Область техники, к которой относится изобретение
Настоящее изобретение относится к оптическому коду, который требуется закреплять на предмете с целью обработки информации. Более конкретно, изобретение относится к оптическому символу, используемому в оптическом коде, способу крепления оптического символа на предмете и способу декодирования.
Изобретение дополнительно относится к коду оптического распознавания. Более конкретно, изобретение относится к технологии считывания кода оптического распознавания (технологии определения контура символов).
Изобретение также относится к коду оптического распознавания. Более конкретно, изобретение относится к эффективному способу восстановления данных для кода оптического распознавания, называемого цветным битовым кодом 1D (Заявка №2006-196705 на японский патент), предложенного автором настоящего изобретения. Изобретение также представляет спецификацию, пригодную для эффективного восстановления данных. Таким образом, настоящее изобретение также относится к методике кодирования кода оптического распознавания.
Уровень техники
Для оптического считывания с целью обработки информации используют различные символы, которые закрепляют на предметах. Например, так называемый штрихкод, с помощью которого записывают информацию в виде черно-белых структур в одномерном направлении, используют уже в течение длительного времени.
Оптический код с использованием цветов
В качестве оптических кодов также широко предлагают коды, в которых используются хроматические цвета, такие как красный и синий (для удобства такие коды, использующие хроматические цвета, будут называться здесь цветными кодами), кроме черного и белого цветов.
Обычно в оптическом коде (системе), в котором используются цвета (использование хроматических цветов), когда происходит изменение цвета при детектировании с помощью считывателя, вероятность того, что соответствующие данные также изменятся, будет выше, чем в черно-белом коде. Вследствие этого возникает проблема, состоящая в том, что оптический код, построенный с использованием цветов, подвержен воздействию ухудшения состояния цветов, неровностей при печати, изменений света освещения и т.п.
Обычный патентный уровень техники
Например, в отмеченном ниже патентном документе 1 раскрыт штрихкод, в котором используют три цвета. Штрихкод построен так, что "1" выражают, когда происходит переход цветов в первом порядке, и "0" выражают, когда происходит переход цветов во втором порядке.
В патентном документе 2, упомянутом ниже, раскрыт код, реализующий повышенную емкость данных путем установки плотности цвета каждого из трех основных цветов с множеством тонов.
В патентном документе 3, упомянутом ниже, раскрыты двумерный код, в котором информация разделена на заданные последовательности битов, в соответствии с возможностями печати принтера, и цвет выбирают и записывают для каждой из разделенных последовательностей битов, способ генерирования двумерного кода и способ восстановления.
В патентном документе 4, упомянутом ниже, раскрыт код, который можно использовать как цветной штрихкод, так же как и общий черно-белый штрихкод.
В упомянутой выше заявке №2006-196705 на японский патент заявитель настоящего изобретения предложил код оптического распознавания, выражающий информацию путем перехода и изменения цветов. Код оптического распознавания называется "цветным битовым кодом 1D". В цветном битовом коде 1D, поскольку ограничения по размерам и форме области, занимаемой каждым из цветов, не установлены, код оптического распознавания может быть нанесен даже на грубую поверхность или на мягкий материал.
Однако, поскольку размер и форма области, занимаемой заданным цветом, не являются постоянными, с помощью обычной техники считывания трудно обрабатывать такой цветной битовый код 1D.
Обычные технологии считывания штрихкода
С другой стороны, хорошо известен так называемый двумерный штрихкод. Обычно двумерный штрихкод выражает данные с помощью черного и белого цветов (светлого и темного) в сегментах, положения которых определены в виде сетки. Обычно "маркировочная структура" (которая относится к структуре двумерного штрихкода, включающего в себя зоны, не содержащие данные, используемые для обозначения границ) интегрирована с "помеченным объектом" в качестве объекта, подвергаемого маркировке. Обычно маркировочная структура интегрирована в поверхность маркированного объекта с помощью печати или тому подобное.
Когда выполняют оптическую съемку (съемку данных в виде данных двумерного изображения с помощью датчика области или тому подобное) для считывания двумерного штрихкода, обычно, часть "маркированного объекта" также снимают (вместе с двумерным штрихкодом).
Даже в случае, когда только "маркировочная структура" плавает в воздухе (например, в случае, когда маркируемый объект, который должен быть промаркирован, представляет собой прозрачный объект, или двумерный штрихкод подвешен на нитке или тому подобное), как правило, неизбежен захват фонового изображения вместе с маркировочной структурой.
Здесь изображение, введенное помимо "маркировочной структуры", в данном случае называется "фоновым изображением". Ввод изображения "маркировочной структуры" называется "маркировочным изображением".
Для декодирования "маркировочного изображения", очевидно, необходимо в качестве первых этапов:
- разделить "маркировочное изображение" и "фоновое изображение" друг от друга,
- распознать точный диапазон "маркировочного изображения".
Такие операции обычно называются "вырезанием" "маркировочного изображения". В случае обычного двумерного штрихкода предпринимают следующие процедуры. Множество специфичных структур (обычно вызываемых "метками вырезания") находят в результате распознавания изображения на изображении, снятом датчиком области. На основе размеров "меток вырезания" и взаимного положения между ними оценивают существующий диапазон двумерного кода. В частности, оценивают диапазон и размер структуры двумерного штрихкода и этот диапазон сегментируют. По данным, считанным из каждого из сегментов, распознают существование двумерного штрихкода в сегменте.
С другой стороны, обычный одномерный штрихкод представляет данные по толщине черных и белых (темных и светлых) полосок. Полоски на обоих концах ненарушенных зон соответствуют "меткам вырезания" в двумерном штрихкоде.
Однако в общих спецификациях одномерного штрихкода предполагается использование линейных "линий сканирования", и считывают темные и светлые структуры на линии. Вследствие этого концепции вырезания маркировочной структуры для отделения ее от фонового изображения не существует.
В одномерном штрихкоде обычно важно выровнять "линию сканирования" с полосками одномерного штрихкода.
Такая операция может быть выполнена различным образом.
Во-первых, она может быть выполнена с помощью визуального наблюдения оператора. Во-вторых, она может быть выполнена путем излучения множества линий сканирования аналогично растровому сканированию. В этом способе штрихкод удерживают в диапазоне, в котором присутствуют линии сканирования, сканируют, используя множество линий сканирования, и декодирование выполняют на основе результата сканирования.
Обычно, как правило, используют первый или второй способ.
Поэтому идея "вырезания" в одномерном штрихкоде является доступной по сравнению с двумерным штрихкодом. С другой стороны, заданная ширина (длина толстых и тонких полосок) необходима для "маркировочной структуры" в штрихкоде, и когда толщина чрезвычайно мала или большая, или в случае, когда скомпонованные вместе полоски изогнуты, очень трудно выполнить декодирование.
Предшествующий уровень техники обычной структуры
Например, в патентном документе 5, упомянутом ниже, раскрыт способ вырезания, позволяющий легко вырезать штрихкод, отделяя его от знаков и рисунков.
В патентном документе 6, упомянутом ниже, раскрыт способ печати штрихкода, включающего в себя большое количество информации на малом пространстве. В частности, он отличается тем, что штрихкод вырезают как набор нижних дуг, имеющих средний угол θ.
В патентном документе 7, упомянутом ниже, раскрыто устройство для считывания двумерного штрихкода. В частности, в нем раскрыта технология, отличающаяся переключением средства декодирования в соответствии с качеством изображения.
Кроме того, в патентном документе 8, упомянутом ниже, раскрыт способ вырезания штрихкода, позволяющий считывать множество штрихкодов. В соответствии с раскрытой здесь технологией, даже если левый и правый края будут нестандартными, их можно будет постоянно распознавать, и, таким образом, можно вырезать множество штрихкодов.
Как описано выше, заявитель настоящего изобретения предложил код оптического распознавания, представляющий информацию в соответствии с переходом и изменением цветов в заявке №2006-196705 на японский патент, упомянутый выше. Код оптического распознавания называется "цветным битовым кодом 1D".
Цветной битовый код 1D имеет структуру, возвращающую цифровое значение, определенное по последовательности множества цветов (сигнальных цветов). Основная спецификация представляет собой разлинованную последовательность (символов кода) цветов (сигнальных цветов).
Поэтому, по мере того как количество представленных данных увеличивается, символ кода становится длинным. В результате увеличивается вероятность того, что весь одиночный символ кода нельзя будет снять одновременно.
В некоторых случаях конкретный одиночный код оптического распознавания, который представляет собой геометрическую фигуру и представляет заданные данные, в частности, называется "символом кода" (или просто "символом"). Конкретный символ кода снимают с помощью камеры CCD (ПЗС, прибор с зарядовой связью) или тому подобного и выполняют заданную обработку изображения для восстановления исходных данных.
На практике предполагаются случаи, когда символ кода не может быть включен в поле зрения изображения камеры и когда часть символа кода закрыта. В таких случаях, поскольку символ кода нельзя снять на одном экране, трудно восстановить данные. Поэтому необходимо, чтобы оператор тщательно снимал данные.
Известен обычный черно-белый штрихкод, основанный на концепции совмещения. В случае когда данные считывают частично, а не полностью, множество частей частично считанных данных снимают и совмещают для восстановления данных исходного единого штрихкода (который представляет собой весь единый символ кода).
Такую технологию совмещения применяют для считывания с помощью растрового сканера и считывания совмещенного двумерного штрихкода. Во время считывания кода данные в значительной степени совмещают на основе особенной структуры, обозначающей конечную точку или центр. На фиг.27 показано состояние совмещения.
На фиг.27 представлен пример штрихкода 3010, в котором используются обычные черные и белые полоски. Линии сканирования вычерчены на штрихкоде. Можно легко понять, что линия 3012 сканирования сканирует только верхнюю левую часть символа кода, и, таким образом, получают только часть левой стороны символа кода. С другой стороны, можно легко понять, что линия 3014 сканирования сканирует только нижнюю правую часть символа кода, и, таким образом, получают только часть правой стороны символа кода.
Очевидно, в таком случае, в результате совмещения данных, снятых путем сканирования двух линий 3012 и 3014 сканирования, может быть снят единый полный символ 3010 кода. Вследствие этого такая технология широко используется.
В такой технологии совмещения считывают структуру частичного снятого кода и определяют, какая из частей была считана. На основе этого определения выполняют совмещение. Поэтому структура штрихкода должна иметь некоторую избыточность.
Следует учесть, что совмещение на основе такой избыточности также можно применять для цветного битового кода 1D для улучшения точности считывания.
Определение цветного битового кода 1D
Определение цветного битового кода 1D, разработанного авторами настоящего изобретения, будет описано ниже. Цветной битовый код 1D определен следующим образом:
- цветной битовый код 1D представляет "ячейки", как области определенного цвета, которые расположены в линию (= "последовательность ячеек");
- используют множество цветов и определенный цвет назначают каждой ячейке;
- ячейки не включают в себя друг друга. Таким образом, ячейка не включена в другую ячейку;
- количество ячеек, составляющих последовательность, представляет собой заранее определенное число; и
- один и тот же цвет не назначают соседним ячейкам, но всегда назначают разные цвета.
Цветной битовый код 1D в принципе генерируют на основе этих условий.
Очевидно, что количество ячеек, видов цветов, используемых фактически, и т.п. изменяются в зависимости от вариантов применения.
Обычный патентный предшествующий уровень техники
Ниже будет описан некоторый обычный предшествующий уровень техники.
Например, в патентном документе 9, упомянутом ниже, раскрыта технология печати ID (ИД, идентификационного) кода с использованием полоски с 4 состояниями и печати локального кода с использованием штрихкода в соответствии со способом "присутствия-отсутствия" полоски, что предотвращает, таким образом, потерю при печати.
В патентном документе 10, упомянутом ниже, раскрыта технология, позволяющая считывать штрихкод даже, когда объект, снятый камерой ПЗС, слабо выражен или отсутствует часть штрихкода.
В патентных документах 8 и 11, упомянутых ниже, раскрыт термочувствительный носитель записи, который включает в себя термочувствительный цветной слой, содержащий цветное соединение, имеющее характеристику поглощения, близкую к инфракрасному диапазону, и в котором структура цветов представляет собой Калра-код (Calra code, система кодирования, введенная в Японии). При этом описано, что даже если в автоматически распознаваемом коде отсутствует некоторая часть, его можно считать.
Патентный документ 1
Выложенная заявка № S63-255783 на японский патент (Патент №2521088)
Патентный документ 2
Выложенная заявка №2002-342702 на японский патент
Патентный документ 3
Выложенная заявка №2003-178277 на японский патент
Патентный документ 4
Выложенная заявка №2004-326582 на японский патент
Патентный документ 5
Выложенная заявка №2005-266907 на японский патент
Патентный документ 6
Выложенная заявка №2005-193578 на японский патент
Патентный документ 7
Выложенная заявка № Н08-305785 на японский патент
Патентный документ 8
Выложенная заявка № Н08-185463 на японский патент
Патентный документ 9
Выложенная заявка №2006-095586 на японский патент
Патентный документ 10
Выложенная заявка №2000-249518 на японский патент
Патентный документ 11
Выложенная заявка № Н08-300827 на японский патент
Сущность изобретения
Задачи, решаемые изобретением
"Задача 1"
Как описано выше, так называемый одномерный штрихкод широко используется на практике как система кодов, в которой коды расположены в одной размерности. Хотя существует некоторое количество видов одномерных штрихкодов, в них используется система кодов, которая кодирует изображения с использованием вариаций ширины черных и белых (темных и светлых) структур, которые расположены поочередно. Следует понимать, что в двумерном штрихкоде используется аналогичная концепция, в которой "ширина" заменена "положением ячейки".
Обычно штрихкод печатают непосредственно на бумаге или на продукте. Поэтому, если описанная выше концепция будет выполнена, как есть, не возникают какие-либо проблемы.
Однако в обстоятельствах, когда штрихкод может быть напечатан только на предмете, размеры которого могут быть изменены, или может быть напечатан неаккуратно, не всегда можно сказать, что способ, основанный на ширине полосок, представляет собой правильный способ. В таком случае, хотя существует потребность в закреплении ИД, пользователь во многих случаях вынужден отказаться от этого способа из-за описанной выше проблемы.
С другой стороны, как описано выше, было предложено достаточное количество так называемых цветных штрихкодов. Однако большинство обычных цветных штрихкодов направлены на увеличение плотности данных. При этом повсеместно можно найти штрихкоды, в которых реализовано увеличенное количество цветов и повышена плотность для увеличения плотности данных, но у которых отсутствует возможность практического использования.
В области обычного черно-белого штрихкода используют обычные технологии в том виде, как есть, и предложения решения проблем практически неизвестны. Это может быть связано с теми обстоятельствами, что обычно используют способ закрепления на предмете закрывающего элемента, на котором напечатан штрихкод, и штрихкод редко печатают непосредственно на предмете, форма которого может изменяться.
Однако способ закрепления закрывающего элемента допускает вероятность незаконного поведения, такого как повторное закрепление закрывающего элемента или замена другим закрывающим элементом. Вследствие этого код, который может быть напечатан непосредственно на предмете, является предпочтительным.
Настоящее изобретение было выполнено с учетом таких проблем, и цель изобретения состоит в том, чтобы предложить новый штрихкод, который не зависит от ширины штрихкода, и обеспечить код с использованием оптического символа, который можно считывать с высокой точностью, даже в ситуации, когда такой код напечатан на предмете, размеры которого изменяются, или точность печати невысока.
"Задача 2"
Название описанного выше цветного битового кода 1D включает в себя обозначение "1D" (одномерный). Однако было бы более соответствующим описать настоящее изобретение в сравнении с обычным двумерным штрихкодом, поскольку используется двумерное изображение области датчика, и при этом обеспечивается определенная толщина и возможность изгиба "маркировочной структуры". Ниже описание будет приведено с соответствующим сравнением с обычным двумерным штрихкодом.
Выше был описан обычный способ вырезания двумерного штрихкода. Однако этот способ имеет основную техническую проблему, состоящую в том, что вырез не может быть выполнен, если структура выреза не может быть точно распознана.
В частности, двумерный штрихкод имеет следующие свойства.
- Если предварительное условие, состоящее в том, что двумерный штрихкод расположен в одной плоскости, не удовлетворяется, в принципе, такой двумерный штрихкод не может быть точно распознан. При этом необходим алгоритм считывания, основанный на предварительном условии, что в определенной степени может возникать ошибка.
- Операция, связанная с поиском специфичной структуры "метки вырезания" должна быть выполнена в состоянии, когда имеется усложненная "структура фонового изображения".
Поэтому необходимо выполнять оценку степени искажения метки вырезания, оценку размера допуска в случае, когда плоскость изогнута, и т.п. при определении меток вырезания в различных структурах фонового изображения. Если такую обработку выполнять полностью, объем обработки становится чрезмерным.
На практике требуется, чтобы пользователь выполнял некоторые вспомогательные операции, такие как увеличение области, занимаемой "маркировочным изображением" на весь экран, и регулировка положения (выполняет установку положения) "маркировочного изображения" на экране.
В случае когда множество штрихкодов присутствуют на изображении, обработка и установка положения становятся более сложными, и требуется более высокая точность. Вследствие этого возникает проблема, связанная с тем, что очень трудно реализовать такую обработку. Таким образом, на практике следует предполагать, что в одном изображении присутствует только один двумерный штрихкод.
Однако цветной битовый код 1D, разработанный авторами настоящего изобретения, представляет собой код, в котором должна быть распознана только компоновка цветов, и такой код является устойчивым к искажениям размеров, размыванию границ, к вариациям и т.п. размера и формы. Естественно для считывания цветной битовый код должен быть вырезан из изображения, в котором такой цветной битовый код был снят вместе с фоновым изображением с помощью датчика области или тому подобное.
Цель настоящего изобретения состоит в том, чтобы обеспечить более простой способ вырезания, в котором используются преимущества цветного битового кода 1D, разработанного авторами настоящего изобретения, который был бы устойчивым к искажениям, размыванию границ, изменениям и т.п. размеров и формы и который отличался бы от обычного двумерного штрихкода.
Другая цель настоящего изобретения состоит в том, чтобы предложить способ вырезания, позволяющий легко вырезать цветной битовый код 1D, даже когда множество цветных битовых кодов 1D присутствует в изображении.
"Задача 3"
(1) Кроме того, поскольку цветной битовый код 1D представляет собой код, полученный путем комбинирования множества видов цветов (например, трех видов), очень трудно генерировать определенную структуру, если не будет обеспечена чрезмерная избыточность. Однако чрезмерная избыточность приводит к увеличению длины последовательности цветов, и, таким образом, становится трудно использовать код на практике.
Одна из характеристик цветного битового кода 1D состоит в том, что множество символов кода можно легко считать одновременно.
Следовательно, авторы настоящего изобретения разработали технологию считывания кода, позволяющую обеспечить одинаковую или лучшую работу и эффекты, чем в обычном способе совмещения, используя способ совмещения символа кода, обозначающего часть данных, с множеством символов и помечая символы, что отличает его от идеи обычного совмещения.
Таким образом, цель настоящего изобретения состоит в том, чтобы предложить код оптического распознавания с улучшенной точностью считывания путем разделения символа кода для цветного битового кода 1D, обозначающего определенные данные, на множество символов кода и маркировки разделенных символов кода.
(2) Другая цель настоящего изобретения состоит в том, чтобы обеспечить технологию в состоянии, в котором множество символов кодов с разным количеством ячеек присутствуют в смешанном виде и когда конец символа кода отсутствует в считываемых данных символа кода, позволяющем детектировать потерю при считывании и предотвращать ошибочное считывание.
Средство решения проблем
"Средство 1"
В настоящем изобретении предложен следующий код для достижения этих целей.
В коде в соответствии с настоящим изобретением ячейки расположены линейно, и специфичные данные обозначены в соответствии с порядком цветов ячеек. В настоящем изобретении предложена кодовая система, которую можно считывать, когда поддерживается непрерывность последовательности цветов и линейная форма (топология).
В качестве способа, представляющего данные, можно использовать не только "порядок цветов", но также и другие способы, такие как способ назначения одного числового значения каждому одному цвету (например, R=0, B=1, …), способ назначения данных для перехода цветов ("CM"="MY"="YC"=0, "CY"="YM"="MC"=1, …) и способ назначения данных для комбинаций цветов.
Здесь термин "линейный" относится к состоянию, в котором ячейки расположены в линию, без разветвлений или пересечений. Если только ячейки являются линейными, линия может быть прямой, искривленной или изогнутой.
Описание терминов
Ниже будут кратко описаны термины, используемые в описании.
Прежде всего, в описании предмет, на котором может быть прикреплен оптический символ, может представлять собой любую материальную вещь. Он необязательно должен представлять собой жесткий предмет, но может представлять собой мягкий предмет, такой как продукт питания. Как описано ниже, в настоящем изобретении предложен оптический символ, устойчивый к искажениям и деформациям предмета. Мягкий предмет, такой как одежда, также включен в термин "предмет" в данном описании.
Контейнер и пакет предмета также включены в термин "предмет". Кроме того, плоский предмет или предмет в форме пластины, такой как лист бумаги, также включен в термин "предмет" в данном описании.
В описании также используются следующие термины.
Код: код представляет собой стандарт для выражения данных в символе. Для того чтобы пояснить, что код представляет собой стандарт, код также можно назвать кодовой системой.
Символ: символ получают путем преобразования данных на основе стандарта. Например, в типичном штрихкоде каждая "черная и белая структура", полученная в результате преобразования данных на основе "стандарта", называемого "штрихкодом", называется символом или "символом штрихкода".
Декодирование: обработка для получения исходных данных из каждого из символов на основе кода называется декодированием.
Считыватель: считыватель представляет собой устройство для считывания символа, закрепленного на предмете. Считываемые данные подвергают декодированию. В результате декодирования получают исходные данные.
Данные: данные представляют собой объект, предназначенный для преобразования в символ. Данные обычно представляют собой цифровые данные, но могут представлять собой буквенные данные или цифровые данные, состоящие из 0 и 1.
В частности, в настоящем изобретении используется следующее средство.
(1) Для решения задач в настоящем изобретении предложен оптический символ, включающий в себя множество ячеек, расположенных линейно, каждая ячейка представляет собой область, которой назначен один цвет, выбранный из группы из "n" цветов, где "n" представляет собой целое число, равное 3 или больше.
(2) В соответствии с изобретением в оптическом символе (1) ячейки расположены непрерывно, без разветвлений или пересечений, и цвета соседних ячеек отличаются друг от друга.
(3) Для решения задач в настоящем изобретении предложен оптический символ, включающий в себя множество ячеек, расположенных линейно, каждая ячейка представляет собой область, которой назначен один цвет, выбранный из группы "n" цветов, в котором ячейки конечной точки, которым назначают другой цвет, кроме этих "n" цветов, предусмотрены на обоих концах линейной компоновки, где "n" представляет собой целое число, равное 3 или больше.
Начальные и конечные точки могут быть идентифицированы с помощью цветов.
(4) В соответствии с изобретением в оптическом символе (1), в оптическом символе (3) цвет первой соседней ячейки как ячейки, соседней с ячейкой конечной точки, представляет собой заданный цвет, который определен заранее из группы из "n" цветов.
При использовании (комбинации) цветов можно идентифицировать начальную и конечную точки.
(5) В соответствии с изобретением в оптическом символе (4) цвет второй соседней ячейки, которая является соседней с первой соседней ячейкой, представляет собой заданный цвет, который определен заранее из группы из "n" цветов.
(6) В соответствии с изобретением в оптическом символе (1) "n" цветов назначены ячейке, соседней с ячейкой конечной точки или с ячейкой в заданном положении рядом с ячейкой конечной точки.
(7) Настоящее изобретение направлено на способ декодирования оптического символа, состоящий в декодировании оптической системы в соответствии с (6), в котором цвет, назначенный соседней ячейке или ячейке в заданном положении, используют для калибровки цвета ячейки.
(8) Настоящее изобретение направлено на способ декодирования оптического символа, состоящий в декодировании оптической системы в соответствии с (6), в котором цвет, назначенный соседней ячейке или ячейке в заданном положении, используют для калибровки разности цветов между ячейками.
(9) В соответствии с изобретением способ (7) или (8) декодирования оптического символа включает в себя этап отслеживания, состоящий в отслеживании ячейки, включенной в оптический символ. На этапе отслеживания ячейку отслеживают на основе разности цветов между цветом, назначенным ячейке конечной точки, и цветом, назначенным соседней ячейке или ячейке в заданном положении.
(10) В соответствии с изобретением, в оптическом символе в соответствии с (3), цвет, назначенный ячейке конечной точки, или аналогичный ему цвет назначают другой области, кроме компоновки ячеек.
(11) Настоящее изобретение направлено на предмет, на котором закреплен оптический символ в соответствии с (3), в котором цвет, назначенный ячейке конечной точки, или аналогичный ему цвет назначают другой области, кроме компоновки ячеек.
(12) В соответствии с изобретением, в предмете в соответствии с (11), цвет, назначенный ячейке конечной точки, или аналогичный ему цвет представляет собой ахроматический цвет, такой как черный или серый.
(13) Для решения задач настоящее изобретение также направлено на оптический символ, включающий в себя множество ячеек конфигурации, расположенных линейно, причем каждая ячейка конфигурации представляет собой область, которой назначен один цвет, выбранный из группы из "n" цветов, в котором ячейке конечной точки назначен другой цвет, кроме этих "n" цветов, и ячейки конфигурации появляются поочередно дважды или больше раз на обоих концах или на одном конце линейной компоновки, где "n" представляет собой целое число, равное 3 или больше.
(14) В соответствии с изобретением, в оптическом символе в соответствии с (1), знак, обозначаемый ячейкой, определяют по взаимному соответствию между ячейкой и цветом ячейки, соседней с данной ячейкой.
(15) В соответствии с изобретением, в оптическом символе (1), проверку, нотацию и т.п. отличают друг от друга в соответствии со способом выражения этого знака ячейкой.
(16) В соответствии с изобретением, в оптическом символе в соответствии с (1), цвет, соответствующий избыточному количеству света от источника света, облучающего оптический символ, не включен в группу из "n" цветов.
(17) Настоящее изобретение направлено на предмет, на котором закреплен оптический символ в соответствии с любым одним из (1)-(6) или любым одним из (13)-(16).
(18) Настоящее изобретение обеспечивает систему кода, в которой используется оптический символ в соответствии с любым одним из (1)-(6) или любым одним из (13)-(16).
(19) Настоящее изобретение направлено на способ декодирования оптического символа в соответствии с любым одним из (1)-(6) или любым одним из (13)-(16), включающий в себя: этап съемки оптического символа и получения данных изображения оптического символа; этап извлечения ячеек конечных точек в начальной точке и в конечной точке из данных изображения; этап отслеживания ячейки конфигурации, предусмотренной между двумя извлеченными ячейками конечных точек в исходной и в конечной точках, на основе ячеек конечных точек; и этап декодирования отслеженной ячейки конфигурации.
(20) В настоящем изобретении предложен способ прикрепления оптического символа в соответствии с любым одним из (1)-(6) или любым одним из (13)-(16) к предмету, включающий в себя: этап генерирования оптического символа на основе данных, предназначенных для записи; и этап прикрепления сгенерированного оптического символа к заданному предмету. Этап прикрепления включает в себя любой из этапа печати оптического символа на предмете, этапа прикрепления оптического символа к предмету с помощью вышивки и этапа закрепления клеящего закрывающего упаковку элемента, на котором нарисован оптический символ.
"Средство 2"
А. Устройство
(21) Для решения этих задач настоящее изобретение дополнительно направлено на устройство распознавания кода оптического распознавания, предназначенное для распознавания кода оптического распознавания, включающее в себя: средство деления, предназначенное для деления данных изображения, полученных в результате формирования изображения кода оптического распознавания на цветные области цветов на основе параметров, обозначающих цвета; и средство определения, предназначенное для определения, является ли каждая из разделенных областей цветов ячейкой, представляющей собой компонент кода оптического распознавания, или нет.
(22) В соответствии с настоящим изобретением, в устройстве распознавания кода оптического распознавания в соответствии с (21), данные изображения строят с помощью данных из трех основных цветов, и параметры, обозначающие цвета, представляют собой данные этих трех основных цветов.
Данные трех основных цветов представляют собой данные, выражающие цвета, например, в соответствии с форматом RGB (ЗКС, зеленый, красный, синий), форматом CMY (ГПЖ, голубой - пурпурный - желтый) или тому подобное.
(23) В соответствии с изобретением, в устройстве распознавания кода оптического распознавания в соответствии с (21), данные изображения строят с помощью данных, обозначающих цвет, включающий в себя оттенок, и параметр, обозначающий цвет в этом оттенке.
Данные, обозначающие цвет, включающие в себя оттенок, представляют собой данные, обозначающие цвет в соответствии с форматом HSV (ОНЗ, оттенок-насыщенность-значение), форматом HLS (ОЯН, оттенок-яркость-насыщенность) или тому подобное, а также в соответствии с форматом ЗКС или форматом ГПЖ. Если только появляется оттенок, можно использовать любую форму или формат. Например, в случае, когда цвет представлен цветоразностным сигналом или тому подобное, этот цветоразностный сигнал или тому подобное также соответствуют примеру данных, представляющих цвет, включающий в себя оттенок. Другие данные, кроме так называемых данных черного и белого, соответствуют примеру данных, обозначающих цвет, включающий в себя оттенок.
(24) В соответствии с изобретением, в устройстве распознавания кода оптического распознавания в соответствии с (21), средство деления выполняет обработку деления области на основе только параметров, обозначающих цвета, без использования какой-либо информации о положении, размере и форме области, предназначенной для разделения.
(25) В соответствии с изобретением, в устройстве распознавания кода оптического распознавания в соответствии с (21), средство деления выполняет обработку формирования изображения, состоящую в увеличении области для каждой из областей, полученных в результате деления.
(26) В соответствии с изобретением, в устройстве распознавания кода оптического распознавания в соответствии с (21), средство деления выполняет обработку формирования изображения, состоящую в уменьшении области для каждой из областей, полученных в результате деления.
(27) В соответствии с изобретением, в устройстве распознавания кода оптического распознавания в соответствии с (21), средство деления преобразует данные изображения в четыре значения или N значений на основе параметров, обозначающих цвета, и делит данные изображения на области цветов на основе этих значений, где N представляет собой положительное целое число.
(28) В соответствии с изобретением, в устройстве распознавания кода оптического распознавания в соответствии с (27), средство определения вырезает структуру одного цветного битового кода 1D или множества цветных битовых кодов 1D на основе только способа компоновки областей (состояние границ, количество областей и совместимость порядка размещения) от каждой из областей, полученных в результате деления.
(29) В соответствии с изобретением, в устройстве распознавания кода оптического распознавания в соответствии с (21), средство деления делит данные изображения на область с одним или больше цветами, которые составляют маркировочную структуру, и область цвета, обозначающего зону, не содержащую данные, и цвет, обозначающий зону, не содержащую данные, представляет собой другой цвет (цвет пробела), чем цвета, из которых построена маркировочная структура.
(30) В соответствии с изобретением, в устройстве распознавания кода оптического распознавания в соответствии с (29), когда целевая область удовлетворяет любому из следующих условий, средство определения определяет, что целевая зона представляет собой кандидат на ячейку как компонент цветного битового кода.
(Состояние "а" промежуточной ячейки) Другие четыре области представляют собой соседние области для целевой области, и цвета этих других четырех областей представляют собой "цвет пробела - другой цвет - цвет пробела - другой цвет" в направлении вдоль окружности вокруг целевой области, находящейся в центре.
(Состояние "b" конечной ячейки) Две другие области представляют собой соседние области вокруг целевой области, и цвета этих других двух областей представляют собой цвет пробела и другой цвет.
Другой цвет представляет собой другой цвет как компонент маркировочной структуры, отличающийся от цвета целевой области.
(31) В соответствии с изобретением, в устройстве распознавания кода оптического распознавания в соответствии с (29) или (30), цвет пробела, обозначающий зону, не содержащую данные, представляет собой белый или черный цвет.
(32) В соответствии с изобретением, в устройстве распознавания кода оптического распознавания в соответствии с (21), когда количество ячеек, составляющих цветной битовый код 1D, в случае, когда предполагается, что целевая область должна представлять собой ячейку как компонент цветного битового кода 1D, совпадает с заданным количеством, средство определения определяет, что целевая область представляет собой кандидат ячейки как компонент цветного битового кода.
(33) В соответствии с изобретением, в устройстве распознавания кода оптического распознавания в соответствии с (21), когда детектируют исходную точку и конечную точку цветного битового кода 1D и одна или больше ячеек, составляющих исходную точку, и одна или больше ячеек, составляющих конечную точку, совпадают с заданными цветами начальной и конечной точек в случае, когда предполагают, что целевая область должна представлять собой ячейку как компонент цветного битового кода 1D, средство определения определяет, что целевая область представляет собой кандидат ячейки как компонента цветного битового кода.
(34) В соответствии с изобретением, в устройстве распознавания кода оптического распознавания в соответствии с (21), когда детектируют промежуточную точку цветного битового кода 1D и одна или больше ячеек, составляющих промежуточную точку, совпадает с заданным цветом промежуточной точки в случае, когда предполагают, что целевая область должна представлять собой ячейку как компонент цветного битового кода 1D, средство определения определяет, что целевая область представляет собой кандидат ячейки как компонента цветного битового кода.
(35) В соответствии с изобретением, в устройстве распознавания кода оптического распознавания в соответствии с любым из (30)-(33), средство определения рассматривает как цветной битовый код группу цветных областей, оцениваемых, как цветной битовый код, состоящий из кандидатов ячеек, составляющих цветной битовый код, и декодирует цветной битовый код для получения исходных данных.
(36) В соответствии с изобретением, в устройстве распознавания кода оптического распознавания в соответствии с (35), когда существует множество групп цветных областей, оцениваемых как цветные битовые коды, каждый из которых состоит из кандидатов ячеек, составляющих цветной битовый код, средство определения декодирует каждую из групп областей как цветной битовый код и декодирует каждый цветной битовый код для получения исходных данных.
В. Программа
(37) Для решения задач в настоящем изобретении предложена программа для обеспечения возможности работы компьютера в качестве устройства распознавания кода оптического распознавания для распознавания кода оптического распознавания, в котором компьютер выполнен с возможностью выполнения: процедуры деления для разделения данных изображения, полученных в результате формирования изображения кода оптического распознавания на цветные области на основе параметров, обозначающих цвета; и процедуры определения, предназначенной для определения, представляет ли собой каждая из разделенных областей цвета ячейку как компонент кода оптического распознавания или нет.
(38) В соответствии с изобретением, в программе в соответствии с (37), данные изображения строят с помощью данных из трех основных цветов, и параметры, обозначающие цвета, представляют собой данные этих трех основных цветов.
(39) В соответствии с изобретением в программе (37) данные изображения строят с помощью данных, обозначающих цвет, включающий в себя оттенок, и параметр, обозначающий цвет, представляет собой оттенок.
(40) В соответствии с изобретением, в программе в соответствии с (37), при выполнении обработки деления выполняют обработку деления области на основе только параметров, обозначающих цвета, без использования какой-либо информации о положении, размерах и форме разделяемой области.
(41) В соответствии с изобретением, в программе в соответствии с (37), при выполнении обработки деления выполняют обработку формирования изображения, состоящую в увеличении области по каждой из областей, полученных в результате деления.
(42) В соответствии с изобретением, в программе в соответствии с (37), при обработке деления выполняют обработку формирования изображения, состоящую в уменьшении области по каждой из областей, полученной в результате деления.
(43) В соответствии с изобретением, в программе в соответствии с (37), при выполнении обработки деления данные изображения преобразуют в четыре значения или N значений на основе параметров, обозначающих цвета, и данные изображения делят на цветные области на основе этих значений, где N представляет собой положительное целое число.
(44) В соответствии с изобретением, в программе в соответствии с (43), в процедуре определения вырезают структуру единого цветного битового кода 1D или множества цветных битовых кодов 1D только на основе способа компоновки областей (состояние границ, количество областей и совместимость порядка компоновки) из каждой из областей, полученных в результате деления.
(45) В соответствии с изобретением, в программе в соответствии с (37), в процедуре деления данные изображения делят на область из одного или больше цветов, составляющих маркирующую структуру, и область цвета, обозначающую зону, не содержащую данные, и цвет, обозначающий зону, не содержащую данные, представляет собой цвет пробела, другой, кроме цветов, составляющих маркировочную структуру.
(46) В соответствии с изобретением, в программе в соответствии с (45), при обработке определения, когда целевая область удовлетворяет любому из следующих условий, определяют, что целевая область представляет собой кандидат ячейки как компонент цветного битового кода.
(Состояние "а" промежуточной ячейки) Другие четыре области представляют собой соседние области вокруг целевой области, и цвета этих других четырех областей представляют собой "цвет пробела - другой цвет - цвет пробела - другой цвет" в направлении вдоль окружности вокруг целевой области, расположенной в центре.
(Состояние "b" конечной ячейки) Две другие области представляют собой соседние области вокруг целевой области, и цвета этих двух других областей представляют собой цвет пробела и другой цвет.
Другой цвет представляет собой другой цвет как компонент маркировочной структуры, отличающейся от цвета целевой области.
(47) В соответствии с изобретением, в программе в соответствии с (45) или (46), цвет пробела, обозначающий зону, не содержащую данные, представляет собой белый или черный цвет.
(48) В соответствии с изобретением, в программе в соответствии с (37), в процедуре определения, когда количество ячеек, составляющих цветовой битовый код 1D, в случае, когда предполагают, что целевая область представляет собой ячейку как компонент цветового битового кода 1D, совпадает с заданным количеством, определяют, что целевая область представляет собой кандидат ячейки как компонент цветного битового кода.
(49) В соответствии с изобретением, в программе в соответствии с (37), в процедуре определения, когда детектируют исходную точку и конечную точку цветного битового кода 1D и одна или больше ячеек, составляющих исходную точку, и одна или больше ячеек, составляющих конечную точку, совпадают с заданными цветами исходной и конечной точек, в случае, когда предполагают, что целевая область представляет собой ячейку как компонент цветного битового кода 1D, определяют, что целевая область представляет собой кандидат ячейки как компонента цветного битового кода.
(50) В соответствии с изобретением, в программе в соответствии с (37), в процедуре определения, когда промежуточную точку цветного битового кода 1D детектируют и одна или больше ячеек, составляющих промежуточную точку, совпадает с заданным цветом промежуточной точки в случае, когда предполагается, что целевая область представляет собой ячейку как компонент цветного битового кода 1D, определяют, что целевая область представляет собой кандидат ячейки как компонента цветного битового кода.
(51) В соответствии с изобретением, в программе в соответствии с любым из (46)-(49), в процедуре определения группу цветных областей, оцененную как цветной битовый код, состоящий из кандидатов ячеек, составляющих цветной битовый код, рассматривают как цветной битовый код и декодируют для получения исходных данных.
(52) В соответствии с изобретением, в программе в соответствии с (51), в процедуре определения, когда существует множество групп цветных областей, оцененных как цветные битовые коды, каждый из которых состоит из кандидатов ячеек, составляющих цветной битовый код, каждую из групп областей рассматривают как цветной битовый код и декодируют для получения исходных данных.
С. Способы
(53) Для решения задач в настоящем изобретении предусмотрен способ распознавания кода оптического распознавания, предназначенный для распознавания кода оптического распознавания, включающий в себя: этап деления, состоящий в делении данных изображения, полученных в результате формирования изображения кода оптического распознавания на цветные области на основе параметров, обозначающих цвета; и этап определения, состоящий в определении, представляет ли собой каждая из разделенных цветных областей ячейку как компонент кода оптического распознавания или нет.
(54) В соответствии с изобретением, в способе распознавания кода оптического распознавания в соответствии с (53), данные изображения строят по данным из трех основных цветов, и параметр, обозначающий цвета, представляет собой данные этих трех основных цветов.
(55) В соответствии с изобретением, в способе распознавания кода оптического распознавания в соответствии с (53), данные изображения строят из данных, обозначающих цвет, включающий в себя оттенок, и параметр, обозначающий цвет, представляет собой оттенок.
(56) В соответствии с изобретением, в способе распознавания кода оптического распознавания в соответствии с (53), на этапе деления выполняют обработку деления области на основе только параметров, обозначающих цвета, без использования какой-либо информации о положении, размерах и форме области, предназначенной для деления.
(57) В соответствии с изобретением, в способе распознавания кода оптического распознавания в соответствии с (53), на этапе деления выполняют обработку формирования изображения, состоящую в увеличении области по каждой из областей, полученных в результате деления.
(58) В соответствии с изобретением, в способе распознавания кода оптического распознавания в соответствии с (53), на этапе деления выполняют обработку формирования изображения, состоящую в уменьшении области по каждой из областей, полученных в результате деления.
(59) В соответствии с изобретением, в способе распознавания кода оптического распознавания в соответствии с (53), на этапе деления данные изображения преобразуют в четыре значения или в N значений на основе параметров, обозначающих цвета, и данные изображения преобразуют в области цветов на основе этих значений, где N представляет собой положительное целое число.
(60) В соответствии с изобретением, в способе распознавания кода оптического распознавания в соответствии с (59), на этапе определения вырезают структуру единого цветного битового кода 1D или множества цветных битовых кодов 1D на основе только способа компоновки областей (состояние границы, количество областей и совместимость порядка компоновки) из каждой из областей, полученных в результате деления.
(61) В соответствии с изобретением, в способе распознавания кода оптического распознавания в соответствии с (53), на этапе деления данные изображения делят на область из одного или больше цветов, составляющих маркировочную структуру, и область цвета, обозначающего зону, не содержащую данные, и цвет, обозначающий зону, не содержащую данные, представляет собой цвет пробела, отличающийся от цветов, составляющих маркировочную структуру.
(62) В соответствии с изобретением, в способе распознавания кода оптического распознавания в соответствии с (61), на этапе определения, когда целевая область удовлетворяет любому из следующих условий, определяют, что целевая область представляет собой кандидат ячейки как компонент цветного битового кода.
(Состояние "а" промежуточной ячейки) Четыре другие области представляют собой соседние области вокруг целевой области, и цвета этих других четырех областей представляют собой "цвет пробела - другой цвет - цвет пробела - другой цвет" в направлении вдоль окружности вокруг целевой области, расположенной в центре.
(Состояние "b" конечной ячейки) Две другие области представляют собой соседние области вокруг целевой области, и цвета этих двух других областей представляют собой цвет пробела и другой цвет.
Другой цвет представляет собой другой цвет как компонент маркировочной структуры, отличающийся от цвета целевой области.
(63) В соответствии с изобретением, в способе распознавания кода оптического распознавания в соответствии с (61) или (62), цвет пробела, обозначающий зону, не содержащую данные, представляет собой белый или черный цвет.
(64) В соответствии с изобретением, в способе распознавания кода оптического распознавания в соответствии с (53), на этапе определения, когда количество ячеек, составляющих цветной битовый код 1D, в случае, когда предполагают, что целевая область представляет собой ячейку как компонент цветного битового кода 1D, совпадает с заданным количеством, определяют, что целевая область представляет собой кандидат ячейки как компонент цветного битового кода.
(65) В соответствии с изобретением, в способе распознавания кода оптического распознавания в соответствии с (53), на этапе определения, когда детектируют исходную точку и конечную точку цветного битового кода 1D и одна или больше ячеек, составляющих исходную точку, и одна или больше ячеек, составляющих конечную точку, совпадают с заданными цветами исходной и конечной точек, в случае, когда предполагают, что целевая область представляет собой ячейку как компонент цветного битового кода 1D, определяют, что целевая область представляет собой кандидат ячейки, как компонента цветного битового кода.
(66) В соответствии с изобретением, в способе распознавания кода оптического распознавания в соответствии с (53), когда детектируют промежуточную точку цветного битового кода 1D и одна или больше ячеек, составляющих промежуточную точку, совпадает с заданным цветом промежуточной точки в случае, когда предполагают, что целевая область представляет собой ячейку как компонент цветного битового кода 1D, средство определения определяет, что целевая область представляет собой кандидат ячейки как компонента цветного битового кода.
(67) В соответствии с изобретением, в способе распознавания кода оптического распознавания в соответствии с любым из (62)-(65), на этапе определения группу цветных областей, оцененную как цветной битовый код, состоящий из кандидатов ячеек, составляющих цветной битовый код, рассматривают как цветной битовый код и декодируют для получения исходных данных.
(68) В соответствии с изобретением, в способе распознавания кода оптического распознавания в соответствии с (67), на этапе определения, когда существует множество групп цветных областей, оцененных как цветные битовые коды, каждый из которых состоит из кандидатов ячеек, составляющих цветной битовый код, каждую из групп областей рассматривают как цветной битовый код, декодируемый для получения исходных данных.
"Средство 3"
(69) Для решения задач в изобретении также предусмотрен код оптического распознавания, включающий в себя заданное количество ячеек, расположенных линейно, причем каждая ячейка представляет собой цветную область, которой назначен заданный цвет, в котором определяют диапазон количества ячеек в одиночном символе кода, и символы кода с различным количеством ячеек разрешают смешивать, если только эти количества находятся в пределах диапазона.
(70) В настоящем изобретении также предусмотрен код оптического распознавания, включающий в себя заданное количество ячеек, расположенных линейно, причем каждая ячейка представляет собой цветную область, которой назначен заданный цвет, в котором данные, которые должны быть выражены, выражают, используя множество кодовых символов.
(71) В соответствии с изобретением, в коде оптического распознавания в соответствии с (70), множество символов кода имеет одинаковое количество ячеек.
(72) В соответствии с изобретением, в коде оптического распознавания в соответствии с (70) или (71), каждый из множества символов кода включает в себя данные идентификации группы для идентификации группы, которой принадлежит множество символов кода, для того, чтобы показать, что символ кода включен в группу из множества символов кода, обозначающих заданные данные, и данные идентификации порядка в группе обозначают порядок символа кода в группе.
(73) В соответствии с изобретением, в коде оптического распознавания в соответствии с (72), данные идентификации группы, предназначенные для идентификации группы, представляют собой данные, выраженные заданной группой ячеек в символе кода.
(74) В соответствии с изобретением, в коде оптического распознавания в соответствии с (72), данные идентификации группы, предназначенные для идентификации группы, представляют собой структуру цветов, выраженную в заданной группе ячеек в символе кода.
(75) В соответствии с изобретением, в коде оптического распознавания в соответствии с (72), данные идентификации порядка в группе представляют собой данные, выраженные заданной группой ячеек в символе кода.
(76) В соответствии с изобретением, в коде оптического распознавания в соответствии с (72), данные идентификации порядка в группе представляют собой структуру цветов, выраженную в заданной группе ячеек в символе кода.
(77) В соответствии с изобретением, в коде оптического распознавания в соответствии с (69) или (70), последовательность цветов для идентификации конца предусмотрена с левого и с правого концов в каждом из символов кода, для предотвращения ошибочного считывания из-за ошибки при считывании конца символа кода, и когда последовательность цветов для идентификации конца считана частично, можно детектировать ошибку считывания.
(78) В соответствии с изобретением, в коде оптического распознавания в соответствии с (77), количество ячеек, составляющих каждый из символов кода, представляет собой N или N-1, при этом количество цветов, используемых каждым из символов кода, равно трем или больше, и ячейка первого цвета расположена в последовательности цветов для идентификации конца на одном конце каждого из символов кода, и ячейка второго цвета расположена как последовательность цветов для идентификации конца на другом конце, где N представляет собой натуральное число, и первый цвет и второй цвет отличаются друг от друга.
(79) В соответствии с изобретением, в коде оптического распознавания в соответствии с (77), количество ячеек, составляющих каждый из символов кода, равно N или N-1, при этом количество цветов, используемых каждым из символов кода, равно трем или больше, последовательность цветов для идентификации конца, предусмотренная на одном конце каждого из символов кода, построена из, в порядке от одного конца, ячейки первого цвета и ячейки второго цвета, и последовательность цветов для идентификации конца, предусмотренная на другом конце каждого из символов кода, построена из, в порядке от другого конца, ячейки первого цвета и ячейки третьего цвета. Первый, второй и третий цвета представляют собой цвета, отличающиеся друг от друга, и N представляет собой натуральное число.
(80) В соответствии с изобретением, в коде оптического распознавания в соответствии с (77), количество ячеек, составляющих каждый из символов кода, равно N или меньше и N-k или больше, количество цветов, используемых каждым из символов кода, равно трем или больше, последовательность цветов для идентификации конца, предусмотренная на одном конце каждого из символов кода, построена из, в порядке от одного конца, ячейки первого цвета и первой повторяющейся части ячейки, последовательность цветов для идентификации конца, предусмотренная на другом конце каждого из символов кода, построена из, в порядке от другого конца, ячейки второго цвета и второй повторяющейся части ячейки, в первой повторяющейся части ячейки, причем ячейки третьего цвета и ячейки второго цвета поочередно соединены с одной оконечной стороны в направлении внутрь символа кода, и общее количество соединенных ячеек составляет k, и во второй повторяющейся части ячейки ячейка третьего цвета и ячейка первого цвета поочередно соединены с другой стороны конца в направлении внутрь символа кода, и общее количество соединенных ячеек равно k, где N представляет собой натуральное число, и k представляет собой целое число, равное 1 или больше и меньшее чем N.
(81) В соответствии с изобретением, в коде оптического распознавания в соответствии с (77), количество ячеек, составляющих каждый из кодовых символов, равно N или меньше и N-k или больше, количество цветов, используемых каждым из символов кода, равно трем или больше, последовательность цветов для идентификации конца, предусмотренная на одном конце каждого из символов кода, построена из, в порядке от одного конца, ячейки первого цвета и первой повторяющейся части ячейки, последовательность цветов для идентификации конца, предусмотренная на другом конце каждого из символов кода, построена из, в порядке от другого конца, ячейки первого цвета и второй повторяющейся части ячейки, в первой повторяющейся части ячейки, ячейка второго цвета и ячейка третьего цвета поочередно соединены с одной стороны конца в направлении внутрь символа кода, и общее количество соединенных ячеек равно k, и во второй повторяющейся части ячейки ячейка третьего цвета и ячейка второго цвета поочередно соединены с другой стороны конца в направлении внутрь символа кода, и общее количество соединенных ячеек равно k, где N представляет собой натуральное число, и k представляет собой целое число, равное 1 или больше и меньше чем N.
(82) Настоящее изобретение также направлено на предмет, к которому прикреплен код оптического распознавания в соответствии с любым из (69)-(81).
[Эффект изобретения]
"Эффект 1"
В соответствии с оптическим символом в соответствии с настоящим изобретением порядок ячеек конфигурации можно определить путем отслеживания ячеек конфигурации. Поскольку данные выражены комбинацией цветов или тому подобное ячеек конфигурации, может быть получена кодовая система, которая не влияет на считывание данных, даже когда изменяется размер ячеек конфигурации.
Поскольку гибкость относительного взаимного положения среди групп ячеек, составляющих символ, высока, символы можно использовать также для предметов с мягкой поверхностью.
Например, символ может быть непосредственно напечатан на пищевом продукте, таком как мягкое мясо, используя пищевые красители. Символ также можно непосредственно печатать на ткани и на мягком предмете.
В обычном оптическом штрихкоде символ прикрепляют к предмету, используя процесс закрепления закрывающего упаковку элемента или тому подобное, и при этом существует значительная вероятность того, что данные могут быть сфальсифицированы путем замены на другой закрывающий упаковку элемент или тому подобное. В отличие от этого, в соответствии с настоящим изобретением, символ может быть непосредственно напечатан даже на мягком предмете. Поэтому существенно затрудняется замена символа другим символом. В результате, в соответствии с изобретением, можно предотвратить фальсификацию данных.
В оптическом символе и системе кода, с использованием оптического символа в соответствии с изобретением, символ построен с помощью линейной компоновки из множества ячеек. До тех пор пока символ остается линейным, он может быть прямым или изогнутым. Поэтому можно получить символ, обладающий гибкостью конструкции.
"Эффект 2"
Как описано выше, в настоящем изобретении группу ячеек, удовлетворяющую условиям "маркировочной структуры" цветного битового кода 1D, во всех данных изображения выделяют из "фонового изображения" на основе характеристик. Поэтому код можно распознавать без использования вспомогательных знаков, таких как "метки вырезания", как в обычном двумерном штрихкоде.
Поэтому обработка и средство поиска метки вырезания отсутствуют в настоящем изобретении. В результате обработки всех данных изображения с помощью заданного способа распознают структуру, соответствующую "маркировочной структуре".
При этом нет необходимости выполнять сложное распознавание образов для вырезания, как в обычных двумерных штрихкодах. При этом могут быть достигнуты простая обработка формирования изображения, обработка распознавания изображения и высокая скорость обработки.
Кроме того, символ распознают с помощью структуры всех данных изображения. В соответствии с этим точное изображение и сложная обработка поиска меток вырезания и выполнение установки положения становятся ненужными. Может быть достигнута простая операция съемки изображения и обработки.
Одновременно с этим простую конфигурацию можно использовать для устройства считывания, программного обеспечения для обработки формирования изображения и электрических цепей (таких, как устройство сохранения), в которых сохраняют программное обеспечение. Вследствие этого, по сравнению с обычной техникой, можно реализовать меньшую стоимость и меньшие размеры.
Код оптического распознавания может быть реализован с низкой точностью маркирования (операция и действие назначения кода оптического распознавания).
В соответствии с настоящим изобретением, даже когда существует множество цветных битовых кодов 1D в одном изображении, группу из всех областей, соответствующих условию, распознают как цветные битовые коды 1D, без применения специального средства, и получают исходные данные. Поэтому даже в случае использования множества цветных битов кодов 1D можно применять простую операцию считывания, такую как в случае, когда используют одиночный цветной битовый код 1D.
"Эффект 3"
Кроме того, как описано выше, в соответствии с изобретением заданные данные могут быть выражены путем использования множества символов кода. Даже в случае когда имеются вариации по количеству ячеек в множестве символов кода, ошибка при считывании (потеря в конечной части), произошедшая во время считывания, может быть детектирована путем предоставления последовательности цветов для идентификации конца, и считывание с ошибкой может быть предотвращено.
В соответствии с настоящим изобретением в состоянии, когда разрешено смешанное присутствие символов кода с различным количеством ячеек, можно детектировать возникновение ошибки при считывании (потеря в конечной части). Таким образом, может быть получен код оптического распознавания, позволяющий предотвращать считывание с ошибкой.
На предмете, на котором закреплен такой код оптического распознавания, заданные данные могут быть выражены с помощью множества символов кода.
На предмете, на котором закреплен такой код оптического распознавания, даже когда совместно присутствуют множество символов кода, имеющих разные количества ячеек, ошибка при считывании (потеря) в конечной части может быть определена более эффективно, и может быть предотвращено считывание с ошибкой.
Краткое описание чертежей
На фиг.1 показана пояснительная схема оптического символа в соответствии с первым вариантом воплощения.
На фиг.2 показана таблица, представляющая соответствие между переходом цветов и данными в первом варианте воплощения.
На фиг.3 показана схема таблицы, представляющей два варианта в первом варианте воплощения.
На фиг.4 показана пояснительная схема, представляющая пример другого оптического символа в первом варианте воплощения.
На фиг.5 показана пояснительная схема, представляющая пример обработки оптического символа по фиг.1 в соответствии с вариантом 1-1 воплощения в декоративном виде.
На фиг.6 представлены три вида таблиц преобразования для преобразования цифр и букв алфавита.
На фиг.7 показана пояснительная схема, представляющая взаимосвязь в направлении изменения цветов.
На фиг.8 показана пояснительная схема, представляющая пример генерирования оптического символа 1010 из "год 2000".
На фиг.9 показана пояснительная схема, представляющая пример подготовки различных таблиц преобразования для цифр.
На фиг.10 показана пояснительная схема, представляющая пример "12345678" (в десятичной системе исчисления).
На фиг.11 показана пояснительная схема, представляющая пример оптического символа, закрепленного на кромке конверта.
На фиг.12 показана пояснительная схема, представляющая пример, в котором цвета конечной ячейки и непосредственно соседней ячейки выглядят повторяющимися несколько раз.
На фиг.13 показана пояснительная схема, представляющая состояние, в котором оптический символ прикреплен к прозрачной пластиковой коробке.
На фиг.14 показана пояснительная схема, представляющая пример результата обработки усреднения цвета данных изображения во втором варианте воплощения.
На фиг.15 показана пояснительная схема, представляющая состояние цветного битового кода 1D, который был вырезан в соответствии со вторым вариантом воплощения.
На фиг.16 показана пояснительная схема, представляющая состояние, в котором данные выражены множеством символов кода в третьем варианте воплощения.
На фиг.17 показана пояснительная схема, представляющая состояние цветного битового кода 1D в случае, когда данные идентификации группы и данные идентификации порядка в группе представлены как структуры цветов.
На фиг.18 показана пояснительная схема, представляющая состояние цветного битового кода 1D в случае, когда данные идентификации группы и данные идентификации порядка в группе представлены как структуры цветов и, в частности, данные идентификации порядка в группе помещены в промежуточное положение кода.
На фиг.19 показана пояснительная схема, представляющая состояние символов кода в случае, когда разрешено совместное присутствие символа кода, имеющего N ячеек, и символа кода, имеющего N-1 ячеек.
На фиг.20 показана пояснительная схема, представляющая состояние символов кода в случае, когда разрешено совместное присутствие символа кода, имеющего N ячеек, и символа кода, имеющего N-2 ячеек.
На фиг.21 показана пояснительная схема, представляющая состояние символов кода в случае, когда разрешено одновременное присутствие символа кода, имеющего N ячеек, и символа кода, имеющего N-3 ячеек.
На фиг.22 показана пояснительная схема, представляющая состояние символов кода в случае, когда разрешено одновременное присутствие символа кода, имеющего N ячеек, и символа кода, имеющего N-4 ячеек.
На фиг.23 показана пояснительная схема кода оптического распознавания в соответствии с другим примером 3-1.
На фиг.24 показана пояснительная схема кода оптического распознавания в соответствии с другим примером 3-2.
На фиг.25 показана пояснительная схема кода оптического распознавания в соответствии с другим примером 3-3.
На фиг.26 показана пояснительная схема кода оптического распознавания в соответствии с другим примером 3-4.
На фиг.27 показана пояснительная схема, представляющая состояние считывания обычного штрихкода с множеством линий сканирования.
Описание номеров ссылочных позиций
1010 оптический символ
1012 ячейка (ячейка конфигурации)
1020 ячейка конечной точки
1022 непосредственно соседняя ячейка
1024 опосредованно соседняя ячейка
1030 ячейка пробела
1032 ячейки для калибровки
R красный
В Синий
Y желтый
W Белый
3010 штрихкод
3012, 3014 линии сканирования
3020 символ кода
3030 символ кода
3040 символ кода
3042 часть структуры группы
3044 часть структуры отображения порядка в группе
3050 символ кода
3060 символ кода
3062 часть структуры отображения порядка в группе
Подробное описание изобретения
"Первый вариант воплощения"
Предпочтительный вариант воплощения настоящего изобретения будет описан ниже со ссылкой на фиг.1-13.
В этом варианте воплощения код, в котором используют оптический символ, имеет форму, в которой ячейки расположены линейно. Оптический символ представляет собой символ в плоской форме, и его закрепляют на различных предметах.
Ячейка (ячейка конфигурации) и ячейка конечной точки
Оптический символ в соответствии с данным вариантом воплощения построен с использованием ячеек и ячеек конечных точек. Ячейка представляет собой диапазон/область, которой назначен один цвет и которая может быть сформирована с различными формами, такими как круг, квадрат, треугольник и т.п. Оптический символ формируют, располагая эти ячейки линейно.
Ячейка конечной точки представляет собой ячейку, расположенную в конечной точке оптического символа, составленного из группы ячеек, соединенных линейно. В данном варианте воплощения ячейка конечной точки представляет собой область/диапазон, которой назначен цвет, отличающийся от цвета, назначенного другой ячейке, кроме цвета, назначенного ячейке конечной точки. Как будет описано ниже, с помощью комбинации (цветов) с другой ячейкой, расположенной смежно с ячейкой конечной точки, можно выразить, является ли конечная точка "начальной точкой" или "конечной точкой".
В случае выражения начальной точки ячейка конечной точки также может называться начальной ячейкой. В случае выражения конечной точки ячейка конечной точки также может называться конечной ячейкой.
В случае конкретного отличия ячеек, которые не являются ячейками конечной точки, от ячейки конечной точки эти ячейки могут называться "ячейками конфигурации".
Линейная форма
Оптический символ в соответствии с данным вариантом воплощения построен путем линейного расположения ячеек. Линейная форма может быть прямой или изогнутой. Если только можно отслеживать соседние ячейки, можно использовать любую линию.
"Пример 1-1"
На фиг.1 представлен пример оптического символа 10, выражающего цифровое значение "12345678" (в десятичной системе исчисления). В примере 1-1 12345678 представлено как "101111000110000101001110" в двоичной форме исчисления. Поэтому в примере 1-1 представлены двоичные цифры "101111000110000101001110".
На фиг.1 квадраты, которым назначен цвет Y (представляющий желтый цвет), цвет М (представляющий пурпурный цвет) и цвет С (представляющий голубой цвет) или тому подобное, представляют собой ячейки 1012. В результате соединения множества ячеек 1012 строят оптический символ 1010.
В примере 1-1 элементы "0" и "1" двоичной системы исчисления выражены, как в таблице, представленной на фиг.2. В частности, "1" и "0" назначают не цветам, а назначают переходам цветов. В примере 1-1 используют черный, голубой (С), пурпурный (М) и желтый (Y) цвета и переходы цветов с Y в C, и с C в M, и с M в Y обозначают "1" (см. фиг.2). Переходы цветов с Y в M, с C в Y и с М в С обозначают "0" (см. фиг.2).
Таким образом, значение текущей цифры определяют на основе значения цвета ячейки 1012 данной цифры и значения цвета ячейки 1012 предыдущей цифры. Цифра относится к части, которой назначено цифровое значение. Ячейка 1012 в части, которой назначена цифра, может называться ячейкой 1012 конфигурации, которую отличают от ячейки 1020 конечной точки и т.п.
В примере 1-1 требуется использовать 24 цифры для выражения двоичных цифр "101111000110000101001110". В примере 1-1 одна цифра соответствует одной ячейке 1012.
В примере 1-1 первые две ячейки 1022 и 1024 (две ячейки 1022 слева) представляют собой ячейки, обозначающие начало, и представляют собой ячейки 1022, которые не соответствуют цифрам цифровых значений, которые должны быть выражены. Таким образом, они не представляют собой ячейки 1012 конфигурации.
Первые две ячейки 1022 и 1024 называются непосредственно соседней ячейкой 1022 и опосредованно соседней ячейкой 1024. Непосредственно соседняя ячейка 1022 и опосредованно соседняя ячейка 1024 отличаются от ячеек 1012 конфигурации, которые выражают данные.
Непосредственно соседняя ячейка 1022 представляет собой ячейку, которая является соседней с ячейкой 1020 конечной точки. Опосредованно соседняя ячейка 1024 не является непосредственно соседней с ячейкой 1020 конечной точки, но является соседней с непосредственно соседней ячейкой 1022 или является соседней с другой опосредованно соседней ячейкой 1024. Ячейка конечной точки 1020 может представлять собой начальную ячейку или конечную ячейку. Таким образом, непосредственно соседняя ячейка 1022 и опосредованно соседняя ячейка 1024 могут присутствовать как на стороне начала, так и на стороне конца.
Как описано выше, черные ячейки с левого конца и с правого конца на фиг.1 представляют собой ячейки 1020а и 1020b конечной точки. С ячейкой 1020а конечной точки (черная) с левого конца (сторона начала) соединена непосредственно соседняя ячейка 1022а. Определено, что цвет Y (желтый) назначают непосредственно соседней ячейке 1022а.
Комбинация "ячейки 1020а конечной точки черного цвета + непосредственно соседней ячейки 1022а цвета Y (желтый)" обозначает сторону начала.
С ячейкой 1020b конечной точки (черная) с правого конца (сторона окончания) непрерывно соединены непосредственно соседняя ячейка 1022b и опосредованно соседняя ячейка 1024b. Определено, что цвет С (голубой) назначен непосредственно соседней ячейке 1022b, и цвет М (пурпурный) назначен опосредованно соседней ячейке 1024b. Комбинация "ячейки 1020b конечной точки черного цвета + непосредственно соседней ячейки 1022b цвета С (голубой) + опосредованно соседней ячейки 1024b цвета М (пурпурный)" обозначает сторону окончания.
При использовании такой компоновки, если находят цвета, которые представляют собой "цвет Y, соединенный с черным" и "цвета С и М, соединенные с черным", можно найти конечные точки (начальную и конечную точки) оптического символа 1010. Используя такие цвета С, М и Y, можно выполнять калибровку цветов.
Как показано в таблице на фиг.2, подготовлены три вида комбинаций цветов, обозначающих цифровые значения "1" и "0",. В примере 1-1 описание данных начинается с правой стороны (цвет М на фиг.1) от цвета Y, представляющего начало. В этом случае первая цифра (1 в данном примере) может иметь два варианта.
На фиг.3 показана таблица, обозначающая пример двух вариантов. В фиг.3 (1) с ячейкой 1012 цвета Y, которая является соседней для окончания 1020 конечной точки (черная), соединены ячейки 1012 цвета С и цвета М в указанном порядке. В результате комбинации ячеек цвета С и М выражена первая цифра "1". Аналогично на фиг.3 (2) ячейки 1012 цветов М и Y в указанном порядке соединены с ячейкой 1012 цвета Y, которая является соседней с ячейкой 1020 конечной точки (черная). С помощью такой комбинации ячеек М и Y выражена "1" первой цифры.
Как показано на фиг.2, другая комбинация, выражающая "1", представляет собой комбинацию цветов Y и С. Однако, поскольку комбинация ячейки 1020 конечной точки и ячейки цвета Y используется для выражения начальной стороны, тот же цвет Y нельзя использовать. Поэтому для выражения "1" следует использовать не комбинацию Y и С, а комбинацию С и М или М и Y. Следовательно, существуют два возможных варианта. Хотя в этом примере был описан случай выражения "1", также существуют две возможности для случае выражения "0".
Аналогично значения цифр последовательно выражают с помощью перехода цветов.
На фиг.2, в результате использования этих вариантов выбора, парность и другие признаки различия (знаки "плюс" и "минус", или выбор двоичных обозначений (серый код или тому подобное)) можно представлять без использования специальной ячейки. Очевидно, что в результате увеличения количества ячеек с левого конца Y и в первой цифре количество вариантов выбора может быть увеличено.
Например, на фиг.4 (1) показан пример случая, когда используют ячейки 1012 цветов С и М в указанном порядке после ячейки 1012 цвета Y. На фиг.4 (2) показан пример случая, когда число "12345678" (в десятичной системе счисления) выражено с помощью серого кода.
Кроме того, аналогично левому концу (сторона начальной точки (начальная сторона)) проверочная цифра, обозначающая количество цифр и т.п., также может быть расположена между конечной цифрой и ячейкой, между цветами М и С конечной ячейки с правого конца (сторона окончания).
Конечная ячейка относится к ячейке 1020 конечной точки, представляющей конец окончания. В примере 1-1 ячейка 1012 цвета С и ячейка 1012 цвета М предусмотрены в указанном порядке рядом с конечной ячейкой (см. фиг.4). Как описано выше, различные функции, такие как проверочная цифра и обозначение количества цифр, также могут быть размещены в этой части.
В описанных выше примерах ячейка 1012 и ячейка 1020 конечной точки расположены на прямой линии, но они могут быть расположены в изогнутом виде. Достаточно, если соединение ячеек 1012 может быть идентифицировано и может быть отслежено.
На фиг.5 показан пример обработки оптического символа, представленного на фиг.1 по примеру 1-1 в виде некоторой конструкции. В качестве формы ячейки 1012 можно использовать разные формы, такие как круг, квадрат и звезда. Если только состояние соединения ячеек 1012 может быть идентифицировано и соседнюю ячейку 1012 можно отследить, ячейки 1012 могут быть расположены линейно, по кругу или в виде изогнутой линии.
"Пример 1-2"
На фиг.6 показан пример непосредственного кодирования цифр, букв алфавита и т.п. (без преобразования в двоичные числа). На фиг.6 представлены три вида таблиц преобразования, представляющие, как преобразуют цифры и буквы алфавита. Три вида преобразований, - преобразование, начинающееся с цвета С, преобразование, начинающееся с цвета М, и преобразование, начинающееся с цвета Y, подготовлены в соответствии с цветом первой ячейки 1012.
В частности, существуют три способа выражения "0": компоновка ячейки 1012 в порядке "YMYCM", компоновка ячейки 1012 в порядке "MCMYC" и компоновка ячейки 1012 в порядке "CYCMY". Один из этих трех способов выбирают в соответствии с цветом предыдущей ячейки 1012, при этом выбирают один из трех способов.
Также в способе в соответствии с примером 1-2, показанным на фиг.6, система кода определена на основе направления изменения цвета соседней ячейки 1012. На фиг.7 показана пояснительная схема, представляющая соотношения направлений изменения цвета. Как показано на фиг.7, изменение цветов "YC" имеет то же значение, что и изменение цветов "СМ" и "MY". Это также понятно из таблицы, показанной на фиг.6. Изменение цветов "YM" имеет то же значение, что и изменения цветов "CY" и "МС". Это также понятно из таблицы, показанной на фиг.6. Аналогично примеру 1-1 любой цвет можно вначале выбрать из трех цветов.
На фиг.8 показан пример генерирования оптического символа 1010 из фразы "year 2000" ("год 2000). Ячейка 1020 конечной точки имеет черный цвет аналогично примеру, показанному на фиг.1, и три цвета, такие как С (голубой), М (пурпурный), и Y (желтый), используют для ячеек 1012. Поскольку "y" выражено как "MYCYMYMY", как показано на фиг.8, для использования последней буквы "Y", в таблице, показанной на фиг.6, выполняют поиск буквы "е", начинающейся с цвета "Y". В результате получают и используют выражение "YCMCYMCM". Поскольку последний знак на сей раз представляет собой цвет "М", выполняют поиск буквы "а", начинающейся с цвета "М". Аналогично, каждый из знаков в выражении "year 2000" преобразуют так, чтобы построить конечный оптический символ 1010 (см. фиг.8).
"Пример 1-3"
Увеличение количества цветов
В примерах 1-1 и 1-2 для представления ошибок при считывании цветов в максимально возможной степени были описаны случаи из трех цветов (ГПЖ). Однако эти три цвета не ограничены цветами ГПЖ, и естественно также можно рассмотреть цвета ЗКС. Хотя цвет ячейки 1020 конечной точки представляет собой черный цвет в приведенном выше описании, ячейка 1020 конечной точки необязательно используется. Если цвет фона черный, ее можно использовать. В случае когда цвет фона не является черным (например, цвет фона представляет собой Y), цвет (Y) можно выбрать как цвет ячейки 1020 конечной точки, и другие цвета можно выбирать для ячеек 1012.
В любом случае любую комбинацию цветов можно использовать, если только различие можно надежно детектировать в соответствии с условиями считывания. Если увеличить количество цветов, используемых в допустимом диапазоне, становится возможным представить больше идей.
В примере 1-3 будет описан случай добавления одного цвета G (зеленый) к YMC. В примере 1-3 ячейка 1012, которой назначен цвет G (зеленый), используется как ячейка пробела. В результате, например, можно эффективно отображать данные и обозначение цифры (= адрес).
На фиг.9 показана таблица преобразования в случае примера 1-3. Как показано на фиг.9, в примере 1-3 используют разные таблицы преобразования для соответствующих цифр. На фиг.10 показан пример выражения "12345678" (в десятичной системе исчисления), в котором использовали эти таблицы преобразования. Как показано на фиг.10, в примере 1-3 ячейки 1010, которым назначен цвет G (зеленый), используют как ячейки 1030 пробела (ячейки, используемые как разделения между цифрами). В результате наличия ячейки 1030 пробела цифры можно легко отличать друг от друга.
Например, с левого конца представлены восемь цифр, и, таким образом, используется таблица из восьми цифр, показанная на фиг.9. Поскольку выражение "YMCYMC" в данной таблице выражает "1", его используют для части первой цифры. Затем ячейка 1010, которой назначен цвет G (зеленый), следует как ячейка 1030 пробела, и дальше помещена седьмая цифра. Для выражения седьмой цифры используют таблицу седьмой цифры, показанную на фиг.9. Когда в этой таблице ищут "2", получают выражение "CYMYMC" и, таким образом, его используют как седьмую цифру. Аналогично операция продолжается до последней первой цифры. В конечном итоге, помещены ячейка 1030 пробела, ячейка 1012 цвета М + ячейка 1012 цвета С, представляющая конец окончания, и ячейка 1020 конечной точки, в результате чего заканчивается конечный оптический символ 1010 (см. фиг.10).
В примере 1-3, поскольку количество цифр (= адрес) и цифровое значение показаны одновременно, положение (цифры) в оптическом символе 1010 может изменяться. Оптический символ 1010 также можно разделить на множество оптических символов 1010. Таким образом, как можно видеть на фиг.9, в примере 1-3 для соответствующих цифр используют соответствующие таблицы преобразования, и результаты преобразования отличаются в разных таблицах. Поэтому на основе структуры результатов преобразования можно легко узнать цифру данных. В любом случае в настоящем изобретении, если количество используемых цветов увеличивается, можно надежно улучшить накопление данных.
"Пример 1-4"
Декодирование оптического символа
Операция считывания оптического символа 1010 и восстановления исходных данных называется декодированием. Хотя существуют различные процедуры декодирования, типичный предпочтительный пример представляет собой следующее.
(1) Изображение заданного предмета, включающее в себя оптический символ 1010, снимают с помощью камеры ПЗС или тому подобное и получают как данные изображения.
Камера ПЗС представляет собой типичный пример датчика, так называемого датчика области. Данные изображения могут быть сняты с использованием других датчиков области.
(2) Из данных изображения получают:
(a) ячейки 1020а и 1020b конечной точки,
(b) ячейку Y (непосредственно соседняя ячейка 1022а), соседнюю с ячейкой 1020а конечной точки, и
(c) ячейку С (непосредственно соседняя ячейка 1022b) + ячейку М (опосредованно соседняя ячейка 1024b), которая является соседней с ячейкой 1020b конечной точки.
Каждая из непосредственно соседней ячейки 1022 и опосредованно соседней ячейки 1024 имеет такую характеристику, что она не имеет ячейки 1012 непрерывной конфигурации на обеих сторонах. Каждая из непосредственно соседней ячейки 1022 и опосредованно соседней ячейки 1024 имеет такую характеристику, что, в случае когда она соединена с ячейкой 1012 конфигурации, ячейка 1012 конфигурации присоединена только с одной стороны. На основе таких конфигураций получают непосредственно соседнюю ячейку 1022 и опосредованно соседнюю ячейку 1024.
(3) Отслеживают и идентифицируют непрерывную последовательность группы ячеек 12 конфигурации, включенную между ячейкой цвета Y (непосредственно соседняя ячейка 1022), которая является соседней с ячейкой 1020а конечной точки (начальной ячейкой), и ячейкой цвета С (непосредственно соседняя ячейка 1022b) + ячейка цвета М (опосредованно соседняя ячейка 1024b).
(4) Белая область в изображении рассматривается как избыточный свет из-за общего отражения, и при этом определяют, что данная область не является частью оптического символа 1010.
(5) Изображение усредняют для каждой заданной области для устранения влияния компонентов шумов, тонких теней, загрязнений и т.п. Другими словами, выполняют устранение шумов в результате фильтрации. Можно использовать медианный фильтр и другие различные общеизвестные средства фильтрации.
(6) Определяют, что другая часть, кроме линейной непрерывной части, соединенной с ячейкой 1012 конфигурации (другая часть, кроме ячеек конфигурации), не представляет собой часть оптического символа 1010, в соответствии с обстоятельствами, такими как тень и цвет фона.
(7) При определении также предпочтительно использовать различие изображений, когда изменяется освещение или тому подобное.
(8) Снимают пики непрерывных следующих компонентов цветов Y, С и М ячейки 1012 конфигурации. На основе спецификации декодирования выполняют кодирование и проверку. Здесь декодирование будет называться кодированием.
Используя такой способ, выполняют декодирование оптического символа 1010.
Краткий итог 1
Как описано выше, система кода, предложенная в данном варианте воплощения, имеет следующие характеристики.
- Что касается оптического символа, используемого в первом варианте воплощения, соседнюю ячейку можно надежно отслеживать с обоих концов, аналогично цепной реакции, используя ячейку 1020 конечной точки, непосредственно соседнюю ячейку 1022 и опосредованно соседнюю ячейку 1024.
- Используемые цвета могут представлять собой только чистые для устройства считывания цвета в соответствии с системой трех основных цветов. Система имеет высокую устойчивость к вариациям при деградации цвета, изменении освещения, условия печати и т.п.
- Поскольку обозначение данных зависит только от порядка цветов выражения, даже когда размер диапазона (ячейки) каждого цвета изменяется, влияние, вносимое при считывании характеристики, невелико.
- Поскольку используется концепция отслеживания соседних ячеек по порядку и считывание цветов каждой из соседних ячеек, влияние, оказываемое на характеристику считывания, невелико, даже в случае узких, изогнутых или сложенных изображений.
- Кроме того, форма каждой ячейки обладает гибкостью. Даже когда ячейка имеет квадратную, треугольную, круглую форму, форму звезды или форму буквы, влияние, оказываемое на характеристику считывания, будет малым.
- Знак (данные), выраженный ячейкой, определяют по взаимосвязи между цветом ячейки и цветом ячейки, соседней с данной ячейкой.
- В соответствии с тем, как выражен знак (данные) ячейки, можно различать проверку, нотацию и т.п.
- Предпочтительно, в зависимости от вида источника света, цвет, соответствующий чрезмерному количеству света, не используется.
Модификации
(1) Предпочтительно предоставить эталонную ячейку, используемую как эталон при считывании, в заданном месте для выполнения калибровки. Эталонная ячейка реализована путем размещения ячеек с цветами С, М и Y в заданных местах.
Калибровку выполняют по цветам ячеек 1012 конфигурации и разностям цветов между ячейками конфигурации.
Для пояснения разности между ячейкой 1012 конфигурации и другой частью выполняют подтверждение (калибровку) разности цвета между ячейкой 1020 конечной точки и ячейкой конфигурации.
Для обеспечения возможности отслеживания цепочки ячеек 1012 конфигурации предпочтительно занимать обе стороны цепочки цветами, которые аналогичны цветам ячеек 1020 конечной точки (и которые можно надежно отличать от цветов ячеек 1012 конфигурации).
В приведенных выше примерах цвета ячеек конфигурации выбирают из группы трех цветов С, М и Y. Для ячеек 1020 конечной точки используют "черный" цвет, отличающийся от этих трех цветов. Поэтому предпочтительно использовать также черный цвет для "обеих сторон".
(2) Один из предпочтительных вариантов применения оптического символа 1010, расположенного непрерывно в одном измерении, как в первом варианте воплощения, состоит в том, что оптический символ 1010 прикрепляют, например, на кромке конверта, в качестве одного из пригодных для использования способов. На фиг.11 показан пример такого варианта применения. На фиг.11 показан пример оптического символа 1010, в котором цвета расположены в линии на кромке конверта. В таком примере оба конца ячейки 1012 конфигурации, в общем, представляют собой тени. Поэтому на практике целесообразно использовать темный ахроматический цвет, аналогичный тени, для ячеек 1020 конечной точки в оптическом символе 1010.
"Обе стороны" относятся к двум направлениям, перпендикулярным направлению продолжения оптического символа 1010.
(3) Для того чтобы различать область за пределами ячейки 1020 конечной точки (цвет конверта на фиг.11), весьма предпочтительно, чтобы цвета ячеек 1020 конечной точки и непосредственно соседних ячеек 1012 появлялись с повторением несколько раз. Такой пример показан на фиг.12.
В примере, показанном на фиг.12, с левого конца (начальная сторона) (1) можно видеть черный цвет (ячейка 1020а конечной точки), расположенный между цветами Y, и одновременно непосредственно соседние ячейки 1022а, которым назначен цвет Y. (2) Среди непосредственно соседних найденных ячеек 1022а можно найти непосредственно соседнюю ячейку 1022а, которая не имеет черный цвет с обеих сторон, то есть непосредственно соседнюю ячейку 1022а, которая не имеет черный цвет (ячейка конечной точки 20), по меньшей мере, с одной из сторон. Найденная непосредственно соседняя ячейка 1022а определена как непосредственно соседняя ячейка 1022а на начальной стороне, и ячейка 10102а калибровки определяет цвет Y для калибровки.
В примере, показанном на фиг.12, поскольку компоновка "черный Y и С" присутствуют на начальной стороне, ячейка конфигурации цвета Y в центре компоновки представляет собой "ячейку 12 конфигурации цвета Y на начальной стороне и ячейку 1012 конфигурации, определяющую цвет Y для калибровки".
Используя такой способ распознавания, можно предотвратить ошибочное распознавание того, что ячейки 12 конфигурации продолжаются до стороны основного цвета, даже когда, например, основной цвет является близким к желтому цвету.
В примере, показанном на фиг.12, набор цветов "ячейки 1020а конечной точки + непосредственно соседней ячейки 1022а" повторяется три раза на начальной стороне. На оконечной стороне окончания набор из цветов "ячейки 1020b конечной точки + непосредственно соседней ячейки 1022b+ опосредованно соседней ячейки 1024b" повторяется три раза на конечной стороне окончания.
(4) В случае прикрепления оптического символа в соответствии с данным вариантом воплощения на прозрачном пластиковом корпусе во многих случаях описанные выше "оба конца" ячеек 1012 конфигурации получаются серыми (ахроматический цвет), близкими к белому. На фиг.13 показана пояснительная схема, представляющая такое состояние. Поэтому в таком случае предпочтительно отслеживать ахроматический цвет ячейки 1012 конфигурации как метку для считывания и декодирования оптического символа.
"Второй вариант воплощения"
Со ссылкой на фиг.14 и 15 ниже подробно будет описан второй предпочтительный вариант воплощения способа вырезания цветного битового кода 1D в соответствии с настоящим изобретением.
1. Определение цветного битового кода 1D
Определение цветного битового кода 1D, разработанного авторами настоящего изобретения, будет представлено ниже. Цветной битовый код 1D определен следующим образом:
- цветной битовый код 1D представляет собой "ячейки" как области заданного цвета, которые расположены в линии (= "последовательность ячеек");
- используют множество цветов, и цвет назначают каждой ячейке;
- ячейки не включают в себя друг друга. Таким образом, ячейка не включена в другую ячейку;
- количество ячеек, составляющих последовательность, представляет собой заданное число; и
- одинаковый цвет не назначают соседним ячейкам, но всегда назначают разные цвета.
Цветной битовый код 1D генерируют, в основном, на основе этих условий.
2. Фактический вырез и декодирование
2.1 Разделение на области цвета
Прежде чем будет выполнен вырез, данные изображения разделяют на области цвета следующим образом.
- Данные изображения, включающие в себя цветной битовый код 1D, снимают с помощью датчика области.
- Данные изображения разделяют на множество областей цвета на основе определения.
Во втором варианте воплощения будет описан пример разделения данных изображения на синий, красный, желтый и белый цвета.
Данный вариант воплощения описан на основе предположения, что цветной битовый код 1D представляет собой последовательность "ячеек" синего, красного и желтого цветов, и количество "ячеек" равно 15. Таким образом, любой из синего, красного и желтого цветов назначают каждой из ячеек цветного битового кода 1D.
Вначале составляют данные "исходного изображения", снятые с помощью датчика области, используя различные цвета, включающие в себя фоновое изображение, и структуры данных "исходного изображения" также являются различными. Выполняют "обработку усреднения цвета", состоящую в разделении на цвета в данных исходного изображения на синий, красный, желтый и ахроматический цвет в цветовом пространстве, и с применением цветов пикселей к областям. Вкратце, пиксели подвергают так называемой обработке маркирования.
Синий, красный и желтый цвета первоначально определены как цвета (синий, красный и желтый), составляющие структуру маркирования цветного битового кода 1D. Однако "синий, красный и желтый цвета", используемые для разделения, соответствуют заданному диапазону цветов, который установлен в цветовом пространстве, с учетом вариаций освещенности, окрашивания, деградации цветов и т.п. Это называется "маркированием цветового диапазона ".
Другими словами, заданный специфичный цвет "красный" используют при маркировании, в то время как цвета в заданном диапазоне цветов, включающем в себя "красный" как центр, распознают как "красный" (диапазон маркирования цветов) при считывании. Это представляет собой описанную выше обработку усреднения цвета.
Ахроматический цвет определен как цвет, находящийся за пределами "диапазона цветов маркирования". Цвет зоны, не содержащей данные, также обрабатывают как цвет, находящийся за пределами "диапазона цветов маркирования". Зона, не содержащая данные, представляет собой другую часть, не составляющую цветной битовый код 1D, и она играет роль разделения между кодами. Вследствие этого зона, не содержащая данные, естественно обрабатывается, как описано выше.
В данном варианте воплощения цвета, находящиеся за пределами диапазона цветов маркирования, распознают как цвета в зоне, не содержащей данные (которые называются цветами пробела), как часть "обработки усреднения цвета", описанной выше. Цвета пробела как цвета, находящиеся в зоне, не содержащей данные, представляют собой, например, белый цвет в данном варианте воплощения. Таким образом, все из цветов, находящиеся за пределами диапазона цветов маркирования, рассматриваются как белый цвет и преобразуются в белый цвет.
Хотя все пиксели, определенные как находящиеся за пределами "диапазона цветов маркирования", преобразуют в белый цвет, можно использовать любые цвета, за исключением синего, красного и желтого цветов (диапазон цветов маркирования). Эта операция также представляет собой часть обработки усреднения цвета.
Во время выполнения "обработки усреднения цвета" по данным "исходного изображения", как описано выше, поступление компонентов шума обычно невозможно предотвратить. Неправильное изменение цвета в очень малой области, соответствующей шумам, можно устранить путем регулировки цвета области на цвет, находящийся на внешней кромке, или путем выполнения обработки удаления шумов, такой как усреднение.
На фиг.14 показан пример результата такой обработки усреднения цвета.
На фиг.14 "структура фонового изображения" преднамеренно установлена аналогичной цветному битовому коду 1D. Количество цветных битовых кодов, детектируемых на фиг.14, составляет только один.
Правильный цветной битовый код 1D, который должен быть детектирован, представляет собой последовательность цветных областей на центральном участке. Хотя некоторые другие последовательности цветных областей присутствуют на фиг.14, они исключены из кандидатов цветных битовых кодов в ходе следующих трех этапов определения. В конечном итоге оставшийся кандидат представляет собой цветной битовый код, предназначенный для детектирования.
2.2. Вырезание и декодирование
Обработка вырезания будет описана ниже.
(1) Этап 1 определения (граничные условия)
Вначале будут определены граничные условия для области каждого цвета.
В частности, в областях цвета, отличающихся от белого цвета, требование, состоящее в том, что область представляет собой "ячейку" как компонент "последовательности ячеек", состоит в том, что удовлетворяется любое из следующих граничных условий.
Условие "а": внешняя кромка области закончена как "белый цвет - другой цвет - белый цвет - другой цвет". В этом случае область соответствует "промежуточной ячейке".
Условие "b": внешняя кромка области закончена как "белый цвет - другой цвет". В этом случае область соответствует "конечной ячейке окончания".
В примере другой цвет относится к цвету, который не является белым цветом, но представляет собой любой из таких трех цветов, как синий, красный и желтый, за исключением цвета ячейки (области) (если эта ячейка является красной, другой цвет является синим или желтым).
"Промежуточная ячейка" представляет собой другую "ячейку", кроме ячеек на обоих концах последовательности ячеек. Поскольку промежуточная ячейка представляет собой компонент последовательности ячеек, присутствуют две соседние ячейки, и цвета этих двух ячеек (областей) отличаются от цвета промежуточной ячейки в соответствии с определением цветного битового кода 1D. Кроме того, в соответствии с определением цветного битового кода 1D, другие области кроме этих двух областей окружены зоной, не содержащей данные. Зона, не содержащая данные, представляет собой область "ахроматического цвета", как описано выше, но ее преобразуют в белый цвет.
В результате, когда область представляет собой промежуточную ячейку в последовательности ячеек, должно удовлетворяться условие "а". Когда условие "а" удовлетворяется, существует вероятность того, что область представляет собой промежуточную ячейку.
"Ячейка окончания" представляет собой "ячейку" на обоих концах последовательности ячейки. Поскольку ячейка окончания представляет собой конечную точку последовательности ячеек, существует только одна соседняя ячейка, и цвет этой одной ячейки (область) отличается от цвета ячейки окончания в соответствии с определением цветного битового кода 1D. Кроме того, в соответствии с определением цветного битового кода 1D, внешняя кромка, отличающаяся от соседней одной области, представляет собой зону, не содержащую данные. Зона, не содержащая данные, представляет собой область "ахроматичного цвета", как описано выше, но она преобразована в белый цвет.
В результате, если область представляет собой заканчивающую ячейку последовательности ячеек, должно удовлетворяться условие "b". Если условие "b" удовлетворяется, высока вероятность того, что область представляет собой заканчивающую ячейку.
Возможно, что область цвета, которая не удовлетворяет ни одному из условий "а" и "b" (например, область, с использованием которой три цвета находятся в контакте без фонового цвета между ними, область, окруженная только одним цветом, и т.п.), представляет собой компонент последовательности ячеек, представляющий ноль. Вследствие этого область цвета определена как "фоновое изображение", и все области цвета, за исключением белого цвета, находящиеся в контакте с областью фонового изображения, определены как области "фонового изображения". Белый цвет соответствует зоне, не содержащей данные, как описано выше.
(2) Этап 2 определения (количества ячеек)
Предполагается, что области цвета, которые остаются как кандидаты (области - кандидаты последовательности ячеек), без исключения при определении этапа 1, расположены в линию. Однако количество областей цвета, расположенных в линию, может отличаться от того, что требуется в цветном битовом коде 1D. Поэтому области цвета дополнительно сужают в соответствии с условием количества ячеек (количество ячеек в цветном битовом коде 1D является известным, ячейки, количество которых соответствует известному количеству, определены как "ячейки", составляющие области цветного битового кода 1D).
(3) Этап 3 определения (условие окончания)
Далее области кода дополнительно сужают в соответствии с условиями окончания цветного битового кода 1D (начальная ячейка (группа) имеет желтый и красный цвета, и конечная ячейка имеет синий цвет). Ячейки окончания имеют два вида ячеек; начальная ячейка (группа) и ячейка окончания (группа). Каждая из начальных ячеек и ячеек окончания состоит из одной или больше ячеек (групп). Во втором варианте воплощения, как описано выше, группа начальной ячейки состоит из двух ячеек, и ячейка окончания состоит из одной ячейки. Установка каждого из цветов называется условием окончания.
Области кода могут быть сужены в соответствии с условиями промежуточной точки вместо условий окончания. Установка цветов таким образом, что промежуточная ячейка, находящаяся в промежуточном положении от обоих концов последовательности ячеек, имеющая желтый, или красный цвет, или синий цвет, называется условием промежуточной точки.
Также предпочтительно использовать условие промежуточной точки вместо условия точки окончания. Кроме того, также предпочтительно проверять условие промежуточной точки в дополнение к условию точки окончания и оставлять только ячейки, удовлетворяющие обоим событиям сужения областей кода.
(4) Этап 4 определения (декодирование)
Делают попытку декодировать области цвета, проходя все из заданных этапов определения 1-3, то есть оставшиеся конечные области кандидата цветного битового кода 1D, в соответствии с порядком цветов. Проверяют соответствие проверочной цифры или тому подобное.
В результате, в конечном итоге, обычно декодируют область (без ошибки), и ее значение "вырезают", и "декодирование" заканчивают.
2.3 Вспомогательная Обработка
(1) Увеличение области
Случай, когда области цвета маркирования не всегда находятся в контакте, также важно предложить, в зависимости от спецификаций маркирования. Также существует случай, когда области цвета расположены аналогично так называемым камням продвижения. Даже в случае, когда отдельные островки цвета будут расположены отдельно друг от друга на заданных расстояниях, цветной битовый код 1D можно запустить, если только компоновка может быть распознана (отслежена).
В данном случае предпочтительно увеличить области цвета до заданного размера и применить алгоритм, предполагающий, что области цвета находятся в контакте друг с другом. Увеличение (расширение) заданной области известно, как основная обработка формирования изображения (например, обработка утолщения линии, состоящая в утолщении тонкой линии), что может быть легко выполнено специалистом в данной области техники.
(2) Уменьшение области
Также возможен случай, когда, в зависимости от спецификаций маркирования, цветные области, состоящие в маркировании, увеличивают, и участки наложения становятся чрезмерными. В этом случае наложение областей цвета увеличивается, и даже предполагается ситуация, в которой порядок компоновки цветных областей нельзя распознать.
В этом случае предпочтительно уменьшить цветные области на заданное количество. Предпочтительно цветные области уменьшают на заданное количество таким образом, что компоновку цветных областей можно распознать, и после этого применяют алгоритм. Снижение (уменьшение) заданной области известно как основная обработка формирования изображения (например, обработка сужения линии, состоящая в сужении линии), которая может быть легко выполнена специалистом в данной области техники.
2.4 Состояние вырезанного цветного битового кода
На фиг.15 показано состояние цветного битового кода 1D, который был вырезан, как описано выше. Как показано на фиг.15, хотя имеется пять наборов (кандидатов) областей цвета, которые, вероятно, могут представлять собой цветной битовый код 1D, только одна линия в центре была вырезана как цветной битовый код 1D и декодирована.
Верхний левый набор исключают на этапе 1 определения по той причине, что условие границы не удовлетворяется. Нижний левый набор также исключают на этапе 1 определения по той же причине - не удовлетворяется условие границы. Набор внизу в центре исключают на этапе 2 определения по той причине, что количество ячеек (10) не соответствует желательному количеству цветных битовых кодов 1D (в данном случае 15). Набор правого конца исключают на этапе 1 определения по той причине, что не удовлетворяется условие границы.
В результате только набор в центре удовлетворяет условию границы и условию количества ячеек (15), и, таким образом, его, в конечном итоге, вырезают как цветной битовый код 1D и декодируют.
На фиг.14 и 15 R представляет собой красный, Y представляет желтый и В представляет собой синий цвета. W представляет собой белый цвет.
3. Разделение на области цвета
В описанном выше разделе "2.1 Разделение на области цвета", например, обработка усреднения цвета состоит в том, что в качестве красного рассматривают весь заданный диапазон красного цвета как центр. Обработку выполняют аналогично в отношении желтого и синего цветов. При этом достаточно использовать различные аппроксимированные области как заданный диапазон. Также предпочтительно устанавливать диапазон на заданном расстоянии Хамминга от чисто красного цвета.
Во многих случаях, поскольку сами данные изображения получают как данные, состоящие из трех основных цветов R (красный), G (зеленый) и В (синий), предпочтительно выполнять обработку усреднения цвета по данным ЗКС.
Также предпочтительно преобразовывать данные ЗКС в формат ОНЗ и затем выполнять обработку усреднения цвета. Само собой разумеется, что ОНЗ представляет собой данные, состоящие из оттенка, насыщенности (также называемой чистотой) и величины, и имеет компоненты оттенка. Вследствие этого существует вероятность того, что расчет по заданному диапазону, используя заданный диапазон на основе красного цвета, заданный диапазон на основе желтого цвета и заданный диапазон на основе синего цвета, становится простым. Очевидно, что другие данные, кроме заданных диапазонов, преобразуют в "белый" цвет, как описано выше. Взаимное преобразование между данными ЗКС и данными ОНЗ выполняют обычно и понятно для специалиста в данной области техники.
Цвета, выраженные как ЗКС и Н (оттенок) в схеме ОНЗ, соответствуют заданному примеру параметров, представляющих цвета, описанные в формуле изобретения.
Такой формат ОНЗ соответствует предпочтительному примеру данных, выражающих цвета, включающие в себя оттенок. Другой формат данных можно использовать, если только будет выражен оттенок.
4. Компьютер и программное средство
(1) Способ распознавания кода оптического распознавания был описан выше. В предшествующих вариантах воплощения, в основном, используют данные цифрового изображения в качестве данных изображения. Вследствие этого предпочтительно выполнять способы, используя аппаратные средства или программные средства, позволяющие обработать такие данные изображения.
Как правило, предпочтительно строить "устройство распознавания кода оптического распознавания" для выполнения операции, используя компьютер и программы, выполняемые компьютером, и выполнять "способ распознавания кода оптического распознавания".
Предпочтительно, такая программа содержится на заданном носителе записи. Например, предпочтительно сохранять программы на различных полупроводниковых накопителях, таких как жесткий диск, различные оптические диски и память типа флэш.
Также предпочтительно строить программы и компьютер в отдельных устройствах. Например, также предпочтительно, чтобы программы были сохранены на сервере, и дистанционный компьютер - клиент выполнял эти программы в сервере через сеть.
(2) Предпочтительно данные изображения обычно снимают с помощью камеры ПЗС или тому подобное. Данные, снятые аналоговой камерой, могут быть преобразованы в цифровой сигнал.
5. Модификации
(1) В приведенном выше примере был описан случай, в котором существует только один цветной битовый код 1D. Однако очевидно, что существует множество цветных битовых кодов 1D. Множество конечных кандидатов оставляют и декодируют для получения исходных данных.
(2) В приведенном выше примере области разделяют путем выполнения обработки усреднения цвета по красному, желтому и синему цветам. Однако можно использовать любые цвета, и количество цветов может быть равно четырем или больше. Также соответствующим образом можно использовать зеленый, голубой, пурпурный цвета и т.п.
(3) В приведенном выше примере все пиксели, определенные как находящиеся за пределами "диапазона цветов маркирования", преобразуют в белый цвет (цвет пробела). Однако цвет пробела может представлять собой любые цвета, за исключением синего, красного и желтого (диапазоны цветов маркирования).
"Третий вариант воплощения"
Со ссылкой на фиг.16-27 будет подробно описан третий предпочтительный вариант воплощения способа вырезания цветного битового кода 1D в соответствии с настоящим изобретением.
Вариант воплощения 3-1. Выражение, использующее множество символов кода
На фиг.16 показан пример, в котором данные разделены на три части, которые выражены тремя символами 3020а, 3020b и 3020с кода. Эти данные выражены, используя группу из трех символов кода (3020а, 3020b и 3020с).
В примере, показанном на фиг.16, группа выражает данные, включающие в себя, в дополнение к "данным", которые должны быть выражены, данные идентификации группы, обозначающие группу, и данные идентификации порядка в группе, обозначающие порядок каждого символа кода в группе.
Три символа 3020 кода включают в себя данные идентификации общей группы. Кроме того, эти три символа кода включают в себя данные идентификации порядка в группе, обозначающие порядок кода в группе, который отличается для каждого кода.
Данные идентификации группы
В примере, показанном на фиг.16 (1), данные идентификации группы представляют собой "00". Первые две цифры данных в символе кода обозначают данные идентификации группы. Как показано на фиг.16, все данные идентификации группы в трех символах кода представляют собой "00". В варианте 3-1 воплощения, поскольку цифры используют как данные идентификации группы, эти данные идентификации группы также называются номером группы.
Пример использования других данных, кроме простого цифрового значения, в качестве данных идентификации группы, описан ниже в варианте 3-2 воплощения.
Данные идентификации порядка в группе
В примере, показанном на фиг.16 (1), данные идентификации порядка в группе представляют собой "00", "01" и "10", и структуры цветов, выражающих эти числа, включены в символы кода.
В варианте 3-1 воплощения, поскольку числа используют как данные идентификации порядка в группе, эти данные идентификации группы также называются номером в группе.
Выражение данных
В примере, показанном на фиг.16 (1), символы кода выражают данные идентификации группы, данные идентификации порядка номера в группе и данные, которые должны быть выражены в этом порядке. Данные, которые должны быть выражены в случае символа верхнего кода, представляют собой 1048576 (в десятичной систем исчисления), которые показаны в двоичном выражении на фиг.16 (1). Аналогично данные, которые должны быть выражены символами среднего кода, представляют собой 1 (в десятичной системе исчисления), что показано в виде двоичного выражения на фиг.16 (1). Данные, которые должны быть выражены символом нижнего кода, составляют 1398101 (в десятичной системе исчисления), что показано в виде двоичного выражения на фиг.16 (1).
В примере, показанном на фиг.16 (1), выражены данные "1048576-1-1398101".
Считывание
В случае, показанном на фиг.16 (1), при считывании цветного битового кода 1D, легко считывать одновременно три символа кода. Это связано с тем, что цветной битовый код 1D занимает заданную область, которая должна быть снята и считана камерой ПЗС или тому подобное, и поскольку происходит съемка заданной области, в принципе, легко получить множество цветных битовых кодов 1D. В обычном так называемом штрихкоде предполагается, что штрихкод имеет линейную форму, при этом во многих случаях сканируют только заданную линию. Следовательно, в принципе, трудно считывать множество обычных штрихкодов.
Поэтому в результате добавления данных идентификации группы, обозначающих группу, и данных идентификации порядка в группе в дополнение к исходным данным, которые должны быть выражены (данные, полученные путем деления исходных данных на три части), можно легко восстановить исходные данные, которые должны быть выражены.
Как описано выше, в третьем варианте воплощения, в отличие от обычного сопоставления, можно получить эффект, равный или превышающий обычное сопоставление, одновременно используя способ разделения символа кода, выражающего одиночную часть данных, в множество частей и помечая разделенные данные.
Другой пример
На фиг.16 (2) показан другой пример. В этом примере данные разделены на символы 3030а, 3030b и 3030с кода, которые записаны. Пример, показанный на фиг.16 (2), является тем же, что и на фиг.16 (1), за исключением момента, состоящего в том, что данные идентификации группы составляют "10", и того момента, что данные, которые должны быть выражены, представляют собой данные "1887436-524351-63".
Вариант 3-2 воплощения. Выражение с использованием множества символов кода (№2)
Также предпочтительно, чтобы данные идентификации группы и данные идентификации порядка в группе были заданы как цветные структуры вместо цифровых данных. Такие примеры показаны на фиг.17 и 18.
На фиг.17 показан пример, в котором данные разделены на три части, которые выражены как три символа 3040а, 3040b и 3040с кода, аналогично фиг.16. Эти данные выражены с помощью группы из трех символов кода (3040а, 3040b и 3040с).
В примере, показанном на фиг.17, данные идентификации группы и данные идентификации порядка в группе выражены в виде последовательности цветных структур.
Данные идентификации группы
В примере, показанном на фиг.17, данные идентификации группы составляют "YCM". В этом примере сами цвета используют как данные идентификации группы, что обозначено частью 3042 структуры группы в символе кода. В примере, показанном на фиг.17 (1), данные идентификации группы представляют собой "YCM", и "YCM" назначают соответствующим цветам в части 3042 структуры группы. Структуру устанавливают для всех трех символов 3040а, 3040b и 3040с кода.
Данные идентификации порядка в группе
В примере, показанном на фиг.17 (1), данные идентификации порядка в группе представляют собой "YMY", "MYM" и "МСМ". Такие структуры цветов, обозначающие порядки в группах, назначают частям 3044 структуры отображения порядка в группе в символе кода.
Когда используют данные идентификации порядка в группе, имеющие такую конфигурацию, как показано на фиг.17, необходимо заранее выразить эти порядки в цветах.
Выражение данных
В примере, показанном на фиг.17 (1), в каждом символе кода структура группы, обозначающая данные идентификации группы, данные, которые должны быть выражены, и данные идентификации порядка числа в группе, выражена в этом порядке. В случае символа 3040а верхнего кода данные, которые должны быть выражены, представляют собой 1048576 (в десятичной системе исчисления), двоичное выражение которых показано на фиг.17 (1). Аналогично данные, которые будут выражены средним символом 3040b кода, равны 1 (в десятичной системе исчисления), двоичное выражение которого показано на фиг.17 (1). Данные, которые должны быть выражены нижним символом 3040с кода, представляют собой 1398101 (в десятичной системе исчисления), двоичное выражение которого показано на фиг.17 (1).
В результате в примере, показанном на фиг.17 (1), выражены данные "1048576-1-1398101".
Другие примеры
(a) На фиг.17 (2) показан другой пример. В этом примере данные разделены на символы 3050а, 3050b и 3050с кода, которые были записаны. Пример, показанный на фиг.17 (2), является таким же, что и на фиг.17 (1), за исключением момента, состоящего в том, что данные идентификации группы представляют собой "MCY", и момента, состоящего в том, что выраженные данные представляют собой данные "1887436-524351-63".
(b) В примере, показанном на фиг.18, данные разделены на символы 3060а, 3060b и 3060с кода, которые были записаны. Пример, показанный на фиг.18, аналогичен примеру по фиг.17 в том, что данные идентификации группы и данные идентификации порядка в группе выражены в виде цветных структур. В примере, показанном на фиг.18, данные, которые должны быть выражены, представляют собой данные "1887436-524351-63" аналогично примеру, показанному на фиг.17.
Пример, показанный на фиг.18, отличается от примера, показанного на фиг.17, "положением" данных идентификации порядка в группе. В примере, показанном на фиг.18, данные идентификации порядка в группе описаны в части 3062 структуры отображения порядка в группе, которая расположена приблизительно в центре символа кода 3060.
Как можно легко понять из примера, показанного на фиг.18, вкратце, данные идентификации порядка в группе и данные идентификации группы могут быть расположены в любом месте, если только они определены заранее.
Вариант 3-3 воплощения
Предотвращение ошибочного считывания
В случае описанных выше примеров (фиг.16-18) обработку считывания выполняют при предположении, что существует множество символов кода. Как описано выше, в так называемом цветном битовом коде 1D в соответствии с третьим вариантом воплощения также можно использовать код, количество ячеек которого в символе кода не определено. Код имеет начальную точку и конечную точку, обозначенные специфическими структурами. В случае когда детектируют специфические структуры, детектируемые структуры распознают (определяют) как начальную точку и конечную точку.
В случае когда количество ячеек в символе кода не определено заранее, существует большая вероятность того, что, когда конец символа кода невозможно снять, из-за, например, ограниченного поля просмотра камеры ПЗС, остальная часть может выражать другие данные (считывание с ошибкой).
Вариант 3-3а воплощения: Ограничения количества ячеек в коде символа
В варианте 3-3а воплощения предложен способ предотвращения считывания с ошибкой в результате ограничения количества ячеек в символе кода.
Самые строгие ограничения представляют собой условие ограничения, что все символы кода имеют одинаковое количество ячеек. При установке такого ограничения ненужные избыточные ячейки проверки можно исключить. Ячейка проверки теперь не представляет собой ячейку, выражающую данные, но представляет собой ячейку для проверки ошибок. Можно использовать ячейки проверки в соответствии с общеизвестными технологиями, такими как четность и CRC (ЦИК, циклический избыточный код).
В частности, поскольку все длины символов одинаковы, по символу кода, конечная часть которого не может быть частично снята, из-за "поля, находящегося вне пределов обзора", наличия препятствия или из-за других факторов, распознают, что количество ячеек является недостаточным. Поэтому можно предотвратить ошибочное считывание (даже если ячейка проверки или тому подобное отсутствует вообще).
В примерах, показанных на фиг.17 и 18, установлены ограничения "все символы кода имеют одинаковую длину символов (количество ячеек)", и три символа кода в каждом из примеров имеют одинаковое количество ячеек.
Вариант 3-3b воплощения: Тестирование условия конечной точки
В некоторых случаях ограничения типа "все символы кода имеют одинаковую длину символа (количество ячеек)" являются слишком строгими для выполнения на практике.
Для ослабления условия использования при выполнении фактической операции также возможно разрешить совместное присутствие символа кода, имеющего N ячеек, и символа кода, имеющего N-1 ячеек, где N представляет собой натуральное число.
В случае установления такого несколько ослабленного ограничения, когда конечная часть символа кода, имеющая N-1 ячейку, не может быть снята, декодирование регулируют в соответствии с условиями количества ячеек, и при этом отсутствует вероятность ошибочного считывания. Однако в этом примере, даже когда одна ячейка конечной части символа кода, имеющего N ячеек, не может быть снята, может быть разрешен символ кода, состоящий из N-1 ячеек, и, таким образом, ограничения декодирования в соответствии с условием количества ячеек не применяют. Вследствие этого существует вероятность считывания с ошибкой.
Поэтому в варианте 3-3b воплощения детектирование считывания с ошибкой анализируют не только на основе условия номера ячейки, но также и на основе состояния конечной точки.
Состояние конечной точки определяет, что цвет ячейки конечной точки с левого конца представляет собой цвет Y, и цвет ячейки конечной точки на правом конце представляет собой цвет С, как показано на фиг.19. Детектирование ошибочного считывания в данном случае будет проанализировано ниже. В настоящем описании конечные точки называются "левым концом" и "правым концом", которые также могут, по существу, эквивалентно называться "начальной точкой" и "конечной точкой".
На фиг.19 ячейки в толстых рамках представляют собой ячейки в конечных точках. На фиг.19 (1)-(4) показаны примеры правильных битовых кодов 1D.
На фиг.19 (1) показан случай, в котором количество ячеек равно N и соседние ячейки с ячейкой Y с левого конца имеют цвет М. На фиг.19 (2) показан случай, когда количество ячеек равно N аналогично случаю (1) и ячейка, соседняя с ячейкой Y с левого конца, имеет цвет С.
На фиг.19 (3) показан случай, когда количество ячеек равно N-1 и ячейка, соседняя с ячейкой Y с левого конца, имеет цвет М. На фиг.19 (4) показан случай, когда количество ячеек равно N-1 аналогично случаю (3) и ячейка, соседняя с ячейкой Y в левом конце, имеет цвет С.
На фиг.19 (5)-(8) показаны состояния, в которых происходит потеря в конечной части во время считывания и которые соответствует фиг.19 (1)-(4) соответственно.
На фиг.19 (5) показано состояние, в котором одна ячейка (ячейка Y) с левого конца была потеряна, когда считывали цветной битовый код 1D по фиг.19 (1). В этом случае очевидно, что, поскольку условия конечной точки (условия, состоящие в том, что левый конец представляет собой цвет Y и правый конец представляет собой цвет С) не удовлетворяются (левый конец не имеет ячейку Y), можно детектировать считывание с ошибкой. Кроме того, в случае, когда цветной битовый код 1D считывают в обратном порядке, аналогично, поскольку условия конечной точки не удовлетворяются, можно детектировать считывание с ошибкой.
На фиг.19 (6) показано состояние, в котором одна ячейка (ячейка Y) с левого конца была потеряна, когда считывали цветной битовый код 1D, показанный на фиг.19 (2). В этом случае очевидно, что, поскольку условия конечной точки (условия, состоящие в том, что левый конец имеет цвет Y, и правый конец имеет цвет С) не удовлетворяются (левый конец не является ячейкой Y), можно детектировать возникновение считывания с ошибкой. Кроме того, в случае, когда цветной битовый код 1D будет считан в обратном порядке, аналогично, поскольку условия конечной точки не удовлетворяются, можно детектировать считывание с ошибкой.
На фиг.19 (7) показано состояние, в котором одна ячейка (ячейка С) на правом конце потеряна, когда считывают цветной битовый код 1D по фиг.19 (1). В этом случае также, поскольку условия конечной точки не удовлетворяются (правый конец не представляет ячейку цвета С), можно детектировать возникновение считывания с ошибкой. Кроме того, в случае, когда считывают цветной битовый код 1D с противоположной стороны, аналогично, поскольку условия конечной точки не удовлетворяются, можно детектировать считывание с ошибкой.
На фиг.19 (8) показано состояние, в котором одна ячейка (ячейка цвета С) с правого конца потеряна, когда был считан цветной битовый код 1D по фиг.19 (2). В этом случае также, поскольку условия конечной точки не удовлетворяются (правый конец не представляет собой ячейку цвета С), можно детектировать возникновение ошибочного считывания. Также в случае, когда цветной битовый код 1D считывают с противоположной стороны, аналогично, поскольку условия конечной точки не удовлетворяются, можно детектировать считывание с ошибкой.
Состояние последовательности ячеек конечной части в цветном битовом коде 1D состоит в том, что правый и левый концы всегда отличаются друг от друга, для того чтобы можно было различать начальную и конечную точки друг от друга. Поэтому в случае, когда один конец из N ячеек нельзя снять, как показано на фиг.19, условия ячейки конечной части (также называются условиями конечной точки) (в данном примере условие, относящееся к цветам Y и С, и состояние, что изменение направления считывания не разрешено) не удовлетворяются. Таким образом, можно детектировать считывание с ошибкой.
Учитывая также условия конечной точки (например, используя последовательность ячеек конечной части, как показано на фиг.19), даже если символ кода, имеющий N ячеек, и символ кода, имеющий N-1 ячейку, существуют одновременно, можно предотвратить ошибочное считывание, связанное с потерей конечной части.
Одновременное присутствие символа кода, имеющего N ячеек, и символа кода, имеющего N-2 ячейки
На фиг.20 показан результат анализа по детектированию считывания с ошибкой в случае, когда разрешено одновременное присутствие символа кода, имеющего N ячеек, и символа кода, имеющего N-2 ячейки.
Условия конечной точки в примере, показанном на фиг.20, состоят в том, что цвета YMC находятся на левом конце (ячейка цвета Y находится на левом конце), и цвета YMC находятся на правом конце (ячейка цвета С находится на правом конце).
В случае условий конечной точки условие последовательности конечной части включает в себя описанные выше условия для случая N ячеек и N-1 ячеек.
Пример, показанный на фиг.20, аналогичен примеру, представленному на фиг.19, когда одна ячейка с левого конца и одна ячейка с правого конца видны следующим образом:
Поэтому также в примере, показанном на фиг.20, считывание с ошибкой в случае одновременного присутствия N ячеек и N-1 ячейки и считывание в обратном порядке можно предотвратить таким же образом, как и в примере, показанном на фиг.19.
В случае, показанном на фиг.20, следует понимать, что условие конечной точки расширено до внутренней стороны символа кода в дополнение к примеру, показанному на фиг.19. В частности, на левом конце, в дополнение к ячейке цвета Y, ячейка цвета М и ячейка цвета С добавлены к внутренней стороне символа кода. На правом конце, в дополнение к ячейке цвета С, ячейки цветов YM добавлены к внутренней стороне символа кода.
Используя условия конечной точки, как показано на фиг.20, последовательность ячеек конечной части всегда отличается от исходной последовательности в любом из случаев, когда потеряны две ячейки на конце.
На фиг.20 (3) ячейка цвета Y на левом конце и ячейка цвета С на правом конце в примере, показанном на фиг.18 (1), потеряны. Очевидно, что условия конечной точки не удовлетворяются, независимо от того, будет ли символ кода считан нормально или в обратном порядке.
На фиг.20 (4) ячейки цветов YM на левом конце в примере, показанном на фиг.18 (1), потеряны. Очевидно, что условия конечной точки не удовлетворяются, независимо от того, будет ли считан символ кода нормально или в обратном порядке.
На фиг.20 (5) ячейки цветов МС на правом конце в примере, показанном на фиг.18 (1), потеряны. Очевидно, что условия конечной точки не удовлетворяются, независимо от того, будет ли символ кода считан нормально или в обратном порядке.
Поэтому в случае, когда две ячейки потеряны в символе кода, имеющем N ячеек, это всегда можно детектировать и, таким образом, предотвратить считывание с ошибкой.
В случае когда одна ячейка потеряна в символе кода, имеющем N ячеек или N-1 ячейку, как показано на фиг.19, можно предотвратить считывание с ошибкой.
В случае когда две или больше ячеек потеряны в символе кода, имеющем N-1 ячейку, количество ячеек не удовлетворяет определенному требованию, при этом возникновение потери можно, таким образом, детектировать и можно предотвратить считывание с ошибкой.
Поэтому, используя последовательность ячеек в конечной части, как показано на фиг.20 (путем использования условий конечной точки), можно разрешить одновременное присутствие (гибкость) символов кода, имеющих от N до N-2 ячеек.
Одновременное присутствие символа кода, имеющего N ячеек, и символа кода, имеющего N-3 ячейки
На фиг.21 показан пример одновременного присутствия символа кода, имеющего N ячеек, и символа кода, имеющего N-3 ячейки.
Условия конечной точки в примере, показанном на фиг.21, состоят в том, что цвета YMCM находятся с левого конца (ячейка цвета Y находится на левом конце), и цвета MYMC находятся на правом конце (ячейка цвета С находится на правом конце).
В случае условий конечной точки условия последовательности конечной части включают в себя описанные выше условия для случая N ячеек и N-1 ячеек (условия, показанные на фиг.19) и условия для случая N ячеек и N-2 ячеек (условия, показанные на фиг.20).
Пример, показанный на фиг.21, аналогичен примеру, показанному на фиг.20 и 19, когда только три ячейки с левого конца и три ячейки с правого конца видны следующим образом
Поэтому считывания с ошибкой в случае одновременного присутствия N ячеек и N-1 ячеек и их считывание в обратном порядке можно предотвратить. Кроме того, считывания с ошибкой в случае одновременного присутствия N ячеек и N-2 ячеек и их обратное считывание можно предотвратить таким же образом.
В случае, показанном на фиг.21, можно понимать, что состояние конечной точки дополнительно расширено до внутренней стороны символа кода, в дополнение к примерам, показанным на фиг.19 и 20. В частности, на левом конце, в дополнение к ячейке цвета Y, ячейка цвета М и ячейка цвета С добавлены к внутренней стороне символа кода и, кроме того, добавлена ячейка цвета М.
На правом конце, в дополнение к ячейке цвета С, ячейки цветов YM добавлены к внутренней стороне символа кода и, кроме того, добавлена ячейка цвета М.
При использовании условия конечной точки, как показано на фиг.21, последовательность ячеек конечной части всегда отличается от оригинальной последовательности в любом из случаев, когда потеряны три ячейки на концах.
На фиг.21 (3) потеряны ячейки цветов YMC с левого конца в примере по фиг.21 (1). Очевидно, что условия конечной точки не удовлетворяются, независимо от того, считывают ли символ кода нормально или в обратном порядке.
На фиг.21 (4) потеряны ячейки цветов YM на левом конце и ячейка цвета С на правом конце в примере, показанном на фиг.21 (1). Очевидно, что условия конечной точки не удовлетворяются, независимо от того, будет ли символ кода считан нормально или в обратном порядке.
На фиг.21 (5) потеряна ячейка цвета Y на левом конце и ячейки цветов МС на правом конце в примере, показанном на фиг.21 (1). Очевидно, что состояния конечной точки не удовлетворяются, независимо от того, считывают ли символ кода нормально или в обратном порядке.
На фиг.21 (6) потеряны ячейки цветов YMC с правой стороны в примере по фиг.21 (1). Очевидно, что условия конечной точки не удовлетворяются, независимо от того, будет ли символ кода считан нормально или в обратном порядке.
Поэтому в случае, когда три ячейки потеряны в символе кода, имеющем N ячеек, это всегда детектируется, и, таким образом, предотвращается ошибочное считывание.
С другой стороны, в случае, когда потеряны две ячейки, и в случае, когда потеряна одна ячейка, как описано на фиг.19 и 20, можно детектировать такую потерю и можно предотвратить считывание с ошибкой.
Поэтому, используя последовательность ячеек в конечной части, как показано на фиг.21 (используя условия конечной точки), можно обеспечить возможность одновременного присутствия (гибкость) символов кода, имеющих от N до N-3 ячеек.
Одновременное присутствие символа кода, имеющего N ячеек, и символа кода, имеющего N-4 ячеек
На фиг.22 показан пример одновременного присутствия символа кода, имеющего N ячеек, и символа кода, имеющего N-4 ячейки.
Условия конечной точки в примере, показанном на фиг.22, состоят в том, что цвета YMCMC находятся на левом конце (ячейка цвета Y находится на левом конце) и цвета YMYMC находятся на правом конце (ячейка цвета С находится на правом конце).
В случае таких условий конечной точки условия последовательности конечной части включают в себя описанные выше условия в случае N ячеек и N-1 ячеек (условие по фиг.19), условия в случае N ячеек и N-2 ячеек (условие по фиг.20) и условия в случае N ячеек и N-3 ячеек (условие по фиг.21).
Пример, показанный на фиг.22, аналогичен примеру, представленному на фиг.19, когда только видны одна ячейка с левого конца и только одна ячейка с правого конца, следующим образом. Аналогично фиг.22 включает в себя условия фиг.20 и 23.
Поэтому считывание с ошибкой в случае одновременного присутствия N ячеек и N-2 ячеек и считывание их в обратном порядке можно предотвратить. Аналогично, считывание с ошибкой в случае одновременного присутствия N ячеек и N-3 ячеек и их считывание в обратном порядке можно предотвратить.
В случае, показанном на фиг.22, можно понимать, что состояние конечной точки дополнительно расширено до внутренней стороны символа кода, в дополнение к примеру, показанному на фиг.19, 20 и 21. В частности, на левом конце, в дополнение к ячейке цвета Y, добавлены ячейка цвета М и ячейка цвета С к внутренней стороне символа кода и, кроме того, добавлены ячейка цвета М и ячейка цвета С.
На правом конце, в дополнение к ячейке цвета С, добавлены ячейки цветов MY с внутренней стороны символа кода, кроме того, добавлена ячейка цвета М и, кроме того, снова добавлена ячейка цвета Y.
На фиг.22 (1) показан символ кода из N ячеек, удовлетворяющий условиям конечной точки. На фиг.22 (2) показан символ кода N-4 ячеек, удовлетворяющий условиям конечной точки.
Используя условия конечной точки, как показано на фиг.22, последовательность ячеек конечной части всегда отличается от оригинальной последовательности в любом из случаев, когда потеряны четыре ячейки на концах.
На фиг.22 (3) потеряны ячейки цветов YMCM с левого конца в примере, показанном на фиг.22 (1). Очевидно, что условия конечной точки не удовлетворяются, независимо от того, будет считан символ кода нормально или в обратном порядке.
На фиг.22 (4) потеряны ячейки цветов YMC на левом конце и ячейка цвета С на правом конце в примере, показанном на фиг.22 (1). Очевидно, что условия конечной точки не удовлетворяются, независимо от того, будет ли символ кода считан нормально или в обратном порядке.
На фиг.22 (5) потеряны ячейки цветов YM на левом конце и ячейки цветов МС на правом конце в примере, показанном на фиг.22 (1). Очевидно, что условия конечной точки не удовлетворяются, независимо от того, будет ли символ кода считан нормально или в обратном порядке.
На фиг.22 (6) потеряны ячейка цвета Y с левого конца и ячейки цветов YMC на правом конце в примере, показанном на фиг.22 (1). Очевидно, что условия конечной точки не удовлетворяются, независимо от того, будет ли символ кода считан нормально или в обратном порядке.
На фиг.22 (7) потеряны ячейки цветов MYMC на правом конце в примере, показанном на фиг.22 (1). Очевидно, что условия конечной точки не удовлетворяются, независимо от того, будет ли символ кода считан нормально или в обратном порядке.
Поэтому, используя последовательность ячеек конечной части, как показано на фиг.22 (используя условия конечной точки), может быть разрешено одновременное присутствие (гибкость) символов кода, имеющих от N до N-4 ячеек.
Краткий итог 3-1
На основе принципа индукции из фиг.19 очевидно, что в цветном битовом коде 1D (Заявка №2006-196705 на японский патент), в котором последовательности цветов идентификации конечной части добавлены с обоих концов символа кода, имеющего N ячеек или N-1 ячейку, скомпонованные из трех цветов, для распознавания, что конечная часть потеряна, путем помещения последовательности цветов идентификации конечной части с правого и с левого концов, при этом достаточно использовать последовательности, описанные ниже, в качестве последовательностей цветов идентификации конечной части.
Достаточно поместить первый цвет как последовательность на левом конце и второй цвет как последовательность на правом конце. Первый и второй цвета отличаются друг от друга.
Очевидно, что, когда даже одна ячейка потеряна на правом или на левом конце, условие конечной точки не удовлетворяется. Это связано с тем, что в цветном битовом коде 1D разные цвета всегда назначают соседним ячейкам.
Даже если одна ячейка будет потеряна на левом конце, первый цвет не будет выглядеть как одна из (левая или правая) ячеек конечной точки, и, таким образом, условие конечной точки, очевидно, не удовлетворяется (даже если учесть случай, в котором правую и левую ячейки поменяли местами). Аналогично, когда даже одна ячейка потеряна на правом конце, второй цвет не выглядит как одна из (левая или правая) ячеек конечной точки, и, таким образом, условие конечной точки, очевидно, не удовлетворяется (даже если учесть случай, в котором правую и левую ячейки поменяли местами). Поэтому, когда одна из ячеек потеряна, условие конечной точки не удовлетворяется. Таким образом, можно точно детектировать считывание с ошибкой.
В случае, показанном на фиг.19, если две или больше ячеек потеряны в конечной части, изменяется количество ячеек. На основе количества ячеек можно определить, что произошла потеря. В случае, показанном на фиг.19, когда потеряна одна ячейка на одном конце символа кода, состоящего из N ячеек, можно распознать как "потерю в части конца", учитывая условия конечной точки, при этом можно предотвратить считывание с ошибкой.
Краткий итог 3-2
Как очевидно, исходя из принципа индукции, на фиг.20, 21 и 22, благодаря тому, что предусмотрены последовательности цвета идентификации конечной части, как описано ниже, на обоих правом и левом концах, можно детектировать потерю ячейки во время считывания.
В частности, такую последовательность идентификации конечной части генерируют, используя следующие этапы (обработку).
Первый этап
Вначале первый и второй цвета помещают с левого и правого концов, располагая, таким образом, исходные последовательности идентификации конечной части. В частности, исходная последовательность, находящаяся в последовательности идентификации конечной части с левого конца, может быть составлена из одной ячейки первого цвета. Исходная последовательность в последовательности идентификации конечной части с правого конца составлена из одной ячейки второго цвета. После этого ячейки последовательно добавляют к последовательности идентификации конечной части, используя следующую обработку.
Второй этап
В случае когда разрешено совместное присутствие символов кода, имеющих от N до N-k ячеек, следующую обработку (обработка левой оконечной стороны и обработка правой оконечной стороны) повторяют k раз. При этом k представляет собой целое число, равное 2 или больше.
Обработка левой оконечной стороны символа кода
На левой конечной стороне символа кода, если ячейка находится на правом конце последовательности идентификации конечной части, то есть ячейка в направлении внутренней стороны символа кода имеет первый или третий цвет, ячейка второго цвета будет вновь размещена. Таким образом, ячейка второго цвета будет добавлена с правого конца последовательности идентификации конечной части.
С другой стороны, на левом конце символа кода, если ячейка на правом конце последовательности идентификации конечной части, то есть ячейка в направлении внутренней стороны символа кода, имеет второй цвет, вновь будет размещена ячейка третьего цвета. Таким образом, ячейка третьего цвета будет добавлена с правого конца последовательности идентификации конечной части.
Обработка правой оконечной стороны символа кода
На правом конце символа кода, если ячейка на левом конце последовательности идентификации конечной части, то есть ячейка, направленная к внутренней стороне символа кода, имеет второй или третий цвет, вновь будет размещена ячейка первого цвета. Таким образом, ячейка первого цвета будет добавлена к левому концу последовательности идентификации конечной части.
С другой стороны, на правом конце символа кода, если ячейка с правого конца последовательности идентификации конечной части, то есть ячейка в направлении внутренней стороны символа кода имеет первый цвет, будет вновь размещена ячейка третьего цвета. Таким образом, ячейка третьего цвета будет добавлена на левом конце последовательности идентификации конечной части.
Используя такую обработку на левом конце символа кода, только ячейка на конце имеет первый цвет, и последовательность "третий цвет - второй цвет - третий цвет - второй цвет" многократно размещают в направлении внутрь от символа кода. С другой стороны, на правом конце символа кода только ячейка, находящаяся на конце, имеет второй цвет, и последовательность "третий цвет - первый цвет - третий цвет - первый цвет" многократно размещают в направлении внутрь от символа кода.
Более точно, последовательность цвета идентификации конечной части генерируют с помощью обработки, описанной выше, следующим образом.
В случае когда количество ячеек, составляющих символ кода, равно N или меньше или равно N-k или больше, идентификацию последовательности цветов конечной части, для предотвращения считывания с ошибкой, выполняют следующим образом, когда количество используемых цветов равно трем.
Последовательность идентификации цвета конечной части с левой стороны
Она построена "ячейкой первого цвета + первой повторяющейся частью ячейки". Ячейка конечной точки на левом конце представляет собой ячейку первого цвета.
Идентификационная последовательность цветов конечной части с правой стороны
Она построена "второй повторяющейся частью ячейки + второй цветной ячейки". Ячейка конечной точки с левого конца представляет собой ячейку второго цвета.
Первая повторяющаяся часть ячейки построена путем поочередного соединения ячейки третьего цвета и ячейки второго цвета со стороны левого конца в направлении внутрь символа кода. Общее количество соединенных ячеек равно k.
Вторая повторяющаяся часть ячейки построена путем поочередного соединения ячейки третьего цвета и ячейки первого цвета со стороны правого конца в направлении внутрь символа кода. Общее количество соединенных ячеек равно k.
N представляет собой натуральное число, и k представляет собой целое число, равное 1 или больше и меньше чем N.
Случаи, представленные на фиг.20 (k=2), фиг.21 (k=3) и фиг.22 (k=4), схематично представлены следующим образом:
В частности, в примерах, показанных на фиг.20-22, первый цвет представляет собой Y, второй цвет представляет собой С, и третий цвет представляет собой М. В этих примерах первый цвет представляет собой Y, второй цвет представляет собой С, и третий цвет представляет собой М. Хотя здесь показана такая комбинация, можно использовать другую комбинацию и другие цвета.
Когда используют последовательности цветов идентификации конечной части, показанные в разделе "Краткий итог_3-2", потерю k ячеек в символе кода, составленном из N ячеек, можно детектировать в случае, когда символы кода, имеющие от N до N-k ячеек, присутствуют в смешанном состоянии.
Потеря k ячеек
Вначале, когда k ячеек потеряны с левого конца, первый цвет не появляется на этом конце. Следовательно, условие конечной точки не удовлетворяется, и возникновение "потери" можно детектировать. Как очевидно из приведенного выше описания, когда k ячеек потеряны на левом конце, ячейка на левом конце становится ячейкой второго или третьего цвета. С другой стороны, ячейка на правом конце остается ячейкой второго цвета. Поэтому очевидно, что условие конечной точки не удовлетворяется.
В случае когда k ячеек потеряны на правом конце, второй цвет не появляется на этом конце. В этом случае также условие конечной точки, очевидно, не удовлетворяется, и "потерю" можно детектировать. Как очевидно из приведенного выше описания, когда k ячеек потеряны на правом конце, ячейка на правом конце становится ячейкой первого или третьего цвета. С другой стороны, ячейка на левом конце остается ячейкой, имеющей первый цвет. Поэтому очевидно, что условие конечной точки не удовлетворяется.
В случае когда одна или больше ячеек потеряны на левом конце, одна или больше ячеек потеряны на правом конце, и в сумме потеряно k ячеек, ячейка первого цвета не появляется ни на правом, ни на левом концах. В результате можно детектировать, что условие конечной точки не удовлетворяется, некоторая ячейка потеряна, и произошло считывание с ошибкой.
Потеря от одной до "k-1" ячеек
Последовательность цветов идентификации конечной части, предложенная в варианте воплощения, была построена на основе принципа индукции. Поскольку последовательность в случае k ячеек включает в себя последовательность k-1 ячеек, естественно можно детектировать потерю k-1 ячеек. Поскольку последовательность k-1 ячеек также включает в себя последовательность k-2 ячеек, потерю k-2 ячеек также можно естественно детектировать. Аналогично можно детектировать потерю любого количества от одной до k-1 ячейки.
Выше было приведено пояснение на основе принципа индукции. Однако интуитивно очевидно, что, когда одна или больше ячеек потеряны на левом конце, одна или больше ячеек потеряны на правом конце, и общее количество потерянных ячеек равно k или меньше, ячейка первого цвета не появляется на этих концах, и условие оконечной точки не удовлетворяется. Следует понимать, что в результате можно детектировать возникновение считывания с ошибкой и потерю ячеек.
Вариант 3-4 воплощения. Другие примеры (Предотвращение 2 считывания с ошибкой)
Другие различные примеры способа, описанного в варианте 3-3 воплощения, будут описаны ниже.
"Другой пример 3-1"
На фиг.23 показан пример, в котором условия конечной точки установлены следующим образом:
Левый конец: цвета YM (ячейка Y находится на левом конце)
Правый конец: цвета CY (ячейка Y находится на правом конце)
В этом примере предложены условия конечной точки, позволяющие детектировать одну потерю в символе кода, состоящем из N ячеек, в условиях, когда разрешено одновременное присутствие символа кода из N ячеек и символа кода из N-1 ячеек (предложены последовательности идентификации конечной части).
Из фиг.23 очевидно, что в случае, когда не происходит потеря ячеек, ячейки на обоих концах представляют собой ячейки Y. Если происходит потеря одной ячейки на одном из правого и левого концов, ячейка, по меньшей мере, на одном из правого и левого концов не становится ячейкой цвета Y, и условия конечной точки, состоящие в том, что ячейки на обоих концах представляют собой ячейки цвета Y, не удовлетворяются.
На фиг.23 (1) показан символ кода, состоящий из N ячеек, удовлетворяющих условиям конечной точки. На фиг.23 (2) показан символ кода, составленный из N-1 ячеек, удовлетворяющих условиям конечной точки.
На фиг.23 (3) показан символ кода, имеющий N-1 ячеек, в результате того, что была потеряна одна ячейка с левой стороны символа кода, состоящего из N ячеек. На фиг.23 (4) показан символ кода, имеющий N-1 ячеек, в результате того, что была потеряна одна ячейка с правой стороны символа кода, состоящего из N ячеек.
Как очевидно из фиг.23 (3) и (4), в случае, когда одна ячейка потеряна, не удовлетворяются условия конечной точки, независимо от того, будет ли символ кода считан нормально или в обратном порядке.
Поэтому, когда используют последовательности идентификации конечной части, показанные на фиг.23, случай возникновения потери одной ячейки в символе кода, состоящем из N ячеек, можно детектировать в условиях, когда разрешено одновременное присутствие символа кода из N ячеек и символа кода из N-1 ячеек.
Пример, показанный на фиг.23, можно обобщить и описать следующим образом:
Левый конец: первый цвет, третий цвет
Правый конец: второй цвет, первый цвет
(на любом конце первый цвет представляет собой ячейку конечной части)
В примере, показанном на фиг.23, цвет Y используют как первый цвет, цвет С используют как второй цвет, и цвет М используют как третий цвет. Очевидно, однако, также предпочтительно назначать другие цвета и использовать другие комбинации цветов.
"Другой пример 3-2"
На фиг.24 показан пример, в котором условия конечной точки установлены следующим образом:
Левый конец: цвета YMC (ячейка цвета Y находится на левом конце)
Правый конец: цвета MCY (ячейка цвета Y находится на правом конце)
В примере аналогично фиг.20 предложены условия конечной точки, позволяющие детектировать две потерянные ячейки в символе кода, составленном из ячеек N по условию, что разрешено одновременное присутствие символа кода из N ячеек и символа кода из N-2 ячеек (предложены последовательности идентификации конечной части).
Аналогично последовательностям идентификации конечной части, описанным выше, в примере, показанном на фиг.24, используется компоновка, в которой одна ячейка была добавлена к каждой из сторон в направлении внутренней стороны последовательности идентификации конечной части примера по фиг.23. Одна ячейка добавлена с каждой из правой и левой сторон.
На фиг.24 (1) показан пример, в котором последовательности идентификации конечной части предусмотрены в символе кода, составленном из N ячеек. На фиг.24 (2) показан пример, в котором последовательности идентификации конечной части предусмотрены в символе кода, составленном из N-1 ячейки.
На фиг.24 (3), (4) и (5) показано состояние, в котором потеря двух ячеек возникла в символе кода, составленном из N ячеек. На фиг.24 (3), (4) и (5) показан случай, в котором одна ячейка потеряна в каждой из правой и левой сторон, случай, в котором две ячейки потеряны с левого конца, и случай, в котором две ячейки потеряны с правого конца, соответственно.
Как очевидно из фиг.24 (1)-(5), в случае, когда потеря ячейки не происходит, ячейки на обоих концах представляют собой ячейки цвета Y. Однако, когда происходит потеря двух ячеек на одном или на обоих из правого и левого концов, как показано на фиг.24 (3), (4) и (5), по меньшей мере, одна из ячеек с правого и с левого концов не становится ячейкой цвета Y, и условия конечной точки, состоящие в том, что ячейки на обоих концах представляют собой ячейки цвета Y, не удовлетворяются.
Поэтому, когда используют последовательности идентификации конечной части, показанные на фиг.24, случай возникновения потери двух ячеек в символе кода, состоящем из N ячеек, можно детектировать при условии, что разрешено одновременное присутствие символа кода из N ячеек и символа кода из N-2 ячеек.
Пример на фиг.24 можно обобщить и описать следующим образом:
Левый конец: первый цвет, третий цвет, второй цвет
Правый конец: третий цвет, второй цвет, первый цвет
(на обоих концах ячейка конечной части имеет первый цвет)
В примере, показанном на фиг.24, цвет Y используют как первый цвет, цвет С используют как второй цвет, и цвет М используют как третий цвет. Однако очевидно, также предпочтительно назначать другие цвета и использовать другие комбинации цветов.
"Другой пример 3-3"
На фиг.25 показан пример, в котором условия конечной точки установлены следующим образом:
Левый конец: цвета YMCM (ячейка цвета Y находится на левом конце)
Правый конец: цвета CMCY (ячейка цвета Y находится на правом конце)
В примере аналогично фиг.21 предложены условия конечной точки, позволяющие детектировать три потерянные ячейки в символе кода, состоящем из N ячеек, при условии, что разрешено одновременное присутствие символа кода из N ячеек и символа кода из N-3 ячеек (предложены последовательности идентификации конечной части).
Аналогично последовательностям идентификации конечной части, описанным выше, в примере по фиг.25 используется компоновка, в которой одну ячейку добавили с каждой из сторон в направлении внутренней стороны последовательности идентификации конечной части примера по фиг.24. Одна ячейка добавлена с каждой из правой и левой сторон.
На фиг.25 (1) показан пример, в котором последовательности идентификации конечной части предусмотрены в символе кода, составленном из N ячеек. На фиг.25 (2) показан пример, в котором последовательности идентификации конечной части предусмотрены в символе кода, составленном из N-3 ячеек.
На фиг.25 (3), (4), (5) и (6) показано состояние, в котором потеря трех ячеек произошла в символе кода, составленном из ячеек N. На фиг.25 (3), (4), (5) и (6) показан случай, в котором три ячейки потеряны на правом конце, случай, в котором две ячейки потеряны на правом конце и одна ячейка потеряна на левом конце, случай, в котором одна ячейка потеряна на правом конце и две ячейки потеряны на левом конце, и случай, котором три ячейки потеряны на левом конце, соответственно.
Как очевидно следует из фиг.25 (1)-(6), в случае, когда не происходит потеря ячеек, ячейки на обоих концах представляют собой ячейки цвета Y. Однако, когда происходит потеря трех ячеек на одном или обоих из правого и левого концов, как показано на фиг.25 (3), (4), (5) и (6), по меньшей мере, одна из ячеек на правом и левом концах не становится ячейкой цвета Y, и условие конечной точки, состоящее в том, что ячейки на обоих концах представляют собой ячейки цвета Y, не удовлетворяется.
Поэтому, когда используют последовательности идентификации конечной части, показанные на фиг.25, случай возникновения потери из трех ячеек в символе кода, составленного из N ячеек, можно детектировать в обстоятельствах, когда разрешено одновременное присутствие символа кода из ячеек N и символа кода из N-3 ячеек.
Пример по фиг.25 можно обобщить и описать следующим образом:
Левый конец: первый цвет, третий цвет, второй цвет, третий цвет (первый цвет представляет собой ячейку конечной части)
Правый конец: второй цвет, третий цвет, второй цвет, первый цвет (первый цвет представляет собой ячейку конечной части)
В примере, показанном на фиг.25, цвет Y используют как первый цвет, цвет С используют как второй цвет, и цвет М используют как третий цвет. Однако очевидно, что также предпочтительно назначать другие цвета и использовать другие комбинации цветов.
"Другой пример 3-4"
На фиг.26 показан пример, в котором условия конечной точки установлены следующим образом:
Левый конец: цвета YMCMC (ячейка цвета Y находится на левом конце)
Правый конец: цвета MCMCY (ячейка цвета Y находится на правом конце)
В примере аналогично фиг.22 предложены условия конечной точки, позволяющие детектировать четыре потерянные ячейки в символе кода из ячеек N, в условиях, когда разрешено одновременное присутствие символа кода из N ячеек и символа кода из N-4 ячеек (предложены последовательности идентификации конечной части).
Аналогично последовательности идентификации конечной части, описанной выше, в примере на фиг.26 используется компоновка, в которой одну ячейка добавили с каждой стороны в направлении внутренней стороны последовательности идентификации конечной части примера по фиг.25. Одну ячейку добавили с каждой из правой и левой стороны.
На фиг.26 (1) показан пример, в котором последовательности идентификации конечной части предусмотрены в символе кода, составленном из N ячеек. На фиг.26 (2) показан пример, где последовательности идентификации конечной части предусмотрены в символе кода, составленном из N-4 ячеек.
На фиг.26 (3), (4), (5), (6) и (7) показано состояние, в котором потеря четырех ячеек произошла в символе кода, составленном из N ячеек. На фиг.26 (3), (4), (5), (6) и (7) показан случай, в котором четыре ячейки потеряны на правом конце, случай, в котором три ячейки потеряны на правом конце и одна ячейка потеряна на левом конце, случай, в котором две ячейки потеряны на правом конце и две ячейки потеряны на левом конце, случай, в котором одна ячейка потеряна на правом конце и три ячейки потеряны на левом конце, и случай, в котором четыре ячейки потеряны на левом конце, соответственно.
Как очевидно показано на фиг.26 (1)-(7), в случае, когда не происходит потеря ячейки, ячейки на обоих концах представляют собой ячейки цвета Y. Однако, когда происходит потеря в сумме четырех ячеек на одном или на обоих из правого и левого концов, как показано на фиг.26 (3), (4), (5), (6) и (7), по меньшей мере, одна из ячеек на правом и левом концах не становится ячейкой цвета Y, и условия конечной точки, в соответствии с которыми ячейки на обоих концах представляют собой ячейку цвета Y, не удовлетворяются.
Поэтому, когда используют последовательности идентификации конечной части, показанные на фиг.26, случай потери четырех ячеек в символе кода, составленном из ячеек N, можно детектировать в обстоятельствах, когда разрешено одновременное присутствие символа кода из N ячеек и символа кода из N-4 ячеек.
Пример на фиг.26 можно обобщить и описать следующим образом:
Левый конец: первый цвет, третий цвет, второй цвет, третий цвет, второй цвет (первый цвет представляет собой ячейку конечной части)
Правый конец: третий цвет, второй цвет, третий цвет, второй цвет, первый цвет (первый цвет представляет собой ячейку конечной части)
В примере, показанном на фиг.26, цвет Y используется как первый цвет, цвет С используется как второй цвет, и цвет М используется как третий цвет. Однако очевидно, также предпочтительно можно назначать другие цвета и использовать другие комбинации цветов.
Краткий итог 3-3
Как очевидно следует, исходя из принципа индукции, из фиг.23, 24, 25 и 26, благодаря тому, что предусмотрены последовательности цветов идентификации конечной части, как описано ниже, как на правом, так и на левом концах, можно детектировать потерю ячейки во время считывания.
В частности, такую последовательность идентификации конечной части генерируют на следующих этапах (процессах).
Первый этап
Вначале первый цвет помещают с левого и правого концов, располагая, таким образом, исходные последовательности идентификации конечной части. В частности, исходная последовательность последовательности идентификации конечной части на левом конце составлена одной ячейкой первого цвета. Исходная последовательность последовательности идентификации конечной части на правом конце составлена из одной ячейки первого цвета. После этого ячейки последовательно добавляют к последовательности идентификации конечной части, используя следующую обработку.
Второй этап
В случае когда разрешено одновременное присутствие символов кода, имеющих от N до N-k ячеек, следующую обработку (обработку стороны левого конца и обработку стороны правого конца) повторяют k раз, где k представляет собой целое число, равное 1 или больше.
Обработка символа кода левой конечной стороны
На левом конце символа кода, если ячейка на правом конце последовательности идентификации конечной части, то есть ячейка в направлении внутренней стороны символа кода, имеет первый или третий цвет, вновь размещают ячейку второго цвета. Таким образом, ячейку второго цвета добавляют с правого конца последовательности идентификации конечной части.
С другой стороны, на левом конце символа кода, если ячейка на правом конце последовательности идентификации конечной части, то есть ячейка в направлении внутренней стороны символа кода, имеет второй цвет, вновь добавляют ячейку третьего цвета. Таким образом, ячейку третьего цвета добавляют с правого конца последовательности идентификации конечной части.
Обработка символа кода на стороне правого конца
На правом конце символа кода, если ячейка на левом конце последовательности идентификации конечной части, то есть ячейка в направлении внутренней стороны символа кода, имеет первый или второй цвет, вновь размещают ячейку третьего цвета. Таким образом, ячейку третьего цвета добавляют на левом конце последовательности идентификации конечной части.
С другой стороны, на правом конце символа кода, если ячейка на правом конце последовательности идентификации конечной части, то есть ячейка в направлении внутренней стороны символа кода, имеет третий цвет, вновь помещают ячейку второго цвета. Таким образом, ячейку второго цвета добавляют на левом конце последовательности идентификации конечной части.
Используя такую обработку, на левом конце символа кода только ячейка на конце имеет первый цвет, и последовательность "второй цвет - третий цвет - второй цвет - третий цвет" повторно помещена в направлении внутрь символа кода. С другой стороны, на правом конце символа кода только ячейка на конце имеет первый цвет, и последовательность "третий цвет - первый цвет - третий цвет - первый цвет" многократно помещена в направлении внутрь символа кода.
Более точно, последовательность цветов идентификации конечной части, генерируемая в результате обработки, как описано выше, представляет собой следующую последовательность.
В случае когда количество ячеек, составляющих символ кода, равно N или меньше или N-k или больше, последовательность цветов идентификации конечной части для предотвращения считывания с ошибкой представляет собой следующее, когда количество используемых цветов равно трем.
Последовательность цветов идентификации конечной части с левой стороны
Она построена как "ячейка первого цвета + первая повторяющаяся часть ячейки". Ячейка конечной точки на левом конце представляет собой ячейку первого цвета.
Последовательность цветов идентификации конечной части с правой стороны
Она построена как "вторая повторяющаяся часть ячейки + ячейка первого цвета". Ячейка конечной точки на левом конце представляет собой ячейку первого цвета.
Первая повторяющаяся часть ячейки построена путем поочередного соединения ячейки второго цвета и ячейки третьего цвета со стороны левого конца в направлении внутрь символа кода. Общее количество соединенных ячеек равно k.
Вторая повторяющаяся часть ячейки построена путем поочередного соединения ячейки третьего цвета и ячейки второго цвета со стороны правого конца в направлении внутрь символа кода. Общее количество соединенных ячеек равно k.
N представляет собой натуральное число, и k представляет собой целое число, равное 1 или больше и меньшее чем N.
Число k соответствует случаю, в котором повторение цветов составляет k раз на обоих концах, за исключением конечных частей.
Примеры, показанные на фиг.23 (k=1), фиг.24 (k=2), фиг.25 (k=3) и фиг.26 (k=4), схематично представлены следующим образом:
В частности, в примерах, показанных на фиг.23-26, первый цвет представляет собой цвет Y, второй цвет представляет собой цвет М, и третий цвет представляет собой цвет С. Очевидно, что можно использовать другие комбинации и другие цвета.
Когда используется последовательность цветов идентификации конечной части, показанная в разделе "краткий итог 3-3", можно детектировать потерю k ячеек в символе кода, составленном из N ячеек, в случае, когда символы кода, имеющие от N до N-k ячеек, присутствуют в смешанном виде.
Потеря k ячеек
Вначале, когда потеряны k ячеек на левом конце, первый цвет не появляется на этом конце. Следовательно, условие конечной точки очевидно не удовлетворяется, и можно детектировать возникновении "потери". Из приведенного выше описания очевидно, что, когда потеряны k ячеек на левом конце, ячейка на левом конце становится ячейкой второго или третьего цвета. С другой стороны, ячейка на правом конце остается ячейкой, имеющей первый цвет. Поэтому очевидно, что условие конечной точки не удовлетворяется.
В случае когда k ячеек потеряны на правом конце, правый конец не будет иметь первый цвет. В этом случае также условие конечной точки, очевидно, не удовлетворяется, и можно детектировать возникновение "потери". Как очевидно следует из приведенного выше описания, когда k ячеек потеряны на правом конце, ячейка на правом конце становится ячейкой второго или третьего цвета. С другой стороны, ячейка на левом конце остается ячейкой, имеющей первый цвет. Поэтому очевидно, условие конечной точки не удовлетворяется.
В случае когда одна или больше ячеек потеряны на левом конце, одна или больше ячеек потеряны на правом конце и всего потеряно k ячеек, ячейка первого цвета не появляется ни на правом, ни на левом концах. В результате этого можно детектировать, что условие конечной точки не удовлетворяется, и некоторая ячейка потеряна, и произошло считывание с ошибкой.
Потеря от одной до "k-1 "ячеек
Последовательности цветов идентификации конечной части, описанные в других примерах 3-1-3-4, построены на основе принципа индукции. Поскольку последовательность в случае k включает в себя последовательность k-1, естественно потеря k-1 ячеек также может быть детектирована. Поскольку последовательность k-1 также включает в себя последовательность k-2, при этом потеря k-2 ячеек также может быть естественно детектирована. Аналогично потеря любого количества от одной ячейки до k-1 ячейки может быть детектирована.
Выше были приведены пояснения на основе принципа индукции. Однако интуитивно очевидно, что, когда одна или больше ячеек потеряны на левом конце, одна или больше ячеек потеряны на правом конце и общее количество потерянных ячеек равно k или меньше, ячейка первого цвета не появляется на этих концах, и условия конечной точки не удовлетворяются. В результате этого можно детектировать возникновение считывания с ошибкой и потерю ячеек.
Другие
Как описано выше, настоящее изобретение имеет аспект, состоящий в восстановлении исходных данных, используя множество символов кода, но не ограничивается этим. Очевидно, что изобретение также можно применять в случае считывания множества символов кода независимо друг от друга.
В случае когда рассматривают восстановление исходных данных, используя множество символов кода, предпочтительно, установить множество символов кода таким образом, чтобы каждый из них имел некоторое значение (такое, как дата, номер серии, цена и т.п.). Таким образом, даже в случае, когда по некоторым причинам исходные данные нельзя полностью восстановить, можно сделать обстоятельства более существенными для подсчета и т.п.
Вариант 3-5 воплощения и другие
(1) Очевидно, что изобретение, состоящее в детектировании "потери" при считывании по условиям конечной точки, то есть последовательности цветов идентификации конечной части, можно применять не только к случаю выражения заданных одиночных данных с помощью множества символов кода, но также и к случаю выражения одиночных данных одним символом кода.
(2) Предпочтительно данные изображения снимают с помощью камеры ПЗС или тому подобное обычным образом. Данные, снятые аналоговой камерой, можно преобразовать в цифровой сигнал.
Реферат заявки относится, в общем, к первому варианту воплощения, рефераты второго и третьего вариантов воплощения будут, например, следующими.
Реферат второго варианта воплощения
Цель изобретения состоит в том, чтобы представить более простой способ вырезания, в котором используются свойства цветного битового кода 1D, разработанного авторами настоящего изобретения, который является устойчивым к искажениям, размытости изображения, вариациям и т.п. по размерам и форме и отличается от обычного двумерного штрихкода.
Прежде всего, данные изображения, включающие в себя цветной битовый код 1D, снимают с помощью датчика области. Данные изображения делят на множество областей цветов на основе определения, является или нет каждая из разделенных областей ячейкой - компонентом цветного битового кода 1D, определяют, используя условие границы, условие количества ячеек, условие конца окончания или тому подобное. Наконец, декодирование выполняют фактически и проверяют, можно ли выполнить декодирование без ошибки или нет. Когда декодирование, в конечном итоге, можно выполнить точно, как описано выше, результат выводят как результат конечного вырезания или результат декодирования. Поэтому цветной бит 1D можно декодировать без использования метки вырезания или тому подобное.
Реферат третьего варианта воплощения
Настоящее изобретение направлено на предоставление кода оптического распознавания, в котором данные, которые должны быть выражены, выражают с помощью множества символов кода. Изобретение предоставляет код оптического распознавания, в случае когда разрешено одновременное присутствие символов кода, имеющих разное количество ячеек, позволяет детектировать потерю при считывании и предотвращает ошибочное распознавание, даже если происходит потеря при считывании на конечных частях.
Заданные данные выражены множеством символов кода. Каждый из символов кода включает в себя: данные идентификации группы, предназначенные для идентификации группы из множества символов кода, и данные идентификации порядка в группе, обозначающие порядок в группе.
Последовательность цветов идентификации конечной части предусмотрена в каждой из правой и левой конечных частях символа кода. Когда при считывании происходит потеря, последовательность цветов идентификации конечной части разрушается, и можно детектировать возникновение потери. Таким образом, можно предотвратить считывание с ошибкой.

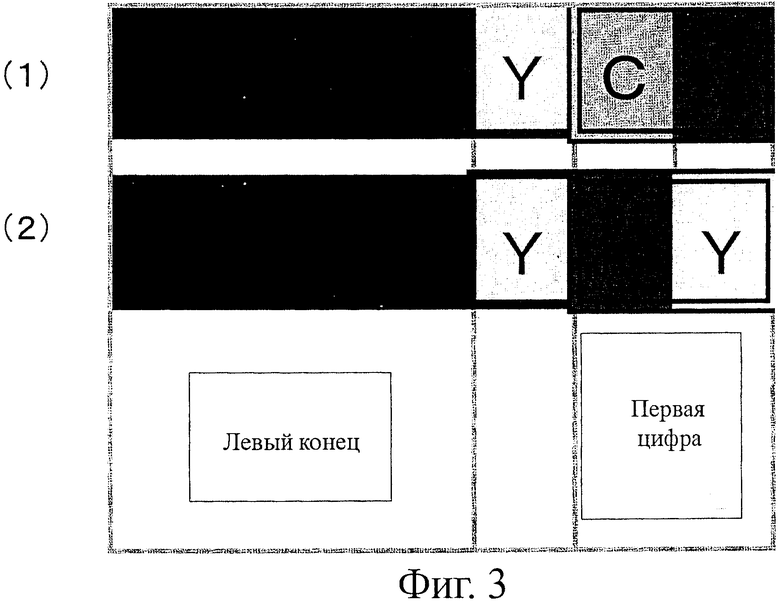
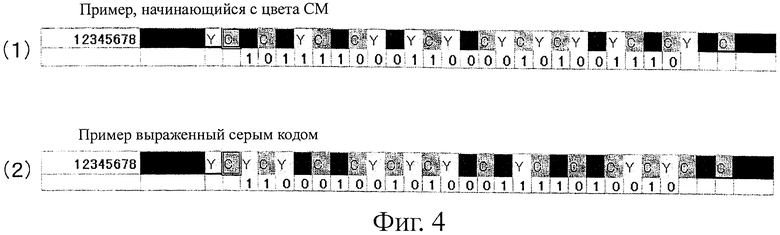


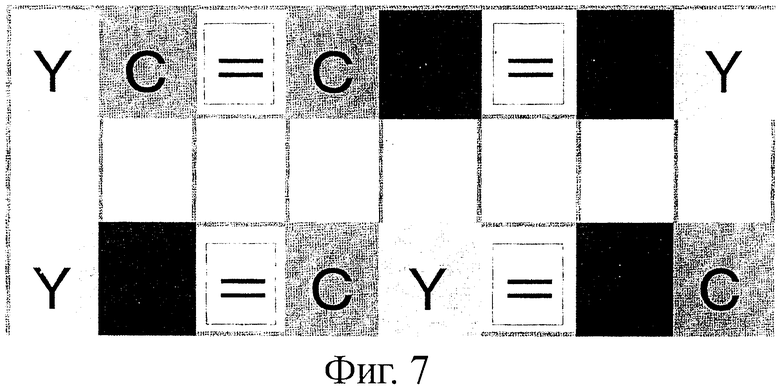




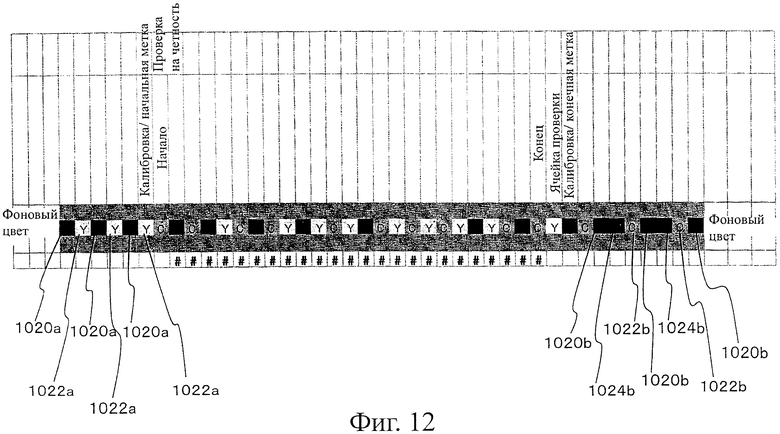

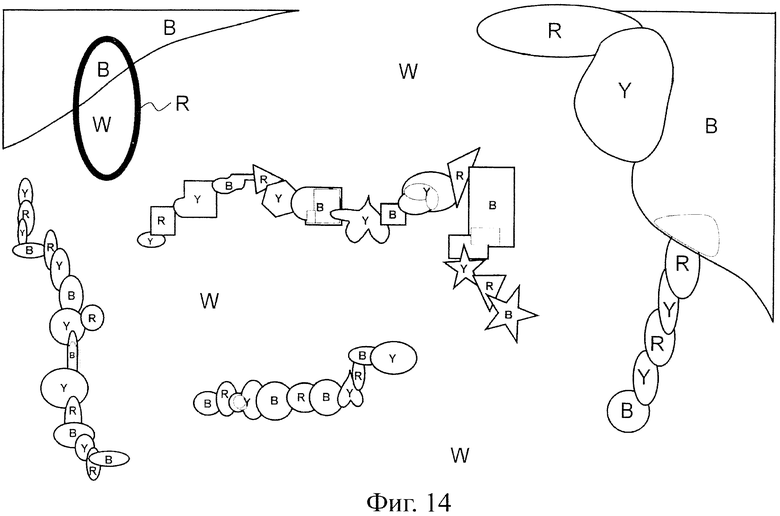
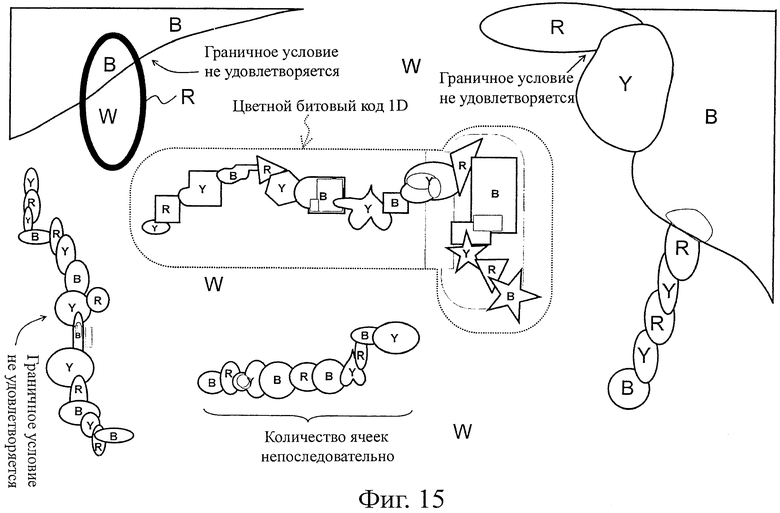
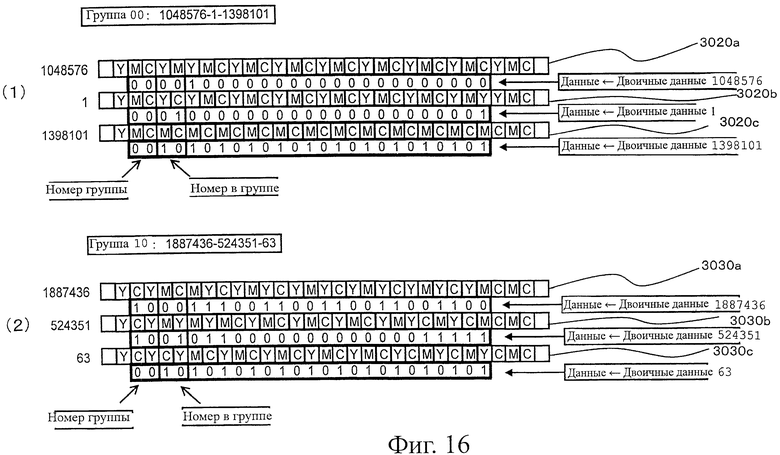
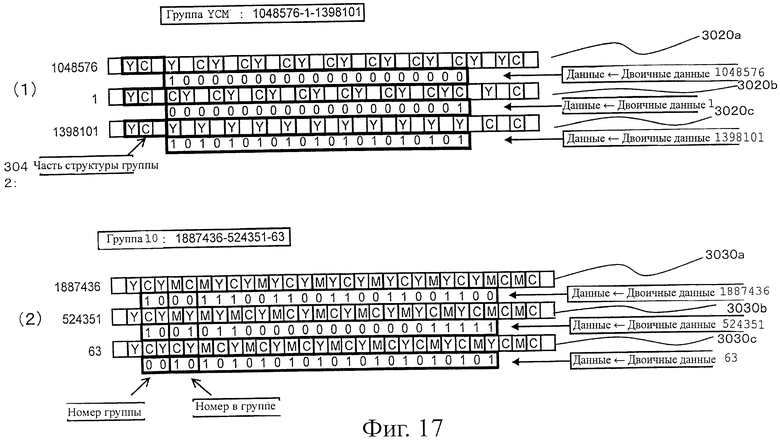
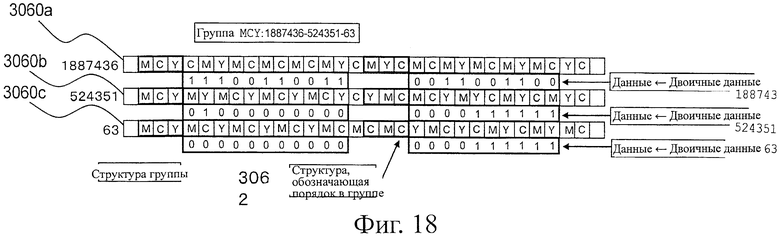

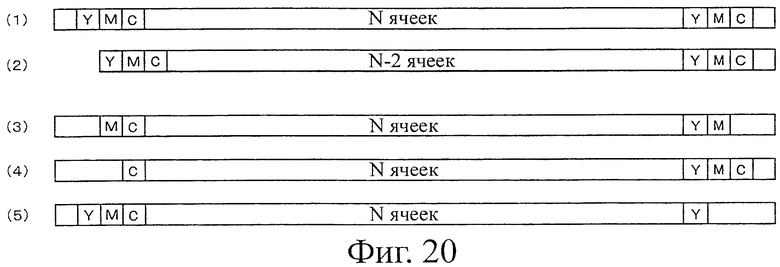
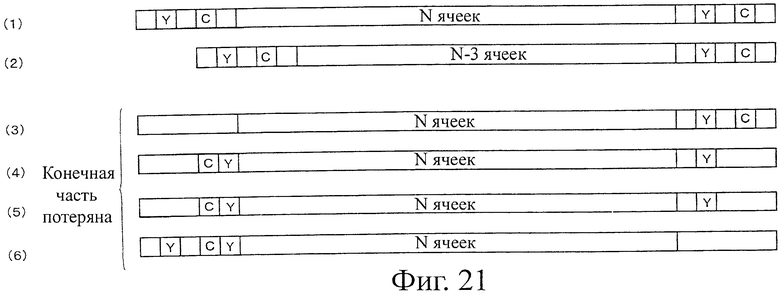





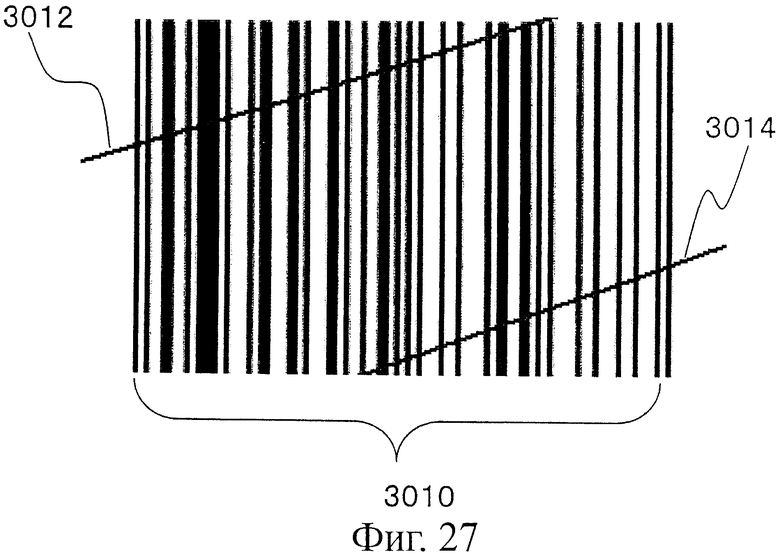
Изобретение относится к устройству и способу распознавания кода оптического распознавания. Техническим результатом является обеспечение высокой точности считывания кода с использованием оптического символа, напечатанного на предмете, размеры которого изменяются или точность печати которого невелика. Устройство распознавания кода оптического распознавания, содержащее средство деления, предназначенное для деления данных изображения, полученных в результате формирования изображения кода оптического распознавания на области цветов на основе параметров, обозначающих цвета, и средство определения, предназначенное для определения, является ли каждая из разделенных областей цветов ячейкой, представляющей собой компонент кода оптического распознавания, или нет, на основании способа компоновки цветов, назначенных областям. 3 н. и 45 з.п. ф-лы, 27 ил.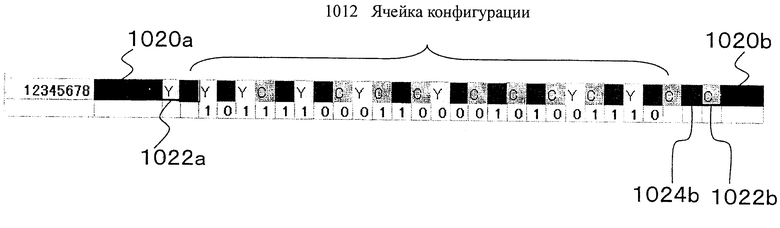
1. Устройство распознавания кода оптического распознавания, содержащее:
средство деления, предназначенное для деления данных изображения, полученных в результате формирования изображения кода оптического распознавания на области цветов на основе параметров, обозначающих цвета; и
средство определения, предназначенное для определения, является ли каждая из разделенных областей цветов ячейкой, представляющей собой компонент кода оптического распознавания, или нет, на основании способа компоновки цветов, назначенных областям.
2. Устройство распознавания кода оптического распознавания по п.1, в котором данные изображения построены с использованием данных трех основных цветов, и параметры, обозначающие цвета, представляют собой данные этих трех основных цветов.
3. Устройство распознавания кода оптического распознавания по п.1, в котором данные изображения построены с использованием данных, обозначающих цвета, включающие в себя оттенок, и параметр, обозначающий цвет, представляет собой оттенок.
4. Устройство распознавания кода оптического распознавания по п.1, в котором средство деления выполняет обработку деления области на основе только параметров, обозначающих цвета, без использования какой-либо информации о положении, измерении и форме области, которая должна быть разделена.
5. Устройство распознавания кода оптического распознавания по п.1, в котором средство деления выполняет обработку формирования изображения, состоящую в увеличении области по каждой из областей, полученных в результате деления.
6. Устройство распознавания кода оптического распознавания по п.1, в котором средство деления выполняет обработку формирования изображения, состоящую в уменьшении области каждой из областей, полученных в результате деления.
7. Устройство распознавания кода оптического распознавания по п.1, в котором средство деления преобразует данные изображения до четырех значений или N значений на основе параметров, обозначающих цвета, и делит данные изображения на области цвета, на основе этих значений,
где N представляет собой положительное целое число.
8. Устройство распознавания кода оптического распознавания по п.7, в котором средство определения вырезает структуру одного цветного битового кода 1D или множества цветных битовых кодов 1D на основе только способа компоновки областей (граничное условие, количество областей и совместимость порядка компоновки) из каждой из областей, полученных в результате деления.
9. Устройство распознавания кода оптического распознавания по п.1,
в котором средство деления делит данные изображения на область одного или больше цветов, составляющих маркировочную структуру, и область цвета, обозначающую зону, не содержащую данные, и
цвет, обозначающий зону, не содержащую данные, представляет собой цвет пробела, который является другим цветом, чем цвета, составляющие маркировочную структуру.
10. Устройство распознавания кода оптического распознавания по п.9,
в котором, когда целевая область удовлетворяет любому из следующих условий, средство определения определяет, что целевая область представляет собой кандидат ячейки, как компонент цветного битового кода:
условие "а" промежуточной ячейки: другие четыре области являются соседними вокруг целевой области, и цвета этих других четырех областей представляют собой цвет пробела - другой цвет - цвет пробела - другой цвет в направлении вдоль окружности вокруг целевой области, расположенной в центре; и
условие "b" конечной ячейки: две другие области являются соседними вокруг целевой области, и цвета этих двух других областей представляют собой цвет пробела и другой цвет, и
другой цвет представляет собой другой цвет, как компонент маркировочной структуры, отличающийся от цвета целевой области.
11. Устройство распознавания кода оптического распознавания по п.9 или 10, в котором цвет пробела, обозначающий зону, не содержащую данные, представляет собой белый или черный цвет.
12. Устройство распознавания кода оптического распознавания по п.1, в котором, когда количество ячеек, составляющих цветной битовый код 1D, в случае, когда предполагается, что целевая область представляет собой ячейку, как компонент цветного битового кода 1D, совпадает с заданным количеством, средство определения определяет, что целевая область представляет собой кандидат ячейки, как компонент цветного битового кода.
13. Устройство распознавания кода оптического распознавания по п.1, в котором, когда начальная точка и конечная точка цветного битового кода 1D детектированы, и одна или больше ячеек, составляющих начальную точку, и одна или больше ячеек, составляющих конечную точку, совпадают с заданными цветами начальной и конечной точек, в случае, когда предполагается, что целевая область представляет собой ячейку, как компонент цветного битового кода 1D, средство определения определяет, что целевая область представляет собой кандидат ячейки как компонент цветного битового кода.
14. Устройство распознавания кода оптического распознавания по п.1, в котором, когда промежуточную точку цветного битового кода 1D детектируют, и одна или больше ячеек, составляющих промежуточную точку, совпадает с заданным цветом промежуточной точки, в случае, когда предполагается, что целевая область представляет собой ячейку, как компонент цветного битового кода 1D, средство определения определяет, что целевая область представляет собой кандидат ячейки, как компонент цветного битового кода.
15. Устройство распознавания кода оптического распознавания по любому из пп.10, 12 и 13, в котором средство определения рассматривает, как цветной битовый код группу областей цветов, оцениваемых как цветной битовый код, состоящий из кандидатов ячеек, составляющих цветной битовый код, и декодирует этот цветной битовый код для получения исходных данных.
16. Устройство распознавания кода оптического распознавания по п.15, в котором, когда присутствует множество групп областей цветов, оцениваемых как цветной битовый код, каждый из которых состоит из кандидатов ячеек, составляющих цветной битовый код, средство определения декодирует каждую из групп областей, как цветной битовый код, и декодирует каждый цветной битовый код, для получения исходных данных.
17. Носитель записи, содержащий записанную на нем программу, обеспечивающую работу компьютера в качестве устройства распознавания кода оптического распознавания, в котором обеспечивается выполнение компьютером:
процедуры деления для разделения данных изображения, полученных в результате формирования изображения кода оптического распознавания на цветные области на основе параметров, обозначающих цвета; и
процедуры определения, предназначенной для определения, представляет ли собой каждая из разделенных областей цвета ячейку, как компонент кода оптического распознавания, или нет, на основании способа компоновки цветов, назначенных областям.
18. Носитель записи по п.17, в котором данные изображения построены с использованием данных трех основных цветов, и параметры, обозначающие цвета, представляют собой данные этих трех основных цветов.
19. Носитель записи по п.17, в котором данные изображения построены с использованием данных, обозначающих цвет, включающий в себя оттенок, и параметр, обозначающий цвет, представляет собой оттенок.
20. Носитель записи по п.17, в котором в процедуре деления выполняют обработку деления области на основе только параметров, обозначающих цвета, без использования какой-либо информации о положении, размере и форме области, предназначенной для деления.
21. Носитель записи по п.17, в котором в процедуре деления выполняют обработку формирования изображения, состоящую в увеличении области по каждой из областей, полученных в результате деления.
22. Носитель записи по п.17, в котором в процедуре деления выполняют обработку формирования изображения, состоящую в уменьшении области по каждой из областей, полученных в результате деления.
23. Носитель записи по п.17, в котором в процедуре деления данные изображения преобразуют в четыре значения или в N значений на основе параметров, обозначающих цвета, и эти данные изображения разделяют на цветные области на основе этих значений,
где N представляет собой положительное целое число.
24. Носитель записи по п.23, в котором в процедуре определения вырезают структуру одного цветного битового кода 1D или множества цветных битовых кодов 1D на основе только способа компоновки областей (граничное условие, количество областей и совместимость порядка компоновки) из каждой из областей, полученных в результате деления.
25. Носитель записи по п.17, в котором в процедуре деления данные изображения делят на область одного или больше цветов, составляющих структуру маркировки, и область цвета, обозначающую зону, не содержащую данные, и
цвет, обозначающий зону, не содержащую данные, представляет собой цвет пробела, другой, чем цвета, составляющие структуру маркировки.
26. Носитель записи по п.25, в котором в процедуре определения, когда целевая область удовлетворяет любому из следующих условий, определяют, что целевая область представляет собой кандидат ячейки, как компонент цветного битового кода:
условие "а" промежуточной ячейки: другие четыре области являются соседними вокруг целевой области, и цвета этих других четырех областей представляют собой "цвет пробела - другой цвет - цвет пробела - другой цвет" в направлении вдоль окружности вокруг целевой области, расположенной в центре; и
условие "b" конечной ячейки: две другие области являются соседними вокруг целевой области, и цвета других двух областей представляют собой цвет пробела и другой цвет, и
другой цвет представляет собой другой цвет, как компонент маркировочной структуры, отличающийся от цвета целевой области.
27. Носитель записи по п.25 или 26, в котором цвет пробела, обозначающий зону, не содержащую данные, представляет собой белый или черный цвет.
28. Носитель записи по п.17, в котором в процедуре определения, когда количество ячеек, составляющих цветной битовый код 1D, в случае, когда предполагают, что целевая область, которая должна представлять собой ячейку, как компонент цветного битового кода 1D, совпадает с заданным числом, определяют, что целевая область представляет собой кандидат ячейки, как компонент цветного битового кода.
29. Носитель записи по п.17, в котором в процедуре определения, когда детектируют начальную точку и конечную точку цветного битового кода 1D, и одна или больше ячеек, составляющих начальную точку, и одна или больше ячеек, составляющих конечную точку, совпадает с заданными цветами начальной и конечной точек в случае, когда предполагают, что целевая область представляет собой ячейку, как компонент цветного битового кода 1D, определяют, что целевая область представляет собой кандидат ячейки, как компонент цветного битового кода.
30. Носитель записи по п.17, в котором в процедуре определения, когда детектируют промежуточную точку цветного битового кода 1D, и одна или больше ячеек, составляющих промежуточную точку, совпадает с заданным цветом промежуточной точки в случае, когда предполагается, что целевая область представляет собой ячейку, как компонент цветного битового кода 1D, определяют, что целевая область представляет собой кандидат ячейки, как компонент цветного битового кода.
31. Носитель записи по любому из пп.26, 28 и 29, в котором в процедуре определения группу цветных областей, оцененную как цветной битовый код, состоящий из кандидатов ячеек, составляющих цветной битовый код, рассматривают как цветной битовый код и декодируют для получения исходных данных.
32. Носитель записи по п.31, в котором в процедуре определения, когда присутствует множество групп цветных областей, оцененных как цветной битовый код, каждая из которых составлена из кандидатов ячеек, составляющих цветной битовый код, каждую из групп области рассматривают как цветной битовый код и декодируют для получения исходных данных.
33. Способ распознавания кода оптического распознавания, содержащий:
этап деления, состоящий в делении данных изображения, полученных в результате формирования изображения кода оптического распознавания на цветные области на основе параметров, обозначающих цвета; и
этап определения, состоящий в определении, на основании способа компоновки цветов, назначенных областям, представляет ли собой каждая из разделенных цветных областей ячейку, как компонент кода оптического распознавания, или нет.
34. Способ распознавания кода оптического распознавания по п.33, в котором данные изображения построены с использованием данных трех основных цветов, и параметры, обозначающие цвета, представляют собой данные трех основных цветов.
35. Способ распознавания кода оптического распознавания по п.33, в котором данные изображения построены с использованием данных, обозначающих цвет, включающий в себя оттенок, и параметр, обозначающий цвет, представляет собой оттенок.
36. Способ распознавания кода оптического распознавания по п.33, в котором на этапе деления выполняют обработку деления области на основе только параметров, обозначающих цвета, без использования какой-либо информации о положении, измерении и форме области, предназначенной для деления.
37. Способ распознавания кода оптического распознавания по п.33, в котором на этапе деления выполняют обработку формирования изображения, состоящую в увеличении области для каждой из областей, полученных в результате деления.
38. Способ распознавания кода оптического распознавания по п.33, в котором на этапе деления выполняют обработку уменьшения области по каждой из областей, полученных в результате деления.
39. Способ распознавания кода оптического распознавания по п.33, в котором на этапе деления данные изображения преобразуют в четыре значения или в N значений на основе параметров, обозначающих цвета, и данные изображения преобразуют в цветные области на основе этих значений,
где N представляет собой положительное целое число.
40. Способ распознавания кода оптического распознавания по п.39, в котором на этапе определения структуру одиночного цветного битового кода 1D или множества цветных битовых кодов 1D вырезают на основе только способа компоновки областей (граничное условие, количество областей и совместимость порядка компоновки) из каждой из областей, полученных в результате деления.
41. Способ распознавания кода оптического распознавания по п.33,
в котором на этапе деления данные изображения делят на область из одного или больше цветов, составляющих маркировочную структуру, и область цвета, обозначающую зону, не содержащую данные, и
цвет, обозначающий зону, не содержащую данные, представляет собой цвет пробела, отличающийся от цветов, составляющих маркировочную структуру.
42. Способ распознавания кода оптического распознавания по п.41,
в котором на этапе определения, когда целевая область удовлетворяет любому из следующих условий, определяют, что целевая область представляет собой кандидат ячейки, как компонент цветного битового кода:
условие "а" промежуточной ячейки: другие четыре области представляют собой соседние области вокруг целевой области, и цвета этих других четырех областей представляют собой "цвет пробела - другой цвет - цвет пробела - другой цвет" в направлении вдоль окружности вокруг целевой области, находящейся в центре; и
условие "b" конечной ячейки: две другие области представляют собой соседние области вокруг целевой области, и цвета этих других двух областей представляют собой цвет пробела и другой цвет, и
другой цвет представляет собой другой цвет, как компонент маркировочной структуры, отличающийся от цвета целевой области.
43. Способ распознавания кода оптического распознавания по п.41 или 42, в котором цвет пробела, обозначающий зону, не содержащую данные, представляет собой белый или черный цвет.
44. Способ распознавания кода оптического распознавания по п.43, в котором на этапе определения, когда количество ячеек, составляющих цветной битовый код 1D, в случае, когда предполагается, что целевая область должна представлять собой ячейку, как компонент цветного битового кода 1D, совпадает с заданным количеством, определяют, что целевая область представляет собой кандидат ячейки, как компонент цветного битового кода.
45. Способ распознавания кода оптического распознавания по п.43, в котором на этапе определения, когда начальную точку и конечную точку цветного битового кода 1D детектируют, и одна или больше ячеек, составляющих начальную точку, и одна или больше ячеек, составляющих конечную точку, совпадает с заданными цветами начальной и конечной точек, в случае, когда предполагается, что целевая область представляет собой ячейку, как компонент цветного битового кода 1D, определяют, что целевая область представляет собой кандидат ячейки, как компонент цветного битового кода.
46. Способ распознавания кода оптического распознавания по п.43, в котором, когда промежуточную точку цветного битового кода 1D детектируют, и одна или больше ячеек, составляющих промежуточную точку, совпадает с заданным цветом промежуточной точки, в случае, когда предполагается, что целевая область представляет собой ячейку, как компонент цветного битового кода 1D, средство определения определяет, что целевая область представляет собой кандидат ячейки, как компонент цветного битового кода.
47. Способ распознавания кода оптического распознавания по любому из пп.42, 44 и 45, в котором на этапе определения группу цветных областей, оцениваемых как цветной битовый код, состоящий из кандидатов ячеек, составляющих цветной битовый код, рассматривают как цветной битовый код и декодируют для получения исходных данных.
48. Способ распознавания кода оптического распознавания по п.47, в котором на этапе определения, когда существует множество групп цветных областей, оцененных как цветные битовые коды, каждый из которых состоит из кандидатов ячеек, составляющих цветной битовый код, каждую из групп областей рассматривают как цветной битовый код, декодируемый для получения исходных данных.
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| МАШИНОЧИТАЕМЫЙ КОД, СПОСОБ И УСТРОЙСТВО КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ | 2001 |
|
RU2251734C2 |
| Печь для непрерывного получения сернистого натрия | 1921 |
|
SU1A1 |
| 0 |
|
SU1612724A1 | |
| RU 2003131888 A, 27.04.2005. | |||

