Предшествующий уровень техники
Предлагаемое изобретение касается способа автоматического распознавания символов, отпечатанных на любом подходящем для этого материале, даже в том случае, когда фон обладает весьма контрастными структурами, вследствие этого сильно интерферирующими со структурой отпечатанных символов.
Подавляющее большинство известных систем распознавания символов подходит к решению этой проблемы, пытаясь отделить символы от фона посредством использования системы пороговых значений, часто весьма хитроумной и сложной.
К сожалению, такая технология не приводит к успеху в тех случаях, когда контраст структур фона является весьма значительным, особенно если положение символов является переменным по отношению к упомянутым структурам. Как следствие, изображения символов в ряде случаев содержат часть знаков фона (тех, которые превышают уровень соответствующего порогового значения) или иногда эти изображения не являются полными, поскольку часть структуры символов не превышает соответствующего порогового значения.
Это, в частности, относится к случаю контроля банковских билетов, на которых печать номеров серии осуществляется в процессе фазы, отдельной (обычно последующей) от фазы печати остального изображения, и обычно с использованием другого печатного оборудования. Таким образом, регистрация не может быть вполне совершенной и, следовательно, номера серии "шевелятся" по отношению к фону.
Это означает, что если эти номера отпечатаны на структурированной зоне данного банковского билета, то есть на зоне, содержащей какой-либо рисунок, то они "шевелятся" или могут быть смещены произвольным образом по отношению к структуре (к рисунку) фона. В дополнение к сказанному выше в упомянутых случаях даже поиск и сегментация символов могут не привести к успеху по причине наличия специфических структур фона.
Действительно, даже с учетом огромного количества вариаций процесс выделения и распознавания символов практически всегда проходит через следующие этапы, при которых осуществляют
- считывание изображений документа и, особенно, объекта, содержащего подлежащие распознаванию символы. Считывание этих изображений обеспечивается посредством электронной камеры, после чего эти изображения обычно подвергаются обработке с целью повышения контраста и снижения помех;
- поиск на изображении (теперь уже электронном) положения символов, подлежащих распознаванию. Этот поиск часто основывается на анализе резких изменений освещенности (типа перехода от белого к черному) и, в частности, пространственного распределения этих переходов;
- сегментацию идентифицированной зоны на участки, каждый из которых содержит только один символ. Эта сегментация осуществляется, например, путем анализа проекции плотности черного на сегмент, параллельный основанию линии символов: минимальные значения этой плотности поддаются корреляции с белым пространством между символами;
- каждый изолированный таким образом символ сопоставляют с прототипами (моделями) всех букв и/или всех цифр, либо с точки зрения степени их совпадения (технологии, известные под английским названием "template matching"), либо с точки зрения последовательности характерных структур, таких, например, как вертикальные линии, горизонтальные линии, наклонные линии и т.п. (технологии, известные под названием "features extraction" или структурный анализ).
В любом случае очевидно, что если часть изображения, сегментированная как символ, содержит структуры, посторонние по отношению к форме самого этого символа (например, линии, принадлежащие структуре фона), опасность несостоятельности или неудачи сравнения с упомянутыми прототипами оказывается весьма высокой. Эта опасность также может быть обусловлена потерей отличительных частей структуры данного символа с последующим резким пороговым переходом в фазе отделения этого символа от фона.
Именно поэтому предшествующие подходы к решению проблемы автоматического распознавания символов, отпечатанных на сильно структурированных фонах, обладающих высокой контрастностью, не являются вполне удовлетворительными.
Краткое описание изобретения
В соответствии с предлагаемым изобретением объекты, на которых печатаются подлежащие распознаванию символы, подвергаются оптическому анализу при помощи хорошо известных оптоэлектронных средств, таких, например, как камера типа CCD (линейная или матричная, черно-белая или цветная) с желаемой разрешающей способностью, для формирования электронных изображений символов, подлежащих распознаванию.
В последующем изложении будет использован термин "изображение" в смысле электронного изображения, в частности, дискретной системы величин световой насыщенности, обычно организованной в виде прямоугольной матрицы. Каждый элемент этой матрицы или так называемый пиксель представляет собой меру интенсивности света, отраженного соответствующей частью объекта. Для цветных изображений их общее описание состоит из трех матриц, соответствующих составляющим красного, зеленого и синего цветов для каждого элемента изображения или пикселя. Для упрощения изложения последующее описание касается случая черно-белого изображения. При этом расширение для цветного изображения осуществляется путем повторения тех же самых операций для трех матриц.
В основу предлагаемого изобретения положена задача реализации автоматического распознавания на электронных изображениях символов, отпечатанных на сильно структурированном фоне, контрастность которого даже может быть сопоставима с контрастностью структур самих этих символов (как это показано на примере, проиллюстрированном на фиг.I/4c).
Первый шаг способа в соответствии с предлагаемым изобретением состоит в формировании модели фона, которая может быть получена путем считывания изображений одного или нескольких образцов, на которых представлен только рисунок фона без всяких символов (как это показано на примере, проиллюстрированном на фиг.I/4б).
В качестве такой модели можно использовать, в частности, среднее арифметическое изображение упомянутых образцов. При этом в случае черно-белых изображений будет получена одна единственная матрица этих усредненных изображений, тогда как в случае цветных изображений этих матриц усредненных изображений будет три, например, матрицы красного, зеленого и синего цветов.
Затем формируют модели подлежащих распознаванию символов (например, букв и/или цифр), либо путем считывания изображений системы этих символов, отпечатанных на белом фоне, либо путем непосредственного использования электронных изображений из информационных компьютерных файлов, которые в настоящее время имеют коммерческое распространение для большинства шрифтов. В первом случае можно сформировать модель каждого подлежащего распознаванию символа в виде усредненного изображения из некоторого числа экземпляров одного и того же символа, отпечатанного на белом фоне.
После того, как сформированы модели всех символов и модель фона, первая фаза данного способа, которую можно назвать "фазой отладки", завершается.
В процессе осуществления последующей фазы распознавания символов выполняются действия в соответствии со следующими этапами:
- осуществляют считывание изображения подлежащего распознаванию образца, содержащего неизвестные символы, отпечатанные на определенном фоне в положениях, которые также являются неизвестными (пример проиллюстрирован на фиг.II/4-а);
- регистрация модели фона вместе со считанным изображением при помощи любой из известных технологий регистрации изображений, например, с использованием метода максимальной корреляции;
- вычитание зарегистрированной модели фона из считанного изображения. Полученное таким образом разностное изображение, где фон будет практически полностью устранен, очень четко выявляет положение символов (пример разностного изображения, которое представляет собой считанное изображение минус зарегистрированная модель фона, показан на фиг.II/4-б);
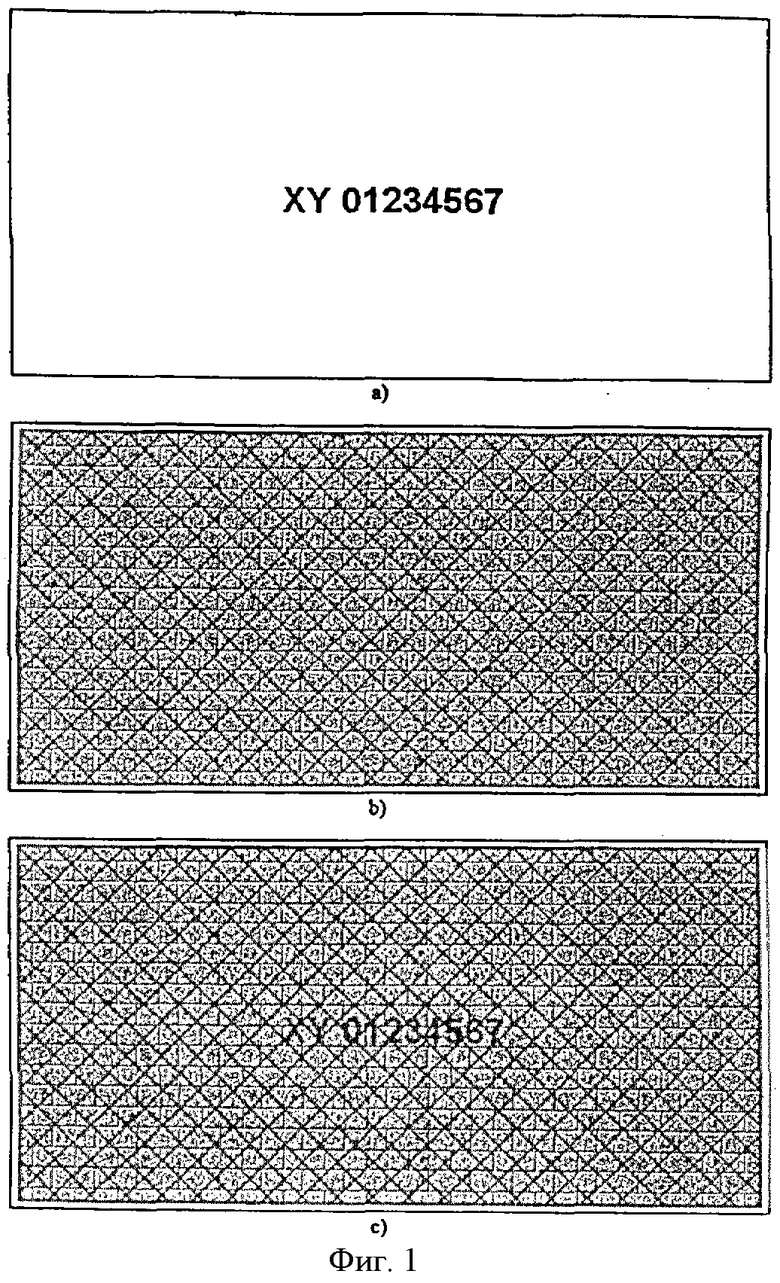
- поиск положения каждого из символов на разностном изображении. Эта операция осуществляется при помощи любой из известных технологий локализации и сегментации символов, например, путем анализа резких переходов насыщенности типа перехода от черного к белому. Таким образом, для каждого положения символа будет выделено элементарное изображение, размеры которого совпадают с размерами моделей символов (на фиг.III/4б показаны примеры элементарных изображений сегментированных символов);
- выделение зарегистрированной модели фона из элементарного изображения фона, соответствующего каждому неизвестному символу;
- комбинирование, для каждого из положений символов, моделей символов с соответствующим элементарным изображением модели фона (см. фиг.III/4-c). Поскольку модель фона была зарегистрирована вместе с фоном изображения, содержащего подлежащие распознаванию символы, в элементарных изображениях, сочетающих модель фона с моделью цифр и/или букв, относительное положение символ-фон оказывается тем же самым, что и в неизвестном изображении. Таким образом, в синтезе для каждого положения символа будут созданы новые прототипы (комбинированные модели) символов (букв и/или цифр) с тем же самым фоном, что и в неизвестном изображении. Одна из разработанных технологий комбинирования будет описана в разделе "Описание нескольких предпочтительных вариантов". Однако здесь может быть использован и любой из методов, предложенных другими авторами;
- сопоставление каждого из неизвестных символов со всеми моделями, комбинированными на предыдущих этапах. Распознавание символа с фоном осуществляется, таким образом, путем сопоставления с моделями символов с тем же самым фоном и в том же самом положении. Здесь можно использовать любые известные технологии распознавания, например, метод "template-matching" или "features extraction" и т.д.
Краткое описание чертежей
На фиг.I/4 представлен пример последовательности символов, отпечатанных на сильно структурированном и обладающих высокой контрастностью фона, причем на виде а) показана последовательность символов, отпечатанных на белом фоне, на виде б) показан рисунок собственного фона и на виде с) показана последовательность символов а), отпечатанная на фоне б).
На фиг.II/4 вид а) полностью соответствует виду с), показанному на фиг.I/4, тогда как вид б) демонстрирует результат вычитания модели зарегистрированного фона из изображения полностью отпечатанного билета.
На фиг.III/4 вид а) демонстрирует участок билета из примера, показанного на предыдущих фигурах, содержащий подлежащие распознаванию символы, и вид б) демонстрирует элементарные изображения, соответствующие каждой позиции символа, в качестве результата сегментации. Вид с) показывает, для каждого положения символа, комбинацию, соответствующую элементарным изображениям зарегистрированного фона с моделями всех возможных символов, то есть комбинированные модели, описанные в тексте. Этот пример наглядно показывает, что подлежащие обработке символы (б) могут быть более эффективно распознаны, если сравнивать с комбинированными моделями (с), чем с моделями символов, отпечатанных на белом фоне (показаны, например, на фиг.III/4-d).
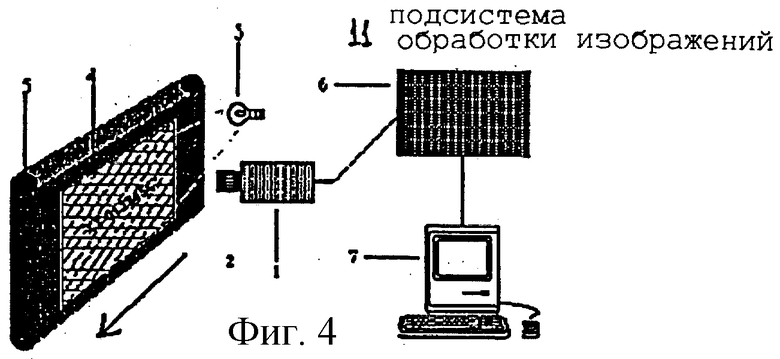
На фиг.IV/4 показана типичная схема построения системы распознавания, описанной в тексте.
Описание предпочтительных вариантов осуществления изобретения
В последующем изложении будет описан в качестве не являющегося ограничительным примера реализации предлагаемого изобретения один из предпочтительных ее вариантов, касающийся автоматического распознавания номеров серий, отпечатанных на банковских билетах.
Действительно, в большинстве типов банковских билетов номер серии частично или полностью печатается прямо на рисунке фона этого билета. Печатание банковских билетов осуществляется, в частности, с использованием смешения различных технологий, обычно, по меньшей мере, офсета и мелкой насечки. Эта последняя технология, в частности, обычно представляет зоны с большим количеством линий очень высокого контраста. Когда печатают номер серии на одной из этих зон, достаточно трудно с использованием обычных технологий отделить символы от фона, а значит и распознать эти символы.
Кроме того, номер серии обычно печатается на заключительной фазе производства, после офсетной печати и мелкой насечки, и на другой печатной машине. Даже если используются весьма сложные и современные системы разметки, относительная регистрация между номерами серии и рисунком фона в результате оказывается скорее переменной, и может обычно "шевелиться" или смещаться в пределах нескольких миллиметров.
На фиг.IV/4 показано построение системы распознавания номеров серии на банковских билетах. Здесь линейная камера CCD 1 со своими линзами 2 и своей системой освещения 3 используется для считывания изображений банковских билетов 4, на которых необходимо прочитать номера серий, пока они транспортируются при помощи всасывающей ленты 5.
Линии сканирования камеры последовательно запоминаются в первом контуре буферного запоминающего устройства подсистемы обработки изображений 6 для формирования электронного изображения каждого банковского билета.
Подсистема обработки изображений 6, которая может быть основана как на специализированной вычислительной аппаратуре, так и на программируемых компьютерах типа DSP (Digital Signal Processor), быстродействующих персональных компьютерах PC и т.д., осуществляют различные операции как в фазе отладки (формирование модели фона и моделей символов), так и в фазе распознавания.
В процессе осуществления фазы отладки модели фона подсистема обработки изображений:
- обеспечивает сбор не пронумерованных изображений банковских билетов, выбранных в качестве "Набора для отладки фона" (НОФ) (EAF) и запоминает этот набор в соответствующем запоминающем устройстве;
- выделяет из набора НОФ одно "эталонное" изображение для регистрации и делает это либо автоматически (например, выделяет первое изображение из набора НОФ), либо с помощью оператора системы, который использует для этого пульт управления 7;
- регистрирует все изображения из набора НОФ, определяя, прежде всего, горизонтальное смещение Δх и вертикальное смещение Δу каждого изображения по отношению к эталонному изображению, и накладывая затем соответствующее смещение -Δх и -Δу. В этом варианте измерение смещения осуществляется с использованием метода максимальной корреляции. Небольшой прямоугольный участок S0 (основа разметки) эталонного изображения с центром, имеющим координаты х0, у0, выбранные, например, оператором (вне зоны надпечатывания символов), сопоставляется с участком S1 тех же размеров, центр которого смещается шаг за шагом на каждую позицию (пиксель) изображения из набора НОФ для того, чтобы найти положение х1, y1, где коэффициент корреляции имеет свое максимальное значение (это соответствует наиболее точному наложению между двумя изображениями). При этом смещение может быть определено следующим выражением:
Δx=х1-х0 и Δу=у1-у0
В соответствии с этим вариантом модель фона Mf формируется в виде среднего арифметического изображения НОФ, зарегистрированных вместе с эталонным изображением.
В процессе осуществления фазы отладки моделей символов подсистема обработки изображений 6:
- обеспечивает сбор изображений совокупности банковских билетов, где на белом фоне отпечатаны все цифры и/или буквы, используемые в номерах серии, каждая поодиночке, и в известных положениях (набор для отладки символов HOC (EAC);
- затем сегментирует изображения из набора EAC в элементарные изображения, каждое из которых содержит один единственный символ. В соответствии с этим вариантом сегментация обеспечивается с использованием стандартной технологии анализа перехода от черного к белому, весьма эффективной в тех случаях, когда символы отпечатаны на белом фоне;
- формирует модель Ms для каждого символа (буквы или цифры) как среднее арифметическое из набора НОС элементарных изображений каждого положения, зарегистрированного, например, вместе с символом первого билета из набора НОС, взятого в качестве эталонного. Регистрация и усреднение осуществляются так же, как и в случае модели фона, но основы разметки совпадают с целым элементарным изображением символа.
Обычно в составе номера серии банковского билета используются буквенные и цифровые символы одного и того же шрифта. Таким образом, обычно будет достаточно одного положения на билетах из набора НОС на символ (один символ А, один символ В и т.д.). В другом случае будет необходимо предусмотреть столько положений на символ, сколько используется различных шрифтов (например, А шрифта New York, А шрифта Courrier, А шрифта Geneve и т.д.).
В процессе осуществления фазы распознавания в соответствии с описываемым здесь вариантом реализации предлагаемого изобретения подсистема обработки изображений 6 после считывания изображения:
- прежде всего, регистрирует изображение фона каждого подлежащего считыванию банковского билета вместе с моделью фона посредством той же основы разметки, которая была использована для отладки модели, и с применением той же технологии корреляции;
- формирует разностное изображение, которое представляет собой зарегистрированное изображение полного билета минус модель фона, после чего осуществляет поиск положений символов. Используемая при этом технология основывается на уже упомянутом выше анализе переходов. Обычно поиск может быть выполнен на ограниченной зоне билета, поскольку печать номера серии может быть смещена по отношению к рисунку фона не более, чем на несколько миллиметров;
- выделяет для каждого положения символа, отмеченного на разностном изображении, соответствующее элементарное изображение модели фона. Будучи зарегистрированным, упомянутое элементарное изображение будет точно представлять собой участок фона, на котором был отпечатан неизвестный символ;
- комбинирует для каждого положения символа соответствующее зарегистрированное элементарное изображение фона Mf с каждой из моделей символов Ms.
Также для каждого положения символа будут получены новые модели, символы плюс фон, с тем же относительным положением, что и на подлежащем считыванию билете. В этом варианте реализации предлагаемого изобретения упомянутая комбинация Мс формируется, пиксель за пикселем, с использованием следующих уравнений:
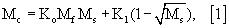
если сначала печатают фон, а затем печатают символы. В противном случае:
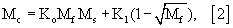
Во всех случаях коэффициенты Ко и K1 представляют собой константы, характеризующие используемые типографские краски и бумагу. В уравнениях [1] и [2] первый член (а именно, произведение KoMfMs) учитывает передающую способность используемых типографских красок и отражающую способность бумаги, тогда как второй член в этих уравнениях связан с отражающей способностью поверхности типографской краски, которая была нанесена последней;
- для каждого положения символа рассчитывает коэффициент корреляции между соответствующим элементарным изображением билета и всеми новыми моделями (символы плюс фон). При этом подлежащий обработке символ распознается как символ комбинированной модели, соответствующей максимальному значению упомянутого коэффициента корреляции;
- в соответствии с этим вариантом реализации предлагаемого изобретения дополнительно проводят сопоставление упомянутого максимального значения коэффициента корреляции с некоторым пороговым значением для того, чтобы проверить качество печати символа и фона элементарных изображений, соответствующих каждому положению символа. Если качество оказывается удовлетворительным (подлежащее обработке элементарное изображение и комбинированная модель являются практически идентичными), коэффициент имеет значение, весьма близкое к 1, тогда как плохое качество будет соответствовать значению коэффициента, более близкому к нулю.
Другие предпочтительные варианты реализации предлагаемого изобретения будут включать:
a) его применение для распознавания символов на документах, отличных от банковских билетов, то есть таких, например, как письма, почтовые карточки, этикетки, банковские или почтовые чеки и т.д.;
b) замену системы транспортировки на ленте на систему транспортировки, подходящую для листов больших размеров, например, на цилиндр по типу используемых в типографских печатных машинах или на систему в соответствии с патентом США №5598006 от 28.01.1998;
c) замену в системе распознавания линейной камеры на матричную камеру;
d) использование усредненного изображения набора изображений НОФ в качестве эталонного изображения для регистрации фона;
e) автоматическое выделение основы разметки для регистрации фона, например, в соответствии с технологией, предложенной в Патенте княжества Монако №2411992479;
f) построение модели фона с использованием способа, отличного от усреднения, например, с использованием технологии, указанной в Патенте США №5778088 от 7.07.1998.
Список использованной литературы
(1) L.Stringa - "Inspection Automatique de la qualite d’impression par un modele elastique" - Патент на изобретение №2411.99.2479, выданный Государственным Министерством княжества Монако (27.04.99).
(2) L.Stringa - "Procedur for Producing A Referance Model etc." - Патент США №5.778.088 - 7 июля 1998 г.
(3) L.Stringa - "Procede de controle automatique de la qualite d’impression d’une image multichrome" - Заявка на Европейский патент №97810160.8-2304.
(4) L.Stringa - "Installation for Quality Control of Printed Sheets, Especially Security Paper" - Патент США №5.598.006 - 28 января 1998 г.
(5) Rice-Nagy-Nartkr - "Optical Character Recognition" - Klumer Academic Publshers - 1999.

Изобретение относится к автоматическому распознаванию символов, напечатанных на структурированном фоне, как это имеет место, например, на банкнотах и ценных бумагах. Его применение позволяет получить технический результат в виде обеспечения реализации автоматического распознавания символов, напечатанных на сильно структурированном фоне. Этот результат достигается благодаря тому, что способ включает в себя следующие этапы: отладки, формирования моделей символов, распознавания, регистрации модели фона вместе с фоном считанного изображения, выделения модели зарегистрированного фона из элементарного изображения фона, комбинирования для каждого положения символа модели букв и/или цифр с элементарным изображением соответствующего фона, создания комбинированных моделей, сопоставления неизвестных символов с комбинированными моделями, распознавания каждого неизвестного символа как соответствующего символа, комбинированная модель которого наилучшим образом накладывается на него в соответствии с технологией “сравнение с шаблоном”. 9 з.п. ф-лы, 4 ил.
 ;
;
Ms≈Mf,
если сначала печатают фон, а затем печатают символы, в противном случае:
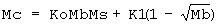 ;
;
Ms≈Mf,
где Mb - модель символа b;
Mf - модель фона;
Ms - модель для каждого символа;
Ко и К1 - коэффициенты, представляющие собой константы.
| Устройство для распознавания изображений | 1983 |
|
SU1215123A1 |
| US 5710830 А, 20.01.1998 | |||
| Кипятильник для воды | 1921 |
|
SU5A1 |
| US 5630037 А, 13.05.1997. | |||

