего текста в виде когнитивной карты, который позволил повысить эффективность анализа информации в условиях персонализированного информационного обеспечения.
Настоящее изобретение может использоваться в рамках различных информационных технологий, например, при обработке результатов информационного поиска; при аналитической обработке документов из заданной области, для разбиения множества текстов из заданной области на классы, в каждом из которых представлены близкие по смыслу документы, а также для визуальной оценки смысла обрабатываемых текстов по их когнитивным картам.
Приведенные примеры реализации настоящего изобретения служат лишь в качестве иллюстраций и никоим образом не ограничивают объема патентных притязаний заявителя, определяемого нижеследующей формулой изобретения.



Изобретение относится к обработке информационных естественно-языковых текстовых материалов. Его использование позволяет получить технический результат в виде автоматизированной обработки информационных текстовых материалов на основе выделения смысловых категорий в текстах на естественном языке с графическим представлением смысла всего текста в виде когнитивной карты, а также в виде повышения эффективности подготовки обрабатываемых информационных текстовых материалов к аналитической их обработке в условиях персонализированного информационного обеспечения. Этот технический результат достигается тем, что предварительно информационные потребности пользователя по определенной тематике формируют в виде ориентированного графа, а обработку текста ведут в фазе препроцессии, включающей этап морфологического анализа текста, этап поиска устойчивых словосочетаний и этап сегментации текста на предложения, в фазе процессии, включающей этап выделения примеров типовых отношений и этап выделения примеров типов объектов, и в фазе постпроцессии, состоящей из этапа формирования элементарных графов и этапа слияния элементарных графов в когнитивную карту. 28 з.п.ф-лы, 8 ил.
| СПОСОБЫ АВТОМАТИЗИРОВАННОЙ ОБРАБОТКИ ИНФОРМАЦИОННЫХ МАТЕРИАЛОВ ДЛЯ ПЕРСОНАЛИЗИРОВАННОГО ИСПОЛЬЗОВАНИЯ | 1996 |
|
RU2096824C1 |
| СПОСОБ ИДЕНТИФИКАЦИИ ОБЪЕКТОВ ПО ИХ ОПИСАНИЯМ | 1999 |
|
RU2167450C2 |
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| US 6138087 A, 24.10.2000 | |||
| US 5808615 A, 15.09.1998. | |||

