Изобретение относится к способу идентификации объектов по их текстовым описаниям и может использоваться, например, в анализе ситуаций, при информационном поиске и т.п.
В настоящее время существуют различные методы идентификации объектов, представленных своими текстовыми описаниями.
К примеру, в патенте РФ N 2066473 (G06F 17/30, публ. 10.09.96) изложен способ идентификации объектов, в котором тексты поступают в информационно-поисковую систему извне, кодируются и хранятся в соответствующей базе данных, а при поступлении сигнала сформированного запроса эти тексты выдаются потребителю.
Данный способ имеет ограниченные возможности, поскольку идентификация в нем производится по кодам, присвоенным текстам, и он не предназначен для проведения развернутых сравнений текстов.
Наиболее близким к предлагаемому является способ идентификации объектов по их описаниям, заключающийся в том, что заранее преобразуют тексты естественного языка в заданных областях знаний в сигналы, пригодные для машинной обработки, осуществляют машинную обработку сигналов, преобразованных из каждого текста, в системе хранения и обработки информации для формирования соответствующих тезаурусов этого текста; осуществляют статистическую обработку слов в тезаурусах каждого текста; объединяют тезаурусы текстов в соответствующие базы данных в упомянутой системе хранения и обработки информации; при необходимости идентификации конкретного объекта в областях знаний формируют запрос к выбранной базе данных путем указания выборки желательных слов, характеризующих конкретный объект; сравнивают выборку слов из сформированного запроса с тезаурусами текстов в выбранной базе данных; по результатам этого сравнения принимают решение об идентификации конкретного объекта (патент РФ N 2107942, G 06 F 17/30, публ. 27.03.98).
Данный способ позволяет найти любой объект по его описанию, если оно имеется в хранилище, путем задания некоторой выборки слов, характеризующих данный объект (или ему подобные). Однако данный способ имеет все же ограниченные возможности, т. е. не позволяет проводить сопоставительного анализа таких объектов, оценивать сходство реальных объектов или ситуаций с объектами или ситуациями, описания которых имеются в хранилище (базе данных).
Поэтому задачей настоящего изобретения является разработка такого способа идентификации объектов по их описаниям, который в результате был бы свободен от указанных выше недостатков, т.е. имел бы более широкие возможности. При этом способ по настоящему изобретению, в отличие от указанных аналогов, позволяет идентифицировать события, ситуации или явления, не ограниченные заранее заданным перечнем и/или количеством показателей, за счет использования практически неограниченного объема дополнительной информации, характеризующей объект, подлежащий идентификации.
Этот технический результат достигается в настоящем изобретении на способ идентификации объектов по их описаниям, заключающийся в том, что: заранее преобразуют тексты естественного языка в заданных областях знаний в сигналы, пригодные для машинной обработки; осуществляют машинную обработку сигналов, преобразованных из каждого текста, в системе хранения и обработки информации для формирования соответствующих тезаурусов этого текста; осуществляют статистическую обработку слов в тезаурусах каждого текста; объединяют тезаурусы текстов в соответствующие базы данных в системе хранения и обработки информации; при необходимости идентификации конкретного объекта в областях знаний формируют запрос к выбранной базе данных путем указания выборки желательных слов, характеризующих конкретный объект; сравнивают выборку слов из сформированного запроса с тезаурусами текстов в выбранной базе данных; по результатам этого сравнения принимают решение об идентификации упомянутого конкретного объекта, благодаря тому, что в процессе формирования тезаурусов каждого текста осуществляют лингвистическую сортировку всех слов этого текста по заранее заданным кластерам; статистическую обработку слов осуществляют для каждого кластера данного текста; осуществляют лингвистическую сортировку всех слов из выборки слов сформированного запроса, аналогичную лингвистической сортировке слов при формировании тезаурусов текстов; в процессе сравнения вычисляют статистическую меру совпадения тезаурусов для выборки слов из сформированного запроса и текстов из выбранной базы данных; решение об идентификации конкретного объекта принимают на основе сопоставления вычисленных статистических мер совпадения для различных текстов.
Дополнительной особенностью данного способа является то, что сигналы преобразованных текстов принимают по электронным каналам связи, подключенным к системе хранения и обработки информации.
При этом электронные каналы связи выбирают из группы, состоящей из по меньшей мере телефонных, телетайпных, факсимильных, радио- и телевизионных каналов связи.
Другая дополнительная особенность данного изобретения состоит в том, что сигналы преобразованных текстов получают в процессе машинного считывания соответствующих текстов в системе хранения и обработки информации.
При этом считывающие устройства выбирают из группы, состоящей из по меньшей мере сканера, телекамеры и видеокамеры.
Еще одной особенностью данного способа является то, что в ходе лингвистической сортировки разбивают весь текст на предложения, выделенные кавычками совокупности слов и слова, в рамках каждого предложения и каждой выделенной кавычками совокупности слов, не являющейся прямой речью, отфильтровывают малозначащие слова естественного языка; в рамках каждого предложения и каждой выделенной кавычками совокупности слов, не являющейся прямой речью, отфильтровывают нейтральные слова заданной области знаний естественного языка; все оставшиеся после фильтрации слова разделяют на имена собственные, аббревиатуры, выделенные кавычками совокупности слов и имена нарицательные и выделяют из них основы слов с учетом грамматических категорий; из полученных основ слов для имен нарицательных, имен собственных, аббревиатур и выделенных кавычками совокупностей слов образуют соответствующие кластеры в тезаурусе данного текста, после чего осуществляют статистическую обработку слов каждого кластера; запоминают тезаурусы каждого текста с разделением на кластеры, в которых каждому слову сопоставляют число его повторений в данном тексте. В этом случае при вынесении решения об идентификации конкретного объекта выбирают те тексты, которые, при сопоставлении статистических мер совпадения, содержат наибольшее количество слов, совпадающих со словами из выборки слов сформированного запроса, и для которых вероятность совпадения тезауруса с тезаурусом сформированного запроса максимальна.
При этом в выбранной базе данных могут использовать тексты за выбранный временной интервал.
В ином случае, конкретным объектом в сформированном запросе является выделенный временной интервал, выборкой слов в сформированном запросе является совокупность всех текстов в заданных областях знаний за выделенный временной интервал, а в выбранной базе данных используют тексты за временной интервал, равный этому выделенному временному интервалу.
Статистическую меру совпадения могут определять как между выделенным временным интервалом из сформированного запроса и равным ему временным интервалом, для которого выбранная база данных содержит по меньшей мере один текст, так и между выделенным временным интервалом из сформированного запроса и временными интервалами той же продолжительности в течение заданного отрезка времени, после чего идентифицируют среди них временной интервал, имеющий наибольшую статистическую меру сходства с выделенным временным интервалом из сформированного запроса.
Из существующего уровня техники не выявлены объекты, которые содержали бы совокупность указанных выше существенных признаков. Это позволяет считать заявленный способ новым.
Из существующего уровня техники не известна также совокупность признаков, отличных от признаков упомянутого выше наиболее близкого аналога. Это позволяет считать заявленный способ обладающим изобретательским уровнем.
Прежде, чем перейти к описанию заявленного способа, целесообразно привести определения некоторых понятий, встречающихся в описании и прилагаемой формуле изобретения.
Тезаурусом какого-либо текста будем называть - в рамках данного изобретения - полную совокупность значащих слов этого текста, т.е. его словарный состав. Отнесение тех или иных слов к разряду значащих осуществляется заранее с учетом, во-первых, смысловой наполненности каждого слова, а во-вторых, тематики той предметной области, к которой относится данный текст.
Кластером для слов тезауруса назовем группу слов сходной природы, - например, имена собственные в тезаурусе любого текста образуют отдельный кластер.
Выборкой слов обозначим некоторую совокупность слов безотносительно к какому бы то ни было тезаурусу или кластеру.
Предлагаемый в данном изобретении способ предназначен в первую очередь для проведения сопоставительного анализа отдельных ситуаций или временных периодов по их текстовым описаниям, хотя его вполне можно применять и в таких областях, как библиотечный поиск или поиск в базах данных.
Предлагаемый способ в своем предпочтительном выполнении основан на том эмпирическом факте, что словарный состав в потоке сообщений прессы за некоторый временной интервал зависит от того, имеется ли, или назревает ли в это время кризисная ситуация в политической, экономической, финансовой, социальной и других сферах общественной жизни. Способ по настоящему изобретению позволяет оценить наличие, отсутствие или назревание кризиса по тому, насколько ситуация в заданном временном интервале сходна (или несходна) с ситуациями в других временных интервалах в прошлом.
В случае применения к библиографическому поиску данное изобретение позволяет, в частности, находить релевантные источники информации по тем выборкам слов, которые задаются в запросе на поиск.
В общем случае, таким образом, данное изобретение решает задачу идентификации объектов по их словесным или текстовым описаниям, т.е. определение того, с какими из уже известных объектов тестируемый объект имеет наибольшее сходство.
Эта задача решается в настоящем изобретении следующим образом.
Прежде всего в системе хранения и обработки информации создается по меньшей мере одна база данных как основа для проведения любых последующих идентификаций. Для этого тексты естественного языка в заданных областях знаний преобразуют в сигналы, пригодные для машинной обработки. Такое преобразование может осуществляться единовременно в тех случаях, когда создается узкоспециальная база данных, количество текстов для которой конечно и пополняется редко. При этом считывание может осуществляться человеком-оператором, который при этом вводит в компьютерную память все встречающиеся слова. Однако, если данное изобретение применяется по своему предпочтительному выполнению, такое преобразование необходимо осуществлять изо дня в день для большого количества текстов. При этом обязательно потребуются автоматические устройства преобразования текстов для их машинного считывания. Такими устройствами могут быть сканеры, телекамеры или видеокамеры. Кроме того, сигналы преобразованных текстов могут приниматься по электронным каналам связи, подключенным к системе хранения и обработки информации. Такими электронными каналами связи могут быть телефонные, телетайпные, факсимильные, радио- или телевизионные каналы связи. В любом случае все тексты преобразуются из вида, воспринимаемого человеком, к виду, воспринимаемому лишь вычислительными машинами.
Первичный отбор текстов для их преобразования к машиночитаемому виду может осуществляться либо оператором на основании некоторых наперед заданных критериев, - например, все, что касается угледобывающей отрасли, либо автоматически, - скажем, все сообщения агентства ИТАР-ТАСС, поступающие по каналам этого агентства. Конкретный принцип отбора будет каждый раз определяться той задачей, на решение которой направлено настоящее изобретение, и не входит в объем патентных притязаний заявителя.
После получения сигналов от преобразования текстов эти сигналы поступают на машинную обработку, в процессе которой для каждого текста формируют соответствующие тезаурусы. Эта машинная обработка сигналов осуществляется на вычислительных машинах, например персональных компьютерах (ПК), объединенных в учрежденческую сеть, либо на отдельном ПК. В дальнейшем изложении для большей ясности будет представлена лишь логическая составляющая этой машинной обработки, т.к. соответствующая обработка сигналов производится, во-первых, с помощью любого подходящего аппаратного обеспечения, а во-вторых, согласно алгоритму именно логической обработки текстов, состоящей в следующем.
Для каждого текста вначале производится лингвистическая сортировка всех слов этого текста. Эта сортировка может осуществляться аналогично тому, как описано в патенте РФ N 2096825 (G 06 F 7/30, публ. 20.11.97), и состоит из нескольких этапов. Сначала текст разделяется на предложения и выделенные кавычками совокупности слов. Затем из каждого предложения и каждой выделенной кавычками совокупности слов обрабатываемого текста удаляют все малозначащие слова - предлоги, союзы, наречия. Все эти слова заранее занесены в так называемый первый стоп-словарь, и совпадение какого-либо слова обрабатываемого текста с одним из слов первого стоп-словаря приводит к удалению этого слова из формируемого тезауруса данного текста. Далее, из каждого предложения и каждой выделенной кавычками совокупности слов обрабатываемого текста удаляют те слова, которые являются нейтральными, т.е. незначащими для той предметной области, к которой относится обрабатываемый текст. Все такие слова занесены в заранее составленный для каждой предметной области так называемый второй стоп-словарь, действие которого аналогично действию первого стоп-словаря.
После этого для обрабатываемого текста предварительно сформирован тезаурус, т.е. в данном случае совокупность всех слов, прошедших через отсеивание обоими стоп-словарями. Затем слова этого тезауруса разбиваются на четыре группы, образованные именами собственными, аббревиатурами, выделенными кавычками совокупностями слов и именами нарицательными. Из слов каждой группы выделяют основы слов с учетом грамматических категорий. Например, в склоняемых аббревиатурах и именах собственных отбрасывают окончания (ГОСТы ---> ГОСТ, Маяковскому ---> Маяковск); в именах нарицательных выполняют более сложное выделение, зависящее от наличия в этом тезаурусе слов с таким же корнем (при наличии в тезаурусе слов "нефтяник", "нефтяной" и "нефть" основой этих слов будет выбрано "нефт", однако в тексте, где не встречается слово "нефть" и его падежные склонения, в качестве основы слов "нефтяник" и "нефтяной" будет выбрано "нефтян"). Для слов в кавычках используется та же процедура.
Из полученных основ слов для имен нарицательных, имен собственных, аббревиатур и выделенных кавычками совокупностей слов образуют соответствующие кластеры в тезаурусе данного текста. При этом каждой основе слова в каждом кластере тезауруса данного текста ставят в соответствие число повторений этой основы в данном тексте. После этого тезаурус данного текста запоминается в соответствующей базе данных системы хранения и обработки информации, возможно, вместе с самим этим текстом. Баз данных может быть несколько в зависимости от назначения и конфигурации системы (например, отдельные базы данных для разных областей знаний), но по меньшей мере в системе хранения и обработки информации должна быть хотя бы одна база данных.
Помимо запоминания тезаурусов каждого текста в системе хранения и обработки информации могут осуществлять формирование общего тезауруса всех текстов за определенный временной интервал, - к примеру, за сутки, или по определенной области знаний, - к примеру, по нефтедобыче. Этот общий тезаурус запоминается в той же базе данных, что и тезаурусы отдельных текстов, или в специально для этого созданной базе данных. Такой общий тезаурус облегчает дальнейшие действия по идентификации ситуации или нахождению источника информации в фонде.
Упомянутые действия по идентификации или поиску могут осуществляться при наличии сформированного фонда тезаурусов. При необходимости подобной идентификации объекта (ситуации или источника информации) выполняются следующие действия.
Для выявления конкретного объекта в какой-либо области знаний формируют запрос к выбранной базе данных путем указания выборки желательных слов, характеризующих этот конкретный объект. Это могут быть любые слова на том языке, на котором были представлены тексты, легшие в основу формирования вышерассмотренного фонда тезаурусов, независимо от того, являются ли они значащими в том смысле, как это обсуждено выше. Выборка в принципе может состоять и из одного слова, что может иметь место при поиске источника информации в некоторой узкоспециальной области знаний (например, название редкого ископаемого животного в палеонтологии для поиска источника информации, содержащего упоминание об этом животном). С другой стороны, выборкой слов может быть и совокупность всех текстов за некоторый выбранный интервал времени.
К полученной выборке слов применяют тот же принцип лингвистической сортировки, что и к текстам. Т.е. слова из этой выборки сортируют по тем же четырем группам, находят основы слов и запоминают в соответствующих кластерах. К словам из сформированной выборки слов в отдельных случаях могут не применять фильтрацию с помощью стоп-словарей и не подсчитывать числа появлений, если, к примеру, задан набор отдельных слов, а не тексты. Полученные кластеры образуют тезаурус сформированной выборки слов. После этого осуществляют сравнение полученного тезауруса выборки слов с тезаурусами текстов из соответствующей базы (баз) данных. Это сравнение может осуществляться по-разному.
В случае простого информационного поиска тезаурус выборки слов сравнивается с тезаурусами всех текстов базы данных либо области знаний указанной в запросе, содержащем эту выборку слов. В случае же идентификации ситуации могут иметь место различные варианты, когда ситуация может задаваться текстами за выбранный временной интервал, - например, за истекшую неделю, а сравнение может производиться с текстами, поступившими в течение такого же временного интервала, заданного конкретно, - например, той же выбранной недели в прошлом, либо с текстами, поступавшими в течение любого временного интервала той же длины в более длинном временном интервале, - например, любой недели за прошедший квартал или год.
Однако, независимо от того, каким образом задан временной интервал (а в общем случае, независимо от объекта идентификации), сравнение тезауруса запросной выборки слов с тезаурусами текстов в базе данных осуществляется путем сопоставления тезауруса выборки слов с каждым тезаурусом текста или с каждым тезаурусом, накопленным за заданный временной интервал (за день, за месяц и т.д.). При этом сравниваются по отдельности все кластеры сравниваемых тезаурусов и для каждого кластера определяется пересечение, т.е. слова, имеющиеся в обоих сравниваемых кластерах. Затем для каждого тезауруса находится мера пересечения, т.е. сумма количества слов, входящих в тезаурус выборки слов и в тезаурус текста(-ов) безотносительно к классификации (кластеру).
Вероятность P совпадения двух тезаурусов определяется как P=P1•P2•... •Pn, где n - количество слов, попавших в пересечение обоих тезаурусов.
Pi (i = 1, ..., n) определяются с помощью следующих зависимостей: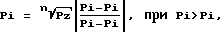
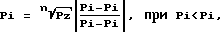
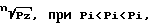
где Pi - частота появления i-го слова в тезаурусе выборки слов;
Pi - частота появления i-го слова в сравниваемом тезаурусе;
Pz - заданное значение допустимой меры определенности факта совпадения двух сравниваемых тезаурусов (доверительная вероятность);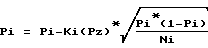 - нижняя граница базового доверительного интервала;
- нижняя граница базового доверительного интервала;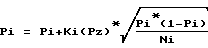 - верхняя граница базового доверительного интервала,
- верхняя граница базового доверительного интервала,
Ki(Pz) - квантиль нормального закона распределения уровня Pz.
В качестве сходного тезауруса выбирается тот, для которого выполнены следующие условия:
1. Количество N слов, попавших в пересечение с тезаурусом выборки слов, максимально.
2. Вероятность P совпадения двух тезаурусов принимает максимальное значение.
После определения статистической меры совпадения двух тезаурусов - запросной выборки слов и текстов из заданной области знаний (в заданном временном интервале) - осуществляют сравнение этой меры с пороговой величиной, установленной заранее, и по результату этого сравнения принимают решение о том, идентифицирован ли исследуемый объект. Например, в случае поиска источника информации по десяти словам в выборке пороговой величиной может быть 1, т.е. источник информации считается идентифицированным при совпадении всех слов выборки со словами текста этого источника информации. В случае оценки ситуации за заданный временной интервал пороговая величина может быть установлена, к примеру, на уровне 0,7. При этом любой временной интервал той же длительности, что и временной интервал, указанный в запросе, для которого статистическая мера сходства окажется больше этого порога, будет считаться интервалом со сходной ситуацией. В другом случае пороговая величина может быть указана как максимальная среди всех найденных, - тогда ситуация будет считаться наиболее сходной с той, которая была во временном интервале, давшем максимальную статистическую меру сходства с временным интервалом, указанным в запросе.
Все рассмотренные выше операции выполняются с помощью общеизвестных программных операций - сравнений, подсчета повторений, вычисления статистических величин и т.п. Конкретный вид соответствующих программ будет определяться конкретным видом аппаратного обеспечения и установленной на нем операционной системы и не являются предметом патентных притязаний заявителя. С другой стороны, для выполнения рассмотренных выше операций может использоваться устройство, аналогичное устройству по патенту РФ N 2113726 (G 06 K 9/00, публ. 20.06.98). Таким образом, из приведенного описания видно, что предлагаемое изобретение позволяет идентифицировать различные объекты с учетом их подобия (статистической меры сходства).
Настоящее изобретение может использоваться в различных областях информационной технологии, например, в информационном поиске, оценке ситуаций и т.д.
Приведенные примеры реализации настоящего изобретения служат лишь в качестве иллюстраций и никоим образом не ограничивают объема патентных притязаний, определяемого нижеследующей формулой изобретения.
Изобретение относится к вычислительной технике и может использоваться для анализа ситуаций, при информационном поиске и т.п. Техническим результатом является расширение возможностей идентификации объекта за счет использования неограниченного объема дополнительной информации, характеризующей этот объект. Для этого в процессе формирования тезаурусов каждого текста осуществляют лингвистическую сортировку всех слов текста по заранее заданным кластерам; статистическую обработку слов осуществляют для каждого кластера данного текста; осуществляют лингвистическую сортировку всех слов из выборки слов сформированного запроса, аналогичную лингвистической сортировке слов при формировании тезаурусов текстов; в процессе сравнения вычисляют статистическую меру совпадения тезаурусов для выборки слов из сформированного запроса и текстов из выбранной базы данных; решение об идентификации конкретного объекта принимают на основе сопоставления вычисленных статистических мер совпадения для различных текстов. 10 з.п. ф-лы.
| СПОСОБ УСТАНОВЛЕНИЯ В ХРАНИЛИЩЕ МЕСТОПОЛОЖЕНИЯ ОБЪЕКТА ПО ПОИСКОВОМУ ТЕМАТИЧЕСКОМУ ПРИЗНАКУ | 1994 |
|
RU2107942C1 |
| УСТРОЙСТВО ОБРАБОТКИ ИНФОРМАЦИИ ДЛЯ ИНФОРМАЦИОННОГО ПОИСКА | 1996 |
|
RU2096825C1 |
| Система для поиска и обработки научно-технической информации | 1981 |
|
SU993273A1 |
| RU 2066473 C1, 10.09.96 | |||
| US 4775956 A, 04.11.88 | |||
| US 4499553 A, 12.02.85 | |||
| УСТРОЙСТВО ДЛЯ УПАКОВКИ ПРОДУКТОВ в ПАКЕТЫ | 0 |
|
SU304191A1 |
| КОМПЬЮТЕРНОЕ УСТРОЙСТВО ДЛЯ ЧТЕНИЯ ПЛОСКОПЕЧАТНОГО ТЕКСТА | 1996 |
|
RU2113726C1 |
