Область техники
Изобретение относится к области компьютерных технологий и может быть использовано при автоматической структуризации компьютерных кодов, адекватных обрабатываемой информации.
Предшествующий уровень техники
Известен способ автоматической структуризации компьютерных кодов, адекватных обрабатываемой информации, включающий выделение из объема поступающей в единицу времени информации ее части, которую выбирают в зависимости от вида информации, например цифровой или текстовой, разбивают поступившую информацию на логически законченные фрагменты, кодируют полученные фрагменты информации и распределяют их по базам данных [Айламазян А.К., Стась Е.В. "Информатика и теория развития". М., Наука, 1989 г.].
Известен также способ автоматической структуризации компьютерных кодов, адекватных обрабатываемой информации, включающий выделение из объема поступающей в единицу времени информации ее части, которую выбирают в зависимости от вида информации, например цифровой и/или текстовой, и/или графической, разбивают поступившую информацию на логически законченные фрагменты, кодируют полученные фрагменты информации, преобразуя их по заданному алгоритму, полученную совокупность преобразованных фрагментов распределяют по базам данных, помещая каждый из фрагментов в соответствующую ему базу [Д.Э.Бэстенс, В.-М.ван ден Берг, Д.Вуд. Нейронные сети и финансовые рынки, М:, Издательство ТВП, 1977 г.].
Недостатками известных способов являются несовершенство обработки компьютерных кодов, адекватных исходной информации, и относительно низкие скорости структуризации компьютерных кодов.
Решаемая задача и достигаемый технический результат
Решаемой изобретением задачей является совершенствование способов автоматической структуризации компьютерных кодов, адекватных обрабатываемой информации, с достижением при этом технического результата в отношении, в частности, повышения скорости структуризации компьютерных кодов. Использование в целом способа автоматической структуризации компьютерных кодов, адекватных обрабатываемой информации, позволяет значительно сэкономить расход вычислительных ресурсов (память, количество операций процессора и т.д.), повысить скорость и точность структуризации компьютерных кодов.
Краткое изложение сущности изобретения
В качестве кратких сведений, раскрывающих сущность изобретения, следует отметить, что достигаемый технический результат обеспечивают с помощью предложенного способа автоматической структуризации компьютерных кодов, адекватных обрабатываемой информации, который включает совокупность операций, осуществляемых по N1-каналам, где N1 выбирают от 1 до 2256. При этом в каждом из N2 каналов, выбираемых в количестве, удовлетворяющем неравенству 1+1/N1≤(N2+α1N1)/N1≤2,3, где α 1 - экспериментальный коэффициент, выбираемый в зависимости от вида информации и от количества источников ее поступления в пределах от 0,61≤ α1≤1,3, выделяют из объема V1 поступающей в единицу времени информации ее часть объема V2, которую выбирают из соотношения в пределах 0,56≤ (V2+α 2V1)/V1≤2,8, где α 2 - экспериментальный коэффициент, выбираемый в зависимости от вида информации в пределах от 0,56≤ α2≤1,8. Разбивают поступившую информацию на логически законченные фрагменты, объемы V3i которых выбирают из соотношения в пределах 0,45≤ (V3i+α3V2)/V2≤2,7, где α 3 - экспериментальный коэффициент, выбираемый в зависимости от особенности их разбиения в пределах от 0,45≤ α3≤1,7, а i выбирают в пределах 1≤ i≤ 2256.
Затем кодируют полученные фрагменты информации, преобразуя их по заданному алгоритму до получения совокупности N-мерных множеств, адекватных преобразуемой исходной информации. Аj элементов вида {Вm, X1, Х2,... Хn}, где j - порядковый номер множества в пределах от 1 до 2256, Вm - идентификатор, X1-Xn - координата элемента относительно начала координат элемента, a m и n выбирают в пределах от 1 до 2256. Полученную совокупность N-мерных множеств сопоставляют с уже накопленными множествами и/или с вновь поступающими множествами по разным каналам, определяют и вырезают пересекающиеся части множеств. После этого вырезанные пересечения множеств и остающиеся после вырезания множества распределяют по базам данных, помещая каждое из одинаковых множеств в соответствующую ему базу данных и каждое из различающихся по какому-то параметру множества в соответствующие этим видам множеств базы данных и помещают на место вырезанных множеств идентификаторы хранящих эти множества баз данных.
Перечень чертежей
Фиг.1. Схема размещения компьютерных кодов, адекватных обрабатываемой информации. Фиг.2. Упрощенная схема осуществления способа для одного канала. Фиг.3. Упрощенная схема осуществления способа для двух каналов. Фиг.4. Упрощенная схема осуществления способа для десяти каналов. Фиг.5. Подробная иллюстрация заявленного способа. Фиг.6. Фрагмент подробной иллюстрации заявленного способа.
Детальное описание и примеры осуществления изобретения
При изложении сведений, подтверждающих возможность осуществления изобретения, целесообразно более детально описать предложенный способ автоматической структуризации компьютерных кодов, адекватных обрабатываемой информации, при описании которого нецелесообразно подробно останавливаться на известных из опубликованных данных особенностях выполнения его операций. При этом целесообразно привести для удобства восприятия информации определения используемых понятий.
Компьютерный код - машинопреобразуемое представление некоторого фрагмента информации (оригинала), в частности, в виде электромагнитных сигналов.
Критерий - это фактор, по которому производят распознавание, например, параметр координата, логическое условие и т.п.
Система критериев - это совокупность критериев, взаимосвязанных их целевой направленностью, в частности их пригодностью для использования в процессе распознавания.
Память - функциональный узел средства реализации способа, фиксирующий на определенный срок обрабатываемую информацию, с возможностью ее дальнейшего воспроизведения, считывания и других видов использования.
Заданный алгоритм - набор правил, по которым преобразуют поступающую по каждому из каналов исходную информацию.
Множество - объединение в единое целое определенных вполне различаемых объектов, которые при этом называются элементами образуемого ими множества [″ Справочник по математике″ , И.Н.Бронштейн, К.А.Семендяев, изд. ″ Наука″ , Москва, 1986. с. 380. п.4.1.2.1].
Различаемый объект - компьютерные коды, адекватные соответствующим фрагментам информации.
Пересечение двух множеств Аj и Aj+k - это множество, которое состоит из элементов, принадлежащих каждому из множеств Aj и Aj+k [″ Справочник по математике″ , И.Н.Бронштейн, К.А.Семендяев, изд. ″ Наука”, Москва, 1986, с.381, п.4.1.3.1], где j и j+k - номера множеств, взятые из области от 1 до 2256, либо, по аналогии, пересечение любого количества структурируемых по заявленному способу множеств.
Далее детально целесообразно остановиться только на отличительных существенных особенностях осуществления операций предложенного способа, заключающихся в том. что способ включает совокупность операций, осуществляемых по N1-каналам, где N1 выбирают от 1 до 2256. Выбор указанного количества каналов в заявленных пределах обеспечивает практически все существующие в настоящее время потребности реализации способа. При этом в каждом из N2 каналов, выбираемых в количестве, удовлетворяющем неравенству 1+1/N1≤(N2+α 1N1)/N1≤2,3, где α 1 - экспериментальный коэффициент, выбираемый в зависимости от вида информации и от количества источников ее поступления в пределах от 0,61≤ α1≤1,3, выделяют из объема V1 поступающей в единицу времени информации ее часть объема V2, которую выбирают из соотношения в пределах 0,56≤ (V2+α 2V1)/V1≤2,8, где α 2 - экспериментальный коэффициент, выбираемый в зависимости от вида информации в пределах от 0,56≤ α2≤1,8. На практике это могут быть разновидности цифровой, текстовой, символьной, графической и смешанной информации. Поступившую информацию разбивают на логически законченные фрагменты, объемы V3i которых выбирают из соотношения в пределах 0,45≤ (V3i+α3V2)/V2≤2,7, где α 3 - экспериментальный коэффициент, выбираемый в зависимости от особенности их разбиения в пределах от 0,45≤ α3≤1,7, а i выбирают в пределах 1≤ i≤ 2256. В числе простейших особенностей разбиения поступившей информации на логически законченные фрагменты можно указать, например, на равные объемы фрагментов или не равные ее разбивают.
Затем кодируют полученные фрагменты информации, преобразуя их по заданному алгоритму до получения совокупности N-мерных множеств, адекватных преобразуемой исходной информации, Aj элементов (и/или фреймов) вида {Вm, Х1, Х2,... Хn), где j - порядковый номер множества в пределах от 1 до 2256, Вm – идентификатор, X1-Xn - координата элемента относительно начала координат элемента, a m и n выбирают в пределах от 1 до 2256. Здесь целесообразно отметить, что указанные элементы часто называют фреймами и каждый элемент имеет свою систему координат. Полученную совокупность N-мерных множеств сопоставляют с уже накопленными множествами и/или с вновь поступающими множествами по разным каналам, определяют и вырезают пересекающиеся части множеств. Сопоставление с уже накопленными множествами и/или с вновь поступающими производят одновременно или последовательно во времени. После этого вырезанные пересечения множеств и остающиеся после вырезания множества распределяют по базам данных, помещая каждое из одинаковых множеств в соответствующую ему базу данных и каждое их paзличающихся по какому-то параметру множества в соответствующие этим видам множеств базы данных и помещают на место вырезанных множеств идентификаторы хранящих эти множества баз данных.
Учитывая использование ряда аналитических соотношений, следует отметить, что для практической реализации из множеств, удовлетворяющих аналитические соотношения значений параметров в заявленных пределах - выбирают для параметров, например, N, N1 или N2 - это целые положительные натуральные числа, а для остальных параметров - это действительные числа, исключая иррациональные, трансцендентные, комплексные, отрицательные и другие технически некорректные или практически не применимые, или не воспроизводимые значения взаимосвязанных параметров.
Промышленная применимость и достижение технического результата
Соответствие критерию промышленная применимость заявленного объекта доказывается как широким получением и использованием описанных приемов компьютерных технологий в массовых масштабах, так и отсутствием в заявленных притязаниях каких-либо практически трудно реализуемых признаков. Достигаемый технический результат, как показали данные экспериментов, может быть реализован только взаимосвязанной совокупностью всех существенных признаков заявленного способа, отраженных в формуле изобретения. Например, при поиске слова ″ Example″ в несортированной, неиндексированной базе данных из 100 миллионов записей или из 100 миллиардов записей количество операций будет примерно одинаковым, т.е. скорость поиска будет наиболее высокой по сравнению с известными способами при адекватных условиях их использования, зависит только от длины запроса и очень слабо зависит от размера базы данных.
Нижние и верхние значения заявленных пределов были получены на основе статистической обработки результатов экспериментальных исследований, анализа и обобщения их и известных из опубликованных источников данных, а также изобретательской интуиции, исходя из условия достижения указанного технического результата. Указанные в формуле изобретения отличия дают основание сделать вывод о новизне данного техническою решения, а совокупность испрашиваемых притязаний - о ее изобретательском уровне, что доказывается как вышеприведенным детальным описанием заявленных объектов, так и следующим описанием примеров практической реализации заявленного способа. Для этого целесообразно привести основные функциональные схемы осуществления способа автоматической структуризации компьютерных кодов, адекватных обрабатываемой информации, при создании баз данных.
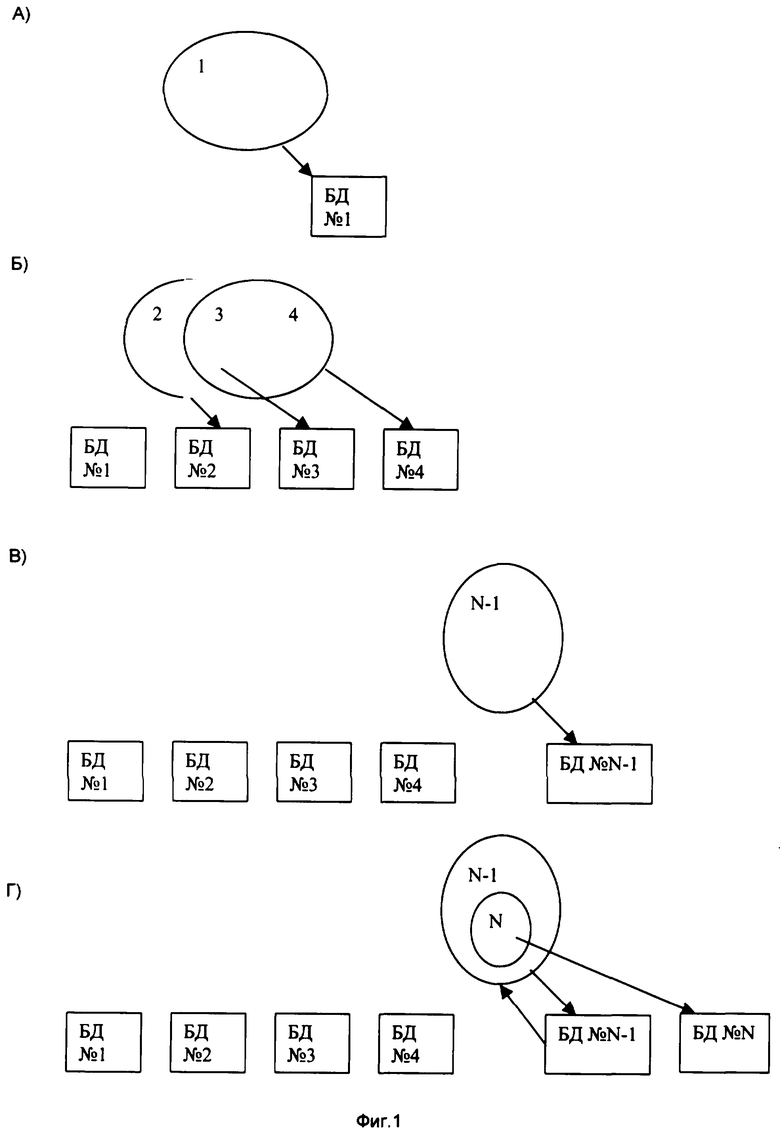
Преобразование компьютерных кодов, адекватных обрабатываемой информации, по предложенному способу частично можно пояснить с помощью Фиг.1А), которая отражает случай, когда поступает первое множество, схематически отображенное в виде овала 1. Так как общая база данных еще пуста, то множество целиком помещается в новую базу БД № 1 данных. Фиг.1Б) отражает случай, когда поступают очередные два множества 2 и 4, содержащие совпадающие элементы. Пересечение множеств 3 вырезается и помещается в соответствующую БД №3, на его место во множества 2 и 4 вставляется идентификатор БД №3, модифицированные множества 2 и 4 помещаются в соответствующие базы данных БД №3 и БД №4.
Фиг.1В) отражает случай, когда поступает очередное множество N-1, не содержащее ни одного совпадающего элемента с предыдущими множествами, поэтому множество N-1 помещается в новую базу данных БД-№N-1. Фиг.1Г) отражает случай, когда поступает очередное множество N, содержащее целиком совпадающие элементы со множеством N-1, хранянящимся в базе данных БД №N-1. Пересечение множеств N вырезается и помещается и соответствующую базу данных БД №N, на его место во множество N-1 вставляется идентификатор базы данных БД №N, соответственно изменяется база данных БД №N-1. Таким образом, в каждой отдельной базе данных БД хранятся множества, не имеющие совпадающих элементов, т.е. ни одно из множеств не пересекается.
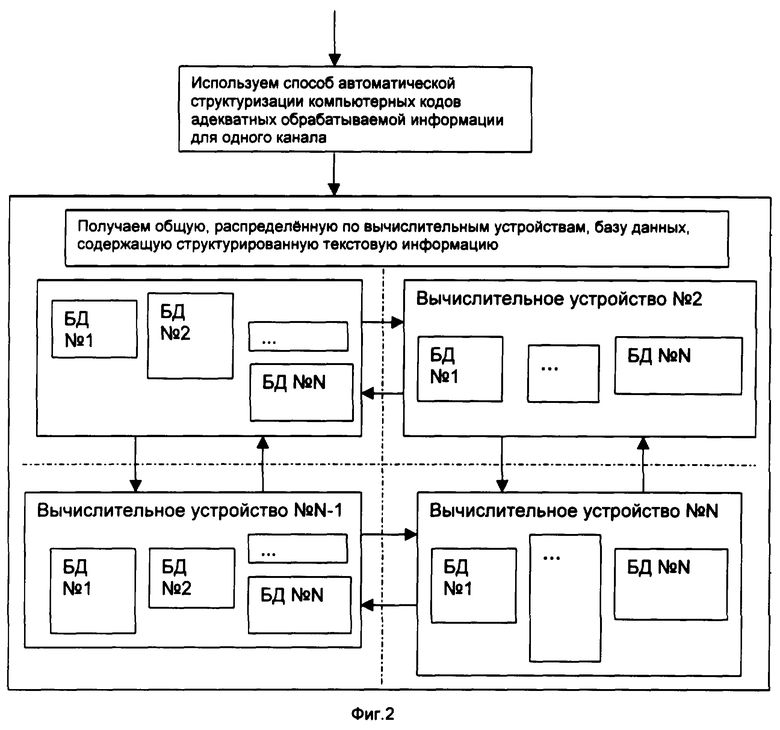
Упрощенные схемы осуществления способа последовательно для одного, двух и 10 каналов приведены соответственно на Фиг.2, Фиг.3 и Фиг.4. На Фиг.2 схематически изображена структурированная база данных текстовой информации, предназначенная для хранения больших массивов текстовой информации с выбором одного канала текстовой информации.
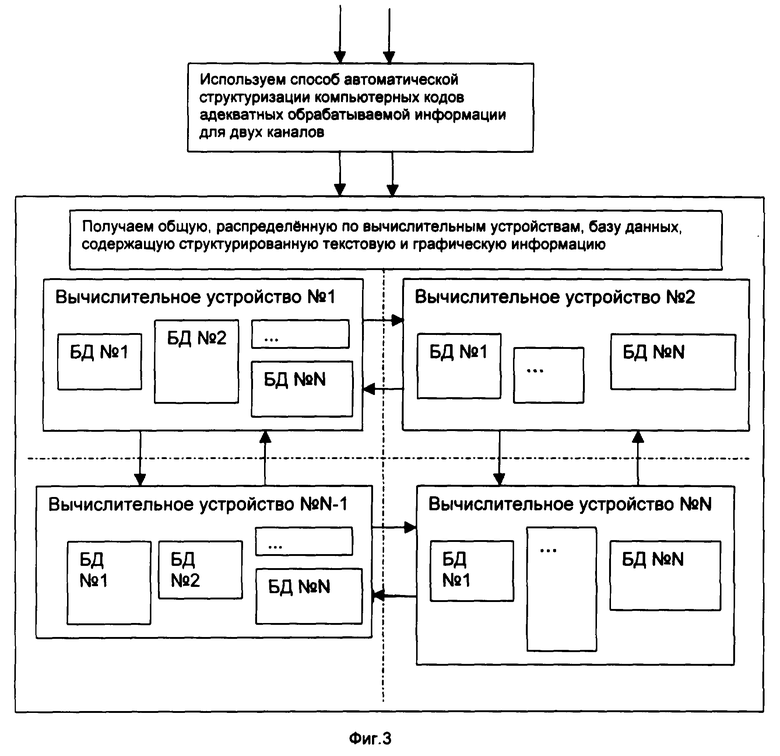
На Фиг.3 схематически изображена структурированная база данных текстовой и графической информации, предназначенная для хранения больших массивов текстовой и графической информации с выбором двух каналов - одного для текстовой информации, второго для графической информации.
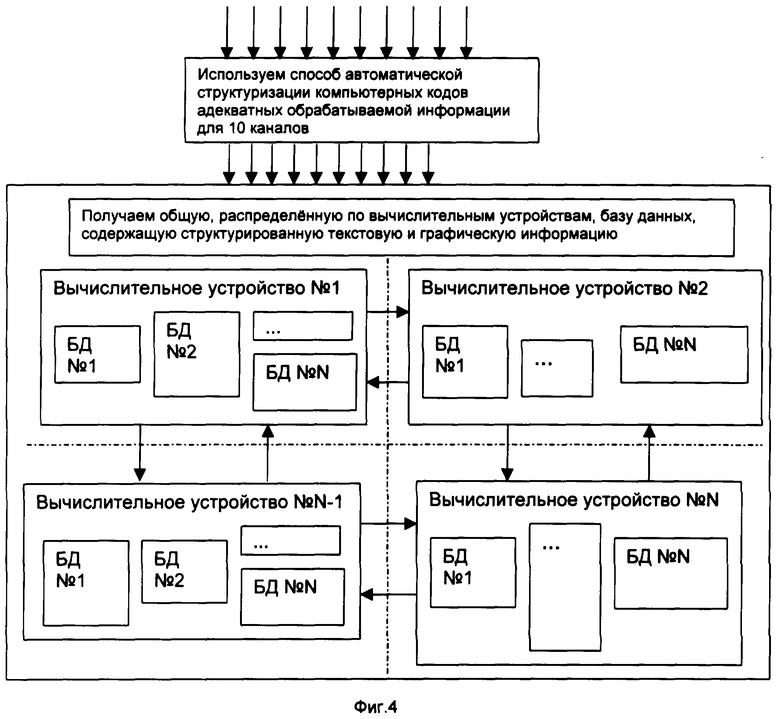
Детально целесообразно охарактеризовать структурированную базу данных текстовой, графической и звуковой информации, предназначенную для хранения больших массивов текстовой, графической и звуковой информации, поступающей одновременно по 10 каналам (Фиг.4), например 6 текстовых, 2 графических и 2 звуковых. Совокупность операций способа, реализованная в устройстве Фиг.4, может быть охарактеризована следующим образом: N1 выбирают равным 10, N2 - от 2 до 6 при α 1=1 для текстовой информации, α 1=0,9 для графической информации, α 1=1,1 для звуковой информации. Выделяют из объема V1=10 000 Кб/с поступающей в единицу времени информации ее часть объема V2=1000 Кб/с при α 2=1 для текстовой информации, α 2=0,8 для графической информации, α 2=1,2 для звуковой информации. Разбивают поступившую информацию на логически законченные фрагменты, объемы которых выбирают из соотношения 1,4≤ (V3i+α 3V2)/V2≤1,6, где α 3=1 для текстовой информации, α 3=0,5 для графической информации, α 3=1,7 для звуковой информации, а i выбирают в пределах 1≤ i≤ 220.
Кодируют полученные фрагменты информации, преобразуя их по заданному алгоритму до получения совокупности N-мерных множеств Аj элементов вида {Вm, X1, X2,... Хn}, где Вm - идентификатор, X1-Xn - координата элемента, aj - порядковый номер множества в пределах от 1 до 263, относительно начала координат элемента (каждый элемент имеет свою систему координат), адекватных преобразуемой исходной информации, где m и n выбирают в пределах от 1 до 263. Полученную совокупность N-мерных множеств сопоставляют с уже накопленными множествами и/или с вновь поступающими (одновременно или последовательно во времени) множествами по разным каналам, выделяют и вырезают пересекающиеся части множеств, после чего вырезанные пересечения множеств и остающиеся после вырезания множества распределяют по базам данных, помещая каждое из одинаковых множеств в соответствующую ему базу данных и каждое из различающихся по какому-то параметру множества в соответствующие этим видам множеств базы данных и помещают на место вырезанных множеств идентификаторы хранящих эти множества баз данных.
Экспериментальным путем при этом была получена скорость автоматической структуризации компьютерных кодов, адекватных обрабатываемой информации, равная 930,55 Кб/с на вычислительном устройстве с четырьмя процессорами Pentium III 800MHz, размером оперативной памяти 1024 Мб.
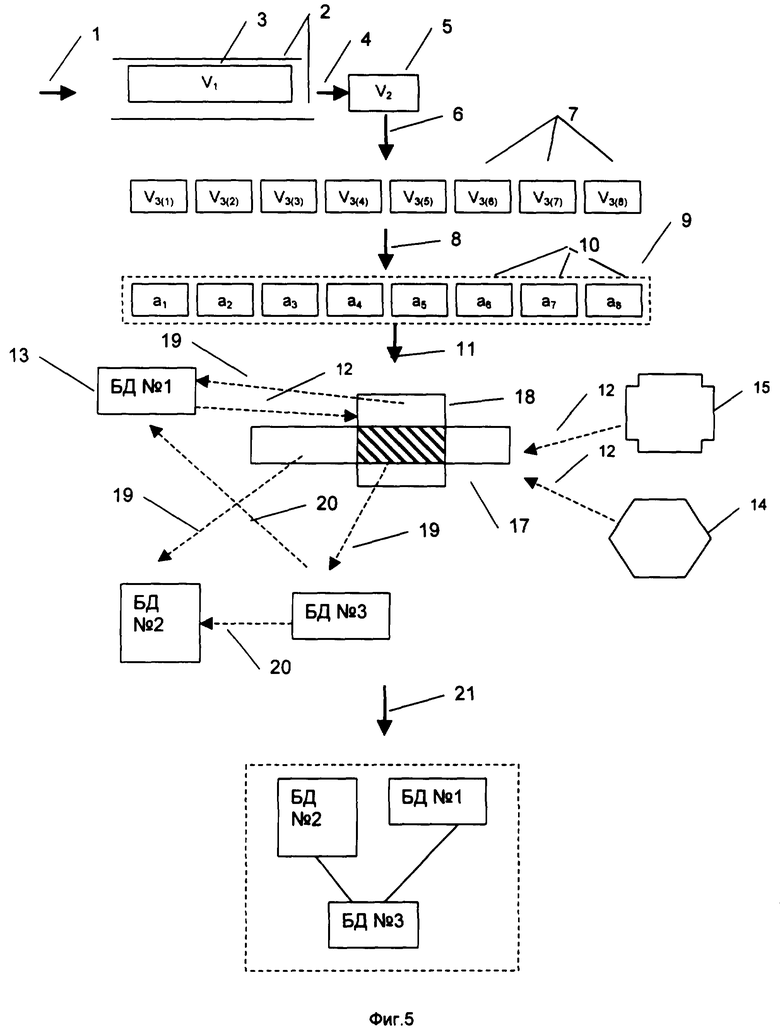
Для иллюстрации заявленного способа в примере Фиг.5 использована структурированная база данных текстовой информации. Эта база данных предназначена для хранения больших массивов текстовой информации. В процессе реализации заявленного способа выбирают (Фиг.5, операция выбирают, изображена стрелкой 1) число каналов (поз. 2) N1 равным 1, N2=1 при α 1=1, по которому передают объем V1 (Фиг.5, позиция 3) информации. Выделяют (Фиг.5, операция выделяют, изображенная стрелкой, обозначена позицией 4) из объема V1=100 Кб/с поступающей в единицу времени информации ее часть (Фиг.5. позиция 5) объема V1=8 б/с, т.е. в данном случае V2 - это фрагмент текстовой информации, например слово ″ аргумент″ , при α 2=0,9.
Затем разбивают (Фиг.5, поз. 6) поступившую информацию на логически законченные фрагменты (Фиг.5, поз. 7), объемы которых выбирают в пределах 1,3≤ (V3(i)+α 3V2)/V2≤1,5, где α 3=1, a i выбирают в пределах 1≤ i≤ 23. В результате получают следующие определенные с использованием выше приведенного аналитического соотношения конкретные значения для объемов фрагментов 7: V3(1)=1 б/с, V3(2)=1 б/с, V3(3)=1 б/с, V3(4)=1 б/с, V3(5)=1 б/с, V3(6)=1 б/с, V3(7)=1 б/с, V3(8)=1 б/с. Выбранные конкретные значения логически законченных фрагментов 7 кодируют (Фиг.5, поз. 8), преобразуя их по заданному алгоритму, в частности для данного примера у=f(x), где f(x)=V3(i)-191, до получения сосокупности N-мерных множеств Aj (поз. 9) элементов ak (поз. 10) вида {Вm, Х1, X2,... Хn}, где Bm - идентификатор, X1-Xn - координата элемента, где j - порядковый номер множества в пределах от 1 до 23, 1≤ k≤ 23, относительно начала координат элемента (каждый элемент ak имеет свою систему координат), адекватных преобразуемой исходной информации, где m и n выбирают в пределах от 1 до 231.
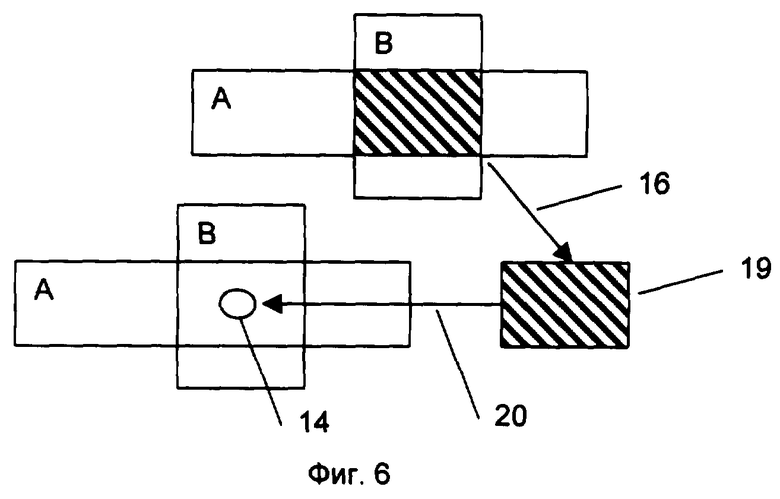
В результате получают преобразованные элементы в данном частном случае вида а1={1, 1}, а2={2, 2}, а3={3, 3}, a4={4, 4}, а5={5, 5}, а6={2, 6}, а7={6, 7}, а8={7, 8}. При этом отдельные идентификаторы (первые цифры в фигурных скобках) элементов множеств могут совпадать в случае совпадения результатов преобразования фрагментов информации по заданному алгоритму. Далее, совокупность операций выполняют как одно целое (Фиг.5. поз. 11). Полученную совокупность N-мерных множеств 9 сопоставляют (Фиг.5. позиция 12) с уже накопленными множествами (например, база данных 13 (БД №1)) и/или с вновь поступающими (одновременно или последовательно во времени) множествами 14 и 15 по разным каналам. Определяют и вырезают (Фиг.6, позиция 16) пересекающиеся части множеств 17 и 18. После чего вырезанные пересечения множеств (Фиг.6, позиция 19) и остающиеся после вырезания множества с замененными частями распределяют (Фиг.5. позиция 19) по базам данных, помещая каждое из одинаковых множеств в соответствующую ему базу данных и каждое из различающихся по какому-то параметру множества в соответствующие этим видам множеств базы данных и помещают (Фиг.5, позиция 20 или Фиг.6, позиция 20) на место вырезанных множеств идентификаторы хранящих эти множества баз данных.
В результате получается (Фиг.5, позиция 21) общая база данных, состоящая из иерархически связанных баз данных - каждая дочерняя база данных представлена своим идентификатором в соответствующих родительских базах данных.
Экспериментальным путем при этом была получена скорость автоматической структуризации компьютерных кодов, адекватных обрабатываемой информации, равная 96 Кб/с на вычислительном устройстве с одним процессором Pentium III 800MHz, размером оперативной памяти 256 Мб.
Кроме указанного выше технического результата практическое осуществление заявленного объекта позволяет существенно расширить возможности его использования применительно, например, к различным видам и объемам поступающей информации, обеспечивает дополнительную возможность высокоэффективной аппаратной реализации (цена/качество/скорость) с применением самых различных типов элементной базы, a также автоматическую адаптацию под решение задач разного типа, в отличие от нейросетей, требующих заранее заданной топологии под каждую конкретную задачу.
Изобретение относится к области компьютерных технологий. Его использование позволяет получить технический результат в виде повышения скорости и точности структуризации компьютерных кодов и экономии расхода вычислительных средств. Технический результат обеспечивают выполнением совокупности операций по N1 каналам, где N1 выбирают от 1 до 2256, в которых разбивают поступившую информацию на логически законченные фрагменты, кодируют по заданному алгоритму до получения совокупности N-мерных множеств адекватных преобразуемой исходной информации Аj элементов вида {Вm, X1, X2,...Хn}, где j - порядковый номер множества в пределах от 1 до 2256, Вm - идентификатор, X1-Xn - координата элемента от начала его координат, m и n выбирают в пределах от 1 до 2256; полученную совокупность множеств сопоставляют с уже накопленными и/или вновь поступающими множествами по разным каналам, определяют и вырезают пересекающиеся части множеств; после этого вырезанные пересечения множеств и остающиеся после вырезания множества распределяют по базам данных, помещая каждое из одинаковых множеств в соответствующую ему базу данных и каждое из различающихся по какому-то параметру множеств в соответствующие этим видам множеств базы данных и помещают на место вырезанных множеств идентификаторы хранящих эти множества баз данных. 6 ил.
Способ автоматической структуризации компьютерных кодов в виде электромагнитных сигналов, адекватных обрабатываемой информации, включающий совокупность операций, автоматически осуществляемых по N1-каналам, где N1 автоматически выбирают от 1 до 2256, таким образом, что в каждом из N2 каналов, автоматически выбираемых в количестве, удовлетворяющем неравенству 1+1/N1≤(N2+α1N1)/N1≤2,3, где α 1 - экспериментальный коэффициент, автоматически выбираемый в зависимости от вида информации, представленной в виде компьютерных кодов, адекватных обрабатываемой информации, и от количества источников её поступления в пределах 0,61≤ α1≤1,3, автоматически выделяют из объёма V1 поступающей в единицу времени информации, представленной в виде компьютерных кодов, адекватных обрабатываемой информации, её часть объёма V2, которую автоматически выбирают из соотношения в пределах 0,56≤ (V2+α2V1)/V1≤2,8, где α 2 - экспериментальный коэффициент, автоматически выбираемый в зависимости от вида информации, представленной в виде компьютерных кодов, адекватных обрабатываемой информации, в пределах 0,56≤ α2≤1,8, автоматически разбивают поступившую информацию, представленную в виде компьютерных кодов, адекватных обрабатываемой информации, на логически законченные фрагменты, объёмы V3i которых автоматически выбирают из соотношения в пределах 0,45≤ (V3i+α3V2)/V2≤2,7, где α 3 - экспериментальный коэффициент, автоматически выбираемый в зависимости от особенности их разбиения в пределах 0,45≤ α3≤1,7, а i автоматически выбирают в пределах 1≤ i≤ 2256, автоматически кодируют полученные фрагменты информации, представленной в виде компьютерных кодов, адекватных обрабатываемой информации, автоматически преобразуя их по заданному алгоритму до получения совокупности N-мерных множеств, содержащих компьютерные коды, адекватные преобразуемой исходной информации, Aj элементов вида {Вm, X1, X2,...Хn}, где j - порядковый номер множества в пределах от 1 до 2256, Вm - идентификатор, X1-Xn - координата элемента относительно начала координат элемента, а m и n автоматически выбирают в пределах от 1 до 2256, полученную совокупность N-мерных множеств автоматически сопоставляют с уже накопленными множествами и/или с вновь автоматически поступающими множествами по разным каналам, автоматически определяют и автоматически вырезают пересекающиеся части множеств, после чего вырезанные пересечения множеств и остающиеся после вырезания множества автоматически распределяют по базам данных, автоматически помещая каждое из одинаковых множеств в соответствующую ему базу данных и каждое из различающихся по какому-то параметру множеств в соответствующие этим видам множеств базы данных, и автоматически помещают на место вырезанных множеств идентификаторы хранящих эти множества баз данных, содержащих компьютерные коды, адекватные обработанной информации.
| СПОСОБ ИДЕНТИФИКАЦИИ ОБЪЕКТОВ ПО ИХ ОПИСАНИЯМ | 1999 |
|
RU2167450C2 |
| СПОСОБ УСТАНОВЛЕНИЯ В ХРАНИЛИЩЕ МЕСТОПОЛОЖЕНИЯ ОБЪЕКТА ПО ПОИСКОВОМУ ТЕМАТИЧЕСКОМУ ПРИЗНАКУ | 1994 |
|
RU2107942C1 |
| УСТРОЙСТВО ОБРАБОТКИ ИНФОРМАЦИИ ДЛЯ ИНФОРМАЦИОННОГО ПОИСКА | 1996 |
|
RU2096825C1 |
| Система для поиска и обработки научно-технической информации | 1981 |
|
SU993273A1 |
| US 6240421 B1, 29.05.2001 | |||
| US 5991709 A, 23.11.1999 | |||
| US 5924096 A, 13.07.1999 | |||
| US 5664177 A, 02.09.1997 | |||
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |
| Приспособление в пере для письма с целью увеличения на нем запаса чернил и уменьшения скорости их высыхания | 1917 |
|
SU96A1 |
| Устройство для остеосинтеза шейки бедренной кости | 1980 |
|
SU971295A1 |

