Область техники, к которой относится изобретение
Настоящее изобретение относится к области информационных технологий, а именно к способу автоматизированной семантической классификации текстов на естественном языке.
Уровень техники
Существуют различные способы автоматизированной семантической (т.е. смысловой) классификации текстов на естественных языках (см., например, патенты РФ №2107943 (опубл. 27.03.1998) и №2108622 (опубл. 10.04.1998), а также заявку ЕПВ №0241717 (опубл. 21.10.1987)).
Вообще говоря, семантическую классификацию текстов на естественном языке нельзя осуществлять непосредственно, поскольку классифицировать в данном случае нужно не по наличию конкретных слов в тексте, а по тому смыслу, который стоит за целыми предложениями и даже абзацами или разделами. Поэтому обычно семантическую классификацию текстов предваряют семантической индексацией этих текстов, которая осуществляется различными способами. При этом важное значение имеет устранение семантической неоднозначности этих текстов.
Такие способы семантической индексации текстов для их последующего сравнения с устранением семантической неоднозначности описаны, например, в патенте РФ №2242048 (опубл. 10.12.2004), в патентах США №6871199 (опубл. 22.03.2005), 7024407 (опубл. 04.04.2006) и 7383169 (опубл. 03.06.2008), в заявках на патент США №2007/0005343 и 2007/0005344 (обе опубл. 04.01.2007), 2008/0097951 (опубл. 24.04.2008), в выложенных заявках Японии №05-128149 (опубл. 25.05.1993), 06-195374 (опубл. 15.07.1994), 10-171806 (опубл. 26.06.1998) и 2005-182438 (опубл. 07.07.2005), в заявке ЕПВ №0853286 (опубл. 15.07.1998).
Наиболее близким к заявленному изобретению можно считать способ автоматизированной семантической индексации текста на естественном языке, раскрытый в патенте РФ №2399959 (опубл. 20.09.2010). В этом способе текст в цифровой форме сегментируют на элементарные единицы первого уровня (слова); формируют для каждой элементарной единицы первого уровня (слова) элементарную единицу второго уровня (нормализованную словоформу); сегментируют текст в цифровой форме на предложения, соответствующие участкам индексируемого текста; выявляют в тексте, в процессе лингвистического анализа, элементарные единицы третьего уровня (устойчивые словосочетания); в процессе многоступенчатого семантико-синтаксического анализа путем обращения к заранее сформированным в базе данных лингвистическим и эвристическим правилам в заранее заданной лингвистической среде, выявляют в каждом из сформированных предложений элементарные единицы четвертого уровня (семантически значимый объект и его атрибут) и семантически значимые отношения между выявленными семантически значимыми объектами, а также между семантически значимыми объектами и атрибутами; формируют в пределах данного текста для каждого из выявленных семантически значимых отношений множество элементарных единиц пятого уровня (триад); индексируют на множестве сформированных триад все связанные семантически значимыми отношениями семантически значимые объекты, а также атрибуты, по отдельности, и все триады вида «семантически значимый объект - семантически значимое отношение - семантически значимый объект», а также все триады вида «семантически значимый объект - семантически значимое отношение - атрибут»; сохраняют в базе данных сформированные триады и полученные индексы вместе со ссылкой на исходный текст, из которого сформированы эти триады.
Недостатком данного способа является отсутствие ранжирования сформированных элементарных единиц четвертого уровня по степени их релевантности к тексту, что приводит к неоправданно большому объему вычислений, связанному с необходимостью использовать для дальнейшей обработки весь сформированный индекс.
Раскрытие изобретения
Цель настоящего изобретения состоит в расширении арсенала способов семантической классификации текстов на естественных языках за счет ускорения процесса сравнения текстов.
Достижение этой цели и получение указанного технического результата обеспечиваются в настоящем изобретении посредством способа автоматизированной семантической классификации текстов на естественном языке, заключающегося в том, что: представляют каждый классифицируемый текст в цифровой форме для последующей автоматической и(или) автоматизированной обработки; осуществляют индексацию каждого классифицируемого текста в цифровой форме, получая: элементарные единицы первого уровня, включающие в себя по меньшей мере слова, элементарные единицы второго уровня, каждая из которых представляет собой нормализованную словоформу, элементарные единицы третьего уровня, каждая из которых представляет собой устойчивое словосочетание в тексте, элементарные единицы четвертого уровня, каждая из которых является семантически значимым объектом и атрибутом, и элементарные единицы пятого уровня, каждая из которых представляет собой триаду либо из двух семантически значимых объектов и семантически значимого отношения между ними, либо из семантически значимого объекта и атрибута и связывающего их семантически значимого отношения; выявляют частоты встречаемости элементарных единиц четвертого уровня и частоты встречаемости семантически значимых отношений; сохраняют в базе данных сформированные элементарные единицы второго, третьего, четвертого и пятого уровней с выявленными частотами встречаемости элементарных единиц четвертого уровня и семантически значимых отношений, а также полученные индексы вместе со ссылками на конкретные предложения данного текста; формируют из триад семантическую сеть таким образом, что первая элементарная единица четвертого уровня последующей триады связывается с такой же второй элементарной единицей четвертого уровня предыдущей триады; осуществляют, в процессе итеративной процедуры, перенормировку частот встречаемости в смысловой вес элементарных единиц четвертого уровня, являющихся вершинами семантической сети, таким образом, что элементарные единицы четвертого уровня, связанные в сети с большим числом других элементарных единиц четвертого уровня с большой частотой встречаемости, увеличивают свой смысловой вес, а прочие элементарные единицы четвертого уровня его равномерно теряют; ранжируют элементарные единицы четвертого уровня по смысловому весу путем сравнения смыслового веса каждой из них с заранее заданным пороговым значением и удаляют элементарные единицы четвертого уровня, имеющие смысловой вес ниже порогового значения; сохраняют в памяти оставшиеся элементарные единицы четвертого уровня со смысловым весом выше порогового, а также семантически значимые отношения между оставшимися элементарными единицами четвертого уровня; выявляют степени пересечения семантической сети классифицируемого текста и семантических сетей текстовых выборок, каковые текстовые выборки составлены из ранее классифицированных текстов и описывают предметные области семантической классификации, при этом степень пересечения выявляют как по вершинам семантических сетей, так и по связям между этими вершинами с учетом смысловых весов вершин рассматриваемых семантических сетей и весовых характеристик их связей, и принимают выявленную степень пересечения семантических сетей классифицируемого текста и конкретной текстовой выборки в качестве величины, характеризующей семантическое подобие классифицируемого текста и данной текстовой выборки; выбирают в качестве класса для классифицируемого текста по меньшей мере одну из предметных областей, степени пересечения семантической сети которых с семантической сетью классифицируемого текста оказываются больше заранее заданного порога.
Особенность способа по настоящему изобретению состоит в том, что при превышении заранее заданного порога степенями пересечения для нескольких предметных областей, предметные области могут ранжировать по степени их близости к классифицируемому тексту.
При этом могут выбирать заданное заранее число предметных областей, к которым относится классифицируемый текст.
Еще одна особенность способа по настоящему изобретению состоит в том, что индексацию осуществляют в процессе выполнения следующих этапов: сегментируют текст в цифровой форме на элементарные единицы первого уровня, включающие в себя, по меньшей мере, слова; сегментируют по графематическим правилам текст в цифровой форме на предложения; формируют для каждой элементарной единицы первого уровня, представляющей собой слово, на основе морфологического анализа элементарные единицы второго уровня, включающие в себя нормализованную словоформу; подсчитывают частоту встречаемости каждой элементарной единицы первого уровня для двух и более соседних единиц первого уровня в данном тексте и объединяют среди элементарных единиц первого уровня последовательности слов, следующих друг за другом в данном тексте, в элементарные единицы третьего уровня, представляющие собой устойчивые сочетания слов, в случае, если для каждых двух и более следующих друг за другом слов в данном тексте разности подсчитанных частот встречаемости этих слов для первого появления данной последовательности слов и для нескольких последующих их появлений для каждой пары слов последовательности остаются неизменными; выявляют, в процессе многоступенчатого семантико-синтаксического анализа путем обращения к заранее сформированным в базе данных лингвистическим и эвристическим правилам в заранее заданной лингвистической среде, в каждом из сформированных предложений семантически значимые объекты и атрибуты - элементарные единицы четвертого уровня; для каждой элементарной единицы четвертого уровня фиксируют тождество по референции между соответствующим семантически значимым объектом, а также атрибутом, и соответствующей анафорической ссылкой при ее наличии в классифицируемом тексте, заменяя каждую анафорическую ссылку на соответствующий ей антецедент; сохраняют в памяти каждый семантически значимый объект и атрибут; выявляют, в процессе многоступенчатого семантико-синтаксического анализа путем обращения к заранее сформированным в базе данных лингвистическим и эвристическим правилам в заранее заданной лингвистической среде, в каждом из сформированных предложений семантически значимые отношения между выявленными единицами четвертого уровня - семантически значимыми объектами, а также между семантически значимыми объектами и атрибутами; присваивают каждому семантически значимому отношению соответствующий тип из хранящейся в базе данных предметной онтологии по тематике той предметной области, к которой относится классифицируемый текст; выявляют на всем тексте частоты встречаемости элементарных единиц четвертого уровня и частоты встречаемости упомянутых семантически значимых отношений; сохраняют в памяти каждое выявленное семантически значимое отношение вместе с присвоенным ему типом; формируют в пределах данного текста для каждого из выявленных семантически значимых отношений, связывающих как соответствующие семантически значимые объекты, так и семантически значимый объект и его атрибут, множество триад, которые являются элементарными единицами пятого уровня; индексируют на множестве сформированных триад по отдельности все связанные семантически значимыми отношениями семантически значимые объекты с их частотами встречаемости, все атрибуты с их частотами встречаемости, и все сформированные триады.
Еще одна особенность способа по настоящему изобретению состоит в том, что степень пересечения двух семантических сетей вычисляют как сумму совпадений элементарных единиц пятого уровня этих двух семантических сетей.
При этом осуществляют этапы, на которых: выбирают в качестве базовой сети ту из двух семантических сетей, в которой после ранжирования и удаления вершин со смысловыми весами ниже порогового значения осталось больше вершин, чем в другой, выбираемой в качестве сравниваемой; находят для каждой вершины базовой сети в сравниваемой сети вершину, являющуюся той же самой элементарной единицей четвертого уровня, т.е. тем же самым семантически значимым объектом, или тем же самым атрибутом; вычисляют, для каждой найденной вершины в каждой из базовой и сравниваемой сетей, величины всех связанных с данной вершиной триад как площади треугольников, стороны которых соответствуют компонентам каждой из этих триад, а угол между сторонами пропорционален весу семантически значимого отношения; выбирают для каждой пары триад, связанных с парой конкретных вершин в базовой и сравниваемой сетях, меньшую из вычисленных величин в качестве степени пересечения упомянутых триад в базовой и сравниваемой сетях; суммируют для каждой из связанных с данной вершиной вершин все выбранные вычисленные величины, получая степень пересечения для данной пары вершин базовой и сравниваемой сетей; нормируют найденную сумму на число семантически значимых объектов и атрибутов, связанных с данной вершиной в той из базовой и сравниваемой сетей, которая содержит больше связанных с данной вершиной вершин; суммируют нормированные суммы по всем вершинам той из базовой и сравниваемой сетей, которая содержит больше вершин; нормируют полученную сумму на число оставшихся в этой сети элементарных единиц четвертого уровня, получая степень пересечения двух семантических сетей.
Краткое описание чертежей
Настоящее изобретение поясняется далее описанием конкретного примера его осуществления и прилагаемыми чертежами.
На Фиг.1 приведена условная блок-схема, поясняющая заявленный способ.
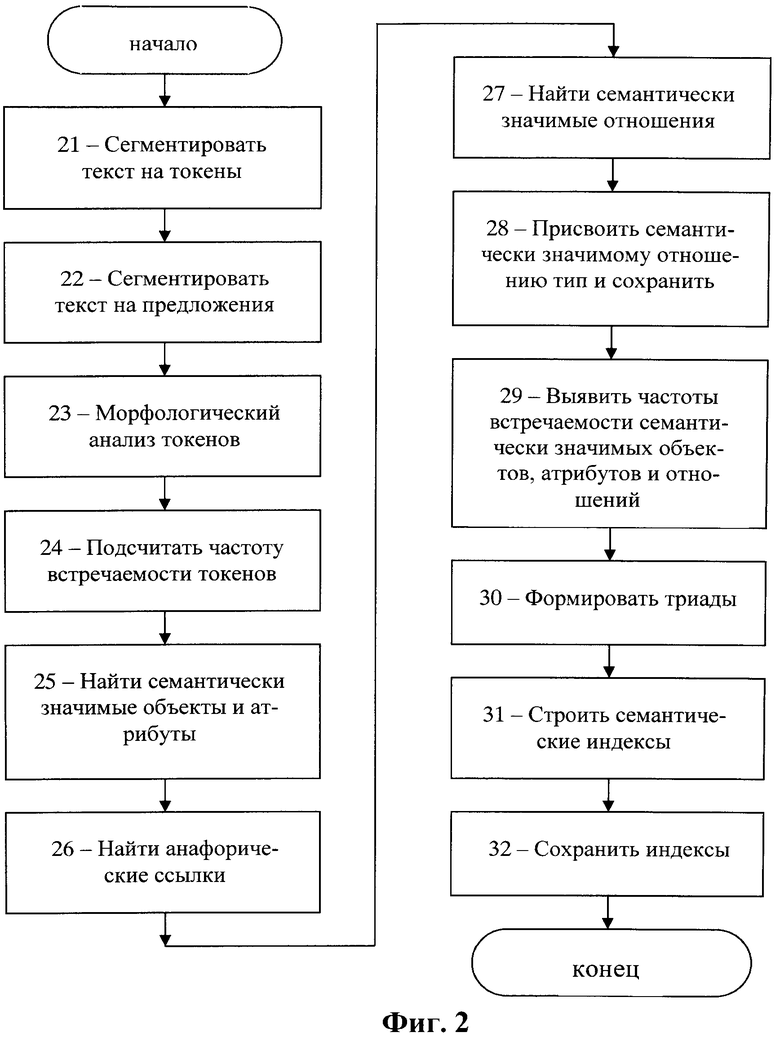
На Фиг.2 приведена блок-схема, поясняющая предпочтительный способ индексации текста.
Подробное описание изобретения
Способ по настоящему изобретению может быть реализован практически в любой вычислительной среде, к примеру, на персональном компьютере, подключенном к внешним базам данных. Этапы осуществления способа иллюстрируются на Фиг.1.
Все дальнейшие пояснения даются в применении к русскому языку, который является одним из самых высокофлективных языков, хотя предложенный способ применим к семантической классификации текстов на любых естественных языках.
Прежде всего, каждый из подлежащих семантической классификации текстов необходимо представить в электронной форме для последующей автоматизированной обработки. Этот этап на Фиг.1 условно обозначен ссылочной позицией 1 и может быть выполнен любым известным способом, например, сканированием текста с последующим распознаванием с помощью общеизвестных средств типа ABBYY FineReader. Если же текст поступает на классификацию из электронной сети, к примеру, из Интернета, то этап его представления в электронной форме выполняется заранее, до размещения этого текста в сети.
Специалистам должно быть понятно, что операции этого и последующих этапов осуществляются с запоминанием промежуточных результатов, например, в оперативном запоминающем устройстве (ОЗУ).
Преобразованный в электронную форму текст поступает на обработку, в процессе которой осуществляется индексация. Эта индексация (этап 2 на Фиг.1) может производиться так же, как это раскрыто, например, в упомянутом в патенте РФ №2399959 или в заявке на патент США 2007/0073533 (опубл. 29.03.2007). В процессе этой индексации получают элементарные единицы текста разных уровней. Элементарные единицы первого уровня включают в себя, по меньшей мере, слова; каждая из элементарных единиц второго уровня представляет собой нормализованную словоформу; каждая из элементарных единиц третьего уровня представляет собой последовательность следующих друг за другом слов в обрабатываемом тексте; каждая из элементарных единиц четвертого уровня является семантически значимым объектом, или атрибутом; каждая из элементарных единиц пятого уровня представляет собой триаду либо из двух семантически значимых объектов и семантически значимого отношения между ними, либо семантически значимый объект и его атрибут, и связывающее их семантически значимое отношение.
Предпочтительно, однако, индексировать текст с помощью способа, заявленного в заявке на патент РФ 2012150734 (приоритет от 27.11.2012) и проиллюстрированного на Фиг.2. В этом способе текст в цифровой форме сначала сегментируется на элементарные единицы первого уровня, включающие в себя, по меньшей мере, слова. В упомянутом патенте РФ №2399959 эти элементарные единицы первого уровня именуются токенами (token). Токеном может быть любой текстовый объект из следующего множества: слова, состоящие каждое из последовательности букв и, возможно, дефисов; последовательность пробелов; знаки препинания; числа. Иногда сюда же относят такие последовательности символов как А300, i150b, и т.п. Выделение токенов всегда осуществляется по достаточно простым правилам, например, как в упомянутом патенте РФ №2399959. На Фиг.2 этот этап условно обозначен ссылочной позицией 21.
Вслед за этим, на этапе 22 (Фиг.2) сегментируют индексируемый текст в цифровой форме на предложения, соответствующие участкам данного текста. Такую сегментацию проводят по графематическим правилам. К примеру, самым простым правилом для выделения предложений является: «Предложением является последовательность токенов, начинающаяся с заглавной буквы и заканчивающаяся точкой».
Далее для каждой элементарной единицы первого уровня (для каждого токена), представляющей собой слово, на основе морфологического анализа формируют соответствующую элементарную единицу второго уровня, представляющую собой нормализованную словоформу, именуемую далее леммой. К примеру, для слова «иду» нормализованной словоформой будет «идти», для слова «красивого» нормализованной словоформой будет «красивый», а для слова «стеной» нормализованная словоформа - «стена». Кроме того, для каждой словоформы указывается часть речи, к которой относится данное слово, и его морфологические характеристики. Естественно, что для разных частей речи эти характеристики различны. К примеру, для существительных и прилагательных это род (мужской - женский - средний), число (единственное - множественное), падеж; для глаголов это вид (совершенный - несовершенный), лицо, число (единственное - множественное); и т.д. Таким образом, для заданного слова его нормализованная словоформа (лемма) + морфологические характеристики, в том числе часть речи, являются его морфом. Одно и то же слово может иметь несколько морфов. Например, слово «стекло» имеет два морфа - один для существительного среднего рода и один для глагола в прошедшем времени. Этот этап условно обозначен на Фиг.2 ссылочной позицией 23.
Следующий этап, условно обозначенный на Фиг.2 ссылочной позицией 24, состоит в том, что для каждой из упомянутых элементарных единиц первого уровня в упомянутом тексте подсчитывают частоту встречаемости. Иначе говоря, определяют, сколько раз каждое слово встречается в обрабатываемом тексте. Эту операцию осуществляют автоматически, например, простым подсчетом частоты встречаемости каждого токена, либо так, как это описано в патенте РФ №2167450 (опубл. 20.05.2001), либо в патенте США №6189002 (опубл. 13.02.2001). Одновременно с подсчетом частоты встречаемости находят для каждых двух и более следующих друг за другом слов в данном тексте разности подсчитанных частот встречаемости этих слов в первое появление этой последовательности слов и в последующие их появления. Если эти разности для первого появления данной последовательности слов и для нескольких последующих их появлений остаются неизменными, такую последовательность слов, следующих друг за другом в данном тексте, (т.е. элементарных единиц второго уровня) объединяют в элементарные единицы третьего уровня, представляющие собой устойчивые словосочетания.
Далее, на следующем этапе, обозначенном на Фиг.2 ссылочной позицией 25, с целью выявления семантически значимых объектов и атрибутов, выполняют многоступенчатый семантико-синтаксический анализ. Такой многоступенчатый семантико-синтаксический анализ выполняют путем обращения к сформированным в базе данных лингвистическим и эвристическим правилам в заранее заданной лингвистической среде. Такой средой может быть, например, лингвистическая среда, упомянутая в вышеуказанной заявке на патент США №2007/0073533 либо в вышеуказанных патентах РФ №2242048 и РФ №2399959, либо любая иная лингвистическая среда, определяющая соответствующие правила, которые позволяют устранять синтаксические и семантические неоднозначности слов и выражений реального текста. Лингвистические и эвристические правила в выбранной среде именуются далее правилами.
Выявление семантически значимых объектов и атрибутов, которые считаются элементарными единицами четвертого уровня, производится в предложении на множестве элементарных единиц первого, второго и(или) третьего уровней.
Для каждого семантически значимого объекта, или атрибута, т.е. элементарной единицы четвертого уровня с присвоенными им типами находят соответствующую ему анафорическую ссылку (если она есть). Например, в предложении «Механика - часть физики, которая изучает закономерности механического движения и причины, вызывающие или изменяющие это движение» анафорической ссылкой к слову «механика» будет местоимение «которая», тогда как слово «механика» будет антецедентом для этой анафоры, и еще, анафорической ссылкой к слову «механическое» будет местоимение «это», тогда как слово «механическое» будет антецедентом для этой анафоры. Этот этап нахождения анафорической ссылки условно обозначен на Фиг.2 ссылочной позицией 26. Каждую анафорическую ссылку заменяют на соответствующий ей антецедент. После этого каждый выявленный семантически значимый объект и атрибут сохраняют в соответствующей памяти.
На следующем этапе, обозначенном на Фиг.2 ссылочной позицией 27, выполняют многоступенчатый семантико-синтаксический анализ, с помощью которого на основе элементарных единиц первого, второго, третьего и четвертого уровней находят с помощью упомянутых правил семантически значимые отношения между семантически значимыми объектами, а также между семантически значимыми объектами и атрибутами.
На этапе, обозначенном на Фиг.2 ссылочной позицией 28, каждому семантически значимому отношению присваивают соответствующий тип из хранящейся в базе данных предметной онтологии по тематике той предметной области, к которой относится индексируемый текст. После этого каждое семантически значимое отношение сохраняют в соответствующей памяти вместе с присвоенным ему типом и найденными для него морфологическими и семантическими атрибутами.
После этого на этапе, обозначенном на Фиг.2 ссылочной позицией 29, выявляют частоты встречаемости семантически значимых объектов и атрибутов, а также частоты встречаемости семантически значимых отношений между семантически значимыми объектами и между семантически значимыми объектами и атрибутами на всем данном тексте. Эту операцию выполняют практически так же, как на этапе 24 для элементарных единиц первого уровня.
На этапе, обозначенном на Фиг.2 ссылочной позицией 30, сохраненные семантически значимые объекты, а также атрибуты, и семантически значимые отношения используют для формирования триад. При этом в пределах индексируемого текста для каждого из выявленных семантически значимых отношений, связывающих определенные семантически значимые объекты и атрибуты, формируют множество триад двух типов. Каждая из множества триад первого типа включает семантически значимое отношение и два семантически значимых объекта, которые связываются этим семантически значимым отношением. Каждая из множества триад второго типа включает семантически значимое отношение, один семантически значимый объект, а также его атрибут, которые связываются этим семантически значимым отношением. Если обозначить два семантически значимых объекта через Oi и Oj, а связывающее их семантически значимое отношение через Rij, то каждую из триад первого типа можно условно представить (изобразить) как Oi→Rij→Oj. Каждая из триад второго типа может быть представлена как Oi→Rim→Am, где Am являются соответствующим атрибутом, a Rim связывающее семантически значимый объект и атрибут семантически значимое отношение. В этих записях индексы i, j, m представляют собой целые числа.
Затем, на этапе, обозначенном на Фиг.2 ссылочной позицией 31, выполняют индексацию текста. При этом индексируют по отдельности на множестве сформированных триад все связанные семантически значимыми отношениями семантически значимые объекты с их частотами встречаемости, все атрибуты с их частотами встречаемости, и все сформированные триады.
Для этого на множестве сформированных триад индексируют все семантически значимые объекты и их атрибуты по отдельности, с их частотами встречаемости, и все триады вида «семантически значимый объект - семантически значимое отношение - семантически значимый объект», а также все триады вида «семантически значимый объект - семантически значимое отношение - атрибут». Сформированные на этапе 30 триады и полученные на этапе 31 индексы вместе со ссылкой на конкретные предложения исходного текста, из которого сформированы эти триады, сохраняют в базе данных (этап 32 на Фиг.2).
Для специалистов очевидно, что упоминавшиеся на отдельных этапах запоминающие устройства могут на деле быть как разными устройствами, так и одним запоминающим устройством достаточного объема. Точно так же отдельные базы данных, упоминавшиеся на соответствующих этапах, могут быть не только физически раздельными базами данных, но и единственной базой данных. Более того, упомянутые запоминающие устройства (памяти) могут хранить ту же самую единственную базу данных, либо хранить по отдельности упомянутые базы данных. Специалистам также понятно, что заявленные в настоящем изобретении способы выполняются в соответствующей вычислительной среде под управлением соответствующих программ, которые записаны на машиночитаемых носителях, предназначенных для непосредственного участия в работе компьютера.
Возвратимся к блок-схеме Фиг.1. На этапе 3 выявляют частоты встречаемости элементарных единиц четвертого уровня (т.е. семантически значимых объектов и атрибутов), а также выявляют частоты встречаемости семантически значимых отношений. Отметим, что сформированные элементарные единицы четвертого уровня сохраняют в базе данных вместе с выявленными частотами встречаемости. Кроме того, сохраняют в базе данных полученные индексы вместе со ссылками на конкретные предложения данного текста.
Затем на этапе 4 в способе по настоящему изобретению формируют семантическую сеть таким образом, что первый семантически значимый объект последующей триады связывается с таким же вторым семантически значимым объектом предыдущей триады. При этом в процессе итеративной процедуры осуществляют перенормировку частот встречаемости семантически значимых объектов и атрибутов в смысловой вес семантически значимых объектов и атрибутов, которые являются вершинами семантической сети. Эту перенормировку осуществляют таким образом, что семантически значимые объекты и атрибуты, связанные в сети с большим числом семантически значимых объектов и атрибутов с большой частотой встречаемости, увеличивают свой смысловой вес, а другие семантически значимые объекты и атрибуты его равномерно теряют (этап 5 на Фиг.1).
Далее элементарные единицы четвертого уровня ранжируют по смысловому весу путем сравнения их смыслового веса с заранее заданным пороговым значением (этап 6 на Фиг.1).
Элементарные единицы четвертого уровня со смысловым весом ниже порогового удаляют (этап 7 на Фиг.1). Оставшиеся элементарные единицы четвертого уровня с весом выше порогового сохраняют в памяти (этап 8). Сохраняют в памяти также семантически значимые отношения между семантически значимыми объектами, а также между семантически значимыми объектами и атрибутами, оставшимися в семантической сети.
Далее, на этапе 9 выявляют степени пересечения построенной семантической сети классифицируемого текста и семантических сетей текстовых выборок. Эти текстовые выборки составляют из ранее классифицированных текстов. Они описывают предметные области той семантической классификации, для которой осуществляется обработка классифицируемого текста. При этом степень пересечения семантических сетей выявляют как по их вершинам, так и по связям между этими вершинами с учетом смысловых весов вершин рассматриваемых семантических сетей и весовых характеристик их связей.
Выявленную степень пересечения семантических сетей классифицируемого текста и конкретной текстовой выборки принимают в качестве величины, характеризующей семантическое подобие классифицируемого текста и данной текстовой выборки. После этого выбирают в качестве класса для классифицируемого текста по меньшей мере одну из предметных областей, степени пересечения семантической сети которых с семантической сетью классифицируемого текста оказываются больше заранее заданного порога (этап 10 на Фиг.1).
Степень пересечения двух семантических сетей, сформированных описанным выше способом, вычисляется как сумма совпадений элементарных единиц пятого уровня этих двух семантических сетей. В принципе, это вычисление может проводиться различными известными специалистам методами.
Предпочтительно, степень пересечения может вычисляться как сумма пересечений элементарных единиц пятого уровня этих двух сетей. Для этого выбирают в качестве базовой сети ту из двух семантических сетей, в которой после ранжирования и удаления вершин со смысловыми весами ниже порогового значения (см. этап 7 на Фиг.1) осталось больше вершин, чем в другой, выбираемой в качестве сравниваемой. Для каждой вершины базовой сети находят в сравниваемой сети вершину, являющуюся той же самой элементарной единицей четвертого уровня, т.е. тем же самым семантически значимым объектом, или тем же самым атрибутом. Для каждой найденной вершины в каждой из базовой и сравниваемой сетей вычисляют величины всех связанных с данной вершиной триад как площади треугольников, стороны которых соответствуют компонентам каждой из этих триад. Это вычисление площади можно осуществлять как нормированное на 100% скалярное произведение на векторах 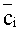
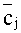
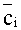
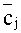
Далее выбирают для каждой пары триад, связанных с парой конкретных вершин в базовой и сравниваемой сетях, меньшую из вычисленных величин в качестве степени пересечения триад в базовой и сравниваемой сетях. Все выбранные вычисленные величины суммируют для каждой из вершин, получая степень пересечения для данной пары вершин базовой и сравниваемой сетей. Найденную сумму нормируют на число семантически значимых объектов и атрибутов, связанных с данной вершиной в той из базовой и сравниваемой сетей, которая содержит больше вершин. Полученные нормированные суммы суммируют теперь уже по всем вершинам той из базовой и сравниваемой сетей, которая содержит больше вершин. Наконец, полученную итоговую сумму нормируют на число оставшихся в этой сети элементарных единиц четвертого уровня, т.е. семантически значимых объектов и атрибутов получая степень пересечения семантических сетей.
Очевидно, что в случае отсутствия в сравниваемой сети какой-либо вершины степень пересечения для этой вершины принимается равной нулю.
Пример
Для иллюстрации осуществления заявленного способа автоматизированной семантической классификации текста на естественном языке рассмотрим следующий пример. Пусть имеется некоторый русскоязычный текст, представленный на Интернет-сайте http://www.unn.ru/rus/priem.htm, и несколько (например, три) выборки текстов, характеризующих классы (предметные области), представленные на этом же сайте. Таким образом, можно считать, что преобразование текстов в электронную форму, обозначенное на Фиг.1 ссылочной позицией 1, уже выполнено.
Типичным примером такого текста является следующий фрагмент:
«Во всем мире экзамен по математике - это письменное решение задач. Письменный характер испытаний считается повсюду столь же обязательным признаком демократического общества, как выборы из нескольких кандидатов. Действительно, на устном экзамене студент полностью беззащитен. Мне случалось слышать, принимая экзамены на кафедре дифференциальных уравнений механико-математического факультета МГУ, экзаменаторов, которые топили за соседним столом студентов, дававших безукоризненные ответы (возможно, превосходящие уровень понимания преподавателя). Известны и такие случаи, когда топили нарочно (иногда от этого можно спасти, вовремя войдя в аудиторию)».
В соответствии с заявленным способом автоматизированной семантической классификации текстов на естественном языке используют предварительно созданную базу синтаксических правил и словарей, в рамках которых будет осуществляться обработка текста и построение семантического индекса. Подобные базы готовятся экспертами-лингвистами, которые на основании своего опыта и знаний определяют последовательность и состав синтаксической обработки текста, характерных для конкретного языка.
Экспертами-лингвистами предварительно строится множество синтаксических правил, которые позволяют с помощью использования также предварительно построенных экспертами-лингвистами соответствующих лингвистических словарей в дальнейшем в обрабатываемых текстах автоматически выявлять конкретные сведения, соответствующие семантически значимым объектам, атрибутам семантически значимых объектов и семантически значимым отношениям, которые могут иметь место между семантически значимыми объектами или между семантически значимыми объектами и атрибутами.
Кроме спецификации предметной области и правил в соответствии с изложенными выше способами используются словари общей и специальной лексики.
В соответствии с заявленным способом автоматизированного семантического сравнения текстов на естественном языке сначала осуществляют сегментацию текста на элементарные единицы - токены (ссылочная позиция 21 на Фиг.2) и морфологический анализ токенов-слов (ссылочная позиция 23 на Фиг.2). В результате выполнения этого этапа исходный текст трансформируется во множество токенов и морфов, которые представлены в Таблице 1 и Таблице 2, соответственно.
Вводные слова и вставные конструкции не несут никакой синтаксической нагрузки, поэтому токены этого типа из дальнейшего анализа исключаются.
Токены-географические названия рассматриваются как одно слово, с морфом, соответствующим морфу главного слова.
Далее, после сегментации текста на токены и морфологического анализа токенов-слов осуществляют выделение устойчивых словосочетаний (ссылочная позиция 24 на Фиг.2). Для этого подсчитывают частоту встречаемости слов в последовательностях из двух и более слов в тексте. Затем сравнивают разности частот встречаемости слов в последовательности для первого появления данной последовательности слов и для нескольких последующих их появлений.
Частоты встречаемости слов при первом появлении последовательности и при ее последующем появлении, а также разности этих частот представлены в Таблице 3.
В результате выполнения этого этапа исходный текст, кроме элементарных единиц первого и второго уровней, дополняется множеством единиц третьего уровня - устойчивыми словосочетаниями. Словосочетания для нашего примера представлены в Таблице 4.
После выполнения вышеуказанных этапов осуществляют фрагментацию обрабатываемого текста на предложения (ссылочная позиция 22 на Фиг.2). В результате выполнения этого этапа сформированные выше множества дополняются множеством предложений, представленных в Таблице 5.
Таким образом, после выполнения всех рассмотренных выше этапов обрабатываемый текст будет сегментирован на предложения, каждое из которых размечено множествами аннотаций элементарных единиц первого, второго и третьего уровней.
Вслед за этим, в соответствии с заявленным способом автоматизированного семантического сравнения текстов на естественном языке, осуществляется выявление семантически значимых объектов и атрибутов (элементарных единиц четвертого уровня) (ссылочная позиция 25 на Фиг.2). Оно производится в каждом предложении на множестве элементарных единиц первого, второго и(или) третьего уровней путем применения заранее сформированного множества лингвистических и эвристических правил с использованием заранее же сформированных соответствующих лингвистических словарей.
Семантико-синтаксическая обработка предложения проводится в несколько этапов. Все этапы будем проводить на тексте, выбранном нами для примера.
1. Членение предложения по знакам пунктуации и союзам (союзным словам и словосочетаниям) на начальные фрагменты и определение типа фрагмента на основе его морфологических характеристик. Для этого используется словарь союзов, союзных слов и словосочетаний.
Границы фрагментов ставятся по всем знакам препинания и союзам (союзным словам и словосочетаниям) без запятой. Кроме того, по словарю союзов определяется, нет ли такого сложного союза, начало которого в соседнем слева фрагменте, а конец в данном. В нашем случае таким союзным словосочетанием является «до тех пор, пока». Если такой союз есть, то запятую переносят перед всем союзом.
Тип фрагмента - одно из следующих значений, указанных в таблице 6. По порядку, указанному в таблице 6, ищется во фрагменте словоформа с соответствующим омонимом, остальные омонимы найденной словоформы не рассматриваются.
2. Объединение исходных отрезков с простыми случаями однородных рядов прилагательных, наречий, существительных и т.п. Признаком однородности выступает наличие сочинительного союза (или запятой), до и после которого должны находиться словоформы одной части речи, у которых есть омонимы, имеющие одинаковую морфологическую информацию. Остальные омонимы не рассматриваются при дальнейшем анализе, таким образом, происходит частичное снятие омонимии.
В нашем примере сочинительным союзом «как» соединены сегменты 2.1 и 2.2, поскольку у токенов 14 («характер») и 26 («выборы») таблицы 1 есть омонимы одной части речи, имеющие одинаковую морфологическую информацию - Им.п. или Вин.п. Тип полученного сегмента - 1.
3. Построение простых синтаксических групп, соответствующих атрибутивному уровню описания (табл.8): признак объекта/субъекта/действия + объект/субъект/действие, мера признака объекта/субъекта/действия + объект/субъект/действие.
Далее в предложениях текста выявляются и раскрываются анафорические ссылки. Для этого в пределах всего обрабатываемого текста в процессе выполнения этапа, обозначенного на Фиг.2 ссылочной позицией 26, находят местоимения, которые могут быть анафорическими ссылками на соответствующие слова, и для местоимений, которые действительно таковыми являются, фиксируют тождество по референции между соответствующим семантически значимым объектом и его анафорической ссылкой. В нашем примере анафоры отсутствуют.
4. Вложение контактно расположенных фрагментов (причастных, деепричастных оборотов, придаточных определительных, etc.) и установление иерархии на фрагментах. Причастный оборот и придаточное определительное будут являться признаком соответствующего объекта, деепричастный оборот - признаком действия.
В нашем примере выполняются следующие вложения:
- фрагмент 4.2 (табл.7) с типом 6 «принимая экзамены на кафедре дифференциальных уравнений механико-математического факультета» является деепричастным оборотом с главным словом «принимая», следовательно, весь фрагмент 4.2 подчиняется глаголу предыдущего фрагмента «слышать»,
- фрагмент 4.5 (табл.8) с типом 5 «дававших безукоризненные ответы» является причастным оборотом с главным словом «дававших», согласованным с существительным «студентов» предыдущего фрагмента по роду и числу, следовательно, весь фрагмент 4.5 подчиняется существительному «студентов», являясь его признаковым описанием. Таким образом, весь фрагмент 4.5 - атрибут (признак) существительного «студентов».
Во втором столбце таблицы 10 показаны полученные после вложения укрупненные фрагменты предложения.
5. Построение множества однозначных морфологических интерпретаций каждого фрагмента.
В пределах каждого предложения осуществляется частичное снятие омонимии на морфологическом уровне путем:
1) выделения групп существительных, согласованных с одним или несколькими прилагательными/причастиями/местоимениями-прилагательными, находящимися в однородной связи (так называемый атрибутивный уровень, описанный выше в п.3);
2) анализа местоположения тире, что снимает омонимию, во-первых, со слово формы «это», поскольку тире перед данной словоформой указывает на то, что «это» - частица, во-вторых, с существительных до и после тире, т.к. у ближайшего к тире существительного справа возможен только именительный падеж, а слева - именительный или творительный. Так, в нашем примере словоформ «это» (токен 8, табл.2) является частицей, а словоформы «экзамен» (токен 4, табл.2) и «решение» (токен 10, табл.2) могут быть употреблены только в винительном падеже;
3) выявления причастных оборотов, стоящих после существительного, и деепричастных оборотов, поскольку такие обороты выделяются запятыми, а существительные, входящие в них зависят от глагольной формы и не могут быть в именительном падеже. Так, в нашем примере словоформы «экзамен» (токен 45, табл.2) и «ответы» (токен 65, табл.2), не могут быть в именительном падеже;
4) выявления предлогов, при этом у подчиненного предлогу существительного убираются те омонимы, которые имеют падеж, не употребляемый с данным предлогом (используется модель управления предлога). В нашем примере:
- предлог «из» (токен 27, табл.1) перед словоформой «кандидатов» (токен 29, табл. 1) не может управлять существительным в винительном падеже;
- предлог «на» (токен 46, табл.1) перед словоформой «кафедре» (токен 47, табл.1) не может управлять существительным в дательном падеже;
- словоформа «мне» (токен 40, табл.1), перед которой предлог отсутствует, не может иметь предложный падеж,
следовательно, эти омонимы убираются из рассмотрения.
В таблице 2 варианты омонимов, которые исключены из рассмотрения в результате частичного снятия омонимии на морфологическом уровне, выделены серым цветом.
6. Объединение фрагментов в простые предложения в составе сложноподчиненного с помощью подчинительных союзов. Подчинительные союзы выступают как границы простых предложений (табл.10, столбец 3).
7. Выявление предикативного минимума (в том числе, основных семантически значимых объектов, и основных семантически-значимых связей - предикатов) предложения путем сравнения его структуры со словарем шаблонов минимальных структурных схем предложений, фрагмент которого приведен в Таблице 11. Результат для нашего примера приведен в Таблице 12.
8. Выделение остальных членов простого предложения (остальных семантически значимых объектов и атрибутов) и остальных семантически значимых связей осуществляется последовательным сравнением слов предложения с актантной структурой глагола из словаря валентностей глаголов. Заполненные валентные гнезда для предикатов текста примера приведены в Таблице 13.
Более подробно рассмотрим предикат топили. Согласно семантической классификации, используемой в словаре валентностей глаголов, он прогнозирует ситуацию воздействия субъекта на объект. Глаголы этого класса имеют формальное выражение вида «существительное в именительном падеже - глагол - существительное в родительном падеже». Таким образом, выявляются основные семантически значимые объекты «экзаменатор», «студент», и основное семантически значимое отношение «воздействие».
9. Построение синтаксических групп внутри полученных простых предложений, в которых актанты предикатов - главные слова, с помощью синтаксических правил, выявляющих синтаксические связи между словами. Построенные группы приведены в Таблице 14.
Таким образом, выявляется множество остальных семантически значимых объектов и атрибутов, а также остальных семантически отношений. Для указанного примера они сведены в Таблицу 15.
После выполнения предыдущих этапов на множестве выделенных элементарных единиц первого, второго, третьего и четвертого уровней с помощью упомянутых правил находят семантически значимые отношения между семантически значимыми объектами. Так, например, в предложении «Во всем мире экзамен по математике - это письменное решение задач» рассматриваемого текста с помощью множества правил, соответствующая которому схема обработки сигналов представлена на Фиг.2 (пункты обработки 1-9), а используемые в этом правиле словари представлены в Таблицах 6-16, выделяются семантически значимое отношение «есть». Другие семантически значимые отношения выделяются с помощью того же самого множества правил. Каждому семантически значимому отношению присваивается его тип. В результате в исходном тексте выделяют семантически значимые отношения. Множество таких семантически значимых отношений с присвоенными им типами для рассматриваемого примера представлено в Таблице 16.
Таким образом, после выполнения всех рассмотренных выше этапов обработки исходный текст будет размечен множеством аннотаций, соответствующих семантически значимым объектам, атрибутам и семантически значимым отношениям между семантически значимыми объектами, а также между семантически значимыми объектам и атрибутами.
После этого на этапе, обозначенном на Фиг.2 ссылочной позицией 29, выявляют частоты встречаемости семантически значимых объектов и атрибутов, а также семантически значимых отношений между семантически значимыми объектами и между семантически значимыми объектами и атрибутами на всем данном тексте. Эту операцию выполняют практически так же, как на этапе 24 для элементарных единиц первого уровня. Фрагмент такого частотного словаря для нашего примера представлен в Таблицах 17 и 18.
Следующий этап, обозначенный на Фиг.2 ссылочной позицией 30, является техническим и выполняется для формирования триад, соответствующих сохраненным семантически значимым объектам, атрибутам и семантически значимым отношениям. Фрагмент множества таких триад для нашего примера представлен в Таблице 19. По сути дела, сформированное множество триад составляет исходные данные для построения семантического индекса, обработанного на предыдущих этапах текста.
На этапе, обозначенном на Фиг.2 ссылочной позицией 31, строят семантический индекс следующим образом: сначала из множества триад, полученных на предыдущем этапе, формируют подмножества триад, каждое из которых соответствует одному семантически значимому объекту с его атрибутами, и каждое полученное подмножество триад используют как вход для одного из стандартных индексаторов, например широко известного свободно распространяемого индексатора Lucene, индексатора поисковой машины Яндекс, индексатора Google или любого другого индексатора, с выхода которого получают уникальный для заданного подмножества триад индекс. Аналогичную последовательность действий выполняют для всех подмножеств триад, соответствующих триадам вида «семантически значимый объект - семантически значимое отношение - семантически значимый объект» и триадам вида «семантически значимый объект - семантически значимое отношение - атрибут», получая множество соответствующих уникальных индексов, которые в совокупности и составляют семантический индекс текста.
На этапе, обозначенном на Фиг.2 ссылочной позицией 32, сформированные на этапе 30 триады и полученные на этапе 31 индексы вместе со ссылкой на исходный текст, из которого сформированы эти триады, сохраняют в базе данных.
В соответствии со способом автоматизированного семантического сравнения текстов на естественном языке из упомянутых триад могут формировать семантическую сеть таким образом, что первый семантически значимый объект последующей триады связывается с таким же вторым семантически значимым объектом предыдущей триады. Пример фрагмента такой семантической сети приведен в Таблице 20.
При этом перед сохранением в базе данных сформированных триад и полученных индексов осуществляется, в процессе итеративной процедуры, перенормировка частот встречаемости семантически значимых объектов и атрибутов, а также частот встречаемости семантически значимых отношений, в смысловой вес семантически значимых объектов и атрибутов, являющихся вершинами семантической сети, таким образом, что семантически значимые объекты или атрибуты, связанные в сети с большим числом семантически значимых объектов или атрибутов, с большой частотой встречаемости увеличивают свой смысловой вес, а другие семантически значимые объекты или атрибуты его равномерно теряют. Пример перенормированных в смысловые веса численных значений весовых коэффициентов понятий семантической сети приведен в Таблице 21. Аналогичным образом обрабатываются выборки текстов, описывающих классы (в данном примере - три), которые должны быть подвергнуты сравнению с классифицируемым текстом.
Далее вычисляют степени пересечения семантических сетей классифицируемого текста и выборок текстов, характеризующих классы (предметные области), как по вершинам, так и по их связям с учетом смысловых весов вершин семантических сетей и весовых характеристик их связей. Пример значений степеней пересечений семантических сетей классифицируемого текста и выборок текстов, описывающих классы (предметные области), приведен в Таблице 22. Степень пересечения классифицируемого текста с классом «Математика» говорит о большем их смысловом подобии, по сравнению с другими классами.
Если выставить порог по отнесению классифицируемого текста к предметным областям (классам) равным 2,00000, текст не попадает ни в один из заданных классов. При выставлении порога равным 1,50000, текст попадает в предметную область «Математика».
Степень пересечения двух семантических сетей, принадлежащих классифицируемому тексту и выборкам текстов, описывающих классы (предметные области), вычисляется как сумма степеней пересечений элементарных единиц пятого уровня этих двух сетей. Эта сумма формируется по всем вершинам той из сетей, у которой больше вершин. Для каждой вершины этой сети находится вершина в другой сети, являющаяся той же элементарной единицей четвертого уровня - тем же семантически значимым объектом или тем же атрибутом. Если такой вершины во второй сети не находится, степень пересечения для этой вершины приравнивается к нулю. Пример значений степеней пересечения вершин семантических сетей классифицируемого текста и выборки текстов, характеризующей один из классов, приведен в Таблице 23.
Для каждой вершины одной семантической сети (для каждого семантически значимого элемента или атрибута - элементарных единиц четвертого уровня) посчитаем степень пересечения с соответствующей вершиной другой семантической сети. В приведенном примере рассматриваем, например, вершину «функция», которая имеется в семантических сетях обоих сравниваемых текстов. Эта степень пересечения вычисляется как сумма степеней пересечения всех семантически значимых объектов и атрибутов, связанных с этой вершиной. В семантических сетях классифицируемого текста и выборки текстов, характеризующей класс «Математика», это «уравнение», «производная», «балл», «решение уравнения» и др., в одной семантической сети, и «уравнение», «производная», «решение уравнения», «порядок» и др. - в другой семантической сети.
Для вершин «функция» вычисляются нормированные на 100% скалярные произведения 99×99×sin(52,2°)/100=77,44 и 99×99×sin(75,6°)/100=94,93 с вершинами «уравнение». И так для всех вершин семантической сети, семантический вес которых превысил пороговое значение (выбранное равным 70 в данном примере).
Суммарная степень пересечения двух семантических сетей по вершине «функция» - 177,49 по всем соседним с ней вершинам семантических сетей нормируется на наибольшее число 120 оставшихся после удаления подпороговых вершин в одной из двух семантических сетей сравниваемых текстов.
Степень пересечения семантических сетей, таким образом, вычисляется суммированием наименьших степеней пересечения из двух пар одноименных семантически значимых понятий или атрибутов двух сравниваемых сетей (см. Таблицу 24). При этом вычисляются семантические пересечения смысловых весов каждого семантически значимого объекта, или атрибута, связанных с этой вершиной в этих двух сетях. Эти семантические пересечения вычисляются как нормированные на 100% скалярные произведения смысловых весов первой и второй вершин, а угол между ними берется пропорциональным нормированной на 100% частоте встречаемости связывающего их семантически значимого отношения. К полученной сумме добавляется меньшее из скалярных произведений. Если во второй сети для данной вершины не находится соответствующего семантически значимого объекта, или атрибута, степень пересечения по этому семантически значимому объекту, или атрибуту, приравнивается нулю. После суммирования по всем семантически значимым объектам или атрибутам, связанным с текущей вершиной, нормируют полученную сумму на наибольшее в двух сетях число семантически значимых объектов и атрибутов, связанных с этой вершины, и переходят к следующей вершине.
Полученная по всем вершинам в одной из сетей (с наибольшим числом вершин) сумма нормируется на число сохраненных после применения обработки на этапе 7 (см. Фиг.1) элементарных единиц четвертого уровня.
Предметная область (класс) «Математика» оказывается предметной областью (классом), к которому относится классифицируемый текст.
Следует еще раз подчеркнуть, что хотя в заявленном способе экспертами-лингвистами предварительно строится множество синтаксических правил и соответствующих лингвистических словарей (в силу чего в названии заявленного способа употреблено определение «автоматизированного»), раскрытая выше семантическая классификация текстов осуществляется без вмешательства оператора.
Таким образом, настоящее изобретение обеспечивает способ семантической классификации текстов на естественном языке практически без участия оператора. Основное отличие этого способа от известных способов состоит в том, что подсчитываются частоты встречаемости элементарных единиц четвертого уровня, т.е. семантически значимых объектов и атрибутов с последующей их перенормировкой в смысловые веса. Объединение триад из семантически значимых объектов и атрибутов с помощью семантически значимых отношений в семантическую сеть обеспечивает быструю классификацию текстов, особенно текстов на высоко флективных языках.
Пояснение к таблице 11:
V(f) - спрягаемые формы глагола (не инфинитив);
Cop(f) - спрягаемые формы связки служебных слов быть, стать, являться;
Inf - инфинитив глагола или связки;
N1, N5 - именительный, творительный падеж субстантива;
Adj1, Adj5 - именительный, творительный падеж прилагательных и страдательных причастий;
Adj(f) - краткие формы и компоративы прилагательных и страдательных причастий.
Предложения с шаблоном Cop(f) N1 могут быть назывными, т.е. глагол-связка там не присутствует в явном виде. В этом случае полагаем предикат - нулевой, обозначаемый как NULL.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ АВТОМАТИЗИРОВАННОГО СЕМАНТИЧЕСКОГО СРАВНЕНИЯ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2013 |
|
RU2538303C1 |
| СПОСОБ АВТОМАТИЗИРОВАННОЙ СЕМАНТИЧЕСКОЙ ИНДЕКСАЦИИ ТЕКСТА НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2012 |
|
RU2518946C1 |
| СПОСОБ И СИСТЕМА СЕМАНТИЧЕСКОЙ ОБРАБОТКИ ТЕКСТОВЫХ ДОКУМЕНТОВ | 2016 |
|
RU2630427C2 |
| СПОСОБ АВТОМАТИЗИРОВАННОЙ ОБРАБОТКИ ТЕКСТА НА ЕСТЕСТВЕННОМ ЯЗЫКЕ ПУТЕМ ЕГО СЕМАНТИЧЕСКОЙ ИНДЕКСАЦИИ, СПОСОБ АВТОМАТИЗИРОВАННОЙ ОБРАБОТКИ КОЛЛЕКЦИИ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ ПУТЕМ ИХ СЕМАНТИЧЕСКОЙ ИНДЕКСАЦИИ И МАШИНОЧИТАЕМЫЕ НОСИТЕЛИ | 2008 |
|
RU2399959C2 |
| СПОСОБ АВТОМАТИЗИРОВАННОЙ ОБРАБОТКИ ИНФОРМАЦИОННЫХ ТЕКСТОВЫХ МАТЕРИАЛОВ | 2003 |
|
RU2242048C2 |
| СПОСОБ СЕМАНТИЧЕСКОЙ ОБРАБОТКИ ЕСТЕСТВЕННОГО ЯЗЫКА С ИСПОЛЬЗОВАНИЕМ ГРАФИЧЕСКОГО ЯЗЫКА-ПОСРЕДНИКА | 2009 |
|
RU2509350C2 |
| Способ определения и классификации понятия исходя из контекста его употребления | 2022 |
|
RU2795870C1 |
| СИСТЕМА И МЕТОД СЕМАНТИЧЕСКОГО ПОИСКА | 2013 |
|
RU2563148C2 |
| СПОСОБ КЛАСТЕРИЗАЦИИ РЕЗУЛЬТАТОВ ПОИСКА В ЗАВИСИМОСТИ ОТ СЕМАНТИКИ | 2014 |
|
RU2564629C1 |
| МЕТОД АНАЛИЗА ТОНАЛЬНОСТИ ТЕКСТОВЫХ ДАННЫХ | 2014 |
|
RU2571373C2 |
Изобретение относится к области информационных технологий. Техническим результатом является ускорение процесса сравнения текстов. В способе автоматизированной семантической классификации текстов на естественном языке представляют каждый классифицируемый текст в цифровой форме для последующей обработки. Индексируют текст, получая элементарные единицы первого-пятого уровней. Выявляют частоты встречаемости единиц четвертого уровня, каждая из которых является семантически значимым объектом или атрибутом, и частоты встречаемости семантически значимых отношений, связывающих семантически значимые объекты, а также объекты и атрибуты. Формируют из триад, являющихся единицами пятого уровня, семантическую сеть. Перенормируют частоты встречаемости в смысловой вес единиц четвертого уровня. Ранжируют единицы четвертого уровня по смысловому весу путем сравнения его с пороговым значением и те, которые имеют вес ниже порогового значения. Выявляют степени пересечения семантических сетей текста и текстовых выборок. Выбирают в качестве класса для текста предметные области, степени пересечения семантической сети которых с семантической сетью текста больше порога. 5 з.п. ф-лы, 2 ил., 24 табл.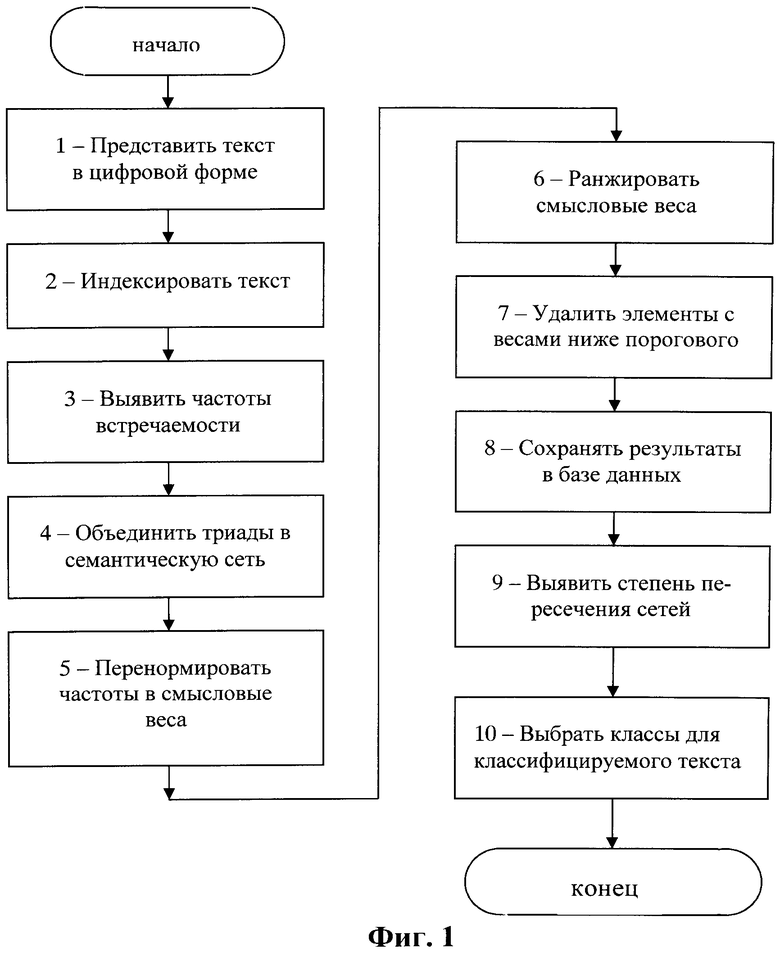
1. Способ автоматизированной семантической классификации текстов на естественном языке, заключающийся в том, что:
- представляют каждый классифицируемый текст в цифровой форме для последующей автоматической и (или) автоматизированной обработки;
- осуществляют индексацию каждого классифицируемого текста в цифровой форме, получая:
- элементарные единицы первого уровня, включающие в себя, по меньшей мере, слова,
- элементарные единицы второго уровня, каждая из которых представляет собой нормализованную словоформу,
- элементарные единицы третьего уровня, каждая из которых представляет собой устойчивое словосочетание в упомянутом тексте,
- элементарные единицы четвертого уровня, каждая из которых является семантически значимым объектом и атрибутом, и
- элементарные единицы пятого уровня, каждая из которых представляет собой триаду либо из двух семантически значимых объектов и семантически значимого отношения между ними, либо из семантически значимого объекта и атрибута и связывающего их семантически значимого отношения;
- выявляют частоты встречаемости элементарных единиц четвертого уровня и частоты встречаемости упомянутых семантически значимых отношений;
- сохраняют в базе данных сформированные элементарные единицы второго, третьего, четвертого и пятого уровней с выявленными частотами встречаемости элементарных единиц четвертого уровня и семантически значимых отношений, а также полученные индексы вместе со ссылками на конкретные предложения данного текста;
- формируют из упомянутых триад семантическую сеть таким образом, что первая элементарная единица четвертого уровня последующей триады связывается с такой же второй элементарной единицей четвертого уровня предыдущей триады;
- осуществляют, в процессе итеративной процедуры, перенормировку упомянутых частот встречаемости в смысловой вес элементарных единиц четвертого уровня, являющихся вершинами семантической сети, таким образом, что элементарные единицы четвертого уровня, связанные в сети с большим числом других элементарных единиц четвертого уровня с большой частотой встречаемости, увеличивают свой смысловой вес, а прочие элементарные единицы четвертого уровня его равномерно теряют;
- ранжируют элементарные единицы четвертого уровня по смысловому весу путем сравнения смыслового веса каждой из них с заранее заданным пороговым значением и удаляют элементарные единицы четвертого уровня, имеющие смысловой вес ниже порогового значения;
- сохраняют в памяти оставшиеся элементарные единицы четвертого уровня со смысловым весом выше порогового, а также семантически значимые отношения между оставшимися элементарными единицами четвертого уровня;
- выявляют степени пересечения упомянутой семантической сети классифицируемого текста и семантических сетей текстовых выборок, каковые текстовые выборки составлены из ранее классифицированных текстов и описывают предметные области упомянутой семантической классификации, при этом упомянутую степень пересечения выявляют как по вершинам упомянутых семантических сетей, так и по связям между этими вершинами с учетом смысловых весов вершин рассматриваемых семантических сетей и весовых характеристик их связей, и принимают выявленную степень пересечения семантических сетей классифицируемого текста и конкретной текстовой выборки в качестве величины, характеризующей семантическое подобие классифицируемого текста и данной текстовой выборки;
- выбирают в качестве класса для классифицируемого текста, по меньшей мере, одну из упомянутых предметных областей, степени пересечения семантической сети которых с семантической сетью упомянутого классифицируемого текста оказываются больше заранее заданного порога.
2. Способ по п.1, в котором при упомянутом превышении упомянутого заранее заданного порога степенями пересечения для нескольких предметных областей, ранжируют упомянутые предметные области по степени их близости к классифицируемому тексту.
3. Способ по п.1 или 2, в котором выбирают заданное заранее число упомянутых предметных областей, к которым относится упомянутый классифицируемый текст.
4. Способ по п.1, в котором упомянутую индексацию осуществляют в процессе выполнения следующих этапов:
- сегментируют текст в цифровой форме на элементарные единицы первого уровня, включающие в себя, по меньшей мере, слова;
- сегментируют по графематическим правилам текст в цифровой форме на предложения;
- формируют для каждой элементарной единицы первого уровня, представляющей собой слово, на основе морфологического анализа элементарные единицы второго уровня, включающие в себя нормализованную словоформу;
- подсчитывают частоту встречаемости каждой элементарной единицы первого уровня для двух и более соседних единиц первого уровня в данном тексте и объединяют среди упомянутых элементарных единиц первого уровня последовательности слов, следующих друг за другом в данном тексте, в элементарные единицы третьего уровня, представляющие собой устойчивые сочетания слов, в случае, если для каждых двух и более следующих друг за другом слов в данном тексте разности подсчитанных частот встречаемости этих слов для первого появления данной последовательности слов и для нескольких последующих их появлений для каждой пары слов последовательности остаются неизменными;
- выявляют, в процессе многоступенчатого семантико-синтаксического анализа путем обращения к заранее сформированным в базе данных лингвистическим и эвристическим правилам в заранее заданной лингвистической среде, в каждом из сформированных предложений семантически значимые объекты и атрибуты - единицы четвертого уровня;
- для каждой элементарной единицы четвертого уровня фиксируют тождество по референции между соответствующим семантически значимым объектом, а также атрибутом, и соответствующей анафорической ссылкой при ее наличии в классифицируемом тексте, заменяя каждую анафорическую ссылку на соответствующий ей антецедент;
- сохраняют в памяти каждый семантически значимый объект и атрибут;
- выявляют, в процессе многоступенчатого семантико-синтаксического анализа путем обращения к заранее сформированным в базе данных лингвистическим и эвристическим правилам в заранее заданной лингвистической среде, в каждом из сформированных предложений семантически значимые отношения между выявленными единицами четвертого уровня - семантически значимыми объектами, а также между семантически значимыми объектами и их атрибутами;
- присваивают каждому семантически значимому отношению соответствующий тип из хранящейся в базе данных предметной онтологии по тематике той предметной области, к которой относится классифицируемый текст;
- выявляют на всем тексте частоты встречаемости элементарных единиц четвертого уровня и частоты встречаемости упомянутых семантически значимых отношений;
- сохраняют в памяти каждое выявленное семантически значимое отношение вместе с присвоенным ему типом;
- формируют в пределах данного текста для каждого из выявленных семантически значимых отношений, связывающих как соответствующие семантически значимые объекты, так и семантически значимый объект и его атрибут, множество триад, которые являются элементарными единицами пятого уровня;
- индексируют на множестве сформированных триад по отдельности все связанные семантически значимыми отношениями семантически значимые объекты с их частотами встречаемости, все атрибуты с их частотами встречаемости, и все сформированные триады.
5. Способ по п.1, в котором упомянутую степень пересечения двух семантических сетей вычисляют как сумму совпадений элементарных единиц пятого уровня этих двух семантических сетей.
6. Способ по п.5, в котором:
- выбирают в качестве базовой сети ту из упомянутых двух семантических сетей, в которой после ранжирования и удаления вершин со смысловыми весами ниже упомянутого порогового значения осталось больше вершин, чем в другой, выбираемой в качестве сравниваемой;
- находят для каждой вершины упомянутой базовой сети в упомянутой сравниваемой сети вершину, являющуюся той же самой элементарной единицей четвертого уровня, т.е. тем же самым семантически значимым объектом, или тем же самым атрибутом;
- вычисляют, для каждой найденной вершины в каждой из упомянутых базовой и сравниваемой сетей, величины всех связанных с данной вершиной упомянутых триад как площади треугольников, стороны которых соответствуют компонентам каждой из этих триад, а угол между сторонами пропорционален весу семантически значимого отношения;
- выбирают для каждой пары упомянутых триад, связанных с парой конкретных вершин в упомянутых базовой и сравниваемой сетях, меньшую из упомянутых вычисленных величин в качестве степени пересечения упомянутых триад в упомянутых базовой и сравниваемой сетях;
- суммируют для каждой из связанных с данной вершиной вершин все выбранные вычисленные величины, получая степень пересечения для данной пары вершин упомянутых базовой и сравниваемой сетей;
- нормируют найденную сумму на число упомянутых семантически значимых объектов и атрибутов, связанных с данной вершиной в той из упомянутых базовой и сравниваемой сетей, которая содержит больше связанных с данной вершиной вершин;
- суммируют нормированные суммы по всем вершинам той из упомянутых базовой и сравниваемой сетей, которая содержит больше вершин;
- нормируют полученную сумму на число оставшихся в этой сети элементарных единиц четвертого уровня, получая упомянутую степень пересечения двух семантических сетей.
| СПОСОБ АВТОМАТИЗИРОВАННОЙ ОБРАБОТКИ ТЕКСТА НА ЕСТЕСТВЕННОМ ЯЗЫКЕ ПУТЕМ ЕГО СЕМАНТИЧЕСКОЙ ИНДЕКСАЦИИ, СПОСОБ АВТОМАТИЗИРОВАННОЙ ОБРАБОТКИ КОЛЛЕКЦИИ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ ПУТЕМ ИХ СЕМАНТИЧЕСКОЙ ИНДЕКСАЦИИ И МАШИНОЧИТАЕМЫЕ НОСИТЕЛИ | 2008 |
|
RU2399959C2 |
| СПОСОБ АВТОМАТИЗИРОВАННОЙ ОБРАБОТКИ ИНФОРМАЦИОННЫХ ТЕКСТОВЫХ МАТЕРИАЛОВ | 2003 |
|
RU2242048C2 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| US 7383169 B1, 03.06.2008 | |||

